
bubbliiiing
commited on
Commit
·
59f4c8e
1
Parent(s):
bfdf817
Create weights
Browse files- LICENSE +201 -0
- README.md +438 -3
- README_en.md +409 -0
- model_index.json +41 -0
- scheduler/scheduler_config.json +18 -0
- text_encoder/config.json +33 -0
- text_encoder/model.safetensors +3 -0
- text_encoder_2/config.json +32 -0
- text_encoder_2/model-00001-of-00002.safetensors +3 -0
- text_encoder_2/model-00002-of-00002.safetensors +3 -0
- text_encoder_2/model.safetensors.index.json +226 -0
- tokenizer/special_tokens_map.json +37 -0
- tokenizer/tokenizer_config.json +57 -0
- tokenizer/vocab.txt +0 -0
- tokenizer_2/special_tokens_map.json +23 -0
- tokenizer_2/spiece.model +3 -0
- tokenizer_2/tokenizer_config.json +39 -0
- transformer/config.json +31 -0
- transformer/diffusion_pytorch_model.safetensors +3 -0
- vae/config.json +57 -0
- vae/diffusion_pytorch_model.safetensors +3 -0
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,3 +1,438 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
frameworks:
|
| 3 |
+
- Pytorch
|
| 4 |
+
license: other
|
| 5 |
+
tasks:
|
| 6 |
+
- text-to-video-synthesis
|
| 7 |
+
|
| 8 |
+
#model-type:
|
| 9 |
+
##如 gpt、phi、llama、chatglm、baichuan 等
|
| 10 |
+
#- gpt
|
| 11 |
+
|
| 12 |
+
#domain:
|
| 13 |
+
##如 nlp、cv、audio、multi-modal
|
| 14 |
+
#- nlp
|
| 15 |
+
|
| 16 |
+
#language:
|
| 17 |
+
##语言代码列表 https://help.aliyun.com/document_detail/215387.html?spm=a2c4g.11186623.0.0.9f8d7467kni6Aa
|
| 18 |
+
#- cn
|
| 19 |
+
|
| 20 |
+
#metrics:
|
| 21 |
+
##如 CIDEr、Blue、ROUGE 等
|
| 22 |
+
#- CIDEr
|
| 23 |
+
|
| 24 |
+
#tags:
|
| 25 |
+
##各种自定义,包括 pretrained、fine-tuned、instruction-tuned、RL-tuned 等训练方法和其他
|
| 26 |
+
#- pretrained
|
| 27 |
+
|
| 28 |
+
#tools:
|
| 29 |
+
##如 vllm、fastchat、llamacpp、AdaSeq 等
|
| 30 |
+
#- vllm
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
# EasyAnimate | 高分辨率长视频生成的端到端解决方案
|
| 34 |
+
😊 EasyAnimate是一个用于生成高分辨率和长视频的端到端解决方案。我们可以训练基于转换器的扩散生成器,训练用于处理长视频的VAE,以及预处理元数据。
|
| 35 |
+
|
| 36 |
+
😊 我们基于DIT,使用transformer进行作为扩散器进行视频与图片生成。
|
| 37 |
+
|
| 38 |
+
😊 Welcome!
|
| 39 |
+
|
| 40 |
+
[](https://arxiv.org/abs/2405.18991)
|
| 41 |
+
[](https://easyanimate.github.io/)
|
| 42 |
+
[](https://modelscope.cn/studios/PAI/EasyAnimate/summary)
|
| 43 |
+
[](https://huggingface.co/spaces/alibaba-pai/EasyAnimate)
|
| 44 |
+
[](https://discord.gg/UzkpB4Bn)
|
| 45 |
+
|
| 46 |
+
[English](./README.md) | 简体中文
|
| 47 |
+
|
| 48 |
+
# 目录
|
| 49 |
+
- [目录](#目录)
|
| 50 |
+
- [简介](#简介)
|
| 51 |
+
- [快速启动](#快速启动)
|
| 52 |
+
- [视频作品](#视频作品)
|
| 53 |
+
- [如何使用](#如何使用)
|
| 54 |
+
- [模型地址](#模型地址)
|
| 55 |
+
- [未来计划](#未来计划)
|
| 56 |
+
- [联系我们](#联系我们)
|
| 57 |
+
- [参考文献](#参考文献)
|
| 58 |
+
- [许可证](#许可证)
|
| 59 |
+
|
| 60 |
+
# 简介
|
| 61 |
+
EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI图片与视频、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps8的视频(EasyAnimateV5,1 ~ 49帧),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
|
| 62 |
+
|
| 63 |
+
我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。
|
| 64 |
+
|
| 65 |
+
新特性:
|
| 66 |
+
