

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -10,18 +10,16 @@ tags:
|
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
| 12 |
- convolutional
|
| 13 |
-
- transformer
|
| 14 |
---
|
| 15 |
|
| 16 |
# BENDR
|
| 17 |
|
| 18 |
-
BENDR (BErt-inspired Neural Data Representations) from Kostas et al (2021) .
|
| 19 |
|
| 20 |
-
> **Architecture-only repository.**
|
| 21 |
> `braindecode.models.BENDR` class. **No pretrained weights are
|
| 22 |
-
> distributed here**
|
| 23 |
-
> data
|
| 24 |
-
> separately.
|
| 25 |
|
| 26 |
## Quick start
|
| 27 |
|
|
@@ -40,277 +38,52 @@ model = BENDR(
|
|
| 40 |
)
|
| 41 |
```
|
| 42 |
|
| 43 |
-
The signal-shape arguments above are
|
| 44 |
-
|
| 45 |
|
| 46 |
## Documentation
|
| 47 |
-
|
| 48 |
-
-
|
| 49 |
-
<https://braindecode.org/stable/generated/braindecode.models.BENDR.html>
|
| 50 |
-
- Interactive browser with live instantiation:
|
| 51 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 52 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/bendr.py#L60>
|
| 53 |
|
| 54 |
-
## Architecture description
|
| 55 |
-
|
| 56 |
-
The block below is the rendered class docstring (parameters,
|
| 57 |
-
references, architecture figure where available).
|
| 58 |
-
|
| 59 |
-
<div class='bd-doc'><main>
|
| 60 |
-
<p>BENDR (BErt-inspired Neural Data Representations) from Kostas et al (2021) [bendr]_.</p>
|
| 61 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#d9534f;color:white;font-size:11px;font-weight:600;margin-right:4px;">Foundation Model</span>
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
.. figure:: https://www.frontiersin.org/files/Articles/653659/fnhum-15-653659-HTML/image_m/fnhum-15-653659-g001.jpg
|
| 66 |
-
:align: center
|
| 67 |
-
:alt: BENDR Architecture
|
| 68 |
-
:width: 1000px
|
| 69 |
-
|
| 70 |
-
The **BENDR** architecture adapts techniques used for language modeling (LM) toward the
|
| 71 |
-
development of encephalography modeling (EM) [bendr]_. It utilizes a self-supervised
|
| 72 |
-
training objective to learn compressed representations of raw EEG signals [bendr]_. The
|
| 73 |
-
model is capable of modeling completely novel raw EEG sequences recorded with differing
|
| 74 |
-
hardware and subjects, aiming for transferable performance across a variety of downstream
|
| 75 |
-
BCI and EEG classification tasks [bendr]_.
|
| 76 |
-
|
| 77 |
-
.. rubric:: Architectural Overview
|
| 78 |
-
|
| 79 |
-
BENDR is adapted from wav2vec 2.0 [wav2vec2]_ and is composed of two main stages: a
|
| 80 |
-
feature extractor (Convolutional stage) that produces BErt-inspired Neural Data
|
| 81 |
-
Representations (BENDR), followed by a transformer encoder (Contextualizer) [bendr]_.
|
| 82 |
-
|
| 83 |
-
.. rubric:: Macro Components
|
| 84 |
-
|
| 85 |
-
- `BENDR.encoder` **(Convolutional Stage/Feature Extractor)**
|
| 86 |
-
- *Operations.* A stack of six short-receptive field 1D convolutions [bendr]_. Each
|
| 87 |
-
block consists of 1D convolution, GroupNorm, and GELU activation.
|
| 88 |
-
- *Role.* Takes raw data :math:`X_{raw}` and dramatically downsamples it to a new
|
| 89 |
-
sequence of vectors (BENDR) [bendr]_. Each resulting vector has a length of 512.
|
| 90 |
-
- `BENDR.contextualizer` **(Transformer Encoder)**
|
| 91 |
-
- *Operations.* A transformer encoder that uses layered, multi-head self-attention
|
| 92 |
-
[bendr]_. It employs T-Fixup weight initialization [tfixup]_ and uses 8 layers
|
| 93 |
-
and 8 heads.
