
final commit to hf
Browse files- README.md +5 -0
- Viz.ipynb +51 -0
- main.py +100 -0
- observations.py +54 -0
- requirements.txt +285 -0
- test.py +18 -0
- tools/__init__.py +1 -0
- tools/dataset.py +141 -0
- tools/utils.py +470 -0
- train.py +26 -0
- viz/final_curve.png +0 -0
- viz/img1.png +0 -0
- viz/img2.png +0 -0
- viz/img3.png +0 -0
- viz/img4.png +0 -0
- viz/img5.png +0 -0
- viz/loss_curve.png +0 -0
- viz/save_plot.py +6 -0
README.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# How to run locally
|
| 2 |
+
|
| 3 |
+
- [ ] ```git clone https://github.com/majauhar/UpsideDownDetector.git```
|
| 4 |
+
- [ ] ```pip install -r requirements.txt```
|
| 5 |
+
- [ ] ```python main.py --epochs=<Integer> --pretrained=[True/False]```
|
Viz.ipynb
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 5,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"ename": "ModuleNotFoundError",
|
| 10 |
+
"evalue": "No module named 'torch'",
|
| 11 |
+
"output_type": "error",
|
| 12 |
+
"traceback": [
|
| 13 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 14 |
+
"\u001b[0;31mModuleNotFoundError\u001b[0m Traceback (most recent call last)",
|
| 15 |
+
"\u001b[0;32m<ipython-input-5-eb42ca6e4af3>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0;32mimport\u001b[0m \u001b[0mtorch\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
|
| 16 |
+
"\u001b[0;31mModuleNotFoundError\u001b[0m: No module named 'torch'"
|
| 17 |
+
]
|
| 18 |
+
}
|
| 19 |
+
],
|
| 20 |
+
"source": []
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": null,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": []
|
| 28 |
+
}
|
| 29 |
+
],
|
| 30 |
+
"metadata": {
|
| 31 |
+
"kernelspec": {
|
| 32 |
+
"display_name": "Python 3",
|
| 33 |
+
"language": "python",
|
| 34 |
+
"name": "python3"
|
| 35 |
+
},
|
| 36 |
+
"language_info": {
|
| 37 |
+
"codemirror_mode": {
|
| 38 |
+
"name": "ipython",
|
| 39 |
+
"version": 3
|
| 40 |
+
},
|
| 41 |
+
"file_extension": ".py",
|
| 42 |
+
"mimetype": "text/x-python",
|
| 43 |
+
"name": "python",
|
| 44 |
+
"nbconvert_exporter": "python",
|
| 45 |
+
"pygments_lexer": "ipython3",
|
| 46 |
+
"version": "3.7.3"
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
"nbformat": 4,
|
| 50 |
+
"nbformat_minor": 2
|
| 51 |
+
}
|
main.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchvision
|
| 3 |
+
from torchvision import datasets, transforms
|
| 4 |
+
from torch.utils.data import Dataset, DataLoader
|
| 5 |
+
from torchvision import models
|
| 6 |
+
import numpy as np
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
from PIL import Image
|
| 9 |
+
import os
|
| 10 |
+
import os.path
|
| 11 |
+
import pickle
|
| 12 |
+
from typing import Any, Callable, Optional, Tuple
|
| 13 |
+
import torchvision.transforms.functional as TF
|
| 14 |
+
|
| 15 |
+
from tools.dataset import UpsideDownDataset
|
| 16 |
+
from train import train
|
| 17 |
+
from test import test
|
| 18 |
+
from observations import observations
|
| 19 |
+
|
| 20 |
+
import torchvision.models as models
|
| 21 |
+
import torch.optim as optim
|
| 22 |
+
|
| 23 |
+
import argparse
|
| 24 |
+
|
| 25 |
+
# setting up the device
|
| 26 |
+
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 27 |
+
|
| 28 |
+
def arg_parser():
|
| 29 |
+
parser = argparse.ArgumentParser(description="Upside Down Image Detector")
|
| 30 |
+
parser.add_argument('--epochs', type=int, default=10)
|
| 31 |
+
parser.add_argument('--pretrained', type=bool, default=True)
|
| 32 |
+
|
| 33 |
+
return parser.parse_args()
|
| 34 |
+
|
| 35 |
+
def main(args):
|
| 36 |
+
# transformations
|
| 37 |
+
train_transform = transforms.Compose([
|
| 38 |
+
transforms.ToTensor()
|
| 39 |
+
])
|
| 40 |
+
|
| 41 |
+
test_transform = transforms.Compose([
|
| 42 |
+
transforms.ToTensor()
|
| 43 |
+
])
|
| 44 |
+
|
| 45 |
+
# downloading CIFAR10 dataset
|
| 46 |
+
trainset = UpsideDownDataset(root='./data', train=True, download=True, transform=train_transform)
|
| 47 |
+
testset = UpsideDownDataset(root='./data', train=False, download=True, transform=test_transform)
|
| 48 |
+
|
| 49 |
+
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, drop_last=True)
|
| 50 |
+
testloader = torch.utils.data.DataLoader(testset, batch_size=128)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
model = models.resnet18(pretrained=args.pretrained)
|
| 54 |
+
model.fc = torch.nn.Linear(512, 2)
|
| 55 |
+
|
| 56 |
+
optimizer = optim.SGD(model.parameters(), lr=0.01)
|
| 57 |
+
# criterion = torch.nn.BCEWithLogitsLoss()
|
| 58 |
+
criterion = torch.nn.CrossEntropyLoss()
|
| 59 |
+
|
| 60 |
+
model, criterion = model.to(DEVICE), criterion.to(DEVICE)
|
| 61 |
+
|
| 62 |
+
print("training started:")
|
| 63 |
+
|
| 64 |
+
loss_values = []
|
| 65 |
+
accuracy_values = []
|
| 66 |
+
for epoch in range(args.epochs):
|
| 67 |
+
print("Epoch {}".format(epoch+1))
|
| 68 |
+
epoch_loss = train(model, trainloader, optimizer, criterion, DEVICE)
|
| 69 |
+
loss_values.append(epoch_loss)
|
| 70 |
+
accuracy = test(model, testloader, criterion, DEVICE)
|
| 71 |
+
accuracy_values.append(accuracy)
|
| 72 |
+
|
| 73 |
+
plt.plot(np.array(loss_values), 'r')
|
| 74 |
+
plt.xlabel('epochs')
|
| 75 |
+
plt.ylabel('losses')
|
| 76 |
+
plt.savefig('./viz/loss_curve.png')
|
| 77 |
+
|
| 78 |
+
fig, ax = plt.subplots()
|
| 79 |
+
ax.plot(np.array(loss_values), color='red', label='losses')
