
text
stringlengths 5
58.6k
| source
stringclasses 470
values | url
stringlengths 49
167
| source_section
stringlengths 0
90
| file_type
stringclasses 1
value | id
stringlengths 3
6
|
|---|---|---|---|---|---|
Sometimes, older CUDA versions may refuse to build with newer compilers. For example, if you have `gcc-9` but CUDA wants `gcc-7`. Usually, installing the latest CUDA toolkit enables support for the newer compiler.
You could also install an older version of the compiler in addition to the one you're currently using (or it may already be installed but it's not used by default and the build system can't see it). To resolve this, you can create a symlink to give the build system visibility to the older compiler.
```bash
# adapt the path to your system
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/debugging.md
|
https://huggingface.co/docs/transformers/en/debugging/#older-cuda-versions
|
#older-cuda-versions
|
.md
|
60_5
|
If you're still having issues with installing DeepSpeed or if you're building DeepSpeed at run time, you can try to prebuild the DeepSpeed modules before installing them. To make a local build for DeepSpeed:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
```
<Tip>
To use NVMe offload, add the `DS_BUILD_AIO=1` parameter to the build command and make sure you install the libaio-dev package system-wide.
</Tip>
Next, you'll have to specify your GPU's architecture by editing the `TORCH_CUDA_ARCH_LIST` variable (find a complete list of NVIDIA GPUs and their corresponding architectures on this [page](https://developer.nvidia.com/cuda-gpus)). To check the PyTorch version that corresponds to your architecture, run the following command:
```bash
python -c "import torch; print(torch.cuda.get_arch_list())"
```
Find the architecture for a GPU with the following command:
<hfoptions id="arch">
<hfoption id="same GPUs">
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
```
</hfoption>
<hfoption id="specific GPU">
To find the architecture for GPU `0`:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
print(torch.cuda.get_device_properties(torch.device('cuda')))
"_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)"
```
This means your GPU architecture is `8.6`.
</hfoption>
</hfoptions>
If you get `8, 6`, then you can set `TORCH_CUDA_ARCH_LIST="8.6"`. For multiple GPUs with different architectures, list them like `TORCH_CUDA_ARCH_LIST="6.1;8.6"`.
It is also possible to not specify `TORCH_CUDA_ARCH_LIST` and the build program automatically queries the GPU architecture of the build. However, it may or may not match the actual GPU on the target machine which is why it is better to explicitly specify the correct architecture.
For training on multiple machines with the same setup, you'll need to make a binary wheel:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
python setup.py build_ext -j8 bdist_wheel
```
This command generates a binary wheel that'll look something like `dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`. Now you can install this wheel locally or on another machine.
```bash
pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/debugging.md
|
https://huggingface.co/docs/transformers/en/debugging/#prebuild
|
#prebuild
|
.md
|
60_6
|
When training or inferencing with `DistributedDataParallel` and multiple GPU, if you run into issue of inter-communication between processes and/or nodes, you can use the following script to diagnose network issues.
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
For example to test how 2 GPUs interact do:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
If both processes can talk to each and allocate GPU memory each will print an OK status.
For more GPUs or nodes adjust the arguments in the script.
You will find a lot more details inside the diagnostics script and even a recipe to how you could run it in a SLURM environment.
An additional level of debug is to add `NCCL_DEBUG=INFO` environment variable as follows:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
This will dump a lot of NCCL-related debug information, which you can then search online if you find that some problems are reported. Or if you're not sure how to interpret the output you can share the log file in an Issue.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/debugging.md
|
https://huggingface.co/docs/transformers/en/debugging/#multi-gpu-network-issues-debug
|
#multi-gpu-network-issues-debug
|
.md
|
60_7
|
<Tip>
This feature is currently available for PyTorch-only.
</Tip>
<Tip>
For multi-GPU training it requires DDP (`torch.distributed.launch`).
</Tip>
<Tip>
This feature can be used with any `nn.Module`-based model.
</Tip>
If you start getting `loss=NaN` or the model exhibits some other abnormal behavior due to `inf` or `nan` in
activations or weights one needs to discover where the first underflow or overflow happens and what led to it. Luckily
you can accomplish that easily by activating a special module that will do the detection automatically.
If you're using [`Trainer`], you just need to add:
```bash
--debug underflow_overflow
```
to the normal command line arguments, or pass `debug="underflow_overflow"` when creating the
[`TrainingArguments`] object.
If you're using your own training loop or another Trainer you can accomplish the same with:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`~debug_utils.DebugUnderflowOverflow`] inserts hooks into the model that immediately after each
forward call will test input and output variables and also the corresponding module's weights. As soon as `inf` or
`nan` is detected in at least one element of the activations or weights, the program will assert and print a report
like this (this was caught with `google/mt5-small` under fp16 mixed precision):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
The example output has been trimmed in the middle for brevity.
The second column shows the value of the absolute largest element, so if you have a closer look at the last few frames,
the inputs and outputs were in the range of `1e4`. So when this training was done under fp16 mixed precision the very
last step overflowed (since under `fp16` the largest number before `inf` is `64e3`). To avoid overflows under
`fp16` the activations must remain way below `1e4`, because `1e4 * 1e4 = 1e8` so any matrix multiplication with
large activations is going to lead to a numerical overflow condition.
At the very start of the trace you can discover at which batch number the problem occurred (here `Detected inf/nan during batch_number=0` means the problem occurred on the first batch).
Each reported frame starts by declaring the fully qualified entry for the corresponding module this frame is reporting
for. If we look just at this frame:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
Here, `encoder.block.2.layer.1.layer_norm` indicates that it was a layer norm for the first layer, of the second
block of the encoder. And the specific calls of the `forward` is `T5LayerNorm`.
Let's look at the last few frames of that report:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
The last frame reports for `Dropout.forward` function with the first entry for the only input and the second for the
only output. You can see that it was called from an attribute `dropout` inside `DenseReluDense` class. We can see
that it happened during the first layer, of the 2nd block, during the very first batch. Finally, the absolute largest
input elements was `6.27e+04` and same for the output was `inf`.
You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
around 62.7K, which is very close to fp16's top limit of 64K. In the next frame we have `Dropout` which renormalizes
the weights, after it zeroed some of the elements, which pushes the absolute max value to more than 64K, and we get an
overflow (`inf`).
As you can see it's the previous frames that we need to look into when the numbers start going into very large for fp16
numbers.
