
Commit
•
c85f333
1
Parent(s):
4858383
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +8 -0
- License +470 -0
- README.md +199 -0
- assets/i2v/blackswan.gif +0 -0
- assets/i2v/chair.gif +0 -0
- assets/i2v/horse.gif +0 -0
- assets/i2v/input/blackswan.png +0 -0
- assets/i2v/input/chair.png +0 -0
- assets/i2v/input/horse.png +0 -0
- assets/i2v/input/sunset.png +0 -0
- assets/i2v/sunset.gif +0 -0
- assets/t2v/child.gif +0 -0
- assets/t2v/couple.gif +3 -0
- assets/t2v/duck.gif +0 -0
- assets/t2v/girl_moose.jpg +0 -0
- assets/t2v/rabbit.gif +0 -0
- assets/t2v/tom.gif +0 -0
- assets/t2v/woman.gif +0 -0
- cog.yaml +25 -0
- configs/inference_i2v_512_v1.0.yaml +83 -0
- configs/inference_t2v_1024_v1.0.yaml +77 -0
- configs/inference_t2v_512_v1.0.yaml +74 -0
- configs/inference_t2v_512_v2.0.yaml +77 -0
- gradio_app.py +58 -0
- lvdm/basics.py +100 -0
- lvdm/common.py +95 -0
- lvdm/distributions.py +95 -0
- lvdm/ema.py +76 -0
- lvdm/models/autoencoder.py +219 -0
- lvdm/models/ddpm3d.py +763 -0
- lvdm/models/samplers/ddim.py +336 -0
- lvdm/models/utils_diffusion.py +104 -0
- lvdm/modules/attention.py +475 -0
- lvdm/modules/encoders/condition.py +392 -0
- lvdm/modules/encoders/ip_resampler.py +136 -0
- lvdm/modules/networks/ae_modules.py +845 -0
- lvdm/modules/networks/openaimodel3d.py +577 -0
- lvdm/modules/x_transformer.py +640 -0
- predict.py +155 -0
- prompts/i2v_prompts/horse.png +0 -0
- prompts/i2v_prompts/seashore.png +0 -0
- prompts/i2v_prompts/test_prompts.txt +2 -0
- prompts/test_prompts.txt +2 -0
- requirements.txt +23 -0
- scripts/evaluation/ddp_wrapper.py +46 -0
- scripts/evaluation/funcs.py +194 -0
- scripts/evaluation/inference.py +137 -0
- scripts/gradio/i2v_test.py +83 -0
- scripts/gradio/t2v_test.py +77 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/t2v/couple.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
*pyc
|
| 3 |
+
.vscode
|
| 4 |
+
__pycache__
|
| 5 |
+
*.egg-info
|
| 6 |
+
|
| 7 |
+
checkpoints
|
| 8 |
+
results
|
License
ADDED
|
@@ -0,0 +1,470 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This license applies to the source codes that are open sourced in connection with the VideoCrafter1.
|
| 2 |
+
|
| 3 |
+
Copyright (C) 2023 THL A29 Limited, a Tencent company.
|
| 4 |
+
|
| 5 |
+
Apache License
|
| 6 |
+
Version 2.0, January 2004
|
| 7 |
+
http://www.apache.org/licenses/
|
| 8 |
+
|
| 9 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 10 |
+
|
| 11 |
+
1. Definitions.
|
| 12 |
+
|
| 13 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 14 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 15 |
+
|
| 16 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 17 |
+
the copyright owner that is granting the License.
|
| 18 |
+
|
| 19 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 20 |
+
other entities that control, are controlled by, or are under common
|
| 21 |
+
control with that entity. For the purposes of this definition,
|
| 22 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 23 |
+
direction or management of such entity, whether by contract or
|
| 24 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 25 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 26 |
+
|
| 27 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 28 |
+
exercising permissions granted by this License.
|
| 29 |
+
|
| 30 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 31 |
+
including but not limited to software source code, documentation
|
| 32 |
+
source, and configuration files.
|
| 33 |
+
|
| 34 |
+
"Object" form shall mean any form resulting from mechanical
|
| 35 |
+
transformation or translation of a Source form, including but
|
| 36 |
+
not limited to compiled object code, generated documentation,
|
| 37 |
+
and conversions to other media types.
|
| 38 |
+
|
| 39 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 40 |
+
Object form, made available under the License, as indicated by a
|
| 41 |
+
copyright notice that is included in or attached to the work
|
| 42 |
+
(an example is provided in the Appendix below).
|
| 43 |
+
|
| 44 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 45 |
+
form, that is based on (or derived from) the Work and for which the
|
| 46 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 47 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 48 |
+
of this License, Derivative Works shall not include works that remain
|
| 49 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 50 |
+
the Work and Derivative Works thereof.
|
| 51 |
+
|
| 52 |
+
"Contribution" shall mean any work of authorship, including
|
| 53 |
+
the original version of the Work and any modifications or additions
|
| 54 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 55 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 56 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 57 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 58 |
+
means any form of electronic, verbal, or written communication sent
|
| 59 |
+
to the Licensor or its representatives, including but not limited to
|
| 60 |
+
communication on electronic mailing lists, source code control systems,
|
| 61 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 62 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 63 |
+
excluding communication that is conspicuously marked or otherwise
|
| 64 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 65 |
+
|
| 66 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 67 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 68 |
+
subsequently incorporated within the Work.
|
| 69 |
+
|
| 70 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 71 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 72 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 73 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 74 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 75 |
+
Work and such Derivative Works in Source or Object form.
|
| 76 |
+
|
| 77 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 78 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 79 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 80 |
+
(except as stated in this section) patent license to make, have made,
|
| 81 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 82 |
+
where such license applies only to those patent claims licensable
|
| 83 |
+
by such Contributor that are necessarily infringed by their
|
| 84 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 85 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 86 |
+
institute patent litigation against any entity (including a
|
| 87 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 88 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 89 |
+
or contributory patent infringement, then any patent licenses
|
| 90 |
+
granted to You under this License for that Work shall terminate
|
| 91 |
+
as of the date such litigation is filed.
|
| 92 |
+
|
| 93 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 94 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 95 |
+
modifications, and in Source or Object form, provided that You
|
| 96 |
+
meet the following conditions:
|
| 97 |
+
|
| 98 |
+
(a) You must give any other recipients of the Work or
|
| 99 |
+
Derivative Works a copy of this License; and
|
| 100 |
+
|
| 101 |
+
(b) You must cause any modified files to carry prominent notices
|
| 102 |
+
stating that You changed the files; and
|
| 103 |
+
|
| 104 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 105 |
+
that You distribute, all copyright, patent, trademark, and
|
| 106 |
+
attribution notices from the Source form of the Work,
|
| 107 |
+
excluding those notices that do not pertain to any part of
|
| 108 |
+
the Derivative Works; and
|
| 109 |
+
|
| 110 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 111 |
+
distribution, then any Derivative Works that You distribute must
|
| 112 |
+
include a readable copy of the attribution notices contained
|
| 113 |
+
within such NOTICE file, excluding those notices that do not
|
| 114 |
+
pertain to any part of the Derivative Works, in at least one
|
| 115 |
+
of the following places: within a NOTICE text file distributed
|
| 116 |
+
as part of the Derivative Works; within the Source form or
|
| 117 |
+
documentation, if provided along with the Derivative Works; or,
|
| 118 |
+
within a display generated by the Derivative Works, if and
|
| 119 |
+
wherever such third-party notices normally appear. The contents
|
| 120 |
+
of the NOTICE file are for informational purposes only and
|
| 121 |
+
do not modify the License. You may add Your own attribution
|
| 122 |
+
notices within Derivative Works that You distribute, alongside
|
| 123 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 124 |
+
that such additional attribution notices cannot be construed
|
| 125 |
+
as modifying the License.
|
| 126 |
+
|
| 127 |
+
You may add Your own copyright statement to Your modifications and
|
| 128 |
+
may provide additional or different license terms and conditions
|
| 129 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 130 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 131 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 132 |
+
the conditions stated in this License.
|
| 133 |
+
|
| 134 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 135 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 136 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 137 |
+
this License, without any additional terms or conditions.
|
| 138 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 139 |
+
the terms of any separate license agreement you may have executed
|
| 140 |
+
with Licensor regarding such Contributions.
|
| 141 |
+
|
| 142 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 143 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 144 |
+
except as required for reasonable and customary use in describing the
|
| 145 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 146 |
+
|
| 147 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 148 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 149 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 150 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 151 |
+
implied, including, without limitation, any warranties or conditions
|
| 152 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 153 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 154 |
+
appropriateness of using or redistributing the Work and assume any
|
| 155 |
+
risks associated with Your exercise of permissions under this License.
|
| 156 |
+
|
| 157 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 158 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 159 |
+
unless required by applicable law (such as deliberate and grossly
|
| 160 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 161 |
+
liable to You for damages, including any direct, indirect, special,
|
| 162 |
+
incidental, or consequential damages of any character arising as a
|
| 163 |
+
result of this License or out of the use or inability to use the
|
| 164 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 165 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 166 |
+
other commercial damages or losses), even if such Contributor
|
| 167 |
+
has been advised of the possibility of such damages.
|
| 168 |
+
|
| 169 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 170 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 171 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 172 |
+
or other liability obligations and/or rights consistent with this
|
| 173 |
+
License. However, in accepting such obligations, You may act only
|
| 174 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 175 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 176 |
+
defend, and hold each Contributor harmless for any liability
|
| 177 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 178 |
+
of your accepting any such warranty or additional liability.
|
| 179 |
+
|
| 180 |
+
10. This code is provided for research purposes only and is
|
| 181 |
+
not to be used for any commercial purposes. By using this code,
|
| 182 |
+
you agree that it will be used solely for academic research, scholarly work,
|
| 183 |
+
and non-commercial activities. Any use of this code for commercial purposes,
|
| 184 |
+
including but not limited to, selling, distributing, or incorporating it into
|
| 185 |
+
commercial products or services, is strictly prohibited. Violation of this
|
| 186 |
+
clause may result in legal actions and penalties.
|
| 187 |
+
|
| 188 |
+
END OF TERMS AND CONDITIONS
|
| 189 |
+
|
| 190 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 191 |
+
|
| 192 |
+
To apply the Apache License to your work, attach the following
|
| 193 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 194 |
+
replaced with your own identifying information. (Don't include
|
| 195 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 196 |
+
comment syntax for the file format. We also recommend that a
|
| 197 |
+
file or class name and description of purpose be included on the
|
| 198 |
+
same "printed page" as the copyright notice for easier
|
| 199 |
+
identification within third-party archives.
|
| 200 |
+
|
| 201 |
+
Copyright [yyyy] [name of copyright owner]
|
| 202 |
+
|
| 203 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 204 |
+
you may not use this file except in compliance with the License.
|
| 205 |
+
You may obtain a copy of the License at
|
| 206 |
+
|
| 207 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 208 |
+
|
| 209 |
+
Unless required by applicable law or agreed to in writing, software
|
| 210 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 211 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 212 |
+
See the License for the specific language governing permissions and
|
| 213 |
+
limitations under the License.
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
Other dependencies and licenses (if such optional components are used):
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
Components under BSD 3-Clause License:
|
| 220 |
+
------------------------------------------------
|
| 221 |
+
1. numpy
|
| 222 |
+
Copyright (c) 2005-2022, NumPy Developers.
|
| 223 |
+
All rights reserved.
|
| 224 |
+
|
| 225 |
+
2. pytorch
|
| 226 |
+
Copyright (c) 2016- Facebook, Inc (Adam Paszke)
|
| 227 |
+
Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
|
| 228 |
+
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
|
| 229 |
+
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
|
| 230 |
+
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
|
| 231 |
+
Copyright (c) 2011-2013 NYU (Clement Farabet)
|
| 232 |
+
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
|
| 233 |
+
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
|
| 234 |
+
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
|
| 235 |
+
|
| 236 |
+
3. torchvision
|
| 237 |
+
Copyright (c) Soumith Chintala 2016,
|
| 238 |
+
All rights reserved.
|
| 239 |
+
|
| 240 |
+
Redistribution and use in source and binary forms, with or without
|
| 241 |
+
modification, are permitted provided that the following conditions are met:
|
| 242 |
+
|
| 243 |
+
* Redistributions of source code must retain the above copyright notice, this
|
| 244 |
+
list of conditions and the following disclaimer.
|
| 245 |
+
|
| 246 |
+
* Redistributions in binary form must reproduce the above copyright notice,
|
| 247 |
+
this list of conditions and the following disclaimer in the documentation
|
| 248 |
+
and/or other materials provided with the distribution.
|
| 249 |
+
|
| 250 |
+
* Neither the name of the copyright holder nor the names of its
|
| 251 |
+
contributors may be used to endorse or promote products derived from
|
| 252 |
+
this software without specific prior written permission.
|
| 253 |
+
|
| 254 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 255 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 256 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 257 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 258 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 259 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 260 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 261 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 262 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 263 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 264 |
+
|
| 265 |
+
Component under Apache v2 License:
|
| 266 |
+
-----------------------------------------------------
|
| 267 |
+
1. timm
|
| 268 |
+
Copyright 2019 Ross Wightman
|
| 269 |
+
|
| 270 |
+
Apache License
|
| 271 |
+
Version 2.0, January 2004
|
| 272 |
+
http://www.apache.org/licenses/
|
| 273 |
+
|
| 274 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 275 |
+
|
| 276 |
+
1. Definitions.
|
| 277 |
+
|
| 278 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 279 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 280 |
+
|
| 281 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 282 |
+
the copyright owner that is granting the License.
|
| 283 |
+
|
| 284 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 285 |
+
other entities that control, are controlled by, or are under common
|
| 286 |
+
control with that entity. For the purposes of this definition,
|
| 287 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 288 |
+
direction or management of such entity, whether by contract or
|
| 289 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 290 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 291 |
+
|
| 292 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 293 |
+
exercising permissions granted by this License.
|
| 294 |
+
|
| 295 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 296 |
+
including but not limited to software source code, documentation
|
| 297 |
+
source, and configuration files.
|
| 298 |
+
|
| 299 |
+
"Object" form shall mean any form resulting from mechanical
|
| 300 |
+
transformation or translation of a Source form, including but
|
| 301 |
+
not limited to compiled object code, generated documentation,
|
| 302 |
+
and conversions to other media types.
|
| 303 |
+
|
| 304 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 305 |
+
Object form, made available under the License, as indicated by a
|
| 306 |
+
copyright notice that is included in or attached to the work
|
| 307 |
+
(an example is provided in the Appendix below).
|
| 308 |
+
|
| 309 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 310 |
+
form, that is based on (or derived from) the Work and for which the
|
| 311 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 312 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 313 |
+
of this License, Derivative Works shall not include works that remain
|
| 314 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 315 |
+
the Work and Derivative Works thereof.
|
| 316 |
+
|
| 317 |
+
"Contribution" shall mean any work of authorship, including
|
| 318 |
+
the original version of the Work and any modifications or additions
|
| 319 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 320 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 321 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 322 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 323 |
+
means any form of electronic, verbal, or written communication sent
|
| 324 |
+
to the Licensor or its representatives, including but not limited to
|
| 325 |
+
communication on electronic mailing lists, source code control systems,
|
| 326 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 327 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 328 |
+
excluding communication that is conspicuously marked or otherwise
|
| 329 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 330 |
+
|
| 331 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 332 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 333 |
+
subsequently incorporated within the Work.
|
| 334 |
+
|
| 335 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 336 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 337 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 338 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 339 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 340 |
+
Work and such Derivative Works in Source or Object form.
|
| 341 |
+
|
| 342 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 343 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 344 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 345 |
+
(except as stated in this section) patent license to make, have made,
|
| 346 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 347 |
+
where such license applies only to those patent claims licensable
|
| 348 |
+
by such Contributor that are necessarily infringed by their
|
| 349 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 350 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 351 |
+
institute patent litigation against any entity (including a
|
| 352 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 353 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 354 |
+
or contributory patent infringement, then any patent licenses
|
| 355 |
+
granted to You under this License for that Work shall terminate
|
| 356 |
+
as of the date such litigation is filed.
|
| 357 |
+
|
| 358 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 359 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 360 |
+
modifications, and in Source or Object form, provided that You
|
| 361 |
+
meet the following conditions:
|
| 362 |
+
|
| 363 |
+
(a) You must give any other recipients of the Work or
|
| 364 |
+
Derivative Works a copy of this License; and
|
| 365 |
+
|
| 366 |
+
(b) You must cause any modified files to carry prominent notices
|
| 367 |
+
stating that You changed the files; and
|
| 368 |
+
|
| 369 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 370 |
+
that You distribute, all copyright, patent, trademark, and
|
| 371 |
+
attribution notices from the Source form of the Work,
|
| 372 |
+
excluding those notices that do not pertain to any part of
|
| 373 |
+
the Derivative Works; and
|
| 374 |
+
|
| 375 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 376 |
+
distribution, then any Derivative Works that You distribute must
|
| 377 |
+
include a readable copy of the attribution notices contained
|
| 378 |
+
within such NOTICE file, excluding those notices that do not
|
| 379 |
+
pertain to any part of the Derivative Works, in at least one
|
| 380 |
+
of the following places: within a NOTICE text file distributed
|
| 381 |
+
as part of the Derivative Works; within the Source form or
|
| 382 |
+
documentation, if provided along with the Derivative Works; or,
|
| 383 |
+
within a display generated by the Derivative Works, if and
|
| 384 |
+
wherever such third-party notices normally appear. The contents
|
| 385 |
+
of the NOTICE file are for informational purposes only and
|
| 386 |
+
do not modify the License. You may add Your own attribution
|
| 387 |
+
notices within Derivative Works that You distribute, alongside
|
| 388 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 389 |
+
that such additional attribution notices cannot be construed
|
| 390 |
+
as modifying the License.
|
| 391 |
+
|
| 392 |
+
You may add Your own copyright statement to Your modifications and
|
| 393 |
+
may provide additional or different license terms and conditions
|
| 394 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 395 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 396 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 397 |
+
the conditions stated in this License.
|
| 398 |
+
|
| 399 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 400 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 401 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 402 |
+
this License, without any additional terms or conditions.
|
| 403 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 404 |
+
the terms of any separate license agreement you may have executed
|
| 405 |
+
with Licensor regarding such Contributions.
|
| 406 |
+
|
| 407 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 408 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 409 |
+
except as required for reasonable and customary use in describing the
|
| 410 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 411 |
+
|
| 412 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 413 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 414 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 415 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 416 |
+
implied, including, without limitation, any warranties or conditions
|
| 417 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 418 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 419 |
+
appropriateness of using or redistributing the Work and assume any
|
| 420 |
+
risks associated with Your exercise of permissions under this License.
|
| 421 |
+
|
| 422 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 423 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 424 |
+
unless required by applicable law (such as deliberate and grossly
|
| 425 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 426 |
+
liable to You for damages, including any direct, indirect, special,
|
| 427 |
+
incidental, or consequential damages of any character arising as a
|
| 428 |
+
result of this License or out of the use or inability to use the
|
| 429 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 430 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 431 |
+
other commercial damages or losses), even if such Contributor
|
| 432 |
+
has been advised of the possibility of such damages.
|
| 433 |
+
|
| 434 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 435 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 436 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 437 |
+
or other liability obligations and/or rights consistent with this
|
| 438 |
+
License. However, in accepting such obligations, You may act only
|
| 439 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 440 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 441 |
+
defend, and hold each Contributor harmless for any liability
|
| 442 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 443 |
+
of your accepting any such warranty or additional liability.
|
| 444 |
+
|
| 445 |
+
END OF TERMS AND CONDITIONS
|
| 446 |
+
|
| 447 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 448 |
+
|
| 449 |
+
To apply the Apache License to your work, attach the following
|
| 450 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 451 |
+
replaced with your own identifying information. (Don't include
|
| 452 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 453 |
+
comment syntax for the file format. We also recommend that a
|
| 454 |
+
file or class name and description of purpose be included on the
|
| 455 |
+
same "printed page" as the copyright notice for easier
|
| 456 |
+
identification within third-party archives.
|
| 457 |
+
|
| 458 |
+
Copyright [yyyy] [name of copyright owner]
|
| 459 |
+
|
| 460 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 461 |
+
you may not use this file except in compliance with the License.
|
| 462 |
+
You may obtain a copy of the License at
|
| 463 |
+
|
| 464 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 465 |
+
|
| 466 |
+
Unless required by applicable law or agreed to in writing, software
|
| 467 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 468 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 469 |
+
See the License for the specific language governing permissions and
|
| 470 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
## ___***VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models***___
|
| 3 |
+
|
| 4 |
+
<a href='https://ailab-cvc.github.io/videocrafter2/'><img src='https://img.shields.io/badge/Project-Page-green'></a>
|
| 5 |
+
<a href='https://arxiv.org/abs/2401.09047'><img src='https://img.shields.io/badge/Technique-Report-red'></a>
|
| 6 |
+
[](https://discord.gg/rrayYqZ4tf)
|
| 7 |
+
<a href='https://huggingface.co/spaces/VideoCrafter/VideoCrafter'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a>
|
| 8 |
+
[](https://github.com/VideoCrafter/VideoCrafter)
|
| 9 |
+
|
| 10 |
+
### 🔥🔥 Our dedicated high-resolution I2V model is released at: :point_right:[DynamiCrafter](https://github.com/Doubiiu/DynamiCrafter)!!!
|
| 11 |
+
|
| 12 |
+
[](https://www.youtube.com/watch?v=0NfmIsNAg-g)
|
| 13 |
+
|
| 14 |
+
### 🔥The VideoCrafter2 Large improvements over VideoCrafter1 with limited data. Better Motion, Better Concept Combination!!!
|
| 15 |
+
|
| 16 |
+
Please Join us and create your own film on [Discord/Floor33](https://discord.gg/rrayYqZ4tf).
|
| 17 |
+
|
| 18 |
+
##### 🎥 Exquisite film, produced by VideoCrafter2, directed by Human
|
| 19 |
+
[](https://www.youtube.com/watch?v=TUsFkW0tK-s)
|
| 20 |
+
|
| 21 |
+
## 🔆 Introduction
|
| 22 |
+
|
| 23 |
+
🤗🤗🤗 VideoCrafter is an open-source video generation and editing toolbox for crafting video content.
|
| 24 |
+
It currently includes the Text2Video and Image2Video models:
|
| 25 |
+
|
| 26 |
+
### 1. Generic Text-to-video Generation
|
| 27 |
+
Click the GIF to access the high-resolution video.
|
| 28 |
+
|
| 29 |
+
<table class="center">
|
| 30 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/d20ee09d-fc32-44a8-9e9a-f12f44b30411"><img src=assets/t2v/tom.gif width="320"></td>
|
| 31 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/f1d9f434-28e8-44f6-a9b8-cffd67e4574d"><img src=assets/t2v/child.gif width="320"></td>
|
| 32 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/bbcfef0e-d8fb-4850-adc0-d8f937c2fa36"><img src=assets/t2v/woman.gif width="320"></td>
|
| 33 |
+
<tr>
|
| 34 |
+
<td style="text-align:center;" width="320">"Tom Cruise's face reflects focus, his eyes filled with purpose and drive."</td>
|
| 35 |
+
<td style="text-align:center;" width="320">"A child excitedly swings on a rusty swing set, laughter filling the air."</td>
|
| 36 |
+
<td style="text-align:center;" width="320">"A young woman with glasses is jogging in the park wearing a pink headband."</td>
|
| 37 |
+
<tr>
|
| 38 |
+
</table >
|
| 39 |
+
|
| 40 |
+
<table class="center">
|
| 41 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/7edafc5a-750e-45f3-a46e-b593751a4b12"><img src=assets/t2v/couple.gif width="320"></td>
|
| 42 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/37fe41c8-31fb-4e77-bcf9-fa159baa6d86"><img src=assets/t2v/rabbit.gif width="320"></td>
|
| 43 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/09791a46-a243-41b8-a6bb-892cdd3a83a2"><img src=assets/t2v/duck.gif width="320"></td>
|
| 44 |
+
<tr>
|
| 45 |
+
<td style="text-align:center;" width="320">"With the style of van gogh, A young couple dances under the moonlight by the lake."</td>
|
| 46 |
+
<td style="text-align:center;" width="320">"A rabbit, low-poly game art style"</td>
|
| 47 |
+
<td style="text-align:center;" width="320">"Impressionist style, a yellow rubber duck floating on the wave on the sunset"</td>
|
| 48 |
+
<tr>
|
| 49 |
+
</table >
|
| 50 |
+
|
| 51 |
+
### 2. Generic Image-to-video Generation
|
| 52 |
+
|
| 53 |
+
<table class="center">
|
| 54 |
+
<td><img src=assets/i2v/input/blackswan.png width="170"></td>
|
| 55 |
+
<td><img src=assets/i2v/input/horse.png width="170"></td>
|
| 56 |
+
<td><img src=assets/i2v/input/chair.png width="170"></td>
|
| 57 |
+
<td><img src=assets/i2v/input/sunset.png width="170"></td>
|
| 58 |
+
<tr>
|
| 59 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/1a57edd9-3fd2-4ce9-8313-89aca95b6ec7"><img src=assets/i2v/blackswan.gif width="170"></td>
|
| 60 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/d671419d-ae49-4889-807e-b841aef60e8a"><img src=assets/i2v/horse.gif width="170"></td>
|
| 61 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/39d730d9-7b47-4132-bdae-4d18f3e651ee"><img src=assets/i2v/chair.gif width="170"></td>
|
| 62 |
+
<td><a href="https://github.com/AILab-CVC/VideoCrafter/assets/18735168/dc8dd0d5-a80d-4f31-94db-f9ea0b13172b"><img src=assets/i2v/sunset.gif width="170"></td>
|
| 63 |
+
<tr>
|
| 64 |
+
<td style="text-align:center;" width="170">"a black swan swims on the pond"</td>
|
| 65 |
+
<td style="text-align:center;" width="170">"a girl is riding a horse fast on grassland"</td>
|
| 66 |
+
<td style="text-align:center;" width="170">"a boy sits on a chair facing the sea"</td>
|
| 67 |
+
<td style="text-align:center;" width="170">"two galleons moving in the wind at sunset"</td>
|
| 68 |
+
|
| 69 |
+
</table >
|
| 70 |
+
|
| 71 |
+
:boom: **You are highly recommended to try our dedicated I2V model [DynamiCrafter](https://github.com/Doubiiu/DynamiCrafter): Higher resolution, Better Dynamics, More Coherence!!!**
|
| 72 |
+
|
| 73 |
+
---
|
| 74 |
+
|
| 75 |
+
## 📝 Changelog
|
| 76 |
+
- __[2024.02.05]__: 🔥🔥 Release new I2V model with the resolution of 640x1024 of VideoCrafter1/DynamiCrafter.
|
| 77 |
+
|
| 78 |
+
- __[2024.01.26]__: Release the 512x320 checkpoint of VideoCrafter2.
|
| 79 |
+
|
| 80 |
+
- __[2024.01.18]__: Release the [VideoCrafter2](https://ailab-cvc.github.io/videocrafter2/) and [Tech Report](https://arxiv.org/abs/2401.09047)!
|
| 81 |
+
|
| 82 |
+
- __[2023.10.30]__: Release [VideoCrafter1](https://arxiv.org/abs/2310.19512) Technical Report!
|
| 83 |
+
|
| 84 |
+
- __[2023.10.13]__: Release the VideoCrafter1, High Quality Video Generation!
|
| 85 |
+
|
| 86 |
+
- __[2023.08.14]__: Release a new version of VideoCrafter on [Discord/Floor33](https://discord.gg/uHaQuThT). Please join us to create your own film!
|
| 87 |
+
|
| 88 |
+
- __[2023.04.18]__: Release a VideoControl model with most of the watermarks removed!
|
| 89 |
+
|
| 90 |
+
- __[2023.04.05]__: Release pretrained Text-to-Video models, VideoLora models, and inference code.
|
| 91 |
+
<br>
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## ⏳ Models
|
| 95 |
+
|
| 96 |
+
|T2V-Models|Resolution|Checkpoints|
|
| 97 |
+
|:---------|:---------|:--------|
|
| 98 |
+
|VideoCrafter2|320x512|[Hugging Face](https://huggingface.co/VideoCrafter/VideoCrafter2/blob/main/model.ckpt)
|
| 99 |
+
|VideoCrafter1|576x1024|[Hugging Face](https://huggingface.co/VideoCrafter/Text2Video-1024/blob/main/model.ckpt)
|
| 100 |
+
|VideoCrafter1|320x512|[Hugging Face](https://huggingface.co/VideoCrafter/Text2Video-512/blob/main/model.ckpt)
|
| 101 |
+
|
| 102 |
+
|I2V-Models|Resolution|Checkpoints|
|
| 103 |
+
|:---------|:---------|:--------|
|
| 104 |
+
|VideoCrafter1|640x1024|[Hugging Face](https://huggingface.co/Doubiiu/DynamiCrafter_1024/blob/main/model.ckpt)
|
| 105 |
+
|VideoCrafter1|320x512|[Hugging Face](https://huggingface.co/VideoCrafter/Image2Video-512/blob/main/model.ckpt)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
## ⚙️ Setup
|
| 110 |
+
|
| 111 |
+
### 1. Install Environment via Anaconda (Recommended)
|
| 112 |
+
```bash
|
| 113 |
+
conda create -n videocrafter python=3.8.5
|
| 114 |
+
conda activate videocrafter
|
| 115 |
+
pip install -r requirements.txt
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
## 💫 Inference
|
| 120 |
+
### 1. Text-to-Video
|
| 121 |
+
|
| 122 |
+
1) Download pretrained T2V models via [Hugging Face](https://huggingface.co/VideoCrafter/VideoCrafter2/blob/main/model.ckpt), and put the `model.ckpt` in `checkpoints/base_512_v2/model.ckpt`.
|
| 123 |
+
2) Input the following commands in terminal.
|
| 124 |
+
```bash
|
| 125 |
+
sh scripts/run_text2video.sh
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
### 2. Image-to-Video
|
| 129 |
+
|
| 130 |
+
1) Download pretrained I2V models via [Hugging Face](https://huggingface.co/VideoCrafter/Image2Video-512-v1.0/blob/main/model.ckpt), and put the `model.ckpt` in `checkpoints/i2v_512_v1/model.ckpt`.
|
| 131 |
+
2) Input the following commands in terminal.
|
| 132 |
+
```bash
|
| 133 |
+
sh scripts/run_image2video.sh
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
### 3. Local Gradio demo
|
| 137 |
+
|
| 138 |
+
1. Download the pretrained T2V and I2V models and put them in the corresponding directory according to the previous guidelines.
|
| 139 |
+
2. Input the following commands in terminal.
|
| 140 |
+
```bash
|
| 141 |
+
python gradio_app.py
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
---
|
| 145 |
+
## 📋 Techinical Report
|
| 146 |
+
😉 VideoCrafter2 Tech report: [VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models](https://arxiv.org/abs/2401.09047)
|
| 147 |
+
|
| 148 |
+
😉 VideoCrafter1 Tech report: [VideoCrafter1: Open Diffusion Models for High-Quality Video Generation](https://arxiv.org/abs/2310.19512)
|
| 149 |
+
<br>
|
| 150 |
+
|
| 151 |
+
## 😉 Citation
|
| 152 |
+
The technical report is currently unavailable as it is still in preparation. You can cite the paper of our image-to-video model and related base model.
|
| 153 |
+
```
|
| 154 |
+
@misc{chen2024videocrafter2,
|
| 155 |
+
title={VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models},
|
| 156 |
+
author={Haoxin Chen and Yong Zhang and Xiaodong Cun and Menghan Xia and Xintao Wang and Chao Weng and Ying Shan},
|
| 157 |
+
year={2024},
|
| 158 |
+
eprint={2401.09047},
|
| 159 |
+
archivePrefix={arXiv},
|
| 160 |
+
primaryClass={cs.CV}
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
@misc{chen2023videocrafter1,
|
| 164 |
+
title={VideoCrafter1: Open Diffusion Models for High-Quality Video Generation},
|
| 165 |
+
author={Haoxin Chen and Menghan Xia and Yingqing He and Yong Zhang and Xiaodong Cun and Shaoshu Yang and Jinbo Xing and Yaofang Liu and Qifeng Chen and Xintao Wang and Chao Weng and Ying Shan},
|
| 166 |
+
year={2023},
|
| 167 |
+
eprint={2310.19512},
|
| 168 |
+
archivePrefix={arXiv},
|
| 169 |
+
primaryClass={cs.CV}
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
@article{xing2023dynamicrafter,
|
| 173 |
+
title={DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors},
|
| 174 |
+
author={Jinbo Xing and Menghan Xia and Yong Zhang and Haoxin Chen and Xintao Wang and Tien-Tsin Wong and Ying Shan},
|
| 175 |
+
year={2023},
|
| 176 |
+
eprint={2310.12190},
|
| 177 |
+
archivePrefix={arXiv},
|
| 178 |
+
primaryClass={cs.CV}
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
@article{he2022lvdm,
|
| 182 |
+
title={Latent Video Diffusion Models for High-Fidelity Long Video Generation},
|
| 183 |
+
author={Yingqing He and Tianyu Yang and Yong Zhang and Ying Shan and Qifeng Chen},
|
| 184 |
+
year={2022},
|
| 185 |
+
eprint={2211.13221},
|
| 186 |
+
archivePrefix={arXiv},
|
| 187 |
+
primaryClass={cs.CV}
|
| 188 |
+
}
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
## 🤗 Acknowledgements
|
| 193 |
+
Our codebase builds on [Stable Diffusion](https://github.com/Stability-AI/stablediffusion).
|
| 194 |
+
Thanks the authors for sharing their awesome codebases!
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
## 📢 Disclaimer
|
| 198 |
+
We develop this repository for RESEARCH purposes, so it can only be used for personal/research/non-commercial purposes.