|
| 80 |
+
ax.tick_params(axis='y', labelcolor='red')
|
| 81 |
+
|
| 82 |
+
ax2 = ax.twinx()
|
| 83 |
+
|
| 84 |
+
ax2.plot(np.array(accuracy_values), color='green', label='accuracy')
|
| 85 |
+
ax2.tick_params(axis='y', labelcolor='green')
|
| 86 |
+
|
| 87 |
+
# plt.xlabel('epochs')
|
| 88 |
+
plt.legend()
|
| 89 |
+
plt.savefig('./viz/final_curve.png')
|
| 90 |
+
|
| 91 |
+
print("accuracy: {}".format(accuracy))
|
| 92 |
+
|
| 93 |
+
observations(model, testloader)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
if __name__ =='__main__':
|
| 99 |
+
args = arg_parser()
|
| 100 |
+
main(args)
|
observations.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def pred_label(model, img):
|
| 7 |
+
model = model.to('cpu')
|
| 8 |
+
img = img.unsqueeze(0)
|
| 9 |
+
logits = model(img)
|
| 10 |
+
pred_probab = torch.nn.Softmax(dim=1)(logits)
|
| 11 |
+
y_pred = pred_probab.argmax(1)
|
| 12 |
+
|
| 13 |
+
return y_pred
|
| 14 |
+
|
| 15 |
+
def save_image(img, title, count):
|
| 16 |
+
fig, ax = plt.subplots()
|
| 17 |
+
imgplot = ax.imshow(img, interpolation='bicubic')
|
| 18 |
+
ax.spines['top'].set_visible(False)
|
| 19 |
+
ax.spines['left'].set_visible(False)
|
| 20 |
+
ax.spines['bottom'].set_visible(False)
|
| 21 |
+
ax.spines['right'].set_visible(False)
|
| 22 |
+
ax.set_xticks([])
|
| 23 |
+
ax.set_yticks([])
|
| 24 |
+
# imgplot = plt.imshow(img, interpolation='bicubic')
|
| 25 |
+
plt.title(title)
|
| 26 |
+
plt.savefig('./viz/img' + str(count))
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def observations(model, testloader):
|
| 30 |
+
for imgs, labels in testloader:
|
| 31 |
+
images = [imgs[0].permute(1, 2, 0),
|
| 32 |
+
imgs[1].permute(1, 2, 0),
|
| 33 |
+
imgs[2].permute(1, 2, 0),
|
| 34 |
+
imgs[3].permute(1, 2, 0),
|
| 35 |
+
imgs[4].permute(1, 2, 0)]
|
| 36 |
+
|
| 37 |
+
pred_label1 = pred_label(model, imgs[0]).item()
|
| 38 |
+
pred_label2 = pred_label(model, imgs[1]).item()
|
| 39 |
+
pred_label3 = pred_label(model, imgs[2]).item()
|
| 40 |
+
pred_label4 = pred_label(model, imgs[3]).item()
|
| 41 |
+
pred_label5 = pred_label(model, imgs[4]).item()
|
| 42 |
+
|
| 43 |
+
titles = ["Pred: {}, Actual: {}".format(pred_label1, labels[0]),
|
| 44 |
+
"Pred: {}, Actual: {}".format(pred_label2, labels[1]),
|
| 45 |
+
"Pred: {}, Actual: {}".format(pred_label3, labels[2]),
|
| 46 |
+
"Pred: {}, Actual: {}".format(pred_label4, labels[3]),
|
| 47 |
+
"Pred: {}, Actual: {}".format(pred_label5, labels[4])]
|
| 48 |
+
|
| 49 |
+
count = 1
|
| 50 |
+
for image, title in zip(images, titles):
|
| 51 |
+
save_image(image, title, count)
|
| 52 |
+
count += 1
|
| 53 |
+
|
| 54 |
+
break
|
requirements.txt
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py==0.10.0
|
| 2 |
+
alabaster==0.7.12
|
| 3 |
+
allennlp==0.8.4
|
| 4 |
+
anaconda-client==1.7.2
|
| 5 |
+
anaconda-navigator==1.9.7
|
| 6 |
+
anaconda-project==0.8.3
|
| 7 |
+
asn1crypto==0.24.0
|
| 8 |
+
astroid==2.2.5
|
| 9 |
+
astropy==3.2.1
|
| 10 |
+
astunparse==1.6.3
|
| 11 |
+
atomicwrites==1.3.0
|
| 12 |
+
attrs==20.1.0
|
| 13 |
+
awscli==1.18.132
|
| 14 |
+
Babel==2.8.0
|
| 15 |
+
backcall==0.1.0
|
| 16 |
+
backports.functools-lru-cache==1.5
|
| 17 |
+
backports.os==0.1.1
|
| 18 |
+
backports.shutil-get-terminal-size==1.0.0
|
| 19 |
+
backports.tempfile==1.0
|
| 20 |
+
backports.weakref==1.0.post1
|
| 21 |
+
beautifulsoup4==4.7.1
|
| 22 |
+
bitarray==0.9.3
|
| 23 |
+
bkcharts==0.2
|
| 24 |
+
bleach==3.1.0
|
| 25 |
+
blis==0.2.4
|
| 26 |
+
bokeh==1.2.0
|
| 27 |
+
boto==2.49.0
|
| 28 |
+
boto3==1.14.55
|
| 29 |
+
botocore==1.17.55
|
| 30 |
+
Bottleneck==1.2.1
|
| 31 |
+
cachetools==4.1.1
|
| 32 |
+
certifi==2021.5.30
|
| 33 |
+
cffi==1.12.3
|
| 34 |
+
chardet==3.0.4
|
| 35 |
+
click==7.1.2
|
| 36 |
+
cloudpickle==1.2.1
|
| 37 |
+
clyent==1.2.2
|
| 38 |
+
colorama==0.4.3
|
| 39 |
+
conda==4.7.10
|
| 40 |
+
conda-build==3.18.8
|
| 41 |
+
conda-package-handling==1.3.11
|
| 42 |
+
conda-verify==3.4.2
|
| 43 |
+
conllu==0.11
|
| 44 |
+
contextlib2==0.5.5
|
| 45 |
+
cryptography==2.7
|
| 46 |
+
cycler==0.10.0
|
| 47 |
+
Cython==0.29.12
|
| 48 |
+
cytoolz==0.10.0
|
| 49 |
+
dask==2.1.0
|
| 50 |
+
decorator==4.4.0
|
| 51 |
+
defusedxml==0.6.0
|
| 52 |
+
detectron2==0.2.1+cu101
|
| 53 |
+
distributed==2.1.0
|
| 54 |
+
docutils==0.15.2
|
| 55 |
+
editdistance==0.5.3
|
| 56 |
+
entrypoints==0.3
|
| 57 |
+
et-xmlfile==1.0.1
|
| 58 |
+
fastapi==0.63.0
|
| 59 |
+
fastcache==1.1.0
|
| 60 |
+
filelock==3.0.12
|
| 61 |
+
flaky==3.7.0
|
| 62 |
+
Flask==1.1.2
|
| 63 |
+
Flask-Cors==3.0.9
|
| 64 |
+
ftfy==5.8
|
| 65 |
+
future==0.17.1
|
| 66 |
+
fvcore==0.1.1.post20200716
|
| 67 |
+
gast==0.3.3
|
| 68 |
+
gdown==3.13.0
|
| 69 |
+
gevent==20.6.2
|
| 70 |
+
glob2==0.7
|
| 71 |
+
gmpy2==2.0.8
|
| 72 |
+
google-auth==1.20.1
|
| 73 |
+
google-auth-oauthlib==0.4.1
|
| 74 |
+
google-pasta==0.2.0
|
| 75 |
+
greenlet==0.4.16
|
| 76 |
+
grpcio==1.31.0
|
| 77 |
+
gunicorn==20.0.4
|
| 78 |
+
h11==0.12.0
|
| 79 |
+
h5py==2.10.0
|
| 80 |
+
heapdict==1.0.0
|
| 81 |
+
html5lib==1.0.1
|
| 82 |
+
idna==2.10
|
| 83 |
+
imageio==2.5.0
|
| 84 |
+
imagesize==1.2.0
|
| 85 |
+
importlib-metadata==1.7.0
|
| 86 |
+
iniconfig==1.0.1
|
| 87 |
+
ipykernel==5.1.1
|
| 88 |
+
ipython==7.6.1
|
| 89 |
+
ipython-genutils==0.2.0
|
| 90 |
+
ipywidgets==7.5.0
|
| 91 |
+
isort==4.3.21
|
| 92 |
+
itsdangerous==1.1.0