Let's match the report to the code from `models/t5/modeling_t5.py`:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
Now it's easy to see the `dropout` call, and all the previous calls as well.
Since the detection is happening in a forward hook, these reports are printed immediately after each `forward`
returns.
Going back to the full report, to act on it and to fix the problem, we need to go a few frames up where the numbers
started to go up and most likely switch to the `fp32` mode here, so that the numbers don't overflow when multiplied
or summed up. Of course, there might be other solutions. For example, we could turn off `amp` temporarily if it's
enabled, after moving the original `forward` into a helper wrapper, like so:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
Since the automatic detector only reports on inputs and outputs of full frames, once you know where to look, you may
want to analyse the intermediary stages of any specific `forward` function as well. In such a case you can use the
`detect_overflow` helper function to inject the detector where you want it, for example:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
You can see that we added 2 of these and now we track if `inf` or `nan` for `forwarded_states` was detected
somewhere in between.
Actually, the detector already reports these because each of the calls in the example above is a `nn.Module`, but
let's say if you had some local direct calculations this is how you'd do that.
Additionally, if you're instantiating the debugger in your own code, you can adjust the number of frames printed from
its default, e.g.:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/debugging.md
|
https://huggingface.co/docs/transformers/en/debugging/#underflow-and-overflow-detection
|
#underflow-and-overflow-detection
|
.md
|
60_8
|
The same debugging class can be used for per-batch tracing with the underflow/overflow detection feature turned off.
Let's say you want to watch the absolute min and max values for all the ingredients of each `forward` call of a given
batch, and only do that for batches 1 and 3. Then you instantiate this class as:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
And now full batches 1 and 3 will be traced using the same format as the underflow/overflow detector does.
Batches are 0-indexed.
This is helpful if you know that the program starts misbehaving after a certain batch number, so you can fast-forward
right to that area. Here is a sample truncated output for such configuration:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
Here you will get a huge number of frames dumped - as many as there were forward calls in your model, so it may or may
not what you want, but sometimes it can be easier to use for debugging purposes than a normal debugger. For example, if
a problem starts happening at batch number 150. So you can dump traces for batches 149 and 150 and compare where
numbers started to diverge.
You can also specify the batch number after which to stop the training, with:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/debugging.md
|
https://huggingface.co/docs/transformers/en/debugging/#specific-batch-absolute-min-and-max-value-tracing
|
#specific-batch-absolute-min-and-max-value-tracing
|
.md
|
60_9
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/
|
.md
|
61_0
|
|
An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
- Load and customize a model configuration.
- Create a model architecture.
- Create a slow and fast tokenizer for text.
- Create an image processor for vision tasks.
- Create a feature extractor for audio tasks.
- Create a processor for multimodal tasks.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#create-a-custom-architecture
|
#create-a-custom-architecture
|
.md
|
61_1
|
A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
- Try a different activation function with the `activation` parameter.
- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#configuration
|
#configuration
|
.md
|
61_2
|
The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. This means models are compatible with each of their respective framework's usage.
<frameworkcontent>
<pt>
Load your custom configuration attributes into the model:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Load your custom configuration attributes into the model:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#model
|
#model
|
.md
|
61_3
|
At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
<frameworkcontent>
<pt>
For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</pt>
<tf>
For example, [`TFDistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`TFDistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</tf>
</frameworkcontent>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#model-heads
|
#model-heads
|
.md
|
61_4
|
The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to its Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
<Tip warning={true}>
Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
</Tip>
If you trained your own tokenizer, you can create one from your *vocabulary* file:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip>
By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#tokenizer
|
#tokenizer
|
.md
|
61_5
|
An image processor processes vision inputs. It inherits from the base [`~image_processing_utils.ImageProcessingMixin`] class.
To use, create an image processor associated with the model you're using. For example, create a default [`ViTImageProcessor`] if you are using [ViT](model_doc/vit) for image classification:
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default image processor parameters.
</Tip>
Modify any of the [`ViTImageProcessor`] parameters to create your custom image processor:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#image-processor
|
#image-processor
|
.md
|
61_6
|
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Backbone.png">
</div>
Computer vision models consist of a backbone, neck, and head. The backbone extracts features from an input image, the neck combines and enhances the extracted features, and the head is used for the main task (e.g., object detection). Start by initializing a backbone in the model config and specify whether you want to load pretrained weights or load randomly initialized weights. Then you can pass the model config to the model head.
For example, to load a [ResNet](../model_doc/resnet) backbone into a [MaskFormer](../model_doc/maskformer) model with an instance segmentation head:
<hfoptions id="backbone">
<hfoption id="pretrained weights">
Set `use_pretrained_backbone=True` to load pretrained ResNet weights for the backbone.
```py
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # head
```
</hfoption>
<hfoption id="random weights">
Set `use_pretrained_backbone=False` to randomly initialize a ResNet backbone.
```py
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=False) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # head
```
You could also load the backbone config separately and then pass it to the model config.
```py
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
backbone_config = ResNetConfig()
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)
```
</hfoption>
</hfoptions id="timm backbone">
[timm](https://hf.co/docs/timm/index) models are loaded within a model with `use_timm_backbone=True` or with [`TimmBackbone`] and [`TimmBackboneConfig`].
Use `use_timm_backbone=True` and `use_pretrained_backbone=True` to load pretrained timm weights for the backbone.
```python
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=True, use_timm_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # head
```
Set `use_timm_backbone=True` and `use_pretrained_backbone=False` to load a randomly initialized timm backbone.
```python
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=False, use_timm_backbone=True) # backbone and neck config
model = MaskFormerForInstanceSegmentation(config) # head
```
You could also load the backbone config and use it to create a `TimmBackbone` or pass it to the model config. Timm backbones will load pretrained weights by default. Set `use_pretrained_backbone=False` to load randomly initialized weights.
```python
from transformers import TimmBackboneConfig, TimmBackbone
backbone_config = TimmBackboneConfig("resnet50", use_pretrained_backbone=False)
# Create a backbone class
backbone = TimmBackbone(config=backbone_config)
# Create a model with a timm backbone
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#backbone
|
#backbone
|
.md
|
61_7
|
A feature extractor processes audio inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`SequenceFeatureExtractor`] class for processing audio inputs.
