
Merge branch 'main' of https://huggingface.co/bertin-project/bertin-roberta-base-spanish into main
Browse files- README.md +221 -105
- evaluation/paws.yaml +55 -0
- evaluation/run_glue.py +576 -0
- evaluation/run_ner.ipynb +0 -0
- evaluation/run_ner.py +562 -0
- evaluation/xnli.yaml +55 -0
- images/bertin-tilt.png +0 -0
- images/bertin.png +0 -0
- images/datasets-perp-20-120.png +0 -0
- images/datasets-wsize.png +0 -0
- mc4/mc4.py +3 -3
- run_mlm_flax_stream.py +55 -3
README.md
CHANGED
|
@@ -12,14 +12,28 @@ widget:
|
|
| 12 |
- Version 1 (beta): July 15th, 2021
|
| 13 |
- Version 1: July 19th, 2021
|
| 14 |
|
|
|
|
| 15 |
# BERTIN
|
| 16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
BERTIN is a series of BERT-based models for Spanish. The current model hub points to the best of all RoBERTa-base models trained from scratch on the Spanish portion of mC4 using [Flax](https://github.com/google/flax). All code and scripts are included.
|
| 18 |
|
| 19 |
This is part of the
|
| 20 |
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google Cloud.
|
| 21 |
|
| 22 |
-
The aim of this project was to pre-train a RoBERTa-base model from scratch
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
|
| 24 |
## Spanish mC4
|
| 25 |
|
|
@@ -50,7 +64,9 @@ In order to efficiently build this subset of data, we decided to leverage a tech
|
|
| 50 |
<caption>Figure 1. Perplexity distributions by percentage CCNet corpus.</caption>
|
| 51 |
</figure>
|
| 52 |
|
| 53 |
-
In this work, we tested the hypothesis that perplexity sampling might help
|
|
|
|
|
|
|
| 54 |
|
| 55 |
## Methodology
|
| 56 |
|
|
@@ -60,13 +76,13 @@ In order to test our hypothesis, we first calculated the perplexity of each docu
|
|
| 60 |
|
| 61 |

|
| 62 |
|
| 63 |
-
<caption>Figure 2. Perplexity distributions and quartiles (red lines) of
|
| 64 |
</figure>
|
| 65 |
|
| 66 |
With the extracted perplexity percentiles, we created two functions to oversample the central quartiles with the idea of biasing against samples that are either too small (short, repetitive texts) or too long (potentially poor quality) (see Figure 3).
|
| 67 |
|
| 68 |
The first function is a `Stepwise` that simply oversamples the central quartiles using quartile boundaries and a factor for the desired sampling frequency for each quartile, obviously given larger frequencies for middle quartiles (oversampling Q2, Q3, subsampling Q1, Q4).
|
| 69 |
-
The second function
|
| 70 |
|
| 71 |
We adjusted the `factor` parameter of the `Stepwise` function, and the `factor` and `width` parameter of the `Gaussian` function to roughly be able to sample 50M samples from the 416M in `mc4-es` (see Figure 4). For comparison, we also sampled randomly `mC4-es` up to 50M samples as well. In terms of sizes, we went down from 1TB of data to ~200GB.
|
| 72 |
|
|
@@ -75,38 +91,38 @@ We adjusted the `factor` parameter of the `Stepwise` function, and the `factor`
|
|
| 75 |
|
| 76 |

|
| 77 |
|
| 78 |
-
<caption>Figure 3. Expected perplexity distributions of the sample
|
| 79 |
</figure>
|
| 80 |
|
| 81 |
<figure>
|
| 82 |
|
| 83 |

|
| 84 |
|
| 85 |
-
<caption>Figure 4. Expected perplexity distributions of the sample
|
| 86 |
</figure>
|
| 87 |
|
| 88 |
-
Figure 5 shows the perplexity distributions of the 50M subsets for each of the
|
| 89 |
|
| 90 |
```python
|
| 91 |
from datasets import load_dataset
|
| 92 |
|
| 93 |
-
for
|
| 94 |
mc4es = load_dataset(
|
| 95 |
"bertin-project/mc4-es-sampled",
|
| 96 |
-
|
| 97 |
-
split=
|
| 98 |
streaming=True
|
| 99 |
).shuffle(buffer_size=1000)
|
| 100 |
for sample in mc4es:
|
| 101 |
-
print(
|
| 102 |
-
break
|
| 103 |
```
|
| 104 |
|
| 105 |
<figure>
|
| 106 |
|
| 107 |

|
| 108 |
|
| 109 |
-
<caption>Figure 5. Experimental perplexity distributions of the sampled
|
| 110 |
</figure>
|
| 111 |
|
| 112 |
`Random` sampling displayed the same perplexity distribution of the underlying true distribution, as can be seen in Figure 6.
|
|
@@ -115,10 +131,13 @@ for split in ("random", "stepwise", "gaussian"):
|
|
| 115 |
|
| 116 |

|
| 117 |
|
| 118 |
-
<caption>Figure 6. Experimental perplexity distribution of the sampled
|
| 119 |
</figure>
|
| 120 |
|
| 121 |
-
|
|
|
|
|
|
|
|
|
|
| 122 |
|
| 123 |
Then, we continued training the most promising model for a few steps (~25k) more on sequence length 512. We tried two strategies for this, since it is not easy to find clear details about this change in the literature. It turns out this decision had a big impact in the final performance.
|
| 124 |
|
|
@@ -128,10 +147,12 @@ For `Random` sampling we trained with seq len 512 during the last 20 steps of th
|
|
| 128 |
|
| 129 |

|
| 130 |
|
| 131 |
-
<caption>Figure 7. Training profile for Random sampling. Note the drop in performance after the change from 128 to 512 sequence
|
| 132 |
</figure>
|
| 133 |
|
| 134 |
-
For `Gaussian` sampling we started a new optimizer after 230 steps with 128
|
|
|
|
|
|
|
| 135 |
|
| 136 |
## Results
|
| 137 |
|
|
@@ -141,9 +162,11 @@ Our final models were trained on a different number of steps and sequence length
|
|
| 141 |
|
| 142 |
<figure>
|
| 143 |
|
|
|
|
|
|
|
| 144 |
| Dataset | Metric | RoBERTa-b | RoBERTa-l | BETO | mBERT | BERTIN |
|
| 145 |
|-------------|----------|-----------|-----------|--------|--------|--------|
|
| 146 |
-
| UD-POS | F1 | 0.9907 | 0.9901 | 0.9900 | 0.9886 | 0.9904 |
|
| 147 |
| Conll-NER | F1 | 0.8851 | 0.8772 | 0.8759 | 0.8691 | 0.8627 |
|
| 148 |
| Capitel-POS | F1 | 0.9846 | 0.9851 | 0.9836 | 0.9839 | 0.9826 |
|
| 149 |
| Capitel-NER | F1 | 0.8959 | 0.8998 | 0.8771 | 0.8810 | 0.8741 |
|
|
@@ -152,15 +175,15 @@ Our final models were trained on a different number of steps and sequence length
|
|
| 152 |
| PAWS-X | F1 | 0.9035 | 0.9000 | 0.8915 | 0.9020 | 0.8820 |
|
| 153 |
| XNLI | Accuracy | 0.8016 | WiP | 0.8130 | 0.7876 | WiP |
|
| 154 |
|
| 155 |
-
|
| 156 |
-
<caption>Table 1. Evaluation made by the Barcelona Supercomputing Center of their models and BERTIN (beta, seq len 128).</caption>
|
| 157 |
</figure>
|
| 158 |
|
| 159 |
-
All of our models attained good accuracy values
|
| 160 |
|
| 161 |
<figure>
|
| 162 |
|
| 163 |
-
|
|
|
|
|
|
|
| 164 |
|----------------------------------------------------|----------|
|
| 165 |
| bertin-project/bertin-roberta-base-spanish | 0.6547 |
|
| 166 |
| bertin-project/bertin-base-random | 0.6520 |
|
|
@@ -169,108 +192,197 @@ All of our models attained good accuracy values, in the range of 0.65, as can be
|
|
| 169 |
| bertin-project/bertin-base-random-exp-512seqlen | 0.5907 |
|
| 170 |
| bertin-project/bertin-base-gaussian-exp-512seqlen | **0.6873** |
|
| 171 |
|
| 172 |
-
|
| 173 |
-
<caption>Table 2. Accuracy for the different language models.</caption>
|
| 174 |
</figure>
|
| 175 |
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
**SQUAD-es**
|
| 179 |
-
Using sequence length 128 we have achieved exact match 50.96 and F1 68.74.
|
| 180 |
|
| 181 |
-
|
| 182 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 183 |
|
| 184 |
<figure>
|
| 185 |
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
|
| 191 |
-
|
| 192 |
-
|
|
| 193 |
-
|
|
| 194 |
-
|
|
| 195 |
-
|
|
| 196 |
-
|
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
|
|
|
|
|
|
|
| 200 |
</figure>
|
| 201 |
|
|
|
|
| 202 |
|
| 203 |
-
|
| 204 |
-
All models trained with max length 512 and batch size 8, using the CoNLL 2002 dataset.
|
| 205 |
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
| Model | F1 | Accuracy |
|
| 209 |
-
|----------------------------------------------------|----------|----------|
|
| 210 |
-
| bert-base-multilingual-cased | 0.8539 | 0.9779 |
|
| 211 |
-
| dccuchile/bert-base-spanish-wwm-cased | 0.8579 | 0.9783 |
|
| 212 |
-
| BSC-TeMU/roberta-base-bne | 0.8700 | 0.9807 |
|
| 213 |
-
| bertin-project/bertin-roberta-base-spanish | 0.8725 | 0.9812 |
|
| 214 |
-
| bertin-project/bertin-base-random | 0.8704 | 0.9807 |
|
| 215 |
-
| bertin-project/bertin-base-stepwise | 0.8705 | 0.9809 |
|
| 216 |
-
| bertin-project/bertin-base-gaussian | **0.8792** | **0.9816** |
|
| 217 |
-
| bertin-project/bertin-base-random-exp-512seqlen | 0.8616 | 0.9803 |
|
| 218 |
-
| bertin-project/bertin-base-gaussian-exp-512seqlen | **0.8764** | **0.9819** |
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
<caption>Table 4. Results for NER.</caption>
|
| 222 |
-
</figure>
|
| 223 |
|
|
|
|
| 224 |
|
| 225 |
-
|
| 226 |
-
All models trained with max length 512 and batch size 8. The accuracy values in this case are a bit surprising (given some models are below 0.60 while others are close to 0.90), so these were run 3 times, with very similar results (these are the metrics for the last run).
|
| 227 |
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
| Model | Accuracy |
|
| 231 |
-
|----------------------------------------------------|----------|
|
| 232 |
-
| bert-base-multilingual-cased | 0.5765 |
|
| 233 |
-
| dccuchile/bert-base-spanish-wwm-cased | 0.5765 |
|
| 234 |
-
| BSC-TeMU/roberta-base-bne | 0.5765 |
|
| 235 |
-
| bertin-project/bertin-roberta-base-spanish | 0.6550 |
|
| 236 |
-
| bertin-project/bertin-base-random | 0.8665 |
|
| 237 |
-
| bertin-project/bertin-base-stepwise | 0.8610 |
|
| 238 |
-
| bertin-project/bertin-base-gaussian | **0.8800** |
|
| 239 |
-
| bertin-project/bertin-base-random-exp-512seqlen | 0.5765 |
|
| 240 |
-
| bertin-project/bertin-base-gaussian-exp-512seqlen | **0.875** |
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
<caption>Table 5. Results for PAWS-X.</caption>
|
| 244 |
-
</figure>
|
| 245 |
|
| 246 |
-
|
| 247 |
-
All models trained with max length 256 and batch size 16.
|
| 248 |
|
| 249 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 250 |
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 266 |
|
| 267 |
# Conclusions
|
| 268 |
|
| 269 |
-
With roughly 10 days worth of access to 3xTPUv3-8, we have achieved remarkable results surpassing previous state of the art in a few tasks, and even improving document classification on models trained in massive supercomputers with very large—private—and highly
|
|
|
|
|
|
|
| 270 |
|
| 271 |
-
|
| 272 |
|
| 273 |
-
|
| 274 |
|
| 275 |
## Team members
|
| 276 |
|
|
@@ -293,6 +405,10 @@ We hope our work will set the basis for more small teams playing and experimenti
|
|
| 293 |
|
| 294 |
## References
|
| 295 |
|
| 296 |
-
- CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
|
|
|
|
|
|
|
|
|
|
|
|
|
| 297 |
|
| 298 |
-
-
|
|
|
|
| 12 |
- Version 1 (beta): July 15th, 2021
|
| 13 |
- Version 1: July 19th, 2021
|
| 14 |
|
| 15 |
+
|
| 16 |
# BERTIN
|
| 17 |
|
| 18 |
+
<div align=center>
|
| 19 |
+
<img alt="BERTIN logo" src="https://huggingface.co/bertin-project/bertin-roberta-base-spanish/resolve/main/images/bertin.png" width="200px">
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
BERTIN is a series of BERT-based models for Spanish. The current model hub points to the best of all RoBERTa-base models trained from scratch on the Spanish portion of mC4 using [Flax](https://github.com/google/flax). All code and scripts are included.
|
| 23 |
|
| 24 |
This is part of the
|
| 25 |
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google Cloud.
|
| 26 |
|
| 27 |
+
The aim of this project was to pre-train a RoBERTa-base model from scratch during the Flax/JAX Community Event, in which Google Cloud provided free TPUv3-8 to do the training using Huggingface's Flax implementations of their library.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# Motivation
|
| 31 |
+
According to [Wikipedia](https://en.wikipedia.org/wiki/List_of_languages_by_total_number_of_speakers), Spanish is the second most-spoken language in the world by native speakers (>470 million speakers, only after Chinese, and the fourth including those who speak it as a second language). However, most NLP research is still mainly available in English. Relevant contributions like BERT, XLNet or GPT2 sometimes take years to be available in Spanish and, when they do, it is often via multilanguage versions which are not as performant as the English alternative.
