
daliprf
commited on
Commit
•
144b876
1
Parent(s):
97b2087
init
Browse files- .gitattributes +3 -0
- Asm_assisted_loss.py +69 -0
- LICENSE +21 -0
- README.md +146 -3
- cnn_model.py +90 -0
- configuration.py +47 -0
- documents/ASMNet_poster.pdf +3 -0
- documents/ASMNet_slides.pdf +3 -0
- documents/graphical_items_in_paper/300W.png +3 -0
- documents/graphical_items_in_paper/300wEval.png +3 -0
- documents/graphical_items_in_paper/300w_asm_study_chart.png +3 -0
- documents/graphical_items_in_paper/Lossfunction.png +3 -0
- documents/graphical_items_in_paper/arch.png +3 -0
- documents/graphical_items_in_paper/num_params.png +3 -0
- documents/graphical_items_in_paper/poseEval.png +3 -0
- documents/graphical_items_in_paper/posesample.png +3 -0
- documents/graphical_items_in_paper/wflw.png +3 -0
- documents/graphical_items_in_paper/wflwEval.png +3 -0
- documents/graphical_items_in_paper/wflw_asm_study_chart.png +3 -0
- image_utility.py +656 -0
- main.py +23 -0
- pca_utility.py +72 -0
- pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5 +3 -0
- pre_trained_models/ASMNet/ASM_loss/ASMNet_WFLW_ASMLoss.h5 +3 -0
- pre_trained_models/ASMNet/MSE_loss/ASMNet_300W_MESLoss.h5 +3 -0
- pre_trained_models/ASMNet/MSE_loss/ASMNet_WFLW_MESLoss.h5 +3 -0
- pre_trained_models/MobileNetV2/ASM_loss/MobileNetV2_300W_ASMLoss.h5 +3 -0
- pre_trained_models/MobileNetV2/ASM_loss/MobileNetV2_WFLW_ASMLoss.h5 +3 -0
- pre_trained_models/MobileNetV2/MSE_loss/MobileNetV2_300W_MESLoss.h5 +3 -0
- pre_trained_models/MobileNetV2/MSE_loss/MobileNetV2_WFLW_MESLoss.h5 +3 -0
- requirements.txt +23 -0
- test.py +40 -0
- train.py +207 -0
.gitattributes
CHANGED
|
@@ -29,3 +29,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 29 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 31 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 31 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.pdf filter=lfs diff=lfs merge=lfs -text
|
Asm_assisted_loss.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tensorflow as tf
|
| 2 |
+
from pca_utility import PCAUtility
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ASMLoss:
|
| 7 |
+
def __init__(self, dataset_name, accuracy):
|
| 8 |
+
self.dataset_name = dataset_name
|
| 9 |
+
self.accuracy = accuracy
|
| 10 |
+
|
| 11 |
+
def calculate_pose_loss(self, x_pr, x_gt):
|
| 12 |
+
return tf.reduce_mean(tf.square(x_gt - x_pr))
|
| 13 |
+
|
| 14 |
+
def calculate_landmark_ASM_assisted_loss(self, landmark_pr, landmark_gt, current_epoch, total_steps):
|
| 15 |
+
"""
|
| 16 |
+
:param landmark_pr:
|
| 17 |
+
:param landmark_gt:
|
| 18 |
+
:param current_epoch:
|
| 19 |
+
:param total_steps:
|
| 20 |
+
:return:
|
| 21 |
+
"""
|
| 22 |
+
# calculating ASMLoss weight:
|
| 23 |
+
asm_weight = 0.5
|
| 24 |
+
if current_epoch < total_steps//3: asm_weight = 2.0
|
| 25 |
+
elif total_steps//3 <= current_epoch < 2*total_steps//3: asm_weight = 1.0
|
| 26 |
+
|
| 27 |
+
# creating the ASM-ground truth
|
| 28 |
+
landmark_gt_asm = self._calculate_asm(input_tensor=landmark_gt)
|
| 29 |
+
|
| 30 |
+
# calculating ASMLoss
|
| 31 |
+
asm_loss = tf.reduce_mean(tf.square(landmark_gt_asm - landmark_pr))
|
| 32 |
+
|
| 33 |
+
# calculating MSELoss
|
| 34 |
+
mse_loss = tf.reduce_mean(tf.square(landmark_gt - landmark_pr))
|
| 35 |
+
|
| 36 |
+
# calculating total loss
|
| 37 |
+
return mse_loss + asm_weight * asm_loss
|
| 38 |
+
|
| 39 |
+
def _calculate_asm(self, input_tensor):
|
| 40 |
+
pca_utility = PCAUtility()
|
| 41 |
+
eigenvalues, eigenvectors, meanvector = pca_utility.load_pca_obj(self.dataset_name, pca_percentages=self.accuracy)
|
| 42 |
+
|
| 43 |
+
input_vector = np.array(input_tensor)
|
| 44 |
+
out_asm_vector = []
|
| 45 |
+
batch_size = input_vector.shape[0]
|
| 46 |
+
for i in range(batch_size):
|
| 47 |
+
b_vector_p = self._calculate_b_vector(input_vector[i], eigenvalues, eigenvectors, meanvector)
|
| 48 |
+
out_asm_vector.append(meanvector + np.dot(eigenvectors, b_vector_p))
|
| 49 |
+
|
| 50 |
+
out_asm_vector = np.array(out_asm_vector)
|
| 51 |
+
return out_asm_vector
|
| 52 |
+
|
| 53 |
+
def _calculate_b_vector(self, predicted_vector, eigenvalues, eigenvectors, meanvector):
|
| 54 |
+
b_vector = np.dot(eigenvectors.T, predicted_vector - meanvector)
|
| 55 |
+
# revised b to be in -3lambda =>
|
| 56 |
+
i = 0
|
| 57 |
+
for b_item in b_vector:
|
| 58 |
+
lambda_i_sqr = 3 * np.sqrt(eigenvalues[i])
|
| 59 |
+
if b_item > 0:
|
| 60 |
+
b_item = min(b_item, lambda_i_sqr)
|
| 61 |
+
else:
|
| 62 |
+
b_item = max(b_item, -1 * lambda_i_sqr)
|
| 63 |
+
b_vector[i] = b_item
|
| 64 |
+
i += 1
|
| 65 |
+
|
| 66 |
+
return b_vector
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Ali Pourramezan Fard
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,146 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[](https://paperswithcode.com/sota/pose-estimation-on-300w-full?p=deep-active-shape-model-for-face-alignment)
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
[](https://paperswithcode.com/sota/face-alignment-on-wflw?p=deep-active-shape-model-for-face-alignment)
|
| 5 |
+
|
| 6 |
+
[](https://paperswithcode.com/sota/face-alignment-on-300w?p=deep-active-shape-model-for-face-alignment)
|
| 7 |
+
|
| 8 |
+
```diff
|
| 9 |
+
! plaese STAR the repo if you like it.
|
| 10 |
+
```
|
| 11 |
+
|
| 12 |
+
# [ASMNet](https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## a Lightweight Deep Neural Network for Face Alignment and Pose Estimation
|
| 16 |
+
|
| 17 |
+
#### Link to the paper:
|
| 18 |
+
https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en
|
| 19 |
+
|
| 20 |
+
#### Link to the paperswithcode.com:
|
| 21 |
+
https://paperswithcode.com/paper/asmnet-a-lightweight-deep-neural-network-for
|
| 22 |
+
|
| 23 |
+
#### Link to the article on Towardsdatascience.com:
|
| 24 |
+
https://aliprf.medium.com/asmnet-a-lightweight-deep-neural-network-for-face-alignment-and-pose-estimation-9e9dfac07094
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
Please cite this work as:
|
| 28 |
+
|
| 29 |
+
@inproceedings{fard2021asmnet,
|
| 30 |
+
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
|
| 31 |
+
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
|
| 32 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 33 |
+
pages={1521--1530},
|
| 34 |
+
year={2021}
|
| 35 |
+
}
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
## Introduction
|
| 39 |
+
|
| 40 |
+
ASMNet is a lightweight Convolutional Neural Network (CNN) which is designed to perform face alignment and pose estimation efficiently while having acceptable accuracy. ASMNet proposed inspired by MobileNetV2, modified to be suitable for face alignment and pose
|
| 41 |
+
estimation, while being about 2 times smaller in terms of number of the parameters. Moreover, Inspired by Active Shape Model (ASM), ASM-assisted loss function is proposed in order to improve the accuracy of facial landmark points detection and pose estimation.
|
| 42 |
+
|
| 43 |
+
## ASMnet Architecture
|
| 44 |
+
Features in a CNN are distributed hierarchically. In other words, the lower layers have features such as edges, and corners which are more suitable for tasks like landmark localization and pose estimation, and deeper layers contain more abstract features that are more suitable for tasks like image classification and image detection. Furthermore, training a network for correlated tasks simultaneously builds a synergy that can improve the performance of each task.
|
| 45 |
+
|
| 46 |
+
Having said that, we designed ASMNe by fusing the features that are available if different layers of the model. Furthermore, by concatenating the features that are collected after each global average pooling layer in the back-propagation process, it will be possible for the network to evaluate the effect of each shortcut path. Following is the ASMNet architecture:
|
| 47 |
+
|
| 48 |
+
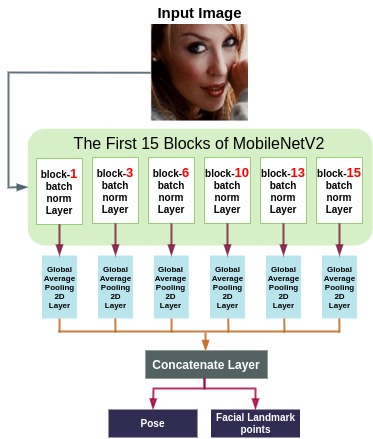
|
| 49 |
+
|
| 50 |
+
The implementation of ASMNet in TensorFlow is provided in the following path:
|
| 51 |
+
https://github.com/aliprf/ASMNet/blob/master/cnn_model.py
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## ASM Loss
|
| 56 |
+
|
| 57 |
+
We proposed a new loss function called ASM-LOSS which utilizes ASM to improve the accuracy of the network. In other words, during the training process, the loss function compares the predicted facial landmark points with their corresponding ground truth as well as the smoothed version the ground truth which is generated using ASM operator. Accordingly, ASM-LOSS guides the network to first learn the smoothed distribution of the facial landmark points. Then, it leads the network to learn the original landmark points. For more detail please refer to the paper.
