
WXinlong
commited on
Commit
•
42fbb33
1
Parent(s):
d137d5b
first init
Browse files- README.md +50 -0
- seggpt_teaser.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,53 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
<div align="center">
|
| 6 |
+
<h1>SegGPT: Segmenting Everything In Context </h1>
|
| 7 |
+
|
| 8 |
+
[Xinlong Wang](https://www.xloong.wang/)<sup>1*</sup>, [Xiaosong Zhang](https://scholar.google.com/citations?user=98exn6wAAAAJ&hl=en)<sup>1*</sup>, [Yue Cao](http://yue-cao.me/)<sup>1*</sup>, [Wen Wang](https://scholar.google.com/citations?user=1ks0R04AAAAJ&hl)<sup>2</sup>, [Chunhua Shen](https://cshen.github.io/)<sup>2</sup>, [Tiejun Huang](https://scholar.google.com/citations?user=knvEK4AAAAAJ&hl=en)<sup>1,3</sup>
|
| 9 |
+
|
| 10 |
+
<sup>1</sup>[BAAI](https://www.baai.ac.cn/english.html), <sup>2</sup>[ZJU](https://www.zju.edu.cn/english/), <sup>3</sup>[PKU](https://english.pku.edu.cn/)
|
| 11 |
+
|
| 12 |
+
Enjoy the [Demo](https://huggingface.co/spaces/BAAI/SegGPT) and [Code](https://github.com/baaivision/Painter/edit/main/SegGPT)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
<br>
|
| 16 |
+
|
| 17 |
+
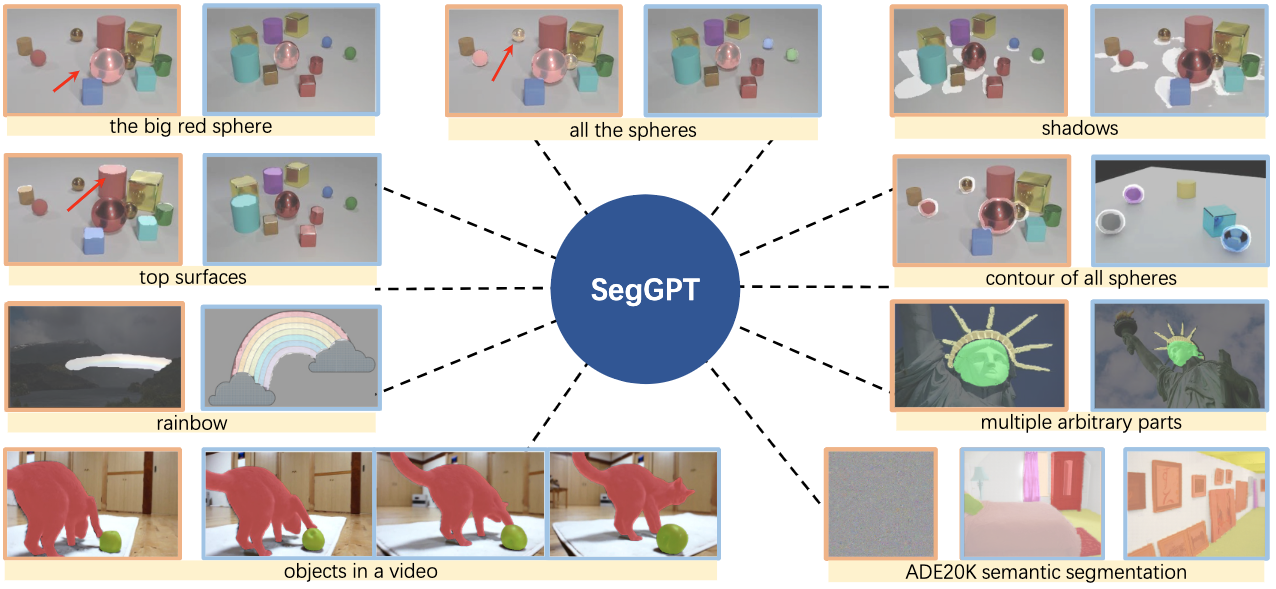
<image src="seggpt_teaser.png" width="720px" />
|
| 18 |
+
<br>
|
| 19 |
+
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
<br>
|
| 23 |
+
|
| 24 |
+
We present SegGPT, a generalist model for segmenting everything in context. With only one single model, SegGPT can perform arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text.
|
| 25 |
+
SegGPT is evaluated on a broad range of tasks, including few-shot semantic segmentation, video object segmentation, semantic segmentation, and panoptic segmentation.
|
| 26 |
+
Our results show strong capabilities in segmenting in-domain and out-of-domain targets, either qualitatively or quantitatively.
|
| 27 |
+
|
| 28 |
+
[[Paper]](https://arxiv.org/abs/2304.03284)
|
| 29 |
+
[[Code]](https://github.com/baaivision/Painter/edit/main/SegGPT)
|
| 30 |
+
[[Demo]](https://huggingface.co/spaces/BAAI/SegGPT)
|
| 31 |
+
|
| 32 |
+
## **Model**
|
| 33 |
+
|
| 34 |
+
A pre-trained SegGPT model is available at [🤗 HF link](https://huggingface.co/BAAI/Painter/blob/main/painter_vit_large.pth).
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Citation
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
@article{SegGPT,
|
| 42 |
+
title={SegGPT: Segmenting Everything In Context},
|
| 43 |
+
author={Wang, Xinlong and Zhang, Xiaosong and Cao, Yue and Wang, Wen and Shen, Chunhua and Huang, Tiejun},
|
| 44 |
+
journal={arXiv preprint arXiv:2304.03284},
|
| 45 |
+
year={2023}
|
| 46 |
+
}
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
## Contact
|
| 50 |
+
|
| 51 |
+
**We are hiring** at all levels at BAAI Vision Team, including full-time researchers, engineers and interns.
|
| 52 |
+
If you are interested in working with us on **foundation model, visual perception and multimodal learning**, please contact [Xinlong Wang](https://www.xloong.wang/) (`wangxinlong@baai.ac.cn`) and [Yue Cao](http://yue-cao.me/) (`caoyue@baai.ac.cn`).
|
| 53 |
+
|
seggpt_teaser.png
ADDED
|