

Upload 11 files
Browse files- ReadMe.md +130 -0
- imgs/SFT-CIRR.png +0 -0
- imgs/SFT-ReMuQ.png +0 -0
- imgs/SFT-WebQA.png +0 -0
- imgs/cir_candi_1.png +0 -0
- imgs/cir_candi_2.png +0 -0
- imgs/cir_query.png +0 -0
- imgs/wiki_candi_1.jpg +0 -0
- imgs/wiki_candi_2.jpg +0 -0
- imgs/zs-benchmark.png +0 -0
- imgs/zs-performance.png +0 -0
ReadMe.md
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
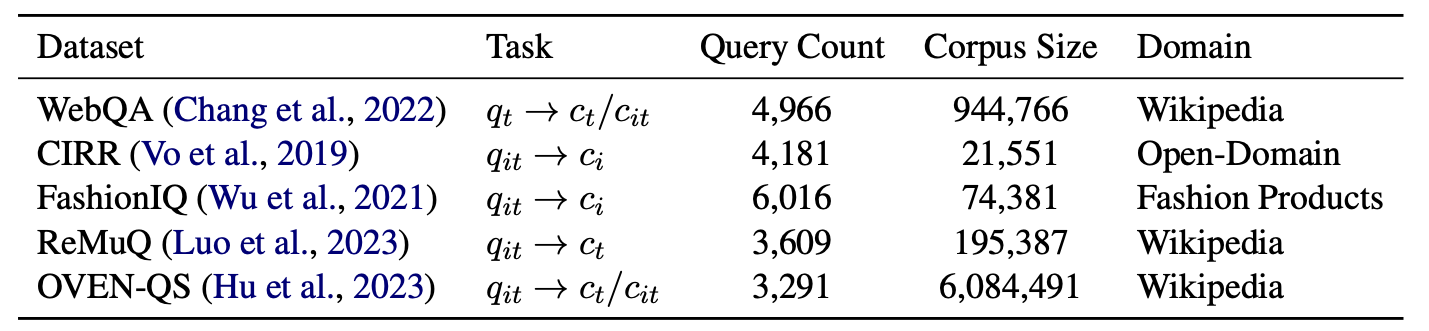
|
|
|
|
|
|
|
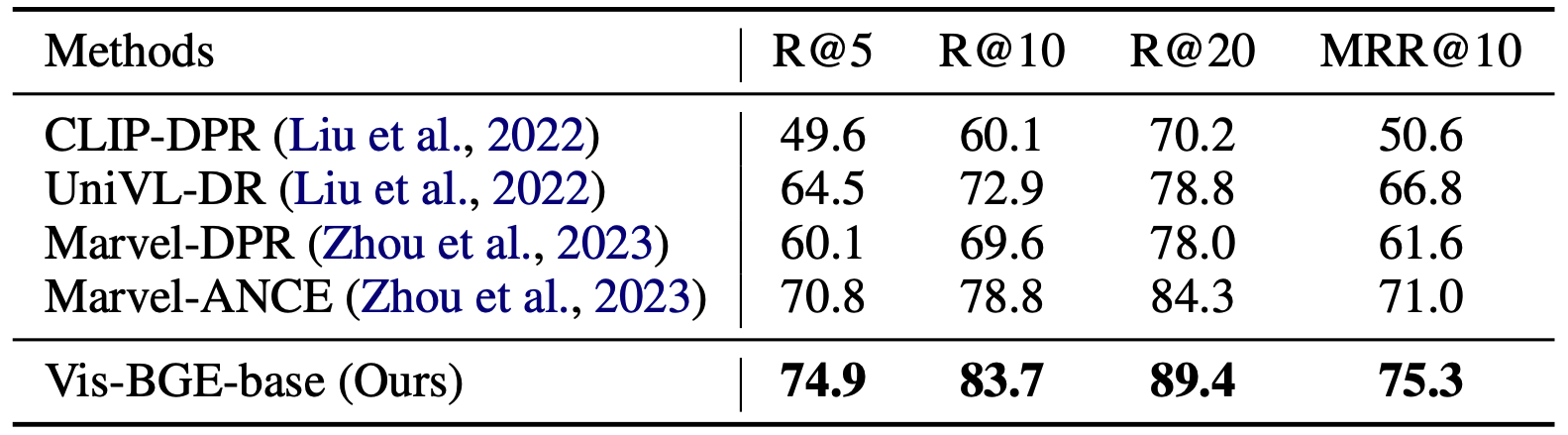
|
|
|
|
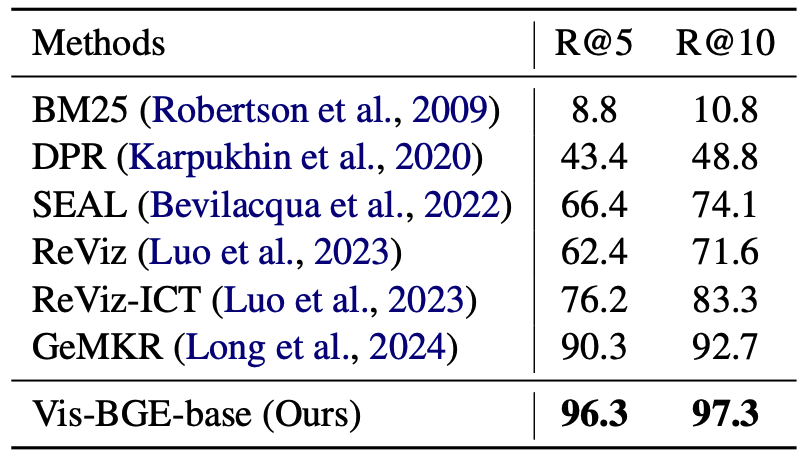
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Visualized BGE
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
In this project, we introduce Visualized-BGE, a universal multi-modal embedding model. By integrating image token embedding into the BGE Text Embedding framework, Visualized-BGE is equipped to handle multi-modal data that extends beyond text in a flexible manner. Visualized-BGE is mainly used for hybrid modal retrieval tasks, including but not limited to:
|
| 5 |
+
|
| 6 |
+
- Multi-Modal Knowledge Retrieval (query: text; candidate: image-text pairs, text, or image) e.g. [WebQA](https://github.com/WebQnA/WebQA)
|
| 7 |
+
- Composed Image Retrieval (query: image-text pair; candidate: images) e.g. [CIRR](), [FashionIQ]()
|
| 8 |
+
