
Commit
•
f185505
1
Parent(s):
06c2ff2
Initial commit
Browse files- .gitattributes +8 -18
- README.md +74 -0
- alphabet.json +3 -0
- chart_1.svg +0 -0
- comparison.png +0 -0
- config.json +83 -0
- katt.wav +0 -0
- language_model/5gram.bin +3 -0
- language_model/attrs.json +1 -0
- language_model/unigrams.txt +0 -0
- lm.py +29 -0
- preprocessor_config.json +9 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +1 -0
- tokenizer_config.json +9 -0
- vocab.json +1 -0
.gitattributes
CHANGED
|
@@ -1,27 +1,17 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.
|
| 6 |
-
*.
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
*.h5 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
*.model filter=lfs diff=lfs merge=lfs -text
|
| 12 |
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 16 |
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 17 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 18 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 4 |
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.tar.gz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 11 |
*.joblib filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 12 |
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
| 14 |
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 15 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 16 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: sv
|
| 3 |
+
datasets:
|
| 4 |
+
- common_voice
|
| 5 |
+
- NST Swedish ASR Database
|
| 6 |
+
- P4
|
| 7 |
+
metrics:
|
| 8 |
+
- wer
|
| 9 |
+
tags:
|
| 10 |
+
- audio
|
| 11 |
+
- automatic-speech-recognition
|
| 12 |
+
- speech
|
| 13 |
+
license: cc0-1.0
|
| 14 |
+
model-index:
|
| 15 |
+
- name: Wav2vec 2.0 large VoxRex Swedish
|
| 16 |
+
results:
|
| 17 |
+
- task:
|
| 18 |
+
name: Speech Recognition
|
| 19 |
+
type: automatic-speech-recognition
|
| 20 |
+
dataset:
|
| 21 |
+
name: Common Voice
|
| 22 |
+
type: common_voice
|
| 23 |
+
args: sv-SE
|
| 24 |
+
metrics:
|
| 25 |
+
- name: Test WER
|
| 26 |
+
type: wer
|
| 27 |
+
value: 9.914
|
| 28 |
+
---
