

Explanations
Browse files- README.md +98 -3
- images/ccnet.png +0 -0
- images/datasets-perp.png +0 -0
- images/datasets-random-comparison.png +0 -0
- images/perp-p95.png +0 -0
- images/perp-resample-gaussian.png +0 -0
- images/perp-resample.png +0 -0
- utils/dataset_perplexity.py +20 -0
- utils/generate_datasets.py +154 -0
README.md
CHANGED
|
@@ -9,16 +9,21 @@ widget:
|
|
| 9 |
- text: "Fui a la librería a comprar un <mask>."
|
| 10 |
---
|
| 11 |
|
|
|
|
|
|
|
|
|
|
| 12 |
# BERTIN
|
| 13 |
|
| 14 |
-
BERTIN is a series of BERT-based models for Spanish.
|
| 15 |
|
| 16 |
This is part of the
|
| 17 |
-
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
|
| 18 |
|
| 19 |
## Spanish mC4
|
| 20 |
|
| 21 |
-
|
|
|
|
|
|
|
| 22 |
|
| 23 |
```bash
|
| 24 |
$ zcat c4/multilingual/c4-es*.tfrecord*.json.gz | wc -l
|
|
@@ -30,6 +35,89 @@ $ zcat c4/multilingual/c4-es*.tfrecord-*.json.gz | jq -r '.text | split(" ") | l
|
|
| 30 |
235303687795
|
| 31 |
```
|
| 32 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
## Team members
|
| 34 |
|
| 35 |
- Javier de la Rosa ([versae](https://huggingface.co/versae))
|
|
@@ -47,3 +135,10 @@ $ zcat c4/multilingual/c4-es*.tfrecord-*.json.gz | jq -r '.text | split(" ") | l
|
|
| 47 |
- [Community Week channel](https://discord.com/channels/858019234139602994/859113060068229190)
|
| 48 |
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
|
| 49 |
- [Model Repository](https://huggingface.co/flax-community/bertin-roberta-large-spanish/)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
- text: "Fui a la librería a comprar un <mask>."
|
| 10 |
---
|
| 11 |
|
| 12 |
+
- Version 1: July 15th, 2021
|
| 13 |
+
- Version 2: July 19th, 2021
|
| 14 |
+
|
| 15 |
# BERTIN
|
| 16 |
|
| 17 |
+
BERTIN is a series of BERT-based models for Spanish. The current model hub points to the best of all RoBERTa-base models trained from scratch on the Spanish portion of mC4 using [Flax](https://github.com/google/flax). All code and scripts are included.
|
| 18 |
|
| 19 |
This is part of the
|
| 20 |
+
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google Cloud.
|
| 21 |
|
| 22 |
## Spanish mC4
|
| 23 |
|
| 24 |
+
mC4 is a multilingual variant of the C4, the Colossal, Cleaned version of Common Crawl's web crawl corpus. While C4 was used to train the T5 text-to-text Transformer models, mC4 comprises natural text in 101 languages drawn from the public Common Crawl web scrape and was used to train mT5, the multilingual version of T5.
|
| 25 |
+
|
| 26 |
+
The Spanish portion of mC4 (`mc4-es`) contains about 416 million samples and 235 billion words in aproximatelly 1TB of uncompressed data.
|
| 27 |
|
| 28 |
```bash
|
| 29 |
$ zcat c4/multilingual/c4-es*.tfrecord*.json.gz | wc -l
|
|
|
|
| 35 |
235303687795
|
| 36 |
```
|
| 37 |
|
| 38 |
+
## Perplexity sampling
|
| 39 |
+
|
| 40 |
+
Since the amount of Spanish text in mC4 is problematic to train a language model in a reasonable time, within the context of the Flax/JAX Community Event by HuggingFace, we explored the posibility of creating an optimal subset of the samples good enough to train a well performing model with roughly one eighth of the data (~50M samples) and in approxiamtely half the steps. The goal was to pre-train a RoBERTa-base model from scratch for the duration of the Flax/JAX Community Event in which Google Cloud provided free TPUv3-8 to do the training using Huggingface's Flax implementations of their library.
