
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
sequencelengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
dynaconf/dynaconf | fastapi | 478 | Make `environment` an alias to `environments` | A common mistake is to pass `environment=True` when it should be `environments`
Solutions:
1. Warn the user
**Did you mean `environments`?**
2. make an alias the same way we did with `settings_file` and `settings_files` | closed | 2020-11-24T17:39:51Z | 2021-03-02T21:26:54Z | https://github.com/dynaconf/dynaconf/issues/478 | [
"Not a Bug",
"RFC"
] | rochacbruno | 0 |
ultralytics/yolov5 | pytorch | 12,909 | Calculate gradients for YOLOv5 - XAI for object detection | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi,
I am trying to calculate gradients for the YOLOv5 model, which is needed for some AI explainability methods. I am not sure if I am using the right approach, but so far I was trying to use DetectMultiBackend class for the model and ComputeLoss class for computing the loss (see the code below). But I am getting an error about the model being not subscriptable, can you tell me how can I calculate the gradient?
`model = DetectMultiBackend(weights=weights, device=device, dnn=dnn, data=data, fp16=half).float().eval()
# We want gradients with respect to the input, so we need to enable it
inputs.requires_grad = True
# Forward pass
pred= model(inputs)
amp = check_amp(model) # check AMP
compute_loss = ComputeLoss(model) # init loss class
loss, loss_items = compute_loss(pred, target.to(device))
scaler = torch.cuda.amp.GradScaler(enabled=amp)
# Backward
scaler.scale(loss).backward()
#scaler.unscale_(optimizer) # unscale gradients - is this step necessary?
gradients = inputs.grad`

### Additional
_No response_ | closed | 2024-04-12T15:48:26Z | 2024-10-20T19:43:34Z | https://github.com/ultralytics/yolov5/issues/12909 | [
"question",
"Stale"
] | zuzell | 7 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,933 | Change translation for a question from the provided models | ### What version of GlobaLeaks are you using?
4.13.22
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Windows, Linux
### Describe the issue
Is it possible to change the "Would you like to tell us who you are?" translation for PT? I've tried to change it from "Gostaria de nos dizer quem você é?" to "Gostaria de nos dizer quem é?" inside de platform, but i can't do it.



### Proposed solution
_No response_ | closed | 2024-01-06T00:54:54Z | 2024-01-06T15:13:40Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3933 | [] | pcinacio | 1 |
marcomusy/vedo | numpy | 44 | jupyter lab support | Thanks for this amazing software. However, it appears that the plot functionality only works for jupyter notebook, and will not work for jupyter lab. When trying to execute "show" command for function plotting, it will simply fail with an error message saying "error displaying widget module not found". Any possibility to correct this issue? Thanks! | open | 2019-08-04T00:31:56Z | 2019-11-09T09:52:00Z | https://github.com/marcomusy/vedo/issues/44 | [
"bug",
"jupyter",
"long-term"
] | jacobdang | 4 |
nvbn/thefuck | python | 1,076 | PytestUnknownMarkWarning | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just open an issue on [GitHub](https://github.com/nvbn/thefuck) with
the following basic information: -->
The output of `thefuck --version` (something like `The Fuck 3.1 using Python
3.5.0 and Bash 4.4.12(1)-release`):
`master` version, commit 6975d30818792f1b37de702fc93c66023c4c50d5, Python 3.8.2
Your system (Debian 7, ArchLinux, Windows, etc.):
Arch Linux
How to reproduce the bug:
py.test
Anything else you think is relevant:
```
tests/test_conf.py:46
/home/alex/Projects/thefuck/tests/test_conf.py:46: PytestUnknownMarkWarning: Unknown pytest.mark.usefixture - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.usefixture('load_source')
tests/functional/test_bash.py:41
/home/alex/Projects/thefuck/tests/functional/test_bash.py:41: PytestUnknownMarkWarning: Unknown pytest.mark.functional - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.functional
tests/functional/test_bash.py:47
/home/alex/Projects/thefuck/tests/functional/test_bash.py:47: PytestUnknownMarkWarning: Unknown pytest.mark.functional - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.functional
tests/functional/test_bash.py:53
/home/alex/Projects/thefuck/tests/functional/test_bash.py:53: PytestUnknownMarkWarning: Unknown pytest.mark.functional - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.functional
tests/functional/test_bash.py:59
/home/alex/Projects/thefuck/tests/functional/test_bash.py:59: PytestUnknownMarkWarning: Unknown pytest.mark.functional - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.functional
...
```
<!-- It's only with enough information that we can do something to fix the problem. -->
| open | 2020-04-09T13:24:29Z | 2020-04-17T15:05:13Z | https://github.com/nvbn/thefuck/issues/1076 | [] | AlexWayfer | 1 |
onnx/onnx | scikit-learn | 6,297 | No Adapter From Version $14 for Mul | # Bug Report
### Is the issue related to model conversion?
<!-- If the ONNX checker reports issues with this model then this is most probably related to the converter used to convert the original framework model to ONNX. Please create this bug in the appropriate converter's GitHub repo (pytorch, tensorflow-onnx, sklearn-onnx, keras-onnx, onnxmltools) to get the best help. -->
Yes.
### Describe the bug
<!-- Please describe the bug clearly and concisely -->
<img width="1481" alt="image" src="https://github.com/user-attachments/assets/b9234fd4-12f8-40b9-a84d-389f71c86d76">
### System information
<!--
- OS Platform and Distribution (*e.g. Linux Ubuntu 20.04*): Mac os and Linux
- ONNX version (*e.g. 1.13*): 1.16.2
- Python version: 3.10.2
- GCC/Compiler version (if compiling from source):
- CMake version:
- Protobuf version:
- Visual Studio version (if applicable):-->
### Reproduction instructions
<!--
- Describe the code to reproduce the behavior.
```
import onnx
model = onnx.load('model.onnx')
...
```
- Attach the ONNX model to the issue (where applicable)-->
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
### Notes
<!-- Any additional information -->
| open | 2024-08-16T13:10:10Z | 2024-09-05T01:48:49Z | https://github.com/onnx/onnx/issues/6297 | [
"bug",
"module: version converter"
] | roachsinai | 3 |
yt-dlp/yt-dlp | python | 12,693 | ERROR: [youtube] Failed to extract any player response | ### Checklist
- [x] I'm asking a question and **not** reporting a bug or requesting a feature
- [x] I've looked through the [README](https://github.com/yt-dlp/yt-dlp#readme)
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've searched [known issues](https://github.com/yt-dlp/yt-dlp/issues/3766), [the FAQ](https://github.com/yt-dlp/yt-dlp/wiki/FAQ), and the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=is%3Aissue%20-label%3Aspam%20%20) for similar questions **including closed ones**. DO NOT post duplicates
### Please make sure the question is worded well enough to be understood
I got this error when trying to make a bot that can play music on discord (used youtube)
ERROR: [youtube] : Failed to extract any player response; please report this issue on https://github.com/yt-dlp/yt-dlp/issues?q= , filling out the appropriate issue template. Confirm you are on the latest version using yt-dlp -U
### Provide verbose output that clearly demonstrates the problem
- [ ] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)
- [ ] If using API, add `'verbose': True` to `YoutubeDL` params instead
- [ ] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below
### Complete Verbose Output
```shell
``` | open | 2025-03-22T05:38:58Z | 2025-03-22T12:51:28Z | https://github.com/yt-dlp/yt-dlp/issues/12693 | [
"question",
"incomplete"
] | HyIsNoob | 5 |
MagicStack/asyncpg | asyncio | 876 | notice callback not awaited | * **asyncpg version**: 0.23.0
* **Python version**: 3.9.2
* **Platform**: Linux
* **Do you use pgbouncer?**: no
* **Did you install asyncpg with pip?**: yes
* **Can the issue be reproduced under both asyncio and
[uvloop](https://github.com/magicstack/uvloop)?**: only experienced it once, without uvloop
```
/root/.local/lib/python3.9/site-packages/asyncpg/connection.py:1435: RuntimeWarning: coroutine 'vacuum_job.<locals>.async_notice_callb' was never awaited
cb(con_ref, message)
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
```
| open | 2022-01-15T02:48:48Z | 2023-12-17T03:01:35Z | https://github.com/MagicStack/asyncpg/issues/876 | [] | ale-dd | 1 |
miguelgrinberg/microblog | flask | 317 | Infinite edit_profile redirect | Thanks for the great tutorial!!
I'm working through chapter 6 and as far as I can tell, my code is the same as v0.6, but my packages may be newer (Flask 2.0.3, flask-wtf 0.15.1).
When I define the edit_profile route, I get an infinite redirect loop after clicking the 'edit profile' link. This additionally has the effect of deleting my username but not email from the database, which causes a bunch of other weird problems. But, if I switch the order of the if and elif statements so that it checks whether the request is a GET first, everything works again:
```
@app.route('/edit_profile', methods=['GET','POST'])
@login_required
def edit_profile():
form=EditProfileForm()
if request.method=='GET':
form.username.data=current_user.username
form.about_me.data=current_user.about_me
elif form.validate_on_submit:
current_user.username = form.username.data
current_user.about_me = form.about_me.data
db.session.commit()
flash('Your changes have been saved.')
return redirect(url_for('edit_profile'))
return render_template('edit_profile.html', title='Edit Profile', form=form)
```
My conda env:
[conda_packages.txt](https://github.com/miguelgrinberg/microblog/files/8189501/conda_packages.txt)
| closed | 2022-03-05T00:59:57Z | 2022-03-09T00:41:53Z | https://github.com/miguelgrinberg/microblog/issues/317 | [
"question"
] | paulsonak | 2 |
microsoft/qlib | machine-learning | 1,628 | descriptor 'lower' for 'str' objects doesn't apply to a 'float' object | I tried updating data on existing datasets retrieved from Yahoo Finance using collector.py but received the following error.
The code used is:
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir ~/desktop/quant_engine/qlib_data/us_data --trading_date 2023-08-16 --end_date 2023-08-17 --region US
"us_data" folder saved those three folders (calendar, features, and instruments) which contain data collected, normalized, and dumped following the instruction.

| closed | 2023-08-18T09:51:57Z | 2024-01-29T15:01:45Z | https://github.com/microsoft/qlib/issues/1628 | [
"question",
"stale"
] | guoz14 | 7 |
pytest-dev/pytest-django | pytest | 448 | Move pypy3 to allowed failures for now | It should not make PRs red. | closed | 2017-01-18T21:47:44Z | 2017-01-20T17:49:33Z | https://github.com/pytest-dev/pytest-django/issues/448 | [] | blueyed | 0 |
deeppavlov/DeepPavlov | tensorflow | 1,462 | levenshtein searcher works incorrectly |
**DeepPavlov version** (you can look it up by running `pip show deeppavlov`): 0.15.0
**Python version**: 3.7.10
**Operating system** (ubuntu linux, windows, ...): ubuntu 20.04
**Issue**: Levenshtein searcher does not take symbols replacements into account
**Command that led to error**:
```
>>> from deeppavlov.models.spelling_correction.levenshtein.searcher_component import LevenshteinSearcher
>>> vocab = set("the cat sat on the mat".split())
>>> abet = set(c for w in vocab for c in w)
>>> searcher = LevenshteinSearcher(abet, vocab)
>>> 'cat' in searcher
True
>>> searcher.transducer.distance('rat', 'cat'),\
... searcher.transducer.distance('cat', 'rat')
(inf, inf)
>>> searcher.transducer.distance('at', 'cat')
1.0
>>> searcher.transducer.distance('rat', 'cat')
inf
>>> searcher.search("rat", 1)
[]
>>> searcher.search("at", 1)
[('mat', 1.0), ('cat', 1.0), ('sat', 1.0)]
```
**Expected output**:
```
>>> searcher.transducer.distance('rat', 'cat')
1.0
>>> searcher.search("rat", 1)
[('mat', 1.0), ('cat', 1.0), ('sat', 1.0)]
```
| closed | 2021-07-04T21:39:27Z | 2023-07-10T11:45:40Z | https://github.com/deeppavlov/DeepPavlov/issues/1462 | [
"bug"
] | oserikov | 1 |
yunjey/pytorch-tutorial | pytorch | 187 | Typos in language model line 79 and generative_adversarial_network line 25-28 | Typos in language model line 79: should initialize optimizer instead of model
Generative_adversarial_network line 25-28: MNIST dataset is greyscale (one channel), transforms need to be modified. | closed | 2019-08-27T09:07:38Z | 2020-01-27T15:11:10Z | https://github.com/yunjey/pytorch-tutorial/issues/187 | [] | qy-yang | 0 |
alteryx/featuretools | scikit-learn | 1,878 | `pd_to_ks_clean` koalas util broken with Woodwork 0.12.0 latlong changes | The broken koalas unit tests (https://github.com/alteryx/featuretools/runs/4973841366?check_suite_focus=true#step:8:147) are all erroring in the setup of `ks_es`, where fully null tuples `(nan, nan)` are getting converted to `(-1, -1)` at some point in `pd_to_ks_clean`, which is causing `TypeError: element in array field latlong: DoubleType can not accept object -1 in type <class 'int'>`. | closed | 2022-02-01T17:13:28Z | 2022-04-01T20:19:56Z | https://github.com/alteryx/featuretools/issues/1878 | [
"bug"
] | tamargrey | 0 |
FactoryBoy/factory_boy | django | 1,028 | 3.3.0 Release | #### Question
In looking through the latest documentation I see there has been an addition to the SQLAlchemy options that can be passed to the meta class. Specifically, [sqlalchemy_session_factory](https://factoryboy.readthedocs.io/en/latest/orms.html#factory.alchemy.SQLAlchemyOptions.sqlalchemy_session_factory) would be very useful. I see that documentation was last updated 5 months ago. I'm curious if you have a sense of when the `3.3.0` release will go out?
I'm also curious if this project is still being activity maintained since the last release was 2 years ago? It might just be stable so that a lot of activity isn't needed but I also wanted to double check that while I'm at it.
Thanks for your support on this project! Factory boy is a fantastic library. | closed | 2023-07-08T00:37:18Z | 2023-07-08T00:38:33Z | https://github.com/FactoryBoy/factory_boy/issues/1028 | [] | ascrookes | 1 |
Kludex/mangum | fastapi | 159 | How can I log the response? | I'd like to log both the full request and full response.
Currently I am logging the full request by using a custom middleware as below:
```
class AWSLoggingMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
logger.info(f'{request.scope.get("aws.event")}')
response = await call_next(request)
return response
```
How could I also log the full response back to aws? | closed | 2021-02-07T02:14:53Z | 2021-11-09T01:44:21Z | https://github.com/Kludex/mangum/issues/159 | [] | erichaus | 4 |
skforecast/skforecast | scikit-learn | 377 | Consider applying for pyOpenSci open peer review | pyOpenSci https://www.pyopensci.org/about-peer-review/ is modeled after rOpenSci and offers a community-led, open peer review process for scientific Python packages. Maybe they would be happy to review skforecast!
(See https://github.com/pyOpenSci/pyopensci.github.io/issues/150) | closed | 2023-03-27T20:13:10Z | 2024-08-08T08:43:12Z | https://github.com/skforecast/skforecast/issues/377 | [] | astrojuanlu | 2 |
seleniumbase/SeleniumBase | pytest | 3,575 | ERR_CONNECTION_RESET with Driver(uc=True) but fine with undetected_chromedriver | Hello everyone and the developer team,
I am experiencing an issue where I get an ERR_CONNECTION_RESET error when using the Driver with `uc=True`. I have tried using the original undetected_chromedriver, and that version works without any problems.
This error is causing the website to function incorrectly, and I discovered it while checking the Network tab.
```
from seleniumbase import Driver
driver = Driver(uc=True)
driver.get('https://sso.dancuquocgia.gov.vn/')
```
<img width="1894" alt="Image" src="https://github.com/user-attachments/assets/48109160-5e93-433a-8ea8-9c59a27e6926" />
Website: https://sso.dancuquocgia.gov.vn/
Please test your driver and improve it for situations like this. Thank you very much! | closed | 2025-03-02T15:16:43Z | 2025-03-03T01:52:39Z | https://github.com/seleniumbase/SeleniumBase/issues/3575 | [
"external",
"UC Mode / CDP Mode"
] | tranngocminhhieu | 2 |
Miserlou/Zappa | django | 1,576 | Feature: Ability to use existing API Gateway | ## Context
Hi, we're a small company in the process of gradually expanding our monolithic elasticbeanstalk application with smaller targeted microservices based on ApiStar / Zappa. We're getting good mileage so far and have deployed a small selection of background task-type services using SNS messaging as triggers, however we'd really like to start adding actual endpoints to our stack that call lambda functions. I've been trying for a couple of days to figure out how to properly setup an API gateway that will proxy to both our existing stack and newer services deployed with zappa. I've tried manually setting up a custom domain for the zappa apps and a cloudfront distro in front of both the existing stack and the new api gateway but am not getting very far. It would be a lot simpler IMO if we could specify an existing API gateway ARN in the zappa_settings.json and elect to use that so that it could integrate with an existing configuration.
## Expected Behavior
Would be great if I could specify "api_gateway_arn" in the zappa_settings.json file to use an existing api gateway
## Actual Behavior
There is no option to do this
## Possible Fix
I guess this is not straightforward given the API gateway is created via a cloudformation template, I guess it'd require moving some of that to boto functions instead ?
