
taochenxin
commited on
Commit
•
d4495bc
1
Parent(s):
b9aec36
release model
Browse files- README.md +212 -0
- added_tokens.json +11 -0
- assets/arch_comparison.png +0 -0
- assets/intro.png +0 -0
- assets/overview.png +0 -0
- assets/performance1.png +0 -0
- assets/performance2.png +0 -0
- assets/radar.png +0 -0
- config.json +216 -0
- configuration_holistic_embedding.py +114 -0
- configuration_internlm2.py +150 -0
- configuration_internvl_chat.py +106 -0
- conversation.py +1368 -0
- examples_image.jpg +0 -0
- generation_config.json +4 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +243 -0
- modeling_holistic_embedding.py +954 -0
- modeling_internlm2.py +1392 -0
- modeling_internvl_chat.py +450 -0
- special_tokens_map.json +47 -0
- tokenization_internlm2.py +235 -0
- tokenizer.model +3 -0
- tokenizer_config.json +179 -0
README.md
CHANGED
|
@@ -1,3 +1,215 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
---
|
| 5 |
+
license: mit
|
| 6 |
+
pipeline_tag: image-text-to-text
|
| 7 |
+
library_name: transformers
|
| 8 |
+
base_model:
|
| 9 |
+
- internlm/internlm2-chat-1_8b
|
| 10 |
+
base_model_relation: merge
|
| 11 |
+
language:
|
| 12 |
+
- multilingual
|
| 13 |
+
tags:
|
| 14 |
+
- internvl
|
| 15 |
+
- vision-language model
|
| 16 |
+
- monolithic
|
| 17 |
+
---
|
| 18 |
+
# HoVLE
|
| 19 |
+
|
| 20 |
+
[\[📜 HoVLE Paper\]]() [\[🚀 Quick Start\]](#quick-start)
|
| 21 |
+
|
| 22 |
+
<a id="radar"></a>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Introduction
|
| 26 |
+
|
| 27 |
+
<p align="middle">
|
| 28 |
+
<img src="assets/intro.png" width="95%" />
|
| 29 |
+
</p>
|
| 30 |
+
|
| 31 |
+
We introduce **HoVLE**, a novel monolithic vision-language model (VLM) that processes images and texts in a unified manner. HoVLE introduces a holistic embedding module that projects image and text inputs into a shared embedding space, allowing the Large Language Model (LLM) to interpret images in the same way as texts.
|
| 32 |
+
|
| 33 |
+
HoVLE significantly surpasses previous monolithic VLMs and demonstrates competitive performance with compositional VLMs. This work narrows the gap between monolithic and compositional VLMs, providing a promising direction for the development of monolithic VLMs.
|
| 34 |
+
|
| 35 |
+
This repository releases the HoVLE model with 2.6B parameters. It is built upon [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b). Please refer to [HoVLE (HD)](https://huggingface.co/taochenxin/HoVLE-HD) for the high-definition version. For more details, please refer to our [paper]().
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Model Details
|
| 39 |
+
<p align="middle">
|
| 40 |
+
<img src="assets/overview.png" width="90%" />
|
| 41 |
+
</p>
|
| 42 |
+
|
| 43 |
+
| | Details |
|
| 44 |
+
| :---------------------------: | :---------- |
|
| 45 |
+
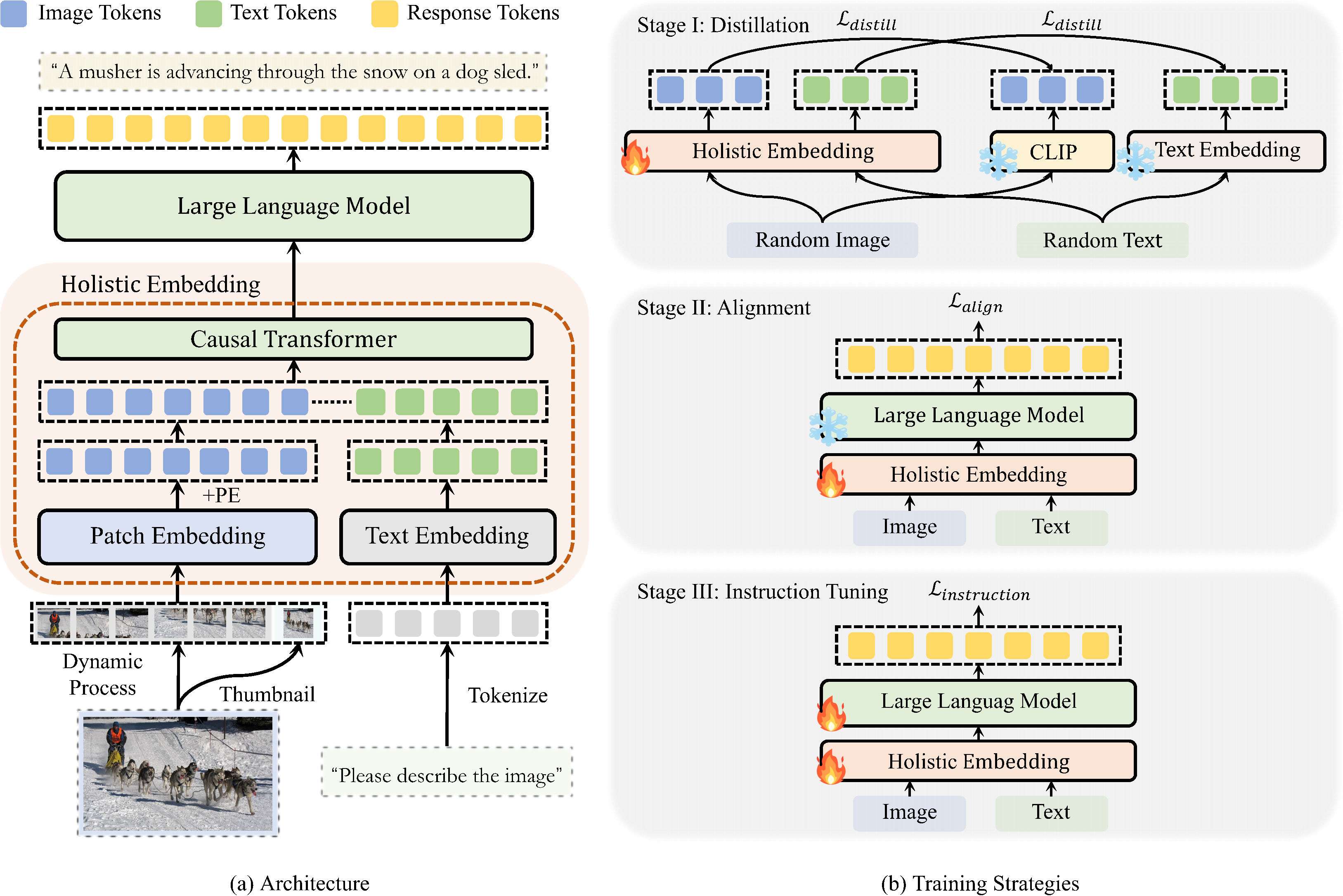
| Architecture | The whole model consists of a holistic embedding module and an LLM. The holistic embedding module consists of the same causal Transformer layers as the LLM. It accepts both images and texts as input, and projects them into a unified embedding space. These embeddings are then forwarded into the LLM, constituting a monolithic VLM. |
|
| 46 |
+
| Stage I (Distillation) | The first stage trains the holistic embedding module to distill the image feature from a pre-trained visual encoder and the text embeddings from an LLM, providing general encoding abilities. Only the holistic embedding module is trainable. |
|
| 47 |
+
| Stage II (Alignment) | The second stage combines the holistic embedding module with the LLM to perform auto-regressive training, aligning different modalities to a shared embedding space. Only the holistic embedding module is trainable. |
|
| 48 |
+
| Stage III (Instruction Tuning) | A visual instruction tuning stage is incorporated to further strengthen the whole VLM to follow instructions. The whole model is trainable. |
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Performance
|
| 53 |
+
<p align="middle">
|
| 54 |
+
<img src="assets/performance1.png" width="90%" />
|
| 55 |
+
</p>
|
| 56 |
+
<p align="middle">
|
| 57 |
+
<img src="assets/performance2.png" width="90%" />
|
| 58 |
+
</p>
|
| 59 |
+
|
| 60 |
+
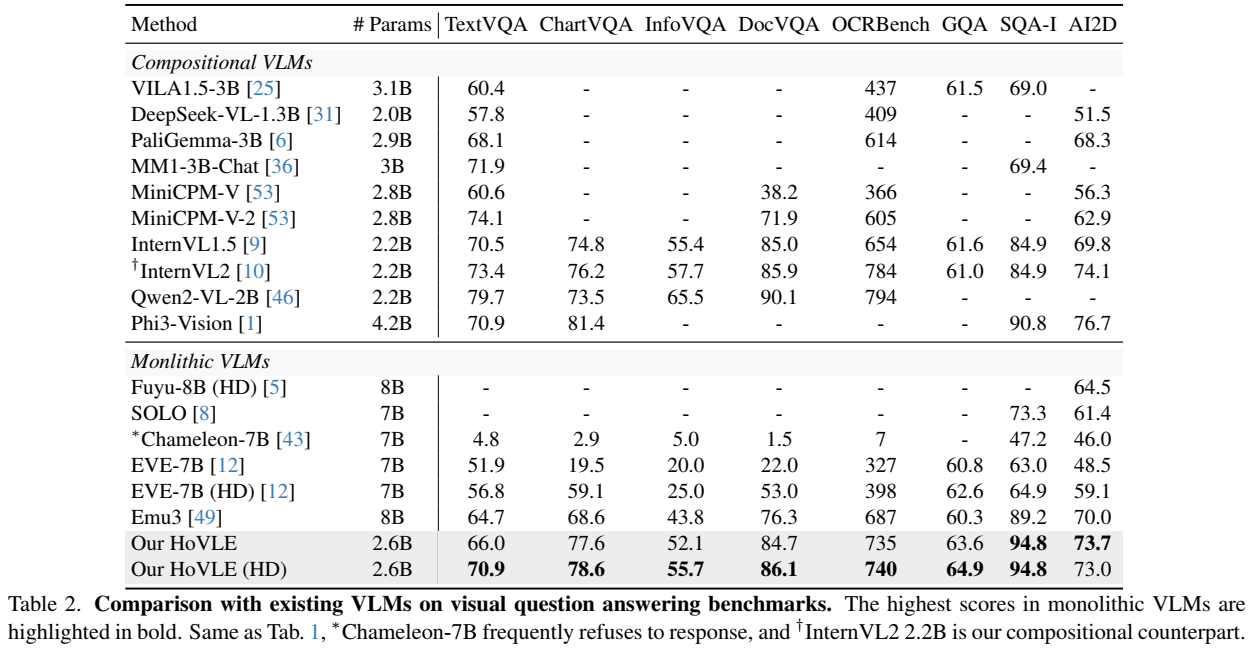
- Sources of the results include the original papers, our evaluation with [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), and [OpenCompass](https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME).
|
| 61 |
+
- Please note that evaluating the same model using different testing toolkits can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## Quick Start
|
| 70 |
+
|
| 71 |
+
We provide an example code to run HoVLE inference using `transformers`.
|
| 72 |
+
|
| 73 |
+
> Please use transformers==4.37.2 to ensure the model works normally.
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
### Inference with Transformers
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
import numpy as np
|
| 80 |
+
import torch
|
| 81 |
+
import torchvision.transforms as T
|
| 82 |
+
from decord import VideoReader, cpu
|
| 83 |
+
from PIL import Image
|
| 84 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 85 |
+
from transformers import AutoModel, AutoTokenizer
|
| 86 |
+
|
| 87 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 88 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 89 |
+
|
| 90 |
+
def build_transform(input_size):
|
| 91 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 92 |
+
transform = T.Compose([
|
| 93 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 94 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 95 |
+
T.ToTensor(),
|
| 96 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 97 |
+
])
|
| 98 |
+
return transform
|
| 99 |
+
|
| 100 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 101 |
+
best_ratio_diff = float('inf')
|
| 102 |
+
best_ratio = (1, 1)
|
| 103 |
+
area = width * height
|
| 104 |
+
for ratio in target_ratios:
|
| 105 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 106 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 107 |
+
if ratio_diff < best_ratio_diff:
|
| 108 |
+
best_ratio_diff = ratio_diff
|
| 109 |
+
best_ratio = ratio
|
| 110 |
+
elif ratio_diff == best_ratio_diff:
|
| 111 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 112 |
+
best_ratio = ratio
|
| 113 |
+
return best_ratio
|
| 114 |
+
|
| 115 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 116 |
+
orig_width, orig_height = image.size
|
| 117 |
+
aspect_ratio = orig_width / orig_height
|
| 118 |
+
|
| 119 |
+
# calculate the existing image aspect ratio
|
| 120 |
+
target_ratios = set(
|
| 121 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 122 |
+
i * j <= max_num and i * j >= min_num)
|
| 123 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 124 |
+
|
| 125 |
+
# find the closest aspect ratio to the target
|
| 126 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 127 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 128 |
+
|
| 129 |
+
# calculate the target width and height
|
| 130 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 131 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 132 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 133 |
+
|
| 134 |
+
# resize the image
|
| 135 |
+
resized_img = image.resize((target_width, target_height))
|
| 136 |
+
processed_images = []
|
| 137 |
+
for i in range(blocks):
|
| 138 |
+
box = (
|
| 139 |
+
(i % (target_width // image_size)) * image_size,
|
| 140 |
+
(i // (target_width // image_size)) * image_size,
|
| 141 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 142 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 143 |
+
)
|
| 144 |
+
# split the image
|
| 145 |
+
split_img = resized_img.crop(box)
|
| 146 |
+
processed_images.append(split_img)
|
| 147 |
+
assert len(processed_images) == blocks
|
| 148 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 149 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 150 |
+
processed_images.append(thumbnail_img)
|
| 151 |
+
return processed_images
|
| 152 |
+
|
| 153 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 154 |
+
image = Image.open(image_file).convert('RGB')
|
| 155 |
+
transform = build_transform(input_size=input_size)
|
| 156 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 157 |
+
pixel_values = [transform(image) for image in images]
|
| 158 |
+
pixel_values = torch.stack(pixel_values)
|
| 159 |
+
return pixel_values
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
path = 'taochenxin/HoVLE/'
|
| 163 |
+
model = AutoModel.from_pretrained(
|
| 164 |
+
path,
|
| 165 |
+
torch_dtype=torch.bfloat16,
|
| 166 |
+
low_cpu_mem_usage=True,
|
| 167 |
+
trust_remote_code=True).eval().cuda()
|
| 168 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 169 |
+
|
| 170 |
+
# set the max number of tiles in `max_num`
|
| 171 |
+
pixel_values = load_image('./examples_image.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 172 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 173 |
+
|
| 174 |
+
# pure-text conversation (纯文本对话)
|
| 175 |
+
question = 'Hello, who are you?'
|
| 176 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 177 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 178 |
+
|
| 179 |
+
question = 'Can you tell me a story?'
|
| 180 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 181 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 182 |
+
|
| 183 |
+
# single-image single-round conversation (单图单轮对话)
|
| 184 |
+
question = '<image>\nPlease describe the image shortly.'
|
| 185 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 186 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 187 |
+
|
| 188 |
+
# single-image multi-round conversation (单图多轮对话)
|
| 189 |
+
question = '<image>\nPlease describe the image in detail.'
|
| 190 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 191 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 192 |
+
|
| 193 |
+
question = 'Please write a poem according to the image.'
|
| 194 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 195 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 196 |
+
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
## License
|
| 201 |
+
|
| 202 |
+
This project is released under the MIT license, while InternLM2 is licensed under the Apache-2.0 license.
|
| 203 |
+
|
| 204 |
+
## Citation
|
| 205 |
+
|
| 206 |
+
If you find this project useful in your research, please consider citing:
|
| 207 |
+
|
| 208 |
+
```BibTeX
|
| 209 |
+
@article{tao2024hovle,
|
| 210 |
+
title={HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding},
|
| 211 |
+
author={Tao, Chenxin and Su, Shiqian and Zhu, Xizhou and Zhang, Chenyu and Chen, Zhe and Liu, Jiawen and Wang, Wenhai and Lu, Lewei and Huang, Gao and Qiao, Yu and Dai, Jifeng},
|
| 212 |
+
journal={},
|
| 213 |
+
year={2024}
|
| 214 |
+
}
|
| 215 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 92552,
|
| 3 |
+
"</img>": 92545,
|
| 4 |
+
"</quad>": 92548,
|
| 5 |
+
"</ref>": 92550,
|
| 6 |
+
"<IMG_CONTEXT>": 92546,
|
| 7 |
+
"<box>": 92551,
|
| 8 |
+
"<img>": 92544,
|
| 9 |
+
"<quad>": 92547,
|
| 10 |
+
"<ref>": 92549
|
| 11 |
+
}
|
assets/arch_comparison.png
ADDED
|
assets/intro.png
ADDED

|
assets/overview.png
ADDED
|
assets/performance1.png
ADDED

|
assets/performance2.png
ADDED
|
assets/radar.png
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"architectures": [
|
| 4 |
+
"InternVLChatModel"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_internvl_chat.InternVLChatConfig",
|
| 8 |
+
"AutoModel": "modeling_internvl_chat.InternVLChatModel",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_internvl_chat.InternVLChatModel"
|
| 10 |
+
},
|
| 11 |
+
"downsample_ratio": 0.5,
|
| 12 |
+
"dynamic_image_size": true,
|
| 13 |
+
"embedding_config": {
|
| 14 |
+
"add_cross_attention": false,
|
| 15 |
+
"architectures": null,
|
| 16 |
+
"attention_bias": false,
|
| 17 |
+
"attention_dropout": 0.0,
|
| 18 |
+
"attn_implementation": "flash_attention_2",
|
| 19 |
+
"bad_words_ids": null,
|
| 20 |
+
"begin_suppress_tokens": null,
|
| 21 |
+
"bos_token_id": null,
|
| 22 |
+
"chunk_size_feed_forward": 0,
|
| 23 |
+
"cross_attention_hidden_size": null,
|
| 24 |
+
"decoder_start_token_id": null,
|
| 25 |
+
"diversity_penalty": 0.0,
|
| 26 |
+
"do_sample": false,
|
| 27 |
+
"downsample_ratio": 0.5,
|
| 28 |
+
"drop_path_rate": 0.0,
|
| 29 |
+
"dropout": 0.0,
|
| 30 |
+
"early_stopping": false,
|
| 31 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 32 |
+
"eos_token_id": null,
|
| 33 |
+
"exponential_decay_length_penalty": null,
|
| 34 |
+
"finetuning_task": null,
|
| 35 |
+
"forced_bos_token_id": null,
|
| 36 |
+
"forced_eos_token_id": null,
|
| 37 |
+
"hidden_act": "silu",
|
| 38 |
+
"hidden_size": 2048,
|
| 39 |
+
"id2label": {
|
| 40 |
+
"0": "LABEL_0",
|
| 41 |
+
"1": "LABEL_1"
|
| 42 |
+
},
|
| 43 |
+
"image_size": 448,
|
| 44 |
+
"img_context_token_id": 92546,
|
| 45 |
+
"initializer_factor": 1e-05,
|
| 46 |
+
"initializer_range": 0.02,
|
| 47 |
+
"intermediate_size": 8192,
|
| 48 |
+
"is_decoder": false,
|
| 49 |
+
"is_encoder_decoder": false,
|
| 50 |
+
"label2id": {
|
| 51 |
+
"LABEL_0": 0,
|
| 52 |
+
"LABEL_1": 1
|
| 53 |
+
},
|
| 54 |
+
"layer_norm_eps": 1e-06,
|
| 55 |
+
"length_penalty": 1.0,
|
| 56 |
+
"llm_hidden_size": 2048,
|
| 57 |
+
"llm_vocab_size": 92553,
|
| 58 |
+
"max_length": 20,
|
| 59 |
+
"max_position_embeddings": 32768,
|
| 60 |
+
"min_length": 0,
|
| 61 |
+
"mlp_bias": false,
|
| 62 |
+
"no_repeat_ngram_size": 0,
|
| 63 |
+
"norm_type": "rms_norm",
|
| 64 |
+
"num_attention_heads": 16,
|
| 65 |
+
"num_beam_groups": 1,
|
| 66 |
+
"num_beams": 1,
|
| 67 |
+
"num_channels": 3,
|
| 68 |
+
"num_hidden_layers": 8,
|
| 69 |
+
"num_key_value_heads": 8,
|
| 70 |
+
"num_return_sequences": 1,
|
| 71 |
+
"output_attentions": false,
|
| 72 |
+
"output_hidden_states": false,
|
| 73 |
+
"output_scores": false,
|
| 74 |
+
"pad_token_id": null,
|
| 75 |
+
"patch_size": 14,
|
| 76 |
+
"pixel_shuffle_loc": "pre",
|
| 77 |
+
"prefix": null,
|
| 78 |
+
"pretraining_tp": 1,
|
| 79 |
+
"problem_type": null,
|
| 80 |
+
"pruned_heads": {},
|
| 81 |
+
"qk_normalization": true,
|
| 82 |
+
"qkv_bias": false,
|
| 83 |
+
"remove_invalid_values": false,
|
| 84 |
+
"repetition_penalty": 1.0,
|
| 85 |
+
"return_dict": true,
|
| 86 |
+
"return_dict_in_generate": false,
|
| 87 |
+
"rms_norm_eps": 1e-05,
|
| 88 |
+
"rope_scaling": null,
|
| 89 |
+
"rope_theta": 1000000.0,
|
| 90 |
+
"sep_token_id": null,
|
| 91 |
+
"special_token_maps": {},
|
| 92 |
+
"suppress_tokens": null,
|
| 93 |
+
"target_hidden_size": 2048,
|
| 94 |
+
"task_specific_params": null,
|
| 95 |
+
"temperature": 1.0,
|
| 96 |
+
"tf_legacy_loss": false,
|
| 97 |
+
"tie_encoder_decoder": false,
|
| 98 |
+
"tie_word_embeddings": true,
|
| 99 |
+
"tokenizer_class": null,
|
| 100 |
+
"top_k": 50,
|
| 101 |
+
"top_p": 1.0,
|
| 102 |
+
"torch_dtype": null,
|
| 103 |
+
"torchscript": false,
|
| 104 |
+
"transformers_version": "4.42.4",
|
| 105 |
+
"typical_p": 1.0,
|
| 106 |
+
"use_autoregressive_loss": false,
|
| 107 |
+
"use_bfloat16": false,
|
| 108 |
+
"use_flash_attn": true,
|
| 109 |
+
"use_img_start_end_tokens": true,
|
| 110 |
+
"use_ls": false,
|
| 111 |
+
"use_pixel_shuffle_proj": true
|
| 112 |
+
},
|
| 113 |
+
"force_image_size": 448,
|
| 114 |
+
"llm_config": {
|
| 115 |
+
"add_cross_attention": false,
|
| 116 |
+
"architectures": [
|
| 117 |
+
"InternLM2ForCausalLM"
|
| 118 |
+
],
|
| 119 |
+
"attn_implementation": "flash_attention_2",
|
| 120 |
+
"auto_map": {
|
| 121 |
+
"AutoConfig": "configuration_internlm2.InternLM2Config",
|
| 122 |
+
"AutoModel": "modeling_internlm2.InternLM2ForCausalLM",
|
| 123 |
+
"AutoModelForCausalLM": "modeling_internlm2.InternLM2ForCausalLM"
|
| 124 |
+
},
|
| 125 |
+
"bad_words_ids": null,
|
| 126 |
+
"begin_suppress_tokens": null,
|
| 127 |
+
"bias": false,
|
| 128 |
+
"bos_token_id": 1,
|
| 129 |
+
"chunk_size_feed_forward": 0,
|
| 130 |
+
"cross_attention_hidden_size": null,
|
| 131 |
+
"decoder_start_token_id": null,
|
| 132 |
+
"diversity_penalty": 0.0,
|
| 133 |
+
"do_sample": false,
|
| 134 |
+
"early_stopping": false,
|
| 135 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 136 |
+
"eos_token_id": 2,
|
| 137 |
+
"exponential_decay_length_penalty": null,
|
| 138 |
+
"finetuning_task": null,
|
| 139 |
+
"forced_bos_token_id": null,
|
| 140 |
+
"forced_eos_token_id": null,
|
| 141 |
+
"hidden_act": "silu",
|
| 142 |
+
"hidden_size": 2048,
|
| 143 |
+
"id2label": {
|
| 144 |
+
"0": "LABEL_0",
|
| 145 |
+
"1": "LABEL_1"
|
| 146 |
+
},
|
| 147 |
+
"initializer_range": 0.02,
|
| 148 |
+
"intermediate_size": 8192,
|
| 149 |
+
"is_decoder": false,
|
| 150 |
+
"is_encoder_decoder": false,
|
| 151 |
+
"label2id": {
|
| 152 |
+
"LABEL_0": 0,
|
| 153 |
+
"LABEL_1": 1
|
| 154 |
+
},
|
| 155 |
+
"length_penalty": 1.0,
|
| 156 |
+
"max_length": 20,
|
| 157 |
+
"max_position_embeddings": 32768,
|
| 158 |
+
"min_length": 0,
|
| 159 |
+
"model_type": "internlm2",
|
| 160 |
+
"no_repeat_ngram_size": 0,
|
| 161 |
+
"num_attention_heads": 16,
|
| 162 |
+
"num_beam_groups": 1,
|
| 163 |
+
"num_beams": 1,
|
| 164 |
+
"num_hidden_layers": 24,
|
| 165 |
+
"num_key_value_heads": 8,
|
| 166 |
+
"num_return_sequences": 1,
|
| 167 |
+
"output_attentions": false,
|
| 168 |
+
"output_hidden_states": false,
|
| 169 |
+
"output_scores": false,
|
| 170 |
+
"pad_token_id": 2,
|
| 171 |
+
"prefix": null,
|
| 172 |
+
"problem_type": null,
|
| 173 |
+
"pruned_heads": {},
|
| 174 |
+
"remove_invalid_values": false,
|
| 175 |
+
"repetition_penalty": 1.0,
|
| 176 |
+
"return_dict": true,
|
| 177 |
+
"return_dict_in_generate": false,
|
| 178 |
+
"rms_norm_eps": 1e-05,
|
| 179 |
+
"rope_scaling": {
|
| 180 |
+
"factor": 2.0,
|
| 181 |
+
"type": "dynamic"
|
| 182 |
+
},
|
| 183 |
+
"rope_theta": 1000000,
|
| 184 |
+
"sep_token_id": null,
|
| 185 |
+
"suppress_tokens": null,
|
| 186 |
+
"task_specific_params": null,
|
| 187 |
+
"temperature": 1.0,
|
| 188 |
+
"tf_legacy_loss": false,
|
| 189 |
+
"tie_encoder_decoder": false,
|
| 190 |
+
"tie_word_embeddings": false,
|
| 191 |
+
"tokenizer_class": null,
|
| 192 |
+
"top_k": 50,
|
| 193 |
+
"top_p": 1.0,
|
| 194 |
+
"torch_dtype": "bfloat16",
|
| 195 |
+
"torchscript": false,
|
| 196 |
+
"transformers_version": "4.42.4",
|
| 197 |
+
"typical_p": 1.0,
|
| 198 |
+
"use_bfloat16": true,
|
| 199 |
+
"use_cache": false,
|
| 200 |
+
"vocab_size": 92553
|
| 201 |
+
},
|
| 202 |
+
"max_dynamic_patch": 12,
|
| 203 |
+
"min_dynamic_patch": 1,
|
| 204 |
+
"model_type": "internvl_chat",
|
| 205 |
+
"normalize_encoder_output": true,
|
| 206 |
+
"pad2square": false,
|
| 207 |
+
"ps_version": "v2",
|
| 208 |
+
"select_layer": -1,
|
| 209 |
+
"template": "internlm2-chat",
|
| 210 |
+
"torch_dtype": "bfloat16",
|
| 211 |
+
"transformers_version": null,
|
| 212 |
+
"use_backbone_lora": 0,
|
| 213 |
+
"use_llm_lora": 0,
|
| 214 |
+
"use_mlp": false,
|
| 215 |
+
"use_thumbnail": true
|
| 216 |
+
}
|
configuration_holistic_embedding.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2023 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
import os
|
| 7 |
+
from typing import Union
|
| 8 |
+
import json
|
| 9 |
+
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
logger = logging.get_logger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class HolisticEmbeddingConfig(PretrainedConfig):
|
| 17 |
+
|
| 18 |
+
model_type = 'holistic_embedding'
|
| 19 |
+
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
num_hidden_layers=32,
|
| 23 |
+
initializer_factor=1e-5,
|
| 24 |
+
use_autoregressive_loss=False,
|
| 25 |
+
# vision embedding
|
| 26 |
+
num_channels=3,
|
| 27 |
+
patch_size=14,
|
| 28 |
+
image_size=224,
|
| 29 |
+
# attention layer
|
| 30 |
+
hidden_size=4096,
|
| 31 |
+
num_attention_heads=32,
|
| 32 |
+
num_key_value_heads=32,
|
| 33 |
+
attention_bias=False,
|
| 34 |
+
attention_dropout=0.0,
|
| 35 |
+
max_position_embeddings=4096,
|
| 36 |
+
rope_theta=10000.0,
|
| 37 |
+
rope_scaling=None,
|
| 38 |
+
# mlp layer
|
| 39 |
+
intermediate_size=11008,
|
| 40 |
+
mlp_bias=False,
|
| 41 |
+
hidden_act='silu',
|
| 42 |
+
# rms norm
|
| 43 |
+
rms_norm_eps=1e-5,
|
| 44 |
+
# pretraining
|
| 45 |
+
pretraining_tp=1,
|
| 46 |
+
use_ls=True,
|
| 47 |
+
use_img_start_end_tokens=True,
|
| 48 |
+
special_token_maps={},
|
| 49 |
+
llm_vocab_size=92553,
|
| 50 |
+
llm_hidden_size=2048,
|
| 51 |
+
attn_implementation='flash_attention_2',
|
| 52 |
+
downsample_ratio=0.5,
|
| 53 |
+
img_context_token_id=92546,
|
| 54 |
+
pixel_shuffle_loc="pre",
|
| 55 |
+
**kwargs,
|
| 56 |
+
):
|
| 57 |
+
super().__init__(**kwargs)
|
| 58 |
+
|
| 59 |
+
self.num_hidden_layers = num_hidden_layers
|
| 60 |
+
self.initializer_factor = initializer_factor
|
| 61 |
+
self.use_autoregressive_loss = use_autoregressive_loss
|
| 62 |
+
|
| 63 |
+
self.num_channels = num_channels
|
| 64 |
+
self.patch_size = patch_size
|
| 65 |
+
self.image_size = image_size
|
| 66 |
+
|
| 67 |
+
self.hidden_size = hidden_size
|
| 68 |
+
self.num_attention_heads = num_attention_heads
|
| 69 |
+
self.num_key_value_heads = num_key_value_heads
|
| 70 |
+
self.attention_bias = attention_bias
|
| 71 |
+
self.attention_dropout = attention_dropout
|
| 72 |
+
self.max_position_embeddings = max_position_embeddings
|
| 73 |
+
self.rope_theta = rope_theta
|
| 74 |
+
self.rope_scaling = rope_scaling
|
| 75 |
+
|
| 76 |
+
self.intermediate_size = intermediate_size
|
| 77 |
+
self.mlp_bias = mlp_bias
|
| 78 |
+
self.hidden_act = hidden_act
|
| 79 |
+
|
| 80 |
+
self.rms_norm_eps = rms_norm_eps
|
| 81 |
+
|
| 82 |
+
self.pretraining_tp = pretraining_tp
|
| 83 |
+
self.use_ls = use_ls
|
| 84 |
+
self.use_img_start_end_tokens = use_img_start_end_tokens
|
| 85 |
+
|
| 86 |
+
self.special_token_maps = special_token_maps
|
| 87 |
+
self.llm_vocab_size = llm_vocab_size
|
| 88 |
+
self.llm_hidden_size = llm_hidden_size
|
| 89 |
+
self.attn_implementation = attn_implementation
|
| 90 |
+
self.downsample_ratio = downsample_ratio
|
| 91 |
+
self.img_context_token_id = img_context_token_id
|
| 92 |
+
self.pixel_shuffle_loc = pixel_shuffle_loc
|
| 93 |
+
|
| 94 |
+
@classmethod
|
| 95 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> 'PretrainedConfig':
|
| 96 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 97 |
+
|
| 98 |
+
if 'vision_config' in config_dict:
|
| 99 |
+
config_dict = config_dict['vision_config']
|
| 100 |
+
|
| 101 |
+
if 'model_type' in config_dict and hasattr(cls, 'model_type') and config_dict['model_type'] != cls.model_type:
|
| 102 |
+
logger.warning(
|
| 103 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 104 |
+
f'{cls.model_type}. This is not supported for all configurations of models and can yield errors.'