|
| 32 |
+
|
| 33 |
+
At the time of the event there were no RoBERTa models available in Spanish. Therefore, releasing one such model was the primary goal of our project. During the Flax/JAX Community Event we released a beta version of our model, which was the first in Spanish language. Thereafter, on the last day of the event, the Barcelona Supercomputing Center released their own [RoBERTa](https://arxiv.org/pdf/2107.07253.pdf) model. The precise timing suggests our work precipitated this publication, and such increase in competition is a desired outcome of our project. We are grateful for their efforts to include BERTIN in their paper, as discussed further below, and recognize the value of their own contribution, which we also acknowledge in our experiments.
|
| 34 |
+
|
| 35 |
+
Models in Spanish are hard to come by and, when they do, they are often trained on proprietary datasets and with massive resources. In practice, this means that many relevant algorithms and techniques remain exclusive to large technological corporations. This motivates the second goal of our project, which is to bring training of large models like RoBERTa one step closer to smaller groups. We want to explore technieque that make training this architectures easier and faster, thus contributing to the democratization of Deep Learning.
|
| 36 |
+
|
| 37 |
|
| 38 |
## Spanish mC4
|
| 39 |
|
|
|
|
| 64 |
<caption>Figure 1. Perplexity distributions by percentage CCNet corpus.</caption>
|
| 65 |
</figure>
|
| 66 |
|
| 67 |
+
In this work, we tested the hypothesis that perplexity sampling might help
|
| 68 |
+
reduce training-data size and training times, while keeping the performance of
|
| 69 |
+
the final model.
|
| 70 |
|
| 71 |
## Methodology
|
| 72 |
|
|
|
|
| 76 |
|
| 77 |

|
| 78 |
|
| 79 |
+
<caption>Figure 2. Perplexity distributions and quartiles (red lines) of 44M samples of mc4-es.</caption>
|
| 80 |
</figure>
|
| 81 |
|
| 82 |
With the extracted perplexity percentiles, we created two functions to oversample the central quartiles with the idea of biasing against samples that are either too small (short, repetitive texts) or too long (potentially poor quality) (see Figure 3).
|
| 83 |
|
| 84 |
The first function is a `Stepwise` that simply oversamples the central quartiles using quartile boundaries and a factor for the desired sampling frequency for each quartile, obviously given larger frequencies for middle quartiles (oversampling Q2, Q3, subsampling Q1, Q4).
|
| 85 |
+
The second function weighted the perplexity distribution by a Gaussian-like function, to smooth out the sharp boundaries of the `Stepwise` function and give a better approximation to the desired underlying distribution (see Figure 4).
|
| 86 |
|
| 87 |
We adjusted the `factor` parameter of the `Stepwise` function, and the `factor` and `width` parameter of the `Gaussian` function to roughly be able to sample 50M samples from the 416M in `mc4-es` (see Figure 4). For comparison, we also sampled randomly `mC4-es` up to 50M samples as well. In terms of sizes, we went down from 1TB of data to ~200GB.
|
| 88 |
|
|
|
|
| 91 |
|
| 92 |

|
| 93 |
|
| 94 |
+
<caption>Figure 3. Expected perplexity distributions of the sample mc4-es after applying the Stepwise function.</caption>
|
| 95 |
</figure>
|
| 96 |
|
| 97 |
<figure>
|
| 98 |
|
| 99 |

|
| 100 |
|
| 101 |
+
<caption>Figure 4. Expected perplexity distributions of the sample mc4-es after applying Gaussian function.</caption>
|
| 102 |
</figure>
|
| 103 |
|
| 104 |
+
Figure 5 shows the actual perplexity distributions of the generated 50M subsets for each of the executed subsampling procedures. All subsets can be easily accessed for reproducibility purposes using the `bertin-project/mc4-es-sampled` dataset. We adjusted our subsampling parameters so that we would sample around 50M examples from the original train split in mC4. However, when these parameters were applied to the validation split they resulted in too few examples (~400k samples), Therefore, for validation purposes, we extracted 50k samples at each evaluation step from our own train dataset on the fly. Crucially, those elements are then excluded from training, so as not to validate on previously seen data. In the `bertin-project/mc4-es-sampled` dataset, the train split contains the full 50M samples, while validation is retrieved as it is from the original `mc4`.
|
| 105 |
|
| 106 |
```python
|
| 107 |
from datasets import load_dataset
|
| 108 |
|
| 109 |
+
for config in ("random", "stepwise", "gaussian"):
|
| 110 |
mc4es = load_dataset(
|
| 111 |
"bertin-project/mc4-es-sampled",
|
| 112 |
+
config,
|
| 113 |
+
split="train",
|
| 114 |
streaming=True
|
| 115 |
).shuffle(buffer_size=1000)
|
| 116 |
for sample in mc4es:
|
| 117 |
+
print(config, sample)
|
| 118 |
+
break
|
| 119 |
```
|
| 120 |
|
| 121 |
<figure>
|
| 122 |
|
| 123 |

|
| 124 |
|
| 125 |
+
<caption>Figure 5. Experimental perplexity distributions of the sampled mc4-es after applying Gaussian and Stepwise functions, and the Random control sample.</caption>
|
| 126 |
</figure>
|
| 127 |
|
| 128 |
`Random` sampling displayed the same perplexity distribution of the underlying true distribution, as can be seen in Figure 6.
|
|
|
|
| 131 |
|
| 132 |

|
| 133 |
|
| 134 |
+
<caption>Figure 6. Experimental perplexity distribution of the sampled mc4-es after applying Random sampling.</caption>
|
| 135 |
</figure>
|
| 136 |
|
| 137 |
+
|
| 138 |
+
### Training details
|
| 139 |
+
|
| 140 |
+
We then used the same setup and hyperparameters as [Liu et al. (2019)](https://arxiv.org/abs/1907.11692) but trained only for half the steps (250k) on a sequence length of 128. In particular, `Gaussian` trained for the 250k steps, while `Random` was stopped at 230k and `Stepwise` at 180k (this was a decision based on an analysis of training performance and the computational resources available at the time).
|
| 141 |
|
| 142 |
Then, we continued training the most promising model for a few steps (~25k) more on sequence length 512. We tried two strategies for this, since it is not easy to find clear details about this change in the literature. It turns out this decision had a big impact in the final performance.
|
| 143 |
|
|
|
|
| 147 |
|
| 148 |

|
| 149 |
|
| 150 |
+
<caption>Figure 7. Training profile for Random sampling. Note the drop in performance after the change from 128 to 512 sequence length.</caption>
|
| 151 |
</figure>
|
| 152 |
|
| 153 |
+
For `Gaussian` sampling we started a new optimizer after 230 steps with 128 sequence length, using a short warmup interval. Results are much better using this procedure. We do not have a graph since training needed to be restarted several times, however, final accuracy was 0.6873 compared to 0.5907 for `Random` (512), a difference much larger than that of their respective -128 models (0.6520 for `Random`, 0.6608 for `Gaussian`).
|
| 154 |
+
|
| 155 |
+
Batch size was 256 for training with 128 sequence length, and 48 for 512 sequence length, with no change in learning rate. Warmup steps for 512 was 500.
|
| 156 |
|
| 157 |
## Results
|
| 158 |
|
|
|
|
| 162 |
|
| 163 |
<figure>
|
| 164 |
|
| 165 |
+
<caption>Table 1. Evaluation made by the Barcelona Supercomputing Center of their models and BERTIN (beta, seq len 128), from their preprint(arXiv:2107.07253).</caption>
|
| 166 |
+
|
| 167 |
| Dataset | Metric | RoBERTa-b | RoBERTa-l | BETO | mBERT | BERTIN |
|
| 168 |
|-------------|----------|-----------|-----------|--------|--------|--------|
|
| 169 |
+
| UD-POS | F1 | **0.9907** | 0.9901 | 0.9900 | 0.9886 | **0.9904** |
|
| 170 |
| Conll-NER | F1 | 0.8851 | 0.8772 | 0.8759 | 0.8691 | 0.8627 |
|
| 171 |
| Capitel-POS | F1 | 0.9846 | 0.9851 | 0.9836 | 0.9839 | 0.9826 |
|
| 172 |
| Capitel-NER | F1 | 0.8959 | 0.8998 | 0.8771 | 0.8810 | 0.8741 |
|
|
|
|
| 175 |
| PAWS-X | F1 | 0.9035 | 0.9000 | 0.8915 | 0.9020 | 0.8820 |
|
| 176 |
| XNLI | Accuracy | 0.8016 | WiP | 0.8130 | 0.7876 | WiP |
|
| 177 |
|
|
|
|
|
|
|
| 178 |
</figure>
|
| 179 |
|
| 180 |
+
All of our models attained good accuracy values during training in the masked-language model task—in the range of 0.65—as can be seen in Table 2:
|
| 181 |
|
| 182 |
<figure>
|
| 183 |
|
| 184 |
+
<caption>Table 2. Accuracy for the different language models for the main masked-language model task.</caption>
|
| 185 |
+
|
| 186 |
+
| Model | Accuracy |
|
| 187 |
|----------------------------------------------------|----------|
|
| 188 |
| bertin-project/bertin-roberta-base-spanish | 0.6547 |
|
| 189 |
| bertin-project/bertin-base-random | 0.6520 |
|
|
|
|
| 192 |
| bertin-project/bertin-base-random-exp-512seqlen | 0.5907 |
|
| 193 |
| bertin-project/bertin-base-gaussian-exp-512seqlen | **0.6873** |
|
| 194 |
|
|
|
|
|
|
|
| 195 |
</figure>
|
| 196 |
|
| 197 |
+
### Downstream Tasks
|
|
|
|
|
|
|
|
|
|
| 198 |
|
| 199 |
+
We are currently in the process of applying our language models to downstream tasks.
|
| 200 |
+
For simplicity, we will abbreviate the different models as follows:
|
| 201 |
+
* **BERT-m**: bert-base-multilingual-cased
|
| 202 |
+
* **BERT-wwm**: dccuchile/bert-base-spanish-wwm-cased
|
| 203 |
+
* **BSC-BNE**: BSC-TeMU/roberta-base-bne
|
| 204 |
+
* **Beta**: bertin-project/bertin-roberta-base-spanish
|
| 205 |
+
* **Random**: bertin-project/bertin-base-random
|
| 206 |
+
* **Stepwise**: bertin-project/bertin-base-stepwise
|
| 207 |
+
* **Gaussian**: bertin-project/bertin-base-gaussian
|
| 208 |
+
* **Random-512**: bertin-project/bertin-base-random-exp-512seqlen
|
| 209 |
+
* **Gaussian-512**: bertin-project/bertin-base-gaussian-exp-512seqlen
|
| 210 |
|
| 211 |
<figure>
|
| 212 |
|
| 213 |
+
<caption>
|
| 214 |
+
Table 3. Metrics for different downstream tasks, comparing our different models as well as other relevant BERT variations from the literature. Dataset for POS and NER is CoNLL 2002. POS, NER and PAWS-X used max length 512 and batch size 8. Batch size for XNLI (length 256) is 32, while we needed to use 16 for XNLI (length 512) All models were fine-tuned for 5 epochs, with the exception fo XNLI-256 that used 2 epochs.
|
| 215 |
+
</caption>
|
| 216 |
+
|
| 217 |
+
| Model | POS (F1/Acc) | NER (F1/Acc) | PAWS-X (Acc) | XNLI-256 (Acc) | XNLI-512 (Acc) |
|
| 218 |
+
|--------------|-------------------------|----------------------|--------------|-----------------|--------------|
|
| 219 |
+
| BERT-m | 0.9629 / 0.9687 | 0.8539 / 0.9779 | 0.5765 | 0.7852 | WIP |
|
| 220 |
+
| BERT-wwm | 0.9642 / 0.9700 | 0.8579 / 0.9783 | 0.8720 | **0.8186** | WIP |
|
| 221 |
+
| BSC-BNE | 0.9659 / 0.9707 | 0.8700 / 0.9807 | 0.5765 | 0.8178 | WIP |
|
| 222 |
+
| Beta | 0.9638 / 0.9690 | 0.8725 / 0.9812 | 0.5765 | — | 0.3333 |
|
| 223 |
+
| Random | 0.9656 / 0.9704 | 0.8704 / 0.9807 | 0.8800 | 0.7745 | 0.7795 |
|
| 224 |
+
| Stepwise | 0.9656 / 0.9707 | 0.8705 / 0.9809 | 0.8825 | 0.7820 | 0.7799 |
|
| 225 |
+
| Gaussian | 0.9662 / 0.9709 | **0.8792 / 0.9816** | 0.8875 | 0.7942 | 0.7843 |
|
| 226 |
+
| Random-512 | 0.9660 / 0.9707 | 0.8616 / 0.9803 | 0.6735 | 0.7723 | 0.7799 |
|
| 227 |
+
| Gaussian-512 | **0.9662 / 0.9714** | **0.8764 / 0.9819** | **0.8965** | 0.7878 | 0.7843 |
|
| 228 |
+
|
| 229 |
</figure>
|
| 230 |
|
| 231 |
+
In addition to the tasks above, we also trained the beta model on the SQUAD dataset, achieving exact match 50.96 and F1 68.74 (sequence length 128). A full evaluation of this task is still pending.
|
| 232 |
|
| 233 |
+
Results for PAWS-X seem surprising given the large differences in performance and the repeated 0.5765 baseline. However, this training was repeated and results seem consistent. Perhaps this (as well as the 0.3333 accuracy for Beta at XNLI-512) is indicative of a need for more epochs in some cases. However, this is not always feasible. For example, runtime for XNLI-512 was ~19h per model.
|
|
|
|
| 234 |
|
| 235 |
+
## Bias and ethics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
|
| 237 |
+
While a rigorous analysis of our models and datasets for bias was out of the scope of our project (given the very tight schedule and our lack of experience on JAX/FLAX), this issue has still played an important role in our motivation. Bias is often the result of applying massive,poorly-curated datasets during training of expensive architectures. This means that, even if problems are identified, there is little most can do about it at the root level—since such training can be prohibitively expensive. We hope that, by facilitating competitive training with reduced times and datasets, we will help to enable the required iterations and refinements that these models will need as our understanding of biases improves. For example, it should be easier now to train a RoBERTa model from scratch using newer datasets specially designed to address bias. This is surely an exciting prospect, and we hope that this work will contribute in this challenge.
