
Commit
•
51c06b8
1
Parent(s):
d0fd410
hpc model
Browse files- README.md +97 -0
- all_results.json +12 -0
- args.json +136 -0
- config.json +45 -0
- env.json +10 -0
- fig/test_confusion_matrix.eps +0 -0
- fig/test_confusion_matrix.png +0 -0
- fig/test_confusion_matrix_norm.eps +0 -0
- fig/test_confusion_matrix_norm.png +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- test_predictions.txt +3 -0
- test_results.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +14 -0
- train_results.json +7 -0
- trainer_state.json +215 -0
- training_args.bin +3 -0
- vocab.txt +0 -0
README.md
CHANGED
|
@@ -1,3 +1,100 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
datasets:
|
| 3 |
+
- BramVanroy/hebban-reviews
|
| 4 |
+
language:
|
| 5 |
+
- nl
|
| 6 |
license: mit
|
| 7 |
+
metrics:
|
| 8 |
+
- accuracy
|
| 9 |
+
- f1
|
| 10 |
+
- precision
|
| 11 |
+
- qwk
|
| 12 |
+
- recall
|
| 13 |
+
model-index:
|
| 14 |
+
- name: bert-base-multilingual-cased-hebban-reviews5
|
| 15 |
+
results:
|
| 16 |
+
- dataset:
|
| 17 |
+
config: filtered_rating
|
| 18 |
+
name: BramVanroy/hebban-reviews - filtered_rating - 2.0.0
|
| 19 |
+
revision: 2.0.0
|
| 20 |
+
split: test
|
| 21 |
+
type: BramVanroy/hebban-reviews
|
| 22 |
+
metrics:
|
| 23 |
+
- name: Test accuracy
|
| 24 |
+
type: accuracy
|
| 25 |
+
value: 0.5898668639053254
|
| 26 |
+
- name: Test f1
|
| 27 |
+
type: f1
|
| 28 |
+
value: 0.5899204480029937
|
| 29 |
+
- name: Test precision
|
| 30 |
+
type: precision
|
| 31 |
+
value: 0.5971431895675179
|
| 32 |
+
- name: Test qwk
|
| 33 |
+
type: qwk
|
| 34 |
+
value: 0.7050840079198698
|
| 35 |
+
- name: Test recall
|
| 36 |
+
type: recall
|
| 37 |
+
value: 0.5898668639053254
|
| 38 |
+
task:
|
| 39 |
+
name: sentiment analysis
|
| 40 |
+
type: text-classification
|
| 41 |
+
tags:
|
| 42 |
+
- sentiment-analysis
|
| 43 |
+
- dutch
|
| 44 |
+
- text
|
| 45 |
+
widget:
|
| 46 |
+
- text: Wauw, wat een leuk boek! Ik heb me er er goed mee vermaakt.
|
| 47 |
+
- text: Nee, deze vond ik niet goed. De auteur doet zijn best om je als lezer mee
|
| 48 |
+
te trekken in het verhaal maar mij overtuigt het alleszins niet.
|
| 49 |
+
- text: Ik vind het niet slecht maar de schrijfstijl trekt me ook niet echt aan. Het
|
| 50 |
+
wordt een beetje saai vanaf het vijfde hoofdstuk
|
| 51 |
---
|
| 52 |
+
|
| 53 |
+
# bert-base-multilingual-cased-hebban-reviews
|
| 54 |
+
|
| 55 |
+
# Dataset
|
| 56 |
+
- dataset_name: BramVanroy/hebban-reviews
|
| 57 |
+
- dataset_config: filtered_rating
|
| 58 |
+
- dataset_revision: 2.0.0
|
| 59 |
+
- labelcolumn: review_rating0