|
| 93 |
+
jdcal==1.4.1
|
| 94 |
+
jedi==0.13.3
|
| 95 |
+
jeepney==0.4
|
| 96 |
+
Jinja2==2.11.2
|
| 97 |
+
jmespath==0.10.0
|
| 98 |
+
joblib==0.16.0
|
| 99 |
+
json5==0.8.4
|
| 100 |
+
jsonnet==0.16.0
|
| 101 |
+
jsonpickle==1.4.1
|
| 102 |
+
jsonschema==3.0.1
|
| 103 |
+
jupyter==1.0.0
|
| 104 |
+
jupyter-client==5.3.1
|
| 105 |
+
jupyter-console==6.0.0
|
| 106 |
+
jupyter-core==4.5.0
|
| 107 |
+
jupyterlab==1.0.2
|
| 108 |
+
jupyterlab-server==1.0.0
|
| 109 |
+
Keras-Preprocessing==1.1.2
|
| 110 |
+
keyring==18.0.0
|
| 111 |
+
kiwisolver==1.2.0
|
| 112 |
+
lazy-object-proxy==1.4.1
|
| 113 |
+
libarchive-c==2.8
|
| 114 |
+
lief==0.9.0
|
| 115 |
+
llvmlite==0.29.0
|
| 116 |
+
locket==0.2.0
|
| 117 |
+
lxml==4.3.4
|
| 118 |
+
Markdown==3.2.2
|
| 119 |
+
MarkupSafe==1.1.1
|
| 120 |
+
matplotlib==3.3.1
|
| 121 |
+
mccabe==0.6.1
|
| 122 |
+
mistune==0.8.4
|
| 123 |
+
mkl-fft==1.0.12
|
| 124 |
+
mkl-random==1.0.2
|
| 125 |
+
mkl-service==2.0.2
|
| 126 |
+
mock==3.0.5
|
| 127 |
+
more-itertools==8.5.0
|
| 128 |
+
mpmath==1.1.0
|
| 129 |
+
msgpack==0.6.1
|
| 130 |
+
multipledispatch==0.6.0
|
| 131 |
+
navigator-updater==0.2.1
|
| 132 |
+
nbconvert==5.5.0
|
| 133 |
+
nbformat==4.4.0
|
| 134 |
+
networkx==2.3
|
| 135 |
+
nltk==3.5
|
| 136 |
+
nose==1.3.7
|
| 137 |
+
notebook==6.0.0
|
| 138 |
+
numba==0.44.1
|
| 139 |
+
numexpr==2.6.9
|
| 140 |
+
numpy==1.18.5
|
| 141 |
+
numpydoc==1.1.0
|
| 142 |
+
oauthlib==3.1.0
|
| 143 |
+
olefile==0.46
|
| 144 |
+
openpyxl==2.6.2
|
| 145 |
+
opt-einsum==3.3.0
|
| 146 |
+
overrides==3.1.0
|
| 147 |
+
packaging==20.4
|
| 148 |
+
pandas==0.24.2
|
| 149 |
+
pandocfilters==1.4.2
|
| 150 |
+
parsimonious==0.8.1
|
| 151 |
+
parso==0.5.0
|
| 152 |
+
partd==1.0.0
|
| 153 |
+
path.py==12.0.1
|
| 154 |
+
pathlib2==2.3.4
|
| 155 |
+
patsy==0.5.1
|
| 156 |
+
pep8==1.7.1
|
| 157 |
+
pexpect==4.7.0
|
| 158 |
+
pickleshare==0.7.5
|
| 159 |
+
Pillow==7.2.0
|
| 160 |
+
pkginfo==1.5.0.1
|
| 161 |
+
plac==0.9.6
|
| 162 |
+
pluggy==0.13.1
|
| 163 |
+
ply==3.11
|
| 164 |
+
portalocker==2.0.0
|
| 165 |
+
prometheus-client==0.7.1
|
| 166 |
+
prompt-toolkit==2.0.9
|
| 167 |
+
protobuf==3.13.0
|
| 168 |
+
psutil==5.6.3
|
| 169 |
+
ptyprocess==0.6.0
|
| 170 |
+
py==1.9.0
|
| 171 |
+
pyasn1==0.4.8
|
| 172 |
+
pyasn1-modules==0.2.8
|
| 173 |
+
pycocotools==2.0.1
|
| 174 |
+
pycodestyle==2.5.0
|
| 175 |
+
pycosat==0.6.3
|
| 176 |
+
pycparser==2.19
|
| 177 |
+
pycrypto==2.6.1
|
| 178 |
+
pycurl==7.43.0.3
|
| 179 |
+
pydantic==1.7.3
|
| 180 |
+
pydot==1.4.1
|
| 181 |
+
pyflakes==2.1.1
|
| 182 |
+
Pygments==2.6.1
|
| 183 |
+
pylint==2.3.1
|
| 184 |
+
pyodbc==4.0.26
|
| 185 |
+
pyOpenSSL==19.0.0
|
| 186 |
+
pyparsing==2.4.7
|
| 187 |
+
pyrsistent==0.14.11
|
| 188 |
+
PySocks==1.7.0
|
| 189 |
+
pytesseract==0.3.8
|
| 190 |
+
pytest==6.0.1
|
| 191 |
+
pytest-arraydiff==0.3
|
| 192 |
+
pytest-astropy==0.5.0
|
| 193 |
+
pytest-doctestplus==0.3.0
|
| 194 |
+
pytest-openfiles==0.3.2
|
| 195 |
+
pytest-remotedata==0.3.1
|
| 196 |
+
python-dateutil==2.8.1
|
| 197 |
+
python-Levenshtein==0.12.0
|
| 198 |
+
pytorch-pretrained-bert==0.6.2
|
| 199 |
+
pytorch3d==0.3.0
|
| 200 |
+
pytz==2020.1
|
| 201 |
+
PyWavelets==1.0.3
|
| 202 |
+
PyYAML==5.3.1
|
| 203 |
+
pyzmq==18.0.0
|
| 204 |
+
QtAwesome==0.5.7
|
| 205 |
+
qtconsole==4.5.1
|
| 206 |
+
QtPy==1.8.0
|
| 207 |
+
regex==2020.7.14
|
| 208 |
+
requests==2.24.0
|
| 209 |
+
requests-oauthlib==1.3.0
|
| 210 |
+
responses==0.12.0
|
| 211 |
+
rope==0.14.0
|
| 212 |
+
rsa==4.5
|
| 213 |
+
ruamel-yaml==0.15.46
|
| 214 |
+
s3transfer==0.3.3
|
| 215 |
+
sacremoses==0.0.43
|
| 216 |
+
scikit-image==0.15.0
|
| 217 |
+
scikit-learn==0.20.0
|
| 218 |
+
scipy==1.4.1
|
| 219 |
+
seaborn==0.9.0
|
| 220 |
+
SecretStorage==3.1.1
|
| 221 |
+
Send2Trash==1.5.0
|
| 222 |
+
sentencepiece==0.1.91
|
| 223 |
+
simplegeneric==0.8.1
|
| 224 |
+
singledispatch==3.4.0.3
|
| 225 |
+
six==1.15.0
|
| 226 |
+
snowballstemmer==2.0.0
|
| 227 |
+
sortedcollections==1.1.2
|
| 228 |
+
sortedcontainers==2.1.0
|
| 229 |
+
soupsieve==1.8
|
| 230 |
+
spacy==2.1.9
|
| 231 |
+
Sphinx==3.2.1
|
| 232 |
+
sphinxcontrib-applehelp==1.0.2
|
| 233 |
+
sphinxcontrib-devhelp==1.0.2
|
| 234 |
+
sphinxcontrib-htmlhelp==1.0.3
|
| 235 |
+
sphinxcontrib-jsmath==1.0.1
|
| 236 |
+
sphinxcontrib-qthelp==1.0.3
|
| 237 |
+
sphinxcontrib-serializinghtml==1.1.4
|
| 238 |
+
sphinxcontrib-websupport==1.1.2
|
| 239 |
+
spyder==3.3.6
|
| 240 |
+
spyder-kernels==0.5.1
|
| 241 |
+
SQLAlchemy==1.3.5
|
| 242 |
+
sqlparse==0.3.1
|
| 243 |
+
srsly==1.0.2
|
| 244 |
+
starlette==0.13.6
|
| 245 |
+
statsmodels==0.10.0
|
| 246 |
+
sympy==1.4
|
| 247 |
+
tables==3.5.2
|
| 248 |
+
tabulate==0.8.7
|
| 249 |
+
tblib==1.4.0
|
| 250 |
+
tensorboard==2.3.0
|
| 251 |
+
tensorboard-plugin-wit==1.7.0
|
| 252 |
+
tensorboardX==2.1
|
| 253 |
+
tensorflow-estimator==2.3.0
|
| 254 |
+
tensorflow-gpu==2.3.0
|
| 255 |
+
termcolor==1.1.0
|
| 256 |
+
terminado==0.8.2
|
| 257 |
+
tesseract-ocr==0.0.1
|
| 258 |
+
testpath==0.4.2
|
| 259 |
+
thinc==7.0.8
|
| 260 |
+
toolz==0.10.0
|
| 261 |
+
tornado==6.0.3
|
| 262 |
+
tqdm==4.48.2
|
| 263 |
+
traitlets==4.3.2
|
| 264 |
+
transformers==2.2.2
|
| 265 |
+
typing-extensions==3.7.4.3
|
| 266 |
+
unicodecsv==0.14.1
|
| 267 |
+
Unidecode==1.1.1
|
| 268 |
+
urllib3==1.25.10
|
| 269 |
+
uvicorn==0.13.3
|
| 270 |
+
wasabi==0.8.0
|
| 271 |
+
wcwidth==0.2.5
|
