
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
sequencelengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
donnemartin/data-science-ipython-notebooks | numpy | 21 | Update Spark notebook to use DataFrames | Spark 1.3 introduced DataFrames:
> A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs.
https://spark.apache.org/docs/1.3.0/sql-programming-guide.html#dataframes
Spark 1.6 introduces DataSets:
> A new Dataset API. This API is an extension of Spark’s DataFrame API that supports static typing and user functions that run directly on existing JVM types (such as user classes, Avro schemas, etc). Dataset’s use the same runtime optimizer as DataFrames, but support compile-time type checking and offer better performance. More details on Datasets can be found on the SPARK-9999 JIRA.
https://databricks.com/blog/2015/11/20/announcing-spark-1-6-preview-in-databricks.html
Note: PySpark will included DataSets in the upcoming Spark 2.0.
| closed | 2015-12-29T18:48:34Z | 2016-02-21T11:26:04Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/21 | [
"enhancement",
"help wanted"
] | donnemartin | 2 |
numba/numba | numpy | 9,434 | Integrate ZLUDA for AMD CUDA |
**Describe the feature**
@sklam,
https://github.com/vosen/ZLUDA
it can give feature run CUDA program on amd video cards if cuda code is optimized, and speed up work on amd. | open | 2024-02-13T08:48:20Z | 2024-02-13T15:46:54Z | https://github.com/numba/numba/issues/9434 | [
"feature_request"
] | GermanAizek | 3 |
unit8co/darts | data-science | 2,238 | Issue with predictions values being too low (explain in body) | Ok, so i got this very frustrating issue where i have some timeseries that are, not linear, but they are cumulative. Its another electricity data usage dataset.
What is going wrong is that the predictions are BELOW/LOWER than the historic series when there is no way that such a pattern would be learned. Since the series values are either 0 or positive i cant fathom why the predictions would start below the last known value.
However, the actual predictions (what is returned by model.predict() are increasing in an accumulative manner, but they start to low.
First i thought that there was some kind of issue with covariates, but removing them still caused the low predictions. First i used lightGBM, and then I tried nbeats and nhits which also showed the same erroneous predictions.
Finally i tried DeepTCN model which does not follow this pattern!
Still, when i look at target_series.tail() I can see that the last values were higher than the predictions. And a pattern that never decreases (though there are patches of same values (i.e. no increase))
#! changing the lags , output_chunk_length and metric parameters does not change this pattern
LGBM_Model = LightGBMModel(
lags=3,
output_chunk_length=3,
metric="rmse",
)
LGBM_Model.fit(target)
preds = LGBM_Model.predict(3)
preds.values()
Its as if the model it not seeing the last values in the target series. Even though i have checked that they are there with target.tail(), plus that TCN seemingly can avoid this pattern.
How would i go about trouble shooting this issue? I just cant understand how those other models would find a decreasing pattern when such a pattern is nowhere in the pretty long series.
To clarify the pattern a bit further: lets say the target series is [1, 2, 2, 3,4 ,5 ,6, 6, 7, 8,8, 9,10] and then the model with model.pred(n=3) would predict [9,10,11] as if it did not look at the last part of the target series. | closed | 2024-02-20T17:39:56Z | 2024-03-12T10:16:12Z | https://github.com/unit8co/darts/issues/2238 | [
"question"
] | Allena101 | 3 |
jstrieb/github-stats | asyncio | 73 | A very good | closed | 2022-06-13T15:58:34Z | 2022-08-15T04:41:41Z | https://github.com/jstrieb/github-stats/issues/73 | [] | Chunorris6 | 0 |
|
trevorstephens/gplearn | scikit-learn | 202 | Why is a large proportion of candidates in the initial population = None? | Hello,
I am working through the example notebook [https://github.com/trevorstephens/gplearn/blob/master/doc/gp_examples.ipynb](url) and am able to reproduce the same results.
When I inspect the initial population `est_gp._programs[0]` only 139 candidates are a gplearn program and the remainder are `None`. I get similar results of a high proportion of the initial population being set to `None` when applying to my own regression problem. Why is this the case?
Line 222 of [https://github.com/trevorstephens/gplearn/blob/master/gplearn/_program.py](url) (I think this is the right place to look) implies this should never happen.
Thank you!
| closed | 2020-06-30T21:05:34Z | 2020-07-01T08:13:43Z | https://github.com/trevorstephens/gplearn/issues/202 | [] | nosb9124 | 3 |
labmlai/annotated_deep_learning_paper_implementations | pytorch | 43 | Vision Transformer | Paper: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) | closed | 2021-04-19T12:03:23Z | 2021-07-17T09:56:19Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/43 | [
"paper implementation"
] | vpj | 4 |
automagica/automagica | automation | 54 | Use Snips for offline NLU and Voice AI | At https://snips.ai we are working on a 100% private-by-design and offline Voice AI platform which would be perfectly suited for what you are doing:
- offline library for NLU that can be used independently: https://github.com/snipsco/snips-nlu
- use the whole platform if you also want to do offline and private-by-design speech recognition | closed | 2019-06-12T07:29:04Z | 2020-01-30T21:55:24Z | https://github.com/automagica/automagica/issues/54 | [
"enhancement"
] | maelp | 2 |
deepinsight/insightface | pytorch | 2,287 | Something Wrong and i got 100% accuracy🥵 | as a beginner of cv, i trained this model on a tesla P4 sever.
in training, i use umd dataset , and reset the parameter after copying configs.
```from easydict import EasyDict as edict
config = edict()
config.margin_list = (1.0, 0.5, 0.0)
config.network = "r100"
config.resume = False
config.output = None
config.embedding_size = 512
config.sample_rate = 1.0
config.fp16 = True
config.momentum = 0.9
config.weight_decay = 5e-4
config.batch_size = 6
config.lr = 0.1
config.verbose = 2000
config.dali = False
config.rec = "../_datasets_/faces_umd"
config.num_classes = 10575
config.num_image = 494414
config.num_epoch = 5
config.warmup_epoch = 0
config.val_targets = ['lfw', 'cfp_fp', "agedb_30"]
```
the log file show the result like this:[training.log](https://dropover.cloud/79bdec)
and the model is here: [model](https://dropover.cloud/859387)
when i want to use the model on few pics selected from IJBC, the result came 100%.
```CUDA_VISIBLE_DEVICES=0 python eval_ijbc.py --model-prefix work_dirs/face_umd_r100/model.pt --image-path IJBC --result-dir work_dirs/face_umd_r100/result --batch-size 100 --job face_umd_r100 --target IJBC --network r100
Time: 0.00 s.
Time: 0.00 s.
files: 300
batch 0
batch 1
batch 2
Time: 9.90 s.
Feature Shape: (300 , 1024) .
(300, 512) (300,)
Finish Calculating 0 template features.
Time: 0.01 s.
Finish 0/1 pairs.
Time: 0.00 s.
+-----------+--------+--------+--------+--------+--------+--------+
| Methods | 1e-06 | 1e-05 | 0.0001 | 0.001 | 0.01 | 0.1 |
+-----------+--------+--------+--------+--------+--------+--------+
| ijbc-IJBC | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
+-----------+--------+--------+--------+--------+--------+--------+```
i couldn't figure it out , and hope someone had solutions. | open | 2023-04-18T14:30:35Z | 2023-04-25T03:18:30Z | https://github.com/deepinsight/insightface/issues/2287 | [] | CMakey | 5 |
ray-project/ray | data-science | 50,825 | CI test linux://python/ray/data:test_numpy_support is flaky | CI test **linux://python/ray/data:test_numpy_support** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8496#01952c44-0d09-482f-a6f3-aa6493261d16
- https://buildkite.com/ray-project/postmerge/builds/8495#01952b53-0f7b-45fe-9a74-7107914282da
- https://buildkite.com/ray-project/postmerge/builds/8495#01952b30-22c6-4a0f-9857-59a7988f67d8
- https://buildkite.com/ray-project/postmerge/builds/8491#01952b00-e020-4d4e-b46a-209c0b3dbf5b
- https://buildkite.com/ray-project/postmerge/builds/8491#01952ad9-1225-449b-84d0-29cfcc6a048c
DataCaseName-linux://python/ray/data:test_numpy_support-END
Managed by OSS Test Policy | closed | 2025-02-22T06:42:20Z | 2025-03-04T06:40:30Z | https://github.com/ray-project/ray/issues/50825 | [
"bug",
"triage",
"data",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 41 |
opengeos/leafmap | jupyter | 932 | `edit_polygons` unable to transform CRS correctly | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- leafmap version: 0.38.8
- Python version: 3.10.12
- Operating System: Ubuntu 20.04.6 LTS
### Description
This issue is similar to #920. `edit_polygons` does not work if `gdf` is not in EPSG:4326.
### What I Did
```py
show_what_fails = True
import leafmap.leafmap as leafmap
import geopandas as gpd
m = leafmap.Map()
m.add_basemap("HYBRID")
gdf = gpd.read_file("https://raw.githubusercontent.com/opengeos/leafmap/master/examples/data/countries.geojson")
if show_what_fails:
gdf = gdf.to_crs("EPSG:3857")
else:
gdf = gdf.to_crs("EPSG:4326")
m.edit_polygons(gdf)
m
```
| closed | 2024-10-24T11:09:15Z | 2024-10-24T12:11:43Z | https://github.com/opengeos/leafmap/issues/932 | [
"bug"
] | patel-zeel | 0 |
HIT-SCIR/ltp | nlp | 249 | 反应个问题 | 语言云的在线演示功能,经常性的崩溃,想看个例子都不行,好几天了都是这样,这两个月不知道碰到多少种这种情况了。希望及时处理!

| closed | 2017-08-16T12:18:21Z | 2017-09-08T06:36:05Z | https://github.com/HIT-SCIR/ltp/issues/249 | [] | licunlin2012 | 3 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,803 | [Nodriver] Features | Consider adding to nodriver some features:
1. For `Element` implement same methods like for tab (`select`, `select_all`, if possible also `find`)
2. For `send_keys` add cdp commands like `keyDown`, `keyUp`. It will mimic events from real keyboard as they are not fired when simply sending text
3. From selenium driverless feature `human mouse move`. It would be good probably to mimic human actions on the website by not simply clicking button, but also moving mouse to it
4. Mimic `human scrolling` (like in intervals with speed by normal distribution). It can probably replace scrolling into view better
5. Some method `switch_to_iframe` to switch to iframe (return `Tab`). It will be quite good because without this option `--disable-web-security`, iframe is created as explicit tab which can be found in targets of driver.
6. !!! Add timeout for cdp commands on send. For some reason when I try to edit outcoming request, after sending some cdp commands, driver will not respond on target updating. Like there are no response probably from the chrome, but it also indefinitely blocks code execution and does not throw anything.
7. (optional) For `Transaction` when it is not completed, property `has_exception` always returns `True` because there are still no value
I will extend this in future probably. | open | 2024-03-23T09:25:53Z | 2024-11-05T04:46:38Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1803 | [] | WindBora | 2 |
inducer/pudb | pytest | 248 | Move themes out to separate files | All current themes are defined inside a `theme.py` module. It looks like the next:
```
elif theme == "midnight":
# {{{ midnight
# Based on XCode's midnight theme
# Looks best in a console with green text against black background
palette_dict.update({
"variables": ("white", "default"),
"var label": ("light blue", "default"),
"var value": ("white", "default"),
...
```
I propose to create a separate folder, for example, `themes`. Each theme will be as a separate file JSON or YAML inside a created folder.
I think the theme is not related to an application. Consider a terminal or popular text editors. All of their themes are separate files which easy to install without changing a code. | closed | 2017-04-11T19:22:31Z | 2023-10-06T17:20:00Z | https://github.com/inducer/pudb/issues/248 | [] | discort | 5 |
ShishirPatil/gorilla | api | 41 | . | closed | 2023-06-08T13:14:41Z | 2023-06-08T22:19:21Z | https://github.com/ShishirPatil/gorilla/issues/41 | [
"hosted-gorilla"
] | aardsyh | 1 |
|
OFA-Sys/Chinese-CLIP | computer-vision | 310 | 请问分词器有没有c++版本的实现? | 如题,谢谢~ | open | 2024-05-07T07:57:38Z | 2024-07-31T07:54:33Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/310 | [] | liumingzhu6060 | 3 |
scikit-image/scikit-image | computer-vision | 7,242 | Unexpected Output Channel Reduction in skimage.transform.rescale without Explicit channel_axis | ### Description:
When using the `skimage.transform.rescale` function to downscale an RGB image without explicitly specifying the `channel_axis`, the output image unexpectedly has two channels instead of the standard three. This is observed when applying the function to the standard RGB image from `skimage.data.astronaut()`. The expected output shape for a rescaled RGB image is `(height, width, 3)`. However, the observed output shape is `(256, 256, 2)`. Since `channel_axis` is an optional parameter, the default behavior should maintain the number of channels in the input image.
### Way to reproduce:
```
import numpy as np
from skimage import transform, data
# Load an RGB image
rgb_image = data.astronaut()
# Rescale the image
rescaled_image = transform.rescale(rgb_image, 0.5)
# Output the shape
print(rescaled_image.shape)
```
#### Expected Behavior:
The output shape should be `(256, 256, 3)` for a correctly rescaled RGB image, preserving the number of channels.
#### Observed Behavior:
The output shape is `(256, 256, 2)`, indicating a reduction in the number of channels.
### Version information:
```Shell
3.9.6 (default, Mar 10 2023, 20:16:38)
[Clang 14.0.3 (clang-1403.0.22.14.1)]
macOS-13.3.1-x86_64-i386-64bit
scikit-image version: 0.22.0
numpy version: 1.26.2
```
| open | 2023-11-16T13:36:46Z | 2024-06-20T02:27:15Z | https://github.com/scikit-image/scikit-image/issues/7242 | [
":page_facing_up: type: Documentation",
":sleeping: Dormant"
] | tokiAi | 8 |
apache/airflow | automation | 47,947 | Missing dependencies between tasks if Airflow Task Group is empty | ### Apache Airflow version
2.10.5
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
Airflow is not honouring the task dependecies for a task if the parent is empty task group
### What you think should happen instead?
If the parent of a task is empty task group
Then it should follow the dependency rule of the parent's parent.
### How to reproduce
Define a dag with 5 tasks
A B C D E
C D belongs to task group test
Dependencies between tasks is
A >> B >> test >> E
C >> D
If task group test is not empty, everything is running fine
If task group test is empty
Ideally behaviour should be A >> B>> E
But tasks A, E are running parallely without honouring the dependencies
Graph view is showing the dependencies correctly but execution is being different
### Operating System
Linux
### Versions of Apache Airflow Providers
_No response_
### Deployment
Other
### Deployment details
_No response_
### Anything else?
_No response_
### Are you willing to submit PR?
- [x] Yes I am willing to submit a PR!
### Code of Conduct
- [x] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
| open | 2025-03-19T09:22:17Z | 2025-03-24T05:41:19Z | https://github.com/apache/airflow/issues/47947 | [
"kind:bug",
"area:core",
"area:TaskGroup",
"needs-triage"
] | purnachandergit | 1 |
OFA-Sys/Chinese-CLIP | computer-vision | 27 | ValueError: host not found: Name or service not known | n你好
运行训练指令 报错如题,请问是哪里的配置有问题 | closed | 2022-12-08T08:00:35Z | 2022-12-08T08:22:55Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/27 | [] | dengfenglai321 | 1 |
smarie/python-pytest-cases | pytest | 284 | Add zip join to combine fixtures | Consider this issue as a feature request please. I suggest to add more flexibility to how parameters for tests are combined. In pytest tests are executed for each combination (cartesian product) of all parameters. I was glad to find fixture_union in pytest cases that introduces flexibility in combining fixture parameters for tests. I suggest to add further options to combine fixtures: zip join to combine fixture sets by position number in a set. This will allow to test actual and expected states determined for each test object in different fixtures:
```
@pytest_fixture_plus(params=[obj1, obj2, obj3])
def actual_state(request):
return produce_actual_state(request.param)
@pytest_fixture_plus(params=[obj1, obj2, obj3])
def expected_state(request):
return produce_expected_state(request.param)
fixture_zip("state", ['actual_state', 'expected_state'])
def test_with_zipped_fixture(state):
assert state.actual_state == state.expected_state
@pytest_parametrize_plus_zip("actual, expected", ['actual_state', 'expected_state'])
def test_with_direct_parametrization(actual, expected):
assert actual == expected
``` | open | 2022-10-16T13:19:56Z | 2022-11-26T22:17:08Z | https://github.com/smarie/python-pytest-cases/issues/284 | [] | tokarenko | 1 |
Neoteroi/BlackSheep | asyncio | 138 | Try using orjson, or adding support for orjson, to the base JSONContent | https://github.com/ijl/orjson | closed | 2021-05-22T15:56:10Z | 2021-07-16T20:01:54Z | https://github.com/Neoteroi/BlackSheep/issues/138 | [
"fixed in branch",
"needs docs"
] | RobertoPrevato | 2 |
gradio-app/gradio | data-visualization | 10,138 | GRADIO_SSR_MODE is not documented | ### Describe the bug
The environment variable `GRADIO_SSR_MODE` is **not** documented in https://www.gradio.app/guides/environment-variables but referenced on these two lines: https://github.com/gradio-app/gradio/blob/3a6151e9422cc3b02b6e815cb5c72f59bebc60c7/gradio/blocks.py#L2460 and https://github.com/gradio-app/gradio/blob/3a6151e9422cc3b02b6e815cb5c72f59bebc60c7/gradio/routes.py#L1621
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
# This is not a code issue. The GRADIO_SSR_MODE will be picked up correctly by the Gradio server but it is not documented.