|
| 29 |
+
# Wav2vec 2.0 large VoxRex Swedish (C)
|
| 30 |
+
|
| 31 |
+
**Disclaimer:** This is a work in progress. See [VoxRex](https://huggingface.co/KBLab/wav2vec2-large-voxrex) for more details.
|
| 32 |
+
|
| 33 |
+
**Update 2022-01-10:** Updated to VoxRex-C version.
|
| 34 |
+
|
| 35 |
+
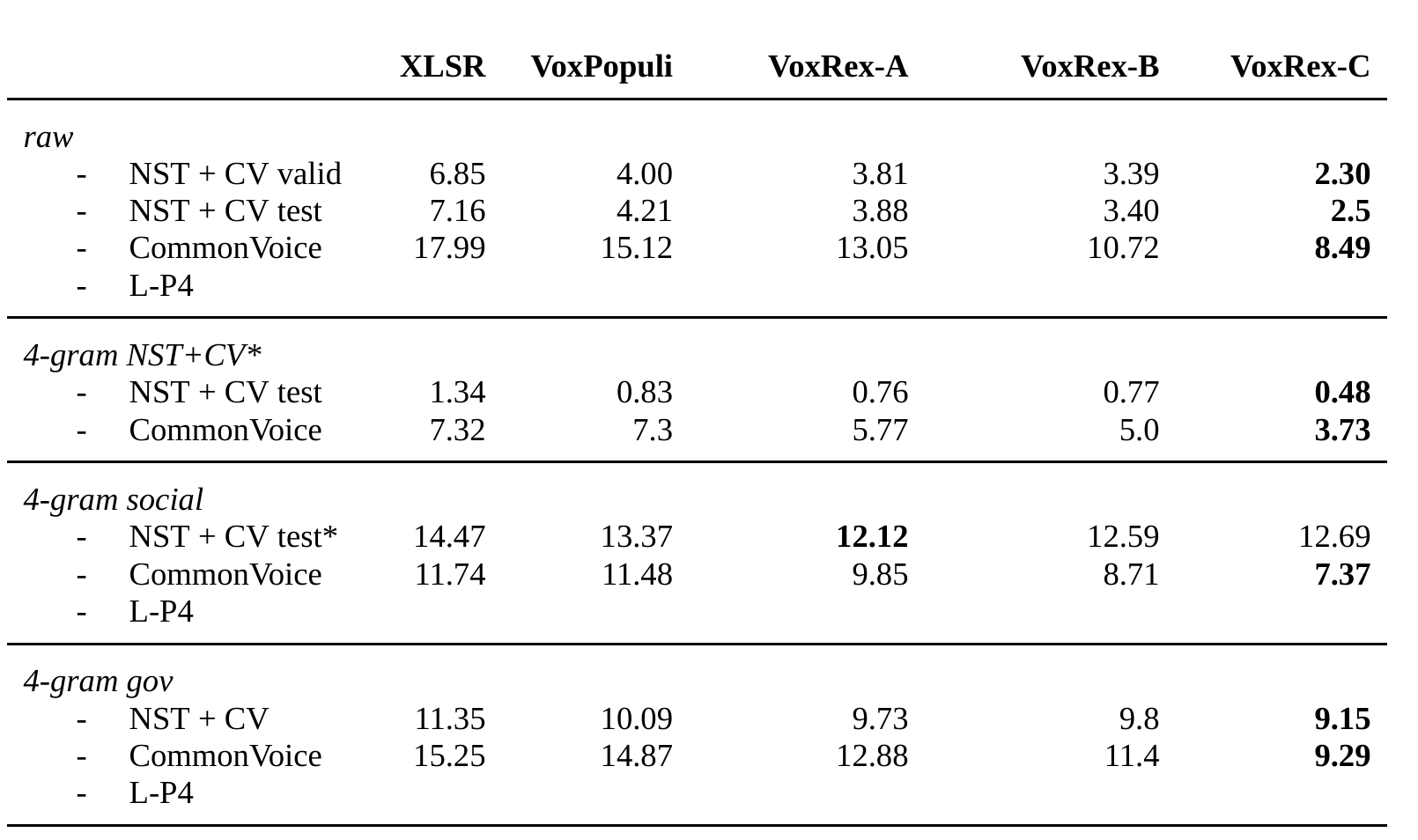
Finetuned version of KBs [VoxRex large](https://huggingface.co/KBLab/wav2vec2-large-voxrex) model using Swedish radio broadcasts, NST and Common Voice data. Evalutation without a language model gives the following: WER for NST + Common Voice test set (2% of total sentences) is **2.5%**. WER for Common Voice test set is **8.49%** directly and **7.37%** with a 4-gram language model.
|
| 36 |
+
|
| 37 |
+
When using this model, make sure that your speech input is sampled at 16kHz.
|
| 38 |
+
|
| 39 |
+
# Performance\*
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
<center><del>*<i>Chart shows performance without the additional 20k steps of Common Voice fine-tuning</i></del></center>
|
| 43 |
+
|
| 44 |
+
## Training
|
| 45 |
+
This model has been fine-tuned for 120000 updates on NST + CommonVoice<del> and then for an additional 20000 updates on CommonVoice only. The additional fine-tuning on CommonVoice hurts performance on the NST+CommonVoice test set somewhat and, unsurprisingly, improves it on the CommonVoice test set. It seems to perform generally better though [citation needed]</del>.
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
+
## Usage
|
| 50 |
+
The model can be used directly (without a language model) as follows:
|
| 51 |
+
```python
|
| 52 |
+
import torch
|
| 53 |
+
import torchaudio
|
| 54 |
+
from datasets import load_dataset
|
| 55 |
+
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
|
| 56 |
+
test_dataset = load_dataset("common_voice", "sv-SE", split="test[:2%]").
|
| 57 |
+
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
|
| 58 |
+
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
|
| 59 |
+
resampler = torchaudio.transforms.Resample(48_000, 16_000)
