
Upload 190 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- MiDaS-master/.gitignore +110 -0
- MiDaS-master/Dockerfile +29 -0
- MiDaS-master/LICENSE +21 -0
- MiDaS-master/README.md +300 -0
- MiDaS-master/environment.yaml +16 -0
- MiDaS-master/figures/Comparison.png +3 -0
- MiDaS-master/figures/Improvement_vs_FPS.png +0 -0
- MiDaS-master/hubconf.py +435 -0
- MiDaS-master/input/.placeholder +0 -0
- MiDaS-master/midas/backbones/beit.py +196 -0
- MiDaS-master/midas/backbones/levit.py +106 -0
- MiDaS-master/midas/backbones/next_vit.py +39 -0
- MiDaS-master/midas/backbones/swin.py +13 -0
- MiDaS-master/midas/backbones/swin2.py +34 -0
- MiDaS-master/midas/backbones/swin_common.py +52 -0
- MiDaS-master/midas/backbones/utils.py +249 -0
- MiDaS-master/midas/backbones/vit.py +221 -0
- MiDaS-master/midas/base_model.py +16 -0
- MiDaS-master/midas/blocks.py +439 -0
- MiDaS-master/midas/dpt_depth.py +166 -0
- MiDaS-master/midas/midas_net.py +76 -0
- MiDaS-master/midas/midas_net_custom.py +128 -0
- MiDaS-master/midas/model_loader.py +242 -0
- MiDaS-master/midas/transforms.py +234 -0
- MiDaS-master/mobile/README.md +70 -0
- MiDaS-master/mobile/android/.gitignore +13 -0
- MiDaS-master/mobile/android/EXPLORE_THE_CODE.md +414 -0
- MiDaS-master/mobile/android/LICENSE +21 -0
- MiDaS-master/mobile/android/README.md +21 -0
- MiDaS-master/mobile/android/app/.gitignore +3 -0
- MiDaS-master/mobile/android/app/build.gradle +56 -0
- MiDaS-master/mobile/android/app/proguard-rules.pro +21 -0
- MiDaS-master/mobile/android/app/src/androidTest/assets/fox-mobilenet_v1_1.0_224_support.txt +3 -0
- MiDaS-master/mobile/android/app/src/androidTest/assets/fox-mobilenet_v1_1.0_224_task_api.txt +3 -0
- MiDaS-master/mobile/android/app/src/androidTest/java/AndroidManifest.xml +5 -0
- MiDaS-master/mobile/android/app/src/androidTest/java/org/tensorflow/lite/examples/classification/ClassifierTest.java +121 -0
- MiDaS-master/mobile/android/app/src/main/AndroidManifest.xml +28 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/CameraActivity.java +717 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/CameraConnectionFragment.java +575 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/ClassifierActivity.java +238 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/LegacyCameraConnectionFragment.java +203 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/AutoFitTextureView.java +72 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/OverlayView.java +48 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/RecognitionScoreView.java +67 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/ResultsView.java +23 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/BorderedText.java +115 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/ImageUtils.java +152 -0
- MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/Logger.java +186 -0
- MiDaS-master/mobile/android/app/src/main/res/drawable-hdpi/ic_launcher.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
MiDaS-master/figures/Comparison.png filter=lfs diff=lfs merge=lfs -text
|
MiDaS-master/.gitignore
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
*.egg-info/
|
| 24 |
+
.installed.cfg
|
| 25 |
+
*.egg
|
| 26 |
+
MANIFEST
|
| 27 |
+
|
| 28 |
+
# PyInstaller
|
| 29 |
+
# Usually these files are written by a python script from a template
|
| 30 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 31 |
+
*.manifest
|
| 32 |
+
*.spec
|
| 33 |
+
|
| 34 |
+
# Installer logs
|
| 35 |
+
pip-log.txt
|
| 36 |
+
pip-delete-this-directory.txt
|
| 37 |
+
|
| 38 |
+
# Unit test / coverage reports
|
| 39 |
+
htmlcov/
|
| 40 |
+
.tox/
|
| 41 |
+
.coverage
|
| 42 |
+
.coverage.*
|
| 43 |
+
.cache
|
| 44 |
+
nosetests.xml
|
| 45 |
+
coverage.xml
|
| 46 |
+
*.cover
|
| 47 |
+
.hypothesis/
|
| 48 |
+
.pytest_cache/
|
| 49 |
+
|
| 50 |
+
# Translations
|
| 51 |
+
*.mo
|
| 52 |
+
*.pot
|
| 53 |
+
|
| 54 |
+
# Django stuff:
|
| 55 |
+
*.log
|
| 56 |
+
local_settings.py
|
| 57 |
+
db.sqlite3
|
| 58 |
+
|
| 59 |
+
# Flask stuff:
|
| 60 |
+
instance/
|
| 61 |
+
.webassets-cache
|
| 62 |
+
|
| 63 |
+
# Scrapy stuff:
|
| 64 |
+
.scrapy
|
| 65 |
+
|
| 66 |
+
# Sphinx documentation
|
| 67 |
+
docs/_build/
|
| 68 |
+
|
| 69 |
+
# PyBuilder
|
| 70 |
+
target/
|
| 71 |
+
|
| 72 |
+
# Jupyter Notebook
|
| 73 |
+
.ipynb_checkpoints
|
| 74 |
+
|
| 75 |
+
# pyenv
|
| 76 |
+
.python-version
|
| 77 |
+
|
| 78 |
+
# celery beat schedule file
|
| 79 |
+
celerybeat-schedule
|
| 80 |
+
|
| 81 |
+
# SageMath parsed files
|
| 82 |
+
*.sage.py
|
| 83 |
+
|
| 84 |
+
# Environments
|
| 85 |
+
.env
|
| 86 |
+
.venv
|
| 87 |
+
env/
|
| 88 |
+
venv/
|
| 89 |
+
ENV/
|
| 90 |
+
env.bak/
|
| 91 |
+
venv.bak/
|
| 92 |
+
|
| 93 |
+
# Spyder project settings
|
| 94 |
+
.spyderproject
|
| 95 |
+
.spyproject
|
| 96 |
+
|
| 97 |
+
# Rope project settings
|
| 98 |
+
.ropeproject
|
| 99 |
+
|
| 100 |
+
# mkdocs documentation
|
| 101 |
+
/site
|
| 102 |
+
|
| 103 |
+
# mypy
|
| 104 |
+
.mypy_cache/
|
| 105 |
+
|
| 106 |
+
*.png
|
| 107 |
+
*.pfm
|
| 108 |
+
*.jpg
|
| 109 |
+
*.jpeg
|
| 110 |
+
*.pt
|
MiDaS-master/Dockerfile
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# enables cuda support in docker
|
| 2 |
+
FROM nvidia/cuda:10.2-cudnn7-runtime-ubuntu18.04
|
| 3 |
+
|
| 4 |
+
# install python 3.6, pip and requirements for opencv-python
|
| 5 |
+
# (see https://github.com/NVIDIA/nvidia-docker/issues/864)
|
| 6 |
+
RUN apt-get update && apt-get -y install \
|
| 7 |
+
python3 \
|
| 8 |
+
python3-pip \
|
| 9 |
+
libsm6 \
|
| 10 |
+
libxext6 \
|
| 11 |
+
libxrender-dev \
|
| 12 |
+
curl \
|
| 13 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 14 |
+
|
| 15 |
+
# install python dependencies
|
| 16 |
+
RUN pip3 install --upgrade pip
|
| 17 |
+
RUN pip3 install torch~=1.8 torchvision opencv-python-headless~=3.4 timm
|
| 18 |
+
|
| 19 |
+
# copy inference code
|
| 20 |
+
WORKDIR /opt/MiDaS
|
| 21 |
+
COPY ./midas ./midas
|
| 22 |
+
COPY ./*.py ./
|
| 23 |
+
|
| 24 |
+
# download model weights so the docker image can be used offline
|
| 25 |
+
RUN cd weights && {curl -OL https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt; cd -; }
|
| 26 |
+
RUN python3 run.py --model_type dpt_hybrid; exit 0
|
| 27 |
+
|
| 28 |
+
# entrypoint (dont forget to mount input and output directories)
|
| 29 |
+
CMD python3 run.py --model_type dpt_hybrid
|
MiDaS-master/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2019 Intel ISL (Intel Intelligent Systems Lab)
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
MiDaS-master/README.md
ADDED
|
@@ -0,0 +1,300 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 2 |
+
|
| 3 |
+
This repository contains code to compute depth from a single image. It accompanies our [paper](https://arxiv.org/abs/1907.01341v3):
|
| 4 |
+
|
| 5 |
+
>Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 6 |
+
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
and our [preprint](https://arxiv.org/abs/2103.13413):
|
| 10 |
+
|
| 11 |
+
> Vision Transformers for Dense Prediction
|
| 12 |
+
> René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
|
| 13 |
+
|
| 14 |
+
For the latest release MiDaS 3.1, a [technical report](https://arxiv.org/pdf/2307.14460.pdf) and [video](https://www.youtube.com/watch?v=UjaeNNFf9sE&t=3s) are available.
|
| 15 |
+
|
| 16 |
+
MiDaS was trained on up to 12 datasets (ReDWeb, DIML, Movies, MegaDepth, WSVD, TartanAir, HRWSI, ApolloScape, BlendedMVS, IRS, KITTI, NYU Depth V2) with
|
| 17 |
+
multi-objective optimization.
|
| 18 |
+
The original model that was trained on 5 datasets (`MIX 5` in the paper) can be found [here](https://github.com/isl-org/MiDaS/releases/tag/v2).
|
| 19 |
+
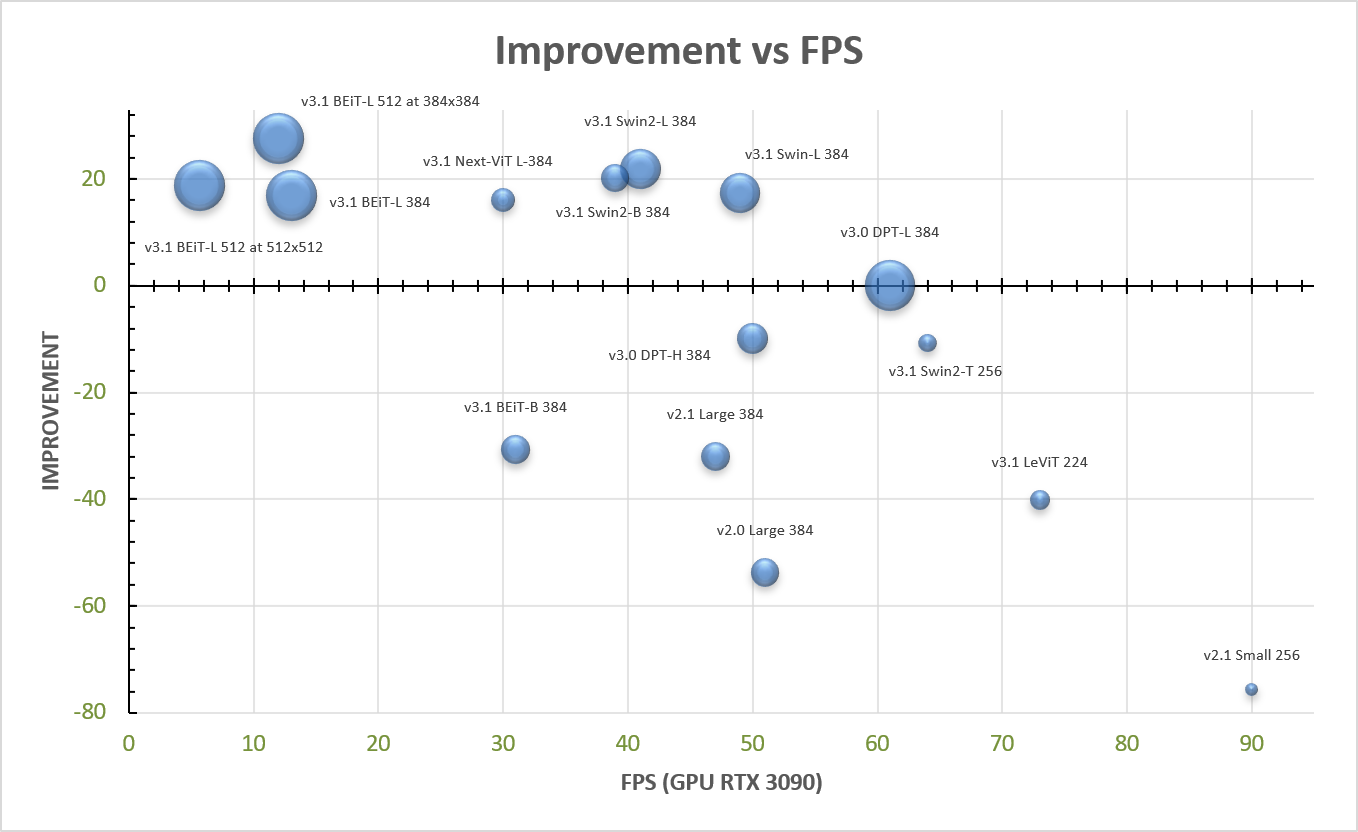
The figure below shows an overview of the different MiDaS models; the bubble size scales with number of parameters.
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
### Setup
|
| 24 |
+
|
| 25 |
+
1) Pick one or more models and download the corresponding weights to the `weights` folder:
|
| 26 |
+
|
| 27 |
+
MiDaS 3.1
|
| 28 |
+
- For highest quality: [dpt_beit_large_512](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)
|
| 29 |
+
- For moderately less quality, but better speed-performance trade-off: [dpt_swin2_large_384](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)
|
| 30 |
+
- For embedded devices: [dpt_swin2_tiny_256](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt), [dpt_levit_224](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)
|
| 31 |
+
- For inference on Intel CPUs, OpenVINO may be used for the small legacy model: openvino_midas_v21_small [.xml](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.xml), [.bin](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.bin)
|
| 32 |
+
|
| 33 |
+
MiDaS 3.0: Legacy transformer models [dpt_large_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) and [dpt_hybrid_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt)
|
| 34 |
+
|
| 35 |
+
MiDaS 2.1: Legacy convolutional models [midas_v21_384](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) and [midas_v21_small_256](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt)
|
| 36 |
+
|
| 37 |
+
1) Set up dependencies:
|
| 38 |
+
|
| 39 |
+
```shell
|
| 40 |
+
conda env create -f environment.yaml
|
| 41 |
+
conda activate midas-py310
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
#### optional
|
| 45 |
+
|
| 46 |
+
For the Next-ViT model, execute
|
| 47 |
+
|
| 48 |
+
```shell
|
| 49 |
+
git submodule add https://github.com/isl-org/Next-ViT midas/external/next_vit
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
For the OpenVINO model, install
|
| 53 |
+
|
| 54 |
+
```shell
|
| 55 |
+
pip install openvino
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
### Usage
|
| 59 |
+
|
| 60 |
+
1) Place one or more input images in the folder `input`.
|
| 61 |
+
|
| 62 |
+
2) Run the model with
|
| 63 |
+
|
| 64 |
+
```shell
|
| 65 |
+
python run.py --model_type <model_type> --input_path input --output_path output
|
| 66 |
+
```
|
| 67 |
+
where ```<model_type>``` is chosen from [dpt_beit_large_512](#model_type), [dpt_beit_large_384](#model_type),
|
| 68 |
+
[dpt_beit_base_384](#model_type), [dpt_swin2_large_384](#model_type), [dpt_swin2_base_384](#model_type),
|
| 69 |
+
[dpt_swin2_tiny_256](#model_type), [dpt_swin_large_384](#model_type), [dpt_next_vit_large_384](#model_type),
|
| 70 |
+
[dpt_levit_224](#model_type), [dpt_large_384](#model_type), [dpt_hybrid_384](#model_type),
|
| 71 |
+
[midas_v21_384](#model_type), [midas_v21_small_256](#model_type), [openvino_midas_v21_small_256](#model_type).
|
| 72 |
+
|
| 73 |
+
3) The resulting depth maps are written to the `output` folder.
|
| 74 |
+
|
| 75 |
+
#### optional
|
| 76 |
+
|
| 77 |
+
1) By default, the inference resizes the height of input images to the size of a model to fit into the encoder. This
|
| 78 |
+
size is given by the numbers in the model names of the [accuracy table](#accuracy). Some models do not only support a single
|
| 79 |
+
inference height but a range of different heights. Feel free to explore different heights by appending the extra
|
| 80 |
+
command line argument `--height`. Unsupported height values will throw an error. Note that using this argument may
|
| 81 |
+
decrease the model accuracy.
|
| 82 |
+
2) By default, the inference keeps the aspect ratio of input images when feeding them into the encoder if this is
|
| 83 |
+
supported by a model (all models except for Swin, Swin2, LeViT). In order to resize to a square resolution,
|
| 84 |
+
disregarding the aspect ratio while preserving the height, use the command line argument `--square`.
|
| 85 |
+
|
| 86 |
+
#### via Camera
|
| 87 |
+
|
| 88 |
+
If you want the input images to be grabbed from the camera and shown in a window, leave the input and output paths
|
| 89 |
+
away and choose a model type as shown above:
|
| 90 |
+
|
| 91 |
+
```shell
|
| 92 |
+
python run.py --model_type <model_type> --side
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
The argument `--side` is optional and causes both the input RGB image and the output depth map to be shown
|
| 96 |
+
side-by-side for comparison.
|
| 97 |
+
|
| 98 |
+
#### via Docker
|
| 99 |
+
|
| 100 |
+
1) Make sure you have installed Docker and the
|
| 101 |
+
[NVIDIA Docker runtime](https://github.com/NVIDIA/nvidia-docker/wiki/Installation-\(Native-GPU-Support\)).
|
| 102 |
+
|
| 103 |
+
2) Build the Docker image:
|
| 104 |
+
|
| 105 |
+
```shell
|
| 106 |
+
docker build -t midas .
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
3) Run inference:
|
| 110 |
+
|
| 111 |
+
```shell
|
| 112 |
+
docker run --rm --gpus all -v $PWD/input:/opt/MiDaS/input -v $PWD/output:/opt/MiDaS/output -v $PWD/weights:/opt/MiDaS/weights midas
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
This command passes through all of your NVIDIA GPUs to the container, mounts the
|
| 116 |
+
`input` and `output` directories and then runs the inference.
|
| 117 |
+
|
| 118 |
+
#### via PyTorch Hub
|
| 119 |
+
|
| 120 |
+
The pretrained model is also available on [PyTorch Hub](https://pytorch.org/hub/intelisl_midas_v2/)
|
| 121 |
+
|
| 122 |
+
#### via TensorFlow or ONNX
|
| 123 |
+
|
| 124 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/tf) in the `tf` subdirectory.
|
| 125 |
+
|
| 126 |
+
Currently only supports MiDaS v2.1.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
#### via Mobile (iOS / Android)
|
| 130 |
+
|
| 131 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/mobile) in the `mobile` subdirectory.
|
| 132 |
+
|
| 133 |
+
#### via ROS1 (Robot Operating System)
|
| 134 |
+
|
| 135 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/ros) in the `ros` subdirectory.
|
| 136 |
+
|
| 137 |
+
Currently only supports MiDaS v2.1. DPT-based models to be added.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
### Accuracy
|
| 141 |
+
|
| 142 |
+
We provide a **zero-shot error** $\epsilon_d$ which is evaluated for 6 different datasets
|
| 143 |
+
(see [paper](https://arxiv.org/abs/1907.01341v3)). **Lower error values are better**.
|
| 144 |
+
$\color{green}{\textsf{Overall model quality is represented by the improvement}}$ ([Imp.](#improvement)) with respect to
|
| 145 |
+
MiDaS 3.0 DPT<sub>L-384</sub>. The models are grouped by the height used for inference, whereas the square training resolution is given by
|
| 146 |
+
the numbers in the model names. The table also shows the **number of parameters** (in millions) and the
|
| 147 |
+
**frames per second** for inference at the training resolution (for GPU RTX 3090):
|
| 148 |
+
|
| 149 |
+
| MiDaS Model | DIW </br><sup>WHDR</sup> | Eth3d </br><sup>AbsRel</sup> | Sintel </br><sup>AbsRel</sup> | TUM </br><sup>δ1</sup> | KITTI </br><sup>δ1</sup> | NYUv2 </br><sup>δ1</sup> | $\color{green}{\textsf{Imp.}}$ </br><sup>%</sup> | Par.</br><sup>M</sup> | FPS</br><sup> </sup> |
|
| 150 |
+
|-----------------------------------------------------------------------------------------------------------------------|-------------------------:|-----------------------------:|------------------------------:|-------------------------:|-------------------------:|-------------------------:|-------------------------------------------------:|----------------------:|--------------------------:|
|
| 151 |
+
| **Inference height 512** | | | | | | | | | |
|
| 152 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1137 | 0.0659 | 0.2366 | **6.13** | 11.56* | **1.86*** | $\color{green}{\textsf{19}}$ | **345** | **5.7** |
|
| 153 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)$\tiny{\square}$ | **0.1121** | **0.0614** | **0.2090** | 6.46 | **5.00*** | 1.90* | $\color{green}{\textsf{34}}$ | **345** | **5.7** |
|
| 154 |
+
| | | | | | | | | | |
|
| 155 |
+
| **Inference height 384** | | | | | | | | | |
|
| 156 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1245 | 0.0681 | **0.2176** | **6.13** | 6.28* | **2.16*** | $\color{green}{\textsf{28}}$ | 345 | 12 |
|
| 157 |
+
| [v3.1 Swin2<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)$\tiny{\square}$ | 0.1106 | 0.0732 | 0.2442 | 8.87 | **5.84*** | 2.92* | $\color{green}{\textsf{22}}$ | 213 | 41 |
|
| 158 |
+
| [v3.1 Swin2<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_base_384.pt)$\tiny{\square}$ | 0.1095 | 0.0790 | 0.2404 | 8.93 | 5.97* | 3.28* | $\color{green}{\textsf{22}}$ | 102 | 39 |
|
| 159 |
+
| [v3.1 Swin<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin_large_384.pt)$\tiny{\square}$ | 0.1126 | 0.0853 | 0.2428 | 8.74 | 6.60* | 3.34* | $\color{green}{\textsf{17}}$ | 213 | 49 |
|
| 160 |
+
| [v3.1 BEiT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_384.pt) | 0.1239 | **0.0667** | 0.2545 | 7.17 | 9.84* | 2.21* | $\color{green}{\textsf{17}}$ | 344 | 13 |
|
| 161 |
+
| [v3.1 Next-ViT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_next_vit_large_384.pt) | **0.1031** | 0.0954 | 0.2295 | 9.21 | 6.89* | 3.47* | $\color{green}{\textsf{16}}$ | **72** | 30 |
|
| 162 |
+
| [v3.1 BEiT<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_base_384.pt) | 0.1159 | 0.0967 | 0.2901 | 9.88 | 26.60* | 3.91* | $\color{green}{\textsf{-31}}$ | 112 | 31 |
|
| 163 |
+
| [v3.0 DPT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) | 0.1082 | 0.0888 | 0.2697 | 9.97 | 8.46 | 8.32 | $\color{green}{\textsf{0}}$ | 344 | **61** |
|
| 164 |
+
| [v3.0 DPT<sub>H-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt) | 0.1106 | 0.0934 | 0.2741 | 10.89 | 11.56 | 8.69 | $\color{green}{\textsf{-10}}$ | 123 | 50 |
|
| 165 |
+
| [v2.1 Large<sub>384</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) | 0.1295 | 0.1155 | 0.3285 | 12.51 | 16.08 | 8.71 | $\color{green}{\textsf{-32}}$ | 105 | 47 |
|
| 166 |
+
| | | | | | | | | | |
|
| 167 |
+
| **Inference height 256** | | | | | | | | | |
|
| 168 |
+
| [v3.1 Swin2<sub>T-256</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt)$\tiny{\square}$ | **0.1211** | **0.1106** | **0.2868** | **13.43** | **10.13*** | **5.55*** | $\color{green}{\textsf{-11}}$ | 42 | 64 |
|
| 169 |
+
| [v2.1 Small<sub>256</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt) | 0.1344 | 0.1344 | 0.3370 | 14.53 | 29.27 | 13.43 | $\color{green}{\textsf{-76}}$ | **21** | **90** |
|
| 170 |
+
| | | | | | | | | | |
|
| 171 |
+
| **Inference height 224** | | | | | | | | | |
|
| 172 |
+
| [v3.1 LeViT<sub>224</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)$\tiny{\square}$ | **0.1314** | **0.1206** | **0.3148** | **18.21** | **15.27*** | **8.64*** | $\color{green}{\textsf{-40}}$ | **51** | **73** |
|
| 173 |
+
|
| 174 |
+
* No zero-shot error, because models are also trained on KITTI and NYU Depth V2\
|
| 175 |
+
$\square$ Validation performed at **square resolution**, either because the transformer encoder backbone of a model
|
| 176 |
+
does not support non-square resolutions (Swin, Swin2, LeViT) or for comparison with these models. All other
|
| 177 |
+
validations keep the aspect ratio. A difference in resolution limits the comparability of the zero-shot error and the
|
| 178 |
+
improvement, because these quantities are averages over the pixels of an image and do not take into account the
|
| 179 |
+
advantage of more details due to a higher resolution.\
|
| 180 |
+
Best values per column and same validation height in bold
|
| 181 |
+
|
| 182 |
+
#### Improvement
|
| 183 |
+
|
| 184 |
+
The improvement in the above table is defined as the relative zero-shot error with respect to MiDaS v3.0
|
| 185 |
+
DPT<sub>L-384</sub> and averaging over the datasets. So, if $\epsilon_d$ is the zero-shot error for dataset $d$, then
|
| 186 |
+
the $\color{green}{\textsf{improvement}}$ is given by $100(1-(1/6)\sum_d\epsilon_d/\epsilon_{d,\rm{DPT_{L-384}}})$%.
|
| 187 |
+
|
| 188 |
+
Note that the improvements of 10% for MiDaS v2.0 → v2.1 and 21% for MiDaS v2.1 → v3.0 are not visible from the
|
| 189 |
+
improvement column (Imp.) in the table but would require an evaluation with respect to MiDaS v2.1 Large<sub>384</sub>
|
| 190 |
+
and v2.0 Large<sub>384</sub> respectively instead of v3.0 DPT<sub>L-384</sub>.
|
| 191 |
+
|
| 192 |
+
### Depth map comparison
|
| 193 |
+
|
| 194 |
+
Zoom in for better visibility
|
| 195 |
+

|
| 196 |
+
|
| 197 |
+
### Speed on Camera Feed
|
| 198 |
+
|
| 199 |
+
Test configuration
|
| 200 |
+
- Windows 10
|
| 201 |
+
- 11th Gen Intel Core i7-1185G7 3.00GHz
|
| 202 |
+
- 16GB RAM
|
| 203 |
+
- Camera resolution 640x480
|
| 204 |
+
- openvino_midas_v21_small_256
|
| 205 |
+
|
| 206 |
+
Speed: 22 FPS
|
| 207 |
+
|
| 208 |
+
### Applications
|
| 209 |
+
|
| 210 |
+
MiDaS is used in the following other projects from Intel Labs:
|
| 211 |
+
|
| 212 |
+
- [ZoeDepth](https://arxiv.org/pdf/2302.12288.pdf) (code available [here](https://github.com/isl-org/ZoeDepth)): MiDaS computes the relative depth map given an image. For metric depth estimation, ZoeDepth can be used, which combines MiDaS with a metric depth binning module appended to the decoder.
|
| 213 |
+
- [LDM3D](https://arxiv.org/pdf/2305.10853.pdf) (Hugging Face model available [here](https://huggingface.co/Intel/ldm3d-4c)): LDM3D is an extension of vanilla stable diffusion designed to generate joint image and depth data from a text prompt. The depth maps used for supervision when training LDM3D have been computed using MiDaS.
|
| 214 |
+
|
| 215 |
+
### Changelog
|
| 216 |
+
|
| 217 |
+
* [Dec 2022] Released [MiDaS v3.1](https://arxiv.org/pdf/2307.14460.pdf):
|
| 218 |
+
- New models based on 5 different types of transformers ([BEiT](https://arxiv.org/pdf/2106.08254.pdf), [Swin2](https://arxiv.org/pdf/2111.09883.pdf), [Swin](https://arxiv.org/pdf/2103.14030.pdf), [Next-ViT](https://arxiv.org/pdf/2207.05501.pdf), [LeViT](https://arxiv.org/pdf/2104.01136.pdf))
|
| 219 |
+
- Training datasets extended from 10 to 12, including also KITTI and NYU Depth V2 using [BTS](https://github.com/cleinc/bts) split
|
| 220 |
+
- Best model, BEiT<sub>Large 512</sub>, with resolution 512x512, is on average about [28% more accurate](#Accuracy) than MiDaS v3.0
|
| 221 |
+
- Integrated live depth estimation from camera feed
|
| 222 |
+
* [Sep 2021] Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See [Gradio Web Demo](https://huggingface.co/spaces/akhaliq/DPT-Large).
|
| 223 |
+
* [Apr 2021] Released MiDaS v3.0:
|
| 224 |
+
- New models based on [Dense Prediction Transformers](https://arxiv.org/abs/2103.13413) are on average [21% more accurate](#Accuracy) than MiDaS v2.1
|
| 225 |
+
- Additional models can be found [here](https://github.com/isl-org/DPT)
|
| 226 |
+
* [Nov 2020] Released MiDaS v2.1:
|
| 227 |
+
- New model that was trained on 10 datasets and is on average about [10% more accurate](#Accuracy) than [MiDaS v2.0](https://github.com/isl-org/MiDaS/releases/tag/v2)
|
| 228 |
+
- New light-weight model that achieves [real-time performance](https://github.com/isl-org/MiDaS/tree/master/mobile) on mobile platforms.
|
| 229 |
+
- Sample applications for [iOS](https://github.com/isl-org/MiDaS/tree/master/mobile/ios) and [Android](https://github.com/isl-org/MiDaS/tree/master/mobile/android)
|
| 230 |
+
- [ROS package](https://github.com/isl-org/MiDaS/tree/master/ros) for easy deployment on robots
|
| 231 |
+
* [Jul 2020] Added TensorFlow and ONNX code. Added [online demo](http://35.202.76.57/).
|
| 232 |
+
* [Dec 2019] Released new version of MiDaS - the new model is significantly more accurate and robust
|
| 233 |
+
* [Jul 2019] Initial release of MiDaS ([Link](https://github.com/isl-org/MiDaS/releases/tag/v1))
|
| 234 |
+
|
| 235 |
+
### Citation
|
| 236 |
+
|
| 237 |
+
Please cite our paper if you use this code or any of the models:
|
| 238 |
+
```
|
| 239 |
+
@ARTICLE {Ranftl2022,
|
| 240 |
+
author = "Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun",
|
| 241 |
+
title = "Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer",
|
| 242 |
+
journal = "IEEE Transactions on Pattern Analysis and Machine Intelligence",
|
| 243 |
+
year = "2022",
|
| 244 |
+
volume = "44",
|
| 245 |
+
number = "3"
|
| 246 |
+
}
|
| 247 |
+
```
|
| 248 |
+
|
| 249 |
+
If you use a DPT-based model, please also cite:
|
| 250 |
+
|
| 251 |
+
```
|
| 252 |
+
@article{Ranftl2021,
|
| 253 |
+
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
|
| 254 |
+
title = {Vision Transformers for Dense Prediction},
|
| 255 |
+
journal = {ICCV},
|
| 256 |
+
year = {2021},
|
| 257 |
+
}
|
| 258 |
+
```
|
| 259 |
+
|
| 260 |
+
Please cite the technical report for MiDaS 3.1 models:
|
| 261 |
+
|
| 262 |
+
```
|
| 263 |
+
@article{birkl2023midas,
|
| 264 |
+
title={MiDaS v3.1 -- A Model Zoo for Robust Monocular Relative Depth Estimation},
|
| 265 |
+
author={Reiner Birkl and Diana Wofk and Matthias M{\"u}ller},
|
| 266 |
+
journal={arXiv preprint arXiv:2307.14460},
|
| 267 |
+
year={2023}
|
| 268 |
+
}
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
For ZoeDepth, please use
|
| 272 |
+
|
| 273 |
+
```
|
| 274 |
+
@article{bhat2023zoedepth,
|
| 275 |
+
title={Zoedepth: Zero-shot transfer by combining relative and metric depth},
|
| 276 |
+
author={Bhat, Shariq Farooq and Birkl, Reiner and Wofk, Diana and Wonka, Peter and M{\"u}ller, Matthias},
|
| 277 |
+
journal={arXiv preprint arXiv:2302.12288},
|
| 278 |
+
year={2023}
|
| 279 |
+
}
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
and for LDM3D
|
| 283 |
+
|
| 284 |
+
```
|
| 285 |
+
@article{stan2023ldm3d,
|
| 286 |
+
title={LDM3D: Latent Diffusion Model for 3D},
|
| 287 |
+
author={Stan, Gabriela Ben Melech and Wofk, Diana and Fox, Scottie and Redden, Alex and Saxton, Will and Yu, Jean and Aflalo, Estelle and Tseng, Shao-Yen and Nonato, Fabio and Muller, Matthias and others},
|
| 288 |
+
journal={arXiv preprint arXiv:2305.10853},
|
| 289 |
+
year={2023}
|
| 290 |
+
}
|
| 291 |
+
```
|
| 292 |
+
|
| 293 |
+
### Acknowledgements
|
| 294 |
+
|
| 295 |
+
Our work builds on and uses code from [timm](https://github.com/rwightman/pytorch-image-models) and [Next-ViT](https://github.com/bytedance/Next-ViT).
|
| 296 |
+
We'd like to thank the authors for making these libraries available.
