

Commit
•
4d28d18
1
Parent(s):
aaadf45
initial commit
Browse files- 1_Pooling/.json +9 -0
- 1_Pooling/config.json +7 -0
- LICENSE +201 -0
- NOTICE +9 -0
- README.md +197 -3
- added_tokens.json +8 -0
- config.json +26 -0
- config_sentence_transformers.json +7 -0
- img/triple-encoder-logo_with_border.png +0 -0
- img/triple-encoder.jpg +0 -0
- modules.json +14 -0
- pytorch_model.bin +3 -0
- sentence_bert_config.json +4 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +13 -0
- vocab.txt +0 -0
1_Pooling/.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 1024,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": true,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false,
|
| 7 |
+
"pooling_mode_weightedmean_tokens": false,
|
| 8 |
+
"pooling_mode_lasttoken": false
|
| 9 |
+
}
|
1_Pooling/config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 1024,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": true,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false
|
| 7 |
+
}
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "{}"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2024 Justus-Jonas Erker, Ubiquitous Knowledge Processing (UKP) Lab, Technische Universität Darmstadt
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
NOTICE
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-------------------------------------------------------------------------------
|
| 2 |
+
Copyright 2024
|
| 3 |
+
Ubiquitous Knowledge Processing (UKP) Lab
|
| 4 |
+
Technische Universität Darmstadt
|
| 5 |
+
|
| 6 |
+
-------------------------------------------------------------------------------
|
| 7 |
+
Third party legal information
|
| 8 |
+
|
| 9 |
+
|
README.md
CHANGED
|
@@ -1,3 +1,197 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<p align="center">
|
| 3 |
+
<img align="center" src="img/triple-encoder-logo_with_border.png" width="430px" />
|
| 4 |
+
</p>
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
🤗 <a href="anonymous" target="_blank">Models</a> | 📊 <a href="anonymous" target="_blank">Datasets</a> | 📃 <a href="anonymous" target="_blank">Paper</a>
|
| 8 |
+
</p>
|
| 9 |
+
|
| 10 |
+
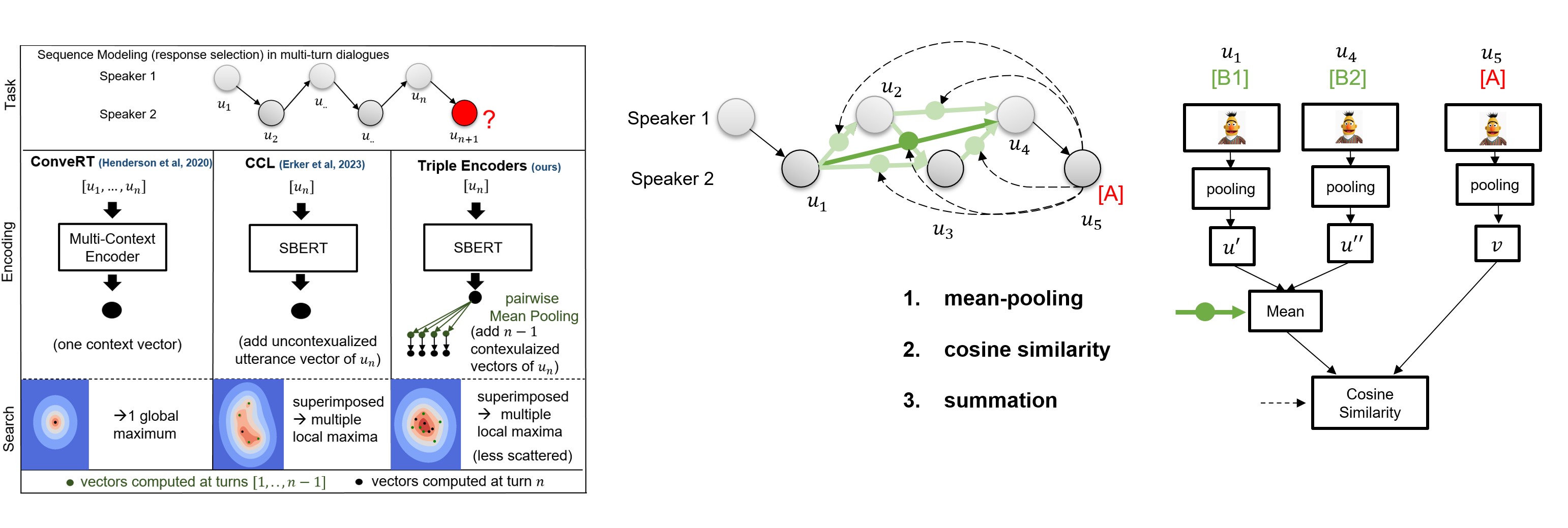
`triple-encoders` are models for contextualizing distributed [Sentence Transformers](https://sbert.net/) representations. This model was trained on the [DailyDialog](https://huggingface.co/datasets/daily_dialog) dataset and can be used for conversational sequence modeling and short-term planning via sequential modular late-interaction:
|
| 11 |
+
<p align="center">
|
| 12 |
+
<img align="center" src="img/triple-encoder.jpg" width="1000px" />
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
Representations are encoded **separately** and the contextualization is **weightless**:
|
| 16 |
+
1. *mean-pooling* to pairwise contextualize sentence representations (creates a distributed query)
|
| 17 |
+
2. *cosine similarity* to measure the similarity between all query vectors and the retrieval candidates.
