
anchor
stringlengths 86
24.4k
| positive
stringlengths 174
15.6k
| negative
stringlengths 76
13.7k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
As engineering students who attend public universities, class sizes of 300 are no rarity. Sadly, that also means that oftentimes, our most important classes can take weeks or months to supply us with feedback for our assignments, hamstringing the learning process and creating a larger disconnect between the professor and the student. A quarter system is 10 weeks long, and having 3 weeks of ungraded assignments means learning 30% of the class without any feedback.
We're also keenly aware that now more than ever, teachers are overworked. The average teacher logs upwards of 180 hours per year on grading alone, making it the most worked-on task outside of actual teaching inside the classroom. The solutions they have right now are few. Hiring extra teaching assistants to aid with grading is an extensive process that demands thorough interviewing to ensure the applicants actually know the material. Simultaneously, money is something that most universities can't spare on extra graders, meaning those that are qualified face heavily inflated workloads. At the moment, it seems there's no feasible out. With less time spent grading, there's more time spent with students.
Enter gradeAI, our AI-based tool that aims to streamline grading by automatically processing assignments and evaluating them based on a given rubric. Our goal isn't to replace the teacher or the TA, but rather to appraise assignments quickly, let educators review and alter judgements made, and expedite grading large volumes of similar assignments.
## What it does
It utilizes AI Agents from Fetch.ai to break down multiple steps of grading assignments. First on the frontend, the teacher can create an assignment in a course, then name it and provide a rubric. As students submit their homework, the assignment will start getting graded after the due date. We have multiple AI Agents with the first being locally run and ported publicaly using Fetch.AI's mailbox. This first agent is responsible for pulling submitted homework files and the associated rubric from our Google Cloud Platform storage. This agent also processes the text and is the handler for sending homework to be graded in our pipeline, and eventually write the processed grades to our database. Next in the process is our pipeline of 4 agents on the Agentverse! The first agent is responsible for sending all of the processed text in a clean format to our next agent which parses the homework into readable chunks. The second agent-let's name it Parser-takes each problem number and associated work with it, and puts them all into an array! Parser does this for both the solution and homework submitted! This agent then sends this data to our third AI Agent and let's name this one Solver! This is where all of the grading happens. This AI Agent cross examines each problem's solution and attempt one at a time, which increases accuracy of grading. We ask this AI Agent to return data in a JSON format with the grade, confidence level, summary, and details for each problem. From there, Solver sends all of the graded problems that it did one by one to ensure accuracy to our last AI Agent on the Agentverse! This last agent aggregates all of the data and sends it back to our first agent being locally ran! Our locally ran agent then writes everything to our database, where we show it on our frontend!
## How we built it
We used the Reflex framework and Fetch.AI to accomplish all of our goals. This proved to be both difficult and convenient, as we never used these technologies before, but everything was written in Python! Thanks to Reflex, we built our entire website in Python, and Fetch.AI is all in python, which was great. In terms of Fetch.AI, we used many of their products such as the Agentverse, mailbox, template agents, and a little bit of DeltaV! We utilized the Agentverse, as it provided a convenient way to deploy our agents and have them run 24/7, which allowed us to keep a constant pipeline! The integrated development environment was also helpful in debugging and creating agents from scratch. Mailbox provided by Fetch.AI allowed our locally ran AI Agent to communicate with all of the deployed agents. Using a combination of all of these tools, we were able to piece together multiple agents with using a combination of openAI's API and OCR. Reflex was also a great tool and we utilized it's documentation and ability to wrap React code to create nice and complex components with functionality.
## Challenges we ran into
We took a big challenge in using technology we've never touched before! Reflex and Fetch.AI were the two major components of our project, and there was a big learning curve. One of the issues we ran into was a lack of documentation. Being a relatively newer product that also had a recent name change, Reflex didn't have as many resources as many of the tools we were more accustomed to. As a result, it took us a while to get the hang of what we were doing, and complex issues such as managing routes and backend integration with GCP were made even more difficult as we searched for solutions. Simpler issues like embedding PDF views of files was also made demanding, and our time frame for design was expanded due to underestimation of what we thought wouldn't be issues.
## Accomplishments that we're proud of
## What we learned
In terms of our web framework, we chose to use Reflex to build out our web app that incorporated Fetch.ai, FAST APIs, and OpenAI APIs. For Reflex, we learned how to develop the architecture of our application by fully understanding the Reflex documentation, and of course, reaching out to the Reflex developers for assistance. Additionally, we learned to link the various pages together and to incorporate components into our pages in order to fully immerse the user(s) and to provide a platform for the students and teachers to view the graded papers and their respective results.
## What's next for gradeAI
Given a time frame of 36 hours, our team had many more features planned than we were able to execute. Primarily, we'd love to add a plagiarism checker, LLM integration for student follow-ups, and textbook breakdowns for relevant questions in the homework. If gradeAI were a product in wide circulation, plagiarism would undoubtedly be the number one threat to its efficacy; as such, this implement demands our most immediate attention. Textbook breakdowns would also be a great quality of life feature we'd love to be able to tackle, but in truth, the feature we'd most look towards would be the LLM integration. Our undertaking of this project was meant to challenge us from the very beginning, and LLM is something we're all excited about and ready to learn and apply.
Outside of features, we're looking to simply run and test a wider variety of materials so gradeAI can be the product it was meant to be. We've been nothing but thoroughly impressed with what we've been able to make, and we hope educators will be too.
There's a long road to come for gradeAI, but whatever comes our way, we're confident we have the tools to ace it. | ## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input. | ## Inspiration
Loneliness affects countless people and over time, it can have significant consequences on a person's mental health. One quarter of Canada's 65+ population live completely alone, which has been scientifically connected to very serious health risks. With the growing population of seniors, this problem only seems to be growing worse, and so we wanted to find a way to help both elderly citizens take care of themselves and their loved ones to take care of them.
## What it does
Claire is an AI chatbot with a UX designed specifically for the less tech-savvy elderly population. It helps seniors to journal and self-reflect, both proven to have mental health benefits, through a simulated social experience. At the same time, it allows caregivers to stay up-to-date on the emotional wellbeing of the elderly. This is all done with natural language processing, used to identify the emotions associated with each conversation session.
## How we built it
We used a React front-end served by a node.js back-end. Messages were sent to Google Cloud's natural language processing API, where we could identify emotions for recording and entities for enhancing the simulated conversation experience. Information on user activity and profiles are maintained in a Firebase database.
## Challenges we ran into
We wanted to use speech-to-text so as to reach an even broader seniors' market, but we ran into technical difficulties with streaming audio from the browser in a consistent way. As a result, we chose simply to have a text-based conversation.
## Accomplishments that we're proud of
Designing a convincing AI chatbot was the biggest challenge. We found that the bot would often miss contextual cues, and interpret responses incorrectly. Over the course of the project, we had to tweak how our bot responded and prompted conversation so that these lapses were minimized. Also, as developers, it was very difficult to design to the needs of a less-tech-saavy target audience. We had to make sure our application was intuitive enough for all users.
## What we learned
We learned how to work with natural language processing to follow a conversation and respond appropriately to human input. As well, we got to further practise our technical skills by applying React, node.js, and Firebase to build a full-stack application.
## What's next for claire
We want to implement an accurate speech-to-text and text-to-speech functionality. We think this is the natural next step to making our product more widely accessible. | partial |
## Inspiration
Two of our teammates have personal experiences with wildfires: one who has lived all her life in California, and one who was exposed to a fire in his uncle's backyard in the same state. We found the recent wildfires especially troubling and thus decided to focus our efforts on doing what we could with technology.
## What it does
CacheTheHeat uses different computer vision algorithms to classify fires from cameras/videos, in particular, those mounted on households for surveillance purposes. It calculates the relative size and rate-of-growth of the fire in order to alert nearby residents if said wildfire may potentially pose a threat. It hosts a database with multiple video sources in order for warnings to be far-reaching and effective.
## How we built it
This software detects the sizes of possible wildfires and the rate at which those fires are growing using Computer Vision/OpenCV. The web-application gives a pre-emptive warning (phone alerts) to nearby individuals using Twilio. It has a MongoDB Stitch database of both surveillance-type videos (as in campgrounds, drones, etc.) and neighborhood cameras that can be continually added to, depending on which neighbors/individuals sign the agreement form using DocuSign. We hope this will help creatively deal with wildfires possibly in the future.
## Challenges we ran into
Among the difficulties we faced, we had the most trouble with understanding the applications of multiple relevant DocuSign solutions for use within our project as per our individual specifications. For example, our team wasn't sure how we could use something like the text tab to enhance our features within our client's agreement.
One other thing we were not fond of was that DocuSign logged us out of the sandbox every few minutes, which was sometimes a pain. Moreover, the development environment sometimes seemed a bit cluttered at a glance, which we discouraged the use of their API.
There was a bug in Google Chrome where Authorize.Net (DocuSign's affiliate) could not process payments due to browser-specific misbehavior. This was brought to the attention of DocuSign staff.
One more thing that was also unfortunate was that DocuSign's GitHub examples included certain required fields for initializing, however, the description of these fields would be differ between code examples and documentation. For example, "ACCOUNT\_ID" might be a synonym for "USERNAME" (not exactly, but same idea).
## Why we love DocuSign
Apart from the fact that the mentorship team was amazing and super-helpful, our team noted a few things about their API. Helpful documentation existed on GitHub with up-to-date code examples clearly outlining the dependencies required as well as offering helpful comments. Most importantly, DocuSign contains everything from A-Z for all enterprise signature/contractual document processing needs. We hope to continue hacking with DocuSign in the future.
## Accomplishments that we're proud of
We are very happy to have experimented with the power of enterprise solutions in making a difference while hacking for resilience. Wildfires, among the most devastating of natural disasters in the US, have had a huge impact on residents of states such as California. Our team has been working hard to leverage existing residential video footage systems for high-risk wildfire neighborhoods.
## What we learned
Our team members learned concepts of various technical and fundamental utility. To list a few such concepts, we include MongoDB, Flask, Django, OpenCV, DocuSign, Fire safety.
## What's next for CacheTheHeat.com
Cache the Heat is excited to commercialize this solution with the support of Wharton Risk Center if possible. | ## How we built it
The sensors consist of the Maxim Pegasus board and any Android phone with our app installed. The two are synchronized at the beginning, and then by moving the "tape" away from the "measure," we can get an accurate measure of distance, even for non-linear surfaces.
## Challenges we ran into
Sometimes high-variance outputs can come out of the sensors we made use of, such as Android gyroscopes. Maintaining an inertial reference frame from our board to the ground as it was rotated proved very difficult and required the use of quaternion rotational transforms. Using the Maxim Pegasus board was difficult as it is a relatively new piece of hardware, and thus, no APIs or libaries have been written for basic functions yet. We had to query for accelerometer and gyro data manually from internal IMU registers with I2C.
## Accomplishments that we're proud of
Full integration with the Maxim board and the flexibility to adapt the software to many different handyman-style use cases, e.g. as a table level, compass, etc. We experimented with and implemented various noise filtering techniques such as Kalman filters and low pass filters to increase the accuracy of our data. In general, working with the Pegasus board involved a lot of low-level read-write operations within internal device registers, so basic tasks like getting accelerometer data became much more complex than we were used to.
## What's next
Other possibilities were listed above, along with the potential to make even better estimates of absolute positioning in space through different statistical algorithms. | ## Inspiration
I love to play board games, but I often can't get a big enough group together to play. This led to my original idea: an AI-powered opponent in Tabletop Simulator who could play virtual board games against you after reading their rules books. This proved to be too ambitious, so I settled on a simplified case for my project: a bot for a modified version of the card game Cheat, built in Python.
## Features
The project features a graphical implementation of Cheat in Pygame and a bot integrated with the OpenAI API that plays against the user.
## Challenges
Towards the end of the hackathon, I had some struggles integrating the OpenAI API and the features it brought into the Pygame piece of my project, but I ultimately found a solution and got the bot working.
## Future Plans
I feel this project is still incomplete, that the bot could be improved to have a longer memory, or that maybe it would be better if I tried a reinforcement learning approach instead. Nevertheless, I enjoyed learning to work with APIs and hope to continue learning with this project, however that may be! | winning |
## Never plan for fun again. Just have it. Now, with CityCrawler.
While squabbling over bars to visit in the city, we pined for a solution to our problem.
And here we find CityCrawler, an app that takes your interests and a couple of other details to immediately plan your ideal trip. So whether it's a pub crawl or a night full of entertainment, CityCrawler will be at your service to help you decide and focus on the conversations that actually matter.
With CityCrawler you can also share your plan with your friends, so no one is left behind.
## Tech Used
On the iOS side, we used RxSwift, and RxAlamoFire to handle asynchronous tasks and network requests.
On the Android side, we used Kotlin, RxKotlin, Retrofit and OkHTTP.
Our backend system consists of a set of stdlib endpoint functions, which are built using the Google Maps Places API, Distance Matrix API, and the Firebase API. We also wrote a custom algorithm to solve the Travelling Salesman Problem based on Kruskal's Minimum Spanning Tree algorithm and the Depth First Tree Tour algorithm.
We have also exposed our Firebase and Google Maps stdlib functions to the public to contribute to that ecosystem. Oh and #OneMoreThing.
### Android Youtube Video - <https://youtu.be/WudxqMyaszQ> | ## **Problem**
* Less than a third of Canada’s fish populations, 29.4 per cent, can confidently be considered healthy and 17 per cent are in the critical zone, where conservation actions are crucial.
* A fishery audit conducted by Oceana Canada, reported that just 30.4 per cent of fisheries in Canada are considered “healthy” and nearly 20 per cent of stocks are “critically depleted.”
### **Lack of monitoring**
"However, short term economics versus long term population monitoring and rebuilding has always been a problem in fisheries decision making. This makes it difficult to manage dealing with major issues, such as species decline, right away." - Marine conservation coordinator, Susanna Fuller
"sharing observations of fish catches via phone apps, or following guidelines to prevent transfer of invasive species by boats, all contribute to helping freshwater fish populations" - The globe and mail
## **Our solution; Aquatrack**
aggregates a bunch of datasets from open canadian portal into a public dashboard!
slide link for more info: <https://www.canva.com/design/DAFCEO85hI0/c02cZwk92ByDkxMW98Iljw/view?utm_content=DAFCEO85hI0&utm_campaign=designshare&utm_medium=link2&utm_source=sharebutton>
The REPO github link: <https://github.com/HikaruSadashi/Aquatrack>
The datasets used:
1) <https://open.canada.ca/data/en/dataset/c9d45753-5820-4fa2-a1d1-55e3bf8e68f3/resource/7340c4ad-b909-4658-bbf3-165a612472de>
2)
<https://open.canada.ca/data/en/dataset/aca81811-4b08-4382-9af7-204e0b9d2448> | ## Inspiration
40 million people in the world are blind, including 20% of all people aged 85 or older. Half a million people suffer paralyzing spinal cord injuries every year. 8.5 million people are affected by Parkinson’s disease, with the vast majority of these being senior citizens. The pervasive difficulty for these individuals to interact with objects in their environment, including identifying or physically taking the medications vital to their health, is unacceptable given the capabilities of today’s technology.
First, we asked ourselves the question, what if there was a vision-powered robotic appliance that could serve as a helping hand to the physically impaired? Then we began brainstorming: Could a language AI model make the interface between these individual’s desired actions and their robot helper’s operations even more seamless? We ended up creating Baymax—a robot arm that understands everyday speech to generate its own instructions for meeting exactly what its loved one wants. Much more than its brilliant design, Baymax is intelligent, accurate, and eternally diligent.
We know that if Baymax was implemented first in high-priority nursing homes, then later in household bedsides and on wheelchairs, it would create a lasting improvement in the quality of life for millions. Baymax currently helps its patients take their medicine, but it is easily extensible to do much more—assisting these same groups of people with tasks like eating, dressing, or doing their household chores.
## What it does
Baymax listens to a user’s requests on which medicine to pick up, then picks up the appropriate pill and feeds it to the user. Note that this could be generalized to any object, ranging from food, to clothes, to common household trinkets, to more. Baymax responds accurately to conversational, even meandering, natural language requests for which medicine to take—making it perfect for older members of society who may not want to memorize specific commands. It interprets these requests to generate its own pseudocode, later translated to robot arm instructions, for following the tasks outlined by its loved one. Subsequently, Baymax delivers the medicine to the user by employing a powerful computer vision model to identify and locate a user’s mouth and make real-time adjustments.
## How we built it
The robot arm by Reazon Labs, a 3D-printed arm with 8 servos as pivot points, is the heart of our project. We wrote custom inverse kinematics software from scratch to control these 8 degrees of freedom and navigate the end-effector to a point in three dimensional space, along with building our own animation methods for the arm to follow a given path. Our animation methods interpolate the arm’s movements through keyframes, or defined positions, similar to how film editors dictate animations. This allowed us to facilitate smooth, yet precise, motion which is safe for the end user.
We built a pipeline to take in speech input from the user and process their request. We wanted users to speak with the robot in natural language, so we used OpenAI’s Whisper system to convert the user commands to text, then used OpenAI’s GPT-4 API to figure out which medicine(s) they were requesting assistance with.
We focused on computer vision to recognize the user’s face and mouth. We used OpenCV to get the webcam live stream and used 3 different Convolutional Neural Networks for facial detection, masking, and feature recognition. We extracted coordinates from the model output to extrapolate facial landmarks and identify the location of the center of the mouth, simultaneously detecting if the user’s mouth is open or closed.
When we put everything together, our result was a functional system where a user can request medicines or pills, and the arm will pick up the appropriate medicines one by one, feeding them to the user while making real time adjustments as it approaches the user’s mouth.
## Challenges we ran into
We quickly learned that working with hardware introduced a lot of room for complications. The robot arm we used was a prototype, entirely 3D-printed yet equipped with high-torque motors, and parts were subject to wear and tear very quickly, which sacrificed the accuracy of its movements. To solve this, we implemented torque and current limiting software and wrote Python code to smoothen movements and preserve the integrity of instruction.
Controlling the arm was another challenge because it has 8 motors that need to be manipulated finely enough in tandem to reach a specific point in 3D space. We had to not only learn how to work with the robot arm SDK and libraries but also comprehend the math and intuition behind its movement. We did this by utilizing forward kinematics and restricted the servo motors’ degrees of freedom to simplify the math. Realizing it would be tricky to write all the movement code from scratch, we created an animation library for the arm in which we captured certain arm positions as keyframes and then interpolated between them to create fluid motion.
Another critical issue was the high latency between the video stream and robot arm’s movement, and we spent much time optimizing our computer vision pipeline to create a near instantaneous experience for our users.
## Accomplishments that we're proud of
As first-time Hackathon participants, we are incredibly proud of the incredible progress we were able to make in a very short amount of time, proving to ourselves that with hard work, passion, and a clear vision, anything is possible. Our team did a fantastic job embracing the challenge of using technology unfamiliar to us, and stepped out of our comfort zones to bring our idea to life. Whether it was building the computer vision model, or learning how to interface the robot arm’s movements with voice controls, we ended up building a robust prototype which far surpassed our initial expectations. One of our greatest successes was coordinating our work so that each function could be pieced together and emerge as a functional robot. Let’s not overlook the success of not eating our hi-chews we were using for testing!
## What we learned
We developed our skills in frameworks we were initially unfamiliar with such as how to apply Machine Learning algorithms in a real-time context. We also learned how to successfully interface software with hardware - crafting complex functions which we could see work in 3-dimensional space. Through developing this project, we also realized just how much social impact a robot arm can have for disabled or elderly populations.
## What's next for Baymax
Envision a world where Baymax, a vigilant companion, eases medication management for those with mobility challenges. First, Baymax can be implemented in nursing homes, then can become a part of households and mobility aids. Baymax is a helping hand, restoring independence to a large disadvantaged group.
This innovation marks an improvement in increasing quality of life for millions of older people, and is truly a human-centric solution in robotic form. | losing |
## What it does
XEN SPACE is an interactive web-based game that incorporates emotion recognition technology and the Leap motion controller to create an immersive emotional experience that will pave the way for the future gaming industry.
# How we built it
We built it using three.js, Leap Motion Controller for controls, and Indico Facial Emotion API. We also used Blender, Cinema4D, Adobe Photoshop, and Sketch for all graphical assets. | ## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part detection model to track movements that correspond to controls for classic games that are ran through an online browser. The user can choose from a variety of classic games such as temple run, super mario, and play them with their body movements.
## How we built it
* The first step was setting up opencv and importing the a body part tracking model from google mediapipe
* Next, based off the position and angles between the landmarks, we created classification functions that detected specific movements such as when an arm or leg was raised or the user jumped.
* Then we correlated these movement identifications to keybinds on the computer. For example when the user raises their right arm it corresponds to the right arrow key
* We then embedded some online games of our choice into our front and and when the user makes a certain movement which corresponds to a certain key, the respective action would happen
* Finally, we created a visually appealing and interactive frontend/loading page where the user can select which game they want to play
## Challenges we ran into
A large challenge we ran into was embedding the video output window into the front end. We tried passing it through an API and it worked with a basic plane video, however the difficulties arose when we tried to pass the video with the body tracking model overlay on it
## Accomplishments that we're proud of
We are proud of the fact that we are able to have a functioning product in the sense that multiple games can be controlled with body part commands of our specification. Thanks to threading optimization there is little latency between user input and video output which was a fear when starting the project.
## What we learned
We learned that it is possible to embed other websites (such as simple games) into our own local HTML sites.
We learned how to map landmark node positions into meaningful movement classifications considering positions, and angles.
We learned how to resize, move, and give priority to external windows such as the video output window
We learned how to run python files from JavaScript to make automated calls to further processes
## What's next for AR.cade
The next steps for AR.cade are to implement a more accurate body tracking model in order to track more precise parameters. This would allow us to scale our product to more modern games that require more user inputs such as Fortnite or Minecraft. | ## Inspiration
One charge of the average EV's battery uses as much electricity as a house uses every 2.5 days. This puts a huge strain on the electrical grid: people usually plug in their car as soon as they get home, during what is already peak demand hours. At this time, not only is electricity the most expensive, but it is also the most carbon-intensive; as much as 20% generated by fossil fuels, even in Ontario, which is not a primarily fossil-fuel dependent region. We can change this: by charging according to our calculated optimal time, not only will our users save money, but save the environment.
## What it does
Given an interval in which the user can charge their car (ex., from when they get home to when they have to leave in the morning), ChargeVerte analyses live and historical data of electricity generation to calculate an interval in which electricity generation is the cleanest. The user can then instruct their car to begin charging at our recommended time, and charge with peace of mind knowing they are using sustainable energy.
## How we built it
ChargeVerte was made using a purely Python-based tech stack. We leveraged various libraries, including requests to make API requests, pandas for data processing, and Taipy for front-end design. Our project pulls data about the electrical grid from the Electricity Maps API in real-time.
## Challenges we ran into
Our biggest challenges were primarily learning how to handle all the different libraries we used within this project, many of which we had never used before, but were eager to try our hand at. One notable challenge we faced was trying to use the Flask API and React to create a Python/JS full-stack app, which we found was difficult to make API GET requests with due to the different data types supported by the respective languages. We made the decision to pivot to Taipy in order to overcome this hurdle.
## Accomplishments that we're proud of
We built a functioning predictive algorithm, which, given a range of time, finds the timespan of electricity with the lowest carbon intensity.
## What we learned
We learned how to design critical processes related to full-stack development, including how to make API requests, design a front-end, and connect a front-end and backend together. We also learned how to program in a team setting, and the many strategies and habits we had to change in order to make it happen.
## What's next for ChargeVerte
A potential partner for ChargeVerte is power-generating companies themselves. Generating companies could package ChargeVerte and a charging timer, such that when a driver plugs in for the night, ChargeVerte will automatically begin charging at off-peak times, without any needed driver oversight. This would reduce costs significantly for the power-generating companies, as they can maintain a flatter demand line and thus reduce the amount of expensive, polluting fossil fuels needed. | winning |
## Inspiration
We wanted to do something fun and exciting, nothing too serious. Slang is a vital component to thrive in today's society. Ever seen Travis Scott go like, "My dawg would prolly do it for a Louis belt", even most menials are not familiar with this slang. Therefore, we are leveraging the power of today's modern platform called "Urban Dictionary" to educate people about today's ways. Showing how today's music is changing with the slang thrown in.
## What it does
You choose your desired song it will print out the lyrics for you and then it will even sing it for you in a robotic voice. It will then look up the urban dictionary meaning of the slang and replace with the original and then it will attempt to sing it.
## How I built it
We utilized Python's Flask framework as well as numerous Python Natural Language Processing libraries. We created the Front end with a Bootstrap Framework. Utilizing Kaggle Datasets and Zdict API's
## Challenges I ran into
Redirecting challenges with Flask were frequent and the excessive API calls made the program super slow.
## Accomplishments that I'm proud of
The excellent UI design along with the amazing outcomes that can be produced from the translation of slang
## What I learned
A lot of things we learned
## What's next for SlangSlack
We are going to transform the way today's menials keep up with growing trends in slang. | ## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conversion isn't always the best. I tend to use unnecessary filler words ("um, umm" etc.) and repeat the same adjectives over and over again. In order to improve my speech through practice against a program, I decided to create this application.
## What it does
InterPrep uses the IBM Watson "Speech-To-Text" API to convert spoken word into text. After doing this, it analyzes the words that are used by the user and highlights certain words that can be avoided, and maybe even improved to create a stronger presentation of ideas. By practicing speaking with InterPrep, one can keep track of their mistakes and improve themselves in time for "speaking events" such as interviews, speeches and/or presentations.
## How I built it
In order to build InterPrep, I used the Stdlib platform to host the site and create the backend service. The IBM Watson API was used to convert spoken word into text. The mediaRecorder API was used to receive and parse spoken text into an audio file which later gets transcribed by the Watson API.
The languages and tools used to build InterPrep are HTML5, CSS3, JavaScript and Node.JS.
## Challenges I ran into
"Speech-To-Text" API's, like the one offered by IBM tend to remove words of profanity, and words that don't exist in the English language. Therefore the word "um" wasn't sensed by the API at first. However, for my application, I needed to sense frequently used filler words such as "um", so that the user can be notified and can improve their overall speech delivery. Therefore, in order to implement this word, I had to create a custom language library within the Watson API platform and then connect it via Node.js on top of the Stdlib platform. This proved to be a very challenging task as I faced many errors and had to seek help from mentors before I could figure it out. However, once fixed, the project went by smoothly.
## Accomplishments that I'm proud of
I am very proud of the entire application itself. Before coming to Qhacks, I only knew how to do Front-End Web Development. I didn't have any knowledge of back-end development or with using API's. Therefore, by creating an application that contains all of the things stated above, I am really proud of the project as a whole. In terms of smaller individual accomplishments, I am very proud of creating my own custom language library and also for using multiple API's in one application successfully.
## What I learned
I learned a lot of things during this hackathon. I learned back-end programming, how to use API's and also how to develop a coherent web application from scratch.
## What's next for InterPrep
I would like to add more features for InterPrep as well as improve the UI/UX in the coming weeks after returning back home. There is a lot that can be done with additional technologies such as Machine Learning and Artificial Intelligence that I wish to further incorporate into my project! | ## WebMS
**Inspiration**
The inspiration came from when one of our team members was in India, and experienced large floods. The floods disabled cell towers and caused much of the population to lose data capabilities. However, they maintained SMS and MMS capabilities, which was a viable asset that was ineffectively utilized. During these floods, some of his relatives would have been helped a lot if they had had access to the internet, even indirectly to get alerts and similar things which they could not have accessed otherwise.
**What it does**
WebMS is a tool that allows the user to access information on the internet using SMS/MMS technology when wifi and cellular service are inaccessible. The user inputs a variety of commands by texting the WebMS number to initialize many different applets such as searching the internet for websites, browsing web pages (via screenshots), accessing weather and more. This all functions by remotely processing the content of the commands sent (on the cloud) and returning the requested information through SMS. Screenshots of the website are sent through MMS, utilizing the Twilio API
**How it works**
WebMS uses the Twilio API to provide this beneficial service. The user can run commands via SMS to receive information from our servers on the cloud. Our servers access the information with their own internet connection, and relay them to the user’s mobile phone via SMS . Many Applets are available such as Web Search, web browsing (via screenshots), important quick information such as weather and alerts, and even some fun games and jokes to lighten the mood.
**How we built it**
WebMS was made possible due to many modern technologies. A major technology that provides the backbone to WebMS (the ability to send and receive SMS and MMS messages) was provided by Twillio. Bing search is used for web indexing with the Microsoft Azure API. Continuity between this applet and the Navigator (Browser) was one of the main priorities behind WebMS. Many different APIs for the appropriate use (such as Accuweather) are used in order to power the quick info applets, that quickly provide info faster than the Navigator. Another significant feature part of WebMS is quick language translation powered by the Google Translate API. Many applets even serve comedic purpose. As WebMS was designed to be expandable, a variety of applets can easily be added to WebMS over time.
**Challenges We Ran into**
WebMS required a lot of work to get to its current position. Before we could focus on our quick applets we had to develop the basebone of the app. We hit some road bumps because a lot of sites contained illegal characters for XML. Our team had no prior experience dealing with issues such as these. We stayed up overnight learning regular expressions and how to use them, before we were able to support all the applets we have now. We were having issues with certain characters causing errors in the code. Sending images via MMS required a lot of work as well. We had to try many different hosts in order to find one that was consistent and reliable enough for our needs. We wanted WebMS to more stable, and not have issues such as crashing as these could be problematic to the user. We also had to find a place to host our code and the headless browser used for scraping. Unfortunately, we ran into some issues setting up some of the APIs as we did not have immediate access to a credit card. However, we were able to overcome most of these challenges before the end of the hackathon.
**Accomplishments that we’re proud of**
We are proud of the technology we developed to solve a major issue. While some of us did not have as much experience with nodeJS, we were able to deliver a well thought out service. We were even able to do extra and deliver quick and fun applets.
**What we learned**
We learned about new and unfamiliar languages and their quirks, like how XML disallows certain characters, and the certain interesting bits of syntax that nodeJS developers have to deal with. We also learned how to send SMS messages through programs and transfer information effectively between two different devices in very different situations.
**Built With**
NodeJS, Twilio, Puppeteer, Express, Google Translate API, Microsoft Azure Search, Accuweather API, (and for the gaming section) A few random fun APIs we found on the internet
**Try it out**
WebMS will be available to early testers at the first expo, and then to the public soon after it becomes more stable and secure. | winning |
## Inspiration
Blockchain has created new opportunities for financial empowerment and decentralized finance (DeFi), but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has been a recent wave of effort to introduce regulations for crypto, but the ease of money laundering proves to be a serious challenge for regulatory bodies like the Canadian Revenue Agency. Recognizing these dangers, we aimed to tackle this issue through BlockXism!
## What it does
BlockXism is an attempt at placing more transparency in the blockchain ecosystem, through a simple verification system. It consists of (1) a self-authenticating service, (2) a ledger of verified users, and (3) rules for how verified and unverified users interact. Users can "verify" themselves by giving proof of identity to our self-authenticating service, which stores their encrypted identity on-chain. A ledger of verified users keeps track of which addresses have been verified, without giving away personal information. Finally, users will lose verification status if they make transactions with an unverified address, preventing suspicious funds from ever entering the verified economy. Importantly, verified users will remain anonymous as long as they are in good standing. Otherwise, such as if they transact with an unverified user, a regulatory body (like the CRA) will gain permission to view their identity (as determined by a smart contract).
Through this system, we create a verified market, where suspicious funds cannot enter the verified economy while flagging suspicious activity. With the addition of a legislation piece (e.g. requiring banks and stores to be verified and only transact with verified users), BlockXism creates a safer and more regulated crypto ecosystem, while maintaining benefits like blockchain’s decentralization, absence of a middleman, and anonymity.
## How we built it
BlockXism is built on a smart contract written in Solidity, which manages the ledger. For our self-authenticating service, we incorporated Circle wallets, which we plan to integrate into a self-sovereign identification system. We simulated the chain locally using Ganache and Metamask. On the application side, we used a combination of React, Tailwind, and ethers.js for the frontend and Express and MongoDB for our backend.
## Challenges we ran into
A challenge we faced was overcoming the constraints when connecting the different tools with one another, meaning we often ran into issues with our fetch requests. For instance, we realized you can only call MetaMask from the frontend, so we had to find an alternative for the backend. Additionally, there were multiple issues with versioning in our local test chain, leading to inconsistent behaviour and some very strange bugs.
## Accomplishments that we're proud of
Since most of our team had limited exposure to blockchain prior to this hackathon, we are proud to have quickly learned about the technologies used in a crypto ecosystem. We are also proud to have built a fully working full-stack web3 MVP with many of the features we originally planned to incorporate.
## What we learned
Firstly, from researching cryptocurrency transactions and fraud prevention on the blockchain, we learned about the advantages and challenges at the intersection of blockchain and finance. We also learned how to simulate how users interact with one another blockchain, such as through peer-to-peer verification and making secure transactions using Circle wallets. Furthermore, we learned how to write smart contracts and implement them with a web application.
## What's next for BlockXism
We plan to use IPFS instead of using MongoDB to better maintain decentralization. For our self-sovereign identity service, we want to incorporate an API to recognize valid proof of ID, and potentially move the logic into another smart contract. Finally, we plan on having a chain scraper to automatically recognize unverified transactions and edit the ledger accordingly. | ## Inspiration
At companies that want to introduce automation into their pipeline, finding the right robot, the cost of a specialized robotics system, and the time it takes to program a specialized robot is very expensive. We looked for solutions in general purpose robotics and imagining how these types of systems can be "trained" for certain tasks and "learn" to become a specialized robot.
## What it does
The Simon System consists of Simon, our robot that learns to perform the human's input actions. There are two "play" fields, one for the human to perform actions and the other for Simon to reproduce actions.
Everything starts with a human action. The Simon System detects human motion and records what happens. Then those actions are interpreted into actions that Simon can take. Then Simon performs those actions in the second play field, making sure to plan efficient paths taking into consideration that it is a robot in the field.
## How we built it
### Hardware
The hardware was really built from the ground up. We CADded the entire model of the two play fields as well as the arches that hold the smartphone cameras here at PennApps. The assembly of the two play fields consist of 100 individual CAD models and took over three hours to fully assemble, making full utilization of lap joints and mechanical advantage to create a structurally sound system. The LEDs in the enclosure communicate with the offboard field controllers using Unix Domain Sockets that simulate a serial port to allow color change for giving a user info on what the state of the fields is.
Simon, the robot, was also constructed completely from scratch. At its core, Simon is an Arduino Nano. It utilizes a dual H Bridge motor driver for controlling its two powered wheels and an IMU for its feedback controls system. It uses a MOSFET for controlling the electromagnet onboard for "grabbing" and "releasing" the cubes that it manipulates. With all of that, the entire motion planning library for Simon was written entirely from scratch. Simon uses a bluetooth module for communicating offboard with the path planning server.
### Software
There are four major software systems in this project. The path planning system uses a modified BFS algorithm taking into account path smoothing with realtime updates from the low-level controls to calibrate path plan throughout execution. The computer vision systems intelligently detect when updates are made to the human control field and acquire normalized grid size of the play field using QR boundaries to create a virtual enclosure. The cv system also determines the orientation of Simon on the field as it travels around. Servers and clients are also instantiated on every part of the stack for communicating with low latency.
## Challenges we ran into
Lack of acrylic for completing the system, so we had to refactor a lot of our hardware designs to accomodate. Robot rotation calibration and path planning due to very small inconsistencies in low level controllers. Building many things from scratch without using public libraries because they aren't specialized enough.
Dealing with smartphone cameras for CV and figuring out how to coordinate across phones with similar aspect ratios and not similar resolutions.
The programs we used don't run on windows such as Unix Domain Sockets so we had to switch to using a Mac as our main system.
## Accomplishments that we're proud of
This thing works, somehow. We wrote modular code this hackathon and a solid running github repo that was utilized.
## What we learned
We got better at CV. First real CV hackathon.
## What's next for The Simon System
More robustness. | ## Inspiration -
I got inspired for making this app when I saw that my friends and family who sometimes tend to not have enough internet bandwidth to spare to an application, and signal drops make calling someone a cumbersome task. Messaging was not included in this app, since I wanted it to be light-weight. It also achieves another goal; making people have a one-on-one conversation, which has reduced day by day as people have started using texting a lot.
## What it does -
This app helps people make calls to their friends/co-workers/acquaintances without using too much of internet bandwidth, when signal drops are frequent and STD calls are not possible. The unavailability of messaging feature helps save more internet data and forces people to talk instead of texting. This helps people be more socially active among their friends.
## How I built it -
This app encompasses multiple technologies and frameworks. This app is a combination of Flutter, Android and Firebase developed with the help of Dart and Java. It was a fun task to make all the UI elements and then inculcate them into the main frontend of the application. The backend uses Google Firebase for it's database and authentication, which is a service from Google for hosting apps with lots of features, and uses Google Cloud platform for all the work. Connecting the frontend and backend was not an easy task, especially for a single person, hence **the App is still under development phase and not yet fully functional.**
## Challenges we ran into -
This whole idea was a pretty big challenge for me. This is my first project in Flutter, and I have never done something on this large scale, so I was totally skeptical about the completion of the project and it's elements. The majority of the time was dedicated to the frontend of the application, but the backend was a big problem especially for a beginner like me, hence the incomplete status.
## Accomplishments that we're proud of -
Despite many of the challenges I ran into, I'm extremely proud of what I've been able to produce over the course of these 36 hours.
## What I learned -
I learned a lot about Flutter and Firebase, and frontend-backend services in general. I learned how to make many new UI widgets and features, a lot of new plugins, connecting Android SDKs to the app and using them for smooth functioning. I learned how Firebase authenticates users and their emails/passwords with the built in authentications features, and how it stores data in containerized formats and uses it in projects, which will be very helpful in my future. One more important thing I learned was how I could keep my code organized and better formatted for easier changes whenever required. And lastly, I learned a lot about Git and how it is useful for such projects.
## What's next for Berufung -
I hope this app will be fully-functioning, and we will add new features such as 2 Factor Authentication, Video calling, and group calling. | winning |
## Inspiration
While munching down on 3 Snickers bars, 10 packs of Welch's Fruit Snacks, a few Red Bulls, and an apple, we were trying to think of a hack idea. It then hit us that we were eating so unhealthy! We realized that as college students, we are often less aware of our eating habits since we are more focused on other priorities. Then came GrubSub, a way for college students to easily discover new foods for their eating habits.
## What it does
Imagine that you have recently been tracking your nutrient intake, but have run into the problem of eating the same foods over and over again. GrubSub allows a user to discover different foods that fulfill their nutritional requirements, substitute missing ingredients in recipes, or simply explore a wider range of eating options.
## How I built it
GrubSub utilizes a large data set of foods with information about their nutritional content such as proteins, carbohydrates, fats, vitamins, and minerals. GrubSub takes in a user-inputted query and finds the best matching entry in the data set. It searches through the list for the entry with the highest number of common words and the shortest length. It then compares this entry with the rest of the data set and outputs a list of foods that are the most similar in nutritional content. Specifically, we rank their similarities by calculating the sum of squared differences of each nutrient variable for each food and our query.
## Challenges I ran into
We used the Django framework to build our web application with the majority of our team not having prior knowledge with the technology. We spent a lot of time figuring out basic functionalities such as sending/receiving information between the front and back ends. We also spent a good amount of time finding a good data set to work with, and preprocessing the data set so that it would be easier to work with and understand.
## Accomplishments that I'm proud of
Finding, preprocessing, and reading in the data set into the Django framework was one of our first big accomplishments since it was the backbone of our project.
## What I learned
We became more familiar with the Django framework and python libraries for data processing.
## What's next for GrubSub
A better underlying data set will naturally make the app better, as there would be more selections and more information with which to make comparisons. We would also want to allow the user to select exactly which nutrients they want to find close substitutes for. We implemented this both in the front and back ends, but were unable to send the correct signals to finish this particular function. We would also like to incorporate recipes and ingredient swapping more explicitly into our app, perhaps by taking a food item and an ingredient, and being able to suggest an appropriate alternative. | ## Inspiration
As we brainstormed areas we could work in for our project, we began to look for inconveniences in each of our lives that we could tackle. One of our teammates unfortunately has a lot of dietary restrictions due to allergies, and as we watched him finding organizers to check ingredients and straining to read the microscopic text on processed foods' packaging, we realized that this was an everyday issue that we could help to resolve, and that the issue is not limited to just our teammate. Thus, we sought to find a way to make his and others' lives easier and simplify the way they check for allergens.
## What it does
Our project scans food items' ingredients lists and identifies allergens within the ingredients list to ensure that a given food item is safe for consumption, as well as putting the tool in a user-friendly web app.
## How we built it
We divided responsibilities and made sure each of us was on the same page when completing our individual parts. Some of us worked on the backend, with initializing databases and creating the script to process camera inputs, and some of us worked on frontend development, striving to create an easy-to-navigate platform for people to use.
## Challenges we ran into
One major challenge we ran into was time management. As newer programmers to hackathons, the pace of the project development was a bit of a shock going into the work. Additionally, there were various incompatibilities between softwares that we ran into, causing a variety of setbacks that ultimately led to most of the issues with the final product.
## Accomplishments that we're proud of
We are very proud of the fact that the tool is functional. Even though the product is certainly far from what we wanted to end up with, we are happy that we were able to at least approach a state of completion.
## What we learned
In the end, our project was a part of the grander learning experience each of us went through. The stress of completing all intended functionality and the difficulties of working under difficult, tiring conditions was a combination that challenged us all, and from those challenges we were able to learn strategies to mitigate such obstacles in the future.
## What's next for foodsense
We hope to be able to finally complete the web app in the way we originally intended. A big regret was definitely that we were not able to execute our plan as we originally meant to, so future development is definitely in the future of the website. | ## Inspiration
We were inspired by the Instagram app, which set out to connect people using photo media.
We believe that the next evolution of connectivity is augmented reality, which allows people to share and bring creations into the world around them. This revolutionary technology has immense potential to help restore the financial security of small businesses, which can no longer offer the same in-person shopping experiences they once did before the pandemic.
## What It Does
Metagram is a social network that aims to restore the connection between people and small businesses. Metagram allows users to scan creative works (food, models, furniture), which are then converted to models that can be experienced by others using AR technology.
## How we built it
We built our front-end UI using React.js, Express/Node.js and used MongoDB to store user data. We used Echo3D to host our models and AR capabilities on the mobile phone. In order to create personalized AR models, we hosted COLMAP and OpenCV scripts on Google Cloud to process images and then turn them into 3D models ready for AR.
## Challenges we ran into
One of the challenges we ran into was hosting software on Google Cloud, as it needed CUDA to run COLMAP. Since this was our first time using AR technology, we faced some hurdles getting to know Echo3D. However, the documentation was very well written, and the API integrated very nicely with our custom models and web app!
## Accomplishments that we're proud of
We are proud of being able to find a method in which we can host COLMAP on Google Cloud and also connect it to the rest of our application. The application is fully functional, and can be accessed by [clicking here](https://meta-match.herokuapp.com/).
## What We Learned
We learned a great deal about hosting COLMAP on Google Cloud. We were also able to learn how to create an AR and how to use Echo3D as we have never previously used it before, and how to integrate it all into a functional social networking web app!
## Next Steps for Metagram
* [ ] Improving the web interface and overall user experience
* [ ] Scan and upload 3D models in a more efficient manner
## Research
Small businesses are the backbone of our economy. They create jobs, improve our communities, fuel innovation, and ultimately help grow our economy! For context, small businesses made up 98% of all Canadian businesses in 2020 and provided nearly 70% of all jobs in Canada [[1]](https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm).
However, the COVID-19 pandemic has devastated small businesses across the country. The Canadian Federation of Independent Business estimates that one in six businesses in Canada will close their doors permanently before the pandemic is over. This would be an economic catastrophe for employers, workers, and Canadians everywhere.
Why is the pandemic affecting these businesses so severely? We live in the age of the internet after all, right? Many retailers believe customers shop similarly online as they do in-store, but the research says otherwise.
The data is clear. According to a 2019 survey of over 1000 respondents, consumers spend significantly more per visit in-store than online [[2]](https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543). Furthermore, a 2020 survey of over 16,000 shoppers found that 82% of consumers are more inclined to purchase after seeing, holding, or demoing products in-store [[3]](https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store).
It seems that our senses and emotions play an integral role in the shopping experience. This fact is what inspired us to create Metagram, an AR app to help restore small businesses.
## References
* [1] <https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm>
* [2] <https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543>
* [3] <https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store> | losing |
## Contributors
Andrea Tongsak, Vivian Zhang, Alyssa Tan, and Mira Tellegen
## Categories
* **Route: Hack for Resilience**
* **Route: Best Education Hack**
## Inspiration
We were inspired to focus our hack on the rise of instagram accounts exposing sexual assault stories from college campuses across the US, including the Case Western Reserve University account **@cwru.survivors**; and the history of sexual assault on campuses nationwide. We wanted to create an iOS app that would help sexual assault survivors and students navigate the dangerous reality of college campuses. With our app, it will be easier for a survivor report instances of harassment, while maintaining the integrity of the user data, and ensuring that data is anonymous and randomized. Our app will map safe and dangerous areas on campus based on user data to help women, minorities, and sexual assault survivors feel protected.
### **"When I looked in the mirror the next day, I could hardly recognize myself. Physically, emotionally, and mentally."** -A submission on @cwru.survivors IG page
Even with the **#MeToo movement**, there's only so much that technology can do. However, we hope that by creating this app, we will help college students take accountability and create a campus culture that can fosters learning and contributes towards social good.
### **"The friendly guy who helps you move and assists senior citizens in the pool is the same guy who assaulted me. One person can be capable of both. Society often fails to wrap its head around the fact that these truths often coexist, they are not mutually exclusive."** - Chanel Miller
## Brainstorming/Refining
* We started with the idea of mapping sexual assaults that happen on college campuses. However, throughout the weekend, we were able to brainstorm a lot of directions to take the app in.
* We considered making the app a platform focused on telling the stories of sexual assault survivors through maps containing quotes, but decided to pivot based on security concerns about protecting the identity of survivors, and to pivot towards an app that had an everyday functionality
* We were interested in implementing an emergency messaging app that would alert friends to dangerous situations on campus, but found similar apps existed, so kept brainstorming towards something more original
* We were inspired by the heat map functionality of SnapMaps, and decided to pursue the idea of creating a map that showed where users had reported danger or sexual assault on campus. With this idea, the app could be interactive for the user, present a platform for sexual assault survivors to share where they had been assaulted, and a hub for women and minorities to check the safety of their surroundings. The app would customize to a campus based on the app users in the area protecting each other
## What it does
## App Purpose
* Our app allows users to create a profile, then sign in to view a map of their college campus or area. The map in the app shows a heat map of dangerous areas on campus, from areas with a lot of assaults or danger reported, to areas where app users have felt safe.
* This map is generated by allowing users to anonymously submit a date, address, and story related to sexual assault or feeling unsafe. Then, the map is generated by the user data
* Therefore, users of the app can assess their safety based on other students' experiences, and understand how to protect themselves on campus.
## Functions
* Account creation and sign in function using **Firebox**, to allow users to have accounts and profiles
* Home screen with heat map of dangerous locations in the area, using the **Mapbox SDK**
* Profile screen, listing contact information and displaying the user's past submissions of dangerous locations
* Submission screen, where users can enter an address, time, and story related to a dangerous area on campus
## How we built it
## Technologies Utilized
* **Mapbox SDK**
* **Github**
* **XCode & Swift**
* **Firebase**
* **Adobe Illustrator**
* **Google Cloud**
* **Canva**
* **Cocoapods**
* **SurveyMonkey**
## Mentors & Help
* Ryan Matsumoto
* Rachel Lovell
## Challenges we ran into
**Mapbox SDK**
* Integrating an outside mapping service came with a variety of difficulties. We ran into problems learning their platform and troubleshooting errors with the Mapbox view. Furthermore, Mapbox has a lot of navigation functionality. Since our goal was a data map with a lot of visual effect and easy readability, we had to translate the Mapbox SDK to be usable with lots of data inputs. This meant coding so that the map would auto-adjust with each new data submission of dangerous locations on campus.
**UI Privacy Concerns**
* The Mapbox SDK was created to be able to pin very specific locations. However, our app deals with data points of locations of sexual assault, or unsafe locations. This brings up the concern of protecting the privacy of the people who submit addresses, and ensuring that users can't see the exact location submitted. So, we had to adjust the code to limit how far a user can zoom in, and to read as a heat map of general location, rather than pins.
**Coding for non-tech users**
* Our app, **viva**, was designed to be used by college students on their nights out, or at parties. The idea would be for them to check the safety of their area while walking home or while out with friends. So, we had to appeal to an audience of young people using the app in their free time or during special occasions. This meant the app would not appeal if it seemed tech-y or hard to use. So, we had to work to incorporate a lot of functionalities, and a user interface that was easy to use and appealing to young people. This included allowing them to make accounts, having an easily readable map, creating a submission page, and incorporating design elements.
## Accomplishments that we're proud of
## What we learned
We learned so much about so many different aspects of coding while hacking this app. First, the majority of the people in our group had never used **Github** before, so even just setting up Github Desktop, coordinating pushes, and allowing permissions was a struggle. We feel we have mastery of Github after the project, whereas before it was brand new. Being remote, we also faced Xcode compatibility issues, to the point that one person in our group couldn't demo the app based on her Xcode version. So, we learned a lot about troubleshooting systems we weren't familiar with, and finding support forums and creative solutions.
In terms of code, we had rarely worked in **Swift**, and never worked in **Mapbox SDK**, so learning how to adapt to a new SDK and integrate it while not knowing everything about the errors appearing was a huge learning experience. This involved working with .netrc files and permissions, and gave us insight to the coding aspect as well as the computers networks aspect of the project.
We also learned how to adapt to an audience, going through many drafts of the UI to hit on one that we thought would appeal to college students.
Last, we learned that what we heard in opening ceremony, about the importance of passion for the code, is true. We all feel like we have personally experienced the feeling of being unsafe on campus. We feel like we understand how difficult it can be for women and minorities on campus to feel at ease, with the culture of sexual predation on women, and the administration's blind eye. We put those emotions into the app, and we found that our shared experience as a group made us feel really connected to the project. Because we invested so much, the other things that we learned sunk in deep.
## What's next for Viva: an iOS app to map dangerous areas on college campuses
* A stretch goal or next step would be to use the **AdaFruit Bluefruit** device to create wearable hardware, that when tapped records danger to the app. This would allow users to easily report danger with the hardware, without opening the app, and have the potential to open up other safety features of the app in the future.
* We conducted a survey of college students, and 95.65% of people who responded thought our app would be an effective way to keep themselves safe on campus. A lot of them additionally requested a way to connect with other survivors or other people who have felt unsafe on campus. One responder suggested we add **"ways to stay calm and remind you that nothing's your fault"**. So, another next step would be to add forums and messaging for users, to forward our goal of connecting survivors through the platform. | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created completely by its users - a program where anyone could rate how well these “hubs” were following COVID-19 safety protocol.
## What it does
Our app allows for users to search a “hub” using a Google Map API, and write a review by rating prompted questions on a scale of 1 to 5 regarding how well the location enforces public health guidelines. Future visitors can then see these reviews and add their own, contributing to a collective safety rating.
## How I built it
We collaborated using Github and Android Studio, and incorporated both a Google Maps API as well integrated Firebase API.
## Challenges I ran into
Our group unfortunately faced a number of unprecedented challenges, including losing a team member mid-hack due to an emergency situation, working with 3 different timezones, and additional technical difficulties. However, we pushed through and came up with a final product we are all very passionate about and proud of!
## Accomplishments that I'm proud of
We are proud of how well we collaborated through adversity, and having never met each other in person before. We were able to tackle a prevalent social issue and come up with a plausible solution that could help bring our communities together, worldwide, similar to how our diverse team was brought together through this opportunity.
## What I learned
Our team brought a wide range of different skill sets to the table, and we were able to learn lots from each other because of our various experiences. From a technical perspective, we improved on our Java and android development fluency. From a team perspective, we improved on our ability to compromise and adapt to unforeseen situations. For 3 of us, this was our first ever hackathon and we feel very lucky to have found such kind and patient teammates that we could learn a lot from. The amount of knowledge they shared in the past 24 hours is insane.
## What's next for SafeHubs
Our next steps for SafeHubs include personalizing user experience through creating profiles, and integrating it into our community. We want SafeHubs to be a new way of staying connected (virtually) to look out for each other and keep our neighbours safe during the pandemic. | ## Inspiration
We wanted to create an immersive virtual reality experience for connecting people and innovating on the many classic party games and gathering and wanted to bring a new twist to connecting with other people leveraging cutting-edge technologies like deep learning and VR.
## What it does
StoryBoxVR is an Intelligent party game optimized by Deep Learning where players enact a spontaneous drama based on an AI generated story-line in a VR environment with constant disruptions of random GIFs and sentiment changes. Secondary users view the VR stream from one main player via an iPhone app and have the ability to interact with their environment, spawning monsters or changing the mood.
## How I built it
Dialogue generated using fairseq, keywords detected using microsoft cognitive toolkit, Unity for VR
## Challenges I ran into
Live streaming Unity
## Accomplishments that I'm proud of
The idea , it's ability to be 'smart and the AI generated script
## What I learned
Connecting different modules is the key to success and requires more time in future.
## What's next for StoryBox | partial |
## Inspiration
Let's face it: Museums, parks, and exhibits need some work in this digital era. Why lean over to read a small plaque when you can get a summary and details by tagging exhibits with a portable device?
There is a solution for this of course: NFC tags are a fun modern technology, and they could be used to help people appreciate both modern and historic masterpieces. Also there's one on your chest right now!
## The Plan
Whenever a tour group, such as a student body, visits a museum, they can streamline their activities with our technology. When a member visits an exhibit, they can scan an NFC tag to get detailed information and receive a virtual collectible based on the artifact. The goal is to facilitate interaction amongst the museum patrons for collective appreciation of the culture. At any time, the members (or, as an option, group leaders only) will have access to a live slack feed of the interactions, keeping track of each other's whereabouts and learning.
## How it Works
When a user tags an exhibit with their device, the Android mobile app (built in Java) will send a request to the StdLib service (built in Node.js) that registers the action in our MongoDB database, and adds a public notification to the real-time feed on slack.
## The Hurdles and the Outcome
Our entire team was green to every technology we used, but our extensive experience and relentless dedication let us persevere. Along the way, we gained experience with deployment oriented web service development, and will put it towards our numerous future projects. Due to our work, we believe this technology could be a substantial improvement to the museum industry.
## Extensions
Our product can be easily tailored for ecotourism, business conferences, and even larger scale explorations (such as cities and campus). In addition, we are building extensions for geotags, collectibles, and information trading. | ## Inspiration
We are very interested in the intersection of the financial sector and engineering, and wanted to find a way to speed up computation time in relation to option pricing through simulations.
## What it does
Bellcrve is a distributed computing network that simulates monte carlo methods on financial instruments to perform option pricing. Using Wolfram as its power source, we are able to converge very fast. The idea was it showcase how much faster these computations become when we distribute across a network of 10 mchines, with up to 10,000 simulations running.
## How we built it
We spun up 10 Virtual Machines on DigitalOcean, setup 8 as the worker nodes, 1 node for the Master, and 1 for the Scheduler to distribute the simulations across the nodes as they became free. We implemented our model using a monte carlo simulation that takes advantage of the Geometric Brownian Motion and Black Scholes Model. GBM is responsible for modeling the assets price path over the course of the simulation. We start the simulation at the stocks current price and observe how it changes as the number of steps increases. The Black Scholes Model is responsible for pricing the stocks theoretical price based on the volatility and time decay. We observed how our simulation converges between the GBM and Black Scholes model as the number of steps and iterations increases, effectively giving us a low error rate.
We developed it using Wolfram, Python, Flask, Dask, React, and Next.JS, D3.JS. Wolfram and Python are responsible for most of the Monte Carlo simulations as well as the backend API and websocket. We used Dask to help manage our distributed network connecting us to our VM's in Digital Ocean. And we used React, and Next.JS to build out the web app and visualized all charts in real-time with D3.JS. Wolfram was crucial to our application being able to converge faster proving that distributing the simulations will help save resources, and speed up simulation times. We packaged up the math behind the Monte Carlo simulation and deployed it as Pypi for others to use.
## Challenges we ran into
We had many challenges along the way, across all fronts. First, we had issues with the websocket trying to connect to our client side, and found out it was due to WSS issues. We then ran into some CORS errors that we were able to sort out. Our formulas kept evolving as we made progress on our application, and we had to account for this change. We realized we needed a different metric from the model and needed to shift in that direction. Setting up the cluster of machines was challenging and took some time to dig into.
## Accomplishments that we're proud of
We are proud to say we pushed a completed application, and deployed it to Vercel. Our application allows users to simulate different stocks and price their options in real time and observe how it converges for different number of simulations.
## What we learned
We learned a lot about websockets, creating real-time visualizations, and having our project depend on the math. This was our first time using Wolfram for our project, and we really enjoyed working with it. We have used similar languages like matlab and python, but we found Wolfram to help us speed up our computations signficantly.
## What's next for Lambda Labs
We hope to continue to improve our application, and bring this to different areas in the financial sector, not just options pricing. | ## Inspiration
We wanted to find a space for collaborating in music via recording on our smartphones and computers. We also wanted this to be a very casual activity and emphasized the collaboration aspect on sharing through Facebook. Since Facebook doesn't have much of a presence in the world of music (like Spotify and SoundCloud), we thought it would be an interesting idea to promote Facebook's API through this hack.
## What it does
Record your singing and/or music and share it for others to work on top of. Share it to Facebook for the world to see!
## How we built it
We used Facebook's Parse (as well as their sharing/login API), Microsoft's Azure hosting, Swift 2.0, and Node.js. iOS users can upload their recordings to Parse, contributing to a mobile newsfeed, and allowing web users to collaborate with them (and vice versa).
## Challenges we ran into
Parsing .m4a files into mp3 files was a seriously painful and lonely journey (Apple prefers .m4a while the rest of the world likes .mp3). Connecting the backend of both our web and mobile apps was also challenging as we had to configure our Parse classes to be ambiguous enough to host users on both an iOS device and a computer. Also, it was difficult to learn Apple's AVFoundation framework to configure and maintain audio files.
## Accomplishments that we're proud of
Our application works on both web and mobile. It was a miracle. We found really good social applications for our app and had an amazing time making it.
## What we learned
We learned further intricacies of iOS development and Javascript, the pains of trying to maintain a simple UI/UX, and how to use Parse as both a web and mobile backend.
## What's next for Byte
We plan to update the app to provide cool audio effects and further layering tricks in the form of studio editing in the next release! We'll also try to provide further compatibility for files outside of just m4a and mp3. | winning |
## Inspiration
While our team might have come from different corners of the country, with various experience in industry,
and a fiery desire to debate whether tabs or spaces are superior, we all faced similar discomforts in our jobs: insensitivity.
Our time in college has shown us that despite the fact people's diverse backgrounds, everyone can achieve greatness.
Nevertheless, workplace calls and water-cooler conversations are plagued with "microaggressions." A microaggression is a subtle indignity or offensive comment that a person communicates to a group. These subtle, yet hurtful comments lead to marginalization in the workplace, which, as studies have shown, can lead to anxiety and depression. Our team's mission was to tackle the unspoken fight on diversity and inclusion in the workplace.
Our inspiration came from this idea of impartial moderation: why is the marginalized employee's responsibility to take the burden
of calling someone out? Pointing out these microaggressions can lead to the reinforcement of stereotypes, and thus, create lose-lose
situations. We believe that if we can shift the responsibility, we can help create a more inclusive work environment, give equal footing for interviewees, and tackle
marginalization in the workplace from the water-cooler up.
## What it does
### EquiBox:
EquiBox is an IoT conference room companion, a speaker, and microphone that comes alive when meetings take place. It monitors different meeting members' sentiment levels by transcribing sound and running AI to detect for insults or non-inclusive behavior. If an insult is detected, EquiBox comes alive with a beep and a warning about micro-aggressions to impartially moderate an inclusive meeting environment. EquiBox sends live data to EquiTrack for further analysis.
### EquiTalk:
EquiTalk is our custom integration with Twilio (a voice platform used for conference calls) to listen to multi-person phone calls to monitor language, transcribe the live conversation, and flag certain phrases that might be insulting. EquiTalk sends live data to EquiTrack for analysis.
### EquiTrack:
EquiTrack is an enterprise analytics platform designed to allow HR departments to leverage the data created by EquiTalk and EquiBox to improve the overall work culture. EquiTrack provides real-time analysis of ongoing conference calls. The administrator can see not only the amount of micro-aggression that occur throughout the meeting but also the direct sentence that triggered the alert. The audio recordings of the conference calls are recorded as well, so administrators can playback the call to resolve discrepancies.
## How we built it
The LevelSet backend consisted of several independent services. EquiTalk uses a Twilio integration to send call data and metadata to our audio server. Similarly, EquiBox uses Google's VoiceKit, along with Houndify's Speech to Text API, to parse the raw audio format. From there, the transcription of the meeting goes to our micro-aggression classifier (hosted on Google Cloud), which combines a BERT Transformer with an SVC to achieve 90% accuracy on our micro-aggression test set. The classified data then travels to the EquiTalk backend (hosted on Microsoft Azure), which stores the conversation and classification data to populate the dashboard.
## Challenges we ran into
One of the biggest challenges that we ran into was creating the training set for the micro classifier. While there were plenty of data sets that including aggressive behavior in general, their examples lacked the subtlety that our model needed to learn. Our solution to this was to crowdsource and augment the set of the microaggressions. We sent a survey out to Stanford students on campus and compiled an extensive list of microaggressions, which allowed our classifier to achieve the accuracy that it did.
## Accomplishments that we're proud of
We're very proud of the accuracy we were able to achieve with our classifier. By using the BERT transformer, our model was able to classify micro-aggressions using only the handful of examples that we collected. While most DNN models required thousands of samples to achieve high accuracy, our micro-aggression dataset consisted of less than 100 possible micro-aggressions.
Additionally, we're proud of our ability to integrate all of the platforms and systems that were required to support the LevelSet suite. Coordinating multiple deployments and connecting several different APIs was definitely a challenge, and we're proud of the outcome.
## What we learned
* By definition, micro-aggressions are almost intangible social nuances picked up by humans. With minimal training data, it is tough to refine our model for classifying these micro-aggressions.
* Audio processing at scale can lead to several complications. Each of the services that use audio had different format specifications, and due to the decentralized nature of our backend infrastructure, merely sending the data over from service to service required additional effort as well. Ultimately, we settled on trying to handle the audio as upstream as we possibly could, thus eliminating the complication from the rest of the pipeline.
* The integration of several independent systems can lead to unexpected bugs. Because of the dependencies, it was hard to unit test the services ahead of time. Since the only way to make sure that everything was working was with an end-to-end test, a lot of bugs didn't arise until the very end of the hackathon.
## What's next for LevelSuite
We will continue to refine our micro-classifier to use tone classification as an input. Additionally, we will integrate the EquiTalk platform into more offline channels like Slack and email. With a longer horizon, we aim to improve equality in the workplace in all stages of employment, from the interview to the exit interview. We want to expand from conference calls to all workplace communication, and we want to create new strategies to inform and disincentivize exclusive behavior. We wish to LevelSet to level the playing the field in the workplace, and we believe that these next steps will help us achieve that. | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | ## Inspiration/What it Does
Kiva is a nonprofit organization that allows anyone to provide micro loans. We wanted to help loaners quantify the impact of their loans in the community of which they are loaning to.
## How I built it
Kiva Impact uses data points from World Bank and United Nations to determine the power of a loan, the importance of the loan (in terms of impact to GNI), and social implications that surround the loan.
## What's next for Kiva Impact
We hope to improve our impact calculator by creating models using historical data. By using machine learning, our algorithm will be able to determine why an impact score was assigned. We also want to improve our data visualization by using more D3 models. In the future, we can use a prediction method to estimate the potential impact of an unfunded project. We can then tell loaners where their money may have the greatest impact before they even issue the loan. | partial |
# 🍅 NutriSnap
### NutriSnap is an intuitive nutrition tracker that seamlessly integrates into your daily life.
## Inspiration
Every time you go to a restaurant, its highly likely that you see someone taking a picture of their food before they eat it. We wanted to create a seamless way for people to keep track of their nutritional intake, minimizing the obstacles required to be aware of the food you consume. Building on the idea that people already often take pictures of the food they eat, we decided to utilize something as simple as one's camera app to keep track of their daily nutritional intake.
## What it does
NutriSnap analyzes pictures of food to detect its nutritional value. After simply scanning a picture of food, it summarizes all its nutritional information and displays it to the user, while also adding it to a log of all consumed food so people have more insight on all the food they consume. NutriSnap has two fundamental features:
* scan UPC codes on purchased items and fetch its nutritional information
* detect food from an image using a public ML food-classification API and estimate its nutritional information
This information is summarized and displayed to the user in a clean and concise manner, taking their recommended daily intake values into account. Furthermore, it is added to a log of all consumed food items so the user can always access a history of their nutritional intake.
## How we built it
The app uses React Native for its frontend and a Python Django API for its backend. If the app detects a UPC code in the photo, it retrieves nutritional information from a [UPC food nutrition API](https://world.openfoodfacts.org) and summarizes its data in a clean and concise manner. If the app fails to detect a UPC code in the photo, it forwards the photo to its Django backend, which proceeds to classify all the food in the image using another [open API](https://www.logmeal.es). All collected nutritional data is forwarded to the [OpenAI API](https://platform.openai.com/docs/guides/text-generation/json-mode) to summarize nutritional information of the food item, and to provide the item with a nutrition rating betwween 1 and 10. This data is displayed to the user, and also added to their log of consumed food.
## What's next for NutriSnap
As a standalone app, NutriSnap is still pretty inconvenient to integrate into your daily life. One amazing update would be to make the API more independent of the frontend, allowing people to sync their Google Photos library so NutriSnap automatically detects and summarizes all consumed food without the need for any manual user input. | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | # ENVISIONATE: HEAR 2 SEE
Believe it or not fellow Hackers, people go outside! And when they go outside, they can get hurt - especially if they have a visual impairment.
Some insight exists on the challenges that people with visual impairments face when it comes to accidents, though the research is only preliminary. A 2011 survey by Manduchi and Kurniawan at the University of Santa Cruz found that while visually impaired people do like to go out, a substantial amount of respondents reported that accidents required medical treatment AND reduced their confidence as independent travellers. Moreover, only 9% use some kind of technical mobility aid. This means that wearable tech for these latter people represents an untapped market with potential for growth!
With this product, we're bringing tech applications to the people who need it most. Easy-to-use hardware combined with our reliable object-detecting mechanism makes this a cutting-edge device for improving blind people's lives!
## Keywords:
* Wearable Tech
* Arduino
* Assistive Devices
* Visual Impairment | winning |
## My Story
I love the outdoors! I wanted to share that love with others and help people discover the gorgeous trails that exist in their own neighbourhoods. Nature is beautiful and we should appreciate Kingston for the incredible city it really is. This is my first ever hackathon, and I wanted to build a project that would be useful for as many people as possible.
## What it does
The "Your Path" web app allows users to discover the trail that's meant for them. It's incredibly user-friendly and beautifully designed. Users can search for a trail that has the amenities they're looking for, find a trail closest to them or even take a look at a random trail!
## How I built it
"Your Path" is a web app built with HTML, CSS, and JavaScript. By far, the most important API in the project is the one provided by OpenDataKingston, an incredible initiative created by the City of Kingston. They offer an awesome API that allowed me to find all the trails within the city and so I could help users find the exact trail they're looking for. I want to ensure that my users will never have to worry about the trails they like being inaccessible. That's why I've made it so the only trails that show up are the ones that are accessible. I also made use of Mapbox and Leaflet.js. That API and library combo allowed me to add all the pins and trails to the map. The City of Kingston API used GeoJSON data for the path which I integrated with Leaflet.js. It was a lot of fun being able to work with real data!
## What I learned
This project taught me all about the OpenDataKingston API, and working with mapping data. I've never used Leaflet.js or Mapbox before so that was fun to learn too. This project really got me interested in GIS (Geographic Information System) mapping software, and the use of GeoJSON.
## What's next for Your Path
With more time, I'd love to add a fully-fledged accounts system, allowing users to save their favourite lists, and create/share rankings.
## Domain.com Challenge
You can find the project at <https://www.yourpath.online>!
## Discord Info
nicowil#6149 and team channel 61 | ## Inspiration
As students, we constantly are sitting in lectures and club meetings, struggling to juggle keeping up with a quick paced conversation and recording notes for future reference. Through our product, we eliminate half of the problem.
## What it does
Note-ify records and then transcribes all of your lectures and meetings, and then allows you to highlight key words and phrases and download only the most important information into a text file.
## How we built it
We used a React, Node, Express stack to build our website. We utilized rev.ai's accurate speech-to-text api to fuel the main goal of our project.
## Challenges we ran into
Learning React is difficult in a short period of time, and interfacing the various components that build up this project proved to be a great challenge.
## Accomplishments that we're proud of
We have a functioning website that will transcribe an uploaded video, and allow you to highlight key words and phrases and download them. We got an end to end product implemented within 24 hours.
## What we learned
Coding continuously is a hard task, and that ensuring the existence of a clear vision and knowledge of how to get there is vital to operating smoothly as a software team.
## What's next for note-ify
Future features that we have in mind include adding a database to allow you to store previous transcripts, live rendition of speech-to-text generation, and more annotative and data analysis options for the user. | ## Inspiration
When you think of the word “nostalgia”, what’s the first thing you think of? Maybe it’s the first time you tried ice cream, or the last concert you’ve been to. It could even be the first time you’ve left the country. Although these seem vastly different and constitute unique experiences, all of these events tie to one key component: memory. Can you imagine losing access to not only your memory, but your experiences and personal history? Currently, more than 55 million people world-wide suffer from dementia with 10 million new cases every year. Many therapies have been devised to combat dementia, such as reminiscence therapy, which uses various stimuli to help patients recall distant memories. Inspired by this, we created Remi, a tool to help dementia victims remember what’s important to them.
## What it does
We give users the option to sign up as a dementia patient, or as an individual signing up on behalf of a patient. Contributors to a patient's profile (friends and family) can then add to the profile descriptions of any memory they have relating to the patient. After this, we use Cohere API to piece together a personalized narration of the memory; this helps patients remember all of their most heartening past memories. We then use an old-fashioned styled answering machine, created with Arduino, and with the click of a button patients can listen to their past memories read to them by a loved one.
## How we built it
Our back-end was created using Flask, where we utilized Kintone API to store and retrieve data from our Kintone database. It also processes the prompts from the front-end using Cohere API in order to generate our personalized memory message; as well, it takes in button inputs from an Arduino UNO to play the text-to-speech. Lastly, our front-end was built using ReactJS and TailwindCSS for seamless user interaction.
## Challenges we ran into
As it was our first time setting up a Flask back-end and using Kintone, we ran into a couple of issues. With our back-end, we had trouble setting up our endpoints to successfully POST and GET data from our database. We also ran into troubles setting up the API token with Kintone to integrate it into our back-end. There were also several hardware limitations with the Arduino UNO, which was probably not the most suitable board for this project. The inability to receive wire-less data or handle large audio files were drawbacks, but we found workarounds that would allow us to demo properly, such-as using USB communication.
## Accomplishments that we're proud of
* Utilizing frontend, backend, hardware, and machine learning libraries in our project
* Delegating tasks and working as a team to put our project together
* Learning a lot of new tech and going to many workshops!
## What we learned
We learned a lot about setting up databases and web frameworks!
## What's next for Remi
Since there were many drawbacks with the hardware, future developments in the project would most likely switch to a board with higher bandwidth and wifi capabilities, such as a Raspberry Pi. We also wanted to add in a feature where contributors to a patient's memory library could record their voices, and our Text-to-Speech AI would mimic them when narrating a story. Reminiscence therapy involves more than narrating memories, so we wanted to add ore sensory features, such as visuals, to invoke memories and nostalgia for the patient as effectively as possible. For example, contributors could submit a picture of their memories along with their description, which could be displayed on an LCD attached to the answering machine design. On the business-end, we hope to collaborate with health professionals to see how we can further help dementia victims. | losing |
## Inspiration
We wanted to get better at sports, but we don't have that much time to perfect our moves.
## What it does
Compares your athletic abilities to other users by building skeletons of both people and showing you where you can improve.
Uses ML to compare your form to a professional's form.
# Tells you improvements.
## How I built it
We used OpenPose to train a dataset we found online and added our own members to train for certain skills. Backend was made in python which takes the skeletons and compares them to our database of trained models to see how you preform. The skeleton for both videos are combined side by side in a video and sent to our react frontend.
## Challenges I ran into
Having multiple libraries out of date and having to compare skeletons.
## Accomplishments that I'm proud of
## What I learned
## What's next for trainYou | ## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0> | ## Inspiration
In an era dominated by information overload, the battle against misinformation is more critical than ever. Misleading articles permeate our digital landscape, driving political polarization and undermining informed discourse. To combat this, we believe in the power of critical thinking. However, the sheer volume of information we encounter daily makes it challenging to remain vigilant against logical fallacies.
## What it does
Enter Biasly, your ally in the fight against flawed arguments. Harnessing the capabilities of Cohere's LLMs, Biasly is a revolutionary tool designed to automatically detect over 20 logical fallacies in writing. With just a click, you can unveil poorly constructed arguments and gain valuable insights into their flaws. But we don't stop there - Biasly provides clear explanations for each identified fallacy, empowering users to understand and counter misinformation effectively.
Detecting 24 logical fallacies:
* Strawman
* False Cause
* Slippery Slope
* Ad Hominem
* Special Pleading
* Loaded Question
* The Gambler Fallacy
* Bandwagon
* Black or White
* Begging the Question
* Appeal to Authority
* Composition/Division
* Appeal to Nature
* Anecdotal
* Appeal to Emotion
* The Fallacy Fallacy
* Tu Quoque
* Personal Incredulity
* Burden of Proof
* Ambiguity
* No True Scotsman
* Genetic
* The Texas Sharpshooter
* Middle Ground
## How we built it
Biasly leverages advanced AI capabilities in a two-step process. First, it employs Cohere Classify, a powerful tool that scans texts to identify logical fallacies. This step serves as the backbone of Biasly's functionality, allowing it to pinpoint flawed arguments accurately. Once a fallacy is detected, Biasly seamlessly moves to the second step, utilizing Cohere Generate. This feature provides clear and concise explanations for each identified fallacy.
## Challenges we ran into
1. Getting good examples for the Cohere Classify API
2. Building intuitive and interactive UI
## Accomplishments that we're proud of
1. Built a reasonably accurate classifier for 24 different logical fallacies
2. Expanded the classifier with generative technologies to provide more guidance to user
3. Cool UI
## What we learned
1. Understanding LLMs and its potential use case
2. Knowing Cohere API inside-out
3. Learning tailwind CSS for the first time and loved it!
## What's next for Biasly - Logical Fallacy Checker
1. Chrome extension to streamline user experience
2. Multi-sentences classification
3. Custom model to reduce REST payload to the Cohere API
4. Minor UI improvement like loading bar and animation | winning |
## Inspiration
The idea for SlideForge came from the struggles researchers face when trying to convert complex academic papers into presentations. Many academics spend countless hours preparing slides for conferences, lectures, or public outreach, often sacrificing valuable time they could be using for research. We wanted to create a tool that could automate this process while ensuring that presentations remain professional, audience-friendly, and adaptable to different contexts.
## What it does
SlideForge takes LaTeX-formatted academic papers and automatically converts them into well-structured presentation slides. It extracts key content such as equations, figures, and citations, then organizes them into a customizable slide format. Users can easily adjust the presentation based on the intended audience—whether it’s for peers, students, or the general public. The platform provides customizable templates, integrates citations, and minimizes the time spent on manual slide creation.
## How we built it
We built SlideForge using a combination of Python for the backend and JavaScript with React for the frontend. The backend handles the LaTeX parsing, converting key elements into slides using Flask to manage the process. We also integrated JSON files to store and organize the structure of presentations, formulas, and images. On the frontend, React is used to create an interactive user interface where users can upload their LaTeX files, adjust presentation settings, and preview the output.
## Challenges we ran into
One of the biggest challenges we faced was ensuring that the LaTeX parser could accurately extract and format complex equations and figures into slide-friendly content. Maintaining academic rigor while making the content accessible to different audiences also required a lot of trial and error with the customizable templates. Finally, integrating the backend and frontend in a way that made the process seamless and efficient posed technical hurdles that required collaboration and creative problem-solving.
## Accomplishments that we're proud of
We’re proud of the fact that SlideForge significantly reduces the time required for researchers to create professional presentations. What used to take hours can now be done in minutes. We’re also proud of the adaptability of our templates, which allow users to target different audiences without needing to redesign their slides from scratch. Additionally, the successful integration of LaTeX parsing and slide generation is a technical achievement we’re particularly proud of.
## What we learned
Throughout this project, we learned a lot about LaTeX and how to parse and handle its complex structures programmatically. We also gained a deeper understanding of user experience design, ensuring that our platform was both intuitive and powerful. From a technical standpoint, integrating the backend and frontend and ensuring smooth communication between the two taught us valuable lessons in full-stack development.
## What's next for SlideForge
Next, we plan to expand SlideForge’s functionality by adding more customization options for users, such as advanced styling and animation features. We’re also looking into integrating cloud storage solutions so users can save and edit their presentations across devices. Additionally, we hope to support more document formats beyond LaTeX, making SlideForge a universal tool for academics and professionals alike. | ## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your writing.
## What it does
We use an LLM to generate sample phrases, sentences, or character strings that target letters you're struggling with. You can input the writing as a photo or directly on the webpage. We then use OCR to parse, score, and give you feedback towards the ultimate goal of character mastery!
## How we built it
We used a simple front end utilizing flexbox layouts, the p5.js library for canvas writing, and simple javascript for logic and UI updates. On the backend, we hosted and developed an API with Flask, allowing us to receive responses from API calls to state-of-the-art OCR, and the newest Chat GPT model. We can also manage user scores with Pythonic logic-based sequence alignment algorithms.
## Challenges we ran into
We really struggled with our concept, tweaking it and revising it until the last minute! However, we believe this hard work really paid off in the elegance and clarity of our web app, UI, and overall concept.
..also sleep 🥲
## Accomplishments that we're proud of
We're really proud of our text recognition and matching. These intelligent systems were not easy to use or customize! We also think we found a creative use for the latest chat-GPT model to flex its utility in its phrase generation for targeted learning. Most importantly though, we are immensely proud of our teamwork, and how everyone contributed pieces to the idea and to the final project.
## What we learned
3 of us have never been to a hackathon before!
3 of us never used Flask before!
All of us have never worked together before!
From working with an entirely new team to utilizing specific frameworks, we learned A TON.... and also, just how much caffeine is too much (hint: NEVER).
## What's Next for Handwriting Teacher
Handwriting Teacher was originally meant to teach Russian cursive, a much more difficult writing system. (If you don't believe us, look at some pictures online) Taking a smart and simple pipeline like this and updating the backend intelligence allows our app to incorporate cursive, other languages, and stylistic aesthetics. Further, we would be thrilled to implement a user authentication system and a database, allowing people to save their work, gamify their learning a little more, and feel a more extended sense of progress. | ## Inspiration
While attending Hack the 6ix, our team had a chance to speak to Advait from the Warp team. We got to learn about terminals and how he got involved with Warp, as well as his interest in developing something completely new for the 21st century. Through this interaction, my team decided we wanted to make an AI-powered developer tool as well, which gave us the idea for Code Cure!
## What it does
Code Cure can call your python file and run it for you. Once it runs, you will see your output as usual in your terminal, but if you experience any errors, our extension runs and gives some suggestions in a pop-up as to how you may fix it.
## How we built it
We made use of Azure's OpenAI service to power our AI code fixing suggestions and used javascript to program the rest of the logic behind our VS code extension.
## Accomplishments that we're proud of
We were able to develop an awesome AI-powered tool that can help users fix errors in their python code. We believe this project will serve as a gateway for more people to learn about programming, as it provides an easier way for people to find solutions to their errors.
## What's next for Code Cure
As of now, we are only able to send our output through a popup on the user's screen. In the future, we would like to implement a stylized tab where we are able to show the user different suggestions using the most powerful AI models available to us. | winning |
## Inspiration
My Grandmother is from Puerto Rico, and she only speaks Spanish. She recently tried applying for passport, but she could not fill out the document because she does not understand English. After doing some research, there are about 45 million people in America alone with a similar issue. And in the world, that number is 6.5 billion. Especially considering America is the most sought out country to live in in the entire world. But now, there is a solution.
## What it does
The cross-platform app allows one to upload important documents converted to one's native language. After the user responds, either manually or vocally in their chosen language, and the document converts back to English, both the questions and answers - then is ready for download and exporting.
## How we built it
Front end implementing flutter, dart.
Back end using Spring with Java, Google Cloud API, Heroku, PDF Box.
## Challenges we ran into
Initially, we wanted to be able to upload and documents, have the software scan the documents, interpret it and convert it to any selected language. However, for our MVP, we were able to successfully implement 4 languages, Spanish, English, Dutch, German.
Another challenge was finding a way to change pdfs in a reliable way.
We wanted to do one form really well as opposed to multiple forms that were jerky, so the Visa Application was our only form.
## Accomplishments that we're proud of
Creating a clean looking app that is simple yet extremely effective. The language updates according to what language the user has set on their settings, so it already has the potential to facilitate people being able to apply for visas, jobs, passports, and fill out tax documents.
## What we learned
First, we learned that making a top-notch UI is rather difficult. It is easy to implement a clean looking app, but much more challenging to build next-level animated designs.
Aside from that, we learned that we can make a significant impact on the community in a very short amount of time.
## What's next for Phillinda.space | ## Inspiration
With elections right around the corner, many young adults are voting for the first time, and may not be equipped with knowledge of the law and current domestic events. We believe that this is a major problem with our nation, and we seek to use open source government data to provide day to day citizens with access to knowledge on legislative activities and current affairs in our nation.
## What it does
OpenLegislation aims to bridge the knowledge gap by providing easy access to legislative information. By leveraging open-source government data, we empower citizens to make informed decisions about the issues that matter most to them. This approach not only enhances civic engagement but also promotes a more educated and participatory democracy Our platform allows users to input an issue they are interested in, and then uses cosine analysis to fetch the most relevant bills currently in Congress related to that issue.
## How we built it
We built this application with a tech stack of MongoDB, ExpressJS, ReactJS, and OpenAI. DataBricks' Llama Index was used to get embeddings for the title of our bill. We used a Vector Search using Atlas's Vector Search and Mongoose for accurate semantic results when searching for a bill. Additionally, Cloudflare's AI Gateway was used to track calls to GPT-4o for insightful analysis of each bill.
## Challenges we ran into
At first, we tried to use OpenAI's embeddings for each bill's title. However, this brought a lot of issues for our scraper as while the embeddings were really good, they took up a lot of storage and were heavily rate limited. This was not feasible at all. To solve this challenge, we pivoted to a smaller model that uses a pre trained transformer to provide embeddings processed locally instead of through an API call. Although the semantic search was slightly worse, we were able to get satisfactory results for our MVP and be able to expand on different, higher-quality models in the future.
## Accomplishments that we're proud of
We are proud that we have used open source software technology and data to empower the people with transparency and knowledge of what is going on in our government and our nation. We have used the most advanced technology that Cloudflare and Databricks provides and leveraged it for the good of the people. On top of that, we are proud of our technical acheivement of our semantic search, giving the people the bills they want to see.
## What we learned
During the development of this project, we learned more of how vector embeddings work and are used to provide the best search results. We learned more of Cloudflare and OpenAI's tools in this development and will definitely be using them on future projects. Most importantly, we learned the value of open source data and technology and the impact it can have on our society.
## What's next for OpenLegislation
For future progress of OpenLegislation, we plan to expand to local states! Constituents can know directly what is going on in their state on top of their country with this addition and actually be able to receive updates on what officials they elected are actually proposing. In addition, we would expand our technology by using more advanced embeddings for more tailored searches. Finally, we would implore more data anlysis methods with help from Cloudflare and DataBricks' Open-Source technologies to help make this important data more available and transparant for the good of society. | ## Inspiration
According to a 2015 study in the American Journal of Infection Control, people touch their faces more than 20 times an hour on average. More concerningly, about 44% of the time involves contact with mucous membranes (e.g. eyes, nose, mouth).
With the onset of the COVID-19 pandemic ravaging our population (with more than 300 million current cases according to the WHO), it's vital that we take preventative steps wherever possible to curb the spread of the virus. Health care professionals are urging us to refrain from touching these mucous membranes of ours as these parts of our face essentially act as pathways to the throat and lungs.
## What it does
Our multi-platform application (a python application, and a hardware wearable) acts to make users aware of the frequency they are touching their faces in order for them to consciously avoid doing so in the future. The web app and python script work by detecting whenever the user's hands reach the vicinity of the user's face and tallies the total number of touches over a span of time. It presents the user with their rate of face touches, images of them touching their faces, and compares their rate with a **global average**!
## How we built it
The base of the application (the hands tracking) was built using OpenCV and tkinter to create an intuitive interface for users. The database integration used CockroachDB to persist user login records and their face touching counts. The website was developed in React to showcase our products. The wearable schematic was written up using Fritzing and the code developed on Arduino IDE. By means of a tilt switch, the onboard microcontroller can detect when a user's hand is in an upright position, which typically only occurs when the hand is reaching up to touch the face. The device alerts the wearer via the buzzing of a vibratory motor/buzzer and the flashing of an LED. The emotion detection analysis component was built using the Google Cloud Vision API.
## Challenges we ran into
After deciding to use opencv and deep vision to determine with live footage if a user was touching their face, we came to the unfortunate conclusion that there isn't a lot of high quality trained algorithms for detecting hands, given the variability of what a hand looks like (open, closed, pointed, etc.).
In addition to this, the CockroachDB documentation was out of date/inconsistent which caused the actual implementation to differ from the documentation examples and a lot of debugging.
## Accomplishments that we're proud of
Despite developing on three different OSes we managed to get our application to work on every platform. We are also proud of the multifaceted nature of our product which covers a variety of use cases. Despite being two projects we still managed to finish on time.
To work around the original idea of detecting overlap between hands detected and faces, we opted to detect for eyes visible and determine whether an eye was covered due to hand contact.
## What we learned
We learned how to use CockroachDB and how it differs from other DBMSes we have used in the past, such as MongoDB and MySQL.
We learned about deep vision, how to utilize opencv with python to detect certain elements from a live web camera, and how intricate the process for generating Haar-cascade models are.
## What's next for Hands Off
Our next steps would be to increase the accuracy of Hands Off to account for specific edge cases (ex. touching hair/glasses/etc.) to ensure false touches aren't reported. As well, to make the application more accessible to users, we would want to port the application to a web app so that it is easily accessible to everyone. Our use of CockroachDB will help with scaling in the future. With our newfound familliarity with opencv, we would like to train our own models to have a more precise and accurate deep vision algorithm that is much better suited to our project's goals. | winning |
## Inspiration
Shashank Ojha, Andreas Joannou, Abdellah Ghassel, Cameron Smith
#

