

Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- LICENSE +74 -0
- LICENSE.txt +74 -0
- Notice +315 -0
- README.md +575 -0
- asset/Hunyuan_DiT_Tech_Report_05140553.pdf +3 -0
- asset/chinese elements understanding.png +3 -0
- asset/cover.png +0 -0
- asset/framework.png +0 -0
- asset/logo.png +0 -0
- asset/long text understanding.png +3 -0
- asset/mllm.png +0 -0
- asset/radar.png +0 -0
- dialoggen/config.json +70 -0
- dialoggen/generation_config.json +6 -0
- dialoggen/model-00001-of-00004.safetensors +3 -0
- dialoggen/model-00002-of-00004.safetensors +3 -0
- dialoggen/model-00003-of-00004.safetensors +3 -0
- dialoggen/model-00004-of-00004.safetensors +3 -0
- dialoggen/model.safetensors.index.json +694 -0
- dialoggen/openai/clip-vit-large-patch14-336/README.md +50 -0
- dialoggen/openai/clip-vit-large-patch14-336/config.json +179 -0
- dialoggen/openai/clip-vit-large-patch14-336/merges.txt +0 -0
- dialoggen/openai/clip-vit-large-patch14-336/preprocessor_config.json +19 -0
- dialoggen/openai/clip-vit-large-patch14-336/pytorch_model.bin +3 -0
- dialoggen/openai/clip-vit-large-patch14-336/special_tokens_map.json +1 -0
- dialoggen/openai/clip-vit-large-patch14-336/tf_model.h5 +3 -0
- dialoggen/openai/clip-vit-large-patch14-336/tokenizer.json +0 -0
- dialoggen/openai/clip-vit-large-patch14-336/tokenizer_config.json +1 -0
- dialoggen/openai/clip-vit-large-patch14-336/vocab.json +0 -0
- dialoggen/special_tokens_map.json +30 -0
- dialoggen/tokenizer.model +3 -0
- dialoggen/tokenizer_config.json +44 -0
- t2i/clip_text_encoder/config.json +34 -0
- t2i/clip_text_encoder/pytorch_model.bin +3 -0
- t2i/model/pytorch_model_ema.pt +3 -0
- t2i/model/pytorch_model_module.pt +3 -0
- t2i/mt5/README.md +130 -0
- t2i/mt5/config.json +28 -0
- t2i/mt5/generation_config.json +7 -0
- t2i/mt5/pytorch_model.bin +3 -0
- t2i/mt5/special_tokens_map.json +1 -0
- t2i/mt5/spiece.model +3 -0
- t2i/mt5/tokenizer_config.json +1 -0
- t2i/sdxl-vae-fp16-fix/config.json +32 -0
- t2i/sdxl-vae-fp16-fix/diffusion_pytorch_model.bin +3 -0
- t2i/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors +3 -0
- t2i/tokenizer/special_tokens_map.json +7 -0
- t2i/tokenizer/tokenizer_config.json +16 -0
- t2i/tokenizer/vocab.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
asset/chinese[[:space:]]elements[[:space:]]understanding.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
asset/long[[:space:]]text[[:space:]]understanding.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
asset/Hunyuan_DiT_Tech_Report_05140553.pdf filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
Tencent Hunyuan Release Date: 2024/5/14
|
| 3 |
+
By clicking to agree or by using, reproducing, modifying, distributing, performing or displaying any portion or element of the Tencent Hunyuan Works, including via any Hosted Service, You will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 4 |
+
1. DEFINITIONS.
|
| 5 |
+
a. “Acceptable Use Policy” shall mean the policy made available by Tencent as set forth in the Exhibit A.
|
| 6 |
+
b. “Agreement” shall mean the terms and conditions for use, reproduction, distribution, modification, performance and displaying of the Hunyuan Works or any portion or element thereof set forth herein.
|
| 7 |
+
c. “Documentation” shall mean the specifications, manuals and documentation for Tencent Hunyuan made publicly available by Tencent.
|
| 8 |
+
d. “Hosted Service” shall mean a hosted service offered via an application programming interface (API), web access, or any other electronic or remote means.
|
| 9 |
+
e. “Licensee,” “You” or “Your” shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Tencent Hunyuan Works for any purpose and in any field of use.
|
| 10 |
+
f. “Materials” shall mean, collectively, Tencent’s proprietary Tencent Hunyuan and Documentation (and any portion thereof) as made available by Tencent under this Agreement.
|
| 11 |
+
g. “Model Derivatives” shall mean all: (i) modifications to Tencent Hunyuan or any Model Derivative of Tencent Hunyuan; (ii) works based on Tencent Hunyuan or any Model Derivative of Tencent Hunyuan; or (iii) any other machine learning model which is created by transfer of patterns of the weights, parameters, operations, or Output of Tencent Hunyuan or any Model Derivative of Tencent Hunyuan, to that model in order to cause that model to perform similarly to Tencent Hunyuan or a Model Derivative of Tencent Hunyuan, including distillation methods, methods that use intermediate data representations, or methods based on the generation of synthetic data Outputs by Tencent Hunyuan or a Model Derivative of Tencent Hunyuan for training that model. For clarity, Outputs by themselves are not deemed Model Derivatives.
|
| 12 |
+
h. “Output” shall mean the information and/or content output of Tencent Hunyuan or a Model Derivative that results from operating or otherwise using Tencent Hunyuan or a Model Derivative, including via a Hosted Service.
|
| 13 |
+
i. “Tencent,” “We” or “Us” shall mean THL A29 Limited.
|
| 14 |
+
j. “Tencent Hunyuan” shall mean the large language models, image/video/audio/3D generation models, and multimodal large language models and their software and algorithms, including trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing made publicly available by Us at https://huggingface.co/Tencent-Hunyuan/HunyuanDiT and https://github.com/Tencent/HunyuanDiT .
|
| 15 |
+
k. “Tencent Hunyuan Works” shall mean: (i) the Materials; (ii) Model Derivatives; and (iii) all derivative works thereof.
|
| 16 |
+
l. “Third Party” or “Third Parties” shall mean individuals or legal entities that are not under common control with Us or You.
|
| 17 |
+
m. “including” shall mean including but not limited to.
|
| 18 |
+
2. GRANT OF RIGHTS.
|
| 19 |
+
We grant You a non-exclusive, worldwide, non-transferable and royalty-free limited license under Tencent’s intellectual property or other rights owned by Us embodied in or utilized by the Materials to use, reproduce, distribute, create derivative works of (including Model Derivatives), and make modifications to the Materials, only in accordance with the terms of this Agreement and the Acceptable Use Policy, and You must not violate (or encourage or permit anyone else to violate) any term of this Agreement or the Acceptable Use Policy.
|
| 20 |
+
3. DISTRIBUTION.
|
| 21 |
+
You may, subject to Your compliance with this Agreement, distribute or make available to Third Parties the Tencent Hunyuan Works, provided that You meet all of the following conditions:
|
| 22 |
+
a. You must provide all such Third Party recipients of the Tencent Hunyuan Works or products or services using them a copy of this Agreement;
|
| 23 |
+
b. You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 24 |
+
c. You are encouraged to: (i) publish at least one technology introduction blogpost or one public statement expressing Your experience of using the Tencent Hunyuan Works; and (ii) mark the products or services developed by using the Tencent Hunyuan Works to indicate that the product/service is “Powered by Tencent Hunyuan”; and
|
| 25 |
+
d. All distributions to Third Parties (other than through a Hosted Service) must be accompanied by a “Notice” text file that contains the following notice: “Tencent Hunyuan is licensed under the Tencent Hunyuan Community License Agreement, Copyright © 2024 Tencent. All Rights Reserved. The trademark rights of “Tencent Hunyuan” are owned by Tencent or its affiliate.”
|
| 26 |
+
You may add Your own copyright statement to Your modifications and, except as set forth in this Section and in Section 5, may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Model Derivatives as a whole, provided Your use, reproduction, modification, distribution, performance and display of the work otherwise complies with the terms and conditions of this Agreement. If You receive Tencent Hunyuan Works from a Licensee as part of an integrated end user product, then this Section 3 of this Agreement will not apply to You.
|
| 27 |
+
4. ADDITIONAL COMMERCIAL TERMS.
|
| 28 |
+
If, on the Tencent Hunyuan version release date, the monthly active users of all products or services made available by or for Licensee is greater than 100 million monthly active users in the preceding calendar month, You must request a license from Tencent, which Tencent may grant to You in its sole discretion, and You are not authorized to exercise any of the rights under this Agreement unless or until Tencent otherwise expressly grants You such rights.
|
| 29 |
+
5. RULES OF USE.
|
| 30 |
+
a. Your use of the Tencent Hunyuan Works must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Tencent Hunyuan Works, which is hereby incorporated by reference into this Agreement. You must include the use restrictions referenced in these Sections 5(a) and 5(b) as an enforceable provision in any agreement (e.g., license agreement, terms of use, etc.) governing the use and/or distribution of Tencent Hunyuan Works and You must provide notice to subsequent users to whom You distribute that Tencent Hunyuan Works are subject to the use restrictions in these Sections 5(a) and 5(b).
|
| 31 |
+
b. You must not use the Tencent Hunyuan Works or any Output or results of the Tencent Hunyuan Works to improve any other large language model (other than Tencent Hunyuan or Model Derivatives thereof).
|
| 32 |
+
6. INTELLECTUAL PROPERTY.
|
| 33 |
+
a. Subject to Tencent’s ownership of Tencent Hunyuan Works made by or for Tencent and intellectual property rights therein, conditioned upon Your compliance with the terms and conditions of this Agreement, as between You and Tencent, You will be the owner of any derivative works and modifications of the Materials and any Model Derivatives that are made by or for You.
|
| 34 |
+
b. No trademark licenses are granted under this Agreement, and in connection with the Tencent Hunyuan Works, Licensee may not use any name or mark owned by or associated with Tencent or any of its affiliates, except as required for reasonable and customary use in describing and distributing the Tencent Hunyuan Works. Tencent hereby grants You a license to use “Tencent Hunyuan” (the “Mark”) solely as required to comply with the provisions of Section 3(c), provided that You comply with any applicable laws related to trademark protection. All goodwill arising out of Your use of the Mark will inure to the benefit of Tencent.
|
| 35 |
+
c. If You commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any person or entity alleging that the Materials or any Output, or any portion of any of the foregoing, infringe any intellectual property or other right owned or licensable by You, then all licenses granted to You under this Agreement shall terminate as of the date such lawsuit or other proceeding is filed. You will defend, indemnify and hold harmless Us from and against any claim by any Third Party arising out of or related to Your or the Third Party’s use or distribution of the Tencent Hunyuan Works.
|
| 36 |
+
d. Tencent claims no rights in Outputs You generate. You and Your users are solely responsible for Outputs and their subsequent uses.
|
| 37 |
+
7. DISCLAIMERS OF WARRANTY AND LIMITATIONS OF LIABILITY.
|
| 38 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tencent Hunyuan Works or to grant any license thereto.
|
| 39 |
+
b. UNLESS AND ONLY TO THE EXTENT REQUIRED BY APPLICABLE LAW, THE TENCENT HUNYUAN WORKS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED “AS IS” WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES OF ANY KIND INCLUDING ANY WARRANTIES OF TITLE, MERCHANTABILITY, NONINFRINGEMENT, COURSE OF DEALING, USAGE OF TRADE, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING, REPRODUCING, MODIFYING, PERFORMING, DISPLAYING OR DISTRIBUTING ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS AND ASSUME ANY AND ALL RISKS ASSOCIATED WITH YOUR OR A THIRD PARTY’S USE OR DISTRIBUTION OF ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS AND YOUR EXERCISE OF RIGHTS AND PERMISSIONS UNDER THIS AGREEMENT.
|
| 40 |
+
c. TO THE FULLEST EXTENT PERMITTED BY APPLICABLE LAW, IN NO EVENT SHALL TENCENT OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, FOR ANY DAMAGES, INCLUDING ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, CONSEQUENTIAL OR PUNITIVE DAMAGES, OR LOST PROFITS OF ANY KIND ARISING FROM THIS AGREEMENT OR RELATED TO ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS, EVEN IF TENCENT OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 41 |
+
8. SURVIVAL AND TERMINATION.
|
| 42 |
+
a. The term of this Agreement shall commence upon Your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 43 |
+
b. We may terminate this Agreement if You breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, You must promptly delete and cease use of the Tencent Hunyuan Works. Sections 6(a), 6(c), 7 and 9 shall survive the termination of this Agreement.
|
| 44 |
+
9. GOVERNING LAW AND JURISDICTION.
|
| 45 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of the Hong Kong Special Administrative Region of the People’s Republic of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 46 |
+
b. Exclusive jurisdiction and venue for any dispute arising out of or relating to this Agreement will be a court of competent jurisdiction in the Hong Kong Special Administrative Region of the People’s Republic of China, and Tencent and Licensee consent to the exclusive jurisdiction of such court with respect to any such dispute.