|
| 94 |
-
- *Role.* Maps the sequence of BENDR vectors to a contextualized sequence. The output
|
| 95 |
-
of a fixed start token is typically used as the aggregate representation for
|
| 96 |
-
downstream classification [bendr]_.
|
| 97 |
-
- `Contextualizer.position_encoder` **(Positional Encoding)**
|
| 98 |
-
- *Operations.* An additive (grouped) convolution layer with a receptive field of 25
|
| 99 |
-
and 16 groups [bendr]_.
|
| 100 |
-
- *Role.* Encodes position information before the input enters the transformer.
|
| 101 |
-
|
| 102 |
-
.. rubric:: How the information is encoded temporally, spatially, and spectrally
|
| 103 |
-
|
| 104 |
-
* **Temporal.**
|
| 105 |
-
The convolutional encoder uses a stack of blocks where the stride matches the receptive
|
| 106 |
-
field (e.g., 3 for the first block, 2 for subsequent blocks) [bendr]_. This process
|
| 107 |
-
downsamples the raw data by a factor of 96, resulting in an effective sampling frequency
|
| 108 |
-
of approximately 2.67 Hz.
|
| 109 |
-
* **Spatial.**
|
| 110 |
-
To maintain simplicity and reduce complexity, the convolutional stage uses **1D
|
| 111 |
-
convolutions** and elects not to mix EEG channels across the first stage [bendr]_. The
|
| 112 |
-
input includes 20 channels (19 EEG channels and one relative amplitude channel).
|
| 113 |
-
* **Spectral.**
|
| 114 |
-
The convolution operations implicitly extract features from the raw EEG signal [bendr]_.
|
| 115 |
-
The representations (BENDR) are derived from the raw waveform using convolutional
|
| 116 |
-
operations followed by sequence modeling [wav2vec2]_.
|
| 117 |
-
|
| 118 |
-
.. rubric:: Additional Mechanisms
|
| 119 |
-
|
| 120 |
-
- **Self-Supervision (Pre-training).** Uses a masked sequence learning approach (adapted
|
| 121 |
-
from wav2vec 2.0 [wav2vec2]_) where contiguous spans of BENDR sequences are masked, and
|
| 122 |
-
the model attempts to reconstruct the original underlying encoded vector based on the
|
| 123 |
-
transformer output and a set of negative distractors [bendr]_.
|
| 124 |
-
- **Regularization.** LayerDrop [layerdrop]_ and Dropout (at probabilities 0.01 and 0.15,
|
| 125 |
-
respectively) are used during pre-training [bendr]_. The implementation also uses T-Fixup
|
| 126 |
-
scaling for parameter initialization [tfixup]_.
|
| 127 |
-
- **Input Conditioning.** A fixed token (a vector filled with the value **-5**) is
|
| 128 |
-
prepended to the BENDR sequence before input to the transformer, serving as the aggregate
|
| 129 |
-
representation token [bendr]_.
|
| 130 |
-
|
| 131 |
-
.. important::
|
| 132 |
-
**Pre-trained Weights Available**
|
| 133 |
-
|
| 134 |
-
This model has pre-trained weights available on the Hugging Face Hub.
|
| 135 |
-
You can load them using:
|
| 136 |
-
|
| 137 |
-
.. code:: python
|
| 138 |
-
from braindecode.models import BENDR
|
| 139 |
-
|
| 140 |
-
# Load pre-trained model from Hugging Face Hub
|
| 141 |
-
# you can specify `n_outputs` for your downstream task
|
| 142 |
-
model = BENDR.from_pretrained("braindecode/braindecode-bendr", n_outputs=2)
|
| 143 |
-
|
| 144 |
-
To push your own trained model to the Hub:
|
| 145 |
-
|
| 146 |
-
.. code:: python
|
| 147 |
-
# After training your model
|
| 148 |
-
model.push_to_hub(
|
| 149 |
-
repo_id="username/my-bendr-model", commit_message="Upload trained BENDR model"
|
| 150 |
-
)
|
| 151 |
-
|
| 152 |
-
Requires installing ``braindecode[hug]`` for Hub integration.
