
Update README.md
Browse files
README.md
CHANGED
|
@@ -29,11 +29,25 @@ inference:
|
|
| 29 |
num_beams: 3
|
| 30 |
do_sample: True
|
| 31 |
---
|
|
|
|
| 32 |
# 💡GENIUS – generating text using sketches!
|
|
|
|
|
|
|
|
|
|
| 33 |
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)**
|
| 34 |
-
- **GitHub: [GENIUS project, GENIUS pre-training, GeniusAug for data augmentation](https://github.com/beyondguo/genius)**
|
| 35 |
|
| 36 |
-
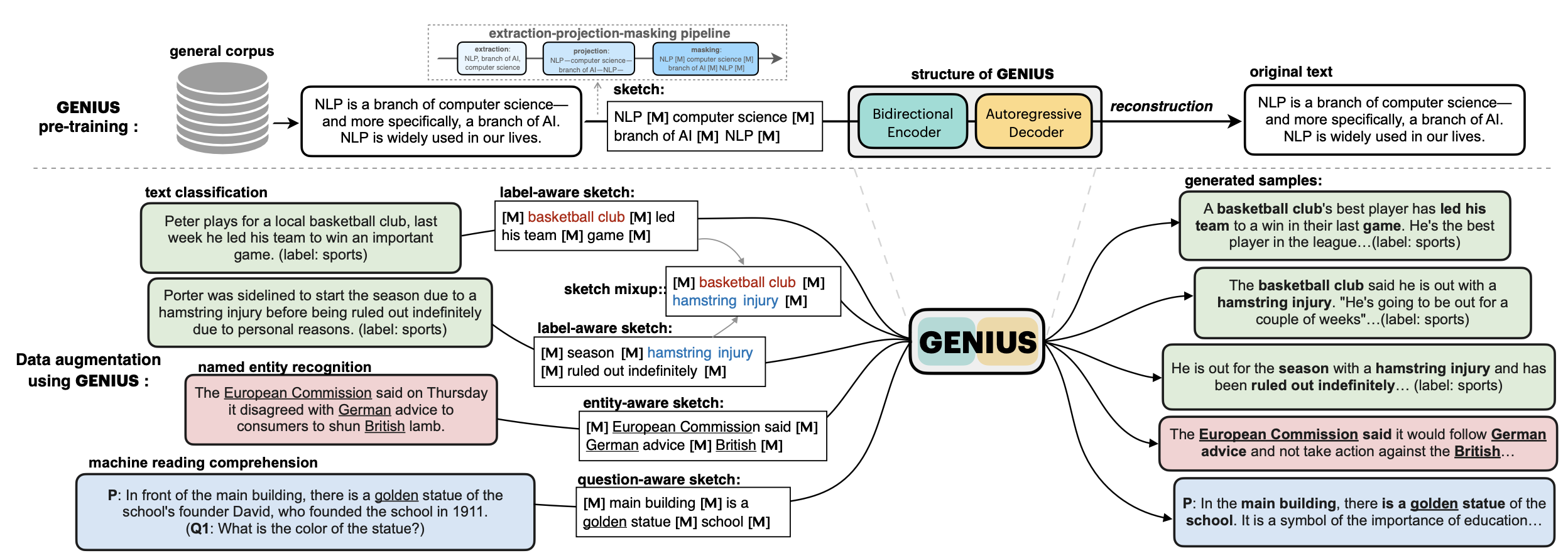
💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
|
| 39 |
**GENIUS** can also be used as a general textual **data augmentation tool** for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA).
|
|
@@ -42,6 +56,7 @@ inference:
|
|
| 42 |
|
| 43 |
|
| 44 |
|
|
|
|
| 45 |
- Models hosted in 🤗 Huggingface:
|
| 46 |
|
| 47 |
**Model variations:**
|
|
@@ -54,7 +69,14 @@ inference:
|
|
| 54 |
| [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences |
|
| 55 |
| [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
|
| 56 |
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |
## Usage
|
| 60 |
|
|
@@ -69,7 +91,6 @@ The sketch which can be composed of:
|
|
| 69 |
- sentences, like `I really like machine learning__I work at Google since last year__`
|
| 70 |
- or a mixup!
