

Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- CITATION.cff +24 -0
- README.md +577 -0
- assets/4090_bs_1.png +0 -0
- assets/4090_bs_8.png +0 -0
- assets/a100_bs_1.png +0 -0
- assets/a100_bs_8.png +0 -0
- assets/collage_full.png +3 -0
- assets/collage_small.png +3 -0
- assets/glowing_256_1.png +0 -0
- assets/glowing_256_2.png +0 -0
- assets/glowing_256_3.png +0 -0
- assets/glowing_512_1.png +0 -0
- assets/glowing_512_2.png +0 -0
- assets/glowing_512_3.png +0 -0
- assets/image2image_256.png +0 -0
- assets/image2image_256_orig.png +0 -0
- assets/image2image_512.png +0 -0
- assets/image2image_512_orig.png +0 -0
- assets/inpainting_256.png +0 -0
- assets/inpainting_256_mask.png +0 -0
- assets/inpainting_256_orig.png +0 -0
- assets/inpainting_512.png +0 -0
- assets/inpainting_512_mask.png +0 -0
- assets/inpainting_512_orig.jpeg +0 -0
- assets/minecraft1.png +0 -0
- assets/minecraft2.png +0 -0
- assets/minecraft3.png +0 -0
- assets/noun1.png +0 -0
- assets/noun2.png +0 -0
- assets/noun3.png +0 -0
- assets/text2image_256.png +0 -0
- assets/text2image_512.png +0 -0
- model_index.json +24 -0
- scheduler/scheduler_config.json +6 -0
- text_encoder/config.json +24 -0
- text_encoder/model.fp16.safetensors +3 -0
- text_encoder/model.safetensors +3 -0
- tokenizer/merges.txt +0 -0
- tokenizer/special_tokens_map.json +30 -0
- tokenizer/tokenizer_config.json +38 -0
- tokenizer/vocab.json +0 -0
- training/A mushroom in [V] style.png +0 -0
- training/A woman working on a laptop in [V] style.jpg +3 -0
- training/generate_images.py +119 -0
- training/training.py +916 -0
- transformer/config.json +26 -0
- transformer/diffusion_pytorch_model.fp16.safetensors +3 -0
- transformer/diffusion_pytorch_model.safetensors +3 -0
- vqvae/config.json +39 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
training/A[[:space:]]woman[[:space:]]working[[:space:]]on[[:space:]]a[[:space:]]laptop[[:space:]]in[[:space:]]\[V\][[:space:]]style.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/collage_small.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/collage_full.png filter=lfs diff=lfs merge=lfs -text
|
CITATION.cff
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cff-version: 1.2.0
|
| 2 |
+
title: 'Amused: An open MUSE model'
|
| 3 |
+
message: >-
|
| 4 |
+
If you use this software, please cite it using the
|
| 5 |
+
metadata from this file.
|
| 6 |
+
type: software
|
| 7 |
+
authors:
|
| 8 |
+
- given-names: Suraj
|
| 9 |
+
family-names: Patil
|
| 10 |
+
- given-names: Berman
|
| 11 |
+
family-names: William
|
| 12 |
+
- given-names: Patrick
|
| 13 |
+
family-names: von Platen
|
| 14 |
+
repository-code: 'https://github.com/huggingface/amused'
|
| 15 |
+
keywords:
|
| 16 |
+
- deep-learning
|
| 17 |
+
- pytorch
|
| 18 |
+
- image-generation
|
| 19 |
+
- text2image
|
| 20 |
+
- image2image
|
| 21 |
+
- language-modeling
|
| 22 |
+
- masked-language-modeling
|
| 23 |
+
license: Apache-2.0
|
| 24 |
+
version: 0.12.1
|
README.md
ADDED
|
@@ -0,0 +1,577 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# amused
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
<sup><sub>Images cherry-picked from 512 and 256 models. Images are degraded to load faster. See ./assets/collage_full.png for originals</sub></sup>
|
| 5 |
+
|
| 6 |
+
[[Paper - TODO]]()
|
| 7 |
+
|
| 8 |
+
| Model | Params |
|
| 9 |
+
|-------|--------|
|
| 10 |
+
| [amused-256](https://huggingface.co/huggingface/amused-256) | 603M |
|
| 11 |
+
| [amused-512](https://huggingface.co/huggingface/amused-512) | 608M |
|
| 12 |
+
|
| 13 |
+
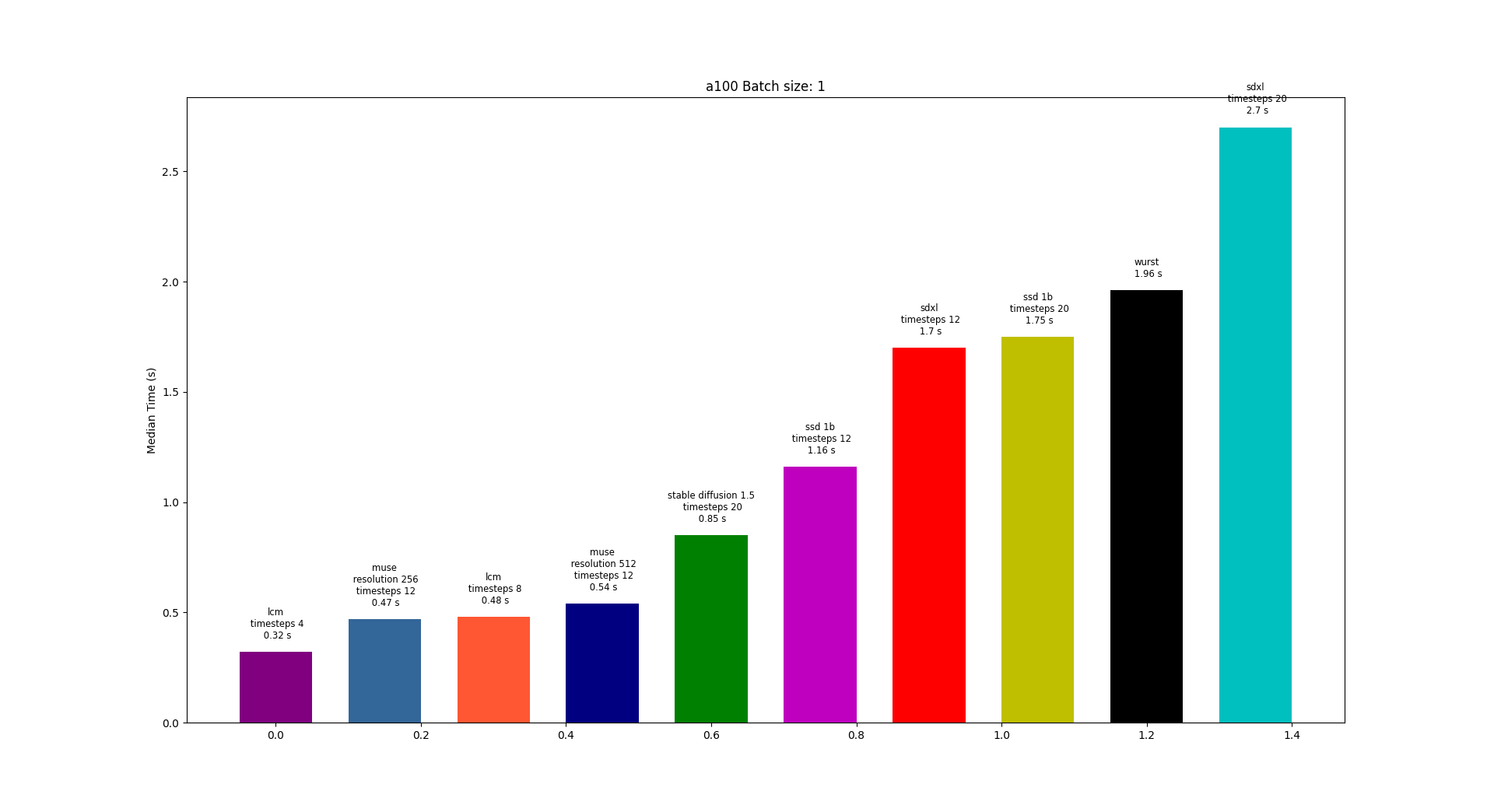
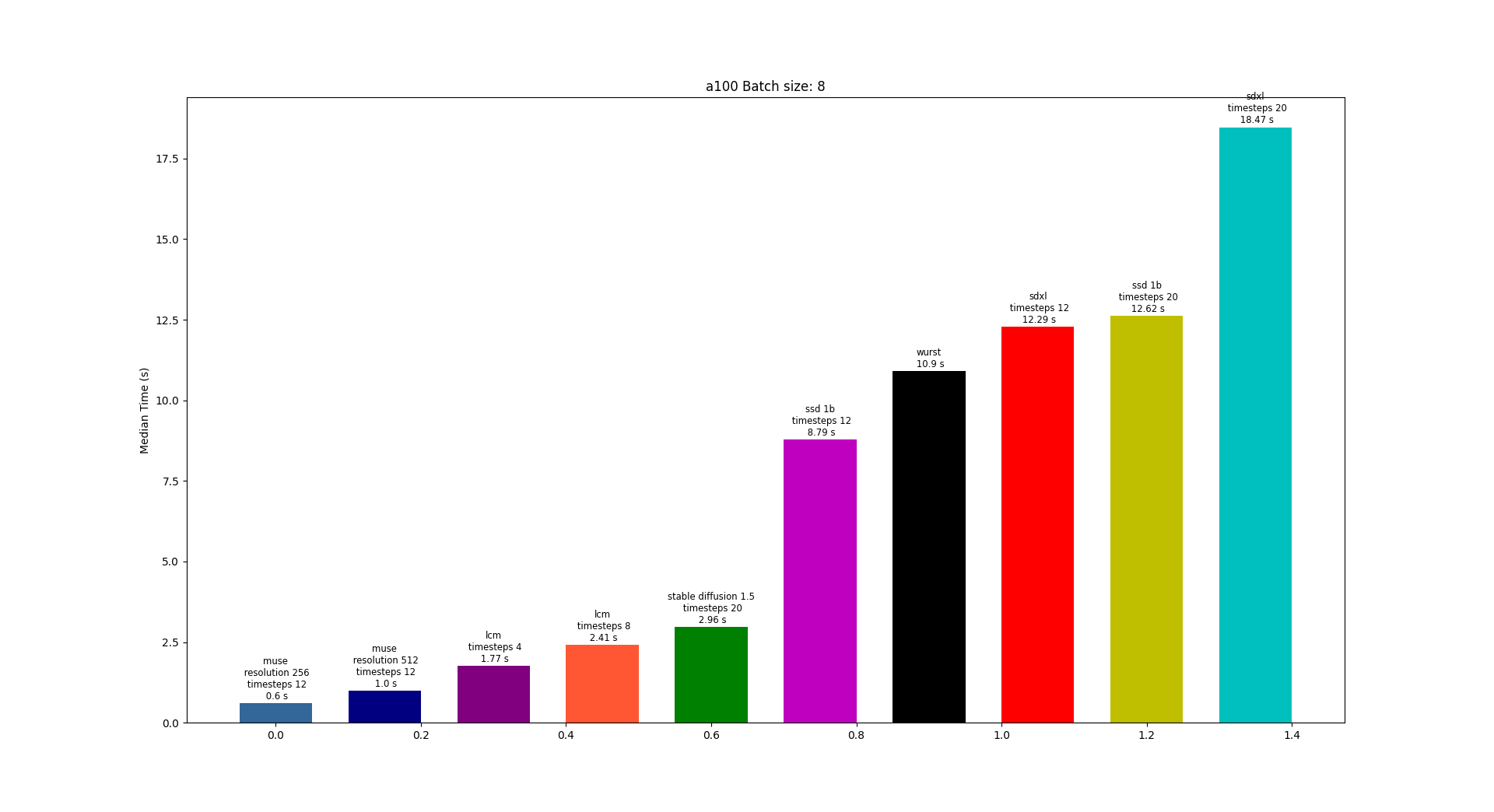
Amused is a lightweight text to image model based off of the [muse](https://arxiv.org/pdf/2301.00704.pdf) architecture. Amused is particularly useful in applications that require a lightweight and fast model such as generating many images quickly at once.
|
| 14 |
+
|
| 15 |
+
Amused is a vqvae token based transformer that can generate an image in fewer forward passes than many diffusion models. In contrast with muse, it uses the smaller text encoder clip instead of t5. Due to its small parameter count and few forward pass generation process, amused can generate many images quickly. This benefit is seen particularly at larger batch sizes.
|
| 16 |
+
|
| 17 |
+
## 1. Usage
|
| 18 |
+
|
| 19 |
+
### Text to image
|
| 20 |
+
|
| 21 |
+
#### 256x256 model
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
import torch
|
| 25 |
+
from diffusers import AmusedPipeline
|
| 26 |
+
|
| 27 |
+
pipe = AmusedPipeline.from_pretrained(
|
| 28 |
+
"huggingface/amused-256", variant="fp16", torch_dtype=torch.float16
|
| 29 |
+
)
|
| 30 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 31 |
+
pipe = pipe.to("cuda")
|
| 32 |
+
|
| 33 |
+
prompt = "cowboy"
|
| 34 |
+
image = pipe(prompt, generator=torch.Generator('cuda').manual_seed(8)).images[0]
|
| 35 |
+
image.save('text2image_256.png')
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+
#### 512x512 model
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
import torch
|
| 44 |
+
from diffusers import AmusedPipeline
|
| 45 |
+
|
| 46 |
+
pipe = AmusedPipeline.from_pretrained(
|
| 47 |
+
"huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
|
| 48 |
+
)
|
| 49 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans n fp16
|
| 50 |
+
pipe = pipe.to("cuda")
|
| 51 |
+
|
| 52 |
+
prompt = "summer in the mountains"
|
| 53 |
+
image = pipe(prompt, generator=torch.Generator('cuda').manual_seed(2)).images[0]
|
| 54 |
+
image.save('text2image_512.png')
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
### Image to image
|
| 60 |
+
|
| 61 |
+
#### 256x256 model
|
| 62 |
+
|
| 63 |
+
```python
|
| 64 |
+
import torch
|
| 65 |
+
from diffusers import AmusedImg2ImgPipeline
|
| 66 |
+
from diffusers.utils import load_image
|
| 67 |
+
|
| 68 |
+
pipe = AmusedImg2ImgPipeline.from_pretrained(
|
| 69 |
+
"huggingface/amused-256", variant="fp16", torch_dtype=torch.float16
|
| 70 |
+
)
|
| 71 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 72 |
+
pipe = pipe.to("cuda")
|
| 73 |
+
|
| 74 |
+
prompt = "apple watercolor"
|
| 75 |
+
input_image = (
|
| 76 |
+
load_image(
|
| 77 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/image2image_256_orig.png"
|
| 78 |
+
)
|
| 79 |
+
.resize((256, 256))
|
| 80 |
+
.convert("RGB")
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
image = pipe(prompt, input_image, strength=0.7, generator=torch.Generator('cuda').manual_seed(3)).images[0]
|
| 84 |
+
image.save('image2image_256.png')
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
 
|
| 88 |
+
|
| 89 |
+
#### 512x512 model
|
| 90 |
+
|
| 91 |
+
```python
|
| 92 |
+
import torch
|
| 93 |
+
from diffusers import AmusedImg2ImgPipeline
|
| 94 |
+
from diffusers.utils import load_image
|
| 95 |
+
|
| 96 |
+
pipe = AmusedImg2ImgPipeline.from_pretrained(
|
| 97 |
+
"huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
|
| 98 |
+
)
|
| 99 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 100 |
+
pipe = pipe.to("cuda")
|
| 101 |
+
|
| 102 |
+
prompt = "winter mountains"
|
| 103 |
+
input_image = (
|
| 104 |
+
load_image(
|
| 105 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/image2image_512_orig.png"
|
| 106 |
+
)
|
| 107 |
+
.resize((512, 512))
|
| 108 |
+
.convert("RGB")
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
image = pipe(prompt, input_image, generator=torch.Generator('cuda').manual_seed(15)).images[0]
|
| 112 |
+
image.save('image2image_512.png')
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
 