|
| 60 |
+
- textcolumn: review_text_without_quotes
|
| 61 |
+
|
| 62 |
+
# Training
|
| 63 |
+
- optim: adamw_hf
|
| 64 |
+
- learning_rate: 5e-05
|
| 65 |
+
- per_device_train_batch_size: 64
|
| 66 |
+
- per_device_eval_batch_size: 64
|
| 67 |
+
- gradient_accumulation_steps: 1
|
| 68 |
+
- max_steps: 5001
|
| 69 |
+
- save_steps: 500
|
| 70 |
+
- metric_for_best_model: qwk
|
| 71 |
+
|
| 72 |
+
# Best checkedpoint based on validation
|
| 73 |
+
- best_metric: 0.697825193570947
|
| 74 |
+
- best_model_checkpoint: trained/hebban-reviews5/bert-base-multilingual-cased/checkpoint-4500
|
| 75 |
+
|
| 76 |
+
# Test results of best checkpoint
|
| 77 |
+
- accuracy: 0.5898668639053254
|
| 78 |
+
- f1: 0.5899204480029937
|
| 79 |
+
- precision: 0.5971431895675179
|
| 80 |
+
- qwk: 0.7050840079198698
|
| 81 |
+
- recall: 0.5898668639053254
|
| 82 |
+
|
| 83 |
+
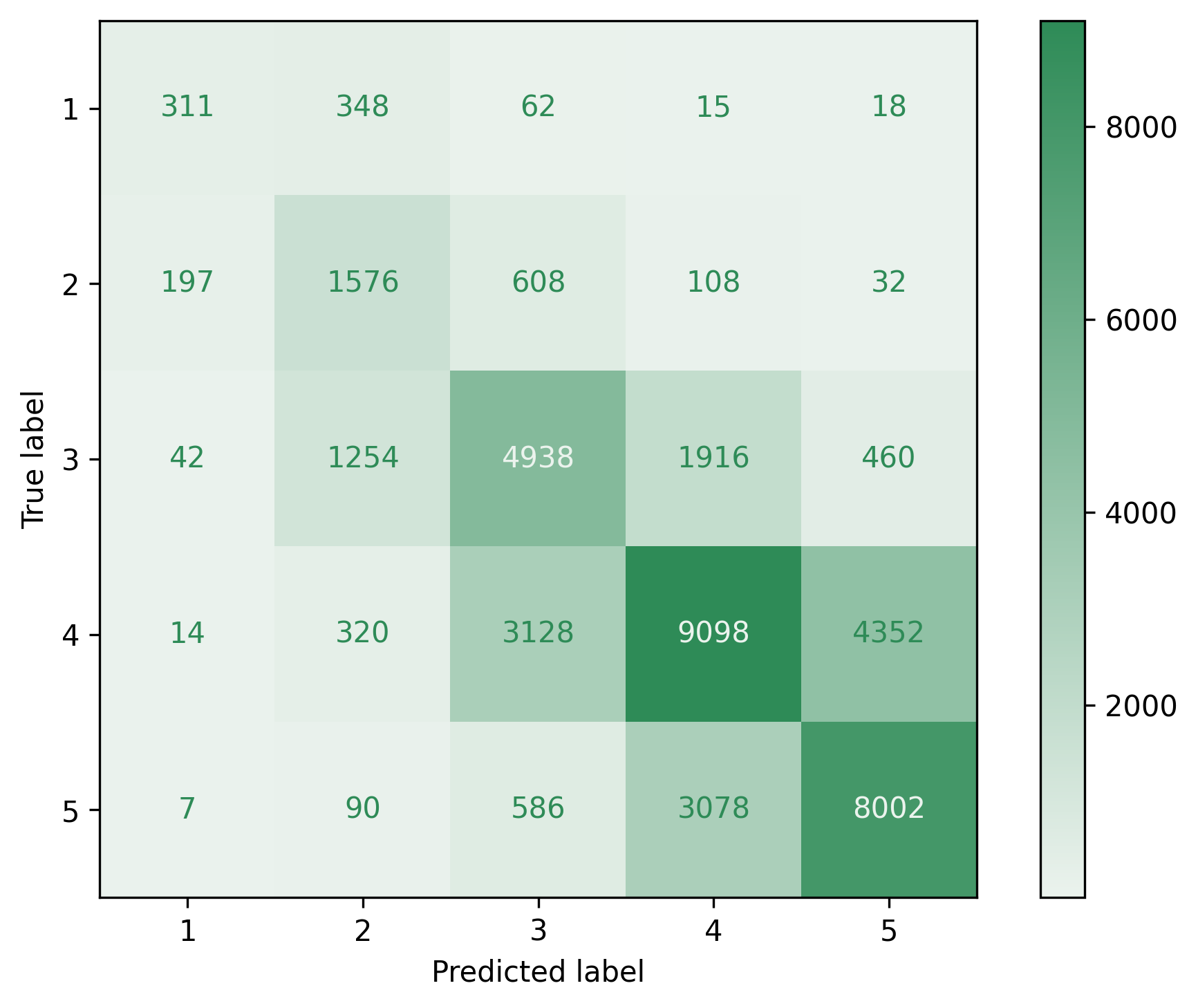
## Confusion matric
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
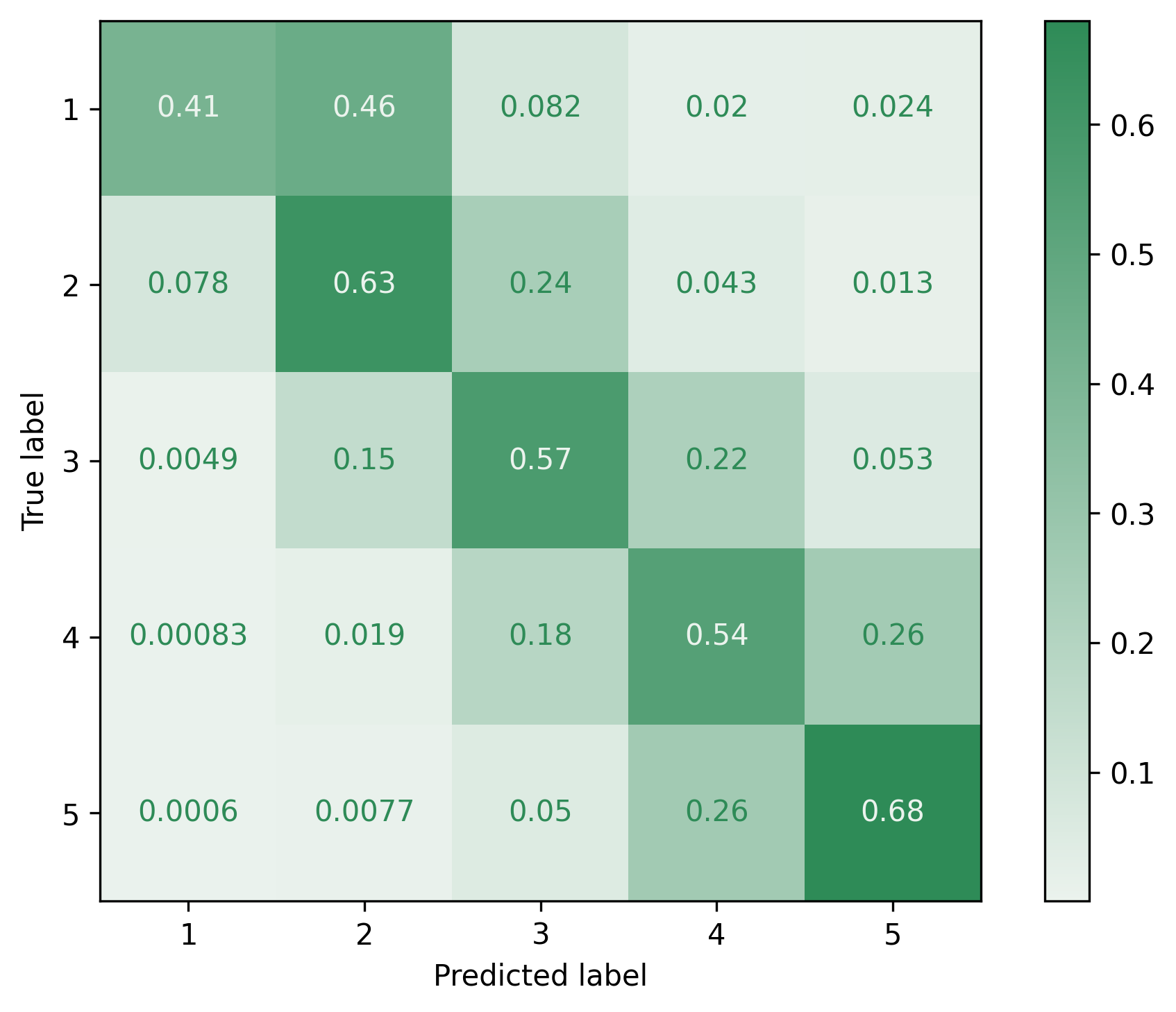
## Normalized confusion matrix
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
# Environment
|
| 92 |
+
- cuda_capabilities: 8.0; 8.0
|
| 93 |
+
- cuda_device_count: 2
|
| 94 |
+
- cuda_devices: NVIDIA A100-SXM4-80GB; NVIDIA A100-SXM4-80GB
|
| 95 |
+
- finetuner_commit: 8159b4c1d5e66b36f68dd263299927ffb8670ebd
|
| 96 |
+
- platform: Linux-4.18.0-305.49.1.el8_4.x86_64-x86_64-with-glibc2.28
|
| 97 |
+
- python_version: 3.9.5
|
| 98 |
+
- toch_version: 1.10.0
|
| 99 |
+
- transformers_version: 4.21.0
|
| 100 |
+
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"accuracy": 0.5898668639053254,
|
| 3 |
+
"epoch": 4.38,
|
| 4 |
+
"f1": 0.5899204480029937,
|
| 5 |
+
"precision": 0.5971431895675179,
|
| 6 |
+
"qwk": 0.7050840079198698,
|
| 7 |
+
"recall": 0.5898668639053254,
|
| 8 |
+
"train_loss": 0.8685172849525287,
|
| 9 |
+
"train_runtime": 2653.5735,
|
| 10 |
+
"train_samples_per_second": 241.232,
|
| 11 |
+
"train_steps_per_second": 1.885
|
| 12 |
+
}
|
args.json
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_n_gpu": 1,
|
| 3 |
+
"adafactor": false,
|
| 4 |
+
"adam_beta1": 0.9,
|
| 5 |
+
"adam_beta2": 0.999,
|
| 6 |
+
"adam_epsilon": 1e-08,
|
| 7 |
+
"auto_find_batch_size": false,
|
| 8 |
+
"bf16": false,
|
| 9 |
+
"bf16_full_eval": false,
|
| 10 |
+
"calculate_qwk": true,
|
| 11 |
+
"data_seed": 42,
|
| 12 |
+
"dataloader_drop_last": false,
|
| 13 |
+
"dataloader_num_workers": 0,
|
| 14 |
+
"dataloader_pin_memory": true,
|
| 15 |
+
"dataset_config": "filtered_rating",
|
| 16 |
+
