
Joshua Lochner
commited on
Commit
•
366d154
1
Parent(s):
ee58f38
Use exact same structure as example
Browse files- .DS_Store +0 -0
- .gitattributes +5 -2
- README.md +29 -2
- added_tokens.json +0 -1
- binary_mask.jpg +0 -0
- config.json +3 -12
- custom_pipeline.py +333 -0
- hircin_the_cat.png +0 -0
- image/.DS_Store +0 -0
- image/binary_mask.jpg +0 -0
- image/mask.jpg +0 -0
- image/raw_output.jpg +0 -0
- rng_state.pth → keras_metadata.pb +2 -2
- mask.jpg +0 -0
- pipeline.py +70 -6
- raw_output.jpg +0 -0
- special_tokens_map.json +0 -1
- scheduler.pt → tf_model.h5 +2 -2
- tokenizer.json +0 -0
- tokenizer_config.json +0 -1
- trainer_state.json +0 -379
- pytorch_model.bin → variables/variables.data-00000-of-00001 +2 -2
- training_args.bin → variables/variables.index +2 -2
- vocab.txt +0 -0
.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
.gitattributes
CHANGED
|
@@ -17,12 +17,15 @@
|
|
| 17 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 18 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 19 |
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 22 |
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 23 |
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 25 |
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 28 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 18 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 19 |
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 22 |
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 23 |
*.tgz filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 24 |
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 25 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
variables.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
variables filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
/Users/mervenoyan/Desktop/seg/pet-segmentation/variables/variables.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
variables.index filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,5 +1,32 @@
|
|
| 1 |
---
