
text
stringlengths 5
58.6k
| source
stringclasses 470
values | url
stringlengths 49
167
| source_section
stringlengths 0
90
| file_type
stringclasses 1
value | id
stringlengths 3
6
|
|---|---|---|---|---|---|
<Tip>
Creating an inference engine is a complex topic, and the "best" solution
will most likely depend on your problem space. Are you on CPU or GPU? Do
you want the lowest latency, the highest throughput, support for
many models, or just highly optimize 1 specific model?
There are many ways to tackle this topic, so what we are going to present is a good default
to get started which may not necessarily be the most optimal solution for you.
</Tip>
The key thing to understand is that we can use an iterator, just like you would [on a
dataset](pipeline_tutorial#using-pipelines-on-a-dataset), since a webserver is basically a system that waits for requests and
treats them as they come in.
Usually webservers are multiplexed (multithreaded, async, etc..) to handle various
requests concurrently. Pipelines on the other hand (and mostly the underlying models)
are not really great for parallelism; they take up a lot of RAM, so it's best to give them all the available resources when they are running or it's a compute-intensive job.
We are going to solve that by having the webserver handle the light load of receiving
and sending requests, and having a single thread handling the actual work.
This example is going to use `starlette`. The actual framework is not really
important, but you might have to tune or change the code if you are using another
one to achieve the same effect.
Create `server.py`:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="google-bert/bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
Now you can start it with:
```bash
uvicorn server:app
```
And you can query it:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
And there you go, now you have a good idea of how to create a webserver!
What is really important is that we load the model only **once**, so there are no copies
of the model on the webserver. This way, no unnecessary RAM is being used.
Then the queuing mechanism allows you to do fancy stuff like maybe accumulating a few
items before inferring to use dynamic batching:
<Tip warning={true}>
The code sample below is intentionally written like pseudo-code for readability.
Do not run this without checking if it makes sense for your system resources!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
Again, the proposed code is optimized for readability, not for being the best code.
First of all, there's no batch size limit which is usually not a
great idea. Next, the timeout is reset on every queue fetch, meaning you could
wait much more than 1ms before running the inference (delaying the first request
by that much).
It would be better to have a single 1ms deadline.
This will always wait for 1ms even if the queue is empty, which might not be the
best since you probably want to start doing inference if there's nothing in the queue.
But maybe it does make sense if batching is really crucial for your use case.
Again, there's really no one best solution.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_webserver.md
|
https://huggingface.co/docs/transformers/en/pipeline_webserver/#using-pipelines-for-a-webserver
|
#using-pipelines-for-a-webserver
|
.md
|
39_1
|
There's a lot that can go wrong in production: out of memory, out of space,
loading the model might fail, the query might be wrong, the query might be
correct but still fail to run because of a model misconfiguration, and so on.
Generally, it's good if the server outputs the errors to the user, so
adding a lot of `try..except` statements to show those errors is a good
idea. But keep in mind it may also be a security risk to reveal all those errors depending
on your security context.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_webserver.md
|
https://huggingface.co/docs/transformers/en/pipeline_webserver/#error-checking
|
#error-checking
|
.md
|
39_2
|
Webservers usually look better when they do circuit breaking. It means they
return proper errors when they're overloaded instead of just waiting for the query indefinitely. Return a 503 error instead of waiting for a super long time or a 504 after a long time.
This is relatively easy to implement in the proposed code since there is a single queue.
Looking at the queue size is a basic way to start returning errors before your
webserver fails under load.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_webserver.md
|
https://huggingface.co/docs/transformers/en/pipeline_webserver/#circuit-breaking
|
#circuit-breaking
|
.md
|
39_3
|
Currently PyTorch is not async aware, and computation will block the main
thread while running. That means it would be better if PyTorch was forced to run
on its own thread/process. This wasn't done here because the code is a lot more
complex (mostly because threads and async and queues don't play nice together).
But ultimately it does the same thing.
This would be important if the inference of single items were long (> 1s) because
in this case, it means every query during inference would have to wait for 1s before
even receiving an error.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_webserver.md
|
https://huggingface.co/docs/transformers/en/pipeline_webserver/#blocking-the-main-thread
|
#blocking-the-main-thread
|
.md
|
39_4
|
In general, batching is not necessarily an improvement over passing 1 item at
a time (see [batching details](./main_classes/pipelines#pipeline-batching) for more information). But it can be very effective
when used in the correct setting. In the API, there is no dynamic
batching by default (too much opportunity for a slowdown). But for BLOOM inference -
which is a very large model - dynamic batching is **essential** to provide a decent experience for everyone.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_webserver.md
|
https://huggingface.co/docs/transformers/en/pipeline_webserver/#dynamic-batching
|
#dynamic-batching
|
.md
|
39_5
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/
|
.md
|
40_0
|
|
[[open-in-colab]]
On this page, we will have a closer look at tokenization.
<Youtube id="VFp38yj8h3A"/>
As we saw in [the preprocessing tutorial](preprocessing), tokenizing a text is splitting it into words or
subwords, which then are converted to ids through a look-up table. Converting words or subwords to ids is
straightforward, so in this summary, we will focus on splitting a text into words or subwords (i.e. tokenizing a text).
More specifically, we will look at the three main types of tokenizers used in 🤗 Transformers: [Byte-Pair Encoding
(BPE)](#byte-pair-encoding), [WordPiece](#wordpiece), and [SentencePiece](#sentencepiece), and show examples
of which tokenizer type is used by which model.
Note that on each model page, you can look at the documentation of the associated tokenizer to know which tokenizer
type was used by the pretrained model. For instance, if we look at [`BertTokenizer`], we can see
that the model uses [WordPiece](#wordpiece).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#summary-of-the-tokenizers
|
#summary-of-the-tokenizers
|
.md
|
40_1
|
Splitting a text into smaller chunks is a task that is harder than it looks, and there are multiple ways of doing so.
For instance, let's look at the sentence `"Don't you love 🤗 Transformers? We sure do."`
<Youtube id="nhJxYji1aho"/>
A simple way of tokenizing this text is to split it by spaces, which would give:
```
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
```
This is a sensible first step, but if we look at the tokens `"Transformers?"` and `"do."`, we notice that the
punctuation is attached to the words `"Transformer"` and `"do"`, which is suboptimal. We should take the
punctuation into account so that a model does not have to learn a different representation of a word and every possible
punctuation symbol that could follow it, which would explode the number of representations the model has to learn.
Taking punctuation into account, tokenizing our exemplary text would give:
```
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
Better. However, it is disadvantageous, how the tokenization dealt with the word `"Don't"`. `"Don't"` stands for
`"do not"`, so it would be better tokenized as `["Do", "n't"]`. This is where things start getting complicated, and
part of the reason each model has its own tokenizer type. Depending on the rules we apply for tokenizing a text, a
different tokenized output is generated for the same text. A pretrained model only performs properly if you feed it an
input that was tokenized with the same rules that were used to tokenize its training data.
[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) are two popular
rule-based tokenizers. Applying them on our example, *spaCy* and *Moses* would output something like:
```
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
As can be seen space and punctuation tokenization, as well as rule-based tokenization, is used here. Space and
punctuation tokenization and rule-based tokenization are both examples of word tokenization, which is loosely defined
as splitting sentences into words. While it's the most intuitive way to split texts into smaller chunks, this
tokenization method can lead to problems for massive text corpora. In this case, space and punctuation tokenization
usually generates a very big vocabulary (the set of all unique words and tokens used). *E.g.*, [Transformer XL](model_doc/transfo-xl) uses space and punctuation tokenization, resulting in a vocabulary size of 267,735!
Such a big vocabulary size forces the model to have an enormous embedding matrix as the input and output layer, which
causes both an increased memory and time complexity. In general, transformers models rarely have a vocabulary size
greater than 50,000, especially if they are pretrained only on a single language.
So if simple space and punctuation tokenization is unsatisfactory, why not simply tokenize on characters?
<Youtube id="ssLq_EK2jLE"/>
While character tokenization is very simple and would greatly reduce memory and time complexity it makes it much harder
for the model to learn meaningful input representations. *E.g.* learning a meaningful context-independent
representation for the letter `"t"` is much harder than learning a context-independent representation for the word
`"today"`. Therefore, character tokenization is often accompanied by a loss of performance. So to get the best of
both worlds, transformers models use a hybrid between word-level and character-level tokenization called **subword**
tokenization.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#introduction
|
#introduction
|
.md
|
40_2
|
<Youtube id="zHvTiHr506c"/>
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller
subwords, but rare words should be decomposed into meaningful subwords. For instance `"annoyingly"` might be
considered a rare word and could be decomposed into `"annoying"` and `"ly"`. Both `"annoying"` and `"ly"` as
stand-alone subwords would appear more frequently while at the same time the meaning of `"annoyingly"` is kept by the
composite meaning of `"annoying"` and `"ly"`. This is especially useful in agglutinative languages such as Turkish,
where you can form (almost) arbitrarily long complex words by stringing together subwords.
Subword tokenization allows the model to have a reasonable vocabulary size while being able to learn meaningful
context-independent representations. In addition, subword tokenization enables the model to process words it has never
seen before, by decomposing them into known subwords. For instance, the [`~transformers.BertTokenizer`] tokenizes
`"I have a new GPU!"` as follows:
```py
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
```
Because we are considering the uncased model, the sentence was lowercased first. We can see that the words `["i", "have", "a", "new"]` are present in the tokenizer's vocabulary, but the word `"gpu"` is not. Consequently, the
tokenizer splits `"gpu"` into known subwords: `["gp" and "##u"]`. `"##"` means that the rest of the token should
be attached to the previous one, without space (for decoding or reversal of the tokenization).
As another example, [`~transformers.XLNetTokenizer`] tokenizes our previously exemplary text as follows:
```py
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet/xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
```
We'll get back to the meaning of those `"▁"` when we look at [SentencePiece](#sentencepiece). As one can see,
the rare word `"Transformers"` has been split into the more frequent subwords `"Transform"` and `"ers"`.
Let's now look at how the different subword tokenization algorithms work. Note that all of those tokenization
algorithms rely on some form of training which is usually done on the corpus the corresponding model will be trained
on.
<a id='byte-pair-encoding'></a>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#subword-tokenization
|
#subword-tokenization
|
.md
|
40_3
|
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/openai-gpt) which uses
spaCy and ftfy, to count the frequency of each word in the training corpus.
After pre-tokenization, a set of unique words has been created and the frequency with which each word occurred in the
training data has been determined. Next, BPE creates a base vocabulary consisting of all symbols that occur in the set
of unique words and learns merge rules to form a new symbol from two symbols of the base vocabulary. It does so until
the vocabulary has attained the desired vocabulary size. Note that the desired vocabulary size is a hyperparameter to
define before training the tokenizer.
As an example, let's assume that after pre-tokenization, the following set of words including their frequency has been
determined:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
Consequently, the base vocabulary is `["b", "g", "h", "n", "p", "s", "u"]`. Splitting all words into symbols of the
base vocabulary, we obtain:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
BPE then counts the frequency of each possible symbol pair and picks the symbol pair that occurs most frequently. In
the example above `"h"` followed by `"u"` is present _10 + 5 = 15_ times (10 times in the 10 occurrences of
`"hug"`, 5 times in the 5 occurrences of `"hugs"`). However, the most frequent symbol pair is `"u"` followed by
`"g"`, occurring _10 + 5 + 5 = 20_ times in total. Thus, the first merge rule the tokenizer learns is to group all
`"u"` symbols followed by a `"g"` symbol together. Next, `"ug"` is added to the vocabulary. The set of words then
becomes
```
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
BPE then identifies the next most common symbol pair. It's `"u"` followed by `"n"`, which occurs 16 times. `"u"`,
`"n"` is merged to `"un"` and added to the vocabulary. The next most frequent symbol pair is `"h"` followed by
`"ug"`, occurring 15 times. Again the pair is merged and `"hug"` can be added to the vocabulary.