Clarity is an interactive smart glass that uses a convolutional neural network, to notify the user of the emotions of those in front of them. This wearable gadget has other smart glass abilities such as the weather and time, viewing daily reminders and weekly schedules, to ensure that users get the best well-rounded experience.
## Problem:
As mental health raises barriers inhibiting people's social skills, innovative technologies must accommodate everyone. Studies have found that individuals with developmental disorders such as Autism and Asperger’s Syndrome have trouble recognizing emotions, thus hindering social experiences. For these reasons, we would like to introduce Clarity. Clarity creates a sleek augmented reality experience that allows the user to detect the emotion of individuals in proximity. In addition, Clarity is integrated with unique and powerful features of smart glasses including weather and viewing daily routines and schedules. With further funding and development, the glasses can incorporate more inclusive features straight from your fingertips and to your eyes.



## Mission Statement:
At Clarity, we are determined to make everyone’s lives easier, specifically to help facilitate social interactions for individuals with developmental disorders. Everyone knows someone impacted by mental health or cognitive disabilities and how meaningful those precious interactions are. Clarity wants to leap forward to make those interactions more memorable, so they can be cherished for a lifetime.


We are first-time Makeathon participants who are determined to learn what it takes to make this project come to life and to impact as many lives as possible. Throughout this Makeathon, we have challenged ourselves to deliver a well-polished product that, with the purpose of doing social good. We are second-year students from Queen's University who are very passionate about designing innovative solutions to better the lives of everyone. We share a mindset to give any task our all and obtain the best results. We have a diverse skillset and throughout the hackathon, we utilized everyone's strengths to work efficiently. This has been a great learning experience for our first makeathon, and even though we have some respective experiences, this was a new journey that proved to be intellectually stimulating for all of us.
## About:
### Market Scope:

Although the main purpose of this device is to help individuals with mental disorders, the applications of Clarity are limitless. Other integral market audiences to our device include:
• Educational Institutions can use Clarity to help train children to learn about emotions and feelings at a young age. Through exposure to such a powerful technology, students can be taught fundamental skills such as sharing, and truly caring by putting themselves in someone else's shoes, or lenses in this case.
• The interview process for social workers can benefit from our device to create a dynamic and thorough experience to determine the ideal person for a task. It can also be used by social workers and emotional intelligence researchers to have better studies and results.
• With further development, this device can be used as a quick tool for psychiatrists to analyze and understand their patients at a deeper level. By assessing individuals in need of help at a faster level, more lives can be saved and improved.
### Whats In It For You:

The first stakeholder to benefit from Clarity is our users. This product provides accessibility right to the eye for almost 75 million users (number of individuals in the world with developmental disorders). The emotion detection system is accessible at a user's disposal and makes it easy to recognize anyone's emotions. Whether one watching a Netflix show or having a live casual conversation, Clarity has got you covered.
Next, Qualcomm could have a significant partnership in the forthcoming of Clarity, as they would be an excellent distributor and partner. With professional machining and Qualcomm's Snapdragon processor, the model is guaranteed to have high performance in a small package.
Due to the various applications mentioned of this product, this product has exponential growth potential in the educational, research, and counselling industry, thus being able to offer significant potential in profit/possibilities for investors and researchers.
## Technological Specifications
## Hardware:
At first, the body of the device was a simple prism with an angled triangle to reflect the light at 90° from the user. The initial intention was to glue the glass reflector to the outer edge of the triangle to complete the 180° reflection. This plan was then scrapped in favour of a more robust mounting system, including a frontal clip for the reflector and a modular cage for the LCD screen. After feeling confident in the primary design, a CAD prototype was printed via a 3D printer. During the construction of the initial prototype, a number of challenges surfaced including dealing with printer errors, component measurement, and manufacturing mistakes. One problem with the prototype was the lack of adhesion to the printing bed. This resulted in raised corners which negatively affected component cooperation. This issue was overcome by introducing a ring of material around the main body. Component measurements and manufacturing mistakes further led to improper fitting between pieces. This was ultimately solved by simplifying the initial design, which had fewer points of failure. The evolution of the CAD files can be seen below.

The material chosen for the prototypes was PLA plastic for its strength to weight ratio and its low price. This material is very lightweight and strong, allowing for a more comfortable experience for the user. Furthermore, inexpensive plastic allows for inexpensive manufacturing.
Clarity runs on a Raspberry Pi Model 4b. The RPi communicates with the OLED screen using the I2C protocol. It additionally powers and communicates with the camera module and outputs a signal to a button to control the glasses. The RPi handles all the image processing, to prepare the image for emotion recognition and create images to be output to the OLED screen.
### Optics:
Clarity uses two reflections to project the image from the screen to the eye of the wearer. The process can be seen in the figure below. First, the light from the LCD screen bounces off the mirror which has a normal line oriented at 45° relative to the viewer. Due to the law of reflection, which states that the angle of incidence is equal to the angle of reflection relative to the normal line, the light rays first make a 90° turn. This results in a horizontal flip in the projected image. Then, similarly, this ray is reflected another 90° against a transparent piece of polycarbonate plexiglass with an anti-reflective coating. This flips the image horizontally once again, resulting in a correctly oriented image. The total length that the light waves must travel should be equivalent to the straight-line distance required for an image to be discernible. This minimum distance is roughly 25 cm for the average person. This led to shifting the screen back within the shell to create a clearer image in the final product.

## Software:

The emotion detection capabilities of Clarity smart glasses are powered by Google Cloud Vision API. The glasses capture a photo of the people in front of the user, runs the photo through the Cloud Vision model using an API key, and outputs a discrete probability distribution of the emotions. This probability distribution is analyzed by Clarity’s code to determine the emotion of the people in the image. The output of the model is sent to the user through the OLED screen using the Pillow library.
The additional features of the smart glasses include displaying the current time, weather, and the user’s daily schedule. These features are implemented using various Python libraries and a text file-based storage system. Clarity allows all the features of the smart glasses to be run concurrently through the implementation of asynchronous programming. Using the asyncio library, the user can iterate through the various functionalities seamlessly.
The glasses are interfaced through a button and the use of Siri. Using an iPhone, Siri can remotely power on the glasses and start the software. From there, users can switch between the various features of Clarity by pressing the button on the side of the glasses.
The software is implemented using a multi-file program that calls functions based on the current state of the glasses, acting as a finite state machine. The program looks for the rising edge of a button impulse to receive inputs from the user, resulting in a change of state and calling the respective function.
## Next Steps:
The next steps include integrating a processor/computer inside the glasses, rather than using raspberry pi. This would allow for the device to take the next step from a prototype stage to a mock mode. The model would also need to have Bluetooth and Wi-Fi integrated, so that the glasses are modular and easily customizable. We may also use magnifying lenses to make the images on the display bigger, with the potential of creating a more dynamic UI.
## Timelines:
As we believe that our device can make a drastic impact in people’s lives, the following diagram is used to show how we will pursue Clarity after this Makathon:

## References:
• <https://cloud.google.com/vision>
• Python Libraries
### Hardware:
All CADs were fully created from scratch. However, inspiration was taken from conventional DIY smartglasses out there.
### Software:
### Research:
• <https://www.vectorstock.com/royalty-free-vector/smart-glasses-vector-3794640>
• <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2781897/>
• <https://www.google.com/search?q=how+many+people+have+autism&rlz=1C1CHZN_enCA993CA993&oq=how+many+people+have+autism+&aqs=chrome..69i57j0i512l2j0i390l5.8901j0j9&sourceid=chrome&ie=UTF-8>
• (<http://labman.phys.utk.edu/phys222core/modules/m8/human_eye.html>)
• <https://mammothmemory.net/physics/mirrors/flat-mirrors/normal-line-and-two-flat-mirrors-at-right-angles.html> | ## Inspiration
A week or so ago, Nyle DiMarco, the model/actor/deaf activist, visited my school and enlightened our students about how his experience as a deaf person was in shows like Dancing with the Stars (where he danced without hearing the music) and America's Next Top Model. Many people on those sets and in the cast could not use American Sign Language (ASL) to communicate with him, and so he had no idea what was going on at times.
## What it does
SpeakAR listens to speech around the user and translates it into a language the user can understand. Especially for deaf users, the visual ASL translations are helpful because that is often their native language.

