
Commit
•
b618c17
1
Parent(s):
5648b77
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- README.md +170 -0
- _assets__/eval crafter.png +0 -0
- _assets__/human eval.png +0 -0
- _assets__/pipeline.png +0 -0
- _assets__/polygon.png +0 -0
- _assets__/video.gif +3 -0
- _assets__/video2.gif +3 -0
- configs.json +1 -0
- interpolation.pt +3 -0
- movq.pt +3 -0
- t2v.pt +3 -0
- t5_projections.pt +3 -0
- video_movq.pt +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
_assets__/video.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
_assets__/video2.gif filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Kandinsky Video 1.1 — a new text-to-video generation model
|
| 2 |
+
## SoTA quality among open-source solutions on <a href="https://evalcrafter.github.io/">EvalCrafter</a> benchmark
|
| 3 |
+
|
| 4 |
+
This repository is the official implementation of Kandinsky Video 1.1 model.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
[](https://huggingface.co/ai-forever/KandinskyVideo) | [Telegram-bot](https://t.me/video_kandinsky_bot) | [Habr post](https://habr.com/ru/companies/sberbank/articles/775554/) | [Our text-to-image model](https://github.com/ai-forever/Kandinsky-3/tree/main)
|
| 8 |
+
|
| 9 |
+
<p>
|
| 10 |
+
<!-- <img src="_assets__/title.jpg" width="800px"/> -->
|
| 11 |
+
<!-- <br> -->
|
| 12 |
+
Our <B>previous</B> model <a href="https://ai-forever.github.io/Kandinsky-3/">Kandinsky Video 1.0</a>, divides the video generation process into two stages: initially generating keyframes at a low FPS and then creating interpolated frames between these keyframes to increase the FPS. In <B>Kandinsky Video 1.1</B>, we further break down the keyframe generation into two extra steps: first, generating the initial frame of the video from the textual prompt using Text to Image <a href="https://github.com/ai-forever/Kandinsky-3">Kandinsky 3.0</a>, and then generating the subsequent keyframes based on the textual prompt and the previously generated first frame. This approach ensures more consistent content across the frames and significantly enhances the overall video quality. Furthermore, the approach allows animating any input image as an additional feature.
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## Pipeline
|
| 18 |
+
|
| 19 |
+
<p align="center">
|
| 20 |
+
<img src="_assets__/pipeline.png" width="800px"/>
|
| 21 |
+
<br>
|
| 22 |
+
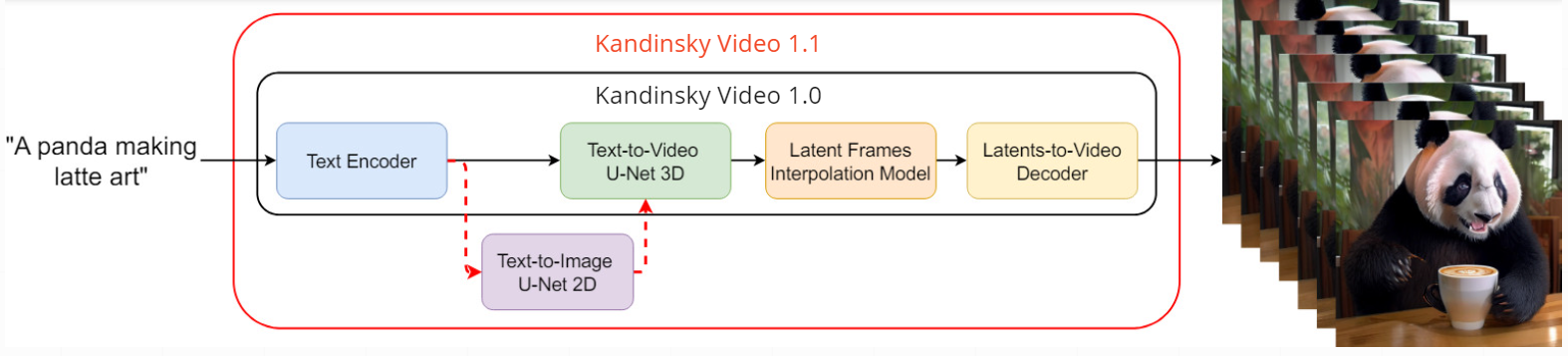
<em>In the <a href="https://ai-forever.github.io/Kandinsky-3/">Kandinsky Video 1.0</a>, the encoded text prompt enters the text-to-video U-Net3D keyframe generation model with temporal layers or blocks, and then the sampled latent keyframes are sent to the latent interpolation model to predict three interpolation frames between