|
| 41 |
+
|
| 42 |
+
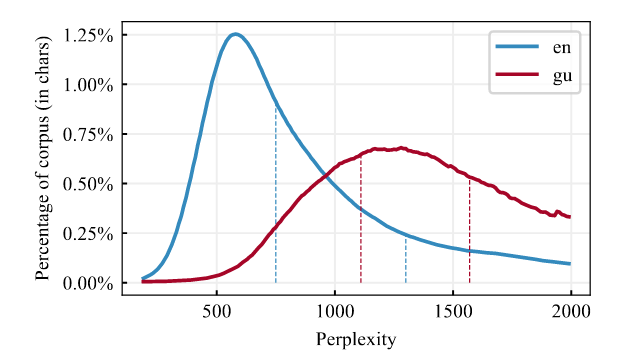
In order to efficiently build this subset of data, we decied to leverage a technique we now call *perplexity sampling* and whose origin can be traced to the constructon of CCNet (Wenzek et al., 2020) and their work extracting high quality monolingual datasets from web crawl data. In their work, the suggest the possibility of applying fast language models traiend on high quality data such as Wikipedia to filter out text that deviates too much from correct expressions of a language (see Figure 1). They also released Kneser-Ney models for 100 languages (Spanish included) as implemented in the KenLM library (Heafield, 2011) and trained on their respective Wikipedias.
|
| 43 |
+
|
| 44 |
+
<figure>
|
| 45 |
+
|
| 46 |
+

|
| 47 |
+
|
| 48 |
+
<caption>Figure 1. Perplexity distributions by percentage CCNet corpus.</caption>
|
| 49 |
+
</figure>
|
| 50 |
+
|
| 51 |
+
In this work, we tested the hyphothesis that perplexity sampling might help reduce training data size and time.
|
| 52 |
+
|
| 53 |
+
## Methodology
|
| 54 |
+
|
| 55 |
+
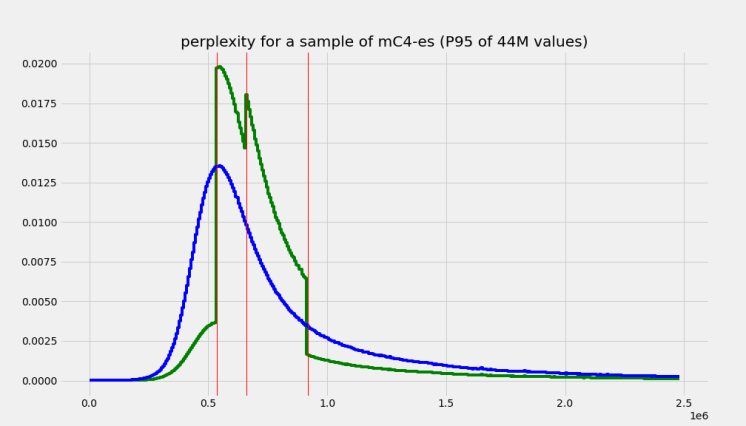
In order to test our hyphothesis, we first calculated the perplexity of each document in the entire mC4-es and extracted its distributions and quartiles. Effectively, we only extracted perplexity values for roughly a quarter of the datatet and plotted its distribution and the corresponding quartiles (see Figure 2).
