
SalazarPevelll
commited on
Commit
•
51c57f8
1
Parent(s):
4d3e4e0
model
Browse files- CoCoSoDa +0 -1
- Figure/CoCoSoDa.png +0 -0
- README.md +86 -0
- dataset/__pycache__/utils.cpython-36.pyc +0 -0
- dataset/get_data.sh +26 -0
- dataset/preprocess.py +47 -0
- dataset/utils.py +46 -0
- model.py +396 -0
- parser/DFG.py +1184 -0
- parser/__init__.py +5 -0
- parser/__pycache__/DFG.cpython-36.pyc +0 -0
- parser/__pycache__/__init__.cpython-36.pyc +0 -0
- parser/__pycache__/utils.cpython-36.pyc +0 -0
- parser/build.py +21 -0
- parser/build.sh +8 -0
- parser/utils.py +98 -0
- run.py +1420 -0
- run_cocosoda.sh +59 -0
- run_fine_tune.sh +55 -0
- run_zero-shot.sh +40 -0
CoCoSoDa
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
Subproject commit 2f2bf8e7994acef846ede7c1078a0b18bc4154d9
|
|
|
|
|
|
Figure/CoCoSoDa.png
ADDED
|
README.md
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
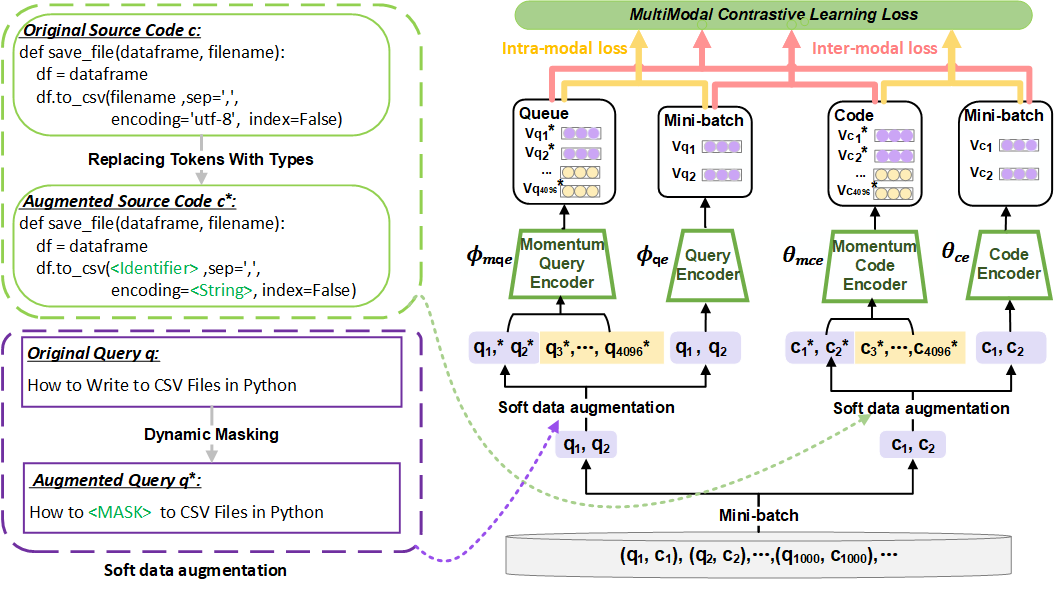
# CoCoSoDa: Effective Contrastive Learning for Code Search
|
| 2 |
+
|
| 3 |
+
Our approach adopts the pre-trained model as the base code/query encoder and optimizes it using multimodal contrastive learning and soft data augmentation.
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
CoCoSoDa is comprised of the following four components:
|
| 8 |
+
* **Pre-trained code/query encoder** captures the semantic information of a code snippet or a natural language query and maps it into a high-dimensional embedding space.
|
| 9 |
+
as the code/query encoder.
|
| 10 |
+
* **Momentum code/query encoder** encodes the samples (code snippets or queries) of current and previous mini-batches to enrich the negative samples.
|
| 11 |
+
|
| 12 |
+
* **Soft data augmentation** is to dynamically mask or replace some tokens in a sample (code/query) to generate a similar sample as a form of data augmentation.
|
| 13 |
+
|
| 14 |
+
* **Multimodal contrastive learning loss function** is used as the optimization objective and consists of inter-modal and intra-modal contrastive learning loss. They are used to minimize the distance of the representations of similar samples and maximize the distance of different samples in the embedding space.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Source code
|
| 19 |
+
### Environment
|
| 20 |
+
```
|
| 21 |
+
conda create -n CoCoSoDa python=3.6 -y
|
| 22 |
+
conda activate CoCoSoDa
|
| 23 |
+
pip install torch==1.10 transformers==4.12.5 seaborn==0.11.2 fast-histogram nltk==3.6.5 networkx==2.5.1 tree_sitter tqdm prettytable gdown more-itertools tensorboardX sklearn
|
| 24 |
+
```
|
| 25 |
+
### Data
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
cd dataset
|
| 29 |
+
bash get_data.sh
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Data statistic is shown in this Table.
|
| 33 |
+
|
| 34 |
+
| PL | Training | Validation | Test | Candidate Codes|
|
| 35 |
+
| :--------- | :------: | :----: | :----: |:----: |
|
| 36 |
+
| Ruby | 24,927 | 1,400 | 1,261 |4,360|
|
| 37 |
+
| JavaScript | 58,025 | 3,885 | 3,291 |13,981|
|
| 38 |
+
| Java | 164,923 | 5,183 | 10,955 |40,347|
|
| 39 |
+
| Go | 167,288 | 7,325 | 8,122 |28,120|
|
| 40 |
+
| PHP | 241,241 | 12,982 | 14,014 |52,660|
|
| 41 |
+
| Python | 251,820 | 13,914 | 14,918 |43,827|
|
| 42 |
+
|
| 43 |
+
It will take about 10min.
|
| 44 |
+
|
| 45 |
+
### Training and Evaualtion
|
| 46 |
+
|
| 47 |
+
We have uploaded the pre-trained model to [huggingface](https://huggingface.co/). You can directly download [DeepSoftwareAnalytics/CoCoSoDa](https://huggingface.co/DeepSoftwareAnalytics/CoCoSoDa) and fine-tune it.
|
| 48 |
+
#### Pre-training (Optional)
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
bash run_cocosoda.sh $lang
|
| 52 |
+
```
|
| 53 |
+
The optimized model is saved in `./saved_models/cocosoda/`. You can upload them to [huggingface](https://huggingface.co/).
|
| 54 |
+
|
| 55 |
+
It will take about 3 days.
|
| 56 |
+
|
| 57 |
+
#### Fine-tuning
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
lang=java
|
| 62 |
+
bash run_fine_tune.sh $lang
|
| 63 |
+
```
|
| 64 |
+
#### Zero-shot running
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
lang=python
|
| 68 |
+
bash run_zero-shot.sh $lang
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
### Results
|
| 73 |
+
|
| 74 |
+
#### The Model Evaluated with MRR
|
| 75 |
+
|
| 76 |
+
| Model | Ruby | Javascript | Go | Python | Java | PHP | Avg. |
|
| 77 |
+
| -------------- | :-------: | :--------: | :-------: | :-------: | :-------: | :-------: | :-------: |
|
| 78 |
+
| CoCoSoDa | **0.818**| **0.764**| **0.921** |**0.757**| **0.763**| **0.703** |**0.788**|
|
| 79 |
+
|
| 80 |
+
## Appendix
|
| 81 |
+
|
| 82 |
+
The description of baselines, addtional experimetal results and discussion are shown in `Appendix/Appendix.pdf`.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Contact
|
| 86 |
+
Feel free to contact Ensheng Shi (enshengshi@qq.com) if you have any further questions or no response to github issue for more than 1 day.
|
dataset/__pycache__/utils.cpython-36.pyc
ADDED
|
Binary file (1.53 kB). View file
|
|
|
dataset/get_data.sh
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/python.zip
|
| 2 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/java.zip
|
| 3 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/ruby.zip
|
| 4 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/javascript.zip
|
| 5 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/go.zip
|
| 6 |
+
# wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/php.zip
|
| 7 |
+
|
| 8 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/python.zip
|
| 9 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/java.zip
|
| 10 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/ruby.zip
|
| 11 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/javascript.zip
|
| 12 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/go.zip
|
| 13 |
+
wget https://huggingface.co/datasets/code_search_net/resolve/main/data/php.zip
|
| 14 |
+
|
| 15 |
+
unzip python.zip
|
| 16 |
+
unzip java.zip
|
| 17 |
+
unzip ruby.zip
|
| 18 |
+
unzip javascript.zip
|
| 19 |
+
unzip go.zip
|
| 20 |
+
unzip php.zip
|
| 21 |
+
rm *.zip
|
| 22 |
+
rm *.pkl
|
| 23 |
+
|
| 24 |
+
python preprocess.py
|
| 25 |
+
rm -r */final
|
| 26 |
+
cd ..
|
dataset/preprocess.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
for language in ['ruby','go','java','javascript','php','python']:
|
| 5 |
+
print(language)
|
| 6 |
+
train,valid,test,codebase=[],[],[], []
|
| 7 |
+
for root, dirs, files in os.walk(language+'/final'):
|
| 8 |
+
for file in files:
|
| 9 |
+
temp=os.path.join(root,file)
|
| 10 |
+
if '.jsonl' in temp:
|
| 11 |
+
if 'train' in temp:
|
| 12 |
+
train.append(temp)
|
| 13 |
+
elif 'valid' in temp:
|
| 14 |
+
valid.append(temp)
|
| 15 |
+
codebase.append(temp)
|
| 16 |
+
elif 'test' in temp:
|
| 17 |
+
test.append(temp)
|
| 18 |
+
codebase.append(temp)
|
| 19 |
+
|
| 20 |
+
train_data,valid_data,test_data,codebase_data={},{},{},{}
|
| 21 |
+
for files,data in [[train,train_data],[valid,valid_data],[test,test_data],[codebase,codebase_data]]:
|
| 22 |
+
for file in files:
|
| 23 |
+
if '.gz' in file:
|
| 24 |
+
os.system("gzip -d {}".format(file))
|
| 25 |
+
file=file.replace('.gz','')
|
| 26 |
+
with open(file) as f:
|
| 27 |
+
for line in f:
|
| 28 |
+
line=line.strip()
|
| 29 |
+
js=json.loads(line)
|
| 30 |
+
data[js['url']]=js
|
| 31 |
+
|
| 32 |
+
with open('{}/codebase.jsonl'.format(language),'w') as f3:
|
| 33 |
+
for tag,data in [['train',train_data],['valid',valid_data],['test',test_data],['test',test_data],['codebase',codebase_data]]:
|
| 34 |
+
with open('{}/{}.jsonl'.format(language,tag),'w') as f1, open("{}/{}.txt".format(language,tag)) as f2:
|
| 35 |
+
for line in f2:
|
| 36 |
+
line=line.strip()
|
| 37 |
+
if line in data:
|
| 38 |
+
js=data[line]
|
| 39 |
+
if tag in ['valid','test']:
|
| 40 |
+
js['original_string']=''
|
| 41 |
+
js['code']=''
|
| 42 |
+
js['code_tokens']=[]
|
| 43 |
+
if tag=='codebase':
|
| 44 |
+
js['docstring']=''
|
| 45 |
+
js['docstring_tokens']=[]
|
| 46 |
+
f1.write(json.dumps(js)+'\n')
|
| 47 |
+
|
dataset/utils.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pickle
|
| 2 |
+
import os
|
| 3 |
+
import json
|
| 4 |
+
import prettytable as pt
|
| 5 |
+
import numpy as np
|
| 6 |
+
import math
|
| 7 |
+
import logging
|
| 8 |
+
logger = logging.getLogger(__name__)
|
| 9 |
+
|
| 10 |
+
def read_json_file(filename):
|
| 11 |
+
with open(filename, 'r') as fp:
|
| 12 |
+
data = fp.readlines()
|
| 13 |
+
if len(data) == 1:
|
| 14 |
+
data = json.loads(data[0])
|
| 15 |
+
else:
|
| 16 |
+
data = [json.loads(line) for line in data]
|
| 17 |
+
return data
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def save_json_data(data_dir, filename, data):
|
| 21 |
+
os.makedirs(data_dir, exist_ok=True)
|
| 22 |
+
file_name = os.path.join(data_dir, filename)
|
| 23 |
+
with open(file_name, 'w') as output:
|
| 24 |
+
if type(data) == list:
|
| 25 |
+
if type(data[0]) in [str, list,dict]:
|
| 26 |
+
for item in data:
|
| 27 |
+
output.write(json.dumps(item))
|
| 28 |
+
output.write('\n')
|
| 29 |
+
|
| 30 |
+
else:
|
| 31 |
+
json.dump(data, output)
|
| 32 |
+
elif type(data) == dict:
|
| 33 |
+
json.dump(data, output)
|
| 34 |
+
else:
|
| 35 |
+
raise RuntimeError('Unsupported type: %s' % type(data))
|
| 36 |
+
logger.info("saved dataset in " + file_name)
|
| 37 |
+
|
| 38 |
+
def save_pickle_data(path_dir, filename, data):
|
| 39 |
+
full_path = path_dir + '/' + filename
|
| 40 |
+
print("Save dataset to: %s" % full_path)
|
| 41 |
+
if not os.path.exists(path_dir):
|
| 42 |
+
os.makedirs(path_dir)
|
| 43 |
+
|
| 44 |
+
with open(full_path, 'wb') as output:
|
| 45 |
+
pickle.dump(data, output,protocol=4)
|
| 46 |
+
|
model.py
ADDED
|
@@ -0,0 +1,396 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from prettytable import PrettyTable
|
| 4 |
+
from torch.nn.modules.activation import Tanh
|
| 5 |
+
import copy
|
| 6 |
+
import logging
|
| 7 |
+
logger = logging.getLogger(__name__)
|
| 8 |
+
from transformers import (WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup,
|
| 9 |
+
RobertaConfig, RobertaModel, RobertaTokenizer)
|
| 10 |
+
def whitening_torch_final(embeddings):
|
| 11 |
+
mu = torch.mean(embeddings, dim=0, keepdim=True)
|
| 12 |
+
cov = torch.mm((embeddings - mu).t(), embeddings - mu)
|
| 13 |
+
u, s, vt = torch.svd(cov)
|
| 14 |
+
W = torch.mm(u, torch.diag(1/torch.sqrt(s)))
|
| 15 |
+
embeddings = torch.mm(embeddings - mu, W)
|
| 16 |
+
return embeddings
|
| 17 |
+
|
| 18 |
+
class BaseModel(nn.Module):
|
| 19 |
+
def __init__(self, ):
|
| 20 |
+
super().__init__()
|
| 21 |
+
|
| 22 |
+
def model_parameters(self):
|
| 23 |
+
table = PrettyTable()
|
| 24 |
+
table.field_names = ["Layer Name", "Output Shape", "Param #"]
|
| 25 |
+
table.align["Layer Name"] = "l"
|
| 26 |
+
table.align["Output Shape"] = "r"
|
| 27 |
+
table.align["Param #"] = "r"
|
| 28 |
+
for name, parameters in self.named_parameters():
|
| 29 |
+
if parameters.requires_grad:
|
| 30 |
+
table.add_row([name, str(list(parameters.shape)), parameters.numel()])
|
| 31 |
+
return table
|
| 32 |
+
class Model(BaseModel):
|
| 33 |
+
def __init__(self, encoder):
|
| 34 |
+
super(Model, self).__init__()
|
| 35 |
+
self.encoder = encoder
|
| 36 |
+
|
| 37 |
+
def forward(self, code_inputs=None, nl_inputs=None):
|
| 38 |
+
# code_inputs [bs, seq]
|
| 39 |
+
if code_inputs is not None:
|
| 40 |
+
outputs = self.encoder(code_inputs,attention_mask=code_inputs.ne(1))[0] #[bs, seq_len, dim]
|
| 41 |
+
outputs = (outputs*code_inputs.ne(1)[:,:,None]).sum(1)/code_inputs.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 42 |
+
return torch.nn.functional.normalize(outputs, p=2, dim=1)
|
| 43 |
+
else:
|
| 44 |
+
outputs = self.encoder(nl_inputs,attention_mask=nl_inputs.ne(1))[0]
|
| 45 |
+
outputs = (outputs*nl_inputs.ne(1)[:,:,None]).sum(1)/nl_inputs.ne(1).sum(-1)[:,None]
|
| 46 |
+
return torch.nn.functional.normalize(outputs, p=2, dim=1)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class Multi_Loss_CoCoSoDa( BaseModel):
|
| 50 |
+
|
| 51 |
+
def __init__(self, base_encoder, args, mlp=False):
|
| 52 |
+
super(Multi_Loss_CoCoSoDa, self).__init__()
|
| 53 |
+
|
| 54 |
+
self.K = args.moco_k
|
| 55 |
+
self.m = args.moco_m
|
| 56 |
+
self.T = args.moco_t
|
| 57 |
+
dim= args.moco_dim
|
| 58 |
+
|
| 59 |
+
# create the encoders
|
| 60 |
+
# num_classes is the output fc dimension
|
| 61 |
+
self.code_encoder_q = base_encoder
|
| 62 |
+
self.code_encoder_k = copy.deepcopy(base_encoder)
|
| 63 |
+
self.nl_encoder_q = base_encoder
|
| 64 |
+
# self.nl_encoder_q = RobertaModel.from_pretrained("roberta-base")
|
| 65 |
+
self.nl_encoder_k = copy.deepcopy(self.nl_encoder_q)
|
| 66 |
+
self.mlp = mlp
|
| 67 |
+
self.time_score= args.time_score
|
| 68 |
+
self.do_whitening = args.do_whitening
|
| 69 |
+
self.do_ineer_loss = args.do_ineer_loss
|
| 70 |
+
self.agg_way = args.agg_way
|
| 71 |
+
self.args = args
|
| 72 |
+
|
| 73 |
+
for param_q, param_k in zip(self.code_encoder_q.parameters(), self.code_encoder_k.parameters()):
|
| 74 |
+
param_k.data.copy_(param_q.data) # initialize
|
| 75 |
+
param_k.requires_grad = False # not update by gradient
|
| 76 |
+
|
| 77 |
+
for param_q, param_k in zip(self.nl_encoder_q.parameters(), self.nl_encoder_k.parameters()):
|
| 78 |
+
param_k.data.copy_(param_q.data) # initialize
|
| 79 |
+
param_k.requires_grad = False # not update by gradient
|
| 80 |
+
|
| 81 |
+
# create the code queue
|
| 82 |
+
torch.manual_seed(3047)
|
| 83 |
+
torch.cuda.manual_seed(3047)
|
| 84 |
+
self.register_buffer("code_queue", torch.randn(dim,self.K ))
|
| 85 |
+
self.code_queue = nn.functional.normalize(self.code_queue, dim=0)
|
| 86 |
+
self.register_buffer("code_queue_ptr", torch.zeros(1, dtype=torch.long))
|
| 87 |
+
# create the masked code queue
|
| 88 |
+
self.register_buffer("masked_code_queue", torch.randn(dim, self.K ))
|
| 89 |
+
self.masked_code_queue = nn.functional.normalize(self.masked_code_queue, dim=0)
|
| 90 |
+
self.register_buffer("masked_code_queue_ptr", torch.zeros(1, dtype=torch.long))
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# create the nl queue
|
| 94 |
+
self.register_buffer("nl_queue", torch.randn(dim, self.K ))
|
| 95 |
+
self.nl_queue = nn.functional.normalize(self.nl_queue, dim=0)
|
| 96 |
+
self.register_buffer("nl_queue_ptr", torch.zeros(1, dtype=torch.long))
|
| 97 |
+
# create the masked nl queue
|
| 98 |
+
self.register_buffer("masked_nl_queue", torch.randn(dim, self.K ))
|
| 99 |
+
self.masked_nl_queue= nn.functional.normalize(self.masked_nl_queue, dim=0)
|
| 100 |
+
self.register_buffer("masked_nl_queue_ptr", torch.zeros(1, dtype=torch.long))
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
@torch.no_grad()
|
| 106 |
+
def _momentum_update_key_encoder(self):
|
| 107 |
+
"""
|
| 108 |
+
Momentum update of the key encoder
|
| 109 |
+
% key encoder的Momentum update
|
| 110 |
+
"""
|
| 111 |
+
for param_q, param_k in zip(self.code_encoder_q.parameters(), self.code_encoder_k.parameters()):
|
| 112 |
+
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
|
| 113 |
+
for param_q, param_k in zip(self.nl_encoder_q.parameters(), self.nl_encoder_k.parameters()):
|
| 114 |
+
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
|
| 115 |
+
if self.mlp:
|
| 116 |
+
for param_q, param_k in zip(self.code_encoder_q_fc.parameters(), self.code_encoder_k_fc.parameters()):
|
| 117 |
+
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
|
| 118 |
+
for param_q, param_k in zip(self.nl_encoder_q_fc.parameters(), self.nl_encoder_k_fc.parameters()):
|
| 119 |
+
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
|
| 120 |
+
|
| 121 |
+
@torch.no_grad()
|
| 122 |
+
def _dequeue_and_enqueue(self, keys, option='code'):
|
| 123 |
+
# gather keys before updating queue
|
| 124 |
+
# keys = concat_all_gather(keys)
|
| 125 |
+
|
| 126 |
+
batch_size = keys.shape[0]
|
| 127 |
+
if option == 'code':
|
| 128 |
+
code_ptr = int(self.code_queue_ptr)
|
| 129 |
+
assert self.K % batch_size == 0 # for simplicity
|
| 130 |
+
|
| 131 |
+
# replace the keys at ptr (dequeue and enqueue)
|
| 132 |
+
try:
|
| 133 |
+
self.code_queue[:, code_ptr:code_ptr + batch_size] = keys.T
|
| 134 |
+
except:
|
| 135 |
+
print(code_ptr)
|
| 136 |
+
print(batch_size)
|
| 137 |
+
print(keys.shape)
|
| 138 |
+
exit(111)
|
| 139 |
+
code_ptr = (code_ptr + batch_size) % self.K # move pointer ptr->pointer
|
| 140 |
+
|
| 141 |
+
self.code_queue_ptr[0] = code_ptr
|
| 142 |
+
|
| 143 |
+
elif option == 'masked_code':
|
| 144 |
+
masked_code_ptr = int(self.masked_code_queue_ptr)
|
| 145 |
+
assert self.K % batch_size == 0 # for simplicity
|
| 146 |
+
|
| 147 |
+
# replace the keys at ptr (dequeue and enqueue)
|
| 148 |
+
try:
|
| 149 |
+
self.masked_code_queue[:, masked_code_ptr:masked_code_ptr + batch_size] = keys.T
|
| 150 |
+
except:
|
| 151 |
+
print(masked_code_ptr)
|
| 152 |
+
print(batch_size)
|
| 153 |
+
print(keys.shape)
|
| 154 |
+
exit(111)
|
| 155 |
+
masked_code_ptr = (masked_code_ptr + batch_size) % self.K # move pointer ptr->pointer
|
| 156 |
+
|
| 157 |
+
self.masked_code_queue_ptr[0] = masked_code_ptr
|
| 158 |
+
|
| 159 |
+
elif option == 'nl':
|
| 160 |
+
|
| 161 |
+
nl_ptr = int(self.nl_queue_ptr)
|
| 162 |
+
assert self.K % batch_size == 0 # for simplicity
|
| 163 |
+
|
| 164 |
+
# replace the keys at ptr (dequeue and enqueue)
|
| 165 |
+
self.nl_queue[:, nl_ptr:nl_ptr + batch_size] = keys.T
|
| 166 |
+
nl_ptr = (nl_ptr + batch_size) % self.K # move pointer ptr->pointer
|
| 167 |
+
|
| 168 |
+
self.nl_queue_ptr[0] = nl_ptr
|
| 169 |
+
elif option == 'masked_nl':
|
| 170 |
+
|
| 171 |
+
masked_nl_ptr = int(self.masked_nl_queue_ptr)
|
| 172 |
+
assert self.K % batch_size == 0 # for simplicity
|
| 173 |
+
|
| 174 |
+
# replace the keys at ptr (dequeue and enqueue)
|
| 175 |
+
self.masked_nl_queue[:, masked_nl_ptr:masked_nl_ptr + batch_size] = keys.T
|
| 176 |
+
masked_nl_ptr = (masked_nl_ptr + batch_size) % self.K # move pointer ptr->pointer
|
| 177 |
+
|
| 178 |
+
self.masked_nl_queue_ptr[0] = masked_nl_ptr
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def forward(self, source_code_q, source_code_k, nl_q,nl_k):
|
| 183 |
+
"""
|
| 184 |
+
Input:
|
| 185 |
+
im_q: a batch of query images
|
| 186 |
+
im_k: a batch of key images
|
| 187 |
+
Output:
|
| 188 |
+
logits, targets
|
| 189 |
+
"""
|
| 190 |
+
if not self.args.do_multi_lang_continue_pre_train:
|
| 191 |
+
# logger.info(".do_multi_lang_continue_pre_train")
|
| 192 |
+
outputs = self.code_encoder_q(source_code_q, attention_mask=source_code_q.ne(1))[0]
|
| 193 |
+
code_q = (outputs*source_code_q.ne(1)[:,:,None]).sum(1)/source_code_q.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 194 |
+
code_q = torch.nn.functional.normalize(code_q, p=2, dim=1)
|
| 195 |
+
# compute query features for nl
|
| 196 |
+
outputs= self.nl_encoder_q(nl_q, attention_mask=nl_q.ne(1))[0] # queries: NxC bs*feature_dim
|
| 197 |
+
nl_q = (outputs*nl_q.ne(1)[:,:,None]).sum(1)/nl_q.ne(1).sum(-1)[:,None]
|
| 198 |
+
nl_q = torch.nn.functional.normalize(nl_q, p=2, dim=1)
|
| 199 |
+
code2nl_logits = torch.einsum("ab,cb->ac", code_q,nl_q )
|
| 200 |
+
# loss = self.loss_fct(scores*20, torch.arange(code_inputs.size(0), device=scores.device))
|
| 201 |
+
code2nl_logits /= self.T
|
| 202 |
+
# label
|
| 203 |
+
code2nl_label = torch.arange(code2nl_logits.size(0), device=code2nl_logits.device)
|
| 204 |
+
return code2nl_logits,code2nl_label, None, None
|
| 205 |
+
if self.agg_way == "avg":
|
| 206 |
+
# compute query features for source code
|
| 207 |
+
outputs = self.code_encoder_q(source_code_q, attention_mask=source_code_q.ne(1))[0]
|
| 208 |
+
code_q = (outputs*source_code_q.ne(1)[:,:,None]).sum(1)/source_code_q.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 209 |
+
code_q = torch.nn.functional.normalize(code_q, p=2, dim=1)
|
| 210 |
+
# compute query features for nl
|
| 211 |
+
outputs= self.nl_encoder_q(nl_q, attention_mask=nl_q.ne(1))[0] # queries: NxC bs*feature_dim
|
| 212 |
+
nl_q = (outputs*nl_q.ne(1)[:,:,None]).sum(1)/nl_q.ne(1).sum(-1)[:,None]
|
| 213 |
+
nl_q = torch.nn.functional.normalize(nl_q, p=2, dim=1)
|
| 214 |
+
|
| 215 |
+
# compute key features
|
| 216 |
+
with torch.no_grad(): # no gradient to keys
|
| 217 |
+
self._momentum_update_key_encoder() # update the key encoder
|
| 218 |