|
| 116 |
+
|
| 117 |
+
### Inpainting
|
| 118 |
+
|
| 119 |
+
#### 256x256 model
|
| 120 |
+
|
| 121 |
+
```python
|
| 122 |
+
import torch
|
| 123 |
+
from diffusers import AmusedInpaintPipeline
|
| 124 |
+
from diffusers.utils import load_image
|
| 125 |
+
from PIL import Image
|
| 126 |
+
|
| 127 |
+
pipe = AmusedInpaintPipeline.from_pretrained(
|
| 128 |
+
"huggingface/amused-256", variant="fp16", torch_dtype=torch.float16
|
| 129 |
+
)
|
| 130 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 131 |
+
pipe = pipe.to("cuda")
|
| 132 |
+
|
| 133 |
+
prompt = "a man with glasses"
|
| 134 |
+
input_image = (
|
| 135 |
+
load_image(
|
| 136 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/inpainting_256_orig.png"
|
| 137 |
+
)
|
| 138 |
+
.resize((256, 256))
|
| 139 |
+
.convert("RGB")
|
| 140 |
+
)
|
| 141 |
+
mask = (
|
| 142 |
+
load_image(
|
| 143 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/inpainting_256_mask.png"
|
| 144 |
+
)
|
| 145 |
+
.resize((256, 256))
|
| 146 |
+
.convert("L")
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
for seed in range(20):
|
| 150 |
+
image = pipe(prompt, input_image, mask, generator=torch.Generator('cuda').manual_seed(seed)).images[0]
|
| 151 |
+
image.save(f'inpainting_256_{seed}.png')
|
| 152 |
+
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
  
|
| 156 |
+
|
| 157 |
+
#### 512x512 model
|
| 158 |
+
|
| 159 |
+
```python
|
| 160 |
+
import torch
|
| 161 |
+
from diffusers import AmusedInpaintPipeline
|
| 162 |
+
from diffusers.utils import load_image
|
| 163 |
+
|
| 164 |
+
pipe = AmusedInpaintPipeline.from_pretrained(
|
| 165 |
+
"huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
|
| 166 |
+
)
|
| 167 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 168 |
+
pipe = pipe.to("cuda")
|
| 169 |
+
|
| 170 |
+
prompt = "fall mountains"
|
| 171 |
+
input_image = (
|
| 172 |
+
load_image(
|
| 173 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/inpainting_512_orig.jpeg"
|
| 174 |
+
)
|
| 175 |
+
.resize((512, 512))
|
| 176 |
+
.convert("RGB")
|
| 177 |
+
)
|
| 178 |
+
mask = (
|
| 179 |
+
load_image(
|
| 180 |
+
"https://raw.githubusercontent.com/huggingface/amused/main/assets/inpainting_512_mask.png"
|
| 181 |
+
)
|
| 182 |
+
.resize((512, 512))
|
| 183 |
+
.convert("L")
|
| 184 |
+
)
|
| 185 |
+
image = pipe(prompt, input_image, mask, generator=torch.Generator('cuda').manual_seed(0)).images[0]
|
| 186 |
+
image.save('inpainting_512.png')
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+

|
| 190 |
+

|
| 191 |
+

|
| 192 |
+
|
| 193 |
+
## 2. Performance
|
| 194 |
+
|
| 195 |
+
Amused inherits performance benefits from original [muse](https://arxiv.org/pdf/2301.00704.pdf).
|
| 196 |
+
|
| 197 |
+
1. Parallel decoding: The model follows a denoising schedule that aims to unmask some percent of tokens at each denoising step. At each step, all masked tokens are predicted, and some number of tokens that the network is most confident about are unmasked. Because multiple tokens are predicted at once, we can generate a full 256x256 or 512x512 image in around 12 steps. In comparison, an autoregressive model must predict a single token at a time. Note that a 256x256 image with the 16x downsampled VAE that muse uses will have 256 tokens.
|
| 198 |
+
|
| 199 |
+
2. Fewer sampling steps: Compared to many diffusion models, muse requires fewer samples.
|
| 200 |
+
|
| 201 |
+
Additionally, amused uses the smaller CLIP as its text encoder instead of T5 compared to muse. Amused is also smaller with ~600M params compared the largest 3B param muse model. Note that being smaller, amused produces comparably lower quality results.
|
| 202 |
+
|
| 203 |
+

|
| 204 |
+

|
| 205 |
+

|
| 206 |
+

|
| 207 |
+
|
| 208 |
+
### Muse performance knobs
|
| 209 |
+
|
| 210 |
+
| | Uncompiled Transformer + regular attention | Uncompiled Transformer + flash attention (ms) | Compiled Transformer (ms) | Speed Up |
|
| 211 |
+
|---------------------|--------------------------------------------|-------------------------|----------------------|----------|
|
| 212 |
+
| 256 Batch Size 1 | 594.7 | 507.7 | 212.1 | 58% |
|
| 213 |
+
| 512 Batch Size 1 | 637 | 547 | 249.9 | 54% |
|
| 214 |
+
| 256 Batch Size 8 | 719 | 628.6 | 427.8 | 32% |
|
| 215 |
+
| 512 Batch Size 8 | 1000 | 917.7 | 703.6 | 23% |
|
| 216 |
+
|
| 217 |
+
Flash attention is enabled by default in the diffusers codebase through torch `F.scaled_dot_product_attention`
|
| 218 |
+
|
| 219 |
+
### torch.compile
|
| 220 |
+
To use torch.compile, simply wrap the transformer in torch.compile i.e.
|
| 221 |
+
|
| 222 |
+
```python
|
| 223 |
+
pipe.transformer = torch.compile(pipe.transformer)
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
Full snippet:
|
| 227 |
+
|
| 228 |
+
```python
|
| 229 |
+
import torch
|
| 230 |
+
from diffusers import AmusedPipeline
|
| 231 |
+
|
| 232 |
+
pipe = AmusedPipeline.from_pretrained(
|
| 233 |
+
"huggingface/amused-256", variant="fp16", torch_dtype=torch.float16
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
# HERE use torch.compile
|
| 237 |
+
pipe.transformer = torch.compile(pipe.transformer)
|
| 238 |
+
|
| 239 |
+
pipe.vqvae.to(torch.float32) # vqvae is producing nans in fp16
|
| 240 |
+
pipe = pipe.to("cuda")
|
| 241 |
+
|
| 242 |
+
prompt = "cowboy"
|
| 243 |
+
image = pipe(prompt, generator=torch.Generator('cuda').manual_seed(8)).images[0]
|
| 244 |
+
image.save('text2image_256.png')
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
## 3. Training
|
| 248 |
+
|
| 249 |
+
Amused can be finetuned on simple datasets relatively cheaply and quickly. Using 8bit optimizers, lora, and gradient accumulation, amused can be finetuned with as little as 5.5 GB. Here are a set of examples for finetuning amused on some relatively simple datasets. These training recipies are aggressively oriented towards minimal resources and fast verification -- i.e. the batch sizes are quite low and the learning rates are quite high. For optimal quality, you will probably want to increase the batch sizes and decrease learning rates.
|
| 250 |
+
|
| 251 |
+
All training examples use fp16 mixed precision and gradient checkpointing. We don't show 8 bit adam + lora as its about the same memory use as just using lora (bitsandbytes uses full precision optimizer states for weights below a minimum size).
|
| 252 |
+
|
| 253 |
+
### Finetuning the 256 checkpoint
|
| 254 |
+
|
| 255 |
+
These examples finetune on this [nouns](https://huggingface.co/datasets/m1guelpf/nouns) dataset.
|
| 256 |
+
|
| 257 |
+
Example results:
|
| 258 |
+
|
| 259 |
+
  