```
### Screenshot
_No response_
### Logs
_No response_
### System Info
```shell
Gradio Environment Information:
------------------------------
Operating System: Linux
gradio version: 5.7.1
gradio_client version: 1.5.0
------------------------------------------------
gradio dependencies in your environment:
aiofiles: 23.2.1
anyio: 4.7.0
audioop-lts is not installed.
fastapi: 0.115.6
ffmpy: 0.4.0
gradio-client==1.5.0 is not installed.
httpx: 0.28.0
huggingface-hub: 0.26.3
jinja2: 3.1.4
markupsafe: 2.1.5
numpy: 2.1.3
orjson: 3.10.12
packaging: 24.2
pandas: 2.2.3
pillow: 11.0.0
pydantic: 2.10.3
pydub: 0.25.1
python-multipart==0.0.12 is not installed.
pyyaml: 6.0.2
ruff: 0.8.2
safehttpx: 0.1.6
semantic-version: 2.10.0
starlette: 0.41.3
tomlkit==0.12.0 is not installed.
typer: 0.15.1
typing-extensions: 4.12.2
urllib3: 2.2.3
uvicorn: 0.32.1
authlib; extra == 'oauth' is not installed.
itsdangerous; extra == 'oauth' is not installed.
gradio_client dependencies in your environment:
fsspec: 2024.9.0
httpx: 0.28.0
huggingface-hub: 0.26.3
packaging: 24.2
typing-extensions: 4.12.2
websockets: 12.0
```
### Severity
I can work around it | closed | 2024-12-05T22:27:43Z | 2024-12-06T20:10:24Z | https://github.com/gradio-app/gradio/issues/10138 | [
"docs/website",
"SSR"
] | anirbanbasu | 0 |
PaddlePaddle/PaddleHub | nlp | 1,705 | AI Studio import paddlehub报错 | 欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本、环境信息
1)PaddleHub和PaddlePaddle版本:请提供您的PaddleHub和PaddlePaddle版本号,例如PaddleHub1.4.1,PaddlePaddle1.6.2
2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本
- 复现信息:如为报错,请给出复现环境、复现步骤
PaddlePaddle 1.8.4
paddlehub 2.2.0
我在AI Studio中运行项目,只要import paddlehub就出错误
Version mismatch in PaddleHub and PaddlePaddle, you need to upgrade PaddlePaddle to version 2.0.0 or above.
如果卸载重新使用其他方式安装,可以import但是使用任何moudle都找不到
AnimeGAN动漫化模型一键应用(含动漫化小程序体验)这个项目 | open | 2021-11-25T13:37:06Z | 2021-11-30T12:21:26Z | https://github.com/PaddlePaddle/PaddleHub/issues/1705 | [
"installation"
] | H-jh20 | 3 |
pydata/xarray | pandas | 9,742 | Pandas Integer Type Doesn't Convert in Dataset | ### What happened?
Converted a Pandas `DataFrame` containing a column of type `pandas.Int64Dtype()` into an Xarray `Dataset`. The data variable doesn't get converted to an Xarray compatible type:
```
Data variables:
0 (dim_0) Int64 27B <class 'xarray.core.extension_array.PandasExte...
```
Additionally, this causes an exception if the Dataset is pickled and subsequently loaded:
`RecursionError: maximum recursion depth exceeded`
### What did you expect to happen?
The data variable ends up as `int64` type. Pickling the Dataset works properly.
### Minimal Complete Verifiable Example
```Python
import pandas as pd
import xarray as xr
import pickle
df = pd.DataFrame([1, 2, 3], dtype=pd.Int64Dtype())
ds = xr.Dataset(df)
dsdump = pickle.dumps(ds)
pickle.loads(dsdump)
```
### MVCE confirmation
- [X] Minimal example — the example is as focused as reasonably possible to demonstrate the underlying issue in xarray.
- [X] Complete example — the example is self-contained, including all data and the text of any traceback.
- [X] Verifiable example — the example copy & pastes into an IPython prompt or [Binder notebook](https://mybinder.org/v2/gh/pydata/xarray/main?urlpath=lab/tree/doc/examples/blank_template.ipynb), returning the result.
- [X] New issue — a search of GitHub Issues suggests this is not a duplicate.
- [X] Recent environment — the issue occurs with the latest version of xarray and its dependencies.
### Relevant log output
```Python
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
Cell In[1], line 8
6 ds = xr.Dataset(df)
7 dsdump = pickle.dumps(ds)
----> 8 pickle.loads(dsdump)
File ~/metis-dev/.venv/lib/python3.12/site-packages/xarray/core/extension_array.py:112, in PandasExtensionArray.__getattr__(self, attr)
111 def __getattr__(self, attr: str) -> object:
--> 112 return getattr(self.array, attr)
File ~/metis-dev/.venv/lib/python3.12/site-packages/xarray/core/extension_array.py:112, in PandasExtensionArray.__getattr__(self, attr)
111 def __getattr__(self, attr: str) -> object:
--> 112 return getattr(self.array, attr)
[... skipping similar frames: PandasExtensionArray.__getattr__ at line 112 (2974 times)]
File ~/metis-dev/.venv/lib/python3.12/site-packages/xarray/core/extension_array.py:112, in PandasExtensionArray.__getattr__(self, attr)
111 def __getattr__(self, attr: str) -> object:
--> 112 return getattr(self.array, attr)
RecursionError: maximum recursion depth exceeded
```
### Anything else we need to know?
Xarray 2024.9.0 does not exhibit this behavior.
### Environment
<details>
INSTALLED VERSIONS
------------------
commit: None
python: 3.12.7 (main, Oct 1 2024, 11:15:50) [GCC 14.2.1 20240910]
python-bits: 64
OS: Linux
OS-release: 6.6.32-1-lts
machine: x86_64
processor:
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: None
libnetcdf: None
xarray: 2024.10.0
pandas: 2.2.3
numpy: 1.26.4
scipy: 1.14.1
netCDF4: None
pydap: None
h5netcdf: None
h5py: None
zarr: 2.18.3
cftime: None
nc_time_axis: None
iris: None
bottleneck: 1.4.2
dask: 2024.10.0
distributed: None
matplotlib: 3.9.2
cartopy: None
seaborn: None
numbagg: None
fsspec: 2024.10.0
cupy: None
pint: None
sparse: None
flox: None
numpy_groupies: None
setuptools: 75.3.0
pip: 23.3.1
conda: None
pytest: None
mypy: None
IPython: 8.29.0
sphinx: None
</details>
| open | 2024-11-07T14:24:29Z | 2025-02-11T22:03:19Z | https://github.com/pydata/xarray/issues/9742 | [
"bug"
] | edwardreed81 | 3 |
nonebot/nonebot2 | fastapi | 2,462 | Plugin: 用户 | ### PyPI 项目名
nonebot-plugin-user
### 插件 import 包名
nonebot_plugin_user
### 标签
[]
### 插件配置项
_No response_ | closed | 2023-11-21T13:29:53Z | 2023-11-22T02:47:23Z | https://github.com/nonebot/nonebot2/issues/2462 | [
"Plugin"
] | he0119 | 1 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,020 | [Feature Request]: Adaptive guidance is supported? | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
Adaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
### Proposed workflow
1. Go to Adaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
2. Source bcvuniandes.github.io/adaptiveguidance-wp/.
### Additional information
_No response_ | open | 2024-06-14T08:41:47Z | 2024-06-14T09:55:19Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16020 | [
"enhancement"
] | bigmover | 1 |
mitmproxy/pdoc | api | 312 | Option to disable magic surrounding __init__ and __new__? | #### Problem Description
I'm trying out pdoc for the first time, and was getting frustrated and confused by all the magic handling around the `__init__` and `__new__` methods, so I spent a lot of time playing with the code to figure out how it works just enough to disable it. However, I'm now dependent on a modified local copy of pdoc, which is unfortunate.
It would be convenient if it were instead implemented as an official option.
I created a mini-project to demonstrate what I mean:
https://github.com/odigity/pdocdemo/tree/main/testcases/constructors
I created a module [testmodule.py](https://github.com/odigity/pdocdemo/blob/main/testcases/constructors/testmodule.py) with every permutation to test, and added before/after screenshots, which I'll inline at the bottom for convenience.
Here's the commit showing what I changed in my local copy of pdoc:
https://github.com/odigity/pdocdemo/commit/46567cbc6cc0ba49aac6a524f6acbe37a452298b
Specifically:
* Stopped pdoc from treating an inherited `__init__` as if it's part of the inheriting class. (`doc.Class._declarations`)
* Stopped pdoc from playing with the identity and docstrings of `__new__` vs `__init__`. (`doc.Class._member_objects`)
* Stopped pdoc from presenting `__init__` as a constructor named after the class with no `self` in signature. (`function` and `nav_members` macros in module template)
* Removed "Inherited Members" section. (`module_contents` block in in module template)
In principle, what I want to achieve is for the docs to actually reflect the source. If I define a custom `__init__` in a class, I want it to show up in the docs - otherwise I don't.
As for the "Inherited Members" section - I primarily removed it to reduce visual noise, though putting it into a pre-collapsed section that can be manually re-opened might be an option I explore in the future. The other reason is because the `is_public` macro still treats `__init__` as public - I didn't change that because I agree with it - but it means that almost every "Inherited Members" section now shows `__init__`, which is noisy because it adds no value.
Sorry for the ramblefest. Hope it made sense.
EDIT: I should mention these docs are for internal use (to document our own Django project), not user-facing, like docs for a library would be. That may explain why my preferences are slightly out of alignment with the defaults.

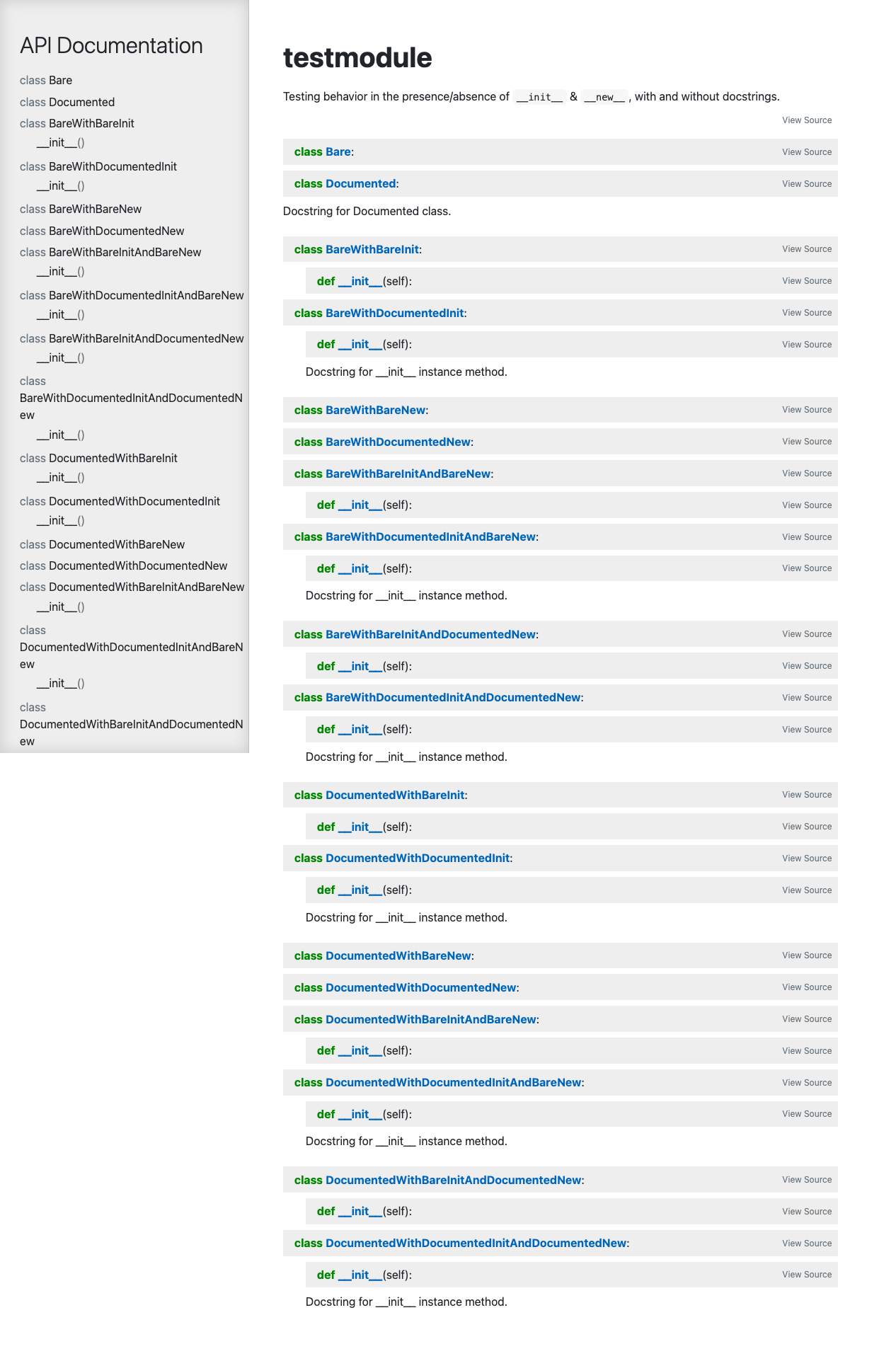 | closed | 2021-11-02T22:14:27Z | 2021-11-09T15:11:05Z | https://github.com/mitmproxy/pdoc/issues/312 | [
"enhancement"
] | odigity | 1 |
brightmart/text_classification | tensorflow | 129 | How about SpanBert | When can I see [SpanBert](https://arxiv.org/pdf/1907.10529.pdf) here | closed | 2019-08-02T06:19:27Z | 2023-05-18T13:39:26Z | https://github.com/brightmart/text_classification/issues/129 | [] | shanghai-Jerry | 0 |
ultralytics/ultralytics | machine-learning | 18,710 | Which hyperparameters are suitable for me? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
Hello. I've already done finetuning and just trained YOLOv11 from scratch. But I have the following problem. Your pretrained model works well with the `car` class in some scenes that I need, but poorly in others that I also need. When I do finetuning of your pretrained model, for some reason, where your model coped well, the quality drops, and where it did not recognize anything, everything is fine. For some reason, somehow finetuning spoils what is already good and improves what was bad. I want to adapt YOLOv11 to work at night.
Can you tell me what hyperparameters I need to set so that everything is fine and the way I need it? YOLOv4 just does what it needs to do for some reason. And I want a newer version of YOLO. Maybe I need to freeze something or turn on augmentation?
Here is my training startup configuration:
```
task: detect
mode: train
model: yolov11m.yaml
data: ./yolov11_custom.yaml
epochs: 500
time: null
patience: 100
batch: 32
imgsz: 640
save: true
save_period: -1
val_period: 1
cache: false
device: 0
workers: 8
project: /YOLOv11_m_night_640
name: yolov11_custom_night
exist_ok: false
pretrained: true
optimizer: auto
verbose: true
seed: 0
deterministic: true
single_cls: false
rect: false
cos_lr: false
close_mosaic: 10
resume: false
amp: true
fraction: 1.0
profile: false
freeze: null
multi_scale: false
overlap_mask: true
mask_ratio: 4
dropout: 0.0
val: true
split: val
save_json: false
save_hybrid: false
conf: null
iou: 0.7
max_det: 300
half: false
dnn: false
plots: true
source: null
vid_stride: 1
stream_buffer: false
visualize: false
augment: false
agnostic_nms: false
classes: null
retina_masks: false
embed: null
show: false
save_frames: false
save_txt: false
save_conf: false
save_crop: false
show_labels: true
show_conf: true
show_boxes: true
line_width: null
format: torchscript
keras: false
optimize: false
int8: false
dynamic: false
simplify: false
opset: null
workspace: 4
nms: false
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5
cls: 0.5
dfl: 1.5
pose: 12.0
kobj: 1.0
label_smoothing: 0.0
nbs: 64
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
bgr: 0.0
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
auto_augment: randaugment
erasing: 0.4
crop_fraction: 1.0
cfg: null
tracker: botsort.yaml
save_dir: /YOLOv11_m_night_640
```
my `yolov11_custom.yaml`:
```
path: ./data
train: ./data/train.txt
val: /data/val.txt
# Classes
names:
0: trailer
1: train
2: trafficlight
3: sign
4: bus
5: truck
6: person
7: bicycle
8: motorcycle
9: car
10: streetlight
```
@glenn-jocher @Y-T-G and others. Please help me.
### Additional
_No response_ | open | 2025-01-16T11:51:54Z | 2025-01-24T06:07:24Z | https://github.com/ultralytics/ultralytics/issues/18710 | [
"question",
"detect"
] | Egorundel | 35 |
Anjok07/ultimatevocalremovergui | pytorch | 704 | here I have error when I run your project in my Mac machine | Last Error Received:
Process: VR Architecture
If this error persists, please contact the developers with the error details.