|
| 199 |
+
****
|
assets/i2v/blackswan.gif
ADDED

|
assets/i2v/chair.gif
ADDED

|
assets/i2v/horse.gif
ADDED

|
assets/i2v/input/blackswan.png
ADDED

|
assets/i2v/input/chair.png
ADDED

|
assets/i2v/input/horse.png
ADDED

|
assets/i2v/input/sunset.png
ADDED

|
assets/i2v/sunset.gif
ADDED
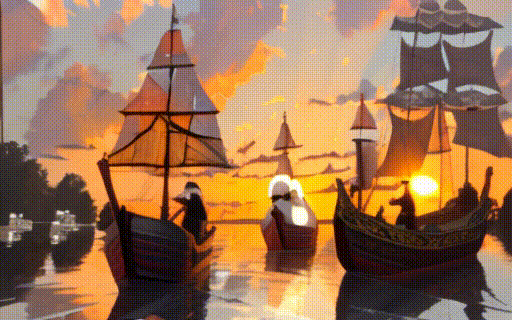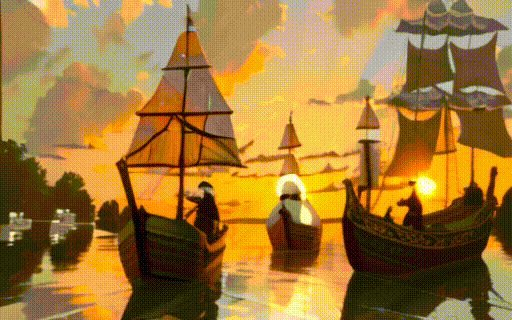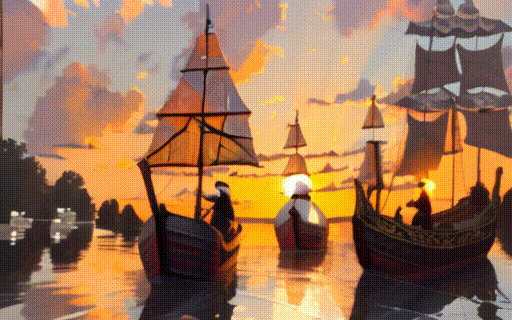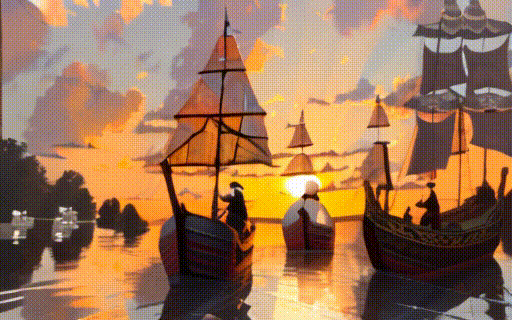
|
assets/t2v/child.gif
ADDED

|
assets/t2v/couple.gif
ADDED

|
Git LFS Details
|
assets/t2v/duck.gif
ADDED

|
assets/t2v/girl_moose.jpg
ADDED

|
assets/t2v/rabbit.gif
ADDED

|
assets/t2v/tom.gif
ADDED

|
assets/t2v/woman.gif
ADDED

|
cog.yaml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration for Cog ⚙️
|
| 2 |
+
# Reference: https://github.com/replicate/cog/blob/main/docs/yaml.md
|
| 3 |
+
|
| 4 |
+
build:
|
| 5 |
+
gpu: true
|
| 6 |
+
system_packages:
|
| 7 |
+
- "libgl1-mesa-glx"
|
| 8 |
+
- "libglib2.0-0"
|
| 9 |
+
python_version: "3.11"
|
| 10 |
+
python_packages:
|
| 11 |
+
- "torch==2.0.1"
|
| 12 |
+
- "opencv-python==4.8.1.78"
|
| 13 |
+
- "torchvision==0.15.2"
|
| 14 |
+
- "pytorch_lightning==2.1.0"
|
| 15 |
+
- "einops==0.7.0"
|
| 16 |
+
- "imageio==2.31.6"
|
| 17 |
+
- "omegaconf==2.3.0"
|
| 18 |
+
- "transformers==4.35.0"
|
| 19 |
+
- "moviepy==1.0.3"
|
| 20 |
+
- "av==10.0.0"
|
| 21 |
+
- "decord==0.6.0"
|
| 22 |
+
- "kornia==0.7.0"
|
| 23 |
+
- "open-clip-torch==2.12.0"
|
| 24 |
+
- "xformers==0.0.21"
|
| 25 |
+
predict: "predict.py:Predictor"
|
configs/inference_i2v_512_v1.0.yaml
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
target: lvdm.models.ddpm3d.LatentVisualDiffusion
|
| 3 |
+
params:
|
| 4 |
+
linear_start: 0.00085
|
| 5 |
+
linear_end: 0.012
|
| 6 |
+
num_timesteps_cond: 1
|
| 7 |
+
timesteps: 1000
|
| 8 |
+
first_stage_key: video
|
| 9 |
+
cond_stage_key: caption
|
| 10 |
+
cond_stage_trainable: false
|
| 11 |
+
conditioning_key: crossattn
|
| 12 |
+
image_size:
|
| 13 |
+
- 40
|
| 14 |
+
- 64
|
| 15 |
+
channels: 4
|
| 16 |
+
scale_by_std: false
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: false
|
| 19 |
+
uncond_type: empty_seq
|
| 20 |
+
use_scale: true
|
| 21 |
+
scale_b: 0.7
|
| 22 |
+
finegrained: true
|
| 23 |
+
unet_config:
|
| 24 |
+
target: lvdm.modules.networks.openaimodel3d.UNetModel
|
| 25 |
+
params:
|
| 26 |
+
in_channels: 4
|
| 27 |
+
out_channels: 4
|
| 28 |
+
model_channels: 320
|
| 29 |
+
attention_resolutions:
|
| 30 |
+
- 4
|
| 31 |
+
- 2
|
| 32 |
+
- 1
|
| 33 |
+
num_res_blocks: 2
|
| 34 |
+
channel_mult:
|
| 35 |
+
- 1
|
| 36 |
+
- 2
|
| 37 |
+
- 4
|
| 38 |
+
- 4
|
| 39 |
+
num_head_channels: 64
|
| 40 |
+
transformer_depth: 1
|
| 41 |
+
context_dim: 1024
|
| 42 |
+
use_linear: true
|
| 43 |
+
use_checkpoint: true
|
| 44 |
+
temporal_conv: true
|
| 45 |
+
temporal_attention: true
|
| 46 |
+
temporal_selfatt_only: true
|
| 47 |
+
use_relative_position: false
|
| 48 |
+
use_causal_attention: false
|
| 49 |
+
use_image_attention: true
|
| 50 |
+
temporal_length: 16
|
| 51 |
+
addition_attention: true
|
| 52 |
+
fps_cond: true
|
| 53 |
+
first_stage_config:
|
| 54 |
+
target: lvdm.models.autoencoder.AutoencoderKL
|
| 55 |
+
params:
|
| 56 |
+
embed_dim: 4
|
| 57 |
+
monitor: val/rec_loss
|
| 58 |
+
ddconfig:
|
| 59 |
+
double_z: true
|
| 60 |
+
z_channels: 4
|
| 61 |
+
resolution: 512
|
| 62 |
+
in_channels: 3
|
| 63 |
+
out_ch: 3
|
| 64 |
+
ch: 128
|
| 65 |
+
ch_mult:
|
| 66 |
+
- 1
|
| 67 |
+
- 2
|
| 68 |
+
- 4
|
| 69 |
+
- 4
|
| 70 |
+
num_res_blocks: 2
|
| 71 |
+
attn_resolutions: []
|
| 72 |
+
dropout: 0.0
|
| 73 |
+
lossconfig:
|
| 74 |
+
target: torch.nn.Identity
|
| 75 |
+
cond_stage_config:
|
| 76 |
+
target: lvdm.modules.encoders.condition.FrozenOpenCLIPEmbedder
|
| 77 |
+
params:
|
| 78 |
+
freeze: true
|
| 79 |
+
layer: penultimate
|
| 80 |
+
cond_img_config:
|
| 81 |
+
target: lvdm.modules.encoders.condition.FrozenOpenCLIPImageEmbedderV2
|
| 82 |
+
params:
|
| 83 |
+
freeze: true
|
configs/inference_t2v_1024_v1.0.yaml
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
target: lvdm.models.ddpm3d.LatentDiffusion
|
| 3 |
+
params:
|
| 4 |
+
linear_start: 0.00085
|
| 5 |
+
linear_end: 0.012
|
| 6 |
+
num_timesteps_cond: 1
|
| 7 |
+
timesteps: 1000
|
| 8 |
+
first_stage_key: video
|
| 9 |
+
cond_stage_key: caption
|
| 10 |
+
cond_stage_trainable: false
|
| 11 |
+
conditioning_key: crossattn
|
| 12 |
+
image_size:
|
| 13 |
+
- 72
|
| 14 |
+
- 128
|
| 15 |
+
channels: 4
|
| 16 |
+
scale_by_std: false
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: false
|
| 19 |
+
uncond_type: empty_seq
|
| 20 |
+
use_scale: true
|
| 21 |
+
fix_scale_bug: true
|
| 22 |
+
unet_config:
|
| 23 |
+
target: lvdm.modules.networks.openaimodel3d.UNetModel
|
| 24 |
+
params:
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions:
|
| 29 |
+
- 4
|
| 30 |
+
- 2
|
| 31 |
+
- 1
|
| 32 |
+
num_res_blocks: 2
|
| 33 |
+
channel_mult:
|
| 34 |
+
- 1
|
| 35 |
+
- 2
|
| 36 |
+
- 4
|
| 37 |
+
- 4
|
| 38 |
+
num_head_channels: 64
|
| 39 |
+
transformer_depth: 1
|
| 40 |
+
context_dim: 1024
|
| 41 |
+
use_linear: true
|
| 42 |
+
use_checkpoint: true
|
| 43 |
+
temporal_conv: false
|
| 44 |
+
temporal_attention: true
|
| 45 |
+
temporal_selfatt_only: true
|
| 46 |
+
use_relative_position: true
|
| 47 |
+
use_causal_attention: false
|
| 48 |
+
temporal_length: 16
|
| 49 |
+
addition_attention: true
|
| 50 |
+
fps_cond: true
|
| 51 |
+
first_stage_config:
|
| 52 |
+
target: lvdm.models.autoencoder.AutoencoderKL
|
| 53 |
+
params:
|
| 54 |
+
embed_dim: 4
|
| 55 |
+
monitor: val/rec_loss
|
| 56 |
+
ddconfig:
|
| 57 |
+
double_z: true
|
| 58 |
+
z_channels: 4
|
| 59 |
+
resolution: 512
|
| 60 |
+
in_channels: 3
|
| 61 |
+
out_ch: 3
|
| 62 |
+
ch: 128
|
| 63 |
+
ch_mult:
|
| 64 |
+
- 1
|
| 65 |
+
- 2
|
| 66 |
+
- 4
|
| 67 |
+
- 4
|
| 68 |
+
num_res_blocks: 2
|
| 69 |
+
attn_resolutions: []
|
| 70 |
+
dropout: 0.0
|
| 71 |
+
lossconfig:
|
| 72 |
+
target: torch.nn.Identity
|
| 73 |
+
cond_stage_config:
|
| 74 |
+
target: lvdm.modules.encoders.condition.FrozenOpenCLIPEmbedder
|
| 75 |
+
params:
|
| 76 |
+
freeze: true
|
| 77 |
+
layer: penultimate
|
configs/inference_t2v_512_v1.0.yaml
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
target: lvdm.models.ddpm3d.LatentDiffusion
|
| 3 |
+
params:
|
| 4 |
+
linear_start: 0.00085
|
| 5 |
+
linear_end: 0.012
|
| 6 |
+
num_timesteps_cond: 1
|
| 7 |
+
timesteps: 1000
|
| 8 |
+
first_stage_key: video
|
| 9 |
+
cond_stage_key: caption
|
| 10 |
+
cond_stage_trainable: false
|
| 11 |
+
conditioning_key: crossattn
|
| 12 |
+
image_size:
|
| 13 |
+
- 40
|
| 14 |
+
- 64
|
| 15 |
+
channels: 4
|
| 16 |
+
scale_by_std: false
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: false
|
| 19 |
+
uncond_type: empty_seq
|
| 20 |
+
unet_config:
|
| 21 |
+
target: lvdm.modules.networks.openaimodel3d.UNetModel
|
| 22 |
+
params:
|
| 23 |
+
in_channels: 4
|
| 24 |
+
out_channels: 4
|
| 25 |
+
model_channels: 320
|
| 26 |
+
attention_resolutions:
|
| 27 |
+
- 4
|
| 28 |
+
- 2
|
| 29 |
+
- 1
|
| 30 |
+
num_res_blocks: 2
|
| 31 |
+
channel_mult:
|
| 32 |
+
- 1
|
| 33 |
+
- 2
|
| 34 |
+
- 4
|
| 35 |
+
- 4
|
| 36 |
+
num_head_channels: 64
|
| 37 |
+
transformer_depth: 1
|
| 38 |
+
context_dim: 1024
|
| 39 |
+
use_linear: true
|
| 40 |
+
use_checkpoint: true
|
| 41 |
+
temporal_conv: false
|
| 42 |
+
temporal_attention: true
|
| 43 |
+
temporal_selfatt_only: true
|
| 44 |
+
use_relative_position: true
|
| 45 |
+
use_causal_attention: false
|
| 46 |
+
temporal_length: 16
|
| 47 |
+
addition_attention: true
|
| 48 |
+
first_stage_config:
|
| 49 |
+
target: lvdm.models.autoencoder.AutoencoderKL
|
| 50 |
+
params:
|
| 51 |
+
embed_dim: 4
|
| 52 |
+
monitor: val/rec_loss
|
| 53 |
+
ddconfig:
|
| 54 |
+
double_z: true
|
| 55 |
+
z_channels: 4
|
| 56 |
+
resolution: 512
|
| 57 |
+
in_channels: 3
|
| 58 |
+
out_ch: 3
|
| 59 |
+
ch: 128
|
| 60 |
+
ch_mult:
|
| 61 |
+
- 1
|
| 62 |
+
- 2
|
| 63 |
+
- 4
|
| 64 |
+
- 4
|
| 65 |
+
num_res_blocks: 2
|
| 66 |
+
attn_resolutions: []
|
| 67 |
+
dropout: 0.0
|
| 68 |
+
lossconfig:
|
| 69 |
+
target: torch.nn.Identity
|
| 70 |
+
cond_stage_config:
|
| 71 |
+
target: lvdm.modules.encoders.condition.FrozenOpenCLIPEmbedder
|
| 72 |
+
params:
|
| 73 |
+
freeze: true
|
| 74 |
+
layer: penultimate
|
configs/inference_t2v_512_v2.0.yaml
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
target: lvdm.models.ddpm3d.LatentDiffusion
|
| 3 |
+
params:
|
| 4 |
+
linear_start: 0.00085
|
| 5 |
+
linear_end: 0.012
|
| 6 |
+
num_timesteps_cond: 1
|
| 7 |
+
timesteps: 1000
|
| 8 |
+
first_stage_key: video
|
| 9 |
+
cond_stage_key: caption
|
| 10 |
+
cond_stage_trainable: false
|
| 11 |
+
conditioning_key: crossattn
|
| 12 |
+
image_size:
|
| 13 |
+
- 40
|
| 14 |
+
- 64
|
| 15 |
+
channels: 4
|
| 16 |
+
scale_by_std: false
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: false
|
| 19 |
+
uncond_type: empty_seq
|
| 20 |
+
use_scale: true
|
| 21 |
+
scale_b: 0.7
|
| 22 |
+
unet_config:
|
| 23 |
+
target: lvdm.modules.networks.openaimodel3d.UNetModel
|
| 24 |
+
params:
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions:
|
| 29 |
+
- 4
|
| 30 |
+
- 2
|
| 31 |
+
- 1
|
| 32 |
+
num_res_blocks: 2
|
| 33 |
+
channel_mult:
|
| 34 |
+
- 1
|
| 35 |
+
- 2
|
| 36 |
+
- 4
|
| 37 |
+
- 4
|
| 38 |
+
num_head_channels: 64
|
| 39 |
+
transformer_depth: 1
|
| 40 |
+
context_dim: 1024
|
| 41 |
+
use_linear: true
|
| 42 |
+
use_checkpoint: true
|
| 43 |
+
temporal_conv: true
|
| 44 |
+
temporal_attention: true
|
| 45 |
+
temporal_selfatt_only: true
|
| 46 |
+
use_relative_position: false
|
| 47 |
+
use_causal_attention: false
|
| 48 |
+
temporal_length: 16
|
| 49 |
+
addition_attention: true
|
| 50 |
+
fps_cond: true
|
| 51 |
+
first_stage_config:
|
| 52 |
+
target: lvdm.models.autoencoder.AutoencoderKL
|
| 53 |
+
params:
|
| 54 |
+
embed_dim: 4
|
| 55 |
+
monitor: val/rec_loss
|
| 56 |
+
ddconfig:
|
| 57 |
+
double_z: true
|
| 58 |
+
z_channels: 4
|
| 59 |
+
resolution: 512
|
| 60 |
+
in_channels: 3
|
| 61 |
+
out_ch: 3
|
| 62 |
+
ch: 128
|
| 63 |
+
ch_mult:
|
| 64 |
+
- 1
|
| 65 |
+
- 2
|
| 66 |
+
- 4
|
| 67 |
+
- 4
|
| 68 |
+
num_res_blocks: 2
|
| 69 |
+
attn_resolutions: []
|
| 70 |
+
dropout: 0.0
|
| 71 |
+
lossconfig:
|
| 72 |
+
target: torch.nn.Identity
|
| 73 |
+
cond_stage_config:
|
| 74 |
+
target: lvdm.modules.encoders.condition.FrozenOpenCLIPEmbedder
|
| 75 |
+
params:
|
| 76 |
+
freeze: true
|
| 77 |
+
layer: penultimate
|
gradio_app.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import gradio as gr
|
| 4 |
+
from scripts.gradio.t2v_test import Text2Video
|
| 5 |
+
sys.path.insert(1, os.path.join(sys.path[0], 'lvdm'))
|
| 6 |
+
|
| 7 |
+
t2v_examples = [
|
| 8 |
+
['an elephant is walking under the sea, 4K, high definition',50, 12,1, 16],
|
| 9 |
+
['an astronaut riding a horse in outer space',25,12,1,16],
|
| 10 |
+
['a monkey is playing a piano',25,12,1,16],
|
| 11 |
+
['A fire is burning on a candle',25,12,1,16],
|
| 12 |
+
['a horse is drinking in the river',25,12,1,16],
|
| 13 |
+
['Robot dancing in times square',25,12,1,16],
|
| 14 |
+
]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def videocrafter_demo(result_dir='./tmp/'):
|
| 18 |
+
text2video = Text2Video(result_dir)
|
| 19 |
+
with gr.Blocks(analytics_enabled=False) as videocrafter_iface:
|
| 20 |
+
gr.Markdown("<div align='center'> <h2> VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models </span> </h2> \
|
| 21 |
+
<a style='font-size:18px;color: #000000' href='https://github.com/AILab-CVC/VideoCrafter'> Github </div>")
|
| 22 |
+
|
| 23 |
+
#######t2v#######
|
| 24 |
+
with gr.Tab(label="Text2Video"):
|
| 25 |
+
with gr.Column():
|
| 26 |
+
with gr.Row().style(equal_height=False):
|
| 27 |
+
with gr.Column():
|
| 28 |
+
input_text = gr.Text(label='Prompts')
|
| 29 |
+
with gr.Row():
|
| 30 |
+
steps = gr.Slider(minimum=1, maximum=60, step=1, elem_id=f"steps", label="Sampling steps", value=50)
|
| 31 |
+
eta = gr.Slider(minimum=0.0, maximum=1.0, step=0.1, label='ETA', value=1.0, elem_id="eta")
|
| 32 |
+
with gr.Row():
|
| 33 |
+
cfg_scale = gr.Slider(minimum=1.0, maximum=30.0, step=0.5, label='CFG Scale', value=12.0, elem_id="cfg_scale")
|
| 34 |
+
fps = gr.Slider(minimum=4, maximum=32, step=1, label='fps', value=16, elem_id="fps")
|
| 35 |
+
send_btn = gr.Button("Send")
|
| 36 |
+
with gr.Tab(label='result'):
|
| 37 |
+
with gr.Row():
|
| 38 |
+
output_video_1 = gr.Video().style(width=512)
|
| 39 |
+
gr.Examples(examples=t2v_examples,
|
| 40 |
+
inputs=[input_text,steps,cfg_scale,eta],
|
| 41 |
+
outputs=[output_video_1],
|
| 42 |
+
fn=text2video.get_prompt,
|
| 43 |
+
cache_examples=False)
|
| 44 |
+
#cache_examples=os.getenv('SYSTEM') == 'spaces')
|
| 45 |
+
send_btn.click(
|
| 46 |
+
fn=text2video.get_prompt,
|
| 47 |
+
inputs=[input_text,steps,cfg_scale,eta,fps],
|
| 48 |
+
outputs=[output_video_1],
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
return videocrafter_iface
|
| 52 |
+
|
| 53 |
+
if __name__ == "__main__":
|
| 54 |
+
result_dir = os.path.join('./', 'results')
|
| 55 |
+
videocrafter_iface = videocrafter_demo(result_dir)
|
| 56 |
+
videocrafter_iface.queue(concurrency_count=1, max_size=10)
|
| 57 |
+
videocrafter_iface.launch()
|
| 58 |
+
# videocrafter_iface.launch(server_name='0.0.0.0', server_port=80)
|
lvdm/basics.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# adopted from
|
| 2 |
+
# https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
|
| 3 |
+
# and
|
| 4 |
+
# https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
|
| 5 |
+
# and
|
| 6 |
+
# https://github.com/openai/guided-diffusion/blob/0ba878e517b276c45d1195eb29f6f5f72659a05b/guided_diffusion/nn.py
|
| 7 |
+
#
|
| 8 |
+
# thanks!
|
| 9 |
+
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
from utils.utils import instantiate_from_config
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def disabled_train(self, mode=True):
|
| 15 |
+
"""Overwrite model.train with this function to make sure train/eval mode
|
| 16 |
+
does not change anymore."""
|
| 17 |
+
return self
|
| 18 |
+
|
| 19 |
+
def zero_module(module):
|
| 20 |
+
"""
|
| 21 |
+
Zero out the parameters of a module and return it.
|
| 22 |
+
"""
|
| 23 |
+
for p in module.parameters():
|
| 24 |
+
p.detach().zero_()
|
| 25 |
+
return module
|
| 26 |
+
|
| 27 |
+
def scale_module(module, scale):
|
| 28 |
+
"""
|
| 29 |
+
Scale the parameters of a module and return it.
|
| 30 |
+
"""
|
| 31 |
+
for p in module.parameters():
|
| 32 |
+
p.detach().mul_(scale)
|
| 33 |
+
return module
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def conv_nd(dims, *args, **kwargs):
|
| 37 |
+
"""
|
| 38 |
+
Create a 1D, 2D, or 3D convolution module.
|
| 39 |
+
"""
|
| 40 |
+
if dims == 1:
|
| 41 |
+
return nn.Conv1d(*args, **kwargs)
|
| 42 |
+
elif dims == 2:
|
| 43 |
+
return nn.Conv2d(*args, **kwargs)
|
| 44 |
+
elif dims == 3:
|
| 45 |
+
return nn.Conv3d(*args, **kwargs)
|
| 46 |
+
raise ValueError(f"unsupported dimensions: {dims}")
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def linear(*args, **kwargs):
|
| 50 |
+
"""
|
| 51 |
+
Create a linear module.
|
| 52 |
+
"""
|
| 53 |
+
return nn.Linear(*args, **kwargs)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def avg_pool_nd(dims, *args, **kwargs):
|
| 57 |
+
"""
|
| 58 |
+
Create a 1D, 2D, or 3D average pooling module.
|
| 59 |
+
"""
|
| 60 |
+
if dims == 1:
|
| 61 |
+
return nn.AvgPool1d(*args, **kwargs)
|
| 62 |
+
elif dims == 2:
|
| 63 |
+
return nn.AvgPool2d(*args, **kwargs)
|
| 64 |
+
elif dims == 3:
|
| 65 |
+
return nn.AvgPool3d(*args, **kwargs)
|
| 66 |
+
raise ValueError(f"unsupported dimensions: {dims}")
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def nonlinearity(type='silu'):
|
| 70 |
+
if type == 'silu':
|
| 71 |
+
return nn.SiLU()
|
| 72 |
+
elif type == 'leaky_relu':
|
| 73 |
+
return nn.LeakyReLU()
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class GroupNormSpecific(nn.GroupNorm):
|
| 77 |
+
def forward(self, x):
|
| 78 |
+
return super().forward(x.float()).type(x.dtype)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def normalization(channels, num_groups=32):
|
| 82 |
+
"""
|
| 83 |
+
Make a standard normalization layer.
|
| 84 |
+
:param channels: number of input channels.
|
| 85 |
+
:return: an nn.Module for normalization.
|
| 86 |
+
"""
|
| 87 |
+
return GroupNormSpecific(num_groups, channels)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class HybridConditioner(nn.Module):
|
| 91 |
+
|
| 92 |
+
def __init__(self, c_concat_config, c_crossattn_config):
|
| 93 |
+
super().__init__()
|
| 94 |
+
self.concat_conditioner = instantiate_from_config(c_concat_config)
|
| 95 |
+
self.crossattn_conditioner = instantiate_from_config(c_crossattn_config)
|
| 96 |
+
|
| 97 |
+
def forward(self, c_concat, c_crossattn):
|
| 98 |
+
c_concat = self.concat_conditioner(c_concat)
|
| 99 |
+
c_crossattn = self.crossattn_conditioner(c_crossattn)
|
| 100 |
+
return {'c_concat': [c_concat], 'c_crossattn': [c_crossattn]}
|
lvdm/common.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from inspect import isfunction
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
import torch.distributed as dist
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def gather_data(data, return_np=True):
|
| 9 |
+
''' gather data from multiple processes to one list '''
|
| 10 |
+
data_list = [torch.zeros_like(data) for _ in range(dist.get_world_size())]
|
| 11 |
+
dist.all_gather(data_list, data) # gather not supported with NCCL
|
| 12 |
+
if return_np:
|
| 13 |
+
data_list = [data.cpu().numpy() for data in data_list]
|
| 14 |
+
return data_list
|
| 15 |
+
|
| 16 |
+
def autocast(f):
|
| 17 |
+
def do_autocast(*args, **kwargs):
|
| 18 |
+
with torch.cuda.amp.autocast(enabled=True,
|
| 19 |
+
dtype=torch.get_autocast_gpu_dtype(),
|
| 20 |
+
cache_enabled=torch.is_autocast_cache_enabled()):
|
| 21 |
+
return f(*args, **kwargs)
|
| 22 |
+
return do_autocast
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def extract_into_tensor(a, t, x_shape):
|
| 26 |
+
b, *_ = t.shape
|
| 27 |
+
out = a.gather(-1, t)
|
| 28 |
+
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def noise_like(shape, device, repeat=False):
|
| 32 |
+
repeat_noise = lambda: torch.randn((1, *shape[1:]), device=device).repeat(shape[0], *((1,) * (len(shape) - 1)))
|
| 33 |
+
noise = lambda: torch.randn(shape, device=device)
|
| 34 |
+
return repeat_noise() if repeat else noise()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def default(val, d):
|
| 38 |
+
if exists(val):
|
| 39 |
+
return val
|
| 40 |
+
return d() if isfunction(d) else d
|
| 41 |
+
|
| 42 |
+
def exists(val):
|
| 43 |
+
return val is not None
|
| 44 |
+
|
| 45 |
+
def identity(*args, **kwargs):
|
| 46 |
+
return nn.Identity()
|
| 47 |
+
|
| 48 |
+
def uniq(arr):
|
| 49 |
+
return{el: True for el in arr}.keys()
|
| 50 |
+
|
| 51 |
+
def mean_flat(tensor):
|
| 52 |
+
"""
|
| 53 |
+
Take the mean over all non-batch dimensions.
|
| 54 |
+
"""
|
| 55 |
+
return tensor.mean(dim=list(range(1, len(tensor.shape))))
|
| 56 |
+
|
| 57 |
+
def ismap(x):
|
| 58 |
+
if not isinstance(x, torch.Tensor):
|
| 59 |
+
return False
|
| 60 |
+
return (len(x.shape) == 4) and (x.shape[1] > 3)
|
| 61 |
+
|
| 62 |
+
def isimage(x):
|
| 63 |
+
if not isinstance(x,torch.Tensor):
|
| 64 |
+
return False
|
| 65 |
+
return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
|
| 66 |
+
|
| 67 |
+
def max_neg_value(t):
|
| 68 |
+
return -torch.finfo(t.dtype).max
|
| 69 |
+
|
| 70 |
+
def shape_to_str(x):
|
| 71 |
+
shape_str = "x".join([str(x) for x in x.shape])
|
| 72 |
+
return shape_str
|
| 73 |
+
|
| 74 |
+
def init_(tensor):
|
| 75 |
+
dim = tensor.shape[-1]
|
| 76 |
+
std = 1 / math.sqrt(dim)
|
| 77 |
+
tensor.uniform_(-std, std)
|
| 78 |
+
return tensor
|
| 79 |
+
|
| 80 |
+
ckpt = torch.utils.checkpoint.checkpoint
|
| 81 |
+
def checkpoint(func, inputs, params, flag):
|
| 82 |
+
"""
|
| 83 |
+
Evaluate a function without caching intermediate activations, allowing for
|
| 84 |
+
reduced memory at the expense of extra compute in the backward pass.
|
| 85 |
+
:param func: the function to evaluate.
|
| 86 |
+
:param inputs: the argument sequence to pass to `func`.
|
| 87 |
+
:param params: a sequence of parameters `func` depends on but does not
|
| 88 |
+
explicitly take as arguments.
|
| 89 |
+
:param flag: if False, disable gradient checkpointing.
|
| 90 |
+
"""
|
| 91 |
+
if flag:
|
| 92 |
+
return ckpt(func, *inputs)
|
| 93 |
+
else:
|
| 94 |
+
return func(*inputs)
|
| 95 |
+
|
lvdm/distributions.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class AbstractDistribution:
|
| 6 |
+
def sample(self):
|
| 7 |
+
raise NotImplementedError()
|
| 8 |
+
|
| 9 |
+
def mode(self):
|
| 10 |
+
raise NotImplementedError()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class DiracDistribution(AbstractDistribution):
|
| 14 |
+
def __init__(self, value):
|
| 15 |
+
self.value = value
|
| 16 |
+
|
| 17 |
+
def sample(self):
|
| 18 |
+
return self.value
|
| 19 |
+
|
| 20 |
+
def mode(self):
|
| 21 |
+
return self.value
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class DiagonalGaussianDistribution(object):
|
| 25 |
+
def __init__(self, parameters, deterministic=False):
|
| 26 |
+
self.parameters = parameters
|
| 27 |
+
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
|
| 28 |
+
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
| 29 |
+
self.deterministic = deterministic
|
| 30 |
+
self.std = torch.exp(0.5 * self.logvar)
|
| 31 |
+
self.var = torch.exp(self.logvar)
|
| 32 |
+
if self.deterministic:
|
| 33 |
+
self.var = self.std = torch.zeros_like(self.mean).to(device=self.parameters.device)
|
| 34 |
+
|
| 35 |
+
def sample(self, noise=None):
|
| 36 |
+
if noise is None:
|
| 37 |
+
noise = torch.randn(self.mean.shape)
|
| 38 |
+
|
| 39 |
+
x = self.mean + self.std * noise.to(device=self.parameters.device)
|
| 40 |
+
return x
|
| 41 |
+
|
| 42 |
+
def kl(self, other=None):
|
| 43 |
+
if self.deterministic:
|
| 44 |
+
return torch.Tensor([0.])
|
| 45 |
+
else:
|
| 46 |
+
if other is None:
|
| 47 |
+
return 0.5 * torch.sum(torch.pow(self.mean, 2)
|
| 48 |
+
+ self.var - 1.0 - self.logvar,
|
| 49 |
+
dim=[1, 2, 3])
|
| 50 |
+
else:
|
| 51 |
+
return 0.5 * torch.sum(
|
| 52 |
+
torch.pow(self.mean - other.mean, 2) / other.var
|
| 53 |
+
+ self.var / other.var - 1.0 - self.logvar + other.logvar,
|
| 54 |
+
dim=[1, 2, 3])
|
| 55 |
+
|
| 56 |
+
def nll(self, sample, dims=[1,2,3]):
|
| 57 |
+
if self.deterministic:
|
| 58 |
+
return torch.Tensor([0.])
|
| 59 |
+
logtwopi = np.log(2.0 * np.pi)
|
| 60 |
+
return 0.5 * torch.sum(
|
| 61 |
+
logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
|
| 62 |
+
dim=dims)
|
| 63 |
+
|
| 64 |
+
def mode(self):
|
| 65 |
+
return self.mean
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def normal_kl(mean1, logvar1, mean2, logvar2):
|
| 69 |
+
"""
|
| 70 |
+
source: https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/losses.py#L12
|
| 71 |
+
Compute the KL divergence between two gaussians.
|
| 72 |
+
Shapes are automatically broadcasted, so batches can be compared to
|
| 73 |
+
scalars, among other use cases.
|
| 74 |
+
"""
|
| 75 |
+
tensor = None
|
| 76 |
+
for obj in (mean1, logvar1, mean2, logvar2):
|
| 77 |
+
if isinstance(obj, torch.Tensor):
|
| 78 |
+
tensor = obj
|
| 79 |
+
break
|
| 80 |
+
assert tensor is not None, "at least one argument must be a Tensor"
|
| 81 |
+
|
| 82 |
+
# Force variances to be Tensors. Broadcasting helps convert scalars to
|
| 83 |
+
# Tensors, but it does not work for torch.exp().
|
| 84 |
+
logvar1, logvar2 = [
|
| 85 |
+
x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
|
| 86 |
+
for x in (logvar1, logvar2)
|
| 87 |
+
]
|
| 88 |
+
|
| 89 |
+
return 0.5 * (
|
| 90 |
+
-1.0
|
| 91 |
+
+ logvar2
|
| 92 |
+
- logvar1
|
| 93 |
+
+ torch.exp(logvar1 - logvar2)
|
| 94 |
+
+ ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
|
| 95 |
+
)
|
lvdm/ema.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class LitEma(nn.Module):
|
| 6 |
+
def __init__(self, model, decay=0.9999, use_num_upates=True):
|
| 7 |
+
super().__init__()
|
| 8 |
+
if decay < 0.0 or decay > 1.0:
|
| 9 |
+
raise ValueError('Decay must be between 0 and 1')
|
| 10 |
+
|
| 11 |
+
self.m_name2s_name = {}
|
| 12 |
+
self.register_buffer('decay', torch.tensor(decay, dtype=torch.float32))
|
| 13 |
+
self.register_buffer('num_updates', torch.tensor(0,dtype=torch.int) if use_num_upates
|
| 14 |
+
else torch.tensor(-1,dtype=torch.int))
|
| 15 |
+
|
| 16 |
+
for name, p in model.named_parameters():
|
| 17 |
+
if p.requires_grad:
|
| 18 |
+
#remove as '.'-character is not allowed in buffers
|
| 19 |
+
s_name = name.replace('.','')
|
| 20 |
+
self.m_name2s_name.update({name:s_name})
|
| 21 |
+
self.register_buffer(s_name,p.clone().detach().data)
|
| 22 |
+
|
| 23 |
+
self.collected_params = []
|
| 24 |
+
|
| 25 |
+
def forward(self,model):
|
| 26 |
+
decay = self.decay
|
| 27 |
+
|
| 28 |
+
if self.num_updates >= 0:
|
| 29 |
+
self.num_updates += 1
|
| 30 |
+
decay = min(self.decay,(1 + self.num_updates) / (10 + self.num_updates))
|
| 31 |
+
|
| 32 |
+
one_minus_decay = 1.0 - decay
|
| 33 |
+
|
| 34 |
+
with torch.no_grad():
|
| 35 |
+
m_param = dict(model.named_parameters())
|
| 36 |
+
shadow_params = dict(self.named_buffers())
|
| 37 |
+
|
| 38 |
+
for key in m_param:
|
| 39 |
+
if m_param[key].requires_grad:
|
| 40 |
+
sname = self.m_name2s_name[key]
|
| 41 |
+
shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
|
| 42 |
+
shadow_params[sname].sub_(one_minus_decay * (shadow_params[sname] - m_param[key]))
|
| 43 |
+
else:
|
| 44 |
+
assert not key in self.m_name2s_name
|
| 45 |
+
|
| 46 |
+
def copy_to(self, model):
|
| 47 |
+
m_param = dict(model.named_parameters())
|
| 48 |
+
shadow_params = dict(self.named_buffers())
|
| 49 |
+
for key in m_param:
|
| 50 |
+
if m_param[key].requires_grad:
|
| 51 |
+
m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
|
| 52 |
+
else:
|
| 53 |
+
assert not key in self.m_name2s_name
|
| 54 |
+
|
| 55 |
+
def store(self, parameters):
|
| 56 |
+
"""
|
| 57 |
+
Save the current parameters for restoring later.
|
| 58 |
+
Args:
|
| 59 |
+
parameters: Iterable of `torch.nn.Parameter`; the parameters to be
|
| 60 |
+
temporarily stored.
|
| 61 |
+
"""
|
| 62 |
+
self.collected_params = [param.clone() for param in parameters]
|
| 63 |
+
|
| 64 |
+
def restore(self, parameters):
|
| 65 |
+
"""
|
| 66 |
+
Restore the parameters stored with the `store` method.
|
| 67 |
+
Useful to validate the model with EMA parameters without affecting the
|
| 68 |
+
original optimization process. Store the parameters before the
|
| 69 |
+
`copy_to` method. After validation (or model saving), use this to
|
| 70 |
+
restore the former parameters.
|
| 71 |
+
Args:
|
| 72 |
+
parameters: Iterable of `torch.nn.Parameter`; the parameters to be
|
| 73 |
+
updated with the stored parameters.
|
| 74 |
+
"""
|
| 75 |
+
for c_param, param in zip(self.collected_params, parameters):
|
| 76 |
+
param.data.copy_(c_param.data)
|
lvdm/models/autoencoder.py
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from contextlib import contextmanager
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import pytorch_lightning as pl
|
| 8 |
+
from lvdm.modules.networks.ae_modules import Encoder, Decoder
|
| 9 |
+
from lvdm.distributions import DiagonalGaussianDistribution
|
| 10 |
+
from utils.utils import instantiate_from_config
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class AutoencoderKL(pl.LightningModule):
|
| 14 |
+
def __init__(self,
|
| 15 |
+
ddconfig,
|
| 16 |
+
lossconfig,
|
| 17 |
+
embed_dim,
|
| 18 |
+
ckpt_path=None,
|
| 19 |
+
ignore_keys=[],
|
| 20 |
+
image_key="image",
|
| 21 |
+
colorize_nlabels=None,
|
| 22 |
+
monitor=None,
|
| 23 |
+
test=False,
|
| 24 |
+
logdir=None,
|
| 25 |
+
input_dim=4,
|
| 26 |
+
test_args=None,
|
| 27 |
+
):
|
| 28 |
+
super().__init__()
|
| 29 |
+
self.image_key = image_key
|
| 30 |
+
self.encoder = Encoder(**ddconfig)
|
| 31 |
+
self.decoder = Decoder(**ddconfig)
|
| 32 |
+
self.loss = instantiate_from_config(lossconfig)
|
| 33 |
+
assert ddconfig["double_z"]
|
| 34 |
+
self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1)
|
| 35 |
+
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
|
| 36 |
+
self.embed_dim = embed_dim
|
| 37 |
+
self.input_dim = input_dim
|
| 38 |
+
self.test = test
|
| 39 |
+
self.test_args = test_args
|
| 40 |
+
self.logdir = logdir
|
| 41 |
+
if colorize_nlabels is not None:
|
| 42 |
+
assert type(colorize_nlabels)==int
|
| 43 |
+
self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
|
| 44 |
+
if monitor is not None:
|
| 45 |
+
self.monitor = monitor
|
| 46 |
+
if ckpt_path is not None:
|
| 47 |
+
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
|
| 48 |
+
if self.test:
|
| 49 |
+
self.init_test()
|
| 50 |
+
|
| 51 |
+
def init_test(self,):
|
| 52 |
+
self.test = True
|
| 53 |
+
save_dir = os.path.join(self.logdir, "test")
|
| 54 |
+
if 'ckpt' in self.test_args:
|
| 55 |
+
ckpt_name = os.path.basename(self.test_args.ckpt).split('.ckpt')[0] + f'_epoch{self._cur_epoch}'
|
| 56 |
+
self.root = os.path.join(save_dir, ckpt_name)
|
| 57 |
+
else:
|
| 58 |
+
self.root = save_dir
|
| 59 |
+
if 'test_subdir' in self.test_args:
|
| 60 |
+
self.root = os.path.join(save_dir, self.test_args.test_subdir)
|
| 61 |
+
|
| 62 |
+
self.root_zs = os.path.join(self.root, "zs")
|
| 63 |
+
self.root_dec = os.path.join(self.root, "reconstructions")
|
| 64 |
+
self.root_inputs = os.path.join(self.root, "inputs")
|
| 65 |
+
os.makedirs(self.root, exist_ok=True)
|
| 66 |
+
|
| 67 |
+
if self.test_args.save_z:
|
| 68 |
+
os.makedirs(self.root_zs, exist_ok=True)
|
| 69 |
+
if self.test_args.save_reconstruction:
|
| 70 |
+
os.makedirs(self.root_dec, exist_ok=True)
|
| 71 |
+
if self.test_args.save_input:
|
| 72 |
+
os.makedirs(self.root_inputs, exist_ok=True)
|
| 73 |
+
assert(self.test_args is not None)
|
| 74 |
+
self.test_maximum = getattr(self.test_args, 'test_maximum', None)
|
| 75 |
+
self.count = 0
|
| 76 |
+
self.eval_metrics = {}
|
| 77 |
+
self.decodes = []
|
| 78 |
+
self.save_decode_samples = 2048
|
| 79 |
+
|
| 80 |
+
def init_from_ckpt(self, path, ignore_keys=list()):
|
| 81 |
+
sd = torch.load(path, map_location="cpu")
|
| 82 |
+
try:
|
| 83 |
+
self._cur_epoch = sd['epoch']
|
| 84 |
+
sd = sd["state_dict"]
|
| 85 |
+
except:
|
| 86 |
+
self._cur_epoch = 'null'
|
| 87 |
+
keys = list(sd.keys())
|
| 88 |
+
for k in keys:
|
| 89 |
+
for ik in ignore_keys:
|
| 90 |
+
if k.startswith(ik):
|
| 91 |
+
print("Deleting key {} from state_dict.".format(k))
|
| 92 |
+
del sd[k]
|
| 93 |
+
self.load_state_dict(sd, strict=False)
|
| 94 |
+
# self.load_state_dict(sd, strict=True)
|
| 95 |
+
print(f"Restored from {path}")
|
| 96 |
+
|
| 97 |
+
def encode(self, x, **kwargs):
|
| 98 |
+
|
| 99 |
+
h = self.encoder(x)
|
| 100 |
+
moments = self.quant_conv(h)
|
| 101 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 102 |
+
return posterior
|
| 103 |
+
|
| 104 |
+
def decode(self, z, **kwargs):
|
| 105 |
+
z = self.post_quant_conv(z)
|
| 106 |
+
dec = self.decoder(z)
|
| 107 |
+
return dec
|
| 108 |
+
|
| 109 |
+
def forward(self, input, sample_posterior=True):
|
| 110 |
+
posterior = self.encode(input)
|
| 111 |
+
if sample_posterior:
|
| 112 |
+
z = posterior.sample()
|
| 113 |
+
else:
|
| 114 |
+
z = posterior.mode()
|
| 115 |
+
dec = self.decode(z)
|
| 116 |
+
return dec, posterior
|
| 117 |
+
|
| 118 |
+
def get_input(self, batch, k):
|
| 119 |
+
x = batch[k]
|
| 120 |
+
if x.dim() == 5 and self.input_dim == 4:
|
| 121 |
+
b,c,t,h,w = x.shape
|
| 122 |
+
self.b = b
|
| 123 |
+
self.t = t
|
| 124 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 125 |
+
|
| 126 |
+
return x
|
| 127 |
+
|
| 128 |
+
def training_step(self, batch, batch_idx, optimizer_idx):
|
| 129 |
+
inputs = self.get_input(batch, self.image_key)
|
| 130 |
+
reconstructions, posterior = self(inputs)
|
| 131 |
+
|
| 132 |
+
if optimizer_idx == 0:
|
| 133 |
+
# train encoder+decoder+logvar
|
| 134 |
+
aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
|
| 135 |
+
last_layer=self.get_last_layer(), split="train")
|
| 136 |
+
self.log("aeloss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
|
| 137 |
+
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False)
|
| 138 |
+
return aeloss
|
| 139 |
+
|
| 140 |
+
if optimizer_idx == 1:
|
| 141 |
+
# train the discriminator
|
| 142 |
+
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
|
| 143 |
+
last_layer=self.get_last_layer(), split="train")
|
| 144 |
+
|
| 145 |
+
self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
|
| 146 |
+
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False)
|
| 147 |
+
return discloss
|
| 148 |
+
|
| 149 |
+
def validation_step(self, batch, batch_idx):
|
| 150 |
+
inputs = self.get_input(batch, self.image_key)
|
| 151 |
+
reconstructions, posterior = self(inputs)
|
| 152 |
+
aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, 0, self.global_step,
|
| 153 |
+
last_layer=self.get_last_layer(), split="val")
|
| 154 |
+
|
| 155 |
+
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, 1, self.global_step,
|
| 156 |
+
last_layer=self.get_last_layer(), split="val")
|
| 157 |
+
|
| 158 |
+
self.log("val/rec_loss", log_dict_ae["val/rec_loss"])
|
| 159 |
+
self.log_dict(log_dict_ae)
|
| 160 |
+
self.log_dict(log_dict_disc)
|
| 161 |
+
return self.log_dict
|
| 162 |
+
|
| 163 |
+
def configure_optimizers(self):
|
| 164 |
+
lr = self.learning_rate
|
| 165 |
+
opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
|
| 166 |
+
list(self.decoder.parameters())+
|
| 167 |
+
list(self.quant_conv.parameters())+
|
| 168 |
+
list(self.post_quant_conv.parameters()),
|
| 169 |
+
lr=lr, betas=(0.5, 0.9))
|
| 170 |
+
opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
|
| 171 |
+
lr=lr, betas=(0.5, 0.9))
|
| 172 |
+
return [opt_ae, opt_disc], []
|
| 173 |
+
|
| 174 |
+
def get_last_layer(self):
|
| 175 |
+
return self.decoder.conv_out.weight
|
| 176 |
+
|
| 177 |
+
@torch.no_grad()
|
| 178 |
+
def log_images(self, batch, only_inputs=False, **kwargs):
|
| 179 |
+
log = dict()
|
| 180 |
+
x = self.get_input(batch, self.image_key)
|
| 181 |
+
x = x.to(self.device)
|
| 182 |
+
if not only_inputs:
|
| 183 |
+
xrec, posterior = self(x)
|
| 184 |
+
if x.shape[1] > 3:
|
| 185 |
+
# colorize with random projection
|
| 186 |
+
assert xrec.shape[1] > 3
|
| 187 |
+
x = self.to_rgb(x)
|
| 188 |
+
xrec = self.to_rgb(xrec)
|
| 189 |
+
log["samples"] = self.decode(torch.randn_like(posterior.sample()))
|
| 190 |
+
log["reconstructions"] = xrec
|
| 191 |
+
log["inputs"] = x
|
| 192 |
+
return log
|
| 193 |
+
|
| 194 |
+
def to_rgb(self, x):
|
| 195 |
+
assert self.image_key == "segmentation"
|
| 196 |
+
if not hasattr(self, "colorize"):
|
| 197 |
+
self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x))
|
| 198 |
+
x = F.conv2d(x, weight=self.colorize)
|
| 199 |
+
x = 2.*(x-x.min())/(x.max()-x.min()) - 1.
|
| 200 |
+
return x
|
| 201 |
+
|
| 202 |
+
class IdentityFirstStage(torch.nn.Module):
|
| 203 |
+
def __init__(self, *args, vq_interface=False, **kwargs):
|
| 204 |
+
self.vq_interface = vq_interface # TODO: Should be true by default but check to not break older stuff
|
| 205 |
+
super().__init__()
|
| 206 |
+
|
| 207 |
+
def encode(self, x, *args, **kwargs):
|
| 208 |
+
return x
|
| 209 |
+
|
| 210 |
+
def decode(self, x, *args, **kwargs):
|
| 211 |
+
return x
|
| 212 |
+
|
| 213 |
+
def quantize(self, x, *args, **kwargs):
|
| 214 |
+
if self.vq_interface:
|
| 215 |
+
return x, None, [None, None, None]
|
| 216 |
+
return x
|
| 217 |
+
|
| 218 |
+
def forward(self, x, *args, **kwargs):
|
| 219 |
+
return x
|
lvdm/models/ddpm3d.py
ADDED
|
@@ -0,0 +1,763 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
wild mixture of
|
| 3 |
+
https://github.com/openai/improved-diffusion/blob/e94489283bb876ac1477d5dd7709bbbd2d9902ce/improved_diffusion/gaussian_diffusion.py
|
| 4 |
+
https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
|
| 5 |
+
https://github.com/CompVis/taming-transformers
|
| 6 |
+
-- merci
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
from functools import partial
|
| 10 |
+
from contextlib import contextmanager
|
| 11 |
+
import numpy as np
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
from einops import rearrange, repeat
|
| 14 |
+
import logging
|
| 15 |
+
mainlogger = logging.getLogger('mainlogger')
|
| 16 |
+
import torch
|
| 17 |
+
import torch.nn as nn
|
| 18 |
+
from torchvision.utils import make_grid
|
| 19 |
+
import pytorch_lightning as pl
|
| 20 |
+
from utils.utils import instantiate_from_config
|
| 21 |
+
from lvdm.ema import LitEma
|
| 22 |
+
from lvdm.distributions import DiagonalGaussianDistribution
|
| 23 |
+
from lvdm.models.utils_diffusion import make_beta_schedule
|
| 24 |
+
from lvdm.modules.encoders.ip_resampler import ImageProjModel, Resampler
|
| 25 |
+
from lvdm.basics import disabled_train
|
| 26 |
+
from lvdm.common import (
|
| 27 |
+
extract_into_tensor,
|
| 28 |
+
noise_like,
|
| 29 |
+
exists,
|
| 30 |
+
default
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
__conditioning_keys__ = {'concat': 'c_concat',
|
| 35 |
+
'crossattn': 'c_crossattn',
|
| 36 |
+
'adm': 'y'}
|
| 37 |
+
|
| 38 |
+
class DDPM(pl.LightningModule):
|
| 39 |
+
# classic DDPM with Gaussian diffusion, in image space
|
| 40 |
+
def __init__(self,
|
| 41 |
+
unet_config,
|
| 42 |
+
timesteps=1000,
|
| 43 |
+
beta_schedule="linear",
|
| 44 |
+
loss_type="l2",
|
| 45 |
+
ckpt_path=None,
|
| 46 |
+
ignore_keys=[],
|
| 47 |
+
load_only_unet=False,
|
| 48 |
+
monitor=None,
|
| 49 |
+
use_ema=True,
|
| 50 |
+
first_stage_key="image",
|
| 51 |
+
image_size=256,
|
| 52 |
+
channels=3,
|
| 53 |
+
log_every_t=100,
|
| 54 |
+
clip_denoised=True,
|
| 55 |
+
linear_start=1e-4,
|
| 56 |
+
linear_end=2e-2,
|
| 57 |
+
cosine_s=8e-3,
|
| 58 |
+
given_betas=None,
|
| 59 |
+
original_elbo_weight=0.,
|
| 60 |
+
v_posterior=0., # weight for choosing posterior variance as sigma = (1-v) * beta_tilde + v * beta
|
| 61 |
+
l_simple_weight=1.,
|
| 62 |
+
conditioning_key=None,
|
| 63 |
+
parameterization="eps", # all assuming fixed variance schedules
|
| 64 |
+
scheduler_config=None,
|
| 65 |
+
use_positional_encodings=False,
|
| 66 |
+
learn_logvar=False,
|
| 67 |
+
logvar_init=0.