|
| 260 |
+
|
| 261 |
+
#### Full finetuning
|
| 262 |
+
|
| 263 |
+
Batch size: 8, Learning rate: 1e-4, Gives decent results in 750-1000 steps
|
| 264 |
+
|
| 265 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 266 |
+
|------------|-----------------------------|------------------|-------------|
|
| 267 |
+
| 8 | 1 | 8 | 19.7 GB |
|
| 268 |
+
| 4 | 2 | 8 | 18.3 GB |
|
| 269 |
+
| 1 | 8 | 8 | 17.9 GB |
|
| 270 |
+
|
| 271 |
+
```sh
|
| 272 |
+
accelerate launch training/training.py \
|
| 273 |
+
--output_dir <output path> \
|
| 274 |
+
--train_batch_size <batch size> \
|
| 275 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 276 |
+
--learning_rate 1e-4 \
|
| 277 |
+
--pretrained_model_name_or_path huggingface/amused-256 \
|
| 278 |
+
--instance_data_dataset 'm1guelpf/nouns' \
|
| 279 |
+
--image_key image \
|
| 280 |
+
--prompt_key text \
|
| 281 |
+
--resolution 256 \
|
| 282 |
+
--mixed_precision fp16 \
|
| 283 |
+
--lr_scheduler constant \
|
| 284 |
+
--validation_prompts \
|
| 285 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a orange-colored body on a dark background' \
|
| 286 |
+
'a pixel art character with square orange glasses, a lips-shaped head and a red-colored body on a light background' \
|
| 287 |
+
'a pixel art character with square blue glasses, a microwave-shaped head and a purple-colored body on a sunny background' \
|
| 288 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a blue-colored body on an orange background' \
|
| 289 |
+
'a pixel art character with square red glasses' \
|
| 290 |
+
'a pixel art character' \
|
| 291 |
+
'square red glasses on a pixel art character' \
|
| 292 |
+
'square red glasses on a pixel art character with a baseball-shaped head' \
|
| 293 |
+
--max_train_steps 10000 \
|
| 294 |
+
--checkpointing_steps 500 \
|
| 295 |
+
--validation_steps 250 \
|
| 296 |
+
--gradient_checkpointing
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
#### Full finetuning + 8 bit adam
|
| 300 |
+
|
| 301 |
+
Note that this training config keeps the batch size low and the learning rate high to get results fast with low resources. However, due to 8 bit adam, it will diverge eventually. If you want to train for longer, you will have to up the batch size and lower the learning rate.
|
| 302 |
+
|
| 303 |
+
Batch size: 16, Learning rate: 2e-5, Gives decent results in ~750 steps
|
| 304 |
+
|
| 305 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 306 |
+
|------------|-----------------------------|------------------|-------------|
|
| 307 |
+
| 16 | 1 | 16 | 20.1 GB |
|
| 308 |
+
| 8 | 2 | 16 | 15.6 GB |
|
| 309 |
+
| 1 | 16 | 16 | 10.7 GB |
|
| 310 |
+
|
| 311 |
+
```sh
|
| 312 |
+
accelerate launch training/training.py \
|
| 313 |
+
--output_dir <output path> \
|
| 314 |
+
--train_batch_size <batch size> \
|
| 315 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 316 |
+
--learning_rate 2e-5 \
|
| 317 |
+
--use_8bit_adam \
|
| 318 |
+
--pretrained_model_name_or_path huggingface/amused-256 \
|
| 319 |
+
--instance_data_dataset 'm1guelpf/nouns' \
|
| 320 |
+
--image_key image \
|
| 321 |
+
--prompt_key text \
|
| 322 |
+
--resolution 256 \
|
| 323 |
+
--mixed_precision fp16 \
|
| 324 |
+
--lr_scheduler constant \
|
| 325 |
+
--validation_prompts \
|
| 326 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a orange-colored body on a dark background' \
|
| 327 |
+
'a pixel art character with square orange glasses, a lips-shaped head and a red-colored body on a light background' \
|
| 328 |
+
'a pixel art character with square blue glasses, a microwave-shaped head and a purple-colored body on a sunny background' \
|
| 329 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a blue-colored body on an orange background' \
|
| 330 |
+
'a pixel art character with square red glasses' \
|
| 331 |
+
'a pixel art character' \
|
| 332 |
+
'square red glasses on a pixel art character' \
|
| 333 |
+
'square red glasses on a pixel art character with a baseball-shaped head' \
|
| 334 |
+
--max_train_steps 10000 \
|
| 335 |
+
--checkpointing_steps 500 \
|
| 336 |
+
--validation_steps 250 \
|
| 337 |
+
--gradient_checkpointing
|
| 338 |
+
```
|
| 339 |
+
|
| 340 |
+
#### Full finetuning + lora
|
| 341 |
+
|
| 342 |
+
Batch size: 16, Learning rate: 8e-4, Gives decent results in 1000-1250 steps
|
| 343 |
+
|
| 344 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 345 |
+
|------------|-----------------------------|------------------|-------------|
|
| 346 |
+
| 16 | 1 | 16 | 14.1 GB |
|
| 347 |
+
| 8 | 2 | 16 | 10.1 GB |
|
| 348 |
+
| 1 | 16 | 16 | 6.5 GB |
|
| 349 |
+
|
| 350 |
+
```sh
|
| 351 |
+
accelerate launch training/training.py \
|
| 352 |
+
--output_dir <output path> \
|
| 353 |
+
--train_batch_size <batch size> \
|
| 354 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 355 |
+
--learning_rate 8e-4 \
|
| 356 |
+
--use_lora \
|
| 357 |
+
--pretrained_model_name_or_path huggingface/amused-256 \
|
| 358 |
+
--instance_data_dataset 'm1guelpf/nouns' \
|
| 359 |
+
--image_key image \
|
| 360 |
+
--prompt_key text \
|
| 361 |
+
--resolution 256 \
|
| 362 |
+
--mixed_precision fp16 \
|
| 363 |
+
--lr_scheduler constant \
|
| 364 |
+
--validation_prompts \
|
| 365 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a orange-colored body on a dark background' \
|
| 366 |
+
'a pixel art character with square orange glasses, a lips-shaped head and a red-colored body on a light background' \
|
| 367 |
+
'a pixel art character with square blue glasses, a microwave-shaped head and a purple-colored body on a sunny background' \
|
| 368 |
+
'a pixel art character with square red glasses, a baseball-shaped head and a blue-colored body on an orange background' \
|
| 369 |
+
'a pixel art character with square red glasses' \
|
| 370 |
+
'a pixel art character' \
|
| 371 |
+
'square red glasses on a pixel art character' \
|
| 372 |
+
'square red glasses on a pixel art character with a baseball-shaped head' \
|
| 373 |
+
--max_train_steps 10000 \
|
| 374 |
+
--checkpointing_steps 500 \
|
| 375 |
+
--validation_steps 250 \
|
| 376 |
+
--gradient_checkpointing
|
| 377 |
+
```
|
| 378 |
+
|
| 379 |
+
### Finetuning the 512 checkpoint
|
| 380 |
+
|
| 381 |
+
These examples finetune on this [minecraft](https://huggingface.co/monadical-labs/minecraft-preview) dataset.
|
| 382 |
+
|
| 383 |
+
Example results:
|
| 384 |
+
|
| 385 |
+
  
|
| 386 |
+
|
| 387 |
+
#### Full finetuning
|
| 388 |
+
|
| 389 |
+
Batch size: 8, Learning rate: 8e-5, Gives decent results in 500-1000 steps
|
| 390 |
+
|
| 391 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 392 |
+
|------------|-----------------------------|------------------|-------------|
|
| 393 |
+
| 8 | 1 | 8 | 24.2 GB |
|
| 394 |
+
| 4 | 2 | 8 | 19.7 GB |
|
| 395 |
+
| 1 | 8 | 8 | 16.99 GB |
|
| 396 |
+
|
| 397 |
+
```sh
|
| 398 |
+
accelerate launch training/training.py \
|
| 399 |
+
--output_dir <output path> \
|
| 400 |
+
--train_batch_size <batch size> \
|
| 401 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 402 |
+
--learning_rate 8e-5 \
|
| 403 |
+
--pretrained_model_name_or_path huggingface/amused-512 \
|
| 404 |
+
--instance_data_dataset 'monadical-labs/minecraft-preview' \
|
| 405 |
+
--prompt_prefix 'minecraft ' \
|
| 406 |
+
--image_key image \
|
| 407 |
+
--prompt_key text \
|
| 408 |
+
--resolution 512 \
|
| 409 |
+
--mixed_precision fp16 \
|
| 410 |
+
--lr_scheduler constant \
|
| 411 |
+
--validation_prompts \
|
| 412 |
+
'minecraft Avatar' \
|
| 413 |
+
'minecraft character' \
|
| 414 |
+
'minecraft' \
|
| 415 |
+
'minecraft president' \
|
| 416 |
+
'minecraft pig' \
|
| 417 |
+
--max_train_steps 10000 \
|
| 418 |
+
--checkpointing_steps 500 \
|
| 419 |
+
--validation_steps 250 \
|
| 420 |
+
--gradient_checkpointing
|
| 421 |
+
```
|
| 422 |
+
|
| 423 |
+
#### Full finetuning + 8 bit adam
|
| 424 |
+
|
| 425 |
+
Batch size: 8, Learning rate: 5e-6, Gives decent results in 500-1000 steps
|
| 426 |
+
|
| 427 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 428 |
+
|------------|-----------------------------|------------------|-------------|
|
| 429 |
+
| 8 | 1 | 8 | 21.2 GB |
|
| 430 |
+
| 4 | 2 | 8 | 13.3 GB |
|
| 431 |
+
| 1 | 8 | 8 | 9.9 GB |
|
| 432 |
+
|
| 433 |
+
```sh
|
| 434 |
+
accelerate launch training/training.py \
|
| 435 |
+
--output_dir <output path> \
|
| 436 |
+
--train_batch_size <batch size> \
|
| 437 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 438 |
+
--learning_rate 5e-6 \
|
| 439 |
+
--pretrained_model_name_or_path huggingface/amused-512 \
|
| 440 |
+
--instance_data_dataset 'monadical-labs/minecraft-preview' \
|
| 441 |
+
--prompt_prefix 'minecraft ' \
|
| 442 |
+
--image_key image \
|
| 443 |
+
--prompt_key text \
|
| 444 |
+
--resolution 512 \
|
| 445 |
+
--mixed_precision fp16 \
|
| 446 |
+
--lr_scheduler constant \
|
| 447 |
+
--validation_prompts \
|
| 448 |
+
'minecraft Avatar' \
|
| 449 |
+
'minecraft character' \
|
| 450 |
+
'minecraft' \
|
| 451 |
+
'minecraft president' \
|
| 452 |
+
'minecraft pig' \
|
| 453 |
+
--max_train_steps 10000 \
|
| 454 |
+
--checkpointing_steps 500 \
|
| 455 |
+
--validation_steps 250 \
|
| 456 |
+
--gradient_checkpointing
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
#### Full finetuning + lora
|
| 460 |
+
|
| 461 |
+
Batch size: 8, Learning rate: 1e-4, Gives decent results in 500-1000 steps
|
| 462 |
+
|
| 463 |
+
| Batch Size | Gradient Accumulation Steps | Effective Total Batch Size | Memory Used |
|
| 464 |
+
|------------|-----------------------------|------------------|-------------|
|
| 465 |
+
| 8 | 1 | 8 | 12.7 GB |
|
| 466 |
+
| 4 | 2 | 8 | 9.0 GB |
|
| 467 |
+
| 1 | 8 | 8 | 5.6 GB |
|
| 468 |
+
|
| 469 |
+
```sh
|
| 470 |
+
accelerate launch training/training.py \
|
| 471 |
+
--output_dir <output path> \
|
| 472 |
+
--train_batch_size <batch size> \
|
| 473 |
+
--gradient_accumulation_steps <gradient accumulation steps> \
|
| 474 |
+
--learning_rate 1e-4 \
|
| 475 |
+
--pretrained_model_name_or_path huggingface/amused-512 \
|
| 476 |
+
--instance_data_dataset 'monadical-labs/minecraft-preview' \
|
| 477 |
+
--prompt_prefix 'minecraft ' \
|
| 478 |
+
--image_key image \
|
| 479 |
+
--prompt_key text \
|
| 480 |
+
--resolution 512 \
|
| 481 |
+
--mixed_precision fp16 \
|
| 482 |
+
--lr_scheduler constant \
|
| 483 |
+
--validation_prompts \
|
| 484 |
+
'minecraft Avatar' \
|
| 485 |
+
'minecraft character' \
|
| 486 |
+
'minecraft' \
|
| 487 |
+
'minecraft president' \
|
| 488 |
+
'minecraft pig' \
|
| 489 |
+
--max_train_steps 10000 \
|
| 490 |
+
--checkpointing_steps 500 \
|
| 491 |
+
--validation_steps 250 \
|
| 492 |
+
--gradient_checkpointing
|
| 493 |
+
```
|
| 494 |
+
|
| 495 |
+
### Styledrop
|
| 496 |
+
|
| 497 |
+
[Styledrop](https://arxiv.org/abs/2306.00983) is an efficient finetuning method for learning a new style from a small number of images. It has an optional first stage to generate human picked additional training samples. The additional training samples can be used to augment the initial images. Our examples exclude the optional additional image selection stage and instead we just finetune on a single image.
|
| 498 |
+
|
| 499 |
+
This is our example style image:
|
| 500 |
+

|
| 501 |
+
|
| 502 |
+
#### 256
|
| 503 |
+
|
| 504 |
+
Example results:
|
| 505 |
+
|
| 506 |
+
  