Raw Error Details:
ValueError: "zero-size array to reduction operation maximum which has no identity"
Traceback Error: "
File "UVR.py", line 4716, in process_start
File "separate.py", line 686, in seperate
File "lib_v5/spec_utils.py", line 112, in normalize
File "numpy/core/_methods.py", line 40, in _amax
"
Error Time Stamp [2023-07-31 16:18:29]
Full Application Settings:
vr_model: 1_HP-UVR
aggression_setting: 10
window_size: 512
batch_size: Default
crop_size: 256
is_tta: False
is_output_image: False
is_post_process: False
is_high_end_process: False
post_process_threshold: 0.2
vr_voc_inst_secondary_model: No Model Selected
vr_other_secondary_model: No Model Selected
vr_bass_secondary_model: No Model Selected
vr_drums_secondary_model: No Model Selected
vr_is_secondary_model_activate: False
vr_voc_inst_secondary_model_scale: 0.9
vr_other_secondary_model_scale: 0.7
vr_bass_secondary_model_scale: 0.5
vr_drums_secondary_model_scale: 0.5
demucs_model: Choose Model
segment: Default
overlap: 0.25
shifts: 2
chunks_demucs: Auto
margin_demucs: 44100
is_chunk_demucs: False
is_chunk_mdxnet: False
is_primary_stem_only_Demucs: False
is_secondary_stem_only_Demucs: False
is_split_mode: True
is_demucs_combine_stems: True
demucs_voc_inst_secondary_model: No Model Selected
demucs_other_secondary_model: No Model Selected
demucs_bass_secondary_model: No Model Selected
demucs_drums_secondary_model: No Model Selected
demucs_is_secondary_model_activate: False
demucs_voc_inst_secondary_model_scale: 0.9
demucs_other_secondary_model_scale: 0.7
demucs_bass_secondary_model_scale: 0.5
demucs_drums_secondary_model_scale: 0.5
demucs_pre_proc_model: No Model Selected
is_demucs_pre_proc_model_activate: False
is_demucs_pre_proc_model_inst_mix: False
mdx_net_model: UVR-MDX-NET Inst HQ 1
chunks: Auto
margin: 44100
compensate: Auto
is_denoise: False
is_invert_spec: False
is_mixer_mode: False
mdx_batch_size: 5
mdx_voc_inst_secondary_model: No Model Selected
mdx_other_secondary_model: No Model Selected
mdx_bass_secondary_model: No Model Selected
mdx_drums_secondary_model: No Model Selected
mdx_is_secondary_model_activate: False
mdx_voc_inst_secondary_model_scale: 0.9
mdx_other_secondary_model_scale: 0.7
mdx_bass_secondary_model_scale: 0.5
mdx_drums_secondary_model_scale: 0.5
is_save_all_outputs_ensemble: True
is_append_ensemble_name: False
chosen_audio_tool: Manual Ensemble
choose_algorithm: Min Spec
time_stretch_rate: 2.0
pitch_rate: 2.0
is_gpu_conversion: True
is_primary_stem_only: False
is_secondary_stem_only: False
is_testing_audio: False
is_add_model_name: False
is_accept_any_input: False
is_task_complete: False
is_normalization: False
is_create_model_folder: False
mp3_bit_set: 320k
save_format: WAV
wav_type_set: PCM_16
help_hints_var: False
model_sample_mode: True
model_sample_mode_duration: 30
demucs_stems: All Stems | closed | 2023-07-31T09:19:36Z | 2023-09-27T23:27:40Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/704 | [] | jygytfugi | 1 |
recommenders-team/recommenders | deep-learning | 1,486 | [BUG] No module named 'reco_utils' | ### Description
Error `No module named 'reco_utils'` in docker test
https://github.com/microsoft/recommenders/tree/main/tools/docker
```
$ docker run -it recommenders:cpu pytest tests/unit -m "not spark and not gpu and not notebooks"
ImportError while loading conftest '/root/recommenders/tests/conftest.py'.
tests/conftest.py:22: in <module>
from reco_utils.common.constants import (
E ModuleNotFoundError: No module named 'reco_utils'
```
### In which platform does it happen?
Linux cpu docker
| closed | 2021-07-26T09:13:14Z | 2021-12-17T08:47:31Z | https://github.com/recommenders-team/recommenders/issues/1486 | [
"bug"
] | xu-song | 3 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 3,042 | In Oct 2023 - drop support for k8s 1.23 | This is an issue to help us remember the policy (see #2591, #2979, #3040) to allow ourselves to drop support for k8s versions as long as major cloud providers has stopped supporting them.
k8s | [GKE EOL](https://endoflife.date/google-kubernetes-engine) | [EKS EOL](https://endoflife.date/amazon-eks) | [AKS EOL](https://docs.microsoft.com/en-gb/azure/aks/supported-kubernetes-versions?tabs=azure-cli#aks-kubernetes-release-calendar) | Comment
-|-|-|-|-
1.23 | 31 Jul 2023 | 11 Oct 2023 | Apr 2023 | We can drop support 01 Oct 2023
1.24 | 31 Oct 2023 | 31 Jan 2024 | Jul 2023 | -
As part of dropping support for k8s 1.23, we can also adjust this configuration that has a fallback for k8s 1.23 or lower.
https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/2a02c402f2a23521f9538aea9a934264da3cc959/jupyterhub/templates/scheduling/user-scheduler/configmap.yaml#L9-L23 | closed | 2023-02-28T09:34:22Z | 2024-01-14T15:07:25Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/3042 | [] | consideRatio | 0 |
pyro-ppl/numpyro | numpy | 1,135 | SA kernel missing model attribute | Trying to load an MCMC run using an SA kernel into `arviz`, I ran into this issue:
```
def test_model(...)
...
kernel = SA(test_model)
mcmc_test = MCMC(kernel, ...)
mcmc_test.run(...)
data_test = az.from_numpyro(mcmc_test)
```
which raises...
```---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/tmp/ipykernel_20194/2118154136.py in <module>
----> 1 data_test = az.from_numpyro(mcmc_test)
~/miniconda3/envs/refit_fvs/lib/python3.9/site-packages/arviz/data/io_numpyro.py in from_numpyro(posterior, prior, posterior_predictive, predictions, constant_data, predictions_constant_data, coords, dims, pred_dims, num_chains)
331 Number of chains used for sampling. Ignored if posterior is present.
332 """
--> 333 return NumPyroConverter(
334 posterior=posterior,
335 prior=prior,
~/miniconda3/envs/refit_fvs/lib/python3.9/site-packages/arviz/data/io_numpyro.py in __init__(self, posterior, prior, posterior_predictive, predictions, constant_data, predictions_constant_data, coords, dims, pred_dims, num_chains)
91 self._samples = samples
92 self.nchains, self.ndraws = posterior.num_chains, posterior.num_samples
---> 93 self.model = self.posterior.sampler.model
94 # model arguments and keyword arguments
95 self._args = self.posterior._args # pylint: disable=protected-access
AttributeError: 'SA' object has no attribute 'model'
```
Looking at the source code and noticing that this works for NUTS and HMC, the missing piece in the SA class seems to be the `model` property... going to prepare a PR to add it in the same manner as it's found in NUTS and HMC classes. | closed | 2021-08-25T16:45:19Z | 2021-08-26T02:53:09Z | https://github.com/pyro-ppl/numpyro/issues/1135 | [] | d-diaz | 0 |
recommenders-team/recommenders | deep-learning | 1,394 | [FEATURE] Upgrade nni and scikit-learn | ### Description
<!--- Describe your expected feature in detail -->
- Upgrade nni from current version (1.5) so that we can use scikit-learn>=0.22.1
- Add nni back to the core option of the pypi package
| open | 2021-05-07T17:25:38Z | 2021-05-07T17:27:38Z | https://github.com/recommenders-team/recommenders/issues/1394 | [
"enhancement"
] | anargyri | 0 |
graphql-python/graphene-sqlalchemy | graphql | 276 | Why is first so slow for default SQLAlchemyConnectionField | ```
requests_monitor = SQLAlchemyConnectionField(
RequestConnection,
request_name=String(),
...
)
def resolve_requests_monitor(self, info, **args):
query = RequestNode.get_query(info)
query = query.join(Request.dataset)
for field, value in args.items():
query = query.filter(getattr(Request, field) == value)
return query
```
The table I was querying has 10 million records. When I ran the following query, it was super slow. But when I added `query.limit(1000)`, it was way faster. This made me wonder if first and last were not applied by default when querying the db and actually applied afterwards. If not, what's the correct way of using it?
```
requestsMonitor(first:1000){
edges{
node{
requestId
}
}
}
```
| closed | 2020-05-11T19:43:40Z | 2023-02-25T00:49:31Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/276 | [] | Xindi-Li | 1 |
marimo-team/marimo | data-visualization | 4,071 | Additional open AI configuation options for editor AI chat and code completion | ### Description
Adding gitlab issue as per discord conversation at https://discord.com/channels/1059888774789730424/1349354519284289536
Setup config `.toml` to add additional optional keywords for httpx session that the openai python library uses under the hood for openAI compatible API/AI assistants that are secured with ssl/tls. Specifically, add in `verify` and `ssl_verify` as keywords for openai in config. See https://www.python-httpx.org/advanced/ssl/ for more examples/options.
### Suggested solution
Based on the discord conversation, it looks like that the changes could be made in:
`marimo/_server/api/endpoints/ai.py`
`marimo/_config/config.py`
I am unsure if the openai client creation can directly be based these parameters or if an httpx_client object would have to be passed to the `http_client` parameter when calling
```
OpenAI(
default_headers={"api-key": key},
api_key=key,
base_url=base_url,
)
```
### Alternative
_No response_
### Additional context
I am uncertain if I will be able to make the pull request, due to some corporate rules we have to follow when contributing (formally at least) to open source projects. | closed | 2025-03-12T20:23:24Z | 2025-03-24T16:12:36Z | https://github.com/marimo-team/marimo/issues/4071 | [
"enhancement",
"help wanted"
] | Ryanphoenix | 3 |
gradio-app/gradio | machine-learning | 10,599 | Image Mask is not working since update | ### Describe the bug
When using stroke in the image mask to mask an area, it stops and not making any mask. this is a issue since gradio 5.12.0
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
```
### Screenshot
_No response_
### Logs
```shell
```
### System Info
```shell
Gradio Environment Information:
------------------------------
Operating System: Linux
gradio version: 5.11.0
gradio_client version: 1.5.3
------------------------------------------------
gradio dependencies in your environment:
aiofiles: 23.2.1
anyio: 4.6.0
audioop-lts is not installed.
fastapi: 0.115.5
ffmpy: 0.4.0
gradio-client==1.5.3 is not installed.
httpx: 0.27.2
huggingface-hub: 0.28.1
jinja2: 3.1.4
markupsafe: 2.1.5
numpy: 1.26.4
orjson: 3.10.7
packaging: 24.2
pandas: 2.2.3
pillow: 10.4.0
pydantic: 2.9.2
pydub: 0.25.1
python-multipart: 0.0.19
pyyaml: 6.0.2
ruff: 0.9.6
safehttpx: 0.1.6
semantic-version: 2.10.0
starlette: 0.41.3
tomlkit: 0.12.0
typer: 0.12.5
typing-extensions: 4.12.2
urllib3: 2.2.3
uvicorn: 0.30.6
authlib; extra == 'oauth' is not installed.
itsdangerous; extra == 'oauth' is not installed.
gradio_client dependencies in your environment:
fsspec: 2024.9.0
httpx: 0.27.2
huggingface-hub: 0.28.1
packaging: 24.2
typing-extensions: 4.12.2
websockets: 12.0
```
### Severity
I can work around it | open | 2025-02-15T09:31:08Z | 2025-02-17T00:47:44Z | https://github.com/gradio-app/gradio/issues/10599 | [
"bug",
"🖼️ ImageEditor"
] | akedia | 1 |
babysor/MockingBird | deep-learning | 990 | 启动python web.py无反应,小白求助 | **Summary[问题简述(一句话)]**
A clear and concise description of what the issue is.
**Env & To Reproduce[复现与环境]**
描述你用的环境、代码版本、模型
**Screenshots[截图(如有)]**
If applicable, add screenshots to help

| open | 2024-03-13T06:01:46Z | 2024-03-13T06:03:48Z | https://github.com/babysor/MockingBird/issues/990 | [] | shenfuqili | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 19,728 | LightningCLI, WandbLogger and save_hyperparameters() inconsistencies | ### Bug description
There are issues when using WandbLogger from a LightningCLI configuration. First, full configuration is not automatically forwarded to the kwargs of the WandbLogger, so configuration is not automatically saved.
This can be fixed with a custom CLI:
```python
class CustomSaveConfigCallback(SaveConfigCallback):
# Saves full training configuration
def save_config(
self, trainer: Trainer, pl_module: LightningModule, stage: _LITERAL_WARN
) -> None:
for logger in trainer.loggers:
if issubclass(type(logger), WandbLogger):
logger.experiment.config.update(self.config.as_dict())
return super().save_config(trainer, pl_module, stage)
```
However, there will still be duplicate hyperparameters on wandb: parameters saved with `save_hyperparameters` are not nested within the relative model or dataclass, but are placed in the root (because `save_hyperparameters` feeds the logger a flattened list).
`save_hyperparameters` should place the updated parameters in the correct config path on wandb, instead of duplicating them at the root.
Logging can be disabled by subclassing WandbLogger
```python
class CustomWandbLogger(WandbLogger):
# Disable unintended hyperparameter logging (already saved on init)
def log_hyperparams(self, *args, **kwargs): ...
```
but then updated (or additional) hyperparameters added when initializing the model won't be stored.
Maybe there's already a better way to fix this behavior (or is it indended)?
### What version are you seeing the problem on?
v2.2
### How to reproduce the bug
Config file:
```python
trainer:
logger:
class_path: WandbLogger
```
Inside a model e.g.
```
class ConvolutionalNetwork(L.LightningModule):
def __init__(
self,
dim_in: int,
num_internal_channels: int,
num_layers: int,
kernel_size: int,
num_neurons_dense: int,
seq_len: int,
):
super().__init__()
self.save_hyperparameters()
``` | open | 2024-04-02T23:38:42Z | 2024-11-19T13:34:06Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19728 | [
"bug",
"needs triage"
] | lsarra | 1 |
nteract/papermill | jupyter | 67 | Default to first cell or prefix a new cell for parameters | When a user doesn't specify a parameter tag cell it would be nice if papermill defaulted to some sane logical setting. Nominally parameterizing the beginning of the notebook seems reasonable and would make adoption of existing notebooks quicker when they have naive inputs. | closed | 2017-12-19T01:44:25Z | 2017-12-19T22:12:32Z | https://github.com/nteract/papermill/issues/67 | [] | MSeal | 0 |
facebookresearch/fairseq | pytorch | 4,683 | Unable to load transformer.wmt18.en-de | ## 🐛 Bug
Loading transformer.wmt18.en-de` from the hub fails despite working in #1287.
The checkpoint has to be specified manually (otherwise a different error appears because `model.pt` does not exist in the archive) but that errors as well.