"dataset_name": "BramVanroy/hebban-reviews",
|
| 17 |
+
"dataset_revision": "2.0.0",
|
| 18 |
+
"ddp_bucket_cap_mb": null,
|
| 19 |
+
"ddp_find_unused_parameters": null,
|
| 20 |
+
"debug": [],
|
| 21 |
+
"deepspeed": null,
|
| 22 |
+
"disable_tqdm": false,
|
| 23 |
+
"do_early_stopping": false,
|
| 24 |
+
"do_eval": true,
|
| 25 |
+
"do_optimize": false,
|
| 26 |
+
"do_predict": true,
|
| 27 |
+
"do_train": true,
|
| 28 |
+
"early_stopping_patience": 1,
|
| 29 |
+
"early_stopping_threshold": 0.0,
|
| 30 |
+
"eval_accumulation_steps": null,
|
| 31 |
+
"eval_delay": 0,
|
| 32 |
+
"eval_steps": 500,
|
| 33 |
+
"evaluation_strategy": "steps",
|
| 34 |
+
"fp16": true,
|
| 35 |
+
"fp16_backend": "auto",
|
| 36 |
+
"fp16_full_eval": false,
|
| 37 |
+
"fp16_opt_level": "O1",
|
| 38 |
+
"fsdp": [],
|
| 39 |
+
"fsdp_min_num_params": 0,
|
| 40 |
+
"fsdp_transformer_layer_cls_to_wrap": null,
|
| 41 |
+
"full_determinism": false,
|
| 42 |
+
"gradient_accumulation_steps": 1,
|
| 43 |
+
"gradient_checkpointing": false,
|
| 44 |
+
"greater_is_better": true,
|
| 45 |
+
"group_by_length": false,
|
| 46 |
+
"half_precision_backend": "cuda_amp",
|
| 47 |
+
"hub_model_id": null,
|
| 48 |
+
"hub_private_repo": false,
|
| 49 |
+
"hub_strategy": "every_save",
|
| 50 |
+
"hub_token": null,
|
| 51 |
+
"ignore_data_skip": false,
|
| 52 |
+
"include_inputs_for_metrics": false,
|
| 53 |
+
"jit_mode_eval": false,
|
| 54 |
+
"label_names": null,
|
| 55 |
+
"label_smoothing_factor": 0.0,
|
| 56 |
+
"labelcolumn": "review_rating0",
|
| 57 |
+
"labelnames": [
|
| 58 |
+
"1",
|
| 59 |
+
"2",
|
| 60 |
+
"3",
|
| 61 |
+
"4",
|
| 62 |
+
"5"
|
| 63 |
+
],
|
| 64 |
+
"learning_rate": 5e-05,
|
| 65 |
+
"length_column_name": "length",
|
| 66 |
+
"load_best_model_at_end": true,
|
| 67 |
+
"local_rank": 0,
|
| 68 |
+
"log_level": -1,
|
| 69 |
+
"log_level_replica": -1,
|
| 70 |
+
"log_on_each_node": true,
|
| 71 |
+
"logging_dir": "trained/hebban-reviews5/bert-base-multilingual-cased/runs/Jul29_00-34-45_node3907.accelgor.os",
|
| 72 |
+
"logging_first_step": false,
|
| 73 |
+
"logging_nan_inf_filter": true,
|
| 74 |
+
"logging_steps": 500,
|
| 75 |
+
"logging_strategy": "steps",
|
| 76 |
+
"lr_scheduler_type": "linear",
|
| 77 |
+
"max_grad_norm": 1.0,
|
| 78 |
+
"max_seq_length": null,
|
| 79 |
+
"max_steps": 5001,
|
| 80 |
+
"max_test_samples": null,
|
| 81 |
+
"max_train_samples": null,
|
| 82 |
+
"max_validation_samples": null,
|
| 83 |
+
"metric_for_best_model": "qwk",
|
| 84 |
+
"model_name_or_path": "bert-base-multilingual-cased",
|
| 85 |
+
"model_revision": "main",
|