## How we built it
We utilized Unity's built-in dictation recognizer API to convert spoken word into text. Then, using a combination of gifs and 3D-modeled hands, we translated that text into ASL. The scripts were written in C#.
## Challenges we ran into
The Microsoft HoloLens requires very specific development tools, and because we had never used the laptops we brought to develop for it before, we had to start setting everything up from scratch. One of our laptops could not "Build" properly at all, so all four of us were stuck using only one laptop. Our original idea of implementing facial recognition could not work due to technical challenges, so we actually had to start over with a **completely new** idea at 5:30PM on Saturday night. The time constraint as well as the technical restrictions on Unity3D reduced the number of features/quality of features we could include in the app.
## Accomplishments that we're proud of
This was our first time developing with the HoloLens at a hackathon. We were completely new to using GIFs in Unity and displaying it in the Hololens. We are proud of overcoming our technical challenges and adapting the idea to suit the technology.
## What we learned
Make sure you have a laptop (with the proper software installed) that's compatible with the device you want to build for.
## What's next for SpeakAR
In the future, we hope to implement reverse communication to enable those fluent in ASL to sign in front of the HoloLens and automatically translate their movements into speech. We also want to include foreign language translation so it provides more value to **deaf and hearing** users. The overall quality and speed of translations can also be improved greatly. | ## Inspiration
One day, one of our teammates was throwing out garbage in his apartment complex and the building manager made him aware that certain plastics he was recycling were soft plastics that can't be recycled.
According to a survey commissioned by Covanta, “2,000 Americans revealed that 62 percent of respondents worry that a lack of knowledge is causing them to recycle incorrectly (Waste360, 2019).” We then found that knowledge of long “Because the reward [and] the repercussions for recycling... aren’t necessarily immediate, it can be hard for people to make the association between their daily habits and those habits’ consequences (HuffingtonPost, 2016)”.
From this research, we found that lack of knowledge or awareness can be detrimental to not only to personal life, but also to meeting government societal, environmental, and sustainability goals.
## What it does
When an individual is unsure of how to dispose of an item, "Bin it" allows them to quickly scan the item and find out not only how to sort it (recycling, compost, etc.) but additional information regarding potential re-use and long-term impact.
## How I built it
After brainstorming before the event, we built it by splitting roles into backend, frontend, and UX design/research. We concepted and prioritized features as we went based on secondary research, experimenting with code, and interviewing a few hackers at the event about recycling habits.
We used Google Vision API for the object recognition / scanning process. We then used Vue and Flask for our development framework.
## Challenges I ran into
We ran into challenges with deployment of the application due to . Getting set up was a challenge that was slowly overcome by our backend developers getting the team set up and troubleshooting.
## Accomplishments that I'm proud of
We were able to work as a team towards a goal, learn, and have fun! We were also able work with multiple Google API's. We completed the core feature of our project.
## What I learned
Learning to work with people in different roles was interesting. Also designing and developing from a technical stand point such as designing for a mobile web UI, deploying an app with Flask, and working with Google API's.
## What's next for Bin it
We hope to review feedback and save this as a great hackathon project to potentially build on, and apply our learnings to future projects, | winning |
## Inspiration
Social-distancing is hard, but little things always add up.
What if person X is standing too close to person Y in the c-mart, and then person Y ends up in the hospital for more than a month battling for their lives? Not finished, that c-mart gets shut down for contaminated merchandise.
All this happened because person X didn't step back.
These types of scenarios, and in hope of going back to normal lives, pushed me to create **Calluna**.
## What Calluna does
Calluna is aimed to be an apple watch application. On the application, you can check out all the notifications you've gotten that day as well as when you've got it and your settings.
When not on the app, you get pinged when your too close to someone who also has the app, making this a great feature for business workforces.
## How Calluna was built
Calluna was very simply built using Figma. I have linked below both design and a fully-fuctionally prototype!
## Challenges we ran into
I had some issues with ideation. I needed something that was useful, simple, and has growth potential. I also had some headaches on the first night that could possibly be due to sleep deprivation and too much coffee that ended up making me sleep till the next morning.
## Accomplishments that we're proud of
I love the design! I feel like this is a project that will be really helpful *especially* during the COVID-19 pandemic.
## What we learned
I learned how to incorporate fonts to accent the color and scene, as well as working with such small frames and how to make it look easy on the eyes!
## What's next for Calluna
I hope to create and publish the ios app with GPS integration, then possibly android too. | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | ### 🌟 Inspiration
We're inspired by the idea that emotions run deeper than a simple 'sad' or 'uplifting.' Our project was born from the realization that personalization is the key to managing emotional states effectively.
### 🤯🔍 What it does?
Our solution is an innovative platform that harnesses the power of AI and emotion recognition to create personalized Spotify playlists. It begins by analyzing a user's emotions, both from facial expressions and text input, to understand their current state of mind. We then use this emotional data, along with the user's music preferences, to curate a Spotify playlist that's tailored to their unique emotional needs.
What sets our solution apart is its ability to go beyond simplistic mood categorizations like 'happy' or 'sad.' We understand that emotions are nuanced, and our deep-thought algorithms ensure that the playlist doesn't worsen the user's emotional state but, rather, optimizes it. This means the music is not just a random collection; it's a therapeutic selection that can help users manage their emotions more effectively.
It's music therapy reimagined for the digital age, offering a new and more profound dimension in emotional support.
### 💡🛠💎 How we built it?
We crafted our project by combining advanced technologies and teamwork. We used Flask, Python, React, and TypeScript for the backend and frontend, alongside the Spotify and OpenAI APIs.
Our biggest challenge was integrating the Spotify API. When we faced issues with an existing wrapper, we created a custom solution to overcome the hurdle.
Throughout the process, our close collaboration allowed us to seamlessly blend emotion recognition, music curation, and user-friendly design, resulting in a platform that enhances emotional well-being through personalized music.
### 🧩🤔💡 Challenges we ran into
🔌 API Integration Complexities: We grappled with integrating and harmonizing multiple APIs.
🎭 Emotion Recognition Precision: Achieving high accuracy in emotion recognition was demanding.
📚 Algorithm Development: Crafting deep-thought algorithms required continuous refinement.
🌐 Cross-Platform Compatibility: Ensuring seamless functionality across devices was a technical challenge.
🔑 Custom Authorization Wrapper: Building a custom solution for Spotify API's authorization proved to be a major hurdle.
### 🏆🥇🎉 Accomplishments that we're proud of
#### Competition Win: 🥇
```
Our victory validates the effectiveness of our innovative project.
```
#### Functional Success: ✔️
```
The platform works seamlessly, delivering on its promise.
```
#### Overcoming Challenges: 🚀
```
Resilience in tackling API complexities and refining algorithms.
```
#### Cross-Platform Success: 🌐
```
Ensured a consistent experience across diverse devices.
```
#### Innovative Solutions: 🚧
```
Developed custom solutions, showcasing adaptability.
```
#### Positive User Impact: 🌟
```
Affirmed our platform's genuine enhancement of emotional well-being.
```
### 🧐📈🔎 What we learned
🛠 Tech Skills: We deepened our technical proficiency.
🤝 Teamwork: Collaboration and communication were key.
🚧 Problem Solving: Challenges pushed us to find innovative solutions.
🌟 User Focus: User feedback guided our development.
🚀 Innovation: We embraced creative thinking.
🌐 Global Impact: Technology can positively impact lives worldwide.
### 🌟👥🚀 What's next for Look 'n Listen
🚀 Scaling Up: Making our platform accessible to more users.
🔄 User Feedback: Continuous improvement based on user input.
🧠 Advanced AI: Integrating more advanced AI for better emotion understanding.
🎵 Enhanced Personalization: Tailoring the music therapy experience even more.
🤝 Partnerships: Collaborating with mental health professionals.
💻 Accessibility: Extending our platform to various devices and platforms. | partial |
## **Inspiration**
Ever had to wipe your hands constantly to search for recipes and ingredients while cooking?
Ever wondered about the difference between your daily nutrition needs and the nutrition of your diets?
Vocal Recipe is an integrated platform where users can easily find everything they need to know about home-cooked meals! Information includes recipes with nutrition information, measurement conversions, daily nutrition needs, cooking tools, and more! The coolest feature of Vocal Recipe is that users can access the platform through voice control, which means they do not need to constantly wipe their hands to search for information while cooking. Our platform aims to support healthy lifestyles and make cooking easier for everyone.
## **How we built Vocal Recipe**
Recipes and nutrition information is implemented by retrieving data from Spoonacular - an integrated food and recipe API.
The voice control system is implemented using Dasha AI - an AI voice recognition system that supports conversation between our platform and the end user.
The measurement conversion tool is implemented using a simple calculator.
## **Challenges and Learning Outcomes**
One of the main challenges we faced was the limited trials that Spoonacular offers for new users. To combat this difficulty, we had to switch between team members' accounts to retrieve data from the API.
Time constraint is another challenge that we faced. We do not have enough time to formulate and develop the whole platform in just 36 hours, thus we broke down the project into stages and completed the first three stages.
It is also our first time using Dasha AI - a relatively new platform which little open source code could be found. We got the opportunity to explore and experiment with this tool. It was a memorable experience. | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | ## Inspiration
I'm a musician, and I often get stumped when making new music because I feel like my ideas don't resonate with me, or my ideas don't motivate me to develop them further. I often have difficulties coming up with chord progressions that I can play melodies along to, as I often come up with a couple of chords and find them too 'boring' to play over.
That's why I created the Harmonizer - to help me create music and help me develop my abilities as a musician.
## What it does
The Harmonizer presents a randomized chord progression to the user. It is then up to the user to take this chord progression, attempt to play it, and see if they are able to play the chord progression or improvise over it. If the user dislikes the given chord progression, they are able to generate a new one.
In order to use the Harmonizer, basic knowledge of music theory and chord building is required.
## How I built it
The Harmonizer was built using Arduino, with its components being connected through the use of a breadboard. I connected an LCD display to the Arduino, which displays menu prompts. The user can cycle through these menu prompts by pressing a button. The user also attains information through the LCD display, as the program gives a chosen chord progression by using this menu.
There is also a small speaker connected to the breadboard, as the Harmonizer was initially designed to play an accompanying bassline to help the user with their improvisation.
## Challenges I ran into
Unfortunately, I wasn't able to get the Harmonizer to play the audio I coded it to play, and I didn't have enough time to debug the issue and get the audio working by the deadline. Because of this, I had to scale down the Harmonizer's functionality and it now has a fraction of the features I initially planned it to have.
## Accomplishments that I'm proud of
I'm proud of submitting this hackathon project! Despite the Harmonizer's shortcomings, I'm glad that I was at least able to produce a working project and "demo" it. This is also my first time building something this complex using an Arduino/hardware, so I'm glad that I was able to build a functional project in the first place.
## What we learned
I learned that debugging is time consuming and often can't be done in one night! Also, through this project, I also learned about different ways the user can interact with the Arduino via different I/O devices and how navigating a simple menu works with hardware.
In addition to this, I gained some experience with working with Arduino's tone() library, as that is what I used to have the Arduino play sounds.
## What's next for The Harmonizer
Getting it to play audio, like I originally intended, is the most pressing goal. Beyond that, I want to make the program more complex and have the Harmonizer generate basslines for more complex chord progressions.
I could also use artificial intelligence to analyze a variety of different jazz songs, and then have AI compose basslines itself. At the moment, the Harmonizer was designed to play basslines that I wrote myself, but listening to these basslines after a while can be repetitive and boring. If the program is able to dynamically create basslines on the fly, it would be a more valuable practice tool for those looking to deepen their musical skills. | winning |
## Inspiration
Since the start of the pandemic, the government has been creating simulations to predict the events of how the disease would progress. Although we can't create something to the degree of accuracy they were able to due to a lack of data and expertise in virology, we tried to create a logical model for diseases and how exactly methods of restoration such as vaccines and cures would work within the population.
## What it does
Starting with a population of healthy people (represented in green) and an infected patient (represented in red), the simulation will take you through each step of how the disease spreads, kills, and is prevented. An infected patient will attempt to spread the disease each iteration based on distance, and each infected patient will have a chance to either die or recover from the disease. Once recovered, they'll be shown with a blue border as they've obtained phase one of "immunity" which can only be amplified to phase two by a successfully developed vaccine. This works because when your body is exposed to the virus, it develops an antibody for it, which has a similar purpose as a vaccine.
## How we built it
We build this web application using HTML, JavaScript, and CSS. We used Google Cloud Compute to host this onto our Domain.com-powered website, [openids.tech](https://openids.tech). After spending many minutes debating which function to use to calculate the probability of a person to be infected when at a certain distance, we finally came up with the following function: f(x) = (-x^2/d^2) + 1 where x is the distance between an infected patient and a healthy human, and d is the maximum distance at which infection can occur. This is probably not an accurate function, but we worked with what we could to try to come up with one that was as realistic as possible.
## Challenges we ran into
We ran into many challenges such as even the most basic of challenges: for example, using Google cloud to host our website and using the wrong variable name. Aside from that, we struggled on making an accurate yet efficient way of determining the distance between **all** people that are alive and on the canvas. In the end, we settled for Manhattan distance, which is less accurate but faster than Euclidean distance.
## Accomplishments that we're proud of
We are proud of being able to being able to figure out how to code a half-decent web application in a language that none of us were initially familiar with. We also managed to accomplish integrating graphs into webpages with newly-generated data.
## What we learned
We have learned that virtual private servers are quite difficult to set up and deploy into a production environment. Moreover, we have learned much more about asynchronous programming languages and how order of execution is very important.
## What's next for Open-IDS
In the future, we are planning to implement more realistic movement into our project, such as when a person gets infected, they move to a location where they are away from other people like self-isolation. We hope that we can continue to improve this simulator, to the point where it can be used practically in order to make wise and informed decisions. | ## Inspiration
I dreamed about the day we would use vaccine passports to travel long before the mRNA vaccines even reached clinical trials. I was just another individual, fortunate enough to experience stability during an unstable time, having a home to feel safe in during this scary time. It was only when I started to think deeper about the effects of travel, or rather the lack thereof, that I remembered the children I encountered in Thailand and Myanmar who relied on tourists to earn $1 USD a day from selling handmade bracelets. 1 in 10 jobs are supported by the tourism industry, providing livelihoods for many millions of people in both developing and developed economies. COVID has cost global tourism $1.2 trillion USD and this number will continue to rise the longer people are apprehensive about travelling due to safety concerns. Although this project is far from perfect, it attempts to tackle vaccine passports in a universal manner in hopes of buying us time to mitigate tragic repercussions caused by the pandemic.
## What it does
* You can login with your email, and generate a personalised interface with yours and your family’s (or whoever you’re travelling with’s) vaccine data
* Universally Generated QR Code after the input of information
* To do list prior to travel to increase comfort and organisation
* Travel itinerary and calendar synced onto the app
* Country-specific COVID related information (quarantine measures, mask mandates etc.) all consolidated in one destination
* Tourism section with activities to do in a city
## How we built it
Project was built using Google QR-code APIs and Glideapps.
## Challenges we ran into
I first proposed this idea to my first team, and it was very well received. I was excited for the project, however little did I know, many individuals would leave for a multitude of reasons. This was not the experience I envisioned when I signed up for my first hackathon as I had minimal knowledge of coding and volunteered to work mostly on the pitching aspect of the project. However, flying solo was incredibly rewarding and to visualise the final project containing all the features I wanted gave me lots of satisfaction. The list of challenges is long, ranging from time-crunching to figuring out how QR code APIs work but in the end, I learned an incredible amount with the help of Google.
## Accomplishments that we're proud of
I am proud of the app I produced using Glideapps. Although I was unable to include more intricate features to the app as I had hoped, I believe that the execution was solid and I’m proud of the purpose my application held and conveyed.
## What we learned
I learned that a trio of resilience, working hard and working smart will get you to places you never thought you could reach. Challenging yourself and continuing to put one foot in front of the other during the most adverse times will definitely show you what you’re made of and what you’re capable of achieving. This is definitely the first of many Hackathons I hope to attend and I’m thankful for all the technical as well as soft skills I have acquired from this experience.
## What's next for FlightBAE
Utilising GeoTab or other geographical softwares to create a logistical approach in solving the distribution of Oyxgen in India as well as other pressing and unaddressed bottlenecks that exist within healthcare. I would also love to pursue a tech-related solution regarding vaccine inequity as it is a current reality for too many. | ## Inspiration
As students of chemical engineering, we are deeply interested in educating students about the wonderful field of chemistry. One of the most difficult things in chemistry is visualizing molecules in 3 dimensions. So for this project, we wanted to make visualizing molecules easy and interactive for students in addition to making it easy for teachers to implement in the classroom.
## What it does
Aimed towards education, ChemistryGO aims to bring 3 dimensional molecular models to students in a convenient way. For example, teachers can integrate pre-prepared pictures of Lewis structures on powerpoints and students can use the ChemistryGO Android application with Google Cardboard (optional) to point their phones to the screen and a 3D ball and stick model representation will pop up. The molecule can be oriented with just a slide of a finger.
## How we built it
The building of the application was split into three parts:
1. Front End Unity Development
We used C# to add functions regarding the orientation of the molecule. We also implemented Vuforia API to pair 3D models with target images.
2. Database creation
Vuforia helped us build a database of target images that were going to be used to pair with 3D models. Scripting was used with Chemspider to gather the list of target images of molecules.
3. Database extraction
For 3D models, PDB files (strict typed file of 3D models, usually used for proteins) of common chemistry molecules were collected and opened with UCSF Chimera, a molecular visualization tool, and converted to .dae files, which were used Unity to produce the model.
## Challenges we ran into
The fact that there were few simple molecules that were already in PDB format made it difficult to make a large database. Needing the image on screen for the 3D molecule to stay. Rotating the 3D molecule. Having a automated method to build the database due to the number of data points and software needed.
## Accomplishments that we're proud of
* Use of PDB formatted files.
* Implemented Vuforia API for image recognition
* Creating an educational application
## What we learned
* Unity
## What's next for ChemistryGO
* Creating the database by script creating PDB files
* Automation of database creation
* A user-friendly interface to upload pictures to corresponding 3D models
* A more robust Android application
* Machine learning molecules | partial |
## Inspiration
In the future we would be driving electric cars. They would have different automatic features, including electronic locks. This system may be vulnerable to the hackers, who would want to unlock the car in public parking lots. So we would like to present **CARSNIC**, a solution to this problem.
## What it does
The device implements a continuous loop, in which the camera is checked in order to detect the theft/car unlocking activity. If there is something suspect, the program iterated in the list of frequencies for the unlocking signal (*315MHz* for US and *433.92MHz* in the rest of the world). If the signal is detected, then the antenna starts to transmit a mirrored signal in order to neutralize the hacker's signal.
We used the propriety that the signal from car keys are sinusoidal, and respects the formula: sin(-x) = -sin(x).
## How I built it
We used a **Raspberry Pi v3** as SBC, a RPI camera and a **RTL-SDR** antenna for RX/TX operations. In order to detect the malicious activity and to analyze the plots of the signals, I used python and **Custom Vision** API from Azure. The admin platform was created using **PowerApps** and **Azure SQL** Databases.
## Challenges I ran into
The main challenge was that I was not experienced in electronics and learned harder how to work with the components.
## Accomplishments that I'm proud of
The main accomplishment was that the MVP was ready for the competition, in order to demonstrate the proposed idea.
## What I learned
In this project I learned mostly how to work with hardware embedded systems, This is my first project with Raspberry Pi and RTL-SDR antenna.
## What's next for CARSNIC
In the next couple of months, I would like to finish the MVP with all the features in the plan: 3D scanning of the structure, acclimatization and automatic parking from an intelligent service sent directly to your car. Then I think the project should be ready to be presented to investors and accelerators. | ## Inspiration
We found that the current price of smart doors on the market is incredibly expensive. We wanted to improve the current technology of smart doors at a fraction of the price. In addition, smart locks are not usually hands free, either requiring the press of a button or going on the User's phone. We wanted to make it as easy and fast as possible for User's to securely unlock their door while blocking intruders.
## What it does
Our product acts as a smart door with two-factor authentication to allow entry. A camera cross-matches your face with an internal database and also uses voice recognition to confirm your identity. Furthermore, the smart door provides useful information for your departure such as weather, temperature and even control of the lights in your home. This way, you can decide how much to put on at the door even if you forgot to check, and you won't forget to turn off the lights when you leave the house.
## How we built it
For the facial recognition portion, we used a Python script & OpenCV through the Qualcomm Dragonboard 410c, where we trained the algorithm to recognize correct and wrong individuals. For the user interaction, we used the Google Home to talk to the User and allow for the vocal confirmation as well as control over all other actions. We then used an Arduino to control a motor that would open and close the door.
## Challenges we ran into
OpenCV was incredibly difficult to work with. We found that the setup on the Qualcomm board was not well documented and we ran into several errors.
## Accomplishments that we're proud of
We are proud of getting OpenCV to work flawlessly and providing a seamless integration between the Google Home, the Qualcomm board and the Arduino. Each part was well designed to work on its own, and allowed for relatively easy integration together.
## What we learned
We learned a lot about working with the Google Home and the Qualcomm board. More specifically, we learned about all the steps required to set up a Google Home, the processes needed to communicate with hardware, and many challenges when developing computer vision algorithms.
## What's next for Eye Lock
We plan to market this product extensively and see it in stores in the future! | ## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | partial |
## Inspiration
We got our inspiration from the countless calorie tracking apps. First of all, there isn't a single website we could find that tracked calories. There are a ton of apps, but not one website. Secondly, None of them offered recipes built in. In our website, the user can search for food items, and directly look at their recipes. Lastly, our nutrition analysis app analyses any food item you've ever heard of.
## What it does
Add food you eat in a day, track your calories, track fat%, and other nutrients, search recipes, and get DETAILED info about any food item/recipe.
## How we built it
Html, min.css, min.js, js, were planning on using deso/auth0 for login but couldnt due to time constraints.
## Challenges we ran into
We initially used react, but couldn't make the full app using react since we used static html to interact with the food apis. We also had another sole recipe finder app which we removed due to it being react only. Integrating the botdoc api was a MAJOR challenge, since we had no prior experience, and had no idea what we were doing basically. A suggestion to the BotDoc team would be to add demo apps to their documentation/tutorials, since currently theres literally nothing available except the documentation. The api is quite unheard of too as of now.
## Accomplishments that we're proud of
Making the website working, and getting it up and running using a github pages deployment
## What we learned
A LOT about botdoc, and refreshed our knowledge of html, css, js.
## What's next for Foodify
Improving the css firstly lol, right now its REALLY REALLY BAD. | ## Inspiration
We love cooking and watching food videos. From the Great British Baking Show to Instagram reels, we are foodies in every way. However, with the 119 billion pounds of food that is wasted annually in the United States, we wanted to create a simple way to reduce waste and try out new recipes.
## What it does
lettuce enables users to create a food inventory using a mobile receipt scanner. It then alerts users when a product approaches its expiration date and prompts them to notify their network if they possess excess food they won't consume in time. In such cases, lettuce notifies fellow users in their network that they can collect the surplus item. Moreover, lettuce offers recipe exploration and automatically checks your pantry and any other food shared by your network's users before suggesting new purchases.
## How we built it
lettuce uses React and Bootstrap for its frontend and uses Firebase for the database, which stores information on all the different foods users have stored in their pantry. We also use a pre-trained image-to-text neural network that enables users to inventory their food by scanning their grocery receipts. We also developed an algorithm to parse receipt text to extract just the food from the receipt.
## Challenges we ran into
One big challenge was finding a way to map the receipt food text to the actual food item. Receipts often use annoying abbreviations for food, and we had to find databases that allow us to map the receipt item to the food item.
## Accomplishments that we're proud of
lettuce has a lot of work ahead of it, but we are proud of our idea and teamwork to create an initial prototype of an app that may contribute to something meaningful to us and the world at large.
## What we learned
We learned that there are many things to account for when it comes to sustainability, as we must balance accessibility and convenience with efficiency and efficacy. Not having food waste would be great, but it's not easy to finish everything in your pantry, and we hope that our app can help find a balance between the two.
## What's next for lettuce
We hope to improve our recipe suggestion algorithm as well as the estimates for when food expires. For example, a green banana will have a different expiration date compared to a ripe banana, and our scanner has a universal deadline for all bananas. | ## Inspiration
The inspiration behind Lexi AI is to provide personalized support for legal advising. We wanted to create a solution that could democratize legal advice, ensuring everyone has the opportunity to understand their rights and options, regardless of financial resources.
## What it does
Lexi AI serves as a virtual attorney, designed to assist individuals in navigating the legal landscape by providing accessible and accurate information. It helps users obtain vital information regarding their legal concerns, particularly those who may not afford traditional legal services. Lexi AI is focused on minor legal matters and helps users understand tenant rights, small claims, traffic violations, and family law issues.
## How We Built It
Lexi AI leverages LLM models.
Data Cleaning:
The data cleaning techniques employed to anonymize asylum petition data involved removing names, personal details, and other identifiable information to protect privacy.
Used Python faker library to anonymise the data.
Used Python nltk to remove non english and non basic ascii characters from the petition data.
We finetuned the LaMini-T5-738M on 15000 asylum petitions. It took around 3 hours for 1epoch and we ran it for 9 hrs. With better computing resources we could make a better legal LLM and could train it better.
We built the frontend using React and the backend with Node.js, and integrated data from public legal databases to provide accurate information. We divided responsibilities for data pre-processing, training the LLM model, and creating the backend API. We deployed the LLM on Google Cloud to ensure scalability and availability. We also ensured that the platform is user-friendly, confidential, and available 24/7.
## Challenges We Ran Into
One of the major challenges we faced was training the AI model to provide accurate and reliable legal information. Identifying suitable data was difficult, as we had multiple rows for a single case proceeding, which required us to combine all rows for the same proceeding in a sequence. We used the LLM to summarize the dataset and further fine-tune it for a large context model. We also had to carefully select data sources to ensure that Lexi AI's responses are both comprehensive and correct. Moreover, creating an intuitive interface that simplifies complex legal language was another hurdle we had to overcome.
## Accomplishments
We successfully developed an AI-driven virtual legal assistant that makes legal advice accessible to all. We managed to fine-tune the LLM model, although we faced issues while deploying it, which we are currently working to resolve. We also integrated the Deepgram Text-to-Speech API to enhance the user experience. We are proud of creating a user-friendly platform that ensures confidentiality and provides useful information in a comprehensible manner. The 24/7 availability feature is another highlight that makes Lexi AI convenient for users.
## What We Learned
Throughout this project, we learned a lot about LLMs, their complexities during training, and the challenges of collecting suitable datasets. We also learned about natural language processing, machine learning algorithms, and the complexities of legal language. Additionally, we gained insights into user experience design and how to make legal information more approachable.
## What's Next for Lexi AI
We could train the LLM on a section of legal law and we could have a special and trained LLM. Eg: Small Claims Bot, Traffic Claims Bot, Harassment and prejudice Bot. Use c2-standard-16, Groq for Running inference for checking the speed of inference. | winning |
Pokemon is a childhood favourite for the 90s kids.
What better way to walk down memory lane (and possibly procrasinate on whatever obligations you have) by looking up your all-time favourite pokemon? This virtual pokedex includes its pokemon type, its base statistics, its attack abilities, an accompanying picture and much more.
Gotta catch'em all! | ## Inspiration
Our Inspiration for this project was discord bots as we always wanted to make one that anyone have fun using. We also wanted to implement our knowledge of API calls which we learned from our courses to get a real understanding of API calls. We also loved Pokemon and decided creating a discord bot that allows people to engage themselves in pokemon adventures would be something we would love to create.
## What it does
The PokemonBot allows one to start a pokemon adventure. By choosing a stater Pokemon (Charmander, Squirtle, or Bulbasaur), the player starts their adventure. The pokemon and stats are saved to a particular player id, and everyone of that particular server is saved to a particular guild id. With the player's starter pokemon, they can hunt in 8 different habitats for new pokemon. They can fight or capture wild rare pokemon and add it to their collection. The Pokemon Bot also gives details on the stats on pokemon hp and opponent hp when battling. Overall, the bot allows discord users to engage themselves in a pokemon game that all members of a server can play.
## How we built it
We built it using python on visual studio code. We also utilized a couple of libraries such as openpyxl, pokebase and discord.py to make this project.
## Challenges we ran into
We ran into a couple of challenges when it came to designing the battle feature as there were many errors and difficult parts to it that we didn't really understand. After collaborative work, we were able to understand the flaws in our code and fix the bugs the battle feature was going through to make it work. The overall project was relatively complex, as it had us experience a whole new field of programming and work with API calls heavily. It was a new experience for us which made it super challenging, but this taught us so much about APIs and working with discord bots.
## Accomplishments that we're proud of
We are proud of the overall product we have developed as the bot works as we intended it to, which is our biggest achievement. We are also proud of how well the bot works on discord and how simple it is for anyone to play with the PokemonBot.
## What we learned
We learned how to work with new libraries like the openpyxl, pokebase and discord.py as this was a new experience for us. Mainly, we learned to work with a lot of API calls as the project data was dependent on the Pokemon API. We also learned important collaboration tacts to effectively work together, and test and debug problems in the code.
## What's next for Pokemon Discord Bot
The next step is to add tournaments and the feature for players to be able to battle each other. We hope to implement multiplayer, as playing solo is fun, but we want people to engage with other people in a discord server. We hope to implement various forms of multiplayer like tournaments, pokemon gyms, battles, etc, where discord users can challenge other discord users and have fun.
Join our bot
<https://discord.gg/BeFWgp9w> | ## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0> | losing |
## Inspiration
Moodly's cause -- fostering positive mental health -- is one very close to my own heart. I struggled with my own mental health over the last year, finding that I wasn't the best at figuring out how I was feeling before it started to impact my day. When I eventually took up journaling, I realized that I could get a feel of my emotional state on a previous day by just reading through my account of it. My verbiage, the events I focused on, the passivity of my voice, it all painted a clear picture of how I was doing.
And that got me thinking.
Did it just have to be through introspection that these patterns could be meaningful? And from that question, Moodly was born.
## What it Does
Moodly is a live audio journal that provides real-time analysis on mood and underlying emotional states. Talk to it while you fold your laundry, walk to class -- however you want to use it. Just talk, about anything you like, and Moodly will process your speech patterns, visualizing useful metrics through a friendly graphical interface.
Moodly was built specifically as an assistive tool for people with mental health disabilities. When your whole day can start to spiral from a small pattern of negative thoughts and feelings, it's extremely important to stay in touch with your emotional state. Moodly allows the user to do exactly that, in an effort-free form factor that feels like the furthest thing from an evaluation.
## How I built it
Moodly is a Python script that combines Rev.ai's speech-to-text software and IBM's Watson tonal analysis suite to provide an accurate and thorough assessment of a speaker's style and content. First, an audio stream is created using PyAudio. Then, that stream is connected via a web socket to Rev.ai's web API to generate a transcript of the session. That transcript is fed via REST API to IBM's Watson analysis, and the interpreted data is displayed using a custom-built graphical interface utilizing the Zelle python library.
## Challenges I ran into
Moodly has multiple processes running at very distinct time scales, so synchronizing all of the processes into a single, smooth user experience was a challenge and a half.
## Accomplishments that I'm proud of
I'm super proud of the graphical interface! This was my first time plotting anything that wasn't a simple line graph in Python, and I really love how the end result came out -- intuitive, clean, and attention-grabbing.
## What I learned
First and foremost: AI is awesome! But more importantly, I learned to ywork efficiently -- without a team, I didn't have time to get bogged down, especially when every library used was a first time for me.
## What's next for Moodly
I'd love to consider more data patterns in order to create more useful and higher-level emotional classifications. | ## Inspiration
Mental Health is a really common problem amongst humans and university students in general. I myself felt I was dealing with mental issues a couple years back and I found it quite difficult to reach out for help as it would make myself look weak to others. I recovered from my illness when I actually got the courage to ask someone for help. After talking with my peers, I found that this is a common problem amongst young adults. I wanted to create a product which provides you with the needed mental health resources without anyone finding out. Your data is never saved so you don't have to worry about anyone ever finding out.
## What it does
This product is called the MHR Finder Bot, but its MHR for short. This bot asks you 10 yes or no questions and then a question about your university, followed by your postal code. After you answer these question(if you feel comfortable), it provides you with some general resources, as well as personalized resources based on your postal code and university.
## How I built it
I built the chatbot using deep learning techniques. The bot is trained on a dataset and gives you resources based on your answers to the 12 questions that it asks you. I used special recurrent neural network to allow the bot to give resources based on the user's responses. I started by making the backend portion of the code. I finished that around the 24 hour mark and then I spent the next 12 hours working on the UI and making it simple and user friendly. I chose colors which aided with mental illnesses and have a easter egg in which the scroll wheel cursor is a heart. This is also very antonymous as mental illness is a very sensitive topic.
## Challenges I ran into
A challenge I ran into was making the UI side of things look appealing and welcoming. Additionally, close to the deadline of the project, I kept getting an error that one of the variables was used before defined and that as a challenging fix but I figured out the problem in the end.
## Accomplishments that we're proud of
I was proud that I was able to get a working Chat Bot done before the deadline considering I was working alone. Additionally, it was my first time using several technologies and libraries in python, so I was quite happy that I was able to use them to effectiveness. Finally, I find it an accomplishment that such a product can help others suffering from mental illnesses.
## What I learned
I improved my knowledge of TensorFlow and learned how to use new libraries such as nltk and pickle. Additionally, I was quite pleased that I was able to learn intents when making a chat bot.
## What's next for MHR Finder Bot
Currently, I made two chat bots over the 36 hours, one which is used finding mental health resources and the other can be used to simulate a normal conversion similar to ChatGPT. I would like to combine these two so that when trying to find mental health resources, you can | ## Inspiration
The inspiration came from the two women on the team, as the app is geared toward female security.
## What it does
A common issue and concern for women on dates is safety. Now that online dating sites are more popular, this raises the concern women may have about going out to meet their date-- is the person crazy? Will they hurt me? Will they abduct me?
While this web app cannot stop something from happening, it was meant to assure the woman that if she was taken against her will then a contact of choice or even the police will be alerted as soon as possible.
The idea is a woman makes a profile and enters her choice of emergency contacts. Before going out on a date, she would select the "DateKnight" option and log where the date was taking place, what time it was taking place, an uploaded picture of the date, a selected check-in time, and a selfie of herself before leaving.
When she is on her date, if she does not check into the app within 10 minutes of her selected check-in time, the emergency contact of her choice is then texted and alerted that she is not responding on her date and she may be in trouble.
After a specified time that alert is sent, if the user still has not checked in the police are called and alerted the location of where the woman should be. Now the date information the woman uploaded before can be used in finding her if she has been abducted.
While this was originally intended for women, it can be used by either gender to make the user feel like even if something were to happen then contacts and the police were quickly alerted that something is wrong.
## How we built it
We created the back end using MySQL in order to effectively store and access the users data across the web app. We also implemented PHP/CSS/HTML to create the front end and bridge it to the back to create core functionality. Using the Twilio API, we filtered fields from our database into real communications with demo users. All components are running a LAMP stack (Linux, Apache, MySQL, PHP) on an EC2 (Elastic Cloud-Compute) instance with Amazon Web Services. We are also using their Cloud9 collaborative IDE to work together in real-time on our project files. We acquired a custom domain (safetea.tech) from Domain.com and connected it to our EC2 instance.
## Challenges we ran into
The idea that we started out with (and spent quite a bit of time on) did not end up being the one we brought to completion. We initially wanted to create a web-app with Python for various data analysis purposes. Unfortunately, this soon became all about learning how to make a web-app with Python rather than how to create a useful implementation of the technology. One of our ideas was not reliant on Python and could easily be adapted to the newly chosen language. There was, however, no way to make up for lost time.
Programming in PHP, error messages were often hidden during the development process and made isolating (and therefore fixing) problems quite tricky. We also only had one member who had prior-experience with this stack's languages, but the general coding backgrounds helped them quickly acquire new and valuable skills.
## Accomplishments that we're proud of
We are proud that we have a demo-ready project. Though we most certainly faced our share of adversity (the person writing this sentence has a net 1 hour(s) of sleep and is so nauseous he does not even want the Insomnia cookies that were purchased for him; Well, they were not all for him but he has a large appetite for the soft, chewy, chocolate chip cookies of Insomnia (use promo code HARRYLOVESINSOMNIA), I digress), we worked together to overcome obstacles.
## What we learned
We learned that maybe if we had planned ahead on the 7 hour car ride like we were SUPPOSED to, then MAYBE we would have shown up knowing what we wanted to pursue and not had to madly scrape ideas together until we got one we really liked and was doable.
## What's next for SafeTEA
Another feature we talked about creating was one called “Party Mode”. The concept behind this is that if a group of friends is planning on going out and drinking they would all log the location they planned to be, the names and contacts of the people they were going with, and then a selected radius.
If the app sensed that a member of the group was outside of the radius selected, it would alert them first that they were too far and give them 10 minutes to get back to their friends. If they did not get back in that radius within 10 minutes, the other people they were out with would be alerted that their friend was beyond the set radius and then tell them the last location they were detected at.
This was designed so that if a group of friends went out and they got separated, no one would be too far away without the others knowing. If one of the friends were abducted and then taken far enough away from the determined location the others would be alerted someone was outside the radius and would be able to try and contact the user, and if given no response, the police quickly.
The feature would be able to be turned off if a member decided they wanted to leave early but would still alert the others that someone had turned it off in case they were not aware.
While this option appears on the web app home page, we were unable to link the location portion (the major component behind it) because we were unable to fund this. | losing |
## Inspiration
Travel planning is a pain. Even after you find the places you want to visit, you still need to find out when they're open, how far away they are from one another, and work within your budget. With Wander, automatically create an itinerary based on your preferences – just pick where you want to go, and we'll handle the rest for you.
## What it does
Wander shows you the top destinations, events, and eats wherever your travels take you, with your preferences, budget, and transportation in mind. For each day of your trip, Wander creates a schedule for you with a selection of places to visit, lunch, and dinner. It plans around your meals, open hours, event times, and destination proximity to make each day run as smoothly as possible.
## How we built it
We built the backend on Node.js and Express which uses the Foursquare API to find relevant food and travel destinations and schedules the itinerary based on the event type, calculated distances, and open hours. The native iOS client is built in Swift.
## Challenges we ran into
We had a hard time finding all the event data that we wanted in one place. In addition, we found it challenging to sync the information between the backend and the client.
## Accomplishments that we're proud of
We’re really proud of our mascot, Little Bloop, and the overall design of our app – we worked hard to make the user experience as smooth as possible. We’re also proud of the way our team worked together (even in the early hours of the morning!), and we really believe that Wander can change the way we travel.
## What we learned
It was surprising to discover that there were so many ways to build off of our original idea for Wander and make it more useful for travelers. After laying the technical foundation for Wander, we kept brainstorming new ways that we could make the itinerary scheduler even more useful, and thinking of more that we could account for – for instance, how open hours of venues could affect the itinerary. We also learned a lot about the importance of design and finding the best user flow in the context of traveling and being mobile.
## What's next for Wander
We would love to continue working on Wander, iterating on the user flow to craft the friendliest end experience while optimizing the algorithms for creating itineraries and generating better destination suggestions. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | ## What does it do?
Our app loads walking tours using Yelp API data stored on a Cockroach DB database. The tour spots get displayed on a map with pictures and short descriptions of the attraction.
## How We Built It
1. Coded an express.js API for serving json files
2. Connected server to cockroach DB
3. Developed front end with Android
4. Connected Android to API server with okHttp library
## Challenges We Came Across
***GIT, AHHHHH!***
## What’s Next for Walky Talky?
We would love to add audio and a more interactive map to the walking tours, and also let users in the community to add their own into the app! | winning |
## Inspiration
The global renewable energy market was valued at **USD 1.21 trillion in 2023** and is projected to grow at a **compound annual growth rate (CAGR) of 17.2% from 2024 to 2030**.
This growth is reflected in the **Renewable Energy Certificate (REC) market**, valued at **USD 12.72 billion in 2023**, which is expected to reach **USD 136.35 billion by 2033** with a **CAGR of 26.71%**. RECs are tradable certificates that certify electricity was generated from renewable energy sources and represent the associated carbon offsets.
For businesses, REC trading presents several advantages. Governments are implementing **Renewable Portfolio Standards (RPS)** that mandate a portion of electricity must come from renewable sources. RECs allow companies to meet these requirements without the need for compliance payments or costly energy infrastructure changes. In addition, many states provide **tax incentives** for renewable energy adoption, such as the upcoming Clean Electricity Investment Tax Credit, which businesses can leverage through REC purchases. By acquiring RECs, companies can also offset their remaining greenhouse gas (GHG) emissions, boosting their **sustainability credentials**—a key factor for consumers, investors, and stakeholders.
Households benefit from REC trading as well. A 6-kilowatt residential solar system can generate approximately seven RECs annually, providing an **additional revenue stream** from renewable energy production.
As more participants enter the REC market, it creates financial incentives for the development of new renewable energy projects, driving the market toward greener energy production. However, the REC market faces challenges, including the **lack of standardized rules and practices** across trading platforms. This fragmentation makes trading RECs across regions difficult and hinders market efficiency.
Furthermore, **limited transparency** around REC pricing and availability reduces market confidence, making it harder for businesses to assess the value of their REC investments. Households also face difficulties accessing the market due to the need for brokers, which leads to **high middleman fees** that reduce profitability. Overcoming these issues is crucial to unlocking the full potential of the REC market and advancing global renewable energy efforts.
## What it does
TradeREC revolutionizes the REC trading marketplace with three essential features:
1. **Automated Verification with OCR and NLP**: By leveraging OCR and NLP, TradeREC **automates the extraction and verification of key data from RECs**, ensuring faster, more accurate processing. This creates a standardized, reliable certification process across platforms, streamlining REC trading globally.
2. **Blockchain for Transparency**: TradeREC uses Hedera and Midnight blockchain technology to provide **secure, transparent records of every transaction**. Immutable logs ensure visibility into REC ownership, pricing, and authenticity, giving participants full confidence in their trades.
3. **Peer-to-Peer Trading via Blockchain**: The platform enables **direct, peer-to-peer REC transactions**, bypassing intermediaries. This reduces fees, making REC trading more accessible and cost-effective for both businesses and households.
## How we built it
The frontend of our platform is built using **Streamlit and Python**, providing a user-friendly interface for seamless interaction. On the backend, we utilize a combination of **MongoDB, Hedera, and Midnight** using Hedera for data storage, Midnight for encryption, and MongoDB for development to leverage blockchain technology for secure and transparent data management. Additionally, our OCR and NLP (powered by the **OpenAI API**) processes are designed to automate accurate verification of Renewable Energy Certificates (RECs) for streamlined trading.
## Challenges we ran into
Throughout the development of this project, we encountered numerous technical and conceptual challenges, each providing valuable learning experiences. Early on, we dedicated significant time to researching carbon caps and RECs, working to understand how these components of energy trading fit together. Our goal was to design an ecosystem that balanced ease of use with robust functionality for the end user.
During backend development, we faced compatibility issues between various blockchain platforms and our development stack. As a result, we opted to integrate MongoDB as a backup to blockchain for our database needs. Ultimately, we successfully implemented the Hydera and Midnight blockchain to secure clean energy trades, while MongoDB proved invaluable for testing and debugging throughout the process.
## Accomplishments that we're proud of
We are proud to have achieved our goal of creating a secure, blockchain-powered platform specifically designed for the Renewable Energy Credit (REC) trading market. By integrating blockchain technology, we ensure transparency and trust in every transaction, allowing users to track REC ownership, pricing, and authenticity with confidence. Our platform connects diverse groups—businesses, households, and renewable energy producers—enabling seamless, peer-to-peer REC trading without the need for intermediaries, reducing costs and simplifying the process.
Additionally, our use of OCR and NLP automates the verification of certificates, ensuring accuracy and speed in validating critical REC data. This combination of blockchain and automated verification not only enhances security and reliability but also delivers a streamlined, customized experience that maximizes functionality while minimizing complexity for all users.
## What we learned
Throughout this project, we gained valuable insights into both the technical and regulatory aspects of the Renewable Energy Credit (REC) market. We deepened our understanding of government regulations surrounding carbon emissions and the incentives promoting clean energy adoption. Technically, we developed a robust blockchain framework to guarantee secure and transparent data storage and trading, while integrating OCR and NLP to automate the verification process of RECs. This project was both exciting and challenging, greatly expanding our technological expertise and enhancing our understanding of the complexities within the energy market.
## What's Next for TradeREC
The conventional blockchain structure faces scalability and privacy issues, such as growing ledger size and potential data exposure through transaction analysis. To address this, we're exploring a Directed Acyclic Graph (DAG)-based blockchain for our REC trading platform. DAG offers improved scalability and enhanced privacy, making it a promising alternative.
Moving forward, we will focus on refining our OCR and NLP algorithms for efficient REC verification while exploring DAG technology to optimize performance and security. We will also collaborate with governments to standardize REC verification, ensuring consistency and compliance with evolving carbon regulations. | ## Inspiration
The cryptocurrency market is an industry which is expanding at an exponential rate. Everyday, thousands new investors of all kinds are getting into this volatile market. With more than 1,500 coins to choose from, it is extremely difficult to choose the wisest investment for those new investors. Our goal is to make it easier for those new investors to select the pearl amongst the sea of cryptocurrency.
## What it does
To directly tackle the challenge of selecting which cryptocurrency to choose, our website has a compare function which can add up to 4 different cryptos. All of the information from the chosen cryptocurrencies are pertinent and displayed in a organized way. We also have a news features for the investors to follow the trendiest news concerning their precious investments. Finally, we have an awesome bot which will answer any questions the user has about cryptocurrency. Our website is simple and elegant to provide a hassle-free user experience.
## How we built it
We started by building a design prototype of our website using Figma. As a result, we had a good idea of our design pattern and Figma provided us some CSS code from the prototype. Our front-end is built with React.js and our back-end with node.js. We used Firebase to host our website. We fetched datas of cryptocurrency from multiple APIs from: CoinMarketCap.com, CryptoCompare.com and NewsApi.org using Axios. Our website is composed of three components: the coin comparison tool, the news feed page, and the chatbot.
## Challenges we ran into
Throughout the hackathon, we ran into many challenges. First, since we had a huge amount of data at our disposal, we had to manipulate them very efficiently to keep a high performant and fast website. Then, there was many bugs we had to solve when integrating Cisco's widget to our code.
## Accomplishments that we're proud of
We are proud that we built a web app with three fully functional features. We worked well as a team and had fun while coding.
## What we learned
We learned to use many new api's including Cisco spark and Nuance nina. Furthermore, to always keep a backup plan when api's are not working in our favor. The distribution of the work was good, overall great team experience.
## What's next for AwsomeHack
* New stats for the crypto compare tools such as the number of twitter, reddit followers. Keeping track of the GitHub commits to provide a level of development activity.
* Sign in, register, portfolio and watchlist .
* Support for desktop applications (Mac/Windows) with electronjs | ## Inspiration
Recognizing the disastrous effects of the auto industry on the environment, our team wanted to find a way to help the average consumer mitigate the effects of automobiles on global climate change. We felt that there was an untapped potential to create a tool that helps people visualize cars' eco-friendliness, and also helps them pick a vehicle that is right for them.
## What it does
CarChart is an eco-focused consumer tool which is designed to allow a consumer to make an informed decision when it comes to purchasing a car. However, this tool is also designed to measure the environmental impact that a consumer would incur as a result of purchasing a vehicle. With this tool, a customer can make an auto purhcase that both works for them, and the environment. This tool allows you to search by any combination of ranges including Year, Price, Seats, Engine Power, CO2 Emissions, Body type of the car, and fuel type of the car. In addition to this, it provides a nice visualization so that the consumer can compare the pros and cons of two different variables on a graph.
## How we built it
We started out by webscraping to gather and sanitize all of the datapoints needed for our visualization. This scraping was done in Python and we stored our data in a Google Cloud-hosted MySQL database. Our web app is built on the Django web framework, with Javascript and P5.js (along with CSS) powering the graphics. The Django site is also hosted in Google Cloud.
## Challenges we ran into
Collectively, the team ran into many problems throughout the weekend. Finding and scraping data proved to be much more difficult than expected since we could not find an appropriate API for our needs, and it took an extremely long time to correctly sanitize and save all of the data in our database, which also led to problems along the way.
Another large issue that we ran into was getting our App Engine to talk with our own database. Unfortunately, since our database requires a white-listed IP, and we were using Google's App Engine (which does not allow static IPs), we spent a lot of time with the Google Cloud engineers debugging our code.
The last challenge that we ran into was getting our front-end to play nicely with our backend code
## Accomplishments that we're proud of
We're proud of the fact that we were able to host a comprehensive database on the Google Cloud platform, in spite of the fact that no one in our group had Google Cloud experience. We are also proud of the fact that we were able to accomplish 90+% the goal we set out to do without the use of any APIs.
## What We learned
Our collaboration on this project necessitated a comprehensive review of git and the shared pain of having to integrate many moving parts into the same project. We learned how to utilize Google's App Engine and utilize Google's MySQL server.
## What's next for CarChart
We would like to expand the front-end to have even more functionality
Some of the features that we would like to include would be:
* Letting users pick lists of cars that they are interested and compare
* Displaying each datapoint with an image of the car
* Adding even more dimensions that the user is allowed to search by
## Check the Project out here!!
<https://pennapps-xx-252216.appspot.com/> | partial |
## Inspiration
In last few years, the world has faced a lots of natural calamities.
The U.S. has sustained 298 weather and climate disasters since 1980 where overall damages/costs reached or exceeded $1 billion (including CPI adjustment to 2021). The total cost of these 298 events exceeds $1.975 trillion.
In 2021 (as of July 9), there have been 8 weather/climate disaster events with losses exceeding $1 billion each to affect the United States. These events included 1 drought event, 2 flooding events, 4 severe storm events, and 1 winter storm event. Overall, these events resulted in the deaths of 331 people and had significant economic effects on the areas impacted. The 1980–2020 annual average is 7.1 events (CPI-adjusted); the annual average for the most recent 5 years (2016–2020) is 16.2 events (CPI-adjusted).
Besides the United States, China and India have taken the hardest hit from natural disasters due to their massive population. Both nations accounted for over 280 crore disaster-affected people between 2000 and 2019, which is around 70 per cent of the global total.
Some 79,732 people have lost their lives and 108 crore people were affected in 321 incidents of natural disasters in India in the same duration, according to the United Nations Office for Disaster Risk Reduction.
While China recorded 577 natural disasters affecting 173 crore people and leading to 1.13 lakh deaths, the United States witnessed 467 incidents affecting 11 crore people in this period.
## What it does
Holonet saves your name, email, phone number, and location. When it gets any upcoming natural disaster updates alerts you via your mail and number.
### Implement Machine Learning
Predict the disasters using some datasets from Kaggle to increase its accuracy
### Disaster Record
Everytime the hardware alert the users about the upcoming disaster, the type of disaster will be stored in the database such that the users can look back the record and use it for report or study
## How we built it
Flask is used to connect the hardware with the backend.
NodeMCU is used to connect the hardware.
C++ is used to write the code for the hardware.
A gyroscope sensor is used for detecting earthquakes. Air quality and temperature sensors are used to detect wildfire
ReactJS is used to design the website that allows users to enter their information for disaster-alert subscription
Cassandra and AstraDB are used to store the user's data
## Challenges we ran into
Map Integration, Hardware and API Connectivity
## Accomplishments that we're proud of
We're proud of completing this project and can hopefully take it further.
## What we learned
We learned how to use React for the front-end, and connect an API to NodeMCU.
## What's next for HoloNet
We'll predict the disasters using some datasets from Kaggle to increase its accuracy. | ## Inspiration
During sweltering summer days, cars can be become very hot very fast. Many people accidentally leave their dogs, or even young children and infants, in their vehicles, while picking up groceries or shopping. Even though they expect to be gone for only 20 minutes or less, during this time, car temperatures can reach about 110 degrees within minutes. 39 children died of heat stroke in overheated cars in 2016, accumulating to hundred of child deaths since 1998. Thousands of pets die per year in these cars. We wanted to stop these tragic and preventable deaths.
## What it does
Hot Dog is an IoT application, using IBM Watson's Node-RED and the Raspberry Pi. Users place the hardware, comprised of the Raspberry Pi and a temperature sensor, near their windshield in the car. Hot Dog will keep track of the temperature within their vehicle while they are running errands. When the measured temperature is about to reach dangerously high-levels and it detects a presence in the car, the application will send a text message to the user, warning them that they are potentially putting their pet/child at risk of heat stroke. If the car does become extremely hot, the app will also call Animal Control or 911 automatically as a second resort. As another addition to the IoT capability, we have a twitter account linked that tweets from the pet's perspective calling for help on a large social scale. In addition, we have made a web application dashboard that displays the live temperature updates, grabs data from a weather api to display heat patterns, graphs the temperatures fetched through the Pi, and displays the tweets.
## How we built it
Our main platform runs on Node-RED, where we have the IoT device as the Raspberry Pi (or for demo purposes, an app that allows us to manually control the temperature). The IoT device connects to many outlet nodes, such as twitter, twilio, and http to send live data to each outlet. On the hardware side, we have the Pi connected to a temperature sensor to retrieve measures and send it to the server. Then, we have the web application created from HTML/CSS, Javascript, and Angular.js to display the live data, also using frameworks such as n3-charts and OpenWeatherMap to visualize the data and give a comprehensive insight into past and projected temperatures in and around the car. Most importantly, the web page displays the status of the car, whether it is dangerous, uncomfortable, or safe at the current moment in the car. We use Twilio to send messages to the user's phone if the car become too hot or to call the authorities in dire situations. We use Twitter to tweet live updates as well.
## Challenges we ran into
As first-time hardware hackers, we were completely new to using microprocessors and microcomputers. We went from trying to use the Raspberry Pi, to the Intel Edison, to the Arduino Uno, back to the Edison, and finally to choosing the Raspberry Pi. We were trying to figure out how to attach a temperature sensor and how to connect the device on Node-RED as an IoT device. After many installations and attempts, we finally managed to retrieve data from a Raspberry Pi. Additionally, we had to simulate the temperature, so we also used a separate IoT device to manually change the temperature. We had troubles learning how to use Node-RED and how to connect nodes and data payloads appropriately. The twitter feature had authorization issues as well. Every step felt like 3 steps back to begin with, but we finally had a product at the end.
## Accomplishments that we're proud of
We made an IoT application that works! We successfully connected the data from the Pi to multiple outlets/platforms including web, Android, and SMS tools. It was amazing to see how Node-RED could so easily send information live onto our phones and other laptops. Our idea actually solves a real-life problem that could potentially save many lives lost every year. All of us see on the news that some small child died of heat stroke while their parents were following their busy schedule and just simply forgot how hot the day was. Way too many helpless pets die from this very issue as well, and our app can work to lower the number of fatalities.
## What we learned
We expanded our horizons beyond simply software and integrated hardware into our hack. We learned of the crazy capabilities of the Raspberry Pi, how to interface the Pi with serial communication, and how to integrate peripheral senors onto the hardware. We learned about the power of Node-RED to connect everything together and more about how node modules work. As students from USC and Stanford and strangers at first, we learned how to emphasize everyone's talents yet also learn a lot about each part of the project.
## What's next for Hot Dog
Ideally, this application will be incorporated into cars across the country or encourage car manufactures to make their own implementations to monitor car temperatures. To improve the accuracy of our hardware, we will add sound sensors to detect noises such as barking or crying along with the temperatures so that users will only get notifications and warnings when the hardware is sure that the owner is out and there is life at risk in the car. The hardware will eventually have LED lights displaying warnings to passerbys when some being is threatened. We aim to educate people about the dangers of leaving lives in hot vehicles as well and raise awareness. We are improving our Android interface and tried making a Android launcher widget as well, so we definitely want to make more mobile apps for Hot Dog to supplement the mobile accessibility and provide information easily on mobile home screens like it does on our existing apps. | # MemoryMatch
## Inspiration 💡
We all have that one cherished childhood photo that holds a special place in our hearts. It's a snapshot that we long to recreate, a moment frozen in time. With MemoryMatch, we aim to turn this dream into reality. Our app not only helps you reminisce about your favorite childhood memories but also guides you through the process of reliving those precious moments.
## What it does ❓
Recreate your favourite memories through MemoryMatch. By leveraging real-time pose estimation technology, MemoryMatch compares the user's current position and the original photo.
1. **Precision Background Calibration:** Upload a photo from your childhood or any meaningful moment. MemoryMatch meticulously calibrates backgrounds, ensuring seamless alignment between the two images.
2. **Real-Time Pose Recreation:** MemoryMatch takes it a step further and utilizes cutting-edge real-time pose estimation technology. The app compares your current position with the original photo and provides step-by-step guidelines to adjust your pose, ensuring a close match to the original photo.
3. **Share or Save**: Once you've successfully matched the pose, share the recreated memories and have them join the challenge! You can also create individual albums to revisit your moments at any time.
## How we built it 🏗️
For the frontend development, we opted for React Native, specifically leveraging the Expo version, due to its cross-platform compatibility. This choice provided the development team with the advantage of testing the application on their individual devices without the need for intricate setups. Within React Native, we seamlessly incorporated several libraries, including TensorFlow JS, facilitating the integration of the pose detection model and collaboration with the skeleton in React Native.
Memory Match, is composed of three discrete modules, each designed to operate independently, thereby lowering the risk of failure and enhancing overall reliability. With this structure we followed a phased, but concurrent, implementation approach We initiated the development by defining our Expo App structure, followed by integration with the design, and incorporation of the Detector.
* Expo App: Serving as the central hub, this module manages and rapidly deploys during development, utilizing base React Native and higher-level libraries for mapping, information retrieval, and image manipulation. This results in a dedicated user pipeline that guides users through the app's functionality.
* Detector: The primary pose detection and estimation mechanism, based on Pose Net and run using TensorFlow JS, provides relative position scoring between two images. This scoring, adapted from a common method used in text analysis for measuring document similarity, ensures a highly accurate measure for the similarity of two poses.
* SIFT: To detect similarities in two images, we employ the extraction of "key points" common between them. Calculating the error between the original and the live image based on the difference in position between each pair of important key points allows us to determine the similarity between the images.
This comprehensive approach ensures the robustness and accuracy of Memory Match across its various modules. This ensured user accessibility, images, and albums were efficiently stored using local storage within the application, allowing users to retrieve their content at any time. This approach aligns with industry best practices and guarantees a robust, user-friendly experience.
## Challenges we ran into 🧩
**OpenCV:**
One of the primary hurdles encountered during the app development process pertained to integrating the openCV library with the mobile application. Given that the majority of the openCV library is structured for native platforms through Objective-C and Java, implementing it natively for each platform proved impractical due to time constraints. Consequently, we made the strategic decision to leverage React Native.
**React Native:**
However, adopting React Native presented its own set of challenges, notably the absence of crucial openCV libraries, leading to the omission of essential functions. This posed a potential hindrance to the overall functionality of the app. To address this limitation, we established a server component using Python to encapsulate the openCV app, enabling image processing by generating an outlined version. Despite these efforts, the resultant files exhibited corruption issues, rendering them unreadable by the React Native Image component.
**Solutions:**
In response to these challenges, we devised a streamlined solution involving a generalized skeleton, accompanied by a separate system for outline mapping implemented through Python and computer vision (CV). It is imperative to note that we explored TensorFlow as a substitute for openCV to load the pose detection model. Additionally, we transitioned from using GLView to Canvas for enhanced compatibility within the React Native framework.
## Accomplishments that we’re proud of 🏆
Despite encountering numerous challenges arising from platform compatibilities, we successfully developed two distinct applications tailored for mobile and desktop platforms.
**Native Machine Learning**
In the mobile application, we implemented a skeleton-based pose detection feature based on TensorFlow JS models, designed to signal when the user's posture aligns with the correct position. On the desktop version, a more robust and intricate system was crafted. This version dynamically generated a layout for the background, prompting users to fit within the designated space. The layout's colour dynamically changed when the user achieved the correct position, serving as a visual indicator of successful alignment.
**Versatility**
One significant accomplishment lies in the versatility of our model. Unlike many systems dependent on specific individuals, our pose detection model adapts seamlessly to the postures of any person, showcasing its broad applicability.
**Experimentation**
Additionally, our team excelled in experimentation within the realms of modelling and computer vision. Despite these fields being largely uncharted territory for our team, we embraced the challenge and successfully created a substantial and innovative solution. This adaptability and pioneering spirit underscore our commitment to pushing boundaries and achieving remarkable outcomes.
## What we learned 🧠
**Technical**
We acquired a profound understanding of computer vision, delving specifically into the intricacies of pose detection. This provided the opportunity to seamlessly integrate our extensive knowledge of linear algebra and advanced mathematical concepts into a sophisticated software framework. The application of such theoretical foundations allowed for the development of a nuanced and highly functional system.
Furthermore, confronted with a team largely unfamiliar with React Native, we embraced the challenge of mastering this technology promptly and applied it directly to our project. This initiative not only broadened our skill set but also enhanced our adaptability, reinforcing our ability to swiftly assimilate new technologies.
**Non-technical**
In addition to technical expertise, our collaborative efforts sharpened our skills in teamwork and efficient task delegation. Through adeptly distributing the workload among team members, we optimized the entire workflow, resulting in accelerated development timelines and streamlined debugging processes. This multifaceted learning experience not only enriched our individual capabilities but also contributed significantly to the overall sophistication and efficiency of our project development.
This experience informed how many of us view Hackathons and our own ability to successfully create something that is brand new to us, if not the world. It has been a massively positive experience, surrounded by excellent people that foster an environment to continue to actively engage in future experiences like this one.
## What’s next for Memory Match 🚀
**MORE POWER!**
We are currently exploring the integration of our Python-developed computer vision system, bolstered by enhanced computational capabilities, into the mobile application. This strategic move is intended to address unresolved issues present in the current app version. Additionally, we are considering the implementation of a cloud service to afford users the convenience of storing their images securely in the cloud, ensuring accessibility from any device.
**Geo Location**
Furthermore, we are contemplating the inclusion of a geolocation feature that notifies users when they are in a specific position where they previously attempted to replicate an image. This functionality aims to streamline the image capture process, automatically organizing the photos into the corresponding folders.
**Shared album**
In addition to these developments, we are exploring the option to add a shared album feature. For instance, people in the same high school can recreate the photo and share it with their classmates after a couple of years.
**Overall**
The roadmap for our application includes a range of possibilities for enhancement, fostering increased intelligence and overall improvement. We are committed to delivering a sophisticated and advanced user experience through strategic feature implementations. | partial |
## [Inspiration](https://media.giphy.com/media/oe8Ii2ZyKl1fy/giphy.gif)
[Money Money Money](https://www.youtube.com/watch?v=ETxmCCsMoD0)
[Poutine](mchacks-poutine.com)
[Money](https://media.giphy.com/media/SBAGQvzGbMR44/giphy.gif)
[Illuminati](http://illuminaticonfirmed.xyz/?secret=mchacks2016)
[Money](https://media.giphy.com/media/13B1WmJg7HwjGU/giphy.gif)
[Our lord and savior,Shia Labeouf](https://www.youtube.com/watch?v=ZXsQAXx_ao0)
[Money](https://media.giphy.com/media/n59dQcO9yaaaY/giphy.gif)
## [What it does](https://media.giphy.com/media/l4KhNPQssDrjr36a4/giphy.gif)
Simulate yourself ["making it rain"](https://media.giphy.com/media/3WyaE6QpdoJTa/giphy.gif) in virtual reality using an [oculus rift](https://media.giphy.com/media/d6Unw9Ke0vCFO/giphy.gif) and a [leap](https://media.giphy.com/media/EfstMjU18SUwM/giphy.gif) motion sensor.. making you feel like even you have [$282.6 Billion in assets](http://www.cppib.com/en/home.html).
## [How we built it](http://i.imgur.com/apDIQhE.webm)
[Magic](https://media.giphy.com/media/VHngktboAlxHW/giphy.gif)
[Unity](https://media.giphy.com/media/uZV9vl2xExtlu/giphy.gif)
[LeapMotion](https://media.giphy.com/media/EfstMjU18SUwM/giphy.gif)
[Google Sketchup](https://media.giphy.com/media/24VfLifkcc7Cg/giphy.gif)
[Sugar, Spice, and Everything Nice.](https://media.giphy.com/media/LUP2aIHiivhcI/giphy.gif)
## [Challenges we ran into](http://tv.giphy.com/futurama)
[No experience with Unity, Leap, or Oculus.](https://media.giphy.com/media/fAjPCZNOtmTLy/giphy.gif)
Our game did not solve [world poverty](http://www.worldbank.org/en/topic/poverty/overview) or [pay our student loans](https://osap.gov.on.ca/).
[Leap motion development still in beta.](https://media.giphy.com/media/LYIrqpwtZ5b1e/giphy.gif)
[Myo was originally chosen over the leap; did not work consistently](https://media.giphy.com/media/cDSrbAVpHBecU/giphy.gif)
[Downloading unity took many hours.](https://media.giphy.com/media/HgyGnsYbEuY3C/giphy.gif)
[Realizing the rift doesnt support OSX](https://media.giphy.com/media/3rgXBPgEKFjLdeE8Yo/giphy.gif)
[Working on 4 other hack ideas and not doing this one until its too late](https://media.giphy.com/media/Nx85vtTY70T3W/giphy.gif)
## Accomplishments that we're proud of
[Our team-building team building microsoft tower.](http://i.imgur.com/A7zlZqH.jpg)
[game is actually able to run...kinda.](https://media.giphy.com/media/pVtulZdJsUuCQ/giphy.gif)
[Mad money.](https://media.giphy.com/media/5fMlYckytHM4g/giphy.gif)
[Learning about money](https://media.giphy.com/media/7mUMoIPGzyFvW/giphy.gif)
[Learning unity, leap, and using the rift](https://media.giphy.com/media/qKltgF7Aw515K/giphy.gif)
[Showing your hands in game with the leap](https://media.giphy.com/media/ltMLWLHyjuHkY/giphy.gif)
[Our game makes you slightly nauseous](https://media.giphy.com/media/3oEdvaWfB09qNbyzZK/giphy.gif)
## What we learned
[Money](https://media.giphy.com/media/TjQnAdKBIc5he/giphy.gif)
[We weren't prepared enough](https://dykewriter.files.wordpress.com/2015/09/justin-trudeau-just-not-ready-canada-conservatives.png)
## What's next for Dank Dollar$
[Solve world poverty](https://media.giphy.com/media/GSE1BzJG4JVbq/giphy.gif)
[Make it less terrible](https://media.giphy.com/media/8rI0mUYTkOXpS/giphy.gif)
[Repeat with real money in real world. hopefully more realistic.](http://45.media.tumblr.com/f0716c4d08e809c1a2fdc5a24bffa4f3/tumblr_nzhmdi4gju1rrx588o1_500.gif)
[add more money](https://media.giphy.com/media/3oEdvbpl0X32bXD2Vi/giphy.gif)
[replace bitcoins](https://media.giphy.com/media/wcwuYrlbkfnqM/giphy.gif)
[add in app purchases and DLCs](https://media.giphy.com/media/z9BW7ApDO6hTq/giphy.gif)
[POUTINE](https://media.giphy.com/media/KG1jbRHkE7pHG/giphy.gif)
[Make america great again](https://media.giphy.com/media/jSB2l4zJ82Rvq/giphy.gif) | ## Inspiration; We want to test the boundaries of Virtual Reality and real life. We want to know if you can immerse yourself so strongly in a Virtual environment that your sensory perception is affected. Can you \_ feel \_ the wind from the virtual environment? Ask yourself if you have goosebumps because of how cold the weather is...virtually? We're going to show you \*\* what the *world* is feeling. \*\*
## What it does; Project HappyMedia interacts with the user on a web application that accesses information about what the world is \_ currently \_ feeling. On the backend, it is moved into a Database (using Mongodb) and the most current (today's) rating is recalled. It then simulates the feelings of the world into a virtual world using Unity. We create a mood sensitive environment through landforms, weather, time of day, etc. The viewer doesn't get to know the mood of the world until they put on the Oculus and *feel* the mood of the world. Our Oculus simulation currently runs separate to the web application because we had no access to an Oculus and wouldn't be able to test the functionality of the front end web application if it ran straight to the Oculus.
## How I built it; The Oculus environments were built in Unity using Oculus and Unity APIs. The Front end was built using Sublime as a text editor and using MongoDB and Node.js. The API we used to get the global happiness takes people's input all across the world and it updates with respect to the timezones (it updates more than once a day). It is built for mood tracking across the globe. The API also gives us information about the global rate of happiness. For our use of it, it also does update as the happiness factor goes up and down throughout the day.
## Challenges I ran into; We ran into a lot of challenges with the database (getting values OUT of the database using indexing in particular). We really wished that MongoDB had a representative that could have assisted us because it seemed like there were some small issues in which we couldn't get enough community support and help with on the internet but they could have quickly resolved. Of course, we cannot reiterate enough how hard it is to try to develop for hardware without having it to debug and test. We were really really interested in using it from the beginning which is why we persisted with the project regardless and we hope it doesn't affect the judging too much that we are not able to provide a full on demo.
## Accomplishments that I'm proud of; Every single team member worked with technology and software that was challenging for them as well as our project was definitely challenging for us from the beginning. We knew that it would have been logical to do a web app OR an Oculus simulation and that linking them was going to be very tricky, however, we were passionate that our idea was extremely worthwhile and any progress we make could later be improved and updated. It's definitely an idea that we are proud to work on and want to continue to see through to the finish.
## What I learned; We all learned an incredible amount from what we worked with in our separate tasks; Unity, Mongo, Node.js, etc. We also learned a lot about modularizing, not really self motivated but simply because we couldn't build the project seamlessly to work from start to finish without the Oculus. Therefore we had to separate it in a manner that could be stitched together easily at a later date. We definitely learned a lot from the talks and workshops along the way and I think that is a large reason we were so motivated not to give up on the two tasks that are independent of eachother but really do go together to make a set. Simply creating an Oculus Rift/Unity world simulation has been done before. It lacks creativity and purpose and mostly makes use of Unity's terrain builder. On the other hand, a Web app simply returning the happiness rating of the world currently is definitely cool, but how long before you forget about it and never use it? It would make almost no impression whatsoever on the user. It could be as forsaken as checking the weather. Together it stimulates interest, curiosity and mystery about the boundaries of Virtual Reality and human connectivity.
## What's next for HappyMedia; We hope to impress the judges with our application of the Oculus Rift API enough to get the DK2 prizes and with that continue to implement our ideas for this. The amount we have done in one weekend on this project is huge, monumental in fact, and if we can work on things at even half the pace we are going to be beta testing in no time. We have high hopes to get something testable by the end of this year and hopefully get some more Unity/Oculus worlds developed as well. | ## Inspiration
How long does class attendance take? 3 minutes? With 60 classes, 4 periods a day, and 180 school days in a year, this program will save a cumulative 72 days every year! Our team recognized that the advent of neural networks yields momentous potential, and one such opportunity is face recognition. We utilized this cutting-edge technology to save time in regards to attendance.
## What it does
The program uses facial recognition to determine who enters and exits the room. With this knowledge, we can keep track of everyone who is inside, everyone who is outside, and the unrecognized people that are inside the room. Furthermore, we can display all of this on a front end html application.
## How I built it
A camera that is mounted by the door sends a live image feed to Raspberry pi, which then transfers that information to Flask. Flask utilizes neural networks and machine learning to study previous images of faces, and when someone enters the room, the program matches the face to a person in the database. Then, the program stores the attendees in the room, the people that are absent, and the unrecognized people. Finally, the front end program uses html, css, and javascript to display the live video feed, the people that are attending or absent, the faces of all unrecognized people.
## Challenges I ran into
When we were using the AWS, we uploaded to the bucket, and that triggered a Lamda. In short, we had too many problematic middle-men, and this was fixed by removing them and communicating directly. Another issue was trying to read from cameras that are not designed for Raspberry pi. Finally, we accidentally pushed the wrong html2 file, causing a huge merge conflict problem.
## Accomplishments that I'm proud of
We were successfully able to integrate neural networks with Flask to recognize faces. We were also able to make everything much more efficient than before.
## What I learned
We learned that it is often better to directly communicate with the needed software. There is no point in having middlemen unless they have a specific use. Furthermore, we also improved our server creating skills and gained many valuable insights. We also taught a team member how to use GIT and how to program in html.
## What's next for Big Brother
We would like to match inputs from external social media sites so that unrecognized attendees could be checked into an event. We also would like to export CSV files that display the attendees, their status, and unrecognized people. | losing |
## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | ## Inspiration
The inspiration came from working with integrated BMCs on server motherboards. These devices are able to control servers remotely without the need of an operating system on the server. This is accomplished by streaming the servers' VGA input and attaching a keyboard via USB. The major pain points about BMCs are that they are normally embedded on the servers, the streamed keyboard input is prone to errors and that since the screen is streamed the screen is not interactable. Our prescriptive design was a small portable device that has the same functionality as the BMC while solving these pain points and adding smart home functionality features.
## Challenges we ran into
Originally, we planned to use the Raspberry Pi 3 because it had an onboard network module which eliminates one step in the integration process. Unfortunately, the Raspberry Pi 3 cannot emulate USB HID devices such as a keyboard, which made it infeasible to use. Once we switched to the Raspberry Pi Pico, which could emulate a keyboard but didn’t have WIFi, we had to integrate it with a network module ESP8266 or ESP32. We encountered difficulties powering the module through the RPI and later discovered that both require 5v while our RPI only provided 3.3v. Furthermore, the RPI Pico does not have USB ports to support the display capture feature we aimed to implement, instead we added additional features.
## What it does
Marcomancer main features are the following:
* Run Macros Remotely via USB Keyboard Emulation
* Programmable Smart Home Voice Activated Macros
* Robust Input Streaming via Web App
* Portable Plug and Play
These features solve two of the major BMC pain points of no portability and error prone input. The system also allows system administrators to reliably program macros to remote servers. Macromancer is not only for tech savvy individuals but also provides smart accessibility to anyone through voice control on their phones to communicate to their PC. As long as you can accomplish a task with just keyboard inputs, you can use Macromancer to send a macro from anywhere.
## How we built it
Hardware: The RPI Pico that waits for keycodes transmitted by the ESP32. ESP32 polls our cloud server for commands.
Software: Google Assistant sends predefined user commands to the cloud server webhook via IFTTT applets. Users can also use our Frontend Web App to manually queue command strings and macros for the ESP32 to poll via a GET API.
## Accomplishments that we're proud of
* Ability for users to add/delete any new commands
* Integrating with the network modules
* The minimum latency
## What we learned
* Flashing firmware on microprocessors
* Emulating keyboard through microprocessors (Adafruit)
* TCP and Checksum error detection
* Activating webhooks with Google Assistant
* How to communicate between microprocessors
## What's next for Macromancer
* Better security (encryption)
* RPI 4 (reduce hardware and allow display capture for text editing)
* Wake on LAN | ## Inspiration
The inspiration behind this hack was going back through lecture videos before a midterm and wishing there was a way to store notes directly onto the video as opposed to taking notes on paper and then having to figure out what time of the video they correspond to. We wanted something that would move with us – if we’re in a 21st century classroom, why not push our note-taking to reflect how we learn?
## What it does
Imagine a video being an interaction of ideas and a platform for conversation instead of a passive, solitary experience. Whether you’re watching a webcast lecture or a kitten video, YAnnotator lets you make your voice heard. Search for a new video, copy a link to an existing video, or join in someone else’s exchange in our application – and then annotate it like you would an interesting article or your lecture notes. You can share the room and collaborate on the markups, bringing the video to life with relevant, timed commentary.
## How we built it
YAnnotator has both a mobile and web interface that communicate with a server running on Azure and AWS. The user can either search for a video using Bing's Video API or they can join an existing room which is made private through a hashing system. Users then have the ability to upload annotations at specific time stamps
## Challenges we ran into
Deploying a web application on Azure turned into a much more involved experience than we expected as our instances kept crashing despite our development considerations. Most of us were unfamiliar with the technologies used in this project, including Node, Angular, and Mongo, so installing and working with these applications was challenging. We had difficulties passing requests between the mobile application and the server as well.
## Accomplishments that we're proud of
We learned and worked successfully on technologies such as Node, Angular, Azure, Mongo, the Bing Video API, and iOS. A lot of these had a steep learning curve, but we’re proud to have stuck with it and put in the time to learn how these developer tools work. Any video link can now be ported into our web application and commented on, and this generated combination of video and annotations can be passed around, referenced at any time, and edited by anyone who has the link. | winning |
## Inspiration
Before the hackathon started, we noticed that the oranges were really tasty so we desired to make a project about oranges, but we also wanted to make a game so we put the ideas together.
## What it does
Squishy Orange is a multiplayer online game where each user controls an orange. There are two game modes: "Catch the Squish" and "Squish Zombies". In "Catch the Squish", one user is the squishy orange and every other user is trying to tag the squish. In "Squish Zombies", one user is the squishy orange and tries to make other oranges squishy by touching them. The winner is the last surviving orange.
## How we built it
We used phaser.io for the game engine and socket.io for real-time communication. Lots of javascript everywhere!
## Challenges we ran into
* getting movements to stay in sync across various scenarios (multiple players in general, new players, inactive tabs, etc.)
* getting different backgrounds
* animated backgrounds
* having different game rooms
* different colored oranges
## Accomplishments that we're proud of
* getting the oranges in sync for movements!
* animated backgrounds
## What we learned
* spritesheets
* syncing game movement
## What's next for Squishy Orange
* items in game
* more game modes | ## Inspiration
The Riff Off idea comes from the movie series Pitch Perfect. Our game works similar to the Riff Off in the movie, except players select the songs from our song bank and play from there to earn points instead of sing.
## What it does
It is a multiplayer mobile application that works on both iOS and Android. It allows players to compete by selecting a song that matches the beat of the previous song and earn score. Players can join the same session by the use of QR codes. Then, the game requires players to constantly change songs that have a similar BPM as the last one being played to earn points. The longer a song stays up, the more points that player earns.
## How we built it
We used ionic with an express + mongo backend hosted on an EC2 instance.
## Challenges we ran into
We ran into way too many challenges. One of the major issues we still have is that android phones are having issues opening up the game page. It worked until the last couple of hours. Also, having multiple devices play the song at the same time was challenging. Also, generating score and syncing it across all players' devices was not easy.
## Accomplishments that we're proud of
* It's pretty
* It doesn't crash like 60% of the time
* As a team of mostly newish hackers we actually finished!!
* Did we mention it's pretty?
## What we learned
For most of our team members it is our first time using ionic. This allowed us to learn many new things like coding in typescript.
## What's next for Beat
Get Android to work seamlessly. There remain some minor styling and integration issues. Also, in our initial planning, points are given for the matching of lyrics on coming in. We did not have enough time to implement that, so our score is currently only generated by time and BPM. The next step would be to include more ways to generate the score to make a more accurate point system. A final detail we can add is that currently the game does not end. We can implement a set amount of time for each game, or allow the players to determine that. | ## Inspiration
## What it does
2D fighter game in which shouting out your enthusiasm is the only way to become stronger!
## How I built it
Android and web app connected through Syncano API.
## Challenges I ran into
* Converting raw microphone data into useful information
* Linking mobile and web app through 3rd party API to achieve reliable UI
## Accomplishments that I'm proud of
## What I learned
## What's next for SuperLoud | partial |
## Inspiration
I read a paper on an app named fingerIO that would use active Sonar and two microphones to trilaterate(length based triangulation) to map where a hand moved. I thought that if you just had the source attempting to identify itself you could take it a step further.
## What it does
It will track in 3D space a phone emitting a designed series of chirps 13 times second. These chirps are inaudible to humans.
## How we built it
We used 3 laptops and and IPhone. We put the coordinates of the laptops and the phones starting position and then began playing the chips at regular intervals. we used this to calculate how far the phone was from each laptop, and then trilaterate the position. We would then plot this in 3D in matplotlib.
## Challenges we ran into
The clock speed of each of the computers is slightly different. Because sound travels at 340 meters per second a drift of less than milliseconds would make it impossible to track. We ended up hard coding in a 0.0000044 second adjusted period of chirps to compensate for this.
## Accomplishments that we're proud of
That it actually worked! Also that we overcame so many obstacles to make something that has never been made before.
## What we learned
We learned a lot about how sonar systems are designed and how to cross-correlate input signals containing random white noise with known signals. We also learned how to use many of the elements in scipy like fourier transforms, frequency modulated chirps, and efficient array operations.
## What's next for Trimaran
I would like to use the complex portion of the fourier transform to identify the phase offset and get distance readings more accurate than even the 96000 Hz sound input rate from our microphones could find. Also, it would be cool to add this to a VR headset like google glass so you could move around in the VR space instead of just moving your head to look around. | ## Inspiration
One of our team members, Nicky, has a significant amount of trouble hearing (subtle) noises! The name behind our application, Tricone, was first canned because of the triangular, hat-like shape of our hardware contraption, which resembled a tricorn. Later, we changed the name to Tricone because of the three types of cones that we have in our retinas -- red, green, and blue -- which represent the color in our world.
## What it does
Tricone is an AR mobile application that uses the direction and location of sounds to provide real-time visualization in order to help people who have trouble with hearing be able to detect their surroundings. The application displays the camera screen with dots, which represent the location and intensity of sounds nearby, and updates as the camera feed is updated as the user moves around.
## How we built it
First thing, we began building through installing Android Studio onto our laptops and then downloading Flutter SDK and the Dart language for the IDE. Then once we fully developed our idea and process, we rented an Arduino 101, 15 Digi-Key components (jumper wires, sound sensors and a soldering kit and iron), and an Adafruit Bluefruit BLE (Bluetooth Low Energy) Breakout wireless protocol. The next day, we wired our components to the Arduino so that the sound sensors formed an equilateral triangle with a 20cm side length each by measuring 120° between the sensors and so that we could establish connectivity between the Arduino with the mobile app.
Our mission was to be able to translate sound waves into identifiable objects based on their location and direction. We determined that we would need hardware components, such as a microcontroller with sensors that had powerful microphones to distinguish between nearby sounds. Then we worked on implementing Bluetooth to connect with our Flutter-based mobile application, which would receive the data from the three sound sensors and convert it into graphics that would appear on the screen of the mobile app. Using Augmented Reality, the mobile application would be able to display the location and intensity of the sounds as according to the camera's directionality.
### Theoretical research and findings behind sound triangulation
In general, sound localization of a sound source is a non-trivial topic to grasp and even produce in such a short amount of time allotted in a hackathon. At first, I was trying to understand how such a process could be replicated and found a plethora of research papers that were insightful and related to this difficult problem. The first topic I found related to sound localization through a single microphone: monaural capturing. Another had used two microphones, but both experiments dealt with ambiguity of the direction of a sound source that could be anywhere in the 2D plane. That is the use of three microphones was settled on for our hackathon project since ambiguity of direction would be lifted with a third microphone in place.
Essentially, we decided to utilize three microphones to localize sound by using each microphone as an edge to an equilateral triangle centered at the origin with a radius of 20. The key here is that the placement of the microphones is non-collinear as a linear placement would still bring ambiguity to a sound that could be behind the mics. The mics would then capture the sound pressure from the sound source and quantify it for determining the location of the source later on. Here, we took the sound pressure from each mic because there is an inverse relationship between sound pressure and distance from an incoming sound, making it quite useful. By creating a linear system from the equations of circles from the three mics as their locations are already known and deriving each mic’s distance to the source as radii, we were able to use Gaussian elimination method to find an identity matrix and its solution as the source’s location. This is how we triangulated the location: the sound source assuming that there is only one location where the three circles mentioned previously can intersect and the position of the mics are always in a triangular formation. This method of formulation was based on the limitations posed by the hardware available and knowledge of higher-level algorithms.
Another way of visualizing the intersection of the three circles is a geometrical image with radical lines, where the intersection of all those lines is the radical center. However, in this specific case, the radical center is simply the intersection based on the previous assumption of one possible intersection with a triangular positioning at the origin. The figure below generalizes this description.
## Challenges we ran into
A significant chunk of time was spent dealing with technical hurdles, since many of us didn't come in with a lot of experience with Flutter and Dart, so we dealt with minor software issues and program bugs. We also had to research a lot of documentation and read plenty of Stack Overflow to understand the science behind our complex idea of detecting direction and distance of sound from our hardware. in order to solve issues we ran into or just to learn how to implement things. Problems with integrating our mobile application with the hardware provided, given the limited range of plugins that Flutter supported, made development tricky and towards the end, we decided to pivot and change technologies to a web application.
We also faced problems more-so on the trivial side, such as not being able to compile our Flutter app for several hours due to Gradle synchronization problems within Android Studio, and other problems that related to the connectivity between the Arduino BLE and our mobile application.
As an alternative, we created a web application to process HTTP requests to substitute Bluetooth connectivity through Google Hosting, which would make web API calls with the technology and host a PWA-based (Progressive Website Application) app and still be compatible for mobile app usage.
## Accomplishments that we're proud of
We are proud of coming up and following through on a multifaceted project idea! We divvied up the work to focus on four key areas: hardware, mobile app AR functionality, network connectivity, and front-end design. Our team as a whole worked incredibly hard on making this a success. Some of our most memorable milestones were: 1) being able to successfully control a smartphone to connect to the Arduino via Bluetooth, and 2) finalizing a theoretical formula for sound triangulation based on mathematical research!
## What we learned
Especially because all of us had little to no prior experience in at least one of the technologies we used, we were all able to learn about how we are able to connect software with hardware, and also conceptualize complex algorithms to make the technology possible. Additionally, we found the importance of pinpointing and outlining the technologies we would use for the hackathon project before immediately jumping into them, as we later determined midway into the day that we would have had more resources if we had selected other frameworks.
However, we all had a pleasant experience taking on a major challenge at HackHarvard, and this learning experience was extremely exciting in terms of what we were able to do within the weekend and the complexity of combining technologies together for widespread applications.
## What's next for TRICONE
Our application and hardware connectivity has significant room to grow; initially, the idea was to have a standalone mobile application that could be easily used as a handheld. At our current prototyping stage, we rely substantially on hardware to be able to produce accurate results. We believe that a mobile application or AR apparatus (ex. HoloLens) is still the end goal, albeit requiring a significant upfront budget for research in technology and funding.
In future work, the method of localization can be improved by increasing the number of microphones to increase accuracy with higher-level algorithms, such as beamforming methods or Multiple Signal Classification (MUSIC), to closely fine-precise the source location. Additionally, in research, fast Fourier Transformations to turn captured sound into a domain of frequencies along with differences in time delays are often used that would be interesting to substitute the comparatively primitive method used originally in this project. We would like to implement an outlier removal method/algorithm that would exclude unrelated sound to ensure localization can still be determined without interruption. Retrospectively, we learned that math is strongly connected in real-world situations and that it can quantify/represent sound that is invisible to the naked eye. | ## Inspiration
We wanted to use Livepeer's features to build a unique streaming experience for gaming content for both streamers and viewers.
Inspired by Twitch, we wanted to create a platform that increases exposure for small and upcoming creators and establish a more unified social ecosystem for viewers, allowing them both to connect and interact on a deeper level.
## What is does
kizuna has aspirations to implement the following features:
* Livestream and upload videos
* View videos (both on a big screen and in a small mini-player for multitasking)
* Interact with friends (on stream, in a private chat, or in public chat)
* View activities of friends
* Highlights smaller, local, and upcoming streamers
## How we built it
Our web-application was built using React, utilizing React Router to navigate through webpages, and Livepeer's API to allow users to upload content and host livestreams on our videos. For background context, Livepeer describes themselves as a decentralized video infracstucture network.
The UI design was made entirely in Figma and was inspired by Twitch. However, as a result of a user research survey, changes to the chat and sidebar were made in order to facilitate a healthier user experience. New design features include a "Friends" page, introducing a social aspect that allows for users of the platform, both streamers and viewers, to interact with each other and build a more meaningful connection.
## Challenges we ran into
We had barriers with the API key provided by Livepeer.studio. This put a halt to the development side of our project. However, we still managed to get our livestreams working and our videos uploading! Implementing the design portion from Figma to the application acted as a barrier as well. We hope to tweak the application in the future to be as accurate to the UX/UI as possible. Otherwise, working with Livepeer's API was a blast, and we cannot wait to continue to develop this project!
You can discover more about Livepeer's API [here](https://livepeer.org/).
## Accomplishments that we're proud of
Our group is proud of the persistance through the all the challenges that confronted us throughout the hackathon. From learning a whole new programming language, to staying awake no matter how tired, we are all proud of each other's dedication to creating a great project.
## What we learned
Although we knew of each other before the hackathon, we all agreed that having teammates that you can collaborate with is a fundamental part to developing a project.
The developers (Josh and Kennedy) learned lot's about implementing API's and working with designers for the first time. For Josh, this was his first time implementing his practiced work from small projects in React. This was Kennedy's first hackathon, where she learned how to implement CSS.
The UX/UI designers (Dorothy and Brian) learned more about designing web-applications as opposed to the mobile-applications they are use to. Through this challenge, they were also able to learn more about Figma's design tools and functions.
## What's next for kizuna
Our team maintains our intention to continue to fully develop this application to its full potential. Although all of us our still learning, we would like to accomplish the next steps in our application:
* Completing the full UX/UI design on the development side, utilizing a CSS framework like Tailwind
* Implementing Lens Protocol to create a unified social community in our application
* Redesign some small aspects of each page
* Implementing filters to categorize streamers, see who is streaming, and categorize genres of stream. | losing |
## Inspiration
Customer reward loyalty programs are becoming more and more centralized, with reduced use of paper coupons that were able to be traded among people and the creation of more app-based claiming platforms (think Starbucks, Chipotle, Snackpass). In addition, with the pandemic, customers and the businesses they visit are losing out on experiences and sales, respectfully. Bazaar aims to bridge this gap by empowering customers and businesses.
## What it does
* Basics
The platform itself is hosted on the Terra blockchain, using reward "tokens" (Bazaars, BAZ) that are minted at 1% of any user purchase from a local business using their Terra wallet. At certain timeframes or purchases at a business, users may also receive a redeemable coupon for that specific business. Users are able to redeem Bazaar tokens for coupons, as well. Using GPS + a shared QR code, the more people purchasing from a company at the same time in a group, the more BAZ will be minted and distributed among the group.
* Walkthrough of Minting:
* User links wallet in app
* User buys item from store with UST
* UST sent through our contract
* Contract mints BAZ to User’s wallet based on how much they spent
* Contract passes UST to restaurant’s wallet
* User-Powered Marketplace
Users are able to sell coupons for Bazaar tokens to other users through the Marketplace. This allows for coupons to still be redeemed at business, bringing traffic and preventing loss of sales.
## How we built it
Our UI is through Android Studio + Java. The tokens are minted and executed through a smart contract on the Terra blockchain using their Python SDK.
## Challenges we ran into
* Figuring out how to use Terra, which SDK to use (python versus javascript), learning how to write and interpret smart contracts/tokens in Rust.
* Combining the python backend with the android studio (by creating a Flask server and using Volley/Retrofit to pass HTTP requests between the two).
## Challenges we ran into
* Figuring out how to use Terra, which SDK to use (python versus javascript), learning how to write and interpret smart contracts/tokens in Rust.
* Combining the python backend with the android studio (by creating a Flask server and using Volley/Retrofit to pass HTTP requests between the two).
## Accomplishments that we're proud of
We are proud of learning how to develop Android apps without having any prior experience. We are also extremely proud of minting our own token and creating a smart contract on the Terra Blockchain which is a very newer platform with limited documentation.
## What we learned
* Learning a new SDK within a couple hours is pretty difficult
* Proper documentation is essential when using a new framework. If the documentation does not detail every step needed it is very hard to reproduce.
## What's next for Bazaar | ## Ark Platform for an IoT powered Local Currency
## Problem:
Many rural communities in America have been underinvested in our modern age. Even urban areas such as Detroit MI, and Scranton PA, have been left behind as their local economies struggle to reach a critical mass from which to grow. This underinvestment has left millions of citizens in a state of economic stagnation with little opportunity for growth.
## Big Picture Solution:
Cryptocurrencies allow us to implement new economic models to empower local communities and spark regional economies. With Ark.io and their Blockchain solutions we implemented a location-specific currency with unique economic models. Using this currency, experiments can be run on a regional scale before being more widely implemented. All without an increase in government debt and with the security of blockchains.
## To Utopia!:
By implementing local currencies in economically depressed areas, we can incentivize investment in the local community, and thus provide more citizens with economic opportunities. As the local economy improves, the currency becomes more valuable, which further spurs growth. The positive feedback could help raise standards of living in areas currently is a state of stagnation.
## Technical Details
\*\* LocalARKCoin (LAC) \*\*
LAC is based off of a fork of the ARK cryptocurrency, with its primary features being its relation to geographical location. Only a specific region can use the currency without fees, and any fees collected are sent back to the region that is being helped economically. The fees are dynamically raised based on the distance from the geographic region in question. All of these rules are implemented within the logic of the blockchain and so cannot by bypassed by individual actors.
\*\* Point of Sale Terminal \*\*
Our proof of concept point of sale terminal consists of the Adafruit Huzzah ESP32 micro-controller board, which has integrated WiFi to connect to the ARK API to verify transactions. The ESP32 connects to a GPS board which allows verification of the location of the transaction, and a NFC breakout board that allows contactless payment with mobile phone cryptocurrency wallets.
\*\* Mobile Wallet App \*\*
In development is a mobile wallet for our local currency which would allow any interested citizen to enter the local cryptocurrency economy. Initiating transactions with other individuals will be simple, and contactless payments allow easy purchases with participating vendors. | ## Inspiration + Impact
This project was inspired by a team member’s sibling who underwent cancer treatment, which limited his ability to communicate. American Sign Language (ASL) enabled the family to connect despite extenuating circumstances. Sign language has the power of bringing together hearing, hard-of-hearing, and deaf individuals. The language barrier between ASL-speakers and non-ASL speakers can lead to misdiagnosis in a medical setting, improper incarceration, lack of attention during an emergency situation, and inability to make connections with others. With just the power of sticky notes and a device, learning possibilities are endless.
## Business Validation
According to the National Institute on Deafness and Other Communication Disorders, 13% of people aged 12 or older have hearing loss in both ears. But the Deaf and hard-of-hearing community are not the only ones who can learn ASL. In a survey conducted of college students, 90% desired to learn American Sign Language but felt intimidated about learning a new language. College students are the next generation of doctors, lawyers, technologists. They are our primary target demographic because they are most open to learning and are about to enter the workforce and independent life. In user interviews, people described learning a new language as “time-consuming,” “hard to retain without practice,” and “beautiful because it helps people communicate and form strong bonds.” This age group enjoys playing brain stimulating games like Wordle and Trivia.
## What StickySign Does (Differently)
StickySign makes language stick, one sign at a time. Through gamification, learning ASL becomes more accessible and fun. Signers learn key terms and become energized to practice ASL outside their community. StickySign differentiates itself from education-giants Duolingo and Quizlet. Duolingo, responsible for 60% of the language learning app shares, does not offer sign language. Quizlet, a leading study tool, does not offer unique, entertaining learning games; it is traditional with matching and flashcards. StickySign can be played anywhere. In a classroom -- yes. On your window -- for sure. On someone’s back -- if you want. Where and however you want to set up your sticky notes, you can. Levels and playing environments are endless.
## How We Built It
Hack Harvard’s Control, Alt, Create theme inspired us to extend StickyAR, a winning project from HackMIT’19, and develop it from being a color-based game to making American Sign Language more accessible to learn. We altered and added to their algorithm to make it respond to questions. Using OpenCV’s Contour Recognition software, StickySign fits images of signs on sticky notes and recognizes hand shapes.
## Challenges We Ran Into
We ran into a few challenges (learning opportunities) which helped us grow as developers and spark new interests in technology. Our first challenge was learning the StickyAR code and ideating how to remake it with our use cases in mind. The other roadblock was getting the code and external hardware (projector + video camera) to work in tandem.
## Accomplishments We Are Proud Of
We are proud of our teamwork and continuous encouragement, despite facing several challenges. Resiliency, hard work, comradery, and coffee carried us to the end. Being able to create an impactful webapp to make ASL more accessible is the biggest reward. It is heartwarming to know our project has the potential to break down communication barriers and empower others to feel connected to American Sign Language.
## What We Learned
Before two weeks ago, none of us attended an in person hackathon; by the end of this event we were amazed by how our minds expanded from all the learning. Researching the psychology of gamification and how this strategy acts as an intrinsic motivator was exciting. We learned about the possibilities and limitations of OpenCV through trial and error, YouTube videos, and mentorship. Jaiden was thrilled to teach the group American Sign Language from her experience interacting both inside her studies and within the Deaf community; now we can fingerspell to each other. Completing this project gave us an appreciation for being scrappy and not afraid to try new things.
## What’s Next for StickySign
StickySign was created with the intention of making American Sign Language more accessible. In future iterations, users can graduate from fingerspelling and learn signs for words. Additionally, with computer vision, the device can give the user feedback on their handshape by a machine-learning trained algorithm. We would conduct a proof-of-concept at State of New York University at Binghamton, which has a rich ASL community and need for ASL-speakers. After inputting this feedback and debugging, we foresee expanding StickySign within another State of New York University and having the university system adopt our application, through annual subscriptions.
We have a vision of partnering with Post-It Note to donate supplies (sticky notes and devices) to communities that are under-resourced. This strategic partnership will not only help our application gain traction but also make it visible to those who may not have been able to learn American Sign Language. Further support and application visibility can come from American Sign Language speaking influencers like Nyle DiMarco and Marlee Matlin using their platform to raise awareness for StickySign.
* Tell us how your experience with MLH’s sponsor technology went.
Give us some feedback about any of the MLH sponsored technology you interacted with at this hackathon. Make sure you mention what tech you're reviewing (e.g. Twilio, GitHub, DeSo etc.).
GitHub allowed us to collaborate on our code with the comfort of our individual laptops. Its open-source capabilities enabled us to expand the StickyAR code. The version-control feature let our team go back to previous edits and debug when necessary. | partial |
## Inspiration
The MIT mailing list free-food is frequently contacted by members of the community offering free food. Students rush to the location of free food, only to find it's been claimed. From the firsthand accounts of other students as well as personal experience, we know that it's incredibly hard to respond fast enough to free food when notified by the mailing list.
## What it does
F3 collects information about free food from the free-food mailing list. The location of the food is parsed from the emails, and then using the phone's GPS and the whereis.mit.edu API, the distance to the food is calculated. Using a combination of the distance and the age of the email, the food listings are sorted.
## How we built it
This app was built with Android Studio using Java and a few different libraries and APIs.
Emails from [free-food@mit.edu](mailto:free-food@mit.edu) are automatically forward to a Gmail account that the app has access to. Using an android mail library, we parsed the location (in the form of various names, nicknames, to determine which building food is located at. Then, the user's location is taken to calculate the distance between the free food and the phone's GPS location. The user receives a list of free food, including the building/location, distance from their own coordinates, and the 'age' of the free food (how long ago the email was sent).
## Challenges we ran into
At first, we wrote the mail reading/parsing code in vanilla Java outside of Android studio. However, when we tried to integrate it with the app, we realized that Java libraries aren't necessarily compatible with Android. Hence, a considerable of time late at night was put toward reworking the mail code to be compatible with Android.
Also, there were difficulties in retrieving GPS coordinates, especially with regard to accessing fine location permissions and various stability issues.
## Accomplishments that we're proud of
* Creating our first app (none of us had prior Android development experience)
* Making horrible puns
## What we learned
* How to sort-of use Android Studio
* How email/IMAP works
* How to use Git/GitHub
* How to use regular expressions
## What's next for f3
* Settings for a search radius
* Refresh periodically in background
* Push(een) notifications
* More Pusheen | ## Inspiration
AI is a super powerful tool for those who know how to prompt it and utilize it for guidance and education rather than just for a final answer. As AI becomes increasingly more accessible to everyone, it is clear that teaching the younger generation to use it properly is incredibly important, so that it does not have a negative impact on their learning and development. This thought process inspired us to create an app that allows a younger child to receive AI assistance in a way that is both fun and engaging, while preventing them from skipping steps in their learning process.
## What it does
mentora is an interactive Voice AI Tutor geared towards elementary and middle school aged students which takes on the form of their favorite fictional characters from movies and TV shows. Users are provided with the ability to write their work onto a whiteboard within the web application while chatting with an emotionally intelligent AI who sounds exactly like the character of their choice. The tutor is specifically engineered to guide the user towards a solution to their problem without revealing or explaining too many steps at a time. mentora gives children a platform to learn how to use AI the right way, highlighting it as a powerful and useful tool for learning rather than a means for taking short cuts.
## How we built it
We built mentora to be a full-stack web application utilizing React for the frontend and Node.js for the backend, with the majority of our code being written in javascript and typescript. Our project required integrating several APIs into a seamless workflow to create an intuitive, voice-driven educational tool. We started by implementing Deepgram, which allowed us to capture and transcribe students' voice inputs in real time. Beyond transcription, Deepgram’s sentiment analysis feature helped detect emotions like frustration or confusion in the child’s tone, enabling our AI to adjust its responses accordingly and provide empathetic assistance.
Next, we integrated Cartesia to clone character voices, making interactions more engaging by allowing children to talk to their favorite characters. This feature gave our AI a personalized feel, as it responded using the selected character’s voice, making the learning experience more enjoyable and relatable for younger users.
For visual interaction, we used Tldraw to develop a dynamic whiteboard interface. This allowed children to upload images or draw directly on the screen, which the AI could interpret to provide relevant feedback. The whiteboard input was synchronized with the audio input, creating a multi-modal learning environment where both voice and visuals were processed together.
Finally, we used the OpenAI API to tie everything together. The API parsed contextual information from previous conversations and the whiteboard to generate thoughtful, step-by-step guidance. This integration ensured the AI could provide appropriate hints without giving away full solutions, fostering meaningful learning while maintaining real-time responsiveness.
## Challenges we ran into
A summary of our biggest challenges:
Combining data from our whiteboard feature with our microphone feature to make a single openAI API call.
Learning how to use and integrate Deepgram and Cartesia APIs to emotionally analyze and describe our audio inputs, and voice clone for AI responses
Finding a high quality photo of Aang from Avatar the Last Airbender
## Accomplishments that we're proud of
We are really proud of the fact that we successfully brought to life the project we set out to build and brainstormed for, while expanding on our ideas in ways that we wouldn’t have even imagined before this weekend. We are also proud of the fact that we created an application that could benefit the next generation by shedding a positive light on the use of AI for students who are just becoming familiar with it.
## What we learned
Building mentora taught us how to integrate multiple APIs into a seamless workflow. We gained hands-on experience with Deepgram, using it to transcribe voice inputs and perform sentiment analysis. We also integrated Cartesia for voice cloning, allowing the AI to respond in the voice of the character selected by the user. Using Tldraw, we created a functional whiteboard interface where students could upload images or write directly, providing visual input alongside audio input for a smoother learning experience. Finally, we used an OpenAI API call to integrate the entire functionality.
The most valuable part of the process was learning how to design a workflow where multiple technologies interacted harmoniously—from capturing voice input and analyzing emotions to generating thoughtful responses through avatars. We also learned how important it was to plan the integration ahead of time. We had many ideas, and we had to try out all of them to see what would work and what would not. While this was initially challenging due to all the moving pieces, creating a structure for what we wanted the final project to look like allowed us to keep the final goal in mind. On the other hand, it was important that we were willing to change focus when better ideas were created and when old ideas had flaws.
Ultimately, this project gave us deeper insights into full-stack development and reinforced the balance of structure vs. adaptability when creating a new product.
## What's next for mentora
There are many next steps we could take and directions we could go with mentora. Ideas we have discussed are deploying the website, creating a custom character creation menu that allows the users to input new characters and voices, improve latency up to real-time speed for back and forth conversation, and broaden the range of subjects that the tutor is well prepared to assist with. | ## Inspiration
The inspiration behind our innovative personal desk assistant was ignited by the fond memories of Furbys, those enchanting electronic companions that captivated children's hearts in the 2000s. These delightful toys, resembling a charming blend of an owl and a hamster, held an irresistible appeal, becoming the coveted must-haves for countless celebrations, such as Christmas or birthdays. The moment we learned that the theme centered around nostalgia, our minds instinctively gravitated toward the cherished toys of our youth, and Furbys became the perfect representation of that cherished era.
Why Furbys? Beyond their undeniable cuteness, these interactive marvels served as more than just toys; they were companions, each one embodying the essence of a cherished childhood friend. Thinking back to those special childhood moments, the idea for our personal desk assistant was sparked. Imagine it as a trip down memory lane to the days of playful joy and the magic of having an imaginary friend. It reflects the real bonds many of us formed during our younger years. Our goal is to bring the spirit of those adored Furbies into a modern, interactive personal assistant—a treasured piece from the past redesigned for today, capturing the memories that shaped our childhoods.
## What it does
Our project is more than just a nostalgic memory; it's a practical and interactive personal assistant designed to enhance daily life. Using facial recognition, the assistant detects the user's emotions and plays mood-appropriate songs, drawing from a range of childhood favorites, such as tunes from the renowned Kidz Bop musical group. With speech-to-text and text-to-speech capabilities, communication is seamless. The Furby-like body of the assistant dynamically moves to follow the user's face, creating an engaging and responsive interaction. Adding a touch of realism, the assistant engages in conversation and tells jokes to bring moments of joy. The integration of a dashboard website with the Furby enhances accessibility and control. Utilizing a chatbot that can efficiently handle tasks, ensuring a streamlined and personalized experience. Moreover, incorporating home security features adds an extra layer of practicality, making our personal desk assistant a comprehensive and essential addition to modern living.
## How we built it
Following extensive planning to outline the implementation of Furby's functions, our team seamlessly transitioned into the execution phase. The incorporation of Cohere's AI platform facilitated the development of a chatbot for our dashboard, enhancing user interaction. To infuse a playful element, ChatGBT was employed for animated jokes and interactive conversations, creating a lighthearted and toy-like atmosphere. Enabling the program to play music based on user emotions necessitated the integration of the Spotify API. Google's speech-to-text was chosen for its cost-effectiveness and exceptional accuracy, ensuring precise results when capturing user input. Given the project's hardware nature, various physical components such as microcontrollers, servos, cameras, speakers, and an Arduino were strategically employed. These elements served to make the Furby more lifelike and interactive, contributing to an enhanced and smoother user experience. The meticulous planning and thoughtful execution resulted in a program that seamlessly integrates diverse functionalities for an engaging and cohesive outcome.
## Challenges we ran into
During the development of our project, we encountered several challenges that required demanding problem-solving skills. A significant hurdle was establishing a seamless connection between the hardware and software components, ensuring the smooth integration of various functionalities for the intended outcome. This demanded a careful balance to guarantee that each feature worked harmoniously with others. Additionally, the creation of a website to display the Furby dashboard brought its own set of challenges, as we strived to ensure it not only functioned flawlessly but also adhered to the desired aesthetic. Overcoming these obstacles required a combination of technical expertise, attention to detail, and a commitment to delivering a cohesive and visually appealing user experience.
## Accomplishments that we're proud of
While embarking on numerous software projects, both in an academic setting and during our personal endeavors, we've consistently taken pride in various aspects of our work. However, the development of our personal assistant stands out as a transformative experience, pushing us to explore new techniques and skills. Venturing into unfamiliar territory, we successfully integrated Spotify to play songs based on facial expressions and working with various hardware components. The initial challenges posed by these tasks required substantial time for debugging and strategic thinking. Yet, after investing dedicated hours in problem-solving, we successfully incorporated these functionalities for Furby. The journey from initial unfamiliarity to practical application not only left us with a profound sense of accomplishment but also significantly elevated the quality of our final product.
## What we learned
Among the many lessons learned, machine learning stood out prominently as it was still a relatively new concept for us!
## What's next for FurMe
The future goals for FurMe include seamless integration with Google Calendar for efficient schedule management, a comprehensive daily overview feature, and productivity tools such as phone detection and a Pomodoro timer to assist users in maximizing their focus and workflow. | losing |
## My Samy helps:
**Young marginalized students**
* Anonymous process: Ability to ask any questions anonymously without feeling judged
* Get relevant resources: More efficient process for them to ask for help and receive immediately relevant information and resources
* Great design and user interface: Easy to use platform with kid friendly interface
* Tailored experience: Computer model is trained to understand their vocabulary
* Accessible anytime: Replaces the need to schedule an appointment and meet someone in person which can be intimidating. App is readily available at any time, any place.
* Free to use platform
**Schools**
* Allows them to support every student simultaneously
* Provides a convenient process as the recommendation system is automatized
* Allows them to receive a general report that highlights the most common issues students experience
**Local businesses**
* Gives them an opportunity to support their community in impactful ways
* Allows them to advertise their services
Business Plan:
<https://drive.google.com/file/d/1JII4UGR2qWOKVjF3txIEqfLUVgaWAY_h/view?usp=sharing> | ## Inspiration
In 2010, when Haiti was rocked by an earthquake that killed over 150,000 people, aid workers manned SMS help lines where victims could reach out for help. Even with the international humanitarian effort, there was not enough manpower to effectively handle the volume of communication. We set out to fix that.
## What it does
EmergAlert takes the place of a humanitarian volunteer at the phone lines, automating basic contact. It allows victims to request help, tell their location, place calls and messages to other people, and inform aid workers about their situation.
## How we built it
We used Mix.NLU to create a Natural Language Understanding model that categorizes and interprets text messages, paired with the Smooch API to handle SMS and Slack contact. We use FHIR to search for an individual's medical history to give more accurate advice.
## Challenges we ran into
Mentoring first time hackers was both a challenge and a joy.
## Accomplishments that we're proud of
Coming to Canada.
## What we learned
Project management is integral to a good hacking experience, as is realistic goal-setting.
## What's next for EmergAlert
Bringing more depth to the NLU responses and available actions would improve the app's helpfulness in disaster situations, and is a good next step for our group. | ## Inspiration
Dietary restrictions and allergies make our community more diverse. However, equality is not shared between people with allergies and people without. It is unfair that people with allergies need to spend an extensive amount of time, effort, and worry to safely explore the universe of flavors. We are inspired and motivated to promote equality within our community.
## What it does
Safe Bite is a platform that bridges info gaps between producers and consumers. Users can input their dietary restrictions at a specific restaurant to receive an output of every dish they can or cannot eat. Restaurants can input their dishes and ingredients without revealing their recipes; this process will keep the restaurant's information private and also notify if the user is eligible to eat.
## How we built it
Our backend was built in Python with the Flask framework, along with our frontend built with HTML, Javascript and CSS. The restaurant’s data was stored within json files that are accessible through the backend. Through the development stage, we ensured that the website was user friendly so that it is accessible for everyone.
## Challenges we ran into
1. Retrieving data through the backend, and being able to integrate it though our frontend
2. Finding data for restaurants database (json files)
3. Some of us are relatively new to Git, and so it was challenging wrap our head around it
4. Finding a unique project idea took us a lot of time
## Accomplishments that we're proud of
As a high school team that is new to many new languages and frameworks we used, we managed to learn and assist each other as a team during our process of project making and successfully built a project that we are proud of.
Debugging error and researching solutions in the given time frame
## What we learned
Use of git and flask in the process of coding. Gaining an in-depth understanding of HTML, CSS, and Python.
## What's next for Safe Bite
Our next step is to link Safe Bite to digital menus and food delivery apps: users could filter and sort dishes they can and cannot eat based on their dietary restriction in their favorite digital menu or food app to maximize efficiency and accessibility.
Another step is to link the ChatGPT API as restaurants input their dishes and ingredients so that ingredients that are similar would be linked and referenced. As an example, if “cheese” is an ingredient, any input like “diary,” “lactose,” “milk,” and “non-vegan” should all point to “cheese” and any dish with that ingredient will be filtered with any of the inputs given above. Ingredients of manufactured goods should also be referenceable. For example, if “soy sauce” was used in the dish, any input like “beans” or “salt” should also result in the dish to be filtered and sorted accordingly. | winning |
## Inspiration
Emergency situations can be extremely sudden and can seem paralyzing, especially for young children. In most cases, children from the ages of 4-10 are unaware of how to respond to a situation that requires contact with first responders, and what the most important information to communicate. In the case of a parent or guardian having a health issue, children are left feeling helpless. We wanted to give children confidence that is key to their healthy cognitive and social development by empowering them with the knowledge of how to quickly and accurately respond in emergency situations, which is why we created Hero Alert.
## What it does
Our product provides a tangible device for kids to interact with, guiding them through the process of making a call to 9-1-1 emergency services. A conversational AI bot uses natural language understanding to listen to the child’s responses and tailor the conversation accordingly, creating a sense that the child is talking to a real emergency operator.
Our device has multiple positive impacts: the educational aspect of encouraging children’s cognitive development skills and preparing them for serious, real-life situations; giving parents more peace of mind, knowing that their child can respond to dire situations; and providing a diverting, engaging game for children to feel like their favorite Marvel superhero while taking the necessary steps to save the day!
## How we built it
On the software side, our first step was to find find images from comic books that closely resemble real-life emergency and crisis scenarios. We implemented our own comic classifier with the help of IBM Watson’s visual recognition service, classifying and re-tagging images made available by Marvel’s Comics API into crisis categories such as fire, violence, water disasters, or unconsciousness. The physical device randomly retrieves and displays these image objects from an mLab database each time a user mimics a 9-1-1 call.
We used the Houndify conversational AI by SoundHound to interpret the voice recordings and generate smart responses. Different emergencies scenarios were stored as pages in Houndify and different responses from the child were stored as commands. We used Houndify’s smart expressions to build up potential user inputs and ensure the correct output was sent back to the Pi.
Running on the Pi was a series of Python scripts, a command engine and an interaction engine, that enabled the flow of data and verified the child’s input.
On the hardware end, we used a Raspberry Pi 3 connected to a Sony Eye camera/microphone to record audio and a small hdmi monitor to display a tagged Marvel image. The telephone 9-1-1 digits were inputted as haptic buttons connected to the Pi’s GPIO pins. All of the electronics were encapsulated in a custom laser cut box that acted as both a prototype for children’s toy and as protection for the electronics.
## Challenges we ran into
The comics from the Marvel API are hand-drawn and don’t come with detailed descriptions, so we had a tough time training a general model to match pictures to each scenario. We ended up creating a custom classifier with IBM Watson’s visual recognition service, using a few pre-selected images from Marvel, then applied that to the entirety of the Marvel imageset to diversify our selection.
The next challenge was creating conversational logic flow that could be applied to a variety of statements a child might say while on the phone. We created several scenarios that involved numerous potential emergency situations and used Houndify’s Smart Expressions to evaluate the response from a child. Matching statements to these expressions allowed us to understand the conversation and provide custom feedback and responses throughout the mock phone call.
We also wanted to make sure that we provide a sense of empowerment for the child. While they should not make unnecessary calls, children should not be afraid or anxious to talk with emergency services during an emergency. We want them to feel comfortable, capable, and strong enough to make that call and help the situation they are in. Our implementation of Marvel Comics allowed us provide some sense of super-power to the children during the calls.
## Accomplishments that we're proud of
Our end product works smoothly and simulates an actual conversation for a variety of crisis scenarios, while providing words of encouragement and an unconventional approach to emergency response. We used a large variety of APIs and platforms and are proud that we were able to have all of them work with one another in a unified product.
## What we learned
We learned that the ideation process and collaboration are keys in solving any wicked problem that exists in society. We also learned that having a multidisciplinary team with very diverse backgrounds and skill sets provides the most comprehensive contributions and challenges us both as individuals and as a team.
## What's next for Hero Alert!
We'd love to get more user feedback and continue development and prototyping of the device in the future, so that one day it will be available on store shelves. | ## Inspiration
In times of disaster, the capacity of rigid networks like cell service and internet dramatically decreases at the same time demand increases as people try to get information and contact loved ones. This can lead to crippled telecom services which can significantly impact first responders in disaster struck areas, especially in dense urban environments where traditional radios don't work well. We wanted to test newer radio and AI/ML technologies to see if we could make a better solution to this problem, which led to this project.
## What it does
Device nodes in the field network to each other and to the command node through LoRa to send messages, which helps increase the range and resiliency as more device nodes join. The command & control center is provided with summaries of reports coming from the field, which are visualized on the map.
## How we built it
We built the local devices using Wio Terminals and LoRa modules provided by Seeed Studio; we also integrated magnetometers into the devices to provide a basic sense of direction. Whisper was used for speech-to-text with Prediction Guard for summarization, keyword extraction, and command extraction, and trained a neural network on Intel Developer Cloud to perform binary image classification to distinguish damaged and undamaged buildings.
## Challenges we ran into
The limited RAM and storage of microcontrollers made it more difficult to record audio and run TinyML as we intended. Many modules, especially the LoRa and magnetometer, did not have existing libraries so these needed to be coded as well which added to the complexity of the project.
## Accomplishments that we're proud of:
* We wrote a library so that LoRa modules can communicate with each other across long distances
* We integrated Intel's optimization of AI models to make efficient, effective AI models
* We worked together to create something that works
## What we learned:
* How to prompt AI models
* How to write drivers and libraries from scratch by reading datasheets
* How to use the Wio Terminal and the LoRa module
## What's next for Meshworks - NLP LoRa Mesh Network for Emergency Response
* We will improve the audio quality captured by the Wio Terminal and move edge-processing of the speech-to-text to increase the transmission speed and reduce bandwidth use.
* We will add a high-speed LoRa network to allow for faster communication between first responders in a localized area
* We will integrate the microcontroller and the LoRa modules onto a single board with GPS in order to improve ease of transportation and reliability | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change. | partial |
## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway, swapping a real therapist with a chatbot trained in giving advice and guidance isn't a very big leap for the person receiving therapy, and it could even save them money. Further, since all the conversations could be recorded if the user chooses, they could track their thoughts and goals, and have the bot respond to them. This is the idea that drove us to build Companion!
## What it does
Companion is a full-stack web application that allows users to be able to record their mood and describe their day and how they feel to promote mindfulness and track their goals, like a diary. There is also a companion, an open-ended chatbot, which the user can talk to about their feelings, problems, goals, etc. With realtime text-to-speech functionality, the user can speak out loud to the bot if they feel it is more natural to do so. If the user finds a companion conversation helpful, enlightening or otherwise valuable, they can choose to attach it to their last diary entry.
## How we built it
We leveraged many technologies such as React.js, Python, Flask, Node.js, Express.js, Mongodb, OpenAI, and AssemblyAI. The chatbot was built using Python and Flask. The backend, which coordinates both the chatbot and a MongoDB database, was built using Node and Express. Speech-to-text functionality was added using the AssemblyAI live transcription API, and the chatbot machine learning models and trained data was built using OpenAI.
## Challenges we ran into
Some of the challenges we ran into were being able to connect between the front-end, back-end and database. We would accidentally mix up what data we were sending or supposed to send in each HTTP call, resulting in a few invalid database queries and confusing errors. Developing the backend API was a bit of a challenge, as we didn't have a lot of experience with user authentication. Developing the API while working on the frontend also slowed things down, as the frontend person would have to wait for the end-points to be devised. Also, since some APIs were relatively new, working with incomplete docs was sometimes difficult, but fortunately there was assistance on Discord if we needed it.
## Accomplishments that we're proud of
We're proud of the ideas we've brought to the table, as well the features we managed to add to our prototype. The chatbot AI, able to help people reflect mindfully, is really the novel idea of our app.
## What we learned
We learned how to work with different APIs and create various API end-points. We also learned how to work and communicate as a team. Another thing we learned is how important the planning stage is, as it can really help with speeding up our coding time when everything is nice and set up with everyone understanding everything.
## What's next for Companion
The next steps for Companion are:
* Ability to book appointments with a live therapists if the user needs it. Perhaps the chatbot can be swapped out for a real therapist for an upfront or pay-as-you-go fee.
* Machine learning model that adapts to what the user has written in their diary that day, that works better to give people sound advice, and that is trained on individual users rather than on one dataset for all users.
## Sample account
If you can't register your own account for some reason, here is a sample one to log into:
Email: [demo@example.com](mailto:demo@example.com)
Password: password | ## Inspiration
A study recently done in the UK learned that 69% of people above the age of 65 lack the IT skills needed to use the internet. Our world's largest resource for information, communication, and so much more is shut off to such a large population. We realized that we can leverage artificial intelligence to simplify completing online tasks for senior citizens or people with disabilities. Thus, we decided to build a voice-powered web agent that can execute user requests (such as booking a flight or ordering an iPad).
## What it does
The first part of Companion is a conversation between the user and a voice AI agent in which the agent understands the user's request and asks follow up questions for specific details. After this call, the web agent generates a plan of attack and executes the task by navigating the to the appropriate website and typing in relevant search details/clicking buttons. While the agent is navigating the web, we stream the agent's actions to the user in real time, allowing the user to monitor how it is browsing/using the web. In addition, each user request is stored in a Pinecone database, to the agent has context about similar past user requests/preferences. The user can also see the live state of the web agent navigation on the app.
## How we built it
We developed Companion using a combination of modern web technologies and tools to create an accessible and user-friendly experience:
For the frontend, we used React, providing a responsive and interactive user interface. We utilized components for input fields, buttons, and real-time feedback to enhance usability as well as integrated VAPI, a voice recognition API, to enable voice commands, making it easier for users with accessibility needs. For the Backend we used Flask to handle API requests and manage the server-side logic. For web automation tasks we leveraged Selenium, allowing the agent to navigate websites and perform actions like filling forms and clicking buttons. We stored user interactions in a Pinecone database to maintain context and improve future interactions by learning user preferences over time, and the user can also view past flows. We hosted the application on a local server during development, with plans for cloud deployment to ensure scalability and accessibility. Thus, Companion can effectively assist users in navigating the web, particularly benefiting seniors and individuals with disabilities.
## Challenges we ran into
We ran into difficulties getting the agent to accurately complete each task. Getting it to take the right steps and always execute the task efficiently was a hard but fun problem. It was also challenging to prompt the voice agent such to effectively communicate with the user and understand their request.
## Accomplishments that we're proud of
Building a complete, end-to-end agentic flow that is able to navigate the web in real time. We think that this project is socially impactful and can make a difference for those with accessibility needs.
## What we learned
The small things that can make or break an AI agent such as the way we display memory, how we ask it to reflect, and what supplemental info we give it (images, annotations, etc.)
## What's next for Companion
Making it work without CSS selectors; training a model to highlight all the places the computer can click because certain buttons can be unreachable for Companion. | Ever wonder where that video clip came from? Probably some show or movie you've never watched. Well with RU Recognized, you can do a reverse video search to find out what show or movie it's from.
## Inspiration
We live in a world rife with movie and tv show references, and not being able to identify these references is a sign of ignorance in our society. More importantly, the feeling of not being able to remember what movie or show that one really funny clip was from can get really frustrating. We wanted to enale every single human on this planet to be able to seek out and enjoy video based content easily but also efficiently. So, we decided to make **Shazam, but for video clips!**
## What it does
RU Recognized takes a user submitted video and uses state of the art algorithms to find the best match for that clip. Once a likely movie or tv show is found, the user is notified and can happily consume the much desired content!
## How we built it
We took on a **3 pronged approach** to tackle this herculean task:
1. Using **AWS Rekognition's** celebrity detection capabilities, potential celebs are spotted in the user submitted video. These identifications have a harsh confidence value cut off to ensure only the best matching algorithm.
2. We scrape the video using **AWS' Optical Character Recognition** (OCR) capabilities to find any identifying text that could help in identification.
3. **Google Cloud's** Speech to Text API allows us to extract the audio into readable plaintext. This info is threaded through Google Cloud Custom Search to find a large unstructured datadump.
To parse and exract useful information from this amourphous data, we also maintained a self-curated, specialized, custom made dataset made from various data banks, including **Kaggle's** actor info, as well as IMDB's incredibly expansive database.
Furthermore, due to the uncertain nature of the recognition API's, we used **clever tricks** such as cross referencing celebrities seen together, and only detecting those that had IMDB links.
Correlating the information extracted from the video with the known variables stored in our database, we are able to make an educated guess at origins of the submitted clip.
## Challenges we ran into
Challenges are an obstacle that our team is used to, and they only serve to make us stronger. That being said, some of the (very frustrating) challenges we ran into while trying to make RU Recognized a good product were:
1. As with a lot of new AI/ML algorithms on the cloud, we struggles alot with getting our accuracy rates up for identified celebrity faces. Since AWS Rekognition is trained on images of celebrities from everyday life, being able to identify a heavily costumed/made-up actor is a massive challenge.
2. Cross-connecting across various cloud platforms such as AWS and GCP lead to some really specific and hard to debug authorization problems.
3. We faced a lot of obscure problems when trying to use AWS to automatically detect the celebrities in the video, without manually breaking it up into frames. This proved to be an obstacle we weren't able to surmount, and we decided to sample the frames at a constant rate and detect people frame by frame.
4. Dataset cleaning took hours upon hours of work and dedicated picking apart. IMDB datasets were too large to parse completely and ended up costing us hours of our time, so we decided to make our own datasets from this and other datasets.
## Accomplishments that we're proud of
Getting the frame by frame analysis to (somewhat) accurately churn out celebrities and being able to connect a ton of clever identification mechanisms was a very rewarding experience. We were effectively able to create an algorithm that uses 3 to 4 different approaches to, in a way, 'peer review' each option, and eliminate incorrect ones.
## What I learned
* Data cleaning is ver very very cumbersome and time intensive
* Not all AI/ML algorithms are magically accurate
## What's next for RU Recognized
Hopefully integrate all this work into an app, that is user friendly and way more accurate, with the entire IMDB database to reference. | partial |
## Inspiration
Metaverse, vision pro, spatial video. It’s no doubt that 3D content is the future. But how can I enjoy or make 3d content without spending over 3K? Or strapping massive goggles to my head? Let's be real, wearing a 3d vision pro while recording your child's birthday party is pretty [dystopian.](https://youtube.com/clip/UgkxXQvv1mxuM06Raw0-rLFGBNUqmGFOx51d?si=nvsDC3h9pz_ls1sz) And spatial video only gets you so far in terms of being able to interact, it's more like a 2.5D video with only a little bit of depth.
How can we relive memories in 3d without having to buy new hardware? Without the friction?
Meet 3dReal, where your best memories got realer. It's a new feature we imagine being integrated in BeReal, the hottest new social media app that prompts users to take an unfiltered snapshot of their day through a random notification. When that notification goes off, you and your friends capture a quick snap of where you are!
The difference with our feature is based on this idea where if you have multiple images of the same area ie. you and your friends are taking BeReals at the same time, we can use AI to generate a 3d scene.
So if the app detects that you are in close proximity to your friends through bluetooth, then you’ll be given the option to create a 3dReal.
## What it does
With just a few images, the AI powered Neural Radiance Fields (NeRF) technology produces an AI reconstruction of your scene, letting you keep your memories in 3d. NeRF is great in that it only needs a few input images from multiple angles, taken at nearly the same time, all which is the core mechanism behind BeReal anyways, making it a perfect application of NeRF.
So what can you do with a 3dReal?
1. View in VR, and be able to interact with the 3d mesh of your memory. You can orbit, pan, and modify how you see this moment captures in the 3dReal
2. Since the 3d mesh allows you to effectively view it however you like, you can do really cool video effects like flying through people or orbiting people without an elaborate robot rig.
3. TURN YOUR MEMORIES INTO THE PHYSICAL WORLD - one great application is connecting people through food. When looking through our own BeReals, we found that a majority of group BeReals were when getting food. With 3dReal, you can savor the moment by reconstructing your friends + food, AND you can 3D print the mesh, getting a snippet of that moment forever.
## How it works
Each of the phones using the app has a countdown then takes a short 2-second "video" (think of this as a live photo) which is sent to our Google Firebase database. We group the videos in Firebase by time captured, clustering them into a single shared "camera event" as a directory with all phone footage captured at that moment. While one camera would not be enough in most cases, by using the network of phones to take the picture simultaneously we have enough data to substantially recreate the scene in 3D. Our local machine polls Firebase for new data. We retrieve it, extract a variety of frames and camera angles from all the devices that just took their picture together, use COLMAP to reconstruct the orientations and positions of the cameras for all frames taken, and then render the scene as a NeRF via NVIDIA's instant-ngp repo. From there, we can export, modify, and view our render for applications such as VR viewing, interactive camera angles for creating videos, and 3D printing.
## Challenges we ran into
We lost our iOS developer team member right before the hackathon (he's still goated just unfortunate with school work) and our team was definitely not as strong as him in that area. Some compromises on functionality were made for the MVP, and thus we focused core features like getting images from multiple phones to export the cool 3dReal.
There were some challenges with splicing the videos for processing into the NeRF model as well.
## Accomplishments that we're proud of
Working final product and getting it done in time - very little sleep this weekend!
## What we learned
A LOT of things out of all our comfort zones - Sunny doing iOS development and Phoebe doing not hardware was very left field, so lots of learning was done this weekend. Alex learned lots about NeRF models.
## What's next for 3dReal
We would love to refine the user experience and also improve our implementation of NeRF - instead of generating a static mesh, our team thinks with a bit more time we could generate a mesh video which means people could literally relive their memories - be able to pan, zoom, and orbit around in them similar to how one views the mesh.
BeReal pls hire 👉👈 | ## Inspiration 💥
Let's be honest... Presentations can be super boring to watch—*and* to present.
But, what if you could bring your biggest ideas to life in a VR world that literally puts you *in* the PowerPoint? Step beyond slides and into the future with SuperStage!
## What it does 🌟
SuperStage works in 3 simple steps:
1. Export any slideshow from PowerPoint, Google Slides, etc. as a series of images and import them into SuperStage.
2. Join your work/team/school meeting from your everyday video conferencing software (Zoom, Google Meet, etc.).
3. Instead of screen-sharing your PowerPoint window, screen-share your SuperStage window!
And just like that, your audience can watch your presentation as if you were Tim Cook in an Apple Keynote. You see a VR environment that feels exactly like standing up and presenting in real life, and the audience sees a 2-dimensional, front-row seat video of you on stage. It’s simple and only requires the presenter to own a VR headset.
Intuition was our goal when designing SuperStage: instead of using a physical laser pointer and remote, we used full-hand tracking to allow you to be the wizard that you are, pointing out content and flicking through your slides like magic. You can even use your hands to trigger special events to spice up your presentation! Make a fist with one hand to switch between 3D and 2D presenting modes, and make two thumbs-up to summon an epic fireworks display. Welcome to the next dimension of presentations!
## How we built it 🛠️
SuperStage was built using Unity 2022.3 and the C# programming language. A Meta Quest 2 headset was the hardware portion of the hack—we used the 4 external cameras on the front to capture hand movements and poses. We built our UI/UX using ray interactables in Unity to be able to flick through slides from a distance.
## Challenges we ran into 🌀
* 2-camera system. SuperStage is unique since we have to present 2 different views—one for the presenter and one for the audience. Some objects and UI in our scene must be occluded from view depending on the camera.
* Dynamic, automatic camera movement, which locked onto the player when not standing in front of a slide and balanced both slide + player when they were in front of a slide.
To build these features, we used multiple rendering layers in Unity where we could hide objects from one camera and make them visible to the other. We also wrote scripting to smoothly interpolate the camera between points and track the Quest position at all times.
## Accomplishments that we're proud of 🎊
* We’re super proud of our hand pose detection and gestures: it really feels so cool to “pull” the camera in with your hands to fullscreen your slides.
* We’re also proud of how SuperStage uses the extra dimension of VR to let you do things that aren’t possible on a laptop: showing and manipulating 3D models with your hands, and immersing the audience in a different 3D environment depending on the slide. These things add so much to the watching experience and we hope you find them cool!
## What we learned 🧠
Justin: I found learning about hand pose detection so interesting. Reading documentation and even anatomy diagrams about terms like finger abduction, opposition, etc. was like doing a science fair project.
Lily: The camera system! Learning how to run two non-conflicting cameras at the same time was super cool. The moment that we first made the switch from 3D -> 2D using a hand gesture was insane to see actually working.
Carolyn: I had a fun time learning to make cool 3D visuals!! I learned so much from building the background environment and figuring out how to create an awesome firework animation—especially because this was my first time working with Unity and C#! I also grew an even deeper appreciation for the power of caffeine… but let’s not talk about that part :)
## What's next for SuperStage ➡️
Dynamically generating presentation boards to spawn as the presenter paces the room
Providing customizable avatars to add a more personal touch to SuperStage
Adding a lip-sync feature that takes volume metrics from the Oculus headset to generate mouth animations | ## Food.C
Like taking pictures of your food? Have Food.C track what you eat to help you eat healthier. We use Keras to detect the content of the photos you take, then match it against its nutrition facts, so you can eat healthier while instagramming your meal. We even use facial recognition to track user profiles and nutritional intake.
## How we built it
We run a flask server with a web application, then we write the camera data to the server on a photograph. This is then classified by Keras (VGG16), and then checked against a SQLite database built from the government nutritional data.
## Challenges we ran into
We ran into some strange encoding bugs when we were sending the images to the classifier. Additionally, using the ImageNet model, and a weak wifi connection made it harder to research things so we had to get resourceful.
## Accomplishments that we're proud of
We didn't have a clue what we were making until late into the hackathon! But we crunched and got it done.
## What we learned
Come prepared! But don't worry about changing plans. And eat your veggies!
## What's next for Food.c
Taking over the world! | winning |
## Inspiration and What it does
We often go out with a lot of amazing friends for trips, restaurants, tourism, weekend expedition and what not. Every encounter has an associated messenger groupchat. We want a way to split money which is better than to discuss on the groupchat, ask people their public key/usernames and pay on a different platform. We've integrated them so that we can do transactions and chat at a single place.
We (our team) believe that **"The Future of money is Digital Currency "** (-Bill Gates), and so, we've integrated payment with Algorand's AlgoCoins with the chat. To make the process as simple as possible without being less robust, we extract payment information out of text as well as voice messages.
## How I built it
We used Google Cloud NLP and IBM Watson Natural Language Understanding apis to extract the relevant information. Voice messages are first converted to text using Rev.ai speech-to-text. We complete the payment using the blockchain set up with Algorand API. All scripts and database will be hosted on the AWS server
## Challenges I ran into
It turned out to be unexpectedly hard to accurately find out the payer and payee. Dealing with the blockchain part was a great learning experience.
## Accomplishments that I'm proud of
that we were able to make it work in less than 24 hours
## What I learned
A lot of different APIs
## What's next for Mess-Blockchain-enger
Different kinds of currencies, more messaging platforms | ## Inspiration
We're tired of seeing invasive advertisements and blatant commercialization all around us. With new AR technology, there may be better ways to help mask and put these advertisements out of sight, or in a new light.
## What it does
By utilizing Vueforia technologies and APIs, we can use image tracking to locate and overlay advertisements with dynamic content.
## How we built it
Using Unity and Microsoft's Universal Window's Platform, we created an application that has robust tracking capabilities.
## Challenges we ran into
Microsoft's UWP platform has many challenges, such as various different requirements and dependencies. Even with experienced Microsoft personel, due to certain areas of lacking implementation, we were ultimately unable to get certain portions of our code running on the Microsoft Hololens device.
## Accomplishments that we're proud of
Using the Vuforia api, we implemented a robust tracking solution while also pairing the powerful api's of giphy to have dynamic, networked content in lieu of these ads.
## What we learned
While Unity and Microsoft's UWP are powerful platforms, sometimes there can be powerful issues that can hinder development in a big way. Using a multitude of devices and supported frameworks, we managed to work around our blocks the best we could in order to demonstrate and develop the core of our application.
## What's next for Ad Block-AR
Hopefully we're going to be extending this software to run on a multitude of devices and technologies, with the ultimate aim of creating one of the most tangible and effective image recognition programs for the future. | # FaceConnect
##### Never lose a connection again! Connect with anyone, any wallet, and send transactions through an image of one's face!
## Inspiration
Have you ever met someone and instantly connected with them, only to realize you forgot to exchange contact information? Or, even worse, you have someone's contact but they are outdated and you have no way of contacting them? I certainly have.
This past week, I was going through some old photos and stumbled upon one from a Grade 5 Summer Camp. It was my first summer camp experience, I was super nervous going in but I had an incredible time with a friend I met there. We did everything together and it was one of my favorite memories from childhood. But there was a catch – I never got their contact, and I'd completely forgotten their name since it's been so long. All I had was a physical photo of us laughing together, and it felt like I'd lost a precious connection forever.
This dilemma got me thinking. The problem of losing touch with people we've shared fantastic moments with is all too common, whether it's at a hackathon, a party, a networking event, or a summer camp. So, I set out to tackle this issue at Hack The Valley.
## What it does
That's why I created FaceConnect, a Discord bot that rekindles these connections using facial recognition. With FaceConnect, you can send connection requests to people as long as you have a picture of their face.
But that's not all. FaceConnect also allows you to view account information and send transactions if you have a friend's face. If you owe your friend money, you can simply use the "transaction" command to complete the payment.
Or even if you find someone's wallet or driver's license, you can send a reach out to them just with their ID photo!
Imagine a world where you never lose contact with your favorite people again.
Join me in a future where no connections are lost. Welcome to FaceConnect!
## Demos
Mobile Registration and Connection Flow (Registering and Detecting my own face!):
<https://github.com/WilliamUW/HackTheValley/assets/25058545/d6fc22ae-b257-4810-a209-12e368128268>
Desktop Connection Flow (Obama + Trump + Me as examples):
<https://github.com/WilliamUW/HackTheValley/assets/25058545/e27ff4e8-984b-42dd-b836-584bc6e13611>
## How I built it
FaceConnect is built on a diverse technology stack:
1. **Computer Vision:** I used OpenCV and the Dlib C++ Library for facial biometric encoding and recognition.
2. **Vector Embeddings:** ChromaDB and Llama Index were used to create vector embeddings of sponsor documentation.
3. **Document Retrieval:** I utilized Langchain to implement document retrieval from VectorDBs.
4. **Language Model:** OpenAI was employed to process user queries.
5. **Messaging:** Twilio API was integrated to enable SMS notifications for contacting connections.
6. **Discord Integration:** The bot was built using the discord.py library to integrate the user flow into Discord.
7. **Blockchain Technologies:** I integrated Hedera to build a decentralized landing page and user authentication. I also interacted with Flow to facilitate seamless transactions.
## Challenges I ran into
Building FaceConnect presented several challenges:
* **Solo Coding:** As some team members had midterm exams, the project was developed solo. This was both challenging and rewarding as it allowed for experimentation with different technologies.
* **New Technologies:** Working with technologies like ICP, Flow, and Hedera for the first time required a significant learning curve. However, this provided an opportunity to develop custom Language Models (LLMs) trained on sponsor documentation to facilitate the learning process.
* **Biometric Encoding:** It was my first time implementing facial biometric encoding and recognition! Although cool, it required some time to find the right tools to convert a face to a biometric hash and then compare these hashes accurately.
## Accomplishments that I'm proud of
I're proud of several accomplishments:
* **Facial Recognition:** Successfully implementing facial recognition technology, allowing users to connect based on photos.
* **Custom LLMs:** Building custom Language Models trained on sponsor documentation, which significantly aided the learning process for new technologies.
* **Real-World Application:** Developing a solution that addresses a common real-world problem - staying in touch with people.
## What I learned
Throughout this hackathon, I learned a great deal:
* **Technology Stacks:** I gained experience with a wide range of technologies, including computer vision, blockchain, and biometric encoding.
* **Solo Coding:** The experience of solo coding, while initially challenging, allowed for greater freedom and experimentation.
* **Documentation:** Building custom LLMs for various technologies, based on sponsor documentation, proved invaluable for rapid learning!
## What's next for FaceConnect
The future of FaceConnect looks promising:
* **Multiple Faces:** Supporting multiple people in a single photo to enhance the ability to reconnect with groups of friends or acquaintances.
* **Improved Transactions:** Expanding the transaction feature to enable users to pay or transfer funds to multiple people at once.
* **Additional Technologies:** Exploring and integrating new technologies to enhance the platform's capabilities and reach beyond Discord!
### Sponsor Information
ICP Challenge:
I leveraged ICP to build a decentralized landing page and implement user authentication so spammers and bots are blocked from accessing our bot.
Built custom LLM trained on ICP documentation to assist me in learning about ICP and building on ICP for the first time!
I really disliked deploying on Netlify and now that I’ve learned to deploy on ICP, I can’t wait to use it for all my web deployments from now on!
Canister ID: be2us-64aaa-aaaaa-qaabq-cai
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/ICP.md>
Best Use of Hedera:
With FaceConnect, you are able to see your Hedera account info using your face, no need to memorize your public key or search your phone for it anymore!
Allow people to send transactions to people based on face! (Wasn’t able to get it working but I have all the prerequisites to make it work in the future - sender Hedera address, recipient Hedera address).
In the future, to pay someone or a vendor in Hedera, you can just scan their face to get their wallet address instead of preparing QR codes or copy and pasting!
I also built a custom LLM trained on Hedera documentation to assist me in learning about Hedera and building on Hedera as a beginner!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/hedera.md>
Best Use of Flow
With FaceConnect, to pay someone or a vendor in Flow, you can just scan their face to get their wallet address instead of preparing QR codes or copy and pasting!
I also built a custom LLM trained on Flow documentation to assist me in learning about Flow and building on Flow as a beginner!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/flow.md>
Georgian AI Challenge Prize
I was inspired by the data sources listed in the document by scraping LinkedIn profile pictures and their faces for obtaining a dataset to test and verify my face recognition model!
I also built a custom LLM trained on Georgian documentation to learn more about the firm!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/GeorgianAI.md>
Best .Tech Domain Name:
FaceCon.tech
Best AI Hack:
Use of AI include:
1. Used Computer Vision with OpenCV and the Dlib C++ Library to implement AI-based facial biometric encoding and recognition.
2. Leveraged ChromaDB and Llama Index to create vector embeddings of sponsor documentation
3. Utilized Langchain to implement document retrieval from VectorDBs
4. Used OpenAI to process user queries for everything Hack the Valley related!
By leveraging AI, FaceConnect has not only addressed a common real-world problem but has also pushed the boundaries of what's possible in terms of human-computer interaction. Its sophisticated AI algorithms and models enable users to connect based on visuals alone, transcending language and other barriers. This innovative use of AI in fostering human connections sets FaceConnect apart as an exceptional candidate for the "Best AI Hack" award.
Best Diversity Hack:
Our project aligns with the Diversity theme by promoting inclusivity and connection across various barriers, including language and disabilities. By enabling people to connect using facial recognition and images, our solution transcends language barriers and empowers individuals who may face challenges related to memory loss, speech, or hearing impairments. It ensures that everyone, regardless of their linguistic or physical abilities, can stay connected and engage with others, contributing to a more diverse and inclusive community where everyone's unique attributes are celebrated and connections are fostered.
Imagine trying to get someone’s contact in Germany, or Thailand, or Ethiopia? Now you can just take a picture!
Best Financial Hack:
FaceConnect is the ideal candidate for "Best Financial Hack" because it revolutionizes the way financial transactions can be conducted in a social context. By seamlessly integrating facial recognition technology with financial transactions, FaceConnect enables users to send and receive payments simply by recognizing the faces of their friends.
This innovation simplifies financial interactions, making it more convenient and secure for users to settle debts, split bills, or pay for services. With the potential to streamline financial processes, FaceConnect offers a fresh perspective on how we handle money within our social circles. This unique approach not only enhances the user experience but also has the potential to disrupt traditional financial systems, making it a standout candidate for the "Best Financial Hack" category. | partial |
## Inspiration
When working in the kitchen, we have to handle many different ingredients, wet foods, and big messes. Constantly searching for the small things you need constantly takes time and is often frustrating. Even more so, to switch back and forth between wet and dry ingredients means frequent hand washing. Messy situations like these are prime examples of where the internet of things and voice commands are most useful, yet there are disappointingly few tools to handle even the most basic tasks. Aroma addresses these challenges by providing a way to automatically manage your inventory of spices and seasonings while also automatically delivering them precisely to you.
## What it does
Aroma is a seasoning delivery tool that can hold multiple spices simultaneously while quickly and precisely providing them to you. To use it, all you have to do is place a bowl or plate under the device and then select what you would like. You can do this using either the in-built touch screen, or by asking a Google Home to dole out specific quantities. Even better, if you're currently working on a recipe, the Google Assistant can automatically provide the seasonings you need at the moment you need them.
## How we built it
The hardware for Aroma is built atop Android Things. Using a custom designed chassis, we developed an interlocking mechanism that can attach to the lids of standard seasoning containers and then automatically measure and dispense the contents. A great deal of time was spent making the system easy to use as a standalone platform. As one might expect, all you need to start is to select the spice from the embedded touch screen. Once the mechanism has adjusted itself, a button becomes available that allows you to keep delivering the selected spice while it is held. Furthermore, it will indicate in real time exactly how much has been dispensed.
However, since our main focus was to make this usable totally hands free, we designed an extensive Google Assistant backend. Not only can the Aroma assistant dispense exact quantities of seasoning, it can also read your recipes aloud and provide the appropriate seasoning where necessary. This was implemented using the actions-on-google API hosted on Firebase.
## Challenges we ran into
Engineering the mechanisms to be able to hold and dispense spices was tricky. In order for the system to be useful, it had to know exactly how much was being released, and could only deliver when it was supposed to. This required a high degree of engineering that isn't usually necessary during a hackathon. As such, the hardest challenge we faced was developing the delivery mechanism. We went through nearly 6 designs before settling on the current one.
## Accomplishments that we're proud of
Not only were we able to deliver a single spice, we were able to deliver any of three spices without requiring a separate servor for each. As such, this technique can be trivially extended to handle far more spices.
## What we learned
Integrating actions-on-google with Android Things was surprisingly easy. We were able to develop reactive message passing with only minimal work. This was also our first project where we did any significant manufacturing, and we learned how to quickly design and iterate to develop a functioning system.
## What's next for Aroma
The implementation of Aroma's interlocking mechanism is somewhat crude due to the materials available. However, with access to better fabrication tools, the whole design could be shrunk signifcantly, allowing denser storage of spices. In addition, there are many ways we could make Aroma smarter, such as determining from context when you might need an ingredient. | ## Inspiration
We recognized how much time meal planning can cause, especially for busy young professionals and students who have little experience cooking. We wanted to provide an easy way to buy healthy, sustainable meals for the week, without compromising the budget or harming the environment.
## What it does
Similar to services like "Hello Fresh", this is a webapp for finding recipes and delivering the ingredients to your house. This is where the similarities end, however. Instead of shipping the ingredients to you directly, our app makes use of local grocery delivery services, such as the one provided by Loblaws. The advantages to this are two-fold: first, it helps keep the price down, as your main fee is for the groceries themselves, instead of paying large amounts in fees to a meal kit company. Second, this is more eco-friendly. Meal kit companies traditionally repackage the ingredients in house into single-use plastic packaging, before shipping it to the user, along with large coolers and ice packs which mostly are never re-used. Our app adds no additional packaging beyond that the groceries initially come in.
## How We built it
We made a web app, with the client side code written using React. The server was written in python using Flask, and was hosted on the cloud using Google App Engine. We used MongoDB Atlas, also hosted on Google Cloud.
On the server, we used the Spoonacular API to search for recipes, and Instacart for the grocery delivery.
## Challenges we ran into
The Instacart API is not publicly available, and there are no public API's for grocery delivery, so we had to reverse engineer this API to allow us to add things to the cart. The Spoonacular API was down for about 4 hours on Saturday evening, during which time we almost entirely switched over to a less functional API, before it came back online and we switched back.
## Accomplishments that we're proud of
Created a functional prototype capable of facilitating the order of recipes through Instacart. Learning new skills, like Flask, Google Cloud and for some of the team React.
## What we've learned
How to reverse engineer an API, using Python as a web server with Flask, Google Cloud, new API's, MongoDB
## What's next for Fiscal Fresh
Add additional functionality on the client side, such as browsing by popular recipes | ## What it does
DocBook provides an easy-to-use web app for patients to easily book a doctor's appointment from the comfort of their own homes. We understand that booking an appointment by phone or in-person can at times be time-consuming or undesirable for self-conscious patients. However, with DocBook, patients can easily bypass this barrier in order to get the medical attention they require without the hassle of making a call or taking the time to visit the office.
## How we built it
DocBook is built using React.js, Express.js, and MongoDB. Over the weekend, we set up a server, built an API and created the front-end of the app.
## Challenges we ran into
* CORS is weird. We did not understand.
* React hooks are also weird. We also did not understand.
* There were many very interesting and distracting attractions like food.
## Accomplishments that we're proud of
As high school students, we did not have the same degree of knowledge as most of the other hackers present at this hackathon. However, this did not stop us from showing up, learning a lot of new technologies, and most importantly, having an awesome weekend. Though there were a lot of obstacles along the way, we are very proud of everything we were able to achieve during this time.
## What's next for DocBook
Despite the **spectacular quality** of our demo product, there are still many features and improvements that we have in mind for DocBook. In addition to a more professional UI, we will continue working on creating a more sophisticated registration portal, appointment booking options, and a UI for doctors to manage their accounts, view a generated timetable and more. | winning |
# HeadlineHound
HeadlineHound is a Typescript-based project that uses natural language processing to summarize news articles for you. With HeadlineHound, you can quickly get the key points of an article without having to read the entire thing. It's perfect for anyone who wants to stay up-to-date with the news but doesn't have the time to read every article in full. Whether you're a busy professional, a student, or just someone who wants to be informed, HeadlineHound is a must-have tool in your arsenal.
## How it Works
HeadlineHound uses natural language processing (NLP) via a fine-tuned ChatGPT to analyze and summarize news articles. It extracts the most relevant sentences and phrases from the article to create a concise summary. The user simply inputs the URL of the article they want summarized, and HeadlineHound does the rest.
## How we built it
We first fine-tuned a ChatGPT model using a dataset containing news articles and their summaries. This involved a lot of trying different datasets, testing various different data cleaning techniques to make our data easier to interpret, and configuring OpenAI LLM in about every way possible :D. Then, after settling on a dataset and model, we fine-tuned the general model with our dataset. Finally, we built this model into our webapp so that we can utilize it to summarize any news article that we pass in. We first take in the news article URL, pass it into an external web scraping API to extract all the article content, and finally feed that into our LLM to summarize the content into a few sentences.
## Challenges we ran into
Our biggest challenge with this project was trying to determine which dataset to use and how much data to train our model on. We ran into a lot of memory issues when trying to train it on very large datasets and this resulted in us having to use less data than we wanted to train it, resulting in summaries that could definitely be improved. Another big challenge that we ran into was determining the best OpenAI model to use for our purposes, and the best method of fine-tuning to apply.
## Accomplishments that we're proud of
We are very proud of the fact that we were able to so quickly learn how to utilize the OpenAI APIs to apply and fine-tune their generalized models to meet our needs. We quickly read through the documentation, played around with the software, and were able to apply it in a way that benefits people. Furthermore, we also developed an entire frontend application to be able to interact with this LLM in an easy way. Finally, we learned how to work together as a team and divide up the work based on our strengths to maximize our efficiency and utilize our time in the best way possible.
## What we learned
We learned a lot about the power of NLP. Natural language processing (NLP) is a fascinating and powerful field, and HeadlineHound is a great example of how we can use LLMs can be used to solve real-world problems. By leveraging these generalized AI models and then fine-tuning them for our purposes, we were able to create a tool that can quickly and accurately summarize news articles. Additionally, we learned that in order to create a useful tool, it's important to understand the needs of the user. With HeadlineHound, we recognized that people are increasingly time-poor and want to be able to stay informed about the news without having to spend their precious time reading articles. By creating a tool that meets this need, we were able to create something that people saw value in.
## What's next for Headline Hound
Here are a few potential next steps for the HeadlineHound project:
Improve the summarization algorithm: While HeadlineHound's summarization algorithm is effective, there is always room for improvement. One potential area of focus could be to improve the algorithm's ability to identify the most important sentences in an article, or to better understand the context of the article in order to generate a more accurate summary.
Add support for more news sources: HeadlineHound currently supports summarizing articles from a wide range of news sources, but there are always more sources to add. Adding support for more sources would make HeadlineHound even more useful to a wider audience.
Add more features: While the current version of HeadlineHound is simple and effective, there are always more features that could be added. For example, adding the ability to search for articles by keyword could make the tool even more useful to users. | ## Inspiration
Why is science inaccessibility such a problem? Every year, there are over two million scientific research papers published globally. This represents a staggering amount of knowledge, innovation, and progress. Yet, around 91.5% of research articles are never accessed by the wider public. Even among those who have access, the dense and technical language used in academic papers often serves as a barrier, deterring readers from engaging with groundbreaking discoveries.
We recognized the urgent need to bridge the gap between academia and the general public. Our mission is to make scientific knowledge accessible to everyone, regardless of their background or expertise. Open insightful.ly: You are presented with 3 top headlines, which are summarized with cohere as “news headlines” for each research article. You also see accompanying photos that are GPT produced.
## What it does
Our goal is that by summarizing long research articles that is difficult to read into headlines that attract people (who can then go on to read the full article or a summarized version), people will be more encouraged to find out more about the scientific world around them. It is also a great way for talented researchers who're writing these articles to gain publicity/recognition for their research. To make the website attractive, we'll be generating AI generated images based on each article using OpenAI's DALL-E 2 API. The site is built using Python, HTML, CSS using Pycharm.
## How we built it
1. Content Aggregation: We start by aggregating peer reviewed research papers from google scholar.
2. Cohere Summarizer API: To summarize both the essence of these papers and to generate a news headline, we used the Cohere Summarizer API.
3. User-Friendly Interface: Building using Python, we designed a scroller web app, inspired by Twitter and insta and the reliability of respected news outlets like The New York Times. Users can explore topics on 'you, 'hot,' and 'explore' pages, just like they would on their favorite news website while being captivated with the social media type attention grabbing scroll app.
4. AI-Generated Visuals: To enhance the user experience, we integrated OpenAI's DALL-E 2 API, which generates images based on each research article. These visuals help users quickly grasp the essence of the content.
5. User Engagement: We introduced a liking system, allowing users to endorse articles they find valuable. Top-liked papers are suggested more frequently, promoting quality content.
## Challenges we ran into
During the development of Insightful.ly, we faced several challenges. These included data aggregation complexities, integrating APIs effectively, and ensuring a seamless user experience. We also encountered issues related to data preprocessing and visualization. Overcoming these hurdles required creative problem-solving and technical agility.
## Accomplishments that we're proud of
We take immense pride in several accomplishments. First, we successfully created a platform that makes reading long research articles engaging and accessible. Second, our liking system encourages user engagement and recognition for researchers. Third, we integrated advanced AI technologies like Cohere Summarizer and OpenAI's DALL-E 2, enhancing our platform's capabilities. Lastly, building a user-friendly web app inspired by social media platforms and respected news outlets has been a significant achievement
## What we learned
Our journey with Insightful.ly has been a profound learning experience. We gained expertise in data aggregation, API integration, web development, user engagement strategies, and problem-solving. We also honed our collaboration skills and became proficient in version control. Most importantly, we deepened our understanding of the impact of our mission to make science and knowledge accessible.
## What's next for Insightful.ly
In the next phase of Insightful.ly, our primary focus is on enriching the user experience and expanding our content. We're committed to making knowledge accessible to an even wider audience by incorporating research articles from diverse domains, enhancing our user interface, and optimizing our platform for mobile accessibility. Furthermore, we aim to harness the latest AI advancements to improve summarization accuracy and generate captivating visuals, ensuring that the content we deliver remains at the forefront of innovation. Beyond technical improvements, we're building a vibrant community of knowledge seekers, facilitating user engagement through features like discussion forums and expert Q&A sessions. Our journey is marked by collaboration, partnerships, and measuring our impact on knowledge accessibility. This is just the beginning of our mission to make knowledge more accessible and insightful for all. | ## Inspiration
We wanted to create a new way to interact with the thousands of amazing shops that use Shopify.
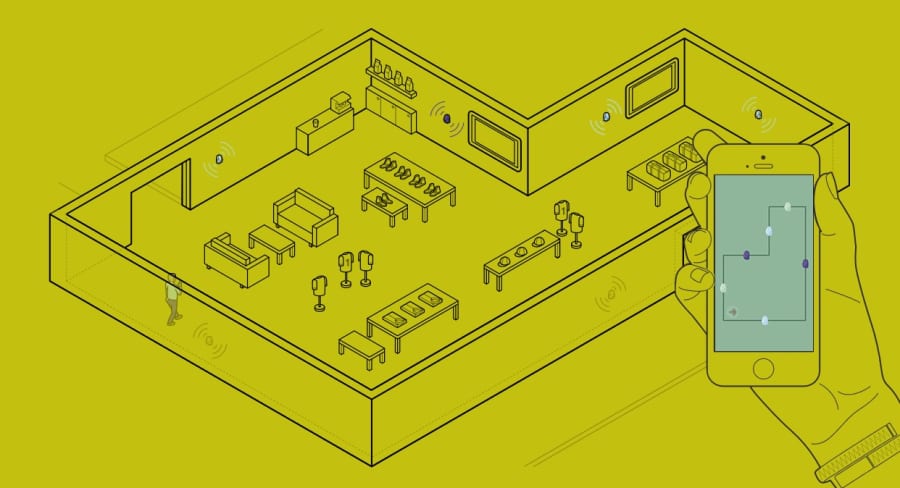
## What it does
Our technology can be implemented inside existing physical stores to help customers get more information about products they are looking at. What is even more interesting is that our concept can be implemented to ad spaces where customers can literally window shop! Just walk in front of an enhanced Shopify ad and voila, you have the product on the sellers store, ready to be ordered right there from wherever you are.
## How we built it
WalkThru is Android app built with the Altbeacon library. Our localisation algorithm allows the application to pull the Shopify page of a specific product when the consumer is in front of it.