|
| 56 |
+
|
| 57 |
+
<figure>
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
<caption>Figure 2. Perplexity distributions and quarties (red lines) of 100M samples of mc4-es.</caption>
|
| 62 |
+
</figure>
|
| 63 |
+
|
| 64 |
+
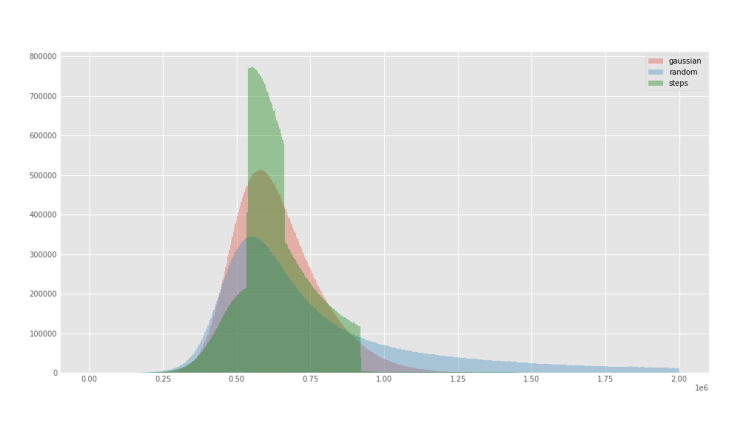
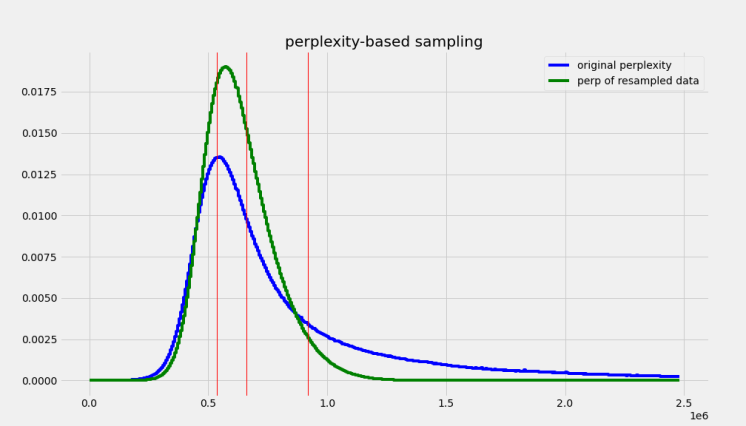
With the extracted perplexity percentiles, we created two functions to oversample the central quartiles with the idea of excluding samples that were neither too small (short, repetitive texts) or too long (potentially poor quality) (see Figure 3). The first function was a `stepwise` that simple oversampled the central quartiles using que quartiles boundaries and a factor for how heavily these should be oversampled. The second function was a gaussian approximation of the `stepwise` function to smoth out the sharp boundaries and give a better approximation of the underlying distribution (see Figure 4). We adjusted the `factor` parameter of the `stepwise` function, and the `factor` and `width` parameter of the `gaussian` function to roughly be able to sample 50M samples from the 416M in `mc4-es` (see Figure 4). For comparison, we also sampled randomply `mc-4` up to 50M samples as well.
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
<figure>
|
| 68 |
+
|
| 69 |
+

|
| 70 |
+
|
| 71 |
+
<caption>Figure 3. Expected perplexity distributions of the sample `mc4-es` after applying `stepwise` function.</caption>
|
| 72 |
+
</figure>
|
| 73 |
+
|
| 74 |
+
<figure>
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
<caption>Figure 4. Expected perplexity distributions of the sample `mc4-es` after applying `gaussian` function.</caption>
|
| 79 |
+
</figure>
|
| 80 |
+
|
| 81 |
+
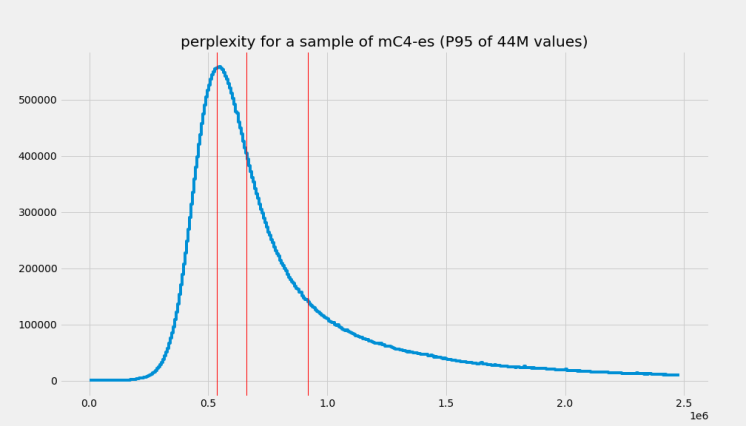
Figure 5 shows the effective perplexity distributions of the 50M subsets for each of the approximations. All subsets can be easily accessed for reproducibility purposes using the `bertin-project/mc4-es-sampled` dataset. Since the validation set was too small to extract a 10% (5M) of the samples using perplexity sampling with the same `factor` and `width`, in our experiments we decided to sample from the training sets. In the `bertin-project/mc4-es-sampled` dataset, the `validation` set pulls the samples from the origina `mc4`.
