
Commit
·
029ef19
1
Parent(s):
4d73f40
Upload 51 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- README.md +159 -0
- examples/ad_1.png +0 -0
- examples/ad_2.png +0 -0
- examples/cook_1.png +0 -0
- examples/cook_2.png +0 -0
- examples/describe_1.png +0 -0
- examples/describe_2.png +0 -0
- examples/fact_1.png +0 -0
- examples/fact_2.png +0 -0
- examples/fix_1.png +0 -0
- examples/fix_2.png +0 -0
- examples/fun_1.png +0 -0
- examples/fun_2.png +0 -0
- examples/logo_1.png +0 -0
- examples/op_1.png +0 -0
- examples/op_2.png +0 -0
- examples/people_1.png +0 -0
- examples/people_2.png +0 -0
- examples/rhyme_1.png +0 -0
- examples/rhyme_2.png +0 -0
- examples/story_1.png +0 -0
- examples/story_2.png +0 -0
- examples/web_1.png +0 -0
- examples/wop_1.png +0 -0
- examples/wop_2.png +0 -0
- figs/examples/ad_1.png +0 -0
- figs/examples/ad_2.png +0 -0
- figs/examples/cook_1.png +0 -0
- figs/examples/cook_2.png +0 -0
- figs/examples/describe_1.png +0 -0
- figs/examples/describe_2.png +0 -0
- figs/examples/fact_1.png +0 -0
- figs/examples/fact_2.png +0 -0
- figs/examples/fix_1.png +0 -0
- figs/examples/fix_2.png +0 -0
- figs/examples/fun_1.png +0 -0
- figs/examples/fun_2.png +0 -0
- figs/examples/logo_1.png +0 -0
- figs/examples/op_1.png +0 -0
- figs/examples/op_2.png +0 -0
- figs/examples/people_1.png +0 -0
- figs/examples/people_2.png +0 -0
- figs/examples/rhyme_1.png +0 -0
- figs/examples/rhyme_2.png +0 -0
- figs/examples/story_1.png +0 -0
- figs/examples/story_2.png +0 -0
- figs/examples/web_1.png +0 -0
- figs/examples/wop_1.png +0 -0
- figs/examples/wop_2.png +0 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
figs/online_demo.png filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figs/overview.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
|
| 2 |
+
[Deyao Zhu](https://tsutikgiau.github.io/)* (On Job Market!), [Jun Chen](https://junchen14.github.io/)* (On Job Market!), [Xiaoqian Shen](https://xiaoqian-shen.github.io), [Xiang Li](https://xiangli.ac.cn), and [Mohamed Elhoseiny](https://www.mohamed-elhoseiny.com/). *Equal Contribution
|
| 3 |
+
|
| 4 |
+
**King Abdullah University of Science and Technology**
|
| 5 |
+
|
| 6 |
+
<a href='https://minigpt-4.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='MiniGPT_4.pdf'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Online Demo
|
| 10 |
+
|
| 11 |
+
Click the image to chat with MiniGPT-4 around your images
|
| 12 |
+
[](https://minigpt-4.github.io)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## Examples
|
| 16 |
+
| | |
|
| 17 |
+
:-------------------------:|:-------------------------:
|
| 18 |
+
 | 
|
| 19 |
+
 | 
|
| 20 |
+
|
| 21 |
+
More examples can be found in the [project page](https://minigpt-4.github.io).
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Introduction
|
| 26 |
+
- MiniGPT-4 aligns a frozen visual encoder from BLIP-2 with a frozen LLM, Vicuna, using just one projection layer.
|
| 27 |
+
- We train MiniGPT-4 with two stages. The first traditional pretraining stage is trained using roughly 5 million aligned image-text pairs in 10 hours using 4 A100s. After the first stage, Vicuna is able to understand the image. But the generation ability of Vicuna is heavilly impacted.
|
| 28 |
+
- To address this issue and improve usability, we propose a novel way to create high-quality image-text pairs by the model itself and ChatGPT together. Based on this, we then create a small (3500 pairs in total) yet high-quality dataset.
|
| 29 |
+
- The second finetuning stage is trained on this dataset in a conversation template to significantly improve its generation reliability and overall usability. To our surprise, this stage is computationally efficient and takes only around 7 minutes with a single A100.
|
| 30 |
+
- MiniGPT-4 yields many emerging vision-language capabilities similar to those demonstrated in GPT-4.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## Getting Started
|
| 37 |
+
### Installation
|
| 38 |
+
|
| 39 |
+
**1. Prepare the code and the environment**
|
| 40 |
+
|
| 41 |
+
Git clone our repository, creating a python environment and ativate it via the following command
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
|
| 45 |
+
cd MiniGPT-4
|
| 46 |
+
conda env create -f environment.yml
|
| 47 |
+
conda activate minigpt4
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
**2. Prepare the pretrained Vicuna weights**
|
| 52 |
+
|
| 53 |
+
The current version of MiniGPT-4 is built on the v0 versoin of Vicuna-13B.
|
| 54 |
+
Please refer to our instruction [here](PrepareVicuna.md)
|
| 55 |
+
to prepare the Vicuna weights.
|
| 56 |
+
The final weights would be in a single folder with the following structure:
|
| 57 |
+
|
| 58 |
+
```
|
| 59 |
+
vicuna_weights
|
| 60 |
+
├── config.json
|
| 61 |
+
├── generation_config.json
|
| 62 |
+
├── pytorch_model.bin.index.json
|
| 63 |
+
├── pytorch_model-00001-of-00003.bin
|
| 64 |
+
...