|
| 153 |
-
|
| 154 |
-
Notes
|
| 155 |
-
-----
|
| 156 |
-
* The full BENDR architecture contains a large number of parameters; configuration (1)
|
| 157 |
-
involved training over **one billion parameters** [bendr]_.
|
| 158 |
-
* Randomly initialized full BENDR architecture was generally ineffective at solving
|
| 159 |
-
downstream tasks without prior self-supervised training [bendr]_.
|
| 160 |
-
* The pre-training task (contrastive predictive coding via masking) is generalizable,
|
| 161 |
-
exhibiting strong uniformity of performance across novel subjects, hardware, and
|
| 162 |
-
tasks [bendr]_.
|
| 163 |
-
|
| 164 |
-
.. warning::
|
| 165 |
-
|
| 166 |
-
**Important:** To utilize the full potential of BENDR, the model requires
|
| 167 |
-
**self-supervised pre-training** on large, unlabeled EEG datasets (like TUEG) followed
|
| 168 |
-
by subsequent fine-tuning on the specific downstream classification task [bendr]_.
|
| 169 |
-
|
| 170 |
-
References
|
| 171 |
-
----------
|
| 172 |
-
.. [bendr] Kostas, D., Aroca-Ouellette, S., & Rudzicz, F. (2021).
|
| 173 |
-
BENDR: Using transformers and a contrastive self-supervised learning task to learn from
|
| 174 |
-
massive amounts of EEG data.
|
| 175 |
-
Frontiers in Human Neuroscience, 15, 653659.
|
| 176 |
-
https://doi.org/10.3389/fnhum.2021.653659
|
| 177 |
-
.. [wav2vec2] Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020).
|
| 178 |
-
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.
|
| 179 |
-
In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Lin (Eds),
|
| 180 |
-
Advances in Neural Information Processing Systems (Vol. 33, pp. 12449-12460).
|
| 181 |
-
https://dl.acm.org/doi/10.5555/3495724.3496768
|
| 182 |
-
.. [tfixup] Huang, T. K., Liang, S., Jha, A., & Salakhutdinov, R. (2020).
|
| 183 |
-
Improving Transformer Optimization Through Better Initialization.
|
| 184 |
-
In International Conference on Machine Learning (pp. 4475-4483). PMLR.
|
| 185 |
-
https://dl.acm.org/doi/10.5555/3524938.3525354
|
| 186 |
-
.. [layerdrop] Fan, A., Grave, E., & Joulin, A. (2020).
|
| 187 |
-
Reducing Transformer Depth on Demand with Structured Dropout.
|
| 188 |
-
International Conference on Learning Representations.
|
| 189 |
-
Retrieved from https://openreview.net/forum?id=SylO2yStDr
|
| 190 |
-
|
| 191 |
-
Parameters
|
| 192 |
-
----------
|
| 193 |
-
encoder_h : int, default=512
|
| 194 |
-
Hidden size (number of output channels) of the convolutional encoder. This determines
|
| 195 |
-
the dimensionality of the BENDR feature vectors produced by the encoder.
|
| 196 |
-
contextualizer_hidden : int, default=3076
|
| 197 |
-
Hidden size of the feedforward layer within each transformer block. The paper uses
|
| 198 |
-
approximately 2x the transformer dimension (3076 ~ 2 x 1536).
|
| 199 |
-
projection_head : bool, default=False
|
| 200 |
-
If True, adds a projection layer at the end of the encoder to project back to the
|
| 201 |
-
input feature size. This is used during self-supervised pre-training but typically
|
| 202 |
-
disabled during fine-tuning.
|
| 203 |
-
drop_prob : float, default=0.1
|
| 204 |
-
Dropout probability applied throughout the model. The paper recommends 0.15 for
|
| 205 |
-
pre-training and 0.0 for fine-tuning. Default is 0.1 as a compromise.
|
| 206 |
-
layer_drop : float, default=0.0
|
| 207 |
-
Probability of dropping entire transformer layers during training (LayerDrop
|
| 208 |
-
regularization [layerdrop]_). The paper uses 0.01 for pre-training and 0.0 for
|
| 209 |
-
fine-tuning.