## Steps to Reproduce
N/A
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: 0.46.2
* Operating System and Python version: 3.6
* The output of `pip freeze`:
ably==1.0.1
apistar==0.5.40
argcomplete==1.9.3
attrs==18.1.0
awscli==1.15.19
backcall==0.1.0
base58==1.0.0
boto3==1.7.0
botocore==1.10.36
cairocffi==0.8.1
CairoSVG==2.1.3
certifi==2018.4.16
cffi==1.11.5
cfn-flip==1.0.3
chardet==3.0.4
click==6.7
colorama==0.3.7
cookies==2.2.1
coverage==4.5.1
cssselect2==0.2.1
decorator==4.3.0
defusedxml==0.5.0
docutils==0.14
durationpy==0.5
et-xmlfile==1.0.1
Faker==0.8.15
Flask==0.12.2
future==0.16.0
hjson==3.0.1
html5lib==1.0.1
humanize==0.5.1
idna==2.7
ipython==6.4.0
ipython-genutils==0.2.0
itsdangerous==0.24
jdcal==1.4
jedi==0.12.0
Jinja2==2.10
jmespath==0.9.3
kappa==0.6.0
lambda-packages==0.20.0
MarkupSafe==1.0
more-itertools==4.1.0
msgpack-python==0.5.6
openpyxl==2.5.3
parso==0.2.1
pdfrw==0.4
pexpect==4.5.0
pickleshare==0.7.4
Pillow==5.1.0
placebo==0.8.1
pluggy==0.6.0
prompt-toolkit==1.0.15
psycopg2==2.7.4
ptyprocess==0.5.2
py==1.5.3
pyasn1==0.4.2
pycparser==2.18
Pygments==2.2.0
PyNaCl==1.2.1
Pyphen==0.9.4
pytest==3.5.1
pytest-cov==2.5.1
pytest-cover==3.0.0
pytest-coverage==0.0
pytest-faker==2.0.0
pytest-mock==1.10.0
-e git+https://github.com/crowdcomms/pytest-sqlalchemy.git@f9c666196d59edd289ecf57704ec7b51cff4440a#egg=pytest_sqlalchemy
python-dateutil==2.6.1
python-slugify==1.2.4
PyYAML==3.12
requests==2.19.0
responses==0.9.0
rsa==3.4.2
s3transfer==0.1.13
simplegeneric==0.8.1
six==1.11.0
SQLAlchemy==1.2.7
text-unidecode==1.2
tinycss2==0.6.1
toml==0.9.4
tqdm==4.19.1
traitlets==4.3.2
troposphere==2.3.0
Unidecode==1.0.22
urllib3==1.23
virtualenv==15.2.0
wcwidth==0.1.7
WeasyPrint==0.42.3
webencodings==0.5.1
Werkzeug==0.14.1
whitenoise==3.3.1
wsgi-request-logger==0.4.6
zappa==0.46.2
| open | 2018-08-01T07:31:55Z | 2020-08-20T21:06:21Z | https://github.com/Miserlou/Zappa/issues/1576 | [] | bharling | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 63 | Request for Cosine Metric Learning | Hi, I'm a newbie to deep learning.
Currently I'm working on a tracking-by-detection project related to [deep sort](https://github.com/nwojke/deep_sort).
In order to customize deepsort for my own classes, I need to train [Cosine Metric Learning](https://github.com/nwojke/cosine_metric_learning).
I've searched around for a pytorch implementation of cosine metric learning on google and it leads me to your repo.
So I was wondering if this is the one that meets my requirement?
If yes, how can I use cosine metric learning from your repo?
Many thanks! | closed | 2020-04-18T17:15:17Z | 2020-04-19T03:40:27Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/63 | [] | pvti | 2 |
2noise/ChatTTS | python | 624 | Linux 运行内存飙升 | Linux 下源码部署 没有GPU 的情况下 只用CPU 内存一直飙升 每执行一次 内存增加一次 直到把内存撑爆
Windows 下运行使用GPU 内存比较稳定
Linux 下是什么情况 有人遇到么 | closed | 2024-07-24T06:14:20Z | 2024-07-24T06:59:48Z | https://github.com/2noise/ChatTTS/issues/624 | [] | cpa519904 | 1 |
modin-project/modin | pandas | 6,489 | REFACTOR: __invert__ should raise a TypeError at API layer for non-integer types | We raise the correct TypeError, but we do at the execution layer. | closed | 2023-08-18T19:29:59Z | 2023-08-24T10:05:55Z | https://github.com/modin-project/modin/issues/6489 | [
"Code Quality 💯",
"P2"
] | mvashishtha | 1 |
2noise/ChatTTS | python | 477 | 出色的工作,请问100k hours 的主模型是否有开源计划 | closed | 2024-06-27T08:41:10Z | 2024-06-28T09:46:16Z | https://github.com/2noise/ChatTTS/issues/477 | [
"documentation"
] | XintaoZhao0805 | 5 |
|
gunthercox/ChatterBot | machine-learning | 1,667 | AttributeError: 'str' object has no attribute 'text' | """
Created on Thu Mar 14 23:59:27 2019
@author: anjarul
"""
from chatterbot import ChatBot
from chatterbot.comparisons import LevenshteinDistance
bot2 = ChatBot('Eagle',
logic_adapters=['chatterbot.logic.BestMatch'
],
preprocessors=[
'chatterbot.preprocessors.clean_whitespace'
],
read_only=True
)
while True:
message = input ('You: ')
reply = bot2.get_response(message)
dist = LevenshteinDistance().compare(message,reply)
print (dist,' sdd')
print('Eagle: ',reply)
if message.strip()=='bye':
print('Eagle: bye')
break;
when i run this, i got an error.
Traceback (most recent call last):
File "two.py", line 51, in <module>
dist = LevenshteinDistance().compare(message,reply)
File "/home/anjarul/anaconda3/lib/python3.6/site-packages/chatterbot/comparisons.py", line 44, in compare
if not statement.text or not other_statement.text:
AttributeError: 'str' object has no attribute 'text'
how can I solve this issue | closed | 2019-03-14T20:44:39Z | 2020-01-10T10:29:14Z | https://github.com/gunthercox/ChatterBot/issues/1667 | [] | anjarul | 3 |
paulpierre/RasaGPT | fastapi | 68 | Telegram no response my message | I did follow all the setting including telegram bot,
but when i send me message, api got response and actions did success, but my telegram din get any response
Chat API:
```
DEBUG:config:Input: hey
19/01/2024
21:27:45
Input: hey
19/01/2024
21:27:45
DEBUG:config:💬 Query received: hey
19/01/2024
21:27:45
💬 Query received: hey
19/01/2024
21:27:45
DEBUG:config:[Document(page_content='hey')]
19/01/2024
21:27:45
[Document(page_content='hey')]
19/01/2024
21:27:46
DEBUG:openai:message='Request to OpenAI API' method=post path=https://api.openai.com/v1/embeddings
19/01/2024
21:27:46
message='Request to OpenAI API' method=post path=https://api.openai.com/v1/embeddings
19/01/2024
21:27:46
DEBUG:openai:api_version=None
19/01/2024
21:27:46
api_version=None
19/01/2024
21:27:46
DEBUG:urllib3.util.retry:Converted retries value: 2 -> Retry(total=2, connect=None, read=None, redirect=None, status=None)
19/01/2024
21:27:46
Converted retries value: 2 -> Retry(total=2, connect=None, read=None, redirect=None, status=None)
19/01/2024
21:27:46
DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): api.openai.com:443
19/01/2024
21:27:46
Starting new HTTPS connection (1): api.openai.com:443
19/01/2024
21:27:46
DEBUG:urllib3.connectionpool:https://api.openai.com:443 "POST /v1/embeddings HTTP/1.1" 200 None
19/01/2024
21:27:46
https://api.openai.com:443 "POST /v1/embeddings HTTP/1.1" 200 None
19/01/2024
21:27:46
DEBUG:openai:message='OpenAI API response' path=https://api.openai.com/v1/embeddings processing_ms=20 request_id=7467ad6e233b8da46c4434d2d726e2eb response_code=200
19/01/2024
21:27:46
message='OpenAI API response' path=https://api.openai.com/v1/embeddings processing_ms=20 request_id=7467ad6e233b8da46c4434d2d726e2eb response_code=200
19/01/2024
21:27:46
/usr/local/lib/python3.9/site-packages/langchain/llms/openai.py:216: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI`
19/01/2024
21:27:46
warnings.warn(
19/01/2024
21:27:46
/usr/local/lib/python3.9/site-packages/langchain/llms/openai.py:811: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI`
19/01/2024
21:27:46
warnings.warn(
19/01/2024
21:27:46
DEBUG:openai:message='Request to OpenAI API' method=post path=https://api.openai.com/v1/chat/completions
19/01/2024
21:27:46
message='Request to OpenAI API' method=post path=https://api.openai.com/v1/chat/completions
19/01/2024
21:27:46
DEBUG:openai:api_version=None
19/01/2024
21:27:46
api_version=None
19/01/2024
21:27:49
DEBUG:urllib3.connectionpool:https://api.openai.com:443 "POST /v1/chat/completions HTTP/1.1" 200 None
19/01/2024
21:27:49
https://api.openai.com:443 "POST /v1/chat/completions HTTP/1.1" 200 None
19/01/2024
21:27:49
DEBUG:openai:message='OpenAI API response' path=https://api.openai.com/v1/chat/completions processing_ms=2486 request_id=99c1f207c677c83dee1a91abe5a65b66 response_code=200
19/01/2024
21:27:49
message='OpenAI API response' path=https://api.openai.com/v1/chat/completions processing_ms=2486 request_id=99c1f207c677c83dee1a91abe5a65b66 response_code=200
19/01/2024
21:27:49
DEBUG:config:💬 LLM result: {
19/01/2024
21:27:49
"message": "Hello! How can I assist you today?",
19/01/2024
21:27:49
"tags": ["greeting"],
19/01/2024
21:27:49
"is_escalate": false
19/01/2024
21:27:49
}
19/01/2024
21:27:49
💬 LLM result: {
19/01/2024
21:27:49
"message": "Hello! How can I assist you today?",
19/01/2024
21:27:49
"tags": ["greeting"],
19/01/2024
21:27:49
"is_escalate": false
19/01/2024
21:27:49
}
19/01/2024
21:27:49
DEBUG:config:Output: { "message": "Hello! How can I assist you today?", "tags": ["greeting"], "is_escalate": false}
19/01/2024
21:27:49
Output: { "message": "Hello! How can I assist you today?", "tags": ["greeting"], "is_escalate": false}
19/01/2024
21:27:49
DEBUG:config:👤 User found: identifier_type=<CHANNEL_TYPE.TELEGRAM: 2> uuid=UUID('65038b55-3012-4a87-b43f-5ff5e8b418b0') identifier='373384804' last_name=None phone=None device_fingerprint=None updated_at=datetime.datetime(2024, 1, 18, 18, 55, 23, 469251) id=1 first_name='Kenny' email=None dob=None created_at=datetime.datetime(2024, 1, 18, 18, 55, 23, 469243)
19/01/2024
21:27:49
👤 User found: identifier_type=<CHANNEL_TYPE.TELEGRAM: 2> uuid=UUID('65038b55-3012-4a87-b43f-5ff5e8b418b0') identifier='373384804' last_name=None phone=None device_fingerprint=None updated_at=datetime.datetime(2024, 1, 18, 18, 55, 23, 469251) id=1 first_name='Kenny' email=None dob=None created_at=datetime.datetime(2024, 1, 18, 18, 55, 23, 469243)
19/01/2024
21:27:49
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): rasa-core:5005
19/01/2024
21:27:49
Starting new HTTP connection (1): rasa-core:5005
19/01/2024
21:27:50
DEBUG:urllib3.connectionpool:http://rasa-core:5005 "POST /webhooks/telegram/webhook HTTP/1.1" 200 7
19/01/2024
21:27:50
http://rasa-core:5005 "POST /webhooks/telegram/webhook HTTP/1.1" 200 7
19/01/2024
21:27:50
DEBUG:config:[🤖 RasaGPT API webhook]
19/01/2024
21:27:50
Posting data: {"update_id": "125010864", "message": {"message_id": 14, "from": {"id": 373384804, "is_bot": false, "first_name": "Kenny", "last_name": "Ong", "username": "youyi1314", "language_code": "en", "is_premium": true}, "chat": {"id": 373384804, "first_name": "Kenny", "last_name": "Ong", "username": "youyi1314", "type": "private"}, "date": 1705670865, "text": "hey", "meta": {"response": "Hello! How can I assist you today?", "tags": ["greeting"], "is_escalate": false, "session_id": "3ad102ef-71a6-466f-99c2-9b144835ed42"}}}
19/01/2024
21:27:50
19/01/2024
21:27:50
[🤖 RasaGPT API webhook]
19/01/2024
21:27:50
Rasa webhook response: success
19/01/2024
21:27:50
[🤖 RasaGPT API webhook]
19/01/2024
21:27:50
Posting data: {"update_id": "125010864", "message": {"message_id": 14, "from": {"id": 373384804, "is_bot": false, "first_name": "Kenny", "last_name": "Ong", "username": "youyi1314", "language_code": "en", "is_premium": true}, "chat": {"id": 373384804, "first_name": "Kenny", "last_name": "Ong", "username": "youyi1314", "type": "private"}, "date": 1705670865, "text": "hey", "meta": {"response": "Hello! How can I assist you today?", "tags": ["greeting"], "is_escalate": false, "session_id": "3ad102ef-71a6-466f-99c2-9b144835ed42"}}}
19/01/2024
21:27:50
19/01/2024
21:27:50
[🤖 RasaGPT API webhook]
19/01/2024
21:27:50
Rasa webhook response: success
```
Chat Actions:
<img width="1728" alt="Screenshot 2024-01-19 at 9 31 46 PM" src="https://github.com/paulpierre/RasaGPT/assets/8391468/7e64efdc-a690-433a-8db4-7437999514ce">
and my telegram din get any message
<img width="1746" alt="Screenshot 2024-01-19 at 9 25 18 PM" src="https://github.com/paulpierre/RasaGPT/assets/8391468/ef6af710-4458-4d18-b173-0d5d62f904bf">
| open | 2024-01-19T13:32:19Z | 2024-01-31T08:02:05Z | https://github.com/paulpierre/RasaGPT/issues/68 | [] | youyi1314 | 0 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 2,937 | Migrate from v1.23 kube-scheduler binary to v1.25 | We run into this issue trying to do it though.
```
E1110 14:36:04.801876 1 run.go:74] "command failed" err="couldn't create resource lock: endpoints lock is removed, migrate to endpointsleases"
``` | closed | 2022-11-10T14:38:59Z | 2022-11-14T10:18:48Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/2937 | [
"maintenance"
] | consideRatio | 1 |
vaexio/vaex | data-science | 1,562 | vaex groupby agg sum of all columns for a larger dataset | I have a dataset consisting of 1800000 rows and 45 columns the operation that I am trying to perform is group by one column, the sum of other columns
the 1st step I did is considering data_df as my data frame and all the columns are numeric
```
columns= data_df.column_names
df_result = df.groupby(columns,agg='sum')
```
the result is Kernal getting restarted the RAM of the system is 32 GB

another approach that I tried
```
df=None
for col in colm:
print("the col is ",col)
if df is None:
df= data_df.groupby(data_df.MSISDN, agg=[vaex.agg.sum(col)])
else:
dfTemp= data_df.groupby(data_df.MSISDN, agg=[vaex.agg.sum(col)])
df =df.join(dfTemp,left_on="MSISDN",right_on ="MSISDN",how ="inner",allow_duplication=True)
del dfTemp
```
here I am able to find the sum up to 11 columns then the kernel gets restarted again is there any other way to get the results using vaex ?
thanks! | closed | 2021-09-02T12:19:20Z | 2022-08-07T19:40:38Z | https://github.com/vaexio/vaex/issues/1562 | [] | spb722 | 2 |
amidaware/tacticalrmm | django | 2,061 | [UI ISSUE] Ping checks output nonsensical | **Is your feature request related to a problem? Please describe.**
The outputs of ping checks are unusable at best.
There is no Y axis explanation, the output does not explain why it failed

**Describe the solution you'd like**
just like cpu and ram the output should be on a chart with the answer time as the X value
output should be readable
and it should do only 1 ping not the default 3 or set the amount and average
**Describe alternatives you've considered**
back to scripting this one :/
| open | 2024-11-04T12:17:19Z | 2024-11-13T10:57:13Z | https://github.com/amidaware/tacticalrmm/issues/2061 | [] | P6g9YHK6 | 2 |
pytorch/pytorch | deep-learning | 149,872 | Do all lazy imports for torch.compile in one place? | When benchmarking torch.compile with warm start, I noticed 2s of time in the backend before pre-grad passes were called. Upon further investigation I discovered this is just the time of lazy imports.
Lazy imports can distort profiles and hide problems, especially when torch.compile behavior changes on the first iteration vs next iterations.
Strawman: put all of the lazy compiles for torch.compile into one function (named "lazy_imports"), call this from somewhere (maybe on the first torch.compile call...), and ensure that it shows up on profiles aptly named | open | 2025-03-24T19:23:54Z | 2025-03-24T19:23:54Z | https://github.com/pytorch/pytorch/issues/149872 | [] | zou3519 | 0 |
microsoft/MMdnn | tensorflow | 58 | [Group convolution in Keras] ResNeXt mxnet -> IR -> keras | Hi
Thank you for a great covert tool.
I am trying to convert from mxnet resnext to keras.
symbol file: http://data.mxnet.io/models/imagenet/resnext/101-layers/resnext-101-64x4d-symbol.json
param file: http://data.mxnet.io/models/imagenet/resnext/101-layers/resnext-101-64x4d-0000.params
I could convert from mxnet to IR with no error,
>python -m mmdnn.conversion._script.convertToIR -f mxnet -n resnext-101-64x4d-symbol.json -w resnext-101-64x4d-0000.params -d resnext-101-64x4d --inputShape 3 224 224
but failed to convert from IR to keras with an error below.
Would you support this model?
Regards,
-----
>python -m mmdnn.conversion._script.IRToCode -f keras --IRModelPath resnext-101-64x4d.pb --dstModelPath keras_resnext-101-64x4d.py
Parse file [resnext-101-64x4d.pb] with binary format successfully.