|
| 507 |
+
|
| 508 |
+
Learning rate: 4e-4, Gives decent results in 1500-2000 steps
|
| 509 |
+
|
| 510 |
+
```sh
|
| 511 |
+
accelerate launch ./training/training.py \
|
| 512 |
+
--output_dir <output path> \
|
| 513 |
+
--mixed_precision fp16 \
|
| 514 |
+
--report_to wandb \
|
| 515 |
+
--use_lora \
|
| 516 |
+
--pretrained_model_name_or_path huggingface/amused-256 \
|
| 517 |
+
--train_batch_size 1 \
|
| 518 |
+
--lr_scheduler constant \
|
| 519 |
+
--learning_rate 4e-4 \
|
| 520 |
+
--validation_prompts \
|
| 521 |
+
'A chihuahua walking on the street in [V] style' \
|
| 522 |
+
'A banana on the table in [V] style' \
|
| 523 |
+
'A church on the street in [V] style' \
|
| 524 |
+
'A tabby cat walking in the forest in [V] style' \
|
| 525 |
+
--instance_data_image './training/A mushroom in [V] style.png' \
|
| 526 |
+
--max_train_steps 10000 \
|
| 527 |
+
--checkpointing_steps 500 \
|
| 528 |
+
--validation_steps 100 \
|
| 529 |
+
--resolution 256
|
| 530 |
+
```
|
| 531 |
+
|
| 532 |
+
#### 512
|
| 533 |
+
|
| 534 |
+
Learning rate: 1e-3, Lora alpha 1, Gives decent results in 1500-2000 steps
|
| 535 |
+
|
| 536 |
+
Example results:
|
| 537 |
+
|
| 538 |
+
  
|
| 539 |
+
|
| 540 |
+
```
|
| 541 |
+
accelerate launch ./training/training.py \
|
| 542 |
+
--output_dir ../styledrop \
|
| 543 |
+
--mixed_precision fp16 \
|
| 544 |
+
--report_to wandb \
|
| 545 |
+
--use_lora \
|
| 546 |
+
--pretrained_model_name_or_path huggingface/amused-512 \
|
| 547 |
+
--train_batch_size 1 \
|
| 548 |
+
--lr_scheduler constant \
|
| 549 |
+
--learning_rate 1e-3 \
|
| 550 |
+
--validation_prompts \
|
| 551 |
+
'A chihuahua walking on the street in [V] style' \
|
| 552 |
+
'A banana on the table in [V] style' \
|
| 553 |
+
'A church on the street in [V] style' \
|
| 554 |
+
'A tabby cat walking in the forest in [V] style' \
|
| 555 |
+
--instance_data_image './training/A mushroom in [V] style.png' \
|
| 556 |
+
--max_train_steps 100000 \
|
| 557 |
+
--checkpointing_steps 500 \
|
| 558 |
+
--validation_steps 100 \
|
| 559 |
+
--resolution 512 \
|
| 560 |
+
--lora_alpha 1
|
| 561 |
+
```
|
| 562 |
+
|
| 563 |
+
## 4. Acknowledgements
|
| 564 |
+
|
| 565 |
+
TODO
|
| 566 |
+
|
| 567 |
+
## 5. Citation
|
| 568 |
+
```
|
| 569 |
+
@misc{patil-etal-2023-amused,
|
| 570 |
+
author = {Suraj Patil and William Berman and Patrick von Platen},
|
| 571 |
+
title = {Amused: An open MUSE model},
|
| 572 |
+
year = {2023},
|
| 573 |
+
publisher = {GitHub},
|
| 574 |
+
journal = {GitHub repository},
|
| 575 |
+
howpublished = {\url{https://github.com/huggingface/amused}}
|
| 576 |
+
}
|
| 577 |
+
```
|
assets/4090_bs_1.png
ADDED

|
assets/4090_bs_8.png
ADDED

|
assets/a100_bs_1.png
ADDED
|
assets/a100_bs_8.png
ADDED
|
assets/collage_full.png
ADDED

|
Git LFS Details
|
assets/collage_small.png
ADDED

|
Git LFS Details
|
assets/glowing_256_1.png
ADDED

|
assets/glowing_256_2.png
ADDED

|
assets/glowing_256_3.png
ADDED

|
assets/glowing_512_1.png
ADDED

|
assets/glowing_512_2.png
ADDED

|
assets/glowing_512_3.png
ADDED

|
assets/image2image_256.png
ADDED

|
assets/image2image_256_orig.png
ADDED

|
assets/image2image_512.png
ADDED

|
assets/image2image_512_orig.png
ADDED

|
assets/inpainting_256.png
ADDED

|
assets/inpainting_256_mask.png
ADDED

|
assets/inpainting_256_orig.png
ADDED

|
assets/inpainting_512.png
ADDED

|
assets/inpainting_512_mask.png
ADDED

|
assets/inpainting_512_orig.jpeg
ADDED

|
assets/minecraft1.png
ADDED

|
assets/minecraft2.png
ADDED

|
assets/minecraft3.png
ADDED

|
assets/noun1.png
ADDED

|
assets/noun2.png
ADDED

|
assets/noun3.png
ADDED

|
assets/text2image_256.png
ADDED

|
assets/text2image_512.png
ADDED

|
model_index.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AmusedPipeline",
|
| 3 |
+
"_diffusers_version": "0.25.0.dev0",
|
| 4 |
+
"scheduler": [
|
| 5 |
+
"diffusers",
|
| 6 |
+
"AmusedScheduler"
|
| 7 |
+
],
|
| 8 |
+
"text_encoder": [
|
| 9 |
+
"transformers",
|
| 10 |
+
"CLIPTextModelWithProjection"
|
| 11 |
+
],
|
| 12 |
+
"tokenizer": [
|
| 13 |
+
"transformers",
|
| 14 |
+
"CLIPTokenizer"
|
| 15 |
+
],
|
| 16 |
+
"transformer": [
|
| 17 |
+
"diffusers",
|
| 18 |
+
"UVit2DModel"
|
| 19 |
+
],
|
| 20 |
+
"vqvae": [
|
| 21 |
+
"diffusers",
|
| 22 |
+
"VQModel"
|
| 23 |
+
]
|
| 24 |
+
}
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AmusedScheduler",
|
| 3 |
+
"_diffusers_version": "0.25.0.dev0",
|
| 4 |
+
"mask_token_id": 8255,
|
| 5 |
+
"masking_schedule": "cosine"
|
| 6 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPTextModelWithProjection"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "quick_gelu",
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 77,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"projection_dim": 768,
|
| 21 |
+
"torch_dtype": "float32",
|
| 22 |
+
"transformers_version": "4.34.1",
|
| 23 |
+
"vocab_size": 49408
|
| 24 |
+
}
|
text_encoder/model.fp16.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:549d39f40a16f8ef48ed56da60cd25a467bd2c70866f4d49196829881b13b7b2
|
| 3 |
+
size 247323896
|
text_encoder/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dae0eabbb1fd83756ed9dd893c17ff2f6825c98555a1e1b96154e2df0739b9e2
|
| 3 |
+
size 494624560
|
tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "!",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<|endoftext|>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": true,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "!",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49406": {
|
| 13 |
+
"content": "<|startoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"49407": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": true,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"bos_token": "<|startoftext|>",
|
| 30 |
+
"clean_up_tokenization_spaces": true,
|
| 31 |
+
"do_lower_case": true,
|
| 32 |
+
"eos_token": "<|endoftext|>",
|
| 33 |
+
"errors": "replace",
|
| 34 |
+
"model_max_length": 77,
|
| 35 |
+
"pad_token": "!",
|
| 36 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 37 |
+
"unk_token": "<|endoftext|>"
|
| 38 |
+
}
|
tokenizer/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training/A mushroom in [V] style.png
ADDED