|
| 18 |
+
3. *summation* to aggregate the similarity (similar to average-based late interaction of [ColBERT](https://github.com/stanford-futuredata/ColBERT)).
|
| 19 |
+
|
| 20 |
+
## Key Features
|
| 21 |
+
- 1️⃣ **One dense vector vs distributed dense vectors**: in our paper we demonstrate that our late interaction-based approach outperforms single-vector representations on long sequences, including zero-shot settings.
|
| 22 |
+
- 🏎️💨 **Relative compute**: as every representation is encoded separately, you only need to encode, compute mixtures and similarities for the latest added representation (in dialog: the latest utterance).
|
| 23 |
+
- 📚 **No Limit on context-length**: our distributed sentence transformer architecture is not limited to any sequence length. You can use your entire sequence as query!
|
| 24 |
+
- 🌎 **Multilingual support**: `triple-encoders` can be used with any [Sentence Transformers](https://sbert.net/) model. This means that you can model multilingual sequences by simply training on a multilingual model checkpoint.
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
## Installation
|
| 28 |
+
You can install `triple-encoders` via pip:
|
| 29 |
+
```bash
|
| 30 |
+
pip install triple-encoders
|
| 31 |
+
```
|
| 32 |
+
Note that `triple-encoders` requires Python 3.6 or higher.
|
| 33 |
+
|
| 34 |
+
# Getting Started
|
| 35 |
+
|
| 36 |
+
Our experiments for sequence modeling and short-term planning conducted in the paper can be found in the `notebooks` folder. The hyperparameter that we used for training are the default parameters in the `trainer.py` file.
|
| 37 |
+
|
| 38 |
+
## Retrieval-based Sequence Modeling
|
| 39 |
+
We provide an example of how to use triple-encoders for conversational sequence modeling (response selection) with 2 dialog speakers. If you want to use triple-encoders for other sequence modeling tasks, you can use the `TripleEncodersForSequenceModeling` class.
|
| 40 |
+
|
| 41 |
+
### Loading the model
|
| 42 |
+
```python
|
| 43 |
+
from triple_encoders.TripleEncodersForConversationalSequenceModeling import TripleEncodersForConversationalSequenceModeling
|
| 44 |
+
|
| 45 |
+
triple_path = 'UKPLab/triple-encoders-dailydialog'
|
| 46 |
+
|
| 47 |
+
# load model
|
| 48 |
+
model = TripleEncodersForConversationalSequenceModeling(triple_path)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
### Inference
|
| 52 |
+
|
| 53 |
+
```python
|
| 54 |
+
# load candidates for response selection
|
| 55 |
+
candidates = ['I am doing great too!','Where did you go?', 'ACL is an interesting conference']
|
| 56 |
+
|
| 57 |
+
# load candidates and store index
|
| 58 |
+
model.load_candidates_from_strings(candidates, output_directory_candidates_dump='output/path/to/save/candidates')
|
| 59 |
+
|
| 60 |
+
# create a sequence
|
| 61 |
+
sequence = model.contextualize_sequence(["Hi!",'Hey, how are you?'], k_last_rows=2)
|
| 62 |
+
|
| 63 |
+
# model sequence (compute scores for candidates)
|
| 64 |
+
sequence = model.sequence_modeling(sequence)
|
| 65 |
+
|
| 66 |
+
# retrieve utterance from dialog partner
|
| 67 |
+
new_utterance = "I'm fine, thanks. How are you?"