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
Then, set the path to the vicuna weight in the model config file
|
| 68 |
+
[here](minigpt4/configs/models/minigpt4.yaml#L16) at Line 16.
|
| 69 |
+
|
| 70 |
+
**3. Prepare the pretrained MiniGPT-4 checkpoint**
|
| 71 |
+
|
| 72 |
+
To play with our pretrained model, download the pretrained checkpoint
|
| 73 |
+
[here](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link).
|
| 74 |
+
Then, set the path to the pretrained checkpoint in the evaluation config file
|
| 75 |
+
in [eval_configs/minigpt4_eval.yaml](eval_configs/minigpt4_eval.yaml#L10) at Line 11.
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
### Launching Demo Locally
|
| 80 |
+
|
| 81 |
+
Try out our demo [demo.py](demo.py) on your local machine by running
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
Here, we load Vicuna as 8 bit by default to save some GPU memory usage.
|
| 88 |
+
Besides, the default beam search width is 1.
|
| 89 |
+
Under this setting, the demo cost about 23G GPU memory.
|
| 90 |
+
If you have a more powerful GPU with larger GPU memory, you can run the model
|
| 91 |
+
in 16 bit by setting low_resource to False in the config file
|
| 92 |
+
[minigpt4_eval.yaml](eval_configs/minigpt4_eval.yaml) and use a larger beam search width.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
### Training
|
| 96 |
+
The training of MiniGPT-4 contains two alignment stages.
|
| 97 |
+
|
| 98 |
+
**1. First pretraining stage**
|
| 99 |
+
|
| 100 |
+
In the first pretrained stage, the model is trained using image-text pairs from Laion and CC datasets
|
| 101 |
+
to align the vision and language model. To download and prepare the datasets, please check
|
| 102 |
+
our [first stage dataset preparation instruction](dataset/README_1_STAGE.md).
|
| 103 |
+
After the first stage, the visual features are mapped and can be understood by the language
|
| 104 |
+
model.
|
| 105 |
+
To launch the first stage training, run the following command. In our experiments, we use 4 A100.
|
| 106 |
+
You can change the save path in the config file
|
| 107 |
+
[train_configs/minigpt4_stage1_pretrain.yaml](train_configs/minigpt4_stage1_pretrain.yaml)
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
A MiniGPT-4 checkpoint with only stage one training can be downloaded
|
| 114 |
+
[here](https://drive.google.com/file/d/1u9FRRBB3VovP1HxCAlpD9Lw4t4P6-Yq8/view?usp=share_link).
|
| 115 |
+
Compared to the model after stage two, this checkpoint generate incomplete and repeated sentences frequently.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
**2. Second finetuning stage**
|
| 119 |
+
|
| 120 |
+
In the second stage, we use a small high quality image-text pair dataset created by ourselves
|
| 121 |
+
and convert it to a conversation format to further align MiniGPT-4.
|
| 122 |
+
To download and prepare our second stage dataset, please check our
|
| 123 |
+
[second stage dataset preparation instruction](dataset/README_2_STAGE.md).
|
| 124 |
+
To launch the second stage alignment,
|
| 125 |
+
first specify the path to the checkpoint file trained in stage 1 in
|
| 126 |
+
[train_configs/minigpt4_stage1_pretrain.yaml](train_configs/minigpt4_stage2_finetune.yaml).
|
| 127 |
+
You can also specify the output path there.
|
| 128 |
+
Then, run the following command. In our experiments, we use 1 A100.
|
| 129 |
+
|
| 130 |
+
```bash
|
| 131 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yaml
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
After the second stage alignment, MiniGPT-4 is able to talk about the image coherently and user-friendly.
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
## Acknowledgement
|
| 140 |
+
|
| 141 |
+
+ [BLIP2](https://huggingface.co/docs/transformers/main/model_doc/blip-2) The model architecture of MiniGPT-4 follows BLIP-2. Don't forget to check this great open-source work if you don't know it before!
|
| 142 |
+
+ [Lavis](https://github.com/salesforce/LAVIS) This repository is built upon Lavis!
|
| 143 |
+
+ [Vicuna](https://github.com/lm-sys/FastChat) The fantastic language ability of Vicuna with only 13B parameters is just amazing. And it is open-source!
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
If you're using MiniGPT-4 in your research or applications, please cite using this BibTeX:
|
| 147 |
+
```bibtex
|
| 148 |
+
@misc{zhu2022minigpt4,
|
| 149 |
+
title={MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models},
|
| 150 |
+
author={Deyao Zhu and Jun Chen and Xiaoqian Shen and xiang Li and Mohamed Elhoseiny},
|
| 151 |
+
year={2023},
|
| 152 |
+
}
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
## License
|
| 157 |
+
This repository is under [BSD 3-Clause License](LICENSE.md).
|
| 158 |
+
Many codes are based on [Lavis](https://github.com/salesforce/LAVIS) with
|
| 159 |
+
BSD 3-Clause License [here](LICENSE_Lavis.md).