|
| 58 |
+
Following is the ASM Loss diagram:
|
| 59 |
+
|
| 60 |
+
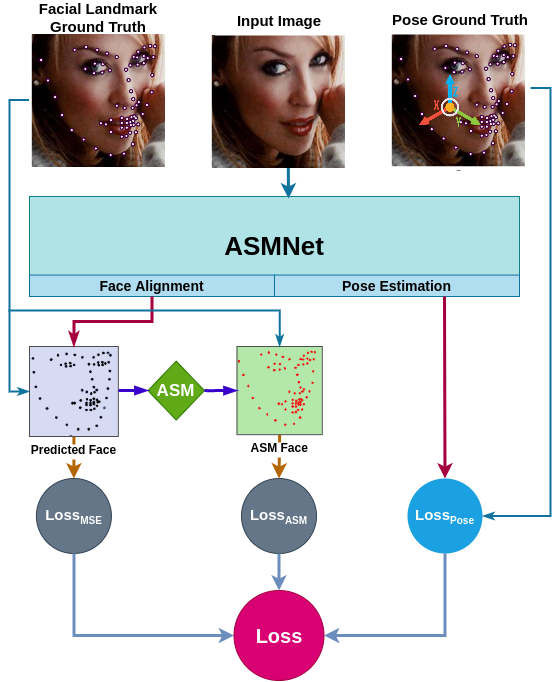
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
## Evaluation
|
| 64 |
+
|
| 65 |
+
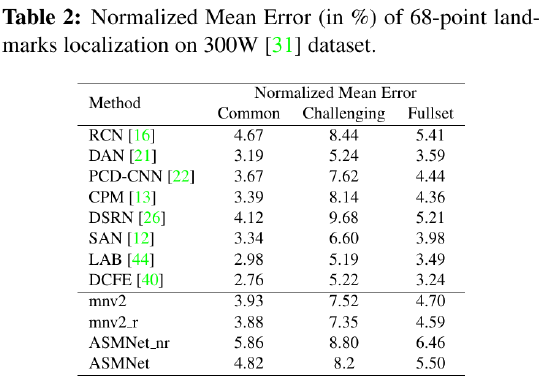
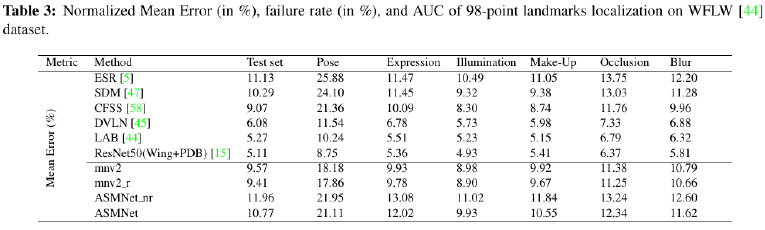
As you can see in the following tables, ASMNet has only 1.4 M parameters which is the smallets comparing to the similar Facial landmark points detection models. Moreover, ASMNet designed to performs Face alignment as well as Pose estimation with a very small CNN while having an acceptable accuracy.
|
| 66 |
+
|
| 67 |
+

|
| 68 |
+
|
| 69 |
+
Although ASMNet is much smaller than the state-of-the-art methods on face alignment, it's performance is also very good and acceptable for many real-world applications:
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
As shown in the following table, ASMNet performs much better that the state-of-the-art models on 300W dataseton Pose estimation task:
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
Following are some samples in order to show the visual performance of ASMNet on 300W and WFLW datasets:
|
| 80 |
+

|
| 81 |
+

|
| 82 |
+
|
| 83 |
+
The visual performance of Pose estimation task using ASMNet is very accurate and the results also are much better than the state-of-the-art pose estimation over 300W dataset:
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
----------------------------------------------------------------------------------------------------------------------------------
|
| 89 |
+
## Installing the requirements
|
| 90 |
+
In order to run the code you need to install python >= 3.5.
|
| 91 |
+
The requirements and the libraries needed to run the code can be installed using the following command:
|
| 92 |
+
|
| 93 |
+
```
|
| 94 |
+
pip install -r requirements.txt
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
## Using the pre-trained models
|
| 99 |
+
You can test and use the preetrained models using the following codes which are available in the following file:
|
| 100 |
+
https://github.com/aliprf/ASMNet/blob/master/main.py
|
| 101 |
+
|
| 102 |
+
```
|
| 103 |
+
tester = Test()
|
| 104 |
+
tester.test_model(ds_name=DatasetName.w300,
|
| 105 |
+
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5')
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
## Training Network from scratch
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
### Preparing Data
|
| 113 |
+
Data needs to be normalized and saved in npy format.
|
| 114 |
+
|
| 115 |
+
### PCA creation
|
| 116 |
+
you can you the pca_utility.py class to create the eigenvalues, eigenvectors, and the meanvector:
|
| 117 |
+
```
|
| 118 |
+
pca_calc = PCAUtility()
|
| 119 |
+
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
|
| 120 |
+
labels_npy_path='./data/w300/normalized_labels/',
|
| 121 |
+
pca_percentages=90)
|
| 122 |
+
```
|
| 123 |
+
### Training
|
| 124 |
+
The training implementation is located in train.py class. You can use the following code to start the training:
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
trainer = Train(arch=ModelArch.ASMNet,
|
| 128 |
+
dataset_name=DatasetName.w300,
|
| 129 |
+
save_path='./',
|
| 130 |
+
asm_accuracy=90)
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
Please cite this work as:
|
| 135 |
+
|
| 136 |
+
@inproceedings{fard2021asmnet,
|
| 137 |
+
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
|
| 138 |
+
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
|
| 139 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 140 |
+
pages={1521--1530},
|
| 141 |
+
year={2021}
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
```diff
|
| 145 |
+
@@plaese STAR the repo if you like it.@@
|
| 146 |
+
```
|
cnn_model.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from configuration import DatasetName, DatasetType, W300Conf, InputDataSize, LearningConfig
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
from tensorflow import keras
|
| 4 |
+
from keras.regularizers import l2, l1
|
| 5 |
+
|
| 6 |
+
from keras.models import Model
|
| 7 |
+
from keras.applications import mobilenet_v2
|
| 8 |
+
from keras.layers import Dense, MaxPooling2D, Conv2D, Flatten, \
|
| 9 |
+
BatchNormalization, GlobalAveragePooling2D, Dropout
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CNNModel:
|
| 13 |
+
def get_model(self, arch, output_len):
|
| 14 |
+
|
| 15 |
+
if arch == 'ASMNet':
|
| 16 |
+
model = self.create_ASMNet(inp_shape=[224, 224, 3], output_len=output_len)
|
| 17 |
+
|
| 18 |
+
elif arch == 'mobileNetV2':
|
| 19 |
+
model = self.create_mobileNet(inp_shape=[224, 224, 3], output_len=output_len)
|
| 20 |
+
|
| 21 |
+
return model
|
| 22 |
+
|
| 23 |
+
def create_mobileNet(self, output_len, inp_shape):
|
| 24 |
+
mobilenet_model = mobilenet_v2.MobileNetV2(input_shape=inp_shape,
|
| 25 |
+
alpha=1.0,
|
| 26 |
+
include_top=True,
|
| 27 |
+
weights=None,
|
| 28 |
+
pooling=None)
|
| 29 |
+
mobilenet_model.layers.pop()
|
| 30 |
+
|
| 31 |
+
x = mobilenet_model.get_layer('global_average_pooling2d_1').output # 1280
|
| 32 |
+
out_landmarks = Dense(output_len, name='O_L')(x)
|
| 33 |
+
out_poses = Dense(LearningConfig.pose_len, name='O_P')(x)
|
| 34 |
+
|
| 35 |
+
inp = mobilenet_model.input
|
| 36 |
+
revised_model = Model(inp, [out_landmarks, out_poses])
|
| 37 |
+
revised_model.summary()
|
| 38 |
+
return revised_model
|
| 39 |
+
|
| 40 |
+
def create_ASMNet(self, output_len, inp_tensor=None, inp_shape=None):
|
| 41 |
+
mobilenet_model = mobilenet_v2.MobileNetV2(input_shape=inp_shape,
|
| 42 |
+
alpha=1.0,
|
| 43 |
+
include_top=True,
|
| 44 |
+
weights=None,
|
| 45 |
+
input_tensor=inp_tensor,
|
| 46 |
+
pooling=None)
|
| 47 |
+
mobilenet_model.layers.pop()
|
| 48 |
+
inp = mobilenet_model.input
|
| 49 |
+
|
| 50 |
+
'''heatmap can not be generated from activation layers, so we use out_relu'''
|
| 51 |
+
block_1_project_BN = mobilenet_model.get_layer('block_1_project_BN').output # 56*56*24
|
| 52 |
+
block_1_project_BN_mpool = GlobalAveragePooling2D()(block_1_project_BN)
|
| 53 |
+
|
| 54 |
+
block_3_project_BN = mobilenet_model.get_layer('block_3_project_BN').output # 28*28*32
|
| 55 |
+
block_3_project_BN_mpool = GlobalAveragePooling2D()(block_3_project_BN)
|
| 56 |
+
|
| 57 |
+
block_6_project_BN = mobilenet_model.get_layer('block_6_project_BN').output # 14*14*64
|
| 58 |
+
block_6_project_BN_mpool = GlobalAveragePooling2D()(block_6_project_BN)
|
| 59 |
+
|
| 60 |
+
block_10_project_BN = mobilenet_model.get_layer('block_10_project_BN').output # 14*14*96
|
| 61 |
+
block_10_project_BN_mpool = GlobalAveragePooling2D()(block_10_project_BN)
|
| 62 |
+
|
| 63 |
+
block_13_project_BN = mobilenet_model.get_layer('block_13_project_BN').output # 7*7*160
|
| 64 |
+
block_13_project_BN_mpool = GlobalAveragePooling2D()(block_13_project_BN)
|
| 65 |
+
|
| 66 |
+
block_15_add = mobilenet_model.get_layer('block_15_add').output # 7*7*160
|
| 67 |
+
block_15_add_mpool = GlobalAveragePooling2D()(block_15_add)
|
| 68 |
+
|
| 69 |
+
x = keras.layers.Concatenate()([block_1_project_BN_mpool, block_3_project_BN_mpool, block_6_project_BN_mpool,