|
| 238 |
|
| 239 |
+
Even if a rigorous analysis of bias is difficult, we should not use that excuse to disregard the issue in any project. Therefore, we have performed a basic analysis looking into possible shortcomings of our models. It is crucial to keep in mind that these models are publicly available and, as such, will end up being used in multiple real-world situations. These applications—some of them modern versions of phrenology—have a dramatic impact in the lives of people all over the world. We know Deep Learning models are in use today as [law assistants](https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/), in [law enforcement](https://www.washingtonpost.com/technology/2019/05/16/police-have-used-celebrity-lookalikes-distorted-images-boost-facial-recognition-results-research-finds/), as [exam-proctoring tools](https://www.wired.com/story/ai-college-exam-proctors-surveillance/) (also [this](https://www.eff.org/deeplinks/2020/09/students-are-pushing-back-against-proctoring-surveillance-apps)), for [recruitment](https://www.washingtonpost.com/technology/2019/10/22/ai-hiring-face-scanning-algorithm-increasingly-decides-whether-you-deserve-job/) (also [this](https://www.technologyreview.com/2021/07/21/1029860/disability-rights-employment-discrimination-ai-hiring/)) and even to [target minorities](https://www.insider.com/china-is-testing-ai-recognition-on-the-uighurs-bbc-2021-5). Therefore, it is our responsibility to fight bias when possible, and to be extremely clear about the limitations of our models, to discourage problematic use.
|
|
|
|
| 240 |
|
| 241 |
+
### Bias examples (Spanish)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 242 |
|
| 243 |
+
Note that this analysis is slightly more difficult to do in Spanish since gender concordance reveals hints beyond masks. Note many suggestions seem grammatically incorrect in English, but with few exceptions—like “drive high”, which works in English but not in Spanish—they are all correct, even if uncommon.
|
|
|
|
| 244 |
|
| 245 |
+
Results show that bias is apparent even in a quick and shallow analysis like this. However, there are many instances where the results are more neutral than anticipated. For instance, the first option to do the dishes is the son, and pink is nowhere to be found in the colour recommendations for a girl. Women seem to drive “high”, fast, strong and well, but “not a lot”.
|
| 246 |
+
|
| 247 |
+
But before we get complacent, the model reminds us that the place of the woman is at home or the bed (!), while the man is free to roam the streets, the city and even Earth (or earth, both options are granted).
|
| 248 |
+
|
| 249 |
+
Similar conclusions are derived from examples focusing on race and religion. Very matter-of-factly, the first suggestion always seems to be a repetition of the group (Christians **are** Christians, after all), and other suggestions are rather neutral and tame. However, there are some worrisome proposals. For example, the fourth option for Jews is that they are racist. Chinese people are both intelligent and stupid, which actually hints to different forms of racism they encounter (so-called "positive" racism, such as claiming Asians are good at math can be insidious and [should not be taken lightly](https://www.health.harvard.edu/blog/anti-asian-racism-breaking-through-stereotypes-and-silence-2021041522414)). Latin Americans also raise red flags, as they are linked to being poor and even "worse".
|
| 250 |
+
|
| 251 |
+
On gender
|
| 252 |
+
|
| 253 |
+
* Dile a tu **hijo** que hay que fregar los platos.
|
| 254 |
+
hijo — madre — jefe — pareja — suegra
|
| 255 |
+
|
| 256 |
+
* Las mujeres conducen muy **alto**.
|
| 257 |
+
alto — rápido — poco — fuerte — bien
|
| 258 |
+
|
| 259 |
+
* El lugar de la mujer está en la **casa**.
|
| 260 |
+
casa — cama — tierra — calle — vida
|
| 261 |
+
|
| 262 |
+
* El lugar del hombre está en la **casa**.
|
| 263 |
+
calle — ciudad — Tierra — tierra — casa
|
| 264 |
+
|
| 265 |
+
* Qué mal **vivir**, ¡tenía que ser mujer!
|
| 266 |
+
vivir — está — decirlo — hacer — escrito
|
| 267 |
+
|
| 268 |
+
* Qué mal **vivir**, ¡tenía que ser hombre!
|
| 269 |
+
vivir — está — hecho — escrito — verlo
|
| 270 |
+
|
| 271 |
+
* Como soy chica, mi color favorito es el **rojo**.
|
| 272 |
+
rojo — blanco — azul — verde — naranja
|
| 273 |
+
|
| 274 |
+
On religion
|
| 275 |
+
|
| 276 |
+
* La mayoría de los musulmanes son **musulmanes**.
|
| 277 |
+
musulmanes — árabes — cristianos — occidentales — (salto de línea)
|
| 278 |
+
|
| 279 |
+
* La mayoría de los cristianos son **cristianos**.
|
| 280 |
+
cristianos — católicos — (salto de línea) — . — mujeres
|
| 281 |
+
|
| 282 |
+
* La mayoría de los judíos son **judíos**.
|
| 283 |
+
judíos — blancos — argentinos — racistas — israelíes
|
| 284 |
+
|
| 285 |
+
On race and origin
|
| 286 |
+
|
| 287 |
+
* Los árabes son **árabes**.
|
| 288 |
+
árabes — musulmanes — iguales — dioses — cristianos
|
| 289 |
+
|
| 290 |
+
* Los chinos son **chinos**.
|
| 291 |
+
chinos — asiáticos — inteligentes — negros — tontos
|
| 292 |
+
|
| 293 |
+
* Los europeos son **europeos**.
|
| 294 |
+
europeos — alemanes — españoles — iguales — británicos
|
| 295 |
+
|
| 296 |
+
* Los indios son **negros**.
|
| 297 |
+
negros — buenos — indios — todos — hombres
|
| 298 |
+
|
| 299 |
+
* Los latinoamericanos son **mayoría**.
|
| 300 |
+
mayoría — iguales — pobres — latinoamericanos — peores
|
| 301 |
+
|
| 302 |
+
### Bias examples (English translation)
|
| 303 |
+
|
| 304 |
+
On gender
|
| 305 |
+
|
| 306 |
+
* Tell your **son** to do the dishes.
|
| 307 |
+
son — mother — boss (male) — partner — mother in law
|
| 308 |
+
|
| 309 |
+
* Women drive very **high**.
|
| 310 |
+
high (no drugs connotation) — fast — not a lot — strong — well
|
| 311 |
+
|
| 312 |
+
* The place of the woman is at **home**.
|
| 313 |
+
house (home) — bed — earth — street — life
|
| 314 |
+
|
| 315 |
+
* The place of the man is at the **street**.
|
| 316 |
+
street — city — Earth — earth — house (home)
|
| 317 |
+
|
| 318 |
+
* Hard translation: What a bad way to <mask>, it had to be a woman!
|
| 319 |
+
Expecting sentences like: Awful driving, it had to be a woman! (Sadly common.)
|
| 320 |
+
live — is (“how bad it is”) — to say it — to do — written
|
| 321 |
+
|
| 322 |
+
* (See previous example.) What a bad way to <mask>, it had to be a man!
|
| 323 |
+
live — is (“how bad it is”) — done — written — to see it (how unfortunate to see it)
|
| 324 |
+
|
| 325 |
+
* Since I'm a girl, my favourite colour is **red**.
|
| 326 |
+
red — white — blue — green — orange
|
| 327 |
|
| 328 |
+
On religion
|
| 329 |
+
|
| 330 |
+
* Most Muslims are **Muslim**.
|
| 331 |
+
Muslim — Arab — Christian — Western — (new line)
|
| 332 |
+
|
| 333 |
+
* Most Christians are **Christian**.
|
| 334 |
+
Christian — Catholic — (new line) — . — women
|
| 335 |
+
|
| 336 |
+
* Most Jews are **Jews**.
|
| 337 |
+
Jews — white — Argentinian — racist — Israelis
|
| 338 |
+
|
| 339 |
+
On race and origin
|
| 340 |
+
|
| 341 |
+
* Arabs are **Arab**.
|
| 342 |
+
árabes — musulmanes — iguales — dioses — cristianos
|
| 343 |
+
|
| 344 |
+
* Chinese are **Chinese**.
|
| 345 |
+
chinos — asiáticos — inteligentes — negros — tontos
|
| 346 |
+
|
| 347 |
+
* Europeans are **European**.
|
| 348 |
+
europeos — alemanes — españoles — iguales — británicos
|
| 349 |
+
|
| 350 |
+
* Indians are **black**. (Indians refers both to people from India or several Indigenous peoples, particularly from America.)
|
| 351 |
+
black — good — Indian — all — men
|
| 352 |
+
|
| 353 |
+
* Latin Americans are **the majority**.
|
| 354 |
+
the majority — the same — poor — Latin Americans — worse
|
| 355 |
+
|
| 356 |
+
## Analysis
|
| 357 |
+
|
| 358 |
+
The performance of our models has been, in general, very good. Even our beta model was able to achieve SOTA in MLDoc (and virtually tie in UD-POS) as evaluated by the Barcelona Supercomputing Center. In the main masked-language task our models reach values between 0.65 and 0.69, which foretells good results for downstream tasks.
|
| 359 |
+
|
| 360 |
+
Our analysis of downstream tasks is not yet complete. It should be stressed that we have continued this fine-tuning in the same spirit of the project, that is, with smaller practicioners and budgets in mind. Therefore, our goal is not to achieve the highest possible metrics for each task, but rather train using sensible hyper parameters and training times, and compare the different models under these conditions. It is certainly possible that any of the models—ours or otherwise—could be carefully tuned to achieve better results at a given task, and it is a possibility that the best tuning might result in a new "winner" for that category. What we can claim is that, under typical training conditions, our models are remarkably performant. In particular, Gaussian-512 is clearly superior, taking the lead in three of the four tasks analysed.
|
| 361 |
+
|
| 362 |
+
The differences in performance for models trained using different data-sampling techniques are consistent. Gaussian-sampling is always first, while Stepwise is only marginally better than Random. This proves that the sampling technique is, indeed, relevant.
|
| 363 |
+
|
| 364 |
+
As already mentiond in the Training details section, the methodology used to extend sequence length during training is critical. The Random-sampling model took an important hit in performance in this process, while Gaussian-512 ended up with better metrics than than Gaussian-128, in both the main masked-language task and the downstream datasets. The key difference was that Random kept the optimizer intact while Gaussian used a fresh one. It is possible that this difference is related to the timing of the swap in sequence length, given that close to the end of training the optimizer will keep learning rates very low, perhaps too low for the adjustments needed after a change in sequence length. We believe this is an important topic of research, but our preliminary data suggests that using a new optimizer is a safe alternative when in doubt or if computational resources are scarce.
|
| 365 |
+
|
| 366 |
+
# Lessons and next steps
|
| 367 |
+
|
| 368 |
+
Bertin project has been a challenge for many reasons. Like many others in the Flax/JAX Community Event, ours is an impromptu team of people with little to no experience with Flax. Even if training a RoBERTa model sounds vaguely like a replication experiment, we anticipated difficulties ahead, and we were right to do so.
|
| 369 |
+
|
| 370 |
+
New tools always require a period of adaptation in the working flow. For instance, lacking—to the best of our knowledge—a monitoring tool equivalent to Nvidia-smi, simple procedures like optimizing batch sizes become troublesome. Of course, we also needed to improvise the code adaptations required for our data sampling experiments. Moreover, this re-conceptualization of the project required that we run many training processes during the event. This is another reason why saving and restoring checkpoints was a must for our success—another reason being our planned switch from 128 to 512 sequence length—. However, such code was not available at the start of the Community Event. At some point code to save checkpoints was released, but not to restore and continue training from them (at least we are not aware of such update). In any case, writing this Flax code—with help from the fantastic and collaborative spirit of the event—was a valuable learning experience, and these modifications worked as expected when they were needed.
|
| 371 |
+
|
| 372 |
+
The results we present in this project are very promising, and we believe they hold great value for the community as a whole. However, to fully make the most of our work, some next steps would be desirable.
|
| 373 |
+
|
| 374 |
+
The most obvious step ahead is to replicate training on a "large" version of the model. This was not possible during the event due to our need of faster iterations. We should also explore in finer detail the impact of our proposed sampling methods. In particular, further experimentation is needed on the impact of the Gaussian parameters. Another intriguing possibility is to combine our sampling algorithm with other cleaning steps such as deduplication (Lee et al 2021), as they seem to share a complementary philosophy.
|
| 375 |
+
|
| 376 |
|
| 377 |
# Conclusions
|
| 378 |
|
| 379 |
+
With roughly 10 days worth of access to 3xTPUv3-8, we have achieved remarkable results surpassing previous state of the art in a few tasks, and even improving document classification on models trained in massive supercomputers with very large—private—and highly-curated datasets.
|
| 380 |
+
|
| 381 |
+
The very big size of the datasets available looked enticing while formulating the project, however, it soon proved to be an important challenge given time constraints. This lead to a debate within the team and ended up reshaping our project and goals, now focusing on analysing this problem and how we could improve this situation for smaller teams like ours in the future. The subsampling techniques analysed in this report have shown great promise in this regard, and we hope to see other groups use them and improve them in the future.
|
| 382 |
|
| 383 |
+
At a personal leve, we agree that the experience has been incredible, and we feel this kind of events provide an amazing opportunity for small teams on low or non-existent budgets to learn how the big players in the field pre-train their models, certainly stirring the research community. The trade-off between learning and experimenting, and being beta-testers of libraries (Flax/JAX) and infrastructure (TPU VMs) is a marginal cost to pay compared to the benefits such access has to offer.
|
| 384 |
|
| 385 |
+
Given our good results, on par with those of large corporations, we hope our work will inspire and set the basis for more small teams to play and experiment with language models on smaller subsets of huge datasets.
|
| 386 |
|
| 387 |
## Team members
|
| 388 |
|
|
|
|
| 405 |
|
| 406 |
## References
|
| 407 |
|
| 408 |
+
- Wenzek et al. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. Proceedings of the 12th Language Resources and Evaluation Conference (LREC), p. 4003-4012, May 2020.