At this stage, the vocabulary is `["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]` and our set of unique words
is represented as
```
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
Assuming, that the Byte-Pair Encoding training would stop at this point, the learned merge rules would then be applied
to new words (as long as those new words do not include symbols that were not in the base vocabulary). For instance,
the word `"bug"` would be tokenized to `["b", "ug"]` but `"mug"` would be tokenized as `["<unk>", "ug"]` since
the symbol `"m"` is not in the base vocabulary. In general, single letters such as `"m"` are not replaced by the
`"<unk>"` symbol because the training data usually includes at least one occurrence of each letter, but it is likely
to happen for very special characters like emojis.
As mentioned earlier, the vocabulary size, *i.e.* the base vocabulary size + the number of merges, is a hyperparameter
to choose. For instance [GPT](model_doc/openai-gpt) has a vocabulary size of 40,478 since they have 478 base characters
and chose to stop training after 40,000 merges.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#byte-pair-encoding-bpe
|
#byte-pair-encoding-bpe
|
.md
|
40_4
|
A base vocabulary that includes all possible base characters can be quite large if *e.g.* all unicode characters are
considered as base characters. To have a better base vocabulary, [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) uses bytes
as the base vocabulary, which is a clever trick to force the base vocabulary to be of size 256 while ensuring that
every base character is included in the vocabulary. With some additional rules to deal with punctuation, the GPT2's
tokenizer can tokenize every text without the need for the <unk> symbol. [GPT-2](model_doc/gpt) has a vocabulary
size of 50,257, which corresponds to the 256 bytes base tokens, a special end-of-text token and the symbols learned
with 50,000 merges.
<a id='wordpiece'></a>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#byte-level-bpe
|
#byte-level-bpe
|
.md
|
40_5
|
WordPiece is the subword tokenization algorithm used for [BERT](model_doc/bert), [DistilBERT](model_doc/distilbert), and [Electra](model_doc/electra). The algorithm was outlined in [Japanese and Korean
Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) and is very similar to
BPE. WordPiece first initializes the vocabulary to include every character present in the training data and
progressively learns a given number of merge rules. In contrast to BPE, WordPiece does not choose the most frequent
symbol pair, but the one that maximizes the likelihood of the training data once added to the vocabulary.
So what does this mean exactly? Referring to the previous example, maximizing the likelihood of the training data is
equivalent to finding the symbol pair, whose probability divided by the probabilities of its first symbol followed by
its second symbol is the greatest among all symbol pairs. *E.g.* `"u"`, followed by `"g"` would have only been
merged if the probability of `"ug"` divided by `"u"`, `"g"` would have been greater than for any other symbol
pair. Intuitively, WordPiece is slightly different to BPE in that it evaluates what it _loses_ by merging two symbols
to ensure it's _worth it_.
<a id='unigram'></a>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#wordpiece
|
#wordpiece
|
.md
|
40_6
|
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
conjunction with [SentencePiece](#sentencepiece).
At each training step, the Unigram algorithm defines a loss (often defined as the log-likelihood) over the training
data given the current vocabulary and a unigram language model. Then, for each symbol in the vocabulary, the algorithm
computes how much the overall loss would increase if the symbol was to be removed from the vocabulary. Unigram then
removes p (with p usually being 10% or 20%) percent of the symbols whose loss increase is the lowest, *i.e.* those
symbols that least affect the overall loss over the training data. This process is repeated until the vocabulary has
reached the desired size. The Unigram algorithm always keeps the base characters so that any word can be tokenized.
Because Unigram is not based on merge rules (in contrast to BPE and WordPiece), the algorithm has several ways of
tokenizing new text after training. As an example, if a trained Unigram tokenizer exhibits the vocabulary:
```
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
```
`"hugs"` could be tokenized both as `["hug", "s"]`, `["h", "ug", "s"]` or `["h", "u", "g", "s"]`. So which one
to choose? Unigram saves the probability of each token in the training corpus on top of saving the vocabulary so that
the probability of each possible tokenization can be computed after training. The algorithm simply picks the most
likely tokenization in practice, but also offers the possibility to sample a possible tokenization according to their
probabilities.
Those probabilities are defined by the loss the tokenizer is trained on. Assuming that the training data consists of
the words \\(x_{1}, \dots, x_{N}\\) and that the set of all possible tokenizations for a word \\(x_{i}\\) is
defined as \\(S(x_{i})\\), then the overall loss is defined as
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
<a id='sentencepiece'></a>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#unigram
|
#unigram
|
.md
|
40_7
|
All tokenization algorithms described so far have the same problem: It is assumed that the input text uses spaces to
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer.
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
The [`XLNetTokenizer`] uses SentencePiece for example, which is also why in the example earlier the
`"▁"` character was included in the vocabulary. Decoding with SentencePiece is very easy since all tokens can just be
concatenated and `"▁"` is replaced by a space.
All transformers models in the library that use SentencePiece use it in combination with unigram. Examples of models
using SentencePiece are [ALBERT](model_doc/albert), [XLNet](model_doc/xlnet), [Marian](model_doc/marian), and [T5](model_doc/t5).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tokenizer_summary.md
|
https://huggingface.co/docs/transformers/en/tokenizer_summary/#sentencepiece
|
#sentencepiece
|
.md
|
40_8
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/
|
.md
|
41_0
|
|
[DeepSpeed](https://www.deepspeed.ai/) is a PyTorch optimization library that makes distributed training memory-efficient and fast. At its core is the [Zero Redundancy Optimizer (ZeRO)](https://hf.co/papers/1910.02054) which enables training large models at scale. ZeRO works in several stages:
* ZeRO-1, optimizer state partitioning across GPUs
* ZeRO-2, gradient partitioning across GPUs
* ZeRO-3, parameter partitioning across GPUs
In GPU-limited environments, ZeRO also enables offloading optimizer memory and computation from the GPU to the CPU to fit and train really large models on a single GPU. DeepSpeed is integrated with the Transformers [`Trainer`] class for all ZeRO stages and offloading. All you need to do is provide a config file or you can use a provided template. For inference, Transformers support ZeRO-3 and offloading since it allows loading huge models.
This guide will walk you through how to deploy DeepSpeed training, the features you can enable, how to setup the config files for different ZeRO stages, offloading, inference, and using DeepSpeed without the [`Trainer`].
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deepspeed
|
#deepspeed
|
.md
|
41_1
|
DeepSpeed is available to install from PyPI or Transformers (for more detailed installation options, take a look at the DeepSpeed [installation details](https://www.deepspeed.ai/tutorials/advanced-install/) or the GitHub [README](https://github.com/microsoft/deepspeed#installation)).
<Tip>
If you're having difficulties installing DeepSpeed, check the [DeepSpeed CUDA installation](../debugging#deepspeed-cuda-installation) guide. While DeepSpeed has a pip installable PyPI package, it is highly recommended to [install it from source](https://www.deepspeed.ai/tutorials/advanced-install/#install-deepspeed-from-source) to best match your hardware and to support certain features, like 1-bit Adam, which aren’t available in the PyPI distribution.
</Tip>
<hfoptions id="install">
<hfoption id="PyPI">
```bash
pip install deepspeed
```
</hfoption>
<hfoption id="Transformers">
```bash
pip install transformers[deepspeed]
```
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#installation
|
#installation
|
.md
|
41_2
|
Before you begin, it is a good idea to check whether you have enough GPU and CPU memory to fit your model. DeepSpeed provides a tool for estimating the required CPU/GPU memory. For example, to estimate the memory requirements for the [bigscience/T0_3B](bigscience/T0_3B) model on a single GPU:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
```
This means you either need a single 80GB GPU without CPU offload or a 8GB GPU and a ~60GB CPU to offload to (these are just the memory requirements for the parameters, optimizer states and gradients, and you'll need a bit more for the CUDA kernels and activations). You should also consider the tradeoff between cost and speed because it'll be cheaper to rent or buy a smaller GPU but it'll take longer to train your model.
If you have enough GPU memory make sure you disable CPU/NVMe offload to make everything faster.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#memory-requirements
|
#memory-requirements
|
.md
|
41_3
|
After you've installed DeepSpeed and have a better idea of your memory requirements, the next step is selecting a ZeRO stage to use. In order of fastest and most memory-efficient:
| Fastest | Memory efficient |
|------------------|------------------|
| ZeRO-1 | ZeRO-3 + offload |
| ZeRO-2 | ZeRO-3 |
| ZeRO-2 + offload | ZeRO-2 + offload |
| ZeRO-3 | ZeRO-2 |
| ZeRO-3 + offload | ZeRO-1 |
To find what works best for you, start with the fastest approach and if you run out of memory, try the next stage which is slower but more memory efficient. Feel free to work in whichever direction you prefer (starting with the most memory efficient or fastest) to discover the appropriate balance between speed and memory usage.
A general process you can use is (start with batch size of 1):
1. enable gradient checkpointing
2. try ZeRO-2
3. try ZeRO-2 and offload the optimizer
4. try ZeRO-3
5. try ZeRO-3 and offload parameters to the CPU
6. try ZeRO-3 and offload parameters and the optimizer to the CPU
7. try lowering various default values like a narrower search beam if you're using the [`~GenerationMixin.generate`] method
8. try mixed half-precision (fp16 on older GPU architectures and bf16 on Ampere) over full-precision weights
9. add more hardware if possible or enable Infinity to offload parameters and the optimizer to a NVMe
10. once you're not running out of memory, measure effective throughput and then try to increase the batch size as large as you can to maximize GPU efficiency
11. lastly, try to optimize your training setup by disabling some offload features or use a faster ZeRO stage and increasing/decreasing the batch size to find the best tradeoff between speed and memory usage
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#select-a-zero-stage
|
#select-a-zero-stage
|
.md
|
41_4
|
DeepSpeed works with the [`Trainer`] class by way of a config file containing all the parameters for configuring how you want setup your training run. When you execute your training script, DeepSpeed logs the configuration it received from [`Trainer`] to the console so you can see exactly what configuration was used.
<Tip>
Find a complete list of DeepSpeed configuration options on the [DeepSpeed Configuration JSON](https://www.deepspeed.ai/docs/config-json/) reference. You can also find more practical examples of various DeepSpeed configuration examples on the [DeepSpeedExamples](https://github.com/microsoft/DeepSpeedExamples) repository or the main [DeepSpeed](https://github.com/microsoft/DeepSpeed) repository. To quickly find specific examples, you can:
```bash
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
# find examples with the Lamb optimizer
grep -i Lamb $(find . -name '*json')
```
</Tip>
The DeepSpeed configuration file is passed as a path to a JSON file if you're training from the command line interface or as a nested `dict` object if you're using the [`Trainer`] in a notebook setting.
<hfoptions id="pass-config">
<hfoption id="path to file">
```py
TrainingArguments(..., deepspeed="path/to/deepspeed_config.json")
```
</hfoption>
<hfoption id="nested dict">
```py
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
args = TrainingArguments(..., deepspeed=ds_config_dict)
trainer = Trainer(model, args, ...)