|
| 70 |
+
block_10_project_BN_mpool, block_13_project_BN_mpool, block_15_add_mpool])
|
| 71 |
+
x = keras.layers.Dropout(rate=0.3)(x)
|
| 72 |
+
''''''
|
| 73 |
+
out_landmarks = Dense(output_len,
|
| 74 |
+
kernel_regularizer=l2(0.01),
|
| 75 |
+
bias_regularizer=l2(0.01),
|
| 76 |
+
name='O_L')(x)
|
| 77 |
+
out_poses = Dense(LearningConfig.pose_len,
|
| 78 |
+
kernel_regularizer=l2(0.01),
|
| 79 |
+
bias_regularizer=l2(0.01),
|
| 80 |
+
name='O_P')(x)
|
| 81 |
+
|
| 82 |
+
revised_model = Model(inp, [out_landmarks, out_poses])
|
| 83 |
+
|
| 84 |
+
revised_model.summary()
|
| 85 |
+
model_json = revised_model.to_json()
|
| 86 |
+
|
| 87 |
+
with open("ASMNet.json", "w") as json_file:
|
| 88 |
+
json_file.write(model_json)
|
| 89 |
+
|
| 90 |
+
return revised_model
|
configuration.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class DatasetName:
|
| 2 |
+
w300 = '300W'
|
| 3 |
+
wflw = 'wflw'
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ModelArch:
|
| 7 |
+
ASMNet = 'ASMNet'
|
| 8 |
+
MNV2 = 'mobileNetV2'
|
| 9 |
+
|
| 10 |
+
class DatasetType:
|
| 11 |
+
data_type_train = 0
|
| 12 |
+
data_type_validation = 1
|
| 13 |
+
data_type_test = 2
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class LearningConfig:
|
| 17 |
+
batch_size = 3
|
| 18 |
+
epochs = 150
|
| 19 |
+
pose_len = 3
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class InputDataSize:
|
| 23 |
+
image_input_size = 224
|
| 24 |
+
pose_len = 3
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class W300Conf:
|
| 28 |
+
W300W_prefix_path = '/media/ali/new_data/300W/' # --> local
|
| 29 |
+
|
| 30 |
+
train_pose = W300W_prefix_path + 'train_set/pose/'
|
| 31 |
+
train_annotation = W300W_prefix_path + 'train_set/annotations/'
|
| 32 |
+
train_image = W300W_prefix_path + 'train_set/images/'
|
| 33 |
+
|
| 34 |
+
test_annotation_path = W300W_prefix_path + 'test_set/annotations/'
|
| 35 |
+
test_image_path = W300W_prefix_path + 'test_set/images/'
|
| 36 |
+
num_of_landmarks = 68
|
| 37 |
+
|
| 38 |
+
class WflwConf:
|
| 39 |
+
Wflw_prefix_path = '/media/ali/new_data/wflw/' # --> local
|
| 40 |
+
|
| 41 |
+
train_pose = Wflw_prefix_path + 'train_set/pose/'
|
| 42 |
+
train_annotation = Wflw_prefix_path + 'train_set/annotations/'
|
| 43 |
+
train_image = Wflw_prefix_path + 'train_set/images/'
|
| 44 |
+
|
| 45 |
+
test_annotation_path = Wflw_prefix_path + 'test_set/annotations/'
|
| 46 |
+
test_image_path = Wflw_prefix_path + 'test_set/images/'
|
| 47 |
+
num_of_landmarks = 98
|
documents/ASMNet_poster.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec90c6d8a9bfd6a424a0c6db9dc78478817b1982e81dad10a958b2195bb84e66
|
| 3 |
+
size 2302669
|
documents/ASMNet_slides.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:68a23834fb100241c8d71a424c58eb29633545055c1720fbe22b194c4bb88f24
|
| 3 |
+
size 2101077
|
documents/graphical_items_in_paper/300W.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/300wEval.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/300w_asm_study_chart.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/Lossfunction.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/arch.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/num_params.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/poseEval.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/posesample.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/wflw.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/wflwEval.png
ADDED

|
Git LFS Details
|
documents/graphical_items_in_paper/wflw_asm_study_chart.png
ADDED

|
Git LFS Details
|
image_utility.py
ADDED
|
@@ -0,0 +1,656 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
import matplotlib
|
| 5 |
+
matplotlib.use('agg')
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
|
| 8 |
+
import math
|
| 9 |
+
from skimage.transform import warp, AffineTransform
|
| 10 |
+
import cv2
|
| 11 |
+
from scipy import misc
|
| 12 |
+
from skimage.transform import rotate
|
| 13 |
+
from PIL import Image
|
| 14 |
+
from PIL import ImageOps
|
| 15 |
+
from skimage.transform import resize
|
| 16 |
+
from skimage import transform
|
| 17 |
+
from skimage.transform import SimilarityTransform, AffineTransform
|
| 18 |
+
import random
|
| 19 |
+
from configuration import DatasetName
|
| 20 |
+
|
| 21 |
+
class ImageUtility:
|
| 22 |
+
|
| 23 |
+
def crop_and_save(self, _image, _label, file_name, num_of_landmarks, dataset_name):
|
| 24 |
+
try:
|
| 25 |
+
'''crop data: we add a small margin to the images'''
|
| 26 |
+
|
| 27 |
+
xy_points, x_points, y_points = self.create_landmarks(landmarks=_label,
|
| 28 |
+
scale_factor_x=1, scale_factor_y=1)
|
| 29 |
+
|
| 30 |
+
# self.print_image_arr(str(x_points[0]), _image, x_points, y_points)
|
| 31 |
+
|
| 32 |
+
img_arr, points_arr = self.cropImg(_image, x_points, y_points, no_padding=False)
|
| 33 |
+
# img_arr = output_img
|
| 34 |
+
# points_arr = t_label
|
| 35 |
+
'''resize image to 224*224'''
|
| 36 |
+
resized_img = resize(img_arr,
|
| 37 |
+
(224, 224, 3),
|
| 38 |
+
anti_aliasing=True)
|
| 39 |
+
dims = img_arr.shape
|
| 40 |
+
height = dims[0]
|
| 41 |
+
width = dims[1]
|
| 42 |
+
scale_factor_y = 224 / height
|
| 43 |
+
scale_factor_x = 224 / width
|
| 44 |
+
|
| 45 |
+
'''rescale and retrieve landmarks'''
|
| 46 |
+
landmark_arr_xy, landmark_arr_x, landmark_arr_y = \
|
| 47 |
+
self.create_landmarks(landmarks=points_arr,
|
| 48 |
+
scale_factor_x=scale_factor_x,
|
| 49 |
+
scale_factor_y=scale_factor_y)
|
| 50 |
+
|
| 51 |
+
min_b = 0.0
|
| 52 |
+
max_b = 224
|
| 53 |
+
if not(min(landmark_arr_x) < min_b or min(landmark_arr_y) < min_b or
|
| 54 |
+
max(landmark_arr_x) > max_b or max(landmark_arr_y) > max_b):
|
| 55 |
+
|
| 56 |
+
# self.print_image_arr(str(landmark_arr_x[0]), resized_img, landmark_arr_x, landmark_arr_y)
|
| 57 |
+
|
| 58 |
+
im = Image.fromarray((resized_img * 255).astype(np.uint8))
|
| 59 |
+
im.save(str(file_name) + '.jpg')
|
| 60 |
+
|
| 61 |
+
pnt_file = open(str(file_name) + ".pts", "w")
|
| 62 |
+
pre_txt = ["version: 1 \n", "n_points: 68 \n", "{ \n"]
|
| 63 |
+
pnt_file.writelines(pre_txt)
|
| 64 |
+
points_txt = ""
|
| 65 |
+
for i in range(0, len(landmark_arr_xy), 2):
|
| 66 |
+
points_txt += str(landmark_arr_xy[i]) + " " + str(landmark_arr_xy[i + 1]) + "\n"
|
| 67 |
+
|
| 68 |
+
pnt_file.writelines(points_txt)
|
| 69 |
+
pnt_file.write("} \n")
|
| 70 |
+
pnt_file.close()
|
| 71 |
+
|
| 72 |
+
except Exception as e:
|
| 73 |
+
print(e)
|
| 74 |
+
|
| 75 |
+
def random_rotate(self, _image, _label, file_name, num_of_landmarks, dataset_name):
|
| 76 |
+
try:
|
| 77 |
+
|
| 78 |
+
xy_points, x_points, y_points = self.create_landmarks(landmarks=_label,
|
| 79 |
+
scale_factor_x=1, scale_factor_y=1)
|
| 80 |
+
# self.print_image_arr(str(xy_points[8]), _image, x_points, y_points)
|
| 81 |
+
|
| 82 |
+
_image, _label = self.cropImg_2time(_image, x_points, y_points)
|
| 83 |
+
|
| 84 |
+
_image = self.__noisy(_image)
|
| 85 |
+
|
| 86 |
+
scale = (np.random.uniform(0.8, 1.0), np.random.uniform(0.8, 1.0))
|
| 87 |
+