|
| 2 |
tags:
|
| 3 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
---
|
| 5 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
tags:
|
| 3 |
+
- image-segmentation
|
| 4 |
+
- generic
|
| 5 |
+
library_name: generic
|
| 6 |
+
dataset:
|
| 7 |
+
- oxfort-iit pets
|
| 8 |
+
widget:
|
| 9 |
+
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-1.jpg
|
| 10 |
+
example_title: Kedis
|
| 11 |
+
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
|
| 12 |
+
example_title: Cat in a Crate
|
| 13 |
+
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-3.jpg
|
| 14 |
+
example_title: Two Cats Chilling
|
| 15 |
+
license: cc0-1.0
|
| 16 |
---
|
| 17 |
+
## Keras semantic segmentation models on the 🤗Hub! 🐶 🐕 🐩
|
| 18 |
+
Full credits go to [François Chollet](https://twitter.com/fchollet).
|
| 19 |
+
|
| 20 |
+
This repository contains the model from [this notebook on segmenting pets using U-net-like architecture](https://keras.io/examples/vision/oxford_pets_image_segmentation/). We've changed the inference part to enable segmentation widget on the Hub. (see ```pipeline.py```)
|
| 21 |
+
|
| 22 |
+
## Background Information
|
| 23 |
+
|
| 24 |
+
Image classification task tells us about a class assigned to an image, and object detection task creates a boundary box on an object in an image. But what if we want to know about the shape of the image? Segmentation models helps us segment images and reveal their shapes. It has many variants, including, panoptic segmentation, instance segmentation and semantic segmentation.This post is on hosting your Keras semantic segmentation models on Hub.
|
| 25 |
+
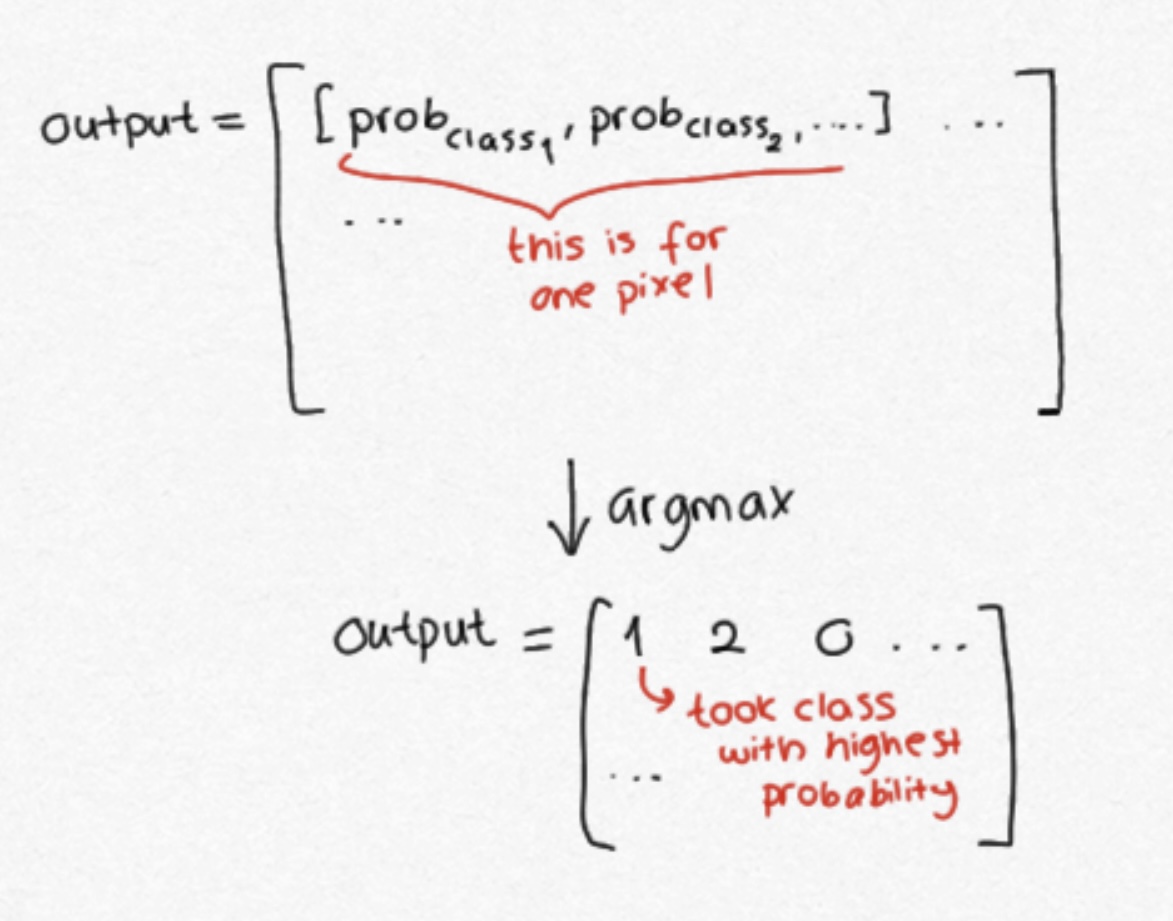
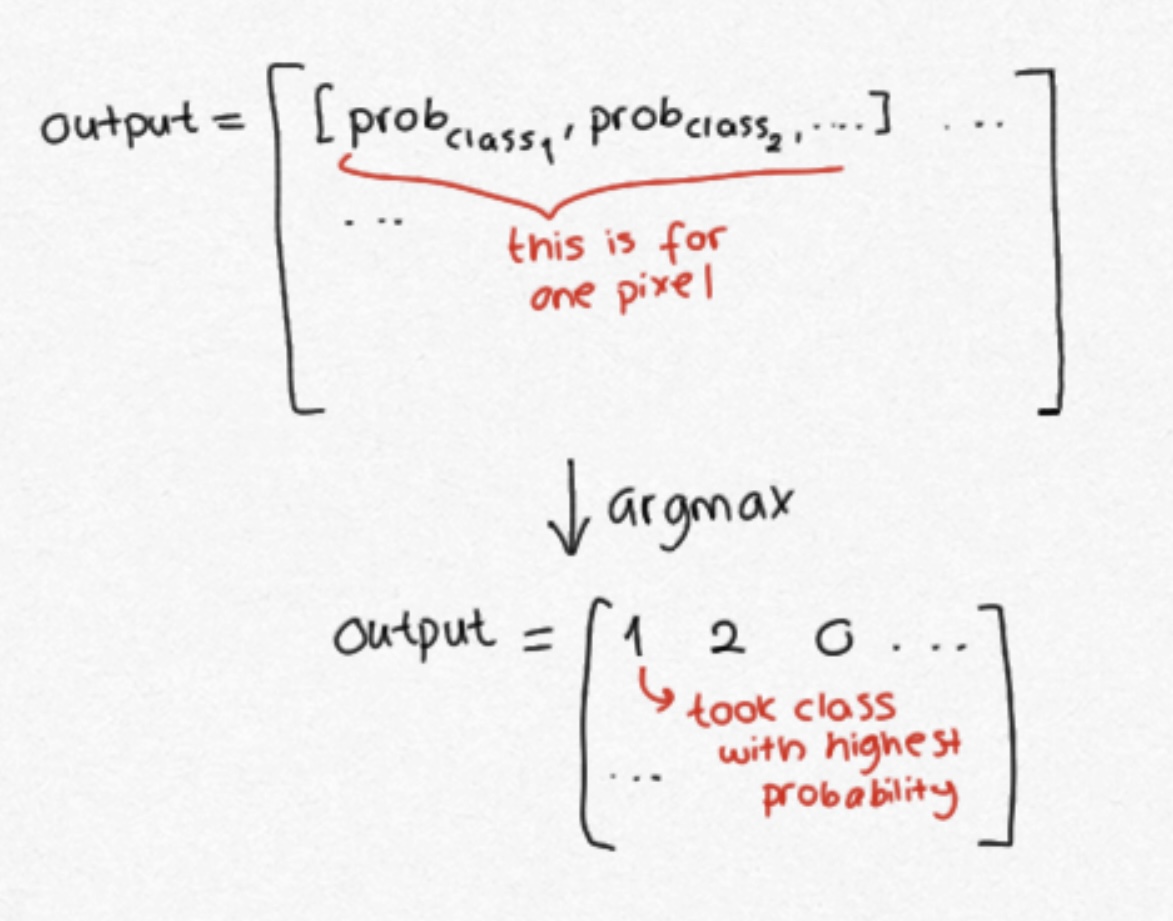
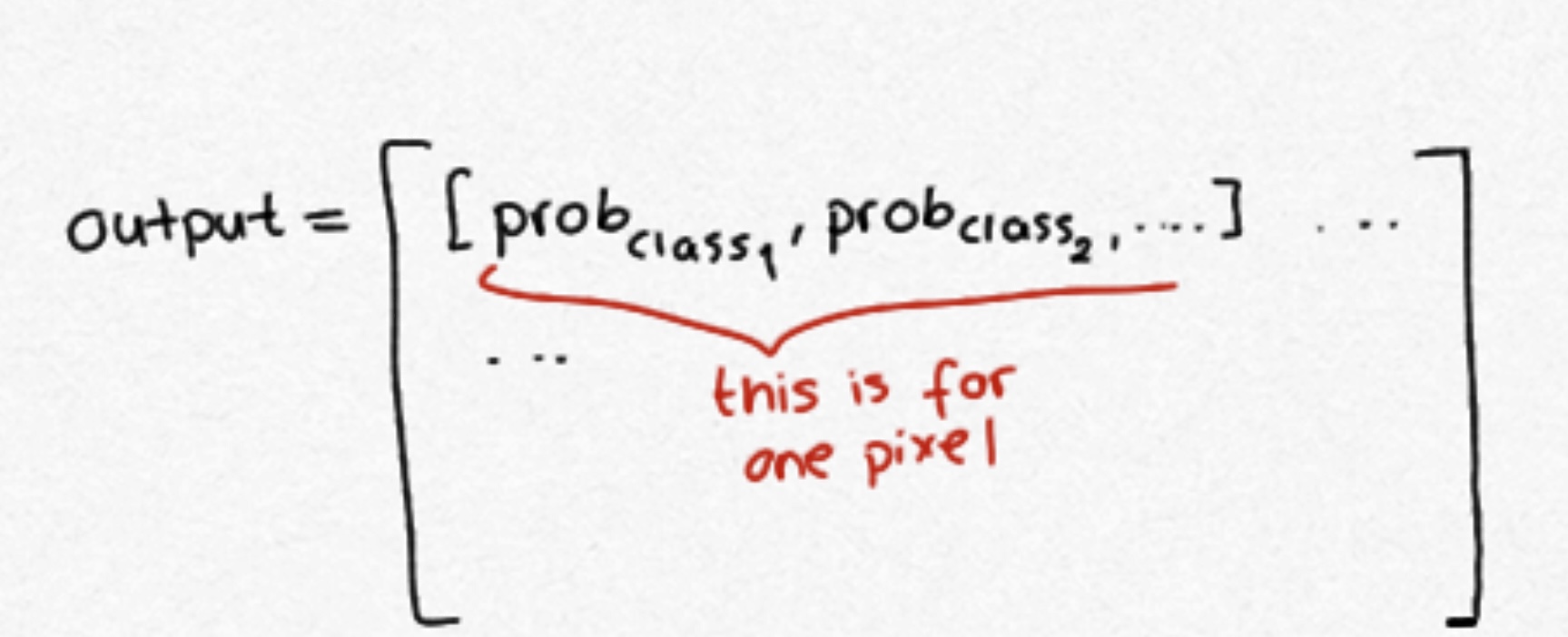
Semantic segmentation models classify pixels, meaning, they assign a class (can be cat or dog) to each pixel. The output of a model looks like following.
|
| 26 |
+

|
| 27 |
+
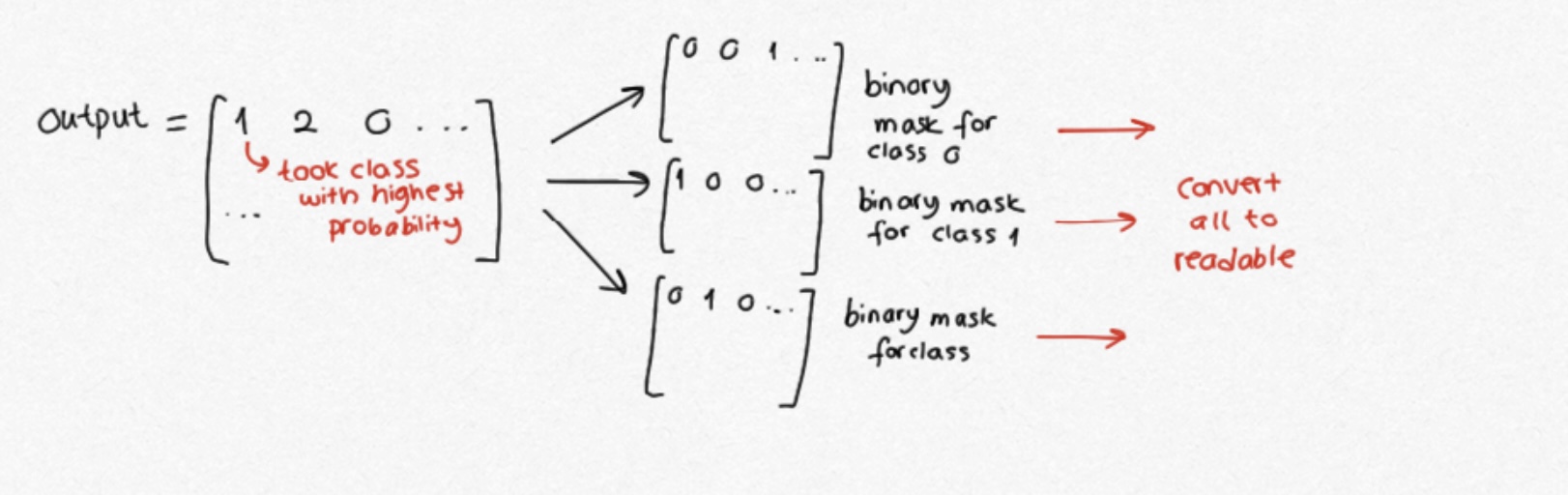
We need to get the best prediction for every pixel.