| 86 |
+
"mp_parameters": "",
|
| 87 |
+
"n_trials": 8,
|
| 88 |
+
"no_cuda": false,
|
| 89 |
+
"num_train_epochs": 3.0,
|
| 90 |
+
"optim": "adamw_hf",
|
| 91 |
+
"output_dir": "trained/hebban-reviews5/bert-base-multilingual-cased",
|
| 92 |
+
"overwrite_cache": false,
|
| 93 |
+
"overwrite_output_dir": true,
|
| 94 |
+
"past_index": -1,
|
| 95 |
+
"per_device_eval_batch_size": 64,
|
| 96 |
+
"per_device_train_batch_size": 64,
|
| 97 |
+
"per_gpu_eval_batch_size": null,
|
| 98 |
+
"per_gpu_train_batch_size": null,
|
| 99 |
+
"prediction_loss_only": false,
|
| 100 |
+
"push_to_hub": false,
|
| 101 |
+
"push_to_hub_model_id": null,
|
| 102 |
+
"push_to_hub_organization": null,
|
| 103 |
+
"push_to_hub_token": null,
|
| 104 |
+
"ray_scope": "all",
|
| 105 |
+
"remove_unused_columns": true,
|
| 106 |
+
"report_to": [
|
| 107 |
+
"tensorboard"
|
| 108 |
+
],
|
| 109 |
+
"resume_from_checkpoint": null,
|
| 110 |
+
"run_name": "trained/hebban-reviews5/bert-base-multilingual-cased",
|
| 111 |
+
"save_on_each_node": false,
|
| 112 |
+
"save_steps": 500,
|
| 113 |
+
"save_strategy": "steps",
|
| 114 |
+
"save_total_limit": null,
|
| 115 |
+
"scheduler_type": null,
|
| 116 |
+
"seed": 42,
|
| 117 |
+
"sharded_ddp": [],
|
| 118 |
+
"skip_memory_metrics": true,
|
| 119 |
+
"split_seed": 42,
|
| 120 |
+
"testsplit_name": "test",
|
| 121 |
+
"textcolumn": "review_text_without_quotes",
|
| 122 |
+
"tf32": null,
|
| 123 |
+
"torchdynamo": null,
|
| 124 |
+
"tpu_metrics_debug": false,
|
| 125 |
+
"tpu_num_cores": null,
|
| 126 |
+
"trainsplit_name": "train",
|
| 127 |
+
"use_class_weights": true,
|
| 128 |
+
"use_ipex": false,
|
| 129 |
+
"use_legacy_prediction_loop": false,
|
| 130 |
+
"validation_size": 0.1,
|
| 131 |
+
"validationsplit_name": "validation",
|
| 132 |
+
"warmup_ratio": 0.0,
|
| 133 |
+
"warmup_steps": 0,
|
| 134 |
+
"weight_decay": 0.0,
|
| 135 |
+
"xpu_backend": null
|
| 136 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "bert-base-multilingual-cased",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"directionality": "bidi",
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_dropout_prob": 0.1,
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"id2label": {
|
| 13 |
+
"0": "1",
|
| 14 |
+
"1": "2",
|
| 15 |
+
"2": "3",
|
| 16 |
+
"3": "4",
|
| 17 |
+
"4": "5"
|
| 18 |
+
},
|
| 19 |
+
"initializer_range": 0.02,
|
| 20 |
+
"intermediate_size": 3072,
|
| 21 |
+
"label2id": {
|
| 22 |
+
"1": 0,
|
| 23 |
+
"2": 1,
|
| 24 |
+
"3": 2,
|
| 25 |
+
"4": 3,
|
| 26 |
+
"5": 4
|
| 27 |
+
},
|
| 28 |
+
"layer_norm_eps": 1e-12,