|
training/A woman working on a laptop in [V] style.jpg
ADDED

|
Git LFS Details
|
training/generate_images.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
from diffusers import AmusedPipeline
|
| 4 |
+
import os
|
| 5 |
+
from peft import PeftModel
|
| 6 |
+
from diffusers import UVit2DModel
|
| 7 |
+
|
| 8 |
+
logger = logging.getLogger(__name__)
|
| 9 |
+
|
| 10 |
+
def parse_args():
|
| 11 |
+
parser = argparse.ArgumentParser()
|
| 12 |
+
parser.add_argument(
|
| 13 |
+
"--pretrained_model_name_or_path",
|
| 14 |
+
type=str,
|
| 15 |
+
default=None,
|
| 16 |
+
required=True,
|
| 17 |
+
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
| 18 |
+
)
|
| 19 |
+
parser.add_argument(
|
| 20 |
+
"--revision",
|
| 21 |
+
type=str,
|
| 22 |
+
default=None,
|
| 23 |
+
required=False,
|
| 24 |
+
help="Revision of pretrained model identifier from huggingface.co/models.",
|
| 25 |
+
)
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--variant",
|
| 28 |
+
type=str,
|
| 29 |
+
default=None,
|
| 30 |
+
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
|
| 31 |
+
)
|
| 32 |
+
parser.add_argument("--style_descriptor", type=str, default="[V]")
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"--load_transformer_from",
|
| 35 |
+
type=str,
|
| 36 |
+
required=False,
|
| 37 |
+
default=None,
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"--load_transformer_lora_from",
|
| 41 |
+
type=str,
|
| 42 |
+
required=False,
|
| 43 |
+
default=None,
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument("--device", type=str, default='cuda')
|
| 46 |
+
parser.add_argument("--batch_size", type=int, default=1)
|
| 47 |
+
parser.add_argument("--write_images_to", type=str, required=True)
|
| 48 |
+
args = parser.parse_args()
|
| 49 |
+
return args
|
| 50 |
+
|
| 51 |
+
def main(args):
|
| 52 |
+
prompts = [
|
| 53 |
+
f"A chihuahua in {args.style_descriptor} style",
|
| 54 |
+
f"A tabby cat in {args.style_descriptor} style",
|
| 55 |
+
f"A portrait of chihuahua in {args.style_descriptor} style",
|
| 56 |
+
f"An apple on the table in {args.style_descriptor} style",
|
| 57 |
+
f"A banana on the table in {args.style_descriptor} style",
|
| 58 |
+
f"A church on the street in {args.style_descriptor} style",
|
| 59 |
+
f"A church in the mountain in {args.style_descriptor} style",
|
| 60 |
+
f"A church in the field in {args.style_descriptor} style",
|
| 61 |
+
f"A church on the beach in {args.style_descriptor} style",
|
| 62 |
+
f"A chihuahua walking on the street in {args.style_descriptor} style",
|
| 63 |
+
f"A tabby cat walking on the street in {args.style_descriptor} style",
|
| 64 |
+
f"A portrait of tabby cat in {args.style_descriptor} style",
|
| 65 |
+
f"An apple on the dish in {args.style_descriptor} style",
|
| 66 |
+
f"A banana on the dish in {args.style_descriptor} style",
|
| 67 |
+
f"A human walking on the street in {args.style_descriptor} style",
|
| 68 |
+
f"A temple on the street in {args.style_descriptor} style",
|
| 69 |
+
f"A temple in the mountain in {args.style_descriptor} style",
|
| 70 |
+
f"A temple in the field in {args.style_descriptor} style",
|
| 71 |
+
f"A temple on the beach in {args.style_descriptor} style",
|
| 72 |
+
f"A chihuahua walking in the forest in {args.style_descriptor} style",
|
| 73 |
+
f"A tabby cat walking in the forest in {args.style_descriptor} style",
|
| 74 |
+
f"A portrait of human face in {args.style_descriptor} style",
|
| 75 |
+
f"An apple on the ground in {args.style_descriptor} style",
|
| 76 |
+
f"A banana on the ground in {args.style_descriptor} style",
|
| 77 |
+
f"A human walking in the forest in {args.style_descriptor} style",
|
| 78 |
+
f"A cabin on the street in {args.style_descriptor} style",
|
| 79 |
+
f"A cabin in the mountain in {args.style_descriptor} style",
|
| 80 |
+
f"A cabin in the field in {args.style_descriptor} style",
|
| 81 |
+
f"A cabin on the beach in {args.style_descriptor} style"
|
| 82 |
+
]
|
| 83 |
+
|
| 84 |
+
logger.warning(f"generating image for {prompts}")
|
| 85 |
+
|
| 86 |
+
logger.warning(f"loading models")
|
| 87 |
+
|
| 88 |
+
pipe_args = {}
|
| 89 |
+
|
| 90 |
+
if args.load_transformer_from is not None:
|
| 91 |
+
pipe_args["transformer"] = UVit2DModel.from_pretrained(args.load_transformer_from)
|
| 92 |
+
|
| 93 |
+
pipe = AmusedPipeline.from_pretrained(
|
| 94 |
+
pretrained_model_name_or_path=args.pretrained_model_name_or_path,
|
| 95 |
+
revision=args.revision,
|
| 96 |
+
variant=args.variant,
|
| 97 |
+
**pipe_args
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
if args.load_transformer_lora_from is not None:
|
| 101 |
+
pipe.transformer = PeftModel.from_pretrained(
|
| 102 |
+
pipe.transformer, os.path.join(args.load_transformer_from), is_trainable=False
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
pipe.to(args.device)
|
| 106 |
+
|
| 107 |
+
logger.warning(f"generating images")
|
| 108 |
+
|
| 109 |
+
os.makedirs(args.write_images_to, exist_ok=True)
|
| 110 |
+
|
| 111 |
+
for prompt_idx in range(0, len(prompts), args.batch_size):
|
| 112 |
+
images = pipe(prompts[prompt_idx:prompt_idx+args.batch_size]).images
|
| 113 |
+
|
| 114 |
+
for image_idx, image in enumerate(images):
|
| 115 |
+
prompt = prompts[prompt_idx+image_idx]
|
| 116 |
+
image.save(os.path.join(args.write_images_to, prompt + ".png"))
|
| 117 |
+
|
| 118 |
+
if __name__ == "__main__":
|
| 119 |
+
main(parse_args())
|
training/training.py
ADDED
|
@@ -0,0 +1,916 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 The HuggingFace Inc. team.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
from contextlib import nullcontext
|
| 17 |
+
import argparse
|
| 18 |
+
import copy
|
| 19 |
+
import logging
|
| 20 |
+
import math
|
| 21 |
+
import os
|
| 22 |
+
import shutil
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
from datasets import load_dataset
|
| 25 |
+
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn.functional as F
|
| 28 |
+
from accelerate import Accelerator
|
| 29 |
+
from accelerate.logging import get_logger
|
| 30 |
+
from accelerate.utils import ProjectConfiguration, set_seed
|
| 31 |
+
from peft import LoraConfig, PeftModel, get_peft_model
|
| 32 |
+
from PIL import Image
|
| 33 |
+
from PIL.ImageOps import exif_transpose
|
| 34 |
+
from torch.utils.data import DataLoader, Dataset, default_collate
|
| 35 |
+
from torchvision import transforms
|
| 36 |
+
from transformers import (
|
| 37 |
+
CLIPTextModelWithProjection,
|
| 38 |
+
CLIPTokenizer,
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
import diffusers.optimization
|
| 42 |
+
from diffusers import AmusedPipeline, AmusedScheduler, EMAModel, UVit2DModel, VQModel
|
| 43 |
+
from diffusers.utils import is_wandb_available
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
if is_wandb_available():
|
| 47 |
+
import wandb
|
| 48 |
+
|
| 49 |
+
logger = get_logger(__name__, log_level="INFO")
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def parse_args():
|
| 53 |
+
parser = argparse.ArgumentParser()
|
| 54 |
+
parser.add_argument(
|
| 55 |
+
"--pretrained_model_name_or_path",
|
| 56 |
+
type=str,
|
| 57 |
+
default=None,
|
| 58 |
+
required=True,
|
| 59 |
+
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
| 60 |
+
)
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--revision",
|
| 63 |
+
type=str,
|
| 64 |
+
default=None,
|
| 65 |
+
required=False,
|
| 66 |
+
help="Revision of pretrained model identifier from huggingface.co/models.",
|
| 67 |
+
)
|
| 68 |
+
parser.add_argument(
|
| 69 |
+
"--variant",
|
| 70 |
+
type=str,
|
| 71 |
+
default=None,
|
| 72 |
+
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
|
| 73 |
+
)
|
| 74 |
+
parser.add_argument(
|
| 75 |
+
"--instance_data_dataset",
|
| 76 |
+
type=str,
|
| 77 |
+
default=None,
|
| 78 |
+
required=False,
|
| 79 |
+
help="A Hugging Face dataset containing the training images",
|
| 80 |
+
)
|
| 81 |
+
parser.add_argument(
|
| 82 |
+
"--instance_data_dir",
|
| 83 |
+
type=str,
|
| 84 |
+
default=None,
|
| 85 |
+
required=False,
|
| 86 |
+
help="A folder containing the training data of instance images.",
|
| 87 |
+
)
|
| 88 |
+
parser.add_argument(
|
| 89 |
+
"--instance_data_image",
|
| 90 |
+
type=str,
|
| 91 |
+
default=None,
|
| 92 |
+
required=False,
|
| 93 |
+
help="A single training image"
|
| 94 |
+
)
|
| 95 |
+
parser.add_argument(
|
| 96 |
+
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
|
| 97 |
+
)
|
| 98 |
+
parser.add_argument(
|
| 99 |
+
"--dataloader_num_workers",
|
| 100 |
+
type=int,
|
| 101 |
+
default=0,
|
| 102 |
+
help=(
|
| 103 |
+
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
|
| 104 |
+
),
|
| 105 |
+
)
|
| 106 |
+
parser.add_argument(
|
| 107 |
+
"--allow_tf32",
|
| 108 |
+
action="store_true",
|
| 109 |
+
help=(
|
| 110 |
+
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
|
| 111 |
+
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
|
| 112 |
+
),
|
| 113 |
+
)
|
| 114 |
+
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
|
| 115 |
+
parser.add_argument("--ema_decay", type=float, default=0.9999)
|
| 116 |
+
parser.add_argument("--ema_update_after_step", type=int, default=0)
|
| 117 |
+
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
|
| 118 |
+
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
|
| 119 |
+
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
|
| 120 |
+
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
|
| 121 |
+
parser.add_argument(
|
| 122 |
+
"--output_dir",
|
| 123 |
+
type=str,
|
| 124 |
+
default="muse_training",
|
| 125 |
+
help="The output directory where the model predictions and checkpoints will be written.",
|
| 126 |
+
)
|
| 127 |
+
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
|
| 128 |
+
parser.add_argument(
|
| 129 |
+
"--logging_dir",
|
| 130 |
+
type=str,
|
| 131 |
+
default="logs",
|
| 132 |
+
help=(
|
| 133 |
+
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
|
| 134 |
+
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
|
| 135 |
+
),
|
| 136 |
+
)
|
| 137 |
+
parser.add_argument(
|
| 138 |
+
"--max_train_steps",
|
| 139 |
+
type=int,
|
| 140 |
+
default=None,
|
| 141 |
+
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
|
| 142 |
+
)
|
| 143 |
+
parser.add_argument(
|
| 144 |
+
"--checkpointing_steps",
|
| 145 |
+
type=int,
|
| 146 |
+
default=500,
|
| 147 |
+
help=(
|
| 148 |
+
"Save a checkpoint of the training state every X updates. Checkpoints can be used for resuming training via `--resume_from_checkpoint`. "
|
| 149 |
+
"In the case that the checkpoint is better than the final trained model, the checkpoint can also be used for inference."
|
| 150 |
+
"Using a checkpoint for inference requires separate loading of the original pipeline and the individual checkpointed model components."
|
| 151 |
+
"See https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint for step by step"
|
| 152 |
+
"instructions."
|
| 153 |
+
),
|
| 154 |
+
)
|
| 155 |
+
parser.add_argument(
|
| 156 |
+
"--logging_steps",
|
| 157 |
+
type=int,
|
| 158 |
+
default=50,
|
| 159 |
+
)
|
| 160 |
+