### To Reproduce
```python3
import torch
torch.hub.load(
'pytorch/fairseq', 'transformer.wmt18.en-de',
checkpoint_file='wmt18.model1.pt',
tokenizer='moses', bpe='subword_nmt'
)
```
Resulting error output:
```
Traceback (most recent call last):
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/_internal/config_loader_impl.py", line 513, in _apply_overrides_to_config
OmegaConf.update(cfg, key, value, merge=True)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/omegaconf.py", line 613, in update
root.__setattr__(last_key, value)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/dictconfig.py", line 285, in __setattr__
raise e
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/dictconfig.py", line 282, in __setattr__
self.__set_impl(key, value)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/dictconfig.py", line 266, in __set_impl
self._set_item_impl(key, value)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/basecontainer.py", line 398, in _set_item_impl
self._validate_set(key, value)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/dictconfig.py", line 143, in _validate_set
self._validate_set_merge_impl(key, value, is_assign=True)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/dictconfig.py", line 156, in _validate_set_merge_impl
self._format_and_raise(
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/base.py", line 95, in _format_and_raise
format_and_raise(
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/_utils.py", line 694, in format_and_raise
_raise(ex, cause)
File "/home/vilda/.local/lib/python3.10/site-packages/omegaconf/_utils.py", line 610, in _raise
raise ex # set end OC_CAUSE=1 for full backtrace
omegaconf.errors.ValidationError: child 'checkpoint.save_interval_updates' is not Optional
full_key: checkpoint.save_interval_updates
reference_type=CheckpointConfig
object_type=CheckpointConfig
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/vilda/mt-metric-estimation/./src/retranslate.py", line 100, in <module>
model = MODELS[args.model](args.direction)
File "/home/vilda/mt-metric-estimation/./src/retranslate.py", line 88, in <lambda>
"w18t": lambda direction: FairSeqWrap(config=f"transformer.wmt18.{direction}"),
File "/home/vilda/mt-metric-estimation/./src/retranslate.py", line 61, in __init__
torch.hub.load(
File "/home/vilda/.local/lib/python3.10/site-packages/torch/hub.py", line 540, in load
model = _load_local(repo_or_dir, model, *args, **kwargs)
File "/home/vilda/.local/lib/python3.10/site-packages/torch/hub.py", line 569, in _load_local
model = entry(*args, **kwargs)
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/models/fairseq_model.py", line 267, in from_pretrained
x = hub_utils.from_pretrained(
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/hub_utils.py", line 82, in from_pretrained
models, args, task = checkpoint_utils.load_model_ensemble_and_task(
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 425, in load_model_ensemble_and_task
state = load_checkpoint_to_cpu(filename, arg_overrides)
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 343, in load_checkpoint_to_cpu
state = _upgrade_state_dict(state)
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 681, in _upgrade_state_dict
state["cfg"] = convert_namespace_to_omegaconf(state["args"])
File "/home/vilda/.local/lib/python3.10/site-packages/fairseq/dataclass/utils.py", line 399, in convert_namespace_to_omegaconf
composed_cfg = compose("config", overrides=overrides, strict=False)
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/experimental/compose.py", line 31, in compose
cfg = gh.hydra.compose_config(
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/_internal/hydra.py", line 507, in compose_config
cfg = self.config_loader.load_configuration(
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/_internal/config_loader_impl.py", line 151, in load_configuration
return self._load_configuration(
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/_internal/config_loader_impl.py", line 277, in _load_configuration
ConfigLoaderImpl._apply_overrides_to_config(config_overrides, cfg)
File "/home/vilda/.local/lib/python3.10/site-packages/hydra/_internal/config_loader_impl.py", line 520, in _apply_overrides_to_config
raise ConfigCompositionException(
hydra.errors.ConfigCompositionException: Error merging override checkpoint.save_interval_updates=null
```
### Environment
- fairseq Version: 0.12.2
- PyTorch Version: 1.12.1+cu116
- OS: Ubuntu Linux 22.04
- How you installed fairseq: pip
- Python version: 3.10.4
- CUDA/cuDNN version: 11.6
(note that this issue is unrelated to #4680) | open | 2022-08-31T13:01:53Z | 2022-08-31T13:06:35Z | https://github.com/facebookresearch/fairseq/issues/4683 | [
"bug",
"needs triage"
] | zouharvi | 0 |
exaloop/codon | numpy | 389 | Type annotation `def f(a: List[int])` not working in codon.jit decorated function | The code
```
import codon
@codon.jit
def f(a: List[int]):
return len(a)
```
raises a `NameError: name 'List' is not defined`, while the same function definition works fine in a pure codon program. Also, other type annotations like `int` work in codon.jit decorated functions. Do I misunderstand something, or is this a bug or missing feature in v0.16.1? | closed | 2023-05-24T20:50:58Z | 2024-11-10T06:09:19Z | https://github.com/exaloop/codon/issues/389 | [] | ypfmde | 1 |
ray-project/ray | machine-learning | 51,121 | CI test linux://doc:doc_code_cgraph_profiling is consistently_failing | CI test **linux://doc:doc_code_cgraph_profiling** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8711#01956a36-520a-4bea-a351-c4b739770614
- https://buildkite.com/ray-project/postmerge/builds/8711#01956a0e-a7de-4ac8-a743-147f7e001fb9
DataCaseName-linux://doc:doc_code_cgraph_profiling-END
Managed by OSS Test Policy | closed | 2025-03-06T07:25:44Z | 2025-03-12T00:56:19Z | https://github.com/ray-project/ray/issues/51121 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 17 |
alteryx/featuretools | scikit-learn | 1,867 | Change features_only to feature_defs_only | When looking at the [DFS](https://featuretools.alteryx.com/en/stable/generated/featuretools.dfs.html#featuretools-dfs) call, I feel that the `features_only` option is misleading. Setting this to `True` only returns definitions and not the feature matrix. So I believe the option should be `feature_defs_only`
#### Code Example
```python
import featuretools as ft
es = ft.demo.load_mock_customer(return_entityset=True)
feature_defs = ft.dfs(
entityset=es,
target_dataframe_name="customers",
agg_primitives=["mean"],
trans_primitives=["time_since_previous"],
features_defs_only=True,
)
feature_defs
```
| closed | 2022-01-26T20:47:31Z | 2023-03-15T20:10:49Z | https://github.com/alteryx/featuretools/issues/1867 | [
"enhancement"
] | dvreed77 | 8 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 116 | 预测时 内存一直在增加 | 你好,想请教下在预测时发现内存一直在涨,能帮忙解答下吗 | open | 2019-05-09T08:58:35Z | 2019-05-10T10:02:08Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/116 | [] | soulbyfeng | 2 |
mwaskom/seaborn | data-visualization | 3,376 | Only display observed categories in legend | Hi,
This is a feature request
**Current behaviour**
When plotting with a `pd.CategoricalDtype(categories=categories)` column as `hue` or `style`, all the elements in `categories` are displayed in the legend, even the categories that don't appear in the data.
**Desired feature**
It would be nice to also have the possibility to only display the observed categories in the legend. For example with a new parameter in `FacetGrid.add_legend`:
```python
g.add_legend(observed_only=True)
```
**Relevance**
This would be useful in case you have multiple plots involving the same categories but not all categories observed in each plot. This way, the colours/style would be coherent between the plots, without overcrowding the legends. | closed | 2023-05-29T12:41:20Z | 2023-05-31T05:59:59Z | https://github.com/mwaskom/seaborn/issues/3376 | [] | PierreGtch | 2 |
xzkostyan/clickhouse-sqlalchemy | sqlalchemy | 245 | The drop table operation does not trigger the before_drop and after_drop events | **Describe the bug**
The `table.drop` and `op.drop_table` operation does not trigger the `before_drop` and `after_drop` events.
**To Reproduce**
Create function as follow:
```
@event.listens_for(Table, "before_drop")
def record_before_event(target, conn, **kwargs):
print("Will never be printed!")
```
drop table `using table.drop()` or `op.drop_table('table')` (if migrations). The function won't be invoked.
**Expected behavior**
Table drop table should trigger an event. | closed | 2023-04-25T01:57:54Z | 2023-04-25T16:08:19Z | https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/245 | [] | vanchaxy | 0 |
ultralytics/ultralytics | pytorch | 19,155 | Remove ultralytics dependency | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I am using python 3.6.9 version and i need to load best.pt of yolo11n model , how to remove the dependency of ultralytics model and load best.pt model
### Additional
_No response_ | open | 2025-02-10T07:58:16Z | 2025-02-10T10:50:24Z | https://github.com/ultralytics/ultralytics/issues/19155 | [
"question",
"dependencies"
] | Gcc1012 | 2 |
alpacahq/example-hftish | numpy | 6 | Trade Updates | Question on this part of the algorithm:
```python
if event == 'fill':
if data.order['side'] == 'buy':
position.update_total_shares(
int(data.order['filled_qty'])
)
else:
position.update_total_shares(
-1 * int(data.order['filled_qty'])
)
position.remove_pending_order(
data.order['id'], data.order['side']
)
```
I'm wondering if it should really be:
```python
if event == 'fill':
if data.order['side'] == 'buy':
position.update_filled_amount(
data.order['id'], int(data.order['filled_qty']),
data.order['side']
)
else:
position.update_filled_amount(
data.order['id'], int(data.order['filled_qty']),
data.order['side']
)
position.remove_pending_order(
data.order['id'], data.order['side']
)
```
Because, I believe, a PARTIALLY_FILLED order can then become FILL order once it is fully filled. Any thoughts or do I have that incorrect? | open | 2019-06-13T15:34:55Z | 2023-12-01T02:52:39Z | https://github.com/alpacahq/example-hftish/issues/6 | [] | mainstringargs | 1 |
bmoscon/cryptofeed | asyncio | 782 | Support bybit candles -> is closed | **Is your feature request related to a problem? Please describe.**
NO
**Describe the solution you'd like**
I would like to store only confirmed data from bybit.
**Describe alternatives you've considered**
Add following to bybit.py
def __init__(self, candle_closed_only=False, **kwargs):
super().__init__(**kwargs)
self.candle_closed_only = candle_closed_only
self.ws_defaults['compression'] = None
Edit following in bybit.py
async def _candle(self, msg: dict, timestamp: float):
'''
{
"topic": "klineV2.1.BTCUSD", //topic name
"data": [{
"start": 1572425640, //start time of the candle
"end": 1572425700, //end time of the candle
"open": 9200, //open price
"close": 9202.5, //close price
"high": 9202.5, //max price
"low": 9196, //min price
"volume": 81790, //volume
"turnover": 8.889247899999999, //turnover
"confirm": False, //snapshot flag
"cross_seq": 297503466,
"timestamp": 1572425676958323 //cross time
}],
"timestamp_e6": 1572425677047994 //server time
}
'''
symbol = self.exchange_symbol_to_std_symbol(msg['topic'].split(".")[-1])
ts = msg['timestamp_e6'] / 1_000_000
for entry in msg['data']:
> if self.candle_closed_only and entry['confirm']:
c = Candle(self.id,
symbol,
entry['start'],
entry['end'],
self.candle_interval,
None,
Decimal(entry['open']),
Decimal(entry['close']),
Decimal(entry['high']),
Decimal(entry['low']),
Decimal(entry['volume']),
> entry['confirm'],
ts,
raw=entry)
await self.callback(CANDLES, c, timestamp)
Can you please add this. Thank you and best regards. | closed | 2022-02-13T17:38:00Z | 2022-03-20T00:03:22Z | https://github.com/bmoscon/cryptofeed/issues/782 | [
"Feature Request"
] | regonw | 2 |
marcomusy/vedo | numpy | 1,028 | Error Thrown: Process finished with exit code -1073740791 (0xC0000409) | Hello,
I am facing a problem with vedo, when I try to load a Mesh via the library like so:
`msh = Mesh(random_pick).rotate_x(x).rotate_y(y).rotate_z(z).pos(0, 0, -380)`
The only message that is given is: Process finished with exit code -1073740791 (0xC0000409)
I have researched that error and it seems to connect to PyQT but my code crashes when loading the mesh so I think it has to come from somewhere else.
Sometimes it throws that error, sometimes it works. I am just at a loss right now. The `random_pick` variable is an .obj-file from a list of these. Here sometimes for example number 4 of the list works and sometimes it doesn´t.
I would appreciate pointers or any help you can provide.
Greetings | closed | 2024-01-19T11:15:48Z | 2024-01-19T13:59:28Z | https://github.com/marcomusy/vedo/issues/1028 | [] | Zud0taki | 8 |
viewflow/viewflow | django | 195 | import bpmn files | is there any ability to import bpmn and automatically generate workflow from bpmn files export designed in bpmn designer and editor apps | closed | 2017-10-09T03:48:52Z | 2021-05-20T00:32:06Z | https://github.com/viewflow/viewflow/issues/195 | [
"request/question",
"dev/flow"
] | molavy | 5 |
agronholm/anyio | asyncio | 11 | [Trio] Task groups are marked inactive early | Code:
```py
import anyio
async def second():
print("This never happens")
async def first(tg):
await anyio.sleep(0)
await tg.spawn(second)
async def main():
async with anyio.create_task_group() as tg:
await tg.spawn(first, tg)
anyio.run(main, backend="trio")
```
Error:
```py
Traceback (most recent call last):
File "/home/laura/dev/discord/curious/aaa.py", line 18, in <module>
anyio.run(main, backend="trio")
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/anyio/__init__.py", line 112, in run
return asynclib.run(func, *args, **backend_options)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/trio/_core/_run.py", line 1337, in run
raise runner.main_task_outcome.error
File "/home/laura/dev/discord/curious/aaa.py", line 15, in main
await tg.spawn(first, tg)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/async_generator/_util.py", line 42, in __aexit__
await self._agen.asend(None)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/async_generator/_impl.py", line 366, in step
return await ANextIter(self._it, start_fn, *args)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/async_generator/_impl.py", line 202, in send
return self._invoke(self._it.send, value)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/async_generator/_impl.py", line 209, in _invoke
result = fn(*args)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/anyio/_backends/trio.py", line 90, in create_task_group
tg._active = False
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/trio/_core/_run.py", line 397, in __aexit__
raise combined_error_from_nursery
File "/home/laura/dev/discord/curious/aaa.py", line 10, in first
await tg.spawn(second)
File "/home/laura/.local/share/virtualenvs/curious-yiBjxk2Q/lib/python3.7/site-packages/anyio/_backends/trio.py", line 78, in spawn
raise RuntimeError('This task group is not active; no new tasks can be spawned.')
RuntimeError: This task group is not active; no new tasks can be spawned.
```
Both curio and asyncio backends allow this to work. | closed | 2018-10-13T14:02:44Z | 2018-10-14T07:00:56Z | https://github.com/agronholm/anyio/issues/11 | [
"bug"
] | Fuyukai | 1 |
unit8co/darts | data-science | 2,012 | Weibull distribution | I got ValueError: Expected parameter scale (Tensor of shape (32, 96, 1)) of distribution Weibull(scale: torch.Size([32, 96, 1]), concentration: torch.Size([32, 96, 1])) to satisfy the constraint GreaterThan(lower_bound=0.0), but found invalid values:tensor([[[ 3.9661e-30],[ 1.2568e+01],[ 6.9787e-08]........while using Weibull likelihood parameter but the input was given while using Laplace and Gaussian Likelihood & code was run successfully. | closed | 2023-09-29T11:13:32Z | 2023-10-16T07:09:29Z | https://github.com/unit8co/darts/issues/2012 | [] | hberande | 1 |
SALib/SALib | numpy | 451 | [Question] Seed variable in analyze function | Hi, I am using the sobol analyze (https://salib.readthedocs.io/en/latest/_modules/SALib/analyze/sobol.html#analyze) I would like to know, what is the purpose of variable seed in the sobol analyze?
Thank you! | closed | 2021-07-15T08:24:53Z | 2021-08-14T06:53:58Z | https://github.com/SALib/SALib/issues/451 | [] | giupardeb | 3 |
tflearn/tflearn | tensorflow | 1,046 | TFLearn model not predicting when using gunicorn | I have the following class as part of my project:
class LSTMSentimentClassifier(SentimentClassifier):
def __init__(self, model_name: str, model_location: str, wordvec_model_location: str, lexicon_location: str):
super(LSTMSentimentClassifier, self).__init__("LSTM_{}".format(model_name))
self.logger = logging.getLogger(__name__)
self.model_name = model_name
self.model_location = model_location
self.numDimensions = 300
self.num_hidden = 128
self.learning_rate = 0.001
self.drop_out = 0.8
tf.reset_default_graph()
net = input_data(shape=[None, self.numDimensions])
net = embedding(net, input_dim=20000, output_dim=self.num_hidden)
net = tflearn.lstm(net, self.num_hidden, return_seq=True)
net = dropout(net, self.drop_out)
net = tflearn.lstm(net, self.num_hidden, return_seq=True)
net = dropout(net, self.drop_out)
net = fully_connected(net, 2, activation='softmax')
net = regression(net, optimizer='adam', learning_rate=self.learning_rate,
loss='mean_square')
self.nn = tflearn.DNN(net, clip_gradients=0., tensorboard_verbose=0)
self.nn.load(model_location)
self.wordvec_model = KeyedVectors.load_word2vec_format(wordvec_model_location)
self.lexicon = pickle.load(open(lexicon_location, 'rb'))
self.logger.info("Inside NRCSentimentClassifier -- "
"Loaded NRC model file for the model: {}".format(model_name))
def word_to_vec(self, sentence: str) -> np.array:
if type(sentence) == str:
sentence = sentence
else:
sentence = sentence[0]
words = sentence.split()
featureVec = [0] * self.numDimensions
for word in words:
try:
try:
featureVec = featureVec + (self.wordvec_model[word] + self.lexicon[word])
except:
featureVec = featureVec + self.wordvec_model[word]
except:
featureVec
Vec = [max(0, val) for val in featureVec]
return np.array(Vec)
def predict_sentiment(self, text: str) -> list:
text_vec = self.word_to_vec(text)
sentiment_classes = ["positive", "negative"]
labels_with_probabilities = {}
model_probabilities = self.nn.predict([text_vec])[0]
for label, probability in zip(sentiment_classes, model_probabilities):
labels_with_probabilities[label] = probability
labels_with_probabilities_sorted = sorted(labels_with_probabilities.items(), key=lambda x: x[1], reverse=True)
print(labels_with_probabilities_sorted)
output = []
for label, probability in labels_with_probabilities_sorted:
label_val = str(label)
probability_val = float(probability)
output.append(SentimentScore(sentence=text, sentiment_class=SentimentClass.get_label_NRC(label_val),
confidence_score=probability_val, sentiment_strength=1.0))
return output
When I run this class as part of a python script eg `python classifier.py` it works with a main method and calling the class with the file paths, giving predictions for sentences that I pass into it, `model.predict_sentiment(sentence)`, where `model = LSTMSentimentClassifier("lstm", path_to_classifier, path_to_wordembeddings, path_to_lexicon)`
However this classifier is part of a larger project that uses `gunicorn` and `falcon`. I can start the project and it loads fine, but when I make an api call using the classifier, the classifier gets stuck at the predict.
I know that the model has loaded correctly but I am confused as to why I can use the above class when running the single python file, but the class predict doesn't work when using it as part of the gunicorn process.
The file locations are correct. I have used prints to verify that a sentence is coming in, it is correctly being turned into a word vector in the correct form and passed into the `nn.predict`, however it is here that the class stops working and gunicorn times out.
Any help would be much appreciated. | open | 2018-04-30T14:18:20Z | 2018-05-10T06:22:13Z | https://github.com/tflearn/tflearn/issues/1046 | [] | rickesh17 | 1 |
RobertCraigie/prisma-client-py | pydantic | 293 | Consider renaming root `OR` query to `ANY` | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
The root `OR` part of a query can be confusing: https://news.ycombinator.com/item?id=30416531#30422118
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Replace the `OR` field with an `ANY` field, for example:
```py
posts = await client.post.find_many(
where={
'OR': [
{'title': {'contains': 'prisma'}},
{'content': {'contains': 'prisma'}},
]
}
)
```
Becomes:
```py
posts = await client.post.find_many(
where={
'ANY': [
{'title': {'contains': 'prisma'}},
{'content': {'contains': 'prisma'}},
]
}
)
```
If we decide to go with this (or similar), the `OR` field should be deprecated first and then removed in a later release.
| open | 2022-02-22T00:20:39Z | 2022-06-12T14:03:02Z | https://github.com/RobertCraigie/prisma-client-py/issues/293 | [
"kind/improvement",
"topic: client",
"level/intermediate",
"priority/medium"
] | RobertCraigie | 2 |
huggingface/datasets | numpy | 7,084 | More easily support streaming local files | ### Feature request
Simplify downloading and streaming datasets locally. Specifically, perhaps add an option to `load_dataset(..., streaming="download_first")` or add better support for streaming symlinked or arrow files.