+
|
| 219 |
+
# shuffle for making use of BN
|
| 220 |
+
# im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
|
| 221 |
+
|
| 222 |
+
# masked code
|
| 223 |
+
outputs = self.code_encoder_k(source_code_k, attention_mask=source_code_k.ne(1))[0] # keys: NxC
|
| 224 |
+
code_k = (outputs*source_code_k.ne(1)[:,:,None]).sum(1)/source_code_k.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 225 |
+
code_k = torch.nn.functional.normalize( code_k, p=2, dim=1)
|
| 226 |
+
# masked nl
|
| 227 |
+
outputs = self.nl_encoder_k(nl_k, attention_mask=nl_k.ne(1))[0] # keys: bs*dim
|
| 228 |
+
nl_k = (outputs*nl_k.ne(1)[:,:,None]).sum(1)/nl_k.ne(1).sum(-1)[:,None]
|
| 229 |
+
nl_k = torch.nn.functional.normalize(nl_k, p=2, dim=1)
|
| 230 |
+
|
| 231 |
+
elif self.agg_way == "cls_pooler":
|
| 232 |
+
# logger.info(self.agg_way )
|
| 233 |
+
# compute query features for source code
|
| 234 |
+
outputs = self.code_encoder_q(source_code_q, attention_mask=source_code_q.ne(1))[1]
|
| 235 |
+
code_q = torch.nn.functional.normalize(code_q, p=2, dim=1)
|
| 236 |
+
# compute query features for nl
|
| 237 |
+
outputs= self.nl_encoder_q(nl_q, attention_mask=nl_q.ne(1))[1] # queries: NxC bs*feature_dim
|
| 238 |
+
nl_q = torch.nn.functional.normalize(nl_q, p=2, dim=1)
|
| 239 |
+
|
| 240 |
+
# compute key features
|
| 241 |
+
with torch.no_grad(): # no gradient to keys
|
| 242 |
+
self._momentum_update_key_encoder() # update the key encoder
|
| 243 |
+
|
| 244 |
+
# shuffle for making use of BN
|
| 245 |
+
# im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
|
| 246 |
+
|
| 247 |
+
# masked code
|
| 248 |
+
outputs = self.code_encoder_k(source_code_k, attention_mask=source_code_k.ne(1))[1] # keys: NxC
|
| 249 |
+
code_k = torch.nn.functional.normalize( code_k, p=2, dim=1)
|
| 250 |
+
# masked nl
|
| 251 |
+
outputs = self.nl_encoder_k(nl_k, attention_mask=nl_k.ne(1))[1] # keys: bs*dim
|
| 252 |
+
nl_k = torch.nn.functional.normalize(nl_k, p=2, dim=1)
|
| 253 |
+
|
| 254 |
+
elif self.agg_way == "avg_cls_pooler":
|
| 255 |
+
# logger.info(self.agg_way )
|
| 256 |
+
outputs = self.code_encoder_q(source_code_q, attention_mask=source_code_q.ne(1))
|
| 257 |
+
code_q_cls = outputs[1]
|
| 258 |
+
outputs = outputs[0]
|
| 259 |
+
code_q_avg = (outputs*source_code_q.ne(1)[:,:,None]).sum(1)/source_code_q.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 260 |
+
code_q = code_q_cls + code_q_avg
|
| 261 |
+
code_q = torch.nn.functional.normalize(code_q, p=2, dim=1)
|
| 262 |
+
# compute query features for nl
|
| 263 |
+
outputs= self.nl_encoder_q(nl_q, attention_mask=nl_q.ne(1))
|
| 264 |
+
nl_q_cls = outputs[1]
|
| 265 |
+
outputs= outputs[0] # queries: NxC bs*feature_dim
|
| 266 |
+
nl_q_avg = (outputs*nl_q.ne(1)[:,:,None]).sum(1)/nl_q.ne(1).sum(-1)[:,None]
|
| 267 |
+
nl_q = nl_q_avg + nl_q_cls
|
| 268 |
+
nl_q = torch.nn.functional.normalize(nl_q, p=2, dim=1)
|
| 269 |
+
|
| 270 |
+
# compute key features
|
| 271 |
+
with torch.no_grad(): # no gradient to keys
|
| 272 |
+
self._momentum_update_key_encoder() # update the key encoder
|
| 273 |
+
|
| 274 |
+
# shuffle for making use of BN
|
| 275 |
+
# im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
|
| 276 |
+
|
| 277 |
+
# masked code
|
| 278 |
+
|
| 279 |
+
outputs = self.code_encoder_k(source_code_k, attention_mask=source_code_k.ne(1))
|
| 280 |
+
code_k_cls = outputs[1] # keys: NxC
|
| 281 |
+
outputs = outputs[0]
|
| 282 |
+
code_k_avg = (outputs*source_code_k.ne(1)[:,:,None]).sum(1)/source_code_k.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 283 |
+
code_k = code_k_cls + code_k_avg
|
| 284 |
+
code_k = torch.nn.functional.normalize( code_k, p=2, dim=1)
|
| 285 |
+
# masked nl
|
| 286 |
+
outputs = self.nl_encoder_k(nl_k, attention_mask=nl_k.ne(1))
|
| 287 |
+
nl_k_cls = outputs[1] # keys: bs*dim
|
| 288 |
+
outputs = outputs[0]
|
| 289 |
+
nl_k_avg = (outputs*nl_k.ne(1)[:,:,None]).sum(1)/nl_k.ne(1).sum(-1)[:,None]
|
| 290 |
+
nl_k = nl_k_cls + nl_k_avg
|
| 291 |
+
nl_k = torch.nn.functional.normalize(nl_k, p=2, dim=1)
|
| 292 |
+
|
| 293 |
+
# ## do_whitening
|
| 294 |
+
# if self.do_whitening:
|
| 295 |
+
# code_q = whitening_torch_final(code_q)
|
| 296 |
+
# code_k = whitening_torch_final(code_k)
|
| 297 |
+
# nl_q = whitening_torch_final(nl_q)
|
| 298 |
+
# nl_k = whitening_torch_final(nl_k)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
## code vs nl
|
| 302 |
+
code2nl_pos = torch.einsum('nc,bc->nb', [code_q, nl_q])
|
| 303 |
+
# negative logits: NxK
|
| 304 |
+
code2nl_neg = torch.einsum('nc,ck->nk', [code_q, self.nl_queue.clone().detach()])
|
| 305 |
+
# logits: Nx(n+K)
|
| 306 |
+
code2nl_logits = torch.cat([self.time_score*code2nl_pos, code2nl_neg], dim=1)
|
| 307 |
+
# apply temperature
|
| 308 |
+
code2nl_logits /= self.T
|
| 309 |
+
# label
|
| 310 |
+
code2nl_label = torch.arange(code2nl_logits.size(0), device=code2nl_logits.device)
|
| 311 |
+
|
| 312 |
+
## code vs masked nl
|
| 313 |
+
code2maskednl_pos = torch.einsum('nc,bc->nb', [code_q, nl_k])
|
| 314 |
+
# negative logits: NxK
|
| 315 |
+
code2maskednl_neg = torch.einsum('nc,ck->nk', [code_q, self.masked_nl_queue.clone().detach()])
|
| 316 |
+
# logits: Nx(n+K)
|
| 317 |
+
code2maskednl_logits = torch.cat([self.time_score*code2maskednl_pos, code2maskednl_neg], dim=1)
|
| 318 |
+
# apply temperature
|
| 319 |
+
code2maskednl_logits /= self.T
|
| 320 |
+
# label
|
| 321 |
+
code2maskednl_label = torch.arange(code2maskednl_logits.size(0), device=code2maskednl_logits.device)
|
| 322 |
+
|
| 323 |
+
## nl vs code
|
| 324 |
+
# nl2code_pos = torch.einsum('nc,nc->n', [nl_q, code_k]).unsqueeze(-1)
|
| 325 |
+
nl2code_pos = torch.einsum('nc,bc->nb', [nl_q, code_q])
|
| 326 |
+
# negative logits: bsxK
|
| 327 |
+
nl2code_neg = torch.einsum('nc,ck->nk', [nl_q, self.code_queue.clone().detach()])
|
| 328 |
+
# nl2code_logits: bsx(n+K)
|
| 329 |
+
nl2code_logits = torch.cat([self.time_score*nl2code_pos, nl2code_neg], dim=1)
|
| 330 |
+
# apply temperature
|
| 331 |
+
nl2code_logits /= self.T
|
| 332 |
+
# label
|
| 333 |
+
nl2code_label = torch.arange(nl2code_logits.size(0), device=nl2code_logits.device)
|
| 334 |
+
|
| 335 |
+
## nl vs masked code
|
| 336 |
+
# nl2code_pos = torch.einsum('nc,nc->n', [nl_q, code_k]).unsqueeze(-1)
|
| 337 |
+
nl2maskedcode_pos = torch.einsum('nc,bc->nb', [nl_q, code_k])
|
| 338 |
+
# negative logits: bsxK
|
| 339 |
+
nl2maskedcode_neg = torch.einsum('nc,ck->nk', [nl_q, self.masked_code_queue.clone().detach()])
|
| 340 |
+
# nl2code_logits: bsx(n+K)
|
| 341 |
+
nl2maskedcode_logits = torch.cat([self.time_score*nl2maskedcode_pos, nl2maskedcode_neg], dim=1)
|
| 342 |
+
# apply temperature
|
| 343 |
+
nl2maskedcode_logits /= self.T
|
| 344 |
+
# label
|
| 345 |
+
nl2maskedcode_label = torch.arange(nl2maskedcode_logits.size(0), device=nl2maskedcode_logits.device)
|
| 346 |
+
|
| 347 |
+
#logit 4*bsx(1+K)
|
| 348 |
+
inter_logits = torch.cat((code2nl_logits, code2maskednl_logits, nl2code_logits ,nl2maskedcode_logits ), dim=0)
|
| 349 |
+
|
| 350 |
+
# labels: positive key indicators
|
| 351 |
+
# inter_labels = torch.zeros(inter_logits.shape[0], dtype=torch.long).cuda()
|
| 352 |
+
inter_labels = torch.cat((code2nl_label, code2maskednl_label, nl2code_label, nl2maskedcode_label), dim=0)
|
| 353 |
+
|
| 354 |
+
if self.do_ineer_loss:
|
| 355 |
+
# logger.info("do_ineer_loss")
|
| 356 |
+
## code vs masked code
|
| 357 |
+
code2maskedcode_pos = torch.einsum('nc,bc->nb', [code_q, code_k])
|
| 358 |
+
# negative logits: NxK
|
| 359 |
+
code2maskedcode_neg = torch.einsum('nc,ck->nk', [code_q, self.masked_code_queue.clone().detach()])
|
| 360 |
+
# logits: Nx(n+K)
|
| 361 |
+
code2maskedcode_logits = torch.cat([self.time_score*code2maskedcode_pos, code2maskedcode_neg], dim=1)
|
| 362 |
+
# apply temperature
|
| 363 |
+
code2maskedcode_logits /= self.T
|
| 364 |
+
# label
|
| 365 |
+
code2maskedcode_label = torch.arange(code2maskedcode_logits.size(0), device=code2maskedcode_logits.device)
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
## nl vs masked nl
|
| 369 |
+
# nl2code_pos = torch.einsum('nc,nc->n', [nl_q, code_k]).unsqueeze(-1)
|
| 370 |
+
nl2maskednl_pos = torch.einsum('nc,bc->nb', [nl_q, nl_k])
|
| 371 |
+
# negative logits: bsxK
|
| 372 |
+
nl2maskednl_neg = torch.einsum('nc,ck->nk', [nl_q, self.masked_nl_queue.clone().detach()])
|
| 373 |
+
# nl2code_logits: bsx(n+K)
|
| 374 |
+
nl2maskednl_logits = torch.cat([self.time_score*nl2maskednl_pos, nl2maskednl_neg], dim=1)
|
| 375 |
+
# apply temperature
|
| 376 |
+
nl2maskednl_logits /= self.T
|
| 377 |
+
# label
|
| 378 |
+
nl2maskednl_label = torch.arange(nl2maskednl_logits.size(0), device=nl2maskednl_logits.device)
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
#logit 6*bsx(1+K)
|
| 382 |
+
inter_logits = torch.cat((inter_logits, code2maskedcode_logits, nl2maskednl_logits), dim=0)
|
| 383 |
+
|
| 384 |
+
# labels: positive key indicators
|
| 385 |
+
# inter_labels = torch.zeros(inter_logits.shape[0], dtype=torch.long).cuda()
|
| 386 |
+
inter_labels = torch.cat(( inter_labels, code2maskedcode_label, nl2maskednl_label ), dim=0)
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
# dequeue and enqueue
|
| 390 |
+
self._dequeue_and_enqueue(code_q, option='code')
|
| 391 |
+
self._dequeue_and_enqueue(nl_q, option='nl')
|
| 392 |
+
self._dequeue_and_enqueue(code_k, option='masked_code')
|
| 393 |
+
self._dequeue_and_enqueue(nl_k, option='masked_nl')
|
| 394 |
+
|
| 395 |
+
return inter_logits, inter_labels, code_q, nl_q
|
| 396 |
+
|
parser/DFG.py
ADDED
|
@@ -0,0 +1,1184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from tree_sitter import Language, Parser
|
| 5 |
+
from .utils import (remove_comments_and_docstrings,
|
| 6 |
+
tree_to_token_index,
|
| 7 |
+
index_to_code_token,
|
| 8 |
+
tree_to_variable_index)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def DFG_python(root_node,index_to_code,states):
|
| 12 |
+
assignment=['assignment','augmented_assignment','for_in_clause']
|
| 13 |
+
if_statement=['if_statement']
|
| 14 |
+
for_statement=['for_statement']
|
| 15 |
+
while_statement=['while_statement']
|
| 16 |
+
do_first_statement=['for_in_clause']
|
| 17 |
+
def_statement=['default_parameter']
|
| 18 |
+
states=states.copy()
|
| 19 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 20 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 21 |
+
if root_node.type==code:
|
| 22 |
+
return [],states
|
| 23 |
+
elif code in states:
|
| 24 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 25 |
+
else:
|
| 26 |
+
if root_node.type=='identifier':
|
| 27 |
+
states[code]=[idx]
|
| 28 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 29 |
+
elif root_node.type in def_statement:
|
| 30 |
+
name=root_node.child_by_field_name('name')
|
| 31 |
+
value=root_node.child_by_field_name('value')
|
| 32 |
+
DFG=[]
|
| 33 |
+
if value is None:
|
| 34 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 35 |
+
for index in indexs:
|
| 36 |
+
idx,code=index_to_code[index]
|
| 37 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 38 |
+
states[code]=[idx]
|
| 39 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 40 |
+
else:
|
| 41 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 42 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 43 |
+
temp,states=DFG_python(value,index_to_code,states)
|
| 44 |
+
DFG+=temp
|
| 45 |
+
for index1 in name_indexs:
|
| 46 |
+
idx1,code1=index_to_code[index1]
|
| 47 |
+
for index2 in value_indexs:
|
| 48 |
+
idx2,code2=index_to_code[index2]
|
| 49 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 50 |
+
states[code1]=[idx1]
|
| 51 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 52 |
+
elif root_node.type in assignment:
|
| 53 |
+
if root_node.type=='for_in_clause':
|
| 54 |
+
right_nodes=[root_node.children[-1]]
|
| 55 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 56 |
+
else:
|
| 57 |
+
if root_node.child_by_field_name('right') is None:
|
| 58 |
+
return [],states
|
| 59 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 60 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 61 |
+
if len(right_nodes)!=len(left_nodes):
|
| 62 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 63 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 64 |
+
if len(left_nodes)==0:
|
| 65 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 66 |
+
if len(right_nodes)==0:
|
| 67 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 68 |
+
DFG=[]
|
| 69 |
+
for node in right_nodes:
|
| 70 |
+
temp,states=DFG_python(node,index_to_code,states)
|
| 71 |
+
DFG+=temp
|
| 72 |
+
|
| 73 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 74 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 75 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 76 |
+
temp=[]
|
| 77 |
+
for token1_index in left_tokens_index:
|
| 78 |
+
idx1,code1=index_to_code[token1_index]
|
| 79 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 80 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 81 |
+
states[code1]=[idx1]
|
| 82 |
+
DFG+=temp
|
| 83 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 84 |
+
elif root_node.type in if_statement:
|
| 85 |
+
DFG=[]
|
| 86 |
+
current_states=states.copy()
|
| 87 |
+
others_states=[]
|
| 88 |
+
tag=False
|
| 89 |
+
if 'else' in root_node.type:
|
| 90 |
+
tag=True
|
| 91 |
+
for child in root_node.children:
|
| 92 |
+
if 'else' in child.type:
|
| 93 |
+
tag=True
|
| 94 |
+
if child.type not in ['elif_clause','else_clause']:
|
| 95 |
+
temp,current_states=DFG_python(child,index_to_code,current_states)
|
| 96 |
+
DFG+=temp
|
| 97 |
+
else:
|
| 98 |
+
temp,new_states=DFG_python(child,index_to_code,states)
|
| 99 |
+
DFG+=temp
|
| 100 |
+
others_states.append(new_states)
|
| 101 |
+
others_states.append(current_states)
|
| 102 |
+
if tag is False:
|
| 103 |
+
others_states.append(states)
|
| 104 |
+
new_states={}
|
| 105 |
+
for dic in others_states:
|
| 106 |
+
for key in dic:
|
| 107 |
+
if key not in new_states:
|
| 108 |
+
new_states[key]=dic[key].copy()
|
| 109 |
+
else:
|
| 110 |
+
new_states[key]+=dic[key]
|
| 111 |
+
for key in new_states:
|
| 112 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 113 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 114 |
+
elif root_node.type in for_statement:
|
| 115 |
+
DFG=[]
|
| 116 |
+
for i in range(2):
|
| 117 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 118 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 119 |
+
if len(right_nodes)!=len(left_nodes):
|
| 120 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 121 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 122 |
+
if len(left_nodes)==0:
|
| 123 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 124 |
+
if len(right_nodes)==0:
|
| 125 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 126 |
+
for node in right_nodes:
|
| 127 |
+
temp,states=DFG_python(node,index_to_code,states)
|
| 128 |
+
DFG+=temp
|
| 129 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 130 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 131 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 132 |
+
temp=[]
|
| 133 |
+
for token1_index in left_tokens_index:
|
| 134 |
+
idx1,code1=index_to_code[token1_index]
|
| 135 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 136 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 137 |
+
states[code1]=[idx1]
|
| 138 |
+
DFG+=temp
|
| 139 |
+
if root_node.children[-1].type=="block":
|
| 140 |
+
temp,states=DFG_python(root_node.children[-1],index_to_code,states)
|
| 141 |
+
DFG+=temp
|
| 142 |
+
dic={}
|
| 143 |
+
for x in DFG:
|
| 144 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 145 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 146 |
+
else:
|
| 147 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 148 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 149 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 150 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 151 |
+
elif root_node.type in while_statement:
|
| 152 |
+
DFG=[]
|
| 153 |
+
for i in range(2):
|
| 154 |
+
for child in root_node.children:
|
| 155 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 156 |
+
DFG+=temp
|
| 157 |
+
dic={}
|
| 158 |
+
for x in DFG:
|
| 159 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 160 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 161 |
+
else:
|
| 162 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 163 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 164 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 165 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 166 |
+
else:
|
| 167 |
+
DFG=[]
|
| 168 |
+
for child in root_node.children:
|
| 169 |
+
if child.type in do_first_statement:
|
| 170 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 171 |
+
DFG+=temp
|
| 172 |
+
for child in root_node.children:
|
| 173 |
+
if child.type not in do_first_statement:
|
| 174 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 175 |
+
DFG+=temp
|
| 176 |
+
|
| 177 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def DFG_java(root_node,index_to_code,states):
|
| 181 |
+
assignment=['assignment_expression']
|
| 182 |
+
def_statement=['variable_declarator']
|
| 183 |
+
increment_statement=['update_expression']
|
| 184 |
+
if_statement=['if_statement','else']
|
| 185 |
+
for_statement=['for_statement']
|
| 186 |
+
enhanced_for_statement=['enhanced_for_statement']
|
| 187 |
+
while_statement=['while_statement']
|
| 188 |
+
do_first_statement=[]
|
| 189 |
+
states=states.copy()
|
| 190 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 191 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 192 |
+
if root_node.type==code:
|
| 193 |
+
return [],states
|
| 194 |
+
elif code in states:
|
| 195 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 196 |
+
else:
|
| 197 |
+
if root_node.type=='identifier':
|
| 198 |
+
states[code]=[idx]
|
| 199 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 200 |
+
elif root_node.type in def_statement:
|
| 201 |
+
name=root_node.child_by_field_name('name')
|
| 202 |
+
value=root_node.child_by_field_name('value')
|
| 203 |
+
DFG=[]
|
| 204 |
+
if value is None:
|
| 205 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 206 |
+
for index in indexs:
|
| 207 |
+
idx,code=index_to_code[index]
|
| 208 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 209 |
+
states[code]=[idx]
|
| 210 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 211 |
+
else:
|
| 212 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 213 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 214 |
+
temp,states=DFG_java(value,index_to_code,states)
|
| 215 |
+
DFG+=temp
|
| 216 |
+
for index1 in name_indexs:
|
| 217 |
+
idx1,code1=index_to_code[index1]
|
| 218 |
+
for index2 in value_indexs:
|
| 219 |
+
idx2,code2=index_to_code[index2]
|
| 220 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 221 |
+
states[code1]=[idx1]
|
| 222 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 223 |
+
elif root_node.type in assignment:
|
| 224 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 225 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 226 |
+
DFG=[]
|
| 227 |
+
temp,states=DFG_java(right_nodes,index_to_code,states)
|
| 228 |
+
DFG+=temp
|
| 229 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 230 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 231 |
+
for index1 in name_indexs:
|
| 232 |
+
idx1,code1=index_to_code[index1]
|
| 233 |
+
for index2 in value_indexs:
|
| 234 |
+
idx2,code2=index_to_code[index2]
|
| 235 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 236 |
+
states[code1]=[idx1]
|
| 237 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 238 |
+
elif root_node.type in increment_statement:
|
| 239 |
+
DFG=[]
|
| 240 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 241 |
+
for index1 in indexs:
|
| 242 |
+
idx1,code1=index_to_code[index1]
|
| 243 |
+
for index2 in indexs:
|
| 244 |
+
idx2,code2=index_to_code[index2]
|
| 245 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 246 |
+
states[code1]=[idx1]
|
| 247 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 248 |
+
elif root_node.type in if_statement:
|
| 249 |
+
DFG=[]
|
| 250 |
+
current_states=states.copy()
|
| 251 |
+
others_states=[]
|
| 252 |
+
flag=False
|
| 253 |
+
tag=False
|
| 254 |
+
if 'else' in root_node.type:
|
| 255 |
+
tag=True
|
| 256 |
+