|
| 28 |
+

|
| 29 |
+
This is still not readable. We have to convert this into different binary masks for each class and convert to a readable format by converting each mask into base64. We will return a list of dicts, and for each dictionary, we have the label itself, the base64 code and a score (semantic segmentation models don't return a score, so we have to return 1.0 for this case). You can find the full implementation in ```pipeline.py```.
|
| 30 |
+

|
| 31 |
+
Now that you know the expected output by the model, you can host your Keras segmentation models (and other semantic segmentation models) in the similar fashion. Try it yourself and host your segmentation models!
|
| 32 |
+

|
added_tokens.json
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
{"NUMBER_PERCENTAGE_TOKEN": 30525, "HYPHENATED_URL_TOKEN": 30524, "START_SELFPROMO_TOKEN": 30536, "START_SPONSOR_TOKEN": 30534, "PROFANITY_TOKEN": 30532, "[Laughter]": 30531, "BETWEEN_SEGMENTS_TOKEN": 30540, "NUMBER_TOKEN": 30526, "SHORT_HYPHENATED_TOKEN": 30527, "END_SPONSOR_TOKEN": 30535, "LONG_WORD_TOKEN": 30528, "EXTRACT_SEGMENTS: ": 30522, "END_INTERACTION_TOKEN": 30539, "[Applause]": 30530, "START_INTERACTION_TOKEN": 30538, "END_SELFPROMO_TOKEN": 30537, "URL_TOKEN": 30523, "NO_SEGMENT_TOKEN": 30533, "[Music]": 30529}
|
|
|
|
|
|
binary_mask.jpg
ADDED
|
config.json
CHANGED
|
@@ -2,15 +2,6 @@
|
|
| 2 |
"id2label": {
|
| 3 |
"0": 0,
|
| 4 |
"1": 1,
|
| 5 |
-
"2": 2
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
"label2id": {
|
| 9 |
-
"0": 0,
|
| 10 |
-
"1": 1,
|
| 11 |
-
"2": 2,
|
| 12 |
-
"3": 3
|
| 13 |
-
},
|
| 14 |
-
"model_type": "bert",
|
| 15 |
-
"vocab_size": 30541
|
| 16 |
-
}
|
|
|
|
| 2 |
"id2label": {
|
| 3 |
"0": 0,
|
| 4 |
"1": 1,
|
| 5 |
+
"2": 2
|
| 6 |
+
}
|
| 7 |
+
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
custom_pipeline.py
ADDED
|
@@ -0,0 +1,333 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import youtube_transcript_api2
|
| 2 |
+
import json
|
| 3 |
+
import re
|
| 4 |
+
import requests
|
| 5 |
+
from transformers import (
|
| 6 |
+
AutoModelForSequenceClassification,
|
| 7 |
+
AutoTokenizer,
|
| 8 |
+
TextClassificationPipeline,
|
| 9 |
+
)
|
| 10 |
+
from typing import Any, Dict, List
|
| 11 |
+
|
| 12 |
+
CATEGORIES = [None, 'SPONSOR', 'SELFPROMO', 'INTERACTION']
|
| 13 |
+
|
| 14 |
+
PROFANITY_RAW = '[ __ ]' # How YouTube transcribes profanity
|
| 15 |
+
PROFANITY_CONVERTED = '*****' # Safer version for tokenizing
|
| 16 |
+
|
| 17 |
+
NUM_DECIMALS = 3
|
| 18 |
+
|
| 19 |
+
# https://www.fincher.org/Utilities/CountryLanguageList.shtml
|
| 20 |
+
# https://lingohub.com/developers/supported-locales/language-designators-with-regions
|
| 21 |
+
LANGUAGE_PREFERENCE_LIST = ['en-GB', 'en-US', 'en-CA', 'en-AU', 'en-NZ', 'en-ZA',
|
| 22 |
+
'en-IE', 'en-IN', 'en-JM', 'en-BZ', 'en-TT', 'en-PH', 'en-ZW',
|
| 23 |
+
'en']
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def parse_transcript_json(json_data, granularity):
|
| 27 |
+
assert json_data['wireMagic'] == 'pb3'
|
| 28 |
+
|
| 29 |
+
assert granularity in ('word', 'chunk')
|
| 30 |
+
|
| 31 |
+
# TODO remove bracketed words?
|
| 32 |
+
# (kiss smacks)
|
| 33 |
+
# (upbeat music)
|
| 34 |
+
# [text goes here]
|
| 35 |
+
|
| 36 |
+
# Some manual transcripts aren't that well formatted... but do have punctuation
|
| 37 |
+
# https://www.youtube.com/watch?v=LR9FtWVjk2c
|
| 38 |
+
|
| 39 |
+
parsed_transcript = []
|
| 40 |
+
|
| 41 |
+
events = json_data['events']
|
| 42 |
+
|
| 43 |
+
for event_index, event in enumerate(events):
|
| 44 |
+
segments = event.get('segs')
|
| 45 |
+
if not segments:
|
| 46 |
+
continue
|
| 47 |
+
|
| 48 |
+
# This value is known (when phrase appears on screen)
|
| 49 |
+
start_ms = event['tStartMs']
|
| 50 |
+
total_characters = 0
|
| 51 |
+
|
| 52 |
+
new_segments = []
|
| 53 |
+
for seg in segments:
|
| 54 |
+
# Replace \n, \t, etc. with space
|
| 55 |
+
text = ' '.join(seg['utf8'].split())
|
| 56 |
+
|
| 57 |
+
# Remove zero-width spaces and strip trailing and leading whitespace
|
| 58 |
+
text = text.replace('\u200b', '').replace('\u200c', '').replace(
|
| 59 |
+
'\u200d', '').replace('\ufeff', '').strip()
|
| 60 |
+
|
| 61 |
+
# Alternatively,
|
| 62 |
+
# text = text.encode('ascii', 'ignore').decode()
|
| 63 |
+
|
| 64 |
+
# Needed for auto-generated transcripts
|
| 65 |
+
text = text.replace(PROFANITY_RAW, PROFANITY_CONVERTED)
|
| 66 |
+
|
| 67 |
+
if not text:
|
| 68 |
+
continue
|
| 69 |
+
|
| 70 |
+
offset_ms = seg.get('tOffsetMs', 0)
|
| 71 |
+
|
| 72 |
+
new_segments.append({
|
| 73 |
+
'text': text,
|
| 74 |
+
'start': round((start_ms + offset_ms)/1000, NUM_DECIMALS)
|
| 75 |
+
})
|
| 76 |
+
|
| 77 |
+
total_characters += len(text)
|
| 78 |
+
|
| 79 |
+
if not new_segments:
|
| 80 |
+
continue
|
| 81 |
+
|
| 82 |
+
if event_index < len(events) - 1:
|
| 83 |
+
next_start_ms = events[event_index + 1]['tStartMs']
|
| 84 |
+
total_event_duration_ms = min(
|
| 85 |
+
event.get('dDurationMs', float('inf')), next_start_ms - start_ms)
|
| 86 |
+
else:
|
| 87 |
+
total_event_duration_ms = event.get('dDurationMs', 0)
|
| 88 |
+
|
| 89 |
+
# Ensure duration is non-negative
|
| 90 |
+
total_event_duration_ms = max(total_event_duration_ms, 0)
|
| 91 |
+
|
| 92 |
+
avg_seconds_per_character = (
|
| 93 |
+
total_event_duration_ms/total_characters)/1000
|
| 94 |
+
|
| 95 |
+
num_char_count = 0
|
| 96 |
+
for seg_index, seg in enumerate(new_segments):
|
| 97 |
+
num_char_count += len(seg['text'])
|
| 98 |
+
|
| 99 |
+
# Estimate segment end
|
| 100 |
+
seg_end = seg['start'] + \
|
| 101 |
+
(num_char_count * avg_seconds_per_character)
|
| 102 |
+
|
| 103 |
+
if seg_index < len(new_segments) - 1:
|
| 104 |
+
# Do not allow longer than next
|
