
Commit
•
b55c824
1
Parent(s):
64b60b2
up
Browse files- README.md +12 -8
- assets/whisper_fr_eval_long_form.png +0 -0
- assets/whisper_fr_eval_short_form.png +0 -0
README.md
CHANGED
|
@@ -119,12 +119,12 @@ Please note that the reported WER is the result after converting numbers to text
|
|
| 119 |
|
| 120 |
All evaluation results on the public datasets can be found [here](https://drive.google.com/drive/folders/1rFIh6yXRVa9RZ0ieZoKiThFZgQ4STPPI?usp=drive_link).
|
| 121 |
|
| 122 |
-
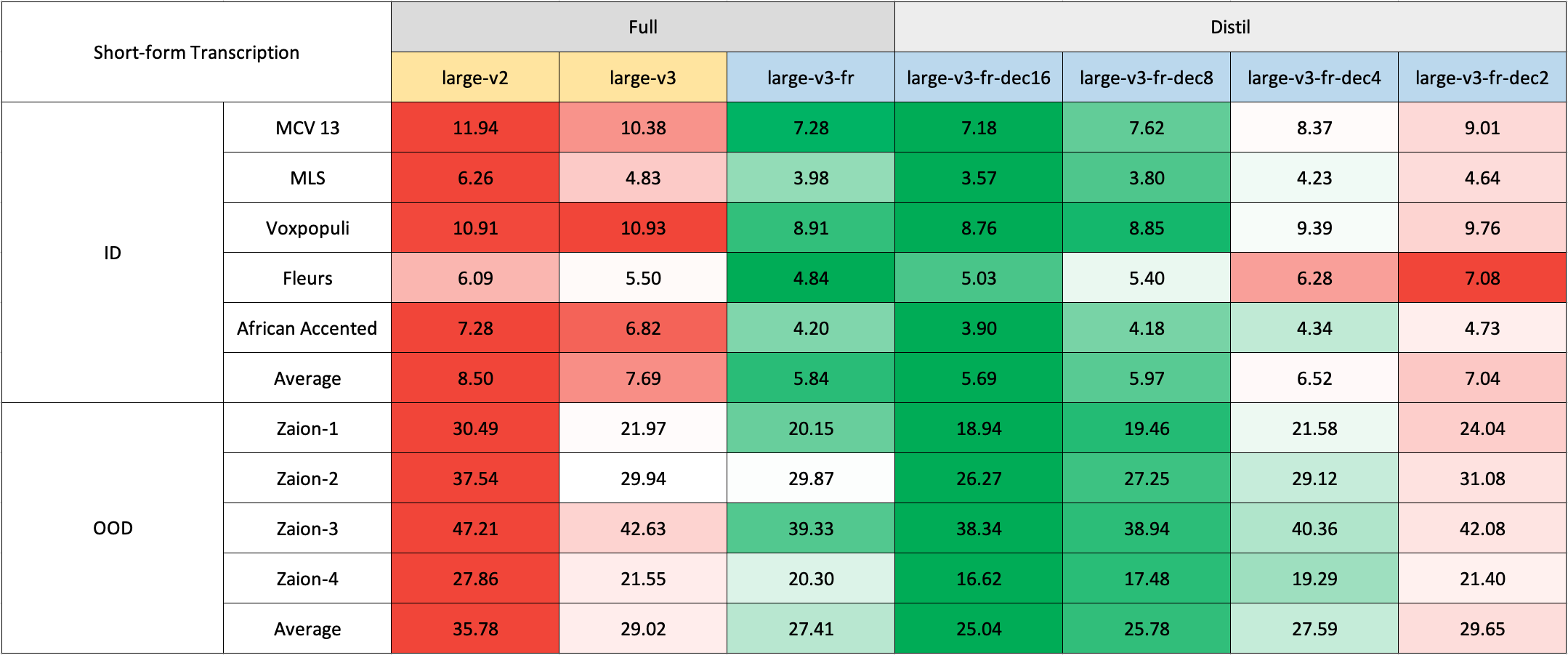
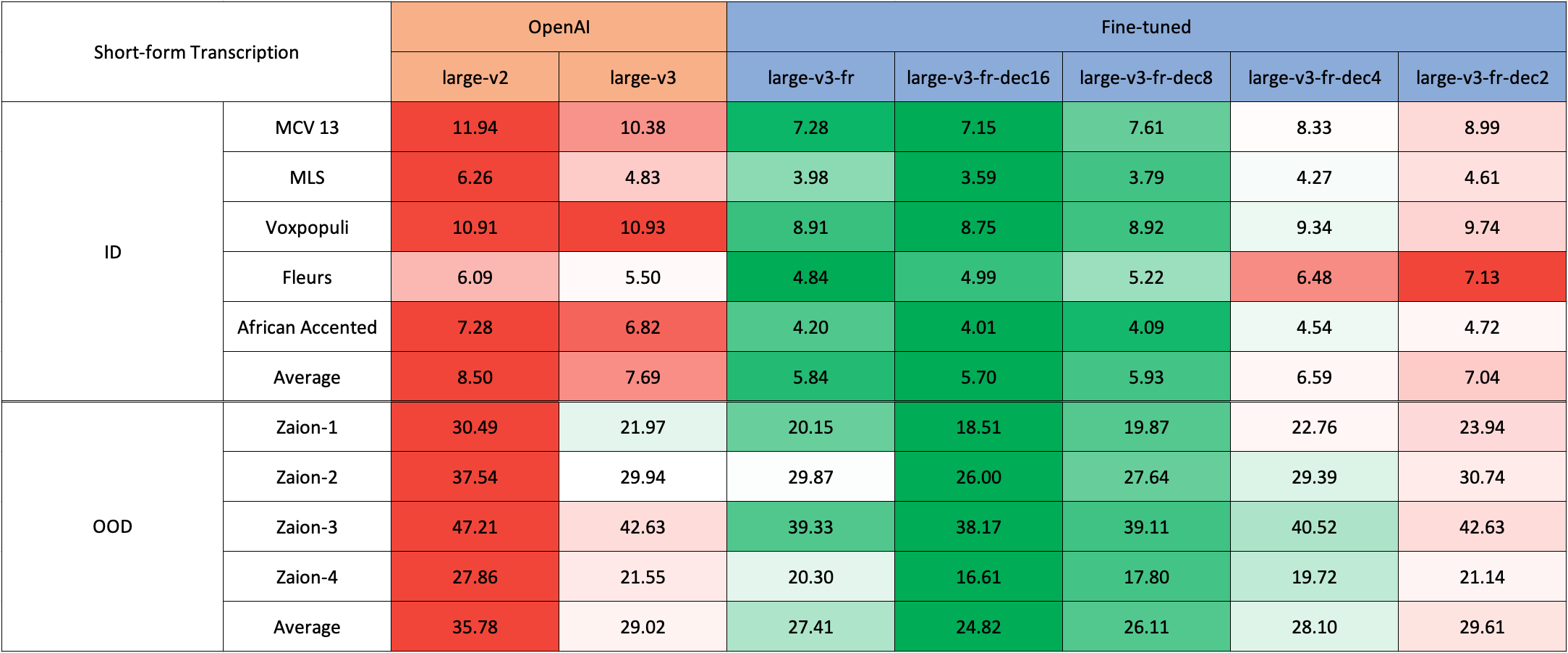
