

Upload 10 files
Browse files- .gitattributes +1 -0
- ESGify.png +3 -0
- ESGify_classes.jpg +0 -0
- ESGify_logo.jpeg +0 -0
- README.md +109 -0
- config.json +129 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +15 -0
- vocab.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
ESGify.png filter=lfs diff=lfs merge=lfs -text
|
ESGify.png
ADDED

|
Git LFS Details
|
ESGify_classes.jpg
ADDED
|
ESGify_logo.jpeg
ADDED
|
|
README.md
CHANGED
|
@@ -1,3 +1,112 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- ESG
|
| 5 |
+
- finance
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
|
| 9 |
---
|
| 10 |
+

|
| 11 |
+
# About ESGify
|
| 12 |
+
<img src="ESGify_logo.jpeg" alt="image" width="20%" height="auto">
|
| 13 |
+
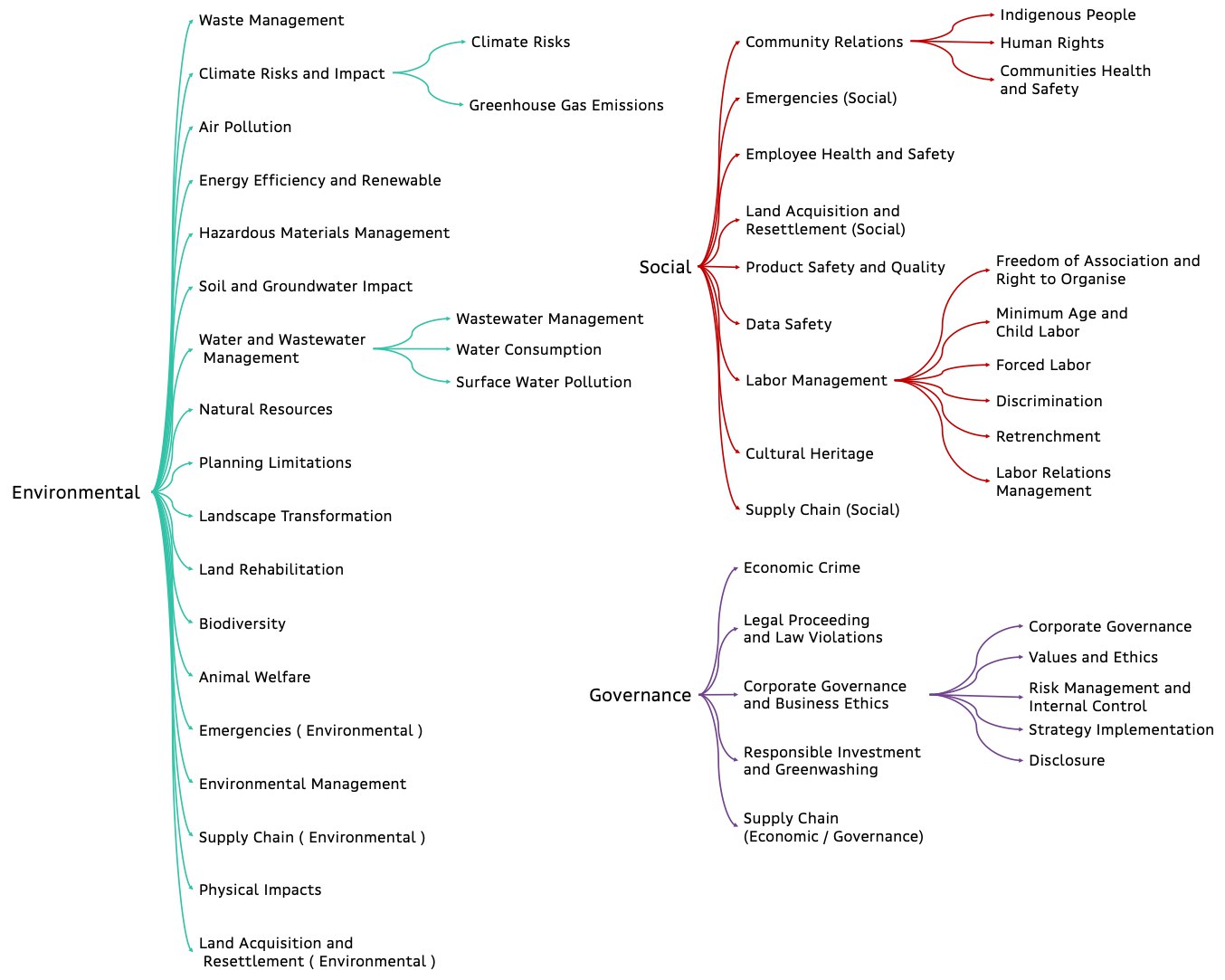
**ESGify** is a model for multilabel news classification with respect to ESG risks. Our custom methodology includes 46 ESG classes and 1 non-relevant to ESG class, resulting in 47 classes in total:
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
# Usage
|
| 18 |
+
|
| 19 |
+
ESGify is based on MPNet architecture but with a custom classification head. The ESGify class is defined is follows.