| 272 |
+
webencodings==0.5.1
|
| 273 |
+
Werkzeug==1.0.1
|
| 274 |
+
widgetsnbextension==3.5.0
|
| 275 |
+
word2number==1.1
|
| 276 |
+
wrapt==1.12.1
|
| 277 |
+
wurlitzer==1.0.2
|
| 278 |
+
xlrd==1.2.0
|
| 279 |
+
XlsxWriter==1.1.8
|
| 280 |
+
xlwt==1.3.0
|
| 281 |
+
yacs==0.1.8
|
| 282 |
+
zict==1.0.0
|
| 283 |
+
zipp==3.1.0
|
| 284 |
+
zope.event==4.4
|
| 285 |
+
zope.interface==5.1.0
|
test.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
def test(model, testloader, criterion, DEVICE):
|
| 4 |
+
model.eval()
|
| 5 |
+
test_loss, correct = 0.0, 0
|
| 6 |
+
|
| 7 |
+
with torch.no_grad():
|
| 8 |
+
for imgs, targets in testloader:
|
| 9 |
+
imgs, targets = imgs.to(DEVICE), targets.to(DEVICE)
|
| 10 |
+
pred = model(imgs)
|
| 11 |
+
loss = criterion(pred, targets)
|
| 12 |
+
test_loss += loss.item()
|
| 13 |
+
correct += (pred.argmax(1) == targets).type(torch.float).sum().item()
|
| 14 |
+
|
| 15 |
+
# test_loss = test_loss / len(testloader)
|
| 16 |
+
accuracy = correct / len(testloader.dataset) * 100
|
| 17 |
+
|
| 18 |
+
return accuracy
|
tools/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from . import dataset
|
tools/dataset.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import check_integrity, download_and_extract_archive
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import os
|
| 5 |
+
import os.path
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pickle
|
| 8 |
+
from typing import Any, Callable, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import torchvision.transforms.functional as TF
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class UpsideDownDataset(Dataset):
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
+
Adapted from torchvision source code.
|
| 17 |
+
|
| 18 |
+
Horizontally flips every other image and makes its label '1',
|
| 19 |
+
otherwise makes its label '0'
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
base_folder = 'cifar-10-batches-py'
|
| 23 |
+
url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
|
| 24 |
+
filename = "cifar-10-python.tar.gz"
|
| 25 |
+
tgz_md5 = 'c58f30108f718f92721af3b95e74349a'
|
| 26 |
+
train_list = [
|
| 27 |
+
['data_batch_1', 'c99cafc152244af753f735de768cd75f'],
|
| 28 |
+
['data_batch_2', 'd4bba439e000b95fd0a9bffe97cbabec'],
|
| 29 |
+
['data_batch_3', '54ebc095f3ab1f0389bbae665268c751'],
|
| 30 |
+
['data_batch_4', '634d18415352ddfa80567beed471001a'],
|
| 31 |
+
['data_batch_5', '482c414d41f54cd18b22e5b47cb7c3cb'],
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
test_list = [
|
| 35 |
+
['test_batch', '40351d587109b95175f43aff81a1287e'],
|
| 36 |
+
]
|
| 37 |
+
meta = {
|
| 38 |
+
'filename': 'batches.meta',
|
| 39 |
+
'key': 'label_names',
|
| 40 |
+
'md5': '5ff9c542aee3614f3951f8cda6e48888',
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
def __init__(
|
| 44 |
+
self,
|
| 45 |
+
root: str,
|
| 46 |
+
train: bool = True,
|
| 47 |
+
transform: Optional[Callable] = None,
|
| 48 |
+
target_transform: Optional[Callable] = None,
|
| 49 |
+
download: bool = False,
|
| 50 |
+
) -> None:
|
| 51 |
+
|
| 52 |
+
# super(CIFAR10, self).__init__(root, transform=transform,
|
| 53 |
+
# target_transform=target_transform)
|
| 54 |
+
|
| 55 |
+
self.train = train # training set or test set
|
| 56 |
+
self.root = root
|
| 57 |
+
self.transform = transform
|
| 58 |
+
self.target_transform = target_transform
|
| 59 |
+
|
| 60 |
+
if download:
|
| 61 |
+
self.download()
|
| 62 |
+
|
| 63 |
+
# if not self._check_integrity():
|
| 64 |
+
# raise RuntimeError('Dataset not found or corrupted.' +
|
| 65 |
+
# ' You can use download=True to download it')
|
| 66 |
+
|
| 67 |
+
if self.train:
|
| 68 |
+
downloaded_list = self.train_list
|
| 69 |
+
else:
|
| 70 |
+
downloaded_list = self.test_list
|
| 71 |
+
|
| 72 |
+
self.data: Any = []
|
| 73 |
+
self.targets = []
|
| 74 |
+
|
| 75 |
+
# now load the picked numpy arrays
|
| 76 |
+
for file_name, checksum in downloaded_list:
|
| 77 |
+
file_path = os.path.join(self.root, self.base_folder, file_name)
|
| 78 |
+
with open(file_path, 'rb') as f:
|
| 79 |
+
entry = pickle.load(f, encoding='latin1')
|
| 80 |
+
self.data.append(entry['data'])
|
| 81 |
+
if 'labels' in entry:
|
| 82 |
+
self.targets.extend(entry['labels'])
|
| 83 |
+
else:
|
| 84 |
+
self.targets.extend(entry['fine_labels'])
|
| 85 |
+
|
| 86 |
+
self.data = np.vstack(self.data).reshape(-1, 3, 32, 32)
|
| 87 |
+
self.data = self.data.transpose((0, 2, 3, 1)) # convert to HWC
|
| 88 |
+
|
| 89 |
+
# self._load_meta()
|
| 90 |
+
|
| 91 |
+
# def _load_meta(self) -> None:
|
| 92 |
+
# path = os.path.join(self.root, self.base_folder, self.meta['filename'])
|
| 93 |
+
# if not check_integrity(path, self.meta['md5']):
|
| 94 |
+
# raise RuntimeError('Dataset metadata file not found or corrupted.' +
|
| 95 |
+
# ' You can use download=True to download it')
|
| 96 |
+
# with open(path, 'rb') as infile:
|
| 97 |
+
# data = pickle.load(infile, encoding='latin1')
|
| 98 |
+
# self.classes = data[self.meta['key']]
|
| 99 |
+
# self.class_to_idx = {_class: i for i, _class in enumerate(self.classes)}
|
| 100 |
+
|
| 101 |
+
def __getitem__(self, index: int) -> Tuple[Any, Any]:
|
| 102 |
+
"""
|
| 103 |
+
Args:
|
| 104 |
+
index (int): Index
|
| 105 |
+
|
| 106 |
+
Returns:
|
| 107 |
+
tuple: (image, target) where target is index of the target class.