Traceback (most recent call last):
File "C:\Anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "C:\Anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\_script\IRToCode.py", line 120, in <module>
_main()
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\_script\IRToCode.py", line 115, in _main
ret = _convert(args)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\_script\IRToCode.py", line 56, in _convert
emitter.run(args.dstModelPath, args.dstWeightPath, args.phase)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\common\DataStructure\emitter.py", line 21, in run
self.save_code(dstNetworkPath, phase)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\common\DataStructure\emitter.py", line 53, in save_code
code = self.gen_code(phase)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\keras\keras2_emitter.py", line 95, in gen_code
func(current_node)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\keras\keras2_emitter.py", line 194, in emit_Conv
return self._emit_convolution(IR_node, 'layers.Conv{}D'.format(dim))
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\keras\keras2_emitter.py", line 179, in _emit_convolution
input_node, padding = self._defuse_padding(IR_node)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\keras\keras2_emitter.py", line 160, in _defuse_padding
padding = self._convert_padding(padding)
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\keras\keras2_emitter.py", line 139, in _convert_padding
padding = convert_onnx_pad_to_tf(padding)[1:-1]
File "C:\Anaconda3\lib\site-packages\mmdnn\conversion\common\utils.py", line 62, in convert_onnx_pad_to_tf
return np.transpose(np.array(pads).reshape([2, -1])).reshape(-1, 2).tolist()
ValueError: cannot reshape array of size 1 into shape (2,newaxis)
| closed | 2018-01-18T13:38:09Z | 2018-12-27T07:32:09Z | https://github.com/microsoft/MMdnn/issues/58 | [
"bug",
"enhancement",
"help wanted"
] | kamikawa | 14 |
HIT-SCIR/ltp | nlp | 58 | 词性"z" | 在PoSTagging的结果中含有“z”词性(依照北大标注规范),但是在Parser的训练数据中没有"z"词性。
一个解决方法是用自动词性+god dep-relation训练一个parser model。
另外,是否需要z词性还是需要再讨论。
| closed | 2014-04-10T02:57:43Z | 2018-06-30T13:52:37Z | https://github.com/HIT-SCIR/ltp/issues/58 | [
"bug"
] | Oneplus | 1 |
davidsandberg/facenet | computer-vision | 1,157 | Liveness detection | Is it possible to do a liveness check and ensure that it is not a printed photo that the user is holding in front of a webcam? | open | 2020-05-30T13:52:49Z | 2020-05-31T21:15:02Z | https://github.com/davidsandberg/facenet/issues/1157 | [] | dan-developer | 1 |
zappa/Zappa | django | 838 | [Migrated] binary_support logic in handler.py (0.51.0) broke compressed text response | Originally from: https://github.com/Miserlou/Zappa/issues/2080 by [martinv13](https://github.com/martinv13)
<!--- Provide a general summary of the issue in the Title above -->
## Context
The `binary_support` setting used to allow compressing response at application level (for instance using `flask_compress`) in version 0.50.0. As of 0.51.0 it no longer works.
## Expected Behavior
<!--- Tell us what should happen -->
Compressed response using flask_compress should be possible.
## Actual Behavior
<!--- Tell us what happens instead -->
In `handler.py`, response is forced through `response.get_data(as_text=True)`, which fails for compressed payload, thus throwing an error. This is due to the modifications in #2029 which fixed a bug (previously all responses where base64 encoded), but introduced this one.
## Possible Fix
<!--- Not obligatory, but suggest a fix or reason for the bug -->
A possibility would be to partially revert to the previous version and just change in `handler.py` the "or" for a "and" in the following condition: `not response.mimetype.startswith("text/") or response.mimetype != "application/json")`. I can propose a simple PR for this.
## Steps to Reproduce
Configure Flask with flask_compress; any text or json response will fail with the following error: `'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte`
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: 0.51.0
* Operating System and Python version: Python 3.7 on Lambda
* Your `zappa_settings.json`: relevant option: binary_support: true
| closed | 2021-02-20T12:52:18Z | 2022-08-16T05:15:29Z | https://github.com/zappa/Zappa/issues/838 | [
"duplicate"
] | jneves | 1 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 163 | Use chtgpt or smth else to parse existing cv and fill plain_text_resume.yaml | Make prompt or smth to use chtgpt or smth else to parse existing cv and fill plain_text_resume.yaml. Automate yaml creating | closed | 2024-08-30T15:40:07Z | 2024-09-01T03:55:57Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/163 | [] | air55555 | 3 |
cvat-ai/cvat | tensorflow | 8,528 | logo, plate and shape recognition | show the system running and codigos | closed | 2024-10-10T08:59:55Z | 2024-10-10T09:17:54Z | https://github.com/cvat-ai/cvat/issues/8528 | [
"invalid"
] | 26092423 | 1 |
iperov/DeepFaceLab | deep-learning | 5,420 | BrokenPipeError, 2xRTX5000, Windows 10 | Hello iperov! I am getting the following error on Windows 10 and 2x RTX 5000.
I have tried:
DeepFaceLab_NVIDIA_build_08_02_2020 (Works on both RTX5000 and 2xRTX5000 )
DeepFaceLab_NVIDIA_RTX3000_series_build_10_09_2021 (Doesn't work on 2xRTX5000, works on single RTX5000)
DeepFaceLab_NVIDIA_RTX3000_series_build_10_20_2021 (Doesn't work on 2xRTX5000, works on single RTX5000)
I am getting the following error after running the "6) train SAEHD.bat" file:
----------------------------------------------------------------
Running trainer.
[new] No saved models found. Enter a name of a new model :
new
Model first run.
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : Quadro RTX 5000
[1] : Quadro RTX 5000
[0,1] Which GPU indexes to choose? :
0,1
[0] Autobackup every N hour ( 0..24 ?:help ) :
0
[n] Write preview history ( y/n ?:help ) :
n
[0] Target iteration :
0
[n] Flip SRC faces randomly ( y/n ?:help ) :
n
[y] Flip DST faces randomly ( y/n ?:help ) :
y
[16] Batch_size ( ?:help ) :
16
[128] Resolution ( 64-640 ?:help ) :
128
[wf] Face type ( h/mf/f/wf/head ?:help ) :
wf
[liae-ud] AE architecture ( ?:help ) :
liae-ud
[256] AutoEncoder dimensions ( 32-1024 ?:help ) :
256
[64] Encoder dimensions ( 16-256 ?:help ) :
64
[64] Decoder dimensions ( 16-256 ?:help ) :
64
[22] Decoder mask dimensions ( 16-256 ?:help ) :
22
[y] Masked training ( y/n ?:help ) :
y
[n] Eyes and mouth priority ( y/n ?:help ) :
n
[n] Uniform yaw distribution of samples ( y/n ?:help ) :
n
[n] Blur out mask ( y/n ?:help ) :
n
[y] Place models and optimizer on GPU ( y/n ?:help ) :
y
[y] Use AdaBelief optimizer? ( y/n ?:help ) :
y
[n] Use learning rate dropout ( n/y/cpu ?:help ) :
n
[y] Enable random warp of samples ( y/n ?:help ) :
y
[0.0] Random hue/saturation/light intensity ( 0.0 .. 0.3 ?:help ) :
0.0
[0.0] GAN power ( 0.0 .. 5.0 ?:help ) :
0.0
[0.0] Face style power ( 0.0..100.0 ?:help ) :
0.0
[0.0] Background style power ( 0.0..100.0 ?:help ) :
0.0
[none] Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :
none
[n] Enable gradient clipping ( y/n ?:help ) :
n
[n] Enable pretraining mode ( y/n ?:help ) :
n
Initializing models: 100%|###############################################################| 5/5 [00:01<00:00, 2.83it/s]
Loading samples: 100%|##############################################################| 654/654 [00:01<00:00, 470.29it/s]
Loading samples: 100%|############################################################| 1619/1619 [00:03<00:00, 498.11it/s]
Exception in thread Thread-37:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-32:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-30:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-50:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-51:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-47:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-44:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-48:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-52:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-41:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-42:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-46:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-38:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-33:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-49:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-40:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-29:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-43:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-31:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-36:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-35:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-34:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-39:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
Exception in thread Thread-45:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 11, in launch_thread
generator._start()
File "E:\DeepFaceLab_NVIDIA_RTX3000_series\_internal\DeepFaceLab\core\joblib\SubprocessGenerator.py", line 43, in _start
p.start()
File "multiprocessing\process.py", line 105, in start
File "multiprocessing\context.py", line 223, in _Popen
File "multiprocessing\context.py", line 322, in _Popen
File "multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "multiprocessing\reduction.py", line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
| closed | 2021-11-01T01:44:40Z | 2021-11-17T11:08:33Z | https://github.com/iperov/DeepFaceLab/issues/5420 | [] | asesli | 5 |
mwaskom/seaborn | data-visualization | 3,491 | Pointplot dodge magnitude appears to have changed | Based on one of the gallery examples; the strip and point plots no longer align:
```python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
iris = sns.load_dataset("iris")
# "Melt" the dataset to "long-form" or "tidy" representation
iris = pd.melt(iris, "species", var_name="measurement")
# Show each observation with a scatterplot
sns.stripplot(
data=iris, x="value", y="measurement", hue="species",
dodge=True, alpha=.25, zorder=1, legend=False
)
# Show the conditional means, aligning each pointplot in the
# center of the strips by adjusting the width allotted to each
# category (.8 by default) by the number of hue levels
sns.pointplot(
data=iris, x="value", y="measurement", hue="species",
dodge=.8 - .8 / 3, palette="dark",
linestyle="none", markers="d", errorbar=None
)
```

| closed | 2023-09-24T18:31:46Z | 2023-09-25T00:20:14Z | https://github.com/mwaskom/seaborn/issues/3491 | [
"bug",
"mod:categorical"
] | mwaskom | 0 |
donnemartin/system-design-primer | python | 949 | Dbms | open | 2024-09-27T00:23:10Z | 2024-12-02T01:13:13Z | https://github.com/donnemartin/system-design-primer/issues/949 | [
"needs-review"
] | Ashishkushwaha7273 | 0 |
|
jpadilla/django-rest-framework-jwt | django | 379 | JWT_PAYLOAD_GET_USER_ID_HANDLER setting ignored in jwt_get_secret_key | In function jwt_get_secret_key() "user_id" is read directly from by payload.get('user_id') which leads to problems when using custom encoding on payload | open | 2017-09-22T08:36:42Z | 2017-12-18T20:15:45Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/379 | [] | SPKorhonen | 1 |
microsoft/qlib | deep-learning | 1,446 | Normalize with the Error:ValueError: need at most 63 handles, got a sequence of length 72 | ## 🐛 Bug Description
When I was tring to normalize the 1min data, use following code,
(env38) C:\Users\Anani>python scripts/data_collector/yahoo/collector.py normalize_data --qlib_data_1d_dir ~/.qlib/qlib_data/cn_data --source_dir ~/.qlib/stock_data/source/cn_data_1min --normalize_dir ~/.qlib/stock_data/source/cn_1min_nor --region CN --interval 1min --max_workers 8
I got this ERROR code,
2023-02-22 21:54:27.234 | INFO | data_collector.utils:get_calendar_list:106 - end of get calendar list: ALL.
[6924:MainThread](2023-02-22 21:55:01,958) INFO - qlib.Initialization - [config.py:416] - default_conf: client.
[6924:MainThread](2023-02-22 21:55:02,858) INFO - qlib.Initialization - [__init__.py:74] - qlib successfully initialized based on client settings.
[6924:MainThread](2023-02-22 21:55:02,859) INFO - qlib.Initialization - [__init__.py:76] - data_path={'__DEFAULT_FREQ': WindowsPath('C:/Users/Anani/.qlib/qlib_data/cn_data')}
Exception in thread Thread-1:
Traceback (most recent call last):
File "C:\Users\Anani\anaconda3\envs\env38\lib\threading.py", line 932, in _bootstrap_inner
self.run()
File "C:\Users\Anani\anaconda3\envs\env38\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "C:\Users\Anani\anaconda3\envs\env38\lib\multiprocessing\pool.py", line 519, in _handle_workers
cls._wait_for_updates(current_sentinels, change_notifier)
File "C:\Users\Anani\anaconda3\envs\env38\lib\multiprocessing\pool.py", line 499, in _wait_for_updates
wait(sentinels, timeout=timeout)
File "C:\Users\Anani\anaconda3\envs\env38\lib\multiprocessing\connection.py", line 879, in wait
ready_handles = _exhaustive_wait(waithandle_to_obj.keys(), timeout)
File "C:\Users\Anani\anaconda3\envs\env38\lib\multiprocessing\connection.py", line 811, in _exhaustive_wait
res = _winapi.WaitForMultipleObjects(L, False, timeout)
ValueError: need at most 63 handles, got a sequence of length 72
## Environment
- Qlib version:0.9.1.99
- Python version: 3.8.12
- OS (`Windows`, `Linux`, `MacOS`): win10 LTSC 1809
- CPU: E5 2696 v3*2, 36C72T
## Additional Notes
I have learned that problem may be caused by the CPU cores >60,
Is it true? if so, how do I limited the cpu cores when do this project?
SIncerely,
| open | 2023-02-22T14:19:49Z | 2024-03-05T04:05:25Z | https://github.com/microsoft/qlib/issues/1446 | [
"bug"
] | louyuenan | 3 |
huggingface/datasets | pandas | 7,168 | sd1.5 diffusers controlnet training script gives new error | ### Describe the bug
This will randomly pop up during training now
```
Traceback (most recent call last):
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1192, in <module>
main(args)
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1041, in main
for step, batch in enumerate(train_dataloader):
File "/usr/local/lib/python3.11/dist-packages/accelerate/data_loader.py", line 561, in __iter__
next_batch = next(dataloader_iter)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/dataloader.py", line 630, in __next__
data = self._next_data()
^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/dataloader.py", line 673, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/_utils/fetch.py", line 50, in fetch
data = self.dataset.__getitems__(possibly_batched_index)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2746, in __getitems__
batch = self.__getitem__(keys)
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2742, in __getitem__
return self._getitem(key)
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2727, in _getitem
formatted_output = format_table(
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 639, in format_table
return formatter(pa_table, query_type=query_type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 407, in __call__
return self.format_batch(pa_table)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 521, in format_batch
batch = self.python_features_decoder.decode_batch(batch)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 228, in decode_batch
return self.features.decode_batch(batch) if self.features else batch
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 2084, in decode_batch
[
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 2085, in <listcomp>
decode_nested_example(self[column_name], value, token_per_repo_id=token_per_repo_id)
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 1403, in decode_nested_example
return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/features/image.py", line 188, in decode_example
image.load() # to avoid "Too many open files" errors
```
### Steps to reproduce the bug
Train on diffusers sd1.5 controlnet example script
This will pop up randomly, you can see in wandb below when i manually resume run everytime this error appears

### Expected behavior
Training to continue without above error
### Environment info
- datasets version: 3.0.0
- Platform: Linux-6.5.0-44-generic-x86_64-with-glibc2.35
- Python version: 3.11.9
- huggingface_hub version: 0.25.1
- PyArrow version: 17.0.0
- Pandas version: 2.2.3
- fsspec version: 2024.6.1
Training on 4090 | closed | 2024-09-25T01:42:49Z | 2024-09-30T05:24:03Z | https://github.com/huggingface/datasets/issues/7168 | [] | Night1099 | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,472 | How to use a pre-trained model for training own dataset? | How to use a pre-trained model for training own dataset? | open | 2022-08-23T06:55:03Z | 2022-09-06T20:35:34Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1472 | [] | TinkingLoeng | 1 |
google-research/bert | nlp | 971 | 请问获得训练好的词向量的值? How to get the pretrained embedding_table? | I wanted to know how to get the word embedding after I pretrain the model. Are there someone kindly tell me? | closed | 2019-12-27T14:03:25Z | 2021-04-26T14:13:54Z | https://github.com/google-research/bert/issues/971 | [] | WHQ1111 | 2 |
microsoft/nlp-recipes | nlp | 73 | [Example] Text classification using MT-DNN | closed | 2019-05-28T16:50:01Z | 2020-01-14T17:51:36Z | https://github.com/microsoft/nlp-recipes/issues/73 | [
"example"
] | saidbleik | 7 |
|
pytest-dev/pytest-html | pytest | 817 | In Selenium pyTest framework getting error as "fixture 'setup_and_teardown' not found" | Working on one selenium script using pyTest framework but while passing setup and teardown method from conftest.py file getting error
PFA script for reference
-
@pytest.mark.usefixtures("setup_and_teardown")
class TestSearch:
def test_search_for_a_valid_product(self):
self.driver.find_element(By.NAME, "search").send_keys("HP")
self.driver.find_element(By.XPATH, "//button\[contains(@class,'btn-default')\]").click()
assert self.driver.find_element(By.LINK_TEXT, "HP LP3065").is_displayed()
-
@pytest.fixture()
def setup_and_teardown(request):
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://tutorialsninja.com/demo/")
request.cls.driver = driver
yield
driver.quit()
-


All error are getting to self.driver as to minimize the code delicacy I have written setup and teardown function in conftest.py file
\` | closed | 2024-06-27T08:00:16Z | 2024-06-27T12:19:11Z | https://github.com/pytest-dev/pytest-html/issues/817 | [] | Tushar7337 | 2 |
healthchecks/healthchecks | django | 127 | C# usage example | ```
using (var client = new System.Net.WebClient())
{
client.DownloadString("ping url");
}
```
I know nothing about C#. Does the above look OK? | closed | 2017-07-19T17:39:28Z | 2018-08-20T09:40:16Z | https://github.com/healthchecks/healthchecks/issues/127 | [] | cuu508 | 3 |
inducer/pudb | pytest | 518 | Exception upon leaving ipython prompt to return to pudb TUI | **Describe the bug**
When I type `!` to drop into an ipython prompt from pudb, upon typing `exit` to return to the pudb TUI I get an error:
```python
*** Pudb UI Exception Encountered: Error while showing error dialog ***
Traceback (most recent call last):
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/pudb/debugger.py", line 455, in user_line
self.interaction(frame)
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/pudb/debugger.py", line 421, in interaction
self.ui.call_with_ui(self.ui.interaction, exc_tuple,
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/pudb/debugger.py", line 2412, in call_with_ui
return f(*args, **kwargs)
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/pudb/debugger.py", line 2709, in interaction
self.event_loop()
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/pudb/debugger.py", line 2665, in event_loop
self.screen.draw_screen(self.size, canvas)
File "/home/pdmurray/.pyenv/versions/3.9.12/lib/python3.9/site-packages/urwid/raw_display.py", line 700, in draw_screen
assert self._started
AssertionError
```
This error appears in the pop-up console at the bottom of the TUI. Once this happens, I am unable to drop back into an ipython prompt by typing `!`, and the error message appears every time I execute the next line of code or do anything.