|
| 210 |
-
activation : :class:`torch.nn.Module`, default=:class:`torch.nn.GELU`
|
| 211 |
-
Activation function used in the encoder convolutional blocks. The paper uses GELU
|
| 212 |
-
activation throughout.
|
| 213 |
-
transformer_layers : int, default=8
|
| 214 |
-
Number of transformer encoder layers in the contextualizer. The paper uses 8 layers.
|
| 215 |
-
transformer_heads : int, default=8
|
| 216 |
-
Number of attention heads in each transformer layer. The paper uses 8 heads with
|
| 217 |
-
head dimension of 192 (1536 / 8).
|
| 218 |
-
position_encoder_length : int, default=25
|
| 219 |
-
Kernel size for the convolutional positional encoding layer. The paper uses a
|
| 220 |
-
receptive field of 25 with 16 groups.
|
| 221 |
-
enc_width : tuple of int, default=(3, 2, 2, 2, 2, 2)
|
| 222 |
-
Kernel sizes for each of the 6 convolutional blocks in the encoder. Each value
|
| 223 |
-
corresponds to one block.
|
| 224 |
-
enc_downsample : tuple of int, default=(3, 2, 2, 2, 2, 2)
|
| 225 |
-
Stride values for each of the 6 convolutional blocks in the encoder. The total
|
| 226 |
-
downsampling factor is the product of all strides (3 x 2 x 2 x 2 x 2 x 2 = 96).
|
| 227 |
-
start_token : int or float, default=-5
|
| 228 |
-
Value used to fill the start token embedding that is prepended to the BENDR sequence
|
| 229 |
-
before input to the transformer. This token's output is used as the aggregate
|
| 230 |
-
representation for classification.
|
| 231 |
-
final_layer : bool, default=True
|
| 232 |
-
If True, includes a final linear classification layer that maps from encoder_h to
|
| 233 |
-
n_outputs. If False, the model outputs the contextualized features directly.
|
| 234 |
-
encoder_only : bool, default=False
|
| 235 |
-
If True, bypass the contextualizer and use 4-chunk temporal pooling on the encoder
|
| 236 |
-
output instead. This corresponds to the encoder-only configuration described in
|
| 237 |
-
Section 2.4 and Table 2 of Kostas et al. (2021) [bendr]_, which outperformed the
|
| 238 |
-
full model on 4 out of 5 downstream tasks. The encoder output is split into 4 equal
|
| 239 |
-
temporal chunks, each chunk is mean-pooled, and the results are concatenated to
|
| 240 |
-
produce a feature vector of size ``encoder_h * 4`` (2048-dim with default settings).
|
| 241 |
-
The contextualizer is still created (to allow loading pretrained weights) but is not
|
| 242 |
-
used in the forward pass. Requires input length of at least
|
| 243 |
-
``4 * product(enc_downsample)`` samples (384 with default downsampling of 96x).
|
| 244 |
-
|
| 245 |
-
.. rubric:: Hugging Face Hub integration
|
| 246 |
-
|
| 247 |
-
When the optional ``huggingface_hub`` package is installed, all models
|
| 248 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 249 |
-
Hugging Face Hub. Install with::
|
| 250 |
-
|
| 251 |
-
pip install braindecode[hub]
|
| 252 |
-
|
| 253 |
-
**Pushing a model to the Hub:**
|
| 254 |
-
|
| 255 |
-
.. code::
|
| 256 |
-
from braindecode.models import BENDR
|
| 257 |
-
|
| 258 |
-
# Train your model
|
| 259 |
-
model = BENDR(n_chans=22, n_outputs=4, n_times=1000)