|
examples/ad_1.png
ADDED

|
examples/ad_2.png
ADDED
|
examples/cook_1.png
ADDED
|
examples/cook_2.png
ADDED

|
examples/describe_1.png
ADDED
|
examples/describe_2.png
ADDED
|
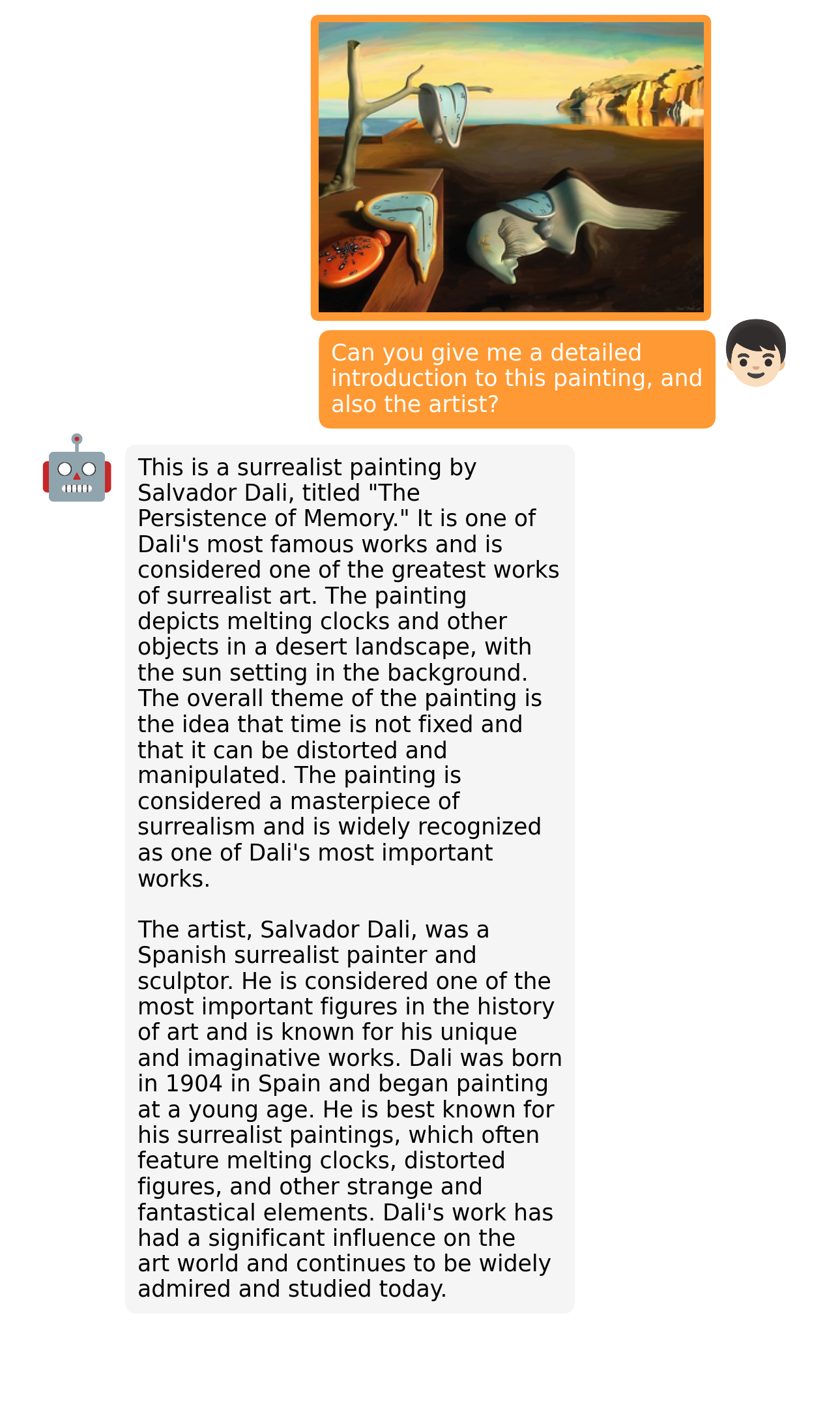
examples/fact_1.png
ADDED

|
examples/fact_2.png
ADDED
|
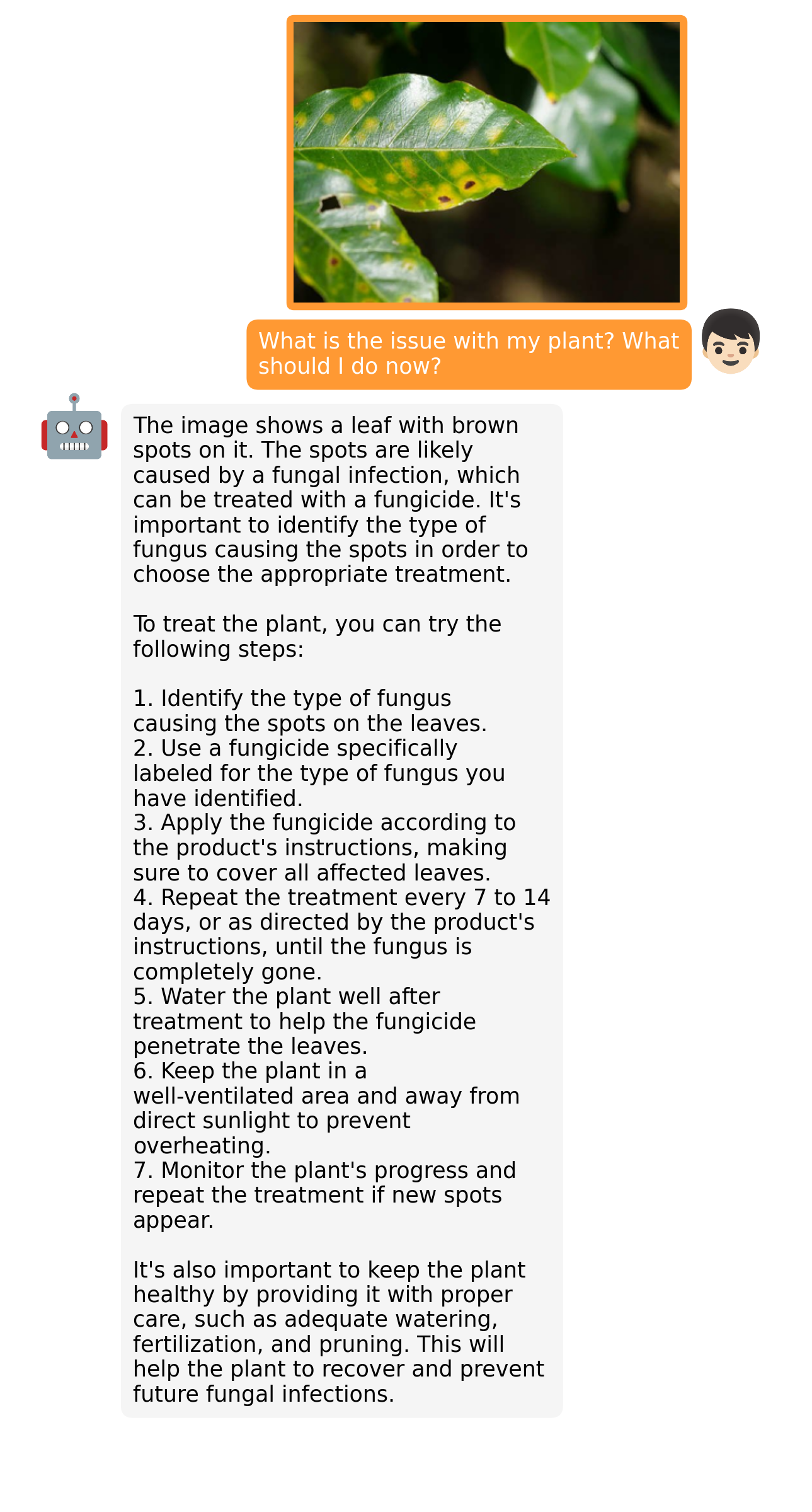
