
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
layout: post
title: "【書齋夜話】245:韭菜的憤怒,再次佔領華爾街 | 斬立決,賴小民身後隱藏了什麼?(2021-1-30)"
date: 2021-01-30T21:44:32.000Z
author: 書齋夜話
from: https://www.youtube.com/watch?v=nyBIRtAbSnc
tags: [ 書齋夜話 ]
categories: [ 書齋夜話 ]
---
<!--1612043072000-->
[【書齋夜話】245:韭菜的憤怒,再次佔領華爾街 | 斬立決,賴小民身後隱藏了什麼?(2021-1-30)](https://www.youtube.com/watch?v=nyBIRtAbSnc)
------
<div>
中共的巨貪官吏賴小民被習近平“斬立決”絕非尋常,背後有多少人和事?2021年注定是多事之秋,建制派在政治上勝利了,大型科技公司還要設法要堵住了眾人之口,但誰都沒有料到,散戶的集體對抗又一次佔領了華爾街。中國有句古話“百姓心中有一桿稱”。雖然以行政收到強迫病毒不能以地區命名,但“中共病毒”仍然感染全世界。常識(commonsense) ✌【書齋夜話】2021年1月29日於聽風論雨齋
</div> | 547 | MIT |
# 节点插件
通常用于使用节点包裹文本加以修饰的场景。例如,`<strong>abc</strong>` `<h2>abc</h2>` 使用一组标签包裹文本或者节点
或者用于设置所有的节点样式。例如缩进,`<p style="padding-left:10px"></p>`,`<h2 style="padding-left:10px"></h2>`,每个块级节点都可以设置缩进样式
一个标签由 `标签名称`、`属性`、`样式` 组成,这三要素最终都会加入 `schema` 规则管理里面,`schema` 是 DOM 树的约束条件列表,标签、样式、属性如果不存在 `schema` 规则里面,都会被过滤遗弃
`ElementPlugin` 插件会把我们设置的`标签名称`、`属性`、`样式`自动组成一个节点,并自动加入到`schema`规则里面
此类插件我们需要继承 `ElementPlugin` 抽象类,`ElementPlugin` 抽象类在继承 `Plugin` 抽象类的基础上扩展了一些属性和方法。所以继承 `ElementPlugin` 的插件也同样拥有`Plugin`抽象类的所有属性和方法
## 继承
继承 `ElementPlugin` 抽象类
```ts
import { ElementPlugin } from '@aomao/engine'
export default class extends ElementPlugin {
...
}
```
## 属性
因为 `ElementPlugin` 继承了 `Plugin` 抽象类,所以 `pluginName` 不要忘记了~
### `tagName`
标签名称,可选
用于包裹文本或节点的标签名称
如果有设置,会自动加入 `schema` 规则管理
```ts
export default class extends ElementPlugin {
...
readonly tagName = "span"
}
```
### `style`
标签的样式,可选
用于设置当前标签的样式,如果此插件没有设置标签名称,样式将作为全局标签的样式,拥有此样式的标签`schema`会判定为合法的,会把样式保留。
如果有设置,会自动加入 `schema` 规则管理
示例:
```ts
export default class extends ElementPlugin {
...
readonly style = {
"font-weight": "bold"
}
}
```
某些情况下我们需要一个动态值,例如字体大小,`<span style="font-size:14px"></span>` 14px 是一个固定的值,如果希望每次执行插件都能替换成`editor.command.execute`传进来的动态值,那么就要使用变量表示
这个变量来源于`editor.command.execute`命令的参数,变量名称由 `@var` + 参数所在位置索引决定。`editor.command.execute("插件名称","参数0","参数1","参数2",...)` 对应的变量名为 `@var0` `@var1` `@var2` ...
```ts
export default class extends ElementPlugin {
...
readonly style = {
"font-size": "@var0"
}
}
```
除了动态设置值以外,我们还可以对节点获取到的值进行格式化。例如,在粘贴某些复制过来的文本时,字体大小单位是 pt,我们需要转换成我们熟悉的 px。这样在执行`editor.command.queryState`时,我们能轻松的获取到预期内的值
```ts
export default class extends ElementPlugin {
...
readonly style = {
'font-size': {
value: '@var0',
format: (value: string) => {
value = this.convertToPX(value);
return value;
},
},
}
}
```
### `attributes`
标签的属性,可选
设置和使用方式与 `style` 一样
```ts
export default class extends ElementPlugin {
...
readonly attributes = {
"data-attr": "@var0"
}
}
```
严格意义上`style`也属性标签上的属性,不过`style`属性比较常用,并且它是以键值对形式出现的,单独罗列出来比较好理解和管理。最终在加入 `schema` 时 `style` 属性会被合并到 `attributes` 字段中。
### `variable`
变量规则,可选
如果 `style` 或 `attributes` 的值有使用动态变量,那么必须要对变量进行规则说明。否则,`@var0`,`@var1` 在 `schema` 中会被当作固定值处理,不符合就会被过滤遗弃
```ts
variable = {
'@var0': {
required: true,
value: /[\d\.]+(pt|px)$/,
},
};
```
对于`@var0`我们使用了以下规则表明
- `required` 必需要有的值
- `value` 正则表达式,可以用`pt` 或 `px`做单位的数值
更多关于 `schema` 规则的设置请在 `文档` -> `基础` -> `结构`阅读
## 方法
### `init`
初始化,可选
`ElementPlugin` 插件已经实现了`init`方法,如果需要使用,需要手动再次调用。否则会出现意料外的情况
```ts
export default class extends ElementPlugin {
...
init(){
super.init()
}
}
```
### `setStyle`
将当前插件 `style` 属性应用到一个节点
```ts
/**
* 将当前插件style属性应用到节点
* @param node 需要设置的节点
* @param args 如果有 `style` 中有动态值,在这里以参数的形式传入,需要注意参数顺序
*/
setStyle(node: NodeInterface | Node, ...args: Array<any>): void
```
### `setAttributes`
将当前插件 `attributes` 属性应用到一个节点
```ts
/**
* 将当前插件attributes属性应用到节点
* @param node 节点
* @param args 如果有 `attributes` 中有动态值,在这里以参数的形式传入,需要注意参数顺序
*/
setAttributes(node: NodeInterface | Node, ...args: Array<any>): void;
```
### `getStyle`
获取一个节点符合当前插件规则的样式
```ts
/**
* 获取节点符合当前插件规则的样式
* @param node 节点
* @returns 样式名称和样式值键值对
*/
getStyle(node: NodeInterface | Node): { [key: string]: string };
```
### `getAttributes`
获取节点符合当前插件规则的属性
```ts
/**
* 获取节点符合当前插件规则的属性
* @param node 节点
* @returns 属性名称和属性值键值对
*/
getAttributes(node: NodeInterface | Node): { [key: string]: string };
```
### `isSelf`
检测当前节点是否符合当前插件设置的规则
```ts
/**
* 检测当前节点是否符合当前插件设置的规则
* @param node 节点
* @returns true | false
*/
isSelf(node: NodeInterface | Node): boolean;
```
### `queryState`
查询插件状态命令,可选
```ts
queryState() {
//不是引擎
if (!isEngine(this.editor)) return;
const { change } = this.editor;
//如果没有属性和样式限制,直接查询是否包含当前标签名称
if (!this.style && !this.attributes)
return change.marks.some(node => node.name === this.tagName);
//获取属性和样式限制内的值集合
const values: Array<string> = [];
change.marks.forEach(node => {
values.push(...Object.values(this.getStyle(node)));
values.push(...Object.values(this.getAttributes(node)));
});
return values.length === 0 ? undefined : values;
}
```
### `execute`
执行插件命令,需要实现
添加一个 mark 标签的例子:
```ts
execute(...args) {
//不是引擎
if (!isEngine(this.editor)) return;
const { change } = this.editor;
//实例化一个当前插件设定的标签名称节点
const markNode = $(`<${this.tagName} />`);
//给节点设置当前插件设定的样式,如果有动态值,自动组合动态参数
this.setStyle(markNode, ...args);
//给节点设置当前插件设定的属性,如果有动态值,自动组合动态参数
this.setAttributes(markNode, ...args);
const { mark } = this.editor;
//查询当前光标位置是否符合当前插件的设置
const trigger = !this.queryState()
if (trigger) {
//在光标处包裹当前插件设置的mark样式标签节点
mark.wrap(markNode);
} else {
//在光标处移除当前插件设置的mark样式标签节点
mark.unwrap(markNode);
}
}
```
### `schema`
获取插件设置的属性和样式所生成的规则,这些规则将添加到 `schema` 对象中
```ts
/**
* 获取插件设置的属性和样式所生成的规则
*/
schema(): SchemaRule | SchemaGlobal | Array<SchemaRule>;
``` | 5,102 | MIT |
# 拙见/ 什么是隐私?
> 程序猿大妈叕叕叕叕叕叕叕叕叕叕一则偏见...
这是大妈在 **ZoomQuiet** 的第**053**篇原创
-------------
## 背景
7.26 一篇文章,
[谈一谈关于隐私的问题!](https://mp.weixin.qq.com/s/jxO9WqLLJvV8GSIP481b8w)
对物联网时代智慧家居背景中,
越来越多的隐私数据被无端上云而产生的后果进行了警告.
这也触发大妈式思考.
-------------
## 现象
> ...某BAT的创始人在公众场合说人们需要牺牲一些隐私来换取便利
虽然, 这是互联网头部大厂的傲慢.
但是, 这么多年下来, 以互联网为背景讨论 `隐私` 已经共识为:
```python
私人数据被智能设备采集到
在本人亳无知觉时被再应用
```
-------------
## 问题
> 值得认真追问的...
- 什么是隐私?
- 什么是私人数据?
- 为什么隐私数据私人反而拿不到?
- ...
-------------
## 断言
> 为了明确本文目标, 先给出一组断言
```python
历史上看根本就没真正的隐私
隐私很可能是个伪概念
应该关注数据权/信息权
而不是隐私问题
```
------------
## 分析
隐私权最早在萨缪尔·D·沃伦(Samuel D. Warren)和路易斯·D·布兰迪斯(Louis D. Brandeis)的"论隐私权"(The Right to Privacy)一文中被定义为个人在通常情况下决定他的思想,观点和情感在多大程度上使别人知悉的权利,每一个人都有决定自己的所有事情不被公之于众,不受他人干涉的权利.
英国"牛津法律大辞典"(The Oxford Companion to Law)认为,隐私权是不受他人干扰的权利,关于人的私生活不受侵犯或不得将人的私生活非法公开的权利要求 .
隐私权包括以下四项权利:
- (1)隐私隐瞒权:隐私隐瞒权是指权利主体对于自己的隐私进行隐瞒,不为人所知的权利.
- (2)隐私利用权:隐私利用权是指自然人对于自己的隐私权积极利用,以满足自己精神,物质等方面需要的权利.
- (3)隐私支配权:隐私支配权是指公民对自己的隐私有权按照自己的意愿进行支配.
- (4)隐私维护权:隐私维护权是指隐私权主体对于自己的隐私享有维护其不受侵犯的权利,在受到非法侵犯时可以寻求公力与私力救济 .
...以及很多其它各种角度的阐述.
而其实, 在英语中,隐私一词是"privacy",含义是独处,秘密,与汉语的意思基本相同. 但似乎汉语的"隐私"一词强调了隐私的主观色彩,而英文的"privacy"一词更注重隐私的客观性,这一点体现了感性的东方文明与理性的西方文明的差异.
简单说从法理意义上讲,隐私应当这样定义:
> 已经发生了的符合道德规范和正当的而又不能或不愿示人事或物,情感活动等.
只是, 隐私无论从哪个角度分析, 都是一个对即有事实的隐瞒权引发的一系列权益.
无论这个事实是什么, 隐私得是所有人原先掌握的, 在自己控制之下的事实.
但是, 在互联网时代, 这一基本前提本身就是站不住脚的.
-------------
### 直觉隐私
先说直觉上自己掌握的事实.
比如性取向;
在古代, 男男之爱, 是视为龙阳之瘾, 虽然不推崇, 但是也并不反感, 只是一种私人雅趣,
被社会认同的.
只是后来其它文化的交融, 才引发了反转;
但是, 现在 LGBTQ 亚文化的崛起, 又将继续反转.
而且, 随着心理学/医学的进步, 对性取向的态度也在持续变化.
原先必须用隐私权来保护的信息, 也可能变的无人关注.
也就是说, 是否愿意公开, 这本身就不是固定的情况, 完全和当前社会风气, 主流意识相关;
即, 隐私中这个 `隐` 本身就是相对的.
另外, 具体个体的所有隐私, 其实无论哪个时代, 嘦想知道, 总是能知道的,
只是成本大小,
以往只有关键人物, 或是价值人士, 会有专门机构进行长期追踪/分析, 以求掌握所有隐私,
以便关键时刻加以利用.
只是随着技术的发展, 掌握普通人越来越多 "隐私" 涉及的平均成本越来越小,
才让普通人有隐私数据的感知了而已.
> 也就是说:
直觉上的隐私,
其实, 一直只是种程度上的感觉,
而事实上, 从来就没有什么隐私是打探不到的;
唯一阻止隐私被收集/分析出来的原因, 不过是成本.
法理/伦理上的约定, 也不过是对即定现实的陈述.
而对隐私的被掌握, 从来没有产生过什么有力的阻止.
毕竟, 隐私数据刺探的结果无非是:
引发利益远远大于法律惩罚, 那么当然不可能阻止这种刺探.
涉及利益远远小于法律惩罚, 那么当然不可能有这种刺探存在.
-------------
### 不自知的隐私
> 隐私, 就是一个对即有事实的隐瞒权引发的一系列权益.
那么, 如果事实是当事人自己都不知道的呢?
这时, 隐私所有人是谁?
比如, 孩子没出生前,是男是女, 对普通人可能并不重要,
但是, 对于王室就非常关键.
问题是, 在没有相关技术支持前, 这种事实是当事儿人自己都不知道的.
那么, 不在自己控制下的信息/数据, 归谁所有?
比如, 现在足月后, 作彩超时, 医生先知道这条信息,
然后, 才问当事人, 是否想知道.
也就是说, 越来越多的"隐私"是由被告之的.
那么, 被告之前, 这类"隐私"属于谁?
类似的, 还有智能冰柜追踪的自家所有食材.
哪种即将过期/腐败, 这种信息是户主本人都难以实时掌握的.
再比如说, 纳米机械人的发展, 将有手段可以实时 7X24 小时不间断的监察人体所有关键指数,
比如心跳以及心血通量的变化,
并通过长期监测, 可以预见到何时时将引发心脏病变.
这类数据甚至于是当事人本身无法掌握也无法理解的事实.
而随着互联网/物联网相关技术的发展,
这类数据将越来越多.
以及, 真正的投资公司, 现在都在租用甚至于采购卫星,
不间隔的通过可见光/红外线/毫米波/..频段来实时观测关注的物产变化.
以便掌握潜在投资对象真正的生产/销售情况.
而通过卫星采集到的公开数据分析出的结果,
很多是对应厂商本身都可能难以实时知道的事实.
类似这种, 当事人自己都不知道的价值数据, 是否算隐私? 归谁所有?
-------------
## 隐私的归隐
文章中相关担心主要有两种:
> ...如硬件供应方的云端和应用,有一种你开一次灯全世界广播了一次的即视感,但是这种方式对用户本身不产生任何的价值,对商业本身可能也不产生任何的价值...
其实, 数据传送到云端,并不代表对全世界广播;
只是穿过全世界, 到达远端一个 IDC 中保管起来;
有在中间被 `劫持` 的危险.
只是, 这种传送行为的规模在互联网中越来越大, 如果没有特殊理由,
根本无人关注你的数据传送.
而将数据保存在云端, 能用最小的成本维护最大的可用性,
这是近端没有云端大规模冗余架构空间无法作到的.
> ...其实这很简单,只要网警们放一个SDK包在微信里面,对敏感话题才进行抓取并上传就可以了
其实, 隐私的法理是通用的, 并不应该有例外,
既然合法爱国时, 有关部门可以随时采集有关 "隐私", 那么, 厂商们为什么不可以?
既然大家都承诺只合法使用.
> ...小编的个人观点:在互联网时代,物权变的模糊,而在物联网时代在如此明确的物权的前提下,万物互联应该以空间为核心,以云端为辅助. 而不是一切皆应该上云.
其实, 物权从来没模糊过, 毕竟涉及产权证/发票/..之类所有权证明.
但是, 数据权/信息权, 却实在随着技术的发展, 越来越纠缠难以界定.
比如, 虽然物理对象, 是当事人拥有的;
但是, 物理对象在被运用/使用过程中产生的数据却并不一定归当事儿人所有;
比如, 打开智能电视, 点播某一平台供给的电影时,
这一次点播行为,虽然是当事人触发的,
但是, 这次点播的数据却是归对应平台所有.
甚至于, 在观看过程中, 当事人瞳孔/呼吸/心跳等等和情绪相关的数据,
被智能电视遥感获知, 以便来自动加速/反复/慢速播放, 加强观影体验;
这类隐私数据, 甚至于没触发任何物权的变化, 只是产生了全新的数据,
唯一可以被计量的物理变化, 可能就是 0.0几度多消耗的电量.
万物互联, 以空间/物理对象为核心, 而不是以流动的使用者为核心,
这是一个自然的回归; 也是一个软件架构的全新视角.
但是, 过程中涉及"隐私"数据的采集/收集/整理/统计/再应用/发布/转发..的控制权,
则因为技术壁垒, 直接将涉及的当事人给无视了,
这可能才是焦虑产生根源.
不过, 随着技术的进步, 对于自己都不知道的情况, 实在难以引发重视.
这时, 就连法律介入都难以界定.
比如, 户住自己采购了监控摄像头,
并和自己手机绑定以便远程随时掌握家中情况;
但是, 手机被盗后, 自己忘记解除绑定;
导致非法分子, 通过手机, 掌握了家中无人的规律, 从容破门搬空了家;
这一过程中, 手机厂商/应用厂商/摄像头厂商都难以追究职责.
除非明确, 摄像头购买后,产生的所有数据都归当事人所有;
那么, 这一家中影像数据通过手机/应用暴露到互联网过程中,
数据所有权不变;
那么, 才可能对意外暴露界定责任.
-------------
> 本人公号所刊载原创内容之知识产权为本人所有,
> 未经许可, 禁止进行转载/摘编/复制及建立镜像等任何使用.
> 欢迎读者沟通交流, 请留言, 或通过邮件交流->
投稿/反馈邮箱:
askdama@googlegroups.com
(邮件列表地址,
当成正常邮件发送邮件就好, 不用订阅, 不用翻越...)
-------------
ZoomQuiet/**[大妈](https://mp.weixin.qq.com/s/N5TuRRbF485D4Q90XdDA7g)**
就是四处 `是也乎,( ̄▽ ̄)` 的那个[大妈](https://mp.weixin.qq.com/s/N5TuRRbF485D4Q90XdDA7g):
```python
私自嗯哼: ZoomQuiet (订阅号: ZoomQuiet42)
原创课程: 蟒营 (订阅号: Mainium)
过往吐糟: Chaos42 (订阅号 PythoniCamp)
as 核心组织者:
PyChina (订阅号: PyChinaOrg)
本地社区:
GDG珠海 (订阅号: GDG-ZhuHai)
TFUG珠海 (订阅号: ZH_TFUG)
```
-------------
好文笔,感叹号年度配额: **1/3**
>> NN 4104 | 4,590 | BSD-2-Clause |
---
title: DevOps -- API Doc
---
> 在编写代码时,需要维护API文档,人工维护wiki/文档很容易造成文档没有及时更新。因此,可以使用编写注释的方式自动生成API Doc,常用的有Swagger,API Doc等,我们最终选择API Doc作为自动生成工具。
通过在函数头部添加以下注释就可以自动生成文档:
```
/**
* @api {post} /gslb/node/ms MS Create
* @apiDescription This API is used by MS to create MS.
* @apiName CreateMS
* @apiGroup Node Management
* @apiHeader {String} Authorization PanoSToken (http://wiki.in.pano.im/display/PANO/Server+Token+and+EncyptedBody)
* @apiHeaderExample {string} Header-Example:
* "Authorization": "PanoSToken xxxxxxxxxxx"
* @apiParam {string} dc Data Center Name
* @apiParam {string} msid ms uuid
* @apiParam {int64} group ms group
* @apiParam {string} address ms address(IP or DNS)
* @apiParam {int64} msLoad ms load(0-1000)
* @apiParam {int64} step load to add when single user join
* @apiParam {string} grayKey internal usage for upgrade
* @apiParamExample {json} Request-Example:
* {
* "dc": "sh01dc1",
* "msid": "abcd",
* "group": 0,
* "address": "1.2.3.4",
* "msLoad": 200,
* "step": 10,
* "grayKey": "Key0.5",
* }
* @apiSuccess (Success 200) StatusOK OK
* @apiError (Failed 400) StatusBadRequest Invalid Input Params
* @apiError (Failed 403) StatusForbidden Invalid Token
* @apiError (Failed 500) StatusInternalServerError Internal Server Error
*/
```
具体语法参照: https://apidocjs.com/
在GitLab CI中可以配置apidoc自动生成的步骤:
```
API Doc:
stage: APIDOC
script:
- apidoc -i ./ -o /opt/output/documents/gslb -t /opt/tools/pano-apidoc-template
tags:
- build
only:
- merge_requests
```
然后使用Http服务器暴露API文档即可。此时代码中修改后,就会更新到API文档服务器中。 | 1,601 | CC0-1.0 |
---
title: CSI 协议
weight: 3
menu:
main:
parent: "编程接口"
summary: Ozone 支持 容器存储接口 (CSI) 协议。你可以通过 Ozone CSI 挂载 Ozone 桶的方式使用 Ozone。
---
<!---
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
容器存储接口 `Container Storage Interface` (CSI) 使存储供应商(SP)能够一次性开发一个插件,并让它跨多个容器编排工作,
就像 Kubernetes 或者 YARN。
获取更多 CSI 的信息,可以参考[SCI spec](https://github.com/container-storage-interface/spec/blob/master/spec.md)
CSI 定义了一个简单的,包含3个接口(Identity, Controller, Node)的 GRPC 接口,它定义了容器编排器如何请求创建新的存储空间或挂载新创建的存储,
但没有定义如何挂载存储。

默认情况下,Ozone CSI 服务使用 S3 FUSE 驱动程序([goofys](https://github.com/kahing/goofys))挂载 Ozone 桶。
其他挂载方式(如专用 NFS 服务或本机FUSE驱动程序)的实现正在进行中。
Ozone CSI 是 CSI 的一种实现,它可以将 Ozone 用作容器的存储卷。
## 入门
首先,我们需要一个带有 s3gateway 的 Ozone 集群,并且它的 OM 和 s3gateway 的端口都可以对 CSI pod 可见,
因为 CSIServer 将会访问 OM 来创建或者删除桶,同时 CSIServer 通过 goofys 创建一个可以访问 s3g 的挂载点来发布卷。
如果你没有一个运行在 Kubernetes 上的 Ozone 集群,你可以参考[Kubernetes]({{< ref "start/Kubernetes.zh.md" >}}) 来创建一个。
使用来自 `kubernetes/examples/ozone`的资源,你可以找到所有需要的 Kubernetes 资源来和指定的 CSI 运行在一起
(参考 `kubernetes/examples/ozone/csi`)
现在,使用如下命令,创建 CSI 相关的资源。
```bash
kubectl create -f /ozone/kubernetes/examples/ozone/csi
```
## 创建 pv-test 并查看结果
通过执行以下命令,创建 pv-test 相关的资源。
```bash
kubectl create -f /ozone/kubernetes/examples/ozone/pv-test
```
连接 pod scm-0 并在 /s3v/pvc* 桶中创建一个键值。
```bash
kubectl exec -it scm-0 bash
[hadoop@scm-0 ~]$ ozone sh bucket list s3v
[ {
"metadata" : { },
"volumeName" : "s3v",
"name" : "pvc-861e2d8b-2232-4cd1-b43c-c0c26697ab6b",
"storageType" : "DISK",
"versioning" : false,
"creationTime" : "2020-06-11T08:19:47.469Z",
"encryptionKeyName" : null
} ]
[hadoop@scm-0 ~]$ ozone sh key put /s3v/pvc-861e2d8b-2232-4cd1-b43c-c0c26697ab6b/A LICENSE.txt
```
现在,通过映射 `ozone-csi-test-webserver-7cbdc5d65c-h5mnn` 端口,我们可以使用浏览器展示其 UI 页面。
```bash
kubectl port-forward ozone-csi-test-webserver-7cbdc5d65c-h5mnn 8000:8000
```
最终,我们可以通过 `http://localhost:8000/` 看到结果
 | 2,707 | Apache-2.0 |
---
ms.assetid: 6b38480e-5b1c-49f0-9d46-8cf22f70f0d2
title: Windows Server 2012 R2 で AD FS 用のラボ環境をセットアップする
description: ''
author: billmath
ms.author: billmath
manager: femila
ms.date: 05/31/2017
ms.topic: article
ms.prod: windows-server
ms.technology: identity-adfs
ms.openlocfilehash: 52199ab8ca6f82443e78e72c6980746fa561363a
ms.sourcegitcommit: 0a0a45bec6583162ba5e4b17979f0b5a0c179ab2
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 03/13/2020
ms.locfileid: "79323124"
---
# <a name="set-up-the-lab-environment-for-ad-fs-in-windows-server-2012-r2"></a>Windows Server 2012 R2 で AD FS 用のラボ環境をセットアップする
このトピックでは、次のチュートリアル ガイドのチュートリアルを完了するために使用できるテスト環境の構成手順を説明します。
- [チュートリアル: iOS デバイスでの Workplace Join](../../ad-fs/operations/Walkthrough--Workplace-Join-with-an-iOS-Device.md)
- [チュートリアル: Windows デバイスでの Workplace Join](../../ad-fs/operations/Walkthrough--Workplace-Join-with-a-Windows-Device.md)
- [チュートリアルガイド: 条件付き Access Control によるリスク管理](../../ad-fs/operations/Walkthrough-Guide--Manage-Risk-with-Conditional-Access-Control.md)
- [チュートリアルガイド: 追加の Multi-Factor Authentication による機密アプリケーションのリスク管理](../../ad-fs/operations/Walkthrough-Guide--Manage-Risk-with-Additional-Multi-Factor-Authentication-for-Sensitive-Applications.md)
> [!NOTE]
> Web サーバーとフェデレーション サーバーを同じコンピューターにインストールすることはお勧めしません。
このテスト環境をセットアップするには、次の手順を完了します。
1. [手順 1: ドメインコントローラー (DC1) を構成する](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_1)
2. [手順 2: デバイス登録サービスを使用してフェデレーションサーバー (ADFS1) を構成する](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_4)
3. [手順 3: web サーバー (WebServ1) とサンプルの要求ベースのアプリケーションを構成する](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_5)
4. [手順 4: クライアントコンピューター (Client1) を構成する](../../ad-fs/deployment/../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_10)
## <a name="BKMK_1"></a>手順 1: ドメインコントローラー (DC1) を構成する
このテスト環境では、ルート Active Directory ドメイン**contoso.com**を呼び出し、 <strong>pass@word1</strong>を管理者パスワードとして指定できます。
- AD DS の役割サービスをインストールし Active Directory Domain Services (AD DS) をインストールして、Windows Server 2012 R2 でコンピューターをドメインコントローラーにします。 この操作により、ドメインコントローラーの作成の一環として AD DS スキーマがアップグレードされます。 詳細と詳細な手順については、「[https://technet.microsoft.com/library/hh472162.aspx](https://technet.microsoft.com/library/hh472162.aspx)」を参照してください。
### <a name="BKMK_2"></a>テスト Active Directory アカウントを作成する
ドメイン コントローラーが機能するようになったら、このドメインにテスト用のグループとユーザー アカウントを作成して、作成したユーザー アカウントをグループ アカウントに追加できます。 このトピックの最初に示したチュートリアル ガイドのチュートリアルを完了するには、これらのアカウントを使用します。
次のアカウントを作成します。
- ユーザー: **Robert Hatley**次の資格情報: ユーザー名: **roth th**および password: <strong>P@ssword</strong>
- グループ: **Finance**
Active Directory (AD) でユーザーアカウントとグループアカウントを作成する方法の詳細については、「 [https://technet.microsoft.com/library/cc783323%28v.aspx](https://technet.microsoft.com/library/cc783323%28v=ws.10%29.aspx)」を参照してください。
**Robert Hatley** アカウントを **Finance** グループに追加します。 Active Directory のグループにユーザーを追加する方法の詳細については、「 [https://technet.microsoft.com/library/cc737130%28v=ws.10%29.aspx](https://technet.microsoft.com/library/cc737130%28v=ws.10%29.aspx)」を参照してください。
### <a name="create-a-gmsa-account"></a>GMSA アカウントの作成
Active Directory フェデレーションサービス (AD FS) (AD FS) のインストールと構成では、グループの管理されたサービスアカウント (GMSA) アカウントが必要です。
##### <a name="to-create-a-gmsa-account"></a>GMSA アカウントを作成するには
1. Windows PowerShell コマンド ウィンドウを開いて、次のコマンドを入力します。
```
Add-KdsRootKey -EffectiveTime (Get-Date).AddHours(-10)
New-ADServiceAccount FsGmsa -DNSHostName adfs1.contoso.com -ServicePrincipalNames http/adfs1.contoso.com
```
## <a name="BKMK_4"></a>手順 2: デバイス登録サービスを使用してフェデレーションサーバー (ADFS1) を構成する
別の仮想マシンをセットアップするには、Windows Server 2012 R2 をインストールし、ドメイン**contoso.com**に接続します。 ドメインに参加した後、コンピューターをセットアップし、AD FS の役割のインストールと構成に進みます。
これらの手順を説明したビデオを視聴するには、「 [Active Directory フェデレーション サービスの使い方ビデオ シリーズ: AD FS サーバー ファームのインストール](https://technet.microsoft.com/video/dn469436)」を参照してください。
### <a name="install-a-server-ssl-certificate"></a>サーバー SSL 証明書のインストール
ADFS1 サーバーのサーバー SSL (Secure Socket Layer) 証明書を、ローカル コンピューター ストアにインストールする必要があります。 この証明書には次の属性が必要です。
- サブジェクト名 (CN): adfs1.contoso.com
- サブジェクト代替名 (DNS): adfs1.contoso.com
- サブジェクト代替名 (DNS): enterpriseregistration.contoso.com
SSL 証明書のセットアップに関する詳細については、「 [エンタープライズ CA を使用してドメイン内の Web サイトで SSL/TLS を構成する](https://social.technet.microsoft.com/wiki/contents/articles/12485.configure-ssltls-on-a-web-site-in-the-domain-with-an-enterprise-ca.aspx)」を参照してください。
「[Active Directory フェデレーション サービスの使い方ビデオ シリーズ: 証明書の更新](https://technet.microsoft.com/video/adfs-updating-certificates)」。
### <a name="install-the-ad-fs-server-role"></a>AD FS サーバーの役割のインストール
##### <a name="to-install-the-federation-service-role-service"></a>フェデレーション サービス役割サービスをインストールするには
1. administrator@contoso.comドメイン管理者アカウントを使用してサーバーにログオンします。
2. サーバー マネージャーを起動します。 サーバー マネージャーを起動するには、Windows の**スタート**画面で **[サーバー マネージャー]** をクリックするか、または Windows デスクトップの Windows タスク バーで **[サーバー マネージャー]** をクリックします。 **[ダッシュボード]** ページにある **[ようこそ]** タイルの **[クイック スタート]** タブで、 **[役割と機能の追加]** をクリックします。 または、 **[管理]** メニューの **[役割と機能の追加]** をクリックする方法もあります。
3. **[開始する前に]** ページで、 **[次へ]** をクリックします。
4. **[インストールの種類の選択]** ページで、 **[役割ベースまたは機能ベースのインストール]** をクリックし、 **[次へ]** をクリックします。
5. **[宛先サーバーの選択]** ページで、 **[サーバー プールからサーバーを選択]** をクリックし、ターゲット コンピューターが選択されていることを確認してから、 **[次へ]** をクリックします。
6. **[サーバーの役割の選択]** ページで、 **[Active Directory フェデレーション サービス]** をクリックし、 **[次へ]** をクリックします。
7. **[機能の選択]** ページで **[次へ]** をクリックします。
8. **[Active Directory フェデレーション サービス (AD FS)]** ページで、 **[次へ]** をクリックします。
9. **[インストール オプションの確認]** ページの情報を確認し、 **[必要に応じて対象サーバーを自動的に再起動する]** チェック ボックスをオンにして、 **[インストール]** をクリックします。
10. **[インストールの進行状況]** ページで、すべてが正常にインストールされたことを確認し、 **[閉じる]** をクリックします。
### <a name="configure-the-federation-server"></a>フェデレーション サーバーの構成
次の手順ではフェデレーション サーバーを構成します。
##### <a name="to-configure-the-federation-server"></a>フェデレーション サーバーを構成するには
1. Server Manager の **[ダッシュボード]** ページで、 **[通知]** フラグをクリックし、 **[サーバーにフェデレーション サービスを構成します]** をクリックします。
**Active Directory フェデレーション サービス構成ウィザード**が開きます。
2. **[ようこそ]** ページで、 **[フェデレーション サーバー ファームに最初のフェデレーション サーバーを作成します]** を選択し、 **[次へ]** をクリックします。
3. **[AD DS への接続]** ページで、このコンピューターが参加している **contoso.com** Active Directory ドメインのドメイン管理者権限を持つアカウントを指定し、 **[次へ]** をクリックします。
4. **[サービスのプロパティの指定]** ページで次の操作を実行してから、 **[次へ]** をクリックします。
- 前の手順で取得した SSL 証明書をインポートします。 この証明書は必須のサービス認証証明書です。 SSL 証明書の保存場所を参照します。
- フェデレーション サービスの名前に「**adfs1.contoso.com**」と入力します。 この値は、Active Directory 証明書サービス (AD CS) に SSL 証明書を登録したときに指定したのと同じ値です。
- フェデレーション サービスの表示名に「**Contoso Corporation**」と入力します。
5. **[サービス アカウントの指定]** ページで、 **[既存のドメイン ユーザー アカウントまたはグループの管理されたサービス アカウントを使用してください]** を選択し、ドメイン コントローラーの作成時に作成した GMSA アカウント **fsgmsa** を指定します。
6. **[構成データベースの指定]** ページで、 **[Windows Internal Database を使用してサーバーにデータベースを作成します]** を選択し、 **[次へ]** をクリックします。
7. **[オプションの確認]** ページで、構成の選択内容を確認し、 **[次へ]** をクリックします。
8. **[前提条件の確認]** ページで、すべての前提条件の確認が正常に完了したことを確認し、 **[構成]** をクリックします。
9. **[結果]** ページで結果を確認し、構成が正常に完了したことを確認してから、 **[フェデレーション サービス展開を完了するために必要な次の手順]** をクリックします。
### <a name="configure-device-registration-service"></a>デバイス登録サービスの構成
次の手順では、ADFS1 サーバーでデバイス登録サービスを構成します。 これらの手順を説明したビデオを視聴するには、「 [Active Directory フェデレーション サービスの使い方ビデオ シリーズ: デバイス登録サービスを有効にする](https://technet.microsoft.com/video/adfs-how-to-enabling-the-device-registration-service)」を参照してください。
##### <a name="to-configure-device-registration-service-for-windows-server-2012-rtm"></a>Windows Server 2012 RTM でデバイス登録サービスを構成するには
1. > [!IMPORTANT]
> **次の手順は、Windows Server 2012 R2 RTM ビルドに適用されます。**
Windows PowerShell コマンド ウィンドウを開いて、次のコマンドを入力します。
```
Initialize-ADDeviceRegistration
```
サービス アカウントの入力を求められたら、「**contoso\fsgmsa$** 」と入力します。
次に、Windows PowerShell コマンドレットを実行します。
```
Enable-AdfsDeviceRegistration
```
2. ADFS1 サーバーで、**AD FS 管理**コンソールの **[認証ポリシー]** に移動します。 **[グローバル プライマリ認証の編集]** を選択します。 **[デバイス認証の有効化]** の横にあるチェック ボックスをオンにして、 **[OK]** をクリックします。
### <a name="add-host-a-and-alias-cname-resource-records-to-dns"></a>ホスト (A) およびエイリアス (CNAME) リソース レコードの DNS への追加
DC1 では、デバイス登録サービス用に次のドメイン ネーム システム (DNS) レコードを作成する必要があります。
|エントリ|種類|Address|
|---------|--------|-----------|
|adfs1|ホスト (A)|AD FS サーバーの IP アドレス|
|enterpriseregistration|エイリアス (CNAME)|adfs1.contoso.com|
次の手順に従って、ホスト (A) リソース レコードを会社のフェデレーション サーバーとデバイス登録サービスの DNS ネーム サーバーに追加できます。
この手順を実行するには、少なくとも Administrators グループのメンバーシップまたは同等の権限を持つメンバーシップが必要です。 適切なアカウントとグループメンバーシップの使用方法の詳細については、「<https://go.microsoft.com/fwlink/?LinkId=83477>」の「ローカルおよびドメインの既定のグループ (<https://go.microsoft.com/fwlink/p/?LinkId=83477>)」を参照してください。
##### <a name="to-add-a-host-a-and-alias-cname-resource-records-to-dns-for-your-federation-server"></a>ホスト (A) およびエイリアス (CNAME) リソース レコードをフェデレーション サーバーの DNS に追加するには
1. DC1 のサーバー マネージャーで、 **[ツール]** メニューの **[DNS]** をクリックし、DNS スナップインを開きます。
2. コンソール ツリーで [DC1] を展開し、 **[前方参照ゾーン]** を展開して **[contoso.com]** を右クリックし、 **[新しいホスト (A または AAAA)]** をクリックします。
3. **[名前]** に AD FS ファームで使用する名前を入力します。 このチュートリアルでは、「**adfs1**」と入力します。
4. **[IP アドレス]** に ADFS1 サーバーの IP アドレスを入力します。 **[ホストの追加]** をクリックします。
5. **[contoso.com]** を右クリックし、 **[新しいエイリアス (CNAME)]** をクリックします。
6. **[新しいリソース レコード]** ダイアログ ボックスで、 **[エイリアス名]** ボックスに「**enterpriseregistration**」と入力します。
7. ターゲット ホスト ボックスの [完全修飾ドメイン名 (FQDN)] に「**adfs1.contoso.com**」と入力し、 **[OK]** をクリックします。
> [!IMPORTANT]
> 実際の展開では、会社に複数のユーザー プリンシパル名 (UPN) サフィックスがある場合、DNS の各 UPN サフィックスに 1 つずつ、複数の CNAME レコードを作成する必要があります。
## <a name="BKMK_5"></a>手順 3: web サーバー (WebServ1) とサンプルの要求ベースのアプリケーションを構成する
Windows Server 2012 R2 オペレーティングシステムをインストールして仮想マシン (WebServ1) をセットアップし、それをドメイン**contoso.com**に接続します。 ドメインに参加したら、Web サーバーの役割のインストールと構成を開始できます。
このトピックの最初に示したチュートリアルを完了するには、フェデレーション サーバー (ADFS1) で保護されたサンプル アプリケーションが必要です。
Windows Identity Foundation SDK ([https://www.microsoft.com/download/details.aspx?id=4451](https://www.microsoft.com/download/details.aspx?id=4451)をダウンロードできます。これには、要求ベースのアプリケーションのサンプルが含まれています。
このサンプルの要求ベースのアプリケーションで Web サーバーをセットアップするには、次の手順を完了する必要があります。
> [!NOTE]
> これらの手順は、Windows Server 2012 R2 オペレーティングシステムを実行する web サーバーでテストされています。
1. [Web サーバーの役割と Windows Identity Foundation をインストールする](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_15)
2. [Windows Identity Foundation SDK をインストールする](../../ad-fs/deployment/../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_13)
3. [単純な要求アプリを IIS で構成する](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_9)
4. [フェデレーションサーバーで証明書利用者信頼を作成する](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_11)
### <a name="BKMK_15"></a>Web サーバーの役割と Windows Identity Foundation をインストールする
1. > [!NOTE]
> Windows Server 2012 R2 のインストールメディアにアクセスできる必要があります。
<strong>administrator@contoso.com</strong>とパスワード<strong>pass@word1</strong>を使用して、WebServ1 にログオンします。
2. サーバー マネージャーを開き、 **[ダッシュボード]** ページにある **[ようこそ]** タイルの **[クイック スタート]** タブで、 **[役割と機能の追加]** をクリックします。 または、 **[管理]** メニューの **[役割と機能の追加]** をクリックする方法もあります。
3. **[開始する前に]** ページで、 **[次へ]** をクリックします。
4. **[インストールの種類の選択]** ページで、 **[役割ベースまたは機能ベースのインストール]** をクリックし、 **[次へ]** をクリックします。
5. **[宛先サーバーの選択]** ページで、 **[サーバー プールからサーバーを選択]** をクリックし、ターゲット コンピューターが選択されていることを確認してから、 **[次へ]** をクリックします。
6. **[サーバーの役割の選択]** ページで、 **[Web サーバー (IIS)]** の横にあるチェック ボックスをオンにして、 **[機能の追加]** をクリックし、 **[次へ]** をクリックします。
7. **[機能の選択]** ページで、 **[Windows Identity Foundation 3.5]** を選択し、 **[次へ]** をクリックします。
8. **[Web サーバーの役割 (IIS)]** ページで、 **[次へ]** をクリックします。
9. **[役割サービスの選択]** ページで、 **[アプリケーション開発]** を選択して展開します。 **[ASP.NET 3.5]** を選択して **[機能の追加]** をクリックし、 **[次へ]** をクリックします。
10. **[インストール オプションの確認]** ページで、 **[代替ソース パスの指定]** をクリックします。 Windows Server 2012 R2 のインストールメディアにある Sxs ディレクトリへのパスを入力します。 たとえば、D:\Sources\Sxs です。 **[OK]** をクリックし、 **[インストール]** をクリックします。
### <a name="BKMK_13"></a>Windows Identity Foundation SDK をインストールする
1. Windowsidentityfoundation-sdk-3.5.msi 3.5 .msi を実行して、Windows Identity Foundation SDK 3.5 (https://www.microsoft.com/download/details.aspx?id=4451)をインストールします。 既定のオプションをすべて選択してください。
### <a name="BKMK_9"></a>単純な要求アプリを IIS で構成する
1. コンピューターの証明書ストアに有効な SSL 証明書をインストールします。 この証明書には、Web サーバーの名前 **webserv1.contoso.com** が含まれている必要があります。
2. C:\Program Files (x86)\Windows Identity Foundation SDK\v3.5\Samples\Quick Start\Web Application\PassiveRedirectBasedClaimsAwareWebApp の内容を C:\Inetpub\Claimapp にコピーします。
3. **Default.aspx.cs** ファイルを編集して、要求のフィルタリングを無効にします。 この手順を実行することで、フェデレーション サーバーが発行するすべての要求がサンプル アプリケーションに表示されます。 次を実行します。
1. **Default.aspx.cs** をテキスト エディターで開きます。
2. ファイル内を検索して `ExpectedClaims`の 2 つ目のインスタンスを見つけます。
3. `IF` ステートメントとその中かっこ全体をコメント アウトします。 行の先頭に "//" (引用符を除く) を入力してコメントを指定します。
4. `FOREACH` ステートメントは次のコード例のようになります。
```
Foreach (claim claim in claimsIdentity.Claims)
{
//Before showing the claims validate that this is an expected claim
//If it is not in the expected claims list then don't show it
//if (ExpectedClaims.Contains( claim.ClaimType ) )
// {
writeClaim( claim, table );
//}
}
```
5. **Default.aspx.cs** を保存して閉じます。
6. **web.config** をテキスト エディターで開きます。
7. `<microsoft.identityModel>` セクション全体を削除します。 `including <microsoft.identityModel>` から `</microsoft.identityModel>`までの内容 (開始および終了タグを含む) をすべて削除します。
8. **web.config** を保存して閉じます。
4. **IIS マネージャーの構成**
1. **インターネット インフォメーション サービス (IIS) マネージャー**を開きます。
2. **[アプリケーション プール]** に移動して **[DefaultAppPool]** を右クリックし、 **[詳細設定]** を選択します。 **[ユーザー プロファイルの読み込み]** を **[True]** に設定して、 **[OK]** をクリックします。
3. **[DefaultAppPool]** を右クリックし、 **[基本設定]** を選択します。 **[.NET CLR バージョン]** を **[.NET CLR バージョン v2.0.50727]** に変更します。
4. **[既定の Web サイト]** を右クリックし、 **[バインドの編集]** を選択します。
5. ポート **443** への **HTTPS** バインドと、インストール済みの SSL 証明書を追加します。
6. **[既定の Web サイト]** を右クリックし、 **[アプリケーションの追加]** を選択します。
7. **claimapp** のエイリアスと **c:\inetpub\claimapp** への物理パスを設定します。
5. フェデレーション サーバーで動作するように **claimapp** を構成するには、次の手順を実行します。
1. FedUtil.exe を実行します (**C:\Program Files (x86)\Windows Identity Foundation SDK\v3.5** にあります)。
2. アプリケーションの構成の場所を " **c:\** " に設定し、アプリケーションの URI にサイトの URL を設定します ( **https://webserv1.contoso.com/claimapp/** )。 **[次へ]** をクリックします。
3. [**既存の STS を使用**する] を選択し、AD FS サーバーのメタデータ URL **https://adfs1.contoso.com/federationmetadata/2007-06/federationmetadata.xml** を参照します。 **[次へ]** をクリックします。
4. **[証明書チェーンの検証を無効にする]** を選択し、 **[次へ]** をクリックします。
5. **[暗号化なし]** を選択し、 **[次へ]** をクリックします。 **[提供された要求]** ページで、 **[次へ]** をクリックします。
6. **[毎日 WS-Federation メタデータを更新するタスクをスケジュールする]** の横にあるチェック ボックスをオンにします。 **[完了]** をクリックします。
7. サンプル アプリケーションの構成が完了しました。 **https://webserv1.contoso.com/claimapp** アプリケーションの URL をテストすると、フェデレーションサーバーにリダイレクトされます。 証明書利用者信頼をまだ構成していないため、フェデレーション サーバーによりエラー ページが表示されます。 つまり、このテストアプリケーションは AD FS によってセキュリティ保護されていません。
Web サーバーで実行されるサンプルアプリケーションを AD FS でセキュリティで保護する必要があります。 これを行うには、フェデレーション サーバー (ADFS1) に証明書利用者信頼を追加します。 これらの手順を説明したビデオを視聴するには、「 [Active Directory フェデレーション サービスの使い方ビデオ シリーズ: 証明書利用者の信頼を追加する](https://technet.microsoft.com/video/adfs-how-to-add-a-relying-party-trust)」を参照してください。
### <a name="BKMK_11"></a>フェデレーションサーバーで証明書利用者信頼を作成する
1. フェデレーション サーバー (ADFS1) で、**AD FS 管理コンソール**の **[証明書利用者信頼]** に移動し、 **[証明書利用者信頼の追加]** をクリックします。
2. **[データ ソースの選択]** ページで、 **[オンラインまたはローカル ネットワークで公開されている証明書利用者についてのデータをインポートする]** を選択して、**claimapp** のメタデータ URL を入力し、 **[次へ]** をクリックします。 FedUtil.exe の実行時にメタデータの .xml ファイルが作成されています。 これは **https://webserv1.contoso.com/claimapp/federationmetadata/2007-06/federationmetadata.xml** にあります。
3. **[表示名の指定]** ページで、証明書利用者信頼 **claimapp** の **[表示名]** を指定し、 **[次へ]** をクリックします。
4. **[多要素認証を今すぐ構成しますか?]** ページで、 **[この証明書利用者信頼に対して多要素認証の設定を今は構成しません]** を選択し、 **[次へ]** をクリックします。
5. **[発行承認規則の選択]** ページで、 **[すべてのユーザーに対してこの証明書利用者へのアクセスを許可する]** を選択し、 **[次へ]** をクリックします。
6. **[信頼の追加の準備完了]** ページで、 **[次へ]** をクリックします。
7. **[要求規則の編集]** ダイアログ ボックスで、 **[規則の追加]** をクリックします。
8. **[規則の種類の選択]** ページで、 **[カスタム規則を使用して要求を送信]** を選択し、 **[次へ]** をクリックします。
9. **[要求規則の構成]** ページで、 **[要求規則名]** ボックスに「**All Claims**」と入力します。 **[カスタム規則]** ボックスに、次の要求規則を入力します。
```
c:[ ]
=> issue(claim = c);
```
10. **[完了]** をクリックし、 **[OK]** をクリックします。
## <a name="BKMK_10"></a>手順 4: クライアントコンピューター (Client1) を構成する
別の仮想マシンをセットアップし、Windows 8.1 をインストールします。 この仮想マシンは、他の仮想マシンと同じ仮想ネットワークに属している必要があります。 このマシンは Contoso ドメインに参加させないでください。
クライアントは、フェデレーション サーバー (ADFS1) で使用される SSL 証明書を信頼する必要があります。これは、「 [Step 2: Configure the federation server (ADFS1) with Device Registration Service](../../ad-fs/deployment/Set-up-the-lab-environment-for-AD-FS-in-Windows-Server-2012-R2.md#BKMK_4)」で設定します。 また、証明書の失効情報の検証が可能になっている必要もあります。
さらに、Client1 にログオンするには、Microsoft アカウントをセットアップして使用する必要があります。
## <a name="see-also"></a>参照
- [Active Directory フェデレーションサービス (AD FS) 方法に関するビデオシリーズ: AD FS サーバーファームのインストール](https://technet.microsoft.com/video/dn469436)
- [Active Directory フェデレーションサービス (AD FS) 方法に関するビデオシリーズ: 証明書の更新](https://technet.microsoft.com/video/adfs-updating-certificates)
- [Active Directory フェデレーションサービス (AD FS) 操作方法ビデオシリーズ: 証明書利用者信頼を追加する](https://technet.microsoft.com/video/adfs-how-to-add-a-relying-party-trust)
- [Active Directory フェデレーションサービス (AD FS) 方法に関するビデオシリーズ: デバイス登録サービスを有効にする](https://technet.microsoft.com/video/adfs-how-to-enabling-the-device-registration-service)
- [Active Directory フェデレーションサービス (AD FS) 方法に関するビデオシリーズ: Web アプリケーションプロキシのインストール](https://technet.microsoft.com/video/dn469438) | 17,655 | CC-BY-4.0 |
### 453. 最小操作次数使数组元素相等
> 题目
[链接](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements/)
> 思路
每次操作n-1个数
> 代码
```js
/**
* @param {number[]} nums
* @return {number}
*/
var minMoves = function(nums) {
const minNum = Math.min(...nums);
let res = 0;
for (const num of nums) {
res += num - minNum;
}
return res;
};
```
> 复杂度分析
时间复杂度:O(n)。
空间复杂度:O(1)。
> 执行
执行用时:60 ms, 在所有 JavaScript 提交中击败了100.00%的用户
内存消耗:41.6 MB, 在所有 JavaScript 提交中击败了37.98%的用户 | 499 | MIT |
---
layout: post
title: "Android 中 scroll 的原理"
subtitle: ""
date: 2014-11-11 12:00:00
author: "boredream"
catalog: false
header-style: text
tags:
- scroll
---
想象一下你拿着放大镜贴很近的看一副巨大的清明上河图, 那放大镜里可以看到的内容是很有限的, 随着放大镜的上下左右移动,就可以看到不同的内容了
android中手机屏幕就相当于这个放大镜, 而看到的内容是画在一个无限大的画布上~
画的内容有限, 而手机屏幕可以看到的东西更有限~ 但是背景画布是无限的
如果把放大镜的移动比作scroll操作,那么可以理解,这个scroll的距离是无限制的~
只不过scroll到有图的地方才能看到内容
参考ScrollView理解, 当child内容过长时,有一部分内容是"看不到"的,相当于"在屏幕之外",
而随着我们的拖动滚动,则慢慢看到剩下的内容,相当于我们拿着放大镜向下移动~
而代码中的这个scroll方法系统提供了两个:
scrollTo和scrollBy
源码如下
```java
/**
* Set the scrolled position of your view. This will cause a call to
* {@link #onScrollChanged(int, int, int, int)} and the view will be
* invalidated.
* @param x the x position to scroll to
* @param y the y position to scroll to
*/
public void scrollTo (int x, int y) {
if (mScrollX != x || mScrollY != y) {
int oldX = mScrollX;
int oldY = mScrollY;
mScrollX = x;
mScrollY = y;
invalidateParentCaches();
onScrollChanged( mScrollX, mScrollY, oldX, oldY);
if (!awakenScrollBars()) {
postInvalidateOnAnimation();
}
}
}
/**
* Move the scrolled position of your view. This will cause a call to
* {@link #onScrollChanged(int, int, int, int)} and the view will be
* invalidated.
* @param x the amount of pixels to scroll by horizontally
* @param y the amount of pixels to scroll by vertically
*/
public void scrollBy( int x, int y) {
scrollTo (mScrollX + x, mScrollY + y);
}
```
* mScrollX 表示离视图起始位置的x水平方向的偏移量
* mScrollY表示离视图起始位置的y垂直方向的偏移量
可以通过getScrollX() 和getScrollY()方法分别获得
两个方法的区别就是
* to参数是绝对值
* by是相对于当前滚动到的位置的增量值
比如:
```java
mScrollX=100, mScrollY=100
scrollTo(20, 20) -> mScrollX=20, mScrollY=20;
scrollBy(20, 20) -> mScrollX=120,mScrollY=120;
```
注意:
这里mScrollX和mScrollY的值是偏移量,是相对于视图起始位置的偏移量~
所以任何view,无论布局是怎么样的,只要是刚初始化未经过scroll的,偏移量都是0~
即mScrollX/Y是相对于自己初始位置的偏移量,而不是相对于其容器的位置坐标 | 2,067 | Apache-2.0 |
---
layout: post
title: "系统信号处理"
subtitle: "signal vs sigaction"
date: 2022-03-08 16:37:00
author: "Ethan"
header-img: "img/home-bg.jpg"
catalog: false
tags:
- 编程基础
---
# 区别
signal函数和sigaction函数是用了处理系统信号(比如SIGINT,SIGTREM)的函数,signal函数比sigaction函数更为简单,需要对某一个信号比如SIGINT指定一个handler,如果程序运行中收到这个信号,则会由handler负责处理。
但需要注意的是,**signal注册的handler只能被使用一次**,调用handler处理相应信号后,之后再收到这个信号将会按照系统**`默认方式`**处理。
因此,如果需要一直让handler处理这个信号,需要每次在handler函数内部重新用signal函数注册一次handler(一般在handler开始处注册),当然,你可以注册另一个自定义的handler。
但这其实依然有可能带来问题,因为有可能在进入handler后,重新注册handler之前,程序又收到了这个信号,比如SIGINT,那么就按照默认方式处理,即退出程序。
但sigaction不会有这样的问题,不需要重新注册,同时sigaction提供了屏蔽指定信号的功能
# 函数声明
signal的函数声明可以说的上是顶尖难度,如下所示:
>void (*signal(int sig, void (*func)(int)))(int)
可以说,初看一头雾水,但利用David Anderson发明的Clockwise/Spiral Rule(见**References**)可以很好地去理解这个声明,规则如下:
- 从变量名开始,顺时针地螺旋前进,逐一分析语句含义,直到所有的token都被读取
- 括号内的token优先分析
So,let's get started.
从signal开始顺时针读取下一个token是(,说明signal是一个函数,进入了括号,那就先把括号内的token都分析完,也就是内部的这个
>(int sig,void (*func)(int))
说明函数第一个形参是int,第二个继续按照Clockwise/Spiral Rule分析,从func开始,顺时针读取下一个是),是括号,那优先处理括号内的token,继续顺时针读取下一个是*,说明func是一个指针,继续顺时针读取下一个,得到(,说明func是一个指针,指向一个函数,函数的参数是int,继续顺时针读取,得到void,说明func是一个指针,指向的函数参数为int,返回值为void。
到此,我们回到signal本身,我们可以得出,signal是一个函数,有两个参数,第一个参数是int,第二个参数是函数指针,继续顺时针读取,得到*,说明signal的返回值是指针,继续读取,得到下一个是(,说明signal的返回值是一个指针,指向函数,函数的参数是int,继续读取,得到void,到此,所有token分析完毕,signal是一个函数,有两个参数,其中参数一是int,参数二是函数指针,是指向参数为int,返回值为void的函数,signal的返回值也是个函数指针,指向参数为int,返回值为void的函数
# 示例程序
下面是signal函数的简单应用
```c
#include<stdio.h>
#include<stdlib.h>
#include<signal.h>
#include<windows.h>
int num=1;
void sigintHandler(int);
int main(void){
signal(SIGINT, sigintHandler);
while(TRUE){
printf("main thread running\n");
Sleep(1000);
raise(SIGINT);
}
}
/* Signal Handler for SIGINT */
void sigintHandler(int sig_num){
signal(SIGINT, sigintHandler);//重新注册,其实可以注册另一个handler函数
if(num<10){
printf("guess what, i am still alive\n");
num++;
}else{
printf("oops, my life ended\n");
getchar();
exit(0);
}
fflush(stdout);
}
```
# 运行结果