To use, create a feature extractor associated with the model you're using. For example, create a default [`Wav2Vec2FeatureExtractor`] if you are using [Wav2Vec2](model_doc/wav2vec2) for audio classification:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
</Tip>
Modify any of the [`Wav2Vec2FeatureExtractor`] parameters to create your custom feature extractor:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#feature-extractor
|
#feature-extractor
|
.md
|
61_8
|
For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps processing classes such as a feature extractor and a tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
Create a feature extractor to handle the audio inputs:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Create a tokenizer to handle the text inputs:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, image processor, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/create_a_model.md
|
https://huggingface.co/docs/transformers/en/create_a_model/#processor
|
#processor
|
.md
|
61_9
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/
|
.md
|
62_0
|
|
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
focuses on practical techniques.
<Tip>
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
</Tip>
When training large models, there are two aspects that should be considered at the same time:
* Data throughput/training time
* Model performance
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
the memory optimization techniques, such as gradient accumulation, can help.
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | Maybe* |
| [torch_empty_cache_steps](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.torch_empty_cache_steps) | No | Yes |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
| [Parameter-Efficient Fine Tuning (PEFT)](#using--peft) | No | Yes |
<Tip>
*Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
large model and a small batch size, the memory use will be larger.
</Tip>
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
with 🤗 Accelerate](#using--accelerate).
If these methods do not result in sufficient gains, you can explore the following options:
* [Look into building your own custom Docker container with efficient software prebuilds](#efficient-software-prebuilds)
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention-and-flash-attention)
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#methods-and-tools-for-efficient-training-on-a-single-gpu
|
#methods-and-tools-for-efficient-training-on-a-single-gpu
|
.md
|
62_1
|
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
higher depending on the hardware being used and the model's dtype.
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
it's an A100 GPU, in which case use multiples of 64.
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
This is where tiling happens and the right multiplier can have a significant speedup.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#batch-size-choice
|
#batch-size-choice
|
.md
|
62_2
|
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
slow down the training process.
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
```
In the above example, your effective batch size becomes 4.
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
[further down in this guide](#using--accelerate).
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
the available GPU resources.
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#gradient-accumulation
|
#gradient-accumulation
|
.md
|
62_3
|
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
This is because there are other components that also require memory storage.
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
```
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using--accelerate).
<Tip>
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#gradient-checkpointing
|
#gradient-checkpointing
|
.md
|
62_4
|
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
in half-precision, while some are still in full precision, the approach is called mixed precision training.
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
the differences between these data types.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#mixed-precision-training
|
#mixed-precision-training
|
.md
|
62_5
|
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
step so no memory is saved here.
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
To enable mixed precision training, set the `fp16` flag to `True`:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
```
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using--accelerate).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#fp16
|
#fp16
|
.md
|
62_6
|
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
is `65504` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
is about the same as fp32 - because both have 8-bits used for the numerical range.
You can enable BF16 in the 🤗 Trainer with:
```python
training_args = TrainingArguments(bf16=True, **default_args)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#bf16
|
#bf16
|
.md
|
62_7
|
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
improvement. All you need to do is to add the following to your code:
```python
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
```
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
You can enable this mode in the 🤗 Trainer:
```python
TrainingArguments(tf32=True, **default_args)
```
<Tip>
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
</Tip>
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#tf32
|
#tf32
|
.md
|
62_8
|
You can speedup the training throughput by using Flash Attention 2 integration in transformers. Check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2) to learn more about how to load a model with Flash Attention 2 modules.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#flash-attention-2
|
#flash-attention-2
|
.md
|
62_9
|
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
Let's take a closer look at two alternatives to AdamW optimizer:
1. `adafactor` which is available in [`Trainer`]
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
For comparison, for a 3B-parameter model, like “google-t5/t5-3b”:
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#optimizer-choice
|
#optimizer-choice
|
.md
|
62_10
|
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
Adafactor may have slower convergence in certain cases.
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
Adafactor can be worse than Adam.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#adafactor
|
#adafactor
|
.md
|
62_11
|
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
idea behind mixed precision training.
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
```
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
First, follow the installation guide in the GitHub [repo](https://github.com/bitsandbytes-foundation/bitsandbytes) to install the `bitsandbytes` library
that implements the 8-bit Adam optimizer.
Next you need to initialize the optimizer. This involves two steps:
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
```py
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
```
Finally, pass the custom optimizer as an argument to the `Trainer`:
```py
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#8-bit-adam
|
#8-bit-adam
|
.md
|
62_12
|
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#multitensor
|
#multitensor
|
.md
|
62_13
|
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
- `DataLoader(pin_memory=True, ...)` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
- `DataLoader(num_workers=4, ...)` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#data-preloading
|
#data-preloading
|
.md
|
62_14
|
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
deep learning training.
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
and launch DeepSpeed:
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#deepspeed-zero
|
#deepspeed-zero
|
.md
|
62_15
|
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
optimize your code by adding a single line of code: `model = torch.compile(model)`.
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
```python
training_args = TrainingArguments(torch_compile=True, **default_args)
```
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
**Debugging backends**:
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
**Training & inference backends**:
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses TorchScript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#using-torchcompile
|
#using-torchcompile
|
.md
|
62_16
|
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it.
As a result the [memory associated to the optimizer states and gradients](https://huggingface.co/docs/transformers/model_memory_anatomy#anatomy-of-models-memory) are greatly reduced.
For example with a vanilla AdamW, the memory requirement for the optimizer state would be:
* fp32 copy of parameters: 4 bytes/param
* Momentum: 4 bytes/param
* Variance: 4 bytes/param
Suppose a model with 7B parameters and 200 million parameters injected with [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora).
The memory requirement for the optimizer state of the plain model would be 12 * 7 = 84 GB (assuming 7B trainable parameters).
Adding Lora increases slightly the memory associated to the model weights and substantially decreases memory requirement for the optimizer state to 12 * 0.2 = 2.4GB.
Read more about PEFT and its detailed usage in [the PEFT documentation](https://huggingface.co/docs/peft/) or [PEFT repository](https://github.com/huggingface/peft).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#using--peft
|
#using--peft
|
.md
|
62_17
|
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
Suppose you have combined the methods in the [`TrainingArguments`] like so:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
```
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
```py
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
```
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
enough steps we run the optimization.
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#using--accelerate
|
#using--accelerate
|
.md
|
62_18
|
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
Next follow the instructions to download and deploy the docker image.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#efficient-software-prebuilds
|
#efficient-software-prebuilds
|
.md
|
62_19
|
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
Mixture of Experts (MoE) into the Transformer models.
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
number of parameters by an order of magnitude without increasing training costs.
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
that trains each expert in a balanced way depending on the input token's position in a sequence.