|
| 68 |
+
):
|
| 69 |
+
super().__init__()
|
| 70 |
+
assert parameterization in ["eps", "x0"], 'currently only supporting "eps" and "x0"'
|
| 71 |
+
self.parameterization = parameterization
|
| 72 |
+
mainlogger.info(f"{self.__class__.__name__}: Running in {self.parameterization}-prediction mode")
|
| 73 |
+
self.cond_stage_model = None
|
| 74 |
+
self.clip_denoised = clip_denoised
|
| 75 |
+
self.log_every_t = log_every_t
|
| 76 |
+
self.first_stage_key = first_stage_key
|
| 77 |
+
self.channels = channels
|
| 78 |
+
self.temporal_length = unet_config.params.temporal_length
|
| 79 |
+
self.image_size = image_size
|
| 80 |
+
if isinstance(self.image_size, int):
|
| 81 |
+
self.image_size = [self.image_size, self.image_size]
|
| 82 |
+
self.use_positional_encodings = use_positional_encodings
|
| 83 |
+
self.model = DiffusionWrapper(unet_config, conditioning_key)
|
| 84 |
+
self.use_ema = use_ema
|
| 85 |
+
if self.use_ema:
|
| 86 |
+
self.model_ema = LitEma(self.model)
|
| 87 |
+
mainlogger.info(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
|
| 88 |
+
|
| 89 |
+
self.use_scheduler = scheduler_config is not None
|
| 90 |
+
if self.use_scheduler:
|
| 91 |
+
self.scheduler_config = scheduler_config
|
| 92 |
+
|
| 93 |
+
self.v_posterior = v_posterior
|
| 94 |
+
self.original_elbo_weight = original_elbo_weight
|
| 95 |
+
self.l_simple_weight = l_simple_weight
|
| 96 |
+
|
| 97 |
+
if monitor is not None:
|
| 98 |
+
self.monitor = monitor
|
| 99 |
+
if ckpt_path is not None:
|
| 100 |
+
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys, only_model=load_only_unet)
|
| 101 |
+
|
| 102 |
+
self.register_schedule(given_betas=given_betas, beta_schedule=beta_schedule, timesteps=timesteps,
|
| 103 |
+
linear_start=linear_start, linear_end=linear_end, cosine_s=cosine_s)
|
| 104 |
+
|
| 105 |
+
self.loss_type = loss_type
|
| 106 |
+
|
| 107 |
+
self.learn_logvar = learn_logvar
|
| 108 |
+
self.logvar = torch.full(fill_value=logvar_init, size=(self.num_timesteps,))
|
| 109 |
+
if self.learn_logvar:
|
| 110 |
+
self.logvar = nn.Parameter(self.logvar, requires_grad=True)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def register_schedule(self, given_betas=None, beta_schedule="linear", timesteps=1000,
|
| 114 |
+
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
|
| 115 |
+
if exists(given_betas):
|
| 116 |
+
betas = given_betas
|
| 117 |
+
else:
|
| 118 |
+
betas = make_beta_schedule(beta_schedule, timesteps, linear_start=linear_start, linear_end=linear_end,
|
| 119 |
+
cosine_s=cosine_s)
|
| 120 |
+
alphas = 1. - betas
|
| 121 |
+
alphas_cumprod = np.cumprod(alphas, axis=0)
|
| 122 |
+
alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1])
|
| 123 |
+
|
| 124 |
+
timesteps, = betas.shape
|
| 125 |
+
self.num_timesteps = int(timesteps)
|
| 126 |
+
self.linear_start = linear_start
|
| 127 |
+
self.linear_end = linear_end
|
| 128 |
+
assert alphas_cumprod.shape[0] == self.num_timesteps, 'alphas have to be defined for each timestep'
|
| 129 |
+
|
| 130 |
+
to_torch = partial(torch.tensor, dtype=torch.float32)
|
| 131 |
+
|
| 132 |
+
self.register_buffer('betas', to_torch(betas))
|
| 133 |
+
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
|
| 134 |
+
self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev))
|
| 135 |
+
|
| 136 |
+
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 137 |
+
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod)))
|
| 138 |
+
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod)))
|
| 139 |
+
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod)))
|
| 140 |
+
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod)))
|
| 141 |
+
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod - 1)))
|
| 142 |
+
|
| 143 |
+
# calculations for posterior q(x_{t-1} | x_t, x_0)
|
| 144 |
+
posterior_variance = (1 - self.v_posterior) * betas * (1. - alphas_cumprod_prev) / (
|
| 145 |
+
1. - alphas_cumprod) + self.v_posterior * betas
|
| 146 |
+
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
|
| 147 |
+
self.register_buffer('posterior_variance', to_torch(posterior_variance))
|
| 148 |
+
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
|
| 149 |
+
self.register_buffer('posterior_log_variance_clipped', to_torch(np.log(np.maximum(posterior_variance, 1e-20))))
|
| 150 |
+
self.register_buffer('posterior_mean_coef1', to_torch(
|
| 151 |
+
betas * np.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod)))
|
| 152 |
+
self.register_buffer('posterior_mean_coef2', to_torch(
|
| 153 |
+
(1. - alphas_cumprod_prev) * np.sqrt(alphas) / (1. - alphas_cumprod)))
|
| 154 |
+
|
| 155 |
+
if self.parameterization == "eps":
|
| 156 |
+
lvlb_weights = self.betas ** 2 / (
|
| 157 |
+
2 * self.posterior_variance * to_torch(alphas) * (1 - self.alphas_cumprod))
|
| 158 |
+
elif self.parameterization == "x0":
|
| 159 |
+
lvlb_weights = 0.5 * np.sqrt(torch.Tensor(alphas_cumprod)) / (2. * 1 - torch.Tensor(alphas_cumprod))
|
| 160 |
+
else:
|
| 161 |
+
raise NotImplementedError("mu not supported")
|
| 162 |
+
# TODO how to choose this term
|
| 163 |
+
lvlb_weights[0] = lvlb_weights[1]
|
| 164 |
+
self.register_buffer('lvlb_weights', lvlb_weights, persistent=False)
|
| 165 |
+
assert not torch.isnan(self.lvlb_weights).all()
|
| 166 |
+
|
| 167 |
+
@contextmanager
|
| 168 |
+
def ema_scope(self, context=None):
|
| 169 |
+
if self.use_ema:
|
| 170 |
+
self.model_ema.store(self.model.parameters())
|
| 171 |
+
self.model_ema.copy_to(self.model)
|
| 172 |
+
if context is not None:
|
| 173 |
+
mainlogger.info(f"{context}: Switched to EMA weights")
|
| 174 |
+
try:
|
| 175 |
+
yield None
|
| 176 |
+
finally:
|
| 177 |
+
if self.use_ema:
|
| 178 |
+
self.model_ema.restore(self.model.parameters())
|
| 179 |
+
if context is not None:
|
| 180 |
+
mainlogger.info(f"{context}: Restored training weights")
|
| 181 |
+
|
| 182 |
+
def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
|
| 183 |
+
sd = torch.load(path, map_location="cpu")
|
| 184 |
+
if "state_dict" in list(sd.keys()):
|
| 185 |
+
sd = sd["state_dict"]
|
| 186 |
+
keys = list(sd.keys())
|
| 187 |
+
for k in keys:
|
| 188 |
+
for ik in ignore_keys:
|
| 189 |
+
if k.startswith(ik):
|
| 190 |
+
mainlogger.info("Deleting key {} from state_dict.".format(k))
|
| 191 |
+
del sd[k]
|
| 192 |
+
missing, unexpected = self.load_state_dict(sd, strict=False) if not only_model else self.model.load_state_dict(
|
| 193 |
+
sd, strict=False)
|
| 194 |
+
mainlogger.info(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
|
| 195 |
+
if len(missing) > 0:
|
| 196 |
+
mainlogger.info(f"Missing Keys: {missing}")
|
| 197 |
+
if len(unexpected) > 0:
|
| 198 |
+
mainlogger.info(f"Unexpected Keys: {unexpected}")
|
| 199 |
+
|
| 200 |
+
def q_mean_variance(self, x_start, t):
|
| 201 |
+
"""
|
| 202 |
+
Get the distribution q(x_t | x_0).
|
| 203 |
+
:param x_start: the [N x C x ...] tensor of noiseless inputs.
|
| 204 |
+
:param t: the number of diffusion steps (minus 1). Here, 0 means one step.
|
| 205 |
+
:return: A tuple (mean, variance, log_variance), all of x_start's shape.
|
| 206 |
+
"""
|
| 207 |
+
mean = (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
|
| 208 |
+
variance = extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
|
| 209 |
+
log_variance = extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
|
| 210 |
+
return mean, variance, log_variance
|
| 211 |
+
|
| 212 |
+
def predict_start_from_noise(self, x_t, t, noise):
|
| 213 |
+
return (
|
| 214 |
+
extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
|
| 215 |
+
extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
def q_posterior(self, x_start, x_t, t):
|
| 219 |
+
posterior_mean = (
|
| 220 |
+
extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
|
| 221 |
+
extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
|
| 222 |
+
)
|
| 223 |
+
posterior_variance = extract_into_tensor(self.posterior_variance, t, x_t.shape)
|
| 224 |
+
posterior_log_variance_clipped = extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
|
| 225 |
+
return posterior_mean, posterior_variance, posterior_log_variance_clipped
|
| 226 |
+
|
| 227 |
+
def p_mean_variance(self, x, t, clip_denoised: bool):
|
| 228 |
+
model_out = self.model(x, t)
|
| 229 |
+
if self.parameterization == "eps":
|
| 230 |
+
x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
|
| 231 |
+
elif self.parameterization == "x0":
|
| 232 |
+
x_recon = model_out
|
| 233 |
+
if clip_denoised:
|
| 234 |
+
x_recon.clamp_(-1., 1.)
|
| 235 |
+
|
| 236 |
+
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
|
| 237 |
+
return model_mean, posterior_variance, posterior_log_variance
|
| 238 |
+
|
| 239 |
+
@torch.no_grad()
|
| 240 |
+
def p_sample(self, x, t, clip_denoised=True, repeat_noise=False):
|
| 241 |
+
b, *_, device = *x.shape, x.device
|
| 242 |
+
model_mean, _, model_log_variance = self.p_mean_variance(x=x, t=t, clip_denoised=clip_denoised)
|
| 243 |
+
noise = noise_like(x.shape, device, repeat_noise)
|
| 244 |
+
# no noise when t == 0
|
| 245 |
+
nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1)))
|
| 246 |
+
return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
|
| 247 |
+
|
| 248 |
+
@torch.no_grad()
|
| 249 |
+
def p_sample_loop(self, shape, return_intermediates=False):
|
| 250 |
+
device = self.betas.device
|
| 251 |
+
b = shape[0]
|
| 252 |
+
img = torch.randn(shape, device=device)
|
| 253 |
+
intermediates = [img]
|
| 254 |
+
for i in tqdm(reversed(range(0, self.num_timesteps)), desc='Sampling t', total=self.num_timesteps):
|
| 255 |
+
img = self.p_sample(img, torch.full((b,), i, device=device, dtype=torch.long),
|
| 256 |
+
clip_denoised=self.clip_denoised)
|
| 257 |
+
if i % self.log_every_t == 0 or i == self.num_timesteps - 1:
|
| 258 |
+
intermediates.append(img)
|
| 259 |
+
if return_intermediates:
|
| 260 |
+
return img, intermediates
|
| 261 |
+
return img
|
| 262 |
+
|
| 263 |
+
@torch.no_grad()
|
| 264 |
+
def sample(self, batch_size=16, return_intermediates=False):
|
| 265 |
+
image_size = self.image_size
|
| 266 |
+
channels = self.channels
|
| 267 |
+
return self.p_sample_loop((batch_size, channels, image_size, image_size),
|
| 268 |
+
return_intermediates=return_intermediates)
|
| 269 |
+
|
| 270 |
+
def q_sample(self, x_start, t, noise=None):
|
| 271 |
+
noise = default(noise, lambda: torch.randn_like(x_start))
|
| 272 |
+
return (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start *
|
| 273 |
+
extract_into_tensor(self.scale_arr, t, x_start.shape) +
|
| 274 |
+
extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
|
| 275 |
+
|
| 276 |
+
def get_input(self, batch, k):
|
| 277 |
+
x = batch[k]
|
| 278 |
+
x = x.to(memory_format=torch.contiguous_format).float()
|
| 279 |
+
return x
|
| 280 |
+
|
| 281 |
+
def _get_rows_from_list(self, samples):
|
| 282 |
+
n_imgs_per_row = len(samples)
|
| 283 |
+
denoise_grid = rearrange(samples, 'n b c h w -> b n c h w')
|
| 284 |
+
denoise_grid = rearrange(denoise_grid, 'b n c h w -> (b n) c h w')
|
| 285 |
+
denoise_grid = make_grid(denoise_grid, nrow=n_imgs_per_row)
|
| 286 |
+
return denoise_grid
|
| 287 |
+
|
| 288 |
+
@torch.no_grad()
|
| 289 |
+
def log_images(self, batch, N=8, n_row=2, sample=True, return_keys=None, **kwargs):
|
| 290 |
+
log = dict()
|
| 291 |
+
x = self.get_input(batch, self.first_stage_key)
|
| 292 |
+
N = min(x.shape[0], N)
|
| 293 |
+
n_row = min(x.shape[0], n_row)
|
| 294 |
+
x = x.to(self.device)[:N]
|
| 295 |
+
log["inputs"] = x
|
| 296 |
+
|
| 297 |
+
# get diffusion row
|
| 298 |
+
diffusion_row = list()
|
| 299 |
+
x_start = x[:n_row]
|
| 300 |
+
|
| 301 |
+
for t in range(self.num_timesteps):
|
| 302 |
+
if t % self.log_every_t == 0 or t == self.num_timesteps - 1:
|
| 303 |
+
t = repeat(torch.tensor([t]), '1 -> b', b=n_row)
|
| 304 |
+
t = t.to(self.device).long()
|
| 305 |
+
noise = torch.randn_like(x_start)
|
| 306 |
+
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
|
| 307 |
+
diffusion_row.append(x_noisy)
|
| 308 |
+
|
| 309 |
+
log["diffusion_row"] = self._get_rows_from_list(diffusion_row)
|
| 310 |
+
|
| 311 |
+
if sample:
|
| 312 |
+
# get denoise row
|
| 313 |
+
with self.ema_scope("Plotting"):
|
| 314 |
+
samples, denoise_row = self.sample(batch_size=N, return_intermediates=True)
|
| 315 |
+
|
| 316 |
+
log["samples"] = samples
|
| 317 |
+
log["denoise_row"] = self._get_rows_from_list(denoise_row)
|
| 318 |
+
|
| 319 |
+
if return_keys:
|
| 320 |
+
if np.intersect1d(list(log.keys()), return_keys).shape[0] == 0:
|
| 321 |
+
return log
|
| 322 |
+
else:
|
| 323 |
+
return {key: log[key] for key in return_keys}
|
| 324 |
+
return log
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
class LatentDiffusion(DDPM):
|
| 328 |
+
"""main class"""
|
| 329 |
+
def __init__(self,
|
| 330 |
+
first_stage_config,
|
| 331 |
+
cond_stage_config,
|
| 332 |
+
num_timesteps_cond=None,
|
| 333 |
+
cond_stage_key="caption",
|
| 334 |
+
cond_stage_trainable=False,
|
| 335 |
+
cond_stage_forward=None,
|
| 336 |
+
conditioning_key=None,
|
| 337 |
+
uncond_prob=0.2,
|
| 338 |
+
uncond_type="empty_seq",
|
| 339 |
+
scale_factor=1.0,
|
| 340 |
+
scale_by_std=False,
|
| 341 |
+
encoder_type="2d",
|
| 342 |
+
only_model=False,
|
| 343 |
+
use_scale=False,
|
| 344 |
+
scale_a=1,
|
| 345 |
+
scale_b=0.3,
|
| 346 |
+
mid_step=400,
|
| 347 |
+
fix_scale_bug=False,
|
| 348 |
+
*args, **kwargs):
|
| 349 |
+
self.num_timesteps_cond = default(num_timesteps_cond, 1)
|
| 350 |
+
self.scale_by_std = scale_by_std
|
| 351 |
+
assert self.num_timesteps_cond <= kwargs['timesteps']
|
| 352 |
+
# for backwards compatibility after implementation of DiffusionWrapper
|
| 353 |
+
ckpt_path = kwargs.pop("ckpt_path", None)
|
| 354 |
+
ignore_keys = kwargs.pop("ignore_keys", [])
|
| 355 |
+
conditioning_key = default(conditioning_key, 'crossattn')
|
| 356 |
+
super().__init__(conditioning_key=conditioning_key, *args, **kwargs)
|
| 357 |
+
|
| 358 |
+
self.cond_stage_trainable = cond_stage_trainable
|
| 359 |
+
self.cond_stage_key = cond_stage_key
|
| 360 |
+
|
| 361 |
+
# scale factor
|
| 362 |
+
self.use_scale=use_scale
|
| 363 |
+
if self.use_scale:
|
| 364 |
+
self.scale_a=scale_a
|
| 365 |
+
self.scale_b=scale_b
|
| 366 |
+
if fix_scale_bug:
|
| 367 |
+
scale_step=self.num_timesteps-mid_step
|
| 368 |
+
else: #bug
|
| 369 |
+
scale_step = self.num_timesteps
|
| 370 |
+
|
| 371 |
+
scale_arr1 = np.linspace(scale_a, scale_b, mid_step)
|
| 372 |
+
scale_arr2 = np.full(scale_step, scale_b)
|
| 373 |
+
scale_arr = np.concatenate((scale_arr1, scale_arr2))
|
| 374 |
+
scale_arr_prev = np.append(scale_a, scale_arr[:-1])
|
| 375 |
+
to_torch = partial(torch.tensor, dtype=torch.float32)
|
| 376 |
+
self.register_buffer('scale_arr', to_torch(scale_arr))
|
| 377 |
+
|
| 378 |
+
try:
|
| 379 |
+
self.num_downs = len(first_stage_config.params.ddconfig.ch_mult) - 1
|
| 380 |
+
except:
|
| 381 |
+
self.num_downs = 0
|
| 382 |
+
if not scale_by_std:
|
| 383 |
+
self.scale_factor = scale_factor
|
| 384 |
+
else:
|
| 385 |
+
self.register_buffer('scale_factor', torch.tensor(scale_factor))
|
| 386 |
+
self.instantiate_first_stage(first_stage_config)
|
| 387 |
+
self.instantiate_cond_stage(cond_stage_config)
|
| 388 |
+
self.first_stage_config = first_stage_config
|
| 389 |
+
self.cond_stage_config = cond_stage_config
|
| 390 |
+
self.clip_denoised = False
|
| 391 |
+
|
| 392 |
+
self.cond_stage_forward = cond_stage_forward
|
| 393 |
+
self.encoder_type = encoder_type
|
| 394 |
+
assert(encoder_type in ["2d", "3d"])
|
| 395 |
+
self.uncond_prob = uncond_prob
|
| 396 |
+
self.classifier_free_guidance = True if uncond_prob > 0 else False
|
| 397 |
+
assert(uncond_type in ["zero_embed", "empty_seq"])
|
| 398 |
+
self.uncond_type = uncond_type
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
self.restarted_from_ckpt = False
|
| 402 |
+
if ckpt_path is not None:
|
| 403 |
+
self.init_from_ckpt(ckpt_path, ignore_keys, only_model=only_model)
|
| 404 |
+
self.restarted_from_ckpt = True
|
| 405 |
+
|
| 406 |
+
|
| 407 |
+
def make_cond_schedule(self, ):
|
| 408 |
+
self.cond_ids = torch.full(size=(self.num_timesteps,), fill_value=self.num_timesteps - 1, dtype=torch.long)
|
| 409 |
+
ids = torch.round(torch.linspace(0, self.num_timesteps - 1, self.num_timesteps_cond)).long()
|
| 410 |
+
self.cond_ids[:self.num_timesteps_cond] = ids
|
| 411 |
+
|
| 412 |
+
def q_sample(self, x_start, t, noise=None):
|
| 413 |
+
noise = default(noise, lambda: torch.randn_like(x_start))
|
| 414 |
+
if self.use_scale:
|
| 415 |
+
return (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start *
|
| 416 |
+
extract_into_tensor(self.scale_arr, t, x_start.shape) +
|
| 417 |
+
extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
|
| 418 |
+
else:
|
| 419 |
+
return (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
|
| 420 |
+
extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
def _freeze_model(self):
|
| 424 |
+
for name, para in self.model.diffusion_model.named_parameters():
|
| 425 |
+
para.requires_grad = False
|
| 426 |
+
|
| 427 |
+
def instantiate_first_stage(self, config):
|
| 428 |
+
model = instantiate_from_config(config)
|
| 429 |
+
self.first_stage_model = model.eval()
|
| 430 |
+
self.first_stage_model.train = disabled_train
|
| 431 |
+
for param in self.first_stage_model.parameters():
|
| 432 |
+
param.requires_grad = False
|
| 433 |
+
|
| 434 |
+
def instantiate_cond_stage(self, config):
|
| 435 |
+
if not self.cond_stage_trainable:
|
| 436 |
+
model = instantiate_from_config(config)
|
| 437 |
+
self.cond_stage_model = model.eval()
|
| 438 |
+
self.cond_stage_model.train = disabled_train
|
| 439 |
+
for param in self.cond_stage_model.parameters():
|
| 440 |
+
param.requires_grad = False
|
| 441 |
+
else:
|
| 442 |
+
model = instantiate_from_config(config)
|
| 443 |
+
self.cond_stage_model = model
|
| 444 |
+
|
| 445 |
+
def get_learned_conditioning(self, c):
|
| 446 |
+
if self.cond_stage_forward is None:
|
| 447 |
+
if hasattr(self.cond_stage_model, 'encode') and callable(self.cond_stage_model.encode):
|
| 448 |
+
c = self.cond_stage_model.encode(c)
|
| 449 |
+
if isinstance(c, DiagonalGaussianDistribution):
|
| 450 |
+
c = c.mode()
|
| 451 |
+
else:
|
| 452 |
+
c = self.cond_stage_model(c)
|
| 453 |
+
else:
|
| 454 |
+
assert hasattr(self.cond_stage_model, self.cond_stage_forward)
|
| 455 |
+
c = getattr(self.cond_stage_model, self.cond_stage_forward)(c)
|
| 456 |
+
return c
|
| 457 |
+
|
| 458 |
+
def get_first_stage_encoding(self, encoder_posterior, noise=None):
|
| 459 |
+
if isinstance(encoder_posterior, DiagonalGaussianDistribution):
|
| 460 |
+
z = encoder_posterior.sample(noise=noise)
|
| 461 |
+
elif isinstance(encoder_posterior, torch.Tensor):
|
| 462 |
+
z = encoder_posterior
|
| 463 |
+
else:
|
| 464 |
+
raise NotImplementedError(f"encoder_posterior of type '{type(encoder_posterior)}' not yet implemented")
|
| 465 |
+
return self.scale_factor * z
|
| 466 |
+
|
| 467 |
+
@torch.no_grad()
|
| 468 |
+
def encode_first_stage(self, x):
|
| 469 |
+
if self.encoder_type == "2d" and x.dim() == 5:
|
| 470 |
+
b, _, t, _, _ = x.shape
|
| 471 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 472 |
+
reshape_back = True
|
| 473 |
+
else:
|
| 474 |
+
reshape_back = False
|
| 475 |
+
|
| 476 |
+
encoder_posterior = self.first_stage_model.encode(x)
|
| 477 |
+
results = self.get_first_stage_encoding(encoder_posterior).detach()
|
| 478 |
+
|
| 479 |
+
if reshape_back:
|
| 480 |
+
results = rearrange(results, '(b t) c h w -> b c t h w', b=b,t=t)
|
| 481 |
+
|
| 482 |
+
return results
|
| 483 |
+
|
| 484 |
+
@torch.no_grad()
|
| 485 |
+
def encode_first_stage_2DAE(self, x):
|
| 486 |
+
|
| 487 |
+
b, _, t, _, _ = x.shape
|
| 488 |
+
results = torch.cat([self.get_first_stage_encoding(self.first_stage_model.encode(x[:,:,i])).detach().unsqueeze(2) for i in range(t)], dim=2)
|
| 489 |
+
|
| 490 |
+
return results
|
| 491 |
+
|
| 492 |
+
def decode_core(self, z, **kwargs):
|
| 493 |
+
if self.encoder_type == "2d" and z.dim() == 5:
|
| 494 |
+
b, _, t, _, _ = z.shape
|
| 495 |
+
z = rearrange(z, 'b c t h w -> (b t) c h w')
|
| 496 |
+
reshape_back = True
|
| 497 |
+
else:
|
| 498 |
+
reshape_back = False
|
| 499 |
+
|
| 500 |
+
z = 1. / self.scale_factor * z
|
| 501 |
+
|
| 502 |
+
results = self.first_stage_model.decode(z, **kwargs)
|
| 503 |
+
|
| 504 |
+
if reshape_back:
|
| 505 |
+
results = rearrange(results, '(b t) c h w -> b c t h w', b=b,t=t)
|
| 506 |
+
return results
|
| 507 |
+
|
| 508 |
+
@torch.no_grad()
|
| 509 |
+
def decode_first_stage(self, z, **kwargs):
|
| 510 |
+
return self.decode_core(z, **kwargs)
|
| 511 |
+
|
| 512 |
+
def apply_model(self, x_noisy, t, cond, **kwargs):
|
| 513 |
+
if isinstance(cond, dict):
|
| 514 |
+
# hybrid case, cond is exptected to be a dict
|
| 515 |
+
pass
|
| 516 |
+
else:
|
| 517 |
+
if not isinstance(cond, list):
|
| 518 |
+
cond = [cond]
|
| 519 |
+
key = 'c_concat' if self.model.conditioning_key == 'concat' else 'c_crossattn'
|
| 520 |
+
cond = {key: cond}
|
| 521 |
+
|
| 522 |
+
x_recon = self.model(x_noisy, t, **cond, **kwargs)
|
| 523 |
+
|
| 524 |
+
if isinstance(x_recon, tuple):
|
| 525 |
+
return x_recon[0]
|
| 526 |
+
else:
|
| 527 |
+
return x_recon
|
| 528 |
+
|
| 529 |
+
def _get_denoise_row_from_list(self, samples, desc=''):
|
| 530 |
+
denoise_row = []
|
| 531 |
+
for zd in tqdm(samples, desc=desc):
|
| 532 |
+
denoise_row.append(self.decode_first_stage(zd.to(self.device)))
|
| 533 |
+
n_log_timesteps = len(denoise_row)
|
| 534 |
+
|
| 535 |
+
denoise_row = torch.stack(denoise_row) # n_log_timesteps, b, C, H, W
|
| 536 |
+
|
| 537 |
+
if denoise_row.dim() == 5:
|
| 538 |
+
# img, num_imgs= n_log_timesteps * bs, grid_size=[bs,n_log_timesteps]
|
| 539 |
+
denoise_grid = rearrange(denoise_row, 'n b c h w -> b n c h w')
|
| 540 |
+
denoise_grid = rearrange(denoise_grid, 'b n c h w -> (b n) c h w')
|
| 541 |
+
denoise_grid = make_grid(denoise_grid, nrow=n_log_timesteps)
|
| 542 |
+
elif denoise_row.dim() == 6:
|
| 543 |
+
# video, grid_size=[n_log_timesteps*bs, t]
|
| 544 |
+
video_length = denoise_row.shape[3]
|
| 545 |
+
denoise_grid = rearrange(denoise_row, 'n b c t h w -> b n c t h w')
|
| 546 |
+
denoise_grid = rearrange(denoise_grid, 'b n c t h w -> (b n) c t h w')
|
| 547 |
+
denoise_grid = rearrange(denoise_grid, 'n c t h w -> (n t) c h w')
|
| 548 |
+
denoise_grid = make_grid(denoise_grid, nrow=video_length)
|
| 549 |
+
else:
|
| 550 |
+
raise ValueError
|
| 551 |
+
|
| 552 |
+
return denoise_grid
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
@torch.no_grad()
|
| 556 |
+
def decode_first_stage_2DAE(self, z, **kwargs):
|
| 557 |
+
|
| 558 |
+
b, _, t, _, _ = z.shape
|
| 559 |
+
z = 1. / self.scale_factor * z
|
| 560 |
+
results = torch.cat([self.first_stage_model.decode(z[:,:,i], **kwargs).unsqueeze(2) for i in range(t)], dim=2)
|
| 561 |
+
|
| 562 |
+
return results
|
| 563 |
+
|
| 564 |
+
|
| 565 |
+
def p_mean_variance(self, x, c, t, clip_denoised: bool, return_x0=False, score_corrector=None, corrector_kwargs=None, **kwargs):
|
| 566 |
+
t_in = t
|
| 567 |
+
model_out = self.apply_model(x, t_in, c, **kwargs)
|
| 568 |
+
|
| 569 |
+
if score_corrector is not None:
|
| 570 |
+
assert self.parameterization == "eps"
|
| 571 |
+
model_out = score_corrector.modify_score(self, model_out, x, t, c, **corrector_kwargs)
|
| 572 |
+
|
| 573 |
+
if self.parameterization == "eps":
|
| 574 |
+
x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
|
| 575 |
+
elif self.parameterization == "x0":
|
| 576 |
+
x_recon = model_out
|
| 577 |
+
else:
|
| 578 |
+
raise NotImplementedError()
|
| 579 |
+
|
| 580 |
+
if clip_denoised:
|
| 581 |
+
x_recon.clamp_(-1., 1.)
|
| 582 |
+
|
| 583 |
+
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
|
| 584 |
+
|
| 585 |
+
if return_x0:
|
| 586 |
+
return model_mean, posterior_variance, posterior_log_variance, x_recon
|
| 587 |
+
else:
|
| 588 |
+
return model_mean, posterior_variance, posterior_log_variance
|
| 589 |
+
|
| 590 |
+
@torch.no_grad()
|
| 591 |
+
def p_sample(self, x, c, t, clip_denoised=False, repeat_noise=False, return_x0=False, \
|
| 592 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None, **kwargs):
|
| 593 |
+
b, *_, device = *x.shape, x.device
|
| 594 |
+
outputs = self.p_mean_variance(x=x, c=c, t=t, clip_denoised=clip_denoised, return_x0=return_x0, \
|
| 595 |
+
score_corrector=score_corrector, corrector_kwargs=corrector_kwargs, **kwargs)
|
| 596 |
+
if return_x0:
|
| 597 |
+
model_mean, _, model_log_variance, x0 = outputs
|
| 598 |
+
else:
|
| 599 |
+
model_mean, _, model_log_variance = outputs
|
| 600 |
+
|
| 601 |
+
noise = noise_like(x.shape, device, repeat_noise) * temperature
|
| 602 |
+
if noise_dropout > 0.:
|
| 603 |
+
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 604 |
+
# no noise when t == 0
|
| 605 |
+
nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1)))
|
| 606 |
+
|
| 607 |
+
if return_x0:
|
| 608 |
+
return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise, x0
|
| 609 |
+
else:
|
| 610 |
+
return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
|
| 611 |
+
|
| 612 |
+
@torch.no_grad()
|
| 613 |
+
def p_sample_loop(self, cond, shape, return_intermediates=False, x_T=None, verbose=True, callback=None, \
|
| 614 |
+
timesteps=None, mask=None, x0=None, img_callback=None, start_T=None, log_every_t=None, **kwargs):
|
| 615 |
+
|
| 616 |
+
if not log_every_t:
|
| 617 |
+
log_every_t = self.log_every_t
|
| 618 |
+
device = self.betas.device
|
| 619 |
+
b = shape[0]
|
| 620 |
+
# sample an initial noise
|
| 621 |
+
if x_T is None:
|
| 622 |
+
img = torch.randn(shape, device=device)
|
| 623 |
+
else:
|
| 624 |
+
img = x_T
|
| 625 |
+
|
| 626 |
+
intermediates = [img]
|
| 627 |
+
if timesteps is None:
|
| 628 |
+
timesteps = self.num_timesteps
|
| 629 |
+
if start_T is not None:
|
| 630 |
+
timesteps = min(timesteps, start_T)
|
| 631 |
+
|
| 632 |
+
iterator = tqdm(reversed(range(0, timesteps)), desc='Sampling t', total=timesteps) if verbose else reversed(range(0, timesteps))
|
| 633 |
+
|
| 634 |
+
if mask is not None:
|
| 635 |
+
assert x0 is not None
|
| 636 |
+
assert x0.shape[2:3] == mask.shape[2:3] # spatial size has to match
|
| 637 |
+
|
| 638 |
+
for i in iterator:
|
| 639 |
+
ts = torch.full((b,), i, device=device, dtype=torch.long)
|
| 640 |
+
if self.shorten_cond_schedule:
|
| 641 |
+
assert self.model.conditioning_key != 'hybrid'
|
| 642 |
+
tc = self.cond_ids[ts].to(cond.device)
|
| 643 |
+
cond = self.q_sample(x_start=cond, t=tc, noise=torch.randn_like(cond))
|
| 644 |
+
|
| 645 |
+
img = self.p_sample(img, cond, ts, clip_denoised=self.clip_denoised, **kwargs)
|
| 646 |
+
if mask is not None:
|
| 647 |
+
img_orig = self.q_sample(x0, ts)
|
| 648 |
+
img = img_orig * mask + (1. - mask) * img
|
| 649 |
+
|
| 650 |
+
if i % log_every_t == 0 or i == timesteps - 1:
|
| 651 |
+
intermediates.append(img)
|
| 652 |
+
if callback: callback(i)
|
| 653 |
+
if img_callback: img_callback(img, i)
|
| 654 |
+
|
| 655 |
+
if return_intermediates:
|
| 656 |
+
return img, intermediates
|
| 657 |
+
return img
|
| 658 |
+
|
| 659 |
+
|
| 660 |
+
class LatentVisualDiffusion(LatentDiffusion):
|
| 661 |
+
def __init__(self, cond_img_config, finegrained=False, random_cond=False, *args, **kwargs):
|
| 662 |
+
super().__init__(*args, **kwargs)
|
| 663 |
+
self.random_cond = random_cond
|
| 664 |
+
self.instantiate_img_embedder(cond_img_config, freeze=True)
|
| 665 |
+
num_tokens = 16 if finegrained else 4
|
| 666 |
+
self.image_proj_model = self.init_projector(use_finegrained=finegrained, num_tokens=num_tokens, input_dim=1024,\
|
| 667 |
+
cross_attention_dim=1024, dim=1280)
|
| 668 |
+
|
| 669 |
+
def instantiate_img_embedder(self, config, freeze=True):
|
| 670 |
+
embedder = instantiate_from_config(config)
|
| 671 |
+
if freeze:
|
| 672 |
+
self.embedder = embedder.eval()
|
| 673 |
+
self.embedder.train = disabled_train
|
| 674 |
+
for param in self.embedder.parameters():
|
| 675 |
+
param.requires_grad = False
|
| 676 |
+
|
| 677 |
+
def init_projector(self, use_finegrained, num_tokens, input_dim, cross_attention_dim, dim):
|
| 678 |
+
if not use_finegrained:
|
| 679 |
+
image_proj_model = ImageProjModel(clip_extra_context_tokens=num_tokens, cross_attention_dim=cross_attention_dim,
|
| 680 |
+
clip_embeddings_dim=input_dim
|
| 681 |
+
)
|
| 682 |
+
else:
|
| 683 |
+
image_proj_model = Resampler(dim=input_dim, depth=4, dim_head=64, heads=12, num_queries=num_tokens,
|
| 684 |
+
embedding_dim=dim, output_dim=cross_attention_dim, ff_mult=4
|
| 685 |
+
)
|
| 686 |
+
return image_proj_model
|
| 687 |
+
|
| 688 |
+
## Never delete this func: it is used in log_images() and inference stage
|
| 689 |
+
def get_image_embeds(self, batch_imgs):
|
| 690 |
+
## img: b c h w
|
| 691 |
+
img_token = self.embedder(batch_imgs)
|
| 692 |
+
img_emb = self.image_proj_model(img_token)
|
| 693 |
+
return img_emb
|
| 694 |
+
|
| 695 |
+
|
| 696 |
+
class DiffusionWrapper(pl.LightningModule):
|
| 697 |
+
def __init__(self, diff_model_config, conditioning_key):
|
| 698 |
+
super().__init__()
|
| 699 |
+
self.diffusion_model = instantiate_from_config(diff_model_config)
|
| 700 |
+
self.conditioning_key = conditioning_key
|
| 701 |
+
|
| 702 |
+
def forward(self, x, t, c_concat: list = None, c_crossattn: list = None,
|
| 703 |
+
c_adm=None, s=None, mask=None, **kwargs):
|
| 704 |
+
# temporal_context = fps is foNone
|
| 705 |
+
if self.conditioning_key is None:
|
| 706 |
+
out = self.diffusion_model(x, t)
|
| 707 |
+
elif self.conditioning_key == 'concat':
|
| 708 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 709 |
+
out = self.diffusion_model(xc, t, **kwargs)
|
| 710 |
+
elif self.conditioning_key == 'crossattn':
|
| 711 |
+
cc = torch.cat(c_crossattn, 1)
|
| 712 |
+
out = self.diffusion_model(x, t, context=cc, **kwargs)
|
| 713 |
+
elif self.conditioning_key == 'hybrid':
|
| 714 |
+
## it is just right [b,c,t,h,w]: concatenate in channel dim
|
| 715 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 716 |
+
cc = torch.cat(c_crossattn, 1)
|
| 717 |
+
out = self.diffusion_model(xc, t, context=cc)
|
| 718 |
+
elif self.conditioning_key == 'resblockcond':
|
| 719 |
+
cc = c_crossattn[0]
|
| 720 |
+
out = self.diffusion_model(x, t, context=cc)
|
| 721 |
+
elif self.conditioning_key == 'adm':
|
| 722 |
+
cc = c_crossattn[0]
|
| 723 |
+
out = self.diffusion_model(x, t, y=cc)
|
| 724 |
+
elif self.conditioning_key == 'hybrid-adm':
|
| 725 |
+
assert c_adm is not None
|
| 726 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 727 |
+
cc = torch.cat(c_crossattn, 1)
|
| 728 |
+
out = self.diffusion_model(xc, t, context=cc, y=c_adm)
|
| 729 |
+
elif self.conditioning_key == 'hybrid-time':
|
| 730 |
+
assert s is not None
|
| 731 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 732 |
+
cc = torch.cat(c_crossattn, 1)
|
| 733 |
+
out = self.diffusion_model(xc, t, context=cc, s=s)
|
| 734 |
+
elif self.conditioning_key == 'concat-time-mask':
|
| 735 |
+
# assert s is not None
|
| 736 |
+
# mainlogger.info('x & mask:',x.shape,c_concat[0].shape)
|
| 737 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 738 |
+
out = self.diffusion_model(xc, t, context=None, s=s, mask=mask)
|
| 739 |
+
elif self.conditioning_key == 'concat-adm-mask':
|
| 740 |
+
# assert s is not None
|
| 741 |
+
# mainlogger.info('x & mask:',x.shape,c_concat[0].shape)
|
| 742 |
+
if c_concat is not None:
|
| 743 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 744 |
+
else:
|
| 745 |
+
xc = x
|
| 746 |
+
out = self.diffusion_model(xc, t, context=None, y=s, mask=mask)
|
| 747 |
+
elif self.conditioning_key == 'hybrid-adm-mask':
|
| 748 |
+
cc = torch.cat(c_crossattn, 1)
|
| 749 |
+
if c_concat is not None:
|
| 750 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 751 |
+
else:
|
| 752 |
+
xc = x
|
| 753 |
+
out = self.diffusion_model(xc, t, context=cc, y=s, mask=mask)
|
| 754 |
+
elif self.conditioning_key == 'hybrid-time-adm': # adm means y, e.g., class index
|
| 755 |
+
# assert s is not None
|
| 756 |
+
assert c_adm is not None
|
| 757 |
+
xc = torch.cat([x] + c_concat, dim=1)
|
| 758 |
+
cc = torch.cat(c_crossattn, 1)
|
| 759 |
+
out = self.diffusion_model(xc, t, context=cc, s=s, y=c_adm)
|
| 760 |
+
else:
|
| 761 |
+
raise NotImplementedError()
|
| 762 |
+
|
| 763 |
+
return out
|
lvdm/models/samplers/ddim.py
ADDED
|
@@ -0,0 +1,336 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
import torch
|
| 4 |
+
from lvdm.models.utils_diffusion import make_ddim_sampling_parameters, make_ddim_timesteps
|
| 5 |
+
from lvdm.common import noise_like
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class DDIMSampler(object):
|
| 9 |
+
def __init__(self, model, schedule="linear", **kwargs):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.model = model
|
| 12 |
+
self.ddpm_num_timesteps = model.num_timesteps
|
| 13 |
+
self.schedule = schedule
|
| 14 |
+
self.counter = 0
|
| 15 |
+
|
| 16 |
+
def register_buffer(self, name, attr):
|
| 17 |
+
if type(attr) == torch.Tensor:
|
| 18 |
+
if attr.device != torch.device("cuda"):
|
| 19 |
+
attr = attr.to(torch.device("cuda"))
|
| 20 |
+
setattr(self, name, attr)
|
| 21 |
+
|
| 22 |
+
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
|
| 23 |
+
self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
|
| 24 |
+
num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
|
| 25 |
+
alphas_cumprod = self.model.alphas_cumprod
|
| 26 |
+
assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
|
| 27 |
+
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
|
| 28 |
+
|
| 29 |
+
self.register_buffer('betas', to_torch(self.model.betas))
|
| 30 |
+
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
|
| 31 |
+
self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
|
| 32 |
+
self.use_scale = self.model.use_scale
|
| 33 |
+
print('DDIM scale', self.use_scale)
|
| 34 |
+
|
| 35 |
+
if self.use_scale:
|
| 36 |
+
self.register_buffer('scale_arr', to_torch(self.model.scale_arr))
|
| 37 |
+
ddim_scale_arr = self.scale_arr.cpu()[self.ddim_timesteps]
|
| 38 |
+
self.register_buffer('ddim_scale_arr', ddim_scale_arr)
|
| 39 |
+
ddim_scale_arr = np.asarray([self.scale_arr.cpu()[0]] + self.scale_arr.cpu()[self.ddim_timesteps[:-1]].tolist())
|
| 40 |
+
self.register_buffer('ddim_scale_arr_prev', ddim_scale_arr)
|
| 41 |
+
|
| 42 |
+
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 43 |
+
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
|
| 44 |
+
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
|
| 45 |
+
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
|
| 46 |
+
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
|
| 47 |
+
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
|
| 48 |
+
|
| 49 |
+
# ddim sampling parameters
|
| 50 |
+
ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
|
| 51 |
+
ddim_timesteps=self.ddim_timesteps,
|
| 52 |
+
eta=ddim_eta,verbose=verbose)
|
| 53 |
+
self.register_buffer('ddim_sigmas', ddim_sigmas)
|
| 54 |
+
self.register_buffer('ddim_alphas', ddim_alphas)
|
| 55 |
+
self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
|
| 56 |
+
self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
|
| 57 |
+
sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
|
| 58 |
+
(1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
|
| 59 |
+
1 - self.alphas_cumprod / self.alphas_cumprod_prev))
|
| 60 |
+
self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
|
| 61 |
+
|
| 62 |
+
@torch.no_grad()
|
| 63 |
+
def sample(self,
|
| 64 |
+
S,
|
| 65 |
+
batch_size,
|
| 66 |
+
shape,
|
| 67 |
+
conditioning=None,
|
| 68 |
+
callback=None,
|
| 69 |
+
normals_sequence=None,
|
| 70 |
+
img_callback=None,
|
| 71 |
+
quantize_x0=False,
|
| 72 |
+
eta=0.,
|
| 73 |
+
mask=None,
|
| 74 |
+
x0=None,
|
| 75 |
+
temperature=1.,
|
| 76 |
+
noise_dropout=0.,
|
| 77 |
+
score_corrector=None,
|
| 78 |
+
corrector_kwargs=None,
|
| 79 |
+
verbose=True,
|
| 80 |
+
schedule_verbose=False,
|
| 81 |
+
x_T=None,
|
| 82 |
+
log_every_t=100,
|
| 83 |
+
unconditional_guidance_scale=1.,
|
| 84 |
+
unconditional_conditioning=None,
|
| 85 |
+
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
|
| 86 |
+
**kwargs
|
| 87 |
+
):
|
| 88 |
+
|
| 89 |
+
# check condition bs
|
| 90 |
+
if conditioning is not None:
|
| 91 |
+
if isinstance(conditioning, dict):
|
| 92 |
+
try:
|
| 93 |
+
cbs = conditioning[list(conditioning.keys())[0]].shape[0]
|
| 94 |
+
except:
|
| 95 |
+
cbs = conditioning[list(conditioning.keys())[0]][0].shape[0]
|
| 96 |
+
|
| 97 |
+
if cbs != batch_size:
|
| 98 |
+
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 99 |
+
else:
|
| 100 |
+
if conditioning.shape[0] != batch_size:
|
| 101 |
+
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
|
| 102 |
+
|
| 103 |
+
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=schedule_verbose)
|
| 104 |
+
|
| 105 |
+
# make shape
|
| 106 |
+
if len(shape) == 3:
|
| 107 |
+
C, H, W = shape
|
| 108 |
+
size = (batch_size, C, H, W)
|
| 109 |
+
elif len(shape) == 4:
|
| 110 |
+
C, T, H, W = shape
|
| 111 |
+
size = (batch_size, C, T, H, W)
|
| 112 |
+
# print(f'Data shape for DDIM sampling is {size}, eta {eta}')
|
| 113 |
+
|
| 114 |
+
samples, intermediates = self.ddim_sampling(conditioning, size,
|
| 115 |
+
callback=callback,
|
| 116 |
+
img_callback=img_callback,
|
| 117 |
+
quantize_denoised=quantize_x0,
|
| 118 |
+
mask=mask, x0=x0,
|
| 119 |
+
ddim_use_original_steps=False,
|
| 120 |
+
noise_dropout=noise_dropout,
|
| 121 |
+
temperature=temperature,
|
| 122 |
+
score_corrector=score_corrector,
|
| 123 |
+
corrector_kwargs=corrector_kwargs,