|
| 60 |
+
# Preprocessing the datasets.
|
| 61 |
+
# We need to read the aduio files as arrays
|
| 62 |
+
def speech_file_to_array_fn(batch):
|
| 63 |
+
speech_array, sampling_rate = torchaudio.load(batch["path"])
|
| 64 |
+
batch["speech"] = resampler(speech_array).squeeze().numpy()
|
| 65 |
+
return batch
|
| 66 |
+
test_dataset = test_dataset.map(speech_file_to_array_fn)
|
| 67 |
+
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
|
| 68 |
+
with torch.no_grad():
|
| 69 |
+
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
|
| 70 |
+
predicted_ids = torch.argmax(logits, dim=-1)
|
| 71 |
+
print("Prediction:", processor.batch_decode(predicted_ids))
|
| 72 |
+
print("Reference:", test_dataset["sentence"][:2])
|
| 73 |
+
```
|
| 74 |
+
|
alphabet.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"labels": ["'", " ", "1", "A", "0", "Z", "S", "E", "K", "3", "Ö", "V", "H", "X", "Å", "M", "C", "8", "R", "J", "I", "5", "6", "U", "P", "D", "Q", "N", "4", "2", "B", "W", "7", "", "G", "F", "T", "Ä", "L", "O", "Y", "É", "9", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "\u00e4", "\u00e5", "\u00e9", "\u00f4", "\u00f6", "\u00fc", "\u2047", "", "<s>", "</s>"], "is_bpe": false}
|
| 2 |
+
|
| 3 |
+
|
chart_1.svg
ADDED

|
comparison.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation_dropout": 0.05,
|
| 3 |
+
"apply_spec_augment": true,
|
| 4 |
+
"architectures": [
|
| 5 |
+
"Wav2Vec2ForCTC"
|
| 6 |
+
],
|
| 7 |
+
"attention_dropout": 0.1,
|
| 8 |
+
"bos_token_id": 1,
|
| 9 |
+
"codevector_dim": 256,
|
| 10 |
+
"contrastive_logits_temperature": 0.1,
|
| 11 |
+
"conv_bias": true,
|
| 12 |
+
"conv_dim": [
|
| 13 |
+
512,
|
| 14 |
+
512,
|
| 15 |
+
512,
|
| 16 |
+
512,
|
| 17 |
+
512,
|
| 18 |
+
512,
|
| 19 |
+
512
|
| 20 |
+
],
|
| 21 |
+
"conv_kernel": [
|
| 22 |
+
10,
|
| 23 |
+
3,
|
| 24 |
+
3,
|
| 25 |
+
3,
|
| 26 |
+
3,
|
| 27 |
+
2,
|
| 28 |
+
2
|
| 29 |
+
],
|
| 30 |
+
"conv_stride": [
|
| 31 |
+
5,
|
| 32 |
+
2,
|
| 33 |
+
2,
|
| 34 |
+
2,
|
| 35 |
+
2,
|
| 36 |
+
2,
|
| 37 |
+
2
|
| 38 |
+
],
|
| 39 |
+
"ctc_loss_reduction": "mean",
|
| 40 |
+
"ctc_zero_infinity": true,
|
| 41 |
+
"diversity_loss_weight": 0.1,
|
| 42 |
+
"do_stable_layer_norm": true,
|
| 43 |
+
"eos_token_id": 2,
|
| 44 |
+
"feat_extract_activation": "gelu",
|
| 45 |
+
"feat_extract_dropout": 0.0,
|
| 46 |
+
"feat_extract_norm": "layer",
|
| 47 |
+
"feat_proj_dropout": 0.05,
|
| 48 |
+
"feat_quantizer_dropout": 0.0,
|
| 49 |
+
"final_dropout": 0.0,
|
| 50 |
+
"gradient_checkpointing": true,
|
| 51 |
+
"hidden_act": "gelu",
|
| 52 |
+
"hidden_dropout": 0.05,
|
| 53 |
+
"hidden_size": 1024,
|
| 54 |
+
"initializer_range": 0.02,
|
| 55 |
+
"intermediate_size": 4096,
|
| 56 |
+
"layer_norm_eps": 1e-05,
|
| 57 |
+
"layerdrop": 0.05,
|
| 58 |
+
"mask_channel_length": 10,
|
| 59 |
+
"mask_channel_min_space": 1,
|
| 60 |
+
"mask_channel_other": 0.0,
|
| 61 |
+
"mask_channel_prob": 0.0,
|
| 62 |
+
"mask_channel_selection": "static",
|
| 63 |
+
"mask_feature_length": 10,
|
| 64 |
+
"mask_feature_prob": 0.0,
|
| 65 |
+
"mask_time_length": 10,
|
| 66 |
+
"mask_time_min_space": 1,
|
| 67 |
+
"mask_time_other": 0.0,
|
| 68 |
+
"mask_time_prob": 0.05,
|
| 69 |
+
"mask_time_selection": "static",
|
| 70 |
+
"model_type": "wav2vec2",
|
| 71 |
+
"num_attention_heads": 16,
|
| 72 |
+
"num_codevector_groups": 2,
|
| 73 |
+
"num_codevectors_per_group": 320,