| 105 |
+
seg_end = min(seg_end, new_segments[seg_index+1]['start'])
|
| 106 |
+
|
| 107 |
+
seg['end'] = round(seg_end, NUM_DECIMALS)
|
| 108 |
+
parsed_transcript.append(seg)
|
| 109 |
+
|
| 110 |
+
final_parsed_transcript = []
|
| 111 |
+
for i in range(len(parsed_transcript)):
|
| 112 |
+
|
| 113 |
+
word_level = granularity == 'word'
|
| 114 |
+
if word_level:
|
| 115 |
+
split_text = parsed_transcript[i]['text'].split()
|
| 116 |
+
elif granularity == 'chunk':
|
| 117 |
+
# Split on space after punctuation
|
| 118 |
+
split_text = re.split(
|
| 119 |
+
r'(?<=[.!?,-;])\s+', parsed_transcript[i]['text'])
|
| 120 |
+
if len(split_text) == 1:
|
| 121 |
+
split_on_whitespace = parsed_transcript[i]['text'].split()
|
| 122 |
+
|
| 123 |
+
if len(split_on_whitespace) >= 8: # Too many words
|
| 124 |
+
# Rather split on whitespace instead of punctuation
|
| 125 |
+
split_text = split_on_whitespace
|
| 126 |
+
else:
|
| 127 |
+
word_level = True
|
| 128 |
+
else:
|
| 129 |
+
raise ValueError('Unknown granularity')
|
| 130 |
+
|
| 131 |
+
segment_end = parsed_transcript[i]['end']
|
| 132 |
+
if i < len(parsed_transcript) - 1:
|
| 133 |
+
segment_end = min(segment_end, parsed_transcript[i+1]['start'])
|
| 134 |
+
|
| 135 |
+
segment_duration = segment_end - parsed_transcript[i]['start']
|
| 136 |
+
|
| 137 |
+
num_chars_in_text = sum(map(len, split_text))
|
| 138 |
+
|
| 139 |
+
num_char_count = 0
|
| 140 |
+
current_offset = 0
|
| 141 |
+
for s in split_text:
|
| 142 |
+
num_char_count += len(s)
|
| 143 |
+
|
| 144 |
+
next_offset = (num_char_count/num_chars_in_text) * segment_duration
|
| 145 |
+
|
| 146 |
+
word_start = round(
|
| 147 |
+
parsed_transcript[i]['start'] + current_offset, NUM_DECIMALS)
|
| 148 |
+
word_end = round(
|
| 149 |
+
parsed_transcript[i]['start'] + next_offset, NUM_DECIMALS)
|
| 150 |
+
|
| 151 |
+
# Make the reasonable assumption that min wps is 1.5
|
| 152 |
+
final_parsed_transcript.append({
|
| 153 |
+
'text': s,
|
| 154 |
+
'start': word_start,
|
| 155 |
+
'end': min(word_end, word_start + 1.5) if word_level else word_end
|
| 156 |
+
})
|
| 157 |
+
current_offset = next_offset
|
| 158 |
+
|
| 159 |
+
return final_parsed_transcript
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def list_transcripts(video_id):
|
| 163 |
+
try:
|
| 164 |
+
return youtube_transcript_api2.YouTubeTranscriptApi.list_transcripts(video_id)
|
| 165 |
+
except json.decoder.JSONDecodeError:
|
| 166 |
+
return None
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
WORDS_TO_REMOVE = [
|
| 170 |
+
'[Music]'
|
| 171 |
+
'[Applause]'
|
| 172 |
+
'[Laughter]'
|
| 173 |
+
]
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def get_words(video_id, transcript_type='auto', fallback='manual', filter_words_to_remove=True, granularity='word'):
|
| 177 |
+
"""Get parsed video transcript with caching system
|
| 178 |
+
returns None if not processed yet and process is False
|
| 179 |
+
"""
|
| 180 |
+
|
| 181 |
+
raw_transcript_json = None
|
| 182 |
+
try:
|
| 183 |
+
transcript_list = list_transcripts(video_id)
|
| 184 |
+
|
| 185 |
+
if transcript_list is not None:
|
| 186 |
+
if transcript_type == 'manual':
|
| 187 |
+
ts = transcript_list.find_manually_created_transcript(
|
| 188 |
+
LANGUAGE_PREFERENCE_LIST)
|
| 189 |
+
else:
|
| 190 |
+
ts = transcript_list.find_generated_transcript(
|
| 191 |
+
LANGUAGE_PREFERENCE_LIST)
|
| 192 |
+
raw_transcript = ts._http_client.get(
|
| 193 |
+
f'{ts._url}&fmt=json3').content
|
| 194 |
+
if raw_transcript:
|
| 195 |
+
raw_transcript_json = json.loads(raw_transcript)
|
| 196 |
+
|
| 197 |
+
except (youtube_transcript_api2.TooManyRequests, youtube_transcript_api2.YouTubeRequestFailed):
|
| 198 |
+
raise # Cannot recover from these errors and do not mark as empty transcript
|
| 199 |
+
|
| 200 |
+
except requests.exceptions.RequestException: # Can recover
|
| 201 |
+
return get_words(video_id, transcript_type, fallback, granularity)
|
| 202 |
+
|
| 203 |
+
except youtube_transcript_api2.CouldNotRetrieveTranscript: # Retrying won't solve
|
| 204 |
+
pass # Mark as empty transcript
|
| 205 |
+
|
| 206 |
+
except json.decoder.JSONDecodeError:
|
| 207 |
+
return get_words(video_id, transcript_type, fallback, granularity)
|
| 208 |
+
|
| 209 |
+
if not raw_transcript_json and fallback is not None:
|
| 210 |
+
return get_words(video_id, transcript_type=fallback, fallback=None, granularity=granularity)
|
| 211 |
+
|
| 212 |
+
if raw_transcript_json:
|
| 213 |
+
processed_transcript = parse_transcript_json(
|
| 214 |
+
raw_transcript_json, granularity)
|
| 215 |
+
if filter_words_to_remove:
|
| 216 |
+
processed_transcript = list(
|
| 217 |
+
filter(lambda x: x['text'] not in WORDS_TO_REMOVE, processed_transcript))
|
| 218 |
+
else:
|
| 219 |
+
processed_transcript = raw_transcript_json # Either None or []
|
| 220 |
+
|
| 221 |
+
return processed_transcript
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def word_start(word):
|
| 225 |
+
return word['start']
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def word_end(word):
|
| 229 |
+
return word.get('end', word['start'])
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
def extract_segment(words, start, end, map_function=None):
|
| 233 |
+
"""Extracts all words with time in [start, end]"""
|
| 234 |
+
|
| 235 |
+
a = max(binary_search_below(words, 0, len(words), start), 0)
|
| 236 |
+
b = min(binary_search_above(words, -1, len(words) - 1, end) + 1, len(words))
|
| 237 |
+
|
| 238 |
+
to_transform = map_function is not None and callable(map_function)
|
| 239 |
+
|
| 240 |
+
return [
|
| 241 |
+
map_function(words[i]) if to_transform else words[i] for i in range(a, b)
|
| 242 |
+
]