|
| 29 |
+
"max_position_embeddings": 512,
|
| 30 |
+
"model_type": "bert",
|
| 31 |
+
"num_attention_heads": 12,
|
| 32 |
+
"num_hidden_layers": 12,
|
| 33 |
+
"pad_token_id": 0,
|
| 34 |
+
"pooler_fc_size": 768,
|
| 35 |
+
"pooler_num_attention_heads": 12,
|
| 36 |
+
"pooler_num_fc_layers": 3,
|
| 37 |
+
"pooler_size_per_head": 128,
|
| 38 |
+
"pooler_type": "first_token_transform",
|
| 39 |
+
"position_embedding_type": "absolute",
|
| 40 |
+
"torch_dtype": "float32",
|
| 41 |
+
"transformers_version": "4.21.0",
|
| 42 |
+
"type_vocab_size": 2,
|
| 43 |
+
"use_cache": true,
|
| 44 |
+
"vocab_size": 119547
|
| 45 |
+
}
|
env.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cuda_capabilities": "8.0; 8.0",
|
| 3 |
+
"cuda_device_count": 2,
|
| 4 |
+
"cuda_devices": "NVIDIA A100-SXM4-80GB; NVIDIA A100-SXM4-80GB",
|
| 5 |
+
"finetuner_commit": "8159b4c1d5e66b36f68dd263299927ffb8670ebd",
|
| 6 |
+
"platform": "Linux-4.18.0-305.49.1.el8_4.x86_64-x86_64-with-glibc2.28",
|
| 7 |
+
"python_version": "3.9.5",
|
| 8 |
+
"toch_version": "1.10.0",
|
| 9 |
+
"transformers_version": "4.21.0"
|
| 10 |
+
}
|
fig/test_confusion_matrix.eps
ADDED
|
The diff for this file is too large to render.
See raw diff
|
fig/test_confusion_matrix.png
ADDED
|
fig/test_confusion_matrix_norm.eps
ADDED
|
The diff for this file is too large to render.
See raw diff
|
fig/test_confusion_matrix_norm.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e8c2d40ee3db8a5806492e53ca9510899d2d5f16169b722ad858b7e134a7f503
|
| 3 |
+
size 711500141
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
test_predictions.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4a20b01868f6a528dbcf295b8388d9c07ad1379bddbfdce3fb931c28260036f4
|
| 3 |
+
size 65128043
|
test_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"accuracy": 0.5898668639053254,
|
| 3 |
+
"f1": 0.5899204480029937,
|
| 4 |
+
"precision": 0.5971431895675179,
|
| 5 |
+
"qwk": 0.7050840079198698,
|
| 6 |
+
"recall": 0.5898668639053254
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"do_lower_case": false,
|
| 4 |
+
"mask_token": "[MASK]",
|
| 5 |
+
"model_max_length": 512,
|
| 6 |
+
"name_or_path": "bert-base-multilingual-cased",
|
| 7 |
+
"pad_token": "[PAD]",
|
| 8 |
+
"sep_token": "[SEP]",
|
| 9 |
+
"special_tokens_map_file": null,
|
| 10 |
+
"strip_accents": null,
|
| 11 |
+
"tokenize_chinese_chars": true,
|
| 12 |
+
"tokenizer_class": "BertTokenizer",
|
| 13 |
+
"unk_token": "[UNK]"
|
| 14 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 4.38,
|
| 3 |
+
"train_loss": 0.8685172849525287,