|
| 108 |
+
"""
|
| 109 |
+
img, target = self.data[index], self.targets[index]
|
| 110 |
+
|
| 111 |
+
# doing this so that it is consistent with all other datasets
|
| 112 |
+
# to return a PIL Image
|
| 113 |
+
img = Image.fromarray(img)
|
| 114 |
+
|
| 115 |
+
if index % 2 == 0:
|
| 116 |
+
img = TF.vflip(img)
|
| 117 |
+
target = 1
|
| 118 |
+
|
| 119 |
+
if index % 2 != 0:
|
| 120 |
+
target = 0
|
| 121 |
+
|
| 122 |
+
if self.transform is not None:
|
| 123 |
+
img = self.transform(img)
|
| 124 |
+
|
| 125 |
+
if self.target_transform is not None:
|
| 126 |
+
target = self.target_transform(target)
|
| 127 |
+
|
| 128 |
+
return img, target
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def __len__(self) -> int:
|
| 132 |
+
return len(self.data)
|
| 133 |
+
|
| 134 |
+
def download(self) -> None:
|
| 135 |
+
# if self._check_integrity():
|
| 136 |
+
# print('Files already downloaded and verified')
|
| 137 |
+
# return
|
| 138 |
+
download_and_extract_archive(self.url, self.root, filename=self.filename, md5=self.tgz_md5)
|
| 139 |
+
|
| 140 |
+
def extra_repr(self) -> str:
|
| 141 |
+
return "Split: {}".format("Train" if self.train is True else "Test")
|
tools/utils.py
ADDED
|
@@ -0,0 +1,470 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import bz2
|
| 2 |
+
import gzip
|
| 3 |
+
import hashlib
|
| 4 |
+
import itertools
|
| 5 |
+
import lzma
|
| 6 |
+
import os
|
| 7 |
+
import os.path
|
| 8 |
+
import pathlib
|
| 9 |
+
import re
|
| 10 |
+
import sys
|
| 11 |
+
import tarfile
|
| 12 |
+
import urllib
|
| 13 |
+
import urllib.error
|
| 14 |
+
import urllib.request
|
| 15 |
+
import warnings
|
| 16 |
+
import zipfile
|
| 17 |
+
from typing import Any, Callable, List, Iterable, Optional, TypeVar, Dict, IO, Tuple, Iterator
|
| 18 |
+
from urllib.parse import urlparse
|
| 19 |
+
|
| 20 |
+
import requests
|
| 21 |
+
import torch
|
| 22 |
+
from torch.utils.model_zoo import tqdm
|
| 23 |
+
|
| 24 |
+
# from .._internally_replaced_utils import (
|
| 25 |
+
# _download_file_from_remote_location,
|
| 26 |
+
# _is_remote_location_available,
|
| 27 |
+
# )
|
| 28 |
+
|
| 29 |
+
def _download_file_from_remote_location(fpath: str, url: str) -> None:
|
| 30 |
+
pass
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def _is_remote_location_available() -> bool:
|
| 34 |
+
return False
|
| 35 |
+
|
| 36 |
+
USER_AGENT = "pytorch/vision"
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def _save_response_content(
|
| 40 |
+
content: Iterator[bytes],
|
| 41 |
+
destination: str,
|
| 42 |
+
length: Optional[int] = None,
|
| 43 |
+
) -> None:
|
| 44 |
+
with open(destination, "wb") as fh, tqdm(total=length) as pbar:
|
| 45 |
+
for chunk in content:
|
| 46 |
+
# filter out keep-alive new chunks
|
| 47 |
+
if not chunk:
|
| 48 |
+
continue
|
| 49 |
+
|
| 50 |
+
fh.write(chunk)
|
| 51 |
+
pbar.update(len(chunk))
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def _urlretrieve(url: str, filename: str, chunk_size: int = 1024 * 32) -> None:
|
| 55 |
+
with urllib.request.urlopen(urllib.request.Request(url, headers={"User-Agent": USER_AGENT})) as response:
|
| 56 |
+
_save_response_content(iter(lambda: response.read(chunk_size), b""), filename, length=response.length)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def gen_bar_updater() -> Callable[[int, int, int], None]:
|
| 60 |
+
warnings.warn("The function `gen_bar_update` is deprecated since 0.13 and will be removed in 0.15.")
|
| 61 |
+
pbar = tqdm(total=None)
|
| 62 |
+
|
| 63 |
+
def bar_update(count, block_size, total_size):
|
| 64 |
+
if pbar.total is None and total_size:
|
| 65 |
+
pbar.total = total_size
|
| 66 |
+
progress_bytes = count * block_size
|
| 67 |
+
pbar.update(progress_bytes - pbar.n)
|
| 68 |
+
|
| 69 |
+
return bar_update
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def calculate_md5(fpath: str, chunk_size: int = 1024 * 1024) -> str:
|
| 73 |
+
# Setting the `usedforsecurity` flag does not change anything about the functionality, but indicates that we are
|
| 74 |
+
# not using the MD5 checksum for cryptography. This enables its usage in restricted environments like FIPS. Without
|
| 75 |
+
# it torchvision.datasets is unusable in these environments since we perform a MD5 check everywhere.
|
| 76 |
+
md5 = hashlib.md5(**dict(usedforsecurity=False) if sys.version_info >= (3, 9) else dict())
|
| 77 |
+
with open(fpath, "rb") as f:
|
| 78 |
+
for chunk in iter(lambda: f.read(chunk_size), b""):
|
| 79 |
+
md5.update(chunk)
|
| 80 |
+
return md5.hexdigest()
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def check_md5(fpath: str, md5: str, **kwargs: Any) -> bool:
|
| 84 |
+
return md5 == calculate_md5(fpath, **kwargs)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def check_integrity(fpath: str, md5: Optional[str] = None) -> bool:
|
| 88 |
+
if not os.path.isfile(fpath):
|
| 89 |
+
return False
|
| 90 |
+
if md5 is None:
|
| 91 |
+
return True
|
| 92 |
+
return check_md5(fpath, md5)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def _get_redirect_url(url: str, max_hops: int = 3) -> str:
|
| 96 |
+
initial_url = url
|
| 97 |
+
headers = {"Method": "HEAD", "User-Agent": USER_AGENT}
|
| 98 |
+
|
| 99 |
+
for _ in range(max_hops + 1):
|
| 100 |
+
with urllib.request.urlopen(urllib.request.Request(url, headers=headers)) as response:
|
| 101 |
+
if response.url == url or response.url is None:
|
| 102 |
+
return url
|
| 103 |
+
|
| 104 |
+
url = response.url
|
| 105 |
+
else:
|
| 106 |
+
raise RecursionError(
|
| 107 |
+
f"Request to {initial_url} exceeded {max_hops} redirects. The last redirect points to {url}."