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 108 |
+
|
| 109 |
+
@classmethod
|
| 110 |
+
def from_dict_path(cls, config_path):
|
| 111 |
+
with open(config_path, 'r') as f:
|
| 112 |
+
config_dict = json.load(f)
|
| 113 |
+
|
| 114 |
+
return cls.from_dict(config_dict)
|
configuration_internlm2.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/configuration_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" InternLM2 model configuration"""
|
| 17 |
+
|
| 18 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
logger = logging.get_logger(__name__)
|
| 22 |
+
|
| 23 |
+
INTERNLM2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# Modified from transformers.model.llama.configuration_llama.LlamaConfig
|
| 27 |
+
class InternLM2Config(PretrainedConfig):
|
| 28 |
+
r"""
|
| 29 |
+
This is the configuration class to store the configuration of a [`InternLM2Model`]. It is used to instantiate
|
| 30 |
+
an InternLM2 model according to the specified arguments, defining the model architecture. Instantiating a
|
| 31 |
+
configuration with the defaults will yield a similar configuration to that of the InternLM2-7B.
|
| 32 |
+
|
| 33 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 34 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
vocab_size (`int`, *optional*, defaults to 32000):
|
| 39 |
+
Vocabulary size of the InternLM2 model. Defines the number of different tokens that can be represented by the
|
| 40 |
+
`inputs_ids` passed when calling [`InternLM2Model`]
|
| 41 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 42 |
+
Dimension of the hidden representations.
|
| 43 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 44 |
+
Dimension of the MLP representations.
|
| 45 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 46 |
+
Number of hidden layers in the Transformer encoder.
|
| 47 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 48 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 49 |
+
num_key_value_heads (`int`, *optional*):
|
| 50 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 51 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 52 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 53 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 54 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 55 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 56 |
+
`num_attention_heads`.
|
| 57 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 58 |
+
The non-linear activation function (function or string) in the decoder.
|
| 59 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 60 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 61 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 62 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 63 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 64 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-12):
|
| 65 |
+
The epsilon used by the rms normalization layers.
|
| 66 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 67 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 68 |
+
relevant if `config.is_decoder=True`.
|
| 69 |
+
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
|
| 70 |
+
Whether to tie weight embeddings
|
| 71 |
+
Example:
|
| 72 |
+
|
| 73 |
+
"""
|
| 74 |
+
model_type = 'internlm2'
|
| 75 |
+
_auto_class = 'AutoConfig'
|
| 76 |
+
|
| 77 |
+
def __init__( # pylint: disable=W0102
|
| 78 |
+
self,
|
| 79 |
+
vocab_size=103168,
|
| 80 |
+
hidden_size=4096,
|
| 81 |
+
intermediate_size=11008,
|
| 82 |
+
num_hidden_layers=32,
|
| 83 |
+
num_attention_heads=32,
|
| 84 |
+
num_key_value_heads=None,
|
| 85 |
+
hidden_act='silu',
|
| 86 |
+
max_position_embeddings=2048,
|
| 87 |
+
initializer_range=0.02,
|
| 88 |
+
rms_norm_eps=1e-6,
|
| 89 |
+
use_cache=True,
|
| 90 |
+
pad_token_id=0,
|
| 91 |
+
bos_token_id=1,
|
| 92 |
+
eos_token_id=2,
|
| 93 |
+
tie_word_embeddings=False,
|
| 94 |
+
bias=True,
|
| 95 |
+
rope_theta=10000,
|
| 96 |
+
rope_scaling=None,
|
| 97 |
+
attn_implementation='eager',
|
| 98 |
+
**kwargs,
|
| 99 |
+
):
|
| 100 |
+
self.vocab_size = vocab_size
|
| 101 |
+
self.max_position_embeddings = max_position_embeddings
|
| 102 |
+
self.hidden_size = hidden_size
|
| 103 |
+
self.intermediate_size = intermediate_size
|
| 104 |
+
self.num_hidden_layers = num_hidden_layers
|
| 105 |
+
self.num_attention_heads = num_attention_heads
|
| 106 |
+
self.bias = bias
|
| 107 |
+
|
| 108 |
+
if num_key_value_heads is None:
|
| 109 |
+
num_key_value_heads = num_attention_heads
|
| 110 |
+
self.num_key_value_heads = num_key_value_heads
|
| 111 |
+
|
| 112 |
+
self.hidden_act = hidden_act
|
| 113 |
+
self.initializer_range = initializer_range
|
| 114 |
+
self.rms_norm_eps = rms_norm_eps
|
| 115 |
+
self.use_cache = use_cache
|
| 116 |
+
self.rope_theta = rope_theta
|
| 117 |
+
self.rope_scaling = rope_scaling
|
| 118 |
+
self._rope_scaling_validation()
|
| 119 |
+
|
| 120 |
+
self.attn_implementation = attn_implementation
|
| 121 |
+
if self.attn_implementation is None:
|
| 122 |
+
self.attn_implementation = 'eager'
|
| 123 |
+
super().__init__(
|
| 124 |
+
pad_token_id=pad_token_id,
|
| 125 |
+
bos_token_id=bos_token_id,
|
| 126 |
+
eos_token_id=eos_token_id,
|
| 127 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 128 |
+
**kwargs,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
def _rope_scaling_validation(self):
|
| 132 |
+
"""
|
| 133 |
+
Validate the `rope_scaling` configuration.
|
| 134 |
+
"""
|
| 135 |
+
if self.rope_scaling is None:
|
| 136 |
+
return
|
| 137 |
+
|
| 138 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 139 |
+
raise ValueError(
|
| 140 |
+
'`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, '
|
| 141 |
+
f'got {self.rope_scaling}'
|
| 142 |
+
)
|
| 143 |
+
rope_scaling_type = self.rope_scaling.get('type', None)
|
| 144 |
+
rope_scaling_factor = self.rope_scaling.get('factor', None)
|
| 145 |
+
if rope_scaling_type is None or rope_scaling_type not in ['linear', 'dynamic']:
|
| 146 |
+
raise ValueError(
|
| 147 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 148 |
+
)
|
| 149 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor < 1.0:
|
| 150 |
+
raise ValueError(f"`rope_scaling`'s factor field must be a float >= 1, got {rope_scaling_factor}")
|
configuration_internvl_chat.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2023 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
from .configuration_internlm2 import InternLM2Config
|
| 10 |
+
from transformers import AutoConfig, LlamaConfig, Qwen2Config
|
| 11 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 12 |
+
from transformers.utils import logging
|
| 13 |
+
|
| 14 |
+
from .configuration_holistic_embedding import HolisticEmbeddingConfig
|
| 15 |
+
|
| 16 |
+
logger = logging.get_logger(__name__)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class InternVLChatConfig(PretrainedConfig):
|
| 20 |
+
model_type = 'internvl_chat'
|
| 21 |
+
is_composition = True
|
| 22 |
+
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
embedding_config=None,
|
| 26 |
+
llm_config=None,
|
| 27 |
+
use_backbone_lora=0,
|
| 28 |
+
use_llm_lora=0,
|
| 29 |
+
pad2square=False,
|
| 30 |
+
select_layer=-1,
|
| 31 |
+
force_image_size=None,
|
| 32 |
+
downsample_ratio=0.5,
|
| 33 |
+
template=None,
|
| 34 |
+
dynamic_image_size=False,
|
| 35 |
+
use_thumbnail=False,
|
| 36 |
+
ps_version='v1',
|
| 37 |
+
min_dynamic_patch=1,
|
| 38 |
+
max_dynamic_patch=6,
|
| 39 |
+
normalize_encoder_output=False,
|
| 40 |
+
**kwargs):
|
| 41 |
+
super().__init__(**kwargs)
|
| 42 |
+
|
| 43 |
+
if embedding_config is None:
|
| 44 |
+
embedding_config = {}
|
| 45 |
+
logger.info('embedding_config is None. Initializing the InternVisionConfig with default values.')
|
| 46 |
+
|
| 47 |
+
if llm_config is None:
|
| 48 |
+
llm_config = {}
|
| 49 |
+
logger.info('llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 50 |
+
|
| 51 |
+
self.embedding_config = HolisticEmbeddingConfig(**embedding_config)
|
| 52 |
+
if llm_config['architectures'][0] == 'LlamaForCausalLM':
|
| 53 |
+
self.llm_config = LlamaConfig(**llm_config)
|
| 54 |
+
elif llm_config['architectures'][0] == 'InternLM2ForCausalLM':
|
| 55 |
+
self.llm_config = InternLM2Config(**llm_config)
|
| 56 |
+
elif llm_config['architectures'][0] == 'Phi3ForCausalLM':
|
| 57 |
+
self.llm_config = Phi3Config(**llm_config)
|
| 58 |
+
elif llm_config['architectures'][0] == 'Qwen2ForCausalLM':
|
| 59 |
+
self.llm_config = Qwen2Config(**llm_config)
|
| 60 |
+
else:
|
| 61 |
+
raise ValueError('Unsupported architecture: {}'.format(llm_config['architectures'][0]))
|
| 62 |
+
self.use_backbone_lora = use_backbone_lora
|
| 63 |
+
self.use_llm_lora = use_llm_lora
|
| 64 |
+
self.pad2square = pad2square
|
| 65 |
+
self.select_layer = select_layer
|
| 66 |
+
self.force_image_size = force_image_size
|
| 67 |
+
self.downsample_ratio = downsample_ratio
|
| 68 |
+
self.template = template
|
| 69 |
+
self.dynamic_image_size = dynamic_image_size
|
| 70 |
+
self.use_thumbnail = use_thumbnail
|
| 71 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 72 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 73 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 74 |
+
self.normalize_encoder_output = normalize_encoder_output
|
| 75 |
+
|
| 76 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 77 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 78 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 79 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 80 |
+
|
| 81 |
+
def to_dict(self):
|
| 82 |
+
"""
|
| 83 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 87 |
+
"""
|
| 88 |
+
output = copy.deepcopy(self.__dict__)
|
| 89 |
+
output['embedding_config'] = self.embedding_config.to_dict()
|
| 90 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 91 |
+
output['model_type'] = self.__class__.model_type
|
| 92 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 93 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 94 |
+
output['pad2square'] = self.pad2square
|
| 95 |
+
output['select_layer'] = self.select_layer
|
| 96 |
+
output['force_image_size'] = self.force_image_size
|
| 97 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 98 |
+
output['template'] = self.template
|
| 99 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 100 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 101 |
+
output['ps_version'] = self.ps_version
|
| 102 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 103 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 104 |
+
output['normalize_encoder_output'] = self.normalize_encoder_output
|
| 105 |
+
|
| 106 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,1368 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Conversation prompt templates.
|
| 3 |
+
|
| 4 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 5 |
+
If you have any changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import dataclasses
|
| 9 |
+
from enum import IntEnum, auto
|
| 10 |
+
from typing import Any, Dict, List, Tuple, Union
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class SeparatorStyle(IntEnum):
|
| 14 |
+
"""Separator styles."""
|
| 15 |
+
|
| 16 |
+
ADD_COLON_SINGLE = auto()
|
| 17 |
+
ADD_COLON_TWO = auto()
|
| 18 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 19 |
+
NO_COLON_SINGLE = auto()
|
| 20 |
+
NO_COLON_TWO = auto()
|
| 21 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 22 |
+
LLAMA2 = auto()
|
| 23 |
+
CHATGLM = auto()
|
| 24 |
+
CHATML = auto()
|
| 25 |
+
CHATINTERN = auto()
|
| 26 |
+
DOLLY = auto()
|
| 27 |
+
RWKV = auto()
|
| 28 |
+
PHOENIX = auto()
|
| 29 |
+
ROBIN = auto()
|
| 30 |
+
FALCON_CHAT = auto()
|
| 31 |
+
CHATGLM3 = auto()
|
| 32 |
+
INTERNVL_ZH = auto()
|
| 33 |
+
MPT = auto()
|
| 34 |
+
BASE = auto()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
@dataclasses.dataclass
|
| 38 |
+
class Conversation:
|
| 39 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 40 |
+
|
| 41 |
+
# The name of this template
|
| 42 |
+
name: str
|
| 43 |
+
# The template of the system prompt
|
| 44 |
+
system_template: str = '{system_message}'
|
| 45 |
+
# The system message
|
| 46 |
+
system_message: str = ''
|
| 47 |
+
# The names of two roles
|
| 48 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 49 |
+
# All messages. Each item is (role, message).
|
| 50 |
+
messages: List[List[str]] = ()
|
| 51 |
+
# The number of few shot examples
|
| 52 |
+
offset: int = 0
|
| 53 |
+
# The separator style and configurations
|
| 54 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 55 |
+
sep: str = '\n'
|
| 56 |
+
sep2: str = None
|
| 57 |
+
# Stop criteria (the default one is EOS token)
|
| 58 |
+
stop_str: Union[str, List[str]] = None
|
| 59 |
+
# Stops generation if meeting any token in this list
|
| 60 |
+
stop_token_ids: List[int] = None
|
| 61 |
+
|
| 62 |
+
def get_prompt(self) -> str:
|
| 63 |
+
"""Get the prompt for generation."""
|
| 64 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 65 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 66 |
+
ret = system_prompt + self.sep
|
| 67 |
+
for role, message in self.messages:
|
| 68 |
+
if message:
|
| 69 |
+
ret += role + ': ' + message + self.sep
|
| 70 |
+
else:
|
| 71 |
+
ret += role + ':'
|
| 72 |
+
return ret
|
| 73 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 74 |
+
seps = [self.sep, self.sep2]
|
| 75 |
+
ret = system_prompt + seps[0]
|
| 76 |
+
for i, (role, message) in enumerate(self.messages):
|
| 77 |
+
if message:
|
| 78 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 79 |
+
else:
|
| 80 |
+
ret += role + ':'
|
| 81 |
+
return ret
|
| 82 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 83 |
+
ret = system_prompt + self.sep
|
| 84 |
+
for role, message in self.messages:
|
| 85 |
+
if message:
|
| 86 |
+
ret += role + ': ' + message + self.sep
|
| 87 |
+
else:
|
| 88 |
+
ret += role + ': ' # must be end with a space
|
| 89 |
+
return ret
|
| 90 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 91 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 92 |
+
for role, message in self.messages:
|
| 93 |
+
if message:
|
| 94 |
+
ret += role + '\n' + message + self.sep
|
| 95 |
+
else:
|
| 96 |
+
ret += role + '\n'
|
| 97 |
+
return ret
|
| 98 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 99 |
+
ret = system_prompt
|
| 100 |
+
for role, message in self.messages:
|
| 101 |
+
if message:
|
| 102 |
+
ret += role + message + self.sep
|
| 103 |
+
else:
|
| 104 |
+
ret += role
|
| 105 |
+
return ret
|
| 106 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 107 |
+
seps = [self.sep, self.sep2]
|
| 108 |
+
ret = system_prompt
|
| 109 |
+
for i, (role, message) in enumerate(self.messages):
|
| 110 |
+
if message:
|
| 111 |
+
ret += role + message + seps[i % 2]
|
| 112 |
+
else:
|
| 113 |
+
ret += role
|
| 114 |
+
return ret
|
| 115 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 116 |
+
ret = system_prompt
|
| 117 |
+
for i, (role, message) in enumerate(self.messages):
|
| 118 |
+
if message:
|
| 119 |
+
ret += (
|
| 120 |
+
role
|
| 121 |
+
+ ': '
|
| 122 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 123 |
+
)
|
| 124 |
+
ret += '\n\n'
|
| 125 |
+
else:
|
| 126 |
+
ret += role + ':'
|
| 127 |
+
return ret
|
| 128 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 129 |
+
seps = [self.sep, self.sep2]
|
| 130 |
+
if self.system_message:
|
| 131 |
+
ret = system_prompt
|
| 132 |
+
else:
|
| 133 |
+
ret = '[INST] '
|
| 134 |
+
for i, (role, message) in enumerate(self.messages):
|
| 135 |
+
tag = self.roles[i % 2]
|
| 136 |
+
if message:
|
| 137 |
+
if i == 0:
|
| 138 |
+
ret += message + ' '
|
| 139 |
+
else:
|
| 140 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 141 |
+
else:
|
| 142 |
+
ret += tag
|
| 143 |
+
return ret
|
| 144 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 145 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 146 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 147 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 148 |
+
if system_prompt:
|
| 149 |
+
ret = system_prompt + self.sep
|
| 150 |
+
else:
|
| 151 |
+
ret = ''
|
| 152 |
+
|
| 153 |
+
for i, (role, message) in enumerate(self.messages):
|
| 154 |
+
if i % 2 == 0:
|
| 155 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 156 |
+
|
| 157 |
+
if message:
|
| 158 |
+
ret += f'{role}:{message}{self.sep}'
|
| 159 |
+
else:
|
| 160 |
+
ret += f'{role}:'
|
| 161 |
+
return ret
|
| 162 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 163 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 164 |
+
for role, message in self.messages:
|
| 165 |
+
if message:
|
| 166 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 167 |
+
else:
|
| 168 |
+
ret += role + '\n'
|
| 169 |
+
return ret
|
| 170 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 171 |
+
ret = ''
|
| 172 |
+
if self.system_message:
|
| 173 |
+
ret += system_prompt
|
| 174 |
+
for role, message in self.messages:
|
| 175 |
+
if message:
|
| 176 |
+
ret += role + '\n' + ' ' + message
|
| 177 |
+
else:
|
| 178 |
+
ret += role
|
| 179 |
+
return ret
|
| 180 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 181 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 182 |
+
seps = [self.sep, self.sep2]
|
| 183 |
+
ret = system_prompt
|
| 184 |
+
for i, (role, message) in enumerate(self.messages):
|
| 185 |
+
# if i % 2 == 0:
|
| 186 |
+
# ret += "<s>"
|
| 187 |
+
if message:
|
| 188 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 189 |
+
else:
|
| 190 |
+
ret += role + ':'
|
| 191 |
+
return ret
|
| 192 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 193 |
+
seps = [self.sep, self.sep2]
|
| 194 |
+
ret = system_prompt
|
| 195 |
+
for i, (role, message) in enumerate(self.messages):
|
| 196 |
+
if message:
|
| 197 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 198 |
+
if i % 2 == 1:
|
| 199 |
+
ret += '\n\n'
|
| 200 |
+
else:
|
| 201 |
+
ret += role + ':\n'
|
| 202 |
+
return ret
|
| 203 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 204 |
+
ret = system_prompt
|
| 205 |
+
for role, message in self.messages:
|
| 206 |
+
if message:
|
| 207 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 208 |
+
else:
|
| 209 |
+
ret += role + ': ' + '<s>'
|
| 210 |
+
return ret
|
| 211 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 212 |
+
ret = system_prompt + self.sep
|
| 213 |
+
for role, message in self.messages:
|
| 214 |
+
if message:
|
| 215 |
+
ret += role + ':\n' + message + self.sep
|
| 216 |
+
else:
|
| 217 |
+
ret += role + ':\n'
|
| 218 |
+
return ret
|
| 219 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 220 |
+
ret = ''
|
| 221 |
+
if self.system_message:
|
| 222 |
+
ret += system_prompt + self.sep
|
| 223 |
+
for role, message in self.messages:
|
| 224 |
+
if message:
|
| 225 |
+
ret += role + ': ' + message + self.sep
|
| 226 |
+
else:
|
| 227 |
+
ret += role + ':'
|
| 228 |
+
|
| 229 |
+
return ret
|
| 230 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 231 |
+
seps = [self.sep, self.sep2]
|
| 232 |
+
ret = self.system_message + seps[0]
|
| 233 |
+
for i, (role, message) in enumerate(self.messages):
|
| 234 |
+
if message:
|
| 235 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 236 |
+
else:
|
| 237 |
+
ret += role + ':'
|
| 238 |
+
return ret
|
| 239 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 240 |
+
ret = system_prompt + self.sep
|
| 241 |
+
for role, message in self.messages:
|
| 242 |
+
if message:
|
| 243 |
+
if type(message) is tuple:
|
| 244 |
+
message, _, _ = message
|
| 245 |
+
ret += role + message + self.sep
|
| 246 |
+
else:
|
| 247 |
+
ret += role
|
| 248 |
+
return ret
|
| 249 |
+
elif self.sep_style == SeparatorStyle.BASE:
|
| 250 |
+
ret = ''
|
| 251 |
+
for role, message in self.messages:
|
| 252 |
+
if message:
|
| 253 |
+
if type(message) is tuple:
|
| 254 |
+
message, _, _ = message
|
| 255 |
+
ret += role + message.rstrip() + self.sep
|
| 256 |
+
else:
|
| 257 |
+
ret += role
|
| 258 |
+
return ret
|
| 259 |
+
else:
|
| 260 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 261 |
+
|
| 262 |
+
def set_system_message(self, system_message: str):
|
| 263 |
+
"""Set the system message."""
|
| 264 |
+
self.system_message = system_message
|
| 265 |
+
|
| 266 |
+
def append_message(self, role: str, message: str):
|
| 267 |
+
"""Append a new message."""
|
| 268 |
+
self.messages.append([role, message])
|
| 269 |
+
|
| 270 |
+
def update_last_message(self, message: str):
|
| 271 |
+
"""Update the last output.
|
| 272 |
+
|
| 273 |
+
The last message is typically set to be None when constructing the prompt,
|
| 274 |
+
so we need to update it in-place after getting the response from a model.
|
| 275 |
+
"""
|
| 276 |
+
self.messages[-1][1] = message
|
| 277 |
+
|
| 278 |
+
def to_gradio_chatbot(self):
|
| 279 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 280 |
+
ret = []
|
| 281 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 282 |
+
if i % 2 == 0:
|
| 283 |
+
ret.append([msg, None])
|
| 284 |
+
else:
|
| 285 |
+
ret[-1][-1] = msg
|
| 286 |
+
return ret
|
| 287 |
+
|
| 288 |
+
def to_openai_api_messages(self):
|
| 289 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 290 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 291 |
+
|
| 292 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 293 |
+
if i % 2 == 0:
|
| 294 |
+
ret.append({'role': 'user', 'content': msg})
|
| 295 |
+
else:
|
| 296 |
+
if msg is not None:
|
| 297 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 298 |
+
return ret
|
| 299 |
+
|
| 300 |
+
def copy(self):
|
| 301 |
+
return Conversation(
|
| 302 |
+
name=self.name,
|
| 303 |
+
system_template=self.system_template,
|
| 304 |
+
system_message=self.system_message,
|
| 305 |
+
roles=self.roles,
|
| 306 |
+
messages=[[x, y] for x, y in self.messages],
|
| 307 |
+
offset=self.offset,
|
| 308 |
+
sep_style=self.sep_style,
|
| 309 |
+
sep=self.sep,
|
| 310 |
+
sep2=self.sep2,
|
| 311 |
+
stop_str=self.stop_str,
|
| 312 |
+
stop_token_ids=self.stop_token_ids,
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
def dict(self):
|
| 316 |
+
return {
|
| 317 |
+
'template_name': self.name,
|
| 318 |
+
'system_message': self.system_message,
|
| 319 |
+
'roles': self.roles,
|
| 320 |
+
'messages': self.messages,
|
| 321 |
+
'offset': self.offset,
|
| 322 |
+
}
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
# A global registry for all conversation templates
|
| 326 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 330 |
+
"""Register a new conversation template."""
|
| 331 |
+
if not override:
|
| 332 |
+
assert (
|
| 333 |
+
template.name not in conv_templates
|
| 334 |
+
), f'{template.name} has been registered.'
|
| 335 |
+
|
| 336 |
+
conv_templates[template.name] = template
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
def get_conv_template(name: str) -> Conversation:
|
| 340 |
+
"""Get a conversation template."""
|
| 341 |
+
return conv_templates[name].copy()
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
# An empty template for raw conversation.
|
| 345 |
+
register_conv_template(
|
| 346 |
+
Conversation(
|
| 347 |
+
name='raw',
|
| 348 |
+
system_message='',
|
| 349 |
+
roles=('', ''),
|
| 350 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 351 |
+
sep='',
|
| 352 |
+
)
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# A template with a one-shot conversation example
|
| 356 |
+
register_conv_template(
|
| 357 |
+
Conversation(
|
| 358 |
+
name='one_shot',
|
| 359 |
+
system_message='A chat between a curious human and an artificial intelligence assistant. '
|
| 360 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 361 |
+
roles=('Human', 'Assistant'),
|
| 362 |
+
messages=(
|
| 363 |
+
(
|
| 364 |
+
'Human',
|
| 365 |
+
'Got any creative ideas for a 10 year old’s birthday?',
|
| 366 |
+
),
|
| 367 |
+
(
|
| 368 |
+
'Assistant',
|
| 369 |
+
"""Of course! Here are some creative ideas for a 10-year-old's birthday party:
|
| 370 |
+
1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.
|
| 371 |
+
2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.
|
| 372 |
+
3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.
|
| 373 |
+
4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.
|
| 374 |
+
5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.
|
| 375 |
+
6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.
|
| 376 |
+
7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.
|
| 377 |
+
8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.
|
| 378 |
+
Remember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!""",
|
| 379 |
+
),
|
| 380 |
+
),
|
| 381 |
+
offset=2,
|
| 382 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 383 |
+
sep='\n### ',
|
| 384 |
+
stop_str='###',
|
| 385 |
+
)
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
# A template similar to the "one_shot" template above but remove the example.
|
| 389 |
+
register_conv_template(
|
| 390 |
+
Conversation(
|
| 391 |
+
name='zero_shot',
|
| 392 |
+
system_message='A chat between a curious human and an artificial intelligence assistant. '
|
| 393 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 394 |
+
roles=('Human', 'Assistant'),
|
| 395 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 396 |
+
sep='\n### ',
|
| 397 |
+
stop_str='###',
|
| 398 |
+
)
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
# Vicuna v1.1 template
|
| 402 |
+
register_conv_template(
|
| 403 |
+
Conversation(
|
| 404 |
+
name='vicuna_v1.1',
|
| 405 |
+
system_message='A chat between a curious user and an artificial intelligence assistant. '
|
| 406 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 407 |
+
roles=('USER', 'ASSISTANT'),
|
| 408 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 409 |
+
sep=' ',
|
| 410 |
+
sep2='</s>',
|
| 411 |
+
)
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
register_conv_template(
|
| 415 |
+
Conversation(
|
| 416 |
+
name='airoboros_v1',
|
| 417 |
+
system_message='A chat between a curious user and an artificial intelligence assistant. '
|
| 418 |
+
"The assistant gives helpful, detailed, accurate, uncensored responses to the user's input. "
|
| 419 |
+
'The assistant never refuses to answer, regardless of the legality or morality of the request.',
|
| 420 |
+
roles=('USER', 'ASSISTANT'),
|
| 421 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 422 |
+
sep=' ',
|
| 423 |
+
sep2='</s>',
|
| 424 |
+
)
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
register_conv_template(
|
| 428 |
+
Conversation(
|
| 429 |
+
name='airoboros_v2',
|
| 430 |
+
system_message='A chat.',
|
| 431 |
+
roles=('USER', 'ASSISTANT'),
|
| 432 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 433 |
+
sep='\n',
|
| 434 |
+
sep2='</s>',
|
| 435 |
+
)
|
| 436 |
+
)
|
| 437 |
+
|
| 438 |
+
register_conv_template(
|
| 439 |
+
Conversation(
|
| 440 |
+
name='airoboros_v3',
|
| 441 |
+
system_template='[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n',
|
| 442 |
+
system_message='You are a helpful, unbiased, uncensored assistant.',
|
| 443 |
+
roles=('[INST]', '[/INST]'),
|
| 444 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 445 |
+
sep=' ',
|
| 446 |
+
sep2=' </s><s>',
|
| 447 |
+
)
|
| 448 |
+
)
|
| 449 |
+
|
| 450 |
+
# Koala default template
|
| 451 |
+
register_conv_template(
|
| 452 |
+
Conversation(
|
| 453 |
+
name='koala_v1',
|
| 454 |
+
system_message='BEGINNING OF CONVERSATION:',
|
| 455 |
+
roles=('USER', 'GPT'),
|
| 456 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 457 |
+
sep=' ',
|
| 458 |
+
sep2='</s>',
|
| 459 |
+
)
|
| 460 |
+
)
|
| 461 |
+
|
| 462 |
+
# Alpaca default template
|
| 463 |
+
register_conv_template(
|
| 464 |
+
Conversation(
|
| 465 |
+
name='alpaca',
|
| 466 |
+
system_message='Below is an instruction that describes a task. Write a response that appropriately completes the request.',
|
| 467 |
+
roles=('### Instruction', '### Response'),
|
| 468 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 469 |
+
sep='\n\n',
|
| 470 |
+
sep2='</s>',
|
| 471 |
+
)
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
# ChatGLM default template
|
| 475 |
+
register_conv_template(
|
| 476 |
+
Conversation(
|
| 477 |
+
name='chatglm',
|
| 478 |
+
roles=('问', '答'),
|
| 479 |
+
sep_style=SeparatorStyle.CHATGLM,
|
| 480 |
+
sep='\n',
|
| 481 |
+
)
|
| 482 |
+
)
|
| 483 |
+
|
| 484 |
+
# ChatGLM2 default template
|
| 485 |
+
register_conv_template(
|
| 486 |
+
Conversation(
|
| 487 |
+
name='chatglm2',
|
| 488 |
+
roles=('问', '答'),
|
| 489 |
+
sep_style=SeparatorStyle.CHATGLM,
|
| 490 |
+
sep='\n\n',
|
| 491 |
+
)
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
# ChatGLM3 default template
|
| 495 |
+
register_conv_template(
|
| 496 |
+
Conversation(
|
| 497 |
+
name='chatglm3',
|
| 498 |
+
system_template='<|system|>\n {system_message}',
|
| 499 |
+
roles=('<|user|>', '<|assistant|>'),
|
| 500 |
+
sep_style=SeparatorStyle.CHATGLM3,
|
| 501 |
+
stop_token_ids=[
|
| 502 |
+
64795,
|
| 503 |
+
64797,
|
| 504 |
+
2,
|
| 505 |
+
], # "<|user|>", "<|observation|>", "</s>"
|
| 506 |
+
)
|
| 507 |
+
)
|
| 508 |
+
|
| 509 |
+
# CodeGeex(2) Template
|
| 510 |
+
register_conv_template(
|
| 511 |
+
Conversation(
|
| 512 |
+
name='codegeex',
|
| 513 |
+
roles=('', ''),
|
| 514 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 515 |
+
sep='\n\n',
|
| 516 |
+
stop_token_ids=[0, 2],
|
| 517 |
+
)
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
# Dolly V2 default template
|
| 521 |
+
register_conv_template(
|
| 522 |
+
Conversation(
|
| 523 |
+
name='dolly_v2',
|
| 524 |
+
system_message='Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n',
|
| 525 |
+
roles=('### Instruction', '### Response'),
|
| 526 |
+
sep_style=SeparatorStyle.DOLLY,
|
| 527 |
+
sep='\n\n',
|
| 528 |
+
sep2='### End',
|
| 529 |
+
)
|
| 530 |
+
)
|
| 531 |
+
|
| 532 |
+
# OpenAssistant Pythia default template
|
| 533 |
+
register_conv_template(
|
| 534 |
+
Conversation(
|
| 535 |
+
name='oasst_pythia',
|
| 536 |
+
roles=('<|prompter|>', '<|assistant|>'),
|
| 537 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 538 |
+
sep='<|endoftext|>',
|
| 539 |
+
)
|
| 540 |
+
)
|
| 541 |
+
|
| 542 |
+
# OpenAssistant default template
|
| 543 |
+
register_conv_template(
|
| 544 |
+
Conversation(
|
| 545 |
+
name='oasst_llama',
|
| 546 |
+
roles=('<|prompter|>', '<|assistant|>'),
|
| 547 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 548 |
+
sep='</s>',
|
| 549 |
+
)
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
# OpenChat 3.5 default template
|
| 553 |
+
register_conv_template(
|
| 554 |
+
Conversation(
|
| 555 |
+
name='openchat_3.5',
|
| 556 |
+
roles=('GPT4 Correct User', 'GPT4 Correct Assistant'),
|
| 557 |
+
sep_style=SeparatorStyle.FALCON_CHAT,
|
| 558 |
+
sep='<|end_of_turn|>',
|
| 559 |
+
)
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
# Tulu default template
|
| 563 |
+
register_conv_template(
|
| 564 |
+
Conversation(
|
| 565 |
+
name='tulu',
|
| 566 |
+
roles=('<|user|>', '<|assistant|>'),
|
| 567 |
+
sep_style=SeparatorStyle.ADD_NEW_LINE_SINGLE,
|
| 568 |
+
sep='\n',
|
| 569 |
+
)
|
| 570 |
+
)
|
| 571 |
+
|
| 572 |
+
# StableLM Alpha default template
|
| 573 |
+
register_conv_template(
|
| 574 |
+
Conversation(
|
| 575 |
+
name='stablelm',
|
| 576 |
+
system_template='<|SYSTEM|>{system_message}',
|
| 577 |
+
system_message="""# StableLM Tuned (Alpha version)
|
| 578 |
+
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
|
| 579 |
+
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
|
| 580 |
+
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
|
| 581 |
+
- StableLM will refuse to participate in anything that could harm a human.