|
| 4 |
+
"train_runtime": 2653.5735,
|
| 5 |
+
"train_samples_per_second": 241.232,
|
| 6 |
+
"train_steps_per_second": 1.885
|
| 7 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.697825193570947,
|
| 3 |
+
"best_model_checkpoint": "trained/hebban-reviews5/bert-base-multilingual-cased/checkpoint-4500",
|
| 4 |
+
"epoch": 4.382997370727432,
|
| 5 |
+
"global_step": 5001,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 0.44,
|
| 12 |
+
"learning_rate": 4.502099580083983e-05,
|
| 13 |
+
"loss": 1.3159,
|
| 14 |
+
"step": 500
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 0.44,
|
| 18 |
+
"eval_accuracy": 0.4912475345167653,
|
| 19 |
+
"eval_f1": 0.48070042281702435,
|
| 20 |
+
"eval_loss": 1.1863828897476196,
|
| 21 |
+
"eval_precision": 0.5054226630223979,
|
| 22 |
+
"eval_qwk": 0.6104106009981652,
|
| 23 |
+
"eval_recall": 0.4912475345167653,
|
| 24 |
+
"eval_runtime": 23.5101,
|
| 25 |
+
"eval_samples_per_second": 690.086,
|
| 26 |
+
"eval_steps_per_second": 5.402,
|
| 27 |
+
"step": 500
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"epoch": 0.88,
|
| 31 |
+
"learning_rate": 4.003199360127974e-05,
|
| 32 |
+
"loss": 1.092,
|
| 33 |
+
"step": 1000
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 0.88,
|
| 37 |
+
"eval_accuracy": 0.5488165680473372,
|
| 38 |
+
"eval_f1": 0.5517553489817303,
|
| 39 |
+
"eval_loss": 1.0387530326843262,
|
| 40 |
+
"eval_precision": 0.5678859988610889,
|
| 41 |
+
"eval_qwk": 0.6346615351470672,
|
| 42 |
+
"eval_recall": 0.5488165680473372,
|
| 43 |
+
"eval_runtime": 23.5201,
|
| 44 |
+
"eval_samples_per_second": 689.794,
|
| 45 |
+
"eval_steps_per_second": 5.4,
|
| 46 |
+
"step": 1000
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"epoch": 1.31,
|
| 50 |
+
"learning_rate": 3.5032993401319734e-05,
|
| 51 |
+
"loss": 0.9709,
|
| 52 |
+
"step": 1500
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 1.31,
|
| 56 |
+
"eval_accuracy": 0.5436390532544378,
|
| 57 |
+
"eval_f1": 0.5408623179767048,
|
| 58 |
+
"eval_loss": 1.0117485523223877,
|
| 59 |
+
"eval_precision": 0.5642348913139151,
|
| 60 |
+
"eval_qwk": 0.6678503252600388,
|
| 61 |
+
"eval_recall": 0.5436390532544378,
|
| 62 |
+
"eval_runtime": 23.6496,
|
| 63 |
+
"eval_samples_per_second": 686.015,
|
| 64 |
+
"eval_steps_per_second": 5.37,
|
| 65 |
+
"step": 1500
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 1.75,
|
| 69 |
+
"learning_rate": 3.0033993201359727e-05,
|
| 70 |
+
"loss": 0.9404,
|
| 71 |
+
"step": 2000
|
| 72 |
+
},
|
| 73 |
+
{
|
| 74 |
+
"epoch": 1.75,
|
| 75 |
+