- Knowledge Retrieval with Multi-Modal Queries (query: image-text pair; candidate: texts) e.g. [ReMuQ]()
|
| 9 |
+
|
| 10 |
+
Moreover, Visualized BGE fully preserves the strong text embedding capabilities of the original BGE model : )
|
| 11 |
+
|
| 12 |
+
## Specs
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
### Model
|
| 17 |
+
| **Model Name** | **Dimension** | **Text Embedding Model** | **Language** | **Weight** |
|
| 18 |
+
| --- | --- | --- | --- | --- |
|
| 19 |
+
| BAAI/bge-visualized-base-en-v1.5 | 768 | [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [🤗 HF link](https://huggingface.co/BAAI/bge-visualized/blob/main/Visualized_base_en_v1.5.pth) |
|
| 20 |
+
| BAAI/bge-visualized-m3 | 1024 | [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [🤗 HF link](https://huggingface.co/BAAI/bge-visualized/blob/main/Visualized_m3.pth) |
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
### Data
|
| 24 |
+
We have generated a hybrid multi-modal dataset consisting of over 500,000 instances for training. The dataset will be released at a later time.
|
| 25 |
+
|
| 26 |
+
## Usage
|
| 27 |
+
### Installation:
|
| 28 |
+
#### Install FlagEmbedding:
|
| 29 |
+
```
|
| 30 |
+
git clone https://github.com/FlagOpen/FlagEmbedding.git
|
| 31 |
+
cd FlagEmbedding
|
| 32 |
+
pip install -e .