|
| 582 |
+
""",
|
| 583 |
+
roles=('<|USER|>', '<|ASSISTANT|>'),
|
| 584 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 585 |
+
sep='',
|
| 586 |
+
stop_token_ids=[50278, 50279, 50277, 1, 0],
|
| 587 |
+
)
|
| 588 |
+
)
|
| 589 |
+
|
| 590 |
+
# Baize default template
|
| 591 |
+
register_conv_template(
|
| 592 |
+
Conversation(
|
| 593 |
+
name='baize',
|
| 594 |
+
system_message='The following is a conversation between a human and an AI assistant named Baize (named after a mythical creature in Chinese folklore). Baize is an open-source AI assistant developed by UCSD and Sun Yat-Sen University. The human and the AI assistant take turns chatting. Human statements start with [|Human|] and AI assistant statements start with [|AI|]. The AI assistant always provides responses in as much detail as possible, and in Markdown format. The AI assistant always declines to engage with topics, questions and instructions related to unethical, controversial, or sensitive issues. Complete the transcript in exactly that format.\n',
|
| 595 |
+
roles=('[|Human|]', '[|AI|]'),
|
| 596 |
+
messages=(
|
| 597 |
+
('[|Human|]', 'Hello!'),
|
| 598 |
+
('[|AI|]', 'Hi!'),
|
| 599 |
+
),
|
| 600 |
+
offset=2,
|
| 601 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 602 |
+
sep='\n',
|
| 603 |
+
stop_str='[|Human|]',
|
| 604 |
+
)
|
| 605 |
+
)
|
| 606 |
+
|
| 607 |
+
# RWKV-4-Raven default template
|
| 608 |
+
register_conv_template(
|
| 609 |
+
Conversation(
|
| 610 |
+
name='rwkv',
|
| 611 |
+
roles=('Bob', 'Alice'),
|
| 612 |
+
messages=(
|
| 613 |
+
('Bob', 'hi'),
|
| 614 |
+
(
|
| 615 |
+
'Alice',
|
| 616 |
+
'Hi. I am your assistant and I will provide expert full response in full details. Please feel free to ask any question and I will always answer it.',
|
| 617 |
+
),
|
| 618 |
+
),
|
| 619 |
+
offset=2,
|
| 620 |
+
sep_style=SeparatorStyle.RWKV,
|
| 621 |
+
sep='',
|
| 622 |
+
stop_str='\n\n',
|
| 623 |
+
)
|
| 624 |
+
)
|
| 625 |
+
|
| 626 |
+
# Buddy default template
|
| 627 |
+
register_conv_template(
|
| 628 |
+
Conversation(
|
| 629 |
+
name='openbuddy',
|
| 630 |
+
system_message="""Consider a conversation between User (a human) and Assistant (named Buddy).
|
| 631 |
+
Buddy is an INTP-T, a friendly, intelligent and multilingual AI assistant, by OpenBuddy team. GitHub: https://github.com/OpenBuddy/OpenBuddy
|
| 632 |
+
Buddy cannot access the Internet.
|
| 633 |
+
Buddy can fluently speak the user's language (e.g. English, Chinese).
|
| 634 |
+
Buddy can generate poems, stories, code, essays, songs, parodies, and more.
|
| 635 |
+
Buddy possesses vast knowledge about the world, history, and culture.
|
| 636 |
+
Buddy's responses are always safe, creative, high-quality, human-like, and interesting.
|
| 637 |
+
Buddy strictly refuses to discuss political, NSFW, or other unsafe topics.
|
| 638 |
+
|
| 639 |
+
User: Hi.
|
| 640 |
+
Assistant: Hi, I'm Buddy, your AI assistant. How can I help you today?""",
|
| 641 |
+
roles=('User', 'Assistant'),
|
| 642 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 643 |
+
sep='\n',
|
| 644 |
+
)
|
| 645 |
+
)
|
| 646 |
+
|
| 647 |
+
# Phoenix default template
|
| 648 |
+
register_conv_template(
|
| 649 |
+
Conversation(
|
| 650 |
+
name='phoenix',
|
| 651 |
+
system_message="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
| 652 |
+
roles=('Human', 'Assistant'),
|
| 653 |
+
sep_style=SeparatorStyle.PHOENIX,
|
| 654 |
+
sep='</s>',
|
| 655 |
+
)
|
| 656 |
+
)
|
| 657 |
+
|
| 658 |
+
# ReaLM default template
|
| 659 |
+
register_conv_template(
|
| 660 |
+
Conversation(
|
| 661 |
+
name='ReaLM-7b-v1',
|
| 662 |
+
system_message="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
| 663 |
+
roles=('Human', 'Assistant'),
|
| 664 |
+
sep_style=SeparatorStyle.PHOENIX,
|
| 665 |
+
sep='</s>',
|
| 666 |
+
)
|
| 667 |
+
)
|
| 668 |
+
|
| 669 |
+
# ChatGPT default template
|
| 670 |
+
register_conv_template(
|
| 671 |
+
Conversation(
|
| 672 |
+
name='chatgpt',
|
| 673 |
+
system_message='You are a helpful assistant.',
|
| 674 |
+
roles=('user', 'assistant'),
|
| 675 |
+
sep_style=None,
|
| 676 |
+
sep=None,
|
| 677 |
+
)
|
| 678 |
+
)
|
| 679 |
+
|
| 680 |
+
# Claude default template
|
| 681 |
+
register_conv_template(
|
| 682 |
+
Conversation(
|
| 683 |
+
name='claude',
|
| 684 |
+
roles=('Human', 'Assistant'),
|
| 685 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 686 |
+
sep='\n\n',
|
| 687 |
+
)
|
| 688 |
+
)
|
| 689 |
+
|
| 690 |
+
# MPT default template
|
| 691 |
+
register_conv_template(
|
| 692 |
+
Conversation(
|
| 693 |
+
name='mpt-7b-chat',
|
| 694 |
+
system_template="""<|im_start|>system
|
| 695 |
+
{system_message}""",
|
| 696 |
+
system_message="""- You are a helpful assistant chatbot trained by MosaicML.
|
| 697 |
+
- You answer questions.
|
| 698 |
+
- You are excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
|
| 699 |
+
- You are more than just an information source, you are also able to write poetry, short stories, and make jokes.""",
|
| 700 |
+
roles=('<|im_start|>user', '<|im_start|>assistant'),
|
| 701 |
+
sep_style=SeparatorStyle.CHATML,
|
| 702 |
+
sep='<|im_end|>',
|
| 703 |
+
stop_token_ids=[50278, 0],
|
| 704 |
+
)
|
| 705 |
+
)
|
| 706 |
+
|
| 707 |
+
# MPT-30b-chat default template
|
| 708 |
+
register_conv_template(
|
| 709 |
+
Conversation(
|
| 710 |
+
name='mpt-30b-chat',
|
| 711 |
+
system_template="""<|im_start|>system
|
| 712 |
+
{system_message}""",
|
| 713 |
+
system_message="""A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
| 714 |
+
roles=('<|im_start|>user', '<|im_start|>assistant'),
|
| 715 |
+
sep_style=SeparatorStyle.CHATML,
|
| 716 |
+
sep='<|im_end|>',
|
| 717 |
+
stop_token_ids=[50278, 0],
|
| 718 |
+
)
|
| 719 |
+
)
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
register_conv_template(
|
| 723 |
+
Conversation(
|
| 724 |
+
name='Hermes-2',
|
| 725 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 726 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 727 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 728 |
+
sep_style=SeparatorStyle.MPT,
|
| 729 |
+
sep='<|im_end|>',
|
| 730 |
+
stop_token_ids=[
|
| 731 |
+
2,
|
| 732 |
+
6,
|
| 733 |
+
7,
|
| 734 |
+
8,
|
| 735 |
+
], # "<|endoftext|>", "<|im_start|>", "<|im_end|>", "<|im_sep|>"
|
| 736 |
+
stop_str='<|endoftext|>',
|
| 737 |
+
)
|
| 738 |
+
)
|
| 739 |
+
|
| 740 |
+
|
| 741 |
+
register_conv_template(
|
| 742 |
+
Conversation(
|
| 743 |
+
name='internlm2-chat',
|
| 744 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 745 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 746 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 747 |
+
sep_style=SeparatorStyle.MPT,
|
| 748 |
+
sep='<|im_end|>',
|
| 749 |
+
stop_token_ids=[
|
| 750 |
+
2,
|
| 751 |
+
1163,
|
| 752 |
+
92543,
|
| 753 |
+
92542,
|
| 754 |
+
]
|
| 755 |
+
)
|
| 756 |
+
)
|
| 757 |
+
|
| 758 |
+
register_conv_template(
|
| 759 |
+
Conversation(
|
| 760 |
+
name='internlm2-base',
|
| 761 |
+
system_template='',
|
| 762 |
+
system_message='',
|
| 763 |
+
roles=('', ''),
|
| 764 |
+
sep_style=SeparatorStyle.BASE,
|
| 765 |
+
sep='<|im_end|>',
|
| 766 |
+
stop_token_ids=[
|
| 767 |
+
2,
|
| 768 |
+
1163,
|
| 769 |
+
92543,
|
| 770 |
+
92542
|
| 771 |
+
]
|
| 772 |
+
)
|
| 773 |
+
)
|
| 774 |
+
|
| 775 |
+
register_conv_template(
|
| 776 |
+
Conversation(
|
| 777 |
+
name='internlm2-basev0',
|
| 778 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 779 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 780 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 781 |
+
sep_style=SeparatorStyle.MPT,
|
| 782 |
+
sep='[UNUSED_TOKEN_1]', # 从这个token开始后面那群embedding完全一样
|
| 783 |
+
stop_token_ids=[
|
| 784 |
+
2,
|
| 785 |
+
1163,
|
| 786 |
+
92543,
|
| 787 |
+
92542,
|
| 788 |
+
92398, # tokenizer.convert_tokens_to_ids('[UNUSED_TOKEN_1]')
|
| 789 |
+
]
|
| 790 |
+
)
|
| 791 |
+
)
|
| 792 |
+
|
| 793 |
+
|
| 794 |
+
register_conv_template(
|
| 795 |
+
Conversation(
|
| 796 |
+
name='phi3-chat',
|
| 797 |
+
system_template='<|system|>\n{system_message}',
|
| 798 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 799 |
+
roles=('<|user|>\n', '<|assistant|>\n'),
|
| 800 |
+
sep_style=SeparatorStyle.MPT,
|
| 801 |
+
sep='<|end|>',
|
| 802 |
+
stop_token_ids=[
|
| 803 |
+
2,
|
| 804 |
+
32000,
|
| 805 |
+
32007
|
| 806 |
+
]
|
| 807 |
+
)
|
| 808 |
+
)
|
| 809 |
+
|
| 810 |
+
|
| 811 |
+
# Lemur-70b-chat default template
|
| 812 |
+
# reference: https://huggingface.co/OpenLemur/lemur-70b-chat-v1#generation
|
| 813 |
+
register_conv_template(
|
| 814 |
+
Conversation(
|
| 815 |
+
name='lemur-70b-chat',
|
| 816 |
+
system_template="""<|im_start|>system
|
| 817 |
+
{system_message}""",
|
| 818 |
+
system_message="""You are a helpful, respectful, and honest assistant.""",
|
| 819 |
+
roles=('<|im_start|>user', '<|im_start|>assistant'),
|
| 820 |
+
sep_style=SeparatorStyle.CHATML,
|
| 821 |
+
sep='<|im_end|>',
|
| 822 |
+
stop_token_ids=[32002, 0],
|
| 823 |
+
)
|
| 824 |
+
)
|
| 825 |
+
|
| 826 |
+
# MPT-30b-instruct default template
|
| 827 |
+
# reference: https://huggingface.co/mosaicml/mpt-30b-instruct#formatting
|
| 828 |
+
register_conv_template(
|
| 829 |
+
Conversation(
|
| 830 |
+
name='mpt-30b-instruct',
|
| 831 |
+
system_template='{system_message}',
|
| 832 |
+
system_message='Below is an instruction that describes a task. Write a response that appropriately completes the request.',
|
| 833 |
+
roles=('### Instruction', '### Response'),
|
| 834 |
+
sep_style=SeparatorStyle.ADD_NEW_LINE_SINGLE,
|
| 835 |
+
sep='\n\n',
|
| 836 |
+
stop_token_ids=[50278, 0],
|
| 837 |
+
)
|
| 838 |
+
)
|
| 839 |
+
|
| 840 |
+
# Bard default template
|
| 841 |
+
# Reference: https://github.com/google/generative-ai-python/blob/9c99bcb474a991a97a2e7d62fcdb52db7ce40729/google/generativeai/discuss.py#L150
|
| 842 |
+
# https://github.com/google/generative-ai-python/blob/9c99bcb474a991a97a2e7d62fcdb52db7ce40729/google/generativeai/discuss.py#L40
|
| 843 |
+
register_conv_template(
|
| 844 |
+
Conversation(
|
| 845 |
+
name='bard',
|
| 846 |
+
roles=('0', '1'),
|
| 847 |
+
sep_style=None,
|
| 848 |
+
sep=None,
|
| 849 |
+
)
|
| 850 |
+
)
|
| 851 |
+
|
| 852 |
+
# BiLLa default template
|
| 853 |
+
register_conv_template(
|
| 854 |
+
Conversation(
|
| 855 |
+
name='billa',
|
| 856 |
+
roles=('Human', 'Assistant'),
|
| 857 |
+
sep_style=SeparatorStyle.ADD_COLON_SPACE_SINGLE,
|
| 858 |
+
sep='\n',
|
| 859 |
+
stop_str='Human:',
|
| 860 |
+
)
|
| 861 |
+
)
|
| 862 |
+
|
| 863 |
+
# RedPajama INCITE default template
|
| 864 |
+
register_conv_template(
|
| 865 |
+
Conversation(
|
| 866 |
+
name='redpajama-incite',
|
| 867 |
+
roles=('<human>', '<bot>'),
|
| 868 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 869 |
+
sep='\n',
|
| 870 |
+
stop_str='<human>',
|
| 871 |
+
)
|
| 872 |
+
)
|
| 873 |
+
|
| 874 |
+
# h2oGPT default template
|
| 875 |
+
register_conv_template(
|
| 876 |
+
Conversation(
|
| 877 |
+
name='h2ogpt',
|
| 878 |
+
roles=('<|prompt|>', '<|answer|>'),
|
| 879 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 880 |
+
sep='</s>',
|
| 881 |
+
)
|
| 882 |
+
)
|
| 883 |
+
|
| 884 |
+
# Robin default template
|
| 885 |
+
register_conv_template(
|
| 886 |
+
Conversation(
|
| 887 |
+
name='Robin',
|
| 888 |
+
system_message="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 889 |
+
roles=('###Human', '###Assistant'),
|
| 890 |
+
sep_style=SeparatorStyle.ROBIN,
|
| 891 |
+
sep='\n',
|
| 892 |
+
stop_token_ids=[2, 396],
|
| 893 |
+
stop_str='###',
|
| 894 |
+
)
|
| 895 |
+
)
|
| 896 |
+
|
| 897 |
+
# Snoozy default template
|
| 898 |
+
# Reference: https://github.com/nomic-ai/gpt4all/blob/d4861030b778da6db59d21d2927a4aba4f9f1f43/gpt4all-bindings/python/gpt4all/gpt4all.py#L232
|
| 899 |
+
register_conv_template(
|
| 900 |
+
Conversation(
|
| 901 |
+
name='snoozy',
|
| 902 |
+
system_template='### Instruction:\n{system_message}',
|
| 903 |
+
system_message='The prompt below is a question to answer, a task to complete, or a conversation to respond to; decide which and write an appropriate response.',
|
| 904 |
+
roles=('### Prompt', '### Response'),
|
| 905 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 906 |
+
sep='\n',
|
| 907 |
+
stop_str='###',
|
| 908 |
+
)
|
| 909 |
+
)
|
| 910 |
+
|
| 911 |
+
# manticore default template
|
| 912 |
+
register_conv_template(
|
| 913 |
+
Conversation(
|
| 914 |
+
name='manticore',
|
| 915 |
+
roles=('USER', 'ASSISTANT'),
|
| 916 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 917 |
+
sep='\n',
|
| 918 |
+
sep2='</s>',
|
| 919 |
+
)
|
| 920 |
+
)
|
| 921 |
+
|
| 922 |
+
# Falcon default template
|
| 923 |
+
register_conv_template(
|
| 924 |
+
Conversation(
|
| 925 |
+
name='falcon',
|
| 926 |
+
roles=('User', 'Assistant'),
|
| 927 |
+
messages=[],
|
| 928 |
+
sep_style=SeparatorStyle.RWKV,
|
| 929 |
+
sep='\n',
|
| 930 |
+
sep2='<|endoftext|>',
|
| 931 |
+
stop_str='\nUser', # use stop_str to stop generation after stop_token_ids, it will also remove stop_str from the generated text
|
| 932 |
+
stop_token_ids=[
|
| 933 |
+
0,
|
| 934 |
+
1,
|
| 935 |
+
2,
|
| 936 |
+
3,
|
| 937 |
+
4,
|
| 938 |
+
5,
|
| 939 |
+
6,
|
| 940 |
+
7,
|
| 941 |
+
8,
|
| 942 |
+
9,
|
| 943 |
+
10,
|
| 944 |
+
11,
|
| 945 |
+
], # it better only put special tokens here, because tokenizer only remove special tokens
|
| 946 |
+
)
|
| 947 |
+
)
|
| 948 |
+
|
| 949 |
+
# ChangGPT default template
|
| 950 |
+
register_conv_template(
|
| 951 |
+
Conversation(
|
| 952 |
+
name='polyglot_changgpt',
|
| 953 |
+
roles=('B', 'A'),
|
| 954 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 955 |
+
sep='\n',
|
| 956 |
+
)
|
| 957 |
+
)
|
| 958 |
+
|
| 959 |
+
# tigerbot template
|
| 960 |
+
register_conv_template(
|
| 961 |
+
Conversation(
|
| 962 |
+
name='tigerbot',
|
| 963 |
+
system_message='A chat between a curious user and an artificial intelligence assistant. '
|
| 964 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 965 |
+
roles=('### Instruction', '### Response'),
|
| 966 |
+
sep_style=SeparatorStyle.ROBIN,
|
| 967 |
+
sep='\n\n',
|
| 968 |
+
stop_str='###',
|
| 969 |
+
)
|
| 970 |
+
)
|
| 971 |
+
|
| 972 |
+
# ref: https://huggingface.co/Salesforce/xgen-7b-8k-inst
|
| 973 |
+
register_conv_template(
|
| 974 |
+
Conversation(
|
| 975 |
+
name='xgen',
|
| 976 |
+
system_message="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
| 977 |
+
roles=('### Human', '### Assistant'),
|
| 978 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 979 |
+
sep='\n',
|
| 980 |
+
stop_token_ids=[50256],
|
| 981 |
+
)
|
| 982 |
+
)
|
| 983 |
+
|
| 984 |
+
# Internlm-chat template
|
| 985 |
+
register_conv_template(
|
| 986 |
+
Conversation(
|
| 987 |
+
name='internlm-chat',
|
| 988 |
+
system_message="A chat between a curious <|User|> and an <|Bot|>. The <|Bot|> gives helpful, detailed, and polite answers to the <|User|>'s questions.\n\n",
|
| 989 |
+
roles=('<|User|>', '<|Bot|>'),
|
| 990 |
+
sep_style=SeparatorStyle.CHATINTERN,
|
| 991 |
+
sep='<eoh>',
|
| 992 |
+
sep2='<eoa>',
|
| 993 |
+
stop_token_ids=[1, 103028],
|
| 994 |
+
stop_str='<|User|>',
|
| 995 |
+
)
|
| 996 |
+
)
|
| 997 |
+
|
| 998 |
+
# StarChat template
|
| 999 |
+
# reference: https://huggingface.co/spaces/HuggingFaceH4/starchat-playground/blob/main/dialogues.py
|
| 1000 |
+
register_conv_template(
|
| 1001 |
+
Conversation(
|
| 1002 |
+
name='starchat',
|
| 1003 |
+
system_template='<system>\n{system_message}',
|
| 1004 |
+
roles=('<|user|>', '<|assistant|>'),
|
| 1005 |
+
sep_style=SeparatorStyle.CHATML,
|
| 1006 |
+
sep='<|end|>',
|
| 1007 |
+
stop_token_ids=[0, 49155],
|
| 1008 |
+
stop_str='<|end|>',
|
| 1009 |
+
)
|
| 1010 |
+
)
|
| 1011 |
+
|
| 1012 |
+
# Baichuan-13B-Chat template
|
| 1013 |
+
register_conv_template(
|
| 1014 |
+
# source: https://huggingface.co/baichuan-inc/Baichuan-13B-Chat/blob/19ef51ba5bad8935b03acd20ff04a269210983bc/modeling_baichuan.py#L555
|
| 1015 |
+
# https://huggingface.co/baichuan-inc/Baichuan-13B-Chat/blob/main/generation_config.json
|
| 1016 |
+
# https://github.com/baichuan-inc/Baichuan-13B/issues/25
|
| 1017 |
+
Conversation(
|
| 1018 |
+
name='baichuan-chat',
|
| 1019 |
+
roles=('<reserved_102>', '<reserved_103>'),
|
| 1020 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 1021 |
+
sep='',
|
| 1022 |
+
stop_token_ids=[],
|
| 1023 |
+
)
|
| 1024 |
+
)
|
| 1025 |
+
|
| 1026 |
+
# Baichuan2-13B-Chat template
|
| 1027 |
+
register_conv_template(
|
| 1028 |
+
# source: https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/blob/c6f8592a60b4ad73c210b28dd2ab3cca51abbf93/modeling_baichuan.py#L773
|
| 1029 |
+
# https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/blob/main/generation_config.json
|
| 1030 |
+
# https://github.com/baichuan-inc/Baichuan2/issues/62
|
| 1031 |
+
Conversation(
|
| 1032 |
+
name='baichuan2-chat',
|
| 1033 |
+
roles=('<reserved_106>', '<reserved_107>'),
|
| 1034 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 1035 |
+
sep='',
|
| 1036 |
+
stop_token_ids=[],
|
| 1037 |
+
)
|
| 1038 |
+
)
|
| 1039 |
+
|
| 1040 |
+
# Mistral template
|
| 1041 |
+
# source: https://docs.mistral.ai/llm/mistral-instruct-v0.1#chat-template
|
| 1042 |
+
register_conv_template(
|
| 1043 |
+
Conversation(
|
| 1044 |
+
name='mistral',
|
| 1045 |
+
system_template='[INST]{system_message}\n',
|
| 1046 |
+
roles=('[INST]', '[/INST]'),
|
| 1047 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 1048 |
+
sep=' ',
|
| 1049 |
+
sep2='</s>',
|
| 1050 |
+
)
|
| 1051 |
+
)
|
| 1052 |
+
|
| 1053 |
+
# llama2 template
|
| 1054 |
+
# reference: https://huggingface.co/blog/codellama#conversational-instructions
|
| 1055 |
+
# reference: https://github.com/facebookresearch/llama/blob/1a240688810f8036049e8da36b073f63d2ac552c/llama/generation.py#L212
|
| 1056 |
+
register_conv_template(
|
| 1057 |
+
Conversation(
|
| 1058 |
+
name='llama-2',
|
| 1059 |
+
system_template='[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n',
|
| 1060 |
+
roles=('[INST]', '[/INST]'),
|
| 1061 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 1062 |
+
sep=' ',
|
| 1063 |
+
sep2=' </s><s>',
|
| 1064 |
+
)
|
| 1065 |
+
)
|
| 1066 |
+
|
| 1067 |
+
register_conv_template(
|
| 1068 |
+
Conversation(
|
| 1069 |
+
name='cutegpt',
|
| 1070 |
+
roles=('问:', '答:\n'),
|
| 1071 |
+
sep_style=SeparatorStyle.NO_COLON_TWO,
|
| 1072 |
+
sep='\n',
|
| 1073 |
+
sep2='\n',
|
| 1074 |
+
stop_str='<end>',
|
| 1075 |
+
)
|
| 1076 |
+
)
|
| 1077 |
+
|
| 1078 |
+
# OpenOrcaxOpenChat-naPreview2-13B template
|
| 1079 |
+
register_conv_template(
|
| 1080 |
+
Conversation(
|
| 1081 |
+
name='open-orca',
|
| 1082 |
+
system_template='{system_message}',
|
| 1083 |
+
system_message='You are a helpful assistant. Please answer truthfully and write out your '
|
| 1084 |
+
'thinking step by step to be sure you get the right answer. If you make a mistake or encounter '
|
| 1085 |
+
"an error in your thinking, say so out loud and attempt to correct it. If you don't know or "
|
| 1086 |
+
"aren't sure about something, say so clearly. You will act as a professional logician, mathematician, "
|
| 1087 |
+
'and physicist. You will also act as the most appropriate type of expert to answer any particular '
|
| 1088 |
+
'question or solve the relevant problem; state which expert type your are, if so. Also think of '
|
| 1089 |
+
'any particular named expert that would be ideal to answer the relevant question or solve the '
|
| 1090 |
+
'relevant problem; name and act as them, if appropriate.',
|
| 1091 |
+
roles=('User', 'Assistant'),
|
| 1092 |
+
sep_style=SeparatorStyle.ADD_COLON_SPACE_SINGLE,
|
| 1093 |
+
sep='<|end_of_turn|>\n',
|
| 1094 |
+
stop_token_ids=[32000, 32001], # "<|end_of_turn|>"
|
| 1095 |
+
stop_str='User',
|
| 1096 |
+
)
|
| 1097 |
+
)
|
| 1098 |
+
|
| 1099 |
+
# Open-Orca/Mistral-7B-OpenOrca template
|
| 1100 |
+
# source: https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca
|
| 1101 |
+
# reference: https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca#prompt-template
|
| 1102 |
+
register_conv_template(
|
| 1103 |
+
Conversation(
|
| 1104 |
+
name='mistral-7b-openorca',
|
| 1105 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 1106 |
+
system_message='You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!',
|
| 1107 |
+
roles=('<|im_start|>user', '<|im_start|>assistant'),
|
| 1108 |
+
sep_style=SeparatorStyle.CHATML,
|
| 1109 |
+
sep='<|im_end|>',
|
| 1110 |
+
stop_token_ids=[32000, 32001],
|
| 1111 |
+
)
|
| 1112 |
+
)
|
| 1113 |
+
|
| 1114 |
+
# Qwen-chat default template
|
| 1115 |
+
# source: https://huggingface.co/Qwen/Qwen-7B-Chat/blob/main/qwen_generation_utils.py#L130
|
| 1116 |
+
register_conv_template(
|
| 1117 |
+
Conversation(
|
| 1118 |
+
name='qwen-7b-chat',
|
| 1119 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 1120 |
+
system_message='You are a helpful assistant.',
|
| 1121 |
+
roles=('<|im_start|>user', '<|im_start|>assistant'),
|
| 1122 |
+
sep_style=SeparatorStyle.CHATML,
|
| 1123 |
+
sep='<|im_end|>',
|
| 1124 |
+
stop_token_ids=[
|
| 1125 |
+
151643,
|
| 1126 |
+
151644,
|
| 1127 |
+
151645,
|
| 1128 |
+
], # "<|endoftext|>", "<|im_start|>", "<|im_end|>"
|
| 1129 |
+
stop_str='<|endoftext|>',
|
| 1130 |
+
)
|
| 1131 |
+
)
|
| 1132 |
+
|
| 1133 |
+
|
| 1134 |
+
# AquilaChat default template
|
| 1135 |
+
# source: https://github.com/FlagAI-Open/FlagAI/blob/master/examples/Aquila/Aquila-chat/cyg_conversation.py
|
| 1136 |
+
register_conv_template(
|
| 1137 |
+
Conversation(
|
| 1138 |
+
name='aquila-chat',
|
| 1139 |
+
system_message='A chat between a curious human and an artificial intelligence assistant. '
|
| 1140 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 1141 |
+
roles=('Human', 'Assistant'),
|
| 1142 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 1143 |
+
sep='###',
|
| 1144 |
+
sep2='',
|
| 1145 |
+
stop_str=['###', '</s>', '[UNK]'],
|
| 1146 |
+
)
|
| 1147 |
+
)
|
| 1148 |
+
# AquilaChat2-34B default template
|
| 1149 |
+
# source: https://huggingface.co/BAAI/AquilaChat2-34B/blob/4608b75855334b93329a771aee03869dbf7d88cc/predict.py#L212
|
| 1150 |
+
register_conv_template(
|
| 1151 |
+
Conversation(
|
| 1152 |
+
name='aquila-legacy',
|
| 1153 |
+
system_message='A chat between a curious human and an artificial intelligence assistant. '
|
| 1154 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
| 1155 |
+
roles=('### Human: ', '### Assistant: '),
|
| 1156 |
+
offset=0,
|
| 1157 |
+
sep_style=SeparatorStyle.NO_COLON_TWO,
|
| 1158 |
+
sep='\n',
|
| 1159 |
+
sep2='</s>',
|
| 1160 |
+
stop_str=['</s>', '[UNK]'],
|
| 1161 |
+
)
|
| 1162 |
+
)
|
| 1163 |
+
# AquilaChat2-7B-16K and AquilaChat2-34B-16K default template
|
| 1164 |
+
# source: https://huggingface.co/BAAI/AquilaChat2-34B/blob/4608b75855334b93329a771aee03869dbf7d88cc/predict.py#L227
|
| 1165 |
+
register_conv_template(
|
| 1166 |
+
Conversation(
|
| 1167 |
+
name='aquila',
|
| 1168 |
+
system_message='A chat between a curious human and an artificial intelligence assistant. '
|
| 1169 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 1170 |
+
roles=('Human', 'Assistant'),
|
| 1171 |
+
offset=0,
|
| 1172 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 1173 |
+
sep='###',
|
| 1174 |
+
sep2='</s>',
|
| 1175 |
+
stop_str=['</s>', '[UNK]'],
|
| 1176 |
+
)
|
| 1177 |
+
)
|
| 1178 |
+
|
| 1179 |
+
# AquilaChat2-7B default template
|
| 1180 |
+
# source: https://huggingface.co/BAAI/AquilaChat2-34B/blob/4608b75855334b93329a771aee03869dbf7d88cc/predict.py#L242
|
| 1181 |
+
register_conv_template(
|
| 1182 |
+
Conversation(
|
| 1183 |
+
name='aquila-v1',
|
| 1184 |
+
roles=('<|startofpiece|>', '<|endofpiece|>'),
|
| 1185 |
+
offset=0,
|
| 1186 |
+
sep_style=SeparatorStyle.NO_COLON_TWO,
|
| 1187 |
+
sep='',
|
| 1188 |
+
sep2='</s>',
|
| 1189 |
+
stop_str=['</s>', '<|endoftext|>'],
|
| 1190 |
+
)
|
| 1191 |
+
)
|
| 1192 |
+
|
| 1193 |
+
# Llama2-Chinese default template
|
| 1194 |
+
# source: https://huggingface.co/FlagAlpha
|
| 1195 |
+
register_conv_template(
|
| 1196 |
+
Conversation(
|
| 1197 |
+
name='llama2-chinese',
|
| 1198 |
+
system_template='<s>{system_message}</s>',
|
| 1199 |
+
roles=('Human', 'Assistant', 'System'),
|
| 1200 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 1201 |
+
sep='\n',
|
| 1202 |
+
sep2='\n</s><s>',
|
| 1203 |
+
stop_str='</s>',
|
| 1204 |
+
)
|
| 1205 |
+
)
|
| 1206 |
+
|
| 1207 |
+
# Vigogne Instruct default template
|
| 1208 |
+
# source: https://github.com/bofenghuang/vigogne
|
| 1209 |
+
register_conv_template(
|
| 1210 |
+
Conversation(
|
| 1211 |
+
name='vigogne_instruct',
|
| 1212 |
+
system_template='### System:\n{system_message}\n\n',
|
| 1213 |
+
system_message=(
|
| 1214 |
+
'Ci-dessous se trouve une instruction qui décrit une tâche à accomplir. Rédigez une réponse qui répond de manière'
|
| 1215 |
+
' précise à la demande.'