parser.add_argument(
|
| 161 |
+
"--checkpoints_total_limit",
|
| 162 |
+
type=int,
|
| 163 |
+
default=None,
|
| 164 |
+
help=(
|
| 165 |
+
"Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
|
| 166 |
+
" See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
|
| 167 |
+
" for more details"
|
| 168 |
+
),
|
| 169 |
+
)
|
| 170 |
+
parser.add_argument(
|
| 171 |
+
"--resume_from_checkpoint",
|
| 172 |
+
type=str,
|
| 173 |
+
default=None,
|
| 174 |
+
help=(
|
| 175 |
+
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
|
| 176 |
+
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
|
| 177 |
+
),
|
| 178 |
+
)
|
| 179 |
+
parser.add_argument(
|
| 180 |
+
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
|
| 181 |
+
)
|
| 182 |
+
parser.add_argument(
|
| 183 |
+
"--gradient_accumulation_steps",
|
| 184 |
+
type=int,
|
| 185 |
+
default=1,
|
| 186 |
+
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
| 187 |
+
)
|
| 188 |
+
parser.add_argument(
|
| 189 |
+
"--learning_rate",
|
| 190 |
+
type=float,
|
| 191 |
+
default=0.0003,
|
| 192 |
+
help="Initial learning rate (after the potential warmup period) to use.",
|
| 193 |
+
)
|
| 194 |
+
parser.add_argument(
|
| 195 |
+
"--scale_lr",
|
| 196 |
+
action="store_true",
|
| 197 |
+
default=False,
|
| 198 |
+
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
|
| 199 |
+
)
|
| 200 |
+
parser.add_argument(
|
| 201 |
+
"--lr_scheduler",
|
| 202 |
+
type=str,
|
| 203 |
+
default="constant",
|
| 204 |
+
help=(
|
| 205 |
+
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
|
| 206 |
+
' "constant", "constant_with_warmup"]'
|
| 207 |
+
),
|
| 208 |
+
)
|
| 209 |
+
parser.add_argument(
|
| 210 |
+
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
| 211 |
+
)
|
| 212 |
+
parser.add_argument(
|
| 213 |
+
"--validation_steps",
|
| 214 |
+
type=int,
|
| 215 |
+
default=100,
|
| 216 |
+
help=(
|
| 217 |
+
"Run validation every X steps. Validation consists of running the prompt"
|
| 218 |
+
" `args.validation_prompt` multiple times: `args.num_validation_images`"
|
| 219 |
+
" and logging the images."
|
| 220 |
+
),
|
| 221 |
+
)
|
| 222 |
+
parser.add_argument(
|
| 223 |
+
"--mixed_precision",
|
| 224 |
+
type=str,
|
| 225 |
+
default=None,
|
| 226 |
+
choices=["no", "fp16", "bf16"],
|
| 227 |
+
help=(
|
| 228 |
+
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
|
| 229 |
+
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
|
| 230 |
+
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
|
| 231 |
+
),
|
| 232 |
+
)
|
| 233 |
+
parser.add_argument(
|
| 234 |
+
"--report_to",
|
| 235 |
+
type=str,
|
| 236 |
+
default="tensorboard",
|
| 237 |
+
help=(
|
| 238 |
+
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
|
| 239 |
+
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
|
| 240 |
+
),
|
| 241 |
+
)
|
| 242 |
+
parser.add_argument("--validation_prompts", type=str, nargs="*")
|
| 243 |
+
parser.add_argument(
|
| 244 |
+
"--resolution",
|
| 245 |
+
type=int,
|
| 246 |
+
default=512,
|
| 247 |
+
help=(
|
| 248 |
+
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
| 249 |
+
" resolution"
|
| 250 |
+
),
|
| 251 |
+
)
|
| 252 |
+
parser.add_argument("--split_vae_encode", type=int, required=False, default=None)
|
| 253 |
+
parser.add_argument("--min_masking_rate", type=float, default=0.0)
|
| 254 |
+
parser.add_argument("--cond_dropout_prob", type=float, default=0.0)
|
| 255 |
+
parser.add_argument("--max_grad_norm", default=None, type=float, help="Max gradient norm.", required=False)
|
| 256 |
+
parser.add_argument("--use_lora", action="store_true", help="TODO")
|
| 257 |
+
parser.add_argument("--lora_r", default=16, type=int)
|
| 258 |
+
parser.add_argument("--lora_alpha", default=32, type=int)
|
| 259 |
+
parser.add_argument("--lora_target_modules", default=["to_q", "to_k", "to_v"], type=str, nargs="+")
|
| 260 |
+
parser.add_argument("--train_text_encoder", action="store_true")
|
| 261 |
+
parser.add_argument("--image_key", type=str, required=False)
|
| 262 |
+
parser.add_argument("--prompt_key", type=str, required=False)
|
| 263 |
+
parser.add_argument(
|
| 264 |
+
"--gradient_checkpointing",
|
| 265 |
+
action="store_true",
|
| 266 |
+
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
|
| 267 |
+
)
|
| 268 |
+
parser.add_argument("--prompt_prefix", type=str, required=False, default=None)
|
| 269 |
+
|
| 270 |
+
args = parser.parse_args()
|
| 271 |
+
|
| 272 |
+
if args.report_to == "wandb":
|
| 273 |
+
if not is_wandb_available():
|
| 274 |
+
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
|
| 275 |
+
|
| 276 |
+
num_datasources = sum([x is not None for x in [args.instance_data_dir, args.instance_data_image, args.instance_data_dataset]])
|
| 277 |
+
|
| 278 |
+
if num_datasources != 1:
|
| 279 |
+
raise ValueError("provide one and only one of `--instance_data_dir`, `--instance_data_image`, or `--instance_data_dataset`")
|
| 280 |
+
|
| 281 |
+
if args.instance_data_dir is not None:
|
| 282 |
+
if not os.path.exists(args.instance_data_dir):
|
| 283 |
+
raise ValueError(f"Does not exist: `--args.instance_data_dir` {args.instance_data_dir}")
|
| 284 |
+
|
| 285 |
+
if args.instance_data_image is not None:
|
| 286 |
+
if not os.path.exists(args.instance_data_image):
|
| 287 |
+
raise ValueError(f"Does not exist: `--args.instance_data_image` {args.instance_data_image}")
|
| 288 |
+
|
| 289 |
+
if args.instance_data_dataset is not None and (args.image_key is None or args.prompt_key is None):
|
| 290 |
+
raise ValueError("`--instance_data_dataset` requires setting `--image_key` and `--prompt_key`")
|
| 291 |
+
|
| 292 |
+
return args
|
| 293 |
+
|
| 294 |
+
class InstanceDataRootDataset(Dataset):
|
| 295 |
+
def __init__(
|
| 296 |
+
self,
|
| 297 |
+
instance_data_root,
|
| 298 |
+
tokenizer,
|
| 299 |
+
size=512,
|
| 300 |
+
):
|
| 301 |
+
self.size = size
|
| 302 |
+
self.tokenizer = tokenizer
|
| 303 |
+
self.instance_images_path = list(Path(instance_data_root).iterdir())
|
| 304 |
+
|
| 305 |
+
def __len__(self):
|
| 306 |
+
return len(self.instance_images_path)
|
| 307 |
+
|
| 308 |
+
def __getitem__(self, index):
|
| 309 |
+
image_path = self.instance_images_path[index % len(self.instance_images_path)]
|
| 310 |
+
instance_image = Image.open(image_path)
|
| 311 |
+
rv = process_image(instance_image, self.size)
|
| 312 |
+
|
| 313 |
+
prompt = os.path.splitext(os.path.basename(image_path))[0]
|
| 314 |
+
rv["prompt_input_ids"] = tokenize_prompt(self.tokenizer, prompt)[0]
|
| 315 |
+
return rv
|
| 316 |
+
|
| 317 |
+
class InstanceDataImageDataset(Dataset):
|
| 318 |
+
def __init__(
|
| 319 |
+
self,
|
| 320 |
+
instance_data_image,
|
| 321 |
+
train_batch_size,
|
| 322 |
+
size=512,
|
| 323 |
+
):
|
| 324 |
+
self.value = process_image(Image.open(instance_data_image), size)
|
| 325 |
+
self.train_batch_size = train_batch_size
|
| 326 |
+
|
| 327 |
+
def __len__(self):
|
| 328 |
+
# Needed so a full batch of the data can be returned. Otherwise will return
|
| 329 |
+
# batches of size 1
|
| 330 |
+
return self.train_batch_size
|
| 331 |
+
|
| 332 |
+
def __getitem__(self, index):
|
| 333 |
+
return self.value
|
| 334 |
+
|
| 335 |
+
class HuggingFaceDataset(Dataset):
|
| 336 |
+
def __init__(
|
| 337 |
+
self,
|
| 338 |
+
hf_dataset,
|
| 339 |
+
tokenizer,
|
| 340 |
+
image_key,
|
| 341 |
+
prompt_key,
|
| 342 |
+
prompt_prefix=None,
|
| 343 |
+
size=512,
|
| 344 |
+
):
|
| 345 |
+
self.size = size
|
| 346 |
+
self.image_key = image_key
|
| 347 |
+
self.prompt_key = prompt_key
|
| 348 |
+
self.tokenizer = tokenizer
|
| 349 |
+
self.hf_dataset = hf_dataset
|
| 350 |
+
self.prompt_prefix = prompt_prefix
|
| 351 |
+
|
| 352 |
+
def __len__(self):
|
| 353 |
+
return len(self.hf_dataset)
|
| 354 |
+
|
| 355 |
+
def __getitem__(self, index):
|
| 356 |
+
item = self.hf_dataset[index]
|
| 357 |
+
|
| 358 |
+
rv = process_image(item[self.image_key], self.size)
|
| 359 |
+
|
| 360 |
+
prompt = item[self.prompt_key]
|
| 361 |
+
|
| 362 |
+
if self.prompt_prefix is not None:
|
| 363 |
+
prompt = self.prompt_prefix + prompt
|
| 364 |
+
|
| 365 |
+
rv["prompt_input_ids"] = tokenize_prompt(self.tokenizer, prompt)[0]
|
| 366 |
+
|
| 367 |
+
return rv
|
| 368 |
+
|
| 369 |
+
def process_image(image, size):
|
| 370 |
+
image = exif_transpose(image)
|
| 371 |
+
|
| 372 |
+
if not image.mode == "RGB":
|
| 373 |
+
image = image.convert("RGB")
|
| 374 |
+
|
| 375 |
+
orig_height = image.height
|
| 376 |
+
orig_width = image.width
|
| 377 |
+
|
| 378 |
+
image = transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR)(image)
|
| 379 |
+
|
| 380 |
+
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(size, size))
|
| 381 |
+
image = transforms.functional.crop(image, c_top, c_left, size, size)
|
| 382 |
+
|
| 383 |
+
image = transforms.ToTensor()(image)
|
| 384 |
+
|
| 385 |
+
micro_conds = torch.tensor(
|
| 386 |
+
[
|
| 387 |
+
orig_width,
|
| 388 |
+
orig_height,
|
| 389 |
+
c_top,
|
| 390 |
+
c_left,
|
| 391 |
+
6.0
|
| 392 |
+
],
|
| 393 |
+
)
|
| 394 |
+
|
| 395 |
+
return {"image": image, "micro_conds": micro_conds}
|
| 396 |
+
|
| 397 |
+
@torch.no_grad()
|
| 398 |
+
def tokenize_prompt(tokenizer, prompt):
|
| 399 |
+
return tokenizer(
|
| 400 |
+
prompt,
|
| 401 |
+
truncation=True,
|
| 402 |
+
padding="max_length",
|
| 403 |
+
max_length=77,
|
| 404 |
+
return_tensors="pt",
|
| 405 |
+
).input_ids
|
| 406 |
+
|
| 407 |
+
def encode_prompt(text_encoder, input_ids):
|
| 408 |
+
outputs = text_encoder(input_ids, return_dict=True, output_hidden_states=True)
|
| 409 |
+
encoder_hidden_states = outputs.hidden_states[-2]
|
| 410 |
+
cond_embeds = outputs[0]
|
| 411 |
+
return encoder_hidden_states, cond_embeds
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
def main(args):
|
| 415 |
+
if args.allow_tf32:
|
| 416 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 417 |
+
|
| 418 |
+
logging_dir = Path(args.output_dir, args.logging_dir)
|
| 419 |
+
|
| 420 |
+
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
|
| 421 |
+
|
| 422 |
+
accelerator = Accelerator(
|
| 423 |
+
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
| 424 |
+
mixed_precision=args.mixed_precision,
|
| 425 |
+
log_with=args.report_to,
|
| 426 |
+
project_config=accelerator_project_config,
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
if accelerator.is_main_process:
|
| 430 |
+
os.makedirs(args.output_dir, exist_ok=True)
|
| 431 |
+
|
| 432 |
+
# Make one log on every process with the configuration for debugging.
|
| 433 |
+
logging.basicConfig(
|
| 434 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 435 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 436 |
+
level=logging.INFO,
|
| 437 |
+
)
|
| 438 |
+
logger.info(accelerator.state, main_process_only=False)
|
| 439 |
+
|
| 440 |
+
if accelerator.is_main_process:
|
| 441 |
+
accelerator.init_trackers("amused", config=vars(copy.deepcopy(args)))
|
| 442 |
+
|
| 443 |
+
if args.seed is not None:
|
| 444 |
+
set_seed(args.seed)
|
| 445 |
+
|
| 446 |
+
resume_from_checkpoint = args.resume_from_checkpoint
|
| 447 |
+
if resume_from_checkpoint:
|
| 448 |
+
if resume_from_checkpoint == "latest":
|
| 449 |
+
# Get the most recent checkpoint
|
| 450 |
+
dirs = os.listdir(args.output_dir)
|
| 451 |
+
dirs = [d for d in dirs if d.startswith("checkpoint")]
|
| 452 |
+
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
|
| 453 |
+
if len(dirs) > 0:
|
| 454 |
+
resume_from_checkpoint = os.path.join(args.output_dir, dirs[-1])
|
| 455 |
+
else:
|
| 456 |
+
resume_from_checkpoint = None
|
| 457 |
+
|
| 458 |
+
if resume_from_checkpoint is None:
|
| 459 |
+
accelerator.print(
|
| 460 |
+
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
|
| 461 |
+
)
|
| 462 |
+
else:
|
| 463 |
+
accelerator.print(f"Resuming from checkpoint {resume_from_checkpoint}")
|
| 464 |
+
|
| 465 |
+
# TODO - will have to fix loading if training text encoder
|
| 466 |
+
text_encoder = CLIPTextModelWithProjection.from_pretrained(
|
| 467 |
+
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
|
| 468 |
+
)
|
| 469 |
+
tokenizer = CLIPTokenizer.from_pretrained(
|
| 470 |
+
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision, variant=args.variant
|
| 471 |
+
)
|
| 472 |
+
vq_model = VQModel.from_pretrained(
|
| 473 |
+
args.pretrained_model_name_or_path, subfolder="vqvae", revision=args.revision, variant=args.variant
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
if args.train_text_encoder:
|
| 477 |
+
text_encoder.train()
|
| 478 |
+
text_encoder.requires_grad_(True)
|
| 479 |
+
else:
|
| 480 |
+
text_encoder.eval()
|
| 481 |
+
text_encoder.requires_grad_(False)
|
| 482 |
+
|
| 483 |
+
vq_model.requires_grad_(False)
|
| 484 |
+
|
| 485 |
+
if args.use_lora:
|
| 486 |
+
model = UVit2DModel.from_pretrained(
|
| 487 |
+
args.pretrained_model_name_or_path, subfolder="transformer", revision=args.revision, variant=args.variant
|
| 488 |
+
)
|
| 489 |
+
|
| 490 |
+
if resume_from_checkpoint is not None:
|
| 491 |
+
model = PeftModel.from_pretrained(
|
| 492 |
+
model, os.path.join(resume_from_checkpoint, "transformer"), is_trainable=True
|
| 493 |
+
)
|
| 494 |
+
else:
|
| 495 |
+
lora_config = LoraConfig(
|
| 496 |
+
r=args.lora_r,
|
| 497 |
+
lora_alpha=args.lora_alpha,
|
| 498 |
+
target_modules=args.lora_target_modules,
|
| 499 |
+
)
|
| 500 |
+
model = get_peft_model(model, lora_config)
|
| 501 |
+
else:
|
| 502 |
+
if resume_from_checkpoint is not None:
|
| 503 |
+
model = UVit2DModel.from_pretrained(resume_from_checkpoint, subfolder="transformer")
|
| 504 |
+
else:
|
| 505 |
+
model = UVit2DModel.from_pretrained(
|
| 506 |
+
args.pretrained_model_name_or_path,
|
| 507 |
+
subfolder="transformer",
|
| 508 |
+
revision=args.revision,
|
| 509 |
+
variant=args.variant,
|
| 510 |
+
)
|
| 511 |
+
|
| 512 |
+
model.train()
|
| 513 |
+
|
| 514 |
+
if args.gradient_checkpointing:
|
| 515 |
+
model.enable_gradient_checkpointing()
|
| 516 |
+
if args.train_text_encoder:
|
| 517 |
+
text_encoder.gradient_checkpointing_enable()
|
| 518 |
+
|
| 519 |
+
if args.use_ema:
|
| 520 |
+
if resume_from_checkpoint is not None:
|
| 521 |
+
ema = EMAModel.from_pretrained(os.path.join(resume_from_checkpoint, "ema_model"), model_cls=UVit2DModel)
|
| 522 |
+
else:
|
| 523 |
+
ema = EMAModel(
|
| 524 |
+
model.parameters(),
|
| 525 |
+
decay=args.ema_decay,
|
| 526 |
+
update_after_step=args.ema_update_after_step,
|
| 527 |
+
model_cls=UVit2DModel,
|
| 528 |
+
model_config=model.config,
|
| 529 |
+
)
|
| 530 |
+
|
| 531 |
+
# TODO - this will save the lora weights in the peft format. We want to save in
|
| 532 |
+
# diffusers format
|
| 533 |
+
def save_model_hook(models, weights, output_dir):
|
| 534 |
+
if accelerator.is_main_process:
|
| 535 |
+
for model in models:
|
| 536 |
+
if isinstance(model, UVit2DModel):
|
| 537 |
+
models[0].save_pretrained(os.path.join(output_dir, "transformer"))
|
| 538 |
+
elif isinstance(model, CLIPTextModelWithProjection):
|
| 539 |
+
models[0].save_pretrained(os.path.join(output_dir, "text_encoder"))
|
| 540 |
+
|
| 541 |
+
weights.pop()
|
| 542 |
+
|
| 543 |
+
if args.use_ema:
|
| 544 |
+
ema.save_pretrained(os.path.join(output_dir, "ema_model"))
|
| 545 |
+
|
| 546 |
+
def load_model_hook(models, input_dir):
|
| 547 |
+
# All models are initially instantiated from the checkpoint and so
|
| 548 |
+
# don't have to be loaded in the accelerate hook
|
| 549 |
+
for _ in range(len(models)):
|
| 550 |
+
models.pop()
|
| 551 |
+
|
| 552 |
+
accelerator.register_load_state_pre_hook(load_model_hook)
|
| 553 |
+
accelerator.register_save_state_pre_hook(save_model_hook)
|
| 554 |
+
|
| 555 |
+
if args.scale_lr:
|
| 556 |
+
args.learning_rate = (
|
| 557 |
+
args.learning_rate * args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
| 558 |
+
)
|
| 559 |
+
|
| 560 |
+
if args.use_8bit_adam:
|
| 561 |
+
try:
|
| 562 |
+
import bitsandbytes as bnb
|
| 563 |
+
except ImportError:
|
| 564 |
+
raise ImportError(
|
| 565 |
+
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
|
| 566 |
+
)
|
| 567 |
+
|
| 568 |
+
optimizer_cls = bnb.optim.AdamW8bit
|
| 569 |
+
else:
|
| 570 |
+
optimizer_cls = torch.optim.AdamW
|
| 571 |
+
|
| 572 |
+
# no decay on bias and layernorm and embedding
|
| 573 |
+
no_decay = ["bias", "layer_norm.weight", "mlm_ln.weight", "embeddings.weight"]
|
| 574 |
+
optimizer_grouped_parameters = [
|
| 575 |
+
{
|
| 576 |
+
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 577 |
+
"weight_decay": args.adam_weight_decay,
|
| 578 |
+
},
|
| 579 |
+
{
|
| 580 |
+
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
|
| 581 |
+
"weight_decay": 0.0,
|
| 582 |
+
},
|
| 583 |
+
]
|
| 584 |
+
|
| 585 |
+
# TODO - does not actually take text encoder parameters
|
| 586 |
+
optimizer = optimizer_cls(
|
| 587 |
+
optimizer_grouped_parameters,
|
| 588 |
+
lr=args.learning_rate,
|
| 589 |
+
betas=(args.adam_beta1, args.adam_beta2),
|
| 590 |
+
weight_decay=args.adam_weight_decay,
|
| 591 |
+
eps=args.adam_epsilon,
|
| 592 |
+
)
|
| 593 |
+
|
| 594 |
+
logger.info("Creating dataloaders and lr_scheduler")
|
| 595 |
+
|
| 596 |
+
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
| 597 |
+
|
| 598 |
+
if args.instance_data_dir is not None:
|
| 599 |
+
dataset = InstanceDataRootDataset(
|
| 600 |
+
instance_data_root=args.instance_data_dir,
|
| 601 |
+
tokenizer=tokenizer,
|
| 602 |
+
size=args.resolution,
|
| 603 |
+
)
|
| 604 |
+
elif args.instance_data_image is not None:
|
| 605 |
+
dataset = InstanceDataImageDataset(
|
| 606 |
+
instance_data_image=args.instance_data_image,
|
| 607 |
+
train_batch_size=args.train_batch_size,
|
| 608 |
+
size=args.resolution,
|
| 609 |
+
)
|
| 610 |
+
elif args.instance_data_dataset is not None:
|
| 611 |
+
dataset = HuggingFaceDataset(
|
| 612 |
+
hf_dataset=load_dataset(args.instance_data_dataset, split="train"),
|
| 613 |
+
tokenizer=tokenizer,
|
| 614 |
+
image_key=args.image_key,
|
| 615 |
+
prompt_key=args.prompt_key,
|
| 616 |
+
prompt_prefix=args.prompt_prefix,
|
| 617 |
+
size=args.resolution,
|
| 618 |
+
)
|
| 619 |
+
else:
|
| 620 |
+
assert False
|
| 621 |
+
|
| 622 |
+
train_dataloader = DataLoader(
|
| 623 |
+
dataset,
|
| 624 |
+
batch_size=args.train_batch_size,
|
| 625 |
+
shuffle=True,
|
| 626 |
+
num_workers=args.dataloader_num_workers,
|
| 627 |
+
collate_fn=default_collate,
|
| 628 |
+
)
|
| 629 |
+
train_dataloader.num_batches = len(train_dataloader)
|
| 630 |
+
|
| 631 |
+
lr_scheduler = diffusers.optimization.get_scheduler(
|
| 632 |
+
args.lr_scheduler,
|
| 633 |
+
optimizer=optimizer,
|
| 634 |
+
num_training_steps=args.max_train_steps*accelerator.num_processes,
|
| 635 |
+
num_warmup_steps=args.lr_warmup_steps*accelerator.num_processes,
|
| 636 |
+
)
|
| 637 |
+
|
| 638 |
+
logger.info("Preparing model, optimizer and dataloaders")
|
| 639 |
+
|
| 640 |
+
if args.train_text_encoder:
|
| 641 |
+
model, optimizer, lr_scheduler, train_dataloader, text_encoder = accelerator.prepare(
|
| 642 |
+
model, optimizer, lr_scheduler, train_dataloader, text_encoder
|
| 643 |
+
)
|
| 644 |
+
else:
|
| 645 |
+
model, optimizer, lr_scheduler, train_dataloader = accelerator.prepare(
|
| 646 |
+
model, optimizer, lr_scheduler, train_dataloader
|
| 647 |
+
)
|
| 648 |
+
|
| 649 |
+
train_dataloader.num_batches = len(train_dataloader)
|
| 650 |
+
|
| 651 |
+
weight_dtype = torch.float32
|
| 652 |
+
if accelerator.mixed_precision == "fp16":
|
| 653 |
+
weight_dtype = torch.float16
|
| 654 |
+
elif accelerator.mixed_precision == "bf16":
|
| 655 |
+
weight_dtype = torch.bfloat16
|
| 656 |
+
|
| 657 |
+
if not args.train_text_encoder:
|
| 658 |
+
text_encoder.to(device=accelerator.device, dtype=weight_dtype)
|
| 659 |
+
|
| 660 |
+
vq_model.to(device=accelerator.device)
|
| 661 |
+
|
| 662 |
+
if args.use_ema:
|
| 663 |
+
ema.to(accelerator.device)
|
| 664 |
+
|
| 665 |
+
with nullcontext() if args.train_text_encoder else torch.no_grad():
|
| 666 |
+
empty_embeds, empty_clip_embeds = encode_prompt(text_encoder, tokenize_prompt(tokenizer, "").to(text_encoder.device, non_blocking=True))
|
| 667 |
+
|
| 668 |
+
# There is a single image, we can just pre-encode the single prompt
|
| 669 |
+
if args.instance_data_image is not None:
|
| 670 |
+
prompt = os.path.splitext(os.path.basename(args.instance_data_image))[0]
|
| 671 |
+
encoder_hidden_states, cond_embeds = encode_prompt(text_encoder, tokenize_prompt(tokenizer, prompt).to(text_encoder.device, non_blocking=True))
|
| 672 |
+
encoder_hidden_states = encoder_hidden_states.repeat(args.train_batch_size, 1, 1)
|
| 673 |
+
cond_embeds = cond_embeds.repeat(args.train_batch_size, 1)
|
| 674 |
+
|
| 675 |
+
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
| 676 |
+
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
|
| 677 |
+
# Afterwards we recalculate our number of training epochs.
|
| 678 |
+
# Note: We are not doing epoch based training here, but just using this for book keeping and being able to
|
| 679 |
+
# reuse the same training loop with other datasets/loaders.
|
| 680 |
+
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
| 681 |
+
|
| 682 |
+
# Train!
|
| 683 |
+
logger.info("***** Running training *****")
|
| 684 |
+
logger.info(f" Num training steps = {args.max_train_steps}")
|
| 685 |
+
logger.info(f" Instantaneous batch size per device = { args.train_batch_size}")
|
| 686 |
+
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
|
| 687 |
+
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
| 688 |
+
|
| 689 |
+
if resume_from_checkpoint is None:
|
| 690 |
+
global_step = 0
|
| 691 |
+
first_epoch = 0
|
| 692 |
+
else:
|
| 693 |
+
accelerator.load_state(resume_from_checkpoint)
|
| 694 |
+
global_step = int(os.path.basename(resume_from_checkpoint).split("-")[1])
|
| 695 |
+
first_epoch = global_step // num_update_steps_per_epoch
|
| 696 |
+
|
| 697 |
+
# As stated above, we are not doing epoch based training here, but just using this for book keeping and being able to
|
| 698 |
+
# reuse the same training loop with other datasets/loaders.
|
| 699 |
+
for epoch in range(first_epoch, num_train_epochs):
|
| 700 |
+
for batch in train_dataloader:
|
| 701 |
+
with torch.no_grad():
|