(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
memory requirements moderately as well.
Most related papers and implementations are built around Tensorflow/TPUs:
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#mixture-of-experts
|
#mixture-of-experts
|
.md
|
62_20
|
PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available. Please refer to [PyTorch scaled dot product attention](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) for a list of supported models and more details.
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_gpu_one.md
|
https://huggingface.co/docs/transformers/en/perf_train_gpu_one/#using-pytorch-native-attention-and-flash-attention
|
#using-pytorch-native-attention-and-flash-attention
|
.md
|
62_21
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/
|
.md
|
63_0
|
|
Install 🤗 Transformers for whichever deep learning library you're working with, setup your cache, and optionally configure 🤗 Transformers to run offline.
🤗 Transformers is tested on Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#installation
|
#installation
|
.md
|
63_1
|
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
Now you're ready to install 🤗 Transformers with the following command:
```bash
pip install transformers
```
For GPU acceleration, install the appropriate CUDA drivers for [PyTorch](https://pytorch.org/get-started/locally) and TensorFlow(https://www.tensorflow.org/install/pip).
Run the command below to check if your system detects an NVIDIA GPU.
```bash
nvidia-smi
```
For CPU-support only, you can conveniently install 🤗 Transformers and a deep learning library in one line. For example, install 🤗 Transformers and PyTorch with:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers and TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM Users
You will need to install the following before installing TensorFlow 2.0
```bash
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers and Flax:
```bash
pip install 'transformers[flax]'
```
Finally, check if 🤗 Transformers has been properly installed by running the following command. It will download a pretrained model:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Then print out the label and score:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#install-with-pip
|
#install-with-pip
|
.md
|
63_2
|
Install 🤗 Transformers from source with the following command:
```bash
pip install git+https://github.com/huggingface/transformers
```
This command installs the bleeding edge `main` version rather than the latest `stable` version. The `main` version is useful for staying up-to-date with the latest developments. For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet. However, this means the `main` version may not always be stable. We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day. If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
Check if 🤗 Transformers has been properly installed by running the following command:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#install-from-source
|
#install-from-source
|
.md
|
63_3
|
You will need an editable install if you'd like to:
* Use the `main` version of the source code.
* Contribute to 🤗 Transformers and need to test changes in the code.
Clone the repository and install 🤗 Transformers with the following commands:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
These commands will link the folder you cloned the repository to and your Python library paths. Python will now look inside the folder you cloned to in addition to the normal library paths. For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/transformers/`.
<Tip warning={true}>
You must keep the `transformers` folder if you want to keep using the library.
</Tip>
Now you can easily update your clone to the latest version of 🤗 Transformers with the following command:
```bash
cd ~/transformers/
git pull
```
Your Python environment will find the `main` version of 🤗 Transformers on the next run.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#editable-install
|
#editable-install
|
.md
|
63_4
|
Install from the conda channel `conda-forge`:
```bash
conda install conda-forge::transformers
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#install-with-conda
|
#install-with-conda
|
.md
|
63_5
|
Pretrained models are downloaded and locally cached at: `~/.cache/huggingface/hub`. This is the default directory given by the shell environment variable `TRANSFORMERS_CACHE`. On Windows, the default directory is given by `C:\Users\username\.cache\huggingface\hub`. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
1. Shell environment variable (default): `HF_HUB_CACHE` or `TRANSFORMERS_CACHE`.
2. Shell environment variable: `HF_HOME`.
3. Shell environment variable: `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
🤗 Transformers will use the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE` if you are coming from an earlier iteration of this library and have set those environment variables, unless you specify the shell environment variable `TRANSFORMERS_CACHE`.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#cache-setup
|
#cache-setup
|
.md
|
63_6
|
Run 🤗 Transformers in a firewalled or offline environment with locally cached files by setting the environment variable `HF_HUB_OFFLINE=1`.
<Tip>
Add [🤗 Datasets](https://huggingface.co/docs/datasets/) to your offline training workflow with the environment variable `HF_DATASETS_OFFLINE=1`.
</Tip>
```bash
HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
This script should run without hanging or waiting to timeout because it won't attempt to download the model from the Hub.
You can also bypass loading a model from the Hub from each [`~PreTrainedModel.from_pretrained`] call with the [`local_files_only`] parameter. When set to `True`, only local files are loaded:
```py
from transformers import T5Model
model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#offline-mode
|
#offline-mode
|
.md
|
63_7
|
Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
* Download a file through the user interface on the [Model Hub](https://huggingface.co/models) by clicking on the ↓ icon.

* Use the [`PreTrainedModel.from_pretrained`] and [`PreTrainedModel.save_pretrained`] workflow:
1. Download your files ahead of time with [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Save your files to a specified directory with [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Now when you're offline, reload your files with [`PreTrainedModel.from_pretrained`] from the specified directory:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Programmatically download files with the [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) library:
1. Install the `huggingface_hub` library in your virtual environment:
```bash
python -m pip install huggingface_hub
```
2. Use the [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) function to download a file to a specific path. For example, the following command downloads the `config.json` file from the [T0](https://huggingface.co/bigscience/T0_3B) model to your desired path:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Once your file is downloaded and locally cached, specify it's local path to load and use it:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
See the [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) section for more details on downloading files stored on the Hub.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#fetch-models-and-tokenizers-to-use-offline
|
#fetch-models-and-tokenizers-to-use-offline
|
.md
|
63_8
|
See below for some of the more common installation issues and how to resolve them.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#troubleshooting
|
#troubleshooting
|
.md
|
63_9
|
Ensure you are using Python 3.9 or later. Run the command below to check your Python version.
```
python --version
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#unsupported-python-version
|
#unsupported-python-version
|
.md
|
63_10
|
Install all required dependencies by running the following command. Ensure you’re in the project directory before executing the command.
```
pip install -r requirements.txt
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#missing-dependencies
|
#missing-dependencies
|
.md
|
63_11
|
If you encounter issues on Windows, you may need to activate Developer Mode. Navigate to Windows Settings > For Developers > Developer Mode.
Alternatively, create and activate a virtual environment as shown below.
```
python -m venv env
.\env\Scripts\activate
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/installation.md
|
https://huggingface.co/docs/transformers/en/installation/#windows-specific
|
#windows-specific
|
.md
|
63_12
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/
|
.md
|
64_0
|
|
[[open-in-colab]]
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#agents-supercharged---multi-agents-external-tools-and-more
|
#agents-supercharged---multi-agents-external-tools-and-more
|
.md
|
64_1
|
> [!TIP]
> If you're new to `transformers.agents`, make sure to first read the main [agents documentation](./agents).