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
EXHIBIT A
|
| 50 |
+
ACCEPTABLE USE POLICY
|
| 51 |
+
|
| 52 |
+
Tencent reserves the right to update this Acceptable Use Policy from time to time.
|
| 53 |
+
Last modified: 2024/5/14
|
| 54 |
+
|
| 55 |
+
Tencent endeavors to promote safe and fair use of its tools and features, including Tencent Hunyuan. You agree not to use Tencent Hunyuan or Model Derivatives:
|
| 56 |
+
1. In any way that violates any applicable national, federal, state, local, international or any other law or regulation;
|
| 57 |
+
2. To harm Yourself or others;
|
| 58 |
+
3. To repurpose or distribute output from Tencent Hunyuan or any Model Derivatives to harm Yourself or others;
|
| 59 |
+
4. To override or circumvent the safety guardrails and safeguards We have put in place;
|
| 60 |
+
5. For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 61 |
+
6. To generate or disseminate verifiably false information and/or content with the purpose of harming others or influencing elections;
|
| 62 |
+
7. To generate or facilitate false online engagement, including fake reviews and other means of fake online engagement;
|
| 63 |
+
8. To intentionally defame, disparage or otherwise harass others;
|
| 64 |
+
9. To generate and/or disseminate malware (including ransomware) or any other content to be used for the purpose of harming electronic systems;
|
| 65 |
+
10. To generate or disseminate personal identifiable information with the purpose of harming others;
|
| 66 |
+
11. To generate or disseminate information (including images, code, posts, articles), and place the information in any public context (including –through the use of bot generated tweets), without expressly and conspicuously identifying that the information and/or content is machine generated;
|
| 67 |
+
12. To impersonate another individual without consent, authorization, or legal right;
|
| 68 |
+
13. To make high-stakes automated decisions in domains that affect an individual’s safety, rights or wellbeing (e.g., law enforcement, migration, medicine/health, management of critical infrastructure, safety components of products, essential services, credit, employment, housing, education, social scoring, or insurance);
|
| 69 |
+
14. In a manner that violates or disrespects the social ethics and moral standards of other countries or regions;
|
| 70 |
+
15. To perform, facilitate, threaten, incite, plan, promote or encourage violent extremism or terrorism;
|
| 71 |
+
16. For any use intended to discriminate against or harm individuals or groups based on protected characteristics or categories, online or offline social behavior or known or predicted personal or personality characteristics;
|
| 72 |
+
17. To intentionally exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 73 |
+
18. For military purposes;
|
| 74 |
+
19. To engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or other professional practices.
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
Tencent Hunyuan Release Date: 2024/5/14
|
| 3 |
+
By clicking to agree or by using, reproducing, modifying, distributing, performing or displaying any portion or element of the Tencent Hunyuan Works, including via any Hosted Service, You will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 4 |
+
1. DEFINITIONS.
|
| 5 |
+
a. “Acceptable Use Policy” shall mean the policy made available by Tencent as set forth in the Exhibit A.
|
| 6 |
+
b. “Agreement” shall mean the terms and conditions for use, reproduction, distribution, modification, performance and displaying of the Hunyuan Works or any portion or element thereof set forth herein.
|
| 7 |
+
c. “Documentation” shall mean the specifications, manuals and documentation for Tencent Hunyuan made publicly available by Tencent.
|
| 8 |
+
d. “Hosted Service” shall mean a hosted service offered via an application programming interface (API), web access, or any other electronic or remote means.
|
| 9 |
+
e. “Licensee,” “You” or “Your” shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Tencent Hunyuan Works for any purpose and in any field of use.
|
| 10 |
+
f. “Materials” shall mean, collectively, Tencent’s proprietary Tencent Hunyuan and Documentation (and any portion thereof) as made available by Tencent under this Agreement.
|
| 11 |
+
g. “Model Derivatives” shall mean all: (i) modifications to Tencent Hunyuan or any Model Derivative of Tencent Hunyuan; (ii) works based on Tencent Hunyuan or any Model Derivative of Tencent Hunyuan; or (iii) any other machine learning model which is created by transfer of patterns of the weights, parameters, operations, or Output of Tencent Hunyuan or any Model Derivative of Tencent Hunyuan, to that model in order to cause that model to perform similarly to Tencent Hunyuan or a Model Derivative of Tencent Hunyuan, including distillation methods, methods that use intermediate data representations, or methods based on the generation of synthetic data Outputs by Tencent Hunyuan or a Model Derivative of Tencent Hunyuan for training that model. For clarity, Outputs by themselves are not deemed Model Derivatives.
|
| 12 |
+
h. “Output” shall mean the information and/or content output of Tencent Hunyuan or a Model Derivative that results from operating or otherwise using Tencent Hunyuan or a Model Derivative, including via a Hosted Service.
|
| 13 |
+
i. “Tencent,” “We” or “Us” shall mean THL A29 Limited.
|
| 14 |
+
j. “Tencent Hunyuan” shall mean the large language models, image/video/audio/3D generation models, and multimodal large language models and their software and algorithms, including trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing made publicly available by Us at https://huggingface.co/Tencent-Hunyuan/HunyuanDiT and https://github.com/Tencent/HunyuanDiT .
|
| 15 |
+
k. “Tencent Hunyuan Works” shall mean: (i) the Materials; (ii) Model Derivatives; and (iii) all derivative works thereof.
|
| 16 |
+
l. “Third Party” or “Third Parties” shall mean individuals or legal entities that are not under common control with Us or You.
|
| 17 |
+
m. “including” shall mean including but not limited to.
|
| 18 |
+
2. GRANT OF RIGHTS.
|
| 19 |
+
We grant You a non-exclusive, worldwide, non-transferable and royalty-free limited license under Tencent’s intellectual property or other rights owned by Us embodied in or utilized by the Materials to use, reproduce, distribute, create derivative works of (including Model Derivatives), and make modifications to the Materials, only in accordance with the terms of this Agreement and the Acceptable Use Policy, and You must not violate (or encourage or permit anyone else to violate) any term of this Agreement or the Acceptable Use Policy.
|
| 20 |
+
3. DISTRIBUTION.
|
| 21 |
+
You may, subject to Your compliance with this Agreement, distribute or make available to Third Parties the Tencent Hunyuan Works, provided that You meet all of the following conditions:
|
| 22 |
+
a. You must provide all such Third Party recipients of the Tencent Hunyuan Works or products or services using them a copy of this Agreement;
|
| 23 |
+
b. You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 24 |
+
c. You are encouraged to: (i) publish at least one technology introduction blogpost or one public statement expressing Your experience of using the Tencent Hunyuan Works; and (ii) mark the products or services developed by using the Tencent Hunyuan Works to indicate that the product/service is “Powered by Tencent Hunyuan”; and
|
| 25 |
+
d. All distributions to Third Parties (other than through a Hosted Service) must be accompanied by a “Notice” text file that contains the following notice: “Tencent Hunyuan is licensed under the Tencent Hunyuan Community License Agreement, Copyright © 2024 Tencent. All Rights Reserved. The trademark rights of “Tencent Hunyuan” are owned by Tencent or its affiliate.”
|
| 26 |
+
You may add Your own copyright statement to Your modifications and, except as set forth in this Section and in Section 5, may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Model Derivatives as a whole, provided Your use, reproduction, modification, distribution, performance and display of the work otherwise complies with the terms and conditions of this Agreement. If You receive Tencent Hunyuan Works from a Licensee as part of an integrated end user product, then this Section 3 of this Agreement will not apply to You.
|
| 27 |
+
4. ADDITIONAL COMMERCIAL TERMS.
|
| 28 |
+
If, on the Tencent Hunyuan version release date, the monthly active users of all products or services made available by or for Licensee is greater than 100 million monthly active users in the preceding calendar month, You must request a license from Tencent, which Tencent may grant to You in its sole discretion, and You are not authorized to exercise any of the rights under this Agreement unless or until Tencent otherwise expressly grants You such rights.
|
| 29 |
+
5. RULES OF USE.
|
| 30 |
+
a. Your use of the Tencent Hunyuan Works must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Tencent Hunyuan Works, which is hereby incorporated by reference into this Agreement. You must include the use restrictions referenced in these Sections 5(a) and 5(b) as an enforceable provision in any agreement (e.g., license agreement, terms of use, etc.) governing the use and/or distribution of Tencent Hunyuan Works and You must provide notice to subsequent users to whom You distribute that Tencent Hunyuan Works are subject to the use restrictions in these Sections 5(a) and 5(b).
|
| 31 |
+
b. You must not use the Tencent Hunyuan Works or any Output or results of the Tencent Hunyuan Works to improve any other large language model (other than Tencent Hunyuan or Model Derivatives thereof).
|
| 32 |
+
6. INTELLECTUAL PROPERTY.
|
| 33 |
+
a. Subject to Tencent’s ownership of Tencent Hunyuan Works made by or for Tencent and intellectual property rights therein, conditioned upon Your compliance with the terms and conditions of this Agreement, as between You and Tencent, You will be the owner of any derivative works and modifications of the Materials and any Model Derivatives that are made by or for You.
|
| 34 |
+
b. No trademark licenses are granted under this Agreement, and in connection with the Tencent Hunyuan Works, Licensee may not use any name or mark owned by or associated with Tencent or any of its affiliates, except as required for reasonable and customary use in describing and distributing the Tencent Hunyuan Works. Tencent hereby grants You a license to use “Tencent Hunyuan” (the “Mark”) solely as required to comply with the provisions of Section 3(c), provided that You comply with any applicable laws related to trademark protection. All goodwill arising out of Your use of the Mark will inure to the benefit of Tencent.
|
| 35 |
+
c. If You commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any person or entity alleging that the Materials or any Output, or any portion of any of the foregoing, infringe any intellectual property or other right owned or licensable by You, then all licenses granted to You under this Agreement shall terminate as of the date such lawsuit or other proceeding is filed. You will defend, indemnify and hold harmless Us from and against any claim by any Third Party arising out of or related to Your or the Third Party’s use or distribution of the Tencent Hunyuan Works.
|
| 36 |
+
d. Tencent claims no rights in Outputs You generate. You and Your users are solely responsible for Outputs and their subsequent uses.
|
| 37 |
+
7. DISCLAIMERS OF WARRANTY AND LIMITATIONS OF LIABILITY.
|
| 38 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tencent Hunyuan Works or to grant any license thereto.
|
| 39 |
+
b. UNLESS AND ONLY TO THE EXTENT REQUIRED BY APPLICABLE LAW, THE TENCENT HUNYUAN WORKS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED “AS IS” WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES OF ANY KIND INCLUDING ANY WARRANTIES OF TITLE, MERCHANTABILITY, NONINFRINGEMENT, COURSE OF DEALING, USAGE OF TRADE, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING, REPRODUCING, MODIFYING, PERFORMING, DISPLAYING OR DISTRIBUTING ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS AND ASSUME ANY AND ALL RISKS ASSOCIATED WITH YOUR OR A THIRD PARTY’S USE OR DISTRIBUTION OF ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS AND YOUR EXERCISE OF RIGHTS AND PERMISSIONS UNDER THIS AGREEMENT.
|
| 40 |
+
c. TO THE FULLEST EXTENT PERMITTED BY APPLICABLE LAW, IN NO EVENT SHALL TENCENT OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, FOR ANY DAMAGES, INCLUDING ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, CONSEQUENTIAL OR PUNITIVE DAMAGES, OR LOST PROFITS OF ANY KIND ARISING FROM THIS AGREEMENT OR RELATED TO ANY OF THE TENCENT HUNYUAN WORKS OR OUTPUTS, EVEN IF TENCENT OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 41 |
+
8. SURVIVAL AND TERMINATION.
|
| 42 |
+
a. The term of this Agreement shall commence upon Your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 43 |
+
b. We may terminate this Agreement if You breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, You must promptly delete and cease use of the Tencent Hunyuan Works. Sections 6(a), 6(c), 7 and 9 shall survive the termination of this Agreement.
|
| 44 |
+
9. GOVERNING LAW AND JURISDICTION.
|
| 45 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of the Hong Kong Special Administrative Region of the People’s Republic of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 46 |
+
b. Exclusive jurisdiction and venue for any dispute arising out of or relating to this Agreement will be a court of competent jurisdiction in the Hong Kong Special Administrative Region of the People’s Republic of China, and Tencent and Licensee consent to the exclusive jurisdiction of such court with respect to any such dispute.
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
EXHIBIT A
|
| 50 |
+
ACCEPTABLE USE POLICY
|
| 51 |
+
|
| 52 |
+
Tencent reserves the right to update this Acceptable Use Policy from time to time.
|
| 53 |
+
Last modified: 2024/5/14
|
| 54 |
+
|
| 55 |
+
Tencent endeavors to promote safe and fair use of its tools and features, including Tencent Hunyuan. You agree not to use Tencent Hunyuan or Model Derivatives:
|
| 56 |
+
1. In any way that violates any applicable national, federal, state, local, international or any other law or regulation;
|
| 57 |
+
2. To harm Yourself or others;
|
| 58 |
+
3. To repurpose or distribute output from Tencent Hunyuan or any Model Derivatives to harm Yourself or others;
|
| 59 |
+
4. To override or circumvent the safety guardrails and safeguards We have put in place;
|
| 60 |
+
5. For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 61 |
+
6. To generate or disseminate verifiably false information and/or content with the purpose of harming others or influencing elections;
|
| 62 |
+
7. To generate or facilitate false online engagement, including fake reviews and other means of fake online engagement;
|
| 63 |
+
8. To intentionally defame, disparage or otherwise harass others;
|
| 64 |
+
9. To generate and/or disseminate malware (including ransomware) or any other content to be used for the purpose of harming electronic systems;
|
| 65 |
+
10. To generate or disseminate personal identifiable information with the purpose of harming others;
|
| 66 |
+
11. To generate or disseminate information (including images, code, posts, articles), and place the information in any public context (including –through the use of bot generated tweets), without expressly and conspicuously identifying that the information and/or content is machine generated;
|
| 67 |
+
12. To impersonate another individual without consent, authorization, or legal right;
|
| 68 |
+
13. To make high-stakes automated decisions in domains that affect an individual’s safety, rights or wellbeing (e.g., law enforcement, migration, medicine/health, management of critical infrastructure, safety components of products, essential services, credit, employment, housing, education, social scoring, or insurance);
|
| 69 |
+
14. In a manner that violates or disrespects the social ethics and moral standards of other countries or regions;
|
| 70 |
+
15. To perform, facilitate, threaten, incite, plan, promote or encourage violent extremism or terrorism;
|
| 71 |
+
16. For any use intended to discriminate against or harm individuals or groups based on protected characteristics or categories, online or offline social behavior or known or predicted personal or personality characteristics;
|
| 72 |
+
17. To intentionally exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 73 |
+
18. For military purposes;
|
| 74 |
+
19. To engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or other professional practices.
|
Notice
ADDED
|
@@ -0,0 +1,315 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Usage and Legal Notices:
|
| 2 |
+
|
| 3 |
+
Tencent is pleased to support the open source community by making Tencent Hunyuan available.
|
| 4 |
+
|
| 5 |
+
Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved. The below software and/or models in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 6 |
+
|
| 7 |
+
Tencent Hunyuan is licensed under the Tencent Hunyuan Community License Agreement except for the third-party components listed below. Tencent Hunyuan does not impose any additional limitations beyond what is outlined in the repsective licenses of these third-party components. Users must comply with all terms and conditions of original licenses of these third-party components and must ensure that the usage of the third party components adheres to all relevant laws and regulations.