### Motivation
I have downloaded FineWeb-edu locally and currently trying to stream the dataset from the local files. I have both the raw parquet files using `hugginface-cli download --repo-type dataset HuggingFaceFW/fineweb-edu` and the processed arrow files using `load_dataset("HuggingFaceFW/fineweb-edu")`.
Streaming the files locally does not work well for both file types for two different reasons.
**Arrow files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/datasets/HuggingFaceFW___fineweb-edu/default/0.0.0/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/fineweb-edu-train-*.arrow"})` resolving the data files is fast, but because `arrow` is not included in the known [extensions file list](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/utils/file_utils.py#L738) , all files are opened and scanned to determine the compression type. Adding `arrow` to the known extension types resolves this issue.
**Parquet files**
When running `load_dataset("arrow", data_files={"train": "~/.cache/huggingface/hub/dataset-HuggingFaceFW___fineweb-edu/snapshots/5b89d1ea9319fe101b3cbdacd89a903aca1d6052/data/CC-MAIN-*/train-*.parquet"})` the paths do not get resolved because the parquet files are symlinked from the blobs (which contain all files in case there are different versions). This occurs because the [pattern matching](https://github.com/huggingface/datasets/blob/ce4a0c573920607bc6c814605734091b06b860e7/src/datasets/data_files.py#L389) checks if the path is a file and does not check for symlinks. Symlinks (at least on my machine) are of type "other".
### Your contribution
I have created a PR for fixing arrow file streaming and symlinks. However, I have not checked locally if the tests work or new tests need to be added.
IMO, the easiest option would be to add a `streaming=download_first` option, but I'm afraid that exceeds my current knowledge of how the datasets library works. https://github.com/huggingface/datasets/pull/7083 | open | 2024-07-31T09:03:15Z | 2024-07-31T09:05:58Z | https://github.com/huggingface/datasets/issues/7084 | [
"enhancement"
] | fschlatt | 0 |
davidteather/TikTok-Api | api | 405 | [BUG] - Exception: Invalid Response | I am trying to use with Django, it was working last week, but now it is showing an error with ``` Exception: Invalid Response ```.
I upgrade the API too. via ``` pip install TikTokApi --upgrade ```. but still showing exception.
Here's the code
```
API = TikTokApi()
results = API.trending(count=VIDEOS_COUNT)
```
**Error Trace**
```
{'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36', 'accept-encoding': 'gzip, deflate, br', 'accept': 'application/json, text/plain, */*', 'Connection': 'keep-alive', 'authority': 'm.tiktok.com', 'method': 'GET', 'path': '/api/item_list/?aid=1988&app_name=tiktok_web&device_platform=web&referer=https%3A%2F%2Fwww.', 'scheme': 'https', 'accept-language': 'en-US,en;q=0.9', 'referer': 'https://www.tiktok.com/', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'cookie': 'tt_webid_v2=746436216'}
Converting response to JSON failed response is below (probably empty)
illegal request...
Internal Server Error
Traceback (most recent call last):
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 103, in getData
return r.json()
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/requests/models.py", line 900, in json
return complexjson.loads(self.text, **kwargs)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 190, in trending
res = self.getData(b, **kwargs)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 113, in getData
raise Exception("Invalid Response")
Exception: Invalid Response
ERROR 2020-12-03 00:01:27,081 log 16905 140297062823680 Internal Server Error: /dashboard/
Traceback (most recent call last):
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 103, in getData
return r.json()
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/requests/models.py", line 900, in json
return complexjson.loads(self.text, **kwargs)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/core/handlers/exception.py", line 34, in inner
response = get_response(request)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/core/handlers/base.py", line 115, in _get_response
response = self.process_exception_by_middleware(e, request)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/core/handlers/base.py", line 113, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/usr/lib/python3.6/contextlib.py", line 52, in inner
return func(*args, **kwds)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/views/generic/base.py", line 71, in view
return self.dispatch(request, *args, **kwargs)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/views/generic/base.py", line 97, in dispatch
return handler(request, *args, **kwargs)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/django/views/generic/edit.py", line 142, in post
return self.form_valid(form)
File "/home/{user}/{DjangoApp}/{DjangoApp}/dashboard/views.py", line 25, in form_valid
'hashtag': hashtag,
File "/home/{user}/{DjangoApp}/{DjangoApp}/utils/tiktok.py", line 86, in generate_video
results = API.trending(count=VIDEOS_COUNT)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 190, in trending
res = self.getData(b, **kwargs)
File "/home/{user}/Documents/venv/lib/python3.6/site-packages/TikTokApi/tiktok.py", line 113, in getData
raise Exception("Invalid Response")
Exception: Invalid Response
```
**Desktop (please complete the following information):**
- OS: Ubuntu 18.04
- TikTokApi Version latest
**Additional context**
| closed | 2020-12-02T19:19:27Z | 2020-12-03T03:08:33Z | https://github.com/davidteather/TikTok-Api/issues/405 | [
"bug"
] | ranahaani | 1 |
mljar/mljar-supervised | scikit-learn | 241 | Warning in EDA | During the analysis of `robert` dataset from OpenML:
```py
Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
``` | closed | 2020-11-24T22:11:58Z | 2021-05-04T07:12:41Z | https://github.com/mljar/mljar-supervised/issues/241 | [] | pplonski | 0 |
PokeAPI/pokeapi | api | 973 | Manaphy evolution trigger | There is no evolution trigger for Manaphy, evolution-chain/250 and pokemon/490
(It should be, being grown up with a ditto with him)
| closed | 2023-11-29T17:56:51Z | 2023-11-29T18:07:38Z | https://github.com/PokeAPI/pokeapi/issues/973 | [] | PabloFriasCampos | 0 |
nonebot/nonebot2 | fastapi | 2,973 | Plugin: Beat Saber查分器 | ### PyPI 项目名
nonebot-plugin-beatsaberscore
### 插件 import 包名
nonebot_plugin_beatsaberscore
### 标签
[{"label":"Beat Saber","color":"#456df1"}]
### 插件配置项
_No response_ | closed | 2024-09-22T05:38:50Z | 2024-10-01T03:47:44Z | https://github.com/nonebot/nonebot2/issues/2973 | [
"Plugin"
] | qwq12738qwq | 10 |
kizniche/Mycodo | automation | 1,159 | Lost remote browser access | Not sure what happened but cannot access mycodo through the browser anymore and get this error message:
Version: 8.12.9
Database: 0187ea22dc4b
Model: Raspberry Pi 3 Model B Rev 1.2
Release:
Distributor ID: Raspbian
Description: Raspbian GNU/Linux 10 (buster)
Release: 10
Codename: buster
Firmware:
Dec 1 2021 15:08:00
Copyright (c) 2012 Broadcom
version 71bd3109023a0c8575585ba87cbb374d2eeb038f (clean) (release) (start_x)
Error (Full Traceback):
Traceback (most recent call last):
File "/var/mycodo-root/env/lib/python3.7/site-packages/flask/app.py", line 2073, in wsgi_app
response = self.full_dispatch_request()
File "/var/mycodo-root/env/lib/python3.7/site-packages/flask/app.py", line 1519, in full_dispatch_request
return self.finalize_request(rv)
File "/var/mycodo-root/env/lib/python3.7/site-packages/flask/app.py", line 1540, in finalize_request
response = self.process_response(response)
File "/var/mycodo-root/env/lib/python3.7/site-packages/flask/app.py", line 1888, in process_response
self.session_interface.save_session(self, ctx.session, response)
File "/var/mycodo-root/env/lib/python3.7/site-packages/flask_session/sessions.py", line 367, in save_session
total_seconds(app.permanent_session_lifetime))
File "/var/mycodo-root/env/lib/python3.7/site-packages/cachelib/file.py", line 147, in set
self._prune()
File "/var/mycodo-root/env/lib/python3.7/site-packages/cachelib/file.py", line 87, in _prune
if self._threshold == 0 or not self._file_count > self._threshold:
File "/var/mycodo-root/env/lib/python3.7/site-packages/cachelib/file.py", line 58, in _file_count
return self.get(self._fs_count_file) or 0
File "/var/mycodo-root/env/lib/python3.7/site-packages/cachelib/file.py", line 127, in get
return pickle.load(f)
EOFError: Ran out of input
I am running off master so kot sure if this has something to do with it | closed | 2022-03-12T19:55:00Z | 2022-03-16T06:55:44Z | https://github.com/kizniche/Mycodo/issues/1159 | [] | jacopienaar | 2 |
httpie/http-prompt | rest-api | 63 | Support "ls" command and endpoint definitions | I've been using this program for a few days now and overall I love it. I'm using it to test endpoints while developing my API.
One issue I have however is that whenever I type `cd`, my muscle memory kicks in and I immediately follow with an `ls` out of habit. It's always a little disappointing when this doesn't work :( I was thinking of ways to solve this, and it would be great if I could pass in my endpoint definition file ala
``` bash
$ http-prompt --specification=my_api_spec.json
```
This would enable http-prompt to do a bunch of smart things like suggest endpoints when I type `ls` or autocomplete parameter names. Could also add a `help` command to view the documentation for any given endpoint. There are a couple of widely used spec formats, with Swagger probably being the most popular
http://nordicapis.com/top-specification-formats-for-rest-apis/
| closed | 2016-07-15T21:29:52Z | 2017-04-17T17:32:26Z | https://github.com/httpie/http-prompt/issues/63 | [
"enhancement",
"todo"
] | michael-lazar | 4 |
axnsan12/drf-yasg | django | 813 | `ImportError: Module "drf_yasg.generators" does not define a "OpenAPISchemaGenerator" attribute/class` after upgrading DRF==3.14.0 | # Bug Report
## Description
After update Django Rest Framework to 3.14.0, Django did not start, because drf-yasg raise exception `ImportError: Could not import 'drf_yasg.generators.OpenAPISchemaGenerator' for API setting 'DEFAULT_GENERATOR_CLASS'. ` Reverting to drf==3.13.1 resolves the issue.
## Is this a regression?
Not sure, there was a similar issue here: https://github.com/axnsan12/drf-yasg/issues/641
## Minimal Reproduction
```python
# settings.py
INSTALLED_APPS = [
...
"drf_yasg",
]
SWAGGER_SETTINGS = {
"SECURITY_DEFINITIONS": {
"Bearer": {
"type": "apiKey",
"in": "header",
"name": "Authorization",
"template": "Bearer {apiKey}",
},
},
"DEFAULT_FIELD_INSPECTORS": [
"drf_yasg.inspectors.CamelCaseJSONFilter",
"drf_yasg.inspectors.InlineSerializerInspector",
"drf_yasg.inspectors.RelatedFieldInspector",
"drf_yasg.inspectors.ChoiceFieldInspector",
"drf_yasg.inspectors.FileFieldInspector",
"drf_yasg.inspectors.DictFieldInspector",
"drf_yasg.inspectors.SimpleFieldInspector",
"drf_yasg.inspectors.StringDefaultFieldInspector",
],
}
```
```python
# urls.py
from drf_yasg import openapi
from drf_yasg.views import get_schema_view
from rest_framework import permissions
schema_view = get_schema_view(
openapi.Info(
title="My API",
default_version="v1",
description="My API",
terms_of_service="https://www.google.com/policies/terms/",
contact=openapi.Contact(email="leohakim@gmail.com"),
license=openapi.License(name="BSD License"),
),
public=True,
permission_classes=(permissions.AllowAny,),
)
```
## Stack trace / Error message
```code
File "/usr/local/lib/python3.9/site-packages/drf_yasg/views.py", line 67, in get_schema_view
_generator_class = generator_class or swagger_settings.DEFAULT_GENERATOR_CLASS
File "/usr/local/lib/python3.9/site-packages/drf_yasg/app_settings.py", line 122, in __getattr__
val = perform_import(val, attr)
File "/usr/local/lib/python3.9/site-packages/rest_framework/settings.py", line 166, in perform_import
return import_from_string(val, setting_name)
File "/usr/local/lib/python3.9/site-packages/rest_framework/settings.py", line 180, in import_from_string
raise ImportError(msg)
ImportError: Could not import 'drf_yasg.generators.OpenAPISchemaGenerator' for API setting 'DEFAULT_GENERATOR_CLASS'. ImportError: Module "drf_yasg.generators" does not define a "OpenAPISchemaGenerator" attribute/class.
```
## Your Environment
```code
drf-yasg=1.21.3
djangorestframework=3.14.0
django=4.1.1
```
| closed | 2022-09-23T11:50:21Z | 2023-10-06T09:52:16Z | https://github.com/axnsan12/drf-yasg/issues/813 | [] | chrismaille | 0 |
Kanaries/pygwalker | pandas | 49 | DataFrame's column names display Unicode | # DataFrame's column names display Unicode
I am using JupyterLab. I encountered an encoding problem when importing a data set. The column names of the DataFrame contain Chinese, but the Chinese is displayed as Unicode. The strange thing is that the value of the field also contains Chinese, but it can be displayed normally.
<img width="772" alt="DXTRyHFcaW" src="https://user-images.githubusercontent.com/59652488/221740595-5ae81295-b90c-43bd-a747-9eecceeef7db.png">
| closed | 2023-02-28T02:49:07Z | 2023-02-28T09:37:54Z | https://github.com/Kanaries/pygwalker/issues/49 | [] | freedomgod | 1 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 807 | There are two instances of different models. If one instance executes db.session.commit (), the other instance immediately print (obj .__ dict__) will be empty. | ---
### Expected behavior
model .__ dict__ Fields where data can be obtained
```sh
root@c57f84919524:/webroot# python manage.py shell
>>> from app.models import *
>>> u = User.query.filter().first()
>>> img = ProjectImages.query.filter().first()
>>> print(img.__dict__)
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7f5b40df7040>, 'id': 1, 'created_at': datetime.datetime(2020, 2, 20, 21, 34, 14), 'image': 'https://cdn.yttys.com/item_1520582553119_0649002690.jpg', 'project_id': 1, 'delete_flag': 0, 'sort': 1}
>>> from app import db
>>> db.session.add(u)
>>> db.session.commit()
>>> print(img.__dict__)
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7f5b40df7040>}
>>>
```
### Actual behavior
```python
obj = model.query.filter().first()
other = model2.query.filter().first()
db.session.add(other)
db.session.commit()
print(obj .__ dict__)
```
The final output is:
```
dict_keys (['_ sa_instance_state'])
```
There are two instances of different models. If one instance executes db.session.commit (), the other instance immediately print (obj .__ dict__) will be empty.
### surroundings
* operating system:
* Python version: 3.8.1
* Flask-SQLAlchemy version: 2.4.1
* SQLAlchemy version: 1.3.13 | closed | 2020-02-26T04:40:11Z | 2020-12-05T19:58:38Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/807 | [] | pcloth | 2 |
plotly/dash-table | plotly | 833 | dash_table.DataTable. When fixed_rows={'headers': True, 'data': 0}, the table gets distorted | When fixed_rows is set to headers = True the page does not resize and is by default distorted (see image on the right with False value compared with the image on the left with True). I use latest version of dash, dash 1.16.2

`app.layout = html.Div([
dash_table.DataTable(
id='datatable-interactivity',
columns=[
{"name": i, "id": i, "deletable": True, "selectable": True} for i in df.columns
],
data=df.to_dict('records'),
editable=False,
hidden_columns=False,
filter_action="native",
sort_action="native",
sort_mode="multi",
column_selectable="multi",
row_selectable=False,
row_deletable=False,
selected_columns=[],
selected_rows=[],
page_action="native",
page_current=0,
fixed_rows={'headers': True, 'data': 0},` | open | 2020-09-28T19:33:05Z | 2020-10-22T16:05:26Z | https://github.com/plotly/dash-table/issues/833 | [] | GeorgeAlexAZ | 1 |
deezer/spleeter | deep-learning | 278 | training using own data [ | <!-- Please respect the title [Discussion] tag. -->
Hi, if i want to use another my own dataset of songs instead of musdb18, whats the steps i should do in using spleeter? | closed | 2020-02-24T03:45:35Z | 2020-02-27T17:20:13Z | https://github.com/deezer/spleeter/issues/278 | [
"question"
] | chenglong96 | 1 |
dropbox/PyHive | sqlalchemy | 391 | Insert / Update Hive Query failing. | I am facing this issue with pyHive. I have connected to Hive on EMR as follows
```from pyhive import hive
config = {'hive.txn.manager':'org.apache.hadoop.hive.ql.lockmgr.DbTxnManager',
'hive.support.concurrency': 'true',
'hive.enforce.bucketing': 'true',
'hive.exec.dynamic.partition.mode': 'nonstrict',
'hive.compactor.initiator.on': 'true',}
connection = hive.connect ("X.X.X.X", configuration= config)
cursor = connection.cursor()
cursor.execute("Update table set x=2 where y=1")
```
I get the following exception Stack trace and I'm not able to point out what the problem is.