In this page we're going to highlight several advanced uses of `transformers.agents`.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#what-is-an-agent
|
#what-is-an-agent
|
.md
|
64_2
|
Multi-agent has been introduced in Microsoft's framework [Autogen](https://huggingface.co/papers/2308.08155).
It simply means having several agents working together to solve your task instead of only one.
It empirically yields better performance on most benchmarks. The reason for this better performance is conceptually simple: for many tasks, rather than using a do-it-all system, you would prefer to specialize units on sub-tasks. Here, having agents with separate tool sets and memories allows to achieve efficient specialization.
You can easily build hierarchical multi-agent systems with `transformers.agents`.
To do so, encapsulate the agent in a [`ManagedAgent`] object. This object needs arguments `agent`, `name`, and a `description`, which will then be embedded in the manager agent's system prompt to let it know how to call this managed agent, as we also do for tools.
Here's an example of making an agent that managed a specific web search agent using our [`DuckDuckGoSearchTool`]:
```py
from transformers.agents import ReactCodeAgent, HfApiEngine, DuckDuckGoSearchTool, ManagedAgent
llm_engine = HfApiEngine()
web_agent = ReactCodeAgent(tools=[DuckDuckGoSearchTool()], llm_engine=llm_engine)
managed_web_agent = ManagedAgent(
agent=web_agent,
name="web_search",
description="Runs web searches for you. Give it your query as an argument."
)
manager_agent = ReactCodeAgent(
tools=[], llm_engine=llm_engine, managed_agents=[managed_web_agent]
)
manager_agent.run("Who is the CEO of Hugging Face?")
```
> [!TIP]
> For an in-depth example of an efficient multi-agent implementation, see [how we pushed our multi-agent system to the top of the GAIA leaderboard](https://huggingface.co/blog/beating-gaia).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#multi-agents
|
#multi-agents
|
.md
|
64_3
|
Let's take again the tool example from main documentation, for which we had implemented a `tool` decorator.
If you need to add variation, like custom attributes for your tool, you can build your tool following the fine-grained method: building a class that inherits from the [`Tool`] superclass.
The custom tool needs:
- An attribute `name`, which corresponds to the name of the tool itself. The name usually describes what the tool does. Since the code returns the model with the most downloads for a task, let's name it `model_download_counter`.
- An attribute `description` is used to populate the agent's system prompt.
- An `inputs` attribute, which is a dictionary with keys `"type"` and `"description"`. It contains information that helps the Python interpreter make educated choices about the input.
- An `output_type` attribute, which specifies the output type.
- A `forward` method which contains the inference code to be executed.
The types for both `inputs` and `output_type` should be amongst [Pydantic formats](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema).
```python
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "string"
def forward(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
```
Now that the custom `HfModelDownloadsTool` class is ready, you can save it to a file named `model_downloads.py` and import it for use.
```python
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
```
You can also share your custom tool to the Hub by calling [`~Tool.push_to_hub`] on the tool. Make sure you've created a repository for it on the Hub and are using a token with read access.
```python
tool.push_to_hub("{your_username}/hf-model-downloads")
```
Load the tool with the [`~Tool.load_tool`] function and pass it to the `tools` parameter in your agent.
```python
from transformers import load_tool, CodeAgent
model_download_tool = load_tool("m-ric/hf-model-downloads")
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#directly-define-a-tool-by-subclassing-tool-and-share-it-to-the-hub
|
#directly-define-a-tool-by-subclassing-tool-and-share-it-to-the-hub
|
.md
|
64_4
|
You can directly import a Space from the Hub as a tool using the [`Tool.from_space`] method!
You only need to provide the id of the Space on the Hub, its name, and a description that will help you agent understand what the tool does. Under the hood, this will use [`gradio-client`](https://pypi.org/project/gradio-client/) library to call the Space.
For instance, let's import the [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) Space from the Hub and use it to generate an image.
```
from transformers import Tool
image_generation_tool = Tool.from_space(
"black-forest-labs/FLUX.1-dev",
name="image_generator",
description="Generate an image from a prompt")
image_generation_tool("A sunny beach")
```
And voilà, here's your image! 🏖️
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sunny_beach.webp">
Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it.
```python
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[image_generation_tool])
agent.run(
"Improve this prompt, then generate an image of it.", prompt='A rabbit wearing a space suit'
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit_spacesuit_flux.webp">
How cool is this? 🤩
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#import-a-space-as-a-tool-
|
#import-a-space-as-a-tool-
|
.md
|
64_5
|
[gradio-tools](https://github.com/freddyaboulton/gradio-tools) is a powerful library that allows using Hugging
Face Spaces as tools. It supports many existing Spaces as well as custom Spaces.
Transformers supports `gradio_tools` with the [`Tool.from_gradio`] method. For example, let's use the [`StableDiffusionPromptGeneratorTool`](https://github.com/freddyaboulton/gradio-tools/blob/main/gradio_tools/tools/prompt_generator.py) from `gradio-tools` toolkit for improving prompts to generate better images.
Import and instantiate the tool, then pass it to the `Tool.from_gradio` method:
```python
from gradio_tools import StableDiffusionPromptGeneratorTool
from transformers import Tool, load_tool, CodeAgent
gradio_prompt_generator_tool = StableDiffusionPromptGeneratorTool()
prompt_generator_tool = Tool.from_gradio(gradio_prompt_generator_tool)
```
> [!WARNING]
> gradio-tools require *textual* inputs and outputs even when working with different modalities like image and audio objects. Image and audio inputs and outputs are currently incompatible.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#use-gradio-tools
|
#use-gradio-tools
|
.md
|
64_6
|
We love Langchain and think it has a very compelling suite of tools.
To import a tool from LangChain, use the `from_langchain()` method.
Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
This tool will need `pip install google-search-results` to work properly.
