
Commit
•
25c822b
1
Parent(s):
33737b6
Update README.md
Browse files
README.md
CHANGED
|
@@ -10,34 +10,33 @@ library_name: transformers
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
-
# Model description: bge-m3-zeroshot-v2.0
|
| 14 |
-
|
| 15 |
|
| 16 |
## zeroshot-v2.0 series of models
|
| 17 |
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
|
| 18 |
These models can do classification without training data and run on both GPUs and CPUs.
|
| 19 |
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 20 |
|
| 21 |
-
The main
|
| 22 |
-
while my older `zeroshot-v1.1` models included training data with non-commercially licensed data.
|
| 23 |
|
| 24 |
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
|
| 25 |
(`entailment` vs. `not_entailment`).
|
| 26 |
This task format is based on the Natural Language Inference task (NLI).
|
| 27 |
-
The task is so universal that any classification task can be reformulated into this task.
|
| 28 |
|
| 29 |
|
| 30 |
## Training data
|
| 31 |
-
|
| 32 |
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
|
| 33 |
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
|
| 34 |
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
|
| 35 |
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
|
| 36 |
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
|
| 37 |
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
|
| 38 |
-
These datasets were added to increase generalization.
|
| 39 |
-
3. Models
|
| 40 |
-
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
|
|
|
|
| 41 |
|
| 42 |
|
| 43 |
## How to use the models
|
|
@@ -47,7 +46,7 @@ from transformers import pipeline
|
|
| 47 |
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 48 |
hypothesis_template = "This text is about {}"
|
| 49 |
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
|
| 50 |
-
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0
|
| 51 |
output = zeroshot_classifier(text, classes_verbalised, hypothesis_template=hypothesis_template, multi_label=False)
|
| 52 |
print(output)
|
| 53 |
```
|
|
@@ -63,7 +62,7 @@ The main reference point is `facebook/bart-large-mnli` which is, at the time of
|
|
| 63 |
|
| 64 |
|
| 65 |
|
| 66 |
-
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0 | roberta-large-zeroshot-v2.0 | deberta-v3-base-zeroshot-v2.0 | deberta-v3-base-zeroshot-v2.0
|
| 67 |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
|
| 68 |
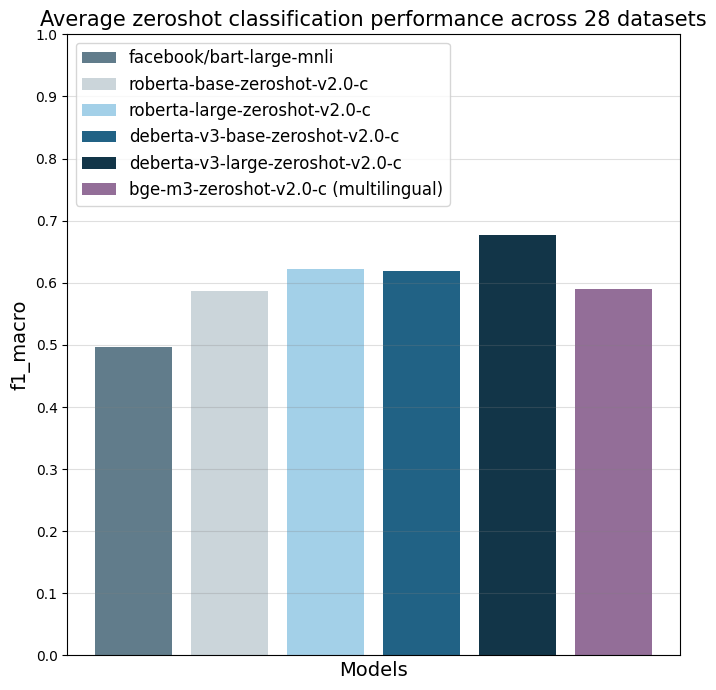
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
|
| 69 |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
|
|
@@ -97,8 +96,8 @@ The main reference point is `facebook/bart-large-mnli` which is, at the time of
|
|
| 97 |
|
| 98 |
|
| 99 |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
|
| 100 |
-
Note that models
|
| 101 |
-
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column). No
|
| 102 |
|
| 103 |
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
|
| 104 |
|
|
@@ -109,10 +108,11 @@ Details on the different datasets are available here: https://github.com/MoritzL
|
|
| 109 |
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
|
| 110 |
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
|
| 111 |
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
|
| 112 |
-
- **commercial use-cases**: models with `-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
|
|
|
| 116 |
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
|
| 117 |
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
|
| 118 |
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
|
|
@@ -120,6 +120,8 @@ mode slower and decrease performance, so if you're only working with texts of up
|
|
| 120 |
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 121 |
|
| 122 |
|
|
|
|
|
|
|
| 123 |
## Reproduction
|
| 124 |
|
| 125 |
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
|
@@ -133,8 +135,9 @@ Biases can come from the underlying foundation model, the human NLI training dat
|
|
| 133 |
|
| 134 |
|
| 135 |
## License
|
| 136 |
-
The foundation model
|
| 137 |
-
The
|
|
|
|
| 138 |
|
| 139 |
## Citation
|
| 140 |
|
|
@@ -171,11 +174,11 @@ text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
|
| 171 |
# formulation 1
|
| 172 |
hypothesis_template = "This text is about {}"
|
| 173 |
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
|
| 174 |
-
# formulation 2
|
| 175 |
hypothesis_template = "The topic of this text is {}"
|
| 176 |
-
classes_verbalized = ["
|
| 177 |
# test different formulations
|
| 178 |
-
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0
|
| 179 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 180 |
print(output)
|
| 181 |
```
|
|
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# Model description: bge-m3-zeroshot-v2.0-c
|
|
|
|
| 14 |
|
| 15 |
## zeroshot-v2.0 series of models
|
| 16 |
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
|
| 17 |
These models can do classification without training data and run on both GPUs and CPUs.