for child in root_node.children:
|
| 257 |
+
if 'else' in child.type:
|
| 258 |
+
tag=True
|
| 259 |
+
if child.type not in if_statement and flag is False:
|
| 260 |
+
temp,current_states=DFG_java(child,index_to_code,current_states)
|
| 261 |
+
DFG+=temp
|
| 262 |
+
else:
|
| 263 |
+
flag=True
|
| 264 |
+
temp,new_states=DFG_java(child,index_to_code,states)
|
| 265 |
+
DFG+=temp
|
| 266 |
+
others_states.append(new_states)
|
| 267 |
+
others_states.append(current_states)
|
| 268 |
+
if tag is False:
|
| 269 |
+
others_states.append(states)
|
| 270 |
+
new_states={}
|
| 271 |
+
for dic in others_states:
|
| 272 |
+
for key in dic:
|
| 273 |
+
if key not in new_states:
|
| 274 |
+
new_states[key]=dic[key].copy()
|
| 275 |
+
else:
|
| 276 |
+
new_states[key]+=dic[key]
|
| 277 |
+
for key in new_states:
|
| 278 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 279 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 280 |
+
elif root_node.type in for_statement:
|
| 281 |
+
DFG=[]
|
| 282 |
+
for child in root_node.children:
|
| 283 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 284 |
+
DFG+=temp
|
| 285 |
+
flag=False
|
| 286 |
+
for child in root_node.children:
|
| 287 |
+
if flag:
|
| 288 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 289 |
+
DFG+=temp
|
| 290 |
+
elif child.type=="local_variable_declaration":
|
| 291 |
+
flag=True
|
| 292 |
+
dic={}
|
| 293 |
+
for x in DFG:
|
| 294 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 295 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 296 |
+
else:
|
| 297 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 298 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 299 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 300 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 301 |
+
elif root_node.type in enhanced_for_statement:
|
| 302 |
+
name=root_node.child_by_field_name('name')
|
| 303 |
+
value=root_node.child_by_field_name('value')
|
| 304 |
+
body=root_node.child_by_field_name('body')
|
| 305 |
+
DFG=[]
|
| 306 |
+
for i in range(2):
|
| 307 |
+
temp,states=DFG_java(value,index_to_code,states)
|
| 308 |
+
DFG+=temp
|
| 309 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 310 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 311 |
+
for index1 in name_indexs:
|
| 312 |
+
idx1,code1=index_to_code[index1]
|
| 313 |
+
for index2 in value_indexs:
|
| 314 |
+
idx2,code2=index_to_code[index2]
|
| 315 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 316 |
+
states[code1]=[idx1]
|
| 317 |
+
temp,states=DFG_java(body,index_to_code,states)
|
| 318 |
+
DFG+=temp
|
| 319 |
+
dic={}
|
| 320 |
+
for x in DFG:
|
| 321 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 322 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 323 |
+
else:
|
| 324 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 325 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 326 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 327 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 328 |
+
elif root_node.type in while_statement:
|
| 329 |
+
DFG=[]
|
| 330 |
+
for i in range(2):
|
| 331 |
+
for child in root_node.children:
|
| 332 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 333 |
+
DFG+=temp
|
| 334 |
+
dic={}
|
| 335 |
+
for x in DFG:
|
| 336 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 337 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 338 |
+
else:
|
| 339 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 340 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 341 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 342 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 343 |
+
else:
|
| 344 |
+
DFG=[]
|
| 345 |
+
for child in root_node.children:
|
| 346 |
+
if child.type in do_first_statement:
|
| 347 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 348 |
+
DFG+=temp
|
| 349 |
+
for child in root_node.children:
|
| 350 |
+
if child.type not in do_first_statement:
|
| 351 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 352 |
+
DFG+=temp
|
| 353 |
+
|
| 354 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 355 |
+
|
| 356 |
+
def DFG_csharp(root_node,index_to_code,states):
|
| 357 |
+
assignment=['assignment_expression']
|
| 358 |
+
def_statement=['variable_declarator']
|
| 359 |
+
increment_statement=['postfix_unary_expression']
|
| 360 |
+
if_statement=['if_statement','else']
|
| 361 |
+
for_statement=['for_statement']
|
| 362 |
+
enhanced_for_statement=['for_each_statement']
|
| 363 |
+
while_statement=['while_statement']
|
| 364 |
+
do_first_statement=[]
|
| 365 |
+
states=states.copy()
|
| 366 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 367 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 368 |
+
if root_node.type==code:
|
| 369 |
+
return [],states
|
| 370 |
+
elif code in states:
|
| 371 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 372 |
+
else:
|
| 373 |
+
if root_node.type=='identifier':
|
| 374 |
+
states[code]=[idx]
|
| 375 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 376 |
+
elif root_node.type in def_statement:
|
| 377 |
+
if len(root_node.children)==2:
|
| 378 |
+
name=root_node.children[0]
|
| 379 |
+
value=root_node.children[1]
|
| 380 |
+
else:
|
| 381 |
+
name=root_node.children[0]
|
| 382 |
+
value=None
|
| 383 |
+
DFG=[]
|
| 384 |
+
if value is None:
|
| 385 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 386 |
+
for index in indexs:
|
| 387 |
+
idx,code=index_to_code[index]
|
| 388 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 389 |
+
states[code]=[idx]
|
| 390 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 391 |
+
else:
|
| 392 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 393 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 394 |
+
temp,states=DFG_csharp(value,index_to_code,states)
|
| 395 |
+
DFG+=temp
|
| 396 |
+
for index1 in name_indexs:
|
| 397 |
+
idx1,code1=index_to_code[index1]
|
| 398 |
+
for index2 in value_indexs:
|
| 399 |
+
idx2,code2=index_to_code[index2]
|
| 400 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 401 |
+
states[code1]=[idx1]
|
| 402 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 403 |
+
elif root_node.type in assignment:
|
| 404 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 405 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 406 |
+
DFG=[]
|
| 407 |
+
temp,states=DFG_csharp(right_nodes,index_to_code,states)
|
| 408 |
+
DFG+=temp
|
| 409 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 410 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 411 |
+
for index1 in name_indexs:
|
| 412 |
+
idx1,code1=index_to_code[index1]
|
| 413 |
+
for index2 in value_indexs:
|
| 414 |
+
idx2,code2=index_to_code[index2]
|
| 415 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 416 |
+
states[code1]=[idx1]
|
| 417 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 418 |
+
elif root_node.type in increment_statement:
|
| 419 |
+
DFG=[]
|
| 420 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 421 |
+
for index1 in indexs:
|
| 422 |
+
idx1,code1=index_to_code[index1]
|
| 423 |
+
for index2 in indexs:
|
| 424 |
+
idx2,code2=index_to_code[index2]
|
| 425 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 426 |
+
states[code1]=[idx1]
|
| 427 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 428 |
+
elif root_node.type in if_statement:
|
| 429 |
+
DFG=[]
|
| 430 |
+
current_states=states.copy()
|
| 431 |
+
others_states=[]
|
| 432 |
+
flag=False
|
| 433 |
+
tag=False
|
| 434 |
+
if 'else' in root_node.type:
|
| 435 |
+
tag=True
|
| 436 |
+
for child in root_node.children:
|
| 437 |
+
if 'else' in child.type:
|
| 438 |
+
tag=True
|
| 439 |
+
if child.type not in if_statement and flag is False:
|
| 440 |
+
temp,current_states=DFG_csharp(child,index_to_code,current_states)
|
| 441 |
+
DFG+=temp
|
| 442 |
+
else:
|
| 443 |
+
flag=True
|
| 444 |
+
temp,new_states=DFG_csharp(child,index_to_code,states)
|
| 445 |
+
DFG+=temp
|
| 446 |
+
others_states.append(new_states)
|
| 447 |
+
others_states.append(current_states)
|
| 448 |
+
if tag is False:
|
| 449 |
+
others_states.append(states)
|
| 450 |
+
new_states={}
|
| 451 |
+
for dic in others_states:
|
| 452 |
+
for key in dic:
|
| 453 |
+
if key not in new_states:
|
| 454 |
+
new_states[key]=dic[key].copy()
|
| 455 |
+
else:
|
| 456 |
+
new_states[key]+=dic[key]
|
| 457 |
+
for key in new_states:
|
| 458 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 459 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 460 |
+
elif root_node.type in for_statement:
|
| 461 |
+
DFG=[]
|
| 462 |
+
for child in root_node.children:
|
| 463 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 464 |
+
DFG+=temp
|
| 465 |
+
flag=False
|
| 466 |
+
for child in root_node.children:
|
| 467 |
+
if flag:
|
| 468 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 469 |
+
DFG+=temp
|
| 470 |
+
elif child.type=="local_variable_declaration":
|
| 471 |
+
flag=True
|
| 472 |
+
dic={}
|
| 473 |
+
for x in DFG:
|
| 474 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 475 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 476 |
+
else:
|
| 477 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 478 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 479 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 480 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 481 |
+
elif root_node.type in enhanced_for_statement:
|
| 482 |
+
name=root_node.child_by_field_name('left')
|
| 483 |
+
value=root_node.child_by_field_name('right')
|
| 484 |
+
body=root_node.child_by_field_name('body')
|
| 485 |
+
DFG=[]
|
| 486 |
+
for i in range(2):
|
| 487 |
+
temp,states=DFG_csharp(value,index_to_code,states)
|
| 488 |
+
DFG+=temp
|
| 489 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 490 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 491 |
+
for index1 in name_indexs:
|
| 492 |
+
idx1,code1=index_to_code[index1]
|
| 493 |
+
for index2 in value_indexs:
|
| 494 |
+
idx2,code2=index_to_code[index2]
|
| 495 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 496 |
+
states[code1]=[idx1]
|
| 497 |
+
temp,states=DFG_csharp(body,index_to_code,states)
|
| 498 |
+
DFG+=temp
|
| 499 |
+
dic={}
|
| 500 |
+
for x in DFG:
|
| 501 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 502 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 503 |
+
else:
|
| 504 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 505 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 506 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 507 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 508 |
+
elif root_node.type in while_statement:
|
| 509 |
+
DFG=[]
|
| 510 |
+
for i in range(2):
|
| 511 |
+
for child in root_node.children:
|
| 512 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 513 |
+
DFG+=temp
|
| 514 |
+
dic={}
|
| 515 |
+
for x in DFG:
|
| 516 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 517 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 518 |
+
else:
|
| 519 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 520 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 521 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 522 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 523 |
+
else:
|
| 524 |
+
DFG=[]
|
| 525 |
+
for child in root_node.children:
|
| 526 |
+
if child.type in do_first_statement:
|
| 527 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 528 |
+
DFG+=temp
|
| 529 |
+
for child in root_node.children:
|
| 530 |
+
if child.type not in do_first_statement:
|
| 531 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 532 |
+
DFG+=temp
|
| 533 |
+
|
| 534 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 535 |
+
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
def DFG_ruby(root_node,index_to_code,states):
|
| 540 |
+
assignment=['assignment','operator_assignment']
|
| 541 |
+
if_statement=['if','elsif','else','unless','when']
|
| 542 |
+
for_statement=['for']
|
| 543 |
+
while_statement=['while_modifier','until']
|
| 544 |
+
do_first_statement=[]
|
| 545 |
+
def_statement=['keyword_parameter']
|
| 546 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 547 |
+
states=states.copy()
|
| 548 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 549 |
+
if root_node.type==code:
|
| 550 |
+
return [],states
|
| 551 |
+
elif code in states:
|
| 552 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 553 |
+
else:
|
| 554 |
+
if root_node.type=='identifier':
|
| 555 |
+
states[code]=[idx]
|
| 556 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 557 |
+
elif root_node.type in def_statement:
|
| 558 |
+
name=root_node.child_by_field_name('name')
|
| 559 |
+
value=root_node.child_by_field_name('value')
|
| 560 |
+
DFG=[]
|
| 561 |
+
if value is None:
|
| 562 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 563 |
+
for index in indexs:
|
| 564 |
+
idx,code=index_to_code[index]
|
| 565 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 566 |
+
states[code]=[idx]
|
| 567 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 568 |
+
else:
|
| 569 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 570 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 571 |
+
temp,states=DFG_ruby(value,index_to_code,states)
|
| 572 |
+
DFG+=temp
|
| 573 |
+
for index1 in name_indexs:
|
| 574 |
+
idx1,code1=index_to_code[index1]
|
| 575 |
+
for index2 in value_indexs:
|
| 576 |
+
idx2,code2=index_to_code[index2]
|
| 577 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 578 |
+
states[code1]=[idx1]
|
| 579 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 580 |
+
elif root_node.type in assignment:
|
| 581 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 582 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 583 |
+
if len(right_nodes)!=len(left_nodes):
|
| 584 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 585 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 586 |
+
if len(left_nodes)==0:
|
| 587 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 588 |
+
if len(right_nodes)==0:
|
| 589 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 590 |
+
if root_node.type=="operator_assignment":
|
| 591 |
+
left_nodes=[root_node.children[0]]
|
| 592 |
+
right_nodes=[root_node.children[-1]]
|
| 593 |
+
|
| 594 |
+
DFG=[]
|
| 595 |
+
for node in right_nodes:
|
| 596 |
+
temp,states=DFG_ruby(node,index_to_code,states)
|
| 597 |
+
DFG+=temp
|
| 598 |
+
|
| 599 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 600 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 601 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 602 |
+
temp=[]
|
| 603 |
+
for token1_index in left_tokens_index:
|
| 604 |
+
idx1,code1=index_to_code[token1_index]
|
| 605 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 606 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 607 |
+
states[code1]=[idx1]
|
| 608 |
+
DFG+=temp
|
| 609 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 610 |
+
elif root_node.type in if_statement:
|
| 611 |
+
DFG=[]
|
| 612 |
+
current_states=states.copy()
|
| 613 |
+
others_states=[]
|
| 614 |
+
tag=False
|
| 615 |
+
if 'else' in root_node.type:
|
| 616 |
+
tag=True
|
| 617 |
+
for child in root_node.children:
|
| 618 |
+
if 'else' in child.type:
|
| 619 |
+
tag=True
|
| 620 |
+
if child.type not in if_statement:
|
| 621 |
+
temp,current_states=DFG_ruby(child,index_to_code,current_states)
|
| 622 |
+
DFG+=temp
|
| 623 |
+
else:
|
| 624 |
+
temp,new_states=DFG_ruby(child,index_to_code,states)
|
| 625 |
+
DFG+=temp
|
| 626 |
+
others_states.append(new_states)
|
| 627 |
+
others_states.append(current_states)
|
| 628 |
+
if tag is False:
|
| 629 |
+
others_states.append(states)
|
| 630 |
+
new_states={}
|
| 631 |
+
for dic in others_states:
|
| 632 |
+
for key in dic:
|
| 633 |
+
if key not in new_states:
|
| 634 |
+
new_states[key]=dic[key].copy()
|
| 635 |
+
else:
|
| 636 |
+
new_states[key]+=dic[key]
|
| 637 |
+
for key in new_states:
|
| 638 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 639 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 640 |
+
elif root_node.type in for_statement:
|
| 641 |
+
DFG=[]
|
| 642 |
+
for i in range(2):
|
| 643 |
+
left_nodes=[root_node.child_by_field_name('pattern')]
|
| 644 |
+
right_nodes=[root_node.child_by_field_name('value')]
|
| 645 |
+
assert len(right_nodes)==len(left_nodes)
|
| 646 |
+
for node in right_nodes:
|
| 647 |
+
temp,states=DFG_ruby(node,index_to_code,states)
|
| 648 |
+
DFG+=temp
|
| 649 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 650 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 651 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 652 |
+
temp=[]
|
| 653 |
+
for token1_index in left_tokens_index:
|
| 654 |
+
idx1,code1=index_to_code[token1_index]
|
| 655 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 656 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 657 |
+
states[code1]=[idx1]
|
| 658 |
+
DFG+=temp
|
| 659 |
+
temp,states=DFG_ruby(root_node.child_by_field_name('body'),index_to_code,states)
|
| 660 |
+
DFG+=temp
|
| 661 |
+
dic={}
|
| 662 |
+
for x in DFG:
|
| 663 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 664 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 665 |
+
else:
|
| 666 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 667 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 668 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 669 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 670 |
+
elif root_node.type in while_statement:
|
| 671 |
+
DFG=[]
|
| 672 |
+
for i in range(2):
|
| 673 |
+
for child in root_node.children:
|
| 674 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 675 |
+
DFG+=temp
|
| 676 |
+
dic={}
|
| 677 |
+
for x in DFG:
|
| 678 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 679 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 680 |
+
else:
|
| 681 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 682 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 683 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 684 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 685 |
+
else:
|
| 686 |
+
DFG=[]
|
| 687 |
+
for child in root_node.children:
|
| 688 |
+
if child.type in do_first_statement:
|
| 689 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 690 |
+
DFG+=temp
|
| 691 |
+
for child in root_node.children:
|
| 692 |
+
if child.type not in do_first_statement:
|
| 693 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 694 |
+
DFG+=temp
|
| 695 |
+
|
| 696 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 697 |
+
|
| 698 |
+
def DFG_go(root_node,index_to_code,states):
|
| 699 |
+
assignment=['assignment_statement',]
|
| 700 |
+
def_statement=['var_spec']
|
| 701 |
+
increment_statement=['inc_statement']
|
| 702 |
+
if_statement=['if_statement','else']
|
| 703 |
+
for_statement=['for_statement']
|
| 704 |
+
enhanced_for_statement=[]
|
| 705 |
+
while_statement=[]
|
| 706 |
+
do_first_statement=[]
|
| 707 |
+
states=states.copy()
|
| 708 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 709 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 710 |
+
if root_node.type==code:
|
| 711 |
+
return [],states
|
| 712 |
+
elif code in states:
|
| 713 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 714 |
+
else:
|
| 715 |
+
if root_node.type=='identifier':
|
| 716 |
+
states[code]=[idx]
|
| 717 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 718 |
+
elif root_node.type in def_statement:
|
| 719 |
+
name=root_node.child_by_field_name('name')
|
| 720 |
+
value=root_node.child_by_field_name('value')
|
| 721 |
+
DFG=[]
|
| 722 |
+
if value is None:
|
| 723 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 724 |
+
for index in indexs:
|
| 725 |
+
idx,code=index_to_code[index]
|
| 726 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 727 |
+
states[code]=[idx]
|
| 728 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 729 |
+
else:
|
| 730 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 731 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 732 |
+
temp,states=DFG_go(value,index_to_code,states)
|
| 733 |
+
DFG+=temp
|
| 734 |
+
for index1 in name_indexs:
|
| 735 |
+
idx1,code1=index_to_code[index1]
|
| 736 |
+
for index2 in value_indexs:
|
| 737 |
+
idx2,code2=index_to_code[index2]
|
| 738 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 739 |
+
states[code1]=[idx1]
|