|
| 124 |
+
x_T=x_T,
|
| 125 |
+
log_every_t=log_every_t,
|
| 126 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 127 |
+
unconditional_conditioning=unconditional_conditioning,
|
| 128 |
+
verbose=verbose,
|
| 129 |
+
**kwargs)
|
| 130 |
+
return samples, intermediates
|
| 131 |
+
|
| 132 |
+
@torch.no_grad()
|
| 133 |
+
def ddim_sampling(self, cond, shape,
|
| 134 |
+
x_T=None, ddim_use_original_steps=False,
|
| 135 |
+
callback=None, timesteps=None, quantize_denoised=False,
|
| 136 |
+
mask=None, x0=None, img_callback=None, log_every_t=100,
|
| 137 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 138 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None, verbose=True,
|
| 139 |
+
cond_tau=1., target_size=None, start_timesteps=None,
|
| 140 |
+
**kwargs):
|
| 141 |
+
device = self.model.betas.device
|
| 142 |
+
print('ddim device', device)
|
| 143 |
+
b = shape[0]
|
| 144 |
+
if x_T is None:
|
| 145 |
+
img = torch.randn(shape, device=device)
|
| 146 |
+
else:
|
| 147 |
+
img = x_T
|
| 148 |
+
|
| 149 |
+
if timesteps is None:
|
| 150 |
+
timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
|
| 151 |
+
elif timesteps is not None and not ddim_use_original_steps:
|
| 152 |
+
subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
|
| 153 |
+
timesteps = self.ddim_timesteps[:subset_end]
|
| 154 |
+
|
| 155 |
+
intermediates = {'x_inter': [img], 'pred_x0': [img]}
|
| 156 |
+
time_range = reversed(range(0,timesteps)) if ddim_use_original_steps else np.flip(timesteps)
|
| 157 |
+
total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
|
| 158 |
+
if verbose:
|
| 159 |
+
iterator = tqdm(time_range, desc='DDIM Sampler', total=total_steps)
|
| 160 |
+
else:
|
| 161 |
+
iterator = time_range
|
| 162 |
+
|
| 163 |
+
init_x0 = False
|
| 164 |
+
clean_cond = kwargs.pop("clean_cond", False)
|
| 165 |
+
for i, step in enumerate(iterator):
|
| 166 |
+
index = total_steps - i - 1
|
| 167 |
+
ts = torch.full((b,), step, device=device, dtype=torch.long)
|
| 168 |
+
if start_timesteps is not None:
|
| 169 |
+
assert x0 is not None
|
| 170 |
+
if step > start_timesteps*time_range[0]:
|
| 171 |
+
continue
|
| 172 |
+
elif not init_x0:
|
| 173 |
+
img = self.model.q_sample(x0, ts)
|
| 174 |
+
init_x0 = True
|
| 175 |
+
|
| 176 |
+
# use mask to blend noised original latent (img_orig) & new sampled latent (img)
|
| 177 |
+
if mask is not None:
|
| 178 |
+
assert x0 is not None
|
| 179 |
+
if clean_cond:
|
| 180 |
+
img_orig = x0
|
| 181 |
+
else:
|
| 182 |
+
img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass? <ddim inversion>
|
| 183 |
+
img = img_orig * mask + (1. - mask) * img # keep original & modify use img
|
| 184 |
+
|
| 185 |
+
index_clip = int((1 - cond_tau) * total_steps)
|
| 186 |
+
if index <= index_clip and target_size is not None:
|
| 187 |
+
target_size_ = [target_size[0], target_size[1]//8, target_size[2]//8]
|
| 188 |
+
img = torch.nn.functional.interpolate(
|
| 189 |
+
img,
|
| 190 |
+
size=target_size_,
|
| 191 |
+
mode="nearest",
|
| 192 |
+
)
|
| 193 |
+
outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
|
| 194 |
+
quantize_denoised=quantize_denoised, temperature=temperature,
|
| 195 |
+
noise_dropout=noise_dropout, score_corrector=score_corrector,
|
| 196 |
+
corrector_kwargs=corrector_kwargs,
|
| 197 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 198 |
+
unconditional_conditioning=unconditional_conditioning,
|
| 199 |
+
x0=x0,
|
| 200 |
+
**kwargs)
|
| 201 |
+
|
| 202 |
+
img, pred_x0 = outs
|
| 203 |
+
if callback: callback(i)
|
| 204 |
+
if img_callback: img_callback(pred_x0, i)
|
| 205 |
+
|
| 206 |
+
if index % log_every_t == 0 or index == total_steps - 1:
|
| 207 |
+
intermediates['x_inter'].append(img)
|
| 208 |
+
intermediates['pred_x0'].append(pred_x0)
|
| 209 |
+
|
| 210 |
+
return img, intermediates
|
| 211 |
+
|
| 212 |
+
@torch.no_grad()
|
| 213 |
+
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
|
| 214 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 215 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None,
|
| 216 |
+
uc_type=None, conditional_guidance_scale_temporal=None, **kwargs):
|
| 217 |
+
b, *_, device = *x.shape, x.device
|
| 218 |
+
if x.dim() == 5:
|
| 219 |
+
is_video = True
|
| 220 |
+
else:
|
| 221 |
+
is_video = False
|
| 222 |
+
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
|
| 223 |
+
e_t = self.model.apply_model(x, t, c, **kwargs) # unet denoiser
|
| 224 |
+
else:
|
| 225 |
+
# with unconditional condition
|
| 226 |
+
if isinstance(c, torch.Tensor):
|
| 227 |
+
e_t = self.model.apply_model(x, t, c, **kwargs)
|
| 228 |
+
e_t_uncond = self.model.apply_model(x, t, unconditional_conditioning, **kwargs)
|
| 229 |
+
elif isinstance(c, dict):
|
| 230 |
+
e_t = self.model.apply_model(x, t, c, **kwargs)
|
| 231 |
+
e_t_uncond = self.model.apply_model(x, t, unconditional_conditioning, **kwargs)
|
| 232 |
+
else:
|
| 233 |
+
raise NotImplementedError
|
| 234 |
+
# text cfg
|
| 235 |
+
if uc_type is None:
|
| 236 |
+
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
|
| 237 |
+
else:
|
| 238 |
+
if uc_type == 'cfg_original':
|
| 239 |
+
e_t = e_t + unconditional_guidance_scale * (e_t - e_t_uncond)
|
| 240 |
+
elif uc_type == 'cfg_ours':
|
| 241 |
+
e_t = e_t + unconditional_guidance_scale * (e_t_uncond - e_t)
|
| 242 |
+
else:
|
| 243 |
+
raise NotImplementedError
|
| 244 |
+
# temporal guidance
|
| 245 |
+
if conditional_guidance_scale_temporal is not None:
|
| 246 |
+
e_t_temporal = self.model.apply_model(x, t, c, **kwargs)
|
| 247 |
+
e_t_image = self.model.apply_model(x, t, c, no_temporal_attn=True, **kwargs)
|
| 248 |
+
e_t = e_t + conditional_guidance_scale_temporal * (e_t_temporal - e_t_image)
|
| 249 |
+
|
| 250 |
+
if score_corrector is not None:
|
| 251 |
+
assert self.model.parameterization == "eps"
|
| 252 |
+
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
|
| 253 |
+
|
| 254 |
+
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
|
| 255 |
+
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
|
| 256 |
+
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
|
| 257 |
+
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
|
| 258 |
+
# select parameters corresponding to the currently considered timestep
|
| 259 |
+
|
| 260 |
+
if is_video:
|
| 261 |
+
size = (b, 1, 1, 1, 1)
|
| 262 |
+
else:
|
| 263 |
+
size = (b, 1, 1, 1)
|
| 264 |
+
a_t = torch.full(size, alphas[index], device=device)
|
| 265 |
+
a_prev = torch.full(size, alphas_prev[index], device=device)
|
| 266 |
+
sigma_t = torch.full(size, sigmas[index], device=device)
|
| 267 |
+
sqrt_one_minus_at = torch.full(size, sqrt_one_minus_alphas[index],device=device)
|
| 268 |
+
|
| 269 |
+
# current prediction for x_0
|
| 270 |
+
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
|
| 271 |
+
if quantize_denoised:
|
| 272 |
+
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
|
| 273 |
+
# direction pointing to x_t
|
| 274 |
+
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
|
| 275 |
+
|
| 276 |
+
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
|
| 277 |
+
if noise_dropout > 0.:
|
| 278 |
+
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 279 |
+
|
| 280 |
+
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
|
| 281 |
+
if self.use_scale:
|
| 282 |
+
scale_arr = self.model.scale_arr if use_original_steps else self.ddim_scale_arr
|
| 283 |
+
scale_t = torch.full(size, scale_arr[index], device=device)
|
| 284 |
+
scale_arr_prev = self.model.scale_arr_prev if use_original_steps else self.ddim_scale_arr_prev
|
| 285 |
+
scale_t_prev = torch.full(size, scale_arr_prev[index], device=device)
|
| 286 |
+
pred_x0 /= scale_t
|
| 287 |
+
x_prev = a_prev.sqrt() * scale_t_prev * pred_x0 + dir_xt + noise
|
| 288 |
+
else:
|
| 289 |
+
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
|
| 290 |
+
|
| 291 |
+
return x_prev, pred_x0
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
@torch.no_grad()
|
| 295 |
+
def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
|
| 296 |
+
# fast, but does not allow for exact reconstruction
|
| 297 |
+
# t serves as an index to gather the correct alphas
|
| 298 |
+
if use_original_steps:
|
| 299 |
+
sqrt_alphas_cumprod = self.sqrt_alphas_cumprod
|
| 300 |
+
sqrt_one_minus_alphas_cumprod = self.sqrt_one_minus_alphas_cumprod
|
| 301 |
+
else:
|
| 302 |
+
sqrt_alphas_cumprod = torch.sqrt(self.ddim_alphas)
|
| 303 |
+
sqrt_one_minus_alphas_cumprod = self.ddim_sqrt_one_minus_alphas
|
| 304 |
+
|
| 305 |
+
if noise is None:
|
| 306 |
+
noise = torch.randn_like(x0)
|
| 307 |
+
|
| 308 |
+
def extract_into_tensor(a, t, x_shape):
|
| 309 |
+
b, *_ = t.shape
|
| 310 |
+
out = a.gather(-1, t)
|
| 311 |
+
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
|
| 312 |
+
|
| 313 |
+
return (extract_into_tensor(sqrt_alphas_cumprod, t, x0.shape) * x0 +
|
| 314 |
+
extract_into_tensor(sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise)
|
| 315 |
+
|
| 316 |
+
@torch.no_grad()
|
| 317 |
+
def decode(self, x_latent, cond, t_start, unconditional_guidance_scale=1.0, unconditional_conditioning=None,
|
| 318 |
+
use_original_steps=False):
|
| 319 |
+
|
| 320 |
+
timesteps = np.arange(self.ddpm_num_timesteps) if use_original_steps else self.ddim_timesteps
|
| 321 |
+
timesteps = timesteps[:t_start]
|
| 322 |
+
|
| 323 |
+
time_range = np.flip(timesteps)
|
| 324 |
+
total_steps = timesteps.shape[0]
|
| 325 |
+
print(f"Running DDIM Sampling with {total_steps} timesteps")
|
| 326 |
+
|
| 327 |
+
iterator = tqdm(time_range, desc='Decoding image', total=total_steps)
|
| 328 |
+
x_dec = x_latent
|
| 329 |
+
for i, step in enumerate(iterator):
|
| 330 |
+
index = total_steps - i - 1
|
| 331 |
+
ts = torch.full((x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long)
|
| 332 |
+
x_dec, _ = self.p_sample_ddim(x_dec, cond, ts, index=index, use_original_steps=use_original_steps,
|
| 333 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 334 |
+
unconditional_conditioning=unconditional_conditioning)
|
| 335 |
+
return x_dec
|
| 336 |
+
|
lvdm/models/utils_diffusion.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
from einops import repeat
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False):
|
| 9 |
+
"""
|
| 10 |
+
Create sinusoidal timestep embeddings.
|
| 11 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
| 12 |
+
These may be fractional.
|
| 13 |
+
:param dim: the dimension of the output.
|
| 14 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 15 |
+
:return: an [N x dim] Tensor of positional embeddings.
|
| 16 |
+
"""
|
| 17 |
+
if not repeat_only:
|
| 18 |
+
half = dim // 2
|
| 19 |
+
freqs = torch.exp(
|
| 20 |
+
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
|
| 21 |
+
).to(device=timesteps.device)
|
| 22 |
+
args = timesteps[:, None].float() * freqs[None]
|
| 23 |
+
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
| 24 |
+
if dim % 2:
|
| 25 |
+
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
| 26 |
+
else:
|
| 27 |
+
embedding = repeat(timesteps, 'b -> b d', d=dim)
|
| 28 |
+
return embedding
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def make_beta_schedule(schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
|
| 32 |
+
if schedule == "linear":
|
| 33 |
+
betas = (
|
| 34 |
+
torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64) ** 2
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
elif schedule == "cosine":
|
| 38 |
+
timesteps = (
|
| 39 |
+
torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s
|
| 40 |
+
)
|
| 41 |
+
alphas = timesteps / (1 + cosine_s) * np.pi / 2
|
| 42 |
+
alphas = torch.cos(alphas).pow(2)
|
| 43 |
+
alphas = alphas / alphas[0]
|
| 44 |
+
betas = 1 - alphas[1:] / alphas[:-1]
|
| 45 |
+
betas = np.clip(betas, a_min=0, a_max=0.999)
|
| 46 |
+
|
| 47 |
+
elif schedule == "sqrt_linear":
|
| 48 |
+
betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)
|
| 49 |
+
elif schedule == "sqrt":
|
| 50 |
+
betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64) ** 0.5
|
| 51 |
+
else:
|
| 52 |
+
raise ValueError(f"schedule '{schedule}' unknown.")
|
| 53 |
+
return betas.numpy()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def make_ddim_timesteps(ddim_discr_method, num_ddim_timesteps, num_ddpm_timesteps, verbose=True):
|
| 57 |
+
if ddim_discr_method == 'uniform':
|
| 58 |
+
c = num_ddpm_timesteps // num_ddim_timesteps
|
| 59 |
+
ddim_timesteps = np.asarray(list(range(0, num_ddpm_timesteps, c)))
|
| 60 |
+
elif ddim_discr_method == 'quad':
|
| 61 |
+
ddim_timesteps = ((np.linspace(0, np.sqrt(num_ddpm_timesteps * .8), num_ddim_timesteps)) ** 2).astype(int)
|
| 62 |
+
else:
|
| 63 |
+
raise NotImplementedError(f'There is no ddim discretization method called "{ddim_discr_method}"')
|
| 64 |
+
|
| 65 |
+
# assert ddim_timesteps.shape[0] == num_ddim_timesteps
|
| 66 |
+
# add one to get the final alpha values right (the ones from first scale to data during sampling)
|
| 67 |
+
steps_out = ddim_timesteps + 1
|
| 68 |
+
if verbose:
|
| 69 |
+
print(f'Selected timesteps for ddim sampler: {steps_out}')
|
| 70 |
+
return steps_out
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def make_ddim_sampling_parameters(alphacums, ddim_timesteps, eta, verbose=True):
|
| 74 |
+
# select alphas for computing the variance schedule
|
| 75 |
+
# print(f'ddim_timesteps={ddim_timesteps}, len_alphacums={len(alphacums)}')
|
| 76 |
+
alphas = alphacums[ddim_timesteps]
|
| 77 |
+
alphas_prev = np.asarray([alphacums[0]] + alphacums[ddim_timesteps[:-1]].tolist())
|
| 78 |
+
|
| 79 |
+
# according the the formula provided in https://arxiv.org/abs/2010.02502
|
| 80 |
+
sigmas = eta * np.sqrt((1 - alphas_prev) / (1 - alphas) * (1 - alphas / alphas_prev))
|
| 81 |
+
if verbose:
|
| 82 |
+
print(f'Selected alphas for ddim sampler: a_t: {alphas}; a_(t-1): {alphas_prev}')
|
| 83 |
+
print(f'For the chosen value of eta, which is {eta}, '
|
| 84 |
+
f'this results in the following sigma_t schedule for ddim sampler {sigmas}')
|
| 85 |
+
return sigmas, alphas, alphas_prev
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
|
| 89 |
+
"""
|
| 90 |
+
Create a beta schedule that discretizes the given alpha_t_bar function,
|
| 91 |
+
which defines the cumulative product of (1-beta) over time from t = [0,1].
|
| 92 |
+
:param num_diffusion_timesteps: the number of betas to produce.
|
| 93 |
+
:param alpha_bar: a lambda that takes an argument t from 0 to 1 and
|
| 94 |
+
produces the cumulative product of (1-beta) up to that
|
| 95 |
+
part of the diffusion process.
|
| 96 |
+
:param max_beta: the maximum beta to use; use values lower than 1 to
|
| 97 |
+
prevent singularities.
|
| 98 |
+
"""
|
| 99 |
+
betas = []
|
| 100 |
+
for i in range(num_diffusion_timesteps):
|
| 101 |
+
t1 = i / num_diffusion_timesteps
|
| 102 |
+
t2 = (i + 1) / num_diffusion_timesteps
|
| 103 |
+
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
| 104 |
+
return np.array(betas)
|
lvdm/modules/attention.py
ADDED
|
@@ -0,0 +1,475 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn, einsum
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange, repeat
|
| 6 |
+
try:
|
| 7 |
+
import xformers
|
| 8 |
+
import xformers.ops
|
| 9 |
+
XFORMERS_IS_AVAILBLE = True
|
| 10 |
+
except:
|
| 11 |
+
XFORMERS_IS_AVAILBLE = False
|
| 12 |
+
from lvdm.common import (
|
| 13 |
+
checkpoint,
|
| 14 |
+
exists,
|
| 15 |
+
default,
|
| 16 |
+
)
|
| 17 |
+
from lvdm.basics import (
|
| 18 |
+
zero_module,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
class RelativePosition(nn.Module):
|
| 22 |
+
""" https://github.com/evelinehong/Transformer_Relative_Position_PyTorch/blob/master/relative_position.py """
|
| 23 |
+
|
| 24 |
+
def __init__(self, num_units, max_relative_position):
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.num_units = num_units
|
| 27 |
+
self.max_relative_position = max_relative_position
|
| 28 |
+
self.embeddings_table = nn.Parameter(torch.Tensor(max_relative_position * 2 + 1, num_units))
|
| 29 |
+
nn.init.xavier_uniform_(self.embeddings_table)
|
| 30 |
+
|
| 31 |
+
def forward(self, length_q, length_k):
|
| 32 |
+
device = self.embeddings_table.device
|
| 33 |
+
range_vec_q = torch.arange(length_q, device=device)
|
| 34 |
+
range_vec_k = torch.arange(length_k, device=device)
|
| 35 |
+
distance_mat = range_vec_k[None, :] - range_vec_q[:, None]
|
| 36 |
+
distance_mat_clipped = torch.clamp(distance_mat, -self.max_relative_position, self.max_relative_position)
|
| 37 |
+
final_mat = distance_mat_clipped + self.max_relative_position
|
| 38 |
+
final_mat = final_mat.long()
|
| 39 |
+
embeddings = self.embeddings_table[final_mat]
|
| 40 |
+
return embeddings
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class CrossAttention(nn.Module):
|
| 44 |
+
|
| 45 |
+
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.,
|
| 46 |
+
relative_position=False, temporal_length=None, img_cross_attention=False):
|
| 47 |
+
super().__init__()
|
| 48 |
+
inner_dim = dim_head * heads
|
| 49 |
+
context_dim = default(context_dim, query_dim)
|
| 50 |
+
|
| 51 |
+
self.scale = dim_head**-0.5
|
| 52 |
+
self.heads = heads
|
| 53 |
+
self.dim_head = dim_head
|
| 54 |
+
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
| 55 |
+
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
| 56 |
+
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
| 57 |
+
self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
|
| 58 |
+
|
| 59 |
+
self.image_cross_attention_scale = 1.0
|
| 60 |
+
self.text_context_len = 77
|
| 61 |
+
self.img_cross_attention = img_cross_attention
|
| 62 |
+
if self.img_cross_attention:
|
| 63 |
+
self.to_k_ip = nn.Linear(context_dim, inner_dim, bias=False)
|
| 64 |
+
self.to_v_ip = nn.Linear(context_dim, inner_dim, bias=False)
|
| 65 |
+
|
| 66 |
+
self.relative_position = relative_position
|
| 67 |
+
if self.relative_position:
|
| 68 |
+
assert(temporal_length is not None)
|
| 69 |
+
self.relative_position_k = RelativePosition(num_units=dim_head, max_relative_position=temporal_length)
|
| 70 |
+
self.relative_position_v = RelativePosition(num_units=dim_head, max_relative_position=temporal_length)
|
| 71 |
+
else:
|
| 72 |
+
## only used for spatial attention, while NOT for temporal attention
|
| 73 |
+
if XFORMERS_IS_AVAILBLE and temporal_length is None:
|
| 74 |
+
self.forward = self.efficient_forward
|
| 75 |
+
|
| 76 |
+
def forward(self, x, context=None, mask=None):
|
| 77 |
+
h = self.heads
|
| 78 |
+
|
| 79 |
+
q = self.to_q(x)
|
| 80 |
+
context = default(context, x)
|
| 81 |
+
## considering image token additionally
|
| 82 |
+
if context is not None and self.img_cross_attention:
|
| 83 |
+
context, context_img = context[:,:self.text_context_len,:], context[:,self.text_context_len:,:]
|
| 84 |
+
k = self.to_k(context)
|
| 85 |
+
v = self.to_v(context)
|
| 86 |
+
k_ip = self.to_k_ip(context_img)
|
| 87 |
+
v_ip = self.to_v_ip(context_img)
|
| 88 |
+
else:
|
| 89 |
+
k = self.to_k(context)
|
| 90 |
+
v = self.to_v(context)
|
| 91 |
+
|
| 92 |
+
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
|
| 93 |
+
sim = torch.einsum('b i d, b j d -> b i j', q, k) * self.scale
|
| 94 |
+
if self.relative_position:
|
| 95 |
+
len_q, len_k, len_v = q.shape[1], k.shape[1], v.shape[1]
|
| 96 |
+
k2 = self.relative_position_k(len_q, len_k)
|
| 97 |
+
sim2 = einsum('b t d, t s d -> b t s', q, k2) * self.scale # TODO check
|
| 98 |
+
sim += sim2
|
| 99 |
+
del k
|
| 100 |
+
|
| 101 |
+
if exists(mask):
|
| 102 |
+
## feasible for causal attention mask only
|
| 103 |
+
max_neg_value = -torch.finfo(sim.dtype).max
|
| 104 |
+
mask = repeat(mask, 'b i j -> (b h) i j', h=h)
|
| 105 |
+
sim.masked_fill_(~(mask>0.5), max_neg_value)
|
| 106 |
+
|
| 107 |
+
# attention, what we cannot get enough of
|
| 108 |
+
sim = sim.softmax(dim=-1)
|
| 109 |
+
out = torch.einsum('b i j, b j d -> b i d', sim, v)
|
| 110 |
+
if self.relative_position:
|
| 111 |
+
v2 = self.relative_position_v(len_q, len_v)
|
| 112 |
+
out2 = einsum('b t s, t s d -> b t d', sim, v2) # TODO check
|
| 113 |
+
out += out2
|
| 114 |
+
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
|
| 115 |
+
|
| 116 |
+
## considering image token additionally
|
| 117 |
+
if context is not None and self.img_cross_attention:
|
| 118 |
+
k_ip, v_ip = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (k_ip, v_ip))
|
| 119 |
+
sim_ip = torch.einsum('b i d, b j d -> b i j', q, k_ip) * self.scale
|
| 120 |
+
del k_ip
|
| 121 |
+
sim_ip = sim_ip.softmax(dim=-1)
|
| 122 |
+
out_ip = torch.einsum('b i j, b j d -> b i d', sim_ip, v_ip)
|
| 123 |
+
out_ip = rearrange(out_ip, '(b h) n d -> b n (h d)', h=h)
|
| 124 |
+
out = out + self.image_cross_attention_scale * out_ip
|
| 125 |
+
del q
|
| 126 |
+
|
| 127 |
+
return self.to_out(out)
|
| 128 |
+
|
| 129 |
+
def efficient_forward(self, x, context=None, mask=None):
|
| 130 |
+
q = self.to_q(x)
|
| 131 |
+
context = default(context, x)
|
| 132 |
+
|
| 133 |
+
## considering image token additionally
|
| 134 |
+
if context is not None and self.img_cross_attention:
|
| 135 |
+
context, context_img = context[:,:self.text_context_len,:], context[:,self.text_context_len:,:]
|
| 136 |
+
k = self.to_k(context)
|
| 137 |
+
v = self.to_v(context)
|
| 138 |
+
k_ip = self.to_k_ip(context_img)
|
| 139 |
+
v_ip = self.to_v_ip(context_img)
|
| 140 |
+
else:
|
| 141 |
+
k = self.to_k(context)
|
| 142 |
+
v = self.to_v(context)
|
| 143 |
+
|
| 144 |
+
b, _, _ = q.shape
|
| 145 |
+
q, k, v = map(
|
| 146 |
+
lambda t: t.unsqueeze(3)
|
| 147 |
+
.reshape(b, t.shape[1], self.heads, self.dim_head)
|
| 148 |
+
.permute(0, 2, 1, 3)
|
| 149 |
+
.reshape(b * self.heads, t.shape[1], self.dim_head)
|
| 150 |
+
.contiguous(),
|
| 151 |
+
(q, k, v),
|
| 152 |
+
)
|
| 153 |
+
# actually compute the attention, what we cannot get enough of
|
| 154 |
+
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=None)
|
| 155 |
+
|
| 156 |
+
## considering image token additionally
|
| 157 |
+
if context is not None and self.img_cross_attention:
|
| 158 |
+
k_ip, v_ip = map(
|
| 159 |
+
lambda t: t.unsqueeze(3)
|
| 160 |
+
.reshape(b, t.shape[1], self.heads, self.dim_head)
|
| 161 |
+
.permute(0, 2, 1, 3)
|
| 162 |
+
.reshape(b * self.heads, t.shape[1], self.dim_head)
|
| 163 |
+
.contiguous(),
|
| 164 |
+
(k_ip, v_ip),
|
| 165 |
+
)
|
| 166 |
+
out_ip = xformers.ops.memory_efficient_attention(q, k_ip, v_ip, attn_bias=None, op=None)
|
| 167 |
+
out_ip = (
|
| 168 |
+
out_ip.unsqueeze(0)
|
| 169 |
+
.reshape(b, self.heads, out.shape[1], self.dim_head)
|
| 170 |
+
.permute(0, 2, 1, 3)
|
| 171 |
+
.reshape(b, out.shape[1], self.heads * self.dim_head)
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if exists(mask):
|
| 175 |
+
raise NotImplementedError
|
| 176 |
+
out = (
|
| 177 |
+
out.unsqueeze(0)
|
| 178 |
+
.reshape(b, self.heads, out.shape[1], self.dim_head)
|
| 179 |
+
.permute(0, 2, 1, 3)
|
| 180 |
+
.reshape(b, out.shape[1], self.heads * self.dim_head)
|
| 181 |
+
)
|
| 182 |
+
if context is not None and self.img_cross_attention:
|
| 183 |
+
out = out + self.image_cross_attention_scale * out_ip
|
| 184 |
+
return self.to_out(out)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class BasicTransformerBlock(nn.Module):
|
| 188 |
+
|
| 189 |
+
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True,
|
| 190 |
+
disable_self_attn=False, attention_cls=None, img_cross_attention=False):
|
| 191 |
+
super().__init__()
|
| 192 |
+
attn_cls = CrossAttention if attention_cls is None else attention_cls
|
| 193 |
+
self.disable_self_attn = disable_self_attn
|
| 194 |
+
self.attn1 = attn_cls(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout,
|
| 195 |
+
context_dim=context_dim if self.disable_self_attn else None)
|
| 196 |
+
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
|
| 197 |
+
self.attn2 = attn_cls(query_dim=dim, context_dim=context_dim, heads=n_heads, dim_head=d_head, dropout=dropout,
|
| 198 |
+
img_cross_attention=img_cross_attention)
|
| 199 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 200 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 201 |
+
self.norm3 = nn.LayerNorm(dim)
|
| 202 |
+
self.checkpoint = checkpoint
|
| 203 |
+
|
| 204 |
+
def forward(self, x, context=None, mask=None):
|
| 205 |
+
## implementation tricks: because checkpointing doesn't support non-tensor (e.g. None or scalar) arguments
|
| 206 |
+
input_tuple = (x,) ## should not be (x), otherwise *input_tuple will decouple x into multiple arguments
|
| 207 |
+
if context is not None:
|
| 208 |
+
input_tuple = (x, context)
|
| 209 |
+
if mask is not None:
|
| 210 |
+
forward_mask = partial(self._forward, mask=mask)
|
| 211 |
+
return checkpoint(forward_mask, (x,), self.parameters(), self.checkpoint)
|
| 212 |
+
if context is not None and mask is not None:
|
| 213 |
+
input_tuple = (x, context, mask)
|
| 214 |
+
return checkpoint(self._forward, input_tuple, self.parameters(), self.checkpoint)
|
| 215 |
+
|
| 216 |
+
def _forward(self, x, context=None, mask=None):
|
| 217 |
+
x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None, mask=mask) + x
|
| 218 |
+
x = self.attn2(self.norm2(x), context=context, mask=mask) + x
|
| 219 |
+
x = self.ff(self.norm3(x)) + x
|
| 220 |
+
return x
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
class SpatialTransformer(nn.Module):
|
| 224 |
+
"""
|
| 225 |
+
Transformer block for image-like data in spatial axis.
|
| 226 |
+
First, project the input (aka embedding)
|
| 227 |
+
and reshape to b, t, d.
|
| 228 |
+
Then apply standard transformer action.
|
| 229 |
+
Finally, reshape to image
|
| 230 |
+
NEW: use_linear for more efficiency instead of the 1x1 convs
|
| 231 |
+
"""
|
| 232 |
+
|
| 233 |
+
def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0., context_dim=None,
|
| 234 |
+
use_checkpoint=True, disable_self_attn=False, use_linear=False, img_cross_attention=False):
|
| 235 |
+
super().__init__()
|
| 236 |
+
self.in_channels = in_channels
|
| 237 |
+
inner_dim = n_heads * d_head
|
| 238 |
+
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
| 239 |
+
if not use_linear:
|
| 240 |
+
self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
| 241 |
+
else:
|
| 242 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 243 |
+
|
| 244 |
+
self.transformer_blocks = nn.ModuleList([
|
| 245 |
+
BasicTransformerBlock(
|
| 246 |
+
inner_dim,
|
| 247 |
+
n_heads,
|
| 248 |
+
d_head,
|
| 249 |
+
dropout=dropout,
|
| 250 |
+
context_dim=context_dim,
|
| 251 |
+
img_cross_attention=img_cross_attention,
|
| 252 |
+
disable_self_attn=disable_self_attn,
|
| 253 |
+
checkpoint=use_checkpoint) for d in range(depth)
|
| 254 |
+
])
|
| 255 |
+
if not use_linear:
|
| 256 |
+
self.proj_out = zero_module(nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0))
|
| 257 |
+
else:
|
| 258 |
+
self.proj_out = zero_module(nn.Linear(inner_dim, in_channels))
|
| 259 |
+
self.use_linear = use_linear
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def forward(self, x, context=None):
|
| 263 |
+
b, c, h, w = x.shape
|
| 264 |
+
x_in = x
|
| 265 |
+
x = self.norm(x)
|
| 266 |
+
if not self.use_linear:
|
| 267 |
+
x = self.proj_in(x)
|
| 268 |
+
x = rearrange(x, 'b c h w -> b (h w) c').contiguous()
|
| 269 |
+
if self.use_linear:
|
| 270 |
+
x = self.proj_in(x)
|
| 271 |
+
for i, block in enumerate(self.transformer_blocks):
|
| 272 |
+
x = block(x, context=context)
|
| 273 |
+
if self.use_linear:
|
| 274 |
+
x = self.proj_out(x)
|
| 275 |
+
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w).contiguous()
|
| 276 |
+
if not self.use_linear:
|
| 277 |
+
x = self.proj_out(x)
|
| 278 |
+
return x + x_in
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
class TemporalTransformer(nn.Module):
|
| 282 |
+
"""
|
| 283 |
+
Transformer block for image-like data in temporal axis.
|
| 284 |
+
First, reshape to b, t, d.
|
| 285 |
+
Then apply standard transformer action.
|
| 286 |
+
Finally, reshape to image
|
| 287 |
+
"""
|
| 288 |
+
def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0., context_dim=None,
|
| 289 |
+
use_checkpoint=True, use_linear=False, only_self_att=True, causal_attention=False,
|
| 290 |
+
relative_position=False, temporal_length=None):
|
| 291 |
+
super().__init__()
|
| 292 |
+
self.only_self_att = only_self_att
|
| 293 |
+
self.relative_position = relative_position
|
| 294 |
+
self.causal_attention = causal_attention
|
| 295 |
+
self.in_channels = in_channels
|
| 296 |
+
inner_dim = n_heads * d_head
|
| 297 |
+
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
| 298 |
+
self.proj_in = nn.Conv1d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
| 299 |
+
if not use_linear:
|
| 300 |
+
self.proj_in = nn.Conv1d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
| 301 |
+
else:
|
| 302 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 303 |
+
|
| 304 |
+
if relative_position:
|
| 305 |
+
assert(temporal_length is not None)
|
| 306 |
+
attention_cls = partial(CrossAttention, relative_position=True, temporal_length=temporal_length)
|
| 307 |
+
else:
|
| 308 |
+
attention_cls = None
|
| 309 |
+
if self.causal_attention:
|
| 310 |
+
assert(temporal_length is not None)
|
| 311 |
+
self.mask = torch.tril(torch.ones([1, temporal_length, temporal_length]))
|
| 312 |
+
|
| 313 |
+
if self.only_self_att:
|
| 314 |
+
context_dim = None
|
| 315 |
+
self.transformer_blocks = nn.ModuleList([
|
| 316 |
+
BasicTransformerBlock(
|
| 317 |
+
inner_dim,
|
| 318 |
+
n_heads,
|
| 319 |
+
d_head,
|
| 320 |
+
dropout=dropout,
|
| 321 |
+
context_dim=context_dim,
|
| 322 |
+
attention_cls=attention_cls,
|
| 323 |
+
checkpoint=use_checkpoint) for d in range(depth)
|
| 324 |
+
])
|
| 325 |
+
if not use_linear:
|
| 326 |
+
self.proj_out = zero_module(nn.Conv1d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0))
|
| 327 |
+
else:
|
| 328 |
+
self.proj_out = zero_module(nn.Linear(inner_dim, in_channels))
|
| 329 |
+
self.use_linear = use_linear
|
| 330 |
+
|
| 331 |
+
def forward(self, x, context=None):
|
| 332 |
+
b, c, t, h, w = x.shape
|
| 333 |
+
x_in = x
|
| 334 |
+
x = self.norm(x)
|
| 335 |
+
x = rearrange(x, 'b c t h w -> (b h w) c t').contiguous()
|
| 336 |
+
if not self.use_linear:
|
| 337 |
+
x = self.proj_in(x)
|
| 338 |
+
x = rearrange(x, 'bhw c t -> bhw t c').contiguous()
|
| 339 |
+
if self.use_linear:
|
| 340 |
+
x = self.proj_in(x)
|
| 341 |
+
|
| 342 |
+
if self.causal_attention:
|
| 343 |
+
mask = self.mask.to(x.device)
|
| 344 |
+
mask = repeat(mask, 'l i j -> (l bhw) i j', bhw=b*h*w)
|
| 345 |
+
else:
|
| 346 |
+
mask = None
|
| 347 |
+
|
| 348 |
+
if self.only_self_att:
|
| 349 |
+
## note: if no context is given, cross-attention defaults to self-attention
|
| 350 |
+
for i, block in enumerate(self.transformer_blocks):
|
| 351 |
+
x = block(x, mask=mask)
|
| 352 |
+
x = rearrange(x, '(b hw) t c -> b hw t c', b=b).contiguous()
|
| 353 |
+
else:
|
| 354 |
+
x = rearrange(x, '(b hw) t c -> b hw t c', b=b).contiguous()
|
| 355 |
+
context = rearrange(context, '(b t) l con -> b t l con', t=t).contiguous()
|
| 356 |
+
for i, block in enumerate(self.transformer_blocks):
|
| 357 |
+
# calculate each batch one by one (since number in shape could not greater then 65,535 for some package)
|
| 358 |
+
for j in range(b):
|
| 359 |
+
context_j = repeat(
|
| 360 |
+
context[j],
|
| 361 |
+
't l con -> (t r) l con', r=(h * w) // t, t=t).contiguous()
|
| 362 |
+
## note: causal mask will not applied in cross-attention case
|
| 363 |
+
x[j] = block(x[j], context=context_j)
|
| 364 |
+
|
| 365 |
+
if self.use_linear:
|
| 366 |
+
x = self.proj_out(x)
|
| 367 |
+
x = rearrange(x, 'b (h w) t c -> b c t h w', h=h, w=w).contiguous()
|
| 368 |
+
if not self.use_linear:
|
| 369 |
+
x = rearrange(x, 'b hw t c -> (b hw) c t').contiguous()
|
| 370 |
+
x = self.proj_out(x)
|
| 371 |
+
x = rearrange(x, '(b h w) c t -> b c t h w', b=b, h=h, w=w).contiguous()
|
| 372 |
+
|
| 373 |
+
return x + x_in
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
class GEGLU(nn.Module):
|
| 377 |
+
def __init__(self, dim_in, dim_out):
|
| 378 |
+
super().__init__()
|
| 379 |
+
self.proj = nn.Linear(dim_in, dim_out * 2)
|
| 380 |
+
|
| 381 |
+
def forward(self, x):
|
| 382 |
+
x, gate = self.proj(x).chunk(2, dim=-1)
|
| 383 |
+
return x * F.gelu(gate)
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
class FeedForward(nn.Module):
|
| 387 |
+
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
|
| 388 |
+
super().__init__()
|
| 389 |
+
inner_dim = int(dim * mult)
|
| 390 |
+
dim_out = default(dim_out, dim)
|
| 391 |
+
project_in = nn.Sequential(
|
| 392 |
+
nn.Linear(dim, inner_dim),
|
| 393 |
+
nn.GELU()
|
| 394 |
+
) if not glu else GEGLU(dim, inner_dim)
|
| 395 |
+
|
| 396 |
+
self.net = nn.Sequential(
|
| 397 |
+
project_in,
|
| 398 |
+
nn.Dropout(dropout),
|
| 399 |
+
nn.Linear(inner_dim, dim_out)
|
| 400 |
+
)
|
| 401 |
+
|
| 402 |
+
def forward(self, x):
|
| 403 |
+
return self.net(x)
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
class LinearAttention(nn.Module):
|
| 407 |
+
def __init__(self, dim, heads=4, dim_head=32):
|
| 408 |
+
super().__init__()
|
| 409 |
+
self.heads = heads
|
| 410 |
+
hidden_dim = dim_head * heads
|
| 411 |
+
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
|
| 412 |
+
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
|
| 413 |
+
|
| 414 |
+
def forward(self, x):
|
| 415 |
+
b, c, h, w = x.shape
|
| 416 |
+
qkv = self.to_qkv(x)
|
| 417 |
+
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3)
|
| 418 |
+
k = k.softmax(dim=-1)
|
| 419 |
+
context = torch.einsum('bhdn,bhen->bhde', k, v)
|
| 420 |
+
out = torch.einsum('bhde,bhdn->bhen', context, q)
|
| 421 |
+
out = rearrange(out, 'b heads c (h w) -> b (heads c) h w', heads=self.heads, h=h, w=w)
|
| 422 |
+
return self.to_out(out)
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
class SpatialSelfAttention(nn.Module):
|
| 426 |
+
def __init__(self, in_channels):
|
| 427 |
+
super().__init__()
|
| 428 |
+
self.in_channels = in_channels
|
| 429 |
+
|
| 430 |
+
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
| 431 |
+
self.q = torch.nn.Conv2d(in_channels,
|
| 432 |
+
in_channels,
|
| 433 |
+
kernel_size=1,
|
| 434 |
+
stride=1,
|
| 435 |
+
padding=0)
|
| 436 |
+
self.k = torch.nn.Conv2d(in_channels,
|
| 437 |
+
in_channels,
|
| 438 |
+
kernel_size=1,
|
| 439 |
+
stride=1,
|
| 440 |
+
padding=0)
|
| 441 |
+
self.v = torch.nn.Conv2d(in_channels,
|
| 442 |
+
in_channels,
|
| 443 |
+
kernel_size=1,
|
| 444 |
+
stride=1,
|
| 445 |
+
padding=0)
|
| 446 |
+
self.proj_out = torch.nn.Conv2d(in_channels,
|
| 447 |
+
in_channels,
|
| 448 |
+
kernel_size=1,
|
| 449 |
+
stride=1,
|
| 450 |
+
padding=0)
|
| 451 |
+
|
| 452 |
+
def forward(self, x):
|
| 453 |
+
h_ = x
|
| 454 |
+
h_ = self.norm(h_)
|
| 455 |
+
q = self.q(h_)
|
| 456 |
+
k = self.k(h_)
|
| 457 |
+
v = self.v(h_)
|
| 458 |
+
|
| 459 |
+
# compute attention
|
| 460 |
+
b,c,h,w = q.shape
|
| 461 |
+
q = rearrange(q, 'b c h w -> b (h w) c')
|
| 462 |
+
k = rearrange(k, 'b c h w -> b c (h w)')
|
| 463 |
+
w_ = torch.einsum('bij,bjk->bik', q, k)
|
| 464 |
+
|
| 465 |
+
w_ = w_ * (int(c)**(-0.5))
|
| 466 |
+
w_ = torch.nn.functional.softmax(w_, dim=2)
|
| 467 |
+
|
| 468 |
+
# attend to values
|
| 469 |
+
v = rearrange(v, 'b c h w -> b c (h w)')
|
| 470 |
+
w_ = rearrange(w_, 'b i j -> b j i')
|
| 471 |
+
h_ = torch.einsum('bij,bjk->bik', v, w_)
|
| 472 |
+
h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h)
|
| 473 |
+
h_ = self.proj_out(h_)
|
| 474 |
+
|
| 475 |
+
return x+h_
|
lvdm/modules/encoders/condition.py
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.utils.checkpoint import checkpoint
|
| 4 |
+
import kornia
|
| 5 |
+
import open_clip
|
| 6 |
+
from transformers import T5Tokenizer, T5EncoderModel, CLIPTokenizer, CLIPTextModel
|
| 7 |
+
from lvdm.common import autocast
|
| 8 |
+
from utils.utils import count_params
|
| 9 |
+
|
| 10 |
+
class AbstractEncoder(nn.Module):
|
| 11 |
+
def __init__(self):
|
| 12 |
+
super().__init__()
|
| 13 |
+
|
| 14 |
+
def encode(self, *args, **kwargs):
|
| 15 |
+
raise NotImplementedError
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class IdentityEncoder(AbstractEncoder):
|
| 19 |
+
|
| 20 |
+
def encode(self, x):
|
| 21 |
+
return x
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class ClassEmbedder(nn.Module):
|
| 25 |
+
def __init__(self, embed_dim, n_classes=1000, key='class', ucg_rate=0.1):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.key = key
|
| 28 |
+
self.embedding = nn.Embedding(n_classes, embed_dim)
|
| 29 |
+
self.n_classes = n_classes
|
| 30 |
+
self.ucg_rate = ucg_rate
|
| 31 |
+
|
| 32 |
+
def forward(self, batch, key=None, disable_dropout=False):
|
| 33 |
+
if key is None:
|
| 34 |
+
key = self.key
|
| 35 |
+
# this is for use in crossattn
|
| 36 |
+
c = batch[key][:, None]
|
| 37 |
+
if self.ucg_rate > 0. and not disable_dropout:
|
| 38 |
+
mask = 1. - torch.bernoulli(torch.ones_like(c) * self.ucg_rate)
|
| 39 |
+
c = mask * c + (1 - mask) * torch.ones_like(c) * (self.n_classes - 1)
|
| 40 |
+
c = c.long()
|
| 41 |
+
c = self.embedding(c)
|
| 42 |
+
return c
|
| 43 |
+
|
| 44 |
+
def get_unconditional_conditioning(self, bs, device="cuda"):
|
| 45 |
+
uc_class = self.n_classes - 1 # 1000 classes --> 0 ... 999, one extra class for ucg (class 1000)
|
| 46 |
+
uc = torch.ones((bs,), device=device) * uc_class
|
| 47 |
+
uc = {self.key: uc}
|
| 48 |
+
return uc
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def disabled_train(self, mode=True):
|
| 52 |
+
"""Overwrite model.train with this function to make sure train/eval mode
|
| 53 |
+
does not change anymore."""