如图所示,程序在收到SIGINT信号后,会转入sigintHandler函数进行处理,直到第10次接收SIGINT信号程序才退出。
# References
- <https://blog.csdn.net/wangzuxi/article/details/44814825>
- http://www.c-faq.com/decl/spiral.anderson.html | 2,335 | Apache-2.0 |
Fecmall扩展-分类产品多语言自动翻译扩展
================
> 通过api引擎,进行多语言自动翻译,对于网站建设初期,您可以只进行基础语言的编辑,其他的多语言通过多语言翻译api进行自动化数据翻译,
节省人力。
### 扩展介绍
对于项目初期,编辑人力有限,对于多语言商城而言,多个语种的翻译非常麻烦,可以使用本扩展,
使用翻译Api引擎,进行自动化翻译成多种语言。
1.支持翻译Fecmall产品数据,分类数据
2.目前实现了的`讯飞翻译`,`google翻译`,`百度翻译`,如果您需要使用其他的翻译引擎,可以根据需要二次开发,架构上可以非常方便的添加其他的任意翻译api引擎。
3.翻译的执行是通过后台的脚本,脚本通过shell进行循环控制,因此不会存在超时的问题。
4.google翻译需要国外信用卡才能申请key,因此还是有一定的门槛。
### 扩展安装
应用市场地址:http://addons.fecmall.com/23681738
应用市场安装扩展文档:[Fecmall 应用市场安装应用扩展](http://www.fecmall.com/doc/fecshop-guide/addons/cn-2.0/guide-fecmall-addons-install.html)
### 科大讯飞配置
> 讯飞的翻译,如果**翻译内容中有html标签,会把标签搞乱!!!因此不适合翻译产品描述,但是这是开发完成后才发现的**,就先这样吧,如果他们翻译api升级
在说把,建议不要使用讯飞翻译
1.科大讯飞注册账户,申请`AppId`,`AppSec`, `AppKey`
1.1科大讯飞-机器翻译
> 基于讯飞自主研发的机器翻译引擎,提供更优质的翻译接口。其中`中英`互译能力媲美大学英语六级水平,目前已逐步支持`英日韩法西俄`等多语种与中文的高品质互译。
**注1**:该翻译器,只能进行`中文`和`其他的语言`的互译,但是其他语言之间不能互译,譬如将`英文`翻译成`法文`,将会报错,其他语言的翻译需要使用`科大讯飞-机器翻译 niutrans`
**注2**:如果您想进行中文和其他语言的互译(基础语言是中文),那么建议使用该翻译引擎,科大讯飞的中外互译效果更好一些, 目前仅支持`英日韩法西俄`
访问网址:https://www.xfyun.cn/services/xftrans ,点击`免费试用`,然后在下图位置处,立即领取·免费包·

进行下单即可,中间存在注册账户,注册账户即可
1.2服务管理
访问:https://www.xfyun.cn/services/xftrans , 点击服务管理
在右侧获取可以看到申请`AppId`,`AppSec`, `AppKey`
2.科大讯飞-机器翻译 niutrans:
> 机器翻译2.0全新上线,基于小牛翻译自主研发的多语种机器翻译引擎,已经支持包括英、日、韩、法、西、俄等100多种语言
**注**:该翻译器,看介绍,不是科大讯飞的,是小牛翻译器,科大讯飞进行了集成。
2.1访问该网址:https://www.xfyun.cn/services/niutrans ,点击`免费试用`,然后在下图位置处,立即领取免费包

进行下单即可。
`科大讯飞-机器翻译` 和 `科大讯飞-机器翻译 niutrans`的`AppId`,`AppSec`, `AppKey`都是完全一致的。
### Google Translate配置
申请key的地址:https://cloud.google.com/translate/docs/basic/setup-basic
Google Translate Api的申请,需要绑定国外的信用卡(地址中没有中国选项),因此,使用需要一定的门槛。
### Baidu 翻译
百度翻译Api:https://api.fanyi.baidu.com/
通用翻译API接入文档: https://api.fanyi.baidu.com/product/113
审核个开发者认证要2天时间,也真是吐了。
### 后台配置
1.进行fecmall后台,填写配置即可

2.对于各个选项的参数,后台的参数后面都有说明,这里不做说明
### console执行翻译脚本
1.使用`科大讯飞-机器翻译` **2020-03-17测试,不能翻译Html,不建议使用**
> 上面已经标注,这里进行重复说明,只能进行`中文`和`其他的语言`的互译,但是其他语言之间不能互译,譬如将`英文`翻译成`法文`,将会报错
,目前,基于讯飞自主研发的机器翻译引擎,提供更优质的翻译接口。其中`中英`互译能力媲美大学英语六级水平,目前已逐步支持`英日韩法西俄`等多语种与中文的高品质互译。
因此,在使用该翻译api引擎,只有下面两种情况支持
1.1基础语言是`cn`,进行翻译的目标语言,目标语言必须是`英日韩法西俄`。
1.2基础语言是`英日韩法西俄`中的一种 ,目标语言是`cn`。
此翻译的优势是,翻译优质,尤其是`中英`,劣势是支持的语言有限。

2.使用科大讯飞-机器翻译 niutrans **2020-03-17测试,不能翻译Html,不建议使用**
> 机器翻译2.0全新上线,基于小牛翻译自主研发的多语种机器翻译引擎,已经支持包括英、日、韩、法、西、俄等100多种语言
,该翻译器,看介绍,不是科大讯飞的,是小牛翻译器,科大讯飞进行了集成。
优势:基础语言和目标语言没有限制,支持100多种语言。
基础上满足您的需要,可以将任意语言进行翻译,多语言支持度堪比`google translate`,但是翻译结果没有对比,
您可以将英文翻译成其他的任意语言,或者将中文翻译成其他的任意语言。
3.使用google翻译Api引擎
google翻译api应该是最好用的,但是,申请有点麻烦, 需要绑定国外信用卡才行。
Api使用的是`https://translate.googleapis.com/language/translate/v2`, 而不是 `https://www.googleapis.com/language/translate/v2`
,因此国内不翻墙也可以进行翻译.
4.百度翻译Api
5.执行脚本
> 在执行脚本前,您需要在后台配置部分,选择相应的翻译Api引擎,以及其他的选项,然后再执行脚本

对于各个选项的参数,后台的参数后面都有说明,这里不做说明
**在执行翻译脚本之前,一定要先备份数据,以免造成损失!!!**
**在执行翻译脚本之前,一定要先备份数据,以免造成损失!!!**
**在执行翻译脚本之前,一定要先备份数据,以免造成损失!!!**
3.1脚本执行命令行
```
cd ./addons/fecmall/fectranslate/shell
sh translate.sh
```
产品的翻译是通过shell进行的循环控制,因此不会存在超时的问题。
3.2如果您的产品比较多,可以通过nohup 执行,这样即使关掉shell窗口,执行也不会终止。
```
nohup sh translate.sh
```
另起一个shell窗口查看执行的log
```
tail -f nohup.out
```
### 二开扩展,让其支持更多的翻译引擎
1.@fectranslate/services/Translate.php
```
public function getEngineList()
{
return [
'Google' => '谷歌翻译',
'Baidu' => '百度翻译',
'Xfyun' => '讯飞云Api',
'Xfyunniutrans' => '讯飞云-小牛翻译Api',
];
}
```
在该函数的返回数组中添加其他的翻译器,譬如添加 'Youdao' => '有道翻译',
2.在文件夹`@fectranslate/services/`下,新建相应的services ,以`有道翻译为例子`,添加文件
@fectranslate/services/Youdao.php
```
<?php
namespace fectranslate\services\translate;
use fecshop\services\Service;
use Yii;
class Baidu extends Service
{
/**
* @param $string | string, 需要翻译的文字
* @param $fromLangCode | string, 需要进行翻译的文字语言
* @param $toLangCode | string, 翻译后的语言
*/
public function translateString($text, $fromLangCode, $toLangCode)
{
// 这里实现有道翻译的api逻辑即可
}
}
``` | 4,154 | BSD-3-Clause |
[](https://www.code-inspector.com/public/project/12/POK/dashboard)
[](https://www.code-inspector.com/public/project/12/POK/dashboard)
[](https://travis-ci.org/pok-kernel)
POK
===
POK kernel, a secure and safe micro-kernel for embedded systems.
More information on https://pok-kernel.github.io/
For commercial support: http://www.reblochon.io.
Contact: pok at gunnm dot org
## 笔记
### 1 获取时间
如果想要在用户程序(即 `examples` 下面的代码)中使用 `pok_time_get` 获取时间,那么要在 `deployment.h` 中定义:
```c
#define POK_NEEDS_GETTICK 1
```
恕我直(tu)言(cao),这个代码的宏定义设计太反人类的。
### 2 新增内核调度
原本的 pok-kernel 似乎本来就是支持抢占的,因为在 `boot.c` 中存在这么一句:
```c
pok_arch_preempt_enable();
```
它会调用对应 ARCH 文件夹下的 `arch.c` 的同名函数实现。
几个重要文件:
+ partition.c: `pok_partition_setup_scheduler`, 60 行左右的位置
+ sched.{c,h}: 添加调度算法
+ schedvalues.h: 添加 `switch-case` 的枚举类型
原本的 kernel 只实现了 RMS 和 RR 调度算法 (参考 `partition.c`, 默认是 RR 调度),要做的就是支持更多的线程调度:
+ POK_SCHED_EDF
+ POK_SCHED_WRR
+ POK_SCHED_PRIORITY
+ POK_SCHED_MLFQ (选做)
目前改动的数据结构:
在 kernel 中:
+ 在 `pok_thread_t` 中新增了 2 成员:`weight` 和 `arrive_time`, 以支持 WRR 算法的实现
- 在 `thread.c` 中均初始化为 0
- 在 `examples` 中的用户程序中,目前可以通过 `pok_thread_attr_t` 中的 `weight, arrive_time` 改变线程的权重
+ 在 `pok_thread_attr_t` 中新增了 2 成员:`weight` 和 `arrive_time`
- 允许在用户程序中通过 `attr` 来修改线程的 `weight` 和 `arrive_time`, 因为内核数据结构用户程序是不可见的
+ 在 `pok_partition_t` 中新增成员:`current_weight`:
- 在 `partition.c` 中初始化为 0
在 libpok 中:
+ 在 `pok_thread_attr_t` 中新增了 2 成员:`weight` 和 `arrive_time`
- 原因同上,用户程序中调用的就是这里的 `attr`
- 最后通过 `libpok` 提供的 API 完成与内核的交互
为了支持分区使用不同的线程调度算法,需要在 `kernel/deployment.h` 中定义:
```c
#define POK_CONFIG_PARTITIONS_SCHEDULER {POK_SCHED_WRR, POK_SCHED_RR, ...}
```
### 3 内核线程调度的函数调用
```c
// 执行当前分区的调度, 是调度开始的地方
pok_sched()
|
V
// 在选中的 partition 中选择一个线程执行(分区调度在线程调度前完成)
pok_elect_thread(elected_partition)
|
V
// 这里就会调用自定义的 pok_sched_part_xxx 调度算法,参考 partition.c 中的 pok_partition_setup_scheduler() 函数
new_partition->sched_func(...)
```
### 4 内核分区调度
在 sched.c 中的 `pok_elect_partition()` 的函数实现。
分区调度其实是通过用户程序中的 `kernel/deployment.h` 中配置如下的宏定义实现的:
```c
/**
* SLOTS 是给每个分区设定一个时间片
* FRAME 是 SLOTS 之和
* ALLOCATION 是分区调度序列(通过分区的 ID 来表示)
* NBSLOTS 表示分区个数
**/
#define POK_CONFIG_SCHEDULING_SLOTS {1000000000, 1000000000, 1000000000, 1000000000}
#define POK_CONFIG_SCHEDULING_MAJOR_FRAME 4000000000
#define POK_CONFIG_SCHEDULING_SLOTS_ALLOCATION {1,1,1,1}
#define POK_CONFIG_SCHEDULING_NBSLOTS 4
``` | 2,588 | BSD-2-Clause |
---
title: OES之九:文件上传下载
author: BeiyanLuansheng
date: 2021-12-30 13:51:10 +0800
categories: [技术积累, Spring-OES]
tags: [Spring, SpringBoot, file]
---
## 上传至服务器本地
上传到服务器本地的指定文件夹下,需要判断目录是否存在,如果不存在就创建,创建好之后就可以把 `MultipartFile` 对象存在指定位置了
```java
import org.oes.biz.service.FileService;
import org.oes.common.config.BizConfigurations;
import org.oes.common.constans.OesConstant;
import org.oes.common.exception.OesServiceException;
import org.oes.common.utils.StringUtils;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
public class FileServiceImpl implements FileService {
@Override
public void uploadFile(MultipartFile file, String fileName) {
if (StringUtils.isBlank(fileName)) {
fileName = file.getOriginalFilename();
}
File dest = new File( BizConfigurations.avatarDictionary + "/" + fileName);
if (!dest.getParentFile().exists()) {
dest.getParentFile().mkdirs();
}
try {
file.transferTo(dest);
} catch (Exception e) {
throw new OesServiceException("文件" + file.getOriginalFilename() + "上传失败");
}
}
}
```
测试
```java
@RequestMapping(value = "file/upload", method = RequestMethod.POST)
public String fileUp(@RequestParam("files") MultipartFile[] files) {
JSONObject object=new JSONObject();
for (MultipartFile file : files) {
fileService.uploadFile(file, null);
}
object.put("success",1);
object.put("result","文件上传成功");
return object.toString();
}
```
在这个 Controller 中使用了 file 数组,如果每次只需要上传一个文件,可以使用单个对象
## 上传至对象存储服务器
### 添加依赖
```xml
<!-- MinIO存储 -->
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.3.4</version>
<exclusions>
<exclusion>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.9.3</version>
</dependency>
```
官方给出的文档可以直接使用 io.minio:minio 但是我在启动的时候遇到了 `okhttp3.RequestBody.create()` 方法的两个参数类型是反的的错误,所以只能把低版本的 okhttp 排掉,使用高版本的,高版本的已经解决了这个问题
MinIO 搭建参见 [MiniIO 入门教程](https://beiyanluansheng.github.io/posts/buildMinIO)
### 配置 Bean
添加配置
```yml
# 系统常量配置
oes:
minio:
endpoint: http://192.168.1.9:9090
root-user: minioadmin
root-password: minioadmin
```
{: file='oes-start/src/main/resources/application-dev.yml'}
创建 Bean
```java
package org.oes.start.tools.minio;
import io.minio.BucketExistsArgs;
import io.minio.MakeBucketArgs;
import io.minio.MinioClient;
import org.oes.common.constans.OesConstant;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Shiro 配置类
*
* @author XuJian
* @since 2022/01/03
*/
@Configuration(proxyBeanMethods = false)
public class MinioConfig {
private static final Logger logger = LoggerFactory.getLogger(MinioConfig.class);
@Value("${oes.minio.endpoint}")
private String endpoint;
@Value("${oes.minio.root-user}")
private String accessKey;
@Value("${oes.minio.root-password}")
private String secretKey;
@Bean
public MinioClient minioClient() {
try {
MinioClient minioClient = MinioClient.builder().endpoint(endpoint).credentials(accessKey, secretKey).build();
boolean isExist = minioClient.bucketExists(BucketExistsArgs.builder().bucket(OesConstant.AVATARS_BUCKET).build());
if(isExist) {
logger.info("avatar 桶已存在,跳过创建");
} else {
// 创建一个名为avatars的存储桶,用于存储照片文件
minioClient.makeBucket(MakeBucketArgs.builder().bucket(OesConstant.AVATARS_BUCKET).build());
}
return minioClient;
} catch (Exception e) {
logger.error("创建 MinioClient 失败", e);
return null;
}
}
}
```
### 文件上传服务
```java
package org.oes.biz.service.impl;
import io.minio.MinioClient;
import io.minio.PutObjectArgs;
import org.oes.biz.service.FileService;
import org.oes.common.exception.OesServiceException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
@Service
public class FileServiceImpl implements FileService {
private static final Logger logger = LoggerFactory.getLogger(FileService.class);
@Resource
private MinioClient minioClient;
/**
* 文件上传服务
*
* @param file 文件
* @param fileName 存储文件名(包含目录路径)
* @param bucket 存储桶
*/
@Override
public void uploadFile(MultipartFile file, String fileName, String bucket) {
try {
minioClient.putObject(
PutObjectArgs.builder().bucket(bucket)
.object(fileName)
.stream(file.getInputStream(), file.getSize(), -1)
.contentType(file.getContentType())
.build());
} catch (Exception e) {
logger.error("上传失败", e);
throw new OesServiceException("文件上传失败,请尝试重新上传!");
}
}
}
```
此处的服务由于是要提供给 Web 端使用的,所以我直接使用了 `MultipartFile` 类型传文件,把它转成 `ImputStream` 再上传
写测试 Controller
```java
@RequestMapping(value = "file/upload", method = RequestMethod.POST)
public String fileUp(@RequestParam("files") MultipartFile[] files) {
for (MultipartFile file : files) {
fileService.uploadFile(file, file.getOriginalFilename(), "test");
}
return "文件上传成功";
}
```


## 参考
<https://cloud.tencent.com/developer/article/1594124> | 6,281 | MIT |
> 本文最初发表于[博客园](),并在[GitHub](https://github.com/smyhvae/Web)上持续更新**前端的系列文章**。欢迎在GitHub上关注我,一起入门和进阶前端。
> 以下是正文。
## 前言
本文主要内容:
- 过渡:transition
- 2D 转换 transform
- 3D 转换 transform
- 动画:animation
## 过渡:transition
`transition`的中文含义是**过渡**。过渡是CSS3中具有颠覆性的一个特征,可以实现元素**不同状态间的平滑过渡**(补间动画),经常用来制作动画效果。
- 补间动画:自动完成从起始状态到终止状态的的过渡。不用管中间的状态。
- 帧动画:通过一帧一帧的画面按照固定顺序和速度播放。如电影胶片。
参考链接:[补间动画基础](http://mux.alimama.com/posts/1009)
transition 包括以下属性:
- `transition-property: all;` 如果希望所有的属性都发生过渡,就使用all。
- `transition-duration: 1s;` 过渡的持续时间。
- `transition-timing-function: linear;` 运动曲线。属性值可以是:
- `linear` 线性
- `ease` 减速
- `ease-in` 加速
- `ease-out` 减速
- `ease-in-out` 先加速后减速
- `transition-delay: 1s;` 过渡延迟。多长时间后再执行这个过渡动画。
上面的四个属性也可以写成**综合属性**:
```javascript
transition: 让哪些属性进行过度 过渡的持续时间 运动曲线 延迟时间;
transition: all 3s linear 0s;
```
其中,`transition-property`这个属性是尤其需要注意的,不同的属性值有不同的现象。我们来示范一下。
如果设置 `transition-property: width`,意思是只让盒子的宽度在变化时进行过渡。效果如下:

如果设置 `transition-property: all`,意思是让盒子的所有属性(包括宽度、背景色等)在变化时都进行过渡。效果如下:

### 案例:小米商品详情
代码:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSS 过渡</title>
<style>
body {
margin: 0;
padding: 0;
background-color: #eeeeee;
}
.content {
width: 800px;
height: 320px;
padding-left: 20px;
margin: 80px auto;
}
.item {
width: 230px;
height: 300px;
text-align: center;
margin-right: 20px;
background-color: #FFF;
float: left;
position: relative;
top: 0;
overflow: hidden; /* 让溢出的内容隐藏起来。意思是让下方的橙色方形先躲起来 */
transition: all .5s; /* 从最初到鼠标悬停时的过渡 */
}
.item img {
margin-top: 30px;
}
.item .desc {
position: absolute;
left: 0;
bottom: -80px;
width: 100%;
height: 80px;
background-color: #ff6700;
transition: all .5s;
}
/* 鼠标悬停时,让 item 整体往上移动5px,且加一点阴影 */
.item:hover {
top: -5px;
box-shadow: 0 0 15px #AAA;
}
/* 鼠标悬停时,让下方的橙色方形现身 */
.item:hover .desc {
bottom: 0;
}
</style>
</head>
<body>
<div class="content">
<div class="item">
<img src="./images/1.png" alt="">
</div>
<div class="item">
<img src="./images/2.png" alt="">
<span class="desc"></span>
</div>
<div class="item">
<img src="./images/3.jpg" alt="">
<span class="desc"></span>
</div>
</div>
</body>
</html>
```
效果如下:

动画效果录制的比较差,但真实体验还是可以的。
工程文件:
- [2018-02-08-小米商品详情过渡](http://download.csdn.net/download/smyhvae/10245871)
## 2D 转换
**转换**是 CSS3 中具有颠覆性的一个特征,可以实现元素的**位移、旋转、变形、缩放**,甚至支持矩阵方式。
转换再配合过渡和动画,可以取代大量早期只能靠 Flash 才可以实现的效果。
在 CSS3 当中,通过 `transform` 转换来实现 2D 转换或者 3D 转换。
- 2D转换包括:缩放、移动、旋转。
我们依次来讲解。
### 1、缩放:`scale`
格式:
```javascript
transform: scale(x, y);
transform: scale(2, 0.5);
```
参数解释: x:表示水平方向的缩放倍数。y:表示垂直方向的缩放倍数。如果只写一个值就是等比例缩放。
取值:大于1表示放大,小于1表示缩小。不能为百分比。
格式举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 1000px;
margin: 100px auto;
}
.box div {
width: 300px;
height: 150px;
background-color: pink;
float: left;
margin-right: 15px;
color: white;
text-align: center;
font: 400 30px/150px “宋体”;
}
.box .box2 {
background-color: green;
transition: all 1s;
}
.box .box2:hover {
/*width: 500px;*/
/*height: 400px;*/
background-color: yellowgreen;
/* transform: css3中用于做变换的属性
scale(x,y):缩放 */
transform: scale(2, 0.5);
}
</style>
</head>
<body>
<div class="box">
<div class="box1">1</div>
<div class="box2">2</div>
<div class="box3">3</div>
</div>
</body>
</html>
```
效果:

上图可以看到,给 box1 设置 2D 转换,并不会把兄弟元素挤走。
### 2、位移:translate
格式:
```javascript
transform: translate(水平位移, 垂直位移);
transform: translate(-50%, -50%);
```
参数解释:
- 参数为百分比,相对于自身移动。
- 正值:向右和向下。 负值:向左和向上。如果只写一个值,则表示水平移动。
格式举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 1000px;
margin: 100px auto;
}
.box > div {
width: 300px;
height: 150px;
border: 1px solid #000;
background-color: red;
float: left;
margin-right: 30px;
}
div:nth-child(2) {
background-color: pink;
transition: all 1s;
}
/* translate:(水平位移,垂直位移)*/
div:nth-child(2):hover {
transform: translate(-50%, -50%);
}
</style>
</head>
<body>
<div class="box">
<div class="box1">1</div>
<div class="box2">2</div>
<div class="box3">3</div>
</div>
</body>
</html>
```
效果:

上图中,因为我在操作的时候,鼠标悬停后,立即进行了略微的移动,所以产生了两次动画。正确的效果应该是下面这样的:

**应用:**让绝对定位中的盒子在父亲里居中
我们知道,如果想让一个**标准流中的盒子在父亲里居中**(水平方向看),可以将其设置`margin: 0 auto`属性。
可如果盒子是绝对定位的,此时已经脱标了,如果还想让其居中(位于父亲的正中间),可以这样做:
```
div {
width: 600px;
height: 60px;
position: absolute; 绝对定位的盒子
left: 50%; 首先,让左边线居中
top: 0;
margin-left: -300px; 然后,向左移动宽度(600px)的一半
}
```
如上方代码所示,我们先让这个宽度为600px的盒子,左边线居中,然后向左移动宽度(600px)的一半,就达到效果了。

现在,我们还可以利用偏移 translate 来做,这也是比较推荐的写法:
```javascript
div {
width: 600px;
height: 60px;
background-color: red;
position: absolute; 绝对定位的盒子
left: 50%; 首先,让左边线居中
top: 0;
transform: translate(-50%); 然后,利用translate,往左走自己宽度的一半【推荐写法】
}
```
### 3、旋转:rotate
格式:
```javascript
transform: rotate(角度);
transform: rotate(45deg);
```
参数解释:正值 顺时针;负值:逆时针。
举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 200px;
height: 200px;
background-color: red;
margin: 50px auto;
color: #fff;
font-size: 50px;
transition: all 2s; /* 过渡:让盒子在进行 transform 转换的时候,有个过渡期 */
}
/* rotate(角度)旋转 */
.box:hover {
transform: rotate(-405deg); /* 鼠标悬停时,让盒子进行旋转 */
}
</style>
</head>
<body>
<div class="box">1</div>
</div>
</body>
</html>
```
效果:

注意,上方代码中,我们给盒子设置了 transform 中的 rotate 旋转,但同时还要给盒子设置 transition 过渡。如果没有这行过渡的代码,旋转会直接一步到位,效果如下:(不是我们期望的效果)

**案例1:**小火箭
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
html,body{
height:100%;
}
body{
background-color: #DE8910;
}
.rocket{
position: absolute;
left:100px;
top:600px;
height: 120px;
transform:translate(-200px ,200px) rotate(45deg);
transition:all 1s ease-in;
}
body:hover .rocket{
transform:translate(500px,-500px) rotate(45deg);
}
</style>
</head>
<body>
<img class="rocket" src="images/rocket.png" alt=""/>
</body>
</html>
```
上方代码中,我们将 transform 的两个小属性合并起来写了。
小火箭图片的url:<http://img.smyhvae.com/20180208-rocket.png>
**案例2:**扑克牌
rotate 旋转时,默认是以盒子的正中心为坐标原点的。如果想**改变旋转的坐标原点**,可以用`transform-origin`属性。格式如下:
```javascript
transform-origin: 水平坐标 垂直坐标;
transform-origin: 50px 50px;
transform-origin: center bottom; //旋转时,以盒子底部的中心为坐标原点
```
我们来看一下 rotate 结合 transform-origin 的用法举例。
代码如下:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
body {
/*background-color: #eee;*/
}
.box {
width: 300px;
height: 440px;
margin: 100px auto;
position: relative;
}
img {
width: 100%;
transition: all 1.5s;
position: absolute; /* 既然扑克牌是叠在一起的,那就都用绝对定位 */
left: 0;
top: 0;
transform-origin: center bottom; /*旋转时,以盒子底部的中心为坐标原点*/
box-shadow: 0 0 3px 0 #666;
}
.box:hover img:nth-child(6) {
transform: rotate(-10deg);
}
.box:hover img:nth-child(5) {
transform: rotate(-20deg);
}
.box:hover img:nth-child(4) {
transform: rotate(-30deg);
}
.box:hover img:nth-child(3) {
transform: rotate(-40deg);
}
.box:hover img:nth-child(2) {
transform: rotate(-50deg);
}
.box:hover img:nth-child(1) {
transform: rotate(-60deg);
}
.box:hover img:nth-child(8) {
transform: rotate(10deg);
}
.box:hover img:nth-child(9) {
transform: rotate(20deg);
}
.box:hover img:nth-child(10) {
transform: rotate(30deg);
}
.box:hover img:nth-child(11) {
transform: rotate(40deg);
}
.box:hover img:nth-child(12) {
transform: rotate(50deg);
}
.box:hover img:nth-child(13) {
transform: rotate(60deg);
}
</style>
</head>
<body>
<div class="box">
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
<img src="images/pk2.png"/>
<img src="images/pk1.png"/>
</div>
</body>
</html>
```
效果如下:

### 4、倾斜
暂略。
## 3D 转换
### 1、旋转:rotateX、rotateY、rotateZ
**3D坐标系(左手坐标系)**

如上图所示,伸出左手,让拇指和食指成“L”形,大拇指向右,食指向上,中指指向前方。拇指、食指和中指分别代表X、Y、Z轴的正方向,这样我们就建立了一个左手坐标系。
浏览器的这个平面,是X轴、Y轴;垂直于浏览器的平面,是Z轴。
**旋转的方向:(左手法则)**
左手握住旋转轴,竖起拇指指向旋转轴的**正方向**,正向就是**其余手指卷曲的方向**。
从上面这句话,我们也能看出:所有的3d旋转,对着正方向去看,都是顺时针旋转。
**格式:**
```javascript
transform: rotateX(360deg); //绕 X 轴旋转360度
transform: rotateY(360deg); //绕 Y 轴旋转360度
transform: rotateZ(360deg); //绕 Z 轴旋转360度
```
**格式举例:**
(1)rotateX 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.rotateX {
width: 300px;
height: 226px;
margin: 200px auto;
/* 透视 :加给变换的父盒子*/
/* 设置的是用户的眼睛距离 平面的距离*/
/* 透视效果只是视觉上的呈现,并不是正真的3d*/
perspective: 110px;
}
img {
/* 过渡*/
transition: transform 2s;
}
/* 所有的3d旋转,对着正方向去看,都是顺时针旋转*/
.rotateX:hover img {
transform: rotateX(360deg);
}
</style>
</head>
<body>
<div class="rotateX">
<img src="images/x.jpg" alt=""/>
</div>
</body>
</html>
```
效果:

上方代码中,我们最好加个透视的属性,方能看到3D的效果;没有这个属性的话,图片旋转的时候,像是压瘪了一样。
而且,透视的是要加给图片的父元素 div,方能生效。我们在后面会讲解透视属性。
(2)rotateY 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.rotateY {
width: 237px;
height: 300px;
margin: 100px auto;
/* 透视 */
perspective: 150px;
}
img {
transition: all 2s; /* 过渡 */
}
.rotateY:hover img {
transform: rotateY(360deg);
}
</style>
</head>
<body>
<div class="rotateY">
<img src="images/y.jpg" alt=""/>
</div>
</body>
</html>
```
效果:

(3)rotateZ 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.rotateZ {
width: 330px;
height: 227px;
margin: 100px auto;
/* 透视*/
perspective: 200px;
}
img {
transition: all 1s;
}
.rotateZ:hover img {
transform: rotateZ(360deg);
}
</style>
</head>
<body>
<div class="rotateZ">
<img src="images/z.jpg" alt=""/>
</div>
</body>
</html>
```
效果:

**案例**:百度钱包的水平翻转效果
现在有下面这张图片素材:

要求做成下面这种效果:

上面这张图片素材其实用的是精灵图。实现的代码如下:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
body {
background-color: cornflowerblue;
}
.box {
width: 300px;
height: 300px;
/*border: 1px solid #000;*/
margin: 50px auto;
position: relative;
}
.box > div {
width: 100%;
height: 100%;
position: absolute;
/*border: 1px solid #000;*/
border-radius: 50%;
transition: all 2s;
backface-visibility: hidden;
}
.box1 {
background: url(images/bg.png) left 0 no-repeat; /*默认显示图片的左半边*/
}
.box2 {
background: url(images/bg.png) right 0 no-repeat;
transform: rotateY(180deg); /*让图片的右半边默认时,旋转180度,就可以暂时隐藏起来*/
}
.box:hover .box1 {
transform: rotateY(180deg); /*让图片的左半边转消失*/
}
.box:hover .box2 {
transform: rotateY(0deg); /*让图片的左半边转出现*/
}
</style>
</head>
<body>
<div class="box">
<div class="box1"></div>
<div class="box2"></div>
</div>
</body>
</html>
```
### 2、移动:translateX、translateY、translateZ
**格式:**
```javascript
transform: translateX(100px); //沿着 X 轴移动
transform: translateY(360px); //沿着 Y 轴移动
transform: translateZ(360px); //沿着 Z 轴移动
```
**格式举例:**
(1)translateX 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 200px;
height: 200px;
background: green;
transition: all 1s;
}
.box:hover {
transform: translateX(100px);
}
</style>
</head>
<body>
<div class="box">
</div>
</body>
</html>
```
效果:

(2)translateY 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 200px;
height: 200px;
background: green;
transition: all 1s;
}
.box:hover {
transform: translateY(100px);
}
</style>
</head>
<body>
<div class="box">
</div>
</body>
</html>
```
效果:

(3)translateZ 举例:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
body {
/* 给box的父元素加透视效果*/
perspective: 1000px;
}
.box {
width: 250px;
height: 250px;
background: green;
transition: all 1s;
margin: 200px auto
}
.box:hover {
/* translateZ必须配合透视来使用*/
transform: translateZ(400px);
}
</style>
</head>
<body>
<div class="box">
</div>
</body>
</html>
```
效果:

上方代码中,如果不加透视属性,是看不到translateZ的效果的。
### 3、透视:perspective
电脑显示屏是一个 2D 平面,图像之所以具有立体感(3D效果),其实只是一种视觉呈现,通过透视可以实现此目的。
透视可以将一个2D平面,在转换的过程当中,呈现3D效果。但仅仅只是视觉呈现出 3d 效果,并不是正真的3d。
格式有两种写法:
- 作为一个属性,设置给父元素,作用于所有3D转换的子元素
- 作为 transform 属性的一个值,做用于元素自身。
格式举例:
```css
perspective: 500px;
```
### 4、3D呈现(transform-style)
3D元素构建是指某个图形是由多个元素构成的,可以给这些元素的**父元素**设置`transform-style: preserve-3d`来使其变成一个真正的3D图形。属性值可以如下:
```css
transform-style: preserve-3d; /* 让 子盒子 位于三维空间里 */
transform-style: flat; /* 让子盒子位于此元素所在的平面内(子盒子被扁平化) */
```
**案例:**立方体
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 250px;
height: 250px;
border: 1px dashed red;
margin: 100px auto;
position: relative;
border-radius: 50%;
/* 让子盒子保持3d效果*/
transform-style: preserve-3d;
/*transform:rotateX(30deg) rotateY(-30deg);*/
animation: gun 8s linear infinite;
}
.box > div {
width: 100%;
height: 100%;
position: absolute;
text-align: center;
line-height: 250px;
font-size: 60px;
color: #daa520;
}
.left {
background-color: rgba(255, 0, 0, 0.3);
/* 变换中心*/
transform-origin: left;
/* 变换*/
transform: rotateY(90deg) translateX(-125px);
}
.right {
background: rgba(0, 0, 255, 0.3);
transform-origin: right;
/* 变换*/
transform: rotateY(90deg) translateX(125px);
}
.forward {
background: rgba(255, 255, 0, 0.3);
transform: translateZ(125px);
}
.back {
background: rgba(0, 255, 255, 0.3);
transform: translateZ(-125px);
}
.up {
background: rgba(255, 0, 255, 0.3);
transform: rotateX(90deg) translateZ(125px);
}
.down {
background: rgba(99, 66, 33, 0.3);
transform: rotateX(-90deg) translateZ(125px);
}
@keyframes gun {
0% {
transform: rotateX(0deg) rotateY(0deg);
}
100% {
transform: rotateX(360deg) rotateY(360deg);
}
}
</style>
</head>
<body>
<div class="box">
<div class="up">上</div>
<div class="down">下</div>
<div class="left">左</div>
<div class="right">右</div>
<div class="forward">前</div>
<div class="back">后</div>
</div>
</body>
</html>
```
## 动画
动画是CSS3中具有颠覆性的特征,可通过设置**多个节点** 来精确控制一个或一组动画,常用来实现**复杂**的动画效果。
### 1、定义动画的步骤
(1)通过@keyframes定义动画;
(2)将这段动画通过百分比,分割成多个节点;然后各节点中分别定义各属性;
(3)在指定元素里,通过 `animation` 属性调用动画。
之前,我们在 js 中定义一个函数的时候,是先定义,再调用:
```javascript
js 定义函数:
function fun(){ 函数体 }
调用:
fun();
```
同样,我们在 CSS3 中**定义动画**的时候,也是**先定义,再调用**:
```javascript
定义动画:
@keyframes 动画名{
from{ 初始状态 }
to{ 结束状态 }
}
调用:
animation: 动画名称 持续时间;
```
其中,animation属性的格式如下:
```javascript
animation: 定义的动画名称 持续时间 执行次数 是否反向 运动曲线 延迟执行。(infinite 表示无限次)
animation: move1 1s alternate linear 3;
animation: move2 4s;
```
**定义动画的格式举例:**
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.box {
width: 100px;
height: 100px;
margin: 100px;
background-color: red;
/* 调用动画*/
/* animation: 动画名称 持续时间 执行次数 是否反向 运动曲线 延迟执行。infinite 表示无限次*/
/*animation: move 1s alternate linear 3;*/
animation: move2 4s;
}
/* 方式一:定义一组动画*/
@keyframes move1 {
from {
transform: translateX(0px) rotate(0deg);
}
to {
transform: translateX(500px) rotate(555deg);
}
}
/* 方式二:定义多组动画*/
@keyframes move2 {
0% {
transform: translateX(0px) translateY(0px);
background-color: red;
border-radius: 0;
}
25% {
transform: translateX(500px) translateY(0px);
}
/*动画执行到 50% 的时候,背景色变成绿色,形状变成圆形*/
50% {
/* 虽然两个方向都有translate,但其实只是Y轴上移动了200px。
因为X轴的500px是相对最开始的原点来说的。可以理解成此时的 translateX 是保存了之前的位移 */
transform: translateX(500px) translateY(200px);
background-color: green;
border-radius: 50%;
}
75% {
transform: translateX(0px) translateY(200px);
}
/*动画执行到 100% 的时候,背景色还原为红色,形状还原为正方形*/
100% {
/*坐标归零,表示回到原点。*/
transform: translateX(0px) translateY(0px);
background-color: red;
border-radius: 0;
}
}
</style>
</head>
<body>
<div class="box">
</div>
</body>
</html>
```
注意好好看代码中的注释。
效果如下:

### 2、动画属性
我们刚刚在调用动画时,animation属性的格式如下:
animation属性的格式如下:
```javascript
animation: 定义的动画名称 持续时间 执行次数 是否反向 运动曲线 延迟执行。(infinite 表示无限次)
animation: move1 1s alternate linear 3;
animation: move2 4s;
```
可以看出,这里的 animation 是综合属性,接下来,我们把这个综合属性拆分看看。
(1)动画名称:
```javascript
animation-name: move;
```
(2)执行一次动画的持续时间:
```javascript
animation-duration: 4s;
```
备注:上面两个属性,是必选项,且顺序固定。
(3)动画的执行次数:
```javascript
animation-iteration-count: 1; //iteration的含义表示迭代
```
属性值`infinite`表示无数次。
(3)动画的方向:
```javascript
animation-direction: alternate;
```
属性值:normal 正常,alternate 反向。
(4)动画延迟执行:
```javascript
animation-delay: 1s;
```
(5)设置动画结束时,盒子的状态:
```javascript
animation-fill-mode: forwards;
```
属性值: forwards:保持动画结束后的状态(默认), backwards:动画结束后回到最初的状态。
(6)运动曲线:
```
animation-timing-function: ease-in;
```
属性值可以是:linear ease-in-out steps()等。
注意,如果把属性值写成**` steps()`**,则表示动画**不是连续执行**,而是间断地分成几步执行。我们接下来专门讲一下属性值 `steps()`。
### steps()的效果
我们还是拿上面的例子来举例,如果在调用动画时,我们写成:
```javascript
animation: move2 4s steps(2);
```
效果如下:

有了属性值 `steps()`,我们就可以作出很多不连续地动画效果。比如时钟;再比如,通过多张静态的鱼,作出一张游动的鱼。
**step()举例:**时钟的简易模型
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
div {
width: 3px;
height: 200px;
background-color: #000;
margin: 100px auto;
transform-origin: center bottom; /* 旋转的中心点是底部 */
animation: myClock 60s steps(60) infinite;
}
@keyframes myClock {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
</style>
</head>
<body>
<div></div>
</body>
</html>
```
上方代码,我们通过一个黑色的长条div,旋转360度,耗时60s,分成60步完成。即可实现。
效果如下:

### 动画举例:摆动的鱼
现在,我们要做下面这种效果:

PS:图片的url是<http://img.smyhvae.com/20180209_1245.gif>,图片较大,如无法观看,可在浏览器中单独打开。
为了作出上面这种效果,要分成两步。
**(1)第一步**:让鱼在原地摆动
鱼在原地摆动并不是一张 gif动图,她其实是由很多张静态图间隔地播放,一秒钟播放完毕,就可以了:

上面这张大图的尺寸是:宽 509 px、高 2160 px。
我们可以理解成,每一帧的尺寸是:宽 509 px、高 270 px。`270 * 8 = 2160`。让上面这张大图,在一秒内从 0px 的位置往上移动2160px,分成8步来移动。就可以实现了。
代码是:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.shark {
width: 509px;
height: 270px; /*盒子的宽高是一帧的宽高*/
border: 1px solid #000;
margin: 100px auto;
background: url(images/shark.png) left top; /* 让图片一开始位于 0 px的位置 */
animation: sharkRun 1s steps(8) infinite; /* 一秒之内,从顶部移动到底部,分八帧, */
}
@keyframes sharkRun {
0% {
}
/* 270 * 8 = 2160 */
100% {
background-position: left -2160px; /* 动画结束时,让图片位于最底部 */
}
}
</style>
</head>
<body>
<div class="sharkBox">
<div class="shark"></div>
</div>
</div>
</body>
</html>
```
效果如下:

我们不妨把上面的动画的持续时间从`1s`改成 `8s`,就可以看到动画的慢镜头:

这下,你应该恍然大悟了。
**(2)第二步**:让鱼所在的盒子向前移动。
实现的原理也很简单,我们在上一步中已经让`shark`这个盒子实现了原地摇摆,现在,让 shark 所在的父盒子 `sharkBox`向前移动,即可。完整版代码是:
```html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
<style>
.shark {
width: 509px;
height: 270px; /* 盒子的宽高是一帧的宽高 */
border: 1px solid #000;
margin: 100px auto;
background: url(images/shark.png) left top; /* 让图片一开始位于 0 px的位置 */
animation: sharkRun 1s steps(8) infinite; /* 一秒之内,从顶部移动到底部,分八帧 */
}
/* 鱼所在的父盒子 */
.sharkBox {
width: 509px;
height: 270px;
animation: sharkBoxRun 20s linear infinite;
}
@keyframes sharkRun {
0% {
}
/* 270 * 8 = 2160 */
100% {
background-position: left -2160px; /* 动画结束时,让图片位于最底部 */
}
}
@keyframes sharkBoxRun {
0% {
transform: translateX(-600px);
}
100% {
transform: translateX(3000px);
}
}
</style>
</head>
<body>
<div class="sharkBox">
<div class="shark"></div>
</div>
</div>
</body>
</html>
```

大功告成。
工程文件如下:
- [2018-02-09-fishes.rar](http://download.csdn.net/download/smyhvae/10255540)
## 我的公众号
想学习**代码之外的技能**?不妨关注我的微信公众号:**千古壹号**(id:`qianguyihao`)。
扫一扫,你将发现另一个全新的世界,而这将是一场美丽的意外:
 | 26,124 | MIT |
# itop
**[在线预览 →](http://itop.ga)**
<!-- vim-markdown-toc -->
## 博客介绍
## 致谢
本博客基于 [mazhuang](https://mazhuang.org)修改,感谢!
[1]: https://github.com/xuxiaolei/chinese-copywriting-guidelines
[2]: https://help.github.com/articles/setting-up-your-pages-site-locally-with-jekyll/
[3]: https://github.com/xuxiaolei/blog/issues/2 | 402 | MIT |
<properties
pageTitle="Mobile Engagement の概念 | Microsoft Azure"
description="Azure Mobile Engagement の概念"
services="mobile-engagement"
documentationCenter="mobile"
authors="piyushjo"
manager="dwrede"
editor="" />
<tags
ms.service="mobile-engagement"
ms.workload="mobile"
ms.tgt_pltfrm="mobile-android"
ms.devlang="na"
ms.topic="get-started-article"
ms.date="02/26/2016"
ms.author="piyushjo" />
# Azure Mobile Engagement の概念
Mobile Engagement は、サポートされているすべてのプラットフォームに共通の概念をいくつかを定義します。この記事では、それらの概念について簡単に説明します。
この記事は、Mobile Engagement を初めて使用する場合に読むことをお勧めします。使用しているプラットフォームに固有のドキュメントも参照してください。プラットフォーム固有のドキュメントには、この記事で説明する概念が詳細に説明され、例および考えられる制限事項が記載されているためです。
## デバイスとユーザー
Mobile Engagement は、各デバイスの一意の識別子を生成することによってユーザーを識別します。この識別子はデバイス ID (または `deviceid`) と呼ばれます。同じデバイスを実行中のすべてのアプリケーションが同じデバイス ID を共有するように生成されます。
暗黙的には、Mobile Engagement では、1 つのデバイスが 1 人のユーザーにのみ属するためユーザーとデバイスは同等の概念であると見なされます。
## セッションとアクティビティ
セッションは、ユーザーが使用を開始してから終了するまでにユーザーによって実行されるアプリケーションの 1 回の使用です。
アクティビティは、1 人のユーザーによって実行されるアプリケーションの特定のサブ パーツ (通常は画面ですが、アプリケーションに適した任意のものにすることができます) の 1 回の使用です。
ユーザーは、一度に 1 つのアクティビティのみを実行できます。
アクティビティは、名前 (64 文字に制限されます) で識別され、必要に応じて (1024 バイトの制限内で) いくつかの追加データを埋め込むことができます。
セッションは、ユーザーが実行する一連のアクティビティから自動的に計算されます。セッションは、ユーザーが最初のアクティビティを開始したときに開始し、最後のアクティビティを終了したときに終了します。これは、セッションを明示的に開始または終了する必要がないことを意味します。代わりに、アクティビティを明示的に開始または停止します。アクティビティが報告されない場合、セッションは報告されません。
## イベント
イベントは、インスタント アクション (ユーザーがボタンを押したり記事を読んだりするなど) のレポートに使用されます。
イベントは、現在のセッションまたは実行中のジョブに関連している場合や、スタンドアロン イベントの場合があります。
イベントは、名前 (64 文字に制限されます) で識別され、必要に応じて (1024 バイトの制限内で) いくつかの追加データを埋め込むことができます。
## エラー
エラーは、アプリケーションで正しく検出された問題 (正しくないユーザー操作や、API 呼び出しの失敗など) をレポートするために使用されます。
エラーは、現在のセッションまたは実行中のジョブに関連している場合や、スタンドアロン エラーの場合があります。
エラーは、名前 (64 文字に制限されます) で識別され、必要に応じて (1024 バイトの制限内で) いくつかの追加データを埋め込むことができます。
## 設定
ジョブは、期間を持つアクション (API 呼び出しの期間、広告の表示時間、バック グラウンド タスクの実行時間、ユーザー操作の期間など) をレポートするために使用されます。
タスクはユーザーの操作なしでバック グラウンドで実行できるため、ジョブはセッションに関連しません。
ジョブは、名前 (64 文字に制限されます) で識別され、必要に応じて (1024 バイトの制限内で) いくつかの追加データを埋め込むことができます。
## クラッシュ
クラッシュは、Mobile Engagement SDK がアプリケーションのエラー (アプリケーションでは検出されない問題がクラッシュを引き起こした場合) をレポートするために自動的に発行します。
## アプリケーション情報
アプリケーション情報 (すなわち app info) は、ユーザーにタグを付けるため、つまりアプリケーションのユーザーに何らかのデータを関連付けるために使用されます (これは、アプリケーション情報が Azure Mobile Engagement プラットフォームのサーバー側に格納される点を除いて、Web の Cookie と同様です)。
アプリケーション情報は、Mobile Engagement SDK の API を使用するか、Mobile Engagement プラットフォームのデバイス API を使用して登録できます。
アプリケーション情報は、デバイスに関連付けられているキー/値ペアです。キーは、アプリケーション情報の名前です (64 文字の ASCII 文字 [a-zA-Z]、[0-9] の数字、およびアンダースコア [\_] に制限されます)。値 (1024 文字に制限されます) には、任意の文字列、整数、日付 (yyyy-MM-dd)、またはブール値 (true または false) を指定できます。
Mobile Engagement 価格条件で定義されている制限内で、任意の数のアプリケーション情報をデバイスに関連付けることができます。指定されたキーについて、Mobile Engagement は最新の値セットのみ追跡します (履歴はありません)。アプリケーション情報の値を設定または変更すると、Mobile Engagement はこのアプリケーション情報の対象ユーザー条件のセット (指定されている場合) の再評価を強制されるため、アプリケーション情報を使用してリアルタイム プッシュをトリガーできます。
## 追加のデータ
追加のデータ (または extras) は、イベント、エラー、アクティビティ、およびジョブにアタッチできる任意のデータです。
extras は JSON オブジェクトと同様に構造化されます。キー/値ペアのツリーで構成されます。キーは、64 文字の ASCII 文字 [a-zA-Z]、[0-9] の数字、およびアンダースコア [\_] に制限され、extras の合計サイズは 1024 文字に制限されます (Mobile Engagement SDK によって JSON でエンコードされた後)。
キー/値ペアのツリー全体が JSON オブジェクトとして格納されます。それにもかかわらず、キー/値の最初のレベルだけが分解されてセグメントのような一部の高度な機能から直接アクセス可能になります (たとえば、値 "scifi" を設定した追加キー "content\_type" を使用して、"content\_viewed" という名前のイベントを過去 1 か月間に 10 回以上送信したすべてのユーザーから構成される "SciFi fans" というセグメントを簡単に定義できます)。したがって、スカラー値 (文字列、日付、整数、ブール値など) を使用したキー/値ペアの単純なリストから構成される extras のみを送信することを強くお勧めします。
## 次のステップ
- [Azure Mobile Engagement 向け Windows ユニバーサル SDK の概要](mobile-engagement-windows-store-sdk-overview.md)
- [Azure モバイル エンゲージメントの Windows Phone Silverlight SDK 概要](mobile-engagement-windows-phone-sdk-overview.md)
- [iOS SDK for Azure Mobile Engagement](mobile-engagement-ios-sdk-overview.md)
- [Android SDK for Azure Mobile Engagement](mobile-engagement-android-sdk-overview.md)
<!---HONumber=AcomDC_0302_2016--> | 3,900 | CC-BY-3.0 |
# 整体知识点
* 后台分层架构模式
* 数据库表设计
* SpringBoot Spring Mybatis 整合
# SpringBoot VS SpringMVC
| SpringBoot | SpringMVC |
| --- | --- |
| 是(整合了很多功能的)工具 | 是框架 |
| 零配置 `yml` | 配置繁琐 `xml` |
| 集成了很多中间件`*.stater` | |
| 内置 `tomcat` | 外置置 `tomcat` |
# 技术选型考虑
* 切合业务
* 社区活跃度
* 团队技术水平
* 版本更新迭代周期
* 试错精神-多体验、多测试
* 安全性
* 成功案例
* 开源精神
# 前后端开发模式(MVVM)
<img src="/assets/images/classOne/01.png">
* 构建聚合项目
<!-- # 数据库建模工具
## PDMan for Mac
# HikariCP 数据库
# MyBatis
## 逆向生成代码
## Mapper
# 事物传播 --> | 485 | MIT |
---
title: 如何:通过命令提示符创建探查器比较报表 | Microsoft Docs
ms.date: 11/04/2016
ms.topic: conceptual
ms.assetid: 00548d16-eb5b-46f7-8a65-862f98a43831
author: mikejo5000
ms.author: mikejo
manager: jillfra
monikerRange: vs-2017
ms.workload:
- multiple
ms.openlocfilehash: d0328e04067770f8837d10d532abb67d16c65e50
ms.sourcegitcommit: 00b71889bd72b6a566586885bdb982cfe807cf54
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 12/03/2019
ms.locfileid: "74776422"
---
# <a name="how-to-create-a-profiler-comparison-report-from-a-command-prompt"></a>如何:通过命令提示符创建探查器比较报告
可生成 [!INCLUDE[vsprvs](../code-quality/includes/vsprvs_md.md)] 分析工具报告,用于比较两个分析数据文件(.vsp 或 .vsps)的性能数据 。 报告显示从一个分析会话到另一个分析会话所发生的差异、性能回归和改进。 报告中的值表示基于指定的首个文件的基线的增量(或变化)。 此增量是通过确定旧值(基准值)与新分析所得结果值之差计算而得。 探查器数据的比较可基于代码中的函数、应用程序中的模块、行、指令指针 (IP) 和类型。
若要列出比较类别和字段的标识符,请键入以下命令行:
**VSPerfReport /querydifftables** *VspFileName1* *VspFileName2*
使用以下语法创建比较报告:
**VSPerfReport /diff** `VspFileName1` *VspFileName2* [ **/** `Options`]
可以向 VSPerfReport /diff 命令行添加下表中的选项。
|选项|说明|
|------------|-----------------|
|DiffThreshold: [Value ]|如果差异低于此百分比阀值,则忽略该差异。 此外,不会显示值低于此阈值的新数据。|
|**DiffTable:** *TableName*|使用此表比较文件。 默认使用函数表。 指定 VSPerfReport /querydifftables 中列出的标识符。|
|**DiffColumn:** *ColumnName*|使用此列对值进行比较。 默认情况下,使用独占样本百分比列。 指定 VSPerfReport /querydifftables 中列出的标识符。| | 1,341 | CC-BY-4.0 |
---
layout: default
title: 通过编辑器添加
---
# 通过卡片编辑器添加音频
<!-- You can use AwesomeTTS to just add or update audio files one-by-one. -->
你可以通过AwesomeTTS来更新或者调整音频文件,但是此方法只能一个一个编辑。
<!-- This method, along with the [on-the-fly method](on-the-fly.html) or the on-demand [presets method](presets.html) might be easier. -->
<!-- ## Instructions -->
## 介绍
1. 在笔记编辑器中选择你想要添加音频的字段。
2. 在工具条中选择小喇叭按钮:mega:
3. 选择一个你希望的语音服务然后做一些配置。
4. 检查输入是否正确。
5. 点击“预览(Preview)”来确认是否是你想要的结果。
6. 点击“记录(Record)”将音频插入到字段中。
<!-- ### Hints -->
### 注意
<!-- - AwesomeTTS will automatically populate the input field of the note editor dialog with whatever was already in the active note field when you opened the dialog. If it was empty, AwesomeTTS will try to populate the input field with whatever is in the system clipboard. The options you set on the [Text tab of the configuration screen](/config/text.html) will apply to this. -->
- AwesomeTTS会自动用你激活的字段内容来填充预览输入框,如果字段为空则会用系统的剪贴板来填充。你可以通过[文本配置](/config/text.html)来应用这些选项。
<!-- - [Mass removal of audio can be done via the card browser](removing.html) later if you decide you do not like the audio you have added to a set of notes. -->
- 如果你想取消生成的音频文件,你可以通过[卡片浏览器批量移除音频](removing.html)来撤销操作。
<!-- - The default keyboard shortcut to launch AwesomeTTS from the note editor dialog is <kbd>Ctrl+T</kbd
> (or <kbd>Cmd+T</kbd
> on Mac OS X.html), which overrides the default Anki shortcut key for LaTeX. If you want to restore the LaTeX shortcut key, you can [change this in AwesomeTTS’s window configuration](/config/windows.html). -->
- 默认的启动AwesomeTTS编辑窗口的快捷键是`Ctrl+T`(Mac OS X是`Cmd+T`),这覆盖了Anki默认启动LaTex的快捷键,如果你想恢复LaTex的快捷键请参考[窗口配置](/config/windows.html)
<!-- ### Screenshots -->
### 截图

> AwesomeTTS的小喇叭

> 记录窗口

> 处理后效果 | 2,015 | MIT |
---
templateKey: blog-post
title: 打造與貓咪一起幸福的理想生活|跟著林子軒獸醫師用科學理解貓行為
date: 2016-12-17T15:04:10.000Z
description: |-
「貓永遠是我們的小小孩,
只要多懂他一點,就能用他真正需要的方式愛他。」
——貓行為獸醫師 林子軒
featuredpost: false
featuredimage: https://pics.seeds.com.tw/courses/cat-behavior/cover_pc.png
tags:
- flavor
- tasting
---
<!--StartFragment-->
# 為了捍衛我的睡眠,我走上貓行為研究這條路
我是全亞洲第一位 IAABC 國際認證的貓行為諮詢師,出版過兩本貓行為書籍,但這並非我原先預期的生涯發展,背後的推手是隻聰明的貓男孩-橘小橘,我生命裡重要的夥伴和家人。
時光倒轉十年前我遇見橘小橘的那天,剛從狗嘴裡死裏逃生的他,眨著渾圓的大眼睛,輕柔地往我身上蹭,彷彿鞋貓劍客翻版,還沒發動招式就得到我整顆心,但自他踏進家門的那刻起,我才發現我犯了養貓最大的錯誤-「以貌取貓」,我們之間的對決從此展開...
<!--EndFragment-->



<!--StartFragment-->
回家沒幾天,橘小橘開始出現各種異常的行為問題,亂撒尿是小事,每天半夜不停哭嚎,創造都市叢林的環繞音效,才讓我既頭痛又心疼。為了安撫他的情緒,我得夜夜抱著顫抖的小橘,直到凌晨重播的八點檔終於演完,才能勉強闔上眼(我因此能倒背如流所有狗血劇情...)。我窮盡各種門路,卻一次次被這隻聰明的貓男孩擊敗,於是轉往國外尋求資源,希望獲得與各國專業動物行為諮詢師交流的機會。
單純秉著一片愛貓的心,我努力通過考核取得認證,成為 IAABC 貓行為研究領域的一份子,進一步與其他成員交流,才終於成功解析小橘的行為問題來自慢性焦慮,並得以對症下藥從根源化解問題。看見他在我懷裡終於不再顫抖,可以安穩地瞇起眼睛入夢,呼嚕呼嚕地,那瞬間,我才知道身為貓奴能感受到最大的快樂,其實就這麼簡單。
感到欣慰之餘,我更看見國內貓咪行為諮詢領域的侷限,從此以破解大眾對貓的迷思為使命,成為專攻貓行為諮詢的獸醫師,我想告訴大家,貓不是神秘、孤僻或難搞,只是你並不理解他。在多年的臨床諮詢經驗中,我更深刻地體悟到,貓行為問題其實大多來自於「人」,每隻個性截然不同的貓咪都有著相同的邏輯天性,但是飼主慣於以主觀的角度解讀,導致傷害一再產生,不僅生活品質低落,也失去照料彼此的信心。反之,當你嘗試以貓的邏輯了解他的需求,你會發現這隻不擅表達情緒的小毛團要求得並不多,而他最努力嘗試的,就是融化你的心。
希望這門線上課程可以給愛貓的你一些指引,即便資源有限,只要掌握貓咪行為的核心原則,除了 WHY,更懂得 HOW(如何去解決),你就能替自己找到最合適的解決方案,創造更和諧的人貓關係,更重要的是,更有自信地為彼此打理好生活。
<!--EndFragment-->

<!--StartFragment-->
# 貓行為獸醫師林子軒
### 講師經歷
IAABC 國際動物行為諮詢協會|貓行為諮詢師(亞洲第一位)
AVSAB 美國獸醫師動物行為協會|會員
杜瑪動物醫院|貓行為門診獸醫師
各大專院校&媒體之貓咪行為諮詢顧問
### 貓行為相關著作
2015《秒懂貓咪,行為學醫師的貓星球解析》
2019《貓邏輯 Cat Logic》
<!--EndFragment-->
<!--StartFragment-->
# 課程章節介紹
### 此次課程設計約 8 小時,我會帶你放下人的主觀意識, 教你用貓的邏輯思考,解決令人頭疼的相處問題。
這是一門系統化的貓咪行為學課程,將帶你從貓的天性、貓與人的互動、貓對環境的需求,以及貓的群體關係,理解貓咪獨特的邏輯與需求,接著探討臨床最常見的貓行為問題。當你們了解貓咪最根本的思考模式和行為目的後,你就能察覺出問題可能的癥結點,並且替自己找到適合且可執行的解決方案。
<!--EndFragment-->
<!--StartFragment-->
# 第一章節《歡迎進入貓咪的世界》




* ・老師介紹與課程介紹
* ・貓咪的天性概論-貓咪為什麼看起來神秘又難搞?
* ・貓咪的性格建立

# 第二章節《貓咪與人的相處》

### 建立關係-理解貓咪的聲音&肢體語言
* ・貓咪的聲音&肢體語言
* ・如何與貓咪建立關係?
* ・親人訓練的正確觀念

### 日常相處-與你的貓咪培養生活默契
* ・溝通&教養原則
* ・作息與生理時鐘調整
* ・響片訓練的原理原則

### 遊戲時光-貓咪的遊戲機制及需求
* ・遊戲的三大滿足條件
* ・互動玩具挑選與有效率的陪玩方式
* ・低成本輕鬆自製藏食玩具

### 減敏訓練-讓你的貓咪生活得更自在
* ・基礎觀念與原則
* ・實例說明:剪指甲

# 第三章節《貓咪對環境的需求》


### 貓咪對環境空間的四大需求
* ・垂直空間需求
* ・躲藏空間需求
* ・地盤標記需求
* ・生活基本需求

### 如何佈置貓咪理想的生活環境
* ・垂直空間:貓跳台、貓走道
* ・躲藏空間:貓窩
* ・地盤標記:貓抓板、貓抓柱
* ・生活需求:貓砂盆、餐碗
* ・其他用品:貓草、費洛蒙用品

### 貓宅空間常見煩惱
* ・貓咪喜歡跳到神桌、中島、流理台怎麼辦?
* ・貓咪喜歡躲在衣櫃、沙發或有危險性的空間怎麼辦?
* ・貓咪總是亂抓家具怎麼辦?

# 第四章節《貓咪的群體關係》


### 貓咪群體關係基本認知
* ・從天性了解貓咪的群體關係
* ・貓咪群體互動模式

### 貓王國地盤觀念
* ・地盤劃分法1:氣味標記(費洛蒙)
* ・地盤劃分法2:視覺標記(貓抓板)

### 多貓家庭教養原則與問題解決
* ・多貓家庭環境用品佈置法則
* ・重要教養觀念
* ・多貓衝突處理機制
* ・如何順利地引薦新貓

# 第五章節《臨床最常見的貓咪行為問題》

其實,貓咪的行為就像一面鏡子,會映照出主人的對待方式,以及環境的潛在問題。
本章節我將帶你從三大核心面向切入,探討臨床常見的貓咪行為問題,讓你更有意識地察覺貓咪異常的行為,舉凡攻擊、焦慮、過度舔舐、異食癖、排泄問題,都會在此章節深入說明。

### 三大核心面向-貓、人、環境
* ・貓咪生心理&多貓互動因子
* ・貓與人互動因子
* ・環境佈置因子

此課程中所提到的觀念以及行為問題臨床案例,旨在幫助各位能夠更好地理解貓咪的需求、行為背後的可能成因,並且覺察貓咪是否可能有行為問題,但是行為問題鑑定仍必須依賴完整的臨床檢驗做為基礎,以便釐清是否有疾病因素,因此若您感覺問題已經嚴重干擾生活品質,一定要尋求專業獸醫師協助,而非自行診斷,才是對貓咪最安全的方式。
# 課程各單元將遵循以下架構, 帶你輕鬆學會貓行為知識,並且實際應用改善生活
<!--EndFragment-->
<!--StartFragment-->
# 富有臨床經驗的獸醫師, 和你分享可靠而實用的貓行為科學
許多貓咪飼主們遇到問題時,上網搜尋通常能輕易地獲得分享與解答,不過卻難以確認資訊是否正確。就如同人們生病時會建議尋求專業協助,在看待貓咪的行為問題上,也是相同的。\
從事獸醫師及貓行為諮詢師這幾年來,我曾為許多飼主進行無數次的診療諮詢、舉辦多場專題講座、撰寫兩本專書,在這門課程中,我會以臨床行為治療經驗和國內外相關研究為根據,將貓行為科學以輕鬆易懂、活潑有趣的方式解說給你聽,並以曾經手過的經典臨床案例,讓你更加明白貓咪的行為邏輯、情緒解讀,以及異常行為背後可能的成因。當你懂得越多,就越能好好服侍你家的貓主子 (誤)!
# 讓你的知識活起來! 課程提供容易執行又有效的行動方案
貓咪不睡覺,半夜在你床上跳?兩隻貓互看不順眼,天天趁你不在家火拼?\
在課程中,我將分享許多可實際解決人貓相處問題的行動方案,我希望在你上完課程後,能將知識融會貫通,實際應用在生活中,對於達成人貓和諧的目標更有信心。比如,我經常遇到飼主困擾於貓咪夜晚不睡覺的問題,長久下來感到身心俱疲。其實只要理解貓咪的生理時鐘,依此在餵食時間及份量、遊戲時間做一點調整,就能讓彼此都一夜好眠。藉由根基於貓行為科學的知識,依循簡單而具體的步驟,相信你會逐漸看到人貓相處的問題有所改善。
<!--EndFragment-->
<!--StartFragment-->
# 貓咪圖文創作者辛卡米克參上! 用有趣活潑的漫畫破題,引起貓奴們的共鳴
有在關注我粉絲團的朋友們,大概都知道我立志成為貓行為梗圖專家 (誤),也喜歡嘗試各種方法,只為了能盡量將正確的貓行為知識傳達給更多人知道,這門課程延續了這樣的概念,因此特別邀請貓咪圖文創作者辛卡米克,為每一個單元繪製單幅漫畫。在課程單元片頭,我們設計以有趣的情境破題,不僅能協助大家更快速理解單元核心主題,相信漫畫中辛卡米克家超鬧事的貓咪們,也一定能引起你的共鳴。這會是一堂知識豐富,卻也逗趣又溫暖的線上課程,希望能幫助到愛貓的你們。
# 貓咪、人、環境— 從三大核心面向,架構化而全面地理解貓咪行為
我們普遍習慣用人類的思考邏輯去判斷貓咪的行為,或是從單一視角去理解問題,因而產生錯誤迷思。比如:「林醫師,貓咪為什麼愛咬我的伴侶腳踝?是不是因為嫉妒?」其實貓咪並沒有這麼複雜的心思,但若他們反覆地做同樣的行為,背後原因究竟是什麼?
這門課程的任務,就是要帶著你從『貓咪本身、貓與人、貓與環境、貓與貓』這四個層面,系統化地去理解貓咪為什麼這樣做?如何滿足貓咪的生活需求?這樣最後我們在談論臨床最常見的『貓行為問題』時,你就能見樹又見林,懂得從多面向地去探討問題可能的成因。課程裡不會提供套模板、治標不治本的答案,因為每一隻貓咪都有其獨特個性,但若從原則性的核心概念出發,學習從貓咪的角度理解他們,或許就能改善互動中的許多衝突,為你和貓咪的和諧生活奠定更紮實的基礎。

# 課程解鎖活動

### 突破1000人
#### 解鎖課程
### 「貓咪逃難指南」
了解更多


### 突破2000人
#### 解鎖課程
### 「貓咪走失處理辦法」
了解更多


# 課後專屬 FB 社團 以及學員限定直播小講堂
正式開課後,將會開設一個專屬於購課學員的FB 社團,供各位學員彼此交流、分享學習心得,我同時會規劃學員限定的 4 場直播小講堂,回覆大家在上課過程中,最常遇到的疑問或困擾,期待與大家在社團直播中交流囉!
社團營運時間:2022.4.20 - 2023.4.20
# 上完這堂課,你將能夠:
* 破除對貓咪行為的常見迷思,從貓行為科學角度去理解行為、肢體語言的含義。
* 透過規律且有品質的互動時間及遊戲,和貓咪建立生活默契,以及「有效的溝通模式」。
* 真正理解貓咪對於環境的基本需求,即使運用有限預算及資源,也能打造出令貓咪自在放鬆的舒適貓宅。
* 理解常見貓行為問題的種類,包含焦慮/排泄/攻擊行為/過度舔毛/異食癖等,並從核心因素去探討行為問題背後的可能成因,及早覺察問題,嘗試從互動方式及環境著手改善。
* 在收編更多貓咪時,擁有正確的知識及評估,來為新貓進入家庭做好準備,預防、甚至是解決衝突,讓每隻貓皇都能舒服地和你生活在一起。
* 更重要的是,不必再因為各種網路教學文章,陷入「自己做得不夠多、不夠好」的擔憂,學習正確的知識觀念,便能在原有的基礎上,為你以及貓咪的生活加分。
# 這堂課適合誰?特別推薦給:
* 與貓相處融洽但想更了解貓咪需求的貓奴
非常用心打理貓咪的生活,把主子照料地服服貼貼,但希望能更加理解在貓咪可愛的外表下,隱藏最真實需求與想要傳達的訊息,讓主子可以過得更舒服輕鬆。同時希望能夠察覺貓咪潛在的行為問題,甚而在問題發生前就先行預防。
* 主子有行為異常的問題卻求助無援的貓奴
主子有各式行為問題包括異食癖、排泄問題、過度舔毛、攻擊行為、焦慮問題...等,希望通盤了解貓咪行為問題可能的肇因,找到適切的解決辦法,讓貓咪可以過得更舒適、快樂。(我強烈建議,無論如何都一定要先尋求專業獸醫諮詢)
* 養了貓後生活品質下降的貓奴
自從養了貓後,因為作息和相處衝突,導致生活品質大幅下降。例如:一到半夜貓咪集體開趴狂歡,東跑西跳,吵得你無法好好睡一覺;清晨鬧鐘都還沒響,主子就跳上床千方百計叫你起床;正要專心工作,主子就對你喵喵叫想要你陪他玩。希望能跟貓咪培養相同的生活頻率與默契,創造平衡的人貓關係與有品質的生活。
* 近期有收編規劃的準貓奴
愛貓許久,近期打算正式收編貓咪,因此著手展開家庭環境的佈置與規劃,以及貓咪飼育知識的了解, 希望能有一堂系統性、完整的課程,幫助自己快速地建立正確的貓行為認知,做好最充足的準備,以縮短彼此的磨合期,讓貓主子能夠良好地融入新家庭。
# 課程影片試看
# 貓行為門診看什麼?
貓行為門診,在獸醫領域中屬於內科的範疇。\
透過諮詢,我替飼主釐清貓咪的行為是否構成問題,並依據完整的臨床檢驗作為基礎,優先確認異常行為背後是否牽涉了疾病因素,若有,以治療為首要之務,接著,才會進一步藉由詳細地問診及觀察,根據貓的外顯行為去分析貓咪產生行為問題的成因,究竟是來自於貓咪的情緒、飼主的養育方式,家中佈置的環境,或是貓咪與其他貓咪相處的模式。
簡單來說,很像是在看貓的身心科!
諸如亂尿尿、攻擊行為(無論是對人或是對其他貓咪)、焦慮問題、過度舔毛,或是異食癖,都是我在門診中最常幫助飼主解決的貓行為問題,除了找出問題根源,我在門診中會提供飼主改善的解決方法,教導飼主如何逐步實踐,進而提升人貓生活的品質。
目前我在**【台北杜瑪動物醫院】**以及**【新竹毛毛村動物醫院】**都有看診,如果你家的貓咪行為怪怪,歡迎一起來找我吧!

# 感謝以下貓助教&場地協助拍攝
### 台中市動物之家后里園區
台灣著名現代化動物收容中心,扭轉昔日收容所陰暗冰冷的刻板印象,讓陽光照耀浪犬浪貓。從動物的需求出發,打造美觀、舒適且友善動物的環境,讓收容犬貓能自在展現最真實的性格,以期提高被認養的機率,此外,致力進行生命教育和動物福利觀念的傳遞。

### 貓欸 Camulet 貓咪主題餐廳
位於新北板橋的貓咪主題餐廳,有貓店員陪吃陪睡,還有中途貓在這裡打工等著認養哦!

# 常見問題Q&A
### 關於課程內容
* Q:請問在哪裡上課?上課時間?
「打造與貓咪一起幸福的理想生活|跟著林子軒獸醫師用科學理解貓行為」為「線上課程」。
課程影片都是預錄好的影片,不是現場直播。我們採用預錄好的影片形式,確保課程內容呈現有一定的水準品質。包含上字幕、字卡及去除講話時的贅字。
課程上線後,你可以隨時隨地透過手機、平板、或電腦在學籽上看課程影片,沒有時間和地點的限制。
* Q: 這門課什麼時候開始上課?
* Q: 請問課程可以看多久?看幾次?
* Q: 請問課程費用包含所有章節嗎?
* Q: 課程解鎖後,要去哪裡看?
* Q: 上課後可以問老師問題嗎?
### 關於課程報名、付款與退費
* Q: 請問人在國外可以報名嗎?
* Q: 我是海外學員,如何付款?
* Q: 購買後沒有收到付款成功通知,怎麼確認已購買完成?
* Q: 看過課程後可以退費嗎?
### 關於登入課程
* Q: 為什麼我登入後沒有顯示課程?
* Q: 可以跟別人購買一組帳號,共用觀看課程嗎?
### 其他問題
* Q: 還有其他問題?
<!--EndFragment--> | 9,999 | MIT |
---
title: 从服务器资源管理器访问 Azure 虚拟机 | Microsoft Docs
description: 概述如何在 Visual Studio 的服务器资源管理器中查看、创建和管理 Azure 虚拟机 (VM)。
services: visual-studio-online
author: ghogen
manager: douge
assetId: eb3afde6-ba90-4308-9ac1-3cc29da4ede0
ms.prod: visual-studio-dev15
ms.technology: vs-azure
ms.custom: vs-azure
ms.workload: azure-vs
ms.topic: conceptual
origin.date: 08/31/2017
ms.date: 09/10/2018
ms.author: v-junlch
ms.openlocfilehash: 7ea08f8c44bf1501050264b0f3665d562c4e429d
ms.sourcegitcommit: d75065296d301f0851f93d6175a508bdd9fd7afc
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/30/2018
ms.locfileid: "52644765"
---
# <a name="accessing-azure-virtual-machines-from-server-explorer"></a>从服务器资源管理器访问 Azure 虚拟机
如果有 Azure 托管的虚拟机,可以在服务器资源管理器中访问它们。 必须首先登录到 Azure 订阅才能查看移动服务。 若要登录,请在服务器资源管理器中打开“Azure”节点的快捷菜单,并选择“连接到 Azure”。
1. 在 Cloud Explorer 中选择虚拟机,并选择 F4 键显示其属性窗口。
下表显示了可用的属性,但这些属性都是只读的。 若要更改这些属性,请使用 [Azure 门户](https://portal.azure.cn)。
| 属性 | 说明 |
| --- | --- |
| DNS 名称 |包含虚拟机 Internet 地址的 URL。 |
| 环境 |对于虚拟机,此属性的值始终为“生产”。 |
| Name |虚拟机的名称。 |
| 大小 |虚拟机的大小,此值反映可用的内存和磁盘空间量。 有关详细信息,请参阅[虚拟机大小](/cloud-services/cloud-services-sizes-specs)。 |
| 状态 |值包括“正在启动”、“已启动”、“正在停止”、“已停止”和“正在检索”状态。 如果出现“正在检索状态”,则表示当前状态未知。 此属性的值不同于 [Azure 门户](https://portal.azure.cn)上使用的值。 |
| SubscriptionID |Azure 帐户的订阅 ID。 可以通过在 [Azure 门户](https://portal.azure.cn)上查看订阅的属性来显示此信息。 |
2. 选择一个终结点节点,并查看“属性” 窗口。
3. 下表描述了可用的终结点属性,但这些属性都是只读的。 若要添加或编辑虚拟机的终结点,请使用 [Azure 门户](https://portal.azure.cn)。
| 属性 | 说明 |
| --- | --- |
| Name |终结点的标识符。 |
| 专用端口 |应用程序的内部网络访问端口。 |
| 协议 |此终结点的传输层使用的协议:TCP 或 UDP。 |
| 公用端口 |用于公开访问应用程序的端口。 |
<!-- Update_Description: update metedata properties --> | 1,714 | CC-BY-4.0 |
# webpack
------
>webpack是一套基于NodeJS的"模块打包工具",
在webpack刚推出的时候就是一个单纯的JS模块打包工具,可以将多个模块的JS文件合并打包到一个文件中
但是随着时间的推移、众多开发者的追捧和众多开发者的贡献
现在webpack不仅仅能够打包JS模块, 还可以打包CSS/LESS/SCSS/图片等其它文件
+ [文档地址](https://www.webpackjs.com/)
##### webpack简单使用步骤:
```node
//1.初始化node
npm init -y
//2.安装webpack
npm install --save-dev webpack
npm install --save-dev webpack-cli
//3.打包
npx webpack 需要打包的js文件
//打包之后的文件会放到dist目录中, 名称叫做main.js
```
## 配置文件webpack.config.js
我们在打包JS文件的时候需要输入: npx webpack index.js
这句指令的含义是: 利用webpack将index.js和它依赖的模块打包到一个文件中
其实在webpack指令中除了可以通过命令行的方式告诉webpack需要打包哪个文件以外,
还可以通过配置文件的方式告诉webpack需要打包哪个文件
配置文件的名称必须叫做: webpack.config.js, 否则直接输入 npx webpack打包会出错
如果要使用其它名称, 那么在输入打包命令时候必须通过 --config 指定配置文件名称
npx webpack --config xxx
##### 常见配置:
```javascript
const path = require("path");
module.exports = {
/*
mode: 指定打包的模式, 模式有两种
一种是开发模式(development): 不会对打包的JS代码进行压缩
还有一种就是上线(生产)模式(production): 会对打包的JS代码进行压缩
* */
mode: "development", // "production" | "development"
/*
entry: 指定需要打包的文件
* */
entry: "./index.js",
/*
output: 指定打包之后的文件输出的路径和输出的文件名称
* */
output: {
/*
filename: 指定打包之后的JS文件的名称
* */
filename: "bundle.js",
/*
path: 指定打包之后的文件存储到什么地方
* */
path: path.resolve(__dirname, "bundle")
}
};
```
## sourcemap
> webpack打包后的文件会自动添加很多代码, 在开发过程中非常不利于我们去调试
因为如果运行webpack打包后的代码,错误提示的内容也是打包后文件的内容
所以为了降低调试的难度, 提高错误代码的阅读性, 我们就需要知道打包后代码和打包之前代码的映射关系
只要有了这个映射关系我们就能很好的显示错误提示的内容, 存储这个映射关系的文件我们就称之为sourcemap
#### 开启方法:
+ 在webpack.config.js中添加`devtool: "配置模式"`,
#### 配置项说明:
eval:
不会单独生成sourcemap文件, 会将映射关系存储到打包的文件中, 并且通过eval存储
优势: 性能最好
缺点: 业务逻辑比较复杂时候提示信息可能不全面不正确
source-map:
会单独生成sourcemap文件, 通过单独文件来存储映射关系
优势: 提示信息全面,可以直接定位到错误代码的行和列
缺点: 打包速度慢
inline:
不会单独生成sourcemap文件, 会将映射关系存储到打包的文件中, 并且通过base64字符串形式存储
cheap:
生成的映射信息只能定位到错误行不能定位到错误列
module:
不仅希望存储我们代码的映射关系, 还希望存储第三方模块映射关系, 以便于第三方模块出错时也能更好的排错
#### 企业中常用配置:
+ 开发模式:
`cheap-module-eval-source-map`
只需要行错误信息, 并且包含第三方模块错误信息, 并且不会生成单独sourcemap文件
+ 线上模式:
`cheap-module-source-map`
只需要行错误信息, 并且包含第三方模块错误信息, 并且会生成单独sourcemap文件
## watch
+ webpack 可以监听打包文件变化,当它们修改后会重新编译打包
那么如何监听打包文件变化呢? 使用 watch
#### watch相关配置watchOptions:
```javascript
/*
poll: 1000 // 每隔多少时间检查一次变动
aggregateTimeout: // 防抖, 和函数防抖一样, 改变过程中不重新打包, 只有改变完成指定时间后才打包
ignored: 排除一些巨大的文件夹, 不需要监控的文件夹, 例如 node_modules
*/
watch: true,
watchOptions: {
aggregateTimeout: 300,
poll: 1000,
ignored: /node_modules/
},
```
## ES6模块
>在 ES6 前, 实现模块化使用的是 RequireJS 或者 seaJS(分别是基于 AMD 规范的模块化库, 和基于 CMD 规范的模块化库)。
ES6 引入了模块化,其设计思想是在编译时就能确定模块的依赖关系,以及输入和输出的变量。
ES6 的模块化分为导出(export) @与导入(import)两个模块。
###### 特点:
+ ES6 的模块自动开启严格模式,不管你有没有在模块头部加上 use strict
+ 模块中可以导入和导出各种类型的变量,如函数,对象,字符串,数字,布尔值,类等。
+ 每个模块都有自己的上下文,每一个模块内声明的变量都是局部变量,不会污染全局作用域。
+ 每一个模块只加载一次(是单例的), 若再去加载同目录下同文件,直接从内存中读取。
##### 导入导出:
```javascript
/*
分开导入导出
export xxx;
import {xxx} from "path";
一次性导入导出
export {xxx, yyy, zzz};
import {xxx, yyy, zzz} from "path";
默认导入导出
export default xxx;
import xxx from "path";
*/
```
##### 注意点:
+ 接收导入变量名必须和导出变量名一致
如果想修改接收变量名可以通过 xxx as newName方式
变量名被修改后原有变量名自动失效
+ 一个模块只能使用一次默认导出, 多次无效
默认导出时, 导入的名称可以和导出的名称不一致
## 配置文件优化
+ 创建三个webpack对的配置文件
+ webpack.config.common.js :公共配置文件
+ webpack.config.dev.js :开发阶段配置文件
+ webpack.config.prod.js :上线阶段配置文件
+ 通过区分项目阶段来对配置文件进行合并
### 合并过程:
1. 安装:
`npm install --save-dev webpack-merge`
2. 进行合并(修改开发阶段和上线阶段的配置文件)
```javascript
const Webpack = require('webpack');
const HtmlWebpackPlugin = require('html-webpack-plugin');
//引入合并插件
const Merge = require("webpack-merge");
//引入公共配置文件
const CommonConfig = require("./webpack.config.common.js");
const DevConfig = {
//配置项
};
//导出合并完的配置文件
module.exports = Merge(CommonConfig, DevConfig);
``` | 3,786 | MIT |
Object基础类
==================
框架基础类,支持动态增删读属性,错误信息管理(setError/getLastError/getErrors)。
1. 实现了\__set,\__get,\__isset,\__unset,\__call魔术方法。
2. 错误信息管理(setError/getLastError/getErrors)让对象业务逻辑封装及对象消息传递变得很简单。
Example #1 使用Object类
```
class MyClass extends \wf\Object {
/**
* 对象错误消息传递实例
* 业务逻辑中设置错误消息后返回false,外部调用时可通getErrors()/getLastError()获取错误信息。
*/
public function demo() {
$this->setError('error 1');
$this->setError('error 2');
return false;
}
}
$my = new MyClass();
// 1、自动创建属性并保存
$my->a1 = 123; // $my->attrs['a1'] = 123;
// 2、判断属性是否存在
true === isset($my->a1); // 通过isset($my->attrs['a1'])实现
// 3、属性位创建则返回null
null === $my->a2;
// 4、智能set/get
$my->setA2(456); // 等价于 $my->a2 = 456;
$my->getA2(); // 等价于 $my->a2;
// 5、错误信息set/get/gets
if(false === $my->demo()) {
$err = $my->getLastError(); // 获取最后一条错误信息
$errs = $my->getErrors(); // 获取全部错误信息
}
``` | 919 | MIT |
---
layout: post
title: 如果你在淘宝卖进口唱片
---
<head>
<!-- Primary Meta Tags -->
<title>如果你在淘宝卖进口唱片</title>
<meta name="title" content="如果你在淘宝卖进口唱片">
<meta name="description" content="二月底淘宝整治贩卖「违规唱片」的店铺。">
<!-- Open Graph / Facebook -->
<meta property="og:type" content="website">
<meta property="og:url" content="https://imisscoverflow.xyz/2020/02/15/2020-02-15-if-you-sell-music-on-taobao/">
<meta property="og:title" content="如果你在淘宝卖进口唱片">
<meta property="og:description" content="二月底淘宝整治贩卖「违规唱片」的店铺。">
<meta property="og:image" content="https://metatags.io/assets/meta-tags-16a33a6a8531e519cc0936fbba0ad904e52d35f34a46c97a2c9f6f7dd7d336f2.png">
<!-- Twitter -->
<meta property="twitter:card" content="summary_large_image">
<meta property="twitter:url" content="http://imisscoverflow.xyz/2020/02/15/2020-02-15-if-you-sell-music-on-taobao/">
<meta property="twitter:title" content="如果你在淘宝卖进口唱片">
<meta property="twitter:description" content="二月底淘宝整治贩卖「违规唱片」的店铺。">
<meta property="twitter:image" content="https://metatags.io/assets/meta-tags-16a33a6a8531e519cc0936fbba0ad904e52d35f34a46c97a2c9f6f7dd7d336f2.png">
</head>
<br>这周初我发现淘宝购物车里面几张「Tokyo Chuo-Line」的唱片失效了。简单说:TCL,东京中央线,是一支日本的爵士乐队,获得过金曲奖的提名。虽然在大陆的知名度相对不是很高,但音乐本身质量很不错。他们没有出品过黑胶格式的唱片,CD 也没有绝版的迹象。本人由于穷,在收藏唱片中会把更加容易退出流通或者更容易被炒起来的唱片放在最高的优先级。TCL 的唱片在这种取向下就只能往后稍稍。<br>
<img src="https://tva1.sinaimg.cn/large/0082zybpgy1gbxa9epvklj30w40u01a2.jpg" alt="IMG_0775" style="zoom:33%;" align='center'/>
<br><!--excerpt-->不过我是知道 TCL 为香港反送中运动发过声的(他们在 Facebook 上明确表态过),被盯上也不是没有可能。2019 年我们先后见证了李志和 my little airport 被封杀,多一个 TCL 也不会太令人惊讶。但我很快就得知这是淘宝针对进口唱片店铺的新一轮整风运动的成果,很多店被一锅端。指望审查者是听过/听说过 TCL 这样的小众艺术家后去精准打击是不现实的,淘宝大概是算准境外艺术家反贼比例会比较大,发挥了一刀切的传统艺能。(btw, 受众极广的反贼,比如李志,待遇是会更加出众的。不仅要下架,淘宝闲鱼豆瓣都要禁止相关关键词显示结果。)<br><br>
在淘宝上买碟,会知道很长一段时间以来,是看不见一些碟上架的,只好加微信。有幸目睹老板们这两天已经轮流出来骂街。以下精选内容截自微信朋友圈:<br><br>
<img src="https://tva1.sinaimg.cn/large/0082zybpgy1gbxazd73hej311x0u04qp.jpg" alt="IMG_0733" style="zoom:50%;" />
<br>「开年第一天,疫情当前惨烈,各行各业即将迎来隆冬,艺文管控也是空前禁收,看这趋势连给大家精神放松的空隙都准备不再留了。」说这话的門唱片主理人谢江川,已经苦苦支持了很多年。門唱片,和比如独音唱片,特别的地方在于他们有实体店,而且他们的实体空间作用不仅是给人一个买碟的地方,也是有乐队参与进来,构成一个更加完整的音乐空间。他们还会参与很多独立音乐人的唱片发行工作。对这些有实体店的店铺来说,网店被关,相当一部分的客流会损失,也许不致命。但你说不准哪一天会不会有人上门去店里翻箱倒柜,找茬说某人的某作品有害社会,把店封了。
<br>爱音乐的人会觉得现实很荒谬,但现实就是这样不乐观。即使你看好风向及时下架被封杀的艺人,侥幸逃过一次次的围剿,你还是要吃饭吧?用爱发电是活不下去的。「台湾的售价里面,5%是版税,20-30%是零售商的利润,20%是生产成本,其余是唱片公司收益。」一张黑胶赚四五十,一张 CD 赚二三十。按照我们这个市场的受众数量计算,一家店一个月能赚多少不会是一个太乐观的数字。疫情进行时,我很喜欢的一家店「熔合音乐」今天下午五点发出了被迫清仓的信息:中古碟全新碟一律七折,以后不再做黑胶唱片。他们的实体店我没有去过,单就淘宝店来说。唱片展示、信息提供和快递的保护方面,熔合做得是最好的。他们也不会随便乱标价(骂的就是你,北京 Li-Pi 唱片)。
<br>
<img src="https://tva1.sinaimg.cn/large/0082zybpgy1gbxccrl362j30v20h8ju1.jpg" alt="image-20200215200717414" style="zoom:50%;" />
<br>坦率地说,我因为有很糟糕的理财理念和消费习惯,是个没积蓄的学生,开不了学意味着没有生活费。但还是东拼西凑了几百块钱,带着兔死狐悲的心情买了几张,完全没有捡到便宜的快乐。追逐梦想很困难,对另一部分人来说则更加的难。中国大陆唱片业者大概就是险象环生,艰难求生,前有堵截,后有追兵,脚下的土壤也不够坚实。我鼓励大家在流媒体当道的时代或多或少继续消费实体音乐。因为这些唱片店,不管是线上还是线下,构成了我们这个神奇的国家音乐生态中看不见但很重要的一部分,他们应该活得比现在更好,让我们一起砸钱来投票。 | 2,928 | MIT |
---
title: 说一说阿里云ossfs
category: aliyun oss ossfs
date: 2016-02-26
tags:
- aliyun
- oss
- ossfs
- 阿里云
categories:
- blogging
isCJKLanguage: true
---
阿里云提供的对象或者文件存储叫[OSS](https://www.aliyun.com/product/oss),为应用程序提供了海量存储,按需付费等服务。应用程序则需要通过[Aliyun OSS](https://www.aliyun.com/product/oss)的各语言SDK才能操作(读,写,遍历等)OSS中的文件。
对运维人员来说,做一些数据维护工作的时候,通过SDK操作[OSS](https://www.aliyun.com/product/oss)中的文件就会比较麻烦。在linux/unix环境下,通常有一些工具把远程文件系统或云盘挂载为本地文件。在网络状况比较好的情况下,操作远程文件就像操作本地文件一样。例如,把[Amazon S3](https://github.com/s3fs-fuse/s3fs-fuse),[Dropbox云盘](https://github.com/joe42/CloudFusion),[可通过ssh登录的远程服务器上的磁盘](https://github.com/libfuse/sshfs)挂载为本地文件系统。
之前也有第三方公司开发的工具把[OSS bucket](https://www.aliyun.com/product/oss)挂载为本地磁盘。出于安全考虑一直为敢使用。
终于,阿里云推出了官方开源版本的[ossfs](https://github.com/aliyun/ossfs),并且提供技术支持(通过工单)。
接下来,聊聊我的使用体会。
<!-- more -->
* 安装,配置都还简单。
* 文档看起来比较详细,但实际操作起来有些就不对。感觉写文档的人,并没有在相应环境上测试过。
* 权限设计的一塌糊涂。[ossfs](https://github.com/aliyun/ossfs)基于[FUSE](https://en.wikipedia.org/wiki/Filesystem_in_Userspace),理当允许非root挂载或卸载OSS bucket。非root用户使用[ossfs](https://github.com/aliyun/ossfs)挂载的文件默认的owner都是**root**! 还好目前有workaround,挂载的时候指定参数,`-ouid=your_uid -ogid=your_gid`来指定文件的owner。
* 性能极其低下!!!一台ECS主机挂载了一个使用内网地址的oss bucket,bucket根下面有2k+子目录(对文件系统而言),bucket内文件总计有28G。然而执行`ls /tmp/<bucket mount point>`超过10分钟都无法完成。而我们[V秘](https://vme360.com)之前用Java实现的[AliyunOSSFS](https://github.com/videome/AliyunOSSFS)执行同样的操作只需要数秒。
* 阿里云相关的技术支持人员及其不专业。很多文件系统,[FUSE](https://en.wikipedia.org/wiki/Filesystem_in_Userspace)等概念都不甚了解。跟他们沟通这些技术问题,首先要花时间进行教育。花费大量时间来沟通,进展确缓慢。
## 总之,[阿里云ossfs](https://github.com/aliyun/ossfs)这个工具远远没有达到**production ready**的质量。无法使用到生产环境中。 | 1,643 | Apache-2.0 |
# 2021-03-23
共 185 条
<!-- BEGIN ZHIHUQUESTIONS -->
<!-- 最后更新时间 Tue Mar 23 2021 23:07:36 GMT+0800 (China Standard Time) -->
1. [「错换人生 28 年」当事人姚策因肝癌去世,如何看待这 28 年被错换的人生?](https://www.zhihu.com/question/450843427)
1. [如何看待南昌大学停运哈啰单车,引进更贵的其他单车,理由却为解决单车停放问题?](https://www.zhihu.com/question/449876845)
1. [如何看待「美国光环」在当代中国青年中消退这一现象,你认为是什么原因造成的?](https://www.zhihu.com/question/450687776)
1. [如何看待清华大学某课程 9:50 上课,八点前教室前三排已被书本占满?](https://www.zhihu.com/question/450613602)
1. [西藏冒险王遗体确认,从冰层打捞出的男尸为王相军,当时情况可能是怎样的?](https://www.zhihu.com/question/450788214)
1. [如何看待网友爆料良品铺子鸡肉肠生蛆,商家称同意赔偿1000元?网红零食食品安全问题如何规范?](https://www.zhihu.com/question/450670795)
1. [如何评价电视剧《山河令》第33-36集,你觉得这个大结局怎么样?](https://www.zhihu.com/question/450874392)
1. [女子拿 offer 后没入职遭 HR 朋友圈晒简历指责,你怎么看女子和 HR 的行为?](https://www.zhihu.com/question/450681573)
1. [马思纯被拍疑似恋情曝光,据悉男方是参加过《乐队的夏天》的盘尼西林乐队主唱张哲轩(小乐),你看好他们吗?](https://www.zhihu.com/question/450806865)
1. [如何看待西安一男子在年会被领导拿烟头烫伤脸,被教育「这样你才能长点记性」?遇到这样的事,你会怎么处理?](https://www.zhihu.com/question/450623455)
1. [辞职过后,工作群是自己退群还是等群主移出?](https://www.zhihu.com/question/404327844)
1. [如何看待「漫画腰」挑战?值得模仿吗?](https://www.zhihu.com/question/450547250)
1. [中俄发布外交部长联合声明释放了哪些信号,会对当前国际局势带来怎样的影响?](https://www.zhihu.com/question/450837070)
1. [你有哪些让人一看就笑死的图片?](https://www.zhihu.com/question/449542337)
1. [三星堆有可能成为「世界第九大奇迹」吗?](https://www.zhihu.com/question/450564126)
1. [母亲身患恶性肿瘤,逼我和女朋友分手,我该如何做?](https://www.zhihu.com/question/448176568)
1. [90 后女博士给新物种命名「派大星」,这是一种怎样的生物?物种命名一般有什么讲究?](https://www.zhihu.com/question/450637881)
1. [高粱大涨 82.1 %,食品价格频繁暴涨,三国央行被迫加息,是否预示大通胀来临?](https://www.zhihu.com/question/450647359)
1. [如何评价荣耀 V40 轻奢版,是否值得入手?](https://www.zhihu.com/question/450596618)
1. [上海科技大学信息学院要求硕士发顶会顶刊才能毕业,985 博士都不要求,这样是否合理?](https://www.zhihu.com/question/450611404)
1. [2021 年 3 月 23 号,A 股为什么暴跌这么惨?](https://www.zhihu.com/question/450823471)
1. [成都某小区多名儿童遭猥亵,嫌疑人系未成年人,案件有哪些值得关注的点?应该如何对受害者进行心理疏导?](https://www.zhihu.com/question/450678200)
1. [如何看待北京交通大学22考研思源教室3月21日开放遭哄抢后,在3月23日被学校强制收回?](https://www.zhihu.com/question/450791071)
1. [小米官宣 3 月 29 日小米 11 Pro、小米 11 Ultra 将正式亮相,有哪些值得关注的?](https://www.zhihu.com/question/450806418)
1. [如何避免间歇性堕落?](https://www.zhihu.com/question/388686475)
1. [三星堆到底涉及怎样的一个文明,可以补一下课吗?](https://www.zhihu.com/question/450397900)
1. [为什么有些人说唐三才是真正的“邪魂师”?](https://www.zhihu.com/question/450043345)
1. [有没有什么一看就是小学生的网名?](https://www.zhihu.com/question/447396757)
1. [现在的年轻人为什么都在一心「搞钱」?](https://www.zhihu.com/question/450839670)
1. [如何看待华南师范本科生一年14篇sci?](https://www.zhihu.com/question/450566025)
1. [如何评价景甜在《司藤》中的表现?](https://www.zhihu.com/question/448203529)
1. [我觉得《进击的巨人》怪诞虫好可怜,为什么大家都要杀它?](https://www.zhihu.com/question/450540617)
1. [玩剧本杀把别人骗急眼了怎么办?](https://www.zhihu.com/question/403823125)
1. [万元电脑都玩不了《赛博朋克2077》,我该怎么办?](https://www.zhihu.com/question/450117423)
1. [有哪些事是上了专科才明白的?](https://www.zhihu.com/question/322703564)
1. [军人的床单为什么都是白色?又有何用处?](https://www.zhihu.com/question/450607304)
1. [为什么说以色列的间谍能力很强大?](https://www.zhihu.com/question/449016871)
1. [谈一个特别帅的男朋友是种怎样的体验?](https://www.zhihu.com/question/365876594)
1. [骁龙 888 在调整好调度后能接近麒麟 9000 吗?](https://www.zhihu.com/question/450206813)
1. [延迟退休影响养老金吗?年轻人生育意愿会受影响吗?](https://www.zhihu.com/question/450689582)
1. [中介未经允许进室友房间帮忙维修,室友的猫受惊乱跑,我手被咬了6个洞,医药费每天小一千,费用该谁出?](https://www.zhihu.com/question/450830083)
1. [如何看待 3 月 23 日百度再次在香港上市?在更熟悉的国内市场环境下,百度能不能翻身?](https://www.zhihu.com/question/450808749)
1. [作为父母,你能接受自己的孩子碌碌无为吗?](https://www.zhihu.com/question/449660969)
1. [宝宝出生多久可以洗澡?](https://www.zhihu.com/question/336710641)
1. [你在什么时候意识到自己的「局限性」?后来是怎么应对的?](https://www.zhihu.com/question/449660946)
1. [人们健身到底是为了什么?](https://www.zhihu.com/question/436302677)
1. [是什么让你突然有了学习的欲望?](https://www.zhihu.com/question/369033564)
1. [猫的什么行为证明它把你当自己人?](https://www.zhihu.com/question/421347011)
1. [有没有特别治愈的句子?](https://www.zhihu.com/question/441984459)
1. [在教育培训机构,教育咨询师如何谈单成功率更大?更能让学生家长动心?](https://www.zhihu.com/question/35731205)
1. [如何评价2021年3月23日发布的黑鲨4系列手机?有哪些亮点和槽点?](https://www.zhihu.com/question/450827348)
1. [什么时候感觉到社会对孕妇的恶意?](https://www.zhihu.com/question/423297136)
1. [请问各位学长学姐大家当年考研复试口语是如何准备的?](https://www.zhihu.com/question/268460229)
1. [有哪些从头甜到尾的青梅竹马文,喜欢平平淡淡不狗血,一直甜的?](https://www.zhihu.com/question/374405076)
1. [如何评价《斗罗大陆》里的唐三?](https://www.zhihu.com/question/375024456)
1. [特斯拉 Model Y 在哪些方面是最有可能翻车的?](https://www.zhihu.com/question/442501004)
1. [如何看待山西大学学生公寓工作日上下午的断电政策?](https://www.zhihu.com/question/450811246)
1. [如何看待 3 月 23 日发布的荣耀 V40 轻奢版?有哪些亮点和不足?](https://www.zhihu.com/question/450680813)
1. [看了十几年的恐怖小说,现在感觉真的没什么恐怖小说能吓着我了,你有什么极其吓人的恐怖小说推荐吗?](https://www.zhihu.com/question/308483390)
1. [浙江大学暂停离校人员邮箱服务,高校毕业生是否有必要继续使用学校邮箱服务?](https://www.zhihu.com/question/450699525)
1. [22 考研的你现在都复习到哪里了?](https://www.zhihu.com/question/411546087)
1. [初中如何考到年级前十?](https://www.zhihu.com/question/353434774)
1. [电子烟将参照卷烟监管,会对电子烟消费带来哪些影响?](https://www.zhihu.com/question/450698204)
1. [成都楼市发布新政,将建立二手房参考价机制,部分楼盘限售期限由 3 年变 5 年,有哪些意义和影响?](https://www.zhihu.com/question/450705022)
1. [如何看待2021科软机试难度?](https://www.zhihu.com/question/450830644)
1. [三星堆和殷墟有啥区别?哪个牛?](https://www.zhihu.com/question/51249517)
1. [如何看待哈尔滨严查生产经营焚烧冥币,称「要无处可买无纸可烧」?祭祀活动中的焚烧行为应该全面禁止吗?](https://www.zhihu.com/question/450608417)
1. [如何看待硕士研究生答辩?](https://www.zhihu.com/question/317931767)
1. [湖人名宿埃尔金·贝勒去世,享年 86 岁,你对他有什么印象?](https://www.zhihu.com/question/450773105)
1. [如何看待英国发生暴乱,大批抗议者冲击布里斯托尔警察局,打砸警察局窗户玻璃?](https://www.zhihu.com/question/450668148)
1. [我国首任核潜艇设计师彭士禄逝世,你想说什么?](https://www.zhihu.com/question/450687543)
1. [痘痘是一辈子都在长吗?](https://www.zhihu.com/question/433086382)
1. [备孕和不备孕区别大吗?](https://www.zhihu.com/question/438113905)
1. [有哪些很有韵味又不俗气的短句适合做个签?](https://www.zhihu.com/question/265579956)
1. [2021 年你决定要入手的数码产品有哪些?](https://www.zhihu.com/question/436883279)
1. [男生眼里的白月光是一个怎么样的存在?](https://www.zhihu.com/question/277228908)
1. [深圳 31 岁女子整容后智力降至 1 岁婴儿水平,为什么会这样?这种情况如何避免?](https://www.zhihu.com/question/450233917)
1. [2022届计算机考研有哪些推荐的院校?](https://www.zhihu.com/question/437678483)
1. [如何看待中国驻法使馆以「小流氓」一词,回怼法国反华学者的辱骂?](https://www.zhihu.com/question/450677021)
1. [在《新世纪福音战士》中真嗣是不是就缺少了个政委?](https://www.zhihu.com/question/426318212)
1. [如何看待外交部发言人宣布中方对彼蒂科菲尔等 10 人和 4 个实体实施制裁?](https://www.zhihu.com/question/450726712)
1. [有什么手机壁纸可以让你捧一年?](https://www.zhihu.com/question/430641061)
1. [如果阿明和阿尼举办婚礼,调查兵团的各位会去参加并送上祝福么?](https://www.zhihu.com/question/443893716)
1. [如何看待黄河大堤内有许多死猪的现象?](https://www.zhihu.com/question/450575059)
1. [在大学如果不加入任何社团和学生组织应该干嘛?](https://www.zhihu.com/question/294755603)
1. [韩剧《窥探》(Mouse)有哪些细思极恐的细节?](https://www.zhihu.com/question/448077552)
1. [操作系统能否知道自己处于虚拟机中?](https://www.zhihu.com/question/359121561)
1. [《一人之下》风天养给王家的拘灵遣将,是不是埋伏着什么后手或者弊病?](https://www.zhihu.com/question/450586244)
1. [张哲瀚和龚俊的演技不相上下,为什么看起来《山河令》对龚俊加成更大?](https://www.zhihu.com/question/450176088)
1. [如果给你六千万,代价是余生都看不见月亮,你会答应吗?](https://www.zhihu.com/question/444969517)
1. [怎么看出一个女人的婚姻幸不幸福?](https://www.zhihu.com/question/276812701)
1. [人在什么情况下会找不到生活的意义?如何应对这种状态?](https://www.zhihu.com/question/449660952)
1. [剑桥英语考试天价考位黑幕曝光,报名费溢价七八倍,机构可锁定八成考位,暴露了哪些问题?该如何整治?](https://www.zhihu.com/question/450788628)
1. [有没有适合发给男朋友的很作的表情包?](https://www.zhihu.com/question/403930549)
1. [如果《龙族三》中绘梨衣,源稚生,源稚女没死,龙族五中路明非到日本后又会怎么样呢?](https://www.zhihu.com/question/281173281)
1. [Doinb 就房管事件正式道歉,你有什么想说的?](https://www.zhihu.com/question/450705943)
1. [如何看待「东京奥运会不接待海外观众」,预估损失超 1500 亿日元?](https://www.zhihu.com/question/450368530)
1. [为什么《原神》的音游活动玩法手感这么差?](https://www.zhihu.com/question/450308105)
1. [开什么车能让人看不出深浅?](https://www.zhihu.com/question/60399965)
1. [机器学习应该准备哪些数学预备知识?](https://www.zhihu.com/question/36324957)
1. [3 月 22 日,中国宣布就涉疆问题对欧洲多名个人及实体实施制裁,释放了什么信号?](https://www.zhihu.com/question/450733396)
1. [如何看待俄外长称中俄关系处于历史最好水平?](https://www.zhihu.com/question/450635810)
1. [如何看待《山河令》第34集预告?](https://www.zhihu.com/question/450730046)
1. [你们都用Python实现了哪些办公自动化?](https://www.zhihu.com/question/441361902)
1. [人类文明若能无限发展下去,必然会走向宇宙深处么?](https://www.zhihu.com/question/446782112)
1. [如何看待出生 40 天女婴遭保姆打耳光,保姆被行拘 15 天?](https://www.zhihu.com/question/450629077)
1. [大学生活怎么也开心不起来怎么办?](https://www.zhihu.com/question/347672970)
1. [高中生怎么才能快乐?](https://www.zhihu.com/question/444888990)
1. [AWE 2021有哪些亮点?](https://www.zhihu.com/question/449417558)
1. [如何看待三星堆考古发掘直播连线盗墓小说作者南派三叔?](https://www.zhihu.com/question/450463840)
1. [迈克尔·乔丹最被人忽视的弱点和强点是什么?](https://www.zhihu.com/question/381742322)
1. [你的舍友能让你反感到什么地步?](https://www.zhihu.com/question/329468701)
1. [为什么泥头车(渣土车)普遍都开得很快?](https://www.zhihu.com/question/20168674)
1. [2021 LPL 春季赛 iG 2:1 V5 锁定季后赛席位,如何评价这场比赛?](https://www.zhihu.com/question/450701332)
1. [过去有哪一个时刻,让你开始放下执念,与生活和解?](https://www.zhihu.com/question/450641470)
1. [有哪些讽刺性极强的文案?](https://www.zhihu.com/question/442190842)
1. [如何长期有效地记住单词?](https://www.zhihu.com/question/305937689)
1. [篮网 113:106 胜奇才,哈登 26 分威少 29 分三双,如何评价这场比赛?](https://www.zhihu.com/question/450604436)
1. [香椿有哪些易上手的家常做法?](https://www.zhihu.com/question/449777043)
1. [有没有那种女追男,男主傲娇最后追妻「火葬场」的言情小说推荐?](https://www.zhihu.com/question/319718396)
1. [有没有什么最让你内心触动的情诗?](https://www.zhihu.com/question/449865474)
1. [最近华为手表的太空人表盘为什么会火?](https://www.zhihu.com/question/450134729)
1. [假如作者不让唐三开挂,结局会怎样?](https://www.zhihu.com/question/449920649)
1. [怎样评价白敬亭、马思纯的新剧《你是我的城池营垒》?](https://www.zhihu.com/question/449239974)
1. [为什么5g题材炒了这么多年,还是没有普及,但是当年换4g的时候却是很快?](https://www.zhihu.com/question/450142028)
1. [有哪些《高达》系列作品给你留下了不可磨灭的印象?](https://www.zhihu.com/question/354042486)
1. [猫咪可以吃水果吗?](https://www.zhihu.com/question/449099936)
1. [如何学好高中历史?](https://www.zhihu.com/question/20167984)
1. [怎么可以淡斑啊?](https://www.zhihu.com/question/330951153)
1. [有哪些沙雕气质满分的朋友圈文案?](https://www.zhihu.com/question/450156741)
1. [如何证明自己是沙雕文案大户?](https://www.zhihu.com/question/438141328)
1. [坚持每天跑步5公里,一年后身体和精神会有什么变化?](https://www.zhihu.com/question/422797771)
1. [如何评价阿里云盘公测,宣布未来也不限速?会给百度网盘带来压力吗?](https://www.zhihu.com/question/450640620)
1. [如何看待刺死女儿 9 岁同桌男子被执行死刑?](https://www.zhihu.com/question/445417919)
1. [有没有生日发的成熟不俗的文案?](https://www.zhihu.com/question/413422913)
1. [如何看待苹果因iPhone 12 系列不含充电器,在巴西被罚款 200 万美元?中国能以同理由罚款吗?](https://www.zhihu.com/question/450509399)
1. [如何评价扎克施耐德爆料的《正义联盟2》废案中出现路易斯出轨超人等剧情?](https://www.zhihu.com/question/447723241)
1. [如何看待「中国人不吃这一套」的周边定制商品火了?「爱国定制新时尚」体现出了什么?](https://www.zhihu.com/question/450491365)
1. [看完扎克·施耐德版的《正义联盟》,你有什么感受?](https://www.zhihu.com/question/450085688)
1. [请问有没有类似《乌合之众》这类让人更能看清生活的书籍推荐?](https://www.zhihu.com/question/447475736)
1. [网传男子偷看少妇洗澡被发现,躲回自己房间后坠亡,家属索赔 88.9 万,该不该赔偿?](https://www.zhihu.com/question/450315310)
1. [怎样自学雅思?](https://www.zhihu.com/question/28431991)
1. [为什么有人说在一线城市月薪 3-5 万的人幸福感最低?你认同吗?](https://www.zhihu.com/question/443469299)
1. [2021 LPL 春季赛 RNG 2:0 RA 提前锁定常规赛前二,你有什么想说的?](https://www.zhihu.com/question/450679746)
1. [室友是二次元怎么相处?](https://www.zhihu.com/question/450552240)
1. [如何看待易会满最新发言称「部分学者、分析师关注外部因素远远超过国内因素」?](https://www.zhihu.com/question/450299255)
1. [如何以「将军出征回来了,他还带回一个怀孕的女子」为开头写一个故事?](https://www.zhihu.com/question/387206244)
1. [如何评价字节跳动收购 MLBB 游戏开发商沐瞳科技?](https://www.zhihu.com/question/450642093)
1. [为什么女生喜欢穿jk?](https://www.zhihu.com/question/449808729)
1. [《创造营 2021》的导师是不是太宽容了?](https://www.zhihu.com/question/442243360)
1. [如何评价《无职转生》第十一集?](https://www.zhihu.com/question/450566418)
1. [怎么让自己变得更加开心起来?](https://www.zhihu.com/question/299527411)
1. [那个让你最长情的爱豆是谁?](https://www.zhihu.com/question/450221257)
1. [作为 00 后的你会生孩子吗?](https://www.zhihu.com/question/449864346)
1. [有哪些好看的小众情头?](https://www.zhihu.com/question/364838629)
1. [很注重一个问题,结婚时门当户对重要,还是彼此相爱重要呢?](https://www.zhihu.com/question/443172002)
1. [如何看待哈尔滨严查生产经营焚烧冥币 :「要无处可买无纸可烧」?](https://www.zhihu.com/question/450619407)
1. [怎么看待《创造营 2021》利路修的顺位感言?](https://www.zhihu.com/question/450408211)
1. [《虹猫蓝兔七侠传》中蓝兔到底应不应该对黑小虎回应点什么?](https://www.zhihu.com/question/449884451)
1. [作家发表作品为什么不喜欢用真名?](https://www.zhihu.com/question/445020832)
1. [你们听到过最恐怖的故事有哪些?](https://www.zhihu.com/question/442359603)
1. [如何让别人心甘情愿地把他所学的教给我?](https://www.zhihu.com/question/38714506)
1. [电脑win10系统有什么好用的软件推荐?](https://www.zhihu.com/question/55582601)
1. [有哪些「春日限定」的时令菜肴?](https://www.zhihu.com/question/449784206)
1. [什么是抗糖化?](https://www.zhihu.com/question/358423618)
1. [用时间放下的人,还要不要再见面?](https://www.zhihu.com/question/447112967)
1. [初三最后一个学期努力还有用吗?](https://www.zhihu.com/question/448026629)
1. [为什么有人讨厌别人说话时夹杂英文?](https://www.zhihu.com/question/31606466)
1. [如何准备2021年的教师编制?](https://www.zhihu.com/question/429140434)
1. [如何看待英特尔回应杨笠代言争议:多元、包容是公司文化重要部分?](https://www.zhihu.com/question/450652563)
1. [有哪些瞬间让你细思恐极?](https://www.zhihu.com/question/443072214)
1. [一个人把一个炸弹扔进我车里,我急忙把炸弹扔出去,结果炸死了路边的另一个人,请问我是否要负刑事责任?](https://www.zhihu.com/question/450417956)
1. [不结婚,老了是不是真的会很惨?](https://www.zhihu.com/question/446978179)
1. [《还珠格格》里,如果皇上先见到的是紫薇,会怎样?](https://www.zhihu.com/question/362175398)
1. [张萌说「好男人要经得起查手机」,你认同吗?恋爱或婚姻中应该查对方手机吗?](https://www.zhihu.com/question/450621757)
1. [如何看待小米将在 3 月 29 日举行的春季新品发布会,你有哪些期待?](https://www.zhihu.com/question/450625816)
1. [重庆一高校体育课引争议:热身跑五公里,三公里限时 15 分钟,学生吐槽「又不是体育学院」,你怎么看?](https://www.zhihu.com/question/450142377)
1. [如何评价所谓小学必背的李商隐诗《送母回乡》,作者竟是现代人李玉臻?](https://www.zhihu.com/question/450324955)
1. [终于接受了自己是一个普通人的事实,这是成熟了还是向社会低头了?](https://www.zhihu.com/question/420819626)
1. [AirPods Pro 戴了总是外耳道发炎,什么原因?](https://www.zhihu.com/question/428688913)
1. [每天坚持冥想的人,最后怎么样了?](https://www.zhihu.com/question/331299818)
1. [大家有可考的有含金量的证书推荐吗 ?](https://www.zhihu.com/question/428848820)
1. [为什么孩子沉迷网络游戏被认为是大问题,而沉迷运动型游戏不同?](https://www.zhihu.com/question/443042437)
1. [不洗脸真的能让皮肤变好吗?](https://www.zhihu.com/question/317026624)
1. [外卖迟到了20分钟,态度也不好,该不该给差评?](https://www.zhihu.com/question/269145266)
<!-- END ZHIHUQUESTIONS --> | 13,655 | MIT |
---
title: "Design Tic-Tac-Toe"
tags: [algorithm]
keywords:
summary:
sidebar: mydoc_sidebar
permalink: algorithm_design_tic_tac_toe.html
folder: algorithm
toc: false
---
## Description
Design a Tic-tac-toe game that is played between two players on a n x n grid.
You may assume the following rules:
1. A move is guaranteed to be valid and is placed on an empty block.
2. Once a winning condition is reached, no more moves is allowed.
3. A player who succeeds in placing n of their marks in a horizontal, vertical, or diagonal row wins the game.
我们默认每次每个玩家落子的地方都是valid的,即我们不必操心玩家怎么落子,他想落在哪里,他选择落子位置的时间复杂度算法等等。
Your TicTacToe object will be instantiated and called as such:
```java
TicTacToe obj = new TicTacToe(n);
int param_1 = obj.move(row,col,player);
```
Follow up: Could you do better than O(n^2) per move() operation?
### Example
```
Given n = 3, assume that player 1 is "X" and player 2 is "O" in the board.
TicTacToe toe = new TicTacToe(3);
toe.move(0, 0, 1); -> Returns 0 (no one wins)
|X| | |
| | | | // Player 1 makes a move at (0, 0).
| | | |
toe.move(0, 2, 2); -> Returns 0 (no one wins)
|X| |O|
| | | | // Player 2 makes a move at (0, 2).
| | | |
toe.move(2, 2, 1); -> Returns 0 (no one wins)
|X| |O|
| | | | // Player 1 makes a move at (2, 2).
| | |X|
toe.move(1, 1, 2); -> Returns 0 (no one wins)
|X| |O|
| |O| | // Player 2 makes a move at (1, 1).
| | |X|
toe.move(2, 0, 1); -> Returns 0 (no one wins)
|X| |O|
| |O| | // Player 1 makes a move at (2, 0).
|X| |X|
toe.move(1, 0, 2); -> Returns 0 (no one wins)
|X| |O|
|O|O| | // Player 2 makes a move at (1, 0).
|X| |X|
toe.move(2, 1, 1); -> Returns 1 (player 1 wins)
|X| |O|
|O|O| | // Player 1 makes a move at (2, 1).
|X|X|X|
```
## Solution 1: 很巧妙的方法,可能有点过于机巧了
Ref: https://leetcode.com/problems/design-tic-tac-toe/
The key observation is that in order to win Tic-Tac-Toe you must have the entire row or column.
Thus, we don't need to keep track of an entire n^2 board. We only need to keep a count for each row and column.
If at any time a row or column matches the size of the board then that player has won.
To keep track of which player, I add one for Player1 and -1 for Player2.
There are two additional variables to keep track of the count of the diagonals. 8
Each time a player places a piece we just need to check the count of that row, column, diagonal and anti-diagonal.
注意!如果这题是一个 OOD 的设计题,那么要注意以下的 和玩家落子即move函数相关的 特殊情况:
* 最后可能无子可落,即 **棋盘已经落满** 的情况
* 还没落满,但 **每个行列和两个对角线都已经没有任何一方赢的可能性了**。即 每一行,每一列,以及2个对角线,都已经有了两个玩家的落子
### Complexity
* Time: O(1),这是 任何一个玩家落子一次以及判断输赢 的时间复杂度。即move函数run一次的TC
* Space: O(n),n是矩阵的行数和列数里更大的那一个
### Java
```java
public class TicTacToe
{
private int size;
private int[] rows; // sum of elements in each row
private int[] cols; // sum of elements in each column
private int diagonal, antiDiagonal;
/** Initialize your data structure here. */
public TicTacToe(int n) {
size = n;
rows = new int[n];
cols = new int[n];
}
/** Player {player} makes a move at ({row}, {col}).
@param row The row of the board.
@param col The column of the board.
@param player The player, can be either 1 or 2.
@return The current winning condition, can be either:
0: No one wins.
1: Player 1 wins.
2: Player 2 wins. */
public int move(int row, int col, int player)
{
int toAdd = 1;
if (player == 2)
toAdd = -1;
// manage rows and columns
rows[row] += toAdd;
if (Math.abs(rows[row]) == size) {
return player;
}
cols[col] += toAdd;
if (Math.abs(cols[col]) == size) {
return player;
}
// manage diagonal and antiDiagonal
if (row == col) {
diagonal += toAdd;
if (Math.abs(diagonal) == size) {
return player;
}
}
if (row + col == size - 1) {
antiDiagonal += toAdd;
if (Math.abs(antiDiagonal) == size) {
return player;
}
}
return 0; // no one won
}
}
```
## Reference
* [Design Tic-Tac-Toe [LeetCode]](https://leetcode.com/problems/design-tic-tac-toe/description/)
{% include links.html %} | 4,372 | MIT |
# 最佳实践
---
## 1 生产者
### 1.1 发送消息注意事项
#### 1 Tags的使用
一个应用尽可能用一个Topic,而消息子类型则可以用tags来标识。tags可以由应用自由设置,只有生产者在发送消息设置了tags,消费方在订阅消息时才可以利用tags通过broker做消息过滤:message.setTags("TagA")。
#### 2 Keys的使用
每个消息在业务层面的唯一标识码要设置到keys字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过topic、key来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
```java
// 订单Id
String orderId = "20034568923546";
message.setKeys(orderId);
```
#### 3 日志的打印
消息发送成功或者失败要打印消息日志,务必要打印SendResult和key字段。send消息方法只要不抛异常,就代表发送成功。发送成功会有多个状态,在sendResult里定义。以下对每个状态进行说明:
- **SEND_OK**
消息发送成功。要注意的是消息发送成功也不意味着它是可靠的。要确保不会丢失任何消息,还应启用同步Master服务器或同步刷盘,即SYNC_MASTER或SYNC_FLUSH。
- **FLUSH_DISK_TIMEOUT**
消息发送成功但是服务器刷盘超时。此时消息已经进入服务器队列(内存),只有服务器宕机,消息才会丢失。消息存储配置参数中可以设置刷盘方式和同步刷盘时间长度,如果Broker服务器设置了刷盘方式为同步刷盘,即FlushDiskType=SYNC_FLUSH(默认为异步刷盘方式),当Broker服务器未在同步刷盘时间内(默认为5s)完成刷盘,则将返回该状态——刷盘超时。
- **FLUSH_SLAVE_TIMEOUT**
消息发送成功,但是服务器同步到Slave时超时。此时消息已经进入服务器队列,只有服务器宕机,消息才会丢失。如果Broker服务器的角色是同步Master,即SYNC_MASTER(默认是异步Master即ASYNC_MASTER),并且从Broker服务器未在同步刷盘时间(默认为5秒)内完成与主服务器的同步,则将返回该状态——数据同步到Slave服务器超时。
- **SLAVE_NOT_AVAILABLE**
消息发送成功,但是此时Slave不可用。如果Broker服务器的角色是同步Master,即SYNC_MASTER(默认是异步Master服务器即ASYNC_MASTER),但没有配置slave Broker服务器,则将返回该状态——无Slave服务器可用。
### 1.2 消息发送失败处理方式
Producer的send方法本身支持内部重试,重试逻辑如下:
- 至多重试2次。
- 如果同步模式发送失败,则轮转到下一个Broker,如果异步模式发送失败,则只会在当前Broker进行重试。这个方法的总耗时时间不超过sendMsgTimeout设置的值,默认10s。
- 如果本身向broker发送消息产生超时异常,就不会再重试。
以上策略也是在一定程度上保证了消息可以发送成功。如果业务对消息可靠性要求比较高,建议应用增加相应的重试逻辑:比如调用send同步方法发送失败时,则尝试将消息存储到db,然后由后台线程定时重试,确保消息一定到达Broker。
上述db重试方式为什么没有集成到MQ客户端内部做,而是要求应用自己去完成,主要基于以下几点考虑:首先,MQ的客户端设计为无状态模式,方便任意的水平扩展,且对机器资源的消耗仅仅是cpu、内存、网络。其次,如果MQ客户端内部集成一个KV存储模块,那么数据只有同步落盘才能较可靠,而同步落盘本身性能开销较大,所以通常会采用异步落盘,又由于应用关闭过程不受MQ运维人员控制,可能经常会发生 kill -9 这样暴力方式关闭,造成数据没有及时落盘而丢失。第三,Producer所在机器的可靠性较低,一般为虚拟机,不适合存储重要数据。综上,建议重试过程交由应用来控制。
### 1.3选择oneway形式发送
通常消息的发送是这样一个过程:
- 客户端发送请求到服务器
- 服务器处理请求
- 服务器向客户端返回应答
所以,一次消息发送的耗时时间是上述三个步骤的总和,而某些场景要求耗时非常短,但是对可靠性要求并不高,例如日志收集类应用,此类应用可以采用oneway形式调用,oneway形式只发送请求不等待应答,而发送请求在客户端实现层面仅仅是一个操作系统系统调用的开销,即将数据写入客户端的socket缓冲区,此过程耗时通常在微秒级。
## 2 消费者
### 2.1 消费过程幂等
RocketMQ无法避免消息重复(Exactly-Once),所以如果业务对消费重复非常敏感,务必要在业务层面进行去重处理。可以借助关系数据库进行去重。首先需要确定消息的唯一键,可以是msgId,也可以是消息内容中的唯一标识字段,例如订单Id等。在消费之前判断唯一键是否在关系数据库中存在。如果不存在则插入,并消费,否则跳过。(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过)
msgId一定是全局唯一标识符,但是实际使用中,可能会存在相同的消息有两个不同msgId的情况(消费者主动重发、因客户端重投机制导致的重复等),这种情况就需要使业务字段进行重复消费。
### 2.2 消费速度慢的处理方式
#### 1 提高消费并行度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。 如下有几种修改消费并行度的方法:
- 同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。
- 提高单个 Consumer 的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax实现。
#### 2 批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量,通过设置 consumer的 consumeMessageBatchMaxSize 返个参数,默认是 1,即一次只消费一条消息,例如设置为 N,那么每次消费的消息数小于等于 N。
#### 3 跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。例如,当某个队列的消息数堆积到100000条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度。示例代码如下:
```java
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
long offset = msgs.get(0).getQueueOffset();
String maxOffset =
msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET);
long diff = Long.parseLong(maxOffset) - offset;
if (diff > 100000) {
// TODO 消息堆积情况的特殊处理
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
// TODO 正常消费过程
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
```
#### 4 优化每条消息消费过程
举例如下,某条消息的消费过程如下:
- 根据消息从 DB 查询【数据 1】
- 根据消息从 DB 查询【数据 2】
- 复杂的业务计算
- 向 DB 插入【数据 3】
- 向 DB 插入【数据 4】
这条消息的消费过程中有4次与 DB的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把DB部署在SSD硬盘,相比于SCSI磁盘,前者的RT会小很多。
### 2.3 消费打印日志
如果消息量较少,建议在消费入口方法打印消息,消费耗时等,方便后续排查问题。
```java
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
log.info("RECEIVE_MSG_BEGIN: " + msgs.toString());
// TODO 正常消费过程
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
```
如果能打印每条消息消费耗时,那么在排查消费慢等线上问题时,会更方便。
### 2.4 其他消费建议
#### 1 关于消费者和订阅
第一件需要注意的事情是,不同的消费者组可以独立的消费一些 topic,并且每个消费者组都有自己的消费偏移量,请确保同一组内的每个消费者订阅信息保持一致。
#### 2 关于有序消息
消费者将锁定每个消息队列,以确保他们被逐个消费,虽然这将会导致性能下降,但是当你关心消息顺序的时候会很有用。我们不建议抛出异常,你可以返回 ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT 作为替代。
#### 3 关于并发消费
顾名思义,消费者将并发消费这些消息,建议你使用它来获得良好性能,我们不建议抛出异常,你可以返回 ConsumeConcurrentlyStatus.RECONSUME_LATER 作为替代。
#### 4 关于消费状态Consume Status
对于并发的消费监听器,你可以返回 RECONSUME_LATER 来通知消费者现在不能消费这条消息,并且希望可以稍后重新消费它。然后,你可以继续消费其他消息。对于有序的消息监听器,因为你关心它的顺序,所以不能跳过消息,但是你可以返回SUSPEND_CURRENT_QUEUE_A_MOMENT 告诉消费者等待片刻。
#### 5 关于Blocking
不建议阻塞监听器,因为它会阻塞线程池,并最终可能会终止消费进程
#### 6 关于线程数设置
消费者使用 ThreadPoolExecutor 在内部对消息进行消费,所以你可以通过设置 setConsumeThreadMin 或 setConsumeThreadMax 来改变它。
#### 7 关于消费位点
当建立一个新的消费者组时,需要决定是否需要消费已经存在于 Broker 中的历史消息CONSUME_FROM_LAST_OFFSET 将会忽略历史消息,并消费之后生成的任何消息。CONSUME_FROM_FIRST_OFFSET 将会消费每个存在于 Broker 中的信息。你也可以使用 CONSUME_FROM_TIMESTAMP 来消费在指定时间戳后产生的消息。
## 3 Broker
### 3.1 Broker 角色
Broker 角色分为 ASYNC_MASTER(异步主机)、SYNC_MASTER(同步主机)以及SLAVE(从机)。如果对消息的可靠性要求比较严格,可以采用 SYNC_MASTER加SLAVE的部署方式。如果对消息可靠性要求不高,可以采用ASYNC_MASTER加SLAVE的部署方式。如果只是测试方便,则可以选择仅ASYNC_MASTER或仅SYNC_MASTER的部署方式。
### 3.2 FlushDiskType
SYNC_FLUSH(同步刷新)相比于ASYNC_FLUSH(异步处理)会损失很多性能,但是也更可靠,所以需要根据实际的业务场景做好权衡。
### 3.3 Broker 配置
| 参数名 | 默认值 | 说明 |
| -------------------------------- | ----------------------------- | ------------------------------------------------------------ |
| listenPort | 10911 | 接受客户端连接的监听端口 |
| namesrvAddr | null | nameServer 地址 |
| brokerIP1 | 网卡的 InetAddress | 当前 broker 监听的 IP |
| brokerIP2 | 跟 brokerIP1 一样 | 存在主从 broker 时,如果在 broker 主节点上配置了 brokerIP2 属性,broker 从节点会连接主节点配置的 brokerIP2 进行同步 |
| brokerName | null | broker 的名称 |
| brokerClusterName | DefaultCluster | 本 broker 所属的 Cluser 名称 |
| brokerId | 0 | broker id, 0 表示 master, 其他的正整数表示 slave |
| storePathRootDir | $HOME/store/ | 存储根路径 |
| storePathCommitLog | $HOME/store/commitlog/ | 存储 commit log 的路径 |
| mappedFileSizeCommitLog | 1024 * 1024 * 1024(1G) | commit log 的映射文件大小 |
| deleteWhen | 04 | 在每天的什么时间删除已经超过文件保留时间的 commit log |
| fileReservedTime | 72 | 以小时计算的文件保留时间 |
| brokerRole | ASYNC_MASTER | SYNC_MASTER/ASYNC_MASTER/SLAVE |
| flushDiskType | ASYNC_FLUSH | SYNC_FLUSH/ASYNC_FLUSH SYNC_FLUSH 模式下的 broker 保证在收到确认生产者之前将消息刷盘。ASYNC_FLUSH 模式下的 broker 则利用刷盘一组消息的模式,可以取得更好的性能。 |
## 4 NameServer
RocketMQ 中,Name Servers 被设计用来做简单的路由管理。其职责包括:
- Brokers 定期向每个名称服务器注册路由数据。
- 名称服务器为客户端,包括生产者,消费者和命令行客户端提供最新的路由信息。
## 5 客户端配置
相对于RocketMQ的Broker集群,生产者和消费者都是客户端。本小节主要描述生产者和消费者公共的行为配置。
### 5.1 客户端寻址方式
RocketMQ可以令客户端找到Name Server, 然后通过Name Server再找到Broker。如下所示有多种配置方式,优先级由高到低,高优先级会覆盖低优先级。
- 代码中指定Name Server地址,多个namesrv地址之间用分号分割
```java
producer.setNamesrvAddr("192.168.0.1:9876;192.168.0.2:9876");
consumer.setNamesrvAddr("192.168.0.1:9876;192.168.0.2:9876");
```
- Java启动参数中指定Name Server地址
```text
-Drocketmq.namesrv.addr=192.168.0.1:9876;192.168.0.2:9876
```
- 环境变量指定Name Server地址
```text
export NAMESRV_ADDR=192.168.0.1:9876;192.168.0.2:9876
```
- HTTP静态服务器寻址(默认)
客户端启动后,会定时访问一个静态HTTP服务器,地址如下:<http://jmenv.tbsite.net:8080/rocketmq/nsaddr>,这个URL的返回内容如下:
```text
192.168.0.1:9876;192.168.0.2:9876
```
客户端默认每隔2分钟访问一次这个HTTP服务器,并更新本地的Name Server地址。URL已经在代码中硬编码,可通过修改/etc/hosts文件来改变要访问的服务器,例如在/etc/hosts增加如下配置:
```text
10.232.22.67 jmenv.taobao.net
```
推荐使用HTTP静态服务器寻址方式,好处是客户端部署简单,且Name Server集群可以热升级。
### 5.2 客户端配置
DefaultMQProducer、TransactionMQProducer、DefaultMQPushConsumer、DefaultMQPullConsumer都继承于ClientConfig类,ClientConfig为客户端的公共配置类。客户端的配置都是get、set形式,每个参数都可以用spring来配置,也可以在代码中配置,例如namesrvAddr这个参数可以这样配置,producer.setNamesrvAddr("192.168.0.1:9876"),其他参数同理。
#### 1 客户端的公共配置
| 参数名 | 默认值 | 说明 |
| ----------------------------- | ------- | ------------------------------------------------------------ |
| namesrvAddr | | Name Server地址列表,多个NameServer地址用分号隔开 |
| clientIP | 本机IP | 客户端本机IP地址,某些机器会发生无法识别客户端IP地址情况,需要应用在代码中强制指定 |
| instanceName | DEFAULT | 客户端实例名称,客户端创建的多个Producer、Consumer实际是共用一个内部实例(这个实例包含网络连接、线程资源等) |
| clientCallbackExecutorThreads | 4 | 通信层异步回调线程数 |
| pollNameServerInteval | 30000 | 轮询Name Server间隔时间,单位毫秒 |
| heartbeatBrokerInterval | 30000 | 向Broker发送心跳间隔时间,单位毫秒 |
| persistConsumerOffsetInterval | 5000 | 持久化Consumer消费进度间隔时间,单位毫秒 |
#### 2 Producer配置
| 参数名 | 默认值 | 说明 |
| -------------------------------- | ---------------- | ------------------------------------------------------------ |
| producerGroup | DEFAULT_PRODUCER | Producer组名,多个Producer如果属于一个应用,发送同样的消息,则应该将它们归为同一组 |
| createTopicKey | TBW102 | 在发送消息时,自动创建服务器不存在的topic,需要指定Key,该Key可用于配置发送消息所在topic的默认路由。 |
| defaultTopicQueueNums | 4 | 在发送消息,自动创建服务器不存在的topic时,默认创建的队列数 |
| sendMsgTimeout | 10000 | 发送消息超时时间,单位毫秒 |
| compressMsgBodyOverHowmuch | 4096 | 消息Body超过多大开始压缩(Consumer收到消息会自动解压缩),单位字节 |
| retryAnotherBrokerWhenNotStoreOK | FALSE | 如果发送消息返回sendResult,但是sendStatus!=SEND_OK,是否重试发送 |
| retryTimesWhenSendFailed | 2 | 如果消息发送失败,最大重试次数,该参数只对同步发送模式起作用 |
| maxMessageSize | 4MB | 客户端限制的消息大小,超过报错,同时服务端也会限制,所以需要跟服务端配合使用。 |
| transactionCheckListener | | 事务消息回查监听器,如果发送事务消息,必须设置 |
| checkThreadPoolMinSize | 1 | Broker回查Producer事务状态时,线程池最小线程数 |
| checkThreadPoolMaxSize | 1 | Broker回查Producer事务状态时,线程池最大线程数 |
| checkRequestHoldMax | 2000 | Broker回查Producer事务状态时,Producer本地缓冲请求队列大小 |
| RPCHook | null | 该参数是在Producer创建时传入的,包含消息发送前的预处理和消息响应后的处理两个接口,用户可以在第一个接口中做一些安全控制或者其他操作。 |
#### 3 PushConsumer配置
| 参数名 | 默认值 | 说明 |
| ---------------------------- | ----------------------------- | ------------------------------------------------------------ |
| consumerGroup | DEFAULT_CONSUMER | Consumer组名,多个Consumer如果属于一个应用,订阅同样的消息,且消费逻辑一致,则应该将它们归为同一组 |
| messageModel | CLUSTERING | 消费模型支持集群消费和广播消费两种 |
| consumeFromWhere | CONSUME_FROM_LAST_OFFSET | Consumer启动后,默认从上次消费的位置开始消费,这包含两种情况:一种是上次消费的位置未过期,则消费从上次中止的位置进行;一种是上次消费位置已经过期,则从当前队列第一条消息开始消费 |
| consumeTimestamp | 半个小时前 | 只有当consumeFromWhere值为CONSUME_FROM_TIMESTAMP时才起作用。 |
| allocateMessageQueueStrategy | AllocateMessageQueueAveragely | Rebalance算法实现策略 |
| subscription | | 订阅关系 |
| messageListener | | 消息监听器 |
| offsetStore | | 消费进度存储 |
| consumeThreadMin | 10 | 消费线程池最小线程数 |
| consumeThreadMax | 20 | 消费线程池最大线程数 |
| consumeConcurrentlyMaxSpan | 2000 | 单队列并行消费允许的最大跨度 |
| pullThresholdForQueue | 1000 | 拉消息本地队列缓存消息最大数 |
| pullInterval | 0 | 拉消息间隔,由于是长轮询,所以为0,但是如果应用为了流控,也可以设置大于0的值,单位毫秒 |
| consumeMessageBatchMaxSize | 1 | 批量消费,一次消费多少条消息 |
| pullBatchSize | 32 | 批量拉消息,一次最多拉多少条 |
#### 4 PullConsumer配置
| 参数名 | 默认值 | 说明 |
| -------------------------------- | ----------------------------- | ------------------------------------------------------------ |
| consumerGroup | DEFAULT_CONSUMER | Consumer组名,多个Consumer如果属于一个应用,订阅同样的消息,且消费逻辑一致,则应该将它们归为同一组 |
| brokerSuspendMaxTimeMillis | 20000 | 长轮询,Consumer拉消息请求在Broker挂起最长时间,单位毫秒 |
| consumerTimeoutMillisWhenSuspend | 30000 | 长轮询,Consumer拉消息请求在Broker挂起超过指定时间,客户端认为超时,单位毫秒 |
| consumerPullTimeoutMillis | 10000 | 非长轮询,拉消息超时时间,单位毫秒 |
| messageModel | BROADCASTING | 消息支持两种模式:集群消费和广播消费 |
| messageQueueListener | | 监听队列变化 |
| offsetStore | | 消费进度存储 |
| registerTopics | | 注册的topic集合 |
| allocateMessageQueueStrategy | AllocateMessageQueueAveragely | Rebalance算法实现策略 |
#### 5 Message数据结构
| 字段名 | 默认值 | 说明 |
| -------------- | ------ | ------------------------------------------------------------ |
| Topic | null | 必填,消息所属topic的名称 |
| Body | null | 必填,消息体 |
| Tags | null | 选填,消息标签,方便服务器过滤使用。目前只支持每个消息设置一个tag |
| Keys | null | 选填,代表这条消息的业务关键词,服务器会根据keys创建哈希索引,设置后,可以在Console系统根据Topic、Keys来查询消息,由于是哈希索引,请尽可能保证key唯一,例如订单号,商品Id等。 |
| Flag | 0 | 选填,完全由应用来设置,RocketMQ不做干预 |
| DelayTimeLevel | 0 | 选填,消息延时级别,0表示不延时,大于0会延时特定的时间才会被消费 |
| WaitStoreMsgOK | TRUE | 选填,表示消息是否在服务器落盘后才返回应答。 |
## 6 系统配置
本小节主要介绍系统(JVM/OS)相关的配置。
### 6.1 JVM选项
推荐使用最新发布的JDK 1.8版本。通过设置相同的Xms和Xmx值来防止JVM调整堆大小以获得更好的性能。简单的JVM配置如下所示:
```
-server -Xms8g -Xmx8g -Xmn4g
```
如果您不关心RocketMQ Broker的启动时间,还有一种更好的选择,就是通过“预触摸”Java堆以确保在JVM初始化期间每个页面都将被分配。那些不关心启动时间的人可以启用它:
-XX:+AlwaysPreTouch
禁用偏置锁定可能会减少JVM暂停,
-XX:-UseBiasedLocking
至于垃圾回收,建议使用带JDK 1.8的G1收集器。
```text
-XX:+UseG1GC -XX:G1HeapRegionSize=16m
-XX:G1ReservePercent=25
-XX:InitiatingHeapOccupancyPercent=30
```
这些GC选项看起来有点激进,但事实证明它在我们的生产环境中具有良好的性能。另外不要把-XX:MaxGCPauseMillis的值设置太小,否则JVM将使用一个小的年轻代来实现这个目标,这将导致非常频繁的minor GC,所以建议使用rolling GC日志文件:
```text
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=30m
```
如果写入GC文件会增加代理的延迟,可以考虑将GC日志文件重定向到内存文件系统:
```text
-Xloggc:/dev/shm/mq_gc_%p.log123
```
### 6.2 Linux内核参数
os.sh脚本在bin文件夹中列出了许多内核参数,可以进行微小的更改然后用于生产用途。下面的参数需要注意,更多细节请参考/proc/sys/vm/*的[文档](https://www.kernel.org/doc/Documentation/sysctl/vm.txt)
- **vm.extra_free_kbytes**,告诉VM在后台回收(kswapd)启动的阈值与直接回收(通过分配进程)的阈值之间保留额外的可用内存。RocketMQ使用此参数来避免内存分配中的长延迟。(与具体内核版本相关)
- **vm.min_free_kbytes**,如果将其设置为低于1024KB,将会巧妙的将系统破坏,并且系统在高负载下容易出现死锁。
- **vm.max_map_count**,限制一个进程可能具有的最大内存映射区域数。RocketMQ将使用mmap加载CommitLog和ConsumeQueue,因此建议将为此参数设置较大的值。(agressiveness --> aggressiveness)
- **vm.swappiness**,定义内核交换内存页面的积极程度。较高的值会增加攻击性,较低的值会减少交换量。建议将值设置为10来避免交换延迟。
- **File descriptor limits**,RocketMQ需要为文件(CommitLog和ConsumeQueue)和网络连接打开文件描述符。我们建议设置文件描述符的值为655350。
- [Disk scheduler](https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/ch06s04s02.html),RocketMQ建议使用I/O截止时间调度器,它试图为请求提供有保证的延迟。
[]([]()) | 17,538 | Apache-2.0 |
---
title: 1つ上のディレクトリ名をとるShellコマンド
date: 2020-05-27 20:00:00
topics:
- ShellScript
type: tech
published: true
---
## 1 つ上のディレクトリ path をとる
```sh
~/.ghq/github.com/elzup/anozonbiyori
$ basename ${PWD%/*}
elzup
```
## 現在のディレクトリ path をとる
```sh
~/.ghq/github.com/elzup/anozonbiyori
$ basename $PWD
anozonbiyori
```
## 2 ディレクトリをとる
```sh
$
~/.ghq/github.com/elzup/anozonbiyori
echo `basename ${PWD%/*}`/`basename $PWD`
elzup/anozonbiyori
```
## 補足
`${PWD%/*}` という部分は文字列置換が働いてます。
参考: [bash の変数内文字列置換まとめ \- Qiita](https://qiita.com/aosho235/items/c36568830a8d47288284)
```sh
$ pwd
/Users/hiro/.ghq/github.com/elzup/anozonbiyori
$ echo ${PWD%/*} # 末尾から/までの非貪欲マッチ部分を削除
/Users/hiro/.ghq/github.com/elzup
$ basename ${PWD%/*}
elzup
$ echo ${${PWD%/*}##*/}
elzup
```
## おまけ: alias 化
推奨はしないよ!
```sh:title=.zshrc
alias basename-current='basename ${PWD}'
alias basename-parent='echo `basename ${PWD%/*}`/`basename $PWD`'
alias reponame=basename-parent
``` | 957 | MIT |
---
title: mac 安装 sshfs
layout: post
category: jekyll
author: 夏泽民
---
{% highlight bash linenos %}
$brew cask install osxfuse
$brew install sshfs
{% endhighlight %}
<!-- more -->
挂载(如果配上ssh key就可以完全自动化了):
sshfs root@192.168.9.109:/opt /opt/s109
卸载:
fusermount -u /opt/s109 | 272 | MIT |
---
title: Jenkins和SonarQube集成
layout: post
category: web
author: 夏泽民
---
Jenkins与SonarQube 集成插件的安装与配置
Jenkins 是一个支持自动化框架的服务器,我们这里不做详细介绍。Jenkins 提供了相关的插件,使得 SonarQube 可以很容易地集成 ,登陆 jenkins,点击"Manage Jenkins",选择“Mange Plugins”点击“Avzilable”,搜索“Sonar”选中“SonarQube Scanner for Jenkins”点击安装插件,安装后好如下图:
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar1.png"/>
点击"Manage Jenkins",选择“Configure System”将SonarQube server的信息填入,点击保存。如图:
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar2.png"/>
在jenkinse服务器上下载sonar-scanner,下载地址:https://sonarsource.bintray.com/Distribution/sonar-scanner-cli/sonar-scanner-cli-3.0.3.778-linux.zip
将下载文件解压至/usr/local/目录下
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar3.png"/>
点击"Manage Jenkins",选择“Global Tool Configuration”,填入jenkins服务器上的SonarQube 客户端路径,点击保存。如图:
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar4.png"/>
在 Jenkins项目构建过程中加入 SonarScanner 进行代码分析
首先需要在新建的 Jenkins 项目的构建环境标签页中勾选"Prepare SonarQube Scanner evironment",增加 Execute SonarQube Scanner 构建步骤。如图:
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar5.png"/>
配置 Execute SonarQube Scanner 构建步骤
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar6.png"/>
sonar.projectKey=testSonar
sonar.projectName=cms
sonar.projectVersion=1.0
sonar.language=java
sonar.java.binaries=/var/lib/jenkins/workspace/cms/7-brand-web-cms/target/classes/
sonar.sources=/var/lib/jenkins/workspace/cms/7-brand-web-cms/src
查看分析结果
在新建的 Jenkins 项目的构建的 Console Output 中可以得到 SonarQube 分析结果的链接,如图:
分析结果报告
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar7.png"/>
具体问题展示:
<img src="{{site.url}}{{site.baseurl}}/img/JenkinsSonar8.png"/>
<!-- more --> | 1,656 | MIT |
#Hello World
有了前面的基础,现在我们来简单分析一下最简单的打印"Hellow World"语句,究竟需要哪些步骤,以此做为后面分析Lua解释器指令的热身.
简单来说,Lua虚拟机在解释执行一个Lua脚本文件,需要经过以下几个步骤:
1. 初始化Lua虚拟机数据结构.
2. 读取Lua脚本文件内容.
3. 依次对Lua脚本文件进行词法分析,语法分析,语义分析,最后生成该文件的Lua虚拟机指令.注意以上的过程仅需要一步遍历,这是Lua解释器做的非常好的地方.
4. 进入Lua虚拟机主循环,将第1步的指令取出来逐个执行.
我们接下来就以一个最简单的Lua代码:
print("Hello World")
来解释前面的步骤是如何进行的.
##实验用C代码
我在自己研究分析Lua解释器原理的时候,由于需要分不同的Lua指令来进行分析,所以我写了一个简单的C代码,根据命令行参数来读取不同的Lua文件来执行,然后我可以gdb来调试这个程序,于是就能较为方便的研究Lua解释器的工作原理.该代码如下:
#include <stdio.h>
#include <lua.h>
#include <lualib.h>
#include <lauxlib.h>
int main(int argc, char *argv[]) {
char *file = NULL;
if (argc == 1) {
file = "my.lua";
} else {
file = argv[1];
}
lua_State *L = lua_open();
luaL_openlibs(L);
luaL_dofile(L, file);
return 0;
}
假设上面的C代码编译生成了test,而前面的那个打印"Hello World"的Lua脚本文件名为"hello.lua",那么执行:
./test hello.lua
就可以解释执行出hello.lua中的代码,通过使用gdb等调试工具,就可以来进一步观察分析Lua解释器的行为.现在以及以后对Lua指令的分析,就是通过这个程序执行不同的Lua脚本文件来进行分析的.
##Lua虚拟机数据结构
在开始下面的分析之前,首先来介绍一下两个重要的数据结构:lua_State以及global_State.
lua_State可以认为是每一个Lua"线程"所独有的一份数据,后面介绍到Lua协程时会明白这里所谓的"线程"是什么意思.
将其中各个成员变量分类介绍以含义如下:
### Lua栈相关
* StkId top:当前Lua栈顶,见Lua栈部分讲解
* StkId base:当前Lua栈底,见Lua栈部分讲解
* StkId stack_last:指向Lua栈最后位置
* StkId stack:指向Lua栈起始位置
* int stacksize:Lua栈大小
### Lua CallInfo数组相关
前面提过,每次函数调用都对应一个CallInfo结构体,
* CallInfo *ci:指向当前函数的CallInfo数据指针
* CallInfo *end_ci:指向CallInfo数组的结束位置
* CallInfo *base_ci:指向CallInfo数组的起始位置
* int size_ci:CallInfo数组的大小
### hook相关
* lu_byte hookmask:hook mask位,分别有以下几种值:LUA_MASKCALL
* lu_byte allowhook;
* int basehookcount;
* int hookcount;
* lua_Hook hook;
### GC相关
* TValue l_gt
* GCObject *openupval; /* list of open upvalues in this stack */
* GCObject *gclist;
### 其他
* CommonHeader:Lua通用数据相关,见第二章
* lu_byte status:当前状态
* global_State l_G:指向全局状态指针,见下面关于global_State的讲解
* const Instruction *savedpc:当前函数的pc指针
* unsigned short nCcalls:记录C调用层数
* unsigned short baseCcalls:????
* struct lua_longjmp *errorJmp; /* current error recover point */
* ptrdiff_t errfunc; /* current error handling function (stack index) */
global_State是一个进程独有的数据结构,它其中的很多数据会被该进程中所有的lua_State所共享.换言之,一个进程只会有一个global_State,但是却可能有多份lua_State,它们之间是一对多的关系.
65 /*
66 ** `global state', shared by all threads of this state
67 */
68 typedef struct global_State {
69 stringtable strt; /* hash table for strings */
70 lua_Alloc frealloc; /* function to reallocate memory */
71 void *ud; /* auxiliary data to `frealloc' */
72 lu_byte currentwhite;
73 lu_byte gcstate; /* state of garbage collector */
74 int sweepstrgc; /* position of sweep in `strt' */
75 GCObject *rootgc; /* list of all collectable objects */
76 GCObject **sweepgc; /* position of sweep in `rootgc' */
77 GCObject *gray; /* list of gray objects */
78 GCObject *grayagain; /* list of objects to be traversed atomically */
79 GCObject *weak; /* list of weak tables (to be cleared) */
80 GCObject *tmudata; /* last element of list of userdata to be GC */
81 Mbuffer buff; /* temporary buffer for string concatentation */
82 lu_mem GCthreshold;
83 lu_mem totalbytes; /* number of bytes currently allocated */
84 lu_mem estimate; /* an estimate of number of bytes actually in use */
85 lu_mem gcdept; /* how much GC is `behind schedule' */
86 int gcpause; /* size of pause between successive GCs */
87 int gcstepmul; /* GC `granularity' */
88 lua_CFunction panic; /* to be called in unprotected errors */
89 TValue l_registry;
90 struct lua_State *mainthread;
91 UpVal uvhead; /* head of double-linked list of all open upvalues */
92 struct Table *mt[NUM_TAGS]; /* metatables for basic types */
93 TString *tmname[TM_N]; /* array with tag-method names */
94 } global_State;
##初始化Lua虚拟机指针
首先来看第一步,调用lua_open函数创建并且初始化一个Lua虚拟机指针,来看看这里具体做了什么事情.
lua_open实际上是一个宏,其最终会调用函数luaL_newstate来创建一个Lua_State指针,这里主要完成的是lua_State结构体的初始化及其成员变量以及global_State结构体的初始化工作.
##读取脚本文件
初始化完毕lua_State结构体之后,下一步就是读取Lua脚本文件,进行词法分析->语法分析->语义分析,最后生成Lua虚拟机指令.这一步的入口是调用luaL_dofile,这也是一个宏:
(lauxlib.h)
111 #define luaL_dofile(L, fn) \
112 (luaL_loadfile(L, fn) || lua_pcall(L, 0, LUA_MULTRET, 0))
可以看到,这个宏包括了两个函数调用,首先调用luaL_loadfile函数,这个函数主要是对Lua脚本进行上述所说的分析,而只有在这个函数返回0也就是调用成功的时候,才会调用lua_pcall函数,这个函数将会根据上一步成功分析完毕之后生成的Lua虚拟机指令来执行.下面依次来看看这几个过程中涉及到的重要函数和数据结构.
###分析Lua脚本文件
这一步涵盖了词法分析,语法分析以及语义分析,Lua解释器的一个特点这几个过程是一遍遍历完成的,因此Lua在这方面的效率很高,但是这也给分析这部分代码带来一定难度.
这部分最终的入口函数是f_parser函数,这里首先不具体深入分析各个分析过程,而是先来具体看看这个函数的代码,明白这个函数执行完毕之后对外部的输出,以及相关的数据结构:
(ldo.c)
490 static void f_parser (lua_State *L, void *ud) {
491 int i;
492 Proto *tf;
493 Closure *cl;
494 struct SParser *p = cast(struct SParser *, ud);
495 int c = luaZ_lookahead(p->z);
496 luaC_checkGC(L);
497 tf = ((c == LUA_SIGNATURE[0]) ? luaU_undump : luaY_parser)(L, p->z,
498 &p->buff, p->name);
499 cl = luaF_newLclosure(L, tf->nups, hvalue(gt(L)));
500 cl->l.p = tf;
501 for (i = 0; i < tf->nups; i++) /* initialize eventual upvalues */
502 cl->l.upvals[i] = luaF_newupval(L);
503 setclvalue(L, L->top, cl);
504 incr_top(L);
505 }
首先看到的是SParser结构体,这个结构体只会在分析过程中使用,在它内部的成员变量有已经读取进内存的Lua脚本文件内容,文件名称等数据.这里将调用luaZ_lookahead函数拿到一个int型数据,以此来判断即将进行分析的内容,是已经经过了luac预编译的二进制内容,还是Lua脚本,根据不同的情况调用不同的parser来进行分析.
第一步分析的结果,最终会返回一个Proto结构体指针,这是一个重要的数据结构,它是用来存放分析完一个Lua函数之后,包括指令,参数,Upvalue等信息,来看看其成员变量的具体含义:
* CommonHeader:Lua通用数据相关的成员,前面已经做过讲解.
* TValue *k: 存放常量的数组.
* Instruction *code:存放指令的数组.
* struct Proto **p:如果本函数中还有内部定义的函数,那么这些内部函数相关的Proto指针就放在这个数组里.
* int *lineinfo:存放对应指令的行号信息,与前面的code数组内的元素一一对应.
* struct LocVar *locvars:存放函数内局部变量的数组.
* TString **upvalues:存放UpValue的数组,至于UpValue的含义,后面会做分析.
* TString *source:Lua脚本文件名.
* int sizeupvalues:前面upvalues数组的大小.
* int sizek:k数组的大小.
* int sizecode:code数组的大小.
* int sizelineinfo:lineinfo数组的大小.
* int sizep:p数组的大小.
* int sizelocvars:localvars数组的大小.
* int linedefined:函数body的第一行行号.
* int lastlinedefined:函数body的最后一行.
* GCObject *gclist:gc链表.
* lu_byte nups:upvalue的数量.
* lu_byte numparams:函数参数数量.
* lu_byte is_vararg:有以下几种取值
```
#define VARARG_HASARG 1
#define VARARG_ISVARARG 2
#define VARARG_NEEDSAR 4
```
* lu_byte maxstacksize:函数最大stack大小,由类型是lu_byte可知,最大是255.
由上面的分析可知,当执行Lua解释器对一个Lua脚本文件进行分析之后,最终返回的就是一个Proto结构体指针,但是需要注意的是,前面对Proto结构体的说明中提过,这个结构体与Lua函数一一对应,但是这个说法并不是特别精确,比如我们这里的测试代码打印一个"Hello World"字符串,这就不是一个函数,但是即便如此,分析完这个文件之后也会有一个对应的Proto结构体,因此需要把Lua函数的概念扩大到Lua模块,可以说一个Lua模块也是一个Lua函数,对一个Lua模块分析也是相当于对一个Lua函数进行分析,只不过这个函数没有参数,没有函数名.
继续下面的分析,返回Proto指针之后,将会创建一个Closure结构体:
(lobject.h)
309 typedef union Closure {
310 CClosure c;
311 LClosure l;
312 } Closure;
从它的定义可知,它既可以用来存放C函数相关信息,也可以用来存放Lua函数相关信息.在这里当然是保存的Lua函数信息,主要就是要将返回的Proto信息保存下来,它将在后面Lua虚拟机执行指令时用到.
最后需要注意的是f_parser函数的最后两句代码,它将Closure指针push到了Lua栈中,同时将栈指针加1,由此可知分析完Lua脚本文件产生的Closure指针一定是在Lua栈顶.
到了这里,已经将分析Lua脚本文件的流程和其中重要的数据结构做了概述,也就是luaL_loadfile函数调用的过程,接下来就是分析如何根据这一步的结果来执行Lua虚拟机指令了.
###虚拟机执行指令
调用luaL_loadfile并且成功返回之后,产生的Closure指针被放在了Lua栈顶,这时需要调用lua_pcall(L, 0, LUA_MULTRET, 0)执行Lua指令.这里对lua_pcall函数参数做一些解释,第一个参数自不必解释;第二个参数表示调用这个函数时的参数数量,前面已经提到过,对一个Lua文件进行分析时也可以看做是分析一个Lua函数,只不过其函数参数数量为0,因此此处传递进来的第二个参数是0;第三个参数表示的该函数返回参数的数量,调用完毕之后将根据这个参数对Lua栈进行调整,同样的由于这里是一个Lua文件,所以需要传递的是LUA_MULTRET这个常量,表示多返回值;最后一个参数表示的是出错处理函数在Lua栈中得位置,只有非0值才有意义.
lua_pcall函数最终会进入luaD_call函数来,可是在此之前,首先需要拿到所调用函数相关的Closure指针,这是如何拿到的呢?前面提到过,f_parser返回的Closure指针会放在Lua栈顶,在lua_pcall中有这么一行代码:
(lapi.c)
819 c.func = L->top - (nargs+1); /* function to be called */
上面分析lua_pcall函数参数的时候提到过,这里传入的nargs参数是0,因为这里是分析一个Lua文件所以没有函数参数,所以这个操作就拿到了上一步中Closure指针在Lua栈中的地址.同时,从这个操作可以知道,在调用一个Lua函数时,该函数的Lua栈从下往上依次是函数Closure,函数的各个参数,这个问题后面具体分析到Lua函数调用再进行展开分析.
继续看看luaD_call函数:
(ldo.c)
369 void luaD_call (lua_State *L, StkId func, int nResults) {
370 if (++L->nCcalls >= LUAI_MAXCCALLS) {
371 if (L->nCcalls == LUAI_MAXCCALLS)
372 luaG_runerror(L, "C stack overflow");
373 else if (L->nCcalls >= (LUAI_MAXCCALLS + (LUAI_MAXCCALLS>>3)))
374 luaD_throw(L, LUA_ERRERR); /* error while handing stack error */
375 }
376 if (luaD_precall(L, func, nResults) == PCRLUA) /* is a Lua function? */
377 luaV_execute(L, 1); /* call it */
378 L->nCcalls--;
379 luaC_checkGC(L);
380 }
这里首先对Lua函数调用层次做判断,接下来调用luaD_precall进行函数调用之前的一些准备工作,这里不展开讨论,简单的说其做的工作有这些:准备好Lua函数栈,创建CallInfo指针并且根据相应信息进行初始化.
到这里,准备工作已经做完了,下面就是调用luaV_execute逐个取出Lua指令来执行:
(lvm.c)
373 void luaV_execute (lua_State *L, int nexeccalls) {
374 LClosure *cl;
375 StkId base;
376 TValue *k;
377 const Instruction *pc;
378 reentry: /* entry point */
379 lua_assert(isLua(L->ci));
380 pc = L->savedpc;
381 cl = &clvalue(L->ci->func)->l;
382 base = L->base;
383 k = cl->p->k;
384 /* main loop of interpreter */
385 for (;;) {
386 const Instruction i = *pc++;
/* 执行Lua指令 */
761 }
762 }
可以看到,luaV_execute函数首先根据CallInfo指针拿到LClosure指针,然后pc指针指向savedpc指针,再逐个从这个pc指针中拿出指令来逐条执行.而这个savedpc指针式在哪里进行初始化的呢,在luaD_precall函数中:
(ldo.c)
293 L->savedpc = p->code; /* starting point */
上面的p就是分析Lua脚本之后生成的Proto指针,而它的code成员变量前面提到过存放的就是分析后的指令.
以上可以看出,其实Proto结构体才是Lua解释器分析Lua脚本过程中最重要的数据结构,而Closure,CallInfo结构体不过是这个过程为了提供给Lua虚拟机执行指令装载Proto结构体用的中间载体,最终用到的还是Proto结构体中得数据.
以上,将如何加载,分析,以及到最终执行Lua指令中间涉及到的重要函数,数据结构做了一些分析,碍于目前的进度,还没有对一些过程进行深入讨论,但是已经对Lua虚拟机的整体流程有了概观的了解,有了骨架,后面就是根据具体的知识点来进行深入分析了. | 9,417 | MIT |
---
layout: post
title: Linux命令-scp 两个服务器之间传输文件和文件夹 (端口相同与不相同)
categories: Linux
tags: Linux
author: Keyon
---
* content
{:toc}
#### 从本机传输文件到另一个服务器
````
scp -P 26443 /home/img/150.png root@10.44.99.26:/home/test
````
* ps: -P 26443 指的是接受文件的服务器的端口号,如果两台服务器的端口号相同,则可以省略该参数.
#### 从本机传输文件夹到另外一个服务器
````
scp -r /home/img/150/ root@10.44.99.26:/home/test
````
#### 从本机器传输文件夹下的所有文件到另一台服务器
````
scp /home/img/150/* root@10.44.99.26:/home/test
````
#### 对拷过去的文件夹重命名
````
scp -r /home/img/150.png root@10.44.99.26:/home/test/160.png
````
* 如果想要获取其他机器的文件只要把后面的命令调换即可
* 命令详解
````
/home/img/150.png: 要传输的文件
root: 目标服务器ssh账号名
@后面: 目标服务器的IP地址
: 后面: 要传输目标服务器的文件保存目录
```` | 664 | MIT |
> **相信大家已经都在对 Flutter 2.10 版本跃跃欲试,本篇就目前升级用 Flutter 2.10 版本遇到的问题做一些总结提炼。**
**事实上按照 Flutter 每个版本的投入使用规律,应该是第三个小版本最稳**,以 Flutter 目前庞大的用户量,每次正式版的发布必然带来各种奇奇怪怪的问题,**一般情况下我推荐 2.10 版本等到 2.10.3 发布再投入生产会更稳妥**,但是如果你等不及官方 `hotfix` ,那么后面的内容可能可以帮助到你。
> 本次如果你是从 2.8 升级的到 2.10 ,那么 dart 层需要调整几乎等于零。
## Kotlin 版本
**首先就项目升级的第一个,也就是最重要的一个,就是升级你的 kotlin 插件版本,这个是强制的**,因为之前的旧版本使用的基本都是 `1.3.x` 的版本,而这些 Flutter 2.10 强制要求 `1.5.31` 以上的版本。
```gradle
buildscript {
- ext.kotlin_version = '1.3.50'
+ ext.kotlin_version = '1.5.31'
```
这里需要注意,**这次升级 Kotlin 版本,会带来一些 Kotlin 包的 API 出现一些 break 的变化** ,所以如果你本身 App 使用了较多 Kotlin 开发,或者插件里使用了一些 Kotlin 的包,就需要注意升级带来的适配成本,例如:
> `ProducerScope` 需要 `override` 新的 `trySend` 方法,但是这个方法需要 `return` 一个 `ChannelResult` , `ChannelResult` 是 `@InternalCoroutinesApi` 。
## Gradle 版本
因为 Kotlin 版本升级了,所以 AGP 插件必须使用最低 `4.0.0` 配合 Gradle `6.1.1` 的版本,也就是:
```gradle
classpath 'com.android.tools.build:gradle:4.0.0'
/
distributionUrl=https://services.gradle.org/distributions/gradle-6.1.1-all.zip
```
因为以前的老版本使用的 AGP 可能是 AGP `3.x` 配合 Gradle `5.x` 的版本,**所以如果升级了 Kotlin 版本,这一步升级就必不可少。**
> 这里顺便放一张 AGP 和 Gradle 之间的版本对应截图
## Android SDK 问题
### cmdline-tools & license
这个问题可能大家不一定会遇到,首先如果你在执行 `flutter doctor` 的时候出现以下情况
```
[!] Android toolchain - develop for Android devices (Android SDK version 31.0.0)
✗ cmdline-tools component is missing
Run `path/to/sdkmanager --install "cmdline-tools;latest"`
See https://developer.android.com/studio/command-line for more details.
✗ Android license status unknown.
Run `flutter doctor --android-licenses` to accept the SDK licenses.
See https://flutter.dev/docs/get-started/install/macos#android-setup for
more details.
```
也就是 `cmdline-tools` 和 `Android license` 都是 `✗` 的显示时,那可能你还需要额外做一些步骤来完善配置。
首先你需要安装 `cmdline-tools` ,如下图所示直接安装就可以了
然后执行 `flutter doctor --android-licenses` ,就可以很简单地完善你的环境的配置。
### Build Tools
其次,如果你在编译 Android Apk 的过程中出现 : `Installed Build Tools revision 31.0.0 is corrupted` 之类的问题:
```
Could not determine the dependencies of task ':app:compileDebugJavaWithJavac'.
> Installed Build Tools revision 31.0.0 is corrupted. Remove and install again using the SDK Manager.
```
那么可以通过执行如下命令行来完成配置 :
```
# change below to your Android SDK path
cd ~/Library/Android/sdk/build-tools/31.0.0 \
&& mv d8 dx \
&& cd lib \
&& mv d8.jar dx.jar
```
> Window 用户可以看 https://stackoverflow.com/questions/68387270/android-studio-error-installed-build-tools-revision-31-0-0-is-corrupted
### NDK
如果你在编译过程中出现 `No version of NDK matched` 的问题:
```
Execution failed for task ':app:stripDebugDebugSymbols'.
> No version of NDK matched the requested version 21.0.6113669. Versions available locally: 19.1.5304403
```
这个问题其实很简单,如图打开你的 `SDK Manager` 下载对应的版本就可以了。
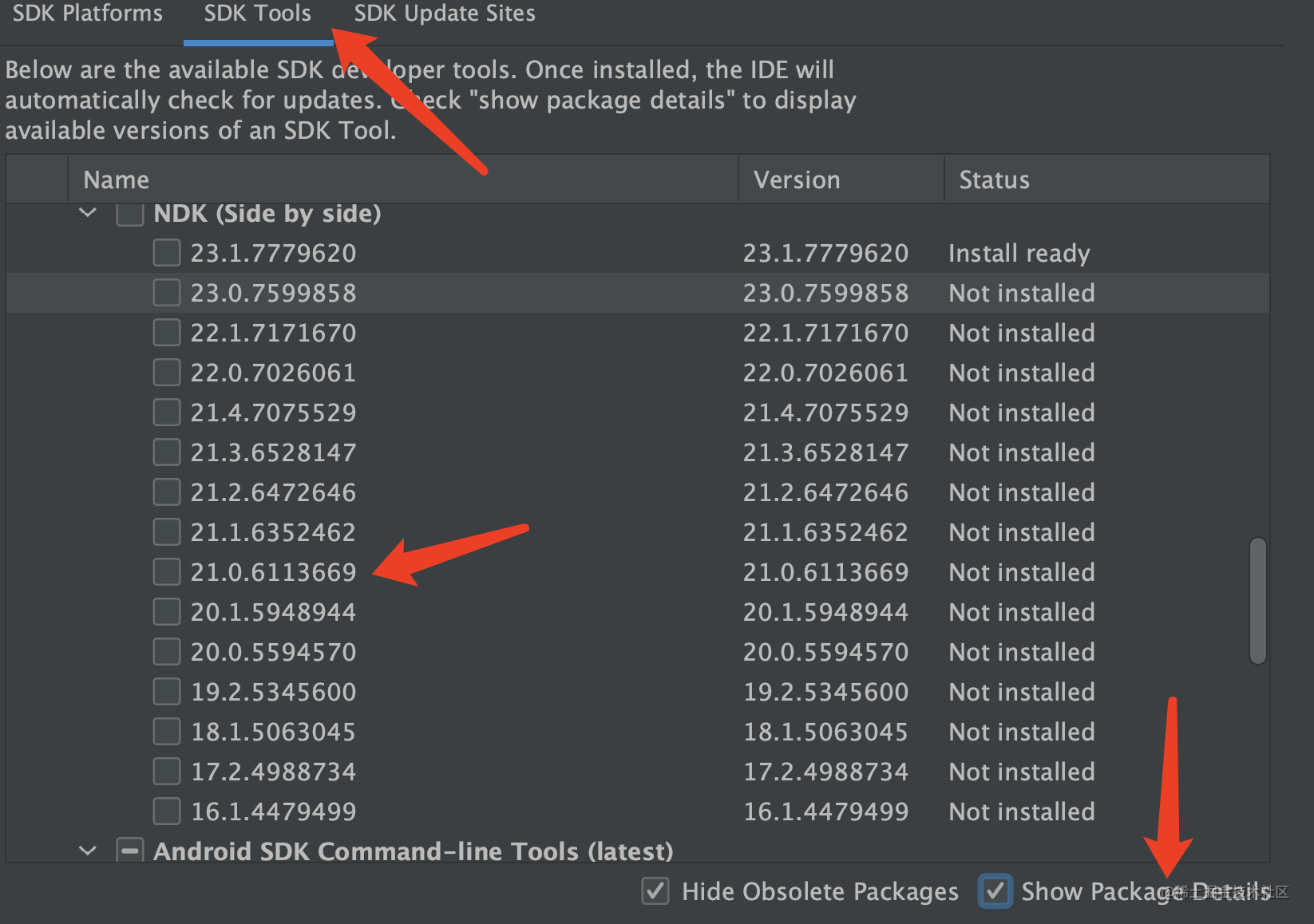
## 本地 AAR 文件问题
因为前面升级了 AGP 版本,这时候就带来一个问题,这个问题仅存在于**你使用的 Flutter Plugin 里的本地的 aar 文件**。
正常情况下编译时就会遇到如果的提示:
```
> Direct local .aar file dependencies are not supported when building an AAR. The resulting AAR would be broken because the classes and Android resources from any local .aar file dependencies would not be packaged in the resulting AAR. Previous versions of the Android Gradle Plugin produce broken AARs in this case too (despite not throwing this error). The following direct local .aar file dependencies of the :********* project caused this error: /Users/guoshuyu/.pub-cache/git/*********-01d03bf549e512f6e15dd539411a8c236d77cd47/android/libs/libc*********.aar, /Users/guoshuyu/.pub-cache/git/*********-01d03bf549e512f6e15dd539411a8c236d77cd47/android/libs/*********.aar, /Users/guoshuyu/.pub-cache/git/*********-01d03bf549e512f6e15dd539411a8c236d77cd47/android/libs/*********.aar
```
这时候听我一声劝,**什么办法都不好使,直接搭一个私服 Maven ,很简单的,把 aar 上传上去,然后远程依赖进来就可以了**。
[Alex](https://juejin.cn/user/606586150596360) 大佬建议的本地 maven 构建也可以:https://www.kikt.top/posts/flutter/plugin/flutter-sdk-import-aar/ 主要就是构建得到一个如下结构的目录:
```
tree .
.
├── com
│ └── pgyer
│ └── sdk
│ ├── 3.0.9
│ │ ├── sdk-3.0.9.aar
│ │ ├── sdk-3.0.9.aar.md5
│ │ ├── sdk-3.0.9.aar.sha1
│ │ ├── sdk-3.0.9.pom
│ │ ├── sdk-3.0.9.pom.md5
│ │ └── sdk-3.0.9.pom.sha1
│ ├── maven-metadata.xml
│ ├── maven-metadata.xml.md5
│ └── maven-metadata.xml.sha1
└── sdk.aar
```
然后配置 android 下的 gradle
```gradle
// 定义一个方法, 用于获取当前moudle的dir
def getCurrentProjectDir() {
String result = ""
rootProject.allprojects { project ->
if (project.properties.get("identityPath").toString() == ":example_for_flutter_plugin_local_maven") { // 这里是flutter的约定, 插件的module名是插件名, :是gradle的约定. project前加:
result = project.properties.get("projectDir").toString()
}
}
return result
}
rootProject.allprojects {
// 这个闭包是循环所有project, 我们让这个仓库可以被所有module找到
def dir = getCurrentProjectDir()
repositories {
google()
jcenter()
maven { // 添加这个指向本地的仓库目录
url "$dir/aar"
}
}
}
dependencies {
implementation "com.pgyer:sdk:3.0.9" // 添加这个, 接着点sync project with gradle file 刷新一下项目就可以了. 是使用api还是implementation根据你的实际情况来看就好了
}
```
## 强制 V2
Android 上在这个版本上就强制要求 V2 的,例如如果之前使用了 `android:name="io.flutter.app.FlutterApplication"` ,那么在编译时你会看到:
```
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Warning
──────────────────────────────────────────────────────────────────────────────
Your Flutter application is created using an older version of the Android
embedding. It is being deprecated in favor of Android embedding v2. Follow the
steps at
https://flutter.dev/go/android-project-migration
to migrate your project. You may also pass the --ignore-deprecation flag to
ignore this check and continue with the deprecated v1 embedding. However,
the v1 Android embedding will be removed in future versions of Flutter.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
The detected reason was:
/Users/guoshuyu/workspace/***/*********/android/app/src/main/AndroidManifest.xml uses `android:name="io.flutter.app.FutterApplication"`
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
```
这里如果你只需要简单删除 `android:name="io.flutter.app.FutterApplication"` 就可以了。
> 更多关于 V2 的可以参考:https://flutter.dev/go/android-project-migration
## Material 图标出现异常
Flutter 2.10 针对 Material Icon 做了一次升级,结果很明显这次发布不小心又挖了个坑,目前问题看起来是**因为某个 issue 的回滚导致部分 icon 的提交也被回退**,所以这部分只能静待 hotfix ,目前官方已经知道这个问题,具体可见:
> https://github.com/flutter/flutter/issues/97767
## iOS CocoaPods not installed
**如果你运行 iOS 出现 `CocoaPods not installed` 的错误提示,那么不要着急,这个是 Android Studio 团队的锅**。
```
Warning: CocoaPods not installed. Skipping pod install.
CocoaPods is used to retrieve the iOS and macOS platform side's plugin code that responds to your plugin usage on the Dart side.
Without CocoaPods, plugins will not work on iOS or macOS.
For more info, see https://flutter.dev/platform-plugins
To install see https://guides.cocoapods.org/using/getting-started.html#installation for instructions.
Exception: CocoaPods not installed or not in valid state.
```
其实你在执行 `flutter doctor` 时可能就是看到提示,说你本地缺少 `CocoaPods` , 但是实际上你本地是有 `CocoaPods` 的,这时候解决的方案有几个可以选择:
- 直接通过命令行 `flutter run` 运行就不会有这个问题;
- 通过命令行 `open /Applications/Android\ Studio.app` 启动 Android Studio ;
- 执行 `chmod +x /Applications/Android\ Studio.app/Contents/bin/printenv` (如果你使用了 `JetBrains Toolbox` ,那 `printenv` 文件路径可能会有所变化)
- 静待 Android Studio 的小版本更新
> 更多可以参考 : https://github.com/flutter/flutter/issues/97251
更新:**新版 Android Studio Patch1 更新已经修复该问题**
 | 7,859 | MIT |
---
layout: post
category: Windows
title: Redirect CMD Output
tagline: 2015-01-23
tags: [windows, .net]
---
今天遇到一个进程调用控制台程序阻塞的问题。
<!--more-->
在程序中调用7z解压文件,今天解压一个大文件时,发现总是解压时卡住。
var process = new Process();
process.StartInfo.FileName = fileName;
process.StartInfo.Arguments = arguments;
process.StartInfo.CreateNoWindow = createNoWindow;
if (createNoWindow)
{
process.StartInfo.UseShellExecute = false;
process.StartInfo.RedirectStandardInput = true;
process.StartInfo.RedirectStandardOutput = true;
process.StartInfo.RedirectStandardError = true;
}
process.Start();
process.WaitForExit();
但是不隐藏控制台窗口时,程序是顺利执行的。查询了相关资料,控制台重定向输出时,是通过管道实现的。
当管道数据达到上限时,会等待数据被读取,在数据被读取之前,是无法继续写入的,程序因此阻塞。考虑到这里我不关心输出结果,于是将重定向都改为false解决。
process.StartInfo.RedirectStandardInput = false;
process.StartInfo.RedirectStandardOutput = false;
process.StartInfo.RedirectStandardError = false; | 951 | CC-BY-4.0 |
<!--  -->
# ssh
Secure Shell(缩写为SSH),由IETF的网络工作小组(Network Working Group)所制定;SSH为一项创建在应用层和传输层基础上的安全协议,为计算机上的Shell(壳层)提供安全的传输和使用环境。
传统的网络服务程序,如rsh、FTP、POP和Telnet其本质上都是不安全的;因为它们在网络上用明文传送数据、用户帐号和用户口令,很容易受到中间人(man-in-the-middle)攻击方式的攻击。就是存在另一个人或者一台机器冒充真正的服务器接收用户传给服务器的数据,然后再冒充用户把数据传给真正的服务器。
而SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用SSH协议可以有效防止远程管理过程中的信息泄露问题。通过SSH可以对所有传输的数据进行加密,也能够防止DNS欺骗和IP欺骗。
SSH之另一项优点为其传输的数据可以是经过压缩的,所以可以加快传输的速度。SSH有很多功能,它既可以代替Telnet,又可以为FTP、POP、甚至为PPP提供一个安全的“通道”。
[ssh-keygen](#ssh-keygen) [ssh-agent](#ssh-agent) [ssh-add](#ssh-add)
## ssh-keygen
### 语法
```Bash
ssh-keygen [-t <type>] [-b <length>] [-C <comment>] [-f <directory>]
```
- <type\>:
- rsa1(SSH-1)
- rsa(SSH-2)
- dsa(SSH-2)
- ecdsa(SSH-5)
- <length\>:
- 单位: bits
- 指定密钥长度。对于RSA密钥,最小要求768位,默认是2048位。DSA密钥必须恰好是1024位(FIPS186-2 标准的要求)
- <comment\>:
- 注释
- <directory\>:
- 保存地址
### 实例
添加RSA密钥
```Bash
ssh-keygen -t rsa -f ~/.ssh/id_rsa_2 -C "taichiyi@foxmail.com"
```
## ssh-agent
`ssh-agent`是一种控制用来保存公钥身份验证所使用的私钥的程序,其实`ssh-agent`就是一个密钥管理器,运行`ssh-agent`以后,使用ssh-add将私钥交给`ssh-agent`保管,其他程序需要身份验证的时候可以将验证申请交给ssh-agent来完成整个认证过程。
### 实例
开启`ssh-agent`
```Bash
$ ssh-agent bash
```
## ssh-add
### 实例
添加密钥到`SSH agent`
```Bash
$ ssh-add ~/.ssh/id_rsa
```
查看`SSH agent`的密钥列表
```Bash
$ ssh-add -l
```
## 管理多组密钥对
您可以创建 ~/.ssh/config 来管理多组密钥对,每一个 SSH 服务器对应一组密钥对。或者,您甚至可以对所有的 SSH 服务器使用同一组密钥对。不过如果您觉得这样不合适,还是编辑配置文件:
### 实例
```Bash
# host1
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa
# host2
Host github.testyi
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_2
``` | 1,674 | MIT |
+++
date = "2017-08-02T16:59:12+09:00"
title = "筑紫丘高校来訪"
tags = []
highlight = true
math = false
[header]
caption = "講義の風景"
image = "post/20170801Lecture_s.png"
+++
母校である筑紫丘高校の生徒18名が東京研修の一貫として原子核科学研究センターに来て、私が行った模擬講義を受講し、理研RIBFを見学しました。
<!--more-->
模擬講義では「原子核で探る物質優勢宇宙」について話をし、反物質が消えたの謎、金などの重い元素が存在する謎、中性子だらけの星の謎について原子核を使った謎への挑戦について紹介しました。初めての母校からの来訪ということで、気合を入れすぎて色々と詰め込みすぎたのか、難しい内容だったようです。次はもう少し噛み砕いた話にしようかと考えています。
生徒の中には同じ市内だったり、卒業中学校が同じだったり、大運動会で応援団をやっていたりと、共通項の多い生徒さんもいて驚きました。
施設見学では理研RIBFにある世界最強の加速器SRCと、BigRIPS, SHARAQ・OEDOなどの主要な装置を紹介し、最先端の研究の現場に触れてもらいました。また、アクティブ標的CATのご先祖さまである霧箱や、BigRIPSを模してプリズムを利用して光を分ける模型「ひかりップス」なども見てもらいました。
これらの装置は8月2日・3日と行われている東京大学の[オープンキャンパス](http://www.u-tokyo.ac.jp/opendays/index.html)でも展示していますので、興味のある方は是非足を運んでみてください。オープンキャンパスでは加速器の模型と加速原理の紹介も行っています。 | 797 | MIT |
---
type: tutorial
layout: tutorial
title: "Kotlin 与 JavaScript 模块合用"
description: "看看如何使用 Kotlin 与 JavaScript 模块进行交互。"
authors: Hadi Hariri
date: 2016-09-30
showAuthorInfo: false
redirect_path: /docs/reference/js-modules
---
在本教程中你将会看到:
* Configure modules when using Gradle
* [在浏览器中通过 AMD 使用 Koltin](#using-amd)
* [在 node.js 中通过 CommonJS 使用 Kotlin](#using-commonjs)
Koltin 所生成的 JavaScript 代码能够兼容异步模块定义(AMD, Asynchronous Module Definition), CommonJS 以及统一模块定义(UMD,Unified Module Definitions)。
* **AMD** 通常是使用在客户端的浏览器上,其概念是可以异步加载模块,从而提高性能和易用性。
* **CommonJS** 通常是使用在服务端的模块系统,特别是适合用于 node.js,Node 模块全都是遵循这样的定义的。 CommonJS 模块也可以通过[Browserify](http://browserify.org/)在浏览器中使用。
* **UMD** 则是试图让模块在客户端和服务端都能使用。
To configure the module output format in Gradle build script, add the following lines:
<div class="multi-language-sample" data-lang="groovy">
<div class="sample" markdown="1" mode="groovy" theme="idea" data-lang="groovy">
```groovy
compileKotlinJs.kotlinOptions.moduleKind = "commonjs"
```
</div>
</div>
<div class="multi-language-sample" data-lang="kotlin">
<div class="sample" markdown="1" mode="kotlin" theme="idea" data-lang="kotlin" data-highlight-only>
```kotlin
tasks.named("compileKotlinJs") {
this as KotlinJsCompile
kotlinOptions.moduleKind = "commonjs"
}
```
</div>
</div>
Available values are: `plain`, `amd`, `commonjs`, `umd`.
For more information, see [JavaScript Modules](http://kotlinlang.org/docs/reference/js-modules.html).
## 使用异步模块定义(AMD)
当我们要开始使用 AMD,首先需要把编译器的选项设置成 AMD。通过这些操作,我们就可以编译出的模块就可以和其他任意常规的 AMD 模块一起使用。
举个例子:
<div class="sample" markdown="1" theme="idea" data-highlight-only>
```kotlin
class Customer(val id: Int, val name: String, val email: String) {
var isPreferred = false
fun makePreferred() {
isPreferred = true
}
}
```
</div>
会生成如下的 JavaScript 代码:
<div class="sample" markdown="1" theme="idea" mode="js">
```javascript
define('customerBL', ['kotlin'], function (Kotlin) {
'use strict';
var _ = Kotlin.defineRootPackage(null, /** @lends _ */ {
Customer: Kotlin.createClass(null, function Customer(id, name, email) {
this.id = id;
this.name = name;
this.email = email;
this.isPreferred = false;
}, /** @lends _.Customer.prototype */ {
makePreferred: function () {
this.isPreferred = true;
}
})
});
Kotlin.defineModule('customerBL', _);
return _;
});
```
</div>
假设我们有个项目的结构如下:
}})
那么可以在 `index.html` 中利用标签中 `data-main` 属性的值来定义 `main.js` 从而引入 `require.js` ,如下所示:
<div class="sample" markdown="1" theme="idea" mode="xml">
```html
<head>
<meta charset="UTF-8">
<title>Sample AMD</title>
<script data-main="scripts/main" src="scripts/require.js"></script>
</head>
```
</div>
其中 `main.js` 的内容如下:
<div class="sample" markdown="1" theme="idea" mode="js">
```javascript
requirejs.config({
paths: {
kotlin: 'out/lib/kotlin.js',
customerBL: 'out/customerBL'
}
});
requirejs(["customerBL"], function (customerBL) {
console.log(customerBL)
});
```
</div>
通过这样的配置,我们就可以访问 `customerBL` 模块里的任意函数了。
## 使用 CommonJS
为了能够配合 node.js 一起使用 Kotlin,我们需要把编译器的选项设置成使用 CommonJs,这样我们的程序编译出来的模块
就可以被 node 的模块系统所使用。
举个例子:
<div class="sample" markdown="1" theme="idea" data-highlight-only>
```kotlin
class Customer(val id: Int, val name: String, val email: String) {
var isPreferred = false
fun makePreferred() {
isPreferred = true
}
}
```
</div>
会生成如下的 JavaScript 代码:
<div class="sample" markdown="1" theme="idea" mode="js">
```javascript
module.exports = function (Kotlin) {
'use strict';
var _ = Kotlin.defineRootPackage(null, /** @lends _ */ {
Customer: Kotlin.createClass(null, function Customer(id, name, email) {
this.id = id;
this.name = name;
this.email = email;
this.isPreferred = false;
}, /** @lends _.Customer.prototype */ {
makePreferred: function () {
this.isPreferred = true;
}
})
});
Kotlin.defineModule('customerBL', _);
return _;
}(require('kotlin'));
```
</div>
函数的最后一行是回调了自身并传递了一个 `kotlin` 参数,该参数代表了基本库。这可以通过以下两种方式获得:
*本地引用*
编译器总会在编译的时候自动生成 kotlin.js 文件。关联该文件最简单的方式就是在编译器选项中设置 `node_modules` 的输出目录。
这样 Node 将会在该目录下彻底查询的时候自动地使用该文件。
}})
*NPM目录*
Kotlin 基本库在[npm](https://www.npmjs.com/)是可用的,因此我们可以轻松地在项目的 `package.json` 文件中以一个依赖的形式进行引用,如下所示:
<div class="sample" markdown="1" theme="idea" mode="js">
```json
{
"name": "node-demo",
"description": "A sample of using Kotlin with node.js",
"version": "0.0.1",
"dependencies": {
"kotlin": ">=1.0.4-eap-111"
}
}
```
</div>
我们可以轻松地在 node.js 代码中通过使用 `require` 函数来导入模块从而可以使用模块里的任意类和函数,如下所示:
<div class="sample" markdown="1" theme="idea" mode="js">
```javascript
var customerBL = require('./scripts/customerBL')
var customer = new customerBL.Customer(1, "Jane Smith", "jane.smith@company.com")
console.dir(customer)
customer.makePreferred()
console.dir(customer)
```
</div>
在这个例子里,我们是把编译输出目录设置成了 `scripts` 文件夹,一旦程序开始运行那么应该会有如下的输出:
}}) | 5,330 | Apache-2.0 |
---
title: Xamarin を使用した watchOS アプリのビルド
description: このドキュメントでは、Xamarin を使用して watchOS アプリをビルドする方法を説明するさまざまなガイドにリンクしています。 リンク先のガイドでは、概要、watchOS ユーザーインターフェイスコントロール、watchOS 機能、デプロイとテスト、およびトラブルシューティングについて説明しています。
ms.prod: xamarin
ms.assetid: 14EAE85E-460A-4145-8C8D-869D176D5C3F
ms.technology: xamarin-ios
author: davidortinau
ms.author: daortin
ms.date: 03/17/2017
ms.openlocfilehash: 3e572e22e6c02e5401ad0e2c2293d601660ac08f
ms.sourcegitcommit: 2fbe4932a319af4ebc829f65eb1fb1816ba305d3
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/29/2019
ms.locfileid: "73030134"
---
# <a name="building-watchos-apps-with-xamarin"></a>Xamarin を使用した watchOS アプリのビルド
  
<!-- watch images courtesy of http://infinitapps.com/bezel/ -->
## <a name="getting-startedioswatchosget-startedindexmd"></a>[はじめに](~/ios/watchos/get-started/index.md)
* [WatchOS の概要](~/ios/watchos/get-started/intro-to-watchos.md)。
* [インストール情報](~/ios/watchos/get-started/installation.md)。
* Xamarin を使用して[最初の watchOS アプリ](~/ios/watchos/get-started/hello-watch.md)をビルドします。
## <a name="user-interfaceioswatchosuser-interfaceindexmd"></a>[ユーザー インターフェイス](~/ios/watchos/user-interface/index.md)
ウォッチキットカタログサンプルアプリに含まれるコントロールの概要 ([画像](~/ios/watchos/user-interface/image.md)、[テーブル](~/ios/watchos/user-interface/menu.md)[メニュー](~/ios/watchos/user-interface/menu.md)、[テキスト入力](~/ios/watchos/user-interface/text-input.md)コントロールなど)。
## <a name="platform-featuresplatformindexmd"></a>[プラットフォーム機能](platform/index.md)
[通知](~/ios/watchos/platform/notifications.md)や[混乱](~/ios/watchos/platform/complications.md)などの watchOS 固有の機能を監視アプリに追加する方法。
## <a name="app-fundamentalsioswatchosapp-fundamentalsindexmd"></a>[アプリの基礎](~/ios/watchos/app-fundamentals/index.md)
WatchOS API のさまざまな側面 ([親アプリケーション](~/ios/watchos/app-fundamentals/parent-app.md)、[アイコン](~/ios/watchos/app-fundamentals/icons.md)、[レイアウト](~/ios/watchos/app-fundamentals/layout.md)、[ナビゲーション](~/ios/watchos/app-fundamentals/navigation.md)、[画面サイズ](~/ios/watchos/app-fundamentals/screen-sizes.md)、[設定](~/ios/watchos/app-fundamentals/settings.md)など) の操作。
## <a name="deployment-and-testingioswatchosdeploy-testindexmd"></a>[配置とテスト](~/ios/watchos/deploy-test/index.md)
Apple Watch アプリのテストデバイスとアプリストアにデプロイするためのチェックリストと手順。
## <a name="troubleshootingioswatchostroubleshootingmd"></a>[トラブルシューティング](~/ios/watchos/troubleshooting.md)
既知の問題と回避策。
## <a name="api-documentationxrefwatchkit"></a>[API ドキュメント](xref:WatchKit)
Watch Kit API のクラスとメソッドのカバレッジ。 | 2,595 | CC-BY-4.0 |
---
title: "備份和還原 SQL Server | Microsoft Docs"
description: "描述 Azure 虛擬機器上執行的 SQL Server 資料庫之備份和還原考量。"
services: virtual-machines-windows
documentationcenter: na
author: rothja
manager: jhubbard
editor:
tags: azure-resource-management
ms.assetid: 95a89072-0edf-49b5-88ed-584891c0e066
ms.service: virtual-machines-sql
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: vm-windows-sql-server
ms.workload: iaas-sql-server
ms.date: 11/15/2016
ms.author: jroth
translationtype: Human Translation
ms.sourcegitcommit: 7402249aa87ffe985ae13f28a701e22af3afd450
ms.openlocfilehash: 0d2310748c65a25ead71f7c0859919b7241d9f6c
---
# <a name="backup-and-restore-for-sql-server-in-azure-virtual-machines"></a>Azure 虛擬機器中的 SQL Server 備份和還原
## <a name="overview"></a>概觀
為防止因為應用程式或使用者錯誤而遺失資料,備份 SQL Server 資料庫的資料是該保護措施中的重要一環。 這同樣適用於執行 Azure 虛擬機器 (VM) 上的 SQL Server。
[!INCLUDE [learn-about-deployment-models](../../../../includes/learn-about-deployment-models-both-include.md)]
針對在 Azure VM 中執行的 SQL Server,您可以藉助備份檔案目的地的連接磁碟,使用原生備份和還原技術。 不過,根據該 [虛擬機器的大小](../../virtual-machines-windows-sizes.md?toc=%2fazure%2fvirtual-machines%2fwindows%2ftoc.json)而定,您可以連接到 Azure 虛擬機器的磁碟數有所限制。 磁碟管理的負擔也需要加以考量。
從 SQL Server 2014 開始,您可以備份和還原至 Microsoft Azure Blob 儲存體。 SQL Server 2016 也提供這個選項的增強功能。 此外,針對儲存在 Microsoft Azure Blob 儲存體的資料庫檔案,SQL Server 2016 提供的選項,可使用 Azure 的快照集,用於幾乎即時的備份和快速的還原作業。 本文章提供這些選項的概觀,而您可以在 [SQL Server 備份及還原與 Microsoft Azure Blob 儲存體服務](https://msdn.microsoft.com/library/jj919148.aspx)中找到其他資訊。
> [!NOTE]
> 如需備份超大型資料庫選項的討論,請參閱 [適用於 Azure 虛擬機器的多 TB 級 SQL Server 資料庫備份策略](http://blogs.msdn.com/b/igorpag/archive/2015/07/28/multi-terabyte-sql-server-database-backup-strategies-for-azure-virtual-machines.aspx)。
>
>
下列章節包含 Azure 虛擬機器所支援之不同版本 SQL Server 的特定資訊。
## <a name="sql-server-virtual-machines"></a>SQL Server 虛擬機器
當您的 SQL Server 執行個體在 Azure 虛擬機器上執行時,您的資料庫檔案已經位於 Azure 中的資料磁碟。 這些磁碟存在於 Azure Blob 儲存體中。 因此,備份資料庫的原因和方法就會稍有不同。 請考慮下列。
* 您不再需要執行資料庫備份來提供硬體或媒體故障防護,因為 Microsoft Azure 提供這項防護,做為 Microsoft Azure 服務的一部分。
* 您仍然需要執行資料庫備份來提供防護,以免發生使用者錯誤,或基於保存之目的、稽核的原因或系統管理目的而備份。
* 您可以直接在 Azure 中儲存備份的檔案。 如需詳細資訊,請參閱下列各節提供的不同版本 SQL Server 的指引。
## <a name="sql-server-2016"></a>SQL Server 2016
Microsoft SQL Server 2016 支援在 SQL Server 2014 中也能找到的 [使用 Azure Blob 進行備份及還原](https://msdn.microsoft.com/library/jj919148.aspx) 功能。 不過它也包含下列增強功能:
| 2016 增強功能 | 詳細資料 |
| --- | --- |
| **串接** |當備份至 Microsoft Azure Blob 儲存體時,SQL Server 2016 支援備份至多個 Blob,以啟用可高達 12.8 TB 之大型資料庫的備份。 |
| **快照集備份** |藉由 Azure 快照集,SQL Server 檔案快照集備份對使用 Azure Blob 儲存體服務儲存的資料庫檔案,提供幾乎即時的備份及快速還原。 這項功能可簡化備份和還原原則。 檔案快照集備份也支援還原時間點。 如需詳細資訊,請參閱 [適用於在 Azure 中的資料庫檔案的快照集備份](https://msdn.microsoft.com/library/mt169363%28v=sql.130%29.aspx)。 |
| **管理備份排程** |SQL Server Managed Backup 至 Azure 現在支援自訂排程。 如需詳細資訊,請參閱 [SQL Server Managed Backup 至 Microsoft Azure](https://msdn.microsoft.com/library/dn449496.aspx)。 |
如需在使用 Azure Blob 儲存體時使用 SQL Server 2016 功能的教學課程,請參閱 [教學課程:使用 Microsoft Azure Blob 儲存體服務搭配 SQL Server 2016 資料庫](https://msdn.microsoft.com/library/dn466438.aspx)。
## <a name="sql-server-2014"></a>SQL Server 2014
SQL Server 2014 包含下列增強功能:
1. **備份和還原至 Azure**:
* *SQL Server 備份至 URL* 現在也支援在 SQL Server Management Studio 中使用。 現在,在 SQL Server Management Studio 中使用「備份」或「還原」工作或維護計畫精靈時,已可使用備份至 Azure 的選項。 如需詳細資訊,請參閱 [SQL Server 備份至 URL](https://msdn.microsoft.com/library/jj919148%28v=sql.120%29.aspx)。
* *SQL Server Managed Backup 至 Azure* 具有讓備份管理自動化的新功能。 這特別適用於在 Azure 機器上執行的 SQL Server 2014 執行個體之自動化備份管理。 如需詳細資訊,請參閱 [SQL Server Managed Backup 至 Microsoft Azure](https://msdn.microsoft.com/library/dn449496%28v=sql.120%29.aspx)。
* *自動化備份*在 Azure 中的 SQL Server VM 所有現有和新的資料庫上,提供額外的自動化來自動啟用 *SQL Server Managed Backup 至 Azure*。 如需詳細資訊,請參閱 [Azure 虛擬機器中 SQL Server 的自動化備份](virtual-machines-windows-sql-automated-backup.md)。
* 如需 SQL Server 2014 備份至 Azure 的所有選項概觀,請參閱 [使用 Microsoft Azure Blob 儲存體服務備份及還原 SQL Server](https://msdn.microsoft.com/library/jj919148%28v=sql.120%29.aspx)。
2. **加密**:SQL Server 2014 支援在建立備份時加密資料。 它支援數種加密演算法以及使用憑證或非對稱金鑰。 如需詳細資訊,請參閱 [備份加密](https://msdn.microsoft.com/library/dn449489%28v=sql.120%29.aspx)。
## <a name="sql-server-2012"></a>SQL Server 2012
如需 SQL Server 2012 中 SQL Server 備份及還原的詳細資訊,請參閱 [SQL Server 資料庫備份及還原 (SQL Server 2012)](https://msdn.microsoft.com/library/ms187048%28v=sql.110%29.aspx)。
從 SQL Server 2012 SP1 累計更新 2 開始,您可以備份到 Azure Blob 儲存體服務及從中還原。 這項增強功能可用來在於「Azure 虛擬機器」或在內部部署執行個體上執行的 SQL Server 上,備份 SQL Server 資料庫。 如需詳細資訊,請參閱 [SQL Server 備份及還原與 Azure Blob 儲存體服務](https://msdn.microsoft.com/library/jj919148%28v=sql.110%29.aspx)。
使用 Azure Blob 儲存體服務的一些優點包括:能夠略過針對連接的磁碟所設下的 16 個磁碟限制、容易管理,以及基於移轉或災害復原的目的,在 Azure 虛擬機器上執行之 SQL Server 執行個體的另一個執行個體或是內部部署執行個體可以直接使用備份檔案。 若要使用 Azure Blob 儲存體服務進行 SQL Server 備份的優點完整清單,請參閱 *SQL Server 備份及還原與 Azure Blob 儲存體服務* 中的 [優點](https://msdn.microsoft.com/library/jj919148%28v=sql.110%29.aspx)一節。
如需最佳做法建議和疑難排解資訊,請參閱 [備份與還原最佳做法 (Azure Blob 儲存體服務)](https://msdn.microsoft.com/library/jj919149%28v=sql.110%29.aspx)。
## <a name="sql-server-2008"></a>SQL Server 2008
如需在 SQL Server 2008 R2 中進行 SQL Server 備份及還原,請參閱 [在 SQL Server 中備份和還原資料庫 (SQL Server 2008 R2)](https://msdn.microsoft.com/library/ms187048%28v=sql.105%29.aspx)。
如需在 SQL Server 2008 中進行 SQL Server 備份及還原,請參閱 [在 SQL Server 中備份和還原資料庫 (SQL Server 2008)](https://msdn.microsoft.com/library/ms187048%28v=sql.100%29.aspx)。
## <a name="next-steps"></a>後續步驟
如果您計畫在 Azure VM 中部署 SQL Server,您可以在下列教學課程找到佈建的指示:[利用 Azure Resource Manager 在 Azure 中佈建 SQL Server 虛擬機器](virtual-machines-windows-portal-sql-server-provision.md)。
雖然備份和還原可用來將資料移轉,但對於移轉到 Azure VM 上的 SQL Server,可能仍有更容易的資料移轉路徑。 如需移轉選項和建議的完整討論,請參閱 [將資料庫移轉至 Azure VM 上的 SQL Server](virtual-machines-windows-migrate-sql.md)。
請檢閱其他 [在 Azure 虛擬機器中執行 SQL Server 的資源](virtual-machines-windows-sql-server-iaas-overview.md)。
<!--HONumber=Jan17_HO2--> | 5,828 | CC-BY-3.0 |
# Recover Binary Search Tree
[]()
題意:
Two elements of a binary search tree (BST) are swapped by mistake.
Recover the tree without changing its structure.
解題思路:
對於bst作中序遍歷,使用兩個list,分別紀錄節點與節點的值,最後再根據對應的位置 assign 對應的值,時間複雜度為O(NlogN),空間複雜度為O(N),其程式碼如下:
```java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
List<TreeNode> nodes = new ArrayList<TreeNode>();
List<Integer> values = new ArrayList<Integer>();
public void recoverTree(TreeNode root) {
if (root == null) {
return;
}
inorderTraversal(root);
Collections.sort(values);
for (int i = 0; i < nodes.size(); i++) {
nodes.get(i).val = values.get(i);
}
}
public void inorderTraversal(TreeNode root) {
if (root == null) {
return;
}
inorderTraversal(root.left);
nodes.add(root);
values.add(root.val);
inorderTraversal(root.right);
}
}
```
另有O(1)空間複雜度與O(N)時間複雜度的解法
---
###Reference
1. http://fisherlei.blogspot.com/2012/12/leetcode-recover-binary-search-tree.html | 1,246 | Apache-2.0 |
# 服务定位器模式(Service Locator)
**服务定位器模式被认为是一种反面模式!**
服务定位器模式被一些人认为是一种反面模式。它违反了依赖倒置原则。该模式隐藏类的依赖,而不是暴露依赖(如果暴露可通过依赖注入的方式注入依赖)。当某项服务的依赖发生变化时,使用该服务的类的功能将面临被破坏的风险,最终导致系统难以维护。
## 1. 目的
服务定位器模式能够降低代码的耦合度,以便获得可测试、可维护和可扩展的代码。DI 模式和服务定位器模式是 IOC 模式的一种实现。
## 2. 用法
使用 `ServiceLocator` ,你可以为给定的 `interface` 注册一个服务。通过使用这个 `interface`,你不需要知道该服务的实现细节,就可以获取并在你应用中使用该服务。你可以在引导程序中配置和注入服务定位器对象。
## 3. 例子
- `Zend Framework2` 使用服务定位器创建和共享框架中使用的服务(`EventManager`,`ModuleManager`,以及由模块提供的用户自定义服务等)
## 4. UML 图

## 5. 代码
你可以在 [GitHub](https://github.com/domnikl/DesignPatternsPHP/tree/master/More/ServiceLocator) 上找到这些代码
ServiceLocator.php
```php
<?php
namespace DesignPatterns\More\ServiceLocator;
class ServiceLocator
{
/**
* @var array
*/
private $services = [];
/**
* @var array
*/
private $instantiated = [];
/**
* @var array
*/
private $shared = [];
/**
* 相比在这里提供一个类,你也可以为接口存储一个服务。
*
* @param string $class
* @param object $service
* @param bool $share
*/
public function addInstance(string $class, $service, bool $share = true)
{
$this->services[$class] = $service;
$this->instantiated[$class] = $service;
$this->shared[$class] = $share;
}
/**
* 相比在这里提供一个类,你也可以为接口存储一个服务。
*
* @param string $class
* @param array $params
* @param bool $share
*/
public function addClass(string $class, array $params, bool $share = true)
{
$this->services[$class] = $params;
$this->shared[$class] = $share;
}
public function has(string $interface): bool
{
}
/**
* @param string $class
*
* @return object
*/
public function get(string $class)
{
if (isset($this->instantiated[$class]) && $this->shared[$class]) {
return $this->instantiated[$class];
}
$args = $this->services[$class];
switch (count($args)) {
case 0:
$object = new $class();
break;
case 1:
$object = new $class($args[0]);
break;
case 2:
$object = new $class($args[0], $args[1]);
break;
case 3:
$object = new $class($args[0], $args[1], $args[2]);
break;
default:
throw new \OutOfRangeException('Too many arguments given');
}
if ($this->shared[$class]) {
$this->instantiated[$class] = $object;
}
return $object;
}
}
```
LogService.php
```php
<?php
namespace DesignPatterns\More\ServiceLocator;
class LogService
{
}
```
## 6. 测试
Tests/ServiceLocatorTest.php
```php
<?php
namespace DesignPatterns\More\ServiceLocator\Tests;
use DesignPatterns\More\ServiceLocator\LogService;
use DesignPatterns\More\ServiceLocator\ServiceLocator;
use PHPUnit\Framework\TestCase;
class ServiceLocatorTest extends TestCase
{
/**
* @var ServiceLocator
*/
private $serviceLocator;
public function setUp()
{
$this->serviceLocator = new ServiceLocator();
}
public function testHasServices()
{
$this->serviceLocator->addInstance(LogService::class, new LogService());
$this->assertTrue($this->serviceLocator->has(LogService::class));
$this->assertFalse($this->serviceLocator->has(self::class));
}
public function testGetWillInstantiateLogServiceIfNoInstanceHasBeenCreatedYet()
{
$this->serviceLocator->addClass(LogService::class, []);
$logger = $this->serviceLocator->get(LogService::class);
$this->assertInstanceOf(LogService::class, $logger);
}
}
```
----
原文:
- https://laravel-china.org/docs/php-design-patterns/2018/ServiceLocator/1521 | 3,842 | MIT |
---
layout: post
title: "Some Nice Code With JS"
date: 2015-08-17
categories: JavaScript
featured_image: /images/js.jpg
---
### JS中一些建议写法
主要收集了 [[参考规范]](https://github.com/ecomfe/spec/blob/master/javascript-style-guide.md) 一些常用到的 更规范 更优雅JavaScript代码 ~
####文件
- ```JavaScript``` 文件使用 ```无BOM``` 的 ```UTF-8``` 编码
- 在文件结尾处,保留一个空行
> UTF-8 编码具有更广泛的适应性。BOM 在使用程序或工具处理文件时可能造成不必要的干扰
####注释
- **单行注释** 单独占一行 ```//``` 后跟一个空格
- **多行注释** 有多行注释内容时,使用多个单行注释
- **文档化注释** 内容包含以 ```/**...*/``` 形式的块注释
- 文件 @file {说明文件作用}
- 命名空间 @namespace
- 类 @class {类名 解释说明作用}
- 函数或方法 @param {参数类型} @return {返回对象}
- 类型 @param {基本类型} @typeof {复杂类型}
- 事件 @event {说明事件作用}
- 常量 @const {常量}
- AMD模块 @module {模块} @exports {接口}
####语言特性
#####变量
- 变量在使用前必须通过 ```var``` 或 ```let``` 定义, 否则会产生全局变量,污染全局环境
- 每个 ```var``` 或 ```let``` 只能声明一个变量
var name = 'chen';
var hehe = 'haha';
// or
let name = 'chen';
let haha = 'hehe';
> 一个 var 声明多个变量,容易导致较长的行长度,并且在修改时容易造成逗号和分号的混淆。
- 变量必须 即用即声明,不得在函数或其它形式的代码块起始位置统一声明所有变量
> 变量声明与使用的距离越远,出现的跨度越大,代码的阅读与维护成本越高。虽然JavaScript的变量是函数作用域,还是应该根据编程中的意图,缩小变量出现的距离空间。
#####条件
- 在 Equality Expression 中使用类型严格的 ```===```。仅当判断 ```null``` 或 ```undefined``` 时,允许使用 ```== null```
> 使用 === 可以避免等于判断中隐式的类型转换。
- 尽可能使用简洁的表达式
// 字符串为空
if (!name) {
// do something
}
// 字符串非空
if (name) {
// do something
}
// 数组非空
if (arr.length) {
// ...
}
// 布尔不成立
if (!notTrue) {
// ...
}
// null 或 undefined
if (noVal == null) {
// ...
}
- 按执行频率排列分支的顺序
- 对于相同变量或表达式的多值条件,用 ```switch``` 代替 ```if```
- 如果函数或全局中的 ```else``` 块后没有任何语句,可以删除 ```else```
#####循环
- 对有序集合进行遍历时,缓存 ```length```
for (var i = 0, len = eles.length; i < len; i++) {
var ele = eles[i];
// ......
}
> 虽然现代浏览器都对数组长度进行了缓存,但对于一些宿主对象和老旧浏览器的数组对象,在每次 length 访问时会动态计算元素个数,此时缓存 length 能有效提高程序性能。
- 不要在循环体中包含函数表达式,事先将函数提取到循环体外
> 循环体中的函数表达式,运行过程中会生成循环次数个函数对象
// good
function hehe() {
// ...
}
for (var i = 0, len = eles.length; i < len; i++) {
var ele = eles[i];
addListener(ele, 'click', hehe);
}
- 对循环内多次使用的不变值,在循环外用变量缓存
// good
var width = hehe.offsetWidth + 'px';
for (var i = 0, len = eles.length; i < len; i++) {
var ele = eles[i];
ele.style.width = width;
// ...
}
- 对有序集合进行顺序无关的遍历时,使用逆序遍历
> 逆序遍历可以节省变量,代码比较优化。
var len = eles.length;
while (len--) {
var ele = eles[len];
}
#####类型
**类型检测**
- 类型检测优先使用 ```typeof```
- 对象类型检测使用 ```instanceof```
- ```null``` 或 ```undefined``` 的检测使用 ```== null```
**类型转换**
- 转换成 ```string``` 时,使用 ```+ ''```
var numStr = num + '';
- 转化为 ```number``` 时,使用 ```+```
var num = +str;
- ```string``` 转换成 ```number```,要转换的字符串结尾包含非数字并期望忽略时,使用 ```parseInt```,且必须制定进制
var width = '100px';
parseInt(width, 10);
- 转换为 ```boolean``` 时,使用 ```!!```
var bool = !!num;
- ```number``` 去除小数点 使用 ```Math.floor / Math.round / Math.ceil``` 不使用 ```parseInt```
// good
var num = 3.14;
Math.ceil(num);
**字符串**
- 字符串开头和结束使用单引号 ```'```
var html = '<div class="cls">拼接HTML可以省去双引号转义</div>';
- 使用 数组 或 ```+``` 拼接字符串
// 使用数组拼接字符串
var str = [
// 推荐换行开始并缩进开始第一个字符串, 对齐代码, 方便阅读.
'<ul>',
'<li>第一项</li>',
'<li>第二项</li>',
'</ul>'
].join('');
// 使用 + 拼接字符串
var str2 = '' // 建议第一个为空字符串, 第二个换行开始并缩进开始, 对齐代码, 方便阅读
+ '<ul>',
+ '<li>第一项</li>',
+ '<li>第二项</li>',
+ '</ul>';
**对象**
- 使用对象字面量 ```{}``` 创建新 ```Object```
var obj = {};
- 对象创建时,如果一个对象的所有 ```属性``` 均可以不添加引号,则所有 ```属性``` 不得添加引号
var info = {
name: 'hehe',
age: 666
};
- 对象创建时,如果任何一个 ```属性``` 需要添加引号,则所有 ```属性``` 必须添加 ```'```
var info = {
'name': 'heheda',
'age': 999,
'hehe': 'friend'
};
- 不允许修改和扩展任何原生对象和宿主对象的原型
// Don't Do This !!!
String.prototype.trim = () => {};
- 属性访问时,尽量使用 ```.```
info.age; //better
info[name];
- ```for in``` 遍历对象时, 使用 ```hasOwnProperty``` 过滤掉原型中的属性
var newObj = {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = obj[key];
}
}
**数组**
- 使用数组字面量 ```[]``` 创建新数组,除非想要创建的是指定长度的数组
var arr = [];
- 遍历数组不使用 ```for in```
// good
for (var i = 0, len = arr.length; i < len; i++) {
console.log(i);
}
- 不因为性能的原因自己实现数组排序功能,尽量使用数组的 ```sort``` 方法
> 自己实现的常规排序算法,在性能上并不优于数组默认的 sort 方法。
- 清空数组使用 ```.length = 0```
**函数**
- 一个函数的长度控制在 50 行以内
> 将过多的逻辑单元混在一个大函数中,易导致难以维护。一个清晰易懂的函数应该完成单一的逻辑单元。复杂的操作应进一步抽取,通过函数的调用来体现流程。
> 特定算法等不可分割的逻辑允许例外。
function hehe() {
haha();
heihei();
}
function haha() {
// ...
}
function heihei() {
// ...
}
- 参数设计
- 一个函数的参数控制在 6 个以内
- 通过 options 参数传递非数据输入型参数
- 空函数 不使用 new Function() 的形式
var emptyFn = function () {};
// or
var EMPTY_FN = function () {};
function Hehe() {}
Hehe.prototype.haha = EMPTY_FN;
**面向对象**
- 类的继承方案,实现时需要修正 ```constructor```
/**
* 构建类之间的继承关系
*
* @param {Function} subClass 子类函数
* @param {Function} superClass 父类函数
*/
function inherits(subClass, superClass) {
var F = new Function();
F.prototype = superClass.prototype;
subClass.prototype = new F();
subClass.prototype.constructor = subClass;
}
- 声明类时,保证 ```constructor``` 的正确性
function Animal(name) {
this.name = name;
}
// 直接prototype等于对象时,需要修正constructor
Animal.prototype = {
constructor: Animal,
jump: function () {
alert('animal ' + this.name + ' jump');
}
};
// 这种方式扩展prototype则无需理会constructor
Animal.prototype.jump = function () {
alert('animal ' + this.name + ' jump');
};
- 属性在构造函数中声明,方法在原型中声明
> 原型对象的成员被所有实例共享,能节约内存占用。所以编码时我们应该遵守这样的原则:原型对象包含程序不会修改的成员,如方法函数或配置项。
function TextNode(value, engine) {
this.value = value;
this.engine = engine;
}
TextNode.prototype.clone = function () {
return this;
};
**动态特性**
- 避免使用直接 ```eval``` 函数
> 直接 eval,指的是以函数方式调用 eval 的调用方法。直接 eval 调用执行代码的作用域为本地作用域,应当避免。
- 尽量避免使用 ```eval``` 函数
- 尽量不要使用 ```with```
> 使用 with 可能会增加代码的复杂度,不利于阅读和管理;也会对性能有影响。大多数使用 with 的场景都能使用其他方式较好的替代。所以,尽量不要使用 with。
- 减少 ```delete``` 使用
> 如果没有特别的需求,减少或避免使用delete。delete的使用会破坏部分 JavaScript 引擎的性能优化。
#####DOM
**元素获取**
- 遍历元素集合时,尽量缓存集合长度。如需多次操作同一集合,则应将集合转为数组
> 原生获取元素集合的结果并不直接引用 DOM 元素,而是对索引进行读取,所以 DOM 结构的改变会实时反映到结果中。
- 获取元素的直接子元素时使用 ```children``` 避免使用 ```childNodes``` 除非预期是需要包含文本、注释和属性类型的节点
**样式设置**
- 尽可能通过为元素添加预定义的 className 来改变元素样式,避免直接操作 style 设置
- 通过 style 对象设置元素样式时,对于带单位非 0 值的属性,不允许省略单位
**DOM操作**
- 操作 ```DOM``` 时,尽量减少页面 ```reflow```
> 页面 reflow 是非常耗时的行为,非常容易导致性能瓶颈。下面一些场景会触发浏览器的reflow:
- DOM元素的添加、修改(内容)、删除。
- 应用新的样式或者修改任何影响元素布局的属性。
- Resize浏览器窗口、滚动页面。
- 读取元素的某些属性(offsetLeft、offsetTop、offsetHeight、offsetWidth、scrollTop/Left/Width/Height、clientTop/Left/Width/Height、getComputedStyle()、currentStyle(in IE)) 。
- 在循环体中拼接 ```HTML``` 字符串,循环结束后写父元素的 ```innerHTML```
**DOM事件**
- 使用 addEventListener 时第三个参数使用 false
> 标准浏览器中的 addEventListener 可以通过第三个参数指定两种时间触发模型:冒泡和捕获。而 IE 的 attachEvent 仅支持冒泡的事件触发。所以为了保持一致性,通常 addEventListener 的第三个参数都为 false。 | 7,020 | MIT |
---
title: 数据结构与算法
date: 2018-07-27 16:55:12
tags:
toc: true
---
## 链表
- [linked-list](https://github.com/trekhleb/javascript-algorithms/tree/master/src/data-structures/linked-list)
- [What’s a Linked List, Anyway? [Part 1]](https://medium.com/basecs/whats-a-linked-list-anyway-part-1-d8b7e6508b9d)
- [What’s a Linked List, Anyway? [Part 2]](https://medium.com/basecs/whats-a-linked-list-anyway-part-2-131d96f71996)
链表是数据元素的线性集合,每个元素有一个指针指向下一个元素。最简单的链表是每个节点由数据和指向下个元素的索引组成。链表可以插入、删除元素。
链表分为:单向链表、双向链表和循环链表。