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
def avg(*items):
|
| 246 |
+
return sum(items)/len(items)
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def binary_search_below(transcript, start_index, end_index, time):
|
| 250 |
+
if start_index >= end_index:
|
| 251 |
+
return end_index
|
| 252 |
+
|
| 253 |
+
middle_index = (start_index + end_index) // 2
|
| 254 |
+
middle = transcript[middle_index]
|
| 255 |
+
middle_time = avg(word_start(middle), word_end(middle))
|
| 256 |
+
|
| 257 |
+
if time <= middle_time:
|
| 258 |
+
return binary_search_below(transcript, start_index, middle_index, time)
|
| 259 |
+
else:
|
| 260 |
+
return binary_search_below(transcript, middle_index + 1, end_index, time)
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
def binary_search_above(transcript, start_index, end_index, time):
|
| 264 |
+
if start_index >= end_index:
|
| 265 |
+
return end_index
|
| 266 |
+
|
| 267 |
+
middle_index = (start_index + end_index + 1) // 2
|
| 268 |
+
middle = transcript[middle_index]
|
| 269 |
+
middle_time = avg(word_start(middle), word_end(middle))
|
| 270 |
+
|
| 271 |
+
if time >= middle_time:
|
| 272 |
+
return binary_search_above(transcript, middle_index, end_index, time)
|
| 273 |
+
else:
|
| 274 |
+
return binary_search_above(transcript, start_index, middle_index - 1, time)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
class SponsorBlockClassificationPipeline(TextClassificationPipeline):
|
| 278 |
+
def __init__(self, model, tokenizer):
|
| 279 |
+
super().__init__(model=model, tokenizer=tokenizer, return_all_scores=True)
|
| 280 |
+
|
| 281 |
+
def preprocess(self, video, **tokenizer_kwargs):
|
| 282 |
+
|
| 283 |
+
words = get_words(video['video_id'])
|
| 284 |
+
segment_words = extract_segment(words, video['start'], video['end'])
|
| 285 |
+
text = ' '.join(x['text'] for x in segment_words)
|
| 286 |
+
|
| 287 |
+
model_inputs = self.tokenizer(
|
| 288 |
+
text, return_tensors=self.framework, **tokenizer_kwargs)
|
| 289 |
+
return {'video': video, 'model_inputs': model_inputs}
|
| 290 |
+
|
| 291 |
+
def _forward(self, data):
|
| 292 |
+
model_outputs = self.model(**data['model_inputs'])
|
| 293 |
+
return {'video': data['video'], 'model_outputs': model_outputs}
|
| 294 |
+
|
| 295 |
+
def postprocess(self, data, function_to_apply=None, return_all_scores=False):
|
| 296 |
+
model_outputs = data['model_outputs']
|
| 297 |
+
|
| 298 |
+
results = super().postprocess(model_outputs, function_to_apply, return_all_scores)
|
| 299 |
+
|
| 300 |
+
for result in results:
|
| 301 |
+
result['label_text'] = CATEGORIES[result['label']]
|
| 302 |
+
|
| 303 |
+
return results # {**data['video'], 'result': results}
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
# model_id = "Xenova/sponsorblock-classifier-v2"
|
| 307 |
+
# model = AutoModelForSequenceClassification.from_pretrained(model_id)
|
| 308 |
+
# tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 309 |
+
|
| 310 |
+
# pl = SponsorBlockClassificationPipeline(model=model, tokenizer=tokenizer)
|
| 311 |
+
data = [{
|
| 312 |
+
'video_id': 'pqh4LfPeCYs',
|
| 313 |
+
'start': 835.933,
|
| 314 |
+
'end': 927.581,
|
| 315 |
+
'category': 'sponsor'
|
| 316 |
+
}]
|
| 317 |
+
# print(pl(data))
|
| 318 |
+
|
| 319 |
+
# MODEL_ID = "Xenova/sponsorblock-classifier-v2"
|
| 320 |
+
class PreTrainedPipeline():
|
| 321 |
+
def __init__(self, path: str):
|
| 322 |
+
# load the model
|
| 323 |
+
self.model = AutoModelForSequenceClassification.from_pretrained(path)
|
| 324 |
+
self.tokenizer = AutoTokenizer.from_pretrained(path)
|
| 325 |
+
self.pipeline = SponsorBlockClassificationPipeline(
|
| 326 |
+
model=self.model, tokenizer=self.tokenizer)
|
| 327 |
+
|
| 328 |
+
def __call__(self, inputs: str) -> List[Dict[str, Any]]:
|
| 329 |
+
json_data = json.loads(inputs)
|
| 330 |
+
return self.pipeline(json_data)
|
| 331 |
+
|
| 332 |
+
# a = PreTrainedPipeline('Xenova/sponsorblock-classifier-v2')(json.dumps(data))
|
| 333 |
+
# print(a)
|
hircin_the_cat.png
ADDED

|
image/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
image/binary_mask.jpg
ADDED

|
image/mask.jpg
ADDED
|
image/raw_output.jpg
ADDED
|
rng_state.pth → keras_metadata.pb
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e7844f7cdd94bacbd2dceb2000b172c07e3a3db345cd29ea0d51d66107ff28e9
|
| 3 |
+
size 563033
|
mask.jpg
ADDED
|
pipeline.py
CHANGED
|
@@ -1,14 +1,78 @@
|
|
|
|
|
| 1 |
from typing import Any, Dict, List
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
class PreTrainedPipeline():
|
| 4 |
def __init__(self, path: str):
|
| 5 |
# load the model
|
| 6 |
-
self.model =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
|
| 8 |
-
|
|
|
|
| 9 |
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
"
|
|
|
|
| 13 |
"score": 1.0,
|
| 14 |
-
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
from typing import Any, Dict, List
|
| 3 |
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
from tensorflow import keras
|
| 6 |
+
import base64
|
| 7 |
+
import io
|
| 8 |
+
import os
|
| 9 |
+
import numpy as np
|
| 10 |
+
from PIL import Image
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
|
| 14 |
class PreTrainedPipeline():
|
| 15 |
def __init__(self, path: str):
|
| 16 |
# load the model
|
| 17 |
+
self.model = keras.models.load_model(os.path.join(path, "tf_model.h5"))
|
| 18 |
+
|
| 19 |
+
def __call__(self, inputs: "Image.Image")-> List[Dict[str, Any]]:
|
| 20 |
+
|
| 21 |
+
# convert img to numpy array, resize and normalize to make the prediction
|
| 22 |
+
img = np.array(inputs)
|
| 23 |
+
|
| 24 |
+
im = tf.image.resize(img, (128, 128))
|
| 25 |
+
im = tf.cast(im, tf.float32) / 255.0
|
| 26 |
+
pred_mask = self.model.predict(im[tf.newaxis, ...])