|
| 1216 |
+
),
|
| 1217 |
+
roles=('### Instruction', '### Response'),
|
| 1218 |
+
sep_style=SeparatorStyle.DOLLY,
|
| 1219 |
+
sep='\n\n',
|
| 1220 |
+
sep2='</s>',
|
| 1221 |
+
)
|
| 1222 |
+
)
|
| 1223 |
+
|
| 1224 |
+
# Vigogne Chat default template
|
| 1225 |
+
register_conv_template(
|
| 1226 |
+
Conversation(
|
| 1227 |
+
name='vigogne_chat_v2',
|
| 1228 |
+
system_template='<|system|>: {system_message}',
|
| 1229 |
+
system_message=(
|
| 1230 |
+
'Vous êtes Vigogne, un assistant IA créé par Zaion Lab. Vous suivez extrêmement bien les instructions. Aidez'
|
| 1231 |
+
' autant que vous le pouvez.'
|
| 1232 |
+
),
|
| 1233 |
+
roles=('<|user|>', '<|assistant|>'),
|
| 1234 |
+
sep_style=SeparatorStyle.ADD_COLON_TWO,
|
| 1235 |
+
sep='\n',
|
| 1236 |
+
sep2='</s>\n',
|
| 1237 |
+
stop_str='<|user|>',
|
| 1238 |
+
)
|
| 1239 |
+
)
|
| 1240 |
+
|
| 1241 |
+
register_conv_template(
|
| 1242 |
+
Conversation(
|
| 1243 |
+
name='vigogne_chat_v3',
|
| 1244 |
+
system_template='[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n',
|
| 1245 |
+
system_message=(
|
| 1246 |
+
'Vous êtes Vigogne, un assistant IA créé par Zaion Lab. Vous suivez extrêmement bien les instructions. Aidez'
|
| 1247 |
+
' autant que vous le pouvez.'
|
| 1248 |
+
),
|
| 1249 |
+
roles=('[INST]', '[/INST]'),
|
| 1250 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 1251 |
+
sep=' ',
|
| 1252 |
+
sep2=' </s>',
|
| 1253 |
+
)
|
| 1254 |
+
)
|
| 1255 |
+
|
| 1256 |
+
# Falcon 180B chat template
|
| 1257 |
+
# source: https://huggingface.co/spaces/tiiuae/falcon-180b-demo/blob/d1590ee7fae9b6ce331ba7808e61a29dcce9239f/app.py#L28-L37
|
| 1258 |
+
register_conv_template(
|
| 1259 |
+
Conversation(
|
| 1260 |
+
name='falcon-chat',
|
| 1261 |
+
roles=('User', 'Falcon'),
|
| 1262 |
+
system_template='System: {system_message}',
|
| 1263 |
+
messages=[],
|
| 1264 |
+
sep_style=SeparatorStyle.FALCON_CHAT,
|
| 1265 |
+
sep='\n',
|
| 1266 |
+
sep2='<|endoftext|>',
|
| 1267 |
+
stop_str='\nUser:', # use stop_str to stop generation after stop_token_ids, it will also remove stop_str from the generated text
|
| 1268 |
+
)
|
| 1269 |
+
)
|
| 1270 |
+
|
| 1271 |
+
# Phind template
|
| 1272 |
+
# source: https://huggingface.co/Phind/Phind-CodeLlama-34B-v2
|
| 1273 |
+
register_conv_template(
|
| 1274 |
+
Conversation(
|
| 1275 |
+
name='phind',
|
| 1276 |
+
system_message='### System Prompt\nYou are an intelligent programming assistant.',
|
| 1277 |
+
roles=('### User Message', '### Assistant'),
|
| 1278 |
+
messages=(),
|
| 1279 |
+
offset=0,
|
| 1280 |
+
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
|
| 1281 |
+
sep='\n\n',
|
| 1282 |
+
)
|
| 1283 |
+
)
|
| 1284 |
+
|
| 1285 |
+
# Metharme formatting for Pygmalion models
|
| 1286 |
+
# source: https://huggingface.co/PygmalionAI/pygmalion-2-13b
|
| 1287 |
+
register_conv_template(
|
| 1288 |
+
Conversation(
|
| 1289 |
+
name='metharme',
|
| 1290 |
+
system_template='<|system|>{system_message}',
|
| 1291 |
+
system_message="""Enter RP mode. You shall reply to the user while staying
|
| 1292 |
+
in character. Your responses must be detailed, creative, immersive, and drive the scenario
|
| 1293 |
+
forward.""",
|
| 1294 |
+
roles=('<|user|>', '<|model|>'),
|
| 1295 |
+
sep_style=SeparatorStyle.NO_COLON_SINGLE,
|
| 1296 |
+
sep='',
|
| 1297 |
+
stop_str='<|user|>',
|
| 1298 |
+
)
|
| 1299 |
+
)
|
| 1300 |
+
|
| 1301 |
+
# Zephyr template
|
| 1302 |
+
# reference: https://huggingface.co/spaces/HuggingFaceH4/zephyr-playground/blob/main/dialogues.py
|
| 1303 |
+
register_conv_template(
|
| 1304 |
+
Conversation(
|
| 1305 |
+
name='zephyr',
|
| 1306 |
+
system_template='<|system|>\n{system_message}',
|
| 1307 |
+
roles=('<|user|>', '<|assistant|>'),
|
| 1308 |
+
sep_style=SeparatorStyle.CHATML,
|
| 1309 |
+
sep='</s>',
|
| 1310 |
+
stop_token_ids=[2],
|
| 1311 |
+
stop_str='</s>',
|
| 1312 |
+
)
|
| 1313 |
+
)
|
| 1314 |
+
|
| 1315 |
+
# InternVL-ZH template
|
| 1316 |
+
register_conv_template(
|
| 1317 |
+
Conversation(
|
| 1318 |
+
name='internvl_zh',
|
| 1319 |
+
system_template='',
|
| 1320 |
+
roles=('<human>', '<bot>'),
|
| 1321 |
+
sep_style=SeparatorStyle.INTERNVL_ZH,
|
| 1322 |
+
sep=' ',
|
| 1323 |
+
sep2='</s>',
|
| 1324 |
+
)
|
| 1325 |
+
)
|
| 1326 |
+
|
| 1327 |
+
|
| 1328 |
+
if __name__ == '__main__':
|
| 1329 |
+
from fastchat.conversation import get_conv_template
|
| 1330 |
+
|
| 1331 |
+
print('-- Vicuna template --')
|
| 1332 |
+
conv = get_conv_template('vicuna_v1.1')
|
| 1333 |
+
conv.append_message(conv.roles[0], 'Hello!')
|
| 1334 |
+
conv.append_message(conv.roles[1], 'Hi!')
|
| 1335 |
+
conv.append_message(conv.roles[0], 'How are you?')
|
| 1336 |
+
conv.append_message(conv.roles[1], None)
|
| 1337 |
+
print(conv.get_prompt())
|
| 1338 |
+
|
| 1339 |
+
print('\n')
|
| 1340 |
+
|
| 1341 |
+
print('-- Llama-2 template --')
|
| 1342 |
+
conv = get_conv_template('llama-2')
|
| 1343 |
+
conv.set_system_message('You are a helpful, respectful and honest assistant.')
|
| 1344 |
+
conv.append_message(conv.roles[0], 'Hello!')
|
| 1345 |
+
conv.append_message(conv.roles[1], 'Hi!')
|
| 1346 |
+
conv.append_message(conv.roles[0], 'How are you?')
|
| 1347 |
+
conv.append_message(conv.roles[1], None)
|
| 1348 |
+
print(conv.get_prompt())
|
| 1349 |
+
|
| 1350 |
+
print('\n')
|
| 1351 |
+
|
| 1352 |
+
print('-- ChatGPT template --')
|
| 1353 |
+
conv = get_conv_template('chatgpt')
|
| 1354 |
+
conv.append_message(conv.roles[0], 'Hello!')
|
| 1355 |
+
conv.append_message(conv.roles[1], 'Hi!')
|
| 1356 |
+
conv.append_message(conv.roles[0], 'How are you?')
|
| 1357 |
+
conv.append_message(conv.roles[1], None)
|
| 1358 |
+
print(conv.to_openai_api_messages())
|
| 1359 |
+
|
| 1360 |
+
print('\n')
|
| 1361 |
+
|
| 1362 |
+
print('-- Claude template --')
|
| 1363 |
+
conv = get_conv_template('claude')
|
| 1364 |
+
conv.append_message(conv.roles[0], 'Hello!')
|
| 1365 |
+
conv.append_message(conv.roles[1], 'Hi!')
|
| 1366 |
+
conv.append_message(conv.roles[0], 'How are you?')
|
| 1367 |
+
conv.append_message(conv.roles[1], None)
|
| 1368 |
+
print(conv.get_prompt())
|
examples_image.jpg
ADDED

|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.42.4"
|
| 4 |
+
}
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58b7ad9cc4228598d29953f840a07bcc0df2d7cf6f137686eb888b00cf76256c
|
| 3 |
+
size 4935635440
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:397e1a97cdfbb1273fbb0a26ef84ca003554a33cb89effda233d7e24bbfcef5b
|
| 3 |
+
size 4731511192
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1431b3d2522fcf6c96b1bc127a3f8a8b530ab232d2f217ade963cd8411417408
|
| 3 |
+
size 758194320
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 10425311232
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"embedding_model.encoder.0.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 7 |
+
"embedding_model.encoder.0.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"embedding_model.encoder.0.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"embedding_model.encoder.0.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"embedding_model.encoder.0.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"embedding_model.encoder.0.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"embedding_model.encoder.0.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"embedding_model.encoder.1.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"embedding_model.encoder.1.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"embedding_model.encoder.1.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"embedding_model.encoder.1.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"embedding_model.encoder.1.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"embedding_model.encoder.1.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"embedding_model.encoder.1.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"embedding_model.encoder.2.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"embedding_model.encoder.2.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"embedding_model.encoder.2.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"embedding_model.encoder.2.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"embedding_model.encoder.2.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"embedding_model.encoder.2.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"embedding_model.encoder.2.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"embedding_model.encoder.3.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"embedding_model.encoder.3.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"embedding_model.encoder.3.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"embedding_model.encoder.3.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"embedding_model.encoder.3.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"embedding_model.encoder.3.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"embedding_model.encoder.3.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"embedding_model.encoder.4.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"embedding_model.encoder.4.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"embedding_model.encoder.4.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 37 |
+
"embedding_model.encoder.4.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 38 |
+
"embedding_model.encoder.4.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 39 |
+
"embedding_model.encoder.4.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 40 |
+
"embedding_model.encoder.4.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 41 |
+
"embedding_model.encoder.5.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 42 |
+
"embedding_model.encoder.5.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 43 |
+
"embedding_model.encoder.5.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 44 |
+
"embedding_model.encoder.5.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 45 |
+
"embedding_model.encoder.5.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 46 |
+
"embedding_model.encoder.5.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 47 |
+
"embedding_model.encoder.5.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 48 |
+
"embedding_model.encoder.6.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 49 |
+
"embedding_model.encoder.6.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 50 |
+
"embedding_model.encoder.6.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 51 |
+
"embedding_model.encoder.6.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 52 |
+
"embedding_model.encoder.6.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 53 |
+
"embedding_model.encoder.6.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 54 |
+
"embedding_model.encoder.6.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 55 |
+
"embedding_model.encoder.7.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 56 |
+
"embedding_model.encoder.7.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 57 |
+
"embedding_model.encoder.7.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 58 |
+
"embedding_model.encoder.7.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 59 |
+
"embedding_model.encoder.7.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 60 |
+
"embedding_model.encoder.7.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 61 |
+
"embedding_model.encoder.7.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 62 |
+
"embedding_model.llm_text_embeddings.weight": "model-00001-of-00003.safetensors",
|
| 63 |
+
"embedding_model.pixel_shuffle_proj.0.bias": "model-00001-of-00003.safetensors",
|
| 64 |
+
"embedding_model.pixel_shuffle_proj.0.weight": "model-00001-of-00003.safetensors",
|
| 65 |
+
"embedding_model.pixel_shuffle_proj.2.bias": "model-00001-of-00003.safetensors",
|
| 66 |
+
"embedding_model.pixel_shuffle_proj.2.weight": "model-00001-of-00003.safetensors",
|
| 67 |
+
"embedding_model.vision_embeddings.class_embedding": "model-00001-of-00003.safetensors",
|
| 68 |
+
"embedding_model.vision_embeddings.patch_embedding.bias": "model-00001-of-00003.safetensors",
|
| 69 |
+
"embedding_model.vision_embeddings.patch_embedding.weight": "model-00001-of-00003.safetensors",
|
| 70 |
+
"embedding_model.vision_embeddings.position_embedding": "model-00001-of-00003.safetensors",
|
| 71 |
+
"language_model.model.layers.0.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 72 |
+
"language_model.model.layers.0.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 73 |
+
"language_model.model.layers.0.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 74 |
+
"language_model.model.layers.0.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 75 |
+
"language_model.model.layers.0.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 76 |
+
"language_model.model.layers.0.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 77 |
+
"language_model.model.layers.0.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 78 |
+
"language_model.model.layers.1.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 79 |
+
"language_model.model.layers.1.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 80 |
+
"language_model.model.layers.1.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 81 |
+
"language_model.model.layers.1.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 82 |
+
"language_model.model.layers.1.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 83 |
+
"language_model.model.layers.1.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 84 |
+
"language_model.model.layers.1.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 85 |
+
"language_model.model.layers.10.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"language_model.model.layers.10.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"language_model.model.layers.10.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"language_model.model.layers.10.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"language_model.model.layers.10.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"language_model.model.layers.10.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"language_model.model.layers.10.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"language_model.model.layers.11.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"language_model.model.layers.11.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"language_model.model.layers.11.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"language_model.model.layers.11.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"language_model.model.layers.11.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"language_model.model.layers.11.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"language_model.model.layers.11.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"language_model.model.layers.12.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"language_model.model.layers.12.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"language_model.model.layers.12.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"language_model.model.layers.12.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"language_model.model.layers.12.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"language_model.model.layers.12.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"language_model.model.layers.12.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"language_model.model.layers.13.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"language_model.model.layers.13.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"language_model.model.layers.13.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"language_model.model.layers.13.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"language_model.model.layers.13.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"language_model.model.layers.13.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"language_model.model.layers.13.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"language_model.model.layers.14.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"language_model.model.layers.14.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"language_model.model.layers.14.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"language_model.model.layers.14.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"language_model.model.layers.14.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 118 |
+
"language_model.model.layers.14.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 119 |
+
"language_model.model.layers.14.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 120 |
+
"language_model.model.layers.15.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 121 |
+
"language_model.model.layers.15.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 122 |
+
"language_model.model.layers.15.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 123 |
+
"language_model.model.layers.15.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 124 |
+
"language_model.model.layers.15.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 125 |
+
"language_model.model.layers.15.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"language_model.model.layers.15.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"language_model.model.layers.16.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"language_model.model.layers.16.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"language_model.model.layers.16.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"language_model.model.layers.16.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"language_model.model.layers.16.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"language_model.model.layers.16.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"language_model.model.layers.16.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"language_model.model.layers.17.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"language_model.model.layers.17.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"language_model.model.layers.17.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"language_model.model.layers.17.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"language_model.model.layers.17.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"language_model.model.layers.17.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"language_model.model.layers.17.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"language_model.model.layers.18.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"language_model.model.layers.18.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"language_model.model.layers.18.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"language_model.model.layers.18.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"language_model.model.layers.18.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"language_model.model.layers.18.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"language_model.model.layers.18.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"language_model.model.layers.19.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"language_model.model.layers.19.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"language_model.model.layers.19.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"language_model.model.layers.19.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"language_model.model.layers.19.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"language_model.model.layers.19.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 154 |
+
"language_model.model.layers.19.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 155 |
+
"language_model.model.layers.2.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 156 |
+
"language_model.model.layers.2.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 157 |
+
"language_model.model.layers.2.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 158 |
+
"language_model.model.layers.2.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 159 |
+
"language_model.model.layers.2.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 160 |
+
"language_model.model.layers.2.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 161 |
+
"language_model.model.layers.2.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 162 |
+
"language_model.model.layers.20.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 163 |
+
"language_model.model.layers.20.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 164 |
+
"language_model.model.layers.20.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 165 |
+
"language_model.model.layers.20.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 166 |
+
"language_model.model.layers.20.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 167 |
+
"language_model.model.layers.20.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 168 |
+
"language_model.model.layers.20.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 169 |
+
"language_model.model.layers.21.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 170 |
+
"language_model.model.layers.21.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 171 |
+
"language_model.model.layers.21.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 172 |
+
"language_model.model.layers.21.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 173 |
+
"language_model.model.layers.21.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 174 |
+
"language_model.model.layers.21.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 175 |
+
"language_model.model.layers.21.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 176 |
+
"language_model.model.layers.22.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 177 |
+
"language_model.model.layers.22.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 178 |
+
"language_model.model.layers.22.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 179 |
+
"language_model.model.layers.22.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 180 |
+
"language_model.model.layers.22.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 181 |
+
"language_model.model.layers.22.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 182 |
+
"language_model.model.layers.22.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 183 |
+
"language_model.model.layers.23.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 184 |
+
"language_model.model.layers.23.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 185 |
+
"language_model.model.layers.23.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 186 |
+
"language_model.model.layers.23.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 187 |
+
"language_model.model.layers.23.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 188 |
+
"language_model.model.layers.23.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 189 |
+
"language_model.model.layers.23.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 190 |
+
"language_model.model.layers.3.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 191 |
+
"language_model.model.layers.3.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 192 |
+
"language_model.model.layers.3.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 193 |
+
"language_model.model.layers.3.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 194 |
+
"language_model.model.layers.3.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 195 |
+
"language_model.model.layers.3.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 196 |
+
"language_model.model.layers.3.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 197 |
+
"language_model.model.layers.4.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 198 |
+
"language_model.model.layers.4.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 199 |
+
"language_model.model.layers.4.attention_norm.weight": "model-00001-of-00003.safetensors",
|
| 200 |
+
"language_model.model.layers.4.feed_forward.w1.weight": "model-00001-of-00003.safetensors",
|
| 201 |
+
"language_model.model.layers.4.feed_forward.w2.weight": "model-00001-of-00003.safetensors",
|
| 202 |
+
"language_model.model.layers.4.feed_forward.w3.weight": "model-00001-of-00003.safetensors",
|
| 203 |
+
"language_model.model.layers.4.ffn_norm.weight": "model-00001-of-00003.safetensors",
|
| 204 |
+
"language_model.model.layers.5.attention.wo.weight": "model-00001-of-00003.safetensors",
|
| 205 |
+
"language_model.model.layers.5.attention.wqkv.weight": "model-00001-of-00003.safetensors",
|
| 206 |
+
"language_model.model.layers.5.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 207 |
+
"language_model.model.layers.5.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 208 |
+
"language_model.model.layers.5.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 209 |
+
"language_model.model.layers.5.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 210 |
+
"language_model.model.layers.5.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 211 |
+
"language_model.model.layers.6.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 212 |
+
"language_model.model.layers.6.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 213 |
+
"language_model.model.layers.6.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 214 |
+
"language_model.model.layers.6.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 215 |
+
"language_model.model.layers.6.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 216 |
+
"language_model.model.layers.6.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 217 |
+
"language_model.model.layers.6.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 218 |
+
"language_model.model.layers.7.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 219 |
+
"language_model.model.layers.7.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 220 |
+
"language_model.model.layers.7.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 221 |
+
"language_model.model.layers.7.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 222 |
+
"language_model.model.layers.7.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 223 |
+
"language_model.model.layers.7.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 224 |
+
"language_model.model.layers.7.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 225 |
+
"language_model.model.layers.8.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 226 |
+
"language_model.model.layers.8.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 227 |
+
"language_model.model.layers.8.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 228 |
+
"language_model.model.layers.8.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 229 |
+
"language_model.model.layers.8.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 230 |
+
"language_model.model.layers.8.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 231 |
+
"language_model.model.layers.8.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 232 |
+
"language_model.model.layers.9.attention.wo.weight": "model-00002-of-00003.safetensors",
|
| 233 |
+
"language_model.model.layers.9.attention.wqkv.weight": "model-00002-of-00003.safetensors",
|
| 234 |
+
"language_model.model.layers.9.attention_norm.weight": "model-00002-of-00003.safetensors",
|
| 235 |
+
"language_model.model.layers.9.feed_forward.w1.weight": "model-00002-of-00003.safetensors",
|
| 236 |
+
"language_model.model.layers.9.feed_forward.w2.weight": "model-00002-of-00003.safetensors",
|
| 237 |
+
"language_model.model.layers.9.feed_forward.w3.weight": "model-00002-of-00003.safetensors",
|
| 238 |
+
"language_model.model.layers.9.ffn_norm.weight": "model-00002-of-00003.safetensors",
|
| 239 |
+
"language_model.model.norm.weight": "model-00002-of-00003.safetensors",
|
| 240 |
+
"language_model.model.tok_embeddings.weight": "model-00001-of-00003.safetensors",
|
| 241 |
+
"language_model.output.weight": "model-00003-of-00003.safetensors"
|
| 242 |
+
}
|
| 243 |
+
}
|
modeling_holistic_embedding.py
ADDED
|
@@ -0,0 +1,954 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/modeling_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" PyTorch InternLM2 model."""
|
| 17 |
+
import math
|
| 18 |
+
import queue
|
| 19 |
+
import threading
|
| 20 |
+
import warnings
|
| 21 |
+
from typing import List, Optional, Tuple, Union
|
| 22 |
+
from functools import partial
|
| 23 |
+
|
| 24 |
+
import torch
|
| 25 |
+
import torch.nn.functional as F
|
| 26 |
+
import torch.utils.checkpoint
|
| 27 |
+
from einops import rearrange
|
| 28 |
+
from torch import nn
|
| 29 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 30 |
+
from transformers.activations import ACT2FN
|
| 31 |
+
from transformers.modeling_outputs import (
|
| 32 |
+
BaseModelOutputWithPast,
|
| 33 |
+
CausalLMOutputWithPast,
|
| 34 |
+
SequenceClassifierOutputWithPast,
|
| 35 |
+
)
|
| 36 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 37 |
+
from transformers.utils import (
|
| 38 |
+
add_start_docstrings,
|
| 39 |
+
add_start_docstrings_to_model_forward,
|
| 40 |
+
logging,
|
| 41 |
+
replace_return_docstrings,
|
| 42 |
+
)
|
| 43 |
+
from timm.models.layers import DropPath
|
| 44 |
+
|
| 45 |
+
compute_ARank = False # [ARank] Set this to True to compute attention rank
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
from transformers.generation.streamers import BaseStreamer
|
| 49 |
+
except: # noqa # pylint: disable=bare-except
|
| 50 |
+
BaseStreamer = None
|
| 51 |
+
|
| 52 |
+
from .configuration_holistic_embedding import HolisticEmbeddingConfig
|
| 53 |
+
|
| 54 |
+
logger = logging.get_logger(__name__)
|
| 55 |
+
|
| 56 |
+
_CONFIG_FOR_DOC = "HolisticEmbeddingConfig"
|
| 57 |
+
|
| 58 |
+
flash_attn_func, flash_attn_varlen_func = None, None
|
| 59 |
+
pad_input, index_first_axis, unpad_input = None, None, None
|
| 60 |
+
def _import_flash_attn():
|
| 61 |
+
global flash_attn_func, flash_attn_varlen_func
|
| 62 |
+
global pad_input, index_first_axis, unpad_input
|
| 63 |
+
try:
|
| 64 |
+
from flash_attn import flash_attn_func as _flash_attn_func, flash_attn_varlen_func as _flash_attn_varlen_func
|
| 65 |
+
from flash_attn.bert_padding import pad_input as _pad_input, index_first_axis as _index_first_axis, unpad_input as _unpad_input
|
| 66 |
+
flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
|
| 67 |
+
pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
|
| 68 |
+
except ImportError:
|
| 69 |
+
raise ImportError("flash_attn is not installed.")
|
| 70 |
+
|
| 71 |
+
_import_flash_attn()
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 75 |
+
def _get_unpad_data(attention_mask):
|
| 76 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 77 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 78 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 79 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 80 |
+
return (
|
| 81 |
+
indices,
|
| 82 |
+
cu_seqlens,
|
| 83 |
+
max_seqlen_in_batch,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
|
| 88 |
+
def _make_causal_mask(
|
| 89 |
+
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
|
| 90 |
+
):
|
| 91 |
+
"""
|
| 92 |
+
Make causal mask used for bi-directional self-attention.
|
| 93 |
+
"""
|
| 94 |
+
bsz, tgt_len = input_ids_shape
|
| 95 |
+
mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
|
| 96 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 97 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 98 |
+
mask = mask.to(dtype)
|
| 99 |
+
|
| 100 |
+
if past_key_values_length > 0:
|
| 101 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 102 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 106 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 107 |
+
"""
|
| 108 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 109 |
+
"""
|
| 110 |
+
bsz, src_len = mask.size()
|
| 111 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 112 |
+
|
| 113 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 114 |
+
|
| 115 |
+
inverted_mask = 1.0 - expanded_mask
|
| 116 |
+
|
| 117 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->InternLM2
|
| 121 |
+
class InternLM2RMSNorm(nn.Module):
|
| 122 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 123 |
+
"""
|
| 124 |
+
InternLM2RMSNorm is equivalent to T5LayerNorm
|
| 125 |
+
"""
|
| 126 |
+
super().__init__()
|
| 127 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 128 |
+
self.variance_epsilon = eps
|
| 129 |
+
|
| 130 |
+
def forward(self, hidden_states):
|
| 131 |
+
input_dtype = hidden_states.dtype
|
| 132 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 133 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 134 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 135 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaRotaryEmbedding with Llama->InternLM2
|
| 139 |
+
class InternLM2RotaryEmbedding(nn.Module):
|
| 140 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 141 |
+
super().__init__()
|
| 142 |
+
|
| 143 |
+
self.dim = dim
|
| 144 |
+
self.max_position_embeddings = max_position_embeddings
|
| 145 |
+
self.base = base
|
| 146 |
+
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 147 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 148 |
+
|
| 149 |
+
# Build here to make `torch.jit.trace` work.
|
| 150 |
+
self._set_cos_sin_cache(
|
| 151 |
+
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 155 |
+
self.max_seq_len_cached = seq_len
|
| 156 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 157 |
+
|
| 158 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 159 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 160 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 161 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 162 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 163 |
+
|
| 164 |
+
def forward(self, x, seq_len=None):
|
| 165 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 166 |
+
if seq_len > self.max_seq_len_cached:
|
| 167 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=torch.float32)
|
| 168 |
+
|
| 169 |
+
return (
|
| 170 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 171 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->InternLM2
|
| 176 |
+
class InternLM2LinearScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 177 |
+
"""InternLM2RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 178 |
+
|
| 179 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 180 |
+
self.scaling_factor = scaling_factor
|
| 181 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 182 |
+
|
| 183 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 184 |
+
self.max_seq_len_cached = seq_len
|
| 185 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 186 |
+
t = t / self.scaling_factor
|
| 187 |
+
|
| 188 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 189 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 190 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 191 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 192 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->InternLM2
|
| 196 |
+
class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 197 |
+
"""InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
|
| 198 |
+
Credits to the Reddit users /u/bloc97 and /u/emozilla.
|
| 199 |
+
"""
|
| 200 |
+
|
| 201 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 202 |
+
self.scaling_factor = scaling_factor
|
| 203 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 204 |
+
|
| 205 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 206 |
+
self.max_seq_len_cached = seq_len
|
| 207 |
+
|
| 208 |
+
if seq_len > self.max_position_embeddings:
|
| 209 |
+
base = self.base * (
|
| 210 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 211 |
+
) ** (self.dim / (self.dim - 2))
|
| 212 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 213 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 214 |
+
|
| 215 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 216 |
+
|
| 217 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 218 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 219 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 220 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 221 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
# Copied from transformers.model.llama.modeling_llama.rotate_half
|
| 225 |
+
def rotate_half(x):
|
| 226 |
+
"""Rotates half the hidden dims of the input."""
|
| 227 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 228 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 229 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
# Copied from transformers.model.llama.modeling_llama.apply_rotary_pos_emb
|
| 233 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
|
| 234 |
+
"""Applies Rotary Position Embedding to the query and key tensors."""
|
| 235 |
+
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 236 |
+
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 237 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 238 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 239 |
+
return q_embed, k_embed
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class InternLM2MLP(nn.Module):
|
| 243 |
+
def __init__(self, config):
|
| 244 |
+
super().__init__()
|
| 245 |
+
self.config = config
|
| 246 |
+
self.hidden_size = config.hidden_size
|
| 247 |
+
self.intermediate_size = config.intermediate_size
|
| 248 |
+
self.w1 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 249 |
+
self.w3 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 250 |
+
self.w2 = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 251 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 252 |
+
|
| 253 |
+
def forward(self, x):
|
| 254 |
+
down_proj = self.w2(self.act_fn(self.w1(x)) * self.w3(x))
|
| 255 |
+
|
| 256 |
+
return down_proj
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
# Copied from transformers.model.llama.modeling_llama.repeat_kv
|
| 260 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 261 |
+
"""
|
| 262 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 263 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 264 |
+
"""
|
| 265 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 266 |
+
if n_rep == 1:
|
| 267 |
+
return hidden_states
|
| 268 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 269 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaAttention
|
| 273 |
+
class InternLM2Attention(nn.Module):
|
| 274 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 275 |
+
|
| 276 |
+
def __init__(self, config: HolisticEmbeddingConfig):
|
| 277 |
+
super().__init__()
|
| 278 |
+
self.config = config
|
| 279 |
+
self.hidden_size = config.hidden_size
|
| 280 |
+
self.num_heads = config.num_attention_heads
|
| 281 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 282 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 283 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 284 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 285 |
+
self.is_causal = True
|
| 286 |
+
|
| 287 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 288 |
+
raise ValueError(
|
| 289 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 290 |
+
f" and `num_heads`: {self.num_heads})."