|
| 23 |
+
two keyframes. An image MoVQ-GAN decoder is used to obtain the final video result. In <B>Kandinsky Video 1.1</B>, text-to-video U-Net3D is also conditioned on text-to-image U-Net2D, which helps to improve the content quality. A temporal MoVQ-GAN decoder is used to decode the final video.</em>
|
| 24 |
+
</p>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
**Architecture details**
|
| 28 |
+
|
| 29 |
+
+ Text encoder (Flan-UL2) - 8.6B
|
| 30 |
+
+ Latent Diffusion U-Net3D - 4.15B
|
| 31 |
+
+ The interpolation model (Latent Diffusion U-Net3D) - 4.0B
|
| 32 |
+
+ Image MoVQ encoder/decoder - 256M
|
| 33 |
+
+ Video (temporal) MoVQ decoder - 556M
|
| 34 |
+
|
| 35 |
+
## How to use
|
| 36 |
+
|
| 37 |
+
<!--Check our jupyter notebooks with examples in `./examples` folder -->
|
| 38 |
+
|
| 39 |
+
### 1. text2video
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
from kandinsky_video import get_T2V_pipeline
|
| 43 |
+
|
| 44 |
+
device_map = 'cuda:0'
|
| 45 |
+
t2v_pipe = get_T2V_pipeline(device_map)
|
| 46 |
+
|
| 47 |
+
prompt = "A cat wearing sunglasses and working as a lifeguard at a pool."
|
| 48 |
+
|
| 49 |
+
fps = 'medium' # ['low', 'medium', 'high']
|
| 50 |
+
motion = 'high' # ['low', 'medium', 'high']
|
| 51 |
+
|
| 52 |
+
video = t2v_pipe(
|
| 53 |
+
prompt,
|
| 54 |
+
width=512, height=512,
|
| 55 |
+
fps=fps,
|
| 56 |
+
motion=motion,
|
| 57 |
+
key_frame_guidance_scale=5.0,
|
| 58 |
+
guidance_weight_prompt=5.0,
|
| 59 |
+
guidance_weight_image=3.0,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
path_to_save = f'./_assets__/video.gif'
|
| 63 |
+
video[0].save(
|
| 64 |
+
path_to_save,
|
| 65 |
+
save_all=True, append_images=video[1:], duration=int(5500/len(video)), loop=0
|
| 66 |
+
)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
<p align="center">
|
| 70 |
+
<img src="_assets__/video.gif" raw=true>
|
| 71 |
+
<br><em>Generated video</em>
|
| 72 |
+
</p>
|
| 73 |
+
|
| 74 |
+
### 2. image2video
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
from kandinsky_video import get_T2V_pipeline
|
| 78 |
+
|
| 79 |
+
device_map = 'cuda:0'
|
| 80 |
+
t2v_pipe = get_T2V_pipeline(device_map)
|
| 81 |
+
|
| 82 |
+
from PIL import Image
|
| 83 |
+
import requests
|
| 84 |
+
from io import BytesIO
|
| 85 |
+
|
| 86 |
+
url = 'https://media.cnn.com/api/v1/images/stellar/prod/gettyimages-1961294831.jpg'
|
| 87 |
+
response = requests.get(url)
|
| 88 |
+
img = Image.open(BytesIO(response.content))
|
| 89 |
+
img.show()
|
| 90 |
+
|
| 91 |
+
prompt = "A panda climbs up a tree."