## Challenges we ran into
Using the Estimote beacons in a crowded environment has it caveats because of interference problems.
## Accomplishments that we're proud of
The localisation of the user is really quick so we can show a product page as soon as you get in front of it.

## What we learned
We learned how to use beacons in Android for localisation.
## What's next for WalkThru
WalkThru can be installed in current brick and mortar shops as well as ad panels all over town. Our next step would be to create a whole app for Shopify customers which lets them see what shops/ads are near them. We would also want to improve our localisation algorithm to 3D space so we can track exactly where a person is in a store. Some analytics could also be integrated in a Shopify app directly in the store admin page where a shop owner would be able to see how much time people spend in what parts of their stores. Our technology could help store owners increase their sells and optimise their stores. | losing |
## Inspiration
We wanted to create a fun and easy way for students to sell items on campus.
## What it does
Pusheen Sell allows users to browse items currently for sale and sell items of their own. Not only is the app quick and easy to use, but it also gives more information about the items on sale through short videos.
## How we built it
The app is built using Xcode 8 and Swift 3, and the backend is handled via Firebase.
## Challenges we ran into
We started out with a much more ambitious project than we could complete in 24 hours, so we had to make some hard decisions and cut features in order to make a working app.
## Accomplishments that we're proud of
We're happy that we were able to get the video processing working.
## What we learned
Proper git management is important, even with a small team in the same place.
## What's next for Pusheen Sell
We would like to add a few more features that we couldn't complete in 24 hours, and eventually get the app in hands of students to start user testing. Eventually, this would be a great app to be used on campuses across the world! | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
Social media has been shown in studies that it thrives on emotional and moral content, particularly angry in nature. In similar studies, these types of posts have shown to have effects on people's well-being, mental health, and view of the world. We wanted to let people take control of their feed and gain insight into the potentially toxic accounts on their social media feed, so they can ultimately decide what to keep and what to remove while putting their mental well-being first. We want to make social media a place for knowledge and positivity, without the anger and hate that it can fuel.
## What it does
The app performs an analysis on all the Twitter accounts the user follows and reads the tweets, checking for negative language and tone. Using machine learning algorithms, the app can detect negative and potentially toxic tweets and accounts to warn users of the potential impact, while giving them the option to act how they see fit with this new information. In creating this app and its purpose, the goal is to **put the user first** and empower them with data.
## How We Built It
We wanted to make this application as accessible as possible, and in doing so, we made it with React Native so both iOS and Android users can use it. We used Twitter OAuth to be able to access who they follow and their tweets while **never storing their token** for privacy and security reasons.
The app sends the request to our web server, written in Kotlin, hosted on Google App Engine where it uses Twitter's API and Google's Machine Learning APIs to perform the analysis and power back the data to the client. By using a multi-threaded approach for the tasks, we streamlined the workflow and reduced response time by **700%**, now being able to manage an order of magnitude more data. On top of that, we integrated GitHub Actions into our project, and, for a hackathon mind you, we have a *full continuous deployment* setup from our IDE to Google Cloud Platform.
## Challenges we ran into
* While library and API integration was no problem in Kotlin, we had to find workarounds for issues regarding GCP deployment and local testing with Google's APIs
* Since being cross-platform was our priority, we had issues integrating OAuth with its requirement for platform access (specifically for callbacks).
* If each tweet was sent individually to Google's ML API, each user could have easily required over 1000+ requests, overreaching our limit. Using our technique to package the tweets together, even though it is unsupported, we were able to reduce those requests to a maximum of 200, well below our limits.
## What's next for pHeed
pHeed has a long journey ahead: from integrating with more social media platforms to new features such as account toxicity tracking and account suggestions. The social media space is one that is rapidly growing and needs a user-first approach to keep it sustainable; ultimately, pHeed can play a strong role in user empowerment and social good. | partial |
## Inspiration
Homelessness is a rampant problem in the US, with over half a million people facing homelessness daily. We want to empower these people to be able to have access to relevant information. Our goal is to pioneer technology that prioritizes the needs of displaced persons and tailor software to uniquely address the specific challenges of homelessness.
## What it does
Most homeless people have basic cell phones with only calling and sms capabilities. Using kiva, they can use their cell phones to leverage technologies previously accessible with the internet. Users are able to text the number attached to kiva and interact with our intelligent chatbot to learn about nearby shelters and obtain directions to head to a shelter of their choice.
## How we built it
We used freely available APIs such as Twilio and Google Cloud in order to create the beta version of kiva. We search for nearby shelters using the Google Maps API and communicate formatted results to the user’s cell phone Twilio’s SMS API.
## Challenges we ran into
The biggest challenge was figuring out how to best utilize technology to help those with limited resources. It would be unreasonable to expect our target demographic to own smartphones and be able to download apps off the app market like many other customers would. Rather, we focused on providing a service that would maximize accessibility. Consequently, kiva is an SMS chat bot, as this allows the most users to access our product at the lowest cost.
## Accomplishments that we're proud of
We succeeded in creating a minimum viable product that produced results! Our current model allows for homeless people to find a list of nearest shelters and obtain walking directions. We built the infrastructure of kiva to be flexible enough to include additional capabilities (i.e. weather and emergency alerts), thus providing a service that can be easily leveraged and expanded in the future.
## What we learned
We learned that intimately understanding the particular needs of your target demographic is important when hacking for social good. Often, it’s easier to create a product and find people who it might apply to, but this is less realistic in philanthropic endeavors. Most applications these days tend to be web focused, but our product is better targeted to people facing homeslessness by using SMS capabilities.
## What's next for kiva
Currently, kiva provides information on homeless shelters. We hope to be able to refine kiva to let users further customize their requests. In the future kiva should be able to provide information about other basic needs such as food and clothing. Additionally, we would love to see kiva as a crowdsourced information platform where people could mark certain places as shelter to improve our database and build a culture of alleviating homelessness. | ## Inspiration
The inspiration for this project came from the group's passion to build health related apps. While blindness is not necessarily something we can heal, it is something that we can combat with technology.
## What it does
This app gives blind individuals the ability to live life with the same ease as any other person. Using beacon software, we are able to provide users with navigational information in heavily populated areas such as subways or or museums. The app uses a simple UI that includes the usage of different numeric swipes or taps to launch certain features of the app. At the opening of the app, the interface is explained in its entirety in a verbal manner. One of the most useful portions of the app is a camera feature that allows users to snap a picture and instantly receive verbal cues depicting what is in their environment. The navigation side of the app is what we primarily focused on, but as a fail safe method the Lyft API was implemented for users to order a car ride out of a worst case scenario.
## How we built it
## Challenges we ran into
We ran into several challenges during development. One of our challenges was attempting to use the Alexa Voice Services API for Android. We wanted to create a skill to be used within the app; however, there was a lack of documentation at our disposal and minimal time to bring it to fruition. Rather than eliminating this feature all together, we collaborated to develop a fully functional voice command system that can command their application to call for a Lyft to their location through the phone rather than the Alexa.
Another issue we encountered was in dealing with the beacons. In a large area like what would be used in a realistic public space and setting, such as a subway station, the beacons would be placed at far enough distances to be individually recognized. Whereas, in such a confined space, the beacon detection overlapped, causing the user to receive multiple different directions simultaneously. Rather than using physical beacons, we leveraged a second mobile application that allows us to create beacons around us with an Android Device.
## Accomplishments that we're proud of
As always, we are a team of students who strive to learn something new at every hackathon we attend. We chose to build an ambitious series of applications within a short and concentrated time frame, and the fact that we were successful in making our idea come to life is what we are the most proud of. Within our application, we worked around as many obstacles that came our way as possible. When we found out that Amazon Alexa wouldn't be compatible with Android, it served as a minor setback to our plan, but we quickly brainstormed a new idea.
Additionally, we were able to develop a fully functional beacon navigation system with built in voice prompts. We managed to develop a UI that is almost entirely nonvisual, rather used audio as our only interface. Given that our target user is blind, we had a lot of difficulty in developing this kind of UI because while we are adapted to visual cues and the luxury of knowing where to tap buttons on our phone screens, the visually impaired aren't. We had to keep this in mind throughout our entire development process, and so voice recognition and tap sequences became a primary focus. Reaching out of our own comfort zones to develop an app for a unique user was another challenge we successfully overcame.
## What's next for Lantern
With a passion for improving health and creating easier accessibility for those with disabilities, we plan to continue working on this project and building off of it. The first thing we want to recognize is how easily adaptable the beacon system is. In this project we focused on the navigation of subway systems: knowing how many steps down to the platform, when they've reached the safe distance away from the train, and when the train is approaching. This idea could easily be brought to malls, museums, dorm rooms, etc. Anywhere that could provide a concern for the blind could benefit from adapting our beacon system to their location.
The second future project we plan to work on is a smart walking stick that uses sensors and visual recognition to detect and announce what elements are ahead, what could potentially be in the user's way, what their surroundings look like, and provide better feedback to the user to assure they don't get misguided or lose their way. | ## MoodBox
### Smart DJ'ing using Facial Recognition
You're hosting a party with your friends. You want to play the hippest music and you’re scared of your friends judging you for your taste in music.
You ask your friends what songs they want to listen to… And only one person replies with that one Bruno Mars song that you’re all sick of listening to.
Well fear not, with MoodBox you can now set a mood and our app will intelligently select the best songs from your friends’ public playlists!
### What it looks like
You set up your laptop on the side of the room so that it has a good view of the room. Create an empty playlist for your party. This playlist will contain all the songs for the night. Run our script with that playlist, sit back and relax.
Feel free to adjust the level of hypeness as your party progresses. Increase the hype as the party hits the drop and then make your songs more chill as the night winds down into the morning. It’s as simple as adjusting a slider in our dank UI.
### Behind the scenes
We used python’s `facial_recognition` package based on `opencv` library to implement facial recognition on ourselves. We have a map from our facial features from spotify user ids, which we use to find the saved songs.
We use the `spotipy` package to manipulate the playlist in real-time. Once we find a new face in the frame, we first read in the current mood from the slider, and find songs in that user’s public library of songs that match the mood set by the host the best.
Once someone is out of the frame for long enough, they get removed from our buffer, and their songs get removed from the playlist. This also ensures that the playlist is empty at the end of the party, and everyone goes home happy. | partial |
## How to use
First, you need an OpenAI account for a unique API key to plug into the openai.api\_key field in the generate\_transcript.py file. You'll also need to authenticate the text-to-speech API with a .json key from Google Cloud. Then, run the following code in the terminal:
```
python3 generate_transcript.py
cd newscast
npm start
```
You'll be able to use Newscast in your browser at <http://localhost:3000/>. Just log in with your Gmail account and you're good to go!
## Inspiration
Newsletters are an underpreciated medium and the experience of accessing them each morning could be made much more convenient if they didn't have to be clicked through one by one. Furthermore, with all the craze around AI, why not have an artificial companion deliver these morning updates to us?
## What it does
Newscast aggregates all newsletters a Gmail user has received during the day and narrates the most salient points from each one using personable AI-generated summaries powered by OpenAI and deployed with React and MUI.
## How we built it
Fetching mail from Gmail API -> Generating transcripts in OpenAI -> Converting text to speech via Google Cloud -> Running on MUI frontend
## Challenges we ran into
Gmail API was surprisingly trickly to operate with; it took a long time to bring the email strings to the form where OpenAi wouldn't struggle with them too much.
## Accomplishments that we're proud of
Building a full-stack app that we could see ourselves using! Successfully tackling a front-end solution on React after spending most of our time doing backend and algos in school.
## What we learned
Integrating APIs with one another, building a workable frontend solution in React and MUI.
## What's next for Newscast
Generating narratives grouped by publication/day/genre. Adding more UI features, e.g. cards pertaining to indidividual newspapers. Building a proper backend (Flask?) to support users and e.g. saving transcripts. | ## Inspiration
When attending crowded lectures or tutorials, it's fairly difficult to discern content from other ambient noise. What if a streamlined pipeline existed to isolate and amplify vocal audio while transcribing text from audio, and providing general context in the form of images? Is there any way to use this technology to minimize access to education? These were the questions we asked ourselves when deciding the scope of our project.
## The Stack
**Front-end :** react-native
**Back-end :** python, flask, sqlalchemy, sqlite
**AI + Pipelining Tech :** OpenAI, google-speech-recognition, scipy, asteroid, RNNs, NLP
## What it does
We built a mobile app which allows users to record video and applies an AI-powered audio processing pipeline.
**Primary use case:** Hard of hearing aid which:
1. Isolates + amplifies sound from a recorded video (pre-trained RNN model)
2. Transcribes text from isolated audio (google-speech-recognition)
3. Generates NLP context from transcription (NLP model)
4. Generates an associated image to topic being discussed (OpenAI API)
## How we built it
* Frameworked UI on Figma
* Started building UI using react-native
* Researched models for implementation
* Implemented neural networks and APIs
* Testing, Testing, Testing
## Challenges we ran into
Choosing the optimal model for each processing step required careful planning. Algorithim design was also important as responses had to be sent back to the mobile device as fast as possible to improve app usability.
## Accomplishments that we're proud of + What we learned
* Very high accuracy achieved for transcription, NLP context, and .wav isolation
* Efficient UI development
* Effective use of each tem member's strengths
## What's next for murmr
* Improve AI pipeline processing, modifying algorithms to decreasing computation time
* Include multi-processing to return content faster
* Integrate user-interviews to improve usability + generally focus more on usability | ## Inspiration
For University of Toronto students, the campus can be so large, that many times it can be difficult to find quiet spaces to study or louder spaces to spend some time with friends. We created UofT SoundSpace to help students find quiet and loud spaces around campus to help reduce conflicts between those who want to study and those who want to talk.
## What it does
SoundSpace relies on having many students record small audio samples at different times to understand when spaces are the quietest or the loudest. Then, when a student needs to find a quiet place to work, or a loud environment to relax in, they can use the app to figure out what locations would be the best choice.
## How we built it
We used Javascript, React Native, Python, GraphQL, and Flask. Our frontend was built with React Native for it to be cross-platform, and we sought to use Python to perform audio analysis to get key details about the audio average amplitude, volume spikes, or reverberation. These details would inform the user on what locations they would prefer.
## Challenges we ran into
Many of the difficulties arose from the collaboration between the front-end and back-end. The front-end of the system works great and looks nice, and we figured out how to perform audio analysis using Python, but we ran into problems transferring the audio files from the front-end to the back-end for processing.
In addition, we ran into problems getting geo-location to work with React Native, as we kept getting errors from extraneous files that we weren't using.
## Accomplishments that we're proud of
Learning new technologies and moving away from our comfort zones to try and build a practical project that can be accessible to anyone. Most of us had little experience with React Native and back-end development, so it was a valuable experience to work through our issues and put together a working product.
## What's next for UofT SoundSpace
We want to have more functionalities that expand to more buildings, specific floors, and rooms. This can ultimately expand to more post-secondary institutions.
Here are a list of the things that we wanted to get done, but couldn't in the time span:
* Login/Register Authentication
* Connection between front-end and back-end
* Getting the current geo-location of the user
* Uploading our data to a database
* Viewing all of the data on the map
* Using Co:here to help the user figure out what locations are best (ex. Where is the quietest place near me? --- The quietest place near you is Sidney Smith.)
Sadly, our group ran into many bugs and installation issues with React Native that halted our progression early on, so we were not able to complete a lot of these features before the deadline.
However, we hope that our idea is inspiring, and believe that our app would serve as a solid foundation for this project given more time! | partial |
## Inspiration
## What it does
Buddy is your personal assistant that monitors your device's screen-on time so you can better understand your phone usage statistics. These newfound insights will help you to optimize your time and understand your usage patterns. Set a maximum screen-on time goal for yourself and your personal assistant, Buddy, will become happier the less you use your device and become more unhappy as you get close to or exceed the limit you set for yourself.
## How we built it
We built an android app using the NativeScript framework while coding in JavaScript. Our graphics were created through the use of Photoshop.
## Challenges we ran into
As it was our team's first time creating an android app, we went through much trial and error. Learning Google Firebase and the NativeScript framework was a welcomed challenge. We also faced some technical limitations two of our 3 computers were unable to emulate the app. Thus our ability to do testing was limited and as a result slowed our overall progress.
## Accomplishments that we're proud of
## What we learned
We were strangers when we met and had different backgrounds of experience. The three of us were separately experienced in either front-end, back-end, and UI/UX which made for a very interesting team dynamic. Handling better CSS, using better classes, and utilizing frameworks such as NativeScript were all things we learned from each other (and the internet).
## What's next for Buddy
Buddy will be venturing on to increase the depth of our phone usage analysis by not only including screen-on time but also usage by app. We also highly value user experience so we are looking into creating more customizable options such as different species of pets, colours of fur, and much more. An IOS app is also being considered as the next step for our product. | 
## Inspiration
Two weeks ago you attended an event and have met some wonderful people to help get through the event, each one of you exchanged contact information and hope to keep in touch with each other. Neither one of you contacted each other and eventually lost contact with each other. A potentially valuable friendship is lost due to neither party taking the initiative to talk to each other before. This is where *UpLync* comes to the rescue, a mobile app that is able to ease the connectivity with lost contacts.
## What it does?
It helps connect to people you have not been in touch for a while, the mobile application also reminds you have not been contacting a certain individual in some time. In addition, it has a word prediction function that allows users to send a simple greeting message using the gestures of a finger.
## Building process
We used mainly react-native to build the app, we use this javascript framework because it has cross platform functionality. Facebook has made a detailed documented tutorial at [link](https://facebook.github.io/react-native) and also [link](http://nativebase.io/) for easier cross-platform coding, we started with
* Designing a user interface that can be easily coded for both iOS and Android
* Functionality of the Lazy Typer
* Touch up with color scheme
* Coming up with a name for the application
* Designing a Logo
## Challenges we ran into
* non of the team members know each other before the event
* Coding in a new environment
* Was to come up with a simple UI that is easy on the eyes
* Keeping people connected through a mobile app
* Reduce the time taken to craft a message and send
## Accomplishments that we're proud of
* Manage to create a product with React-Native for the first time
* We are able to pick out a smooth font and colour scheme to polish up the UI
* Enabling push notifications to remind the user to reply
* The time taken to craft a message was reduced by 35% with the help of our lazy typing function
## What we learned.
We are able to learn the ins-and-outs of react-native framework, it saves us work to use android studio to create the application.
## What's next for UpLync
The next step for UpLync is to create an AI that learns the way how the user communicates with their peers and provide a suitable sentence structure. This application offers room to provide support for other languages and hopefully move into wearable technology. | ## About the Project
### TLDR:
Caught a fish? Take a snap. Our AI-powered app identifies the catch, keeps track of stats, and puts that fish in your 3d, virtual, interactive aquarium! Simply click on any fish in your aquarium, and all its details — its rarity, location, and more — appear, bringing your fishing memories back to life. Also, depending on the fish you catch, reel in achievements, such as your first fish caught (ever!), or your first 20 incher. The cherry on top? All users’ catches are displayed on an interactive map (built with Leaflet), where you can discover new fishing spots, or plan to get your next big catch :)
### Inspiration
Our journey began with a simple observation: while fishing creates lasting memories, capturing those moments often falls short. We realized that a picture might be worth a thousand words, but a well-told fish tale is priceless. This spark ignited our mission to blend the age-old art of fishing with cutting-edge AI technology.
### What We Learned
Diving into this project was like casting into uncharted waters – exhilarating and full of surprises. We expanded our skills in:
* Integrating AI models (Google's Gemini LLM) for image recognition and creative text generation
* Crafting seamless user experiences in React
* Building robust backend systems with Node.js and Express
* Managing data with MongoDB Atlas
* Creating immersive 3D environments using Three.js
But beyond the technical skills, we learned the art of transforming a simple idea into a full-fledged application that brings joy and preserves memories.
### How We Built It
Our development process was as meticulously planned as a fishing expedition:
1. We started by mapping out the user journey, from snapping a photo to exploring their virtual aquarium.
2. The frontend was crafted in React, ensuring a responsive and intuitive interface.
3. We leveraged Three.js to create an engaging 3D aquarium, bringing caught fish to life in a virtual environment.
4. Our Node.js and Express backend became the sturdy boat, handling requests and managing data flow.
5. MongoDB Atlas served as our net, capturing and storing each precious catch securely.
6. The Gemini AI was our expert fishing guide, identifying species and spinning yarns about each catch.
### Challenges We Faced
Like any fishing trip, we encountered our fair share of challenges:
* **Integrating Gemini AI**: Ensuring accurate fish identification and generating coherent, engaging stories required fine-tuning and creative problem-solving.
* **3D Rendering**: Creating a performant and visually appealing aquarium in Three.js pushed our graphics programming skills to the limit.
* **Data Management**: Structuring our database to efficiently store and retrieve diverse catch data presented unique challenges.
* **User Experience**: Balancing feature-rich functionality with an intuitive, streamlined interface was a constant tug-of-war.
Despite these challenges, or perhaps because of them, our team grew stronger and more resourceful. Each obstacle overcome was like landing a prized catch, making the final product all the more rewarding.
As we cast our project out into the world, we're excited to see how it will evolve and grow, much like the tales of fishing adventures it's designed to capture. | partial |
## 💡 Inspiration 💡
The idea for Foodbox was inspired by the growing problem of food waste in our society. According to the United Nations, one-third of all food produced globally is wasted, which not only has a significant environmental impact but also a social one, as so many people are struggling with food insecurity. We realized that grocery stores often have a surplus of certain products that don't sell well, and we wanted to find a way to help them move this inventory and avoid waste. At the same time, we saw an opportunity for consumers to discover new products at a discounted price.
Another inspiration for Foodbox was the increasing awareness of the environmental impact of our food choices. Food production is a major contributor to greenhouse gas emissions and deforestation, and by reducing food waste, we can also reduce our environmental footprint. We believe that Foodbox is a small but meaningful step in the right direction, and we hope that it will inspire others to think creatively about how they can also make a positive impact on the planet and their communities.
## 🛠️ What it does 🛠️
Foodbox is a platform that helps to reduce food waste and promote sustainability. We partner with local grocery stores to offer a 20% discount on their least popular items and package them in a "food mystery box" for our customers to purchase. This way, grocery stores can move their inventory and avoid waste, while customers can discover new products at discounted prices. The items in the box are drawn randomly, so customers can try new things and experiment with different products. Our platform also has a rating system where customers can rate the products they received and this will help the store to know which products are popular among customers. With Foodbox, we hope to create a win-win situation for both the stores and customers, while also making a positive impact on the environment.
## 🏗️ How we built it 🏗️
Our team built the Foodbox web application using Next.js, a framework for building server-rendered React applications. We used Tailwind CSS for styling and Supabase PostgreSQL as our database management system. The final application was deployed using Vercel, a platform for hosting and deploying web applications. With these technologies, we were able to create a fast, responsive, and visually appealing application that is easy to use and navigate. The combination of these technologies allowed us to quickly and efficiently build the application, allowing us to focus on the core functionality of the project.
## 🧗♂️ Challenges we ran into 🧗♂️
Upon meeting initially on the morning of the hackathon, we quickly put together a really good digital receipt app idea! But after doing some research and realizing our great new original idea wasn’t so original after all, we ended up thinking of a food loot box idea in the line for lunch! The best ideas really do come from the strangest places.
## 🏆 Accomplishments that we're proud of 🏆
Kelly: I’d had experience using Adobe XD for mockups at my job as a part-time web designer, but I’d never really used Figma to do the same thing! I’m proud that I managed to learn how to use new software proficiently in one night which allowed me to easily cooperate with my front-end teammates!
Abraham: I’m familiar with React and front-end development in general but I have not used many of the frameworks we used in this project. I was excited to learn and implement Next.js and Tailwind CSS and I am proud of the pages I’ve created using them. I’m also proud of our adaptability to change when we had to accept that our old idea was no longer viable and come up with a new one, throwing away all our previous planning.
Amir: I'm really proud of the idea my team came up with for Foodbox and how we made it happen. I also had a blast playing around with Framer motion and Tailwind, it helped me level up my CSS and React animation skills. It was a great hackathon experience!
Calder: I got to work with 2 new technologies: FastAPI and Beautifulsoup. I learned a ton about parsing HTML and creating an API! Expanding my skills on the server side and working with my awesome teammates made this hackathon a special one.
## 📕 What we learned 📕
During this hackathon, my team and I faced a lot of challenges, but we also had a lot of fun. We learned that it's important to take breaks and have fun to stay motivated and refreshed. We also made some awesome connections with sponsors and other teams. We were able to learn from other participants and sponsors about their experiences and ideas. This helped us to have different perspectives on the problem we were trying to solve and helped us to come up with more creative solutions. And let me tell you, we totally crushed the cup-stacking competition thanks to the strategy we learned. Overall, it was a great learning experience for all of us. We walked away with new skills, new connections, and a sense of accomplishment.
## ⏭️ What's next for Foodbox ⏭️
The next step for Foodbox is to continue to expand our partnerships with local grocery stores. By working with more stores, we can offer a wider variety of products to our customers and help even more stores avoid food waste. We also plan to continue to improve the customer experience by gathering feedback and using it to make our platform more user-friendly. We also plan to expand our efforts to educate our customers about food waste and the environmental impact of their food choices. Finally, we will be looking at other ways to leverage technology, such as artificial intelligence, to further personalize the experience for our customers and make even better recommendations based on their preferences. | ## Inspiration
We recognized how much time meal planning can cause, especially for busy young professionals and students who have little experience cooking. We wanted to provide an easy way to buy healthy, sustainable meals for the week, without compromising the budget or harming the environment.
## What it does
Similar to services like "Hello Fresh", this is a webapp for finding recipes and delivering the ingredients to your house. This is where the similarities end, however. Instead of shipping the ingredients to you directly, our app makes use of local grocery delivery services, such as the one provided by Loblaws. The advantages to this are two-fold: first, it helps keep the price down, as your main fee is for the groceries themselves, instead of paying large amounts in fees to a meal kit company. Second, this is more eco-friendly. Meal kit companies traditionally repackage the ingredients in house into single-use plastic packaging, before shipping it to the user, along with large coolers and ice packs which mostly are never re-used. Our app adds no additional packaging beyond that the groceries initially come in.
## How We built it
We made a web app, with the client side code written using React. The server was written in python using Flask, and was hosted on the cloud using Google App Engine. We used MongoDB Atlas, also hosted on Google Cloud.
On the server, we used the Spoonacular API to search for recipes, and Instacart for the grocery delivery.
## Challenges we ran into
The Instacart API is not publicly available, and there are no public API's for grocery delivery, so we had to reverse engineer this API to allow us to add things to the cart. The Spoonacular API was down for about 4 hours on Saturday evening, during which time we almost entirely switched over to a less functional API, before it came back online and we switched back.
## Accomplishments that we're proud of
Created a functional prototype capable of facilitating the order of recipes through Instacart. Learning new skills, like Flask, Google Cloud and for some of the team React.
## What we've learned
How to reverse engineer an API, using Python as a web server with Flask, Google Cloud, new API's, MongoDB
## What's next for Fiscal Fresh
Add additional functionality on the client side, such as browsing by popular recipes | ## Inspiration
The alarming surge in suicide rates among farmers in developing countries begs the question: What is driving these individuals to such a desperate point? Their relentless pursuit of higher yields has led many to employ excessive quantities of fertilizers and pesticides, with the hope of boosting their crop output. However, instead of reaping financial benefits, these practices often result in mounting debts and profound despair, ultimately pushing some farmers to take their own lives. What's more, the overdose of fertilizers not only contributes to soil pollution but also leads to diminishing yields over time, creating a detrimental feedback loop. This perilous combination of financial strain, environmental degradation, and declining agricultural productivity underscores the urgent need for comprehensive solutions to safeguard farmer well-being, promote environmental sustainability, and ensure the long-term success of agriculture in these regions.
## What it does
At CropNsoil, our cutting-edge program harnesses crucial data, such as farm location, size, soil nitrogen levels, and pH, to meticulously craft the **optimal intercropping strategy** for your fields.
We utilize advanced modeling techniques to determine the most harmonious crop combinations and their precise spatial arrangement. Our primary goal is to enhance your revenue, all while promoting sustainability and safeguarding the Earth's precious soil.
By intelligently pairing crops that complement each other's growth, we create a synergy that significantly boosts overall efficiency by reducing the need of excess fertilizers and pesticides. This increases your income, reduces the risk factor associated with failure of one crop, but also plays a pivotal role in protecting our environment.
Furthermore, our custom intercropping patterns are tailored to harness the unique attributes of your specific location. This ensures that your agricultural practices are aligned with the environmental conditions of your farm. By making the most of what your land has to offer, we contribute to a sustainable farming future that safeguards our soil and protects our planet.
## How we built it
The process began with a vast database containing valuable insights into soil conditions, weather patterns, and historical crop yields, specific to your region. These data formed the bedrock of our project.
We harnessed the power of machine learning, a cutting-edge technology, to make sense of this wealth of information. Our team diligently trained the models, using the historic data, to accurately classify crops based on weather and soil conditions.
This finely tuned machine learning model then goes a step further, recommending the ideal intercropping pattern. The primary objective is to maximize your revenue, all while promoting sustainability.
The final decision on the cropping pattern is made with precision, taking into account the compatibility of crops and their revenue potential. This process is a testament to the harmonious coexistence of data, technology, and agricultural wisdom, ensuring that your land thrives while benefiting both your financial well-being and the environment.
The technologies we used were python, react, javascript, HTML, CSS, MongoDB, Node.JS, Tailwind CSS.
Based on the crops and the spatial arrangement generated we explain the farmer on what is the logic behind choosing that arrangement.
Also we provide a plan of action to the farmer specified for their crops according to the stage of crop growth they are in.
## Challenges we ran into
Understanding the problem and the idea. Trying to minimize the scope and build this project in the given timeframe.
Calling the machine learning model into the frontend.
## Accomplishments that we're proud of
Coming up with a efficient, sustainable and effective solution to the problem. Creating a comprehensive model.
Were a team of members from diverse backgrounds. Coming together and working as an efficient team.
**Making a very good looking Github Repo which adds a unique personality to our project and showing all the main components of our project. Also, using commits related to hack for the future**
## What we learned
Learned about soils and the necessities of cropping system.
Creating frontend models several tools.
## What's next for CropNsoil
In the future we see the data collection that is done currently by asking the farmers to be done by the automated drones using sensors (winner HackHarvard 2022). | winning |
## Inspiration
We were motivated to tackle linguistic challenges in the educational sector after juxtaposing our personal experience with current news.
There are currently over 70 million asylum seekers, refugees, or internally-displaced people around the globe, and this statistic highlights the problem of individuals from different linguistic backgrounds being forced to assimilate into a culture and language different than theirs. As one of our teammates was an individual seeking a new home in a new country, we had first hand perspective at how difficult this transition was. In addition, our other team members had volunteered extensively within the educational system in developing communities, both locally and globally, and saw a similar need with individuals being unable to meet the community’s linguistics standards.
We also iterated upon our idea to ensure that we are holistically supporting our communities by making sure we consider the financial implications of taking the time to refine your language skills instead of working.
## What it does
Fluently’s main purpose is to provide equitable education worldwide. By providing a user customized curriculum and linguistic practice, students can further develop their understanding of their language. It can help students focus on areas where they need the most improvement. This can help them make progress at their own pace and feel more confident in their language skills while also practicing comprehension skills. By using artificial intelligence to analyze pronunciation, our site provides feedback that is both personalized and objective.
## How we built it
Developing the web application was no easy feat.
As we were searching for an AI model to help us through our journey we stumbled upon OpenAI, specifically Microsoft Azure’s cognitive systems that utilize OpenAI’s comprehensive abilities in language processing. This API gave us the ability to analyze voice patterns and fluency and transcribe passages that are mentioned in the application. Figuring out the documentation as well as how the AI will be interacting with the user was most important for us to execute properly since the AI would be acting as the tutor/mentor for the students in these cases. We developed a diagram that would break down the passages read to the student phonetically and give them a score of 100 for how well each word was pronounced based on the API’s internal grading system. As it is our first iteration of the web app, we wanted to explore how much information we could extract from the user to see what is most valuable to display to them in the future.
Integrating the API with the web host was a new feat for us as a young team. We were confident in our python abilities to host the AI services and found a library by the name of Flask that would help us write html and javascript code to help support the front end of the application through python. By using Flask, we were able to host our AI services with python while also continuously managing our front end through python scripts.
This gave room for the development of our backend systems which are Convex and Auth0. Auth0 was utilized to give members coming into the application a unique experience by having them sign into a personalized account. The account is then sent into the Convex database to be used as a storage base for their progress in learning and their development of skills over time. All in all, each component of the application from the AI learning models, generating custom passages for the user, to the backend that communicated between the Javascript and Python server host that streamlines the process of storing user data, came with its own challenges but came together seamlessly as we guide the user from our simple login system to the passage generator and speech analyzer to give the audience constructive feedback on their fluency and pronunciation.
## Challenges we ran into
As a majority beginning team, this was our first time working with many of the different technologies, especially with AI APIs. We need to be patient working with key codes and going through an experiment process of trying different mini tests out to then head to the major goal that we were headed towards. One major issue that we faced was the visualization of data to the user. We found it hard to synthesize the analysis that was done by the AI to translate to the user to make sure they are confident in what they need to improve on. To solve this problem we first sought out how much information we could extract from the AI and then in future iterations we would simply display the output of feedback.
Another issue we ran into was the application of convex into the application. The major difficulty came from developing javascript functions that would communicate back to the python server hosting the site. This was resolved thankfully; we are grateful for the Convex mentors at the conference that helped us develop personalized javascript functions that work seamlessly with our Auth0 authentication and the rest of the application to record users that come and go.
## Accomplishments that we're proud of:
One accomplishment that we are proud of was the implementation of Convex and Auth0 with Flask and Python. As python is a rare language to host web servers in and isn't the primary target language for either service, we managed to piece together a way to fit both services into our project by collaboration with the team at Convex to help us out. This gave way to a strong authentication platform for our web application and for helping us start a database to store user data onto.
Another accomplishment was the transition of using a React Native application to using Flask with Python. As none of the group has seen Flask before or worked for it for that matter, we really had to hone in our abilities to learn on the fly and apply what we knew prior about python to make the web app work with this system.
Additionally, we take pride in our work with OpenAI, specifically Azure. We researched our roadblocks in finding a voice recognition AI to implement our natural language processing vision. We are proud of how we were able to display resilience and conviction to our overall mission for education to use new technology to build a better tool.
## What we learned
As beginners at our first hackathon, not only did we learn about the technical side of building a project, we were also able to hone our teamwork skills as we dove headfirst into a project with individuals we had never worked with before.
As a group, we collectively learned about every aspect of coding a project, from refining our terminal skills to working with unique technology like Microsoft Azure Cognitive Services. We also were able to better our skillset with new cutting edge technologies like Convex and OpenAI.
We were able to come out of this experience not only growing as programmers but also as individuals who are confident they can take on the real world challenges of today to build a better tomorrow.
## What's next?
We hope to continue to build out the natural language processing applications to offer the technology in other languages. In addition, we hope to hone to integrate other educational resources, such as videos or quizzes to continue to build other linguistic and reading skill sets. We would also love to explore the cross section with gaming and natural language processing to see if we can make it a more engaging experience for the user. In addition, we hope to expand the ethical considerations by building a donation platform that allows users to donate money to the developing community and pay forward the generosity to ensure that others are able to benefit from refining their linguistic abilities. The money would then go to a prominent community in need that uses our platform to fund further educational resources in their community.
## Bibliography
United Nations High Commissioner for Refugees. “Global Forced Displacement Tops 70 Million.” UNHCR, UNHCR, The UN Refugee Agency, <https://www.unhcr.org/en-us/news/stories/2019/6/5d08b6614/global-forced-displacement-tops-70-million.html>. | ## Inspiration
We created ASL Bridgify to address the need for an interactive real time pose-estimation based learning model for ASL. In a post-pandemic world, we foresee that working from home and more remote experiences signals the need to communicate with individuals with hearing disabilities. It is a feature that is missing from various video conferencing, learning, and entertainment - based platforms. Shockingly, Duolingo the number 1 language learning platform does not teach ASL.
## What it does
ASLBridgify is an educational platform that specifically focuses on the learning of ASL. We provide comprehensive modules that help you learn languages in scientifically proven ways. We provide easy to follow UI and personalized AI assistance in your learning journey. We realize that the future of AI comes in more than chatbot form, so our AI models are integrated within video to track hand-movement using Media pipe and TensorFlow.
## How we built it
We created an educational platform by leveraging many technologies. Our frontend uses Next.js, Tailwind and Supabase. Our backend used Python libraries such as PyTorch, TensorFlow, and Keras to train our LLMs with the use of Intel Developer Cloud GPU and CPU to expedite the training. We connected the Frontend with the Backend with Flask. Moreover, we combined our trained models with Google Search API OpenAI API for Retrival-Augemented-Generation (RAG)
## Challenges we ran into
The biggest challenge was time. The time it took to train one Large Language Model, even when using Intel Developer Cloud GPU capabilities was immense. It was a roadblock because we couldn't test any other code on one computer until the LLM was done training. Initially we tried to preprocess both words and sentences using hand pose to map ASL and using encoder decoder architecture, but we were not able to complete this because of the time constraint. ASL sentences is something we want to incorporate in the future.
## Accomphishments we are proud of
We successfully trained preliminary large language models using PyTorch GPUs on the Intel Cloud from scratch. We're thrilled to integrate this accomplishment into our frontend. Through implementing three AI tools—each using different methods such as calling an API and building with IPEX—we've gained valuable insights into AI. Our excitement grows as we introduce our one-of-a-kind educational platform for ASL to the world. | ## Inspiration
The original inspiration behind Bevrian was the Webtoon “Tacit”, by KimDazzi. In the story, the characters could control their drones with their minds to fight zombies, deliver supplies, etc. Of course, the technology behind the mind-controlled drones was never fully explained. Our initial plan was to make an EEG or ECG drone but the design had limitations both in terms of getting the hardware and cost. Therefore, we went with a simpler version of the concept using motion detection via an accelerometer.
Tacit: <https://www.webtoons.com/en/action/tacit/list?title_no=3178>
## What it does
Our project uses accelerometer and gyroscope data to enable users to control a DJI Tello drone (forward, backwards, left and right) using just their hand motions. The takeoff, landing and up and down of the drone is controlled via a push button.
## How we built it
A GY-521 accelerometer was the primary sensor utilized in the project. It features a 3-axis gyroscope, a 3-axis accelerometer, a digital motion processor (DMP), and a temperature sensor. We fed the accelerometer’s data into an Arduino Uno, which processed and outputted it in a specific format needed to fly the drone. A second Arduino Uno was running the standard firmata software, which allowed us to run Python scripts on it with third-party libraries. The library we used to fly the DJI Tello was djitellopy. The Python script we wrote read in the processed gyroscope data from the first Arduino Uno and relayed the appropriate commands to the DJI Tello via Wifi.
## Challenges we ran into
The first challenge we ran into was setting up the Raspberry Pi. The one we had was a Raspberry Pi 3 that did not connect regardless of what we tried (it was not able to boot up or connect to a monitor/laptop), and we were not able to obtain another one on short notice, due to the shipping times and chip shortages. As such, we had to switch our initial plan to an Arduino-only one.
The second challenge we ran into was associated with the RF433 transceiver module. We tried countless blogs and Youtube tutorials and even sample codes, following the procedures cautiously step by steps, we even made a copper antenna as we thought the transceiver had range issues, but none of it led to any readings. The idea was to connect the accelerometer to the transmitter, which would then transmit the sensor data to a receiver connected to a computer. This would allow the user to have a detached, portable module that they can freely utilize to control the drone. However, the transceiver did not end up functioning properly, and we could not obtain a replacement or substitute on short notice.
The last challenge we ran into was associated with the accelerometer itself. Apart from the fact that the 3-axis accelerometer + 3-axis gyroscope was not readable by the Python library we were using (pyfirmata) to control the drone, the sensor also ended up being slightly faulty in its readings. Namely, we wanted to utilize the gyroscope and accelerometer data to move the drone forward and backwards, up/down, and yaw left/right, but one of the axes was giving faulty readings. Subsequently, we were able to program the drone to move using the remaining 2 axes for the functions of forwards/backwards as well as left/right.
## Accomplishments that we're proud of
We're proud of being able to accurately read the data from our accelerometer to effectively and intuitively pilot a drone using motion controls, despite all the challenges we faced.
## What we learned
The main thing we learned was that working with hardware comes with its own set of challenges that are much different than software. When components don’t work, the debugging process often takes longer and there are more opportunities for failure. Setting up controllers such as the Raspberry Pi is also much more different than setting up a basic script for a web app. Nonetheless, we learned a lot about signal processing and hands-on electronics.
## What's next for Bevrian: The Motion-Controlled Drone
Our next step is implementing wireless communication via Bluetooth, Wi-Fi, or RF communication for the project. The goal is to be able to have a detached module (no PC connection) that can be strapped to a user’s hand, which communicates wirelessly with the drone, just like the concepts seen in the webtoon “Tacit.” | partial |
## Inspiration
It’s difficult to practice languages and speaking in general without having natural conversations. It's even harder to gauge improvement accurately and consistently. These factors make it extremely difficult to commit to learning a language, even if one has the will to do so. Parla aims to ameliorate these problems in a very straightforward way.
## What it does
Parla is the AI chat bot that has a real, natural conversation with you in your language of choice. Choose a language and a topic, and let the conversation flow naturally. As language learners ourselves, we made it a priority for Parla to be of use to learners of varying skill levels. Thus, Parla will adapt to your skill level throughout the conversation, giving more thought provoking prompts the higher your proficiency. When the conversation is over, Parla will analyze your speech, notifying you of grammatical errors, and giving recommendations on how to improve individual responses as well as your overall conversational ability. Parla will also provide useful metrics including speech timing, and will gauge your confidence level.
## How we built it
* React/Next.js for the frontend
* Flask/Python for the backend
* Cohere chat API for providing conversational responses
* Cohere generate API for providing recommendations
* Google cloud API for voice to text and text to speech, as well as translation
* LanguageTool API for detecting grammatical errors in speech
## Challenges we ran into
We spent a lot of time trying to train custom models on Cohere to detect grammatical errors in many different languages before realizing that this was a gargantuan task. We also had difficulty with deciding how best to support different languages - we were ultimately decided to only support the ones that Cohere inherently supports, which are English, French, German, Spanish, and Italian. None of us had any significant experience using LLMs and NLP frameworks. Many thanks to all the representatives at Cohere that helped us think through our project and its limitations!
## Accomplishments that we're proud of
* At many points in the project we were fully convinced that our project was flat out impossible. We're incredibly proud that we were able to stay true to the initial goal of providing an adaptable chatting partner for language learning that could provide good, accurate feedback.
* We feel that we explored a lot of the capabilities of Cohere, and we're proud that we ended up using a subset of the features that we feel made the most sense for our use case instead of the "everything but the kitchen sink" approach we initially went with for selecting features to use.
## What we learned
* Jeffrey: Usage of LLMs, training models, and their limitations.
* Jueun: Collaborating with super cool devs :)
* Dylan: Using and training models on cohere.
* Bryan: The many pitfalls of training your own model.
## What's next for Parla
Ultimately, Parla would like to support and be able to converse in all major languages. We'd also like to provide feedback beyond grammar and general recommendations, including improved sentence structure, diction, and even tone/speech variance. We're also interested in training Parla for more specific purposes such as language exam preparation. | ## About
Learning a foreign language can pose challenges, particularly without opportunities for conversational practice. Enter SpyLingo! Enhance your language proficiency by engaging in missions designed to extract specific information from targets. You select a conversation topic, and the spy agency devises a set of objectives for you to query the target about, thereby completing the mission. Users can choose their native language and the language they aim to learn. The website and all interfaces seamlessly translate into their native tongue, while missions are presented in the foreign language.
## Features
* Choose a conversation topic provided by the spy agency and it will generate a designated target and a set of objectives to discuss.
* Engage the target in dialogue in the foreign language on any subject! As you achieve objectives, they'll be automatically marked off your mission list.
* Witness dynamically generated images of the target, reflecting the topics they discuss, after each response.
* Enhance listening skills with automatically generated audio of the target's response.
* Translate the entire message into your native language for comprehension checks.
* Instantly translate any selected word within the conversation context, providing additional examples of its usage in the foreign language, which can be bookmarked for future review.
* Access hints for formulating questions about the objectives list to guide interactions with the target.
* Your messages are automatically checked for grammar and spelling, with explanations in your native language for correcting foreign language errors.
## How we built it
With the time constraint of the hackathon, this project was built entirely on the frontend of a web application. The TogetherAI API was used for all text and image generation and the ElevenLabs API was used for audio generation. The OpenAI API was used for detecting spelling and grammar mistakes.
## Challenges we ran into
The largest challenge of this project was building something that can work seamlessly in **812 different native-foreign language combinations.** There was a lot of time spent on polishing the user experience to work with different sized text, word parsing, different punctuation characters, etc.
Even more challenging was the prompt engineering required to ensure the AI would speak in the language it is supposed to. The chat models frequently would revert to English if the prompt was in English, even if the prompt specified the model should respond in a different language. As a result, there are **over 800** prompts used, as each one has to be translated into every language supported during build time.
There was also a lot of challenges in reducing the latency of the API responses to make for a pleasant user experience. After many rounds of performance optimizations, the app now effectively generates the text, audio, and images in perceived real time.
## Accomplishments that I'm proud of
The biggest challenges also yielded the biggest accomplishments in my eyes. Building a chatbot that can be interacted with in any language and operates in real time by myself in the time limit was certainly no small task.
I'm also exceptionally proud of the fact that I honestly think it's fun to play. I've had many projects that get dumped on a dusty shelf once completed, but the fact that I fully intend to keep using this after the hackathon to improve my language skills makes me very happy.
## What we learned
I had never used these APIs before beginning this hackathon, so there was quite a bit of documentation that I had to read to understand for how to correctly stream the text & audio generation.
## What's next for SpyLingo
There are still more features that I'd like to add, like different types of missions for the user. I also think the image prompting can use some more work since I'm not as familiar with image generation.
I would like to productionize this project and setup a proper backend & database for it. Maybe I'll set up a stripe integration and make it available for the public too! | ## Inspiration ✨
Seeing friends' lives being ruined through **unhealthy** attachment to video games. Struggling with regulating your emotions properly is one of the **biggest** negative effects of video games.
## What it does 🍎
YourHP is a webapp/discord bot designed to improve the mental health of gamers. By using ML and AI, when specific emotion spikes are detected, voice recordings are queued *accordingly*. When the sensor detects anger, calming reassurance is played. When happy, encouragement is given, to keep it up, etc.
The discord bot is an additional fun feature that sends messages with the same intention to improve mental health. It sends advice, motivation, and gifs when commands are sent by users.
## How we built it 🔧
Our entire web app is made using Javascript, CSS, and HTML. For our facial emotion detection, we used a javascript library built using TensorFlow API called FaceApi.js. Emotions are detected by what patterns can be found on the face such as eyebrow direction, mouth shape, and head tilt. We used their probability value to determine the emotional level and played voice lines accordingly.
The timer is a simple build that alerts users when they should take breaks from gaming and sends sound clips when the timer is up. It uses Javascript, CSS, and HTML.
## Challenges we ran into 🚧
Capturing images in JavaScript, making the discord bot, and hosting on GitHub pages, were all challenges we faced. We were constantly thinking of more ideas as we built our original project which led us to face time limitations and was not able to produce some of the more unique features to our webapp. This project was also difficult as we were fairly new to a lot of the tools we used. Before this Hackathon, we didn't know much about tensorflow, domain names, and discord bots.
## Accomplishments that we're proud of 🏆
We're proud to have finished this product to the best of our abilities. We were able to make the most out of our circumstances and adapt to our skills when obstacles were faced. Despite being sleep deprived, we still managed to persevere and almost kept up with our planned schedule.
## What we learned 🧠
We learned many priceless lessons, about new technology, teamwork, and dedication. Most importantly, we learned about failure, and redirection. Throughout the last few days, we were humbled and pushed to our limits. Many of our ideas were ambitious and unsuccessful, allowing us to be redirected into new doors and opening our minds to other possibilities that worked better.
## Future ⏭️
YourHP will continue to develop on our search for a new way to combat mental health caused by video games. Technological improvements to our systems such as speech to text can also greatly raise the efficiency of our product and towards reaching our goals! | losing |
## Inspiration
The idea addresses a very natural curiosity to live and experience the world as someone else, and out of the progress with the democratization of VR with the Cardboard, we tried to create a method for people to "upload" their life to others. The name is a reference to Sharon Creech's quote on empathy in Walk Two Moons: "You can't judge a man until you've walked two moons in his moccasins", which resonated with our mission.
## What it does
Moonlens consists of a pipeline of three aspects that connects the uploaders to the audience. Uploaders use the camera-glasses to record, and then upload the video onto the website along with the data from the camera-glasses's gyro-accelerometer data (use explained below). The website communicates with the iOS app and allows the app to playback the video in split-screen.
To prevent motion sickness, the viewer has to turn his head in the same orientation as the uploader for the video to come into view, as otherwise the experience will disturb the vestibular system. This orientation requirement warrants the use of the gyro-accelerometer in the camera-glasses to compare to the iPhone's orientation tracking data.
## How we built it
The three components of the pipeline:
1. Camera-glasses: using the high framerate and high resolution of mini sports cameras, we took apart the camera and attached it to a pair of glasses. The camera-glasses sport a combination of gyroscope and accelerometer that start synchronously with the camera's recording, and the combination of the camera and Arduino processor for the gyro-accelerometer outputs both the video file and the orientation data to be uploaded onto the website.
2. Website: The website is for the uploaders to transfer the individual video-orientation data pairs to the database. The website was designed with Three.js, along with the externally designed logo and buttons. It uses Linode servers to handle PHP requests for the file uploads.
3. App: The app serves as the consumer endpoint for the pipeline, and allows consumers to view all the videos in the database. The app features automatic split-screen, and videos in the app are of similar format with 360 videos except for the difference that the video only spans a portion of the spherical projection, and the viewer has to follow the metaphorical gaze of the uploader through following the video's movements.
## Challenges we ran into
A major challenge early on was in dealing with possible motion sickness in uploaders rotating their heads while the viewers don't; this confuses the brain as the visual cortex receives the rotational cue but the inner ear, which acts as the gyro for the brain, doesn't, which is the main cause for VR sickness. We came up with the solution to have the viewer turn his or her head, and this approach focuses the viewer toward what's important (what the uploader's gaze is on) and also increases the interactivity of the video.
In building the camera, we did not have the resources for a flat surface to mount the boards and batteries for the camera. Despite this, we found that our lanyards for Treehacks, when hot-glue-gunned together, made quite a good surface, and ended up using this for our prototype.
In the process of deploying the website, we had several cases of PHP not working out, and thus spent quite a bit of time trying to deploy. We ended up learning much about the backend that we hadn't previously known through these struggles and ultimately got the right amount of help to overcome the issues.
## Accomplishments that we're proud of
We were very productive from the beginning to the end, and made consistent progress and had clear goals. We worked very well as a team, and had a great system for splitting up work based on our specialties, whether that be web, app dev, or hardware.
Building the app was a great achievement as our app specialist JR never built an app in VR before, and he figured out the nuances of working with the gyroscope and accelerometer of the phone in great time and polished the app very well.
We're also quite proud of having built the camera on top of basic plastic glasses and our Treehacks lanyards, and Richard, who specializes in hardware, was resourceful in making the camera and hacking the camera.
For the web part, Dillon and Jerry designed the backend and frontend, which was an uphill battle due to technical complications with PHP and deploying. However, the website came together nicely as the backend finally resolved the complications and the frontend was finished with the design.
## What we learned
We learned how to build with brand new tools, such as Linode, and also relied on our own past skills in development to split up work in a reasonable and efficient manner. In addition, we learned by building around VR, which was a field that many of the team members did not have exposure before.
## What's next for Moonlens
In the future, we will make the prototype camera-glasses much more compact, and hopefully streamline a process for directly producing video to uploading with minimal assistance from the computer. As people use the app, creating a positive environment between uploaders and viewers would be necessary and having the uploaders earn money from ads would be a great way to grow the community, and hopefully given time, the world can better connect and understand each other through seeing others' experiences. | ## Inspiration
We realized how visually-impaired people find it difficult to perceive the objects coming near to them, or when they are either out on road, or when they are inside a building. They encounter potholes and stairs and things get really hard for them. We decided to tackle the issue of accessibility to support the Government of Canada's initiative to make work and public places completely accessible!
## What it does
This is an IoT device which is designed to be something wearable or that can be attached to any visual aid being used. What it does is that it uses depth perception to perform obstacle detection, as well as integrates Google Assistant for outdoor navigation and all the other "smart activities" that the assistant can do. The assistant will provide voice directions (which can be geared towards using bluetooth devices easily) and the sensors will help in avoiding obstacles which helps in increasing self-awareness. Another beta-feature was to identify moving obstacles and play sounds so the person can recognize those moving objects (eg. barking sounds for a dog etc.)
## How we built it
Its a raspberry-pi based device and we integrated Google Cloud SDK to be able to use the vision API and the Assistant and all the other features offered by GCP. We have sensors for depth perception and buzzers to play alert sounds as well as camera and microphone.
## Challenges we ran into
It was hard for us to set up raspberry-pi, having had no background with it. We had to learn how to integrate cloud platforms with embedded systems and understand how micro controllers work, especially not being from the engineering background and 2 members being high school students. Also, multi-threading was a challenge for us in embedded architecture
## Accomplishments that we're proud of
After hours of grinding, we were able to get the raspberry-pi working, as well as implementing depth perception and location tracking using Google Assistant, as well as object recognition.
## What we learned
Working with hardware is tough, even though you could see what is happening, it was hard to interface software and hardware.
## What's next for i4Noi
We want to explore more ways where i4Noi can help make things more accessible for blind people. Since we already have Google Cloud integration, we could integrate our another feature where we play sounds of living obstacles so special care can be done, for example when a dog comes in front, we produce barking sounds to alert the person. We would also like to implement multi-threading for our two processes and make this device as wearable as possible, so it can make a difference to the lives of the people. | ## Inspiration: Recent earthquake in Turkey & Syria where more than 28,000 people lost their lives, 85000 injured and 1.3 million displaced. People still alive and buried under the debris could not be rescued timely.
## What it does: The project can be used to provide timely information to the rescuers so that disaster can be managed effectively. In case of a disaster rescuers are flooded with millions of messages and phone calls, it is hard for them to prioritize the area most severely affected. Using this project, a message may be sent either by the victim or bystanders to the rescue team via a mobile app. The system then provides the rescue team with the messages along with their count and region details ( currently zip code but it may be enhanced to Lat/Long) which help them in efficiently deploying the available resources.
## How we built it: The project has been built using the Solace Cloud platform. The mobile application has been developed on android.
## Challenges we ran into : Technical issues were faced in integration with the Solace cloud. Less familiarity with Kotlin was also challenging.
## Accomplishments that we're proud of: Successfully building a cloud application.
## What we learned: Developing a cloud application.
## What's next for Earthquake Disaster Management using Solace: This is a small prototype which has been built. In future it will be upgraded to a real life system. | winning |
# HearU

## Inspiration
Speech is one of the fundamental ways for us to communicate with each other, but many are left out of this channel of communication. Around half a billion people around the world suffer from hearing loss, this is something we wanted to address and help remedy.
Without the ability to hear, many are locked out of professional opportunities to advance their careers especially for jobs requiring leadership and teamwork. Even worse, many have trouble creating fulfilling relationships with others due to this communication hurdle.
Our aim is to make this an issue of the past and allow those living with hearing loss to be able to do everything they wish to do easily.
HearU is the first step in achieving this dream.