- 更新到v5版本,最大支持1024x1024,49帧, 6s, 8fps视频生成,拓展模型规模到12B,应用MMDIT结构,支持不同输入的控制模型,支持中文与英文双语预测。[ 2024.11.08 ]
|
| 67 |
+
- 更新到v4版本,最大支持1024x1024,144帧, 6s, 24fps视频生成,支持文、图、视频生视频,单个模型可支持512到1280任意分辨率,支持中文与英文双语预测。[ 2024.08.15 ]
|
| 68 |
+
- 更新到v3版本,最大支持960x960,144帧,6s, 24fps视频生成,支持文与图生视频模型。[ 2024.07.01 ]
|
| 69 |
+
- ModelScope-Sora“数据导演”创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!其使用EasyAnimate作为基础模型,探究数据处理对于模型训练的作用。立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532219),了解赛事详情。[ 2024.06.17 ]
|
| 70 |
+
- 更新到v2版本,最大支持768x768,144帧,6s, 24fps视频生成。[ 2024.05.26 ]
|
| 71 |
+
- 创建代码!现在支持 Windows 和 Linux。[ 2024.04.12 ]
|
| 72 |
+
|
| 73 |
+
功能概览:
|
| 74 |
+
- [数据预处理](#data-preprocess)
|
| 75 |
+
- [训练VAE](#vae-train)
|
| 76 |
+
- [训练DiT](#dit-train)
|
| 77 |
+
- [模型生成](#video-gen)
|
| 78 |
+
|
| 79 |
+
我们的ui界面如下:
|
| 80 |
+
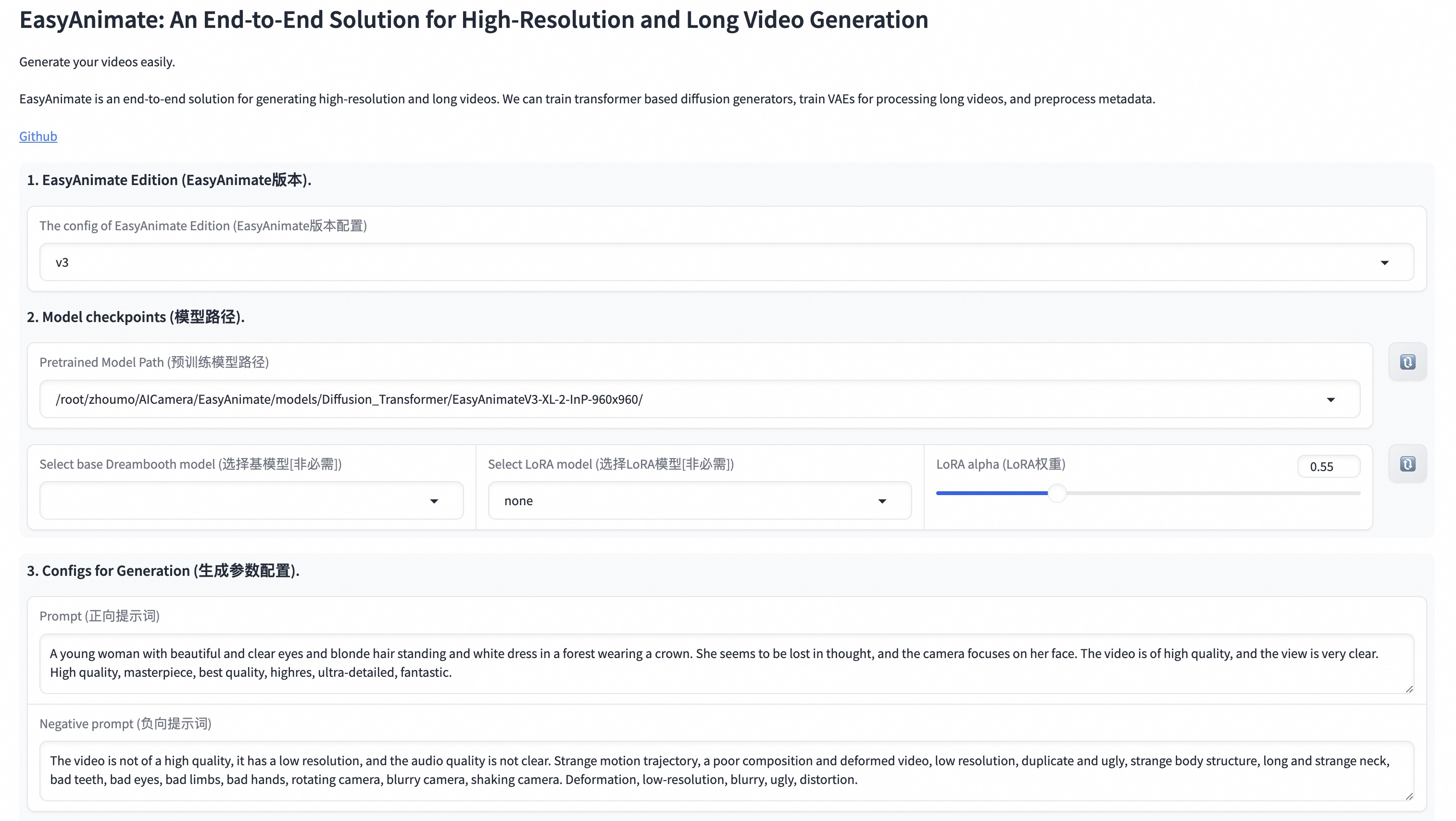
|
| 81 |
+
|
| 82 |
+
# 快速启动
|
| 83 |
+
### 1. 云使用: AliyunDSW/Docker
|
| 84 |
+
#### a. 通过阿里云 DSW
|
| 85 |
+
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。
|
| 86 |
+
|
| 87 |
+
阿里云在[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动EasyAnimate
|
| 88 |
+
|
| 89 |
+
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate)
|
| 90 |
+
|
| 91 |
+
#### b. 通过ComfyUI
|
| 92 |
+
我们的ComfyUI界面如下,具体查看[ComfyUI README](comfyui/README.md)。
|
| 93 |
+
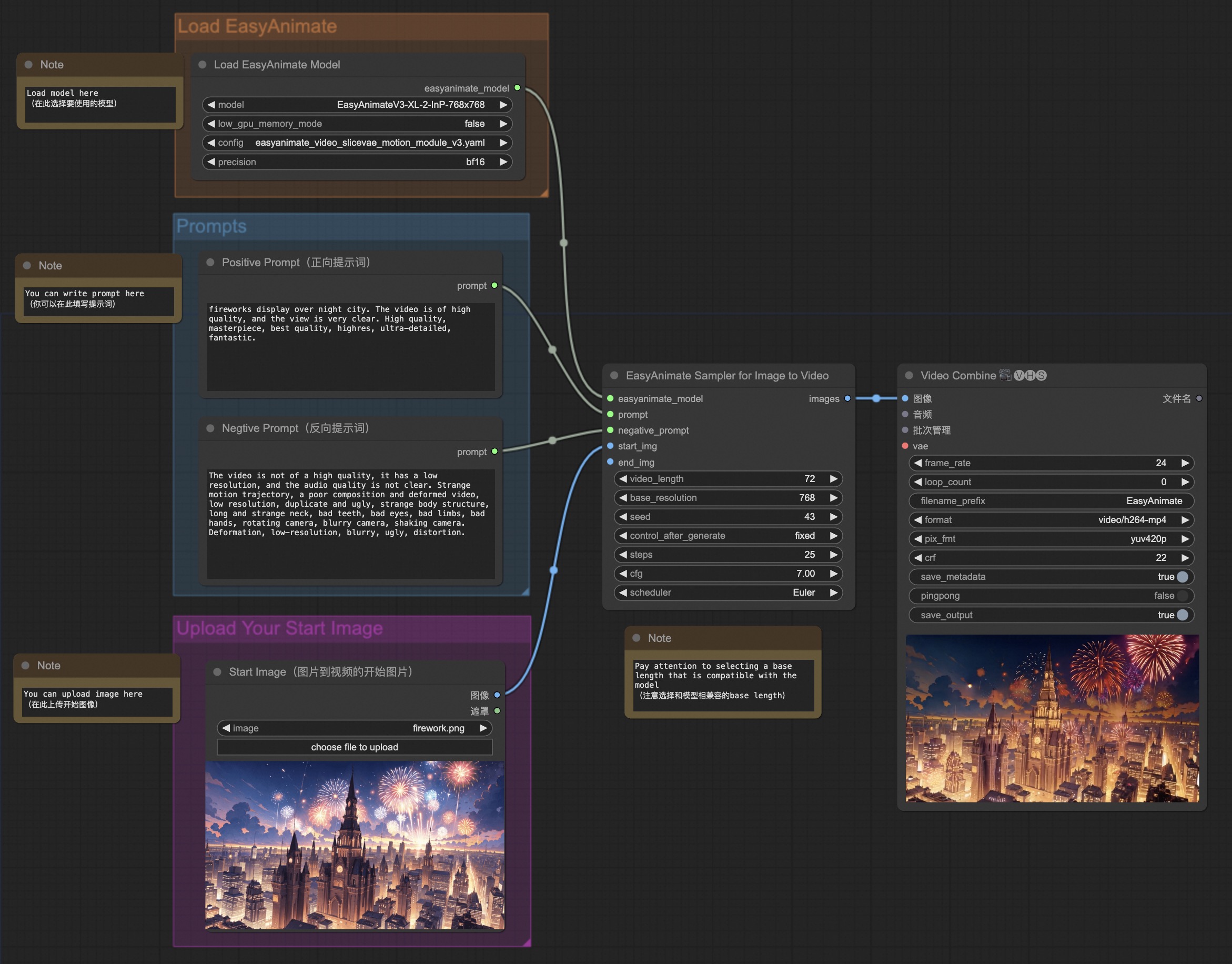
|
| 94 |
+
|
| 95 |
+
#### c. 通过docker
|
| 96 |
+
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
|
| 97 |
+
```
|
| 98 |
+
# pull image
|
| 99 |
+
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 100 |
+
|
| 101 |
+
# enter image
|
| 102 |
+
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 103 |
+
|
| 104 |
+
# clone code
|
| 105 |
+
git clone https://github.com/aigc-apps/EasyAnimate.git
|
| 106 |
+
|
| 107 |
+
# enter EasyAnimate's dir
|
| 108 |
+
cd EasyAnimate
|
| 109 |
+
|
| 110 |
+
# download weights
|
| 111 |
+
mkdir models/Diffusion_Transformer
|
| 112 |
+
mkdir models/Motion_Module
|
| 113 |
+
mkdir models/Personalized_Model
|
| 114 |
+
|
| 115 |
+
# Please use the hugginface link or modelscope link to download the EasyAnimateV5 model.
|
| 116 |
+
# I2V models
|
| 117 |
+
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP
|
| 118 |
+
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP
|
| 119 |
+
# T2V models
|
| 120 |
+
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh
|
| 121 |
+
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
### 2. 本地安装: 环境检查/下载/安装
|
| 125 |
+
#### a. 环境检查
|
| 126 |
+
我们已验证EasyAnimate可在以下环境中执行:
|
| 127 |
+
|
| 128 |
+
Windows 的详细信息:
|
| 129 |
+
- 操作系统 Windows 10
|
| 130 |
+
- python: python3.10 & python3.11
|
| 131 |
+
- pytorch: torch2.2.0
|
| 132 |
+
- CUDA: 11.8 & 12.1
|
| 133 |
+
- CUDNN: 8+
|
| 134 |
+
- GPU: Nvidia-3060 12G
|
| 135 |
+
|
| 136 |
+
Linux 的详细信息:
|
| 137 |
+
- 操作系统 Ubuntu 20.04, CentOS
|
| 138 |
+
- python: python3.10 & python3.11
|
| 139 |
+
- pytorch: torch2.2.0
|
| 140 |
+
- CUDA: 11.8 & 12.1
|
| 141 |
+
- CUDNN: 8+
|
| 142 |
+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
|
| 143 |
+
|
| 144 |
+
我们需要大约 60GB 的可用磁盘空间,请检查!