|
| 54 |
+
return self
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class FrozenT5Embedder(AbstractEncoder):
|
| 58 |
+
"""Uses the T5 transformer encoder for text"""
|
| 59 |
+
|
| 60 |
+
def __init__(self, version="google/t5-v1_1-large", device="cuda", max_length=77,
|
| 61 |
+
freeze=True): # others are google/t5-v1_1-xl and google/t5-v1_1-xxl
|
| 62 |
+
super().__init__()
|
| 63 |
+
self.tokenizer = T5Tokenizer.from_pretrained(version)
|
| 64 |
+
self.transformer = T5EncoderModel.from_pretrained(version)
|
| 65 |
+
self.device = device
|
| 66 |
+
self.max_length = max_length # TODO: typical value?
|
| 67 |
+
if freeze:
|
| 68 |
+
self.freeze()
|
| 69 |
+
|
| 70 |
+
def freeze(self):
|
| 71 |
+
self.transformer = self.transformer.eval()
|
| 72 |
+
# self.train = disabled_train
|
| 73 |
+
for param in self.parameters():
|
| 74 |
+
param.requires_grad = False
|
| 75 |
+
|
| 76 |
+
def forward(self, text):
|
| 77 |
+
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
|
| 78 |
+
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
|
| 79 |
+
tokens = batch_encoding["input_ids"].to(self.device)
|
| 80 |
+
outputs = self.transformer(input_ids=tokens)
|
| 81 |
+
|
| 82 |
+
z = outputs.last_hidden_state
|
| 83 |
+
return z
|
| 84 |
+
|
| 85 |
+
def encode(self, text):
|
| 86 |
+
return self(text)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class FrozenCLIPEmbedder(AbstractEncoder):
|
| 90 |
+
"""Uses the CLIP transformer encoder for text (from huggingface)"""
|
| 91 |
+
LAYERS = [
|
| 92 |
+
"last",
|
| 93 |
+
"pooled",
|
| 94 |
+
"hidden"
|
| 95 |
+
]
|
| 96 |
+
|
| 97 |
+
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77,
|
| 98 |
+
freeze=True, layer="last", layer_idx=None): # clip-vit-base-patch32
|
| 99 |
+
super().__init__()
|
| 100 |
+
assert layer in self.LAYERS
|
| 101 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(version)
|
| 102 |
+
self.transformer = CLIPTextModel.from_pretrained(version)
|
| 103 |
+
self.device = device
|
| 104 |
+
self.max_length = max_length
|
| 105 |
+
if freeze:
|
| 106 |
+
self.freeze()
|
| 107 |
+
self.layer = layer
|
| 108 |
+
self.layer_idx = layer_idx
|
| 109 |
+
if layer == "hidden":
|
| 110 |
+
assert layer_idx is not None
|
| 111 |
+
assert 0 <= abs(layer_idx) <= 12
|
| 112 |
+
|
| 113 |
+
def freeze(self):
|
| 114 |
+
self.transformer = self.transformer.eval()
|
| 115 |
+
# self.train = disabled_train
|
| 116 |
+
for param in self.parameters():
|
| 117 |
+
param.requires_grad = False
|
| 118 |
+
|
| 119 |
+
def forward(self, text):
|
| 120 |
+
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
|
| 121 |
+
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
|
| 122 |
+
tokens = batch_encoding["input_ids"].to(self.device)
|
| 123 |
+
outputs = self.transformer(input_ids=tokens, output_hidden_states=self.layer == "hidden")
|
| 124 |
+
if self.layer == "last":
|
| 125 |
+
z = outputs.last_hidden_state
|
| 126 |
+
elif self.layer == "pooled":
|
| 127 |
+
z = outputs.pooler_output[:, None, :]
|
| 128 |
+
else:
|
| 129 |
+
z = outputs.hidden_states[self.layer_idx]
|
| 130 |
+
return z
|
| 131 |
+
|
| 132 |
+
def encode(self, text):
|
| 133 |
+
return self(text)
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class ClipImageEmbedder(nn.Module):
|
| 137 |
+
def __init__(
|
| 138 |
+
self,
|
| 139 |
+
model,
|
| 140 |
+
jit=False,
|
| 141 |
+
device='cuda' if torch.cuda.is_available() else 'cpu',
|
| 142 |
+
antialias=True,
|
| 143 |
+
ucg_rate=0.
|
| 144 |
+
):
|
| 145 |
+
super().__init__()
|
| 146 |
+
from clip import load as load_clip
|
| 147 |
+
self.model, _ = load_clip(name=model, device=device, jit=jit)
|
| 148 |
+
|
| 149 |
+
self.antialias = antialias
|
| 150 |
+
|
| 151 |
+
self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
|
| 152 |
+
self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
|
| 153 |
+
self.ucg_rate = ucg_rate
|
| 154 |
+
|
| 155 |
+
def preprocess(self, x):
|
| 156 |
+
# normalize to [0,1]
|
| 157 |
+
x = kornia.geometry.resize(x, (224, 224),
|
| 158 |
+
interpolation='bicubic', align_corners=True,
|
| 159 |
+
antialias=self.antialias)
|
| 160 |
+
x = (x + 1.) / 2.
|
| 161 |
+
# re-normalize according to clip
|
| 162 |
+
x = kornia.enhance.normalize(x, self.mean, self.std)
|
| 163 |
+
return x
|
| 164 |
+
|
| 165 |
+
def forward(self, x, no_dropout=False):
|
| 166 |
+
# x is assumed to be in range [-1,1]
|
| 167 |
+
out = self.model.encode_image(self.preprocess(x))
|
| 168 |
+
out = out.to(x.dtype)
|
| 169 |
+
if self.ucg_rate > 0. and not no_dropout:
|
| 170 |
+
out = torch.bernoulli((1. - self.ucg_rate) * torch.ones(out.shape[0], device=out.device))[:, None] * out
|
| 171 |
+
return out
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
class FrozenOpenCLIPEmbedder(AbstractEncoder):
|
| 175 |
+
"""
|
| 176 |
+
Uses the OpenCLIP transformer encoder for text
|
| 177 |
+
"""
|
| 178 |
+
LAYERS = [
|
| 179 |
+
# "pooled",
|
| 180 |
+
"last",
|
| 181 |
+
"penultimate"
|
| 182 |
+
]
|
| 183 |
+
|
| 184 |
+
def __init__(self, arch="ViT-H-14", version="laion2b_s32b_b79k", device="cuda", max_length=77,
|
| 185 |
+
freeze=True, layer="last"):
|
| 186 |
+
super().__init__()
|
| 187 |
+
assert layer in self.LAYERS
|
| 188 |
+
model, _, _ = open_clip.create_model_and_transforms(arch, device=torch.device('cpu'))
|
| 189 |
+
del model.visual
|
| 190 |
+
self.model = model
|
| 191 |
+
|
| 192 |
+
self.device = device
|
| 193 |
+
self.max_length = max_length
|
| 194 |
+
if freeze:
|
| 195 |
+
self.freeze()
|
| 196 |
+
self.layer = layer
|
| 197 |
+
if self.layer == "last":
|
| 198 |
+
self.layer_idx = 0
|
| 199 |
+
elif self.layer == "penultimate":
|
| 200 |
+
self.layer_idx = 1
|
| 201 |
+
else:
|
| 202 |
+
raise NotImplementedError()
|
| 203 |
+
|
| 204 |
+
def freeze(self):
|
| 205 |
+
self.model = self.model.eval()
|
| 206 |
+
for param in self.parameters():
|
| 207 |
+
param.requires_grad = False
|
| 208 |
+
|
| 209 |
+
def forward(self, text):
|
| 210 |
+
self.device = self.model.positional_embedding.device
|
| 211 |
+
tokens = open_clip.tokenize(text)
|
| 212 |
+
z = self.encode_with_transformer(tokens.to(self.device))
|
| 213 |
+
return z
|
| 214 |
+
|
| 215 |
+
def encode_with_transformer(self, text):
|
| 216 |
+
x = self.model.token_embedding(text) # [batch_size, n_ctx, d_model]
|
| 217 |
+
x = x + self.model.positional_embedding
|
| 218 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 219 |
+
x = self.text_transformer_forward(x, attn_mask=self.model.attn_mask)
|
| 220 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 221 |
+
x = self.model.ln_final(x)
|
| 222 |
+
return x
|
| 223 |
+
|
| 224 |
+
def text_transformer_forward(self, x: torch.Tensor, attn_mask=None):
|
| 225 |
+
for i, r in enumerate(self.model.transformer.resblocks):
|
| 226 |
+
if i == len(self.model.transformer.resblocks) - self.layer_idx:
|
| 227 |
+
break
|
| 228 |
+
if self.model.transformer.grad_checkpointing and not torch.jit.is_scripting():
|
| 229 |
+
x = checkpoint(r, x, attn_mask)
|
| 230 |
+
else:
|
| 231 |
+
x = r(x, attn_mask=attn_mask)
|
| 232 |
+
return x
|
| 233 |
+
|
| 234 |
+
def encode(self, text):
|
| 235 |
+
return self(text)
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
class FrozenOpenCLIPImageEmbedder(AbstractEncoder):
|
| 239 |
+
"""
|
| 240 |
+
Uses the OpenCLIP vision transformer encoder for images
|
| 241 |
+
"""
|
| 242 |
+
|
| 243 |
+
def __init__(self, arch="ViT-H-14", version="laion2b_s32b_b79k", device="cuda", max_length=77,
|
| 244 |
+
freeze=True, layer="pooled", antialias=True, ucg_rate=0.):
|
| 245 |
+
super().__init__()
|
| 246 |
+
model, _, _ = open_clip.create_model_and_transforms(arch, device=torch.device('cpu'),
|
| 247 |
+
pretrained=version, )
|
| 248 |
+
del model.transformer
|
| 249 |
+
self.model = model
|
| 250 |
+
|
| 251 |
+
self.device = device
|
| 252 |
+
self.max_length = max_length
|
| 253 |
+
if freeze:
|
| 254 |
+
self.freeze()
|
| 255 |
+
self.layer = layer
|
| 256 |
+
if self.layer == "penultimate":
|
| 257 |
+
raise NotImplementedError()
|
| 258 |
+
self.layer_idx = 1
|
| 259 |
+
|
| 260 |
+
self.antialias = antialias
|
| 261 |
+
|
| 262 |
+
self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
|
| 263 |
+
self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
|
| 264 |
+
self.ucg_rate = ucg_rate
|
| 265 |
+
|
| 266 |
+
def preprocess(self, x):
|
| 267 |
+
# normalize to [0,1]
|
| 268 |
+
x = kornia.geometry.resize(x, (224, 224),
|
| 269 |
+
interpolation='bicubic', align_corners=True,
|
| 270 |
+
antialias=self.antialias)
|
| 271 |
+
x = (x + 1.) / 2.
|
| 272 |
+
# renormalize according to clip
|
| 273 |
+
x = kornia.enhance.normalize(x, self.mean, self.std)
|
| 274 |
+
return x
|
| 275 |
+
|
| 276 |
+
def freeze(self):
|
| 277 |
+
self.model = self.model.eval()
|
| 278 |
+
for param in self.parameters():
|
| 279 |
+
param.requires_grad = False
|
| 280 |
+
|
| 281 |
+
@autocast
|
| 282 |
+
def forward(self, image, no_dropout=False):
|
| 283 |
+
z = self.encode_with_vision_transformer(image)
|
| 284 |
+
if self.ucg_rate > 0. and not no_dropout:
|
| 285 |
+
z = torch.bernoulli((1. - self.ucg_rate) * torch.ones(z.shape[0], device=z.device))[:, None] * z
|
| 286 |
+
return z
|
| 287 |
+
|
| 288 |
+
def encode_with_vision_transformer(self, img):
|
| 289 |
+
img = self.preprocess(img)
|
| 290 |
+
x = self.model.visual(img)
|
| 291 |
+
return x
|
| 292 |
+
|
| 293 |
+
def encode(self, text):
|
| 294 |
+
return self(text)
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class FrozenOpenCLIPImageEmbedderV2(AbstractEncoder):
|
| 299 |
+
"""
|
| 300 |
+
Uses the OpenCLIP vision transformer encoder for images
|
| 301 |
+
"""
|
| 302 |
+
|
| 303 |
+
def __init__(self, arch="ViT-H-14", version="laion2b_s32b_b79k", device="cuda",
|
| 304 |
+
freeze=True, layer="pooled", antialias=True):
|
| 305 |
+
super().__init__()
|
| 306 |
+
model, _, _ = open_clip.create_model_and_transforms(arch, device=torch.device('cpu'),
|
| 307 |
+
pretrained=version, )
|
| 308 |
+
del model.transformer
|
| 309 |
+
self.model = model
|
| 310 |
+
self.device = device
|
| 311 |
+
|
| 312 |
+
if freeze:
|
| 313 |
+
self.freeze()
|
| 314 |
+
self.layer = layer
|
| 315 |
+
if self.layer == "penultimate":
|
| 316 |
+
raise NotImplementedError()
|
| 317 |
+
self.layer_idx = 1
|
| 318 |
+
|
| 319 |
+
self.antialias = antialias
|
| 320 |
+
self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
|
| 321 |
+
self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
def preprocess(self, x):
|
| 325 |
+
# normalize to [0,1]
|
| 326 |
+
x = kornia.geometry.resize(x, (224, 224),
|
| 327 |
+
interpolation='bicubic', align_corners=True,
|
| 328 |
+
antialias=self.antialias)
|
| 329 |
+
x = (x + 1.) / 2.
|
| 330 |
+
# renormalize according to clip
|
| 331 |
+
x = kornia.enhance.normalize(x, self.mean, self.std)
|
| 332 |
+
return x
|
| 333 |
+
|
| 334 |
+
def freeze(self):
|
| 335 |
+
self.model = self.model.eval()
|
| 336 |
+
for param in self.model.parameters():
|
| 337 |
+
param.requires_grad = False
|
| 338 |
+
|
| 339 |
+
def forward(self, image, no_dropout=False):
|
| 340 |
+
## image: b c h w
|
| 341 |
+
z = self.encode_with_vision_transformer(image)
|
| 342 |
+
return z
|
| 343 |
+
|
| 344 |
+
def encode_with_vision_transformer(self, x):
|
| 345 |
+
x = self.preprocess(x)
|
| 346 |
+
|
| 347 |
+
# to patches - whether to use dual patchnorm - https://arxiv.org/abs/2302.01327v1
|
| 348 |
+
if self.model.visual.input_patchnorm:
|
| 349 |
+
# einops - rearrange(x, 'b c (h p1) (w p2) -> b (h w) (c p1 p2)')
|
| 350 |
+
x = x.reshape(x.shape[0], x.shape[1], self.model.visual.grid_size[0], self.model.visual.patch_size[0], self.model.visual.grid_size[1], self.model.visual.patch_size[1])
|
| 351 |
+
x = x.permute(0, 2, 4, 1, 3, 5)
|
| 352 |
+
x = x.reshape(x.shape[0], self.model.visual.grid_size[0] * self.model.visual.grid_size[1], -1)
|
| 353 |
+
x = self.model.visual.patchnorm_pre_ln(x)
|
| 354 |
+
x = self.model.visual.conv1(x)
|
| 355 |
+
else:
|
| 356 |
+
x = self.model.visual.conv1(x) # shape = [*, width, grid, grid]
|
| 357 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 358 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 359 |
+
|
| 360 |
+
# class embeddings and positional embeddings
|
| 361 |
+
x = torch.cat(
|
| 362 |
+
[self.model.visual.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device),
|
| 363 |
+
x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 364 |
+
x = x + self.model.visual.positional_embedding.to(x.dtype)
|
| 365 |
+
|
| 366 |
+
# a patch_dropout of 0. would mean it is disabled and this function would do nothing but return what was passed in
|
| 367 |
+
x = self.model.visual.patch_dropout(x)
|
| 368 |
+
x = self.model.visual.ln_pre(x)
|
| 369 |
+
|
| 370 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 371 |
+
x = self.model.visual.transformer(x)
|
| 372 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 373 |
+
|
| 374 |
+
return x
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
class FrozenCLIPT5Encoder(AbstractEncoder):
|
| 378 |
+
def __init__(self, clip_version="openai/clip-vit-large-patch14", t5_version="google/t5-v1_1-xl", device="cuda",
|
| 379 |
+
clip_max_length=77, t5_max_length=77):
|
| 380 |
+
super().__init__()
|
| 381 |
+
self.clip_encoder = FrozenCLIPEmbedder(clip_version, device, max_length=clip_max_length)
|
| 382 |
+
self.t5_encoder = FrozenT5Embedder(t5_version, device, max_length=t5_max_length)
|
| 383 |
+
print(f"{self.clip_encoder.__class__.__name__} has {count_params(self.clip_encoder) * 1.e-6:.2f} M parameters, "
|
| 384 |
+
f"{self.t5_encoder.__class__.__name__} comes with {count_params(self.t5_encoder) * 1.e-6:.2f} M params.")
|
| 385 |
+
|
| 386 |
+
def encode(self, text):
|
| 387 |
+
return self(text)
|
| 388 |
+
|
| 389 |
+
def forward(self, text):
|
| 390 |
+
clip_z = self.clip_encoder.encode(text)
|
| 391 |
+
t5_z = self.t5_encoder.encode(text)
|
| 392 |
+
return [clip_z, t5_z]
|
lvdm/modules/encoders/ip_resampler.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class ImageProjModel(nn.Module):
|
| 8 |
+
"""Projection Model"""
|
| 9 |
+
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.cross_attention_dim = cross_attention_dim
|
| 12 |
+
self.clip_extra_context_tokens = clip_extra_context_tokens
|
| 13 |
+
self.proj = nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
| 14 |
+
self.norm = nn.LayerNorm(cross_attention_dim)
|
| 15 |
+
|
| 16 |
+
def forward(self, image_embeds):
|
| 17 |
+
#embeds = image_embeds
|
| 18 |
+
embeds = image_embeds.type(list(self.proj.parameters())[0].dtype)
|
| 19 |
+
clip_extra_context_tokens = self.proj(embeds).reshape(-1, self.clip_extra_context_tokens, self.cross_attention_dim)
|
| 20 |
+
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
| 21 |
+
return clip_extra_context_tokens
|
| 22 |
+
|
| 23 |
+
# FFN
|
| 24 |
+
def FeedForward(dim, mult=4):
|
| 25 |
+
inner_dim = int(dim * mult)
|
| 26 |
+
return nn.Sequential(
|
| 27 |
+
nn.LayerNorm(dim),
|
| 28 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 29 |
+
nn.GELU(),
|
| 30 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def reshape_tensor(x, heads):
|
| 35 |
+
bs, length, width = x.shape
|
| 36 |
+
#(bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
| 37 |
+
x = x.view(bs, length, heads, -1)
|
| 38 |
+
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
| 39 |
+
x = x.transpose(1, 2)
|
| 40 |
+
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
| 41 |
+
x = x.reshape(bs, heads, length, -1)
|
| 42 |
+
return x
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class PerceiverAttention(nn.Module):
|
| 46 |
+
def __init__(self, *, dim, dim_head=64, heads=8):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.scale = dim_head**-0.5
|
| 49 |
+
self.dim_head = dim_head
|
| 50 |
+
self.heads = heads
|
| 51 |
+
inner_dim = dim_head * heads
|
| 52 |
+
|
| 53 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 54 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 55 |
+
|
| 56 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 57 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 58 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def forward(self, x, latents):
|
| 62 |
+
"""
|
| 63 |
+
Args:
|
| 64 |
+
x (torch.Tensor): image features
|
| 65 |
+
shape (b, n1, D)
|
| 66 |
+
latent (torch.Tensor): latent features
|
| 67 |
+
shape (b, n2, D)
|
| 68 |
+
"""
|
| 69 |
+
x = self.norm1(x)
|
| 70 |
+
latents = self.norm2(latents)
|
| 71 |
+
|
| 72 |
+
b, l, _ = latents.shape
|
| 73 |
+
|
| 74 |
+
q = self.to_q(latents)
|
| 75 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 76 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 77 |
+
|
| 78 |
+
q = reshape_tensor(q, self.heads)
|
| 79 |
+
k = reshape_tensor(k, self.heads)
|
| 80 |
+
v = reshape_tensor(v, self.heads)
|
| 81 |
+
|
| 82 |
+
# attention
|
| 83 |
+
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
| 84 |
+
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
| 85 |
+
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
| 86 |
+
out = weight @ v
|
| 87 |
+
|
| 88 |
+
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
| 89 |
+
|
| 90 |
+
return self.to_out(out)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class Resampler(nn.Module):
|
| 94 |
+
def __init__(
|
| 95 |
+
self,
|
| 96 |
+
dim=1024,
|
| 97 |
+
depth=8,
|
| 98 |
+
dim_head=64,
|
| 99 |
+
heads=16,
|
| 100 |
+
num_queries=8,
|
| 101 |
+
embedding_dim=768,
|
| 102 |
+
output_dim=1024,
|
| 103 |
+
ff_mult=4,
|
| 104 |
+
):
|
| 105 |
+
super().__init__()
|
| 106 |
+
|
| 107 |
+
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
| 108 |
+
|
| 109 |
+
self.proj_in = nn.Linear(embedding_dim, dim)
|
| 110 |
+
|
| 111 |
+
self.proj_out = nn.Linear(dim, output_dim)
|
| 112 |
+
self.norm_out = nn.LayerNorm(output_dim)
|
| 113 |
+
|
| 114 |
+
self.layers = nn.ModuleList([])
|
| 115 |
+
for _ in range(depth):
|
| 116 |
+
self.layers.append(
|
| 117 |
+
nn.ModuleList(
|
| 118 |
+
[
|
| 119 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 120 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 121 |
+
]
|
| 122 |
+
)
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
def forward(self, x):
|
| 126 |
+
|
| 127 |
+
latents = self.latents.repeat(x.size(0), 1, 1)
|
| 128 |
+
|
| 129 |
+
x = self.proj_in(x)
|
| 130 |
+
|
| 131 |
+
for attn, ff in self.layers:
|
| 132 |
+
latents = attn(x, latents) + latents
|
| 133 |
+
latents = ff(latents) + latents
|
| 134 |
+
|
| 135 |
+
latents = self.proj_out(latents)
|
| 136 |
+
return self.norm_out(latents)
|
lvdm/modules/networks/ae_modules.py
ADDED
|
@@ -0,0 +1,845 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pytorch_diffusion + derived encoder decoder
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from utils.utils import instantiate_from_config
|
| 8 |
+
from lvdm.modules.attention import LinearAttention
|
| 9 |
+
|
| 10 |
+
def nonlinearity(x):
|
| 11 |
+
# swish
|
| 12 |
+
return x*torch.sigmoid(x)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def Normalize(in_channels, num_groups=32):
|
| 16 |
+
return torch.nn.GroupNorm(num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LinAttnBlock(LinearAttention):
|
| 21 |
+
"""to match AttnBlock usage"""
|
| 22 |
+
def __init__(self, in_channels):
|
| 23 |
+
super().__init__(dim=in_channels, heads=1, dim_head=in_channels)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class AttnBlock(nn.Module):
|
| 27 |
+
def __init__(self, in_channels):
|
| 28 |
+
super().__init__()
|
| 29 |
+
self.in_channels = in_channels
|
| 30 |
+
|
| 31 |
+
self.norm = Normalize(in_channels)
|
| 32 |
+
self.q = torch.nn.Conv2d(in_channels,
|
| 33 |
+
in_channels,
|
| 34 |
+
kernel_size=1,
|
| 35 |
+
stride=1,
|
| 36 |
+
padding=0)
|
| 37 |
+
self.k = torch.nn.Conv2d(in_channels,
|
| 38 |
+
in_channels,
|
| 39 |
+
kernel_size=1,
|
| 40 |
+
stride=1,
|
| 41 |
+
padding=0)
|
| 42 |
+
self.v = torch.nn.Conv2d(in_channels,
|
| 43 |
+
in_channels,
|
| 44 |
+
kernel_size=1,
|
| 45 |
+
stride=1,
|
| 46 |
+
padding=0)
|
| 47 |
+
self.proj_out = torch.nn.Conv2d(in_channels,
|
| 48 |
+
in_channels,
|
| 49 |
+
kernel_size=1,
|
| 50 |
+
stride=1,
|
| 51 |
+
padding=0)
|
| 52 |
+
|
| 53 |
+
def forward(self, x):
|
| 54 |
+
h_ = x
|
| 55 |
+
h_ = self.norm(h_)
|
| 56 |
+
q = self.q(h_)
|
| 57 |
+
k = self.k(h_)
|
| 58 |
+
v = self.v(h_)
|
| 59 |
+
|
| 60 |
+
# compute attention
|
| 61 |
+
b,c,h,w = q.shape
|
| 62 |
+
q = q.reshape(b,c,h*w) # bcl
|
| 63 |
+
q = q.permute(0,2,1) # bcl -> blc l=hw
|
| 64 |
+
k = k.reshape(b,c,h*w) # bcl
|
| 65 |
+
|
| 66 |
+
w_ = torch.bmm(q,k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
| 67 |
+
w_ = w_ * (int(c)**(-0.5))
|
| 68 |
+
w_ = torch.nn.functional.softmax(w_, dim=2)
|
| 69 |
+
|
| 70 |
+
# attend to values
|
| 71 |
+
v = v.reshape(b,c,h*w)
|
| 72 |
+
w_ = w_.permute(0,2,1) # b,hw,hw (first hw of k, second of q)
|
| 73 |
+
h_ = torch.bmm(v,w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
| 74 |
+
h_ = h_.reshape(b,c,h,w)
|
| 75 |
+
|
| 76 |
+
h_ = self.proj_out(h_)
|
| 77 |
+
|
| 78 |
+
return x+h_
|
| 79 |
+
|
| 80 |
+
def make_attn(in_channels, attn_type="vanilla"):
|
| 81 |
+
assert attn_type in ["vanilla", "linear", "none"], f'attn_type {attn_type} unknown'
|
| 82 |
+
#print(f"making attention of type '{attn_type}' with {in_channels} in_channels")
|
| 83 |
+
if attn_type == "vanilla":
|
| 84 |
+
return AttnBlock(in_channels)
|
| 85 |
+
elif attn_type == "none":
|
| 86 |
+
return nn.Identity(in_channels)
|
| 87 |
+
else:
|
| 88 |
+
return LinAttnBlock(in_channels)
|
| 89 |
+
|
| 90 |
+
class Downsample(nn.Module):
|
| 91 |
+
def __init__(self, in_channels, with_conv):
|
| 92 |
+
super().__init__()
|
| 93 |
+
self.with_conv = with_conv
|
| 94 |
+
self.in_channels = in_channels
|
| 95 |
+
if self.with_conv:
|
| 96 |
+
# no asymmetric padding in torch conv, must do it ourselves
|
| 97 |
+
self.conv = torch.nn.Conv2d(in_channels,
|
| 98 |
+
in_channels,
|
| 99 |
+
kernel_size=3,
|
| 100 |
+
stride=2,
|
| 101 |
+
padding=0)
|
| 102 |
+
def forward(self, x):
|
| 103 |
+
if self.with_conv:
|
| 104 |
+
pad = (0,1,0,1)
|
| 105 |
+
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
| 106 |
+
x = self.conv(x)
|
| 107 |
+
else:
|
| 108 |
+
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
| 109 |
+
return x
|
| 110 |
+
|
| 111 |
+
class Upsample(nn.Module):
|
| 112 |
+
def __init__(self, in_channels, with_conv):
|
| 113 |
+
super().__init__()
|
| 114 |
+
self.with_conv = with_conv
|
| 115 |
+
self.in_channels = in_channels
|
| 116 |
+
if self.with_conv:
|
| 117 |
+
self.conv = torch.nn.Conv2d(in_channels,
|
| 118 |
+
in_channels,
|
| 119 |
+
kernel_size=3,
|
| 120 |
+
stride=1,
|
| 121 |
+
padding=1)
|
| 122 |
+
|
| 123 |
+
def forward(self, x):
|
| 124 |
+
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
| 125 |
+
if self.with_conv:
|
| 126 |
+
x = self.conv(x)
|
| 127 |
+
return x
|
| 128 |
+
|
| 129 |
+
def get_timestep_embedding(timesteps, embedding_dim):
|
| 130 |
+
"""
|
| 131 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models:
|
| 132 |
+
From Fairseq.
|
| 133 |
+
Build sinusoidal embeddings.
|
| 134 |
+
This matches the implementation in tensor2tensor, but differs slightly
|
| 135 |
+
from the description in Section 3.5 of "Attention Is All You Need".