# scale = (1, 1)
|
| 88 |
+
|
| 89 |
+
rot = np.random.uniform(-1 * 0.55, 0.55)
|
| 90 |
+
translation = (0, 0)
|
| 91 |
+
shear = 0
|
| 92 |
+
|
| 93 |
+
tform = AffineTransform(
|
| 94 |
+
scale=scale, # ,
|
| 95 |
+
rotation=rot,
|
| 96 |
+
translation=translation,
|
| 97 |
+
shear=np.deg2rad(shear)
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
output_img = transform.warp(_image, tform.inverse, mode='symmetric')
|
| 101 |
+
|
| 102 |
+
sx, sy = scale
|
| 103 |
+
t_matrix = np.array([
|
| 104 |
+
[sx * math.cos(rot), -sy * math.sin(rot + shear), 0],
|
| 105 |
+
[sx * math.sin(rot), sy * math.cos(rot + shear), 0],
|
| 106 |
+
[0, 0, 1]
|
| 107 |
+
])
|
| 108 |
+
landmark_arr_xy, landmark_arr_x, landmark_arr_y = self.create_landmarks(_label, 1, 1)
|
| 109 |
+
label = np.array(landmark_arr_x + landmark_arr_y).reshape([2, num_of_landmarks])
|
| 110 |
+
marging = np.ones([1, num_of_landmarks])
|
| 111 |
+
label = np.concatenate((label, marging), axis=0)
|
| 112 |
+
|
| 113 |
+
label_t = np.dot(t_matrix, label)
|
| 114 |
+
lbl_flat = np.delete(label_t, 2, axis=0).reshape([2*num_of_landmarks])
|
| 115 |
+
|
| 116 |
+
t_label = self.__reorder(lbl_flat, num_of_landmarks)
|
| 117 |
+
|
| 118 |
+
'''crop data: we add a small margin to the images'''
|
| 119 |
+
xy_points, x_points, y_points = self.create_landmarks(landmarks=t_label,
|
| 120 |
+
scale_factor_x=1, scale_factor_y=1)
|
| 121 |
+
img_arr, points_arr = self.cropImg(output_img, x_points, y_points, no_padding=False)
|
| 122 |
+
# img_arr = output_img
|
| 123 |
+
# points_arr = t_label
|
| 124 |
+
'''resize image to 224*224'''
|
| 125 |
+
resized_img = resize(img_arr,
|
| 126 |
+
(224, 224, 3),
|
| 127 |
+
anti_aliasing=True)
|
| 128 |
+
dims = img_arr.shape
|
| 129 |
+
height = dims[0]
|
| 130 |
+
width = dims[1]
|
| 131 |
+
scale_factor_y = 224 / height
|
| 132 |
+
scale_factor_x = 224 / width
|
| 133 |
+
|
| 134 |
+
'''rescale and retrieve landmarks'''
|
| 135 |
+
landmark_arr_xy, landmark_arr_x, landmark_arr_y = \
|
| 136 |
+
self.create_landmarks(landmarks=points_arr,
|
| 137 |
+
scale_factor_x=scale_factor_x,
|
| 138 |
+
scale_factor_y=scale_factor_y)
|
| 139 |
+
|
| 140 |
+
min_b = 0.0
|
| 141 |
+
max_b = 224
|
| 142 |
+
if dataset_name == DatasetName.cofw:
|
| 143 |
+
min_b = 5.0
|
| 144 |
+
max_b = 214
|
| 145 |
+
|
| 146 |
+
if not(min(landmark_arr_x) < 0 or min(landmark_arr_y) < min_b or
|
| 147 |
+
max(landmark_arr_x) > 224 or max(landmark_arr_y) > max_b):
|
| 148 |
+
|
| 149 |
+
# self.print_image_arr(str(landmark_arr_x[0]), resized_img, landmark_arr_x, landmark_arr_y)
|
| 150 |
+
|
| 151 |
+
im = Image.fromarray((resized_img * 255).astype(np.uint8))
|
| 152 |
+
im.save(str(file_name) + '.jpg')
|
| 153 |
+
|
| 154 |
+
pnt_file = open(str(file_name) + ".pts", "w")
|
| 155 |
+
pre_txt = ["version: 1 \n", "n_points: 68 \n", "{ \n"]
|
| 156 |
+
pnt_file.writelines(pre_txt)
|
| 157 |
+
points_txt = ""
|
| 158 |
+
for i in range(0, len(landmark_arr_xy), 2):
|
| 159 |
+
points_txt += str(landmark_arr_xy[i]) + " " + str(landmark_arr_xy[i + 1]) + "\n"
|
| 160 |
+
|
| 161 |
+
pnt_file.writelines(points_txt)
|
| 162 |
+
pnt_file.write("} \n")
|
| 163 |
+
pnt_file.close()
|
| 164 |
+
|
| 165 |
+
return t_label, output_img
|
| 166 |
+
except Exception as e:
|
| 167 |
+
print(e)
|
| 168 |
+
return None, None
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def random_rotate_m(self, _image, _label_img, file_name):
|
| 172 |
+
|
| 173 |
+
rot = random.uniform(-80.9, 80.9)
|
| 174 |
+
|
| 175 |
+
output_img = rotate(_image, rot, resize=True)
|
| 176 |
+
output_img_lbl = rotate(_label_img, rot, resize=True)
|
| 177 |
+
|
| 178 |
+
im = Image.fromarray((output_img * 255).astype(np.uint8))
|
| 179 |
+
im_lbl = Image.fromarray((output_img_lbl * 255).astype(np.uint8))
|
| 180 |
+
|
| 181 |
+
im_m = ImageOps.mirror(im)
|
| 182 |
+
im_lbl_m = ImageOps.mirror(im_lbl)
|
| 183 |
+
|
| 184 |
+
im.save(str(file_name)+'.jpg')
|
| 185 |
+
# im_lbl.save(str(file_name)+'_lbl.jpg')
|
| 186 |
+
|
| 187 |
+
im_m.save(str(file_name) + '_m.jpg')
|
| 188 |
+
# im_lbl_m.save(str(file_name) + '_m_lbl.jpg')
|
| 189 |
+
|
| 190 |
+
im_lbl_ar = np.array(im_lbl)
|
| 191 |
+
im_lbl_m_ar = np.array(im_lbl_m)
|
| 192 |
+
|
| 193 |
+
self.__save_label(im_lbl_ar, file_name, np.array(im))
|
| 194 |
+
self.__save_label(im_lbl_m_ar, file_name+"_m", np.array(im_m))
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def __save_label(self, im_lbl_ar, file_name, img_arr):
|
| 198 |
+
|
| 199 |
+
im_lbl_point = []
|
| 200 |
+
for i in range(im_lbl_ar.shape[0]):
|
| 201 |
+
for j in range(im_lbl_ar.shape[1]):
|
| 202 |
+
if im_lbl_ar[i, j] != 0:
|
| 203 |
+
im_lbl_point.append(j)
|
| 204 |
+
im_lbl_point.append(i)
|
| 205 |
+
|
| 206 |
+
pnt_file = open(str(file_name)+".pts", "w")
|
| 207 |
+
|
| 208 |
+
pre_txt = ["version: 1 \n", "n_points: 68 \n", "{ \n"]
|
| 209 |
+
pnt_file.writelines(pre_txt)
|
| 210 |
+
points_txt = ""
|
| 211 |
+
for i in range(0, len(im_lbl_point), 2):
|
| 212 |
+
points_txt += str(im_lbl_point[i]) + " " + str(im_lbl_point[i+1]) + "\n"
|
| 213 |
+
|
| 214 |
+
pnt_file.writelines(points_txt)
|
| 215 |
+
pnt_file.write("} \n")
|
| 216 |
+
pnt_file.close()
|
| 217 |
+
|
| 218 |
+
'''crop data: we add a small margin to the images'''
|
| 219 |
+
xy_points, x_points, y_points = self.create_landmarks(landmarks=im_lbl_point,
|
| 220 |
+
scale_factor_x=1, scale_factor_y=1)
|
| 221 |
+
img_arr, points_arr = self.cropImg(img_arr, x_points, y_points)
|
| 222 |
+
|
| 223 |
+
'''resize image to 224*224'''
|
| 224 |
+
resized_img = resize(img_arr,
|
| 225 |
+
(224, 224, 3),
|
| 226 |
+
anti_aliasing=True)
|
| 227 |
+
dims = img_arr.shape
|
| 228 |
+
height = dims[0]
|
| 229 |
+
width = dims[1]
|
| 230 |
+
scale_factor_y = 224 / height
|
| 231 |
+
scale_factor_x = 224 / width
|
| 232 |
+
|
| 233 |
+
'''rescale and retrieve landmarks'''
|
| 234 |
+
landmark_arr_xy, landmark_arr_x, landmark_arr_y = \
|
| 235 |
+
self.create_landmarks(landmarks=points_arr,
|
| 236 |
+
scale_factor_x=scale_factor_x,
|
| 237 |
+
scale_factor_y=scale_factor_y)
|
| 238 |
+
|
| 239 |
+
im = Image.fromarray((resized_img * 255).astype(np.uint8))
|
| 240 |
+
im.save(str(im_lbl_point[0])+'.jpg')
|
| 241 |
+
# self.print_image_arr(im_lbl_point[0], resized_img, landmark_arr_x, landmark_arr_y)
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def augment(self, _image, _label, num_of_landmarks):
|
| 245 |
+
|
| 246 |
+
# face = misc.face(gray=True)
|
| 247 |
+
#
|
| 248 |
+
# rotate_face = ndimage.rotate(_image, 45)
|
| 249 |
+
# self.print_image_arr(_label[0], rotate_face, [],[])
|
| 250 |
+
|
| 251 |
+
# hue_img = tf.image.random_hue(_image, max_delta=0.1) # max_delta must be in the interval [0, 0.5].
|
| 252 |
+
# sat_img = tf.image.random_saturation(hue_img, lower=0.0, upper=3.0)
|
| 253 |
+
#
|
| 254 |
+
# sat_img = K.eval(sat_img)
|
| 255 |
+
#
|
| 256 |
+
_image = self.__noisy(_image)
|
| 257 |
+
|
| 258 |
+
shear = 0
|
| 259 |
+
|
| 260 |
+
# rot = 0.0
|
| 261 |
+
'''this scale has problem'''
|
| 262 |
+
# scale = (random.uniform(0.8, 1.00), random.uniform(0.8, 1.00))
|