|
| 145 |
+
|
| 146 |
+
#### b. 权重放置
|
| 147 |
+
我们最好将[权重](#model-zoo)按照指定路径进行放置:
|
| 148 |
+
|
| 149 |
+
EasyAnimateV5:
|
| 150 |
+
```
|
| 151 |
+
📦 models/
|
| 152 |
+
├── 📂 Diffusion_Transformer/
|
| 153 |
+
│ ├── 📂 EasyAnimateV5-12b-zh-InP/
|
| 154 |
+
│ └── 📂 EasyAnimateV5-12b-zh/
|
| 155 |
+
├── 📂 Personalized_Model/
|
| 156 |
+
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
# 视频作品
|
| 160 |
+
所展示的结果都是图生视频获得。
|
| 161 |
+
|
| 162 |
+
### EasyAnimateV5-12b-zh-InP
|
| 163 |
+
|
| 164 |
+
Resolution-1024
|
| 165 |
+
|
| 166 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 167 |
+
<tr>
|
| 168 |
+
<td>
|
| 169 |
+
<video src="https://github.com/user-attachments/assets/bb393b7c-ba33-494c-ab06-b314adea9fc1" width="100%" controls autoplay loop></video>
|
| 170 |
+
</td>
|
| 171 |
+
<td>
|
| 172 |
+
<video src="https://github.com/user-attachments/assets/cb0d0253-919d-4dd6-9dc1-5cd94443c7f1" width="100%" controls autoplay loop></video>
|
| 173 |
+
</td>
|
| 174 |
+
<td>
|
| 175 |
+
<video src="https://github.com/user-attachments/assets/09ed361f-c0c5-4025-aad7-71fe1a1a52b1" width="100%" controls autoplay loop></video>
|
| 176 |
+
</td>
|
| 177 |
+
<td>
|
| 178 |
+
<video src="https://github.com/user-attachments/assets/9f42848d-34eb-473f-97ea-a5ebd0268106" width="100%" controls autoplay loop></video>
|
| 179 |
+
</td>
|
| 180 |
+
</tr>
|
| 181 |
+
</table>
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
Resolution-768
|
| 185 |
+
|
| 186 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 187 |
+
<tr>
|
| 188 |
+
<td>
|
| 189 |
+
<video src="https://github.com/user-attachments/assets/903fda91-a0bd-48ee-bf64-fff4e4d96f17" width="100%" controls autoplay loop></video>
|
| 190 |
+
</td>
|
| 191 |
+
<td>
|
| 192 |
+
<video src="https://github.com/user-attachments/assets/407c6628-9688-44b6-b12d-77de10fbbe95" width="100%" controls autoplay loop></video>
|
| 193 |
+
</td>
|
| 194 |
+
<td>
|
| 195 |
+
<video src="https://github.com/user-attachments/assets/ccf30ec1-91d2-4d82-9ce0-fcc585fc2f21" width="100%" controls autoplay loop></video>
|
| 196 |
+
</td>
|
| 197 |
+
<td>
|
| 198 |
+
<video src="https://github.com/user-attachments/assets/5dfe0f92-7d0d-43e0-b7df-0ff7b325663c" width="100%" controls autoplay loop></video>
|
| 199 |
+
</td>
|
| 200 |
+
</tr>
|
| 201 |
+
</table>
|
| 202 |
+
|
| 203 |
+
Resolution-512
|
| 204 |
+
|
| 205 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 206 |
+
<tr>
|
| 207 |
+
<td>
|
| 208 |
+
<video src="https://github.com/user-attachments/assets/2b542b85-be19-4537-9607-9d28ea7e932e" width="100%" controls autoplay loop></video>
|
| 209 |
+
</td>
|
| 210 |
+
<td>
|
| 211 |
+
<video src="https://github.com/user-attachments/assets/c1662745-752d-4ad2-92bc-fe53734347b2" width="100%" controls autoplay loop></video>
|
| 212 |
+
</td>
|
| 213 |
+
<td>
|
| 214 |
+
<video src="https://github.com/user-attachments/assets/8bec3d66-50a3-4af5-a381-be2c865825a0" width="100%" controls autoplay loop></video>
|
| 215 |
+
</td>
|
| 216 |
+
<td>
|
| 217 |
+
<video src="https://github.com/user-attachments/assets/bcec22f4-732c-446f-958c-2ebbfd8f94be" width="100%" controls autoplay loop></video>
|
| 218 |
+
</td>
|
| 219 |
+
</tr>
|
| 220 |
+
</table>
|
| 221 |
+
|
| 222 |
+
### EasyAnimateV5-12b-zh-Control
|
| 223 |
+
|
| 224 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 225 |
+
<tr>
|
| 226 |
+
<td>
|
| 227 |
+
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video>
|
| 228 |
+
</td>
|
| 229 |
+
<td>
|
| 230 |
+
<video src="https://github.com/user-attachments/assets/fce43c0b-81fa-4ab2-9ca7-78d786f520e6" width="100%" controls autoplay loop></video>
|
| 231 |
+
</td>
|
| 232 |
+
<td>
|
| 233 |
+
<video src="https://github.com/user-attachments/assets/b208b92c-5add-4ece-a200-3dbbe47b93c3" width="100%" controls autoplay loop></video>
|
| 234 |
+
</td>
|
| 235 |
+
<tr>
|
| 236 |
+
<td>
|
| 237 |
+
<video src="https://github.com/user-attachments/assets/3aec95d5-d240-49fb-a9e9-914446c7a4cf" width="100%" controls autoplay loop></video>
|
| 238 |
+
</td>
|
| 239 |
+
<td>
|
| 240 |
+
<video src="https://github.com/user-attachments/assets/60fa063b-5c1f-485f-b663-09bd6669de3f" width="100%" controls autoplay loop></video>
|
| 241 |
+
</td>
|
| 242 |
+
<td>
|
| 243 |
+
<video src="https://github.com/user-attachments/assets/4adde728-8397-42f3-8a2a-23f7b39e9a1e" width="100%" controls autoplay loop></video>
|
| 244 |
+
</td>
|
| 245 |
+
</tr>
|
| 246 |
+
</table>
|
| 247 |
+
|
| 248 |
+
# 如何使用
|
| 249 |
+
|
| 250 |
+
<h3 id="video-gen">1. 生成 </h3>
|
| 251 |
+
|
| 252 |
+
#### a、运行python文件
|
| 253 |
+
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
|
| 254 |
+
- 步骤2:在predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。
|
| 255 |
+
- 步骤3:运行predict_t2v.py文件,等待生成结果,结果保存在samples/easyanimate-videos文件夹中。
|
| 256 |
+
- 步骤4:如果想结合自己训练的其他backbone与Lora,则看情况修改predict_t2v.py中的predict_t2v.py和lora_path。
|
| 257 |
+
|
| 258 |
+
#### b、通过ui界面
|
| 259 |
+
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
|
| 260 |
+
- 步骤2:运行app.py文件,进入gradio页面。
|
| 261 |
+
- 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
|
| 262 |
+
|
| 263 |
+
#### c、通过comfyui
|
| 264 |
+
具体查看[ComfyUI README](comfyui/README.md)。
|
| 265 |
+
|
| 266 |
+
#### d、显存节省方案
|
| 267 |
+
由于EasyAnimateV5的参数非常大,我们需要考虑显存节省方案,以节省显存适应消费级显卡。我们给每个预测文件都提供了GPU_memory_mode,可以在model_cpu_offload,model_cpu_offload_and_qfloat8,sequential_cpu_offload中进行选择。
|
| 268 |
+
|
| 269 |
+
- model_cpu_offload代表整个模型在使用后会进入cpu,可以节省部分显存。
|
| 270 |
+
- model_cpu_offload_and_qfloat8代表整个模型在使用后会进入cpu,并且对transformer模型进行了float8的量化,可以节省更多的显存。
|
| 271 |
+
- sequential_cpu_offload代表模型的每一层在使用后会进入cpu,速度较慢,节省大量显存。
|
| 272 |
+
|
| 273 |
+
qfloat8会降低模型的性能,但可以节省更多的显存。如果显存足够,推荐使用model_cpu_offload。
|
| 274 |
+
|
| 275 |
+
### 2. 模型训练
|
| 276 |
+
一个完整的EasyAnimate训练链路应该包括数据预处理、Video VAE训练、Video DiT训练。其中Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。
|
| 277 |
+
|
| 278 |
+
<h4 id="data-preprocess">a.数据预处理</h4>
|
| 279 |
+
|
| 280 |
+
我们给出了一个简单的demo通过图片数据训练lora模型,详情可以查看[wiki](https://github.com/aigc-apps/EasyAnimate/wiki/Training-Lora)。
|
| 281 |
+
|
| 282 |
+
一个完整的长视频切分、清洗、描述的数据预处理链路可以参考video caption部分的[README](easyanimate/video_caption/README.md)进行。
|
| 283 |
+
|
| 284 |
+
如果期望训练一个文生图视频的生成模型,您需要以这种格式排列数据集。
|
| 285 |
+
```
|
| 286 |
+
📦 project/
|
| 287 |
+
├── 📂 datasets/
|
| 288 |
+
│ ├── 📂 internal_datasets/
|
| 289 |
+
│ ├── 📂 train/
|
| 290 |
+
│ │ ├── 📄 00000001.mp4
|
| 291 |
+
│ │ ├── 📄 00000002.jpg
|
| 292 |
+
│ │ └── 📄 .....
|
| 293 |
+
│ └── 📄 json_of_internal_datasets.json
|
| 294 |
+
```
|
| 295 |
+
|
| 296 |
+
json_of_internal_datasets.json是一个标准的json文件。json中的file_path可以被设置为相对路径,如下所示:
|
| 297 |
+
```json
|
| 298 |
+
[
|
| 299 |
+
{
|
| 300 |
+
"file_path": "train/00000001.mp4",
|
| 301 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 302 |
+
"type": "video"
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"file_path": "train/00000002.jpg",
|
| 306 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 307 |
+
"type": "image"
|
| 308 |
+
},
|
| 309 |
+
.....
|
| 310 |
+
]
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
你也可以将路径设置为绝对路径:
|
| 314 |
+
```json
|
| 315 |
+
[
|
| 316 |
+
{
|
| 317 |
+
"file_path": "/mnt/data/videos/00000001.mp4",
|
| 318 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 319 |
+
"type": "video"
|
| 320 |
+
},
|
| 321 |
+
{
|
| 322 |
+
"file_path": "/mnt/data/train/00000001.jpg",
|
| 323 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 324 |
+
"type": "image"
|
| 325 |
+
},
|
| 326 |
+
.....
|
| 327 |
+
]
|
| 328 |
+
```
|
| 329 |
+
<h4 id="vae-train">b. Video VAE训练 (可选)</h4>
|
| 330 |
+
Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。
|
| 331 |
+
|
| 332 |
+
如果想要进行训练,可以参考video vae部分的[README](easyanimate/vae/README.md)进行。
|
| 333 |
+
|
| 334 |
+
<h4 id="dit-train">c. Video DiT训练 </h4>
|
| 335 |
+
|
| 336 |
+
如果数据预处理时,数据的格式为相对路径,则进入scripts/train.sh进行如下设置。
|
| 337 |
+
```
|
| 338 |
+
export DATASET_NAME="datasets/internal_datasets/"
|
| 339 |
+
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
|
| 340 |
+
|
| 341 |
+
...
