

Update README.md
Browse files
README.md
CHANGED
|
@@ -15,7 +15,7 @@ Text classification technology is widely used in various industries such as dial
|
|
| 15 |
However, there are many challenges in industrial-level text classification practices, including diverse tasks, limited data availability and label transfer difficulty.
|
| 16 |
To address these issues, UTC models text classification as a matching task between labels and text, based on the idea of Unified Semantic Matching (USM).
|
| 17 |
Thus, it can handle multiple classification tasks with a single model, reducing development and machine costs and achieving good zero/few-shot transfer performance.
|
| 18 |
-
|
| 19 |
|
| 20 |
|
| 21 |
USM Paper: https://arxiv.org/abs/2301.03282
|
|
@@ -23,9 +23,8 @@ USM Paper: https://arxiv.org/abs/2301.03282
|
|
| 23 |
PaddleNLP released UTC model for various text classification tasks which use ERNIE models as the pre-trained language models and were finetuned on a large amount of text classification data.
|
| 24 |
|
| 25 |
|
| 26 |
-
![UTC-diagram]()
|
| 27 |
|
| 28 |
-
![UTC-benchmarks]()
|
| 29 |
|
| 30 |
## Available Models
|
| 31 |
|
|
@@ -36,7 +35,9 @@ PaddleNLP released UTC model for various text classification tasks which use ERN
|
|
| 36 |
|
| 37 |
## Performance on Text Dataset
|
| 38 |
|
| 39 |
-
|
|
|
|
|
|
|
| 40 |
|
| 41 |
|
| 42 |
|
|
|
|
| 15 |
However, there are many challenges in industrial-level text classification practices, including diverse tasks, limited data availability and label transfer difficulty.
|
| 16 |
To address these issues, UTC models text classification as a matching task between labels and text, based on the idea of Unified Semantic Matching (USM).
|
| 17 |
Thus, it can handle multiple classification tasks with a single model, reducing development and machine costs and achieving good zero/few-shot transfer performance.
|
| 18 |
+
|
| 19 |
|
| 20 |
|
| 21 |
USM Paper: https://arxiv.org/abs/2301.03282
|
|
|
|
| 23 |
PaddleNLP released UTC model for various text classification tasks which use ERNIE models as the pre-trained language models and were finetuned on a large amount of text classification data.
|
| 24 |
|
| 25 |
|
| 26 |
+
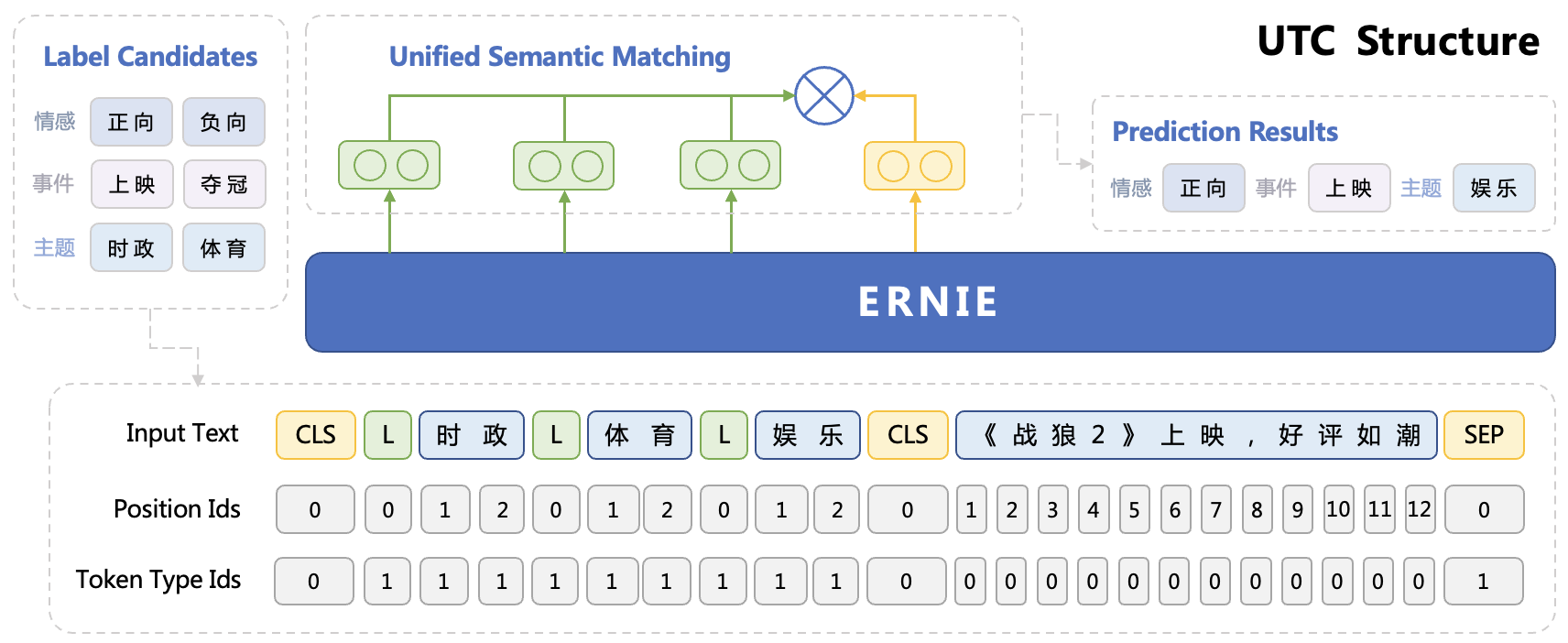
|
| 27 |
|
|
|
|
| 28 |
|
| 29 |
## Available Models
|
| 30 |
|
|
|
|
| 35 |
|
| 36 |
## Performance on Text Dataset
|
| 37 |
|
| 38 |
+
UTC won the 1st place on both [ZeroCLUE](https://www.cluebenchmarks.com/zeroclue.html) and [FewCLUE](https://www.cluebenchmarks.com/fewclue.html) benchmarks.
|
| 39 |
+
|
| 40 |
+

|
| 41 |
|
| 42 |
|
| 43 |
|