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
from datasets import load_dataset
|
| 85 |
+
|
| 86 |
+
for split in ("random", "stepwise", "gaussian"):
|
| 87 |
+
mc4es = load_dataset(
|
| 88 |
+
"bertin-project/mc4-es-sampled",
|
| 89 |
+
"train",
|
| 90 |
+
split=split,
|
| 91 |
+
streaming=True
|
| 92 |
+
).shuffle(buffer_size=1000)
|
| 93 |
+
for sample in mc4es:
|
| 94 |
+
print(split, sample)
|
| 95 |
+
break
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
<figure>
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
<caption>Figure 5. Real perplexity distributions of the sampled `mc4-es` after applying `gaussian` and `stepwise` functions.</caption>
|
| 103 |
+
</figure>
|
| 104 |
+
|
| 105 |
+
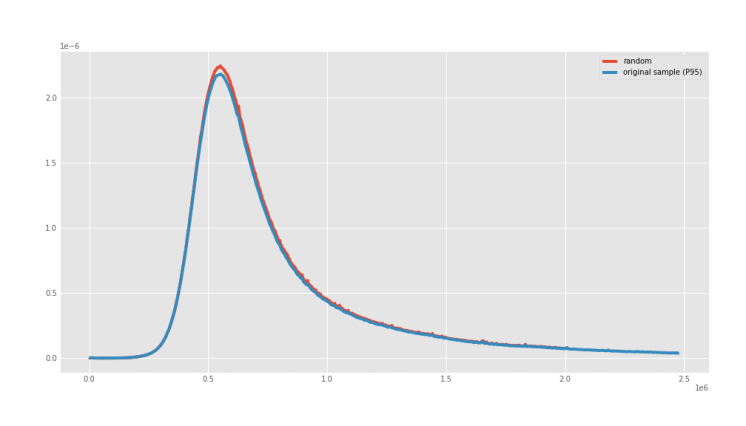
The `random` sampling also displayed the same perplexity distribution of the underlying true distribution, as it can be seen in Figure 6.
|
| 106 |
+
|
| 107 |
+
<figure>
|
| 108 |
+
|
| 109 |
+

|
| 110 |
+
|
| 111 |
+
<caption>Figure 6. Real perplexity distributions of the sampled `mc4-es` after applying `random` sampling.</caption>
|
| 112 |
+
</figure>
|
| 113 |
+
|
| 114 |
+
We then used the same setup as in Liu et al. (2019) but trained only for half the steps (250k) on a sequence length of 128. Then, we continue training the most promising model for 25k more on sequence length of 512.
|
| 115 |
+
|
| 116 |
+
## Results
|
| 117 |
+
|
| 118 |
+
The first version of the model...
|
| 119 |
+
|
| 120 |
+
|
| 121 |
## Team members
|
| 122 |
|
| 123 |
- Javier de la Rosa ([versae](https://huggingface.co/versae))
|
|
|
|
| 135 |
- [Community Week channel](https://discord.com/channels/858019234139602994/859113060068229190)
|
| 136 |
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
|
| 137 |
- [Model Repository](https://huggingface.co/flax-community/bertin-roberta-large-spanish/)
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## References
|
| 141 |
+
|
| 142 |
+
- CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data, Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, Edouard Grave, Proceedings of the 12th Language Resources and Evaluation Conference (LREC), p. 4003-4012, May 2020.