|
| 68 |
+
|
| 69 |
+
# pass it to the model with dialog_partner=True
|
| 70 |
+
sequence = model.contextualize_utterance(new_utterance, sequence, dialog_partner=True)
|
| 71 |
+
|
| 72 |
+
# model sequence (compute scores for candidates)
|
| 73 |
+
sequence = model.sequence_modeling(sequence)
|
| 74 |
+
|
| 75 |
+
# retrieve candidates to provide a response
|
| 76 |
+
response = model.retrieve_candidates(sequence, 3)
|
| 77 |
+
response
|
| 78 |
+
#(['I am doing great too!','Where did you go?', 'ACL is an interesting conference'],
|
| 79 |
+
# tensor([0.4944, 0.2392, 0.0483]))
|
| 80 |
+
```
|
| 81 |
+
**Speed:**
|
| 82 |
+
- Time to load candidates: 31.815 ms
|
| 83 |
+
- Time to contextualize sequence: 18.078 ms
|
| 84 |
+
- Time to model sequence: 0.256 ms
|
| 85 |
+
- Time to contextualize new utterance: 15.858 ms
|
| 86 |
+
- Time to model new utterance: 0.213 ms
|
| 87 |
+
- Time to retrieve candidates: 0.093 ms
|
| 88 |
+
|
| 89 |
+
### Evaluation
|
| 90 |
+
```python
|
| 91 |
+
from datasets import load_dataset
|
| 92 |
+
|
| 93 |
+
dataset = load_dataset("daily_dialog")
|
| 94 |
+
test = dataset['test']['dialog']
|
| 95 |
+
|
| 96 |
+
df = model.evaluate_seq_dataset(test, k_last_rows=2)
|
| 97 |
+
df
|
| 98 |
+
# pandas dataframe with the average rank for each history length
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
## Short-Term Planning (STP)
|
| 102 |
+
Short-term planning enables you to re-rank candidate replies from LLMs to reach a goal utterance over multiple turns.
|
| 103 |
+
|
| 104 |
+
### Inference
|
| 105 |
+
|
| 106 |
+
```python
|
| 107 |
+
from triple_encoders.TripleEncodersForSTP import TripleEncodersForSTP
|
| 108 |
+
|
| 109 |
+
model = TripleEncodersForSTP(triple_path)
|
| 110 |
+
|
| 111 |
+
context = ['Hey, how are you ?',
|
| 112 |
+
'I am good, how about you ?',
|
| 113 |
+
'I am good too.']
|
| 114 |
+
|
| 115 |
+
candidates = ['Want to eat something out ?',
|
| 116 |
+
'Want to go for a walk ?']
|
| 117 |
+
|
| 118 |
+
goal = ' I am hungry.'
|
| 119 |
+
|
| 120 |
+
result = model.short_term_planning(candidates, goal, context)
|
| 121 |
+
|
| 122 |
+
result
|
| 123 |
+
# 'Want to eat something out ?'
|
| 124 |
+
```
|
| 125 |
+
### Evaluation
|
| 126 |
+
|
| 127 |
+
```python
|
| 128 |
+
from datasets import load_dataset
|
| 129 |
+
from triple_encoders.TripleEncodersForSTP import TripleEncodersForSTP
|
| 130 |
+
|
| 131 |
+
dataset = load_dataset("daily_dialog")
|
| 132 |
+
test = dataset['test']['dialog']
|
| 133 |
+
|
| 134 |
+
model = TripleEncodersForSTP(triple_path, llm_model_name_or_path='your favorite large language model')
|
| 135 |
+
|
| 136 |
+
df = model.evaluate_stp_dataset(test)
|
| 137 |
+
# pandas dataframe with the average rank and Hits@k for each history length, goal_distance
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# Training Triple Encoders
|
| 142 |
+
You can train your own triple encoders with Contextualized Curved Contrastive Learning (C3L) using our trainer.
|
| 143 |
+
The hyperparameters that we used for training are the default parameters in the `trainer.py` file.
|
| 144 |
+
Note that we pre-trained our best model with Curved Contrastive Learning (CCL) (from [imaginaryNLP](https://github.com/Justus-Jonas/imaginaryNLP)) before training with C3L.