```
TExecuteStatementResp(status=TStatus(statusCode=3, infoMessages=[
'*org.apache.hive.service.cli.HiveSQLException:Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask:28:27', 'org.apache.hive.service.cli.operation.Operation:toSQLException:Operation.java:380',
'org.apache.hive.service.cli.operation.SQLOperation:runQuery:SQLOperation.java:257',
'org.apache.hive.service.cli.operation.SQLOperation:runInternal:SQLOperation.java:293',
'org.apache.hive.service.cli.operation.Operation:run:Operation.java:320',
'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatementInternal:HiveSessionImpl.java:530',
'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatement:HiveSessionImpl.java:506',
'sun.reflect.GeneratedMethodAccessor16:invoke::-1',
'sun.reflect.DelegatingMethodAccessorImpl:invoke:DelegatingMethodAccessorImpl.java:43',
'java.lang.reflect.Method:invoke:Method.java:498',
'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:78',
'org.apache.hive.service.cli.session.HiveSessionProxy:access$000:HiveSessionProxy.java:36',
'org.apache.hive.service.cli.session.HiveSessionProxy$1:run:HiveSessionProxy.java:63',
'java.security.AccessController:doPrivileged:AccessController.java:-2',
'javax.security.auth.Subject:doAs:Subject.java:422',
'org.apache.hadoop.security.UserGroupInformation:doAs:UserGroupInformation.java:1926',
'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:59',
'com.sun.proxy.$Proxy35:executeStatement::-1',
'org.apache.hive.service.cli.CLIService:executeStatement:CLIService.java:280',
'org.apache.hive.service.cli.thrift.ThriftCLIService:ExecuteStatement:ThriftCLIService.java:531',
'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1437',
'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1422',
'org.apache.thrift.ProcessFunction:process:ProcessFunction.java:39',
'org.apache.thrift.TBaseProcessor:process:TBaseProcessor.java:39',
'org.apache.hive.service.auth.TSetIpAddressProcessor:process:TSetIpAddressProcessor.java:56',
'org.apache.thrift.server.TThreadPoolServer$WorkerProcess:run:TThreadPoolServer.java:286',
'java.util.concurrent.ThreadPoolExecutor:runWorker:ThreadPoolExecutor.java:1149',
'java.util.concurrent.ThreadPoolExecutor$Worker:run:ThreadPoolExecutor.java:624',
'java.lang.Thread:run:Thread.java:748'],
sqlState='08S01', errorCode=1, errorMessage='Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask'), operationHandle=None)
```
When I run the **exact same query on EMR it is executing successfully** (The table has been set up as an ACID table stored as ORC and transactions enabled)
Select queries are working fine with the connection set up as shown above. I seem to get the same error on inserts and updates.
I'm not sure if there is a configuration that I'm missing to add to my connection or if it is an issue on Pyhive.
Any help would be appreciated.
Thanks. | closed | 2021-05-20T17:07:15Z | 2021-05-24T05:57:06Z | https://github.com/dropbox/PyHive/issues/391 | [] | nikhilkamath91 | 1 |
mars-project/mars | scikit-learn | 2,697 | [BUG] `use_arrow_dtype` doesn't work when read a directory path for `read_parquet` | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
`use_arrow_dtype` doesn't work when read a directory path for `read_parquet`
**To Reproduce**
``` Python
In [26]: df = md.read_parquet(tempdir, use_arrow_dtype=True)
In [27]: df.dtypes
Out[27]:
a int64
b object
c float64
dtype: object
```
Expected dtypes should be:
``` Python
In [14]: df.dtypes
Out[14]:
a int64
b Arrow[string]
c float64
dtype: object
```
**Expected behavior**
A clear and concise description of what you expected to happen.
**Additional context**
Add any other context about the problem here.
| closed | 2022-02-10T09:55:52Z | 2022-02-10T16:08:13Z | https://github.com/mars-project/mars/issues/2697 | [
"type: bug",
"mod: dataframe"
] | hekaisheng | 0 |
matterport/Mask_RCNN | tensorflow | 2,288 | Where is 28x28 mask to binary mask conversion | I am a beginner in Mask-RCNN. The model predicts a 28x28 segmentation mask then converted to a binary mask of coordinates of the original image to superimpose on it. I cannot understand what code does that job? Kindly guide. | open | 2020-07-20T20:18:42Z | 2020-07-20T20:20:04Z | https://github.com/matterport/Mask_RCNN/issues/2288 | [] | gireek | 0 |
mitmproxy/mitmproxy | python | 7,511 | Addon error: Flow is not killable | #### Problem Description
~~~
> mitmproxy -r sky-phone-login.txt
Errors logged during startup:
Addon error: Flow is not killable.
Traceback (most recent call last):
File "mitmproxy\addons\disable_h2c.py", line 41, in request
File "mitmproxy\addons\disable_h2c.py", line 33, in process_flow
File "mitmproxy\flow.py", line 235, in kill
mitmproxy.exceptions.ControlException: Flow is not killable.
~~~
#### Steps to reproduce the behavior:
~~~
: save.file @shown sky-phone-login.txt
~~~
#### System Information
~~~
Mitmproxy: 10.3.0 binary
Python: 3.12.3
OpenSSL: OpenSSL 3.2.1 30 Jan 2024
Platform: Windows-10-10.0.18363-SP0
~~~ | closed | 2025-01-27T02:50:58Z | 2025-01-27T13:59:29Z | https://github.com/mitmproxy/mitmproxy/issues/7511 | [
"kind/bug",
"help wanted",
"area/addons"
] | 3052 | 5 |
matterport/Mask_RCNN | tensorflow | 2,660 | AttributeError: 'str' object has no attribute 'decode' | When I ran 'saving.load_weights_from_hdf5_group_by_name(f, layers)',which is the line 2135 of mrcnn/model.py,the AttributeError raised as: 'str' object has no attribute 'decode' | open | 2021-08-02T09:05:03Z | 2021-08-04T02:55:47Z | https://github.com/matterport/Mask_RCNN/issues/2660 | [] | ashing-zhang | 2 |
nerfstudio-project/nerfstudio | computer-vision | 3,335 | Memory accumulation on the GPU - and a Fix! | I experienced OOM with very big datasets and realised the images were accumulating on the GPU. After a lot of digging I found that here:
https://github.com/nerfstudio-project/nerfstudio/blob/702886b213a5942b64250b3c4dc632e62237a511/nerfstudio/data/datamanagers/full_images_datamanager.py#L347
Because a deepcopy of the original tensor is not made, the cpu_cached images are transferred to the GPU and left there taking up memory quickly. Modifying the data dictionary does modify the underlying cached_train.
Interestingly a deepcopy is performed here: https://github.com/nerfstudio-project/nerfstudio/blob/702886b213a5942b64250b3c4dc632e62237a511/nerfstudio/data/datamanagers/full_images_datamanager.py#L373
I would argue that we don't want the dataset to accumulate on the GPU and a deepcopy should be added. | closed | 2024-07-26T16:52:31Z | 2024-08-23T18:04:33Z | https://github.com/nerfstudio-project/nerfstudio/issues/3335 | [] | Jovp | 2 |
PokeAPI/pokeapi | graphql | 585 | basculin is not found | - Provide a clear description of the issue.
There is no entry for basculin - pokemon number 550.
- Provide a clear description of the steps to reproduce.
1. Search for basculin https://pokeapi.co/api/v2/pokemon/basculin
2. Returns undefined
- Provide a clear description of the expected behavior.
I expected info on basculin. | closed | 2021-03-07T20:49:39Z | 2021-03-08T09:14:01Z | https://github.com/PokeAPI/pokeapi/issues/585 | [] | Whisperyraptor | 3 |
postmanlabs/httpbin | api | 150 | Is there any request quota limit per IP to httpbin.org/status ? | I am writing a small js/html5 app to monitor my internet connection. For this I need to "ping" an external service to check if the device is connected to the internet. Httpbin/status/200 seems to be just what I was looking for, however my app will ping the service every 3 seconds or so (e.g. that means a peak of 28k times a day).
For me only using it, I guess that will be okay, however I plan to release it on github, so hundreds of users will probably start to use it.
Do you have any quota limit in place that I should be aware of before releasing it?
| closed | 2014-07-18T09:28:36Z | 2018-04-26T17:51:02Z | https://github.com/postmanlabs/httpbin/issues/150 | [] | adrian7 | 3 |
plotly/dash | jupyter | 3,044 | html.Script not rendering the javascript code | Hi,
I'm trying to run a javascript code wrapped in `html.Script`. But it's not rendering the JS code.
```
recharts_js = """
const { BarChart, Bar, XAxis, YAxis, Tooltip, Legend, CartesianGrid, ResponsiveContainer } = Recharts;
const data = [
{ dmu: "dmu1", "Efficiency score": 100, Status: "Efficient" },
{ dmu: "dmu2", "Efficiency score": 78, Status: "InEfficient" },
{ dmu: "dmu3", "Efficiency score": 100, Status: "Efficient" },
{ dmu: "dmu4", "Efficiency score": 100, Status: "Efficient" },
{ dmu: "dmu5", "Efficiency score": 89, Status: "InEfficient" },
{ dmu: "dmu6", "Efficiency score": 95, Status: "InEfficient" },
];
class CustomBarChart extends React.Component {
render() {
return (
<Recharts.BarChart
width={600}
height={400}
data={data}
margin={{ top: 20, right: 30, left: 20, bottom: 5 }}
>
<Recharts.CartesianGrid strokeDasharray="3 3" />
<Recharts.XAxis dataKey="dmu" />
<Recharts.YAxis />
<Recharts.Tooltip />
<Recharts.Legend
payload={[
{ value: "Efficient", type: "square", id: "ID01", color: "#FFA500" }, // Orange for Efficient
{ value: "InEfficient", type: "square", id: "ID02", color: "#32CD32" }, // Green for InEfficient
]}
/>
<Recharts.Bar dataKey="Efficiency score">
{data.map((entry, index) => (
<Recharts.Cell
key={`cell-${index}`}
fill={entry.Status === "Efficient" ? "#FFA500" : "#32CD32"}
/>
))}
</Recharts.Bar>
</Recharts.BarChart>
);
}
}
ReactDOM.render(<CustomBarChart />, document.getElementById('recharts-container'));
"""
html.Div(
[
html.Script(children=recharts_js),
],
)
``` | closed | 2024-10-16T18:13:35Z | 2024-10-16T19:39:13Z | https://github.com/plotly/dash/issues/3044 | [] | namakshenas | 1 |
biolab/orange3 | data-visualization | 6,942 | Change in the Neighbours widget | @BlazZupan started a discussion about the Neighbours widgets. He basically, wanted an output Data with distances to *all* data instance, and overlooked that he can achieve the same effect by unchecking the checkbox that limits the number of neighbours.
Here are some notes:
**Neighbours**:
- Add missing distances (normalized Euclidean and Manhatta). (Note to self: an input with distances is not a solution because it would incur quadratic time complexity).
- Add an output Data with all instance and their distances to the reference, and **make it lazy**. The output is superfluous, but somehow consistent with other widgets that output subsets, and it's harmless if lazy.
- Perhaps: remove the checkbox, keep line edit. This is still a matter of discussion; removing the checkbox requires some code for backward compatibilitty.
We also discussed how to provide distances to multiple references. One option was an additional input to Distances of type Data Table that would represent reference examples), and an output with distances to all those instance. The problems with this solution are
- potentially many meta columns with distances
- Distances can currently be connected only to a few widgets, which is nice. With the additional output, it can be connected to almost everything, so the pop-up is populated with lots and lots of widgets.
- We want additional options, like a column that contains an id of the closest reference, or some kind of aggregation (min, max, avg) of distances to refrences.
We haven't decided anything, but it seems this calls for a new widget. | open | 2024-11-29T10:21:14Z | 2024-11-29T11:08:23Z | https://github.com/biolab/orange3/issues/6942 | [] | janezd | 0 |
pyqtgraph/pyqtgraph | numpy | 2,373 | __all__ write in wrong place | __all__ statements should be placed in head of python file.
(btw: use '''import *''' is not good practice in code)
| open | 2022-07-23T10:14:47Z | 2023-09-30T17:57:37Z | https://github.com/pyqtgraph/pyqtgraph/issues/2373 | [
"good first issue",
"hacktoberfest"
] | dingo9 | 3 |
aleju/imgaug | deep-learning | 202 | uint16 SegmentationMapOnImage | I think it is quite common to encode masks using uint16, therefore I would suggest to enable this format for the `SegmentationMapOnImage` class.
It seems like this format is not supported yet: https://github.com/aleju/imgaug/blob/69ac72ef4f2b9d5de62c7813dcf3427ca4a604b5/imgaug/imgaug.py#L4814 | closed | 2018-11-07T00:47:56Z | 2019-01-06T15:25:21Z | https://github.com/aleju/imgaug/issues/202 | [
"enhancement",
"TODO"
] | martinruenz | 2 |
joke2k/django-environ | django | 187 | Support sqlite database urls relative to project path. | When developing it makes sense to have the database file in the local repository directory, to have a `dev.env` which is valid for all developers it needs to be relative..
I have been doing hacks in settings.py to get around it for a few years now but I would like a discussion about how to maybe integrate such a feature into django-environ.
This basically just assumes that if the the file is at the root of the system it's instead relative but I'm looking for a way to get rid of these in every project..
```py
for db in DATABASES:
if DATABASES[db]['ENGINE'] == 'django.db.backends.sqlite3':
if os.path.split(DATABASES[db]['NAME'])[0] == "/":
DATABASES[db]['NAME'] = root(DATABASES[db]['NAME'][1:])
```
I am thinking that this is kind of sane because no one proably stores the database in the root of the file system but making it optional by having a `sqlite_root` argument to the db-url function maybe works?
```py
root = environ.Path(__file__) - 2
...
DATABASES = {
'default': env.db(sqlite_root=root()),
}
```
I think that both relative AND absolute paths should work.
One option which I think might work safely for triggering a relative path instead of absolute is to do it when host is `.` or some other reserved name which isn't really a hostname. It should error out if `sqlite_root` was not provided to the url parse function.
```py
DATABASE_URL=sqlite://./db.sqlite3
```
Please share your opinions on this.. | closed | 2018-06-27T06:51:44Z | 2021-09-01T15:30:53Z | https://github.com/joke2k/django-environ/issues/187 | [
"enhancement"
] | thomasf | 7 |
voxel51/fiftyone | computer-vision | 5,278 | [DOCS] Encounter ValueError When Following User Guide Annotation Label Schema | ### URL(s) with the issue
[User Guide: annotation label schema](https://docs.voxel51.com/user_guide/annotation.html#label-schema)
### Description of proposal (what needs changing)
**Description of Error**
I encountered following error when I use the schema provided in user guide
`ValueError: Attribute 'attr3' of type 'text' requires a list of values`
**Potential Fix**
I resolved the error by adding in `"values":[]` after line 24. But I'm not sure if this is the best approach to address this problem.
The code example would be look like:
```
anno_key = "..."
label_schema = {
"new_field": {
"type": "classifications",
"classes": ["class1", "class2"],
"attributes": {
"attr1": {
"type": "select",
"values": ["val1", "val2"],
"default": "val1",
},
"attr2": {
"type": "radio",
"values": [True, False],
"default": False,
}
},
},
"existing_field": {
"classes": ["class3", "class4"],
"attributes": {
"attr3": {
"type": "text",
"values":[]
}
}
},
}
dataset.annotate(anno_key, label_schema=label_schema)
```
**Other questions**
I'm using label schema to construct annotation task in CVAT. My understanding is that by including `existing_field`, I could modify existing annotation on CVAT. However, when I do so I got:
`A field with label type 'detections' is already being annotated. Ignoring field 'ground_truth'...`
(ground_truth here is my `existing_field`)
and the `existing_field` is not loaded to CVAT. Can someone enlighten me where I made a mistake or direct me to relevant docs. Thanks in advance
### Willingness to contribute
The FiftyOne Community encourages documentation contributions. Would you or another member of your organization be willing to contribute a fix for this documentation issue to the FiftyOne codebase?
- [ ] Yes. I can contribute a documentation fix independently
- [x] Yes. I would be willing to contribute a documentation fix with guidance from the FiftyOne community
- [ ] No. I cannot contribute a documentation fix at this time
| open | 2024-12-16T03:59:46Z | 2024-12-16T03:59:46Z | https://github.com/voxel51/fiftyone/issues/5278 | [
"documentation"
] | Yuxuan1998 | 0 |
miguelgrinberg/python-socketio | asyncio | 1,246 | Getting 403 while connecting to websocket | I have used python-socketio with FastAPI & Uvicorn as server, But when I try to connect to socket using the below mentioned URL getting 403 as response
Dependency:
python-engineio 3.14.2
python-socketio 4.6.1
uvicorn 0.22.0
fastapi 0.97.0
URL to connect: ws://localhost:5050/ws
**Code:**
```
import uvicorn
from engineio import ASGIApp
from fastapi import FastAPI
from socketio import AsyncServer
app = FastAPI(title=__name__)
sio = AsyncServer(async_mode="asgi", cors_allowed_origins="*", always_connect=True)
socket_app = ASGIApp(sio, other_asgi_app=app)
app.mount(path='/ws', app=socket_app, name="SocketServer")
if __name__ == "__main__":
uvicorn.run(
"__main__:app",
host="0.0.0.0",
port=5050,
reload=False
)
```
***Response***
Error: Unexpected server response: 403
| closed | 2023-10-05T13:59:49Z | 2023-10-05T15:17:32Z | https://github.com/miguelgrinberg/python-socketio/issues/1246 | [] | vasu-dholakiya | 0 |
jupyterhub/jupyterhub-deploy-docker | jupyter | 45 | Network and config issues when starting jupyterhub | I have a working jupyterhub installation (based mostly on Andrea Zonca's instructions [https://zonca.github.io/2016/04/jupyterhub-sdsc-cloud.html] and it worked flawlessly for a machine-learning workshop. However, I now want to upgrade to using jupyterlab with my hub, and unfortunately experienced much the same problems as https://github.com/jupyterhub/jupyterhub-deploy-docker/issues/26. I could access jupyterlab from the hub by manually changing the url once I had logged in, but was unable to have it as the default url. Hence I'm trying your docker deployment of the hub :)
My first issue arises with nginx on the host. If I have the service running and I start the hub I get the following error:
```
ERROR: for jupyterhub Cannot start service hub: driver failed programming external connectivity on endpoint jupyterhub (dd0d984e99ddb8ce10900a489c82f96d42ab9f84e9b4977d874c85f0e0374096): Error starting userland proxy: listen tcp 0.0.0.0:443: bind: address already in use
ERROR: for hub Cannot start service hub: driver failed programming external connectivity on endpoint jupyterhub (dd0d984e99ddb8ce10900a489c82f96d42ab9f84e9b4977d874c85f0e0374096): Error starting userland proxy: listen tcp 0.0.0.0:443: bind: address already in use
ERROR: Encountered errors while bringing up the project.
