

17bb0dec11463d631246396d1fd41a12e712a7c448379b1988fb7025603f8e54
Browse files- README.md +4 -3
- model/optimized_model.pkl +2 -2
- plots.png +0 -0
README.md
CHANGED
|
@@ -37,16 +37,17 @@ metrics:
|
|
| 37 |

|
| 38 |
|
| 39 |
**Important remarks:**
|
| 40 |
-
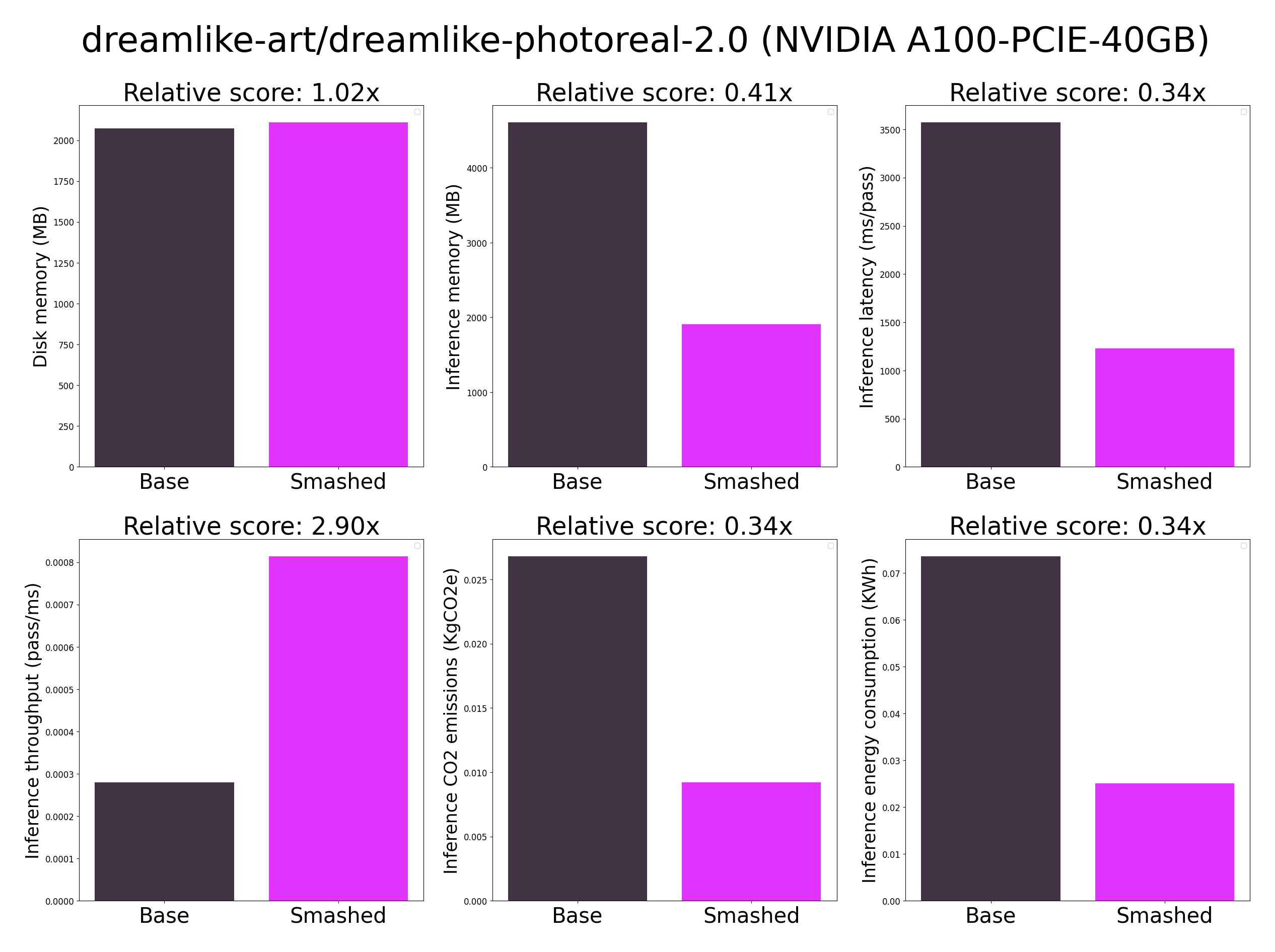
- The quality of the model output might slightly vary compared to the base model.
|
| 41 |
- These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in config.json and are obtained after a hardware warmup. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...).
|
| 42 |
- You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
|
|
|
| 43 |
|
| 44 |
## Setup
|
| 45 |
|
| 46 |
You can run the smashed model with these steps:
|
| 47 |
|
| 48 |
-
0. Check
|
| 49 |
-
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take 15 minutes to install.
|
| 50 |
```bash
|
| 51 |
pip install pruna-engine[gpu]==0.6.0 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
|
| 52 |
```
|
|
|
|
| 37 |