examples/fix_1.png
ADDED
|
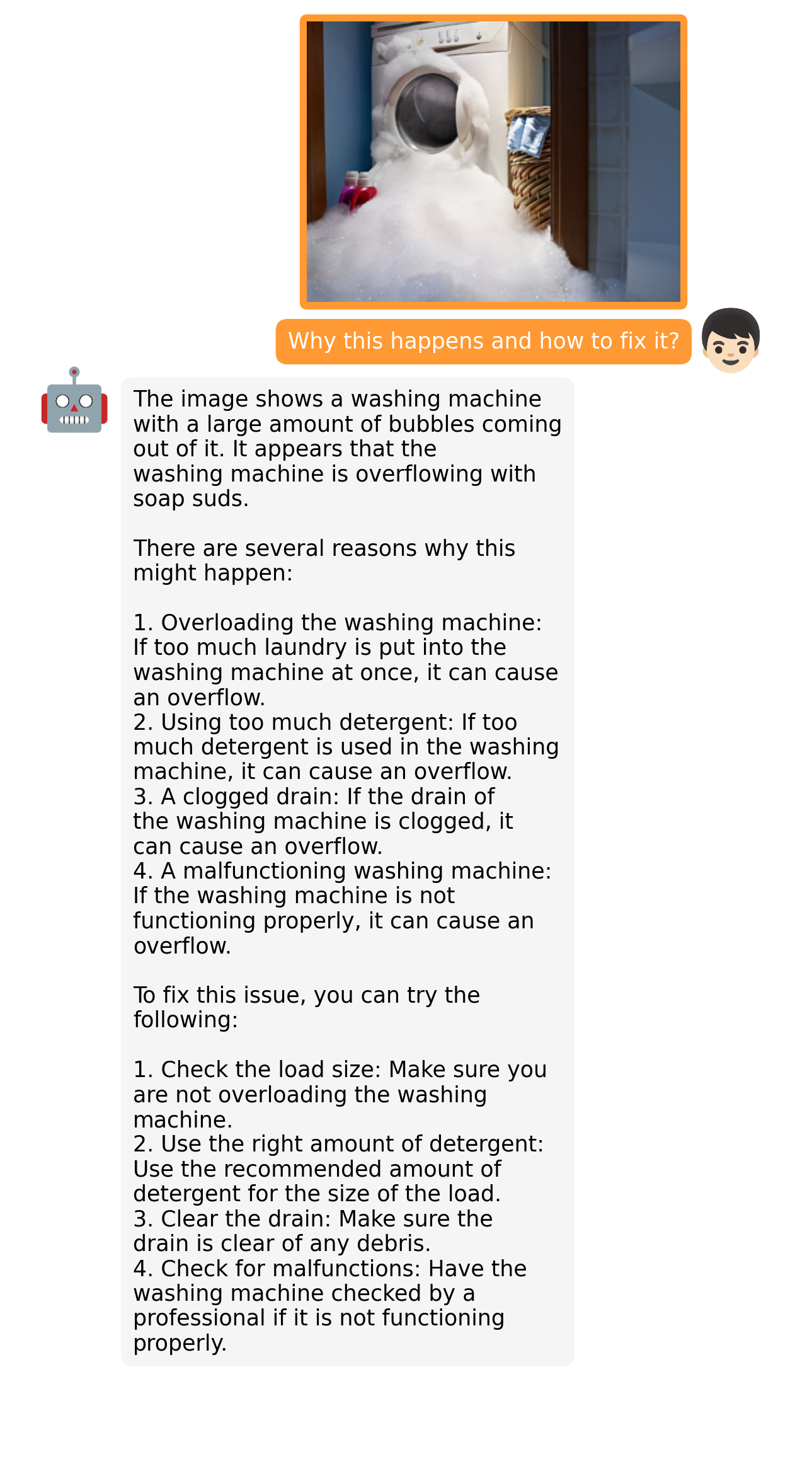
examples/fix_2.png
ADDED
|
examples/fun_1.png
ADDED

|
examples/fun_2.png
ADDED

|
examples/logo_1.png
ADDED
|
|
examples/op_1.png
ADDED
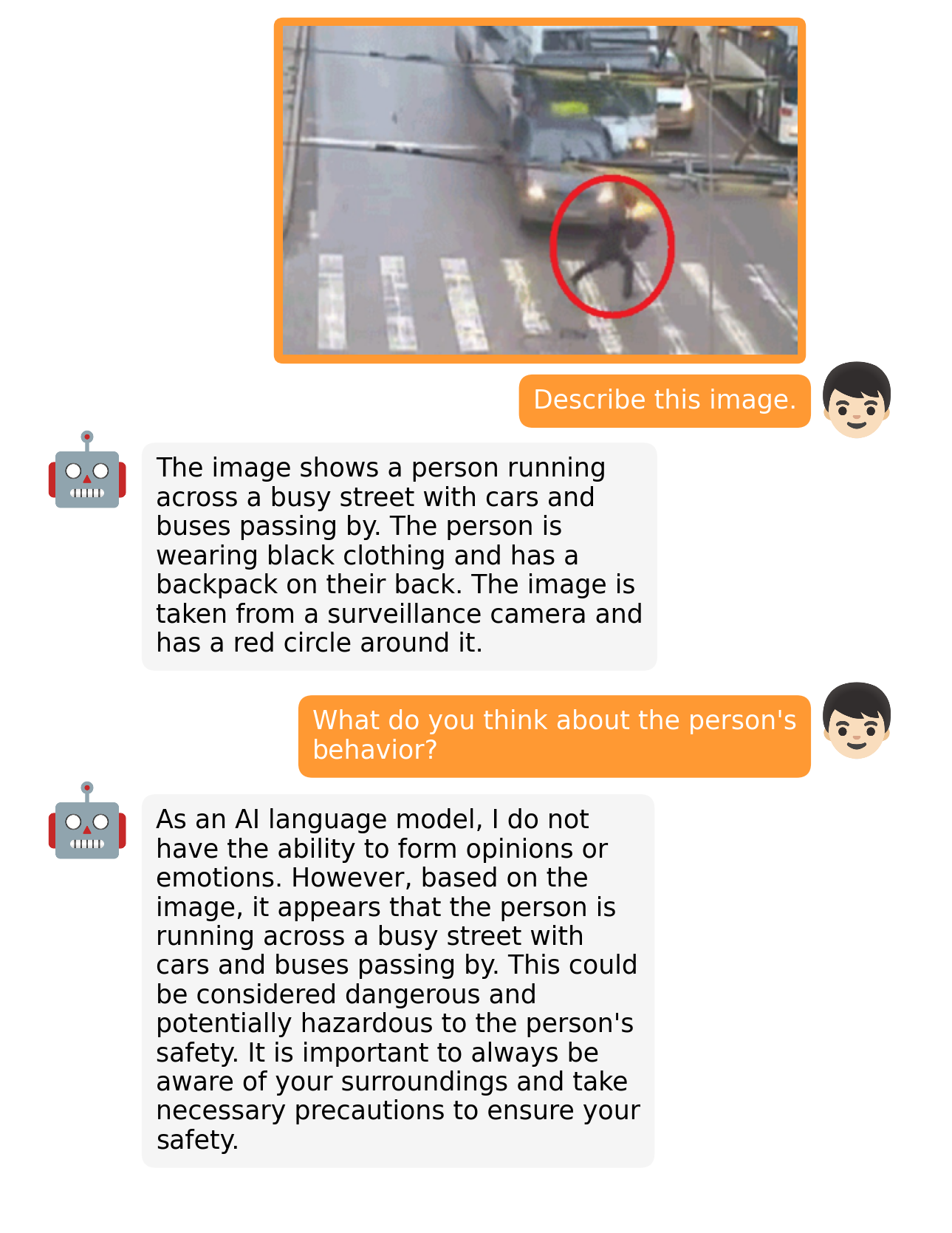
|
examples/op_2.png
ADDED
|
examples/people_1.png