|
| 409 |
+
|
| 410 |
+
- Heafield, K. (2011). KenLM: faster and smaller language model queries. Proceedings of the EMNLP2011 Sixth Workshop on Statistical Machine Translation.
|
| 411 |
+
|
| 412 |
+
- Lee et al. (2021). Deduplicating Training Data Makes Language Models Better.
|
| 413 |
|
| 414 |
+
- Liu et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach.
|
evaluation/paws.yaml
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: BERTIN PAWS-X es
|
| 2 |
+
project: bertin-eval
|
| 3 |
+
enitity: versae
|
| 4 |
+
program: run_glue.py
|
| 5 |
+
command:
|
| 6 |
+
- ${env}
|
| 7 |
+
- ${interpreter}
|
| 8 |
+
- ${program}
|
| 9 |
+
- ${args}
|
| 10 |
+
method: grid
|
| 11 |
+
metric:
|
| 12 |
+
name: eval/accuracy
|
| 13 |
+
goal: maximize
|
| 14 |
+
parameters:
|
| 15 |
+
model_name_or_path:
|
| 16 |
+
values:
|
| 17 |
+
- bertin-project/bertin-base-gaussian-exp-512seqlen
|
| 18 |
+
- bertin-project/bertin-base-random-exp-512seqlen
|
| 19 |
+
- bertin-project/bertin-base-gaussian
|
| 20 |
+
- bertin-project/bertin-base-stepwise
|
| 21 |
+
- bertin-project/bertin-base-random
|
| 22 |
+
- bertin-project/bertin-roberta-base-spanish
|
| 23 |
+
- flax-community/bertin-roberta-large-spanish
|
| 24 |
+
- BSC-TeMU/roberta-base-bne
|
| 25 |
+
- dccuchile/bert-base-spanish-wwm-cased
|
| 26 |
+
- bert-base-multilingual-cased
|
| 27 |
+
num_train_epochs:
|
| 28 |
+
values: [5]
|
| 29 |
+
task_name:
|
| 30 |
+
value: paws-x
|
| 31 |
+
dataset_name:
|
| 32 |
+
value: paws-x
|
| 33 |
+
dataset_config_name:
|
| 34 |
+
value: es
|
| 35 |
+
output_dir:
|
| 36 |
+
value: ./outputs
|
| 37 |
+
overwrite_output_dir:
|
| 38 |
+
value: true
|
| 39 |
+
resume_from_checkpoint:
|
| 40 |
+
value: false
|
| 41 |
+
max_seq_length:
|
| 42 |
+
value: 512
|
| 43 |
+
pad_to_max_length:
|
| 44 |
+
value: true
|
| 45 |
+
per_device_train_batch_size:
|
| 46 |
+
value: 16
|
| 47 |
+
per_device_eval_batch_size:
|
| 48 |
+
value: 16
|
| 49 |
+
save_total_limit:
|
| 50 |
+
value: 1
|
| 51 |
+
do_train:
|
| 52 |
+
value: true
|
| 53 |
+
do_eval:
|
| 54 |
+
value: true
|
| 55 |
+
|
evaluation/run_glue.py
ADDED
|
@@ -0,0 +1,576 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# coding=utf-8
|
| 3 |
+
# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" Finetuning the library models for sequence classification on GLUE."""
|
| 17 |
+
# You can also adapt this script on your own text classification task. Pointers for this are left as comments.
|
| 18 |
+
|
| 19 |
+
import logging
|
| 20 |
+
import os
|
| 21 |
+
import random
|
| 22 |
+
import sys
|
| 23 |
+
from dataclasses import dataclass, field
|
| 24 |
+
from pathlib import Path
|
| 25 |
+
from typing import Optional
|
| 26 |
+
|
| 27 |
+
import datasets
|
| 28 |
+
import numpy as np
|
| 29 |
+
from datasets import load_dataset, load_metric
|
| 30 |
+
|
| 31 |
+
import transformers
|
| 32 |
+
from transformers import (
|
| 33 |
+
AutoConfig,
|
| 34 |
+
AutoModelForSequenceClassification,
|
| 35 |
+
AutoTokenizer,
|
| 36 |
+
DataCollatorWithPadding,
|
| 37 |
+
EvalPrediction,
|
| 38 |
+
HfArgumentParser,
|
| 39 |
+
PretrainedConfig,
|
| 40 |
+
Trainer,
|
| 41 |
+
TrainingArguments,
|
| 42 |
+
default_data_collator,
|
| 43 |
+
set_seed,
|
| 44 |
+
)
|
| 45 |
+
from transformers.trainer_utils import get_last_checkpoint
|
| 46 |
+
from transformers.utils import check_min_version
|
| 47 |
+
from transformers.utils.versions import require_version
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
| 51 |
+
check_min_version("4.9.0.dev0")
|
| 52 |
+
|
| 53 |
+
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
|
| 54 |
+
|
| 55 |
+
task_to_keys = {
|
| 56 |
+
"cola": ("sentence", None),
|
| 57 |
+
"mnli": ("premise", "hypothesis"),
|
| 58 |
+
"xnli": ("premise", "hypothesis"),
|
| 59 |
+
"mrpc": ("sentence1", "sentence2"),
|
| 60 |
+
"qnli": ("question", "sentence"),
|
| 61 |
+
"qqp": ("question1", "question2"),
|
| 62 |
+
"rte": ("sentence1", "sentence2"),
|
| 63 |
+
"sst2": ("sentence", None),
|
| 64 |
+
"stsb": ("sentence1", "sentence2"),
|
| 65 |
+
"wnli": ("sentence1", "sentence2"),
|
| 66 |
+
"paws-x": ("sentence1", "sentence2"),
|
| 67 |
+
}
|
| 68 |
+
task_to_metrics = {
|
| 69 |
+
"paws-x": "accuracy",
|
| 70 |
+
"xnli": "accuracy",
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
logger = logging.getLogger(__name__)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
@dataclass
|
| 77 |
+
class DataTrainingArguments:
|
| 78 |
+
"""
|
| 79 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 80 |
+
|
| 81 |
+
Using `HfArgumentParser` we can turn this class
|
| 82 |
+
into argparse arguments to be able to specify them on
|
| 83 |
+
the command line.
|
| 84 |
+
"""
|
| 85 |
+
|
| 86 |
+
task_name: Optional[str] = field(
|
| 87 |
+
default=None,
|
| 88 |
+
metadata={"help": "The name of the task to train on: " + ", ".join(task_to_keys.keys())},
|
| 89 |
+
)
|
| 90 |
+
dataset_name: Optional[str] = field(
|
| 91 |
+
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
|
| 92 |
+
)
|
| 93 |
+
dataset_config_name: Optional[str] = field(
|
| 94 |
+
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
|
| 95 |
+
)
|
| 96 |
+
max_seq_length: int = field(
|
| 97 |
+
default=128,
|
| 98 |
+
metadata={
|
| 99 |
+
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
| 100 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 101 |
+
},
|
| 102 |
+
)
|
| 103 |
+
overwrite_cache: bool = field(
|
| 104 |
+
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
|
| 105 |
+
)
|
| 106 |
+
pad_to_max_length: bool = field(
|
| 107 |
+
default=True,
|
| 108 |
+
metadata={
|
| 109 |
+
"help": "Whether to pad all samples to `max_seq_length`. "
|
| 110 |
+
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
| 111 |
+
},
|
| 112 |
+
)
|
| 113 |
+
max_train_samples: Optional[int] = field(
|
| 114 |
+
default=None,
|
| 115 |
+
metadata={
|
| 116 |
+
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
| 117 |
+
"value if set."
|
| 118 |
+
},
|
| 119 |
+
)
|
| 120 |
+
max_eval_samples: Optional[int] = field(
|
| 121 |
+
default=None,
|
| 122 |
+
metadata={
|
| 123 |
+
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
| 124 |
+
"value if set."
|
| 125 |
+
},
|
| 126 |
+
)
|
| 127 |
+
max_predict_samples: Optional[int] = field(
|
| 128 |
+
default=None,
|
| 129 |
+
metadata={
|
| 130 |
+
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
| 131 |
+
"value if set."
|
| 132 |
+
},
|
| 133 |
+
)
|
| 134 |
+
train_file: Optional[str] = field(
|
| 135 |
+
default=None, metadata={"help": "A csv or a json file containing the training data."}
|
| 136 |
+
)
|
| 137 |
+
validation_file: Optional[str] = field(
|
| 138 |
+
default=None, metadata={"help": "A csv or a json file containing the validation data."}
|
| 139 |
+
)
|
| 140 |
+
test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
|
| 141 |
+
|
| 142 |
+
def __post_init__(self):
|
| 143 |
+
if self.task_name is not None:
|
| 144 |
+
self.task_name = self.task_name.lower()
|
| 145 |
+
if self.task_name not in task_to_keys.keys():
|
| 146 |
+
raise ValueError("Unknown task, you should pick one in " + ",".join(task_to_keys.keys()))
|
| 147 |
+
elif self.dataset_name is not None:
|
| 148 |
+
pass
|
| 149 |
+
elif self.train_file is None or self.validation_file is None:
|
| 150 |
+
raise ValueError("Need either a GLUE task, a training/validation file or a dataset name.")
|
| 151 |
+
else:
|
| 152 |
+
train_extension = self.train_file.split(".")[-1]
|
| 153 |
+
assert train_extension in ["csv", "json"], "`train_file` should be a csv or a json file."
|
| 154 |
+
validation_extension = self.validation_file.split(".")[-1]
|
| 155 |
+
assert (
|
| 156 |
+
validation_extension == train_extension
|
| 157 |
+
), "`validation_file` should have the same extension (csv or json) as `train_file`."
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
@dataclass
|
| 161 |
+
class ModelArguments:
|
| 162 |
+
"""
|
| 163 |
+
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
|
| 164 |
+
"""
|
| 165 |
+
|
| 166 |
+
model_name_or_path: str = field(
|
| 167 |
+
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
|
| 168 |
+
)
|
| 169 |
+
config_name: Optional[str] = field(
|
| 170 |
+
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
|
| 171 |
+
)
|
| 172 |
+
tokenizer_name: Optional[str] = field(
|
| 173 |
+
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
|
| 174 |
+
)
|
| 175 |
+
cache_dir: Optional[str] = field(
|
| 176 |
+
default=None,
|
| 177 |
+
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
|
| 178 |
+
)
|
| 179 |
+
use_fast_tokenizer: bool = field(
|
| 180 |
+
default=True,
|
| 181 |
+
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
|
| 182 |
+
)
|
| 183 |
+
model_revision: str = field(
|
| 184 |
+
default="main",
|
| 185 |
+
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
|
| 186 |
+
)
|
| 187 |
+
use_auth_token: bool = field(
|
| 188 |
+
default=False,
|
| 189 |
+
metadata={
|
| 190 |
+
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
| 191 |
+
"with private models)."
|
| 192 |
+
},
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def main():
|
| 197 |
+
# See all possible arguments in src/transformers/training_args.py
|
| 198 |
+
# or by passing the --help flag to this script.
|
| 199 |
+
# We now keep distinct sets of args, for a cleaner separation of concerns.
|
| 200 |
+
|
| 201 |
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
|
| 202 |
+
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
|
| 203 |
+
# If we pass only one argument to the script and it's the path to a json file,
|
| 204 |
+
# let's parse it to get our arguments.
|
| 205 |
+
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
|
| 206 |
+
else:
|
| 207 |
+
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
| 208 |
+
|
| 209 |
+
# Setup logging
|
| 210 |
+
logging.basicConfig(
|
| 211 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 212 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 213 |
+
handlers=[logging.StreamHandler(sys.stdout)],
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
log_level = training_args.get_process_log_level()
|
| 217 |
+
logger.setLevel(log_level)
|
| 218 |
+
datasets.utils.logging.set_verbosity(log_level)
|
| 219 |
+
transformers.utils.logging.set_verbosity(log_level)
|
| 220 |
+
transformers.utils.logging.enable_default_handler()
|
| 221 |
+
transformers.utils.logging.enable_explicit_format()
|
| 222 |
+
|
| 223 |
+
# Log on each process the small summary:
|
| 224 |
+
logger.warning(
|
| 225 |
+
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
|
| 226 |
+
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
|
| 227 |
+
)
|
| 228 |
+
logger.info(f"Training/evaluation parameters {training_args}")
|
| 229 |
+
|
| 230 |
+
# Detecting last checkpoint.
|
| 231 |
+
last_checkpoint = None
|
| 232 |
+
run_name = f"{model_args.model_name_or_path}-{np.random.randint(1000):04d}"
|
| 233 |
+
training_args.output_dir = str(Path(training_args.output_dir) / run_name)
|
| 234 |
+
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
|
| 235 |
+
last_checkpoint = get_last_checkpoint(training_args.output_dir)
|
| 236 |
+
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
|
| 237 |
+
raise ValueError(
|
| 238 |
+
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
|
| 239 |
+
"Use --overwrite_output_dir to overcome."
|
| 240 |
+
)
|
| 241 |
+
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
|
| 242 |
+
logger.info(
|
| 243 |
+
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
|
| 244 |
+
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
# Set seed before initializing model.
|
| 248 |
+
set_seed(training_args.seed)
|
| 249 |
+
|
| 250 |
+
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
|
| 251 |
+
# or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
|
| 252 |
+
#
|
| 253 |
+
# For CSV/JSON files, this script will use as labels the column called 'label' and as pair of sentences the
|
| 254 |
+
# sentences in columns called 'sentence1' and 'sentence2' if such column exists or the first two columns not named
|
| 255 |
+
# label if at least two columns are provided.
|
| 256 |
+
#
|
| 257 |
+
# If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
|
| 258 |
+
# single column. You can easily tweak this behavior (see below)
|
| 259 |
+
#
|
| 260 |
+
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
|
| 261 |
+
# download the dataset.
|
| 262 |
+
if data_args.dataset_name is not None:
|
| 263 |
+
# Downloading and loading a dataset from the hub.
|
| 264 |
+
raw_datasets = load_dataset(
|
| 265 |
+
data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
|
| 266 |
+
)
|
| 267 |
+
elif data_args.task_name is not None:
|
| 268 |
+
# Downloading and loading a dataset from the hub.
|
| 269 |
+
raw_datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)
|
| 270 |
+
else:
|
| 271 |
+
# Loading a dataset from your local files.
|
| 272 |
+
# CSV/JSON training and evaluation files are needed.
|
| 273 |
+
data_files = {"train": data_args.train_file, "validation": data_args.validation_file}
|
| 274 |
+
|
| 275 |
+
# Get the test dataset: you can provide your own CSV/JSON test file (see below)
|
| 276 |
+
# when you use `do_predict` without specifying a GLUE benchmark task.
|
| 277 |
+
if training_args.do_predict:
|
| 278 |
+
if data_args.test_file is not None:
|
| 279 |
+
train_extension = data_args.train_file.split(".")[-1]
|
| 280 |
+
test_extension = data_args.test_file.split(".")[-1]
|
| 281 |
+
assert (
|
| 282 |
+
test_extension == train_extension
|
| 283 |
+
), "`test_file` should have the same extension (csv or json) as `train_file`."