## What it does
HearU is an inexpensive and easy-to-use device designed to help those with hearing loss understand the world around them by giving them subtitles for the world.
The device attaches directly to the user’s arm and automatically transcribes any speech heard by it to the user onto the attached screen. The device then adds the transcription on a new line to make sure it is distinct for the user.
A vibration motor is also added to alert the user when a new message is added. The device also has a built-in hazard detection to determine if there are hazards in the area such as fire alarms. HearU also allows the user to store conversations that took place locally on the device for privacy.
Most Importantly, HearU allows the user to interact with ease with others around them.
## How we built it
HearU is based on a Raspberry Pi 4, and uses a display, microphone and a servo motor to operate and interface with the user. A Python script analyzes the data from the microphone, and updates the google cloud API, recording the real-time speech and then displaying the information on the attached screen. Additionally, it uses the pyaudio module to measure the decibels of the sounds surrounding the device, and it is graphically presented to the user. The frontend is then rendered with a python library called pyQT. The entire device is enclosed in a custom-built 3d printed housing unit that is attached to the user’s arm.
This project required a large number of different parts that were not standard as we were trying to minimize size as much as possible but ended up integrating beautifully together.

## Challenges we ran into
The biggest challenge that we ran into was hardware availability. I needed to scavenge for parts between multiple different sites, which made connecting “interesting” to say the least since we had to use 4 HDMI connectors to get the right angles we needed. Finding a screen that was affordable, that would arrive on time and the right size for the project was not easy.
Trying to fit all the components into something that would fit on an arm was extremely difficult as well and we had to compromise in certain areas such as having the power supply in the pocket for weight and size constraints. We started using a raspberry pi zero w at first but found it was too underpowered for what we wanted to do so we had to switch to the pi4. This meant we had to redesign the enclosure.
We were not able to get adequate time to build the extra features we wanted such as automatic translation since we were waiting on the delivery of the parts, as well as spending a lot of time troubleshooting the pi. We even had the power cut out for one of our developers who had all the frontend code locally saved!
In the end, we are happy with what we were able to create in the time frame given.
## Accomplishments that we're proud of
I’m proud of getting the whole hack to work at all! Like I mentioned above, the hardware was an issue to get integrated and we were under a major time crunch. Plus working with a team remotely for a hardware project was difficult and our goal was very ambitious.
We are very proud that we were able to achieve it!
## What we learned
We learned how to create dense electronic devices that manage space effectively and we now have a better understanding of the iterative engineering design process as we went through three iterations of the project. We also learned how to use google cloud as it was the first time any of us have used it. Furthermore, we learned how to create a good-looking UI using just python and pyqt. Lastly, we learned how to manipulate audio and various audio fingerprinting algorithms to match audio to sounds in the environment.
## What's next for HearU
There are many things that we can do to improve HearU.
We would like to unlock the potential for even more communication by adding automatic language translation to break down all borders.
We can also miniaturize the hardware immensely by using more custom-built electronics, to allow HearU to be as cumbersome and as easy to use as possible.
We would work on Integrating a camera to track users’ hands so that we can convert sign language into speech so that those with hearing impairments can easily communicate with others, even if they don’t know sign language.
 | ## Inspiration
About 0.2 - 2% of the population suffers from deaf-blindness and many of them do not have the necessary resources to afford accessible technology. This inspired us to build a low cost tactile, braille based system that can introduce accessibility into many new situations that was previously not possible.
## What it does
We use 6 servo motors controlled by Arduino that mimic braille style display by raising or lowering levers based upon what character to display. By doing this twice per second, even long sentences can be transmitted to the person. All the person needs to do is put their palm on the device. We believe this method is easier to learn and comprehend as well as way cheaper than refreshable braille displays which usually cost more than $5,000 on an average.
## How we built it
We use Arduino and to send commands, we use PySerial which is a Python Library. To simulate the reader, we have also build a smartbot with it that relays information to the device. For that we have used Google's Dialogflow.
We believe that the production cost of this MVP is less than $25 so this product is commercially viable too.
## Challenges we ran into
It was a huge challenge to get the ports working with Arduino. Even with the code right, pyserial was unable to send commands to Arduino. We later realized after long hours of struggle that the key to get it to work is to give some time to the port to open and initialize. So by adding a wait of two seconds and then sending the command, we finally got it to work.
## Accomplishments that we're proud of
This was our first hardware have to pulling something like that together a lot of fun!
## What we learned
There were a lot of things that were learnt including the Arduino port problem. We learnt a lot about hardware too and how serial ports function. We also learnt about pulses and how sending certain amount of pulses we are able to set the servo to a particular position.
## What's next for AddAbility
We plan to extend this to other businesses by promoting it. Many kiosks and ATMs can be integrated with this device at a very low cost and this would allow even more inclusion in the society. We also plan to reduce the prototype size by using smaller motors and using steppers to move the braille dots up and down. This is believed to further bring the cost down to around $15. | ## Inspiration
At the heart of our vision for the **U**niversal **P**rivy **C**ompass app was a simple yet powerful belief: everyone's educational journey should be as seamless and stress-free as possible. We recognized that something as basic as locating a washroom on a sprawling campus can be a source of unnecessary anxiety and distraction. Our app is more than just a guide to the nearest washroom; it's a community committed to enhancing the everyday bathroom break.
## What it does
UPC is the ultimate restroom locator webapp designed with responsiveness and convenience in mind for those stressful moments where you really need to go. Quickly find the nearest male, female, or gender-neutral bathrooms with additional information about the cleanliness, availability, and other important services such as stocked Menstrual Products. Never visited the building before? Thats fine as we integrated mappedin interior navigation to guide you safely to your golden throne. Say goodbye to restroom hunting and save your time with UPC, your ultimate privy compass!
Additionally, we know its hard to keep an accurate track of all the washrooms on UPC so we award **PeePee** reputation points to users who decide to give back to the UPC community by submitting reviews on washrooms, updating the status on recent changes in cleanliness, as well a submitting new washrooms that are not in the system already when they are in proximity of the washroom.
## How we built it
We were first motivated by MappedIns examples and docs and wanted to try to make something to do with cartography and decided to tackle this problem that many students have. We used NextJS and supabase to build most of our app, and mapbox and mappedin for many of our beautiful map components.
## Challenges we ran into
map hard
git hard
tailwind hard
sleep none
stomach hurt
## What we learned
This project was the first hackathon experience for 2/3 of us so it was interesting getting things started. We sure learned a lot!
## What's next for team UPC!
We'd like to actually further develop the incentives for users to document bathroom data. Probably look into adding more mappedin maps of other buildings! | partial |
## Inspiration
Witnessing the atrocities(protests, vandalism, etc.) caused by the recent presidential election, we want to make the general public (especially for the minorities and the oppressed) be more safe.
## What it does
It provides the users with live news update happening near them, alerts them if they travel near vicinity of danger, and provide them an emergency tool to contact their loved ones if they get into a dangerous situation.
## How we built it
* We crawl the latest happenings/events using Bing News API and summarize them using Smmry API.
* Thanks to Alteryx's API, we also managed to crawl tweets which will inform the users regarding the latest news surrounding them with good accuracy.
* All of these data are then projected to Google Map which will inform user about any happening near them in easy-to-understand summarized format.
* Using Pittney Bowes' API (GeoCode function), we alert the closest contacts of the user with the address name where the user is located.
## Challenges we ran into
Determining the credibility of tweets is incredibly hard
## Accomplishments that we're proud of
Actually to get this thing to work.
## What's next for BeSafe
Better UI/UX and maybe a predictive capability. | ## Inspiration
With the effects of climate change becoming more and more apparent, we wanted to make a tool that allows users to stay informed on current climate events and stay safe by being warned of nearby climate warnings.
## What it does
Our web app has two functions. One of the functions is to show a map of the entire world that displays markers on locations of current climate events like hurricanes, wildfires, etc. The other function allows users to submit their phone numbers to us, which subscribes the user to regular SMS updates through Twilio if there are any dangerous climate events in their vicinity. This SMS update is sent regardless of whether the user has the app open or not, allowing users to be sure that they will get the latest updates in case of any severe or dangerous weather patterns.
## How we built it
We used Angular to build our frontend. With that, we used the Google Maps API to show the world map along with markers, with information we got from our server. The server gets this climate data from the NASA EONET API. The server also uses Twilio along with Google Firebase to allow users to sign up and receive text message updates about severe climate events in their vicinity (within 50km).
## Challenges we ran into
For the front end, one of the biggest challenges was the markers on the map. Not only, did we need to place markers on many different climate event locations, but we wanted the markers to have different icons based on weather events. We also wanted to be able to filter the marker types for a better user experience. For the back end, we had challenges to figure out Twilio to be able to text users, Google firebase for user sign-in, and MongoDB for database operation. Using these tools was a challenge at first because this was our first time using these tools. We also ran into problems trying to accurately calculate a user's vicinity to current events due to the complex nature of geographical math, but after a lot of number crunching, and the use of a helpful library, we were accurately able to determine if any given event is within 50km of a users position based solely on the coordiantes.
## Accomplishments that we're proud of
We are really proud to make an app that not only informs users but can also help them in dangerous situations. We are also proud of ourselves for finding solutions to the tough technical challenges we ran into.
## What we learned
We learned how to use all the different tools that we used for the first time while making this project. We also refined our front-end and back-end experience and knowledge.
## What's next for Natural Event Tracker
We want to perhaps make the map run faster and have more features for the user, like more information, etc. We also are interested in finding more ways to help our users stay safer during future climate events that they may experience. | ## Inspiration
**The Tales of Detective Toasty** draws deep inspiration from visual novels like **Persona** and **Ghost Trick** and we wanted to play homage to our childhood games through the fusion of art, music, narrative, and technology. Our goal was to explore the possibilities of AI within game development. We used AI to create detailed character sprites, immersive backgrounds, and engaging slide art. This approach allows players to engage deeply with the game's characters, navigating through dialogues and piecing together clues in a captivating murder mystery that feels personal and expansive. By enriching the narrative in this way, we invite players into Detective Toasty’s charming yet suspense-filled world.
## What It Does
In **The Tales of Detective Toasty**, players step into the shoes of the famous detective Toasty, trapped on a boat with four suspects in a gripping AI-powered murder mystery. The game challenges you to investigate suspects, explore various rooms, and piece together the story through your interactions. Your AI-powered assistant enhances these interactions by providing dynamic dialogue, ensuring that each playthrough is unique. We aim to expand the game with more chapters and further develop inventory systems and crime scene investigations.
## How We Built It
Our project was crafted using **Ren'py**, a Python-based visual novel engine, and Python. We wrote our scripts from scratch, given Ren'py’s niche adoption. Integration of the ChatGPT API allowed us to develop a custom AI assistant that adapts dialogues based on player's question, enhancing the storytelling as it is trained on the world of Detective Toasty. Visual elements were created using Dall-E and refined with Procreate, while Superimpose helped in adding transparent backgrounds to sprites. The auditory landscape was enriched with music and effects sourced from YouTube, and the UI was designed with Canva.
## Challenges We Ran Into
Our main challenge was adjusting the ChatGPT prompts to ensure the AI-generated dialogues fit seamlessly within our narrative, maintaining consistency and advancing the plot effectively. Being our first hackathon, we also faced a steep learning curve with tools like ChatGPT and other OpenAI utilities and learning about the functionalities of Ren'Py and debugging. We struggled with learning character design transitions and refining our artwork, teaching us valuable lessons through trial and error. Furthermore, we had difficulties with character placement, sizing, and overall UI so we had to learn all the components on how to solve this issue and learn an entirely new framework from scratch.
## Accomplishments That We’re Proud Of
Participating in our first hackathon and pushing the boundaries of interactive storytelling has been rewarding. We are proud of our teamwork and the gameplay experience we've managed to create, and we're excited about the future of our game development journey.
## What We Learned
This project sharpened our skills in game development under tight deadlines and understanding of the balance required between storytelling and coding in game design. It also improved our collaborative abilities within a team setting.
## What’s Next for The Tales of Detective Toasty
Looking ahead, we plan to make the gameplay experience better by introducing more complex story arcs, deeper AI interactions, and advanced game mechanics to enhance the unpredictability and engagement of the mystery. Planned features include:
* **Dynamic Inventory System**: An inventory that updates with both scripted and AI-generated evidence.
* **Interactive GPT for Character Dialogues**: Enhancing character interactions with AI support to foster a unique and dynamic player experience.
* **Expanded Storyline**: Introducing additional layers and mysteries to the game to deepen the narrative and player involvement.
* *and more...* :D | partial |
## Inspiration
We have all faced it and yes, the struggle is real. So much that I'm doing the project alone :`) We badly need a teammate finder application for hackathons. And it doesn't just do that. It is an all in one app to build your skills as well as help you along the way in the hackathon.
## What it does
This is a Web app that encompasses multiple features:
* Firebase Authentication
This app uses firebase authentication for sign in and sign up pages.
* User rating
This app uses OAuth with Devpost to login and rates the user based on the number of hackathons they attended, number of projects submitted and the hackathons the user has won. It gives the user a star rating out of 5.
* Intelligent assessment of skills with OAuth
After the user logins with Devpost Account, it assess the strengths of the user. It spans over 6 domains, namely, frontend, design, backend, AI and ML, Mobile Dev, and Cloud and Devops. It checks the quality of the projects as well with the number of upvotes as well.
* Teammate searches:
This feature helps the user filter other teammates based on your requirement for the team. It does a domain level and hackathon level search. It sorts the results based on decreasing order of rating. You can also try refined search where you can specify definitive skills and technologies like Node.js or React.js and then filter out the resources.
* Chat rooms
The app enables you to chat with the matched teammates or discuss with potential matches. This can be implemented with socket.io.
* Skill Assessment tests
The app helps you develop your skills in various domains with the help of short quizzes. It so updates your profile with your latest skills.
* Ask a mentor
The app helps the hacker contact a mentor when you are stuck with the development. It sends an email to the mentor that is matched and the mentor can contact the user.
* Mid-hack Cravings
Hungry between hacking? The app helps you locate nearest eateries that have takeaways and order food from there. This was built with radar.io and Google places api.
* Mentorship program
This app aims to have a special mentorship program for women and non binary folk. This is to reduce the gender gap in the STEM field.
* First time hackers
The app also provides resources and links that help first time hackers enjoy the most out of the event.
* Hackathon Calendar
The app also has a feature to check out the hackathons happening in the weekend with Google calendar API.
## How I built it
I built the prototype with the help of figma. I also made the components in React as well as React native to have a cross platform performance. The backend was hosted on firebasee and Google maps and places api along with Radar.io was used to built the map to locate local eateries. Google forms was used for the mentorship program for women and non binary people in tech. I also used scikit-learn and Tensorflow to analyse the data in each user's hacker stats and assign ratings and determine strengths.
## Challenges I ran into
* This was my first time trying React-native and it took a while for me to experiment with it.
* It is also the first time I'm using Google API and check out the different features it provides.
* The prototype was extremely intricate and detailed and it was difficult to replicate the same.
## Accomplishments that I'm proud of
The prototype is fully functional with a ton of features that makes it a good project that can be scaled into a full scale startup.
## What I learned
I learned how to use React-Native and expo. I also learned to use Radar.io and Google places API. I learned to prototype accurately in Figma.
## What's next for Tinthon
Tinthon has to be made into a full scale mobile and Web app and add more features like
* Add more social features and have points for schools most active on the app
* Reporting harassment online
* A mental wellness widget to cope up with the 24 hour sleepless drive
* Quality assessment of the hack submitted for the hackathon to help and improvise the MVP created. | ## Inspiration
As Chinese military general Sun Tzu's famously said: "Every battle is won before it is fought."
The phrase implies that planning and strategy - not the battles - win wars. Similarly, successful traders commonly quote the phrase: "Plan the trade and trade the plan."

Just like in war, planning ahead can often mean the difference between success and failure. After recent events of the election, there was a lot of panic and emotional trading in the financial markets but there were very few applications that help handle the emotional side of training, and being able to trade the plan not on your emotions.
Investing Hero was created to help investors be aware and learn more about the risks of emotional trading and trading in general.
## What it does
This application is a tool to help investors manage their risk and help them learn more about the stock-market.
This is accomplished through many ways, one of which is tracking each transaction in the market and ensuring that the investor trade's their plan.
This application does live analysis on trades, taking in real-time stock-market data, processing the data and delivering the proper guidance through at chat-style artificial intelligent user experience.
## How we built it
We started a NodeJS server to make a REST API, which our iOS application uses to get a lot of the data shown inside the app.
We also have a Web Front-End (angularJS) which we use to monitor the information on the server, and simulate the oscillation of the prices in the stock market.
Both the iOS app, and the web Front-End are in sync, and as soon as any information is edited/deleted on either one, the other one will also show the changes in real-time.
Nasdaq-On-Demand gets us the stock prices, and that's where we go from.
## Challenges we ran into
* Real-time database connection using Firebase
* Live stock market data not being available over the weekend, and us having to simulate it
## Accomplishments that we're proud of
We made a seamless platform that is in complete sync at all times.
## What we learned