```
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deepspeed-configuration-file
|
#deepspeed-configuration-file
|
.md
|
41_5
|
There are three types of configuration parameters:
1. Some of the configuration parameters are shared by [`Trainer`] and DeepSpeed, and it can be difficult to identify errors when there are conflicting definitions. To make it easier, these shared configuration parameters are configured from the [`Trainer`] command line arguments.
2. Some configuration parameters that are automatically derived from the model configuration so you don't need to manually adjust these values. The [`Trainer`] uses a configuration value `auto` to determine set the most correct or efficient value. You could set your own configuration parameters explicitly, but you must take care to ensure the [`Trainer`] arguments and DeepSpeed configuration parameters agree. Mismatches may cause the training to fail in very difficult to detect ways!
3. Some configuration parameters specific to DeepSpeed only which need to be manually set based on your training needs.
You could also modify the DeepSpeed configuration and edit [`TrainingArguments`] from it:
1. Create or load a DeepSpeed configuration to use as the main configuration
2. Create a [`TrainingArguments`] object based on these DeepSpeed configuration values
Some values, such as `scheduler.params.total_num_steps` are calculated by the [`Trainer`] during training.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deepspeed-and-trainer-parameters
|
#deepspeed-and-trainer-parameters
|
.md
|
41_6
|
There are three configurations, each corresponding to a different ZeRO stage. Stage 1 is not as interesting for scalability, and this guide focuses on stages 2 and 3. The `zero_optimization` configuration contains all the options for what to enable and how to configure them. For a more detailed explanation of each parameter, take a look at the [DeepSpeed Configuration JSON](https://www.deepspeed.ai/docs/config-json/) reference.
<Tip warning={true}>
DeepSpeed doesn’t validate parameter names and any typos fallback on the parameter's default setting. You can watch the DeepSpeed engine startup log messages to see what values it is going to use.
</Tip>
The following configurations must be setup with DeepSpeed because the [`Trainer`] doesn't provide equivalent command line arguments.
<hfoptions id="zero-config">
<hfoption id="ZeRO-1">
ZeRO-1 shards the optimizer states across GPUs, and you can expect a tiny speed up. The ZeRO-1 config can be setup like this:
```yml
{
"zero_optimization": {
"stage": 1
}
}
```
</hfoption>
<hfoption id="ZeRO-2">
ZeRO-2 shards the optimizer and gradients across GPUs. This stage is primarily used for training since its features are not relevant to inference. Some important parameters to configure for better performance include:
* `offload_optimizer` should be enabled to reduce GPU memory usage.
* `overlap_comm` when set to `true` trades off increased GPU memory usage to lower allreduce latency. This feature uses 4.5x the `allgather_bucket_size` and `reduce_bucket_size` values. In this example, they're set to `5e8` which means it requires 9GB of GPU memory. If your GPU memory is 8GB or less, you should reduce `overlap_comm` to lower the memory requirements and prevent an out-of-memory (OOM) error.
* `allgather_bucket_size` and `reduce_bucket_size` trade off available GPU memory for communication speed. The smaller their values, the slower communication is and the more GPU memory is available. You can balance, for example, whether a bigger batch size is more important than a slightly slower training time.
* `round_robin_gradients` is available in DeepSpeed 0.4.4 for CPU offloading. It parallelizes gradient copying to CPU memory among ranks by fine-grained gradient partitioning. Performance benefit grows with gradient accumulation steps (more copying between optimizer steps) or GPU count (increased parallelism).
```yml
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
"round_robin_gradients": true
}
}
```
</hfoption>
<hfoption id="ZeRO-3">
ZeRO-3 shards the optimizer, gradient, and parameters across GPUs. Unlike ZeRO-2, ZeRO-3 can also be used for inference, in addition to training, because it allows large models to be loaded on multiple GPUs. Some important parameters to configure include:
* `device: "cpu"` can help if you're running out of GPU memory and if you have free CPU memory available. This allows offloading model parameters to the CPU.
* `pin_memory: true` can improve throughput, but less memory becomes available for other processes because the pinned memory is reserved for the specific process that requested it and it's typically accessed much faster than normal CPU memory.
* `stage3_max_live_parameters` is the upper limit on how many full parameters you want to keep on the GPU at any given time. Reduce this value if you encounter an OOM error.
* `stage3_max_reuse_distance` is a value for determining when a parameter is used again in the future, and it helps decide whether to throw the parameter away or to keep it. If the parameter is going to be reused (if the value is less than `stage3_max_reuse_distance`), then it is kept to reduce communication overhead. This is super helpful when activation checkpointing is enabled and you want to keep the parameter in the forward recompute until the backward pass. But reduce this value if you encounter an OOM error.
* `stage3_gather_16bit_weights_on_model_save` consolidates fp16 weights when a model is saved. For large models and multiple GPUs, this is expensive in terms of memory and speed. You should enable it if you're planning on resuming training.
* `sub_group_size` controls which parameters are updated during the optimizer step. Parameters are grouped into buckets of `sub_group_size` and each bucket is updated one at a time. When used with NVMe offload, `sub_group_size` determines when model states are moved in and out of CPU memory from during the optimization step. This prevents running out of CPU memory for extremely large models. `sub_group_size` can be left to its default value if you aren't using NVMe offload, but you may want to change it if you:
1. Run into an OOM error during the optimizer step. In this case, reduce `sub_group_size` to reduce memory usage of the temporary buffers.
2. The optimizer step is taking a really long time. In this case, increase `sub_group_size` to improve bandwidth utilization as a result of increased data buffers.
* `reduce_bucket_size`, `stage3_prefetch_bucket_size`, and `stage3_param_persistence_threshold` are dependent on a model's hidden size. It is recommended to set these values to `auto` and allow the [`Trainer`] to automatically assign the values.
```yml
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
You can use the [`deepspeed.zero.Init`](https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.Init) context manager to initialize a model faster:
```py
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("google-t5/t5-small")
model = T5ForConditionalGeneration(config)
```
For pretrained models, the DeepSped config file needs to have `is_deepspeed_zero3_enabled: true` setup in [`TrainingArguments`] and it needs a ZeRO configuration enabled. The [`TrainingArguments`] object must be created **before** calling the model [`~PreTrainedModel.from_pretrained`].
```py
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("google-t5/t5-small")
trainer = Trainer(model=model, args=training_args, ...)
```
You'll need ZeRO-3 if the fp16 weights don't fit on a single GPU. If you're able to load fp16 weights, then make sure you specify `torch_dtype=torch.float16` in [`~PreTrainedModel.from_pretrained`].
Another consideration for ZeRO-3 is if you have multiple GPUs, no single GPU has all the parameters unless it's the parameters for the currently executing layer. To access all parameters from all the layers at once, such as loading pretrained model weights in [`~PreTrainedModel.from_pretrained`], one layer is loaded at a time and immediately partitioned to all GPUs. This is because for very large models, it isn't possible to load the weights on one GPU and then distribute them across the other GPUs due to memory limitations.
If you encounter a model parameter weight that looks like the following, where `tensor([1.])` or the parameter size is 1 instead of a larger multi-dimensional shape, this means the parameter is partitioned and this is a ZeRO-3 placeholder.
```py
tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
```
<Tip>
For more information about initializing large models with ZeRO-3 and accessing the parameters, take a look at the [Constructing Massive Models](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models) and [Gathering Parameters](https://deepspeed.readthedocs.io/en/latest/zero3.html#gathering-parameters) guides.
</Tip>
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#zero-configuration
|
#zero-configuration
|
.md
|
41_7
|
[ZeRO-Infinity](https://hf.co/papers/2104.07857) allows offloading model states to the CPU and/or NVMe to save even more memory. Smart partitioning and tiling algorithms allow each GPU to send and receive very small amounts of data during offloading such that a modern NVMe can fit an even larger total memory pool than is available to your training process. ZeRO-Infinity requires ZeRO-3.
Depending on the CPU and/or NVMe memory available, you can offload both the [optimizer states](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) and [parameters](https://www.deepspeed.ai/docs/config-json/#parameter-offloading), just one of them, or none. You should also make sure the `nvme_path` is pointing to an NVMe device, because while it still works with a normal hard drive or solid state drive, it'll be significantly slower. With a modern NVMe, you can expect peak transfer speeds of ~3.5GB/s for read and ~3GB/s for write operations. Lastly, [run a benchmark](https://github.com/microsoft/DeepSpeed/issues/998) on your training setup to determine the optimal `aio` configuration.
The example ZeRO-3/Infinity configuration file below sets most of the parameter values to `auto`, but you could also manually add these values.
```yml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#nvme-configuration
|
#nvme-configuration
|
.md
|
41_8
|
There are a number of important parameters to specify in the DeepSpeed configuration file which are briefly described in this section.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deepspeed-features
|
#deepspeed-features
|
.md
|
41_9
|
Activation and gradient checkpointing trades speed for more GPU memory which allows you to overcome scenarios where your GPU is out of memory or to increase your batch size for better performance. To enable this feature:
1. For a Hugging Face model, set `model.gradient_checkpointing_enable()` or `--gradient_checkpointing` in the [`Trainer`].
2. For a non-Hugging Face model, use the DeepSpeed [Activation Checkpointing API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html). You could also replace the Transformers modeling code and replace `torch.utils.checkpoint` with the DeepSpeed API. This approach is more flexible because you can offload the forward activations to the CPU memory instead of recalculating them.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#activationgradient-checkpointing
|
#activationgradient-checkpointing
|
.md
|
41_10
|
DeepSpeed and Transformers optimizer and scheduler can be mixed and matched as long as you don't enable `offload_optimizer`. When `offload_optimizer` is enabled, you could use a non-DeepSpeed optimizer (except for LAMB) as long as it has both a CPU and GPU implementation.
<Tip warning={true}>
The optimizer and scheduler parameters for the config file can be set from the command line to avoid hard to find errors. For example, if the learning rate is set to a different value in another place you can override it from the command line. Aside from the optimizer and scheduler parameters, you'll need to ensure your [`Trainer`] command line arguments match the DeepSpeed configuration.
</Tip>
<hfoptions id="opt-sched">
<hfoption id="optimizer">
DeepSpeed offers several [optimizers](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters) (Adam, AdamW, OneBitAdam, and LAMB) but you can also import other optimizers from PyTorch. If you don't configure the optimizer in the config, the [`Trainer`] automatically selects AdamW and either uses the supplied values or the default values for the following parameters from the command line: `lr`, `adam_beta1`, `adam_beta2`, `adam_epsilon`, `weight_decay`.
You can set the parameters to `"auto"` or manually input your own desired values.
```yaml
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
```
You can also use an unsupported optimizer by adding the following to the top level configuration.
```yaml
{
"zero_allow_untested_optimizer": true
}
```
From DeepSpeed==0.8.3 on, if you want to use offload, you'll also need to the following to the top level configuration because offload works best with DeepSpeed's CPU Adam optimizer.
```yaml
{
"zero_force_ds_cpu_optimizer": false
}
```
</hfoption>
<hfoption id="scheduler">
DeepSpeed supports the LRRangeTest, OneCycle, WarmupLR and WarmupDecayLR learning rate [schedulers](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters).
Transformers and DeepSpeed provide two of the same schedulers:
* WarmupLR is the same as `--lr_scheduler_type constant_with_warmup` in Transformers
* WarmupDecayLR is the same as `--lr_scheduler_type linear` in Transformers (this is the default scheduler used in Transformers)
If you don't configure the scheduler in the config, the [`Trainer`] automatically selects WarmupDecayLR and either uses the supplied values or the default values for the following parameters from the command line: `warmup_min_lr`, `warmup_max_lr`, `warmup_num_steps`, `total_num_steps` (automatically calculated during run time if `max_steps` is not provided).