|
| 342 |
+
|
| 343 |
+
train_data_format="normal"
|
| 344 |
+
```
|
| 345 |
+
|
| 346 |
+
如果数据的格式为绝对路径,则进入scripts/train.sh进行如下设置。
|
| 347 |
+
```
|
| 348 |
+
export DATASET_NAME=""
|
| 349 |
+
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
最后运行scripts/train.sh。
|
| 353 |
+
```sh
|
| 354 |
+
sh scripts/train.sh
|
| 355 |
+
```
|
| 356 |
+
|
| 357 |
+
关于一些参数的设置细节,可以查看[Readme Train](scripts/README_TRAIN.md)与[Readme Lora](scripts/README_TRAIN_LORA.md)
|
| 358 |
+
|
| 359 |
+
<details>
|
| 360 |
+
<summary>(Obsolete) EasyAnimateV1:</summary>
|
| 361 |
+
如果你想训练EasyAnimateV1。请切换到git分支v1。
|
| 362 |
+
</details>
|
| 363 |
+
|
| 364 |
+
# 模型地址
|
| 365 |
+
EasyAnimateV5:
|
| 366 |
+
|
| 367 |
+
| 名称 | 种类 | 存储���间 | Hugging Face | Model Scope | 描述 |
|
| 368 |
+
|--|--|--|--|--|--|
|
| 369 |
+
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP)| 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
|
| 370 |
+
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-Control) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-Control)| 官方的视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
|
| 371 |
+
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh)| 官方的文生视频权重。可用于进行下游任务的fientune。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以49帧、每秒8帧进行训练,支持中文与英文双语预测 |
|
| 372 |
+
|
| 373 |
+
<details>
|
| 374 |
+
<summary>(Obsolete) EasyAnimateV4:</summary>
|
| 375 |
+
|
| 376 |
+
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | 描述 |
|
| 377 |
+
|--|--|--|--|--|--|
|
| 378 |
+
| EasyAnimateV4-XL-2-InP.tar.gz | EasyAnimateV4 | 解压前 8.9 GB / 解压后 14.0 GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV4-XL-2-InP.tar.gz) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV4-XL-2-InP)| 官方的图生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以144帧、每秒24帧进行训练 |
|
| 379 |
+
</details>
|
| 380 |
+
|
| 381 |
+
<details>
|
| 382 |
+
<summary>(Obsolete) EasyAnimateV3:</summary>
|
| 383 |
+
|
| 384 |
+
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | 描述 |
|
| 385 |
+
|--|--|--|--|--|--|
|
| 386 |
+
| EasyAnimateV3-XL-2-InP-512x512.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-512x512)| 官方的512x512分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
|
| 387 |
+
| EasyAnimateV3-XL-2-InP-768x768.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-768x768.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-768x768) | 官方的768x768分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
|
| 388 |
+
| EasyAnimateV3-XL-2-InP-960x960.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-960x960.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-960x960) | 官方的960x960(720P)分辨率的图生视频权重。以144帧、每秒24帧进行训练 |
|
| 389 |
+
</details>
|
| 390 |
+
|
| 391 |
+
<details>
|
| 392 |
+
<summary>(Obsolete) EasyAnimateV2:</summary>
|
| 393 |
+
|
| 394 |
+
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | 描述 |
|
| 395 |
+
|--|--|--|--|--|--|
|
| 396 |
+
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-512x512)| 官方的512x512分辨率的重量。以144帧、每秒24帧进行训练 |
|
| 397 |
+
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-768x768.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768) | 官方的768x768分辨率的重量。以144帧、每秒24帧进行训练 |
|
| 398 |
+
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimatev2_minimalism_lora.safetensors)| - | 使用特定类型的图像进行lora训练的结果。图片可从这里[下载](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/Minimalism.zip). |
|
| 399 |
+
</details>
|
| 400 |
+
|
| 401 |
+
<details>
|
| 402 |
+
<summary>(Obsolete) EasyAnimateV1:</summary>
|
| 403 |
+
|
| 404 |
+
### 1、运动权重
|
| 405 |
+
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|
| 406 |
+
|--|--|--|--|--|
|
| 407 |
+
| easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 |
|
| 408 |
+
|
| 409 |
+
### 2、其他权重
|
| 410 |
+
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|
| 411 |
+
|--|--|--|--|--|
|
| 412 |
+
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights |
|
| 413 |
+
| easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets |
|
| 414 |
+
| easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets |
|
| 415 |
+
</details>
|
| 416 |
+
|
| 417 |
+
# 未来计划
|
| 418 |
+
- 支持更大规模参数量的文视频生成模型。
|
| 419 |
+
|
| 420 |
+
# 联系我们
|
| 421 |
+
1. 扫描下方二维码或搜索群号:77450006752 来加入钉钉群。
|
| 422 |
+
2. 扫描下方二维码来加入微信群(如果二维码失效,可扫描最右边同学的微信,邀请您入群)
|
| 423 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/>
|
| 424 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/wechat.jpg" alt="Wechat group" width="30%"/>
|
| 425 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/person.jpg" alt="Person" width="30%"/>
|
| 426 |
+
|
| 427 |
+
# 参考文献
|
| 428 |
+
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 429 |
+
- magvit: https://github.com/google-research/magvit
|
| 430 |
+
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
|
| 431 |
+
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
|
| 432 |
+
- Open-Sora: https://github.com/hpcaitech/Open-Sora
|
| 433 |
+
- Animatediff: https://github.com/guoyww/AnimateDiff
|
| 434 |
+
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
|
| 435 |
+
- HunYuan DiT: https://github.com/tencent/HunyuanDiT
|
| 436 |
+
|
| 437 |
+
# 许可证
|
| 438 |
+
本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
|
README_en.md
ADDED
|
@@ -0,0 +1,409 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 📷 EasyAnimate | An End-to-End Solution for High-Resolution and Long Video Generation
|
| 2 |
+
😊 EasyAnimate is an end-to-end solution for generating high-resolution and long videos. We can train transformer based diffusion generators, train VAEs for processing long videos, and preprocess metadata.
|
| 3 |
+
|
| 4 |
+
😊 We use DIT and transformer as a diffuser for video and image generation.
|
| 5 |
+
|
| 6 |
+
😊 Welcome!
|
| 7 |
+
|
| 8 |
+
[](https://arxiv.org/abs/2405.18991)
|
| 9 |
+
[](https://easyanimate.github.io/)
|
| 10 |
+
[](https://modelscope.cn/studios/PAI/EasyAnimate/summary)
|
| 11 |
+
[](https://huggingface.co/spaces/alibaba-pai/EasyAnimate)
|
| 12 |
+
[](https://discord.gg/UzkpB4Bn)
|
| 13 |
+
|
| 14 |
+
English | [简体中文](./README_zh-CN.md)
|
| 15 |
+
|
| 16 |
+
# Table of Contents
|
| 17 |
+
- [Table of Contents](#table-of-contents)
|
| 18 |
+
- [Introduction](#introduction)
|
| 19 |
+
- [Quick Start](#quick-start)
|
| 20 |
+
- [Video Result](#video-result)
|
| 21 |
+
- [How to use](#how-to-use)
|
| 22 |
+
- [Model zoo](#model-zoo)
|
| 23 |
+
- [TODO List](#todo-list)
|
| 24 |
+
- [Contact Us](#contact-us)
|
| 25 |
+
- [Reference](#reference)
|
| 26 |
+
- [License](#license)
|
| 27 |
+
|
| 28 |
+
# Introduction
|
| 29 |
+
EasyAnimate is a pipeline based on the transformer architecture, designed for generating AI images and videos, and for training baseline models and Lora models for Diffusion Transformer. We support direct prediction from pre-trained EasyAnimate models, allowing for the generation of videos with various resolutions, approximately 6 seconds in length, at 8fps (EasyAnimateV5, 1 to 49 frames). Additionally, users can train their own baseline and Lora models for specific style transformations.
|
| 30 |
+
|
| 31 |
+
We will support quick pull-ups from different platforms, refer to [Quick Start](#quick-start).
|
| 32 |
+
|
| 33 |
+
**New Features:**
|
| 34 |
+
- **Updated to v5**, supporting video generation up to 1024x1024, 49 frames, 6s, 8fps, with expanded model scale to 12B, incorporating the MMDIT structure, and enabling control models with diverse inputs; supports bilingual predictions in Chinese and English. [2024.11.08]
|
| 35 |
+
- **Updated to v4**, allowing for video generation up to 1024x1024, 144 frames, 6s, 24fps; supports video generation from text, image, and video, with a single model handling resolutions from 512 to 1280; bilingual predictions in Chinese and English enabled. [2024.08.15]
|
| 36 |
+
- **Updated to v3**, supporting video generation up to 960x960, 144 frames, 6s, 24fps, from text and image. [2024.07.01]
|
| 37 |
+
- **ModelScope-Sora “Data Director” Creative Race** — The third Data-Juicer Big Model Data Challenge is now officially launched! Utilizing EasyAnimate as the base model, it explores the impact of data processing on model training. Visit the [competition website](https://tianchi.aliyun.com/competition/entrance/532219) for details. [2024.06.17]
|
| 38 |
+
- **Updated to v2**, supporting video generation up to 768x768, 144 frames, 6s, 24fps. [2024.05.26]
|
| 39 |
+
- **Code Created!** Now supporting Windows and Linux. [2024.04.12]
|
| 40 |
+
|
| 41 |
+
Function:
|
| 42 |
+
- [Data Preprocessing](#data-preprocess)
|
| 43 |
+
- [Train VAE](#vae-train)
|
| 44 |
+
- [Train DiT](#dit-train)
|
| 45 |
+
- [Video Generation](#video-gen)
|
| 46 |
+
|
| 47 |
+
Our UI interface is as follows:
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
# Quick Start
|
| 51 |
+
### 1. Cloud usage: AliyunDSW/Docker
|
| 52 |
+
#### a. From AliyunDSW
|
| 53 |
+
DSW has free GPU time, which can be applied once by a user and is valid for 3 months after applying.
|
| 54 |
+
|
| 55 |
+
Aliyun provide free GPU time in [Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1), get it and use in Aliyun PAI-DSW to start EasyAnimate within 5min!
|
| 56 |
+
|
| 57 |
+
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate)
|
| 58 |
+
|
| 59 |
+
#### b. From ComfyUI
|
| 60 |
+
Our ComfyUI is as follows, please refer to [ComfyUI README](comfyui/README.md) for details.
|
| 61 |
+

|
| 62 |
+
|
| 63 |
+
#### c. From docker
|
| 64 |
+
If you are using docker, please make sure that the graphics card driver and CUDA environment have been installed correctly in your machine.