|
| 143 |
+
|
| 144 |
+
- Heafield, K. (2011). KenLM: faster and smaller language model queries. In Proceedings of the EMNLP2011 Sixth Workshop on Statistical Machine Translation.
|
images/ccnet.png
ADDED
|
images/datasets-perp.png
ADDED
|
images/datasets-random-comparison.png
ADDED
|
images/perp-p95.png
ADDED
|
images/perp-resample-gaussian.png
ADDED
|
images/perp-resample.png
ADDED
|
utils/dataset_perplexity.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import kenlm
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
model = kenlm.Model("../es.arpa.bin")
|
| 6 |
+
|
| 7 |
+
def get_perplexity(doc):
|
| 8 |
+
doc_log_score, doc_length = 0, 0
|
| 9 |
+
for line in doc.split("\n"):
|
| 10 |
+
log_score = model.score(line)
|
| 11 |
+
length = len(line.split()) + 1
|
| 12 |
+
doc_log_score += log_score
|
| 13 |
+
doc_length += length
|
| 14 |
+
return 10.0 ** (-doc_log_score / doc_length)
|
| 15 |
+
|
| 16 |
+
with open("mc4-es-train-50M-stats.csv", "w") as csv:
|
| 17 |
+
with open("mc4-es-train-50M-steps.jsonl", "r") as data:
|
| 18 |
+
for line in tqdm(data):
|
| 19 |
+
text = json.loads(line)["text"]
|
| 20 |
+
csv.write(f"{len(text.split())},{get_perplexity(text)}\n")
|
utils/generate_datasets.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
from datasets import load_dataset
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
# Setup logging
|
| 6 |
+
logging.basicConfig(
|
| 7 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 8 |
+
level="INFO",
|
| 9 |
+
datefmt="[%X]",
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
# Log on each process the small summary:
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
!wget http://dl.fbaipublicfiles.com/cc_net/lm/es.arpa.bin
|
| 15 |
+
mc4 = load_dataset(
|
| 16 |
+
"./mc4",
|
| 17 |
+
"es",
|
| 18 |
+
split="train",
|
| 19 |
+
sampling_method="steps",
|
| 20 |
+
perplexity_model="./es.arpa.bin",
|
| 21 |
+
sampling_factor=1.5e5,
|
| 22 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 23 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 24 |
+
total = 0
|
| 25 |
+
with open("mc4-es-train-50M-steps.jsonl", "w") as f:
|
| 26 |
+
for sample in tqdm(mc4, total=50_000_000):
|
| 27 |
+
f.write(json.dumps(sample) + "\n")
|
| 28 |
+
total += 1
|
| 29 |
+
if total >= 50_000_000:
|
| 30 |
+
break
|
| 31 |
+
|
| 32 |
+
mc4val = load_dataset(
|
| 33 |
+
"./mc4",
|
| 34 |
+
"es",
|
| 35 |
+
split="validation",
|
| 36 |
+
sampling_method="steps",
|
| 37 |
+
perplexity_model="./es.arpa.bin",
|
| 38 |
+
sampling_factor=5e5,
|
| 39 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 40 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 41 |
+
total = 0
|
| 42 |
+
with open("mc4-es-validation-5M-steps.jsonl", "w") as f:
|
| 43 |
+
for sample in tqdm(mc4val, total=5_000_000):
|
| 44 |
+
f.write(json.dumps(sample) + "\n")
|
| 45 |
+
total += 1
|
| 46 |
+
if total >= 5_000_000:
|
| 47 |
+
break
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# ------------------
|
| 51 |
+
|
| 52 |
+
import json
|
| 53 |
+
import logging
|
| 54 |
+
from datasets import load_dataset
|
| 55 |
+
from tqdm import tqdm
|
| 56 |
+
# Setup logging
|
| 57 |
+
logging.basicConfig(
|
| 58 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 59 |
+
level="INFO",
|
| 60 |
+