|
| 8 |
+
|
| 9 |
+
For avoidance of doubts, Tencent Hunyuan means the large language models and their software and algorithms, including trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing made publicly available by Tencent in accordance with Tencent Hunyuan Community License Agreement.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
Other dependencies and licenses:
|
| 14 |
+
|
| 15 |
+
Open Source Software Licensed under the BSD 3-Clause License and Other Licenses of the Third-Party Components therein:
|
| 16 |
+
--------------------------------------------------------------------
|
| 17 |
+
1. torch
|
| 18 |
+
Copyright (c) 2016- Facebook, Inc (Adam Paszke)
|
| 19 |
+
Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
|
| 20 |
+
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
|
| 21 |
+
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
|
| 22 |
+
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
|
| 23 |
+
Copyright (c) 2011-2013 NYU (Clement Farabet)
|
| 24 |
+
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
|
| 25 |
+
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
|
| 26 |
+
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
Terms of the BSD 3-Clause:
|
| 30 |
+
--------------------------------------------------------------------
|
| 31 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 32 |
+
|
| 33 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 34 |
+
|
| 35 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 36 |
+
|
| 37 |
+
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 38 |
+
|
| 39 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 40 |
+
|
| 41 |
+
For the license of other third party components, please refer to the following URL:
|
| 42 |
+
https://github.com/pytorch/pytorch/blob/v1.13.1/LICENSE
|
| 43 |
+
https://github.com/pytorch/pytorch/blob/v1.13.1/NOTICE
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
Open Source Software Licensed under the BSD 3-Clause License and Other Licenses of the Third-Party Components therein:
|
| 48 |
+
--------------------------------------------------------------------
|
| 49 |
+
1. pandas
|
| 50 |
+
Copyright (c) 2008-2011, AQR Capital Management, LLC, Lambda Foundry, Inc. and PyData Development Team
|
| 51 |
+
All rights reserved.
|
| 52 |
+
|
| 53 |
+
Copyright (c) 2011-2023, Open source contributors.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
A copy of the BSD 3-Clause is included in this file.
|
| 57 |
+
|
| 58 |
+
For the license of other third party components, please refer to the following URL:
|
| 59 |
+
https://github.com/pandas-dev/pandas/blob/v2.0.3/LICENSE
|
| 60 |
+
https://github.com/pandas-dev/pandas/tree/v2.0.3/LICENSES
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Open Source Software Licensed under the BSD 3-Clause License and Other Licenses of the Third-Party Components therein:
|
| 65 |
+
--------------------------------------------------------------------
|
| 66 |
+
1. numpy
|
| 67 |
+
Copyright (c) 2005-2022, NumPy Developers.
|
| 68 |
+
All rights reserved.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
A copy of the BSD 3-Clause is included in this file.
|
| 72 |
+
|
| 73 |
+
For the license of other third party components, please refer to the following URL:
|
| 74 |
+
https://github.com/numpy/numpy/blob/v1.24.4/LICENSE.txt
|
| 75 |
+
https://github.com/numpy/numpy/blob/v1.24.4/LICENSES_bundled.txt
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
Open Source Software/Model Licensed under the BSD 3-Clause License and Other Licenses of the Third-Party Components therein:
|
| 80 |
+
--------------------------------------------------------------------
|
| 81 |
+
1. Megatron-LM
|
| 82 |
+
Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
A copy of the BSD 3-Clause is included in this file.
|
| 86 |
+
|
| 87 |
+
For the license of other third party components, please refer to the following URL:
|
| 88 |
+
https://github.com/NVIDIA/Megatron-LM/blob/main/LICENSE
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
Open Source Software/Models Licensed under the Apache License Version 2.0:
|
| 93 |
+
The below software in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2023 THL A29 Limited.
|
| 94 |
+
--------------------------------------------------------------------
|
| 95 |
+
1. diffusers
|
| 96 |
+
Copyright (c) diffusers original author and authors
|
| 97 |
+
Please note this software has been modified by Tencent in this distribution.
|
| 98 |
+
|
| 99 |
+
2. transformers
|
| 100 |
+
Copyright (c) transformers original author and authors
|
| 101 |
+
|
| 102 |
+
3. timm
|
| 103 |
+
Copyright 2019 Ross Wightman
|
| 104 |
+
|
| 105 |
+
4. text-to-text-transfer-transformer
|
| 106 |
+
Copyright (c) text-to-text-transfer-transformer original author and authors
|
| 107 |
+
Please note this software has been modified by Tencent in this distribution.
|
| 108 |
+
|
| 109 |
+
5. pytorch-fid
|
| 110 |
+
Copyright (c) pytorch-fid original author and authors
|
| 111 |
+
Please note this software has been modified by Tencent in this distribution.
|
| 112 |
+
|
| 113 |
+
6. Image-Quality-Assessment-Toolbox
|
| 114 |
+
Copyright 2021 Qunliang Xing
|
| 115 |
+
|
| 116 |
+
7. accelerate
|
| 117 |
+
Copyright (c) accelerate original author and authors
|
| 118 |
+
|
| 119 |
+
8. IP-Adapter
|
| 120 |
+
Copyright (c) IP-Adapter original author and authors
|
| 121 |
+
Please note this software has been modified by Tencent in this distribution.
|
| 122 |
+
|
| 123 |
+
9. mT5
|
| 124 |
+
Copyright (c) mT5 original author and authors
|
| 125 |
+
|
| 126 |
+
10. Mistral-7B
|
| 127 |
+
Copyright (c) 2024 Mistral AI, All rights reserved
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
Terms of the Apache License Version 2.0:
|
| 131 |
+
--------------------------------------------------------------------
|
| 132 |
+
Apache License
|
| 133 |
+
|
| 134 |
+
Version 2.0, January 2004
|
| 135 |
+
|
| 136 |
+
http://www.apache.org/licenses/
|
| 137 |
+
|
| 138 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 139 |
+
1. Definitions.
|
| 140 |
+
|
| 141 |
+
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
|
| 142 |
+
|
| 143 |
+
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
|
| 144 |
+
|
| 145 |
+
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
|
| 146 |
+
|
| 147 |
+
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
|
| 148 |
+
|
| 149 |
+
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
|
| 150 |
+
|
| 151 |
+
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
|
| 152 |
+
|
| 153 |
+
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
|
| 154 |
+
|
| 155 |
+
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
|
| 156 |
+
|
| 157 |
+
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
|
| 158 |
+
|
| 159 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
|
| 160 |
+
|
| 161 |
+
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
|
| 162 |
+
|
| 163 |
+
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
|
| 164 |
+
|
| 165 |
+
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 166 |
+
|
| 167 |
+
You must give any other recipients of the Work or Derivative Works a copy of this License; and
|
| 168 |
+
|
| 169 |
+
You must cause any modified files to carry prominent notices stating that You changed the files; and
|
| 170 |
+
|
| 171 |
+
You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
|
| 172 |
+
|
| 173 |
+
If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
|
| 174 |
+
|
| 175 |
+
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
|
| 176 |
+
|
| 177 |
+
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
|
| 178 |
+
|
| 179 |
+
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
|
| 180 |
+
|
| 181 |
+
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
|
| 182 |
+
|
| 183 |
+
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
|
| 184 |
+
|
| 185 |
+
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
|
| 186 |
+
|
| 187 |
+
END OF TERMS AND CONDITIONS
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
Open Source Software/Model Licensed under the BSD 3-Clause License:
|
| 192 |
+
--------------------------------------------------------------------
|
| 193 |
+
1. torchvision
|
| 194 |
+
Copyright (c) Soumith Chintala 2016,
|
| 195 |
+
All rights reserved.
|
| 196 |
+
|
| 197 |
+
2. flash_attn
|
| 198 |
+
Copyright (c) 2022, the respective contributors, as shown by the AUTHORS file.
|
| 199 |
+
All rights reserved.
|
| 200 |
+
|
| 201 |
+
3. apex
|
| 202 |
+
Copyright (c) apex original author and authors
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
A copy of the BSD 3-Clause is included in this file.
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
Open Source Software Licensed under the HPND License:
|
| 210 |
+
--------------------------------------------------------------------
|
| 211 |
+
1. Pillow
|
| 212 |
+
Copyright © 2010-2023 by Jeffrey A. Clark (Alex) and contributors.
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
Terms of the HPND License:
|
| 216 |
+
--------------------------------------------------------------------
|
| 217 |
+
The Python Imaging Library (PIL) is
|
| 218 |
+
|
| 219 |
+
Copyright © 1997-2011 by Secret Labs AB
|
| 220 |
+
Copyright © 1995-2011 by Fredrik Lundh
|
| 221 |
+
|
| 222 |
+
Pillow is the friendly PIL fork. It is
|
| 223 |
+
|
| 224 |
+
Copyright © 2010-2023 by Jeffrey A. Clark (Alex) and contributors.
|
| 225 |
+
|
| 226 |
+
Like PIL, Pillow is licensed under the open source HPND License:
|
| 227 |
+
|
| 228 |
+
By obtaining, using, and/or copying this software and/or its associated
|
| 229 |
+
documentation, you agree that you have read, understood, and will comply
|
| 230 |
+
with the following terms and conditions:
|
| 231 |
+
|
| 232 |
+
Permission to use, copy, modify and distribute this software and its
|
| 233 |
+
documentation for any purpose and without fee is hereby granted,
|
| 234 |
+
provided that the above copyright notice appears in all copies, and that
|
| 235 |
+
both that copyright notice and this permission notice appear in supporting
|
| 236 |
+
documentation, and that the name of Secret Labs AB or the author not be
|
| 237 |
+
used in advertising or publicity pertaining to distribution of the software
|
| 238 |
+
without specific, written prior permission.
|
| 239 |
+
|
| 240 |
+
SECRET LABS AB AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS
|
| 241 |
+
SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS.
|
| 242 |
+
IN NO EVENT SHALL SECRET LABS AB OR THE AUTHOR BE LIABLE FOR ANY SPECIAL,
|
| 243 |
+
INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM
|
| 244 |
+
LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE
|
| 245 |
+
OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR
|
| 246 |
+
PERFORMANCE OF THIS SOFTWARE.
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
Open Source Software/Model Licensed under the MIT License:
|
| 251 |
+
The below software in this distribution may have been modified by Tencent.
|
| 252 |
+
--------------------------------------------------------------------
|
| 253 |
+
1. einops
|
| 254 |
+
Copyright (c) 2018 Alex Rogozhnikov
|
| 255 |
+
|
| 256 |
+
2. loguru
|
| 257 |
+
Copyright (c) 2017
|
| 258 |
+
|
| 259 |
+
3. Chinese-CLIP
|
| 260 |
+
Copyright (c) 2012-2022 OFA-Sys Team
|
| 261 |
+
Copyright (c) 2012-2022 Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, John Miller, Hongseok Namkoong, Hannaneh Hajishirzi, Ali Farhadi, Ludwig Schmidt
|
| 262 |
+
|
| 263 |
+
4. DeepSpeed
|
| 264 |
+
Copyright (c) Microsoft Corporation.
|
| 265 |
+
|
| 266 |
+
5. glid-3-xl
|
| 267 |
+
Copyright (c) 2021 OpenAI
|
| 268 |
+
|
| 269 |
+
6. lazysizes
|
| 270 |
+
Copyright (c) 2015 Alexander Farkas
|
| 271 |
+
|
| 272 |
+
7. thingsvision
|
| 273 |
+
Copyright (c) 2021 Vision and Computational Cognition Group
|
| 274 |
+
|
| 275 |
+
8. sd-vae-ft-ema
|
| 276 |
+
Copyright (c) sd-vae-ft-ema original author and authors
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
Terms of the MIT License:
|
| 280 |
+
--------------------------------------------------------------------
|
| 281 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
| 282 |
+
|
| 283 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 284 |
+
|
| 285 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
Open Source Software Licensed under the MIT License and Other Licenses of the Third-Party Components therein:
|
| 290 |
+
--------------------------------------------------------------------
|
| 291 |
+
1. tqdm
|
| 292 |
+
Copyright (c) 2013 noamraph
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
A copy of the MIT is included in this file.
|
| 296 |
+
|
| 297 |
+
For the license of other third party components, please refer to the following URL:
|
| 298 |
+
https://github.com/tqdm/tqdm/blob/v4.66.1/LICENCE
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
Open Source Software/Model Licensed under the MIT License and Other Licenses of the Third-Party Components therein:
|
| 303 |
+
The below software in this distribution may have been modified by Tencent.
|
| 304 |
+
--------------------------------------------------------------------
|
| 305 |
+
1. generative-models
|
| 306 |
+
Copyright (c) 2023 Stability AI
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
A copy of the MIT is included in this file.
|
| 310 |
+
|
| 311 |
+
For the license of other third party components, please refer to the following URL:
|
| 312 |
+
https://github.com/Stability-AI/generative-models/blob/main/LICENSE-CODE
|
| 313 |
+
https://github.com/Stability-AI/generative-models/tree/main/model_licenses
|
| 314 |
+
|
| 315 |
+
|
README.md
ADDED
|
@@ -0,0 +1,575 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: hunyuan-dit
|
| 3 |
+
license: other
|
| 4 |
+
license_name: tencent-hunyuan-community
|
| 5 |
+
license_link: https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/LICENSE.txt
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
- zh
|
| 9 |
+
---
|
| 10 |
+
<!-- ## **HunyuanDiT** -->
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<img src="https://raw.githubusercontent.com/Tencent/HunyuanDiT/main/asset/logo.png" height=100>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
# Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
This repo contains PyTorch model definitions, pre-trained weights and inference/sampling code for our paper exploring Hunyuan-DiT. You can find more visualizations on our [project page](https://dit.hunyuan.tencent.com/).
|
| 20 |
+
|
| 21 |
+
> [**Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding**](https://arxiv.org/abs/2405.08748) <br>
|
| 22 |
+
|
| 23 |
+
> [**DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation**](https://arxiv.org/abs/2403.08857) <br>
|
| 24 |
+
|
| 25 |
+
## 🔥🔥🔥 News!!
|
| 26 |
+
* Jun 13, 2024: :zap: HYDiT-v1.1 version is released, which mitigates the issue of image oversaturation and alleviates the watermark issue. Please check [HunyuanDiT-v1.1 ](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT-v1.1) and
|
| 27 |
+
[Distillation-v1.1](https://huggingface.co/Tencent-Hunyuan/Distillation-v1.1) for more details.
|
| 28 |
+
* Jun 13, 2024: :truck: The training code is released, offering [full-parameter training](#full-parameter-training) and [LoRA training](#lora).
|
| 29 |
+
* Jun 06, 2024: :tada: Hunyuan-DiT is now available in ComfyUI. Please check [ComfyUI](#using-comfyui) for more details.
|
| 30 |
+
* Jun 06, 2024: 🚀 We introduce Distillation version for Hunyuan-DiT acceleration, which achieves **50%** acceleration on NVIDIA GPUs. Please check [Distillation](https://huggingface.co/Tencent-Hunyuan/Distillation) for more details.
|
| 31 |
+
* Jun 05, 2024: 🤗 Hunyuan-DiT is now available in 🤗 Diffusers! Please check the [example](#using--diffusers) below.
|
| 32 |
+
* Jun 04, 2024: :globe_with_meridians: Support Tencent Cloud links to download the pretrained models! Please check the [links](#-download-pretrained-models) below.
|
| 33 |
+
* May 22, 2024: 🚀 We introduce TensorRT version for Hunyuan-DiT acceleration, which achieves **47%** acceleration on NVIDIA GPUs. Please check [TensorRT-libs](https://huggingface.co/Tencent-Hunyuan/TensorRT-libs) for instructions.