|
| 92 |
+
|
| 93 |
+
fps = 'medium' # ['low', 'medium', 'high']
|
| 94 |
+
motion = 'medium' # ['low', 'medium', 'high']
|
| 95 |
+
|
| 96 |
+
video = t2v_pipe(
|
| 97 |
+
prompt,
|
| 98 |
+
image=img,
|
| 99 |
+
width=640, height=384,
|
| 100 |
+
fps=fps,
|
| 101 |
+
motion=motion,
|
| 102 |
+
key_frame_guidance_scale=5.0,
|
| 103 |
+
guidance_weight_prompt=5.0,
|
| 104 |
+
guidance_weight_image=3.0,
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
path_to_save = f'./_assets__/video2.gif'
|
| 108 |
+
video[0].save(
|
| 109 |
+
path_to_save,
|
| 110 |
+
save_all=True, append_images=video[1:], duration=int(5500/len(video)), loop=0
|
| 111 |
+
)
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
<p align="center">
|
| 115 |
+
<img src="https://media.cnn.com/api/v1/images/stellar/prod/gettyimages-1961294831.jpg" width="50%"><br>
|
| 116 |
+
<em>Input image.</em>
|
| 117 |
+
</p>
|
| 118 |
+
|
| 119 |
+
<p align="center">
|
| 120 |
+
<img src="_assets__/video2.gif"><br>
|
| 121 |
+
<em>Generated Video.</em>
|
| 122 |
+
</p>
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
## Results
|
| 126 |
+
|
| 127 |
+
<p align="center">
|
| 128 |
+
<img src="_assets__/eval crafter.png" align="center" width="50%">
|
| 129 |
+
<br>
|
| 130 |
+
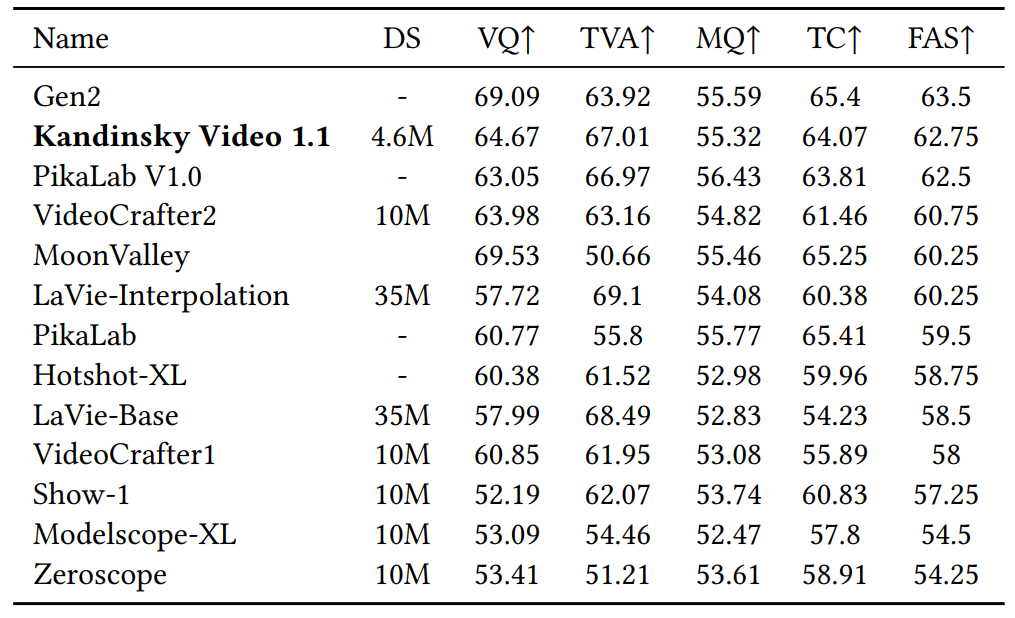
<em> Kandinsky Video 1.1 achieves second place overall and best open source model on <a href="https://evalcrafter.github.io/">EvalCrafter</a> text to video benchmark. VQ: visual quality, TVA: text-video alignment, MQ: motion quality, TC: temporal consistency and FAS: final average score.