```
If I stop nginx, the hub starts with no errors, but the site won't load. The logs do however show an error with the config:
```
docker logs jupyterhub
[E 2017-09-11 02:17:41.976 JupyterHub application:569] Exception while loading config file /srv/jupyterhub/jupyterhub_config.py
Traceback (most recent call last):
File "/opt/conda/lib/python3.5/site-packages/traitlets/config/application.py", line 557, in _load_config_files
config = loader.load_config()
File "/opt/conda/lib/python3.5/site-packages/traitlets/config/loader.py", line 457, in load_config
self._read_file_as_dict()
File "/opt/conda/lib/python3.5/site-packages/traitlets/config/loader.py", line 489, in _read_file_as_dict
py3compat.execfile(conf_filename, namespace)
File "/opt/conda/lib/python3.5/site-packages/ipython_genutils/py3compat.py", line 185, in execfile
exec(compiler(f.read(), fname, 'exec'), glob, loc)
File "/srv/jupyterhub/jupyterhub_config.py", line 80, in <module>
name = parts[0]
IndexError: list index out of range
[I 2017-09-11 02:17:41.980 JupyterHub app:745] Writing cookie_secret to /srv/jupyterhub/jupyterhub_cookie_secret
[W 2017-09-11 02:17:42.302 JupyterHub app:365]
Generating CONFIGPROXY_AUTH_TOKEN. Restarting the Hub will require restarting the proxy.
Set CONFIGPROXY_AUTH_TOKEN env or JupyterHub.proxy_auth_token config to avoid this message.
[W 2017-09-11 02:17:42.336 JupyterHub app:864] No admin users, admin interface will be unavailable.
[W 2017-09-11 02:17:42.337 JupyterHub app:865] Add any administrative users to `c.Authenticator.admin_users` in config.
[I 2017-09-11 02:17:42.337 JupyterHub app:892] Not using whitelist. Any authenticated user will be allowed.
[I 2017-09-11 02:17:42.360 JupyterHub app:1453] Hub API listening on http://127.0.0.1:8081/hub/
[W 2017-09-11 02:17:42.364 JupyterHub app:1174] Running JupyterHub without SSL. I hope there is SSL termination happening somewhere else...
[I 2017-09-11 02:17:42.364 JupyterHub app:1176] Starting proxy @ http://*:8000/
02:17:42.628 - info: [ConfigProxy] Proxying http://*:8000 to http://127.0.0.1:8081
02:17:42.633 - info: [ConfigProxy] Proxy API at http://127.0.0.1:8001/api/routes
[I 2017-09-11 02:17:42.675 JupyterHub app:1485] JupyterHub is now running at http://127.0.0.1:8000/
```
So, to me it looks as though the userlist isn't there? When I build the image it says it's copying it, so not sure whats happening.
I'm doing all this on a VM running on Openstack with Ubuntu 16.04, and I'm using Docker version 17.06.1-ce, build 874a737, docker-compose version 1.16.1, build 6d1ac21. I want to use PAM and local user accounts so I commented out references to oauth in the Dockerfile and Makefile (previously I was using the systemuser rather than the singleuser, is this another potential source of problems?).
I plan on trying kubernetes and helm in the future, but having never used either, this seemed like the easiest and quickest way to get what I want. Any advice on how to proceed greatly appreciated. | closed | 2017-09-11T03:49:45Z | 2022-12-05T00:55:01Z | https://github.com/jupyterhub/jupyterhub-deploy-docker/issues/45 | [
"question"
] | lachlancampbell | 1 |
sqlalchemy/sqlalchemy | sqlalchemy | 12,425 | create table + reflection for parenthesis around server defaults that contain spaces, all DBs | ### Describe the bug
When using `metadata.reflect` on a sqlite3 table with a "_timestamp_" column defined as:
`timestamp DATETIME NOT NULL DEFAULT (datetime(CURRENT_TIMESTAMP, 'localtime'))`
the resulting metadata is:
`datetime(CURRENT_TIMESTAMP, 'localtime')`
without the surrounding parentheses and
`metadata.create_all(engine)`
will fail.
### Optional link from https://docs.sqlalchemy.org which documents the behavior that is expected
_No response_
### SQLAlchemy Version in Use
2.0.38.
### DBAPI (i.e. the database driver)
pysqlite
### Database Vendor and Major Version
SQLite
### Python Version
Python 3.12.3
### Operating system
Linux
### To Reproduce
```python
import sqlite3
conn: sqlite3.Connection = sqlite3.connect("tmp.db")
# Create a table
conn.execute("""CREATE TABLE IF NOT EXISTS recipients
(key INTEGER PRIMARY KEY,
"campaign_id" INTEGER,
"campaign_name" TEXT,
"email_id" TEXT,
"send_date" TEXT,
"delivered_date" TEXT,
"open_date" TEXT,
"total_opens" INTEGER,
"total_apple_mpp_opens" INTEGER,
"unsubscribe_date" TEXT,
"hard_bounce_date" TEXT,
"hard_bounce_reason" TEXT,
"soft_bounce_date" TEXT,
"soft_bounce_reason" TEXT,
"open_ip" TEXT,
"click_ip" TEXT,
"unsubscribe_ip" TEXT,
"clicked_links_count" INTEGER,
"complaint_date" TEXT,
"click_date" TEXT,
"click_url" TEXT,
timestamp DATETIME NOT NULL DEFAULT (datetime(CURRENT_TIMESTAMP, 'localtime'))
);""")
conn.close()
from sqlacodegen.generators import SQLModelGenerator
from sqlalchemy import MetaData, create_engine
# Define the SQLite URL
sqlite_url = "sqlite:///tmp.db"
engine = create_engine(sqlite_url)
# Reflect metadata
metadata = MetaData()
# Reflect db
metadata.reflect(bind=engine)
new_engine = create_engine("sqlite:///tmp2.db")
metadata.create_all(new_engine
```
### Error
```
# Copy the complete stack trace and error message here, including SQL log output if applicable.
```
---------------------------------------------------------------------------
OperationalError Traceback (most recent call last)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1964, in Connection._exec_single_context(self, dialect, context, statement, parameters)
1963 if not evt_handled:
-> 1964 self.dialect.do_execute(
1965 cursor, str_statement, effective_parameters, context
1966 )
1968 if self._has_events or self.engine._has_events:
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/default.py:942, in DefaultDialect.do_execute(self, cursor, statement, parameters, context)
941 def do_execute(self, cursor, statement, parameters, context=None):
--> 942 cursor.execute(statement, parameters)
OperationalError: near "(": syntax error
The above exception was the direct cause of the following exception:
OperationalError Traceback (most recent call last)
Cell In[34], line 2
1 new_engine = create_engine("sqlite:///tmp2.db")
----> 2 metadata.create_all(new_engine)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/schema.py:5907, in MetaData.create_all(self, bind, tables, checkfirst)
5883 def create_all(
5884 self,
5885 bind: _CreateDropBind,
5886 tables: Optional[_typing_Sequence[Table]] = None,
5887 checkfirst: bool = True,
5888 ) -> None:
5889 """Create all tables stored in this metadata.
5890
5891 Conditional by default, will not attempt to recreate tables already
(...) 5905
5906 """
-> 5907 bind._run_ddl_visitor(
5908 ddl.SchemaGenerator, self, checkfirst=checkfirst, tables=tables
5909 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:3249, in Engine._run_ddl_visitor(self, visitorcallable, element, **kwargs)
3242 def _run_ddl_visitor(
3243 self,
3244 visitorcallable: Type[Union[SchemaGenerator, SchemaDropper]],
3245 element: SchemaItem,
3246 **kwargs: Any,
3247 ) -> None:
3248 with self.begin() as conn:
-> 3249 conn._run_ddl_visitor(visitorcallable, element, **kwargs)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:2456, in Connection._run_ddl_visitor(self, visitorcallable, element, **kwargs)
2444 def _run_ddl_visitor(
2445 self,
2446 visitorcallable: Type[Union[SchemaGenerator, SchemaDropper]],
2447 element: SchemaItem,
2448 **kwargs: Any,
2449 ) -> None:
2450 """run a DDL visitor.
2451
2452 This method is only here so that the MockConnection can change the
2453 options given to the visitor so that "checkfirst" is skipped.
2454
2455 """
-> 2456 visitorcallable(self.dialect, self, **kwargs).traverse_single(element)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/visitors.py:664, in ExternalTraversal.traverse_single(self, obj, **kw)
662 meth = getattr(v, "visit_%s" % obj.__visit_name__, None)
663 if meth:
--> 664 return meth(obj, **kw)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/ddl.py:928, in SchemaGenerator.visit_metadata(self, metadata)
926 for table, fkcs in collection:
927 if table is not None:
--> 928 self.traverse_single(
929 table,
930 create_ok=True,
931 include_foreign_key_constraints=fkcs,
932 _is_metadata_operation=True,
933 )
934 else:
935 for fkc in fkcs:
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/visitors.py:664, in ExternalTraversal.traverse_single(self, obj, **kw)
662 meth = getattr(v, "visit_%s" % obj.__visit_name__, None)
663 if meth:
--> 664 return meth(obj, **kw)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/ddl.py:966, in SchemaGenerator.visit_table(self, table, create_ok, include_foreign_key_constraints, _is_metadata_operation)
957 if not self.dialect.supports_alter:
958 # e.g., don't omit any foreign key constraints
959 include_foreign_key_constraints = None
961 CreateTable(
962 table,
963 include_foreign_key_constraints=(
964 include_foreign_key_constraints
965 ),
--> 966 )._invoke_with(self.connection)
968 if hasattr(table, "indexes"):
969 for index in table.indexes:
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/ddl.py:314, in ExecutableDDLElement._invoke_with(self, bind)
312 def _invoke_with(self, bind):
313 if self._should_execute(self.target, bind):
--> 314 return bind.execute(self)
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1416, in Connection.execute(self, statement, parameters, execution_options)
1414 raise exc.ObjectNotExecutableError(statement) from err
1415 else:
-> 1416 return meth(
1417 self,
1418 distilled_parameters,
1419 execution_options or NO_OPTIONS,
1420 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/sql/ddl.py:180, in ExecutableDDLElement._execute_on_connection(self, connection, distilled_params, execution_options)
177 def _execute_on_connection(
178 self, connection, distilled_params, execution_options
179 ):
--> 180 return connection._execute_ddl(
181 self, distilled_params, execution_options
182 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1527, in Connection._execute_ddl(self, ddl, distilled_parameters, execution_options)
1522 dialect = self.dialect
1524 compiled = ddl.compile(
1525 dialect=dialect, schema_translate_map=schema_translate_map
1526 )
-> 1527 ret = self._execute_context(
1528 dialect,
1529 dialect.execution_ctx_cls._init_ddl,
1530 compiled,
1531 None,
1532 exec_opts,
1533 compiled,
1534 )
1535 if self._has_events or self.engine._has_events:
1536 self.dispatch.after_execute(
1537 self,
1538 ddl,
(...) 1542 ret,
1543 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1843, in Connection._execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)
1841 return self._exec_insertmany_context(dialect, context)
1842 else:
-> 1843 return self._exec_single_context(
1844 dialect, context, statement, parameters
1845 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1983, in Connection._exec_single_context(self, dialect, context, statement, parameters)
1980 result = context._setup_result_proxy()
1982 except BaseException as e:
-> 1983 self._handle_dbapi_exception(
1984 e, str_statement, effective_parameters, cursor, context
1985 )
1987 return result
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:2352, in Connection._handle_dbapi_exception(self, e, statement, parameters, cursor, context, is_sub_exec)
2350 elif should_wrap:
2351 assert sqlalchemy_exception is not None
-> 2352 raise sqlalchemy_exception.with_traceback(exc_info[2]) from e
2353 else:
2354 assert exc_info[1] is not None
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/base.py:1964, in Connection._exec_single_context(self, dialect, context, statement, parameters)
1962 break
1963 if not evt_handled:
-> 1964 self.dialect.do_execute(
1965 cursor, str_statement, effective_parameters, context
1966 )
1968 if self._has_events or self.engine._has_events:
1969 self.dispatch.after_cursor_execute(
1970 self,
1971 cursor,
(...) 1975 context.executemany,
1976 )
File ~/Projects/Imported/Fadim_ltd/2025/zcrm/.venv/lib/python3.12/site-packages/sqlalchemy/engine/default.py:942, in DefaultDialect.do_execute(self, cursor, statement, parameters, context)
941 def do_execute(self, cursor, statement, parameters, context=None):
--> 942 cursor.execute(statement, parameters)
OperationalError: (sqlite3.OperationalError) near "(": syntax error
[SQL:
CREATE TABLE campaigns (
"key" INTEGER,
id INTEGER,
name TEXT,
type TEXT,
status TEXT,
"testSent" INTEGER,
header TEXT,
footer TEXT,
sender TEXT,
"replyTo" TEXT,
"toField" TEXT,
"previewText" TEXT,
tag TEXT,
"inlineImageActivation" INTEGER,
"mirrorActive" INTEGER,
recipients TEXT,
statistics TEXT,
"htmlContent" TEXT,
subject TEXT,
"scheduledAt" TEXT,
"createdAt" TEXT,
"modifiedAt" TEXT,
"shareLink" TEXT,
"sentDate" TEXT,
"sendAtBestTime" INTEGER,
"abTesting" INTEGER,
timestamp DATETIME DEFAULT datetime(CURRENT_TIMESTAMP, 'localtime') NOT NULL,
PRIMARY KEY ("key")
)
]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
### Additional context
_No response_ | closed | 2025-03-12T14:12:45Z | 2025-03-18T12:17:44Z | https://github.com/sqlalchemy/sqlalchemy/issues/12425 | [
"bug",
"mysql",
"sqlite",
"reflection"
] | adalseno | 3 |
huggingface/peft | pytorch | 2,097 | loftq_utils.py depdends on huggingface_hub.errors, which doesn't appear in some versions of huggingface_hub | ### System Info
loftq_utils.py refers to huggingface_hub.errors
Should the requirements.txt include huggingface_hub?
I have huggingface_hub version 0.19.4 and it does not have huggingface_hub.errors.
Is there a workaround or another version of huggingface_hub?
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder
- [X] My own task or dataset (give details below)
### Reproduction
Should the requirements.txt include huggingface_hub?
I have huggingface_hub version 0.19.4 and it does not have huggingface_hub.errors.
Is there a workaround or another version of huggingface_hub?
### Expected behavior
Should the requirements.txt include huggingface_hub?
I have huggingface_hub version 0.19.4 and it does not have huggingface_hub.errors.
Is there a workaround or another version of huggingface_hub? | closed | 2024-09-25T18:44:40Z | 2024-10-28T10:49:04Z | https://github.com/huggingface/peft/issues/2097 | [] | mashoutsider | 4 |
gunthercox/ChatterBot | machine-learning | 1,609 | ChatterBot | Can I know what all are the advantages and disadvantages of using ChatterBot to build a bot? | closed | 2019-02-05T15:39:05Z | 2019-12-11T12:36:14Z | https://github.com/gunthercox/ChatterBot/issues/1609 | [] | AfrahAsif | 2 |
huggingface/datasets | machine-learning | 6,989 | cache in nfs error | ### Describe the bug
- When reading dataset, a cache will be generated to the ~/. cache/huggingface/datasets directory
- When using .map and .filter operations, runtime cache will be generated to the /tmp/hf_datasets-* directory
- The default is to use the path of tempfile.tempdir
- If I modify this path to the NFS disk, an error will be reported, but the program will continue to run
- https://github.com/huggingface/datasets/blob/main/src/datasets/config.py#L257
```
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 315, in _bootstrap
self.run()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 616, in _run_server
server.serve_forever()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 182, in serve_forever
sys.exit(0)
SystemExit: 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 300, in _run_finalizers
finalizer()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 224, in __call__
res = self._callback(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 133, in _remove_temp_dir
rmtree(tempdir)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 718, in rmtree
_rmtree_safe_fd(fd, path, onerror)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 675, in _rmtree_safe_fd
onerror(os.unlink, fullname, sys.exc_info())
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 673, in _rmtree_safe_fd
os.unlink(entry.name, dir_fd=topfd)
OSError: [Errno 16] Device or resource busy: '.nfs000000038330a012000030b4'
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 315, in _bootstrap
self.run()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 616, in _run_server
server.serve_forever()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/managers.py", line 182, in serve_forever
sys.exit(0)
SystemExit: 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 300, in _run_finalizers
finalizer()
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 224, in __call__
res = self._callback(*self._args, **self._kwargs)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/site-packages/multiprocess/util.py", line 133, in _remove_temp_dir
rmtree(tempdir)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 718, in rmtree
_rmtree_safe_fd(fd, path, onerror)
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 675, in _rmtree_safe_fd
onerror(os.unlink, fullname, sys.exc_info())
File "/home/wzp/miniconda3/envs/dask/lib/python3.8/shutil.py", line 673, in _rmtree_safe_fd
os.unlink(entry.name, dir_fd=topfd)
OSError: [Errno 16] Device or resource busy: '.nfs0000000400064d4a000030e5'
```
### Steps to reproduce the bug
```
import os
import time
import tempfile
from datasets import load_dataset
def add_column(sample):
# print(type(sample))
# time.sleep(0.1)
sample['__ds__stats__'] = {'data': 123}
return sample
def filt_column(sample):
# print(type(sample))
if len(sample['content']) > 10:
return True
else:
return False
if __name__ == '__main__':
input_dir = '/mnt/temp/CN/small' # some json dataset
dataset = load_dataset('json', data_dir=input_dir)
temp_dir = '/media/release/release/temp/temp' # a nfs folder
os.makedirs(temp_dir, exist_ok=True)
# change huggingface-datasets runtime cache in nfs(default in /tmp)
tempfile.tempdir = temp_dir
aa = dataset.map(add_column, num_proc=64)
aa = aa.filter(filt_column, num_proc=64)
print(aa)
```
### Expected behavior
no error occur
### Environment info
datasets==2.18.0
ubuntu 20.04 | open | 2024-06-21T02:09:22Z | 2025-01-29T11:44:04Z | https://github.com/huggingface/datasets/issues/6989 | [] | simplew2011 | 1 |
lucidrains/vit-pytorch | computer-vision | 14 | Patch To Embedding correct? | In line 95 of ViT [[self.patch_to_embedding = nn.Linear(patch_dim, dim)]]
Is it supposed to be a nn.Linear layer? I believe its a learnable tensor. The paper says "E is a trainable linear projection that maps each vectorized patch to the model dimension D". Yannic also referred E as a linear projection matrix. Could you please share your thoughts?