|
| 27 |
+
|
| 28 |
+
# take the best performing class for each pixel
|
| 29 |
+
# the output of argmax looks like this [[1, 2, 0], ...]
|
| 30 |
+
pred_mask_arg = tf.argmax(pred_mask, axis=-1)
|
| 31 |
+
|
| 32 |
+
labels = []
|
| 33 |
+
|
| 34 |
+
# convert the prediction mask into binary masks for each class
|
| 35 |
+
binary_masks = {}
|
| 36 |
+
mask_codes = {}
|
| 37 |
+
|
| 38 |
+
# when we take tf.argmax() over pred_mask, it becomes a tensor object
|
| 39 |
+
# the shape becomes TensorShape object, looking like this TensorShape([128])
|
| 40 |
+
# we need to take get shape, convert to list and take the best one
|
| 41 |
+
|
| 42 |
+
rows = pred_mask_arg[0][1].get_shape().as_list()[0]
|
| 43 |
+
cols = pred_mask_arg[0][2].get_shape().as_list()[0]
|
| 44 |
+
|
| 45 |
+
for cls in range(pred_mask.shape[-1]):
|
| 46 |
+
|
| 47 |
+
binary_masks[f"mask_{cls}"] = np.zeros(shape = (pred_mask.shape[1], pred_mask.shape[2])) #create masks for each class
|
| 48 |
+
|
| 49 |
+
for row in range(rows):
|
| 50 |
+
|
| 51 |
+
for col in range(cols):
|
| 52 |
+
|
| 53 |
+
if pred_mask_arg[0][row][col] == cls:
|
| 54 |
+
|
| 55 |
+
binary_masks[f"mask_{cls}"][row][col] = 1
|
| 56 |
+
else:
|
| 57 |
+
binary_masks[f"mask_{cls}"][row][col] = 0
|
| 58 |
+
|
| 59 |
+
mask = binary_masks[f"mask_{cls}"]
|
| 60 |
+
mask *= 255
|
| 61 |
+
img = Image.fromarray(mask.astype(np.int8), mode="L")
|
| 62 |
+
|
| 63 |
+
# we need to make it readable for the widget
|
| 64 |
+
with io.BytesIO() as out:
|
| 65 |
+
img.save(out, format="PNG")
|
| 66 |
+
png_string = out.getvalue()
|
| 67 |
+
mask = base64.b64encode(png_string).decode("utf-8")
|
| 68 |
|
| 69 |
+
mask_codes[f"mask_{cls}"] = mask
|
| 70 |
+
|
| 71 |
|
| 72 |
+
# widget needs the below format, for each class we return label and mask string
|
| 73 |
+
labels.append({
|
| 74 |
+
"label": f"LABEL_{cls}",
|
| 75 |
+
"mask": mask_codes[f"mask_{cls}"],
|
| 76 |
"score": 1.0,
|
| 77 |
+
})
|
| 78 |
+
return labels
|
raw_output.jpg
ADDED
|
special_tokens_map.json
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
{"unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]", "cls_token": "[CLS]", "mask_token": "[MASK]"}
|
|
|
|
|
|
scheduler.pt → tf_model.h5
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0258ea75c11d977fae78f747902e48541c5e6996d3d5c700175454ffeb42aa0f
|
| 3 |
+
size 63661584
|
tokenizer.json
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
{"do_lower_case": true, "unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]", "cls_token": "[CLS]", "mask_token": "[MASK]", "tokenize_chinese_chars": true, "strip_accents": null, "model_max_length": 512, "special_tokens_map_file": null, "name_or_path": "models/classifier-85000", "tokenizer_class": "BertTokenizer"}
|
|
|
|
|
|
trainer_state.json
DELETED
|
@@ -1,379 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"best_metric": null,
|
| 3 |
-
"best_model_checkpoint": null,
|
| 4 |
-
"epoch": 1.8509766855702583,
|
| 5 |
-
"global_step": 235000,
|
| 6 |
-
"is_hyper_param_search": false,
|
| 7 |
-
"is_local_process_zero": true,
|
| 8 |
-
"is_world_process_zero": true,
|
| 9 |
-
"log_history": [
|
| 10 |
-
{
|
| 11 |
-
"epoch": 0.04,
|
| 12 |
-
"learning_rate": 1.921235034656585e-05,
|
| 13 |
-
"loss": 0.3334,
|
| 14 |
-
"step": 5000
|
| 15 |
-
},
|
| 16 |
-
{
|
| 17 |
-
"epoch": 0.08,
|
| 18 |
-
"learning_rate": 1.8424700693131696e-05,
|
| 19 |
-
"loss": 0.3387,
|
| 20 |
-
"step": 10000
|
| 21 |
-
},
|
| 22 |
-
{
|
| 23 |
-
"epoch": 0.12,
|
| 24 |
-
"learning_rate": 1.7637051039697544e-05,
|
| 25 |
-
"loss": 0.3327,
|
| 26 |
-
"step": 15000
|
| 27 |
-
},
|
| 28 |
-
{
|
| 29 |
-
"epoch": 0.16,
|
| 30 |
-
"learning_rate": 1.684940138626339e-05,
|
| 31 |
-
"loss": 0.3492,
|
| 32 |
-
"step": 20000
|
| 33 |
-
},
|
| 34 |
-
{
|
| 35 |
-
"epoch": 0.2,
|
| 36 |
-
"learning_rate": 1.606175173282924e-05,
|
| 37 |
-
"loss": 0.3349,
|
| 38 |
-
"step": 25000
|
| 39 |
-
},
|
| 40 |
-
{
|
| 41 |
-
"epoch": 0.2,
|
| 42 |
-
"eval_accuracy": 0.9155995845794678,
|
| 43 |
-
"eval_loss": 0.389266699552536,
|
| 44 |
-
"eval_runtime": 551.1932,
|
| 45 |
-
"eval_samples_per_second": 51.289,
|
| 46 |
-
"eval_steps_per_second": 12.823,
|
| 47 |
-
"step": 25000
|
| 48 |
-
},
|
| 49 |
-
{
|
| 50 |
-
"epoch": 0.24,
|
| 51 |
-
"learning_rate": 1.5274102079395087e-05,
|
| 52 |
-
"loss": 0.3279,
|
| 53 |
-
"step": 30000
|
| 54 |
-
},
|
| 55 |
-
{
|
| 56 |
-
"epoch": 0.28,
|
| 57 |
-
"learning_rate": 1.4486452425960932e-05,
|
| 58 |
-
"loss": 0.3301,
|
| 59 |
-
"step": 35000
|
| 60 |
-
},
|
| 61 |
-
{
|
| 62 |
-
"epoch": 0.32,
|
| 63 |
-
"learning_rate": 1.369880277252678e-05,
|
| 64 |
-
"loss": 0.3243,
|
| 65 |
-
"step": 40000
|
| 66 |
-
},
|
| 67 |
-
{
|
| 68 |
-
"epoch": 0.35,