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def _get_google_drive_file_id(url: str) -> Optional[str]:
|
| 112 |
+
parts = urlparse(url)
|
| 113 |
+
|
| 114 |
+
if re.match(r"(drive|docs)[.]google[.]com", parts.netloc) is None:
|
| 115 |
+
return None
|
| 116 |
+
|
| 117 |
+
match = re.match(r"/file/d/(?P<id>[^/]*)", parts.path)
|
| 118 |
+
if match is None:
|
| 119 |
+
return None
|
| 120 |
+
|
| 121 |
+
return match.group("id")
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def download_url(
|
| 125 |
+
url: str, root: str, filename: Optional[str] = None, md5: Optional[str] = None, max_redirect_hops: int = 3
|
| 126 |
+
) -> None:
|
| 127 |
+
"""Download a file from a url and place it in root.
|
| 128 |
+
|
| 129 |
+
Args:
|
| 130 |
+
url (str): URL to download file from
|
| 131 |
+
root (str): Directory to place downloaded file in
|
| 132 |
+
filename (str, optional): Name to save the file under. If None, use the basename of the URL
|
| 133 |
+
md5 (str, optional): MD5 checksum of the download. If None, do not check
|
| 134 |
+
max_redirect_hops (int, optional): Maximum number of redirect hops allowed
|
| 135 |
+
"""
|
| 136 |
+
root = os.path.expanduser(root)
|
| 137 |
+
if not filename:
|
| 138 |
+
filename = os.path.basename(url)
|
| 139 |
+
fpath = os.path.join(root, filename)
|
| 140 |
+
|
| 141 |
+
os.makedirs(root, exist_ok=True)
|
| 142 |
+
|
| 143 |
+
# check if file is already present locally
|
| 144 |
+
if check_integrity(fpath, md5):
|
| 145 |
+
print("Using downloaded and verified file: " + fpath)
|
| 146 |
+
return
|
| 147 |
+
|
| 148 |
+
if _is_remote_location_available():
|
| 149 |
+
_download_file_from_remote_location(fpath, url)
|
| 150 |
+
else:
|
| 151 |
+
# expand redirect chain if needed
|
| 152 |
+
url = _get_redirect_url(url, max_hops=max_redirect_hops)
|
| 153 |
+
|
| 154 |
+
# check if file is located on Google Drive
|
| 155 |
+
file_id = _get_google_drive_file_id(url)
|
| 156 |
+
if file_id is not None:
|
| 157 |
+
return download_file_from_google_drive(file_id, root, filename, md5)
|
| 158 |
+
|
| 159 |
+
# download the file
|
| 160 |
+
try:
|
| 161 |
+
print("Downloading " + url + " to " + fpath)
|
| 162 |
+
_urlretrieve(url, fpath)
|
| 163 |
+
except (urllib.error.URLError, OSError) as e: # type: ignore[attr-defined]
|
| 164 |
+
if url[:5] == "https":
|
| 165 |
+
url = url.replace("https:", "http:")
|
| 166 |
+
print("Failed download. Trying https -> http instead. Downloading " + url + " to " + fpath)
|
| 167 |
+
_urlretrieve(url, fpath)
|
| 168 |
+
else:
|
| 169 |
+
raise e
|
| 170 |
+
|
| 171 |
+
# check integrity of downloaded file
|
| 172 |
+
if not check_integrity(fpath, md5):
|
| 173 |
+
raise RuntimeError("File not found or corrupted.")
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def list_dir(root: str, prefix: bool = False) -> List[str]:
|
| 177 |
+
"""List all directories at a given root
|
| 178 |
+
|
| 179 |
+
Args:
|
| 180 |
+
root (str): Path to directory whose folders need to be listed
|
| 181 |
+
prefix (bool, optional): If true, prepends the path to each result, otherwise
|
| 182 |
+
only returns the name of the directories found
|
| 183 |
+
"""
|
| 184 |
+
root = os.path.expanduser(root)
|
| 185 |
+
directories = [p for p in os.listdir(root) if os.path.isdir(os.path.join(root, p))]
|
| 186 |
+
if prefix is True:
|
| 187 |
+
directories = [os.path.join(root, d) for d in directories]
|
| 188 |
+
return directories
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def list_files(root: str, suffix: str, prefix: bool = False) -> List[str]:
|
| 192 |
+
"""List all files ending with a suffix at a given root
|
| 193 |
+
|
| 194 |
+
Args:
|
| 195 |
+
root (str): Path to directory whose folders need to be listed
|
| 196 |
+
suffix (str or tuple): Suffix of the files to match, e.g. '.png' or ('.jpg', '.png').
|
| 197 |
+
It uses the Python "str.endswith" method and is passed directly
|
| 198 |
+
prefix (bool, optional): If true, prepends the path to each result, otherwise
|
| 199 |
+
only returns the name of the files found
|
| 200 |
+
"""
|
| 201 |
+
root = os.path.expanduser(root)
|
| 202 |
+
files = [p for p in os.listdir(root) if os.path.isfile(os.path.join(root, p)) and p.endswith(suffix)]
|
| 203 |
+
if prefix is True:
|
| 204 |
+
files = [os.path.join(root, d) for d in files]
|
| 205 |
+
return files
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def _extract_gdrive_api_response(response, chunk_size: int = 32 * 1024) -> Tuple[bytes, Iterator[bytes]]:
|
| 209 |
+
content = response.iter_content(chunk_size)
|
| 210 |
+
first_chunk = None
|
| 211 |
+
# filter out keep-alive new chunks
|
| 212 |
+
while not first_chunk:
|
| 213 |
+
first_chunk = next(content)
|
| 214 |
+
content = itertools.chain([first_chunk], content)
|
| 215 |
+
|
| 216 |
+
try:
|
| 217 |
+
match = re.search("<title>Google Drive - (?P<api_response>.+?)</title>", first_chunk.decode())
|
| 218 |
+
api_response = match["api_response"] if match is not None else None
|
| 219 |
+
except UnicodeDecodeError:
|
| 220 |
+
api_response = None
|
| 221 |
+
return api_response, content
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def download_file_from_google_drive(file_id: str, root: str, filename: Optional[str] = None, md5: Optional[str] = None):
|
| 225 |
+
"""Download a Google Drive file from and place it in root.
|
| 226 |
+
|
| 227 |
+
Args:
|
| 228 |
+
file_id (str): id of file to be downloaded
|
| 229 |
+
root (str): Directory to place downloaded file in
|
| 230 |
+
filename (str, optional): Name to save the file under. If None, use the id of the file.
|
| 231 |
+
md5 (str, optional): MD5 checksum of the download. If None, do not check
|
| 232 |
+
"""
|
| 233 |
+
# Based on https://stackoverflow.com/questions/38511444/python-download-files-from-google-drive-using-url
|
| 234 |
+
|
| 235 |
+
root = os.path.expanduser(root)
|
| 236 |
+
if not filename:
|
| 237 |
+
filename = file_id
|
| 238 |
+
fpath = os.path.join(root, filename)
|
| 239 |
+
|
| 240 |
+
os.makedirs(root, exist_ok=True)
|
| 241 |
+
|
| 242 |
+
if check_integrity(fpath, md5):
|
| 243 |
+
print(f"Using downloaded {'and verified ' if md5 else ''}file: {fpath}")
|
| 244 |
+
|
| 245 |
+
url = "https://drive.google.com/uc"
|
| 246 |
+
params = dict(id=file_id, export="download")
|
| 247 |
+
with requests.Session() as session:
|
| 248 |
+
response = session.get(url, params=params, stream=True)
|
| 249 |
+
|
| 250 |
+
for key, value in response.cookies.items():
|
| 251 |
+
if key.startswith("download_warning"):
|
| 252 |
+
token = value
|
| 253 |
+
break
|
| 254 |
+
else:
|
| 255 |
+
api_response, content = _extract_gdrive_api_response(response)
|
| 256 |
+
token = "t" if api_response == "Virus scan warning" else None
|
| 257 |
+
|
| 258 |
+
if token is not None:
|
| 259 |
+
response = session.get(url, params=dict(params, confirm=token), stream=True)
|
| 260 |
+
api_response, content = _extract_gdrive_api_response(response)
|
| 261 |
+
|
| 262 |
+
if api_response == "Quota exceeded":
|
| 263 |
+
raise RuntimeError(
|
| 264 |
+
f"The daily quota of the file {filename} is exceeded and it "
|
| 265 |
+
f"can't be downloaded. This is a limitation of Google Drive "
|
| 266 |
+
f"and can only be overcome by trying again later."