|
| 297 |
+
|
| 298 |
+
### License
|
| 299 |
+
|
| 300 |
+
MIT License
|
MiDaS-master/environment.yaml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: midas-py310
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
dependencies:
|
| 6 |
+
- nvidia::cudatoolkit=11.7
|
| 7 |
+
- python=3.10.8
|
| 8 |
+
- pytorch::pytorch=1.13.0
|
| 9 |
+
- torchvision=0.14.0
|
| 10 |
+
- pip=22.3.1
|
| 11 |
+
- numpy=1.23.4
|
| 12 |
+
- pip:
|
| 13 |
+
- opencv-python==4.6.0.66
|
| 14 |
+
- imutils==0.5.4
|
| 15 |
+
- timm==0.6.12
|
| 16 |
+
- einops==0.6.0
|
MiDaS-master/figures/Comparison.png
ADDED

|
Git LFS Details
|
MiDaS-master/figures/Improvement_vs_FPS.png
ADDED
|
MiDaS-master/hubconf.py
ADDED
|
@@ -0,0 +1,435 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dependencies = ["torch"]
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
from midas.dpt_depth import DPTDepthModel
|
| 6 |
+
from midas.midas_net import MidasNet
|
| 7 |
+
from midas.midas_net_custom import MidasNet_small
|
| 8 |
+
|
| 9 |
+
def DPT_BEiT_L_512(pretrained=True, **kwargs):
|
| 10 |
+
""" # This docstring shows up in hub.help()
|
| 11 |
+
MiDaS DPT_BEiT_L_512 model for monocular depth estimation
|
| 12 |
+
pretrained (bool): load pretrained weights into model
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
model = DPTDepthModel(
|
| 16 |
+
path=None,
|
| 17 |
+
backbone="beitl16_512",
|
| 18 |
+
non_negative=True,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
if pretrained:
|
| 22 |
+
checkpoint = (
|
| 23 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt"
|
| 24 |
+
)
|
| 25 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 26 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 27 |
+
)
|
| 28 |
+
model.load_state_dict(state_dict)
|
| 29 |
+
|
| 30 |
+
return model
|
| 31 |
+
|
| 32 |
+
def DPT_BEiT_L_384(pretrained=True, **kwargs):
|
| 33 |
+
""" # This docstring shows up in hub.help()
|
| 34 |
+
MiDaS DPT_BEiT_L_384 model for monocular depth estimation
|
| 35 |
+
pretrained (bool): load pretrained weights into model
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
model = DPTDepthModel(
|
| 39 |
+
path=None,
|
| 40 |
+
backbone="beitl16_384",
|
| 41 |
+
non_negative=True,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
if pretrained:
|
| 45 |
+
checkpoint = (
|
| 46 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_384.pt"
|
| 47 |
+
)
|
| 48 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 49 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 50 |
+
)
|
| 51 |
+
model.load_state_dict(state_dict)
|
| 52 |
+
|
| 53 |
+
return model
|
| 54 |
+
|
| 55 |
+
def DPT_BEiT_B_384(pretrained=True, **kwargs):
|
| 56 |
+
""" # This docstring shows up in hub.help()
|
| 57 |
+
MiDaS DPT_BEiT_B_384 model for monocular depth estimation
|
| 58 |
+
pretrained (bool): load pretrained weights into model
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
model = DPTDepthModel(
|
| 62 |
+
path=None,
|
| 63 |
+
backbone="beitb16_384",
|
| 64 |
+
non_negative=True,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
if pretrained:
|
| 68 |
+
checkpoint = (
|
| 69 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_base_384.pt"
|
| 70 |
+
)
|
| 71 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 72 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 73 |
+
)
|
| 74 |
+
model.load_state_dict(state_dict)
|
| 75 |
+
|
| 76 |
+
return model
|
| 77 |
+
|
| 78 |
+
def DPT_SwinV2_L_384(pretrained=True, **kwargs):
|
| 79 |
+
""" # This docstring shows up in hub.help()
|
| 80 |
+
MiDaS DPT_SwinV2_L_384 model for monocular depth estimation
|
| 81 |
+
pretrained (bool): load pretrained weights into model
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
model = DPTDepthModel(
|
| 85 |
+
path=None,
|
| 86 |
+
backbone="swin2l24_384",
|
| 87 |
+
non_negative=True,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if pretrained:
|
| 91 |
+
checkpoint = (
|
| 92 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt"
|
| 93 |
+
)
|
| 94 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 95 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 96 |
+
)
|
| 97 |
+
model.load_state_dict(state_dict)
|
| 98 |
+
|
| 99 |
+
return model
|
| 100 |
+
|
| 101 |
+
def DPT_SwinV2_B_384(pretrained=True, **kwargs):
|
| 102 |
+
""" # This docstring shows up in hub.help()
|
| 103 |
+
MiDaS DPT_SwinV2_B_384 model for monocular depth estimation
|
| 104 |
+
pretrained (bool): load pretrained weights into model
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
model = DPTDepthModel(
|
| 108 |
+
path=None,
|
| 109 |
+
backbone="swin2b24_384",
|
| 110 |
+
non_negative=True,
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
if pretrained:
|
| 114 |
+
checkpoint = (
|
| 115 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_base_384.pt"
|
| 116 |
+
)
|
| 117 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 118 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 119 |
+
)
|
| 120 |
+
model.load_state_dict(state_dict)
|
| 121 |
+
|
| 122 |
+
return model
|
| 123 |
+
|
| 124 |
+
def DPT_SwinV2_T_256(pretrained=True, **kwargs):
|
| 125 |
+
""" # This docstring shows up in hub.help()
|
| 126 |
+
MiDaS DPT_SwinV2_T_256 model for monocular depth estimation
|
| 127 |
+
pretrained (bool): load pretrained weights into model
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
model = DPTDepthModel(
|
| 131 |
+
path=None,
|
| 132 |
+
backbone="swin2t16_256",
|
| 133 |
+
non_negative=True,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
if pretrained:
|
| 137 |
+
checkpoint = (
|
| 138 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt"
|
| 139 |
+
)
|
| 140 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 141 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 142 |
+
)
|
| 143 |
+
model.load_state_dict(state_dict)
|
| 144 |
+
|
| 145 |
+
return model
|
| 146 |
+
|
| 147 |
+
def DPT_Swin_L_384(pretrained=True, **kwargs):
|
| 148 |
+
""" # This docstring shows up in hub.help()
|
| 149 |
+
MiDaS DPT_Swin_L_384 model for monocular depth estimation
|
| 150 |
+
pretrained (bool): load pretrained weights into model
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
model = DPTDepthModel(
|
| 154 |
+
path=None,
|
| 155 |
+
backbone="swinl12_384",
|
| 156 |
+
non_negative=True,
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
if pretrained:
|
| 160 |
+
checkpoint = (
|
| 161 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin_large_384.pt"
|
| 162 |
+
)
|
| 163 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 164 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 165 |
+
)
|
| 166 |
+
model.load_state_dict(state_dict)
|
| 167 |
+
|
| 168 |
+
return model
|
| 169 |
+
|
| 170 |
+
def DPT_Next_ViT_L_384(pretrained=True, **kwargs):
|
| 171 |
+
""" # This docstring shows up in hub.help()
|
| 172 |
+
MiDaS DPT_Next_ViT_L_384 model for monocular depth estimation
|
| 173 |
+
pretrained (bool): load pretrained weights into model
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
model = DPTDepthModel(
|
| 177 |
+
path=None,
|
| 178 |
+
backbone="next_vit_large_6m",
|
| 179 |
+
non_negative=True,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if pretrained:
|
| 183 |
+
checkpoint = (
|
| 184 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_next_vit_large_384.pt"
|
| 185 |
+
)
|
| 186 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 187 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 188 |
+
)
|
| 189 |
+
model.load_state_dict(state_dict)
|
| 190 |
+
|
| 191 |
+
return model
|
| 192 |
+
|
| 193 |
+
def DPT_LeViT_224(pretrained=True, **kwargs):
|
| 194 |
+
""" # This docstring shows up in hub.help()
|
| 195 |
+
MiDaS DPT_LeViT_224 model for monocular depth estimation
|
| 196 |
+
pretrained (bool): load pretrained weights into model
|
| 197 |
+
"""
|
| 198 |
+
|
| 199 |
+
model = DPTDepthModel(
|
| 200 |
+
path=None,
|
| 201 |
+
backbone="levit_384",
|
| 202 |
+
non_negative=True,
|
| 203 |
+
head_features_1=64,
|
| 204 |
+
head_features_2=8,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
if pretrained:
|
| 208 |
+
checkpoint = (
|
| 209 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt"
|
| 210 |
+
)
|
| 211 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 212 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 213 |
+
)
|
| 214 |
+
model.load_state_dict(state_dict)
|
| 215 |
+
|
| 216 |
+
return model
|
| 217 |
+
|
| 218 |
+
def DPT_Large(pretrained=True, **kwargs):
|
| 219 |
+
""" # This docstring shows up in hub.help()
|
| 220 |
+
MiDaS DPT-Large model for monocular depth estimation
|
| 221 |
+
pretrained (bool): load pretrained weights into model
|
| 222 |
+
"""
|
| 223 |
+
|
| 224 |
+
model = DPTDepthModel(
|
| 225 |
+
path=None,
|
| 226 |
+
backbone="vitl16_384",
|
| 227 |
+
non_negative=True,
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
if pretrained:
|
| 231 |
+
checkpoint = (
|
| 232 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt"
|
| 233 |
+
)
|
| 234 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 235 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 236 |
+
)
|
| 237 |
+
model.load_state_dict(state_dict)
|
| 238 |
+
|
| 239 |
+
return model
|
| 240 |
+
|
| 241 |
+
def DPT_Hybrid(pretrained=True, **kwargs):
|
| 242 |
+
""" # This docstring shows up in hub.help()
|
| 243 |
+
MiDaS DPT-Hybrid model for monocular depth estimation
|
| 244 |
+
pretrained (bool): load pretrained weights into model
|
| 245 |
+
"""
|
| 246 |
+
|
| 247 |
+
model = DPTDepthModel(
|
| 248 |
+
path=None,
|
| 249 |
+
backbone="vitb_rn50_384",
|
| 250 |
+
non_negative=True,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
if pretrained:
|
| 254 |
+
checkpoint = (
|
| 255 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt"
|
| 256 |
+
)
|
| 257 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 258 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 259 |
+
)
|
| 260 |
+
model.load_state_dict(state_dict)
|
| 261 |
+
|
| 262 |
+
return model
|
| 263 |
+
|
| 264 |
+
def MiDaS(pretrained=True, **kwargs):
|
| 265 |
+
""" # This docstring shows up in hub.help()
|
| 266 |
+
MiDaS v2.1 model for monocular depth estimation
|
| 267 |
+
pretrained (bool): load pretrained weights into model
|
| 268 |
+
"""
|
| 269 |
+
|
| 270 |
+
model = MidasNet()
|
| 271 |
+
|
| 272 |
+
if pretrained:
|
| 273 |
+
checkpoint = (
|
| 274 |
+
"https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt"
|
| 275 |
+
)
|
| 276 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 277 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 278 |
+
)
|
| 279 |
+
model.load_state_dict(state_dict)
|
| 280 |
+
|
| 281 |
+
return model
|
| 282 |
+
|
| 283 |
+
def MiDaS_small(pretrained=True, **kwargs):
|
| 284 |
+
""" # This docstring shows up in hub.help()
|
| 285 |
+
MiDaS v2.1 small model for monocular depth estimation on resource-constrained devices
|
| 286 |
+
pretrained (bool): load pretrained weights into model
|
| 287 |
+
"""
|
| 288 |
+
|
| 289 |
+
model = MidasNet_small(None, features=64, backbone="efficientnet_lite3", exportable=True, non_negative=True, blocks={'expand': True})
|
| 290 |
+
|
| 291 |
+
if pretrained:
|
| 292 |
+
checkpoint = (
|
| 293 |
+
"https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt"
|
| 294 |
+
)
|
| 295 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 296 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 297 |
+
)
|
| 298 |
+
model.load_state_dict(state_dict)
|
| 299 |
+
|
| 300 |
+
return model
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def transforms():
|
| 304 |
+
import cv2
|
| 305 |
+
from torchvision.transforms import Compose
|
| 306 |
+
from midas.transforms import Resize, NormalizeImage, PrepareForNet
|
| 307 |
+
from midas import transforms
|
| 308 |
+
|
| 309 |
+
transforms.default_transform = Compose(
|
| 310 |
+
[
|
| 311 |
+
lambda img: {"image": img / 255.0},
|
| 312 |
+
Resize(
|
| 313 |
+
384,
|
| 314 |
+
384,
|
| 315 |
+
resize_target=None,
|
| 316 |
+
keep_aspect_ratio=True,
|
| 317 |
+
ensure_multiple_of=32,
|
| 318 |
+
resize_method="upper_bound",
|
| 319 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 320 |
+
),
|
| 321 |
+
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 322 |
+
PrepareForNet(),
|
| 323 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 324 |
+
]
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
transforms.small_transform = Compose(
|
| 328 |
+
[
|
| 329 |
+
lambda img: {"image": img / 255.0},
|
| 330 |
+
Resize(
|
| 331 |
+
256,
|
| 332 |
+
256,
|
| 333 |
+
resize_target=None,
|
| 334 |
+
keep_aspect_ratio=True,
|
| 335 |
+
ensure_multiple_of=32,
|
| 336 |
+
resize_method="upper_bound",
|
| 337 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 338 |
+
),
|
| 339 |
+
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 340 |
+
PrepareForNet(),
|
| 341 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 342 |
+
]
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
transforms.dpt_transform = Compose(
|
| 346 |
+
[
|
| 347 |
+
lambda img: {"image": img / 255.0},
|
| 348 |
+
Resize(
|
| 349 |
+
384,
|
| 350 |
+
384,
|
| 351 |
+
resize_target=None,
|
| 352 |
+
keep_aspect_ratio=True,
|
| 353 |
+
ensure_multiple_of=32,
|
| 354 |
+
resize_method="minimal",
|
| 355 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 356 |
+
),
|
| 357 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 358 |
+
PrepareForNet(),
|
| 359 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 360 |
+
]
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
transforms.beit512_transform = Compose(
|
| 364 |
+
[
|
| 365 |
+
lambda img: {"image": img / 255.0},
|
| 366 |
+
Resize(
|
| 367 |
+
512,
|
| 368 |
+
512,
|
| 369 |
+
resize_target=None,
|
| 370 |
+
keep_aspect_ratio=True,
|
| 371 |
+
ensure_multiple_of=32,
|
| 372 |
+
resize_method="minimal",
|
| 373 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 374 |
+
),
|
| 375 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 376 |
+
PrepareForNet(),
|
| 377 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 378 |
+
]
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
transforms.swin384_transform = Compose(
|
| 382 |
+
[
|
| 383 |
+
lambda img: {"image": img / 255.0},
|
| 384 |
+
Resize(
|
| 385 |
+
384,
|
| 386 |
+
384,
|
| 387 |
+
resize_target=None,
|
| 388 |
+
keep_aspect_ratio=False,
|
| 389 |
+
ensure_multiple_of=32,
|
| 390 |
+
resize_method="minimal",
|
| 391 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 392 |
+
),
|
| 393 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 394 |
+
PrepareForNet(),
|
| 395 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 396 |
+
]
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
transforms.swin256_transform = Compose(
|
| 400 |
+
[
|
| 401 |
+
lambda img: {"image": img / 255.0},
|
| 402 |
+
Resize(
|
| 403 |
+
256,
|
| 404 |
+
256,
|
| 405 |
+
resize_target=None,
|
| 406 |
+
keep_aspect_ratio=False,
|
| 407 |
+
ensure_multiple_of=32,
|
| 408 |
+
resize_method="minimal",
|
| 409 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 410 |
+
),
|
| 411 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 412 |
+
PrepareForNet(),
|
| 413 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 414 |
+
]
|
| 415 |
+
)
|
| 416 |
+
|
| 417 |
+
transforms.levit_transform = Compose(
|
| 418 |
+
[
|
| 419 |
+
lambda img: {"image": img / 255.0},
|
| 420 |
+
Resize(
|
| 421 |
+
224,
|
| 422 |
+
224,
|
| 423 |
+
resize_target=None,
|
| 424 |
+
keep_aspect_ratio=False,
|
| 425 |
+
ensure_multiple_of=32,
|
| 426 |
+
resize_method="minimal",
|
| 427 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 428 |
+
),
|
| 429 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 430 |
+
PrepareForNet(),
|
| 431 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 432 |
+
]
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
return transforms
|
MiDaS-master/input/.placeholder
ADDED
|
File without changes
|
MiDaS-master/midas/backbones/beit.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
import torch
|
| 3 |
+
import types
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .utils import forward_adapted_unflatten, make_backbone_default
|
| 9 |
+
from timm.models.beit import gen_relative_position_index
|
| 10 |
+
from torch.utils.checkpoint import checkpoint
|
| 11 |
+
from typing import Optional
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def forward_beit(pretrained, x):
|
| 15 |
+
return forward_adapted_unflatten(pretrained, x, "forward_features")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def patch_embed_forward(self, x):
|
| 19 |
+
"""
|
| 20 |
+
Modification of timm.models.layers.patch_embed.py: PatchEmbed.forward to support arbitrary window sizes.
|
| 21 |
+
"""
|
| 22 |
+
x = self.proj(x)
|
| 23 |
+
if self.flatten:
|
| 24 |
+
x = x.flatten(2).transpose(1, 2)
|
| 25 |
+
x = self.norm(x)
|
| 26 |
+
return x
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def _get_rel_pos_bias(self, window_size):
|
| 30 |
+
"""
|
| 31 |
+
Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
|
| 32 |
+
"""
|
| 33 |
+
old_height = 2 * self.window_size[0] - 1
|
| 34 |
+
old_width = 2 * self.window_size[1] - 1
|
| 35 |
+
|
| 36 |
+
new_height = 2 * window_size[0] - 1
|
| 37 |
+
new_width = 2 * window_size[1] - 1
|
| 38 |
+
|
| 39 |
+
old_relative_position_bias_table = self.relative_position_bias_table
|
| 40 |
+
|
| 41 |
+
old_num_relative_distance = self.num_relative_distance
|
| 42 |
+
new_num_relative_distance = new_height * new_width + 3
|
| 43 |
+
|
| 44 |
+
old_sub_table = old_relative_position_bias_table[:old_num_relative_distance - 3]
|
| 45 |
+
|
| 46 |
+
old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
|
| 47 |
+
new_sub_table = F.interpolate(old_sub_table, size=(new_height, new_width), mode="bilinear")
|
| 48 |
+
new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
|
| 49 |
+
|
| 50 |
+
new_relative_position_bias_table = torch.cat(
|
| 51 |
+
[new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3:]])
|
| 52 |
+
|
| 53 |
+
key = str(window_size[1]) + "," + str(window_size[0])
|
| 54 |
+
if key not in self.relative_position_indices.keys():
|
| 55 |
+
self.relative_position_indices[key] = gen_relative_position_index(window_size)
|
| 56 |
+
|
| 57 |
+
relative_position_bias = new_relative_position_bias_table[
|
| 58 |
+
self.relative_position_indices[key].view(-1)].view(
|
| 59 |
+
window_size[0] * window_size[1] + 1,
|
| 60 |
+
window_size[0] * window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
|
| 61 |
+
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 62 |
+
return relative_position_bias.unsqueeze(0)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def attention_forward(self, x, resolution, shared_rel_pos_bias: Optional[torch.Tensor] = None):
|
| 66 |
+
"""
|
| 67 |
+
Modification of timm.models.beit.py: Attention.forward to support arbitrary window sizes.
|
| 68 |
+
"""
|
| 69 |
+
B, N, C = x.shape
|
| 70 |
+
|
| 71 |
+
qkv_bias = torch.cat((self.q_bias, self.k_bias, self.v_bias)) if self.q_bias is not None else None
|
| 72 |
+
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
|
| 73 |
+
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
|
| 74 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 75 |
+
|
| 76 |
+
q = q * self.scale
|
| 77 |
+
attn = (q @ k.transpose(-2, -1))
|
| 78 |
+
|
| 79 |
+
if self.relative_position_bias_table is not None:
|
| 80 |
+
window_size = tuple(np.array(resolution) // 16)
|
| 81 |
+
attn = attn + self._get_rel_pos_bias(window_size)
|
| 82 |
+
if shared_rel_pos_bias is not None:
|
| 83 |
+
attn = attn + shared_rel_pos_bias
|
| 84 |
+
|
| 85 |
+
attn = attn.softmax(dim=-1)
|
| 86 |
+
attn = self.attn_drop(attn)
|
| 87 |
+
|
| 88 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
|
| 89 |
+
x = self.proj(x)
|
| 90 |
+
x = self.proj_drop(x)
|
| 91 |
+
return x
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def block_forward(self, x, resolution, shared_rel_pos_bias: Optional[torch.Tensor] = None):
|
| 95 |
+
"""
|
| 96 |
+
Modification of timm.models.beit.py: Block.forward to support arbitrary window sizes.
|
| 97 |
+
"""
|
| 98 |
+
if self.gamma_1 is None:
|
| 99 |
+
x = x + self.drop_path(self.attn(self.norm1(x), resolution, shared_rel_pos_bias=shared_rel_pos_bias))
|
| 100 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 101 |
+
else:
|
| 102 |
+
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x), resolution,
|
| 103 |
+
shared_rel_pos_bias=shared_rel_pos_bias))
|
| 104 |
+
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
|
| 105 |
+
return x
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def beit_forward_features(self, x):
|
| 109 |
+
"""
|
| 110 |
+
Modification of timm.models.beit.py: Beit.forward_features to support arbitrary window sizes.
|
| 111 |
+
"""
|
| 112 |
+
resolution = x.shape[2:]
|
| 113 |
+
|
| 114 |
+
x = self.patch_embed(x)
|
| 115 |
+
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
|
| 116 |
+
if self.pos_embed is not None:
|
| 117 |
+
x = x + self.pos_embed
|
| 118 |
+
x = self.pos_drop(x)
|
| 119 |
+
|
| 120 |
+
rel_pos_bias = self.rel_pos_bias() if self.rel_pos_bias is not None else None
|
| 121 |
+
for blk in self.blocks:
|
| 122 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 123 |
+
x = checkpoint(blk, x, shared_rel_pos_bias=rel_pos_bias)
|
| 124 |
+
else:
|
| 125 |
+
x = blk(x, resolution, shared_rel_pos_bias=rel_pos_bias)
|
| 126 |
+
x = self.norm(x)
|
| 127 |
+
return x
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def _make_beit_backbone(
|
| 131 |
+
model,
|
| 132 |
+
features=[96, 192, 384, 768],
|
| 133 |
+
size=[384, 384],
|
| 134 |
+
hooks=[0, 4, 8, 11],
|
| 135 |
+
vit_features=768,
|
| 136 |
+
use_readout="ignore",
|
| 137 |
+
start_index=1,
|
| 138 |
+
start_index_readout=1,
|
| 139 |
+
):
|
| 140 |
+
backbone = make_backbone_default(model, features, size, hooks, vit_features, use_readout, start_index,
|
| 141 |
+
start_index_readout)
|
| 142 |
+
|
| 143 |
+
backbone.model.patch_embed.forward = types.MethodType(patch_embed_forward, backbone.model.patch_embed)
|
| 144 |
+
backbone.model.forward_features = types.MethodType(beit_forward_features, backbone.model)
|
| 145 |
+
|
| 146 |
+
for block in backbone.model.blocks:
|
| 147 |
+
attn = block.attn
|
| 148 |
+
attn._get_rel_pos_bias = types.MethodType(_get_rel_pos_bias, attn)
|
| 149 |
+
attn.forward = types.MethodType(attention_forward, attn)
|
| 150 |
+
attn.relative_position_indices = {}
|
| 151 |
+
|
| 152 |
+
block.forward = types.MethodType(block_forward, block)
|
| 153 |
+
|
| 154 |
+
return backbone
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def _make_pretrained_beitl16_512(pretrained, use_readout="ignore", hooks=None):
|
| 158 |
+
model = timm.create_model("beit_large_patch16_512", pretrained=pretrained)
|
| 159 |
+
|
| 160 |
+
hooks = [5, 11, 17, 23] if hooks is None else hooks
|
| 161 |
+
|
| 162 |
+
features = [256, 512, 1024, 1024]
|
| 163 |
+
|
| 164 |
+
return _make_beit_backbone(
|
| 165 |
+
model,
|
| 166 |
+
features=features,
|
| 167 |
+
size=[512, 512],
|
| 168 |
+
hooks=hooks,
|
| 169 |
+
vit_features=1024,
|
| 170 |
+
use_readout=use_readout,
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def _make_pretrained_beitl16_384(pretrained, use_readout="ignore", hooks=None):
|
| 175 |
+
model = timm.create_model("beit_large_patch16_384", pretrained=pretrained)
|
| 176 |
+
|
| 177 |
+
hooks = [5, 11, 17, 23] if hooks is None else hooks
|
| 178 |
+
return _make_beit_backbone(
|
| 179 |
+
model,
|
| 180 |
+
features=[256, 512, 1024, 1024],
|
| 181 |
+
hooks=hooks,
|
| 182 |
+
vit_features=1024,
|
| 183 |
+
use_readout=use_readout,
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def _make_pretrained_beitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 188 |
+
model = timm.create_model("beit_base_patch16_384", pretrained=pretrained)
|
| 189 |
+
|
| 190 |
+
hooks = [2, 5, 8, 11] if hooks is None else hooks
|
| 191 |
+
return _make_beit_backbone(
|
| 192 |
+
model,
|
| 193 |
+
features=[96, 192, 384, 768],
|
| 194 |
+
hooks=hooks,
|
| 195 |
+
use_readout=use_readout,
|
| 196 |
+
)
|
MiDaS-master/midas/backbones/levit.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from .utils import activations, get_activation, Transpose
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def forward_levit(pretrained, x):
|
| 10 |
+
pretrained.model.forward_features(x)
|
| 11 |
+
|
| 12 |
+
layer_1 = pretrained.activations["1"]
|
| 13 |
+
layer_2 = pretrained.activations["2"]
|
| 14 |
+
layer_3 = pretrained.activations["3"]
|
| 15 |
+
|
| 16 |
+
layer_1 = pretrained.act_postprocess1(layer_1)
|
| 17 |
+
layer_2 = pretrained.act_postprocess2(layer_2)
|
| 18 |
+
layer_3 = pretrained.act_postprocess3(layer_3)
|
| 19 |
+
|
| 20 |
+
return layer_1, layer_2, layer_3
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def _make_levit_backbone(
|
| 24 |
+
model,
|
| 25 |
+
hooks=[3, 11, 21],
|
| 26 |
+
patch_grid=[14, 14]
|
| 27 |
+
):
|
| 28 |
+
pretrained = nn.Module()
|
| 29 |
+
|
| 30 |
+
pretrained.model = model
|
| 31 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 32 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 33 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 34 |
+
|
| 35 |
+
pretrained.activations = activations
|
| 36 |
+
|
| 37 |
+
patch_grid_size = np.array(patch_grid, dtype=int)
|
| 38 |
+
|
| 39 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 40 |
+
Transpose(1, 2),
|
| 41 |
+
nn.Unflatten(2, torch.Size(patch_grid_size.tolist()))
|
| 42 |
+
)
|
| 43 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 44 |
+
Transpose(1, 2),
|
| 45 |
+
nn.Unflatten(2, torch.Size((np.ceil(patch_grid_size / 2).astype(int)).tolist()))
|
| 46 |
+
)
|
| 47 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 48 |
+
Transpose(1, 2),
|
| 49 |
+
nn.Unflatten(2, torch.Size((np.ceil(patch_grid_size / 4).astype(int)).tolist()))
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return pretrained
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class ConvTransposeNorm(nn.Sequential):
|
| 56 |
+
"""
|
| 57 |
+
Modification of
|
| 58 |
+
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/levit.py: ConvNorm
|
| 59 |
+
such that ConvTranspose2d is used instead of Conv2d.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self, in_chs, out_chs, kernel_size=1, stride=1, pad=0, dilation=1,
|
| 64 |
+
groups=1, bn_weight_init=1):
|
| 65 |
+
super().__init__()
|
| 66 |
+
self.add_module('c',
|
| 67 |
+
nn.ConvTranspose2d(in_chs, out_chs, kernel_size, stride, pad, dilation, groups, bias=False))
|
| 68 |
+
self.add_module('bn', nn.BatchNorm2d(out_chs))
|
| 69 |
+
|
| 70 |
+
nn.init.constant_(self.bn.weight, bn_weight_init)
|
| 71 |
+
|
| 72 |
+
@torch.no_grad()
|
| 73 |
+
def fuse(self):
|
| 74 |
+
c, bn = self._modules.values()
|
| 75 |
+
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 76 |
+
w = c.weight * w[:, None, None, None]
|
| 77 |
+
b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 78 |
+
m = nn.ConvTranspose2d(
|
| 79 |
+
w.size(1), w.size(0), w.shape[2:], stride=self.c.stride,
|
| 80 |
+
padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
|
| 81 |
+
m.weight.data.copy_(w)
|
| 82 |
+
m.bias.data.copy_(b)
|
| 83 |
+
return m
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def stem_b4_transpose(in_chs, out_chs, activation):
|
| 87 |
+
"""
|
| 88 |
+
Modification of
|
| 89 |
+
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/levit.py: stem_b16
|
| 90 |
+
such that ConvTranspose2d is used instead of Conv2d and stem is also reduced to the half.
|
| 91 |
+
"""
|
| 92 |
+
return nn.Sequential(
|
| 93 |
+
ConvTransposeNorm(in_chs, out_chs, 3, 2, 1),
|
| 94 |
+
activation(),
|
| 95 |
+
ConvTransposeNorm(out_chs, out_chs // 2, 3, 2, 1),
|
| 96 |
+
activation())
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def _make_pretrained_levit_384(pretrained, hooks=None):
|
| 100 |
+
model = timm.create_model("levit_384", pretrained=pretrained)
|
| 101 |
+
|
| 102 |
+
hooks = [3, 11, 21] if hooks == None else hooks
|
| 103 |
+
return _make_levit_backbone(
|
| 104 |
+
model,
|
| 105 |
+
hooks=hooks
|
| 106 |
+
)
|
MiDaS-master/midas/backbones/next_vit.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from .utils import activations, forward_default, get_activation
|
| 7 |
+
|
| 8 |
+
from ..external.next_vit.classification.nextvit import *
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def forward_next_vit(pretrained, x):
|
| 12 |
+
return forward_default(pretrained, x, "forward")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _make_next_vit_backbone(
|
| 16 |
+
model,
|
| 17 |
+
hooks=[2, 6, 36, 39],
|
| 18 |
+
):
|
| 19 |
+
pretrained = nn.Module()
|
| 20 |
+
|
| 21 |
+
pretrained.model = model
|
| 22 |
+
pretrained.model.features[hooks[0]].register_forward_hook(get_activation("1"))
|
| 23 |
+
pretrained.model.features[hooks[1]].register_forward_hook(get_activation("2"))
|
| 24 |
+
pretrained.model.features[hooks[2]].register_forward_hook(get_activation("3"))
|
| 25 |
+
pretrained.model.features[hooks[3]].register_forward_hook(get_activation("4"))
|
| 26 |
+
|
| 27 |
+
pretrained.activations = activations
|
| 28 |
+
|
| 29 |
+
return pretrained
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def _make_pretrained_next_vit_large_6m(hooks=None):
|
| 33 |
+
model = timm.create_model("nextvit_large")
|
| 34 |
+
|
| 35 |
+
hooks = [2, 6, 36, 39] if hooks == None else hooks
|
| 36 |
+
return _make_next_vit_backbone(
|
| 37 |
+
model,
|
| 38 |
+
hooks=hooks,
|
| 39 |
+
)
|
MiDaS-master/midas/backbones/swin.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
from .swin_common import _make_swin_backbone
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def _make_pretrained_swinl12_384(pretrained, hooks=None):
|
| 7 |
+
model = timm.create_model("swin_large_patch4_window12_384", pretrained=pretrained)
|
| 8 |
+
|
| 9 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 10 |
+
return _make_swin_backbone(
|
| 11 |
+
model,
|
| 12 |
+
hooks=hooks
|
| 13 |
+
)
|
MiDaS-master/midas/backbones/swin2.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
from .swin_common import _make_swin_backbone
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def _make_pretrained_swin2l24_384(pretrained, hooks=None):
|
| 7 |
+
model = timm.create_model("swinv2_large_window12to24_192to384_22kft1k", pretrained=pretrained)
|
| 8 |
+
|
| 9 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 10 |
+
return _make_swin_backbone(
|
| 11 |
+
model,
|
| 12 |
+
hooks=hooks
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _make_pretrained_swin2b24_384(pretrained, hooks=None):
|
| 17 |
+
model = timm.create_model("swinv2_base_window12to24_192to384_22kft1k", pretrained=pretrained)
|
| 18 |
+
|
| 19 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 20 |
+
return _make_swin_backbone(
|
| 21 |
+
model,
|
| 22 |
+
hooks=hooks
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _make_pretrained_swin2t16_256(pretrained, hooks=None):
|
| 27 |
+
model = timm.create_model("swinv2_tiny_window16_256", pretrained=pretrained)
|
| 28 |
+
|
| 29 |
+
hooks = [1, 1, 5, 1] if hooks == None else hooks
|
| 30 |
+
return _make_swin_backbone(
|
| 31 |
+
model,
|
| 32 |
+
hooks=hooks,
|
| 33 |
+
patch_grid=[64, 64]
|
| 34 |
+
)
|
MiDaS-master/midas/backbones/swin_common.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from .utils import activations, forward_default, get_activation, Transpose
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def forward_swin(pretrained, x):
|
| 10 |
+
return forward_default(pretrained, x)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def _make_swin_backbone(
|
| 14 |
+
model,
|
| 15 |
+
hooks=[1, 1, 17, 1],
|
| 16 |
+
patch_grid=[96, 96]
|
| 17 |
+
):
|
| 18 |
+
pretrained = nn.Module()
|
| 19 |
+
|
| 20 |
+
pretrained.model = model
|
| 21 |
+
pretrained.model.layers[0].blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 22 |
+
pretrained.model.layers[1].blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 23 |
+
pretrained.model.layers[2].blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 24 |
+
pretrained.model.layers[3].blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 25 |
+
|
| 26 |
+
pretrained.activations = activations
|
| 27 |
+
|
| 28 |
+
if hasattr(model, "patch_grid"):
|
| 29 |
+
used_patch_grid = model.patch_grid
|
| 30 |
+
else:
|
| 31 |
+
used_patch_grid = patch_grid
|
| 32 |
+
|
| 33 |
+
patch_grid_size = np.array(used_patch_grid, dtype=int)
|
| 34 |
+
|
| 35 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 36 |
+
Transpose(1, 2),
|
| 37 |
+
nn.Unflatten(2, torch.Size(patch_grid_size.tolist()))
|
| 38 |
+
)
|
| 39 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 40 |
+
Transpose(1, 2),
|
| 41 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 2).tolist()))
|
| 42 |
+
)
|
| 43 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 44 |
+
Transpose(1, 2),
|
| 45 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 4).tolist()))
|
| 46 |
+
)
|
| 47 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 48 |
+
Transpose(1, 2),
|
| 49 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 8).tolist()))
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return pretrained
|
MiDaS-master/midas/backbones/utils.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Slice(nn.Module):
|
| 7 |
+
def __init__(self, start_index=1):
|
| 8 |
+
super(Slice, self).__init__()
|
| 9 |
+
self.start_index = start_index
|
| 10 |
+
|
| 11 |
+
def forward(self, x):
|
| 12 |
+
return x[:, self.start_index:]
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class AddReadout(nn.Module):
|
| 16 |
+
def __init__(self, start_index=1):
|
| 17 |
+
super(AddReadout, self).__init__()
|
| 18 |
+
self.start_index = start_index
|
| 19 |
+
|
| 20 |
+
def forward(self, x):
|
| 21 |
+
if self.start_index == 2:
|
| 22 |
+
readout = (x[:, 0] + x[:, 1]) / 2
|
| 23 |
+
else:
|
| 24 |
+
readout = x[:, 0]
|
| 25 |
+
return x[:, self.start_index:] + readout.unsqueeze(1)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class ProjectReadout(nn.Module):
|
| 29 |
+
def __init__(self, in_features, start_index=1):
|
| 30 |
+
super(ProjectReadout, self).__init__()
|
| 31 |
+
self.start_index = start_index
|
| 32 |
+
|
| 33 |
+
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index:])
|
| 37 |
+
features = torch.cat((x[:, self.start_index:], readout), -1)
|
| 38 |
+
|
| 39 |
+
return self.project(features)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class Transpose(nn.Module):
|
| 43 |
+
def __init__(self, dim0, dim1):
|
| 44 |
+
super(Transpose, self).__init__()
|
| 45 |
+
self.dim0 = dim0
|
| 46 |
+
self.dim1 = dim1
|
| 47 |
+
|
| 48 |
+
def forward(self, x):
|
| 49 |
+
x = x.transpose(self.dim0, self.dim1)
|
| 50 |
+
return x
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
activations = {}
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_activation(name):
|
| 57 |
+
def hook(model, input, output):
|
| 58 |
+
activations[name] = output
|
| 59 |
+
|
| 60 |
+
return hook
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def forward_default(pretrained, x, function_name="forward_features"):
|
| 64 |
+
exec(f"pretrained.model.{function_name}(x)")
|
| 65 |
+
|
| 66 |
+
layer_1 = pretrained.activations["1"]
|
| 67 |
+
layer_2 = pretrained.activations["2"]
|
| 68 |
+
layer_3 = pretrained.activations["3"]
|
| 69 |
+
layer_4 = pretrained.activations["4"]
|
| 70 |
+
|
| 71 |
+
if hasattr(pretrained, "act_postprocess1"):
|
| 72 |
+
layer_1 = pretrained.act_postprocess1(layer_1)
|
| 73 |
+
if hasattr(pretrained, "act_postprocess2"):
|
| 74 |
+
layer_2 = pretrained.act_postprocess2(layer_2)
|
| 75 |
+
if hasattr(pretrained, "act_postprocess3"):
|
| 76 |
+
layer_3 = pretrained.act_postprocess3(layer_3)
|
| 77 |
+
if hasattr(pretrained, "act_postprocess4"):
|
| 78 |
+
layer_4 = pretrained.act_postprocess4(layer_4)
|
| 79 |
+
|
| 80 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def forward_adapted_unflatten(pretrained, x, function_name="forward_features"):
|
| 84 |
+
b, c, h, w = x.shape
|
| 85 |
+
|
| 86 |
+
exec(f"glob = pretrained.model.{function_name}(x)")
|
| 87 |
+
|
| 88 |
+
layer_1 = pretrained.activations["1"]
|
| 89 |
+
layer_2 = pretrained.activations["2"]
|
| 90 |
+
layer_3 = pretrained.activations["3"]
|
| 91 |
+
layer_4 = pretrained.activations["4"]
|
| 92 |
+
|
| 93 |
+
layer_1 = pretrained.act_postprocess1[0:2](layer_1)
|
| 94 |
+
layer_2 = pretrained.act_postprocess2[0:2](layer_2)
|
| 95 |
+
layer_3 = pretrained.act_postprocess3[0:2](layer_3)
|
| 96 |
+
layer_4 = pretrained.act_postprocess4[0:2](layer_4)
|
| 97 |
+
|
| 98 |
+
unflatten = nn.Sequential(
|
| 99 |
+
nn.Unflatten(
|
| 100 |
+
2,
|
| 101 |
+
torch.Size(
|
| 102 |
+
[
|
| 103 |
+
h // pretrained.model.patch_size[1],
|
| 104 |
+
w // pretrained.model.patch_size[0],
|
| 105 |
+
]
|
| 106 |
+
),
|
| 107 |
+
)