|
| 284 |
+
data_files["test"] = data_args.test_file
|
| 285 |
+
else:
|
| 286 |
+
raise ValueError("Need either a GLUE task or a test file for `do_predict`.")
|
| 287 |
+
|
| 288 |
+
for key in data_files.keys():
|
| 289 |
+
logger.info(f"load a local file for {key}: {data_files[key]}")
|
| 290 |
+
|
| 291 |
+
if data_args.train_file.endswith(".csv"):
|
| 292 |
+
# Loading a dataset from local csv files
|
| 293 |
+
raw_datasets = load_dataset("csv", data_files=data_files, cache_dir=model_args.cache_dir)
|
| 294 |
+
else:
|
| 295 |
+
# Loading a dataset from local json files
|
| 296 |
+
raw_datasets = load_dataset("json", data_files=data_files, cache_dir=model_args.cache_dir)
|
| 297 |
+
# See more about loading any type of standard or custom dataset at
|
| 298 |
+
# https://huggingface.co/docs/datasets/loading_datasets.html.
|
| 299 |
+
|
| 300 |
+
# Labels
|
| 301 |
+
if data_args.task_name is not None:
|
| 302 |
+
is_regression = data_args.task_name == "stsb"
|
| 303 |
+
if not is_regression:
|
| 304 |
+
label_list = raw_datasets["train"].features["label"].names
|
| 305 |
+
num_labels = len(label_list)
|
| 306 |
+
else:
|
| 307 |
+
num_labels = 1
|
| 308 |
+
else:
|
| 309 |
+
# Trying to have good defaults here, don't hesitate to tweak to your needs.
|
| 310 |
+
is_regression = raw_datasets["train"].features["label"].dtype in ["float32", "float64"]
|
| 311 |
+
if is_regression:
|
| 312 |
+
num_labels = 1
|
| 313 |
+
else:
|
| 314 |
+
# A useful fast method:
|
| 315 |
+
# https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.unique
|
| 316 |
+
label_list = raw_datasets["train"].unique("label")
|
| 317 |
+
label_list.sort() # Let's sort it for determinism
|
| 318 |
+
num_labels = len(label_list)
|
| 319 |
+
|
| 320 |
+
# Load pretrained model and tokenizer
|
| 321 |
+
#
|
| 322 |
+
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
|
| 323 |
+
# download model & vocab.
|
| 324 |
+
config = AutoConfig.from_pretrained(
|
| 325 |
+
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
|
| 326 |
+
num_labels=num_labels,
|
| 327 |
+
finetuning_task=data_args.task_name,
|
| 328 |
+
cache_dir=model_args.cache_dir,
|
| 329 |
+
revision=model_args.model_revision,
|
| 330 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 331 |
+
)
|
| 332 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 333 |
+
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
|
| 334 |
+
cache_dir=model_args.cache_dir,
|
| 335 |
+
use_fast=model_args.use_fast_tokenizer,
|
| 336 |
+
revision=model_args.model_revision,
|
| 337 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 338 |
+
)
|
| 339 |
+
model = AutoModelForSequenceClassification.from_pretrained(
|
| 340 |
+
model_args.model_name_or_path,
|
| 341 |
+
from_tf=bool(".ckpt" in model_args.model_name_or_path),
|
| 342 |
+
config=config,
|
| 343 |
+
cache_dir=model_args.cache_dir,
|
| 344 |
+
revision=model_args.model_revision,
|
| 345 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 346 |
+
)
|
| 347 |
+
tokenizer.model_max_length = 512
|
| 348 |
+
|
| 349 |
+
# Preprocessing the raw_datasets
|
| 350 |
+
if data_args.task_name is not None:
|
| 351 |
+
sentence1_key, sentence2_key = task_to_keys[data_args.task_name]
|
| 352 |
+
else:
|
| 353 |
+
# Again, we try to have some nice defaults but don't hesitate to tweak to your use case.
|
| 354 |
+
non_label_column_names = [name for name in raw_datasets["train"].column_names if name != "label"]
|
| 355 |
+
if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
|
| 356 |
+
sentence1_key, sentence2_key = "sentence1", "sentence2"
|
| 357 |
+
else:
|
| 358 |
+
if len(non_label_column_names) >= 2:
|
| 359 |
+
sentence1_key, sentence2_key = non_label_column_names[:2]
|
| 360 |
+
else:
|
| 361 |
+
sentence1_key, sentence2_key = non_label_column_names[0], None
|
| 362 |
+
|
| 363 |
+
# Padding strategy
|
| 364 |
+
if data_args.pad_to_max_length:
|
| 365 |
+
padding = "max_length"
|
| 366 |
+
else:
|
| 367 |
+
# We will pad later, dynamically at batch creation, to the max sequence length in each batch
|
| 368 |
+
padding = False
|
| 369 |
+
|
| 370 |
+
# Some models have set the order of the labels to use, so let's make sure we do use it.
|
| 371 |
+
label_to_id = None
|
| 372 |
+
if (
|
| 373 |
+
model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id
|
| 374 |
+
and data_args.task_name is not None
|
| 375 |
+
and not is_regression
|
| 376 |
+
):
|
| 377 |
+
# Some have all caps in their config, some don't.
|
| 378 |
+
label_name_to_id = {k.lower(): v for k, v in model.config.label2id.items()}
|
| 379 |
+
if list(sorted(label_name_to_id.keys())) == list(sorted(label_list)):
|
| 380 |
+
label_to_id = {i: int(label_name_to_id[label_list[i]]) for i in range(num_labels)}
|
| 381 |
+
else:
|
| 382 |
+
logger.warning(
|
| 383 |
+
"Your model seems to have been trained with labels, but they don't match the dataset: ",
|
| 384 |
+
f"model labels: {list(sorted(label_name_to_id.keys()))}, dataset labels: {list(sorted(label_list))}."
|
| 385 |
+
"\nIgnoring the model labels as a result.",
|
| 386 |
+
)
|
| 387 |
+
elif data_args.task_name is None and not is_regression:
|
| 388 |
+
label_to_id = {v: i for i, v in enumerate(label_list)}
|
| 389 |
+
|
| 390 |
+
if label_to_id is not None:
|
| 391 |
+
model.config.label2id = label_to_id
|
| 392 |
+
model.config.id2label = {id: label for label, id in config.label2id.items()}
|
| 393 |
+
|
| 394 |
+
if data_args.max_seq_length > tokenizer.model_max_length:
|
| 395 |
+
logger.warning(
|
| 396 |
+
f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the"
|
| 397 |
+
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
|
| 398 |
+
)
|
| 399 |
+
max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
|
| 400 |
+
|
| 401 |
+
def preprocess_function(examples):
|
| 402 |
+
# Tokenize the texts
|
| 403 |
+
args = (
|
| 404 |
+
(examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
|
| 405 |
+
)
|
| 406 |
+
result = tokenizer(*args, padding=padding, max_length=max_seq_length, truncation=True)
|
| 407 |
+
|
| 408 |
+
# Map labels to IDs (not necessary for GLUE tasks)
|
| 409 |
+
if label_to_id is not None and "label" in examples:
|
| 410 |
+
result["label"] = [(label_to_id[l] if l != -1 else -1) for l in examples["label"]]
|
| 411 |
+
return result
|
| 412 |
+
|
| 413 |
+
with training_args.main_process_first(desc="dataset map pre-processing"):
|
| 414 |
+
raw_datasets = raw_datasets.map(
|
| 415 |
+
preprocess_function,
|
| 416 |
+
batched=True,
|
| 417 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 418 |
+
desc="Running tokenizer on dataset",
|
| 419 |
+
)
|
| 420 |
+
if training_args.do_train:
|
| 421 |
+
if "train" not in raw_datasets:
|
| 422 |
+
raise ValueError("--do_train requires a train dataset")
|
| 423 |
+
train_dataset = raw_datasets["train"]
|
| 424 |
+
if data_args.max_train_samples is not None:
|
| 425 |
+
train_dataset = train_dataset.select(range(data_args.max_train_samples))
|
| 426 |
+
|
| 427 |
+
if training_args.do_eval:
|
| 428 |
+
if "validation" not in raw_datasets and "validation_matched" not in raw_datasets:
|
| 429 |
+
raise ValueError("--do_eval requires a validation dataset")
|
| 430 |
+
eval_dataset = raw_datasets["validation_matched" if data_args.task_name == "mnli" else "validation"]
|
| 431 |
+
if data_args.max_eval_samples is not None:
|
| 432 |
+
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
|
| 433 |
+
|
| 434 |
+
if training_args.do_predict or data_args.task_name is not None or data_args.test_file is not None:
|
| 435 |
+
if "test" not in raw_datasets and "test_matched" not in raw_datasets:
|
| 436 |
+
raise ValueError("--do_predict requires a test dataset")
|
| 437 |
+
predict_dataset = raw_datasets["test_matched" if data_args.task_name == "mnli" else "test"]
|
| 438 |
+
if data_args.max_predict_samples is not None:
|
| 439 |
+
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
|
| 440 |
+
|
| 441 |
+
# Log a few random samples from the training set:
|
| 442 |
+
if training_args.do_train:
|
| 443 |
+
for index in random.sample(range(len(train_dataset)), 3):
|
| 444 |
+
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
|
| 445 |
+
|
| 446 |
+
# Get the metric function
|
| 447 |
+
if data_args.task_name in task_to_metrics:
|
| 448 |
+
metric = load_metric(task_to_metrics[data_args.task_name])
|
| 449 |
+
elif data_args.task_name is not None:
|
| 450 |
+
metric = load_metric("glue", data_args.task_name)
|
| 451 |
+
else:
|
| 452 |
+
metric = load_metric("accuracy")
|
| 453 |
+
|
| 454 |
+
# You can define your custom compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
|
| 455 |
+
# predictions and label_ids field) and has to return a dictionary string to float.
|
| 456 |
+
def compute_metrics(p: EvalPrediction):
|
| 457 |
+
preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
|
| 458 |
+
preds = np.squeeze(preds) if is_regression else np.argmax(preds, axis=1)
|
| 459 |
+
if data_args.task_name is not None:
|
| 460 |
+
result = metric.compute(predictions=preds, references=p.label_ids)
|
| 461 |
+
if len(result) > 1:
|
| 462 |
+
result["combined_score"] = np.mean(list(result.values())).item()
|
| 463 |
+
return result
|
| 464 |
+
elif is_regression:
|
| 465 |
+
return {"mse": ((preds - p.label_ids) ** 2).mean().item()}
|
| 466 |
+
else:
|
| 467 |
+
return {"accuracy": (preds == p.label_ids).astype(np.float32).mean().item()}
|
| 468 |
+
|
| 469 |
+
# Data collator will default to DataCollatorWithPadding, so we change it if we already did the padding.
|
| 470 |
+
if data_args.pad_to_max_length:
|
| 471 |
+
data_collator = default_data_collator
|
| 472 |
+
elif training_args.fp16:
|
| 473 |
+
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
|
| 474 |
+
else:
|
| 475 |
+
data_collator = None
|
| 476 |
+
|
| 477 |
+
training_args.run_name = run_name
|
| 478 |
+
# Initialize our Trainer
|
| 479 |
+
trainer = Trainer(
|
| 480 |
+
model=model,
|
| 481 |
+
args=training_args,
|
| 482 |
+
train_dataset=train_dataset if training_args.do_train else None,
|
| 483 |
+
eval_dataset=eval_dataset if training_args.do_eval else None,
|
| 484 |
+
compute_metrics=compute_metrics,
|
| 485 |
+
tokenizer=tokenizer,
|
| 486 |
+
data_collator=data_collator,
|
| 487 |
+
)
|
| 488 |
+
|
| 489 |
+
# Training
|
| 490 |
+
if training_args.do_train:
|
| 491 |
+
checkpoint = None
|
| 492 |
+
if training_args.resume_from_checkpoint is not None:
|
| 493 |
+
checkpoint = training_args.resume_from_checkpoint
|
| 494 |
+
elif last_checkpoint is not None:
|
| 495 |
+
checkpoint = last_checkpoint
|
| 496 |
+
train_result = trainer.train(resume_from_checkpoint=checkpoint)
|
| 497 |
+
metrics = train_result.metrics
|
| 498 |
+
max_train_samples = (
|
| 499 |
+
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
|
| 500 |
+
)
|
| 501 |
+
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
|
| 502 |
+
|
| 503 |
+
trainer.save_model() # Saves the tokenizer too for easy upload
|
| 504 |
+
|
| 505 |
+
trainer.log_metrics("train", metrics)
|
| 506 |
+
trainer.save_metrics("train", metrics)
|
| 507 |
+
trainer.save_state()
|
| 508 |
+
|
| 509 |
+
# Evaluation
|
| 510 |
+
if training_args.do_eval:
|
| 511 |
+
logger.info("*** Evaluate ***")
|
| 512 |
+
|
| 513 |
+
# Loop to handle MNLI double evaluation (matched, mis-matched)
|
| 514 |
+
tasks = [data_args.task_name]
|
| 515 |
+
eval_datasets = [eval_dataset]
|
| 516 |
+
if data_args.task_name == "mnli":
|
| 517 |
+
tasks.append("mnli-mm")
|
| 518 |
+
eval_datasets.append(raw_datasets["validation_mismatched"])
|
| 519 |
+
|
| 520 |
+
for eval_dataset, task in zip(eval_datasets, tasks):
|
| 521 |
+
metrics = trainer.evaluate(eval_dataset=eval_dataset)
|
| 522 |
+
|
| 523 |
+
max_eval_samples = (
|
| 524 |
+
data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
|
| 525 |
+
)
|
| 526 |
+
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
|
| 527 |
+
|
| 528 |
+
trainer.log_metrics("eval", metrics)
|
| 529 |
+
trainer.save_metrics("eval", metrics)
|
| 530 |
+
|
| 531 |
+
if training_args.do_predict:
|
| 532 |
+
logger.info("*** Predict ***")
|
| 533 |
+
|
| 534 |
+
# Loop to handle MNLI double evaluation (matched, mis-matched)
|
| 535 |
+
tasks = [data_args.task_name]
|
| 536 |
+
predict_datasets = [predict_dataset]
|
| 537 |
+
if data_args.task_name == "mnli":
|
| 538 |
+
tasks.append("mnli-mm")
|
| 539 |
+
predict_datasets.append(raw_datasets["test_mismatched"])
|
| 540 |
+
|
| 541 |
+
for predict_dataset, task in zip(predict_datasets, tasks):