You can set the parameters to `"auto"` or manually input your own desired values.
```yaml
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#optimizer-and-scheduler
|
#optimizer-and-scheduler
|
.md
|
41_11
|
Deepspeed supports fp32, fp16, and bf16 mixed precision.
<hfoptions id="precision">
<hfoption id="fp32">
If your model doesn't work well with mixed precision, for example if it wasn't pretrained in mixed precision, you may encounter overflow or underflow issues which can cause NaN loss. For these cases, you should use full fp32 precision by explicitly disabling the default fp16 mode.
```yaml
{
"fp16": {
"enabled": false
}
}
```
For Ampere GPUs and PyTorch > 1.7, it automatically switches to the more efficient [tf32](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices) format for some operations but the results are still in fp32. You can control it from the [`Trainer`] by setting `--tf32` to enable it, and `--tf32 0` or `--no_tf32` to disable it.
</hfoption>
<hfoption id="fp16">
To configure PyTorch AMP-like fp16 mixed precision reduces memory usage and accelerates training speed. [`Trainer`] automatically enables or disables fp16 based on the value of `args.fp16_backend`, and the rest of the config can be set by you. fp16 is enabled from the command line when the following arguments are passed: `--fp16`, `--fp16_backend amp` or `--fp16_full_eval`.
```yaml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
For additional DeepSpeed fp16 training options, take a look at the [FP16 Training Options](https://www.deepspeed.ai/docs/config-json/#fp16-training-options) reference.
To configure Apex-like fp16 mixed precision, setup the config as shown below with `"auto"` or your own values. [`Trainer`] automatically configure `amp` based on the values of `args.fp16_backend` and `args.fp16_opt_level`. It can also be enabled from the command line when the following arguments are passed: `--fp16`, `--fp16_backend apex` or `--fp16_opt_level 01`.
```yaml
{
"amp": {
"enabled": "auto",
"opt_level": "auto"
}
}
```
</hfoption>
<hfoption id="bf16">
To use bf16, you'll need at least DeepSpeed==0.6.0. bf16 has the same dynamic range as fp32 and doesn’t require loss scaling. However, if you use [gradient accumulation](#gradient-accumulation) with bf16, gradients are accumulated in bf16 which may not be desired because this format's low precision can lead to lossy accumulation.
bf16 can be setup in the config file or enabled from the command line when the following arguments are passed: `--bf16` or `--bf16_full_eval`.
```yaml
{
"bf16": {
"enabled": "auto"
}
}
```
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#precision
|
#precision
|
.md
|
41_12
|
The batch size can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets `train_micro_batch_size_per_gpu` to the value of args.`per_device_train_batch_size` and `train_batch_size` to `args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`.
```yaml
{
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto"
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#batch-size
|
#batch-size
|
.md
|
41_13
|
Gradient accumulation can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets it to the value of `args.gradient_accumulation_steps`.
```yaml
{
"gradient_accumulation_steps": "auto"
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#gradient-accumulation
|
#gradient-accumulation
|
.md
|
41_14
|
Gradient clipping can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets it to the value of `args.max_grad_norm`.
```yaml
{
"gradient_clipping": "auto"
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#gradient-clipping
|
#gradient-clipping
|
.md
|
41_15
|
For communication collectives like reduction, gathering and scattering operations, a separate data type is used.
All gather and scatter operations are performed in the same data type the data is in. For example, if you're training with bf16, the data is also gathered in bf16 because gathering is a non-lossy operation.
Reduce operations are lossy, for example when gradients are averaged across multiple GPUs. When the communication is done in fp16 or bf16, it is more likely to be lossy because adding multiple numbers in low precision isn't exact. This is especially the case with bf16 which has a lower precision than fp16. For this reason, fp16 is the default for reduction operations because the loss is minimal when averaging gradients.
You can choose the communication data type by setting the `communication_data_type` parameter in the config file. For example, choosing fp32 adds a small amount of overhead but ensures the reduction operation is accumulated in fp32 and when it is ready, it is downcasted to whichever half-precision dtype you're training in.
```yaml
{
"communication_data_type": "fp32"
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#communication-data-type
|
#communication-data-type
|
.md
|
41_16
|
[Universal Checkpointing](https://www.deepspeed.ai/tutorials/universal-checkpointing) is an efficient and flexible feature for saving and loading model checkpoints. It enables seamless model training continuation and fine-tuning across different model architectures, parallelism techniques, and training configurations.
Resume training with a universal checkpoint by setting [load_universal](https://www.deepspeed.ai/docs/config-json/#checkpoint-options) to `true` in the config file.
```yaml
{
"checkpoint": {
"load_universal": true
}
}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#universal-checkpointing
|
#universal-checkpointing
|
.md
|
41_17
|
DeepSpeed can be deployed by different launchers such as [torchrun](https://pytorch.org/docs/stable/elastic/run.html), the `deepspeed` launcher, or [Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch#using-accelerate-launch). To deploy, add `--deepspeed ds_config.json` to the [`Trainer`] command line. It’s recommended to use DeepSpeed’s [`add_config_arguments`](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) utility to add any necessary command line arguments to your code.
This guide will show you how to deploy DeepSpeed with the `deepspeed` launcher for different training setups. You can check out this [post](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400) for more practical usage examples.
<hfoptions id="deploy">
<hfoption id="multi-GPU">
To deploy DeepSpeed on multiple GPUs, add the `--num_gpus` parameter. If you want to use all available GPUs, you don't need to add `--num_gpus`. The example below uses 2 GPUs.
```bash
deepspeed --num_gpus=2 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
</hfoption>
<hfoption id="single-GPU">
To deploy DeepSpeed on a single GPU, add the `--num_gpus` parameter. It isn't necessary to explicitly set this value if you only have 1 GPU because DeepSpeed deploys all GPUs it can see on a given node.
```bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
DeepSpeed is still useful with just 1 GPU because you can:
1. Offload some computations and memory to the CPU to make more GPU resources available to your model to use a larger batch size or fit a very large model that normally won't fit.
2. Minimize memory fragmentation with it's smart GPU memory management system which also allows you to fit bigger models and data batches.
<Tip>
Set the `allgather_bucket_size` and `reduce_bucket_size` values to 2e8 in the [ZeRO-2](#zero-configuration) configuration file to get better performance on a single GPU.
</Tip>
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deployment
|
#deployment
|
.md
|
41_18
|
A node is one or more GPUs for running a workload. A more powerful setup is a multi-node setup which can be launched with the `deepspeed` launcher. For this guide, let's assume there are two nodes with 8 GPUs each. The first node can be accessed `ssh hostname1` and the second node with `ssh hostname2`. Both nodes must be able to communicate with each other locally over ssh without a password.
By default, DeepSpeed expects your multi-node environment to use a shared storage. If this is not the case and each node can only see the local filesystem, you need to adjust the config file to include a [`checkpoint`](https://www.deepspeed.ai/docs/config-json/#checkpoint-options) to allow loading without access to a shared filesystem:
```yaml
{
"checkpoint": {
"use_node_local_storage": true
}
}
```
You could also use the [`Trainer`]'s `--save_on_each_node` argument to automatically add the above `checkpoint` to your config.
<hfoptions id="multinode">
<hfoption id="torchrun">
For [torchrun](https://pytorch.org/docs/stable/elastic/run.html), you have to ssh to each node and run the following command on both of them. The launcher waits until both nodes are synchronized before launching the training.
```bash
torchrun --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
```
</hfoption>
<hfoption id="deepspeed">
For the `deepspeed` launcher, start by creating a `hostfile`.
```bash
hostname1 slots=8
hostname2 slots=8
```
Then you can launch the training with the following command. The `deepspeed` launcher automatically launches the command on both nodes at once.
```bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
```
Check out the [Resource Configuration (multi-node)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) guide for more details about configuring multi-node compute resources.
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#multi-node-deployment
|
#multi-node-deployment
|
.md
|
41_19
|
In a SLURM environment, you'll need to adapt your SLURM script to your specific SLURM environment. An example SLURM script may look like:
```bash
#SBATCH --job-name=test-nodes # name
#SBATCH --nodes=2 # nodes
#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
#SBATCH --cpus-per-task=10 # number of cores per tasks
#SBATCH --gres=gpu:8 # number of gpus
#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
#SBATCH --output=%x-%j.out # output file name
export GPUS_PER_NODE=8
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=9901
srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
--nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port $MASTER_PORT \
your_program.py <normal cl args> --deepspeed ds_config.json'
```
Then you can schedule your multi-node deployment with the following command which launches training simultaneously on all nodes.
```bash
sbatch launch.slurm
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#slurm
|
#slurm
|
.md
|
41_20
|
The `deepspeed` launcher doesn't support deployment from a notebook so you'll need to emulate the distributed environment. However, this only works for 1 GPU. If you want to use more than 1 GPU, you must use a multi-process environment for DeepSpeed to work. This means you have to use the `deepspeed` launcher which can't be emulated as shown here.
```py
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# Now proceed as normal, plus pass the DeepSpeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
```
If you want to create the config file on the fly in the notebook in the current directory, you could have a dedicated cell.
```py
%%bash
cat <<'EOT' > ds_config_zero3.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
EOT
```
If the training script is in a file and not in a notebook cell, you can launch `deepspeed` normally from the shell in a notebook cell. For example, to launch `run_translation.py`:
```py
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
```
You could also use `%%bash` magic and write multi-line code to run the shell program, but you won't be able to view the logs until training is complete. With `%%bash` magic, you don't need to emulate a distributed environment.
```py
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#notebook
|
#notebook
|
.md
|
41_21
|
DeepSpeed stores the main full precision fp32 weights in custom checkpoint optimizer files (the glob pattern looks like `global_step*/*optim_states.pt`) and are saved under the normal checkpoint.
<hfoptions id="save">
<hfoption id="fp16">
A model trained with ZeRO-2 saves the pytorch_model.bin weights in fp16. To save the model weights in fp16 for a model trained with ZeRO-3, you need to set `"stage3_gather_16bit_weights_on_model_save": true` because the model weights are partitioned across multiple GPUs. Otherwise, the [`Trainer`] won't save the weights in fp16 and it won't create a pytorch_model.bin file. This is because DeepSpeed's state_dict contains a placeholder instead of the real weights and you won't be able to load them.
```yaml
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
</hfoption>
<hfoption id="fp32">
The full precision weights shouldn't be saved during training because it can require a lot of memory. It is usually best to save the fp32 weights offline after training is complete. But if you have a lot of free CPU memory, it is possible to save the fp32 weights during training. This section covers both online and offline approaches.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#save-model-weights
|
#save-model-weights
|
.md
|
41_22
|
You must have saved at least one checkpoint to load the latest checkpoint as shown in the following:
```py
from transformers.trainer_utils import get_last_checkpoint
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
If you've enabled the `--load_best_model_at_end` parameter to track the best checkpoint in [`TrainingArguments`], you can finish training first and save the final model explicitly. Then you can reload it as shown below:
```py
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
<Tip>
Once `load_state_dict_from_zero_checkpoint` is run, the model is no longer usable in DeepSpeed in the context of the same application. You'll need to initialize the DeepSpeed engine again since `model.load_state_dict(state_dict)` removes all the DeepSpeed magic from it. Only use this at the very end of training.