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
_save_response_content(content, fpath)
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def _extract_tar(from_path: str, to_path: str, compression: Optional[str]) -> None:
|
| 273 |
+
with tarfile.open(from_path, f"r:{compression[1:]}" if compression else "r") as tar:
|
| 274 |
+
tar.extractall(to_path)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
_ZIP_COMPRESSION_MAP: Dict[str, int] = {
|
| 278 |
+
".bz2": zipfile.ZIP_BZIP2,
|
| 279 |
+
".xz": zipfile.ZIP_LZMA,
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
def _extract_zip(from_path: str, to_path: str, compression: Optional[str]) -> None:
|
| 284 |
+
with zipfile.ZipFile(
|
| 285 |
+
from_path, "r", compression=_ZIP_COMPRESSION_MAP[compression] if compression else zipfile.ZIP_STORED
|
| 286 |
+
) as zip:
|
| 287 |
+
zip.extractall(to_path)
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
_ARCHIVE_EXTRACTORS: Dict[str, Callable[[str, str, Optional[str]], None]] = {
|
| 291 |
+
".tar": _extract_tar,
|
| 292 |
+
".zip": _extract_zip,
|
| 293 |
+
}
|
| 294 |
+
_COMPRESSED_FILE_OPENERS: Dict[str, Callable[..., IO]] = {
|
| 295 |
+
".bz2": bz2.open,
|
| 296 |
+
".gz": gzip.open,
|
| 297 |
+
".xz": lzma.open,
|
| 298 |
+
}
|
| 299 |
+
_FILE_TYPE_ALIASES: Dict[str, Tuple[Optional[str], Optional[str]]] = {
|
| 300 |
+
".tbz": (".tar", ".bz2"),
|
| 301 |
+
".tbz2": (".tar", ".bz2"),
|
| 302 |
+
".tgz": (".tar", ".gz"),
|
| 303 |
+
}
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def _detect_file_type(file: str) -> Tuple[str, Optional[str], Optional[str]]:
|
| 307 |
+
"""Detect the archive type and/or compression of a file.
|
| 308 |
+
|
| 309 |
+
Args:
|
| 310 |
+
file (str): the filename
|
| 311 |
+
|
| 312 |
+
Returns:
|
| 313 |
+
(tuple): tuple of suffix, archive type, and compression
|
| 314 |
+
|
| 315 |
+
Raises:
|
| 316 |
+
RuntimeError: if file has no suffix or suffix is not supported
|
| 317 |
+
"""
|
| 318 |
+
suffixes = pathlib.Path(file).suffixes
|
| 319 |
+
if not suffixes:
|
| 320 |
+
raise RuntimeError(
|
| 321 |
+
f"File '{file}' has no suffixes that could be used to detect the archive type and compression."
|
| 322 |
+
)
|
| 323 |
+
suffix = suffixes[-1]
|
| 324 |
+
|
| 325 |
+
# check if the suffix is a known alias
|
| 326 |
+
if suffix in _FILE_TYPE_ALIASES:
|
| 327 |
+
return (suffix, *_FILE_TYPE_ALIASES[suffix])
|
| 328 |
+
|
| 329 |
+
# check if the suffix is an archive type
|
| 330 |
+
if suffix in _ARCHIVE_EXTRACTORS:
|
| 331 |
+
return suffix, suffix, None
|
| 332 |
+
|
| 333 |
+
# check if the suffix is a compression
|
| 334 |
+
if suffix in _COMPRESSED_FILE_OPENERS:
|
| 335 |
+
# check for suffix hierarchy
|
| 336 |
+
if len(suffixes) > 1:
|
| 337 |
+
suffix2 = suffixes[-2]
|
| 338 |
+
|
| 339 |
+
# check if the suffix2 is an archive type
|
| 340 |
+
if suffix2 in _ARCHIVE_EXTRACTORS:
|
| 341 |
+
return suffix2 + suffix, suffix2, suffix
|
| 342 |
+
|
| 343 |
+
return suffix, None, suffix
|
| 344 |
+
|
| 345 |
+
valid_suffixes = sorted(set(_FILE_TYPE_ALIASES) | set(_ARCHIVE_EXTRACTORS) | set(_COMPRESSED_FILE_OPENERS))
|
| 346 |
+
raise RuntimeError(f"Unknown compression or archive type: '{suffix}'.\nKnown suffixes are: '{valid_suffixes}'.")
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
def _decompress(from_path: str, to_path: Optional[str] = None, remove_finished: bool = False) -> str:
|
| 350 |
+
r"""Decompress a file.
|
| 351 |
+
|
| 352 |
+
The compression is automatically detected from the file name.
|
| 353 |
+
|
| 354 |
+
Args:
|
| 355 |
+
from_path (str): Path to the file to be decompressed.
|
| 356 |
+
to_path (str): Path to the decompressed file. If omitted, ``from_path`` without compression extension is used.
|
| 357 |
+
remove_finished (bool): If ``True``, remove the file after the extraction.
|
| 358 |
+
|
| 359 |
+
Returns:
|
| 360 |
+
(str): Path to the decompressed file.
|
| 361 |
+
"""
|
| 362 |
+
suffix, archive_type, compression = _detect_file_type(from_path)
|
| 363 |
+
if not compression:
|
| 364 |
+
raise RuntimeError(f"Couldn't detect a compression from suffix {suffix}.")
|
| 365 |
+
|
| 366 |
+
if to_path is None:
|
| 367 |
+
to_path = from_path.replace(suffix, archive_type if archive_type is not None else "")
|
| 368 |
+
|
| 369 |
+
# We don't need to check for a missing key here, since this was already done in _detect_file_type()
|
| 370 |
+
compressed_file_opener = _COMPRESSED_FILE_OPENERS[compression]
|
| 371 |
+
|
| 372 |
+
with compressed_file_opener(from_path, "rb") as rfh, open(to_path, "wb") as wfh:
|
| 373 |
+
wfh.write(rfh.read())
|
| 374 |
+
|
| 375 |
+
if remove_finished:
|
| 376 |
+
os.remove(from_path)
|
| 377 |
+
|
| 378 |
+
return to_path
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
def extract_archive(from_path: str, to_path: Optional[str] = None, remove_finished: bool = False) -> str:
|
| 382 |
+
"""Extract an archive.
|
| 383 |
+
|
| 384 |
+
The archive type and a possible compression is automatically detected from the file name. If the file is compressed
|
| 385 |
+
but not an archive the call is dispatched to :func:`decompress`.
|
| 386 |
+
|
| 387 |
+
Args:
|
| 388 |
+
from_path (str): Path to the file to be extracted.