|
| 34 |
+
* May 22, 2024: 💬 We support demo running multi-turn text2image generation now. Please check the [script](#using-gradio) below.
|
| 35 |
+
|
| 36 |
+
## 🤖 Try it on the web
|
| 37 |
+
|
| 38 |
+
Welcome to our web-based [**Tencent Hunyuan Bot**](https://hunyuan.tencent.com/bot/chat), where you can explore our innovative products! Just input the suggested prompts below or any other **imaginative prompts containing drawing-related keywords** to activate the Hunyuan text-to-image generation feature. Unleash your creativity and create any picture you desire, **all for free!**
|
| 39 |
+
|
| 40 |
+
You can use simple prompts similar to natural language text
|
| 41 |
+
|
| 42 |
+
> 画一只穿着西装的猪
|
| 43 |
+
>
|
| 44 |
+
> draw a pig in a suit
|
| 45 |
+
>
|
| 46 |
+
> 生成一幅画,赛博朋克风,跑车
|
| 47 |
+
>
|
| 48 |
+
> generate a painting, cyberpunk style, sports car
|
| 49 |
+
|
| 50 |
+
or multi-turn language interactions to create the picture.
|
| 51 |
+
|
| 52 |
+
> 画一个木制的鸟
|
| 53 |
+
>
|
| 54 |
+
> draw a wooden bird
|
| 55 |
+
>
|
| 56 |
+
> 变成玻璃的
|
| 57 |
+
>
|
| 58 |
+
> turn into glass
|
| 59 |
+
|
| 60 |
+
## 📑 Open-source Plan
|
| 61 |
+
|
| 62 |
+
- Hunyuan-DiT (Text-to-Image Model)
|
| 63 |
+
- [x] Inference
|
| 64 |
+
- [x] Checkpoints
|
| 65 |
+
- [x] Distillation Version
|
| 66 |
+
- [x] TensorRT Version
|
| 67 |
+
- [x] Training
|
| 68 |
+
- [x] Lora
|
| 69 |
+
- [ ] Controlnet (Pose, Canny, Depth, Tile)
|
| 70 |
+
- [ ] IP-adapter
|
| 71 |
+
- [ ] Hunyuan-DiT-XL checkpoints (0.7B model)
|
| 72 |
+
- [ ] Caption model (Re-caption the raw image-text pairs)
|
| 73 |
+
- [DialogGen](https://github.com/Centaurusalpha/DialogGen) (Prompt Enhancement Model)
|
| 74 |
+
- [x] Inference
|
| 75 |
+
- [X] Web Demo (Gradio)
|
| 76 |
+
- [x] Multi-turn T2I Demo (Gradio)
|
| 77 |
+
- [X] Cli Demo
|
| 78 |
+
- [X] ComfyUI
|
| 79 |
+
- [X] Diffusers
|
| 80 |
+
- [ ] WebUI
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Contents
|
| 84 |
+
- [Hunyuan-DiT](#hunyuan-dit--a-powerful-multi-resolution-diffusion-transformer-with-fine-grained-chinese-understanding)
|
| 85 |
+
- [Abstract](#abstract)
|
| 86 |
+
- [🎉 Hunyuan-DiT Key Features](#-hunyuan-dit-key-features)
|
| 87 |
+
- [Chinese-English Bilingual DiT Architecture](#chinese-english-bilingual-dit-architecture)
|
| 88 |
+
- [Multi-turn Text2Image Generation](#multi-turn-text2image-generation)
|
| 89 |
+
- [📈 Comparisons](#-comparisons)
|
| 90 |
+
- [🎥 Visualization](#-visualization)
|
| 91 |
+
- [📜 Requirements](#-requirements)
|
| 92 |
+
- [🛠 Dependencies and Installation](#%EF%B8%8F-dependencies-and-installation)
|
| 93 |
+
- [🧱 Download Pretrained Models](#-download-pretrained-models)
|
| 94 |
+
- [:truck: Training](#truck-training)
|
| 95 |
+
- [Data Preparation](#data-preparation)
|
| 96 |
+
- [Full Parameter Training](#full-parameter-training)
|
| 97 |
+
- [LoRA](#lora)
|
| 98 |
+
- [🔑 Inference](#-inference)
|
| 99 |
+
- [Using Gradio](#using-gradio)
|
| 100 |
+
- [Using Diffusers](#using--diffusers)
|
| 101 |
+
- [Using Command Line](#using-command-line)
|
| 102 |
+
- [More Configurations](#more-configurations)
|
| 103 |
+
- [Using ComfyUI](#using-comfyui)
|
| 104 |
+
- [🚀 Acceleration (for Linux)](#-acceleration-for-linux)
|
| 105 |
+
- [🔗 BibTeX](#-bibtex)
|
| 106 |
+
|
| 107 |
+
## **Abstract**
|
| 108 |
+
|
| 109 |
+
We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully designed the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-round multi-modal dialogue with users, generating and refining images according to the context.
|
| 110 |
+
Through our carefully designed holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
## 🎉 **Hunyuan-DiT Key Features**
|
| 114 |
+
### **Chinese-English Bilingual DiT Architecture**
|
| 115 |
+
Hunyuan-DiT is a diffusion model in the latent space, as depicted in figure below. Following the Latent Diffusion Model, we use a pre-trained Variational Autoencoder (VAE) to compress the images into low-dimensional latent spaces and train a diffusion model to learn the data distribution with diffusion models. Our diffusion model is parameterized with a transformer. To encode the text prompts, we leverage a combination of pre-trained bilingual (English and Chinese) CLIP and multilingual T5 encoder.
|
| 116 |
+
<p align="center">
|
| 117 |
+
<img src="https://raw.githubusercontent.com/Tencent/HunyuanDiT/main/asset/framework.png" height=450>
|
| 118 |
+
</p>
|
| 119 |
+
|
| 120 |
+
### Multi-turn Text2Image Generation
|
| 121 |
+
Understanding natural language instructions and performing multi-turn interaction with users are important for a
|
| 122 |
+
text-to-image system. It can help build a dynamic and iterative creation process that bring the user’s idea into reality
|
| 123 |
+
step by step. In this section, we will detail how we empower Hunyuan-DiT with the ability to perform multi-round
|
| 124 |
+
conversations and image generation. We train MLLM to understand the multi-round user dialogue
|
| 125 |
+
and output the new text prompt for image generation.
|
| 126 |
+
<p align="center">
|
| 127 |
+
<img src="https://raw.githubusercontent.com/Tencent/HunyuanDiT/main/asset/mllm.png" height=300>
|
| 128 |
+
</p>
|
| 129 |
+
|
| 130 |
+
## 📈 Comparisons
|
| 131 |
+
In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
|
| 132 |
+
|
| 133 |
+
<p align="center">
|
| 134 |
+
<table>
|
| 135 |
+
<thead>
|
| 136 |
+
<tr>
|
| 137 |
+
<th rowspan="2">Model</th> <th rowspan="2">Open Source</th> <th>Text-Image Consistency (%)</th> <th>Excluding AI Artifacts (%)</th> <th>Subject Clarity (%)</th> <th rowspan="2">Aesthetics (%)</th> <th rowspan="2">Overall (%)</th>
|
| 138 |
+
</tr>
|
| 139 |
+
</thead>
|
| 140 |
+
<tbody>
|
| 141 |
+
<tr>
|
| 142 |
+
<td>SDXL</td> <td> ✔ </td> <td>64.3</td> <td>60.6</td> <td>91.1</td> <td>76.3</td> <td>42.7</td>
|
| 143 |
+
</tr>
|
| 144 |
+
<tr>
|
| 145 |
+
<td>PixArt-α</td> <td> ✔</td> <td>68.3</td> <td>60.9</td> <td>93.2</td> <td>77.5</td> <td>45.5</td>
|
| 146 |
+
</tr>
|
| 147 |
+
<tr>
|
| 148 |
+
<td>Playground 2.5</td> <td>✔</td> <td>71.9</td> <td>70.8</td> <td>94.9</td> <td>83.3</td> <td>54.3</td>
|
| 149 |
+
</tr>
|
| 150 |
+
|
| 151 |
+
<tr>
|
| 152 |
+
<td>SD 3</td> <td>✘</td> <td>77.1</td> <td>69.3</td> <td>94.6</td> <td>82.5</td> <td>56.7</td>
|
| 153 |
+
|
| 154 |
+
</tr>
|
| 155 |
+
<tr>
|
| 156 |
+
<td>MidJourney v6</td><td>✘</td> <td>73.5</td> <td>80.2</td> <td>93.5</td> <td>87.2</td> <td>63.3</td>
|
| 157 |
+
</tr>
|
| 158 |
+
<tr>
|
| 159 |
+
<td>DALL-E 3</td><td>✘</td> <td>83.9</td> <td>80.3</td> <td>96.5</td> <td>89.4</td> <td>71.0</td>
|
| 160 |
+
</tr>
|
| 161 |
+
<tr style="font-weight: bold; background-color: #f2f2f2;">
|
| 162 |
+
<td>Hunyuan-DiT</td><td>✔</td> <td>74.2</td> <td>74.3</td> <td>95.4</td> <td>86.6</td> <td>59.0</td>
|
| 163 |
+
</tr>
|
| 164 |
+
</tbody>
|
| 165 |
+
</table>
|
| 166 |
+
</p>
|
| 167 |
+
|
| 168 |
+
## 🎥 Visualization
|
| 169 |
+
|
| 170 |
+
* **Chinese Elements**
|
| 171 |
+
<p align="center">
|
| 172 |
+
<img src="https://raw.githubusercontent.com/Tencent/HunyuanDiT/main/asset/chinese elements understanding.png" height=220>
|
| 173 |
+
</p>
|
| 174 |
+
|
| 175 |
+
* **Long Text Input**
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
<p align="center">
|
| 179 |
+
<img src="https://raw.githubusercontent.com/Tencent/HunyuanDiT/main/asset/long text understanding.png" height=310>
|
| 180 |
+
</p>
|
| 181 |
+
|
| 182 |
+
* **Multi-turn Text2Image Generation**
|
| 183 |
+
|
| 184 |
+
https://github.com/Tencent/tencent.github.io/assets/27557933/94b4dcc3-104d-44e1-8bb2-dc55108763d1
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
---
|
| 189 |
+
|
| 190 |
+
## 📜 Requirements
|
| 191 |
+
|
| 192 |
+
This repo consists of DialogGen (a prompt enhancement model) and Hunyuan-DiT (a text-to-image model).
|
| 193 |
+
|
| 194 |
+
The following table shows the requirements for running the models (batch size = 1):
|
| 195 |
+
|
| 196 |
+
| Model | --load-4bit (DialogGen) | GPU Peak Memory | GPU |
|
| 197 |
+
|:-----------------------:|:-----------------------:|:---------------:|:---------------:|
|
| 198 |
+
| DialogGen + Hunyuan-DiT | ✘ | 32G | A100 |
|
| 199 |
+
| DialogGen + Hunyuan-DiT | ✔ | 22G | A100 |
|
| 200 |
+
| Hunyuan-DiT | - | 11G | A100 |
|
| 201 |
+
| Hunyuan-DiT | - | 14G | RTX3090/RTX4090 |
|
| 202 |
+
|
| 203 |
+
* An NVIDIA GPU with CUDA support is required.
|
| 204 |
+
* We have tested V100 and A100 GPUs.
|
| 205 |
+
* **Minimum**: The minimum GPU memory required is 11GB.
|
| 206 |
+
* **Recommended**: We recommend using a GPU with 32GB of memory for better generation quality.
|
| 207 |
+
* Tested operating system: Linux
|
| 208 |
+
|
| 209 |
+
## 🛠️ Dependencies and Installation
|
| 210 |
+
|
| 211 |
+
Begin by cloning the repository:
|
| 212 |
+
```shell
|
| 213 |
+
git clone https://github.com/tencent/HunyuanDiT
|
| 214 |
+
cd HunyuanDiT
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
### Installation Guide for Linux
|
| 218 |
+
|
| 219 |
+
We provide an `environment.yml` file for setting up a Conda environment.
|
| 220 |
+
Conda's installation instructions are available [here](https://docs.anaconda.com/free/miniconda/index.html).
|
| 221 |
+
|
| 222 |
+
```shell
|
| 223 |
+
# 1. Prepare conda environment
|
| 224 |
+
conda env create -f environment.yml
|
| 225 |
+
|
| 226 |
+
# 2. Activate the environment
|
| 227 |
+
conda activate HunyuanDiT
|
| 228 |
+
|
| 229 |
+
# 3. Install pip dependencies
|
| 230 |
+
python -m pip install -r requirements.txt
|
| 231 |
+
|
| 232 |
+
# 4. (Optional) Install flash attention v2 for acceleration (requires CUDA 11.6 or above)
|
| 233 |
+
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.1.2.post3
|
| 234 |
+
```
|
| 235 |
+
|
| 236 |
+
## 🧱 Download Pretrained Models
|
| 237 |
+
To download the model, first install the huggingface-cli. (Detailed instructions are available [here](https://huggingface.co/docs/huggingface_hub/guides/cli).)
|
| 238 |
+
|
| 239 |
+
```shell
|
| 240 |
+
python -m pip install "huggingface_hub[cli]"
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
Then download the model using the following commands:
|
| 244 |
+
|
| 245 |
+
```shell
|
| 246 |
+
# Create a directory named 'ckpts' where the model will be saved, fulfilling the prerequisites for running the demo.
|
| 247 |
+
mkdir ckpts
|
| 248 |
+
# Use the huggingface-cli tool to download the model.
|
| 249 |
+
# The download time may vary from 10 minutes to 1 hour depending on network conditions.
|
| 250 |
+
huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
<details>
|
| 254 |
+
<summary>💡Tips for using huggingface-cli (network problem)</summary>
|
| 255 |
+
|
| 256 |
+
##### 1. Using HF-Mirror
|
| 257 |
+
|
| 258 |
+
If you encounter slow download speeds in China, you can try a mirror to speed up the download process. For example,
|
| 259 |
+
|
| 260 |
+
```shell
|
| 261 |
+
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
##### 2. Resume Download
|
| 265 |
+
|
| 266 |
+
`huggingface-cli` supports resuming downloads. If the download is interrupted, you can just rerun the download
|
| 267 |
+
command to resume the download process.
|
| 268 |
+
|
| 269 |
+
Note: If an `No such file or directory: 'ckpts/.huggingface/.gitignore.lock'` like error occurs during the download
|
| 270 |
+
process, you can ignore the error and rerun the download command.