|
| 131 |
+
</em>
|
| 132 |
+
</p>
|
| 133 |
+
|
| 134 |
+
<p align="center">
|
| 135 |
+
<img src="_assets__/polygon.png" raw=true align="center" width="50%">
|
| 136 |
+
<br>
|
| 137 |
+
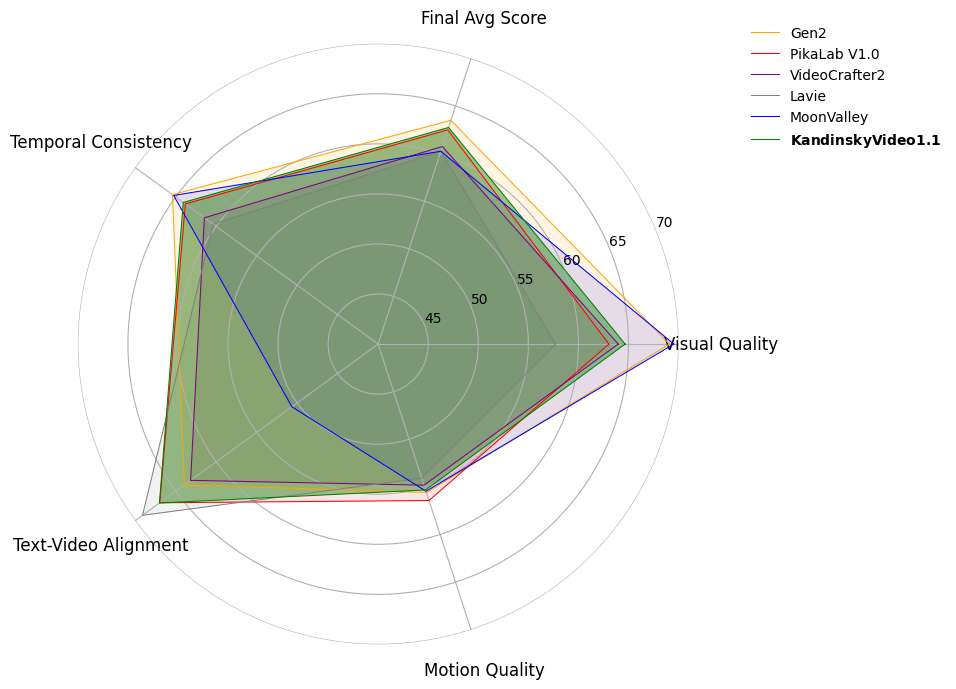
<em> Polygon-radar chart representing the performance of Kandinsky Video 1.1 on <a href="https://evalcrafter.github.io/">EvalCrafter</a> benchmark.
|
| 138 |
+
</em>
|
| 139 |
+
</p>
|
| 140 |
+
|
| 141 |
+
<p align="center">
|
| 142 |
+
<img src="_assets__/human eval.png" raw=true align="center" width="50%">
|
| 143 |
+
<br>
|
| 144 |
+
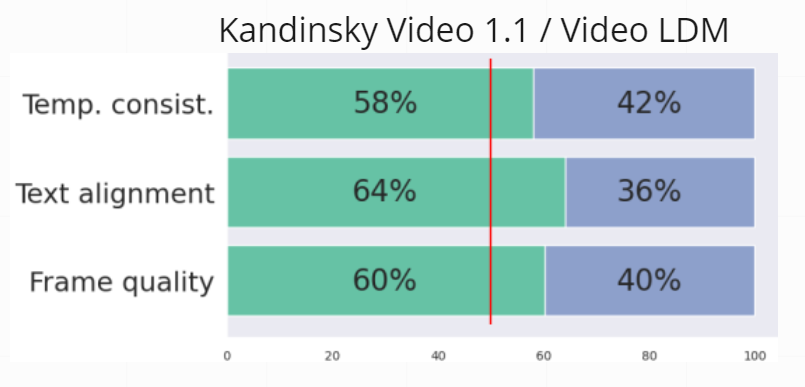
<em> Human evaluation study results. The bars in the plot correspond to the percentage of “wins” in the side-by-side comparison of model generations. We compare our model with <a href="https://arxiv.org/abs/2304.08818">Video LDM</a>.