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
if layer_1.ndim == 3:
|
| 111 |
+
layer_1 = unflatten(layer_1)
|
| 112 |
+
if layer_2.ndim == 3:
|
| 113 |
+
layer_2 = unflatten(layer_2)
|
| 114 |
+
if layer_3.ndim == 3:
|
| 115 |
+
layer_3 = unflatten(layer_3)
|
| 116 |
+
if layer_4.ndim == 3:
|
| 117 |
+
layer_4 = unflatten(layer_4)
|
| 118 |
+
|
| 119 |
+
layer_1 = pretrained.act_postprocess1[3: len(pretrained.act_postprocess1)](layer_1)
|
| 120 |
+
layer_2 = pretrained.act_postprocess2[3: len(pretrained.act_postprocess2)](layer_2)
|
| 121 |
+
layer_3 = pretrained.act_postprocess3[3: len(pretrained.act_postprocess3)](layer_3)
|
| 122 |
+
layer_4 = pretrained.act_postprocess4[3: len(pretrained.act_postprocess4)](layer_4)
|
| 123 |
+
|
| 124 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def get_readout_oper(vit_features, features, use_readout, start_index=1):
|
| 128 |
+
if use_readout == "ignore":
|
| 129 |
+
readout_oper = [Slice(start_index)] * len(features)
|
| 130 |
+
elif use_readout == "add":
|
| 131 |
+
readout_oper = [AddReadout(start_index)] * len(features)
|
| 132 |
+
elif use_readout == "project":
|
| 133 |
+
readout_oper = [
|
| 134 |
+
ProjectReadout(vit_features, start_index) for out_feat in features
|
| 135 |
+
]
|
| 136 |
+
else:
|
| 137 |
+
assert (
|
| 138 |
+
False
|
| 139 |
+
), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
|
| 140 |
+
|
| 141 |
+
return readout_oper
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def make_backbone_default(
|
| 145 |
+
model,
|
| 146 |
+
features=[96, 192, 384, 768],
|
| 147 |
+
size=[384, 384],
|
| 148 |
+
hooks=[2, 5, 8, 11],
|
| 149 |
+
vit_features=768,
|
| 150 |
+
use_readout="ignore",
|
| 151 |
+
start_index=1,
|
| 152 |
+
start_index_readout=1,
|
| 153 |
+
):
|
| 154 |
+
pretrained = nn.Module()
|
| 155 |
+
|
| 156 |
+
pretrained.model = model
|
| 157 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 158 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 159 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 160 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 161 |
+
|
| 162 |
+
pretrained.activations = activations
|
| 163 |
+
|
| 164 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index_readout)
|
| 165 |
+
|
| 166 |
+
# 32, 48, 136, 384
|
| 167 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 168 |
+
readout_oper[0],
|
| 169 |
+
Transpose(1, 2),
|
| 170 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 171 |
+
nn.Conv2d(
|
| 172 |
+
in_channels=vit_features,
|
| 173 |
+
out_channels=features[0],
|
| 174 |
+
kernel_size=1,
|
| 175 |
+
stride=1,
|
| 176 |
+
padding=0,
|
| 177 |
+
),
|
| 178 |
+
nn.ConvTranspose2d(
|
| 179 |
+
in_channels=features[0],
|
| 180 |
+
out_channels=features[0],
|
| 181 |
+
kernel_size=4,
|
| 182 |
+
stride=4,
|
| 183 |
+
padding=0,
|
| 184 |
+
bias=True,
|
| 185 |
+
dilation=1,
|
| 186 |
+
groups=1,
|
| 187 |
+
),
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 191 |
+
readout_oper[1],
|
| 192 |
+
Transpose(1, 2),
|
| 193 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 194 |
+
nn.Conv2d(
|
| 195 |
+
in_channels=vit_features,
|
| 196 |
+
out_channels=features[1],
|
| 197 |
+
kernel_size=1,
|
| 198 |
+
stride=1,
|
| 199 |
+
padding=0,
|
| 200 |
+
),
|
| 201 |
+
nn.ConvTranspose2d(
|
| 202 |
+
in_channels=features[1],
|
| 203 |
+
out_channels=features[1],
|
| 204 |
+
kernel_size=2,
|
| 205 |
+
stride=2,
|
| 206 |
+
padding=0,
|
| 207 |
+
bias=True,
|
| 208 |
+
dilation=1,
|
| 209 |
+
groups=1,
|
| 210 |
+
),
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 214 |
+
readout_oper[2],
|
| 215 |
+
Transpose(1, 2),
|
| 216 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 217 |
+
nn.Conv2d(
|
| 218 |
+
in_channels=vit_features,
|
| 219 |
+
out_channels=features[2],
|
| 220 |
+
kernel_size=1,
|
| 221 |
+
stride=1,
|
| 222 |
+
padding=0,
|
| 223 |
+
),
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 227 |
+
readout_oper[3],
|
| 228 |
+
Transpose(1, 2),
|
| 229 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 230 |
+
nn.Conv2d(
|
| 231 |
+
in_channels=vit_features,
|
| 232 |
+
out_channels=features[3],
|
| 233 |
+
kernel_size=1,
|
| 234 |
+
stride=1,
|
| 235 |
+
padding=0,
|
| 236 |
+
),
|
| 237 |
+
nn.Conv2d(
|
| 238 |
+
in_channels=features[3],
|
| 239 |
+
out_channels=features[3],
|
| 240 |
+
kernel_size=3,
|
| 241 |
+
stride=2,
|
| 242 |
+
padding=1,
|
| 243 |
+
),
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
pretrained.model.start_index = start_index
|
| 247 |
+
pretrained.model.patch_size = [16, 16]
|
| 248 |
+
|
| 249 |
+
return pretrained
|
MiDaS-master/midas/backbones/vit.py
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import timm
|
| 4 |
+
import types
|
| 5 |
+
import math
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .utils import (activations, forward_adapted_unflatten, get_activation, get_readout_oper,
|
| 9 |
+
make_backbone_default, Transpose)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def forward_vit(pretrained, x):
|
| 13 |
+
return forward_adapted_unflatten(pretrained, x, "forward_flex")
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _resize_pos_embed(self, posemb, gs_h, gs_w):
|
| 17 |
+
posemb_tok, posemb_grid = (
|
| 18 |
+
posemb[:, : self.start_index],
|
| 19 |
+
posemb[0, self.start_index:],
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
gs_old = int(math.sqrt(len(posemb_grid)))
|
| 23 |
+
|
| 24 |
+
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
|
| 25 |
+
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
|
| 26 |
+
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
|
| 27 |
+
|
| 28 |
+
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
|
| 29 |
+
|
| 30 |
+
return posemb
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def forward_flex(self, x):
|
| 34 |
+
b, c, h, w = x.shape
|
| 35 |
+
|
| 36 |
+
pos_embed = self._resize_pos_embed(
|
| 37 |
+
self.pos_embed, h // self.patch_size[1], w // self.patch_size[0]
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
B = x.shape[0]
|
| 41 |
+
|
| 42 |
+
if hasattr(self.patch_embed, "backbone"):
|
| 43 |
+
x = self.patch_embed.backbone(x)
|
| 44 |
+
if isinstance(x, (list, tuple)):
|
| 45 |
+
x = x[-1] # last feature if backbone outputs list/tuple of features
|
| 46 |
+
|
| 47 |
+
x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
|
| 48 |
+
|
| 49 |
+
if getattr(self, "dist_token", None) is not None:
|
| 50 |
+
cls_tokens = self.cls_token.expand(
|
| 51 |
+
B, -1, -1
|
| 52 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 53 |
+
dist_token = self.dist_token.expand(B, -1, -1)
|
| 54 |
+
x = torch.cat((cls_tokens, dist_token, x), dim=1)
|
| 55 |
+
else:
|
| 56 |
+
if self.no_embed_class:
|
| 57 |
+
x = x + pos_embed
|
| 58 |
+
cls_tokens = self.cls_token.expand(
|
| 59 |
+
B, -1, -1
|
| 60 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 61 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 62 |
+
|
| 63 |
+
if not self.no_embed_class:
|
| 64 |
+
x = x + pos_embed
|
| 65 |
+
x = self.pos_drop(x)
|
| 66 |
+
|
| 67 |
+
for blk in self.blocks:
|
| 68 |
+
x = blk(x)
|
| 69 |
+
|
| 70 |
+
x = self.norm(x)
|
| 71 |
+
|
| 72 |
+
return x
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def _make_vit_b16_backbone(
|
| 76 |
+
model,
|
| 77 |
+
features=[96, 192, 384, 768],
|
| 78 |
+
size=[384, 384],
|
| 79 |
+
hooks=[2, 5, 8, 11],
|
| 80 |
+
vit_features=768,
|
| 81 |
+
use_readout="ignore",
|
| 82 |
+
start_index=1,
|
| 83 |
+
start_index_readout=1,
|
| 84 |
+
):
|
| 85 |
+
pretrained = make_backbone_default(model, features, size, hooks, vit_features, use_readout, start_index,
|
| 86 |
+
start_index_readout)
|
| 87 |
+
|
| 88 |
+
# We inject this function into the VisionTransformer instances so that
|
| 89 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 90 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 91 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 92 |
+
_resize_pos_embed, pretrained.model
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
return pretrained
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def _make_pretrained_vitl16_384(pretrained, use_readout="ignore", hooks=None):
|
| 99 |
+
model = timm.create_model("vit_large_patch16_384", pretrained=pretrained)
|
| 100 |
+
|
| 101 |
+
hooks = [5, 11, 17, 23] if hooks == None else hooks
|
| 102 |
+
return _make_vit_b16_backbone(
|
| 103 |
+
model,
|
| 104 |
+
features=[256, 512, 1024, 1024],
|
| 105 |
+
hooks=hooks,
|
| 106 |
+
vit_features=1024,
|
| 107 |
+
use_readout=use_readout,
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def _make_pretrained_vitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 112 |
+
model = timm.create_model("vit_base_patch16_384", pretrained=pretrained)
|
| 113 |
+
|
| 114 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 115 |
+
return _make_vit_b16_backbone(
|
| 116 |
+
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def _make_vit_b_rn50_backbone(
|
| 121 |
+
model,
|
| 122 |
+
features=[256, 512, 768, 768],
|
| 123 |
+
size=[384, 384],
|
| 124 |
+
hooks=[0, 1, 8, 11],
|
| 125 |
+
vit_features=768,
|
| 126 |
+
patch_size=[16, 16],
|
| 127 |
+
number_stages=2,
|
| 128 |
+
use_vit_only=False,
|
| 129 |
+
use_readout="ignore",
|
| 130 |
+
start_index=1,
|
| 131 |
+
):
|
| 132 |
+
pretrained = nn.Module()
|
| 133 |
+
|
| 134 |
+
pretrained.model = model
|
| 135 |
+
|
| 136 |
+
used_number_stages = 0 if use_vit_only else number_stages
|
| 137 |
+
for s in range(used_number_stages):
|
| 138 |
+
pretrained.model.patch_embed.backbone.stages[s].register_forward_hook(
|
| 139 |
+
get_activation(str(s + 1))
|
| 140 |
+
)
|
| 141 |
+
for s in range(used_number_stages, 4):
|
| 142 |
+
pretrained.model.blocks[hooks[s]].register_forward_hook(get_activation(str(s + 1)))
|
| 143 |
+
|
| 144 |
+
pretrained.activations = activations
|
| 145 |
+
|
| 146 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 147 |
+
|
| 148 |
+
for s in range(used_number_stages):
|
| 149 |
+
value = nn.Sequential(nn.Identity(), nn.Identity(), nn.Identity())
|
| 150 |
+
exec(f"pretrained.act_postprocess{s + 1}=value")
|
| 151 |
+
for s in range(used_number_stages, 4):
|
| 152 |
+
if s < number_stages:
|
| 153 |
+
final_layer = nn.ConvTranspose2d(
|
| 154 |
+
in_channels=features[s],
|
| 155 |
+
out_channels=features[s],
|
| 156 |
+
kernel_size=4 // (2 ** s),
|
| 157 |
+
stride=4 // (2 ** s),
|
| 158 |
+
padding=0,
|
| 159 |
+
bias=True,
|
| 160 |
+
dilation=1,
|
| 161 |
+
groups=1,
|
| 162 |
+
)
|
| 163 |
+
elif s > number_stages:
|
| 164 |
+
final_layer = nn.Conv2d(
|
| 165 |
+
in_channels=features[3],
|
| 166 |
+
out_channels=features[3],
|
| 167 |
+
kernel_size=3,
|
| 168 |
+
stride=2,
|
| 169 |
+
padding=1,
|
| 170 |
+
)
|
| 171 |
+
else:
|
| 172 |
+
final_layer = None
|
| 173 |
+
|
| 174 |
+
layers = [
|
| 175 |
+
readout_oper[s],
|
| 176 |
+
Transpose(1, 2),
|
| 177 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 178 |
+
nn.Conv2d(
|
| 179 |
+
in_channels=vit_features,
|
| 180 |
+
out_channels=features[s],
|
| 181 |
+
kernel_size=1,
|
| 182 |
+
stride=1,
|
| 183 |
+
padding=0,
|
| 184 |
+
),
|
| 185 |
+
]
|
| 186 |
+
if final_layer is not None:
|
| 187 |
+
layers.append(final_layer)
|
| 188 |
+
|
| 189 |
+
value = nn.Sequential(*layers)
|
| 190 |
+
exec(f"pretrained.act_postprocess{s + 1}=value")
|
| 191 |
+
|
| 192 |
+
pretrained.model.start_index = start_index
|
| 193 |
+
pretrained.model.patch_size = patch_size
|
| 194 |
+
|
| 195 |
+
# We inject this function into the VisionTransformer instances so that
|
| 196 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 197 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 198 |
+
|
| 199 |
+
# We inject this function into the VisionTransformer instances so that
|
| 200 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 201 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 202 |
+
_resize_pos_embed, pretrained.model
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
return pretrained
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def _make_pretrained_vitb_rn50_384(
|
| 209 |
+
pretrained, use_readout="ignore", hooks=None, use_vit_only=False
|
| 210 |
+
):
|
| 211 |
+
model = timm.create_model("vit_base_resnet50_384", pretrained=pretrained)
|
| 212 |
+
|
| 213 |
+
hooks = [0, 1, 8, 11] if hooks == None else hooks
|
| 214 |
+
return _make_vit_b_rn50_backbone(
|
| 215 |
+
model,
|
| 216 |
+
features=[256, 512, 768, 768],
|
| 217 |
+
size=[384, 384],
|
| 218 |
+
hooks=hooks,
|
| 219 |
+
use_vit_only=use_vit_only,
|
| 220 |
+
use_readout=use_readout,
|
| 221 |
+
)
|
MiDaS-master/midas/base_model.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BaseModel(torch.nn.Module):
|
| 5 |
+
def load(self, path):
|
| 6 |
+
"""Load model from file.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
path (str): file path
|
| 10 |
+
"""
|
| 11 |
+
parameters = torch.load(path, map_location=torch.device('cpu'))
|
| 12 |
+
|
| 13 |
+
if "optimizer" in parameters:
|
| 14 |
+
parameters = parameters["model"]
|
| 15 |
+
|
| 16 |
+
self.load_state_dict(parameters)
|
MiDaS-master/midas/blocks.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .backbones.beit import (
|
| 5 |
+
_make_pretrained_beitl16_512,
|
| 6 |
+
_make_pretrained_beitl16_384,
|
| 7 |
+
_make_pretrained_beitb16_384,
|
| 8 |
+
forward_beit,
|
| 9 |
+
)
|
| 10 |
+
from .backbones.swin_common import (
|
| 11 |
+
forward_swin,
|
| 12 |
+
)
|
| 13 |
+
from .backbones.swin2 import (
|
| 14 |
+
_make_pretrained_swin2l24_384,
|
| 15 |
+
_make_pretrained_swin2b24_384,
|
| 16 |
+
_make_pretrained_swin2t16_256,
|
| 17 |
+
)
|
| 18 |
+
from .backbones.swin import (
|
| 19 |
+
_make_pretrained_swinl12_384,
|
| 20 |
+
)
|
| 21 |
+
from .backbones.levit import (
|
| 22 |
+
_make_pretrained_levit_384,
|
| 23 |
+
forward_levit,
|
| 24 |
+
)
|
| 25 |
+
from .backbones.vit import (
|
| 26 |
+
_make_pretrained_vitb_rn50_384,
|
| 27 |
+
_make_pretrained_vitl16_384,
|
| 28 |
+
_make_pretrained_vitb16_384,
|
| 29 |
+
forward_vit,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None,
|
| 33 |
+
use_vit_only=False, use_readout="ignore", in_features=[96, 256, 512, 1024]):
|
| 34 |
+
if backbone == "beitl16_512":
|
| 35 |
+
pretrained = _make_pretrained_beitl16_512(
|
| 36 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 37 |
+
)
|
| 38 |
+
scratch = _make_scratch(
|
| 39 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 40 |
+
) # BEiT_512-L (backbone)
|
| 41 |
+
elif backbone == "beitl16_384":
|
| 42 |
+
pretrained = _make_pretrained_beitl16_384(
|
| 43 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 44 |
+
)
|
| 45 |
+
scratch = _make_scratch(
|
| 46 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 47 |
+
) # BEiT_384-L (backbone)
|
| 48 |
+
elif backbone == "beitb16_384":
|
| 49 |
+
pretrained = _make_pretrained_beitb16_384(
|
| 50 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 51 |
+
)
|
| 52 |
+
scratch = _make_scratch(
|
| 53 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 54 |
+
) # BEiT_384-B (backbone)
|
| 55 |
+
elif backbone == "swin2l24_384":
|
| 56 |
+
pretrained = _make_pretrained_swin2l24_384(
|
| 57 |
+
use_pretrained, hooks=hooks
|
| 58 |
+
)
|
| 59 |
+
scratch = _make_scratch(
|
| 60 |
+
[192, 384, 768, 1536], features, groups=groups, expand=expand
|
| 61 |
+
) # Swin2-L/12to24 (backbone)
|
| 62 |
+
elif backbone == "swin2b24_384":
|
| 63 |
+
pretrained = _make_pretrained_swin2b24_384(
|
| 64 |
+
use_pretrained, hooks=hooks
|
| 65 |
+
)
|
| 66 |
+
scratch = _make_scratch(
|
| 67 |
+
[128, 256, 512, 1024], features, groups=groups, expand=expand
|
| 68 |
+
) # Swin2-B/12to24 (backbone)
|
| 69 |
+
elif backbone == "swin2t16_256":
|
| 70 |
+
pretrained = _make_pretrained_swin2t16_256(
|
| 71 |
+
use_pretrained, hooks=hooks
|
| 72 |
+
)
|
| 73 |
+
scratch = _make_scratch(
|
| 74 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 75 |
+
) # Swin2-T/16 (backbone)
|
| 76 |
+
elif backbone == "swinl12_384":
|
| 77 |
+
pretrained = _make_pretrained_swinl12_384(
|
| 78 |
+
use_pretrained, hooks=hooks
|
| 79 |
+
)
|
| 80 |
+
scratch = _make_scratch(
|
| 81 |
+
[192, 384, 768, 1536], features, groups=groups, expand=expand
|
| 82 |
+
) # Swin-L/12 (backbone)
|
| 83 |
+
elif backbone == "next_vit_large_6m":
|
| 84 |
+
from .backbones.next_vit import _make_pretrained_next_vit_large_6m
|
| 85 |
+
pretrained = _make_pretrained_next_vit_large_6m(hooks=hooks)
|
| 86 |
+
scratch = _make_scratch(
|
| 87 |
+
in_features, features, groups=groups, expand=expand
|
| 88 |
+
) # Next-ViT-L on ImageNet-1K-6M (backbone)
|
| 89 |
+
elif backbone == "levit_384":
|
| 90 |
+
pretrained = _make_pretrained_levit_384(
|
| 91 |
+
use_pretrained, hooks=hooks
|
| 92 |
+
)
|
| 93 |
+
scratch = _make_scratch(
|
| 94 |
+
[384, 512, 768], features, groups=groups, expand=expand
|
| 95 |
+
) # LeViT 384 (backbone)
|
| 96 |
+
elif backbone == "vitl16_384":
|
| 97 |
+
pretrained = _make_pretrained_vitl16_384(
|
| 98 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 99 |
+
)
|
| 100 |
+
scratch = _make_scratch(
|
| 101 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 102 |
+
) # ViT-L/16 - 85.0% Top1 (backbone)
|
| 103 |
+
elif backbone == "vitb_rn50_384":
|
| 104 |
+
pretrained = _make_pretrained_vitb_rn50_384(
|
| 105 |
+
use_pretrained,
|
| 106 |
+
hooks=hooks,
|
| 107 |
+
use_vit_only=use_vit_only,
|
| 108 |
+
use_readout=use_readout,
|
| 109 |
+
)
|
| 110 |
+
scratch = _make_scratch(
|
| 111 |
+
[256, 512, 768, 768], features, groups=groups, expand=expand
|
| 112 |
+
) # ViT-H/16 - 85.0% Top1 (backbone)
|
| 113 |
+
elif backbone == "vitb16_384":
|
| 114 |
+
pretrained = _make_pretrained_vitb16_384(
|
| 115 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 116 |
+
)
|
| 117 |
+
scratch = _make_scratch(
|
| 118 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 119 |
+
) # ViT-B/16 - 84.6% Top1 (backbone)
|
| 120 |
+
elif backbone == "resnext101_wsl":
|
| 121 |
+
pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
|
| 122 |
+
scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 123 |
+
elif backbone == "efficientnet_lite3":
|
| 124 |
+
pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
|
| 125 |
+
scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 126 |
+
else:
|
| 127 |
+
print(f"Backbone '{backbone}' not implemented")
|
| 128 |
+
assert False
|
| 129 |
+
|
| 130 |
+
return pretrained, scratch
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _make_scratch(in_shape, out_shape, groups=1, expand=False):
|
| 134 |
+
scratch = nn.Module()
|
| 135 |
+
|
| 136 |
+
out_shape1 = out_shape
|
| 137 |
+
out_shape2 = out_shape
|
| 138 |
+
out_shape3 = out_shape
|
| 139 |
+
if len(in_shape) >= 4:
|
| 140 |
+
out_shape4 = out_shape
|
| 141 |
+
|
| 142 |
+
if expand:
|
| 143 |
+
out_shape1 = out_shape
|
| 144 |
+
out_shape2 = out_shape*2
|
| 145 |
+
out_shape3 = out_shape*4
|
| 146 |
+
if len(in_shape) >= 4:
|
| 147 |
+
out_shape4 = out_shape*8
|
| 148 |
+
|
| 149 |
+
scratch.layer1_rn = nn.Conv2d(
|
| 150 |
+
in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 151 |
+
)
|
| 152 |
+
scratch.layer2_rn = nn.Conv2d(
|
| 153 |
+
in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 154 |
+
)
|
| 155 |
+
scratch.layer3_rn = nn.Conv2d(
|
| 156 |
+
in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 157 |
+
)
|
| 158 |
+
if len(in_shape) >= 4:
|
| 159 |
+
scratch.layer4_rn = nn.Conv2d(
|
| 160 |
+
in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
return scratch
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
|
| 167 |
+
efficientnet = torch.hub.load(
|
| 168 |
+
"rwightman/gen-efficientnet-pytorch",
|
| 169 |
+
"tf_efficientnet_lite3",
|
| 170 |
+
pretrained=use_pretrained,
|
| 171 |
+
exportable=exportable
|
| 172 |
+
)
|
| 173 |
+
return _make_efficientnet_backbone(efficientnet)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def _make_efficientnet_backbone(effnet):
|
| 177 |
+
pretrained = nn.Module()
|
| 178 |
+
|
| 179 |
+
pretrained.layer1 = nn.Sequential(
|
| 180 |
+
effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
|
| 181 |
+
)
|
| 182 |
+
pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
|
| 183 |
+
pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
|
| 184 |
+
pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
|
| 185 |
+
|
| 186 |
+
return pretrained
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def _make_resnet_backbone(resnet):
|
| 190 |
+
pretrained = nn.Module()
|
| 191 |
+
pretrained.layer1 = nn.Sequential(
|
| 192 |
+
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
pretrained.layer2 = resnet.layer2
|
| 196 |
+
pretrained.layer3 = resnet.layer3
|
| 197 |
+
pretrained.layer4 = resnet.layer4
|
| 198 |
+
|
| 199 |
+
return pretrained
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def _make_pretrained_resnext101_wsl(use_pretrained):
|
| 203 |
+
resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
|
| 204 |
+
return _make_resnet_backbone(resnet)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class Interpolate(nn.Module):
|
| 209 |
+
"""Interpolation module.
|
| 210 |
+
"""
|
| 211 |
+
|
| 212 |
+
def __init__(self, scale_factor, mode, align_corners=False):
|
| 213 |
+
"""Init.
|
| 214 |
+
|
| 215 |
+
Args:
|
| 216 |
+
scale_factor (float): scaling
|
| 217 |
+
mode (str): interpolation mode
|
| 218 |
+
"""
|
| 219 |
+
super(Interpolate, self).__init__()
|
| 220 |
+
|
| 221 |
+
self.interp = nn.functional.interpolate
|
| 222 |
+
self.scale_factor = scale_factor
|
| 223 |
+
self.mode = mode
|
| 224 |
+
self.align_corners = align_corners
|
| 225 |
+
|
| 226 |
+
def forward(self, x):
|
| 227 |
+
"""Forward pass.
|
| 228 |
+
|
| 229 |
+
Args:
|
| 230 |
+
x (tensor): input
|
| 231 |
+
|
| 232 |
+
Returns:
|
| 233 |
+
tensor: interpolated data
|
| 234 |
+
"""
|
| 235 |
+
|
| 236 |
+
x = self.interp(
|
| 237 |
+
x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
return x
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
class ResidualConvUnit(nn.Module):
|
| 244 |
+
"""Residual convolution module.
|
| 245 |
+
"""
|
| 246 |
+
|
| 247 |
+
def __init__(self, features):
|
| 248 |
+
"""Init.
|
| 249 |
+
|
| 250 |
+
Args:
|
| 251 |
+
features (int): number of features
|
| 252 |
+
"""
|
| 253 |
+
super().__init__()
|
| 254 |
+
|
| 255 |
+
self.conv1 = nn.Conv2d(
|
| 256 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
self.conv2 = nn.Conv2d(
|
| 260 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 261 |
+
)
|
| 262 |
+
|
| 263 |
+
self.relu = nn.ReLU(inplace=True)
|
| 264 |
+
|
| 265 |
+
def forward(self, x):
|
| 266 |
+
"""Forward pass.
|
| 267 |
+
|
| 268 |
+
Args:
|
| 269 |
+
x (tensor): input
|
| 270 |
+
|
| 271 |
+
Returns:
|
| 272 |
+
tensor: output
|
| 273 |
+
"""
|
| 274 |
+
out = self.relu(x)
|
| 275 |
+
out = self.conv1(out)
|
| 276 |
+
out = self.relu(out)
|
| 277 |
+
out = self.conv2(out)
|
| 278 |
+
|
| 279 |
+
return out + x
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
class FeatureFusionBlock(nn.Module):
|
| 283 |
+
"""Feature fusion block.
|
| 284 |
+
"""
|
| 285 |
+
|
| 286 |
+
def __init__(self, features):
|
| 287 |
+
"""Init.
|
| 288 |
+
|
| 289 |
+
Args:
|
| 290 |
+
features (int): number of features
|
| 291 |
+
"""
|
| 292 |
+
super(FeatureFusionBlock, self).__init__()
|
| 293 |
+
|
| 294 |
+
self.resConfUnit1 = ResidualConvUnit(features)
|
| 295 |
+
self.resConfUnit2 = ResidualConvUnit(features)
|
| 296 |
+
|
| 297 |
+
def forward(self, *xs):
|
| 298 |
+
"""Forward pass.
|
| 299 |
+
|
| 300 |
+
Returns:
|
| 301 |
+
tensor: output
|
| 302 |
+
"""
|
| 303 |
+
output = xs[0]
|
| 304 |
+
|
| 305 |
+
if len(xs) == 2:
|
| 306 |
+
output += self.resConfUnit1(xs[1])
|
| 307 |
+
|
| 308 |
+
output = self.resConfUnit2(output)
|
| 309 |
+
|
| 310 |
+
output = nn.functional.interpolate(
|
| 311 |
+
output, scale_factor=2, mode="bilinear", align_corners=True
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
return output
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class ResidualConvUnit_custom(nn.Module):
|
| 320 |
+
"""Residual convolution module.
|
| 321 |
+
"""
|
| 322 |
+
|
| 323 |
+
def __init__(self, features, activation, bn):
|
| 324 |
+
"""Init.
|
| 325 |
+
|
| 326 |
+
Args:
|
| 327 |
+
features (int): number of features
|
| 328 |
+
"""
|
| 329 |
+
super().__init__()
|
| 330 |
+
|
| 331 |
+
self.bn = bn
|
| 332 |
+
|
| 333 |
+
self.groups=1
|
| 334 |
+
|
| 335 |
+
self.conv1 = nn.Conv2d(
|
| 336 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
self.conv2 = nn.Conv2d(
|
| 340 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
if self.bn==True:
|
| 344 |
+
self.bn1 = nn.BatchNorm2d(features)
|
| 345 |
+
self.bn2 = nn.BatchNorm2d(features)
|
| 346 |
+
|
| 347 |
+
self.activation = activation
|
| 348 |
+
|
| 349 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 350 |
+
|
| 351 |
+
def forward(self, x):
|
| 352 |
+
"""Forward pass.
|
| 353 |
+
|
| 354 |
+
Args:
|
| 355 |
+
x (tensor): input
|
| 356 |
+
|
| 357 |
+
Returns:
|
| 358 |
+
tensor: output
|
| 359 |
+
"""
|
| 360 |
+
|
| 361 |
+
out = self.activation(x)
|
| 362 |
+
out = self.conv1(out)
|
| 363 |
+
if self.bn==True:
|
| 364 |
+
out = self.bn1(out)
|
| 365 |
+
|
| 366 |
+
out = self.activation(out)
|
| 367 |
+
out = self.conv2(out)
|
| 368 |
+
if self.bn==True:
|
| 369 |
+
out = self.bn2(out)
|
| 370 |
+
|
| 371 |
+
if self.groups > 1:
|
| 372 |
+
out = self.conv_merge(out)
|
| 373 |
+
|
| 374 |
+
return self.skip_add.add(out, x)
|
| 375 |
+
|
| 376 |
+
# return out + x
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class FeatureFusionBlock_custom(nn.Module):
|
| 380 |
+
"""Feature fusion block.
|
| 381 |
+
"""
|
| 382 |
+
|
| 383 |
+
def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True, size=None):
|
| 384 |
+
"""Init.
|
| 385 |
+
|
| 386 |
+
Args:
|
| 387 |
+
features (int): number of features
|
| 388 |
+
"""
|
| 389 |
+
super(FeatureFusionBlock_custom, self).__init__()
|
| 390 |
+
|
| 391 |
+
self.deconv = deconv
|
| 392 |
+
self.align_corners = align_corners
|
| 393 |
+
|
| 394 |
+
self.groups=1
|
| 395 |
+
|
| 396 |
+
self.expand = expand
|
| 397 |
+
out_features = features
|
| 398 |
+
if self.expand==True:
|
| 399 |
+
out_features = features//2
|
| 400 |
+
|
| 401 |
+
self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
|
| 402 |
+
|
| 403 |
+
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
|
| 404 |
+
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
|
| 405 |
+
|
| 406 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 407 |
+
|
| 408 |
+
self.size=size
|
| 409 |
+
|
| 410 |
+
def forward(self, *xs, size=None):
|
| 411 |
+
"""Forward pass.
|
| 412 |
+
|
| 413 |
+
Returns:
|
| 414 |
+
tensor: output
|
| 415 |
+
"""
|
| 416 |
+
output = xs[0]
|
| 417 |
+
|
| 418 |
+
if len(xs) == 2:
|
| 419 |
+
res = self.resConfUnit1(xs[1])
|
| 420 |
+
output = self.skip_add.add(output, res)
|
| 421 |
+
# output += res
|
| 422 |
+
|
| 423 |
+
output = self.resConfUnit2(output)
|
| 424 |
+
|
| 425 |
+
if (size is None) and (self.size is None):
|
| 426 |
+
modifier = {"scale_factor": 2}
|
| 427 |
+
elif size is None:
|
| 428 |
+
modifier = {"size": self.size}
|
| 429 |
+
else:
|
| 430 |
+
modifier = {"size": size}
|
| 431 |
+
|
| 432 |
+
output = nn.functional.interpolate(
|
| 433 |
+
output, **modifier, mode="bilinear", align_corners=self.align_corners
|
| 434 |
+
)
|
| 435 |
+
|
| 436 |
+
output = self.out_conv(output)
|
| 437 |
+
|
| 438 |
+
return output
|
| 439 |
+
|
MiDaS-master/midas/dpt_depth.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .base_model import BaseModel
|
| 5 |
+
from .blocks import (
|
| 6 |
+
FeatureFusionBlock_custom,
|
| 7 |
+
Interpolate,
|
| 8 |
+
_make_encoder,
|
| 9 |
+
forward_beit,
|
| 10 |
+
forward_swin,
|
| 11 |
+
forward_levit,
|
| 12 |
+
forward_vit,
|
| 13 |
+
)
|
| 14 |
+
from .backbones.levit import stem_b4_transpose
|
| 15 |
+
from timm.models.layers import get_act_layer
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _make_fusion_block(features, use_bn, size = None):
|
| 19 |
+
return FeatureFusionBlock_custom(
|
| 20 |
+
features,
|
| 21 |
+
nn.ReLU(False),
|
| 22 |
+
deconv=False,
|
| 23 |
+
bn=use_bn,
|
| 24 |
+
expand=False,
|
| 25 |
+
align_corners=True,
|
| 26 |
+
size=size,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class DPT(BaseModel):
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
head,
|
| 34 |
+
features=256,
|
| 35 |
+
backbone="vitb_rn50_384",
|
| 36 |
+
readout="project",
|
| 37 |
+
channels_last=False,
|
| 38 |
+
use_bn=False,
|
| 39 |
+
**kwargs
|
| 40 |
+
):
|
| 41 |
+
|
| 42 |
+
super(DPT, self).__init__()
|
| 43 |
+
|
| 44 |
+
self.channels_last = channels_last
|
| 45 |
+
|
| 46 |
+
# For the Swin, Swin 2, LeViT and Next-ViT Transformers, the hierarchical architectures prevent setting the
|
| 47 |
+
# hooks freely. Instead, the hooks have to be chosen according to the ranges specified in the comments.
|
| 48 |
+
hooks = {
|
| 49 |
+
"beitl16_512": [5, 11, 17, 23],
|
| 50 |
+
"beitl16_384": [5, 11, 17, 23],
|
| 51 |
+
"beitb16_384": [2, 5, 8, 11],
|
| 52 |
+
"swin2l24_384": [1, 1, 17, 1], # Allowed ranges: [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 53 |
+
"swin2b24_384": [1, 1, 17, 1], # [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 54 |
+
"swin2t16_256": [1, 1, 5, 1], # [0, 1], [0, 1], [ 0, 5], [ 0, 1]
|
| 55 |
+
"swinl12_384": [1, 1, 17, 1], # [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 56 |
+
"next_vit_large_6m": [2, 6, 36, 39], # [0, 2], [3, 6], [ 7, 36], [37, 39]
|
| 57 |
+
"levit_384": [3, 11, 21], # [0, 3], [6, 11], [14, 21]
|
| 58 |
+
"vitb_rn50_384": [0, 1, 8, 11],
|
| 59 |
+
"vitb16_384": [2, 5, 8, 11],
|
| 60 |
+
"vitl16_384": [5, 11, 17, 23],
|
| 61 |
+
}[backbone]
|
| 62 |
+
|
| 63 |
+
if "next_vit" in backbone:
|
| 64 |
+
in_features = {
|
| 65 |
+
"next_vit_large_6m": [96, 256, 512, 1024],
|
| 66 |
+
}[backbone]
|
| 67 |
+
else:
|
| 68 |
+
in_features = None
|
| 69 |
+
|
| 70 |
+
# Instantiate backbone and reassemble blocks
|
| 71 |
+
self.pretrained, self.scratch = _make_encoder(
|
| 72 |
+
backbone,
|
| 73 |
+
features,
|
| 74 |
+
False, # Set to true of you want to train from scratch, uses ImageNet weights
|
| 75 |
+
groups=1,
|
| 76 |
+
expand=False,
|
| 77 |
+
exportable=False,
|
| 78 |
+
hooks=hooks,
|
| 79 |
+
use_readout=readout,
|
| 80 |
+
in_features=in_features,
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
self.number_layers = len(hooks) if hooks is not None else 4
|
| 84 |
+
size_refinenet3 = None
|
| 85 |
+
self.scratch.stem_transpose = None
|
| 86 |
+
|
| 87 |
+
if "beit" in backbone:
|
| 88 |
+
self.forward_transformer = forward_beit
|
| 89 |
+
elif "swin" in backbone:
|
| 90 |
+
self.forward_transformer = forward_swin
|
| 91 |
+
elif "next_vit" in backbone:
|
| 92 |
+
from .backbones.next_vit import forward_next_vit
|
| 93 |
+
self.forward_transformer = forward_next_vit
|
| 94 |
+
elif "levit" in backbone:
|
| 95 |
+
self.forward_transformer = forward_levit
|
| 96 |
+
size_refinenet3 = 7
|
| 97 |
+
self.scratch.stem_transpose = stem_b4_transpose(256, 128, get_act_layer("hard_swish"))
|
| 98 |
+
else:
|
| 99 |
+
self.forward_transformer = forward_vit
|
| 100 |
+
|
| 101 |
+
self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
|
| 102 |
+
self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
|
| 103 |
+
self.scratch.refinenet3 = _make_fusion_block(features, use_bn, size_refinenet3)
|
| 104 |
+
if self.number_layers >= 4:
|
| 105 |
+
self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
|
| 106 |
+
|
| 107 |
+
self.scratch.output_conv = head
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
if self.channels_last == True:
|
| 112 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 113 |
+
|
| 114 |
+
layers = self.forward_transformer(self.pretrained, x)
|
| 115 |
+
if self.number_layers == 3:
|
| 116 |
+
layer_1, layer_2, layer_3 = layers
|
| 117 |
+
else:
|
| 118 |
+
layer_1, layer_2, layer_3, layer_4 = layers
|
| 119 |
+
|
| 120 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 121 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 122 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 123 |
+
if self.number_layers >= 4:
|
| 124 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 125 |
+
|
| 126 |
+
if self.number_layers == 3:
|
| 127 |
+
path_3 = self.scratch.refinenet3(layer_3_rn, size=layer_2_rn.shape[2:])
|
| 128 |
+
else:
|
| 129 |
+
path_4 = self.scratch.refinenet4(layer_4_rn, size=layer_3_rn.shape[2:])
|
| 130 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn, size=layer_2_rn.shape[2:])
|
| 131 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn, size=layer_1_rn.shape[2:])
|
| 132 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 133 |
+
|
| 134 |
+
if self.scratch.stem_transpose is not None:
|
| 135 |
+
path_1 = self.scratch.stem_transpose(path_1)
|
| 136 |
+
|
| 137 |
+
out = self.scratch.output_conv(path_1)
|
| 138 |
+
|
| 139 |
+
return out
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
class DPTDepthModel(DPT):
|
| 143 |
+
def __init__(self, path=None, non_negative=True, **kwargs):
|
| 144 |
+
features = kwargs["features"] if "features" in kwargs else 256
|
| 145 |
+
head_features_1 = kwargs["head_features_1"] if "head_features_1" in kwargs else features
|
| 146 |
+
head_features_2 = kwargs["head_features_2"] if "head_features_2" in kwargs else 32
|
| 147 |
+
kwargs.pop("head_features_1", None)
|
| 148 |
+
kwargs.pop("head_features_2", None)
|
| 149 |
+
|
| 150 |
+
head = nn.Sequential(
|
| 151 |
+
nn.Conv2d(head_features_1, head_features_1 // 2, kernel_size=3, stride=1, padding=1),
|
| 152 |
+
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
| 153 |
+
nn.Conv2d(head_features_1 // 2, head_features_2, kernel_size=3, stride=1, padding=1),
|
| 154 |
+
nn.ReLU(True),
|
| 155 |
+
nn.Conv2d(head_features_2, 1, kernel_size=1, stride=1, padding=0),
|
| 156 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 157 |
+
nn.Identity(),
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
super().__init__(head, **kwargs)
|
| 161 |
+
|
| 162 |
+
if path is not None:
|
| 163 |
+
self.load(path)
|
| 164 |
+
|
| 165 |
+
def forward(self, x):
|
| 166 |
+
return super().forward(x).squeeze(dim=1)
|
MiDaS-master/midas/midas_net.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=256, non_negative=True):
|
| 17 |
+
"""Init.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 21 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 22 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 23 |
+
"""
|
| 24 |
+
print("Loading weights: ", path)
|
| 25 |
+
|
| 26 |
+
super(MidasNet, self).__init__()
|
| 27 |
+
|
| 28 |
+
use_pretrained = False if path is None else True
|
| 29 |
+
|
| 30 |
+
self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained)
|
| 31 |
+
|
| 32 |
+
self.scratch.refinenet4 = FeatureFusionBlock(features)
|
| 33 |
+
self.scratch.refinenet3 = FeatureFusionBlock(features)
|
| 34 |
+
self.scratch.refinenet2 = FeatureFusionBlock(features)
|
| 35 |
+
self.scratch.refinenet1 = FeatureFusionBlock(features)
|
| 36 |
+
|
| 37 |
+
self.scratch.output_conv = nn.Sequential(
|
| 38 |
+
nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
|
| 39 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 40 |
+
nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
|
| 41 |
+
nn.ReLU(True),
|
| 42 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 43 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
if path:
|
| 47 |
+
self.load(path)
|
| 48 |
+
|
| 49 |
+
def forward(self, x):
|
| 50 |
+
"""Forward pass.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
x (tensor): input data (image)
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
tensor: depth
|
| 57 |
+
"""
|
| 58 |
+
|
| 59 |
+
layer_1 = self.pretrained.layer1(x)
|
| 60 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 61 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 62 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 63 |
+
|
| 64 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 65 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 66 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 67 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 68 |
+
|
| 69 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 70 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 71 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 72 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 73 |
+
|
| 74 |
+
out = self.scratch.output_conv(path_1)
|
| 75 |
+
|
| 76 |
+
return torch.squeeze(out, dim=1)
|
MiDaS-master/midas/midas_net_custom.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, FeatureFusionBlock_custom, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet_small(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=64, backbone="efficientnet_lite3", non_negative=True, exportable=True, channels_last=False, align_corners=True,
|
| 17 |
+
blocks={'expand': True}):
|
| 18 |
+
"""Init.