|
| 38 |
|
| 39 |
**Important remarks:**
|
| 40 |
+
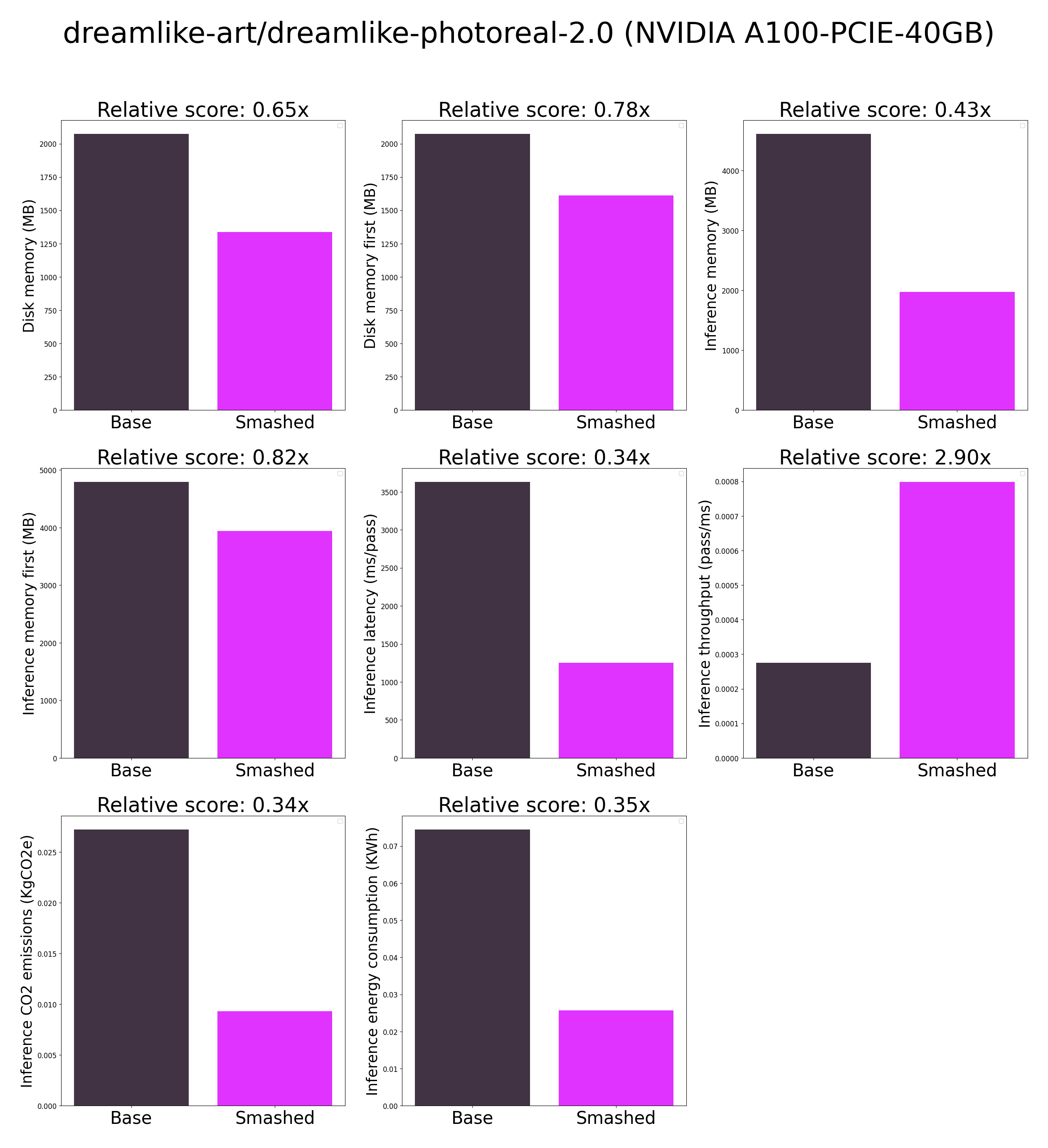
- The quality of the model output might slightly vary compared to the base model.
|
| 41 |
- These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in config.json and are obtained after a hardware warmup. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...).
|
| 42 |
- You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 43 |
+
- Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 44 |
|
| 45 |
## Setup
|
| 46 |
|
| 47 |
You can run the smashed model with these steps:
|
| 48 |
|
| 49 |
+
0. Check that you have linux, python 3.10, and cuda 12.1.0 requirements installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`.
|
| 50 |
+
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take up to 15 minutes to install.
|
| 51 |
```bash
|
| 52 |
pip install pruna-engine[gpu]==0.6.0 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
|
| 53 |
```
|
model/optimized_model.pkl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:209928bdafec6c9451c21c2df1776c36cc0721f88524683e8d262240ea7c19a0
|
| 3 |
+
size 2135159766
|
plots.png
CHANGED
|
|