**To Reproduce**
Steps to reproduce the behavior:
1. Configure pudb to use `ipython` as its shell.
2. Add a breakpoint with `import pudb; pudb.set_trace()` in a script.
3. Execute the script. Then type `!` to drop into an ipython prompt, and then `exit` to return to pudb. The error message should appear in the console drawer.
This error appears consistently across both my desktop and laptop on any python script I'm debugging.
**Expected behavior**
I should be able to enter and exit the `ipython` prompt without triggering an error.
**Screenshots**
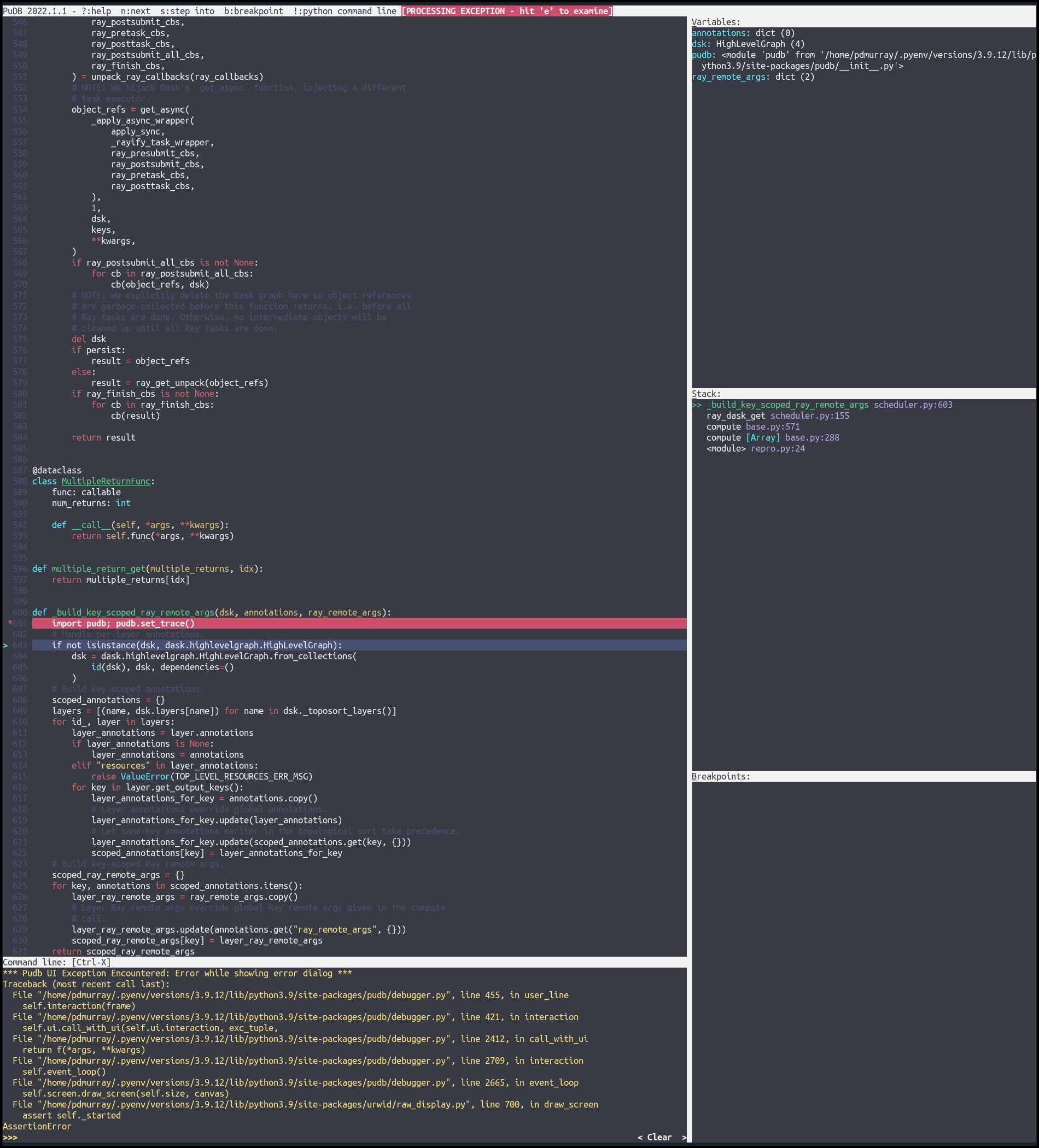
**Versions**
pudb 2022.1.1
python 3.9
| closed | 2022-05-26T17:36:36Z | 2022-05-26T23:07:38Z | https://github.com/inducer/pudb/issues/518 | [
"Bug"
] | peytondmurray | 1 |
skforecast/skforecast | scikit-learn | 167 | module 'sklearn' has no attribute 'pipeline' | Good afternoon!!
When trying to implement :
```
forecaster = ForecasterAutoreg(
regressor = XGBRegressor(),
lags = 24
)
forecaster
```
I get the following error:
`module 'sklearn' has no attribute 'pipeline'`
I looked a lot though internet and somesone said that import sklearn.pipeline would resolve the problem for the moment, but that's not my case... the error remains...
I would be so gratefull if someone helps me!
Thanks a lot
| closed | 2022-06-22T11:00:45Z | 2022-08-08T09:42:38Z | https://github.com/skforecast/skforecast/issues/167 | [
"documentation",
"question"
] | AraceliAL | 2 |
jupyter-book/jupyter-book | jupyter | 1,612 | Issue on page /코스피_코스닥_순위/2022-01-20.html | Your issue content here. | closed | 2022-01-22T12:31:18Z | 2022-02-22T01:00:04Z | https://github.com/jupyter-book/jupyter-book/issues/1612 | [] | funnyfrog | 2 |
cvat-ai/cvat | computer-vision | 9,198 | need to map the cvat to local machine ip | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
_No response_
### Expected Behavior
_No response_
### Possible Solution
_No response_
### Context
my cvat tool is running fine on localhost:8080 now i want it to run on my machine ip so that anyone in the network can access the tool and do the anotation
### Environment
```Markdown
``` | closed | 2025-03-11T05:47:12Z | 2025-03-13T09:33:00Z | https://github.com/cvat-ai/cvat/issues/9198 | [
"question"
] | ashishbbr03 | 1 |
plotly/plotly.py | plotly | 4,468 | Python 3.6 tests are not running on CircleCI missing Chrome Driver | ```
Chrome version major is 120
Installed version of Google Chrome is 120.0.6099.129
404
Matching Chrome Driver Version 404'd, falling back to first matching major version.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 790 100 790 0 0 56428 0 --:--:-- --:--:-- --:--:-- 56428
New ChromeDriver version to be installed: 1204232
1204232 will be installed
curl: (22) The requested URL returned error: 404
Exited with code exit status 22
``` | closed | 2023-12-21T21:41:56Z | 2023-12-21T22:10:02Z | https://github.com/plotly/plotly.py/issues/4468 | [] | archmoj | 1 |
polakowo/vectorbt | data-visualization | 523 | vbt telegram signal time error | I have a error from ---> UPDATE_EVERY = vbt.utils.datetime_.datetime_to_ms(TIMEFRAME) how can i fix ? | open | 2022-11-12T20:31:22Z | 2024-03-17T01:48:47Z | https://github.com/polakowo/vectorbt/issues/523 | [
"stale"
] | denizhantoy | 1 |
mckinsey/vizro | plotly | 869 | Numerical values in selector with non-numerical column don't work | ### Which package?
vizro
### Package version
0.1.26
### Description
> [!NOTE]
> Not urgent, let's wait until after pydantic v2 to fix.
If a column contains only numerical values but is `object` type (as can happen when you load data from a file) then it's correctly considered a categorical variable so given selector `vm.Dropdown` by default. However, filtering on it won't work.
The root cause is:
1. pydantic model has `OptionsType = Union[list[StrictBool], list[float], list[str], list[date], list[OptionsDictType]]` and casts options to `float`
2. `_filter_isin` is then comparing series of `object`s to `float`, which doesn't return anything
This is a problem with at least Dropdown, Checklist, RadioItems and probably affects more than just numerical types.
Possible fixes:
* change order of `Union` in pydantic field definition but without breaking anything else so need to be careful
* something in `_filter_isin` that does conversions
* rethink which selectors are allowed when, which I think is a bit wrong anyway because e.g. `RangeSlider` should be usable for ordinal data. Also understand the `bool` case from https://github.com/mckinsey/vizro/issues/445
* for now, just cast your column to the right type
### How to Reproduce
[PyCafe snippet](https://py.cafe/snippet/vizro/v1?pycafe-app-view=false&pycafe-edit-enable=true#c=H4sIAOE8M2cEA41SXW-bMBT9K8hPRKIWHy1pIjFpXdVtb1MftocYRU5swBLYzJhULMp_3zWGNNVWpYBk7r3nnnOu7SPaK8bRGommVdp4B_FHK9xAru482nmHhsip1FLJIANfy4gstGoc2pvqP21A5GUJG7qreTcjoL3a0nJbagEMRLLCy4AMP1JDnzRtuH8kqBm2e1X3jSRo7W0IiggKPIJityQE5aeFbYXSBTQHpn9ymHZmaLkvpIEWIltacsAdGvwD_nwiPXiMMDXPCHroS5Bwub0Cw5JL02UbQH8uv4JjvxBlr3l2OYXPwPq2sN4zViwW-ZlAGq1q1_4kasO172yB0oXFwOt4zfdG6QyAz5QJ9d3wpvMd1egahgXFnaKaOfOPc-jbgUDDLvmIHc_AX-BdL2prbgIusO6lDwgUIM1_90Lzxk4H5z6e06csxBGOb0eA3bK5AGE7mEpJSLSDYoLxm0OI4xRHUKrpoHqD1kd04LoTFhWDgFLmWb3Y9ESlIQrQvgJPmgNoc67A_ei4geKLYKZC6-guDFAj5C8XJi76xkVZgY4NBYO2QtT8AVg7rr_ATlMhuX5HwUJvdg4LkJZaXoRO-Sk4Y15dTEL3Kxyv0jRJw_u7NE5X0f-5oe-VkrYtboe3xHocfGaNohAvwyRJk1V0myyTcPUurbNzfSOmwa5twjz_G3NnmWr2t7z7iCbcZUjT-projLOq9j0F42HApdvkp7-qY833eAQAAA)
```python
import vizro.models as vm
import pandas as pd
from vizro import Vizro
from vizro.tables import dash_ag_grid
df = pd.DataFrame({"my_column": ["1", "2", "3"]})
# Uncomment this line to see the bug
# df["my_column"] = df["my_column"].astype(int)
page = vm.Page(
title="Bug",
components=[vm.AgGrid(figure=dash_ag_grid(data_frame=df))],
controls=[vm.Filter(column="my_column", selector=vm.RadioItems())],
)
dashboard = vm.Dashboard(pages=[page])
Vizro().build(dashboard).run()
```
### Output
_No response_
### Code of Conduct
- [X] I agree to follow the [Code of Conduct](https://github.com/mckinsey/vizro/blob/main/CODE_OF_CONDUCT.md). | open | 2024-11-12T11:41:04Z | 2024-11-12T11:41:09Z | https://github.com/mckinsey/vizro/issues/869 | [
"Bug Report :bug:"
] | antonymilne | 0 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,509 | [Bug]: Issue with /progress endpoint | ### Checklist
- [x] The issue exists after disabling all extensions
- [x] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [x] The issue exists in the current version of the webui
- [x] The issue has not been reported before recently
- [ ] The issue has been reported before but has not been fixed yet
### What happened?
/progress now takes up to 2-3 seconds to respond per query. It used to be almost instant. Using a highly outdated of this code base, I was able to query progress very rapidly. Using a more recent version, it's very slow.
### Steps to reproduce the problem
Call the /progress endpoint and count how many milliseconds elapsed
### What should have happened?
We expect a very fast response for snappy progress bar updating (under 250 ms), but it takes about 2-3 seconds to respond