|
| 145 |
+
</em>
|
| 146 |
+
</p>
|
| 147 |
+
|
| 148 |
+
# Authors
|
| 149 |
+
|
| 150 |
+
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse), [Google Scholar](https://scholar.google.com/citations?user=D-Ko0oAAAAAJ&hl=ru)
|
| 151 |
+
+ Zein Shaheen: [Github](https://github.com/zeinsh), [Google Scholar](https://scholar.google.ru/citations?user=bxlgMxMAAAAJ&hl=en)
|
| 152 |
+
+ Viacheslav Vasilev: [Github](https://github.com/vivasilev), [Google Scholar](https://scholar.google.com/citations?user=redAz-kAAAAJ&hl=ru&oi=sra)
|
| 153 |
+
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
| 154 |
+
+ Elizaveta Dakhova: [Github](https://github.com/LizaDakhova)
|
| 155 |
+
+ Anastasia Lysenko: [Github](https://github.com/LysenkoAnastasia)
|
| 156 |
+
+ Sergey Markov
|
| 157 |
+
+ Denis Dimitrov: [Github](https://github.com/denndimitrov), [Google Scholar](https://scholar.google.com/citations?user=3JSIJpYAAAAJ&hl=ru&oi=ao)
|
| 158 |
+
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey), [Google Scholar](https://scholar.google.com/citations?user=q0lIfCEAAAAJ&hl=ru)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
## BibTeX
|
| 162 |
+
If you use our work in your research, please cite our publication:
|
| 163 |
+
```
|
| 164 |
+
@article{arkhipkin2023fusionframes,
|
| 165 |
+
title = {FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline},
|
| 166 |
+
author = {Arkhipkin, Vladimir and Shaheen, Zein and Vasilev, Viacheslav and Dakhova, Elizaveta and Kuznetsov, Andrey and Dimitrov, Denis},
|
| 167 |
+
journal = {arXiv preprint arXiv:2311.13073},
|
| 168 |
+
year = {2023},
|
| 169 |
+
}
|
| 170 |
+
```
|
_assets__/eval crafter.png
ADDED
|
_assets__/human eval.png
ADDED
|
_assets__/pipeline.png
ADDED
|
_assets__/polygon.png
ADDED
|
_assets__/video.gif
ADDED

|
Git LFS Details
|
_assets__/video2.gif
ADDED

|
Git LFS Details
|
configs.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"text_encoder": {"tokens_length": 128, "context_dim": 4096, "weights_path": "google/flan-ul2", "low_cpu_mem_usage": true, "load_in_8bit": false, "load_in_4bit": false}, "image_movq": {"configs": {"temporal": false, "temporal_attention_block": false, "temporal_kernel_size": [3, 3, 3], "temporal_conv_padding": [1, 1, 1], "double_z": false, "z_channels": 4, "resolution": 256, "in_channels": 3, "out_ch": 3, "ch": 256, "ch_mult": [1, 2, 2, 4], "num_res_blocks": 2, "attn_resolutions": [32], "dropout": 0.0}}, "video_movq": {"configs": {"temporal": true, "temporal_attention_block": true, "temporal_kernel_size": [3, 3, 3], "temporal_conv_padding": [1, 1, 1], "double_z": false, "z_channels": 4, "resolution": 256, "in_channels": 3, "out_ch": 3, "ch": 256, "ch_mult": [1, 2, 2, 4], "num_res_blocks": 2, "attn_resolutions": [32], "dropout": 0.0}}, "t2v": {"configs": {"model_channels": 384, "num_channels": 9, "out_channels": 4, "init_channels": 192, "time_embed_dim": 1536, "context_dim": 4096, "groups": 32, "head_dim": 64, "expansion_ratio": 4, "compression_ratio": 2, "dim_mult": [1, 2, 4, 8], "num_blocks": [3, 3, 3, 3], "add_cross_attention": [false, true, true, true], "add_self_attention": [false, true, true, true], "noise_augmentation": true, "motion_score": true}}, "interpolation": {"configs": {"model_channels": 384, "num_channels": 20, "out_channels": 12, "init_channels": 192, "time_embed_dim": 1536, "context_dim": 4096, "groups": 32, "head_dim": 64, "expansion_ratio": 4, "compression_ratio": 2, "dim_mult": [1, 2, 4, 8], "num_blocks": [3, 3, 3, 3], "add_cross_attention": [false, true, true, true], "add_self_attention": [false, true, true, true]}}}
|
interpolation.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19b1c41e2b341051d267f1d7cc2b590e37531063afbf7bbb3adcb60c864edb02
|
| 3 |
+
size 7960934714
|
movq.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ad3a981f7cd5cd19ff85382319039b94be4c2c11760bf46079d96bb84ca98ef
|
| 3 |
+
size 1082549221
|
t2v.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:526b1ce47f565ecce3f2ada22f38673505b8e2bde276743bbd60cff74902da7a
|
| 3 |
+
size 8299187091
|
t5_projections.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bf7d965493a9735760327ef2bfda8c7a1b6646196ea7ddff1f62549c1818f789
|
| 3 |
+
size 134286094
|
video_movq.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:889994182dda30f42d6737a2d78e532eb5a983e7ab115fa58d489b9aa6a53427
|
| 3 |
+
size 2664736205
|