```python
from langchain.agents import load_tools
from transformers import Tool, ReactCodeAgent
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = ReactCodeAgent(tools=[search_tool])
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#use-langchain-tools
|
#use-langchain-tools
|
.md
|
64_7
|
You can leverage `gradio.Chatbot` to display your agent's thoughts using `stream_to_gradio`, here is an example:
```py
import gradio as gr
from transformers import (
load_tool,
ReactCodeAgent,
HfApiEngine,
stream_to_gradio,
)
# Import tool from Hub
image_generation_tool = load_tool("m-ric/text-to-image")
llm_engine = HfApiEngine("meta-llama/Meta-Llama-3-70B-Instruct")
# Initialize the agent with the image generation tool
agent = ReactCodeAgent(tools=[image_generation_tool], llm_engine=llm_engine)
def interact_with_agent(task):
messages = []
messages.append(gr.ChatMessage(role="user", content=task))
yield messages
for msg in stream_to_gradio(agent, task):
messages.append(msg)
yield messages + [
gr.ChatMessage(role="assistant", content="⏳ Task not finished yet!")
]
yield messages
with gr.Blocks() as demo:
text_input = gr.Textbox(lines=1, label="Chat Message", value="Make me a picture of the Statue of Liberty.")
submit = gr.Button("Run illustrator agent!")
chatbot = gr.Chatbot(
label="Agent",
type="messages",
avatar_images=(
None,
"https://em-content.zobj.net/source/twitter/53/robot-face_1f916.png",
),
)
submit.click(interact_with_agent, [text_input], [chatbot])
if __name__ == "__main__":
demo.launch()
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/agents_advanced.md
|
https://huggingface.co/docs/transformers/en/agents_advanced/#display-your-agent-run-in-a-cool-gradio-interface
|
#display-your-agent-run-in-a-cool-gradio-interface
|
.md
|
64_8
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/
|
.md
|
65_0
|
|
When you open a pull request on 🤗 Transformers, a fair number of checks will be run to make sure the patch you are adding is not breaking anything existing. Those checks are of four types:
- regular tests
- documentation build
- code and documentation style
- general repository consistency
In this document, we will take a stab at explaining what those various checks are and the reason behind them, as well as how to debug them locally if one of them fails on your PR.
Note that, ideally, they require you to have a dev install:
```bash
pip install transformers[dev]
```
or for an editable install:
```bash
pip install -e .[dev]
```
inside the Transformers repo. Since the number of optional dependencies of Transformers has grown a lot, it's possible you don't manage to get all of them. If the dev install fails, make sure to install the Deep Learning framework you are working with (PyTorch, TensorFlow and/or Flax) then do
```bash
pip install transformers[quality]
```
or for an editable install:
```bash
pip install -e .[quality]
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#checks-on-a-pull-request
|
#checks-on-a-pull-request
|
.md
|
65_1
|
All the jobs that begin with `ci/circleci: run_tests_` run parts of the Transformers testing suite. Each of those jobs focuses on a part of the library in a certain environment: for instance `ci/circleci: run_tests_pipelines_tf` runs the pipelines test in an environment where TensorFlow only is installed.
Note that to avoid running tests when there is no real change in the modules they are testing, only part of the test suite is run each time: a utility is run to determine the differences in the library between before and after the PR (what GitHub shows you in the "Files changes" tab) and picks the tests impacted by that diff. That utility can be run locally with:
```bash
python utils/tests_fetcher.py
```
from the root of the Transformers repo. It will:
1. Check for each file in the diff if the changes are in the code or only in comments or docstrings. Only the files with real code changes are kept.
2. Build an internal map that gives for each file of the source code of the library all the files it recursively impacts. Module A is said to impact module B if module B imports module A. For the recursive impact, we need a chain of modules going from module A to module B in which each module imports the previous one.
3. Apply this map on the files gathered in step 1, which gives us the list of model files impacted by the PR.
4. Map each of those files to their corresponding test file(s) and get the list of tests to run.
When executing the script locally, you should get the results of step 1, 3 and 4 printed and thus know which tests are run. The script will also create a file named `test_list.txt` which contains the list of tests to run, and you can run them locally with the following command:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
```
Just in case anything slipped through the cracks, the full test suite is also run daily.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#tests
|
#tests
|
.md
|
65_2
|
The `build_pr_documentation` job builds and generates a preview of the documentation to make sure everything looks okay once your PR is merged. A bot will add a link to preview the documentation in your PR. Any changes you make to the PR are automatically updated in the preview. If the documentation fails to build, click on **Details** next to the failed job to see where things went wrong. Often, the error is as simple as a missing file in the `toctree`.
If you're interested in building or previewing the documentation locally, take a look at the [`README.md`](https://github.com/huggingface/transformers/tree/main/docs) in the docs folder.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#documentation-build
|
#documentation-build
|
.md
|
65_3
|
Code formatting is applied to all the source files, the examples and the tests using `black` and `ruff`. We also have a custom tool taking care of the formatting of docstrings and `rst` files (`utils/style_doc.py`), as well as the order of the lazy imports performed in the Transformers `__init__.py` files (`utils/custom_init_isort.py`). All of this can be launched by executing
```bash
make style
```
The CI checks those have been applied inside the `ci/circleci: check_code_quality` check. It also runs `ruff`, that will have a basic look at your code and will complain if it finds an undefined variable, or one that is not used. To run that check locally, use
```bash
make quality
```
This can take a lot of time, so to run the same thing on only the files you modified in the current branch, run
```bash
make fixup
```
This last command will also run all the additional checks for the repository consistency. Let's have a look at them.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#code-and-documentation-style
|
#code-and-documentation-style
|
.md
|
65_4
|
This regroups all the tests to make sure your PR leaves the repository in a good state, and is performed by the `ci/circleci: check_repository_consistency` check. You can locally run that check by executing the following:
```bash
make repo-consistency
```
This checks that:
- All objects added to the init are documented (performed by `utils/check_repo.py`)
- All `__init__.py` files have the same content in their two sections (performed by `utils/check_inits.py`)
- All code identified as a copy from another module is consistent with the original (performed by `utils/check_copies.py`)
- All configuration classes have at least one valid checkpoint mentioned in their docstrings (performed by `utils/check_config_docstrings.py`)
- All configuration classes only contain attributes that are used in corresponding modeling files (performed by `utils/check_config_attributes.py`)
- The translations of the READMEs and the index of the doc have the same model list as the main README (performed by `utils/check_copies.py`)
- The auto-generated tables in the documentation are up to date (performed by `utils/check_table.py`)
- The library has all objects available even if not all optional dependencies are installed (performed by `utils/check_dummies.py`)
- All docstrings properly document the arguments in the signature of the object (performed by `utils/check_docstrings.py`)
Should this check fail, the first two items require manual fixing, the last four can be fixed automatically for you by running the command
```bash
make fix-copies
```
Additional checks concern PRs that add new models, mainly that:
- All models added are in an Auto-mapping (performed by `utils/check_repo.py`)
<!-- TODO Sylvain, add a check that makes sure the common tests are implemented.-->
- All models are properly tested (performed by `utils/check_repo.py`)
<!-- TODO Sylvain, add the following
- All models are added to the main README, inside the main doc
- All checkpoints used actually exist on the Hub
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#repository-consistency
|
#repository-consistency
|
.md
|
65_5
|
Since the Transformers library is very opinionated with respect to model code, and each model should fully be implemented in a single file without relying on other models, we have added a mechanism that checks whether a copy of the code of a layer of a given model stays consistent with the original. This way, when there is a bug fix, we can see all other impacted models and choose to trickle down the modification or break the copy.