|
| 65 |
+
|
| 66 |
+
Then execute the following commands in this way:
|
| 67 |
+
```
|
| 68 |
+
# pull image
|
| 69 |
+
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 70 |
+
|
| 71 |
+
# enter image
|
| 72 |
+
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
|
| 73 |
+
|
| 74 |
+
# clone code
|
| 75 |
+
git clone https://github.com/aigc-apps/EasyAnimate.git
|
| 76 |
+
|
| 77 |
+
# enter EasyAnimate's dir
|
| 78 |
+
cd EasyAnimate
|
| 79 |
+
|
| 80 |
+
# download weights
|
| 81 |
+
mkdir models/Diffusion_Transformer
|
| 82 |
+
mkdir models/Motion_Module
|
| 83 |
+
mkdir models/Personalized_Model
|
| 84 |
+
|
| 85 |
+
# Please use the hugginface link or modelscope link to download the EasyAnimateV5 model.
|
| 86 |
+
# I2V models
|
| 87 |
+
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP
|
| 88 |
+
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP
|
| 89 |
+
# T2V models
|
| 90 |
+
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh
|
| 91 |
+
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
### 2. Local install: Environment Check/Downloading/Installation
|
| 95 |
+
#### a. Environment Check
|
| 96 |
+
We have verified EasyAnimate execution on the following environment:
|
| 97 |
+
|
| 98 |
+
The detailed of Windows:
|
| 99 |
+
- OS: Windows 10
|
| 100 |
+
- python: python3.10 & python3.11
|
| 101 |
+
- pytorch: torch2.2.0
|
| 102 |
+
- CUDA: 11.8 & 12.1
|
| 103 |
+
- CUDNN: 8+
|
| 104 |
+
- GPU: Nvidia-3060 12G
|
| 105 |
+
|
| 106 |
+
The detailed of Linux:
|
| 107 |
+
- OS: Ubuntu 20.04, CentOS
|
| 108 |
+
- python: python3.10 & python3.11
|
| 109 |
+
- pytorch: torch2.2.0
|
| 110 |
+
- CUDA: 11.8 & 12.1
|
| 111 |
+
- CUDNN: 8+
|
| 112 |
+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
|
| 113 |
+
|
| 114 |
+
We need about 60GB available on disk (for saving weights), please check!
|
| 115 |
+
|
| 116 |
+
#### b. Weights
|
| 117 |
+
We'd better place the [weights](#model-zoo) along the specified path:
|
| 118 |
+
|
| 119 |
+
EasyAnimateV5:
|
| 120 |
+
```
|
| 121 |
+
📦 models/
|
| 122 |
+
├── 📂 Diffusion_Transformer/
|
| 123 |
+
│ ├── 📂 EasyAnimateV5-12b-zh-InP/
|
| 124 |
+
│ └── 📂 EasyAnimateV5-12b-zh/
|
| 125 |
+
├── 📂 Personalized_Model/
|
| 126 |
+
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
# 视频作品
|
| 130 |
+
The results displayed are all based on image.
|
| 131 |
+
|
| 132 |
+
### EasyAnimateV5-12b-zh-InP
|
| 133 |
+
|
| 134 |
+
Resolution-1024
|
| 135 |
+
|
| 136 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 137 |
+
<tr>
|
| 138 |
+
<td>
|
| 139 |
+
<video src="https://github.com/user-attachments/assets/bb393b7c-ba33-494c-ab06-b314adea9fc1" width="100%" controls autoplay loop></video>
|
| 140 |
+
</td>
|
| 141 |
+
<td>
|
| 142 |
+
<video src="https://github.com/user-attachments/assets/cb0d0253-919d-4dd6-9dc1-5cd94443c7f1" width="100%" controls autoplay loop></video>
|
| 143 |
+
</td>
|
| 144 |
+
<td>
|
| 145 |
+
<video src="https://github.com/user-attachments/assets/09ed361f-c0c5-4025-aad7-71fe1a1a52b1" width="100%" controls autoplay loop></video>
|
| 146 |
+
</td>
|
| 147 |
+
<td>
|
| 148 |
+
<video src="https://github.com/user-attachments/assets/9f42848d-34eb-473f-97ea-a5ebd0268106" width="100%" controls autoplay loop></video>
|
| 149 |
+
</td>
|
| 150 |
+
</tr>
|
| 151 |
+
</table>
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
Resolution-768
|
| 155 |
+
|
| 156 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 157 |
+
<tr>
|
| 158 |
+
<td>
|
| 159 |
+
<video src="https://github.com/user-attachments/assets/903fda91-a0bd-48ee-bf64-fff4e4d96f17" width="100%" controls autoplay loop></video>
|
| 160 |
+
</td>
|
| 161 |
+
<td>
|
| 162 |
+
<video src="https://github.com/user-attachments/assets/407c6628-9688-44b6-b12d-77de10fbbe95" width="100%" controls autoplay loop></video>
|
| 163 |
+
</td>
|
| 164 |
+
<td>
|
| 165 |
+
<video src="https://github.com/user-attachments/assets/ccf30ec1-91d2-4d82-9ce0-fcc585fc2f21" width="100%" controls autoplay loop></video>
|
| 166 |
+
</td>
|
| 167 |
+
<td>
|
| 168 |
+
<video src="https://github.com/user-attachments/assets/5dfe0f92-7d0d-43e0-b7df-0ff7b325663c" width="100%" controls autoplay loop></video>
|
| 169 |
+
</td>
|
| 170 |
+
</tr>
|
| 171 |
+
</table>
|
| 172 |
+
|
| 173 |
+
Resolution-512
|
| 174 |
+
|
| 175 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 176 |
+
<tr>
|
| 177 |
+
<td>
|
| 178 |
+
<video src="https://github.com/user-attachments/assets/2b542b85-be19-4537-9607-9d28ea7e932e" width="100%" controls autoplay loop></video>
|
| 179 |
+
</td>
|
| 180 |
+
<td>
|
| 181 |
+
<video src="https://github.com/user-attachments/assets/c1662745-752d-4ad2-92bc-fe53734347b2" width="100%" controls autoplay loop></video>
|
| 182 |
+
</td>
|
| 183 |
+
<td>
|
| 184 |
+
<video src="https://github.com/user-attachments/assets/8bec3d66-50a3-4af5-a381-be2c865825a0" width="100%" controls autoplay loop></video>
|
| 185 |
+
</td>
|
| 186 |
+
<td>
|
| 187 |
+
<video src="https://github.com/user-attachments/assets/bcec22f4-732c-446f-958c-2ebbfd8f94be" width="100%" controls autoplay loop></video>
|
| 188 |
+
</td>
|
| 189 |
+
</tr>
|
| 190 |
+
</table>
|
| 191 |
+
|
| 192 |
+
### EasyAnimateV5-12b-zh-Control
|
| 193 |
+
|
| 194 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 195 |
+
<tr>
|
| 196 |
+
<td>
|
| 197 |
+
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video>
|
| 198 |
+
</td>
|
| 199 |
+
<td>
|
| 200 |
+
<video src="https://github.com/user-attachments/assets/fce43c0b-81fa-4ab2-9ca7-78d786f520e6" width="100%" controls autoplay loop></video>
|
| 201 |
+
</td>
|
| 202 |
+
<td>
|
| 203 |
+
<video src="https://github.com/user-attachments/assets/b208b92c-5add-4ece-a200-3dbbe47b93c3" width="100%" controls autoplay loop></video>
|
| 204 |
+
</td>
|
| 205 |
+
<tr>
|
| 206 |
+
<td>
|
| 207 |
+
<video src="https://github.com/user-attachments/assets/3aec95d5-d240-49fb-a9e9-914446c7a4cf" width="100%" controls autoplay loop></video>
|
| 208 |
+
</td>
|
| 209 |
+
<td>
|
| 210 |
+
<video src="https://github.com/user-attachments/assets/60fa063b-5c1f-485f-b663-09bd6669de3f" width="100%" controls autoplay loop></video>
|
| 211 |
+
</td>
|
| 212 |
+
<td>
|
| 213 |
+
<video src="https://github.com/user-attachments/assets/4adde728-8397-42f3-8a2a-23f7b39e9a1e" width="100%" controls autoplay loop></video>
|
| 214 |
+
</td>
|
| 215 |
+
</tr>
|
| 216 |
+
</table>
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
# How to use
|
| 220 |
+
|
| 221 |
+
<h3 id="video-gen">1. Inference </h3>
|
| 222 |
+
|
| 223 |
+
#### a. Using Python Code
|
| 224 |
+
- Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder.
|
| 225 |
+
- Step 2: Modify prompt, neg_prompt, guidance_scale, and seed in the predict_t2v.py file.
|
| 226 |
+
- Step 3: Run the predict_t2v.py file, wait for the generated results, and save the results in the samples/easyanimate-videos folder.
|
| 227 |
+
- Step 4: If you want to combine other backbones you have trained with Lora, modify the predict_t2v.py and Lora_path in predict_t2v.py depending on the situation.
|
| 228 |
+
|
| 229 |
+
#### b. Using webui
|
| 230 |
+
- Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder.
|
| 231 |
+
- Step 2: Run the app.py file to enter the graph page.
|
| 232 |
+
- Step 3: Select the generated model based on the page, fill in prompt, neg_prompt, guidance_scale, and seed, click on generate, wait for the generated result, and save the result in the samples folder.
|
| 233 |
+
|
| 234 |
+
#### c. From ComfyUI
|
| 235 |
+
Please refer to [ComfyUI README](comfyui/README.md) for details.
|
| 236 |
+
|
| 237 |
+
#### d. GPU Memory Saving Schemes
|
| 238 |
+
|
| 239 |
+
Due to the large parameters of EasyAnimateV5, we need to consider GPU memory saving schemes to conserve memory. We provide a `GPU_memory_mode` option for each prediction file, which can be selected from `model_cpu_offload`, `model_cpu_offload_and_qfloat8`, and `sequential_cpu_offload`.
|
| 240 |
+
|
| 241 |
+
- `model_cpu_offload` indicates that the entire model will be offloaded to the CPU after use, saving some GPU memory.
|
| 242 |
+
- `model_cpu_offload_and_qfloat8` indicates that the entire model will be offloaded to the CPU after use, and the transformer model is quantized to float8, saving even more GPU memory.
|
| 243 |
+
- `sequential_cpu_offload` means that each layer of the model will be offloaded to the CPU after use, which is slower but saves a substantial amount of GPU memory.