### What browsers do you use to access the UI ?
_No response_
### Sysinfo
{
"Platform": "Windows-10-10.0.19045-SP0",
"Python": "3.10.6",
"Version": "1.8.0-RC",
"Commit": "<none>",
"Script path": "C:\\Max\\stable-diffusion-webui-master",
"Data path": "C:\\Max\\stable-diffusion-webui-master",
"Extensions dir": "C:\\Max\\stable-diffusion-webui-master\\extensions",
"Checksum": "fdad020d36f25d89efa333f36e71bbe032b6b5fd1f2d4c043354e52fcfc2477e",
"Commandline": [
"launch.py",
"--api"
],
"Torch env info": {
"torch_version": "2.1.2+cu121",
"is_debug_build": "False",
"cuda_compiled_version": "12.1",
"gcc_version": null,
"clang_version": null,
"cmake_version": null,
"os": "Microsoft Windows 10 Pro",
"libc_version": "N/A",
"python_version": "3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] (64-bit runtime)",
"python_platform": "Windows-10-10.0.19045-SP0",
"is_cuda_available": "True",
"cuda_runtime_version": "11.8.89\r",
"cuda_module_loading": "LAZY",
"nvidia_driver_version": "546.01",
"nvidia_gpu_models": "GPU 0: NVIDIA GeForce RTX 2060 SUPER",
"cudnn_version": null,
"pip_version": "pip3",
"pip_packages": [
"numpy==1.26.2",
"open-clip-torch==2.20.0",
"pytorch-lightning==1.9.4",
"torch==2.1.2+cu121",
"torchdiffeq==0.2.3",
"torchmetrics==1.3.2",
"torchsde==0.2.6",
"torchvision==0.16.2+cu121"
],
"conda_packages": null,
"hip_compiled_version": "N/A",
"hip_runtime_version": "N/A",
"miopen_runtime_version": "N/A",
"caching_allocator_config": "",
"is_xnnpack_available": "True",
"cpu_info": [
"Architecture=9",
"CurrentClockSpeed=3500",
"DeviceID=CPU0",
"Family=107",
"L2CacheSize=3072",
"L2CacheSpeed=",
"Manufacturer=AuthenticAMD",
"MaxClockSpeed=3500",
"Name=AMD Ryzen 5 3600 6-Core Processor ",
"ProcessorType=3",
"Revision=28928"
]
},
"Exceptions": [],
"CPU": {
"model": "AMD64 Family 23 Model 113 Stepping 0, AuthenticAMD",
"count logical": 12,
"count physical": 6
},
"RAM": {
"total": "64GB",
"used": "33GB",
"free": "31GB"
},
"Extensions": [],
"Inactive extensions": [],
"Environment": {
"COMMANDLINE_ARGS": "--api",
"GRADIO_ANALYTICS_ENABLED": "False"
},
"Config": {
"ldsr_steps": 100,
"ldsr_cached": false,
"SCUNET_tile": 256,
"SCUNET_tile_overlap": 8,
"SWIN_tile": 192,
"SWIN_tile_overlap": 8,
"SWIN_torch_compile": false,
"hypertile_enable_unet": false,
"hypertile_enable_unet_secondpass": false,
"hypertile_max_depth_unet": 3,
"hypertile_max_tile_unet": 256,
"hypertile_swap_size_unet": 3,
"hypertile_enable_vae": false,
"hypertile_max_depth_vae": 3,
"hypertile_max_tile_vae": 128,
"hypertile_swap_size_vae": 3,
"sd_model_checkpoint": "v1-5-pruned-emaonly.safetensors [6ce0161689]",
"sd_checkpoint_hash": "6ce0161689b3853acaa03779ec93eafe75a02f4ced659bee03f50797806fa2fa"
},
"Startup": {
"total": 12.934616565704346,
"records": {
"initial startup": 0.02251911163330078,
"prepare environment/checks": 0.008507728576660156,
"prepare environment/git version info": 0.03803229331970215,
"prepare environment/torch GPU test": 2.395559549331665,
"prepare environment/clone repositores": 0.15162944793701172,
"prepare environment/run extensions installers": 0.0,
"prepare environment": 2.630760908126831,
"launcher": 0.0025022029876708984,
"import torch": 4.942748308181763,
"import gradio": 1.000359296798706,
"setup paths": 1.1354761123657227,
"import ldm": 0.006005048751831055,
"import sgm": 0.0,
"initialize shared": 0.2747361660003662,
"other imports": 0.608522891998291,
"opts onchange": 0.0005004405975341797,
"setup SD model": 0.0005002021789550781,
"setup codeformer": 0.001501321792602539,
"setup gfpgan": 0.014012336730957031,
"set samplers": 0.0,
"list extensions": 0.0015010833740234375,
"restore config state file": 0.0,
"list SD models": 0.0010008811950683594,
"list localizations": 0.0,
"load scripts/custom_code.py": 0.003503084182739258,
"load scripts/img2imgalt.py": 0.0005006790161132812,
"load scripts/loopback.py": 0.0005002021789550781,
"load scripts/outpainting_mk_2.py": 0.0,
"load scripts/poor_mans_outpainting.py": 0.0005006790161132812,
"load scripts/postprocessing_caption.py": 0.0005002021789550781,
"load scripts/postprocessing_codeformer.py": 0.0,
"load scripts/postprocessing_create_flipped_copies.py": 0.0005004405975341797,
"load scripts/postprocessing_focal_crop.py": 0.001001119613647461,
"load scripts/postprocessing_gfpgan.py": 0.0,
"load scripts/postprocessing_split_oversized.py": 0.0005002021789550781,
"load scripts/postprocessing_upscale.py": 0.0005006790161132812,
"load scripts/processing_autosized_crop.py": 0.0,
"load scripts/prompt_matrix.py": 0.0005002021789550781,
"load scripts/prompts_from_file.py": 0.0005004405975341797,
"load scripts/sd_upscale.py": 0.0,
"load scripts/xyz_grid.py": 0.0020017623901367188,
"load scripts/ldsr_model.py": 0.759652853012085,
"load scripts/lora_script.py": 0.1301114559173584,
"load scripts/scunet_model.py": 0.0245211124420166,
"load scripts/swinir_model.py": 0.025524139404296875,
"load scripts/hotkey_config.py": 0.0004982948303222656,
"load scripts/extra_options_section.py": 0.0005002021789550781,
"load scripts/hypertile_script.py": 0.047541141510009766,
"load scripts/hypertile_xyz.py": 0.0005004405975341797,
"load scripts/soft_inpainting.py": 0.0005004405975341797,
"load scripts/comments.py": 0.022018909454345703,
"load scripts/refiner.py": 0.0005006790161132812,
"load scripts/seed.py": 0.0005002021789550781,
"load scripts": 1.0233795642852783,
"load upscalers": 0.004503726959228516,
"refresh VAE": 0.0015015602111816406,
"refresh textual inversion templates": 0.0,
"scripts list_optimizers": 0.0010006427764892578,
"scripts list_unets": 0.0,
"reload hypernetworks": 0.0010008811950683594,
"initialize extra networks": 0.011510133743286133,
"scripts before_ui_callback": 0.0020012855529785156,
"create ui": 0.5604817867279053,
"gradio launch": 0.47290897369384766,
"add APIs": 0.2502129077911377,
"app_started_callback/lora_script.py": 0.0005006790161132812,
"app_started_callback": 0.0005006790161132812
}
},
"Packages": [
"accelerate==0.21.0",
"aenum==3.1.15",
"aiofiles==23.2.1",
"aiohttp==3.9.3",
"aiosignal==1.3.1",
"altair==5.3.0",
"antlr4-python3-runtime==4.9.3",
"anyio==3.7.1",
"async-timeout==4.0.3",
"attrs==23.2.0",
"blendmodes==2022",
"certifi==2024.2.2",
"charset-normalizer==3.3.2",
"clean-fid==0.1.35",
"click==8.1.7",
"clip==1.0",
"colorama==0.4.6",
"contourpy==1.2.1",
"cycler==0.12.1",
"deprecation==2.1.0",
"einops==0.4.1",
"exceptiongroup==1.2.0",
"facexlib==0.3.0",
"fastapi==0.94.0",
"ffmpy==0.3.2",
"filelock==3.13.3",
"filterpy==1.4.5",
"fonttools==4.51.0",
"frozenlist==1.4.1",
"fsspec==2024.3.1",
"ftfy==6.2.0",
"gitdb==4.0.11",
"gitpython==3.1.32",
"gradio-client==0.5.0",
"gradio==3.41.2",
"h11==0.12.0",
"httpcore==0.15.0",
"httpx==0.24.1",
"huggingface-hub==0.22.2",
"idna==3.6",
"imageio==2.34.0",
"importlib-resources==6.4.0",
"inflection==0.5.1",
"jinja2==3.1.3",
"jsonmerge==1.8.0",
"jsonschema-specifications==2023.12.1",
"jsonschema==4.21.1",
"kiwisolver==1.4.5",
"kornia==0.6.7",
"lark==1.1.2",
"lazy-loader==0.4",
"lightning-utilities==0.11.2",
"llvmlite==0.42.0",
"markupsafe==2.1.5",
"matplotlib==3.8.4",
"mpmath==1.3.0",
"multidict==6.0.5",
"networkx==3.2.1",
"numba==0.59.1",
"numpy==1.26.2",
"omegaconf==2.2.3",
"open-clip-torch==2.20.0",
"opencv-python==4.9.0.80",
"orjson==3.10.0",
"packaging==24.0",
"pandas==2.2.1",
"piexif==1.1.3",
"pillow==9.5.0",
"pip==22.2.1",
"protobuf==3.20.0",
"psutil==5.9.5",
"pydantic==1.10.15",
"pydub==0.25.1",
"pyparsing==3.1.2",
"python-dateutil==2.9.0.post0",
"python-multipart==0.0.9",
"pytorch-lightning==1.9.4",
"pytz==2024.1",
"pywavelets==1.6.0",
"pyyaml==6.0.1",
"referencing==0.34.0",
"regex==2023.12.25",
"requests==2.31.0",
"resize-right==0.0.2",
"rpds-py==0.18.0",
"safetensors==0.4.2",
"scikit-image==0.21.0",
"scipy==1.13.0",
"semantic-version==2.10.0",
"sentencepiece==0.2.0",
"setuptools==63.2.0",
"six==1.16.0",
"smmap==5.0.1",
"sniffio==1.3.1",
"spandrel==0.1.6",
"starlette==0.26.1",
"sympy==1.12",
"tifffile==2024.2.12",
"timm==0.9.16",
"tokenizers==0.13.3",
"tomesd==0.1.3",
"toolz==0.12.1",
"torch==2.1.2+cu121",
"torchdiffeq==0.2.3",
"torchmetrics==1.3.2",
"torchsde==0.2.6",
"torchvision==0.16.2+cu121",
"tqdm==4.66.2",
"trampoline==0.1.2",
"transformers==4.30.2",
"typing-extensions==4.11.0",
"tzdata==2024.1",
"urllib3==2.2.1",
"uvicorn==0.29.0",
"wcwidth==0.2.13",
"websockets==11.0.3",
"yarl==1.9.4"
]
}
### Console logs
```Shell
venv "C:\Max\stable-diffusion-webui-master\venv\Scripts\Python.exe"
fatal: not a git repository (or any of the parent directories): .git
fatal: not a git repository (or any of the parent directories): .git
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: 1.8.0-RC
Commit hash: <none>
Launching Web UI with arguments: --api
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
Loading weights [6ce0161689] from C:\Max\stable-diffusion-webui-master\models\Stable-diffusion\v1-5-pruned-emaonly.safetensors
Creating model from config: C:\Max\stable-diffusion-webui-master\configs\v1-inference.yaml
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 12.9s (prepare environment: 2.6s, import torch: 4.9s, import gradio: 1.0s, setup paths: 1.1s, initialize shared: 0.3s, other imports: 0.6s, load scripts: 1.0s, create ui: 0.6s, gradio launch: 0.5s, add APIs: 0.3s).
Applying attention optimization: Doggettx... done.
Model loaded in 4.9s (load weights from disk: 0.7s, create model: 0.6s, apply weights to model: 2.8s, apply dtype to VAE: 0.2s, load textual inversion embeddings: 0.3s, calculate empty prompt: 0.3s).
100%|████████████████████████████████████████████████████████████████████████████████| 100/100 [00:13<00:00, 7.64it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 100/100 [00:12<00:00, 7.97it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 100/100 [00:12<00:00, 7.94it/s]
```
### Additional information
_No response_ | open | 2024-04-14T02:57:41Z | 2024-04-19T03:03:30Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15509 | [
"bug-report"
] | monsieurpooh | 2 |
huggingface/transformers | pytorch | 36,295 | [Bugs] RuntimeError: No CUDA GPUs are available in transformers v4.48.0 or above when running Ray RLHF example | ### System Info
- `transformers` version: 4.48.0
- Platform: Linux-3.10.0-1127.el7.x86_64-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.5.2
- Accelerate version: 1.0.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: Yes
- Using GPU in script?: Yes
- GPU type: NVIDIA A800-SXM4-80GB
### Who can help?
@ArthurZucker
### Information
- [x] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
Hi for all!
I failed to run the vLLM project RLHF example script. The code is exactly same as the vLLM docs page: https://docs.vllm.ai/en/latest/getting_started/examples/rlhf.html
The error messages are:
```
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] Error executing method 'init_device'. This might cause deadlock in distributed execution.
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] Traceback (most recent call last):
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/worker/worker_base.py", line 566, in execute_method
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] return run_method(target, method, args, kwargs)
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/utils.py", line 2220, in run_method
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] return func(*args, **kwargs)
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/worker/worker.py", line 155, in init_device
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] torch.cuda.set_device(self.device)
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] File "/usr/local/miniconda3/lib/python3.10/site-packages/torch/cuda/__init__.py", line 478, in set_device
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] torch._C._cuda_setDevice(device)
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] File "/usr/local/miniconda3/lib/python3.10/site-packages/torch/cuda/__init__.py", line 319, in _lazy_init
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] torch._C._cuda_init()
(MyLLM pid=70946) ERROR 02-20 15:38:34 worker_base.py:574] RuntimeError: No CUDA GPUs are available
(MyLLM pid=70946) Exception raised in creation task: The actor died because of an error raised in its creation task, ray::MyLLM.__init__() (pid=70946, ip=11.163.37.230, actor_id=202b48118215566c51057a0101000000, repr=<test_ray_vllm_rlhf.MyLLM object at 0x7fb7453669b0>)
(MyLLM pid=70946) File "/data/cfs/workspace/test_ray_vllm_rlhf.py", line 96, in __init__
(MyLLM pid=70946) super().__init__(*args, **kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/utils.py", line 1051, in inner
(MyLLM pid=70946) return fn(*args, **kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/entrypoints/llm.py", line 242, in __init__
(MyLLM pid=70946) self.llm_engine = self.engine_class.from_engine_args(
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/engine/llm_engine.py", line 484, in from_engine_args
(MyLLM pid=70946) engine = cls(
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/engine/llm_engine.py", line 273, in __init__
(MyLLM pid=70946) self.model_executor = executor_class(vllm_config=vllm_config, )
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/executor/executor_base.py", line 262, in __init__
(MyLLM pid=70946) super().__init__(*args, **kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/executor/executor_base.py", line 51, in __init__
(MyLLM pid=70946) self._init_executor()
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/executor/ray_distributed_executor.py", line 90, in _init_executor
(MyLLM pid=70946) self._init_workers_ray(placement_group)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/executor/ray_distributed_executor.py", line 355, in _init_workers_ray
(MyLLM pid=70946) self._run_workers("init_device")
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/executor/ray_distributed_executor.py", line 476, in _run_workers
(MyLLM pid=70946) self.driver_worker.execute_method(sent_method, *args, **kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/worker/worker_base.py", line 575, in execute_method
(MyLLM pid=70946) raise e
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/worker/worker_base.py", line 566, in execute_method
(MyLLM pid=70946) return run_method(target, method, args, kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/utils.py", line 2220, in run_method
(MyLLM pid=70946) return func(*args, **kwargs)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/vllm/worker/worker.py", line 155, in init_device
(MyLLM pid=70946) torch.cuda.set_device(self.device)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/torch/cuda/__init__.py", line 478, in set_device
(MyLLM pid=70946) torch._C._cuda_setDevice(device)
(MyLLM pid=70946) File "/usr/local/miniconda3/lib/python3.10/site-packages/torch/cuda/__init__.py", line 319, in _lazy_init
(MyLLM pid=70946) torch._C._cuda_init()
(MyLLM pid=70946) RuntimeError: No CUDA GPUs are available
```
I found in transformers==4.47.1 the script could run normally. However when I tried transformers==4.48.0, 4.48.1 and 4.49.0 I got the error messages above. Then I checked pip envs with `pip list` and found only transformers versions are different.
I've tried to change vllm version between 0.7.0 and 0.7.2, the behavior is the same.
Related Ray issues:
* https://github.com/vllm-project/vllm/issues/13597
* https://github.com/vllm-project/vllm/issues/13230
### Expected behavior
The script runs normally. | open | 2025-02-20T07:58:49Z | 2025-03-22T08:03:03Z | https://github.com/huggingface/transformers/issues/36295 | [
"bug"
] | ArthurinRUC | 3 |
automagica/automagica | automation | 44 | Create Ubuntu/Linux Branch (Maybe related to #32) | Hey Oakwood,
I was wondering if you have already analyzed what changes/mods must be made to Automagica to create a version that could work on remote VNC servers.
I use python RPA a lot in my job a similair project called pybotlib that I mostly use the ubuntu-branch to create RPAs for different clients and deploy them to lightweight ubuntu cloud desktops.
In my expirience only very specific windows corporation software like SAP netweaver will not run on a a linux, but most types of RPA automations can be done without a problem in linux.
I am a huge fan of automagica and would like to work on making a linux friendly version that later I could use in my package pybotlib for higher level commands. https://github.com/dkatz23238/pybotlib (Work in progress).
I will be glad, if pertinent, to create a linux branch for automagica with guidance.
If there is a known list of work to do Ill be glad to start working on it, if not I can also go ahead and analyze what needs to be changed/ported.
Many thanks!
| closed | 2019-04-10T14:17:38Z | 2019-04-14T15:37:47Z | https://github.com/automagica/automagica/issues/44 | [] | dkatz23238 | 2 |
jupyter/nbviewer | jupyter | 299 | Raw cells are rendered differently in nbviewer | It seems that line breaks in raw cells are rendered differently in nbviewer.
For example, in the first few lines of the following notebook:
http://nbviewer.ipython.org/github/pierrelux/notebooks/blob/master/Starcluster%20and%20IPython%20tutorial.ipynb
| closed | 2014-06-10T16:43:30Z | 2014-06-10T17:20:15Z | https://github.com/jupyter/nbviewer/issues/299 | [] | pierrelux | 1 |
BlinkDL/RWKV-LM | pytorch | 237 | NCCL watchdog thread terminated with exception: CUDA error: an illegal memory access was encountered | Hi, I just want to train a small version of RWKV-V5-169m model from scratch
I implement it with huggingface:
```
import torch
from transformers import AutoTokenizer, AutoConfig
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
config = AutoConfig.from_pretrained("RWKV/rwkv-4-169m-pile")
tiny_rwkv_configs = {
"num_hidden_layers": 4,
"hidden_size": 256,
"intermediate_size": 1024,
"attention_hidden_size": 256,
"vocab_size": 20480,
}
"""
implement config with tiny_rwkv_configs:
e.g., config.num_hidden_layers = tiny_rwkv_configs['num_hidden_layers']
"""
model = AutoModelForCausalLM.from_config(config)
"""
initialize dataloader, optimizer, etc
"""
for sample in dataloader:
outputs = model(sample)
loss = outputs.loss
```
But, when I backward the loss, I encounter the bug:
```
You are using a CUDA device ('NVIDIA A100-PCIE-40GB') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
Sanity Checking: | | 0/? [00:00<?, ?it/s]/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
Sanity Checking DataLoader 0: 0%| | 0/1 [00:00<?, ?it/s]/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
/nvme1/zecheng/modelzipper/projects/state-space-model/custom_dataset/AR_ywj.py:116: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
Epoch 0: 0%| | 3/1398 [00:00<02:55, 7.95it/s, v_num=tzc, train_lm_loss=nan.0, train_ppl=[E ProcessGroupNCCL.cpp:916] [Rank 0] NCCL watchdog thread terminated with exception: CUDA error: an illegal memory access was encountered
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at ../c10/cuda/CUDAException.cpp:44 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7faa88159617 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x64 (0x7faa8811498d in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #2: c10::cuda::c10_cuda_check_implementation(int, char const*, char const*, int, bool) + 0x118 (0x7faa88215128 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10_cuda.so)
frame #3: c10d::ProcessGroupNCCL::WorkNCCL::finishedGPUExecutionInternal() const + 0x80 (0x7faa8914b250 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #4: c10d::ProcessGroupNCCL::WorkNCCL::isCompleted() + 0x58 (0x7faa8914f078 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #5: c10d::ProcessGroupNCCL::workCleanupLoop() + 0x250 (0x7faa89165910 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #6: c10d::ProcessGroupNCCL::ncclCommWatchdog() + 0x78 (0x7faa89165c18 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #7: <unknown function> + 0xc819d (0x7faacd94619d in /home/amax/anaconda3/envs/zecheng/bin/../lib/libstdc++.so.6)
frame #8: <unknown function> + 0x8609 (0x7fab09939609 in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #9: clone + 0x43 (0x7fab0985e353 in /lib/x86_64-linux-gnu/libc.so.6)
terminate called after throwing an instance of 'std::runtime_error'
what(): [Rank 0] NCCL watchdog thread terminated with exception: CUDA error: an illegal memory access was encountered
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at ../c10/cuda/CUDAException.cpp:44 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7faa88159617 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x64 (0x7faa8811498d in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #2: c10::cuda::c10_cuda_check_implementation(int, char const*, char const*, int, bool) + 0x118 (0x7faa88215128 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libc10_cuda.so)
frame #3: c10d::ProcessGroupNCCL::WorkNCCL::finishedGPUExecutionInternal() const + 0x80 (0x7faa8914b250 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #4: c10d::ProcessGroupNCCL::WorkNCCL::isCompleted() + 0x58 (0x7faa8914f078 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #5: c10d::ProcessGroupNCCL::workCleanupLoop() + 0x250 (0x7faa89165910 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #6: c10d::ProcessGroupNCCL::ncclCommWatchdog() + 0x78 (0x7faa89165c18 in /home/amax/anaconda3/envs/zecheng/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #7: <unknown function> + 0xc819d (0x7faacd94619d in /home/amax/anaconda3/envs/zecheng/bin/../lib/libstdc++.so.6)
frame #8: <unknown function> + 0x8609 (0x7fab09939609 in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #9: clone + 0x43 (0x7fab0985e353 in /lib/x86_64-linux-gnu/libc.so.6)
```
`Worth noting` that I train the mode from scratch, and I only implement 4-layer of RWKV with custom setting, the loss becomes `nan.0` @www
Does anyone encounter this issue?
| open | 2024-04-15T19:11:29Z | 2024-04-16T09:51:49Z | https://github.com/BlinkDL/RWKV-LM/issues/237 | [] | ZetangForward | 1 |
apify/crawlee-python | automation | 832 | Unable to stop crawler. Facing error: "'PlaywrightCrawler' object has no attribute 'stop'" | ## Bug Report: `stop()` method missing in Python PlaywrightCrawler
### Description
While using the Python SDK of Crawlee with PlaywrightCrawler, I encountered an issue where the `stop()` method mentioned in the documentation is not available. This is particularly problematic when trying to implement custom crawling logic that requires programmatic stopping of the crawler.