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from collections import OrderedDict
|
| 23 |
+
from transformers import MPNetPreTrainedModel, MPNetModel, AutoTokenizer
|
| 24 |
+
import torch
|
| 25 |
+
|
| 26 |
+
# Mean Pooling - Take attention mask into account for correct averaging
|
| 27 |
+
def mean_pooling(model_output, attention_mask):
|
| 28 |
+
token_embeddings = model_output #First element of model_output contains all token embeddings
|
| 29 |
+
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 30 |
+
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
|
| 31 |
+
|
| 32 |
+
# Definition of ESGify class because of custom,sentence-transformers like, mean pooling function and classifier head
|
| 33 |
+
class ESGify(MPNetPreTrainedModel):
|
| 34 |
+
"""Model for Classification ESG risks from text."""
|
| 35 |
+
|
| 36 |
+
def __init__(self,config): #tuning only the head
|
| 37 |
+
"""
|
| 38 |
+
"""
|
| 39 |
+
super().__init__(config)
|
| 40 |
+
# Instantiate Parts of model
|
| 41 |
+
self.mpnet = MPNetModel(config,add_pooling_layer=False)
|
| 42 |
+
self.id2label = config.id2label
|
| 43 |
+
self.label2id = config.label2id
|
| 44 |
+
self.classifier = torch.nn.Sequential(OrderedDict([('norm',torch.nn.BatchNorm1d(768)),
|
| 45 |
+
('linear',torch.nn.Linear(768,512)),
|
| 46 |
+
('act',torch.nn.ReLU()),
|
| 47 |
+
('batch_n',torch.nn.BatchNorm1d(512)),
|
| 48 |
+
('drop_class', torch.nn.Dropout(0.2)),
|
| 49 |
+
('class_l',torch.nn.Linear(512 ,47))]))
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def forward(self, input_ids, attention_mask):
|
| 53 |
+
# Feed input to mpnet model
|
| 54 |
+
outputs = self.mpnet(input_ids=input_ids,
|
| 55 |
+
attention_mask=attention_mask)
|
| 56 |
+
|
| 57 |
+
# mean pooling dataset and eed input to classifier to compute logits
|
| 58 |
+
logits = self.classifier( mean_pooling(outputs['last_hidden_state'],attention_mask))
|
| 59 |
+
|
| 60 |
+
# apply sigmoid
|
| 61 |
+
logits = 1.0 / (1.0 + torch.exp(-logits))
|
| 62 |
+
return logits
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
After defining model class, we initialize ESGify and tokenizer with the pre-trained weights
|
| 66 |
+
|
| 67 |
+
```python
|
| 68 |
+
model = ESGify.from_pretrained('ai-lab/ESGify')
|
| 69 |
+
tokenizer = AutoTokenizer.from_pretrained('ai-lab/ESGify')
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Getting results from the model:
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
texts = ['text1','text2']
|
| 76 |
+
to_model = tokenizer.batch_encode_plus(
|
| 77 |
+
texts,
|
| 78 |
+
add_special_tokens=True,
|
| 79 |
+
max_length=512,
|
| 80 |
+
return_token_type_ids=False,
|
| 81 |
+
padding="max_length",
|
| 82 |
+
truncation=True,
|
| 83 |
+
return_attention_mask=True,
|
| 84 |
+
return_tensors='pt',
|
| 85 |
+
)
|
| 86 |
+
results = model(**to_model)
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
To identify top-3 classes by relevance and their scores:
|
| 90 |
+
|
| 91 |
+
```python
|
| 92 |
+
for i in torch.topk(results, k=3).indices.tolist()[0]:
|
| 93 |
+
print(f"{model.id2label[i]}: {np.round(results.flatten()[i].item(), 3)}")
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
For example, for the news "She faced employment rejection because of her gender", we get the following top-3 labels:
|
| 97 |
+
```
|
| 98 |
+
Discrimination: 0.944
|
| 99 |
+
Strategy Implementation: 0.82
|
| 100 |
+
Indigenous People: 0.499
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
Before training our model, we masked words related to Organisation, Date, Country, and Person to prevent false associations between these entities and risks. Hence, we recommend to process text with FLAIR NER model before inference.
