

Llama2 7b Ctranslate2 int8 quantized version
Browse files- README.md +77 -1
- config.json +6 -0
- gitattributes +35 -0
- model.bin +3 -0
- tokenizer.model +3 -0
- vocabulary.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,79 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
tags:
|
| 3 |
+
- ctranslate2
|
| 4 |
---
|
| 5 |
+
"Ctranslate2" is an amazing library that runs these models. They are faster, more accurate, and use less VRAM/RAM than GGML and GPTQ models.
|
| 6 |
+
|
| 7 |
+
How to run with instructions: https://github.com/BBC-Esq
|
| 8 |
+
- COMING SOON
|
| 9 |
+
|
| 10 |
+
Learn more about the amazing "ctranslate2" technology:"
|
| 11 |
+
- https://github.com/OpenNMT/CTranslate2
|
| 12 |
+
- https://opennmt.net/CTranslate2/index.html
|
| 13 |
+
|
| 14 |
+
<details>
|
| 15 |
+
<summary><b>Compatibility and Data Formats</b></summary>
|
| 16 |
+
|
| 17 |
+
| Format | Approximate Size Compared to `float32` | Nvidia GPU Required "Compute" | Accuracy Summary |
|
| 18 |
+
|-----------------|----------------------------|-----------------|--------------------------|
|
| 19 |
+
| `float32` | 100% | 1.0 | Offers more precision and a wider range. Most un-quantized models use this. |
|
| 20 |
+
| `int16` | 51.37% | 1.0 | Same as `int8` but with a larger range. |
|
| 21 |
+
| `float16` | 50.00% | 5.3 (e.g. Nvidia 10 Series and Higher) | Suitable for scientific computations; balance between precision and memory. |
|
| 22 |
+
| `bfloat16` | 50.00% | 8.0 (e.g. Nvidia 30 Series and Higher) | Often used in neural network training; larger exponent range than `float16`. |
|
| 23 |
+
| `int8_float32` | 27.47% | test manually (see below) | Combines low precision integer with high precision float. Useful for mixed data. |
|
| 24 |
+
| `int8_float16` | 26.10% | test manually (see below) | Combines low precision integer with medium precision float. Saves memory. |
|
| 25 |
+
| `int8_bfloat16` | 26.10% | test manually (see below) | Combines low precision integer with reduced precision float. Efficient for neural nets. |
|
| 26 |
+
| `int8` | 25% | 1.0 | Lower precision, suitable for whole numbers within a specific range. Often used where memory is crucial. |
|
| 27 |
+
|
| 28 |
+
| Web Link | Description |
|
| 29 |
+
|-------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|
|
| 30 |
+
| [CUDA GPUs Supported](https://en.wikipedia.org/wiki/CUDA#GPUs_supported) | See what level of "compute" your Nvidia GPU supports. |
|
| 31 |
+
| [CTranslate2 Quantization](https://opennmt.net/CTranslate2/quantization.html#implicit-type-conversion-on-load) | Even if your GPU/CPU doesn't support the data type of the model you download, "ctranslate2" will automatically run the model in a way that's compatible. |
|
| 32 |
+
| [Bfloat16 Floating-Point Format](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format#bfloat16_floating-point_format) | Visualize data formats. |
|
| 33 |
+
| [Nvidia Floating-Point](https://docs.nvidia.com/cuda/floating-point/index.html) | Technical discussion. |
|
| 34 |
+
</details>
|
| 35 |
+
|
| 36 |
+
<details>
|
| 37 |
+
|
| 38 |
+
<summary><b>Check Compatibility Manually</b></summary>
|
| 39 |
+
Open a command prompt and run the following commands (may require CUDA toolkit and cuDNN installed as well, need to doublecheck this):
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
pip install ctranslate2
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
python
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
import ctranslate2
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
Check GPU/CUDA compatibility:
|
| 54 |
+
|
| 55 |
+
```python
|
| 56 |
+
ctranslate2.get_supported_compute_types("cuda")
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
Check CPU compatibility:
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
ctranslate2.get_supported_compute_types("cpu")
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
It will print out your CPU/GPU compatibility. For example, a system with a 4090 GPU and 13900k would have the following compatibility:
|
| 66 |
+
|
| 67 |
+
| | **CPU** | **GPU** |
|
| 68 |
+
|-----------------|---------|---------|
|
| 69 |
+
| **`float32`** | ✅ | ✅ |
|
| 70 |
+
| **`int16`** | ✅ | |
|
| 71 |
+
| **`float16`** | | ✅ |
|
| 72 |
+
| **`bfloat16`** | | ✅ |
|
| 73 |
+
| **`int8_float32`** | ✅ | ✅ |
|
| 74 |
+
| **`int8_float16`** | | ✅ |
|
| 75 |
+
| **`int8_bfloat16`** | | ✅ |
|
| 76 |
+
| **`int8`** | ✅ | ✅ |
|
| 77 |
+
</details>
|
| 78 |
+
|
| 79 |
+
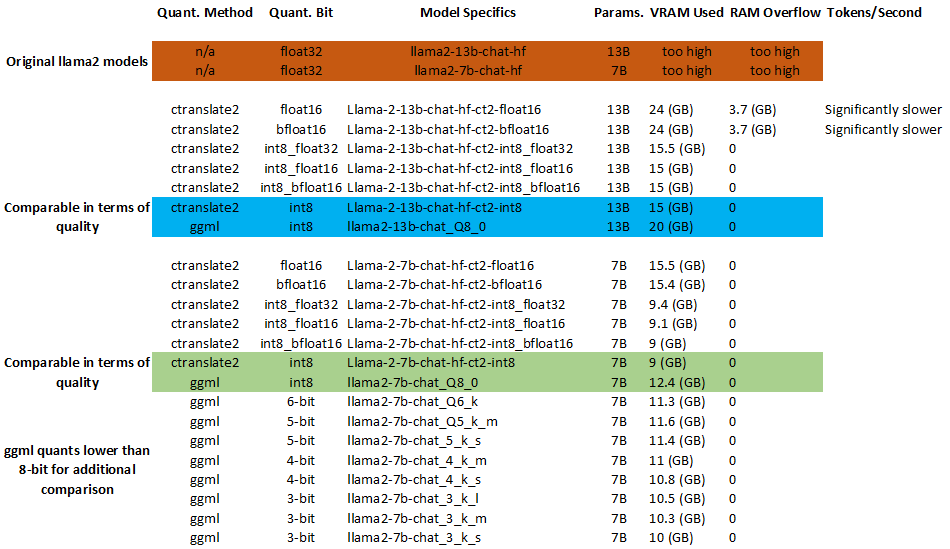
|
config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"eos_token": "</s>",
|
| 4 |
+
"layer_norm_epsilon": 1e-06,
|
| 5 |
+
"unk_token": "<unk>"
|
| 6 |
+
}
|
gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eaf78562a5d1b37baeda6871df9f3eed17136506a4c161de5b2652c87882e3c7
|
| 3 |
+
size 6744404022
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
vocabulary.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|