When attempting to call `pw_crawler.stop()` from within the request handler, I receive the error:
`AttributeError: 'PlaywrightCrawler' object has no attribute 'stop'`
### Expected Behavior
According to the documentation, we should be able to call `crawler.stop()` to gracefully terminate the crawling process. This is especially important when implementing custom logic like:
- Stopping after processing specific content types
- Handling custom request limits
- Managing crawler state based on business logic
### Current Behavior
The Python implementation of PlaywrightCrawler doesn't expose the `stop()` method, making it impossible to programmatically stop the crawler from within async request handlers or navigation hooks.
### Impact
Without a proper stop mechanism, developers are forced to:
- Raise exceptions to terminate crawling (which feels hacky)
- Implement complex state management
- Cannot gracefully stop the crawler while preserving the crawled data
- Risk potential memory leaks or resource management issues
### Environment
- Crawlee Python: 3.11
- Python Version: 3.11
- Platform: Linux/Docker
### Additional Context
This is critical for production environments where we need precise control over the crawling process, especially when:
- Implementing custom request limits
- Handling mixed content types (web pages and files)
- Managing crawler resources in containerized environments
- Implementing graceful shutdown mechanisms
Would appreciate clarification on the recommended approach for programmatically stopping the crawler in the Python SDK. | closed | 2024-12-19T13:49:26Z | 2024-12-20T16:41:49Z | https://github.com/apify/crawlee-python/issues/832 | [
"t-tooling"
] | abhichek | 3 |
jmcnamara/XlsxWriter | pandas | 1,102 | Bug: No exception when adding two autofilters | ### Current behavior
In converting code from pandas to Polars, I neglected to see that Polars adds autofilters by default in [write_excel](https://docs.pola.rs/api/python/dev/reference/api/polars.DataFrame.write_excel.html). My prior code was adding autofilters manually via xlsxwriter. Thus switching to Polars, autofilters were being added twice. The Python code ran fine, but when opening the resulting workbook Excel needed to repair the file. The log stated:
```
Removed Feature: AutoFilter from /xl/tables/table1.xml part (Table)
Removed Feature: Table from /xl/tables/table1.xml part (Table)
```
Took me a bit to figure out what was going on.
### Expected behavior
Not necessarily expected, but perhaps more desirable would be for xlsxwriter to detect the situation (assuming my diagnosis is correct - which I am not certain of) and raise an informative error message.
Not sure if this is feasible - if it isn't, then I thought just having this (closed) issue with the error message would possibly let others stumble upon a potential somewhat common case (switching from pandas to Polars).
### Sample code to reproduce
```markdown
import polars as pl
import xlsxwriter
workbook = xlsxwriter.Workbook('test.xlsx')
df = pl.DataFrame({"a": [1, 1, 2], "b": [3, 4, 5]})
df.write_excel(workbook, worksheet="A")
ws = workbook.get_worksheet_by_name("A")
ws.autofilter(0, 0, len(df)-1, len(df.columns)-1)
workbook.close()
```
### Environment
```markdown
- XlsxWriter version: 3.2.0
- Python version: 3.10.15
- Excel version: 16.91
- OS: macOS 14.7
```
### Any other information
This might be similar to:
- #999
- #739
### OpenOffice and LibreOffice users
- [X] I have tested the output file with Excel. | closed | 2024-11-26T13:29:44Z | 2025-01-01T20:14:06Z | https://github.com/jmcnamara/XlsxWriter/issues/1102 | [
"bug",
"ready to close"
] | rhshadrach-8451 | 2 |
tqdm/tqdm | jupyter | 661 | Reopening a completed/finished/closed bar | When I re-create tq object to reset the progress bar, it creates a new one. I would like to re-use the existing one in the console. Can you please let me know how I can reset the existing progress bar? | open | 2019-01-21T15:15:47Z | 2019-01-26T18:59:54Z | https://github.com/tqdm/tqdm/issues/661 | [
"p4-enhancement-future 🧨"
] | akaniklaus | 15 |
xlwings/xlwings | automation | 2,517 | Support legacy chart sheets for printing to pdf | #### OS (e.g. Windows 11 )
#### Versions of xlwings, Excel and Python (e.g. 0.32.2, Office 365, Python 3.12.3)
#### Describe your issue (incl. Traceback!)
Can't specify precisely which sheets should be printed as workbook contains "legacy" chart sheets.
```python
Traceback (most recent call last):
File "C:\GitHub\db-ashrae140\.venv\Lib\site-packages\xlwings\_xlwindows.py", line 199, in __getattr__
v = getattr(self._inner, item)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\GitHub\db-ashrae140\.venv\Lib\site-packages\win32com\client\__init__.py", line 582, in __getattr__
raise AttributeError(
AttributeError: '<win32com.gen_py.Microsoft Excel 16.0 Object Library._Chart instance at 0x1704525008912>' object has no attribute 'to_pdf'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "c:\GitHub\db-ashrae140\step4.py", line 14, in <module>
generate_workbook_pdf(workbook_path, include_sheets)
File "c:\GitHub\db-ashrae140\step4.py", line 6, in generate_workbook_pdf
wb.api.Sheets(23).to_pdf()
^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\GitHub\db-ashrae140\.venv\Lib\site-packages\xlwings\_xlwindows.py", line 221, in __getattr__
self._oleobj_.GetIDsOfNames(0, item)
pywintypes.com_error: (-2147352570, 'Unknown name.', None, None)
```
#### Include a minimal code sample to reproduce the issue (and attach a sample workbook if required!)
```python
with xw.Book(workbook_path) as wb:
wb.api.Sheets(23).to_pdf()
```
| closed | 2024-09-16T14:08:38Z | 2024-09-16T19:25:16Z | https://github.com/xlwings/xlwings/issues/2517 | [] | Tokarzewski | 3 |
PaddlePaddle/PaddleHub | nlp | 1,789 | 关于使用文档中的代码示例报错的问题 | 地址:https://www.paddlepaddle.org.cn/hubdetail?name=ultra_light_fast_generic_face_detector_1mb_320&en_category=FaceDetection
or
https://www.paddlepaddle.org.cn/hubdetail?name=ace2p&en_category=ImageSegmentation

此处多了`(` 根据初步测试发现此处使用的两个文档都有一样的情况
不知道是特意这样子出现的还是什么原因,希望官方看一下。 | closed | 2022-02-11T11:35:21Z | 2022-02-25T08:28:51Z | https://github.com/PaddlePaddle/PaddleHub/issues/1789 | [] | jhcgt4869 | 1 |
ranaroussi/yfinance | pandas | 2,075 | Any way to get more news? | `ticker.news` seems to return 8 to 10 news articles.
However, Yahoo Finance can offer many more than 8 to 10 news articles per ticker: https://finance.yahoo.com/quote/MSFT/news/ (keep scrolling down).
Is there a way to get more than 8 to 10 news articles with yfinance? | closed | 2024-10-06T01:04:33Z | 2025-02-16T20:02:27Z | https://github.com/ranaroussi/yfinance/issues/2075 | [] | kintonc | 1 |
tfranzel/drf-spectacular | rest-api | 453 | Detect path parameter type for nested routes from rest_framework_nested | To create nested Viewsets, I'm using https://github.com/alanjds/drf-nested-routers
Route registration happens like this:
```py
router = DefaultRouter()
connections_router = NestedSimpleRouter(router, r'connections', lookup='connection')
clients_router.register(r'members', MembersViewSet, basename='connections-members')
```
and methods in viewset are expected an additional keyword argument with `<lookup>_pk`:
```py
class MembersViewSet:
def list(request, connection_id):
# ...
```
This will log a warning:
```js
Warning #0: MembersViewSet: could not derive type of path parameter "connection_pk" because model "<class 'accounts.models.Member'>" did contain no such field. Consider annotating parameter with @extend_schema. Defaulting to "string".
``` | closed | 2021-07-07T12:29:17Z | 2022-03-15T08:36:50Z | https://github.com/tfranzel/drf-spectacular/issues/453 | [
"enhancement",
"fix confirmation pending"
] | tiholic | 14 |
smarie/python-pytest-cases | pytest | 12 | Change all examples so that they are more intuitive | For example
Cases: Orange, Strawberry
Test: test_fruit
Test steps (only for the pytest-steps example):
- peel (may fail)
- mix (does not depend on peel)
- eat (depends on mix)
| closed | 2018-07-27T10:29:35Z | 2019-04-05T19:39:51Z | https://github.com/smarie/python-pytest-cases/issues/12 | [
"enhancement"
] | smarie | 2 |
deepfakes/faceswap | deep-learning | 1,056 | AttributeError: 'module' object has no attribute 'abc' | Question is as on the title. Don't know how to deal with it. Plz help me!!!
The concrete information(Maybe is a noob question since I am using python the first time.):
E:\gitfile\faceswap>py -2 faceswap.py
Setting Faceswap backend to NVIDIA
Traceback (most recent call last):
File "faceswap.py", line 5, in <module>
from lib.cli import args
File "E:\gitfile\faceswap\lib\cli\args.py", line 11, in <module>
from lib.utils import get_backend
File "E:\gitfile\faceswap\lib\utils.py", line 589, in <module>
class KerasFinder(importlib.abc.MetaPathFinder):
AttributeError: 'module' object has no attribute 'abc' | closed | 2020-08-30T16:08:22Z | 2020-09-05T18:54:00Z | https://github.com/deepfakes/faceswap/issues/1056 | [] | ChocolateJin | 1 |
gunthercox/ChatterBot | machine-learning | 2,065 | Chatbot Low confidence response does not work | Hello,
My Bestmatch Logic Adapter is set as such:
```
{
"import_path": "chatterbot.logic.BestMatch",
"statement_comparison_function": "chatterbot.comparisons.levenshtein_distance",
"maximum_similarity_threshold": 0.90,
"default_response": "Sorry. I can not find the exact answer.",
}
```
From my understanding, the bot should discard any response with confidence less than 0.9 and return the default response. However in my case, the bot returns statements with very low confidence as the response.

As you can see above, it chose a response with confidence of just 0.21
**Library Version:**
Chatterbot==1.1.0
nltk==3.5 | closed | 2020-10-30T10:29:33Z | 2025-03-14T21:41:06Z | https://github.com/gunthercox/ChatterBot/issues/2065 | [] | Siddikulus | 1 |
pallets-eco/flask-wtf | flask | 45 | Documentation flask-wtf 0.8 import | from flaskext.wtf import Form, TextField, Required
is now
from flask.ext.wtf import Form, TextField, Required
| closed | 2012-07-09T10:15:38Z | 2021-05-30T01:24:46Z | https://github.com/pallets-eco/flask-wtf/issues/45 | [] | bw9ubwo | 0 |
Lightning-AI/pytorch-lightning | data-science | 20,341 | Impove how argument passing via CLI and config file is handled in regards to argument linking | ### Description & Motivation
I was working on several larger projects and I noticed that the behavior or argument linking is somewhat arbitrary. I propose to make this more consistent to avoid user confusion. Furthermore I propose to write a documentation page for this, since the one from jsonargmarse is not sufficient due to some nuances in combination with lighnting CLI.
### Pitch
I would like to make the behavior of passing arguments via cli and config file more consistent in regards to argument linking. There are several aspects to this that I still need to figure out. I will start by writing test cases and update on the go.
### Alternatives
_No response_
### Additional context
_No response_
cc @borda | open | 2024-10-14T20:40:09Z | 2024-10-14T20:40:30Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20341 | [
"feature",
"needs triage"
] | MrWhatZitToYaa | 0 |
iperov/DeepFaceLab | machine-learning | 5,579 | anyone knows how to fix memory error? | i tried to use saehd but there was this thing called memory error and when i try to use quick96 it runs, what is the problem? i got rtx 3060 (sorry for bad english, english is not my main language) | open | 2022-11-01T10:08:41Z | 2023-06-08T23:05:13Z | https://github.com/iperov/DeepFaceLab/issues/5579 | [] | grievesp | 1 |
InstaPy/InstaPy | automation | 5,890 | Couldn't follow 'Username'! ~user is inaccessible | <!-- Did you know that we have a Discord channel ? Join us: https://discord.gg/FDETsht -->
<!-- Is this a Feature Request ? Please, check out our Wiki first https://github.com/timgrossmann/InstaPy/wiki -->
## Expected Behavior
User is being followed
## Current Behavior
Error is being thrown:
`Couldn't follow 'Username'! ~user is inaccessible`
It seems like selenium isn't able to get the button element. There was an attempted fix in https://github.com/timgrossmann/InstaPy/issues/5298, but that doesn't fix it for me. Maybe Instagram changed their code.
## Possible Solution (optional)
This was the presented solution in https://github.com/timgrossmann/InstaPy/issues/5298, but it's not working for me. The change was made in xpath_compile.py:
```
xpath["get_buttons_from_dialog"] = {
"follow_button": "//div/button[text()='Follow']",
"unfollow_button": "//div/button[text() = 'Following']",
}
```
## InstaPy configuration
Doesn't seem to be a config issue | closed | 2020-11-13T12:51:36Z | 2020-12-13T20:19:23Z | https://github.com/InstaPy/InstaPy/issues/5890 | [
"in progress"
] | v0lumehi | 2 |
lux-org/lux | pandas | 268 | Lux SQL Functionality | closed | 2021-02-18T05:25:08Z | 2021-02-19T19:19:54Z | https://github.com/lux-org/lux/issues/268 | [
"Epic"
] | thyneb19 | 0 |
|
strawberry-graphql/strawberry | fastapi | 3,465 | Improve how we find concrete type for generic in interfaces (and potentially unions) | Pretty much what's written here:
https://github.com/strawberry-graphql/strawberry/pull/3463/files#diff-9db4ecb0b6a9104731da4af6d847961cbc88e4085f4f23f4fcfceb1b22e2fd35R456-R464 | open | 2024-04-20T20:07:53Z | 2025-03-20T15:56:42Z | https://github.com/strawberry-graphql/strawberry/issues/3465 | [] | patrick91 | 4 |
bendichter/brokenaxes | matplotlib | 32 | width_ratios and height_ratios ignored | The height_ratios and width_ratios are ignored in the case where the axis is defined in a subplot_spec. Minimal example:
```python
fig = plt.figure(constrained_layout=False, figsize=(5,4))
generalGridSpec = GridSpec(2, 1, figure=fig)
bax1 = brokenaxes(xlims=((0, 0.5),(.7, 5)), subplot_spec=generalGridSpec[0], width_ratios=[5, 1], d=False, despine=False)
x = np.linspace(0, 5, 300)
bax1.plot(x, np.sin(x*30))
bax2 = brokenaxes(xlims=((0, 1), (2, 6)), subplot_spec=generalGridSpec[1], width_ratios=[1, 10], d=False, despine=False)
x = np.random.poisson(3, 1000)
bax2.hist(x, histtype='bar')
``` | closed | 2019-04-28T15:10:30Z | 2019-04-29T08:53:09Z | https://github.com/bendichter/brokenaxes/issues/32 | [] | webermarcolivier | 2 |
recommenders-team/recommenders | machine-learning | 1,222 | [FEATURE] Efficiency enhancement in surprise_utils.py | ### Description
In `recommenders/reco_utils/recommender/surprise/surprise_utils.py compute_ranking_predictions` function, the code will try to get unique items or users in every for-loop step, which will decrease the efficiency.
### Expected behavior with the suggested feature
Better to use memory to improve code efficiency,
```python
users = data[usercol].unique()
items = data[itemcol].unique()
for user in users:
for item in items:
...