|
| 104 |
+
An example of such preprocessing is given in https://colab.research.google.com/drive/15YcTW9KPSWesZ6_L4BUayqW_omzars0l?usp=sharing.
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
# Training procedure
|
| 108 |
+
|
| 109 |
+
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model.
|
| 110 |
+
Next, we do the domain-adaptation procedure by Mask Language Modeling with using texts of ESG reports.
|
| 111 |
+
Finally, we fine-tune our model on 2000 texts with manually annotation of ESG specialists.
|
| 112 |
+
|
config.json
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "ai-forever/rubert-base",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"ESGify_ru"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"directionality": "bidi",
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_dropout_prob": 0.1,
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-12,
|
| 15 |
+
"max_position_embeddings": 512,
|
| 16 |
+
"model_type": "bert",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 0,
|
| 20 |
+
"pooler_fc_size": 768,
|
| 21 |
+
"pooler_num_attention_heads": 12,
|
| 22 |
+
"pooler_num_fc_layers": 3,
|
| 23 |
+
"pooler_size_per_head": 128,
|
| 24 |
+
"pooler_type": "first_token_transform",
|
| 25 |
+
"position_embedding_type": "absolute",
|
| 26 |
+
"torch_dtype": "float32",
|
| 27 |
+
"transformers_version": "4.30.1",
|
| 28 |
+
"type_vocab_size": 2,
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 120138,
|
| 31 |
+
"id2label": {"0": "Legal Proceedings & Law Violations",
|
| 32 |
+
"1": "Biodiversity",
|
| 33 |
+
"2": "Communities Health and Safety",
|
| 34 |
+
"3": "Land Acquisition and Resettlement (S)",
|
| 35 |
+
"4": "Emergencies (Social)",
|
| 36 |
+
"5": "Corporate Governance",
|
| 37 |
+
"6": "Responsible Investment & Greenwashing",
|
| 38 |
+
"7": "Not Relevant to ESG",
|
| 39 |
+
"8": "Economic Crime",
|
| 40 |
+
"9": "Emergencies (Environmental)",
|
| 41 |
+
"10": "Hazardous Materials Management",
|
| 42 |
+
"11": "Environmental Management",
|
| 43 |
+
"12": "Landscape Transformation",
|
| 44 |
+
"13": "Human Rights",
|
| 45 |
+
"14": "Climate Risks",
|
| 46 |
+
"15": "Labor Relations Management",
|
| 47 |
+
"16": "Freedom of Association and Right to Organise",
|
| 48 |
+
"17": "Employee Health and Safety",
|
| 49 |
+
"18": "Surface Water Pollution",
|
| 50 |
+
"19": "Animal Welfare",
|
| 51 |
+
"20": "Water Consumption",
|
| 52 |
+
"21": "Disclosure",
|
| 53 |
+
"22": "Product Safety and Quality",
|
| 54 |
+
"23": "Greenhouse Gas Emissions",
|
| 55 |
+
"24": "Indigenous People",
|
| 56 |
+
"25": "Cultural Heritage",
|
| 57 |
+
"26": "Air Pollution",
|
| 58 |
+
"27": "Waste Management",
|
| 59 |
+
"28": "Soil and Groundwater Impact",
|
| 60 |
+
"29": "Forced Labour",
|
| 61 |
+
"30": "Wastewater Management",
|
| 62 |
+
"31": "Natural Resources",
|
| 63 |
+
"32": "Physical Impacts",
|
| 64 |
+
"33": "Values and Ethics",
|
| 65 |
+
"34": "Risk Management and Internal Control",
|
| 66 |
+
"35": "Supply Chain (Environmental)",
|
| 67 |
+
"36": "Supply Chain (Social)",
|
| 68 |
+
"37": "Discrimination",
|
| 69 |
+
"38": "Minimum Age and Child Labour",
|
| 70 |
+
"39": "Planning Limitations",