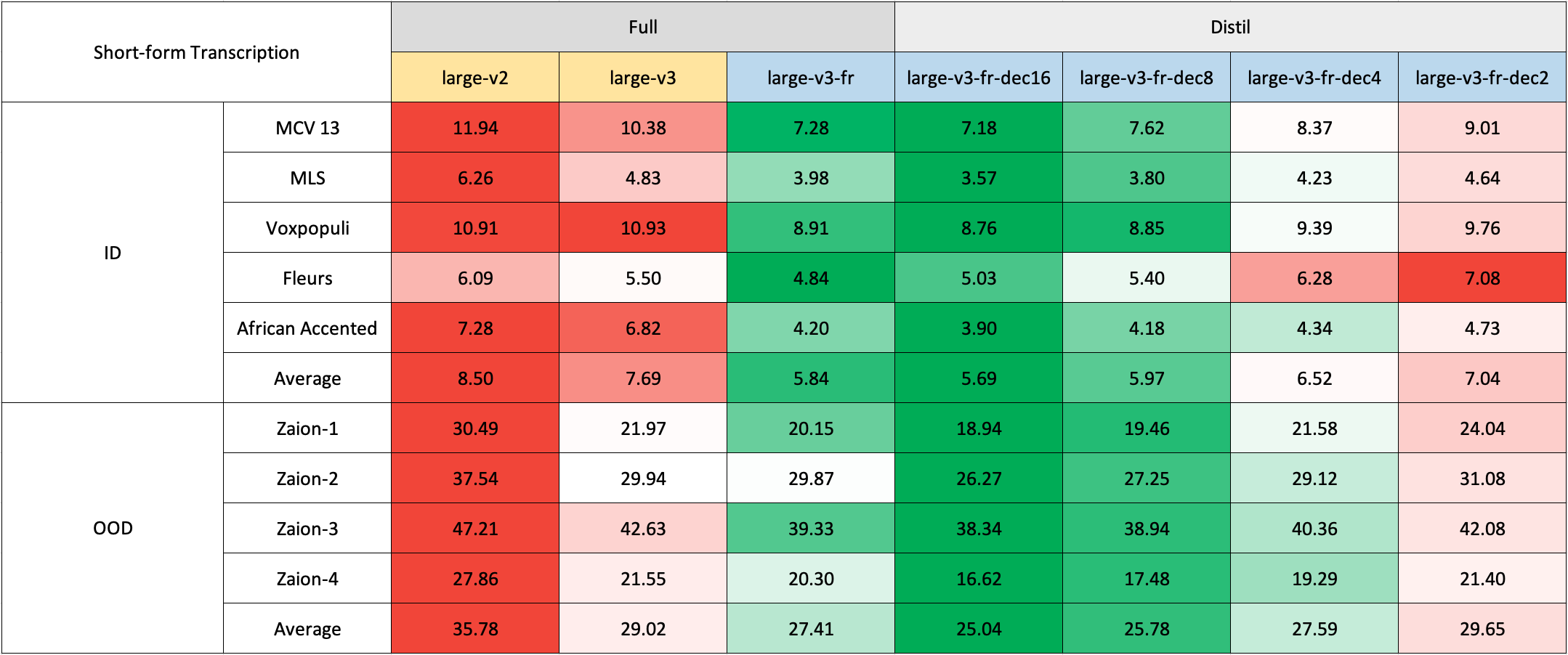
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we evaluated using internal test sets from [Zaion Lab](https://zaion.ai/). These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology. If you come across any public datasets suitable for our purposes, please let us know.
|
| 123 |
-
|
| 124 |
### Short-Form Transcription
|
| 125 |
|
| 126 |
|
| 127 |
|
|
|
|
|
|
|
| 128 |
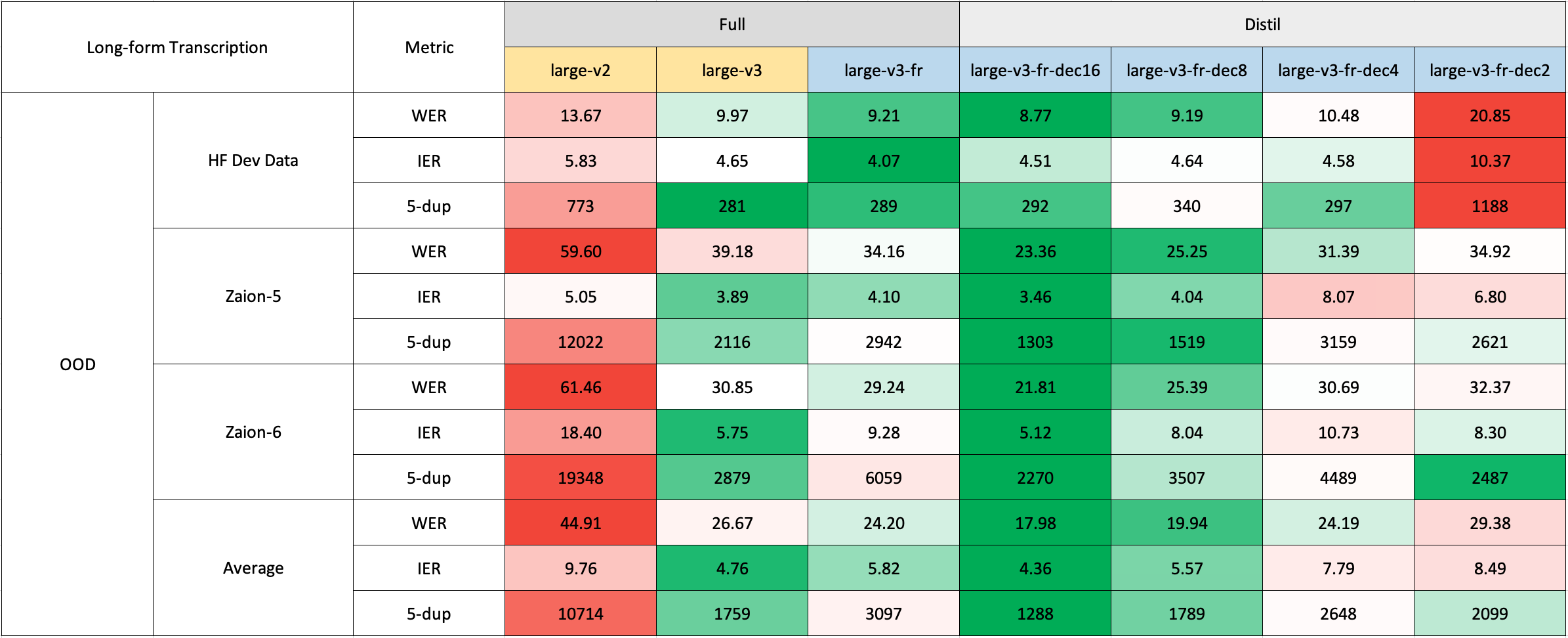
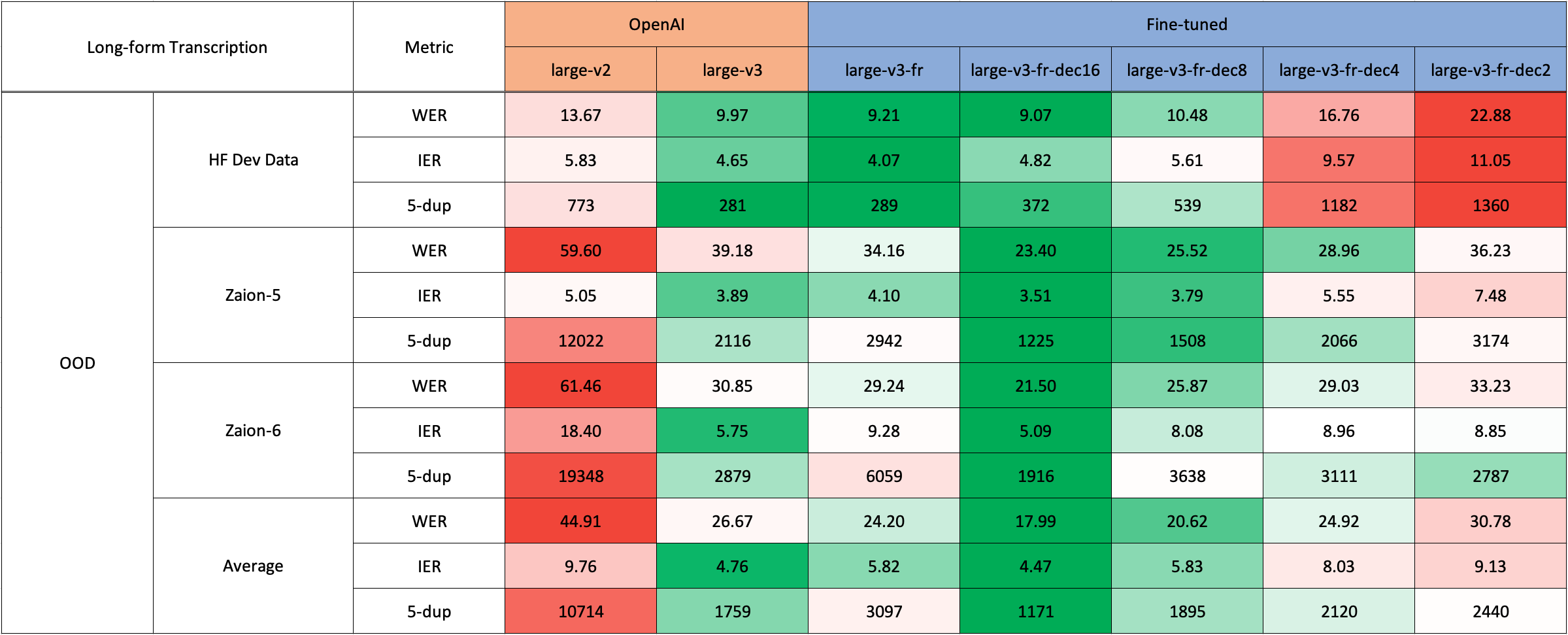
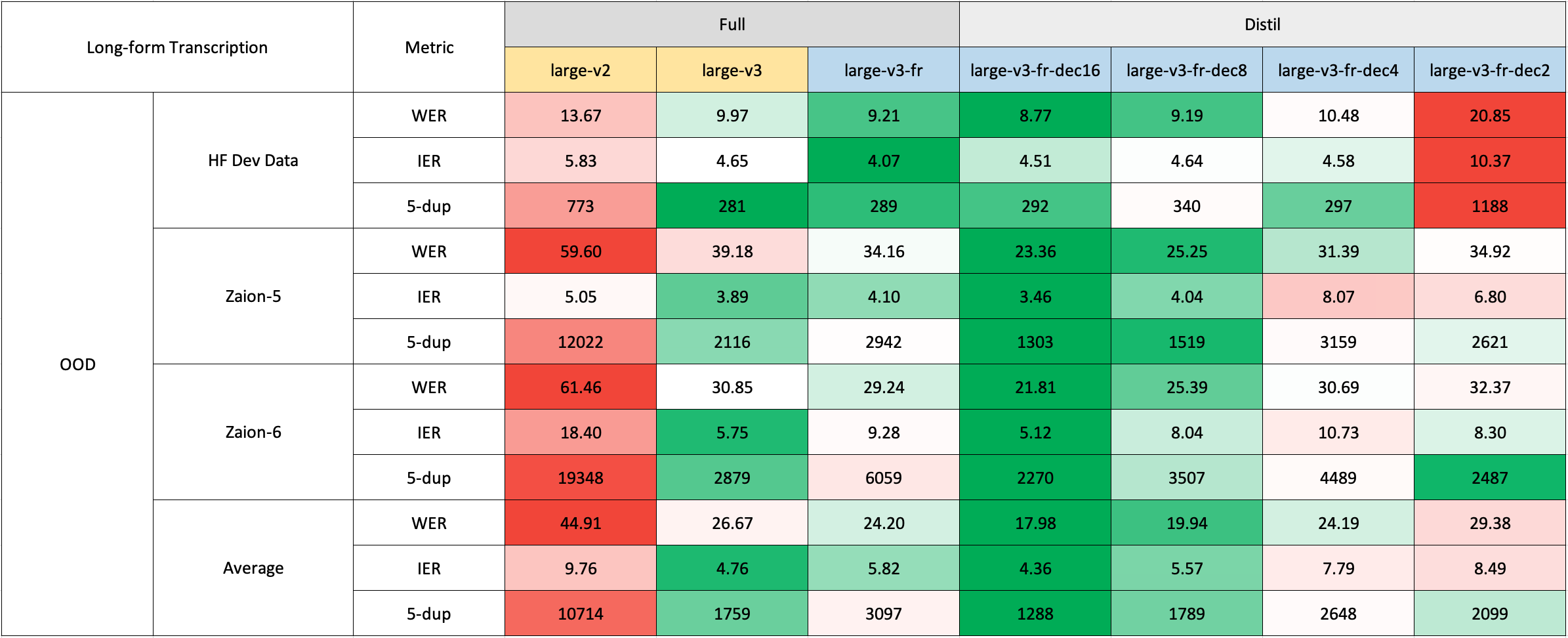