|
| 136 |
+
"""
|
| 137 |
+
assert len(timesteps.shape) == 1
|
| 138 |
+
|
| 139 |
+
half_dim = embedding_dim // 2
|
| 140 |
+
emb = math.log(10000) / (half_dim - 1)
|
| 141 |
+
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
|
| 142 |
+
emb = emb.to(device=timesteps.device)
|
| 143 |
+
emb = timesteps.float()[:, None] * emb[None, :]
|
| 144 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
| 145 |
+
if embedding_dim % 2 == 1: # zero pad
|
| 146 |
+
emb = torch.nn.functional.pad(emb, (0,1,0,0))
|
| 147 |
+
return emb
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class ResnetBlock(nn.Module):
|
| 152 |
+
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False,
|
| 153 |
+
dropout, temb_channels=512):
|
| 154 |
+
super().__init__()
|
| 155 |
+
self.in_channels = in_channels
|
| 156 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 157 |
+
self.out_channels = out_channels
|
| 158 |
+
self.use_conv_shortcut = conv_shortcut
|
| 159 |
+
|
| 160 |
+
self.norm1 = Normalize(in_channels)
|
| 161 |
+
self.conv1 = torch.nn.Conv2d(in_channels,
|
| 162 |
+
out_channels,
|
| 163 |
+
kernel_size=3,
|
| 164 |
+
stride=1,
|
| 165 |
+
padding=1)
|
| 166 |
+
if temb_channels > 0:
|
| 167 |
+
self.temb_proj = torch.nn.Linear(temb_channels,
|
| 168 |
+
out_channels)
|
| 169 |
+
self.norm2 = Normalize(out_channels)
|
| 170 |
+
self.dropout = torch.nn.Dropout(dropout)
|
| 171 |
+
self.conv2 = torch.nn.Conv2d(out_channels,
|
| 172 |
+
out_channels,
|
| 173 |
+
kernel_size=3,
|
| 174 |
+
stride=1,
|
| 175 |
+
padding=1)
|
| 176 |
+
if self.in_channels != self.out_channels:
|
| 177 |
+
if self.use_conv_shortcut:
|
| 178 |
+
self.conv_shortcut = torch.nn.Conv2d(in_channels,
|
| 179 |
+
out_channels,
|
| 180 |
+
kernel_size=3,
|
| 181 |
+
stride=1,
|
| 182 |
+
padding=1)
|
| 183 |
+
else:
|
| 184 |
+
self.nin_shortcut = torch.nn.Conv2d(in_channels,
|
| 185 |
+
out_channels,
|
| 186 |
+
kernel_size=1,
|
| 187 |
+
stride=1,
|
| 188 |
+
padding=0)
|
| 189 |
+
|
| 190 |
+
def forward(self, x, temb):
|
| 191 |
+
h = x
|
| 192 |
+
h = self.norm1(h)
|
| 193 |
+
h = nonlinearity(h)
|
| 194 |
+
h = self.conv1(h)
|
| 195 |
+
|
| 196 |
+
if temb is not None:
|
| 197 |
+
h = h + self.temb_proj(nonlinearity(temb))[:,:,None,None]
|
| 198 |
+
|
| 199 |
+
h = self.norm2(h)
|
| 200 |
+
h = nonlinearity(h)
|
| 201 |
+
h = self.dropout(h)
|
| 202 |
+
h = self.conv2(h)
|
| 203 |
+
|
| 204 |
+
if self.in_channels != self.out_channels:
|
| 205 |
+
if self.use_conv_shortcut:
|
| 206 |
+
x = self.conv_shortcut(x)
|
| 207 |
+
else:
|
| 208 |
+
x = self.nin_shortcut(x)
|
| 209 |
+
|
| 210 |
+
return x+h
|
| 211 |
+
|
| 212 |
+
class Model(nn.Module):
|
| 213 |
+
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
|
| 214 |
+
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
|
| 215 |
+
resolution, use_timestep=True, use_linear_attn=False, attn_type="vanilla"):
|
| 216 |
+
super().__init__()
|
| 217 |
+
if use_linear_attn: attn_type = "linear"
|
| 218 |
+
self.ch = ch
|
| 219 |
+
self.temb_ch = self.ch*4
|
| 220 |
+
self.num_resolutions = len(ch_mult)
|
| 221 |
+
self.num_res_blocks = num_res_blocks
|
| 222 |
+
self.resolution = resolution
|
| 223 |
+
self.in_channels = in_channels
|
| 224 |
+
|
| 225 |
+
self.use_timestep = use_timestep
|
| 226 |
+
if self.use_timestep:
|
| 227 |
+
# timestep embedding
|
| 228 |
+
self.temb = nn.Module()
|
| 229 |
+
self.temb.dense = nn.ModuleList([
|
| 230 |
+
torch.nn.Linear(self.ch,
|
| 231 |
+
self.temb_ch),
|
| 232 |
+
torch.nn.Linear(self.temb_ch,
|
| 233 |
+
self.temb_ch),
|
| 234 |
+
])
|
| 235 |
+
|
| 236 |
+
# downsampling
|
| 237 |
+
self.conv_in = torch.nn.Conv2d(in_channels,
|
| 238 |
+
self.ch,
|
| 239 |
+
kernel_size=3,
|
| 240 |
+
stride=1,
|
| 241 |
+
padding=1)
|
| 242 |
+
|
| 243 |
+
curr_res = resolution
|
| 244 |
+
in_ch_mult = (1,)+tuple(ch_mult)
|
| 245 |
+
self.down = nn.ModuleList()
|
| 246 |
+
for i_level in range(self.num_resolutions):
|
| 247 |
+
block = nn.ModuleList()
|
| 248 |
+
attn = nn.ModuleList()
|
| 249 |
+
block_in = ch*in_ch_mult[i_level]
|
| 250 |
+
block_out = ch*ch_mult[i_level]
|
| 251 |
+
for i_block in range(self.num_res_blocks):
|
| 252 |
+
block.append(ResnetBlock(in_channels=block_in,
|
| 253 |
+
out_channels=block_out,
|
| 254 |
+
temb_channels=self.temb_ch,
|
| 255 |
+
dropout=dropout))
|
| 256 |
+
block_in = block_out
|
| 257 |
+
if curr_res in attn_resolutions:
|
| 258 |
+
attn.append(make_attn(block_in, attn_type=attn_type))
|
| 259 |
+
down = nn.Module()
|
| 260 |
+
down.block = block
|
| 261 |
+
down.attn = attn
|
| 262 |
+
if i_level != self.num_resolutions-1:
|
| 263 |
+
down.downsample = Downsample(block_in, resamp_with_conv)
|
| 264 |
+
curr_res = curr_res // 2
|
| 265 |
+
self.down.append(down)
|
| 266 |
+
|
| 267 |
+
# middle
|
| 268 |
+
self.mid = nn.Module()
|
| 269 |
+
self.mid.block_1 = ResnetBlock(in_channels=block_in,
|
| 270 |
+
out_channels=block_in,
|
| 271 |
+
temb_channels=self.temb_ch,
|
| 272 |
+
dropout=dropout)
|
| 273 |
+
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
|
| 274 |
+
self.mid.block_2 = ResnetBlock(in_channels=block_in,
|
| 275 |
+
out_channels=block_in,
|
| 276 |
+
temb_channels=self.temb_ch,
|
| 277 |
+
dropout=dropout)
|
| 278 |
+
|
| 279 |
+
# upsampling
|
| 280 |
+
self.up = nn.ModuleList()
|
| 281 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 282 |
+
block = nn.ModuleList()
|
| 283 |
+
attn = nn.ModuleList()
|
| 284 |
+
block_out = ch*ch_mult[i_level]
|
| 285 |
+
skip_in = ch*ch_mult[i_level]
|
| 286 |
+
for i_block in range(self.num_res_blocks+1):
|
| 287 |
+
if i_block == self.num_res_blocks:
|
| 288 |
+
skip_in = ch*in_ch_mult[i_level]
|
| 289 |
+
block.append(ResnetBlock(in_channels=block_in+skip_in,
|
| 290 |
+
out_channels=block_out,
|
| 291 |
+
temb_channels=self.temb_ch,
|
| 292 |
+
dropout=dropout))
|
| 293 |
+
block_in = block_out
|
| 294 |
+
if curr_res in attn_resolutions:
|
| 295 |
+
attn.append(make_attn(block_in, attn_type=attn_type))
|
| 296 |
+
up = nn.Module()
|
| 297 |
+
up.block = block
|
| 298 |
+
up.attn = attn
|
| 299 |
+
if i_level != 0:
|
| 300 |
+
up.upsample = Upsample(block_in, resamp_with_conv)
|
| 301 |
+
curr_res = curr_res * 2
|
| 302 |
+
self.up.insert(0, up) # prepend to get consistent order
|
| 303 |
+
|
| 304 |
+
# end
|
| 305 |
+
self.norm_out = Normalize(block_in)
|
| 306 |
+
self.conv_out = torch.nn.Conv2d(block_in,
|
| 307 |
+
out_ch,
|
| 308 |
+
kernel_size=3,
|
| 309 |
+
stride=1,
|
| 310 |
+
padding=1)
|
| 311 |
+
|
| 312 |
+
def forward(self, x, t=None, context=None):
|
| 313 |
+
#assert x.shape[2] == x.shape[3] == self.resolution
|
| 314 |
+
if context is not None:
|
| 315 |
+
# assume aligned context, cat along channel axis
|
| 316 |
+
x = torch.cat((x, context), dim=1)
|
| 317 |
+
if self.use_timestep:
|
| 318 |
+
# timestep embedding
|
| 319 |
+
assert t is not None
|
| 320 |
+
temb = get_timestep_embedding(t, self.ch)
|
| 321 |
+
temb = self.temb.dense[0](temb)
|
| 322 |
+
temb = nonlinearity(temb)
|
| 323 |
+
temb = self.temb.dense[1](temb)
|
| 324 |
+
else:
|
| 325 |
+
temb = None
|
| 326 |
+
|
| 327 |
+
# downsampling
|
| 328 |
+
hs = [self.conv_in(x)]
|
| 329 |
+
for i_level in range(self.num_resolutions):
|
| 330 |
+
for i_block in range(self.num_res_blocks):
|
| 331 |
+
h = self.down[i_level].block[i_block](hs[-1], temb)
|
| 332 |
+
if len(self.down[i_level].attn) > 0:
|
| 333 |
+
h = self.down[i_level].attn[i_block](h)
|
| 334 |
+
hs.append(h)
|
| 335 |
+
if i_level != self.num_resolutions-1:
|
| 336 |
+
hs.append(self.down[i_level].downsample(hs[-1]))
|
| 337 |
+
|
| 338 |
+
# middle
|
| 339 |
+
h = hs[-1]
|
| 340 |
+
h = self.mid.block_1(h, temb)
|
| 341 |
+
h = self.mid.attn_1(h)
|
| 342 |
+
h = self.mid.block_2(h, temb)
|
| 343 |
+
|
| 344 |
+
# upsampling
|
| 345 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 346 |
+
for i_block in range(self.num_res_blocks+1):
|
| 347 |
+
h = self.up[i_level].block[i_block](
|
| 348 |
+
torch.cat([h, hs.pop()], dim=1), temb)
|
| 349 |
+
if len(self.up[i_level].attn) > 0:
|
| 350 |
+
h = self.up[i_level].attn[i_block](h)
|
| 351 |
+
if i_level != 0:
|
| 352 |
+
h = self.up[i_level].upsample(h)
|
| 353 |
+
|
| 354 |
+
# end
|
| 355 |
+
h = self.norm_out(h)
|
| 356 |
+
h = nonlinearity(h)
|
| 357 |
+
h = self.conv_out(h)
|
| 358 |
+
return h
|
| 359 |
+
|
| 360 |
+
def get_last_layer(self):
|
| 361 |
+
return self.conv_out.weight
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class Encoder(nn.Module):
|
| 365 |
+
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
|
| 366 |
+
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
|
| 367 |
+
resolution, z_channels, double_z=True, use_linear_attn=False, attn_type="vanilla",
|
| 368 |
+
**ignore_kwargs):
|
| 369 |
+
super().__init__()
|
| 370 |
+
if use_linear_attn: attn_type = "linear"
|
| 371 |
+
self.ch = ch
|
| 372 |
+
self.temb_ch = 0
|
| 373 |
+
self.num_resolutions = len(ch_mult)
|
| 374 |
+
self.num_res_blocks = num_res_blocks
|
| 375 |
+
self.resolution = resolution
|
| 376 |
+
self.in_channels = in_channels
|
| 377 |
+
|
| 378 |
+
# downsampling
|
| 379 |
+
self.conv_in = torch.nn.Conv2d(in_channels,
|
| 380 |
+
self.ch,
|
| 381 |
+
kernel_size=3,
|
| 382 |
+
stride=1,
|
| 383 |
+
padding=1)
|
| 384 |
+
|
| 385 |
+
curr_res = resolution
|
| 386 |
+
in_ch_mult = (1,)+tuple(ch_mult)
|
| 387 |
+
self.in_ch_mult = in_ch_mult
|
| 388 |
+
self.down = nn.ModuleList()
|
| 389 |
+
for i_level in range(self.num_resolutions):
|
| 390 |
+
block = nn.ModuleList()
|
| 391 |
+
attn = nn.ModuleList()
|
| 392 |
+
block_in = ch*in_ch_mult[i_level]
|
| 393 |
+
block_out = ch*ch_mult[i_level]
|
| 394 |
+
for i_block in range(self.num_res_blocks):
|
| 395 |
+
block.append(ResnetBlock(in_channels=block_in,
|
| 396 |
+
out_channels=block_out,
|
| 397 |
+
temb_channels=self.temb_ch,
|
| 398 |
+
dropout=dropout))
|
| 399 |
+
block_in = block_out
|
| 400 |
+
if curr_res in attn_resolutions:
|
| 401 |
+
attn.append(make_attn(block_in, attn_type=attn_type))
|
| 402 |
+
down = nn.Module()
|
| 403 |
+
down.block = block
|
| 404 |
+
down.attn = attn
|
| 405 |
+
if i_level != self.num_resolutions-1:
|
| 406 |
+
down.downsample = Downsample(block_in, resamp_with_conv)
|
| 407 |
+
curr_res = curr_res // 2
|
| 408 |
+
self.down.append(down)
|
| 409 |
+
|
| 410 |
+
# middle
|
| 411 |
+
self.mid = nn.Module()
|
| 412 |
+
self.mid.block_1 = ResnetBlock(in_channels=block_in,
|
| 413 |
+
out_channels=block_in,
|
| 414 |
+
temb_channels=self.temb_ch,
|
| 415 |
+
dropout=dropout)
|
| 416 |
+
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
|
| 417 |
+
self.mid.block_2 = ResnetBlock(in_channels=block_in,
|
| 418 |
+
out_channels=block_in,
|
| 419 |
+
temb_channels=self.temb_ch,
|
| 420 |
+
dropout=dropout)
|
| 421 |
+
|
| 422 |
+
# end
|
| 423 |
+
self.norm_out = Normalize(block_in)
|
| 424 |
+
self.conv_out = torch.nn.Conv2d(block_in,
|
| 425 |
+
2*z_channels if double_z else z_channels,
|
| 426 |
+
kernel_size=3,
|
| 427 |
+
stride=1,
|
| 428 |
+
padding=1)
|
| 429 |
+
|
| 430 |
+
def forward(self, x):
|
| 431 |
+
# timestep embedding
|
| 432 |
+
temb = None
|
| 433 |
+
|
| 434 |
+
# print(f'encoder-input={x.shape}')
|
| 435 |
+
# downsampling
|
| 436 |
+
hs = [self.conv_in(x)]
|
| 437 |
+
# print(f'encoder-conv in feat={hs[0].shape}')
|
| 438 |
+
for i_level in range(self.num_resolutions):
|
| 439 |
+
for i_block in range(self.num_res_blocks):
|
| 440 |
+
h = self.down[i_level].block[i_block](hs[-1], temb)
|
| 441 |
+
# print(f'encoder-down feat={h.shape}')
|
| 442 |
+
if len(self.down[i_level].attn) > 0:
|
| 443 |
+
h = self.down[i_level].attn[i_block](h)
|
| 444 |
+
hs.append(h)
|
| 445 |
+
if i_level != self.num_resolutions-1:
|
| 446 |
+
# print(f'encoder-downsample (input)={hs[-1].shape}')
|
| 447 |
+
hs.append(self.down[i_level].downsample(hs[-1]))
|
| 448 |
+
# print(f'encoder-downsample (output)={hs[-1].shape}')
|
| 449 |
+
|
| 450 |
+
# middle
|
| 451 |
+
h = hs[-1]
|
| 452 |
+
h = self.mid.block_1(h, temb)
|
| 453 |
+
# print(f'encoder-mid1 feat={h.shape}')
|
| 454 |
+
h = self.mid.attn_1(h)
|
| 455 |
+
h = self.mid.block_2(h, temb)
|
| 456 |
+
# print(f'encoder-mid2 feat={h.shape}')
|
| 457 |
+
|
| 458 |
+
# end
|
| 459 |
+
h = self.norm_out(h)
|
| 460 |
+
h = nonlinearity(h)
|
| 461 |
+
h = self.conv_out(h)
|
| 462 |
+
# print(f'end feat={h.shape}')
|
| 463 |
+
return h
|
| 464 |
+
|
| 465 |
+
|
| 466 |
+
class Decoder(nn.Module):
|
| 467 |
+
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
|
| 468 |
+
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
|
| 469 |
+
resolution, z_channels, give_pre_end=False, tanh_out=False, use_linear_attn=False,
|
| 470 |
+
attn_type="vanilla", **ignorekwargs):
|
| 471 |
+
super().__init__()
|
| 472 |
+
if use_linear_attn: attn_type = "linear"
|
| 473 |
+
self.ch = ch
|
| 474 |
+
self.temb_ch = 0
|
| 475 |
+
self.num_resolutions = len(ch_mult)
|
| 476 |
+
self.num_res_blocks = num_res_blocks
|
| 477 |
+
self.resolution = resolution
|
| 478 |
+
self.in_channels = in_channels
|
| 479 |
+
self.give_pre_end = give_pre_end
|
| 480 |
+
self.tanh_out = tanh_out
|
| 481 |
+
|
| 482 |
+
# compute in_ch_mult, block_in and curr_res at lowest res
|
| 483 |
+
in_ch_mult = (1,)+tuple(ch_mult)
|
| 484 |
+
block_in = ch*ch_mult[self.num_resolutions-1]
|
| 485 |
+
curr_res = resolution // 2**(self.num_resolutions-1)
|
| 486 |
+
self.z_shape = (1,z_channels,curr_res,curr_res)
|
| 487 |
+
print("AE working on z of shape {} = {} dimensions.".format(
|
| 488 |
+
self.z_shape, np.prod(self.z_shape)))
|
| 489 |
+
|
| 490 |
+
# z to block_in
|
| 491 |
+
self.conv_in = torch.nn.Conv2d(z_channels,
|
| 492 |
+
block_in,
|
| 493 |
+
kernel_size=3,
|
| 494 |
+
stride=1,
|
| 495 |
+
padding=1)
|
| 496 |
+
|
| 497 |
+
# middle
|
| 498 |
+
self.mid = nn.Module()
|
| 499 |
+
self.mid.block_1 = ResnetBlock(in_channels=block_in,
|
| 500 |
+
out_channels=block_in,
|
| 501 |
+
temb_channels=self.temb_ch,
|
| 502 |
+
dropout=dropout)
|
| 503 |
+
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
|
| 504 |
+
self.mid.block_2 = ResnetBlock(in_channels=block_in,
|
| 505 |
+
out_channels=block_in,
|
| 506 |
+
temb_channels=self.temb_ch,
|
| 507 |
+
dropout=dropout)
|
| 508 |
+
|
| 509 |
+
# upsampling
|
| 510 |
+
self.up = nn.ModuleList()
|
| 511 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 512 |
+
block = nn.ModuleList()
|
| 513 |
+
attn = nn.ModuleList()
|
| 514 |
+
block_out = ch*ch_mult[i_level]
|
| 515 |
+
for i_block in range(self.num_res_blocks+1):
|
| 516 |
+
block.append(ResnetBlock(in_channels=block_in,
|
| 517 |
+
out_channels=block_out,
|
| 518 |
+
temb_channels=self.temb_ch,
|
| 519 |
+
dropout=dropout))
|
| 520 |
+
block_in = block_out
|
| 521 |
+
if curr_res in attn_resolutions:
|
| 522 |
+
attn.append(make_attn(block_in, attn_type=attn_type))
|
| 523 |
+
up = nn.Module()
|
| 524 |
+
up.block = block
|
| 525 |
+
up.attn = attn
|
| 526 |
+
if i_level != 0:
|
| 527 |
+
up.upsample = Upsample(block_in, resamp_with_conv)
|
| 528 |
+
curr_res = curr_res * 2
|
| 529 |
+
self.up.insert(0, up) # prepend to get consistent order
|
| 530 |
+
|
| 531 |
+
# end
|
| 532 |
+
self.norm_out = Normalize(block_in)
|
| 533 |
+
self.conv_out = torch.nn.Conv2d(block_in,
|
| 534 |
+
out_ch,
|
| 535 |
+
kernel_size=3,
|
| 536 |
+
stride=1,
|
| 537 |
+
padding=1)
|
| 538 |
+
|
| 539 |
+
def forward(self, z):
|
| 540 |
+
#assert z.shape[1:] == self.z_shape[1:]
|
| 541 |
+
self.last_z_shape = z.shape
|
| 542 |
+
|
| 543 |
+
# print(f'decoder-input={z.shape}')
|
| 544 |
+
# timestep embedding
|
| 545 |
+
temb = None
|
| 546 |
+
|
| 547 |
+
# z to block_in
|
| 548 |
+
h = self.conv_in(z)
|
| 549 |
+
# print(f'decoder-conv in feat={h.shape}')
|
| 550 |
+
|
| 551 |
+
# middle
|
| 552 |
+
h = self.mid.block_1(h, temb)
|
| 553 |
+
h = self.mid.attn_1(h)
|
| 554 |
+
h = self.mid.block_2(h, temb)
|
| 555 |
+
# print(f'decoder-mid feat={h.shape}')
|
| 556 |
+
|
| 557 |
+
# upsampling
|
| 558 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 559 |
+
for i_block in range(self.num_res_blocks+1):
|
| 560 |
+
h = self.up[i_level].block[i_block](h, temb)
|
| 561 |
+
if len(self.up[i_level].attn) > 0:
|
| 562 |
+
h = self.up[i_level].attn[i_block](h)
|
| 563 |
+
# print(f'decoder-up feat={h.shape}')
|
| 564 |
+
if i_level != 0:
|
| 565 |
+
h = self.up[i_level].upsample(h)
|
| 566 |
+
# print(f'decoder-upsample feat={h.shape}')
|
| 567 |
+
|
| 568 |
+
# end
|
| 569 |
+
if self.give_pre_end:
|
| 570 |
+
return h
|
| 571 |
+
|
| 572 |
+
h = self.norm_out(h)
|
| 573 |
+
h = nonlinearity(h)
|
| 574 |
+
h = self.conv_out(h)
|
| 575 |
+
# print(f'decoder-conv_out feat={h.shape}')
|
| 576 |
+
if self.tanh_out:
|
| 577 |
+
h = torch.tanh(h)
|
| 578 |
+
return h
|
| 579 |
+
|
| 580 |
+
|
| 581 |
+
class SimpleDecoder(nn.Module):
|
| 582 |
+
def __init__(self, in_channels, out_channels, *args, **kwargs):
|
| 583 |
+
super().__init__()
|
| 584 |
+
self.model = nn.ModuleList([nn.Conv2d(in_channels, in_channels, 1),
|
| 585 |
+
ResnetBlock(in_channels=in_channels,
|
| 586 |
+
out_channels=2 * in_channels,
|
| 587 |
+
temb_channels=0, dropout=0.0),
|
| 588 |
+
ResnetBlock(in_channels=2 * in_channels,
|
| 589 |
+
out_channels=4 * in_channels,
|
| 590 |
+
temb_channels=0, dropout=0.0),
|
| 591 |
+
ResnetBlock(in_channels=4 * in_channels,
|
| 592 |
+
out_channels=2 * in_channels,
|
| 593 |
+
temb_channels=0, dropout=0.0),
|
| 594 |
+
nn.Conv2d(2*in_channels, in_channels, 1),
|
| 595 |
+
Upsample(in_channels, with_conv=True)])
|
| 596 |
+
# end
|
| 597 |
+
self.norm_out = Normalize(in_channels)
|
| 598 |
+
self.conv_out = torch.nn.Conv2d(in_channels,
|
| 599 |
+
out_channels,
|
| 600 |
+
kernel_size=3,
|
| 601 |
+
stride=1,
|
| 602 |
+
padding=1)
|
| 603 |
+
|
| 604 |
+
def forward(self, x):
|
| 605 |
+
for i, layer in enumerate(self.model):
|
| 606 |
+
if i in [1,2,3]:
|
| 607 |
+
x = layer(x, None)
|
| 608 |
+
else:
|
| 609 |
+
x = layer(x)
|
| 610 |
+
|
| 611 |
+
h = self.norm_out(x)
|
| 612 |
+
h = nonlinearity(h)
|
| 613 |
+
x = self.conv_out(h)
|
| 614 |
+
return x
|
| 615 |
+
|
| 616 |
+
|
| 617 |
+
class UpsampleDecoder(nn.Module):
|
| 618 |
+
def __init__(self, in_channels, out_channels, ch, num_res_blocks, resolution,
|
| 619 |
+
ch_mult=(2,2), dropout=0.0):
|
| 620 |
+
super().__init__()
|
| 621 |
+
# upsampling
|
| 622 |
+
self.temb_ch = 0
|
| 623 |
+
self.num_resolutions = len(ch_mult)
|
| 624 |
+
self.num_res_blocks = num_res_blocks
|
| 625 |
+
block_in = in_channels
|
| 626 |
+
curr_res = resolution // 2 ** (self.num_resolutions - 1)
|
| 627 |
+
self.res_blocks = nn.ModuleList()
|
| 628 |
+
self.upsample_blocks = nn.ModuleList()
|
| 629 |
+
for i_level in range(self.num_resolutions):
|
| 630 |
+
res_block = []
|
| 631 |
+
block_out = ch * ch_mult[i_level]
|
| 632 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 633 |
+
res_block.append(ResnetBlock(in_channels=block_in,
|
| 634 |
+
out_channels=block_out,
|
| 635 |
+
temb_channels=self.temb_ch,
|
| 636 |
+
dropout=dropout))
|
| 637 |
+
block_in = block_out
|
| 638 |
+
self.res_blocks.append(nn.ModuleList(res_block))
|
| 639 |
+
if i_level != self.num_resolutions - 1:
|
| 640 |
+
self.upsample_blocks.append(Upsample(block_in, True))
|
| 641 |
+
curr_res = curr_res * 2
|
| 642 |
+
|
| 643 |
+
# end
|
| 644 |
+
self.norm_out = Normalize(block_in)
|
| 645 |
+
self.conv_out = torch.nn.Conv2d(block_in,
|
| 646 |
+
out_channels,
|
| 647 |
+
kernel_size=3,
|
| 648 |
+
stride=1,
|
| 649 |
+
padding=1)
|
| 650 |
+
|
| 651 |
+
def forward(self, x):
|
| 652 |
+
# upsampling
|
| 653 |
+
h = x
|
| 654 |
+
for k, i_level in enumerate(range(self.num_resolutions)):
|
| 655 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 656 |
+
h = self.res_blocks[i_level][i_block](h, None)
|
| 657 |
+
if i_level != self.num_resolutions - 1:
|
| 658 |
+
h = self.upsample_blocks[k](h)
|
| 659 |
+
h = self.norm_out(h)
|
| 660 |
+
h = nonlinearity(h)
|
| 661 |
+
h = self.conv_out(h)
|
| 662 |
+
return h
|
| 663 |
+
|
| 664 |
+
|
| 665 |
+
class LatentRescaler(nn.Module):
|
| 666 |
+
def __init__(self, factor, in_channels, mid_channels, out_channels, depth=2):
|
| 667 |
+
super().__init__()
|
| 668 |
+
# residual block, interpolate, residual block
|
| 669 |
+
self.factor = factor
|
| 670 |
+
self.conv_in = nn.Conv2d(in_channels,
|
| 671 |
+
mid_channels,
|
| 672 |
+
kernel_size=3,
|
| 673 |
+
stride=1,
|
| 674 |
+
padding=1)
|
| 675 |
+
self.res_block1 = nn.ModuleList([ResnetBlock(in_channels=mid_channels,
|
| 676 |
+
out_channels=mid_channels,
|
| 677 |
+
temb_channels=0,
|
| 678 |
+
dropout=0.0) for _ in range(depth)])
|
| 679 |
+
self.attn = AttnBlock(mid_channels)
|
| 680 |
+
self.res_block2 = nn.ModuleList([ResnetBlock(in_channels=mid_channels,
|
| 681 |
+
out_channels=mid_channels,
|
| 682 |
+
temb_channels=0,
|
| 683 |
+
dropout=0.0) for _ in range(depth)])
|
| 684 |
+
|
| 685 |
+
self.conv_out = nn.Conv2d(mid_channels,
|
| 686 |
+
out_channels,
|
| 687 |
+
kernel_size=1,
|
| 688 |
+
)
|
| 689 |
+
|
| 690 |
+
def forward(self, x):
|
| 691 |
+
x = self.conv_in(x)
|
| 692 |
+
for block in self.res_block1:
|
| 693 |
+
x = block(x, None)
|
| 694 |
+
x = torch.nn.functional.interpolate(x, size=(int(round(x.shape[2]*self.factor)), int(round(x.shape[3]*self.factor))))
|
| 695 |
+
x = self.attn(x)
|
| 696 |
+
for block in self.res_block2:
|
| 697 |
+
x = block(x, None)
|
| 698 |
+
x = self.conv_out(x)
|
| 699 |
+
return x
|
| 700 |
+
|
| 701 |
+
|
| 702 |
+
class MergedRescaleEncoder(nn.Module):
|
| 703 |
+
def __init__(self, in_channels, ch, resolution, out_ch, num_res_blocks,
|
| 704 |
+
attn_resolutions, dropout=0.0, resamp_with_conv=True,
|
| 705 |
+
ch_mult=(1,2,4,8), rescale_factor=1.0, rescale_module_depth=1):
|
| 706 |
+
super().__init__()
|
| 707 |
+
intermediate_chn = ch * ch_mult[-1]
|
| 708 |
+
self.encoder = Encoder(in_channels=in_channels, num_res_blocks=num_res_blocks, ch=ch, ch_mult=ch_mult,
|
| 709 |
+
z_channels=intermediate_chn, double_z=False, resolution=resolution,
|
| 710 |
+
attn_resolutions=attn_resolutions, dropout=dropout, resamp_with_conv=resamp_with_conv,
|
| 711 |
+
out_ch=None)
|
| 712 |
+
self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=intermediate_chn,
|
| 713 |
+
mid_channels=intermediate_chn, out_channels=out_ch, depth=rescale_module_depth)
|
| 714 |
+
|
| 715 |
+
def forward(self, x):
|
| 716 |
+
x = self.encoder(x)
|
| 717 |
+
x = self.rescaler(x)
|
| 718 |
+
return x
|
| 719 |
+
|
| 720 |
+
|
| 721 |
+
class MergedRescaleDecoder(nn.Module):
|
| 722 |
+
def __init__(self, z_channels, out_ch, resolution, num_res_blocks, attn_resolutions, ch, ch_mult=(1,2,4,8),
|
| 723 |
+
dropout=0.0, resamp_with_conv=True, rescale_factor=1.0, rescale_module_depth=1):
|
| 724 |
+
super().__init__()
|
| 725 |
+
tmp_chn = z_channels*ch_mult[-1]
|
| 726 |
+
self.decoder = Decoder(out_ch=out_ch, z_channels=tmp_chn, attn_resolutions=attn_resolutions, dropout=dropout,
|
| 727 |
+
resamp_with_conv=resamp_with_conv, in_channels=None, num_res_blocks=num_res_blocks,
|
| 728 |
+
ch_mult=ch_mult, resolution=resolution, ch=ch)
|
| 729 |
+
self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=z_channels, mid_channels=tmp_chn,
|
| 730 |
+
out_channels=tmp_chn, depth=rescale_module_depth)
|
| 731 |
+
|
| 732 |
+
def forward(self, x):
|
| 733 |
+
x = self.rescaler(x)
|
| 734 |
+
x = self.decoder(x)
|
| 735 |
+
return x
|
| 736 |
+
|
| 737 |
+
|
| 738 |
+
class Upsampler(nn.Module):
|
| 739 |
+
def __init__(self, in_size, out_size, in_channels, out_channels, ch_mult=2):
|
| 740 |
+
super().__init__()
|
| 741 |
+
assert out_size >= in_size
|
| 742 |
+
num_blocks = int(np.log2(out_size//in_size))+1
|
| 743 |
+
factor_up = 1.+ (out_size % in_size)
|
| 744 |
+
print(f"Building {self.__class__.__name__} with in_size: {in_size} --> out_size {out_size} and factor {factor_up}")
|
| 745 |
+
self.rescaler = LatentRescaler(factor=factor_up, in_channels=in_channels, mid_channels=2*in_channels,
|
| 746 |
+
out_channels=in_channels)
|
| 747 |
+
self.decoder = Decoder(out_ch=out_channels, resolution=out_size, z_channels=in_channels, num_res_blocks=2,
|
| 748 |
+
attn_resolutions=[], in_channels=None, ch=in_channels,
|
| 749 |
+
ch_mult=[ch_mult for _ in range(num_blocks)])
|
| 750 |
+
|
| 751 |
+
def forward(self, x):
|
| 752 |
+
x = self.rescaler(x)
|
| 753 |
+
x = self.decoder(x)
|
| 754 |
+
return x
|
| 755 |
+
|
| 756 |
+
|
| 757 |
+
class Resize(nn.Module):
|
| 758 |
+
def __init__(self, in_channels=None, learned=False, mode="bilinear"):
|
| 759 |
+
super().__init__()
|
| 760 |
+
self.with_conv = learned
|
| 761 |
+
self.mode = mode
|
| 762 |
+
if self.with_conv:
|
| 763 |
+
print(f"Note: {self.__class__.__name} uses learned downsampling and will ignore the fixed {mode} mode")
|
| 764 |
+
raise NotImplementedError()
|
| 765 |
+
assert in_channels is not None
|
| 766 |
+
# no asymmetric padding in torch conv, must do it ourselves
|
| 767 |
+
self.conv = torch.nn.Conv2d(in_channels,
|
| 768 |
+
in_channels,
|
| 769 |
+
kernel_size=4,
|
| 770 |
+
stride=2,
|
| 771 |
+
padding=1)
|
| 772 |
+
|
| 773 |
+
def forward(self, x, scale_factor=1.0):
|
| 774 |
+
if scale_factor==1.0:
|
| 775 |
+
return x
|
| 776 |
+
else:
|
| 777 |
+
x = torch.nn.functional.interpolate(x, mode=self.mode, align_corners=False, scale_factor=scale_factor)
|
| 778 |
+
return x
|
| 779 |
+
|
| 780 |
+
class FirstStagePostProcessor(nn.Module):
|
| 781 |
+
|
| 782 |
+
def __init__(self, ch_mult:list, in_channels,
|
| 783 |
+
pretrained_model:nn.Module=None,
|
| 784 |
+
reshape=False,
|
| 785 |
+
n_channels=None,
|
| 786 |
+
dropout=0.,
|
| 787 |
+
pretrained_config=None):
|
| 788 |
+
super().__init__()
|
| 789 |
+
if pretrained_config is None:
|
| 790 |
+
assert pretrained_model is not None, 'Either "pretrained_model" or "pretrained_config" must not be None'
|
| 791 |
+
self.pretrained_model = pretrained_model
|
| 792 |
+
else:
|
| 793 |
+
assert pretrained_config is not None, 'Either "pretrained_model" or "pretrained_config" must not be None'
|
| 794 |
+
self.instantiate_pretrained(pretrained_config)
|
| 795 |
+
|
| 796 |
+
self.do_reshape = reshape
|
| 797 |
+
|
| 798 |
+
if n_channels is None:
|
| 799 |
+
n_channels = self.pretrained_model.encoder.ch
|
| 800 |
+
|
| 801 |
+
self.proj_norm = Normalize(in_channels,num_groups=in_channels//2)
|
| 802 |
+
self.proj = nn.Conv2d(in_channels,n_channels,kernel_size=3,
|
| 803 |
+
stride=1,padding=1)
|
| 804 |
+
|
| 805 |
+
blocks = []
|
| 806 |
+
downs = []
|
| 807 |
+
ch_in = n_channels
|
| 808 |
+
for m in ch_mult:
|
| 809 |
+
blocks.append(ResnetBlock(in_channels=ch_in,out_channels=m*n_channels,dropout=dropout))
|
| 810 |
+
ch_in = m * n_channels
|
| 811 |
+
downs.append(Downsample(ch_in, with_conv=False))
|
| 812 |
+
|
| 813 |
+
self.model = nn.ModuleList(blocks)
|
| 814 |
+
self.downsampler = nn.ModuleList(downs)
|
| 815 |
+
|
| 816 |
+
|
| 817 |
+
def instantiate_pretrained(self, config):
|
| 818 |
+
model = instantiate_from_config(config)
|
| 819 |
+
self.pretrained_model = model.eval()
|
| 820 |
+
# self.pretrained_model.train = False
|
| 821 |
+
for param in self.pretrained_model.parameters():
|
| 822 |
+
param.requires_grad = False
|
| 823 |
+
|
| 824 |
+
|
| 825 |
+
@torch.no_grad()
|
| 826 |
+
def encode_with_pretrained(self,x):
|
| 827 |
+
c = self.pretrained_model.encode(x)
|
| 828 |
+
if isinstance(c, DiagonalGaussianDistribution):
|
| 829 |
+
c = c.mode()
|
| 830 |
+
return c
|
| 831 |
+
|
| 832 |
+
def forward(self,x):
|
| 833 |
+
z_fs = self.encode_with_pretrained(x)
|
| 834 |
+
z = self.proj_norm(z_fs)
|
| 835 |
+
z = self.proj(z)
|
| 836 |
+
z = nonlinearity(z)
|
| 837 |
+
|
| 838 |
+
for submodel, downmodel in zip(self.model,self.downsampler):
|
| 839 |
+
z = submodel(z,temb=None)
|
| 840 |
+
z = downmodel(z)
|
| 841 |
+
|
| 842 |
+
if self.do_reshape:
|
| 843 |
+
z = rearrange(z,'b c h w -> b (h w) c')
|
| 844 |
+
return z
|
| 845 |
+
|
lvdm/modules/networks/openaimodel3d.py
ADDED
|
@@ -0,0 +1,577 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from abc import abstractmethod
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from lvdm.models.utils_diffusion import timestep_embedding
|
| 8 |
+
from lvdm.common import checkpoint
|
| 9 |
+
from lvdm.basics import (
|
| 10 |
+
zero_module,
|
| 11 |
+
conv_nd,
|
| 12 |
+
linear,
|
| 13 |
+
avg_pool_nd,
|
| 14 |
+
normalization
|
| 15 |
+
)
|
| 16 |
+
from lvdm.modules.attention import SpatialTransformer, TemporalTransformer
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class TimestepBlock(nn.Module):
|
| 20 |
+
"""
|
| 21 |
+
Any module where forward() takes timestep embeddings as a second argument.
|
| 22 |
+
"""
|
| 23 |
+
@abstractmethod
|
| 24 |
+
def forward(self, x, emb):
|
| 25 |
+
"""
|
| 26 |
+
Apply the module to `x` given `emb` timestep embeddings.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
|
| 31 |
+
"""
|
| 32 |
+
A sequential module that passes timestep embeddings to the children that
|
| 33 |
+
support it as an extra input.
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
def forward(self, x, emb, context=None, batch_size=None):
|
| 37 |
+
for layer in self:
|
| 38 |
+
if isinstance(layer, TimestepBlock):
|
| 39 |
+
x = layer(x, emb, batch_size)
|
| 40 |
+
elif isinstance(layer, SpatialTransformer):
|
| 41 |
+
x = layer(x, context)
|
| 42 |
+
elif isinstance(layer, TemporalTransformer):
|
| 43 |
+
x = rearrange(x, '(b f) c h w -> b c f h w', b=batch_size)
|
| 44 |
+
x = layer(x, context)
|
| 45 |
+
x = rearrange(x, 'b c f h w -> (b f) c h w')
|
| 46 |
+
else:
|
| 47 |
+
x = layer(x,)
|
| 48 |
+
return x
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class Downsample(nn.Module):
|
| 52 |
+
"""
|
| 53 |
+
A downsampling layer with an optional convolution.
|
| 54 |
+
:param channels: channels in the inputs and outputs.
|
| 55 |
+
:param use_conv: a bool determining if a convolution is applied.
|
| 56 |
+
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
| 57 |
+
downsampling occurs in the inner-two dimensions.
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
|
| 61 |
+
super().__init__()
|
| 62 |
+
self.channels = channels
|
| 63 |
+
self.out_channels = out_channels or channels
|
| 64 |
+
self.use_conv = use_conv
|
| 65 |
+
self.dims = dims
|
| 66 |
+
stride = 2 if dims != 3 else (1, 2, 2)
|
| 67 |
+
if use_conv:
|
| 68 |
+
self.op = conv_nd(
|
| 69 |
+
dims, self.channels, self.out_channels, 3, stride=stride, padding=padding
|
| 70 |
+
)
|
| 71 |
+
else:
|
| 72 |
+
assert self.channels == self.out_channels
|
| 73 |
+
self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
|
| 74 |
+
|
| 75 |
+
def forward(self, x):
|
| 76 |
+
assert x.shape[1] == self.channels
|
| 77 |
+
return self.op(x)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class Upsample(nn.Module):
|
| 81 |
+
"""
|
| 82 |
+
An upsampling layer with an optional convolution.
|
| 83 |
+
:param channels: channels in the inputs and outputs.
|
| 84 |
+
:param use_conv: a bool determining if a convolution is applied.
|
| 85 |
+
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
| 86 |
+
upsampling occurs in the inner-two dimensions.
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
|
| 90 |
+
super().__init__()
|
| 91 |
+
self.channels = channels
|
| 92 |
+
self.out_channels = out_channels or channels
|
| 93 |
+
self.use_conv = use_conv
|
| 94 |
+
self.dims = dims
|
| 95 |
+
if use_conv:
|
| 96 |
+
self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=padding)
|
| 97 |
+
|
| 98 |
+
def forward(self, x):
|
| 99 |
+
assert x.shape[1] == self.channels
|
| 100 |
+
if self.dims == 3:
|
| 101 |
+
x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode='nearest')
|
| 102 |
+
else:
|
| 103 |
+
x = F.interpolate(x, scale_factor=2, mode='nearest')
|
| 104 |
+
if self.use_conv:
|
| 105 |
+
x = self.conv(x)
|
| 106 |
+
return x
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class ResBlock(TimestepBlock):
|
| 110 |
+
"""
|
| 111 |
+
A residual block that can optionally change the number of channels.
|
| 112 |
+
:param channels: the number of input channels.
|
| 113 |
+
:param emb_channels: the number of timestep embedding channels.
|
| 114 |
+
:param dropout: the rate of dropout.
|
| 115 |
+
:param out_channels: if specified, the number of out channels.
|
| 116 |
+
:param use_conv: if True and out_channels is specified, use a spatial
|
| 117 |
+
convolution instead of a smaller 1x1 convolution to change the
|
| 118 |
+
channels in the skip connection.
|
| 119 |
+
:param dims: determines if the signal is 1D, 2D, or 3D.
|
| 120 |
+
:param up: if True, use this block for upsampling.
|
| 121 |
+
:param down: if True, use this block for downsampling.
|
| 122 |
+
"""
|
| 123 |
+
|
| 124 |
+
def __init__(
|
| 125 |
+
self,
|
| 126 |
+
channels,
|
| 127 |
+
emb_channels,
|
| 128 |
+
dropout,
|
| 129 |
+
out_channels=None,
|
| 130 |
+
use_scale_shift_norm=False,
|
| 131 |
+
dims=2,
|
| 132 |
+
use_checkpoint=False,
|
| 133 |
+
use_conv=False,
|
| 134 |
+
up=False,
|
| 135 |
+
down=False,
|
| 136 |
+
use_temporal_conv=False,
|
| 137 |
+
tempspatial_aware=False
|
| 138 |
+
):
|
| 139 |
+
super().__init__()
|
| 140 |
+
self.channels = channels
|
| 141 |
+
self.emb_channels = emb_channels
|
| 142 |
+
self.dropout = dropout
|
| 143 |
+
self.out_channels = out_channels or channels
|
| 144 |
+
self.use_conv = use_conv
|
| 145 |
+
self.use_checkpoint = use_checkpoint
|
| 146 |
+
self.use_scale_shift_norm = use_scale_shift_norm
|
| 147 |
+
self.use_temporal_conv = use_temporal_conv
|
| 148 |
+
|
| 149 |
+
self.in_layers = nn.Sequential(
|
| 150 |
+
normalization(channels),
|
| 151 |
+
nn.SiLU(),
|
| 152 |
+
conv_nd(dims, channels, self.out_channels, 3, padding=1),
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
self.updown = up or down
|
| 156 |
+
|
| 157 |
+
if up:
|
| 158 |
+
self.h_upd = Upsample(channels, False, dims)
|
| 159 |
+
self.x_upd = Upsample(channels, False, dims)
|
| 160 |
+
elif down:
|
| 161 |
+
self.h_upd = Downsample(channels, False, dims)
|
| 162 |
+
self.x_upd = Downsample(channels, False, dims)
|
| 163 |
+
else:
|
| 164 |
+
self.h_upd = self.x_upd = nn.Identity()
|
| 165 |
+
|
| 166 |
+
self.emb_layers = nn.Sequential(
|
| 167 |
+
nn.SiLU(),
|
| 168 |
+
nn.Linear(
|
| 169 |
+
emb_channels,
|
| 170 |
+
2 * self.out_channels if use_scale_shift_norm else self.out_channels,
|
| 171 |
+
),
|
| 172 |
+
)
|
| 173 |
+
self.out_layers = nn.Sequential(
|
| 174 |
+
normalization(self.out_channels),
|
| 175 |
+
nn.SiLU(),
|
| 176 |
+
nn.Dropout(p=dropout),
|
| 177 |
+
zero_module(nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1)),
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
if self.out_channels == channels:
|
| 181 |
+
self.skip_connection = nn.Identity()
|
| 182 |
+
elif use_conv:
|
| 183 |
+
self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
|
| 184 |
+
else:
|
| 185 |
+
self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
|
| 186 |
+
|
| 187 |
+
if self.use_temporal_conv:
|
| 188 |
+
self.temopral_conv = TemporalConvBlock(
|
| 189 |
+
self.out_channels,
|
| 190 |
+
self.out_channels,
|
| 191 |
+
dropout=0.1,
|
| 192 |
+
spatial_aware=tempspatial_aware
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
def forward(self, x, emb, batch_size=None):
|
| 196 |
+
"""
|
| 197 |
+
Apply the block to a Tensor, conditioned on a timestep embedding.
|
| 198 |
+
:param x: an [N x C x ...] Tensor of features.
|
| 199 |
+
:param emb: an [N x emb_channels] Tensor of timestep embeddings.
|
| 200 |
+
:return: an [N x C x ...] Tensor of outputs.
|
| 201 |
+
"""
|
| 202 |
+
input_tuple = (x, emb,)
|
| 203 |
+
if batch_size:
|
| 204 |
+
forward_batchsize = partial(self._forward, batch_size=batch_size)
|
| 205 |
+
return checkpoint(forward_batchsize, input_tuple, self.parameters(), self.use_checkpoint)
|
| 206 |
+
return checkpoint(self._forward, input_tuple, self.parameters(), self.use_checkpoint)
|
| 207 |
+
|
| 208 |
+
def _forward(self, x, emb, batch_size=None,):
|
| 209 |
+
if self.updown:
|
| 210 |
+
in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
|
| 211 |
+
h = in_rest(x)
|
| 212 |
+
h = self.h_upd(h)
|
| 213 |
+
x = self.x_upd(x)
|
| 214 |
+
h = in_conv(h)
|
| 215 |
+
else:
|
| 216 |
+
h = self.in_layers(x)
|
| 217 |
+
emb_out = self.emb_layers(emb).type(h.dtype)
|
| 218 |
+
while len(emb_out.shape) < len(h.shape):
|
| 219 |
+
emb_out = emb_out[..., None]
|
| 220 |
+
if self.use_scale_shift_norm:
|
| 221 |
+
out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
|
| 222 |
+
scale, shift = torch.chunk(emb_out, 2, dim=1)
|
| 223 |
+
h = out_norm(h) * (1 + scale) + shift
|
| 224 |
+
h = out_rest(h)
|
| 225 |
+
else:
|
| 226 |
+
h = h + emb_out
|
| 227 |
+
h = self.out_layers(h)
|
| 228 |
+
h = self.skip_connection(x) + h
|
| 229 |
+
|
| 230 |
+
if self.use_temporal_conv and batch_size:
|
| 231 |
+
h = rearrange(h, '(b t) c h w -> b c t h w', b=batch_size)
|
| 232 |
+
h = self.temopral_conv(h)
|
| 233 |
+
h = rearrange(h, 'b c t h w -> (b t) c h w')
|
| 234 |
+
return h
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class TemporalConvBlock(nn.Module):
|
| 238 |
+
"""
|
| 239 |
+
Adapted from modelscope: https://github.com/modelscope/modelscope/blob/master/modelscope/models/multi_modal/video_synthesis/unet_sd.py
|
| 240 |
+
"""
|
| 241 |
+
|
| 242 |
+
def __init__(self, in_channels, out_channels=None, dropout=0.0, spatial_aware=False):
|
| 243 |
+
super(TemporalConvBlock, self).__init__()
|
| 244 |
+
if out_channels is None:
|
| 245 |
+
out_channels = in_channels
|
| 246 |
+
self.in_channels = in_channels
|
| 247 |
+
self.out_channels = out_channels
|
| 248 |
+
kernel_shape = (3, 1, 1) if not spatial_aware else (3, 3, 3)
|
| 249 |
+
padding_shape = (1, 0, 0) if not spatial_aware else (1, 1, 1)
|
| 250 |
+
|
| 251 |
+
# conv layers
|
| 252 |
+
self.conv1 = nn.Sequential(
|
| 253 |
+
nn.GroupNorm(32, in_channels), nn.SiLU(),
|
| 254 |
+
nn.Conv3d(in_channels, out_channels, kernel_shape, padding=padding_shape))
|
| 255 |
+
self.conv2 = nn.Sequential(
|
| 256 |
+
nn.GroupNorm(32, out_channels), nn.SiLU(), nn.Dropout(dropout),
|
| 257 |
+
nn.Conv3d(out_channels, in_channels, kernel_shape, padding=padding_shape))
|
| 258 |
+
self.conv3 = nn.Sequential(
|
| 259 |
+
nn.GroupNorm(32, out_channels), nn.SiLU(), nn.Dropout(dropout),
|
| 260 |
+
nn.Conv3d(out_channels, in_channels, (3, 1, 1), padding=(1, 0, 0)))
|
| 261 |
+
self.conv4 = nn.Sequential(
|
| 262 |
+
nn.GroupNorm(32, out_channels), nn.SiLU(), nn.Dropout(dropout),
|
| 263 |
+
nn.Conv3d(out_channels, in_channels, (3, 1, 1), padding=(1, 0, 0)))
|
| 264 |
+
|
| 265 |
+
# zero out the last layer params,so the conv block is identity
|
| 266 |
+
nn.init.zeros_(self.conv4[-1].weight)
|
| 267 |
+
nn.init.zeros_(self.conv4[-1].bias)
|
| 268 |
+
|
| 269 |
+
def forward(self, x):
|
| 270 |
+
identity = x
|
| 271 |
+
x = self.conv1(x)
|
| 272 |
+
x = self.conv2(x)
|
| 273 |
+
x = self.conv3(x)
|
| 274 |
+
x = self.conv4(x)
|
| 275 |
+
|
| 276 |
+
return x + identity
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
class UNetModel(nn.Module):
|
| 280 |
+
"""
|
| 281 |
+
The full UNet model with attention and timestep embedding.
|
| 282 |
+
:param in_channels: in_channels in the input Tensor.
|
| 283 |
+
:param model_channels: base channel count for the model.
|
| 284 |
+
:param out_channels: channels in the output Tensor.
|
| 285 |
+
:param num_res_blocks: number of residual blocks per downsample.
|
| 286 |
+
:param attention_resolutions: a collection of downsample rates at which
|
| 287 |
+
attention will take place. May be a set, list, or tuple.
|
| 288 |
+
For example, if this contains 4, then at 4x downsampling, attention
|
| 289 |
+
will be used.
|
| 290 |
+
:param dropout: the dropout probability.
|
| 291 |
+
:param channel_mult: channel multiplier for each level of the UNet.
|
| 292 |
+
:param conv_resample: if True, use learned convolutions for upsampling and
|
| 293 |
+
downsampling.
|
| 294 |
+
:param dims: determines if the signal is 1D, 2D, or 3D.
|
| 295 |
+
:param num_classes: if specified (as an int), then this model will be
|
| 296 |
+
class-conditional with `num_classes` classes.
|
| 297 |
+
:param use_checkpoint: use gradient checkpointing to reduce memory usage.
|
| 298 |
+
:param num_heads: the number of attention heads in each attention layer.
|
| 299 |
+
:param num_heads_channels: if specified, ignore num_heads and instead use
|
| 300 |
+
a fixed channel width per attention head.
|
| 301 |
+
:param num_heads_upsample: works with num_heads to set a different number
|
| 302 |
+
of heads for upsampling. Deprecated.
|
| 303 |
+
:param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
|
| 304 |
+
:param resblock_updown: use residual blocks for up/downsampling.