```
### Other Comments
| closed | 2020-10-27T21:25:18Z | 2020-10-29T14:10:30Z | https://github.com/recommenders-team/recommenders/issues/1222 | [
"enhancement"
] | zhaisw | 3 |
litestar-org/litestar | pydantic | 3,596 | Docs: typo in channels docs ``create_route_handlers`` -> ``create_ws_route_handlers`` | ### Reported by
[Coffee](https://discord.com/users/489485360645275650) in Discord: [#general](https://discord.com/channels/919193495116337154/919193495690936353/1254898206089809960)
### Description
Btw, there is a small typo (https://docs.litestar.dev/latest/usage/channels.html#id9) "create_route_handlers"
### MCVE
N/A
### Logs
N/A
### Litestar Version
Main | closed | 2024-06-24T21:13:03Z | 2025-03-20T15:54:46Z | https://github.com/litestar-org/litestar/issues/3596 | [
"Documentation :books:",
"Help Wanted :sos:",
"Good First Issue"
] | byte-bot-app[bot] | 9 |
sigmavirus24/github3.py | rest-api | 242 | Gist API now truncates large files | https://developer.github.com/changes/2014-05-06-gist-api-now-truncating-large-files/
| closed | 2014-05-06T13:32:16Z | 2014-05-27T01:31:48Z | https://github.com/sigmavirus24/github3.py/issues/242 | [] | esacteksab | 2 |
Urinx/WeixinBot | api | 283 | 大佬登录是get请求吧 | open | 2019-12-14T09:35:41Z | 2019-12-14T09:35:41Z | https://github.com/Urinx/WeixinBot/issues/283 | [] | kirkzhangtech | 0 |
|
hzwer/ECCV2022-RIFE | computer-vision | 382 | Unable to install requirements | Trying to install the requierments for RIFE results in this error:
```Collecting numpy<=1.23.5,>=1.16 (from -r requirements.txt (line 1))
Using cached numpy-1.23.5.tar.gz (10.7 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [33 lines of output]
Traceback (most recent call last):
File "C:\Users\Logan\anaconda3\envs\AInUS\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\Users\Logan\anaconda3\envs\AInUS\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Logan\anaconda3\envs\AInUS\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 112, in get_requires_for_build_wheel
backend = _build_backend()
^^^^^^^^^^^^^^^^
File "C:\Users\Logan\anaconda3\envs\AInUS\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 77, in _build_backend
obj = import_module(mod_path)
^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Logan\anaconda3\envs\AInUS\Lib\importlib\__init__.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1310, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 995, in exec_module
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "C:\Users\Logan\AppData\Local\Temp\pip-build-env-uoqpqv_l\overlay\Lib\site-packages\setuptools\__init__.py", line 16, in <module>
import setuptools.version
File "C:\Users\Logan\AppData\Local\Temp\pip-build-env-uoqpqv_l\overlay\Lib\site-packages\setuptools\version.py", line 1, in <module>
import pkg_resources
File "C:\Users\Logan\AppData\Local\Temp\pip-build-env-uoqpqv_l\overlay\Lib\site-packages\pkg_resources\__init__.py", line 2172, in <module>
register_finder(pkgutil.ImpImporter, find_on_path)
^^^^^^^^^^^^^^^^^^^
AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.```
Does anyone know how i could fix this? Thank you
| open | 2024-12-11T20:25:42Z | 2024-12-12T06:38:24Z | https://github.com/hzwer/ECCV2022-RIFE/issues/382 | [] | zup7mn | 1 |
huggingface/peft | pytorch | 2,112 | PEFT Config checking update request | ### Feature request
Position: In peft/tuners/lora/model.py --> LoRaModel._check_new_adapter_config()
The source code suggests a TODO:

Please complete this checking function ASAP.
### Motivation
When I tried to load multiple LoRA adapters into one base model, a ValueError was raised:

After tracing the source code, I found that the adapter config checking function was not completed. So, please complete it.
### Your contribution
NA | closed | 2024-09-30T02:31:44Z | 2024-10-01T01:01:26Z | https://github.com/huggingface/peft/issues/2112 | [] | lemingshen | 4 |
openapi-generators/openapi-python-client | fastapi | 381 | Optional nullable model properties are deserialized from `UNSET` to `None` | **Describe the bug**
If a model has an optional nullable model property, then in the `from_dict`, if the key is not present in the dictionary, it is deserialized as `None` instead of `UNSET`.
This is also true for enum properties, and probably other types as well, but we haven't done an exhaustive search.
**To Reproduce**
This can already be seen in `end_to_end_tests/golden-record/my_test_api_client/models/a_model.py:345`, where the deserialized value is initialized to `None`.
**Expected behavior**
`UNSET` keys should be deserialized as `UNSET`.
**OpenAPI Spec File**
Existing `openapi.json`
**Desktop (please complete the following information):**
- OS: [e.g. macOS 10.15.1]
- Python Version: [e.g. 3.8.0]
- openapi-python-client version [e.g. 0.1.0]
**Additional context**
| closed | 2021-04-07T13:54:55Z | 2021-05-12T14:39:06Z | https://github.com/openapi-generators/openapi-python-client/issues/381 | [
"🐞bug"
] | forest-benchling | 3 |
scikit-learn/scikit-learn | machine-learning | 30,015 | `chance_level_kw` in `RocCurveDisplay` raises an error when using valid matplotlib args | ### Describe the bug
When passing additional keyword arguments to the random classifier's line via the `chance_level_kw` argument, some arguments raise an error even though they are valid `matplotlib.pyplot.plot()` arguments. The error occurs with the `c` and `ls` arguments.
The reason is that in `scikit-learn/sklearn/metrics/_plot/roc_curve.py`, the following code exists:
```python
chance_level_line_kw = {
"label": "Chance level (AUC = 0.5)",
"color": "k",
"linestyle": "--",
}
if chance_level_kw is not None:
chance_level_line_kw.update(**chance_level_kw)
```
Matplotlib raises an error when both `color` and `c`, or `linestyle` and `ls` are specified (this happens with other arguments too, but these are not relevant here since scikit-learn does not set values for them).
This behavior may also occur with other future classes, especially `CapCurveDisplay` (in development #28972).
A quick fix might look like this:
```python
if 'ls' in chance_level_kw:
chance_level_kw['linestyle'] = chance_level_kw['ls']
del chance_level_kw['ls']
if 'c' in chance_level_kw:
chance_level_kw['color'] = chance_level_kw['c']
del chance_level_kw['c']
chance_level_line_kw = {
"label": "Chance level (AUC = 0.5)",
"color": "k",
"linestyle": "--",
}
if chance_level_kw is not None:
chance_level_line_kw.update(**chance_level_kw)
```
### Steps/Code to Reproduce
```python
from sklearn import metrics
display = metrics.RocCurveDisplay.from_predictions(
y_true=[0, 0, 1, 1],
y_pred=[0.1, 0.4, 0.35, 0.8],
plot_chance_level=True,
chance_level_kw={'ls': '--'}
)
```
### Expected Results

### Actual Results
`TypeError: Got both 'linestyle' and 'ls', which are aliases of one another`
### Versions
```shell
System:
python: 3.12.5 (main, Aug 6 2024, 19:08:49) [Clang 15.0.0 (clang-1500.3.9.4)]
executable: /Users/josephbarbier/Desktop/scikit-learn/sklearn-env/bin/python
machine: macOS-14.6.1-arm64-arm-64bit
Python dependencies:
sklearn: 1.6.dev0
pip: 24.2
setuptools: 69.5.1
numpy: 2.1.2
scipy: 1.14.1
Cython: 3.0.11
pandas: None
matplotlib: 3.9.2
joblib: 1.4.2
threadpoolctl: 3.5.0
Built with OpenMP: True
threadpoolctl info:
user_api: openmp
internal_api: openmp
num_threads: 10
prefix: libomp
filepath: /opt/homebrew/Cellar/libomp/18.1.8/lib/libomp.dylib
version: None
```
| closed | 2024-10-06T13:18:55Z | 2024-10-17T20:30:59Z | https://github.com/scikit-learn/scikit-learn/issues/30015 | [
"Bug"
] | JosephBARBIERDARNAL | 3 |
benlubas/molten-nvim | jupyter | 141 | [Help] How to access output buffer as shown in the example | How to access output buffer as shown in the example so that I can copy text from the output?
Your tutorial video seems to be using `<localleader>o`, but the command is not listed.
Thanks | closed | 2024-01-31T17:39:13Z | 2024-02-01T00:30:53Z | https://github.com/benlubas/molten-nvim/issues/141 | [] | ayghri | 1 |
vimalloc/flask-jwt-extended | flask | 327 | Explictly pass `jwt_header` and `jwt_data` to callback functions | Currently, if you want to get some token data, you can use `get_raw_jwt()` in *some* situations. Not only is it inconsistent on when you can do that, but it's not at all apparently that this is allowed since it's relying on global state. In this new release, we will instead explicitly pass in `jwt_headers` and `jwt_data` to these callback functions whenever possible, and only store the decoded jwt in `_app_ctx_stack.top` once all of the validations have finished.
We can see how this looks in 62fe7836f9d014f4d0ee84b2f82e86b66d449557. | closed | 2020-06-02T03:08:03Z | 2021-01-18T15:35:29Z | https://github.com/vimalloc/flask-jwt-extended/issues/327 | [] | vimalloc | 3 |
jupyter-book/jupyter-book | jupyter | 1,344 | Run code client-side with JupyterLite | It would be amazing to be able to use this with JupyterLite:
https://github.com/jtpio/jupyterlite
The Binder integration takes users to a separate page (with a long start-up time; most give up) and Thebelab also requires a server and has a significant start-up cost. As long as the desired computation is minimal, it can run in the user's browser very quickly.
This is a highly speculative "feature request," but I'm pointing out here in case you hadn't heard about it, as a possible future integration. I don't know the architecture well enough to know how hard it would be | open | 2021-05-29T17:32:29Z | 2022-03-10T09:34:54Z | https://github.com/jupyter-book/jupyter-book/issues/1344 | [
"enhancement"
] | jpivarski | 27 |
open-mmlab/mmdetection | pytorch | 11,271 | 为什么很多模型frozen_stages都设置成1? | 关于冻结frozen_stages=1和frozen_stages=-1参数,两种是依据什么设置的呢?两种参数在性能上有什么差别吗?期待您的解答 | open | 2023-12-11T04:43:00Z | 2023-12-11T04:47:07Z | https://github.com/open-mmlab/mmdetection/issues/11271 | [] | JoJoliking | 0 |
ultralytics/ultralytics | deep-learning | 18,731 | predict result | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
I'm using yolo11 with pycharm. If i run self.model.predict(source=pil_image, conf=0.55)
" 0: 640x640 1 CAT, 21.0ms Speed: 5.9ms preprocess, 21.0ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)"
the result will be output like this. Is there a parameter that can disable this message?
### Additional
_No response_ | open | 2025-01-17T10:28:06Z | 2025-01-17T10:45:17Z | https://github.com/ultralytics/ultralytics/issues/18731 | [
"question"
] | kunsungwoo | 2 |
SALib/SALib | numpy | 508 | Why are mu and sigma values set to nan when we do sensitivity analysis with morris for groups ? | 
Hi, I'm doing a sensitivity analysis on groups of parameters but facing a small problem.
In the example above, the mu and sigma values for the groups having more than one parameter are set to nan.
This is done inside the function "_compute_grouped_sigma" in SALib\analyze\morris.py with the following line of code:
np.copyto(sigma, np.NAN, where=groups.sum(axis=0) != 1).
**suggested solution:**
Can we just call "_compute_grouped_metric" instead of "_compute_grouped_sigma" ? Setting the deviation and mean to nan does not make any sense for me or is the way I'm thinking wrong? | closed | 2022-05-10T16:59:26Z | 2022-06-02T11:26:04Z | https://github.com/SALib/SALib/issues/508 | [] | OuSk95 | 2 |
albumentations-team/albumentations | machine-learning | 2,308 | Add `max_aspect_ratio` Parameter to `BboxParams` for Filtering Bounding Boxes Based on Aspect Ratio | ## Feature description
Add a new parameter, `max_aspect_ratio`, to the `BboxParams` class in Albumentations. This parameter would filter bounding boxes based on their aspect ratio, calculated as:
$\text{aspect ratio} = \max\left(\frac{\text{width}}{\text{height}}, \frac{\text{height}}{\text{width}}\right)$
Bounding boxes with an aspect ratio exceeding the specified `max_aspect_ratio` threshold would be removed. This would improve preprocessing by eliminating bounding boxes that are highly distorted or unrealistic, particularly after augmentations like perspective or affine transformations.
### Motivation and context
This feature aligns with Albumentations' goal of providing flexible and robust augmentation tools for computer vision tasks. Filtering bounding boxes based on aspect ratio is a standard practice in object detection pipelines to maintain high-quality annotations, as demonstrated in the YOLO preprocessing steps.
By including `max_aspect_ratio` as a parameter in `BboxParams`, users can:
- Remove bounding boxes that have been overly distorted by augmentations.
- Ensure annotations remain meaningful and usable for training.
- Customize bounding box filtering to fit the specific needs of their datasets.
This feature builds upon existing functionality such as `min_area`, `min_width`, and `min_height`, complementing them to provide a more comprehensive bounding box filtering pipeline.
Relevant example: [[YOLO bounding box filtering logic](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/augment.py#L1264)](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/augment.py#L1264).
---
### Possible implementation
Add the `max_aspect_ratio` parameter to the `BboxParams` class with the following behavior:
1. **Parameter Definition:**
Add `max_aspect_ratio` as an optional parameter with a default value of `None` (no filtering applied).
```python
class BboxParams:
def __init__(
self,
format: str,
label_fields: Optional[Sequence[str]] = None,
min_area: float = 0.0,
min_visibility: float = 0.0,
min_width: float = 0.0,
min_height: float = 0.0,
max_aspect_ratio: Optional[float] = None, # New parameter
check_each_transform: bool = True,
clip: bool = False,
filter_invalid_bboxes: bool = False,
):
```
2. **Integration:**
Incorporate the aspect ratio filtering into the existing bounding box processing pipeline, ensuring compatibility with other filters like `min_area` and `min_visibility`.
4. **Backward Compatibility:**
Defaulting `max_aspect_ratio` to `None` ensures backward compatibility with existing workflows.
### Alternatives
An alternative would be for users to manually filter bounding boxes based on their aspect ratio outside the Albumentations pipeline. However, this approach is less efficient, introduces redundancy, and increases the complexity of user code.
### Additional context
This feature mirrors a similar implementation in YOLO's preprocessing pipeline, where bounding boxes are filtered based on size, area ratio, and aspect ratio after augmentations. Incorporating this functionality into Albumentations would enhance its utility for object detection tasks.
Example reference:
- YOLO bounding box filtering: [[YOLO's box_candidates method](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/augment.py#L1264)](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/augment.py#L1264).
Use case:
```python
params = A.BboxParams(
format="yolo",
max_aspect_ratio=10.0, # Remove bounding boxes with extreme aspect ratios
min_area=0.0,
min_visibility=0.0,
)
```
This feature would help users create more reliable pipelines and ensure bounding boxes remain valid and useful after augmentations. | closed | 2025-01-27T11:34:55Z | 2025-01-28T00:02:59Z | https://github.com/albumentations-team/albumentations/issues/2308 | [
"enhancement"
] | CristoJV | 0 |
gunthercox/ChatterBot | machine-learning | 2,157 | Error when running ChatterBot | I just pasted this:
```
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
chatbot = ChatBot('Ron Obvious')
# Create a new trainer for the chatbot
trainer = ChatterBotCorpusTrainer(chatbot)
# Train the chatbot based on the english corpus
trainer.train("chatterbot.corpus.english")
# Get a response to an input statement
chatbot.get_response("Hello, how are you today?")
```
into a .py file and run it with `python3.6 ~/Desktop/Basic\ Usage.py`
and terminal returns
```
➜ ~ python3.6 /Users/brandonli/Desktop/Basic\ Usage.py
Traceback (most recent call last):
File "/Users/brandonli/Desktop/Basic Usage.py", line 4, in <module>
chatbot = ChatBot('Ron Obvious')
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/chatterbot/chatterbot.py", line 28, in __init__
self.storage = utils.initialize_class(storage_adapter, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/chatterbot/utils.py", line 33, in initialize_class
return Class(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/chatterbot/storage/sql_storage.py", line 20, in __init__
super().__init__(**kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/chatterbot/storage/storage_adapter.py", line 21, in __init__
'tagger_language', languages.ENG
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/chatterbot/tagging.py", line 13, in __init__
self.nlp = spacy.load(self.language.ISO_639_1.lower())
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/spacy/__init__.py", line 51, in load
name, vocab=vocab, disable=disable, exclude=exclude, config=config
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/spacy/util.py", line 330, in load_model
raise IOError(Errors.E941.format(name=name, full=OLD_MODEL_SHORTCUTS[name]))
OSError: [E941] Can't find model 'en'. It looks like you're trying to load a model from a shortcut, which is obsolete as of spaCy v3.0. To load the model, use its full name instead:
nlp = spacy.load("en_core_web_sm")
For more details on the available models, see the models directory: https://spacy.io/models. If you want to create a blank model, use spacy.blank: nlp = spacy.blank("en")
➜ ~
```
this whole chunk.
Now I am extremely puzzled on what I need to do. Any help? Thanks | closed | 2021-05-11T09:46:55Z | 2021-05-11T10:03:09Z | https://github.com/gunthercox/ChatterBot/issues/2157 | [] | simonfalke-01 | 0 |
jumpserver/jumpserver | django | 14,199 | [Question] Can't login Jumpserver | ### Product Version
4.1.0
### Product Edition
- [X] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [X] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### Environment Information
RHEL 8.4
### 🤔 Question Description
After upgrading from 3.8.1 to 4.1.0, some users can't login Jumpserver like: Access web site Jumpserver -> Login Account -> Input OTP -> Return Screen Login Jumpserver again.
Most of users use Chrome version 128.
Now bypass through use microsoft edge or incognito tab chrome.
How can I do to fix it?