|
| 69 |
-
"learning_rate": 1.2911153119092628e-05,
|
| 70 |
-
"loss": 0.293,
|
| 71 |
-
"step": 45000
|
| 72 |
-
},
|
| 73 |
-
{
|
| 74 |
-
"epoch": 0.39,
|
| 75 |
-
"learning_rate": 1.2123503465658477e-05,
|
| 76 |
-
"loss": 0.3053,
|
| 77 |
-
"step": 50000
|
| 78 |
-
},
|
| 79 |
-
{
|
| 80 |
-
"epoch": 0.39,
|
| 81 |
-
"eval_accuracy": 0.9235231876373291,
|
| 82 |
-
"eval_loss": 0.3810465931892395,
|
| 83 |
-
"eval_runtime": 542.4272,
|
| 84 |
-
"eval_samples_per_second": 52.118,
|
| 85 |
-
"eval_steps_per_second": 13.03,
|
| 86 |
-
"step": 50000
|
| 87 |
-
},
|
| 88 |
-
{
|
| 89 |
-
"epoch": 0.43,
|
| 90 |
-
"learning_rate": 1.1335853812224324e-05,
|
| 91 |
-
"loss": 0.3126,
|
| 92 |
-
"step": 55000
|
| 93 |
-
},
|
| 94 |
-
{
|
| 95 |
-
"epoch": 0.47,
|
| 96 |
-
"learning_rate": 1.0548204158790173e-05,
|
| 97 |
-
"loss": 0.3072,
|
| 98 |
-
"step": 60000
|
| 99 |
-
},
|
| 100 |
-
{
|
| 101 |
-
"epoch": 0.51,
|
| 102 |
-
"learning_rate": 9.760554505356018e-06,
|
| 103 |
-
"loss": 0.2957,
|
| 104 |
-
"step": 65000
|
| 105 |
-
},
|
| 106 |
-
{
|
| 107 |
-
"epoch": 0.55,
|
| 108 |
-
"learning_rate": 8.972904851921865e-06,
|
| 109 |
-
"loss": 0.2968,
|
| 110 |
-
"step": 70000
|
| 111 |
-
},
|
| 112 |
-
{
|
| 113 |
-
"epoch": 0.59,
|
| 114 |
-
"learning_rate": 8.185255198487714e-06,
|
| 115 |
-
"loss": 0.2882,
|
| 116 |
-
"step": 75000
|
| 117 |
-
},
|
| 118 |
-
{
|
| 119 |
-
"epoch": 0.59,
|
| 120 |
-
"eval_accuracy": 0.9224973320960999,
|
| 121 |
-
"eval_loss": 0.37537074089050293,
|
| 122 |
-
"eval_runtime": 521.9317,
|
| 123 |
-
"eval_samples_per_second": 54.164,
|
| 124 |
-
"eval_steps_per_second": 13.542,
|
| 125 |
-
"step": 75000
|
| 126 |
-
},
|
| 127 |
-
{
|
| 128 |
-
"epoch": 0.63,
|
| 129 |
-
"learning_rate": 7.3976055450535615e-06,
|
| 130 |
-
"loss": 0.2754,
|
| 131 |
-
"step": 80000
|
| 132 |
-
},
|
| 133 |
-
{
|
| 134 |
-
"epoch": 0.67,
|
| 135 |
-
"learning_rate": 6.6099558916194085e-06,
|
| 136 |
-
"loss": 0.2607,
|
| 137 |
-
"step": 85000
|
| 138 |
-
},
|
| 139 |
-
{
|
| 140 |
-
"epoch": 0.71,
|
| 141 |
-
"learning_rate": 5.8223062381852555e-06,
|
| 142 |
-
"loss": 0.2818,
|
| 143 |
-
"step": 90000
|
| 144 |
-
},
|
| 145 |
-
{
|
| 146 |
-
"epoch": 0.75,
|
| 147 |
-
"learning_rate": 5.034656584751103e-06,
|
| 148 |
-
"loss": 0.2736,
|
| 149 |
-
"step": 95000
|
| 150 |
-
},
|
| 151 |
-
{
|
| 152 |
-
"epoch": 0.79,
|
| 153 |
-
"learning_rate": 4.24700693131695e-06,
|
| 154 |
-
"loss": 0.2644,
|
| 155 |
-
"step": 100000
|
| 156 |
-
},
|
| 157 |
-
{
|
| 158 |
-
"epoch": 0.79,
|
| 159 |
-
"eval_accuracy": 0.9297842383384705,
|
| 160 |
-
"eval_loss": 0.3645715117454529,
|
| 161 |
-
"eval_runtime": 521.9055,
|
| 162 |
-
"eval_samples_per_second": 54.167,
|
| 163 |
-
"eval_steps_per_second": 13.543,
|
| 164 |
-
"step": 100000
|
| 165 |
-
},
|
| 166 |
-
{
|
| 167 |
-
"epoch": 0.83,
|
| 168 |
-
"learning_rate": 3.459357277882798e-06,
|
| 169 |
-
"loss": 0.2552,
|
| 170 |
-
"step": 105000
|
| 171 |
-
},
|
| 172 |
-
{
|
| 173 |
-
"epoch": 0.87,
|
| 174 |
-
"learning_rate": 2.6717076244486457e-06,
|
| 175 |
-
"loss": 0.266,
|
| 176 |
-
"step": 110000
|
| 177 |
-
},
|
| 178 |
-
{
|
| 179 |
-
"epoch": 0.91,
|
| 180 |
-
"learning_rate": 1.884057971014493e-06,
|
| 181 |
-
"loss": 0.2684,
|
| 182 |
-
"step": 115000
|
| 183 |
-
},
|
| 184 |
-
{
|
| 185 |
-
"epoch": 0.95,
|
| 186 |
-
"learning_rate": 1.0964083175803404e-06,
|
| 187 |
-
"loss": 0.2501,
|
| 188 |
-
"step": 120000
|
| 189 |
-
},
|
| 190 |
-
{
|
| 191 |
-
"epoch": 0.98,
|
| 192 |
-
"learning_rate": 3.087586641461878e-07,
|
| 193 |
-
"loss": 0.273,
|
| 194 |
-
"step": 125000
|
| 195 |
-
},
|
| 196 |
-
{
|
| 197 |
-
"epoch": 0.98,
|
| 198 |
-
"eval_accuracy": 0.9299964904785156,
|
| 199 |
-
"eval_loss": 0.3369257152080536,
|
| 200 |
-
"eval_runtime": 522.7551,
|
| 201 |
-
"eval_samples_per_second": 54.079,
|
| 202 |
-
"eval_steps_per_second": 13.521,
|
| 203 |
-
"step": 125000
|
| 204 |
-
},
|
| 205 |
-
{
|
| 206 |
-
"epoch": 1.02,
|
| 207 |
-
"learning_rate": 1.7952110901071204e-05,
|
| 208 |
-
"loss": 0.2834,
|
| 209 |
-
"step": 130000
|
| 210 |
-
},
|
| 211 |
-
{
|
| 212 |
-
"epoch": 1.06,
|
| 213 |
-
"learning_rate": 1.787334593572779e-05,
|
| 214 |
-
"loss": 0.3047,
|
| 215 |
-
"step": 135000
|
| 216 |
-
},
|
| 217 |
-
{
|
| 218 |
-
"epoch": 1.1,
|
| 219 |
-
"learning_rate": 1.7794580970384373e-05,
|
| 220 |
-
"loss": 0.2963,
|
| 221 |
-
"step": 140000
|
| 222 |
-
},
|
| 223 |
-
{
|
| 224 |
-
"epoch": 1.14,
|
| 225 |
-
"learning_rate": 1.771581600504096e-05,
|
| 226 |
-
"loss": 0.3031,
|
| 227 |
-
"step": 145000
|
| 228 |
-
},
|
| 229 |
-
{
|
| 230 |
-
"epoch": 1.18,
|
| 231 |
-
"learning_rate": 1.7637051039697544e-05,
|
| 232 |
-
"loss": 0.3033,
|
| 233 |
-
"step": 150000
|