|
| 71 |
|
| 72 |
-
(the `__` is the mask token. Use `<mask>` for English, and `[MASK]` for Chinese)
|
| 73 |
|
| 74 |
### How to use the model
|
| 75 |
#### 1. If you already have a sketch in mind, and want to get a paragraph based on it...
|
|
@@ -95,3 +116,43 @@ TODO: we are also building a python package for more convenient use of GENIUS, w
|
|
| 95 |
#### 2. If you have an NLP dataset (e.g. classification) and want to do data augmentation to enlarge your dataset...
|
| 96 |
|
| 97 |
Please check [genius/augmentation_clf](https://github.com/beyondguo/genius/tree/master/augmentation_clf) and [genius/augmentation_ner_qa](https://github.com/beyondguo/genius/tree/master/augmentation_ner_qa), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
num_beams: 3
|
| 30 |
do_sample: True
|
| 31 |
---
|
| 32 |
+
|
| 33 |
# 💡GENIUS – generating text using sketches!
|
| 34 |
+
|
| 35 |
+
**基于草稿的文本生成模型**
|
| 36 |
+
|
| 37 |
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)**
|
|
|
|
| 38 |
|
| 39 |
+
💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches.
|
| 40 |
+
|
| 41 |
+
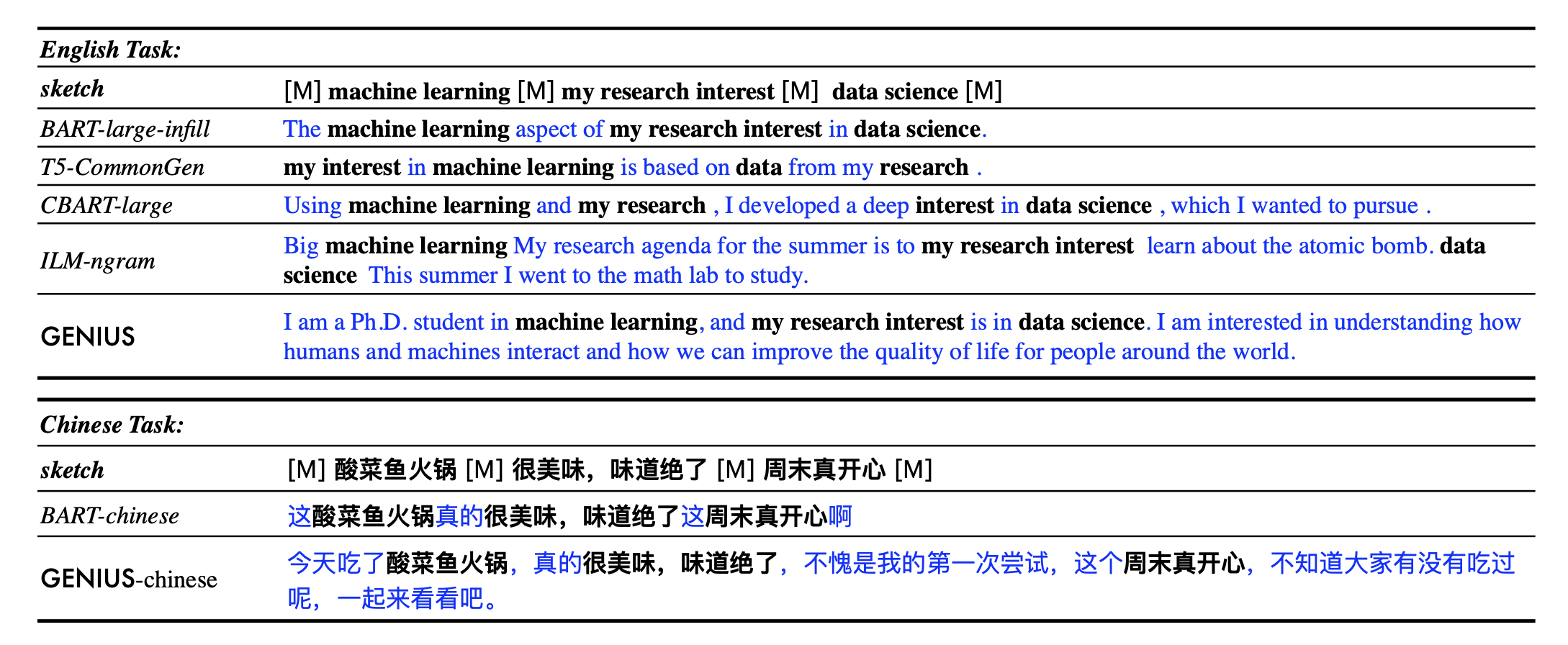
**Example 1:**
|
| 42 |
+
|
| 43 |
+
- sketch: `__ machine learning __ my research interest __ data science __`
|
| 44 |
+
- **GENIUS**: `I am a Ph.D. student in machine learning, and my research interest is in data science. I am interested in understanding how humans and machines interact and how we can improve the quality of life for people around the world.`
|
| 45 |
+
|
| 46 |
+
**Example 2:**
|
| 47 |
+
|
| 48 |
+
- sketch: `自然语言处理__谷歌__通用人工智能__`
|
| 49 |
+
- **GENIUS**: `自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。 `
|
| 50 |
+
|
| 51 |
|
| 52 |
|
| 53 |
**GENIUS** can also be used as a general textual **data augmentation tool** for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA).