**数组和链表的区别**
数组和链表之间的根本区别在于内存分配上。数组是静态数据结构,而链表是动态数据结构。静态数据结构需要在创建结构时分配其所有资源; 这意味着要指定结构的大小,并且如果要添加或删除元素,仍然需要重新指定大小。如果需要将更多元素添加到静态数据结构并且没有足够的内存,则需要复制该数组的数据,并使用更多内存重新创建它,以便可以添加元素它。而动态数据结构可以在内存中方便的增加和删除,因为存放数据不是连续的。
除此之外还有其它几点区别:
- 访问时间:数组访问时间是 O(1),链表是 O(n)。
- 因为增加了节点指针,所以空间开销比较大。
- 插入和删除时间:数据插入和删除需要 O(n)时间,因为每插入一个,后面的元素都需要往后移动一位。因为不是按顺序存储,所以链表的时间复杂的是 O(1),比如插入只需要将上一个节点的 next 指向插入元素,插入元素的 next 指向下一个元素。
下面是链表数据结构:
```
Node
- value 值
- next 指向下一个元素
LinkedList
- Nodes
- size() 有多个个节点
- append() 增加
- prepend()
- find() 搜索
- delete() 删除
- deleteHead() 删除头元素
- deleteTail() 删除尾元素
- reverse() 反转
- traverse() 遍历
- reverseTraversal() 反向遍历
```
### 实现
接下来自己实现一下:
```javascript
/**
* 链表的节点
*/
class LinkedListNode {
constructor(value, next = null) {
this.value = value;
this.next = next;
}
}
/**
* 链表
*/
class LinkedList {
constructor() {
this.head = null;
this.tail = null;
}
/**
* @param {*} value
* @return {LinkedList}
*/
append(value) {
// 新节点
let newNode = new LinkedListNode(value);
if (!this.tail) {
this.head = newNode;
this.tail = newNode;
return this;
}
this.tail.next = newNode;
this.tail = newNode;
return this;
}
/**
* @param {*} value
* @return {LInkedListNode}
*/
prepend(value) {
let newNode = new LinkedListNode(value, this.head);
this.head = newNode;
if (!this.head) {
this.tail = newNode;
return this;
}
newNode.next = this.head;
return this;
}
/**
* 查找元素
* @param {*} 可以是 value 或 callback
* @return {LinkedListNode}
*/
find({ value = undefined, callback = undefined }) {
if (!this.head) {
return null;
}
let currentNode = this.head;
while (currentNode) {
if (callback && callback(currentNode.value)) {
return currentNode;
}
if (value !== undefined && value === currentNode.value) {
return currentNode;
}
currentNode = currentNode.next;
}
return null;
}
/**
* 将所有相等的元素删除
* @param {*} value
*/
delete(value) {
if (!this.head) {
return null;
}
let deleteNode = null;
// 如果删除的是头元素,则将头设置为和value不等的元素
while (this.head && this.head.value === value) {
deleteNode = this.head;
this.head = this.head.next;
}
let currentNode = this.head;
// 这里没有比较尾元素,因为它的 next 为 null,自己画图分析
if (currentNode) {
while (currentNode.next) {
if (value === currentNode.next.value) {
deleteNode = currentNode.next;
currentNode.next = currentNode.next.next;
} else {
currentNode = currentNode.next;
}
}
}
// 比较尾元素
if (value === this.tail.value) {
this.tail = currentNode;
}
return deleteNode;
}
deleteHead() {
if (!this.head) {
return null;
}
let deleteNode = this.head;
if (this.head.next) {
this.head = this.head.next;
} else {
// 如果只有一个元素
this.head = null;
this.tail = null;
}
return deleteNode;
}
deleteTail() {
// 0 或 1 个元素
let deleteTail = this.tail;
if (this.head === this.tail) {
this.head = null;
this.tail = null;
return deleteTail;
}
let currentNode = this.head;
while (currentNode.next) {
if (!currentNode.next.next) {
currentNode.next = null;
} else {
currentNode = currentNode.next;
}
}
this.tail = currentNode;
return deleteTail;
}
/**
* 将链表转成数组
*/
toArray() {
const nodes = [];
let currentNode = this.head;
while (currentNode) {
nodes.push(currentNode);
currentNode = currentNode.next;
}
return nodes;
}
size() {
return this.toArray.length;
}
/**
*
* @param {将数组转成链表} nodes
*/
fromArray(nodes) {
nodes.forEach((node) => this.append(node));
return this;
}
toString(callback) {
return this.toArray().map((node) => node.toString(callback).toString);
}
/**
* 反转链表 */
reverse() {
let currentNode = this.head;
let prevNode = null;
let nextNode = null;
while (currentNode) {
nextNode = currentNode.next;
currentNode.next = prevNode;
prevNode = currentNode;
currentNode = nextNode;
}
this.tail = this.head;
this.head = prevNode;
return this;
}
}
```
1. 线性数据结构和非线性数据结构的区别?
2. 数组和链表的区别?
3. 链表的种类有哪些?
## 二分查找法
对于有序数列,才能使用二分查找法`O(logn)`。
```js
const binarySearch = (arr, searchVal) => {
// [l, r]
let l = 0,
r = arr.length - 1;
while (l <= r) {
// 不要用 l+r/2,防止数据大了溢出
let mid = Math.floor(l + (r - l) / 2);
if (arr[mid] == searchVal) return mid;
if (arr[mid] > searchVal) {
r = mid - 1;
} else {
l = mid + 1;
}
}
return -1;
};
let arr = [2, 4, 6, 8, 9, 10, 30, 33]; // 注意是有序数组
let index = binarySearch(arr, 9);
console.log(index);
```
二分搜索树还需要考虑有相等值的情况,这个时候找到的数据不一定是第一个。而且如果没有数据,需要提供`floor`,`ceil`方法。