ADDED

|
examples/people_2.png
ADDED

|
examples/rhyme_1.png
ADDED
|
examples/rhyme_2.png
ADDED

|
examples/story_1.png
ADDED
|
examples/story_2.png
ADDED
|
examples/web_1.png
ADDED

|
examples/wop_1.png
ADDED
|
examples/wop_2.png
ADDED

|
figs/examples/ad_1.png
ADDED
|
figs/examples/ad_2.png
ADDED

|
figs/examples/cook_1.png
ADDED
|
figs/examples/cook_2.png
ADDED
|
figs/examples/describe_1.png
ADDED
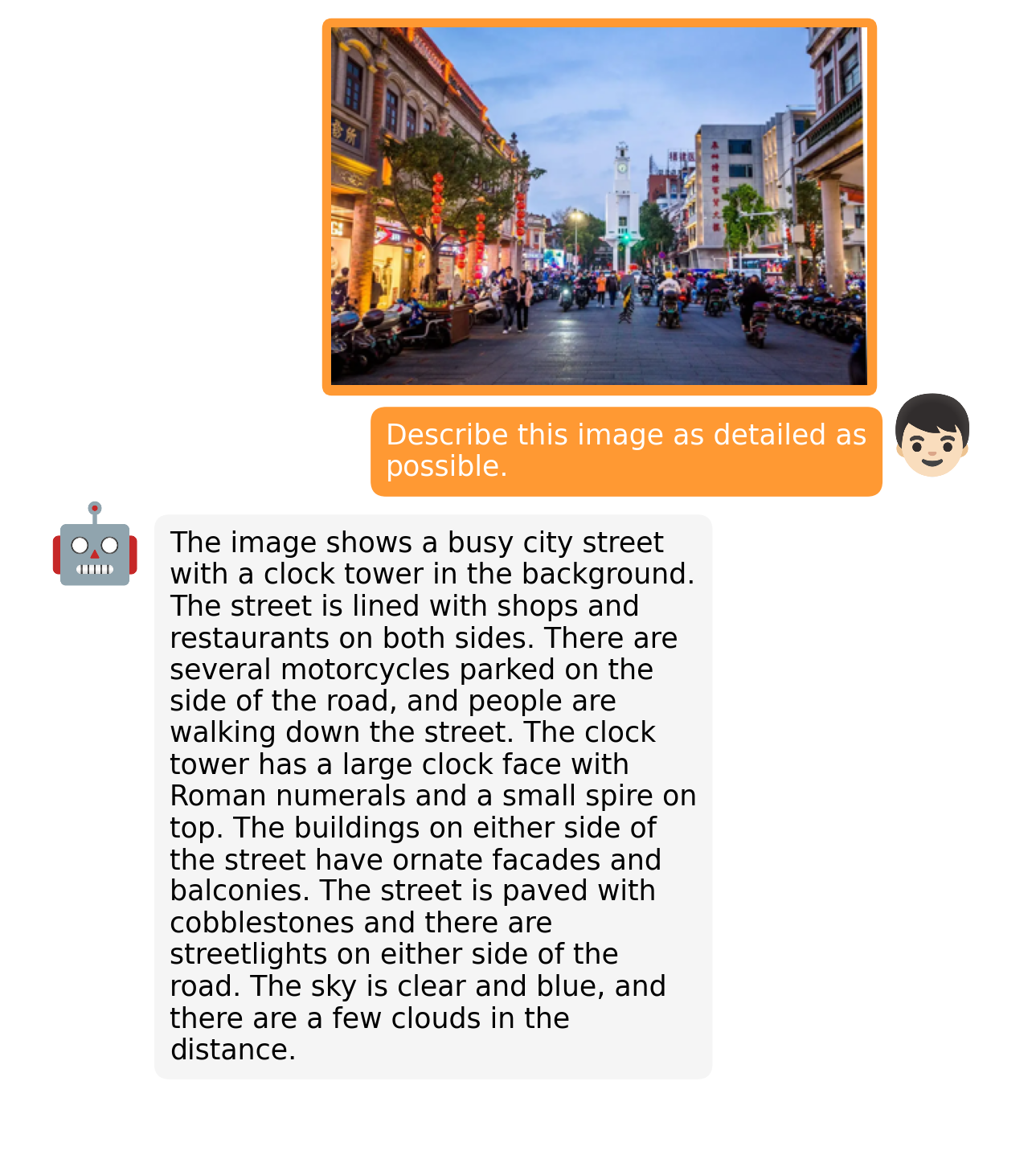
|
figs/examples/describe_2.png
ADDED
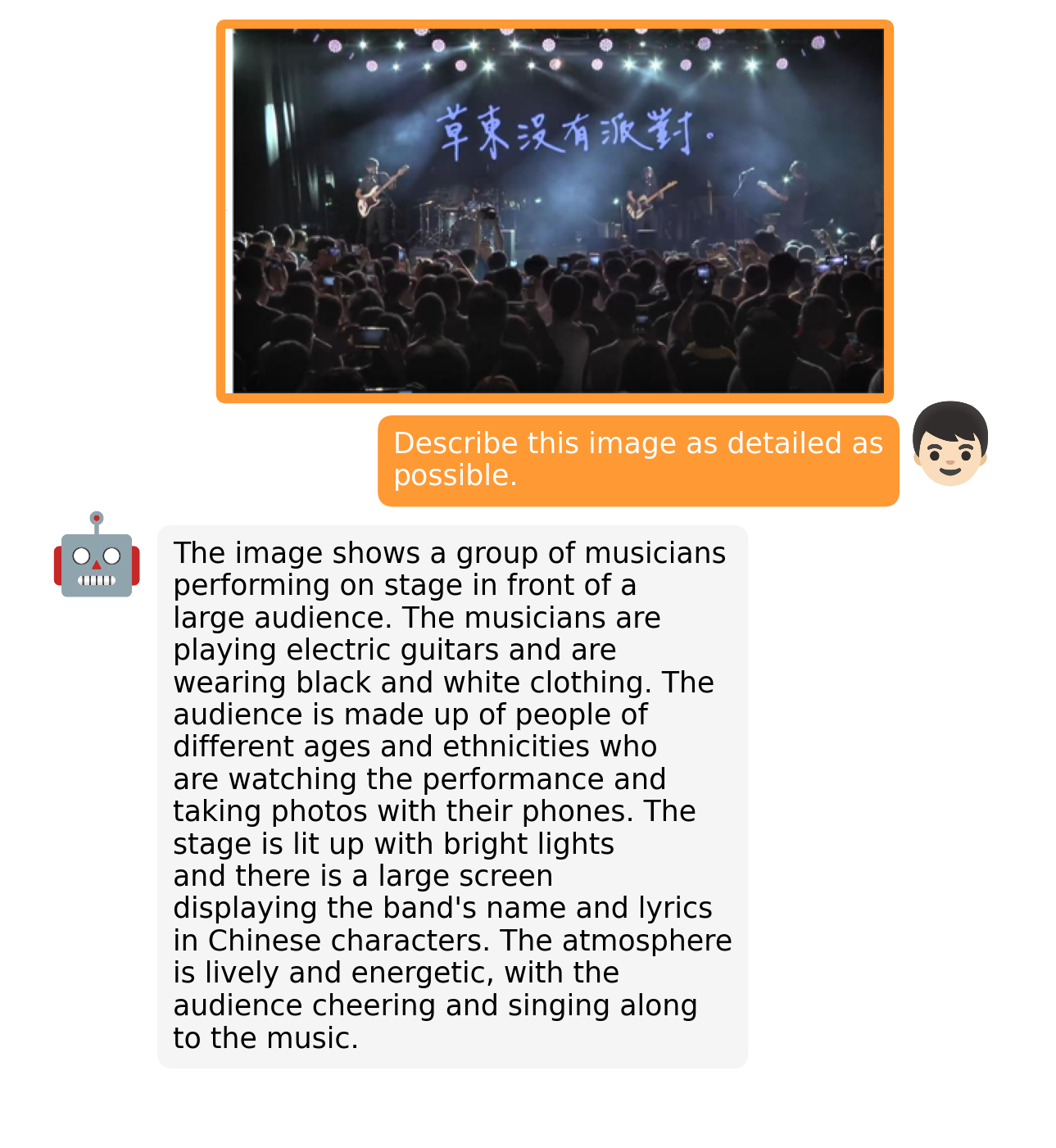
|
figs/examples/fact_1.png
ADDED
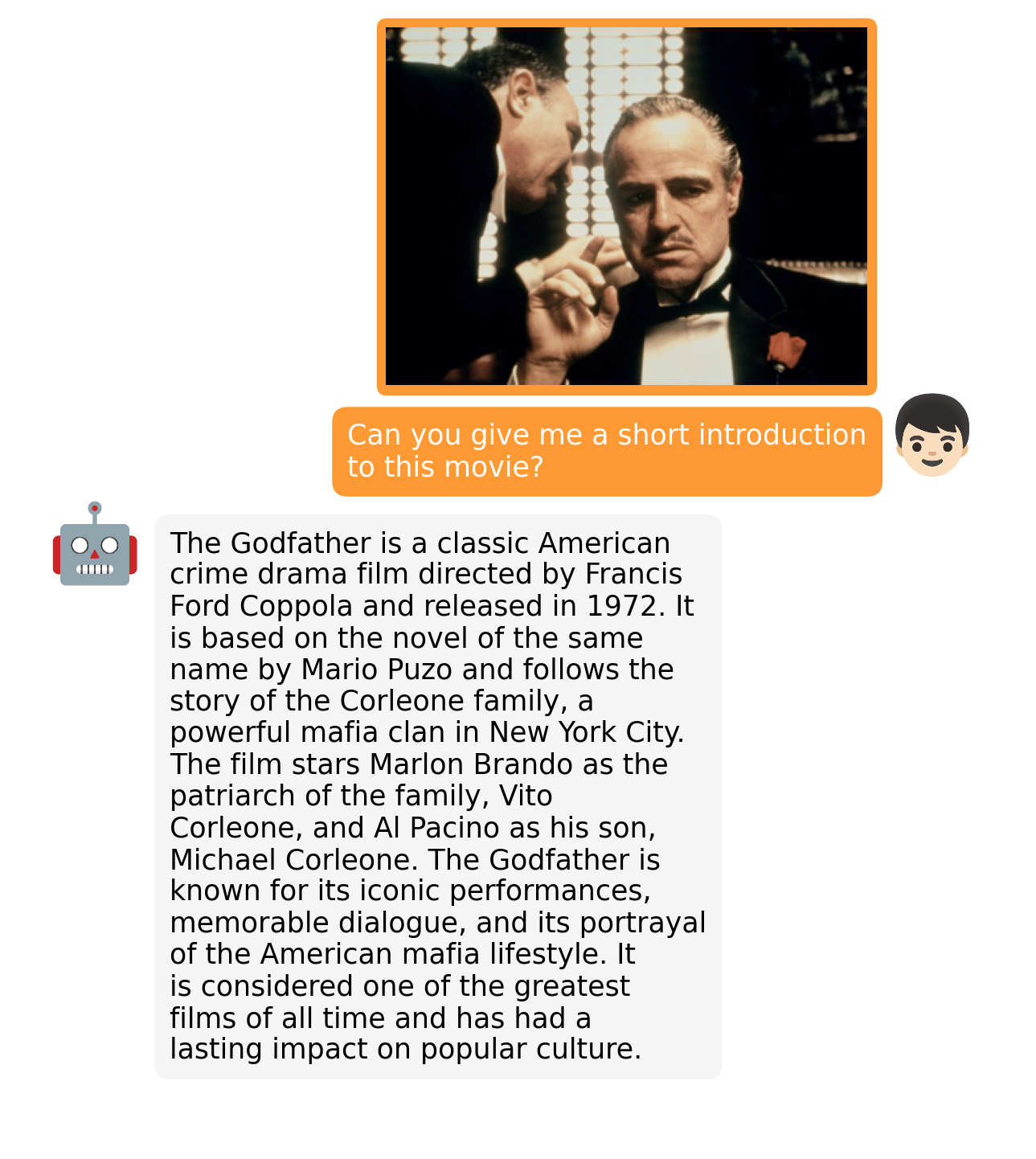
|