</Tip>
You can also extract and load the state_dict of the fp32 weights:
```py
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
model = model.cpu()
model.load_state_dict(state_dict)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#online
|
#online
|
.md
|
41_23
|
DeepSpeed provides a zero_to_fp32.py script at the top-level of the checkpoint folder for extracting weights at any point. This is a standalone script and you don't need a configuration file or [`Trainer`].
For example, if your checkpoint folder looked like this:
```bash
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
```
To reconstruct the fp32 weights from the DeepSpeed checkpoint (ZeRO-2 or ZeRO-3) subfolder `global_step1`, run the following command to create and consolidate the full fp32 weights from multiple GPUs into a single pytorch_model.bin file. The script automatically discovers the subfolder containing the checkpoint.
```py
python zero_to_fp32.py . pytorch_model.bin
```
<Tip>
Run `python zero_to_fp32.py -h` for more usage details. The script requires 2x the general RAM of the final fp32 weights.
</Tip>
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#offline
|
#offline
|
.md
|
41_24
|
[ZeRO Inference](https://www.deepspeed.ai/2022/09/09/zero-inference.html) places the model weights in CPU or NVMe memory to avoid burdening the GPU which makes it possible to run inference with huge models on a GPU. Inference doesn't require any large additional amounts of memory for the optimizer states and gradients so you can fit much larger batches and/or sequence lengths on the same hardware.
ZeRO Inference shares the same configuration file as [ZeRO-3](#zero-configuration), and ZeRO-2 and ZeRO-1 configs won't work because they don't provide any benefits for inference.
To run ZeRO Inference, pass your usual training arguments to the [`TrainingArguments`] class and add the `--do_eval` argument.
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#zero-inference
|
#zero-inference
|
.md
|
41_25
|
DeepSpeed also works with Transformers without the [`Trainer`] class. This is handled by the [`HfDeepSpeedConfig`] which only takes care of gathering ZeRO-3 parameters and splitting a model across multiple GPUs when you call [`~PreTrainedModel.from_pretrained`].
<Tip>
If you want everything automatically taken care of for you, try using DeepSpeed with the [`Trainer`]! You'll need to follow the [DeepSpeed documentation](https://www.deepspeed.ai/), and manually configure the parameter values in the config file (you can't use the `"auto"` value).
</Tip>
To efficiently deploy ZeRO-3, you must instantiate the [`HfDeepSpeedConfig`] object before the model and keep that object alive:
<hfoptions id="models">
<hfoption id="pretrained model">
```py
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
model = AutoModel.from_pretrained("openai-community/gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
</hfoption>
<hfoption id="non-pretrained model">
[`HfDeepSpeedConfig`] is not required for ZeRO-1 or ZeRO-2.
```py
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
config = AutoConfig.from_pretrained("openai-community/gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
</hfoption>
</hfoptions>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#non-trainer-deepspeed-integration
|
#non-trainer-deepspeed-integration
|
.md
|
41_26
|
To run ZeRO Inference without the [`Trainer`] in cases where you can’t fit a model onto a single GPU, try using additional GPUs or/and offloading to CPU memory. The important nuance to understand here is that the way ZeRO is designed, you can process different inputs on different GPUs in parallel.
Make sure to:
* disable CPU offload if you have enough GPU memory (since it slows things down).
* enable bf16 if you have an Ampere or newer GPU to make things faster. If you don’t have one of these GPUs, you may enable fp16 as long as you don’t use a model pretrained in bf16 (T5 models) because it may lead to an overflow error.
Take a look at the following script to get a better idea of how to run ZeRO Inference without the [`Trainer`] on a model that won't fit on a single GPU.
```py
#!/usr/bin/env python
# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
# into a single GPU
#
# 1. Use 1 GPU with CPU offload
# 2. Or use multiple GPUs instead
#
# First you need to install deepspeed: pip install deepspeed
#
# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
#
# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
# process multiple inputs at once.
#
# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
# run faster if you don't want offload to CPU - so disable that section then.
#
# To deploy on 1 gpu:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# To deploy on 2 gpus:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
# distributed setup
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# batch size has to be divisible by world_size, but can be bigger than world_size
train_batch_size = 1 * world_size
# ds_config notes
#
# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
# faster.
#
# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
# all official t5 models are bf16-pretrained
#
# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
# - want CPU offload
#
# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
# - which params should remain on gpus - the larger the value the smaller the offload size
#
# For in-depth info on Deepspeed config see
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# keeping the same format as json for consistency, except it uses lower case for true/false
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# next line instructs transformers to partition the model directly over multiple gpus using
# deepspeed.zero.Init when model's `from_pretrained` method is called.
#
# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
#
# otherwise the model will first be loaded normally and only partitioned at forward time which is
# less efficient and when there is little CPU RAM may fail
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
# now a model can be loaded.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# initialise Deepspeed ZeRO and store only the engine object
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # inference
# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
# If you use more GPUs adjust for more.
# And of course if you have just one input to process you then need to pass the same string to both gpus
# If you use only one GPU, then you will have only rank 0.
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
```
Save the script as t0.py and launch it:
```bash
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
```
This is a very basic example and you'll want to adapt it to your use case.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#non-trainer-zero-inference
|
#non-trainer-zero-inference
|
.md
|
41_27
|
Using multiple GPUs with ZeRO-3 for generation requires synchronizing the GPUs by setting `synced_gpus=True` in the [`~GenerationMixin.generate`] method. Otherwise, if one GPU is finished generating before another one, the whole system hangs because the remaining GPUs haven't received the weight shard from the GPU that finished first.
For Transformers>=4.28, if `synced_gpus` is automatically set to `True` if multiple GPUs are detected during generation.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#generate
|
#generate
|
.md
|
41_28
|
When you encounter an issue, you should consider whether DeepSpeed is the cause of the problem because often it isn't (unless it's super obviously and you can see DeepSpeed modules in the exception)! The first step should be to retry your setup without DeepSpeed, and if the problem persists, then you can report the issue. If the issue is a core DeepSpeed problem and unrelated to the Transformers integration, open an Issue on the [DeepSpeed repository](https://github.com/microsoft/DeepSpeed).
For issues related to the Transformers integration, please provide the following information:
* the full DeepSpeed config file
* the command line arguments of the [`Trainer`], or [`TrainingArguments`] arguments if you're scripting the [`Trainer`] setup yourself (don't dump the [`TrainingArguments`] which has dozens of irrelevant entries)
* the outputs of:
```bash
python -c 'import torch; print(f"torch: {torch.__version__}")'
python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
```
* a link to a Google Colab notebook to reproduce the issue
* if impossible, a standard and non-custom dataset we can use and also try to use an existing example to reproduce the issue with
The following sections provide a guide for resolving two of the most common issues.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#troubleshoot
|
#troubleshoot
|
.md
|
41_29
|
When the DeepSpeed process is killed during launch without a traceback, that usually means the program tried to allocate more CPU memory than your system has or your process tried to allocate more CPU memory than allowed leading the OS kernel to terminate the process. In this case, check whether your configuration file has either `offload_optimizer`, `offload_param` or both configured to offload to the CPU.
If you have NVMe and ZeRO-3 setup, experiment with offloading to the NVMe ([estimate](https://deepspeed.readthedocs.io/en/latest/memory.html) the memory requirements for your model).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#deepspeed-process-killed-at-startup
|
#deepspeed-process-killed-at-startup
|
.md
|
41_30
|
NaN loss often occurs when a model is pretrained in bf16 and then you try to use it with fp16 (especially relevant for TPU trained models). To resolve this, use fp32 or bf16 if your hardware supports it (TPU, Ampere GPUs or newer).
The other issue may be related to using fp16. For example, if this is your fp16 configuration:
```yaml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
You might see the following `OVERFLOW!` messages in the logs:
```bash
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
```
This means the DeepSpeed loss scaler is unable to find a scaling coefficient to overcome loss overflow. To fix it, try a higher `initial_scale_power` value (32 usually works).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#nan-loss
|
#nan-loss
|
.md
|
41_31
|
DeepSpeed ZeRO is a powerful technology for training and loading very large models for inference with limited GPU resources, making it more accessible to everyone. To learn more about DeepSpeed, feel free to read the [blog posts](https://www.microsoft.com/en-us/research/search/?q=deepspeed), [documentation](https://www.deepspeed.ai/getting-started/), and [GitHub repository](https://github.com/microsoft/deepspeed).
The following papers are also a great resource for learning more about ZeRO:
* [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://hf.co/papers/1910.02054)
* [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://hf.co/papers/2101.06840)
* [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://hf.co/papers/2104.07857)
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/deepspeed.md
|
https://huggingface.co/docs/transformers/en/deepspeed/#resources
|
#resources
|
.md
|
41_32
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/index.md
|
https://huggingface.co/docs/transformers/en/index/
|
.md
|
42_0
|
|
State-of-the-art Machine Learning for [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), and [JAX](https://jax.readthedocs.io/en/latest/).
🤗 Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you the time and resources required to train a model from scratch. These models support common tasks in different modalities, such as:
📝 **Natural Language Processing**: text classification, named entity recognition, question answering, language modeling, code generation, summarization, translation, multiple choice, and text generation.<br>
🖼️ **Computer Vision**: image classification, object detection, and segmentation.<br>
🗣️ **Audio**: automatic speech recognition and audio classification.<br>
🐙 **Multimodal**: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
🤗 Transformers support framework interoperability between PyTorch, TensorFlow, and JAX. This provides the flexibility to use a different framework at each stage of a model's life; train a model in three lines of code in one framework, and load it for inference in another. Models can also be exported to a format like ONNX and TorchScript for deployment in production environments.
Join the growing community on the [Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), or [Discord](https://discord.com/invite/JfAtkvEtRb) today!
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/index.md
|
https://huggingface.co/docs/transformers/en/index/#-transformers
|
#-transformers
|
.md
|
42_1
|
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/index.md
|
https://huggingface.co/docs/transformers/en/index/#if-you-are-looking-for-custom-support-from-the-hugging-face-team
|
#if-you-are-looking-for-custom-support-from-the-hugging-face-team
|
.md
|
42_2
|
The documentation is organized into five sections:
- **GET STARTED** provides a quick tour of the library and installation instructions to get up and running.
- **TUTORIALS** are a great place to start if you're a beginner. This section will help you gain the basic skills you need to start using the library.
- **HOW-TO GUIDES** show you how to achieve a specific goal, like finetuning a pretrained model for language modeling or how to write and share a custom model.
- **CONCEPTUAL GUIDES** offers more discussion and explanation of the underlying concepts and ideas behind models, tasks, and the design philosophy of 🤗 Transformers.
- **API** describes all classes and functions:
- **MAIN CLASSES** details the most important classes like configuration, model, tokenizer, and pipeline.
- **MODELS** details the classes and functions related to each model implemented in the library.