| 740 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 741 |
+
elif root_node.type in assignment:
|
| 742 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 743 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 744 |
+
DFG=[]
|
| 745 |
+
temp,states=DFG_go(right_nodes,index_to_code,states)
|
| 746 |
+
DFG+=temp
|
| 747 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 748 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 749 |
+
for index1 in name_indexs:
|
| 750 |
+
idx1,code1=index_to_code[index1]
|
| 751 |
+
for index2 in value_indexs:
|
| 752 |
+
idx2,code2=index_to_code[index2]
|
| 753 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 754 |
+
states[code1]=[idx1]
|
| 755 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 756 |
+
elif root_node.type in increment_statement:
|
| 757 |
+
DFG=[]
|
| 758 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 759 |
+
for index1 in indexs:
|
| 760 |
+
idx1,code1=index_to_code[index1]
|
| 761 |
+
for index2 in indexs:
|
| 762 |
+
idx2,code2=index_to_code[index2]
|
| 763 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 764 |
+
states[code1]=[idx1]
|
| 765 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 766 |
+
elif root_node.type in if_statement:
|
| 767 |
+
DFG=[]
|
| 768 |
+
current_states=states.copy()
|
| 769 |
+
others_states=[]
|
| 770 |
+
flag=False
|
| 771 |
+
tag=False
|
| 772 |
+
if 'else' in root_node.type:
|
| 773 |
+
tag=True
|
| 774 |
+
for child in root_node.children:
|
| 775 |
+
if 'else' in child.type:
|
| 776 |
+
tag=True
|
| 777 |
+
if child.type not in if_statement and flag is False:
|
| 778 |
+
temp,current_states=DFG_go(child,index_to_code,current_states)
|
| 779 |
+
DFG+=temp
|
| 780 |
+
else:
|
| 781 |
+
flag=True
|
| 782 |
+
temp,new_states=DFG_go(child,index_to_code,states)
|
| 783 |
+
DFG+=temp
|
| 784 |
+
others_states.append(new_states)
|
| 785 |
+
others_states.append(current_states)
|
| 786 |
+
if tag is False:
|
| 787 |
+
others_states.append(states)
|
| 788 |
+
new_states={}
|
| 789 |
+
for dic in others_states:
|
| 790 |
+
for key in dic:
|
| 791 |
+
if key not in new_states:
|
| 792 |
+
new_states[key]=dic[key].copy()
|
| 793 |
+
else:
|
| 794 |
+
new_states[key]+=dic[key]
|
| 795 |
+
for key in states:
|
| 796 |
+
if key not in new_states:
|
| 797 |
+
new_states[key]=states[key]
|
| 798 |
+
else:
|
| 799 |
+
new_states[key]+=states[key]
|
| 800 |
+
for key in new_states:
|
| 801 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 802 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 803 |
+
elif root_node.type in for_statement:
|
| 804 |
+
DFG=[]
|
| 805 |
+
for child in root_node.children:
|
| 806 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 807 |
+
DFG+=temp
|
| 808 |
+
flag=False
|
| 809 |
+
for child in root_node.children:
|
| 810 |
+
if flag:
|
| 811 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 812 |
+
DFG+=temp
|
| 813 |
+
elif child.type=="for_clause":
|
| 814 |
+
if child.child_by_field_name('update') is not None:
|
| 815 |
+
temp,states=DFG_go(child.child_by_field_name('update'),index_to_code,states)
|
| 816 |
+
DFG+=temp
|
| 817 |
+
flag=True
|
| 818 |
+
dic={}
|
| 819 |
+
for x in DFG:
|
| 820 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 821 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 822 |
+
else:
|
| 823 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 824 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 825 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 826 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 827 |
+
else:
|
| 828 |
+
DFG=[]
|
| 829 |
+
for child in root_node.children:
|
| 830 |
+
if child.type in do_first_statement:
|
| 831 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 832 |
+
DFG+=temp
|
| 833 |
+
for child in root_node.children:
|
| 834 |
+
if child.type not in do_first_statement:
|
| 835 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 836 |
+
DFG+=temp
|
| 837 |
+
|
| 838 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 839 |
+
|
| 840 |
+
|
| 841 |
+
|
| 842 |
+
|
| 843 |
+
def DFG_php(root_node,index_to_code,states):
|
| 844 |
+
assignment=['assignment_expression','augmented_assignment_expression']
|
| 845 |
+
def_statement=['simple_parameter']
|
| 846 |
+
increment_statement=['update_expression']
|
| 847 |
+
if_statement=['if_statement','else_clause']
|
| 848 |
+
for_statement=['for_statement']
|
| 849 |
+
enhanced_for_statement=['foreach_statement']
|
| 850 |
+
while_statement=['while_statement']
|
| 851 |
+
do_first_statement=[]
|
| 852 |
+
states=states.copy()
|
| 853 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 854 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 855 |
+
if root_node.type==code:
|
| 856 |
+
return [],states
|
| 857 |
+
elif code in states:
|
| 858 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 859 |
+
else:
|
| 860 |
+
if root_node.type=='identifier':
|
| 861 |
+
states[code]=[idx]
|
| 862 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 863 |
+
elif root_node.type in def_statement:
|
| 864 |
+
name=root_node.child_by_field_name('name')
|
| 865 |
+
value=root_node.child_by_field_name('default_value')
|
| 866 |
+
DFG=[]
|
| 867 |
+
if value is None:
|
| 868 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 869 |
+
for index in indexs:
|
| 870 |
+
idx,code=index_to_code[index]
|
| 871 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 872 |
+
states[code]=[idx]
|
| 873 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 874 |
+
else:
|
| 875 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 876 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 877 |
+
temp,states=DFG_php(value,index_to_code,states)
|
| 878 |
+
DFG+=temp
|
| 879 |
+
for index1 in name_indexs:
|
| 880 |
+
idx1,code1=index_to_code[index1]
|
| 881 |
+
for index2 in value_indexs:
|
| 882 |
+
idx2,code2=index_to_code[index2]
|
| 883 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 884 |
+
states[code1]=[idx1]
|
| 885 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 886 |
+
elif root_node.type in assignment:
|
| 887 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 888 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 889 |
+
DFG=[]
|
| 890 |
+
temp,states=DFG_php(right_nodes,index_to_code,states)
|
| 891 |
+
DFG+=temp
|
| 892 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 893 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 894 |
+
for index1 in name_indexs:
|
| 895 |
+
idx1,code1=index_to_code[index1]
|
| 896 |
+
for index2 in value_indexs:
|
| 897 |
+
idx2,code2=index_to_code[index2]
|
| 898 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 899 |
+
states[code1]=[idx1]
|
| 900 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 901 |
+
elif root_node.type in increment_statement:
|
| 902 |
+
DFG=[]
|
| 903 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 904 |
+
for index1 in indexs:
|
| 905 |
+
idx1,code1=index_to_code[index1]
|
| 906 |
+
for index2 in indexs:
|
| 907 |
+
idx2,code2=index_to_code[index2]
|
| 908 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 909 |
+
states[code1]=[idx1]
|
| 910 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 911 |
+
elif root_node.type in if_statement:
|
| 912 |
+
DFG=[]
|
| 913 |
+
current_states=states.copy()
|
| 914 |
+
others_states=[]
|
| 915 |
+
flag=False
|
| 916 |
+
tag=False
|
| 917 |
+
if 'else' in root_node.type:
|
| 918 |
+
tag=True
|
| 919 |
+
for child in root_node.children:
|
| 920 |
+
if 'else' in child.type:
|
| 921 |
+
tag=True
|
| 922 |
+
if child.type not in if_statement and flag is False:
|
| 923 |
+
temp,current_states=DFG_php(child,index_to_code,current_states)
|
| 924 |
+
DFG+=temp
|
| 925 |
+
else:
|
| 926 |
+
flag=True
|
| 927 |
+
temp,new_states=DFG_php(child,index_to_code,states)
|
| 928 |
+
DFG+=temp
|
| 929 |
+
others_states.append(new_states)
|
| 930 |
+
others_states.append(current_states)
|
| 931 |
+
new_states={}
|
| 932 |
+
for dic in others_states:
|
| 933 |
+
for key in dic:
|
| 934 |
+
if key not in new_states:
|
| 935 |
+
new_states[key]=dic[key].copy()
|
| 936 |
+
else:
|
| 937 |
+
new_states[key]+=dic[key]
|
| 938 |
+
for key in states:
|
| 939 |
+
if key not in new_states:
|
| 940 |
+
new_states[key]=states[key]
|
| 941 |
+
else:
|
| 942 |
+
new_states[key]+=states[key]
|
| 943 |
+
for key in new_states:
|
| 944 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 945 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 946 |
+
elif root_node.type in for_statement:
|
| 947 |
+
DFG=[]
|
| 948 |
+
for child in root_node.children:
|
| 949 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 950 |
+
DFG+=temp
|
| 951 |
+
flag=False
|
| 952 |
+
for child in root_node.children:
|
| 953 |
+
if flag:
|
| 954 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 955 |
+
DFG+=temp
|
| 956 |
+
elif child.type=="assignment_expression":
|
| 957 |
+
flag=True
|
| 958 |
+
dic={}
|
| 959 |
+
for x in DFG:
|
| 960 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 961 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 962 |
+
else:
|
| 963 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 964 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 965 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 966 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 967 |
+
elif root_node.type in enhanced_for_statement:
|
| 968 |
+
name=None
|
| 969 |
+
value=None
|
| 970 |
+
for child in root_node.children:
|
| 971 |
+
if child.type=='variable_name' and value is None:
|
| 972 |
+
value=child
|
| 973 |
+
elif child.type=='variable_name' and name is None:
|
| 974 |
+
name=child
|
| 975 |
+
break
|
| 976 |
+
body=root_node.child_by_field_name('body')
|
| 977 |
+
DFG=[]
|
| 978 |
+
for i in range(2):
|
| 979 |
+
temp,states=DFG_php(value,index_to_code,states)
|
| 980 |
+
DFG+=temp
|
| 981 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 982 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 983 |
+
for index1 in name_indexs:
|
| 984 |
+
idx1,code1=index_to_code[index1]
|
| 985 |
+
for index2 in value_indexs:
|
| 986 |
+
idx2,code2=index_to_code[index2]
|
| 987 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 988 |
+
states[code1]=[idx1]
|
| 989 |
+
temp,states=DFG_php(body,index_to_code,states)
|
| 990 |
+
DFG+=temp
|
| 991 |
+
dic={}
|
| 992 |
+
for x in DFG:
|
| 993 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 994 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 995 |
+
else:
|
| 996 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 997 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 998 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 999 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1000 |
+
elif root_node.type in while_statement:
|
| 1001 |
+
DFG=[]
|
| 1002 |
+
for i in range(2):
|
| 1003 |
+
for child in root_node.children:
|
| 1004 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1005 |
+
DFG+=temp
|
| 1006 |
+
dic={}
|
| 1007 |
+
for x in DFG:
|
| 1008 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1009 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1010 |
+
else:
|
| 1011 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1012 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1013 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1014 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1015 |
+
else:
|
| 1016 |
+
DFG=[]
|
| 1017 |
+
for child in root_node.children:
|
| 1018 |
+
if child.type in do_first_statement:
|
| 1019 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1020 |
+
DFG+=temp
|
| 1021 |
+
for child in root_node.children:
|
| 1022 |
+
if child.type not in do_first_statement:
|
| 1023 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1024 |
+
DFG+=temp
|
| 1025 |
+
|
| 1026 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1027 |
+
|
| 1028 |
+
|
| 1029 |
+
def DFG_javascript(root_node,index_to_code,states):
|
| 1030 |
+
assignment=['assignment_pattern','augmented_assignment_expression']
|
| 1031 |
+
def_statement=['variable_declarator']
|
| 1032 |
+
increment_statement=['update_expression']
|
| 1033 |
+
if_statement=['if_statement','else']
|
| 1034 |
+
for_statement=['for_statement']
|
| 1035 |
+
enhanced_for_statement=[]
|
| 1036 |
+
while_statement=['while_statement']
|
| 1037 |
+
do_first_statement=[]
|
| 1038 |
+
states=states.copy()
|
| 1039 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 1040 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 1041 |
+
if root_node.type==code:
|
| 1042 |
+
return [],states
|
| 1043 |
+
elif code in states:
|
| 1044 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 1045 |
+
else:
|
| 1046 |
+
if root_node.type=='identifier':
|
| 1047 |
+
states[code]=[idx]
|
| 1048 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 1049 |
+
elif root_node.type in def_statement:
|
| 1050 |
+
name=root_node.child_by_field_name('name')
|
| 1051 |
+
value=root_node.child_by_field_name('value')
|
| 1052 |
+
DFG=[]
|
| 1053 |
+
if value is None:
|
| 1054 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 1055 |
+
for index in indexs:
|
| 1056 |
+
idx,code=index_to_code[index]
|
| 1057 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 1058 |
+
states[code]=[idx]
|
| 1059 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1060 |
+
else:
|
| 1061 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 1062 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 1063 |
+
temp,states=DFG_javascript(value,index_to_code,states)
|
| 1064 |
+
DFG+=temp
|
| 1065 |
+
for index1 in name_indexs:
|
| 1066 |
+
idx1,code1=index_to_code[index1]
|
| 1067 |
+
for index2 in value_indexs:
|
| 1068 |
+
idx2,code2=index_to_code[index2]
|
| 1069 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 1070 |
+
states[code1]=[idx1]
|
| 1071 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1072 |
+
elif root_node.type in assignment:
|
| 1073 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 1074 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 1075 |
+
DFG=[]
|
| 1076 |
+
temp,states=DFG_javascript(right_nodes,index_to_code,states)
|
| 1077 |
+
DFG+=temp
|
| 1078 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 1079 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 1080 |
+
for index1 in name_indexs:
|
| 1081 |
+
idx1,code1=index_to_code[index1]
|
| 1082 |
+
for index2 in value_indexs:
|
| 1083 |
+
idx2,code2=index_to_code[index2]
|
| 1084 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 1085 |
+
states[code1]=[idx1]
|
| 1086 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1087 |
+
elif root_node.type in increment_statement:
|
| 1088 |
+
DFG=[]
|
| 1089 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 1090 |
+
for index1 in indexs:
|
| 1091 |
+
idx1,code1=index_to_code[index1]
|
| 1092 |
+
for index2 in indexs:
|
| 1093 |
+
idx2,code2=index_to_code[index2]
|
| 1094 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 1095 |
+
states[code1]=[idx1]
|
| 1096 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1097 |
+
elif root_node.type in if_statement:
|
| 1098 |
+
DFG=[]
|
| 1099 |
+
current_states=states.copy()
|
| 1100 |
+
others_states=[]
|
| 1101 |
+
flag=False
|
| 1102 |
+
tag=False
|
| 1103 |
+
if 'else' in root_node.type:
|
| 1104 |
+
tag=True
|
| 1105 |
+
for child in root_node.children:
|
| 1106 |
+
if 'else' in child.type:
|
| 1107 |
+
tag=True
|
| 1108 |
+
if child.type not in if_statement and flag is False:
|
| 1109 |
+
temp,current_states=DFG_javascript(child,index_to_code,current_states)
|
| 1110 |
+
DFG+=temp
|
| 1111 |
+
else:
|
| 1112 |
+
flag=True
|
| 1113 |
+
temp,new_states=DFG_javascript(child,index_to_code,states)
|
| 1114 |
+
DFG+=temp
|
| 1115 |
+
others_states.append(new_states)
|
| 1116 |
+
others_states.append(current_states)
|
| 1117 |
+
if tag is False:
|
| 1118 |
+
others_states.append(states)
|
| 1119 |
+
new_states={}
|
| 1120 |
+
for dic in others_states:
|
| 1121 |
+
for key in dic:
|
| 1122 |
+
if key not in new_states:
|
| 1123 |
+
new_states[key]=dic[key].copy()
|
| 1124 |
+
else:
|
| 1125 |
+
new_states[key]+=dic[key]
|
| 1126 |
+
for key in states:
|
| 1127 |
+
if key not in new_states:
|
| 1128 |
+
new_states[key]=states[key]
|
| 1129 |
+
else:
|
| 1130 |
+
new_states[key]+=states[key]
|
| 1131 |
+
for key in new_states:
|
| 1132 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 1133 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 1134 |
+
elif root_node.type in for_statement:
|
| 1135 |
+
DFG=[]
|
| 1136 |
+
for child in root_node.children:
|
| 1137 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1138 |
+
DFG+=temp
|
| 1139 |
+
flag=False
|
| 1140 |
+
for child in root_node.children:
|
| 1141 |
+
if flag:
|
| 1142 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1143 |
+
DFG+=temp
|
| 1144 |
+
elif child.type=="variable_declaration":
|
| 1145 |
+
flag=True
|
| 1146 |
+
dic={}
|
| 1147 |
+
for x in DFG:
|
| 1148 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1149 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1150 |
+
else:
|
| 1151 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1152 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1153 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1154 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1155 |
+
elif root_node.type in while_statement:
|
| 1156 |
+
DFG=[]
|
| 1157 |
+
for i in range(2):
|
| 1158 |
+
for child in root_node.children:
|
| 1159 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1160 |
+
DFG+=temp
|
| 1161 |
+
dic={}
|
| 1162 |
+
for x in DFG:
|
| 1163 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1164 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1165 |
+
else:
|
| 1166 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1167 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1168 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1169 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1170 |
+
else:
|
| 1171 |
+
DFG=[]
|
| 1172 |
+
for child in root_node.children:
|
| 1173 |
+
if child.type in do_first_statement:
|
| 1174 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1175 |
+
DFG+=temp
|
| 1176 |
+
for child in root_node.children:
|
| 1177 |
+
if child.type not in do_first_statement:
|
| 1178 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1179 |
+
DFG+=temp
|
| 1180 |
+
|
| 1181 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1182 |
+
|
| 1183 |
+
|
| 1184 |
+
|
parser/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import (remove_comments_and_docstrings,
|
| 2 |
+
tree_to_token_index,
|
| 3 |
+
index_to_code_token,
|
| 4 |
+
tree_to_variable_index)
|
| 5 |
+
from .DFG import DFG_python,DFG_java,DFG_ruby,DFG_go,DFG_php,DFG_javascript,DFG_csharp
|
parser/__pycache__/DFG.cpython-36.pyc
ADDED
|
Binary file (33.8 kB). View file
|
|
|
parser/__pycache__/__init__.cpython-36.pyc
ADDED
|
Binary file (442 Bytes). View file
|
|
|
parser/__pycache__/utils.cpython-36.pyc
ADDED
|
Binary file (2.39 kB). View file
|
|
|
parser/build.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from tree_sitter import Language, Parser
|
| 5 |
+
|
| 6 |
+
Language.build_library(
|
| 7 |
+
# Store the library in the `build` directory
|
| 8 |
+
'my-languages.so',
|
| 9 |
+
|
| 10 |
+
# Include one or more languages
|
| 11 |
+
[
|
| 12 |
+
'tree-sitter-go',
|
| 13 |
+
'tree-sitter-javascript',
|
| 14 |
+
'tree-sitter-python',
|
| 15 |
+
'tree-sitter-php',
|
| 16 |
+
'tree-sitter-java',
|
| 17 |
+
'tree-sitter-ruby',
|
| 18 |
+
'tree-sitter-c-sharp',
|
| 19 |
+
]
|
| 20 |
+
)
|
| 21 |
+
|
parser/build.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
git clone https://github.com/tree-sitter/tree-sitter-go
|
| 2 |
+
git clone https://github.com/tree-sitter/tree-sitter-javascript
|
| 3 |
+
git clone https://github.com/tree-sitter/tree-sitter-python
|
| 4 |
+
git clone https://github.com/tree-sitter/tree-sitter-ruby
|
| 5 |
+
git clone https://github.com/tree-sitter/tree-sitter-php
|
| 6 |
+
git clone https://github.com/tree-sitter/tree-sitter-java
|
| 7 |
+
git clone https://github.com/tree-sitter/tree-sitter-c-sharp
|
| 8 |
+
python build.py
|
parser/utils.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from io import StringIO
|
| 3 |
+
import tokenize
|
| 4 |
+
def remove_comments_and_docstrings(source,lang):
|
| 5 |
+
if lang in ['python']:
|
| 6 |
+
"""
|
| 7 |
+
Returns 'source' minus comments and docstrings.