|
| 33 |
+
```
|
| 34 |
+
#### Another Core Packages:
|
| 35 |
+
```
|
| 36 |
+
pip install torchvision timm einops ftfy
|
| 37 |
+
```
|
| 38 |
+
You don't need to install `xformer` and `apex`. They are not essential for inference and can often cause issues.
|
| 39 |
+
|
| 40 |
+
### Generate Embedding for Multi-Modal Data:
|
| 41 |
+
You have the flexibility to use Visualized-BGE encoding for multi-modal data in various formats. This includes data that is exclusively text-based, solely image-based, or a combination of both text and image data.
|
| 42 |
+
|
| 43 |
+
> **Note:** Please download the model weight file ([bge-visualized-base-en-v1.5](https://huggingface.co/BAAI/bge-visualized/resolve/main/Visualized_base_en_v1.5.pth?download=true), [bge-visualized-m3](https://huggingface.co/BAAI/bge-visualized/resolve/main/Visualized_m3.pth?download=true)) in advance and pass the path to the `model_weight` parameter.
|
| 44 |
+
|
| 45 |
+
- Composed Image Retrival
|
| 46 |
+
``` python
|
| 47 |
+
############ Use Visualized BGE doing composed image retrieval
|
| 48 |
+
import torch
|
| 49 |
+
from FlagEmbedding.visual.modeling import Visualized_BGE
|
| 50 |
+
|
| 51 |
+
model = Visualized_BGE(model_name_bge = "BAAI/bge-base-en-v1.5", model_weight="path: Visualized_base_en_v1.5.pth")
|
| 52 |
+
model.eval()
|
| 53 |
+
with torch.no_grad():
|
| 54 |
+
query_emb = model.encode(image="./imgs/cir_query.png", text="Make the background dark, as if the camera has taken the photo at night")
|
| 55 |
+
candi_emb_1 = model.encode(image="./imgs/cir_candi_1.png")
|
| 56 |
+
candi_emb_2 = model.encode(image="./imgs/cir_candi_2.png")
|
| 57 |
+
|
| 58 |
+
sim_1 = query_emb @ candi_emb_1.T
|
| 59 |
+
sim_2 = query_emb @ candi_emb_2.T
|
| 60 |
+
print(sim_1, sim_2) # tensor([[0.8750]]) tensor([[0.7816]])
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
- Multi-Modal Knowledge Retrieval
|
| 64 |
+
``` python
|
| 65 |
+
####### Use Visualized BGE doing multi-modal knowledge retrieval
|
| 66 |
+
import torch
|
| 67 |
+
from FlagEmbedding.visual.modeling import Visualized_BGE
|
| 68 |
+
|
| 69 |
+
model = Visualized_BGE(model_name_bge = "BAAI/bge-base-en-v1.5", model_weight="path: Visualized_base_en_v1.5.pth")
|
| 70 |
+
|
| 71 |
+
with torch.no_grad():
|
| 72 |
+
query_emb = model.encode(text="Are there sidewalks on both sides of the Mid-Hudson Bridge?")
|
| 73 |
+
candi_emb_1 = model.encode(text="The Mid-Hudson Bridge, spanning the Hudson River between Poughkeepsie and Highland.", image="./imgs/wiki_candi_1.jpg")
|
| 74 |
+
candi_emb_2 = model.encode(text="Golden_Gate_Bridge", image="./imgs/wiki_candi_2.jpg")
|
| 75 |
+
candi_emb_3 = model.encode(text="The Mid-Hudson Bridge was designated as a New York State Historic Civil Engineering Landmark by the American Society of Civil Engineers in 1983. The bridge was renamed the \"Franklin Delano Roosevelt Mid-Hudson Bridge\" in 1994.")