- **INTERNAL HELPERS** details utility classes and functions used internally.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/index.md
|
https://huggingface.co/docs/transformers/en/index/#contents
|
#contents
|
.md
|
42_3
|
The table below represents the current support in the library for each of those models, whether they have a Python
tokenizer (called "slow"). A "fast" tokenizer backed by the 🤗 Tokenizers library, whether they have support in Jax (via
Flax), PyTorch, and/or TensorFlow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Aria](model_doc/aria) | ✅ | ❌ | ❌ |
| [AriaText](model_doc/aria_text) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bamba](model_doc/bamba) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
| [Cohere2](model_doc/cohere2) | ✅ | ❌ | ❌ |
| [ColPali](model_doc/colpali) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [DAC](model_doc/dac) | ✅ | ❌ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiffLlama](model_doc/diffllama) | ✅ | ❌ | ❌ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ✅ |
| [DINOv2 with Registers](model_doc/dinov2_with_registers) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [Emu3](model_doc/emu3) | ✅ | ❌ | ❌ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [Falcon3](model_doc/falcon3) | ✅ | ❌ | ✅ |
| [FalconMamba](model_doc/falcon_mamba) | ✅ | ❌ | ❌ |
| [FastSpeech2Conformer](model_doc/fastspeech2_conformer) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
| [Gemma](model_doc/gemma) | ✅ | ❌ | ✅ |
| [Gemma2](model_doc/gemma2) | ✅ | ❌ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLM](model_doc/glm) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Granite](model_doc/granite) | ✅ | ❌ | ❌ |
| [GraniteMoeMoe](model_doc/granitemoe) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [Helium](model_doc/helium) | ✅ | ❌ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [I-JEPA](model_doc/ijepa) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
| [Idefics3](model_doc/idefics3) | ✅ | ❌ | ❌ |
| [Idefics3VisionTransformer](model_doc/idefics3_vision) | ❌ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
| [LLaVa-NeXT-Video](model_doc/llava_next_video) | ✅ | ❌ | ❌ |
| [LLaVA-Onevision](model_doc/llava_onevision) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
| [mamba2](model_doc/mamba2) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mimi](model_doc/mimi) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
| [Mllama](model_doc/mllama) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [ModernBERT](model_doc/modernbert) | ✅ | ❌ | ❌ |
| [Moonshine](model_doc/moonshine) | ✅ | ❌ | ❌ |
| [Moshi](model_doc/moshi) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nemotron](model_doc/nemotron) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
| [OLMo2](model_doc/olmo2) | ✅ | ❌ | ❌ |
| [OLMoE](model_doc/olmoe) | ✅ | ❌ | ❌ |
| [OmDet-Turbo](model_doc/omdet-turbo) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
| [Phimoe](model_doc/phimoe) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [Pixtral](model_doc/pixtral) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
| [Qwen2Audio](model_doc/qwen2_audio) | ✅ | ❌ | ❌ |
| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
| [Qwen2VL](model_doc/qwen2_vl) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [TextNet](model_doc/textnet) | ✅ | ❌ | ❌ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [TimmWrapperModel](model_doc/timm_wrapper) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
| [UDOP](model_doc/udop) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [ViTPose](model_doc/vitpose) | ✅ | ❌ | ❌ |
| [ViTPoseBackbone](model_doc/vitpose_backbone) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
| [Zamba](model_doc/zamba) | ✅ | ❌ | ❌ |
| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
<!-- End table-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/index.md
|
https://huggingface.co/docs/transformers/en/index/#supported-models-and-frameworks
|
#supported-models-and-frameworks
|
.md
|
42_4
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/
|
.md
|
43_0
|
|
[[open-in-colab]]
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this guide, we will go over the effective techniques for efficient LLM deployment:
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#optimizing-llms-for-speed-and-memory
|
#optimizing-llms-for-speed-and-memory
|
.md
|
43_1
|
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we can now directly use the result to convert bytes into Gigabytes.
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
29.0260648727417
```
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
Let's call it now for the next experiment.
```python
flush()
```
From the Accelerate library, you can also use a device-agnostic utility method called [release_memory](https://github.com/huggingface/accelerate/blob/29be4788629b772a3b722076e433b5b3b5c85da3/src/accelerate/utils/memory.py#L63), which takes various hardware backends like XPU, MLU, NPU, MPS, and more into account.
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/bitsandbytes-foundation/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
```
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
Now, let's run our example again and measure the memory usage.
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
15.219234466552734
```
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
```python
del model
del pipe
```
```python
flush()
```
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
9.543574333190918
```
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
```python
del model
del pipe
```
```python
flush()
```
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#1-lower-precision
|
#1-lower-precision
|
.md
|
43_2
|
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
```python
long_prompt = 10 * system_prompt + prompt
```
We instantiate our model again in bfloat16 precision.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
````
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
37.668193340301514
```
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
```python
flush()
```
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is able to use Flash Attention.
```python
model.to_bettertransformer()
```
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
32.617331981658936
```
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
```py
flush()
```
For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#2-flash-attention
|
#2-flash-attention
|
.md
|
43_3
|
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#3-architectural-innovations
|
#3-architectural-innovations
|
.md
|
43_4
|
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
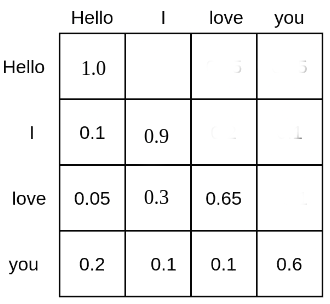
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
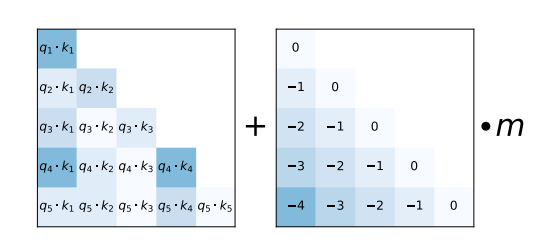
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#31-improving-positional-embeddings-of-llms
|
#31-improving-positional-embeddings-of-llms
|
.md
|
43_5
|
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation). We have an entire guide dedicated to caches [here](./kv_cache).
<Tip warning={true}>
Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#32-the-key-value-cache
|
#32-the-key-value-cache
|
.md
|
43_6
|
The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, its computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
```python
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
```
**Output**:
```
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of
```
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**Output**:
```
7864320000
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#321-multi-round-conversation
|
#321-multi-round-conversation
|
.md
|
43_7
|
[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#322-multi-query-attention-mqa
|
#322-multi-query-attention-mqa
|
.md
|
43_8
|
[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#323-grouped-query-attention-gqa
|
#323-grouped-query-attention-gqa
|
.md
|
43_9
|
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/llm_tutorial_optimization.md
|
https://huggingface.co/docs/transformers/en/llm_tutorial_optimization/#conclusion
|
#conclusion
|
.md
|
43_10
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/
|
.md
|
44_0
|
|
Everyone is welcome to contribute, and we value everybody's contribution. Code
contributions are not the only way to help the community. Answering questions, helping
others, and improving the documentation are also immensely valuable.
It also helps us if you spread the word! Reference the library in blog posts
about the awesome projects it made possible, shout out on Twitter every time it has
helped you, or simply ⭐️ the repository to say thank you.
However you choose to contribute, please be mindful and respect our
[code of conduct](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md).
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#contribute-to--transformers
|
#contribute-to--transformers
|
.md
|
44_1
|
There are several ways you can contribute to 🤗 Transformers:
* Fix outstanding issues with the existing code.
* Submit issues related to bugs or desired new features.
* Implement new models.
* Contribute to the examples or to the documentation.
If you don't know where to start, there is a special [Good First
Issue](https://github.com/huggingface/transformers/contribute) listing. It will give you a list of
open issues that are beginner-friendly and help you start contributing to open-source. The best way to do that is to open a Pull Request and link it to the issue that you'd like to work on. We try to give priority to opened PRs as we can easily track the progress of the fix, and if the contributor does not have time anymore, someone else can take the PR over.
For something slightly more challenging, you can also take a look at the [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) list. In general though, if you feel like you know what you're doing, go for it and we'll help you get there! 🚀
> All contributions are equally valuable to the community. 🥰
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#ways-to-contribute
|
#ways-to-contribute
|
.md
|
44_2
|
If you notice an issue with the existing code and have a fix in mind, feel free to [start contributing](#create-a-pull-request) and open a Pull Request!
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#fixing-outstanding-issues
|
#fixing-outstanding-issues
|
.md
|
44_3
|
Do your best to follow these guidelines when submitting a bug-related issue or a feature
request. It will make it easier for us to come back to you quickly and with good
feedback.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#submitting-a-bug-related-issue-or-feature-request
|
#submitting-a-bug-related-issue-or-feature-request
|
.md
|
44_4
|
The 🤗 Transformers library is robust and reliable thanks to users who report the problems they encounter.
Before you report an issue, we would really appreciate it if you could **make sure the bug was not
already reported** (use the search bar on GitHub under Issues). Your issue should also be related to bugs in the library itself, and not your code. If you're unsure whether the bug is in your code or the library, please ask in the [forum](https://discuss.huggingface.co/) or on our [discord](https://discord.com/invite/hugging-face-879548962464493619) first. This helps us respond quicker to fixing issues related to the library versus general questions.
> [!TIP]
> We have a [docs bot](https://huggingface.co/spaces/huggingchat/hf-docs-chat), and we highly encourage you to ask all your questions there. There is always a chance your bug can be fixed with a simple flag 👾🔫
Once you've confirmed the bug hasn't already been reported, please include the following information in your issue so we can quickly resolve it:
* Your **OS type and version** and **Python**, **PyTorch** and
**TensorFlow** versions when applicable.
* A short, self-contained, code snippet that allows us to reproduce the bug in
less than 30s.
* The *full* traceback if an exception is raised.
* Attach any other additional information, like screenshots, you think may help.
To get the OS and software versions automatically, run the following command:
```bash
transformers-cli env
```
You can also run the same command from the root of the repository:
```bash
python src/transformers/commands/transformers_cli.py env
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#did-you-find-a-bug
|
#did-you-find-a-bug
|
.md
|
44_5
|
If there is a new feature you'd like to see in 🤗 Transformers, please open an issue and describe:
1. What is the *motivation* behind this feature? Is it related to a problem or frustration with the library? Is it a feature related to something you need for a project? Is it something you worked on and think it could benefit the community?
Whatever it is, we'd love to hear about it!
2. Describe your requested feature in as much detail as possible. The more you can tell us about it, the better we'll be able to help you.
3. Provide a *code snippet* that demonstrates the features usage.
4. If the feature is related to a paper, please include a link.
If your issue is well written we're already 80% of the way there by the time you create it.
We have added [templates](https://github.com/huggingface/transformers/tree/main/templates) to help you get started with your issue.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#do-you-want-a-new-feature
|
#do-you-want-a-new-feature
|
.md
|
44_6
|
New models are constantly released and if you want to implement a new model, please provide the following information:
* A short description of the model and a link to the paper.
* Link to the implementation if it is open-sourced.
* Link to the model weights if they are available.
If you are willing to contribute the model yourself, let us know so we can help you add it to 🤗 Transformers!
We have a technical guide for [how to add a model to 🤗 Transformers](https://huggingface.co/docs/transformers/add_new_model).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#do-you-want-to-implement-a-new-model
|
#do-you-want-to-implement-a-new-model
|
.md
|
44_7
|
We're always looking for improvements to the documentation that make it more clear and accurate. Please let us know how the documentation can be improved such as typos and any content that is missing, unclear or inaccurate. We'll be happy to make the changes or help you make a contribution if you're interested!
For more details about how to generate, build, and write the documentation, take a look at the documentation [README](https://github.com/huggingface/transformers/tree/main/docs).
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#do-you-want-to-add-documentation
|
#do-you-want-to-add-documentation
|
.md
|
44_8
|
Before writing any code, we strongly advise you to search through the existing PRs or
issues to make sure nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
You will need basic `git` proficiency to contribute to
🤗 Transformers. While `git` is not the easiest tool to use, it has the greatest
manual. Type `git --help` in a shell and enjoy! If you prefer books, [Pro
Git](https://git-scm.com/book/en/v2) is a very good reference.
You'll need **[Python 3.9](https://github.com/huggingface/transformers/blob/main/setup.py#L449)** or above to contribute to 🤗 Transformers. Follow the steps below to start contributing:
1. Fork the [repository](https://github.com/huggingface/transformers) by
clicking on the **[Fork](https://github.com/huggingface/transformers/fork)** button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
🚨 **Do not** work on the `main` branch!