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
### 2. Model Training
|
| 247 |
+
A complete EasyAnimate training pipeline should include data preprocessing, Video VAE training, and Video DiT training. Among these, Video VAE training is optional because we have already provided a pre-trained Video VAE.
|
| 248 |
+
|
| 249 |
+
<h4 id="data-preprocess">a. data preprocessing</h4>
|
| 250 |
+
|
| 251 |
+
We have provided a simple demo of training the Lora model through image data, which can be found in the [wiki](https://github.com/aigc-apps/EasyAnimate/wiki/Training-Lora) for details.
|
| 252 |
+
|
| 253 |
+
A complete data preprocessing link for long video segmentation, cleaning, and description can refer to [README](./easyanimate/video_caption/README.md) in the video captions section.
|
| 254 |
+
|
| 255 |
+
If you want to train a text to image and video generation model. You need to arrange the dataset in this format.
|
| 256 |
+
|
| 257 |
+
```
|
| 258 |
+
📦 project/
|
| 259 |
+
├── 📂 datasets/
|
| 260 |
+
│ ├── 📂 internal_datasets/
|
| 261 |
+
│ ├── 📂 train/
|
| 262 |
+
│ │ ├── 📄 00000001.mp4
|
| 263 |
+
│ │ ├── 📄 00000002.jpg
|
| 264 |
+
│ │ └── 📄 .....
|
| 265 |
+
│ └── 📄 json_of_internal_datasets.json
|
| 266 |
+
```
|
| 267 |
+
|
| 268 |
+
The json_of_internal_datasets.json is a standard JSON file. The file_path in the json can to be set as relative path, as shown in below:
|
| 269 |
+
```json
|
| 270 |
+
[
|
| 271 |
+
{
|
| 272 |
+
"file_path": "train/00000001.mp4",
|
| 273 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 274 |
+
"type": "video"
|
| 275 |
+
},
|
| 276 |
+
{
|
| 277 |
+
"file_path": "train/00000002.jpg",
|
| 278 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 279 |
+
"type": "image"
|
| 280 |
+
},
|
| 281 |
+
.....
|
| 282 |
+
]
|
| 283 |
+
```
|
| 284 |
+
|
| 285 |
+
You can also set the path as absolute path as follow:
|
| 286 |
+
```json
|
| 287 |
+
[
|
| 288 |
+
{
|
| 289 |
+
"file_path": "/mnt/data/videos/00000001.mp4",
|
| 290 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 291 |
+
"type": "video"
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"file_path": "/mnt/data/train/00000001.jpg",
|
| 295 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 296 |
+
"type": "image"
|
| 297 |
+
},
|
| 298 |
+
.....
|
| 299 |
+
]
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
<h4 id="vae-train">b. Video VAE training (optional)</h4>
|
| 303 |
+
|
| 304 |
+
Video VAE training is an optional option as we have already provided pre trained Video VAEs.
|
| 305 |
+
If you want to train video vae, you can refer to [README](easyanimate/vae/README.md) in the video vae section.
|
| 306 |
+
|
| 307 |
+
<h4 id="dit-train">c. Video DiT training </h4>
|
| 308 |
+
|
| 309 |
+
If the data format is relative path during data preprocessing, please set ```scripts/train.sh``` as follow.
|
| 310 |
+
```
|
| 311 |
+
export DATASET_NAME="datasets/internal_datasets/"
|
| 312 |
+
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
If the data format is absolute path during data preprocessing, please set ```scripts/train.sh``` as follow.
|
| 316 |
+
```
|
| 317 |
+
export DATASET_NAME=""
|
| 318 |
+
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
|
| 319 |
+
```
|
| 320 |
+
|
| 321 |
+
Then, we run scripts/train.sh.
|
| 322 |
+
```sh
|
| 323 |
+
sh scripts/train.sh
|
| 324 |
+
```
|
| 325 |
+
|
| 326 |
+
For details on setting some parameters, please refer to [Readme Train](scripts/README_TRAIN.md) and [Readme Lora](scripts/README_TRAIN_LORA.md).
|
| 327 |
+
|
| 328 |
+
<details>
|
| 329 |
+
<summary>(Obsolete) EasyAnimateV1:</summary>
|
| 330 |
+
If you want to train EasyAnimateV1. Please switch to the git branch v1.
|
| 331 |
+
</details>
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
# Model zoo
|
| 335 |
+
|
| 336 |
+
EasyAnimateV5:
|
| 337 |
+
|
| 338 |
+
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|
| 339 |
+
|--|--|--|--|--|--|
|
| 340 |
+
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP) | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. |
|
| 341 |
+
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-Control) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-Control) | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc. Supports video prediction at multiple resolutions (512, 768, 1024) and is trained with 49 frames at 8 frames per second. Bilingual prediction in Chinese and English is supported. |
|
| 342 |
+
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. |
|
| 343 |
+
|
| 344 |
+
<details>
|
| 345 |
+
<summary>(Obsolete) EasyAnimateV4:</summary>
|
| 346 |
+
|
| 347 |
+
| Name | Type | Storage Space | Url | Hugging Face | Description |
|
| 348 |
+
|--|--|--|--|--|--|
|
| 349 |
+
| EasyAnimateV4-XL-2-InP.tar.gz | EasyAnimateV4 | Before extraction: 8.9 GB \/ After extraction: 14.0 GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV4-XL-2-InP.tar.gz) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV4-XL-2-InP)| Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 144 frames at a rate of 24 frames per second. |
|
| 350 |
+
</details>
|
| 351 |
+
|
| 352 |
+
<details>
|
| 353 |
+
<summary>(Obsolete) EasyAnimateV3:</summary>
|
| 354 |
+
|
| 355 |
+
| Name | Type | Storage Space | Url | Hugging Face | Description |
|
| 356 |
+
|--|--|--|--|--|--|
|
| 357 |
+
| EasyAnimateV3-XL-2-InP-512x512.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-512x512) | EasyAnimateV3 official weights for 512x512 text and image to video resolution. Training with 144 frames and fps 24 |
|
| 358 |
+
| EasyAnimateV3-XL-2-InP-768x768.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-768x768.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-768x768) | EasyAnimateV3 official weights for 768x768 text and image to video resolution. Training with 144 frames and fps 24 |
|
| 359 |
+
| EasyAnimateV3-XL-2-InP-960x960.tar | EasyAnimateV3 | 18.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-960x960.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-960x960) | EasyAnimateV3 official weights for 960x960 text and image to video resolution. Training with 144 frames and fps 24 |
|
| 360 |
+
</details>
|
| 361 |
+
|
| 362 |
+
<details>
|
| 363 |
+
<summary>(Obsolete) EasyAnimateV2:</summary>
|
| 364 |
+
| Name | Type | Storage Space | Url | Hugging Face | Description |
|
| 365 |
+
|--|--|--|--|--|--|
|
| 366 |
+
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-512x512) | EasyAnimateV2 official weights for 512x512 resolution. Training with 144 frames and fps 24 |
|
| 367 |
+
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-768x768.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768) | EasyAnimateV2 official weights for 768x768 resolution. Training with 144 frames and fps 24 |
|
| 368 |
+
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimatev2_minimalism_lora.safetensors) | - | A lora training with a specifial type images. Images can be downloaded from [Url](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v2/Minimalism.zip). |
|
| 369 |
+
</details>
|
| 370 |
+
|
| 371 |
+
<details>
|
| 372 |
+
<summary>(Obsolete) EasyAnimateV1:</summary>
|
| 373 |
+
|
| 374 |
+
### 1、Motion Weights
|
| 375 |
+
| Name | Type | Storage Space | Url | Description |
|
| 376 |
+
|--|--|--|--|--|
|
| 377 |
+
| easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 |
|
| 378 |
+
|
| 379 |
+
### 2、Other Weights
|
| 380 |
+
| Name | Type | Storage Space | Url | Description |
|
| 381 |
+
|--|--|--|--|--|
|
| 382 |
+
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights |
|
| 383 |
+
| easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets |
|
| 384 |
+
| easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets |
|
| 385 |
+
</details>
|
| 386 |
+
|
| 387 |
+
# TODO List
|
| 388 |
+
- Support model with larger params.