Learned about Heroku, Firebase & Swift Animations.
We also learned about the different ways a User Experience built on research can help the user get much more out of an application.
## What's next for Investment Hero
Improved AI bot & more advanced ordering options (i.e. limit orders). | ## Personal Statement
It all started when our team member (definitely not Parth), let's call him Marth, had a crush on a girl who was a big fan of guitar music. He decided to impress her by playing her favorite song on the guitar, but there was one problem - Marth had never played the guitar before.
Determined to win her over, Marth spent weeks practicing the song, but he just couldn't get the hang of it. He even resorted to using YouTube tutorials, but it was no use. He was about to give up when he had a crazy idea - what if he could make the guitar play the song for him?
That's when our team got to work. We spent months developing an attachment that could automatically parse any song from the internet and play it on the guitar. We used innovative arm technology to strum the strings and servos on the headstock to press the chords, ensuring perfect sound every time.
Finally, the day arrived for Marth to show off his new invention to the girl of his dreams. He nervously set up the attachment on his guitar and selected her favorite song. As the guitar began to play, the girl was amazed. She couldn't believe how effortlessly Marth was playing the song. Little did she know, he had a secret weapon!
Marth's invention not only won over the girl, but it also sparked the idea for our revolutionary product. Now, guitar players of all levels can effortlessly play any song they desire. And it all started with a boy, a crush, and a crazy idea.
## Inspiration
Our product, Strum it Up, was inspired by one team member's struggle to impress a girl with his guitar skills. After realizing he couldn't play, he and the team set out to create a solution that would allow anyone to play any song on the guitar with ease.
## What it does
Strum it Up is an attachment for the guitar that automatically parses any song from the internet and uses an innovative arm technology to strum the strings and servos on the headstock to help press the chords, ensuring perfect sound every time.
## How we built it
We spent hours developing Strum it Up using a combination of hardware and software. We used APIs to parse songs from the internet, custom-built arm technology to strum the strings, and servos on the headstock to press the chords.
## Challenges we ran into
One of the biggest challenges we faced was ensuring that the guitar attachment could accurately strum and press the chords on a wide range of guitar models. This was because different models have different actions (action is the height between strings and the fretboard, the more the height, the harder you need to press the string) We also had to ensure that the sound quality was top-notch and that the attachment was easy to use.
## Accomplishments that we're proud of
We're incredibly proud of the final product - Strum it Up. It's a game-changer for guitar players of all levels and allows anyone to play any song with ease. We're also proud of the innovative technology we developed, which has the potential to revolutionize the music industry.
## What we learned
Throughout the development process, we learned a lot about guitar playing, sound engineering, and hardware development. We also learned the importance of persistence, dedication, and teamwork when it comes to bringing a product to market.
## What's next for Strum it Up
We're excited to see where Strum it Up will take us next. We plan to continue improving the attachment, adding new features, and expanding our reach to guitar players all over the world. We also hope to explore how our technology can be used in other musical applications. | partial |
## Inspiration
Have you ever wished to give a memorable dining experience to your loved ones, regardless of their location? We were inspired by the desire to provide our friends and family with a taste of our favorite dining experiences, no matter where they might be.
## What it does
It lets you book and pay for a meal of someone you care about.
## How we built it
Languages:-
Javascript, html, mongoDB, Aello API
Methodologies:-
- Simple and accessible UI
- database management
- blockchain contract validation
- AI chatBot
## Challenges we ran into
1. We have to design the friendly front-end user interface for both customers and restaurant partner which of them have their own functionality. Furthermore, we needed to integrate numerous concepts into our backend system, aggregating information from various APIs and utilizing Google Cloud for the storage of user data.
2. Given the abundance of information requiring straightforward organization, we had to carefully consider how to ensure an efficient user experience.
## Accomplishments that we're proud of
We have designed the flow of product development that clearly show us the potential of idea that able to scale in the future.
## What we learned
3. System Design: Through this project, we have delved deep into the intricacies of system design. We've learned how to architect and structure systems efficiently, considering scalability, performance, and user experience. This understanding is invaluable as it forms the foundation for creating robust and user-friendly solutions.
4. Collaboration: Working as a team has taught us the significance of effective collaboration. We've realized that diverse skill sets and perspectives can lead to innovative solutions. Communication, coordination, and the ability to leverage each team member's strengths have been essential in achieving our project goals.
5. Problem-Solving: Challenges inevitably arise during any project. Our experiences have honed our problem-solving skills, enabling us to approach obstacles with creativity and resilience. We've learned to break down complex issues into manageable tasks and find solutions collaboratively.
6. Adaptability: In the ever-evolving field of technology, adaptability is crucial. We've learned to embrace new tools, technologies, and methodologies as needed to keep our project on track and ensure it remains relevant in a dynamic landscape.collaborative as a team.
## What's next for Meal Treat
We want to integrate more tools for personalization, including a chatbot that supports customers in RSVPing their spot in the restaurant. This chatbot, utilizing Google Cloud's Dialogflow, will be trained to handle scheduling tasks. Next, we also plan to use Twilio's services to communicate with our customers through text SMS. Last but not least, we expect to incorporate blockchain technology to encrypt customer information, making it easier for the restaurant to manage and enhance protection, especially given our international services. Lastly, we aim to design an ecosystem that enhances the dining experience for everyone and fosters stronger relationships through meal care. | ## Inspiration
The world today has changed significantly because of COVID 19, with the increased prominence of food delivery services. We decided to get people back into the kitchen to cook for themselves again. Additionally, everyone has a lot of groceries that they never get around to eating because they don't know what to make. We wanted to make a service that would make it easier than ever to cook based on what you already have.
## What it does
Recognizes food ingredients through pictures taken on a smartphone, to build a catalog of ingredients lying around the house. These ingredients are then processed into delicious recipes that you can make at home. Common ingredients and the location of users are also stored to help reduce waste from local grocery stores through better demographic data.
## How we built it
We used to express and Node for the backend and react native for the front end. To process the images we used the Google Vision API to detect the ingredients. The final list of ingredients was then sent to the Spoonacular API to find recipes that best match the ingredients at hand. Finally, we used CockroachDB to store the locational and ingredient data of users, so they can be used for data analysis in the future.
## Challenges we ran into
* Working with Android is much more challenging than expected.
* Filtering food words for the image recognition suggestion.
* Team members having multiple time zones.
* Understanding and formatting inputs and outputs of APIs used
## Accomplishments that we're proud of
* We have an awesome-looking UI prototype to demonstrate our vision with our app.
* We were able to build our app with tools that we are unfamiliar with prior to the hackathon.
* We have a functional app apk that's ready to demonstrate to everyone at the hackathon.
* We were able to create something collaboratively in a team of people each with a drastically different skill set.
## What we learned
* Spoonacular API
* React Native
* Google Vision API
* CockroachDB
## What's next for Foodeck
* Implement personalized recipe suggestions using machine learning techniques. ( Including health and personal preferences )
* Learn user behavior of a certain region and make more localized recipe recommendations for each region.
* Implement an optional login system for increased personalization that can be transferred through d
* Extend to multi-platform, allowing users to sync the profile throughout different devices.
Integrate with grocery delivery services such as instacart, uber eats. | ## Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
## What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
## How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
## Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
## Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
## What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
## The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification. | losing |
## Inspiration
Understanding and expressing emotions can be a complex and challenging journey. Many people struggle to connect and identify with their feelings, which can be overwhelming and confusing. Let It Out was born from the desire to create a supportive space where users can explore and engage with their emotions, fostering self-awareness and personal growth. Whether Let It Out is used as a safe place to vent, to recount good memories, or to explore sources of anxiety, Let It Out is here to support users with any emotion they may be experiencing.
## What it does
The user is first prompted to record a vocal burst, to attempt to express their emotions in a purely primitive and natural way. Even when the user isn’t sure what emotion lies at the source of this vocal expression, with the power of Hume AI, Let It Out analyzes the user’s expression, and identifies an emotion present in the user. The user is then routed to a personalized journal prompt and template, designed to guide the user through a short session of self discovery, compassion, and reflection. The user is able to view an analysis past entries in their journal from ChatGPT which provides insights about the user’s emotional experiences across the dates they have journaled.
## How we built it
Let It Out is a full stack web app. The front end is built with Next.js, Typescript, Chakra UI, and TinyMCE API for the custom journaling templates and embedded text editor. The back end is built with Python and Flask, which connects to Hume AI’s Streaming API to analyze the user’s vocal burst, OpenAI’s ChatGPT API to analyze the user’s journals, and MongoDB to integrate user authentication and store the user’s journals for future reflection.
## Challenges we ran into
The main challenges we ran into came in our first project idea, in which we faced API paywalls and a lack of ideas to go forward with. However after attending Hume’s workshop we made a quick transition into this project and adapted well. We also ran into issues with slow run times which we greatly lessened by integrating Hume’s Streaming API rather than Batch API, and optimizing other aspects of our application.
## Accomplishments we’re proud of
We are proud of how full the project turned out, at first it felt vague and without much direction, but as we continued to develop this project, new ideas were formed and we managed to reach something fairly well-rounded.
## What we learned
We learned how to integrate modern technologies into our projects to create a rich and complex application. We learned how to connect different parts of a complex program, like building the front and back end separately but in parallel. Our beginner hacker learned how fun it can be to create in a fast-paced environment like a hackathon
## What’s next for Let It Out
We want to improve the journal analysis ability of our application by incorporating some kind of emotionally intelligent model rather than just base ChatGPT, we think we can do this by creating a custom model with Hume that would provide the summarization and analysis tools of ChatGPT but also include the emotional intelligence of Hume’s models. | ## Inspiration
In today's world, the mental health crisis is on the rise, and finding a therapist has become increasingly difficult due to factors like the economy, accessibility, and finding the right fit. We believe everyone should have the opportunity to overcome their mental health challenges and have meaningful companions to rely on. Through the EVI (Empathic Voice Interface) model on Vercel, individuals are provided a safe space to express themselves without fear. Our mission is to empower people to openly share their thoughts and navigate through their mental health challenges, all for free, with just a click.
## What it does
Our project is a comprehensive mental health support system that includes our AI-powered therapy bot, user authentication, and personalized user profiles. By training Hume.ai's Empathic Voice Interface (EVI) with in-context learning and integrating the model into Vercel, we enable users to have meaningful conversations with the AI and work through their mental health challenges, getting advice, companionship, and more. Additionally, users can sign up or log in to create a profile that includes their personal information and emergency contacts, and our system ensures that all interactions are securely managed within the platform.
## How we built it
We gathered real-life therapist conversations. From there, we integrated a GPT 4-mini Hume AI model, training it with various real-world examples of therapist conversations with patients, understanding how they are feeling based on their tone and the way they are talking (sentiment analysis) and being able to provide them with the necessary advice they are looking for. We also altered the temperature to give them more specific responses to their particular questions but also allowed them to express themselves openly. For the front end, we first attempted to use React Native and Javascript before finally deciding to do HTML/CSS and Javascript to create a responsive and user-friendly website. After that, we needed database integration for the user authentication in which we attempted to use MongoDB, but we decided to utilize API localStorage. This setup allowed us to keep the front end lightweight while efficiently managing data from the backend database.
## Challenges we ran into
We encountered significant challenges connecting the front and back end, particularly establishing smooth communication between the two, which was more difficult than anticipated. While inputting our Hume AI into an HTML file, the HTML file was not able to capture the voice feature of Hume AI. To fix this, we deployed the model into a vercel app and implemented a link to the app in the HTML file. On the front-end side, we struggled with setting up a database for user authentication. Initially, we used MongoDB, but after facing connection issues, we had to explore alternative database solutions such as the API localStorage.
## What we learned & Accomplishments that we're proud of
During this project, we gained hands-on experience tackling the mental health crisis and integrating AI tools into existing systems. We learned the importance of adaptability, especially when transitioning from MongoDB to other database solutions for user authentication. Additionally, we improved our skills in debugging, API development, and managing the interaction between the front end and back end.
We’re proud of our resilience in the face of technical hurdles, git overwrites, and our ability to pivot when necessary. Despite these challenges, we successfully delivered a working solution, which is a major accomplishment for our team.
## What's next for Deeper Connections
In the future, to enhance the AI model's functionality, we can implement a system to flag trigger words during conversations with users. This feature would integrate with the emergency contact information from the "My Connections" page, adding an extra layer of protection as we tackle mental health crises. | ## Inspiration for Creating sketch-it
Art is fundamentally about the process of creation, and seeing as many of us have forgotten this, we are inspired to bring this reminder to everyone. In this world of incredibly sophisticated artificial intelligence models (many of which can already generate an endless supply of art), now more so than ever, we must remind ourselves that our place in this world is not only to create but also to experience our uniquely human lives.
## What it does
Sketch-it accepts any image and breaks down how you can sketch that image into 15 easy-to-follow steps so that you can follow along one line at a time.
## How we built it
On the front end, we used Flask as a web development framework and an HTML form that allows users to upload images to the server.
On the backend, we used Python libraries ski-kit image and Matplotlib to create visualizations of the lines that make up that image. We broke down the process into frames and adjusted the features of the image to progressively create a more detailed image.
## Challenges we ran into
We initially had some issues with scikit-image, as it was our first time using it, but we soon found our way around fixing any importing errors and were able to utilize it effectively.
## Accomplishments that we're proud of
Challenging ourselves to use frameworks and libraries we haven't used earlier and grinding the project through until the end!😎
## What we learned
We learned a lot about personal working styles, the integration of different components on the front and back end side, as well as some new possible projects we would want to try out in the future!
## What's next for sketch-it
Adding a feature that converts the step-by-step guideline into a video for an even more seamless user experience! | losing |
## Inspiration
As victims, bystanders and perpetrators of cyberbullying, we felt it was necessary to focus our efforts this weekend on combating an issue that impacts 1 in 5 Canadian teens. As technology continues to advance, children are being exposed to vulgarities online at a much younger age than before.
## What it does
**Prof**(ani)**ty** searches through any webpage a child may access, censors black-listed words and replaces them with an appropriate emoji. This easy to install chrome extension is accessible for all institutional settings or even applicable home devices.
## How we built it
We built a Google chrome extension using JavaScript (JQuery), HTML, and CSS. We also used regular expressions to detect and replace profanities on webpages. The UI was developed with Sketch.
## Challenges we ran into
Every member of our team was a first-time hacker, with little web development experience. We learned how to use JavaScript and Sketch on the fly. We’re incredibly grateful for the mentors who supported us and guided us while we developed these new skills (shout out to Kush from Hootsuite)!
## Accomplishments that we're proud of
Learning how to make beautiful webpages.
Parsing specific keywords from HTML elements.
Learning how to use JavaScript, HTML, CSS and Sketch for the first time.
## What we learned
The manifest.json file is not to be messed with.
## What's next for PROFTY
Expand the size of our black-list.
Increase robustness so it parses pop-up messages as well, such as live-stream comments. | ## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your writing.
## What it does
We use an LLM to generate sample phrases, sentences, or character strings that target letters you're struggling with. You can input the writing as a photo or directly on the webpage. We then use OCR to parse, score, and give you feedback towards the ultimate goal of character mastery!
## How we built it
We used a simple front end utilizing flexbox layouts, the p5.js library for canvas writing, and simple javascript for logic and UI updates. On the backend, we hosted and developed an API with Flask, allowing us to receive responses from API calls to state-of-the-art OCR, and the newest Chat GPT model. We can also manage user scores with Pythonic logic-based sequence alignment algorithms.
## Challenges we ran into
We really struggled with our concept, tweaking it and revising it until the last minute! However, we believe this hard work really paid off in the elegance and clarity of our web app, UI, and overall concept.
..also sleep 🥲
## Accomplishments that we're proud of
We're really proud of our text recognition and matching. These intelligent systems were not easy to use or customize! We also think we found a creative use for the latest chat-GPT model to flex its utility in its phrase generation for targeted learning. Most importantly though, we are immensely proud of our teamwork, and how everyone contributed pieces to the idea and to the final project.
## What we learned
3 of us have never been to a hackathon before!
3 of us never used Flask before!
All of us have never worked together before!
From working with an entirely new team to utilizing specific frameworks, we learned A TON.... and also, just how much caffeine is too much (hint: NEVER).
## What's Next for Handwriting Teacher
Handwriting Teacher was originally meant to teach Russian cursive, a much more difficult writing system. (If you don't believe us, look at some pictures online) Taking a smart and simple pipeline like this and updating the backend intelligence allows our app to incorporate cursive, other languages, and stylistic aesthetics. Further, we would be thrilled to implement a user authentication system and a database, allowing people to save their work, gamify their learning a little more, and feel a more extended sense of progress. | ## Inspiration
JARVIS is the famous virtual assistant of Tony Stark, and it displays whatever Tony requests in a physically interactive hologram. While we are limited in that we do not have access to physically interactive holograms, we are able to replicate JARVIS's creativity, visualization and understanding with... STEVE!
## What it does
STEVE takes in verbal inputs, full sentences in whatever phrasing, and interprets what you would like it to show. For example, you can say "STEVE, give me a pendulum", and STEVE draws out a pendulum. Then, you can give STEVE what angle the pendulum should swing from, or change the length of the string, or the mass of the ball, and STEVE will adjust the animation accordingly. You can also tell it to plot the relationship between any two variables in the simulation, and STEVE shows you a live graph of the relationship of the given variables.
## How we built it
We used a Physics engine to simulate the physics of our objects, tweaked it accordingly to fit our desired format/look, and implemented it to display it as we wanted. We also used co:here's NLP, with a training dataset of 350 examples to make STEVE's understanding of inputs flexible, and voice-to-text to translate the verbal inputs to strings that STEVE can interpret.
## Challenges we ran into
It was incredibly hard to create the examples for STEVE to learn from, specifically examples that would teach it to be able to understand all given sentences. The NLP would at times train STEVE to misunderstand us, and we had to change our dataset accordingly. The physics engine we used also required a Herculean effort to understand and implement, and also to pick apart to display it to fit our format. We then had to code quite a complex HTML page with CSS to create a user-friendly interface, that is fully interactive at every stage.
## Accomplishments that we're proud of
We love how our front-end looks, going as far as to include an animated waveform as a visual indicator of detected audio input. The implementation of the physics engine also makes us incredibly proud of ourselves, because it was a vastly complicated system that we had to pick apart and understand, as well as be able to weave into our code. We also felt like proud parents when we saw STEVE get better and better at understanding us through the NLP.
## What we learned
We learned that data abstraction is hard! The physics engine was difficult to understand, but through this experience we learned how physics engines work and how it simulated the movements of the objects in it. We also learned how precise our example dataset has to be for the NLP to learn adequately, and in a broader sense, the applications of NLP.
## What's next for STEVE
Currently, we are focused on Physics models, but we are hoping to be able to implement all kinds of visualization, including drawings, images of any kind, or even simulations of experiments from other areas of science. | winning |
## Inspiration
iPonzi started off as a joke between us, but we decided that PennApps was the perfect place to make our dream a reality.
## What it does
The app requires the user to sign up using an email and/or social logins. After purchasing the application and creating an account, you can refer your friends to the app. For every person you refer, you are given $3, and the app costs $5. All proceeds will go to Doctors' Without Borders. A leader board of the most successful recruiters and the total amount of money donated will be updated.
## How I built it
Google Polymer, service workers, javascript, shadow-dom
## Challenges I ran into
* Learning a new framework
* Live deployment to firebase hosting
## Accomplishments that I'm proud of
* Mobile like experience offline
* App shell architecture and subsequent load times.
* Contributing to pushing the boundaries of web
## What I learned
* Don't put payment API's into production in 2 days.
* DOM module containment
## What's next for iPonzi
* Our first donation
* Expanding the number of causes we support by giving the user a choice of where their money goes.
* Adding addition features to the app
* Production | # About the Project: U-Plan
## Inspiration
We're from Arizona, and yes—it really is incredibly hot. Having lived here for 2.5 years, each year seems to get hotter than the last. During a casual conversation with an Uber driver in Boston, we chatted about the weather. She mentioned that even the snowfall has been decreasing there. This got us thinking deeply about what's really happening to our climate.
It's clear that climate change isn't some far-off concern; it's unfolding right now with far-reaching consequences around the world. Take Hurricane Milton in Florida, for example—it was so severe that even scientists and predictive models couldn't foresee its full impact. This realization made us wonder how we could contribute to a solution.
One significant way is by tackling the issue of **Urban Heat Islands (UHIs)**. These UHIs not only make cities hotter but also contribute to the larger problem of global warming. But what exactly are Urban Heat Islands?
## What We Learned
Diving into research, we learned that **Urban Heat Islands** are areas within cities that experience higher temperatures than their surrounding rural regions due to human activities and urban infrastructure. Materials like concrete and asphalt absorb and store heat during the day, releasing it slowly at night, leading to significant temperature differences.
Understanding the impact of UHIs on energy consumption, air quality, and public health highlighted the urgency of addressing this issue. We realized that mitigating UHIs could play a crucial role in combating climate change and improving urban livability.
## How We Built U-Plan
With this knowledge, we set out to create **U-Plan**—an innovative platform that empowers urban planners, architects, and developers to design more sustainable cities. Here's how we built it:
* **Leveraging Satellite Imagery**: We integrated high-resolution satellite data to analyze temperatures, vegetation health (NDVI), and water content (NDWI) across urban areas.
* **Data Analysis and Visualization**: Utilizing GIS technologies, we developed interactive heat maps that users can explore by simply entering a zip code.
* **AI-Powered Chatbot**: We incorporated an AI assistant to provide insights into UHI effects, causes, and mitigation strategies specific to any selected location.
* **Tailored Recommendations**: The platform offers architectural and urban planning suggestions, such as using reflective materials, green roofs, and increasing green spaces to naturally reduce surface temperatures.
* **User-Friendly Interface**: Focused on accessibility, we designed an intuitive interface that caters to both technical and non-technical users.
## Challenges We Faced
Building U-Plan wasn't without its hurdles:
* **Data Complexity**: Integrating various datasets (temperature, NDVI, NDWI, NDBI) required sophisticated data processing and normalization techniques to ensure accuracy.
* **Scalability**: Handling large volumes of data for real-time analysis challenged us to optimize our backend infrastructure.
* **Algorithm Development**: Crafting algorithms that provide actionable insights and accurate sustainability scores involved extensive research and testing.
* **User Experience**: Striking the right balance between detailed data presentation and user-friendly design required multiple iterations and user feedback sessions.
## What's Next for U-Plan
We started with Urban Heat Islands because they are a pressing issue that directly affects the livability of cities and contributes significantly to global warming. By focusing on UHIs, we could provide immediate solutions to reduce urban temperatures and energy consumption.
Moving forward, we plan to expand U-Plan into a comprehensive platform offering a wide range of data-driven insights, making it the go-to resource for urban planners to design sustainable, efficient, and resilient cities. Our roadmap includes:
* **Adding More Environmental Factors**: Incorporating air quality indices, pollution levels, and noise pollution data.
* **Predictive Analytics**: Developing models to forecast urban growth patterns and potential environmental impacts.
* **Collaboration Tools**: Enabling teams to work together within the platform, sharing insights and coordinating projects.
* **Global Expansion**: Adapting U-Plan for international use with localized data and multilingual support.
---
# What's in it for our Market Audience?
* **Data-Driven Insights**: U-Plan empowers urban planners, architects, developers, and property owners with precise, actionable data to make informed decisions.
* **Sustainable Solutions**: Helps users design buildings and urban spaces that reduce heat retention, combating Urban Heat Islands and contributing to climate change mitigation.
* **Cost and Energy Efficiency**: Offers strategies to lower energy consumption and reduce reliance on air conditioning, leading to significant cost savings.
* **Regulatory Compliance**: Assists in meeting environmental regulations and sustainability standards, simplifying the approval process.
* **Competitive Advantage**: Enhances reputation by showcasing a commitment to sustainable, forward-thinking design practices.
## Why Would They Use It?
* **Comprehensive Analysis Tools**: Access to advanced features like real-time satellite imagery, detailed heat maps, and predictive modeling.
* **Personalized Recommendations**: Tailored advice for both new constructions and retrofitting existing buildings to improve energy efficiency and reduce heat retention.
* **User-Friendly Interface**: An intuitive platform that's easy to navigate, even for those without technical expertise.
* **Expert Support**: Premium users gain access to expert consultants and an AI-powered chatbot for personalized guidance.
* **Collaboration Features**: Ability to share maps and data with team members and stakeholders, facilitating better project coordination. | ## Inspiration 🎀
Reduce stress and make womans lives a bit simpler
Many woman suffer from the complications that come from periods. We wanted to develop a web page that gives woman personlised advice that they could impliment in their daily lives and reduce the symptoms that they have to deal with during before or after their menstrual cycle.
## What it does👧
Our web app takes input about the users symptoms and displays personlised advice on ways to adjust daily habits in correspondence to their input which can help reduce such overbearing symptoms
## How we built it ʕ•́ᴥ•̀ʔっ🔨
We used Streamlit with python in order to create a web page that takes input from the user and displays the personlised advise correspondingly.
## Challenges we ran into ⌛
We wanted to add a database so that every user could have their own personlised page but we faced difficulties while downloading the requied software. We will however definitely impliment this in the future
## Accomplishments that we're proud of (っ^▿^)۶🍸🌟🍺٩(˘◡˘ )
We are proud to impliment our idea in such little time and strive to make our app more helpful for woman
## What we learned 👸
We learned about the vast number of symptoms that woman face during their menstrual cycle and would like develop our app as much as we can to lend a hand to this delimma
## What's next for 28 🩸♛
We will develop a database and create personlised web pages more on par with each user and add notifications as reminders such as food intake
All woman have different bodies so we would like our app to be more helpful for each and every one of them.
We will collect more data from proffesionals in order to help a wider number of problems that are faced by woman during this time. | partial |
## Inspiration
Us college students all can relate to having a teacher that was not engaging enough during lectures or mumbling to the point where we cannot hear them at all. Instead of finding solutions to help the students outside of the classroom, we realized that the teachers need better feedback to see how they can improve themselves to create better lecture sessions and better ratemyprofessor ratings.
## What it does
Morpheus is a machine learning system that analyzes a professor’s lesson audio in order to differentiate between various emotions portrayed through his speech. We then use an original algorithm to grade the lecture. Similarly we record and score the professor’s body language throughout the lesson using motion detection/analyzing software. We then store everything on a database and show the data on a dashboard which the professor can access and utilize to improve their body and voice engagement with students. This is all in hopes of allowing the professor to be more engaging and effective during their lectures through their speech and body language.
## How we built it
### Visual Studio Code/Front End Development: Sovannratana Khek
Used a premade React foundation with Material UI to create a basic dashboard. I deleted and added certain pages which we needed for our specific purpose. Since the foundation came with components pre build, I looked into how they worked and edited them to work for our purpose instead of working from scratch to save time on styling to a theme. I needed to add a couple new original functionalities and connect to our database endpoints which required learning a fetching library in React. In the end we have a dashboard with a development history displayed through a line graph representing a score per lecture (refer to section 2) and a selection for a single lecture summary display. This is based on our backend database setup. There is also space available for scalability and added functionality.
### PHP-MySQL-Docker/Backend Development & DevOps: Giuseppe Steduto
I developed the backend for the application and connected the different pieces of the software together. I designed a relational database using MySQL and created API endpoints for the frontend using PHP. These endpoints filter and process the data generated by our machine learning algorithm before presenting it to the frontend side of the dashboard. I chose PHP because it gives the developer the option to quickly get an application running, avoiding the hassle of converters and compilers, and gives easy access to the SQL database. Since we’re dealing with personal data about the professor, every endpoint is only accessible prior authentication (handled with session tokens) and stored following security best-practices (e.g. salting and hashing passwords). I deployed a PhpMyAdmin instance to easily manage the database in a user-friendly way.
In order to make the software easily portable across different platforms, I containerized the whole tech stack using docker and docker-compose to handle the interaction among several containers at once.
### MATLAB/Machine Learning Model for Speech and Emotion Recognition: Braulio Aguilar Islas
I developed a machine learning model to recognize speech emotion patterns using MATLAB’s audio toolbox, simulink and deep learning toolbox. I used the Berlin Database of Emotional Speech To train my model. I augmented the dataset in order to increase accuracy of my results, normalized the data in order to seamlessly visualize it using a pie chart, providing an easy and seamless integration with our database that connects to our website.
### Solidworks/Product Design Engineering: Riki Osako
Utilizing Solidworks, I created the 3D model design of Morpheus including fixtures, sensors, and materials. Our team had to consider how this device would be tracking the teacher’s movements and hearing the volume while not disturbing the flow of class. Currently the main sensors being utilized in this product are a microphone (to detect volume for recording and data), nfc sensor (for card tapping), front camera, and tilt sensor (for vertical tilting and tracking professor). The device also has a magnetic connector on the bottom to allow itself to change from stationary position to mobility position. It’s able to modularly connect to a holonomic drivetrain to move freely around the classroom if the professor moves around a lot. Overall, this allowed us to create a visual model of how our product would look and how the professor could possibly interact with it. To keep the device and drivetrain up and running, it does require USB-C charging.
### Figma/UI Design of the Product: Riki Osako
Utilizing Figma, I created the UI design of Morpheus to show how the professor would interact with it. In the demo shown, we made it a simple interface for the professor so that all they would need to do is to scan in using their school ID, then either check his lecture data or start the lecture. Overall, the professor is able to see if the device is tracking his movements and volume throughout the lecture and see the results of their lecture at the end.
## Challenges we ran into
Riki Osako: Two issues I faced was learning how to model the product in a way that would feel simple for the user to understand through Solidworks and Figma (using it for the first time). I had to do a lot of research through Amazon videos and see how they created their amazon echo model and looking back in my UI/UX notes in the Google Coursera Certification course that I’m taking.
Sovannratana Khek: The main issues I ran into stemmed from my inexperience with the React framework. Oftentimes, I’m confused as to how to implement a certain feature I want to add. I overcame these by researching existing documentation on errors and utilizing existing libraries. There were some problems that couldn’t be solved with this method as it was logic specific to our software. Fortunately, these problems just needed time and a lot of debugging with some help from peers, existing resources, and since React is javascript based, I was able to use past experiences with JS and django to help despite using an unfamiliar framework.
Giuseppe Steduto: The main issue I faced was making everything run in a smooth way and interact in the correct manner. Often I ended up in a dependency hell, and had to rethink the architecture of the whole project to not over engineer it without losing speed or consistency.
Braulio Aguilar Islas: The main issue I faced was working with audio data in order to train my model and finding a way to quantify the fluctuations that resulted in different emotions when speaking. Also, the dataset was in german
## Accomplishments that we're proud of
Achieved about 60% accuracy in detecting speech emotion patterns, wrote data to our database, and created an attractive dashboard to present the results of the data analysis while learning new technologies (such as React and Docker), even though our time was short.
## What we learned
As a team coming from different backgrounds, we learned how we could utilize our strengths in different aspects of the project to smoothly operate. For example, Riki is a mechanical engineering major with little coding experience, but we were able to allow his strengths in that area to create us a visual model of our product and create a UI design interface using Figma. Sovannratana is a freshman that had his first hackathon experience and was able to utilize his experience to create a website for the first time. Braulio and Gisueppe were the most experienced in the team but we were all able to help each other not just in the coding aspect, with different ideas as well.
## What's next for Untitled
We have a couple of ideas on how we would like to proceed with this project after HackHarvard and after hibernating for a couple of days.
From a coding standpoint, we would like to improve the UI experience for the user on the website by adding more features and better style designs for the professor to interact with. In addition, add motion tracking data feedback to the professor to get a general idea of how they should be changing their gestures.
We would also like to integrate a student portal and gather data on their performance and help the teacher better understand where the students need most help with.
From a business standpoint, we would like to possibly see if we could team up with our university, Illinois Institute of Technology, and test the functionality of it in actual classrooms. | ## Inspiration
Ideas for interactions from:
* <http://paperprograms.org/>
* <http://dynamicland.org/>
but I wanted to go from the existing computer down, rather from the bottom up, and make something that was a twist on the existing desktop: Web browser, Terminal, chat apps, keyboard, windows.
## What it does
Maps your Mac desktop windows onto pieces of paper + tracks a keyboard and lets you focus on whichever one is closest to the keyboard. Goal is to make something you might use day-to-day as a full computer.
## How I built it
A webcam and pico projector mounted above desk + OpenCV doing basic computer vision to find all the pieces of paper and the keyboard.
## Challenges I ran into
* Reliable tracking under different light conditions.
* Feedback effects from projected light.
* Tracking the keyboard reliably.
* Hooking into macOS to control window focus
## Accomplishments that I'm proud of
Learning some CV stuff, simplifying the pipelines I saw online by a lot and getting better performance (binary thresholds are great), getting a surprisingly usable system.
Cool emergent things like combining pieces of paper + the side ideas I mention below.
## What I learned
Some interesting side ideas here:
* Playing with the calibrated camera is fun on its own; you can render it in place and get a cool ghost effect
* Would be fun to use a deep learning thing to identify and compute with arbitrary objects
## What's next for Computertop Desk
* Pointing tool (laser pointer?)
* More robust CV pipeline? Machine learning?
* Optimizations: run stuff on GPU, cut latency down, improve throughput
* More 'multiplayer' stuff: arbitrary rotations of pages, multiple keyboards at once | ## Inspiration
Insurance companies have access to mostly negative data: (crashes, tickets, and more) leaving some drivers without the opportunity to prove themselves. We wanted to develop a win-win program to reduce distracted driving by incentivizing responsible drivers with lower insurance rates while providing insurance companies with data to improve their insight accuracy.
## What it does
WatchDog allows drivers to self-report their focused driving while avoiding excessive intrusion. The mobile app captures a video recording of the person behind the wheel as they drive. After the trip ends, the driver can choose whether or not they want to send this video to WatchDog where it is then processed by machine learning and assigned a specific score. Drivers can view their progress overtime and improve their score before sending in their data for discounted insurance rates.
## How I built it
The mobile app was build using React Native. Our backend used Flask and nginx for networking. Image recognition was accomplished using a CNN build with PyTorch and trained with the StateFarm distracted drivers dataset.
## Challenges I ran into
Getting large amounts of data to be efficiently sent to the backend.
## Accomplishments that I'm proud of
The CNN was able to achieve an accuracy of 87% with limited training. If given more time to train, the accuracy could be even better. | winning |
### **Carely: Connecting Seniors and Their Families, Supporting Caregivers at Every Step**
#### **Understanding the Silent Crisis: Dementia and Loneliness**
🌍 **A Growing Global Challenge:**
Dementia is swiftly becoming a global health emergency, currently affecting approximately 55 million individuals worldwide. This number is projected to escalate to 139 million by 2050 due to aging populations ([MDPI](https://www.mdpi.com/)). Each statistic represents a loved one grappling with memory loss and profound isolation.
🧠 **The Cognitive Toll:**
Dementia fundamentally erodes memory, thinking, and communication abilities, disrupting everyday life. Simple tasks like remembering names or following conversations become increasingly challenging ([Frontiers](https://www.frontiersin.org/)). This cognitive decline is not only a mental struggle but also a deeply emotional one, leading to intense feelings of loneliness.
#### **The Deepening Link: Loneliness and Dementia**
🤝 **Loneliness Amplifies Risk:**
Research indicates that loneliness increases the likelihood of developing dementia by 50% ([MDPI](https://www.mdpi.com/)). The absence of social and cognitive engagement accelerates brain atrophy, hastening cognitive decline.
👂 **Sensory Impairments:**
Hearing and vision loss further isolate individuals, reducing opportunities for interaction and companionship. This isolation not only heightens loneliness but also exacerbates cognitive deterioration ([MDPI](https://www.mdpi.com/)).
#### **Health Complications: The Ripple Effects of Loneliness**
* **Depression:**
Up to 64% of lonely individuals are at a higher risk of developing depression, which can intensify cognitive decline and worsen dementia symptoms ([Frontiers](https://www.frontiersin.org/)).
* **Cardiovascular Health:**
Loneliness is linked to a 29% increased risk of heart disease and a 32% higher risk of stroke. These cardiovascular issues significantly contribute to vascular dementia and other cognitive impairments ([Frontiers](https://www.frontiersin.org/)).
#### **The Caregiver Crisis: Burnout and Beyond**
😔 **Caregiver Burnout:**
Caregivers are the unsung heroes in the fight against dementia, yet caregiver burnout affects **40-70%** of caregivers ([National Alliance for Caregiving & AARP, 2020](https://www.aarp.org/content/dam/aarp/research/surveys_statistics/2020/201016-caregiving-research.doi.10.26419-2Fres.00189.001.pdf)). This burnout can lead to severe emotional distress, depression, and even physical health issues, jeopardizing the quality of care provided.
📉 **Statistics on Caregiver Burnout:**
* **80%** of caregivers experience significant stress ([National Alliance for Caregiving & AARP, 2020](https://www.aarp.org/content/dam/aarp/research/surveys_statistics/2020/201016-caregiving-research.doi.10.26419-2Fres.00189.001.pdf)).
* **50%** of caregivers report feeling emotionally exhausted ([National Alliance for Caregiving & AARP, 2020](https://www.aarp.org/content/dam/aarp/research/surveys_statistics/2020/201016-caregiving-research.doi.10.26419-2Fres.00189.001.pdf)).
* **20%** of caregivers face chronic health conditions due to prolonged stress ([National Alliance for Caregiving & AARP, 2020](https://www.aarp.org/content/dam/aarp/research/surveys_statistics/2020/201016-caregiving-research.doi.10.26419-2Fres.00189.001.pdf)).
#### **Revitalizing Support: Introducing Carely**
##### **Our Mission:**
Carely is dedicated to combating loneliness and supporting caregivers by providing compassionate companionship, enhancing cognitive and physical engagement, and safeguarding mental health.
##### **A Family Story**
My family’s journey with my grandfather, who battles both dementia and clinical depression, inspired Carely. Watching him struggle with confusion and loneliness highlighted the urgent need for a solution that not only supports him but also alleviates the emotional toll on caregivers. Carely was born from this heartfelt mission to ensure no one feels alone in their twilight years.
##### **Key Features:**
🗣️ **Personalized Companionship:**
Carely engages users in heartfelt conversations using the voices of their closest loved ones. By reminiscing about shared memories, Carely helps improve memory, alleviate loneliness, and uplift spirits.
👥 **Caregiver Support:**
Carely monitors the well-being of both patients and caregivers. By detecting signs of confusion or emotional distress in dementia and Parkinson’s patients, Carely can prompt timely interventions, preventing caregiver burnout and enhancing overall care quality.
🏃♂️ **Active Living:**
Carely encourages daily physical activity through personalized exercise challenges. Utilizing OpenCV and Google's MediaPipe, Carely ensures exercises are performed safely, promoting both physical health and cognitive function.
#### **How Carely Works: The Technology Behind the Compassion**
**Backend Infrastructure:**
* **Flask with Python:** Powers the core application, ensuring seamless functionality.
* **OpenAI:** Creates AI assistants that capture the memory and tone of loved ones, trained on past social media chat data.
* **Cartesia AI:** Generates authentic voice responses, closely mimicking the voices of important people in the user’s life.
* **Hume API:** Recognizes user emotions, allowing Carely to respond empathetically and promptly.
* **OpenCV & MediaPipe:** Provide accurate exercise posture correction, ensuring safe physical activity.
* **Twilio:** Notifies the caregivers in case of distress.
**Advanced Tools Integration:**
* **Hume:** An emotionally intelligent API that detects and interprets user emotions.
* **Cartesia:** The leading voice cloning project that enhances the realism and emotional depth of voice interactions.
**Integration Strategy:**
Carely combines emotion recognition from Hume with voice emotion settings in Cartesia, creating empathetic and contextually relevant interactions. The TEN agent analyzes photos and videos to generate personalized and joyful conversations based on meaningful past interactions.
#### **Overcoming Challenges: Our Journey**
🔗 **Seamless Integrations:**
Integrating diverse AI technologies was complex, particularly syncing deep fake video capabilities with the app. While realistic videos of loved ones were successfully created, full integration remains a future objective due to resource constraints.
🎭 **Personality Matching:**
Ensuring AI assistants accurately reflect the personalities of loved ones required extensive fine-tuning. Despite these challenges, Carely delivers highly personalized and engaging user experiences.
#### **Proud Milestones: What Was Achieved**
❤️🩹 **Unified Vision:**
Driven by personal experiences with grandparents facing memory loss and loneliness, our team is passionate about creating a meaningful solution. Carely embodies our commitment to making each day happier and more connected for those we love.
#### **The Road Ahead: Future Enhancements**
👩💻 **AI Avatars:**
Implementing deep fake technology to create lifelike avatars of loved ones, enhancing the sense of connection and realism in interactions.
📸 **Multimedia Integration:**
Incorporating image and video-based content to enrich conversations and provide a more immersive experience.
🎮 **Gamification:**
Introducing gamified activities to make the recovery process engaging and motivating for users.
👭 **Community Building:**
Creating a supportive community for patients and caregivers to foster a sense of belonging and mutual support.
#### **Focusing on Caregivers and Parkinson’s Patients**
* **Caregiver Burnout Prevention:**
Carely detects risky situations and emotional distress in caregivers, offering timely support to prevent burnout and depression. This feature is potentially life-saving, ensuring caregivers remain healthy and effective.
* **Parkinson’s Disease Support:**
With up to 80% of Parkinson’s patients developing dementia, Carely targets preventive treatments for older individuals, especially those with limited family support or living in remote areas. Early interventions through speech therapy and memory revival can significantly delay cognitive decline ([SpringerLink](https://link.springer.com/)).
#### **Join Us in Making a Difference**
At Carely, we are dedicated to giving our elderly loved ones beautiful memories to cherish, keeping them engaged, and ensuring they never feel alone. Together, we can create a world where every grandparent feels loved, supported, and connected.
---
[^4]: [National Alliance for Caregiving & AARP, 2020](https://www.aarp.org/content/dam/aarp/research/surveys_statistics/2020/201016-caregiving-research.doi.10.26419-2Fres.00189.001.pdf) | # 🌿Send this link to a friend to video call :)) <http://bit.ly/tryme-nwhacks>
## Inspiration 💡
Unprecedented times, unpresidented times, it's no secret that there's a lot going on right now.
Devastating stories about the declining mental health of seniors in long-term care ring all too familiar to us (ref. [this](https://www.cbc.ca/news/canada/british-columbia/covid-bc-care-homes-seniors-isolation-1.5865061), [this](https://www.nationalobserver.com/2020/12/28/news/isolation-and-fear-dying-alone), and [this](https://www.burnabynow.com/local-news/loneliness-and-loss-burnaby-seniors-not-alone-in-covids-isolation-crisis-3141316)).
Social isolation and the lack of external stimulation are fuels for cognitive decline and depression, which in turn increase the risk of dementia, high blood pressure, and stroke. Although attempts have been made to connect seniors through platforms such as Zoom, they have been burdensome to staff resources, as 75% of residents require assistance in their use.
On the other side of the age spectrum, thousands of youth volunteers have been displaced from their regular in-person activities, many of which are now scrambling to find alternative ways to give back, to gain exposure to the "real world", or even just to fulfill their required volunteer hours for school.
In the struggle also lies the opportunity to promote something the world desperately needs more of: intergenerational connection. **How can we bring together these two very different groups of people in a way that is accessible, entertaining, and educational?**
## Introducing Dialogue!! 🤙
Imagine Omegle and Duolingo had a better, safer child that was made specifically for the elderly! Dialogue is a web application that connects seniors and youth volunteers with alike interests and spoken languages.
Users are smoothly onboarded with a few questions about themselves: whether they are a senior/volunteer, name, interests, and preferred language. Our matching algorithm will then pair each senior with a youth volunteer, where they will then enter a private video chat room to meet each other and talk! The UI/UX of this app also has a major focus on ease of use and accessibility for seniors, something traditional video-chatting platforms lack.
For seniors, practicing to converse in a foreign language and talking about their favourite interests and stories can promote mental stimulation and greater well-being. For youth volunteers, this can be a valuable opportunity to learn, absorb wisdom, and foster empathy.
Research shows that intergenerational programs increase self-esteem and feelings of well-being for both older and younger participants. Dialogue is our way of contributing to building stronger communities with members that can come together to support and respect one another.
## How we built it
The back-end of the application was created using Express.js and MongoDB. For the live video chatting feature, we used the socket.io library with WebRTC and PeerJS.
The front-end was implemented using React Native (give or take 12821739 dependencies). We deployed using Expo, used Redux to manage global state and implemented Axios to connect the back-end.
To deploy, we used Heroku. All design features were created from scratch using Figma and Adobe AfterEffects!
## Challenges we ran into
Designing for seniors 🤔how do you design an app for people that don't usually use apps? 🤔 While scoping out our project, we always came back to the question of whether a certain feature was too "complex" or difficult to understand. We had to recognize that a vast majority of seniors suffered from impairments such as memory loss, slowed reaction speed, and vision/auditory deficits. We also had to make sure that this type of technology can be used in the circumstance that care workers aren't able to assist seniors in its operation (due to staffing shortages).
On the development side of things, we faced a few challenges with connecting back-end and front-end components, as well as deployment and video rendering.
## What we learned
Anson: I learned how to code a functional React front-end app and connect it to endpoints! Wrestled with expo, tested with postman, speed ran a Redux course, used Axios, and napped on the floor. 💤
Jennifer: This was my first time developing back-end, so I learned a lot about different JavaScript functions, libraries and frameworks. I also learned how to implement live video-calling with [socket.io](http://socket.io) !
Kelly: It's not every day that I get to design an experience specifically for seniors, which posed an entirely new design challenge for me! Learned about various accessibility guidelines and guides in general for elderly web design, as well as working with Lottie animations.
Lucy: This was my first time deploying an API during a hackathon! It was also my first time connecting a React app and a Express server together.
## What's next
Our next steps definitely include making our app more accessible for seniors of all abilities. This could include auditory instructions for the visually impaired, adding ASL into a 'language' option, and customizable privacy settings. We would also like to create easier authentication in our sign-in process and to refine our matching algorithm. Making the app scalable to larger quantities of care homes and volunteers is also on our radar! | ## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | losing |
## Inspiration
We set out to transport the quintessential college student experience to anywhere you like, in a portable package. We were frustrated that ramen noodles are not convenient to pack as a to go meal. We set out to make instant noodle into any time noodle, and make a product useful for a useless and improbable scenario.
## What it does
Our product allows the user to convert a standard cup noodle package into a take-on-the-go container and travel with this popular comfort food. Users can pre-pour in hot water, take the cup noodle on the go without fear of soup leaking, and keep their noodles and soup separate until eating. Whenever they are ready ready, users can have a delicious, perfectly cooked cup noodle anywhere. Finally, the product collapses compactly and can be easily stored in any bag.
## How we built it
The final prototype mostly consists of materials that are as accessible as ramen noodles should be: paper, tape, and some string. The bottom plate is a 3D printed plate.
## Challenges we ran into
Right off the bat, we knew we would not be able prototype the ideal collapsing silicone strainer and sealing gaskets that we envisioned for our product (view a similar strainer [here](https://www.surlatable.com/lekue-collapsible-steamer/PRO-2393775.html?dwvar_PRO-2393775_color=Green)). Without enough time to source, mold, and cure some sort of rubber product, we opted to make a expandable representation out of paper and string.
We had originally planned on making a minimum viable product using 3D printed base, lid, and strainer. However, our 3D printer failed overnight. However, we overcame this challenge by scrapping together materials around our workspace and prototyping by hand.
The last and most frustrating challenging was not a technical challenge but a logistical one. We were working on campus and got locked out of our workspace in the middle of the night. Reluctantly, we left all of our work and belongings and trudge, jacketless, home in the -15°C weather.
## Accomplishments that we're proud of
This is our first makeathon! Our main goal for this makeathon was to make something for fun, and we definitely succeeded.
In addition, we are proud that we were able to overcome the challenges during the process. It was demoralizing to lose the chance to show off our work in its full capacity, but we believed that this good idea would speak for itself even with the most bare bones prototype.
Finally, we are proud of our purely mechanical invention! We believe in simplicity and elegance, so we made a no-fuss product that does its job, no electronics needed.
## What we learned
Time management. We definitely felt the time crunch, especially when our 3D printer failed overnight. We learned some important lessons in rapid prototyping and how to make things more efficient to maximize success.
## What's next for BrothBros
First, we want a plastic prototype of our parts. This will allow us to refine the interfaces in the product and discover any problems with the design. Next, we'd want to add in straps, plastic strap adjusters, sealing gaskets, and clasp-on closure to make our product fully functional. Then, we stress test the product to identify failure modes and improve it. Finally, we will make this a mass-producible and widely available product if Nissin sponsors us. | ## Inspiration
The inspiration behind FightBite originated from the Brave Wilderness youtube channel, particularly the [Bites and Stings series](https://www.youtube.com/watch?v=SMJHJ0i86ts&list=PLbfmhGxamZ83v9OKDa4eV_IlY2W-PLK6X). When watching the series, we were terrified by the amount of destruction that could be caused by such minuscule beings. We were also inspired by the overwhelming 725,000 yearly deaths from mosquito-borne diseases. As a group, we decided to think of a solution, and this solution eventually became FightBite.
## What it does
FightBite is a modular and interactive phone application that allows users to quickly and effectively take a picture of a bug bite or take an existing picture and get instant feedback on the type of bug bite, whether it be a mosquito, tick, or even bed-bug bite. In addition to detecting the bug type, FightBite also pulls up the relevant medical information for bite treatment. To use FightBite, simply tap on the start button, and then choose to either take a picture from the phone’s camera, or directly pick the bug bite from the gallery! Once an image has been selected, the user has the option of saving the image for future reference, discarding it and selecting a new image, or if they are satisfied, scanning the picture with our own AI for bite analysis.
## How we built it
As FightBite is a phone based application, we decided to use react native for our front end design. As we intend for FightBite to work on both IOS, and android operating systems, react native allows us to write a single codebase that renders to native platforms, saving us the problem of creating two separate applications. Our neural network was created and trained with Pytorch, and was built on top of the DenseNet121 model. We then used transfer learning in order to adapt this pretrained network to our own problem. Finally, we created an API Endpoint with Flask and deployed it with Heroku.
## Challenges we ran into
Over the past 48 hours, we faced various issues, mainly relating to the overall setup of react native and its many modules that we implemented. As this is our first time creating a phone application using React Native, we first had to take time to learn the documentation from scratch. Furthermore, we ran into issues regarding react native camera being deprecated due to lack of maintenance, so we were forced to use expo-camera instead, causing many delays. In addition to front end issues, we did not have any major access to a pre-existing dataset, so the majority of our data was compiled manually. This led to the size of our dataset being limited, which hurt the training of the model greatly.
## Accomplishments that we're proud of
After completing HackThe6ix, our team is extremely proud that we managed to create our first ever functioning full stack mobile application in less than 48 hours. Although our team had some experience with web development such as HTML, CSS and Javascript, we never worked with react native before, so being able to implement a new language in creating a fully functional phone application is a huge accomplishment to our learning. Furthermore, this is our first ever “real” machine learning project with Pytorch, and we are extremely proud that we were able to build and deploy a machine learning model within 36 hours.
## What we learned
We have learned many new skills after participating in HackThe6ix. Mainly, we learned more about phone app development through using React Native, and developed the ability to create an aesthetically pleasing application for both IPhone and Android devices. In addition, we also learned a lot about preparing and collecting data, along with training and evaluating a machine learning model. We also further enhanced our capabilities with Flask, as our team had very little experience with the framework coming into Hack The 6ix.
## What's next for FightBite
Our first priority of FightBite is to ultimately expand our dataset, with more bug bites, and more images per type of bite, in order to quickly and accurately diagnose bug bites, for faster treatment and recovery. In particular, we plan to add some of the more deadly variants of bug bites(like black widow bites, brown recluse spider bites) in order to save as many lives as possible before it becomes too late. We also hope to add more depth to our bite analysis, like detecting potential diseases(an example of such could be detecting skin-lesions in tick bites like [here](https://arxiv.org/abs/2011.11459?context=cs.CV). | ## Inspiration
With the recent Corona Virus outbreak, we noticed a major issue in charitable donations of equipment/supplies ending up in the wrong hands or are lost in transit. How can donors know their support is really reaching those in need? At the same time, those in need would benefit from a way of customizing what they require, almost like a purchasing experience.
With these two needs in mind, we created Promise. A charity donation platform to ensure the right aid is provided to the right place.
## What it does
Promise has two components. First, a donation request view to submitting aid requests and confirm aids was received. Second, a donor world map view of where donation requests are coming from.
The request view allows aid workers, doctors, and responders to specificity the quantity/type of aid required (for our demo we've chosen quantity of syringes, medicine, and face masks as examples) after verifying their identity by taking a picture with their government IDs. We verify identities through Microsoft Azure's face verification service. Once a request is submitted, it and all previous requests will be visible in the donor world view.
The donor world view provides a Google Map overlay for potential donors to look at all current donation requests as pins. Donors can select these pins, see their details and make the choice to make a donation. Upon donating, donors are presented with a QR code that would be applied to the aid's packaging.
Once the aid has been received by the requesting individual(s), they would scan the QR code, confirm it has been received or notify the donor there's been an issue with the item/loss of items. The comments of the recipient are visible to the donor on the same pin.
## How we built it
Frontend: React
Backend: Flask, Node
DB: MySQL, Firebase Realtime DB
Hosting: Firebase, Oracle Cloud
Storage: Firebase
API: Google Maps, Azure Face Detection, Azure Face Verification
Design: Figma, Sketch
## Challenges we ran into
Some of the APIs we used had outdated documentation.
Finding a good of ensuring information flow (the correct request was referred to each time) for both the donor and recipient.
## Accomplishments that we're proud of
We utilized a good number of new technologies and created a solid project in the end which we believe has great potential for good.
We've built a platform that is design-led, and that we believe works well in practice, for both end-users and the overall experience.
## What we learned
Utilizing React states in a way that benefits a multi-page web app
Building facial recognition authentication with MS Azure
## What's next for Promise
Improve detail of information provided by a recipient on QR scan. Give donors a statistical view of how much aid is being received so both donors and recipients can better action going forward.
Add location-based package tracking similar to Amazon/Arrival by Shopify for transparency | losing |
We were inspired by the Robo-dog that was taking the world by storm, with its quadruped shape and its complex systems that allowed its legs to move rapidly and fluidly.
It is an eight-legged animatronic that is able to move around and grab objects for you, scare off your friends, and even pick up things from the ground.
It was built with parts that were 3D printed from Nylon Carbon Fiber, and they were then combined with two Adafruit servo I2C Modules and an Arduino Nano. They were then programmed using techniques from inverse kinematics to determine optimal movements to reach certain points in space.
The largest challenge that we faced was the programming. Due to the very large amount of servo motors, it made it so that ordinary programming techniques would not be able to be used. This caused numerous problems later as more power led to more weight, which led to more complex equations being used to calculate the movement of the robot.
The biggest thing we learned that there is no such thing as true reliability in a hardware project. There are always some things waiting to go wrong, and you will have no choice but to stay resilient and solve the problems accordingly.
We hope that in the future, we will be able to implement more algorithms into Black Widow to make it now of the animatronics with the most complex movement in the world. Our next step includes using gyroscopic properties and a counterweight characteristic to create an "cat-falling" effect, which the robot will always be able to land on its feet. | ## Inspiration:
As a group of 4 people who met each other for the first time, we saw this event as an inspiring opportunity to learn new technology and face challenges that we were wholly unfamiliar with. Although intuitive when combined, every feature of this project was a distant puzzle piece of our minds that has been collaboratively brought together to create the puzzle you see today over the past three days. Our inspiration was not solely based upon relying on the minimum viable product; we strived to work on any creative idea sitting in the corner of our minds, anticipating its time to shine. As a result of this incredible yet elusive strategy, we were able to bring this idea to action and customize countless features in the most innovative and enabling ways possible.
## Purpose:
This project involves almost every technology we could possibly work with - and even not work with! Per the previous work experience of Laurance and Ian in the drone sector, both from a commercial and a developer standpoint, our project’s principal axis revolved around drones and their limitations. We improved and implemented features that previously seemed to be the limitations of drones. Gesture control and speech recognition were the main features created, designed to empower users with the ability to seamlessly control the drone. Due to the high threshold commonly found within controllers, many people struggle to control drones properly in tight areas. This can result in physical, mental, material, and environmental damages which are harmful to the development of humans. Laurence was handling all the events at the back end by using web sockets, implementing gesture controllers, and adding speech-to-text commands. As another aspect of the project, we tried to add value to the drone by designing 3D-printed payload mounts using SolidWorks and paying increased attention to detail. It was essential for our measurements to be as exact as possible to reduce errors when 3D printing. The servo motors mount onto the payload mount and deploy the payload by moving its shaft. This innovation allows the drone to drop packages, just as we initially calculated in our 11th-grade physics classes. As using drones for mailing purposes was not our first intention, our main idea continuously evolved around building something even more mind-blowing - innovation! We did not stop! :D
## How We Built it?
The prototype started in small but working pieces. Every person was working on something related to their interests and strengths to let their imaginations bloom. Kevin was working on programming with the DJI Tello SDK to integrate the decisions made by the API into actual drone movements. The vital software integration to make the drone work was tested and stabilized by Kevin. Additionally, he iteratively worked on designing the mount to perfectly fit onto the drone and helped out with hardware issues.
Ian was responsible for setting up the camera streaming. He set up the MONA Server and broadcast the drone through an RTSP protocol to obtain photos. We had to code an iterative python script that automatically takes a screenshot every few seconds. Moreover, he worked toward making the board static until it received a Bluetooth signal from the laptop. At the next step, it activated the Servo motor and pump.
But how does the drone know what it knows?
The drone is able to recognize fire with almost 97% accuracy through deep learning. Paniz was responsible for training the CNN model for image classification between non-fire and fire pictures. The model has been registered and ready for use to receive data from the drone to detect fire.
Challenges we ran into:
There were many challenges that we faced and had to find a way around them in order to make the features work together as a system. Our most significant challenge was the lack of cross-compatibility between software, libraries, modules, and networks. As an example, Kevin had to find an alternative path to connect the drone to the laptop since the UDP network protocol was unresponsive. Moreover, he had to investigate gesture integration with drones during this first prototype testing. On the other hand, Ian struggled to connect the different sensors to the drone due to their heavy weight. Moreover, the hardware compatibility called for deep analysis and research since the source of error was unresolved. Laurence was responsible for bringing all the pieces together and integrating them through each feature individually. He was successful not only through his technical proficiencies but also through continuous integration - another main challenge that he resolved. Moreover, the connection between gesture movement and drone movement due to responsiveness was another main challenge that he faced. Data collection was another main challenge our team faced due to an insufficient amount of proper datasets for fire. Inadequate library and software versions and the incompatibility of virtual and local environments led us to migrate the project from local completion to cloud servers.
## Things we have learned:
Almost every one of us had to work with at least one new technology such as the DJI SDK, New Senos Modulos, and Python packages. This project helped us to earn new skills in a short amount of time with a maximized focus on productivity :D As we ran into different challenges, we learned from our mistakes and tried to eliminate repetitive mistakes as much as possible, one after another.
## What is next for Fire Away?
Although we weren't able to fully develop all of our ideas here are some future adventures we have planned for Fire Away :
Scrubbing Twitter for user entries indicating a potential nearby fire.
Using Cohere APIs for fluent user speech recognition
Further develop and improve the deep learning algorithm to handle of variety of natural disasters | ## Inspiration
Growing up in the early 2000s, communiplant's founding team knew what it was like to grow up in vibrant communities, interconnected interpersonal and naturally.
Today's post-covid fragmented society lacks the community and optimism that kept us going. The lack of optimism is especially evident through our climate crisis: an issue that falls outside most individuals loci of control.
That said, we owe it to ourselves and future generations to keep hope for a better future alive, **and that future starts on the communal level**. Here at Communiplant, we hope to help communities realize the beauty of street-level biodiversity, shepherding the optimism needed for a brighter future.
## What it does
Communiplant allows community members to engage with their community while realizing their jurisdiction's potential for sustainable development. Firstly, the communiplant analyzes satellite imagery using machine learning and computer vision models to calculate the community's NDMI vegetation indices. Beyond that, community members can individually contribute to their community on Commuiplant by uploading images of various flora and fauna they see daily in their community. Using computer vision models, our system can label the plantlife uploaded to the system, serving as a mosaic representing the communities biodiversity.
Finally, to further engage with their communities, users can participate in the community through participation in a variety of community events.
## How we built it
Communitech is a fullstack web application developed using React & Vite for the frontend, and Django on the backend. We used AWS's cloud suite for relational data storage: storing user records. Beyond that, however, we used AWS to implement the algorithms necessary for the complex categorizations that we needed to make. Namely. we used AWS S3 object storage to maintain our various clusters.
Finally, we used a variety of browser-level apis, including but not limited to the google maps API and the google earth engine API.
## Challenges we ran into
While UOttahack6 has been incredibly rewarding, it has not been without it challenges. Namely, we found that attempting to use bleeding-edge new technologies that we had little experience with in conjunction led to a host of technical issues.
First and most significantly, we found it difficult implementing cloud based artificial intelligence workflows for the first time.
We also had a lot of issues with some of the browser-level maps APIs, as we found that the documentation for some of those resources was insufficient for our experience level.
## Accomplishments that we're proud of
Regardless of the final result, we are happy to have made a final product with a concrete use case that has potential to become major player in the sustainability space.
All in all however, we are mainly proud that through it all we were able to show technical resilience. There were many late night moments where we didn't really see a way out, or where we would have to cut out a significant amount of functionality from our final product. Regardless we pushed though, and those experiences are what we will end up remembering UOttahack for.
## What's next for Communiplant
The future is bright for Communplant with many features on the way. Of these, the most significant are related to the mapping functionality. Currently, user inputted flora and fauna live only in a photo album on the community page. Going forwards we hope to have images linked to geographic points, or pins on the map.
Regardless of Communiplant's future actions, however, we will keep our guarantee to support sustainability on all scales. | losing |
## Inspiration
The post-COVID era has increased the number of in-person events and need for public speaking. However, more individuals are anxious to publicly articulate their ideas, whether this be through a presentation for a class, a technical workshop, or preparing for their next interview. It is often difficult for audience members to catch the true intent of the presenter, hence key factors including tone of voice, verbal excitement and engagement, and physical body language can make or break the presentation.
A few weeks ago during our first project meeting, we were responsible for leading the meeting and were overwhelmed with anxiety. Despite knowing the content of the presentation and having done projects for a while, we understood the impact that a single below-par presentation could have. To the audience, you may look unprepared and unprofessional, despite knowing the material and simply being nervous. Regardless of their intentions, this can create a bad taste in the audience's mouths.
As a result, we wanted to create a judgment-free platform to help presenters understand how an audience might perceive their presentation. By creating Speech Master, we provide an opportunity for presenters to practice without facing a real audience while receiving real-time feedback.
## Purpose
Speech Master aims to provide a practice platform for practice presentations with real-time feedback that captures details in regard to your body language and verbal expressions. In addition, presenters can invite real audience members to practice where the audience member will be able to provide real-time feedback that the presenter can use to improve.
While presenting, presentations will be recorded and saved for later reference for them to go back and see various feedback from the ML models as well as live audiences. They are presented with a user-friendly dashboard to cleanly organize their presentations and review for upcoming events.
After each practice presentation, the data is aggregated during the recording and process to generate a final report. The final report includes the most common emotions expressed verbally as well as times when the presenter's physical body language could be improved. The timestamps are also saved to show the presenter when the alerts rose and what might have caused such alerts in the first place with the video playback.
## Tech Stack
We built the web application using [Next.js v14](https://nextjs.org), a React-based framework that seamlessly integrates backend and frontend development. We deployed the application on [Vercel](https://vercel.com), the parent company behind Next.js. We designed the website using [Figma](https://www.figma.com/) and later styled it with [TailwindCSS](https://tailwindcss.com) to streamline the styling allowing developers to put styling directly into the markup without the need for extra files. To maintain code formatting and linting via [Prettier](https://prettier.io/) and [EsLint](https://eslint.org/). These tools were run on every commit by pre-commit hooks configured by [Husky](https://typicode.github.io/husky/).
[Hume AI](https://hume.ai) provides the [Speech Prosody](https://hume.ai/products/speech-prosody-model/) model with a streaming API enabled through native WebSockets allowing us to provide emotional analysis in near real-time to a presenter. The analysis would aid the presenter in depicting the various emotions with regard to tune, rhythm, and timbre.
Google and [Tensorflow](https://www.tensorflow.org) provide the [MoveNet](https://www.tensorflow.org/hub/tutorials/movenet#:%7E:text=MoveNet%20is%20an%20ultra%20fast,17%20keypoints%20of%20a%20body.) model is a large improvement over the prior [PoseNet](https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5) model which allows for real-time pose detection. MoveNet is an ultra-fast and accurate model capable of depicting 17 body points and getting 30+ FPS on modern devices.
To handle authentication, we used [Next Auth](https://next-auth.js.org) to sign in with Google hooked up to a [Prisma Adapter](https://authjs.dev/reference/adapter/prisma) to interface with [CockroachDB](https://www.cockroachlabs.com), allowing us to maintain user sessions across the web app. [Cloudinary](https://cloudinary.com), an image and video management system, was used to store and retrieve videos. [Socket.io](https://socket.io) was used to interface with Websockets to enable the messaging feature to allow audience members to provide feedback to the presenter while simultaneously streaming video and audio. We utilized various services within Git and Github to host our source code, run continuous integration via [Github Actions](https://github.com/shahdivyank/speechmaster/actions), make [pull requests](https://github.com/shahdivyank/speechmaster/pulls), and keep track of [issues](https://github.com/shahdivyank/speechmaster/issues) and [projects](https://github.com/users/shahdivyank/projects/1).
## Challenges
It was our first time working with Hume AI and a streaming API. We had experience with traditional REST APIs which are used for the Hume AI batch API calls, but the streaming API was more advantageous to provide real-time analysis. Instead of an HTTP client such as Axios, it required creating our own WebSockets client and calling the API endpoint from there. It was also a hurdle to capture and save the correct audio format to be able to call the API while also syncing audio with the webcam input.
We also worked with Tensorflow for the first time, an end-to-end machine learning platform. As a result, we faced many hurdles when trying to set up Tensorflow and get it running in a React environment. Most of the documentation uses Python SDKs or vanilla HTML/CSS/JS which were not possible for us. Attempting to convert the vanilla JS to React proved to be more difficult due to the complexities of execution orders and React's useEffect and useState hooks. Eventually, a working solution was found, however, it can still be improved to better its performance and bring fewer bugs.
We originally wanted to use the Youtube API for video management where users would be able to post and retrieve videos from their personal accounts. Next Auth and YouTube did not originally agree in terms of available scopes and permissions, but once resolved, more issues arose. We were unable to find documentation regarding a Node.js SDK and eventually even reached our quota. As a result, we decided to drop YouTube as it did not provide a feasible solution and found Cloudinary.
## Accomplishments
We are proud of being able to incorporate Machine Learning into our applications for a meaningful purpose. We did not want to reinvent the wheel by creating our own models but rather use the existing and incredibly powerful models to create new solutions. Although we did not hit all the milestones that were hoping to achieve, we are still proud of the application that we were able to make in such a short amount of time and be able to deploy the project as well.
Most notably, we are proud of our Hume AI and Tensorflow integrations that took our application to the next level. Those 2 features took the most time, but they were also the most rewarding as in the end, we got to see real-time updates of our emotional and physical states. We are proud of being able to run the application and get feedback in real-time, which gives small cues to the presenter on what to improve without risking distracting the presenter completely.
## What we learned
Each of the developers learned something valuable as each of us worked with a new technology that we did not know previously. Notably, Prisma and its integration with CockroachDB and its ability to make sessions and general usage simple and user-friendly. Interfacing with CockroachDB barely had problems and was a powerful tool to work with.
We also expanded our knowledge with WebSockets, both native and Socket.io. Our prior experience was more rudimentary, but building upon that knowledge showed us new powers that WebSockets have both when used internally with the application and with external APIs and how they can introduce real-time analysis.
## Future of Speech Master
The first step for Speech Master will be to shrink the codebase. Currently, there is tons of potential for components to be created and reused. Structuring the code to be more strict and robust will ensure that when adding new features the codebase will be readable, deployable, and functional. The next priority will be responsiveness, due to the lack of time many components appear strangely on different devices throwing off the UI and potentially making the application unusable.
Once the current codebase is restructured, then we would be able to focus on optimization primarily on the machine learning models and audio/visual. Currently, there are multiple instances of audio and visual that are being used to show webcam footage, stream footage to other viewers, and sent to HumeAI for analysis. By reducing the number of streams, we should expect to see significant performance improvements with which we can upgrade our audio/visual streaming to use something more appropriate and robust.
In terms of new features, Speech Master would benefit greatly from additional forms of audio analysis such as speed and volume. Different presentations and environments require different talking speeds and volumes of speech required. Given some initial parameters, Speech Master should hopefully be able to reflect on those measures. In addition, having transcriptions that can be analyzed for vocabulary and speech, ensuring that appropriate language is used for a given target audience would drastically improve the way a presenter could prepare for a presentation. | ## Inspiration
In the wake of a COVID-altered reality, where the lack of resources continuously ripples throughout communities, Heckler.AI emerges as a beacon for students, young professionals, those without access to mentorship and individuals seeking to harness vital presentation skills. Our project is a transformative journey, empowering aspiring leaders to conquer their fears. In a world, where connections faltered, Heckler.AI fills the void, offering a lifeline for growth and social resurgence. We're not just cultivating leaders; we're fostering a community of resilient individuals, breaking barriers, and shaping a future where every voice matters. Join us in the journey of empowerment, where opportunities lost become the stepping stones for a brighter tomorrow. Heckler.AI: Where anxiety transforms into confidence, and leaders emerge from every corner.
## What it does
Heckler.AI is your personalized guide to mastering the art of impactful communication. Our advanced system meticulously tracks hand and arm movements, decodes facial cues from smiles to disinterest, and assesses your posture. This real-time analysis provides actionable feedback, helping you refine your presentation skills. Whether you're a student, young professional, or seeking mentorship, Heckler.AI is the transformative tool that not only empowers you to convey confidence but also builds a community of resilient communicators. Join us in this journey where your every move becomes a step towards becoming a compelling and confident leader. Heckler.AI: Precision in every gesture, resonance in every presentation.
## How we built it
We used OpenCV and the MediaPipe framework to detect movements and train machine learning models. The resulting model could identify key postures that affect your presentation skills and give accurate feedback to fast-track your soft skills development. To detect pivotal postures in the presentation, we used several Classification Models, such as Logistic Regression, Ridge Classifier, Random Forest Classifier, and Gradient Boosting Classifier. Afterwards, we select the best performing model, and use the predictions personalized to our project's needs.
## Challenges we ran into
Implementing webcam into taipy was difficult since there was no pre-built library. Our solution was to use a custom GUI component, which is an extension mechanism that allows developers to add their own visual elements into Taipy's GUI. In the beginning we also wanted to use a websocket to provide real-time feedback, but we deemed it too difficult to build with our limited timeline. Incorporating a custom webcam into Taipy was full of challenges, and each developer's platform was different and required different setups. In hindsight, we could've also used Docker to containerize the images for a more efficient process.
Furthermore, we had difficulties deploying Taipy to our custom domain name, "hecklerai.tech". Since Taipy is built of Flask, we tried different methods, such as deploying on Vercel, using Heroku, and Gunicorn, but our attempts were in vain. A potential solution would be deploying on a virtual machine through cloud hosting platforms like AWS, which could be implemented in the future.
## Accomplishments that we're proud of
We are proud of ourselves for making so much progress in such little time with regards to a project that we thought was too ambitious. We were able to clear most of the key milestones of the project.
## What we learned
We learnt how to utilize mediapipe and use it as the core technology for our project. We learnt about how to manipulate the different points of the body to accurately use these quantifiers to assess the posture and other key metrics of presenters, such as facial expression and hand gestures. We also took the time to learn more about taipy and use it to power our front end, building a beautiful user friendly interface that displays a video feed through the user's webcam.
## What's next for Heckler.ai
At Heckler.AI, we're committed to continuous improvement. Next on our agenda is refining the model's training, ensuring unparalleled accuracy in analyzing hand and arm movements, facial cues, and posture. We're integrating a full-scale application that not only addresses your presentation issues live but goes a step further. Post-video analysis will be a game-changer, offering in-depth insights into precise moments that need improvement. Our vision is to provide users with a comprehensive tool, empowering them not just in the moment but guiding their growth beyond, creating a seamless journey from identifying issues to mastering the art of compelling communication. Stay tuned for a Heckler.AI that not only meets your needs but anticipates and addresses them before you even realize. Elevate your communication with Heckler.AI: Your growth, our commitment. | ## Inspiration
During this COVID-19 pandemic time, most of us are working or studying at home. We've all had moments where we wanted to go to the library to study but we can't; or wanted to go and hang out with friends and chat about life, but we can't. The number of covid cases is declining steadily, but how about our mental health? We are having much fewer social interactions than normal. From a poll conducted by KFF, 53% of adults in the United States reported that their mental health has been negatively impacted due to worry and stress over the coronavirus time.
With all that, we wanted to come up with a way to address the social anxieties we have caused by the pandemic.
## What it does
**What's in my zoo?!** is a web app that allows individuals to chat, call, or live streaming within an online room. What makes our app different from other chat apps? All of the session rooms can be made public so everyone sees it can join. Each room could be a working environment or a library/study environment.
Apart from exploring and joining others’ rooms, you can also create one room on your own, of course. With only a room type (study or work) and a room topic, you can find strangers online who are interested in your topic and join your room, so you won’t be alone studying or working!!! You can also invite your friends to join your room by sharing the room id with them, so you can study/work with them online just the same as you were in real life!!! (there’s also an option to make your room private, so you and your friends will not be bothered by any strangers).
Inside each session room, there will be a panel that displays the time you spend for this work/study session(also known as the Zoo time in our app). We plan to keep track of every work/study session for each user and display their daily Zoo time in the form of charts and diagrams. Apart from your own Zoo time displayed within the session, there’s a separate panel displaying the current Zoo time for all users inside the room. This is also known as the ‘leaderboard’ to show who spent the most time inside the session studying/working.
Okay, I know you may wonder now, up until here, where’s the zoo in our app name coming from? Here comes the interesting part!! To help increase our user’s productivity, every time they use the app, they will have the chance to win a random animal badge after finishing a session. The badges they hold will later turn into “real’ animals moving around in their virtual zoo in the main page. You can also check out your animal badge collection on the gallery page.
Animals have different levels of rarity (rarity by the chances to get them). The longer you spent in a session studying/working, the higher chance you would have to earn more rare animals. So study/work hard and get your animal badges!!!
With the collection and zoo display feature in our app, users can share and show off their zoo to friends. Isn’t that fun to collect and build your zoo while studying/working with high productivity and not being alone at the same time? Start using our **What’s in my zoo?!** now!!!
(Demo of the main page)
## How we built it
Our web app is hosted on the **google cloud** compute engine. We used Adobe XD to deign the user interfaces of our app. The front-end used ReactJS and the back-end used NodeJS. We used firebase for site user authentication. For instant messaging and live video streaming, we used the message distribution service provided by **Solace**. It significantly decreased the complexity and the pressure on our back-end. For storing and retrieving all the user data, we used RESTful API from **DataStax**. The domain and DNS lookup service of our website is provided by **domain.com**.
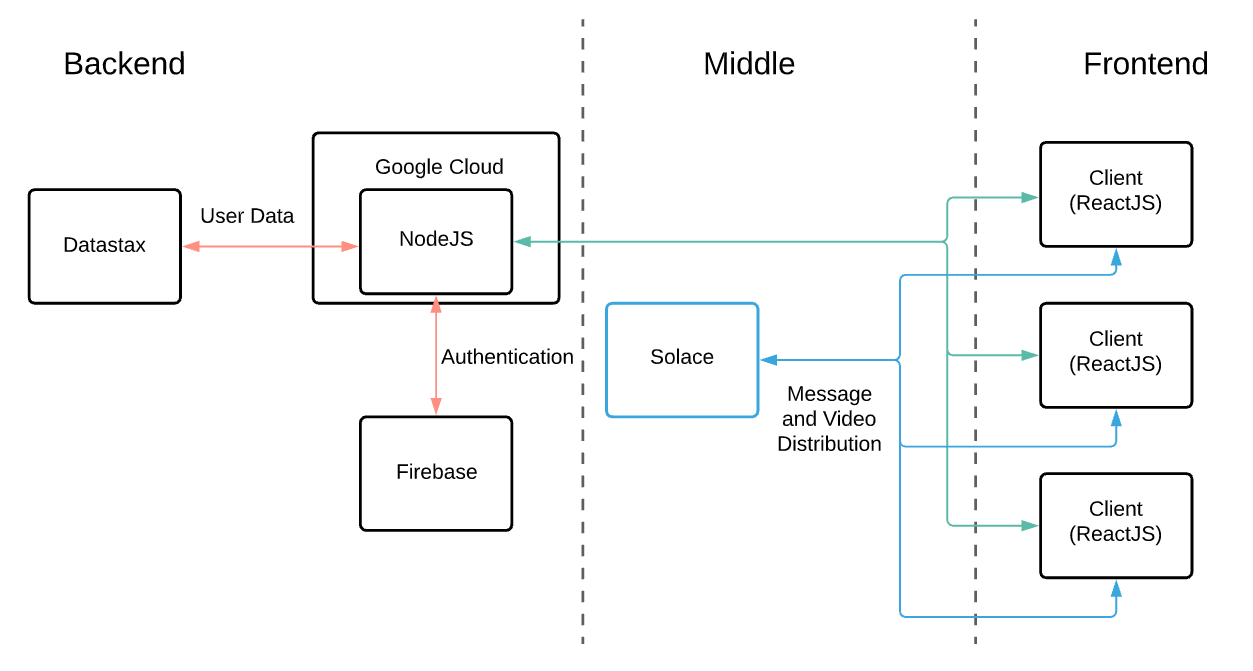
## Challenges we ran into
1. Time took to reading documents and make sample codes work is way longer than expected.
2. Front-end development and implementation are harder than we thought and took more time than we expected. We’ve faced many tiny problems when trying to implement animations on the web.
## Accomplishments that we're proud of
1. We are so proud of the idea of this web app we came up with. During this pandemic time, we faced situations where we have questions about a school class but we can’t seek help as much as we do in real life. Or it is just too boring for working from home and sometimes we just want to talk to someone. Our app would perfectly solve the problems. Not only provided a platform for making more friends online, but our app would also boost your study/work productivity. Our app is also perfect for people who have less self-control. By sharing a room to work/study together, people can discipline and help each other.
2. Our web app is designed to host multiple sessions and each session needs to support instant messaging and video streaming between multiple users. This can significantly increase the complexity of our back-end and can certainly hurt the scalability of our app. To solve this, we used the message distribution service provided by Solace. This is the first time we learned and used this service on our project. It decreases a lot of pressure on our back-end.
## What we learned
1. Excellent teamwork! Good things happened during this hard time.
2. Use NodeJS to support the back-end.
3. Backend connection to DataStax for database deployment.
4. Solace message distribution and live video streaming on top of it.
5. Web Animation.
6. Adobe XD for the design phase.
## What's next for What's in my Zoo?!
Our app is intended to increase productivity and increase the level of social interaction at the same time. More features will be added if we want to continue this project after the Hackathon. More features could be but not limited to:
1. Competition Zoo time between friends.
2. Share zoo and badge achievement through social platforms.
3. Unique daily schedule for every user. Mixed with study/work session and the interest group/club or school/work social session.
4. Penalty for not completing their session.
5. Gallery collection that displays all the animal badges that users hold, with the rarity of the animal also shown.
6. Virtual AI that monitors the session room to make sure everyone follows the rule in each session. | winning |
## Inspiration
With summer time around the corner, it was natural that new problems would arise. One idea that we liked a lot was our struggles to find ice cream truck ice cream. Those soft serve cones, SpongeBob popsicles, and name brand ice cream sandwiches are awesome, but it's often hard to find these trucks. At the same time, we also stumbled across a website that mapped out locations in San Fransisco that were dirty. Taking these 2 ideas, we decided to make an app that tracks ice cream trucks.
## What it does
Scoop scouter is a community driven app, that dynamically updates based on sightings of ice cream trucks. Users can take pictures of sightings of ice cream trucks, which is where an image processing model would determine if the image was an ice cream truck (which is to prevent spam and fraud). If it was a real truck, the image and coordinates are stored in cloud based database and a coordinate marker is dropped on the map on where the truck was sighted. Markers don't last forever and sightings disappear off the map after a certain amount of time. Users can also search addresses on the search bar to find trucks in that area as well.
## How we built it
Our app was made in Android Studio, which is written in Java and XML. We used OpenCV and open source datasets to train our model which determined if the image was of an ice cream truck. Our backend was done with Google Cloud Platform and Firebase/Firestore which integrated well with the rest of the google created products. For mockups, we used Figma to plan out our project entirely.
## Challenges we ran into
This was our first time using OpenCV, firebase and android studio together in one project and it was challenging integrating them all together. The Google Maps API was also a bit tricky to use as well. Some features that we would like to put in were not featured due to time constraints.
## Accomplishments that we're proud of
We were so proud of all the work we were able to accomplish. Our app dynamically changed over time, with the addition of new information into our database and we were able to successfully integrate a lot of the features we wanted, such as a camera, search bar and finding location and distance between points. Overall, we were very happy with what we made and proud that we accomplished so much.
## What we learned
We learned that sometimes, even the most simple sounding ideas, can be very difficult to implement. Also, no matter how much someone claims they know what they're doing, they always learn more while working.
## What's next for Scoop Scouter
We plan on working on this project, revisiting the concept and continuing to practice with the technologies used as they all seemed very interesting. | ## Inspiration
Picture this, I was all ready to go to Yale and just hack away. I wanted to hack without any worry. I wanted to come home after hacking and feel that I had accomplished a functional app that I could see people using. I was not sure if I wanted to team up with anyone, but I signed up to be placed on a UMD team. Unfortunately none of the team members wanted to group up, so I developed this application alone.
I volunteered at Technica last week and saw that chaos that is team formation and I saw the team formation at YHack. I think there is a lot of room for team formation to be more fleshed out, so that is what I set out on trying to fix. I wanted to build an app that could make team building at hackathons efficiently.
## What it does
Easily set up "Event rooms" for hackathons, allowing users to join the room, specify their interests, and message other participants that are LFT (looking for team). Once they have formed a team, they can easily get out of the chatroom simply by holding their name down and POOF, no longer LFT!
## How I built it
I built a Firebase server that stores a database of events. Events hold information obviously regarding the event as well as a collection of all members that are LFT. After getting acquainted with Firebase, I just took the application piece by piece. First order of business was adding an event, and then displaying all events, and then getting an individual event, adding a user, deleting a user, viewing all users and then beautifying with lots of animations and proper Material design.
## Challenges I ran into
Android Animation still seems to be much more complex than it needs to be, so that was a challenge and a half. I want my applications to flow, but the meticulousness of Android and its fragmentation problems can cause a brain ache.
## Accomplishments that I'm proud of
In general, I am very proud with the state of the app. I think it serves a very nifty core purpose that can be utilized in the future. Additionally, I am proud of the application's simplicity. I think I set out on a really solid and feasible goal for this weekend that I was able to accomplish.
I really enjoyed the fact that I was able to think about my project, plan ahead, implement piece by piece, go back and rewrite, etc until I had a fully functional app. This project helped me realize that I am a strong developer.
## What I learned
Do not be afraid to erase code that I already wrote. If it's broken and I have lots of spaghetti code, it's much better to try and take a step back, rethink the problem, and then attempt to fix the issues and move forward.
## What's next for Squad Up
I hope to continue to update the project as well as provide more functionalities. I'm currently trying to get a published .apk on my Namecheap domain (squadupwith.me), but I'm not sure how long this DNS propagation will take. Also, I currently have the .apk to only work for Android 7.1.1, so I will have to go back and add backwards compatibility for the android users who are not on the glorious nexus experience. | ## Inspiration
While searching for ideas, our team came across an ECG dataset that was classified and labeled into categories for normal and abnormal patterns. While examining the abnormal patterns, it was observed that most seizure patterns had a small window that transitioned from a typical pattern to a seizure pattern around a 15-second window. Most of the accidents and damage in seizures are caused by falling, lack of help, or getting caught in disadvantaged situations -driving, cooking, etc.- detecting this short period in real-time and predicting a seizure with machine learning to warn the user seemed as somewhat of a viable solution. After this initial ideation, sharing patient data such as allergies, medicinal history, emergency contacts, previous seizures, and essential information at the moment of attack for the emergency workers was thought out in the case of unresponsiveness from the user to the app's notification.
## What does it do?
The system contains the following:
Three main agents.
A smartwatch with an accurate ECG sensor.
A machine learning algorithm on the cloud.
An integrated notification app on mobile phones to retrieve patient information during attacks.
The workflow includes a constant data transfer between the smartwatch and the machine learning algorithm to detect anomalies. If an attack is predicted, a notification prompts the user to check if this is a false positive prediction. Nothing is triggered if the user confirms nothing is wrong and dismisses the warning. The seizure protocol starts if the notification stays unattended or is answered as positive.
Seizure Protocol Includes:
-The user is warned by the prediction and should have found a safe space/position/situation to handle the seizure
-Alarms from both synced devices, mobile, and smartwatch
-Display of the FHIR patient history on the synced device, allergies, medicinal data, and fundamental id info for emergency healthcare workers
-Contacting emergency numbers recorded for the individual
With the help of the app, we prevent further damage by accidents by predicting the seizure. After the episode, we help the emergency workers have a smoother experience assisting the patient.
## Building the System
We attempted to use Zepp's smartwatch development environment to create a smartwatch app to track and communicate with the cloud (Though there have been problems with the ECG sensors, which will be mentioned in the challenges section.) For the machine learning algorithm, we used an LSTM model (Long-Short Term Memory Networks) to slice up the continuously fed data and classify between "normal" and "abnormal" states after training it on both Mit-Bih Epileptic Seizure Recognition datasets we have found. If the "abnormal" form has been observed for more than the threshold, we have classified it as a "seizure predictor." When the state changed to the seizure protocol, we had two ways of information transfer, one is to the smartwatch as an alarm/notification, and the other one to the synced mobile app to display information. For the mobile app, we have created a React Native app for the users to create profiles and transfer/display health information via the InterSystem's FHIR.js package. While in the "listening" state, the app waits for the seizure notification. When it receives it, it fetches and displays health information/history/emergency contacts and anything that can be useful to the emergency healthcare worker on the lock screen without unlocking the phone. Thus, providing a safer and smoother experience for the patient and the healthcare workers.
## Challenges
There have been several challenges and problems that we have encountered in this project. Some of them stayed unresolved, and some of them received quick fixes.
The first problem was using the ECG function of the Zepp watches. Because the watch ECG function was disabled in the U.S. due to a legal issue with the FDA, we could not pull up live data in the Hackathon. We resolved this issue by finding a premade ECG dataset and doing the train-test-validation on this premade dataset for the sake of providing a somewhat performing model for the Hackathon.
The second problem we encountered was that we could only measure our accuracy with our relatively mid-sized dataset. In the future, testing it with various datasets, trying sequential algorithms, and optimizing layers and performance would be advised. In the current state, without a live information feed and a comprehensive dataset, it is hard to be sure about the issues of overfitting/underfitting the dataset.
## Accomplishments
We could create a viable machine learning algorithm to predict seizures in a concise time frame, which took a lot of effort, research, and trials, especially in the beginning since we switched from plain RNN to LSTM due to the short-time frame problem. However, our algorithm works with a plausible accuracy (Keeping in mind that we cannot check for overfitting/underfitting without a diverse dataset). Another achievement we are proud of is that we attempted to build a project with many branches, like ReactApp, Zepp Integration, and Machine Learning in Python, which forced us to experience a product-development process in a super-dense mode.
But most importantly, attending the Hackathon and meeting with amazing people that both organized, supported, and competed in it was an achievement to appreciate!
## Points to Take Home
The most discussed point we learned was that integrating many APIs is a rather daunting process in terms of developing something within 24 hours. It was much harder to adapt and link these different technologies together, even though we had anticipated it before attempting it. The second point we learned was that we needed to be careful about our resources during the challenges. Especially our assumption about the live-data feed from the watch made us stumble in the development process a bit. However, these problems make Hackathons a learning experience, so it's all good!
## Future for PulseBud
The plans might include sharpening the ML with a variety of dense and large-scale datasets and optimizing the prediction methodology to reach the lowest latency with the highest accuracy. We might also try to run it on the watch itself if it can get a robust state like that. Also, setting personalized thresholds for each user would be much more efficient in terms of notification frequency if the person is an outlier. Also, handling the live data feed to the algorithm should be the priority. If these can be done to the full extent, this application can be a very comfortable quality of life change for many people who experience or might experience seizures. | losing |
## Inspiration
We have firsthand knowledge from our close family and friends who are doctors serving in rural communities across America. They have shared with us their experiences of burnout due to the extensive manual back-office tasks they are required to handle, such as patient pre-authorization claims (PAs), in addition to their primary responsibility of serving their patients. Upon conducting further research, we have discovered that this is not just an isolated issue within our circle but rather a systemic problem that plagues the entire hospital industry.
Today, administrative complexity is costing the healthcare industry a staggering $265.6 billion annually. Furthermore, over 30% of the country's rural hospitals are at risk of closure due to financial instability, with a projected increase of 16% in the year 2023. If these hospitals close down, over ~57M Americans will be without care. Moreover, according to an AMA 2022 Physician Survey, 88% of physicians say burnout associated with PA is extremely high, and 34% report that PAs led to serious adverse events for patient care due to insurance rejections preventing needed care.
## What it does
MediFlow automates back-office administrative work for hospitals, focusing on workflow experience and exacerbated in rural hospital environments. MediFlow seeks to be both a core system of record for electronic health records and a vertical AI tool that leverages proprietary hospital data to enhance. In this vein, MediFlow currently offers tools to automate 3 hospital administration processes.
Prior Authorization. MediFlow can shorten the process of requesting prior authorization from insurance companies, i.e. approval for treatment/pharmaceutical coverage, from weeks to minutes by reducing the error rate of this manual process. By taking in information from the EHR and using LLMs to generate likely treatment codes, a process that normally takes staffers 45 minutes to even complete can be done in <3 minutes.
Patient-Meeting Summaries. Using OpenAI’s Whisper, MediFlow can summarize doctor meetings and store summaries in an object store for future use when initiating prior authorization requests.
Patient Intake and Client Relationship Management. MediFlow enables easy patient intake for new and recurring patients as well as a top-down view of a hospital’s clientele.
## How we built it
We used Convex as our database and its serverless functions to build the backend for our app. We finetuned llama’s 13bn parameter LLM model with 1,200 examples of doctor-patient summaries with MonsterAPI’s ML fine-tuning suite. We also used MonsterAPI’s hosted Whisper endpoint for voice transcription. To handle unstructured data for prior authorization, we used OpenAI’s GPT3 API and prompt engineering to retrieve siloed information from noisy data. We used React and TypeScript in a node environment to build out our friend end with Turbo as a tool to manage our mono repo. Finally, we used Clerk for user authentication and log in our platform.
## Challenges we ran into
Defining the specific products we wanted to build was challenging as the medical space was large and something we were unfamiliar with. We ran into issues configuring our convex environment initially and found working with different insurance health codes extremely difficult and confusing. Additionally, it was difficult to find datasets to fine-tune our models and ensure high accuracy in our highly-context dependent environment.
## Accomplishments that we're proud of
We’re proud of building out multiple features instead of the initial tool we set out to build. We’re proud of building a multi-modal AI solution on top of a traditional enterprise software platform and effectively resolving a challenge faced by rural hospitals.
## What we learned
We learned how to fine-tune models, how voice diffusion and transformer models work, and the medical workflow process for doctors and rural hospitals.
## What's next for MediFlow
Convex Cron functions
Go multiproduct | ## our why
Dialects, Lingoes, Creoles, Acrolects are more than just words, more than just languages - there are a means for cultural immersion, intangible pieces of tradition and history passed down through generations.
Remarkably two of the industry giants lag far behind - Google Translate doesn't support translations for the majority of dialects and ChatGPT's responses can be likened to a dog meowing or a cat barking.
Aiden grew up in Trinidad and Tobago, a native creole (patois) speaker; Nuween in Afghanistan making memories with his extended family in hazaragi, and Halle and Savvy though Canadian show their love and appreciation at home, in Cantonese and Mandarin, with their parents who are both 1st gen immigrants.
How can we bring dialect speakers and even non-dialect speakers alike together? How can we traverse cultures, when the infrastructure to do so isn’t up to par?
## pitta-patta, our solution
Metet Pitta-Patta—an LLM-powered, voice-to-text web app designed to bridge cultural barriers and bring people together through language, no matter where they are. With our innovative dialect translation system for underrepresented minorities, we enable users to seamlessly convert between standard English and dialects. Currently, we support Trinidadian Creole as our proof of concept, with plans to expand further, championing a cause dear to all of us.
## our building journey
Model:
Our project is built on a Sequence-to-Sequence (Seq2Seq) model, tailored to translate Trinidadian Creole slang to English and back. The encoder compresses the input into a context vector, while the decoder generates the output sequence. We chose Long Short-Term Memory (LSTM) networks to handle the complexity of sequential data.
To prepare our data, we clean it by removing unnecessary prefixes and adding start and end tokens to guide the model. We then tokenize the text, converting words to integers and defining an out-of-vocabulary token for unknown words. Finally, we pad the sequences to ensure they’re uniform in length.
The architecture includes an embedding layer that turns words into dense vectors, capturing their meanings. As the encoder processes each word, it produces hidden states that initialize the decoder, which predicts the next word in the sequence.
Our decode\_sequence() function takes care of translating Trinidadian Creole into English, generating one word at a time until it reaches the end. This allows us to create meaningful connections through language, one sentence at a time.
Frontend:
The Front end was done using stream-lit.
**Challenges we ran into**
1. This was our first time using Databricks and their services - while we did get Tensorflow up, it was pretty painful to utilize spark and also attempting to run llm models within the databricks environment - we eventually abandoned that plan.
2. We had a bit of difficulty connecting the llm to the backend - a small chink along the way, where calling the model would always result in retraining - slight tweaks in the logic fixed this.
3. We had a few issues in training the llm in terms of the data format of the input - this was fixed with the explicit encoder and decoder logic
**Accomplishments that we're proud of**
1. This was our first time using streamlit to build the front-end and in the end it was done quite smoothly.
2. We trained an llm to recognise and complete dialect!
## looking far, far, ahead
We envision an exciting timeline for Pitta-Patta. Our goal is to develop a Software Development Kit (SDK) that small translation companies can utilize, empowering them to integrate our dialect translation capabilities into their platforms. This will not only broaden access to underrepresented dialects but also elevate the importance of cultural nuances in communication.
Additionally, we plan to create a consumer-focused web app that makes our translation tools accessible to everyday users. This app will not only facilitate seamless communication but also serve as a cultural exchange platform, allowing users to explore the richness of various dialects and connect with speakers around the world. With these initiatives, we aim to inspire a new wave of cultural understanding and appreciation.
Made with coffee, red bull, and pizza. | If we take a moment to stop and think of those who can't speak or hear, we will realize and be thankful for what we have. To make the lives of these differently ables people, we needed to come up with a solution and here we present you with Proximity.
Proximity uses the Myo armband for sign recognition and an active voice for speech recognition. The armband is trained on a ML model reads the signs made by human hands and interprets them, thereby, helping the speech impaired to share their ideas and communicate with people and digital assistants alike. The service is also for those who are hearing impaired, so that they can know when somebody is calling their name or giving them a task.
We're proud of successfully recognizing a few gestures and setting up a web app that understands and learns the name of a person. Apart from that we have calibrated a to-do list that can enable the hearing impaired people to actively note down tasks assigned to them.
We learned an entirely new language, Lua to set up and use the Myo Armband SDK. Apart from that we used vast array of languages, scripts, APIs, and products for different parts of the product including Python, C++, Lua, Js, NodeJs, HTML, CSS, the Azure Machine Learning Studio, and Google Firebase.
We look forward to explore the unlimited opportunities with Proximity. From training it to recognize the entire American Sign Language using the powerful computing capabilities of the Azure Machine Learning Studio to advancing our speech recognition app for it to understand more complex conversations. Proximity should integrate seamlessly into the lives of the differently abled. | partial |
# GitCheck
## Inspiration
As a student, it was a big life adjustment for me when I began my first technical internship. And to make things more difficult, the coding standard at my company was entirely different from any coding I've done at hackathons or for my school projects! There are many industry standards for code styling that students like me are not well-prepared for. For this reason, our project seeks to help others improve their code style with our simple to use and practical web application to be prepared for real on-the-job development.
## What it does
GitCheck is a web service that can automatically grade your GitHub projects according to standard style guidelines and provide detailed feedback on the breakdown of your major styling mistakes. On top of that, our service gives an overall rating of your profile and each of your repositories. You can see where you specifically need to improve to bring your ratings up and become a better developer. Company recruiters can also easily discover top-tier talent and experience in candidates by searching their ratings with our service.
## Future Work
We plan to add styling guidelines for all major coding languages, and accommodate specific style guidelines for different companies to prepare students on an even deeper level.
## Setup
```
npm install
pip install -r requirements.txt
```
Add database password to environment variables
On mac:
Run this in terminal OR add this to `~/.bashrc`
```
export PENNAPPS_MONGO_PASSWORD="password_here"
```
On windows:
```
setx PENNAPPS_MONGO_PASSWORD password_here
```
### Running
```
node app.js
```
Open browser to `http://localhost:7000`
### Docker instructions (optional)
Build:
```
docker build -t codechecker . --build-arg mongo_password=<password_here>
```
Run
```
docker run -t -p 7000:7000 codechecker
```
Stop
```
docker stop $(docker ps -a -q --filter ancestor=codechecker --format="{{.ID}}")
``` | ## 💡 Inspiration
Whenever I was going through educational platforms, I always wanted to use one website to store everything. The notes, lectures, quizzes and even the courses were supposed to be accessed from different apps. I was inspired by how to create a centralized platform that acknowledges learning diversity. Also to enforce a platform where many people can **collaborate, learn and grow.**
## 🔎 What it does
By using **Assembly AI** and incorporating a model which focuses on enhancing the user experience by providing **Speech-to-text** functionality. My application enforces a sense of security in which the person decides when to study, and then, they can choose from ML transcription with summarization and labels, studying techniques to optimize time and comprehension, and an ISR(Incremental Static Regeneration) platform which continuously provides support. **The tools used can be scaled as the contact with APIs and CMSs is easy to *vertically* scale**.
## 🚧 How we built it
* **Frontend**: built in React but optimized with **NextJS** with extensive use of TailwindCSS and Chakra UI.
* **Backend**: Authentication with Sanity CMS, Typescript and GraphQL/GROQ used to power a serverless async Webhook engine for an API Interface.
* **Infrastructure**: All connected from **NodeJS** and implemented with *vertical* scaling technology.
* **Machine learning**: Summarization/Transcription/Labels from the **AssemblyAI** API and then providing an optimized strategy for that.
* **Branding, design and UI**: Elements created in Procreate and some docs in ChakraUI.
* **Test video**: Using CapCut to add and remove videos.
## 🛑 Challenges we ran into
* Implementing ISR technology to an app such as this required a lot of tension and troubleshooting. However, I made sure to complete it.
* Including such successful models and making a connection with them was hard through typescript and axios. However, when learning the full version, we were fully ready to combat it and succeed. I actually have optimized one of the algorithm's attributes with asynchronous recursion.