"eval_accuracy": 0.5279215976331361,
|
| 76 |
+
"eval_f1": 0.5218328433667149,
|
| 77 |
+
"eval_loss": 1.0087615251541138,
|
| 78 |
+
"eval_precision": 0.5543969942392576,
|
| 79 |
+
"eval_qwk": 0.6748096376745845,
|
| 80 |
+
"eval_recall": 0.5279215976331361,
|
| 81 |
+
"eval_runtime": 23.476,
|
| 82 |
+
"eval_samples_per_second": 691.088,
|
| 83 |
+
"eval_steps_per_second": 5.41,
|
| 84 |
+
"step": 2000
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"epoch": 2.19,
|
| 88 |
+
"learning_rate": 2.503499300139972e-05,
|
| 89 |
+
"loss": 0.8657,
|
| 90 |
+
"step": 2500
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"epoch": 2.19,
|
| 94 |
+
"eval_accuracy": 0.5708826429980276,
|
| 95 |
+
"eval_f1": 0.5692427852436814,
|
| 96 |
+
"eval_loss": 1.0947091579437256,
|
| 97 |
+
"eval_precision": 0.5827881052454773,
|
| 98 |
+
"eval_qwk": 0.6863988830193634,
|
| 99 |
+
"eval_recall": 0.5708826429980276,
|
| 100 |
+
"eval_runtime": 23.3841,
|
| 101 |
+
"eval_samples_per_second": 693.805,
|
| 102 |
+
"eval_steps_per_second": 5.431,
|
| 103 |
+
"step": 2500
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"epoch": 2.63,
|
| 107 |
+
"learning_rate": 2.0035992801439712e-05,
|
| 108 |
+
"loss": 0.8004,
|
| 109 |
+
"step": 3000
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"epoch": 2.63,
|
| 113 |
+
"eval_accuracy": 0.5539940828402367,
|
| 114 |
+
"eval_f1": 0.5591418616361084,
|
| 115 |
+
"eval_loss": 1.0360697507858276,
|
| 116 |
+
"eval_precision": 0.5772334772150153,
|
| 117 |
+
"eval_qwk": 0.6712182177231302,
|
| 118 |
+
"eval_recall": 0.5539940828402367,
|
| 119 |
+
"eval_runtime": 23.5321,
|
| 120 |
+
"eval_samples_per_second": 689.441,
|
| 121 |
+
"eval_steps_per_second": 5.397,
|
| 122 |
+
"step": 3000
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"epoch": 3.07,
|
| 126 |
+
"learning_rate": 1.5046990601879624e-05,
|
| 127 |
+
"loss": 0.7687,
|
| 128 |
+
"step": 3500
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"epoch": 3.07,
|
| 132 |
+
"eval_accuracy": 0.5808678500986193,
|
| 133 |
+
"eval_f1": 0.5832607549463982,
|
| 134 |
+
"eval_loss": 1.2274583578109741,
|
| 135 |
+
"eval_precision": 0.5914789641012546,
|
| 136 |
+
"eval_qwk": 0.689381177306146,
|
| 137 |
+
"eval_recall": 0.5808678500986193,
|
| 138 |
+
"eval_runtime": 23.7912,
|
| 139 |
+
"eval_samples_per_second": 681.932,
|
| 140 |
+
"eval_steps_per_second": 5.338,
|
| 141 |
+
"step": 3500
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"epoch": 3.51,
|
| 145 |
+
"learning_rate": 1.0047990401919617e-05,
|
| 146 |
+
"loss": 0.6773,
|
| 147 |
