
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,6 +7,9 @@ tags:
|
|
| 7 |
pipeline_tag: zero-shot-classification
|
| 8 |
library_name: transformers
|
| 9 |
license: mit
|
|
|
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
# Model description: deberta-v3-base-zeroshot-v2.0
|
|
@@ -61,7 +64,7 @@ print(output)
|
|
| 61 |
|
| 62 |
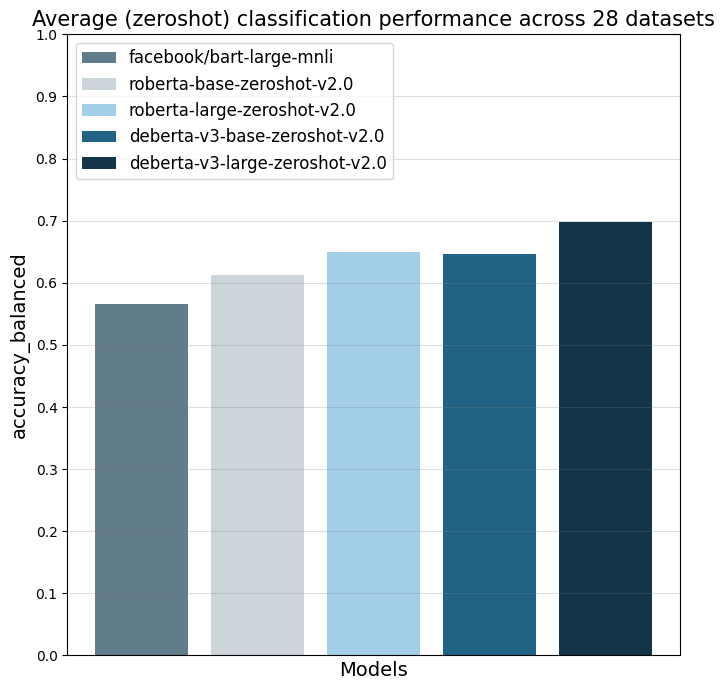
The model was evaluated on 28 different text classification tasks with the [balanced_accuracy](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html) metric.
|
| 63 |
The main reference point is `facebook/bart-large-mnli` which is at the time of writing (27.03.24) the most used commercially-friendly 0-shot classifier.
|
| 64 |
-
The different
|
| 65 |
|
| 66 |
|
| 67 |
|
|
@@ -101,17 +104,19 @@ The different `...zeroshot-v2.0` models were all trained with the same data and
|
|
| 101 |
|
| 102 |
## When to use which model
|
| 103 |
|
| 104 |
-
- deberta-v3 vs. roberta: deberta-v3 performs clearly better than roberta, but it is slower.
|
| 105 |
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
|
| 106 |
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
|
| 107 |
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
|
| 108 |
- `zeroshot-v1.1` vs. `zeroshot-v2.0` models: My `zeroshot-v1.1` models (see [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f)))
|
| 109 |
perform better on these 28 datasets, but they are trained on several datasets with non-commercial licenses.
|
| 110 |
For commercial users, I therefore recommend using a v2.0 model and non-commercial users might get better performance with a v1.1 model.
|
|
|
|
|
|
|
| 111 |
|
| 112 |
## Reproduction
|
| 113 |
|
| 114 |
-
Reproduction code is available
|
| 115 |
|
| 116 |
|
| 117 |
|
|
@@ -165,4 +170,4 @@ classes_verbalized = ["CDU", "SPD", "Greens"]
|
|
| 165 |
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-base-zeroshot-v2.0")
|
| 166 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 167 |
print(output)
|
| 168 |
-
```
|
|
|
|
| 7 |
pipeline_tag: zero-shot-classification
|
| 8 |
library_name: transformers
|
| 9 |
license: mit
|
| 10 |
+
datasets:
|
| 11 |
+
- nyu-mll/multi_nli
|
| 12 |
+
- fever
|
| 13 |
---
|
| 14 |
|
| 15 |
# Model description: deberta-v3-base-zeroshot-v2.0
|
|
|
|
| 64 |
|
| 65 |
The model was evaluated on 28 different text classification tasks with the [balanced_accuracy](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html) metric.
|
| 66 |
The main reference point is `facebook/bart-large-mnli` which is at the time of writing (27.03.24) the most used commercially-friendly 0-shot classifier.
|
| 67 |
+
The different `zeroshot-v2.0` models were all trained with the same data and the only difference is the underlying foundation model.
|
| 68 |
|
| 69 |

|
| 70 |
|
|
|
|
| 104 |
|
| 105 |
## When to use which model
|
| 106 |
|
| 107 |
+
- deberta-v3-zeroshot vs. roberta-zeroshot: deberta-v3 performs clearly better than roberta, but it is slower.
|
| 108 |
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
|
| 109 |
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
|
| 110 |
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
|
| 111 |
- `zeroshot-v1.1` vs. `zeroshot-v2.0` models: My `zeroshot-v1.1` models (see [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f)))
|
| 112 |
perform better on these 28 datasets, but they are trained on several datasets with non-commercial licenses.
|
| 113 |
For commercial users, I therefore recommend using a v2.0 model and non-commercial users might get better performance with a v1.1 model.
|
| 114 |
+
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 115 |
+
|
| 116 |
|
| 117 |
## Reproduction
|
| 118 |
|
| 119 |
+
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
| 120 |
|
| 121 |
|
| 122 |
|
|
|
|
| 170 |
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-base-zeroshot-v2.0")
|
| 171 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 172 |
print(output)
|
| 173 |
+
```
|