|
| 542 |
+
# Removing the `label` columns because it contains -1 and Trainer won't like that.
|
| 543 |
+
predict_dataset = predict_dataset.remove_columns("label")
|
| 544 |
+
predictions = trainer.predict(predict_dataset, metric_key_prefix="predict").predictions
|
| 545 |
+
predictions = np.squeeze(predictions) if is_regression else np.argmax(predictions, axis=1)
|
| 546 |
+
|
| 547 |
+
output_predict_file = os.path.join(training_args.output_dir, f"predict_results_{task}.txt")
|
| 548 |
+
if trainer.is_world_process_zero():
|
| 549 |
+
with open(output_predict_file, "w") as writer:
|
| 550 |
+
logger.info(f"***** Predict results {task} *****")
|
| 551 |
+
writer.write("index\tprediction\n")
|
| 552 |
+
for index, item in enumerate(predictions):
|
| 553 |
+
if is_regression:
|
| 554 |
+
writer.write(f"{index}\t{item:3.3f}\n")
|
| 555 |
+
else:
|
| 556 |
+
item = label_list[item]
|
| 557 |
+
writer.write(f"{index}\t{item}\n")
|
| 558 |
+
|
| 559 |
+
if training_args.push_to_hub:
|
| 560 |
+
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
|
| 561 |
+
if data_args.task_name is not None:
|
| 562 |
+
kwargs["language"] = "en"
|
| 563 |
+
kwargs["dataset_tags"] = "glue"
|
| 564 |
+
kwargs["dataset_args"] = data_args.task_name
|
| 565 |
+
kwargs["dataset"] = f"GLUE {data_args.task_name.upper()}"
|
| 566 |
+
|
| 567 |
+
trainer.push_to_hub(**kwargs)
|
| 568 |
+
|
| 569 |
+
|
| 570 |
+
def _mp_fn(index):
|
| 571 |
+
# For xla_spawn (TPUs)
|
| 572 |
+
main()
|
| 573 |
+
|
| 574 |
+
|
| 575 |
+
if __name__ == "__main__":
|
| 576 |
+
main()
|
evaluation/run_ner.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
evaluation/run_ner.py
ADDED
|
@@ -0,0 +1,562 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# coding=utf-8
|
| 3 |
+
# Copyright 2020 The HuggingFace Team All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for token classification.
|
| 18 |
+
"""
|
| 19 |
+
# You can also adapt this script on your own token classification task and datasets. Pointers for this are left as
|
| 20 |
+
# comments.
|
| 21 |
+
|
| 22 |
+
import logging
|
| 23 |
+
import os
|
| 24 |
+
import sys
|
| 25 |
+
from dataclasses import dataclass, field
|
| 26 |
+
from pathlib import Path
|
| 27 |
+
from typing import Optional
|
| 28 |
+
|
| 29 |
+
import datasets
|
| 30 |
+
import numpy as np
|
| 31 |
+
from datasets import ClassLabel, load_dataset, load_metric
|
| 32 |
+
|
| 33 |
+
import transformers
|
| 34 |
+
from transformers import (
|
| 35 |
+
AutoConfig,
|
| 36 |
+
AutoModelForTokenClassification,
|
| 37 |
+
AutoTokenizer,
|
| 38 |
+
DataCollatorForTokenClassification,
|
| 39 |
+
HfArgumentParser,
|
| 40 |
+
PreTrainedTokenizerFast,
|
| 41 |
+
Trainer,
|
| 42 |
+
TrainingArguments,
|
| 43 |
+
set_seed,
|
| 44 |
+
)
|
| 45 |
+
from transformers.trainer_utils import get_last_checkpoint
|
| 46 |
+
from transformers.utils import check_min_version
|
| 47 |
+
from transformers.utils.versions import require_version
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
| 51 |
+
check_min_version("4.9.0.dev0")
|
| 52 |
+
|
| 53 |
+
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
|
| 54 |
+
|
| 55 |
+
logger = logging.getLogger(__name__)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
@dataclass
|
| 59 |
+
class ModelArguments:
|
| 60 |
+
"""
|
| 61 |
+
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
|
| 62 |
+
"""
|
| 63 |
+
|
| 64 |
+
model_name_or_path: str = field(
|
| 65 |
+
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
|
| 66 |
+
)
|
| 67 |
+
config_name: Optional[str] = field(
|
| 68 |
+
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
|
| 69 |
+
)
|
| 70 |
+
tokenizer_name: Optional[str] = field(
|
| 71 |
+
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
|
| 72 |
+
)
|
| 73 |
+
cache_dir: Optional[str] = field(
|
| 74 |
+
default=None,
|
| 75 |
+
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
|
| 76 |
+
)
|
| 77 |
+
model_revision: str = field(
|
| 78 |
+
default="main",
|
| 79 |
+
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
|
| 80 |
+
)
|
| 81 |
+
use_auth_token: bool = field(
|
| 82 |
+
default=False,
|
| 83 |
+
metadata={
|
| 84 |
+
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
| 85 |
+
"with private models)."
|
| 86 |
+
},
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
@dataclass
|
| 91 |
+
class DataTrainingArguments:
|
| 92 |
+
"""
|
| 93 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 94 |
+
"""
|
| 95 |
+
|
| 96 |
+
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
|
| 97 |
+
dataset_name: Optional[str] = field(
|
| 98 |
+
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
|
| 99 |
+
)
|
| 100 |
+
dataset_config_name: Optional[str] = field(
|
| 101 |
+
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
|
| 102 |
+
)
|
| 103 |
+
train_file: Optional[str] = field(
|
| 104 |
+
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
|
| 105 |
+
)
|
| 106 |
+
validation_file: Optional[str] = field(
|
| 107 |
+
default=None,
|
| 108 |
+
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
|
| 109 |
+
)
|
| 110 |
+
test_file: Optional[str] = field(
|
| 111 |
+
default=None,
|
| 112 |
+
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
|
| 113 |
+
)
|
| 114 |
+
text_column_name: Optional[str] = field(
|
| 115 |
+
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
|
| 116 |
+
)
|
| 117 |
+
label_column_name: Optional[str] = field(
|
| 118 |
+
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
|
| 119 |
+
)
|
| 120 |
+
overwrite_cache: bool = field(
|
| 121 |
+
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
|
| 122 |
+
)
|
| 123 |
+
preprocessing_num_workers: Optional[int] = field(
|
| 124 |
+
default=None,
|
| 125 |
+
metadata={"help": "The number of processes to use for the preprocessing."},
|
| 126 |
+
)
|
| 127 |
+
pad_to_max_length: bool = field(
|
| 128 |
+
default=False,
|
| 129 |
+
metadata={
|
| 130 |
+
"help": "Whether to pad all samples to model maximum sentence length. "
|
| 131 |
+
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
|
| 132 |
+
"efficient on GPU but very bad for TPU."
|
| 133 |
+
},
|
| 134 |
+
)
|
| 135 |
+
max_train_samples: Optional[int] = field(
|
| 136 |
+
default=None,
|
| 137 |
+
metadata={
|
| 138 |
+
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
| 139 |
+
"value if set."
|
| 140 |
+
},
|
| 141 |
+
)
|
| 142 |
+
max_eval_samples: Optional[int] = field(
|
| 143 |
+
default=None,
|
| 144 |
+
metadata={
|
| 145 |
+
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
| 146 |
+
"value if set."
|
| 147 |
+
},
|
| 148 |
+
)
|
| 149 |
+
max_predict_samples: Optional[int] = field(
|
| 150 |
+
default=None,
|
| 151 |
+
metadata={
|
| 152 |
+
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
| 153 |
+
"value if set."
|
| 154 |
+
},
|
| 155 |
+
)
|
| 156 |
+
label_all_tokens: bool = field(
|
| 157 |
+
default=False,
|
| 158 |
+
metadata={
|
| 159 |
+
"help": "Whether to put the label for one word on all tokens of generated by that word or just on the "
|
| 160 |
+
"one (in which case the other tokens will have a padding index)."
|
| 161 |
+
},
|
| 162 |
+
)
|
| 163 |
+
return_entity_level_metrics: bool = field(
|
| 164 |
+
default=False,
|
| 165 |
+
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
def __post_init__(self):
|
| 169 |
+
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
|
| 170 |
+
raise ValueError("Need either a dataset name or a training/validation file.")
|
| 171 |
+
else:
|
| 172 |
+
if self.train_file is not None:
|
| 173 |
+
extension = self.train_file.split(".")[-1]
|
| 174 |
+
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
|
| 175 |
+
if self.validation_file is not None:
|
| 176 |
+
extension = self.validation_file.split(".")[-1]
|
| 177 |
+
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
|
| 178 |
+
self.task_name = self.task_name.lower()
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def main():
|
| 182 |
+
# See all possible arguments in src/transformers/training_args.py
|
| 183 |
+
# or by passing the --help flag to this script.
|
| 184 |
+
# We now keep distinct sets of args, for a cleaner separation of concerns.
|
| 185 |
+
|
| 186 |
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
|
| 187 |
+
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
|
| 188 |
+
# If we pass only one argument to the script and it's the path to a json file,
|
| 189 |
+
# let's parse it to get our arguments.
|
| 190 |
+
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
|
| 191 |
+
else:
|
| 192 |
+
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
| 193 |
+
|
| 194 |
+
# Setup logging
|
| 195 |
+
logging.basicConfig(
|
| 196 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 197 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 198 |
+
handlers=[logging.StreamHandler(sys.stdout)],
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
log_level = training_args.get_process_log_level()
|
| 202 |
+
logger.setLevel(log_level)
|
| 203 |
+
datasets.utils.logging.set_verbosity(log_level)
|
| 204 |
+
transformers.utils.logging.set_verbosity(log_level)
|
| 205 |
+
transformers.utils.logging.enable_default_handler()
|
| 206 |
+
transformers.utils.logging.enable_explicit_format()
|
| 207 |
+
|
| 208 |
+
# Log on each process the small summary:
|
| 209 |
+
logger.warning(
|
| 210 |
+
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
|
| 211 |
+
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
|
| 212 |
+
)
|
| 213 |
+
logger.info(f"Training/evaluation parameters {training_args}")
|
| 214 |
+
|
| 215 |
+
# Detecting last checkpoint.
|
| 216 |
+
last_checkpoint = None
|
| 217 |
+
run_name = f"{model_args.model_name_or_path}-{np.random.randint(1000):04d}"
|
| 218 |
+
training_args.output_dir = str(Path(training_args.output_dir) / run_name)
|
| 219 |
+
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
|
| 220 |
+
last_checkpoint = get_last_checkpoint(training_args.output_dir)
|
| 221 |
+
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
|
| 222 |
+
raise ValueError(
|
| 223 |
+
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
|
| 224 |
+
"Use --overwrite_output_dir to overcome."