|
| 76 |
+
|
| 77 |
+
sim_1 = query_emb @ candi_emb_1.T
|
| 78 |
+
sim_2 = query_emb @ candi_emb_2.T
|
| 79 |
+
sim_3 = query_emb @ candi_emb_3.T
|
| 80 |
+
print(sim_1, sim_2, sim_3) # tensor([[0.6932]]) tensor([[0.4441]]) tensor([[0.6415]])
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
- Multilingual Multi-Modal Retrieval
|
| 84 |
+
``` python
|
| 85 |
+
##### Use M3 doing Multilingual Multi-Modal Retrieval
|
| 86 |
+
|
| 87 |
+
import torch
|
| 88 |
+
from FlagEmbedding.visual.modeling import Visualized_BGE
|
| 89 |
+
|
| 90 |
+
model = Visualized_BGE(model_name_bge = "BAAI/bge-m3", model_weight="path: Visualized_m3.pth")
|
| 91 |
+
model.eval()
|
| 92 |
+
with torch.no_grad():
|
| 93 |
+
query_emb = model.encode(image="./imgs/cir_query.png", text="一匹马牵着这辆车")
|
| 94 |
+
candi_emb_1 = model.encode(image="./imgs/cir_candi_1.png")
|
| 95 |
+
candi_emb_2 = model.encode(image="./imgs/cir_candi_2.png")
|
| 96 |
+
|
| 97 |
+
sim_1 = query_emb @ candi_emb_1.T
|
| 98 |
+
sim_2 = query_emb @ candi_emb_2.T
|
| 99 |
+
print(sim_1, sim_2) # tensor([[0.7026]]) tensor([[0.8075]])
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
## Evaluation Result
|
| 103 |
+
Visualized BGE delivers outstanding zero-shot performance across multiple hybrid modal retrieval tasks. It can also serve as a base model for downstream fine-tuning for hybrid modal retrieval tasks.
|
| 104 |
+
#### Zero-shot Performance
|
| 105 |
+
- Statistical information of the zero-shot multi-modal retrieval benchmark datasets. During the zero-shot evaluation, we utilize the queries from the validation or test set of each dataset to perform retrieval assessments within the entire corpus of the respective dataset.
|
| 106 |
+

|
| 107 |
+
|
| 108 |
+
- Zero-shot evaluation results with Recall@5 on various hybrid multi-modal retrieval benchmarks. The -MM notation indicates baseline models that have undergone multi-modal training on our generated data.
|
| 109 |
+

|
| 110 |
+
|
| 111 |
+
#### Fine-tuning on Downstream Tasks
|
| 112 |
+
- Supervised fine-tuning performance on the WebQA dataset. All retrievals are performed on the entire deduplicated corpus.
|
| 113 |
+

|
| 114 |
+
- Supervised fine-tuning performance on the CIRR test set.
|
| 115 |
+

|
| 116 |
+
- Supervised fine-tuning performance on the ReMuQ test set.
|
| 117 |
+

|
| 118 |
+
## FAQ
|
| 119 |
+
|
| 120 |
+
**Q1: Can Visualized BGE be used for cross-modal retrieval (text to image)?**
|
| 121 |
+
|
| 122 |
+
A1: While it is technically possible, it's not the recommended use case. Our model focus on augmenting hybrid modal retrieval tasks with visual capabilities.
|
| 123 |
+
|
| 124 |
+
## Acknowledgement
|
| 125 |
+
The image token embedding model in this project is built upon the foundations laid by [EVA-CLIP](https://github.com/baaivision/EVA/tree/master/EVA-CLIP).
|
| 126 |
+
|
| 127 |
+
## Citation
|
| 128 |
+
If you find this repository useful, please consider giving a star ⭐ and citation
|
| 129 |
+
> Paper will be released soon
|
| 130 |
+
|
imgs/SFT-CIRR.png
ADDED

|
imgs/SFT-ReMuQ.png
ADDED
|
imgs/SFT-WebQA.png
ADDED
|
imgs/cir_candi_1.png
ADDED

|
imgs/cir_candi_2.png
ADDED

|
imgs/cir_query.png
ADDED

|
imgs/wiki_candi_1.jpg
ADDED

|
imgs/wiki_candi_2.jpg
ADDED

|
imgs/zs-benchmark.png
ADDED
|
imgs/zs-performance.png
ADDED

|