|
| 389 |
+
|
| 390 |
+
# Contact Us
|
| 391 |
+
1. Use Dingding to search group 77450006752 or Scan to join
|
| 392 |
+
2. You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you.
|
| 393 |
+
|
| 394 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/>
|
| 395 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/wechat.jpg" alt="Wechat group" width="30%"/>
|
| 396 |
+
<img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/person.jpg" alt="Person" width="30%"/>
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
# Reference
|
| 400 |
+
- magvit: https://github.com/google-research/magvit
|
| 401 |
+
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
|
| 402 |
+
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
|
| 403 |
+
- Open-Sora: https://github.com/hpcaitech/Open-Sora
|
| 404 |
+
- Animatediff: https://github.com/guoyww/AnimateDiff
|
| 405 |
+
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
|
| 406 |
+
- HunYuan DiT: https://github.com/tencent/HunyuanDiT
|
| 407 |
+
|
| 408 |
+
# License
|
| 409 |
+
This project is licensed under the [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
|
model_index.json
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "EasyAnimatePipeline_Multi_Text_Encoder",
|
| 3 |
+
"_diffusers_version": "0.31.0.dev0",
|
| 4 |
+
"feature_extractor": [
|
| 5 |
+
null,
|
| 6 |
+
null
|
| 7 |
+
],
|
| 8 |
+
"requires_safety_checker": true,
|
| 9 |
+
"safety_checker": [
|
| 10 |
+
null,
|
| 11 |
+
null
|
| 12 |
+
],
|
| 13 |
+
"scheduler": [
|
| 14 |
+
"diffusers",
|
| 15 |
+
"DDPMScheduler"
|
| 16 |
+
],
|
| 17 |
+
"text_encoder": [
|
| 18 |
+
"transformers",
|
| 19 |
+
"BertModel"
|
| 20 |
+
],
|
| 21 |
+
"text_encoder_2": [
|
| 22 |
+
"transformers",
|
| 23 |
+
"T5EncoderModel"
|
| 24 |
+
],
|
| 25 |
+
"tokenizer": [
|
| 26 |
+
"transformers",
|
| 27 |
+
"BertTokenizer"
|
| 28 |
+
],
|
| 29 |
+
"tokenizer_2": [
|
| 30 |
+
"transformers",
|
| 31 |
+
"T5Tokenizer"
|
| 32 |
+
],
|
| 33 |
+
"transformer": [
|
| 34 |
+
"diffusers",
|
| 35 |
+
"Transformer2DModel"
|
| 36 |
+
],
|
| 37 |
+
"vae": [
|
| 38 |
+
"diffusers",
|
| 39 |
+
"AutoencoderKL"
|
| 40 |
+
]
|
| 41 |
+
}
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "DDIMScheduler",
|
| 3 |
+
"_diffusers_version": "0.31.0.dev0",
|
| 4 |
+
"beta_end": 0.012,
|
| 5 |
+
"beta_schedule": "scaled_linear",
|
| 6 |
+
"beta_start": 0.00085,
|
| 7 |
+
"clip_sample": false,
|
| 8 |
+
"clip_sample_range": 1.0,
|
| 9 |
+
"num_train_timesteps": 1000,
|
| 10 |
+
"prediction_type": "v_prediction",
|
| 11 |
+
"rescale_betas_zero_snr": true,
|
| 12 |
+
"sample_max_value": 1.0,
|
| 13 |
+
"set_alpha_to_one": true,
|
| 14 |
+
"snr_shift_scale": 1.0,
|
| 15 |
+
"steps_offset": 0,
|
| 16 |
+
"timestep_spacing": "trailing",
|
| 17 |
+
"trained_betas": null
|
| 18 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"BertModel"
|
| 4 |
+
],
|
| 5 |
+
"attention_probs_dropout_prob": 0.1,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"directionality": "bidi",
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "gelu",
|
| 11 |
+
"hidden_dropout_prob": 0.1,
|
| 12 |
+
"hidden_size": 1024,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 4096,
|
| 15 |
+
"layer_norm_eps": 1e-12,
|
| 16 |
+
"max_position_embeddings": 512,
|
| 17 |
+
"model_type": "bert",
|
| 18 |
+
"num_attention_heads": 16,
|
| 19 |
+
"num_hidden_layers": 24,
|
| 20 |
+
"output_past": true,
|
| 21 |
+
"pad_token_id": 0,
|
| 22 |
+
"pooler_fc_size": 768,
|
| 23 |
+
"pooler_num_attention_heads": 12,
|
| 24 |
+
"pooler_num_fc_layers": 3,
|
| 25 |
+
"pooler_size_per_head": 128,
|
| 26 |
+
"pooler_type": "first_token_transform",
|
| 27 |
+
"position_embedding_type": "absolute",
|
| 28 |
+
"torch_dtype": "float32",
|
| 29 |
+
"transformers_version": "4.41.1",
|
| 30 |
+
"type_vocab_size": 2,
|
| 31 |
+
"use_cache": true,
|
| 32 |
+
"vocab_size": 47020
|
| 33 |
+
}
|
text_encoder/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c6c6348af2cb4d5852fe51102ce39605903dbe7925c005cf8995506cc21ea914
|
| 3 |
+
size 1408188288
|
text_encoder_2/config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"T5EncoderModel"
|
| 4 |
+
],
|
| 5 |
+
"classifier_dropout": 0.0,
|
| 6 |
+
"d_ff": 5120,
|
| 7 |
+
"d_kv": 64,
|
| 8 |
+
"d_model": 2048,
|
| 9 |
+
"decoder_start_token_id": 0,
|
| 10 |
+
"dense_act_fn": "gelu_new",
|
| 11 |
+
"dropout_rate": 0.1,
|
| 12 |
+
"eos_token_id": 1,
|
| 13 |
+
"feed_forward_proj": "gated-gelu",
|
| 14 |
+
"initializer_factor": 1.0,
|
| 15 |
+
"is_encoder_decoder": true,
|
| 16 |
+
"is_gated_act": true,
|
| 17 |
+
"layer_norm_epsilon": 1e-06,
|
| 18 |
+
"model_type": "t5",
|
| 19 |
+
"num_decoder_layers": 24,
|
| 20 |
+
"num_heads": 32,
|
| 21 |
+
"num_layers": 24,
|
| 22 |
+
"output_past": true,
|
| 23 |
+
"pad_token_id": 0,
|
| 24 |
+
"relative_attention_max_distance": 128,
|
| 25 |
+
"relative_attention_num_buckets": 32,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"tokenizer_class": "T5Tokenizer",
|
| 28 |
+
"torch_dtype": "float32",
|
| 29 |
+
"transformers_version": "4.41.1",
|
| 30 |
+
"use_cache": true,
|
| 31 |
+
"vocab_size": 250112
|
| 32 |
+
}
|
text_encoder_2/model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2c0c539ab8e8fba3877cc94bc483e427f74c525f817a809b028ebc8d96d75a94
|
| 3 |
+
size 4993585936
|
text_encoder_2/model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3b49976cb1fe40da28a600d783f4686024c97eb01f224c54305cce55ddcd8a5e
|
| 3 |
+
size 1686275552
|
text_encoder_2/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 6679834624
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"encoder.block.0.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 7 |
+
"encoder.block.0.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"encoder.block.0.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"encoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"encoder.block.0.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"encoder.block.0.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"encoder.block.0.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"encoder.block.0.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"encoder.block.1.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 17 |
+
"encoder.block.1.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"encoder.block.1.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 19 |
+
"encoder.block.1.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"encoder.block.1.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"encoder.block.1.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"encoder.block.1.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"encoder.block.10.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"encoder.block.10.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"encoder.block.10.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"encoder.block.10.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 29 |
+
"encoder.block.10.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"encoder.block.10.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 33 |
+
"encoder.block.10.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"encoder.block.11.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"encoder.block.11.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"encoder.block.11.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"encoder.block.11.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"encoder.block.11.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"encoder.block.11.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"encoder.block.11.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"encoder.block.12.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"encoder.block.12.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"encoder.block.12.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"encoder.block.12.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"encoder.block.12.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 49 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"encoder.block.12.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 51 |
+
"encoder.block.12.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"encoder.block.13.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 53 |
+
"encoder.block.13.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"encoder.block.13.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 55 |
+
"encoder.block.13.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"encoder.block.13.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 57 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 59 |
+
"encoder.block.13.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"encoder.block.13.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 61 |
+
"encoder.block.14.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"encoder.block.14.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 63 |
+
"encoder.block.14.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"encoder.block.14.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 65 |
+
"encoder.block.14.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 67 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"encoder.block.14.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 69 |
+
"encoder.block.14.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"encoder.block.15.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 71 |
+
"encoder.block.15.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 72 |
+
"encoder.block.15.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 73 |
+
"encoder.block.15.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 74 |
+
"encoder.block.15.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 75 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 76 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 77 |
+
"encoder.block.15.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 78 |
+
"encoder.block.15.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 79 |
+
"encoder.block.16.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 80 |
+
"encoder.block.16.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 81 |
+
"encoder.block.16.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 82 |
+
"encoder.block.16.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 83 |
+
"encoder.block.16.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 84 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 85 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 86 |
+
"encoder.block.16.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 87 |
+
"encoder.block.16.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 88 |
+
"encoder.block.17.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 89 |
+
"encoder.block.17.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 90 |
+
"encoder.block.17.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 91 |
+
"encoder.block.17.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 92 |
+
"encoder.block.17.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 93 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 94 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 95 |
+
"encoder.block.17.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 96 |
+
"encoder.block.17.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 97 |
+
"encoder.block.18.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 98 |
+
"encoder.block.18.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 99 |
+
"encoder.block.18.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 100 |
+
"encoder.block.18.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 101 |
+
"encoder.block.18.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 102 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 103 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 104 |
+
"encoder.block.18.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 105 |
+
"encoder.block.18.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 106 |
+
"encoder.block.19.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 107 |
+
"encoder.block.19.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 108 |
+
"encoder.block.19.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 109 |
+
"encoder.block.19.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 110 |
+
"encoder.block.19.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 111 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 112 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 113 |
+
"encoder.block.19.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 114 |
+
"encoder.block.19.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 115 |
+
"encoder.block.2.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"encoder.block.2.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 117 |