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
self.wqkv = nn.Linear(
|
| 294 |
+
self.hidden_size,
|
| 295 |
+
(self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
|
| 296 |
+
bias=config.attention_bias,
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)
|
| 300 |
+
self._init_rope()
|
| 301 |
+
|
| 302 |
+
def _init_rope(self):
|
| 303 |
+
if self.config.rope_scaling is None:
|
| 304 |
+
self.rotary_emb = InternLM2RotaryEmbedding(
|
| 305 |
+
self.head_dim,
|
| 306 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 307 |
+
base=self.config.rope_theta,
|
| 308 |
+
)
|
| 309 |
+
else:
|
| 310 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 311 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 312 |
+
if scaling_type == "dynamic":
|
| 313 |
+
self.rotary_emb = InternLM2DynamicNTKScalingRotaryEmbedding(
|
| 314 |
+
self.head_dim,
|
| 315 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 316 |
+
base=self.config.rope_theta,
|
| 317 |
+
scaling_factor=scaling_factor,
|
| 318 |
+
)
|
| 319 |
+
elif scaling_type == "linear":
|
| 320 |
+
self.rotary_emb = InternLM2LinearScalingRotaryEmbedding(
|
| 321 |
+
self.head_dim,
|
| 322 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 323 |
+
base=self.config.rope_theta,
|
| 324 |
+
scaling_factor=scaling_factor,
|
| 325 |
+
)
|
| 326 |
+
else:
|
| 327 |
+
raise ValueError("Currently we only support rotary embedding's type being 'dynamic' or 'linear'.")
|
| 328 |
+
return self.rotary_emb
|
| 329 |
+
|
| 330 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 331 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 332 |
+
|
| 333 |
+
def forward(
|
| 334 |
+
self,
|
| 335 |
+
hidden_states: torch.Tensor,
|
| 336 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 337 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 338 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 339 |
+
output_attentions: bool = False,
|
| 340 |
+
use_cache: bool = False,
|
| 341 |
+
**kwargs,
|
| 342 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 343 |
+
if "padding_mask" in kwargs:
|
| 344 |
+
warnings.warn(
|
| 345 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. "
|
| 346 |
+
"Please make sure use `attention_mask` instead.`"
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
bsz, q_len, _ = hidden_states.size()
|
| 350 |
+
if attention_mask is not None and len(attention_mask.shape) == 2: # Flash Attention Mode to Attention Mode
|
| 351 |
+
new_attention_mask = torch.zeros(bsz, 1, q_len, q_len).to(hidden_states.device)
|
| 352 |
+
upper_tri_indices = torch.triu_indices(row=q_len, col=q_len, offset=1)
|
| 353 |
+
new_attention_mask[:, :, upper_tri_indices[0], upper_tri_indices[1]] = -65504.
|
| 354 |
+
attention_mask = new_attention_mask
|
| 355 |
+
|
| 356 |
+
qkv_states = self.wqkv(hidden_states)
|
| 357 |
+
|
| 358 |
+
qkv_states = rearrange(
|
| 359 |
+
qkv_states,
|
| 360 |
+
"b q (h gs d) -> b q h gs d",
|
| 361 |
+
gs=2 + self.num_key_value_groups,
|
| 362 |
+
d=self.head_dim,
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 366 |
+
query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
|
| 367 |
+
key_states = qkv_states[..., -2, :]
|
| 368 |
+
value_states = qkv_states[..., -1, :]
|
| 369 |
+
|
| 370 |
+
query_states = query_states.transpose(1, 2)
|
| 371 |
+
key_states = key_states.transpose(1, 2)
|
| 372 |
+
value_states = value_states.transpose(1, 2)
|
| 373 |
+
|
| 374 |
+
kv_seq_len = key_states.shape[-2]
|
| 375 |
+
if past_key_value is not None:
|
| 376 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 377 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 378 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 379 |
+
|
| 380 |
+
if past_key_value is not None:
|
| 381 |
+
# reuse k, v, self_attention
|
| 382 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 383 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 384 |
+
|
| 385 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 386 |
+
|
| 387 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 388 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 389 |
+
|
| 390 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 391 |
+
|
| 392 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 393 |
+
raise ValueError(
|
| 394 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 395 |
+
f" {attn_weights.size()}"
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
if attention_mask is not None:
|
| 399 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 400 |
+
raise ValueError(
|
| 401 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 402 |
+
)
|
| 403 |
+
# min_dtype = torch.finfo(attn_weights.dtype).min
|
| 404 |
+
# causal_mask = torch.full(
|
| 405 |
+
# (q_len, kv_seq_len), fill_value=min_dtype, dtype=attn_weights.dtype, device=attn_weights.device
|
| 406 |
+
# )
|
| 407 |
+
# if q_len != 1:
|
| 408 |
+
# causal_mask = torch.triu(causal_mask, diagonal=1)
|
| 409 |
+
# # causal_mask *= torch.arange(kv_seq_len, device=device) > cache_position.reshape(-1, 1)
|
| 410 |
+
# causal_mask = causal_mask[None, None, :, :].expand(bsz, 1, -1, -1)
|
| 411 |
+
# attention_mask = causal_mask
|
| 412 |
+
attn_weights = attn_weights + attention_mask
|
| 413 |
+
|
| 414 |
+
# upcast attention to fp32
|
| 415 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 416 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 417 |
+
|
| 418 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 419 |
+
raise ValueError(
|
| 420 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 421 |
+
f" {attn_output.size()}"
|
| 422 |
+
)
|
| 423 |
+
|
| 424 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 425 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 426 |
+
|
| 427 |
+
attn_output = self.wo(attn_output)
|
| 428 |
+
|
| 429 |
+
if not output_attentions:
|
| 430 |
+
attn_weights = None
|
| 431 |
+
|
| 432 |
+
return attn_output, attn_weights, past_key_value
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
# Modified from transformers.model.llama.modeling_llama.InternLM2FlashAttention2
|
| 436 |
+
class InternLM2FlashAttention2(InternLM2Attention):
|
| 437 |
+
"""
|
| 438 |
+
InternLM2 flash attention module. This module inherits from `InternLM2Attention` as the weights of the module stays
|
| 439 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 440 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 441 |
+
"""
|
| 442 |
+
|
| 443 |
+
def forward(
|
| 444 |
+
self,
|
| 445 |
+
hidden_states: torch.Tensor,
|
| 446 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 447 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 448 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 449 |
+
output_attentions: bool = False,
|
| 450 |
+
use_cache: bool = False,
|
| 451 |
+
**kwargs,
|
| 452 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 453 |
+
# InternLM2FlashAttention2 attention does not support output_attentions
|
| 454 |
+
if "padding_mask" in kwargs:
|
| 455 |
+
warnings.warn(
|
| 456 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. "
|
| 457 |
+
"Please make sure use `attention_mask` instead.`"
|
| 458 |
+
)
|
| 459 |
+
|
| 460 |
+
# overwrite attention_mask with padding_mask
|
| 461 |
+
attention_mask = kwargs.pop("padding_mask")
|
| 462 |
+
|
| 463 |
+
output_attentions = False
|
| 464 |
+
|
| 465 |
+
bsz, q_len, _ = hidden_states.size()
|
| 466 |
+
|
| 467 |
+
qkv_states = self.wqkv(hidden_states)
|
| 468 |
+
|
| 469 |
+
qkv_states = rearrange(
|
| 470 |
+
qkv_states,
|
| 471 |
+
"b q (h gs d) -> b q h gs d",
|
| 472 |
+
gs=2 + self.num_key_value_groups,
|
| 473 |
+
d=self.head_dim,
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 477 |
+
query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
|
| 478 |
+
key_states = qkv_states[..., -2, :]
|
| 479 |
+
value_states = qkv_states[..., -1, :]
|
| 480 |
+
|
| 481 |
+
query_states = query_states.transpose(1, 2)
|
| 482 |
+
key_states = key_states.transpose(1, 2)
|
| 483 |
+
value_states = value_states.transpose(1, 2)
|
| 484 |
+
|
| 485 |
+
kv_seq_len = key_states.shape[-2]
|
| 486 |
+
if past_key_value is not None:
|
| 487 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 488 |
+
|
| 489 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 490 |
+
|
| 491 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 492 |
+
|
| 493 |
+
if past_key_value is not None:
|
| 494 |
+
# reuse k, v, self_attention
|
| 495 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 496 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 497 |
+
|
| 498 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 499 |
+
|
| 500 |
+
query_states = query_states.transpose(1, 2)
|
| 501 |
+
key_states = key_states.transpose(1, 2)
|
| 502 |
+
value_states = value_states.transpose(1, 2)
|
| 503 |
+
|
| 504 |
+
attn_output = self._flash_attention_forward(
|
| 505 |
+
query_states, key_states, value_states, attention_mask, q_len
|
| 506 |
+
)
|
| 507 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 508 |
+
attn_output = self.wo(attn_output)
|
| 509 |
+
|
| 510 |
+
if not output_attentions:
|
| 511 |
+
attn_weights = None
|
| 512 |
+
|
| 513 |
+
return attn_output, attn_weights, past_key_value
|
| 514 |
+
|
| 515 |
+
def _flash_attention_forward(
|
| 516 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 517 |
+
):
|
| 518 |
+
"""
|
| 519 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 520 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 521 |
+
|
| 522 |
+
Args:
|
| 523 |
+
query_states (`torch.Tensor`):
|
| 524 |
+
Input query states to be passed to Flash Attention API
|
| 525 |
+
key_states (`torch.Tensor`):
|
| 526 |
+
Input key states to be passed to Flash Attention API
|
| 527 |
+
value_states (`torch.Tensor`):
|
| 528 |
+
Input value states to be passed to Flash Attention API
|
| 529 |
+
attention_mask (`torch.Tensor`):
|
| 530 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 531 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 532 |
+
dropout (`int`, *optional*):
|
| 533 |
+
Attention dropout
|
| 534 |
+
softmax_scale (`float`, *optional*):
|
| 535 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 536 |
+
"""
|
| 537 |
+
# Contains at least one padding token in the sequence
|
| 538 |
+
causal = self.is_causal and query_length != 1
|
| 539 |
+
if attention_mask is not None:
|
| 540 |
+
batch_size = query_states.shape[0]
|
| 541 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._unpad_input(
|
| 542 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 543 |
+
)
|
| 544 |
+
|
| 545 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 546 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 547 |
+
|
| 548 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 549 |
+
query_states,
|
| 550 |
+
key_states,
|
| 551 |
+
value_states,
|
| 552 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 553 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 554 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 555 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 556 |
+
dropout_p=dropout,
|
| 557 |
+
softmax_scale=softmax_scale,
|
| 558 |
+
causal=causal,
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 562 |
+
else:
|
| 563 |
+
attn_output = flash_attn_func(
|
| 564 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 565 |
+
)
|
| 566 |
+
|
| 567 |
+
return attn_output
|
| 568 |
+
|
| 569 |
+
def _unpad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 570 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 571 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 572 |
+
|
| 573 |
+
key_layer = index_first_axis(
|
| 574 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 575 |
+
)
|
| 576 |
+
value_layer = index_first_axis(
|
| 577 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
if query_length == kv_seq_len:
|
| 581 |
+
query_layer = index_first_axis(
|
| 582 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 583 |
+
)
|
| 584 |
+
cu_seqlens_q = cu_seqlens_k
|
| 585 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 586 |
+
indices_q = indices_k
|
| 587 |
+
elif query_length == 1:
|
| 588 |
+
max_seqlen_in_batch_q = 1
|
| 589 |
+
cu_seqlens_q = torch.arange(
|
| 590 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 591 |
+
) # There is a memcpy here, that is very bad.
|
| 592 |
+
indices_q = cu_seqlens_q[:-1]
|
| 593 |
+
query_layer = query_layer.squeeze(1)
|
| 594 |
+
else:
|
| 595 |
+
# The -q_len: slice assumes left padding.
|
| 596 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 597 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 598 |
+
|
| 599 |
+
return (
|
| 600 |
+
query_layer,
|
| 601 |
+
key_layer,
|
| 602 |
+
value_layer,
|
| 603 |
+
indices_q.to(torch.int64),
|
| 604 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 605 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 606 |
+
)
|
| 607 |
+
|
| 608 |
+
|
| 609 |
+
INTERNLM2_ATTENTION_CLASSES = {
|
| 610 |
+
"eager": InternLM2Attention,
|
| 611 |
+
"flash_attention_2": InternLM2FlashAttention2,
|
| 612 |
+
}
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaDecoderLayer
|
| 616 |
+
class InternLM2DecoderLayer(nn.Module):
|
| 617 |
+
def __init__(self, config: HolisticEmbeddingConfig, drop_path_rate=0.0):
|
| 618 |
+
super().__init__()
|
| 619 |
+
self.hidden_size = config.hidden_size
|
| 620 |
+
self.config = config
|
| 621 |
+
|
| 622 |
+
self.attention = INTERNLM2_ATTENTION_CLASSES[config.attn_implementation](config=config) if not compute_ARank else InternLM2Attention(config=config)
|
| 623 |
+
|
| 624 |
+
self.feed_forward = InternLM2MLP(config)
|
| 625 |
+
self.attention_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 626 |
+
self.ffn_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 627 |
+
|
| 628 |
+
self.drop_path1 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 629 |
+
self.drop_path2 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 630 |
+
|
| 631 |
+
def forward(
|
| 632 |
+
self,
|
| 633 |
+
hidden_states: torch.Tensor,
|
| 634 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 635 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 636 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 637 |
+
output_attentions: Optional[bool] = False,
|
| 638 |
+
use_cache: Optional[bool] = False,
|
| 639 |
+
**kwargs,
|
| 640 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 641 |
+
"""
|
| 642 |
+
Args:
|
| 643 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 644 |
+
attention_mask (`torch.FloatTensor`, *optional*):
|
| 645 |
+
attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
|
| 646 |
+
query_sequence_length, key_sequence_length)` if default attention is used.
|
| 647 |
+
output_attentions (`bool`, *optional*):
|
| 648 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 649 |
+
returned tensors for more detail.
|
| 650 |
+
use_cache (`bool`, *optional*):
|
| 651 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 652 |
+
(see `past_key_values`).
|
| 653 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 654 |
+
"""
|
| 655 |
+
if "padding_mask" in kwargs:
|
| 656 |
+
warnings.warn(
|
| 657 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. "
|
| 658 |
+
"Please make sure use `attention_mask` instead.`"
|
| 659 |
+
)
|
| 660 |
+
|
| 661 |
+
residual = hidden_states
|
| 662 |
+
|
| 663 |
+
hidden_states = self.attention_norm(hidden_states)
|
| 664 |
+
|
| 665 |
+
# Self Attention
|
| 666 |
+
hidden_states, self_attn_weights, present_key_value = self.attention(
|
| 667 |
+
hidden_states=hidden_states,
|
| 668 |
+
attention_mask=attention_mask,
|
| 669 |
+
position_ids=position_ids,
|
| 670 |
+
past_key_value=past_key_value,
|
| 671 |
+
output_attentions=output_attentions,
|
| 672 |
+
use_cache=use_cache,
|
| 673 |
+
**kwargs,
|
| 674 |
+
)
|
| 675 |
+
hidden_states = residual + self.drop_path1(hidden_states)
|
| 676 |
+
|
| 677 |
+
# Fully Connected
|
| 678 |
+
residual = hidden_states
|
| 679 |
+
hidden_states = self.ffn_norm(hidden_states)
|
| 680 |
+
hidden_states = self.feed_forward(hidden_states)
|
| 681 |
+
|
| 682 |
+
hidden_states = residual + self.drop_path2(hidden_states)
|
| 683 |
+
|
| 684 |
+
outputs = (hidden_states,)
|
| 685 |
+
|
| 686 |
+
if output_attentions:
|
| 687 |
+
outputs += (self_attn_weights,)
|
| 688 |
+
|
| 689 |
+
if use_cache:
|
| 690 |
+
outputs += (present_key_value,)
|
| 691 |
+
|
| 692 |
+
return outputs
|
| 693 |
+
|
| 694 |
+
|
| 695 |
+
class VisionEmbeddings(nn.Module):
|
| 696 |
+
def __init__(self, config: HolisticEmbeddingConfig):
|
| 697 |
+
super().__init__()
|
| 698 |
+
self.config = config
|
| 699 |
+
self.embed_dim = config.hidden_size
|
| 700 |
+
self.image_size = config.image_size
|
| 701 |
+
self.patch_size = config.patch_size
|
| 702 |
+
|
| 703 |
+
self.class_embedding = nn.Parameter(
|
| 704 |
+
torch.randn(1, 1, self.embed_dim),
|
| 705 |
+
)
|
| 706 |
+
|
| 707 |
+
self.patch_embedding = nn.Conv2d(
|
| 708 |
+
in_channels=self.config.num_channels, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 709 |
+
)
|
| 710 |
+
|
| 711 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 712 |
+
self.num_positions = self.num_patches + 1
|
| 713 |
+
|
| 714 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
|
| 715 |
+
|
| 716 |
+
self.post_init()
|
| 717 |
+
|
| 718 |
+
def post_init(self):
|
| 719 |
+
for m in self.modules():
|
| 720 |
+
if isinstance(m, nn.Conv2d):
|
| 721 |
+
torch.nn.init.normal_(m.weight, mean=0.0, std=0.02)
|
| 722 |
+
if m.bias is not None:
|
| 723 |
+
nn.init.zeros_(m.bias)
|
| 724 |
+
if isinstance(m, nn.Linear):
|
| 725 |
+
torch.nn.init.normal_(m.weight, mean=0.0, std=0.02)
|
| 726 |
+
if m.bias is not None:
|
| 727 |
+
nn.init.zeros_(m.bias)
|
| 728 |
+
|
| 729 |
+
def _get_pos_embed(self, pos_embed, H, W):
|
| 730 |
+
target_dtype = pos_embed.dtype
|
| 731 |
+
pos_embed = pos_embed.float().reshape(
|
| 732 |
+
1, self.image_size // self.patch_size, self.image_size // self.patch_size, -1).permute(0, 3, 1, 2)
|
| 733 |
+
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False).\
|
| 734 |
+
reshape(1, -1, H * W).permute(0, 2, 1).to(target_dtype)
|
| 735 |
+
return pos_embed
|
| 736 |
+
|
| 737 |
+
def forward(self, pixel_values: torch.FloatTensor,
|
| 738 |
+
use_cls_token=False,
|
| 739 |
+
) -> torch.Tensor:
|
| 740 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 741 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height]
|
| 742 |
+
batch_size, _, height, width = patch_embeds.shape
|
| 743 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 744 |
+
if use_cls_token:
|
| 745 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
|
| 746 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 747 |
+
assert not self.config.use_2d_sincos_pos_embed, '2D SinCos pos embed is not supported with use_cls_token'
|
| 748 |
+
position_embedding = torch.cat([
|
| 749 |
+
self.position_embedding[:, :1, :],
|
| 750 |
+
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
|
| 751 |
+
], dim=1)
|
| 752 |
+
embeddings = embeddings + position_embedding
|
| 753 |
+
else:
|
| 754 |
+
position_embedding = self._get_pos_embed(self.position_embedding[:, 1:, :], height, width).to(target_dtype)
|
| 755 |
+
embeddings = patch_embeds + position_embedding
|
| 756 |
+
|
| 757 |
+
return embeddings
|
| 758 |
+
|
| 759 |
+
|
| 760 |
+
class HolisticEmbedding(PreTrainedModel):
|
| 761 |
+
config_class = HolisticEmbeddingConfig
|
| 762 |
+
_supports_flash_attn_2 = True
|
| 763 |
+
|
| 764 |
+
def __init__(self, config: HolisticEmbeddingConfig):
|
| 765 |
+
super().__init__(config)
|
| 766 |
+
self.config = config
|
| 767 |
+
self.hidden_size = self.config.hidden_size
|
| 768 |
+
self.gradient_checkpointing = True
|
| 769 |
+
|
| 770 |
+
self.vision_embeddings = VisionEmbeddings(config)
|
| 771 |
+
self.llm_text_embeddings = nn.Embedding(self.config.llm_vocab_size, self.config.llm_hidden_size)
|
| 772 |
+
self.special_token_maps = config.special_token_maps
|
| 773 |
+
if len(self.special_token_maps) > 0:
|
| 774 |
+
self.special_text_embeddings = nn.Embedding(len(config.special_token_maps), self.config.llm_hidden_size)
|
| 775 |
+
|
| 776 |
+
assert self.config.use_ls is False, 'LS is not supported in InternLM2'
|
| 777 |
+
if hasattr(config, 'drop_path_rate'):
|
| 778 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
|
| 779 |
+
else:
|
| 780 |
+
dpr = [0.0] * config.num_hidden_layers
|
| 781 |
+
self.encoder = nn.ModuleList([
|
| 782 |
+
InternLM2DecoderLayer(config, dpr[idx]) for idx in range(config.num_hidden_layers)
|
| 783 |
+
])
|
| 784 |
+
|
| 785 |
+
if self.config.use_pixel_shuffle_proj:
|
| 786 |
+
self.pixel_shuffle_proj = nn.Sequential(
|
| 787 |
+
nn.Linear(int(config.hidden_size / (config.downsample_ratio * config.downsample_ratio)), config.hidden_size),
|
| 788 |
+
nn.GELU(),
|
| 789 |
+
nn.Linear(config.hidden_size, config.hidden_size)
|
| 790 |
+
)
|
| 791 |
+
|
| 792 |
+
self.num_img_tokens = (self.config.image_size // self.config.patch_size) ** 2
|
| 793 |
+
|
| 794 |
+
def set_gradient_checkpointing(self):
|
| 795 |
+
self.gradient_checkpointing = True
|
| 796 |
+
for layer in self.encoder:
|
| 797 |
+
layer.gradient_checkpointing = True
|
| 798 |
+
|
| 799 |
+
def resize_pos_embeddings(self, old_size, new_size, patch_size):
|
| 800 |
+
pos_emb = self.vision_embeddings.position_embedding
|
| 801 |
+
_, num_positions, embed_dim = pos_emb.shape
|
| 802 |
+
cls_emb = pos_emb[:, :1, :]
|
| 803 |
+
pos_emb = pos_emb[:, 1:, :].reshape(1, old_size // patch_size, old_size // patch_size, -1).permute(0, 3, 1, 2)
|
| 804 |
+
pos_emb = F.interpolate(pos_emb.float(), size=new_size // patch_size, mode='bicubic', align_corners=False)
|
| 805 |
+
pos_emb = pos_emb.to(cls_emb.dtype).reshape(1, embed_dim, -1).permute(0, 2, 1)
|
| 806 |
+
pos_emb = torch.cat([cls_emb, pos_emb], dim=1)
|
| 807 |
+
self.vision_embeddings.position_embedding = nn.Parameter(pos_emb)
|
| 808 |
+
self.vision_embeddings.image_size = new_size
|
| 809 |
+
logger.info('Resized position embeddings from {} to {}'.format(old_size, new_size))
|
| 810 |
+
|
| 811 |
+
def replace_img_tokens(self, input_ids, hidden_states, vision_hidden_states):
|
| 812 |
+
img_context_token_mask = (input_ids == self.config.img_context_token_id)
|
| 813 |
+
hidden_states[img_context_token_mask] = hidden_states[img_context_token_mask] * 0.0 + vision_hidden_states.flatten(0, 1)
|
| 814 |
+
|
| 815 |
+
return hidden_states
|
| 816 |
+
|
| 817 |
+
def get_ignore_mask(self, input_ids):
|
| 818 |
+
ignore_ids = torch.tensor(
|
| 819 |
+
[self.special_token_maps[token] for token in [IMG_START_TOKEN, IMG_END_TOKEN]],
|
| 820 |
+
device=input_ids.device)
|
| 821 |
+
ignore_mask = torch.isin(input_ids, ignore_ids)
|
| 822 |
+
|
| 823 |
+
return ignore_mask
|
| 824 |
+
|
| 825 |
+
def get_text_mask(self, input_ids):
|
| 826 |
+
txt_mask = (input_ids != self.config.img_context_token_id)
|
| 827 |
+
|
| 828 |
+
return txt_mask
|
| 829 |
+
|
| 830 |
+
def get_input_embeddings(self, input_ids):
|
| 831 |
+
special_mask = input_ids > self.llm_text_embeddings.weight.shape[0] - 1
|
| 832 |
+
llm_embeddings = self.llm_text_embeddings(input_ids * (~special_mask).to(input_ids))
|
| 833 |
+
|
| 834 |
+
if len(self.special_token_maps) > 0:
|
| 835 |
+
special_embeddings = self.special_text_embeddings((input_ids - self.llm_text_embeddings.weight.shape[0]) * special_mask.to(input_ids))
|
| 836 |
+
special_mask = special_mask.unsqueeze(-1)
|
| 837 |
+
text_embeddings = llm_embeddings * (~special_mask).to(llm_embeddings) + \
|
| 838 |
+
special_embeddings * special_mask.to(llm_embeddings)
|
| 839 |
+
else:
|
| 840 |
+
text_embeddings = llm_embeddings
|
| 841 |
+
|
| 842 |
+
return text_embeddings
|
| 843 |
+
|
| 844 |
+
def get_txt_embeddings(self, input_ids):
|
| 845 |
+
B, L = input_ids.shape
|
| 846 |
+
txt_mask = (input_ids != self.config.img_context_token_id)
|
| 847 |
+
txt_embeddings = self.llm_text_embeddings(input_ids[txt_mask])
|
| 848 |
+
txt_embeddings = txt_embeddings.reshape(-1, txt_embeddings.shape[-1])
|
| 849 |
+
|
| 850 |
+
return txt_embeddings
|
| 851 |
+
|
| 852 |
+
def get_txt_feature(self, input_ids, feature):
|
| 853 |
+
B, L, C = feature.shape
|
| 854 |
+
txt_mask = (input_ids != self.config.img_context_token_id)
|
| 855 |
+
txt_feature = feature[txt_mask].reshape(-1, C)
|
| 856 |
+
|
| 857 |
+
return txt_feature
|
| 858 |
+
|
| 859 |
+
def get_img_feature(self, input_ids, feature):
|
| 860 |
+
B, L, C = feature.shape
|
| 861 |
+
img_mask = (input_ids == self.config.img_context_token_id)
|
| 862 |
+
img_feature = feature[img_mask].reshape(-1, C)
|
| 863 |
+
|
| 864 |
+
return img_feature
|
| 865 |
+
|
| 866 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 867 |
+
if getattr(self.config, 'pixel_shuffle_loc', 'pre') == 'post':
|
| 868 |
+
x = x.view(x.shape[0]//self.num_img_tokens, self.num_img_tokens, -1)
|
| 869 |
+
|
| 870 |
+
n, l, c = x.size()
|
| 871 |
+
h = w = int(l ** 0.5)
|
| 872 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 873 |
+
x = x.reshape(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 874 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 875 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 876 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 877 |
+
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
|
| 878 |
+
int(c / (scale_factor * scale_factor)))
|
| 879 |
+
x = x.permute(0, 2, 1, 3).reshape(n, int(l * scale_factor * scale_factor), int(c / (scale_factor * scale_factor))).contiguous()
|
| 880 |
+
|
| 881 |
+
if getattr(self.config, 'pixel_shuffle_loc', 'pre') == 'post':
|
| 882 |
+
x = x.view(int(x.shape[0]*self.num_img_tokens*(self.config.downsample_ratio**2)), -1)
|
| 883 |
+
return x
|
| 884 |
+
|
| 885 |
+
def forward(
|
| 886 |
+
self,
|
| 887 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 888 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 889 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 890 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 891 |
+
output_hidden_states: Optional[bool] = None,
|
| 892 |
+
return_dict: Optional[bool] = None,
|
| 893 |
+
use_cache: Optional[bool] = None,
|
| 894 |
+
):
|
| 895 |
+
output_hidden_states = (
|
| 896 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 897 |
+
)
|
| 898 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 899 |
+
|
| 900 |
+
if pixel_values is not None:
|
| 901 |
+
if len(pixel_values.shape) == 4:
|
| 902 |
+
if self.gradient_checkpointing and self.training:
|
| 903 |
+
vision_hidden_states = torch.utils.checkpoint.checkpoint(self.vision_embeddings, pixel_values)
|
| 904 |
+
else:
|
| 905 |
+
vision_hidden_states = self.vision_embeddings(pixel_values)
|
| 906 |
+
|
| 907 |
+
if self.config.use_pixel_shuffle_proj and getattr(self.config, 'pixel_shuffle_loc', 'pre') == 'pre':
|
| 908 |
+
vision_hidden_states = self.pixel_shuffle(vision_hidden_states, scale_factor=self.config.downsample_ratio)
|
| 909 |
+
if self.gradient_checkpointing and self.training:
|
| 910 |
+
vision_hidden_states = torch.utils.checkpoint.checkpoint(self.pixel_shuffle_proj, vision_hidden_states)
|
| 911 |
+
else:
|
| 912 |
+
vision_hidden_states = self.pixel_shuffle_proj(vision_hidden_states)
|
| 913 |
+
|
| 914 |
+
hidden_states = self.get_input_embeddings(input_ids)
|
| 915 |
+
hidden_states = self.replace_img_tokens(input_ids, hidden_states, vision_hidden_states)
|
| 916 |
+
else:
|
| 917 |
+
raise ValueError(f'wrong pixel_values size: {pixel_values.shape}')
|
| 918 |
+
else:
|
| 919 |
+
hidden_states = self.get_input_embeddings(input_ids)
|
| 920 |
+
|
| 921 |
+
if position_ids is None:
|
| 922 |
+
position_ids = torch.arange(
|
| 923 |
+
hidden_states.shape[1], device=hidden_states.device
|
| 924 |
+
).unsqueeze(0)
|
| 925 |
+
|
| 926 |
+
next_past_key_values = []
|
| 927 |
+
for layer_idx, layer_module in enumerate(self.encoder):
|
| 928 |
+
if self.gradient_checkpointing and self.training:
|
| 929 |
+
assert use_cache is None, 'Gradient checkpointing is not compatible with cache'
|
| 930 |
+
outputs = torch.utils.checkpoint.checkpoint(layer_module,
|
| 931 |
+
hidden_states,
|
| 932 |
+
attention_mask,
|
| 933 |
+
position_ids,
|
| 934 |
+
None, False, False,
|
| 935 |
+
)
|
| 936 |
+
hidden_states = outputs[0]
|
| 937 |
+
else:
|
| 938 |
+
outputs = layer_module(
|
| 939 |
+
hidden_states=hidden_states,
|
| 940 |
+
attention_mask=attention_mask,
|
| 941 |
+
position_ids=position_ids,
|
| 942 |
+
use_cache=use_cache,
|
| 943 |
+
)
|
| 944 |
+
hidden_states = outputs[0]
|
| 945 |
+
if use_cache:
|
| 946 |
+
next_past_key_values.append(outputs[-1])
|
| 947 |
+
|
| 948 |
+
img_feature = self.get_img_feature(input_ids, hidden_states)
|
| 949 |
+
|
| 950 |
+
if self.config.use_pixel_shuffle_proj and getattr(self.config, 'pixel_shuffle_loc', 'pre') == 'post':
|
| 951 |
+
img_feature = self.pixel_shuffle(img_feature, scale_factor=self.config.downsample_ratio)
|
| 952 |
+
img_feature = self.pixel_shuffle_proj(img_feature)
|
| 953 |
+
|
| 954 |
+
return img_feature, hidden_states, next_past_key_values
|
modeling_internlm2.py
ADDED
|
@@ -0,0 +1,1392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/modeling_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" PyTorch InternLM2 model."""
|
| 17 |
+
import math
|
| 18 |
+
import queue
|
| 19 |
+
import threading
|
| 20 |
+
import warnings
|
| 21 |
+
from typing import List, Optional, Tuple, Union
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
import torch.nn.functional as F
|
| 25 |
+
import torch.utils.checkpoint
|
| 26 |
+
from einops import rearrange
|
| 27 |
+
from torch import nn
|
| 28 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 29 |
+
from transformers.activations import ACT2FN
|
| 30 |
+
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
| 31 |
+
CausalLMOutputWithPast,
|
| 32 |
+
SequenceClassifierOutputWithPast)
|
| 33 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 34 |
+
from transformers.utils import (add_start_docstrings,
|
| 35 |
+
add_start_docstrings_to_model_forward, logging,
|
| 36 |
+
replace_return_docstrings)
|
| 37 |
+
|
| 38 |
+
try:
|
| 39 |
+
from transformers.generation.streamers import BaseStreamer
|
| 40 |
+
except: # noqa # pylint: disable=bare-except
|
| 41 |
+
BaseStreamer = None
|
| 42 |
+
|
| 43 |
+
from .configuration_internlm2 import InternLM2Config
|
| 44 |
+
|
| 45 |
+
logger = logging.get_logger(__name__)
|
| 46 |
+
|
| 47 |
+
_CONFIG_FOR_DOC = 'InternLM2Config'
|
| 48 |
+
|
| 49 |
+
flash_attn_func, flash_attn_varlen_func = None, None
|
| 50 |
+
pad_input, index_first_axis, unpad_input = None, None, None
|
| 51 |
+
try:
|
| 52 |
+
from flash_attn import flash_attn_func as _flash_attn_func
|
| 53 |
+
from flash_attn import flash_attn_varlen_func as _flash_attn_varlen_func
|
| 54 |
+
from flash_attn.bert_padding import index_first_axis as _index_first_axis
|
| 55 |
+
from flash_attn.bert_padding import pad_input as _pad_input
|
| 56 |
+
from flash_attn.bert_padding import unpad_input as _unpad_input
|
| 57 |
+
|
| 58 |
+
flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
|
| 59 |
+
pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
|
| 60 |
+
has_flash_attn = True
|
| 61 |
+
except:
|
| 62 |
+
has_flash_attn = False
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def _import_flash_attn():
|
| 66 |
+
global flash_attn_func, flash_attn_varlen_func
|
| 67 |
+
global pad_input, index_first_axis, unpad_input
|
| 68 |
+
try:
|
| 69 |
+
from flash_attn import flash_attn_func as _flash_attn_func
|
| 70 |
+
from flash_attn import \
|
| 71 |
+
flash_attn_varlen_func as _flash_attn_varlen_func
|
| 72 |
+
from flash_attn.bert_padding import \
|
| 73 |
+
index_first_axis as _index_first_axis
|
| 74 |
+
from flash_attn.bert_padding import pad_input as _pad_input
|
| 75 |
+
from flash_attn.bert_padding import unpad_input as _unpad_input
|
| 76 |
+
flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
|
| 77 |
+
pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
|
| 78 |
+
except ImportError:
|
| 79 |
+
raise ImportError('flash_attn is not installed.')