### Expected Behavior
_No response_
### Additional Information
_No response_ | closed | 2024-09-19T04:08:23Z | 2024-10-10T06:49:01Z | https://github.com/jumpserver/jumpserver/issues/14199 | [
"🤔 Question"
] | tsukiazuma | 7 |
unit8co/darts | data-science | 1,939 | [BUG] semaphore or lock released too many times | **Describe the bug**
I am learning darts and optuna hyperparameter optimization from the guide: https://unit8co.github.io/darts/userguide/hyperparameter_optimization.html#hyperparameter-optimization-with-optuna. I trained the model using GPU and 4 workers, got the error:
```
Metric val_loss improved by 0.010 >= min_delta = 0.001. New best score: 0.651
Epoch 0: 100%|██████████████████████████████████████████████████████████████████| 3/3 [02:20<00:00, 46.78s/it, train_loss=1.830]
Exception in thread QueueFeederThread:
Exception in thread QueueFeederThread:
Traceback (most recent call last):
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/queues.py", line 239, in _feed
reader_close()
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/connection.py", line 177, in close
self._close()
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/connection.py", line 361, in _close
_close(self._handle)
OSError: [Errno 9] Bad file descriptor
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/dev/miniconda3/envs/pf/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/home/dev/miniconda3/envs/pf/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/queues.py", line 271, in _feed
queue_sem.release()
ValueError: semaphore or lock released too many times
Exception ignored in: <function _ConnectionBase.__del__ at 0x7fc62620c820>
Traceback (most recent call last):
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/connection.py", line 132, in __del__
self._close()
File "/home/dev/miniconda3/envs/pf/lib/python3.10/multiprocessing/connection.py", line 361, in _close
_close(self._handle)
OSError: [Errno 9] Bad file descriptor
GPU available: True (cuda), used: True
```
**To Reproduce**
The code is from https://unit8co.github.io/darts/userguide/hyperparameter_optimization.html#hyperparameter-optimization-with-optuna
**Expected behavior**
No error
**System (please complete the following information):**
- Python version: 3.10.12
- darts version: 0.24.0
| open | 2023-08-08T05:46:23Z | 2024-10-16T14:08:12Z | https://github.com/unit8co/darts/issues/1939 | [
"bug",
"gpu"
] | jacktang | 3 |
pytest-dev/pytest-qt | pytest | 309 | compare QTextCharFormat | Hi,
would y ou accept a PR to compare QTextCharFormat and QTextBlockFormat ?
something like that :
```python
def compare_char_format(lhs, rhs, exclude=[]):
attrs = [
"anchorHref",
"anchorName",
"anchorNames",
"font",
"fontCapitalization",
"fontFamilies",
"fontFamily",
"fontFixedPitch",
"fontHintingPreference",
"fontItalic",
"fontKerning",
"fontLetterSpacing",
"fontLetterSpacingType",
"fontOverline",
"fontPointSize",
"fontStretch",
"fontStrikeOut",
"fontStyleHint",
"fontStyleName",
"fontStyleStrategy",
"fontUnderline",
"fontWeight",
"tableCellColumnSpan",
"tableCellRowSpan",
"textOutline",
"toolTip",
"underlineColor",
"underlineStyle",
"verticalAlignment",
]
for attr in attrs:
if attr in exclude:
continue
r = getattr(lhs, attr)()
l = getattr(rhs, attr)()
assert r == l, f"{attr}: {r}!={l}"
return True
```
| closed | 2020-06-15T11:50:32Z | 2020-06-15T20:28:12Z | https://github.com/pytest-dev/pytest-qt/issues/309 | [] | jgirardet | 2 |
onnx/onnxmltools | scikit-learn | 111 | Adding support for more sklearn models | Hi,
For the sklearn model conversion, can you please add support for below models?
sklearn.decomposition.PCA
sklearn.naive_bayes.BernoulliNB
sklearn.naive_bayes.MultinomialNB
sklearn.linear_model.LassoLars
| closed | 2018-07-18T18:18:29Z | 2018-11-14T16:11:13Z | https://github.com/onnx/onnxmltools/issues/111 | [] | YunsongB | 1 |
jonaswinkler/paperless-ng | django | 146 | Data migration from sqlite to Postgres fails | Hey,
(it's me again).
I have 400 working documents in my -ng instance. The next step was to migrate SQLite to Postgres.
After I setup everything and started a bash within the paperless-ng container (which is linked to the postgres database), I run into the following error:
```
INFO 2020-12-16 20:18:10,377 filelock Lock 140092644583696 released on /usr/src/paperless/src/../media/media.lock
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.StringDataRightTruncation: value too long for type character varying(128)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "manage.py", line 11, in <module>
execute_from_command_line(sys.argv)
File "/usr/local/lib/python3.7/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line
utility.execute()
File "/usr/local/lib/python3.7/site-packages/django/core/management/__init__.py", line 395, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/usr/local/lib/python3.7/site-packages/django/core/management/base.py", line 330, in run_from_argv
self.execute(*args, **cmd_options)
File "/usr/local/lib/python3.7/site-packages/django/core/management/base.py", line 371, in execute
output = self.handle(*args, **options)
File "/usr/local/lib/python3.7/site-packages/django/core/management/commands/loaddata.py", line 72, in handle
self.loaddata(fixture_labels)
File "/usr/local/lib/python3.7/site-packages/django/core/management/commands/loaddata.py", line 114, in loaddata
self.load_label(fixture_label)
File "/usr/local/lib/python3.7/site-packages/django/core/management/commands/loaddata.py", line 181, in load_label
obj.save(using=self.using)
```
I guess some title or something seems to be to long? | closed | 2020-12-16T19:25:23Z | 2021-03-14T14:52:17Z | https://github.com/jonaswinkler/paperless-ng/issues/146 | [] | jannislehmann | 2 |
tensorflow/tensor2tensor | deep-learning | 1,382 | Getting out of hbm memory error on TPU | ### Description
Trying to train a language model -
t2t-trainer --model=lstm_seq2seq --hparams_set=lstm_seq2seq --problem=languagemodel_lm1b8k_packed --train_steps=250000 --eval_steps=8 --data_dir=$DATA_DIR --output_dir=$OUT_DIR --use_tpu=True --cloud_tpu_name=$TPU_NAME --hparams='optimizer=Adafactor, weight_dtype=bfloat16, hidden_size=1024, batch_size=1024'
Getting the following error (copied imp stuffs only)
I tried to change the batch number. But no success. This is relatively a smaller model, 2 layer LSTM, 1024 hidden, 8k vocab (arguments take on 64 MB). But program takes more than 8 GB. Why is it so? Is there anyway I can use more than 1 TPU?
```
INFO:tensorflow:Error recorded from training_loop: Compilation failure: Ran out of memory in memory space hbm. Used 8.83G of 8.00G hbm. Exceeded hbm capacity by 848.88M.
Total hbm usage >= 8.83G:
reserved 528.00M
program 8.25G
arguments 64.32M (99.9% utilization)
Output size 64.32M (99.9% utilization); shares 64.25M with arguments.
Program hbm requirement 8.25G:
reserved 4.0K
global 65.0K
HLO temp 8.25G (100.0% utilization, 0.0% fragmentation (1.01M))
Largest program allocations in hbm:
1. Size: 4.00G
Operator: op_name="XLA_Args"
Shape: bf16[256,2048,4096]{2,1,0}
Unpadded size: 4.00G
XLA label: %arg_tuple.1996.1402 = (s32[], s32[], f32[], f32[4,1024]{1,0}, bf16[4,1024]{1,0}, f32[4,1024]{1,0}, bf16[4,1024]{1,0}, s32[4]{0}, s32[], s32[], f32[4,1024]{1,0}, f32[], bf16[], bf16[], s32[], bf16[2048,4096]{1,0}, bf16[4096]{0}, bf16[2048,4096]{1,0}, bf16[...
Allocation type: HLO temp
==========================
2. Size: 4.00G
Shape: bf16[256,2048,4096]{2,1,0}
Unpadded size: 4.00G
XLA label: %arg_tuple.3500.0 = (s32[], f32[2048,4096]{1,0}, f32[4096]{0}, f32[2048,4096]{1,0}, f32[4096]{0}, s32[], f32[4,1024]{1,0}, f32[4,1024]{1,0}, f32[4,1024]{1,0}, f32[4,1024]{1,0}, bf16[], bf16[], bf16[], bf16[], (pred[256,4]{1,0}, s32[]), (bf16[256,4,1024]{2,...
Allocation type: HLO temp
==========================
3. Size: 32.06M
Operator: op_type="Reshape" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross_entropy/softmax_cross_entropy_with_logits/Reshape_1"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %reshape.101.remat4 = f32[1024,8201]{0,1} reshape(f32[4,256,1,1,8201]{1,0,4,2,3} %fusion.250.remat4), sharding={maximal device=0}, metadata={op_type="Reshape" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross...
Allocation type: HLO temp
==========================
4. Size: 32.06M
Operator: op_type="SoftmaxCrossEntropyWithLogits" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross_entropy/softmax_cross_entropy_with_logits"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %fusion.247 = (f32[1024]{0}, f32[1024,8201]{0,1}) fusion(f32[1024]{0} %log.remat2, f32[1024,8201]{0,1} %reshape.101.remat4, f32[1024]{0} %reduce.5, bf16[1024,1024]{1,0} %bitcast.45, bf16[8201,1024]{1,0} %get-tuple-element.1637), kind=kOutput, calls=%fused_...
Allocation type: HLO temp
==========================
5. Size: 32.06M
Operator: op_type="MatMul" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/symbol_modality_8201_1024_1/softmax/MatMul"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %fusion.213.remat4.1.remat3 = f32[1024,8201]{0,1} fusion(bf16[1024,1024]{1,0} %bitcast.45, bf16[8201,1024]{1,0} %get-tuple-element.1637), kind=kOutput, calls=%fused_computation.200.clone.clone.clone.clone.1.clone.clone.clone, sharding={maximal device=0}, m...
Allocation type: HLO temp
==========================
TPU compilation failed
[[{{node tpu_compile_succeeded_assert/_4879872842451564100/_21}} = TPUCompileSucceededAssert[_device="/job:worker/replica:0/task:0/device:CPU:0"](TPUReplicate/_compile/_14987246518586785693/_20)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[{{node tpu_compile_succeeded_assert/_4879872842451564100/_21_G306}} = _Recv[client_terminated=false, recv_device="/job:worker/replica:0/task:0/device:TPU:7", send_device="/job:worker/replica:0/task:0/device:CPU:0", send_device_incarnation=-5499342681075470468, tensor_name="edge_226_tpu_compile_succeeded_assert/_4879872842451564100/_21", tensor_type=DT_FLOAT, _device="/job:worker/replica:0/task:0/device:TPU:7"]()]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
INFO:tensorflow:training_loop marked as finished
WARNING:tensorflow:Reraising captured error
Traceback (most recent call last):
File "/usr/local/bin/t2t-trainer", line 33, in <module>
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "/usr/local/bin/t2t-trainer", line 28, in main
t2t_trainer.main(argv)
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/bin/t2t_trainer.py", line 393, in main
execute_schedule(exp)
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/bin/t2t_trainer.py", line 349, in execute_schedule
getattr(exp, FLAGS.schedule)()
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/utils/trainer_lib.py", line 438, in continuous_train_and_eval
self._eval_spec)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/training.py", line 471, in train_and_evaluate
return executor.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/training.py", line 637, in run
getattr(self, task_to_run)()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/training.py", line 647, in run_worker
return self._start_distributed_training()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/training.py", line 788, in _start_distributed_training
saving_listeners=saving_listeners)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py", line 2409, in train
rendezvous.raise_errors()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/python/tpu/error_handling.py", line 128, in raise_errors
six.reraise(typ, value, traceback)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py", line 2403, in train
saving_listeners=saving_listeners
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator.py", line 354, in train
loss = self._train_model(input_fn, hooks, saving_listeners)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator.py", line 1207, in _train_model
return self._train_model_default(input_fn, hooks, saving_listeners)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator.py", line 1241, in _train_model_default
saving_listeners)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator.py", line 1471, in _train_with_estimator_spec
_, loss = mon_sess.run([estimator_spec.train_op, estimator_spec.loss])
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 671, in run
run_metadata=run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 1156, in run
run_metadata=run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 1255, in run
raise six.reraise(*original_exc_info)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 1240, in run
return self._sess.run(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 1312, in run
run_metadata=run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 1076, in run
return self._sess.run(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 929, in run
run_metadata_ptr)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1152, in _run
feed_dict_tensor, options, run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1328, in _do_run
run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1348, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: Compilation failure: Ran out of memory in memory space hbm. Used 8.83G of 8.00G hbm. Exceeded hbm capacity by 848.88M.
Total hbm usage >= 8.83G:
reserved 528.00M
program 8.25G
arguments 64.32M (99.9% utilization)
Output size 64.32M (99.9% utilization); shares 64.25M with arguments.
Program hbm requirement 8.25G:
reserved 4.0K
global 65.0K
HLO temp 8.25G (100.0% utilization, 0.0% fragmentation (1.01M))
Largest program allocations in hbm:
1. Size: 4.00G
Operator: op_name="XLA_Args"
Shape: bf16[256,2048,4096]{2,1,0}
Unpadded size: 4.00G
XLA label: %arg_tuple.1996.1402 = (s32[], s32[], f32[], f32[4,1024]{1,0}, bf16[4,1024]{1,0}, f32[4,1024]{1,0}, bf16[4,1024]{1,0}, s32[4]{0}, s32[], s32[], f32[4,1024]{1,0}, f32[], bf16[], bf16[], s32[], bf16[2048,4096]{1,0}, bf16[4096]{0}, bf16[2048,4096]{1,0}, bf16[...
Allocation type: HLO temp
==========================
2. Size: 4.00G
Shape: bf16[256,2048,4096]{2,1,0}
Unpadded size: 4.00G
XLA label: %arg_tuple.3500.0 = (s32[], f32[2048,4096]{1,0}, f32[4096]{0}, f32[2048,4096]{1,0}, f32[4096]{0}, s32[], f32[4,1024]{1,0}, f32[4,1024]{1,0}, f32[4,1024]{1,0}, f32[4,1024]{1,0}, bf16[], bf16[], bf16[], bf16[], (pred[256,4]{1,0}, s32[]), (bf16[256,4,1024]{2,...
Allocation type: HLO temp
==========================
3. Size: 32.06M
Operator: op_type="Reshape" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross_entropy/softmax_cross_entropy_with_logits/Reshape_1"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %reshape.101.remat4 = f32[1024,8201]{0,1} reshape(f32[4,256,1,1,8201]{1,0,4,2,3} %fusion.250.remat4), sharding={maximal device=0}, metadata={op_type="Reshape" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross...
Allocation type: HLO temp
==========================
4. Size: 32.06M
Operator: op_type="SoftmaxCrossEntropyWithLogits" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/padded_cross_entropy/smoothing_cross_entropy/softmax_cross_entropy_with_logits"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %fusion.247 = (f32[1024]{0}, f32[1024,8201]{0,1}) fusion(f32[1024]{0} %log.remat2, f32[1024,8201]{0,1} %reshape.101.remat4, f32[1024]{0} %reduce.5, bf16[1024,1024]{1,0} %bitcast.45, bf16[8201,1024]{1,0} %get-tuple-element.1637), kind=kOutput, calls=%fused_...
Allocation type: HLO temp
==========================
5. Size: 32.06M
Operator: op_type="MatMul" op_name="lstm_seq2seq/parallel_0_6/lstm_seq2seq/lstm_seq2seq/symbol_modality_8201_1024_1/softmax/MatMul"
Shape: f32[1024,8201]{0,1}
Unpadded size: 32.04M
Extra memory due to padding: 28.0K (1.0x expansion)
XLA label: %fusion.213.remat4.1.remat3 = f32[1024,8201]{0,1} fusion(bf16[1024,1024]{1,0} %bitcast.45, bf16[8201,1024]{1,0} %get-tuple-element.1637), kind=kOutput, calls=%fused_computation.200.clone.clone.clone.clone.1.clone.clone.clone, sharding={maximal device=0}, m...
Allocation type: HLO temp
==========================
TPU compilation failed
[[{{node tpu_compile_succeeded_assert/_4879872842451564100/_21}} = TPUCompileSucceededAssert[_device="/job:worker/replica:0/task:0/device:CPU:0"](TPUReplicate/_compile/_14987246518586785693/_20)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[{{node tpu_compile_succeeded_assert/_4879872842451564100/_21_G306}} = _Recv[client_terminated=false, recv_device="/job:worker/replica:0/task:0/device:TPU:7", send_device="/job:worker/replica:0/task:0/device:CPU:0", send_device_incarnation=-5499342681075470468, tensor_name="edge_226_tpu_compile_succeeded_assert/_4879872842451564100/_21", tensor_type=DT_FLOAT, _device="/job:worker/replica:0/task:0/device:TPU:7"]()]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
```
### Environment information
```
OS: <Linux version 4.9.0-8-amd64 running on gcloud>
$ pip freeze | grep tensor
# mesh-tensorflow==0.0.5
tensor2tensor==1.12.0
tensorboard==1.12.0
tensorflow==1.12.0
tensorflow-metadata==0.9.0
tensorflow-probability==0.5.0
$ python -V
# Python 2.7.13
```
| closed | 2019-01-18T21:17:41Z | 2020-05-31T22:53:14Z | https://github.com/tensorflow/tensor2tensor/issues/1382 | [] | ranjeethks | 11 |
SYSTRAN/faster-whisper | deep-learning | 922 | why faster-whisper is slower than the origin whisper model | For the same whisper model (small), faster-whisper is even slower than origin whisper model.
To load the model, my code is :
"""
from faster_whisper import WhisperModel
model=WhisperModel("small", device='cpu',compute_type='int8'
"""
the CPU is 8 core Intel(R) Xeon(R) Gold 6346@3.1GHZ.
Does anyone encounter the same issue? | open | 2024-07-22T02:49:03Z | 2024-07-23T05:41:04Z | https://github.com/SYSTRAN/faster-whisper/issues/922 | [] | ASHLEYDX | 1 |
chaoss/augur | data-visualization | 2,605 | Self-Merge Rates metric API | The canonical definition is here: https://chaoss.community/?p=5306 | open | 2023-11-30T18:00:40Z | 2023-11-30T18:21:07Z | https://github.com/chaoss/augur/issues/2605 | [
"API",
"first-timers-only"
] | sgoggins | 0 |
apache/airflow | automation | 47,196 | Improve integration testing for AIP-72 | ### Body
This is a meta task to improve the integration tests between task sdk and task execution API to avoid any bugs. Right now, things are tested in pieces. Not a priority for 3.0.
### Committer
- [x] I acknowledge that I am a maintainer/committer of the Apache Airflow project. | open | 2025-02-28T06:59:42Z | 2025-02-28T06:59:42Z | https://github.com/apache/airflow/issues/47196 | [
"kind:meta"
] | amoghrajesh | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.