|
| 389 |
+
to_path (str): Path to the directory the file will be extracted to. If omitted, the directory of the file is
|
| 390 |
+
used.
|
| 391 |
+
remove_finished (bool): If ``True``, remove the file after the extraction.
|
| 392 |
+
|
| 393 |
+
Returns:
|
| 394 |
+
(str): Path to the directory the file was extracted to.
|
| 395 |
+
"""
|
| 396 |
+
if to_path is None:
|
| 397 |
+
to_path = os.path.dirname(from_path)
|
| 398 |
+
|
| 399 |
+
suffix, archive_type, compression = _detect_file_type(from_path)
|
| 400 |
+
if not archive_type:
|
| 401 |
+
return _decompress(
|
| 402 |
+
from_path,
|
| 403 |
+
os.path.join(to_path, os.path.basename(from_path).replace(suffix, "")),
|
| 404 |
+
remove_finished=remove_finished,
|
| 405 |
+
)
|
| 406 |
+
|
| 407 |
+
# We don't need to check for a missing key here, since this was already done in _detect_file_type()
|
| 408 |
+
extractor = _ARCHIVE_EXTRACTORS[archive_type]
|
| 409 |
+
|
| 410 |
+
extractor(from_path, to_path, compression)
|
| 411 |
+
if remove_finished:
|
| 412 |
+
os.remove(from_path)
|
| 413 |
+
|
| 414 |
+
return to_path
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
def download_and_extract_archive(
|
| 418 |
+
url: str,
|
| 419 |
+
download_root: str,
|
| 420 |
+
extract_root: Optional[str] = None,
|
| 421 |
+
filename: Optional[str] = None,
|
| 422 |
+
md5: Optional[str] = None,
|
| 423 |
+
remove_finished: bool = False,
|
| 424 |
+
) -> None:
|
| 425 |
+
download_root = os.path.expanduser(download_root)
|
| 426 |
+
if extract_root is None:
|
| 427 |
+
extract_root = download_root
|
| 428 |
+
if not filename:
|
| 429 |
+
filename = os.path.basename(url)
|
| 430 |
+
|
| 431 |
+
download_url(url, download_root, filename, md5)
|
| 432 |
+
|
| 433 |
+
archive = os.path.join(download_root, filename)
|
| 434 |
+
print(f"Extracting {archive} to {extract_root}")
|
| 435 |
+
extract_archive(archive, extract_root, remove_finished)
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
def iterable_to_str(iterable: Iterable) -> str:
|
| 439 |
+
return "'" + "', '".join([str(item) for item in iterable]) + "'"
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
T = TypeVar("T", str, bytes)
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
def verify_str_arg(
|
| 446 |
+
value: T,
|
| 447 |
+
arg: Optional[str] = None,
|
| 448 |
+
valid_values: Iterable[T] = None,
|
| 449 |
+
custom_msg: Optional[str] = None,
|
| 450 |
+
) -> T:
|
| 451 |
+
if not isinstance(value, torch._six.string_classes):
|
| 452 |
+
if arg is None:
|
| 453 |
+
msg = "Expected type str, but got type {type}."
|
| 454 |
+
else:
|
| 455 |
+
msg = "Expected type str for argument {arg}, but got type {type}."
|
| 456 |
+
msg = msg.format(type=type(value), arg=arg)
|
| 457 |
+
raise ValueError(msg)
|
| 458 |
+
|
| 459 |
+
if valid_values is None:
|
| 460 |
+
return value
|
| 461 |
+
|
| 462 |
+
if value not in valid_values:
|
| 463 |
+
if custom_msg is not None:
|
| 464 |
+
msg = custom_msg
|
| 465 |
+
else:
|
| 466 |
+
msg = "Unknown value '{value}' for argument {arg}. Valid values are {{{valid_values}}}."
|
| 467 |
+
msg = msg.format(value=value, arg=arg, valid_values=iterable_to_str(valid_values))
|
| 468 |
+
raise ValueError(msg)
|
| 469 |
+
|
| 470 |
+
return value
|
train.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
def train(model, trainloader, optimizer, criterion, DEVICE):
|
| 4 |
+
model.train()
|
| 5 |
+
|
| 6 |
+
running_loss = 0
|
| 7 |
+
for itr, data in enumerate(trainloader):
|
| 8 |
+
# print(itr)
|
| 9 |
+
# print(data[0].shape, data[1].shape)
|
| 10 |
+
# print(len(trainloader))
|
| 11 |
+
# if itr % 100 == 0:
|
| 12 |
+
# print("itr: {}".format(itr))
|
| 13 |
+
optimizer.zero_grad()
|
| 14 |
+
|
| 15 |
+
imgs, target = data[0].to(DEVICE), data[1].to(DEVICE)
|
| 16 |
+
output_logits = model(imgs)
|
| 17 |
+
loss = criterion( output_logits, target)
|
| 18 |
+
|
| 19 |
+
running_loss = loss.item()
|
| 20 |
+
loss.backward()
|
| 21 |
+
optimizer.step()
|
| 22 |
+
|
| 23 |
+
epoch_loss = running_loss/len(trainloader)
|
| 24 |
+
print("epoch loss = {}".format(epoch_loss))
|
| 25 |
+
|
| 26 |
+
return epoch_loss
|
viz/final_curve.png
ADDED
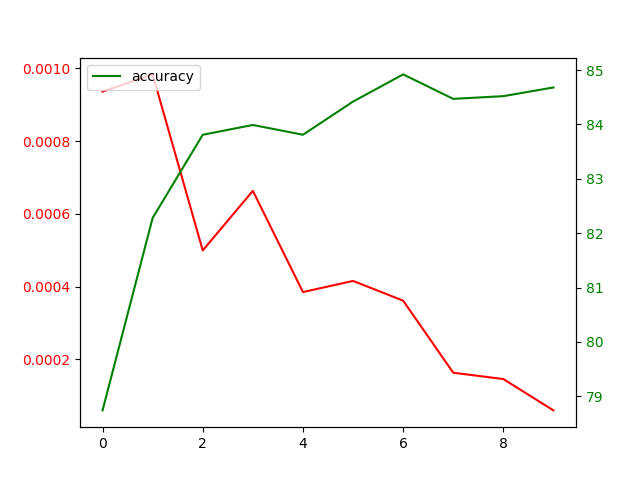
|
viz/img1.png
ADDED

|
viz/img2.png
ADDED

|
viz/img3.png
ADDED

|
viz/img4.png
ADDED

|
viz/img5.png
ADDED

|
viz/loss_curve.png
ADDED
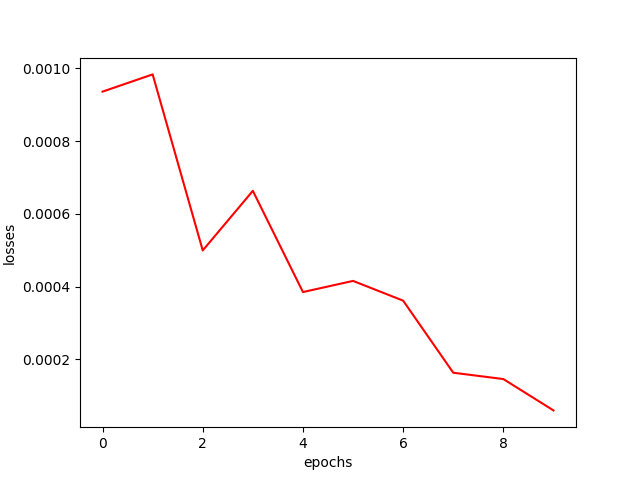
|
viz/save_plot.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
|
| 4 |
+
def save_plot(*arrays):
|
| 5 |
+
for array in args:
|
| 6 |
+
|