|
| 271 |
+
|
| 272 |
+
</details>
|
| 273 |
+
|
| 274 |
+
---
|
| 275 |
+
|
| 276 |
+
All models will be automatically downloaded. For more information about the model, visit the Hugging Face repository [here](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT).
|
| 277 |
+
|
| 278 |
+
| Model | #Params | Huggingface Download URL | Tencent Cloud Download URL |
|
| 279 |
+
|:------------------:|:-------:|:-------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------:|
|
| 280 |
+
| mT5 | 1.6B | [mT5](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/mt5) | [mT5](https://dit.hunyuan.tencent.com/download/HunyuanDiT/mt5.zip) |
|
| 281 |
+
| CLIP | 350M | [CLIP](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/clip_text_encoder) | [CLIP](https://dit.hunyuan.tencent.com/download/HunyuanDiT/clip_text_encoder.zip) |
|
| 282 |
+
| Tokenizer | - | [Tokenizer](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/tokenizer) | [Tokenizer](https://dit.hunyuan.tencent.com/download/HunyuanDiT/tokenizer.zip) |
|
| 283 |
+
| DialogGen | 7.0B | [DialogGen](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/dialoggen) | [DialogGen](https://dit.hunyuan.tencent.com/download/HunyuanDiT/dialoggen.zip) |
|
| 284 |
+
| sdxl-vae-fp16-fix | 83M | [sdxl-vae-fp16-fix](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/sdxl-vae-fp16-fix) | [sdxl-vae-fp16-fix](https://dit.hunyuan.tencent.com/download/HunyuanDiT/sdxl-vae-fp16-fix.zip) |
|
| 285 |
+
| Hunyuan-DiT | 1.5B | [Hunyuan-DiT](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/model) | [Hunyuan-DiT](https://dit.hunyuan.tencent.com/download/HunyuanDiT/model.zip) |
|
| 286 |
+
| Data demo | - | - | [Data demo](https://dit.hunyuan.tencent.com/download/HunyuanDiT/data_demo.zip) |
|
| 287 |
+
|
| 288 |
+
## :truck: Training
|
| 289 |
+
|
| 290 |
+
### Data Preparation
|
| 291 |
+
|
| 292 |
+
Refer to the commands below to prepare the training data.
|
| 293 |
+
|
| 294 |
+
1. Install dependencies
|
| 295 |
+
|
| 296 |
+
We offer an efficient data management library, named IndexKits, supporting the management of reading hundreds of millions of data during training, see more in [docs](https://github.com/Tencent/HunyuanDiT/blob/main/IndexKits/README.md).
|
| 297 |
+
```shell
|
| 298 |
+
# 1 Install dependencies
|
| 299 |
+
cd HunyuanDiT
|
| 300 |
+
pip install -e ./IndexKits
|
| 301 |
+
```
|
| 302 |
+
2. Data download
|
| 303 |
+
|
| 304 |
+
Feel free to download the [data demo](https://dit.hunyuan.tencent.com/download/HunyuanDiT/data_demo.zip).
|
| 305 |
+
```shell
|
| 306 |
+
# 2 Data download
|
| 307 |
+
wget -O ./dataset/data_demo.zip https://dit.hunyuan.tencent.com/download/HunyuanDiT/data_demo.zip
|
| 308 |
+
unzip ./dataset/data_demo.zip -d ./dataset
|
| 309 |
+
mkdir ./dataset/porcelain/arrows ./dataset/porcelain/jsons
|
| 310 |
+
```
|
| 311 |
+
3. Data conversion
|
| 312 |
+
|
| 313 |
+
Create a CSV file for training data with the fields listed in the table below.
|
| 314 |
+
|
| 315 |
+
| Fields | Required | Description | Example |
|
| 316 |
+
|:---------------:| :------: |:----------------:|:-----------:|
|
| 317 |
+
| `image_path` | Required | image path | `./dataset/porcelain/images/0.png` |
|
| 318 |
+
| `text_zh` | Required | text | 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 |
|
| 319 |
+
| `md5` | Optional | image md5 (Message Digest Algorithm 5) | `d41d8cd98f00b204e9800998ecf8427e` |
|
| 320 |
+
| `width` | Optional | image width | `1024 ` |
|
| 321 |
+
| `height` | Optional | image height | ` 1024 ` |
|
| 322 |
+
|
| 323 |
+
> ⚠️ Optional fields like MD5, width, and height can be omitted. If omitted, the script below will automatically calculate them. This process can be time-consuming when dealing with large-scale training data.
|
| 324 |
+
|
| 325 |
+
We utilize [Arrow](https://github.com/apache/arrow) for training data format, offering a standard and efficient in-memory data representation. A conversion script is provided to transform CSV files into Arrow format.
|
| 326 |
+
```shell
|
| 327 |
+
# 3 Data conversion
|
| 328 |
+
python ./hydit/data_loader/csv2arrow.py ./dataset/porcelain/csvfile/image_text.csv ./dataset/porcelain/arrows
|
| 329 |
+
```
|
| 330 |
+
|
| 331 |
+
4. Data Selection and Configuration File Creation
|
| 332 |
+
|
| 333 |
+
We configure the training data through YAML files. In these files, you can set up standard data processing strategies for filtering, copying, deduplicating, and more regarding the training data. For more details, see [docs](IndexKits/docs/MakeDataset.md).
|
| 334 |
+
|
| 335 |
+
For a sample file, please refer to [file](https://github.com/Tencent/HunyuanDiT/blob/main/dataset/yamls/porcelain.yaml). For a full parameter configuration file, see [file](https://github.com/Tencent/HunyuanDiT/blob/main/IndexKits/docs/MakeDataset.md).
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
5. Create training data index file using YAML file.
|
| 339 |
+
|
| 340 |
+
```shell
|
| 341 |
+
# Single Resolution Data Preparation
|
| 342 |
+
idk base -c dataset/yamls/porcelain.yaml -t dataset/porcelain/jsons/porcelain.json
|
| 343 |
+
|
| 344 |
+
# Multi Resolution Data Preparation
|
| 345 |
+
idk multireso -c dataset/yamls/porcelain_mt.yaml -t dataset/porcelain/jsons/porcelain_mt.json
|
| 346 |
+
```
|
| 347 |
+
|
| 348 |
+
The directory structure for `porcelain` dataset is:
|
| 349 |
+
|
| 350 |
+
```shell
|
| 351 |
+
cd ./dataset
|
| 352 |
+
|
| 353 |
+
porcelain
|
| 354 |
+
├──images/ (image files)
|
| 355 |
+
│ ├──0.png
|
| 356 |
+
│ ├──1.png
|
| 357 |
+
│ ├──......
|
| 358 |
+
├──csvfile/ (csv files containing text-image pairs)
|
| 359 |
+
│ ├──image_text.csv
|
| 360 |
+
├──arrows/ (arrow files containing all necessary training data)
|
| 361 |
+
│ ├──00000.arrow
|
| 362 |
+
│ ├──00001.arrow
|
| 363 |
+
│ ├──......
|
| 364 |
+
├──jsons/ (final training data index files which read data from arrow files during training)
|
| 365 |
+
│ ├──porcelain.json
|
| 366 |
+
│ ├──porcelain_mt.json
|
| 367 |
+
```
|
| 368 |
+
|
| 369 |
+
### Full-parameter Training
|
| 370 |
+
|
| 371 |
+
To leverage DeepSpeed in training, you have the flexibility to control **single-node** / **multi-node** training by adjusting parameters such as `--hostfile` and `--master_addr`. For more details, see [link](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node).
|
| 372 |
+
|
| 373 |
+
```shell
|
| 374 |
+
# Single Resolution Data Preparation
|
| 375 |
+
PYTHONPATH=./ sh hydit/train.sh --index-file dataset/porcelain/jsons/porcelain.json
|
| 376 |
+
|
| 377 |
+
# Multi Resolution Data Preparation
|
| 378 |
+
PYTHONPATH=./ sh hydit/train.sh --index-file dataset/porcelain/jsons/porcelain.json --multireso --reso-step 64
|
| 379 |
+
```
|
| 380 |
+
|
| 381 |
+
### LoRA
|
| 382 |
+
|
| 383 |
+
We provide training and inference scripts for LoRA, detailed in the [guidances](https://github.com/Tencent/HunyuanDiT/blob/main/lora/README.md).
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
## 🔑 Inference
|
| 387 |
+
|
| 388 |
+
### Using Gradio
|
| 389 |
+
|
| 390 |
+
Make sure the conda environment is activated before running the following command.
|
| 391 |
+
|
| 392 |
+
```shell
|
| 393 |
+
# By default, we start a Chinese UI.
|
| 394 |
+
python app/hydit_app.py
|
| 395 |
+
|
| 396 |
+
# Using Flash Attention for acceleration.
|
| 397 |
+
python app/hydit_app.py --infer-mode fa
|
| 398 |
+
|
| 399 |
+
# You can disable the enhancement model if the GPU memory is insufficient.
|
| 400 |
+
# The enhancement will be unavailable until you restart the app without the `--no-enhance` flag.
|
| 401 |
+
python app/hydit_app.py --no-enhance
|
| 402 |
+
|
| 403 |
+
# Start with English UI
|
| 404 |
+
python app/hydit_app.py --lang en
|
| 405 |
+
|
| 406 |
+
# Start a multi-turn T2I generation UI.
|
| 407 |
+
# If your GPU memory is less than 32GB, use '--load-4bit' to enable 4-bit quantization, which requires at least 22GB of memory.
|
| 408 |
+
python app/multiTurnT2I_app.py
|
| 409 |
+
```
|
| 410 |
+
Then the demo can be accessed through http://0.0.0.0:443. It should be noted that the 0.0.0.0 here needs to be X.X.X.X with your server IP.
|
| 411 |
+
|
| 412 |
+
### Using 🤗 Diffusers
|
| 413 |
+
|
| 414 |
+
Please install PyTorch version 2.0 or higher in advance to satisfy the requirements of the specified version of the diffusers library.
|
| 415 |
+
|
| 416 |
+
Install 🤗 diffusers, ensuring that the version is at least 0.28.1:
|
| 417 |
+
|
| 418 |
+
```shell
|
| 419 |
+
pip install git+https://github.com/huggingface/diffusers.git
|
| 420 |
+
```
|
| 421 |
+
or
|
| 422 |
+
```shell
|
| 423 |
+
pip install diffusers
|
| 424 |
+
```
|
| 425 |
+
|
| 426 |
+
You can generate images with both Chinese and English prompts using the following Python script:
|
| 427 |
+
```py
|
| 428 |
+
import torch
|
| 429 |
+
from diffusers import HunyuanDiTPipeline
|
| 430 |
+
|
| 431 |
+
pipe = HunyuanDiTPipeline.from_pretrained("Tencent-Hunyuan/HunyuanDiT-Diffusers", torch_dtype=torch.float16)
|
| 432 |
+
pipe.to("cuda")
|
| 433 |
+
|
| 434 |
+
# You may also use English prompt as HunyuanDiT supports both English and Chinese
|
| 435 |
+
# prompt = "An astronaut riding a horse"
|
| 436 |
+
prompt = "一个宇航员在骑马"
|
| 437 |
+
image = pipe(prompt).images[0]
|
| 438 |
+
```
|
| 439 |
+
You can use our distilled model to generate images even faster:
|
| 440 |
+
|
| 441 |
+
```py
|
| 442 |
+
import torch
|
| 443 |
+
from diffusers import HunyuanDiTPipeline
|
| 444 |
+
|
| 445 |
+
pipe = HunyuanDiTPipeline.from_pretrained("Tencent-Hunyuan/HunyuanDiT-Diffusers-Distilled", torch_dtype=torch.float16)
|
| 446 |
+
pipe.to("cuda")
|
| 447 |
+
|
| 448 |
+
# You may also use English prompt as HunyuanDiT supports both English and Chinese
|
| 449 |
+
# prompt = "An astronaut riding a horse"
|
| 450 |
+
prompt = "一个宇航员在骑马"
|
| 451 |
+
image = pipe(prompt, num_inference_steps=25).images[0]
|
| 452 |
+
```
|
| 453 |
+
More details can be found in [HunyuanDiT-Diffusers-Distilled](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT-Diffusers-Distilled)
|
| 454 |
+
|
| 455 |
+
### Using Command Line
|
| 456 |
+
|
| 457 |
+
We provide several commands to quick start:
|
| 458 |
+
|
| 459 |
+
```shell
|
| 460 |
+
# Prompt Enhancement + Text-to-Image. Torch mode
|
| 461 |
+
python sample_t2i.py --prompt "渔舟唱晚"
|
| 462 |
+
|
| 463 |
+
# Only Text-to-Image. Torch mode
|
| 464 |
+
python sample_t2i.py --prompt "渔舟唱晚" --no-enhance
|
| 465 |
+
|
| 466 |
+
# Only Text-to-Image. Flash Attention mode
|
| 467 |
+
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚"
|
| 468 |
+
|
| 469 |
+
# Generate an image with other image sizes.
|
| 470 |
+
python sample_t2i.py --prompt "渔舟唱晚" --image-size 1280 768
|
| 471 |
+
|
| 472 |
+
# Prompt Enhancement + Text-to-Image. DialogGen loads with 4-bit quantization, but it may loss performance.
|
| 473 |
+
python sample_t2i.py --prompt "渔舟唱晚" --load-4bit
|
| 474 |
+
|
| 475 |
+
```
|
| 476 |
+
|
| 477 |
+
More example prompts can be found in [example_prompts.txt](example_prompts.txt)
|
| 478 |
+
|
| 479 |
+
### More Configurations
|
| 480 |
+
|
| 481 |
+
We list some more useful configurations for easy usage:
|
| 482 |
+
|
| 483 |
+
| Argument | Default | Description |
|
| 484 |
+
|:---------------:|:---------:|:---------------------------------------------------:|
|
| 485 |
+
| `--prompt` | None | The text prompt for image generation |
|
| 486 |
+
| `--image-size` | 1024 1024 | The size of the generated image |
|
| 487 |
+
| `--seed` | 42 | The random seed for generating images |
|
| 488 |
+
| `--infer-steps` | 100 | The number of steps for sampling |
|
| 489 |
+
| `--negative` | - | The negative prompt for image generation |
|
| 490 |
+
| `--infer-mode` | torch | The inference mode (torch, fa, or trt) |
|
| 491 |
+
| `--sampler` | ddpm | The diffusion sampler (ddpm, ddim, or dpmms) |
|
| 492 |
+
| `--no-enhance` | False | Disable the prompt enhancement model |
|
| 493 |
+
| `--model-root` | ckpts | The root directory of the model checkpoints |
|
| 494 |
+
| `--load-key` | ema | Load the student model or EMA model (ema or module) |
|
| 495 |
+
| `--load-4bit` | Fasle | Load DialogGen model with 4bit quantization |
|
| 496 |
+
|
| 497 |
+
### Using ComfyUI
|
| 498 |
+
|
| 499 |
+
We provide several commands to quick start:
|
| 500 |
+
|
| 501 |
+
```shell
|
| 502 |
+
# Download comfyui code
|
| 503 |
+
git clone https://github.com/comfyanonymous/ComfyUI.git
|
| 504 |
+
|
| 505 |
+
# Install torch, torchvision, torchaudio
|
| 506 |
+
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117
|
| 507 |
+
|
| 508 |
+
# Install Comfyui essential python package
|
| 509 |
+
cd ComfyUI
|
| 510 |
+
pip install -r requirements.txt
|
| 511 |
+
|
| 512 |
+
# ComfyUI has been successfully installed!
|
| 513 |
+
|
| 514 |
+
# Download model weight as before or link the existing model folder to ComfyUI.
|
| 515 |
+
python -m pip install "huggingface_hub[cli]"
|
| 516 |
+
mkdir models/hunyuan
|
| 517 |
+
huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./models/hunyuan/ckpts
|
| 518 |
+
|
| 519 |
+
# Move to the ComfyUI custom_nodes folder and copy comfyui-hydit folder from HunyuanDiT Repo.
|
| 520 |
+
cd custom_nodes
|
| 521 |
+
cp -r ${HunyuanDiT}/comfyui-hydit ./
|
| 522 |
+
cd comfyui-hydit
|
| 523 |
+
|
| 524 |
+
# Install some essential python Package.
|
| 525 |
+
pip install -r requirements.txt
|
| 526 |
+
|
| 527 |
+
# Our tool has been successfully installed!
|
| 528 |
+
|
| 529 |
+
# Go to ComfyUI main folder
|
| 530 |
+
cd ../..