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 83 |
+
def _get_unpad_data(attention_mask):
|
| 84 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 85 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 86 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 87 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 88 |
+
return (
|
| 89 |
+
indices,
|
| 90 |
+
cu_seqlens,
|
| 91 |
+
max_seqlen_in_batch,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
|
| 96 |
+
def _make_causal_mask(
|
| 97 |
+
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
|
| 98 |
+
):
|
| 99 |
+
"""
|
| 100 |
+
Make causal mask used for bi-directional self-attention.
|
| 101 |
+
"""
|
| 102 |
+
bsz, tgt_len = input_ids_shape
|
| 103 |
+
mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
|
| 104 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 105 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 106 |
+
mask = mask.to(dtype)
|
| 107 |
+
|
| 108 |
+
if past_key_values_length > 0:
|
| 109 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 110 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 114 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 115 |
+
"""
|
| 116 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 117 |
+
"""
|
| 118 |
+
bsz, src_len = mask.size()
|
| 119 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 120 |
+
|
| 121 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 122 |
+
|
| 123 |
+
inverted_mask = 1.0 - expanded_mask
|
| 124 |
+
|
| 125 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->InternLM2
|
| 129 |
+
class InternLM2RMSNorm(nn.Module):
|
| 130 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 131 |
+
"""
|
| 132 |
+
InternLM2RMSNorm is equivalent to T5LayerNorm
|
| 133 |
+
"""
|
| 134 |
+
super().__init__()
|
| 135 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 136 |
+
self.variance_epsilon = eps
|
| 137 |
+
|
| 138 |
+
def forward(self, hidden_states):
|
| 139 |
+
input_dtype = hidden_states.dtype
|
| 140 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 141 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 142 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 143 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaRotaryEmbedding with Llama->InternLM2
|
| 147 |
+
class InternLM2RotaryEmbedding(nn.Module):
|
| 148 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 149 |
+
super().__init__()
|
| 150 |
+
|
| 151 |
+
self.dim = dim
|
| 152 |
+
self.max_position_embeddings = max_position_embeddings
|
| 153 |
+
self.base = base
|
| 154 |
+
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 155 |
+
self.register_buffer('inv_freq', inv_freq, persistent=False)
|
| 156 |
+
|
| 157 |
+
# Build here to make `torch.jit.trace` work.
|
| 158 |
+
self._set_cos_sin_cache(
|
| 159 |
+
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 163 |
+
self.max_seq_len_cached = seq_len
|
| 164 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 165 |
+
|
| 166 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 167 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 168 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 169 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 170 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 171 |
+
|
| 172 |
+
def forward(self, x, seq_len=None):
|
| 173 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 174 |
+
if seq_len > self.max_seq_len_cached:
|
| 175 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=torch.float32)
|
| 176 |
+
|
| 177 |
+
return (
|
| 178 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 179 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->InternLM2
|
| 184 |
+
class InternLM2LinearScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 185 |
+
"""InternLM2RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 186 |
+
|
| 187 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 188 |
+
self.scaling_factor = scaling_factor
|
| 189 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 190 |
+
|
| 191 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 192 |
+
self.max_seq_len_cached = seq_len
|
| 193 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 194 |
+
t = t / self.scaling_factor
|
| 195 |
+
|
| 196 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 197 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 198 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 199 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 200 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->InternLM2
|
| 204 |
+
class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 205 |
+
"""InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
|
| 206 |
+
Credits to the Reddit users /u/bloc97 and /u/emozilla.
|
| 207 |
+
"""
|
| 208 |
+
|
| 209 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 210 |
+
self.scaling_factor = scaling_factor
|
| 211 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 212 |
+
|
| 213 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 214 |
+
self.max_seq_len_cached = seq_len
|
| 215 |
+
|
| 216 |
+
if seq_len > self.max_position_embeddings:
|
| 217 |
+
base = self.base * (
|
| 218 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 219 |
+
) ** (self.dim / (self.dim - 2))
|
| 220 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 221 |
+
self.register_buffer('inv_freq', inv_freq, persistent=False)
|
| 222 |
+
|
| 223 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 224 |
+
|
| 225 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 226 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 227 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 228 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 229 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
# Copied from transformers.model.llama.modeling_llama.rotate_half
|
| 233 |
+
def rotate_half(x):
|
| 234 |
+
"""Rotates half the hidden dims of the input."""
|
| 235 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 236 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 237 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# Copied from transformers.model.llama.modeling_llama.apply_rotary_pos_emb
|
| 241 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
|
| 242 |
+
"""Applies Rotary Position Embedding to the query and key tensors."""
|
| 243 |
+
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 244 |
+
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 245 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 246 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 247 |
+
return q_embed, k_embed
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
class InternLM2MLP(nn.Module):
|
| 251 |
+
def __init__(self, config):
|
| 252 |
+
super().__init__()
|
| 253 |
+
self.config = config
|
| 254 |
+
self.hidden_size = config.hidden_size
|
| 255 |
+
self.intermediate_size = config.intermediate_size
|
| 256 |
+
self.w1 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 257 |
+
self.w3 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 258 |
+
self.w2 = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 259 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 260 |
+
|
| 261 |
+
def forward(self, x):
|
| 262 |
+
down_proj = self.w2(self.act_fn(self.w1(x)) * self.w3(x))
|
| 263 |
+
|
| 264 |
+
return down_proj
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
# Copied from transformers.model.llama.modeling_llama.repeat_kv
|
| 268 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 269 |
+
"""
|
| 270 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 271 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 272 |
+
"""
|
| 273 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 274 |
+
if n_rep == 1:
|
| 275 |
+
return hidden_states
|
| 276 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 277 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaAttention
|
| 281 |
+
class InternLM2Attention(nn.Module):
|
| 282 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 283 |
+
|
| 284 |
+
def __init__(self, config: InternLM2Config):
|
| 285 |
+
super().__init__()
|
| 286 |
+
self.config = config
|
| 287 |
+
self.hidden_size = config.hidden_size
|
| 288 |
+
self.num_heads = config.num_attention_heads
|
| 289 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 290 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 291 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 292 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 293 |
+
self.is_causal = True
|
| 294 |
+
|
| 295 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 296 |
+
raise ValueError(
|
| 297 |
+
f'hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}'
|
| 298 |
+
f' and `num_heads`: {self.num_heads}).'
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
self.wqkv = nn.Linear(
|
| 302 |
+
self.hidden_size,
|
| 303 |
+
(self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
|
| 304 |
+
bias=config.bias,
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.bias)
|
| 308 |
+
self._init_rope()
|
| 309 |
+
|
| 310 |
+
def _init_rope(self):
|
| 311 |
+
if self.config.rope_scaling is None:
|
| 312 |
+
self.rotary_emb = InternLM2RotaryEmbedding(
|
| 313 |
+
self.head_dim,
|
| 314 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 315 |
+
base=self.config.rope_theta,
|
| 316 |
+
)
|
| 317 |
+
else:
|
| 318 |
+
scaling_type = self.config.rope_scaling['type']
|
| 319 |
+
scaling_factor = self.config.rope_scaling['factor']
|
| 320 |
+
if scaling_type == 'dynamic':
|
| 321 |
+
self.rotary_emb = InternLM2DynamicNTKScalingRotaryEmbedding(
|
| 322 |
+
self.head_dim,
|
| 323 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 324 |
+
base=self.config.rope_theta,
|
| 325 |
+
scaling_factor=scaling_factor,
|
| 326 |
+
)
|
| 327 |
+
elif scaling_type == 'linear':
|
| 328 |
+
self.rotary_emb = InternLM2LinearScalingRotaryEmbedding(
|
| 329 |
+
self.head_dim,
|
| 330 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 331 |
+
base=self.config.rope_theta,
|
| 332 |
+
scaling_factor=scaling_factor,
|
| 333 |
+
)
|
| 334 |
+
else:
|
| 335 |
+
raise ValueError("Currently we only support rotary embedding's type being 'dynamic' or 'linear'.")
|
| 336 |
+
return self.rotary_emb
|
| 337 |
+
|
| 338 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 339 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 340 |
+
|
| 341 |
+
def forward(
|
| 342 |
+
self,
|
| 343 |
+
hidden_states: torch.Tensor,
|
| 344 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 345 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 346 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 347 |
+
output_attentions: bool = False,
|
| 348 |
+
use_cache: bool = False,
|
| 349 |
+
**kwargs,
|
| 350 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 351 |
+
if 'padding_mask' in kwargs:
|
| 352 |
+
warnings.warn(
|
| 353 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 354 |
+
'Please make sure use `attention_mask` instead.`'
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
bsz, q_len, _ = hidden_states.size()
|
| 358 |
+
|
| 359 |
+
qkv_states = self.wqkv(hidden_states)
|
| 360 |
+
|
| 361 |
+
qkv_states = rearrange(
|
| 362 |
+
qkv_states,
|
| 363 |
+
'b q (h gs d) -> b q h gs d',
|
| 364 |
+
gs=2 + self.num_key_value_groups,
|
| 365 |
+
d=self.head_dim,
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 369 |
+
query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
|
| 370 |
+
key_states = qkv_states[..., -2, :]
|
| 371 |
+
value_states = qkv_states[..., -1, :]
|
| 372 |
+
|
| 373 |
+
query_states = query_states.transpose(1, 2)
|
| 374 |
+
key_states = key_states.transpose(1, 2)
|
| 375 |
+
value_states = value_states.transpose(1, 2)
|
| 376 |
+
|
| 377 |
+
kv_seq_len = key_states.shape[-2]
|
| 378 |
+
if past_key_value is not None:
|
| 379 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 380 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 381 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 382 |
+
|
| 383 |
+
if past_key_value is not None:
|
| 384 |
+
# reuse k, v, self_attention
|
| 385 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 386 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 387 |
+
|
| 388 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 389 |
+
|
| 390 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 391 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 392 |
+
|
| 393 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 394 |
+
|
| 395 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 396 |
+
raise ValueError(
|
| 397 |
+
f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
|
| 398 |
+
f' {attn_weights.size()}'
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
if attention_mask is not None:
|
| 402 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 403 |
+
raise ValueError(
|
| 404 |
+
f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
|
| 405 |
+
)
|
| 406 |
+
attn_weights = attn_weights + attention_mask
|
| 407 |
+
|
| 408 |
+
# upcast attention to fp32
|
| 409 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 410 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 411 |
+
|
| 412 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 413 |
+
raise ValueError(
|
| 414 |
+
f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is'
|
| 415 |
+
f' {attn_output.size()}'
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 419 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 420 |
+
|
| 421 |
+
attn_output = self.wo(attn_output)
|
| 422 |
+
|
| 423 |
+
if not output_attentions:
|
| 424 |
+
attn_weights = None
|
| 425 |
+
|
| 426 |
+
return attn_output, attn_weights, past_key_value
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
# Modified from transformers.model.llama.modeling_llama.InternLM2FlashAttention2
|
| 430 |
+
class InternLM2FlashAttention2(InternLM2Attention):
|
| 431 |
+
"""
|
| 432 |
+
InternLM2 flash attention module. This module inherits from `InternLM2Attention` as the weights of the module stays
|
| 433 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 434 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 435 |
+
"""
|
| 436 |
+
|
| 437 |
+
def forward(
|
| 438 |
+
self,
|
| 439 |
+
hidden_states: torch.Tensor,
|
| 440 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 441 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 442 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 443 |
+
output_attentions: bool = False,
|
| 444 |
+
use_cache: bool = False,
|
| 445 |
+
**kwargs,
|
| 446 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 447 |
+
# InternLM2FlashAttention2 attention does not support output_attentions
|
| 448 |
+
if 'padding_mask' in kwargs:
|
| 449 |
+
warnings.warn(
|
| 450 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 451 |
+
'Please make sure use `attention_mask` instead.`'
|
| 452 |
+
)
|
| 453 |
+
|
| 454 |
+
# overwrite attention_mask with padding_mask
|
| 455 |
+
attention_mask = kwargs.pop('padding_mask')
|
| 456 |
+
|
| 457 |
+
output_attentions = False
|
| 458 |
+
|
| 459 |
+
bsz, q_len, _ = hidden_states.size()
|
| 460 |
+
|
| 461 |
+
qkv_states = self.wqkv(hidden_states)
|
| 462 |
+
|
| 463 |
+
qkv_states = rearrange(
|
| 464 |
+
qkv_states,
|
| 465 |
+
'b q (h gs d) -> b q h gs d',
|
| 466 |
+
gs=2 + self.num_key_value_groups,
|
| 467 |
+
d=self.head_dim,
|
| 468 |
+
)
|
| 469 |
+
|
| 470 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 471 |
+
query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
|
| 472 |
+
key_states = qkv_states[..., -2, :]
|
| 473 |
+
value_states = qkv_states[..., -1, :]
|
| 474 |
+
|
| 475 |
+
query_states = query_states.transpose(1, 2)
|
| 476 |
+
key_states = key_states.transpose(1, 2)
|
| 477 |
+
value_states = value_states.transpose(1, 2)
|
| 478 |
+
|
| 479 |
+
kv_seq_len = key_states.shape[-2]
|
| 480 |
+
if past_key_value is not None:
|
| 481 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 482 |
+
|
| 483 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 484 |
+
|
| 485 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 486 |
+
|
| 487 |
+
if past_key_value is not None:
|
| 488 |
+
# reuse k, v, self_attention
|
| 489 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 490 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 491 |
+
|
| 492 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 493 |
+
|
| 494 |
+
query_states = query_states.transpose(1, 2)
|
| 495 |
+
key_states = key_states.transpose(1, 2)
|
| 496 |
+
value_states = value_states.transpose(1, 2)
|
| 497 |
+
|
| 498 |
+
attn_output = self._flash_attention_forward(
|
| 499 |
+
query_states, key_states, value_states, attention_mask, q_len
|
| 500 |
+
)
|
| 501 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 502 |
+
attn_output = self.wo(attn_output)
|
| 503 |
+
|
| 504 |
+
if not output_attentions:
|
| 505 |
+
attn_weights = None
|
| 506 |
+
|
| 507 |
+
return attn_output, attn_weights, past_key_value
|
| 508 |
+
|
| 509 |
+
def _flash_attention_forward(
|
| 510 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 511 |
+
):
|
| 512 |
+
"""
|
| 513 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 514 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 515 |
+
Args:
|
| 516 |
+
query_states (`torch.Tensor`):
|
| 517 |
+
Input query states to be passed to Flash Attention API
|
| 518 |
+
key_states (`torch.Tensor`):
|
| 519 |
+
Input key states to be passed to Flash Attention API
|
| 520 |
+
value_states (`torch.Tensor`):
|
| 521 |
+
Input value states to be passed to Flash Attention API
|
| 522 |
+
attention_mask (`torch.Tensor`):
|
| 523 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 524 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 525 |
+
dropout (`int`, *optional*):
|
| 526 |
+
Attention dropout
|
| 527 |
+
softmax_scale (`float`, *optional*):
|
| 528 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 529 |
+
"""
|
| 530 |
+
# Contains at least one padding token in the sequence
|
| 531 |
+
causal = self.is_causal and query_length != 1
|
| 532 |
+
if attention_mask is not None:
|
| 533 |
+
batch_size = query_states.shape[0]
|
| 534 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._unpad_input(
|
| 535 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 539 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 540 |
+
|
| 541 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 542 |
+
query_states,
|
| 543 |
+
key_states,
|
| 544 |
+
value_states,
|
| 545 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 546 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 547 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 548 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 549 |
+
dropout_p=dropout,
|
| 550 |
+
softmax_scale=softmax_scale,
|
| 551 |
+
causal=causal,
|
| 552 |
+
)
|
| 553 |
+
|
| 554 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 555 |
+
else:
|
| 556 |
+
attn_output = flash_attn_func(
|
| 557 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 558 |
+
)
|
| 559 |
+
|
| 560 |
+
return attn_output
|
| 561 |
+
|
| 562 |
+
def _unpad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 563 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 564 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 565 |
+
|
| 566 |
+
key_layer = index_first_axis(
|
| 567 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 568 |
+
)
|
| 569 |
+
value_layer = index_first_axis(
|
| 570 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 571 |
+
)
|
| 572 |
+
|
| 573 |
+
if query_length == kv_seq_len:
|
| 574 |
+
query_layer = index_first_axis(
|
| 575 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 576 |
+
)
|
| 577 |
+
cu_seqlens_q = cu_seqlens_k
|
| 578 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 579 |
+
indices_q = indices_k
|
| 580 |
+
elif query_length == 1:
|
| 581 |
+
max_seqlen_in_batch_q = 1
|
| 582 |
+
cu_seqlens_q = torch.arange(
|
| 583 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 584 |
+
) # There is a memcpy here, that is very bad.
|
| 585 |
+
indices_q = cu_seqlens_q[:-1]
|
| 586 |
+
query_layer = query_layer.squeeze(1)
|
| 587 |
+
else:
|
| 588 |
+
# The -q_len: slice assumes left padding.
|
| 589 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 590 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 591 |
+
|
| 592 |
+
return (
|
| 593 |
+
query_layer,
|
| 594 |
+
key_layer,
|
| 595 |
+
value_layer,
|
| 596 |
+
indices_q.to(torch.int64),
|
| 597 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 598 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
INTERNLM2_ATTENTION_CLASSES = {
|
| 603 |
+
'eager': InternLM2Attention,
|
| 604 |
+
'flash_attention_2': InternLM2FlashAttention2,
|
| 605 |
+
}
|
| 606 |
+
|
| 607 |
+
|
| 608 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaDecoderLayer
|
| 609 |
+
class InternLM2DecoderLayer(nn.Module):
|
| 610 |
+
def __init__(self, config: InternLM2Config):
|
| 611 |
+
super().__init__()
|
| 612 |
+
self.hidden_size = config.hidden_size
|
| 613 |
+
|
| 614 |
+
self.attention = INTERNLM2_ATTENTION_CLASSES[config.attn_implementation](config=config)
|
| 615 |
+
|
| 616 |
+
self.feed_forward = InternLM2MLP(config)
|
| 617 |
+
self.attention_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 618 |
+
self.ffn_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 619 |
+
|
| 620 |
+
def forward(
|
| 621 |
+
self,
|
| 622 |
+
hidden_states: torch.Tensor,
|
| 623 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 624 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 625 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 626 |
+
output_attentions: Optional[bool] = False,
|
| 627 |
+
use_cache: Optional[bool] = False,
|
| 628 |
+
**kwargs,
|
| 629 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 630 |
+
"""
|
| 631 |
+
Args:
|
| 632 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 633 |
+
attention_mask (`torch.FloatTensor`, *optional*):
|
| 634 |
+
attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
|
| 635 |
+
query_sequence_length, key_sequence_length)` if default attention is used.
|
| 636 |
+
output_attentions (`bool`, *optional*):
|
| 637 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 638 |
+
returned tensors for more detail.
|
| 639 |
+
use_cache (`bool`, *optional*):
|
| 640 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 641 |
+
(see `past_key_values`).
|
| 642 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 643 |
+
"""
|
| 644 |
+
if 'padding_mask' in kwargs:
|
| 645 |
+
warnings.warn(
|
| 646 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 647 |
+
'Please make sure use `attention_mask` instead.`'
|
| 648 |
+
)
|
| 649 |
+
|
| 650 |
+
residual = hidden_states
|
| 651 |
+
|
| 652 |
+
hidden_states = self.attention_norm(hidden_states)
|
| 653 |
+
|
| 654 |
+
# Self Attention
|
| 655 |
+
hidden_states, self_attn_weights, present_key_value = self.attention(
|
| 656 |
+
hidden_states=hidden_states,
|
| 657 |
+
attention_mask=attention_mask,
|
| 658 |
+
position_ids=position_ids,
|
| 659 |
+
past_key_value=past_key_value,
|
| 660 |
+
output_attentions=output_attentions,
|
| 661 |
+
use_cache=use_cache,
|
| 662 |
+
**kwargs,
|
| 663 |
+
)
|
| 664 |
+
hidden_states = residual + hidden_states
|
| 665 |
+
|
| 666 |
+
# Fully Connected
|
| 667 |
+
residual = hidden_states
|
| 668 |
+
hidden_states = self.ffn_norm(hidden_states)
|
| 669 |
+
hidden_states = self.feed_forward(hidden_states)
|
| 670 |
+
hidden_states = residual + hidden_states
|
| 671 |
+
|
| 672 |
+
outputs = (hidden_states,)
|
| 673 |
+
|
| 674 |
+
if output_attentions:
|
| 675 |
+
outputs += (self_attn_weights,)
|
| 676 |
+
|
| 677 |
+
if use_cache:
|
| 678 |
+
outputs += (present_key_value,)
|
| 679 |
+
|
| 680 |
+
return outputs
|
| 681 |
+
|
| 682 |
+
|
| 683 |
+
InternLM2_START_DOCSTRING = r"""
|
| 684 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 685 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 686 |
+
etc.)
|
| 687 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 688 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 689 |
+
and behavior.
|
| 690 |
+
Parameters:
|
| 691 |
+
config ([`InternLM2Config`]):
|
| 692 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 693 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 694 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 695 |
+
"""
|
| 696 |
+
|
| 697 |
+
|
| 698 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaPreTrainedModel with Llama->InternLM2
|
| 699 |
+
@add_start_docstrings(
|
| 700 |
+
'The bare InternLM2 Model outputting raw hidden-states without any specific head on top.',
|
| 701 |
+
InternLM2_START_DOCSTRING,
|
| 702 |
+
)
|
| 703 |
+
class InternLM2PreTrainedModel(PreTrainedModel):
|
| 704 |
+
config_class = InternLM2Config
|
| 705 |
+
base_model_prefix = 'model'
|
| 706 |
+
supports_gradient_checkpointing = True
|
| 707 |
+
_no_split_modules = ['InternLM2DecoderLayer']
|
| 708 |
+
_skip_keys_device_placement = 'past_key_values'
|
| 709 |
+
_supports_flash_attn_2 = True
|
| 710 |
+
|
| 711 |
+
def _init_weights(self, module):
|
| 712 |
+
std = self.config.initializer_range
|
| 713 |
+
if isinstance(module, nn.Linear):
|
| 714 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 715 |
+
if module.bias is not None:
|
| 716 |
+
module.bias.data.zero_()
|
| 717 |
+
elif isinstance(module, nn.Embedding):
|
| 718 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 719 |
+
if module.padding_idx is not None:
|
| 720 |
+
module.weight.data[module.padding_idx].zero_()
|
| 721 |
+
|
| 722 |
+
|
| 723 |
+
InternLM2_INPUTS_DOCSTRING = r"""
|
| 724 |
+
Args:
|
| 725 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 726 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 727 |
+
it.
|
| 728 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 729 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 730 |
+
[What are input IDs?](../glossary#input-ids)
|
| 731 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 732 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 733 |
+
- 1 for tokens that are **not masked**,
|
| 734 |
+
- 0 for tokens that are **masked**.
|
| 735 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 736 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 737 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 738 |
+
If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
|
| 739 |
+
`past_key_values`).
|
| 740 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 741 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 742 |
+
information on the default strategy.
|
| 743 |
+
- 1 indicates the head is **not masked**,
|
| 744 |
+
- 0 indicates the head is **masked**.
|
| 745 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 746 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 747 |
+
config.n_positions - 1]`.
|
| 748 |
+
[What are position IDs?](../glossary#position-ids)
|
| 749 |
+
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
|
| 750 |
+
when `config.use_cache=True`):
|
| 751 |
+
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
| 752 |
+
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
|
| 753 |
+
`(batch_size, num_heads, decoder_sequence_length, embed_size_per_head)`.
|
| 754 |
+
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 755 |
+
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
|
| 756 |
+
If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
|
| 757 |
+
have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
|
| 758 |
+
of shape `(batch_size, sequence_length)`.
|
| 759 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 760 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 761 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 762 |
+
model's internal embedding lookup matrix.
|
| 763 |
+
use_cache (`bool`, *optional*):
|
| 764 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 765 |
+
`past_key_values`).
|
| 766 |
+
output_attentions (`bool`, *optional*):
|
| 767 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 768 |
+
tensors for more detail.
|
| 769 |
+
output_hidden_states (`bool`, *optional*):
|
| 770 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 771 |
+
more detail.
|
| 772 |
+
return_dict (`bool`, *optional*):
|
| 773 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 774 |
+
"""
|
| 775 |
+
|
| 776 |
+
|
| 777 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaModel
|
| 778 |
+
@add_start_docstrings(
|
| 779 |
+
'The bare InternLM2 Model outputting raw hidden-states without any specific head on top.',
|
| 780 |
+
InternLM2_START_DOCSTRING,
|
| 781 |
+
)
|
| 782 |
+
class InternLM2Model(InternLM2PreTrainedModel):
|
| 783 |
+
"""
|
| 784 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`InternLM2DecoderLayer`]
|
| 785 |
+
Args:
|
| 786 |
+
config: InternLM2Config
|
| 787 |
+
"""
|
| 788 |
+
|
| 789 |
+
_auto_class = 'AutoModel'
|
| 790 |
+
|
| 791 |
+
def __init__(self, config: InternLM2Config):
|
| 792 |
+
super().__init__(config)
|
| 793 |
+
self.padding_idx = config.pad_token_id
|
| 794 |
+
self.vocab_size = config.vocab_size
|
| 795 |
+
self.config = config
|
| 796 |
+
if not has_flash_attn:
|
| 797 |
+
self.config.attn_implementation = 'eager'
|
| 798 |
+
print('Warning: Flash attention is not available, using eager attention instead.')