|
| 71 |
+
"40": "Data Safety",
|
| 72 |
+
"41": "Strategy Implementation",
|
| 73 |
+
"42": "Energy Efficiency and Renewables",
|
| 74 |
+
"43": "Land Acquisition and Resettlement (E)",
|
| 75 |
+
"44": "Supply Chain (Economic / Governance)",
|
| 76 |
+
"45": "Land Rehabilitation",
|
| 77 |
+
"46": "Retrenchment",
|
| 78 |
+
"47":"Positive"
|
| 79 |
+
},
|
| 80 |
+
"label2id":{"Legal Proceedings & Law Violations": "0",
|
| 81 |
+
"Biodiversity": "1",
|
| 82 |
+
"Communities Health and Safety": "2",
|
| 83 |
+
"Land Acquisition and Resettlement (S)": "3",
|
| 84 |
+
"Emergencies (Social)": "4",
|
| 85 |
+
"Corporate Governance": "5",
|
| 86 |
+
"Responsible Investment & Greenwashing": "6",
|
| 87 |
+
"Not Relevant to ESG": "7",
|
| 88 |
+
"Economic Crime": "8",
|
| 89 |
+
"Emergencies (Environmental)": "9",
|
| 90 |
+
"Hazardous Materials Management": "10",
|
| 91 |
+
"Environmental Management": "11",
|
| 92 |
+
"Landscape Transformation": "12",
|
| 93 |
+
"Human Rights": "13",
|
| 94 |
+
"Climate Risks": "14",
|
| 95 |
+
"Labor Relations Management": "15",
|
| 96 |
+
"Freedom of Association and Right to Organise": "16",
|
| 97 |
+
"Employee Health and Safety": "17",
|
| 98 |
+
"Surface Water Pollution": "18",
|
| 99 |
+
"Animal Welfare": "19",
|
| 100 |
+
"Water Consumption": "20",
|
| 101 |
+
"Disclosure": "21",
|
| 102 |
+
"Product Safety and Quality": "22",
|
| 103 |
+
"Greenhouse Gas Emissions": "23",
|
| 104 |
+
"Indigenous People": "24",
|
| 105 |
+
"Cultural Heritage": "25",
|
| 106 |
+
"Air Pollution": "26",
|
| 107 |
+
"Waste Management": "27",
|
| 108 |
+
"Soil and Groundwater Impact": "28",
|
| 109 |
+
"Forced Labour": "29",
|
| 110 |
+
"Wastewater Management": "30",
|
| 111 |
+
"Natural Resources": "31",
|
| 112 |
+
"Physical Impacts": "32",
|
| 113 |
+
"Values and Ethics": "33",
|
| 114 |
+
"Risk Management and Internal Control": "34",
|
| 115 |
+
"Supply Chain (Environmental)": "35",
|
| 116 |
+
"Supply Chain (Social)": "36",
|
| 117 |
+
"Discrimination": "37",
|
| 118 |
+
"Minimum Age and Child Labour": "38",
|
| 119 |
+
"Planning Limitations": "39",
|
| 120 |
+
"Data Safety": "40",
|
| 121 |
+
"Strategy Implementation": "41",
|
| 122 |
+
"Energy Efficiency and Renewables": "42",
|
| 123 |
+
"Land Acquisition and Resettlement (E)": "43",
|
| 124 |
+
"Supply Chain (Economic / Governance)": "44",
|
| 125 |
+
"Land Rehabilitation": "45",
|
| 126 |
+
"Retrenchment": "46",
|
| 127 |
+
"Positive":"47"}
|
| 128 |
+
|
| 129 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:28f80348b43849ada02addc53fa454eb8873b117f4ded7ec4c676d6c0051dd37
|
| 3 |
+
size 712633885
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"do_basic_tokenize": true,
|
| 4 |
+
"do_lower_case": true,
|
| 5 |
+
"mask_token": "[MASK]",
|
| 6 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 7 |
+
"never_split": null,
|
| 8 |
+
"pad_token": "[PAD]",
|
| 9 |
+
"sep_token": "[SEP]",
|
| 10 |
+
"special_tokens_map_file": null,
|
| 11 |
+
"strip_accents": null,
|
| 12 |
+
"tokenize_chinese_chars": true,
|
| 13 |
+
"tokenizer_class": "BertTokenizer",
|
| 14 |
+
"unk_token": "[UNK]"
|
| 15 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|