|
| 19 |
+
|
| 20 |
+
Args:
|
| 21 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 22 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 23 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 24 |
+
"""
|
| 25 |
+
print("Loading weights: ", path)
|
| 26 |
+
|
| 27 |
+
super(MidasNet_small, self).__init__()
|
| 28 |
+
|
| 29 |
+
use_pretrained = False if path else True
|
| 30 |
+
|
| 31 |
+
self.channels_last = channels_last
|
| 32 |
+
self.blocks = blocks
|
| 33 |
+
self.backbone = backbone
|
| 34 |
+
|
| 35 |
+
self.groups = 1
|
| 36 |
+
|
| 37 |
+
features1=features
|
| 38 |
+
features2=features
|
| 39 |
+
features3=features
|
| 40 |
+
features4=features
|
| 41 |
+
self.expand = False
|
| 42 |
+
if "expand" in self.blocks and self.blocks['expand'] == True:
|
| 43 |
+
self.expand = True
|
| 44 |
+
features1=features
|
| 45 |
+
features2=features*2
|
| 46 |
+
features3=features*4
|
| 47 |
+
features4=features*8
|
| 48 |
+
|
| 49 |
+
self.pretrained, self.scratch = _make_encoder(self.backbone, features, use_pretrained, groups=self.groups, expand=self.expand, exportable=exportable)
|
| 50 |
+
|
| 51 |
+
self.scratch.activation = nn.ReLU(False)
|
| 52 |
+
|
| 53 |
+
self.scratch.refinenet4 = FeatureFusionBlock_custom(features4, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 54 |
+
self.scratch.refinenet3 = FeatureFusionBlock_custom(features3, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 55 |
+
self.scratch.refinenet2 = FeatureFusionBlock_custom(features2, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 56 |
+
self.scratch.refinenet1 = FeatureFusionBlock_custom(features1, self.scratch.activation, deconv=False, bn=False, align_corners=align_corners)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
self.scratch.output_conv = nn.Sequential(
|
| 60 |
+
nn.Conv2d(features, features//2, kernel_size=3, stride=1, padding=1, groups=self.groups),
|
| 61 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 62 |
+
nn.Conv2d(features//2, 32, kernel_size=3, stride=1, padding=1),
|
| 63 |
+
self.scratch.activation,
|
| 64 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 65 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 66 |
+
nn.Identity(),
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
if path:
|
| 70 |
+
self.load(path)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
"""Forward pass.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
x (tensor): input data (image)
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
tensor: depth
|
| 81 |
+
"""
|
| 82 |
+
if self.channels_last==True:
|
| 83 |
+
print("self.channels_last = ", self.channels_last)
|
| 84 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
layer_1 = self.pretrained.layer1(x)
|
| 88 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 89 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 90 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 91 |
+
|
| 92 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 93 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 94 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 95 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 99 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 100 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 101 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 102 |
+
|
| 103 |
+
out = self.scratch.output_conv(path_1)
|
| 104 |
+
|
| 105 |
+
return torch.squeeze(out, dim=1)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def fuse_model(m):
|
| 110 |
+
prev_previous_type = nn.Identity()
|
| 111 |
+
prev_previous_name = ''
|
| 112 |
+
previous_type = nn.Identity()
|
| 113 |
+
previous_name = ''
|
| 114 |
+
for name, module in m.named_modules():
|
| 115 |
+
if prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d and type(module) == nn.ReLU:
|
| 116 |
+
# print("FUSED ", prev_previous_name, previous_name, name)
|
| 117 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name, name], inplace=True)
|
| 118 |
+
elif prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d:
|
| 119 |
+
# print("FUSED ", prev_previous_name, previous_name)
|
| 120 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name], inplace=True)
|
| 121 |
+
# elif previous_type == nn.Conv2d and type(module) == nn.ReLU:
|
| 122 |
+
# print("FUSED ", previous_name, name)
|
| 123 |
+
# torch.quantization.fuse_modules(m, [previous_name, name], inplace=True)
|
| 124 |
+
|
| 125 |
+
prev_previous_type = previous_type
|
| 126 |
+
prev_previous_name = previous_name
|
| 127 |
+
previous_type = type(module)
|
| 128 |
+
previous_name = name
|
MiDaS-master/midas/model_loader.py
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from midas.dpt_depth import DPTDepthModel
|
| 5 |
+
from midas.midas_net import MidasNet
|
| 6 |
+
from midas.midas_net_custom import MidasNet_small
|
| 7 |
+
from midas.transforms import Resize, NormalizeImage, PrepareForNet
|
| 8 |
+
|
| 9 |
+
from torchvision.transforms import Compose
|
| 10 |
+
|
| 11 |
+
default_models = {
|
| 12 |
+
"dpt_beit_large_512": "weights/dpt_beit_large_512.pt",
|
| 13 |
+
"dpt_beit_large_384": "weights/dpt_beit_large_384.pt",
|
| 14 |
+
"dpt_beit_base_384": "weights/dpt_beit_base_384.pt",
|
| 15 |
+
"dpt_swin2_large_384": "weights/dpt_swin2_large_384.pt",
|
| 16 |
+
"dpt_swin2_base_384": "weights/dpt_swin2_base_384.pt",
|
| 17 |
+
"dpt_swin2_tiny_256": "weights/dpt_swin2_tiny_256.pt",
|
| 18 |
+
"dpt_swin_large_384": "weights/dpt_swin_large_384.pt",
|
| 19 |
+
"dpt_next_vit_large_384": "weights/dpt_next_vit_large_384.pt",
|
| 20 |
+
"dpt_levit_224": "weights/dpt_levit_224.pt",
|
| 21 |
+
"dpt_large_384": "weights/dpt_large_384.pt",
|
| 22 |
+
"dpt_hybrid_384": "weights/dpt_hybrid_384.pt",
|
| 23 |
+
"midas_v21_384": "weights/midas_v21_384.pt",
|
| 24 |
+
"midas_v21_small_256": "weights/midas_v21_small_256.pt",
|
| 25 |
+
"openvino_midas_v21_small_256": "weights/openvino_midas_v21_small_256.xml",
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def load_model(device, model_path, model_type="dpt_large_384", optimize=True, height=None, square=False):
|
| 30 |
+
"""Load the specified network.
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
device (device): the torch device used
|
| 34 |
+
model_path (str): path to saved model
|
| 35 |
+
model_type (str): the type of the model to be loaded
|
| 36 |
+
optimize (bool): optimize the model to half-integer on CUDA?
|
| 37 |
+
height (int): inference encoder image height
|
| 38 |
+
square (bool): resize to a square resolution?
|
| 39 |
+
|
| 40 |
+
Returns:
|
| 41 |
+
The loaded network, the transform which prepares images as input to the network and the dimensions of the
|
| 42 |
+
network input
|
| 43 |
+
"""
|
| 44 |
+
if "openvino" in model_type:
|
| 45 |
+
from openvino.runtime import Core
|
| 46 |
+
|
| 47 |
+
keep_aspect_ratio = not square
|
| 48 |
+
|
| 49 |
+
if model_type == "dpt_beit_large_512":
|
| 50 |
+
model = DPTDepthModel(
|
| 51 |
+
path=model_path,
|
| 52 |
+
backbone="beitl16_512",
|
| 53 |
+
non_negative=True,
|
| 54 |
+
)
|
| 55 |
+
net_w, net_h = 512, 512
|
| 56 |
+
resize_mode = "minimal"
|
| 57 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 58 |
+
|
| 59 |
+
elif model_type == "dpt_beit_large_384":
|
| 60 |
+
model = DPTDepthModel(
|
| 61 |
+
path=model_path,
|
| 62 |
+
backbone="beitl16_384",
|
| 63 |
+
non_negative=True,
|
| 64 |
+
)
|
| 65 |
+
net_w, net_h = 384, 384
|
| 66 |
+
resize_mode = "minimal"
|
| 67 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 68 |
+
|
| 69 |
+
elif model_type == "dpt_beit_base_384":
|
| 70 |
+
model = DPTDepthModel(
|
| 71 |
+
path=model_path,
|
| 72 |
+
backbone="beitb16_384",
|
| 73 |
+
non_negative=True,
|
| 74 |
+
)
|
| 75 |
+
net_w, net_h = 384, 384
|
| 76 |
+
resize_mode = "minimal"
|
| 77 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 78 |
+
|
| 79 |
+
elif model_type == "dpt_swin2_large_384":
|
| 80 |
+
model = DPTDepthModel(
|
| 81 |
+
path=model_path,
|
| 82 |
+
backbone="swin2l24_384",
|
| 83 |
+
non_negative=True,
|
| 84 |
+
)
|
| 85 |
+
net_w, net_h = 384, 384
|
| 86 |
+
keep_aspect_ratio = False
|
| 87 |
+
resize_mode = "minimal"
|
| 88 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 89 |
+
|
| 90 |
+
elif model_type == "dpt_swin2_base_384":
|
| 91 |
+
model = DPTDepthModel(
|
| 92 |
+
path=model_path,
|
| 93 |
+
backbone="swin2b24_384",
|
| 94 |
+
non_negative=True,
|
| 95 |
+
)
|
| 96 |
+
net_w, net_h = 384, 384
|
| 97 |
+
keep_aspect_ratio = False
|
| 98 |
+
resize_mode = "minimal"
|
| 99 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 100 |
+
|
| 101 |
+
elif model_type == "dpt_swin2_tiny_256":
|
| 102 |
+
model = DPTDepthModel(
|
| 103 |
+
path=model_path,
|
| 104 |
+
backbone="swin2t16_256",
|
| 105 |
+
non_negative=True,
|
| 106 |
+
)
|
| 107 |
+
net_w, net_h = 256, 256
|
| 108 |
+
keep_aspect_ratio = False
|
| 109 |
+
resize_mode = "minimal"
|
| 110 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 111 |
+
|
| 112 |
+
elif model_type == "dpt_swin_large_384":
|
| 113 |
+
model = DPTDepthModel(
|
| 114 |
+
path=model_path,
|
| 115 |
+
backbone="swinl12_384",
|
| 116 |
+
non_negative=True,
|
| 117 |
+
)
|
| 118 |
+
net_w, net_h = 384, 384
|
| 119 |
+
keep_aspect_ratio = False
|
| 120 |
+
resize_mode = "minimal"
|
| 121 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 122 |
+
|
| 123 |
+
elif model_type == "dpt_next_vit_large_384":
|
| 124 |
+
model = DPTDepthModel(
|
| 125 |
+
path=model_path,
|
| 126 |
+
backbone="next_vit_large_6m",
|
| 127 |
+
non_negative=True,
|
| 128 |
+
)
|
| 129 |
+
net_w, net_h = 384, 384
|
| 130 |
+
resize_mode = "minimal"
|
| 131 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 132 |
+
|
| 133 |
+
# We change the notation from dpt_levit_224 (MiDaS notation) to levit_384 (timm notation) here, where the 224 refers
|
| 134 |
+
# to the resolution 224x224 used by LeViT and 384 is the first entry of the embed_dim, see _cfg and model_cfgs of
|
| 135 |
+
# https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/levit.py
|
| 136 |
+
# (commit id: 927f031293a30afb940fff0bee34b85d9c059b0e)
|
| 137 |
+
elif model_type == "dpt_levit_224":
|
| 138 |
+
model = DPTDepthModel(
|
| 139 |
+
path=model_path,
|
| 140 |
+
backbone="levit_384",
|
| 141 |
+
non_negative=True,
|
| 142 |
+
head_features_1=64,
|
| 143 |
+
head_features_2=8,
|
| 144 |
+
)
|
| 145 |
+
net_w, net_h = 224, 224
|
| 146 |
+
keep_aspect_ratio = False
|
| 147 |
+
resize_mode = "minimal"
|
| 148 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 149 |
+
|
| 150 |
+
elif model_type == "dpt_large_384":
|
| 151 |
+
model = DPTDepthModel(
|
| 152 |
+
path=model_path,
|
| 153 |
+
backbone="vitl16_384",
|
| 154 |
+
non_negative=True,
|
| 155 |
+
)
|
| 156 |
+
net_w, net_h = 384, 384
|
| 157 |
+
resize_mode = "minimal"
|
| 158 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 159 |
+
|
| 160 |
+
elif model_type == "dpt_hybrid_384":
|
| 161 |
+
model = DPTDepthModel(
|
| 162 |
+
path=model_path,
|
| 163 |
+
backbone="vitb_rn50_384",
|
| 164 |
+
non_negative=True,
|
| 165 |
+
)
|
| 166 |
+
net_w, net_h = 384, 384
|
| 167 |
+
resize_mode = "minimal"
|
| 168 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 169 |
+
|
| 170 |
+
elif model_type == "midas_v21_384":
|
| 171 |
+
model = MidasNet(model_path, non_negative=True)
|
| 172 |
+
net_w, net_h = 384, 384
|
| 173 |
+
resize_mode = "upper_bound"
|
| 174 |
+
normalization = NormalizeImage(
|
| 175 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
elif model_type == "midas_v21_small_256":
|
| 179 |
+
model = MidasNet_small(model_path, features=64, backbone="efficientnet_lite3", exportable=True,
|
| 180 |
+
non_negative=True, blocks={'expand': True})
|
| 181 |
+
net_w, net_h = 256, 256
|
| 182 |
+
resize_mode = "upper_bound"
|
| 183 |
+
normalization = NormalizeImage(
|
| 184 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
elif model_type == "openvino_midas_v21_small_256":
|
| 188 |
+
ie = Core()
|
| 189 |
+
uncompiled_model = ie.read_model(model=model_path)
|
| 190 |
+
model = ie.compile_model(uncompiled_model, "CPU")
|
| 191 |
+
net_w, net_h = 256, 256
|
| 192 |
+
resize_mode = "upper_bound"
|
| 193 |
+
normalization = NormalizeImage(
|
| 194 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
else:
|
| 198 |
+
print(f"model_type '{model_type}' not implemented, use: --model_type large")
|
| 199 |
+
assert False
|
| 200 |
+
|
| 201 |
+
if not "openvino" in model_type:
|
| 202 |
+
print("Model loaded, number of parameters = {:.0f}M".format(sum(p.numel() for p in model.parameters()) / 1e6))
|
| 203 |
+
else:
|
| 204 |
+
print("Model loaded, optimized with OpenVINO")
|
| 205 |
+
|
| 206 |
+
if "openvino" in model_type:
|
| 207 |
+
keep_aspect_ratio = False
|
| 208 |
+
|
| 209 |
+
if height is not None:
|
| 210 |
+
net_w, net_h = height, height
|
| 211 |
+
|
| 212 |
+
transform = Compose(
|
| 213 |
+
[
|
| 214 |
+
Resize(
|
| 215 |
+
net_w,
|
| 216 |
+
net_h,
|
| 217 |
+
resize_target=None,
|
| 218 |
+
keep_aspect_ratio=keep_aspect_ratio,
|
| 219 |
+
ensure_multiple_of=32,
|
| 220 |
+
resize_method=resize_mode,
|
| 221 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 222 |
+
),
|
| 223 |
+
normalization,
|
| 224 |
+
PrepareForNet(),
|
| 225 |
+
]
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
if not "openvino" in model_type:
|
| 229 |
+
model.eval()
|
| 230 |
+
|
| 231 |
+
if optimize and (device == torch.device("cuda")):
|
| 232 |
+
if not "openvino" in model_type:
|
| 233 |
+
model = model.to(memory_format=torch.channels_last)
|
| 234 |
+
model = model.half()
|
| 235 |
+
else:
|
| 236 |
+
print("Error: OpenVINO models are already optimized. No optimization to half-float possible.")
|
| 237 |
+
exit()
|
| 238 |
+
|
| 239 |
+
if not "openvino" in model_type:
|
| 240 |
+
model.to(device)
|
| 241 |
+
|
| 242 |
+
return model, transform, net_w, net_h
|
MiDaS-master/midas/transforms.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
|
| 7 |
+
"""Rezise the sample to ensure the given size. Keeps aspect ratio.
|
| 8 |
+
|
| 9 |
+
Args:
|
| 10 |
+
sample (dict): sample
|
| 11 |
+
size (tuple): image size
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
tuple: new size
|
| 15 |
+
"""
|
| 16 |
+
shape = list(sample["disparity"].shape)
|
| 17 |
+
|
| 18 |
+
if shape[0] >= size[0] and shape[1] >= size[1]:
|
| 19 |
+
return sample
|
| 20 |
+
|
| 21 |
+
scale = [0, 0]
|
| 22 |
+
scale[0] = size[0] / shape[0]
|
| 23 |
+
scale[1] = size[1] / shape[1]
|
| 24 |
+
|
| 25 |
+
scale = max(scale)
|
| 26 |
+
|
| 27 |
+
shape[0] = math.ceil(scale * shape[0])
|
| 28 |
+
shape[1] = math.ceil(scale * shape[1])
|
| 29 |
+
|
| 30 |
+
# resize
|
| 31 |
+
sample["image"] = cv2.resize(
|
| 32 |
+
sample["image"], tuple(shape[::-1]), interpolation=image_interpolation_method
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
sample["disparity"] = cv2.resize(
|
| 36 |
+
sample["disparity"], tuple(shape[::-1]), interpolation=cv2.INTER_NEAREST
|
| 37 |
+
)
|
| 38 |
+
sample["mask"] = cv2.resize(
|
| 39 |
+
sample["mask"].astype(np.float32),
|
| 40 |
+
tuple(shape[::-1]),
|
| 41 |
+
interpolation=cv2.INTER_NEAREST,
|
| 42 |
+
)
|
| 43 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 44 |
+
|
| 45 |
+
return tuple(shape)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Resize(object):
|
| 49 |
+
"""Resize sample to given size (width, height).
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
width,
|
| 55 |
+
height,
|
| 56 |
+
resize_target=True,
|
| 57 |
+
keep_aspect_ratio=False,
|
| 58 |
+
ensure_multiple_of=1,
|
| 59 |
+
resize_method="lower_bound",
|
| 60 |
+
image_interpolation_method=cv2.INTER_AREA,
|
| 61 |
+
):
|
| 62 |
+
"""Init.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
width (int): desired output width
|
| 66 |
+
height (int): desired output height
|
| 67 |
+
resize_target (bool, optional):
|
| 68 |
+
True: Resize the full sample (image, mask, target).
|
| 69 |
+
False: Resize image only.
|
| 70 |
+
Defaults to True.
|
| 71 |
+
keep_aspect_ratio (bool, optional):
|
| 72 |
+
True: Keep the aspect ratio of the input sample.
|
| 73 |
+
Output sample might not have the given width and height, and
|
| 74 |
+
resize behaviour depends on the parameter 'resize_method'.
|
| 75 |
+
Defaults to False.
|
| 76 |
+
ensure_multiple_of (int, optional):
|
| 77 |
+
Output width and height is constrained to be multiple of this parameter.
|
| 78 |
+
Defaults to 1.
|
| 79 |
+
resize_method (str, optional):
|
| 80 |
+
"lower_bound": Output will be at least as large as the given size.
|
| 81 |
+
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
| 82 |
+
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
| 83 |
+
Defaults to "lower_bound".
|
| 84 |
+
"""
|
| 85 |
+
self.__width = width
|
| 86 |
+
self.__height = height
|
| 87 |
+
|
| 88 |
+
self.__resize_target = resize_target
|
| 89 |
+
self.__keep_aspect_ratio = keep_aspect_ratio
|
| 90 |
+
self.__multiple_of = ensure_multiple_of
|
| 91 |
+
self.__resize_method = resize_method
|
| 92 |
+
self.__image_interpolation_method = image_interpolation_method
|
| 93 |
+
|
| 94 |
+
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
| 95 |
+
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 96 |
+
|
| 97 |
+
if max_val is not None and y > max_val:
|
| 98 |
+
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 99 |
+
|
| 100 |
+
if y < min_val:
|
| 101 |
+
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 102 |
+
|
| 103 |
+
return y
|
| 104 |
+
|
| 105 |
+
def get_size(self, width, height):
|
| 106 |
+
# determine new height and width
|
| 107 |
+
scale_height = self.__height / height
|
| 108 |
+
scale_width = self.__width / width
|
| 109 |
+
|
| 110 |
+
if self.__keep_aspect_ratio:
|
| 111 |
+
if self.__resize_method == "lower_bound":
|
| 112 |
+
# scale such that output size is lower bound
|
| 113 |
+
if scale_width > scale_height:
|
| 114 |
+
# fit width
|
| 115 |
+
scale_height = scale_width
|
| 116 |
+
else:
|
| 117 |
+
# fit height
|
| 118 |
+
scale_width = scale_height
|
| 119 |
+
elif self.__resize_method == "upper_bound":
|
| 120 |
+
# scale such that output size is upper bound
|
| 121 |
+
if scale_width < scale_height:
|
| 122 |
+
# fit width
|
| 123 |
+
scale_height = scale_width
|
| 124 |
+
else:
|
| 125 |
+
# fit height
|
| 126 |
+
scale_width = scale_height
|
| 127 |
+
elif self.__resize_method == "minimal":
|
| 128 |
+
# scale as least as possbile
|
| 129 |
+
if abs(1 - scale_width) < abs(1 - scale_height):
|
| 130 |
+
# fit width
|
| 131 |
+
scale_height = scale_width
|
| 132 |
+
else:
|
| 133 |
+
# fit height
|
| 134 |
+
scale_width = scale_height
|
| 135 |
+
else:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"resize_method {self.__resize_method} not implemented"
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
if self.__resize_method == "lower_bound":
|
| 141 |
+
new_height = self.constrain_to_multiple_of(
|
| 142 |
+
scale_height * height, min_val=self.__height
|
| 143 |
+
)
|
| 144 |
+
new_width = self.constrain_to_multiple_of(
|
| 145 |
+
scale_width * width, min_val=self.__width
|
| 146 |
+
)
|
| 147 |
+
elif self.__resize_method == "upper_bound":
|
| 148 |
+
new_height = self.constrain_to_multiple_of(
|
| 149 |
+
scale_height * height, max_val=self.__height
|
| 150 |
+
)
|
| 151 |
+
new_width = self.constrain_to_multiple_of(
|
| 152 |
+
scale_width * width, max_val=self.__width
|
| 153 |
+
)
|
| 154 |
+
elif self.__resize_method == "minimal":
|
| 155 |
+
new_height = self.constrain_to_multiple_of(scale_height * height)
|
| 156 |
+
new_width = self.constrain_to_multiple_of(scale_width * width)
|
| 157 |
+
else:
|
| 158 |
+
raise ValueError(f"resize_method {self.__resize_method} not implemented")
|
| 159 |
+
|
| 160 |
+
return (new_width, new_height)
|
| 161 |
+
|
| 162 |
+
def __call__(self, sample):
|
| 163 |
+
width, height = self.get_size(
|
| 164 |
+
sample["image"].shape[1], sample["image"].shape[0]
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# resize sample
|
| 168 |
+
sample["image"] = cv2.resize(
|
| 169 |
+
sample["image"],
|
| 170 |
+
(width, height),
|
| 171 |
+
interpolation=self.__image_interpolation_method,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if self.__resize_target:
|
| 175 |
+
if "disparity" in sample:
|
| 176 |
+
sample["disparity"] = cv2.resize(
|
| 177 |
+
sample["disparity"],
|
| 178 |
+
(width, height),
|
| 179 |
+
interpolation=cv2.INTER_NEAREST,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if "depth" in sample:
|
| 183 |
+
sample["depth"] = cv2.resize(
|
| 184 |
+
sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
sample["mask"] = cv2.resize(
|
| 188 |
+
sample["mask"].astype(np.float32),
|
| 189 |
+
(width, height),
|
| 190 |
+
interpolation=cv2.INTER_NEAREST,
|
| 191 |
+
)
|
| 192 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 193 |
+
|
| 194 |
+
return sample
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class NormalizeImage(object):
|
| 198 |
+
"""Normlize image by given mean and std.
|
| 199 |
+
"""
|
| 200 |
+
|
| 201 |
+
def __init__(self, mean, std):
|
| 202 |
+
self.__mean = mean
|
| 203 |
+
self.__std = std
|
| 204 |
+
|
| 205 |
+
def __call__(self, sample):
|
| 206 |
+
sample["image"] = (sample["image"] - self.__mean) / self.__std
|
| 207 |
+
|
| 208 |
+
return sample
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class PrepareForNet(object):
|
| 212 |
+
"""Prepare sample for usage as network input.
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
def __init__(self):
|
| 216 |
+
pass
|
| 217 |
+
|
| 218 |
+
def __call__(self, sample):
|
| 219 |
+
image = np.transpose(sample["image"], (2, 0, 1))
|
| 220 |
+
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
|
| 221 |
+
|
| 222 |
+
if "mask" in sample:
|
| 223 |
+
sample["mask"] = sample["mask"].astype(np.float32)
|
| 224 |
+
sample["mask"] = np.ascontiguousarray(sample["mask"])
|
| 225 |
+
|
| 226 |
+
if "disparity" in sample:
|
| 227 |
+
disparity = sample["disparity"].astype(np.float32)
|
| 228 |
+
sample["disparity"] = np.ascontiguousarray(disparity)
|
| 229 |
+
|
| 230 |
+
if "depth" in sample:
|
| 231 |
+
depth = sample["depth"].astype(np.float32)
|
| 232 |
+
sample["depth"] = np.ascontiguousarray(depth)
|
| 233 |
+
|
| 234 |
+
return sample
|
MiDaS-master/mobile/README.md
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Mobile version of MiDaS for iOS / Android - Monocular Depth Estimation
|
| 2 |
+
|
| 3 |
+
### Accuracy
|
| 4 |
+
|
| 5 |
+
* Old small model - ResNet50 default-decoder 384x384
|
| 6 |
+
* New small model - EfficientNet-Lite3 small-decoder 256x256
|
| 7 |
+
|
| 8 |
+
**Zero-shot error** (the lower - the better):
|
| 9 |
+
|
| 10 |
+
| Model | DIW WHDR | Eth3d AbsRel | Sintel AbsRel | Kitti δ>1.25 | NyuDepthV2 δ>1.25 | TUM δ>1.25 |
|
| 11 |
+
|---|---|---|---|---|---|---|
|
| 12 |
+
| Old small model 384x384 | **0.1248** | 0.1550 | **0.3300** | **21.81** | 15.73 | 17.00 |
|
| 13 |
+
| New small model 256x256 | 0.1344 | **0.1344** | 0.3370 | 29.27 | **13.43** | **14.53** |
|
| 14 |
+
| Relative improvement, % | -8 % | **+13 %** | -2 % | -34 % | **+15 %** | **+15 %** |
|
| 15 |
+
|
| 16 |
+
None of Train/Valid/Test subsets of datasets (DIW, Eth3d, Sintel, Kitti, NyuDepthV2, TUM) were not involved in Training or Fine Tuning.
|
| 17 |
+
|
| 18 |
+
### Inference speed (FPS) on iOS / Android
|
| 19 |
+
|
| 20 |
+
**Frames Per Second** (the higher - the better):
|
| 21 |
+
|
| 22 |
+
| Model | iPhone CPU | iPhone GPU | iPhone NPU | OnePlus8 CPU | OnePlus8 GPU | OnePlus8 NNAPI |
|
| 23 |
+
|---|---|---|---|---|---|---|
|
| 24 |
+
| Old small model 384x384 | 0.6 | N/A | N/A | 0.45 | 0.50 | 0.50 |
|
| 25 |
+
| New small model 256x256 | 8 | 22 | **30** | 6 | **22** | 4 |
|
| 26 |
+
| SpeedUp, X times | **12.8x** | - | - | **13.2x** | **44x** | **8x** |
|
| 27 |
+
|
| 28 |
+
N/A - run-time error (no data available)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
#### Models:
|
| 32 |
+
|
| 33 |
+
* Old small model - ResNet50 default-decoder 1x384x384x3, batch=1 FP32 (converters: Pytorch -> ONNX - [onnx_tf](https://github.com/onnx/onnx-tensorflow) -> (saved model) PB -> TFlite)
|
| 34 |
+
|
| 35 |
+
(Trained on datasets: RedWeb, MegaDepth, WSVD, 3D Movies, DIML indoor)
|
| 36 |
+
|
| 37 |
+
* New small model - EfficientNet-Lite3 small-decoder 1x256x256x3, batch=1 FP32 (custom converter: Pytorch -> TFlite)
|
| 38 |
+
|
| 39 |
+
(Trained on datasets: RedWeb, MegaDepth, WSVD, 3D Movies, DIML indoor, HRWSI, IRS, TartanAir, BlendedMVS, ApolloScape)
|
| 40 |
+
|
| 41 |
+
#### Frameworks for training and conversions:
|
| 42 |
+
```
|
| 43 |
+
pip install torch==1.6.0 torchvision==0.7.0
|
| 44 |
+
pip install tf-nightly-gpu==2.5.0.dev20201031 tensorflow-addons==0.11.2 numpy==1.18.0
|
| 45 |
+
git clone --depth 1 --branch v1.6.0 https://github.com/onnx/onnx-tensorflow
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
#### SoC - OS - Library:
|
| 49 |
+
|
| 50 |
+
* iPhone 11 (A13 Bionic) - iOS 13.7 - TensorFlowLiteSwift 0.0.1-nightly
|
| 51 |
+
* OnePlus 8 (Snapdragon 865) - Andoird 10 - org.tensorflow:tensorflow-lite-task-vision:0.0.0-nightly
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### Citation
|
| 55 |
+
|
| 56 |
+
This repository contains code to compute depth from a single image. It accompanies our [paper](https://arxiv.org/abs/1907.01341v3):
|
| 57 |
+
|
| 58 |
+
>Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 59 |
+
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
|
| 60 |
+
|
| 61 |
+
Please cite our paper if you use this code or any of the models:
|
| 62 |
+
```
|
| 63 |
+
@article{Ranftl2020,
|
| 64 |
+
author = {Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun},
|
| 65 |
+
title = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer},
|
| 66 |
+
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
|
| 67 |
+
year = {2020},
|
| 68 |
+
}
|
| 69 |
+
```
|
| 70 |
+
|
MiDaS-master/mobile/android/.gitignore
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.iml
|
| 2 |
+
.gradle
|
| 3 |
+
/local.properties
|
| 4 |
+
/.idea/libraries
|
| 5 |
+
/.idea/modules.xml
|
| 6 |
+
/.idea/workspace.xml
|
| 7 |
+
.DS_Store
|
| 8 |
+
/build
|
| 9 |
+
/captures
|
| 10 |
+
.externalNativeBuild
|
| 11 |
+
|
| 12 |
+
/.gradle/
|
| 13 |
+
/.idea/
|
MiDaS-master/mobile/android/EXPLORE_THE_CODE.md
ADDED
|
@@ -0,0 +1,414 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TensorFlow Lite Android image classification example
|
| 2 |
+
|
| 3 |
+
This document walks through the code of a simple Android mobile application that
|
| 4 |
+
demonstrates
|
| 5 |
+
[image classification](https://www.tensorflow.org/lite/models/image_classification/overview)
|
| 6 |
+
using the device camera.
|
| 7 |
+
|
| 8 |
+
## Explore the code
|
| 9 |
+
|
| 10 |
+
We're now going to walk through the most important parts of the sample code.
|
| 11 |
+
|
| 12 |
+
### Get camera input
|
| 13 |
+
|
| 14 |
+
This mobile application gets the camera input using the functions defined in the
|
| 15 |
+
file
|
| 16 |
+
[`CameraActivity.java`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/app/src/main/java/org/tensorflow/lite/examples/classification/CameraActivity.java).
|
| 17 |
+
This file depends on
|
| 18 |
+
[`AndroidManifest.xml`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/app/src/main/AndroidManifest.xml)
|
| 19 |
+
to set the camera orientation.
|
| 20 |
+
|
| 21 |
+
`CameraActivity` also contains code to capture user preferences from the UI and
|
| 22 |
+
make them available to other classes via convenience methods.
|
| 23 |
+
|
| 24 |
+
```java
|
| 25 |
+
model = Model.valueOf(modelSpinner.getSelectedItem().toString().toUpperCase());
|
| 26 |
+
device = Device.valueOf(deviceSpinner.getSelectedItem().toString());
|
| 27 |
+
numThreads = Integer.parseInt(threadsTextView.getText().toString().trim());
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
### Classifier
|
| 31 |
+
|
| 32 |
+
This Image Classification Android reference app demonstrates two implementation
|
| 33 |
+
solutions,
|
| 34 |
+
[`lib_task_api`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_task_api)
|
| 35 |
+
that leverages the out-of-box API from the
|
| 36 |
+
[TensorFlow Lite Task Library](https://www.tensorflow.org/lite/inference_with_metadata/task_library/image_classifier),
|
| 37 |
+
and
|
| 38 |
+
[`lib_support`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_support)
|
| 39 |
+
that creates the custom inference pipleline using the
|
| 40 |
+
[TensorFlow Lite Support Library](https://www.tensorflow.org/lite/inference_with_metadata/lite_support).
|
| 41 |
+
|
| 42 |
+
Both solutions implement the file `Classifier.java` (see
|
| 43 |
+
[the one in lib_task_api](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_task_api/src/main/java/org/tensorflow/lite/examples/classification/tflite/Classifier.java)
|
| 44 |
+
and
|
| 45 |
+
[the one in lib_support](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_support/src/main/java/org/tensorflow/lite/examples/classification/tflite/Classifier.java))
|
| 46 |
+
that contains most of the complex logic for processing the camera input and
|
| 47 |
+
running inference.