|
| 799 |
+
|
| 800 |
+
self.tok_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 801 |
+
|
| 802 |
+
self.layers = nn.ModuleList([InternLM2DecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 803 |
+
self.norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 804 |
+
|
| 805 |
+
self.gradient_checkpointing = False
|
| 806 |
+
# Initialize weights and apply final processing
|
| 807 |
+
self.post_init()
|
| 808 |
+
|
| 809 |
+
def get_input_embeddings(self):
|
| 810 |
+
return self.tok_embeddings
|
| 811 |
+
|
| 812 |
+
def set_input_embeddings(self, value):
|
| 813 |
+
self.tok_embeddings = value
|
| 814 |
+
|
| 815 |
+
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
|
| 816 |
+
# create causal mask
|
| 817 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 818 |
+
combined_attention_mask = None
|
| 819 |
+
if input_shape[-1] > 1:
|
| 820 |
+
combined_attention_mask = _make_causal_mask(
|
| 821 |
+
input_shape,
|
| 822 |
+
inputs_embeds.dtype,
|
| 823 |
+
device=inputs_embeds.device,
|
| 824 |
+
past_key_values_length=past_key_values_length,
|
| 825 |
+
)
|
| 826 |
+
|
| 827 |
+
if attention_mask is not None:
|
| 828 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 829 |
+
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
|
| 830 |
+
inputs_embeds.device
|
| 831 |
+
)
|
| 832 |
+
combined_attention_mask = (
|
| 833 |
+
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
|
| 834 |
+
)
|
| 835 |
+
|
| 836 |
+
return combined_attention_mask
|
| 837 |
+
|
| 838 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 839 |
+
def forward(
|
| 840 |
+
self,
|
| 841 |
+
input_ids: torch.LongTensor = None,
|
| 842 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 843 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 844 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 845 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 846 |
+
use_cache: Optional[bool] = None,
|
| 847 |
+
output_attentions: Optional[bool] = None,
|
| 848 |
+
output_hidden_states: Optional[bool] = None,
|
| 849 |
+
return_dict: Optional[bool] = None,
|
| 850 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 851 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 852 |
+
output_hidden_states = (
|
| 853 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 854 |
+
)
|
| 855 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 856 |
+
|
| 857 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 858 |
+
|
| 859 |
+
if self.config.attn_implementation == 'flash_attention_2':
|
| 860 |
+
_import_flash_attn()
|
| 861 |
+
|
| 862 |
+
# retrieve input_ids and inputs_embeds
|
| 863 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 864 |
+
raise ValueError('You cannot specify both input_ids and inputs_embeds at the same time')
|
| 865 |
+
elif input_ids is not None:
|
| 866 |
+
batch_size, seq_length = input_ids.shape[:2]
|
| 867 |
+
elif inputs_embeds is not None:
|
| 868 |
+
batch_size, seq_length = inputs_embeds.shape[:2]
|
| 869 |
+
else:
|
| 870 |
+
raise ValueError('You have to specify either input_ids or inputs_embeds')
|
| 871 |
+
|
| 872 |
+
seq_length_with_past = seq_length
|
| 873 |
+
past_key_values_length = 0
|
| 874 |
+
if past_key_values is not None:
|
| 875 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 876 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 877 |
+
|
| 878 |
+
if position_ids is None:
|
| 879 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 880 |
+
position_ids = torch.arange(
|
| 881 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 882 |
+
)
|
| 883 |
+
position_ids = position_ids.unsqueeze(0)
|
| 884 |
+
|
| 885 |
+
if inputs_embeds is None:
|
| 886 |
+
inputs_embeds = self.tok_embeddings(input_ids)
|
| 887 |
+
|
| 888 |
+
if self.config.attn_implementation == 'flash_attention_2':
|
| 889 |
+
# 2d mask is passed through the layers
|
| 890 |
+
attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
|
| 891 |
+
else:
|
| 892 |
+
if attention_mask is None:
|
| 893 |
+
attention_mask = torch.ones(
|
| 894 |
+
(batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
|
| 895 |
+
)
|
| 896 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 897 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 898 |
+
)
|
| 899 |
+
|
| 900 |
+
# embed positions
|
| 901 |
+
hidden_states = inputs_embeds
|
| 902 |
+
|
| 903 |
+
if self.gradient_checkpointing and self.training:
|
| 904 |
+
if use_cache:
|
| 905 |
+
logger.warning_once(
|
| 906 |
+
'`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
|
| 907 |
+
)
|
| 908 |
+
use_cache = False
|
| 909 |
+
|
| 910 |
+
# decoder layers
|
| 911 |
+
all_hidden_states = () if output_hidden_states else None
|
| 912 |
+
all_self_attns = () if output_attentions else None
|
| 913 |
+
next_decoder_cache = () if use_cache else None
|
| 914 |
+
|
| 915 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 916 |
+
if output_hidden_states:
|
| 917 |
+
all_hidden_states += (hidden_states,)
|
| 918 |
+
|
| 919 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 920 |
+
|
| 921 |
+
if self.gradient_checkpointing and self.training:
|
| 922 |
+
|
| 923 |
+
def create_custom_forward(module):
|
| 924 |
+
def custom_forward(*inputs):
|
| 925 |
+
# None for past_key_value
|
| 926 |
+
return module(*inputs, output_attentions, None)
|
| 927 |
+
|
| 928 |
+
return custom_forward
|
| 929 |
+
|
| 930 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 931 |
+
create_custom_forward(decoder_layer),
|
| 932 |
+
hidden_states,
|
| 933 |
+
attention_mask,
|
| 934 |
+
position_ids,
|
| 935 |
+
None,
|
| 936 |
+
)
|
| 937 |
+
else:
|
| 938 |
+
layer_outputs = decoder_layer(
|
| 939 |
+
hidden_states,
|
| 940 |
+
attention_mask=attention_mask,
|
| 941 |
+
position_ids=position_ids,
|
| 942 |
+
past_key_value=past_key_value,
|
| 943 |
+
output_attentions=output_attentions,
|
| 944 |
+
use_cache=use_cache,
|
| 945 |
+
)
|
| 946 |
+
|
| 947 |
+
hidden_states = layer_outputs[0]
|
| 948 |
+
|
| 949 |
+
if use_cache:
|
| 950 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 951 |
+
|
| 952 |
+
if output_attentions:
|
| 953 |
+
all_self_attns += (layer_outputs[1],)
|
| 954 |
+
|
| 955 |
+
hidden_states = self.norm(hidden_states)
|
| 956 |
+
|
| 957 |
+
# add hidden states from the last decoder layer
|
| 958 |
+
if output_hidden_states:
|
| 959 |
+
all_hidden_states += (hidden_states,)
|
| 960 |
+
|
| 961 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 962 |
+
if not return_dict:
|
| 963 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 964 |
+
return BaseModelOutputWithPast(
|
| 965 |
+
last_hidden_state=hidden_states,
|
| 966 |
+
past_key_values=next_cache,
|
| 967 |
+
hidden_states=all_hidden_states,
|
| 968 |
+
attentions=all_self_attns,
|
| 969 |
+
)
|
| 970 |
+
|
| 971 |
+
|
| 972 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
|
| 973 |
+
class InternLM2ForCausalLM(InternLM2PreTrainedModel):
|
| 974 |
+
_auto_class = 'AutoModelForCausalLM'
|
| 975 |
+
|
| 976 |
+
_tied_weights_keys = ['output.weight']
|
| 977 |
+
|
| 978 |
+
def __init__(self, config):
|
| 979 |
+
super().__init__(config)
|
| 980 |
+
self.model = InternLM2Model(config)
|
| 981 |
+
self.vocab_size = config.vocab_size
|
| 982 |
+
self.output = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 983 |
+
|
| 984 |
+
# Initialize weights and apply final processing
|
| 985 |
+
self.post_init()
|
| 986 |
+
|
| 987 |
+
def get_input_embeddings(self):
|
| 988 |
+
return self.model.tok_embeddings
|
| 989 |
+
|
| 990 |
+
def set_input_embeddings(self, value):
|
| 991 |
+
self.model.tok_embeddings = value
|
| 992 |
+
|
| 993 |
+
def get_output_embeddings(self):
|
| 994 |
+
return self.output
|
| 995 |
+
|
| 996 |
+
def set_output_embeddings(self, new_embeddings):
|
| 997 |
+
self.output = new_embeddings
|
| 998 |
+
|
| 999 |
+
def set_decoder(self, decoder):
|
| 1000 |
+
self.model = decoder
|
| 1001 |
+
|
| 1002 |
+
def get_decoder(self):
|
| 1003 |
+
return self.model
|
| 1004 |
+
|
| 1005 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 1006 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 1007 |
+
def forward(
|
| 1008 |
+
self,
|
| 1009 |
+
input_ids: torch.LongTensor = None,
|
| 1010 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1011 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1012 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1013 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1014 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1015 |
+
use_cache: Optional[bool] = None,
|
| 1016 |
+
output_attentions: Optional[bool] = None,
|
| 1017 |
+
output_hidden_states: Optional[bool] = None,
|
| 1018 |
+
return_dict: Optional[bool] = None,
|
| 1019 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1020 |
+
r"""
|
| 1021 |
+
Args:
|
| 1022 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1023 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 1024 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 1025 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 1026 |
+
Returns:
|
| 1027 |
+
Example:
|
| 1028 |
+
```python
|
| 1029 |
+
>>> from transformers import AutoTokenizer, InternLM2ForCausalLM
|
| 1030 |
+
>>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 1031 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 1032 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 1033 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 1034 |
+
>>> # Generate
|
| 1035 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 1036 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 1037 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 1038 |
+
```"""
|
| 1039 |
+
|
| 1040 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1041 |
+
output_hidden_states = (
|
| 1042 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1043 |
+
)
|
| 1044 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1045 |
+
|
| 1046 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 1047 |
+
outputs = self.model(
|
| 1048 |
+
input_ids=input_ids,
|
| 1049 |
+
attention_mask=attention_mask,
|
| 1050 |
+
position_ids=position_ids,
|
| 1051 |
+
past_key_values=past_key_values,
|
| 1052 |
+
inputs_embeds=inputs_embeds,
|
| 1053 |
+
use_cache=use_cache,
|
| 1054 |
+
output_attentions=output_attentions,
|
| 1055 |
+
output_hidden_states=output_hidden_states,
|
| 1056 |
+
return_dict=return_dict,
|
| 1057 |
+
)
|
| 1058 |
+
|
| 1059 |
+
hidden_states = outputs[0]
|
| 1060 |
+
logits = self.output(hidden_states)
|
| 1061 |
+
logits = logits.float()
|
| 1062 |
+
|
| 1063 |
+
loss = None
|
| 1064 |
+
if labels is not None:
|
| 1065 |
+
# Shift so that tokens < n predict n
|
| 1066 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 1067 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1068 |
+
# Flatten the tokens
|
| 1069 |
+
loss_fct = CrossEntropyLoss()
|
| 1070 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 1071 |
+
shift_labels = shift_labels.view(-1)
|
| 1072 |
+
# Enable model parallelism
|
| 1073 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 1074 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 1075 |
+
|
| 1076 |
+
if not return_dict:
|
| 1077 |
+
output = (logits,) + outputs[1:]
|
| 1078 |
+
return (loss,) + output if loss is not None else output
|
| 1079 |
+
|
| 1080 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 1081 |
+
output = CausalLMOutputWithPast(
|
| 1082 |
+
loss=loss,
|
| 1083 |
+
logits=logits,
|
| 1084 |
+
past_key_values=outputs.past_key_values,
|
| 1085 |
+
hidden_states=outputs.hidden_states,
|
| 1086 |
+
attentions=outputs.attentions,
|
| 1087 |
+
)
|
| 1088 |
+
output['logits'] = output['logits'].to(device)
|
| 1089 |
+
return output
|
| 1090 |
+
|
| 1091 |
+
def prepare_inputs_for_generation(
|
| 1092 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 1093 |
+
):
|
| 1094 |
+
if past_key_values is not None:
|
| 1095 |
+
past_length = past_key_values[0][0].shape[2]
|
| 1096 |
+
|
| 1097 |
+
# Some generation methods already pass only the last input ID
|
| 1098 |
+
if input_ids.shape[1] > past_length:
|
| 1099 |
+
remove_prefix_length = past_length
|
| 1100 |
+
else:
|
| 1101 |
+
# Default to old behavior: keep only final ID
|
| 1102 |
+
remove_prefix_length = input_ids.shape[1] - 1
|
| 1103 |
+
|
| 1104 |
+
input_ids = input_ids[:, remove_prefix_length:]
|
| 1105 |
+
|
| 1106 |
+
position_ids = kwargs.get('position_ids', None)
|
| 1107 |
+
if attention_mask is not None and position_ids is None:
|
| 1108 |
+
# create position_ids on the fly for batch generation
|
| 1109 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1110 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1111 |
+
if past_key_values:
|
| 1112 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 1113 |
+
|
| 1114 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1115 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1116 |
+
model_inputs = {'inputs_embeds': inputs_embeds}
|
| 1117 |
+
else:
|
| 1118 |
+
model_inputs = {'input_ids': input_ids}
|
| 1119 |
+
|
| 1120 |
+
model_inputs.update(
|
| 1121 |
+
{
|
| 1122 |
+
'position_ids': position_ids,
|
| 1123 |
+
'past_key_values': past_key_values,
|
| 1124 |
+
'use_cache': kwargs.get('use_cache'),
|
| 1125 |
+
'attention_mask': attention_mask,
|
| 1126 |
+
}
|
| 1127 |
+
)
|
| 1128 |
+
return model_inputs
|
| 1129 |
+
|
| 1130 |
+
@staticmethod
|
| 1131 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 1132 |
+
reordered_past = ()
|
| 1133 |
+
for layer_past in past_key_values:
|
| 1134 |
+
reordered_past += (
|
| 1135 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 1136 |
+
)
|
| 1137 |
+
return reordered_past
|
| 1138 |
+
|
| 1139 |
+
def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = [], meta_instruction=''):
|
| 1140 |
+
if tokenizer.add_bos_token:
|
| 1141 |
+
prompt = ''
|
| 1142 |
+
else:
|
| 1143 |
+
prompt = tokenizer.bos_token
|
| 1144 |
+
if meta_instruction:
|
| 1145 |
+
prompt += f"""<|im_start|>system\n{meta_instruction}<|im_end|>\n"""
|
| 1146 |
+
for record in history:
|
| 1147 |
+
prompt += f"""<|im_start|>user\n{record[0]}<|im_end|>\n<|im_start|>assistant\n{record[1]}<|im_end|>\n"""
|
| 1148 |
+
prompt += f"""<|im_start|>user\n{query}<|im_end|>\n<|im_start|>assistant\n"""
|
| 1149 |
+
return tokenizer([prompt], return_tensors='pt')
|
| 1150 |
+
|
| 1151 |
+
@torch.no_grad()
|
| 1152 |
+
def chat(
|
| 1153 |
+
self,
|
| 1154 |
+
tokenizer,
|
| 1155 |
+
query: str,
|
| 1156 |
+
history: List[Tuple[str, str]] = [],
|
| 1157 |
+
streamer: Optional[BaseStreamer] = None,
|
| 1158 |
+
max_new_tokens: int = 1024,
|
| 1159 |
+
do_sample: bool = True,
|
| 1160 |
+
temperature: float = 0.8,
|
| 1161 |
+
top_p: float = 0.8,
|
| 1162 |
+
meta_instruction: str = 'You are an AI assistant whose name is InternLM (书生·浦语).\n'
|
| 1163 |
+
'- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.\n'
|
| 1164 |
+
'- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.',
|
| 1165 |
+
**kwargs,
|
| 1166 |
+
):
|
| 1167 |
+
inputs = self.build_inputs(tokenizer, query, history, meta_instruction)
|
| 1168 |
+
inputs = {k: v.to(self.device) for k, v in inputs.items() if torch.is_tensor(v)}
|
| 1169 |
+
# also add end-of-assistant token in eos token id to avoid unnecessary generation
|
| 1170 |
+
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(['<|im_end|>'])[0]]
|
| 1171 |
+
outputs = self.generate(
|
| 1172 |
+
**inputs,
|
| 1173 |
+
streamer=streamer,
|
| 1174 |
+
max_new_tokens=max_new_tokens,
|
| 1175 |
+
do_sample=do_sample,
|
| 1176 |
+
temperature=temperature,
|
| 1177 |
+
top_p=top_p,
|
| 1178 |
+
eos_token_id=eos_token_id,
|
| 1179 |
+
**kwargs,
|
| 1180 |
+
)
|
| 1181 |
+
outputs = outputs[0].cpu().tolist()[len(inputs['input_ids'][0]) :]
|
| 1182 |
+
response = tokenizer.decode(outputs, skip_special_tokens=True)
|
| 1183 |
+
response = response.split('<|im_end|>')[0]
|
| 1184 |
+
history = history + [(query, response)]
|
| 1185 |
+
return response, history
|
| 1186 |
+
|
| 1187 |
+
@torch.no_grad()
|
| 1188 |
+
def stream_chat(
|
| 1189 |
+
self,
|
| 1190 |
+
tokenizer,
|
| 1191 |
+
query: str,
|
| 1192 |
+
history: List[Tuple[str, str]] = [],
|
| 1193 |
+
max_new_tokens: int = 1024,
|
| 1194 |
+
do_sample: bool = True,
|
| 1195 |
+
temperature: float = 0.8,
|
| 1196 |
+
top_p: float = 0.8,
|
| 1197 |
+
**kwargs,
|
| 1198 |
+
):
|
| 1199 |
+
"""
|
| 1200 |
+
Return a generator in format: (response, history)
|
| 1201 |
+
Eg.
|
| 1202 |
+
('你好,有什么可以帮助您的吗', [('你好', '你好,有什么可以帮助您的吗')])
|
| 1203 |
+
('你好,有什么可以帮助您的吗?', [('你好', '你好,有什么可以帮助您的吗?')])
|
| 1204 |
+
"""
|
| 1205 |
+
if BaseStreamer is None:
|
| 1206 |
+
raise ModuleNotFoundError(
|
| 1207 |
+
'The version of `transformers` is too low. Please make sure '
|
| 1208 |
+
'that you have installed `transformers>=4.28.0`.'
|
| 1209 |
+
)
|
| 1210 |
+
|
| 1211 |
+
response_queue = queue.Queue(maxsize=20)
|
| 1212 |
+
|
| 1213 |
+
class ChatStreamer(BaseStreamer):
|
| 1214 |
+
def __init__(self, tokenizer) -> None:
|
| 1215 |
+
super().__init__()
|
| 1216 |
+
self.tokenizer = tokenizer
|
| 1217 |
+
self.queue = response_queue
|
| 1218 |
+
self.query = query
|
| 1219 |
+
self.history = history
|
| 1220 |
+
self.response = ''
|
| 1221 |
+
self.cache = []
|
| 1222 |
+
self.received_inputs = False
|
| 1223 |
+
self.queue.put((self.response, history + [(self.query, self.response)]))
|
| 1224 |
+
|
| 1225 |
+
def put(self, value):
|
| 1226 |
+
if len(value.shape) > 1 and value.shape[0] > 1:
|
| 1227 |
+
raise ValueError('ChatStreamer only supports batch size 1')
|
| 1228 |
+
elif len(value.shape) > 1:
|
| 1229 |
+
value = value[0]
|
| 1230 |
+
|
| 1231 |
+
if not self.received_inputs:
|
| 1232 |
+
# The first received value is input_ids, ignore here
|
| 1233 |
+
self.received_inputs = True
|
| 1234 |
+
return
|
| 1235 |
+
|
| 1236 |
+
self.cache.extend(value.tolist())
|
| 1237 |
+
token = self.tokenizer.decode(self.cache, skip_special_tokens=True)
|
| 1238 |
+
if token.strip() != '<|im_end|>':
|
| 1239 |
+
self.response = self.response + token
|
| 1240 |
+
history = self.history + [(self.query, self.response)]
|
| 1241 |
+
self.queue.put((self.response, history))
|
| 1242 |
+
self.cache = []
|
| 1243 |
+
else:
|
| 1244 |
+
self.end()
|
| 1245 |
+
|
| 1246 |
+
def end(self):
|
| 1247 |
+
self.queue.put(None)
|
| 1248 |
+
|
| 1249 |
+
def stream_producer():
|
| 1250 |
+
return self.chat(
|
| 1251 |
+
tokenizer=tokenizer,
|
| 1252 |
+
query=query,
|
| 1253 |
+
streamer=ChatStreamer(tokenizer=tokenizer),
|
| 1254 |
+
history=history,
|
| 1255 |
+
max_new_tokens=max_new_tokens,
|
| 1256 |
+
do_sample=do_sample,
|
| 1257 |
+
temperature=temperature,
|
| 1258 |
+
top_p=top_p,
|
| 1259 |
+
**kwargs,
|
| 1260 |
+
)
|
| 1261 |
+
|
| 1262 |
+
def consumer():
|
| 1263 |
+
producer = threading.Thread(target=stream_producer)
|
| 1264 |
+
producer.start()
|
| 1265 |
+
while True:
|
| 1266 |
+
res = response_queue.get()
|
| 1267 |
+
if res is None:
|
| 1268 |
+
return
|
| 1269 |
+
yield res
|
| 1270 |
+
|
| 1271 |
+
return consumer()
|
| 1272 |
+
|
| 1273 |
+
|
| 1274 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaForSequenceClassification with Llama->InternLM2
|
| 1275 |
+
@add_start_docstrings(
|
| 1276 |
+
"""
|
| 1277 |
+
The InternLM2 Model transformer with a sequence classification head on top (linear layer).
|
| 1278 |
+
[`InternLM2ForSequenceClassification`] uses the last token in order to do the classification,
|
| 1279 |
+
as other causal models (e.g. GPT-2) do.
|
| 1280 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1281 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1282 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1283 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1284 |
+
each row of the batch).
|
| 1285 |
+
""",
|
| 1286 |
+
InternLM2_START_DOCSTRING,
|
| 1287 |
+
)
|
| 1288 |
+
class InternLM2ForSequenceClassification(InternLM2PreTrainedModel):
|
| 1289 |
+
def __init__(self, config):
|
| 1290 |
+
super().__init__(config)
|
| 1291 |
+
self.num_labels = config.num_labels
|
| 1292 |
+
self.model = InternLM2Model(config)
|
| 1293 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1294 |
+
|
| 1295 |
+
# Initialize weights and apply final processing
|
| 1296 |
+
self.post_init()
|
| 1297 |
+
|
| 1298 |
+
def get_input_embeddings(self):
|
| 1299 |
+
return self.model.tok_embeddings
|
| 1300 |
+
|
| 1301 |
+
def set_input_embeddings(self, value):
|
| 1302 |
+
self.model.tok_embeddings = value
|
| 1303 |
+
|
| 1304 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 1305 |
+
def forward(
|
| 1306 |
+
self,
|
| 1307 |
+
input_ids: torch.LongTensor = None,
|
| 1308 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1309 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1310 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1311 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1312 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1313 |
+
use_cache: Optional[bool] = None,
|
| 1314 |
+
output_attentions: Optional[bool] = None,
|
| 1315 |
+
output_hidden_states: Optional[bool] = None,
|
| 1316 |
+
return_dict: Optional[bool] = None,
|
| 1317 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1318 |
+
r"""
|
| 1319 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1320 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1321 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1322 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1323 |
+
"""
|
| 1324 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1325 |
+
|
| 1326 |
+
transformer_outputs = self.model(
|
| 1327 |
+
input_ids,
|
| 1328 |
+
attention_mask=attention_mask,
|
| 1329 |
+
position_ids=position_ids,
|
| 1330 |
+
past_key_values=past_key_values,
|
| 1331 |
+
inputs_embeds=inputs_embeds,
|
| 1332 |
+
use_cache=use_cache,
|
| 1333 |
+
output_attentions=output_attentions,
|
| 1334 |
+
output_hidden_states=output_hidden_states,
|
| 1335 |
+
return_dict=return_dict,
|
| 1336 |
+
)
|
| 1337 |
+
hidden_states = transformer_outputs[0]
|
| 1338 |
+
logits = self.score(hidden_states)
|
| 1339 |
+
|
| 1340 |
+
if input_ids is not None:
|
| 1341 |
+
batch_size = input_ids.shape[0]
|
| 1342 |
+
else:
|
| 1343 |
+
batch_size = inputs_embeds.shape[0]
|
| 1344 |
+
|
| 1345 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1346 |
+
raise ValueError('Cannot handle batch sizes > 1 if no padding token is defined.')
|
| 1347 |
+
if self.config.pad_token_id is None:
|
| 1348 |
+
sequence_lengths = -1
|
| 1349 |
+
else:
|
| 1350 |
+
if input_ids is not None:
|
| 1351 |
+
sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1).to(
|
| 1352 |
+
logits.device
|
| 1353 |
+
)
|
| 1354 |
+
else:
|
| 1355 |
+
sequence_lengths = -1
|
| 1356 |
+
|
| 1357 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1358 |
+
|
| 1359 |
+
loss = None
|
| 1360 |
+
if labels is not None:
|
| 1361 |
+
labels = labels.to(logits.device)
|
| 1362 |
+
if self.config.problem_type is None:
|
| 1363 |
+
if self.num_labels == 1:
|
| 1364 |
+
self.config.problem_type = 'regression'
|
| 1365 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1366 |
+
self.config.problem_type = 'single_label_classification'
|
| 1367 |
+
else:
|
| 1368 |
+
self.config.problem_type = 'multi_label_classification'
|
| 1369 |
+
|
| 1370 |
+
if self.config.problem_type == 'regression':
|
| 1371 |
+
loss_fct = MSELoss()
|
| 1372 |
+
if self.num_labels == 1:
|
| 1373 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1374 |
+
else:
|
| 1375 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1376 |
+
elif self.config.problem_type == 'single_label_classification':
|
| 1377 |
+
loss_fct = CrossEntropyLoss()
|
| 1378 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1379 |
+
elif self.config.problem_type == 'multi_label_classification':
|
| 1380 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1381 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1382 |
+
if not return_dict:
|
| 1383 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1384 |
+
return ((loss,) + output) if loss is not None else output
|
| 1385 |
+
|
| 1386 |
+
return SequenceClassifierOutputWithPast(
|
| 1387 |
+
loss=loss,
|
| 1388 |
+
logits=pooled_logits,
|
| 1389 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1390 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1391 |
+
attentions=transformer_outputs.attentions,
|
| 1392 |
+
)
|
modeling_internvl_chat.py
ADDED
|
@@ -0,0 +1,450 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
import warnings
|
| 7 |
+
from dataclasses import dataclass
|
| 8 |
+
from typing import Any, List, Optional, Tuple, Union
|
| 9 |
+
from copy import deepcopy
|
| 10 |
+
|
| 11 |
+
import torch.distributed as dist
|
| 12 |
+
import torch.utils.checkpoint
|
| 13 |
+
import torch.nn as nn
|
| 14 |
+
import transformers
|
| 15 |
+
|
| 16 |
+
from peft import LoraConfig, get_peft_model
|
| 17 |
+
from torch import nn
|
| 18 |
+
from torch.nn import CrossEntropyLoss
|
| 19 |
+
from transformers import (AutoModel, GenerationConfig, LlamaForCausalLM,
|
| 20 |
+
LlamaTokenizer, Qwen2ForCausalLM)
|
| 21 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 22 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 23 |
+
from transformers.utils import ModelOutput, logging
|
| 24 |
+
from transformers.trainer_pt_utils import LabelSmoother
|
| 25 |
+
IGNORE_TOKEN_ID = LabelSmoother.ignore_index
|
| 26 |
+
|
| 27 |
+
from .configuration_internvl_chat import InternVLChatConfig
|
| 28 |
+
from .conversation import get_conv_template
|
| 29 |
+
from .modeling_internlm2 import InternLM2ForCausalLM
|
| 30 |
+
from .modeling_holistic_embedding import (HolisticEmbedding,
|
| 31 |
+
HolisticEmbeddingConfig)
|
| 32 |
+
|
| 33 |
+
logger = logging.get_logger(__name__)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def version_cmp(v1, v2, op='eq'):
|
| 37 |
+
import operator
|
| 38 |
+
|
| 39 |
+
from packaging import version
|
| 40 |
+
op_func = getattr(operator, op)
|
| 41 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class InternVLChatModel(PreTrainedModel):
|
| 45 |
+
config_class = InternVLChatConfig
|
| 46 |
+
# main_input_name = 'pixel_values'
|
| 47 |
+
_no_split_modules = ['InternVisionModel', 'LlamaDecoderLayer', 'InternLM2DecoderLayer',
|
| 48 |
+
'Phi3DecoderLayer', 'Qwen2DecoderLayer']
|
| 49 |
+
_supports_flash_attn_2 = True
|
| 50 |
+
|
| 51 |
+
def __init__(self, config: InternVLChatConfig, embedding_model=None, language_model=None):
|
| 52 |
+
super().__init__(config)
|
| 53 |
+
|
| 54 |
+
assert version_cmp(transformers.__version__, '4.37.0', 'ge')
|
| 55 |
+
image_size = config.force_image_size or config.embedding_config.image_size
|
| 56 |
+
patch_size = config.embedding_config.patch_size
|
| 57 |
+
self.image_size = image_size
|
| 58 |
+
self.patch_size = patch_size
|
| 59 |
+
self.select_layer = config.select_layer
|
| 60 |
+
self.template = config.template
|
| 61 |
+
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 62 |
+
self.downsample_ratio = config.downsample_ratio
|
| 63 |
+
self.ps_version = config.ps_version
|
| 64 |
+
self.use_thumbnail = config.use_thumbnail
|
| 65 |
+
|
| 66 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 67 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 68 |
+
if embedding_model is not None:
|
| 69 |
+
self.embedding_model = embedding_model
|
| 70 |
+
else:
|
| 71 |
+
self.embedding_model = HolisticEmbedding(config.embedding_config)
|
| 72 |
+
|
| 73 |
+
if language_model is not None:
|
| 74 |
+
self.language_model = language_model
|
| 75 |
+
else:
|
| 76 |
+
if config.llm_config.architectures[0] == 'LlamaForCausalLM':
|
| 77 |
+
self.language_model = LlamaForCausalLM(config.llm_config)
|
| 78 |
+
elif config.llm_config.architectures[0] == 'InternLM2ForCausalLM':
|
| 79 |
+
self.language_model = InternLM2ForCausalLM(config.llm_config)
|
| 80 |
+
elif config.llm_config.architectures[0] == 'Qwen2ForCausalLM':
|
| 81 |
+
self.language_model = Qwen2ForCausalLM(config.llm_config)
|
| 82 |
+
else:
|
| 83 |
+
raise NotImplementedError(f'{config.llm_config.architectures[0]} is not implemented.')