|
| 8 |
+
"""
|
| 9 |
+
io_obj = StringIO(source)
|
| 10 |
+
out = ""
|
| 11 |
+
prev_toktype = tokenize.INDENT
|
| 12 |
+
last_lineno = -1
|
| 13 |
+
last_col = 0
|
| 14 |
+
for tok in tokenize.generate_tokens(io_obj.readline):
|
| 15 |
+
token_type = tok[0]
|
| 16 |
+
token_string = tok[1]
|
| 17 |
+
start_line, start_col = tok[2]
|
| 18 |
+
end_line, end_col = tok[3]
|
| 19 |
+
ltext = tok[4]
|
| 20 |
+
if start_line > last_lineno:
|
| 21 |
+
last_col = 0
|
| 22 |
+
if start_col > last_col:
|
| 23 |
+
out += (" " * (start_col - last_col))
|
| 24 |
+
# Remove comments:
|
| 25 |
+
if token_type == tokenize.COMMENT:
|
| 26 |
+
pass
|
| 27 |
+
# This series of conditionals removes docstrings:
|
| 28 |
+
elif token_type == tokenize.STRING:
|
| 29 |
+
if prev_toktype != tokenize.INDENT:
|
| 30 |
+
# This is likely a docstring; double-check we're not inside an operator:
|
| 31 |
+
if prev_toktype != tokenize.NEWLINE:
|
| 32 |
+
if start_col > 0:
|
| 33 |
+
out += token_string
|
| 34 |
+
else:
|
| 35 |
+
out += token_string
|
| 36 |
+
prev_toktype = token_type
|
| 37 |
+
last_col = end_col
|
| 38 |
+
last_lineno = end_line
|
| 39 |
+
temp=[]
|
| 40 |
+
for x in out.split('\n'):
|
| 41 |
+
if x.strip()!="":
|
| 42 |
+
temp.append(x)
|
| 43 |
+
return '\n'.join(temp)
|
| 44 |
+
elif lang in ['ruby']:
|
| 45 |
+
return source
|
| 46 |
+
else:
|
| 47 |
+
def replacer(match):
|
| 48 |
+
s = match.group(0)
|
| 49 |
+
if s.startswith('/'):
|
| 50 |
+
return " " # note: a space and not an empty string
|
| 51 |
+
else:
|
| 52 |
+
return s
|
| 53 |
+
pattern = re.compile(
|
| 54 |
+
r'//.*?$|/\*.*?\*/|\'(?:\\.|[^\\\'])*\'|"(?:\\.|[^\\"])*"',
|
| 55 |
+
re.DOTALL | re.MULTILINE
|
| 56 |
+
)
|
| 57 |
+
temp=[]
|
| 58 |
+
for x in re.sub(pattern, replacer, source).split('\n'):
|
| 59 |
+
if x.strip()!="":
|
| 60 |
+
temp.append(x)
|
| 61 |
+
return '\n'.join(temp)
|
| 62 |
+
|
| 63 |
+
def tree_to_token_index(root_node):
|
| 64 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 65 |
+
return [(root_node.start_point,root_node.end_point)]
|
| 66 |
+
else:
|
| 67 |
+
code_tokens=[]
|
| 68 |
+
for child in root_node.children:
|
| 69 |
+
code_tokens+=tree_to_token_index(child)
|
| 70 |
+
return code_tokens
|
| 71 |
+
|
| 72 |
+
def tree_to_variable_index(root_node,index_to_code):
|
| 73 |
+
if (len(root_node.children)==0 or root_node.type=='string') and root_node.type!='comment':
|
| 74 |
+
index=(root_node.start_point,root_node.end_point)
|
| 75 |
+
_,code=index_to_code[index]
|
| 76 |
+
if root_node.type!=code:
|
| 77 |
+
return [(root_node.start_point,root_node.end_point)]
|
| 78 |
+
else:
|
| 79 |
+
return []
|
| 80 |
+
else:
|
| 81 |
+
code_tokens=[]
|
| 82 |
+
for child in root_node.children:
|
| 83 |
+
code_tokens+=tree_to_variable_index(child,index_to_code)
|
| 84 |
+
return code_tokens
|
| 85 |
+
|
| 86 |
+
def index_to_code_token(index,code):
|
| 87 |
+
start_point=index[0]
|
| 88 |
+
end_point=index[1]
|
| 89 |
+
if start_point[0]==end_point[0]:
|
| 90 |
+
s=code[start_point[0]][start_point[1]:end_point[1]]
|
| 91 |
+
else:
|
| 92 |
+
s=""
|
| 93 |
+
s+=code[start_point[0]][start_point[1]:]
|
| 94 |
+
for i in range(start_point[0]+1,end_point[0]):
|
| 95 |
+
s+=code[i]
|
| 96 |
+
s+=code[end_point[0]][:end_point[1]]
|
| 97 |
+
return s
|
| 98 |
+
|
run.py
ADDED
|
@@ -0,0 +1,1420 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
|
| 18 |
+
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
|
| 19 |
+
using a masked language modeling (MLM) loss.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
from unittest import removeResult
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
import argparse
|
| 25 |
+
import logging
|
| 26 |
+
import os
|
| 27 |
+
# os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:24"
|
| 28 |
+
import pickle
|
| 29 |
+
import random
|
| 30 |
+
import torch
|
| 31 |
+
import json
|
| 32 |
+
from random import choice
|
| 33 |
+
import numpy as np
|
| 34 |
+
from itertools import cycle
|
| 35 |
+
from model import Model,Multi_Loss_CoCoSoDa
|
| 36 |
+
from torch.nn import CrossEntropyLoss
|
| 37 |
+
from torch.utils.data import DataLoader, Dataset, SequentialSampler, RandomSampler
|
| 38 |
+
from transformers import (WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup,
|
| 39 |
+
RobertaConfig, RobertaModel, RobertaTokenizer)
|
| 40 |
+
|
| 41 |
+
logger = logging.getLogger(__name__)
|
| 42 |
+
from tqdm import tqdm
|
| 43 |
+
import multiprocessing
|
| 44 |
+
cpu_cont = 16
|
| 45 |
+
|
| 46 |
+
from parser import DFG_python,DFG_java,DFG_ruby,DFG_go,DFG_php,DFG_javascript
|
| 47 |
+
from parser import (remove_comments_and_docstrings,
|
| 48 |
+
tree_to_token_index,
|
| 49 |
+
index_to_code_token,
|
| 50 |
+
tree_to_variable_index)
|
| 51 |
+
from tree_sitter import Language, Parser
|
| 52 |
+
import sys
|
| 53 |
+
sys.path.append("dataset")
|
| 54 |
+
torch.cuda.set_per_process_memory_fraction(0.8)
|
| 55 |
+
from utils import save_json_data, save_pickle_data
|
| 56 |
+
dfg_function={
|
| 57 |
+
'python':DFG_python,
|
| 58 |
+
'java':DFG_java,
|
| 59 |
+
'ruby':DFG_ruby,
|
| 60 |
+
'go':DFG_go,
|
| 61 |
+
'php':DFG_php,
|
| 62 |
+
'javascript':DFG_javascript
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
parsers={}
|
| 66 |
+
for lang in dfg_function:
|
| 67 |
+
LANGUAGE = Language('parser/my-languages.so', lang)
|
| 68 |
+
parser = Parser()
|
| 69 |
+
parser.set_language(LANGUAGE)
|
| 70 |
+
parser = [parser,dfg_function[lang]]
|
| 71 |
+
parsers[lang]= parser
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
ruby_special_token = ['keyword', 'identifier', 'separators', 'simple_symbol', 'constant', 'instance_variable',
|
| 75 |
+
'operator', 'string_content', 'integer', 'escape_sequence', 'comment', 'hash_key_symbol',
|
| 76 |
+
'global_variable', 'heredoc_beginning', 'heredoc_content', 'heredoc_end', 'class_variable',]
|
| 77 |
+
|
| 78 |
+
java_special_token = ['keyword', 'identifier', 'type_identifier', 'separators', 'operator', 'decimal_integer_literal',
|
| 79 |
+
'void_type', 'string_literal', 'decimal_floating_point_literal',
|
| 80 |
+
'boolean_type', 'null_literal', 'comment', 'hex_integer_literal', 'character_literal']
|
| 81 |
+
|
| 82 |
+
go_special_token = ['keyword', 'identifier', 'separators', 'type_identifier', 'int_literal', 'operator',
|
| 83 |
+
'field_identifier', 'package_identifier', 'comment', 'escape_sequence', 'raw_string_literal',
|
| 84 |
+
'rune_literal', 'label_name', 'float_literal']
|
| 85 |
+
|
| 86 |
+
javascript_special_token =['keyword', 'separators', 'identifier', 'property_identifier', 'operator',
|
| 87 |
+
'number', 'string_fragment', 'comment', 'regex_pattern', 'shorthand_property_identifier_pattern',
|
| 88 |
+
'shorthand_property_identifier', 'regex_flags', 'escape_sequence', 'statement_identifier']
|
| 89 |
+
|
| 90 |
+
php_special_token =['text', 'php_tag', 'name', 'operator', 'keyword', 'string', 'integer', 'separators', 'comment',
|
| 91 |
+
'escape_sequence', 'ERROR', 'boolean', 'namespace', 'class', 'extends']
|
| 92 |
+
|
| 93 |
+
python_special_token =['keyword', 'identifier', 'separators', 'operator', '"', 'integer',
|
| 94 |
+
'comment', 'none', 'escape_sequence']
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
special_token={
|
| 98 |
+
'python':python_special_token,
|
| 99 |
+
'java':java_special_token,
|
| 100 |
+
'ruby':ruby_special_token,
|
| 101 |
+
'go':go_special_token,
|
| 102 |
+
'php':php_special_token,
|
| 103 |
+
'javascript':javascript_special_token
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
all_special_token = []
|
| 107 |
+
for key, value in special_token.items():
|
| 108 |
+
all_special_token = list(set(all_special_token ).union(set(value)))
|
| 109 |
+
|
| 110 |
+
def lalign(x, y, alpha=2):
|
| 111 |
+
x = torch.tensor(x)
|
| 112 |
+
y= torch.tensor(y)
|
| 113 |
+
return (x - y).norm(dim=1).pow(alpha).mean()
|
| 114 |
+
# code2nl_pos = torch.einsum('nc,nc->n', [x, y]).unsqueeze(-1)
|
| 115 |
+
|
| 116 |
+
# return code2nl_pos.mean()
|
| 117 |
+
|
| 118 |
+
def lunif(x, t=2):
|
| 119 |
+
x = torch.tensor(x)
|
| 120 |
+
sq_pdist = torch.pdist(x, p=2).pow(2)
|
| 121 |
+
return sq_pdist.mul(-t).exp().mean().log()
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def cal_r1_r5_r10(ranks):
|
| 126 |
+
r1,r5,r10= 0,0,0
|
| 127 |
+
data_len= len(ranks)
|
| 128 |
+
for item in ranks:
|
| 129 |
+
if item >=1:
|
| 130 |
+
r1 +=1
|
| 131 |
+
r5 += 1
|
| 132 |
+
r10 += 1
|
| 133 |
+
elif item >=0.2:
|
| 134 |
+
r5+= 1
|
| 135 |
+
r10+=1
|
| 136 |
+
elif item >=0.1:
|
| 137 |
+
r10 +=1
|
| 138 |
+
result = {"R@1":round(r1/data_len,3), "R@5": round(r5/data_len,3), "R@10": round(r10/data_len,3)}
|
| 139 |
+
return result
|
| 140 |
+
|
| 141 |
+
#remove comments, tokenize code and extract dataflow
|
| 142 |
+
def extract_dataflow(code, parser,lang):
|
| 143 |
+
#remove comments
|
| 144 |
+
try:
|
| 145 |
+
code=remove_comments_and_docstrings(code,lang)
|
| 146 |
+
except:
|
| 147 |
+
pass
|
| 148 |
+
#obtain dataflow
|
| 149 |
+
if lang=="php":
|
| 150 |
+
code="<?php"+code+"?>"
|
| 151 |
+
try:
|
| 152 |
+
tree = parser[0].parse(bytes(code,'utf8'))
|
| 153 |
+
root_node = tree.root_node
|
| 154 |
+
tokens_index=tree_to_token_index(root_node)
|
| 155 |
+
code=code.split('\n')
|
| 156 |
+
code_tokens=[index_to_code_token(x,code) for x in tokens_index]
|
| 157 |
+
index_to_code={}
|
| 158 |
+
for idx,(index,code) in enumerate(zip(tokens_index,code_tokens)):
|
| 159 |
+
index_to_code[index]=(idx,code)
|
| 160 |
+
try:
|
| 161 |
+
DFG,_=parser[1](root_node,index_to_code,{})
|
| 162 |
+
except:
|
| 163 |
+
DFG=[]
|
| 164 |
+
DFG=sorted(DFG,key=lambda x:x[1])
|
| 165 |
+
indexs=set()
|
| 166 |
+
for d in DFG:
|
| 167 |
+
if len(d[-1])!=0:
|
| 168 |
+
indexs.add(d[1])
|
| 169 |
+
for x in d[-1]:
|
| 170 |
+
indexs.add(x)
|
| 171 |
+
new_DFG=[]
|
| 172 |
+
for d in DFG:
|
| 173 |
+
if d[1] in indexs:
|
| 174 |
+
new_DFG.append(d)
|
| 175 |
+
dfg=new_DFG
|
| 176 |
+
except:
|
| 177 |
+
dfg=[]
|
| 178 |
+
return code_tokens,dfg
|
| 179 |
+
|
| 180 |
+
#remove comments, tokenize code and extract dataflow
|
| 181 |
+
def tokenizer_source_code(code, parser,lang):
|
| 182 |
+
#remove comments
|
| 183 |
+
try:
|
| 184 |
+
code=remove_comments_and_docstrings(code,lang)
|
| 185 |
+
except:
|
| 186 |
+
pass
|
| 187 |
+
#obtain dataflow
|
| 188 |
+
if lang=="php":
|
| 189 |
+
code="<?php"+code+"?>"
|
| 190 |
+
try:
|
| 191 |
+
tree = parser[0].parse(bytes(code,'utf8'))
|
| 192 |
+
root_node = tree.root_node
|
| 193 |
+
tokens_index=tree_to_token_index(root_node)
|
| 194 |
+
code=code.split('\n')
|
| 195 |
+
code_tokens=[index_to_code_token(x,code) for x in tokens_index]
|
| 196 |
+
except:
|
| 197 |
+
dfg=[]
|
| 198 |
+
return code_tokens
|
| 199 |
+
|
| 200 |
+
class InputFeatures(object):
|
| 201 |
+
"""A single training/test features for a example."""
|
| 202 |
+
def __init__(self,
|
| 203 |
+
code_tokens,
|
| 204 |
+
code_ids,
|
| 205 |
+
# position_idx,
|
| 206 |
+
# dfg_to_code,
|
| 207 |
+
# dfg_to_dfg,
|
| 208 |
+
nl_tokens,
|
| 209 |
+
nl_ids,
|
| 210 |
+
url,
|
| 211 |
+
|
| 212 |
+
):
|
| 213 |
+
self.code_tokens = code_tokens
|
| 214 |
+
self.code_ids = code_ids
|
| 215 |
+
# self.position_idx=position_idx
|
| 216 |
+
# self.dfg_to_code=dfg_to_code
|
| 217 |
+
# self.dfg_to_dfg=dfg_to_dfg
|
| 218 |
+
self.nl_tokens = nl_tokens
|
| 219 |
+
self.nl_ids = nl_ids
|
| 220 |
+
self.url=url
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
class TypeAugInputFeatures(object):
|
| 224 |
+
"""A single training/test features for a example."""
|
| 225 |
+
def __init__(self,
|
| 226 |
+
code_tokens,
|
| 227 |
+
code_ids,
|
| 228 |
+
# position_idx,
|
| 229 |
+
code_type,
|
| 230 |
+
code_type_ids,
|
| 231 |
+
nl_tokens,
|
| 232 |
+
nl_ids,
|
| 233 |
+
url,
|
| 234 |
+
|
| 235 |
+
):
|
| 236 |
+
self.code_tokens = code_tokens
|
| 237 |
+
self.code_ids = code_ids
|
| 238 |
+
# self.position_idx=position_idx
|
| 239 |
+
self.code_type=code_type
|
| 240 |
+
self.code_type_ids=code_type_ids
|
| 241 |
+
self.nl_tokens = nl_tokens
|
| 242 |
+
self.nl_ids = nl_ids
|
| 243 |
+
self.url=url
|
| 244 |
+
|
| 245 |
+
def convert_examples_to_features(js):
|
| 246 |
+
js,tokenizer,args=js
|
| 247 |
+
#code
|
| 248 |
+
if args.lang == "java_mini":
|
| 249 |
+
parser=parsers["java"]
|
| 250 |
+
else:
|
| 251 |
+
parser=parsers[js["language"]]
|
| 252 |
+
# code
|
| 253 |
+
code_tokens=tokenizer_source_code(js['original_string'],parser,args.lang)
|
| 254 |
+
code_tokens=" ".join(code_tokens[:args.code_length-2])
|
| 255 |
+
code_tokens=tokenizer.tokenize(code_tokens)[:args.code_length-2]
|
| 256 |
+
code_tokens =[tokenizer.cls_token]+code_tokens+[tokenizer.sep_token]
|
| 257 |
+
code_ids = tokenizer.convert_tokens_to_ids(code_tokens)
|
| 258 |
+
padding_length = args.code_length - len(code_ids)
|
| 259 |
+
code_ids+=[tokenizer.pad_token_id]*padding_length
|
| 260 |
+
|
| 261 |
+
#nl
|
| 262 |
+
nl=' '.join(js['docstring_tokens'])
|
| 263 |
+
nl_tokens=tokenizer.tokenize(nl)[:args.nl_length-2]
|
| 264 |
+
nl_tokens =[tokenizer.cls_token]+nl_tokens+[tokenizer.sep_token]
|
| 265 |
+
nl_ids = tokenizer.convert_tokens_to_ids(nl_tokens)
|
| 266 |
+
padding_length = args.nl_length - len(nl_ids)
|
| 267 |
+
nl_ids+=[tokenizer.pad_token_id]*padding_length
|
| 268 |
+
|
| 269 |
+
return InputFeatures(code_tokens,code_ids,nl_tokens,nl_ids,js['url'])
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def convert_examples_to_features_aug_type(js):
|
| 273 |
+
js,tokenizer,args=js
|
| 274 |
+
#code
|
| 275 |
+
if args.lang == "java_mini":
|
| 276 |
+
parser=parsers["java"]
|
| 277 |
+
else:
|
| 278 |
+
parser=parsers[js["language"]]
|
| 279 |
+
# code
|
| 280 |
+
token_type_role = js[ 'bpe_token_type_role']
|
| 281 |
+
code_token = [item[0] for item in token_type_role]
|
| 282 |
+
# code = ' '.join(code_token[:args.code_length-4])
|
| 283 |
+
# code_tokens = tokenizer.tokenize(code)[:args.code_length-4]
|
| 284 |
+
code_tokens = code_token[:args.code_length-4]
|
| 285 |
+
code_tokens =[tokenizer.cls_token,"<encoder-only>",tokenizer.sep_token]+code_tokens+[tokenizer.sep_token]
|
| 286 |
+
code_ids = tokenizer.convert_tokens_to_ids(code_tokens)
|
| 287 |
+
padding_length = args.code_length - len(code_ids)
|
| 288 |
+
code_ids += [tokenizer.pad_token_id]*padding_length
|
| 289 |
+
|
| 290 |
+
# code type
|
| 291 |
+
code_type_token = [item[-1] for item in token_type_role]
|
| 292 |
+
# code_type= ' '.join(code_type_token[:args.code_length-4])
|
| 293 |
+
# code_type_tokens = tokenizer.tokenize(code_type)[:args.code_length-4]
|
| 294 |
+
code_type_tokens = code_type_token[:args.code_length-4]
|
| 295 |
+
code_type_tokens =[tokenizer.cls_token,"<encoder-only>",tokenizer.sep_token]+code_type_tokens+[tokenizer.sep_token]
|
| 296 |
+
code_type_ids = tokenizer.convert_tokens_to_ids(code_type_tokens)
|
| 297 |
+
padding_length = args.code_length - len(code_type_ids)
|
| 298 |
+
code_type_ids += [tokenizer.pad_token_id]*padding_length
|
| 299 |
+
|
| 300 |
+
#nl
|
| 301 |
+
nl=' '.join(js['docstring_tokens'])
|
| 302 |
+
nl_tokens = tokenizer.tokenize(nl)[:args.nl_length-4]
|
| 303 |
+
nl_tokens = [tokenizer.cls_token,"<encoder-only>",tokenizer.sep_token]+nl_tokens+[tokenizer.sep_token]
|
| 304 |
+
nl_ids = tokenizer.convert_tokens_to_ids(nl_tokens)
|
| 305 |
+
padding_length = args.nl_length - len(nl_ids)
|
| 306 |
+
nl_ids += [tokenizer.pad_token_id]*padding_length
|
| 307 |
+
|
| 308 |
+
return TypeAugInputFeatures(code_tokens,code_ids,code_type_tokens,code_type_ids,nl_tokens,nl_ids,js['url'])
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
class TextDataset(Dataset):
|
| 312 |
+
def __init__(self, tokenizer, args, file_path=None,pool=None):
|
| 313 |
+
self.args=args
|
| 314 |
+
prefix=file_path.split('/')[-1][:-6]
|
| 315 |
+
cache_file=args.output_dir+'/'+prefix+'.pkl'
|
| 316 |
+
n_debug_samples = args.n_debug_samples
|
| 317 |
+
# if 'codebase' in file_path:
|
| 318 |
+
# n_debug_samples = 100000
|
| 319 |
+
if 'train' in file_path:
|
| 320 |
+
self.split = "train"
|
| 321 |
+
else:
|
| 322 |
+
self.split = "other"
|
| 323 |
+
if os.path.exists(cache_file):
|
| 324 |
+
self.examples=pickle.load(open(cache_file,'rb'))
|
| 325 |
+
if args.debug:
|
| 326 |
+
self.examples= self.examples[:n_debug_samples]
|
| 327 |
+
else:
|
| 328 |
+
self.examples = []
|
| 329 |
+
data=[]
|
| 330 |
+
if args.debug:
|
| 331 |
+
with open(file_path, encoding="utf-8") as f:
|
| 332 |
+
for line in f:
|
| 333 |
+
line=line.strip()
|
| 334 |
+
js=json.loads(line)
|
| 335 |
+
data.append((js,tokenizer,args))
|
| 336 |
+
if len(data) >= n_debug_samples:
|
| 337 |
+
break
|
| 338 |
+
else:
|
| 339 |
+
with open(file_path, encoding="utf-8") as f:
|
| 340 |
+
for line in f:
|
| 341 |
+
line=line.strip()
|
| 342 |
+
js=json.loads(line)
|
| 343 |
+
data.append((js,tokenizer,args))
|
| 344 |
+
|
| 345 |
+
if self.args.data_aug_type == "replace_type":
|
| 346 |
+
self.examples=pool.map(convert_examples_to_features_aug_type, tqdm(data,total=len(data)))
|
| 347 |
+
else:
|
| 348 |
+
self.examples=pool.map(convert_examples_to_features, tqdm(data,total=len(data)))
|
| 349 |
+
|
| 350 |
+
if 'train' in file_path:
|
| 351 |
+
for idx, example in enumerate(self.examples[:3]):
|
| 352 |
+
logger.info("*** Example ***")
|
| 353 |
+
logger.info("idx: {}".format(idx))
|
| 354 |
+
logger.info("code_tokens: {}".format([x.replace('\u0120','_') for x in example.code_tokens]))
|
| 355 |
+
logger.info("code_ids: {}".format(' '.join(map(str, example.code_ids))))
|
| 356 |
+
logger.info("nl_tokens: {}".format([x.replace('\u0120','_') for x in example.nl_tokens]))
|
| 357 |
+
logger.info("nl_ids: {}".format(' '.join(map(str, example.nl_ids))))
|
| 358 |
+
|
| 359 |
+
def __len__(self):
|
| 360 |
+
return len(self.examples)
|
| 361 |
+
|
| 362 |
+
def __getitem__(self, item):
|
| 363 |
+
if self.args.data_aug_type == "replace_type":
|
| 364 |
+
return (torch.tensor(self.examples[item].code_ids),
|
| 365 |
+
torch.tensor(self.examples[item].code_type_ids),
|
| 366 |
+
torch.tensor(self.examples[item].nl_ids))
|
| 367 |
+
else:
|
| 368 |
+
return (torch.tensor(self.examples[item].code_ids),
|
| 369 |
+
torch.tensor(self.examples[item].nl_ids),
|
| 370 |
+
torch.tensor(self.examples[item].code_tokens),
|
| 371 |
+
torch.tensor(self.examples[item].nl_tokens))
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
def convert_examples_to_features_unixcoder(js,tokenizer,args):
|
| 375 |
+
"""convert examples to token ids"""
|
| 376 |
+
code = ' '.join(js['code_tokens']) if type(js['code_tokens']) is list else ' '.join(js['code_tokens'].split())
|
| 377 |
+
code_tokens = tokenizer.tokenize(code)[:args.code_length-4]
|
| 378 |
+
code_tokens =[tokenizer.cls_token,"<encoder-only>",tokenizer.sep_token]+code_tokens+[tokenizer.sep_token]
|
| 379 |
+
code_ids = tokenizer.convert_tokens_to_ids(code_tokens)
|
| 380 |
+
padding_length = args.code_length - len(code_ids)
|
| 381 |
+
code_ids += [tokenizer.pad_token_id]*padding_length
|
| 382 |
+
|
| 383 |
+
nl = ' '.join(js['docstring_tokens']) if type(js['docstring_tokens']) is list else ' '.join(js['doc'].split())
|
| 384 |
+
nl_tokens = tokenizer.tokenize(nl)[:args.nl_length-4]
|
| 385 |
+
nl_tokens = [tokenizer.cls_token,"<encoder-only>",tokenizer.sep_token]+nl_tokens+[tokenizer.sep_token]
|
| 386 |
+
nl_ids = tokenizer.convert_tokens_to_ids(nl_tokens)
|
| 387 |
+
padding_length = args.nl_length - len(nl_ids)
|
| 388 |
+
nl_ids += [tokenizer.pad_token_id]*padding_length
|
| 389 |
+
|
| 390 |
+
return InputFeatures(code_tokens,code_ids,nl_tokens,nl_ids,js['url'] if "url" in js else js["retrieval_idx"])
|
| 391 |
+
|
| 392 |
+
class TextDataset_unixcoder(Dataset):
|
| 393 |
+
def __init__(self, tokenizer, args, file_path=None, pooler=None):
|
| 394 |
+
self.examples = []
|
| 395 |
+
data = []
|
| 396 |
+
n_debug_samples = args.n_debug_samples
|
| 397 |
+
with open(file_path) as f:
|
| 398 |
+
if "jsonl" in file_path:
|
| 399 |
+
for line in f:
|
| 400 |
+
line = line.strip()
|
| 401 |
+
js = json.loads(line)
|
| 402 |
+
if 'function_tokens' in js:
|
| 403 |
+
js['code_tokens'] = js['function_tokens']
|
| 404 |
+
data.append(js)
|
| 405 |
+
if args.debug and len(data) >= n_debug_samples:
|
| 406 |
+
break
|
| 407 |
+
elif "codebase"in file_path or "code_idx_map" in file_path:
|
| 408 |
+
js = json.load(f)
|
| 409 |
+
for key in js:
|
| 410 |
+
temp = {}
|
| 411 |
+
temp['code_tokens'] = key.split()
|
| 412 |
+
temp["retrieval_idx"] = js[key]
|
| 413 |
+
temp['doc'] = ""
|
| 414 |
+
temp['docstring_tokens'] = ""
|
| 415 |
+
data.append(temp)
|
| 416 |
+
if args.debug and len(data) >= n_debug_samples:
|
| 417 |
+
break
|
| 418 |
+
elif "json" in file_path:
|
| 419 |
+
for js in json.load(f):
|
| 420 |
+
data.append(js)
|
| 421 |
+
if args.debug and len(data) >= n_debug_samples:
|
| 422 |
+
break
|
| 423 |
+
# if "test" in file_path:
|
| 424 |
+
# data = data[-200:]
|
| 425 |
+
for js in data:
|
| 426 |
+
self.examples.append(convert_examples_to_features_unixcoder(js,tokenizer,args))
|
| 427 |
+
|
| 428 |
+
if "train" in file_path:
|
| 429 |
+
# self.examples = self.examples[:128]
|
| 430 |
+
for idx, example in enumerate(self.examples[:3]):
|
| 431 |
+
logger.info("*** Example ***")
|
| 432 |
+
logger.info("idx: {}".format(idx))
|
| 433 |
+
logger.info("code_tokens: {}".format([x.replace('\u0120','_') for x in example.code_tokens]))
|
| 434 |
+
logger.info("code_ids: {}".format(' '.join(map(str, example.code_ids))))
|
| 435 |
+
logger.info("nl_tokens: {}".format([x.replace('\u0120','_') for x in example.nl_tokens]))
|
| 436 |
+
logger.info("nl_ids: {}".format(' '.join(map(str, example.nl_ids))))
|
| 437 |
+
|
| 438 |
+
def __len__(self):
|
| 439 |
+
return len(self.examples)
|
| 440 |
+
|
| 441 |
+
def __getitem__(self, i):
|
| 442 |
+
return (torch.tensor(self.examples[i].code_ids),torch.tensor(self.examples[i].nl_ids))
|
| 443 |
+
# return (torch.tensor(self.examples[i].code_ids),
|
| 444 |
+
# torch.tensor(self.examples[i].nl_ids),
|
| 445 |
+
# [self.examples[i].code_tokens],
|
| 446 |
+
# [self.examples[i].nl_tokens])
|
| 447 |
+
|
| 448 |
+
def set_seed(seed=42):
|
| 449 |
+
random.seed(seed)
|
| 450 |
+
os.environ['PYHTONHASHSEED'] = str(seed)
|
| 451 |
+
np.random.seed(seed)
|
| 452 |
+
torch.manual_seed(seed)
|
| 453 |
+
torch.cuda.manual_seed(seed)
|
| 454 |
+
torch.cuda.manual_seed_all(seed) # all gpus
|
| 455 |
+
torch.backends.cudnn.deterministic = True
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
def mask_tokens(inputs,tokenizer,mlm_probability):
|
| 459 |
+
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
|
| 460 |
+
labels = inputs.clone()
|
| 461 |
+
# We sample a few tokens in each sequence for masked-LM training (with probability args.mlm_probability defaults to 0.15 in Bert/RoBERTa)
|
| 462 |
+
probability_matrix = torch.full(labels.shape, mlm_probability).to(inputs.device)
|
| 463 |
+
special_tokens_mask = [tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in
|
| 464 |
+
labels.tolist()] # for masking special token
|
| 465 |
+
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool).to(inputs.device), value=0.0)
|
| 466 |
+
if tokenizer._pad_token is not None:
|
| 467 |
+
padding_mask = labels.eq(tokenizer.pad_token_id)
|
| 468 |
+
probability_matrix.masked_fill_(padding_mask, value=0.0) # masked padding
|
| 469 |
+
|
| 470 |
+
masked_indices = torch.bernoulli(probability_matrix).bool() # will decide who will be masked
|
| 471 |
+
labels[~masked_indices] = -100 # We only compute loss on masked tokens
|
| 472 |
+
|
| 473 |
+
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
|
| 474 |
+
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool().to(inputs.device) & masked_indices
|
| 475 |
+
inputs[indices_replaced] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
|
| 476 |
+
|
| 477 |
+
# 10% of the time, we replace masked input tokens with random word
|
| 478 |
+
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool().to(inputs.device) & masked_indices & ~indices_replaced
|
| 479 |
+
random_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long).to(inputs.device)
|
| 480 |
+
inputs[indices_random] = random_words[indices_random]
|
| 481 |
+
|
| 482 |
+
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
|
| 483 |
+
return inputs, labels
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
def replace_with_type_tokens(inputs,replaces,tokenizer,mlm_probability):
|
| 487 |
+
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
|
| 488 |
+
labels = inputs.clone()
|
| 489 |
+
# We sample a few tokens in each sequence for masked-LM training (with probability args.mlm_probability defaults to 0.15 in Bert/RoBERTa)
|
| 490 |
+
probability_matrix = torch.full(labels.shape, mlm_probability).to(inputs.device)
|
| 491 |
+
special_tokens_mask = [tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in
|
| 492 |
+
labels.tolist()] # for masking special token
|
| 493 |
+
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool).to(inputs.device), value=0.0)
|
| 494 |
+
if tokenizer._pad_token is not None:
|
| 495 |
+
padding_mask = labels.eq(tokenizer.pad_token_id)
|
| 496 |
+
probability_matrix.masked_fill_(padding_mask, value=0.0) # masked padding
|
| 497 |
+
|
| 498 |
+
masked_indices = torch.bernoulli(probability_matrix).bool() # will decide who will be masked
|
| 499 |
+
labels[~masked_indices] = -100 # We only compute loss on masked tokens
|
| 500 |
+
|
| 501 |
+
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
|
| 502 |
+
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool().to(inputs.device) & masked_indices
|
| 503 |
+
inputs[indices_replaced] = replaces[indices_replaced]
|
| 504 |
+
|
| 505 |
+
return inputs, labels
|
| 506 |
+
|
| 507 |
+
def replace_special_token_with_type_tokens(inputs, speical_token_ids, tokenizer, mlm_probability):
|
| 508 |
+
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
|
| 509 |
+
labels = inputs.clone()
|
| 510 |
+
probability_matrix = torch.full(labels.shape,0.0).to(inputs.device)
|
| 511 |
+
probability_matrix.masked_fill_(labels.eq(speical_token_ids).to(inputs.device), value=mlm_probability)
|
| 512 |
+
masked_indices = torch.bernoulli(probability_matrix).bool() # will decide who will be masked
|
| 513 |
+
labels[~masked_indices] = -100 # We only compute loss on masked tokens
|
| 514 |
+
|
| 515 |
+
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
|
| 516 |
+
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool().to(inputs.device) & masked_indices
|
| 517 |
+
inputs[indices_replaced] = speical_token_ids
|
| 518 |
+
|
| 519 |
+
return inputs, labels
|
| 520 |
+
|
| 521 |
+
def replace_special_token_with_mask(inputs, speical_token_ids, tokenizer, mlm_probability):
|
| 522 |
+
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
|
| 523 |
+
labels = inputs.clone()
|
| 524 |
+
probability_matrix = torch.full(labels.shape,0.0).to(inputs.device)
|
| 525 |
+
probability_matrix.masked_fill_(labels.eq(speical_token_ids).to(inputs.device), value=mlm_probability)
|
| 526 |
+
masked_indices = torch.bernoulli(probability_matrix).bool() # will decide who will be masked
|
| 527 |
+
labels[~masked_indices] = -100 # We only compute loss on masked tokens
|
| 528 |
+
|
| 529 |
+
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
|
| 530 |
+
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool().to(inputs.device) & masked_indices
|
| 531 |
+
inputs[indices_replaced] =tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
|
| 532 |
+
|
| 533 |
+
return inputs, labels
|
| 534 |
+
|
| 535 |
+
def train(args, model, tokenizer,pool):
|
| 536 |
+
|
| 537 |
+
""" Train the model """
|
| 538 |
+
if args.data_aug_type == "replace_type" :
|
| 539 |
+
train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 540 |
+
else:
|
| 541 |
+
# if "unixcoder" in args.model_name_or_path or "coco" in args.model_name_or_path :
|
| 542 |
+
train_dataset=TextDataset_unixcoder(tokenizer, args, args.train_data_file, pool)
|
| 543 |
+
# else:
|
| 544 |
+
# train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 545 |
+
train_sampler = RandomSampler(train_dataset)
|
| 546 |
+
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size,num_workers=4,drop_last=True)
|
| 547 |
+
|
| 548 |
+
model.to(args.device)
|
| 549 |
+
if args.local_rank not in [-1, 0]:
|
| 550 |
+
torch.distributed.barrier()
|
| 551 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 552 |
+
optimizer_grouped_parameters = [
|
| 553 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 554 |
+
'weight_decay': args.weight_decay},
|
| 555 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 556 |
+
]
|
| 557 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=1e-8)
|
| 558 |
+
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_dataloader)*args.num_train_epochs)
|
| 559 |
+
|
| 560 |
+
# multi-gpu training (should be after apex fp16 initialization)
|
| 561 |
+
if args.n_gpu > 1:
|
| 562 |
+
model = torch.nn.DataParallel(model)