| 263 |
+
|
| 264 |
+
scale = (1, 1)
|
| 265 |
+
|
| 266 |
+
rot = np.random.uniform(-1 * 0.008, 0.008)
|
| 267 |
+
|
| 268 |
+
tform = AffineTransform(scale=scale, rotation=rot, shear=shear,
|
| 269 |
+
translation=(0, 0))
|
| 270 |
+
|
| 271 |
+
output_img = warp(_image, tform.inverse, output_shape=(_image.shape[0], _image.shape[1]))
|
| 272 |
+
|
| 273 |
+
sx, sy = scale
|
| 274 |
+
t_matrix = np.array([
|
| 275 |
+
[sx * math.cos(rot), -sy * math.sin(rot + shear), 0],
|
| 276 |
+
[sx * math.sin(rot), sy * math.cos(rot + shear), 0],
|
| 277 |
+
[0, 0, 1]
|
| 278 |
+
])
|
| 279 |
+
landmark_arr_xy, landmark_arr_x, landmark_arr_y = self.create_landmarks(_label, 1, 1)
|
| 280 |
+
label = np.array(landmark_arr_x + landmark_arr_y).reshape([2, num_of_landmarks])
|
| 281 |
+
marging = np.ones([1, num_of_landmarks])
|
| 282 |
+
label = np.concatenate((label, marging), axis=0)
|
| 283 |
+
|
| 284 |
+
label_t = np.dot(t_matrix, label)
|
| 285 |
+
lbl_flat = np.delete(label_t, 2, axis=0).reshape([num_of_landmarks*2])
|
| 286 |
+
|
| 287 |
+
t_label = self.__reorder(lbl_flat, num_of_landmarks)
|
| 288 |
+
return t_label, output_img
|
| 289 |
+
|
| 290 |
+
def __noisy(self, image):
|
| 291 |
+
noise_typ = random.randint(0, 5)
|
| 292 |
+
# if True or noise_typ == 0 :#"gauss":
|
| 293 |
+
# row, col, ch = image.shape
|
| 294 |
+
# mean = 0
|
| 295 |
+
# var = 0.001
|
| 296 |
+
# sigma = var ** 0.1
|
| 297 |
+
# gauss = np.random.normal(mean, sigma, (row, col, ch))
|
| 298 |
+
# gauss = gauss.reshape(row, col, ch)
|
| 299 |
+
# noisy = image + gauss
|
| 300 |
+
# return noisy
|
| 301 |
+
if 1 <= noise_typ <= 2:# "s&p":
|
| 302 |
+
row, col, ch = image.shape
|
| 303 |
+
s_vs_p = 0.5
|
| 304 |
+
amount = 0.04
|
| 305 |
+
out = np.copy(image)
|
| 306 |
+
# Salt mode
|
| 307 |
+
num_salt = np.ceil(amount * image.size * s_vs_p)
|
| 308 |
+
coords = [np.random.randint(0, i - 1, int(num_salt))
|
| 309 |
+
for i in image.shape]
|
| 310 |
+
out[coords] = 1
|
| 311 |
+
|
| 312 |
+
# Pepper mode
|
| 313 |
+
num_pepper = np.ceil(amount * image.size * (1. - s_vs_p))
|
| 314 |
+
coords = [np.random.randint(0, i - 1, int(num_pepper))
|
| 315 |
+
for i in image.shape]
|
| 316 |
+
out[coords] = 0
|
| 317 |
+
return out
|
| 318 |
+
|
| 319 |
+
# elif 5 <=noise_typ <= 7: #"speckle":
|
| 320 |
+
# row, col, ch = image.shape
|
| 321 |
+
# gauss = np.random.randn(row, col, ch)
|
| 322 |
+
# gauss = gauss.reshape(row, col, ch)
|
| 323 |
+
# noisy = image + image * gauss
|
| 324 |
+
# return noisy
|
| 325 |
+
else:
|
| 326 |
+
return image
|
| 327 |
+
|
| 328 |
+
def __reorder(self, input_arr, num_of_landmarks):
|
| 329 |
+
out_arr = []
|
| 330 |
+
for i in range(num_of_landmarks):
|
| 331 |
+
out_arr.append(input_arr[i])
|
| 332 |
+
k = num_of_landmarks + i
|
| 333 |
+
out_arr.append(input_arr[k])
|
| 334 |
+
return np.array(out_arr)
|
| 335 |
+
|
| 336 |
+
def print_image_arr_heat(self, k, image):
|
| 337 |
+
plt.figure()
|
| 338 |
+
plt.imshow(image)
|
| 339 |
+
implot = plt.imshow(image)
|
| 340 |
+
plt.axis('off')
|
| 341 |
+
plt.savefig('heat' + str(k) + '.png', bbox_inches='tight')
|
| 342 |
+
plt.clf()
|
| 343 |
+
|
| 344 |
+
def print_image_arr(self, k, image, landmarks_x, landmarks_y):
|
| 345 |
+
plt.figure()
|
| 346 |
+
plt.imshow(image)
|
| 347 |
+
implot = plt.imshow(image)
|
| 348 |
+
|
| 349 |
+
plt.scatter(x=landmarks_x[:], y=landmarks_y[:], c='black', s=20)
|
| 350 |
+
plt.scatter(x=landmarks_x[:], y=landmarks_y[:], c='white', s=15)
|
| 351 |
+
plt.axis('off')
|
| 352 |
+
plt.savefig('sss' + str(k) + '.png', bbox_inches='tight')
|
| 353 |
+
# plt.show()
|
| 354 |
+
plt.clf()
|
| 355 |
+
|
| 356 |
+
def create_landmarks_from_normalized_original_img(self, img, landmarks, width, height, x_center, y_center, x1, y1, scale_x, scale_y):
|
| 357 |
+
# landmarks_splited = _landmarks.split(';')
|
| 358 |
+
landmark_arr_xy = []
|
| 359 |
+
landmark_arr_x = []
|
| 360 |
+
landmark_arr_y = []
|
| 361 |
+
|
| 362 |
+
for j in range(0, len(landmarks), 2):
|
| 363 |
+
x = ((x_center - float(landmarks[j]) * width)*scale_x) + x1
|
| 364 |
+
y = ((y_center - float(landmarks[j + 1]) * height)*scale_y) + y1
|
| 365 |
+
|
| 366 |
+
landmark_arr_xy.append(x)
|
| 367 |
+
landmark_arr_xy.append(y)
|
| 368 |
+
|
| 369 |
+
landmark_arr_x.append(x)
|
| 370 |
+
landmark_arr_y.append(y)
|
| 371 |
+
|
| 372 |
+
img = cv2.circle(img, (int(x), int(y)), 2, (255, 14, 74), 2)
|
| 373 |
+
img = cv2.circle(img, (int(x), int(y)), 1, (0, 255, 255), 1)
|
| 374 |
+
|
| 375 |
+
return landmark_arr_xy, landmark_arr_x, landmark_arr_y, img
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
def create_landmarks_from_normalized(self, landmarks, width, height, x_center, y_center):
|
| 379 |
+
|
| 380 |
+
# landmarks_splited = _landmarks.split(';')
|
| 381 |
+
landmark_arr_xy = []
|
| 382 |
+
landmark_arr_x = []
|
| 383 |
+
landmark_arr_y = []
|
| 384 |
+
|
| 385 |
+
for j in range(0, len(landmarks), 2):
|
| 386 |
+
x = x_center - float(landmarks[j]) * width
|
| 387 |
+
y = y_center - float(landmarks[j + 1]) * height
|
| 388 |
+
|
| 389 |
+
landmark_arr_xy.append(x)
|
| 390 |
+
landmark_arr_xy.append(y) # [ x1, y1, x2,y2 ]
|
| 391 |
+
|
| 392 |
+
landmark_arr_x.append(x) # [x1, x2]
|
| 393 |
+
landmark_arr_y.append(y) # [y1, y2]
|
| 394 |
+
|
| 395 |
+
return landmark_arr_xy, landmark_arr_x, landmark_arr_y
|
| 396 |
+
|
| 397 |
+
def create_landmarks(self, landmarks, scale_factor_x, scale_factor_y):
|
| 398 |
+
# landmarks_splited = _landmarks.split(';')
|
| 399 |
+
landmark_arr_xy = []
|
| 400 |
+
landmark_arr_x = []
|
| 401 |
+
landmark_arr_y = []
|
| 402 |
+
for j in range(0, len(landmarks), 2):
|
| 403 |
+
|
| 404 |
+
x = float(landmarks[j]) * scale_factor_x
|
| 405 |
+
y = float(landmarks[j + 1]) * scale_factor_y
|
| 406 |
+
|
| 407 |
+
landmark_arr_xy.append(x)
|
| 408 |
+
landmark_arr_xy.append(y) # [ x1, y1, x2,y2 ]
|
| 409 |
+
|
| 410 |
+
landmark_arr_x.append(x) # [x1, x2]
|
| 411 |
+
landmark_arr_y.append(y) # [y1, y2]
|
| 412 |
+
|
| 413 |
+
return landmark_arr_xy, landmark_arr_x, landmark_arr_y
|
| 414 |
+
|
| 415 |
+
def create_landmarks_aflw(self, landmarks, scale_factor_x, scale_factor_y):
|
| 416 |
+
# landmarks_splited = _landmarks.split(';')
|
| 417 |
+
landmark_arr_xy = []
|
| 418 |
+
landmark_arr_x = []
|
| 419 |
+
landmark_arr_y = []
|
| 420 |
+
for j in range(0, len(landmarks), 2):
|
| 421 |
+
if landmarks[j][0] == 1:
|
| 422 |
+
x = float(landmarks[j][1]) * scale_factor_x
|
| 423 |
+
y = float(landmarks[j][2]) * scale_factor_y
|
| 424 |
+
|
| 425 |
+
landmark_arr_xy.append(x)
|
| 426 |
+
landmark_arr_xy.append(y) # [ x1, y1, x2,y2 ]
|
| 427 |
+
|
| 428 |
+
landmark_arr_x.append(x) # [x1, x2]
|
| 429 |
+
landmark_arr_y.append(y) # [y1, y2]
|
| 430 |
+
|
| 431 |
+
return landmark_arr_xy, landmark_arr_x, landmark_arr_y
|
| 432 |
+
|
| 433 |
+
def random_augmentation(self, lbl, img, number_of_landmark):
|
| 434 |
+
# a = random.randint(0, 2)
|
| 435 |
+
# if a == 0:
|
| 436 |
+
# img, lbl = self.__add_margin(img, img.shape[0], lbl)
|
| 437 |
+
|
| 438 |
+
'''this function has problem!!!'''