+ Learning a Query Language such as **GROQ**(really similar to GraphQL) was difficult but we were able to use it with the Sanity plugin and use the **codebases** that was automatically used by them.
## ✔️ Accomplishments that we're proud of
Literally, the front end and the backend required technologies and frameworks that were way beyond what I knew 3 months ago. **However I learned a lot in the space between to fuel my passion to learn**. But over the past few weeks, I planned and saw the docs of **AssemblyAI**, learned **GROQ**, implemented **ISR** and put that through a \**Content Management Service (CMS) \**.
## 📚 What we learned
Throughout Hack the North 2022 and prior, I learned a variety of different frameworks, techniques, and APIs to build such an idea. When starting coding I felt like I was going ablaze as the techs were going together like **bread and butter**.
## 🔭 What's next for SlashNotes?
While I was able to complete a considerable amount of the project in the given timeframe, there are still places where I can improve:
* Implementation in the real world! I aim to push this out to google cloud.
* Integration with school-course systems and proving the backend by adding more scaling and tips for user retention. | ## Inspiration
Our spark to tackle this project was ignited by a teammate's immersive internship at a prestigious cardiovascular research society, where they served as a dedicated data engineer. Their firsthand encounters with the intricacies of healthcare data management and the pressing need for innovative solutions led us to the product we present to you here.
Additionally, our team members drew motivation from a collective passion for pushing the boundaries of generative AI and natural language processing. As technology enthusiasts, we were collectively driven to harness the power of AI to revolutionize the healthcare sector, ensuring that our work would have a lasting impact on improving patient care and research.
With these varied sources of inspiration fueling our project, we embarked on a mission to develop a cutting-edge application that seamlessly integrates AI and healthcare data, ultimately paving the way for advancements in data analysis and processing with generative AI in the healthcare sector.
## What it does
Fluxus is an end to end workspace for data processing and analytics for healthcare workers. We leverage LLMs to translate text to SQL. The model is preprocessed to specifically handle Intersystems IRIS SQL syntax. We chose Intersystems as our database for storing electronic health records (EHRs) because this enabled us to leverage their integratedML queries. Not only can healthcare workers generate fully functional SQL queries for their datasets with simple text prompts, they now can perform instantaneous predictive analysis on datasets with no effort. The power of AI is incredible isn't it.
For example, a user can simply type in "Calculate the average BMI for children and youth from the Body Measures table." and our app will output
"SELECT AVG(BMXBMI) FROM P\_BMX WHERE BMDSTATS = '1';"
and you can simply run it on the built in intersystems database. With Intersystems IntegratedML, with the simple input of "create a model named DemographicsPrediction to predict the language of ACASI Interview based on age and marital status from the Demographics table.", our app will output
"CREATE MODEL DemographicsPrediction PREDICTING (AIALANGA) FROM P\_DEMO TRAIN MODEL DemographicsPrediction VALIDATE MODEL DemographicsPrediction FROM P\_DEMO SELECT \* FROM INFORMATION\_SCHEMA.ML\_VALIDATION\_METRICS;"
to instantly create train and validate an ML model that you can perform predictive analysis on with integratedML's "PREDICT" command. It's THAT simple!
Researchers and medical professionals working with big data now don't need to worry about the intricacies of SQL syntax, the obscurity of healthcare record formatting - column names and table names that do not give much information, and the need to manually dive into large datasets to find what they're looking for. With simple text prompts data processing becomes a no effort task, and predictive modelling with ML models becomes equally as effortless. See how tables come together without having to browse through large datasets with our DAG visualizations of connected tables/schemas.
## How we built it
Our project incorporated a multitude of components that went into the development. It was both overwhelming, but also satisfying seeing so many parts come together.
Frontend: The frontend was developed in Vue.js and utilized many modern day component libraries to give off a friendly UI. We also incorporated a visualization tool using third party graph libraries to draw directed acyclic graph (DAG) workflows between tables, showing the connection from one table to another that has been developed after querying the original table. To show this workflow in real time, we implemented a SQL parser API (node-sql-parser) to get a list of source tables used in the LLM generated query and used the DAGs to visually represent the list of source tables in connection to the newly modified/created table.
Backend: We used Flask for the backend of our web service, handling multiple API endpoints from our data sources and LLM/prompt engineering functionality.
Intersystems: We connected an IRIS intersystems database to our application and loaded it with a load of healthcare data leveraging intersystems libraries for connectors with Python.
LLMs: We originally started looking into OpenAI's codex models and their integration, but ultimately worked with GPT-3.5 turbo which made it easy to fine-tune our data (to a certain degree) so our LLM could detect prompts and generate syntactically accurate queries with a high degree of accuracy. We wrapped the LLM and preprocessing of prompt engineering features as an API endpoint to integrate with our backend.
## Challenges we ran into
* LLMs are not as magical as they look. There was nothing for us to train the kind of datasets that are used in healthcare. We had to manually push entire database schemas for our LLM to recognize and to attempt to fine-tune on in order to get queries that were accurate. This was intensive manual labour and a lot of frustrating failures with trying to fine-tune on both current and legacy LLM models provided by OpenAI. Ultimately we came to a promising result that delivered a solid degree of accuracy with some fine-tuning.
* Integrating everything together - putting together countless API endpoints (honestly felt like writing production code at a certain point), hosting to our frontend, wrapping the LLM as an API endpoint. Ultimately there's definitely pain points that still need to be addressed, and we plan to make this a long term project that will help us identify bottlenecks that we didn't have time to address within these 24 hours, while simultaneously expanding on our application.
## Accomplishments that we're proud of
We were all aware of how much we aimed to get done in a mere span of 24 hours. It seemed near impossible. But we were all on a mission, and had the drive to bring a whole new experience to data analytics and processing to the healthcare industry by leveraging the incredible power of generative AI. The satisfaction of seeing our LLM work, trying to fine-tune manually configured data hundreds of lines long and having it accurately give us queries for IRIS including integratedML queries, the frontend come to life, the countless API endpoints work and the integration of all our services for an application with high levels of functionality. Our team came together from different parts of the globe for this hackathon, but we were warriors that instantly clicked as a team and made the most of these past 24 hours by powered through day and night to deliver this product.
## What we learned
Just how insane AI honestly is.
A lot about SQL syntax, working with Intersystems, the highs and lows of generative AI, about all there is to know about current natural language to SQL processes leveraging generative AI thanks to like 5+ research papers.
## What's next for Fluxus
* Develop an admin platform so users can put in their own datasets
* Fine-tune the LLM for larger schemas and more prompts
* buying a hard drive | losing |
# Food Cloud
Curbing food waste for a sustainable future
## Inspiration
The awareness vertical - Every year food companies throw away an excess amount of food. According to the Food and Agriculture Organization of the United Nations, “roughly one-third of the food produced in the world for human consumption every year — approximately 1.3 billion tonnes — gets lost or wasted.”
## What it does
With this in mind, we brainstormed a way for food companies and restaurants to make use of the extra amount of food produced. With the two day time constraints and team skills, we decided to make a web application for a normal consumer to buy excess food based on the desired location radius. The business would signup and login to post food. The consumer would be able to buy discounted food from the post.
How we built it
For our project, we built our web pages using HTML, CSS, and JavaScript. Our choice of database was Firebase, and we used it with flask as our framework. Our backend was created using Flask and Python.
## Challenges we ran into
A challenge was using Flask with Firebase. The documentation was skewed to a pure Python solution with python-admin. Time should have been used to pyrebase, a python wrapper for the Firebase API. Another challenge was developing for the real-time database section for Firebase. We opted for Firestore instead.
Accomplishments that we're proud of
We are proud of the idea and the application made. We did code it completely on scratch and used productively utilize agile methodologies. The idea is very unique and we hope to be able to spread awareness of saving food waste with this application.
## What we learned
Everyone learned different things throughout this project. However, after discussing and solving our problems, we have all gained a better understanding of the full stack environment. We have also all learned how to use firebase for web applications alongside Flask.
## What's next for FoodCloud
The next steps for FoodCloud would be having better design or identity. Projects should have consistency with the design as noted by the Scott Forstall, creator of IOS. Another must-have feature is having a better schema with the user/business Firebase database. | ## Inspiration
Today’s education system is flawed. Since birth, children have been told to learn by doing and being curious. Once at the age of 5, this all changes. Children are pushed into classrooms and are expected to consume spoon fed information, instead of learning it themselves. This causes children to grow out of this innate method of learning, and are left with an unnatural and ineffective method. As they age, many children lose their innate curiosity for knowledge,and are now are no longer excited to learn.
The statistics are evident. In Canada, 4 provinces are significantly below the national mean grades in science. Science is a subject that revolves around a person’s drive to ask questions about the world, and due to our current way of learning, it’s no wonder why children are not interested in this field.
For this reason, we wanted to make an educational application that doesn’t teach. Instead, it promotes the innate curiosity of children to reignite. Using an app we created, Curio, children can discover new aspects of their world, based off of what they are curious to know.
## Our mission
Our mission is to motivate children to be curious and ask questions. Some of the most brilliant minds within our world grew up searching for knowledge instead of being spoon fed it by others. Using Curio, children are not forced to learn; instead they are encouraged to. By searching through our everyday world, children can discover new information that they may not have otherwise searched for.
## Target audience
Our target audience is 8-12 year olds. These children are young and are either about to be introduced or have just recently introduced into science as a subject.
## How it works
Curio is a smartphone application that has the ability to scan objects in your environment using augmented reality. Once an object has been found, the user can click on the object to learn curiosity sparking information about it (such as composition, environmental impact, how it’s made, etc.) as well as to earn XP. After specific object types have been scanned, the user may be prompted about a challenge to further promote exploration. If completed, the user will obtain XP. The amount of XP the user accumulates will be put on a leaderboard to compete with friends. This gamification element keeps the user engaged and continuously wanting to search for new items and information.
## Intentional usage
We intended for our app to be used outside of the classroom. Teachers can either give this app as a tool for children to at home (with no expectations as to what they find or use it so that it does not become homework), or for parents to encourage their children to use at home.
## How we built it
We started by looking at several tools such as TensorFlow plugin for Unity in order to fully utilize the capability of camera-based object recognition. We then explored the possibility of using ARkit for iOS to build our project on mobile devices, finally after some consultation and research, we ended up using the VuForia to build our object recognition logic and pattern since the tools they offered was the most intuitive and disposable to us at the time. Additionally, the object scanning tools were easy to use and recognize using the scanning platform software.
## Challenges we ran into
Picking the right tools based on our build objective and our design goal was the primary challenge of this Hack. We spent some time researching and determining the right tool used to implement our design vision. After some initial research and testing we’ve concluded that learning algorithms may have had limited fidelity in terms of object recognition for what we wanted to include to our project. Subsequently, we’ve decided to use our implement our own version of object recognition and object scanning through the use of Vuforia, this way we could control the object recognition, it’s implementation to a more fine and granular level. This allowed us to record and implement several objects we thought were useful and appropriate for our project.
In addition to this, we also reviewed some of our design choices along the way while we were implementing our UI/UX, we asked ourselves if our design was sound and followed the vision and core of the original design objective. This meant that there were several choices and features that were modified or completely omitted after some consideration.
## Accomplishments that we're proud of
We are proud of the fact we were able to implement a functioning object recognition tool based on AR. The object recognition portion of the tool is relatively high in its fidelity and design and we were able to get consistent results when we tried object recognition again and again.
Also, we are also proud of our ability to delegate tasks and workload amongst ourselves. We had a team with a wide range of abilities and skills. During this project, we were able to utilize everyone’s skills and capabilities for most of our design process. This meant that everyone had an important part to contribute to our design and build.
## What we learned
One of the main concepts that we learned during this project is that there’s a fine line between teaching and offering information. If the information that is being offered is not interesting to the user, it gives the effect that the app is trying to teach. However, if the information is interesting and unknown to the user, then the app will spark the user’s curiosity to find out more information. Due to this reason, as we created the app, if we did not step away and reconsider what we were making, we would begin to stray away from our initial goal.
## What’s next and the future of Curio
In the future, we would begin by creating a library of found objects. From there, we would also increase the number of objects that can be detected by Curio. We would also add other gamification challenges that would engage the user to continue to keep playing. Finally, we would implement the social aspect of Curio. This would include leaderboards, friends, etc.
We believe that Curio has a bright future ahead of it. In the classroom, Curio can become one of the main tools for learning instead of assigning homework. As an example, teachers can have an optional challenge within the app that gets rewarded every friday. From there, science based businesses can even make use of this tool. For example, science museums such as Science North can make Curio a tool to discover items around the museum. The children could then use their XP as cash to buy science based objects such as rocks, plants, etc.
## The business plan
We will be offering the use of this app free of charge to users who sign up and provide basic information such as location, age, and user interest. The plan is to use the app to gather data in an ethical way and analyze it to provide insight to educators and career counselors about the users interest, engagement and level that are closest to their location (school/educational facility). The analysis and data provision services would be subject to a subscription fee for schools and educators wishing to obtain analytics and insight for users and students that are attending their institution. Additionally classroom packages and trials can also be offered and be introduced to schools who are interested in exploring the possibility and capability of the app. Lastly we will also work with online education bodies and learning platforms to provide an opportunity for our users to fully engage and learn in their ecosystem. | ## Inspiration
We both love karaoke, but there are lots of obstacles:
* going to a physical karaoke is expensive and inconvenient
* youtube karaoke videos not always matches your vocal (key) range, and there is also no playback
* existing karaoke apps have limited songs, not flexible based on your music taste
## What it does
Vioke is a karaoke web-app that supports pitch-changing, on/off vocal switching, and real-time playback, simulating the real karaoke experience. Unlike traditional karaoke machines, Vioke is accesible anytime, anywhere, from your own devices.
## How we built it
**Frontend**
The frontend is built with React, and it handles settings including on/off playback, on/off vocal, and pitch changing.
**Backend**
The backend is built in Python. It leverages source separation ML library to extract instrumental tracks.
It also uses a pitch-shifting library to adjust the key of a song.
## Challenges we ran into
* Playback latency
* Backend library compatibily conflicts
* Integration between frontend and backend
* Lack of GPU / computational power for audio processing
## Accomplishments that we're proud of
* We were able to learn and implement audio processing, an area we did not have experience with before.
* We built a product that can can be used in the future.
* Scrolling lyrics is epic
* It works!!
## What's next for Vioke
* Caching processed audio to eventually create a data source that we can leverage from to reduce processing time.
* Train models for source separation in other languages (we found that the pre-built library mostly just supports English vocals).
* If time and resources allow, we can scale it to a platform where people can share their karaoke playlists and post their covers. | losing |
## Inspiration
We took inspiration from the multitude of apps that help to connect those who are missing to those who are searching for their loved ones and others affected by natural disaster, especially flooding. We wanted to design a product that not only helped to locate those individuals, but also to rescue those in danger. Through the combination of these services, the process of recovering after natural disasters is streamlined and much more efficient than other solutions.
## What it does
Spotted uses a drone to capture and send real-time images of flooded areas. Spotted then extracts human shapes from these images and maps the location of each individual onto a map and assigns each victim a volunteer to cover everyone in need of help. Volunteers can see the location of victims in real time through the mobile or web app and are provided with the best routes for the recovery effort.
## How we built it
The backbone of both our mobile and web applications is HERE.com’s intelligent mapping API. The two APIs that we used were the Interactive Maps API to provide a forward-facing client for volunteers to get an understanding of how an area is affected by flood and the Routing API to connect volunteers to those in need in the most efficient route possible. We also used machine learning and image recognition to identify victims and where they are in relation to the drone. The app was written in java, and the mobile site was written with html, js, and css.
## Challenges we ran into
All of us had a little experience with web development, so we had to learn a lot because we wanted to implement a web app that was similar to the mobile app.
## Accomplishments that we're proud of
Accomplishment: We are most proud that our app can collect and stores data that is available for flood research and provide real-time assignment to volunteers in order to ensure everyone is covered in the shortest time
## What we learned
We learned a great deal about integrating different technologies including XCode, . We also learned a lot about web development and the intertwining of different languages and technologies like html, css, and javascript.
## What's next for Spotted
Future of Spotted: We think the future of Spotted is going to be bright! Certainly, it is tremendously helpful for the users, and at the same time, the program improves its own functionality as data available increases. We might implement a machine learning feature to better utilize the data and predict the situation in target areas. What's more, we believe the accuracy of this prediction function will grow exponentially as data size increases. Another important feature is that we will be developing optimization algorithms to provide a real-time most efficient solution for the volunteers. Other future development might be its involvement with specific charity groups and research groups and work on specific locations outside US. | ## Inspiration
Natural disasters do more than just destroy property—they disrupt lives, tear apart communities, and hinder our progress toward a sustainable future. One of our team members from Rice University experienced this firsthand during a recent hurricane in Houston. Trees were uprooted, infrastructure was destroyed, and delayed response times put countless lives at risk.
* **Emotional Impact**: The chaos and helplessness during such events are overwhelming.
* **Urgency for Change**: We recognized the need for swift damage assessment to aid authorities in locating those in need and deploying appropriate services.
* **Sustainability Concerns**: Rebuilding efforts often use non-eco-friendly methods, leading to significant carbon footprints.
Inspired by these challenges, we aim to leverage AI, computer vision, and peer networks to provide rapid, actionable damage assessments. Our AI assistant can detect people in distress and deliver crucial information swiftly, bridging the gap between disaster and recovery.
## What it Does
The Garuda Dashboard offers a comprehensive view of current, upcoming, and past disasters across the country:
* **Live Dashboard**: Displays a heatmap of affected areas updated via a peer-to-peer network.
* **Drones Damage Analysis**: Deploy drones to survey and mark damaged neighborhoods using the Llava Vision-Language Model and generate reports for the Recovery Team.
* **Detailed Reporting**: Reports have annotations to classify damage types [tree, road, roof, water], human rescue needs, site accessibility [Can response team get to the site by land], and suggest equipment dispatch [Cranes, Ambulance, Fire Control].
* **Drowning Alert**: The drone footage can detect when it identifies a drowning subject and immediately call rescue teams
* **AI-Generated Summary**: Reports on past disasters include recovery costs, carbon footprint, and total asset/life damage.
## How We Built It
* **Front End**: Developed with Next.js for an intuitive user interface tailored for emergency use.
* **Data Integration**: Utilized Google Maps API for heatmaps and energy-efficient routing.
* **Real-Time Updates**: Custom Flask API records hot zones when users upload disaster videos.
* **AI Models**: Employed MSNet for real-time damage assessment on GPUs and Llava VLM for detailed video analysis.
* **Secure Storage**: Images and videos stored on Firebase database.
## Challenges We Faced
* **Model Integration**: Adapting MSNet with outdated dependencies required deep understanding of technical papers.
* **VLM Setup**: Implementing Llava VLM was challenging due to lack of prior experience.
* **Efficiency Issues**: Running models on personal computers led to inefficiencies.
## Accomplishments We're Proud Of
* **Technical Skills**: Mastered API integration, technical paper analysis, and new technologies like VLMs.
* **Innovative Impact**: Combined emerging technologies for disaster detection and recovery measures.
* **Complex Integration**: Successfully merged backend, frontend, and GPU components under time constraints.
## What We Learned
* Expanded full-stack development skills and explored new AI models.
* Realized the potential of coding experience in tackling real-world problems with interdisciplinary solutions.
* Balanced MVP features with user needs throughout development.
## What's Next for Garuda
* **Drone Integration**: Enable drones to autonomously call EMS services and deploy life-saving equipment.
* **Collaboration with EMS**: Partner with emergency services for widespread national and global adoption.
* **Broader Impact**: Expand software capabilities to address various natural disasters beyond hurricanes. | ## Inspiration
Artificial Intelligence is the defining innovation of our time. We wanted to see how this technology could be used to supplement and optimize education.
## What it does
Lotus is a place where you can neatly store all your course materials - text, docs, pdfs, image scans, and even lecture audio! Lotus parses the contents of these files and saves them so that it can readily generate summaries, outlines, flashcards and quizzes at your request, using your provided files as context.
## How we built it
We built Lotus's frontend using Next.js, React and Tailwind. We wrote the backend using Node.js, employing the APIs of Microsoft Azure and OpenAI for input parsing and output generation. Finally, we store our data using MongoDB.
## Challenges we ran into
We faced many issues when trying to get the Optical Character Recognition (OCR) algorithm to work, which we needed in order to extract the text from image scans. Additionally, the state management required for this project was more intricate than any we've worked on before, mainly due to the file organization system that we created.
## Accomplishments that we're proud of
What we are most proud of is the fact that we created an app that we ourselves would use. We are also proud that we completed the project and that it is functional.
## What we learned
While building Lotus, we greatly improved our technical skills as we faced many technical issues that required a great deal of patience and creativity to deal with. We also learned to work well together and grew closer as a team.
## What's next for Lotus
First, we plan to make use of Lotus in the coming weeks to study for our midterms. As we do, we will gain a better understanding of the strengths and weaknesses of the app, as well as additional features that would make Lotus even more effective in optimizing education. Some features that we have planned are handwriting recognition, audio output, and translation. | winning |
## Inspiration
After spending some time in the hospital last year, I quickly became aware of just how isolating and scary the experience can be. And after hearing one of my good friend’s stories of her own experience being hospitalized, I was sure that I could use our experiences to help other patients, and other people all around the world. My friend found herself in an Italian hospital, oceans away from home in a country whose language she didn't speak. This is an unfortunate reality that many face, though applications such as Google Translate can help to bridge the gaps in communication that can occur during these tense moments. However, without any Google Translate for sign language, as well as a 2022 *Reuters Health* article which reported that nearly one-third of hospitals in the US don't offer any sign language interpreters at all, I knew that this was likely an experience which was all too familiar for those who rely on signing to communicate. From there, my project began, and just as quickly as it did, it grew and became something that can apply to many situations outside of healthcare as well.
## How it's Built & What it Does
My project acts a sort of sign language translator in which the user can sign into a camera, have their actions and hand gestures analyzed, and then the text equivalent of their signs will be displayed on the screen. Currently, my application supports American Sign Language (ASL) to English text translations for static letter signs. I built my project by first creating a machine learning model to recognize American Sign Language (ASL) letters. I trained the model using the Sign Language MNIST dataset in Python and PyTorch. Once the model was trained, I converted it to ONNX format to make it compatible with JavaScript for web deployment. On the front end, I used HTML, CSS, and JavaScript to create a simple user interface. The web app captures hand gestures using a webcam, processes the images, and then translates the detected signs into text displayed on the screen.
## Challenges I Faced
I ran into many challenges while bringing my project ideas to life. The first major obstacle that put a pause on my project development was the time requirement for training my model using the Sign Language MNIST dataset. My old MacBook, with its slower CPU, significantly increased the training time, forcing me to stop the process after only 20 epochs. This incomplete training caused some performance issues, leading to a higher rate of errors than expected, as the model had not fully parsed and analyzed the dataset. Another challenge was transitioning from Python to JavaScript when integrating the front end of the application. Initially, I had trained and developed my model in PyTorch, which produced a .pt model. However, for web deployment, I had to convert this model to an ONNX format compatible with JavaScript. This process introduced additional complexity, as I faced issues with mismatched input shapes and difficulty loading the model correctly in the browser. The switch from Python to JavaScript for model inference posed significant challenges, requiring me to rethink how I handled model inputs and outputs, particularly with the ONNX runtime.
## What I Learned
Throughout the making of this project, I learned a lot about working with machine learning models and their deployment. Having never worked with any sort of machine learning before, one of the biggest lessons for me was learning how to bridge the gap between different technologies — from training a model in Python using PyTorch to converting it for use in a JavaScript-based web app. I also gained experience in handling the challenges that come with working across both back-end and front-end environments. Additionally, I improved my skills in debugging, especially when integrating complex machine learning models with front-end interfaces.
## What's Next for SimplySign
The future of SimplySign includes the addition of words, phrases, and full sentences, as well as other common sign languages such as British Sign Language (BSL), Spanish Sign Language (SSL), French Sign language (FSL), and more. Additionally, I would like to continue to work on my user interface and improve the overall design of the project, including adding subtitles to display the detected text as well as incorporating text-to-speech functionality. After that, utilizing an application such as Unity to create a mobile app which supports IOS and Android builds would help spread my project and put it in the hands of those who could benefit from it. | ## Inspiration 🌎
One of the challenges in our multicultural country is providing healthcare to non-verbal or non-English speaking patients.
Health care professionals often face a challenge when communicating with these patients. Bedside workers are not provided a translator and often rely on the patient's family for communication. This leads to miscommunication with the patient and misinformation from the family that may not be entirely truthful when answering questions involving medical history.
This also creates a problem when the nurses are trying to fully inform their patients before receiving their consent for a treatment. Nurses are liable is they don't received informed consent and communicating with non-verbal or non-English speaking patients can become increasing stressful for this reason.
Our team wanted address all of these problems while improving the efficiency and quality of life for these hard working, under staffed professionals.
## What does it do 🤔
Our application provides a system to help healthcare workers communicate with non-verbal and non-English speaking patients in a user friendly manner using real-time transcription and translating, graphical pain indicators, and visual symptom assessment surveys.
## How we built it 🔨
Using AssemblyAI + Google Translate API we created a real-time transcription and translating system that can cross the language barrier between the patient and the healthcare worker.
Interactive healthcare diagrams made using HTML and JavaScript designed to be simple and user-friendly were constructed to help patients visually communicate with professionals quickly.
All of the data is stored for later use in a secure hospital database to help keep track of patients' progress and make for easy data sharing between shifts of nurses.
## Challenges we ran into 🔎
Configuring the translations API and incorporating it into a browser environment proved to be very difficult when developing the backend. After hours of reading documentation, consulting mentors, and trying different approaches we finally got these tools to work seamlessly for our subtitle generator.
## Accomplishments that we're proud of 💪
We were able to implement real-time captioning using AssemblyAI and translation using the Google Translate API. We are also proud that we made a fully functioning web application in only 36 hours without the use of a framework. We think our program can provide real benefits to the healthcare industry.
## What we learned 🧠
We all learned how to use AssemblyAI and some of us learned JavaScript for the first time. We got to build on our UI development skills and refine our knowledge of databases.
## Looking Forward ⏩
We plan to implement foreign to English language translation to improve communication between the patient and nurse. With more time, we would have added functionality for nurses to customize the symptoms questionnaire and patient needs menu to further improve user experience. | ## Inspiration
We were inspired by the Instagram app, which set out to connect people using photo media.
We believe that the next evolution of connectivity is augmented reality, which allows people to share and bring creations into the world around them. This revolutionary technology has immense potential to help restore the financial security of small businesses, which can no longer offer the same in-person shopping experiences they once did before the pandemic.
## What It Does
Metagram is a social network that aims to restore the connection between people and small businesses. Metagram allows users to scan creative works (food, models, furniture), which are then converted to models that can be experienced by others using AR technology.
## How we built it
We built our front-end UI using React.js, Express/Node.js and used MongoDB to store user data. We used Echo3D to host our models and AR capabilities on the mobile phone. In order to create personalized AR models, we hosted COLMAP and OpenCV scripts on Google Cloud to process images and then turn them into 3D models ready for AR.
## Challenges we ran into
One of the challenges we ran into was hosting software on Google Cloud, as it needed CUDA to run COLMAP. Since this was our first time using AR technology, we faced some hurdles getting to know Echo3D. However, the documentation was very well written, and the API integrated very nicely with our custom models and web app!
## Accomplishments that we're proud of
We are proud of being able to find a method in which we can host COLMAP on Google Cloud and also connect it to the rest of our application. The application is fully functional, and can be accessed by [clicking here](https://meta-match.herokuapp.com/).
## What We Learned
We learned a great deal about hosting COLMAP on Google Cloud. We were also able to learn how to create an AR and how to use Echo3D as we have never previously used it before, and how to integrate it all into a functional social networking web app!
## Next Steps for Metagram
* [ ] Improving the web interface and overall user experience
* [ ] Scan and upload 3D models in a more efficient manner
## Research
Small businesses are the backbone of our economy. They create jobs, improve our communities, fuel innovation, and ultimately help grow our economy! For context, small businesses made up 98% of all Canadian businesses in 2020 and provided nearly 70% of all jobs in Canada [[1]](https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm).
However, the COVID-19 pandemic has devastated small businesses across the country. The Canadian Federation of Independent Business estimates that one in six businesses in Canada will close their doors permanently before the pandemic is over. This would be an economic catastrophe for employers, workers, and Canadians everywhere.
Why is the pandemic affecting these businesses so severely? We live in the age of the internet after all, right? Many retailers believe customers shop similarly online as they do in-store, but the research says otherwise.
The data is clear. According to a 2019 survey of over 1000 respondents, consumers spend significantly more per visit in-store than online [[2]](https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543). Furthermore, a 2020 survey of over 16,000 shoppers found that 82% of consumers are more inclined to purchase after seeing, holding, or demoing products in-store [[3]](https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store).
It seems that our senses and emotions play an integral role in the shopping experience. This fact is what inspired us to create Metagram, an AR app to help restore small businesses.
## References
* [1] <https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm>
* [2] <https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543>
* [3] <https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store> | partial |
## Contributors
Andrea Tongsak, Vivian Zhang, Alyssa Tan, and Mira Tellegen
## Categories
* **Route: Hack for Resilience**
* **Route: Best Education Hack**
## Inspiration
We were inspired to focus our hack on the rise of instagram accounts exposing sexual assault stories from college campuses across the US, including the Case Western Reserve University account **@cwru.survivors**; and the history of sexual assault on campuses nationwide. We wanted to create an iOS app that would help sexual assault survivors and students navigate the dangerous reality of college campuses. With our app, it will be easier for a survivor report instances of harassment, while maintaining the integrity of the user data, and ensuring that data is anonymous and randomized. Our app will map safe and dangerous areas on campus based on user data to help women, minorities, and sexual assault survivors feel protected.
### **"When I looked in the mirror the next day, I could hardly recognize myself. Physically, emotionally, and mentally."** -A submission on @cwru.survivors IG page
Even with the **#MeToo movement**, there's only so much that technology can do. However, we hope that by creating this app, we will help college students take accountability and create a campus culture that can fosters learning and contributes towards social good.
### **"The friendly guy who helps you move and assists senior citizens in the pool is the same guy who assaulted me. One person can be capable of both. Society often fails to wrap its head around the fact that these truths often coexist, they are not mutually exclusive."** - Chanel Miller
## Brainstorming/Refining
* We started with the idea of mapping sexual assaults that happen on college campuses. However, throughout the weekend, we were able to brainstorm a lot of directions to take the app in.
* We considered making the app a platform focused on telling the stories of sexual assault survivors through maps containing quotes, but decided to pivot based on security concerns about protecting the identity of survivors, and to pivot towards an app that had an everyday functionality
* We were interested in implementing an emergency messaging app that would alert friends to dangerous situations on campus, but found similar apps existed, so kept brainstorming towards something more original
* We were inspired by the heat map functionality of SnapMaps, and decided to pursue the idea of creating a map that showed where users had reported danger or sexual assault on campus. With this idea, the app could be interactive for the user, present a platform for sexual assault survivors to share where they had been assaulted, and a hub for women and minorities to check the safety of their surroundings. The app would customize to a campus based on the app users in the area protecting each other
## What it does
## App Purpose
* Our app allows users to create a profile, then sign in to view a map of their college campus or area. The map in the app shows a heat map of dangerous areas on campus, from areas with a lot of assaults or danger reported, to areas where app users have felt safe.
* This map is generated by allowing users to anonymously submit a date, address, and story related to sexual assault or feeling unsafe. Then, the map is generated by the user data
* Therefore, users of the app can assess their safety based on other students' experiences, and understand how to protect themselves on campus.
## Functions
* Account creation and sign in function using **Firebox**, to allow users to have accounts and profiles
* Home screen with heat map of dangerous locations in the area, using the **Mapbox SDK**
* Profile screen, listing contact information and displaying the user's past submissions of dangerous locations
* Submission screen, where users can enter an address, time, and story related to a dangerous area on campus
## How we built it
## Technologies Utilized
* **Mapbox SDK**
* **Github**
* **XCode & Swift**
* **Firebase**
* **Adobe Illustrator**
* **Google Cloud**
* **Canva**
* **Cocoapods**
* **SurveyMonkey**
## Mentors & Help
* Ryan Matsumoto
* Rachel Lovell
## Challenges we ran into
**Mapbox SDK**
* Integrating an outside mapping service came with a variety of difficulties. We ran into problems learning their platform and troubleshooting errors with the Mapbox view. Furthermore, Mapbox has a lot of navigation functionality. Since our goal was a data map with a lot of visual effect and easy readability, we had to translate the Mapbox SDK to be usable with lots of data inputs. This meant coding so that the map would auto-adjust with each new data submission of dangerous locations on campus.
**UI Privacy Concerns**
* The Mapbox SDK was created to be able to pin very specific locations. However, our app deals with data points of locations of sexual assault, or unsafe locations. This brings up the concern of protecting the privacy of the people who submit addresses, and ensuring that users can't see the exact location submitted. So, we had to adjust the code to limit how far a user can zoom in, and to read as a heat map of general location, rather than pins.
**Coding for non-tech users**
* Our app, **viva**, was designed to be used by college students on their nights out, or at parties. The idea would be for them to check the safety of their area while walking home or while out with friends. So, we had to appeal to an audience of young people using the app in their free time or during special occasions. This meant the app would not appeal if it seemed tech-y or hard to use. So, we had to work to incorporate a lot of functionalities, and a user interface that was easy to use and appealing to young people. This included allowing them to make accounts, having an easily readable map, creating a submission page, and incorporating design elements.
## Accomplishments that we're proud of
## What we learned
We learned so much about so many different aspects of coding while hacking this app. First, the majority of the people in our group had never used **Github** before, so even just setting up Github Desktop, coordinating pushes, and allowing permissions was a struggle. We feel we have mastery of Github after the project, whereas before it was brand new. Being remote, we also faced Xcode compatibility issues, to the point that one person in our group couldn't demo the app based on her Xcode version. So, we learned a lot about troubleshooting systems we weren't familiar with, and finding support forums and creative solutions.
In terms of code, we had rarely worked in **Swift**, and never worked in **Mapbox SDK**, so learning how to adapt to a new SDK and integrate it while not knowing everything about the errors appearing was a huge learning experience. This involved working with .netrc files and permissions, and gave us insight to the coding aspect as well as the computers networks aspect of the project.
We also learned how to adapt to an audience, going through many drafts of the UI to hit on one that we thought would appeal to college students.
Last, we learned that what we heard in opening ceremony, about the importance of passion for the code, is true. We all feel like we have personally experienced the feeling of being unsafe on campus. We feel like we understand how difficult it can be for women and minorities on campus to feel at ease, with the culture of sexual predation on women, and the administration's blind eye. We put those emotions into the app, and we found that our shared experience as a group made us feel really connected to the project. Because we invested so much, the other things that we learned sunk in deep.
## What's next for Viva: an iOS app to map dangerous areas on college campuses
* A stretch goal or next step would be to use the **AdaFruit Bluefruit** device to create wearable hardware, that when tapped records danger to the app. This would allow users to easily report danger with the hardware, without opening the app, and have the potential to open up other safety features of the app in the future.
* We conducted a survey of college students, and 95.65% of people who responded thought our app would be an effective way to keep themselves safe on campus. A lot of them additionally requested a way to connect with other survivors or other people who have felt unsafe on campus. One responder suggested we add **"ways to stay calm and remind you that nothing's your fault"**. So, another next step would be to add forums and messaging for users, to forward our goal of connecting survivors through the platform. | ## Inspiration
I, Jennifer Wong, went through many mental health hurdles and struggled to get the specific help that I needed. I was fortunate to find a relatable therapist that gave me an educational understanding of my mental health, which helped me understand my past and accept it. I was able to afford this access to mental health care and connect with a therapist similar to me, but that's not the case for many racial minorities. I saw the power of mental health education and wanted to spread it to others.
## What it does
Takes a personalized assessment of your background and mental health in order to provide a curated and self-guided educational program based on your cultural experiences.
You can journal about your reflections as you learn through watching each video. Videos are curated as an MVP, but eventually, we want to hire therapists to create these educational videos.
## How we built it
## Challenges we ran into
* We had our engineers drop the project or couldn't attend the working sessions, so there were issues with the workload. Also, there were issues with technical feasibility since knowledge on Swift was limited.
## Accomplishments that we're proud of
Proud that overall, we were able to create a fully functioning app that still achieves our mission. We were happy to get the journal tool completed, which was the most complicated.
## What we learned
We learned how to cut scope when we lost engineers on the team.
## What's next for Empathie (iOS)
We will get more customer validation about the problem and see if our idea resonates with people. We are currently getting feedback from therapists who work with people of color.
In the future, we would love to partner with schools to provide these types of self-guided services since there's a shortage of therapists, especially for underserved school districts. | ## Inspiration
Health and fitness are gaining an ever-increasing relevance in the field of technology.
With the wave of health and workout trends, we want to target what this underdeveloped field lacks with our first hackathon project.
We wanted to create an app that records users' workout plans and tracks their
progress in their muscle areas. This type of tracking has not been developed for
public use. Thus, our project 'story' was inspired to record their body reformation 'story.'
## What it does
This project tracks and analyzes detailed personal workout progress, such as rep targets for each muscle part, providing a progression graph and detailed feedback with a body heatmap illustrating the number of reps done for the user.
## How we built it
With an avid dream and a newbie team, we first decided on the main functions of our project and the overall website design, and then we split groups into the backend and frontend.
## Challenges we ran into
We are all beginners, but that wall did not stop us from pushing our limits and applying our skills. Every step of the way was a learning opportunity.
We had to learn CSS and SQLite on the go to incorporate the elements we wanted on our webpage.
## Accomplishments that we're proud of
We're proud to start building on a project that will have a great impact on the health and fitness community and the tech industry one day.
As the proverb goes, "Sometimes the smallest step in the right direction ends up being the biggest step." Our newcomer project is that first small step with great potential.
## What we learned
All steps to creating this project have been a good lesson on setting up websites and the rigor a team needs to create a project. We needed teamwork to coordinate the work and planning of the project. One team focused on CSS and design, and the other focused on the backend with Python and SQLite.
## What's next for Musclee
I believe our project has a lot of potential for improvement and expansion.
Our project idea is modern and new. We believe it will inspire and optimize people's workouts and keep their fitness on track. Thus, we will continue to work on this project as a passion project. | partial |
## Inspiration
Insurance Companies spend millions of dollars on carrying marketing campaigns to attract customers and sell their policies.These marketing campaigns involve giving people promotional offers, reaching out to them via mass marketing like email, flyers etc., these marketing campaigns usually last for few months to almost years and the results of such huge campaigns are inedible when raw.
## What it does
Intellisurance visualizes such campaign data and allows the insurance companies to understand and digest such data. These visualizations help the company decide whom to target next, how to grow their business? and what kind of campaigns or best media practices to reach to a majority of their potential customer base.
## How we built it
We wanted to give the insurance companies a clear overview of how their past marketing campaigns were, the pros , the cons, the ways to target a more specific group, the best practices etc. We also give information of how they gained customers over the period. Most key factor being the geographic location, we chose to display it over a map.
## Challenges we ran into
When we are dealing with the insurance campaign data we are dealing with millions of rows, compressing that data into usable information.
## Accomplishments that we're proud of
This part was the most challenging part where we pulled really necessary data and had algorithms to help users experience almost no lag while using the application. | ## Inspiration
When we first read Vitech's challenge for processing and visualizing their data, we were collectively inspired to explore a paradigm of programming that very few of us had any experience with, machine learning. With that in mind, the sentiment of the challenge themed around health care established relevant and impactful implications for the outcome of our project. We believe that using machine learning and data science to improve the customer experience of people in the market for insurance plans, would not only result in a more profitable model for insurance companies but improve the lives of the countless people who struggle to choose the best insurance plans for themselves at the right costs.
## What it does
Our scripts are built to parse, process, and format the data provided by Vitech's live V3 API database. The data is initially filtered using Solr queries and then formatted into a more adaptable comma-separated variable (CSV) file. This data is then processed by a different script through several machine learning algorithms in order to extract meaningful data about the relationship between an individual's personal details and the plan that they are most likely to choose. Additionally, we have provided visualizations created in R that helped us interpret the many data points more effectively.
## How we built it
We initially explored all of the ideas that we had regarding how exactly we planned to process the data and proceeded to pick Python as a suitable language and interface in which we believed that we could accomplish all of our goals. The first step was parsing and formatting data after which we began observing it through the visualization tools provided by R. Once we had a rough idea about how our data is distributed, we continued by making models using the h2o Python library in order to model our data.
## Challenges we ran into
Since none of us had much experience with machine learning prior to this project, we dived into many software tools we had never even seen before. Furthermore, the data provided by Vitech had many variables to track, so our deficiency in understanding of the insurance market truly slowed down our progress in making better models for our data.
## Accomplishments that we're proud of
We are very proud that we got as far as we did even though out product is not finalized. Going into this initially, we did not know how much we could learn and accomplish and yet we managed to implement fairly complex tools for analyzing and processing data. We have learned greatly from the entire experience as a team and are now inspired to continue exploring data science and the power of data science tools.
## What we learned
We have learned a lot about the nuances of processing and working with big data and about what software tools are available to us for future use.
## What's next for Vitech Insurance Data Processing and Analysis
We hope to further improve our modeling to get more meaningful and applicable results. The next barrier to overcome is definitely related to our lack of field expertise in the realm of the insurance market which would further allow us to make more accurate and representative models of the data. | ## Inspiration
In 2019, close to 400 people in Canada died due to distracted drivers. They also cause an estimated $102.3 million worth of damages. While some modern cars have pedestrian collision avoidance systems, most drivers on the road lack the technology to audibly cue the driver if they may be distracted. We want to improve driver attentiveness and safety in high pedestrian areas such as crosswalks, parking lots, and residential areas. Our solution is more economical and easier to implement than installing a full suite of sensors and software onto an existing car, which makes it perfect for users who want peace of mind for themselves and their loved ones.
## What it does
EyeWare combines the eye-tracking capabilities of the **AdHawk MindLink** with the onboard camera to provide pedestrian tracking and driver attentiveness feedback through audio cues. We label the pedestrian based on their risk of collision; GREEN for seen pedestrians, YELLOW for unseen far pedestrians, and RED for unseen near pedestrians. A warning chime is played when the pedestrian gets too close to get the driver.
## How we built it
Using the onboard camera of the **AdHawk MindLink**, we pass video to the **openCV** machine learning algorithm to classify and detect people (pedestrians) based on their perceived distance from the user and assign them unique IDs. Simultaneously, we use the **AdHawk Python API** to track the user's gaze and cross-reference the detected pedestrians to ensure that the driver has seen the pedestrian.
## Challenges we ran into
The biggest challenge was integrating the complex and cross-domain systems in little time. Over the last 36 hours, we learned and developed applications using the MindFlex glasses and AdHawk API, utilized object detection with **YOLO** (You Only Look Once) machine learning algorithms, and **SORT** object tracking algorithms.
## Accomplishments that we're proud of
We got two major technologies working during this hackathon: the eye tracking and machine learning! Getting the **MindLink** to work with **OpenCV** was groundbreaking and enabled our machine learning algorithm to run directly using **MindLink’s** camera stream. Though the process was technically complex and complicated, we are proud that we are able to accomplish it in the end. We're also incredibly proud of the beautiful pitch deck. Our domain.com domain name (eyede.tech) is also a pun on "ID tech", "eye detect", and "I detect".
## What we learned
In this hackathon, we had the privilege of working with the AdHawk team to bring the MindFlex eye tracking glasses to life. We learned so much about eye tracking APIs and their technologies as a whole. We also worked extensively with object detection algorithms like YOLO, OpenCV for image processing, and SORT algorithm for object tracking for temporal consistency.
## What's next for Eyeware
Our platform is highly portable can be easily retrofitted to existing vehicles and be used by drivers around the world. We are excited to partner with OEMs and make this feature more widely available to people. Furthermore, we were limited by the mobile compute power at the hackathon, so removing that limit will also enable us to use more powerful object detection and tracking algorithms like deepSort. | partial |
## Inspiration
There’s simply no quality control for most online recipes. One day, we came across a NY Times beef stew recipe with 5.0 stars at over 17,000 ratings. You think it’d be perfect, right? Nope, every review essentially boiled down to “It was great after I added XXX” or “Wonderful after I subbed YYY for XXX.” After reading through all these suggestions, it barely resembled the original recipe. But what if we could aggregate the most common modifications together, succinctly summarize them, and conveniently display it to the user? Sous Chef is a Google Chrome extension aimed at helping home cooks in a hurry by using NLP to analyze and summarize reviews and modifications.
## What it does
Sous Chef is a Chrome extension that uses NLP with the co:here API to extract, identify, and summarize the top review suggestions based on user reviews of a recipe.
**From the user’s perspective:** they first open up a recipe website. Think food.com, allrecipes.com, etc. While scrolling through the recipe, the extension displays summaries of the top recommended modifications based on the review data. The user can then click on each modification to read the full review to learn more.
**Behind the scenes:** when a user opens a recipe website, our extension uses web scraping to extract reviews and ratings. It then uses classification through the co:here API to identify which reviews are suggestions rather than general comments. Then, it sorts through this data to obtain the suggestions with the highest rating. It then feeds these back into another co:here model to summarize them before sending it back to the extension for the user to interact with.
## How we built it
Sorted through 600+ reviews from a food.com review dataset.
Labeled them as suggestions or non suggestions and wrote summaries of the suggestions. Fed all that data into a co:here NLP model.
Wrote a Google Chrome extension using HTML, CSS, Javascript and JQuery. When the extension detects the user has moved onto a recipe website, it passes the website URL to a backend Flask endpoint. The endpoint takes reviews from the website and classifies them with the labels “suggestions” or “non-suggestions” using the co:here API. The top suggestions are fed back into co:here to summarize them. The suggestions are passed back to the Chrome extension to be displayed.
## Challenges we ran into
-Interpretability of co:here NLP models (since we don’t really see what’s happening behind the scenes)
-Fine tuning (which would update weights of existing co:here model) somehow had significantly decreased confidence compared to standard modeling
-Annoying nuances in writing Chrome extensions
-Annoyances in web scraping with Selenium and BeautifulSoup
-Lots of fun debugging due to lack of sleep
## Accomplishments that we're proud of
-Accuracy of NLP and smooth integration using co:here
-Streamlined User Experience:
-Easy-to-use Chrome extension
-Concise and accurate suggestions
## What we learned
-How to create a Chrome extension!
-How to effectively integrate co:here into our product
-Applying NLP to real-world problems
## What's next for Sous Chef
-Compatibility with other food websites
-Addition of parameters for user to interactively filter recommendations (i.e. ingredient type)
-Incorporation of recipe step that each recommendation refers to + visual aid | ## Inspiration
During our brainstorming, we were thinking about what we have in common as students and what we do often.
We are all students and want to cook at home to save money, but we often find ourselves in a situation where we have tons of ingredients that we cannot properly combine. With that in mind, we came up with an idea to build an app that helps you find the recipes that you can cook at home.
We are all excited about the project as it is something that a lot of people can utilize on a daily basis.
## What it does
Imagine you find yourself in a situation where you have some leftover chicken, pasta, milk, and spices. You can **open Mealify, input your ingredients, and get a list of recipes that you can cook with that inventory**.
## How we built it
For that idea, we decided to build a mobile app to ease the use of daily users - although you can also use it in the browser. Since our project is a full stack application, we enhanced our knowledge of all the stages of development. We started from finding the appropriate data, parsing it to the format we need and creating an appropriate SQL database. We then created our own backend API that is responsible for all the requests that our application uses - autocomplete of an ingredient for a user and actual finding of the ‘closest’ recipe. By using the custom created endpoints, we made the client part communicate with it by making appropriate requests and fetching responses. We then created the frontend part that lets a user naturally communicate with Mealify - using dynamic lists, different input types, and scrolling. The application is easy to use and does not rely on the user's proper inputs - we implemented the autocomplete option, and gave the option for units to not worry about proper spelling from a user.
## Challenges we ran into
We also recognized that it is possible that someone’s favorite meal is not in our database. In that case, we made a way to add a recipe to the database from a url. We used an ingredient parser to scan for all the ingredients needed for that recipe from the url. We then used Cohere to parse through the text on the url and find the exact quantity and units of the ingredient.
One challenge we faced was finding an API that could return recipes based on our ingredients and input parameters. So we decided to build our own API to solve that issue. Moreover, working on finding the ‘closest’ recipe algorithm was not trivial either. For that, we built a linear regression to find what would be the recipe that has the lowest cost for a user to buy additional ingredients. After the algorithm is performed, a user is presented with a number of recipes sorted in the order of ‘price’ - whether a user can already cook it or there's a small number of ingredients that needs to be purchased.
## Accomplishments that we're proud of
We're proud of how we were able to build a full-stack app and NLP model in such a short time.
## What we learned
We learned how to use Flutter, CockRoachDB, co:here, and building our API to deploy a full-stack mobile app and NLP model.
## What's next for Mealify
We can add additional functionality to let users add their own recipes! Eventually, we wouldn't rely as much our database and the users themselves can serve as the database by adding recipes. | ## Inspiration
Before the hackathon started, we noticed that the oranges were really tasty so we desired to make a project about oranges, but we also wanted to make a game so we put the ideas together.
## What it does
Squishy Orange is a multiplayer online game where each user controls an orange. There are two game modes: "Catch the Squish" and "Squish Zombies". In "Catch the Squish", one user is the squishy orange and every other user is trying to tag the squish. In "Squish Zombies", one user is the squishy orange and tries to make other oranges squishy by touching them. The winner is the last surviving orange.
## How we built it
We used phaser.io for the game engine and socket.io for real-time communication. Lots of javascript everywhere!
## Challenges we ran into
* getting movements to stay in sync across various scenarios (multiple players in general, new players, inactive tabs, etc.)
* getting different backgrounds
* animated backgrounds
* having different game rooms
* different colored oranges
## Accomplishments that we're proud of
* getting the oranges in sync for movements!
* animated backgrounds
## What we learned
* spritesheets
* syncing game movement
## What's next for Squishy Orange
* items in game
* more game modes | losing |
## Inspiration
We saw the sad reality that people often attending hackathons don't exercise regularly or do so while coding. We decided to come up with a solution
## What it does
Lets a user log in, and watch short fitness videos of exercises they can do while attending a hackathon
## How we built it
We used HTML & CSS for the frontend, python & sqlite3 for the backend and django to merge all three. We also deployed a DCL worker
## Challenges we ran into
Learning django and authenticating users in a short span of time
## Accomplishments that we're proud of
Getting a functioning webapp up in a short time
## What we learned
How do design a website, how to deploy a website, simple HTML, python objects, django header tags
## What's next for ActiveHawk
We want to make activehawk the Tiktok of hackathon fitness. we plan on adding more functionality for apps as well as a live chat room for instructors using the Twello api | ## Inspiration
We love the playing the game and were disappointed in the way that there wasnt a nice web implementation of the game that we could play with each other remotely. So we fixed that.
## What it does
Allows between 5 and 10 players to play Avalon over the web app.
## How we built it
We made extensive use of Meteor and forked a popular game called [Spyfall](https://github.com/evanbrumley/spyfall) to build it out. This game had a very basic subset of rules that were applicable to Avalon. Because of this we added a lot of the functionality we needed on top of Spyfall to make the Avalon game mechanics work.
## Challenges we ran into
Building realtime systems is hard. Moreover, using a framework like Meteor that makes a lot of things easy by black boxing them is also difficult by the same token. So a lot of the time we struggled with making things work that happened to not be able to work within the context of the framework we were using. We also ended up starting the project over again multiple times since we realized that we were going down a path in which it was impossible to build that application.
## Accomplishments that we're proud of
It works. Its crisp. Its clean. Its responsive. Its synchronized across clients.
## What we learned
Meteor is magic. We learned how to use a lot of the more magical client synchronization features to deal with race conditions and the difficulties of making a realtime application.
## What's next for Avalon
Fill out the different roles, add a chat client, integrate with a video chat feature. | ## Inspiration:
The inspiration behind Pisces stemmed from our collective frustration with the time-consuming and often tedious process of creating marketing materials from scratch. We envisioned a tool that could streamline this process, allowing marketers to focus on strategy rather than mundane tasks.
## Learning:
Throughout the development of Pisces, we learned the intricate nuances of natural language processing and machine learning algorithms. We delved into the psychology of marketing, understanding how to tailor content to specific target audiences effectively.
## Building:
We started by gathering a diverse team with expertise in marketing, software development, and machine learning. Collaborating closely, we designed Pisces to utilize cutting-edge algorithms to analyze input data and generate high-quality marketing materials autonomously.
## Challenges:
One of the main challenges we faced was training the machine learning models to accurately understand and interpret product descriptions. We also encountered hurdles in fine-tuning the algorithms to generate diverse and engaging content consistently. Despite the challenges, our dedication and passion for innovation drove us forward. Pisces is not just a project; it's a testament to our perseverance and commitment to revolutionizing the marketing industry.
## Interested to Learn More?
**Read from the PROS!**
Pisces has the power to transform marketing teams by reducing the need for extensive manpower. With traditional methods, it might take a team of 50 individuals to create comprehensive marketing campaigns. However, with Pisces, this workforce can be streamlined to just 5 people or even less. Imagine the time saved by automating the creation of ads, videos, and audience insights! Instead of spending weeks on brainstorming sessions and content creation, marketers can now allocate their time more strategically, focusing on refining their strategies and analyzing campaign performance. This tool isn't just a time-saver; it's a game-changer for the future of marketing. By harnessing the efficiency of Pisces, companies can launch campaigns faster, adapt to market trends more seamlessly, and ultimately, achieve greater success in their marketing endeavors. Pisces can be effectively used across various industries and marketing verticals. Whether you're a small startup looking to establish your brand presence or a multinational corporation aiming to scale your marketing efforts globally, Pisces empowers you to create compelling campaigns with minimal effort and maximum impact.
## Demos
Walkthrough (bad compression): [YouTube Link](https://www.youtube.com/watch?v=VGiHuQ7Ha9w)
Muted Demo (for ui/ux purposes): [YouTube Link](https://youtu.be/56MRUErwfPc) | partial |
## Inspiration
Across the globe, a critical shortage of qualified teachers poses a significant challenge to education. The average student-to-teacher ratio in primary schools worldwide stands at an alarming **23:1!** In some regions of Africa, this ratio skyrockets to an astonishing **40:1**. [Research 1](https://data.worldbank.org/indicator/SE.PRM.ENRL.TC.ZS) and [Research 2](https://read.oecd-ilibrary.org/education/education-at-a-glance-2023_e13bef63-en#page11)
As populations continue to explode, the demand for quality education has never been higher, yet the *supply of capable teachers is dwindling*. This results in students receiving neither the attention nor the **personalized support** they desperately need from their educators.
Moreover, a staggering **20% of students** experience social anxiety when seeking help from their teachers. This anxiety can severely hinder their educational performance and overall learning experience. [Research 3](https://www.cambridge.org/core/journals/psychological-medicine/article/much-more-than-just-shyness-the-impact-of-social-anxiety-disorder-on-educational-performance-across-the-lifespan/1E0D728FDAF1049CDD77721EB84A8724)
While many educational platforms leverage generative AI to offer personalized support, we envision something even more revolutionary. Introducing **TeachXR—a fully voiced, interactive, and hyper-personalized AI** teacher that allows students to engage just like they would with a real educator, all within the immersive realm of extended reality.
*Imagine a world where every student has access to a dedicated tutor who can cater to their unique learning styles and needs. With TeachXR, we can transform education, making personalized learning accessible to all. Join us on this journey to revolutionize education and bridge the gap in teacher shortages!*
## What it does
**Introducing TeachVR: Your Interactive XR Study Assistant**
TeachVR is not just a simple voice-activated Q&A AI; it’s a **fully interactive extended reality study assistant** designed to enhance your learning experience. Here’s what it can do:
* **Intuitive Interaction**: Use natural hand gestures to circle the part of a textbook page that confuses you.
* **Focused Questions**: Ask specific questions about the selected text for summaries, explanations, or elaborations.
* **Human-like Engagement**: Interact with TeachVR just like you would with a real person, enjoying **milliseconds response times** and a human voice powered by **Vapi.ai**.
* **Multimodal Learning**: Visualize the concepts you’re asking about, aiding in deeper understanding.
* **Personalized and Private**: All interactions are tailored to your unique learning style and remain completely confidential.
### How to Ask Questions:
1. **Circle the Text**: Point your finger and circle the paragraph you want to inquire about.
2. **OK Gesture**: Use the OK gesture to crop the image and submit your question.
### TeachVR's Capabilities:
* **Summarization**: Gain a clear understanding of the paragraph's meaning. TeachVR captures both book pages to provide context.
* **Examples**: Receive relevant examples related to the paragraph.
* **Visualization**: When applicable, TeachVR can present a visual representation of the concepts discussed.
* **Unlimited Queries**: Feel free to ask anything! If it’s something your teacher can answer, TeachVR can too!
### Interactive and Dynamic:
TeachVR operates just like a human. You can even interrupt the AI if you feel it’s not addressing your needs effectively!
## How we built it
**TeachXR: A Technological Innovation in Education**
TeachXR is the culmination of advanced technologies, built on a microservice architecture. Each component focuses on delivering essential functionalities:
### 1. Gesture Detection and Image Cropping
We have developed and fine-tuned a **hand gesture detection system** that reliably identifies gestures for cropping based on **MediaPipe gesture detection**. Additionally, we created a custom **bounding box cropping algorithm** to ensure that the desired paragraphs are accurately cropped by users for further Q&A.
### 2. OCR (Word Detection)
Utilizing **Google AI OCR service**, we efficiently detect words within the cropped paragraphs, ensuring speed, accuracy, and stability. Given our priority on latency—especially when simulating interactions like pointing at a book—this approach aligns perfectly with our objectives.
### 3. Real-time Data Orchestration
Our goal is to replicate the natural interaction between a student and a teacher as closely as possible. As mentioned, latency is critical. To facilitate the transfer of image and text data, as well as real-time streaming from the OCR service to the voiced assistant, we built a robust data flow system using the **SingleStore database**. Its powerful real-time data processing and lightning-fast queries enable us to achieve sub-1-second cropping and assistant understanding for prompt question-and-answer interactions.
### 4. Voiced Assistant
To ensure a natural interaction between students and TeachXR, we leverage **Vapi**, a natural voice interaction orchestration service that enhances our feature development. By using **DeepGram** for transcription, **Google Gemini 1.5 flash model** as the AI “brain,” and **Cartesia** for a natural voice, we provide a unique and interactive experience with your virtual teacher—all within TeachXR.
## Challenges we ran into
### Challenges in Developing TeachXR
Building the architecture to keep the user-cropped image in sync with the chat on the frontend posed a significant challenge. Due to the limitations of the **Meta Quest 3**, we had to run local gesture detection directly on the headset and stream the detected image to another microservice hosted in the cloud. This required us to carefully adjust the size and details of the images while deploying a hybrid model of microservices. Ultimately, we successfully navigated these challenges.
Another difficulty was tuning our voiced assistant. The venue we were working in was quite loud, making background noise inevitable. We had to fine-tune several settings to ensure our assistant provided a smooth and natural interaction experience.
## Accomplishments that we're proud of
### Achievements
We are proud to present a complete and functional MVP! The cropped image and all related processes occur in **under 1 second**, significantly enhancing the natural interaction between the student and **TeachVR**.
## What we learned
### Developing a Great AI Application
We successfully transformed a solid idea into reality by utilizing the right tools and technologies.
There are many excellent pre-built solutions available, such as **Vapi**, which has been invaluable in helping us implement a voice interface. It provides a user-friendly and intuitive experience, complete with numerous settings and plug-and-play options for transcription, models, and voice solutions.
## What's next for TeachXR
We’re excited to think of the future of **TeachXR** holds even greater innovations! we’ll be considering\**adaptive learning algorithms*\* that tailor content in real-time based on each student’s progress and engagement.
Additionally, we will work on integrating **multi-language support** to ensure that students from diverse backgrounds can benefit from personalized education. With these enhancements, TeachXR will not only bridge the teacher shortage gap but also empower every student to thrive, no matter where they are in the world! | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | Investormate is a automated financial assistant for investors, providing them financial data
Investormate provides a simple, easy-to-use interface for retrieving financial data from any company on the NASDAQ. It can retrieve not only the prices, but it also calculates technical indicators such as the exponential moving average and stochastic oscillator values.
It has a minimalist design and provides data in a very clean fashion so users do not have to dig tons of financial information to get what they want. Investormate also interprets natural language so no complex syntax is required to make a query. | winning |
## Inspiration
With everything being done virtually these days, including this hackathon, we spend a lot of time at our desks and behind screens. It's more important now than ever before to take breaks from time to time, but it's easy to get lost in our activities. Studies show that breaks increases over overall energy and productivity, and decreases exhaustion and fatigue. If only we had something to help us from forgetting..
## What it does
The screen connected to the microcontrollers tells you when it's time to give your eyes a break, or to move around a bit to get some exercise. Currently, it tells you to take a 20-second break for your eyes for every 20 minutes of sitting, and a few minutes of break to exercise for every hour of sitting.
## How we built it
The hardware includes a RPi 3B+, aluminum foil contacts underneath the chair cushion, a screen, and wires to connect all these components. The software includes the RPi.GPIO library for reading the signal from the contacts and the tkinter library for the GUI displayed on the screen.
## Challenges we ran into
Some python libraries were written for Python 2 and others for Python 3, so we took some time to resolve these dependency issues. The compliant structure underneath the cushion had to be a specific size and rigidity to allow the contacts to move appropriately when someone gets up/sits down on the chair. Finally, the contacts were sometimes inconsistent in the signals they sent to the microcontrollers.
## Accomplishments that we're proud of
We built this system in a few hours and were successful in not spending all night or all day working on the project!
## What we learned
Tkinter takes some time to learn to properly utilize its features, and hardware debugging needs to be a very thorough process!
## What's next for iBreak
Other kinds of reminders could be implemented later like reminder to drink water, or some custom exercises that involve sit up/down repeatedly. | ## Inspiration
As a startup founder, it is often difficult to raise money, but the amount of equity that is given up can be alarming for people who are unsure if they want the gasoline of traditional venture capital. With VentureBits, startup founders take a royalty deal and dictate exactly the amount of money they are comfortable raising. Also, everyone can take risks on startups as there are virtually no starting minimums to invest.
## What it does
VentureBits allows consumers to browse a plethora of early stage startups that are looking for funding. In exchange for giving them money anonymously, the investors will gain access to a royalty deal proportional to the amount of money they've put into a company's fund. Investors can support their favorite founders every month with a subscription, or they can stop giving money to less promising companies at any time. VentureBits also allows startup founders who feel competent to raise just enough money to sustain them and work full-time as well as their teams without losing a lot of long term value via an equity deal.
## How we built it
We drew out the schematics on the whiteboards after coming up with the idea at YHack. We thought about our own experiences as founders and used that to guide the UX design.
## Challenges we ran into
We ran into challenges with finance APIs as we were not familiar with them. A lot of finance APIs require approval to use in any official capacity outside of pure testing.
## Accomplishments that we're proud of
We're proud that we were able to create flows for our app and even get a lot of our app implemented in react native. We also began to work on structuring the data for all of the companies on the network in firebase.
## What we learned
We learned that finance backends and logic to manage small payments and crypto payments can take a lot of time and a lot of fees. It is a hot space to be in, but ultimately one that requires a lot of research and careful study.
## What's next for VentureBits
We plan to see where the project takes us if we run it by some people in the community who may be our target demographic. | # JARVIS-MUSIC
Have a song stuck in your head but can't sing it? Use our web app to play the music that's on your mind!
Overall, we are building a web application for users to find songs by lirycs or any information that is related to your song.
In our web home page, you press the audio recording button to sing your songs, or tell something about your song.
We use google speech to text API to convert your voice to text and show it to you.
Of course, you can always input the text directly, if you are uncomfortable about saying anything.
The text is transformed to our server side. We have a machine learning algorithm to search for the most related song.
Here is our algorithm to search the song. We firstly download tons of songs using the Genius API. We build a word filtering API using the standard library (stdlib). The word filtering API filters bad words (such as "fuck") in the lyrics of the songs. We then index the songs to our database. Given your input text, i.e., a query, our unsupervised algorithm aims to find the most relevant song. We use the Vector Space Model and doc2vec to build our unsupervised algorithm.
Basically, Vector Space Model locates the exact words that you want to search and doc2vec extracts the semantic meaning of your input text and the lyrics, such that we are not lossing any information. We give a score of each song, denoting how relevant the song is to the input text. We rank the songs based the returned scores. and return the top five songs. We not only return song name and singer name, but also return YouTube links for you to check out! | winning |
## Inspiration
Have you ever used a budgeting app? Do you set budgets for each month?
I use a budgeting app and when I check my weekly spending, I always realize I spent a $100 too much!
So, we decided to make something proactive rather than reactive that will help you immensely in your spending decisions.
## What it does
The app will alert you in real-time when you enter places like coffee shop, grocery store, restaurant, bar, etc. and tell you how much budget you have left for that paticular place type. It will tell you something like "You have $40 left in your Grocery Budget" or "You have $11 left in your Coffee Budget". This way you can make better spending decision.
## How we built it
We used Android platform and Google Places API to built the app.
## Challenges we ran into
It was hard to implement Google Places API automatically without the app running in the background. Our plan was to send real-time alerts to a wearable device but we did not have access to any, so we decided to use make the smart phone app instead.
## Accomplishments that we're proud of
Implementing Google Places API and quering data from Firebase in real-time using in-built GPS successfully without the use of Wi-Fi or Bluetooth.
## What we learned
We learned querying data from Firebase and learned how we can identify places around easily using Google Places API
## What's next for Budget Easy
We want to parter with a bank or budgeting app which tracks user's spending and integrate this proactive feature into their app! | ## 💡Inspiration💡
According to statistics, hate crimes and street violence have exponentially increased and the violence does not end there. Many oppressed groups face physical and emotional racial hostility in the same way. These crimes harm not only the victims but also people who have a similar identity. Aside from racial identities, all genders reported feeling more anxious about exploring the outside environment due to higher crime rates. After witnessing an upsurge in urban violence and fear of the outside world, We developed Walk2gether, an app that addresses the issue of feeling unsafe when venturing out alone and fundamentally alters the way we travel.
## 🏗What it does🏗
It offers a remedy to the stress that comes with walking outside, especially alone. We noticed that incorporating the option of travelling with friends lessens anxiety, and has a function to raise information about local criminal activity to help people make informed travel decisions. It also provides the possibility to adjust settings to warn the user of specific situations and incorporates heat map technology that displays red alert zones in real-time, allowing the user to chart their route comfortably. Its campaign for social change is closely tied with our desire to see more people, particularly women, outside without being concerned about being aware of their surroundings and being burdened by fears.
## 🔥How we built it🔥
How can we make women feel more secure while roaming about their city? How can we bring together student travellers for a safer journey? These questions helped us outline the issues we wanted to address as we moved into the design stage. And then we created a website using HTML/CSS/JS and used Figma as a tool to prepare the prototype. We have Used Auth0 for Multifactor Authentication. CircleCi is used so that we can deploy the website in a smooth and easy to verify pipelining system. AssemblyAi is used for speech transcription and is associated with Twilio for Messaging and Connecting Friends for the journey to destination. Twilio SMS is also used for alerts and notification ratings. We have also used Coil for Membership using Web Based Monitization and also for donation to provide better safety route facilities.
## 🛑 Challenges we ran into🛑
The problem we encountered was the market viability - there are many safety and crime reporting apps on the app store. Many of them, however, were either paid, had poor user interfaces, or did not plan routes based on reported occurrences. Also, The challenging part was coming up with a solution because there were additional features that might have been included, but we only had to pick the handful that was most critical to get started with the product.
Also, Our team began working on the hack a day before the deadline, and we ran into some difficulties while tackling numerous problems. Learning how to work with various technology came with a learning curve. We have ideas for other features that we'd like to include in the future, but we wanted to make sure that what we had was production-ready and had a pleasant user experience first.
## 🏆Accomplishments that we're proud of: 🏆
We gather a solution to this problem and create an app which is very viable and could be widely used by women, college students and any other frequent walkers!
Also, We completed the front-end and backend within the tight deadlines we were given, and we are quite pleased with the final outcome. We are also proud that we learned so many technologies and completed the whole project with just 2 members on the team.
## What we learned
We discovered critical safety trends and pain points that our product may address. Over the last few years, urban centres have seen a significant increase in hate crimes and street violence, and the internet has made individuals feel even more isolated.
## 💭What's next for Walk2gether💭
Some of the features incorporated in the coming days would be addressing detailed crime mapping and offering additional facts to facilitate learning about the crimes happening. | ## Inspiration
Not all hackers wear capes - but not all capes get washed correctly. Dorming on a college campus the summer before our senior year of high school, we realized how difficult it was to decipher laundry tags and determine the correct settings to use while juggling a busy schedule and challenging classes. We decided to try Google's up and coming **AutoML Vision API Beta** to detect and classify laundry tags, to save headaches, washing cycles, and the world.
## What it does
L.O.A.D identifies the standardized care symbols on tags, considers the recommended washing settings for each item of clothing, clusters similar items into loads, and suggests care settings that optimize loading efficiency and prevent unnecessary wear and tear.
## How we built it
We took reference photos of hundreds of laundry tags (from our fellow hackers!) to train a Google AutoML Vision model. After trial and error and many camera modules, we built an Android app that allows the user to scan tags and fetch results from the model via a call to the Google Cloud API.
## Challenges we ran into
Acquiring a sufficiently sized training image dataset was especially challenging. While we had a sizable pool of laundry tags available here at PennApps, our reference images only represent a small portion of the vast variety of care symbols. As a proof of concept, we focused on identifying six of the most common care symbols we saw.
We originally planned to utilize the Android Things platform, but issues with image quality and processing power limited our scanning accuracy. Fortunately, the similarities between Android Things and Android allowed us to shift gears quickly and remain on track.
## Accomplishments that we're proud of
We knew that we would have to painstakingly acquire enough reference images to train a Google AutoML Vision model with crowd-sourced data, but we didn't anticipate just how awkward asking to take pictures of laundry tags could be. We can proudly say that this has been an uniquely interesting experience.
We managed to build our demo platform entirely out of salvaged sponsor swag.
## What we learned
As high school students with little experience in machine learning, Google AutoML Vision gave us a great first look into the world of AI. Working with Android and Google Cloud Platform gave us a lot of experience working in the Google ecosystem.
Ironically, working to translate the care-symbols has made us fluent in laundry. Feel free to ask us any questions,
## What's next for Load Optimization Assistance Device
We'd like to expand care symbol support and continue to train the machine-learned model with more data. We'd also like to move away from pure Android, and integrate the entire system into a streamlined hardware package. | partial |
This device uses the Google Cloud Vision and Text To Speech APIs to identify obstacles in the path of someone using the device. Foresight is intended to be worn as a guide for the visually impaired so that they can feel safer travelling on their own without the need of a caretaker or a white cane. | ## Inspiration
1) We have created a unique device that allows the blind to walk freely and notice obstacles similarly to how a person with functioning senses would
2) Blind people commonly use walking canes (probing canes) for avoid colliding with obstacles. Carrying the cane around can be a nuisance and does not free the hands. It is incapable of detecting objects in common conditions, such as a horizontal pole raised above the ground.
3) Ultimately, we believe this technology gives wearers confidence to roam more freely. After witnessing blind students' difficulties navigating around campus, our achievable goal here is to replace the cane for walking, free a blind person's hands, and inspire a strong sense of pride in them.
## What it does
Now You See Me provides a wearer a relatable infinite-resolution (hampered first only by human physical limits) grid that allows them to more enjoy walking as it is for everyone else, with out final concept device being a nearly invisible device that does not draw attention to the user like a cane does.
The most important information is what is directly in front of us (and our feet!). For this purpose we use both depth (for distance to object and warning), and a camera for object recognition to differentiate humans. Given our combined objectives, (to give important spatial information, notify of people, and also gauge proximity to objects) this is how our technology differs from the rest. We would use an electrode array with mathematical tricks inspired by Neuroscience for stimulation to create a "fake" feeling on the person’s skin (effectively creating a tactile interpretation). When a person is detected and we are looking at them, motor vibration feedback occurs to use emotions from Google Cloud Platform.
## How I built it
We built this technology to be fast, unlike only using motors as feedback. Our idea is small enough that could be used on a more convenient part of body. We also wanted it to be modular. Considering that people also have varying levels of sensitivity, which research can prove, the ability to add more or less electrodes. Studies interpreting vibrations as a form of navigation information agrees with our notion of vibrating in regards to a nearby object to signal avoiding that direction. In the end we were able to make a prototype of a system that would contain a dual camera (for depth and objects),open CV code for detection of the object and a shock pattern along 4 electrodes that would help the person to know the location. The depth would then be impltemented through vibrations to give a more instant reaction stimulus -works completely offline to be fast and in real time -uses both depth and computer vision -cloud to continuously update, with a continuously updated model to get better, but not reliant -rapid, haptic feedback and patterns to be interpreted
## Challenges I ran into
There is a tug of war for improving the situation without the complexity of describing the entirety of the visual field. -deciding the best way to represent the visual field without being too complex while still signaling key information. Whether to use a grid or a graded system. -finding hardware the would allow us to use proximity and computer vision to simulate an eye. -the depth percepting AI program
## Accomplishments that I'm proud of
By being modular in nature, we are able to make the device meet the needs of the user depending on degree of visual impairedness. A way in which this device is also relevant to everyone is that this device is capable of depth-perception, which provides a way to navigate the dark, while also using camera feedback in daytime, provided object recognition / feedback for object detection for navigation. The depth of the research we did to take into account various aspects, such as case-by-case scenarios (the possible option to switch functions on and off), learning time, sensitivity difference, and the best ways / places to relay camera information tactically. Works with cloud to keep getting better
## What I learned
We did a lot of research to understand the mechanisms previously used, and understanding the different aspects of relaying information in a tactal manner while avoiding as many drawbacks that could change from case-to -case as possible. Balance cool technology to be practical and avoid the trap of not keeping the user’s best interest in mind.
## What's next for Now You See Me
You can have three motors to give left, middle, right sides that vibrate when something is proximal. in this way our project is innovative because it offers two modes of information, depth and objects through motors and shocks Use for detecting sidewalks, depth perception to inform where to step Detect people, object detection for hands for application in like hand shakes and reaching out to hand something. We can make some more amazing systems - actually put deaf and blind people in communication by using leap motion! Leap motion has 10 finger detection and has been started being used to translate sign language. A big aspect is how to relay the information to the person, below, how both tactile and auditory preferred BUT THE BIG ISSUE with auditiory is that it takes away information the person could be getting by hearing what is around them (like a car coming down the road). All this information would presumably get very confusing, and constantly having to shift attention between machine information and people speaking to you could be difficult. THAT IS WHY we have also devised a method to solve this issue. A sensor based system that allows the user to selectively use recognition tools to distiguish between objects being relayed to them tactically. Help someone to navigate the world is how we are social creatures, so beyond audio relay, being told if there are people around you is important. We wouldnt want this to be too overwhelming either though so this could be controlled by a switch since in a crowded space this wouldnt be useful. | Copyright 2018 The Social-Engineer Firewall (SEF)
Written by Christopher Ngo, Jennifer Zou, Kyle O'Brien, and Omri Gabay.
Founded Treehacks 2018, Stanford University.
## Inspiration
No matter how secure your code is, the biggest cybersecurity vulnerability is the human vector. It takes very little to exploit an end-user with social engineering, yet the consequences are severe.
Practically every platform, from banking to social media, to email and corporate data, implements some form of self-service password reset feature based on security questions to authenticate the account “owner.”
Most people wouldn’t think twice to talk about their favourite pet or first car, yet such sensitive information is all that stands between a social engineer and total control of all your private accounts.
## What it does
The Social-Engineer Firewall (SEF) aims to protect us from these threats. Upon activation, SEF actively monitors for known attack signatures with voice to speech transcription courtesy of SoundHound’s Houndify engine. SEF is the world’s first solution to protect the OSI Level 8 (end-user/human) from social engineer attacks.
## How it was built
SEF is a Web Application written in React-Native deployed on Microsoft Azure with node.js. iOS and Android app versions are powered by Expo. Real-time audio monitoring is powered by the Houndify SDK API.
## Todo List
Complete development of TensorFlow model
## Development challenges
Our lack of experience with new technologies provided us with many learning opportunities. | losing |
## Introduction
[Best Friends Animal Society](http://bestfriends.org)'s mission is to **bring about a time when there are No More Homeless Pets**
They have an ambitious goal of **reducing the death of homeless pets by 4 million/year**
(they are doing some amazing work in our local communities and definitely deserve more support from us)
## How this project fits in
Originally, I was only focusing on a very specific feature (adoption helper).
But after conversations with awesome folks at Best Friends came a realization that **bots can fit into a much bigger picture in how the organization is being run** to not only **save resources**, but also **increase engagement level** and **lower the barrier of entry points** for strangers to discover and become involved with the organization (volunteering, donating, etc.)
This "design hack" comprises of seven different features and use cases for integrating Facebook Messenger Bot to address Best Friends's organizational and operational needs with full mockups and animated demos:
1. Streamline volunteer sign-up process
2. Save human resource with FAQ bot
3. Lower the barrier for pet adoption
4. Easier donations
5. Increase visibility and drive engagement
6. Increase local event awareness
7. Realtime pet lost-and-found network
I also "designed" ~~(this is a design hack right)~~ the backend service architecture, which I'm happy to have discussions about too!
## How I built it
```
def design_hack():
s = get_sketch()
m = s.make_awesome_mockups()
k = get_apple_keynote()
return k.make_beautiful_presentation(m)
```
## Challenges I ran into
* Coming up with a meaningful set of features that can organically fit into the existing organization
* ~~Resisting the urge to write code~~
## What I learned
* Unique organizational and operational challenges that Best Friends is facing
* How to use Sketch
* How to create ~~quasi-~~prototypes with Keynote
## What's next for Messenger Bots' Best Friends
* Refine features and code :D | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
Domain Name: voicebase.tech
We were inspired by the fact that there are over 466 million people in the world with disabling hearing loss and globally the number of people of all ages visually impaired is estimated to be over 285 million. (WHO, 2018 & 2010, respectively) Yet, despite this pandemic creating numerous additional barriers for people with disabilities, there have not been many accessible, convenient, or affordable solutions.
Most people who are deaf and hearing-impaired depend on the ability to read lips to converse with others, and a facial covering that impedes communication can increase frustration and affect their mental health. When the volume of speech is reduced, the listener must concentrate harder to understand and follow the communication. Couple this reduction in volume with the inability to lip-read, and it can make it very frustrating for hard-of-hearing and deaf individuals, as well as the general population.
## What it does
Voicebase helps people by transcribing speech into text on their screen in real-time.
## How we built it
HTML, CSS, Javascript, Twilio API, Google Cloud Speech to Text API
## Challenges we ran into
Team Members with low bandwidth unable to communicate at times, time zone differences.
## Accomplishments that we're proud of
Learning more about how to use Twilio API's for the first time, Google Cloud, and also read documentation from other API's we were considering like Assembly AI.
## What we learned
API's, Google Cloud, HTML, CSS, Javascript
Teamwork, Communication
## What's next for Voicebase
Continuing to work on the integration, front end and database aspect. | winning |
## Inspiration
**Powerful semantic search for your life does not currently exist.**
Google and ChatGPT have brought the world’s information to our fingertips, yet our personal search engines — Spotlight on Mac, and search on iOS or Android — are insufficient.
Google Assistant and Siri tried to solve these problems by allowing us to search and perform tasks with just our voice, yet their use remains limited to a narrow range of tasks. **Recent advancement in large language models has enabled a significant transformation in what's possible with our devices.**
## What it does
That's why we made Best AI Buddy, or BAIB for short.
**BAIB (pronounced "babe") is designed to seamlessly answer natural language queries about your life.** BAIB builds an index of your personal data — text messages, emails, photos, among others — and runs a search pipeline on top of that data to answer questions.
For example, you can ask BAIB to give you gift recommendations for a close friend. BAIB looks pertinent interactions you've had with that friend and generates gift ideas based on their hobbies, interests, and personality. To support its recommendations, **BAIB cites parts of past text conversations you had with that friend.**
Or you can ask BAIB to tell you about what happened the last time you went skiing with friends. BAIB intelligently combines information from the ski group chat, AirBnB booking information from email, and your Google Photos to provide you a beautiful synopsis of your recent adventure.
**BAIB understands “hidden deadlines”** — that form you need to fill out by Friday or that internship decision deadline due next week — and keeps track of them for you, sending you notifications as these “hidden deadlines” approach.
**Privacy is an essential concern.** BAIB currently only runs on M1+ Macs. We are working on running a full-fledged LLM on the Apple Neural Engine to ensure that all information and processing is kept on-device. We believe that this is the only future of BAIB that is both safe and maximally helpful.
## How we built it
Eventually, we plan to build a full-fledged desktop application, but for now we have built a prototype using the SvelteKit framework and the Skeleton.dev UI library. We use **Bun as our TypeScript runtime & toolkit.**
**Python backend.** Our backend is built in Python with FastAPI, using a few hacks (check out our GitHub) to connect to your Mac’s contacts and iMessage database. We use the Google API to connect to Gmail + photos.
**LLM-guided search.** A language model makes the decisions about what information should be retrieved — what keywords to search through different databases — and when to generate a response or continue accumulating more information. A beautiful, concise answer to a user query is often a result of many LLM prompts and aggregation events.
**Retrieval augmented generation.** We experimented with vector databases and context-window based RAG, finding the latter to be more effective.
**Notifications.** We have a series of “notepads” on which the LLM can jot down information, such as deadlines. We then later use a language model to generate notifications to ensure you don’t miss any crucial events.
## Challenges we ran into
**Speed.** LLM-guided search is inherently slow, bottlenecked by inference performance. We had a lot of difficulty filtering data before giving it to the LLM for summarization and reasoning in a way that maximizes flexibility while minimizing cost.
**Prompt engineering.** LLMs don’t do what you tell them, especially the smaller ones. Learning to deal with it in a natural way and work around the LLMs idiosyncrasies was important for achieving good results in the end.
**Vector search.** Had issues with InterSystems and getting the vector database to work.
## Accomplishments that we're proud of
**BAIB is significantly more powerful than we thought.** As we played around with BAIB and asked fun questions like “what are the weirdest texts that Tony has sent me?”, its in-depth analysis on Tony’s weird texts were incredibly accurate: “Tony mentions that maybe his taste buds have become too American… This reflection on cultural and dietary shifts is interesting and a bit unusual in the context of a casual conversation.” This has increased our conviction in the long-term potential of this idea. We truly believe that this product must and will exist with or without us.
**Our team organization was good (for a hackathon).** We split our team into the backend team and the frontend team. We’re proud that we made something useful and beautiful.
## What we learned
Prompt engineering is very important. As we progressed through the project, we were able to speed up the response significantly and increase the quality by just changing the way we framed our question.
ChatGPT 4.0 is more expensive than we thought.
Further conviction that personal assistants will have a huge stake in the future.
Energy drinks were not as effective as expected.
## What's next for BAIB
Building this powerful prototype gave us a glimpse of what BAIB could really become. We believe that BAIB can be integrated into all aspects of life. For example, integrating with other communication methods like Discord, Slack, and Facebook will allow the personal assistant to gain a level of organization and analysis that would not be previously possible.
Imagine getting competing offers at different companies and being able to ask BAIB, who can combine the knowledge of the internet with the context of your family and friends to help give you enough information to make a decision.
We want to continue the development of BAIB after this hackathon and build it as an app on your phone to truly become the Best AI Buddy. | ## Inspiration
A close friend of ours was excited about her future at Stanford and beyond– she had a supportive partner, and a bright future ahead of her. But when she found out she was unexpectedly pregnant, her world turned upside down. She was shocked and scared, unsure of what to do. She knew that having a child right now wasn't an option for her. She wasn't ready, financially or emotionally, to take on the responsibility of motherhood. But with the recent overturn of Roe v Wade, she wasn't sure what her options were for an abortion.
She turned to ChatGPT for answers, hoping to find accurate and reliable information. She typed in her questions, and the AI-powered language model responded with what seemed like helpful advice.
But as she dug deeper into the information she was getting, she began to realize that not all of it was accurate. The sources that ChatGPT was referring to for clinics were in locations where abortion was no longer legal. She started to feel overwhelmed and confused. She didn't know who to trust or where to turn for accurate information about her options. She felt trapped like her fate was being decided by forces beyond her control.
With that, we realized that ChatGPT and its underlying technology (GPT3) was incredibly powerful, but had extremely systematic and foundational flaws. These are technologies that now millions are beginning to rely on, but it struggles with issues that are intrinsic to the value it’s meant to provide. We knew that it was necessary to build something better, safer, more accurate, and leveraged tools – specifically retrieval augmentation – in order to improve accuracy and provide responses based on information that the system hasn’t been trained on (for instance events and content since 2021). Enter Golden Retriever.
## What it does
Imagine having access to an intelligent assistant that can help you navigate the vast sea of information out there. In many ways, we have that with ChatGPT and GPT3, but Golden Retriever, our tool, puts an end to character limitations on prompts/queries, eliminates the risk of “hallucination,” meaning answering questions incorrectly and inaccurately but confidently, and answers the questions you need to be answered (including and especially when you probe it) with incredible depth and detail. Further, it allows you to provide sources you’d want it to analyze, whereas current GPT tools are limited to information it has been trained on. Retrieval augmentation is a game-changing technology, and entirely revolutionizes the way we approach closed-domain question answering.
That’s why we built Golden Retriever. How does Golden Retriever circumvent these challenges? Golden Retriever uses a data structure that allows for a larger prompt size and gives you the freedom to connect to any external data source.
The use case we envision as incredibly pertinent in today’s world is legal counsel – traditionally, it’s expensive, inaccessible, and is a resource that most underrepresented and marginalized communities in the United States don’t have adequate access to. Golden Retriever is a revolutionary tool that can provide you with reliable legal advice when you can't afford to consult a legal professional. Whether you're facing a legal issue but don't have the time or money to consult a lawyer, or you simply want to gain a better understanding of your legal rights and responsibilities, such as when it comes to abortion, Golden Retriever can help.
As it pertains to this use case, with Golden Retriever, you can easily connect to a wide range of external data sources, including legal databases, court cases, and legal articles, to obtain accurate and up-to-date information about the legal issue you're facing. You can ask specific legal questions and receive detailed responses that take into account the context and specifics of your situation. You can even probe it to get specific advice based on your personal circumstances.
For example, imagine you're facing a difficult decision related to abortion, but you don't have the resources to consult a legal professional. Using Golden Retriever which leverages GPT Index, you can input your query and obtain a detailed response that outlines your legal rights and responsibilities, as well as any potential legal remedies available to you – it all simply depends on the information you’re looking for and ask.
## How we built it
First, we loaded in the data using a Data Connector called SimpleDirectoryReader, which parses over a specified directory containing files that contain the data. Then, we wrote a Python script where we used GPTKeywordTableIndex as the interface that would connect our data with a GPT LLM using GPTIndex. We feed the pre-trained LLM with a large corpus of text that acts as the knowledge database of the GPT model. Then we group chunks of the textual data into nodes and extract the keywords from the nodes, also building a direct mapping from each keyword back to its corresponding node.
Then we prompt the user for a query in a GUI created in Flask. GPT Keyword Table Index gets a list of tuples that contain the nodes that store chunks of relevant textual data. We extract relevant keywords from the query and match those with pre-extracted node keywords to fetch the corresponding nodes. Once we have the nodes, we prepend the information in the nodes to the query and feed that into GPT to create an object response. This object contains the summarized text that will be displayed to the user and all the nodes' information that contributed to this summary. We are able to essentially cite the information we display to the user, where each node is uniquely identified by a Doc id.
## Challenges we ran into
When we gave a query and found a bunch of keywords on pre-processed nodes, it wasn’t hard to generate an effective response, but it was hard to find the source of the text, and finding what chunks of data from our database our system was using to construct a response. Meaning, one of the key features of our product was that the response shows exactly what information from our database it used to derive the conclusion it came to — generally, the system is “memoryless” and cannot be asked for effective and detailed follow-up questions about where it specifically generated that information. Nevertheless, we overcame this challenge and found out how to access the object where the data of the source leveraged for the response was being sourced.
## Accomplishments that we're proud of
Hallucination is considered one of the more dangerous and hard-to-diagnose issues within GPT3. When asked for sources to back up answers, GPT3 is capable of hallucinating sources, providing entirely rational-sounding justifications for its answers. Further, to properly prompt these tools to create unique and well-crafted answers, detailed prompts are necessary. Often, we’d even want prompts to leverage research articles, news articles, books, and extremely large data sets. Not only have we reduced hallucination to a negligible degree, but we’ve eliminated the limitations that come with maximum query sizes, and enabled any type of source and any quantity of sources to be leveraged in query responses and analyses.
This is a new frontier, and we’re excited and honored to have the privilege of bringing it about.
## What we learned
Our team members learned the entire lifecycle of a project in such a nascent phase – from researching current discoveries and work to building and leveraging these tools in unison with our own goals, to eventually using these outputs to make them easy to interface and interact with. When it comes to human-facing technologies such as chatbots and question-answering, human feedback and interaction are vital. In just 36 hours, we replicated this entire lifecycle, from the ideation phase to research, to build on top of current infrastructures, to developing new APIs and interfaces that are easy and fun to interact with. Given that one of the problems we’re attempting to solve is inaccessibility, doing so is vital.
## What's next for Golden Retriever: Retrieval Augmented GPT
Our current application of choice for Golden Retriever is making legal counsel more accurate, accessible, and affordable to broader audiences whether it comes to criminal or civil law. However, we genuinely see Golden Retriever as being an application to almost any use case – namely and most directly education, content generation for marketing and writing, and medical diagnoses. The guarantee we obtain from all inferences, answers, and analyses being backed by sources, and being able to feed in sources through retrieval augmentation that the system wasn’t even trained on, broadens the array of use cases beyond what we might have ever envisioned prior for AI chatbots. | ## Inspiration
Many hackers cast their vision forward, looking for futuristic solutions for problems in the present. Instead, we cast our eyes backwards in time, looking to find our change in restoration and recreation. We were drawn to the ancient Athenian Agora -- a marketplace; not one where merchants sold goods, but one where thinkers and orators debated, discussed, and deliberated (with one another?) pressing social-political ideas and concerns. The foundation of community engagement in its era, the premise of the Agora survived in one form or another over the years in the various public spaces that have been focal points for communities to come together -- from churches to community centers.
In recent years, however, local community engagement has dwindled with the rise in power of modern technology and the Internet. When you're talking to a friend on the other side of the world, you're not talking a friend on the other side of the street. When you're organising with activists across countries, you're not organising with activists in your neighbourhood. The Internet has been a powerful force internationally, but Agora aims to restore some of the important ideas and institutions that it has left behind -- to make it just as powerful a force locally.
## What it does
Agora uses users' mobile phone's GPS location to determine the neighbourhood or city district they're currently in. With that information, they may enter a chat group specific to that small area. Having logged-on via Facebook, they're identified by their first name and thumbnail. Users can then chat and communicate with one another -- making it easy to plan neighbourhood events and stay involved in your local community.
## How we built it
Agora coordinates a variety of public tools and services (for something...). The application was developed using Android Studio (Java, XML). We began with the Facebook login API, which we used to distinguish and provide some basic information about our users. That led directly into the Google Maps Android API, which was a crucial component of our application. We drew polygons onto the map corresponding to various local neighbourhoods near the user. For the detailed and precise neighbourhood boundary data, we relied on StatsCan's census tracts, exporting the data as a .gml and then parsing it via python. With this completed, we had almost 200 polygons -- easily covering Hamilton and the surrounding areas - and a total of over 50,000 individual vertices. Upon pressing the map within the borders of any neighbourhood, the user will join that area's respective chat group.
## Challenges we ran into
The chat server was our greatest challenge; in particular, large amounts of structural work would need to be implemented on both the client and the server in order to set it up. Unfortunately, the other challenges we faced while developing the Android application diverted attention and delayed process on it. The design of the chat component of the application was also closely tied with our other components as well; such as receiving the channel ID from the map's polygons, and retrieving Facebook-login results to display user identification.
A further challenge, and one generally unexpected, came in synchronizing our work as we each tackled various aspects of a complex project. With little prior experience in Git or Android development, we found ourselves quickly in a sink-or-swim environment; learning about both best practices and dangerous pitfalls. It was demanding, and often-frustrating early on, but paid off immensely as the hack came together and the night went on.
## Accomplishments that we're proud of
1) Building a functioning Android app that incorporated a number of challenging elements.
2) Being able to make something that is really unique and really important. This is an issue that isn't going away and that is at the heart of a lot of social deterioration. Fixing it is key to effective positive social change -- and hopefully this is one step in that direction.
## What we learned
1) Get Git to Get Good. It's incredible how much of a weight of our shoulders it was to not have to worry about file versions or maintenance, given the sprawling size of an Android app. Git handled it all, and I don't think any of us will be working on a project without it again.
## What's next for Agora
First and foremost, the chat service will be fully expanded and polished. The next most obvious next step is towards expansion, which could be easily done via incorporating further census data. StatsCan has data for all of Canada that could be easily extracted, and we could rely on similar data sets from the U.S. Census Bureau to move international. Beyond simply expanding our scope, however, we would also like to add various other methods of engaging with the local community. One example would be temporary chat groups that form around given events -- from arts festivals to protests -- which would be similarly narrow in scope but not constrained to pre-existing neighbourhood definitions. | losing |
# Stegano
## End-to-end steganalysis and steganography tool
#### Demo at <https://stanleyzheng.tech>
Please see the video before reading documentation, as the video is more brief: <https://youtu.be/47eLlklIG-Q>
A technicality, GitHub user RonanAlmeida ghosted our group after committing react template code, which has been removed in its entirety.
### What is steganalysis and steganography?
Steganography is the practice of concealing a message within a file, usually an image. It can be done one of 3 ways, JMiPOD, UNIWARD, or UERD. These are beyond the scope of this hackathon, but each algorithm must have its own unique bruteforce tools and methods, contributing to the massive compute required to crack it.
Steganoanalysis is the opposite of steganography; either detecting or breaking/decoding steganographs. Think of it like cryptanalysis and cryptography.
### Inspiration
We read an article about the use of steganography in Al Qaeda, notably by Osama Bin Laden[1]. The concept was interesting. The advantage of steganography over cryptography alone is that the intended secret message does not attract attention to itself as an object of scrutiny. Plainly visible encrypted messages, no matter how unbreakable they are, arouse interest.
Another curious case was its use by Russian spies, who communicated in plain sight through images uploaded to public websites hiding steganographed messages.[2]
Finally, we were utterly shocked by how difficult these steganographs were to decode - 2 images sent to the FBI claiming to hold a plan to bomb 11 airliners took a year to decode. [3] We thought to each other, "If this is such a widespread and powerful technique, why are there so few modern solutions?"
Therefore, we were inspired to do this project to deploy a model to streamline steganalysis; also to educate others on stegography and steganalysis, two underappreciated areas.
### What it does
Our app is split into 3 parts. Firstly, we provide users a way to encode their images with a steganography technique called least significant bit, or LSB. It's a quick and simple way to encode a message into an image.
This is followed by our decoder, which decodes PNG's downloaded from our LSB steganograph encoder. In this image, our decoder can be seen decoding a previoustly steganographed image:

