
Update model
Browse files- README.md +106 -0
- config.json +22 -0
- confusion_matrix.png +0 -0
- model.pkl +3 -0
README.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: sklearn
|
| 3 |
+
tags:
|
| 4 |
+
- sklearn
|
| 5 |
+
- skops
|
| 6 |
+
- tabular-classification
|
| 7 |
+
model_file: model.pkl
|
| 8 |
+
widget:
|
| 9 |
+
structuredData:
|
| 10 |
+
word:
|
| 11 |
+
- lathem
|
| 12 |
+
- meer
|
| 13 |
+
- slaen
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# Model description
|
| 17 |
+
|
| 18 |
+
Middle Dutch NER with PassiveAgressiveClassifier
|
| 19 |
+
|
| 20 |
+
## Intended uses & limitations
|
| 21 |
+
|
| 22 |
+
This model is not ready to be used in production.
|
| 23 |
+
|
| 24 |
+
## Training Procedure
|
| 25 |
+
|
| 26 |
+
TESTING
|
| 27 |
+
|
| 28 |
+
### Hyperparameters
|
| 29 |
+
|
| 30 |
+
The model is trained with below hyperparameters.
|
| 31 |
+
|
| 32 |
+
<details>
|
| 33 |
+
<summary> Click to expand </summary>
|
| 34 |
+
|
| 35 |
+
| Hyperparameter | Value |
|
| 36 |
+
|---------------------------|----------------------------------------------------------------------|
|
| 37 |
+
| memory | |
|
| 38 |
+
| steps | [('vectorizer', CountVectorizer()), ('classifier', MultinomialNB())] |
|
| 39 |
+
| verbose | False |
|
| 40 |
+
| vectorizer | CountVectorizer() |
|
| 41 |
+
| classifier | MultinomialNB() |
|
| 42 |
+
| vectorizer__analyzer | word |
|
| 43 |
+
| vectorizer__binary | False |
|
| 44 |
+
| vectorizer__decode_error | strict |
|
| 45 |
+
| vectorizer__dtype | <class 'numpy.int64'> |
|
| 46 |
+
| vectorizer__encoding | utf-8 |
|
| 47 |
+
| vectorizer__input | content |
|
| 48 |
+
| vectorizer__lowercase | True |
|
| 49 |
+
| vectorizer__max_df | 1.0 |
|
| 50 |
+
| vectorizer__max_features | |
|
| 51 |
+
| vectorizer__min_df | 1 |
|
| 52 |
+
| vectorizer__ngram_range | (1, 1) |
|
| 53 |
+
| vectorizer__preprocessor | |
|
| 54 |
+
| vectorizer__stop_words | |
|
| 55 |
+
| vectorizer__strip_accents | |
|
| 56 |
+
| vectorizer__token_pattern | (?u)\b\w\w+\b |
|
| 57 |
+
| vectorizer__tokenizer | |
|
| 58 |
+
| vectorizer__vocabulary | |
|
| 59 |
+
| classifier__alpha | 1.0 |
|
| 60 |
+
| classifier__class_prior | |
|
| 61 |
+
| classifier__fit_prior | True |
|
| 62 |
+
|
| 63 |
+
</details>
|
| 64 |
+
|
| 65 |
+
### Model Plot
|
| 66 |
+
|
| 67 |
+
The model plot is below.
|
| 68 |
+
|
| 69 |
+
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('vectorizer', CountVectorizer()),('classifier', MultinomialNB())])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" ><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('vectorizer', CountVectorizer()),('classifier', MultinomialNB())])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-2" type="checkbox" ><label for="sk-estimator-id-2" class="sk-toggleable__label sk-toggleable__label-arrow">CountVectorizer</label><div class="sk-toggleable__content"><pre>CountVectorizer()</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-3" type="checkbox" ><label for="sk-estimator-id-3" class="sk-toggleable__label sk-toggleable__label-arrow">MultinomialNB</label><div class="sk-toggleable__content"><pre>MultinomialNB()</pre></div></div></div></div></div></div></div>
|
| 70 |
+
|
| 71 |
+
## Evaluation Results
|
| 72 |
+
|
| 73 |
+
You can find the details about evaluation process and the evaluation results.
|
| 74 |
+
|
| 75 |
+
| Metric | Value |
|
| 76 |
+
|-------------------------|----------|
|
| 77 |
+
| accuracy including 'O' | 0.905322 |
|
| 78 |
+
| f1 score including 'O | 0.905322 |
|
| 79 |
+
| precision excluding 'O' | 0.892857 |
|
| 80 |
+
| recall excluding 'O' | 0.404732 |
|
| 81 |
+
| f1 excluding 'O' | 0.556984 |
|
| 82 |
+
|
| 83 |
+
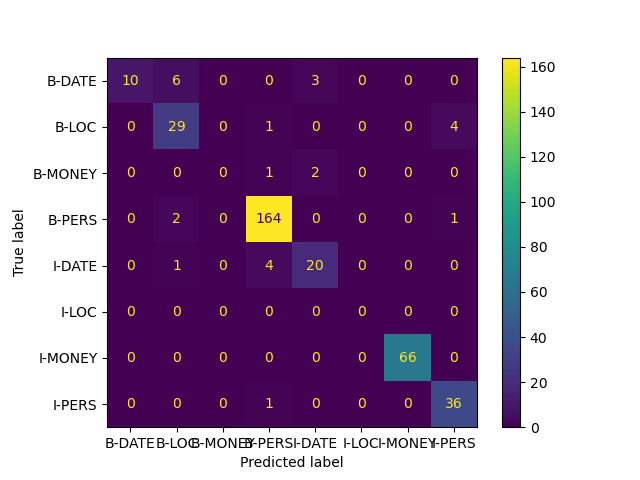
### Confusion Matrix
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
# How to Get Started with the Model
|
| 88 |
+
|
| 89 |
+
[More Information Needed]
|
| 90 |
+
|
| 91 |
+
# Model Card Authors
|
| 92 |
+
|
| 93 |
+
Alassea TEST
|
| 94 |
+
|
| 95 |
+
# Model Card Contact
|
| 96 |
+
|
| 97 |
+
You can contact the model card authors through following channels:
|
| 98 |
+
[More Information Needed]
|
| 99 |
+
|
| 100 |
+
# Citation
|
| 101 |
+
|
| 102 |
+
**BibTeX**
|
| 103 |
+
|
| 104 |
+
```
|
| 105 |
+
@inproceedings{...,year={2022}}
|
| 106 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"sklearn": {
|
| 3 |
+
"columns": [
|
| 4 |
+
"word"
|
| 5 |
+
],
|
| 6 |
+
"environment": [
|
| 7 |
+
"scikit-learn=1.1.3"
|
| 8 |
+
],
|
| 9 |
+
"example_input": {
|
| 10 |
+
"word": [
|
| 11 |
+
"lathem",
|
| 12 |
+
"meer",
|
| 13 |
+
"slaen"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
"model": {
|
| 17 |
+
"file": "model.pkl"
|
| 18 |
+
},
|
| 19 |
+
"model_format": "pickle",
|
| 20 |
+
"task": "tabular-classification"
|
| 21 |
+
}
|
| 22 |
+
}
|
confusion_matrix.png
ADDED
|
model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a75348eb1531248a0d2c352dee87b6cf592a5d22ba52d208589e7b694d499423
|
| 3 |
+
size 836005
|