datefmt="[%X]",
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# Log on each process the small summary:
|
| 64 |
+
logger = logging.getLogger(__name__)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
mc4 = load_dataset(
|
| 68 |
+
"./mc4",
|
| 69 |
+
"es",
|
| 70 |
+
split="train",
|
| 71 |
+
sampling_method="gaussian",
|
| 72 |
+
perplexity_model="../es.arpa.bin",
|
| 73 |
+
sampling_factor=0.78,
|
| 74 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 75 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 76 |
+
total = 0
|
| 77 |
+
with open("mc4-es-train-50M-gaussian.jsonl", "w") as f:
|
| 78 |
+
for sample in tqdm(mc4, total=50_000_000):
|
| 79 |
+
f.write(json.dumps(sample) + "\n")
|
| 80 |
+
total += 1
|
| 81 |
+
if total >= 50_000_000:
|
| 82 |
+
break
|
| 83 |
+
mc4val = load_dataset(
|
| 84 |
+
"./mc4",
|
| 85 |
+
"es",
|
| 86 |
+
split="validation",
|
| 87 |
+
sampling_method="gaussian",
|
| 88 |
+
perplexity_model="../es.arpa.bin",
|
| 89 |
+
sampling_factor=1,
|
| 90 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 91 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 92 |
+
total = 0
|
| 93 |
+
with open("mc4-es-validation-5M-gaussian.jsonl", "w") as f:
|
| 94 |
+
for sample in tqdm(mc4val, total=5_000_000):
|
| 95 |
+
f.write(json.dumps(sample) + "\n")
|
| 96 |
+
total += 1
|
| 97 |
+
if total >= 5_000_000:
|
| 98 |
+
break
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
# ------------------
|
| 102 |
+
|
| 103 |
+
import json
|
| 104 |
+
import logging
|
| 105 |
+
from datasets import load_dataset
|
| 106 |
+
from tqdm import tqdm
|
| 107 |
+
# Setup logging
|
| 108 |
+
logging.basicConfig(
|
| 109 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 110 |
+
level="INFO",
|
| 111 |
+
datefmt="[%X]",
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
# Log on each process the small summary:
|
| 115 |
+
logger = logging.getLogger(__name__)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
mc4 = load_dataset(
|
| 119 |
+
"./mc4",
|
| 120 |
+
"es",
|
| 121 |
+
split="train",
|
| 122 |
+
sampling_method="random",
|
| 123 |
+
perplexity_model="../es.arpa.bin",
|
| 124 |
+
sampling_factor=0.5,
|
| 125 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 126 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 127 |
+
total = 0
|
| 128 |
+
with open("mc4-es-train-50M-random.jsonl", "w") as f:
|
| 129 |
+
for sample in tqdm(mc4, total=50_000_000):
|
| 130 |
+
f.write(json.dumps(sample) + "\n")
|
| 131 |
+
total += 1
|
| 132 |
+
if total >= 50_000_000:
|
| 133 |
+
break
|
| 134 |
+
mc4val = load_dataset(
|
| 135 |
+
"./mc4",
|
| 136 |
+
"es",
|
| 137 |
+
split="validation",
|
| 138 |
+
sampling_method="random",
|
| 139 |
+
perplexity_model="../es.arpa.bin",
|
| 140 |
+
sampling_factor=0.5,
|
| 141 |
+
boundaries=[536394.99320948,662247.50212365,919250.87225178],
|
| 142 |
+
streaming=True).shuffle(buffer_size=10000, seed=2021)
|
| 143 |
+
total = 0
|
| 144 |
+
with open("mc4-es-validation-5M-random.jsonl", "w") as f:
|
| 145 |
+
for sample in tqdm(mc4val, total=5_000_000):
|
| 146 |
+
f.write(json.dumps(sample) + "\n")
|
| 147 |
+
total += 1
|
| 148 |
+
if total >= 5_000_000:
|
| 149 |
+
break
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
------------
|
| 154 |
+
|