<Tip>
If a file is a full copy of another file, you should register it in the constant `FULL_COPIES` of `utils/check_copies.py`.
</Tip>
This mechanism relies on comments of the form `# Copied from xxx`. The `xxx` should contain the whole path to the class of function which is being copied below. For instance, `RobertaSelfOutput` is a direct copy of the `BertSelfOutput` class, so you can see [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289) it has a comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
```
Note that instead of applying this to a whole class, you can apply it to the relevant methods that are copied from. For instance [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598) you can see how `RobertaPreTrainedModel._init_weights` is copied from the same method in `BertPreTrainedModel` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
```
Sometimes the copy is exactly the same except for names: for instance in `RobertaAttention`, we use `RobertaSelfAttention` instead of `BertSelfAttention` but other than that, the code is exactly the same. This is why `# Copied from` supports simple string replacements with the following syntax: `Copied from xxx with foo->bar`. This means the code is copied with all instances of `foo` being replaced by `bar`. You can see how it used [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L304C1-L304C86) in `RobertaAttention` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
```
Note that there shouldn't be any spaces around the arrow (unless that space is part of the pattern to replace of course).
You can add several patterns separated by a comma. For instance here `CamemberForMaskedLM` is a direct copy of `RobertaForMaskedLM` with two replacements: `Roberta` to `Camembert` and `ROBERTA` to `CAMEMBERT`. You can see [here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929) this is done with the comment:
```py
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
```
If the order matters (because one of the replacements might conflict with a previous one), the replacements are executed from left to right.
<Tip>
If the replacements change the formatting (if you replace a short name by a very long name for instance), the copy is checked after applying the auto-formatter.
</Tip>
Another way when the patterns are just different casings of the same replacement (with an uppercased and a lowercased variants) is just to add the option `all-casing`. [Here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237) is an example in `MobileBertForSequenceClassification` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
```
In this case, the code is copied from `BertForSequenceClassification` by replacing:
- `Bert` by `MobileBert` (for instance when using `MobileBertModel` in the init)
- `bert` by `mobilebert` (for instance when defining `self.mobilebert`)
- `BERT` by `MOBILEBERT` (in the constant `MOBILEBERT_INPUTS_DOCSTRING`)
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md
|
https://huggingface.co/docs/transformers/en/pr_checks/#check-copies
|
#check-copies
|
.md
|
65_6
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md
|
https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/
|
.md
|
66_0
|
|
Built-in Tensor Parallelism (TP) is now available with certain models using PyTorch. Tensor parallelism shards a model onto multiple GPUs, enabling larger model sizes, and parallelizes computations such as matrix multiplication.
To enable tensor parallel, pass the argument `tp_plan="auto"` to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
# Initialize distributed
rank = int(os.environ["RANK"])
device = torch.device(f"cuda:{rank}")
torch.distributed.init_process_group("nccl", device_id=device)
# Retrieve tensor parallel model
model = AutoModelForCausalLM.from_pretrained(
model_id,
tp_plan="auto",
)
# Prepare input tokens
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt = "Can I help"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
# Distributed run
outputs = model(inputs)
```
You can use `torchrun` to launch the above script with multiple processes, each mapping to a GPU:
```
torchrun --nproc-per-node 4 demo.py
```
PyTorch tensor parallel is currently supported for the following models:
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
You can request to add tensor parallel support for another model by opening a GitHub Issue or Pull Request.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md
|
https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#multi-gpu-inference
|
#multi-gpu-inference
|
.md
|
66_1
|
You can benefit from considerable speedups for inference, especially for inputs with large batch size or long sequences.
For a single forward pass on [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel) with a sequence length of 512 and various batch sizes, the expected speedup is as follows:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Meta-Llama-3-8B-Instruct%2C%20seqlen%20%3D%20512%2C%20python%2C%20w_%20compile.png">
</div>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md
|
https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#expected-speedups
|
#expected-speedups
|
.md
|
66_2
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md
|
https://huggingface.co/docs/transformers/en/tflite/
|
.md
|
67_0
|
|
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) is a lightweight framework for deploying machine learning models
on resource-constrained devices, such as mobile phones, embedded systems, and Internet of Things (IoT) devices.
TFLite is designed to optimize and run models efficiently on these devices with limited computational power, memory, and
power consumption.
A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension.
🤗 Optimum offers functionality to export 🤗 Transformers models to TFLite through the `exporters.tflite` module.
For the list of supported model architectures, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/tflite/overview).