|
| 563 |
+
|
| 564 |
+
# Train!
|
| 565 |
+
logger.info("***** Running training *****")
|
| 566 |
+
logger.info(" Num examples = %d", len(train_dataset))
|
| 567 |
+
logger.info(" Num Epochs = %d", args.num_train_epochs)
|
| 568 |
+
logger.info(" Num quene = %d", args.moco_k)
|
| 569 |
+
logger.info(" Instantaneous batch size per GPU = %d", args.train_batch_size//args.n_gpu)
|
| 570 |
+
logger.info(" Total train batch size = %d", args.train_batch_size)
|
| 571 |
+
logger.info(" Total optimization steps = %d", len(train_dataloader)*args.num_train_epochs)
|
| 572 |
+
|
| 573 |
+
model.zero_grad()
|
| 574 |
+
model.train()
|
| 575 |
+
tr_num,tr_loss,best_mrr=0,0,-1
|
| 576 |
+
loss_fct = CrossEntropyLoss()
|
| 577 |
+
# if args.model_type == "multi-loss-cocosoda" :
|
| 578 |
+
if args.model_type in ["no_aug_cocosoda", "multi-loss-cocosoda"] :
|
| 579 |
+
if args.do_continue_pre_trained:
|
| 580 |
+
logger.info("do_continue_pre_trained")
|
| 581 |
+
elif args.do_fine_tune:
|
| 582 |
+
logger.info("do_fine_tune")
|
| 583 |
+
special_token_list = special_token[args.lang]
|
| 584 |
+
special_token_id_list = tokenizer.convert_tokens_to_ids(special_token_list)
|
| 585 |
+
model_eval = model.module if hasattr(model,'module') else model
|
| 586 |
+
for idx in range(args.num_train_epochs):
|
| 587 |
+
print(idx)
|
| 588 |
+
for step,batch in enumerate(train_dataloader):
|
| 589 |
+
|
| 590 |
+
#get inputs
|
| 591 |
+
code_inputs = batch[0].to(args.device)
|
| 592 |
+
nl_inputs = batch[1].to(args.device)
|
| 593 |
+
#get code and nl vectors
|
| 594 |
+
nl_outputs = model_eval.nl_encoder_q(nl_inputs, attention_mask=nl_inputs.ne(1))
|
| 595 |
+
nl_vec =nl_outputs [1]
|
| 596 |
+
code_outputs = model_eval.code_encoder_q(code_inputs, attention_mask=code_inputs.ne(1))
|
| 597 |
+
code_vec =code_outputs [1]
|
| 598 |
+
# code_vec = model(code_inputs=code_inputs)
|
| 599 |
+
# nl_vec = model(nl_inputs=nl_inputs)
|
| 600 |
+
torch.cuda.empty_cache()
|
| 601 |
+
tr_num+=1
|
| 602 |
+
#calculate scores and loss
|
| 603 |
+
scores = torch.einsum("ab,cb->ac",nl_vec,code_vec)
|
| 604 |
+
|
| 605 |
+
loss = loss_fct(scores*20, torch.arange(code_inputs.size(0), device=scores.device))
|
| 606 |
+
|
| 607 |
+
tr_loss += loss.item()
|
| 608 |
+
|
| 609 |
+
if (step+1)% args.eval_frequency==0:
|
| 610 |
+
logger.info("epoch {} step {} loss {}".format(idx,step+1,round(tr_loss/tr_num,5)))
|
| 611 |
+
tr_loss=0
|
| 612 |
+
tr_num=0
|
| 613 |
+
|
| 614 |
+
#backward
|
| 615 |
+
loss.backward()
|
| 616 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 617 |
+
optimizer.step()
|
| 618 |
+
optimizer.zero_grad()
|
| 619 |
+
scheduler.step()
|
| 620 |
+
torch.cuda.empty_cache()
|
| 621 |
+
|
| 622 |
+
results = evaluate(args, model, tokenizer,args.eval_data_file, pool, eval_when_training=True)
|
| 623 |
+
for key, value in results.items():
|
| 624 |
+
logger.info(" %s = %s", key, round(value,4))
|
| 625 |
+
|
| 626 |
+
#save best model
|
| 627 |
+
if results['eval_mrr']>best_mrr:
|
| 628 |
+
best_mrr=results['eval_mrr']
|
| 629 |
+
logger.info(" "+"*"*20)
|
| 630 |
+
logger.info(" Best mrr:%s",round(best_mrr,4))
|
| 631 |
+
logger.info(" "+"*"*20)
|
| 632 |
+
|
| 633 |
+
checkpoint_prefix = 'checkpoint-best-mrr'
|
| 634 |
+
output_dir = os.path.join(args.output_dir, '{}'.format(checkpoint_prefix))
|
| 635 |
+
if not os.path.exists(output_dir):
|
| 636 |
+
os.makedirs(output_dir)
|
| 637 |
+
model_to_save = model.module if hasattr(model,'module') else model
|
| 638 |
+
output_dir = os.path.join(output_dir, '{}'.format('model.bin'))
|
| 639 |
+
torch.save(model_to_save.state_dict(), output_dir)
|
| 640 |
+
logger.info("Saving model checkpoint to %s", output_dir)
|
| 641 |
+
|
| 642 |
+
output_dir_epoch = os.path.join(args.output_dir, '{}'.format(idx))
|
| 643 |
+
if not os.path.exists(output_dir_epoch):
|
| 644 |
+
os.makedirs(output_dir_epoch)
|
| 645 |
+
model_to_save = model.module if hasattr(model,'module') else model
|
| 646 |
+
output_dir_epoch = os.path.join(output_dir_epoch, '{}'.format('model.bin'))
|
| 647 |
+
torch.save(model_to_save.state_dict(), output_dir_epoch)
|
| 648 |
+
logger.info("Saving model checkpoint to %s", output_dir_epoch)
|
| 649 |
+
|
| 650 |
+
def multi_lang_continue_pre_train(args, model, tokenizer,pool):
|
| 651 |
+
""" Train the model """
|
| 652 |
+
#get training dataset
|
| 653 |
+
if "unixcoder" in args.model_name_or_path:
|
| 654 |
+
train_datasets = []
|
| 655 |
+
for train_data_file in args.couninue_pre_train_data_files:
|
| 656 |
+
train_dataset=TextDataset_unixcoder(tokenizer, args, train_data_file, pool)
|
| 657 |
+
train_datasets.append(train_dataset)
|
| 658 |
+
else:
|
| 659 |
+
train_datasets = []
|
| 660 |
+
for train_data_file in args.couninue_pre_train_data_files:
|
| 661 |
+
train_dataset=TextDataset(tokenizer, args, train_data_file, pool)
|
| 662 |
+
train_datasets.append(train_dataset)
|
| 663 |
+
|
| 664 |
+
train_samplers = [RandomSampler(train_dataset) for train_dataset in train_datasets]
|
| 665 |
+
# https://blog.csdn.net/weixin_44966641/article/details/124878064
|
| 666 |
+
train_dataloaders = [cycle(DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size,drop_last=True)) for train_dataset,train_sampler in zip(train_datasets,train_samplers)]
|
| 667 |
+
t_total = args.max_steps
|
| 668 |
+
|
| 669 |
+
#get optimizer and scheduler
|
| 670 |
+
# Prepare optimizer and schedule (linear warmup and decay)https://huggingface.co/transformers/v3.3.1/training.html
|
| 671 |
+
model.to(args.device)
|
| 672 |
+
if args.local_rank not in [-1, 0]:
|
| 673 |
+
torch.distributed.barrier()
|
| 674 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 675 |
+
optimizer_grouped_parameters = [
|
| 676 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 677 |
+
'weight_decay': 0.01},
|
| 678 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 679 |
+
]
|
| 680 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=1e-8)
|
| 681 |
+
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.num_warmup_steps,num_training_steps=t_total)
|
| 682 |
+
|
| 683 |
+
# Train!
|
| 684 |
+
training_data_length = sum ([len(item) for item in train_datasets])
|
| 685 |
+
logger.info("***** Running training *****")
|
| 686 |
+
logger.info(" Num examples = %d", training_data_length)
|
| 687 |
+
logger.info(" Num Epochs = %d", args.num_train_epochs)
|
| 688 |
+
logger.info(" Num quene = %d", args.moco_k)
|
| 689 |
+
logger.info(" Instantaneous batch size per GPU = %d", args.train_batch_size//args.n_gpu)
|
| 690 |
+
logger.info(" Total train batch size = %d", args.train_batch_size)
|
| 691 |
+
|
| 692 |
+
checkpoint_last = os.path.join(args.output_dir, 'checkpoint-last')
|
| 693 |
+
scheduler_last = os.path.join(checkpoint_last, 'scheduler.pt')
|
| 694 |
+
optimizer_last = os.path.join(checkpoint_last, 'optimizer.pt')
|
| 695 |
+
if os.path.exists(scheduler_last):
|
| 696 |
+
scheduler.load_state_dict(torch.load(scheduler_last, map_location="cpu"))
|
| 697 |
+
if os.path.exists(optimizer_last):
|
| 698 |
+
optimizer.load_state_dict(torch.load(optimizer_last, map_location="cpu"))
|
| 699 |
+
if args.local_rank == 0:
|
| 700 |
+
torch.distributed.barrier()
|
| 701 |
+
if args.fp16:
|
| 702 |
+
try:
|
| 703 |
+
from apex import amp
|
| 704 |
+
except ImportError:
|
| 705 |
+
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
|
| 706 |
+
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
|
| 707 |
+
|
| 708 |
+
# multi-gpu training (should be after apex fp16 initialization)
|
| 709 |
+
if args.n_gpu > 1:
|
| 710 |
+
model = torch.nn.DataParallel(model)
|
| 711 |
+
|
| 712 |
+
# Distributed training (should be after apex fp16 initialization)
|
| 713 |
+
if args.local_rank != -1:
|
| 714 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank%args.gpu_per_node],
|
| 715 |
+
output_device=args.local_rank%args.gpu_per_node,
|
| 716 |
+
find_unused_parameters=True)
|
| 717 |
+
|
| 718 |
+
loss_fct = CrossEntropyLoss()
|
| 719 |
+
set_seed(args.seed) # Added here for reproducibility (even between python 2 and 3)
|
| 720 |
+
probs=[len(x) for x in train_datasets]
|
| 721 |
+
probs=[x/sum(probs) for x in probs]
|
| 722 |
+
probs=[x**0.7 for x in probs]
|
| 723 |
+
probs=[x/sum(probs) for x in probs]
|
| 724 |
+
# global_step = args.start_step
|
| 725 |
+
model.zero_grad()
|
| 726 |
+
model.train()
|
| 727 |
+
|
| 728 |
+
global_step = args.start_step
|
| 729 |
+
step=0
|
| 730 |
+
tr_loss, logging_loss,avg_loss,tr_nb, best_mrr = 0.0, 0.0,0.0,0,-1
|
| 731 |
+
tr_num=0
|
| 732 |
+
special_token_list = all_special_token
|
| 733 |
+
special_token_id_list = tokenizer.convert_tokens_to_ids(special_token_list)
|
| 734 |
+
while True:
|
| 735 |
+
|
| 736 |
+
train_dataloader=np.random.choice(train_dataloaders, 1, p=probs)[0]
|
| 737 |
+
# train_dataloader=train_dataloader[0]
|
| 738 |
+
step+=1
|
| 739 |
+
batch=next(train_dataloader)
|
| 740 |
+
# source_ids= batch.to(args.device)
|
| 741 |
+
model.train()
|
| 742 |
+
# loss = model(source_ids)
|
| 743 |
+
code_inputs = batch[0].to(args.device)
|
| 744 |
+
code_transformations_ids = code_inputs.clone()
|
| 745 |
+
nl_inputs = batch[1].to(args.device)
|
| 746 |
+
nl_transformations_ids= nl_inputs.clone()
|
| 747 |
+
|
| 748 |
+
if step%4 == 0:
|
| 749 |
+
code_transformations_ids[:, 3:], _ = mask_tokens(code_inputs.clone()[:, 3:] ,tokenizer,args.mlm_probability)
|
| 750 |
+
nl_transformations_ids[:, 3:], _ = mask_tokens(nl_inputs.clone()[:, 3:] ,tokenizer,args.mlm_probability)
|
| 751 |
+
elif step%4 == 1:
|
| 752 |
+
code_types = code_inputs.clone()
|
| 753 |
+
code_transformations_ids[:, 3:], _ = replace_with_type_tokens(code_inputs.clone()[:, 3:] ,code_types.clone()[:, 3:],tokenizer,args.mlm_probability)
|
| 754 |
+
elif step%4 == 2:
|
| 755 |
+
random.seed( step)
|
| 756 |
+
choice_token_id = choice(special_token_id_list)
|
| 757 |
+
code_transformations_ids[:, 3:], _ = replace_special_token_with_type_tokens(code_inputs.clone()[:, 3:], choice_token_id, tokenizer,args.mlm_probability)
|
| 758 |
+
elif step%4 == 3:
|
| 759 |
+
random.seed( step)
|
| 760 |
+
choice_token_id = choice(special_token_id_list)
|
| 761 |
+
code_transformations_ids[:, 3:], _ = replace_special_token_with_mask(code_inputs.clone()[:, 3:], choice_token_id, tokenizer,args.mlm_probability)
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
tr_num+=1
|
| 765 |
+
inter_output, inter_target, _, _= model(source_code_q=code_inputs, source_code_k=code_transformations_ids,
|
| 766 |
+
nl_q=nl_inputs , nl_k=nl_transformations_ids )
|
| 767 |
+
|
| 768 |
+
|
| 769 |
+
|
| 770 |
+
# loss_fct = CrossEntropyLoss()
|
| 771 |
+
loss = loss_fct(20*inter_output, inter_target)
|
| 772 |
+
|
| 773 |
+
if args.n_gpu > 1:
|
| 774 |
+
loss = loss.mean() # mean() to average on multi-gpu parallel training
|
| 775 |
+
|
| 776 |
+
|
| 777 |
+
if args.gradient_accumulation_steps > 1:
|
| 778 |
+
loss = loss / args.gradient_accumulation_steps
|
| 779 |
+
|
| 780 |
+
if args.fp16:
|
| 781 |
+
with amp.scale_loss(loss, optimizer) as scaled_loss:
|
| 782 |
+
scaled_loss.backward()
|
| 783 |
+
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
|
| 784 |
+
else:
|
| 785 |
+
loss.backward()
|
| 786 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 787 |
+
|
| 788 |
+
tr_loss += loss.item()
|
| 789 |
+
if (step+1)% args.eval_frequency==0:
|
| 790 |
+
logger.info("step {} loss {}".format(step+1,round(tr_loss/tr_num,5)))
|
| 791 |
+
tr_loss=0
|
| 792 |
+
tr_num=0
|
| 793 |
+
|
| 794 |
+
if (step + 1) % args.gradient_accumulation_steps == 0:
|
| 795 |
+
optimizer.step()
|
| 796 |
+
optimizer.zero_grad()
|
| 797 |
+
scheduler.step()
|
| 798 |
+
global_step += 1
|
| 799 |
+
output_flag=True
|
| 800 |
+
avg_loss=round((tr_loss - logging_loss) /(global_step- tr_nb),6)
|
| 801 |
+
|
| 802 |
+
if global_step %100 == 0:
|
| 803 |
+
logger.info(" global steps (step*gradient_accumulation_steps ): %s loss: %s", global_step, round(avg_loss,6))
|
| 804 |
+
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
|
| 805 |
+
logging_loss = tr_loss
|
| 806 |
+
tr_nb=global_step
|
| 807 |
+
|
| 808 |
+
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
|
| 809 |
+
checkpoint_prefix = 'checkpoint-mrr'
|
| 810 |
+
# results = evaluate(args, model, tokenizer,pool=pool,eval_when_training=True)
|
| 811 |
+
results = evaluate(args, model, tokenizer,args.eval_data_file, pool, eval_when_training=True)
|
| 812 |
+
|
| 813 |
+
# for key, value in results.items():
|
| 814 |
+
# logger.info(" %s = %s", key, round(value,6))
|
| 815 |
+
logger.info(" %s = %s", 'eval_mrr', round(results['eval_mrr'],6))
|
| 816 |
+
|
| 817 |
+
if results['eval_mrr']>best_mrr:
|
| 818 |
+
best_mrr=results['eval_mrr']
|
| 819 |
+
logger.info(" "+"*"*20)
|
| 820 |
+
logger.info(" Best mrr:%s",round(best_mrr,4))
|
| 821 |
+
logger.info(" "+"*"*20)
|
| 822 |
+
|
| 823 |
+
output_dir = os.path.join(args.output_dir, '{}'.format('checkpoint-best-mrr'))
|
| 824 |
+
if not os.path.exists(output_dir):
|
| 825 |
+
os.makedirs(output_dir)
|
| 826 |
+
model_to_save = model.module if hasattr(model,'module') else model
|
| 827 |
+
output_dir = os.path.join(output_dir, '{}'.format('model.bin'))
|
| 828 |
+
torch.save(model_to_save.state_dict(), output_dir)
|
| 829 |
+
logger.info("Saving model checkpoint to %s", output_dir)
|
| 830 |
+
|
| 831 |
+
|
| 832 |
+
|
| 833 |
+
# Save model checkpoint
|
| 834 |
+
output_dir = os.path.join(args.output_dir, '{}-{}-{}'.format(checkpoint_prefix, global_step,round(results['eval_mrr'],6)))
|
| 835 |
+
if not os.path.exists(output_dir):
|
| 836 |
+
os.makedirs(output_dir)
|
| 837 |
+
model_to_save = model.module.code_encoder_q if hasattr(model,'module') else model.code_encoder_q # Take care of distributed/parallel training
|
| 838 |
+
model_to_save.save_pretrained(output_dir)
|
| 839 |
+
torch.save(args, os.path.join(output_dir, 'training_args.bin'))
|
| 840 |
+
logger.info("Saving model checkpoint to %s", output_dir)
|
| 841 |
+
|
| 842 |
+
# _rotate_checkpoints(args, checkpoint_prefix)
|
| 843 |
+
|
| 844 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-last')
|
| 845 |
+
if not os.path.exists(last_output_dir):
|
| 846 |
+
os.makedirs(last_output_dir)
|
| 847 |
+
model_to_save.save_pretrained(last_output_dir)
|
| 848 |
+
idx_file = os.path.join(last_output_dir, 'idx_file.txt')
|
| 849 |
+
with open(idx_file, 'w', encoding='utf-8') as idxf:
|
| 850 |
+
idxf.write(str(0) + '\n')
|
| 851 |
+
|
| 852 |
+
torch.save(optimizer.state_dict(), os.path.join(last_output_dir, "optimizer.pt"))
|
| 853 |
+
torch.save(scheduler.state_dict(), os.path.join(last_output_dir, "scheduler.pt"))
|
| 854 |
+
logger.info("Saving optimizer and scheduler states to %s", last_output_dir)
|
| 855 |
+
|
| 856 |
+
step_file = os.path.join(last_output_dir, 'step_file.txt')
|
| 857 |
+
with open(step_file, 'w', encoding='utf-8') as stepf:
|
| 858 |
+
stepf.write(str(global_step) + '\n')
|
| 859 |
+
|
| 860 |
+
if args.max_steps > 0 and global_step > args.max_steps:
|
| 861 |
+
break
|
| 862 |
+
|
| 863 |
+
|
| 864 |
+
def evaluate(args, model, tokenizer,file_name,pool, eval_when_training=False):
|
| 865 |
+
# if "unixcoder" in args.model_name_or_path or "coco" in args.model_name_or_path :
|
| 866 |
+
dataset_class = TextDataset_unixcoder
|
| 867 |
+
# else:
|
| 868 |
+
# dataset_class = TextDataset
|
| 869 |
+
query_dataset = dataset_class(tokenizer, args, file_name, pool)
|
| 870 |
+
query_sampler = SequentialSampler(query_dataset)
|
| 871 |
+
query_dataloader = DataLoader(query_dataset, sampler=query_sampler, batch_size=args.eval_batch_size,num_workers=4)
|
| 872 |
+
|
| 873 |
+
code_dataset = dataset_class(tokenizer, args, args.codebase_file, pool)
|
| 874 |
+
code_sampler = SequentialSampler(code_dataset)
|
| 875 |
+
code_dataloader = DataLoader(code_dataset, sampler=code_sampler, batch_size=args.eval_batch_size,num_workers=4)
|
| 876 |
+
|
| 877 |
+
# multi-gpu evaluate
|
| 878 |
+
if args.n_gpu > 1 and eval_when_training is False:
|
| 879 |
+
model = torch.nn.DataParallel(model)