|
| 260 |
-
# ... training code ...
|
| 261 |
-
|
| 262 |
-
# Push to the Hub
|
| 263 |
-
model.push_to_hub(
|
| 264 |
-
repo_id="username/my-bendr-model",
|
| 265 |
-
commit_message="Initial model upload",
|
| 266 |
-
)
|
| 267 |
-
|
| 268 |
-
**Loading a model from the Hub:**
|
| 269 |
-
|
| 270 |
-
.. code::
|
| 271 |
-
from braindecode.models import BENDR
|
| 272 |
-
|
| 273 |
-
# Load pretrained model
|
| 274 |
-
model = BENDR.from_pretrained("username/my-bendr-model")
|
| 275 |
-
|
| 276 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 277 |
-
model = BENDR.from_pretrained("username/my-bendr-model", n_outputs=4)
|
| 278 |
-
|
| 279 |
-
**Extracting features and replacing the head:**
|
| 280 |
|
| 281 |
-
|
| 282 |
-
import torch
|
| 283 |
|
| 284 |
-
|
| 285 |
-
# Extract encoder features (consistent dict across all models)
|
| 286 |
-
out = model(x, return_features=True)
|
| 287 |
-
features = out["features"]
|
| 288 |
|
| 289 |
-
# Replace the classification head
|
| 290 |
-
model.reset_head(n_outputs=10)
|
| 291 |
|
| 292 |
-
|
| 293 |
|
| 294 |
-
|
| 295 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 296 |
|
| 297 |
-
config = model.get_config() # all __init__ params
|
| 298 |
-
with open("config.json", "w") as f:
|
| 299 |
-
json.dump(config, f)
|
| 300 |
|
| 301 |
-
|
| 302 |
|
| 303 |
-
|
| 304 |
-
|
| 305 |
-
|
|
|
|
| 306 |
|
| 307 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 308 |
-
</div>
|
| 309 |
|
| 310 |
## Citation
|
| 311 |
|
| 312 |
-
|
| 313 |
-
*References* section above) and braindecode:
|
| 314 |
|
| 315 |
```bibtex
|
| 316 |
@article{aristimunha2025braindecode,
|
|
|
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
| 12 |
- convolutional
|
|
|
|
| 13 |
---
|
| 14 |
|
| 15 |
# BENDR
|
| 16 |
|
| 17 |
+
BENDR (BErt-inspired Neural Data Representations) from Kostas et al (2021) [bendr].
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.BENDR` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.BENDR.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/bendr.py#L60>
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
|
|
|
| 52 |
|
| 53 |
+
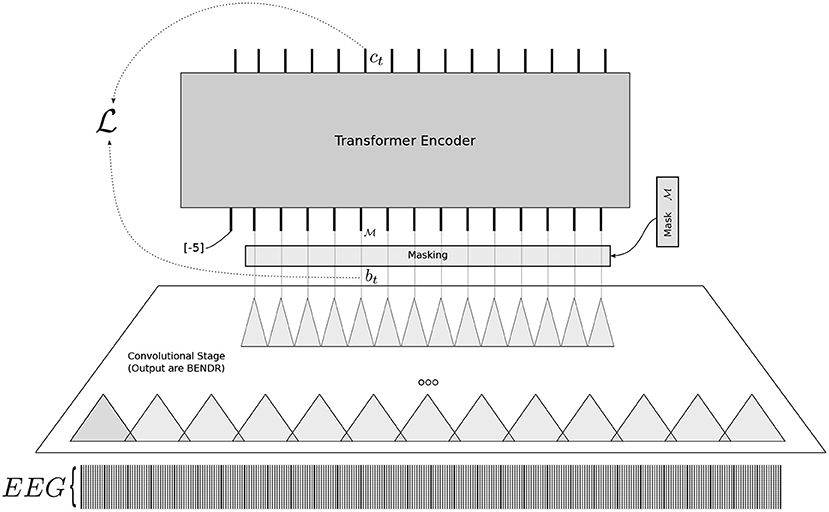
|
|
|
|
|
|
|
|
|
|
| 54 |
|
|
|
|
|
|
|
| 55 |
|
| 56 |
+
## Parameters
|
| 57 |
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `encoder_h` | int, default=512 | Hidden size (number of output channels) of the convolutional encoder. This determines the dimensionality of the BENDR feature vectors produced by the encoder. |
|
| 61 |
+
| `contextualizer_hidden` | int, default=3076 | Hidden size of the feedforward layer within each transformer block. The paper uses approximately 2x the transformer dimension (3076 ~ 2 x 1536). |
|
| 62 |
+
| `projection_head` | bool, default=False | If True, adds a projection layer at the end of the encoder to project back to the input feature size. This is used during self-supervised pre-training but typically disabled during fine-tuning. |
|
| 63 |
+
| `drop_prob` | float, default=0.1 | Dropout probability applied throughout the model. The paper recommends 0.15 for pre-training and 0.0 for fine-tuning. Default is 0.1 as a compromise. |
|
| 64 |
+
| `layer_drop` | float, default=0.0 | Probability of dropping entire transformer layers during training (LayerDrop regularization [layerdrop]). The paper uses 0.01 for pre-training and 0.0 for fine-tuning. |
|
| 65 |
+