|
| 145 |
+
|
| 146 |
+
```python
|
| 147 |
+
from triple_encoders.trainer import TripleEncoderTrainer
|
| 148 |
+
from datasets import load_dataset
|
| 149 |
+
|
| 150 |
+
dataset = load_dataset("daily_dialog")
|
| 151 |
+
|
| 152 |
+
trainer = TripleEncoderTrainer(base_model_name_or_path=,
|
| 153 |
+
batch_size=48,
|
| 154 |
+
observation_window=5,
|
| 155 |
+
speaker_token=True, # used for conversational sequence modeling
|
| 156 |
+
num_epochs=3,
|
| 157 |
+
warmup_steps=10000)
|
| 158 |
+
|
| 159 |
+
trainer.generate_datasets(
|
| 160 |
+
dataset["train"]["dialog"],
|
| 161 |
+
dataset["validation"]["dialog"],
|
| 162 |
+
dataset["test"]["dialog"],
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
trainer.train("output/path/to/save/model")
|
| 167 |
+
```
|
| 168 |
+
## Citation
|
| 169 |
+
If you use triple-encoders in your research, please cite the following paper:
|
| 170 |
+
```
|
| 171 |
+
% todo
|
| 172 |
+
@article{anonymous,
|
| 173 |
+
title={Triple Encoders: Represenations That Fire Together, Wire Together},
|
| 174 |
+
author={Justus-Jonas Erker, Florian Mai, Nils Reimers, Gerasimos Spanakis, Iryna Gurevych},
|
| 175 |
+
journal={axiv},
|
| 176 |
+
year={2024}
|
| 177 |
+
}
|
| 178 |
+
```
|
| 179 |
+
# Contact
|
| 180 |
+
Contact person: Justus-Jonas Erker, justus-jonas.erker@tu-darmstadt.de
|
| 181 |
+
|
| 182 |
+
https://www.ukp.tu-darmstadt.de/
|
| 183 |
+
|
| 184 |
+
https://www.tu-darmstadt.de/
|
| 185 |
+
|
| 186 |
+
Don't hesitate to send us an e-mail or report an issue, if something is broken (and it shouldn't be) or if you have further questions.
|
| 187 |
+
This repository contains experimental software and is published for the sole purpose of giving additional background details on the respective publication.
|
| 188 |
+
|
| 189 |
+
# License
|
| 190 |
+
triple-encoders is licensed under the Apache License, Version 2.0. See [LICENSE](LICENSE) for the full license text.
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
### Acknowledgement
|
| 194 |
+
this package is based upon the [imaginaryNLP](https://github.com/Justus-Jonas/imaginaryNLP) and [Sentence Transformers](https://sbert.net/).
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
added_tokens.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"[AFTER]": 30523,
|
| 3 |
+
"[B1]": 30526,
|
| 4 |
+
"[B2]": 30527,
|
| 5 |
+
"[BEFORE]": 30522,
|
| 6 |
+
"[E]": 30525,
|
| 7 |
+
"[O]": 30524
|
| 8 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/netscratch/erker/models/Daily/gte_large_imaginaryEmbedding_UserToken_B42_5Fold_UPtoE15_thenlper_gte/15000/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"gradient_checkpointing": false,
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_dropout_prob": 0.1,
|
| 11 |
+
"hidden_size": 1024,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 4096,
|
| 14 |
+
"layer_norm_eps": 1e-12,
|
| 15 |
+
"max_position_embeddings": 512,
|
| 16 |
+
"model_type": "bert",
|
| 17 |
+
"num_attention_heads": 16,
|
| 18 |
+
"num_hidden_layers": 24,
|
| 19 |
+
"pad_token_id": 0,
|
| 20 |
+
"position_embedding_type": "absolute",
|
| 21 |
+
"torch_dtype": "float32",
|
| 22 |
+
"transformers_version": "4.31.0",
|
| 23 |
+
"type_vocab_size": 2,
|
| 24 |
+
"use_cache": true,
|
| 25 |
+
"vocab_size": 30528
|
| 26 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "2.2.2",
|
| 4 |
+
"transformers": "4.31.0",
|
| 5 |
+
"pytorch": "1.10.0a0+0aef44c"
|
| 6 |
+
}
|
| 7 |
+
}
|
img/triple-encoder-logo_with_border.png
ADDED
|
|
img/triple-encoder.jpg
ADDED
|
modules.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
}
|
| 14 |
+
]
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8b2bf5d4fe2abf0c84367b205e5d22522f6f46f75aa399bf8a4a0f543b9e1766
|
| 3 |
+
size 1340721011
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 512,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"clean_up_tokenization_spaces": true,
|
| 3 |
+
"cls_token": "[CLS]",
|
| 4 |
+
"do_lower_case": true,
|
| 5 |
+
"mask_token": "[MASK]",
|
| 6 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 7 |
+
"pad_token": "[PAD]",
|
| 8 |
+
"sep_token": "[SEP]",
|
| 9 |
+
"strip_accents": null,
|
| 10 |
+
"tokenize_chinese_chars": true,
|
| 11 |
+
"tokenizer_class": "BertTokenizer",
|
| 12 |
+
"unk_token": "[UNK]"
|
| 13 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|