|
| 880 |
+
|
| 881 |
+
# Eval!
|
| 882 |
+
logger.info("***** Running evaluation on %s *****"%args.lang)
|
| 883 |
+
logger.info(" Num queries = %d", len(query_dataset))
|
| 884 |
+
logger.info(" Num codes = %d", len(code_dataset))
|
| 885 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 886 |
+
|
| 887 |
+
|
| 888 |
+
model.eval()
|
| 889 |
+
model_eval = model.module if hasattr(model,'module') else model
|
| 890 |
+
code_vecs=[]
|
| 891 |
+
nl_vecs=[]
|
| 892 |
+
for batch in query_dataloader:
|
| 893 |
+
nl_inputs = batch[-1].to(args.device)
|
| 894 |
+
with torch.no_grad():
|
| 895 |
+
if args.model_type == "base" :
|
| 896 |
+
nl_vec = model(nl_inputs=nl_inputs)
|
| 897 |
+
|
| 898 |
+
elif args.model_type in ["cocosoda" ,"no_aug_cocosoda", "multi-loss-cocosoda"]:
|
| 899 |
+
outputs = model_eval.nl_encoder_q(nl_inputs, attention_mask=nl_inputs.ne(1))
|
| 900 |
+
if args.agg_way == "avg":
|
| 901 |
+
outputs = outputs [0]
|
| 902 |
+
nl_vec = (outputs*nl_inputs.ne(1)[:,:,None]).sum(1)/nl_inputs.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 903 |
+
elif args.agg_way == "cls_pooler":
|
| 904 |
+
nl_vec =outputs [1]
|
| 905 |
+
elif args.agg_way == "avg_cls_pooler":
|
| 906 |
+
nl_vec =outputs [1] + (outputs[0]*nl_inputs.ne(1)[:,:,None]).sum(1)/nl_inputs.ne(1).sum(-1)[:,None]
|
| 907 |
+
nl_vec = torch.nn.functional.normalize( nl_vec, p=2, dim=1)
|
| 908 |
+
if args.do_whitening:
|
| 909 |
+
nl_vec=whitening_torch_final(nl_vec)
|
| 910 |
+
|
| 911 |
+
|
| 912 |
+
|
| 913 |
+
nl_vecs.append(nl_vec.cpu().numpy())
|
| 914 |
+
|
| 915 |
+
for batch in code_dataloader:
|
| 916 |
+
with torch.no_grad():
|
| 917 |
+
code_inputs = batch[0].to(args.device)
|
| 918 |
+
if args.model_type == "base" :
|
| 919 |
+
code_vec = model(code_inputs=code_inputs)
|
| 920 |
+
elif args.model_type in ["cocosoda" ,"no_aug_cocosoda", "multi-loss-cocosoda"]:
|
| 921 |
+
# code_vec = model_eval.code_encoder_q(code_inputs, attention_mask=code_inputs.ne(1))[1]
|
| 922 |
+
outputs = model_eval.code_encoder_q(code_inputs, attention_mask=code_inputs.ne(1))
|
| 923 |
+
if args.agg_way == "avg":
|
| 924 |
+
outputs = outputs [0]
|
| 925 |
+
code_vec = (outputs*code_inputs.ne(1)[:,:,None]).sum(1)/code_inputs.ne(1).sum(-1)[:,None] # None作为ndarray或tensor的索引作用是增加维度,
|
| 926 |
+
elif args.agg_way == "cls_pooler":
|
| 927 |
+
code_vec=outputs [1]
|
| 928 |
+
elif args.agg_way == "avg_cls_pooler":
|
| 929 |
+
code_vec=outputs [1] + (outputs[0]*code_inputs.ne(1)[:,:,None]).sum(1)/code_inputs.ne(1).sum(-1)[:,None]
|
| 930 |
+
code_vec = torch.nn.functional.normalize(code_vec, p=2, dim=1)
|
| 931 |
+
if args.do_whitening:
|
| 932 |
+
code_vec=whitening_torch_final(code_vec)
|
| 933 |
+
|
| 934 |
+
|
| 935 |
+
|
| 936 |
+
code_vecs.append(code_vec.cpu().numpy())
|
| 937 |
+
|
| 938 |
+
model.train()
|
| 939 |
+
code_vecs=np.concatenate(code_vecs,0)
|
| 940 |
+
nl_vecs=np.concatenate(nl_vecs,0)
|
| 941 |
+
|
| 942 |
+
scores=np.matmul(nl_vecs,code_vecs.T)
|
| 943 |
+
|
| 944 |
+
sort_ids=np.argsort(scores, axis=-1, kind='quicksort', order=None)[:,::-1]
|
| 945 |
+
|
| 946 |
+
nl_urls=[]
|
| 947 |
+
code_urls=[]
|
| 948 |
+
for example in query_dataset.examples:
|
| 949 |
+
nl_urls.append(example.url)
|
| 950 |
+
|
| 951 |
+
for example in code_dataset.examples:
|
| 952 |
+
code_urls.append(example.url)
|
| 953 |
+
|
| 954 |
+
ranks=[]
|
| 955 |
+
for url, sort_id in zip(nl_urls,sort_ids):
|
| 956 |
+
rank=0
|
| 957 |
+
find=False
|
| 958 |
+
for idx in sort_id[:1000]:
|
| 959 |
+
if find is False:
|
| 960 |
+
rank+=1
|
| 961 |
+
if code_urls[idx]==url:
|
| 962 |
+
find=True
|
| 963 |
+
if find:
|
| 964 |
+
ranks.append(1/rank)
|
| 965 |
+
else:
|
| 966 |
+
ranks.append(0)
|
| 967 |
+
if args.save_evaluation_reuslt:
|
| 968 |
+
evaluation_result = {"nl_urls":nl_urls, "code_urls":code_urls,"sort_ids":sort_ids[:,:10],"ranks":ranks}
|
| 969 |
+
save_pickle_data(args.save_evaluation_reuslt_dir, "evaluation_result.pkl",evaluation_result)
|
| 970 |
+
result = cal_r1_r5_r10(ranks)
|
| 971 |
+
result["eval_mrr"] = round(float(np.mean(ranks)),3)
|
| 972 |
+
return result
|
| 973 |
+
|
| 974 |
+
|
| 975 |
+
def parse_args():
|
| 976 |
+
parser = argparse.ArgumentParser()
|
| 977 |
+
# soda
|
| 978 |
+
parser.add_argument('--data_aug_type',default="replace_type",choices=["replace_type", "random_mask" ,"other"], help="the ways of soda",required=False)
|
| 979 |
+
parser.add_argument('--aug_type_way',default="random_replace_type",choices=["random_replace_type", "replace_special_type" ,"replace_special_type_with_mask"], help="the ways of soda",required=False)
|
| 980 |
+
parser.add_argument('--print_align_unif_loss', action='store_true', help='print_align_unif_loss', required=False)
|
| 981 |
+
parser.add_argument('--do_ineer_loss', action='store_true', help='print_align_unif_loss', required=False)
|
| 982 |
+
parser.add_argument('--only_save_the_nl_code_vec', action='store_true', help='print_align_unif_loss', required=False)
|
| 983 |
+
parser.add_argument('--do_zero_short', action='store_true', help='print_align_unif_loss', required=False)
|
| 984 |
+
parser.add_argument('--agg_way',default="cls_pooler",choices=["avg", "cls_pooler","avg_cls_pooler" ], help="base is codebert/graphcoder/unixcoder",required=False)
|
| 985 |
+
parser.add_argument('--weight_decay',default=0.01, type=float,required=False)
|
| 986 |
+
parser.add_argument('--do_single_lang_continue_pre_train', action='store_true', help='do_single_lang_continue_pre_train', required=False)
|
| 987 |
+
parser.add_argument('--save_evaluation_reuslt', action='store_true', help='save_evaluation_reuslt', required=False)
|
| 988 |
+
parser.add_argument('--save_evaluation_reuslt_dir', type=str, help='save_evaluation_reuslt', required=False)
|
| 989 |
+
parser.add_argument('--epoch', type=int, default=50,
|
| 990 |
+
help="random seed for initialization")
|
| 991 |
+
# new continue pre-training
|
| 992 |
+
parser.add_argument('--fp16', action='store_true',
|
| 993 |
+
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit")
|
| 994 |
+
parser.add_argument("--local_rank", type=int, default=-1,
|
| 995 |
+
help="For distributed training: local_rank")
|
| 996 |
+
parser.add_argument("--loaded_model_filename", type=str, required=False,
|
| 997 |
+
help="loaded_model_filename")
|
| 998 |
+
parser.add_argument("--loaded_codebert_model_filename", type=str, required=False,
|
| 999 |
+
help="loaded_model_filename")
|
| 1000 |
+
parser.add_argument('--do_multi_lang_continue_pre_train', action='store_true', help='do_multi_lang_continue_pre_train', required=False)
|
| 1001 |
+
parser.add_argument("--couninue_pre_train_data_files", default=["dataset/ruby/train.jsonl", "dataset/java/train.jsonl",], type=str, nargs='+', required=False,
|
| 1002 |
+
help="The input training data files (some json files).")
|
| 1003 |
+
# parser.add_argument("--couninue_pre_train_data_files", default=["dataset/go/train.jsonl", "dataset/java/train.jsonl",
|
| 1004 |
+
# "dataset/javascript/train.jsonl", "dataset/php/train.jsonl", "dataset/python/train.jsonl", "dataset/ruby/train.jsonl",], type=list, required=False,
|
| 1005 |
+
# help="The input training data files (some json files).")
|
| 1006 |
+
parser.add_argument('--do_continue_pre_trained', action='store_true', help='debug mode', required=False)
|
| 1007 |
+
parser.add_argument('--do_fine_tune', action='store_true', help='debug mode', required=False)
|
| 1008 |
+
parser.add_argument('--do_whitening', action='store_true', help='do_whitening https://github.com/Jun-jie-Huang/WhiteningBERT', required=False)
|
| 1009 |
+
parser.add_argument("--time_score", default=1, type=int,help="cosine value * time_score")
|
| 1010 |
+
parser.add_argument("--max_steps", default=100, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.")
|
| 1011 |
+
parser.add_argument("--num_warmup_steps", default=0, type=int, help="num_warmup_steps")
|
| 1012 |
+
parser.add_argument('--gradient_accumulation_steps', type=int, default=1,
|
| 1013 |
+
help="Number of updates steps to accumulate before performing a backward/update pass.")
|
| 1014 |
+
parser.add_argument('--logging_steps', type=int, default=50,
|
| 1015 |
+
help="Log every X updates steps.")
|
| 1016 |
+
parser.add_argument('--save_steps', type=int, default=50,
|
| 1017 |
+
help="Save checkpoint every X updates steps.")
|
| 1018 |
+
# new moco
|
| 1019 |
+
parser.add_argument('--moco_type',default="encoder_queue",choices=["encoder_queue","encoder_momentum_encoder_queue" ], help="base is codebert/graphcoder/unixcoder",required=False)
|
| 1020 |
+
|
| 1021 |
+
|
| 1022 |
+
# debug
|
| 1023 |
+
parser.add_argument('--use_best_mrr_model', action='store_true', help='cosine_space', required=False)
|
| 1024 |
+
parser.add_argument('--debug', action='store_true', help='debug mode', required=False)
|
| 1025 |
+
parser.add_argument('--n_debug_samples', type=int, default=100, required=False)
|
| 1026 |
+
parser.add_argument("--max_codeblock_num", default=10, type=int,
|
| 1027 |
+
help="Optional NL input sequence length after tokenization.")
|
| 1028 |
+
parser.add_argument('--hidden_size', type=int, default=768, required=False)
|
| 1029 |
+
parser.add_argument("--eval_frequency", default=1, type=int, required=False)
|
| 1030 |
+
parser.add_argument("--mlm_probability", default=0.1, type=float, required=False)
|
| 1031 |
+
|
| 1032 |
+
# model type
|
| 1033 |
+
parser.add_argument('--do_avg', action='store_true', help='avrage hidden status', required=False)
|
| 1034 |
+
parser.add_argument('--model_type',default="base",choices=["base", "cocosoda","multi-loss-cocosoda","no_aug_cocosoda"], help="base is codebert/graphcoder/unixcoder",required=False)
|
| 1035 |
+
# moco
|
| 1036 |
+
# moco specific configs:
|
| 1037 |
+
parser.add_argument('--moco_dim', default=768, type=int,
|
| 1038 |
+
help='feature dimension (default: 768)')
|
| 1039 |
+
parser.add_argument('--moco_k', default=32, type=int,
|
| 1040 |
+
help='queue size; number of negative keys (default: 65536), which is divided by 32, etc.')
|
| 1041 |
+
parser.add_argument('--moco_m', default=0.999, type=float,
|
| 1042 |
+
help='moco momentum of updating key encoder (default: 0.999)')
|
| 1043 |
+
parser.add_argument('--moco_t', default=0.07, type=float,
|
| 1044 |
+
help='softmax temperature (default: 0.07)')
|
| 1045 |
+
|
| 1046 |
+
# options for moco v2
|
| 1047 |
+
parser.add_argument('--mlp', action='store_true',help='use mlp head')
|
| 1048 |
+
|
| 1049 |
+
## Required parameters
|
| 1050 |
+
parser.add_argument("--train_data_file", default="dataset/java/train.jsonl", type=str, required=False,
|
| 1051 |
+
help="The input training data file (a json file).")
|
| 1052 |
+
parser.add_argument("--output_dir", default="saved_models/pre-train", type=str, required=False,
|
| 1053 |
+
help="The output directory where the model predictions and checkpoints will be written.")
|
| 1054 |
+
parser.add_argument("--eval_data_file", default="dataset/java/valid.jsonl", type=str,
|
| 1055 |
+
help="An optional input evaluation data file to evaluate the MRR(a jsonl file).")
|
| 1056 |
+
parser.add_argument("--test_data_file", default="dataset/java/test.jsonl", type=str,
|
| 1057 |
+
help="An optional input test data file to test the MRR(a josnl file).")
|
| 1058 |
+
parser.add_argument("--codebase_file", default="dataset/java/codebase.jsonl", type=str,
|
| 1059 |
+
help="An optional input test data file to codebase (a jsonl file).")
|
| 1060 |
+
|
| 1061 |
+
parser.add_argument("--lang", default="java", type=str,
|
| 1062 |
+
help="language.")
|
| 1063 |
+
|
| 1064 |
+
parser.add_argument("--model_name_or_path", default="DeepSoftwareAnalytics/CoCoSoDa", type=str,
|
| 1065 |
+
help="The model checkpoint for weights initialization.")
|
| 1066 |
+
parser.add_argument("--config_name", default="DeepSoftwareAnalytics/CoCoSoDa", type=str,
|
| 1067 |
+
help="Optional pretrained config name or path if not the same as model_name_or_path")
|
| 1068 |
+
parser.add_argument("--tokenizer_name", default="DeepSoftwareAnalytics/CoCoSoDa", type=str,
|
| 1069 |
+
help="Optional pretrained tokenizer name or path if not the same as model_name_or_path")
|
| 1070 |
+
|
| 1071 |
+
parser.add_argument("--nl_length", default=50, type=int,
|
| 1072 |
+
help="Optional NL input sequence length after tokenization.")
|
| 1073 |
+
parser.add_argument("--code_length", default=100, type=int,
|
| 1074 |
+
help="Optional Code input sequence length after tokenization.")
|
| 1075 |
+
parser.add_argument("--data_flow_length", default=0, type=int,
|
| 1076 |
+
help="Optional Data Flow input sequence length after tokenization.",required=False)
|
| 1077 |
+
|
| 1078 |
+
parser.add_argument("--do_train", action='store_true',
|
| 1079 |
+
help="Whether to run training.")
|
| 1080 |
+
parser.add_argument("--do_eval", action='store_true',
|
| 1081 |
+
help="Whether to run eval on the dev set.")
|
| 1082 |
+
parser.add_argument("--do_test", action='store_true',
|
| 1083 |
+
help="Whether to run eval on the test set.")
|
| 1084 |
+
|
| 1085 |
+
parser.add_argument("--train_batch_size", default=4, type=int,
|
| 1086 |
+
help="Batch size for training.")
|
| 1087 |
+
parser.add_argument("--eval_batch_size", default=4, type=int,
|
| 1088 |
+
help="Batch size for evaluation.")
|
| 1089 |
+
parser.add_argument("--learning_rate", default=2e-5, type=float,
|
| 1090 |
+
help="The initial learning rate for Adam.")
|
| 1091 |
+
parser.add_argument("--max_grad_norm", default=1.0, type=float,
|
| 1092 |
+
help="Max gradient norm.")
|
| 1093 |
+
parser.add_argument("--num_train_epochs", default=4, type=int,
|
| 1094 |
+
help="Total number of training epochs to perform.")
