
Upload 9 files
Browse files- .gitattributes +5 -0
- aspiration_mel_band_roformer_less_aggr_sdr_18.1201.ckpt +3 -0
- aspiration_mel_band_roformer_sdr_18.9845.ckpt +3 -0
- config_aspiration_mel_band_roformer.yaml +77 -0
- example_audio/example_aspiration.wav +3 -0
- example_audio/example_aspiration_less_aggr.wav +3 -0
- example_audio/example_other.wav +3 -0
- example_audio/example_other_less_aggr.wav +3 -0
- example_audio/example_raw.wav +3 -0
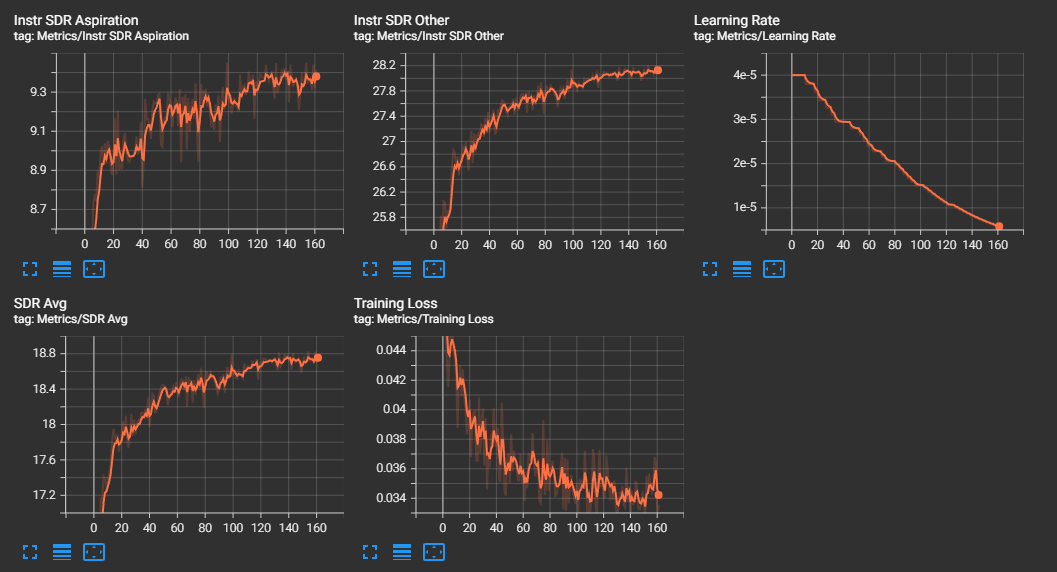
- training_logs.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
example_audio/example_aspiration_less_aggr.wav filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
example_audio/example_aspiration.wav filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
example_audio/example_other_less_aggr.wav filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
example_audio/example_other.wav filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
example_audio/example_raw.wav filter=lfs diff=lfs merge=lfs -text
|
aspiration_mel_band_roformer_less_aggr_sdr_18.1201.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83bfe991cec4fbadde9f30d1f79cd5293ad0b1f936256be327bba5cbb4883374
|
| 3 |
+
size 835982664
|
aspiration_mel_band_roformer_sdr_18.9845.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e791258c866c6c8da66052693d8cc3b64f1f42c01e052dbdc570cd278380cc5
|
| 3 |
+
size 835983746
|
config_aspiration_mel_band_roformer.yaml
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
audio:
|
| 2 |
+
chunk_size: 352800
|
| 3 |
+
dim_f: 1024
|
| 4 |
+
dim_t: 801 # don't work (use in model)
|
| 5 |
+
hop_length: 441 # don't work (use in model)
|
| 6 |
+
n_fft: 2048
|
| 7 |
+
num_channels: 2
|
| 8 |
+
sample_rate: 44100
|
| 9 |
+
min_mean_abs: 0.000
|
| 10 |
+
|
| 11 |
+
model:
|
| 12 |
+
dim: 256
|
| 13 |
+
depth: 8
|
| 14 |
+
stereo: true
|
| 15 |
+
num_stems: 2
|
| 16 |
+
time_transformer_depth: 1
|
| 17 |
+
freq_transformer_depth: 1
|
| 18 |
+
linear_transformer_depth: 0
|
| 19 |
+
num_bands: 60
|
| 20 |
+
dim_head: 64
|
| 21 |
+
heads: 8
|
| 22 |
+
attn_dropout: 0.1
|
| 23 |
+
ff_dropout: 0.1
|
| 24 |
+
flash_attn: True
|
| 25 |
+
dim_freqs_in: 1025
|
| 26 |
+
sample_rate: 44100 # needed for mel filter bank from librosa
|
| 27 |
+
stft_n_fft: 2048
|
| 28 |
+
stft_hop_length: 441
|
| 29 |
+
stft_win_length: 2048
|
| 30 |
+
stft_normalized: False
|
| 31 |
+
mask_estimator_depth: 2
|
| 32 |
+
multi_stft_resolution_loss_weight: 1.0
|
| 33 |
+
multi_stft_resolutions_window_sizes: !!python/tuple