|
| 531 |
+
# Run the ComfyUI Lauch command
|
| 532 |
+
python main.py --listen --port 80
|
| 533 |
+
|
| 534 |
+
# Running ComfyUI successfully!
|
| 535 |
+
```
|
| 536 |
+
More details can be found in [ComfyUI README](comfyui-hydit/README.md)
|
| 537 |
+
|
| 538 |
+
## 🚀 Acceleration (for Linux)
|
| 539 |
+
|
| 540 |
+
- We provide TensorRT version of HunyuanDiT for inference acceleration (faster than flash attention).
|
| 541 |
+
See [Tencent-Hunyuan/TensorRT-libs](https://huggingface.co/Tencent-Hunyuan/TensorRT-libs) for more details.
|
| 542 |
+
|
| 543 |
+
- We provide Distillation version of HunyuanDiT for inference acceleration.
|
| 544 |
+
See [Tencent-Hunyuan/Distillation](https://huggingface.co/Tencent-Hunyuan/Distillation) for more details.
|
| 545 |
+
|
| 546 |
+
## 🔗 BibTeX
|
| 547 |
+
If you find [Hunyuan-DiT](https://arxiv.org/abs/2405.08748) or [DialogGen](https://arxiv.org/abs/2403.08857) useful for your research and applications, please cite using this BibTeX:
|
| 548 |
+
|
| 549 |
+
```BibTeX
|
| 550 |
+
@misc{li2024hunyuandit,
|
| 551 |
+
title={Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding},
|
| 552 |
+
author={Zhimin Li and Jianwei Zhang and Qin Lin and Jiangfeng Xiong and Yanxin Long and Xinchi Deng and Yingfang Zhang and Xingchao Liu and Minbin Huang and Zedong Xiao and Dayou Chen and Jiajun He and Jiahao Li and Wenyue Li and Chen Zhang and Rongwei Quan and Jianxiang Lu and Jiabin Huang and Xiaoyan Yuan and Xiaoxiao Zheng and Yixuan Li and Jihong Zhang and Chao Zhang and Meng Chen and Jie Liu and Zheng Fang and Weiyan Wang and Jinbao Xue and Yangyu Tao and Jianchen Zhu and Kai Liu and Sihuan Lin and Yifu Sun and Yun Li and Dongdong Wang and Mingtao Chen and Zhichao Hu and Xiao Xiao and Yan Chen and Yuhong Liu and Wei Liu and Di Wang and Yong Yang and Jie Jiang and Qinglin Lu},
|
| 553 |
+
year={2024},
|
| 554 |
+
eprint={2405.08748},
|
| 555 |
+
archivePrefix={arXiv},
|
| 556 |
+
primaryClass={cs.CV}
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
@article{huang2024dialoggen,
|
| 560 |
+
title={DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation},
|
| 561 |
+
author={Huang, Minbin and Long, Yanxin and Deng, Xinchi and Chu, Ruihang and Xiong, Jiangfeng and Liang, Xiaodan and Cheng, Hong and Lu, Qinglin and Liu, Wei},
|
| 562 |
+
journal={arXiv preprint arXiv:2403.08857},
|
| 563 |
+
year={2024}
|
| 564 |
+
}
|
| 565 |
+
```
|
| 566 |
+
|
| 567 |
+
## Start History
|
| 568 |
+
|
| 569 |
+
<a href="https://star-history.com/#Tencent/HunyuanDiT&Date">
|
| 570 |
+
<picture>
|
| 571 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=Tencent/HunyuanDiT&type=Date&theme=dark" />
|
| 572 |
+
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=Tencent/HunyuanDiT&type=Date" />
|
| 573 |
+
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=Tencent/HunyuanDiT&type=Date" />
|
| 574 |
+
</picture>
|
| 575 |
+
</a>
|
asset/Hunyuan_DiT_Tech_Report_05140553.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:417a55a94d3a903af4b8b047eaec7a896a78c37ac58fd2b14ee9cd6233002cc0
|
| 3 |
+
size 38858394
|
asset/chinese elements understanding.png
ADDED

|
Git LFS Details
|
asset/cover.png
ADDED
|
asset/framework.png
ADDED

|
asset/logo.png
ADDED
|
|
asset/long text understanding.png
ADDED

|
Git LFS Details
|
asset/mllm.png
ADDED
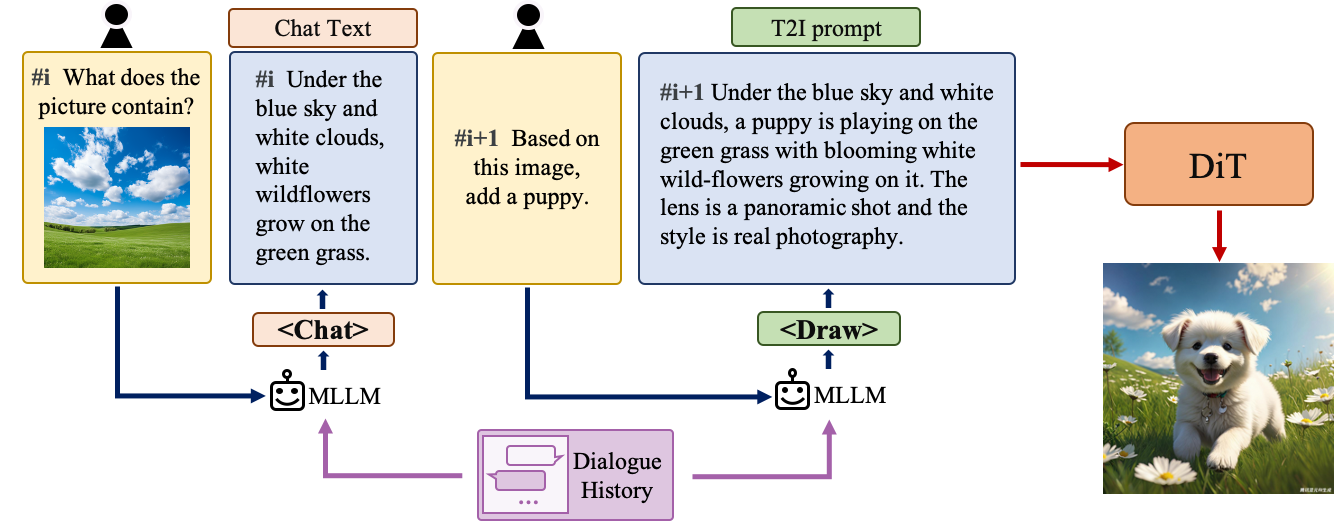
|
asset/radar.png
ADDED

|
dialoggen/config.json
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlavaMistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 1,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"freeze_mm_mlp_adapter": false,
|
| 10 |
+
"freeze_mm_vision_resampler": false,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 4096,
|
| 13 |
+
"image_aspect_ratio": "anyres",
|
| 14 |
+
"image_crop_resolution": 224,
|
| 15 |
+
"image_grid_pinpoints": [
|
| 16 |
+
[
|
| 17 |
+
336,
|
| 18 |
+
672
|
| 19 |
+
],
|
| 20 |
+
[
|
| 21 |
+
672,
|
| 22 |
+
336
|
| 23 |
+
],
|
| 24 |
+
[
|
| 25 |
+
672,
|
| 26 |
+
672
|
| 27 |
+
],
|
| 28 |
+
[
|
| 29 |
+
1008,
|
| 30 |
+
336
|
| 31 |
+
],
|
| 32 |
+
[
|
| 33 |
+
336,
|
| 34 |
+
1008
|
| 35 |
+
]
|
| 36 |
+
],
|
| 37 |
+
"image_split_resolution": 224,
|
| 38 |
+
"initializer_range": 0.02,
|
| 39 |
+
"intermediate_size": 14336,
|
| 40 |
+
"max_position_embeddings": 32768,
|
| 41 |
+
"mm_hidden_size": 1024,
|
| 42 |
+
"mm_patch_merge_type": "spatial_unpad",
|
| 43 |
+
"mm_projector_lr": null,
|
| 44 |
+
"mm_projector_type": "mlp2x_gelu",
|
| 45 |
+
"mm_resampler_type": null,
|
| 46 |
+
"mm_use_im_patch_token": false,
|
| 47 |
+
"mm_use_im_start_end": false,
|
| 48 |
+
"mm_vision_select_feature": "patch",
|
| 49 |
+
"mm_vision_select_layer": -2,
|
| 50 |
+
"mm_vision_tower": "openai/clip-vit-large-patch14-336",
|
| 51 |
+
"mm_vision_tower_lr": 2e-06,
|
| 52 |
+
"model_type": "llava_mistral",
|
| 53 |
+
"num_attention_heads": 32,
|
| 54 |
+
"num_hidden_layers": 32,
|
| 55 |
+
"num_key_value_heads": 8,
|
| 56 |
+
"rms_norm_eps": 1e-05,
|
| 57 |
+
"rope_theta": 1000000.0,
|
| 58 |
+
"sliding_window": null,
|
| 59 |
+
"tie_word_embeddings": false,
|
| 60 |
+
"tokenizer_model_max_length": 4096,
|
| 61 |
+
"tokenizer_padding_side": "left",
|
| 62 |
+
"torch_dtype": "float16",
|
| 63 |
+
"transformers_version": "4.37.2",
|
| 64 |
+
"tune_mm_mlp_adapter": false,
|
| 65 |
+
"tune_mm_vision_resampler": false,
|
| 66 |
+
"unfreeze_mm_vision_tower": true,
|
| 67 |
+
"use_cache": true,
|
| 68 |
+
"use_mm_proj": true,
|
| 69 |
+
"vocab_size": 32000
|
| 70 |
+
}
|
dialoggen/generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.37.2"
|
| 6 |
+
}
|
dialoggen/model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:637b0ec71c788f9f66299c2584c8b0fcf4526bbc039ad38ceb38e5490f9af1ed
|
| 3 |
+
size 4943170528
|
dialoggen/model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44a76e4d75f4a8f4f50bde7def9e8f34ed3cfd6aa581ec72e6f89da2af400450
|
| 3 |
+
size 4999819232
|
dialoggen/model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:caa253af62d8d3462e0bc8b1dbfd8deef144bc648b918c5321e2e66be55fc361
|
| 3 |
+
size 4927407880
|
dialoggen/model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cd131cf8ade9f39ba17b218d832cedd32eb709969ec02aaf1faec69b22830695
|
| 3 |
+
size 262144128
|
dialoggen/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,694 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 15132446720
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"model.image_newline": "model-00001-of-00004.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 28 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 29 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 31 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 35 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 36 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 89 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 91 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 98 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 101 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 103 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 110 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 118 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 119 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 120 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 121 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 125 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 126 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 127 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 129 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 130 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 134 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 137 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 139 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 143 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 144 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 146 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 152 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 153 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 154 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 155 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 156 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 157 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 161 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 162 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 163 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 164 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 170 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 173 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 182 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 197 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 199 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 206 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 209 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 211 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 217 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 218 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 219 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 220 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 224 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 225 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 233 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 235 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 242 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 244 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 245 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 246 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 247 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 251 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 252 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 253 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 254 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 255 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 256 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 260 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 269 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 271 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 278 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 281 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 283 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 288 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 290 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"model.mm_projector.0.bias": "model-00003-of-00004.safetensors",
|
| 298 |
+
"model.mm_projector.0.weight": "model-00003-of-00004.safetensors",
|
| 299 |
+
"model.mm_projector.2.bias": "model-00003-of-00004.safetensors",
|
| 300 |
+
"model.mm_projector.2.weight": "model-00003-of-00004.safetensors",
|
| 301 |
+
"model.norm.weight": "model-00003-of-00004.safetensors",
|
| 302 |
+
"model.vision_tower.vision_tower.vision_model.embeddings.class_embedding": "model-00003-of-00004.safetensors",
|
| 303 |
+
"model.vision_tower.vision_tower.vision_model.embeddings.patch_embedding.weight": "model-00003-of-00004.safetensors",
|
| 304 |
+
"model.vision_tower.vision_tower.vision_model.embeddings.position_embedding.weight": "model-00003-of-00004.safetensors",
|
| 305 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 306 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 307 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 308 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 309 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 310 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 311 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 312 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 313 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 314 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 315 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 316 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 317 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 318 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 319 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 320 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 321 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 322 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 323 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 324 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 325 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 326 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 327 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 328 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 329 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 330 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 331 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 332 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 333 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 334 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 335 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 336 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 337 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 338 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 339 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 340 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 341 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 342 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 343 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 344 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 345 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 346 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 347 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 348 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 349 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 350 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 351 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 352 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 353 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 354 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 355 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 356 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 357 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 358 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 359 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 360 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 361 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 362 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 363 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 364 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 365 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 366 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 367 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 368 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 369 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 370 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 371 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 372 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 373 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 374 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 375 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 376 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 377 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 378 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 379 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 380 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 381 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 382 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 383 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 384 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 385 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 386 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 387 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 388 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 389 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 390 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 391 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 392 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 393 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 394 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 395 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 396 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 397 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 398 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 399 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 400 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 401 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 402 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 403 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 404 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 405 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 406 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 407 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 408 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 409 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 410 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 411 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 412 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 413 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 414 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 415 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 416 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 417 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 418 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 419 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 420 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 421 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 