|
| 18 |
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 19 |
|
| 20 |
+
The main update of this `zeroshot-v2.0` series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
|
|
|
|
| 21 |
|
| 22 |
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
|
| 23 |
(`entailment` vs. `not_entailment`).
|
| 24 |
This task format is based on the Natural Language Inference task (NLI).
|
| 25 |
+
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
|
| 26 |
|
| 27 |
|
| 28 |
## Training data
|
| 29 |
+
Models with a "`-c`" in the name are trained on two types of fully commercially-friendly data:
|
| 30 |
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
|
| 31 |
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
|
| 32 |
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
|
| 33 |
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
|
| 34 |
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
|
| 35 |
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
|
| 36 |
+
These datasets were added to increase generalization.
|
| 37 |
+
3. Models without a "`-c`" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
|
| 38 |
+
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
|
| 39 |
+
where `used_in_v1.1==True`.
|
| 40 |
|
| 41 |
|
| 42 |
## How to use the models
|
|
|
|
| 46 |
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 47 |
hypothesis_template = "This text is about {}"
|
| 48 |
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
|
| 49 |
+
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
|
| 50 |
output = zeroshot_classifier(text, classes_verbalised, hypothesis_template=hypothesis_template, multi_label=False)
|
| 51 |
print(output)
|
| 52 |
```
|
|
|
|
| 62 |

|
| 63 |
|
| 64 |
|
| 65 |
+
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) |
|
| 66 |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
|
| 67 |
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
|
| 68 |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
|
|
|
|
| 96 |
|
| 97 |
|
| 98 |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
|
| 99 |
+
Note that models without a "`-c`" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
|
| 100 |
+
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column). No model was trained on test data.
|
| 101 |
|
| 102 |
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
|
| 103 |
|
|
|
|
| 108 |
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
|
| 109 |
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
|
| 110 |
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
|
| 111 |
+
- **commercial use-cases**: models with "`-c`" in the title are guaranteed to be trained on only commercially-friendly data.
|
| 112 |
+
Models without a "`-c`" were trained on more data and perform better, but include data with non-commercial licenses.
|
| 113 |
+
Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements,
|
| 114 |
+
the models with "`-c`" in the title are recommended.
|
| 115 |
+
- **Multilingual/non-English use-cases**: use [bge-m3-zeroshot-v2.0](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0) or [bge-m3-zeroshot-v2.0-c](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0-c).
|
| 116 |
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
|
| 117 |
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
|
| 118 |
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
|
|
|
|
| 120 |
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 121 |
|
| 122 |
|
| 123 |
+
|
| 124 |
+
|
| 125 |
## Reproduction
|
| 126 |
|
| 127 |
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
|
|
|
| 135 |
|
| 136 |
|
| 137 |
## License
|
| 138 |
+
The foundation model was published under the MIT license.
|
| 139 |
+
The licenses of the training data vary depending on the model, see above.
|
| 140 |
+
|
| 141 |
|
| 142 |
## Citation
|
| 143 |
|
|
|
|
| 174 |
# formulation 1
|
| 175 |
hypothesis_template = "This text is about {}"
|
| 176 |
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
|
| 177 |
+
# formulation 2 depending on your use-case
|
| 178 |
hypothesis_template = "The topic of this text is {}"
|
| 179 |
+
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
|
| 180 |
# test different formulations
|
| 181 |
+
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
|
| 182 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 183 |
print(output)
|
| 184 |
```
|