To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model),
or view help in command line:
```bash
optimum-cli export tflite --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `google-bert/bert-base-uncased`, run the following command:
```bash
optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
```
You should see the logs indicating progress and showing where the resulting `model.tflite` is saved, like this:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md
|
https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite
|
#export-to-tflite
|
.md
|
67_1
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/
|
.md
|
68_0
|
|
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#optimize-inference-using-torchcompile
|
#optimize-inference-using-torchcompile
|
.md
|
68_1
|
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to(DEVICE)
+ model = torch.compile(model)
```
`compile()`comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune`takes longer than `reduce-overhead`but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch`version 2.0.1.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#benefits-of-torchcompile
|
#benefits-of-torchcompile
|
.md
|
68_2
|
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#benchmarking-code
|
#benchmarking-code
|
.md
|
68_3
|
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to(device)
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device)
with torch.no_grad():
_ = model(**processed_input)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-classification-with-vit
|
#image-classification-with-vit
|
.md
|
68_4
|
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to(device)
with torch.no_grad():
_ = model(**inputs)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#object-detection-with-detr
|
#object-detection-with-detr
|
.md
|
68_5
|
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to(device)
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()`and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
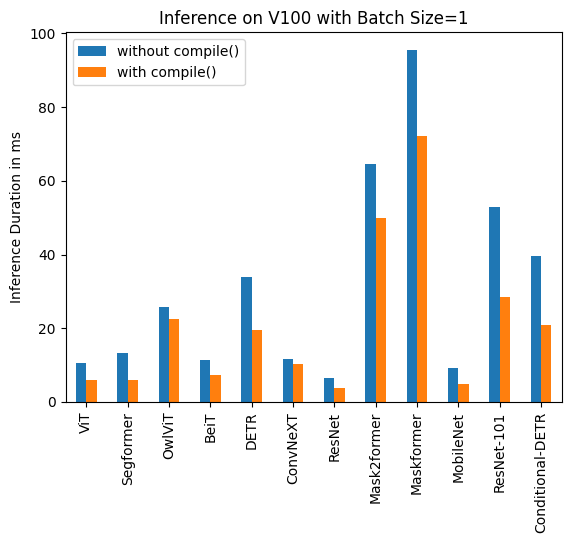
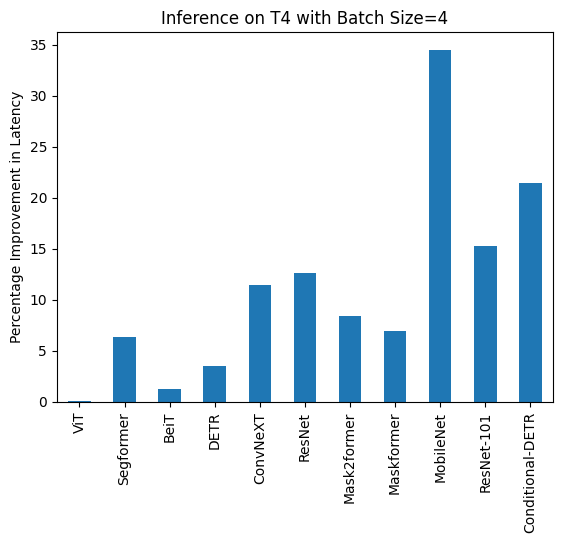
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer
|
#image-segmentation-with-segformer
|
.md
|
68_6
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-1
|
#a100-batch-size-1
|
.md
|
68_7
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-4
|
#a100-batch-size-4
|
.md
|
68_8
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-16
|
#a100-batch-size-16
|
.md
|
68_9
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-1
|
#v100-batch-size-1
|
.md
|
68_10
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-4
|
#v100-batch-size-4
|
.md
|
68_11
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-16
|
#v100-batch-size-16
|
.md
|
68_12
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-1
|
#t4-batch-size-1
|
.md
|
68_13
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-4
|
#t4-batch-size-4
|
.md
|
68_14
|
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-16
|
#t4-batch-size-16
|
.md
|
68_15
|
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#pytorch-nightly
|
#pytorch-nightly
|
.md
|
68_16
|
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100
|
#a100
|
.md
|
68_17
|
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4
|
#t4
|
.md
|
68_18
|
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100
|
#v100
|
.md
|
68_19
|
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#reduce-overhead
|
#reduce-overhead
|
.md
|
68_20
|
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100
|
#a100
|
.md
|
68_21
|
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md
|
https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4
|
#t4
|
.md
|
68_22
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md
|
https://huggingface.co/docs/transformers/en/perf_train_special/
|
.md
|
69_0
|
|
Previously, training models on a Mac was limited to the CPU only. With the release of PyTorch v1.12, you can take advantage of training models with Apple's silicon GPUs for significantly faster performance and training. This is powered in PyTorch by integrating Apple's Metal Performance Shaders (MPS) as a backend. The [MPS backend](https://pytorch.org/docs/stable/notes/mps.html) implements PyTorch operations as custom Metal shaders and places these modules on a `mps` device.
<Tip warning={true}>
Some PyTorch operations are not implemented in MPS yet and will throw an error. To avoid this, you should set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU kernels instead (you'll still see a `UserWarning`).
<br>
If you run into any other errors, please open an issue in the [PyTorch](https://github.com/pytorch/pytorch/issues) repository because the [`Trainer`] only integrates the MPS backend.
</Tip>
With the `mps` device set, you can:
* train larger networks or batch sizes locally
* reduce data retrieval latency because the GPU's unified memory architecture allows direct access to the full memory store
* reduce costs because you don't need to train on cloud-based GPUs or add additional local GPUs
Get started by making sure you have PyTorch installed. MPS acceleration is supported on macOS 12.3+.
```bash
pip install torch torchvision torchaudio
```
[`TrainingArguments`] uses the `mps` device by default if it's available which means you don't need to explicitly set the device. For example, you can run the [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) script with the MPS backend automatically enabled without making any changes.
```diff
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
- --use_mps_device \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
Backends for [distributed setups](https://pytorch.org/docs/stable/distributed.html#backends) like `gloo` and `nccl` are not supported by the `mps` device which means you can only train on a single GPU with the MPS backend.
You can learn more about the MPS backend in the [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) blog post.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md
|
https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon
|
#pytorch-training-on-apple-silicon
|
.md
|
69_1
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
``
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md
|
https://huggingface.co/docs/transformers/en/tiktoken/
|
.md
|
70_0
|
|
Support for tiktoken model files is seamlessly integrated in 🤗 transformers when loading models
`from_pretrained` with a `tokenizer.model` tiktoken file on the Hub, which is automatically converted into our
[fast tokenizer](https://huggingface.co/docs/transformers/main/en/main_classes/tokenizer#transformers.PreTrainedTokenizerFast).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md
|
https://huggingface.co/docs/transformers/en/tiktoken/#tiktoken-and-interaction-with-transformers
|
#tiktoken-and-interaction-with-transformers
|
.md
|
70_1
|
- gpt2
- llama3
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md
|
https://huggingface.co/docs/transformers/en/tiktoken/#known-models-that-were-released-with-a-tiktokenmodel
|
#known-models-that-were-released-with-a-tiktokenmodel
|
.md
|
70_2
|
In order to load `tiktoken` files in `transformers`, ensure that the `tokenizer.model` file is a tiktoken file and it
will automatically be loaded when loading `from_pretrained`. Here is how one would load a tokenizer and a model, which
can be loaded from the exact same file:
```py
from transformers import AutoTokenizer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, subfolder="original")
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md
|
https://huggingface.co/docs/transformers/en/tiktoken/#example-usage
|
#example-usage
|
.md
|
70_3
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.