### Long-Form Transcription
|
| 129 |
|
| 130 |
|
|
@@ -137,7 +137,7 @@ The long-form transcription was run using the 🤗 Hugging Face pipeline for qui
|
|
| 137 |
|
| 138 |
The model can easily used with the 🤗 Hugging Face [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) class for audio transcription.
|
| 139 |
|
| 140 |
-
For long-form transcription (> 30 seconds), you can activate the process by passing the `chunk_length_s` argument. This approach segments the audio into smaller segments, processes them in parallel, and then joins them at the strides by
|
| 141 |
|
| 142 |
```python
|
| 143 |
import torch
|
|
@@ -201,8 +201,8 @@ model = AutoModelForSpeechSeq2Seq.from_pretrained(
|
|
| 201 |
model.to(device)
|
| 202 |
|
| 203 |
# Example audio
|
| 204 |
-
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test"
|
| 205 |
-
sample =
|
| 206 |
|
| 207 |
# Extract feautres
|
| 208 |
input_features = processor(
|
|
@@ -222,7 +222,11 @@ print(transcription)
|
|
| 222 |
|
| 223 |
### Speculative Decoding
|
| 224 |
|
| 225 |
-
[Speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding) can be
|
|
|
|
|
|
|
|
|
|
|
|
|
| 226 |
|
| 227 |
```python
|
| 228 |
import torch
|
|
@@ -441,9 +445,9 @@ We've collected a composite dataset consisting of over 2,500 hours of French spe
|
|
| 441 |
|
| 442 |
Given that some datasets, like MLS, only offer text without case or punctuation, we employed a customized version of 🤗 [Speechbox](https://github.com/huggingface/speechbox) to restore case and punctuation from a limited set of symbols using the [bofenghuang/whisper-large-v2-cv11-french](bofenghuang/whisper-large-v2-cv11-french) model.