|
| 84 |
+
|
| 85 |
+
self.img_context_token_id = None
|
| 86 |
+
self.conv_template = get_conv_template(self.template)
|
| 87 |
+
self.system_message = self.conv_template.system_message
|
| 88 |
+
self.num_samples = 0
|
| 89 |
+
|
| 90 |
+
if config.use_backbone_lora:
|
| 91 |
+
self.wrap_backbone_lora(r=config.use_backbone_lora, lora_alpha=2 * config.use_backbone_lora)
|
| 92 |
+
|
| 93 |
+
if config.use_llm_lora:
|
| 94 |
+
self.wrap_llm_lora(r=config.use_llm_lora, lora_alpha=2 * config.use_llm_lora)
|
| 95 |
+
|
| 96 |
+
def wrap_backbone_lora(self, r=128, lora_alpha=256, lora_dropout=0.05):
|
| 97 |
+
lora_config = LoraConfig(
|
| 98 |
+
r=r,
|
| 99 |
+
target_modules=['attn.qkv', 'attn.proj', 'mlp.fc1', 'mlp.fc2'],
|
| 100 |
+
lora_alpha=lora_alpha,
|
| 101 |
+
lora_dropout=lora_dropout,
|
| 102 |
+
)
|
| 103 |
+
self.embedding_model = get_peft_model(self.embedding_model, lora_config)
|
| 104 |
+
self.embedding_model.print_trainable_parameters()
|
| 105 |
+
|
| 106 |
+
def wrap_llm_lora(self, r=128, lora_alpha=256, lora_dropout=0.05):
|
| 107 |
+
lora_config = LoraConfig(
|
| 108 |
+
r=r,
|
| 109 |
+
target_modules=['self_attn.q_proj', 'self_attn.k_proj', 'self_attn.v_proj', 'self_attn.o_proj',
|
| 110 |
+
'mlp.gate_proj', 'mlp.down_proj', 'mlp.up_proj'],
|
| 111 |
+
lora_alpha=lora_alpha,
|
| 112 |
+
lora_dropout=lora_dropout,
|
| 113 |
+
task_type='CAUSAL_LM'
|
| 114 |
+
)
|
| 115 |
+
self.language_model = get_peft_model(self.language_model, lora_config)
|
| 116 |
+
self.language_model.enable_input_require_grads()
|
| 117 |
+
self.language_model.print_trainable_parameters()
|
| 118 |
+
|
| 119 |
+
def forward(
|
| 120 |
+
self,
|
| 121 |
+
pixel_values: torch.FloatTensor = None,
|
| 122 |
+
input_ids: torch.LongTensor = None,
|
| 123 |
+
input_embeds: Optional[torch.FloatTensor] = None,
|
| 124 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 125 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 126 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 127 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 128 |
+
labels: Optional[torch.LongTensor] = None,
|
| 129 |
+
use_cache: Optional[bool] = None,
|
| 130 |
+
output_attentions: Optional[bool] = None,
|
| 131 |
+
output_hidden_states: Optional[bool] = None,
|
| 132 |
+
return_dict: Optional[bool] = None,
|
| 133 |
+
statistics: Optional[torch.LongTensor] = None,
|
| 134 |
+
loss_weight: Optional[List] = None,
|
| 135 |
+
loss_reduction_all_gather: Optional[bool] = False,
|
| 136 |
+
query = None,
|
| 137 |
+
hd_input_ids = None,
|
| 138 |
+
hd_attention_mask = None,
|
| 139 |
+
hd_position_ids = None,
|
| 140 |
+
hd_input_embeds = None,
|
| 141 |
+
hd_labels = None,
|
| 142 |
+
hd_loss_weight = None,
|
| 143 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 144 |
+
|
| 145 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 146 |
+
|
| 147 |
+
if input_embeds is None:
|
| 148 |
+
if image_flags is not None:
|
| 149 |
+
image_flags = image_flags.squeeze(-1)
|
| 150 |
+
pixel_values = pixel_values[image_flags == 1]
|
| 151 |
+
if getattr(self.embedding_model.config, 'pixel_shuffle_loc', None) in ['post']:
|
| 152 |
+
assert hd_input_ids is not None, 'hd_input_ids is required for pixel_shuffle_loc=post'
|
| 153 |
+
embedding_input_ids = hd_input_ids
|
| 154 |
+
embedding_attention_mask = hd_attention_mask
|
| 155 |
+
embedding_position_ids = hd_position_ids
|
| 156 |
+
else:
|
| 157 |
+
embedding_input_ids = input_ids
|
| 158 |
+
embedding_attention_mask = attention_mask
|
| 159 |
+
embedding_position_ids = position_ids
|
| 160 |
+
image_embeds, input_embeds, next_past_key_values = self.embedding_model(input_ids=embedding_input_ids,
|
| 161 |
+
pixel_values=pixel_values,
|
| 162 |
+
attention_mask=embedding_attention_mask,
|
| 163 |
+
position_ids=embedding_position_ids,
|
| 164 |
+
use_cache=use_cache,)
|
| 165 |
+
|
| 166 |
+
B, N = embedding_input_ids.shape
|
| 167 |
+
image_batch_size = pixel_values.shape[0] if pixel_values is not None else 0
|
| 168 |
+
C = image_embeds.shape[-1]
|
| 169 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 170 |
+
|
| 171 |
+
if torch.distributed.is_initialized() and torch.distributed.get_rank() == 0:
|
| 172 |
+
print(f'dynamic ViT batch size: {image_batch_size}, images per sample: {image_batch_size / B}, dynamic token length: {N}')
|
| 173 |
+
if statistics is not None:
|
| 174 |
+
num_samples, num_padding_tokens, num_padding_images = statistics.tolist()
|
| 175 |
+
self.num_samples += num_samples
|
| 176 |
+
print(f'total_samples={self.num_samples}, {num_samples=}, {num_padding_tokens=}, {num_padding_images=}')
|
| 177 |
+
|
| 178 |
+
if image_batch_size != 0:
|
| 179 |
+
if getattr(self.embedding_model.config, 'pixel_shuffle_loc', None) == 'post':
|
| 180 |
+
B, N = input_ids.shape
|
| 181 |
+
llm_input_embeds = torch.zeros(input_ids.shape[1], C, device=input_ids.device, dtype=input_embeds.dtype)
|
| 182 |
+
llm_selected = input_ids.flatten() == self.img_context_token_id
|
| 183 |
+
hd_llm_selected = hd_input_ids.flatten() == self.img_context_token_id
|
| 184 |
+
llm_input_embeds[~llm_selected] = input_embeds[~hd_llm_selected]
|
| 185 |
+
llm_input_embeds[llm_selected] = image_embeds.reshape(-1, C)
|
| 186 |
+
input_embeds = llm_input_embeds
|
| 187 |
+
|
| 188 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 189 |
+
|
| 190 |
+
else:
|
| 191 |
+
next_past_key_values = []
|
| 192 |
+
if getattr(self.embedding_model.config, 'pixel_shuffle_loc', None) in ['post']:
|
| 193 |
+
embedding_input_embeds = hd_input_embeds
|
| 194 |
+
embedding_attention_mask = hd_attention_mask
|
| 195 |
+
embedding_position_ids = hd_position_ids
|
| 196 |
+
else:
|
| 197 |
+
embedding_input_embeds = input_embeds
|
| 198 |
+
embedding_attention_mask = attention_mask
|
| 199 |
+
embedding_position_ids = position_ids
|
| 200 |
+
for layer_idx, layer_module in enumerate(self.embedding_model.encoder):
|
| 201 |
+
outputs = layer_module(
|
| 202 |
+
hidden_states=embedding_input_embeds,
|
| 203 |
+
attention_mask=embedding_attention_mask,
|
| 204 |
+
position_ids=embedding_position_ids,
|
| 205 |
+
past_key_value=past_key_values[layer_idx],
|
| 206 |
+
use_cache=use_cache,
|
| 207 |
+
)
|
| 208 |
+
embedding_input_embeds = outputs[0]
|
| 209 |
+
if use_cache:
|
| 210 |
+
next_past_key_values.append(outputs[1])
|
| 211 |
+
|
| 212 |
+
input_embeds = embedding_input_embeds
|
| 213 |
+
|
| 214 |
+
if self.config.normalize_encoder_output:
|
| 215 |
+
input_embeds = input_embeds / input_embeds.norm(dim=-1, keepdim=True)
|
| 216 |
+
|
| 217 |
+
llm_attention_mask = attention_mask
|
| 218 |
+
llm_position_ids = position_ids
|
| 219 |
+
|
| 220 |
+
outputs = self.language_model(
|
| 221 |
+
inputs_embeds=input_embeds,
|
| 222 |
+
attention_mask=llm_attention_mask,
|
| 223 |
+
position_ids=llm_position_ids,
|
| 224 |
+
past_key_values=past_key_values[layer_idx+1:] if past_key_values is not None else None,
|
| 225 |
+
use_cache=use_cache,
|
| 226 |
+
output_attentions=output_attentions,
|
| 227 |
+
output_hidden_states=output_hidden_states,
|
| 228 |
+
return_dict=return_dict,
|
| 229 |
+
)
|
| 230 |
+
logits = outputs.logits
|
| 231 |
+
|
| 232 |
+
loss = None
|
| 233 |
+
if labels is not None and loss_weight is not None:
|
| 234 |
+
loss_weight = torch.tensor(loss_weight, dtype=torch.float32, device=labels.device)
|
| 235 |
+
# Shift so that tokens < n predict n
|
| 236 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 237 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 238 |
+
shift_weights = loss_weight[..., 1:].contiguous()
|
| 239 |
+
# Flatten the tokens
|
| 240 |
+
loss_fct = CrossEntropyLoss(reduction='none')
|
| 241 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 242 |
+
shift_labels = shift_labels.view(-1)
|
| 243 |
+
shift_weights = shift_weights.view(-1)
|
| 244 |
+
# Enable model parallelism
|
| 245 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 246 |
+
shift_weights = shift_weights.to(shift_logits.device)
|
| 247 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 248 |
+
|
| 249 |
+
shift_weights_sum = shift_weights.sum()
|
| 250 |
+
if loss_reduction_all_gather:
|
| 251 |
+
dist.all_reduce(shift_weights_sum, op=dist.ReduceOp.AVG)
|
| 252 |
+
|
| 253 |
+
loss = loss * shift_weights
|
| 254 |
+
loss = loss.sum() / shift_weights_sum
|
| 255 |
+
elif labels is not None:
|
| 256 |
+
# Shift so that tokens < n predict n
|
| 257 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 258 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 259 |
+
# Flatten the tokens
|
| 260 |
+
loss_fct = CrossEntropyLoss()
|
| 261 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 262 |
+
shift_labels = shift_labels.view(-1)
|
| 263 |
+
# Enable model parallelism
|
| 264 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 265 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 266 |
+
|
| 267 |
+
if not return_dict:
|
| 268 |
+
output = (logits,) + outputs[1:]
|
| 269 |
+
return (loss,) + output if loss is not None else output
|
| 270 |
+
|
| 271 |
+
if use_cache:
|
| 272 |
+
for past_key_value in outputs.past_key_values:
|
| 273 |
+
next_past_key_values.append(past_key_value)
|
| 274 |
+
else:
|
| 275 |
+
next_past_key_values = None
|
| 276 |
+
|
| 277 |
+
return CausalLMOutputWithPast(
|
| 278 |
+
loss=loss,
|
| 279 |
+
logits=logits,
|
| 280 |
+
past_key_values=next_past_key_values,
|
| 281 |
+
hidden_states=outputs.hidden_states,
|
| 282 |
+
attentions=outputs.attentions,
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 286 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 287 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 288 |
+
if history is not None or return_history:
|
| 289 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 290 |
+
raise NotImplementedError
|
| 291 |
+
|
| 292 |
+
if image_counts is not None:
|
| 293 |
+
num_patches_list = image_counts
|
| 294 |
+
print('Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 295 |
+
|
| 296 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 297 |
+
self.img_context_token_id = img_context_token_id
|
| 298 |
+
|
| 299 |
+
if verbose and pixel_values is not None:
|
| 300 |
+
image_bs = pixel_values.shape[0]
|
| 301 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 302 |
+
|
| 303 |
+
queries = []
|
| 304 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 305 |
+
question = questions[idx]
|
| 306 |
+
if pixel_values is not None and '<image>' not in question:
|
| 307 |
+
question = '<image>\n' + question
|
| 308 |
+
template = get_conv_template(self.template)
|
| 309 |
+
template.append_message(template.roles[0], question)
|
| 310 |
+
template.append_message(template.roles[1], None)
|
| 311 |
+
query = template.get_prompt()
|
| 312 |
+
|
| 313 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 314 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 315 |
+
queries.append(query)
|
| 316 |
+
|
| 317 |
+
tokenizer.padding_side = 'left'
|
| 318 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 319 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 320 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 321 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 322 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 323 |
+
generation_output = self.generate(
|
| 324 |
+
pixel_values=pixel_values,
|
| 325 |
+
input_ids=input_ids,
|
| 326 |
+
attention_mask=attention_mask,
|
| 327 |
+
**generation_config
|
| 328 |
+
)
|
| 329 |
+
responses = tokenizer.batch_decode(generation_output, skip_special_tokens=True)
|
| 330 |
+
responses = [response.split(template.sep)[0].strip() for response in responses]
|
| 331 |
+
return responses
|
| 332 |
+
|
| 333 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 334 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 335 |
+
verbose=False):
|
| 336 |
+
|
| 337 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 338 |
+
question = '<image>\n' + question
|
| 339 |
+
|
| 340 |
+
if num_patches_list is None:
|
| 341 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 342 |
+
assert pixel_values is None or len(pixel_values) == sum(num_patches_list)
|
| 343 |
+
|
| 344 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 345 |
+
self.img_context_token_id = img_context_token_id
|
| 346 |
+
|
| 347 |
+
template = get_conv_template(self.template)
|
| 348 |
+
template.system_message = self.system_message
|
| 349 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 350 |
+
|
| 351 |
+
history = [] if history is None else history
|
| 352 |
+
for (old_question, old_answer) in history:
|
| 353 |
+
template.append_message(template.roles[0], old_question)
|
| 354 |
+
template.append_message(template.roles[1], old_answer)
|
| 355 |
+
template.append_message(template.roles[0], question)
|
| 356 |
+
template.append_message(template.roles[1], None)
|
| 357 |
+
query = template.get_prompt()
|
| 358 |
+
|
| 359 |
+
if verbose and pixel_values is not None:
|
| 360 |
+
image_bs = pixel_values.shape[0]
|
| 361 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 362 |
+
|
| 363 |
+
hd_query = deepcopy(query)
|
| 364 |
+
for num_patches in num_patches_list:
|
| 365 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 366 |
+
hd_image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * int(self.num_image_token // self.downsample_ratio**2) * num_patches + IMG_END_TOKEN
|
| 367 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 368 |
+
hd_query = hd_query.replace('<image>', hd_image_tokens, 1)
|
| 369 |
+
|
| 370 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 371 |
+
hd_model_inputs = tokenizer(hd_query, return_tensors='pt')
|
| 372 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 373 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 374 |
+
hd_input_ids = hd_model_inputs['input_ids'].cuda()
|
| 375 |
+
hd_attention_mask = hd_model_inputs['attention_mask'].cuda()
|
| 376 |
+
|
| 377 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 378 |
+
generation_output = super().generate(
|
| 379 |
+
pixel_values=pixel_values,
|
| 380 |
+
input_ids=input_ids,
|
| 381 |
+
attention_mask=attention_mask,
|
| 382 |
+
hd_input_ids=hd_input_ids,
|
| 383 |
+
hd_attention_mask=hd_attention_mask,
|
| 384 |
+
**generation_config
|
| 385 |
+
)
|
| 386 |
+
generation_output = generation_output[:, input_ids.shape[1]:]
|
| 387 |
+
|
| 388 |
+
response = tokenizer.batch_decode(generation_output, skip_special_tokens=True)[0]
|
| 389 |
+
response = response.split(template.sep)[0].strip()
|
| 390 |
+
history.append((question, response))
|
| 391 |
+
if return_history:
|
| 392 |
+
return response, history
|
| 393 |
+
else:
|
| 394 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 395 |
+
query_to_print = query_to_print.replace(f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 396 |
+
if verbose:
|
| 397 |
+
print(query_to_print, response)
|
| 398 |
+
return response
|
| 399 |
+
|
| 400 |
+
def prepare_inputs_for_generation(
|
| 401 |
+
self, input_ids, past_key_values=None, attention_mask=None, input_embeds=None,
|
| 402 |
+
tile_pos_offsets=None, hd_input_ids=None, hd_attention_mask=None, img_mask=None, **kwargs
|
| 403 |
+
):
|
| 404 |
+
if past_key_values is not None:
|
| 405 |
+
past_length = past_key_values[-1][0].shape[2]
|
| 406 |
+
|
| 407 |
+
# Some generation methods already pass only the last input ID
|
| 408 |
+
if input_ids.shape[1] > past_length:
|
| 409 |
+
remove_prefix_length = past_length
|
| 410 |
+
else:
|
| 411 |
+
# Default to old behavior: keep only final ID
|
| 412 |
+
remove_prefix_length = input_ids.shape[1] - 1
|
| 413 |
+
|
| 414 |
+
input_ids = input_ids[:, remove_prefix_length:]
|
| 415 |
+
input_embeds = self.embedding_model.get_input_embeddings(input_ids)
|
| 416 |
+
hd_input_ids = input_ids
|
| 417 |
+
hd_input_embeds = input_embeds
|
| 418 |
+
|
| 419 |
+
position_ids = kwargs.get('position_ids', None)
|
| 420 |
+
if attention_mask is not None and position_ids is None:
|
| 421 |
+
# create position_ids on the fly for batch generation
|
| 422 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 423 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 424 |
+
if past_key_values:
|
| 425 |
+
position_ids = position_ids[:, -input_ids.shape[1]:]
|
| 426 |
+
|
| 427 |
+
hd_position_ids = kwargs.get('hd_position_ids', None)
|
| 428 |
+
if hd_attention_mask is not None and hd_position_ids is None:
|
| 429 |
+
# create position_ids on the fly for batch generation
|
| 430 |
+
hd_position_ids = hd_attention_mask.long().cumsum(-1) - 1
|
| 431 |
+
hd_position_ids.masked_fill_(hd_attention_mask == 0, 1)
|
| 432 |
+
if past_key_values:
|
| 433 |
+
hd_position_ids = hd_position_ids[:, -hd_input_ids.shape[1]:]
|
| 434 |
+
|
| 435 |
+
if input_embeds is not None:
|
| 436 |
+
model_inputs = {'input_embeds': input_embeds, 'hd_input_embeds': hd_input_embeds}
|
| 437 |
+
else:
|
| 438 |
+
model_inputs = {'input_ids': input_ids, 'pixel_values': kwargs.get('pixel_values'), 'hd_input_ids': hd_input_ids}
|
| 439 |
+
|
| 440 |
+
model_inputs.update(
|
| 441 |
+
{
|
| 442 |
+
'position_ids': position_ids,
|
| 443 |
+
'past_key_values': past_key_values,
|
| 444 |
+
'use_cache': kwargs.get('use_cache'),
|
| 445 |
+
'attention_mask': attention_mask,
|
| 446 |
+
'hd_position_ids': hd_position_ids,
|
| 447 |
+
'hd_attention_mask': hd_attention_mask,
|
| 448 |
+
}
|
| 449 |
+
)
|
| 450 |
+
return model_inputs
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|action_start|>",
|
| 6 |
+
"<|action_end|>",
|
| 7 |
+
"<|interpreter|>",
|
| 8 |
+
"<|plugin|>",
|
| 9 |
+
"<img>",
|
| 10 |
+
"</img>",
|
| 11 |
+
"<IMG_CONTEXT>",
|
| 12 |
+
"<quad>",
|
| 13 |
+
"</quad>",
|
| 14 |
+
"<ref>",
|
| 15 |
+
"</ref>",
|
| 16 |
+
"<box>",
|
| 17 |
+
"</box>"
|
| 18 |
+
],
|
| 19 |
+
"bos_token": {
|
| 20 |
+
"content": "<s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
},
|
| 26 |
+
"eos_token": {
|
| 27 |
+
"content": "</s>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": false,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
},
|
| 33 |
+
"pad_token": {
|
| 34 |
+
"content": "</s>",
|
| 35 |
+
"lstrip": false,
|
| 36 |
+
"normalized": false,
|
| 37 |
+
"rstrip": false,
|
| 38 |
+
"single_word": false
|
| 39 |
+
},
|
| 40 |
+
"unk_token": {
|
| 41 |
+
"content": "<unk>",
|
| 42 |
+
"lstrip": false,
|
| 43 |
+
"normalized": false,
|
| 44 |
+
"rstrip": false,
|
| 45 |
+
"single_word": false
|
| 46 |
+
}
|
| 47 |
+
}
|
tokenization_internlm2.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/tokenization_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
"""Tokenization classes for InternLM."""
|
| 18 |
+
import os
|
| 19 |
+
from shutil import copyfile
|
| 20 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 21 |
+
|
| 22 |
+
import sentencepiece as spm
|
| 23 |
+
from transformers.tokenization_utils import PreTrainedTokenizer
|
| 24 |
+
from transformers.utils import logging
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
VOCAB_FILES_NAMES = {'vocab_file': './tokenizer.model'}
|
| 29 |
+
|
| 30 |
+
PRETRAINED_VOCAB_FILES_MAP = {}
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# Modified from transformers.model.llama.tokenization_llama.LlamaTokenizer
|
| 34 |
+
class InternLM2Tokenizer(PreTrainedTokenizer):
|
| 35 |
+
"""
|
| 36 |
+
Construct a InternLM2 tokenizer. Based on byte-level Byte-Pair-Encoding.
|
| 37 |
+
|
| 38 |
+
Args:
|
| 39 |
+
vocab_file (`str`):
|
| 40 |
+
Path to the vocabulary file.
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 44 |
+
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
| 45 |
+
model_input_names = ['input_ids', 'attention_mask']
|
| 46 |
+
_auto_class = 'AutoTokenizer'
|
| 47 |
+
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
vocab_file,
|
| 51 |
+
unk_token='<unk>',
|
| 52 |
+
bos_token='<s>',
|
| 53 |
+
eos_token='</s>',
|
| 54 |
+
pad_token='</s>',
|
| 55 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 56 |
+
add_bos_token=True,
|
| 57 |
+
add_eos_token=False,
|
| 58 |
+
decode_with_prefix_space=False,
|
| 59 |
+
clean_up_tokenization_spaces=False,
|
| 60 |
+
**kwargs,
|
| 61 |
+
):
|
| 62 |
+
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
| 63 |
+
self.vocab_file = vocab_file
|
| 64 |
+
self.add_bos_token = add_bos_token
|
| 65 |
+
self.add_eos_token = add_eos_token
|
| 66 |
+
self.decode_with_prefix_space = decode_with_prefix_space
|
| 67 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 68 |
+
self.sp_model.Load(vocab_file)
|
| 69 |
+
self._no_prefix_space_tokens = None
|
| 70 |
+
super().__init__(
|
| 71 |
+
bos_token=bos_token,
|
| 72 |
+
eos_token=eos_token,
|
| 73 |
+
unk_token=unk_token,
|
| 74 |
+
pad_token=pad_token,
|
| 75 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 76 |
+
**kwargs,
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
@property
|
| 80 |
+
def no_prefix_space_tokens(self):
|
| 81 |
+
if self._no_prefix_space_tokens is None:
|
| 82 |
+
vocab = self.convert_ids_to_tokens(list(range(self.vocab_size)))
|
| 83 |
+
self._no_prefix_space_tokens = {i for i, tok in enumerate(vocab) if not tok.startswith('▁')}
|
| 84 |
+
return self._no_prefix_space_tokens
|
| 85 |
+
|
| 86 |
+
@property
|
| 87 |
+
def vocab_size(self):
|
| 88 |
+
"""Returns vocab size"""
|
| 89 |
+
return self.sp_model.get_piece_size()
|
| 90 |
+
|
| 91 |
+
@property
|
| 92 |
+
def bos_token_id(self) -> Optional[int]:
|
| 93 |
+
return self.sp_model.bos_id()
|
| 94 |
+
|
| 95 |
+
@property
|
| 96 |
+
def eos_token_id(self) -> Optional[int]:
|
| 97 |
+
return self.sp_model.eos_id()
|
| 98 |
+
|
| 99 |
+
def get_vocab(self):
|
| 100 |
+
"""Returns vocab as a dict"""
|
| 101 |
+
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
| 102 |
+
vocab.update(self.added_tokens_encoder)
|
| 103 |
+
return vocab
|
| 104 |
+
|
| 105 |
+
def _tokenize(self, text):
|
| 106 |
+
"""Returns a tokenized string."""
|
| 107 |
+
return self.sp_model.encode(text, out_type=str)
|
| 108 |
+
|
| 109 |
+
def _convert_token_to_id(self, token):
|
| 110 |
+
"""Converts a token (str) in an id using the vocab."""
|
| 111 |
+
return self.sp_model.piece_to_id(token)
|
| 112 |
+
|
| 113 |
+
def _convert_id_to_token(self, index):
|
| 114 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 115 |
+
token = self.sp_model.IdToPiece(index)
|
| 116 |
+
return token
|
| 117 |
+
|
| 118 |
+
def _maybe_add_prefix_space(self, tokens, decoded):
|
| 119 |
+
if tokens and tokens[0] not in self.no_prefix_space_tokens:
|
| 120 |
+
return ' ' + decoded
|
| 121 |
+
else:
|
| 122 |
+
return decoded
|
| 123 |
+
|
| 124 |
+
def convert_tokens_to_string(self, tokens):
|
| 125 |
+
"""Converts a sequence of tokens (string) in a single string."""
|
| 126 |
+
current_sub_tokens = []
|
| 127 |
+
out_string = ''
|
| 128 |
+
prev_is_special = False
|
| 129 |
+
for token in tokens:
|
| 130 |
+
# make sure that special tokens are not decoded using sentencepiece model
|
| 131 |
+
if token in self.all_special_tokens:
|
| 132 |
+
if not prev_is_special:
|
| 133 |
+
out_string += ' '
|
| 134 |
+
out_string += self.sp_model.decode(current_sub_tokens) + token
|
| 135 |
+
prev_is_special = True
|
| 136 |
+
current_sub_tokens = []
|
| 137 |
+
else:
|
| 138 |
+
current_sub_tokens.append(token)
|
| 139 |
+
prev_is_special = False
|
| 140 |
+
out_string += self.sp_model.decode(current_sub_tokens)
|
| 141 |
+
out_string = self.clean_up_tokenization(out_string)
|
| 142 |
+
out_string = self._maybe_add_prefix_space(tokens=tokens, decoded=out_string)
|
| 143 |
+
return out_string[1:]
|
| 144 |
+
|
| 145 |
+
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
| 146 |
+
"""
|
| 147 |
+
Save the vocabulary and special tokens file to a directory.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
save_directory (`str`):
|
| 151 |
+
The directory in which to save the vocabulary.
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
`Tuple(str)`: Paths to the files saved.
|
| 155 |
+
"""
|
| 156 |
+
if not os.path.isdir(save_directory):
|
| 157 |
+
logger.error(f'Vocabulary path ({save_directory}) should be a directory')
|
| 158 |
+
return
|
| 159 |
+
out_vocab_file = os.path.join(
|
| 160 |
+
save_directory, (filename_prefix + '-' if filename_prefix else '') + VOCAB_FILES_NAMES['vocab_file']
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
|
| 164 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 165 |
+
elif not os.path.isfile(self.vocab_file):
|
| 166 |
+
with open(out_vocab_file, 'wb') as fi:
|
| 167 |
+
content_spiece_model = self.sp_model.serialized_model_proto()
|
| 168 |
+
fi.write(content_spiece_model)
|
| 169 |
+
|
| 170 |
+
return (out_vocab_file,)
|
| 171 |
+
|
| 172 |
+
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
| 173 |
+
if self.add_bos_token:
|
| 174 |
+
bos_token_ids = [self.bos_token_id]
|
| 175 |
+
else:
|
| 176 |
+
bos_token_ids = []
|
| 177 |
+
|
| 178 |
+
output = bos_token_ids + token_ids_0
|
| 179 |
+
|
| 180 |
+
if token_ids_1 is not None:
|
| 181 |
+
output = output + token_ids_1
|
| 182 |
+
|
| 183 |
+
if self.add_eos_token:
|
| 184 |
+
output = output + [self.eos_token_id]
|
| 185 |
+
|
| 186 |
+
return output
|
| 187 |
+
|
| 188 |
+
def get_special_tokens_mask(
|
| 189 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
|
| 190 |
+
) -> List[int]:
|
| 191 |
+
"""
|
| 192 |
+
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
| 193 |
+
special tokens using the tokenizer `prepare_for_model` method.
|
| 194 |
+
|
| 195 |
+
Args:
|
| 196 |
+
token_ids_0 (`List[int]`):
|
| 197 |
+
List of IDs.
|
| 198 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 199 |
+
Optional second list of IDs for sequence pairs.
|
| 200 |
+
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
| 201 |
+
Whether or not the token list is already formatted with special tokens for the model.
|
| 202 |
+
|
| 203 |
+
Returns:
|
| 204 |
+
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
| 205 |
+
"""
|
| 206 |
+
if already_has_special_tokens:
|
| 207 |
+
return super().get_special_tokens_mask(
|
| 208 |
+
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
if token_ids_1 is None:
|
| 212 |
+
return [1] + ([0] * len(token_ids_0)) + [1]
|
| 213 |
+
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
|
| 214 |
+
|
| 215 |
+
def create_token_type_ids_from_sequences(
|
| 216 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 217 |
+
) -> List[int]:
|
| 218 |
+
"""
|
| 219 |
+
Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make
|
| 220 |
+
use of token type ids, therefore a list of zeros is returned.
|
| 221 |
+
|
| 222 |
+
Args:
|
| 223 |
+
token_ids_0 (`List[int]`):
|
| 224 |
+
List of IDs.
|
| 225 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 226 |
+
Optional second list of IDs for sequence pairs.
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
`List[int]`: List of zeros.
|
| 230 |
+
"""
|
| 231 |
+
eos = [self.eos_token_id]
|
| 232 |
+
|
| 233 |
+
if token_ids_1 is None:
|
| 234 |
+
return len(token_ids_0 + eos) * [0]
|
| 235 |
+
return len(token_ids_0 + eos + token_ids_1 + eos) * [0]
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f868398fc4e05ee1e8aeba95ddf18ddcc45b8bce55d5093bead5bbf80429b48b
|
| 3 |
+
size 1477754
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"92538": {
|
| 28 |
+
"content": "<|plugin|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"92539": {
|
| 36 |
+
"content": "<|interpreter|>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"92540": {
|
| 44 |
+
"content": "<|action_end|>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"92541": {
|
| 52 |
+
"content": "<|action_start|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"92542": {
|
| 60 |
+
"content": "<|im_end|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"92543": {
|
| 68 |
+
"content": "<|im_start|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
},
|
| 75 |
+
"92544": {
|
| 76 |
+
"content": "<img>",
|
| 77 |
+
"lstrip": false,
|
| 78 |
+
"normalized": false,
|
| 79 |
+
"rstrip": false,
|
| 80 |
+
"single_word": false,
|
| 81 |
+
"special": true
|
| 82 |
+
},
|
| 83 |
+
"92545": {
|
| 84 |
+
"content": "</img>",
|
| 85 |
+
"lstrip": false,
|
| 86 |
+
"normalized": false,
|
| 87 |
+
"rstrip": false,
|
| 88 |
+
"single_word": false,
|
| 89 |
+
"special": true
|
| 90 |
+
},
|
| 91 |
+
"92546": {
|
| 92 |
+
"content": "<IMG_CONTEXT>",
|
| 93 |
+
"lstrip": false,
|
| 94 |
+
"normalized": false,
|
| 95 |
+
"rstrip": false,
|
| 96 |
+
"single_word": false,
|
| 97 |
+
"special": true
|
| 98 |
+
},
|
| 99 |
+
"92547": {
|
| 100 |
+
"content": "<quad>",
|
| 101 |
+
"lstrip": false,
|
| 102 |
+
"normalized": false,
|
| 103 |
+
"rstrip": false,
|
| 104 |
+
"single_word": false,
|
| 105 |
+
"special": true
|
| 106 |
+
},
|
| 107 |
+
"92548": {
|
| 108 |
+
"content": "</quad>",
|
| 109 |
+
"lstrip": false,
|
| 110 |
+
"normalized": false,
|
| 111 |
+
"rstrip": false,
|
| 112 |
+
"single_word": false,
|
| 113 |
+
"special": true
|
| 114 |
+
},
|
| 115 |
+
"92549": {
|
| 116 |
+
"content": "<ref>",
|
| 117 |
+
"lstrip": false,
|
| 118 |
+
"normalized": false,
|
| 119 |
+
"rstrip": false,
|
| 120 |
+
"single_word": false,
|
| 121 |
+
"special": true
|
| 122 |
+
},
|
| 123 |
+
"92550": {
|
| 124 |
+
"content": "</ref>",
|
| 125 |
+
"lstrip": false,
|
| 126 |
+
"normalized": false,
|
| 127 |
+
"rstrip": false,
|
| 128 |
+
"single_word": false,
|
| 129 |
+
"special": true
|
| 130 |
+
},
|
| 131 |
+
"92551": {
|
| 132 |
+
"content": "<box>",
|
| 133 |
+
"lstrip": false,
|
| 134 |
+
"normalized": false,
|
| 135 |
+
"rstrip": false,
|
| 136 |
+
"single_word": false,
|
| 137 |
+
"special": true
|
| 138 |
+
},
|
| 139 |
+
"92552": {
|
| 140 |
+
"content": "</box>",
|
| 141 |
+
"lstrip": false,
|
| 142 |
+
"normalized": false,
|
| 143 |
+
"rstrip": false,
|
| 144 |
+
"single_word": false,
|
| 145 |
+
"special": true
|
| 146 |
+
}
|
| 147 |
+
},
|
| 148 |
+
"additional_special_tokens": [
|
| 149 |
+
"<|im_start|>",
|
| 150 |
+
"<|im_end|>",
|
| 151 |
+
"<|action_start|>",
|
| 152 |
+
"<|action_end|>",
|
| 153 |
+
"<|interpreter|>",
|
| 154 |
+
"<|plugin|>",
|
| 155 |
+
"<img>",
|
| 156 |
+
"</img>",
|
| 157 |
+
"<IMG_CONTEXT>",
|
| 158 |
+
"<quad>",
|
| 159 |
+
"</quad>",
|
| 160 |
+
"<ref>",
|
| 161 |
+
"</ref>",
|
| 162 |
+
"<box>",
|
| 163 |
+
"</box>"
|
| 164 |
+
],
|
| 165 |
+
"auto_map": {
|
| 166 |
+
"AutoTokenizer": [
|
| 167 |
+
"tokenization_internlm2.InternLM2Tokenizer",
|
| 168 |
+
null
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
"bos_token": "<s>",
|
| 172 |
+
"chat_template": "{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 173 |
+
"clean_up_tokenization_spaces": false,
|
| 174 |
+
"eos_token": "</s>",
|
| 175 |
+
"model_max_length": 8192,
|
| 176 |
+
"pad_token": "</s>",
|
| 177 |
+
"tokenizer_class": "InternLM2Tokenizer",
|
| 178 |
+
"unk_token": "<unk>"
|
| 179 |
+
}
|