|
| 48 |
+
|
| 49 |
+
Two subclasses of the `Classifier` exist, as in `ClassifierFloatMobileNet.java`
|
| 50 |
+
and `ClassifierQuantizedMobileNet.java`, which contain settings for both
|
| 51 |
+
floating point and
|
| 52 |
+
[quantized](https://www.tensorflow.org/lite/performance/post_training_quantization)
|
| 53 |
+
models.
|
| 54 |
+
|
| 55 |
+
The `Classifier` class implements a static method, `create`, which is used to
|
| 56 |
+
instantiate the appropriate subclass based on the supplied model type (quantized
|
| 57 |
+
vs floating point).
|
| 58 |
+
|
| 59 |
+
#### Using the TensorFlow Lite Task Library
|
| 60 |
+
|
| 61 |
+
Inference can be done using just a few lines of code with the
|
| 62 |
+
[`ImageClassifier`](https://www.tensorflow.org/lite/inference_with_metadata/task_library/image_classifier)
|
| 63 |
+
in the TensorFlow Lite Task Library.
|
| 64 |
+
|
| 65 |
+
##### Load model and create ImageClassifier
|
| 66 |
+
|
| 67 |
+
`ImageClassifier` expects a model populated with the
|
| 68 |
+
[model metadata](https://www.tensorflow.org/lite/convert/metadata) and the label
|
| 69 |
+
file. See the
|
| 70 |
+
[model compatibility requirements](https://www.tensorflow.org/lite/inference_with_metadata/task_library/image_classifier#model_compatibility_requirements)
|
| 71 |
+
for more details.
|
| 72 |
+
|
| 73 |
+
`ImageClassifierOptions` allows manipulation on various inference options, such
|
| 74 |
+
as setting the maximum number of top scored results to return using
|
| 75 |
+
`setMaxResults(MAX_RESULTS)`, and setting the score threshold using
|
| 76 |
+
`setScoreThreshold(scoreThreshold)`.
|
| 77 |
+
|
| 78 |
+
```java
|
| 79 |
+
// Create the ImageClassifier instance.
|
| 80 |
+
ImageClassifierOptions options =
|
| 81 |
+
ImageClassifierOptions.builder().setMaxResults(MAX_RESULTS).build();
|
| 82 |
+
imageClassifier = ImageClassifier.createFromFileAndOptions(activity,
|
| 83 |
+
getModelPath(), options);
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
`ImageClassifier` currently does not support configuring delegates and
|
| 87 |
+
multithread, but those are on our roadmap. Please stay tuned!
|
| 88 |
+
|
| 89 |
+
##### Run inference
|
| 90 |
+
|
| 91 |
+
`ImageClassifier` contains builtin logic to preprocess the input image, such as
|
| 92 |
+
rotating and resizing an image. Processing options can be configured through
|
| 93 |
+
`ImageProcessingOptions`. In the following example, input images are rotated to
|
| 94 |
+
the up-right angle and cropped to the center as the model expects a square input
|
| 95 |
+
(`224x224`). See the
|
| 96 |
+
[Java doc of `ImageClassifier`](https://github.com/tensorflow/tflite-support/blob/195b574f0aa9856c618b3f1ad87bd185cddeb657/tensorflow_lite_support/java/src/java/org/tensorflow/lite/task/core/vision/ImageProcessingOptions.java#L22)
|
| 97 |
+
for more details about how the underlying image processing is performed.
|
| 98 |
+
|
| 99 |
+
```java
|
| 100 |
+
TensorImage inputImage = TensorImage.fromBitmap(bitmap);
|
| 101 |
+
int width = bitmap.getWidth();
|
| 102 |
+
int height = bitmap.getHeight();
|
| 103 |
+
int cropSize = min(width, height);
|
| 104 |
+
ImageProcessingOptions imageOptions =
|
| 105 |
+
ImageProcessingOptions.builder()
|
| 106 |
+
.setOrientation(getOrientation(sensorOrientation))
|
| 107 |
+
// Set the ROI to the center of the image.
|
| 108 |
+
.setRoi(
|
| 109 |
+
new Rect(
|
| 110 |
+
/*left=*/ (width - cropSize) / 2,
|
| 111 |
+
/*top=*/ (height - cropSize) / 2,
|
| 112 |
+
/*right=*/ (width + cropSize) / 2,
|
| 113 |
+
/*bottom=*/ (height + cropSize) / 2))
|
| 114 |
+
.build();
|
| 115 |
+
|
| 116 |
+
List<Classifications> results = imageClassifier.classify(inputImage,
|
| 117 |
+
imageOptions);
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
The output of `ImageClassifier` is a list of `Classifications` instance, where
|
| 121 |
+
each `Classifications` element is a single head classification result. All the
|
| 122 |
+
demo models are single head models, therefore, `results` only contains one
|
| 123 |
+
`Classifications` object. Use `Classifications.getCategories()` to get a list of
|
| 124 |
+
top-k categories as specified with `MAX_RESULTS`. Each `Category` object
|
| 125 |
+
contains the srting label and the score of that category.
|
| 126 |
+
|
| 127 |
+
To match the implementation of
|
| 128 |
+
[`lib_support`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_support),
|
| 129 |
+
`results` is converted into `List<Recognition>` in the method,
|
| 130 |
+
`getRecognitions`.
|
| 131 |
+
|
| 132 |
+
#### Using the TensorFlow Lite Support Library
|
| 133 |
+
|
| 134 |
+
##### Load model and create interpreter
|
| 135 |
+
|
| 136 |
+
To perform inference, we need to load a model file and instantiate an
|
| 137 |
+
`Interpreter`. This happens in the constructor of the `Classifier` class, along
|
| 138 |
+
with loading the list of class labels. Information about the device type and
|
| 139 |
+
number of threads is used to configure the `Interpreter` via the
|
| 140 |
+
`Interpreter.Options` instance passed into its constructor. Note that if a GPU,
|
| 141 |
+
DSP (Digital Signal Processor) or NPU (Neural Processing Unit) is available, a
|
| 142 |
+
[`Delegate`](https://www.tensorflow.org/lite/performance/delegates) can be used
|
| 143 |
+
to take full advantage of these hardware.
|
| 144 |
+
|
| 145 |
+
Please note that there are performance edge cases and developers are adviced to
|
| 146 |
+
test with a representative set of devices prior to production.
|
| 147 |
+
|
| 148 |
+
```java
|
| 149 |
+
protected Classifier(Activity activity, Device device, int numThreads) throws
|
| 150 |
+
IOException {
|
| 151 |
+
tfliteModel = FileUtil.loadMappedFile(activity, getModelPath());
|
| 152 |
+
switch (device) {
|
| 153 |
+
case NNAPI:
|
| 154 |
+
nnApiDelegate = new NnApiDelegate();
|
| 155 |
+
tfliteOptions.addDelegate(nnApiDelegate);
|
| 156 |
+
break;
|
| 157 |
+
case GPU:
|
| 158 |
+
gpuDelegate = new GpuDelegate();
|
| 159 |
+
tfliteOptions.addDelegate(gpuDelegate);
|
| 160 |
+
break;
|
| 161 |
+
case CPU:
|
| 162 |
+
break;
|
| 163 |
+
}
|
| 164 |
+
tfliteOptions.setNumThreads(numThreads);
|
| 165 |
+
tflite = new Interpreter(tfliteModel, tfliteOptions);
|
| 166 |
+
labels = FileUtil.loadLabels(activity, getLabelPath());
|
| 167 |
+
...
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
For Android devices, we recommend pre-loading and memory mapping the model file
|
| 171 |
+
to offer faster load times and reduce the dirty pages in memory. The method
|
| 172 |
+
`FileUtil.loadMappedFile` does this, returning a `MappedByteBuffer` containing
|
| 173 |
+
the model.
|
| 174 |
+
|
| 175 |
+
The `MappedByteBuffer` is passed into the `Interpreter` constructor, along with
|
| 176 |
+
an `Interpreter.Options` object. This object can be used to configure the
|
| 177 |
+
interpreter, for example by setting the number of threads (`.setNumThreads(1)`)
|
| 178 |
+
or enabling [NNAPI](https://developer.android.com/ndk/guides/neuralnetworks)
|
| 179 |
+
(`.addDelegate(nnApiDelegate)`).
|
| 180 |
+
|
| 181 |
+
##### Pre-process bitmap image
|
| 182 |
+
|
| 183 |
+
Next in the `Classifier` constructor, we take the input camera bitmap image,
|
| 184 |
+
convert it to a `TensorImage` format for efficient processing and pre-process
|
| 185 |
+
it. The steps are shown in the private 'loadImage' method:
|
| 186 |
+
|
| 187 |
+
```java
|
| 188 |
+
/** Loads input image, and applys preprocessing. */
|
| 189 |
+
private TensorImage loadImage(final Bitmap bitmap, int sensorOrientation) {
|
| 190 |
+
// Loads bitmap into a TensorImage.
|
| 191 |
+
image.load(bitmap);
|
| 192 |
+
|
| 193 |
+
// Creates processor for the TensorImage.
|
| 194 |
+
int cropSize = Math.min(bitmap.getWidth(), bitmap.getHeight());
|
| 195 |
+
int numRoration = sensorOrientation / 90;
|
| 196 |
+
ImageProcessor imageProcessor =
|
| 197 |
+
new ImageProcessor.Builder()
|
| 198 |
+
.add(new ResizeWithCropOrPadOp(cropSize, cropSize))
|
| 199 |
+
.add(new ResizeOp(imageSizeX, imageSizeY, ResizeMethod.BILINEAR))
|
| 200 |
+
.add(new Rot90Op(numRoration))
|
| 201 |
+
.add(getPreprocessNormalizeOp())
|
| 202 |
+
.build();
|
| 203 |
+
return imageProcessor.process(inputImageBuffer);
|
| 204 |
+
}
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
The pre-processing is largely the same for quantized and float models with one
|
| 208 |
+
exception: Normalization.
|
| 209 |
+
|
| 210 |
+
In `ClassifierFloatMobileNet`, the normalization parameters are defined as:
|
| 211 |
+
|
| 212 |
+
```java
|
| 213 |
+
private static final float IMAGE_MEAN = 127.5f;
|
| 214 |
+
private static final float IMAGE_STD = 127.5f;
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
In `ClassifierQuantizedMobileNet`, normalization is not required. Thus the
|
| 218 |
+
nomalization parameters are defined as:
|
| 219 |
+
|
| 220 |
+
```java
|
| 221 |
+
private static final float IMAGE_MEAN = 0.0f;
|
| 222 |
+
private static final float IMAGE_STD = 1.0f;
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
##### Allocate output object
|
| 226 |
+
|
| 227 |
+
Initiate the output `TensorBuffer` for the output of the model.
|
| 228 |
+
|
| 229 |
+
```java
|
| 230 |
+
/** Output probability TensorBuffer. */
|
| 231 |
+
private final TensorBuffer outputProbabilityBuffer;
|
| 232 |
+
|
| 233 |
+
//...
|
| 234 |
+
// Get the array size for the output buffer from the TensorFlow Lite model file
|
| 235 |
+
int probabilityTensorIndex = 0;
|
| 236 |
+
int[] probabilityShape =
|
| 237 |
+
tflite.getOutputTensor(probabilityTensorIndex).shape(); // {1, 1001}
|
| 238 |
+
DataType probabilityDataType =
|
| 239 |
+
tflite.getOutputTensor(probabilityTensorIndex).dataType();
|
| 240 |
+
|
| 241 |
+
// Creates the output tensor and its processor.
|
| 242 |
+
outputProbabilityBuffer =
|
| 243 |
+
TensorBuffer.createFixedSize(probabilityShape, probabilityDataType);
|
| 244 |
+
|
| 245 |
+
// Creates the post processor for the output probability.
|
| 246 |
+
probabilityProcessor =
|
| 247 |
+
new TensorProcessor.Builder().add(getPostprocessNormalizeOp()).build();
|
| 248 |
+
```
|
| 249 |
+
|
| 250 |
+
For quantized models, we need to de-quantize the prediction with the NormalizeOp
|
| 251 |
+
(as they are all essentially linear transformation). For float model,
|
| 252 |
+
de-quantize is not required. But to uniform the API, de-quantize is added to
|
| 253 |
+
float model too. Mean and std are set to 0.0f and 1.0f, respectively. To be more
|
| 254 |
+
specific,
|
| 255 |
+
|
| 256 |
+
In `ClassifierQuantizedMobileNet`, the normalized parameters are defined as:
|
| 257 |
+
|
| 258 |
+
```java
|
| 259 |
+
private static final float PROBABILITY_MEAN = 0.0f;
|
| 260 |
+
private static final float PROBABILITY_STD = 255.0f;
|
| 261 |
+
```
|
| 262 |
+
|
| 263 |
+
In `ClassifierFloatMobileNet`, the normalized parameters are defined as:
|
| 264 |
+
|
| 265 |
+
```java
|
| 266 |
+
private static final float PROBABILITY_MEAN = 0.0f;
|
| 267 |
+
private static final float PROBABILITY_STD = 1.0f;
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
##### Run inference
|
| 271 |
+
|
| 272 |
+
Inference is performed using the following in `Classifier` class:
|
| 273 |
+
|
| 274 |
+
```java
|
| 275 |
+
tflite.run(inputImageBuffer.getBuffer(),
|
| 276 |
+
outputProbabilityBuffer.getBuffer().rewind());
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
##### Recognize image
|
| 280 |
+
|
| 281 |
+
Rather than call `run` directly, the method `recognizeImage` is used. It accepts
|
| 282 |
+
a bitmap and sensor orientation, runs inference, and returns a sorted `List` of
|
| 283 |
+
`Recognition` instances, each corresponding to a label. The method will return a
|
| 284 |
+
number of results bounded by `MAX_RESULTS`, which is 3 by default.
|
| 285 |
+
|
| 286 |
+
`Recognition` is a simple class that contains information about a specific
|
| 287 |
+
recognition result, including its `title` and `confidence`. Using the
|
| 288 |
+
post-processing normalization method specified, the confidence is converted to
|
| 289 |
+
between 0 and 1 of a given class being represented by the image.
|
| 290 |
+
|
| 291 |
+
```java
|
| 292 |
+
/** Gets the label to probability map. */
|
| 293 |
+
Map<String, Float> labeledProbability =
|
| 294 |
+
new TensorLabel(labels,
|
| 295 |
+
probabilityProcessor.process(outputProbabilityBuffer))
|
| 296 |
+
.getMapWithFloatValue();
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
A `PriorityQueue` is used for sorting.
|
| 300 |
+
|
| 301 |
+
```java
|
| 302 |
+
/** Gets the top-k results. */
|
| 303 |
+
private static List<Recognition> getTopKProbability(
|
| 304 |
+
Map<String, Float> labelProb) {
|
| 305 |
+
// Find the best classifications.
|
| 306 |
+
PriorityQueue<Recognition> pq =
|
| 307 |
+
new PriorityQueue<>(
|
| 308 |
+
MAX_RESULTS,
|
| 309 |
+
new Comparator<Recognition>() {
|
| 310 |
+
@Override
|
| 311 |
+
public int compare(Recognition lhs, Recognition rhs) {
|
| 312 |
+
// Intentionally reversed to put high confidence at the head of
|
| 313 |
+
// the queue.
|
| 314 |
+
return Float.compare(rhs.getConfidence(), lhs.getConfidence());
|
| 315 |
+
}
|
| 316 |
+
});
|
| 317 |
+
|
| 318 |
+
for (Map.Entry<String, Float> entry : labelProb.entrySet()) {
|
| 319 |
+
pq.add(new Recognition("" + entry.getKey(), entry.getKey(),
|
| 320 |
+
entry.getValue(), null));
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
final ArrayList<Recognition> recognitions = new ArrayList<>();
|
| 324 |
+
int recognitionsSize = Math.min(pq.size(), MAX_RESULTS);
|
| 325 |
+
for (int i = 0; i < recognitionsSize; ++i) {
|
| 326 |
+
recognitions.add(pq.poll());
|
| 327 |
+
}
|
| 328 |
+
return recognitions;
|
| 329 |
+
}
|
| 330 |
+
```
|
| 331 |
+
|
| 332 |
+
### Display results
|
| 333 |
+
|
| 334 |
+
The classifier is invoked and inference results are displayed by the
|
| 335 |
+
`processImage()` function in
|
| 336 |
+
[`ClassifierActivity.java`](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/app/src/main/java/org/tensorflow/lite/examples/classification/ClassifierActivity.java).
|
| 337 |
+
|
| 338 |
+
`ClassifierActivity` is a subclass of `CameraActivity` that contains method
|
| 339 |
+
implementations that render the camera image, run classification, and display
|
| 340 |
+
the results. The method `processImage()` runs classification on a background
|
| 341 |
+
thread as fast as possible, rendering information on the UI thread to avoid
|
| 342 |
+
blocking inference and creating latency.
|
| 343 |
+
|
| 344 |
+
```java
|
| 345 |
+
@Override
|
| 346 |
+
protected void processImage() {
|
| 347 |
+
rgbFrameBitmap.setPixels(getRgbBytes(), 0, previewWidth, 0, 0, previewWidth,
|
| 348 |
+
previewHeight);
|
| 349 |
+
final int imageSizeX = classifier.getImageSizeX();
|
| 350 |
+
final int imageSizeY = classifier.getImageSizeY();
|
| 351 |
+
|
| 352 |
+
runInBackground(
|
| 353 |
+
new Runnable() {
|
| 354 |
+
@Override
|
| 355 |
+
public void run() {
|
| 356 |
+
if (classifier != null) {
|
| 357 |
+
final long startTime = SystemClock.uptimeMillis();
|
| 358 |
+
final List<Classifier.Recognition> results =
|
| 359 |
+
classifier.recognizeImage(rgbFrameBitmap, sensorOrientation);
|
| 360 |
+
lastProcessingTimeMs = SystemClock.uptimeMillis() - startTime;
|
| 361 |
+
LOGGER.v("Detect: %s", results);
|
| 362 |
+
|
| 363 |
+
runOnUiThread(
|
| 364 |
+
new Runnable() {
|
| 365 |
+
@Override
|
| 366 |
+
public void run() {
|
| 367 |
+
showResultsInBottomSheet(results);
|
| 368 |
+
showFrameInfo(previewWidth + "x" + previewHeight);
|
| 369 |
+
showCropInfo(imageSizeX + "x" + imageSizeY);
|
| 370 |
+
showCameraResolution(imageSizeX + "x" + imageSizeY);
|
| 371 |
+
showRotationInfo(String.valueOf(sensorOrientation));
|
| 372 |
+
showInference(lastProcessingTimeMs + "ms");
|
| 373 |
+
}
|
| 374 |
+
});
|
| 375 |
+
}
|
| 376 |
+
readyForNextImage();
|
| 377 |
+
}
|
| 378 |
+
});
|
| 379 |
+
}
|
| 380 |
+
```
|
| 381 |
+
|
| 382 |
+
Another important role of `ClassifierActivity` is to determine user preferences
|
| 383 |
+
(by interrogating `CameraActivity`), and instantiate the appropriately
|
| 384 |
+
configured `Classifier` subclass. This happens when the video feed begins (via
|
| 385 |
+
`onPreviewSizeChosen()`) and when options are changed in the UI (via
|
| 386 |
+
`onInferenceConfigurationChanged()`).
|
| 387 |
+
|
| 388 |
+
```java
|
| 389 |
+
private void recreateClassifier(Model model, Device device, int numThreads) {
|
| 390 |
+
if (classifier != null) {
|
| 391 |
+
LOGGER.d("Closing classifier.");
|
| 392 |
+
classifier.close();
|
| 393 |
+
classifier = null;
|
| 394 |
+
}
|
| 395 |
+
if (device == Device.GPU && model == Model.QUANTIZED) {
|
| 396 |
+
LOGGER.d("Not creating classifier: GPU doesn't support quantized models.");
|
| 397 |
+
runOnUiThread(
|
| 398 |
+
() -> {
|
| 399 |
+
Toast.makeText(this, "GPU does not yet supported quantized models.",
|
| 400 |
+
Toast.LENGTH_LONG)
|
| 401 |
+
.show();
|
| 402 |
+
});
|
| 403 |
+
return;
|
| 404 |
+
}
|
| 405 |
+
try {
|
| 406 |
+
LOGGER.d(
|
| 407 |
+
"Creating classifier (model=%s, device=%s, numThreads=%d)", model,
|
| 408 |
+
device, numThreads);
|
| 409 |
+
classifier = Classifier.create(this, model, device, numThreads);
|
| 410 |
+
} catch (IOException e) {
|
| 411 |
+
LOGGER.e(e, "Failed to create classifier.");
|
| 412 |
+
}
|
| 413 |
+
}
|
| 414 |
+
```
|
MiDaS-master/mobile/android/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020 Alexey
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
MiDaS-master/mobile/android/README.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MiDaS on Android smartphone by using TensorFlow-lite (TFLite)
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
* Either use Android Studio for compilation.
|
| 5 |
+
|
| 6 |
+
* Or use ready to install apk-file:
|
| 7 |
+
* Or use URL: https://i.diawi.com/CVb8a9
|
| 8 |
+
* Or use QR-code:
|
| 9 |
+
|
| 10 |
+
Scan QR-code or open URL -> Press `Install application` -> Press `Download` and wait for download -> Open -> Install -> Open -> Press: Allow MiDaS to take photo and video from the camera While using the APP
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
----
|
| 15 |
+
|
| 16 |
+
To use another model, you should convert it to `model_opt.tflite` and place it to the directory: `models\src\main\assets`
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
----
|
| 20 |
+
|
| 21 |
+
Original repository: https://github.com/isl-org/MiDaS
|
MiDaS-master/mobile/android/app/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/build
|
| 2 |
+
|
| 3 |
+
/build/
|
MiDaS-master/mobile/android/app/build.gradle
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
apply plugin: 'com.android.application'
|
| 2 |
+
|
| 3 |
+
android {
|
| 4 |
+
compileSdkVersion 28
|
| 5 |
+
defaultConfig {
|
| 6 |
+
applicationId "org.tensorflow.lite.examples.classification"
|
| 7 |
+
minSdkVersion 21
|
| 8 |
+
targetSdkVersion 28
|
| 9 |
+
versionCode 1
|
| 10 |
+
versionName "1.0"
|
| 11 |
+
|
| 12 |
+
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
|
| 13 |
+
}
|
| 14 |
+
buildTypes {
|
| 15 |
+
release {
|
| 16 |
+
minifyEnabled false
|
| 17 |
+
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
|
| 18 |
+
}
|
| 19 |
+
}
|
| 20 |
+
aaptOptions {
|
| 21 |
+
noCompress "tflite"
|
| 22 |
+
}
|
| 23 |
+
compileOptions {
|
| 24 |
+
sourceCompatibility = '1.8'
|
| 25 |
+
targetCompatibility = '1.8'
|
| 26 |
+
}
|
| 27 |
+
lintOptions {
|
| 28 |
+
abortOnError false
|
| 29 |
+
}
|
| 30 |
+
flavorDimensions "tfliteInference"
|
| 31 |
+
productFlavors {
|
| 32 |
+
// The TFLite inference is built using the TFLite Support library.
|
| 33 |
+
support {
|
| 34 |
+
dimension "tfliteInference"
|
| 35 |
+
}
|
| 36 |
+
// The TFLite inference is built using the TFLite Task library.
|
| 37 |
+
taskApi {
|
| 38 |
+
dimension "tfliteInference"
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
dependencies {
|
| 45 |
+
implementation fileTree(dir: 'libs', include: ['*.jar'])
|
| 46 |
+
supportImplementation project(":lib_support")
|
| 47 |
+
taskApiImplementation project(":lib_task_api")
|
| 48 |
+
implementation 'androidx.appcompat:appcompat:1.0.0'
|
| 49 |
+
implementation 'androidx.coordinatorlayout:coordinatorlayout:1.0.0'
|
| 50 |
+
implementation 'com.google.android.material:material:1.0.0'
|
| 51 |
+
|
| 52 |
+
androidTestImplementation 'androidx.test.ext:junit:1.1.1'
|
| 53 |
+
androidTestImplementation 'com.google.truth:truth:1.0.1'
|
| 54 |
+
androidTestImplementation 'androidx.test:runner:1.2.0'
|
| 55 |
+
androidTestImplementation 'androidx.test:rules:1.1.0'
|
| 56 |
+
}
|
MiDaS-master/mobile/android/app/proguard-rules.pro
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Add project specific ProGuard rules here.
|
| 2 |
+
# You can control the set of applied configuration files using the
|
| 3 |
+
# proguardFiles setting in build.gradle.
|
| 4 |
+
#
|
| 5 |
+
# For more details, see
|
| 6 |
+
# http://developer.android.com/guide/developing/tools/proguard.html
|
| 7 |
+
|
| 8 |
+
# If your project uses WebView with JS, uncomment the following
|
| 9 |
+
# and specify the fully qualified class name to the JavaScript interface
|
| 10 |
+
# class:
|
| 11 |
+
#-keepclassmembers class fqcn.of.javascript.interface.for.webview {
|
| 12 |
+
# public *;
|
| 13 |
+
#}
|
| 14 |
+
|
| 15 |
+
# Uncomment this to preserve the line number information for
|
| 16 |
+
# debugging stack traces.
|
| 17 |
+
#-keepattributes SourceFile,LineNumberTable
|
| 18 |
+
|
| 19 |
+
# If you keep the line number information, uncomment this to
|
| 20 |
+
# hide the original source file name.
|
| 21 |
+
#-renamesourcefileattribute SourceFile
|
MiDaS-master/mobile/android/app/src/androidTest/assets/fox-mobilenet_v1_1.0_224_support.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
red_fox 0.79403335
|
| 2 |
+
kit_fox 0.16753247
|
| 3 |
+
grey_fox 0.03619214
|
MiDaS-master/mobile/android/app/src/androidTest/assets/fox-mobilenet_v1_1.0_224_task_api.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
red_fox 0.85
|
| 2 |
+
kit_fox 0.13
|
| 3 |
+
grey_fox 0.02
|
MiDaS-master/mobile/android/app/src/androidTest/java/AndroidManifest.xml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="utf-8"?>
|
| 2 |
+
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
|
| 3 |
+
package="org.tensorflow.lite.examples.classification">
|
| 4 |
+
<uses-sdk />
|
| 5 |
+
</manifest>
|
MiDaS-master/mobile/android/app/src/androidTest/java/org/tensorflow/lite/examples/classification/ClassifierTest.java
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
package org.tensorflow.lite.examples.classification;
|
| 18 |
+
|
| 19 |
+
import static com.google.common.truth.Truth.assertThat;
|
| 20 |
+
|
| 21 |
+
import android.content.res.AssetManager;
|
| 22 |
+
import android.graphics.Bitmap;
|
| 23 |
+
import android.graphics.BitmapFactory;
|
| 24 |
+
import android.util.Log;
|
| 25 |
+
import androidx.test.ext.junit.runners.AndroidJUnit4;
|
| 26 |
+
import androidx.test.platform.app.InstrumentationRegistry;
|
| 27 |
+
import androidx.test.rule.ActivityTestRule;
|
| 28 |
+
import java.io.IOException;
|
| 29 |
+
import java.io.InputStream;
|
| 30 |
+
import java.util.ArrayList;
|
| 31 |
+
import java.util.Iterator;
|
| 32 |
+
import java.util.List;
|
| 33 |
+
import java.util.Scanner;
|
| 34 |
+
import org.junit.Assert;
|
| 35 |
+
import org.junit.Rule;
|
| 36 |
+
import org.junit.Test;
|
| 37 |
+
import org.junit.runner.RunWith;
|
| 38 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier;
|
| 39 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Device;
|
| 40 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Model;
|
| 41 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Recognition;
|
| 42 |
+
|
| 43 |
+
/** Golden test for Image Classification Reference app. */
|
| 44 |
+
@RunWith(AndroidJUnit4.class)
|
| 45 |
+
public class ClassifierTest {
|
| 46 |
+
|
| 47 |
+
@Rule
|
| 48 |
+
public ActivityTestRule<ClassifierActivity> rule =
|
| 49 |
+
new ActivityTestRule<>(ClassifierActivity.class);
|
| 50 |
+
|
| 51 |
+
private static final String[] INPUTS = {"fox.jpg"};
|
| 52 |
+
private static final String[] GOLDEN_OUTPUTS_SUPPORT = {"fox-mobilenet_v1_1.0_224_support.txt"};
|
| 53 |
+
private static final String[] GOLDEN_OUTPUTS_TASK = {"fox-mobilenet_v1_1.0_224_task_api.txt"};
|
| 54 |
+
|
| 55 |
+
@Test
|
| 56 |
+
public void classificationResultsShouldNotChange() throws IOException {
|
| 57 |
+
ClassifierActivity activity = rule.getActivity();
|
| 58 |
+
Classifier classifier = Classifier.create(activity, Model.FLOAT_MOBILENET, Device.CPU, 1);
|
| 59 |
+
for (int i = 0; i < INPUTS.length; i++) {
|
| 60 |
+
String imageFileName = INPUTS[i];
|
| 61 |
+
String goldenOutputFileName;
|
| 62 |
+
// TODO(b/169379396): investigate the impact of the resize algorithm on accuracy.
|
| 63 |
+
// This is a temporary workaround to set different golden rest results as the preprocessing
|
| 64 |
+
// of lib_support and lib_task_api are different. Will merge them once the above TODO is
|
| 65 |
+
// resolved.