|
| 34 |
+
- 4096
|
| 35 |
+
- 2048
|
| 36 |
+
- 1024
|
| 37 |
+
- 512
|
| 38 |
+
- 256
|
| 39 |
+
multi_stft_hop_size: 147
|
| 40 |
+
multi_stft_normalized: False
|
| 41 |
+
|
| 42 |
+
training:
|
| 43 |
+
batch_size: 1
|
| 44 |
+
gradient_accumulation_steps: 8
|
| 45 |
+
grad_clip: 0
|
| 46 |
+
instruments:
|
| 47 |
+
- aspiration
|
| 48 |
+
- other
|
| 49 |
+
lr: 4.0e-05
|
| 50 |
+
patience: 2
|
| 51 |
+
reduce_factor: 0.95
|
| 52 |
+
target_instrument: null
|
| 53 |
+
num_epochs: 1000
|
| 54 |
+
num_steps: 1000
|
| 55 |
+
q: 0.95
|
| 56 |
+
coarse_loss_clip: true
|
| 57 |
+
ema_momentum: 0.999
|
| 58 |
+
optimizer: adam
|
| 59 |
+
other_fix: false # it's needed for checking on multisong dataset if other is actually instrumental
|
| 60 |
+
use_amp: true # enable or disable usage of mixed precision (float16) - usually it must be true
|
| 61 |
+
|
| 62 |
+
augmentations:
|
| 63 |
+
enable: true # enable or disable all augmentations (to fast disable if needed)
|
| 64 |
+
loudness: true # randomly change loudness of each stem on the range (loudness_min; loudness_max)
|
| 65 |
+
loudness_min: 0.5
|
| 66 |
+
loudness_max: 1.5
|
| 67 |
+
mixup: false # mix several stems of same type with some probability (only works for dataset types: 1, 2, 3)
|
| 68 |
+
mixup_probs: !!python/tuple # 2 additional stems of the same type (1st with prob 0.2, 2nd with prob 0.02)
|
| 69 |
+
- 0.2
|
| 70 |
+
- 0.02
|
| 71 |
+
mixup_loudness_min: 0.5
|
| 72 |
+
mixup_loudness_max: 1.5
|
| 73 |
+
|
| 74 |
+
inference:
|
| 75 |
+
batch_size: 4
|
| 76 |
+
dim_t: 801
|
| 77 |
+
num_overlap: 2
|
example_audio/example_aspiration.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b6cd29a264c89dfa56181acbabadc8ed655753ddce4b9c3989dd6f2177c65d8
|
| 3 |
+
size 7722112
|
example_audio/example_aspiration_less_aggr.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e49b1c086b201df1fd64268c8a2a9705f6bdadf34b2a89733063305ec4bcf283
|
| 3 |
+
size 7722112
|
example_audio/example_other.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f8f99bf6e994f7b71f683f8d05b593394bb6cbe6b4d5e6965ada35b7174e687
|
| 3 |
+
size 7722112
|
example_audio/example_other_less_aggr.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ce6d2e9b34156225fe0d78575b8ee4190881dc83b4e135ce2e8277aa3d0a0b4
|
| 3 |
+
size 7722112
|
example_audio/example_raw.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:95ad1500c55e0e91e32f3bae5accb2d7353a0c22ff67e5ab84987485846b7e57
|
| 3 |
+
size 1936046
|
training_logs.png
ADDED
|