422 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 423 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 424 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 425 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 426 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 427 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 428 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 429 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 430 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 431 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 432 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 433 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 434 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 435 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 436 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 437 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 438 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 439 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 440 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 441 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 442 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 443 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 444 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 445 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 446 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 447 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 448 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 449 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 450 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 451 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 452 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 453 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 454 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 455 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 456 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 457 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 458 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 459 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 460 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 461 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 462 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 463 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 464 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 465 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 466 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 467 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 468 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 469 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 470 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 471 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 472 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 473 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 474 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 475 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 476 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 477 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 478 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 479 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 480 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 481 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 482 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 483 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 484 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 485 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 486 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 487 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 488 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 489 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 490 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 491 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 492 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 493 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 494 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 495 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 496 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 497 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 498 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 499 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 500 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 501 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 502 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 503 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 504 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 505 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 506 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 507 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 508 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 509 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 510 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 511 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 512 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 513 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 514 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 515 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 516 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 517 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 518 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 519 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 520 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 521 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 522 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 523 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 524 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 525 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 526 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 527 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 528 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 529 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 530 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 531 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 532 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 533 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 534 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 535 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 536 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 537 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 538 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 539 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 540 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 541 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 542 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 543 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 544 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 545 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 546 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 547 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 548 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 549 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 550 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 551 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 552 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 553 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 554 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 555 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 556 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 557 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 558 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 559 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 560 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 561 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 562 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 563 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 564 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 565 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 566 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 567 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 568 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 569 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 570 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 571 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 572 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 573 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 574 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 575 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 576 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 577 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 578 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 579 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 580 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 581 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 582 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 583 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 584 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 585 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 586 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 587 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 588 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 589 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 590 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 591 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 592 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 593 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 594 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 595 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 596 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 597 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 598 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 599 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 600 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 601 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 602 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 603 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 604 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 605 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 606 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 607 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 608 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 609 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 610 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 611 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 612 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 613 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 614 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 615 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 616 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 617 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 618 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 619 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 620 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 621 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 622 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 623 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 624 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 625 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 626 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 627 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 628 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 629 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 630 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 631 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 632 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 633 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 634 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 635 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 636 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 637 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 638 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 639 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 640 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 641 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 642 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 643 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 644 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 645 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 646 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 647 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 648 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 649 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 650 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 651 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 652 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 653 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 654 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 655 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 656 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 657 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 658 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 659 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 660 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 661 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 662 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 663 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 664 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 665 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 666 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 667 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 668 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 669 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 670 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 671 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 672 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 673 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.layer_norm1.bias": "model-00003-of-00004.safetensors",
|
| 674 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.layer_norm1.weight": "model-00003-of-00004.safetensors",
|
| 675 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.layer_norm2.bias": "model-00003-of-00004.safetensors",
|
| 676 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.layer_norm2.weight": "model-00003-of-00004.safetensors",
|
| 677 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.mlp.fc1.bias": "model-00003-of-00004.safetensors",
|
| 678 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.mlp.fc1.weight": "model-00003-of-00004.safetensors",
|
| 679 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.mlp.fc2.bias": "model-00003-of-00004.safetensors",
|
| 680 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.mlp.fc2.weight": "model-00003-of-00004.safetensors",
|
| 681 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 682 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 683 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.bias": "model-00003-of-00004.safetensors",
|
| 684 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.weight": "model-00003-of-00004.safetensors",
|
| 685 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 686 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 687 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 688 |
+
"model.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 689 |
+
"model.vision_tower.vision_tower.vision_model.post_layernorm.bias": "model-00003-of-00004.safetensors",
|
| 690 |
+
"model.vision_tower.vision_tower.vision_model.post_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 691 |
+
"model.vision_tower.vision_tower.vision_model.pre_layrnorm.bias": "model-00003-of-00004.safetensors",
|
| 692 |
+
"model.vision_tower.vision_tower.vision_model.pre_layrnorm.weight": "model-00003-of-00004.safetensors"
|
| 693 |
+
}
|
| 694 |
+
}
|
dialoggen/openai/clip-vit-large-patch14-336/README.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- generated_from_keras_callback
|
| 4 |
+
widget:
|
| 5 |
+
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
|
| 6 |
+
candidate_labels: playing music, playing sports
|
| 7 |
+
example_title: Cat & Dog
|
| 8 |
+
model-index:
|
| 9 |
+
- name: clip-vit-large-patch14-336
|
| 10 |
+
results: []
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
<!-- This model card has been generated automatically according to the information Keras had access to. You should
|
| 14 |
+
probably proofread and complete it, then remove this comment. -->
|
| 15 |
+
|
| 16 |
+
# clip-vit-large-patch14-336
|
| 17 |
+
|
| 18 |
+
This model was trained from scratch on an unknown dataset.
|
| 19 |
+
It achieves the following results on the evaluation set:
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## Model description
|
| 23 |
+
|
| 24 |
+
More information needed
|
| 25 |
+
|
| 26 |
+
## Intended uses & limitations
|
| 27 |
+
|
| 28 |
+
More information needed
|
| 29 |
+
|
| 30 |
+
## Training and evaluation data
|
| 31 |
+
|
| 32 |
+
More information needed
|
| 33 |
+
|
| 34 |
+
## Training procedure
|
| 35 |
+
|
| 36 |
+
### Training hyperparameters
|
| 37 |
+
|
| 38 |
+
The following hyperparameters were used during training:
|
| 39 |
+
- optimizer: None
|
| 40 |
+
- training_precision: float32
|
| 41 |
+
|
| 42 |
+
### Training results
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
### Framework versions
|
| 47 |
+
|
| 48 |
+
- Transformers 4.21.3
|
| 49 |
+