| 702 |
+
micro_conds = batch["micro_conds"].to(accelerator.device, non_blocking=True)
|
| 703 |
+
pixel_values = batch["image"].to(accelerator.device, non_blocking=True)
|
| 704 |
+
|
| 705 |
+
batch_size = pixel_values.shape[0]
|
| 706 |
+
|
| 707 |
+
split_batch_size = args.split_vae_encode if args.split_vae_encode is not None else batch_size
|
| 708 |
+
num_splits = math.ceil(batch_size / split_batch_size)
|
| 709 |
+
image_tokens = []
|
| 710 |
+
for i in range(num_splits):
|
| 711 |
+
start_idx = i * split_batch_size
|
| 712 |
+
end_idx = min((i + 1) * split_batch_size, batch_size)
|
| 713 |
+
bs = pixel_values.shape[0]
|
| 714 |
+
image_tokens.append(
|
| 715 |
+
vq_model.quantize(vq_model.encode(pixel_values[start_idx:end_idx]).latents)[2][2].reshape(
|
| 716 |
+
bs, -1
|
| 717 |
+
)
|
| 718 |
+
)
|
| 719 |
+
image_tokens = torch.cat(image_tokens, dim=0)
|
| 720 |
+
|
| 721 |
+
batch_size, seq_len = image_tokens.shape
|
| 722 |
+
|
| 723 |
+
timesteps = torch.rand(batch_size, device=image_tokens.device)
|
| 724 |
+
mask_prob = torch.cos(timesteps * math.pi * 0.5)
|
| 725 |
+
mask_prob = mask_prob.clip(args.min_masking_rate)
|
| 726 |
+
|
| 727 |
+
num_token_masked = (seq_len * mask_prob).round().clamp(min=1)
|
| 728 |
+
batch_randperm = torch.rand(batch_size, seq_len, device=image_tokens.device).argsort(dim=-1)
|
| 729 |
+
mask = batch_randperm < num_token_masked.unsqueeze(-1)
|
| 730 |
+
|
| 731 |
+
mask_id = accelerator.unwrap_model(model).config.vocab_size - 1
|
| 732 |
+
input_ids = torch.where(mask, mask_id, image_tokens)
|
| 733 |
+
labels = torch.where(mask, image_tokens, -100)
|
| 734 |
+
|
| 735 |
+
if args.cond_dropout_prob > 0.0:
|
| 736 |
+
assert encoder_hidden_states is not None
|
| 737 |
+
|
| 738 |
+
batch_size = encoder_hidden_states.shape[0]
|
| 739 |
+
|
| 740 |
+
mask = (
|
| 741 |
+
torch.zeros((batch_size, 1, 1), device=encoder_hidden_states.device).float().uniform_(0, 1)
|
| 742 |
+
< args.cond_dropout_prob
|
| 743 |
+
)
|
| 744 |
+
|
| 745 |
+
empty_embeds_ = empty_embeds.expand(batch_size, -1, -1)
|
| 746 |
+
encoder_hidden_states = torch.where(
|
| 747 |
+
(encoder_hidden_states * mask).bool(), encoder_hidden_states, empty_embeds_
|
| 748 |
+
)
|
| 749 |
+
|
| 750 |
+
empty_clip_embeds_ = empty_clip_embeds.expand(batch_size, -1)
|
| 751 |
+
cond_embeds = torch.where((cond_embeds * mask.squeeze(-1)).bool(), cond_embeds, empty_clip_embeds_)
|
| 752 |
+
|
| 753 |
+
bs = input_ids.shape[0]
|
| 754 |
+
vae_scale_factor = 2 ** (len(vq_model.config.block_out_channels) - 1)
|
| 755 |
+
resolution = args.resolution // vae_scale_factor
|
| 756 |
+
input_ids = input_ids.reshape(bs, resolution, resolution)
|
| 757 |
+
|
| 758 |
+
if "prompt_input_ids" in batch:
|
| 759 |
+
with nullcontext() if args.train_text_encoder else torch.no_grad():
|
| 760 |
+
encoder_hidden_states, cond_embeds = encode_prompt(text_encoder, batch["prompt_input_ids"].to(accelerator.device, non_blocking=True))
|
| 761 |
+
|
| 762 |
+
# Train Step
|
| 763 |
+
with accelerator.accumulate(model):
|
| 764 |
+
codebook_size = accelerator.unwrap_model(model).config.codebook_size
|
| 765 |
+
|
| 766 |
+
logits = (
|
| 767 |
+
model(
|
| 768 |
+
input_ids=input_ids,
|
| 769 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 770 |
+
micro_conds=micro_conds,
|
| 771 |
+
pooled_text_emb=cond_embeds,
|
| 772 |
+
)
|
| 773 |
+
.reshape(bs, codebook_size, -1)
|
| 774 |
+
.permute(0, 2, 1)
|
| 775 |
+
.reshape(-1, codebook_size)
|
| 776 |
+
)
|
| 777 |
+
|
| 778 |
+
loss = F.cross_entropy(
|
| 779 |
+
logits,
|
| 780 |
+
labels.view(-1),
|
| 781 |
+
ignore_index=-100,
|
| 782 |
+
reduction="mean",
|
| 783 |
+
)
|
| 784 |
+
|
| 785 |
+
# Gather the losses across all processes for logging (if we use distributed training).
|
| 786 |
+
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
|
| 787 |
+
avg_masking_rate = accelerator.gather(mask_prob.repeat(args.train_batch_size)).mean()
|
| 788 |
+
|
| 789 |
+
accelerator.backward(loss)
|
| 790 |
+
|
| 791 |
+
if args.max_grad_norm is not None and accelerator.sync_gradients:
|
| 792 |
+
accelerator.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 793 |
+
|
| 794 |
+
optimizer.step()
|
| 795 |
+
lr_scheduler.step()
|
| 796 |
+
|
| 797 |
+
optimizer.zero_grad(set_to_none=True)
|
| 798 |
+
|
| 799 |
+
# Checks if the accelerator has performed an optimization step behind the scenes
|
| 800 |
+
if accelerator.sync_gradients:
|
| 801 |
+
if args.use_ema:
|
| 802 |
+
ema.step(model.parameters())
|
| 803 |
+
|
| 804 |
+
if (global_step + 1) % args.logging_steps == 0:
|
| 805 |
+
logs = {
|
| 806 |
+
"step_loss": avg_loss.item(),
|
| 807 |
+
"lr": lr_scheduler.get_last_lr()[0],
|
| 808 |
+
"avg_masking_rate": avg_masking_rate.item(),
|
| 809 |
+
}
|
| 810 |
+
accelerator.log(logs, step=global_step + 1)
|
| 811 |
+
|
| 812 |
+
logger.info(
|
| 813 |
+
f"Step: {global_step + 1} "
|
| 814 |
+
f"Loss: {avg_loss.item():0.4f} "
|
| 815 |
+
f"LR: {lr_scheduler.get_last_lr()[0]:0.6f}"
|
| 816 |
+
)
|
| 817 |
+
|
| 818 |
+
if (global_step + 1) % args.checkpointing_steps == 0:
|
| 819 |
+
save_checkpoint(args, accelerator, global_step + 1)
|
| 820 |
+
|
| 821 |
+
if (global_step + 1) % args.validation_steps == 0 and accelerator.is_main_process:
|
| 822 |
+
if args.use_ema:
|
| 823 |
+
ema.store(model.parameters())
|
| 824 |
+
ema.copy_to(model.parameters())
|
| 825 |
+
|
| 826 |
+
with torch.no_grad():
|
| 827 |
+
logger.info("Generating images...")
|
| 828 |
+
|
| 829 |
+
model.eval()
|
| 830 |
+
|
| 831 |
+
if args.train_text_encoder:
|
| 832 |
+
text_encoder.eval()
|
| 833 |
+
|
| 834 |
+
scheduler = AmusedScheduler.from_pretrained(
|
| 835 |
+
args.pretrained_model_name_or_path,
|
| 836 |
+
subfolder="scheduler",
|
| 837 |
+
revision=args.revision,
|
| 838 |
+
variant=args.variant,
|
| 839 |
+
)
|
| 840 |
+
|
| 841 |
+
pipe = AmusedPipeline(
|
| 842 |
+
transformer=accelerator.unwrap_model(model),
|
| 843 |
+
tokenizer=tokenizer,
|
| 844 |
+
text_encoder=text_encoder,
|
| 845 |
+
vqvae=vq_model,
|
| 846 |
+
scheduler=scheduler,
|
| 847 |
+
)
|
| 848 |
+
|
| 849 |
+
pil_images = pipe(prompt=args.validation_prompts).images
|
| 850 |
+
wandb_images = [
|
| 851 |
+
wandb.Image(image, caption=args.validation_prompts[i])
|
| 852 |
+
for i, image in enumerate(pil_images)
|
| 853 |
+
]
|
| 854 |
+
|
| 855 |
+
wandb.log({"generated_images": wandb_images}, step=global_step + 1)
|
| 856 |
+
|
| 857 |
+
model.train()
|
| 858 |
+
|
| 859 |
+
if args.train_text_encoder:
|
| 860 |
+
text_encoder.train()
|
| 861 |
+
|
| 862 |
+
if args.use_ema:
|
| 863 |
+
ema.restore(model.parameters())
|
| 864 |
+
|
| 865 |
+
global_step += 1
|
| 866 |
+
|
| 867 |
+
# Stop training if max steps is reached
|
| 868 |
+
if global_step >= args.max_train_steps:
|
| 869 |
+
break
|
| 870 |
+
# End for
|
| 871 |
+
|
| 872 |
+
accelerator.wait_for_everyone()
|
| 873 |
+
|
| 874 |
+
# Evaluate and save checkpoint at the end of training
|
| 875 |
+
save_checkpoint(args, accelerator, global_step)
|
| 876 |
+
|
| 877 |
+
# Save the final trained checkpoint
|
| 878 |
+
if accelerator.is_main_process:
|
| 879 |
+
model = accelerator.unwrap_model(model)
|
| 880 |
+
if args.use_ema:
|
| 881 |
+
ema.copy_to(model.parameters())
|
| 882 |
+
model.save_pretrained(args.output_dir)
|
| 883 |
+
|
| 884 |
+
accelerator.end_training()
|
| 885 |
+
|
| 886 |
+
|
| 887 |
+
def save_checkpoint(args, accelerator, global_step):
|
| 888 |
+
output_dir = args.output_dir
|
| 889 |
+
|
| 890 |
+
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
|
| 891 |
+
if accelerator.is_main_process and args.checkpoints_total_limit is not None:
|
| 892 |
+
checkpoints = os.listdir(output_dir)
|
| 893 |
+
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
|
| 894 |
+
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
|
| 895 |
+
|
| 896 |
+
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
|
| 897 |
+
if len(checkpoints) >= args.checkpoints_total_limit:
|
| 898 |
+
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
|
| 899 |
+
removing_checkpoints = checkpoints[0:num_to_remove]
|
| 900 |
+
|
| 901 |
+
logger.info(
|
| 902 |
+
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
|
| 903 |
+
)
|
| 904 |
+
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
|
| 905 |
+
|
| 906 |
+
for removing_checkpoint in removing_checkpoints:
|
| 907 |
+
removing_checkpoint = os.path.join(output_dir, removing_checkpoint)
|
| 908 |
+
shutil.rmtree(removing_checkpoint)
|
| 909 |
+
|
| 910 |
+
save_path = Path(output_dir) / f"checkpoint-{global_step}"
|
| 911 |
+
accelerator.save_state(save_path)
|
| 912 |
+
logger.info(f"Saved state to {save_path}")
|
| 913 |
+
|
| 914 |
+
|
| 915 |
+
if __name__ == "__main__":
|
| 916 |
+
main(parse_args())
|
transformer/config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UVit2DModel",
|
| 3 |
+
"_diffusers_version": "0.25.0.dev0",
|
| 4 |
+
"attention_dropout": 0.0,
|
| 5 |
+
"block_num_heads": 12,
|
| 6 |
+
"block_out_channels": 768,
|
| 7 |
+
"codebook_size": 8192,
|
| 8 |
+
"cond_embed_dim": 768,
|
| 9 |
+
"downsample": false,
|
| 10 |
+
"encoder_hidden_size": 768,
|
| 11 |
+
"hidden_dropout": 0.0,
|
| 12 |
+
"hidden_size": 1024,
|
| 13 |
+
"in_channels": 768,
|
| 14 |
+
"intermediate_size": 2816,
|
| 15 |
+
"layer_norm_eps": 1e-06,
|
| 16 |
+
"ln_elementwise_affine": true,
|
| 17 |
+
"micro_cond_embed_dim": 1280,
|
| 18 |
+
"micro_cond_encode_dim": 256,
|
| 19 |
+
"num_attention_heads": 16,
|
| 20 |
+
"num_hidden_layers": 22,
|
| 21 |
+
"num_res_blocks": 3,
|
| 22 |
+
"sample_size": 16,
|
| 23 |
+
"upsample": false,
|
| 24 |
+
"use_bias": false,
|
| 25 |
+
"vocab_size": 8256
|
| 26 |
+
}
|
transformer/diffusion_pytorch_model.fp16.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:49b6e7c8f858a6f9f6ef4f240aea9e46046f9c12ff919b81247f20f299dec272
|
| 3 |
+
size 1207130008
|
transformer/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9cc8627bf729474c628762c22668a3e0aaf9fef347480bb23937a98828e0936c
|
| 3 |
+
size 2414205728
|
vqvae/config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "VQModel",
|
| 3 |
+
"_diffusers_version": "0.25.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
256,
|
| 9 |
+
512,
|
| 10 |
+
768
|
| 11 |
+
],
|
| 12 |
+
"down_block_types": [
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D",
|
| 16 |
+
"DownEncoderBlock2D",
|
| 17 |
+
"DownEncoderBlock2D"
|
| 18 |
+
],
|
| 19 |
+
"in_channels": 3,
|
| 20 |
+
"latent_channels": 64,
|
| 21 |
+
"layers_per_block": 2,
|
| 22 |
+
"lookup_from_codebook": true,
|
| 23 |
+
"mid_block_add_attention": false,
|
| 24 |
+
"norm_num_groups": 32,
|
| 25 |
+
"norm_type": "group",
|
| 26 |
+
"num_vq_embeddings": 8192,
|
| 27 |
+
"out_channels": 3,
|
| 28 |
+
"sample_size": 32,
|
| 29 |
+
"scaling_factor": 0.18215,
|
| 30 |
+
"up_block_types": [
|
| 31 |
+
"UpDecoderBlock2D",
|
| 32 |
+
"UpDecoderBlock2D",
|
| 33 |
+
"UpDecoderBlock2D",
|
| 34 |
+
"UpDecoderBlock2D",
|
| 35 |
+
"UpDecoderBlock2D"
|
| 36 |
+
],
|
| 37 |
+
"vq_embed_dim": null,
|
| 38 |
+
"force_upcast": true
|
| 39 |
+
}
|