|
| 66 |
+
if (Classifier.TAG.equals("ClassifierWithSupport")) {
|
| 67 |
+
goldenOutputFileName = GOLDEN_OUTPUTS_SUPPORT[i];
|
| 68 |
+
} else {
|
| 69 |
+
goldenOutputFileName = GOLDEN_OUTPUTS_TASK[i];
|
| 70 |
+
}
|
| 71 |
+
Bitmap input = loadImage(imageFileName);
|
| 72 |
+
List<Recognition> goldenOutput = loadRecognitions(goldenOutputFileName);
|
| 73 |
+
|
| 74 |
+
List<Recognition> result = classifier.recognizeImage(input, 0);
|
| 75 |
+
Iterator<Recognition> goldenOutputIterator = goldenOutput.iterator();
|
| 76 |
+
|
| 77 |
+
for (Recognition actual : result) {
|
| 78 |
+
Assert.assertTrue(goldenOutputIterator.hasNext());
|
| 79 |
+
Recognition expected = goldenOutputIterator.next();
|
| 80 |
+
assertThat(actual.getTitle()).isEqualTo(expected.getTitle());
|
| 81 |
+
assertThat(actual.getConfidence()).isWithin(0.01f).of(expected.getConfidence());
|
| 82 |
+
}
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
private static Bitmap loadImage(String fileName) {
|
| 87 |
+
AssetManager assetManager =
|
| 88 |
+
InstrumentationRegistry.getInstrumentation().getContext().getAssets();
|
| 89 |
+
InputStream inputStream = null;
|
| 90 |
+
try {
|
| 91 |
+
inputStream = assetManager.open(fileName);
|
| 92 |
+
} catch (IOException e) {
|
| 93 |
+
Log.e("Test", "Cannot load image from assets");
|
| 94 |
+
}
|
| 95 |
+
return BitmapFactory.decodeStream(inputStream);
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
private static List<Recognition> loadRecognitions(String fileName) {
|
| 99 |
+
AssetManager assetManager =
|
| 100 |
+
InstrumentationRegistry.getInstrumentation().getContext().getAssets();
|
| 101 |
+
InputStream inputStream = null;
|
| 102 |
+
try {
|
| 103 |
+
inputStream = assetManager.open(fileName);
|
| 104 |
+
} catch (IOException e) {
|
| 105 |
+
Log.e("Test", "Cannot load probability results from assets");
|
| 106 |
+
}
|
| 107 |
+
Scanner scanner = new Scanner(inputStream);
|
| 108 |
+
List<Recognition> result = new ArrayList<>();
|
| 109 |
+
while (scanner.hasNext()) {
|
| 110 |
+
String category = scanner.next();
|
| 111 |
+
category = category.replace('_', ' ');
|
| 112 |
+
if (!scanner.hasNextFloat()) {
|
| 113 |
+
break;
|
| 114 |
+
}
|
| 115 |
+
float probability = scanner.nextFloat();
|
| 116 |
+
Recognition recognition = new Recognition(null, category, probability, null);
|
| 117 |
+
result.add(recognition);
|
| 118 |
+
}
|
| 119 |
+
return result;
|
| 120 |
+
}
|
| 121 |
+
}
|
MiDaS-master/mobile/android/app/src/main/AndroidManifest.xml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
|
| 2 |
+
package="org.tensorflow.lite.examples.classification">
|
| 3 |
+
|
| 4 |
+
<uses-sdk />
|
| 5 |
+
|
| 6 |
+
<uses-permission android:name="android.permission.CAMERA" />
|
| 7 |
+
|
| 8 |
+
<uses-feature android:name="android.hardware.camera" />
|
| 9 |
+
<uses-feature android:name="android.hardware.camera.autofocus" />
|
| 10 |
+
|
| 11 |
+
<application
|
| 12 |
+
android:allowBackup="true"
|
| 13 |
+
android:icon="@mipmap/ic_launcher"
|
| 14 |
+
android:label="@string/tfe_ic_app_name"
|
| 15 |
+
android:roundIcon="@mipmap/ic_launcher_round"
|
| 16 |
+
android:supportsRtl="true"
|
| 17 |
+
android:theme="@style/AppTheme.ImageClassification">
|
| 18 |
+
<activity
|
| 19 |
+
android:name=".ClassifierActivity"
|
| 20 |
+
android:label="@string/tfe_ic_app_name"
|
| 21 |
+
android:screenOrientation="portrait">
|
| 22 |
+
<intent-filter>
|
| 23 |
+
<action android:name="android.intent.action.MAIN" />
|
| 24 |
+
<category android:name="android.intent.category.LAUNCHER" />
|
| 25 |
+
</intent-filter>
|
| 26 |
+
</activity>
|
| 27 |
+
</application>
|
| 28 |
+
</manifest>
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/CameraActivity.java
ADDED
|
@@ -0,0 +1,717 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
package org.tensorflow.lite.examples.classification;
|
| 18 |
+
|
| 19 |
+
import android.Manifest;
|
| 20 |
+
import android.app.Fragment;
|
| 21 |
+
import android.content.Context;
|
| 22 |
+
import android.content.pm.PackageManager;
|
| 23 |
+
import android.graphics.Bitmap;
|
| 24 |
+
import android.graphics.Canvas;
|
| 25 |
+
import android.graphics.Color;
|
| 26 |
+
import android.graphics.Paint;
|
| 27 |
+
import android.graphics.RectF;
|
| 28 |
+
import android.hardware.Camera;
|
| 29 |
+
import android.hardware.camera2.CameraAccessException;
|
| 30 |
+
import android.hardware.camera2.CameraCharacteristics;
|
| 31 |
+
import android.hardware.camera2.CameraManager;
|
| 32 |
+
import android.hardware.camera2.params.StreamConfigurationMap;
|
| 33 |
+
import android.media.Image;
|
| 34 |
+
import android.media.Image.Plane;
|
| 35 |
+
import android.media.ImageReader;
|
| 36 |
+
import android.media.ImageReader.OnImageAvailableListener;
|
| 37 |
+
import android.os.Build;
|
| 38 |
+
import android.os.Bundle;
|
| 39 |
+
import android.os.Handler;
|
| 40 |
+
import android.os.HandlerThread;
|
| 41 |
+
import android.os.Trace;
|
| 42 |
+
import androidx.annotation.NonNull;
|
| 43 |
+
import androidx.annotation.UiThread;
|
| 44 |
+
import androidx.appcompat.app.AppCompatActivity;
|
| 45 |
+
import android.util.Size;
|
| 46 |
+
import android.view.Surface;
|
| 47 |
+
import android.view.TextureView;
|
| 48 |
+
import android.view.View;
|
| 49 |
+
import android.view.ViewTreeObserver;
|
| 50 |
+
import android.view.WindowManager;
|
| 51 |
+
import android.widget.AdapterView;
|
| 52 |
+
import android.widget.ImageView;
|
| 53 |
+
import android.widget.LinearLayout;
|
| 54 |
+
import android.widget.Spinner;
|
| 55 |
+
import android.widget.TextView;
|
| 56 |
+
import android.widget.Toast;
|
| 57 |
+
import com.google.android.material.bottomsheet.BottomSheetBehavior;
|
| 58 |
+
import java.nio.ByteBuffer;
|
| 59 |
+
import java.util.List;
|
| 60 |
+
import org.tensorflow.lite.examples.classification.env.ImageUtils;
|
| 61 |
+
import org.tensorflow.lite.examples.classification.env.Logger;
|
| 62 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Device;
|
| 63 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Model;
|
| 64 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Recognition;
|
| 65 |
+
|
| 66 |
+
public abstract class CameraActivity extends AppCompatActivity
|
| 67 |
+
implements OnImageAvailableListener,
|
| 68 |
+
Camera.PreviewCallback,
|
| 69 |
+
View.OnClickListener,
|
| 70 |
+
AdapterView.OnItemSelectedListener {
|
| 71 |
+
private static final Logger LOGGER = new Logger();
|
| 72 |
+
|
| 73 |
+
private static final int PERMISSIONS_REQUEST = 1;
|
| 74 |
+
|
| 75 |
+
private static final String PERMISSION_CAMERA = Manifest.permission.CAMERA;
|
| 76 |
+
protected int previewWidth = 0;
|
| 77 |
+
protected int previewHeight = 0;
|
| 78 |
+
private Handler handler;
|
| 79 |
+
private HandlerThread handlerThread;
|
| 80 |
+
private boolean useCamera2API;
|
| 81 |
+
private boolean isProcessingFrame = false;
|
| 82 |
+
private byte[][] yuvBytes = new byte[3][];
|
| 83 |
+
private int[] rgbBytes = null;
|
| 84 |
+
private int yRowStride;
|
| 85 |
+
private Runnable postInferenceCallback;
|
| 86 |
+
private Runnable imageConverter;
|
| 87 |
+
private LinearLayout bottomSheetLayout;
|
| 88 |
+
private LinearLayout gestureLayout;
|
| 89 |
+
private BottomSheetBehavior<LinearLayout> sheetBehavior;
|
| 90 |
+
protected TextView recognitionTextView,
|
| 91 |
+
recognition1TextView,
|
| 92 |
+
recognition2TextView,
|
| 93 |
+
recognitionValueTextView,
|
| 94 |
+
recognition1ValueTextView,
|
| 95 |
+
recognition2ValueTextView;
|
| 96 |
+
protected TextView frameValueTextView,
|
| 97 |
+
cropValueTextView,
|
| 98 |
+
cameraResolutionTextView,
|
| 99 |
+
rotationTextView,
|
| 100 |
+
inferenceTimeTextView;
|
| 101 |
+
protected ImageView bottomSheetArrowImageView;
|
| 102 |
+
private ImageView plusImageView, minusImageView;
|
| 103 |
+
private Spinner modelSpinner;
|
| 104 |
+
private Spinner deviceSpinner;
|
| 105 |
+
private TextView threadsTextView;
|
| 106 |
+
|
| 107 |
+
//private Model model = Model.QUANTIZED_EFFICIENTNET;
|
| 108 |
+
//private Device device = Device.CPU;
|
| 109 |
+
private Model model = Model.FLOAT_EFFICIENTNET;
|
| 110 |
+
private Device device = Device.GPU;
|
| 111 |
+
private int numThreads = -1;
|
| 112 |
+
|
| 113 |
+
@Override
|
| 114 |
+
protected void onCreate(final Bundle savedInstanceState) {
|
| 115 |
+
LOGGER.d("onCreate " + this);
|
| 116 |
+
super.onCreate(null);
|
| 117 |
+
getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON);
|
| 118 |
+
|
| 119 |
+
setContentView(R.layout.tfe_ic_activity_camera);
|
| 120 |
+
|
| 121 |
+
if (hasPermission()) {
|
| 122 |
+
setFragment();
|
| 123 |
+
} else {
|
| 124 |
+
requestPermission();
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
threadsTextView = findViewById(R.id.threads);
|
| 128 |
+
plusImageView = findViewById(R.id.plus);
|
| 129 |
+
minusImageView = findViewById(R.id.minus);
|
| 130 |
+
modelSpinner = findViewById(R.id.model_spinner);
|
| 131 |
+
deviceSpinner = findViewById(R.id.device_spinner);
|
| 132 |
+
bottomSheetLayout = findViewById(R.id.bottom_sheet_layout);
|
| 133 |
+
gestureLayout = findViewById(R.id.gesture_layout);
|
| 134 |
+
sheetBehavior = BottomSheetBehavior.from(bottomSheetLayout);
|
| 135 |
+
bottomSheetArrowImageView = findViewById(R.id.bottom_sheet_arrow);
|
| 136 |
+
|
| 137 |
+
ViewTreeObserver vto = gestureLayout.getViewTreeObserver();
|
| 138 |
+
vto.addOnGlobalLayoutListener(
|
| 139 |
+
new ViewTreeObserver.OnGlobalLayoutListener() {
|
| 140 |
+
@Override
|
| 141 |
+
public void onGlobalLayout() {
|
| 142 |
+
if (Build.VERSION.SDK_INT < Build.VERSION_CODES.JELLY_BEAN) {
|
| 143 |
+
gestureLayout.getViewTreeObserver().removeGlobalOnLayoutListener(this);
|
| 144 |
+
} else {
|
| 145 |
+
gestureLayout.getViewTreeObserver().removeOnGlobalLayoutListener(this);
|
| 146 |
+
}
|
| 147 |
+
// int width = bottomSheetLayout.getMeasuredWidth();
|
| 148 |
+
int height = gestureLayout.getMeasuredHeight();
|
| 149 |
+
|
| 150 |
+
sheetBehavior.setPeekHeight(height);
|
| 151 |
+
}
|
| 152 |
+
});
|
| 153 |
+
sheetBehavior.setHideable(false);
|
| 154 |
+
|
| 155 |
+
sheetBehavior.setBottomSheetCallback(
|
| 156 |
+
new BottomSheetBehavior.BottomSheetCallback() {
|
| 157 |
+
@Override
|
| 158 |
+
public void onStateChanged(@NonNull View bottomSheet, int newState) {
|
| 159 |
+
switch (newState) {
|
| 160 |
+
case BottomSheetBehavior.STATE_HIDDEN:
|
| 161 |
+
break;
|
| 162 |
+
case BottomSheetBehavior.STATE_EXPANDED:
|
| 163 |
+
{
|
| 164 |
+
bottomSheetArrowImageView.setImageResource(R.drawable.icn_chevron_down);
|
| 165 |
+
}
|
| 166 |
+
break;
|
| 167 |
+
case BottomSheetBehavior.STATE_COLLAPSED:
|
| 168 |
+
{
|
| 169 |
+
bottomSheetArrowImageView.setImageResource(R.drawable.icn_chevron_up);
|
| 170 |
+
}
|
| 171 |
+
break;
|
| 172 |
+
case BottomSheetBehavior.STATE_DRAGGING:
|
| 173 |
+
break;
|
| 174 |
+
case BottomSheetBehavior.STATE_SETTLING:
|
| 175 |
+
bottomSheetArrowImageView.setImageResource(R.drawable.icn_chevron_up);
|
| 176 |
+
break;
|
| 177 |
+
}
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
@Override
|
| 181 |
+
public void onSlide(@NonNull View bottomSheet, float slideOffset) {}
|
| 182 |
+
});
|
| 183 |
+
|
| 184 |
+
recognitionTextView = findViewById(R.id.detected_item);
|
| 185 |
+
recognitionValueTextView = findViewById(R.id.detected_item_value);
|
| 186 |
+
recognition1TextView = findViewById(R.id.detected_item1);
|
| 187 |
+
recognition1ValueTextView = findViewById(R.id.detected_item1_value);
|
| 188 |
+
recognition2TextView = findViewById(R.id.detected_item2);
|
| 189 |
+
recognition2ValueTextView = findViewById(R.id.detected_item2_value);
|
| 190 |
+
|
| 191 |
+
frameValueTextView = findViewById(R.id.frame_info);
|
| 192 |
+
cropValueTextView = findViewById(R.id.crop_info);
|
| 193 |
+
cameraResolutionTextView = findViewById(R.id.view_info);
|
| 194 |
+
rotationTextView = findViewById(R.id.rotation_info);
|
| 195 |
+
inferenceTimeTextView = findViewById(R.id.inference_info);
|
| 196 |
+
|
| 197 |
+
modelSpinner.setOnItemSelectedListener(this);
|
| 198 |
+
deviceSpinner.setOnItemSelectedListener(this);
|
| 199 |
+
|
| 200 |
+
plusImageView.setOnClickListener(this);
|
| 201 |
+
minusImageView.setOnClickListener(this);
|
| 202 |
+
|
| 203 |
+
model = Model.valueOf(modelSpinner.getSelectedItem().toString().toUpperCase());
|
| 204 |
+
device = Device.valueOf(deviceSpinner.getSelectedItem().toString());
|
| 205 |
+
numThreads = Integer.parseInt(threadsTextView.getText().toString().trim());
|
| 206 |
+
}
|
| 207 |
+
|
| 208 |
+
protected int[] getRgbBytes() {
|
| 209 |
+
imageConverter.run();
|
| 210 |
+
return rgbBytes;
|
| 211 |
+
}
|
| 212 |
+
|
| 213 |
+
protected int getLuminanceStride() {
|
| 214 |
+
return yRowStride;
|
| 215 |
+
}
|
| 216 |
+
|
| 217 |
+
protected byte[] getLuminance() {
|
| 218 |
+
return yuvBytes[0];
|
| 219 |
+
}
|
| 220 |
+
|
| 221 |
+
/** Callback for android.hardware.Camera API */
|
| 222 |
+
@Override
|
| 223 |
+
public void onPreviewFrame(final byte[] bytes, final Camera camera) {
|
| 224 |
+
if (isProcessingFrame) {
|
| 225 |
+
LOGGER.w("Dropping frame!");
|
| 226 |
+
return;
|
| 227 |
+
}
|
| 228 |
+
|
| 229 |
+
try {
|
| 230 |
+
// Initialize the storage bitmaps once when the resolution is known.
|
| 231 |
+
if (rgbBytes == null) {
|
| 232 |
+
Camera.Size previewSize = camera.getParameters().getPreviewSize();
|
| 233 |
+
previewHeight = previewSize.height;
|
| 234 |
+
previewWidth = previewSize.width;
|
| 235 |
+
rgbBytes = new int[previewWidth * previewHeight];
|
| 236 |
+
onPreviewSizeChosen(new Size(previewSize.width, previewSize.height), 90);
|
| 237 |
+
}
|
| 238 |
+
} catch (final Exception e) {
|
| 239 |
+
LOGGER.e(e, "Exception!");
|
| 240 |
+
return;
|
| 241 |
+
}
|
| 242 |
+
|
| 243 |
+
isProcessingFrame = true;
|
| 244 |
+
yuvBytes[0] = bytes;
|
| 245 |
+
yRowStride = previewWidth;
|
| 246 |
+
|
| 247 |
+
imageConverter =
|
| 248 |
+
new Runnable() {
|
| 249 |
+
@Override
|
| 250 |
+
public void run() {
|
| 251 |
+
ImageUtils.convertYUV420SPToARGB8888(bytes, previewWidth, previewHeight, rgbBytes);
|
| 252 |
+
}
|
| 253 |
+
};
|
| 254 |
+
|
| 255 |
+
postInferenceCallback =
|
| 256 |
+
new Runnable() {
|
| 257 |
+
@Override
|
| 258 |
+
public void run() {
|
| 259 |
+
camera.addCallbackBuffer(bytes);
|
| 260 |
+
isProcessingFrame = false;
|
| 261 |
+
}
|
| 262 |
+
};
|
| 263 |
+
processImage();
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
/** Callback for Camera2 API */
|
| 267 |
+
@Override
|
| 268 |
+
public void onImageAvailable(final ImageReader reader) {
|
| 269 |
+
// We need wait until we have some size from onPreviewSizeChosen
|
| 270 |
+
if (previewWidth == 0 || previewHeight == 0) {
|
| 271 |
+
return;
|
| 272 |
+
}
|
| 273 |
+
if (rgbBytes == null) {
|
| 274 |
+
rgbBytes = new int[previewWidth * previewHeight];
|
| 275 |
+
}
|
| 276 |
+
try {
|
| 277 |
+
final Image image = reader.acquireLatestImage();
|
| 278 |
+
|
| 279 |
+
if (image == null) {
|
| 280 |
+
return;
|
| 281 |
+
}
|
| 282 |
+
|
| 283 |
+
if (isProcessingFrame) {
|
| 284 |
+
image.close();
|
| 285 |
+
return;
|
| 286 |
+
}
|
| 287 |
+
isProcessingFrame = true;
|
| 288 |
+
Trace.beginSection("imageAvailable");
|
| 289 |
+
final Plane[] planes = image.getPlanes();
|
| 290 |
+
fillBytes(planes, yuvBytes);
|
| 291 |
+
yRowStride = planes[0].getRowStride();
|
| 292 |
+
final int uvRowStride = planes[1].getRowStride();
|
| 293 |
+
final int uvPixelStride = planes[1].getPixelStride();
|
| 294 |
+
|
| 295 |
+
imageConverter =
|
| 296 |
+
new Runnable() {
|
| 297 |
+
@Override
|
| 298 |
+
public void run() {
|
| 299 |
+
ImageUtils.convertYUV420ToARGB8888(
|
| 300 |
+
yuvBytes[0],
|
| 301 |
+
yuvBytes[1],
|
| 302 |
+
yuvBytes[2],
|
| 303 |
+
previewWidth,
|
| 304 |
+
previewHeight,
|
| 305 |
+
yRowStride,
|
| 306 |
+
uvRowStride,
|
| 307 |
+
uvPixelStride,
|
| 308 |
+
rgbBytes);
|
| 309 |
+
}
|
| 310 |
+
};
|
| 311 |
+
|
| 312 |
+
postInferenceCallback =
|
| 313 |
+
new Runnable() {
|
| 314 |
+
@Override
|
| 315 |
+
public void run() {
|
| 316 |
+
image.close();
|
| 317 |
+
isProcessingFrame = false;
|
| 318 |
+
}
|
| 319 |
+
};
|
| 320 |
+
|
| 321 |
+
processImage();
|
| 322 |
+
} catch (final Exception e) {
|
| 323 |
+
LOGGER.e(e, "Exception!");
|
| 324 |
+
Trace.endSection();
|
| 325 |
+
return;
|
| 326 |
+
}
|
| 327 |
+
Trace.endSection();
|
| 328 |
+
}
|
| 329 |
+
|
| 330 |
+
@Override
|
| 331 |
+
public synchronized void onStart() {
|
| 332 |
+
LOGGER.d("onStart " + this);
|
| 333 |
+
super.onStart();
|
| 334 |
+
}
|
| 335 |
+
|
| 336 |
+
@Override
|
| 337 |
+
public synchronized void onResume() {
|
| 338 |
+
LOGGER.d("onResume " + this);
|
| 339 |
+
super.onResume();
|
| 340 |
+
|
| 341 |
+
handlerThread = new HandlerThread("inference");
|
| 342 |
+
handlerThread.start();
|
| 343 |
+
handler = new Handler(handlerThread.getLooper());
|
| 344 |
+
}
|
| 345 |
+
|
| 346 |
+
@Override
|
| 347 |
+
public synchronized void onPause() {
|
| 348 |
+
LOGGER.d("onPause " + this);
|
| 349 |
+
|
| 350 |
+
handlerThread.quitSafely();
|
| 351 |
+
try {
|
| 352 |
+
handlerThread.join();
|
| 353 |
+
handlerThread = null;
|
| 354 |
+
handler = null;
|
| 355 |
+
} catch (final InterruptedException e) {
|
| 356 |
+
LOGGER.e(e, "Exception!");
|
| 357 |
+
}
|
| 358 |
+
|
| 359 |
+
super.onPause();
|
| 360 |
+
}
|
| 361 |
+
|
| 362 |
+
@Override
|
| 363 |
+
public synchronized void onStop() {
|
| 364 |
+
LOGGER.d("onStop " + this);
|
| 365 |
+
super.onStop();
|
| 366 |
+
}
|
| 367 |
+
|
| 368 |
+
@Override
|
| 369 |
+
public synchronized void onDestroy() {
|
| 370 |
+
LOGGER.d("onDestroy " + this);
|
| 371 |
+
super.onDestroy();
|
| 372 |
+
}
|
| 373 |
+
|
| 374 |
+
protected synchronized void runInBackground(final Runnable r) {
|
| 375 |
+
if (handler != null) {
|
| 376 |
+
handler.post(r);
|
| 377 |
+
}
|
| 378 |
+
}
|
| 379 |
+
|
| 380 |
+
@Override
|
| 381 |
+
public void onRequestPermissionsResult(
|
| 382 |
+
final int requestCode, final String[] permissions, final int[] grantResults) {
|
| 383 |
+
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
|
| 384 |
+
if (requestCode == PERMISSIONS_REQUEST) {
|
| 385 |
+
if (allPermissionsGranted(grantResults)) {
|
| 386 |
+
setFragment();
|
| 387 |
+
} else {
|
| 388 |
+
requestPermission();
|
| 389 |
+
}
|
| 390 |
+
}
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
private static boolean allPermissionsGranted(final int[] grantResults) {
|
| 394 |
+
for (int result : grantResults) {
|
| 395 |
+
if (result != PackageManager.PERMISSION_GRANTED) {
|
| 396 |
+
return false;
|
| 397 |
+
}
|
| 398 |
+
}
|
| 399 |
+
return true;
|
| 400 |
+
}
|
| 401 |
+
|
| 402 |
+
private boolean hasPermission() {
|
| 403 |
+
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
|
| 404 |
+
return checkSelfPermission(PERMISSION_CAMERA) == PackageManager.PERMISSION_GRANTED;
|
| 405 |
+
} else {
|
| 406 |
+
return true;
|
| 407 |
+
}
|
| 408 |
+
}
|
| 409 |
+
|
| 410 |
+
private void requestPermission() {
|
| 411 |
+
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
|
| 412 |
+
if (shouldShowRequestPermissionRationale(PERMISSION_CAMERA)) {
|
| 413 |
+
Toast.makeText(
|
| 414 |
+
CameraActivity.this,
|
| 415 |
+
"Camera permission is required for this demo",
|
| 416 |
+
Toast.LENGTH_LONG)
|
| 417 |
+
.show();
|
| 418 |
+
}
|
| 419 |
+
requestPermissions(new String[] {PERMISSION_CAMERA}, PERMISSIONS_REQUEST);
|
| 420 |
+
}
|
| 421 |
+
}
|
| 422 |
+
|
| 423 |
+
// Returns true if the device supports the required hardware level, or better.
|
| 424 |
+
private boolean isHardwareLevelSupported(
|
| 425 |
+
CameraCharacteristics characteristics, int requiredLevel) {
|
| 426 |
+
int deviceLevel = characteristics.get(CameraCharacteristics.INFO_SUPPORTED_HARDWARE_LEVEL);
|
| 427 |
+
if (deviceLevel == CameraCharacteristics.INFO_SUPPORTED_HARDWARE_LEVEL_LEGACY) {
|
| 428 |
+
return requiredLevel == deviceLevel;
|
| 429 |
+
}
|
| 430 |
+
// deviceLevel is not LEGACY, can use numerical sort
|
| 431 |
+
return requiredLevel <= deviceLevel;
|
| 432 |
+
}
|
| 433 |
+
|
| 434 |
+
private String chooseCamera() {
|
| 435 |
+
final CameraManager manager = (CameraManager) getSystemService(Context.CAMERA_SERVICE);
|
| 436 |
+
try {
|
| 437 |
+
for (final String cameraId : manager.getCameraIdList()) {
|
| 438 |
+
final CameraCharacteristics characteristics = manager.getCameraCharacteristics(cameraId);
|
| 439 |
+
|
| 440 |
+
// We don't use a front facing camera in this sample.
|
| 441 |
+
final Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);
|
| 442 |
+
if (facing != null && facing == CameraCharacteristics.LENS_FACING_FRONT) {
|
| 443 |
+
continue;
|
| 444 |
+
}
|
| 445 |
+
|
| 446 |
+
final StreamConfigurationMap map =
|
| 447 |
+
characteristics.get(CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
|
| 448 |
+
|
| 449 |
+
if (map == null) {
|
| 450 |
+
continue;
|
| 451 |
+
}
|
| 452 |
+
|
| 453 |
+
// Fallback to camera1 API for internal cameras that don't have full support.
|
| 454 |
+
// This should help with legacy situations where using the camera2 API causes
|
| 455 |
+
// distorted or otherwise broken previews.
|
| 456 |
+
useCamera2API =
|
| 457 |
+
(facing == CameraCharacteristics.LENS_FACING_EXTERNAL)
|
| 458 |
+
|| isHardwareLevelSupported(
|
| 459 |
+
characteristics, CameraCharacteristics.INFO_SUPPORTED_HARDWARE_LEVEL_FULL);
|
| 460 |
+
LOGGER.i("Camera API lv2?: %s", useCamera2API);
|
| 461 |
+
return cameraId;
|
| 462 |
+
}
|
| 463 |
+
} catch (CameraAccessException e) {
|
| 464 |
+
LOGGER.e(e, "Not allowed to access camera");
|
| 465 |
+
}
|
| 466 |
+
|
| 467 |
+
return null;
|
| 468 |
+
}
|
| 469 |
+
|
| 470 |
+
protected void setFragment() {
|
| 471 |
+
String cameraId = chooseCamera();
|
| 472 |
+
|
| 473 |
+
Fragment fragment;
|
| 474 |
+
if (useCamera2API) {
|
| 475 |
+
CameraConnectionFragment camera2Fragment =
|
| 476 |
+
CameraConnectionFragment.newInstance(
|
| 477 |
+
new CameraConnectionFragment.ConnectionCallback() {
|
| 478 |
+
@Override
|
| 479 |
+
public void onPreviewSizeChosen(final Size size, final int rotation) {
|
| 480 |
+
previewHeight = size.getHeight();
|
| 481 |
+
previewWidth = size.getWidth();
|
| 482 |
+
CameraActivity.this.onPreviewSizeChosen(size, rotation);
|
| 483 |
+
}
|
| 484 |
+
},
|
| 485 |
+
this,
|
| 486 |
+
getLayoutId(),
|
| 487 |
+
getDesiredPreviewFrameSize());
|
| 488 |
+
|
| 489 |
+
camera2Fragment.setCamera(cameraId);
|
| 490 |
+
fragment = camera2Fragment;
|
| 491 |
+
} else {
|
| 492 |
+
fragment =
|
| 493 |
+
new LegacyCameraConnectionFragment(this, getLayoutId(), getDesiredPreviewFrameSize());
|
| 494 |
+
}
|
| 495 |
+
|
| 496 |
+
getFragmentManager().beginTransaction().replace(R.id.container, fragment).commit();
|
| 497 |
+
}
|
| 498 |
+
|
| 499 |
+
protected void fillBytes(final Plane[] planes, final byte[][] yuvBytes) {
|
| 500 |
+
// Because of the variable row stride it's not possible to know in
|
| 501 |
+
// advance the actual necessary dimensions of the yuv planes.
|
| 502 |
+
for (int i = 0; i < planes.length; ++i) {
|
| 503 |
+
final ByteBuffer buffer = planes[i].getBuffer();
|
| 504 |
+
if (yuvBytes[i] == null) {
|
| 505 |
+
LOGGER.d("Initializing buffer %d at size %d", i, buffer.capacity());
|
| 506 |
+
yuvBytes[i] = new byte[buffer.capacity()];
|
| 507 |
+
}
|
| 508 |
+
buffer.get(yuvBytes[i]);
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
|
| 512 |
+
protected void readyForNextImage() {
|
| 513 |
+
if (postInferenceCallback != null) {
|
| 514 |
+
postInferenceCallback.run();
|
| 515 |
+
}
|
| 516 |
+
}
|
| 517 |
+
|
| 518 |
+
protected int getScreenOrientation() {
|
| 519 |
+
switch (getWindowManager().getDefaultDisplay().getRotation()) {
|
| 520 |
+
case Surface.ROTATION_270:
|
| 521 |
+
return 270;
|
| 522 |
+
case Surface.ROTATION_180:
|
| 523 |
+
return 180;
|
| 524 |
+
case Surface.ROTATION_90:
|
| 525 |
+
return 90;
|
| 526 |
+
default:
|
| 527 |
+
return 0;
|
| 528 |
+
}
|
| 529 |
+
}
|
| 530 |
+
|
| 531 |
+
@UiThread
|
| 532 |
+
protected void showResultsInTexture(float[] img_array, int imageSizeX, int imageSizeY) {
|
| 533 |
+
float maxval = Float.NEGATIVE_INFINITY;
|
| 534 |
+
float minval = Float.POSITIVE_INFINITY;
|
| 535 |
+
for (float cur : img_array) {
|
| 536 |
+
maxval = Math.max(maxval, cur);
|
| 537 |
+
minval = Math.min(minval, cur);
|
| 538 |
+
}
|
| 539 |
+
float multiplier = 0;
|
| 540 |
+
if ((maxval - minval) > 0) multiplier = 255 / (maxval - minval);
|
| 541 |
+
|
| 542 |
+
int[] img_normalized = new int[img_array.length];
|
| 543 |
+
for (int i = 0; i < img_array.length; ++i) {
|
| 544 |
+
float val = (float) (multiplier * (img_array[i] - minval));
|
| 545 |
+
img_normalized[i] = (int) val;
|
| 546 |
+
}
|
| 547 |
+
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
TextureView textureView = findViewById(R.id.textureView3);
|
| 551 |
+
//AutoFitTextureView textureView = (AutoFitTextureView) findViewById(R.id.texture);
|
| 552 |
+
|
| 553 |
+
if(textureView.isAvailable()) {
|
| 554 |
+
int width = imageSizeX;
|
| 555 |
+
int height = imageSizeY;
|
| 556 |
+
|
| 557 |
+
Canvas canvas = textureView.lockCanvas();
|
| 558 |
+
canvas.drawColor(Color.BLUE);
|
| 559 |
+
Paint paint = new Paint();
|
| 560 |
+
paint.setStyle(Paint.Style.FILL);
|
| 561 |
+
paint.setARGB(255, 150, 150, 150);
|
| 562 |
+
|
| 563 |
+
int canvas_size = Math.min(canvas.getWidth(), canvas.getHeight());
|
| 564 |
+
|
| 565 |
+
Bitmap bitmap = Bitmap.createBitmap(width, height, Bitmap.Config.RGB_565);
|
| 566 |
+
|
| 567 |
+
for (int ii = 0; ii < width; ii++) //pass the screen pixels in 2 directions
|
| 568 |
+
{
|
| 569 |
+
for (int jj = 0; jj < height; jj++) {
|
| 570 |
+
//int val = img_normalized[ii + jj * width];
|
| 571 |
+
int index = (width - ii - 1) + (height - jj - 1) * width;
|
| 572 |
+
if(index < img_array.length) {
|
| 573 |
+
int val = img_normalized[index];
|
| 574 |
+
bitmap.setPixel(ii, jj, Color.rgb(val, val, val));
|
| 575 |
+
}
|
| 576 |
+
}
|
| 577 |
+
}
|
| 578 |
+
|
| 579 |
+
canvas.drawBitmap(bitmap, null, new RectF(0, 0, canvas_size, canvas_size), null);
|
| 580 |
+
|
| 581 |
+
textureView.unlockCanvasAndPost(canvas);
|
| 582 |
+
|
| 583 |
+
}
|
| 584 |
+
|
| 585 |
+
}
|
| 586 |
+
|
| 587 |
+
protected void showResultsInBottomSheet(List<Recognition> results) {
|
| 588 |
+
if (results != null && results.size() >= 3) {
|
| 589 |
+
Recognition recognition = results.get(0);
|
| 590 |
+
if (recognition != null) {
|
| 591 |
+
if (recognition.getTitle() != null) recognitionTextView.setText(recognition.getTitle());
|
| 592 |
+
if (recognition.getConfidence() != null)
|
| 593 |
+
recognitionValueTextView.setText(
|
| 594 |
+
String.format("%.2f", (100 * recognition.getConfidence())) + "%");
|
| 595 |
+
}
|
| 596 |
+
|
| 597 |
+
Recognition recognition1 = results.get(1);
|
| 598 |
+
if (recognition1 != null) {
|
| 599 |
+
if (recognition1.getTitle() != null) recognition1TextView.setText(recognition1.getTitle());
|
| 600 |
+
if (recognition1.getConfidence() != null)
|
| 601 |
+
recognition1ValueTextView.setText(
|
| 602 |
+
String.format("%.2f", (100 * recognition1.getConfidence())) + "%");
|
| 603 |
+
}
|
| 604 |
+
|
| 605 |
+
Recognition recognition2 = results.get(2);
|
| 606 |
+
if (recognition2 != null) {
|
| 607 |
+
if (recognition2.getTitle() != null) recognition2TextView.setText(recognition2.getTitle());
|
| 608 |
+
if (recognition2.getConfidence() != null)
|
| 609 |
+
recognition2ValueTextView.setText(
|
| 610 |
+
String.format("%.2f", (100 * recognition2.getConfidence())) + "%");
|
| 611 |
+
}
|
| 612 |
+
}
|
| 613 |
+
}
|
| 614 |
+
|
| 615 |
+
protected void showFrameInfo(String frameInfo) {
|
| 616 |
+
frameValueTextView.setText(frameInfo);
|
| 617 |
+
}
|
| 618 |
+
|
| 619 |
+
protected void showCropInfo(String cropInfo) {
|
| 620 |
+
cropValueTextView.setText(cropInfo);
|
| 621 |
+
}
|
| 622 |
+
|
| 623 |
+
protected void showCameraResolution(String cameraInfo) {
|
| 624 |
+
cameraResolutionTextView.setText(cameraInfo);
|
| 625 |
+
}
|
| 626 |
+
|
| 627 |
+
protected void showRotationInfo(String rotation) {
|
| 628 |
+
rotationTextView.setText(rotation);
|
| 629 |
+
}
|
| 630 |
+
|
| 631 |
+
protected void showInference(String inferenceTime) {
|
| 632 |
+
inferenceTimeTextView.setText(inferenceTime);
|
| 633 |
+
}
|
| 634 |
+
|
| 635 |
+
protected Model getModel() {
|
| 636 |
+
return model;
|
| 637 |
+
}
|
| 638 |
+
|
| 639 |
+
private void setModel(Model model) {
|
| 640 |
+
if (this.model != model) {
|
| 641 |
+
LOGGER.d("Updating model: " + model);
|
| 642 |
+
this.model = model;
|
| 643 |
+
onInferenceConfigurationChanged();
|
| 644 |
+
}
|
| 645 |
+
}
|
| 646 |
+
|
| 647 |
+
protected Device getDevice() {
|
| 648 |
+
return device;
|
| 649 |
+
}
|
| 650 |
+
|
| 651 |
+
private void setDevice(Device device) {
|
| 652 |
+
if (this.device != device) {
|
| 653 |
+
LOGGER.d("Updating device: " + device);
|
| 654 |
+
this.device = device;
|
| 655 |
+
final boolean threadsEnabled = device == Device.CPU;
|
| 656 |
+
plusImageView.setEnabled(threadsEnabled);
|
| 657 |
+
minusImageView.setEnabled(threadsEnabled);
|
| 658 |
+
threadsTextView.setText(threadsEnabled ? String.valueOf(numThreads) : "N/A");
|
| 659 |
+
onInferenceConfigurationChanged();
|
| 660 |
+
}
|
| 661 |
+
}
|
| 662 |
+
|
| 663 |
+
protected int getNumThreads() {
|
| 664 |
+
return numThreads;
|
| 665 |
+
}
|
| 666 |
+
|
| 667 |
+
private void setNumThreads(int numThreads) {
|
| 668 |
+
if (this.numThreads != numThreads) {
|
| 669 |
+
LOGGER.d("Updating numThreads: " + numThreads);
|
| 670 |
+
this.numThreads = numThreads;
|
| 671 |
+
onInferenceConfigurationChanged();
|
| 672 |
+
}
|
| 673 |
+
}
|
| 674 |
+
|
| 675 |
+
protected abstract void processImage();
|
| 676 |
+
|
| 677 |
+
protected abstract void onPreviewSizeChosen(final Size size, final int rotation);
|
| 678 |
+
|
| 679 |
+
protected abstract int getLayoutId();
|
| 680 |
+
|
| 681 |
+
protected abstract Size getDesiredPreviewFrameSize();
|
| 682 |
+
|
| 683 |
+
protected abstract void onInferenceConfigurationChanged();
|
| 684 |
+
|
| 685 |
+
@Override
|
| 686 |
+
public void onClick(View v) {
|
| 687 |
+
if (v.getId() == R.id.plus) {
|
| 688 |
+
String threads = threadsTextView.getText().toString().trim();
|
| 689 |
+
int numThreads = Integer.parseInt(threads);
|
| 690 |
+
if (numThreads >= 9) return;
|
| 691 |
+
setNumThreads(++numThreads);
|
| 692 |
+
threadsTextView.setText(String.valueOf(numThreads));
|
| 693 |
+
} else if (v.getId() == R.id.minus) {
|
| 694 |
+
String threads = threadsTextView.getText().toString().trim();
|
| 695 |
+
int numThreads = Integer.parseInt(threads);
|
| 696 |
+
if (numThreads == 1) {
|
| 697 |
+
return;
|
| 698 |
+
}
|
| 699 |
+
setNumThreads(--numThreads);
|
| 700 |
+
threadsTextView.setText(String.valueOf(numThreads));
|
| 701 |
+
}
|
| 702 |
+
}
|
| 703 |
+
|
| 704 |
+
@Override
|
| 705 |
+
public void onItemSelected(AdapterView<?> parent, View view, int pos, long id) {
|
| 706 |
+
if (parent == modelSpinner) {
|
| 707 |
+
setModel(Model.valueOf(parent.getItemAtPosition(pos).toString().toUpperCase()));
|
| 708 |
+
} else if (parent == deviceSpinner) {
|
| 709 |
+
setDevice(Device.valueOf(parent.getItemAtPosition(pos).toString()));
|
| 710 |
+
}
|
| 711 |
+
}
|
| 712 |
+
|
| 713 |
+
@Override
|
| 714 |
+
public void onNothingSelected(AdapterView<?> parent) {
|
| 715 |
+
// Do nothing.
|
| 716 |
+
}
|
| 717 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/CameraConnectionFragment.java
ADDED
|
@@ -0,0 +1,575 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
package org.tensorflow.lite.examples.classification;
|
| 18 |
+
|
| 19 |
+
import android.annotation.SuppressLint;
|
| 20 |
+
import android.app.Activity;
|
| 21 |
+
import android.app.AlertDialog;
|
| 22 |
+
import android.app.Dialog;
|
| 23 |
+
import android.app.DialogFragment;
|
| 24 |
+
import android.app.Fragment;
|
| 25 |
+
import android.content.Context;
|
| 26 |
+
import android.content.DialogInterface;
|
| 27 |
+
import android.content.res.Configuration;
|
| 28 |
+
import android.graphics.ImageFormat;
|
| 29 |
+
import android.graphics.Matrix;
|
| 30 |
+
import android.graphics.RectF;
|
| 31 |
+
import android.graphics.SurfaceTexture;
|
| 32 |
+
import android.hardware.camera2.CameraAccessException;
|
| 33 |
+
import android.hardware.camera2.CameraCaptureSession;
|
| 34 |
+
import android.hardware.camera2.CameraCharacteristics;
|
| 35 |
+
import android.hardware.camera2.CameraDevice;
|
| 36 |
+
import android.hardware.camera2.CameraManager;
|
| 37 |
+
import android.hardware.camera2.CaptureRequest;
|
| 38 |
+
import android.hardware.camera2.CaptureResult;
|
| 39 |
+
import android.hardware.camera2.TotalCaptureResult;
|
| 40 |
+
import android.hardware.camera2.params.StreamConfigurationMap;
|
| 41 |
+
import android.media.ImageReader;
|
| 42 |
+
import android.media.ImageReader.OnImageAvailableListener;
|
| 43 |
+
import android.os.Bundle;
|
| 44 |
+
import android.os.Handler;
|
| 45 |
+
import android.os.HandlerThread;
|
| 46 |
+
import android.text.TextUtils;
|
| 47 |
+
import android.util.Size;
|
| 48 |
+
import android.util.SparseIntArray;
|
| 49 |
+
import android.view.LayoutInflater;
|
| 50 |
+
import android.view.Surface;
|
| 51 |
+
import android.view.TextureView;
|
| 52 |
+
import android.view.View;
|
| 53 |
+
import android.view.ViewGroup;
|
| 54 |
+
import android.widget.Toast;
|
| 55 |
+
import java.util.ArrayList;
|
| 56 |
+
import java.util.Arrays;
|
| 57 |
+
import java.util.Collections;
|
| 58 |
+
import java.util.Comparator;
|
| 59 |
+
import java.util.List;
|
| 60 |
+
import java.util.concurrent.Semaphore;
|
| 61 |
+
import java.util.concurrent.TimeUnit;
|
| 62 |
+
import org.tensorflow.lite.examples.classification.customview.AutoFitTextureView;
|
| 63 |
+
import org.tensorflow.lite.examples.classification.env.Logger;
|
| 64 |
+
|
| 65 |
+
/**
|
| 66 |
+
* Camera Connection Fragment that captures images from camera.
|
| 67 |
+
*
|
| 68 |
+
* <p>Instantiated by newInstance.</p>
|
| 69 |
+
*/
|
| 70 |
+
@SuppressWarnings("FragmentNotInstantiable")
|
| 71 |
+
public class CameraConnectionFragment extends Fragment {
|
| 72 |
+
private static final Logger LOGGER = new Logger();
|
| 73 |
+
|
| 74 |
+
/**
|
| 75 |
+
* The camera preview size will be chosen to be the smallest frame by pixel size capable of
|
| 76 |
+
* containing a DESIRED_SIZE x DESIRED_SIZE square.