|
| 439 |
+
# img, lbl = self.__add_margin(img, img.shape[0], lbl)
|
| 440 |
+
|
| 441 |
+
# else:
|
| 442 |
+
# img, lbl = self.__negative_crop(img, lbl)
|
| 443 |
+
|
| 444 |
+
# i = random.randint(0, 2)
|
| 445 |
+
# if i == 0:
|
| 446 |
+
# img, lbl = self.__rotate(img, lbl, 90, img.shape[0], img.shape[1])
|
| 447 |
+
# elif i == 1:
|
| 448 |
+
# img, lbl = self.__rotate(img, lbl, 180, img.shape[0], img.shape[1])
|
| 449 |
+
# else:
|
| 450 |
+
# img, lbl = self.__rotate(img, lbl, 270, img.shape[0], img.shape[1])
|
| 451 |
+
|
| 452 |
+
# k = random.randint(0, 3)
|
| 453 |
+
# if k > 0:
|
| 454 |
+
# img = self.__change_color(img)
|
| 455 |
+
#
|
| 456 |
+
img = self.__noisy(img)
|
| 457 |
+
|
| 458 |
+
lbl = np.reshape(lbl, [number_of_landmark*2])
|
| 459 |
+
return lbl, img
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
def cropImg_2time(self, img, x_s, y_s):
|
| 463 |
+
min_x = max(0, int(min(x_s) - 100))
|
| 464 |
+
max_x = int(max(x_s) + 100)
|
| 465 |
+
min_y = max(0, int(min(y_s) - 100))
|
| 466 |
+
max_y = int(max(y_s) + 100)
|
| 467 |
+
|
| 468 |
+
crop = img[min_y:max_y, min_x:max_x]
|
| 469 |
+
|
| 470 |
+
new_x_s = []
|
| 471 |
+
new_y_s = []
|
| 472 |
+
new_xy_s = []
|
| 473 |
+
|
| 474 |
+
for i in range(len(x_s)):
|
| 475 |
+
new_x_s.append(x_s[i] - min_x)
|
| 476 |
+
new_y_s.append(y_s[i] - min_y)
|
| 477 |
+
new_xy_s.append(x_s[i] - min_x)
|
| 478 |
+
new_xy_s.append(y_s[i] - min_y)
|
| 479 |
+
return crop, new_xy_s
|
| 480 |
+
|
| 481 |
+
def cropImg(self, img, x_s, y_s, no_padding=False):
|
| 482 |
+
margin1 = random.randint(0, 10)
|
| 483 |
+
margin2 = random.randint(0, 10)
|
| 484 |
+
margin3 = random.randint(0, 10)
|
| 485 |
+
margin4 = random.randint(0, 10)
|
| 486 |
+
|
| 487 |
+
if no_padding:
|
| 488 |
+
min_x = max(0, int(min(x_s)))
|
| 489 |
+
max_x = int(max(x_s))
|
| 490 |
+
min_y = max(0, int(min(y_s)))
|
| 491 |
+
max_y = int(max(y_s))
|
| 492 |
+
else:
|
| 493 |
+
min_x = max(0, int(min(x_s) - margin1))
|
| 494 |
+
max_x = int(max(x_s) + margin2)
|
| 495 |
+
min_y = max(0, int(min(y_s) - margin3))
|
| 496 |
+
max_y = int(max(y_s) + margin4)
|
| 497 |
+
|
| 498 |
+
crop = img[min_y:max_y, min_x:max_x]
|
| 499 |
+
|
| 500 |
+
new_x_s = []
|
| 501 |
+
new_y_s = []
|
| 502 |
+
new_xy_s = []
|
| 503 |
+
|
| 504 |
+
for i in range(len(x_s)):
|
| 505 |
+
new_x_s.append(x_s[i] - min_x)
|
| 506 |
+
new_y_s.append(y_s[i] - min_y)
|
| 507 |
+
new_xy_s.append(x_s[i] - min_x)
|
| 508 |
+
new_xy_s.append(y_s[i] - min_y)
|
| 509 |
+
|
| 510 |
+
# imgpr.print_image_arr(k, crop, new_x_s, new_y_s)
|
| 511 |
+
# imgpr.print_image_arr_2(i, img, x_s, y_s, [min_x, max_x], [min_y, max_y])
|
| 512 |
+
|
| 513 |
+
return crop, new_xy_s
|
| 514 |
+
|
| 515 |
+
def __negative_crop(self, img, landmarks):
|
| 516 |
+
|
| 517 |
+
landmark_arr_xy, x_s, y_s = self.create_landmarks(landmarks, 1, 1)
|
| 518 |
+
min_x = img.shape[0] // random.randint(5, 15)
|
| 519 |
+
max_x = img.shape[0] - (img.shape[0] // random.randint(15, 20))
|
| 520 |
+
min_y = img.shape[0] // random.randint(5, 15)
|
| 521 |
+
max_y = img.shape[0] - (img.shape[0] // random.randint(15, 20))
|
| 522 |
+
|
| 523 |
+
crop = img[min_y:max_y, min_x:max_x]
|
| 524 |
+
|
| 525 |
+
new_x_s = []
|
| 526 |
+
new_y_s = []
|
| 527 |
+
new_xy_s = []
|
| 528 |
+
|
| 529 |
+
for i in range(len(x_s)):
|
| 530 |
+
new_x_s.append(x_s[i] - min_x)
|
| 531 |
+
new_y_s.append(y_s[i] - min_y)
|
| 532 |
+
new_xy_s.append(x_s[i] - min_x)
|
| 533 |
+
new_xy_s.append(y_s[i] - min_y)
|
| 534 |
+
|
| 535 |
+
# imgpr.print_image_arr(crop.shape[0], crop, new_x_s, new_y_s)
|
| 536 |
+
# imgpr.print_image_arr_2(crop.shape[0], crop, x_s, y_s, [min_x, max_x], [min_y, max_y])
|
| 537 |
+
|
| 538 |
+
return crop, new_xy_s
|
| 539 |
+
|
| 540 |
+
def __add_margin(self, img, img_w, lbl):
|
| 541 |
+
marging_width = img_w // random.randint(15, 20)
|
| 542 |
+
direction = random.randint(0, 4)
|
| 543 |
+
|
| 544 |
+
if direction == 1:
|
| 545 |
+
margings = np.random.random([img_w, int(marging_width), 3])
|
| 546 |
+
img = np.concatenate((img, margings), axis=1)
|
| 547 |
+
|
| 548 |
+
if direction == 2:
|
| 549 |
+
margings_1 = np.random.random([img_w, int(marging_width), 3])
|
| 550 |
+
img = np.concatenate((img, margings_1), axis=1)
|
| 551 |
+
|
| 552 |
+
marging_width_1 = img_w // random.randint(15, 20)
|
| 553 |
+
margings_2 = np.random.random([int(marging_width_1), img_w + int(marging_width), 3])
|
| 554 |
+
img = np.concatenate((img, margings_2), axis=0)
|
| 555 |
+
|
| 556 |
+
if direction == 3: # need chane labels
|
| 557 |
+
margings_1 = np.random.random([img_w, int(marging_width), 3])
|
| 558 |
+
img = np.concatenate((margings_1, img), axis=1)
|
| 559 |
+
lbl = self.__transfer_lbl(int(marging_width), lbl, [1, 0])
|
| 560 |
+
|
| 561 |
+
marging_width_1 = img_w // random.randint(15, 20)
|
| 562 |
+
margings_2 = np.random.random([int(marging_width_1), img_w + int(marging_width), 3])
|
| 563 |
+
img = np.concatenate((margings_2, img), axis=0)
|
| 564 |
+
lbl = self.__transfer_lbl(int(marging_width_1), lbl, [0, 1])
|
| 565 |
+
|
| 566 |
+
if direction == 4: # need chane labels
|
| 567 |
+
margings_1 = np.random.random([img_w, int(marging_width), 3])
|
| 568 |
+
img = np.concatenate((margings_1, img), axis=1)
|
| 569 |
+
lbl = self.__transfer_lbl(int(marging_width), lbl, [1, 0])
|
| 570 |
+
img_w1 = img_w + int(marging_width)
|
| 571 |
+
|
| 572 |
+
marging_width_1 = img_w // random.randint(15, 20)
|
| 573 |
+
margings_2 = np.random.random([int(marging_width_1), img_w1, 3])
|
| 574 |
+
img = np.concatenate((margings_2, img), axis=0)
|
| 575 |
+
lbl = self.__transfer_lbl(int(marging_width_1), lbl, [0, 1])
|
| 576 |
+
img_w2 = img_w + int(marging_width_1)
|
| 577 |
+
|
| 578 |
+
marging_width_1 = img_w // random.randint(15, 20)
|
| 579 |
+
margings_1 = np.random.random([img_w2, int(marging_width_1), 3])
|
| 580 |
+
img = np.concatenate((img, margings_1), axis=1)
|
| 581 |
+
|
| 582 |
+
marging_width_1 = img_w // random.randint(15, 20)
|
| 583 |
+
margings_2 = np.random.random([int(marging_width_1), img.shape[1], 3])
|
| 584 |
+
img = np.concatenate((img, margings_2), axis=0)
|
| 585 |
+
|
| 586 |
+
return img, lbl
|
| 587 |
+
|
| 588 |
+
def __void_image(self, img, img_w, ):
|
| 589 |
+
marging_width = int(img_w / random.randint(7, 16))
|
| 590 |
+
direction = random.randint(0, 1)
|
| 591 |
+
direction = 0
|
| 592 |
+
if direction == 0:
|
| 593 |
+
np.delete(img, 100, 1)
|
| 594 |
+
# img[:, 0:marging_width, :] = 0
|
| 595 |
+
elif direction == 1:
|
| 596 |
+
img[img_w - marging_width:img_w, :, :] = 0
|
| 597 |
+
if direction == 2:
|
| 598 |
+
img[:, img_w - marging_width:img_w, :] = 0
|
| 599 |
+
|
| 600 |
+
return img
|
| 601 |
+
|
| 602 |
+
def __change_color(self, img):
|
| 603 |
+
# color_arr = np.random.random([img.shape[0], img.shape[1]])
|
| 604 |
+
color_arr = np.zeros([img.shape[0], img.shape[1]])
|
| 605 |
+
axis = random.randint(0, 4)
|
| 606 |
+
|
| 607 |
+
if axis == 0: # red
|
| 608 |
+
img_mono = img[:, :, 0]
|
| 609 |
+
new_img = np.stack([img_mono, color_arr, color_arr], axis=2)
|
| 610 |
+
elif axis == 1: # green
|
| 611 |
+
img_mono = img[:, :, 1]
|
| 612 |
+
new_img = np.stack([color_arr, img_mono, color_arr], axis=2)
|
| 613 |
+
elif axis == 2: # blue
|
| 614 |
+
img_mono = img[:, :, 1]
|
| 615 |
+
new_img = np.stack([color_arr, img_mono, color_arr], axis=2)
|
| 616 |
+
elif axis == 3: # gray scale
|
| 617 |
+
img_mono = img[:, :, 0]
|
| 618 |
+
new_img = np.stack([img_mono, img_mono, img_mono], axis=2)
|
| 619 |
+
else: # random noise
|
| 620 |
+
color_arr = np.random.random([img.shape[0], img.shape[1]])
|
| 621 |
+
img_mono = img[:, :, 0]
|
| 622 |
+
new_img = np.stack([img_mono, img_mono, color_arr], axis=2)
|
| 623 |
+
|
| 624 |
+
return new_img
|
| 625 |
+
|
| 626 |
+
def __rotate_origin_only(self, xy_arr, radians, xs, ys):
|
| 627 |
+
"""Only rotate a point around the origin (0, 0)."""