|
| 74 |
+
"num_conv_pos_embedding_groups": 16,
|
| 75 |
+
"num_conv_pos_embeddings": 128,
|
| 76 |
+
"num_feat_extract_layers": 7,
|
| 77 |
+
"num_hidden_layers": 24,
|
| 78 |
+
"num_negatives": 100,
|
| 79 |
+
"pad_token_id": 0,
|
| 80 |
+
"proj_codevector_dim": 256,
|
| 81 |
+
"transformers_version": "4.8.2",
|
| 82 |
+
"vocab_size": 46
|
| 83 |
+
}
|
katt.wav
ADDED
|
Binary file (399 kB). View file
|
|
|
language_model/5gram.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c803936922612f71cf0abdb37763c18d24624e36bfa4abac20187cc17b88541d
|
| 3 |
+
size 1981380707
|
language_model/attrs.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"alpha": 0.5, "beta": 1.5, "unk_score_offset": -10.0, "score_boundary": true}
|
language_model/unigrams.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
lm.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import Wav2Vec2ProcessorWithLM
|
| 2 |
+
import torchaudio
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from datasets import load_dataset
|
| 6 |
+
from transformers import AutoModelForCTC, AutoProcessor
|
| 7 |
+
import torchaudio.functional as F
|
| 8 |
+
|
| 9 |
+
# processor = Wav2Vec2ProcessorWithLM.from_pretrained(".")
|
| 10 |
+
|
| 11 |
+
model_id = "."
|
| 12 |
+
|
| 13 |
+
sample_iter = iter(load_dataset("mozilla-foundation/common_voice_7_0", "sv-SE", split="test", streaming=True, use_auth_token=True))
|
| 14 |
+
|
| 15 |
+
sample = next(sample_iter)
|
| 16 |
+
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
|
| 17 |
+
|
| 18 |
+
model = AutoModelForCTC.from_pretrained(model_id)
|
| 19 |
+
processor = AutoProcessor.from_pretrained(model_id)
|
| 20 |
+
|
| 21 |
+
input_values = processor(resampled_audio, return_tensors="pt").input_values
|
| 22 |
+
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
logits = model(input_values).logits
|
| 25 |
+
import pdb
|
| 26 |
+
pdb.set_trace()
|
| 27 |
+
|
| 28 |
+
transcription = processor.batch_decode(logits.numpy()).text
|
| 29 |
+
print(transcription)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_normalize": true,
|
| 3 |
+
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
|
| 4 |
+
"feature_size": 1,
|
| 5 |
+
"padding_side": "right",
|
| 6 |
+
"padding_value": 0,
|
| 7 |
+
"return_attention_mask": true,
|
| 8 |
+
"sampling_rate": 16000
|
| 9 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7138b3f9c5700388ddbd8b08a194290529778aba95327e7445a621cbe24ef508
|
| 3 |
+
size 1262106353
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "eos_token": "</s>", "unk_token": "<unk>", "pad_token": "<pad>"}
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token" : "<s>",
|
| 3 |
+
"do_lower_case" : true,
|
| 4 |
+
"eos_token" : "</s>",
|
| 5 |
+
"pad_token" : "<pad>",
|
| 6 |
+
"tokenizer_class" : "Wav2Vec2CTCTokenizer",
|
| 7 |
+
"unk_token" : "<unk>",
|
| 8 |
+
"word_delimiter_token" : "|"
|
| 9 |
+
}
|
vocab.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"<pad>": 0, "<s>": 1, "</s>": 2, "<unk>": 3, "|": 4, "T": 5, "E": 6, "A": 7, "N": 8, "R": 9, "S": 10, "I": 11, "L": 12, "D": 13, "O": 14, "M": 15, "K": 16, "G": 17, "U": 18, "V": 19, "F": 20, "H": 21, "Ä": 22, "Å": 23, "P": 24, "Ö": 25, "B": 26, "J": 27, "C": 28, "Y": 29, "X": 30, "W": 31, "Z": 32, "É": 33, "Q": 34, "8": 35, "2": 36, "5": 37, "9": 38, "1": 39, "6": 40, "7": 41, "3": 42, "4": 43, "0": 44, "'": 45}
|