|
| 77 |
+
*/
|
| 78 |
+
private static final int MINIMUM_PREVIEW_SIZE = 320;
|
| 79 |
+
|
| 80 |
+
/** Conversion from screen rotation to JPEG orientation. */
|
| 81 |
+
private static final SparseIntArray ORIENTATIONS = new SparseIntArray();
|
| 82 |
+
|
| 83 |
+
private static final String FRAGMENT_DIALOG = "dialog";
|
| 84 |
+
|
| 85 |
+
static {
|
| 86 |
+
ORIENTATIONS.append(Surface.ROTATION_0, 90);
|
| 87 |
+
ORIENTATIONS.append(Surface.ROTATION_90, 0);
|
| 88 |
+
ORIENTATIONS.append(Surface.ROTATION_180, 270);
|
| 89 |
+
ORIENTATIONS.append(Surface.ROTATION_270, 180);
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
/** A {@link Semaphore} to prevent the app from exiting before closing the camera. */
|
| 93 |
+
private final Semaphore cameraOpenCloseLock = new Semaphore(1);
|
| 94 |
+
/** A {@link OnImageAvailableListener} to receive frames as they are available. */
|
| 95 |
+
private final OnImageAvailableListener imageListener;
|
| 96 |
+
/** The input size in pixels desired by TensorFlow (width and height of a square bitmap). */
|
| 97 |
+
private final Size inputSize;
|
| 98 |
+
/** The layout identifier to inflate for this Fragment. */
|
| 99 |
+
private final int layout;
|
| 100 |
+
|
| 101 |
+
private final ConnectionCallback cameraConnectionCallback;
|
| 102 |
+
private final CameraCaptureSession.CaptureCallback captureCallback =
|
| 103 |
+
new CameraCaptureSession.CaptureCallback() {
|
| 104 |
+
@Override
|
| 105 |
+
public void onCaptureProgressed(
|
| 106 |
+
final CameraCaptureSession session,
|
| 107 |
+
final CaptureRequest request,
|
| 108 |
+
final CaptureResult partialResult) {}
|
| 109 |
+
|
| 110 |
+
@Override
|
| 111 |
+
public void onCaptureCompleted(
|
| 112 |
+
final CameraCaptureSession session,
|
| 113 |
+
final CaptureRequest request,
|
| 114 |
+
final TotalCaptureResult result) {}
|
| 115 |
+
};
|
| 116 |
+
/** ID of the current {@link CameraDevice}. */
|
| 117 |
+
private String cameraId;
|
| 118 |
+
/** An {@link AutoFitTextureView} for camera preview. */
|
| 119 |
+
private AutoFitTextureView textureView;
|
| 120 |
+
/** A {@link CameraCaptureSession } for camera preview. */
|
| 121 |
+
private CameraCaptureSession captureSession;
|
| 122 |
+
/** A reference to the opened {@link CameraDevice}. */
|
| 123 |
+
private CameraDevice cameraDevice;
|
| 124 |
+
/** The rotation in degrees of the camera sensor from the display. */
|
| 125 |
+
private Integer sensorOrientation;
|
| 126 |
+
/** The {@link Size} of camera preview. */
|
| 127 |
+
private Size previewSize;
|
| 128 |
+
/** An additional thread for running tasks that shouldn't block the UI. */
|
| 129 |
+
private HandlerThread backgroundThread;
|
| 130 |
+
/** A {@link Handler} for running tasks in the background. */
|
| 131 |
+
private Handler backgroundHandler;
|
| 132 |
+
/**
|
| 133 |
+
* {@link TextureView.SurfaceTextureListener} handles several lifecycle events on a {@link
|
| 134 |
+
* TextureView}.
|
| 135 |
+
*/
|
| 136 |
+
private final TextureView.SurfaceTextureListener surfaceTextureListener =
|
| 137 |
+
new TextureView.SurfaceTextureListener() {
|
| 138 |
+
@Override
|
| 139 |
+
public void onSurfaceTextureAvailable(
|
| 140 |
+
final SurfaceTexture texture, final int width, final int height) {
|
| 141 |
+
openCamera(width, height);
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
@Override
|
| 145 |
+
public void onSurfaceTextureSizeChanged(
|
| 146 |
+
final SurfaceTexture texture, final int width, final int height) {
|
| 147 |
+
configureTransform(width, height);
|
| 148 |
+
}
|
| 149 |
+
|
| 150 |
+
@Override
|
| 151 |
+
public boolean onSurfaceTextureDestroyed(final SurfaceTexture texture) {
|
| 152 |
+
return true;
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
@Override
|
| 156 |
+
public void onSurfaceTextureUpdated(final SurfaceTexture texture) {}
|
| 157 |
+
};
|
| 158 |
+
/** An {@link ImageReader} that handles preview frame capture. */
|
| 159 |
+
private ImageReader previewReader;
|
| 160 |
+
/** {@link CaptureRequest.Builder} for the camera preview */
|
| 161 |
+
private CaptureRequest.Builder previewRequestBuilder;
|
| 162 |
+
/** {@link CaptureRequest} generated by {@link #previewRequestBuilder} */
|
| 163 |
+
private CaptureRequest previewRequest;
|
| 164 |
+
/** {@link CameraDevice.StateCallback} is called when {@link CameraDevice} changes its state. */
|
| 165 |
+
private final CameraDevice.StateCallback stateCallback =
|
| 166 |
+
new CameraDevice.StateCallback() {
|
| 167 |
+
@Override
|
| 168 |
+
public void onOpened(final CameraDevice cd) {
|
| 169 |
+
// This method is called when the camera is opened. We start camera preview here.
|
| 170 |
+
cameraOpenCloseLock.release();
|
| 171 |
+
cameraDevice = cd;
|
| 172 |
+
createCameraPreviewSession();
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
@Override
|
| 176 |
+
public void onDisconnected(final CameraDevice cd) {
|
| 177 |
+
cameraOpenCloseLock.release();
|
| 178 |
+
cd.close();
|
| 179 |
+
cameraDevice = null;
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
@Override
|
| 183 |
+
public void onError(final CameraDevice cd, final int error) {
|
| 184 |
+
cameraOpenCloseLock.release();
|
| 185 |
+
cd.close();
|
| 186 |
+
cameraDevice = null;
|
| 187 |
+
final Activity activity = getActivity();
|
| 188 |
+
if (null != activity) {
|
| 189 |
+
activity.finish();
|
| 190 |
+
}
|
| 191 |
+
}
|
| 192 |
+
};
|
| 193 |
+
|
| 194 |
+
@SuppressLint("ValidFragment")
|
| 195 |
+
private CameraConnectionFragment(
|
| 196 |
+
final ConnectionCallback connectionCallback,
|
| 197 |
+
final OnImageAvailableListener imageListener,
|
| 198 |
+
final int layout,
|
| 199 |
+
final Size inputSize) {
|
| 200 |
+
this.cameraConnectionCallback = connectionCallback;
|
| 201 |
+
this.imageListener = imageListener;
|
| 202 |
+
this.layout = layout;
|
| 203 |
+
this.inputSize = inputSize;
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
/**
|
| 207 |
+
* Given {@code choices} of {@code Size}s supported by a camera, chooses the smallest one whose
|
| 208 |
+
* width and height are at least as large as the minimum of both, or an exact match if possible.
|
| 209 |
+
*
|
| 210 |
+
* @param choices The list of sizes that the camera supports for the intended output class
|
| 211 |
+
* @param width The minimum desired width
|
| 212 |
+
* @param height The minimum desired height
|
| 213 |
+
* @return The optimal {@code Size}, or an arbitrary one if none were big enough
|
| 214 |
+
*/
|
| 215 |
+
protected static Size chooseOptimalSize(final Size[] choices, final int width, final int height) {
|
| 216 |
+
final int minSize = Math.max(Math.min(width, height), MINIMUM_PREVIEW_SIZE);
|
| 217 |
+
final Size desiredSize = new Size(width, height);
|
| 218 |
+
|
| 219 |
+
// Collect the supported resolutions that are at least as big as the preview Surface
|
| 220 |
+
boolean exactSizeFound = false;
|
| 221 |
+
final List<Size> bigEnough = new ArrayList<Size>();
|
| 222 |
+
final List<Size> tooSmall = new ArrayList<Size>();
|
| 223 |
+
for (final Size option : choices) {
|
| 224 |
+
if (option.equals(desiredSize)) {
|
| 225 |
+
// Set the size but don't return yet so that remaining sizes will still be logged.
|
| 226 |
+
exactSizeFound = true;
|
| 227 |
+
}
|
| 228 |
+
|
| 229 |
+
if (option.getHeight() >= minSize && option.getWidth() >= minSize) {
|
| 230 |
+
bigEnough.add(option);
|
| 231 |
+
} else {
|
| 232 |
+
tooSmall.add(option);
|
| 233 |
+
}
|
| 234 |
+
}
|
| 235 |
+
|
| 236 |
+
LOGGER.i("Desired size: " + desiredSize + ", min size: " + minSize + "x" + minSize);
|
| 237 |
+
LOGGER.i("Valid preview sizes: [" + TextUtils.join(", ", bigEnough) + "]");
|
| 238 |
+
LOGGER.i("Rejected preview sizes: [" + TextUtils.join(", ", tooSmall) + "]");
|
| 239 |
+
|
| 240 |
+
if (exactSizeFound) {
|
| 241 |
+
LOGGER.i("Exact size match found.");
|
| 242 |
+
return desiredSize;
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
// Pick the smallest of those, assuming we found any
|
| 246 |
+
if (bigEnough.size() > 0) {
|
| 247 |
+
final Size chosenSize = Collections.min(bigEnough, new CompareSizesByArea());
|
| 248 |
+
LOGGER.i("Chosen size: " + chosenSize.getWidth() + "x" + chosenSize.getHeight());
|
| 249 |
+
return chosenSize;
|
| 250 |
+
} else {
|
| 251 |
+
LOGGER.e("Couldn't find any suitable preview size");
|
| 252 |
+
return choices[0];
|
| 253 |
+
}
|
| 254 |
+
}
|
| 255 |
+
|
| 256 |
+
public static CameraConnectionFragment newInstance(
|
| 257 |
+
final ConnectionCallback callback,
|
| 258 |
+
final OnImageAvailableListener imageListener,
|
| 259 |
+
final int layout,
|
| 260 |
+
final Size inputSize) {
|
| 261 |
+
return new CameraConnectionFragment(callback, imageListener, layout, inputSize);
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
/**
|
| 265 |
+
* Shows a {@link Toast} on the UI thread.
|
| 266 |
+
*
|
| 267 |
+
* @param text The message to show
|
| 268 |
+
*/
|
| 269 |
+
private void showToast(final String text) {
|
| 270 |
+
final Activity activity = getActivity();
|
| 271 |
+
if (activity != null) {
|
| 272 |
+
activity.runOnUiThread(
|
| 273 |
+
new Runnable() {
|
| 274 |
+
@Override
|
| 275 |
+
public void run() {
|
| 276 |
+
Toast.makeText(activity, text, Toast.LENGTH_SHORT).show();
|
| 277 |
+
}
|
| 278 |
+
});
|
| 279 |
+
}
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
@Override
|
| 283 |
+
public View onCreateView(
|
| 284 |
+
final LayoutInflater inflater, final ViewGroup container, final Bundle savedInstanceState) {
|
| 285 |
+
return inflater.inflate(layout, container, false);
|
| 286 |
+
}
|
| 287 |
+
|
| 288 |
+
@Override
|
| 289 |
+
public void onViewCreated(final View view, final Bundle savedInstanceState) {
|
| 290 |
+
textureView = (AutoFitTextureView) view.findViewById(R.id.texture);
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
@Override
|
| 294 |
+
public void onActivityCreated(final Bundle savedInstanceState) {
|
| 295 |
+
super.onActivityCreated(savedInstanceState);
|
| 296 |
+
}
|
| 297 |
+
|
| 298 |
+
@Override
|
| 299 |
+
public void onResume() {
|
| 300 |
+
super.onResume();
|
| 301 |
+
startBackgroundThread();
|
| 302 |
+
|
| 303 |
+
// When the screen is turned off and turned back on, the SurfaceTexture is already
|
| 304 |
+
// available, and "onSurfaceTextureAvailable" will not be called. In that case, we can open
|
| 305 |
+
// a camera and start preview from here (otherwise, we wait until the surface is ready in
|
| 306 |
+
// the SurfaceTextureListener).
|
| 307 |
+
if (textureView.isAvailable()) {
|
| 308 |
+
openCamera(textureView.getWidth(), textureView.getHeight());
|
| 309 |
+
} else {
|
| 310 |
+
textureView.setSurfaceTextureListener(surfaceTextureListener);
|
| 311 |
+
}
|
| 312 |
+
}
|
| 313 |
+
|
| 314 |
+
@Override
|
| 315 |
+
public void onPause() {
|
| 316 |
+
closeCamera();
|
| 317 |
+
stopBackgroundThread();
|
| 318 |
+
super.onPause();
|
| 319 |
+
}
|
| 320 |
+
|
| 321 |
+
public void setCamera(String cameraId) {
|
| 322 |
+
this.cameraId = cameraId;
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
/** Sets up member variables related to camera. */
|
| 326 |
+
private void setUpCameraOutputs() {
|
| 327 |
+
final Activity activity = getActivity();
|
| 328 |
+
final CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
|
| 329 |
+
try {
|
| 330 |
+
final CameraCharacteristics characteristics = manager.getCameraCharacteristics(cameraId);
|
| 331 |
+
|
| 332 |
+
final StreamConfigurationMap map =
|
| 333 |
+
characteristics.get(CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
|
| 334 |
+
|
| 335 |
+
sensorOrientation = characteristics.get(CameraCharacteristics.SENSOR_ORIENTATION);
|
| 336 |
+
|
| 337 |
+
// Danger, W.R.! Attempting to use too large a preview size could exceed the camera
|
| 338 |
+
// bus' bandwidth limitation, resulting in gorgeous previews but the storage of
|
| 339 |
+
// garbage capture data.
|
| 340 |
+
previewSize =
|
| 341 |
+
chooseOptimalSize(
|
| 342 |
+
map.getOutputSizes(SurfaceTexture.class),
|
| 343 |
+
inputSize.getWidth(),
|
| 344 |
+
inputSize.getHeight());
|
| 345 |
+
|
| 346 |
+
// We fit the aspect ratio of TextureView to the size of preview we picked.
|
| 347 |
+
final int orientation = getResources().getConfiguration().orientation;
|
| 348 |
+
if (orientation == Configuration.ORIENTATION_LANDSCAPE) {
|
| 349 |
+
textureView.setAspectRatio(previewSize.getWidth(), previewSize.getHeight());
|
| 350 |
+
} else {
|
| 351 |
+
textureView.setAspectRatio(previewSize.getHeight(), previewSize.getWidth());
|
| 352 |
+
}
|
| 353 |
+
} catch (final CameraAccessException e) {
|
| 354 |
+
LOGGER.e(e, "Exception!");
|
| 355 |
+
} catch (final NullPointerException e) {
|
| 356 |
+
// Currently an NPE is thrown when the Camera2API is used but not supported on the
|
| 357 |
+
// device this code runs.
|
| 358 |
+
ErrorDialog.newInstance(getString(R.string.tfe_ic_camera_error))
|
| 359 |
+
.show(getChildFragmentManager(), FRAGMENT_DIALOG);
|
| 360 |
+
throw new IllegalStateException(getString(R.string.tfe_ic_camera_error));
|
| 361 |
+
}
|
| 362 |
+
|
| 363 |
+
cameraConnectionCallback.onPreviewSizeChosen(previewSize, sensorOrientation);
|
| 364 |
+
}
|
| 365 |
+
|
| 366 |
+
/** Opens the camera specified by {@link CameraConnectionFragment#cameraId}. */
|
| 367 |
+
private void openCamera(final int width, final int height) {
|
| 368 |
+
setUpCameraOutputs();
|
| 369 |
+
configureTransform(width, height);
|
| 370 |
+
final Activity activity = getActivity();
|
| 371 |
+
final CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
|
| 372 |
+
try {
|
| 373 |
+
if (!cameraOpenCloseLock.tryAcquire(2500, TimeUnit.MILLISECONDS)) {
|
| 374 |
+
throw new RuntimeException("Time out waiting to lock camera opening.");
|
| 375 |
+
}
|
| 376 |
+
manager.openCamera(cameraId, stateCallback, backgroundHandler);
|
| 377 |
+
} catch (final CameraAccessException e) {
|
| 378 |
+
LOGGER.e(e, "Exception!");
|
| 379 |
+
} catch (final InterruptedException e) {
|
| 380 |
+
throw new RuntimeException("Interrupted while trying to lock camera opening.", e);
|
| 381 |
+
}
|
| 382 |
+
}
|
| 383 |
+
|
| 384 |
+
/** Closes the current {@link CameraDevice}. */
|
| 385 |
+
private void closeCamera() {
|
| 386 |
+
try {
|
| 387 |
+
cameraOpenCloseLock.acquire();
|
| 388 |
+
if (null != captureSession) {
|
| 389 |
+
captureSession.close();
|
| 390 |
+
captureSession = null;
|
| 391 |
+
}
|
| 392 |
+
if (null != cameraDevice) {
|
| 393 |
+
cameraDevice.close();
|
| 394 |
+
cameraDevice = null;
|
| 395 |
+
}
|
| 396 |
+
if (null != previewReader) {
|
| 397 |
+
previewReader.close();
|
| 398 |
+
previewReader = null;
|
| 399 |
+
}
|
| 400 |
+
} catch (final InterruptedException e) {
|
| 401 |
+
throw new RuntimeException("Interrupted while trying to lock camera closing.", e);
|
| 402 |
+
} finally {
|
| 403 |
+
cameraOpenCloseLock.release();
|
| 404 |
+
}
|
| 405 |
+
}
|
| 406 |
+
|
| 407 |
+
/** Starts a background thread and its {@link Handler}. */
|
| 408 |
+
private void startBackgroundThread() {
|
| 409 |
+
backgroundThread = new HandlerThread("ImageListener");
|
| 410 |
+
backgroundThread.start();
|
| 411 |
+
backgroundHandler = new Handler(backgroundThread.getLooper());
|
| 412 |
+
}
|
| 413 |
+
|
| 414 |
+
/** Stops the background thread and its {@link Handler}. */
|
| 415 |
+
private void stopBackgroundThread() {
|
| 416 |
+
backgroundThread.quitSafely();
|
| 417 |
+
try {
|
| 418 |
+
backgroundThread.join();
|
| 419 |
+
backgroundThread = null;
|
| 420 |
+
backgroundHandler = null;
|
| 421 |
+
} catch (final InterruptedException e) {
|
| 422 |
+
LOGGER.e(e, "Exception!");
|
| 423 |
+
}
|
| 424 |
+
}
|
| 425 |
+
|
| 426 |
+
/** Creates a new {@link CameraCaptureSession} for camera preview. */
|
| 427 |
+
private void createCameraPreviewSession() {
|
| 428 |
+
try {
|
| 429 |
+
final SurfaceTexture texture = textureView.getSurfaceTexture();
|
| 430 |
+
assert texture != null;
|
| 431 |
+
|
| 432 |
+
// We configure the size of default buffer to be the size of camera preview we want.
|
| 433 |
+
texture.setDefaultBufferSize(previewSize.getWidth(), previewSize.getHeight());
|
| 434 |
+
|
| 435 |
+
// This is the output Surface we need to start preview.
|
| 436 |
+
final Surface surface = new Surface(texture);
|
| 437 |
+
|
| 438 |
+
// We set up a CaptureRequest.Builder with the output Surface.
|
| 439 |
+
previewRequestBuilder = cameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
|
| 440 |
+
previewRequestBuilder.addTarget(surface);
|
| 441 |
+
|
| 442 |
+
LOGGER.i("Opening camera preview: " + previewSize.getWidth() + "x" + previewSize.getHeight());
|
| 443 |
+
|
| 444 |
+
// Create the reader for the preview frames.
|
| 445 |
+
previewReader =
|
| 446 |
+
ImageReader.newInstance(
|
| 447 |
+
previewSize.getWidth(), previewSize.getHeight(), ImageFormat.YUV_420_888, 2);
|
| 448 |
+
|
| 449 |
+
previewReader.setOnImageAvailableListener(imageListener, backgroundHandler);
|
| 450 |
+
previewRequestBuilder.addTarget(previewReader.getSurface());
|
| 451 |
+
|
| 452 |
+
// Here, we create a CameraCaptureSession for camera preview.
|
| 453 |
+
cameraDevice.createCaptureSession(
|
| 454 |
+
Arrays.asList(surface, previewReader.getSurface()),
|
| 455 |
+
new CameraCaptureSession.StateCallback() {
|
| 456 |
+
|
| 457 |
+
@Override
|
| 458 |
+
public void onConfigured(final CameraCaptureSession cameraCaptureSession) {
|
| 459 |
+
// The camera is already closed
|
| 460 |
+
if (null == cameraDevice) {
|
| 461 |
+
return;
|
| 462 |
+
}
|
| 463 |
+
|
| 464 |
+
// When the session is ready, we start displaying the preview.
|
| 465 |
+
captureSession = cameraCaptureSession;
|
| 466 |
+
try {
|
| 467 |
+
// Auto focus should be continuous for camera preview.
|
| 468 |
+
previewRequestBuilder.set(
|
| 469 |
+
CaptureRequest.CONTROL_AF_MODE,
|
| 470 |
+
CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
|
| 471 |
+
// Flash is automatically enabled when necessary.
|
| 472 |
+
previewRequestBuilder.set(
|
| 473 |
+
CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH);
|
| 474 |
+
|
| 475 |
+
// Finally, we start displaying the camera preview.
|
| 476 |
+
previewRequest = previewRequestBuilder.build();
|
| 477 |
+
captureSession.setRepeatingRequest(
|
| 478 |
+
previewRequest, captureCallback, backgroundHandler);
|
| 479 |
+
} catch (final CameraAccessException e) {
|
| 480 |
+
LOGGER.e(e, "Exception!");
|
| 481 |
+
}
|
| 482 |
+
}
|
| 483 |
+
|
| 484 |
+
@Override
|
| 485 |
+
public void onConfigureFailed(final CameraCaptureSession cameraCaptureSession) {
|
| 486 |
+
showToast("Failed");
|
| 487 |
+
}
|
| 488 |
+
},
|
| 489 |
+
null);
|
| 490 |
+
} catch (final CameraAccessException e) {
|
| 491 |
+
LOGGER.e(e, "Exception!");
|
| 492 |
+
}
|
| 493 |
+
}
|
| 494 |
+
|
| 495 |
+
/**
|
| 496 |
+
* Configures the necessary {@link Matrix} transformation to `mTextureView`. This method should be
|
| 497 |
+
* called after the camera preview size is determined in setUpCameraOutputs and also the size of
|
| 498 |
+
* `mTextureView` is fixed.
|
| 499 |
+
*
|
| 500 |
+
* @param viewWidth The width of `mTextureView`
|
| 501 |
+
* @param viewHeight The height of `mTextureView`
|
| 502 |
+
*/
|
| 503 |
+
private void configureTransform(final int viewWidth, final int viewHeight) {
|
| 504 |
+
final Activity activity = getActivity();
|
| 505 |
+
if (null == textureView || null == previewSize || null == activity) {
|
| 506 |
+
return;
|
| 507 |
+
}
|
| 508 |
+
final int rotation = activity.getWindowManager().getDefaultDisplay().getRotation();
|
| 509 |
+
final Matrix matrix = new Matrix();
|
| 510 |
+
final RectF viewRect = new RectF(0, 0, viewWidth, viewHeight);
|
| 511 |
+
final RectF bufferRect = new RectF(0, 0, previewSize.getHeight(), previewSize.getWidth());
|
| 512 |
+
final float centerX = viewRect.centerX();
|
| 513 |
+
final float centerY = viewRect.centerY();
|
| 514 |
+
if (Surface.ROTATION_90 == rotation || Surface.ROTATION_270 == rotation) {
|
| 515 |
+
bufferRect.offset(centerX - bufferRect.centerX(), centerY - bufferRect.centerY());
|
| 516 |
+
matrix.setRectToRect(viewRect, bufferRect, Matrix.ScaleToFit.FILL);
|
| 517 |
+
final float scale =
|
| 518 |
+
Math.max(
|
| 519 |
+
(float) viewHeight / previewSize.getHeight(),
|
| 520 |
+
(float) viewWidth / previewSize.getWidth());
|
| 521 |
+
matrix.postScale(scale, scale, centerX, centerY);
|
| 522 |
+
matrix.postRotate(90 * (rotation - 2), centerX, centerY);
|
| 523 |
+
} else if (Surface.ROTATION_180 == rotation) {
|
| 524 |
+
matrix.postRotate(180, centerX, centerY);
|
| 525 |
+
}
|
| 526 |
+
textureView.setTransform(matrix);
|
| 527 |
+
}
|
| 528 |
+
|
| 529 |
+
/**
|
| 530 |
+
* Callback for Activities to use to initialize their data once the selected preview size is
|
| 531 |
+
* known.
|
| 532 |
+
*/
|
| 533 |
+
public interface ConnectionCallback {
|
| 534 |
+
void onPreviewSizeChosen(Size size, int cameraRotation);
|
| 535 |
+
}
|
| 536 |
+
|
| 537 |
+
/** Compares two {@code Size}s based on their areas. */
|
| 538 |
+
static class CompareSizesByArea implements Comparator<Size> {
|
| 539 |
+
@Override
|
| 540 |
+
public int compare(final Size lhs, final Size rhs) {
|
| 541 |
+
// We cast here to ensure the multiplications won't overflow
|
| 542 |
+
return Long.signum(
|
| 543 |
+
(long) lhs.getWidth() * lhs.getHeight() - (long) rhs.getWidth() * rhs.getHeight());
|
| 544 |
+
}
|
| 545 |
+
}
|
| 546 |
+
|
| 547 |
+
/** Shows an error message dialog. */
|
| 548 |
+
public static class ErrorDialog extends DialogFragment {
|
| 549 |
+
private static final String ARG_MESSAGE = "message";
|
| 550 |
+
|
| 551 |
+
public static ErrorDialog newInstance(final String message) {
|
| 552 |
+
final ErrorDialog dialog = new ErrorDialog();
|
| 553 |
+
final Bundle args = new Bundle();
|
| 554 |
+
args.putString(ARG_MESSAGE, message);
|
| 555 |
+
dialog.setArguments(args);
|
| 556 |
+
return dialog;
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
@Override
|
| 560 |
+
public Dialog onCreateDialog(final Bundle savedInstanceState) {
|
| 561 |
+
final Activity activity = getActivity();
|
| 562 |
+
return new AlertDialog.Builder(activity)
|
| 563 |
+
.setMessage(getArguments().getString(ARG_MESSAGE))
|
| 564 |
+
.setPositiveButton(
|
| 565 |
+
android.R.string.ok,
|
| 566 |
+
new DialogInterface.OnClickListener() {
|
| 567 |
+
@Override
|
| 568 |
+
public void onClick(final DialogInterface dialogInterface, final int i) {
|
| 569 |
+
activity.finish();
|
| 570 |
+
}
|
| 571 |
+
})
|
| 572 |
+
.create();
|
| 573 |
+
}
|
| 574 |
+
}
|
| 575 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/ClassifierActivity.java
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
package org.tensorflow.lite.examples.classification;
|
| 18 |
+
|
| 19 |
+
import android.graphics.Bitmap;
|
| 20 |
+
import android.graphics.Bitmap.Config;
|
| 21 |
+
import android.graphics.Typeface;
|
| 22 |
+
import android.media.ImageReader.OnImageAvailableListener;
|
| 23 |
+
import android.os.SystemClock;
|
| 24 |
+
import android.util.Size;
|
| 25 |
+
import android.util.TypedValue;
|
| 26 |
+
import android.view.TextureView;
|
| 27 |
+
import android.view.ViewStub;
|
| 28 |
+
import android.widget.TextView;
|
| 29 |
+
import android.widget.Toast;
|
| 30 |
+
import java.io.IOException;
|
| 31 |
+
import java.util.List;
|
| 32 |
+
import java.util.ArrayList;
|
| 33 |
+
|
| 34 |
+
import org.tensorflow.lite.examples.classification.customview.AutoFitTextureView;
|
| 35 |
+
import org.tensorflow.lite.examples.classification.env.BorderedText;
|
| 36 |
+
import org.tensorflow.lite.examples.classification.env.Logger;
|
| 37 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier;
|
| 38 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Device;
|
| 39 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Model;
|
| 40 |
+
|
| 41 |
+
import android.widget.ImageView;
|
| 42 |
+
import android.graphics.Bitmap;
|
| 43 |
+
import android.graphics.BitmapFactory;
|
| 44 |
+
import android.graphics.Canvas;
|
| 45 |
+
import android.graphics.Color;
|
| 46 |
+
import android.graphics.Paint;
|
| 47 |
+
import android.graphics.Rect;
|
| 48 |
+
import android.graphics.RectF;
|
| 49 |
+
import android.graphics.PixelFormat;
|
| 50 |
+
import java.nio.ByteBuffer;
|
| 51 |
+
|
| 52 |
+
public class ClassifierActivity extends CameraActivity implements OnImageAvailableListener {
|
| 53 |
+
private static final Logger LOGGER = new Logger();
|
| 54 |
+
private static final Size DESIRED_PREVIEW_SIZE = new Size(640, 480);
|
| 55 |
+
private static final float TEXT_SIZE_DIP = 10;
|
| 56 |
+
private Bitmap rgbFrameBitmap = null;
|
| 57 |
+
private long lastProcessingTimeMs;
|
| 58 |
+
private Integer sensorOrientation;
|
| 59 |
+
private Classifier classifier;
|
| 60 |
+
private BorderedText borderedText;
|
| 61 |
+
/** Input image size of the model along x axis. */
|
| 62 |
+
private int imageSizeX;
|
| 63 |
+
/** Input image size of the model along y axis. */
|
| 64 |
+
private int imageSizeY;
|
| 65 |
+
|
| 66 |
+
@Override
|
| 67 |
+
protected int getLayoutId() {
|
| 68 |
+
return R.layout.tfe_ic_camera_connection_fragment;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
@Override
|
| 72 |
+
protected Size getDesiredPreviewFrameSize() {
|
| 73 |
+
return DESIRED_PREVIEW_SIZE;
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
@Override
|
| 77 |
+
public void onPreviewSizeChosen(final Size size, final int rotation) {
|
| 78 |
+
final float textSizePx =
|
| 79 |
+
TypedValue.applyDimension(
|
| 80 |
+
TypedValue.COMPLEX_UNIT_DIP, TEXT_SIZE_DIP, getResources().getDisplayMetrics());
|
| 81 |
+
borderedText = new BorderedText(textSizePx);
|
| 82 |
+
borderedText.setTypeface(Typeface.MONOSPACE);
|
| 83 |
+
|
| 84 |
+
recreateClassifier(getModel(), getDevice(), getNumThreads());
|
| 85 |
+
if (classifier == null) {
|
| 86 |
+
LOGGER.e("No classifier on preview!");
|
| 87 |
+
return;
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
previewWidth = size.getWidth();
|
| 91 |
+
previewHeight = size.getHeight();
|
| 92 |
+
|
| 93 |
+
sensorOrientation = rotation - getScreenOrientation();
|
| 94 |
+
LOGGER.i("Camera orientation relative to screen canvas: %d", sensorOrientation);
|
| 95 |
+
|
| 96 |
+
LOGGER.i("Initializing at size %dx%d", previewWidth, previewHeight);
|
| 97 |
+
rgbFrameBitmap = Bitmap.createBitmap(previewWidth, previewHeight, Config.ARGB_8888);
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
@Override
|
| 101 |
+
protected void processImage() {
|
| 102 |
+
rgbFrameBitmap.setPixels(getRgbBytes(), 0, previewWidth, 0, 0, previewWidth, previewHeight);
|
| 103 |
+
final int cropSize = Math.min(previewWidth, previewHeight);
|
| 104 |
+
|
| 105 |
+
runInBackground(
|
| 106 |
+
new Runnable() {
|
| 107 |
+
@Override
|
| 108 |
+
public void run() {
|
| 109 |
+
if (classifier != null) {
|
| 110 |
+
final long startTime = SystemClock.uptimeMillis();
|
| 111 |
+
//final List<Classifier.Recognition> results =
|
| 112 |
+
// classifier.recognizeImage(rgbFrameBitmap, sensorOrientation);
|
| 113 |
+
final List<Classifier.Recognition> results = new ArrayList<>();
|
| 114 |
+
|
| 115 |
+
float[] img_array = classifier.recognizeImage(rgbFrameBitmap, sensorOrientation);
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
/*
|
| 119 |
+
float maxval = Float.NEGATIVE_INFINITY;
|
| 120 |
+
float minval = Float.POSITIVE_INFINITY;
|
| 121 |
+
for (float cur : img_array) {
|
| 122 |
+
maxval = Math.max(maxval, cur);
|
| 123 |
+
minval = Math.min(minval, cur);
|
| 124 |
+
}
|
| 125 |
+
float multiplier = 0;
|
| 126 |
+
if ((maxval - minval) > 0) multiplier = 255 / (maxval - minval);
|
| 127 |
+
|
| 128 |
+
int[] img_normalized = new int[img_array.length];
|
| 129 |
+
for (int i = 0; i < img_array.length; ++i) {
|
| 130 |
+
float val = (float) (multiplier * (img_array[i] - minval));
|
| 131 |
+
img_normalized[i] = (int) val;
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
TextureView textureView = findViewById(R.id.textureView3);
|
| 137 |
+
//AutoFitTextureView textureView = (AutoFitTextureView) findViewById(R.id.texture);
|
| 138 |
+
|
| 139 |
+
if(textureView.isAvailable()) {
|
| 140 |
+
int width = imageSizeX;
|
| 141 |
+
int height = imageSizeY;
|
| 142 |
+
|
| 143 |
+
Canvas canvas = textureView.lockCanvas();
|
| 144 |
+
canvas.drawColor(Color.BLUE);
|
| 145 |
+
Paint paint = new Paint();
|
| 146 |
+
paint.setStyle(Paint.Style.FILL);
|
| 147 |
+
paint.setARGB(255, 150, 150, 150);
|
| 148 |
+
|
| 149 |
+
int canvas_size = Math.min(canvas.getWidth(), canvas.getHeight());
|
| 150 |
+
|
| 151 |
+
Bitmap bitmap = Bitmap.createBitmap(width, height, Bitmap.Config.RGB_565);
|
| 152 |
+
|
| 153 |
+
for (int ii = 0; ii < width; ii++) //pass the screen pixels in 2 directions
|
| 154 |
+
{
|
| 155 |
+
for (int jj = 0; jj < height; jj++) {
|
| 156 |
+
//int val = img_normalized[ii + jj * width];
|
| 157 |
+
int index = (width - ii - 1) + (height - jj - 1) * width;
|
| 158 |
+
if(index < img_array.length) {
|
| 159 |
+
int val = img_normalized[index];
|
| 160 |
+
bitmap.setPixel(ii, jj, Color.rgb(val, val, val));
|
| 161 |
+
}
|
| 162 |
+
}
|
| 163 |
+
}
|
| 164 |
+
|
| 165 |
+
canvas.drawBitmap(bitmap, null, new RectF(0, 0, canvas_size, canvas_size), null);
|
| 166 |
+
|
| 167 |
+
textureView.unlockCanvasAndPost(canvas);
|
| 168 |
+
|
| 169 |
+
}
|
| 170 |
+
*/
|
| 171 |
+
|
| 172 |
+
lastProcessingTimeMs = SystemClock.uptimeMillis() - startTime;
|
| 173 |
+
LOGGER.v("Detect: %s", results);
|
| 174 |
+
|
| 175 |
+
runOnUiThread(
|
| 176 |
+
new Runnable() {
|
| 177 |
+
@Override
|
| 178 |
+
public void run() {
|
| 179 |
+
//showResultsInBottomSheet(results);
|
| 180 |
+
showResultsInTexture(img_array, imageSizeX, imageSizeY);
|
| 181 |
+
showFrameInfo(previewWidth + "x" + previewHeight);
|
| 182 |
+
showCropInfo(imageSizeX + "x" + imageSizeY);
|
| 183 |
+
showCameraResolution(cropSize + "x" + cropSize);
|
| 184 |
+
showRotationInfo(String.valueOf(sensorOrientation));
|
| 185 |
+
showInference(lastProcessingTimeMs + "ms");
|
| 186 |
+
}
|
| 187 |
+
});
|
| 188 |
+
}
|
| 189 |
+
readyForNextImage();
|
| 190 |
+
}
|
| 191 |
+
});
|
| 192 |
+
}
|
| 193 |
+
|
| 194 |
+
@Override
|
| 195 |
+
protected void onInferenceConfigurationChanged() {
|
| 196 |
+
if (rgbFrameBitmap == null) {
|
| 197 |
+
// Defer creation until we're getting camera frames.
|
| 198 |
+
return;
|
| 199 |
+
}
|
| 200 |
+
final Device device = getDevice();
|
| 201 |
+
final Model model = getModel();
|
| 202 |
+
final int numThreads = getNumThreads();
|
| 203 |
+
runInBackground(() -> recreateClassifier(model, device, numThreads));
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
private void recreateClassifier(Model model, Device device, int numThreads) {
|
| 207 |
+
if (classifier != null) {
|
| 208 |
+
LOGGER.d("Closing classifier.");
|
| 209 |
+
classifier.close();
|
| 210 |
+
classifier = null;
|
| 211 |
+
}
|
| 212 |
+
if (device == Device.GPU
|
| 213 |
+
&& (model == Model.QUANTIZED_MOBILENET || model == Model.QUANTIZED_EFFICIENTNET)) {
|
| 214 |
+
LOGGER.d("Not creating classifier: GPU doesn't support quantized models.");
|
| 215 |
+
runOnUiThread(
|
| 216 |
+
() -> {
|
| 217 |
+
Toast.makeText(this, R.string.tfe_ic_gpu_quant_error, Toast.LENGTH_LONG).show();
|
| 218 |
+
});
|
| 219 |
+
return;
|
| 220 |
+
}
|
| 221 |
+
try {
|
| 222 |
+
LOGGER.d(
|
| 223 |
+
"Creating classifier (model=%s, device=%s, numThreads=%d)", model, device, numThreads);
|
| 224 |
+
classifier = Classifier.create(this, model, device, numThreads);
|
| 225 |
+
} catch (IOException | IllegalArgumentException e) {
|
| 226 |
+
LOGGER.e(e, "Failed to create classifier.");
|
| 227 |
+
runOnUiThread(
|
| 228 |
+
() -> {
|
| 229 |
+
Toast.makeText(this, e.getMessage(), Toast.LENGTH_LONG).show();
|
| 230 |
+
});
|
| 231 |
+
return;
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
// Updates the input image size.