|
| 305 |
+
"""
|
| 306 |
+
|
| 307 |
+
def __init__(self,
|
| 308 |
+
in_channels,
|
| 309 |
+
model_channels,
|
| 310 |
+
out_channels,
|
| 311 |
+
num_res_blocks,
|
| 312 |
+
attention_resolutions,
|
| 313 |
+
dropout=0.0,
|
| 314 |
+
channel_mult=(1, 2, 4, 8),
|
| 315 |
+
conv_resample=True,
|
| 316 |
+
dims=2,
|
| 317 |
+
context_dim=None,
|
| 318 |
+
use_scale_shift_norm=False,
|
| 319 |
+
resblock_updown=False,
|
| 320 |
+
num_heads=-1,
|
| 321 |
+
num_head_channels=-1,
|
| 322 |
+
transformer_depth=1,
|
| 323 |
+
use_linear=False,
|
| 324 |
+
use_checkpoint=False,
|
| 325 |
+
temporal_conv=False,
|
| 326 |
+
tempspatial_aware=False,
|
| 327 |
+
temporal_attention=True,
|
| 328 |
+
temporal_selfatt_only=True,
|
| 329 |
+
use_relative_position=True,
|
| 330 |
+
use_causal_attention=False,
|
| 331 |
+
temporal_length=None,
|
| 332 |
+
use_fp16=False,
|
| 333 |
+
addition_attention=False,
|
| 334 |
+
use_image_attention=False,
|
| 335 |
+
temporal_transformer_depth=1,
|
| 336 |
+
fps_cond=False,
|
| 337 |
+
):
|
| 338 |
+
super(UNetModel, self).__init__()
|
| 339 |
+
if num_heads == -1:
|
| 340 |
+
assert num_head_channels != -1, 'Either num_heads or num_head_channels has to be set'
|
| 341 |
+
if num_head_channels == -1:
|
| 342 |
+
assert num_heads != -1, 'Either num_heads or num_head_channels has to be set'
|
| 343 |
+
|
| 344 |
+
self.in_channels = in_channels
|
| 345 |
+
self.model_channels = model_channels
|
| 346 |
+
self.out_channels = out_channels
|
| 347 |
+
self.num_res_blocks = num_res_blocks
|
| 348 |
+
self.attention_resolutions = attention_resolutions
|
| 349 |
+
self.dropout = dropout
|
| 350 |
+
self.channel_mult = channel_mult
|
| 351 |
+
self.conv_resample = conv_resample
|
| 352 |
+
self.temporal_attention = temporal_attention
|
| 353 |
+
time_embed_dim = model_channels * 4
|
| 354 |
+
self.use_checkpoint = use_checkpoint
|
| 355 |
+
self.dtype = torch.float16 if use_fp16 else torch.float32
|
| 356 |
+
self.addition_attention=addition_attention
|
| 357 |
+
self.use_image_attention = use_image_attention
|
| 358 |
+
self.fps_cond=fps_cond
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
self.time_embed = nn.Sequential(
|
| 363 |
+
linear(model_channels, time_embed_dim),
|
| 364 |
+
nn.SiLU(),
|
| 365 |
+
linear(time_embed_dim, time_embed_dim),
|
| 366 |
+
)
|
| 367 |
+
if self.fps_cond:
|
| 368 |
+
self.fps_embedding = nn.Sequential(
|
| 369 |
+
linear(model_channels, time_embed_dim),
|
| 370 |
+
nn.SiLU(),
|
| 371 |
+
linear(time_embed_dim, time_embed_dim),
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
self.input_blocks = nn.ModuleList(
|
| 375 |
+
[
|
| 376 |
+
TimestepEmbedSequential(conv_nd(dims, in_channels, model_channels, 3, padding=1))
|
| 377 |
+
]
|
| 378 |
+
)
|
| 379 |
+
if self.addition_attention:
|
| 380 |
+
self.init_attn=TimestepEmbedSequential(
|
| 381 |
+
TemporalTransformer(
|
| 382 |
+
model_channels,
|
| 383 |
+
n_heads=8,
|
| 384 |
+
d_head=num_head_channels,
|
| 385 |
+
depth=transformer_depth,
|
| 386 |
+
context_dim=context_dim,
|
| 387 |
+
use_checkpoint=use_checkpoint, only_self_att=temporal_selfatt_only,
|
| 388 |
+
causal_attention=use_causal_attention, relative_position=use_relative_position,
|
| 389 |
+
temporal_length=temporal_length))
|
| 390 |
+
|
| 391 |
+
input_block_chans = [model_channels]
|
| 392 |
+
ch = model_channels
|
| 393 |
+
ds = 1
|
| 394 |
+
for level, mult in enumerate(channel_mult):
|
| 395 |
+
for _ in range(num_res_blocks):
|
| 396 |
+
layers = [
|
| 397 |
+
ResBlock(ch, time_embed_dim, dropout,
|
| 398 |
+
out_channels=mult * model_channels, dims=dims, use_checkpoint=use_checkpoint,
|
| 399 |
+
use_scale_shift_norm=use_scale_shift_norm, tempspatial_aware=tempspatial_aware,
|
| 400 |
+
use_temporal_conv=temporal_conv
|
| 401 |
+
)
|
| 402 |
+
]
|
| 403 |
+
ch = mult * model_channels
|
| 404 |
+
if ds in attention_resolutions:
|
| 405 |
+
if num_head_channels == -1:
|
| 406 |
+
dim_head = ch // num_heads
|
| 407 |
+
else:
|
| 408 |
+
num_heads = ch // num_head_channels
|
| 409 |
+
dim_head = num_head_channels
|
| 410 |
+
layers.append(
|
| 411 |
+
SpatialTransformer(ch, num_heads, dim_head,
|
| 412 |
+
depth=transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 413 |
+
use_checkpoint=use_checkpoint, disable_self_attn=False,
|
| 414 |
+
img_cross_attention=self.use_image_attention
|
| 415 |
+
)
|
| 416 |
+
)
|
| 417 |
+
if self.temporal_attention:
|
| 418 |
+
layers.append(
|
| 419 |
+
TemporalTransformer(ch, num_heads, dim_head,
|
| 420 |
+
depth=temporal_transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 421 |
+
use_checkpoint=use_checkpoint, only_self_att=temporal_selfatt_only,
|
| 422 |
+
causal_attention=use_causal_attention, relative_position=use_relative_position,
|
| 423 |
+
temporal_length=temporal_length
|
| 424 |
+
)
|
| 425 |
+
)
|
| 426 |
+
self.input_blocks.append(TimestepEmbedSequential(*layers))
|
| 427 |
+
input_block_chans.append(ch)
|
| 428 |
+
if level != len(channel_mult) - 1:
|
| 429 |
+
out_ch = ch
|
| 430 |
+
self.input_blocks.append(
|
| 431 |
+
TimestepEmbedSequential(
|
| 432 |
+
ResBlock(ch, time_embed_dim, dropout,
|
| 433 |
+
out_channels=out_ch, dims=dims, use_checkpoint=use_checkpoint,
|
| 434 |
+
use_scale_shift_norm=use_scale_shift_norm,
|
| 435 |
+
down=True
|
| 436 |
+
)
|
| 437 |
+
if resblock_updown
|
| 438 |
+
else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
| 439 |
+
)
|
| 440 |
+
)
|
| 441 |
+
ch = out_ch
|
| 442 |
+
input_block_chans.append(ch)
|
| 443 |
+
ds *= 2
|
| 444 |
+
|
| 445 |
+
if num_head_channels == -1:
|
| 446 |
+
dim_head = ch // num_heads
|
| 447 |
+
else:
|
| 448 |
+
num_heads = ch // num_head_channels
|
| 449 |
+
dim_head = num_head_channels
|
| 450 |
+
layers = [
|
| 451 |
+
ResBlock(ch, time_embed_dim, dropout,
|
| 452 |
+
dims=dims, use_checkpoint=use_checkpoint,
|
| 453 |
+
use_scale_shift_norm=use_scale_shift_norm, tempspatial_aware=tempspatial_aware,
|
| 454 |
+
use_temporal_conv=temporal_conv
|
| 455 |
+
),
|
| 456 |
+
SpatialTransformer(ch, num_heads, dim_head,
|
| 457 |
+
depth=transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 458 |
+
use_checkpoint=use_checkpoint, disable_self_attn=False,
|
| 459 |
+
img_cross_attention=self.use_image_attention
|
| 460 |
+
)
|
| 461 |
+
]
|
| 462 |
+
if self.temporal_attention:
|
| 463 |
+
layers.append(
|
| 464 |
+
TemporalTransformer(ch, num_heads, dim_head,
|
| 465 |
+
depth=temporal_transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 466 |
+
use_checkpoint=use_checkpoint, only_self_att=temporal_selfatt_only,
|
| 467 |
+
causal_attention=use_causal_attention, relative_position=use_relative_position,
|
| 468 |
+
temporal_length=temporal_length
|
| 469 |
+
)
|
| 470 |
+
)
|
| 471 |
+
layers.append(
|
| 472 |
+
ResBlock(ch, time_embed_dim, dropout,
|
| 473 |
+
dims=dims, use_checkpoint=use_checkpoint,
|
| 474 |
+
use_scale_shift_norm=use_scale_shift_norm, tempspatial_aware=tempspatial_aware,
|
| 475 |
+
use_temporal_conv=temporal_conv
|
| 476 |
+
)
|
| 477 |
+
)
|
| 478 |
+
self.middle_block = TimestepEmbedSequential(*layers)
|
| 479 |
+
|
| 480 |
+
self.output_blocks = nn.ModuleList([])
|
| 481 |
+
for level, mult in list(enumerate(channel_mult))[::-1]:
|
| 482 |
+
for i in range(num_res_blocks + 1):
|
| 483 |
+
ich = input_block_chans.pop()
|
| 484 |
+
layers = [
|
| 485 |
+
ResBlock(ch + ich, time_embed_dim, dropout,
|
| 486 |
+
out_channels=mult * model_channels, dims=dims, use_checkpoint=use_checkpoint,
|
| 487 |
+
use_scale_shift_norm=use_scale_shift_norm, tempspatial_aware=tempspatial_aware,
|
| 488 |
+
use_temporal_conv=temporal_conv
|
| 489 |
+
)
|
| 490 |
+
]
|
| 491 |
+
ch = model_channels * mult
|
| 492 |
+
if ds in attention_resolutions:
|
| 493 |
+
if num_head_channels == -1:
|
| 494 |
+
dim_head = ch // num_heads
|
| 495 |
+
else:
|
| 496 |
+
num_heads = ch // num_head_channels
|
| 497 |
+
dim_head = num_head_channels
|
| 498 |
+
layers.append(
|
| 499 |
+
SpatialTransformer(ch, num_heads, dim_head,
|
| 500 |
+
depth=transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 501 |
+
use_checkpoint=use_checkpoint, disable_self_attn=False,
|
| 502 |
+
img_cross_attention=self.use_image_attention
|
| 503 |
+
)
|
| 504 |
+
)
|
| 505 |
+
if self.temporal_attention:
|
| 506 |
+
layers.append(
|
| 507 |
+
TemporalTransformer(ch, num_heads, dim_head,
|
| 508 |
+
depth=temporal_transformer_depth, context_dim=context_dim, use_linear=use_linear,
|
| 509 |
+
use_checkpoint=use_checkpoint, only_self_att=temporal_selfatt_only,
|
| 510 |
+
causal_attention=use_causal_attention, relative_position=use_relative_position,
|
| 511 |
+
temporal_length=temporal_length
|
| 512 |
+
)
|
| 513 |
+
)
|
| 514 |
+
if level and i == num_res_blocks:
|
| 515 |
+
out_ch = ch
|
| 516 |
+
layers.append(
|
| 517 |
+
ResBlock(ch, time_embed_dim, dropout,
|
| 518 |
+
out_channels=out_ch, dims=dims, use_checkpoint=use_checkpoint,
|
| 519 |
+
use_scale_shift_norm=use_scale_shift_norm,
|
| 520 |
+
up=True
|
| 521 |
+
)
|
| 522 |
+
if resblock_updown
|
| 523 |
+
else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
| 524 |
+
)
|
| 525 |
+
ds //= 2
|
| 526 |
+
self.output_blocks.append(TimestepEmbedSequential(*layers))
|
| 527 |
+
|
| 528 |
+
self.out = nn.Sequential(
|
| 529 |
+
normalization(ch),
|
| 530 |
+
nn.SiLU(),
|
| 531 |
+
zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
|
| 532 |
+
)
|
| 533 |
+
|
| 534 |
+
def forward(self, x, timesteps, context=None, features_adapter=None, fps=16, **kwargs):
|
| 535 |
+
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
|
| 536 |
+
emb = self.time_embed(t_emb)
|
| 537 |
+
|
| 538 |
+
if self.fps_cond:
|
| 539 |
+
if type(fps) == int:
|
| 540 |
+
fps = torch.full_like(timesteps, fps)
|
| 541 |
+
fps_emb = timestep_embedding(fps,self.model_channels, repeat_only=False)
|
| 542 |
+
emb += self.fps_embedding(fps_emb)
|
| 543 |
+
|
| 544 |
+
b,_,t,_,_ = x.shape
|
| 545 |
+
## repeat t times for context [(b t) 77 768] & time embedding
|
| 546 |
+
context = context.repeat_interleave(repeats=t, dim=0)
|
| 547 |
+
emb = emb.repeat_interleave(repeats=t, dim=0)
|
| 548 |
+
|
| 549 |
+
## always in shape (b t) c h w, except for temporal layer
|
| 550 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 551 |
+
|
| 552 |
+
h = x.type(self.dtype)
|
| 553 |
+
adapter_idx = 0
|
| 554 |
+
hs = []
|
| 555 |
+
for id, module in enumerate(self.input_blocks):
|
| 556 |
+
h = module(h, emb, context=context, batch_size=b)
|
| 557 |
+
if id ==0 and self.addition_attention:
|
| 558 |
+
h = self.init_attn(h, emb, context=context, batch_size=b)
|
| 559 |
+
## plug-in adapter features
|
| 560 |
+
if ((id+1)%3 == 0) and features_adapter is not None:
|
| 561 |
+
h = h + features_adapter[adapter_idx]
|
| 562 |
+
adapter_idx += 1
|
| 563 |
+
hs.append(h)
|
| 564 |
+
if features_adapter is not None:
|
| 565 |
+
assert len(features_adapter)==adapter_idx, 'Wrong features_adapter'
|
| 566 |
+
|
| 567 |
+
h = self.middle_block(h, emb, context=context, batch_size=b)
|
| 568 |
+
for module in self.output_blocks:
|
| 569 |
+
h = torch.cat([h, hs.pop()], dim=1)
|
| 570 |
+
h = module(h, emb, context=context, batch_size=b)
|
| 571 |
+
h = h.type(x.dtype)
|
| 572 |
+
y = self.out(h)
|
| 573 |
+
|
| 574 |
+
# reshape back to (b c t h w)
|
| 575 |
+
y = rearrange(y, '(b t) c h w -> b c t h w', b=b)
|
| 576 |
+
return y
|
| 577 |
+
|
lvdm/modules/x_transformer.py
ADDED
|
@@ -0,0 +1,640 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""shout-out to https://github.com/lucidrains/x-transformers/tree/main/x_transformers"""
|
| 2 |
+
from functools import partial
|
| 3 |
+
from inspect import isfunction
|
| 4 |
+
from collections import namedtuple
|
| 5 |
+
from einops import rearrange, repeat
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn, einsum
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
# constants
|
| 11 |
+
DEFAULT_DIM_HEAD = 64
|
| 12 |
+
|
| 13 |
+
Intermediates = namedtuple('Intermediates', [
|
| 14 |
+
'pre_softmax_attn',
|
| 15 |
+
'post_softmax_attn'
|
| 16 |
+
])
|
| 17 |
+
|
| 18 |
+
LayerIntermediates = namedtuple('Intermediates', [
|
| 19 |
+
'hiddens',
|
| 20 |
+
'attn_intermediates'
|
| 21 |
+
])
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class AbsolutePositionalEmbedding(nn.Module):
|
| 25 |
+
def __init__(self, dim, max_seq_len):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.emb = nn.Embedding(max_seq_len, dim)
|
| 28 |
+
self.init_()
|
| 29 |
+
|
| 30 |
+
def init_(self):
|
| 31 |
+
nn.init.normal_(self.emb.weight, std=0.02)
|
| 32 |
+
|
| 33 |
+
def forward(self, x):
|
| 34 |
+
n = torch.arange(x.shape[1], device=x.device)
|
| 35 |
+
return self.emb(n)[None, :, :]
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class FixedPositionalEmbedding(nn.Module):
|
| 39 |
+
def __init__(self, dim):
|
| 40 |
+
super().__init__()
|
| 41 |
+
inv_freq = 1. / (10000 ** (torch.arange(0, dim, 2).float() / dim))
|
| 42 |
+
self.register_buffer('inv_freq', inv_freq)
|
| 43 |
+
|
| 44 |
+
def forward(self, x, seq_dim=1, offset=0):
|
| 45 |
+
t = torch.arange(x.shape[seq_dim], device=x.device).type_as(self.inv_freq) + offset
|
| 46 |
+
sinusoid_inp = torch.einsum('i , j -> i j', t, self.inv_freq)
|
| 47 |
+
emb = torch.cat((sinusoid_inp.sin(), sinusoid_inp.cos()), dim=-1)
|
| 48 |
+
return emb[None, :, :]
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# helpers
|
| 52 |
+
|
| 53 |
+
def exists(val):
|
| 54 |
+
return val is not None
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def default(val, d):
|
| 58 |
+
if exists(val):
|
| 59 |
+
return val
|
| 60 |
+
return d() if isfunction(d) else d
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def always(val):
|
| 64 |
+
def inner(*args, **kwargs):
|
| 65 |
+
return val
|
| 66 |
+
return inner
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def not_equals(val):
|
| 70 |
+
def inner(x):
|
| 71 |
+
return x != val
|
| 72 |
+
return inner
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def equals(val):
|
| 76 |
+
def inner(x):
|
| 77 |
+
return x == val
|
| 78 |
+
return inner
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def max_neg_value(tensor):
|
| 82 |
+
return -torch.finfo(tensor.dtype).max
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
# keyword argument helpers
|
| 86 |
+
|
| 87 |
+
def pick_and_pop(keys, d):
|
| 88 |
+
values = list(map(lambda key: d.pop(key), keys))
|
| 89 |
+
return dict(zip(keys, values))
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def group_dict_by_key(cond, d):
|
| 93 |
+
return_val = [dict(), dict()]
|
| 94 |
+
for key in d.keys():
|
| 95 |
+
match = bool(cond(key))
|
| 96 |
+
ind = int(not match)
|
| 97 |
+
return_val[ind][key] = d[key]
|
| 98 |
+
return (*return_val,)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def string_begins_with(prefix, str):
|
| 102 |
+
return str.startswith(prefix)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def group_by_key_prefix(prefix, d):
|
| 106 |
+
return group_dict_by_key(partial(string_begins_with, prefix), d)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def groupby_prefix_and_trim(prefix, d):
|
| 110 |
+
kwargs_with_prefix, kwargs = group_dict_by_key(partial(string_begins_with, prefix), d)
|
| 111 |
+
kwargs_without_prefix = dict(map(lambda x: (x[0][len(prefix):], x[1]), tuple(kwargs_with_prefix.items())))
|
| 112 |
+
return kwargs_without_prefix, kwargs
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# classes
|
| 116 |
+
class Scale(nn.Module):
|
| 117 |
+
def __init__(self, value, fn):
|
| 118 |
+
super().__init__()
|
| 119 |
+
self.value = value
|
| 120 |
+
self.fn = fn
|
| 121 |
+
|
| 122 |
+
def forward(self, x, **kwargs):
|
| 123 |
+
x, *rest = self.fn(x, **kwargs)
|
| 124 |
+
return (x * self.value, *rest)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class Rezero(nn.Module):
|
| 128 |
+
def __init__(self, fn):
|
| 129 |
+
super().__init__()
|
| 130 |
+
self.fn = fn
|
| 131 |
+
self.g = nn.Parameter(torch.zeros(1))
|
| 132 |
+
|
| 133 |
+
def forward(self, x, **kwargs):
|
| 134 |
+
x, *rest = self.fn(x, **kwargs)
|
| 135 |
+
return (x * self.g, *rest)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class ScaleNorm(nn.Module):
|
| 139 |
+
def __init__(self, dim, eps=1e-5):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.scale = dim ** -0.5
|
| 142 |
+
self.eps = eps
|
| 143 |
+
self.g = nn.Parameter(torch.ones(1))
|
| 144 |
+
|
| 145 |
+
def forward(self, x):
|
| 146 |
+
norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
|
| 147 |
+
return x / norm.clamp(min=self.eps) * self.g
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class RMSNorm(nn.Module):
|
| 151 |
+
def __init__(self, dim, eps=1e-8):
|
| 152 |
+
super().__init__()
|
| 153 |
+
self.scale = dim ** -0.5
|
| 154 |
+
self.eps = eps
|
| 155 |
+
self.g = nn.Parameter(torch.ones(dim))
|
| 156 |
+
|
| 157 |
+
def forward(self, x):
|
| 158 |
+
norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
|
| 159 |
+
return x / norm.clamp(min=self.eps) * self.g
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class Residual(nn.Module):
|
| 163 |
+
def forward(self, x, residual):
|
| 164 |
+
return x + residual
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class GRUGating(nn.Module):
|
| 168 |
+
def __init__(self, dim):
|
| 169 |
+
super().__init__()
|
| 170 |
+
self.gru = nn.GRUCell(dim, dim)
|
| 171 |
+
|
| 172 |
+
def forward(self, x, residual):
|
| 173 |
+
gated_output = self.gru(
|
| 174 |
+
rearrange(x, 'b n d -> (b n) d'),
|
| 175 |
+
rearrange(residual, 'b n d -> (b n) d')
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
return gated_output.reshape_as(x)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
# feedforward
|
| 182 |
+
|
| 183 |
+
class GEGLU(nn.Module):
|
| 184 |
+
def __init__(self, dim_in, dim_out):
|
| 185 |
+
super().__init__()
|
| 186 |
+
self.proj = nn.Linear(dim_in, dim_out * 2)
|
| 187 |
+
|
| 188 |
+
def forward(self, x):
|
| 189 |
+
x, gate = self.proj(x).chunk(2, dim=-1)
|
| 190 |
+
return x * F.gelu(gate)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
class FeedForward(nn.Module):
|
| 194 |
+
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
|
| 195 |
+
super().__init__()
|
| 196 |
+
inner_dim = int(dim * mult)
|
| 197 |
+
dim_out = default(dim_out, dim)
|
| 198 |
+
project_in = nn.Sequential(
|
| 199 |
+
nn.Linear(dim, inner_dim),
|
| 200 |
+
nn.GELU()
|
| 201 |
+
) if not glu else GEGLU(dim, inner_dim)
|
| 202 |
+
|
| 203 |
+
self.net = nn.Sequential(
|
| 204 |
+
project_in,
|
| 205 |
+
nn.Dropout(dropout),
|
| 206 |
+
nn.Linear(inner_dim, dim_out)
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
def forward(self, x):
|
| 210 |
+
return self.net(x)
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
# attention.
|
| 214 |
+
class Attention(nn.Module):
|
| 215 |
+
def __init__(
|
| 216 |
+
self,
|
| 217 |
+
dim,
|
| 218 |
+
dim_head=DEFAULT_DIM_HEAD,
|
| 219 |
+
heads=8,
|
| 220 |
+
causal=False,
|
| 221 |
+
mask=None,
|
| 222 |
+
talking_heads=False,
|
| 223 |
+
sparse_topk=None,
|
| 224 |
+
use_entmax15=False,
|
| 225 |
+
num_mem_kv=0,
|
| 226 |
+
dropout=0.,
|
| 227 |
+
on_attn=False
|
| 228 |
+
):
|
| 229 |
+
super().__init__()
|
| 230 |
+
if use_entmax15:
|
| 231 |
+
raise NotImplementedError("Check out entmax activation instead of softmax activation!")
|
| 232 |
+
self.scale = dim_head ** -0.5
|
| 233 |
+
self.heads = heads
|
| 234 |
+
self.causal = causal
|
| 235 |
+
self.mask = mask
|
| 236 |
+
|
| 237 |
+
inner_dim = dim_head * heads
|
| 238 |
+
|
| 239 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 240 |
+
self.to_k = nn.Linear(dim, inner_dim, bias=False)
|
| 241 |
+
self.to_v = nn.Linear(dim, inner_dim, bias=False)
|
| 242 |
+
self.dropout = nn.Dropout(dropout)
|
| 243 |
+
|
| 244 |
+
# talking heads
|
| 245 |
+
self.talking_heads = talking_heads
|
| 246 |
+
if talking_heads:
|
| 247 |
+
self.pre_softmax_proj = nn.Parameter(torch.randn(heads, heads))
|
| 248 |
+
self.post_softmax_proj = nn.Parameter(torch.randn(heads, heads))
|
| 249 |
+
|
| 250 |
+
# explicit topk sparse attention
|
| 251 |
+
self.sparse_topk = sparse_topk
|
| 252 |
+
|
| 253 |
+
# entmax
|
| 254 |
+
#self.attn_fn = entmax15 if use_entmax15 else F.softmax
|
| 255 |
+
self.attn_fn = F.softmax
|
| 256 |
+
|
| 257 |
+
# add memory key / values
|
| 258 |
+
self.num_mem_kv = num_mem_kv
|
| 259 |
+
if num_mem_kv > 0:
|
| 260 |
+
self.mem_k = nn.Parameter(torch.randn(heads, num_mem_kv, dim_head))
|
| 261 |
+
self.mem_v = nn.Parameter(torch.randn(heads, num_mem_kv, dim_head))
|
| 262 |
+
|
| 263 |
+
# attention on attention
|
| 264 |
+
self.attn_on_attn = on_attn
|
| 265 |
+
self.to_out = nn.Sequential(nn.Linear(inner_dim, dim * 2), nn.GLU()) if on_attn else nn.Linear(inner_dim, dim)
|
| 266 |
+
|
| 267 |
+
def forward(
|
| 268 |
+
self,
|
| 269 |
+
x,
|
| 270 |
+
context=None,
|
| 271 |
+
mask=None,
|
| 272 |
+
context_mask=None,
|
| 273 |
+
rel_pos=None,
|
| 274 |
+
sinusoidal_emb=None,
|
| 275 |
+
prev_attn=None,
|
| 276 |
+
mem=None
|
| 277 |
+
):
|
| 278 |
+
b, n, _, h, talking_heads, device = *x.shape, self.heads, self.talking_heads, x.device
|
| 279 |
+
kv_input = default(context, x)
|
| 280 |
+
|
| 281 |
+
q_input = x
|
| 282 |
+
k_input = kv_input
|
| 283 |
+
v_input = kv_input
|
| 284 |
+
|
| 285 |
+
if exists(mem):
|
| 286 |
+
k_input = torch.cat((mem, k_input), dim=-2)
|
| 287 |
+
v_input = torch.cat((mem, v_input), dim=-2)
|
| 288 |
+
|
| 289 |
+
if exists(sinusoidal_emb):
|
| 290 |
+
# in shortformer, the query would start at a position offset depending on the past cached memory
|
| 291 |
+
offset = k_input.shape[-2] - q_input.shape[-2]
|
| 292 |
+
q_input = q_input + sinusoidal_emb(q_input, offset=offset)
|
| 293 |
+
k_input = k_input + sinusoidal_emb(k_input)
|
| 294 |
+
|
| 295 |
+
q = self.to_q(q_input)
|
| 296 |
+
k = self.to_k(k_input)
|
| 297 |
+
v = self.to_v(v_input)
|
| 298 |
+
|
| 299 |
+
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), (q, k, v))
|
| 300 |
+
|
| 301 |
+
input_mask = None
|
| 302 |
+
if any(map(exists, (mask, context_mask))):
|
| 303 |
+
q_mask = default(mask, lambda: torch.ones((b, n), device=device).bool())
|
| 304 |
+
k_mask = q_mask if not exists(context) else context_mask
|
| 305 |
+
k_mask = default(k_mask, lambda: torch.ones((b, k.shape[-2]), device=device).bool())
|
| 306 |
+
q_mask = rearrange(q_mask, 'b i -> b () i ()')
|
| 307 |
+
k_mask = rearrange(k_mask, 'b j -> b () () j')
|
| 308 |
+
input_mask = q_mask * k_mask
|
| 309 |
+
|
| 310 |
+
if self.num_mem_kv > 0:
|
| 311 |
+
mem_k, mem_v = map(lambda t: repeat(t, 'h n d -> b h n d', b=b), (self.mem_k, self.mem_v))
|
| 312 |
+
k = torch.cat((mem_k, k), dim=-2)
|
| 313 |
+
v = torch.cat((mem_v, v), dim=-2)
|
| 314 |
+
if exists(input_mask):
|
| 315 |
+
input_mask = F.pad(input_mask, (self.num_mem_kv, 0), value=True)
|
| 316 |
+
|
| 317 |
+
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
|
| 318 |
+
mask_value = max_neg_value(dots)
|
| 319 |
+
|
| 320 |
+
if exists(prev_attn):
|
| 321 |
+
dots = dots + prev_attn
|
| 322 |
+
|
| 323 |
+
pre_softmax_attn = dots
|
| 324 |
+
|
| 325 |
+
if talking_heads:
|
| 326 |
+
dots = einsum('b h i j, h k -> b k i j', dots, self.pre_softmax_proj).contiguous()
|
| 327 |
+
|
| 328 |
+
if exists(rel_pos):
|
| 329 |
+
dots = rel_pos(dots)
|
| 330 |
+
|
| 331 |
+
if exists(input_mask):
|
| 332 |
+
dots.masked_fill_(~input_mask, mask_value)
|
| 333 |
+
del input_mask
|
| 334 |
+
|
| 335 |
+
if self.causal:
|
| 336 |
+
i, j = dots.shape[-2:]
|
| 337 |
+
r = torch.arange(i, device=device)
|
| 338 |
+
mask = rearrange(r, 'i -> () () i ()') < rearrange(r, 'j -> () () () j')
|
| 339 |
+
mask = F.pad(mask, (j - i, 0), value=False)
|
| 340 |
+
dots.masked_fill_(mask, mask_value)
|
| 341 |
+
del mask
|
| 342 |
+
|
| 343 |
+
if exists(self.sparse_topk) and self.sparse_topk < dots.shape[-1]:
|
| 344 |
+
top, _ = dots.topk(self.sparse_topk, dim=-1)
|
| 345 |
+
vk = top[..., -1].unsqueeze(-1).expand_as(dots)
|
| 346 |
+
mask = dots < vk
|
| 347 |
+
dots.masked_fill_(mask, mask_value)
|
| 348 |
+
del mask
|
| 349 |
+
|
| 350 |
+
attn = self.attn_fn(dots, dim=-1)
|
| 351 |
+
post_softmax_attn = attn
|
| 352 |
+
|
| 353 |
+
attn = self.dropout(attn)
|
| 354 |
+
|
| 355 |
+
if talking_heads:
|
| 356 |
+
attn = einsum('b h i j, h k -> b k i j', attn, self.post_softmax_proj).contiguous()
|
| 357 |
+
|
| 358 |
+
out = einsum('b h i j, b h j d -> b h i d', attn, v)
|
| 359 |
+
out = rearrange(out, 'b h n d -> b n (h d)')
|
| 360 |
+
|
| 361 |
+
intermediates = Intermediates(
|
| 362 |
+
pre_softmax_attn=pre_softmax_attn,
|
| 363 |
+
post_softmax_attn=post_softmax_attn
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
return self.to_out(out), intermediates
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class AttentionLayers(nn.Module):
|
| 370 |
+
def __init__(
|
| 371 |
+
self,
|
| 372 |
+
dim,
|
| 373 |
+
depth,
|
| 374 |
+
heads=8,
|
| 375 |
+
causal=False,
|
| 376 |
+
cross_attend=False,
|
| 377 |
+
only_cross=False,
|
| 378 |
+
use_scalenorm=False,
|
| 379 |
+
use_rmsnorm=False,
|
| 380 |
+
use_rezero=False,
|
| 381 |
+
rel_pos_num_buckets=32,
|
| 382 |
+
rel_pos_max_distance=128,
|
| 383 |
+
position_infused_attn=False,
|
| 384 |
+
custom_layers=None,
|
| 385 |
+
sandwich_coef=None,
|
| 386 |
+
par_ratio=None,
|
| 387 |
+
residual_attn=False,
|
| 388 |
+
cross_residual_attn=False,
|
| 389 |
+
macaron=False,
|
| 390 |
+
pre_norm=True,
|
| 391 |
+
gate_residual=False,
|
| 392 |
+
**kwargs
|
| 393 |
+
):
|
| 394 |
+
super().__init__()
|
| 395 |
+
ff_kwargs, kwargs = groupby_prefix_and_trim('ff_', kwargs)
|
| 396 |
+
attn_kwargs, _ = groupby_prefix_and_trim('attn_', kwargs)
|
| 397 |
+
|
| 398 |
+
dim_head = attn_kwargs.get('dim_head', DEFAULT_DIM_HEAD)
|
| 399 |
+
|
| 400 |
+
self.dim = dim
|
| 401 |
+
self.depth = depth
|
| 402 |
+
self.layers = nn.ModuleList([])
|
| 403 |
+
|
| 404 |
+
self.has_pos_emb = position_infused_attn
|
| 405 |
+
self.pia_pos_emb = FixedPositionalEmbedding(dim) if position_infused_attn else None
|
| 406 |
+
self.rotary_pos_emb = always(None)
|
| 407 |
+
|
| 408 |
+
assert rel_pos_num_buckets <= rel_pos_max_distance, 'number of relative position buckets must be less than the relative position max distance'
|
| 409 |
+
self.rel_pos = None
|
| 410 |
+
|
| 411 |
+
self.pre_norm = pre_norm
|
| 412 |
+
|
| 413 |
+
self.residual_attn = residual_attn
|
| 414 |
+
self.cross_residual_attn = cross_residual_attn
|
| 415 |
+
|
| 416 |
+
norm_class = ScaleNorm if use_scalenorm else nn.LayerNorm
|
| 417 |
+
norm_class = RMSNorm if use_rmsnorm else norm_class
|
| 418 |
+
norm_fn = partial(norm_class, dim)
|
| 419 |
+
|
| 420 |
+
norm_fn = nn.Identity if use_rezero else norm_fn
|
| 421 |
+
branch_fn = Rezero if use_rezero else None
|
| 422 |
+
|
| 423 |
+
if cross_attend and not only_cross:
|
| 424 |
+
default_block = ('a', 'c', 'f')
|
| 425 |
+
elif cross_attend and only_cross:
|
| 426 |
+
default_block = ('c', 'f')
|
| 427 |
+
else:
|
| 428 |
+
default_block = ('a', 'f')
|
| 429 |
+
|
| 430 |
+
if macaron:
|
| 431 |
+
default_block = ('f',) + default_block
|
| 432 |
+
|
| 433 |
+
if exists(custom_layers):
|
| 434 |
+
layer_types = custom_layers
|
| 435 |
+
elif exists(par_ratio):
|
| 436 |
+
par_depth = depth * len(default_block)
|
| 437 |
+
assert 1 < par_ratio <= par_depth, 'par ratio out of range'
|
| 438 |
+
default_block = tuple(filter(not_equals('f'), default_block))
|
| 439 |
+
par_attn = par_depth // par_ratio
|
| 440 |
+
depth_cut = par_depth * 2 // 3 # 2 / 3 attention layer cutoff suggested by PAR paper
|
| 441 |
+
par_width = (depth_cut + depth_cut // par_attn) // par_attn
|
| 442 |
+
assert len(default_block) <= par_width, 'default block is too large for par_ratio'
|
| 443 |
+
par_block = default_block + ('f',) * (par_width - len(default_block))
|
| 444 |
+
par_head = par_block * par_attn
|
| 445 |
+
layer_types = par_head + ('f',) * (par_depth - len(par_head))
|
| 446 |
+
elif exists(sandwich_coef):
|
| 447 |
+
assert sandwich_coef > 0 and sandwich_coef <= depth, 'sandwich coefficient should be less than the depth'
|
| 448 |
+
layer_types = ('a',) * sandwich_coef + default_block * (depth - sandwich_coef) + ('f',) * sandwich_coef
|
| 449 |
+
else:
|
| 450 |
+
layer_types = default_block * depth
|
| 451 |
+
|
| 452 |
+
self.layer_types = layer_types
|
| 453 |
+
self.num_attn_layers = len(list(filter(equals('a'), layer_types)))
|
| 454 |
+
|
| 455 |
+
for layer_type in self.layer_types:
|
| 456 |
+
if layer_type == 'a':
|
| 457 |
+
layer = Attention(dim, heads=heads, causal=causal, **attn_kwargs)
|
| 458 |
+
elif layer_type == 'c':
|
| 459 |
+
layer = Attention(dim, heads=heads, **attn_kwargs)
|
| 460 |
+
elif layer_type == 'f':
|
| 461 |
+
layer = FeedForward(dim, **ff_kwargs)
|
| 462 |
+
layer = layer if not macaron else Scale(0.5, layer)
|
| 463 |
+
else:
|
| 464 |
+
raise Exception(f'invalid layer type {layer_type}')
|
| 465 |
+
|
| 466 |
+
if isinstance(layer, Attention) and exists(branch_fn):
|
| 467 |
+
layer = branch_fn(layer)
|
| 468 |
+
|
| 469 |
+
if gate_residual:
|
| 470 |
+
residual_fn = GRUGating(dim)
|
| 471 |
+
else:
|
| 472 |
+
residual_fn = Residual()
|
| 473 |
+
|
| 474 |
+
self.layers.append(nn.ModuleList([
|
| 475 |
+
norm_fn(),
|
| 476 |
+
layer,
|
| 477 |
+
residual_fn
|
| 478 |
+
]))
|
| 479 |
+
|
| 480 |
+
def forward(
|
| 481 |
+
self,
|
| 482 |
+
x,
|
| 483 |
+
context=None,
|
| 484 |
+
mask=None,
|
| 485 |
+
context_mask=None,
|
| 486 |
+
mems=None,
|
| 487 |
+
return_hiddens=False
|
| 488 |
+
):
|
| 489 |
+
hiddens = []
|
| 490 |
+
intermediates = []
|
| 491 |
+
prev_attn = None
|
| 492 |
+
prev_cross_attn = None
|
| 493 |
+
|
| 494 |
+
mems = mems.copy() if exists(mems) else [None] * self.num_attn_layers
|
| 495 |
+
|
| 496 |
+
for ind, (layer_type, (norm, block, residual_fn)) in enumerate(zip(self.layer_types, self.layers)):
|
| 497 |
+
is_last = ind == (len(self.layers) - 1)
|
| 498 |
+
|
| 499 |
+
if layer_type == 'a':
|
| 500 |
+
hiddens.append(x)
|
| 501 |
+
layer_mem = mems.pop(0)
|
| 502 |
+
|
| 503 |
+
residual = x
|
| 504 |
+
|
| 505 |
+
if self.pre_norm:
|
| 506 |
+
x = norm(x)
|
| 507 |
+
|
| 508 |
+
if layer_type == 'a':
|
| 509 |
+
out, inter = block(x, mask=mask, sinusoidal_emb=self.pia_pos_emb, rel_pos=self.rel_pos,
|
| 510 |
+
prev_attn=prev_attn, mem=layer_mem)
|
| 511 |
+
elif layer_type == 'c':
|
| 512 |
+
out, inter = block(x, context=context, mask=mask, context_mask=context_mask, prev_attn=prev_cross_attn)
|
| 513 |
+
elif layer_type == 'f':
|
| 514 |
+
out = block(x)
|
| 515 |
+
|
| 516 |
+
x = residual_fn(out, residual)
|
| 517 |
+
|
| 518 |
+
if layer_type in ('a', 'c'):
|
| 519 |
+
intermediates.append(inter)
|
| 520 |
+
|
| 521 |
+
if layer_type == 'a' and self.residual_attn:
|
| 522 |
+
prev_attn = inter.pre_softmax_attn
|
| 523 |
+
elif layer_type == 'c' and self.cross_residual_attn:
|
| 524 |
+
prev_cross_attn = inter.pre_softmax_attn
|
| 525 |
+
|
| 526 |
+
if not self.pre_norm and not is_last:
|
| 527 |
+
x = norm(x)
|
| 528 |
+
|
| 529 |
+
if return_hiddens:
|
| 530 |
+
intermediates = LayerIntermediates(
|
| 531 |
+
hiddens=hiddens,
|
| 532 |
+
attn_intermediates=intermediates
|
| 533 |
+
)
|
| 534 |
+
|
| 535 |
+
return x, intermediates
|
| 536 |
+
|
| 537 |
+
return x
|
| 538 |
+
|
| 539 |
+
|
| 540 |
+
class Encoder(AttentionLayers):
|
| 541 |
+
def __init__(self, **kwargs):
|
| 542 |
+
assert 'causal' not in kwargs, 'cannot set causality on encoder'
|
| 543 |
+
super().__init__(causal=False, **kwargs)
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
class TransformerWrapper(nn.Module):
|
| 548 |
+
def __init__(
|
| 549 |
+
self,
|
| 550 |
+
*,
|
| 551 |
+
num_tokens,
|
| 552 |
+
max_seq_len,
|
| 553 |
+
attn_layers,
|
| 554 |
+
emb_dim=None,
|
| 555 |
+
max_mem_len=0.,
|
| 556 |
+
emb_dropout=0.,
|
| 557 |
+
num_memory_tokens=None,
|
| 558 |
+
tie_embedding=False,
|
| 559 |
+
use_pos_emb=True
|
| 560 |
+
):
|
| 561 |
+
super().__init__()
|
| 562 |
+
assert isinstance(attn_layers, AttentionLayers), 'attention layers must be one of Encoder or Decoder'
|
| 563 |
+
|
| 564 |
+
dim = attn_layers.dim
|
| 565 |
+
emb_dim = default(emb_dim, dim)
|
| 566 |
+
|
| 567 |
+
self.max_seq_len = max_seq_len
|
| 568 |
+
self.max_mem_len = max_mem_len
|
| 569 |
+
self.num_tokens = num_tokens
|
| 570 |
+
|
| 571 |
+
self.token_emb = nn.Embedding(num_tokens, emb_dim)
|
| 572 |
+
self.pos_emb = AbsolutePositionalEmbedding(emb_dim, max_seq_len) if (
|
| 573 |
+
use_pos_emb and not attn_layers.has_pos_emb) else always(0)
|
| 574 |
+
self.emb_dropout = nn.Dropout(emb_dropout)
|
| 575 |
+
|
| 576 |
+
self.project_emb = nn.Linear(emb_dim, dim) if emb_dim != dim else nn.Identity()
|
| 577 |
+
self.attn_layers = attn_layers
|
| 578 |
+
self.norm = nn.LayerNorm(dim)
|
| 579 |
+
|
| 580 |
+
self.init_()
|
| 581 |
+
|
| 582 |
+
self.to_logits = nn.Linear(dim, num_tokens) if not tie_embedding else lambda t: t @ self.token_emb.weight.t()
|
| 583 |
+
|
| 584 |
+
# memory tokens (like [cls]) from Memory Transformers paper
|
| 585 |
+
num_memory_tokens = default(num_memory_tokens, 0)
|
| 586 |
+
self.num_memory_tokens = num_memory_tokens
|
| 587 |
+
if num_memory_tokens > 0:
|
| 588 |
+
self.memory_tokens = nn.Parameter(torch.randn(num_memory_tokens, dim))
|
| 589 |
+
|
| 590 |
+
# let funnel encoder know number of memory tokens, if specified
|
| 591 |
+
if hasattr(attn_layers, 'num_memory_tokens'):
|
| 592 |
+
attn_layers.num_memory_tokens = num_memory_tokens
|
| 593 |
+
|
| 594 |
+
def init_(self):
|
| 595 |
+
nn.init.normal_(self.token_emb.weight, std=0.02)
|
| 596 |
+
|
| 597 |
+
def forward(
|
| 598 |
+
self,
|
| 599 |
+
x,
|
| 600 |
+
return_embeddings=False,
|
| 601 |
+
mask=None,
|
| 602 |
+
return_mems=False,
|
| 603 |
+
return_attn=False,
|
| 604 |
+
mems=None,
|
| 605 |
+
**kwargs
|
| 606 |
+
):
|
| 607 |
+
b, n, device, num_mem = *x.shape, x.device, self.num_memory_tokens
|
| 608 |
+
x = self.token_emb(x)
|
| 609 |
+
x += self.pos_emb(x)
|
| 610 |
+
x = self.emb_dropout(x)
|
| 611 |
+
|
| 612 |
+
x = self.project_emb(x)
|
| 613 |
+
|
| 614 |
+
if num_mem > 0:
|
| 615 |
+
mem = repeat(self.memory_tokens, 'n d -> b n d', b=b)
|
| 616 |
+
x = torch.cat((mem, x), dim=1)
|
| 617 |
+
|
| 618 |
+
# auto-handle masking after appending memory tokens
|
| 619 |
+
if exists(mask):
|
| 620 |
+
mask = F.pad(mask, (num_mem, 0), value=True)
|
| 621 |
+
|
| 622 |
+
x, intermediates = self.attn_layers(x, mask=mask, mems=mems, return_hiddens=True, **kwargs)
|
| 623 |
+
x = self.norm(x)
|
| 624 |
+
|
| 625 |
+
mem, x = x[:, :num_mem], x[:, num_mem:]
|
| 626 |
+
|
| 627 |
+
out = self.to_logits(x) if not return_embeddings else x
|
| 628 |
+
|
| 629 |
+
if return_mems:
|
| 630 |
+
hiddens = intermediates.hiddens
|
| 631 |
+
new_mems = list(map(lambda pair: torch.cat(pair, dim=-2), zip(mems, hiddens))) if exists(mems) else hiddens
|
| 632 |
+
new_mems = list(map(lambda t: t[..., -self.max_mem_len:, :].detach(), new_mems))
|
| 633 |
+
return out, new_mems
|
| 634 |
+
|
| 635 |
+
if return_attn:
|
| 636 |
+
attn_maps = list(map(lambda t: t.post_softmax_attn, intermediates.attn_intermediates))
|
| 637 |
+
return out, attn_maps
|
| 638 |
+
|
| 639 |
+
return out
|
| 640 |
+
|
predict.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Prediction interface for Cog ⚙️
|
| 2 |
+
# https://github.com/replicate/cog/blob/main/docs/python.md
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
import sys
|
| 7 |
+
import argparse
|
| 8 |
+
import random
|
| 9 |
+
from omegaconf import OmegaConf
|
| 10 |
+
from einops import rearrange, repeat
|
| 11 |
+
import torch
|
| 12 |
+
import torchvision
|
| 13 |
+
from pytorch_lightning import seed_everything
|
| 14 |
+
from cog import BasePredictor, Input, Path
|
| 15 |
+
|
| 16 |
+
sys.path.insert(0, "scripts/evaluation")
|
| 17 |
+
from funcs import (
|
| 18 |
+
batch_ddim_sampling,
|
| 19 |
+
load_model_checkpoint,
|
| 20 |
+
load_image_batch,
|
| 21 |
+
get_filelist,
|
| 22 |
+
)
|
| 23 |
+
from utils.utils import instantiate_from_config
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class Predictor(BasePredictor):
|
| 27 |
+
def setup(self) -> None:
|
| 28 |
+
"""Load the model into memory to make running multiple predictions efficient"""
|
| 29 |
+
|
| 30 |
+
ckpt_path_base = "checkpoints/base_1024_v1/model.ckpt"
|
| 31 |
+
config_base = "configs/inference_t2v_1024_v1.0.yaml"
|
| 32 |
+
ckpt_path_i2v = "checkpoints/i2v_512_v1/model.ckpt"
|
| 33 |
+
config_i2v = "configs/inference_i2v_512_v1.0.yaml"
|
| 34 |
+
|
| 35 |
+
config_base = OmegaConf.load(config_base)
|
| 36 |
+
model_config_base = config_base.pop("model", OmegaConf.create())
|
| 37 |
+
self.model_base = instantiate_from_config(model_config_base)
|
| 38 |
+
self.model_base = self.model_base.cuda()
|
| 39 |
+
self.model_base = load_model_checkpoint(self.model_base, ckpt_path_base)
|
| 40 |
+
self.model_base.eval()
|
| 41 |
+
|
| 42 |
+
config_i2v = OmegaConf.load(config_i2v)
|
| 43 |
+
model_config_i2v = config_i2v.pop("model", OmegaConf.create())
|
| 44 |
+
self.model_i2v = instantiate_from_config(model_config_i2v)
|
| 45 |
+
self.model_i2v = self.model_i2v.cuda()
|
| 46 |
+
self.model_i2v = load_model_checkpoint(self.model_i2v, ckpt_path_i2v)
|
| 47 |
+
self.model_i2v.eval()
|
| 48 |
+
|
| 49 |
+
def predict(
|
| 50 |
+
self,
|
| 51 |
+
task: str = Input(
|
| 52 |
+
description="Choose the task.",
|
| 53 |
+
choices=["text2video", "image2video"],
|
| 54 |
+
default="text2video",
|
| 55 |
+
),
|
| 56 |
+
prompt: str = Input(
|
| 57 |
+
description="Prompt for video generation.",
|
| 58 |
+
default="A tiger walks in the forest, photorealistic, 4k, high definition.",
|
| 59 |
+
),
|
| 60 |
+
image: Path = Input(
|
| 61 |
+
description="Input image for image2video task.", default=None
|
| 62 |
+
),
|
| 63 |
+
ddim_steps: int = Input(description="Number of denoising steps.", default=50),
|
| 64 |
+
unconditional_guidance_scale: float = Input(
|
| 65 |
+
description="Classifier-free guidance scale.", default=12.0
|
| 66 |
+
),
|
| 67 |
+
seed: int = Input(
|
| 68 |
+
description="Random seed. Leave blank to randomize the seed", default=None
|
| 69 |
+
),
|
| 70 |
+
save_fps: int = Input(
|
| 71 |
+
description="Frame per second for the generated video.", default=10
|
| 72 |
+
),
|
| 73 |
+
) -> Path:
|
| 74 |
+
|
| 75 |
+
width = 1024 if task == "text2video" else 512
|
| 76 |
+
height = 576 if task == "text2video" else 320
|
| 77 |
+
model = self.model_base if task == "text2video" else self.model_i2v
|
| 78 |
+
|
| 79 |
+
if task == "image2video":
|
| 80 |
+
assert image is not None, "Please provide image for image2video generation."
