
Training in progress, step 4183
Browse files- adapter_config.json +19 -0
- adapter_model.bin +3 -0
- cf.png +0 -0
- cf.txt +7 -0
- class_report.txt +13 -0
- merges.txt +0 -0
- special_tokens_map.json +15 -0
- tokenizer.json +0 -0
- tokenizer_config.json +15 -0
- training_args.bin +3 -0
- vocab.json +0 -0
adapter_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"base_model_name_or_path": "roberta-large",
|
| 3 |
+
"bias": "none",
|
| 4 |
+
"fan_in_fan_out": false,
|
| 5 |
+
"inference_mode": true,
|
| 6 |
+
"init_lora_weights": true,
|
| 7 |
+
"lora_alpha": 16,
|
| 8 |
+
"lora_dropout": 0.05,
|
| 9 |
+
"modules_to_save": [
|
| 10 |
+
"classifier"
|
| 11 |
+
],
|
| 12 |
+
"peft_type": "LORA",
|
| 13 |
+
"r": 8,
|
| 14 |
+
"target_modules": [
|
| 15 |
+
"query",
|
| 16 |
+
"value"
|
| 17 |
+
],
|
| 18 |
+
"task_type": null
|
| 19 |
+
}
|
adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:53a584ce07fc41ba9be31caaa4d1014b16ef534000be60fe95c4639a3ac698fa
|
| 3 |
+
size 7409629
|
cf.png
ADDED
|
cf.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
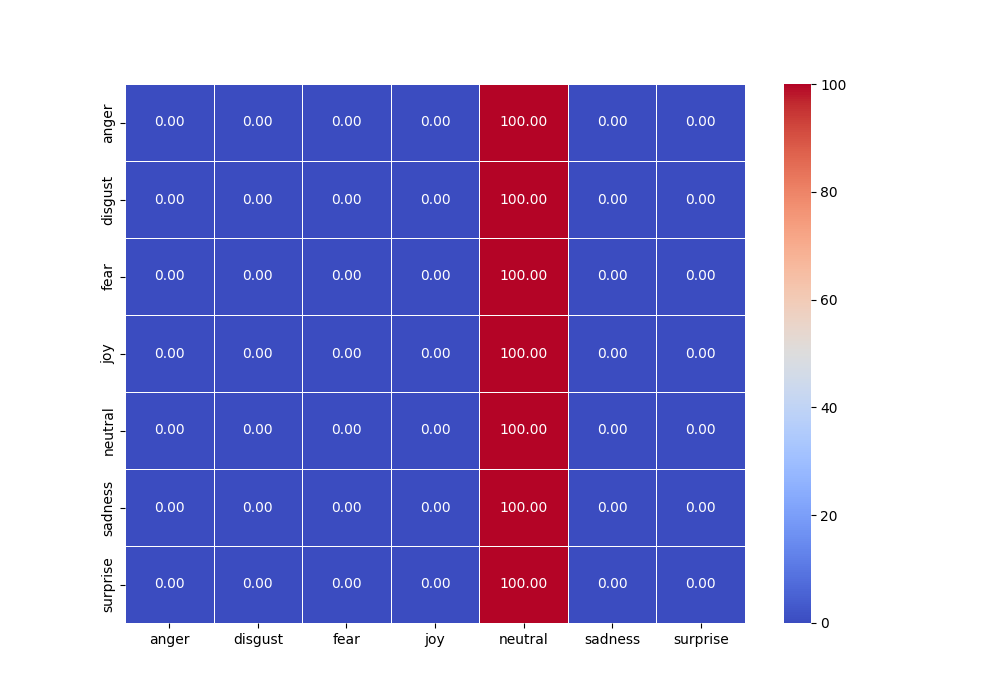
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 2 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 3 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 4 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 5 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 6 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
| 7 |
+
0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
|
class_report.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
precision recall f1-score support
|
| 2 |
+
|
| 3 |
+
0anger 0.00 0.00 0.00 1855
|
| 4 |
+
1disgust 0.00 0.00 0.00 480
|
| 5 |
+
2fear 0.00 0.00 0.00 1554
|
| 6 |
+
3joy 0.00 0.00 0.00 5993
|
| 7 |
+
4neutral 0.45 1.00 0.62 10689
|
| 8 |
+
5sadness 0.00 0.00 0.00 2220
|
| 9 |
+
6surprise 0.00 0.00 0.00 1113
|
| 10 |
+
|
| 11 |
+
accuracy 0.45 23904
|
| 12 |
+
macro avg 0.06 0.14 0.09 23904
|
| 13 |
+
weighted avg 0.20 0.45 0.28 23904
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"cls_token": "<s>",
|
| 4 |
+
"eos_token": "</s>",
|
| 5 |
+
"mask_token": {
|
| 6 |
+
"content": "<mask>",
|
| 7 |
+
"lstrip": true,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"pad_token": "<pad>",
|
| 13 |
+
"sep_token": "</s>",
|
| 14 |
+
"unk_token": "<unk>"
|
| 15 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": "<s>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"cls_token": "<s>",
|
| 6 |
+
"eos_token": "</s>",
|
| 7 |
+
"errors": "replace",
|
| 8 |
+
"mask_token": "<mask>",
|
| 9 |
+
"model_max_length": 512,
|
| 10 |
+
"pad_token": "<pad>",
|
| 11 |
+
"sep_token": "</s>",
|
| 12 |
+
"tokenizer_class": "RobertaTokenizer",
|
| 13 |
+
"trim_offsets": true,
|
| 14 |
+
"unk_token": "<unk>"
|
| 15 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:53785ed2f79ab735e7adbf5cb415d6f0950359439ca433b566cfe1ddb60bba58
|
| 3 |
+
size 4091
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|