NB: I have modified and run E as a nn.parameter type tensor and produces similar results | closed | 2020-10-18T02:49:23Z | 2020-10-18T06:00:26Z | https://github.com/lucidrains/vit-pytorch/issues/14 | [] | tahmid0007 | 3 |
open-mmlab/mmdetection | pytorch | 11,408 | calculate the values of mAP65, mAP85, mAP85 and mAP95 | How to calculate the values of mAP65, mAP85, mAP85 and mAP95 | open | 2024-01-19T14:02:48Z | 2024-01-31T01:44:50Z | https://github.com/open-mmlab/mmdetection/issues/11408 | [] | 1234ab5678 | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,094 | Does anyone train synthesizer based on @mbdash encoder? | Hi guys, did anyone train the synthesizer using @mbdash trained 1M steps encoder (Embedding size=768)afterwards? Cause I find the encoder is really good but his older synthesizer is only based on original encoder and in Tensorflow form, I can't use it in Pytorch code now.
Feel free to post more about synthesizers! | open | 2022-07-02T22:59:34Z | 2022-07-02T22:59:34Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1094 | [] | zhuochunli | 0 |
vitalik/django-ninja | rest-api | 360 | Multiple authentication/authorizations | Hi there, wondering how does one auhenticate and authorize a route. I'm doing this way:
```
@router.get('auth/', auth=[AuthBearer(), account_required], response=UserSchema)
def user_detail(request):
return request.user
```
Where `AuthBearer` is a class that extends `HttpBearer` and has an `authenticate` method that checks for the token received (as explained in the docs: https://django-ninja.rest-framework.com/tutorial/authentication/#http-bearer).
And `account_required` is a method that checks if user has an account (`hasattr(request.user, 'account') and request.user.account is not None`) (docs: https://django-ninja.rest-framework.com/tutorial/authentication/#custom-function)
When I hit this endpoint, code is touched on `AuthBearer.authenticate` but does not on `account_required`. So I assume that, for multiple auth, I must have done something wrong. Since for single auth (`auth=account_required`), the `account_required` method is touched.
- If I change from `list` to `set` I got the same result.
- It always touches only the one in the first position. If I change to `auth=[account_required, AuthBearer()]`, then `account_required` is touched instead of `AuthBearer.authenticate`.
What am I doing wrong? Thank you, and congrats for this amazing library! | closed | 2022-02-14T22:39:08Z | 2023-04-14T00:48:36Z | https://github.com/vitalik/django-ninja/issues/360 | [] | gabrielfgularte | 9 |
httpie/cli | python | 681 | Fix Travis / tests | https://travis-ci.org/jakubroztocil/httpie/jobs/385658131#L598-L616 | closed | 2018-05-30T12:15:43Z | 2018-06-09T10:13:59Z | https://github.com/httpie/cli/issues/681 | [
"help wanted"
] | jkbrzt | 3 |
jupyter/docker-stacks | jupyter | 1,540 | ci maintenance: queue workflows or jobs with new GitHub workflow `concurrency` option? | I think this GitHub workflow thingy can be really useful. It makes two workflows being triggered not run in parallell if they are within the same group. This will make us queue workflows in sequence.
```yaml
concurrency:
group: ${{ github.head_ref }}
```
This can also be applied to specific jobs, but not steps within jobs. This makes it even more valuable if we manage to split apart our build workflow into multiple separate jobs and then merges them into a single later. By doing so, we can mark the job that does the push to github and could run into merge conflicts marked to belong to a specific concurrency group to ensure that never happens rather than marking the entire workflow with all steps that could happen cuncurrently. | closed | 2021-11-26T12:54:06Z | 2022-02-28T20:48:37Z | https://github.com/jupyter/docker-stacks/issues/1540 | [
"type:Maintenance"
] | consideRatio | 1 |
piskvorky/gensim | data-science | 2,710 | Distributed LDA Connection refused - Dispatcher host is always 127.0.0.1 | ## Problem description
I am trying to run the distributed LDA on multiple machines. Following this tutorial: https://radimrehurek.com/gensim/models/lda_worker.html
Setup is working but once I run the distributed lda I get the following error:

Dispatcher worker recognizes that there are lda-workers available but they cannot connect to the dispatcher.

The dispatcher host is always 127.0.0.1
I have also tried setting the host ip on the dispatcher but no luck
```
python -m gensim.models.lda_dispatcher --host HOST_IP &
```
Nameserver is recognized on other machines and shows the correct ip. | open | 2019-12-26T07:55:35Z | 2020-12-22T01:10:24Z | https://github.com/piskvorky/gensim/issues/2710 | [] | arshad115 | 2 |
cvat-ai/cvat | computer-vision | 8,912 | searching metod | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
https://docs.cvat.ai/docs/manual/advanced/search/
add featuring in textbox search by image name.
### Describe the solution you'd like
in the text box you can write the name of image and the filter show the image with the tags directly
### Describe alternatives you've considered
_No response_
### Additional context
_No response_ | closed | 2025-01-09T08:30:50Z | 2025-01-15T15:14:17Z | https://github.com/cvat-ai/cvat/issues/8912 | [
"duplicate",
"enhancement"
] | ArreguiInescop | 2 |
twelvedata/twelvedata-python | matplotlib | 35 | Dependabot can't resolve your Python dependency files | Dependabot can't resolve your Python dependency files.
As a result, Dependabot couldn't update your dependencies.
The error Dependabot encountered was:
```
ERROR: ERROR: Could not find a version that matches mplfinance>=0.12
Skipped pre-versions: 0.11.1a0, 0.11.1a0, 0.11.1a1, 0.11.1a1, 0.12.0a0, 0.12.0a0, 0.12.0a1, 0.12.0a1, 0.12.0a2, 0.12.0a2, 0.12.0a3, 0.12.0a3, 0.12.3a0, 0.12.3a0, 0.12.3a1, 0.12.3a1, 0.12.3a2, 0.12.3a2, 0.12.3a3, 0.12.3a3, 0.12.4a0, 0.12.4a0, 0.12.5a1, 0.12.5a1, 0.12.5a2, 0.12.5a2, 0.12.5a3, 0.12.5a3, 0.12.6a0, 0.12.6a0, 0.12.6a1, 0.12.6a1, 0.12.6a2, 0.12.6a2, 0.12.6a3, 0.12.6a3, 0.12.7a0, 0.12.7a0, 0.12.7a3, 0.12.7a3, 0.12.7a4, 0.12.7a4, 0.12.7a5, 0.12.7a5, 0.12.7a7, 0.12.7a7, 0.12.7a10, 0.12.7a10, 0.12.7a12, 0.12.7a12, 0.12.7a17, 0.12.7a17
There are incompatible versions in the resolved dependencies.
[pipenv.exceptions.ResolutionFailure]: return resolve_deps(
[pipenv.exceptions.ResolutionFailure]: File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 718, in resolve_deps
[pipenv.exceptions.ResolutionFailure]: resolved_tree, hashes, markers_lookup, resolver = actually_resolve_deps(
[pipenv.exceptions.ResolutionFailure]: File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 480, in actually_resolve_deps
[pipenv.exceptions.ResolutionFailure]: resolved_tree = resolver.resolve()
[pipenv.exceptions.ResolutionFailure]: File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 395, in resolve
[pipenv.exceptions.ResolutionFailure]: raise ResolutionFailure(message=str(e))
[pipenv.exceptions.ResolutionFailure]: pipenv.exceptions.ResolutionFailure: ERROR: ERROR: Could not find a version that matches mplfinance>=0.12
[pipenv.exceptions.ResolutionFailure]: Skipped pre-versions: 0.11.1a0, 0.11.1a0, 0.11.1a1, 0.11.1a1, 0.12.0a0, 0.12.0a0, 0.12.0a1, 0.12.0a1, 0.12.0a2, 0.12.0a2, 0.12.0a3, 0.12.0a3, 0.12.3a0, 0.12.3a0, 0.12.3a1, 0.12.3a1, 0.12.3a2, 0.12.3a2, 0.12.3a3, 0.12.3a3, 0.12.4a0, 0.12.4a0, 0.12.5a1, 0.12.5a1, 0.12.5a2, 0.12.5a2, 0.12.5a3, 0.12.5a3, 0.12.6a0, 0.12.6a0, 0.12.6a1, 0.12.6a1, 0.12.6a2, 0.12.6a2, 0.12.6a3, 0.12.6a3, 0.12.7a0, 0.12.7a0, 0.12.7a3, 0.12.7a3, 0.12.7a4, 0.12.7a4, 0.12.7a5, 0.12.7a5, 0.12.7a7, 0.12.7a7, 0.12.7a10, 0.12.7a10, 0.12.7a12, 0.12.7a12, 0.12.7a17, 0.12.7a17
[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.
First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.
Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.
Hint: try $ pipenv lock --pre if it is a pre-release dependency.
ERROR: ERROR: Could not find a version that matches mplfinance>=0.12
Skipped pre-versions: 0.11.1a0, 0.11.1a0, 0.11.1a1, 0.11.1a1, 0.12.0a0, 0.12.0a0, 0.12.0a1, 0.12.0a1, 0.12.0a2, 0.12.0a2, 0.12.0a3, 0.12.0a3, 0.12.3a0, 0.12.3a0, 0.12.3a1, 0.12.3a1, 0.12.3a2, 0.12.3a2, 0.12.3a3, 0.12.3a3, 0.12.4a0, 0.12.4a0, 0.12.5a1, 0.12.5a1, 0.12.5a2, 0.12.5a2, 0.12.5a3, 0.12.5a3, 0.12.6a0, 0.12.6a0, 0.12.6a1, 0.12.6a1, 0.12.6a2, 0.12.6a2, 0.12.6a3, 0.12.6a3, 0.12.7a0, 0.12.7a0, 0.12.7a3, 0.12.7a3, 0.12.7a4, 0.12.7a4, 0.12.7a5, 0.12.7a5, 0.12.7a7, 0.12.7a7, 0.12.7a10, 0.12.7a10, 0.12.7a12, 0.12.7a12, 0.12.7a17, 0.12.7a17
There are incompatible versions in the resolved dependencies.
['Traceback (most recent call last):\n', ' File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 501, in create_spinner\n yield sp\n', ' File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 649, in venv_resolve_deps\n c = resolve(cmd, sp)\n', ' File "/usr/local/.pyenv/versions/3.9.4/lib/python3.9/site-packages/pipenv/utils.py", line 539, in resolve\n sys.exit(c.return_code)\n', 'SystemExit: 1\n']
```
If you think the above is an error on Dependabot's side please don't hesitate to get in touch - we'll do whatever we can to fix it.
[View the update logs](https://app.dependabot.com/accounts/twelvedata/update-logs/77915359). | closed | 2021-04-26T07:38:17Z | 2021-05-04T11:32:19Z | https://github.com/twelvedata/twelvedata-python/issues/35 | [] | dependabot-preview[bot] | 0 |
netbox-community/netbox | django | 18,181 | Create & Add another IP address on interfaces is not working correctly | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
V4.1.7
### Python Version
3.12
### Steps to Reproduce
1.add IP address to a interface..
2. click create & add another.
3. add ip address details and click create.
### Expected Behavior
should add second ip address to interface
### Observed Behavior
pop says IP Address has been created but when go back to device interface tab the IP address is no where to be seen | closed | 2024-12-09T15:49:17Z | 2025-01-31T19:33:27Z | https://github.com/netbox-community/netbox/issues/18181 | [
"type: bug",
"status: accepted",
"severity: low"
] | dashton956-alt | 0 |
wger-project/wger | django | 930 | DoesNotExist at /en/software/features - Language matching query does not exist. | ## Steps to Reproduce
I did a clean install, following the docker guide for setting up a docker production instance (used the default docker-compose).
**Expected results:**
enter ip:port and access the WebUI with default credentials
**Actual results:**
Continuously getting a django error
<details>
<summary>Logs</summary>
<!--
Any logs you think would be useful (if you have a local instance)
-->
```bash
Environment:
Request Method: GET
Request URL: http://10.100.10.2/en/software/features
Django Version: 3.2.10
Python Version: 3.9.5
Installed Applications:
('django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.messages',
'django.contrib.sessions',
'django.contrib.sites',
'django.contrib.staticfiles',
'django_extensions',
'storages',
'wger.config',
'wger.core',
'wger.mailer',
'wger.exercises',
'wger.gym',
'wger.manager',
'wger.nutrition',
'wger.software',
'wger.utils',
'wger.weight',
'wger.gallery',
'wger.measurements',
'captcha',
'django.contrib.sitemaps',
'easy_thumbnails',
'compressor',
'crispy_forms',
'rest_framework',
'rest_framework.authtoken',
'django_filters',
'django_bootstrap_breadcrumbs',
'corsheaders')
Installed Middleware:
('corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'wger.utils.middleware.JavascriptAJAXRedirectionMiddleware',
'wger.utils.middleware.WgerAuthenticationMiddleware',
'wger.utils.middleware.RobotsExclusionMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.middleware.locale.LocaleMiddleware')
Traceback (most recent call last):
File "/home/wger/src/wger/utils/language.py", line 54, in load_language
language = Language.objects.get(short_name=used_language)
File "/usr/local/lib/python3.9/dist-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/django/db/models/query.py", line 435, in get
raise self.model.DoesNotExist(
During handling of the above exception (Language matching query does not exist.), another exception occurred:
File "/usr/local/lib/python3.9/dist-packages/django/core/handlers/exception.py", line 47, in inner
response = get_response(request)
File "/usr/local/lib/python3.9/dist-packages/django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/wger/src/wger/software/views.py", line 37, in features
return render(request, 'features.html', context)
File "/usr/local/lib/python3.9/dist-packages/django/shortcuts.py", line 19, in render
content = loader.render_to_string(template_name, context, request, using=using)
File "/usr/local/lib/python3.9/dist-packages/django/template/loader.py", line 62, in render_to_string
return template.render(context, request)
File "/usr/local/lib/python3.9/dist-packages/django/template/backends/django.py", line 61, in render
return self.template.render(context)
File "/usr/local/lib/python3.9/dist-packages/django/template/base.py", line 168, in render
with context.bind_template(self):
File "/usr/lib/python3.9/contextlib.py", line 117, in __enter__
return next(self.gen)
File "/usr/local/lib/python3.9/dist-packages/django/template/context.py", line 244, in bind_template
updates.update(processor(self.request))
File "/home/wger/src/wger/utils/context_processor.py", line 28, in processor
language = load_language()
File "/home/wger/src/wger/utils/language.py", line 57, in load_language
language = Language.objects.get(short_name="en")
File "/usr/local/lib/python3.9/dist-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/django/db/models/query.py", line 435, in get
raise self.model.DoesNotExist(
Exception Type: DoesNotExist at /en/software/features
Exception Value: Language matching query does not exist.
```
Attached a full report:
[DoesNotExist at _en_software_features.pdf](https://github.com/wger-project/wger/files/7797751/DoesNotExist.at._en_software_features.pdf)
</details>
**At the bottom it is mentioned, that I am seeing this stack Trace because Django Debug was set to True. But the prod.env is set to False...** | closed | 2022-01-01T14:04:31Z | 2022-01-03T21:19:34Z | https://github.com/wger-project/wger/issues/930 | [] | mirisbowring | 6 |
waditu/tushare | pandas | 881 | pro_bar获取不到50ETF数据 | Hi Jimmy,
在尝试用pro_bar获取50ETF数据(华夏基金的:510050.SH)时,返回为None
代码如下:
pro = ts.pro_api('my token')
df = ts.pro_bar(pro_api=pro, ts_code='510050.SH', adj='qfq', start_date='20180101', end_date='20181011',asset='fd')
print(df)
返回为None (注意,asset='i','e','fd'都分别试过,都返回是None)
问题:
1、pro_bar是否可以获取510050.SH的数据?
2、如果可以,是否可以获取5分钟数据:freq=5min?
3、获取的数据(日线或者分钟数据),adj='qfq'是否有效?(现在我用的ts.bar来获取的,但是获取时adj='qfq'是没有用的。所以我不清楚pro_bar是否会修正这一点?)
谢谢 | closed | 2018-12-25T14:42:29Z | 2018-12-29T15:23:23Z | https://github.com/waditu/tushare/issues/881 | [] | Suckhard | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.