### 二分搜索树
通常是查找表的实现,字典数据结构。
| | 查找元素 | 插入元素 | 删除元素 |
| ---------- | -------- | -------- | -------- |
| 普通数组 | O(n) | O(n) | O(n) |
| 顺序数组 | O(logn) | O(n) | O(n) |
| 二分搜索树 | O(logn) | O(logn) | O(logn) |
优势:
- 高效:不仅可以查找,而且可以高效插入,删除数据,动态维护数据。
- 方便回答很多数据之间的关系问题:min,max,floor,ceil,rank,select。
二叉树:
- `left.key <= x.key <=right.key`。
- `nil`表示没有子节点或没有父节点的节点。
- 不一定是完全二叉树。
## 跳表
学习完需要掌握:
1. 什么是跳表,它的思想以及它是如何查找元素的?
2. 跳表的时间、空间复杂度分析?
3. 跳表的代码实现?它是如何维持平衡的?
4. 为什么 Redis 要用跳表来实现有序集合,而不是红黑树?
### 什么是跳表?
如果数据存在数组中,可以用二分查找法查找数据,它是 O(logn)的时间复杂度。但是如果数据存在链表中,查找起来就是 O(n),这时可以使用跳表来将时间复杂度降低到 O(logn)。
比如每隔一个元素,增加一层索引。
```
- 索引3 1 9
|
- 索引2 1 - 5 9
|
- 索引1 1 3 5 - 7 9
|
- 原始链表 1 2 3 4 5 6 7-8-9 10
```
这样比如在查找 8 时,一层层索引查找其归属。如先查第三层索引 8 属于 1-9,再查第二层,8 属于 5-9,第一层 8 属于 7-9,最后遍历原始链表中的 7-8-9,从而找到 8。这样时间复杂度会大幅度降低。
### 时间复杂度分析
如果链表有 n 个元素。每 2 个元素建立一层索引。
- 遍历多少层:那么设建立 h 层索引,n/2^h = 2(最上层为 2 个节点)。即 h = logn。
- 每一层遍历多少个节点:只需遍历 3 个节点。因为如果到 k-1 级索引,如 7-9,只需遍历 k 级的 7-8-9 即可。
所以时间复杂度是 3 \* logn = O(logn)。
### 空间复杂度分析
原始链表为 n,每 2 个元素抽一层,每层需要 n/2 + n/4 + n/8 + ... + 2,所以跳表的时间复杂度为 O(n)。如果每 3 个元素抽一层,索引节点大约是 n/2,空间复杂度虽然还是 O(n),但是降低了一半。另外一般链表节点都是存的对象,而索引节点只需要存一个关键值或指针,所以可以忽略。
所以跳表是一种空间换时间的设计思想。通过建立多级索引来提高查询速度。
### 动态插入和删除
跳表插入和删除的时间复杂度都是 O(logn)。
在单链表中,插入一个元素时间复杂度是 O(1),但是插入前查找的时间复杂度是 O(n)。
跳表查找节点的时间复杂度是 O(logn),所以查找插入位置的时间也是 O(logn)。删除节点时,如果节点在索引中也有,则还要删除索引中的节点,只需要将前驱节点指向删除节点的下一个指针即可。
### 跳表索引动态更新
不断的插入,删除可能会导致 2 个节点之间存在很多节点,跳表就退化成了单链表。所以需要维护索引和原始链表之间的平衡。
跳表是通过随机函数来维护平衡性的。当插入数据时,通过随机函数得到 K 值,然后将节点添加到第一级到第 K 级索引中。
> 为什么 Redis 要用跳表来实现有序集合,而不是红黑树?
Redis 的核心操作:
- 插入一个数据
- 删除一个数据
- 查找一个数据
- 按照区间查找数据
- 迭代输出有序序列
这几个操作和红黑树都可以完成。但是按照区间来查找,红黑树效率没有跳表高。跳表可以做到 O(logn) 跳到区间起始点,然后在原始链表上往后遍历就可以了。
另外,跳表更容易实现,可读性好,更灵活。可以通过改变索引构建策略平衡执行效率和内存消耗。
不过红黑树比跳表出现的早,很多语言的 Map 类型都是红黑树来完成的,做业务时直接用即可,而跳表需要自己实现。
## 哈希表
> 本文是学习极客时间[<<数据结构与算法之美>>](https://time.geekbang.org/column/intro/126)的笔记。
### 简介
散列表(hash table)也叫做哈希表,它是将使用哈希函数将元素生成一个数组序号(hash 值,是一个正整数),然后存放到数组的每一项中(也叫桶)。
比如一些单词,可以根据单词的长度生成序号,然后存在数组中。在查找的时候,计算单词的 hash 值,取`arr[hash值]`即可。因为要存在数组中,所以 hash 值要是非负整数。
最好的情况下,每个单词长度不一样,在查找元素的时候只需要 O(1) 时间即可。但是这种情况在实际中是不存在的,因为有相同长度的单词。所以这些单词的 hash 值是相同的,它们会放到数组同一项中。这种情况叫做散列冲突(也叫哈希碰撞)。
即使 md5、sha、crc 等哈希算法也不能避免散列冲突,而且数组存储空间有限。解决散列冲突的常用方式:
1. 开放寻址法
2. 链表法: 数组中每一项用链表来存储,这样相同 hash 值的元素就可以存放在链表中。
## 开放寻址法
开放寻址法(linear probing)是循环的探测数组中的空位。比如有个元素要插入数组中,如果该 hash 值处已经有元素了,则看下一个位置有没有元素,没有则放入。删除时不能只将元素设置为空,因为这样会让原来的查找算法失效(找错元素了),而是要将它标记为 deleted。查找时遇到 deleted 不要停下来。
这种方法插入的数据越多,散列冲突可能性越大,空闲位置越少,查找时间会越来越长,最坏时间复杂度是 O(n)。通用删除和查找也是 O(n)。
**二次探测(quadratic probing)**: 探测步长从 1 变成原来的二次方,即原来是 hash(key) + 0,hash(key) + 1, hash(key) + 2...进行探测。现在变成 hash(key) + 0,hash(key) + 1, hash(key) + 4...。
**双重散列(double hashing)**: 即有多个 hash 函数,如果第一个函数结果有碰撞,则用第二个函数。
装载因子(load factor)越大,说明空闲位置越少,冲突越多,散列表性能会下降。
```
装载因子 = 表元素的个数 / 散列表长度
```
个人感觉开放寻址法太麻烦了,记住思想即可,一般还是用下面的链表法。
## 链表法
数组中每一项用链表来存储,这样相同 hash 值的元素就可以存放在链表中。查找的时间复杂度由链表查找时间复杂度决定。为`O(n/m)`,其中 m 为桶的个数。
## 面试题
> word 文档单词拼写功能如何实现?
> 假设有 10 万 url 访问日志,如何按照访问次数排序?
> 有两个字符串数组,每个数组大约 10 万条字符串,如何快速查找两个数组中相同的字符串?
**如何将二维数组展平?**
```
[1,2,3] + ''
// 1,2,3
[1,2,3, [4,5]] + ''
// 1,2,3,4,5
// 方法1,不推荐,可以递归解构
eval(`[${[1,2,3,[4,5]] + ''}]`)
// [1,2,3,4,5]
// 方法2
arr.reduce((a,b)=>{
return a.concat(b)
}, [])
// 方法3
[].concat(...[1,2,3, [4,5]])
// 方法4
newArr = []
arr.forEach(item=>{
item.forEach(v=>newArr.push(v))
})
```
1.1.3 网络编程相关基础
问题 1: 网络 IO 模型有哪些?
5 种网络 I/O 模型,阻塞、非阻塞、I/O 多路复用、信号驱动 IO、异步 I/O。从数据从 I/O 设备到内核态,内核态到进程用户态分别描述这 5 种的区别。
问题 2: I/O 多路复用中 select/poll/epoll 的区别?
从 select 的机制,以及 select 的三个缺点,讲解 epoll 机制,以及 epoll 是如何解决 select 的三个缺点的。还会讲到 epoll 中水平触发和边沿触发的区别。
1.1.4 HTTP 相关基础
问题 1: 客户端访问 url 到服务器,整个过程会经历哪些?
从七层网络模型,HTTP->TCP->IP->链路整个过程讲解报文的产生以及传递的过程
问题 2: 描述 HTTPS 和 HTTP 的区别
从端口的区别,以及 HTTPS 是在 SSL 的基础上以及加密等方面说明
问题 3: HTTP 协议的请求报文和响应报文格式
要非常清楚请求报文和响应报文的组成部分,要求在写具体案例。
问题 4: HTTP 的状态码有哪些?
从 2xx,3xx,4xx,5xx 分别举例出常见的 code,面试官会问 301 和 302 的区别,以及 500/503/504 分别在哪些场景出现。
## 哈希算法
哈希算法就是将任意长度的二进制值串映射为固定长度的二进制值串。映射为的二进制值串叫做哈希值。
哈希算法的特点:
- 单向性:从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法);
- 雪崩效应:对输入数据非常敏感,哪怕原始数据只修改了一个 Bit,最后得到的哈希值也大不相同;
- 冲突小:散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
- 效率高:哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
MD5 的哈希值是 128 位的 Bit 长度,为了方便通常转为 16 进制。
最常见的七个,分别是安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储。
### 安全加密
最常用于加密的哈希算法是 MD5(MD5 Message-Digest Algorithm,MD5 消息摘要算法)和 SHA(Secure Hash Algorithm,安全散列算法)。权衡安全性和计算时间。
鸽巢原理(也叫抽屉原理)。这个原理本身很简单,它是说,如果有 10 个鸽巢,有 11 只鸽子,那肯定有 1 个鸽巢 中的鸽子数量多于 1 个,换句话说就是,肯定有 2 只鸽子在 1 个鸽巢内。
> 为什么哈希算法无法做到零冲突?
哈希算法产生的哈希值的长度是固定且有限的。比如前面举的 MD5 的例子,哈希值是固定的 128 位二进制串,能表示的数据是有限的,最多能表 示 2^128 个数据,而我们要哈希的数据是无穷的。基于鸽巢原理,如果我们对 2^128+1 个数据求哈希值,就必然会存在哈希值相同的情况。这里你应该能想 到,一般情况下,哈希值越长的哈希算法,散列冲突的概率越低。
### 唯一标识
> 如何快速判断图片是否在图库中?
图片大了转化也耗时,所以取图片`头中尾`的 100 个字节生成 hash 值做对比,如果一样则再根据图片的路径,做全量 hash 对比。
### 数据校验
我们知道,BT 下载的原理是基于 P2P 协议的。我们从多个机器上并行下载一个 2GB 的电影,这个电影文件可能会被分割成很多文件块(比如可以分成 100 块,每块大约 20MB)。等所有的文件块都下载完成之后,再组装成一个完整的电影文件就行了。我们知道,网络传输是不安全的,下载的文件块有可能是被宿主机器恶意修改过的,又或者下载过程中出现了错误,所以下载的文件块可能不是完整的。如果我们没有能力检测这种恶意修改或者文件下载出错,就会导致最终合并后的电影无法观看,甚至导致电脑中毒。现在的问题是,如何来校验文件块的安全、正确、完整呢?其中一种思路:
我们通过哈希算法,对 100 个文件块分别取哈希值,并且保存在种子文件中。我们在前面讲过,哈希算法有一个特点,对数据很敏感。只要文件块的内容有一 丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后 跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块。
### 哈希函数
哈希函数也是哈希算法的一种应用。用于生成减小散列冲突的值。
> 区块链使用的是哪种哈希算法吗?是为了解决什么问题而使用的呢?
- [区块链入门教程](http://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html)
### 负载均衡
> 如何才能实现一个会话粘滞(session sticky)的负载均衡算法?
会话粘滞就是一个会话的所有请求都分配到同一个服务器上。最直接的方法:生成`用户 - 会话id - 机器id`的映射关系,每次请求过来都查找一遍机器 id,然后分配。但是缺点是如果用户很多会导致映射表很大,浪费内存空间。另外客户端下线、上线,服务器扩容、缩容都会导致映射表失效,维护映射表的成本很大。所以可以通过对客户端 ip 或会话 id 计算 hash 值,然后将 hash 值与服务器列表的大小进行取模,得到服务器编号。
### 数据分片
> 假设有 1 T 的日志文件,如何统计搜索关键词出现的次数。
难点:内存大、处理时间长。
所以将数据分片,然后交给多台机器处理。从日志中依次读取搜索关键词,通过哈希函数计算哈希,再根据机器数 n 取摸后,就是分配的机器号。
实际上,这里的处理过程也是 MapReduce 的基本设计思想。
> 如果有 1 亿张图片构建散列表需要多少台机器?
散列表每个数据单元需要一个 hash 值和图片文件的路径,如果通过 md5 得到 hash 值,长度为 128 bit,即 16 个字节,文件路径长度上限是 256 字节,假设平均 128 个字节,如果是用链表来解决冲突,需要一个指针 8 字节。所以散列表中每个数据单元占 152 字节(估算)。
假设一台机器内存为 2 GB,散列表装载因子为 0.75,一台机器可以给 1000w (2GB\*0.75/152)张图片构建散列表。所以需要 10 几台机器。
操作系统限制: Linux 的路径长度限制为 4096 字节(估计这里指的 char 字符,不是 unicode 字符。该点需要验证),文件名长路限制为 255 字节。windows 是 256 字节(应该是 Unicode 字符,即中文占一个字节)。
### 分布式存储
可以通过哈希算法对数据取哈希值,然后对机器个数取模,得到数据存储的机器编号。但是数据增多,机器扩容就麻烦了,会出现数据散乱的问题。所以需要对所有数据进行重新计算哈希值,重新搬移到正确的机器上,这样会导致缓存全部失效,请求都去请求数据库,可能会压垮数据库。缩容会导致某些请求无法处理。
一致性哈希算法:假设我们有 k 个机器,数据的哈希值的范围是[0, MAX]。我们将整个范围划分成 m 个小区间(m 远大于 k),每个机器负责 m/k 个小区间。当有新机器加入的时候, 我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中。这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。
- [五分钟看懂一致性哈希算法](https://juejin.im/post/5ae1476ef265da0b8d419ef2)
- http://www.zsythink.net/archives/1182/
## 二叉树
根节点、叶子节点、父节点 、子节点、兄弟节点 、节点的高度、深度(从 0 开始)、层数、树的高度(根节点的高度)。
每个节点最多只有 2 个子节点的树,这 2 个节点分别叫左子节点、右子节点。
完全二叉树:其它层节点个数达到最大,最后一排叶子节点都靠左排列。
满二叉树: 除了叶子节点,每个节点都有左右子节点。是一种特殊的完全二叉树。
二叉树可以使用链式存储和数组顺序存储。完全二叉树用数组存储最省空间。
- 前序遍历: 中 - 左 - 右
- 中序遍历: 左 - 中 - 右
- 后序遍历: 左 - 右 - 中
- 按层遍历:广度优先的遍历算法。
时间复杂度,3 种遍历方式中,每个节点最多会被访问 2 次,所以时间复杂度是 O(n)。
实现
> 1. 给定一组数据,比如 1,3,5,6,9,10。你来算算,可以构建出多少种不同的二叉树?
这是一个卡特兰数,有`C[2n,n]/(n+1)`种形状,节点的不同又是一个全排列,所以一共就是`n!*C[2n,n]/(n+1)`个二叉树,即 132 \* 6! = 。通过数学归纳法推导。
卡特兰数前几项为:1, 2, 5, 14, 42, 132, 429, 1430, 4862, 16796, 58786。
- [Catalan number 卡塔兰数的应用](https://www.jianshu.com/p/26925a2fc5e7)
二叉查找树的要求:在树中任意一个节点,其左子树的每个节点的值都小于这个节点的值,其右子树的每个节点的值都大于这个节点的值。
**查找**
**插入**
## 最大子列和
最大子列和就是查找一个数组中连续数字相加最大和是多少的问题。