| `activation` | :class:`torch.nn.Module`, default=:class:`torch.nn.GELU` | Activation function used in the encoder convolutional blocks. The paper uses GELU activation throughout. |
|
| 66 |
+
| `transformer_layers` | int, default=8 | Number of transformer encoder layers in the contextualizer. The paper uses 8 layers. |
|
| 67 |
+
| `transformer_heads` | int, default=8 | Number of attention heads in each transformer layer. The paper uses 8 heads with head dimension of 192 (1536 / 8). |
|
| 68 |
+
| `position_encoder_length` | int, default=25 | Kernel size for the convolutional positional encoding layer. The paper uses a receptive field of 25 with 16 groups. |
|
| 69 |
+
| `enc_width` | tuple of int, default=(3, 2, 2, 2, 2, 2) | Kernel sizes for each of the 6 convolutional blocks in the encoder. Each value corresponds to one block. |
|
| 70 |
+
| `enc_downsample` | tuple of int, default=(3, 2, 2, 2, 2, 2) | Stride values for each of the 6 convolutional blocks in the encoder. The total downsampling factor is the product of all strides (3 x 2 x 2 x 2 x 2 x 2 = 96). |
|
| 71 |
+
| `start_token` | int or float, default=-5 | Value used to fill the start token embedding that is prepended to the BENDR sequence before input to the transformer. This token's output is used as the aggregate representation for classification. |
|
| 72 |
+
| `final_layer` | bool, default=True | If True, includes a final linear classification layer that maps from encoder_h to n_outputs. If False, the model outputs the contextualized features directly. |
|
| 73 |
+
| `encoder_only` | bool, default=False | If True, bypass the contextualizer and use 4-chunk temporal pooling on the encoder output instead. This corresponds to the encoder-only configuration described in Section 2.4 and Table 2 of Kostas et al. (2021) [bendr], which outperformed the full model on 4 out of 5 downstream tasks. The encoder output is split into 4 equal temporal chunks, each chunk is mean-pooled, and the results are concatenated to produce a feature vector of size `encoder_h * 4` (2048-dim with default settings). The contextualizer is still created (to allow loading pretrained weights) but is not used in the forward pass. Requires input length of at least `4 * product(enc_downsample)` samples (384 with default downsampling of 96x). |
|
| 74 |
|
|
|
|
|
|
|
|
|
|
| 75 |
|
| 76 |
+
## References
|
| 77 |
|
| 78 |
+
1. Kostas, D., Aroca-Ouellette, S., & Rudzicz, F. (2021). BENDR: Using transformers and a contrastive self-supervised learning task to learn from massive amounts of EEG data. Frontiers in Human Neuroscience, 15, 653659. https://doi.org/10.3389/fnhum.2021.653659
|
| 79 |
+
2. Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Lin (Eds), Advances in Neural Information Processing Systems (Vol. 33, pp. 12449-12460). https://dl.acm.org/doi/10.5555/3495724.3496768
|
| 80 |
+
3. Huang, T. K., Liang, S., Jha, A., & Salakhutdinov, R. (2020). Improving Transformer Optimization Through Better Initialization. In International Conference on Machine Learning (pp. 4475-4483). PMLR. https://dl.acm.org/doi/10.5555/3524938.3525354
|
| 81 |
+
4. Fan, A., Grave, E., & Joulin, A. (2020). Reducing Transformer Depth on Demand with Structured Dropout. International Conference on Learning Representations. Retrieved from https://openreview.net/forum?id=SylO2yStDr
|
| 82 |
|
|
|
|
|
|
|
| 83 |
|
| 84 |
## Citation
|
| 85 |
|
| 86 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 87 |
|
| 88 |
```bibtex
|
| 89 |
@article{aristimunha2025braindecode,
|