|
| 235 |
+
imageSizeX = classifier.getImageSizeX();
|
| 236 |
+
imageSizeY = classifier.getImageSizeY();
|
| 237 |
+
}
|
| 238 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/LegacyCameraConnectionFragment.java
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
package org.tensorflow.lite.examples.classification;
|
| 2 |
+
|
| 3 |
+
/*
|
| 4 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 5 |
+
*
|
| 6 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 7 |
+
* you may not use this file except in compliance with the License.
|
| 8 |
+
* You may obtain a copy of the License at
|
| 9 |
+
*
|
| 10 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 11 |
+
*
|
| 12 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 13 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 14 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 15 |
+
* See the License for the specific language governing permissions and
|
| 16 |
+
* limitations under the License.
|
| 17 |
+
*/
|
| 18 |
+
|
| 19 |
+
import android.annotation.SuppressLint;
|
| 20 |
+
import android.app.Fragment;
|
| 21 |
+
import android.graphics.SurfaceTexture;
|
| 22 |
+
import android.hardware.Camera;
|
| 23 |
+
import android.hardware.Camera.CameraInfo;
|
| 24 |
+
import android.os.Bundle;
|
| 25 |
+
import android.os.Handler;
|
| 26 |
+
import android.os.HandlerThread;
|
| 27 |
+
import android.util.Size;
|
| 28 |
+
import android.util.SparseIntArray;
|
| 29 |
+
import android.view.LayoutInflater;
|
| 30 |
+
import android.view.Surface;
|
| 31 |
+
import android.view.TextureView;
|
| 32 |
+
import android.view.View;
|
| 33 |
+
import android.view.ViewGroup;
|
| 34 |
+
import java.io.IOException;
|
| 35 |
+
import java.util.List;
|
| 36 |
+
import org.tensorflow.lite.examples.classification.customview.AutoFitTextureView;
|
| 37 |
+
import org.tensorflow.lite.examples.classification.env.ImageUtils;
|
| 38 |
+
import org.tensorflow.lite.examples.classification.env.Logger;
|
| 39 |
+
|
| 40 |
+
public class LegacyCameraConnectionFragment extends Fragment {
|
| 41 |
+
private static final Logger LOGGER = new Logger();
|
| 42 |
+
/** Conversion from screen rotation to JPEG orientation. */
|
| 43 |
+
private static final SparseIntArray ORIENTATIONS = new SparseIntArray();
|
| 44 |
+
|
| 45 |
+
static {
|
| 46 |
+
ORIENTATIONS.append(Surface.ROTATION_0, 90);
|
| 47 |
+
ORIENTATIONS.append(Surface.ROTATION_90, 0);
|
| 48 |
+
ORIENTATIONS.append(Surface.ROTATION_180, 270);
|
| 49 |
+
ORIENTATIONS.append(Surface.ROTATION_270, 180);
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
private Camera camera;
|
| 53 |
+
private Camera.PreviewCallback imageListener;
|
| 54 |
+
private Size desiredSize;
|
| 55 |
+
/** The layout identifier to inflate for this Fragment. */
|
| 56 |
+
private int layout;
|
| 57 |
+
/** An {@link AutoFitTextureView} for camera preview. */
|
| 58 |
+
private AutoFitTextureView textureView;
|
| 59 |
+
/**
|
| 60 |
+
* {@link TextureView.SurfaceTextureListener} handles several lifecycle events on a {@link
|
| 61 |
+
* TextureView}.
|
| 62 |
+
*/
|
| 63 |
+
private final TextureView.SurfaceTextureListener surfaceTextureListener =
|
| 64 |
+
new TextureView.SurfaceTextureListener() {
|
| 65 |
+
@Override
|
| 66 |
+
public void onSurfaceTextureAvailable(
|
| 67 |
+
final SurfaceTexture texture, final int width, final int height) {
|
| 68 |
+
|
| 69 |
+
int index = getCameraId();
|
| 70 |
+
camera = Camera.open(index);
|
| 71 |
+
|
| 72 |
+
try {
|
| 73 |
+
Camera.Parameters parameters = camera.getParameters();
|
| 74 |
+
List<String> focusModes = parameters.getSupportedFocusModes();
|
| 75 |
+
if (focusModes != null
|
| 76 |
+
&& focusModes.contains(Camera.Parameters.FOCUS_MODE_CONTINUOUS_PICTURE)) {
|
| 77 |
+
parameters.setFocusMode(Camera.Parameters.FOCUS_MODE_CONTINUOUS_PICTURE);
|
| 78 |
+
}
|
| 79 |
+
List<Camera.Size> cameraSizes = parameters.getSupportedPreviewSizes();
|
| 80 |
+
Size[] sizes = new Size[cameraSizes.size()];
|
| 81 |
+
int i = 0;
|
| 82 |
+
for (Camera.Size size : cameraSizes) {
|
| 83 |
+
sizes[i++] = new Size(size.width, size.height);
|
| 84 |
+
}
|
| 85 |
+
Size previewSize =
|
| 86 |
+
CameraConnectionFragment.chooseOptimalSize(
|
| 87 |
+
sizes, desiredSize.getWidth(), desiredSize.getHeight());
|
| 88 |
+
parameters.setPreviewSize(previewSize.getWidth(), previewSize.getHeight());
|
| 89 |
+
camera.setDisplayOrientation(90);
|
| 90 |
+
camera.setParameters(parameters);
|
| 91 |
+
camera.setPreviewTexture(texture);
|
| 92 |
+
} catch (IOException exception) {
|
| 93 |
+
camera.release();
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
camera.setPreviewCallbackWithBuffer(imageListener);
|
| 97 |
+
Camera.Size s = camera.getParameters().getPreviewSize();
|
| 98 |
+
camera.addCallbackBuffer(new byte[ImageUtils.getYUVByteSize(s.height, s.width)]);
|
| 99 |
+
|
| 100 |
+
textureView.setAspectRatio(s.height, s.width);
|
| 101 |
+
|
| 102 |
+
camera.startPreview();
|
| 103 |
+
}
|
| 104 |
+
|
| 105 |
+
@Override
|
| 106 |
+
public void onSurfaceTextureSizeChanged(
|
| 107 |
+
final SurfaceTexture texture, final int width, final int height) {}
|
| 108 |
+
|
| 109 |
+
@Override
|
| 110 |
+
public boolean onSurfaceTextureDestroyed(final SurfaceTexture texture) {
|
| 111 |
+
return true;
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
@Override
|
| 115 |
+
public void onSurfaceTextureUpdated(final SurfaceTexture texture) {}
|
| 116 |
+
};
|
| 117 |
+
/** An additional thread for running tasks that shouldn't block the UI. */
|
| 118 |
+
private HandlerThread backgroundThread;
|
| 119 |
+
|
| 120 |
+
@SuppressLint("ValidFragment")
|
| 121 |
+
public LegacyCameraConnectionFragment(
|
| 122 |
+
final Camera.PreviewCallback imageListener, final int layout, final Size desiredSize) {
|
| 123 |
+
this.imageListener = imageListener;
|
| 124 |
+
this.layout = layout;
|
| 125 |
+
this.desiredSize = desiredSize;
|
| 126 |
+
}
|
| 127 |
+
|
| 128 |
+
@Override
|
| 129 |
+
public View onCreateView(
|
| 130 |
+
final LayoutInflater inflater, final ViewGroup container, final Bundle savedInstanceState) {
|
| 131 |
+
return inflater.inflate(layout, container, false);
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
@Override
|
| 135 |
+
public void onViewCreated(final View view, final Bundle savedInstanceState) {
|
| 136 |
+
textureView = (AutoFitTextureView) view.findViewById(R.id.texture);
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
@Override
|
| 140 |
+
public void onActivityCreated(final Bundle savedInstanceState) {
|
| 141 |
+
super.onActivityCreated(savedInstanceState);
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
@Override
|
| 145 |
+
public void onResume() {
|
| 146 |
+
super.onResume();
|
| 147 |
+
startBackgroundThread();
|
| 148 |
+
// When the screen is turned off and turned back on, the SurfaceTexture is already
|
| 149 |
+
// available, and "onSurfaceTextureAvailable" will not be called. In that case, we can open
|
| 150 |
+
// a camera and start preview from here (otherwise, we wait until the surface is ready in
|
| 151 |
+
// the SurfaceTextureListener).
|
| 152 |
+
|
| 153 |
+
if (textureView.isAvailable()) {
|
| 154 |
+
if (camera != null) {
|
| 155 |
+
camera.startPreview();
|
| 156 |
+
}
|
| 157 |
+
} else {
|
| 158 |
+
textureView.setSurfaceTextureListener(surfaceTextureListener);
|
| 159 |
+
}
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
@Override
|
| 163 |
+
public void onPause() {
|
| 164 |
+
stopCamera();
|
| 165 |
+
stopBackgroundThread();
|
| 166 |
+
super.onPause();
|
| 167 |
+
}
|
| 168 |
+
|
| 169 |
+
/** Starts a background thread and its {@link Handler}. */
|
| 170 |
+
private void startBackgroundThread() {
|
| 171 |
+
backgroundThread = new HandlerThread("CameraBackground");
|
| 172 |
+
backgroundThread.start();
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
/** Stops the background thread and its {@link Handler}. */
|
| 176 |
+
private void stopBackgroundThread() {
|
| 177 |
+
backgroundThread.quitSafely();
|
| 178 |
+
try {
|
| 179 |
+
backgroundThread.join();
|
| 180 |
+
backgroundThread = null;
|
| 181 |
+
} catch (final InterruptedException e) {
|
| 182 |
+
LOGGER.e(e, "Exception!");
|
| 183 |
+
}
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
protected void stopCamera() {
|
| 187 |
+
if (camera != null) {
|
| 188 |
+
camera.stopPreview();
|
| 189 |
+
camera.setPreviewCallback(null);
|
| 190 |
+
camera.release();
|
| 191 |
+
camera = null;
|
| 192 |
+
}
|
| 193 |
+
}
|
| 194 |
+
|
| 195 |
+
private int getCameraId() {
|
| 196 |
+
CameraInfo ci = new CameraInfo();
|
| 197 |
+
for (int i = 0; i < Camera.getNumberOfCameras(); i++) {
|
| 198 |
+
Camera.getCameraInfo(i, ci);
|
| 199 |
+
if (ci.facing == CameraInfo.CAMERA_FACING_BACK) return i;
|
| 200 |
+
}
|
| 201 |
+
return -1; // No camera found
|
| 202 |
+
}
|
| 203 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/AutoFitTextureView.java
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
package org.tensorflow.lite.examples.classification.customview;
|
| 18 |
+
|
| 19 |
+
import android.content.Context;
|
| 20 |
+
import android.util.AttributeSet;
|
| 21 |
+
import android.view.TextureView;
|
| 22 |
+
|
| 23 |
+
/** A {@link TextureView} that can be adjusted to a specified aspect ratio. */
|
| 24 |
+
public class AutoFitTextureView extends TextureView {
|
| 25 |
+
private int ratioWidth = 0;
|
| 26 |
+
private int ratioHeight = 0;
|
| 27 |
+
|
| 28 |
+
public AutoFitTextureView(final Context context) {
|
| 29 |
+
this(context, null);
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
public AutoFitTextureView(final Context context, final AttributeSet attrs) {
|
| 33 |
+
this(context, attrs, 0);
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
public AutoFitTextureView(final Context context, final AttributeSet attrs, final int defStyle) {
|
| 37 |
+
super(context, attrs, defStyle);
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
/**
|
| 41 |
+
* Sets the aspect ratio for this view. The size of the view will be measured based on the ratio
|
| 42 |
+
* calculated from the parameters. Note that the actual sizes of parameters don't matter, that is,
|
| 43 |
+
* calling setAspectRatio(2, 3) and setAspectRatio(4, 6) make the same result.
|
| 44 |
+
*
|
| 45 |
+
* @param width Relative horizontal size
|
| 46 |
+
* @param height Relative vertical size
|
| 47 |
+
*/
|
| 48 |
+
public void setAspectRatio(final int width, final int height) {
|
| 49 |
+
if (width < 0 || height < 0) {
|
| 50 |
+
throw new IllegalArgumentException("Size cannot be negative.");
|
| 51 |
+
}
|
| 52 |
+
ratioWidth = width;
|
| 53 |
+
ratioHeight = height;
|
| 54 |
+
requestLayout();
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
@Override
|
| 58 |
+
protected void onMeasure(final int widthMeasureSpec, final int heightMeasureSpec) {
|
| 59 |
+
super.onMeasure(widthMeasureSpec, heightMeasureSpec);
|
| 60 |
+
final int width = MeasureSpec.getSize(widthMeasureSpec);
|
| 61 |
+
final int height = MeasureSpec.getSize(heightMeasureSpec);
|
| 62 |
+
if (0 == ratioWidth || 0 == ratioHeight) {
|
| 63 |
+
setMeasuredDimension(width, height);
|
| 64 |
+
} else {
|
| 65 |
+
if (width < height * ratioWidth / ratioHeight) {
|
| 66 |
+
setMeasuredDimension(width, width * ratioHeight / ratioWidth);
|
| 67 |
+
} else {
|
| 68 |
+
setMeasuredDimension(height * ratioWidth / ratioHeight, height);
|
| 69 |
+
}
|
| 70 |
+
}
|
| 71 |
+
}
|
| 72 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/OverlayView.java
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.customview;
|
| 17 |
+
|
| 18 |
+
import android.content.Context;
|
| 19 |
+
import android.graphics.Canvas;
|
| 20 |
+
import android.util.AttributeSet;
|
| 21 |
+
import android.view.View;
|
| 22 |
+
import java.util.LinkedList;
|
| 23 |
+
import java.util.List;
|
| 24 |
+
|
| 25 |
+
/** A simple View providing a render callback to other classes. */
|
| 26 |
+
public class OverlayView extends View {
|
| 27 |
+
private final List<DrawCallback> callbacks = new LinkedList<DrawCallback>();
|
| 28 |
+
|
| 29 |
+
public OverlayView(final Context context, final AttributeSet attrs) {
|
| 30 |
+
super(context, attrs);
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
public void addCallback(final DrawCallback callback) {
|
| 34 |
+
callbacks.add(callback);
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
@Override
|
| 38 |
+
public synchronized void draw(final Canvas canvas) {
|
| 39 |
+
for (final DrawCallback callback : callbacks) {
|
| 40 |
+
callback.drawCallback(canvas);
|
| 41 |
+
}
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
/** Interface defining the callback for client classes. */
|
| 45 |
+
public interface DrawCallback {
|
| 46 |
+
public void drawCallback(final Canvas canvas);
|
| 47 |
+
}
|
| 48 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/RecognitionScoreView.java
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.customview;
|
| 17 |
+
|
| 18 |
+
import android.content.Context;
|
| 19 |
+
import android.graphics.Canvas;
|
| 20 |
+
import android.graphics.Paint;
|
| 21 |
+
import android.util.AttributeSet;
|
| 22 |
+
import android.util.TypedValue;
|
| 23 |
+
import android.view.View;
|
| 24 |
+
import java.util.List;
|
| 25 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Recognition;
|
| 26 |
+
|
| 27 |
+
public class RecognitionScoreView extends View implements ResultsView {
|
| 28 |
+
private static final float TEXT_SIZE_DIP = 16;
|
| 29 |
+
private final float textSizePx;
|
| 30 |
+
private final Paint fgPaint;
|
| 31 |
+
private final Paint bgPaint;
|
| 32 |
+
private List<Recognition> results;
|
| 33 |
+
|
| 34 |
+
public RecognitionScoreView(final Context context, final AttributeSet set) {
|
| 35 |
+
super(context, set);
|
| 36 |
+
|
| 37 |
+
textSizePx =
|
| 38 |
+
TypedValue.applyDimension(
|
| 39 |
+
TypedValue.COMPLEX_UNIT_DIP, TEXT_SIZE_DIP, getResources().getDisplayMetrics());
|
| 40 |
+
fgPaint = new Paint();
|
| 41 |
+
fgPaint.setTextSize(textSizePx);
|
| 42 |
+
|
| 43 |
+
bgPaint = new Paint();
|
| 44 |
+
bgPaint.setColor(0xcc4285f4);
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
@Override
|
| 48 |
+
public void setResults(final List<Recognition> results) {
|
| 49 |
+
this.results = results;
|
| 50 |
+
postInvalidate();
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
@Override
|
| 54 |
+
public void onDraw(final Canvas canvas) {
|
| 55 |
+
final int x = 10;
|
| 56 |
+
int y = (int) (fgPaint.getTextSize() * 1.5f);
|
| 57 |
+
|
| 58 |
+
canvas.drawPaint(bgPaint);
|
| 59 |
+
|
| 60 |
+
if (results != null) {
|
| 61 |
+
for (final Recognition recog : results) {
|
| 62 |
+
canvas.drawText(recog.getTitle() + ": " + recog.getConfidence(), x, y, fgPaint);
|
| 63 |
+
y += (int) (fgPaint.getTextSize() * 1.5f);
|
| 64 |
+
}
|
| 65 |
+
}
|
| 66 |
+
}
|
| 67 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/customview/ResultsView.java
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.customview;
|
| 17 |
+
|
| 18 |
+
import java.util.List;
|
| 19 |
+
import org.tensorflow.lite.examples.classification.tflite.Classifier.Recognition;
|
| 20 |
+
|
| 21 |
+
public interface ResultsView {
|
| 22 |
+
public void setResults(final List<Recognition> results);
|
| 23 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/BorderedText.java
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.env;
|
| 17 |
+
|
| 18 |
+
import android.graphics.Canvas;
|
| 19 |
+
import android.graphics.Color;
|
| 20 |
+
import android.graphics.Paint;
|
| 21 |
+
import android.graphics.Paint.Align;
|
| 22 |
+
import android.graphics.Paint.Style;
|
| 23 |
+
import android.graphics.Rect;
|
| 24 |
+
import android.graphics.Typeface;
|
| 25 |
+
import java.util.Vector;
|
| 26 |
+
|
| 27 |
+
/** A class that encapsulates the tedious bits of rendering legible, bordered text onto a canvas. */
|
| 28 |
+
public class BorderedText {
|
| 29 |
+
private final Paint interiorPaint;
|
| 30 |
+
private final Paint exteriorPaint;
|
| 31 |
+
|
| 32 |
+
private final float textSize;
|
| 33 |
+
|
| 34 |
+
/**
|
| 35 |
+
* Creates a left-aligned bordered text object with a white interior, and a black exterior with
|
| 36 |
+
* the specified text size.
|
| 37 |
+
*
|
| 38 |
+
* @param textSize text size in pixels
|
| 39 |
+
*/
|
| 40 |
+
public BorderedText(final float textSize) {
|
| 41 |
+
this(Color.WHITE, Color.BLACK, textSize);
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
/**
|
| 45 |
+
* Create a bordered text object with the specified interior and exterior colors, text size and
|
| 46 |
+
* alignment.
|
| 47 |
+
*
|
| 48 |
+
* @param interiorColor the interior text color
|
| 49 |
+
* @param exteriorColor the exterior text color
|
| 50 |
+
* @param textSize text size in pixels
|
| 51 |
+
*/
|
| 52 |
+
public BorderedText(final int interiorColor, final int exteriorColor, final float textSize) {
|
| 53 |
+
interiorPaint = new Paint();
|
| 54 |
+
interiorPaint.setTextSize(textSize);
|
| 55 |
+
interiorPaint.setColor(interiorColor);
|
| 56 |
+
interiorPaint.setStyle(Style.FILL);
|
| 57 |
+
interiorPaint.setAntiAlias(false);
|
| 58 |
+
interiorPaint.setAlpha(255);
|
| 59 |
+
|
| 60 |
+
exteriorPaint = new Paint();
|
| 61 |
+
exteriorPaint.setTextSize(textSize);
|
| 62 |
+
exteriorPaint.setColor(exteriorColor);
|
| 63 |
+
exteriorPaint.setStyle(Style.FILL_AND_STROKE);
|
| 64 |
+
exteriorPaint.setStrokeWidth(textSize / 8);
|
| 65 |
+
exteriorPaint.setAntiAlias(false);
|
| 66 |
+
exteriorPaint.setAlpha(255);
|
| 67 |
+
|
| 68 |
+
this.textSize = textSize;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
public void setTypeface(Typeface typeface) {
|
| 72 |
+
interiorPaint.setTypeface(typeface);
|
| 73 |
+
exteriorPaint.setTypeface(typeface);
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
public void drawText(final Canvas canvas, final float posX, final float posY, final String text) {
|
| 77 |
+
canvas.drawText(text, posX, posY, exteriorPaint);
|
| 78 |
+
canvas.drawText(text, posX, posY, interiorPaint);
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
public void drawLines(Canvas canvas, final float posX, final float posY, Vector<String> lines) {
|
| 82 |
+
int lineNum = 0;
|
| 83 |
+
for (final String line : lines) {
|
| 84 |
+
drawText(canvas, posX, posY - getTextSize() * (lines.size() - lineNum - 1), line);
|
| 85 |
+
++lineNum;
|
| 86 |
+
}
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
public void setInteriorColor(final int color) {
|
| 90 |
+
interiorPaint.setColor(color);
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
public void setExteriorColor(final int color) {
|
| 94 |
+
exteriorPaint.setColor(color);
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
public float getTextSize() {
|
| 98 |
+
return textSize;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
public void setAlpha(final int alpha) {
|
| 102 |
+
interiorPaint.setAlpha(alpha);
|
| 103 |
+
exteriorPaint.setAlpha(alpha);
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
public void getTextBounds(
|
| 107 |
+
final String line, final int index, final int count, final Rect lineBounds) {
|
| 108 |
+
interiorPaint.getTextBounds(line, index, count, lineBounds);
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
public void setTextAlign(final Align align) {
|
| 112 |
+
interiorPaint.setTextAlign(align);
|
| 113 |
+
exteriorPaint.setTextAlign(align);
|
| 114 |
+
}
|
| 115 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/ImageUtils.java
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.env;
|
| 17 |
+
|
| 18 |
+
import android.graphics.Bitmap;
|
| 19 |
+
import android.os.Environment;
|
| 20 |
+
import java.io.File;
|
| 21 |
+
import java.io.FileOutputStream;
|
| 22 |
+
|
| 23 |
+
/** Utility class for manipulating images. */
|
| 24 |
+
public class ImageUtils {
|
| 25 |
+
// This value is 2 ^ 18 - 1, and is used to clamp the RGB values before their ranges
|
| 26 |
+
// are normalized to eight bits.
|
| 27 |
+
static final int kMaxChannelValue = 262143;
|
| 28 |
+
|
| 29 |
+
@SuppressWarnings("unused")
|
| 30 |
+
private static final Logger LOGGER = new Logger();
|
| 31 |
+
|
| 32 |
+
/**
|
| 33 |
+
* Utility method to compute the allocated size in bytes of a YUV420SP image of the given
|
| 34 |
+
* dimensions.
|
| 35 |
+
*/
|
| 36 |
+
public static int getYUVByteSize(final int width, final int height) {
|
| 37 |
+
// The luminance plane requires 1 byte per pixel.
|
| 38 |
+
final int ySize = width * height;
|
| 39 |
+
|
| 40 |
+
// The UV plane works on 2x2 blocks, so dimensions with odd size must be rounded up.
|
| 41 |
+
// Each 2x2 block takes 2 bytes to encode, one each for U and V.
|
| 42 |
+
final int uvSize = ((width + 1) / 2) * ((height + 1) / 2) * 2;
|
| 43 |
+
|
| 44 |
+
return ySize + uvSize;
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
/**
|
| 48 |
+
* Saves a Bitmap object to disk for analysis.
|
| 49 |
+
*
|
| 50 |
+
* @param bitmap The bitmap to save.
|
| 51 |
+
*/
|
| 52 |
+
public static void saveBitmap(final Bitmap bitmap) {
|
| 53 |
+
saveBitmap(bitmap, "preview.png");
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
/**
|
| 57 |
+
* Saves a Bitmap object to disk for analysis.
|
| 58 |
+
*
|
| 59 |
+
* @param bitmap The bitmap to save.
|
| 60 |
+
* @param filename The location to save the bitmap to.
|
| 61 |
+
*/
|
| 62 |
+
public static void saveBitmap(final Bitmap bitmap, final String filename) {
|
| 63 |
+
final String root =
|
| 64 |
+
Environment.getExternalStorageDirectory().getAbsolutePath() + File.separator + "tensorflow";
|
| 65 |
+
LOGGER.i("Saving %dx%d bitmap to %s.", bitmap.getWidth(), bitmap.getHeight(), root);
|
| 66 |
+
final File myDir = new File(root);
|
| 67 |
+
|
| 68 |
+
if (!myDir.mkdirs()) {
|
| 69 |
+
LOGGER.i("Make dir failed");
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
final String fname = filename;
|
| 73 |
+
final File file = new File(myDir, fname);
|
| 74 |
+
if (file.exists()) {
|
| 75 |
+
file.delete();
|
| 76 |
+
}
|
| 77 |
+
try {
|
| 78 |
+
final FileOutputStream out = new FileOutputStream(file);
|
| 79 |
+
bitmap.compress(Bitmap.CompressFormat.PNG, 99, out);
|
| 80 |
+
out.flush();
|
| 81 |
+
out.close();
|
| 82 |
+
} catch (final Exception e) {
|
| 83 |
+
LOGGER.e(e, "Exception!");
|
| 84 |
+
}
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
public static void convertYUV420SPToARGB8888(byte[] input, int width, int height, int[] output) {
|
| 88 |
+
final int frameSize = width * height;
|
| 89 |
+
for (int j = 0, yp = 0; j < height; j++) {
|
| 90 |
+
int uvp = frameSize + (j >> 1) * width;
|
| 91 |
+
int u = 0;
|
| 92 |
+
int v = 0;
|
| 93 |
+
|
| 94 |
+
for (int i = 0; i < width; i++, yp++) {
|
| 95 |
+
int y = 0xff & input[yp];
|
| 96 |
+
if ((i & 1) == 0) {
|
| 97 |
+
v = 0xff & input[uvp++];
|
| 98 |
+
u = 0xff & input[uvp++];
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
output[yp] = YUV2RGB(y, u, v);
|
| 102 |
+
}
|
| 103 |
+
}
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
private static int YUV2RGB(int y, int u, int v) {
|
| 107 |
+
// Adjust and check YUV values
|
| 108 |
+
y = (y - 16) < 0 ? 0 : (y - 16);
|
| 109 |
+
u -= 128;
|
| 110 |
+
v -= 128;
|
| 111 |
+
|
| 112 |
+
// This is the floating point equivalent. We do the conversion in integer
|
| 113 |
+
// because some Android devices do not have floating point in hardware.
|
| 114 |
+
// nR = (int)(1.164 * nY + 2.018 * nU);
|
| 115 |
+
// nG = (int)(1.164 * nY - 0.813 * nV - 0.391 * nU);
|
| 116 |
+
// nB = (int)(1.164 * nY + 1.596 * nV);
|
| 117 |
+
int y1192 = 1192 * y;
|
| 118 |
+
int r = (y1192 + 1634 * v);
|
| 119 |
+
int g = (y1192 - 833 * v - 400 * u);
|
| 120 |
+
int b = (y1192 + 2066 * u);
|
| 121 |
+
|
| 122 |
+
// Clipping RGB values to be inside boundaries [ 0 , kMaxChannelValue ]
|
| 123 |
+
r = r > kMaxChannelValue ? kMaxChannelValue : (r < 0 ? 0 : r);
|
| 124 |
+
g = g > kMaxChannelValue ? kMaxChannelValue : (g < 0 ? 0 : g);
|
| 125 |
+
b = b > kMaxChannelValue ? kMaxChannelValue : (b < 0 ? 0 : b);
|
| 126 |
+
|
| 127 |
+
return 0xff000000 | ((r << 6) & 0xff0000) | ((g >> 2) & 0xff00) | ((b >> 10) & 0xff);
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
public static void convertYUV420ToARGB8888(
|
| 131 |
+
byte[] yData,
|
| 132 |
+
byte[] uData,
|
| 133 |
+
byte[] vData,
|
| 134 |
+
int width,
|
| 135 |
+
int height,
|
| 136 |
+
int yRowStride,
|
| 137 |
+
int uvRowStride,
|
| 138 |
+
int uvPixelStride,
|
| 139 |
+
int[] out) {
|
| 140 |
+
int yp = 0;
|
| 141 |
+
for (int j = 0; j < height; j++) {
|
| 142 |
+
int pY = yRowStride * j;
|
| 143 |
+
int pUV = uvRowStride * (j >> 1);
|
| 144 |
+
|
| 145 |
+
for (int i = 0; i < width; i++) {
|
| 146 |
+
int uv_offset = pUV + (i >> 1) * uvPixelStride;
|
| 147 |
+
|
| 148 |
+
out[yp++] = YUV2RGB(0xff & yData[pY + i], 0xff & uData[uv_offset], 0xff & vData[uv_offset]);
|
| 149 |
+
}
|
| 150 |
+
}
|
| 151 |
+
}
|
| 152 |
+
}
|
MiDaS-master/mobile/android/app/src/main/java/org/tensorflow/lite/examples/classification/env/Logger.java
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
==============================================================================*/
|
| 15 |
+
|
| 16 |
+
package org.tensorflow.lite.examples.classification.env;
|
| 17 |
+
|
| 18 |
+
import android.util.Log;
|
| 19 |
+
import java.util.HashSet;
|
| 20 |
+
import java.util.Set;
|
| 21 |
+
|
| 22 |
+
/** Wrapper for the platform log function, allows convenient message prefixing and log disabling. */
|
| 23 |
+
public final class Logger {
|
| 24 |
+
private static final String DEFAULT_TAG = "tensorflow";
|
| 25 |
+
private static final int DEFAULT_MIN_LOG_LEVEL = Log.DEBUG;
|
| 26 |
+
|
| 27 |
+
// Classes to be ignored when examining the stack trace
|
| 28 |
+
private static final Set<String> IGNORED_CLASS_NAMES;
|
| 29 |
+
|
| 30 |
+
static {
|
| 31 |
+
IGNORED_CLASS_NAMES = new HashSet<String>(3);
|
| 32 |
+
IGNORED_CLASS_NAMES.add("dalvik.system.VMStack");
|
| 33 |
+
IGNORED_CLASS_NAMES.add("java.lang.Thread");
|
| 34 |
+
IGNORED_CLASS_NAMES.add(Logger.class.getCanonicalName());
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
private final String tag;
|
| 38 |
+
private final String messagePrefix;
|
| 39 |
+
private int minLogLevel = DEFAULT_MIN_LOG_LEVEL;
|
| 40 |
+
|
| 41 |
+
/**
|
| 42 |
+
* Creates a Logger using the class name as the message prefix.
|
| 43 |
+
*
|
| 44 |
+
* @param clazz the simple name of this class is used as the message prefix.
|
| 45 |
+
*/
|
| 46 |
+
public Logger(final Class<?> clazz) {
|
| 47 |
+
this(clazz.getSimpleName());
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
/**
|
| 51 |
+
* Creates a Logger using the specified message prefix.
|
| 52 |
+
*
|
| 53 |
+
* @param messagePrefix is prepended to the text of every message.
|
| 54 |
+
*/
|
| 55 |
+
public Logger(final String messagePrefix) {
|
| 56 |
+
this(DEFAULT_TAG, messagePrefix);
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
/**
|
| 60 |
+
* Creates a Logger with a custom tag and a custom message prefix. If the message prefix is set to
|
| 61 |
+
*
|
| 62 |
+
* <pre>null</pre>
|
| 63 |
+
*
|
| 64 |
+
* , the caller's class name is used as the prefix.
|
| 65 |
+
*
|
| 66 |
+
* @param tag identifies the source of a log message.
|
| 67 |
+
* @param messagePrefix prepended to every message if non-null. If null, the name of the caller is
|
| 68 |
+
* being used
|
| 69 |
+
*/
|
| 70 |
+
public Logger(final String tag, final String messagePrefix) {
|
| 71 |
+
this.tag = tag;
|
| 72 |
+
final String prefix = messagePrefix == null ? getCallerSimpleName() : messagePrefix;
|
| 73 |
+
this.messagePrefix = (prefix.length() > 0) ? prefix + ": " : prefix;
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
/** Creates a Logger using the caller's class name as the message prefix. */
|
| 77 |
+
public Logger() {
|
| 78 |
+
this(DEFAULT_TAG, null);
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
/** Creates a Logger using the caller's class name as the message prefix. */
|
| 82 |
+
public Logger(final int minLogLevel) {
|
| 83 |
+
this(DEFAULT_TAG, null);
|
| 84 |
+
this.minLogLevel = minLogLevel;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
/**
|
| 88 |
+
* Return caller's simple name.
|
| 89 |
+
*
|
| 90 |
+
* <p>Android getStackTrace() returns an array that looks like this: stackTrace[0]:
|
| 91 |
+
* dalvik.system.VMStack stackTrace[1]: java.lang.Thread stackTrace[2]:
|
| 92 |
+
* com.google.android.apps.unveil.env.UnveilLogger stackTrace[3]:
|
| 93 |
+
* com.google.android.apps.unveil.BaseApplication
|
| 94 |
+
*
|
| 95 |
+
* <p>This function returns the simple version of the first non-filtered name.
|
| 96 |
+
*
|
| 97 |
+
* @return caller's simple name
|
| 98 |
+
*/
|
| 99 |
+
private static String getCallerSimpleName() {
|
| 100 |
+
// Get the current callstack so we can pull the class of the caller off of it.
|
| 101 |
+
final StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
|
| 102 |
+
|
| 103 |
+
for (final StackTraceElement elem : stackTrace) {
|
| 104 |
+
final String className = elem.getClassName();
|
| 105 |
+
if (!IGNORED_CLASS_NAMES.contains(className)) {
|
| 106 |
+
// We're only interested in the simple name of the class, not the complete package.
|
| 107 |
+
final String[] classParts = className.split("\\.");
|
| 108 |
+
return classParts[classParts.length - 1];
|
| 109 |
+
}
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
return Logger.class.getSimpleName();
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
public void setMinLogLevel(final int minLogLevel) {
|
| 116 |
+
this.minLogLevel = minLogLevel;
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
public boolean isLoggable(final int logLevel) {
|
| 120 |
+
return logLevel >= minLogLevel || Log.isLoggable(tag, logLevel);
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
private String toMessage(final String format, final Object... args) {
|
| 124 |
+
return messagePrefix + (args.length > 0 ? String.format(format, args) : format);
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
public void v(final String format, final Object... args) {
|
| 128 |
+
if (isLoggable(Log.VERBOSE)) {
|
| 129 |
+
Log.v(tag, toMessage(format, args));
|
| 130 |
+
}
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
public void v(final Throwable t, final String format, final Object... args) {
|
| 134 |
+
if (isLoggable(Log.VERBOSE)) {
|
| 135 |
+
Log.v(tag, toMessage(format, args), t);
|
| 136 |
+
}
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
public void d(final String format, final Object... args) {
|
| 140 |
+
if (isLoggable(Log.DEBUG)) {
|
| 141 |
+
Log.d(tag, toMessage(format, args));
|
| 142 |
+
}
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
public void d(final Throwable t, final String format, final Object... args) {
|
| 146 |
+
if (isLoggable(Log.DEBUG)) {
|
| 147 |
+
Log.d(tag, toMessage(format, args), t);
|
| 148 |
+
}
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
public void i(final String format, final Object... args) {
|
| 152 |
+
if (isLoggable(Log.INFO)) {
|
| 153 |
+
Log.i(tag, toMessage(format, args));
|
| 154 |
+
}
|
| 155 |
+
}
|
| 156 |
+
|
| 157 |
+
public void i(final Throwable t, final String format, final Object... args) {
|
| 158 |
+
if (isLoggable(Log.INFO)) {
|
| 159 |
+
Log.i(tag, toMessage(format, args), t);
|
| 160 |
+
}
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
public void w(final String format, final Object... args) {
|
| 164 |
+
if (isLoggable(Log.WARN)) {
|
| 165 |
+
Log.w(tag, toMessage(format, args));
|
| 166 |
+
}
|
| 167 |
+
}
|
| 168 |
+
|
| 169 |
+
public void w(final Throwable t, final String format, final Object... args) {
|
| 170 |
+
if (isLoggable(Log.WARN)) {
|
| 171 |
+
Log.w(tag, toMessage(format, args), t);
|
| 172 |
+
}
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
public void e(final String format, final Object... args) {
|
| 176 |
+
if (isLoggable(Log.ERROR)) {
|
| 177 |
+
Log.e(tag, toMessage(format, args));
|
| 178 |
+
}
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
public void e(final Throwable t, final String format, final Object... args) {
|
| 182 |
+
if (isLoggable(Log.ERROR)) {
|
| 183 |
+
Log.e(tag, toMessage(format, args), t);
|
| 184 |
+
}
|
| 185 |
+
}
|
| 186 |
+
}
|
MiDaS-master/mobile/android/app/src/main/res/drawable-hdpi/ic_launcher.png
ADDED

|