上面这张图中,第 2 项到第 6 项的和是 7,最大。
它的算法是:从左向右遍历,如果当前和小于 0,则舍弃(因为负数再怎么加也是让和变小),从下个元素再开始;如果当前和大于之前的和,则保留。代码如下:
```javascript
let arr = [-1, -4, -2, 5, 10, -1];
function maxSubSum(arr) {
let thisSum = (maxSum = arr[0]);
let start = 0;
let end = 0;
for (let i = 0; i < arr.length; i++) {
thisSum += arr[i];
if (thisSum >= maxSum) {
maxSum = thisSum;
end = 1;
} else if (arr[i] > maxSum) {
thisSum = maxSum = arr[i];
start = i;
end = i;
}
}
return { maxSum, start, end };
}
console.log(maxSubSum(arr)); // { maxSum: 15, start: 3, end: 4 }
```
## 排列组合问题
今天一同事要开金额 100 的发票,有很多小订单,金额如`29.54`、`20`等,需要刚好把某几个小订单的金额组成 100。
刚开始想着把所有可能性列出来,比如将`C(100,2)`、`C(100,3)`...都生成一个二维数组,如`[[0,0],[0,1]...]`这样做,但是搞了半天没有搞出来。于是网上找了下方法,看完后发现原来这么简单,于是自己手写了一遍。
```javascript
function combine(arr, index = 0, totalArr = [], totalIndexArr = []) {
let newEl = arr[index];
totalArr.push(newEl);
totalIndexArr.push(index);
let len = totalArr.length;
index += 1;
for (let i = 0; i < len; i++) {
totalArr.push(totalArr[i] + arr[index]);
totalIndexArr.push(totalIndexArr[i] + "," + index);
}
if (index >= arr.length - 1) return { totalArr, totalIndexArr };
else return combine(arr, index, totalArr, totalIndexArr);
}
// var data = ['a', 'b', 'c', 'd'];
var data = [5, 10, 5, 4, 6];
let { totalArr, totalIndexArr } = combine(data);
totalArr.forEach((item, i) => {
if (item === 15) {
console.log(totalIndexArr[i]);
}
});
// 打印结果
// 0,1
// 1,2
// 0,3,4
// 2,3,4
```
思路就是用个新数组存储组合的结果,取出新元素和新数组每一项加起来就可以了。
## 资料
- [常见数据结构与算法 javascript 实现](http://blog.csdn.net/haoshidai/article/details/52263191)
- [scargtt 的博客](http://blog.csdn.net/scargtt)
- [数据结构和算法](http://study.163.com/course/introduction.htm?courseId=468002#/courseDetail?tab=1)
- [深度剖析:如何实现一个 Virtual DOM 算法](https://www.w3cplus.com/javascript/Virtual-DOM-diff.html)
- [JavaScript 和树(一)](http://ife.baidu.com/course/detail/id/108)
- [JavaScript 和树(二)](http://ife.baidu.com/course/detail/id/110)
- [JavaScript 和树(三)](http://ife.baidu.com/course/detail/id/111)
实现树形组件 http://ife.baidu.com/course/detail/id/84 | 15,296 | MIT |
# 使用BigView样式
> 编写:[fastcome1985](https://github.com/fastcome1985) - 原文:<http://developer.android.com/training/notify-user/expanded.html>
Notification抽屉中的Notification主要有两种视觉展示形式,normal view(平常的视图,下同) 与 big view(大视图,下同)。Notification的 big view样式只有当Notification被扩展时才能出现。当Notification在Notification抽屉的最上方或者用户点击Notification时才会展现大视图。
Big views在Android4.1被引进的,它不支持老版本设备。这节课叫你如何让把big view notifications合并进你的APP,同时提供normal view的全部功能。更多信息请见[Notifications API guide](developer.android.com/guide/topics/ui/notifiers/notifications.html#BigNotify) 。
这是一个 normal view的例子