|
|
|
|
| 56 |

|
| 57 |
|
| 58 |
|
| 59 |
+
|
| 60 |
- Models hosted in 🤗 Huggingface:
|
| 61 |
|
| 62 |
**Model variations:**
|
|
|
|
| 69 |
| [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences |
|
| 70 |
| [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
|
| 71 |
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
More Examples:
|
| 78 |
+
|
| 79 |
+
|
| 80 |
|
| 81 |
## Usage
|
| 82 |
|
|
|
|
| 91 |
- sentences, like `I really like machine learning__I work at Google since last year__`
|
| 92 |
- or a mixup!
|
| 93 |
|
|
|
|
| 94 |
|
| 95 |
### How to use the model
|
| 96 |
#### 1. If you already have a sketch in mind, and want to get a paragraph based on it...
|
|
|
|
| 116 |
#### 2. If you have an NLP dataset (e.g. classification) and want to do data augmentation to enlarge your dataset...
|
| 117 |
|
| 118 |
Please check [genius/augmentation_clf](https://github.com/beyondguo/genius/tree/master/augmentation_clf) and [genius/augmentation_ner_qa](https://github.com/beyondguo/genius/tree/master/augmentation_ner_qa), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## Augmentation Experiments:
|
| 123 |
+
Data augmentation is an important application for natural language generation (NLG) models, which is also a valuable evaluation of whether the generated text can be used in real applications.
|
| 124 |
+
- Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes.
|
| 125 |
+
- Text Classification Datasets: [HuffPost](https://huggingface.co/datasets/khalidalt/HuffPost), [BBC](https://huggingface.co/datasets/SetFit/bbc-news), [SST2](https://huggingface.co/datasets/glue), [IMDB](https://huggingface.co/datasets/imdb), [Yahoo](https://huggingface.co/datasets/yahoo_answers_topics), [20NG](https://huggingface.co/datasets/newsgroup).
|
| 126 |
+
- Base classifier: [DistilBERT](https://huggingface.co/distilbert-base-cased)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
In-distribution (ID) evaluations:
|
| 130 |
+
| Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. |
|
| 131 |
+
|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
|
| 132 |
+
| none | 79.17 | **96.16** | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 |
|
| 133 |
+
| EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 |
|
| 134 |
+
| BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 |
|
| 135 |
+
| MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 |
|
| 136 |
+
| C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 |
|
| 137 |
+
| LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 |
|
| 138 |
+
| STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 |
|
| 139 |
+
| **GeniusAug** | 81.43 | 95.74 | 49.60 | 50.38 | **80.16** | 78.82 | 72.68 |
|
| 140 |
+
| **GeniusAug-f** | **81.82** | 95.99 | **50.42** | **50.81** | 79.40 | **80.57** | **73.17** |
|
| 141 |
+
|
| 142 |
+
Out-of-distribution (OOD) evaluations:
|
| 143 |
+
| | Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. |
|
| 144 |
+
|------------|:----------:|:----------:|:----------:|:----------:|:----------:|
|
| 145 |
+
| none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 |
|
| 146 |
+
| EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 |
|
| 147 |
+
| BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 |
|
| 148 |
+
| MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 |
|
| 149 |
+
| C-MLM | 64.94 | **67.80** | 74.98 | 71.78 | 69.87 |
|
| 150 |
+
| LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 |
|
| 151 |
+
| STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 |
|
| 152 |
+
| **GeniusAug** | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 |
|
| 153 |
+
| **GeniusAug-f** | **76.18** | 66.89 | **77.45** | **80.36** | **75.22** |
|
| 154 |
+
|
| 155 |
+
### BibTeX entry and citation info
|
| 156 |
+
TBD
|
| 157 |
+
|
| 158 |
+
|