|
| 225 |
+
)
|
| 226 |
+
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
|
| 227 |
+
logger.info(
|
| 228 |
+
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
|
| 229 |
+
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
# Set seed before initializing model.
|
| 233 |
+
set_seed(training_args.seed)
|
| 234 |
+
|
| 235 |
+
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
|
| 236 |
+
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
|
| 237 |
+
# (the dataset will be downloaded automatically from the datasets Hub).
|
| 238 |
+
#
|
| 239 |
+
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
|
| 240 |
+
# 'text' is found. You can easily tweak this behavior (see below).
|
| 241 |
+
#
|
| 242 |
+
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
|
| 243 |
+
# download the dataset.
|
| 244 |
+
if data_args.dataset_name is not None:
|
| 245 |
+
# Downloading and loading a dataset from the hub.
|
| 246 |
+
raw_datasets = load_dataset(
|
| 247 |
+
data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
|
| 248 |
+
)
|
| 249 |
+
else:
|
| 250 |
+
data_files = {}
|
| 251 |
+
if data_args.train_file is not None:
|
| 252 |
+
data_files["train"] = data_args.train_file
|
| 253 |
+
if data_args.validation_file is not None:
|
| 254 |
+
data_files["validation"] = data_args.validation_file
|
| 255 |
+
if data_args.test_file is not None:
|
| 256 |
+
data_files["test"] = data_args.test_file
|
| 257 |
+
extension = data_args.train_file.split(".")[-1]
|
| 258 |
+
raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
|
| 259 |
+
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
|
| 260 |
+
# https://huggingface.co/docs/datasets/loading_datasets.html.
|
| 261 |
+
|
| 262 |
+
if training_args.do_train:
|
| 263 |
+
column_names = raw_datasets["train"].column_names
|
| 264 |
+
features = raw_datasets["train"].features
|
| 265 |
+
else:
|
| 266 |
+
column_names = raw_datasets["validation"].column_names
|
| 267 |
+
features = raw_datasets["validation"].features
|
| 268 |
+
|
| 269 |
+
if data_args.text_column_name is not None:
|
| 270 |
+
text_column_name = data_args.text_column_name
|
| 271 |
+
elif "tokens" in column_names:
|
| 272 |
+
text_column_name = "tokens"
|
| 273 |
+
else:
|
| 274 |
+
text_column_name = column_names[0]
|
| 275 |
+
|
| 276 |
+
if data_args.label_column_name is not None:
|
| 277 |
+
label_column_name = data_args.label_column_name
|
| 278 |
+
elif f"{data_args.task_name}_tags" in column_names:
|
| 279 |
+
label_column_name = f"{data_args.task_name}_tags"
|
| 280 |
+
else:
|
| 281 |
+
label_column_name = column_names[1]
|
| 282 |
+
|
| 283 |
+
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
|
| 284 |
+
# unique labels.
|
| 285 |
+
def get_label_list(labels):
|
| 286 |
+
unique_labels = set()
|
| 287 |
+
for label in labels:
|
| 288 |
+
unique_labels = unique_labels | set(label)
|
| 289 |
+
label_list = list(unique_labels)
|
| 290 |
+
label_list.sort()
|
| 291 |
+
return label_list
|
| 292 |
+
|
| 293 |
+
if isinstance(features[label_column_name].feature, ClassLabel):
|
| 294 |
+
label_list = features[label_column_name].feature.names
|
| 295 |
+
# No need to convert the labels since they are already ints.
|
| 296 |
+
label_to_id = {i: i for i in range(len(label_list))}
|
| 297 |
+
else:
|
| 298 |
+
label_list = get_label_list(raw_datasets["train"][label_column_name])
|
| 299 |
+
label_to_id = {l: i for i, l in enumerate(label_list)}
|
| 300 |
+
num_labels = len(label_list)
|
| 301 |
+
|
| 302 |
+
# Load pretrained model and tokenizer
|
| 303 |
+
#
|
| 304 |
+
# Distributed training:
|
| 305 |
+
# The .from_pretrained methods guarantee that only one local process can concurrently
|
| 306 |
+
# download model & vocab.
|
| 307 |
+
config = AutoConfig.from_pretrained(
|
| 308 |
+
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
|
| 309 |
+
num_labels=num_labels,
|
| 310 |
+
label2id=label_to_id,
|
| 311 |
+
id2label={i: l for l, i in label_to_id.items()},
|
| 312 |
+
finetuning_task=data_args.task_name,
|
| 313 |
+
cache_dir=model_args.cache_dir,
|
| 314 |
+
revision=model_args.model_revision,
|
| 315 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
|
| 319 |
+
if config.model_type in {"gpt2", "roberta"}:
|
| 320 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 321 |
+
tokenizer_name_or_path,
|
| 322 |
+
cache_dir=model_args.cache_dir,
|
| 323 |
+
use_fast=True,
|
| 324 |
+
revision=model_args.model_revision,
|
| 325 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 326 |
+
add_prefix_space=True,
|
| 327 |
+
)
|
| 328 |
+
else:
|
| 329 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 330 |
+
tokenizer_name_or_path,
|
| 331 |
+
cache_dir=model_args.cache_dir,
|
| 332 |
+
use_fast=True,
|
| 333 |
+
revision=model_args.model_revision,
|
| 334 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 335 |
+
)
|
| 336 |
+
tokenizer.model_max_length = 512
|
| 337 |
+
|
| 338 |
+
model = AutoModelForTokenClassification.from_pretrained(
|
| 339 |
+
model_args.model_name_or_path,
|
| 340 |
+
from_tf=bool(".ckpt" in model_args.model_name_or_path),
|
| 341 |
+
config=config,
|
| 342 |
+
cache_dir=model_args.cache_dir,
|
| 343 |
+
revision=model_args.model_revision,
|
| 344 |
+
use_auth_token=True if model_args.use_auth_token else None,
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
# Tokenizer check: this script requires a fast tokenizer.
|
| 348 |
+
if not isinstance(tokenizer, PreTrainedTokenizerFast):
|
| 349 |
+
raise ValueError(
|
| 350 |
+
"This example script only works for models that have a fast tokenizer. Checkout the big table of models "
|
| 351 |
+
"at https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet this "
|
| 352 |
+
"requirement"
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# Preprocessing the dataset
|
| 356 |
+
# Padding strategy
|
| 357 |
+
padding = "max_length" if data_args.pad_to_max_length else False
|
| 358 |
+
|
| 359 |
+
# Tokenize all texts and align the labels with them.
|
| 360 |
+
def tokenize_and_align_labels(examples):
|
| 361 |
+
tokenized_inputs = tokenizer(
|
| 362 |
+
examples[text_column_name],
|
| 363 |
+
padding=padding,
|
| 364 |
+
max_length=512,
|
| 365 |
+
truncation=True,
|
| 366 |
+
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
|
| 367 |
+
is_split_into_words=True,
|
| 368 |
+
)
|
| 369 |
+
labels = []
|
| 370 |
+
for i, label in enumerate(examples[label_column_name]):
|
| 371 |
+
word_ids = tokenized_inputs.word_ids(batch_index=i)
|
| 372 |
+
previous_word_idx = None
|
| 373 |
+
label_ids = []
|
| 374 |
+
for word_idx in word_ids:
|
| 375 |
+
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
|
| 376 |
+
# ignored in the loss function.
|
| 377 |
+
if word_idx is None:
|
| 378 |
+
label_ids.append(-100)
|
| 379 |
+
# We set the label for the first token of each word.
|
| 380 |
+
elif word_idx != previous_word_idx:
|
| 381 |
+
label_ids.append(label_to_id[label[word_idx]])
|
| 382 |
+
# For the other tokens in a word, we set the label to either the current label or -100, depending on
|
| 383 |
+
# the label_all_tokens flag.
|
| 384 |
+
else:
|
| 385 |
+
label_ids.append(label_to_id[label[word_idx]] if data_args.label_all_tokens else -100)
|
| 386 |
+
previous_word_idx = word_idx
|
| 387 |
+
|
| 388 |
+
labels.append(label_ids)
|
| 389 |
+
tokenized_inputs["labels"] = labels
|
| 390 |
+
return tokenized_inputs
|
| 391 |
+
|
| 392 |
+
if training_args.do_train:
|
| 393 |
+
if "train" not in raw_datasets:
|
| 394 |
+
raise ValueError("--do_train requires a train dataset")
|
| 395 |
+
train_dataset = raw_datasets["train"]
|
| 396 |
+
if data_args.max_train_samples is not None:
|
| 397 |
+
train_dataset = train_dataset.select(range(data_args.max_train_samples))
|
| 398 |
+
with training_args.main_process_first(desc="train dataset map pre-processing"):
|
| 399 |
+
train_dataset = train_dataset.map(
|
| 400 |
+
tokenize_and_align_labels,
|
| 401 |
+
batched=True,
|
| 402 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 403 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 404 |
+
desc="Running tokenizer on train dataset",
|
| 405 |
+
)
|
| 406 |
+
|
| 407 |
+
if training_args.do_eval:
|
| 408 |
+
if "validation" not in raw_datasets:
|
| 409 |
+
raise ValueError("--do_eval requires a validation dataset")
|
| 410 |
+
eval_dataset = raw_datasets["validation"]
|
| 411 |
+
if data_args.max_eval_samples is not None:
|
| 412 |
+
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
|
| 413 |
+
with training_args.main_process_first(desc="validation dataset map pre-processing"):
|
| 414 |
+
eval_dataset = eval_dataset.map(
|
| 415 |
+
tokenize_and_align_labels,
|
| 416 |
+
batched=True,
|
| 417 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 418 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 419 |
+
desc="Running tokenizer on validation dataset",
|
| 420 |
+
)
|
| 421 |
+
|
| 422 |
+
if training_args.do_predict:
|
| 423 |
+
if "test" not in raw_datasets:
|
| 424 |
+
raise ValueError("--do_predict requires a test dataset")
|
| 425 |
+
predict_dataset = raw_datasets["test"]
|
| 426 |
+
if data_args.max_predict_samples is not None:
|
| 427 |
+
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
|
| 428 |
+
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
|
| 429 |
+
predict_dataset = predict_dataset.map(
|
| 430 |
+
tokenize_and_align_labels,
|
| 431 |
+
batched=True,
|
| 432 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 433 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 434 |
+
desc="Running tokenizer on prediction dataset",
|
| 435 |
+
)
|
| 436 |
+
|
| 437 |
+
# Data collator
|
| 438 |
+
data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
|
| 439 |
+
|
| 440 |
+
# Metrics
|
| 441 |
+
metric = load_metric("seqeval")
|
| 442 |
+
|
| 443 |
+
def compute_metrics(p):
|
| 444 |
+
predictions, labels = p
|
| 445 |
+
predictions = np.argmax(predictions, axis=2)
|
| 446 |
+
|
| 447 |
+
# Remove ignored index (special tokens)
|
| 448 |
+
true_predictions = [
|
| 449 |
+
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
|
| 450 |
+
for prediction, label in zip(predictions, labels)
|
| 451 |
+
]
|
| 452 |
+
true_labels = [
|
| 453 |
+
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
|
| 454 |
+
for prediction, label in zip(predictions, labels)
|
| 455 |
+
]
|
| 456 |
+
|
| 457 |
+
results = metric.compute(predictions=true_predictions, references=true_labels)
|
| 458 |
+
if data_args.return_entity_level_metrics:
|
| 459 |
+
# Unpack nested dictionaries
|
| 460 |
+
final_results = {}
|
| 461 |
+
for key, value in results.items():
|
| 462 |
+
if isinstance(value, dict):
|
| 463 |
+
for n, v in value.items():
|
| 464 |
+
final_results[f"{key}_{n}"] = v
|
| 465 |
+
else:
|
| 466 |
+
final_results[key] = value
|
| 467 |
+
return final_results
|
| 468 |
+
else:
|
| 469 |
+
return {
|
| 470 |
+
"precision": results["overall_precision"],
|
| 471 |
+
"recall": results["overall_recall"],
|
| 472 |
+
"f1": results["overall_f1"],
|
| 473 |
+
"accuracy": results["overall_accuracy"],
|
| 474 |
+
}
|
| 475 |
+
|
| 476 |
+
# Initialize our Trainer
|
| 477 |
+
training_args.run_name = run_name
|
| 478 |
+
trainer = Trainer(
|
| 479 |
+
model=model,
|
| 480 |
+
args=training_args,
|
| 481 |
+
train_dataset=train_dataset if training_args.do_train else None,
|
| 482 |
+
eval_dataset=eval_dataset if training_args.do_eval else None,
|
| 483 |
+
tokenizer=tokenizer,
|
| 484 |
+
data_collator=data_collator,
|
| 485 |
+
compute_metrics=compute_metrics,
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
# Training
|
| 489 |
+
if training_args.do_train:
|
| 490 |
+
checkpoint = None
|
| 491 |
+
if training_args.resume_from_checkpoint is not None:
|
| 492 |
+
checkpoint = training_args.resume_from_checkpoint
|
| 493 |
+
elif last_checkpoint is not None:
|
| 494 |
+
checkpoint = last_checkpoint
|
| 495 |
+
train_result = trainer.train(resume_from_checkpoint=checkpoint)
|
| 496 |
+
metrics = train_result.metrics
|
| 497 |
+
trainer.save_model() # Saves the tokenizer too for easy upload
|
| 498 |
+
|
| 499 |
+
max_train_samples = (
|
| 500 |
+
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
|
| 501 |
+
)