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
If 🤗 Transformers was already installed in the virtual environment, remove
it with `pip uninstall transformers` before reinstalling it in editable
mode with the `-e` flag.
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
which should be enough for most use cases.
5. Develop the features in your branch.
As you work on your code, you should make sure the test suite
passes. Run the tests impacted by your changes like this:
```bash
pytest tests/<TEST_TO_RUN>.py
```
For more information about tests, check out the
[Testing](https://huggingface.co/docs/transformers/testing) guide.
🤗 Transformers relies on `black` and `ruff` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
make fixup
```
This target is also optimized to only work with files modified by the PR you're working on.
If you prefer to run the checks one after the other, the following command applies the
style corrections:
```bash
make style
```
🤗 Transformers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
controls are run by the CI, but you can run the same checks with:
```bash
make quality
```
Finally, we have a lot of scripts to make sure we don't forget to update
some files when adding a new model. You can run these scripts with:
```bash
make repo-consistency
```
To learn more about those checks and how to fix any issues with them, check out the
[Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
If you're modifying documents under the `docs/source` directory, make sure the documentation can still be built. This check will also run in the CI when you open a pull request. To run a local check
make sure you install the documentation builder:
```bash
pip install ".[docs]"
```
Run the following command from the root of the repository:
```bash
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
```
This will build the documentation in the `~/tmp/test-build` folder where you can inspect the generated
Markdown files with your favorite editor. You can also preview the docs on GitHub when you open a pull request.
Once you're happy with your changes, add the changed files with `git add` and
record your changes locally with `git commit`:
```bash
git add modified_file.py
git commit
```
Please remember to write [good commit
messages](https://chris.beams.io/posts/git-commit/) to clearly communicate the changes you made!
To keep your copy of the code up to date with the original
repository, rebase your branch on `upstream/branch` *before* you open a pull request or if requested by a maintainer:
```bash
git fetch upstream
git rebase upstream/main
```
Push your changes to your branch:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
If you've already opened a pull request, you'll need to force push with the `--force` flag. Otherwise, if the pull request hasn't been opened yet, you can just push your changes normally.
6. Now you can go to your fork of the repository on GitHub and click on **Pull Request** to open a pull request. Make sure you tick off all the boxes on our [checklist](#pull-request-checklist) below. When you're ready, you can send your changes to the project maintainers for review.
7. It's ok if maintainers request changes, it happens to our core contributors
too! So everyone can see the changes in the pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#create-a-pull-request
|
#create-a-pull-request
|
.md
|
44_9
|
☐ The pull request title should summarize your contribution.<br>
☐ If your pull request addresses an issue, please mention the issue number in the pull
request description to make sure they are linked (and people viewing the issue know you
are working on it).<br>
☐ To indicate a work in progress please prefix the title with `[WIP]`. These are
useful to avoid duplicated work, and to differentiate it from PRs ready to be merged.<br>
☐ Make sure existing tests pass.<br>
☐ If adding a new feature, also add tests for it.<br>
- If you are adding a new model, make sure you use
`ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)` to trigger the common tests.
- If you are adding new `@slow` tests, make sure they pass using
`RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`.
- If you are adding a new tokenizer, write tests and make sure
`RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py` passes.
- CircleCI does not run the slow tests, but GitHub Actions does every night!<br>
☐ All public methods must have informative docstrings (see
[`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py)
for an example).<br>
☐ Due to the rapidly growing repository, don't add any images, videos and other
non-text files that'll significantly weigh down the repository. Instead, use a Hub
repository such as [`hf-internal-testing`](https://huggingface.co/hf-internal-testing)
to host these files and reference them by URL. We recommend placing documentation
related images in the following repository:
[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
You can open a PR on this dataset repository and ask a Hugging Face member to merge it.
For more information about the checks run on a pull request, take a look at our [Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#pull-request-checklist
|
#pull-request-checklist
|
.md
|
44_10
|
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
the [tests](https://github.com/huggingface/transformers/tree/main/tests) folder and examples tests in the
[examples](https://github.com/huggingface/transformers/tree/main/examples) folder.
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
repository, specify a *path to a subfolder or a test file* to run the test:
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
```
Similarly, for the `examples` directory, specify a *path to a subfolder or test file* to run the test. For example, the following command tests the text classification subfolder in the PyTorch `examples` directory:
```bash
pip install -r examples/xxx/requirements.txt # only needed the first time
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
In fact, this is actually how our `make test` and `make test-examples` commands are implemented (not including the `pip install`)!
You can also specify a smaller set of tests in order to test only the feature
you're working on.
By default, slow tests are skipped but you can set the `RUN_SLOW` environment variable to
`yes` to run them. This will download many gigabytes of models so make sure you
have enough disk space, a good internet connection or a lot of patience!
<Tip warning={true}>
Remember to specify a *path to a subfolder or a test file* to run the test. Otherwise, you'll run all the tests in the `tests` or `examples` folder, which will take a very long time!
</Tip>
```bash
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
Like the slow tests, there are other environment variables available which are not enabled by default during testing:
- `RUN_CUSTOM_TOKENIZERS`: Enables tests for custom tokenizers.
- `RUN_PT_FLAX_CROSS_TESTS`: Enables tests for PyTorch + Flax integration.
- `RUN_PT_TF_CROSS_TESTS`: Enables tests for TensorFlow + PyTorch integration.
More environment variables and additional information can be found in the [testing_utils.py](https://github.com/huggingface/transformers/blob/main/src/transformers/testing_utils.py).
🤗 Transformers uses `pytest` as a test runner only. It doesn't use any
`pytest`-specific features in the test suite itself.
This means `unittest` is fully supported. Here's how to run tests with
`unittest`:
```bash
python -m unittest discover -s tests -t . -v
python -m unittest discover -s examples -t examples -v
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#tests
|
#tests
|
.md
|
44_11
|
For documentation strings, 🤗 Transformers follows the [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html).
Check our [documentation writing guide](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification)
for more information.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#style-guide
|
#style-guide
|
.md
|
44_12
|
On Windows (unless you're working in [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) or WSL), you need to configure git to transform Windows `CRLF` line endings to Linux `LF` line endings:
```bash
git config core.autocrlf input
```
One way to run the `make` command on Windows is with MSYS2:
1. [Download MSYS2](https://www.msys2.org/), and we assume it's installed in `C:\msys64`.
2. Open the command line `C:\msys64\msys2.exe` (it should be available from the **Start** menu).
3. Run in the shell: `pacman -Syu` and install `make` with `pacman -S make`.
4. Add `C:\msys64\usr\bin` to your PATH environment variable.
You can now use `make` from any terminal (PowerShell, cmd.exe, etc.)! 🎉
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#develop-on-windows
|
#develop-on-windows
|
.md
|
44_13
|
When updating the main branch of a forked repository, please follow these steps to avoid pinging the upstream repository which adds reference notes to each upstream PR, and sends unnecessary notifications to the developers involved in these PRs.
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md
|
https://huggingface.co/docs/transformers/en/contributing/#sync-a-forked-repository-with-upstream-main-the-hugging-face-repository
|
#sync-a-forked-repository-with-upstream-main-the-hugging-face-repository
|
.md
|
44_14
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/
|
.md
|
45_0
|
|
The [`pipeline`] makes it simple to use any model from the [Hub](https://huggingface.co/models) for inference on any language, computer vision, speech, and multimodal tasks. Even if you don't have experience with a specific modality or aren't familiar with the underlying code behind the models, you can still use them for inference with the [`pipeline`]! This tutorial will teach you to:
* Use a [`pipeline`] for inference.
* Use a specific tokenizer or model.
* Use a [`pipeline`] for audio, vision, and multimodal tasks.
<Tip>
Take a look at the [`pipeline`] documentation for a complete list of supported tasks and available parameters.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipelines-for-inference
|
#pipelines-for-inference
|
.md
|
45_1
|
While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains
all the task-specific pipelines. The [`pipeline`] automatically loads a default model and a preprocessing class capable
of inference for your task. Let's take the example of using the [`pipeline`] for automatic speech recognition (ASR), or
speech-to-text.
1. Start by creating a [`pipeline`] and specify the inference task:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. Pass your input to the [`pipeline`]. In the case of speech recognition, this is an audio input file:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
Not the result you had in mind? Check out some of the [most downloaded automatic speech recognition models](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
on the Hub to see if you can get a better transcription.
Let's try the [Whisper large-v2](https://huggingface.co/openai/whisper-large-v2) model from OpenAI. Whisper was released
2 years later than Wav2Vec2, and was trained on close to 10x more data. As such, it beats Wav2Vec2 on most downstream
benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2.
Let's give it a try here to see how it performs. Set `torch_dtype="auto"` to automatically load the most memory-efficient data type the weights are stored in.
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", torch_dtype="auto")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
Now this result looks more accurate! For a deep-dive comparison on Wav2Vec2 vs Whisper, refer to the [Audio Transformers Course](https://huggingface.co/learn/audio-course/chapter5/asr_models).
We really encourage you to check out the Hub for models in different languages, models specialized in your field, and more.
You can check out and compare model results directly from your browser on the Hub to see if it fits or
handles corner cases better than other ones.
And if you don't find a model for your use case, you can always start [training](training) your own!
If you have several inputs, you can pass your input as a list:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
Pipelines are great for experimentation as switching from one model to another is trivial; however, there are some ways to optimize them for larger workloads than experimentation. See the following guides that dive into iterating over whole datasets or using pipelines in a webserver:
of the docs:
* [Using pipelines on a dataset](#using-pipelines-on-a-dataset)
* [Using pipelines for a webserver](./pipeline_webserver)
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage
|
#pipeline-usage
|
.md
|
45_2
|
[`pipeline`] supports many parameters; some are task specific, and some are general to all pipelines.
In general, you can specify parameters anywhere you want:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
Let's check out 3 important ones:
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#parameters
|
#parameters
|
.md
|
45_3
|
If you use `device=n`, the pipeline automatically puts the model on the specified device.
This will work regardless of whether you are using PyTorch or Tensorflow.
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
If the model is too large for a single GPU and you are using PyTorch, you can set `torch_dtype='float16'` to enable FP16 precision inference. Usually this would not cause significant performance drops but make sure you evaluate it on your models!
Alternatively, you can set `device_map="auto"` to automatically
determine how to load and store the model weights. Using the `device_map` argument requires the 🤗 [Accelerate](https://huggingface.co/docs/accelerate)
package:
```bash
pip install --upgrade accelerate
```
The following code automatically loads and stores model weights across devices:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
Note that if `device_map="auto"` is passed, there is no need to add the argument `device=device` when instantiating your `pipeline` as you may encounter some unexpected behavior!
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#device
|
#device
|
.md
|
45_4
|
By default, pipelines will not batch inference for reasons explained in detail [here](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching). The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
But if it works in your use case, you can use:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
This runs the pipeline on the 4 provided audio files, but it will pass them in batches of 2
to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you.
The output should always match what you would have received without batching. It is only meant as a way to help you get more speed out of a pipeline.
Pipelines can also alleviate some of the complexities of batching because, for some pipelines, a single item (like a long audio file) needs to be chunked into multiple parts to be processed by a model. The pipeline performs this [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) for you.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#batch-size
|
#batch-size
|
.md
|
45_5
|
All tasks provide task specific parameters which allow for additional flexibility and options to help you get your job done.