| 234 |
-
},
|
| 235 |
-
{
|
| 236 |
-
"epoch": 1.18,
|
| 237 |
-
"eval_accuracy": 0.9257162809371948,
|
| 238 |
-
"eval_loss": 0.4006378650665283,
|
| 239 |
-
"eval_runtime": 519.4649,
|
| 240 |
-
"eval_samples_per_second": 54.421,
|
| 241 |
-
"eval_steps_per_second": 13.606,
|
| 242 |
-
"step": 150000
|
| 243 |
-
},
|
| 244 |
-
{
|
| 245 |
-
"epoch": 1.22,
|
| 246 |
-
"learning_rate": 1.755828607435413e-05,
|
| 247 |
-
"loss": 0.3024,
|
| 248 |
-
"step": 155000
|
| 249 |
-
},
|
| 250 |
-
{
|
| 251 |
-
"epoch": 1.26,
|
| 252 |
-
"learning_rate": 1.7479521109010713e-05,
|
| 253 |
-
"loss": 0.3135,
|
| 254 |
-
"step": 160000
|
| 255 |
-
},
|
| 256 |
-
{
|
| 257 |
-
"epoch": 1.3,
|
| 258 |
-
"learning_rate": 1.74007561436673e-05,
|
| 259 |
-
"loss": 0.3137,
|
| 260 |
-
"step": 165000
|
| 261 |
-
},
|
| 262 |
-
{
|
| 263 |
-
"epoch": 1.34,
|
| 264 |
-
"learning_rate": 1.732199117832388e-05,
|
| 265 |
-
"loss": 0.3227,
|
| 266 |
-
"step": 170000
|
| 267 |
-
},
|
| 268 |
-
{
|
| 269 |
-
"epoch": 1.38,
|
| 270 |
-
"learning_rate": 1.7243226212980467e-05,
|
| 271 |
-
"loss": 0.3246,
|
| 272 |
-
"step": 175000
|
| 273 |
-
},
|
| 274 |
-
{
|
| 275 |
-
"epoch": 1.38,
|
| 276 |
-
"eval_accuracy": 0.924018383026123,
|
| 277 |
-
"eval_loss": 0.3924681842327118,
|
| 278 |
-
"eval_runtime": 518.8244,
|
| 279 |
-
"eval_samples_per_second": 54.489,
|
| 280 |
-
"eval_steps_per_second": 13.623,
|
| 281 |
-
"step": 175000
|
| 282 |
-
},
|
| 283 |
-
{
|
| 284 |
-
"epoch": 1.42,
|
| 285 |
-
"learning_rate": 1.7164461247637053e-05,
|
| 286 |
-
"loss": 0.3281,
|
| 287 |
-
"step": 180000
|
| 288 |
-
},
|
| 289 |
-
{
|
| 290 |
-
"epoch": 1.46,
|
| 291 |
-
"learning_rate": 1.708569628229364e-05,
|
| 292 |
-
"loss": 0.3256,
|
| 293 |
-
"step": 185000
|
| 294 |
-
},
|
| 295 |
-
{
|
| 296 |
-
"epoch": 1.5,
|
| 297 |
-
"learning_rate": 1.700693131695022e-05,
|
| 298 |
-
"loss": 0.313,
|
| 299 |
-
"step": 190000
|
| 300 |
-
},
|
| 301 |
-
{
|
| 302 |
-
"epoch": 1.54,
|
| 303 |
-
"learning_rate": 1.6928166351606807e-05,
|
| 304 |
-
"loss": 0.3313,
|
| 305 |
-
"step": 195000
|
| 306 |
-
},
|
| 307 |
-
{
|
| 308 |
-
"epoch": 1.58,
|
| 309 |
-
"learning_rate": 1.684940138626339e-05,
|
| 310 |
-
"loss": 0.2953,
|
| 311 |
-
"step": 200000
|
| 312 |
-
},
|
| 313 |
-
{
|
| 314 |
-
"epoch": 1.58,
|
| 315 |
-
"eval_accuracy": 0.9212592840194702,
|
| 316 |
-
"eval_loss": 0.3895967900753021,
|
| 317 |
-
"eval_runtime": 526.2623,
|
| 318 |
-
"eval_samples_per_second": 53.718,
|
| 319 |
-
"eval_steps_per_second": 13.431,
|
| 320 |
-
"step": 200000
|
| 321 |
-
},
|
| 322 |
-
{
|
| 323 |
-
"epoch": 1.61,
|
| 324 |
-
"learning_rate": 1.6770636420919976e-05,
|
| 325 |
-
"loss": 0.3103,
|
| 326 |
-
"step": 205000
|
| 327 |
-
},
|
| 328 |
-
{
|
| 329 |
-
"epoch": 1.65,
|
| 330 |
-
"learning_rate": 1.669187145557656e-05,
|
| 331 |
-
"loss": 0.3089,
|
| 332 |
-
"step": 210000
|
| 333 |
-
},
|
| 334 |
-
{
|
| 335 |
-
"epoch": 1.69,
|
| 336 |
-
"learning_rate": 1.6613106490233147e-05,
|
| 337 |
-
"loss": 0.3095,
|
| 338 |
-
"step": 215000
|
| 339 |
-
},
|
| 340 |
-
{
|
| 341 |
-
"epoch": 1.73,
|
| 342 |
-
"learning_rate": 1.653434152488973e-05,
|
| 343 |
-
"loss": 0.3288,
|
| 344 |
-
"step": 220000
|
| 345 |
-
},
|
| 346 |
-
{
|
| 347 |
-
"epoch": 1.77,
|
| 348 |
-
"learning_rate": 1.6455576559546316e-05,
|
| 349 |
-
"loss": 0.3199,
|
| 350 |
-
"step": 225000
|
| 351 |
-
},
|
| 352 |
-
{
|
| 353 |
-
"epoch": 1.77,
|
| 354 |
-
"eval_accuracy": 0.9203749299049377,
|
| 355 |
-
"eval_loss": 0.3942428529262543,
|
| 356 |
-
"eval_runtime": 520.6801,
|
| 357 |
-
"eval_samples_per_second": 54.294,
|
| 358 |
-
"eval_steps_per_second": 13.575,
|
| 359 |
-
"step": 225000
|
| 360 |
-
},
|
| 361 |
-
{
|
| 362 |
-
"epoch": 1.81,
|
| 363 |
-
"learning_rate": 1.6376811594202898e-05,
|
| 364 |
-
"loss": 0.306,
|
| 365 |
-
"step": 230000
|
| 366 |
-
},
|
| 367 |
-
{
|
| 368 |
-
"epoch": 1.85,
|
| 369 |
-
"learning_rate": 1.6298046628859484e-05,
|
| 370 |
-
"loss": 0.3104,
|
| 371 |
-
"step": 235000
|
| 372 |
-
}
|
| 373 |
-
],
|
| 374 |
-
"max_steps": 1269600,
|
| 375 |
-
"num_train_epochs": 10,
|
| 376 |
-
"total_flos": 2.473283070586798e+17,
|
| 377 |
-
"trial_name": null,
|
| 378 |
-
"trial_params": null
|
| 379 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pytorch_model.bin → variables/variables.data-00000-of-00001
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e3c27336aaecafd070749d833780e6603b9c25caf01a037c0ef9a93ff3b0c36c
|
| 3 |
+
size 63405929
|
training_args.bin → variables/variables.index
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c109c3a99fb1bfbd8298c3f63cfee52e1bd8e8f10f138796eddbac360eaa0de1
|
| 3 |
+
size 17873
|
vocab.txt
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|