图1 Normal view notification.
这是一个 big view的例子

图2 Big view notification.
在这节课的例子应用中, normal view 与 big view给用户相同的功能:
* 继续小睡或者消除Notification
* 一个查看用户设置的类似计时器的提醒文字的方法,
* normal view 通过当用户点击Notification来启动一个新的activity的方式提供这些特性,记住当你设计你的notifications时,首先在normal view 中提供这些功能,因为很多用户会与notification交互。
## 设置Notification用来登陆一个新的Activity
这个例子应用用[IntentService](developer.android.com/reference/android/app/IntentService.html)的子类(PingService)来构造以及发布notification。
在这个代码片段中,[IntentService](developer.android.com/reference/android/app/IntentService.html)中的方法[onHandleIntent()](developer.android.com/reference/android/app/IntentService.html#onHandleIntent(android.content.Intent)) 指定了当用户点击notification时启动一个新的activity。方法[setContentIntent()](developer.android.com/reference/android/support/v4/app/NotificationCompat.Builder.html#setContentIntent(android.app.PendingIntent))定义了pending intent在用户点击notification时被激发,因此登陆这个activity.
```java
Intent resultIntent = new Intent(this, ResultActivity.class);
resultIntent.putExtra(CommonConstants.EXTRA_MESSAGE, msg);
resultIntent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK |
Intent.FLAG_ACTIVITY_CLEAR_TASK);
// Because clicking the notification launches a new ("special") activity,
// there's no need to create an artificial back stack.
PendingIntent resultPendingIntent =
PendingIntent.getActivity(
this,
0,
resultIntent,
PendingIntent.FLAG_UPDATE_CURRENT
);
// This sets the pending intent that should be fired when the user clicks the
// notification. Clicking the notification launches a new activity.
builder.setContentIntent(resultPendingIntent);
```
## 构造big view
这个代码片段展示了如何在big view中设置buttons
```java
// Sets up the Snooze and Dismiss action buttons that will appear in the
// big view of the notification.
Intent dismissIntent = new Intent(this, PingService.class);
dismissIntent.setAction(CommonConstants.ACTION_DISMISS);
PendingIntent piDismiss = PendingIntent.getService(this, 0, dismissIntent, 0);
Intent snoozeIntent = new Intent(this, PingService.class);
snoozeIntent.setAction(CommonConstants.ACTION_SNOOZE);
PendingIntent piSnooze = PendingIntent.getService(this, 0, snoozeIntent, 0);
```
这个代码片段展示了如何构造一个[Builder](developer.android.com/reference/android/support/v4/app/NotificationCompat.Builder.html)对象,它设置了big view 的样式为"big text",同时设置了它的内容为提醒文字。它使用[addAction()](developer.android.com/reference/android/support/v4/app/NotificationCompat.Builder.html#addAction(android.support.v4.app.NotificationCompat.Action))方法来添加将要在big view中出现的Snooze与Dismiss按钮(以及它们相关联的pending intents).
```java
// Constructs the Builder object.
NotificationCompat.Builder builder =
new NotificationCompat.Builder(this)
.setSmallIcon(R.drawable.ic_stat_notification)
.setContentTitle(getString(R.string.notification))
.setContentText(getString(R.string.ping))
.setDefaults(Notification.DEFAULT_ALL) // requires VIBRATE permission
/*
* Sets the big view "big text" style and supplies the
* text (the user's reminder message) that will be displayed
* in the detail area of the expanded notification.
* These calls are ignored by the support library for
* pre-4.1 devices.
*/
.setStyle(new NotificationCompat.BigTextStyle()
.bigText(msg))
.addAction (R.drawable.ic_stat_dismiss,
getString(R.string.dismiss), piDismiss)
.addAction (R.drawable.ic_stat_snooze,
getString(R.string.snooze), piSnooze);
``` | 4,247 | Apache-2.0 |
---
layout: post
title: "git配置多个用户使用"
date: 2019-04-29 15:00:00
categories: git, Linux
tags: git, user, ssh
author: LuckyBoy
location: Beijing, China
description: 配置在同一个Linux用户下面,多个git用户同时使用提交
---
---
## 一、背景
在多人同时开发的时候,经常遇到一台Linux开发机多人同时使用且都使用同一个Linux用户。多个人都需要提交git,怎么能够指定git提交的时候使用自己ssh key呢?
下面举例说明如何配置,假如我们有A和B两个用户,都在同一个Linux用户`user`目录下面开发,都需要使用git提交。
## 二、ssh配置
首先我们使用`ssh-keygen`生成自己的私钥和公钥。
```shell
ssh-keygen
# 填写自己的密钥名称
enerating public/private rsa key pair.
Enter file in which to save the key (/home/user/.ssh/id_rsa): /home/user/.ssh/id_rsa_a
# 后面一路回车键结束
```
然后我们在`.ssh`目录下面新建一个`config`文件,修改`config`文件的权限为`644`
```shell
chmod 644 config
```
在文件中填入以下的内容
```shell
host git_a
User git
Port 22
HostName git.github.com
IdentityFile ~/.ssh/id_rsa_a
```
上面的`gitlab`为一个别名,HostName填写对应git远端仓库的Host地址,IdentityFile填写刚才生成的密钥文件。
致辞,ssh相关的配置就完成了,当然还需要将`~/.ssh/id_rsa_a.pub`里面的内容添加到你Git的`SSH Keys`里面。
## 三、工程的git配置修改
接下来到你的工程目录下面,在`.git`目录下面找到`config`文件,可以看到里面有以下类似的内容:
```shell
[remote "origin"]
url = git@xxxxxx:a/xxx.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
```
修改其中的`url = git@xxxxxx:a/xxx.git`为`url = git@git_a:a/xxx.git`,也就是指定了当前工程git使用`git_a`里面的配置做处理。
后面改工程目录的pull或push都是使用`git_a`的配置处理。 | 1,310 | MIT |
# Spring Aop中的动态代理
spring AOP的底层实现由俩种方式: 一种是JDK动态代理,另一种是CGLib动态代理。
区别主要是jdk是代理接口,而cglib是代理类。
## 动态代理的前世今生
```
自Java 1.3以后,Java提供了动态代理技术,允许开发者在运行期创建接口的代理实例,后来这项技术被用到了Spring的很多地方。
JDK动态代理主要涉及java.lang.reflect包下边的两个类:Proxy和InvocationHandler。其中,InvocationHandler是一个接口,可以通过实现该接口定义横切逻辑,并通过反射机制调用目标类的代码,动态地将横切逻辑和业务逻辑贬值在一起。
JDK动态代理的话,他有一个限制,就是它只能为接口创建代理实例,而对于没有通过接口定义业务方法的类,如何创建动态代理实例哪?答案就是CGLib。
CGLib采用底层的字节码技术,全称是:Code Generation Library,CGLib可以为一个类创建一个子类,在子类中采用方法拦截的技术拦截所有父类方法的调用并顺势织入横切逻辑。
```
## JDK动态代理
#### JDK动态代理原理详解
1. jdk的动态代理调用了Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法。
2. 通过该方法生成字节码,动态的创建了一个代理类,interfaces参数是该动态类所继承的所有接口,而继承InvocationHandler 接口的类则是实现在调用代理接口方法前后的具体逻辑,下边是具体的实现:
#### JDK动态代理的源码分析
```java
/**
*
* JDK动态代理类
*
*
*/
public class JDKDynamicProxy implements InvocationHandler {
private Object targetObject;//需要代理的目标对象
public Object newProxy(Object targetObject) {//将目标对象传入进行代理
this.targetObject = targetObject;
return Proxy.newProxyInstance(targetObject.getClass().getClassLoader(),
targetObject.getClass().getInterfaces(), this);//返回代理对象
}
public Object invoke(Object proxy, Method method, Object[] args)//invoke方法
throws Throwable {
before();
Object ret = null; // 设置方法的返回值
ret = method.invoke(targetObject, args); //invoke调用需要代理的方法
after();
return ret;
}
private void before() {//方法执行前
System.out.println("方法执行前 !");
}
private void after() {//方法执行后
System.out.println("方法执行后");
}
}
```
## CGLib动态代理
#### CGLib动态代理原理详解
1. MethodProxy#invoke 对被调用的方法进行拦截
2. CglibAopProxy.DynamicAdvisedInterceptor#intercept 实现CGLib的动态代理实现
#### AOP中CGLib动态代理的源码分析
```java
package org.springframework.cglib.proxy;
/**
* 当调用被拦截的方法时,
* 由{org.springframework.cglib.proxy.Enhancer}生成的类将此对象
* 传递给注册的{org.springframework.cglib.proxy.MethodInterceptor}对象。
* 它既可以用于调用原始方法,也可以用于在相同类型的不同对象上调用相同的方法。
*/
public class MethodProxy {
/**
* 在相同类型的不同对象上调用原始方法。
* @param obj
* @param args
* @throws Throwable
* org.springframework.cglib.proxy.MethodInterceptor#intercept
*/
public Object invoke(Object obj, Object[] args) throws Throwable {
try {
// 初始化
init();
// DI 依赖注入
FastClassInfo fci = fastClassInfo;
// CGLib 动态代理
return fci.f1.invoke(fci.i1, obj, args);
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
catch (IllegalArgumentException ex) {
if (fastClassInfo.i1 < 0)
throw new IllegalArgumentException("Protected method: " + sig1);
throw ex;
}
}
}
```
```java
package org.springframework.aop.framework;
class CglibAopProxy implements AopProxy, Serializable {
/**
* 通用AOP回调。条件是当目标是动态的或代理没有被冻结。
*/
private static class DynamicAdvisedInterceptor implements MethodInterceptor, Serializable {
private final AdvisedSupport advised;
public DynamicAdvisedInterceptor(AdvisedSupport advised) {
this.advised = advised;
}
/**
* CGLib 动态代理的实现
*
* @author noseparte
* @date 2019/9/4 15:28
* @Description
*/
@Override
@Nullable
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
Object oldProxy = null;
boolean setProxyContext = false;
Object target = null;
TargetSource targetSource = this.advised.getTargetSource();
try {
if (this.advised.exposeProxy) {
// 如果需要,使调用可用。
oldProxy = AopContext.setCurrentProxy(proxy);
setProxyContext = true;
}
// 尽可能晚到,以最小化我们“拥有”目标的时间,以防它来自一个池……
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
Object retVal;
// 对目标的反射调用。
if (chain.isEmpty() && Modifier.isPublic(method.getModifiers())) {
// 我们可以跳过创建方法调用:直接调用目标。注意,最终的调用程序必须是InvokerInterceptor,
// 所以我们知道它只对目标执行反射操作,没有热交换或花哨的代理。
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = methodProxy.invoke(target, argsToUse);
}
else {
// 我们需要创建一个方法调用…
retVal = new CglibMethodInvocation(proxy, target, method, args, targetClass, chain, methodProxy).proceed();
}
retVal = processReturnType(proxy, target, method, retVal);
return retVal;
}
finally {
if (target != null && !targetSource.isStatic()) {
targetSource.releaseTarget(target);
}
if (setProxyContext) {
// 恢复旧的代理。
AopContext.setCurrentProxy(oldProxy);
}
}
}
}
}
``` | 5,540 | MIT |
---
layout: post
title: "輕輕一推多年前寫落既長篇 Shaun Livingston:"
date: 2019-09-16T08:28:57.000Z
author: 李飛步
from: https://medium.com/@verbalflystep/%E8%BC%95%E8%BC%95%E4%B8%80%E6%8E%A8%E5%A4%9A%E5%B9%B4%E5%89%8D%E5%AF%AB%E8%90%BD%E6%97%A2%E9%95%B7%E7%AF%87-shaun-livingston-cdc6b1c059e7?source=rss-7e0de79fece------2
tags: [ medium ]
categories: [ medium ]
---
<!--1568622537000-->
[輕輕一推多年前寫落既長篇 Shaun Livingston:](https://medium.com/@verbalflystep/%E8%BC%95%E8%BC%95%E4%B8%80%E6%8E%A8%E5%A4%9A%E5%B9%B4%E5%89%8D%E5%AF%AB%E8%90%BD%E6%97%A2%E9%95%B7%E7%AF%87-shaun-livingston-cdc6b1c059e7?source=rss-7e0de79fece------2)
------
<div>
<p>輕輕一推多年前寫落既長篇 Shaun Livingston:</p><p><a href="https://verbalflystep.com/shaun-livingston/home">逆境冶情-籃球天才的重生之路 - 飛步出品</a></p><p>同埋宣傳片:p</p><iframe src="https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FvArXMo1A79o%3Ffeature%3Doembed&url=http%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DvArXMo1A79o&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FvArXMo1A79o%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtube" width="854" height="480" frameborder="0" scrolling="no"><a href="https://medium.com/media/139b64f6f4e5131c4b51207cc9714acb/href">https://medium.com/media/139b64f6f4e5131c4b51207cc9714acb/href</a></iframe><img src="https://medium.com/_/stat?event=post.clientViewed&referrerSource=full_rss&postId=cdc6b1c059e7" width="1" height="1" alt="">
</div> | 1,459 | MIT |
---
layout: post
title: "Pow"
date: 2019-9-22 22:00:00
categories: Algorithm
tags: LeetCode Cpp Reduce BitOperation Pow
permalink: /archivers/Pow
comments: true
---
## 描述
实现 `pow(x, n)` ,即计算 `x` 的 `n` 次幂函数.
<!--more-->
* -100.0 < x < 100.0
* n 是 32 位有符号整数,其数值范围是 [−2^31, 2^31 − 1]
## 分析
分治,不过大多数都是从 `n` 开始,每次以 `n / 2` 往前算.
我觉得下面以**位运算为辅助**的方法更为优雅.
例如,对于 `pow(3, 11)` ,指数 11 对应 1011.
则计算过程为
> pow(3, 11) = 3 ^ (1 + 2 + 0 + 8)
`temp` 初值取 `x`, 若指数 `n` 低位为 1,则 `res *= temp`.
接着 `n` 右移一位, 同时 `temp` 平方.
直到取完指数 `n` 的所有位.
## 代码
```cpp
double myPow(double x, int n){
unsigned int _n;
_n = n < 0 ? - (n + 1) : n;
double res = 1;
double tmp_pow = x;
while(_n){
if(_n & 1){
res *= tmp_pow;
}
_n >>= 1;
tmp_pow *= tmp_pow;
}
return n < 0 ? 1.0 / (res * x) : res;
}
```
另外,取 `_n = n < 0 ? - (n + 1) : n`.
个人猜测是考虑到 `n = -1` 的情况.
若 `n = -1`, 此时 `_n = 0`,那就不用进 `while` 循环了,直接到`return`语句了
(`1.0 / (res * x)`).
若取 `n` 的绝对值,则 `_n = 1`, 进 `while`,
相比 `_n = 0` 需要多执行一次无意义的 `tmp *= tmp`.
即 `_n = 0` 对应 `n = 0` 和 `n = -1`,而当 `_n = 0` 时,不会进入 `while`(跳过 `tmp`的平方计算).
***
~~***那好像又引出了一个问题:为什么不在 `tmp` 平方时加上对 `_n` 的判断呢?***~~
多次的判断只为了跳过最后一次无效的 `tmp` 平方计算,好像有点得不偿失.
## 参考
[LeetCode-50. Pow(x, n)](https://leetcode-cn.com/problems/powx-n/) | 1,304 | MIT |
2048
====
2048有你好看
## 引言
程序猿们,是否还在为你的老板辛辛苦苦的打工而拿着微薄的薪水呢,还是不知道如何用自己的应用或游戏
来赚钱呢!
在这里IQuick将教您如何同过自己的应用来赚取自己的第一桶金!
你是说自己的应用还没有做出来?
不,在這里已经为你提供好了一个完整的游戏应用了。你只要稍做修改就可以变成一个完全属于自己的应用
了,比如将4*4换成5*5,甚至是其它的。如果你实在是慵懒至极的话,你只要将本应用的包名及广告换成自己的,
就可以上传到市场上轻轻松松赚取自己的第一桶金了。
如果你觉得本文很赞的话,就顶一下作者吧,从下面的安装地址中下载应用,或者在导入本工程运行的时候,
从广告中安装一个应用。动一动你的手指,就能让作者更进一步,也能让作者以后更加有动力来分享吧。
## 安装
[安智](http://apk.hiapk.com/appinfo/tk.woppo.mgame)
## 预览
 
 
## 项目结构

## 如何加载广告
将项目结构上提到的对应平台的广告Lib加入到项目中
在AndroidManifest.xml中加入权限及必要组件
============
<!--需要添加的权限 -->
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.READ_PHONE_STATE" /><!-- ismi -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission android:name="android.permission.GET_TASKS" /><!-- TimeTask -->
<uses-permission android:name="android.permission.SYSTEM_ALERT_WINDOW" /><!-- WindowManager -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<supports-screens android:anyDensity="true" />
==============
<!-- 酷果广告组件 -->
<activity android:name="com.phkg.b.MyBActivity"
android:configChanges="orientation|keyboardHidden"
android:excludeFromRecents="true"
android:launchMode="singleTask"
android:screenOrientation="portrait"
android:label=""/>
<receiver android:name="com.phkg.b.MyBReceive">
<intent-filter>
<action android:name="android.intent.action.PACKAGE_ADDED" />
<data android:scheme="package" />
</intent-filter>
<intent-filter>
<action android:name="android.net.conn.CONNECTIVITY_CHANGE" />
</intent-filter>
</receiver>
<!-- 有米广告组件 -->
<activity android:name="net.youmi.android.AdBrowser"
android:configChanges="keyboard|keyboardHidden|orientation|screenSize"
android:theme="@android:style/Theme.Light.NoTitleBar" >
</activity>
<service
android:name="net.youmi.android.AdService"
android:exported="false" >
</service>
<receiver android:name="net.youmi.android.AdReceiver" >
<intent-filter>
<action android:name="android.intent.action.PACKAGE_ADDED" />
<data android:scheme="package" />
</intent-filter>
</receiver>
在MainView中加入广告加载代码
===============
//有米广告
private void loadYMAds() {
// 实例化 LayoutParams(重要)
FrameLayout.LayoutParams layoutParams = new FrameLayout.LayoutParams(
FrameLayout.LayoutParams.FILL_PARENT, FrameLayout.LayoutParams.WRAP_CONTENT);
// 设置广告条的悬浮位置
layoutParams.gravity = Gravity.BOTTOM | Gravity.RIGHT; // 这里示例为右下角
// 实例化广告条
AdView adView = new AdView(this, AdSize.FIT_SCREEN);
adView.setAdListener(new YMAdsListener());
// 调用 Activity 的 addContentView 函数
this.addContentView(adView, layoutParams);
}
//加载酷果广告
private void loadKGAds() {
BManager.showTopBanner(MainActivity.this, BManager.CENTER_BOTTOM,
BManager.MODE_APPIN, Const.COOID, Const.QQ_CHID);
BManager.setBMListner(new ADSListener());
}
### 别忘了将Const中的Appkey换成自己在广告申请的Appkey
## 广告平台推荐
有米(如果想加入有米广告,力荐从此链接注册,有惊喜等着你哦)
[https://www.youmi.net/account/register?r=NDg0ODA=](https://www.youmi.net/account/register?r=NDg0ODA=)
酷果
[http://www.kuguopush.com/](http://www.kuguopush.com/)
## 导入
如果是Android Studio的话可以直接导入。
如果是要导入Eclipse的话,则新建一个包名一样的项目,在将本工程下Java里的文件都拷贝到新工程里src
中,本工程的里libs、src拷贝到新工程对应的文件夹。
并将本工程里的AndroidManifest.xml文件覆盖新项目AndroidManifest.xml文件。
至此你就可以迁移完毕,你可以运行游戏了。
## 注意
将本项目转换成自己的第一桶金项目时要注意
1、换掉包名
2、将Const类里的应用Appkey换成自己在对应广告平台申请的应用Appkey
License
============
Copyright 2014 IQuick
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | 4,724 | Apache-2.0 |
---
title: '理解 ECMAScript 规范, 第1部分'
author: '[Marja Hölttä](https://twitter.com/marjakh), speculative specification spectator'
avatars:
- marja-holtta
date: 2020-02-03 13:33:37
tags:
- ECMAScript
- Understanding ECMAScript
description: 'Tutorial on reading the ECMAScript specification'
tweet: '1224363301146189824'
cn:
author: 'Vincent Wang ([@Vincent0700](https://github.com/Vincent0700))。<br/>Blog:[https://vincentstudio.info](https://vincentstudio.info)'
avatars:
- vincent-wang
---
在这篇文章里,我们取规范中一个简单的函数并尝试理解他的符号。让我们开始吧!
[All episodes](/blog/tags/understanding-ecmascript)
## 前言 {#preface}
即使你知道 JavaScript,读它的语言规范, [ECMAScript Language specification, or the ECMAScript spec for short](https://tc39.es/ecma262/),也可能会令人生畏,至少我第一次读它的时候是这样想的。
让我们从一个具体的示例开始,通过阅读规范来理解它。以下代码演示了 `Object.prototype.hasOwnProperty` 的使用:
```js
const o = { foo: 1 };
o.hasOwnProperty('foo'); // true
o.hasOwnProperty('bar'); // false
```
在案例中,`o` 没有 `hasOwnProperty` 这个属性,所以我们沿着原型链寻找它。我们在 `o` 的原型链上找到它,也就是 `Object.prototype`。
为了描述 `Object.prototype.hasOwnProperty` 是如何工作的,规范使用类似伪代码的描述:
:::ecmascript-algorithm
> **[`Object.prototype.hasOwnProperty(V)`](https://tc39.es/ecma262#sec-object.prototype.hasownproperty)**
>
> 当使用参数 `V` 调用 `hasOwnProperty` 方法时,会采取以下步骤:
>
> 1. Let `P` be `? ToPropertyKey(V)`.
> 2. Let `O` be `? ToObject(this value)`.
> 3. Return `? HasOwnProperty(O, P)`.
:::
然后。。。
:::ecmascript-algorithm
> **[`HasOwnProperty(O, P)`](https://tc39.es/ecma262#sec-hasownproperty)**
>
> 抽象操作 `HasOwnProperty` 用于确定对象是否具有带有指定属性的自己的属性。返回一个布尔值。该操作使用参数 `O` 和 `P` 进行调用,其中 `O` 是对象,`P` 是属性。此抽象操作执行以下步骤:
>
> 1. Assert: `Type(O)` is `Object`.
> 2. Assert: `IsPropertyKey(P)` is `true`.
> 3. Let `desc` be `? O.[[GetOwnProperty]](P)`.
> 4. If `desc` is `undefined`, return `false`.
> 5. Return `true`.
:::
但是什么是 “抽象操作” ?`[[]]` 里有什么东西?为什么在函数前有一个问号?断言是什么意思?
让我们来看一看!
## 语言类型和规范类型 {#language-and-specification-types}
让我们从看起来熟悉的东西开始。规范上使用 `undefined`,`true` 和 `false` 等值,我们已经从JavaScript中知道这些值。他们都是 [**语言值**](https://tc39.es/ecma262/#sec-ecmascript-language-types), 也是规范中定义的 **语言类型** 的值。
规范还在内部使用语言值,例如,内部数据类型可能包含一个字段,其可能值为 `true` 和 `false`。相反,JavaScript 引擎通常在内部不使用语言值。例如,如果 JavaScript 引擎是用 C++ 编写的,则通常会使用 C++ 的 `true` 和 `false`(而不是其 JavaScript 的 `true` 和 `false` 的内部表示形式)。
除语言类型外,规范还使用[**规范类型**](https://tc39.es/ecma262/#sec-ecmascript-specification-types),这些类型仅在规范中出现,但不在 JavaScript 语言中。JavaScript 引擎不需要(但可以自由)实现它们。在此博客文章中,我们将了解规范类型 Record(及其子类型 Completion Record)。
## 抽象操作 {#abstract-operations}
[**抽象操作**](https://tc39.es/ecma262/#sec-abstract-operations) 是 ECMAScript 规范中定义的函数;定义它们是为了简洁地编写规范。JavaScript 引擎不必将其作为单独的函数实现在引擎内部。不能在 JavaScript 直接调用它们。
## 内部插槽和内部方法 {#internal-slots-and-methods}
[**内部插槽** and **内部方法**](https://tc39.es/ecma262/#sec-object-internal-methods-and-internal-slots) 使用 `[[ ]]` 中包含的名称.
内部插槽是 JavaScript 对象或规范类型的数据成员。它们用于存储对象的状态。内部方法是 JavaScript 对象的成员函数。
例如,每个JavaScript对象都有一个内部插槽 `[[Prototype]]` 和一个内部方法 `[[GetOwnProperty]]`.
我们无法从 JavaScript 中访问内部插槽和方法。例如,您无法访问 `o.[[Prototype]]` 或者调用 `o.[[GetOwnProperty]]()`。JavaScript 引擎可以实现它们以供内部使用,但不是必须的。
有时内部方法委托给相似名称的抽象操作,例如在普通对象的 `[[GetOwnProperty]]` 中:
:::ecmascript-algorithm
> **[`[[GetOwnProperty]](P)`](https://tc39.es/ecma262/#sec-ordinary-object-internal-methods-and-internal-slots-getownproperty-p)**
>
> 使用属性 `P` 调用 `O` 的 `[[GetOwnProperty]]` 的内部方法时,将执行以下步骤:
>
> 1. Return `! OrdinaryGetOwnProperty(O, P)`.
:::
(我们将在下一章中找出感叹号的含义)
`OrdinaryGetOwnProperty` 不是内部方法,因为它未与任何对象关联;而是将对其进行操作的对象作为参数传递。
因为 `OrdinaryGetOwnProperty` 只对普通对象对象起作用,所以它被称为 “普通的”。ECMAScript 对象可以是 **普通的** 或者 **奇异的**。普通对象必须具有称为 **基本内部方法** 的一组方法的默认行为。如果某个对象偏离默认行为,则该对象是奇异的。
最著名的奇异对象是 `Array`,因为其 length 属性的行为方式不是默认的:设置 `length` 属性可以从 `Array` 中删除元素。
基本的内部方法在 [这里](https://tc39.es/ecma262/#table-5) 列出。
## Completion records {#completion-records}
问号和感叹号是什么呢?要了解它们,我们需要查看 [**Completion Records**](https://tc39.es/ecma262/#sec-completion-record-specification-type)!
Completion Record 是一种规范类型(仅出于规范目的而定义)。JavaScript 引擎不必具有相应的内部数据类型。
Completion Record 是一种 “记录” —— 一种具有一组固定的命名字段的数据类型。一个 Completion Record 包含三个字段:
:::table-wrapper
| 名称 | 描述 |
--- | ---
| `[[Type]]` | `normal`,`break`,`continue`,`return` 或 `throw` 之一。除了 `normal` 以外的其他类型都是 **突然中止**.|
| `[[Value]]` | 结束时产生的值,例如,函数的返回值或异常(如果引发了异常)。|
| `[[Target]]` | 用于定向控制转移(与本博客文章无关)|
:::
每个抽象操作都隐式返回一个 Completion Record。即使看起来抽象操作会返回一个简单的类型,例如Boolean,它也将被隐式包装为具有 `normal` 类型的 Completion Record (请参见 [Implicit Completion Values](https://tc39.es/ecma262/#sec-implicit-completion-values)).
注1:规范在这方面并不完全一致;有些帮助函数返回裸值,并且其返回值按原样使用,而无需从 Completion Record 中提取值。从上下文中通常可以清楚地看出这一点。
注2:规范的编辑人员正在研究如何使 Completion Record 的处理更加明确.
如果算法引发异常,则意味着返回带有 `[[Type]]` `throw` 的 Completion Record,它的 `[[Value]]` 是一个异常对象的。我们暂且忽略 `break`,`continue` 和 `return` 类型。
[`ReturnIfAbrupt(argument)`](https://tc39.es/ecma262/#sec-returnifabrupt) 意味着采取以下步骤:
:::ecmascript-algorithm
<!-- markdownlint-disable blanks-around-lists -->
> 1. If `argument` is abrupt, return `argument`
> 2. Set `argument` to `argument.[[Value]]`.
<!-- markdownlint-enable blanks-around-lists -->
:::
也就是说,我们检查 Completion Record;如果是突然终止的类型,我们会立即返回。否则,我们从完成记录中提取值。
`ReturnIfAbrupt` 可能看起来像一个函数调用,但事实并非如此。它会导致返回 `ReturnIfAbrupt()` 的函数返回,而不是返回 `ReturnIfAbrupt` 函数本身的函数。它更像是C语言中的宏.
`ReturnIfAbrupt` 可以这样使用:
:::ecmascript-algorithm
<!-- markdownlint-disable blanks-around-lists -->
> 1. Let `obj` be `Foo()`. (`obj` 是一个 Completion Record。)
> 2. `ReturnIfAbrupt(obj)`
> 3. `Bar(obj)`. (如果程序能走到这,则 `obj` 是从 Completion Record 提取出的值。)
<!-- markdownlint-enable blanks-around-lists -->
:::
[问号](https://tc39.es/ecma262/#sec-returnifabrupt-shorthands) 的含义:`? Foo()` 等同于 `ReturnIfAbrupt(Foo())`.
同样,`Let val be ! Foo()` 等同于:
:::ecmascript-algorithm
<!-- markdownlint-disable blanks-around-lists -->
> 1. Let `val` be `Foo()`.
> 2. Assert: `val` is not an abrupt completion.
> 3. Set `val` to `val.[[Value]]`.
<!-- markdownlint-enable blanks-around-lists -->
:::
利用这些知识,我们可以像这样重写 `Object.prototype.hasOwnProperty`:
:::ecmascript-algorithm
> **`Object.prototype.hasOwnProperty(V)`**
>
> 1. Let `P` be `ToPropertyKey(V)`.
> 2. If `P` is an abrupt completion, return `P`
> 3. Set `P` to `P.[[Value]]`
> 4. Let `O` be `ToObject(this value)`.
> 5. If `O` is an abrupt completion, return `O`
> 6. Set `O` to `O.[[Value]]`
> 7. Let `temp` be `HasOwnProperty(O, P)`.
> 8. If `temp` is an abrupt completion, return `temp`
> 9. Let `temp` be `temp.[[Value]]`
> 10. Return `NormalCompletion(temp)`
:::
我们可以这样重写 `HasOwnProperty`:
:::ecmascript-algorithm
> **`HasOwnProperty(O, P)`**
>
> 1. Assert: `Type(O)` is `Object`.
> 2. Assert: `IsPropertyKey(P)` is `true`.
> 3. Let `desc` be `O.[[GetOwnProperty]](P)`.
> 4. If `desc` is an abrupt completion, return `desc`
> 5. Set `desc` to `desc.[[Value]]`
> 6. If `desc` is `undefined`, return `NormalCompletion(false)`.
> 7. Return `NormalCompletion(true)`.
:::
我们也可以重写不带感叹号的的内部方法 `[[GetOwnProperty]]`:
:::ecmascript-algorithm
<!-- markdownlint-disable blanks-around-lists -->
> **`O.[[GetOwnProperty]]`**
>
> 1. Let `temp` be `OrdinaryGetOwnProperty(O, P)`.
> 2. Assert: `temp` is not an abrupt completion.
> 3. Let `temp` be `temp.[[Value]]`.
> 4. Return `NormalCompletion(temp)`.
<!-- markdownlint-enable blanks-around-lists -->
:::
在这里,我们假设 `temp` 是一个全新的临时变量,不会与其他任何冲突。
我们还使用了以下知识:当 return 语句返回除 Completion Record 以外的其他内容时,它隐式包装在 `NormalCompletion` 中.
### 换个话题:`Return ? Foo()` {#side-track}
规范中使用 `Return ? Foo()` —— 为什么用问号
`Return ? Foo()` 展开如下:
:::ecmascript-algorithm
<!-- markdownlint-disable blanks-around-lists -->
> 1. Let `temp` be `Foo()`.
> 2. If `temp` is an abrupt completion, return `temp`.
> 3. Set `temp` to `temp.[[Value]]`.
> 4. Return `NormalCompletion(temp)`.
<!-- markdownlint-enable blanks-around-lists -->
:::
## 断言 {#asserts}
与 `Return Foo()` 相同;无论是突然终止还是正常终止,其行为方式都相同。
规范中断言了算法的不变条件。为了清楚起见,添加了它们,但没有对实现添加任何要求 —— 实现中不必检查它们。
## 继续 {#moving-on}
我们已经建立了阅读规范所需的知识,如 `Object.prototype.hasOwnProperty` 之类的简单方法和诸如 `HasOwnProperty` 之类的抽象操作。它们仍然会委托到其他抽象操作,但是基于此博客文章,我们应该能够弄清楚它们的作用。我们还将会遇到属性描述符,这是另一种规范类型。

## 有用的链接 {#usful-links}
[How to Read the ECMAScript Specification](https://timothygu.me/es-howto/): a tutorial which covers much of the material covered in this post, from a slightly different angle. | 8,347 | Apache-2.0 |
# A My Batis Demo
## 通过注解映射Mapper
```Java
import java.util.List;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import com.sinosoft.ids.schema.VersionContent;
@Mapper
public interface VersionContentMapper {
@Select("SELECT * FROM Version_Content WHERE versionNo = #{versionNo}")
List<VersionContent> findByVersionNo(@Param("versionNo") String versionNo);
@Select("SELECT count(*) FROM Version_Content WHERE versionNo = #{versionNo}")
Integer countByVersionNo(@Param("versionNo") String versionNo);
}
```
## 通过Mapper配置文件使用Mybatis
通过Mapper配置文件使用Mybatis,需要指定Mapper文件路径,以及将Mapper文件和Service类映射起来,Mapper配置文件的路径不需要和`namespace`的一致
### SpringBoot中配置Mybatis的Mapper路径
```Pproperties
# mybatis
mybatis.mapper-locations=classpath:mapper/*.xml
```
### 通过Mapper配置文件和Service类映射
Mapper配置文件中有属性`namespace`可以指定对应的java类是哪个
## 参考
- [SpringBoot+Mybatis 整合 xml配置使用+免xml使用](https://blog.csdn.net/nanbiebao6522/article/details/80630302)
- [springboot集成mybatis xml方式](https://blog.csdn.net/lr131425/article/details/76269236)
- [Mybatis 框架使用的最核心内容(二):mapper.xml中常用的标签详解](https://blog.csdn.net/qq_29233973/article/details/51433924) | 1,215 | MIT |
# RMQ对接示例
## 介绍
RMQ对接示例,请先根据[RMQ项目依赖](https://www.showdoc.cc/rmq?page_id=1812484091467621 "RMQ项目依赖"),准备好RMQ运行环境。
# [中文文档](https://www.showdoc.cc/rmq?page_id=1820953552972418 "中文文档")
## 示例源码仓库地址
| 源码仓库地址 |
| ------------ |
| https://gitee.com/NuLiing/reliable-message-samples |
| https://github.com/a327919006/reliable-message-samples |
## 示例代码流程说明
示例代码模拟简单的充值业务,上层系统为支付系统,负责处理支付订单,下层系统为业务系统,负责处理充值订单以及操作账户金额。
```
1. 调用下层系统充值接口,生成充值订单与支付订单。
2. 模拟银行回调上层系统支付成功接口。上层系统调用RMQ预发送消息 --> 执行业务操作(修改支付订单状态)--> 异步调用RMQ确认发送消息。
3. 下层业务系统收到消息 --> 执行业务操作(修改支付订单状态,修改账户余额)--> 调用RMQ确认消费消息。
```
## 初始化示例代码数据库
下载项目源码并解压,执行 "数据库初始化SQL脚本",正常情况下会自动创建数据库(**reliable-message-sample**)以及生成**3**张表。"数据库初始化SQL脚本" 路径为:
```
/reliable-message-samples/sql/rmq-sample-init.sql
```
## 运行示例代码
#### 运行RMQ
先根据RMQ中文文档《[快速入门](https://www.showdoc.cc/rmq?page_id=1815635527586509 "快速入门")》,运行RMQ系统。
------------
### 配置、运行示例代码
#### 配置
配置文件路径:
```
/reliable-message-samples/spring-boot-sample/src/main/resources/application.yaml
```
配置文件说明:
```yaml
# 运行端口
server:
port: 10010
mybatis:
typeAliasesPackage: com.cn.rmq.sample.model.po
mapperLocations: classpath:com/cn/rmq/sample/mapper/*.xml
spring:
# 数据库连接配置
datasource:
url: jdbc:mysql://127.0.0.1:3306/reliable-message-sample?useUnicode=true&characterEncoding=utf-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
hikari:
connection-test-query: SELECT 1
# ActiveMQ配置
activemq:
broker-url: tcp://127.0.0.1:61616
user: admin
password: admin
# Dubbo配置
dubbo:
application:
name: spring-boot-sample
logger: slf4j
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
port: 20882
scan:
base-packages: com.cn.rmq.sample.service.impl
```
#### 运行
模块基于SpringBoot构建,可使用Maven命令(mvn package)打成jar包运行(java -jar)。
调试阶段可直接在IDE中运行ServiceApplication。文件路径为:
```
/reliable-message-samples/spring-boot-sample/src/main/java/com/cn/rmq/service/BootSampleApplication.java
```
------------
## 调用示例接口
示例代码集成了Swagger组件,方便接口调试。
```
访问地址: http://127.0.0.1:10010/swagger-ui.html
```
#### 生成订单
调用接口成功后将生成待支付的充值订单与支付订单。接口响应数据data为订单ID,用于下一步模拟支付成功回调。


#### 支付回调
模拟银行支付成功回调,成功调用接口后可查看数据库数据,充值订单、支付订单状态改变成已支付,账户金额已增加。

 | 2,714 | Apache-2.0 |
---
layout: post
title: "RTOS学习笔记-FreeRTOS源码"
categories: RTOS
tags: ARM RTOS FreeRTOS Cortex-M
author: Will
---
* content
{:toc}
通过FreeRTOS官网资料,已经可以很好的使用FreeRTOS了,再深入的理解就需要深入到源码层,接下来就阅读源码,FreeRTOS版本v9.0.0,平台为ARM Cortex-M4,编译工具为ARM MDK。
FreeRTOS需要关注的源码:
```
//核心代码
list.c
task.c
queue.c
//平台相关,STM32(ARM Cortex-M4)
port.c
//已经分析过,Memory Management相关
heap_x.c
//非核心代码
event_groups.c
timers.c
croutine.c
```
## List
FreeRTOS核心数据结构List,源码查看list.c,List以及ListItem数据结构如下:
```c
/*
* Definition of the only type of object that a list can contain.
*/
struct xLIST_ITEM
{
listFIRST_LIST_ITEM_INTEGRITY_CHECK_VALUE
configLIST_VOLATILE TickType_t xItemValue;
struct xLIST_ITEM * configLIST_VOLATILE pxNext;
struct xLIST_ITEM * configLIST_VOLATILE pxPrevious;
void * pvOwner;
void * configLIST_VOLATILE pvContainer;
listSECOND_LIST_ITEM_INTEGRITY_CHECK_VALUE
};
typedef struct xLIST_ITEM ListItem_t; /* For some reason lint wants this as two separate definitions. */
/*
* Definition of the type of queue used by the scheduler.
*/
typedef struct xLIST
{
listFIRST_LIST_INTEGRITY_CHECK_VALUE
configLIST_VOLATILE UBaseType_t uxNumberOfItems;
ListItem_t * configLIST_VOLATILE pxIndex;
MiniListItem_t xListEnd;
listSECOND_LIST_INTEGRITY_CHECK_VALUE
} List_t;
```
通过list.c源码的阅读,可以看出这是一个双向链表结构,图中的`List`表示这个双向链表,而`ListItem`就是双向链表里的节点,这些节点根据xItemValue的值的大小做了排序,如下图所示:

继续阅读源码,就能更深入的理解为什么这么定义数据结构,以及实际是如何使用的。
## Tasks
task创建函数xTaskCreate()
```c
BaseType_t xTaskCreate(...)
{
//任务控制块TCB
TCB_t *pxNewTCB;
...
//分配堆内存给newTask的TCB和stack,注意portSTACK_GROWTH
//初始化stack
pxNewTCB->pxStack = pxStack;
...
//newTask初始化
prvInitialiseNewTask(...);
//将task的TCB加入到Ready Tasks List
prvAddNewTaskToReadyList(pxNewTCB);
...
}
```
这里有一个数据结构`TCB`,这个数据结构里面定义了所有与task相关的成员,数据结构比较大,暂时先不做过多说明,继续阅读源码,在接下来的源码中剖析`TCB`成员,以及前面的`List`如何使用。
```c
static void prvInitialiseNewTask(...)
{
...
//如果启用Stack Overflow检查
//则将stack初始化为特定值tskSTACK_FILL_BYTE
( void ) memset( pxNewTCB->pxStack, ( int ) tskSTACK_FILL_BYTE, ( size_t ) ulStackDepth * sizeof( StackType_t ) );
...
//局部变量,先计算出stack的栈顶指针 pxTopOfStack
pxTopOfStack = pxNewTCB->pxStack + ( ulStackDepth - ( uint32_t ) 1 );
//地址对齐操作,stack操作更快
pxTopOfStack = ( StackType_t * ) ( ( ( portPOINTER_SIZE_TYPE ) pxTopOfStack ) & ( ~( ( portPOINTER_SIZE_TYPE ) portBYTE_ALIGNMENT_MASK ) ) );
...
//保存pxNewTCB->pcTaskName
...
//保存task优先级
pxNewTCB->uxPriority = uxPriority;
#if ( configUSE_MUTEXES == 1 )
{
//Mutex有优先级继承,这里保存task原始的优先级
pxNewTCB->uxBasePriority = uxPriority;
pxNewTCB->uxMutexesHeld = 0;
}
#endif /* configUSE_MUTEXES */
//ListItem_t初始化,状态与事件ListItem
//Task在Ready/Blocked/Suspended某个状态时,此ListItem_t会挂到相应的List
vListInitialiseItem( &( pxNewTCB->xStateListItem ) );
//task相关的某个Event List会指向这个ListItem_t,如Queue满了而阻塞,将其挂接到等待入队的List
vListInitialiseItem( &( pxNewTCB->xEventListItem ) );
//ListItem_t->pvOwener指向此task的TCB
listSET_LIST_ITEM_OWNER( &( pxNewTCB->xStateListItem ), pxNewTCB );
//设置ListItem_t->xItemValue为优先级取反
//逻辑优先级是数字越大优先级越高,存储的时候取反,数字越小优先级越高
//配合前面List数据结构, 按照xItemValue大小排序,那么双链表首节点都是优先级最大的节点
listSET_LIST_ITEM_VALUE( &( pxNewTCB->xEventListItem ), ( TickType_t ) configMAX_PRIORITIES - ( TickType_t ) uxPriority );
//ListItem_t->pvOwener指向此task的TCB
listSET_LIST_ITEM_OWNER( &( pxNewTCB->xEventListItem ), pxNewTCB );
...
//task notification相关初始化
#if ( configUSE_TASK_NOTIFICATIONS == 1 )
{
pxNewTCB->ulNotifiedValue = 0;
pxNewTCB->ucNotifyState = taskNOT_WAITING_NOTIFICATION;
}
#endif
...
//初始化stack,详见此函数解读,可了解stack保存内容及顺序
pxNewTCB->pxTopOfStack = pxPortInitialiseStack( pxTopOfStack, pxTaskCode, pvParameters );
...
}
static void prvAddNewTaskToReadyList( TCB_t *pxNewTCB )
{
//进入临界区
taskENTER_CRITICAL();
{
uxCurrentNumberOfTasks++;
if( pxCurrentTCB == NULL )
{
//没有任务或者其他任务都在Suspend状态
//全局变量pxCurrentTCB指向此task TCB,永远指向当前运行的task TCB
pxCurrentTCB = pxNewTCB;
if( uxCurrentNumberOfTasks == ( UBaseType_t ) 1 )
{
//第一个任务,初始化Task List,详见对此函数的解读
prvInitialiseTaskLists();
}
}
else
{
//如果task调度还未开始,pxCurrentTCB指向优先级最大的那个task TCB
if( xSchedulerRunning == pdFALSE )
{
if( pxCurrentTCB->uxPriority <= pxNewTCB->uxPriority )
{
pxCurrentTCB = pxNewTCB;
}
}
}
uxTaskNumber++;
#if ( configUSE_TRACE_FACILITY == 1 )
{
/* Add a counter into the TCB for tracing only. */
pxNewTCB->uxTCBNumber = uxTaskNumber;
}
#endif /* configUSE_TRACE_FACILITY */
//将此task TCB插入到pxReadyTasksLists相应优先级List尾部
prvAddTaskToReadyList( pxNewTCB );
...
}
//退出临界区
taskEXIT_CRITICAL();
//如果此时task开始调度,如果新task优先级更高,则立即发起一次调度
if( xSchedulerRunning != pdFALSE )
{
if( pxCurrentTCB->uxPriority < pxNewTCB->uxPriority )
{
//强制产生一次调度,发起PendSV中断
taskYIELD_IF_USING_PREEMPTION();
}
}
}
StackType_t *pxPortInitialiseStack(StackType_t *pxTopOfStack, TaskFunction_t pxCode, void *pvParameters)
{
pxTopOfStack--;
//状态寄存器入栈
*pxTopOfStack = portINITIAL_XPSR; /* xPSR */
pxTopOfStack--;
//PC指针入栈
*pxTopOfStack = ( ( StackType_t ) pxCode ) & portSTART_ADDRESS_MASK; /* PC */
pxTopOfStack--;
//链接返回寄存器入栈,保存返回地址
*pxTopOfStack = ( StackType_t ) prvTaskExitError; /* LR */
/* Save code space by skipping register initialisation. */
pxTopOfStack -= 5; /* R12, R3, R2 and R1. */
*pxTopOfStack = ( StackType_t ) pvParameters; /* R0 */
/* A save method is being used that requires each task to maintain its own exec return value. */
pxTopOfStack--;
*pxTopOfStack = portINITIAL_EXEC_RETURN; //返回值
pxTopOfStack -= 8; /* R11, R10, R9, R8, R7, R6, R5 and R4. */
return pxTopOfStack;
}
static void prvInitialiseTaskLists( void )
{
UBaseType_t uxPriority;
//每个优先级创建一个Ready List,组成Ready List数组
for( uxPriority = ( UBaseType_t ) 0U; uxPriority < ( UBaseType_t ) configMAX_PRIORITIES; uxPriority++ )
{
vListInitialise( &( pxReadyTasksLists[ uxPriority ] ) );
}
//创建Delay Task List
vListInitialise( &xDelayedTaskList1 );
vListInitialise( &xDelayedTaskList2 );
//创建Pending Ready List
vListInitialise( &xPendingReadyList );
#if ( INCLUDE_vTaskDelete == 1 )
{
vListInitialise( &xTasksWaitingTermination );
}
#endif /* INCLUDE_vTaskDelete */
#if ( INCLUDE_vTaskSuspend == 1 )
{
//创建Suspend Task List
vListInitialise( &xSuspendedTaskList );
}
#endif /* INCLUDE_vTaskSuspend */
/* Start with pxDelayedTaskList using list1 and the pxOverflowDelayedTaskList using list2. */
pxDelayedTaskList = &xDelayedTaskList1;
pxOverflowDelayedTaskList = &xDelayedTaskList2;
}
```
Task创建的过程已经基本清楚了,接着再看task调度过程,通过函数vTaskStartScheduler()启动调度:
```c
void vTaskStartScheduler( void )
{
//先创建Idle Task
xReturn = xTaskCreate(prvIdleTask, ...
...
//如果用到Timers,还要创建Timers的task
#if ( configUSE_TIMERS == 1 )
{
if( xReturn == pdPASS )
{
xReturn = xTimerCreateTimerTask();
}
}
#endif /* configUSE_TIMERS */
if( xReturn == pdPASS )
{
portDISABLE_INTERRUPTS();
xNextTaskUnblockTime = portMAX_DELAY;
//调度开始标志置位
xSchedulerRunning = pdTRUE;
//RTOS Tick初始化为0
xTickCount = ( TickType_t ) 0U;
//设置systick产生RTOS需要的Tick中断,与平台移植相关,详见分析
xPortStartScheduler();
...
}
...
}
BaseType_t xPortStartScheduler( void )
{
...
//将PendSV和SysTick中断优先级设置为最低,与RTOS运行优先级相同
portNVIC_SYSPRI2_REG |= portNVIC_PENDSV_PRI;
portNVIC_SYSPRI2_REG |= portNVIC_SYSTICK_PRI;
//启动Systick
vPortSetupTimerInterrupt();
//初始化嵌套计数为0
uxCriticalNesting = 0;
//浮点运算协处理器相关配置
prvEnableVFP();
*( portFPCCR ) |= portASPEN_AND_LSPEN_BITS;
//启动第一个task
prvStartFirstTask();
//不会执行到这里!!!
return 0;
}
void vPortSetupTimerInterrupt( void )
{
#if configUSE_TICKLESS_IDLE == 1
{
//计算1Tick=多少Systick时钟频率计数
ulTimerCountsForOneTick = ( configSYSTICK_CLOCK_HZ / configTICK_RATE_HZ );
//低功耗每次关闭Systick的最大Tick数,更好的理解需要看前面Tickless模式低功耗的解读
xMaximumPossibleSuppressedTicks = portMAX_24_BIT_NUMBER / ulTimerCountsForOneTick;
//Cpu Cycles的补偿值,还是应用在Tickless模式低功耗
ulStoppedTimerCompensation = portMISSED_COUNTS_FACTOR / ( configCPU_CLOCK_HZ / configSYSTICK_CLOCK_HZ );
}
#endif /* configUSE_TICKLESS_IDLE */
//Systick tick中断加载值及使能,期望的频率是由宏configTICK_RATE_HZ定义(1ms中断)
portNVIC_SYSTICK_LOAD_REG = ( configSYSTICK_CLOCK_HZ / configTICK_RATE_HZ ) - 1UL;
portNVIC_SYSTICK_CTRL_REG = ( portNVIC_SYSTICK_CLK_BIT | portNVIC_SYSTICK_INT_BIT | portNVIC_SYSTICK_ENABLE_BIT );
}
__asm void prvStartFirstTask( void )
{
PRESERVE8
/* Use the NVIC offset register to locate the stack. */
//0xE000ED08是Cortex-M4向量表偏移量寄存器(VTOR)的地址
//起始地址存储着MSP即主堆栈指针
ldr r0, =0xE000ED08
ldr r0, [r0]
ldr r0, [r0]
/* Set the msp back to the start of the stack. */
msr msp, r0
/* Globally enable interrupts. */
//使能全局中断
cpsie i
cpsie f
dsb
isb
/* Call SVC to start the first task. */
svc 0 //触发SVC中断,SVC中断处理函数启动第一个task
nop
nop
}
//SVC中断处理函数
__asm void vPortSVCHandler( void )
{
PRESERVE8
ldr r3, =pxCurrentTCB //将pxCurrentTCB的值作为地址赋值给r3
ldr r1, [r3] //将pxCurrentTCB指针指向的值,当前task TCB的地址赋值给r1
ldr r0, [r1] //取得当前要运行的task栈顶指针,并赋值给r0,由此理解为什么TCB数据结构的第一项必须设计为栈顶指针
ldmia r0!, {r4-r11} //寄存器r4~r11出栈
msr psp, r0 //栈顶指针赋给线程堆栈指针PSP
isb
mov r0, #0
msr basepri, r0
bx r14 //跳转执行目标task
}
```
三个特殊的中断及中断处理函数,Systick/SVC/PendSV,这也是在移植FreeRTOS时需要特别注意的地方,Systick产生RTOS需要的Tick中断,其中断处理函数与RTOS密切相关,SVC如上所示启动Task,PendSV用于task调度切换,Systick/PendSV配置成了最低优先级,在中断抢占的前提下,PendSV被抢占但是在处理完高优先级的任务后,依然会进入中断处理函数处理,这样不会打断高优先级的任务,也能完成任务的调度切换。
Task调度机制启动后,任务就开始执行,FreeRTOS里面的任务切换一般在PendSV中断处理函数里面进行,而PendSV中断则是由Systick中断中触发的,也就是系统Tick中断中判断是否有任务需要切换,需要则产生PendSV中断,然后再PendSV中断处理函数里面执行切换操作。另外,在xCreateTask()过程分析中(Idle Task里面也有这样的操作),我们也见到了直接切换的方式taskYIELD(),产生PendSV中断。总结2种方式:
```c
//第一种,直接产生PendSV中断
portYIELD或者portYIELD_FROM_ISR
#define portYIELD()
{
portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT;
__dsb( portSY_FULL_READ_WRITE );
__isb( portSY_FULL_READ_WRITE );
}
//第二种,判断是否有task需要切换,然后再决定是否产生PendSV中断
void xPortSysTickHandler( void )
{
vPortRaiseBASEPRI();
{
if(xTaskIncrementTick() != pdFALSE)
{
portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT;
}
}
vPortClearBASEPRIFromISR();
}
```
具体的切换过程即为PendSV的中断处理函数,汇编+C实现,还是有一些ARM Cortex-M4相关的部分放置在port.c中,而且这部分C语言也很难实现。
```
__asm void xPortPendSVHandler( void )
{
extern uxCriticalNesting;
extern pxCurrentTCB;
extern vTaskSwitchContext;
PRESERVE8
//先进行当前task的入栈操作,task的栈指针寄存器使用psp
//中断服务程序处理之前,自动入栈xPSR、PC、LR、R12、R3~R0
mrs r0, psp
isb
/* Get the location of the current TCB. */
ldr r3, =pxCurrentTCB
ldr r2, [r3]
/* Is the task using the FPU context? If so, push high vfp registers. */
//FPU入栈
tst r14, #0x10
it eq
vstmdbeq r0!, {s16-s31}
/* Save the core registers. */
//其他寄存器入栈
stmdb r0!, {r4-r11, r14}
/* Save the new top of stack into the first member of the TCB. */
//更新最新的栈指针到当前task TCB首地址(即第一项保存当前栈指针)
str r0, [r2]
//R3入栈,后面调用vTaskSwitchContext(),此函数从ReadyList里取出即将运行的task TCB赋值给pxCurrentTCB
//R3保存了pxCurrentTCB地址
stmdb sp!, {r3}
mov r0, #configMAX_SYSCALL_INTERRUPT_PRIORITY
msr basepri, r0
dsb
isb
bl vTaskSwitchContext
mov r0, #0
msr basepri, r0
ldmia sp!, {r3}
//恢复R3,此时的pxCurrentTCB已经指向了即将运行的task TCB
/* The first item in pxCurrentTCB is the task top of stack. */
//取得task TCB的栈指针
ldr r1, [r3]
ldr r0, [r1]
/* Pop the core registers. */
//部分寄存器出栈
ldmia r0!, {r4-r11, r14}
/* Is the task using the FPU context? If so, pop the high vfp registers too. */
//FPU出栈
tst r14, #0x10
it eq
vldmiaeq r0!, {s16-s31}
//将task的当前栈指针赋值给psp
msr psp, r0
isb
bx r14 //跳转至即将运行的task运行,R0~R3、R12、LR、PC、xPSR自动出栈
}
```
Cortex-M4提供了2个栈指针MSP和PSP,PSP就是MCU正常运行时使用的栈指针,因此一般PSP都指向了某个task的栈,而MSP在异常情况下使用,MSP一般指向的是整个系统的栈,两个栈指针寄存器分工不同。通过上面的过程,也可以看到出栈入栈的顺序:
```
| | Stack
|-------------|
| xPSR |
| PC |
| LR |
| R12 |
| R3 |
| ... |
| R0 |
| R14 |
| R11 |
| ... |
| R4 | <-PSP
|-------------|
| |
```
Task相关的创建、调度及切换的源码基本读了一遍,还有些细节暂放一下,继续阅读。
## Queue
队列应用于任务间通讯,可以在任务与任务之间,中断服务程序与任务之间传递消息,消息是通过Copy进队列的方式传递的,队列维护消息体本身,多了一次Copy而不是使用引用,对消息体本身的安全性和完整性有益。另外,Semaphore/Mutex也是借助Queue实现的,需要对Queue进一步的理解。
队列的数据结构定义为xQUEUE,此结构较大,暂时不对其细致的理解,后面阅读源码过程中深入理解,再看队列创建函数xQueueCreate(),实际是xQueueGenericCreate()函数。
```c
QueueHandle_t xQueueGenericCreate(...)
{
//Queue分配堆内存
//初始化Queue
prvInitialiseNewQueue(...);
}
```
为Queue分配堆内存大小及顺序:Queue_t结构体+队列消息内容占用内存总和。
```
|-----------------------|
| Queue_t结构体 |
|-----------------------|
| Queue所有队列项 |
|-----------------------|
```
再看具体的Queue初始化源码:
```c
static void prvInitialiseNewQueue(...)
{
...
//初始化完善Queue_t数据结构的各项
if( uxItemSize == ( UBaseType_t ) 0 )
{
//Mutex时没有队列消息项,直接指向Queue_t首地址
pxNewQueue->pcHead = ( int8_t * ) pxNewQueue;
}
else
{
//队列头指向队列消息项的首地址
pxNewQueue->pcHead = ( int8_t * ) pucQueueStorage;
}
pxNewQueue->uxLength = uxQueueLength;
pxNewQueue->uxItemSize = uxItemSize;
//更多的初始化,继续深入阅读
( void ) xQueueGenericReset(pxNewQueue, pdTRUE);
...
}
BaseType_t xQueueGenericReset(QueueHandle_t xQueue, BaseType_t xNewQueue)
{
...
taskENTER_CRITICAL();
{
//tail指向队列尾
pxQueue->pcTail = pxQueue->pcHead + ( pxQueue->uxLength * pxQueue->uxItemSize );
//当前队列里的队列项个数
pxQueue->uxMessagesWaiting = ( UBaseType_t ) 0U;
//指向下一个可写的队列项,用于队列入队时向队尾添加队列项
pxQueue->pcWriteTo = pxQueue->pcHead;
//指向最后一个队列项,用于队列入队时向队首添加队列项
pxQueue->u.pcReadFrom = pxQueue->pcHead + ( ( pxQueue->uxLength - ( UBaseType_t ) 1U ) * pxQueue->uxItemSize );
//初始化Queue Lock时接收和发送的队列项
pxQueue->cRxLock = queueUNLOCKED;
pxQueue->cTxLock = queueUNLOCKED;
...
//初始化了2个List,记录了等待超时和接收消息的tasks List
vListInitialise( &( pxQueue->xTasksWaitingToSend ) );
vListInitialise( &( pxQueue->xTasksWaitingToReceive ) );
}
taskEXIT_CRITICAL();
return pdPASS;
}
```
初始化完成后的Queue模型如下图所示:

前面是Queue_t结构,后面紧跟着的Item_x为实际队列项(队列消息体),Queue_t中的两个List存储的是与此队列相关联的tasks。继续看xQueueSend()也就是xQueueGenericSend()源码
```c
BaseType_t xQueueGenericSend(...)
{
...
for(;;)
{
taskENTER_CRITICAL();
{
//检查队列是否满,如果是overwrite方式直接入队
if( ( pxQueue->uxMessagesWaiting < pxQueue->uxLength ) || ( xCopyPosition == queueOVERWRITE ) )
{
//三种入队方式:队尾,队首和overwrite
//特别注意当用作Mutex使用时,返回值可能为True,即需要切换到更高优先级任务,需要执行任务调度
xYieldRequired = prvCopyDataToQueue( pxQueue, pvItemToQueue, xCopyPosition );
...
//先忽略掉Queue Sets的情况
//如果有tasks正在等待接收队列消息
if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE )
{
//如果有任务在等待队列消息,则将此任务添加进任务Ready List
if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE )
{
queueYIELD_IF_USING_PREEMPTION();
}
}
else if (xYieldRequired != pdFALSE)
{
//仅用作Mutex时,释放Mutex后调度任务(Mutex有优先级继承)
queueYIELD_IF_USING_PREEMPTION();
}
else
{
}
taskEXIT_CRITICAL();
return pdPASS;
}
else //队列满,且非overwrite方式入队
{
if( xTicksToWait == ( TickType_t ) 0 )
{
//队列满了,而且没有设置超时等待,则直接退出,返回队列满错误
taskEXIT_CRITICAL();
return errQUEUE_FULL;
}
else if( xEntryTimeSet == pdFALSE )
{
//队列满了,而且设置了超时等待,则初始化了一个timeout数据结构
vTaskSetTimeOutState( &xTimeOut );
xEntryTimeSet = pdTRUE;
}
else
{
}
}
}
taskEXIT_CRITICAL();
//退出临界区,此处可能会有任务调度
//全部任务挂起,阻止任务调度
vTaskSuspendAll();
//锁定Queue,将Queue_t里的rxLock和txLock设置为Lock,阻止了任务调度,但是中断处理程序里还是可以对Queue进行操作,因此对Queue上锁
prvLockQueue( pxQueue );
if( xTaskCheckForTimeOut( &xTimeOut, &xTicksToWait ) == pdFALSE )
{
//队列等待超时未过期
if( prvIsQueueFull( pxQueue ) != pdFALSE )
{
//队列满
//将当前task加入到等待此队列入队的等待List和延时List
vTaskPlaceOnEventList( &( pxQueue->xTasksWaitingToSend ), xTicksToWait );
//解锁队列
prvUnlockQueue( pxQueue );
//将tasks从PendingReadyList移至ReadyList
if( xTaskResumeAll() == pdFALSE )
{
portYIELD_WITHIN_API();
}
}
else
{
//队列未满
//解锁队列,恢复挂起的所有任务,没有return,继续for循环
prvUnlockQueue( pxQueue );
( void ) xTaskResumeAll();
}
}
else
{
//设置的队列等待超时过期
prvUnlockQueue( pxQueue );
//挂起的tasks全部恢复,返回队列满错误
( void ) xTaskResumeAll();
return errQUEUE_FULL;
}
}
}
```
队列入队后,如果队列未满,将等待此队列消息的List(xTasksWaitingToReceive)中需要解除阻塞的task从等待消息的List中删除,然后将其添加进任务Ready List中,然后再与当前运行的task的优先级做一下比较,如果优先级更高则产生一次调度。详见函数xTaskRemoveFromEventList()。
如果队列满了,则情况稍微复杂一些,如果队列入队时没有设置阻塞等待时间,即xTicksToWait=0,则直接返回队列满错误;如果设置了阻塞等待时间,而且时间未到,则将当前运行的task加入到等待此队列入队的等待List里(xTasksWaitingToSend),还要将此任务加入到延时List中,可参考函数vTaskPlaceOnEventList(),解锁队列,恢复所有挂起的任务,恢复调度,如果此时有更高优先级的任务Ready,则产生一次任务调度;如果设置了阻塞时间,而且时间到,则解锁Queue,恢复所有挂起的任务,恢复调度,返回队列满错误。
接着再看一下中断处理函数里相关的Queue的操作函数xQueueGenericSendFromISR()
```c
BaseType_t xQueueGenericSendFromISR(...)
{
...
uxSavedInterruptStatus = portSET_INTERRUPT_MASK_FROM_ISR();
{
if( ( pxQueue->uxMessagesWaiting < pxQueue->uxLength ) || ( xCopyPosition == queueOVERWRITE ) )
{
//队列未满或overwrite
//入队,分三种方式:队尾、队首、overwrite
( void ) prvCopyDataToQueue( pxQueue, pvItemToQueue, xCopyPosition );
if( cTxLock == queueUNLOCKED )
{
//如果队列unlock
...
//队列非空
if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE )
{
//如果有任务在等待队列消息,则将此任务添加进任务Ready List
if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE )
{
//设置为pdTRUE,则代表需要一次任务切换
if( pxHigherPriorityTaskWoken != NULL )
{
*pxHigherPriorityTaskWoken = pdTRUE;
}
}
}
}
else
{
//如果队列lock,此时不可以操作队列,只有tx锁计数器加1
pxQueue->cTxLock = ( int8_t ) ( cTxLock + 1 );
}
xReturn = pdPASS;
}
else
{
//队列满了,直接返回队列满错误
xReturn = errQUEUE_FULL;
}
}
portCLEAR_INTERRUPT_MASK_FROM_ISR( uxSavedInterruptStatus );
return xReturn;
}
```
中断服务程序里的队列入队操作就要简单许多,不同的处理是在队列被锁定后,不再做任何操作了,直接将cTxLock计数器加1,在队列被解锁后,根据计数器的值,依次处理相关的队列项。
再接着看出队函数xQueueReceive(),也就是xQueueGenericReceive(),与入队的操作相反,基本逻辑非常类似。
```c
BaseType_t xQueueGenericReceive(...)
{
...
for( ;; )
{
taskENTER_CRITICAL();
{
const UBaseType_t uxMessagesWaiting = pxQueue->uxMessagesWaiting;
//等待消息队列项非空
if( uxMessagesWaiting > ( UBaseType_t ) 0 )
{
pcOriginalReadPosition = pxQueue->u.pcReadFrom;
//出队操作,不像前面入队那样分三种情况了,出队只有copy操作
prvCopyDataFromQueue( pxQueue, pvBuffer );
if( xJustPeeking == pdFALSE )
{
//需要移除队列消息项,一般情况都采用这种操作,走这个分支
pxQueue->uxMessagesWaiting = uxMessagesWaiting - 1;
#if ( configUSE_MUTEXES == 1 )
{
//Mutex时的操作
if( pxQueue->uxQueueType == queueQUEUE_IS_MUTEX )
{
pxQueue->pxMutexHolder = ( int8_t * ) pvTaskIncrementMutexHeldCount();
}
}
#endif
if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToSend ) ) == pdFALSE )
{
//队列等待发送List非空,有task在等待向队列发送消息
//将此任务添加进任务Ready List
if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToSend ) ) != pdFALSE )
{
//如果有任务需要调度,产生一次任务调度
queueYIELD_IF_USING_PREEMPTION();
}
}
}
else
{
//不需要移除队列消息项
pxQueue->u.pcReadFrom = pcOriginalReadPosition;
if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE )
{
if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE )
{
queueYIELD_IF_USING_PREEMPTION();
}
}
}
taskEXIT_CRITICAL();
return pdPASS;
}
else
{
//等待消息队列项为空
if( xTicksToWait == ( TickType_t ) 0 )
{
//设置等待阻塞超时时间为0,则直接返回队列空错误
taskEXIT_CRITICAL();
return errQUEUE_EMPTY;
}
else if( xEntryTimeSet == pdFALSE )
{
//设置了等待阻塞超时时间,则初始化一个TimeOut数据结构
vTaskSetTimeOutState( &xTimeOut );
xEntryTimeSet = pdTRUE;
}
else
{
}
}
}
taskEXIT_CRITICAL();
//退出临界区,此处可能会有任务调度
//所有任务挂起,阻止任务调度
vTaskSuspendAll();
//Queue锁定,此时可以处理中断,中断处理程序里可能对队列有操作
prvLockQueue( pxQueue );
if( xTaskCheckForTimeOut( &xTimeOut, &xTicksToWait ) == pdFALSE )
{
//等待阻塞超时时间未到
if( prvIsQueueEmpty( pxQueue ) != pdFALSE )
{
//队列未空
#if ( configUSE_MUTEXES == 1 )
{
//Mutex时的操作
if( pxQueue->uxQueueType == queueQUEUE_IS_MUTEX )
{
taskENTER_CRITICAL();
{
vTaskPriorityInherit( ( void * ) pxQueue->pxMutexHolder );
}
taskEXIT_CRITICAL();
}
}
#endif
//将任务加入到等待接收队列消息的List和延时List
vTaskPlaceOnEventList( &( pxQueue->xTasksWaitingToReceive ), xTicksToWait );
//Queue解锁
prvUnlockQueue( pxQueue );
//挂起的任务全部恢复,并启动调度
if( xTaskResumeAll() == pdFALSE )
{
//如果有调度需要,产生一次调度
portYIELD_WITHIN_API();
}
}
esle
{
//队列为非空
prvUnlockQueue( pxQueue );
( void ) xTaskResumeAll();
}
}
else
{
//等待阻塞超时时间到
//Queue解锁,恢复挂起的任务,开启任务调度
prvUnlockQueue( pxQueue );
( void ) xTaskResumeAll();
if( prvIsQueueEmpty( pxQueue ) != pdFALSE )
{
//队列未空,返回队列空错误
return errQUEUE_EMPTY;
}
}
}
}
```
另一个中断处理程序里的函数xQueueReceiveFromISR()也与相应的入队时类似。
```c
BaseType_t xQueueReceiveFromISR(...)
{
uxSavedInterruptStatus = portSET_INTERRUPT_MASK_FROM_ISR();
{
const UBaseType_t uxMessagesWaiting = pxQueue->uxMessagesWaiting;
if( uxMessagesWaiting > ( UBaseType_t ) 0 )
{
...
//将队列消息项copy出队列
prvCopyDataFromQueue( pxQueue, pvBuffer );
pxQueue->uxMessagesWaiting = uxMessagesWaiting - 1;
if( cRxLock == queueUNLOCKED )
{
//队列unlock
if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToSend ) ) == pdFALSE )
{
//有task等待向队列发送消息,将此task从等待发送队列的List中移除,并加入到任务的Ready List里
if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToSend ) ) != pdFALSE )
{
if( pxHigherPriorityTaskWoken != NULL )
{
//有任务调度,将任务调度标志置位pdTRUE
*pxHigherPriorityTaskWoken = pdTRUE;
}
}
}
}
else
{
//队列lock,队列不进行操作,将rxLock计数器加1,后面队列解锁后再依次做相应的处理
pxQueue->cRxLock = ( int8_t ) ( cRxLock + 1 );
}
}
else
{
//队列里没有接收的消息,直接返回失败错误
xReturn = pdFAIL;
}
}
portCLEAR_INTERRUPT_MASK_FROM_ISR( uxSavedInterruptStatus );
return xReturn;
}
```
## Semaphore & Mutex
信号量和互斥量也是基于Queue实现的,有了前面阅读Queue相关源码的基础,继续阅读这两者就能更好的理解。
Binary Semaphore创建函数xSemaphoreCreateBinary(),从下面的宏定义看出创建了一个type为queueQUEUE_TYPE_BINARY_SEMAPHORE,队列size为1,队列项size为0的队列。
```c
#define xSemaphoreCreateBinary()
xQueueGenericCreate( ( UBaseType_t ) 1, semSEMAPHORE_QUEUE_ITEM_LENGTH, queueQUEUE_TYPE_BINARY_SEMAPHORE )
```
Counting Semaphore创建函数xSemaphoreCreateCounting(),由下面的代码可以看出是创建一个type为queueQUEUE_TYPE_COUNTING_SEMAPHORE,队列size为创建时的参数uxMaxCount(计数最大值),队列项size为0的队列。另一个初始化时的参数uxInitialCount是信号量的初始值(即为队列里消息项的个数)。
```c
#define xSemaphoreCreateCounting( uxMaxCount, uxInitialCount )
xQueueCreateCountingSemaphore( ( uxMaxCount ), ( uxInitialCount ) )
QueueHandle_t xQueueCreateCountingSemaphore(...)
{
QueueHandle_t xHandle;
xHandle = xQueueGenericCreate( uxMaxCount, queueSEMAPHORE_QUEUE_ITEM_LENGTH, queueQUEUE_TYPE_COUNTING_SEMAPHORE );
if( xHandle != NULL )
{
( ( Queue_t * ) xHandle )->uxMessagesWaiting = uxInitialCount;
}
return xHandle;
}
```
Mutex的创建函数xSemaphoreCreateMutex(),由下面的代码可以看出,创建了一个type为queueQUEUE_TYPE_MUTEX,队列size为1,队列项size为0的队列。
```c
#define xSemaphoreCreateMutex() xQueueCreateMutex( queueQUEUE_TYPE_MUTEX )
QueueHandle_t xQueueCreateMutex( const uint8_t ucQueueType )
{
Queue_t *pxNewQueue;
const UBaseType_t uxMutexLength = ( UBaseType_t ) 1, uxMutexSize = ( UBaseType_t ) 0;
pxNewQueue = ( Queue_t * ) xQueueGenericCreate( uxMutexLength, uxMutexSize, ucQueueType );
prvInitialiseMutex( pxNewQueue );
return pxNewQueue;
}
static void prvInitialiseMutex( Queue_t *pxNewQueue )
{
if( pxNewQueue != NULL )
{
//实际是在Mutex情况下,将Queue_t的pcTail和pcHead赋予了新的意义
pxNewQueue->pxMutexHolder = NULL;
pxNewQueue->uxQueueType = queueQUEUE_IS_MUTEX;
//用于Recursive Mutex
pxNewQueue->u.uxRecursiveCallCount = 0;
//这里相当于先释放了Mutex,即使用Mutex第一次就可以获取资源,区别于Binary Semaphore
( void ) xQueueGenericSend( pxNewQueue, NULL, ( TickType_t ) 0U, queueSEND_TO_BACK );
}
}
```
通过Mutex和Binary Semaphore的初始化源码可以看出,在使用上Mutex创建完成后,可以直接获得资源,然后用完了再释放;而Binary Semaphore不同,创建完成后不能直接获取到,需要先释放再获取。
Recursive Mutex的创建函数xSemaphoreCreateRecursiveMutex(),实际与Mutex初始化相同,只是一个类型的区别queueQUEUE_TYPE_RECURSIVE_MUTEX,默认FreeRTOS不打开此功能。
```c
#define xSemaphoreCreateRecursiveMutex() xQueueCreateMutex( queueQUEUE_TYPE_RECURSIVE_MUTEX )
```
接着看Semaphore和Mutex的Take和Give,其中Binary Semaphore/Semaphore/Mutex的API相同,Recursive Mutex有单独的API
```c
//Take操作就是Queue的出队操作
#define xSemaphoreTake( xSemaphore, xBlockTime )
xQueueGenericReceive( ( QueueHandle_t ) ( xSemaphore ), NULL, ( xBlockTime ), pdFALSE )
//特别注意Mutex不能在中断中使用,因此这个API只适用于Semaphore
#define xSemaphoreTakeFromISR( xSemaphore, pxHigherPriorityTaskWoken )
xQueueReceiveFromISR( ( QueueHandle_t ) ( xSemaphore ), NULL, ( pxHigherPriorityTaskWoken ) )
//Give操作就是Queue的入队操作
#define xSemaphoreGive(xSemaphore)
xQueueGenericSend( ( QueueHandle_t ) ( xSemaphore ), NULL, semGIVE_BLOCK_TIME, queueSEND_TO_BACK )
//特别注意Mutex不能在中断中使用,因此这个API只适用于Semaphore
#define xSemaphoreGiveFromISR( xSemaphore, pxHigherPriorityTaskWoken )
xQueueGiveFromISR( ( QueueHandle_t ) ( xSemaphore ), ( pxHigherPriorityTaskWoken ) )
```
Give操作就是Queue的入队操作,队列满了就返回满错误;未满则入队,计算加1,判断是否有任务阻塞,如果有则任务调度。Take操作就是Queue的出队操作,队列不为空,则计数减1,判断是否有任务入队阻塞,如果有则任务调度;队列为空,阻塞等待时间为0,则直接返回空错误;队列为空,阻塞等待时间不为0,则任务阻塞,并将任务加入延时列表。特别注意Mutex不能在中断处理函数中操作。
Recursive Mutex的Take和Give的API区别于其他3个
```c
#define xSemaphoreTakeRecursive( xMutex, xBlockTime )
xQueueTakeMutexRecursive( ( xMutex ), ( xBlockTime ) )
BaseType_t xQueueTakeMutexRecursive( QueueHandle_t xMutex, TickType_t xTicksToWait )
{
BaseType_t xReturn;
Queue_t * const pxMutex = ( Queue_t * ) xMutex;
if( pxMutex->pxMutexHolder == ( void * ) xTaskGetCurrentTaskHandle() )
{
//非第一次调用此API,此时pxMutexHolder与当前task的TCB相同,直接uxRecursiveCallCount加1,不用去操作队列函数;如果此时是另一个任务Take,则会到下面的分支阻塞在xQueueGenericReceive
//同一个任务只要递归Mutex没有将所有Take的次数Give掉,就直接进入这个分支;同一个任务一旦Give掉所有的Take次数,pxMutexHolder置为NULL,就会进入下面的分支,此时有其他任务想Take此Mutex会获得Take的机会
( pxMutex->u.uxRecursiveCallCount )++;
xReturn = pdPASS;
}
else
{
//如果第一次调用此API去Take递归Mutex,将当前Task的TCB赋值给pxMutexHolder,然后将uxRecursiveCallCount加1
//如果递归Mutex的Give所有Take的次数,将pxMutexHolder置为NULL,则又进入到这个分支,如果此时有其他任务Take递归Mutex,则会获得机会,否则只能被阻塞在xQueueGenericReceive
xReturn = xQueueGenericReceive( pxMutex, NULL, xTicksToWait, pdFALSE );
if( xReturn != pdFAIL )
{
( pxMutex->u.uxRecursiveCallCount )++;
}
}
return xReturn;
}
#define xSemaphoreGiveRecursive( xMutex )
xQueueGiveMutexRecursive( ( xMutex ) )
BaseType_t xQueueGiveMutexRecursive( QueueHandle_t xMutex )
{
BaseType_t xReturn;
Queue_t * const pxMutex = ( Queue_t * ) xMutex;
//判断是否在同一个任务中Give
if( pxMutex->pxMutexHolder == ( void * ) xTaskGetCurrentTaskHandle() )
{
//通过uxRecursiveCallCount计数递归,每次Give操作此值减1
( pxMutex->u.uxRecursiveCallCount )--;
if( pxMutex->u.uxRecursiveCallCount == ( UBaseType_t ) 0 )
{
//如果Give的次数刚好与Take的次数相等,向pxMutex队列里发送一条消息,pxMutexHolder置为NULL,这样Give次数过多就不会再走进这个分支,而是直接返回错误;另外如果有其他任务需要Take递归Mutex,则获得机会,即释放了递归Mutex
( void ) xQueueGenericSend( pxMutex, NULL, queueMUTEX_GIVE_BLOCK_TIME, queueSEND_TO_BACK );
}
xReturn = pdPASS;
}
else
{
//如果不在同一个任务中直接返回错误,还有Give的次数超过了Take的次数也会走到这里
xReturn = pdFAIL;
}
return xReturn;
}
```
由上面的源码可以看出,Mutex需要在同一个任务中获取释放,作为资源共享锁的使用方式,pxMutexHolder会记录创建Mutex时的task TCB,Take和Give时都会判断是否是在同一个task中,如果不是直接返回错误。而Binary Semaphore没有优先级继承,而且可以在任意的任务中获取释放。
Mutex具有优先级继承,主要用作资源共享时,提升当前获得Mutex的任务的优先级至等待此资源的所有任务中的最高优先级,尽最大可能的避免优先级翻转造成的危害(高优先级任务一直得不到资源一直被挂起,或者直接死锁了)。
可以看出,Semaphore和Mutex都是使用Queue实现的,只用到了Queue的头部分,即Queue_t结构体,而Queue的队列项则为空。Binary Semaphore/Semaphore/Mutex/Recursive Mutex各有自己的创建API,最终都是调用的Queue的创建函数;Binary Semaphore/Semaphore/Mutex的Take和Give操作API相同,Recursive Mutex有自己的单独的API操作;Semaphore有中断相关的API,但是Mutex不能在中断处理程序中执行,Mutex具有优先级继承,而且必须在同一个任务中Take和Give,而Semaphore没有优先级继承,可以在任意的任务中Take,然后在任意的任务中Give,或者反过来操作。
## Task Notifications
Task Notifications是FreeRTOS V8.2.0之后新增的功能,官方文档结论是比Queue/Semaphore/Mutex/Event Groups更快,使用RAM更少,可以携带长度为1的消息内容,完全基于Task实现。
Task TCB数据结构里相关的定义如下:
```c
typedef struct tskTaskControlBlock
{
...
#if( configUSE_TASK_NOTIFICATIONS == 1 )
volatile uint32_t ulNotifiedValue;
volatile uint8_t ucNotifyState;
#endif
...
} tskTCB;
```
Task Notifications的发送通知函数xTaskGenericNotify()
```c
typedef enum
{
eNoAction = 0, //发送通知但不使用ulValue值,无通知内容
eSetBits, //被通知的任务的通知值按bit或ulValue
eIncrement, //被通知的任务的通知值加1
eSetValueWithOverwrite, //被通知任务的通知值直接设置成ulValue,无论之前的通知值是否已经被读取
eSetValueWithoutOverwrite //之前的任务通知值被读取后,再更新被通知任务的通知值,如果没有读取则丢弃当前的ulValue
} eNotifyAction;
BaseType_t xTaskGenericNotify(...)
{
TCB_t * pxTCB;
BaseType_t xReturn = pdPASS;
uint8_t ucOriginalNotifyState;
pxTCB = ( TCB_t * ) xTaskToNotify;
taskENTER_CRITICAL();
{
if( pulPreviousNotificationValue != NULL )
{
//函数传入的参数,将ulNotifiedValue更新前的值赋值给这个传入参数,发送通知的task获得更新前的通知值
*pulPreviousNotificationValue = pxTCB->ulNotifiedValue;
}
//保存ucNotifyState
ucOriginalNotifyState = pxTCB->ucNotifyState;
//更新ucNotifyState
pxTCB->ucNotifyState = taskNOTIFICATION_RECEIVED;
//更新通知的方法,详见eNotifyAction枚举定义
switch( eAction )
{
case eSetBits :
pxTCB->ulNotifiedValue |= ulValue;
break;
case eIncrement :
( pxTCB->ulNotifiedValue )++;
break;
case eSetValueWithOverwrite :
pxTCB->ulNotifiedValue = ulValue;
break;
case eSetValueWithoutOverwrite :
if( ucOriginalNotifyState != taskNOTIFICATION_RECEIVED )
{
pxTCB->ulNotifiedValue = ulValue;
}
else
{
xReturn = pdFAIL;
}
break;
case eNoAction:
break;
}
if( ucOriginalNotifyState == taskWAITING_NOTIFICATION )
{
//被通知的任务正好在等待通知的状态,则将其添加到任务Ready List
( void ) uxListRemove( &( pxTCB->xStateListItem ) );
prvAddTaskToReadyList( pxTCB );
#if( configUSE_TICKLESS_IDLE != 0 )
{
prvResetNextTaskUnblockTime();
}
#endif
if( pxTCB->uxPriority > pxCurrentTCB->uxPriority )
{
//如果发现等待通知的任务优先级更高,则触发一次任务调度
taskYIELD_IF_USING_PREEMPTION();
}
}
taskEXIT_CRITICAL();
return xReturn;
}
```
从上面的源码可以看出任务通知的机制非常简洁,与任务本身相关,将相关的信息填写到任务TCB之后,判断等待通知的任务优先级是否更高,如果更高则直接触发一次任务调度。由此,可以理解任务只能等待在一个任务通知上,也可以获得长度为1的消息内容,这也有别于Semaphore/Queue等方式,但是简洁高效是其最大的特点,在某些场景下可以使用此方式。
中断处理函数里的任务通知函数与非中断保护的函数类似,只是增加了开关中断保护;而等待任务通知不能在中断中执行,等待通知函数ulTaskNotifyTake()和xTaskNotifyWait(),直接看xTaskNotifyWait()
```c
BaseType_t xTaskNotifyWait(...)
{
BaseType_t xReturn;
taskENTER_CRITICAL();
{
//如果任务没有收到通知
if( pxCurrentTCB->ucNotifyState != taskNOTIFICATION_RECEIVED )
{
pxCurrentTCB->ulNotifiedValue &= ~ulBitsToClearOnEntry;
//将任务状态设置为等待通知状态
pxCurrentTCB->ucNotifyState = taskWAITING_NOTIFICATION;
if( xTicksToWait > ( TickType_t ) 0 )
{
//如果设置了阻塞等待超时时间,则将任务加入Delay List
prvAddCurrentTaskToDelayedList( xTicksToWait, pdTRUE );
//触发任务调度
portYIELD_WITHIN_API();
}
}
}
taskEXIT_CRITICAL();
//退出临界区,如果有任务调度,则任务被挂起
taskENTER_CRITICAL();
{
if( pulNotificationValue != NULL )
{
//通知值赋值给函数传入参数,返回给调用者
*pulNotificationValue = pxCurrentTCB->ulNotifiedValue;
}
if( pxCurrentTCB->ucNotifyState == taskWAITING_NOTIFICATION )
{
//没有收到通知值,可能是阻塞等待超时或者阻塞等待超时为0,直接返回错误
xReturn = pdFALSE;
}
else
{
//收到了通知
pxCurrentTCB->ulNotifiedValue &= ~ulBitsToClearOnExit;
xReturn = pdTRUE;
}
//重置状态为非等待通知状态
pxCurrentTCB->ucNotifyState = taskNOT_WAITING_NOTIFICATION;
}
taskEXIT_CRITICAL();
}
```
Task Notifications基本就阅读完成了,简洁高效而且占用RAM少,可以实现轻量级Queue,Binary Semaphore, Semaphore和Event Groups,具有很高的效率优势,但是也要注意使用限制,只能有1个任务接收通知,发送通知的任务不能因为无法发送通知而进入阻塞状态。 | 33,501 | MIT |
---
layout: single
title: Macbook操作
categories:
- 参考
tags:
- macos
---
* content
{:toc}
#### 快捷键
| 文本 | 文件 | 其他 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | :----------------------------------------------------------- |
| Command-C 拷贝<br/>Command-V 粘贴<br/>Command-X 剪切<br/>Command-Z 撤销<br/>Command-A 全选<br/>command-S 保存<br/>Command-F 查找 | Command <- 删除文件<br/>Command c 拷贝文件<br/>Command v 粘贴文件<br/>Command option v 移动文件 | Command Shift 4 选取截图<br/>Command Shift 3 全屏截图<br/>Control 空格 切换输入法 |
<!--more-->
#### 触控板
```
单指点 鼠标左键
双指点 鼠标右键
双指上下滑 滚动页面
双指张合 页面放大缩小
三指上滑 多界面切换
四指张开 桌面
四指合并 程序
```
#### 命令
```shell
# screen
screen /dev/cu.usbserial-0001 115200 打开串口
screen -ls 查看
ctrl + a + d 退出screen
# minicom
minicom -D /dev/cu.usbserial-0001 -b 115200 -C $(date +%Y-%m-%d_%H%M%S).log
esc+z 退出
``` | 1,079 | MIT |
# day7
## Summary
函数
## 函数定义
```
func functionName([parameter list]) [returnTypes]{
//body
}
//函数由func关键字进行声明。
//functionName:代表函数名。
//parameter list:代表参数列表,函数的参数是可选的,可以包含参数也可以不包含参数。
//returnTypes:返回值类型,返回值是可选的,可以有返回值,也可以没有返回值。
//body:用于写函数的具体逻辑
```
### 例子
```
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
var ret int
/* 调用函数并返回最大值 */
ret = max(a, b)
fmt.Printf( "最大值是 : %d\n", ret )
}
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int {
/* 定义局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
```
## 变长参数
在对函数进行传参时,函数接受的传参根据实际传入长度进行变化
```
func main() {
slice := []int{7, 9, 3, 5, 1}
x := min(slice...)
fmt.Printf("The minimum is: %d", x)
}
func min(s ...int) int {
if len(s) == 0 {
return 0
}
min := s[0]
for _, v := range s {
if v < min {
min = v
}
}
return min
}
```
## 函数返回多个值
func div(a, b float64) (float64, error) {
if b == 0 {
return 0, errors.New("The divisor cannot be zero.")
}
return a / b, nil
}
func main() {
result, err := div(1, 2)
if err != nil {
fmt.Printf("error: %v", err)
return
}
fmt.Println("result: ", result)
}
## 命名返回值
```
func div(a, b float64) (result float64, err error) {
if b == 0 {
return 0, errors.New("被除数不能等于0")
}
result = a / b
return
}
```
## 匿名函数
```
func main() {
f := func() string {
return "hello world"
}
fmt.Println(f())
}
```
## 闭包
Go 语言支持匿名函数,可作为闭包。匿名函数是一个"内联"语句或表达式。匿名函数的优越性在于可以直接使用函数内的变量,不必申明。
```
package main
import "fmt"
func getSequence() func() int {
i:=0
return func() int {
i+=1
return i
}
}
func main(){
/* nextNumber 为一个函数,函数 i 为 0 */
nextNumber := getSequence()
/* 调用 nextNumber 函数,i 变量自增 1 并返回 */
fmt.Println(nextNumber())
fmt.Println(nextNumber())
fmt.Println(nextNumber())
/* 创建新的函数 nextNumber1,并查看结果 */
nextNumber1 := getSequence()
fmt.Println(nextNumber1())
fmt.Println(nextNumber1())
}
/*
1
2
3
1
2
*/
``` | 2,021 | Apache-2.0 |
---
title: 将解决方案迁移到 SQL 数据仓库 | Microsoft 文档
description: 有关将解决方案转移到 Azure SQL 数据仓库平台的迁移指南。
services: sql-data-warehouse
author: jrowlandjones
manager: craigg
ms.service: sql-data-warehouse
ms.topic: conceptual
ms.component: implement
ms.date: 04/17/2018
ms.author: jrj
ms.reviewer: igorstan
ms.openlocfilehash: b3e01968c74060bd0dc366609275d63753ad62dd
ms.sourcegitcommit: 1fb353cfca800e741678b200f23af6f31bd03e87
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 08/30/2018
ms.locfileid: "43306700"
---
# <a name="migrate-your-solution-to-azure-sql-data-warehouse"></a>将解决方案迁移到 Azure SQL 数据仓库
请参阅将现有数据库解决方案迁移到 Azure SQL 数据仓库所涉及的内容。
## <a name="profile-your-workload"></a>配置工作负载
在迁移之前,需要确定 SQL 数据仓库是适用于工作负载的理想解决方案。 SQL 数据仓库是分布式系统,旨在对大型数据进行分析。 迁移到 SQL 数据仓库需要一些设计更改,这些更改不难理解但可能需要一些时间才能实现。 如果业务要求企业级的数据仓库,那么花费一些时间来实现这些优点是值得的。 但是,如果不需要改进 SQL 数据仓库,那么使用 SQL Server 或 Azure SQL 数据库则更经济实惠。
在以下情况下,请考虑使用 SQL 数据仓库:
- 具有 1 TB 或数 TB 的数据
- 计划对大量数据运行分析
- 需要能够缩放计算和存储
- 想要在不需要资源时通过暂停计算来节省成本。
不要将 SQL 数据仓库用于具有以下特点的操作 (OLTP) 工作负载:
- 高频率读取和写入
- 大量的单一实例选择
- 大容量单行插入
- 逐行处理需求
- 不兼容的格式(JSON 和 XML)
## <a name="plan-the-migration"></a>规划迁移
在决定要将现有解决方案迁移到 SQL 数据仓库后,请务必在开始操作之前先规划迁移。
规划的一个目标是确保数据、表架构以及代码与 SQL 数据仓库兼容。 当前系统和 SQL 数据仓库之间存在一些需要解决的兼容性差异。 此外,将大量数据迁移到 Azure 需要时间。 更具体的规划可以加快将数据迁移到 Azure 的速度。
规划的另一个目标是进行设计方面的调整,以确保解决方案可以使用 SQL 数据仓库提供的高查询性能。 由于针对缩放性设计数据仓库引入了不同的设计模式,因此传统的方法不一定最合适。 尽管在迁移后可以进行某些设计调整,但是在过程中尽早进行更改可以为以后的操作节省时间。
若要执行成功迁移,需要迁移表架构、代码和数据。 有关以下迁移主题的指南,请参阅:
- [迁移架构](sql-data-warehouse-migrate-schema.md)
- [迁移代码](sql-data-warehouse-migrate-code.md)
- [迁移数据](sql-data-warehouse-migrate-data.md)。
<!--
## Perform the migration
## Deploy the solution
## Validate the migration
-->
## <a name="next-steps"></a>后续步骤
CAT(客户顾问团队)也有一些很好的通过博客发布的 SQL 数据仓库指南。 请参阅他们的[在实践中将数据迁移到 Azure SQL 数据仓库][Migrating data to Azure SQL Data Warehouse in practice]一文,了解有关迁移的更多指南。
<!--Image references-->
<!--Article references-->
<!--MSDN references-->
<!--Other Web references-->
[Migrating data to Azure SQL Data Warehouse in practice]: https://blogs.msdn.microsoft.com/sqlcat/2016/08/18/migrating-data-to-azure-sql-data-warehouse-in-practice/ | 2,156 | CC-BY-4.0 |
---
title: 光学新闻 20210807
urlname: OpticsNews20210807
date: 2021-08-07 16:00:00
tag: [光学新闻]
categories: 光学新闻
photo: https://cdn.jsdelivr.net/gh/Sterncat/BlogPics/OpticsNews/20210807/0.png
---
**本周五篇光学新闻**:
1. 高光谱传感器的开发公司Spectricity融资1600万美元 ---
2. ToF传感器厂商聚芯微电子完成数亿元C轮融资 ---
3. 美军寻求“第四代”红外解决方案 ---
4. Quanergy展示了基于光学相控阵技术,探测距离达100m的固态激光雷达---
5. 偏振三维成像技术的原理和研究进展
<!--more-->
-----
## 高光谱传感器的开发公司Spectricity融资1600万美元
评论:致力于为移动和消费类设备提供高光谱传感解决方案的领先供应商[Spectricity](https://spectricity.com),近日宣布完成1600万美元B轮融资,以进一步加快高光谱传感器的开发和大规模量产,用于从可穿戴到智能手机和物联网领域的大批量、低成本应用。Spectricity是一家fabless公司,总部在比利时,2017年建立,致力于开发可以用在移动设备上的高光谱传感解决方案。Atlantic Bridge、Capricorn Fusion中国基金和上海半导体装备和材料基金(SSMEF)等全球领先投资者参与了Spectricity此轮融资,此前的A轮投资者imec.xpand和XTRION也继续跟投了本轮融资。此轮融资完成后,Spectricity的融资总额已经达到2400万美元。
光谱成像技术,其本质是充分利用了物质对不同电磁波谱的吸收或辐射特性,在普通的二维空间成像的基础上,增加了一维的光谱信息。成像光谱可以同时获取影像信息与像元的光谱信息,根据光谱分辨率不同介绍下多光谱成像、高光谱成像技术; 多光谱技术(Multispectral):目标物波段数在3-30之间(通常大于等于3个);高光谱成像(Hypespectral):目标物波段数在100-300之间,光谱分辨率一般会更精细。
对于Spectricity的产品,哪家手机公司会去尝鲜,以及Spectricity或者手机终端公司基于这种技术能开发出何种应用,以及搭配该应用的算法都十分重要。根据2021年3月发布的一篇关于紧凑型光谱仪市场的文章,到2024年,新兴的芯片级光谱仪年出货量将增长至超过3亿颗。新型光谱仪的尺寸将缩小至半导体芯片的尺寸。
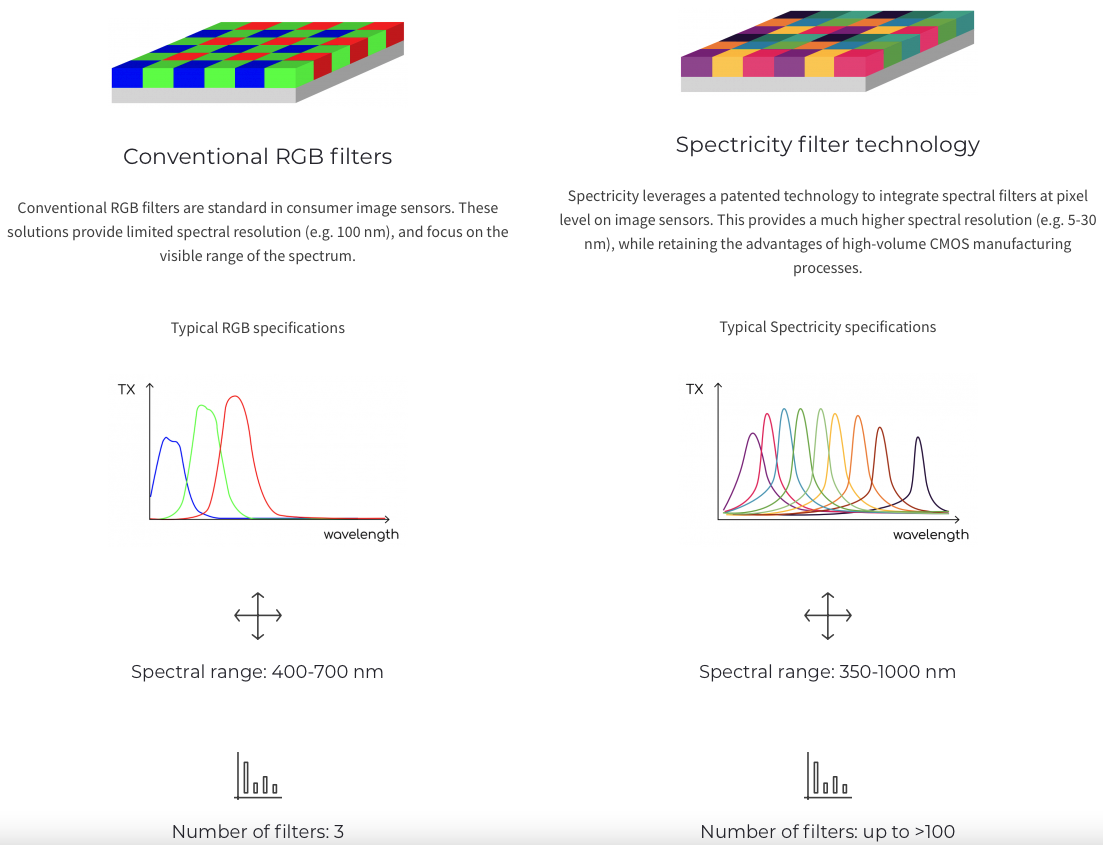
[新闻稿](https://www.businesswire.com/news/home/20210802005848/en/Spectricity-Raises-€14-Million-Series-B-Funding-as-It-Accelerates-Plans-to-Deliver-Industry-Leading-Hyperspectral-Sensing-to-Mobile-and-Consumer-Devices)
-----
## ToF传感器厂商聚芯微电子完成数亿元C轮融资
评论:模拟与混合信号芯片设计公司[聚芯微电子](https://www.si-in.com/home)宣布完成数亿元C轮融资。本轮融资由多家知名半导体产业资本联合投资,包括小米长江产业基金、华为哈勃投资、华业天成(老股东增持)、恒信华业以及一家行业顶尖的产业链基金。结合此前几轮OPPO战投、和利资本、源码资本、湖杉资本、将门创投等专业机构的加持,聚芯微电子成为获得了三大手机品牌战略投资的模拟与混合信号芯片设计公司。
武汉市聚芯微电子有限责任公司成立于2016年1月,是一家专注于高性能模拟与混合信号芯片设计的创新型高科技公司,总部位于武汉光谷未来科技城,并在欧洲、深圳和上海设立有研发中心。公司由多位在欧美拥有丰富半导体行业经验的留学归国人员创办,核心团队聚集了在企业管理、产品研发、市场销售、财务管理和生产制造等各环节拥有卓越业绩的行业精英。
公司拥有3D光学和智能音频两大产品线,其中智能音频功放凭借差异化的产品及优秀的性价比已得到主流手机厂商的认可,而用于3D成像的飞行时间(Time-of-Flight)传感器采用了背照式(BSI)技术,具有高精度、小像素尺寸、高分辨率、低功耗、全集成等特点,打破欧美国际厂商的垄断,可广泛应用于人工智能、人脸识别、自动驾驶、AR/VR、3D建模、动作捕捉、机器视觉等领域,在手机、安防、汽车等主流市场拥有光明的商业落地前景。在过往的经历中,聚芯微电子的团队拥有多项业界“第一”:开发出国内首款基于BSI(背照式)工艺的高分辨率ToF图像传感器;开发并量产了业内第一款模拟输入的智能音频功放产品,以及行业最低噪声的传感器信号调理芯片。
模拟与混合信号芯片设计近些年是电子消费品的一个重要竞争领域,近期美国对高端芯片制造的各种封锁也让中国企业开始重视投资中国芯片设计公司。国际上类似公司有TI,Analog Device,AMS,ST等公司。

[新闻稿](https://optics.org/news/12/7/38)
-----
## 美军寻求“第四代”红外解决方案
评论:在近期圣地亚哥举办的SPIE Optics + Photonics会议上,来自美军C5ISR Center’s Night Vision and Electronic Sensors Directorate (C51SR夜视和电子传感董事会)的Nibir Dhar做了题目为“Infrared technology: What is on the Horizon?”的演讲。主题主要是下一代红外传感技术。他提出红外传感关注的6个重点领域,其中包括长距离精确打击,下一代战场载具,垂直起降航空器,网络技术,航空和导弹防御,最大化致死,他提出红外技术可以极大辅助这些领域。前三代的军用红外技术为:
1. 1970s-1980s:扫描MWIR和冷却LWIR传感器
2. 1990s:结合了长线性TDI PV扫描阵列的扫描MWIR和小型MW/LW Staring array
3. 2000s:双波段LW/MW大型多功能阵列,包括片上处理和高工作温度
他认为下一个系统主要包含这些需要提升的方面:规模性,传感,渲染,速度,融合和处理。包括系统小型化和更高的处理速度。
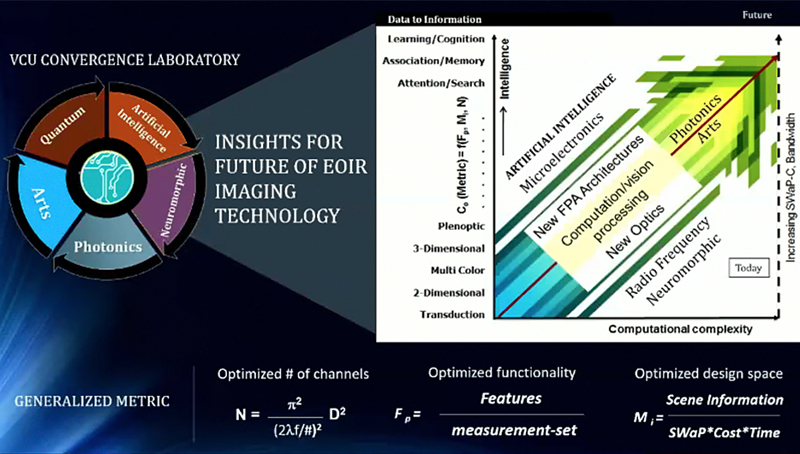
[新闻稿](https://optics.org/news/12/8/5)
-----
## Quanergy展示了基于光学相控阵技术,探测距离达100m的固态激光雷达
评论:[Quanergy](https://quanergy.com),总部在Sunnyvale的激光雷达公司,近期展示了基于光学相控阵(optical phased array,OPA)的最新开发的固态激光雷达。这次发布的S3系列激光雷达,使用了OPA技术和CMOS解决方案,可以实现大规模生产。该公司的测试和Zero Electric Vehicle(ZEV)公司合作进行,ZEV公司是提供电动汽车电器控制平台的公司。S3系列相控阵型固态激光雷达完全没有移动部件,依赖相控阵技术调制光线指向方向,系统的抗震动抗撞击和信赖性比起普通的使用旋转方案或者MEMS反射镜的方案都大大提升,这次该公司把探测距离提升至100m可以算是很大的一步。该系列达到了了10万小时平均失效时间,目标价格要小于$500美元。不过其他探测性能对比使用其他方案如何需要具体研究该种雷达的spec。

[新闻稿](https://quanergy.com/pressrel/quanergy-demonstrates-the-industry-first-opa-based-solid-state-lidar-with-100-meter-range/)
-----
## 偏振三维成像技术的原理和研究进展
评论:西安电子科技大学,西安市计算成像重点实验室的几位作者,四月在红外和毫米波学报上发布了“偏振三维成像技术的原理和研究进展”,摘要如下:近年来偏振三维成像技术因具有精度高、作用距离远和受杂散光影响小等特点得以蓬勃发展,但利用目标反射光偏振特性进行法向量精确求解的问题一直没有真正得到解决,成为制约该技术发展的瓶颈。此外,由于目标表面镜面反射光与漫反射光间的相互干扰,造成高精度偏振三维成像实现困难。该综述介绍了偏振三维成像物理机理、目标表面出射光偏振特性,以及偏振三维成像研究进展。最后总结了目前偏振三维成像面临的问题和未来的发展方向。
文章主要说明的就是使用偏振三维成像可以实现更高精度的三维成像,而且有各种优势。近些年小型化偏振传感器的发展和VCSEL的发展都很迅速,可能我们很快就能看到一些电子消费品类的应用了。
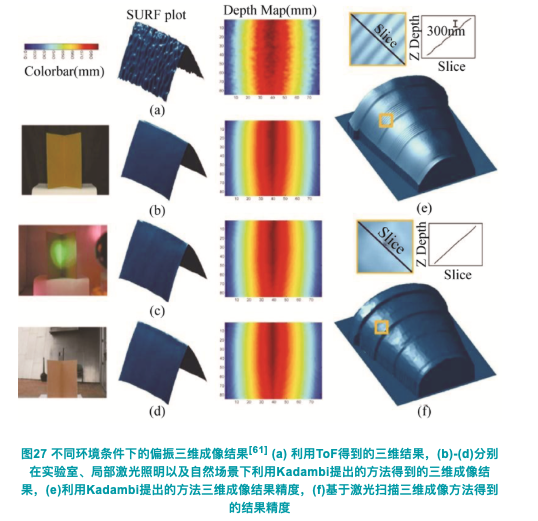
[论文](http://journal.sitp.ac.cn/hwyhmb/hwyhmbcn/article/html/2020178)
-----
这里记录值得分享的光学科技内容,欢迎投稿或推荐科技内容。
版权声明: 感谢您的阅读,本文由[超光](https://faster-than-light.net/)版权所有。如若转载,请注明出处。 | 4,322 | MIT |
<!--
* @Date: 2020-09-27 19:48:27
* @LastEditors: hu.wenjun
* @LastEditTime: 2020-09-27 20:06:45
-->
[redux源码解析](https://juejin.im/post/6844903861862268942#heading-7) | 171 | MIT |