|
| 628 |
+
rotated = []
|
| 629 |
+
for xy in xy_arr:
|
| 630 |
+
x, y = xy
|
| 631 |
+
xx = x * math.cos(radians) + y * math.sin(radians)
|
| 632 |
+
yy = -x * math.sin(radians) + y * math.cos(radians)
|
| 633 |
+
rotated.append([xx + xs, yy + ys])
|
| 634 |
+
return np.array(rotated)
|
| 635 |
+
|
| 636 |
+
def __rotate(self, img, landmark_old, degree, img_w, img_h, num_of_landmarks):
|
| 637 |
+
landmark_old = np.reshape(landmark_old, [num_of_landmarks, 2])
|
| 638 |
+
|
| 639 |
+
theta = math.radians(degree)
|
| 640 |
+
|
| 641 |
+
if degree == 90:
|
| 642 |
+
landmark = self.__rotate_origin_only(landmark_old, theta, 0, img_h)
|
| 643 |
+
return np.rot90(img, 3, axes=(-2, 0)), landmark
|
| 644 |
+
elif degree == 180:
|
| 645 |
+
landmark = self.__rotate_origin_only(landmark_old, theta, img_h, img_w)
|
| 646 |
+
return np.rot90(img, 2, axes=(-2, 0)), landmark
|
| 647 |
+
elif degree == 270:
|
| 648 |
+
landmark = self.__rotate_origin_only(landmark_old, theta, img_w, 0)
|
| 649 |
+
return np.rot90(img, 1, axes=(-2, 0)), landmark
|
| 650 |
+
|
| 651 |
+
def __transfer_lbl(self, marging_width_1, lbl, axis_arr):
|
| 652 |
+
new_lbl = []
|
| 653 |
+
for i in range(0, len(lbl), 2):
|
| 654 |
+
new_lbl.append(lbl[i] + marging_width_1 * axis_arr[0])
|
| 655 |
+
new_lbl.append(lbl[i + 1] + marging_width_1 * axis_arr[1])
|
| 656 |
+
return np.array(new_lbl)
|
main.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from train import Train
|
| 2 |
+
from test import Test
|
| 3 |
+
from configuration import DatasetName, ModelArch
|
| 4 |
+
from pca_utility import PCAUtility
|
| 5 |
+
if __name__ == '__main__':
|
| 6 |
+
'''use the pretrained model'''
|
| 7 |
+
tester = Test()
|
| 8 |
+
tester.test_model(ds_name=DatasetName.w300,
|
| 9 |
+
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5')
|
| 10 |
+
|
| 11 |
+
'''training model from scratch'''
|
| 12 |
+
# pretrain prerequisites
|
| 13 |
+
# 1- PCA calculation:
|
| 14 |
+
pca_calc = PCAUtility()
|
| 15 |
+
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
|
| 16 |
+
labels_npy_path='./data/w300/normalized_labels/',
|
| 17 |
+
pca_percentages=90)
|
| 18 |
+
|
| 19 |
+
# Train:
|
| 20 |
+
trainer = Train(arch=ModelArch.ASMNet,
|
| 21 |
+
dataset_name=DatasetName.w300,
|
| 22 |
+
save_path='./',
|
| 23 |
+
asm_accuracy=90)
|
pca_utility.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from configuration import DatasetName, DatasetType, W300Conf, InputDataSize, LearningConfig, WflwConf
|
| 2 |
+
from image_utility import ImageUtility
|
| 3 |
+
from sklearn.decomposition import PCA, IncrementalPCA
|
| 4 |
+
from sklearn.decomposition import TruncatedSVD
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pickle
|
| 7 |
+
import os
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from numpy import save, load
|
| 10 |
+
import math
|
| 11 |
+
from PIL import Image
|
| 12 |
+
from numpy import save, load
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class PCAUtility:
|
| 16 |
+
eigenvalues_prefix = "_eigenvalues_"
|
| 17 |
+
eigenvectors_prefix = "_eigenvectors_"
|
| 18 |
+
meanvector_prefix = "_meanvector_"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def create_pca_from_npy(self, dataset_name, labels_npy_path, pca_percentages):
|
| 23 |
+
"""
|
| 24 |
+
generate and save eigenvalues, eigenvectors, meanvector
|
| 25 |
+
:param labels_npy_path: the path to the normalized labels that are save in npy format.
|
| 26 |
+
:param pca_percentages: % of eigenvalues that will be used
|
| 27 |
+
:return: generate
|
| 28 |
+
"""
|
| 29 |
+
path = labels_npy_path
|
| 30 |
+
print('PCA calculation started: loading labels')
|
| 31 |
+
|
| 32 |
+
lbl_arr = []
|
| 33 |
+
for file in tqdm(os.listdir(path)):
|
| 34 |
+
if file.endswith(".npy"):
|
| 35 |
+
npy_file = os.path.join(path, file)
|
| 36 |
+
lbl_arr.append(load(npy_file))
|
| 37 |
+
|
| 38 |
+
lbl_arr = np.array(lbl_arr)
|
| 39 |
+
|
| 40 |
+
reduced_lbl_arr, eigenvalues, eigenvectors = self._func_PCA(lbl_arr, pca_percentages)
|
| 41 |
+
mean_lbl_arr = np.mean(lbl_arr, axis=0)
|
| 42 |
+
eigenvectors = eigenvectors.T
|
| 43 |
+
|
| 44 |
+
save('./pca_obj/' + dataset_name + self.eigenvalues_prefix + str(pca_percentages), eigenvalues)
|
| 45 |
+
save('./pca_obj/' + dataset_name + self.eigenvectors_prefix + str(pca_percentages), eigenvectors)
|
| 46 |
+
save('./pca_obj/' + dataset_name + self.meanvector_prefix + str(pca_percentages), mean_lbl_arr)
|
| 47 |
+
|
| 48 |
+
def load_pca_obj(self, dataset_name, pca_percentages):
|
| 49 |
+
eigenvalues = np.load('./pca_obj/' + dataset_name + self.eigenvalues_prefix + str(pca_percentages))
|
| 50 |
+
eigenvectors = np.load('./pca_obj/' + dataset_name + self.eigenvectors_prefix + str(pca_percentages))
|
| 51 |
+
meanvector = np.load('./pca_obj/' + dataset_name + self.meanvector_prefix + str(pca_percentages))
|
| 52 |
+
return eigenvalues, eigenvectors, meanvector
|
| 53 |
+
|
| 54 |
+
def _func_PCA(self, input_data, pca_postfix):
|
| 55 |
+
input_data = np.array(input_data)
|
| 56 |
+
pca = PCA(n_components=pca_postfix / 100)
|
| 57 |
+
# pca = PCA(n_components=0.98)
|
| 58 |
+
# pca = IncrementalPCA(n_components=50, batch_size=50)
|
| 59 |
+
pca.fit(input_data)
|
| 60 |
+
pca_input_data = pca.transform(input_data)
|
| 61 |
+
eigenvalues = pca.explained_variance_
|
| 62 |
+
eigenvectors = pca.components_
|
| 63 |
+
return pca_input_data, eigenvalues, eigenvectors
|
| 64 |
+
|
| 65 |
+
def __svd_func(self, input_data, pca_postfix):
|
| 66 |
+
svd = TruncatedSVD(n_components=50)
|
| 67 |
+
svd.fit(input_data)
|
| 68 |
+
pca_input_data = svd.transform(input_data)
|
| 69 |
+
eigenvalues = svd.explained_variance_
|
| 70 |
+
eigenvectors = svd.components_
|
| 71 |
+
return pca_input_data, eigenvalues, eigenvectors
|
| 72 |
+
# U, S, VT = svd(input_data)
|
pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f12bcb0cc89d1f83b80ead7757f351113f0a919b31c14e5c153f88d7a4fc1d1
|
| 3 |
+
size 17690416
|
pre_trained_models/ASMNet/ASM_loss/ASMNet_WFLW_ASMLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0eb70af0c1be3b7214889523e599c9ceedb0041029fb3c08ab41a73697777f78
|
| 3 |
+
size 18076832
|
pre_trained_models/ASMNet/MSE_loss/ASMNet_300W_MESLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f9c072f7e0c2b3482ff42592db49693c5eaf272beaec0c9e0ed5c212c10e7fb3
|
| 3 |
+
size 17690416
|
pre_trained_models/ASMNet/MSE_loss/ASMNet_WFLW_MESLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58dab640965d280c19251fc8331d6ad8a3a693ec96625ca47b1658ece156242a
|
| 3 |
+
size 18076832
|
pre_trained_models/MobileNetV2/ASM_loss/MobileNetV2_300W_ASMLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3293865821660e229edfb11e9c5e2d0eab75c54aedbf8e14fb3801076b5712bc
|
| 3 |
+
size 29631480
|
pre_trained_models/MobileNetV2/ASM_loss/MobileNetV2_WFLW_ASMLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62fb8a844437d56c9b9f2d05ba0bc23eaeff40871a5bbfa898348eec4cafa4cd
|
| 3 |
+
size 30551608
|
pre_trained_models/MobileNetV2/MSE_loss/MobileNetV2_300W_MESLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:452739aab8ec9d3e6a2121325015cf78cb0e3720c968710019896052769d005c
|
| 3 |
+
size 29631480
|
pre_trained_models/MobileNetV2/MSE_loss/MobileNetV2_WFLW_MESLoss.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62abc61af5ae022895ea7619419ff8b11d3f83f5130368243b29d3d55c1a9700
|
| 3 |
+
size 30551608
|
requirements.txt
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# for cuda 9
|
| 2 |
+
# pip install torch==1.2.0+cu92 torchvision==0.4.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html
|
| 3 |
+
#
|
| 4 |
+
#torch
|
| 5 |
+
#torchvision
|
| 6 |
+
bottleneck
|
| 7 |
+
numpy==1.19.2
|
| 8 |
+
#tensorflow==1.14.0
|
| 9 |
+
tensorflow==2.3.1
|
| 10 |
+
#tensorflow-gpu==1.14
|
| 11 |
+
# keras==2.2.4
|
| 12 |
+
keras==2.4.3
|
| 13 |
+
matplotlib
|
| 14 |
+
opencv-python
|
| 15 |
+
opencv-contrib-python
|
| 16 |
+
scipy
|
| 17 |
+
scikit-learn
|
| 18 |
+
scikit-image
|
| 19 |
+
Pillow
|
| 20 |
+
tqdm
|
| 21 |
+
efficientnet
|
| 22 |
+
# tfkerassurgeon
|
| 23 |
+
tensorboard
|
test.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from configuration import DatasetName, WflwConf, W300Conf, DatasetType, LearningConfig, InputDataSize
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import os.path
|
| 6 |
+
import scipy.io as sio
|
| 7 |
+
from cnn_model import CNNModel
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import numpy as np
|
| 10 |
+
from os import listdir
|
| 11 |
+
from os.path import isfile, join
|
| 12 |
+
from scipy.integrate import simps
|
| 13 |
+
from scipy.integrate import trapz
|
| 14 |
+
import matplotlib.pyplot as plt
|
| 15 |
+
from skimage.io import imread
|
| 16 |
+
|
| 17 |
+
class Test:
|
| 18 |
+
def test_model(self, pretrained_model_path, ds_name):
|
| 19 |
+
if ds_name == DatasetName.w300:
|
| 20 |
+
test_annotation_path = W300Conf.test_annotation_path
|
| 21 |
+
test_image_path = W300Conf.test_image_path
|
| 22 |
+
elif ds_name == DatasetName.wflw:
|
| 23 |
+
test_annotation_path = WflwConf.test_annotation_path
|
| 24 |
+
test_image_path = WflwConf.test_image_path
|
| 25 |
+
|
| 26 |
+
model = tf.keras.models.load_model(pretrained_model_path)
|
| 27 |
+