+
"step": 4000
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"epoch": 3.51,
|
| 151 |
+
"eval_accuracy": 0.5830251479289941,
|
| 152 |
+
"eval_f1": 0.5826927994622666,
|
| 153 |
+
"eval_loss": 1.222939133644104,
|
| 154 |
+
"eval_precision": 0.5930910696407776,
|
| 155 |
+
"eval_qwk": 0.6959801434105679,
|
| 156 |
+
"eval_recall": 0.5830251479289941,
|
| 157 |
+
"eval_runtime": 23.6989,
|
| 158 |
+
"eval_samples_per_second": 684.589,
|
| 159 |
+
"eval_steps_per_second": 5.359,
|
| 160 |
+
"step": 4000
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"epoch": 3.94,
|
| 164 |
+
"learning_rate": 5.048990201959608e-06,
|
| 165 |
+
"loss": 0.6584,
|
| 166 |
+
"step": 4500
|
| 167 |
+
},
|
| 168 |
+
{
|
| 169 |
+
"epoch": 3.94,
|
| 170 |
+
"eval_accuracy": 0.5886341222879684,
|
| 171 |
+
"eval_f1": 0.5886427250282493,
|
| 172 |
+
"eval_loss": 1.281541347503662,
|
| 173 |
+
"eval_precision": 0.5969768120377853,
|
| 174 |
+
"eval_qwk": 0.697825193570947,
|
| 175 |
+
"eval_recall": 0.5886341222879684,
|
| 176 |
+
"eval_runtime": 23.7004,
|
| 177 |
+
"eval_samples_per_second": 684.544,
|
| 178 |
+
"eval_steps_per_second": 5.359,
|
| 179 |
+
"step": 4500
|
| 180 |
+
},
|
| 181 |
+
{
|
| 182 |
+
"epoch": 4.38,
|
| 183 |
+
"learning_rate": 4.999000199960008e-08,
|
| 184 |
+
"loss": 0.5961,
|
| 185 |
+
"step": 5000
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"epoch": 4.38,
|
| 189 |
+
"eval_accuracy": 0.5894354043392505,
|
| 190 |
+
"eval_f1": 0.5909264551740898,
|
| 191 |
+
"eval_loss": 1.359961748123169,
|
| 192 |
+
"eval_precision": 0.5997451050742093,
|
| 193 |
+
"eval_qwk": 0.6969542849451541,
|
| 194 |
+
"eval_recall": 0.5894354043392505,
|
| 195 |
+
"eval_runtime": 23.5424,
|
| 196 |
+
"eval_samples_per_second": 689.138,
|
| 197 |
+
"eval_steps_per_second": 5.395,
|
| 198 |
+
"step": 5000
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"epoch": 4.38,
|
| 202 |
+
"step": 5001,
|
| 203 |
+
"total_flos": 1.6839139993111757e+17,
|
| 204 |
+
"train_loss": 0.8685172849525287,
|
| 205 |
+
"train_runtime": 2653.5735,
|
| 206 |
+
"train_samples_per_second": 241.232,
|
| 207 |
+
"train_steps_per_second": 1.885
|
| 208 |
+
}
|
| 209 |
+
],
|
| 210 |
+
"max_steps": 5001,
|
| 211 |
+
"num_train_epochs": 5,
|
| 212 |
+
"total_flos": 1.6839139993111757e+17,
|
| 213 |
+
"trial_name": null,
|
| 214 |
+
"trial_params": null
|
| 215 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e298551f089369377fb5d6d386f38e031de6fb9fbac68db00070b86d1cae8f97
|
| 3 |
+
size 3439
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|