|
| 81 |
+
|
| 82 |
+
if seed is None:
|
| 83 |
+
seed = int.from_bytes(os.urandom(2), "big")
|
| 84 |
+
print(f"Using seed: {seed}")
|
| 85 |
+
seed_everything(seed)
|
| 86 |
+
|
| 87 |
+
args = argparse.Namespace(
|
| 88 |
+
mode="base" if task == "text2video" else "i2v",
|
| 89 |
+
savefps=save_fps,
|
| 90 |
+
n_samples=1,
|
| 91 |
+
ddim_steps=ddim_steps,
|
| 92 |
+
ddim_eta=1.0,
|
| 93 |
+
bs=1,
|
| 94 |
+
height=height,
|
| 95 |
+
width=width,
|
| 96 |
+
frames=-1,
|
| 97 |
+
fps=28 if task == "text2video" else 8,
|
| 98 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 99 |
+
unconditional_guidance_scale_temporal=None,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
## latent noise shape
|
| 103 |
+
h, w = args.height // 8, args.width // 8
|
| 104 |
+
frames = model.temporal_length if args.frames < 0 else args.frames
|
| 105 |
+
channels = model.channels
|
| 106 |
+
|
| 107 |
+
batch_size = 1
|
| 108 |
+
noise_shape = [batch_size, channels, frames, h, w]
|
| 109 |
+
fps = torch.tensor([args.fps] * batch_size).to(model.device).long()
|
| 110 |
+
prompts = [prompt]
|
| 111 |
+
text_emb = model.get_learned_conditioning(prompts)
|
| 112 |
+
|
| 113 |
+
if args.mode == "base":
|
| 114 |
+
cond = {"c_crossattn": [text_emb], "fps": fps}
|
| 115 |
+
elif args.mode == "i2v":
|
| 116 |
+
cond_images = load_image_batch([str(image)], (args.height, args.width))
|
| 117 |
+
cond_images = cond_images.to(model.device)
|
| 118 |
+
img_emb = model.get_image_embeds(cond_images)
|
| 119 |
+
imtext_cond = torch.cat([text_emb, img_emb], dim=1)
|
| 120 |
+
cond = {"c_crossattn": [imtext_cond], "fps": fps}
|
| 121 |
+
else:
|
| 122 |
+
raise NotImplementedError
|
| 123 |
+
|
| 124 |
+
## inference
|
| 125 |
+
batch_samples = batch_ddim_sampling(
|
| 126 |
+
model,
|
| 127 |
+
cond,
|
| 128 |
+
noise_shape,
|
| 129 |
+
args.n_samples,
|
| 130 |
+
args.ddim_steps,
|
| 131 |
+
args.ddim_eta,
|
| 132 |
+
args.unconditional_guidance_scale,
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
out_path = "/tmp/output.mp4"
|
| 136 |
+
vid_tensor = batch_samples[0]
|
| 137 |
+
video = vid_tensor.detach().cpu()
|
| 138 |
+
video = torch.clamp(video.float(), -1.0, 1.0)
|
| 139 |
+
video = video.permute(2, 0, 1, 3, 4) # t,n,c,h,w
|
| 140 |
+
|
| 141 |
+
frame_grids = [
|
| 142 |
+
torchvision.utils.make_grid(framesheet, nrow=int(args.n_samples))
|
| 143 |
+
for framesheet in video
|
| 144 |
+
] # [3, 1*h, n*w]
|
| 145 |
+
grid = torch.stack(frame_grids, dim=0) # stack in temporal dim [t, 3, n*h, w]
|
| 146 |
+
grid = (grid + 1.0) / 2.0
|
| 147 |
+
grid = (grid * 255).to(torch.uint8).permute(0, 2, 3, 1)
|
| 148 |
+
torchvision.io.write_video(
|
| 149 |
+
out_path,
|
| 150 |
+
grid,
|
| 151 |
+
fps=args.savefps,
|
| 152 |
+
video_codec="h264",
|
| 153 |
+
options={"crf": "10"},
|
| 154 |
+
)
|
| 155 |
+
return Path(out_path)
|
prompts/i2v_prompts/horse.png
ADDED

|
prompts/i2v_prompts/seashore.png
ADDED

|
prompts/i2v_prompts/test_prompts.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
horses are walking on the grassland
|
| 2 |
+
a boy and a girl are talking on the seashore
|
prompts/test_prompts.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
A tiger walks in the forest, photorealistic, 4k, high definition
|
| 2 |
+
A boat moving on the sea, flowers and grassland on the shore
|
requirements.txt
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
decord==0.6.0
|
| 2 |
+
einops==0.3.0
|
| 3 |
+
imageio==2.9.0
|
| 4 |
+
numpy==1.24.2
|
| 5 |
+
omegaconf==2.1.1
|
| 6 |
+
opencv_python
|
| 7 |
+
pandas==2.0.0
|
| 8 |
+
Pillow==9.5.0
|
| 9 |
+
pytorch_lightning==1.8.3
|
| 10 |
+
PyYAML==6.0
|
| 11 |
+
setuptools==65.6.3
|
| 12 |
+
torch==2.0.0
|
| 13 |
+
torchvision
|
| 14 |
+
tqdm==4.65.0
|
| 15 |
+
transformers==4.25.1
|
| 16 |
+
moviepy
|
| 17 |
+
av
|
| 18 |
+
xformers
|
| 19 |
+
gradio
|
| 20 |
+
timm
|
| 21 |
+
scikit-learn
|
| 22 |
+
open_clip_torch==2.22.0
|
| 23 |
+
kornia
|
scripts/evaluation/ddp_wrapper.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import datetime
|
| 2 |
+
import argparse, importlib
|
| 3 |
+
from pytorch_lightning import seed_everything
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.distributed as dist
|
| 7 |
+
|
| 8 |
+
def setup_dist(local_rank):
|
| 9 |
+
if dist.is_initialized():
|
| 10 |
+
return
|
| 11 |
+
torch.cuda.set_device(local_rank)
|
| 12 |
+
torch.distributed.init_process_group('nccl', init_method='env://')
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_dist_info():
|
| 16 |
+
if dist.is_available():
|
| 17 |
+
initialized = dist.is_initialized()
|
| 18 |
+
else:
|
| 19 |
+
initialized = False
|
| 20 |
+
if initialized:
|
| 21 |
+
rank = dist.get_rank()
|
| 22 |
+
world_size = dist.get_world_size()
|
| 23 |
+
else:
|
| 24 |
+
rank = 0
|
| 25 |
+
world_size = 1
|
| 26 |
+
return rank, world_size
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
if __name__ == '__main__':
|
| 30 |
+
now = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
|
| 31 |
+
parser = argparse.ArgumentParser()
|
| 32 |
+
parser.add_argument("--module", type=str, help="module name", default="inference")
|
| 33 |
+
parser.add_argument("--local_rank", type=int, nargs="?", help="for ddp", default=0)
|
| 34 |
+
args, unknown = parser.parse_known_args()
|
| 35 |
+
inference_api = importlib.import_module(args.module, package=None)
|
| 36 |
+
|
| 37 |
+
inference_parser = inference_api.get_parser()
|
| 38 |
+
inference_args, unknown = inference_parser.parse_known_args()
|
| 39 |
+
|
| 40 |
+
seed_everything(inference_args.seed)
|
| 41 |
+
setup_dist(args.local_rank)
|
| 42 |
+
torch.backends.cudnn.benchmark = True
|
| 43 |
+
rank, gpu_num = get_dist_info()
|
| 44 |
+
|
| 45 |
+
print("@CoLVDM Inference [rank%d]: %s"%(rank, now))
|
| 46 |
+
inference_api.run_inference(inference_args, gpu_num, rank)
|
scripts/evaluation/funcs.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, sys, glob
|
| 2 |
+
import numpy as np
|
| 3 |
+
from collections import OrderedDict
|
| 4 |
+
from decord import VideoReader, cpu
|
| 5 |
+
import cv2
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torchvision
|
| 9 |
+
sys.path.insert(1, os.path.join(sys.path[0], '..', '..'))
|
| 10 |
+
from lvdm.models.samplers.ddim import DDIMSampler
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def batch_ddim_sampling(model, cond, noise_shape, n_samples=1, ddim_steps=50, ddim_eta=1.0,\
|
| 14 |
+
cfg_scale=1.0, temporal_cfg_scale=None, **kwargs):
|
| 15 |
+
ddim_sampler = DDIMSampler(model)
|
| 16 |
+
uncond_type = model.uncond_type
|
| 17 |
+
batch_size = noise_shape[0]
|
| 18 |
+
|
| 19 |
+
## construct unconditional guidance
|
| 20 |
+
if cfg_scale != 1.0:
|
| 21 |
+
if uncond_type == "empty_seq":
|
| 22 |
+
prompts = batch_size * [""]
|
| 23 |
+
#prompts = N * T * [""] ## if is_imgbatch=True
|
| 24 |
+
uc_emb = model.get_learned_conditioning(prompts)
|
| 25 |
+
elif uncond_type == "zero_embed":
|
| 26 |
+
c_emb = cond["c_crossattn"][0] if isinstance(cond, dict) else cond
|
| 27 |
+
uc_emb = torch.zeros_like(c_emb)
|
| 28 |
+
|
| 29 |
+
## process image embedding token
|
| 30 |
+
if hasattr(model, 'embedder'):
|
| 31 |
+
uc_img = torch.zeros(noise_shape[0],3,224,224).to(model.device)
|
| 32 |
+
## img: b c h w >> b l c
|
| 33 |
+
uc_img = model.get_image_embeds(uc_img)
|
| 34 |
+
uc_emb = torch.cat([uc_emb, uc_img], dim=1)
|
| 35 |
+
|
| 36 |
+
if isinstance(cond, dict):
|
| 37 |
+
uc = {key:cond[key] for key in cond.keys()}
|
| 38 |
+
uc.update({'c_crossattn': [uc_emb]})
|
| 39 |
+
else:
|
| 40 |
+
uc = uc_emb
|
| 41 |
+
else:
|
| 42 |
+
uc = None
|
| 43 |
+
|
| 44 |
+
x_T = None
|
| 45 |
+
batch_variants = []
|
| 46 |
+
#batch_variants1, batch_variants2 = [], []
|
| 47 |
+
for _ in range(n_samples):
|
| 48 |
+
if ddim_sampler is not None:
|
| 49 |
+
kwargs.update({"clean_cond": True})
|
| 50 |
+
samples, _ = ddim_sampler.sample(S=ddim_steps,
|
| 51 |
+
conditioning=cond,
|
| 52 |
+
batch_size=noise_shape[0],
|
| 53 |
+
shape=noise_shape[1:],
|
| 54 |
+
verbose=False,
|
| 55 |
+
unconditional_guidance_scale=cfg_scale,
|
| 56 |
+
unconditional_conditioning=uc,
|
| 57 |
+
eta=ddim_eta,
|
| 58 |
+
temporal_length=noise_shape[2],
|
| 59 |
+
conditional_guidance_scale_temporal=temporal_cfg_scale,
|
| 60 |
+
x_T=x_T,
|
| 61 |
+
**kwargs
|
| 62 |
+
)
|
| 63 |
+
## reconstruct from latent to pixel space
|
| 64 |
+
batch_images = model.decode_first_stage_2DAE(samples)
|
| 65 |
+
batch_variants.append(batch_images)
|
| 66 |
+
## batch, <samples>, c, t, h, w
|
| 67 |
+
batch_variants = torch.stack(batch_variants, dim=1)
|
| 68 |
+
return batch_variants
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def get_filelist(data_dir, ext='*'):
|
| 72 |
+
file_list = glob.glob(os.path.join(data_dir, '*.%s'%ext))
|
| 73 |
+
file_list.sort()
|
| 74 |
+
return file_list
|
| 75 |
+
|
| 76 |
+
def get_dirlist(path):
|
| 77 |
+
list = []
|
| 78 |
+
if (os.path.exists(path)):
|
| 79 |
+
files = os.listdir(path)
|
| 80 |
+
for file in files:
|
| 81 |
+
m = os.path.join(path,file)
|
| 82 |
+
if (os.path.isdir(m)):
|
| 83 |
+
list.append(m)
|
| 84 |
+
list.sort()
|
| 85 |
+
return list
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def load_model_checkpoint(model, ckpt):
|
| 89 |
+
def load_checkpoint(model, ckpt, full_strict):
|
| 90 |
+
state_dict = torch.load(ckpt, map_location="cpu")
|
| 91 |
+
try:
|
| 92 |
+
## deepspeed
|
| 93 |
+
new_pl_sd = OrderedDict()
|
| 94 |
+
for key in state_dict['module'].keys():
|
| 95 |
+
new_pl_sd[key[16:]]=state_dict['module'][key]
|
| 96 |
+
model.load_state_dict(new_pl_sd, strict=full_strict)
|
| 97 |
+
except:
|
| 98 |
+
if "state_dict" in list(state_dict.keys()):
|
| 99 |
+
state_dict = state_dict["state_dict"]
|
| 100 |
+
model.load_state_dict(state_dict, strict=full_strict)
|
| 101 |
+
return model
|
| 102 |
+
load_checkpoint(model, ckpt, full_strict=True)
|
| 103 |
+
print('>>> model checkpoint loaded.')
|
| 104 |
+
return model
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def load_prompts(prompt_file):
|
| 108 |
+
f = open(prompt_file, 'r')
|
| 109 |
+
prompt_list = []
|
| 110 |
+
for idx, line in enumerate(f.readlines()):
|
| 111 |
+
l = line.strip()
|
| 112 |
+
if len(l) != 0:
|
| 113 |
+
prompt_list.append(l)
|
| 114 |
+
f.close()
|
| 115 |
+
return prompt_list
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def load_video_batch(filepath_list, frame_stride, video_size=(256,256), video_frames=16):
|
| 119 |
+
'''
|
| 120 |
+
Notice about some special cases:
|
| 121 |
+
1. video_frames=-1 means to take all the frames (with fs=1)
|
| 122 |
+
2. when the total video frames is less than required, padding strategy will be used (repreated last frame)
|
| 123 |
+
'''
|
| 124 |
+
fps_list = []
|
| 125 |
+
batch_tensor = []
|
| 126 |
+
assert frame_stride > 0, "valid frame stride should be a positive interge!"
|
| 127 |
+
for filepath in filepath_list:
|
| 128 |
+
padding_num = 0
|
| 129 |
+
vidreader = VideoReader(filepath, ctx=cpu(0), width=video_size[1], height=video_size[0])
|
| 130 |
+
fps = vidreader.get_avg_fps()
|
| 131 |
+
total_frames = len(vidreader)
|
| 132 |
+
max_valid_frames = (total_frames-1) // frame_stride + 1
|
| 133 |
+
if video_frames < 0:
|
| 134 |
+
## all frames are collected: fs=1 is a must
|
| 135 |
+
required_frames = total_frames
|
| 136 |
+
frame_stride = 1
|
| 137 |
+
else:
|
| 138 |
+
required_frames = video_frames
|
| 139 |
+
query_frames = min(required_frames, max_valid_frames)
|
| 140 |
+
frame_indices = [frame_stride*i for i in range(query_frames)]
|
| 141 |
+
|
| 142 |
+
## [t,h,w,c] -> [c,t,h,w]
|
| 143 |
+
frames = vidreader.get_batch(frame_indices)
|
| 144 |
+
frame_tensor = torch.tensor(frames.asnumpy()).permute(3, 0, 1, 2).float()
|
| 145 |
+
frame_tensor = (frame_tensor / 255. - 0.5) * 2
|
| 146 |
+
if max_valid_frames < required_frames:
|
| 147 |
+
padding_num = required_frames - max_valid_frames
|
| 148 |
+
frame_tensor = torch.cat([frame_tensor, *([frame_tensor[:,-1:,:,:]]*padding_num)], dim=1)
|
| 149 |
+
print(f'{os.path.split(filepath)[1]} is not long enough: {padding_num} frames padded.')
|
| 150 |
+
batch_tensor.append(frame_tensor)
|
| 151 |
+
sample_fps = int(fps/frame_stride)
|
| 152 |
+
fps_list.append(sample_fps)
|
| 153 |
+
|
| 154 |
+
return torch.stack(batch_tensor, dim=0)
|
| 155 |
+
|
| 156 |
+
from PIL import Image
|
| 157 |
+
def load_image_batch(filepath_list, image_size=(256,256)):
|
| 158 |
+
batch_tensor = []
|
| 159 |
+
for filepath in filepath_list:
|
| 160 |
+
_, filename = os.path.split(filepath)
|
| 161 |
+
_, ext = os.path.splitext(filename)
|
| 162 |
+
if ext == '.mp4':
|
| 163 |
+
vidreader = VideoReader(filepath, ctx=cpu(0), width=image_size[1], height=image_size[0])
|
| 164 |
+
frame = vidreader.get_batch([0])
|
| 165 |
+
img_tensor = torch.tensor(frame.asnumpy()).squeeze(0).permute(2, 0, 1).float()
|
| 166 |
+
elif ext == '.png' or ext == '.jpg':
|
| 167 |
+
img = Image.open(filepath).convert("RGB")
|
| 168 |
+
rgb_img = np.array(img, np.float32)
|
| 169 |
+
#bgr_img = cv2.imread(filepath, cv2.IMREAD_COLOR)
|
| 170 |
+
#bgr_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2RGB)
|
| 171 |
+
rgb_img = cv2.resize(rgb_img, (image_size[1],image_size[0]), interpolation=cv2.INTER_LINEAR)
|
| 172 |
+
img_tensor = torch.from_numpy(rgb_img).permute(2, 0, 1).float()
|
| 173 |
+
else:
|
| 174 |
+
print(f'ERROR: <{ext}> image loading only support format: [mp4], [png], [jpg]')
|
| 175 |
+
raise NotImplementedError
|
| 176 |
+
img_tensor = (img_tensor / 255. - 0.5) * 2
|
| 177 |
+
batch_tensor.append(img_tensor)
|
| 178 |
+
return torch.stack(batch_tensor, dim=0)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def save_videos(batch_tensors, savedir, filenames, fps=10):
|
| 182 |
+
# b,samples,c,t,h,w
|
| 183 |
+
n_samples = batch_tensors.shape[1]
|
| 184 |
+
for idx, vid_tensor in enumerate(batch_tensors):
|
| 185 |
+
video = vid_tensor.detach().cpu()
|
| 186 |
+
video = torch.clamp(video.float(), -1., 1.)
|
| 187 |
+
video = video.permute(2, 0, 1, 3, 4) # t,n,c,h,w
|
| 188 |
+
frame_grids = [torchvision.utils.make_grid(framesheet, nrow=int(n_samples)) for framesheet in video] #[3, 1*h, n*w]
|
| 189 |
+
grid = torch.stack(frame_grids, dim=0) # stack in temporal dim [t, 3, n*h, w]
|
| 190 |
+
grid = (grid + 1.0) / 2.0
|
| 191 |
+
grid = (grid * 255).to(torch.uint8).permute(0, 2, 3, 1)
|
| 192 |
+
savepath = os.path.join(savedir, f"{filenames[idx]}.mp4")
|
| 193 |
+
torchvision.io.write_video(savepath, grid, fps=fps, video_codec='h264', options={'crf': '10'})
|
| 194 |
+
|
scripts/evaluation/inference.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse, os, sys, glob, yaml, math, random
|
| 2 |
+
import datetime, time
|
| 3 |
+
import numpy as np
|
| 4 |
+
from omegaconf import OmegaConf
|
| 5 |
+
from collections import OrderedDict
|
| 6 |
+
from tqdm import trange, tqdm
|
| 7 |
+
from einops import repeat
|
| 8 |
+
from einops import rearrange, repeat
|
| 9 |
+
from functools import partial
|
| 10 |
+
import torch
|
| 11 |
+
from pytorch_lightning import seed_everything
|
| 12 |
+
|
| 13 |
+
from funcs import load_model_checkpoint, load_prompts, load_image_batch, get_filelist, save_videos
|
| 14 |
+
from funcs import batch_ddim_sampling
|
| 15 |
+
from utils.utils import instantiate_from_config
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_parser():
|
| 19 |
+
parser = argparse.ArgumentParser()
|
| 20 |
+
parser.add_argument("--seed", type=int, default=20230211, help="seed for seed_everything")
|
| 21 |
+
parser.add_argument("--mode", default="base", type=str, help="which kind of inference mode: {'base', 'i2v'}")
|
| 22 |
+
parser.add_argument("--ckpt_path", type=str, default=None, help="checkpoint path")
|
| 23 |
+
parser.add_argument("--config", type=str, help="config (yaml) path")
|
| 24 |
+
parser.add_argument("--prompt_file", type=str, default=None, help="a text file containing many prompts")
|
| 25 |
+
parser.add_argument("--savedir", type=str, default=None, help="results saving path")
|
| 26 |
+
parser.add_argument("--savefps", type=str, default=10, help="video fps to generate")
|
| 27 |
+
parser.add_argument("--n_samples", type=int, default=1, help="num of samples per prompt",)
|
| 28 |
+
parser.add_argument("--ddim_steps", type=int, default=50, help="steps of ddim if positive, otherwise use DDPM",)
|
| 29 |
+
parser.add_argument("--ddim_eta", type=float, default=1.0, help="eta for ddim sampling (0.0 yields deterministic sampling)",)
|
| 30 |
+
parser.add_argument("--bs", type=int, default=1, help="batch size for inference")
|
| 31 |
+
parser.add_argument("--height", type=int, default=512, help="image height, in pixel space")
|
| 32 |
+
parser.add_argument("--width", type=int, default=512, help="image width, in pixel space")
|
| 33 |
+
parser.add_argument("--frames", type=int, default=-1, help="frames num to inference")
|
| 34 |
+
parser.add_argument("--fps", type=int, default=24)
|
| 35 |
+
parser.add_argument("--unconditional_guidance_scale", type=float, default=1.0, help="prompt classifier-free guidance")
|
| 36 |
+
parser.add_argument("--unconditional_guidance_scale_temporal", type=float, default=None, help="temporal consistency guidance")
|
| 37 |
+
## for conditional i2v only
|
| 38 |
+
parser.add_argument("--cond_input", type=str, default=None, help="data dir of conditional input")
|
| 39 |
+
return parser
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def run_inference(args, gpu_num, gpu_no, **kwargs):
|
| 43 |
+
## step 1: model config
|
| 44 |
+
## -----------------------------------------------------------------
|
| 45 |
+
config = OmegaConf.load(args.config)
|
| 46 |
+
#data_config = config.pop("data", OmegaConf.create())
|
| 47 |
+
model_config = config.pop("model", OmegaConf.create())
|
| 48 |
+
model = instantiate_from_config(model_config)
|
| 49 |
+
model = model.cuda(gpu_no)
|
| 50 |
+
assert os.path.exists(args.ckpt_path), f"Error: checkpoint [{args.ckpt_path}] Not Found!"
|
| 51 |
+
model = load_model_checkpoint(model, args.ckpt_path)
|
| 52 |
+
model.eval()
|
| 53 |
+
|
| 54 |
+
## sample shape
|
| 55 |
+
assert (args.height % 16 == 0) and (args.width % 16 == 0), "Error: image size [h,w] should be multiples of 16!"
|
| 56 |
+
## latent noise shape
|
| 57 |
+
h, w = args.height // 8, args.width // 8
|
| 58 |
+
frames = model.temporal_length if args.frames < 0 else args.frames
|
| 59 |
+
channels = model.channels
|
| 60 |
+
|
| 61 |
+
## saving folders
|
| 62 |
+
os.makedirs(args.savedir, exist_ok=True)
|
| 63 |
+
|
| 64 |
+
## step 2: load data
|
| 65 |
+
## -----------------------------------------------------------------
|
| 66 |
+
assert os.path.exists(args.prompt_file), "Error: prompt file NOT Found!"
|
| 67 |
+
prompt_list = load_prompts(args.prompt_file)
|
| 68 |
+
num_samples = len(prompt_list)
|
| 69 |
+
filename_list = [f"{id+1:04d}" for id in range(num_samples)]
|
| 70 |
+
|
| 71 |
+
samples_split = num_samples // gpu_num
|
| 72 |
+
residual_tail = num_samples % gpu_num
|
| 73 |
+
print(f'[rank:{gpu_no}] {samples_split}/{num_samples} samples loaded.')
|
| 74 |
+
indices = list(range(samples_split*gpu_no, samples_split*(gpu_no+1)))
|
| 75 |
+
if gpu_no == 0 and residual_tail != 0:
|
| 76 |
+
indices = indices + list(range(num_samples-residual_tail, num_samples))
|
| 77 |
+
prompt_list_rank = [prompt_list[i] for i in indices]
|
| 78 |
+
|
| 79 |
+
## conditional input
|
| 80 |
+
if args.mode == "i2v":
|
| 81 |
+
## each video or frames dir per prompt
|
| 82 |
+
cond_inputs = get_filelist(args.cond_input, ext='[mpj][pn][4gj]') # '[mpj][pn][4gj]'
|
| 83 |
+
assert len(cond_inputs) == num_samples, f"Error: conditional input ({len(cond_inputs)}) NOT match prompt ({num_samples})!"
|
| 84 |
+
filename_list = [f"{os.path.split(cond_inputs[id])[-1][:-4]}" for id in range(num_samples)]
|
| 85 |
+
cond_inputs_rank = [cond_inputs[i] for i in indices]
|
| 86 |
+
|
| 87 |
+
filename_list_rank = [filename_list[i] for i in indices]
|
| 88 |
+
|
| 89 |
+
## step 3: run over samples
|
| 90 |
+
## -----------------------------------------------------------------
|
| 91 |
+
start = time.time()
|
| 92 |
+
n_rounds = len(prompt_list_rank) // args.bs
|
| 93 |
+
n_rounds = n_rounds+1 if len(prompt_list_rank) % args.bs != 0 else n_rounds
|
| 94 |
+
for idx in range(0, n_rounds):
|
| 95 |
+
print(f'[rank:{gpu_no}] batch-{idx+1} ({args.bs})x{args.n_samples} ...')
|
| 96 |
+
idx_s = idx*args.bs
|
| 97 |
+
idx_e = min(idx_s+args.bs, len(prompt_list_rank))
|
| 98 |
+
batch_size = idx_e - idx_s
|
| 99 |
+
filenames = filename_list_rank[idx_s:idx_e]
|
| 100 |
+
noise_shape = [batch_size, channels, frames, h, w]
|
| 101 |
+
fps = torch.tensor([args.fps]*batch_size).to(model.device).long()
|
| 102 |
+
|
| 103 |
+
prompts = prompt_list_rank[idx_s:idx_e]
|
| 104 |
+
if isinstance(prompts, str):
|
| 105 |
+
prompts = [prompts]
|
| 106 |
+
#prompts = batch_size * [""]
|
| 107 |
+
text_emb = model.get_learned_conditioning(prompts)
|
| 108 |
+
|
| 109 |
+
if args.mode == 'base':
|
| 110 |
+
cond = {"c_crossattn": [text_emb], "fps": fps}
|
| 111 |
+
elif args.mode == 'i2v':
|
| 112 |
+
#cond_images = torch.zeros(noise_shape[0],3,224,224).to(model.device)
|
| 113 |
+
cond_images = load_image_batch(cond_inputs_rank[idx_s:idx_e], (args.height, args.width))
|
| 114 |
+
cond_images = cond_images.to(model.device)
|
| 115 |
+
img_emb = model.get_image_embeds(cond_images)
|
| 116 |
+
imtext_cond = torch.cat([text_emb, img_emb], dim=1)
|
| 117 |
+
cond = {"c_crossattn": [imtext_cond], "fps": fps}
|
| 118 |
+
else:
|
| 119 |
+
raise NotImplementedError
|
| 120 |
+
|
| 121 |
+
## inference
|
| 122 |
+
batch_samples = batch_ddim_sampling(model, cond, noise_shape, args.n_samples, \
|
| 123 |
+
args.ddim_steps, args.ddim_eta, args.unconditional_guidance_scale, **kwargs)
|
| 124 |
+
## b,samples,c,t,h,w
|
| 125 |
+
save_videos(batch_samples, args.savedir, filenames, fps=args.savefps)
|
| 126 |
+
|
| 127 |
+
print(f"Saved in {args.savedir}. Time used: {(time.time() - start):.2f} seconds")
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
if __name__ == '__main__':
|
| 131 |
+
now = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
|
| 132 |
+
print("@CoLVDM Inference: %s"%now)
|
| 133 |
+
parser = get_parser()
|
| 134 |
+
args = parser.parse_args()
|
| 135 |
+
seed_everything(args.seed)
|
| 136 |
+
rank, gpu_num = 0, 1
|
| 137 |
+
run_inference(args, gpu_num, rank)
|
scripts/gradio/i2v_test.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
from omegaconf import OmegaConf
|
| 4 |
+
import torch
|
| 5 |
+
from scripts.evaluation.funcs import load_model_checkpoint, load_image_batch, save_videos, batch_ddim_sampling
|
| 6 |
+
from utils.utils import instantiate_from_config
|
| 7 |
+
from huggingface_hub import hf_hub_download
|
| 8 |
+
|
| 9 |
+
class Image2Video():
|
| 10 |
+
def __init__(self,result_dir='./tmp/',gpu_num=1) -> None:
|
| 11 |
+
self.download_model()
|
| 12 |
+
self.result_dir = result_dir
|
| 13 |
+
if not os.path.exists(self.result_dir):
|
| 14 |
+
os.mkdir(self.result_dir)
|
| 15 |
+
ckpt_path='checkpoints/i2v_512_v1/model.ckpt'
|
| 16 |
+
config_file='configs/inference_i2v_512_v1.0.yaml'
|
| 17 |
+
config = OmegaConf.load(config_file)
|
| 18 |
+
model_config = config.pop("model", OmegaConf.create())
|
| 19 |
+
model_config['params']['unet_config']['params']['use_checkpoint']=False
|
| 20 |
+
model_list = []
|
| 21 |
+
for gpu_id in range(gpu_num):
|
| 22 |
+
model = instantiate_from_config(model_config)
|
| 23 |
+
# model = model.cuda(gpu_id)
|
| 24 |
+
assert os.path.exists(ckpt_path), "Error: checkpoint Not Found!"
|
| 25 |
+
model = load_model_checkpoint(model, ckpt_path)
|
| 26 |
+
model.eval()
|
| 27 |
+
model_list.append(model)
|
| 28 |
+
self.model_list = model_list
|
| 29 |
+
self.save_fps = 8
|
| 30 |
+
|
| 31 |
+
def get_image(self, image, prompt, steps=50, cfg_scale=12.0, eta=1.0, fps=16):
|
| 32 |
+
torch.cuda.empty_cache()
|
| 33 |
+
print('start:', prompt, time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
|
| 34 |
+
start = time.time()
|
| 35 |
+
gpu_id=0
|
| 36 |
+
if steps > 60:
|
| 37 |
+
steps = 60
|
| 38 |
+
model = self.model_list[gpu_id]
|
| 39 |
+
model = model.cuda()
|
| 40 |
+
batch_size=1
|
| 41 |
+
channels = model.model.diffusion_model.in_channels
|
| 42 |
+
frames = model.temporal_length
|
| 43 |
+
h, w = 320 // 8, 512 // 8
|
| 44 |
+
noise_shape = [batch_size, channels, frames, h, w]
|
| 45 |
+
|
| 46 |
+
# text cond
|
| 47 |
+
text_emb = model.get_learned_conditioning([prompt])
|
| 48 |
+
|
| 49 |
+
# img cond
|
| 50 |
+
img_tensor = torch.from_numpy(image).permute(2, 0, 1).float()
|
| 51 |
+
img_tensor = (img_tensor / 255. - 0.5) * 2
|
| 52 |
+
img_tensor = img_tensor.unsqueeze(0)
|
| 53 |
+
cond_images = img_tensor.to(model.device)
|
| 54 |
+
img_emb = model.get_image_embeds(cond_images)
|
| 55 |
+
imtext_cond = torch.cat([text_emb, img_emb], dim=1)
|
| 56 |
+
cond = {"c_crossattn": [imtext_cond], "fps": fps}
|
| 57 |
+
|
| 58 |
+
## inference
|
| 59 |
+
batch_samples = batch_ddim_sampling(model, cond, noise_shape, n_samples=1, ddim_steps=steps, ddim_eta=eta, cfg_scale=cfg_scale)
|
| 60 |
+
## b,samples,c,t,h,w
|
| 61 |
+
prompt_str = prompt.replace("/", "_slash_") if "/" in prompt else prompt
|
| 62 |
+
prompt_str = prompt_str.replace(" ", "_") if " " in prompt else prompt_str
|
| 63 |
+
prompt_str=prompt_str[:30]
|
| 64 |
+
|
| 65 |
+
save_videos(batch_samples, self.result_dir, filenames=[prompt_str], fps=self.save_fps)
|
| 66 |
+
print(f"Saved in {prompt_str}. Time used: {(time.time() - start):.2f} seconds")
|
| 67 |
+
model = model.cpu()
|
| 68 |
+
return os.path.join(self.result_dir, f"{prompt_str}.mp4")
|
| 69 |
+
|
| 70 |
+
def download_model(self):
|
| 71 |
+
REPO_ID = 'VideoCrafter/Image2Video-512'
|
| 72 |
+
filename_list = ['model.ckpt']
|
| 73 |
+
if not os.path.exists('./checkpoints/i2v_512_v1/'):
|
| 74 |
+
os.makedirs('./checkpoints/i2v_512_v1/')
|
| 75 |
+
for filename in filename_list:
|
| 76 |
+
local_file = os.path.join('./checkpoints/i2v_512_v1/', filename)
|
| 77 |
+
if not os.path.exists(local_file):
|
| 78 |
+
hf_hub_download(repo_id=REPO_ID, filename=filename, local_dir='./checkpoints/i2v_512_v1/', local_dir_use_symlinks=False)
|
| 79 |
+
|
| 80 |
+
if __name__ == '__main__':
|
| 81 |
+
i2v = Image2Video()
|
| 82 |
+
video_path = i2v.get_image('prompts/i2v_prompts/horse.png','horses are walking on the grassland')
|
| 83 |
+
print('done', video_path)
|
scripts/gradio/t2v_test.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
from omegaconf import OmegaConf
|
| 4 |
+
import torch
|
| 5 |
+
from scripts.evaluation.funcs import load_model_checkpoint, save_videos, batch_ddim_sampling
|
| 6 |
+
from utils.utils import instantiate_from_config
|
| 7 |
+
from huggingface_hub import hf_hub_download
|
| 8 |
+
|
| 9 |
+
class Text2Video():
|
| 10 |
+
def __init__(self,result_dir='./tmp/',gpu_num=1) -> None:
|
| 11 |
+
self.download_model()
|
| 12 |
+
self.result_dir = result_dir
|
| 13 |
+
if not os.path.exists(self.result_dir):
|
| 14 |
+
os.mkdir(self.result_dir)
|
| 15 |
+
ckpt_path='checkpoints/base_512_v2/model.ckpt'
|
| 16 |
+
config_file='configs/inference_t2v_512_v2.0.yaml'
|
| 17 |
+
config = OmegaConf.load(config_file)
|
| 18 |
+
model_config = config.pop("model", OmegaConf.create())
|
| 19 |
+
model_config['params']['unet_config']['params']['use_checkpoint']=False
|
| 20 |
+
model_list = []
|
| 21 |
+
for gpu_id in range(gpu_num):
|
| 22 |
+
model = instantiate_from_config(model_config)
|
| 23 |
+
# model = model.cuda(gpu_id)
|
| 24 |
+
assert os.path.exists(ckpt_path), "Error: checkpoint Not Found!"
|
| 25 |
+
model = load_model_checkpoint(model, ckpt_path)
|
| 26 |
+
model.eval()
|
| 27 |
+
model_list.append(model)
|
| 28 |
+
self.model_list = model_list
|
| 29 |
+
self.save_fps = 8
|
| 30 |
+
|
| 31 |
+
def get_prompt(self, prompt, steps=50, cfg_scale=12.0, eta=1.0, fps=16):
|
| 32 |
+
torch.cuda.empty_cache()
|
| 33 |
+
print('start:', prompt, time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
|
| 34 |
+
start = time.time()
|
| 35 |
+
gpu_id=0
|
| 36 |
+
if steps > 60:
|
| 37 |
+
steps = 60
|
| 38 |
+
model = self.model_list[gpu_id]
|
| 39 |
+
model = model.cuda()
|
| 40 |
+
batch_size=1
|
| 41 |
+
channels = model.model.diffusion_model.in_channels
|
| 42 |
+
frames = model.temporal_length
|
| 43 |
+
h, w = 320 // 8, 512 // 8
|
| 44 |
+
noise_shape = [batch_size, channels, frames, h, w]
|
| 45 |
+
|
| 46 |
+
# text cond
|
| 47 |
+
text_emb = model.get_learned_conditioning([prompt])
|
| 48 |
+
cond = {"c_crossattn": [text_emb], "fps": fps}
|
| 49 |
+
|
| 50 |
+
## inference
|
| 51 |
+
batch_samples = batch_ddim_sampling(model, cond, noise_shape, n_samples=1, ddim_steps=steps, ddim_eta=eta, cfg_scale=cfg_scale)
|
| 52 |
+
## b,samples,c,t,h,w
|
| 53 |
+
prompt_str = prompt.replace("/", "_slash_") if "/" in prompt else prompt
|
| 54 |
+
prompt_str = prompt_str.replace(" ", "_") if " " in prompt else prompt_str
|
| 55 |
+
prompt_str=prompt_str[:30]
|
| 56 |
+
|
| 57 |
+
save_videos(batch_samples, self.result_dir, filenames=[prompt_str], fps=self.save_fps)
|
| 58 |
+
print(f"Saved in {prompt_str}. Time used: {(time.time() - start):.2f} seconds")
|
| 59 |
+
model=model.cpu()
|
| 60 |
+
return os.path.join(self.result_dir, f"{prompt_str}.mp4")
|
| 61 |
+
|
| 62 |
+
def download_model(self):
|
| 63 |
+
REPO_ID = 'VideoCrafter/VideoCrafter2'
|
| 64 |
+
filename_list = ['model.ckpt']
|
| 65 |
+
if not os.path.exists('./checkpoints/base_512_v2/'):
|
| 66 |
+
os.makedirs('./checkpoints/base_512_v2/')
|
| 67 |
+
for filename in filename_list:
|
| 68 |
+
local_file = os.path.join('./checkpoints/base_512_v2/', filename)
|
| 69 |
+
|
| 70 |
+
if not os.path.exists(local_file):
|
| 71 |
+
hf_hub_download(repo_id=REPO_ID, filename=filename, local_dir='./checkpoints/base_512_v2/', local_dir_use_symlinks=False)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
if __name__ == '__main__':
|
| 75 |
+
t2v = Text2Video()
|
| 76 |
+
video_path = t2v.get_prompt('a black swan swims on the pond')
|
| 77 |
+
print('done', video_path)
|