For instance, the [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] method has a `return_timestamps` parameter which sounds promising for subtitling videos:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
As you can see, the model inferred the text and also outputted **when** the various sentences were pronounced.
There are many parameters available for each task, so check out each task's API reference to see what you can tinker with!
For instance, the [`~transformers.AutomaticSpeechRecognitionPipeline`] has a `chunk_length_s` parameter which is helpful
for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically
cannot handle on its own:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}
```
If you can't find a parameter that would really help you out, feel free to [request it](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters
|
#task-specific-parameters
|
.md
|
45_6
|
The pipeline can also run inference on a large dataset. The easiest way we recommend doing this is by using an iterator:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
The iterator `data()` yields each result, and the pipeline automatically
recognizes the input is iterable and will start fetching the data while
it continues to process it on the GPU (this uses [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) under the hood).
This is important because you don't have to allocate memory for the whole dataset
and you can feed the GPU as fast as possible.
Since batching could speed things up, it may be useful to try tuning the `batch_size` parameter here.
The simplest way to iterate over a dataset is to just load one from 🤗 [Datasets](https://github.com/huggingface/datasets/):
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset
|
#using-pipelines-on-a-dataset
|
.md
|
45_7
|
<Tip>
Creating an inference engine is a complex topic which deserves it's own
page.
</Tip>
[Link](./pipeline_webserver)
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-for-a-webserver
|
#using-pipelines-for-a-webserver
|
.md
|
45_8
|
Using a [`pipeline`] for vision tasks is practically identical.
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#vision-pipeline
|
#vision-pipeline
|
.md
|
45_9
|
Using a [`pipeline`] for NLP tasks is practically identical.
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#text-pipeline
|
#text-pipeline
|
.md
|
45_10
|
The [`pipeline`] supports more than one modality. For example, a visual question answering (VQA) task combines text and image. Feel free to use any image link you like and a question you want to ask about the image. The image can be a URL or a local path to the image.
For example, if you use this [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
To run the example above you need to have [`pytesseract`](https://pypi.org/project/pytesseract/) installed in addition to 🤗 Transformers:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#multimodal-pipeline
|
#multimodal-pipeline
|
.md
|
45_11
|
You can easily run `pipeline` on large models using 🤗 `accelerate`! First make sure you have installed `accelerate` with `pip install accelerate`.
First load your model using `device_map="auto"`! We will use `facebook/opt-1.3b` for our example.
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
You can also pass 8-bit loaded models if you install `bitsandbytes` and add the argument `load_in_8bit=True`
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
Note that you can replace the checkpoint with any Hugging Face model that supports large model loading, such as BLOOM.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipeline-on-large-models-with--accelerate
|
#using-pipeline-on-large-models-with--accelerate
|
.md
|
45_12
|
Pipelines are automatically supported in [Gradio](https://github.com/gradio-app/gradio/), a library that makes creating beautiful and user-friendly machine learning apps on the web a breeze. First, make sure you have Gradio installed:
```
pip install gradio
```
Then, you can create a web demo around an image classification pipeline (or any other pipeline) in a single line of code by calling Gradio's [`Interface.from_pipeline`](https://www.gradio.app/docs/interface#interface-from-pipeline) function to launch the pipeline. This creates an intuitive drag-and-drop interface in your browser:
```py
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()
```
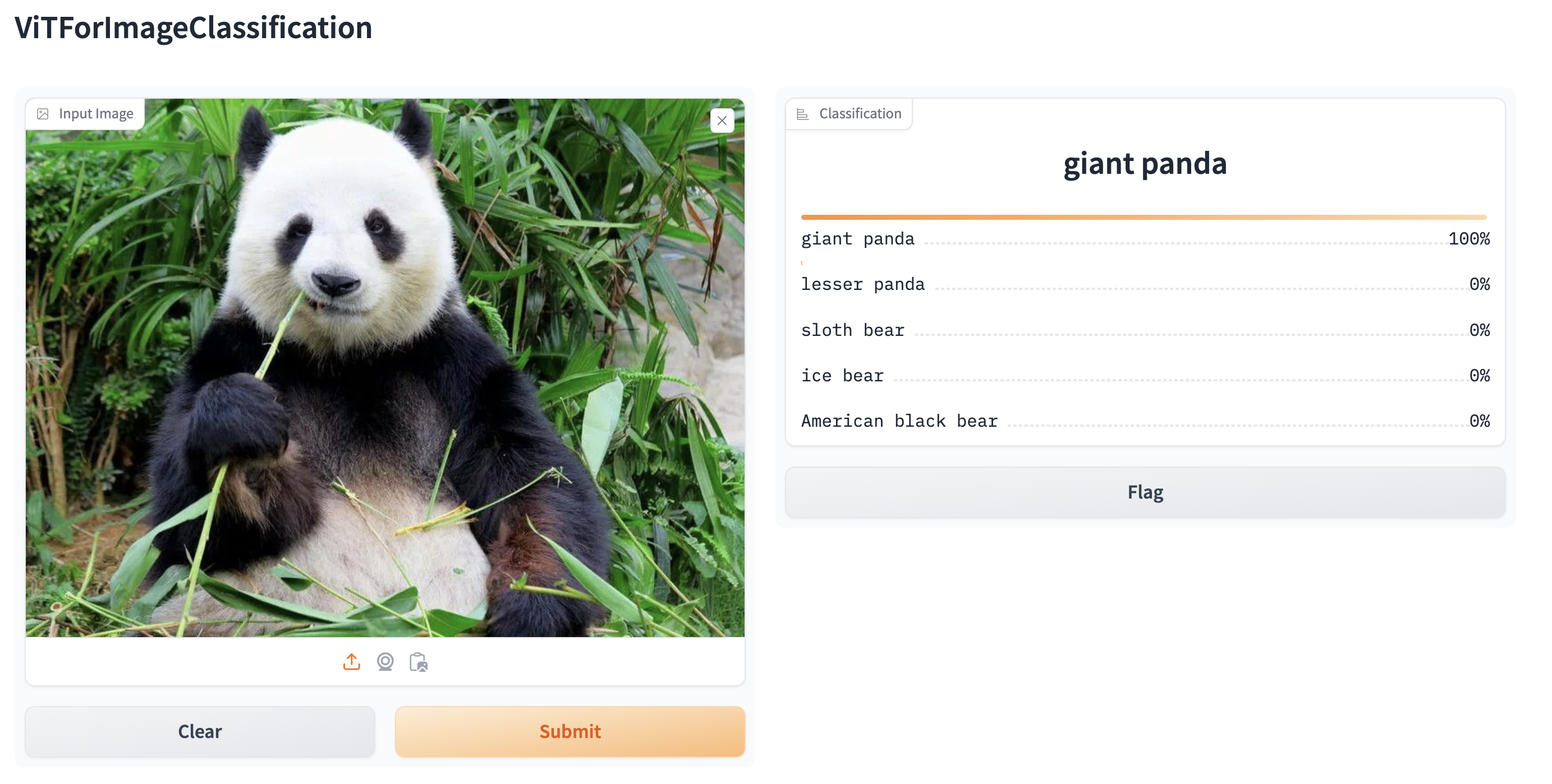
By default, the web demo runs on a local server. If you'd like to share it with others, you can generate a temporary public
link by setting `share=True` in `launch()`. You can also host your demo on [Hugging Face Spaces](https://huggingface.co/spaces) for a permanent link.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md
|
https://huggingface.co/docs/transformers/en/pipeline_tutorial/#creating-web-demos-from-pipelines-with-gradio
|
#creating-web-demos-from-pipelines-with-gradio
|
.md
|
45_13
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/
|
.md
|
46_0
|
|
[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a data parallel method that shards a model's parameters, gradients and optimizer states across the number of available GPUs (also called workers or *rank*). Unlike [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html), FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency and allows you to train much larger models on fewer GPUs. FSDP is integrated with the Accelerate, a library for easily managing training in distributed environments, which means it is available for use from the [`Trainer`] class.
Before you start, make sure Accelerate is installed and at least PyTorch 2.1.0 or newer.
```bash
pip install accelerate
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#fully-sharded-data-parallel
|
#fully-sharded-data-parallel
|
.md
|
46_1
|
To start, run the [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to create a configuration file for your training environment. Accelerate uses this configuration file to automatically setup the correct training environment based on your selected training options in `accelerate config`.
```bash
accelerate config
```
When you run `accelerate config`, you'll be prompted with a series of options to configure your training environment. This section covers some of the most important FSDP options. To learn more about the other available FSDP options, take a look at the [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) parameters.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#fsdp-configuration
|
#fsdp-configuration
|
.md
|
46_2
|
FSDP offers a number of sharding strategies to select from:
* `FULL_SHARD` - shards model parameters, gradients and optimizer states across workers; select `1` for this option
* `SHARD_GRAD_OP`- shard gradients and optimizer states across workers; select `2` for this option
* `NO_SHARD` - don't shard anything (this is equivalent to DDP); select `3` for this option
* `HYBRID_SHARD` - shard model parameters, gradients and optimizer states within each worker where each worker also has a full copy; select `4` for this option
* `HYBRID_SHARD_ZERO2` - shard gradients and optimizer states within each worker where each worker also has a full copy; select `5` for this option
This is enabled by the `fsdp_sharding_strategy` flag.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#sharding-strategy
|
#sharding-strategy
|
.md
|
46_3
|
You could also offload parameters and gradients when they are not in use to the CPU to save even more GPU memory and help you fit large models where even FSDP may not be sufficient. This is enabled by setting `fsdp_offload_params: true` when running `accelerate config`.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#cpu-offload
|
#cpu-offload
|
.md
|
46_4
|
FSDP is applied by wrapping each layer in the network. The wrapping is usually applied in a nested way where the full weights are discarded after each forward pass to save memory for use in the next layer. The *auto wrapping* policy is the simplest way to implement this and you don't need to change any code. You should select `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` to wrap a Transformer layer and `fsdp_transformer_layer_cls_to_wrap` to specify which layer to wrap (for example `BertLayer`).
Otherwise, you can choose a size-based wrapping policy where FSDP is applied to a layer if it exceeds a certain number of parameters. This is enabled by setting `fsdp_wrap_policy: SIZE_BASED_WRAP` and `min_num_param` to the desired size threshold.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#wrapping-policy
|
#wrapping-policy
|
.md
|
46_5
|
Intermediate checkpoints should be saved with `fsdp_state_dict_type: SHARDED_STATE_DICT` because saving the full state dict with CPU offloading on rank 0 takes a lot of time and often results in `NCCL Timeout` errors due to indefinite hanging during broadcasting. You can resume training with the sharded state dicts with the [`~accelerate.Accelerator.load_state`] method.
```py
# directory containing checkpoints
accelerator.load_state("ckpt")
```
However, when training ends, you want to save the full state dict because sharded state dict is only compatible with FSDP.
```py
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir)
```
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#checkpointing
|
#checkpointing
|
.md
|
46_6
|
[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html) supports FSDP training for TPUs and it can be enabled by modifying the FSDP configuration file generated by `accelerate config`. In addition to the sharding strategies and wrapping options specified above, you can add the parameters shown below to the file.
```yaml
xla: True # must be set to True to enable PyTorch/XLA
xla_fsdp_settings: # XLA-specific FSDP parameters
xla_fsdp_grad_ckpt: True # use gradient checkpointing
```
The [`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128) allow you to configure additional XLA-specific parameters for FSDP.
|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md
|
https://huggingface.co/docs/transformers/en/fsdp/#tpu
|
#tpu
|
.md
|
46_7
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.