figs/examples/fact_2.png
ADDED
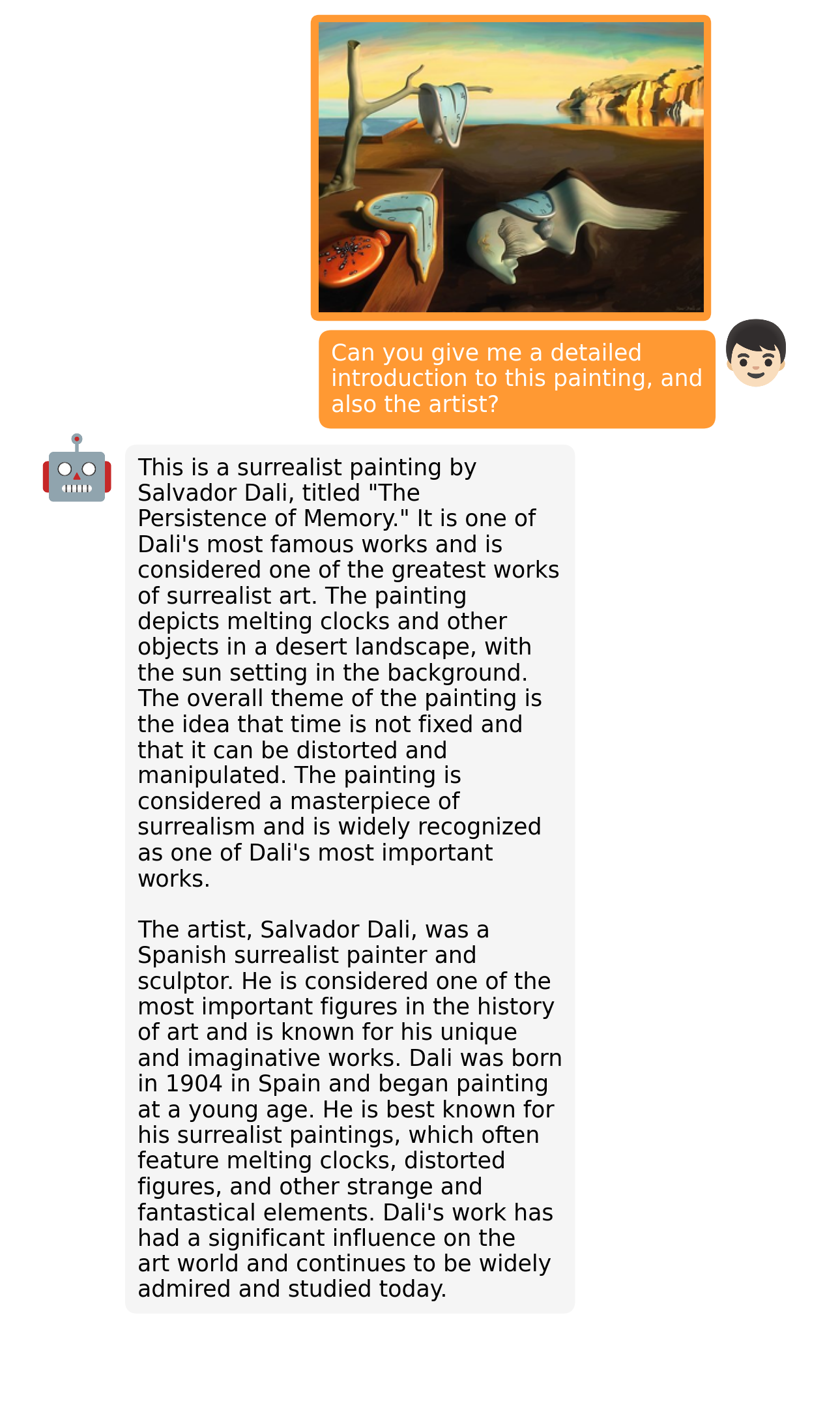
|
figs/examples/fix_1.png
ADDED

|
figs/examples/fix_2.png
ADDED
|
figs/examples/fun_1.png
ADDED
|
figs/examples/fun_2.png
ADDED

|
figs/examples/logo_1.png
ADDED
|
|
figs/examples/op_1.png
ADDED

|
figs/examples/op_2.png
ADDED
|
figs/examples/people_1.png
ADDED

|
figs/examples/people_2.png
ADDED

|
figs/examples/rhyme_1.png
ADDED
|
figs/examples/rhyme_2.png
ADDED

|
figs/examples/story_1.png
ADDED

|
figs/examples/story_2.png
ADDED

|
figs/examples/web_1.png
ADDED

|
figs/examples/wop_1.png
ADDED

|
figs/examples/wop_2.png
ADDED

|