- TensorFlow 2.8.2
|
| 50 |
+
- Tokenizers 0.12.1
|
dialoggen/openai/clip-vit-large-patch14-336/config.json
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "openai/clip-vit-large-patch14-336",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPModel"
|
| 5 |
+
],
|
| 6 |
+
"initializer_factor": 1.0,
|
| 7 |
+
"logit_scale_init_value": 2.6592,
|
| 8 |
+
"model_type": "clip",
|
| 9 |
+
"projection_dim": 768,
|
| 10 |
+
"text_config": {
|
| 11 |
+
"_name_or_path": "",
|
| 12 |
+
"add_cross_attention": false,
|
| 13 |
+
"architectures": null,
|
| 14 |
+
"attention_dropout": 0.0,
|
| 15 |
+
"bad_words_ids": null,
|
| 16 |
+
"bos_token_id": 0,
|
| 17 |
+
"chunk_size_feed_forward": 0,
|
| 18 |
+
"cross_attention_hidden_size": null,
|
| 19 |
+
"decoder_start_token_id": null,
|
| 20 |
+
"diversity_penalty": 0.0,
|
| 21 |
+
"do_sample": false,
|
| 22 |
+
"dropout": 0.0,
|
| 23 |
+
"early_stopping": false,
|
| 24 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 25 |
+
"eos_token_id": 2,
|
| 26 |
+
"exponential_decay_length_penalty": null,
|
| 27 |
+
"finetuning_task": null,
|
| 28 |
+
"forced_bos_token_id": null,
|
| 29 |
+
"forced_eos_token_id": null,
|
| 30 |
+
"hidden_act": "quick_gelu",
|
| 31 |
+
"hidden_size": 768,
|
| 32 |
+
"id2label": {
|
| 33 |
+
"0": "LABEL_0",
|
| 34 |
+
"1": "LABEL_1"
|
| 35 |
+
},
|
| 36 |
+
"initializer_factor": 1.0,
|
| 37 |
+
"initializer_range": 0.02,
|
| 38 |
+
"intermediate_size": 3072,
|
| 39 |
+
"is_decoder": false,
|
| 40 |
+
"is_encoder_decoder": false,
|
| 41 |
+
"label2id": {
|
| 42 |
+
"LABEL_0": 0,
|
| 43 |
+
"LABEL_1": 1
|
| 44 |
+
},
|
| 45 |
+
"layer_norm_eps": 1e-05,
|
| 46 |
+
"length_penalty": 1.0,
|
| 47 |
+
"max_length": 20,
|
| 48 |
+
"max_position_embeddings": 77,
|
| 49 |
+
"min_length": 0,
|
| 50 |
+
"model_type": "clip_text_model",
|
| 51 |
+
"no_repeat_ngram_size": 0,
|
| 52 |
+
"num_attention_heads": 12,
|
| 53 |
+
"num_beam_groups": 1,
|
| 54 |
+
"num_beams": 1,
|
| 55 |
+
"num_hidden_layers": 12,
|
| 56 |
+
"num_return_sequences": 1,
|
| 57 |
+
"output_attentions": false,
|
| 58 |
+
"output_hidden_states": false,
|
| 59 |
+
"output_scores": false,
|
| 60 |
+
"pad_token_id": 1,
|
| 61 |
+
"prefix": null,
|
| 62 |
+
"problem_type": null,
|
| 63 |
+
"projection_dim": 768,
|
| 64 |
+
"pruned_heads": {},
|
| 65 |
+
"remove_invalid_values": false,
|
| 66 |
+
"repetition_penalty": 1.0,
|
| 67 |
+
"return_dict": true,
|
| 68 |
+
"return_dict_in_generate": false,
|
| 69 |
+
"sep_token_id": null,
|
| 70 |
+
"task_specific_params": null,
|
| 71 |
+
"temperature": 1.0,
|
| 72 |
+
"tf_legacy_loss": false,
|
| 73 |
+
"tie_encoder_decoder": false,
|
| 74 |
+
"tie_word_embeddings": true,
|
| 75 |
+
"tokenizer_class": null,
|
| 76 |
+
"top_k": 50,
|
| 77 |
+
"top_p": 1.0,
|
| 78 |
+
"torch_dtype": null,
|
| 79 |
+
"torchscript": false,
|
| 80 |
+
"transformers_version": "4.21.3",
|
| 81 |
+
"typical_p": 1.0,
|
| 82 |
+
"use_bfloat16": false,
|
| 83 |
+
"vocab_size": 49408
|
| 84 |
+
},
|
| 85 |
+
"text_config_dict": {
|
| 86 |
+
"hidden_size": 768,
|
| 87 |
+
"intermediate_size": 3072,
|
| 88 |
+
"num_attention_heads": 12,
|
| 89 |
+
"num_hidden_layers": 12,
|
| 90 |
+
"projection_dim": 768
|
| 91 |
+
},
|
| 92 |
+
"torch_dtype": "float32",
|
| 93 |
+
"transformers_version": null,
|
| 94 |
+
"vision_config": {
|
| 95 |
+
"_name_or_path": "",
|
| 96 |
+
"add_cross_attention": false,
|
| 97 |
+
"architectures": null,
|
| 98 |
+
"attention_dropout": 0.0,
|
| 99 |
+
"bad_words_ids": null,
|
| 100 |
+
"bos_token_id": null,
|
| 101 |
+
"chunk_size_feed_forward": 0,
|
| 102 |
+
"cross_attention_hidden_size": null,
|
| 103 |
+
"decoder_start_token_id": null,
|
| 104 |
+
"diversity_penalty": 0.0,
|
| 105 |
+
"do_sample": false,
|
| 106 |
+
"dropout": 0.0,
|
| 107 |
+
"early_stopping": false,
|
| 108 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 109 |
+
"eos_token_id": null,
|
| 110 |
+
"exponential_decay_length_penalty": null,
|
| 111 |
+
"finetuning_task": null,
|
| 112 |
+
"forced_bos_token_id": null,
|
| 113 |
+
"forced_eos_token_id": null,
|
| 114 |
+
"hidden_act": "quick_gelu",
|
| 115 |
+
"hidden_size": 1024,
|
| 116 |
+
"id2label": {
|
| 117 |
+
"0": "LABEL_0",
|
| 118 |
+
"1": "LABEL_1"
|
| 119 |
+
},
|
| 120 |
+
"image_size": 336,
|
| 121 |
+
"initializer_factor": 1.0,
|
| 122 |
+
"initializer_range": 0.02,
|
| 123 |
+
"intermediate_size": 4096,
|
| 124 |
+
"is_decoder": false,
|
| 125 |
+
"is_encoder_decoder": false,
|
| 126 |
+
"label2id": {
|
| 127 |
+
"LABEL_0": 0,
|
| 128 |
+
"LABEL_1": 1
|
| 129 |
+
},
|
| 130 |
+
"layer_norm_eps": 1e-05,
|
| 131 |
+
"length_penalty": 1.0,
|
| 132 |
+
"max_length": 20,
|
| 133 |
+
"min_length": 0,
|
| 134 |
+
"model_type": "clip_vision_model",
|
| 135 |
+
"no_repeat_ngram_size": 0,
|
| 136 |
+
"num_attention_heads": 16,
|
| 137 |
+
"num_beam_groups": 1,
|
| 138 |
+
"num_beams": 1,
|
| 139 |
+
"num_channels": 3,
|
| 140 |
+
"num_hidden_layers": 24,
|
| 141 |
+
"num_return_sequences": 1,
|
| 142 |
+
"output_attentions": false,
|
| 143 |
+
"output_hidden_states": false,
|
| 144 |
+
"output_scores": false,
|
| 145 |
+
"pad_token_id": null,
|
| 146 |
+
"patch_size": 14,
|
| 147 |
+
"prefix": null,
|
| 148 |
+
"problem_type": null,
|
| 149 |
+
"projection_dim": 768,
|
| 150 |
+
"pruned_heads": {},
|
| 151 |
+
"remove_invalid_values": false,
|
| 152 |
+
"repetition_penalty": 1.0,
|
| 153 |
+
"return_dict": true,
|
| 154 |
+
"return_dict_in_generate": false,
|
| 155 |
+
"sep_token_id": null,
|
| 156 |
+
"task_specific_params": null,
|
| 157 |
+
"temperature": 1.0,
|
| 158 |
+
"tf_legacy_loss": false,
|
| 159 |
+
"tie_encoder_decoder": false,
|
| 160 |
+
"tie_word_embeddings": true,
|
| 161 |
+
"tokenizer_class": null,
|
| 162 |
+
"top_k": 50,
|
| 163 |
+
"top_p": 1.0,
|
| 164 |
+
"torch_dtype": null,
|
| 165 |
+
"torchscript": false,
|
| 166 |
+
"transformers_version": "4.21.3",
|
| 167 |
+
"typical_p": 1.0,
|
| 168 |
+
"use_bfloat16": false
|
| 169 |
+
},
|
| 170 |
+
"vision_config_dict": {
|
| 171 |
+
"hidden_size": 1024,
|
| 172 |
+
"image_size": 336,
|
| 173 |
+
"intermediate_size": 4096,
|
| 174 |
+
"num_attention_heads": 16,
|
| 175 |
+
"num_hidden_layers": 24,
|
| 176 |
+
"patch_size": 14,
|
| 177 |
+
"projection_dim": 768
|
| 178 |
+
}
|
| 179 |
+
}
|
dialoggen/openai/clip-vit-large-patch14-336/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dialoggen/openai/clip-vit-large-patch14-336/preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 336,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.48145466,
|
| 9 |
+
0.4578275,
|
| 10 |
+
0.40821073
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.26862954,
|
| 14 |
+
0.26130258,
|
| 15 |
+
0.27577711
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 336
|
| 19 |
+
}
|
dialoggen/openai/clip-vit-large-patch14-336/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c6032c2e0caae3dc2d4fba35535fa6307dbb49df59c7e182b1bc4b3329b81801
|
| 3 |
+
size 1711974081
|
dialoggen/openai/clip-vit-large-patch14-336/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": {"content": "<|startoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "eos_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "unk_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "pad_token": "<|endoftext|>"}
|
dialoggen/openai/clip-vit-large-patch14-336/tf_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d12828ca8f0f3c92194f277b7d893da7f2fb7824d0b99dedb305eb48eb46bb7f
|
| 3 |
+
size 1712454232
|
dialoggen/openai/clip-vit-large-patch14-336/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dialoggen/openai/clip-vit-large-patch14-336/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"unk_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "bos_token": {"content": "<|startoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "eos_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "pad_token": "<|endoftext|>", "add_prefix_space": false, "errors": "replace", "do_lower_case": true, "name_or_path": "openai/clip-vit-base-patch32", "model_max_length": 77, "special_tokens_map_file": "/home/suraj/.cache/huggingface/transformers/18a566598f286c9139f88160c99f84eec492a26bd22738fa9cb44d5b7e0a5c76.cce1206abbad28826f000510f22f354e53e66a97f7c23745a7dfe27609cc07f5", "tokenizer_class": "CLIPTokenizer"}
|
dialoggen/openai/clip-vit-large-patch14-336/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dialoggen/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
dialoggen/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
dialoggen/tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{{ bos_token }}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '[INST] ' + message['content'] + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ message['content'] + eos_token}}{% else %}{{ raise_exception('Only user and assistant roles are supported!') }}{% endif %}{% endfor %}",
|
| 33 |
+
"clean_up_tokenization_spaces": false,
|
| 34 |
+
"eos_token": "</s>",
|
| 35 |
+
"legacy": true,
|
| 36 |
+
"model_max_length": 4096,
|
| 37 |
+
"pad_token": "<unk>",
|
| 38 |
+
"padding_side": "left",
|
| 39 |
+
"sp_model_kwargs": {},
|
| 40 |
+
"spaces_between_special_tokens": false,
|
| 41 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 42 |
+
"unk_token": "<unk>",
|
| 43 |
+
"use_default_system_prompt": false
|
| 44 |
+
}
|
t2i/clip_text_encoder/config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "hfl/chinese-roberta-wwm-ext-large",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"classifier_dropout": null,
|
| 9 |
+
"directionality": "bidi",
|
| 10 |
+
"eos_token_id": 2,
|
| 11 |
+
"hidden_act": "gelu",
|
| 12 |
+
"hidden_dropout_prob": 0.1,
|
| 13 |
+
"hidden_size": 1024,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 4096,
|
| 16 |
+
"layer_norm_eps": 1e-12,
|
| 17 |
+
"max_position_embeddings": 512,
|
| 18 |
+
"model_type": "bert",
|
| 19 |
+
"num_attention_heads": 16,
|
| 20 |
+
"num_hidden_layers": 24,
|
| 21 |
+
"output_past": true,
|
| 22 |
+
"pad_token_id": 0,
|
| 23 |
+
"pooler_fc_size": 768,
|
| 24 |
+
"pooler_num_attention_heads": 12,
|
| 25 |
+
"pooler_num_fc_layers": 3,
|
| 26 |
+
"pooler_size_per_head": 128,
|
| 27 |
+
"pooler_type": "first_token_transform",
|
| 28 |
+
"position_embedding_type": "absolute",
|
| 29 |
+
"torch_dtype": "float32",
|
| 30 |
+
"transformers_version": "4.22.1",
|
| 31 |
+
"type_vocab_size": 2,
|
| 32 |
+
"use_cache": true,
|
| 33 |
+
"vocab_size": 47020
|
| 34 |
+
}
|
t2i/clip_text_encoder/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:77fd65c751513310fe575e0ef59963743f89a4955ee5c79d7468157b27e83c51
|
| 3 |
+
size 3936679395
|
t2i/model/pytorch_model_ema.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d4346b267437ab07eefb22fd689fe6c322e3356eca798b3297e0344244f7843
|
| 3 |
+
size 6000267989
|
t2i/model/pytorch_model_module.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1c3cb36d521a186ad37b168a88029b59bb031e71e8e7a2c2afb7a4ed19628de0
|
| 3 |
+
size 3000100562
|
t2i/mt5/README.md
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- multilingual
|
| 4 |
+
- af
|
| 5 |
+
- am
|
| 6 |
+
- ar
|
| 7 |
+
- az
|
| 8 |
+
- be
|
| 9 |
+
- bg
|
| 10 |
+
- bn
|
| 11 |
+
- ca
|
| 12 |
+
- ceb
|
| 13 |
+
- co
|
| 14 |
+
- cs
|
| 15 |
+
- cy
|
| 16 |
+
- da
|
| 17 |
+
- de
|
| 18 |
+
- el
|
| 19 |
+
- en
|
| 20 |
+
- eo
|
| 21 |
+
- es
|
| 22 |
+
- et
|
| 23 |
+
- eu
|
| 24 |
+
- fa
|
| 25 |
+
- fi
|
| 26 |
+
- fil
|
| 27 |
+
- fr
|
| 28 |
+
- fy
|
| 29 |
+
- ga
|
| 30 |
+
- gd
|
| 31 |
+
- gl
|
| 32 |
+
- gu
|
| 33 |
+
- ha
|
| 34 |
+
- haw
|
| 35 |
+
- hi
|
| 36 |
+
- hmn
|
| 37 |
+
- ht
|
| 38 |
+
- hu
|
| 39 |
+
- hy
|
| 40 |
+
- ig
|
| 41 |
+
- is
|
| 42 |
+
- it
|
| 43 |
+
- iw
|
| 44 |
+
- ja
|
| 45 |
+
- jv
|
| 46 |
+
- ka
|
| 47 |
+
- kk
|
| 48 |
+
- km
|
| 49 |
+
- kn
|
| 50 |
+
- ko
|
| 51 |
+
- ku
|
| 52 |
+
- ky
|
| 53 |
+
- la
|
| 54 |
+
- lb
|
| 55 |
+
- lo
|
| 56 |
+
- lt
|
| 57 |
+
- lv
|
| 58 |
+
- mg
|
| 59 |
+
- mi
|
| 60 |
+
- mk
|
| 61 |
+
- ml
|
| 62 |
+
- mn
|
| 63 |
+
- mr
|
| 64 |
+
- ms
|
| 65 |
+
- mt
|
| 66 |
+
- my
|
| 67 |
+
- ne
|
| 68 |
+
- nl
|
| 69 |
+
- no
|
| 70 |
+
- ny
|
| 71 |
+
- pa
|
| 72 |
+
- pl
|
| 73 |
+
- ps
|
| 74 |
+
- pt
|
| 75 |
+
- ro
|
| 76 |
+
- ru
|
| 77 |
+
- sd
|
| 78 |
+
- si
|
| 79 |
+
- sk
|
| 80 |
+
- sl
|
| 81 |
+
- sm
|
| 82 |
+
- sn
|
| 83 |
+
- so
|
| 84 |
+
- sq
|
| 85 |
+
- sr
|
| 86 |
+
- st
|
| 87 |
+
- su
|
| 88 |
+
- sv
|
| 89 |
+
- sw
|
| 90 |
+
- ta
|
| 91 |
+
- te
|
| 92 |
+
- tg
|
| 93 |
+
- th
|
| 94 |
+
- tr
|
| 95 |
+
- uk
|
| 96 |
+
- und
|
| 97 |
+
- ur
|
| 98 |
+
- uz
|
| 99 |
+
- vi
|
| 100 |
+
- xh
|
| 101 |
+
- yi
|
| 102 |
+
- yo
|
| 103 |
+
- zh
|
| 104 |
+
- zu
|
| 105 |
+
datasets:
|
| 106 |
+
- mc4
|
| 107 |
+
|
| 108 |
+
license: apache-2.0
|
| 109 |
+
---
|
| 110 |
+
|
| 111 |
+
[Google's mT5](https://github.com/google-research/multilingual-t5)
|
| 112 |
+
|
| 113 |
+
mT5 is pretrained on the [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) corpus, covering 101 languages:
|
| 114 |
+
|
| 115 |
+
Afrikaans, Albanian, Amharic, Arabic, Armenian, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Burmese, Catalan, Cebuano, Chichewa, Chinese, Corsican, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hmong, Hungarian, Icelandic, Igbo, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish, Kyrgyz, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Mongolian, Nepali, Norwegian, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Samoan, Scottish Gaelic, Serbian, Shona, Sindhi, Sinhala, Slovak, Slovenian, Somali, Sotho, Spanish, Sundanese, Swahili, Swedish, Tajik, Tamil, Telugu, Thai, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, West Frisian, Xhosa, Yiddish, Yoruba, Zulu.
|
| 116 |
+
|
| 117 |
+
**Note**: mT5 was only pre-trained on mC4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
|
| 118 |
+
|
| 119 |
+
Pretraining Dataset: [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual)
|
| 120 |
+
|
| 121 |
+
Other Community Checkpoints: [here](https://huggingface.co/models?search=mt5)
|
| 122 |
+
|
| 123 |
+
Paper: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
|
| 124 |
+
|
| 125 |
+
Authors: *Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel*
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
## Abstract
|
| 129 |
+
|
| 130 |
+
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
|
t2i/mt5/config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/home/patrick/t5/mt5-xl",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MT5ForConditionalGeneration"
|
| 5 |
+
],
|
| 6 |
+
"d_ff": 5120,
|
| 7 |
+
"d_kv": 64,
|
| 8 |
+
"d_model": 2048,
|
| 9 |
+
"decoder_start_token_id": 0,
|
| 10 |
+
"dropout_rate": 0.1,
|
| 11 |
+
"eos_token_id": 1,
|
| 12 |
+
"feed_forward_proj": "gated-gelu",
|
| 13 |
+
"initializer_factor": 1.0,
|
| 14 |
+
"is_encoder_decoder": true,
|
| 15 |
+
"layer_norm_epsilon": 1e-06,
|
| 16 |
+
"model_type": "mt5",
|
| 17 |
+
"num_decoder_layers": 24,
|
| 18 |
+
"num_heads": 32,
|
| 19 |
+
"num_layers": 24,
|
| 20 |
+
"output_past": true,
|
| 21 |
+
"pad_token_id": 0,
|
| 22 |
+
"relative_attention_num_buckets": 32,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"tokenizer_class": "T5Tokenizer",
|
| 25 |
+
"transformers_version": "4.10.0.dev0",
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"vocab_size": 250112
|
| 28 |
+
}
|
t2i/mt5/generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"decoder_start_token_id": 0,
|
| 4 |
+
"eos_token_id": 1,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.27.0.dev0"
|
| 7 |
+
}
|
t2i/mt5/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e32f17c56414bb6834731148889b4314c2b6532824346a55ab7c1c54eb394dce
|
| 3 |
+
size 14970735570
|
t2i/mt5/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"eos_token": "</s>", "unk_token": "<unk>", "pad_token": "<pad>"}
|
t2i/mt5/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef78f86560d809067d12bac6c09f19a462cb3af3f54d2b8acbba26e1433125d6
|
| 3 |
+
size 4309802
|
t2i/mt5/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"eos_token": "</s>", "unk_token": "<unk>", "pad_token": "<pad>", "extra_ids": 0, "additional_special_tokens": null, "special_tokens_map_file": "/home/patrick/.cache/torch/transformers/685ac0ca8568ec593a48b61b0a3c272beee9bc194a3c7241d15dcadb5f875e53.f76030f3ec1b96a8199b2593390c610e76ca8028ef3d24680000619ffb646276", "tokenizer_file": null, "name_or_path": "google/mt5-small"}
|
t2i/sdxl-vae-fp16-fix/config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.18.0.dev0",
|
| 4 |
+
"_name_or_path": ".",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"block_out_channels": [
|
| 7 |
+
128,
|
| 8 |
+
256,
|
| 9 |
+
512,
|
| 10 |
+
512
|
| 11 |
+
],
|
| 12 |
+
"down_block_types": [
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D",
|
| 16 |
+
"DownEncoderBlock2D"
|
| 17 |
+
],
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 512,
|
| 24 |
+
"scaling_factor": 0.13025,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"force_upcast": false
|
| 32 |
+
}
|
t2i/sdxl-vae-fp16-fix/diffusion_pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:37eb3e09ae1ce3d6891ddf809ca927b618e501091142cf07fdd9cd170e3a046f
|
| 3 |
+
size 334712113
|
t2i/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b909373b28f2137098b0fd9dbc6f97f8410854f31f84ddc9fa04b077b0ace2c
|
| 3 |
+
size 334643238
|
t2i/tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
t2i/tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"do_basic_tokenize": true,
|
| 4 |
+
"do_lower_case": true,
|
| 5 |
+
"mask_token": "[MASK]",
|
| 6 |
+
"name_or_path": "hfl/chinese-roberta-wwm-ext",
|
| 7 |
+
"never_split": null,
|
| 8 |
+
"pad_token": "[PAD]",
|
| 9 |
+
"sep_token": "[SEP]",
|
| 10 |
+
"special_tokens_map_file": "/home/chenweifeng/.cache/huggingface/hub/models--hfl--chinese-roberta-wwm-ext/snapshots/5c58d0b8ec1d9014354d691c538661bf00bfdb44/special_tokens_map.json",
|
| 11 |
+
"strip_accents": null,
|
| 12 |
+
"tokenize_chinese_chars": true,
|
| 13 |
+
"tokenizer_class": "BertTokenizer",
|
| 14 |
+
"unk_token": "[UNK]",
|
| 15 |
+
"model_max_length": 77
|
| 16 |
+
}
|
t2i/tokenizer/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|