|
| 443 |
|
| 444 |
-
However, even within these datasets, we observed certain quality issues. These ranged from mismatches between audio and transcription in terms of language or content, poorly segmented utterances, to missing words in scripted speech, etc. We
|
| 445 |
|
| 446 |
-
For training, we employed the script available in the 🤗 Transformers repository. The model training took place on the [Jean-Zay supercomputer](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html) at GENCI, and we extend our gratitude to the IDRIS team for their responsive support throughout the project.
|
| 447 |
|
| 448 |
## Acknowledgements
|
| 449 |
|
|
|
|
| 119 |
|
| 120 |
All evaluation results on the public datasets can be found [here](https://drive.google.com/drive/folders/1rFIh6yXRVa9RZ0ieZoKiThFZgQ4STPPI?usp=drive_link).
|
| 121 |
|
|
|
|
|
|
|
| 122 |
### Short-Form Transcription
|
| 123 |
|
| 124 |

|
| 125 |
|
| 126 |
+
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we evaluated using internal test sets from [Zaion Lab](https://zaion.ai/). These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology.
|
| 127 |
+
|
| 128 |
### Long-Form Transcription
|
| 129 |
|
| 130 |

|
|
|
|
| 137 |
|
| 138 |
The model can easily used with the 🤗 Hugging Face [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) class for audio transcription.
|
| 139 |
|
| 140 |
+
For long-form transcription (> 30 seconds), you can activate the process by passing the `chunk_length_s` argument. This approach segments the audio into smaller segments, processes them in parallel, and then joins them at the strides by finding the longest common sequence. While this chunked long-form approach may have a slight compromise in performance compared to OpenAI's sequential algorithm, it provides 9x faster inference speed.
|
| 141 |
|
| 142 |
```python
|
| 143 |
import torch
|
|
|
|
| 201 |
model.to(device)
|
| 202 |
|
| 203 |
# Example audio
|
| 204 |
+
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
|
| 205 |
+
sample = dataset[0]["audio"]
|
| 206 |
|
| 207 |
# Extract feautres
|
| 208 |
input_features = processor(
|
|
|
|
| 222 |
|
| 223 |
### Speculative Decoding
|
| 224 |
|
| 225 |
+
[Speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding) can be achieved using a draft model, essentially a distilled version of Whisper. This approach guarantees identical outputs to using the main Whisper model alone, offers a 2x faster inference speed, and incurs only a slight increase in memory overhead.
|
| 226 |
+
|
| 227 |
+
Since the distilled Whisper has the same encoder as the original, only its decoder need to be loaded, and encoder outputs are shared between the main and draft models during inference.
|
| 228 |
+
|
| 229 |
+
Using speculative decoding with the Hugging Face pipeline is simple - just specify the `assistant_model` within the generation configurations.
|
| 230 |
|
| 231 |
```python
|
| 232 |
import torch
|
|
|
|
| 445 |
|
| 446 |
Given that some datasets, like MLS, only offer text without case or punctuation, we employed a customized version of 🤗 [Speechbox](https://github.com/huggingface/speechbox) to restore case and punctuation from a limited set of symbols using the [bofenghuang/whisper-large-v2-cv11-french](bofenghuang/whisper-large-v2-cv11-french) model.
|
| 447 |
|
| 448 |
+
However, even within these datasets, we observed certain quality issues. These ranged from mismatches between audio and transcription in terms of language or content, poorly segmented utterances, to missing words in scripted speech, etc. We've built a pipeline to filter out many of these problematic utterances, aiming to enhance the dataset's quality. As a result, we excluded more than 10% of the data, and when we retrained the model, we noticed a significant reduction of hallucination.
|
| 449 |
|
| 450 |
+
For training, we employed the [script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py) available in the 🤗 Transformers repository. The model training took place on the [Jean-Zay supercomputer](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html) at GENCI, and we extend our gratitude to the IDRIS team for their responsive support throughout the project.
|
| 451 |
|
| 452 |
## Acknowledgements
|
| 453 |
|
assets/whisper_fr_eval_long_form.png
CHANGED
|
|
assets/whisper_fr_eval_short_form.png
CHANGED
|
|