+
"encoder.block.2.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"encoder.block.2.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 119 |
+
"encoder.block.2.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"encoder.block.2.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"encoder.block.2.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"encoder.block.20.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 125 |
+
"encoder.block.20.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 126 |
+
"encoder.block.20.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 127 |
+
"encoder.block.20.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 128 |
+
"encoder.block.20.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 129 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 130 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 131 |
+
"encoder.block.20.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 132 |
+
"encoder.block.20.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 133 |
+
"encoder.block.21.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 134 |
+
"encoder.block.21.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 135 |
+
"encoder.block.21.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 136 |
+
"encoder.block.21.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 137 |
+
"encoder.block.21.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 138 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 139 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 140 |
+
"encoder.block.21.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 141 |
+
"encoder.block.21.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 142 |
+
"encoder.block.22.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 143 |
+
"encoder.block.22.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 144 |
+
"encoder.block.22.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 145 |
+
"encoder.block.22.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 146 |
+
"encoder.block.22.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 147 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 148 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 149 |
+
"encoder.block.22.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 150 |
+
"encoder.block.22.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 151 |
+
"encoder.block.23.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 152 |
+
"encoder.block.23.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 153 |
+
"encoder.block.23.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 154 |
+
"encoder.block.23.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 155 |
+
"encoder.block.23.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 156 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 157 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 158 |
+
"encoder.block.23.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 159 |
+
"encoder.block.23.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 160 |
+
"encoder.block.3.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 161 |
+
"encoder.block.3.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"encoder.block.3.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 163 |
+
"encoder.block.3.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"encoder.block.3.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"encoder.block.3.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"encoder.block.3.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"encoder.block.4.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 170 |
+
"encoder.block.4.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"encoder.block.4.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"encoder.block.4.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"encoder.block.4.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"encoder.block.4.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"encoder.block.4.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"encoder.block.5.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"encoder.block.5.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"encoder.block.5.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 181 |
+
"encoder.block.5.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"encoder.block.5.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 184 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 185 |
+
"encoder.block.5.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"encoder.block.5.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"encoder.block.6.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 188 |
+
"encoder.block.6.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"encoder.block.6.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"encoder.block.6.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"encoder.block.6.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"encoder.block.6.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"encoder.block.6.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"encoder.block.7.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 197 |
+
"encoder.block.7.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"encoder.block.7.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 199 |
+
"encoder.block.7.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 200 |
+
"encoder.block.7.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 202 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 203 |
+
"encoder.block.7.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 204 |
+
"encoder.block.7.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"encoder.block.8.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 206 |
+
"encoder.block.8.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 207 |
+
"encoder.block.8.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"encoder.block.8.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 209 |
+
"encoder.block.8.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 211 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"encoder.block.8.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 213 |
+
"encoder.block.8.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"encoder.block.9.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 215 |
+
"encoder.block.9.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"encoder.block.9.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"encoder.block.9.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 218 |
+
"encoder.block.9.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 219 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 220 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 221 |
+
"encoder.block.9.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 222 |
+
"encoder.block.9.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 223 |
+
"encoder.final_layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"shared.weight": "model-00001-of-00002.safetensors"
|
| 225 |
+
}
|
| 226 |
+
}
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": {
|
| 3 |
+
"content": "[CLS]",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"mask_token": {
|
| 10 |
+
"content": "[MASK]",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "[PAD]",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"sep_token": {
|
| 24 |
+
"content": "[SEP]",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"unk_token": {
|
| 31 |
+
"content": "[UNK]",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
}
|
| 37 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"100": {
|
| 12 |
+
"content": "[UNK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"101": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"102": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"103": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"clean_up_tokenization_spaces": true,
|
| 45 |
+
"cls_token": "[CLS]",
|
| 46 |
+
"do_basic_tokenize": true,
|
| 47 |
+
"do_lower_case": true,
|
| 48 |
+
"mask_token": "[MASK]",
|
| 49 |
+
"model_max_length": 77,
|
| 50 |
+
"never_split": null,
|
| 51 |
+
"pad_token": "[PAD]",
|
| 52 |
+
"sep_token": "[SEP]",
|
| 53 |
+
"strip_accents": null,
|
| 54 |
+
"tokenize_chinese_chars": true,
|
| 55 |
+
"tokenizer_class": "BertTokenizer",
|
| 56 |
+
"unk_token": "[UNK]"
|
| 57 |
+
}
|
tokenizer/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_2/special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token": {
|
| 3 |
+
"content": "</s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"pad_token": {
|
| 10 |
+
"content": "<pad>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"unk_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer_2/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef78f86560d809067d12bac6c09f19a462cb3af3f54d2b8acbba26e1433125d6
|
| 3 |
+
size 4309802
|
tokenizer_2/tokenizer_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": true,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "<pad>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"1": {
|
| 13 |
+
"content": "</s>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"2": {
|
| 21 |
+
"content": "<unk>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [],
|
| 30 |
+
"clean_up_tokenization_spaces": true,
|
| 31 |
+
"eos_token": "</s>",
|
| 32 |
+
"extra_ids": 0,
|
| 33 |
+
"legacy": true,
|
| 34 |
+
"model_max_length": 256,
|
| 35 |
+
"pad_token": "<pad>",
|
| 36 |
+
"sp_model_kwargs": {},
|
| 37 |
+
"tokenizer_class": "T5Tokenizer",
|
| 38 |
+
"unk_token": "<unk>"
|
| 39 |
+
}
|
transformer/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "EasyAnimateTransformer3DModel",
|
| 3 |
+
"_diffusers_version": "0.30.1",
|
| 4 |
+
"activation_fn": "gelu-approximate",
|
| 5 |
+
"add_noise_in_inpaint_model": true,
|
| 6 |
+
"after_norm": false,
|
| 7 |
+
"attention_head_dim": 64,
|
| 8 |
+
"clip_channels": null,
|
| 9 |
+
"dropout": 0.0,
|
| 10 |
+
"enable_clip_in_inpaint": false,
|
| 11 |
+
"enable_text_attention_mask": false,
|
| 12 |
+
"flip_sin_to_cos": true,
|
| 13 |
+
"freq_shift": 0,
|
| 14 |
+
"in_channels": 33,
|
| 15 |
+
"mmdit_layers": 18,
|
| 16 |
+
"norm_elementwise_affine": true,
|
| 17 |
+
"norm_eps": 1e-05,
|
| 18 |
+
"num_attention_heads": 48,
|
| 19 |
+
"num_layers": 36,
|
| 20 |
+
"out_channels": 16,
|
| 21 |
+
"patch_size": 2,
|
| 22 |
+
"ref_channels": null,
|
| 23 |
+
"resize_inpaint_mask_directly": true,
|
| 24 |
+
"sample_height": 60,
|
| 25 |
+
"sample_width": 90,
|
| 26 |
+
"text_embed_dim": 1024,
|
| 27 |
+
"text_embed_dim_t5": 2048,
|
| 28 |
+
"time_embed_dim": 512,
|
| 29 |
+
"time_position_encoding_type": "3d_rope",
|
| 30 |
+
"timestep_activation_fn": "silu"
|
| 31 |
+
}
|
transformer/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0b0a9bf4570cbab1a6f558464ef5f26f440eb5c5db309daa37c9080ccb0b89f
|
| 3 |
+
size 13626329072
|
vae/config.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKLMagvit",
|
| 3 |
+
"_diffusers_version": "0.30.1",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
512,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"cache_compression_vae": false,
|
| 12 |
+
"cache_mag_vae": true,
|
| 13 |
+
"ch": 128,
|
| 14 |
+
"ch_mult": [
|
| 15 |
+
1,
|
| 16 |
+
2,
|
| 17 |
+
4,
|
| 18 |
+
4
|
| 19 |
+
],
|
| 20 |
+
"down_block_types": [
|
| 21 |
+
"SpatialDownBlock3D",
|
| 22 |
+
"SpatialTemporalDownBlock3D",
|
| 23 |
+
"SpatialTemporalDownBlock3D",
|
| 24 |
+
"SpatialTemporalDownBlock3D"
|
| 25 |
+
],
|
| 26 |
+
"force_upcast": true,
|
| 27 |
+
"in_channels": 3,
|
| 28 |
+
"latent_channels": 16,
|
| 29 |
+
"layers_per_block": 2,
|
| 30 |
+
"mid_block_attention_type": "spatial",
|
| 31 |
+
"mid_block_num_attention_heads": 1,
|
| 32 |
+
"mid_block_type": "MidBlock3D",
|
| 33 |
+
"mid_block_use_attention": true,
|
| 34 |
+
"mini_batch_decoder": 1,
|
| 35 |
+
"mini_batch_encoder": 4,
|
| 36 |
+
"norm_num_groups": 32,
|
| 37 |
+
"num_attention_heads": 1,
|
| 38 |
+
"out_channels": 3,
|
| 39 |
+
"sample_size": 256,
|
| 40 |
+
"scaling_factor": 0.7125,
|
| 41 |
+
"slice_compression_vae": false,
|
| 42 |
+
"slice_mag_vae": false,
|
| 43 |
+
"spatial_group_norm": true,
|
| 44 |
+
"tile_overlap_factor": 0.25,
|
| 45 |
+
"tile_sample_min_size": 384,
|
| 46 |
+
"up_block_types": [
|
| 47 |
+
"SpatialUpBlock3D",
|
| 48 |
+
"SpatialTemporalUpBlock3D",
|
| 49 |
+
"SpatialTemporalUpBlock3D",
|
| 50 |
+
"SpatialTemporalUpBlock3D"
|
| 51 |
+
],
|
| 52 |
+
"upcast_vae": false,
|
| 53 |
+
"use_gc_blocks": null,
|
| 54 |
+
"use_tiling": false,
|
| 55 |
+
"use_tiling_decoder": false,
|
| 56 |
+
"use_tiling_encoder": false
|
| 57 |
+
}
|
vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ab16eb7106569c71524595019dae13931a1bd3832241c0c1abbd54ccc7b2faa
|
| 3 |
+
size 985942732
|