|
| 28 |
+
for i, file in tqdm(enumerate(os.listdir(test_image_path))):
|
| 29 |
+
# load image and then normalize it
|
| 30 |
+
img = imread(test_image_path + file)/255.0
|
| 31 |
+
|
| 32 |
+
# prediction
|
| 33 |
+
prediction = model.predict(np.expand_dims(img, axis=0))
|
| 34 |
+
|
| 35 |
+
# the first dimension is landmark point
|
| 36 |
+
landmark_predicted = prediction[0][0]
|
| 37 |
+
|
| 38 |
+
# the second dimension is the pose
|
| 39 |
+
pose_predicted = prediction[1][0]
|
| 40 |
+
|
train.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from configuration import DatasetName, WflwConf, W300Conf, DatasetType, LearningConfig, InputDataSize
|
| 2 |
+
from cnn_model import CNNModel
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
import tensorflow.keras as keras
|
| 5 |
+
import numpy as np
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import math
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
from sklearn.utils import shuffle
|
| 10 |
+
from sklearn.model_selection import train_test_split
|
| 11 |
+
from numpy import save, load, asarray
|
| 12 |
+
import csv
|
| 13 |
+
from skimage.io import imread
|
| 14 |
+
import pickle
|
| 15 |
+
from image_utility import ImageUtility
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
import os
|
| 18 |
+
from Asm_assisted_loss import ASMLoss
|
| 19 |
+
from cnn_model import CNNModel
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class Train:
|
| 23 |
+
def __init__(self, arch, dataset_name, save_path, asm_accuracy=90):
|
| 24 |
+
"""
|
| 25 |
+
:param arch:
|
| 26 |
+
:param dataset_name:
|
| 27 |
+
:param save_path:
|
| 28 |
+
:param asm_accuracy:
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
self.dataset_name = dataset_name
|
| 32 |
+
self.save_path = save_path
|
| 33 |
+
self.arch = arch
|
| 34 |
+
self.asm_accuracy = asm_accuracy
|
| 35 |
+
|
| 36 |
+
if dataset_name == DatasetName.w300:
|
| 37 |
+
self.num_landmark = W300Conf.num_of_landmarks * 2
|
| 38 |
+
self.img_path = W300Conf.train_image
|
| 39 |
+
self.annotation_path = W300Conf.train_annotation
|
| 40 |
+
self.pose_path = W300Conf.train_pose
|
| 41 |
+
|
| 42 |
+
if dataset_name == DatasetName.wflw:
|
| 43 |
+
self.num_landmark = WflwConf.num_of_landmarks * 2
|
| 44 |
+
self.img_path = WflwConf.train_image
|
| 45 |
+
self.annotation_path = WflwConf.train_annotation
|
| 46 |
+
self.pose_path = WflwConf.train_pose
|
| 47 |
+
|
| 48 |
+
def train(self, weight_path):
|
| 49 |
+
"""
|
| 50 |
+
|
| 51 |
+
:param weight_path:
|
| 52 |
+
:return:
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
'''create loss'''
|
| 56 |
+
c_loss = ASMLoss(dataset_name=self.dataset_name, accuracy=90)
|
| 57 |
+
cnn = CNNModel()
|
| 58 |
+
'''making models'''
|
| 59 |
+
model = cnn.get_model(arch=self.arch, output_len=self.num_landmark)
|
| 60 |
+
if weight_path is not None:
|
| 61 |
+
model.load_weights(weight_path)
|
| 62 |
+
|
| 63 |
+
'''create sample generator'''
|
| 64 |
+
image_names, landmark_names, pose_names = self._create_generators()
|
| 65 |
+
|
| 66 |
+
'''create train configuration'''
|
| 67 |
+
step_per_epoch = len(image_names) // LearningConfig.batch_size
|
| 68 |
+
|
| 69 |
+
'''start train:'''
|
| 70 |
+
optimizer = tf.keras.optimizers.Adam(lr=1e-2, decay=1e-5)
|
| 71 |
+
for epoch in range(LearningConfig.epochs):
|
| 72 |
+
image_names, landmark_names, pose_names = shuffle(image_names, landmark_names, pose_names)
|
| 73 |
+
for batch_index in range(step_per_epoch):
|
| 74 |
+
'''load annotation and images'''
|
| 75 |
+
images, annotation_gr, poses_gr = self._get_batch_sample(
|
| 76 |
+
batch_index=batch_index,
|
| 77 |
+
img_filenames=image_names,
|
| 78 |
+
landmark_filenames=landmark_names,
|
| 79 |
+
pose_filenames=pose_names)
|
| 80 |
+
|
| 81 |
+
'''convert to tensor'''
|
| 82 |
+
images = tf.cast(images, tf.float32)
|
| 83 |
+
annotation_gr = tf.cast(annotation_gr, tf.float32)
|
| 84 |
+
poses_gr = tf.cast(poses_gr, tf.float32)
|
| 85 |
+
|
| 86 |
+
'''train step'''
|
| 87 |
+
self.train_step(epoch=epoch,
|
| 88 |
+
step=batch_index,
|
| 89 |
+
total_steps=step_per_epoch,
|
| 90 |
+
model=model,
|
| 91 |
+
images=images,
|
| 92 |
+
annotation_gt=annotation_gr,
|
| 93 |
+
poses_gt=poses_gr,
|
| 94 |
+
optimizer=optimizer,
|
| 95 |
+
c_loss=c_loss)
|
| 96 |
+
'''save weights'''
|
| 97 |
+
model.save(self.save_path + self.arch + str(epoch) + '_' + self.dataset_name)
|
| 98 |
+
|
| 99 |
+
def train_step(self, epoch, step, total_steps, model, images, annotation_gt, poses_gt, optimizer, c_loss):
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
:param epoch:
|
| 103 |
+
:param step:
|
| 104 |
+
:param total_steps:
|
| 105 |
+
:param model:
|
| 106 |
+
:param images:
|
| 107 |
+
:param annotation_gt:
|
| 108 |
+
:param poses_gt:
|
| 109 |
+
:param optimizer:
|
| 110 |
+
:param c_loss:
|
| 111 |
+
:return:
|
| 112 |
+
"""
|
| 113 |
+
|
| 114 |
+
with tf.GradientTape() as tape:
|
| 115 |
+
'''create annotation_predicted'''
|
| 116 |
+
annotation_predicted, pose_predicted = model(images, training=True)
|
| 117 |
+
'''calculate loss'''
|
| 118 |
+
mse_loss, asm_loss = c_loss.calculate_landmark_ASM_assisted_loss(landmark_pr=annotation_predicted,
|
| 119 |
+
landmark_gt=annotation_gt,
|
| 120 |
+
current_epoch=epoch,
|
| 121 |
+
total_steps=total_steps)
|
| 122 |
+
pose_loss = c_loss.calculate_pose_loss(x_pr=pose_predicted, x_gt=poses_gt)
|
| 123 |
+
|
| 124 |
+
'''calculate loss'''
|
| 125 |
+
total_loss = mse_loss + asm_loss + pose_loss
|
| 126 |
+
|
| 127 |
+
'''calculate gradient'''
|
| 128 |
+
gradients_of_model = tape.gradient(total_loss, model.trainable_variables)
|
| 129 |
+
'''apply Gradients:'''
|
| 130 |
+
optimizer.apply_gradients(zip(gradients_of_model, model.trainable_variables))
|
| 131 |
+
'''printing loss Values: '''
|
| 132 |
+
tf.print("->EPOCH: ", str(epoch), "->STEP: ", str(step) + '/' + str(total_steps), ' -> : total_loss: ',
|
| 133 |
+
total_loss)
|
| 134 |
+
|
| 135 |
+
def _create_generators(self):
|
| 136 |
+
"""
|
| 137 |
+
:return:
|
| 138 |
+
"""
|
| 139 |
+
image_names, landmark_filenames, pose_names = \
|
| 140 |
+
self._create_image_and_labels_name(img_path=self.img_path,
|
| 141 |
+
annotation_path=self.annotation_path,
|
| 142 |
+
pose_path=self.pose_path)
|
| 143 |
+
return image_names, landmark_filenames, pose_names
|
| 144 |
+
|
| 145 |
+
def _create_image_and_labels_name(self, img_path, annotation_path, pose_path):
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
:param img_path:
|
| 149 |
+
:param annotation_path:
|
| 150 |
+
:param pose_path:
|
| 151 |
+
:return:
|
| 152 |
+
"""
|
| 153 |
+
img_filenames = []
|
| 154 |
+
landmark_filenames = []
|
| 155 |
+
poses_filenames = []
|
| 156 |
+
|
| 157 |
+
for file in os.listdir(img_path):
|
| 158 |
+
if file.endswith(".jpg") or file.endswith(".png"):
|
| 159 |
+
lbl_file = str(file)[:-3] + "npy" # just name
|
| 160 |
+
pose_file = str(file)[:-3] + "npy" # just name
|
| 161 |
+
if os.path.exists(annotation_path + lbl_file) and os.path.exists(pose_path + lbl_file):
|
| 162 |
+
img_filenames.append(str(file))
|
| 163 |
+
landmark_filenames.append(lbl_file)
|
| 164 |
+
poses_filenames.append(pose_file)
|
| 165 |
+
|
| 166 |
+
return np.array(img_filenames), np.array(landmark_filenames), np.array(poses_filenames)
|
| 167 |
+
|
| 168 |
+
def _get_batch_sample(self, batch_index, img_filenames, landmark_filenames, pose_filenames):
|
| 169 |
+
"""
|
| 170 |
+
:param batch_index:
|
| 171 |
+
:param img_filenames:
|
| 172 |
+
:param landmark_filenames:
|
| 173 |
+
:param pose_filenames:
|
| 174 |
+
:return:
|
| 175 |
+
"""
|
| 176 |
+
|
| 177 |
+
'''create batch data and normalize images'''
|
| 178 |
+
batch_img = img_filenames[
|
| 179 |
+
batch_index * LearningConfig.batch_size:(batch_index + 1) * LearningConfig.batch_size]
|
| 180 |
+
batch_lnd = landmark_filenames[
|
| 181 |
+
batch_index * LearningConfig.batch_size:(batch_index + 1) * LearningConfig.batch_size]
|
| 182 |
+
batch_pose = pose_filenames[
|
| 183 |
+
batch_index * LearningConfig.batch_size:(batch_index + 1) * LearningConfig.batch_size]
|
| 184 |
+
'''create img and annotations'''
|
| 185 |
+
img_batch = np.array([imread(self.img_path + file_name) for file_name in batch_img]) / 255.0
|
| 186 |
+
lnd_batch = np.array([self._load_and_normalize(self.annotation_path + file_name) for file_name in batch_lnd])
|
| 187 |
+
pose_batch = np.array([load(self.pose_path + file_name) for file_name in batch_pose])
|
| 188 |
+
|
| 189 |
+
return img_batch, lnd_batch, pose_batch
|
| 190 |
+
|
| 191 |
+
def _load_and_normalize(self, point_path):
|
| 192 |
+
"""
|
| 193 |
+
:param point_path:
|
| 194 |
+
:return:
|
| 195 |
+
"""
|
| 196 |
+
|
| 197 |
+
annotation = load(point_path)
|
| 198 |
+
'''normalize landmarks'''
|
| 199 |
+
width = InputDataSize.image_input_size
|
| 200 |
+
height = InputDataSize.image_input_size
|
| 201 |
+
x_center = width / 2
|
| 202 |
+
y_center = height / 2
|
| 203 |
+
annotation_norm = []
|
| 204 |
+
for p in range(0, len(annotation), 2):
|
| 205 |
+
annotation_norm.append((x_center - annotation[p]) / width)
|
| 206 |
+
annotation_norm.append((y_center - annotation[p + 1]) / height)
|
| 207 |
+
return annotation_norm
|