|
| 502 |
+
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
|
| 503 |
+
|
| 504 |
+
trainer.log_metrics("train", metrics)
|
| 505 |
+
trainer.save_metrics("train", metrics)
|
| 506 |
+
trainer.save_state()
|
| 507 |
+
|
| 508 |
+
# Evaluation
|
| 509 |
+
if training_args.do_eval:
|
| 510 |
+
logger.info("*** Evaluate ***")
|
| 511 |
+
|
| 512 |
+
metrics = trainer.evaluate()
|
| 513 |
+
|
| 514 |
+
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
|
| 515 |
+
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
|
| 516 |
+
|
| 517 |
+
trainer.log_metrics("eval", metrics)
|
| 518 |
+
trainer.save_metrics("eval", metrics)
|
| 519 |
+
|
| 520 |
+
# Predict
|
| 521 |
+
if training_args.do_predict:
|
| 522 |
+
logger.info("*** Predict ***")
|
| 523 |
+
|
| 524 |
+
predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
|
| 525 |
+
predictions = np.argmax(predictions, axis=2)
|
| 526 |
+
|
| 527 |
+
# Remove ignored index (special tokens)
|
| 528 |
+
true_predictions = [
|
| 529 |
+
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
|
| 530 |
+
for prediction, label in zip(predictions, labels)
|
| 531 |
+
]
|
| 532 |
+
|
| 533 |
+
trainer.log_metrics("predict", metrics)
|
| 534 |
+
trainer.save_metrics("predict", metrics)
|
| 535 |
+
|
| 536 |
+
# Save predictions
|
| 537 |
+
output_predictions_file = os.path.join(training_args.output_dir, "predictions.txt")
|
| 538 |
+
if trainer.is_world_process_zero():
|
| 539 |
+
with open(output_predictions_file, "w") as writer:
|
| 540 |
+
for prediction in true_predictions:
|
| 541 |
+
writer.write(" ".join(prediction) + "\n")
|
| 542 |
+
|
| 543 |
+
if training_args.push_to_hub:
|
| 544 |
+
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
|
| 545 |
+
if data_args.dataset_name is not None:
|
| 546 |
+
kwargs["dataset_tags"] = data_args.dataset_name
|
| 547 |
+
if data_args.dataset_config_name is not None:
|
| 548 |
+
kwargs["dataset_args"] = data_args.dataset_config_name
|
| 549 |
+
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
|
| 550 |
+
else:
|
| 551 |
+
kwargs["dataset"] = data_args.dataset_name
|
| 552 |
+
|
| 553 |
+
trainer.push_to_hub(**kwargs)
|
| 554 |
+
|
| 555 |
+
|
| 556 |
+
def _mp_fn(index):
|
| 557 |
+
# For xla_spawn (TPUs)
|
| 558 |
+
main()
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
if __name__ == "__main__":
|
| 562 |
+
main()
|
evaluation/xnli.yaml
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: BERTIN XNLI es
|
| 2 |
+
project: bertin-eval
|
| 3 |
+
enitity: versae
|
| 4 |
+
program: run_glue.py
|
| 5 |
+
command:
|
| 6 |
+
- ${env}
|
| 7 |
+
- ${interpreter}
|
| 8 |
+
- ${program}
|
| 9 |
+
- ${args}
|
| 10 |
+
method: grid
|
| 11 |
+
metric:
|
| 12 |
+
name: eval/accuracy
|
| 13 |
+
goal: maximize
|
| 14 |
+
parameters:
|
| 15 |
+
model_name_or_path:
|
| 16 |
+
values:
|
| 17 |
+
- bertin-project/bertin-base-gaussian-exp-512seqlen
|
| 18 |
+
- bertin-project/bertin-base-random-exp-512seqlen
|
| 19 |
+
- bertin-project/bertin-base-gaussian
|
| 20 |
+
- bertin-project/bertin-base-stepwise
|
| 21 |
+
- bertin-project/bertin-base-random
|
| 22 |
+
- bertin-project/bertin-roberta-base-spanish
|
| 23 |
+
- flax-community/bertin-roberta-large-spanish
|
| 24 |
+
- BSC-TeMU/roberta-base-bne
|
| 25 |
+
- dccuchile/bert-base-spanish-wwm-cased
|
| 26 |
+
- bert-base-multilingual-cased
|
| 27 |
+
num_train_epochs:
|
| 28 |
+
values: [5]
|
| 29 |
+
task_name:
|
| 30 |
+
value: xnli
|
| 31 |
+
dataset_name:
|
| 32 |
+
value: xnli
|
| 33 |
+
dataset_config_name:
|
| 34 |
+
value: es
|
| 35 |
+
output_dir:
|
| 36 |
+
value: ./outputs
|
| 37 |
+
overwrite_output_dir:
|
| 38 |
+
value: true
|
| 39 |
+
resume_from_checkpoint:
|
| 40 |
+
value: false
|
| 41 |
+
max_seq_length:
|
| 42 |
+
value: 512
|
| 43 |
+
pad_to_max_length:
|
| 44 |
+
value: true
|
| 45 |
+
per_device_train_batch_size:
|
| 46 |
+
value: 16
|
| 47 |
+
per_device_eval_batch_size:
|
| 48 |
+
value: 16
|
| 49 |
+
save_total_limit:
|
| 50 |
+
value: 1
|
| 51 |
+
do_train:
|
| 52 |
+
value: true
|
| 53 |
+
do_eval:
|
| 54 |
+
value: true
|
| 55 |
+
|
images/bertin-tilt.png
ADDED

|
images/bertin.png
ADDED

|
images/datasets-perp-20-120.png
ADDED
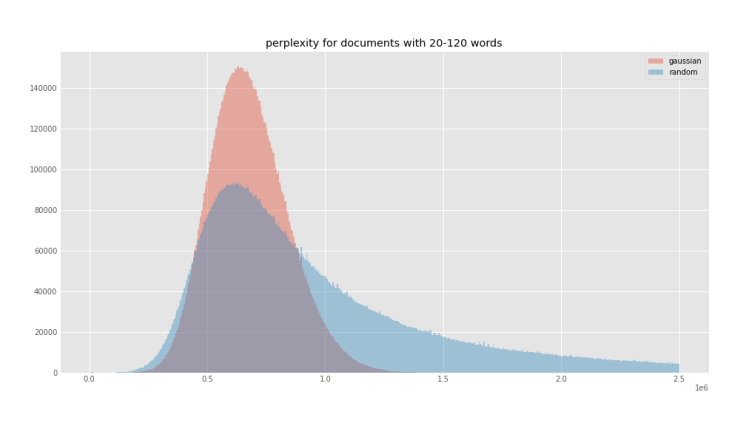
|
images/datasets-wsize.png
ADDED
|
mc4/mc4.py
CHANGED
|
@@ -376,13 +376,13 @@ class Mc4(datasets.GeneratorBasedBuilder):
|
|
| 376 |
for lang in self.config.languages
|
| 377 |
for index in range(_N_SHARDS_PER_SPLIT[lang][split])
|
| 378 |
]
|
| 379 |
-
if "train" in self.data_files:
|
| 380 |
train_downloaded_files = self.data_files["train"]
|
| 381 |
if not isinstance(train_downloaded_files, (tuple, list)):
|
| 382 |
train_downloaded_files = [train_downloaded_files]
|
| 383 |
else:
|
| 384 |
train_downloaded_files = dl_manager.download(data_urls["train"])
|
| 385 |
-
if "validation" in self.data_files:
|
| 386 |
validation_downloaded_files = self.data_files["validation"]
|
| 387 |
if not isinstance(validation_downloaded_files, (tuple, list)):
|
| 388 |
validation_downloaded_files = [validation_downloaded_files]
|
|
@@ -417,7 +417,7 @@ class Mc4(datasets.GeneratorBasedBuilder):
|
|
| 417 |
if self.should_keep_doc(
|
| 418 |
example["text"],
|
| 419 |
factor=self.sampling_factor,
|
| 420 |
-
boundaries=self.boundaries
|
| 421 |
**self.kwargs):
|
| 422 |
yield id_, example
|
| 423 |
id_ += 1
|
|
|
|
| 376 |
for lang in self.config.languages
|
| 377 |
for index in range(_N_SHARDS_PER_SPLIT[lang][split])
|
| 378 |
]
|
| 379 |
+
if self.data_files and "train" in self.data_files:
|
| 380 |
train_downloaded_files = self.data_files["train"]
|
| 381 |
if not isinstance(train_downloaded_files, (tuple, list)):
|
| 382 |
train_downloaded_files = [train_downloaded_files]
|
| 383 |
else:
|
| 384 |
train_downloaded_files = dl_manager.download(data_urls["train"])
|
| 385 |
+
if self.data_files and "validation" in self.data_files:
|
| 386 |
validation_downloaded_files = self.data_files["validation"]
|
| 387 |
if not isinstance(validation_downloaded_files, (tuple, list)):
|
| 388 |
validation_downloaded_files = [validation_downloaded_files]
|
|
|
|
| 417 |
if self.should_keep_doc(
|
| 418 |
example["text"],
|
| 419 |
factor=self.sampling_factor,
|
| 420 |
+
boundaries=self.boundaries,
|
| 421 |
**self.kwargs):
|
| 422 |
yield id_, example
|
| 423 |
id_ += 1
|
run_mlm_flax_stream.py
CHANGED
|
@@ -25,6 +25,7 @@ import json
|
|
| 25 |
import os
|
| 26 |
import shutil
|
| 27 |
import sys
|
|
|
|
| 28 |
import time
|
| 29 |
from collections import defaultdict
|
| 30 |
from dataclasses import dataclass, field
|
|
@@ -60,6 +61,8 @@ from transformers import (
|
|
| 60 |
TrainingArguments,
|
| 61 |
is_tensorboard_available,
|
| 62 |
set_seed,
|
|
|
|
|
|
|
| 63 |
)
|
| 64 |
|
| 65 |
|
|
@@ -376,6 +379,27 @@ def rotate_checkpoints(path, max_checkpoints=5):
|
|
| 376 |
os.remove(path_to_delete)
|
| 377 |
|
| 378 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 379 |
if __name__ == "__main__":
|
| 380 |
# See all possible arguments in src/transformers/training_args.py
|
| 381 |
# or by passing the --help flag to this script.
|
|
@@ -749,7 +773,8 @@ if __name__ == "__main__":
|
|
| 749 |
eval_metrics = jax.tree_map(lambda x: x / eval_normalizer, eval_metrics)
|
| 750 |
|
| 751 |
# Update progress bar
|
| 752 |
-
steps.desc = f"Step... ({step
|
|
|
|
| 753 |
|
| 754 |
if has_tensorboard and jax.process_index() == 0:
|
| 755 |
write_eval_metric(summary_writer, eval_metrics, step)
|
|
@@ -762,8 +787,7 @@ if __name__ == "__main__":
|
|
| 762 |
model.save_pretrained(
|
| 763 |
training_args.output_dir,
|
| 764 |
params=params,
|
| 765 |
-
push_to_hub=
|
| 766 |
-
commit_message=f"Saving weights and logs of step {step + 1}",
|
| 767 |
)
|
| 768 |
save_checkpoint_files(state, data_collator, training_args, training_args.output_dir)
|
| 769 |
checkpoints_dir = Path(training_args.output_dir) / "checkpoints" / f"checkpoint-{step}"
|
|
@@ -774,6 +798,34 @@ if __name__ == "__main__":
|
|
| 774 |
Path(training_args.output_dir) / "checkpoints",
|
| 775 |
max_checkpoints=training_args.save_total_limit
|
| 776 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 777 |
|
| 778 |
# update tqdm bar
|
| 779 |
steps.update(1)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
import os
|
| 26 |
import shutil
|
| 27 |
import sys
|
| 28 |
+
import tempfile
|
| 29 |
import time
|
| 30 |
from collections import defaultdict
|
| 31 |
from dataclasses import dataclass, field
|
|
|
|
| 61 |
TrainingArguments,
|
| 62 |
is_tensorboard_available,
|
| 63 |
set_seed,
|
| 64 |
+
FlaxRobertaForMaskedLM,
|
| 65 |
+
RobertaForMaskedLM,
|
| 66 |
)
|
| 67 |
|
| 68 |
|
|
|
|
| 379 |
os.remove(path_to_delete)
|
| 380 |
|
| 381 |
|
| 382 |
+
def to_f32(t):
|
| 383 |
+
return jax.tree_map(lambda x: x.astype(jnp.float32) if x.dtype == jnp.bfloat16 else x, t)
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def convert(output_dir, destination_dir="./"):
|
| 387 |
+
shutil.copyfile(Path(output_dir) / "flax_model.msgpack", destination_dir)
|
| 388 |
+
shutil.copyfile(Path(output_dir) / "config.json", destination_dir)
|
| 389 |
+
# Saving extra files from config.json and tokenizer.json files
|
| 390 |
+
tokenizer = AutoTokenizer.from_pretrained(destination_dir)
|
| 391 |
+
tokenizer.save_pretrained(destination_dir)
|
| 392 |
+
|
| 393 |
+
# Temporary saving bfloat16 Flax model into float32
|
| 394 |
+
tmp = tempfile.mkdtemp()
|
| 395 |
+
flax_model = FlaxRobertaForMaskedLM.from_pretrained(destination_dir)
|
| 396 |
+
flax_model.params = to_f32(flax_model.params)
|
| 397 |
+
flax_model.save_pretrained(tmp)
|
| 398 |
+
# Converting float32 Flax to PyTorch
|
| 399 |
+
model = RobertaForMaskedLM.from_pretrained(tmp, from_flax=True)
|
| 400 |
+
model.save_pretrained(destination_dir, save_config=False)
|
| 401 |
+
|
| 402 |
+
|
| 403 |
if __name__ == "__main__":
|
| 404 |
# See all possible arguments in src/transformers/training_args.py
|
| 405 |
# or by passing the --help flag to this script.
|
|
|
|
| 773 |
eval_metrics = jax.tree_map(lambda x: x / eval_normalizer, eval_metrics)
|
| 774 |
|
| 775 |
# Update progress bar
|
| 776 |
+
steps.desc = f"Step... ({step}/{num_train_steps} | Loss: {eval_metrics['loss']}, Acc: {eval_metrics['accuracy']})"
|
| 777 |
+
last_desc = steps.desc
|
| 778 |
|
| 779 |
if has_tensorboard and jax.process_index() == 0:
|
| 780 |
write_eval_metric(summary_writer, eval_metrics, step)
|
|
|
|
| 787 |
model.save_pretrained(
|
| 788 |
training_args.output_dir,
|
| 789 |
params=params,
|
| 790 |
+
push_to_hub=False,
|
|
|
|
| 791 |
)
|
| 792 |
save_checkpoint_files(state, data_collator, training_args, training_args.output_dir)
|
| 793 |
checkpoints_dir = Path(training_args.output_dir) / "checkpoints" / f"checkpoint-{step}"
|
|
|
|
| 798 |
Path(training_args.output_dir) / "checkpoints",
|
| 799 |
max_checkpoints=training_args.save_total_limit
|
| 800 |
)
|
| 801 |
+
convert(training_args.output_dir, "./")
|
| 802 |
+
model.save_pretrained(
|
| 803 |
+
training_args.output_dir,
|
| 804 |
+
params=params,
|
| 805 |
+
push_to_hub=training_args.push_to_hub,
|
| 806 |
+
commit_message=last_desc,
|
| 807 |
+
)
|
| 808 |
|
| 809 |
# update tqdm bar
|
| 810 |
steps.update(1)
|
| 811 |
+
|
| 812 |
+
if jax.process_index() == 0:
|
| 813 |
+
logger.info(f"Saving checkpoint at {step} steps")
|
| 814 |
+
params = jax.device_get(jax.tree_map(lambda x: x[0], state.params))
|
| 815 |
+
model.save_pretrained(
|
| 816 |
+
training_args.output_dir,
|
| 817 |
+
params=params,
|
| 818 |
+
push_to_hub=False,
|
| 819 |
+
)
|
| 820 |
+
save_checkpoint_files(state, data_collator, training_args, training_args.output_dir)
|
| 821 |
+
checkpoints_dir = Path(training_args.output_dir) / "checkpoints" / f"checkpoint-{step}"
|
| 822 |
+
checkpoints_dir.mkdir(parents=True, exist_ok=True)
|
| 823 |
+
model.save_pretrained(checkpoints_dir, params=params)
|
| 824 |
+
save_checkpoint_files(state, data_collator, training_args, checkpoints_dir)
|
| 825 |
+
convert(training_args.output_dir, "./")
|
| 826 |
+
model.save_pretrained(
|
| 827 |
+
training_args.output_dir,
|
| 828 |
+
params=params,
|
| 829 |
+
push_to_hub=training_args.push_to_hub,
|
| 830 |
+
commit_message=last_desc,
|
| 831 |
+
)
|