|
| 1095 |
+
|
| 1096 |
+
parser.add_argument('--seed', type=int, default=3407,
|
| 1097 |
+
help="random seed for initialization")
|
| 1098 |
+
|
| 1099 |
+
#print arguments
|
| 1100 |
+
args = parser.parse_args()
|
| 1101 |
+
return args
|
| 1102 |
+
|
| 1103 |
+
def create_model(args,model,tokenizer, config=None):
|
| 1104 |
+
# logger.info("args.data_aug_type %s"%args.data_aug_type)
|
| 1105 |
+
# replace token with type
|
| 1106 |
+
if args.data_aug_type in ["replace_type" , "other"] and not args.only_save_the_nl_code_vec:
|
| 1107 |
+
special_tokens_dict = {'additional_special_tokens': all_special_token}
|
| 1108 |
+
logger.info(" new token %s"%(str(special_tokens_dict)))
|
| 1109 |
+
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
|
| 1110 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 1111 |
+
|
| 1112 |
+
if (args.loaded_model_filename) and ("pytorch_model.bin" in args.loaded_model_filename):
|
| 1113 |
+
logger.info("reload pytorch model from {}".format(args.loaded_model_filename))
|
| 1114 |
+
model.load_state_dict(torch.load(args.loaded_model_filename),strict=False)
|
| 1115 |
+
# model.from_pretrain
|
| 1116 |
+
if args.model_type == "base" :
|
| 1117 |
+
model= Model(model)
|
| 1118 |
+
elif args.model_type == "multi-loss-cocosoda":
|
| 1119 |
+
model= Multi_Loss_CoCoSoDa(model,args, args.mlp)
|
| 1120 |
+
if (args.loaded_model_filename) and ("pytorch_model.bin" not in args.loaded_model_filename) :
|
| 1121 |
+
logger.info("reload model from {}".format(args.loaded_model_filename))
|
| 1122 |
+
model.load_state_dict(torch.load(args.loaded_model_filename))
|
| 1123 |
+
# model.load_state_dict(torch.load(args.loaded_model_filename,strict=False))
|
| 1124 |
+
# model.from_pretrained(args.loaded_model_filename)
|
| 1125 |
+
if (args.loaded_codebert_model_filename) :
|
| 1126 |
+
logger.info("reload pytorch model from {}".format(args.loaded_codebert_model_filename))
|
| 1127 |
+
model.load_state_dict(torch.load(args.loaded_codebert_model_filename),strict=False)
|
| 1128 |
+
logger.info(model.model_parameters())
|
| 1129 |
+
|
| 1130 |
+
|
| 1131 |
+
return model
|
| 1132 |
+
|
| 1133 |
+
def main():
|
| 1134 |
+
|
| 1135 |
+
args = parse_args()
|
| 1136 |
+
#set log
|
| 1137 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 1138 |
+
datefmt='%m/%d/%Y %H:%M:%S',level=logging.INFO )
|
| 1139 |
+
#set device
|
| 1140 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 1141 |
+
args.n_gpu = torch.cuda.device_count()
|
| 1142 |
+
args.device = device
|
| 1143 |
+
logger.info("device: %s, n_gpu: %s",device, args.n_gpu)
|
| 1144 |
+
|
| 1145 |
+
pool = multiprocessing.Pool(cpu_cont)
|
| 1146 |
+
|
| 1147 |
+
# Set seed
|
| 1148 |
+
set_seed(args.seed)
|
| 1149 |
+
|
| 1150 |
+
#build model
|
| 1151 |
+
|
| 1152 |
+
if "codet5" in args.model_name_or_path:
|
| 1153 |
+
config = T5Config.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1154 |
+
tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1155 |
+
model = T5ForConditionalGeneration.from_pretrained(args.model_name_or_path)
|
| 1156 |
+
model = model.encoder
|
| 1157 |
+
else:
|
| 1158 |
+
config = RobertaConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1159 |
+
tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1160 |
+
model = RobertaModel.from_pretrained(args.model_name_or_path)
|
| 1161 |
+
model=create_model(args,model,tokenizer,config)
|
| 1162 |
+
|
| 1163 |
+
logger.info("Training/evaluation parameters %s", args)
|
| 1164 |
+
args.start_step = 0
|
| 1165 |
+
|
| 1166 |
+
model.to(args.device)
|
| 1167 |
+
|
| 1168 |
+
# Training
|
| 1169 |
+
if args.do_multi_lang_continue_pre_train:
|
| 1170 |
+
multi_lang_continue_pre_train(args, model, tokenizer, pool)
|
| 1171 |
+
output_tokenizer_dir = os.path.join(args.output_dir,"tokenzier")
|
| 1172 |
+
if not os.path.exists(output_tokenizer_dir):
|
| 1173 |
+
os.makedirs( output_tokenizer_dir)
|
| 1174 |
+
tokenizer.save_pretrained( output_tokenizer_dir)
|
| 1175 |
+
if args.do_train:
|
| 1176 |
+
train(args, model, tokenizer, pool)
|
| 1177 |
+
|
| 1178 |
+
|
| 1179 |
+
# Evaluation
|
| 1180 |
+
results = {}
|
| 1181 |
+
|
| 1182 |
+
if args.do_eval:
|
| 1183 |
+
checkpoint_prefix = 'checkpoint-best-mrr/model.bin'
|
| 1184 |
+
output_dir = os.path.join(args.output_dir, '{}'.format(checkpoint_prefix))
|
| 1185 |
+
if (not args.only_save_the_nl_code_vec) and (not args.do_zero_short) :
|
| 1186 |
+
model.load_state_dict(torch.load(output_dir),strict=False)
|
| 1187 |
+
model.to(args.device)
|
| 1188 |
+
result=evaluate(args, model, tokenizer,args.eval_data_file, pool)
|
| 1189 |
+
logger.info("***** Eval valid results *****")
|
| 1190 |
+
for key in sorted(result.keys()):
|
| 1191 |
+
logger.info(" %s = %s", key, str(round(result[key],4)))
|
| 1192 |
+
|
| 1193 |
+
if args.do_test:
|
| 1194 |
+
|
| 1195 |
+
logger.info("runnning test")
|
| 1196 |
+
checkpoint_prefix = 'checkpoint-best-mrr/model.bin'
|
| 1197 |
+
output_dir = os.path.join(args.output_dir, '{}'.format(checkpoint_prefix))
|
| 1198 |
+
if (not args.only_save_the_nl_code_vec) and (not args.do_zero_short) :
|
| 1199 |
+
model.load_state_dict(torch.load(output_dir),strict=False)
|
| 1200 |
+
model.to(args.device)
|
| 1201 |
+
result=evaluate(args, model, tokenizer,args.test_data_file, pool)
|
| 1202 |
+
logger.info("***** Eval test results *****")
|
| 1203 |
+
for key in sorted(result.keys()):
|
| 1204 |
+
logger.info(" %s = %s", key, str(round(result[key],4)))
|
| 1205 |
+
save_json_data(args.output_dir, "result.jsonl", result)
|
| 1206 |
+
return results
|
| 1207 |
+
|
| 1208 |
+
|
| 1209 |
+
def gen_vector():
|
| 1210 |
+
|
| 1211 |
+
args = parse_args()
|
| 1212 |
+
#set log
|
| 1213 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 1214 |
+
datefmt='%m/%d/%Y %H:%M:%S',level=logging.INFO )
|
| 1215 |
+
#set device
|
| 1216 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 1217 |
+
args.n_gpu = torch.cuda.device_count()
|
| 1218 |
+
args.device = device
|
| 1219 |
+
logger.info("device: %s, n_gpu: %s",device, args.n_gpu)
|
| 1220 |
+
|
| 1221 |
+
pool = multiprocessing.Pool(cpu_cont)
|
| 1222 |
+
|
| 1223 |
+
# Set seed
|
| 1224 |
+
set_seed(args.seed)
|
| 1225 |
+
if "codet5" in args.model_name_or_path:
|
| 1226 |
+
config = T5Config.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1227 |
+
tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1228 |
+
model = T5ForConditionalGeneration.from_pretrained(args.model_name_or_path)
|
| 1229 |
+
model = model.encoder
|
| 1230 |
+
else:
|
| 1231 |
+
config = RobertaConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1232 |
+
tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1233 |
+
model = RobertaModel.from_pretrained(args.model_name_or_path)
|
| 1234 |
+
model=create_model(args,model,tokenizer,config)
|
| 1235 |
+
|
| 1236 |
+
if args.data_aug_type == "replace_type" :
|
| 1237 |
+
train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 1238 |
+
else:
|
| 1239 |
+
# if "unixcoder" in args.model_name_or_path or "coco" in args.model_name_or_path :
|
| 1240 |
+
train_dataset=TextDataset_unixcoder(tokenizer, args, args.train_data_file, pool)
|
| 1241 |
+
# else:
|
| 1242 |
+
# train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 1243 |
+
train_sampler = SequentialSampler(train_dataset)
|
| 1244 |
+
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size,num_workers=4,drop_last=False)
|
| 1245 |
+
|
| 1246 |
+
for idx in range(args.num_train_epochs):
|
| 1247 |
+
output_dir_epoch = os.path.join(args.output_dir, '{}'.format(idx))
|
| 1248 |
+
output_dir_epoch = os.path.join(output_dir_epoch, '{}'.format('model.bin'))
|
| 1249 |
+
|
| 1250 |
+
model.load_state_dict(torch.load(output_dir_epoch),strict=False)
|
| 1251 |
+
model.to(args.device)
|
| 1252 |
+
|
| 1253 |
+
model_eval = model.module if hasattr(model,'module') else model
|
| 1254 |
+
|
| 1255 |
+
all_nl_vec = []
|
| 1256 |
+
all_code_vec = []
|
| 1257 |
+
|
| 1258 |
+
for step,batch in enumerate(train_dataloader):
|
| 1259 |
+
code_inputs = batch[0].to(args.device)
|
| 1260 |
+
nl_inputs = batch[1].to(args.device)
|
| 1261 |
+
#get code and nl vectors
|
| 1262 |
+
nl_outputs = model_eval.nl_encoder_q(nl_inputs, attention_mask=nl_inputs.ne(1))
|
| 1263 |
+
nl_vec =nl_outputs [1]
|
| 1264 |
+
code_outputs = model_eval.code_encoder_q(code_inputs, attention_mask=code_inputs.ne(1))
|
| 1265 |
+
code_vec =code_outputs [1]
|
| 1266 |
+
all_nl_vec.append(nl_vec.detach().cpu().numpy())
|
| 1267 |
+
all_code_vec.append(code_vec.detach().cpu().numpy())
|
| 1268 |
+
all_nl_vec = np.concatenate(all_nl_vec, axis=0)
|
| 1269 |
+
all_code_vec = np.concatenate(all_code_vec, axis=0)
|
| 1270 |
+
print(all_nl_vec.shape, all_code_vec.shape)
|
| 1271 |
+
np.save("/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/" + str(idx) + "/all_nl_vec.npy", all_nl_vec)
|
| 1272 |
+
np.save("/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/" + str(idx) + "/all_code_vec.npy", all_code_vec)
|
| 1273 |
+
idxs = [i for i in range(len(all_nl_vec))]
|
| 1274 |
+
for epoch in range(1,2):
|
| 1275 |
+
idxs_dir_path = "/home/yiming/cocosoda/CoCoSoDa/saved_models/codesearch_contrastive_learning/Model/Epoch_" + str(epoch)
|
| 1276 |
+
if os.path.exists(idxs_dir_path):
|
| 1277 |
+
pass
|
| 1278 |
+
else:
|
| 1279 |
+
os.mkdir(idxs_dir_path)
|
| 1280 |
+
idxs_path = idxs_dir_path + "/index.json"
|
| 1281 |
+
json_file = open(idxs_path, mode='w')
|
| 1282 |
+
json.dump(idxs, json_file, indent=4)
|
| 1283 |
+
|
| 1284 |
+
if args.data_aug_type == "replace_type" :
|
| 1285 |
+
test_dataset=TextDataset(tokenizer, args, args.test_data_file, pool)
|
| 1286 |
+
else:
|
| 1287 |
+
# if "unixcoder" in args.model_name_or_path or "coco" in args.model_name_or_path :
|
| 1288 |
+
test_dataset=TextDataset_unixcoder(tokenizer, args, args.test_data_file, pool)
|
| 1289 |
+
# else:
|
| 1290 |
+
# test_dataset=TextDataset(tokenizer, args, args.test_data_file, pool)
|
| 1291 |
+
test_sampler = SequentialSampler(test_dataset)
|
| 1292 |
+
test_dataloader = DataLoader(test_dataset, sampler=test_sampler, batch_size=args.train_batch_size,num_workers=4,drop_last=False)
|
| 1293 |
+
|
| 1294 |
+
for idx in range(args.num_train_epochs):
|
| 1295 |
+
output_dir_epoch = os.path.join(args.output_dir, '{}'.format(idx))
|
| 1296 |
+
output_dir_epoch = os.path.join(output_dir_epoch, '{}'.format('model.bin'))
|
| 1297 |
+
|
| 1298 |
+
model.load_state_dict(torch.load(output_dir_epoch),strict=False)
|
| 1299 |
+
model.to(args.device)
|
| 1300 |
+
|
| 1301 |
+
model_eval = model.module if hasattr(model,'module') else model
|
| 1302 |
+
|
| 1303 |
+
all_nl_vec = []
|
| 1304 |
+
all_code_vec = []
|
| 1305 |
+
|
| 1306 |
+
for step,batch in enumerate(test_dataloader):
|
| 1307 |
+
code_inputs = batch[0].to(args.device)
|
| 1308 |
+
nl_inputs = batch[1].to(args.device)
|
| 1309 |
+
#get code and nl vectors
|
| 1310 |
+
nl_outputs = model_eval.nl_encoder_q(nl_inputs, attention_mask=nl_inputs.ne(1))
|
| 1311 |
+
nl_vec =nl_outputs [1]
|
| 1312 |
+
code_outputs = model_eval.code_encoder_q(code_inputs, attention_mask=code_inputs.ne(1))
|
| 1313 |
+
code_vec =code_outputs [1]
|
| 1314 |
+
all_nl_vec.append(nl_vec.detach().cpu().numpy())
|
| 1315 |
+
all_code_vec.append(code_vec.detach().cpu().numpy())
|
| 1316 |
+
all_nl_vec = np.concatenate(all_nl_vec, axis=0)
|
| 1317 |
+
all_code_vec = np.concatenate(all_code_vec, axis=0)
|
| 1318 |
+
print(all_nl_vec.shape, all_code_vec.shape)
|
| 1319 |
+
np.save("/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/" + str(idx) + "/test_all_nl_vec.npy", all_nl_vec)
|
| 1320 |
+
np.save("/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/" + str(idx) + "/test_all_code_vec.npy", all_code_vec)
|
| 1321 |
+
|
| 1322 |
+
def gen_label():
|
| 1323 |
+
|
| 1324 |
+
args = parse_args()
|
| 1325 |
+
#set log
|
| 1326 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 1327 |
+
datefmt='%m/%d/%Y %H:%M:%S',level=logging.INFO )
|
| 1328 |
+
#set device
|
| 1329 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 1330 |
+
args.n_gpu = torch.cuda.device_count()
|
| 1331 |
+
args.device = device
|
| 1332 |
+
logger.info("device: %s, n_gpu: %s",device, args.n_gpu)
|
| 1333 |
+
|
| 1334 |
+
pool = multiprocessing.Pool(cpu_cont)
|
| 1335 |
+
|
| 1336 |
+
# # Set seed
|
| 1337 |
+
# set_seed(args.seed)
|
| 1338 |
+
# if "codet5" in args.model_name_or_path:
|
| 1339 |
+
# config = T5Config.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1340 |
+
# tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1341 |
+
# model = T5ForConditionalGeneration.from_pretrained(args.model_name_or_path)
|
| 1342 |
+
# model = model.encoder
|
| 1343 |
+
# else:
|
| 1344 |
+
# config = RobertaConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 1345 |
+
# tokenizer = RobertaTokenizer.from_pretrained(args.tokenizer_name)
|
| 1346 |
+
# model = RobertaModel.from_pretrained(args.model_name_or_path)
|
| 1347 |
+
# model=create_model(args,model,tokenizer,config)
|
| 1348 |
+
|
| 1349 |
+
# if args.data_aug_type == "replace_type" :
|
| 1350 |
+
# train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 1351 |
+
# else:
|
| 1352 |
+
# # if "unixcoder" in args.model_name_or_path or "coco" in args.model_name_or_path :
|
| 1353 |
+
# train_dataset=TextDataset_unixcoder(tokenizer, args, args.train_data_file, pool)
|
| 1354 |
+
# # else:
|
| 1355 |
+
# # train_dataset=TextDataset(tokenizer, args, args.train_data_file, pool)
|
| 1356 |
+
# train_sampler = SequentialSampler(train_dataset)
|
| 1357 |
+
# train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size,num_workers=4,drop_last=False)
|
| 1358 |
+
|
| 1359 |
+
code_list = []
|
| 1360 |
+
docstring_list = []
|
| 1361 |
+
|
| 1362 |
+
with open(args.train_data_file, 'rt') as gz_file:
|
| 1363 |
+
for line in gz_file:
|
| 1364 |
+
data = json.loads(line)
|
| 1365 |
+
code = data['code']
|
| 1366 |
+
docstring = data['docstring']
|
| 1367 |
+
|
| 1368 |
+
# 将 code 和 docstring 添加到列表中
|
| 1369 |
+
code_list.append(code)
|
| 1370 |
+
docstring_list.append(docstring)
|
| 1371 |
+
|
| 1372 |
+
print(len(code_list))
|
| 1373 |
+
print(len(docstring_list))
|
| 1374 |
+
|
| 1375 |
+
# print(code_list[0])
|
| 1376 |
+
# print(docstring_list[0])
|
| 1377 |
+
|
| 1378 |
+
code_output_file = '/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/code_list.json'
|
| 1379 |
+
docstring_output_file = '/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/docstring_list.json'
|
| 1380 |
+
|
| 1381 |
+
# 存储 code_list 到 JSON 文件
|
| 1382 |
+
with open(code_output_file, 'w') as file:
|
| 1383 |
+
json.dump(code_list, file)
|
| 1384 |
+
|
| 1385 |
+
# 存储 docstring_list 到 JSON 文件
|
| 1386 |
+
with open(docstring_output_file, 'w') as file:
|
| 1387 |
+
json.dump(docstring_list, file)
|
| 1388 |
+
|
| 1389 |
+
code_list = []
|
| 1390 |
+
docstring_list = []
|
| 1391 |
+
|
| 1392 |
+
with open(args.test_data_file, 'rt') as gz_file:
|
| 1393 |
+
for line in gz_file:
|
| 1394 |
+
data = json.loads(line)
|
| 1395 |
+
code = data['code']
|
| 1396 |
+
docstring = data['docstring']
|
| 1397 |
+
|
| 1398 |
+
# 将 code 和 docstring 添加到列表中
|
| 1399 |
+
code_list.append(code)
|
| 1400 |
+
docstring_list.append(docstring)
|
| 1401 |
+
|
| 1402 |
+
print(len(code_list))
|
| 1403 |
+
print(len(docstring_list))
|
| 1404 |
+
|
| 1405 |
+
code_output_file = '/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/test_code_list.json'
|
| 1406 |
+
docstring_output_file = '/home/yiming/cocosoda/CoCoSoDa/saved_models/fine_tune/ruby/test_docstring_list.json'
|
| 1407 |
+
|
| 1408 |
+
# 存储 code_list 到 JSON 文件
|
| 1409 |
+
with open(code_output_file, 'w') as file:
|
| 1410 |
+
json.dump(code_list, file)
|
| 1411 |
+
|
| 1412 |
+
# 存储 docstring_list 到 JSON 文件
|
| 1413 |
+
with open(docstring_output_file, 'w') as file:
|
| 1414 |
+
json.dump(docstring_list, file)
|
| 1415 |
+
|
| 1416 |
+
if __name__ == "__main__":
|
| 1417 |
+
# main()
|
| 1418 |
+
# gen_vector()
|
| 1419 |
+
gen_label()
|
| 1420 |
+
|
run_cocosoda.sh
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lang=ruby
|
| 2 |
+
current_time=$(date "+%Y%m%d%H%M%S")
|
| 3 |
+
# current_time=tmp
|
| 4 |
+
|
| 5 |
+
code_length=64
|
| 6 |
+
nl_length=64
|
| 7 |
+
|
| 8 |
+
model_type=multi-loss-cocosoda #"base", "cocosoda"
|
| 9 |
+
moco_k=1024
|
| 10 |
+
moco_m=0.999
|
| 11 |
+
lr=2e-5
|
| 12 |
+
moco_t=0.07
|
| 13 |
+
|
| 14 |
+
epoch=10
|
| 15 |
+
batch_size=128
|
| 16 |
+
max_steps=100000
|
| 17 |
+
save_steps=1000
|
| 18 |
+
data_aug_type="replace_type"
|
| 19 |
+
couninue_pre_train_data_files='dataset/java/train.jsonl dataset/javascript/train.jsonl dataset/python/train.jsonl dataset/php/train.jsonl dataset/go/train.jsonl dataset/ruby/train.jsonl'
|
| 20 |
+
CUDA_VISIBLE_DEVICES="0,1"
|
| 21 |
+
base_model=unixcoder
|
| 22 |
+
|
| 23 |
+
function continue_pre_train () {
|
| 24 |
+
output_dir=./saved_models/cocosoda/
|
| 25 |
+
mkdir -p $output_dir
|
| 26 |
+
echo ${output_dir}
|
| 27 |
+
CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES} python run.py --eval_frequency 100 \
|
| 28 |
+
--moco_m ${moco_m} --moco_t ${moco_t} \
|
| 29 |
+
--output_dir ${output_dir} \
|
| 30 |
+
--moco_k ${moco_k} \
|
| 31 |
+
--model_type ${model_type} \
|
| 32 |
+
--data_aug_type other \
|
| 33 |
+
--config_name=microsoft/${base_model}-base \
|
| 34 |
+
--model_name_or_path=microsoft/${base_model}-base \
|
| 35 |
+
--tokenizer_name=microsoft/${base_model}-base \
|
| 36 |
+
--lang=$lang \
|
| 37 |
+
--do_test \
|
| 38 |
+
--time_score 1 \
|
| 39 |
+
--do_multi_lang_continue_pre_train \
|
| 40 |
+
--max_steps ${max_steps} \
|
| 41 |
+
--save_steps ${save_steps} \
|
| 42 |
+
--gradient_accumulation_steps 1 \
|
| 43 |
+
--logging_steps 50 \
|
| 44 |
+
--couninue_pre_train_data_files ${couninue_pre_train_data_files} \
|
| 45 |
+
--train_data_file=dataset/$lang/train.jsonl \
|
| 46 |
+
--eval_data_file=dataset/$lang/valid.jsonl \
|
| 47 |
+
--test_data_file=dataset/$lang/test.jsonl \
|
| 48 |
+
--codebase_file=dataset/$lang/codebase.jsonl \
|
| 49 |
+
--num_train_epochs ${epoch} \
|
| 50 |
+
--code_length ${code_length} \
|
| 51 |
+
--nl_length ${nl_length} \
|
| 52 |
+
--train_batch_size ${batch_size} \
|
| 53 |
+
--eval_batch_size 64 \
|
| 54 |
+
--learning_rate ${lr} \
|
| 55 |
+
--seed 123456 2>&1| tee ${output_dir}/save_tokenizer.log
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
continue_pre_train
|
run_fine_tune.sh
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lang=$1
|
| 2 |
+
current_time=$(date "+%Y%m%d%H%M%S")
|
| 3 |
+
|
| 4 |
+
code_length=64
|
| 5 |
+
nl_length=64
|
| 6 |
+
|
| 7 |
+
model_type=multi-loss-cocosoda #"base", "cocosoda"
|
| 8 |
+
moco_k=1024
|
| 9 |
+
moco_m=0.999
|
| 10 |
+
lr=2e-5
|
| 11 |
+
moco_t=0.07
|
| 12 |
+
|
| 13 |
+
batch_size=64
|
| 14 |
+
max_steps=1000
|
| 15 |
+
save_steps=100
|
| 16 |
+
aug_type_way=random_replace_type
|
| 17 |
+
data_aug_type=random_mask
|
| 18 |
+
|
| 19 |
+
base_model=DeepSoftwareAnalytics/CoCoSoDa
|
| 20 |
+
epoch=5
|
| 21 |
+
# echo ${base_model}
|
| 22 |
+
CUDA_VISIBLE_DEVICES="0,1"
|
| 23 |
+
# exit 111
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
function fine-tune () {
|
| 27 |
+
output_dir=./saved_models/fine_tune/${lang}
|
| 28 |
+
mkdir -p $output_dir
|
| 29 |
+
echo ${output_dir}
|
| 30 |
+
CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES} python run.py --eval_frequency 100 \
|
| 31 |
+
--moco_m ${moco_m} --moco_t ${moco_t} \
|
| 32 |
+
--model_type ${model_type} \
|
| 33 |
+
--output_dir ${output_dir} \
|
| 34 |
+
--data_aug_type ${data_aug_type} \
|
| 35 |
+
--moco_k ${moco_k} \
|
| 36 |
+
--config_name=${base_model} \
|
| 37 |
+
--model_name_or_path=${base_model} \
|
| 38 |
+
--tokenizer_name=${base_model} \
|
| 39 |
+
--lang=$lang \
|
| 40 |
+
--do_train \
|
| 41 |
+
--do_test \
|
| 42 |
+
--train_data_file=dataset/$lang/train.jsonl \
|
| 43 |
+
--eval_data_file=dataset/$lang/valid.jsonl \
|
| 44 |
+
--test_data_file=dataset/$lang/test.jsonl \
|
| 45 |
+
--codebase_file=dataset/$lang/codebase.jsonl \
|
| 46 |
+
--num_train_epochs ${epoch} \
|
| 47 |
+
--code_length ${code_length} \
|
| 48 |
+
--nl_length ${nl_length} \
|
| 49 |
+
--train_batch_size ${batch_size} \
|
| 50 |
+
--eval_batch_size 64 \
|
| 51 |
+
--learning_rate ${lr} \
|
| 52 |
+
--seed 123456 2>&1| tee ${output_dir}/running.log
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
fine-tune
|
run_zero-shot.sh
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lang=$1
|
| 2 |
+
current_time=$(date "+%Y%m%d%H%M%S")
|
| 3 |
+
code_length=256
|
| 4 |
+
nl_length=128
|
| 5 |
+
model_type=cocosoda #"base", "cocosoda" ,"multi-loss-cocosoda"
|
| 6 |
+
moco_k=1024
|
| 7 |
+
moco_m=0.999
|
| 8 |
+
lr=2e-5
|
| 9 |
+
moco_t=0.07
|
| 10 |
+
max_steps=1000
|
| 11 |
+
aug_type_way=random_replace_type
|
| 12 |
+
data_aug_type=random_mask
|
| 13 |
+
base_model=DeepSoftwareAnalytics/CoCoSoDa
|
| 14 |
+
CUDA_VISIBLE_DEVICES=0
|
| 15 |
+
|
| 16 |
+
function zero-shot () {
|
| 17 |
+
output_dir=./saved_models/zero-shot/${lang}
|
| 18 |
+
mkdir -p $output_dir
|
| 19 |
+
|
| 20 |
+
CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES} python run.py --eval_frequency 100 \
|
| 21 |
+
--do_zero_short \
|
| 22 |
+
--moco_m ${moco_m} --moco_t ${moco_t} \
|
| 23 |
+
--model_type ${model_type} \
|
| 24 |
+
--output_dir ${output_dir} \
|
| 25 |
+
--data_aug_type ${data_aug_type} \
|
| 26 |
+
--moco_k ${moco_k} \
|
| 27 |
+
--config_name=${base_model} \
|
| 28 |
+
--model_name_or_path=${base_model} \
|
| 29 |
+
--tokenizer_name=${base_model} \
|
| 30 |
+
--lang=$lang \
|
| 31 |
+
--do_test \
|
| 32 |
+
--test_data_file=dataset/$lang/test.jsonl \
|
| 33 |
+
--codebase_file=dataset/$lang/codebase.jsonl \
|
| 34 |
+
--code_length ${code_length} \
|
| 35 |
+
--nl_length ${nl_length} \
|
| 36 |
+
--eval_batch_size 128 \
|
| 37 |
+
--learning_rate ${lr} \
|
| 38 |
+
--seed 123456 2>&1| tee ${output_dir}/running.log
|
| 39 |
+
}
|
| 40 |
+
zero-shot
|