Finally, we have a model (learn more about the model itself in the section below) which classifies an image into 4 categories: unstegographed, MiPOD, UNIWARD, or UERD. You can input an image into the encoder, then save it, and input the encoded and original images into the model, and they will be distinguished from each other. In this image, we are inferencing our model on the image we decoded earlier, and it is correctly identified as stegographed.

### How I built it (very technical machine learning)
We used data from a previous Kaggle competition, [ALASKA2 Image Steganalysis](https://www.kaggle.com/c/alaska2-image-steganalysis). This dataset presented a large problem in its massive size, of 305 000 512x512 images, or about 30gb. I first tried training on it with my local GPU alone, but at over 40 hours for an Efficientnet b3 model, it wasn't within our timeline for this hackathon. I ended up running this model on dual Tesla V100's with mixed precision, bringing the training time to about 10 hours. We then inferred on the train set and distilled a second model, an Efficientnet b1 (a smaller, faster model). This was trained on the RTX3090.
The entire training pipeline was built with PyTorch and optimized with a number of small optimizations and tricks I used in previous Kaggle competitions.
Top solutions in the Kaggle competition use techniques that marginally increase score while hugely increasing inference time, such as test time augmentation (TTA) or ensembling. In the interest of scalibility and low latency, we used neither of these. These are by no means the most optimized hyperparameters, but with only a single fold, we didn't have good enough cross validation, or enough time, to tune them more. Considering we achieved 95% of the performance of the State of the Art with a tiny fraction of the compute power needed due to our use of mixed precision and lack of TTA and ensembling, I'm very proud.
One aspect of this entire pipeline I found very interesting was the metric. The metric is a weighted area under receiver operating characteristic (AUROC, often abbreviated as AUC), biased towards the true positive rate and against the false positive rate. This way, as few unstegographed images are mislabelled as possible.
### What I learned
I learned about a ton of resources I would have never learned otherwise. I've used GCP for cloud GPU instances, but never for hosting, and was super suprised by the utility; I will definitely be using it more in the future.
I also learned about stenography and steganalysis; these were fields I knew very little about, but was very interested in, and this hackathon proved to be the perfect place to learn more and implement ideas.
### What's next for Stegano - end-to-end steganlaysis tool
We put a ton of time into the Steganalysis aspect of our project, expecting there to be a simple steganography library in python to be easy to use. We found 2 libraries, one of which had not been updated for 5 years; ultimantely we chose stegano[4], the namesake for our project. We'd love to create our own module, adding more algorithms for steganography and incorporating audio data and models.
Scaling to larger models is also something we would love to do - Efficientnet b1 offered us the best mix of performance and speed at this time, but further research into the new NFNet models or others could yeild significant performance uplifts on the modelling side, but many GPU hours are needed.
## References
1. <https://www.wired.com/2001/02/bin-laden-steganography-master/>
2. <https://www.wired.com/2010/06/alleged-spies-hid-secret-messages-on-public-websites/>
3. <https://www.giac.org/paper/gsec/3494/steganography-age-terrorism/102620>
4. <https://pypi.org/project/stegano/> | ## Inspiration
In a lot of mass shootings, there is a significant delay from the time at which police arrive at the scene, and the time at which the police engage the shooter. They often have difficulty determining the number of shooters and their location. ViGCam fixes this problem.
## What it does
ViGCam spots and tracks weapons as they move through buildings. It uses existing camera infrastructure, location tags and Google Vision to recognize weapons. The information is displayed on an app which alerts users to threat location.
Our system could also be used to identify wounded people after an emergency incident, such as an earthquake.
## How we built it
We used Raspberry Pi and Pi Cameras to simulate an existing camera infrastructure. Each individual Pi runs a Python script where all images taken from the cameras are then sent to our Django server. Then, the images are sent directly to Google Vision API and return a list of classifications. All the data collected from the Raspberry Pis can be visualized on our React app.
## Challenges we ran into
SSH connection does not work on the HackMIT network and because of this, our current setup involves turning one camera on before activating the second. In a real world situation, we would be using an existing camera network, and not our raspberry pi cameras to collect video data.
We also have had a difficult time getting consistent identification of our objects as weapons. This is largely because, for obvious reasons, we cannot bring in actual weapons. Up close however, we have consistent identification of team member items.
Using our current server set up, we consistently get server overload errors. So we have an extended delay between each image send. Given time, we would implement an actual camera network, and also modify our system so that it would perform object recognition on videos as opposed to basic pictures. This would improve our accuracy. Web sockets can be used to display the data collected in real time.
## Accomplishments that we’re proud of
1) It works!!! (We successfully completed our project in 24 hours.)
2) We learned to use Google Cloud API.
3) We also learned how to use raspberry pi. Prior to this, none on our team had any hardware experience.
## What we learned
1) We learned about coding in a real world environment
2) We learned about working on a team.
## What's next for ViGCam
We are planning on working through our kinks and adding video analysis. We could add sound detection for gunshots to detect emergent situations more accurately. We could also use more machine learning models to predict where the threat is going and distinguish between threats and police officers. The system can be made more robust by causing the app to update in real time. Finally, we would add the ability to use law enforcement emergency alert infrastructure to alert people in the area of shooter location in real time. If we are successful in these aspects, we are hoping to either start a company, or sell our idea. | ## Inspiration
We really enjoy playing the game minesweeper, so we decided to try to implement a version of it ourselves.
## What it does
The current implementation doesn't fully work.
## How we built it
We used a 2D tile array to create a board and track user movements to follow the game minesweeper.
## Challenges we ran into
It was difficult to figure out how to blast the board when a tile had no bombs around it.
## Accomplishments that we're proud of
We tried our best.
## What we learned
We learned how to do game development and mouse interaction with the project.
## What's next for Calhacks: the sweeper
Make it more functional. | winning |
## Inspiration
We're avid hackers, and every hack we've done thus far has involved hardware. The hardest part is always setting up communication between the various hardware components it's -- like reinventing the internet protocol everytime you make an IoT device. Except the internet protocol is beautiful, and your code is jank. So we decided we'd settle that problem once and for all, both for out future hacks and for hackers in general.
## What it does
Now, all the code needed for an IoT device is python. You write some python code for your computer, some for the microcontroller, and we seamlessly integrate between them. And we help predict how much better your code base is as a result.
## How we built it
Microcontrollers, because they are bare-metal, don't actually run python. So we wrote a python transpiler that automatically converts python code into bare-metal-compliant C code. Then we seamlessly, securely, and efficiently transfer data between the various hardware components using our own channels protocol. The end result is that you only ever need to look at python. Based on that and certain assumptions of usage, we model how much we are able to improve your coding experience.
## Challenges we ran into
We attempted to implement a full lexical analyzer in its complex, abstract glory. That was a mistake.
## Accomplishments that we're proud of
Because the set of languages described by regex is basically equivalent to the set of all decidable problems in computer science, we used regex in place of the lexical analyzer, which was pretty interesting.
More generally, however, this was a big project with many moving parts, and a large code base. The fact that our team was able to put everything together, get things done, and come up with creative solutions on the fly was fantastic.
## What we learned
Organization with tools like trello is important.
Compilers are complex.
Merging disparate pieces of interlocking code is a difficult but rewarding process.
And many miscellaneous python tips and tricks.
## What's next for Kharon
We intend to keep updating the project to make it more robust, general, and power. Potential routes for this include more depth in the theory of the field, integrating more AI, or just commenting our code more thoroughly so others can understand it.
This project will be useful to us and other hardware hackers in the future! -- that's why we'll keep working on this :) | ## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | ## Inspiration
I love playing the guitar, and I thought it would be interesting to have a teleprompter for guitar sheet music, as it could double as a metronome and a replacement for standard paper sheet music. Guitar sheet music, or *tab*, is much simpler than standard sheet music: It's presented in a somewhat unstandardized text based format, with six lines of hyphens representing strings on a guitar, and integers along the lines to indicate the placement of the notes (on the guitar's frets). The horizontal position of the notes in a bar roughly indicates the note's timing, though there is no universal way to specify a note's length.
```
Q=120, 3/4 time
G G/B C G/B
e|--------------------|-------------------|-0----------0--2---|-3-----------------|
B|--3----------0--1---|-3-----------------|------1--3---------|-------------------|
G|o------0--2---------|-------0-----0-----|-------------------|-------0-----0-----|
D|o-------------------|-------------------|-------------------|-------------------|
A|-------------0------|-2-----------------|-3-----------------|-2-----------------|
E|--3-----------------|-------------------|-------------------|-------------------|
Am G D G/B G D7
e|--------------------|-------------------|-------------------|-------------------|
B|--1----3--1--0------|-0----1--0---------|------------0------|-------------------|
G|----------------2---|------------2--0---|------0--2-----0---|-2-----------------|
D|--------------------|-------------------|-4-----------------|-0----0------------|
A|--0-----------------|-------------------|-5----2------------|---------3--2--0---|
E|--------------------|-3-----------------|------------3------|-------------------|
```
For example, here are the first 8 measures of Bach's Minuet in G major. [source: Ultimate Guitar](https://tabs.ultimate-guitar.com/tab/christian-petzold/minuet-in-g-major-tabs-189404)
Many popular tab sites have an autoscrolling feature, which performs a similar music-teleprompter-like role, suggesting a need for something like TabRunner.
## What it does
I built:
1. React-based tab parser to take in tab like the one above and extract out the note data into a machine instruction inspired encoding.
2. An Arduino-powered hardware device that takes in the encoded data and renders it onto an 128x64 OLED screen, one measure at a time, with buttons that control the tempo (the delay between measures).
## How we built it
1. Used the [ES8266 OLED SSD1306](https://github.com/ThingPulse/esp8266-oled-ssd1306) library to render lines (representing guitar strings) and circles with numbers in them (representing notes).
2. Built a small application with ReactJS for frontend and minimal styling that has a textbox for notes.
.
3. Made up a way to represent "Note" objects, and ran the tab, which was just a standard, ASCII string, through a gauntlet of string manipulation functions to ultimately build up an array of Note data objects.
4. Developed an encoding to represent note objects. Inspired by machine instructions, I took the note data, which was a collection of ints/floats, and converted it into a single 12 bit binary value.
```
0b0SSS_HHHH_FFFF
```
S are string bits, representing one of the six strings (ie. 001 = high E, 010 = B, etc)
H are horizontal position/timing bits - stored as a value to be normalized from 0 to 15, with 0 representing the left end of a measure and 15 representing the right end.
F are the fret bits. There are 19 frets on a standard guitar but I've never seen anything above 15 used, nor are the higher frets particularly playable.
5. Used bit manipulation to parse out the note data from the integer encoding in the Arduino, then used that information to generate X/Y/Bar coordinates in which to render the notes.
6. Added utility functions and wired up some buttons to control the speed, as well as left and right solid bar indicators to show when the start/end of a song is, since it loops through all the bars of a song, infinitely.
## Challenges we ran into
* Processing the string data using elementary string functions was quite difficult, requiring a 4 dimensional array and a lot of scribbling odd shapes on paper
* Interfacing the Javascript objects into Arduino readable (ie. C++) code was harder than expected. I thought I could just use the standard JSON (Javascript Object Notation) string encode/decode functions but that produced a lot of issues, so I had to come up with that custom integer encoding to flatten the objects into integers, then a few bit manipulations to decode them.
## Accomplishments that we're proud of
* Building this in time!
* Coming up with an elegant encoding for notes
* I think some of the tab parsing is somewhat clever, if messy
## What we learned
* A lot about how/why to use bit manipulation
* How to wire buttons with an Arduino
* How to create a nice control loop with good feedback
* How to deal with multidimensional arrays (harder than expected!) in Arduino code
## What's next for TabRunner
* Extending this for Ukelele tab, with supporting 4 strings instead of 6
* Adding more complex tab notation like hammer on/pull off parsing
* More buttons to reset/fast forward
* Rotary encoder for tempo setting rather than buttons
* Larger screen/better assembly to mount easily to a guitar, improved visibility | winning |
## Inspiration
A therapeutic app that's almost as therapeutic as it was to make, "dots" is a simple web app that only takes your name and as input, and outputs some positive words and reassuring energy.
## What it does
This app will quell your deepest insecurities, and empower you to carry on with your day and do your best!
## How I built it
Very simple html, css, sass, and javascript.
## Challenges I ran into
Learning everything, especially javascript
## Accomplishments that I'm proud of
My first app! Yay!
## What I learned
If you code long enough you can completely forget that you need to pee.
## What's next for dots
Next steps: add some animated elements! | ## Inspiration
With many people's stressful, fast-paced lives, there is not always time for reflection and understanding of our feelings. Journaling is a powerful way to help reflect but it can often be not only overwhelming to start on a blank page, but hard to figure out even what to write. We were inspired to provide the user with prompts and questions to give them a starting point for their reflection. In addition, we created features that summarized the user's thoughts into a short blurb to help them contextualize and reflect on their day and emotions.
## What it does
Whispers is an app that aims to help the user talk about and decipher their emotions by talking with Whisper, the app mascot, as the adorable cat prompts you with questions about your day in an effort to help you reflect and sum up your emotions. Through the use of randomly generated prompts, Whispers collects your responses to create a summary of your day and tries to help you figure out what emotions you are feeling.
## How we built it
The back-end was developed with Node.js libraries and the Co:here API to collect the user-inputted data and summarize it. Furthermore, the classify functionality from Co:here was used to conduct sentiment analysis on the user's inputs to determine the general emotions of their answers
The front-end was developed with React-native and UX designs from Figma. Express.js was used as middleware to connect the front-end to back-end.
## Challenges we ran into
Overall, we did not run into any new challenges when it comes to development. We had issues with debugging and connecting the front-end to the back-end. There was also trouble with resolving dependencies both within back--end and conducting requests from front-end for analysis. We resolved this using Express.js as a simple, easy-to-use middleware.
In addition, we had trouble translating some of our UI elements to the front-end. To resolve this, we used both online resources and re-adjusted our scope.
## Accomplishments that we're proud of
We are proud of the model that was made for our backend which was trained on a massive dataset to summarize the user's thoughts and emotions. Additionally, we are proud of the chat feature that prompts the user with questions as they go along and our overall UI design. Our team worked hard on this challenging project.
## What we learned
We learned a lot about front-end development and adjusting our scope as we go along. This helped us learn to resolve problems efficiently and quickly. We also learned a lot while working with our backend of how to train Co:here models and connect both the front-end and back-end and perform requests to the server.
## What's next for Whispers
We would like to continue to develop Whispers with several more features. The first would be a user authentication and login system so that it could be used across several platforms and users. Additionally, we would like to add voice-to-text functionality to our chat journaling feature to improve on the accessibility of our app. Lastly, we would like to expand on the archive functions so that users can go back further than just the current week and see their journals and emotions from previous weeks or months | ## What it does
Take a picture, get a 3D print of it!
## Challenges we ran into
The 3D printers going poof on the prints.
## How we built it
* AI model transforms the picture into depth data. Then post-processing was done to make it into a printable 3D model. And of course, real 3D printing.
* MASV to transfer the 3D model files seamlessly.
* RBC reward system to incentivize users to engage more.
* Cohere to edit image prompts to be culturally appropriate for Flux to generate images.
* Groq to automatically edit the 3D models via LLMs.
* VoiceFlow to create an AI agent that guides the user through the product. | losing |
## Inspiration
## What it does
PhyloForest helps researchers and educators by improving how we see phylogenetic trees. Strong, useful data visualization is key to new discoveries and patterns. Thanks to our product, users have a greater ability to perceive depth of trees by communicating widths rather than lengths. The length between proteins is based on actual lengths scaled to size.
## How we built it
We used EggNOG to get phylogenetic trees in Newick format, then parsed them using a recursive algorithm to get the differences between the protein group in question. We connected names to IDs using the EBI (European Bioinformatics Institute) database, then took the lengths between the proteins and scaled them to size for our Unity environment. After we put together all this information, we went through an extensive integration process with Unity. We used EBI APIs for Taxon information, EggNOG gave us NCBI (National Center for Biotechnology Information) identities and structure. We could not use local NCBI lookup (as eggNOG does) due to the limitations of Virtual Reality headsets, so we used the EBI taxon lookup API instead to make the tree interactive and accurately reflect the taxon information of each species in question. Lastly, we added UI components to make the app easy to use for both educators and researchers.
## Challenges we ran into
Parsing the EggNOG Newick tree was our first challenge because there was limited documentation and data sets were very large. Therefore, it was difficult to debug results, especially with the Unity interface. We also had difficulty finding a database that could connect NCBI IDs to taxon information with our VR headset. We also had to implement a binary tree structure from scratch in C#. Lastly, we had difficulty scaling the orthologs horizontally in VR, in a way that would preserve the true relationships between the species.
## Accomplishments that we're proud of
The user experience is very clean and immersive, allowing anyone to visualize these orthologous groups. Furthermore, we think this occupies a unique space that intersects the fields of VR and genetics. Our features, such as depth and linearized length, would not be as cleanly implemented in a 2-dimensional model.
## What we learned
We learned how to parse Newick trees, how to display a binary tree with branches dependent on certain lengths, and how to create a model that relates large amounts of data on base pair differences in DNA sequences to something that highlights these differences in an innovative way.
## What's next for PhyloForest
Making the UI more intuitive so that anyone would feel comfortable using it. We would also like to display more information when you click on each ortholog in a group. We want to expand the amount of proteins people can select, and we would like to manipulate proteins by dragging branches to better identify patterns between orthologs. | ## Inspiration
Every musician knows that moment of confusion, that painful silence as onlookers shuffle awkward as you frantically turn the page of the sheet music in front of you. While large solo performances may have people in charge of turning pages, for larger scale ensemble works this obviously proves impractical. At this hackathon, inspired by the discussion around technology and music at the keynote speech, we wanted to develop a tool that could aid musicians.
Seeing AdHawks's MindLink demoed at the sponsor booths, ultimately give us a clear vision for our hack. MindLink, a deceptively ordinary looking pair of glasses, has the ability to track the user's gaze in three dimensions, recognizes events such as blinks and even has an external camera to display the user's view. Blown away by the possibility and opportunities this device offered, we set out to build a hands-free sheet music tool that simplifies working with digital sheet music.
## What it does
Noteation is a powerful sheet music reader and annotator. All the musician needs to do is to upload a pdf of the piece they plan to play. Noteation then displays the first page of the music and waits for eye commands to turn to the next page, providing a simple, efficient and most importantly stress-free experience for the musician as they practice and perform. Noteation also enables users to annotate on the sheet music, just as they would on printed sheet music and there are touch controls that allow the user to select, draw, scroll and flip as they please.
## How we built it
Noteation is a web app built using React and Typescript. Interfacing with the MindLink hardware was done on Python using AdHawk's SDK with Flask and CockroachDB to link the frontend with the backend.
## Challenges we ran into
One challenge we came across was deciding how to optimally allow the user to turn page using eye gestures. We tried building regression-based models using the eye-gaze data stream to predict when to turn the page and built applications using Qt to study the effectiveness of these methods. Ultimately, we decided to turn the page using right and left wink commands as this was the most reliable technique that also preserved the musicians' autonomy, allowing them to flip back and forth as needed.
Strategizing how to structure the communication between the front and backend was also a challenging problem to work on as it is important that there is low latency between receiving a command and turning the page. Our solution using Flask and CockroachDB provided us with a streamlined and efficient way to communicate the data stream as well as providing detailed logs of all events.
## Accomplishments that we're proud of
We're so proud we managed to build a functioning tool that we, for certain, believe is super useful. As musicians this is something that we've legitimately thought would be useful in the past, and granted access to pioneering technology to make that happen was super exciting. All while working with a piece of cutting-edge hardware technology that we had zero experience in using before this weekend.
## What we learned
One of the most important things we learnt this weekend were the best practices to use when collaborating on project in a time crunch. We also learnt to trust each other to deliver on our sub-tasks and helped where we could. The most exciting thing that we learnt while learning to use these cool technologies, is that the opportunities are endless in tech and the impact, limitless.
## What's next for Noteation: Music made Intuitive
Some immediate features we would like to add to Noteation is to enable users to save the pdf with their annotations and add landscape mode where the pages can be displayed two at a time. We would also really like to explore more features of MindLink and allow users to customize their control gestures. There's even possibility of expanding the feature set beyond just changing pages, especially for non-classical musicians who might have other electronic devices to potentially control. The possibilities really are endless and are super exciting to think about! | ## Inspiration
```
**In 9th grade, we were each given a cup of a clear liquid. We were told to walk around the class and exchange our cup of liquid with three other people in the class.**
```
\_One person in our class had a chemical that would cause the mixed liquid to turn red once two liquids were combined. The red liquid indicated that that person was infected. Each exchange consisted of pouring all the liquid from one cup to another, mixing, and pouring half of it back. At the end of the exercise, we were surprised to find that 90% of the class had been infected in just 3 exchanges by one single person. This exercise outlined how easy it is for an epidemic to turn into an uncontrollable pandemic. In this situation, prevention is the only effective method for stopping an epidemic. So, our team decided to create a product focused on aiding epidemiologists prevent epidemic outbreaks.
## How it works
The user enters a disease into our search filter and clicks on the disease he/she is looking for. The user then gets a map on where that the disease was mentioned the most in the past month with places where it was recently mentioned a lot on Twitter. This provides data on the spread of disease/
## How we built it
```
The website uses a Twitter API to access Tiwtter's post database. We used Flask to connect front-end and back-end.
```
## Challenges we ran into
```
One of the biggest challenges we ran into was definitely our skill and experience level with coding and web design which were both well...sub-par. We only knew a basic amount of HTML and CSS. When we first started designing our website, it looked like one of those pages that appear when the actual page of a website can't load fast enough. It took us a fair amount of googling and mentorship to get our website to look professional. But that wasn't even the hard part. None of us were familiar with back-end design, nor did we know the software required to connect front-end and back-end. We only recently discovered what an API was and by recently I mean 2 days ago, as in the day before the Hackathon started. We didn't know about the Python Flask required to connect our front-end and back-end, the javascript required for managing search results, and the Restful Python with JSON required to bring specific parts of the Twitter API database to users. In fact, by the time I send this devpost out, we're probably still working on the back-end because we still haven't figured out how to make it work. (But we promise it will work out by the deadline). Another challenge was our group dynamic. We struggled at the beginning to agree on an idea. But, in the end, we fleshed out our ideas and came to an unconditional agreement.
```
## Accomplishments that we're proud of
```
When my group told me that they were serious about making something that was obviously way beyond our skill level, I told them to snap back to reality because we didn't know how to make the vast majority of the things we wanted to make. In fact, we didn't even know what was required to make what we wanted to make. I'm actually really glad they didn't listen to me because we ended up doing things that we would have never imagined we do. Looking back, it's actually pretty incredible that we were able to make a professional looking and functioning site, coming in with basic HTML and CSS abilities. I'm really proud of the courage my team had to dive into unknown waters and be willing to learn, even if they risk having no tangible things to show for it.
```
## What we learned
```
From Googling, soliciting help from mentors and our peers, we got to sharpen the knowledge we already had about web design while getting exposure to so many other languages with different syntaxes and functions. Before HW3 I had no idea what bootstrap, css
```
## What's next for Reverse Outbreak
```
We will improve the algorithm of our website, develop an app, and incorporate more epidemics around the world.
``` | winning |
## Inspiration
Imagine a world where the number of mass shootings in the U.S. per year don't align with the number of days. With the recent Thousand Oaks shooting, we wanted to make something that would accurately predict the probability that a place has a mass shooting given a zipcode and future date.
## What it does
When you type in a zipcode, the corresponding city is queried in the prediction results of our neural network in order to get a probability. This probability is scaled accordingly and represented as a red circle of varying size on our U.S. map. We also made a donation link that takes in credit card information and processes it.
## How we built it
We trained our neural network with datasets on gun violence in various cities. We did a ton of dataset cleaning in order to find just what we needed, and trained our network using scikit-learn. We also used the stdlib api in order to pass data around so that the input zipcode could be sent to the right place, and we also used the Stripe api to handle credit card donation transactions. We used d3.js and other external topological javascript libraries in order to create a map of the U.S. that could be decorated. We then put it all together with some javascript, HTML and CSS.
## Challenges we ran into
We had lots of challenges with this project. d3.js was hard to jump right into, as it is such a huge library that correlates data with visualization. Cleaning the data was challenging as well, because people tend not to think twice before throwing data into a big csv. Sending data around files without the usage of a server was challenging, and we managed to bypass that with the stdlib api.
## Accomplishments that we're proud of
A trained neural network that predicts the probability of a mass shooting given a zipcode. A beautiful topological map of the United States in d3. Integration of microservices through APIs we had never used before.
## What we learned
Doing new things is hard, but ultimately worthwhile!
## What's next for Ceasefire
We will be working on a better, real-time mapping of mass shootings data. We will also need to improve our neural network by tidying up our data more. | ## Inspiration
In the aftermath of the recent mass shooting in Las Vegas, our prayers are with the 59 people who lost their lives and the 527 people who were badly injured.
But are our prayers sufficient? In this technology age, with machine learning and other powerful AI algorithms being invented and used heavily in systems all over the world, we took this opportunity provided by Cal Hacks to build something that has the potential to have a social impact on the world by aiming to prevent such incidents of mass shootings.
## What it does?
**Snipe** is a real-time recognition system to prevent the use of illegal guns for evil purposes.
Firstly, the system analyses real-time video feed provided by security cams or cell phone by sampling frames and detecting whether is there a person holding a gun/rifle in the frames. This detects a suspicious person holding a gun in public and alerts the watching security. Most of the guns used for malicious intent are bought illegally, this system can also be used to tackle this scenario (avoidance scenario).
Secondly, it also detects the motion of the arm before someone is about to fire a gun. The system then immediately notifies the police and the officials via email and SMS, so that they can prepare to mobilize without delay and tackle the situation accordingly.
Thirdly, the system recognizes the sound of a rifle/gun being fired and sounds an alarm in nearby locations to warn the people around and avoid the situation.
This system meant to aid the law enforcement to be more efficient and help people avoid such situations. This is an honest effort to use our knowledge in computer science in order to create something to make this world a better place.
## How we built it?
Our system relies on OpenCV to sample and process the real-time video stream for all machine learning components to use.
1) Image Recognition/ Object Detection: This component uses the powerful Microsoft's Cognitive Services API and Azure to classify the frames. We trained the model using our custom data images. The sampled frames are classified on the cloud telling us whether is there a gun bearing human in the image with a probability distribution.
2) Arm Motion recognition: The Arm Motion detection detects whether a person is about to fire a gun/rifle. It also uses the Microsoft's custom vision cognitive API to detect the position of the arms. We use an optimized algorithm on the client side to detect whether the returned probability distribution from API represents the gun firing motion.
3) Sound Detection: Finally to detect the sound of a rifle/gun been fired, we use NEC's sound recognition API to detect the same. Once the program detects that the API returned true for the sound chunk, we sound an alarm to warn people.
The entire application was built in C++.
## Challenges we ran into
Machine learning algorithms need a lot of data for training in order to get highly accurate results. This being a limited time hackathon, we found it hard to collect a lot of data to achieve the desired high accuracy of classification. But we managed to train the model reasonably well (around 80% accuracy in object detection, around 75% in arm motion detection) using the time we had to collect the required data.
## Accomplishments that we're proud of
The issue of mass shootings is pressing globally. We are proud to achieve a solution for the same that has a practical application. Our system may not be perfect but if it can prevent even 1 of 5 shooting incidents, then we are on the right route to accomplish our mission. The social impact that our product can have is inspiring for us and hopefully, it motivates other hackers to build applications that can truly have a positive impact on the world.
## What we learned?
Hackathons are a great way to develop something cool and useful in a day or two. Thanking CalHacks for hosting such a great event and helping us network with the industry's brightest and fellow hackers. Machine learning is the future of computing and using it for our project was a great experience.
## What's next for Snipe?
With proper guidance from our university's professors, we aim to better the machine learning algorithms and get better results. In the future scope, we plan to include emotion and behavior detection in the system to improve it further in detecting suspicious activity before a mishap. | ## Inspiration
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for ford ev
NA | partial |
## Inspiration
According to the Washington Post (June 2023), since Columbine in 1999, more than 356,000 students in the U.S. have experienced gun violence at school.
Students of all ages should be able to learn comfortably and safely within the walls of their classroom.
Quality education is a UN Sustainable Development goal and can only be achieved when the former becomes a reality. As college students, especially in the midst of the latest UNC-Chapel Hill school shooting, we understand threats lie even within the safety of our campus and have grown up knowing the tragedies of school shootings.
This problem is heavily influenced by politics and thus there is an unclear timeline for concrete and effective solutions to be implemented. The intention of our AI model is to contribute a proactive approach that requires only a few pieces of technology but is capable of an immediate response to severe events.
## What it does
Our machine learning model is trained to recognize active threats with displayed weapons. When the camera senses that a person has a knife, it automatically calls 911. We also created a machine learning model that uses CCTV camera footage of perpetrators with guns.
Specifically, this model was meant to be catered towards guns to address the rising safety issues in education. However, for the purpose of training our model and safety precautions, we could not take training data pictures with a gun and thus opted for knives. We used the online footage as a means to also train on real guns.
## How we built it
We obtained an SD card with the IOS for Raspberry Pi, then added the Viam server to the Raspberry Pi. Viam provides a platform to build a machine learning model on their server.
We searched the web and imported CCTV images of people with and without guns and tried to find a wide variety of these types of images. We also integrated a camera with the Raspberry Pi to take additional images of ourselves with a knife as training data. In our photos we held the knife in different positions, different lighting, and different people's hands. The more variety in the photos provided a stronger model. Using our data from both sources and the Viam platform we went through each image and identified the knife or gun in the picture by using a border bounding box functionality. Then we trained two separate ML models, one that would be trained off the images in CCTV footage, and one model using our own images as training data.
After testing for recognition, we used a program that connects the Visual Studio development environment to our hardware. We integrated Twilio into our project which allowed for an automated call feature. In our program, we ran the ML model using our camera and checked for the appearance of a knife. As a result, upon detection of a weapon, our program immediately alerts the police. In this case, a personal phone number was used instead of authorities to highlight our system’s effectiveness.
## Challenges we ran into
Challenges we ran into include connection issues, training and testing limitations, and setup issues.
Internet connectivity presented as a consistent challenge throughout the building process. Due to the number of people on one network at the hackathon, we used a hotspot for internet connection, and the hotspot connectivity was often variable. This led to our Raspberry Pi and Viam connections failing, and we had to restart many times, slowing our progress.
In terms of training, we were limited in the locations we could train our model in. Since the hotspot disconnected if we moved locations, we could only train the model in one room. Ideally, we would have liked to train in different locations with different lighting to improve our model accuracy.
Furthermore, we trained a machine learning model with guns, but this was difficult to test for both safety reasons and a lack of resources to do so. In order to verify the accuracy of our model, it would be optimal to test with a real gun in front of a CCTV camera. However, this was not feasible with the hackathon environment.
Finally, we had numerous setup issues, including connecting the Raspberry Pi to the SSH, making sure the camera was working after setup and configuration, importing CCTV images, and debugging. We discovered that the hotspot that we connected the Raspberry Pi and the laptop to had an apostrophe in its name, which was the root of the issue with connecting to the SSH. We solved the problem with the camera by adding a webcam camera in the Viam server rather than a transform camera. Importing the CCTV images was a process that included reading the images into the Raspberry Pi in order to access them in Viam. Debugging to facilitate the integration of software with hardware was achieved through iteration and testing.
We would like to thank Nick, Khari, Matt, and Hazal from Viam, as well as Lizzie from Twilio, for helping us work through these obstacles.
## Accomplishments that we're proud of
We're proud that we could create a functional and impactful model within this 36 hour hackathon period.
As a team of Computer Science, Mechanical Engineering, and Biomedical Engineering majors, we definitely do not look like the typical hackathon theme. However, we were able to use our various skill sets, from hardware analysis, code compilation, and design to achieve our goals.
Additionally, as it was our first hackathon, we developed a completely new set of skills: both soft and technical. Given the pressure, time crunch, and range of new technical equipment at our fingertips, it was an uplifting experience. We were able to create a prototype that directly addresses a topic that is dear to us, while also communicating effectively with working professionals.
## What we learned
We expanded our skills with a breadth of new technical skills in both hardware and software. We learned how to utilize a Raspberry Pi, and connect this hardware with the machine learning platform in Viam. We also learned how to build a machine learning model by labeling images, training a model for object detection, and deploying the model for results. During this process, we gained knowledge about what images were deemed good/useful data. On the software end, we learned how to integrate a Python program that connects with the Viam machine learning platform and how to write a program involving a Twilio number to automate calling.
## What's next for Project LearnSafe
We hope to improve our machine learning model in a multifaceted manner. First, we would incorporate a camera with better quality and composition for faster image processing. This would make detection in our model more efficient and effective. Moreover, adding more images to our model would amplify our database in order to make our model more accurate. Images in different locations with different lighting would improve pattern recognition and expand the scope of detection. Implementing a rotating camera would also enhance our system. Finally, we would test our machine learning model for guns with CCTV, and modify both models to include more weaponry.
Today’s Security. Tomorrow’s Education. | ## Inspiration
In the aftermath of the recent mass shooting in Las Vegas, our prayers are with the 59 people who lost their lives and the 527 people who were badly injured.
But are our prayers sufficient? In this technology age, with machine learning and other powerful AI algorithms being invented and used heavily in systems all over the world, we took this opportunity provided by Cal Hacks to build something that has the potential to have a social impact on the world by aiming to prevent such incidents of mass shootings.
## What it does?
**Snipe** is a real-time recognition system to prevent the use of illegal guns for evil purposes.
Firstly, the system analyses real-time video feed provided by security cams or cell phone by sampling frames and detecting whether is there a person holding a gun/rifle in the frames. This detects a suspicious person holding a gun in public and alerts the watching security. Most of the guns used for malicious intent are bought illegally, this system can also be used to tackle this scenario (avoidance scenario).
Secondly, it also detects the motion of the arm before someone is about to fire a gun. The system then immediately notifies the police and the officials via email and SMS, so that they can prepare to mobilize without delay and tackle the situation accordingly.
Thirdly, the system recognizes the sound of a rifle/gun being fired and sounds an alarm in nearby locations to warn the people around and avoid the situation.
This system meant to aid the law enforcement to be more efficient and help people avoid such situations. This is an honest effort to use our knowledge in computer science in order to create something to make this world a better place.
## How we built it?
Our system relies on OpenCV to sample and process the real-time video stream for all machine learning components to use.
1) Image Recognition/ Object Detection: This component uses the powerful Microsoft's Cognitive Services API and Azure to classify the frames. We trained the model using our custom data images. The sampled frames are classified on the cloud telling us whether is there a gun bearing human in the image with a probability distribution.
2) Arm Motion recognition: The Arm Motion detection detects whether a person is about to fire a gun/rifle. It also uses the Microsoft's custom vision cognitive API to detect the position of the arms. We use an optimized algorithm on the client side to detect whether the returned probability distribution from API represents the gun firing motion.
3) Sound Detection: Finally to detect the sound of a rifle/gun been fired, we use NEC's sound recognition API to detect the same. Once the program detects that the API returned true for the sound chunk, we sound an alarm to warn people.
The entire application was built in C++.
## Challenges we ran into
Machine learning algorithms need a lot of data for training in order to get highly accurate results. This being a limited time hackathon, we found it hard to collect a lot of data to achieve the desired high accuracy of classification. But we managed to train the model reasonably well (around 80% accuracy in object detection, around 75% in arm motion detection) using the time we had to collect the required data.
## Accomplishments that we're proud of
The issue of mass shootings is pressing globally. We are proud to achieve a solution for the same that has a practical application. Our system may not be perfect but if it can prevent even 1 of 5 shooting incidents, then we are on the right route to accomplish our mission. The social impact that our product can have is inspiring for us and hopefully, it motivates other hackers to build applications that can truly have a positive impact on the world.
## What we learned?
Hackathons are a great way to develop something cool and useful in a day or two. Thanking CalHacks for hosting such a great event and helping us network with the industry's brightest and fellow hackers. Machine learning is the future of computing and using it for our project was a great experience.
## What's next for Snipe?
With proper guidance from our university's professors, we aim to better the machine learning algorithms and get better results. In the future scope, we plan to include emotion and behavior detection in the system to improve it further in detecting suspicious activity before a mishap. | ### Inspiration
We were inspired by the power of storytelling in children's development. We wanted to create an interactive platform that fuels kids' imaginations, allowing them to craft their own stories through simple voice or text inputs, bringing their creativity to life with visuals and narration.
### What it does
StorySpark is a kid-friendly platform that generates personalized stories from voice or text prompts, creates matching visuals, and narrates the story with a slideshow. It’s designed to be engaging and educational, sparking creativity while being easy to use. We also offer a terminal-friendly version for flexibility.
### How we built it
We used the Gemini API for generating stories, LMNT for converting text to speech, and Deepgram for speech-to-text functionality. The Fetch.ai uAgents framework enables the terminal-friendly version, ensuring accessibility for all users. The core technologies work seamlessly to deliver a fun, interactive experience.
### Challenges we ran into
One challenge was ensuring the seamless integration of the various APIs, especially managing real-time story generation, image creation, and audio synchronization. We also worked on optimizing the terminal version for users who prefer a non-browser experience.
### Accomplishments that we're proud of
We’re proud of building an engaging platform that brings together story generation, visuals, and audio for a unique storytelling experience. Successfully implementing the terminal version using Fetch.ai uAgents was another achievement that makes our platform versatile.
### What we learned
We learned how to integrate multiple APIs effectively, ensuring smooth real-time interaction between story, visuals, and audio. Additionally, working with Fetch.ai uAgents gave us deeper insights into creating user-friendly terminal applications.
### What's next for StorySpark
Next, we plan to enhance the AI capabilities to allow for more complex storylines, add more customization options for visuals, and introduce multilingual support. We’ll also continue refining the user experience and expanding the platform’s reach to engage more children globally. | partial |
## Inspiration
LookAhead's goal is to **enhance the lives of visually impaired people** by improving and simplifying their daily experiences. At Hack the North 2023, we were also granted **a unique opportunity** to work with **AdHawk's powerful eye-tracking technology** for free. Recognizing this as a special opportunity with potential to help many people, we also wanted to integrate this feature into our project, which is ultimately what led us to our topic.
## What it does
LookAhead **supports the visually impaired** through cutting-edge **eye-tracking technology** glasses. It has two main features, which are **object identification and description** and **obstacle warnings**. Users can easily switch between these three modes and interact with the software through Iris, our **built-in voice-activated assistant**!
## How we built it
The main technology that we use is **AdHawk's Mind-Link Glasses**, which records through a small camera on the glasses' frame and can detect **eye / pupil movements**. Additionally, we used several Python libraries to handle **video processing** and **AI analysis** on the software side, including **OpenCV**, **Google Cloud Vision API**, **SpeechRecognition**, and **PyAudio**.
## Challenges we ran into
The biggest technical challenge that we faced, which took a large portion of our time to resolve, was figuring out what **the statistics** that AdHawk provides meant (in particular the physical coordinates). Being a **niche technology** with limited documentations, our questions were not simply answered online, and we became more and more concerned about how to use the data properly. In the end, we brought our questions to **the AdHawk's sponsoring booth themselves**. With their help, we were finally able to calibrate the glasses and optimize our accuracies.
## Accomplishments that we're proud of
Firstly, we are proud as a team for **mastering this high-level, specialized technology** in such a short period of time. Our chosen topic emerged from **team consensus**, so each of us had **genuine interest** in learning the hardware and libraries for this project. Secondly, we each take our individual pride in having the motivation to **power through**, especially during **the 2nd night** when we barely slept. Even if we were tempted by a good night's sleep, having the presence of the other enduring group members around helped us pour in our best work until the sun rose.
## What we learned
Given the **experimental** and **trial-and-error** nature of our project, a lot of scientific research had to be done to collect necessary variables to understand **patterns**, **relations** and **bounds**. We took this as an experience to practice our **scientific skills**, in organizing data and conducting several **experiments** with adjusted parameters efficiently.
In terms of hard-skills, this was definitely a learning experience for all of us to work with this type of **hardware**. It is likely that we will not have the chance to use this amazing technology for free again in the future, which is why we cherished this opportunity and **pushed our learning to its limits** (by that, I mean we goofed around a lot and did crazy things with the tech).
## What's next for LookAhead
One of the charms of our project is its **scalability**. Adding new features is simple, since the baseline of eye-tracking and image recognition - the hardest part - is already done. Some **new features** that we plan to add in the future are text-reading modes, caution with stairs, facial emotion detecting, target object locator, and many more ideas. With many promising modern advancements and leading companies conducting research in the field, the **outlook is bright for eye-tracking technology** in the near future. | ## Inspiration
With many vaccines having time constraints when taken out of storage, we made a solution to notify users when they can receive a vaccine in their area! In addition we made a way to track and confirm a user's vaccine.
## What it does
The user downloads an app and will be prompted to fill in his health card information. The users location along with his age is then stored in our database. The vaccine delivery site can then send a signal and all users with in a certain area will receive a notification that they can receive a vaccine at the site.
Vaccine delivery site's can also enter a QR code on the user's device, this will record proof of vaccination and can be checked later on.
## How we built it
We built the mobile app using React Native, and expo for push notifications.
We used a python http server to push the location data to Cassandra.
We used a dotnet core web application to create a web api where we can register and check information as well as send signals
A Node.js server is running in the background receiving messages from the PubSub+ and sending notifications to the user.
We used datastax's astra for the database! As well as it's associated drivers.
## Challenges we ran into
A lot.
## Accomplishments that we're proud of
Learning new things!
## What we learned
## What's next for Vaccine Alerts/Tracking | # Nexus, **Empowering Voices, Creating Connections**.
## Inspiration
The inspiration for our project, Nexus, comes from our experience as individuals with unique interests and challenges. Often, it isn't easy to meet others with these interests or who can relate to our challenges through traditional social media platforms.
With Nexus, people can effortlessly meet and converse with others who share these common interests and challenges, creating a vibrant community of like-minded individuals.
Our aim is to foster meaningful connections and empower our users to explore, engage, and grow together in a space that truly understands and values their uniqueness.
## What it Does
In Nexus, we empower our users to tailor their conversational experience. You have the flexibility to choose how you want to connect with others. Whether you prefer one-on-one interactions for more intimate conversations or want to participate in group discussions, our application Nexus has got you covered.
We allow users to either get matched with a single person, fostering deeper connections, or join one of the many voice chats to speak in a group setting, promoting diverse discussions and the opportunity to engage with a broader community. With Nexus, the power to connect is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tool:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* DaisyUI for animations and UI components
* 100ms live for real-time audio communication
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel perfect icons
* Vite for simplified building and fast dev server
* Convex for vector search over our database
* React-router for client-side navigation
* Convex for real-time server and end-to-end type safety
* 100ms for real-time audio infrastructure and client SDK
* MLH for our free .tech domain
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used Convex and 100ms, it took a lot of research and heads-down coding to get Nexus working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Nexus.
* Working with **very** poor internet throughout the duration of the hackathon, we estimate it cost us multiple hours of development time.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Nexus.
* Learning a ton of new technologies we would have never come across without Cal Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
* Integrating 100ms well enough to experience bullet-proof audio communication.
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Nexus
* Make Nexus rooms only open at a cadence, ideally twice each day, formalizing the "meeting" aspect for users.
* Allow users to favorite or persist their favorite matches to possibly re-connect in the future.
* Create more options for users within rooms to interact with not just their own audio and voice but other users as well.
* Establishing a more sophisticated and bullet-proof matchmaking service and algorithm.
## 🚀 Contributors 🚀
| | | | |
| --- | --- | --- | --- |
| [Jeff Huang](https://github.com/solderq35) | [Derek Williams](https://github.com/derek-williams00) | [Tom Nyuma](https://github.com/Nyumat) | [Sankalp Patil](https://github.com/Sankalpsp21) | | losing |
## Inspiration
I came to this hackathon wanting to expand my front-end development skills. I asked around and people recommended me to check out the React framework from Facebook. I was undecided whether to try Angular 2 or React but after doing some light research I decided upon React. This project was more of a learning experience and was completed following online tutorials.
## What it does
You enter two Github usernames and it compares them using an algorithm, assigns a numeric score, and finally declares a winner.
## How I built it
I built it using the React framework and its respective ecosystem. (Babel, Webpack, JSX)
## Challenges I ran into
The initial setup of the React project was difficult to understand and time-consuming at first. After reading a few tutorials on Webpack and Babel I was able to put the pieces together and understand the purpose of each component.
## Accomplishments that I'm proud of
I was able to learn the essential concepts and nuisances of an awesome framework during a hackathon and now look forward to becoming more proficient and making sophisticated single-page applications. | ## Inspiration
We were inspired by our collective experiences as college students always struggling to find a way to use ingredients that we have at home but it's always hard to find what's doable with the current inventory. Most times, those ingredients are left to waste because we don't know how to incorporate different ingredients for a meal. So we searched for recipe APIs to see how we could solve this problem.
## What it does
It is a website that returns a list of recipe titles and links for users to follow based on the ingredients that they enter in the search bar.
## How we built it
We used Spoonacular API to get the recipe titles and links based on the ingredients entered. We used HTML/CSS/JS to form the website.
## Challenges we ran into
Trying to get the API to work from the HTML/JS code. Authorization errors kept coming up. It was also really difficult to find a feasible idea with our current skill set as beginners. We had to pivot several times until we ended up here.
## Accomplishments that we're proud of
We're proud that we got the API to work and connect with our website. We're proud that the project works and that it's useful.
## What we learned
We learned how to use APIs and how to make websites.
## What's next for SpoonFULL
Having more features that can make the website nicer. Having more parameters in the apiURL to make it more specific. We also aim to better educate college students about sustainability and grocery buying habits through this website. | ## Inspiration
More creators are coming online to create entertaining content for fans across the globe. On platforms like Twitch and YouTube, creators have amassed billions of dollars in revenue thanks to loyal fans who return to be part of the experiences they create.
Most of these experiences feel transactional, however: Twitch creators mostly generate revenue from donations, subscriptions, and currency like "bits," where Twitch often takes a hefty 50% of the revenue from the transaction.
Creators need something new in their toolkit. Fans want to feel like they're part of something.
## Purpose
Moments enables creators to instantly turn on livestreams that can be captured as NFTs for live fans at any moment, powered by livepeer's decentralized video infrastructure network.
>
> "That's a moment."
>
>
>
During a stream, there often comes a time when fans want to save a "clip" and share it on social media for others to see. When such a moment happens, the creator can press a button and all fans will receive a non-fungible token in their wallet as proof that they were there for it, stamped with their viewer number during the stream.
Fans can rewatch video clips of their saved moments in their Inventory page.
## Description
Moments is a decentralized streaming service that allows streamers to save and share their greatest moments with their fans as NFTs. Using Livepeer's decentralized streaming platform, anyone can become a creator. After fans connect their wallet to watch streams, creators can mass send their viewers tokens of appreciation in the form of NFTs (a short highlight clip from the stream, a unique badge etc.) Viewers can then build their collection of NFTs through their inventory. Many streamers and content creators have short viral moments that get shared amongst their fanbase. With Moments, a bond is formed with the issuance of exclusive NFTs to the viewers that supported creators at their milestones. An integrated chat offers many emotes for viewers to interact with as well. | losing |
## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience better for the carpool driver. Additionally, by encouraging more people to choose carpooling at a way of commuting, we hope to work towards more sustainable cities.
## What it does
FaceLyft is a web app that includes features that allow drivers to lock or unlock their car from their device, as well as request payments from riders through facial recognition. Facial recognition is also implemented as an account verification to make signing into your account secure yet effortless.
## How we built it
We used IBM Watson Visual Recognition as a way to recognize users from a live image; After which they can request money from riders in the carpool by taking a picture of them and calling our API that leverages the Interac E-transfer API. We utilized Firebase from the Google Cloud Platform and the SmartCar API to control the car. We built our own API using stdlib which collects information from Interac, IBM Watson, Firebase and SmartCar API's.
## Challenges we ran into
IBM Facial Recognition software isn't quite perfect and doesn't always accurately recognize the person in the images we send it. There were also many challenges that came up as we began to integrate several APIs together to build our own API in Standard Library. This was particularly tough when considering the flow for authenticating the SmartCar as it required a redirection of the url.
## Accomplishments that we're proud of
We successfully got all of our APIs to work together! (SmartCar API, Firebase, Watson, StdLib,Google Maps, and our own Standard Library layer). Other tough feats we accomplished was the entire webcam to image to API flow that wasn't trivial to design or implement.
## What's next for FaceLyft
While creating FaceLyft, we created a security API for requesting for payment via visual recognition. We believe that this API can be used in so many more scenarios than carpooling and hope we can expand this API into different user cases. | ## Inspiration
As lane-keep assist and adaptive cruise control features are becoming more available in commercial vehicles, we wanted to explore the potential of a dedicated collision avoidance system
## What it does
We've created an adaptive, small-scale collision avoidance system that leverages Apple's AR technology to detect an oncoming vehicle in the system's field of view and respond appropriately, by braking, slowing down, and/or turning
## How we built it
Using Swift and ARKit, we built an image-detecting app which was uploaded to an iOS device. The app was used to recognize a principal other vehicle (POV), get its position and velocity, and send data (corresponding to a certain driving mode) to an HTTP endpoint on Autocode. This data was then parsed and sent to an Arduino control board for actuating the motors of the automated vehicle
## Challenges we ran into
One of the main challenges was transferring data from an iOS app/device to Arduino. We were able to solve this by hosting a web server on Autocode and transferring data via HTTP requests. Although this allowed us to fetch the data and transmit it via Bluetooth to the Arduino, latency was still an issue and led us to adjust the danger zones in the automated vehicle's field of view accordingly
## Accomplishments that we're proud of
Our team was all-around unfamiliar with Swift and iOS development. Learning the Swift syntax and how to use ARKit's image detection feature in a day was definitely a proud moment. We used a variety of technologies in the project and finding a way to interface with all of them and have real-time data transfer between the mobile app and the car was another highlight!
## What we learned
We learned about Swift and more generally about what goes into developing an iOS app. Working with ARKit has inspired us to build more AR apps in the future
## What's next for Anti-Bumper Car - A Collision Avoidance System
Specifically for this project, solving an issue related to file IO and reducing latency would be the next step in providing a more reliable collision avoiding system. Hopefully one day this project can be expanded to a real-life system and help drivers stay safe on the road | ## **Inspiration**
In our current society, we recognize that financial literacy is often a privilege rather than a right. Many individuals and communities lack access to trusted and supported education for investment knowledge. In addition, the complexity of financial markets can be intimidating, leaving many to fear how to start learning. Just as information was democratized in our society with WiFi, Diversifile, aims to provide easy access for users to begin their journeys and learn personalized investment strategies. Regardless of background or experience, Diversifile was created to teach and spread diversity in investments and life.
## **What it Does**
Our platform uses a multitude of tools to provide a service that offers real-time financial data and analysis easily. By leveraging MATLAB, the website can both extract real-time data and generate easy-to-read candlestick graphs while classifying common patterns and trends. With this financial data, Diversifile will assign a risk rating, giving users confidence in their decisions. Along with real-time data analysis, Diversifile is also a service that empowers individuals by providing tools specifically and specially prepared for the user. After a short quiz, information about the user's personality will be connected with the account allowing for highly personalized education and suggestions based on the Big Five Model.
## **How We Built It**
We built Diversifile from scratch, utilizing Next.js and Tailwind CSS for our front-end design and MongoDB Atlas to power our backend database. MATLAB was used to generate data from various publicly traded companies and analyze their respective historical candlestick patterns to display on our platform. Auth0 was implemented to create a user account/authentication system within the platform. On top of our principal program, we built an Adobe Express add-on using their JavaScript package to allow users to import our generated candlestick patterns onto different forms of media with ease on Adobe Express.
## **Challenges We Ran Into**
Throughout the 36-hour hackathon, we used a plethora of tools, technologies, and frameworks. As a result, we frequently ran into many expected and unexpected problems. Since we decided to use a variety of tools, technologies, and frameworks, problems arose frequently. One of the biggest challenges we faced was the implementation of our MATLAB algorithm with the back-end. We discovered a way to run MATLAB .m scripts in our Node.js backend through child processes. The integration with the front-end and database was also a challenge as there were numerous APIs we had to design and implement. Having to struggle with Auth0 and the Adobe Express add-on documentation definitely took time and effort to figure out but eventually with time and perseverance, we were able to accomplish what we envisioned with these technologies.
## **Accomplishments That We're Proud Of**
With our completed program, we are proud to have used a large variety of technologies that will enhance our platform's functionality. Our team strived for ambition, integrating a multitude of tools and systems which also contributed greatly to our mission of bridging the financial literacy gap in our society. Knowing the difficulty of completing certain types of projects, it was a significant achievement as we effectively collaborated by sharing our skills, experience and knowledge which combined all the elements into one cohesive and functional platform.
## **What We Learned**
Once again, the highlight of our teamwork is our collaboration and seemingly mind-reading understanding of one another. Throughout the project and seeing the huge pile of work with technology we had not used before, we had to learn to work with each other quickly. With our team set up to have collective leadership, we were able to constantly remain on the same page for the entire duration as if we shared the same mind. This allowed us to seamlessly swap tasks and roles in milliseconds to give another teammate a break or find a more efficient way to tackle our hurdles.
## **What's Next for Diversifile**
At Diversifile's current state, we believe it perfectly demonstrates the solution when catering our services toward novice users starting their journey in investment. However, our idea fundamentally was inclusivity, meaning we intend to allow for more advanced users to also enjoy the perks of our website. To cater to the more advanced users, we plan to implement even more candlestick patterns and even include an easy-access method for SEC filings. Finally, the addition of a financial literacy assistant chatbot will be a benefit to all users as it provides answers and support to queries big and small. | winning |
# Rune
A flexible gesture-motion controller for IoT devices, allowing you to intuitively interface with your newest smart products. Leveraging a custom machine learning model deployed on TensorFlow and the communication capabilities of both the Qualcomm DragonBoard and NodeMCU, the system is capable of discerning between 10 discrete gestures in real-time.
**Hardware**
* Qualcomm DragonBoard 410c
* NodeMCU ESP32
* MPU 9250 9-axis IMU
**Software**
* Python
* C
* TensorFlow
* Numpy
* MQTT Messaging Protocol (Mosquitto Client)
## Nothing is Ever Easy
We faced the challenge of having a Raspberry Pi break on us during the event, turning a comfortable pace into an intense grind in an instant. It was a major setback, but we were able to recover by bringing up a Qualcomm DragonBoard development kit from scratch (which allowed us to pick up right where we left off and continue developing Rune).
## Learning Through Failure
Our attempts at implementing a complicated multi-device communication scheme may have cost us time, but they afforded us the opportunity to take a deep dive into the inner workings of Debian Linux. From the protocols behind IoT communication to the nitty-gritty issues of dependency resolution, as a team we gained an immense amount of knowledge as we solved the problems which blocked us.
## Architecture
Low level communication is handled via the MQTT messaging protocol with devices running on a shared wireless network. The DragonBoard subscribes to a topic using an instance of the Mosquitto client, where it receives messages pushed the the NodeMCU-IMU sensor combination.
A python script parses received MQTT messages and feeds them into our machine learning model, which then determines what gesture was performed. This gesture is then free to be handled however is convenient for the user, i.e. submitted as a POST request to a web front-end.
## License
This project is licensed under the terms of the MIT license. | ## Inspiration
During a school-funded event for individuals with learning disabilities, we noticed a communication barrier due to students’ limited ability to understand sign language. The current solution of using camera recognition fails to be feasible since pulling out a phone during a conversation is impractical and the individual may not consent to being recorded at all. To effectively bridge this gap, we developed SignSpeak, a wearable real-time translator that uses flex sensors to instantly translate sign language gestures. This innovation promotes effective communication, fostering equality and inclusion for all.
## What it does
SignSpeak is a real-time American Sign Language to Speech translation device, eliminating the need of a translator for the hearing impaired. We’ve built a device that consists of both hardware and software components. The hardware component includes flex sensors to detect ASL gestures, while the software component processes the captured data, stores it in a MongoDB database and uses our customized recurrent neural network to convert it into spoken language. This integration ensures a seamless user experience, allowing the hearing-impaired/deaf population to independently communicate, enhancing accessibility and inclusivity for individuals with disabilities.
## How we built it
Our hardware, an Arduino Mega, facilitates flex sensor support, enabling the measurement of ten sensors for each finger. We quantified finger positions in volts, with a linear mapping of 5V to 1023 for precise sensitivity. The data includes a 2D array of voltage values and timestamps.
We labeled data using MongoDB through a Python serial API, efficiently logging and organizing sensor data. MongoDB's flexibility with unstructured data was key in adapting to the changing nature of data during various hand gestures.
After reviewing research, we chose a node-based RNN algorithm. Using TensorFlow, we shaped and conformed data for accuracy. Training was done with 80% test and 20% validation, achieving 84% peak accuracy. Real-time input from COM5 is parsed through the RNN model for gesture sequence and voice translation using text-to-speech.
## Challenges we ran into
A lot of our challenges stemmed from hardware and software problems related to our sensors. In relation to hardware, the sensors, over time adjusted to positions of flexion, resulting in uncalibrated sensors. Another prominent issue was the calibration of our 3D data from our sensors into a 2D array as an RNN input as each sign was a different length. Through constant debugging and speaking with mentors, we were able to pad the sequence and solve the issue.
## Accomplishments that we're proud of
We’re most proud of being able to combine software with hardware, as our team mostly specialized in hardware before the event. It was especially rewarding to see 84% accuracy on our own custom trained dataset, proving the validity of our concept.
## What's next for SignSpeak
SignSpeak aims to expand our database whilst impacting our hardware to PCBs in order to allow for larger and wider public translation. | ## Inspiration
I was walking down the streets of Toronto and noticed how there always seemed to be cigarette butts outside of any building. It felt disgusting for me, especially since they polluted the city so much. After reading a few papers on studies revolving around cigarette butt litter, I noticed that cigarette litter is actually the #1 most littered object in the world and is toxic waste. Here are some quick facts
* About **4.5 trillion** cigarette butts are littered on the ground each year
* 850,500 tons of cigarette butt litter is produced each year. This is about **6 and a half CN towers** worth of litter which is huge! (based on weight)
* In the city of Hamilton, cigarette butt litter can make up to **50%** of all the litter in some years.
* The city of San Fransico spends up to $6 million per year on cleaning up the cigarette butt litter
Thus our team decided that we should develop a cost-effective robot to rid the streets of cigarette butt litter
## What it does
Our robot is a modern-day Wall-E. The main objectives of the robot are to:
1. Safely drive around the sidewalks in the city
2. Detect and locate cigarette butts on the ground
3. Collect and dispose of the cigarette butts
## How we built it
Our basic idea was to build a robot with a camera that could find cigarette butts on the ground and collect those cigarette butts with a roller-mechanism. Below are more in-depth explanations of each part of our robot.
### Software
We needed a method to be able to easily detect cigarette butts on the ground, thus we used computer vision. We made use of this open-source project: [Mask R-CNN for Object Detection and Segmentation](https://github.com/matterport/Mask_RCNN) and [pre-trained weights](https://www.immersivelimit.com/datasets/cigarette-butts). We used a Raspberry Pi and a Pi Camera to take pictures of cigarettes, process the image Tensorflow, and then output coordinates of the location of the cigarette for the robot. The Raspberry Pi would then send these coordinates to an Arduino with UART.
### Hardware
The Arduino controls all the hardware on the robot, including the motors and roller-mechanism. The basic idea of the Arduino code is:
1. Drive a pre-determined path on the sidewalk
2. Wait for the Pi Camera to detect a cigarette
3. Stop the robot and wait for a set of coordinates from the Raspberry Pi to be delivered with UART
4. Travel to the coordinates and retrieve the cigarette butt
5. Repeat
We use sensors such as a gyro and accelerometer to detect the speed and orientation of our robot to know exactly where to travel. The robot uses an ultrasonic sensor to avoid obstacles and make sure that it does not bump into humans or walls.
### Mechanical
We used Solidworks to design the chassis, roller/sweeper-mechanism, and mounts for the camera of the robot. For the robot, we used VEX parts to assemble it. The mount was 3D-printed based on the Solidworks model.
## Challenges we ran into
1. Distance: Working remotely made designing, working together, and transporting supplies challenging. Each group member worked on independent sections and drop-offs were made.
2. Design Decisions: We constantly had to find the most realistic solution based on our budget and the time we had. This meant that we couldn't cover a lot of edge cases, e.g. what happens if the robot gets stolen, what happens if the robot is knocked over ...
3. Shipping Complications: Some desired parts would not have shipped until after the hackathon. Alternative choices were made and we worked around shipping dates
## Accomplishments that we're proud of
We are proud of being able to efficiently organize ourselves and create this robot, even though we worked remotely, We are also proud of being able to create something to contribute to our environment and to help keep our Earth clean.
## What we learned
We learned about machine learning and Mask-RCNN. We never dabbled with machine learning much before so it was awesome being able to play with computer-vision and detect cigarette-butts. We also learned a lot about Arduino and path-planning to get the robot to where we need it to go. On the mechanical side, we learned about different intake systems and 3D modeling.
## What's next for Cigbot
There is still a lot to do for Cigbot. Below are some following examples of parts that could be added:
* Detecting different types of trash: It would be nice to be able to gather not just cigarette butts, but any type of trash such as candy wrappers or plastic bottles, and to also sort them accordingly.
* Various Terrains: Though Cigbot is made for the sidewalk, it may encounter rough terrain, especially in Canada, so we figured it would be good to add some self-stabilizing mechanism at some point
* Anti-theft: Cigbot is currently small and can easily be picked up by anyone. This would be dangerous if we left the robot in the streets since it would easily be damaged or stolen (eg someone could easily rip off and steal our Raspberry Pi). We need to make it larger and more robust.
* Environmental Conditions: Currently, Cigbot is not robust enough to handle more extreme weather conditions such as heavy rain or cold. We need a better encasing to ensure Cigbot can withstand extreme weather.
## Sources
* <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3397372/>
* <https://www.cbc.ca/news/canada/hamilton/cigarette-butts-1.5098782>
* [https://www.nationalgeographic.com/environment/article/cigarettes-story-of-plastic#:~:text=Did%20You%20Know%3F-,About%204.5%20trillion%20cigarettes%20are%20discarded%20each%20year%20worldwide%2C%20making,as%20long%20as%2010%20years](https://www.nationalgeographic.com/environment/article/cigarettes-story-of-plastic#:%7E:text=Did%20You%20Know%3F-,About%204.5%20trillion%20cigarettes%20are%20discarded%20each%20year%20worldwide%2C%20making,as%20long%20as%2010%20years). | losing |
## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used React Native and Smart Contracts along with Celo's SDK to discover BlockChain and the conglomerate use cases associated with these technologies. This includes group insurance, financial literacy, personal investment.
## What it does
Allows users in shared communities to pool their funds and use our platform to easily invest in different stock and companies for which they are passionate about with a decreased/shared risk.
## How we built it
* Smart Contract for the transfer of funds on the blockchain made using Solidity
* A robust backend and authentication system made using node.js, express.js, and MongoDB.
* Elegant front end made with react-native and Celo's SDK.
## Challenges we ran into
Unfamiliar with the tech stack used to create this project and the BlockChain technology.
## What we learned
We learned the many new languages and frameworks used. This includes building cross-platform mobile apps on react-native, the underlying principles of BlockChain technology such as smart contracts, and decentralized apps.
## What's next for *PoolNVest*
Expanding our API to select low-risk stocks and allows the community to vote upon where to invest the funds.
Refine and improve the proof of concept into a marketable MVP and tailor the UI towards the specific use cases as mentioned above. | ## Inspiration
We wanted to do something fun and exciting, nothing too serious. Slang is a vital component to thrive in today's society. Ever seen Travis Scott go like, "My dawg would prolly do it for a Louis belt", even most menials are not familiar with this slang. Therefore, we are leveraging the power of today's modern platform called "Urban Dictionary" to educate people about today's ways. Showing how today's music is changing with the slang thrown in.
## What it does
You choose your desired song it will print out the lyrics for you and then it will even sing it for you in a robotic voice. It will then look up the urban dictionary meaning of the slang and replace with the original and then it will attempt to sing it.
## How I built it
We utilized Python's Flask framework as well as numerous Python Natural Language Processing libraries. We created the Front end with a Bootstrap Framework. Utilizing Kaggle Datasets and Zdict API's
## Challenges I ran into
Redirecting challenges with Flask were frequent and the excessive API calls made the program super slow.
## Accomplishments that I'm proud of
The excellent UI design along with the amazing outcomes that can be produced from the translation of slang
## What I learned
A lot of things we learned
## What's next for SlangSlack
We are going to transform the way today's menials keep up with growing trends in slang. | # SteakAI
### Introducing SteakAI, a web application that uses machine learning to correctly identify the doneness of your steak
*OUR STORY:*
Lousy steak is an issue that we have been personally affected by, and we wanted to create a solution that combats the violation of beautiful cuts of beef. Using a cutting-edge machine-learning algorithm to identify the doneness of a steak correctly, we made sure you will never have to endure a garbage steak again.
In addition to this, Covid forced many people to stay home and learn how to cook, and our web application helps people cook the restaurant-quality steak of their dreams.
AND THAT'S NOT ALL! The future of food service is automation and our application helps to serve the customer a perfect steak every time.
*FRONT END:*
* SteakAI's front end is coded using HTML, CSS, and Flask
* Two pages are displayed to users: A home page giving instructions on what the user should do, and the result of the machine learning algorithm.
*BACK END*:
* A machine learning algorithm is implemented using TensorFlow and Keras to identify the doneness of a steak correctly
Make sure the latest versions of the following are installed for your python version:
* TensorFlow
* Keras
* Flask
* Werkzeug | winning |
## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how much money they lose by being lazy, they might start to change their habits. We took this idea and added a full visualisation aspect of the app to make a complete budgeting app.
## What it does
Our app allows users to log in, and it then retrieves user data to visually represent the most interesting data from that user's financial history, as well as their utilities spending.
## How we built it
We used HTML, CSS, and JavaScript as our front-end, and then used Arduino to get light sensor data, and Nessie to retrieve user financial data.
## Challenges we ran into
To seamlessly integrate our multiple technologies, and to format our graphs in a way that is both informational and visually attractive.
## Accomplishments that we're proud of
We are proud that we have a finished product that does exactly what we wanted it to do and are proud to demo.
## What we learned
We learned about making graphs using JavaScript, as well as using Bootstrap in websites to create pleasing and mobile-friendly interfaces. We also learned about integrating hardware and software into one app.
## What's next for Budge
We want to continue to add more graphs and tables to provide more information about your bank account data, and use AI to make our app give personal recommendations catered to an individual's personal spending. | ## Inspiration
SustainaPal is a project that was born out of a shared concern for the environment and a strong desire to make a difference. We were inspired by the urgent need to combat climate change and promote sustainable living. Seeing the increasing impact of human activities on the planet's health, we felt compelled to take action and contribute to a greener future.
## What it does
At its core, SustainaPal is a mobile application designed to empower individuals to make sustainable lifestyle choices. It serves as a friendly and informative companion on the journey to a more eco-conscious and environmentally responsible way of life. The app helps users understand the environmental impact of their daily choices, from transportation to energy consumption and waste management. With real-time climate projections and gamification elements, SustainaPal makes it fun and engaging to adopt sustainable habits.
## How we built it
The development of SustainaPal involved a multi-faceted approach, combining technology, data analysis, and user engagement. We opted for a React Native framework, and later incorporated Expo, to ensure the app's cross-platform compatibility. The project was structured with a focus on user experience, making it intuitive and accessible for users of all backgrounds.
We leveraged React Navigation and React Redux for managing the app's navigation and state management, making it easier for users to navigate and interact with the app's features. Data privacy and security were paramount, so robust measures were implemented to safeguard user information.
## Challenges we ran into
Throughout the project, we encountered several challenges. Integrating complex AI algorithms for climate projections required a significant amount of development effort. We also had to fine-tune the gamification elements to strike the right balance between making the app fun and motivating users to make eco-friendly choices.
Another challenge was ensuring offline access to essential features, as the app's user base could span areas with unreliable internet connectivity. We also grappled with providing a wide range of educational insights in a user-friendly format.
## Accomplishments that we're proud of
Despite the challenges, we're incredibly proud of what we've achieved with SustainaPal. The app successfully combines technology, data analysis, and user engagement to empower individuals to make a positive impact on the environment. We've created a user-friendly platform that not only informs users but also motivates them to take action.
Our gamification elements have been well-received, and users are enthusiastic about earning rewards for their eco-conscious choices. Additionally, the app's offline access and comprehensive library of sustainability resources have made it a valuable tool for users, regardless of their internet connectivity.
## What we learned
Developing SustainaPal has been a tremendous learning experience. We've gained insights into the complexities of AI algorithms for climate projections and the importance of user-friendly design. Data privacy and security have been areas where we've deepened our knowledge to ensure user trust.
We've also learned that small actions can lead to significant changes. The collective impact of individual choices is a powerful force in addressing environmental challenges. SustainaPal has taught us that education and motivation are key drivers for change.
## What's next for SustainaPal
The journey doesn't end with the current version of SustainaPal. In the future, we plan to further enhance the app's features and expand its reach. We aim to strengthen data privacy and security, offer multi-language support, and implement user support for a seamless experience.
SustainaPal will also continue to evolve with more integrations, such as wearable devices, customized recommendations, and options for users to offset their carbon footprint. We look forward to fostering partnerships with eco-friendly businesses and expanding our analytics and reporting capabilities for research and policy development.
Our vision for SustainaPal is to be a global movement, and we're excited to be on this journey towards a healthier planet. Together, we can make a lasting impact on the world. | ## Inspiration
Save plate is an app that focuses on narrowing the equity differences in society.It is made with the passion to solve the SDG goals such as zero hunger, Improving life on land, sustainable cities and communities and responsible consumption and production.
## What it does
It helps give a platform to food facilities to distribute their untouched meals to the shelter via the plate saver app. It asks the restaurant to provide the number of meals that are available and could be picked up by the shelters. It also gives the flexibility to provide any kind of food restriction to respect cultural and health restrictions for food.
## How we built it
* Jav
## Challenges we ran into
There were many challenges that I and my teammates ran into were learning new skills, teamwork and brainstorming.
## Accomplishments that we're proud of
Creating maps, working with
## What we learned
We believe our app is needed not only in one region but entire world, we all are taking steps towards building a safe community for everyone Therefore we see our app's potential to run in collaboration with UN and together we fight world hunger. | winning |
## Inspiration
Have you ever wanted to go tandem biking but lacked the most important thing, a partner? We realize that this is a widespread issue and hope to help tandem bikers of all kinds, including both recreational users and those who seek commuting solutions.
## What it does
Our project helps you find a suitable tandem biking partner using a tinder-like system. We develop routes and the program also includes features such as playlist curation and smart conversation starters.
## How we built it
The web app was developed using django.
## Challenges we ran into
Developing an actual swipe mechanism was fairly difficult.
## Accomplishments that we're proud of
We're proud of our members' ingenuity in developing solutions utilizing django, an interface with which we all lacked experience.
## What we learned
We learned that tons of people are actually really interested in tandem biking and would download the app.
## What's next for Tander
Three. Seat. Tandem. Bike. | ## Inspiration
As we were brainstorming ideas that we felt we could grow and expand upon we came to a common consensus. Finding a roommate for residence. We all found the previous program was very unappealing and difficult, during our first year we heard so many roommate horror stories. We felt providing a more modern and accustomed model, that hasn’t been explored before, towards finding a roommate would extremely benefit the process and effectiveness of securing a future roommate and more importantly a friend for the next generations.
## What it does
The program is a fully functional full stack web app that allows users to log in or create a profile, and find other students for roommates. The program includes a chat functionality which creates a chat room between two people (only once they've both matched with one another). The product also automatically recommends users as roommates based on an AI model which reads data from a database filled with metrics that the user sets when creating their profile, such as their program of study, sleep schedule, etc.
## How we built it
We first tackled the front end aspect by creating a rough template of what we imagined our final product would look like with React.js. After we set up a database using MonogoDB to act as our backend to the project and to store our users profiles, data, and messages. Once our database was secured we connected the backend to the frontend through Python using libraries such as Flask, PyMongo, and Panadas. Our python code would read through the database and use an AI model to compute a score for the compatibility between two people. Finally, we cleaned up our frontend and formatted our application to look nice and pretty.
## Challenges we ran into
As we had no experience with full-stack development, figuring out how to develop the backend and connect it with the front end was a very difficult challenge. Thankfully, using our resources and some intuition, we were able to overcome this. With such a drastic knowledge gap going into the project, another challenge was keeping our team on time and on track. We needed to make sure we weren't spending too much time learning something that wouldn't help our project or too much time trying to incorporate a function that wouldn't have a large impact on the abilities of the final product.
## Accomplishments that we're proud of
We are proud that we were able to create a fully functioning full-stack application with practically no knowledge in that field. We're especially proud of our accomplishment of learning so many new things in such a short amount of time. The feeling of satisfaction and pride we felt after coming up with a unique idea, overcoming many challenges, and finally reaching our desired goal is immeasurable.
## What we learned
None of us knew how to use the technologies we used during the project. There was definitely a learning curve with incorporating multiple technologies that we had not used before into a cohesive app, but we learned how to properly divide and plan out our workload between the four of us. We gained experience in assessing our own strengths and weaknesses as well as our teammates and gained strong knowledge in multiple languages, full-stack concepts, AI, libraries, and databases.
## What's next for RoomMate
In the near future, we plan to fully host our website on a public domain name, rather than having it work from the console. We also hope to expand our questionnaire and survey in order to further tailor our search results depending on users' preferences and improve users' experience with the site. | ## Inspiration
We got the idea for this app after one of our teammates shared that during her summer internship in China, she could not find basic over the counter medication that she needed. She knew the brand name of the medication in English, however, she was unfamiliar with the local pharmaceutical brands and she could not read Chinese.
## Links
* [FYIs for your Spanish pharmacy visit](http://nolongernative.com/visiting-spanish-pharmacy/)
* [Comparison of the safety information on drug labels in three developed countries: The USA, UK and Canada](https://www.sciencedirect.com/science/article/pii/S1319016417301433)
* [How to Make Sure You Travel with Medication Legally](https://www.nytimes.com/2018/01/19/travel/how-to-make-sure-you-travel-with-medication-legally.html)
## What it does
This mobile app allows users traveling to different countries to find the medication they need. They can input the brand name in the language/country they know and get the name of the same compound in the country they are traveling to. The app provides a list of popular brand names for that type of product, along with images to help the user find the medicine at a pharmacy.
## How we built it
We used Beautiful Soup to scrape Drugs.com to create a database of 20 most popular active ingredients in over the counter medication. We included in our database the name of the compound in 6 different languages/countries, as well as the associated brand names in the 6 different countries.
We stored our database on MongoDB Atlas and used Stitch to connect it to our React Native front-end.
Our Android app was built with Android Studio and connected to the MongoDB Atlas database via the Stitch driver.
## Challenges we ran into
We had some trouble connecting our React Native app to the MongoDB database since most of our team members had little experience with these platforms. We revised the schema for our data multiple times in order to find the optimal way of representing fields that have multiple values.
## Accomplishments that we're proud of
We're proud of how far we got considering how little experience we had. We learned a lot from this Hackathon and we are very proud of what we created. We think that healthcare and finding proper medication is one of the most important things in life, and there is a lack of informative apps for getting proper healthcare abroad, so we're proud that we came up with a potential solution to help travellers worldwide take care of their health.
## What we learned
We learned a lot of React Native and MongoDB while working on this project. We also learned what the most popular over the counter medications are and what they're called in different countries.
## What's next for SuperMed
We hope to continue working on our MERN skills in the future so that we can expand SuperMed to include even more data from a variety of different websites. We hope to also collect language translation data and use ML/AI to automatically translate drug labels into different languages. This would provide even more assistance to travelers around the world. | losing |
## Problem
Attendance at office hours has been shown to be positively correlated with academic standing. However, 66% of students never attend office hours. Two significant contributing factors to this lack of attendance are the time and location of the office hours. See studies [here](http://www.tandfonline.com/doi/abs/10.1080/15512169.2013.835554?src=recsys&journalCode=upse20) and [here](https://www.facultyfocus.com/articles/teaching-professor-blog/students-dont-attend-office-hours/)
## Solution
Our solution is an easy-to-use website that makes office hours accessible online. Students submit questions to the teacher, and teachers respond to these questions by video. Students can view previous questions and answers, which are recorded in association with individual questions.
## Our Mission
* Improve office hours attendance
* Reduce the friction of attending office hours
* Improve student academic performance
## Process
Front-end Design:
* Used Sketch to draw up a outline of website
* Coded the design using HTML, Javascript, and CSS.
Back-end Design:
* Used Django (Python) to build complex database structure
Video Streaming API:
* Determined best API for project is YouTube Live Streaming API, but did not have time to implement it
## Challenges
* Implementing and understanding the YouTube Live Streaming API
* Issue with date ranges and time zones, so kept all times in UTC
* Publishing website from front-end
## Accomplishments
* Domain hosting set up [here](www.ruminate.exampleschool.net)
* Functional local website with admin editing and website updating
* Business plan with initial, beginning, and future strategies for Ruminate
## Our Future
Near future, we plan to connect with specific teachers at Cornell University to test and provide feedback on the software. We will survey some of their students to measure the efficacy of the software on the student's office hour attendance and academic standing. Some functionality we want to add is attendance statistics for the teachers. Later, we plan on expanding into other Upstate New York colleges and generating revenue by creating a biannual subscription service. We will attempt integrate our web service into Blackboard or Canvas to reduce friction of signing up. | ## Inspiration
We were inspired by a [recent article](https://www.cbc.ca/news/canada/manitoba/manitoba-man-heart-stops-toronto-airport-1.5430605) that we saw on the news, where there was a man who suffered a cardiac arrest while waiting for his plane. With the help of a bystander who was able to administer the AED and the CPR, he was able to make a full recovery.
We wanted to build a solution that is able to connect victims of cardiac arrests with bystanders who are willing to help, thereby [increasing their survival rates](https://www.ahajournals.org/doi/10.1161/CIRCOUTCOMES.109.889576) . We truly believe in the goodness and willingness of people to help.
## Problem Space
We wanted to be laser-focused in the problem that we are solving - helping victims of cardiac arrests. We did tons of research to validate that this was a problem to begin with, before diving deeper into the solution-ing space.
We also found that there are laws protecting those who try to offer help - indemnifying them of liabilities while performing CPR or AED: [Good Samaritan and the Chase Mceachern Act](https://www.toronto.ca/community-people/public-safety-alerts/training-first-aid-courses/). So why not ask everyone to help?
## What it does
Hero is a web and app based platform that empowers community members to assist in time sensitive medical emergencies especially cardiac arrests, by providing them a ML optimised route that maximizes the CA victim's chances of survival.
We have 2 components - Hero Command and Hero Deploy.
1) **Hero Command** is the interface that the EMS uses. It allows the location of cardiac arrests to be shown on a single map, as well as the nearby first-responders and AED Equipment. We scrapped the Ontario Goverment's AED listing to provide an accurate geo-location of an AED for each area.
Hero Command has a **ML Model** working in the background to find out the optimal route that the first-responder should take: should they go straight to the victim and perform CPR, or should they detour and collect the AED before proceeding to the victim (of which will take some time). This is done by training our model on a sample dataset and calculating an estimated survival percentage for each of the two routes.
2) **Hero Deploy** is the mobile application that our community of first-responders use. It will allow them to accept/reject the request, and provide the location and navigation instructions. It will also provide hands-free CPR audio guidance so that the community members can focus on CPR. \* Cue the Staying Alive music by the BeeGees \*
## How we built it
With so much passion, hard work and an awesome team. And honestly, youtube tutorials.
## Challenges I ran into
We **did not know how** to create an app - all of us were either web devs or data analysts. This meant that we had to watch alot of tutorials and articles to get up to speed. We initially considered abandoning this idea because of the inability to create an app, but we are so happy that we managed to do it together.
## Accomplishments that I'm proud of
Our team learnt so much things in the past few days, especially tech stacks and concepts that were super unfamiliar to us. We are glad to have created something that is viable, working, and has the potential to change how the world works and lives.
We built 3 things - ML Model, Web Interface and a Mobile Application
## What I learned
Hard work takes you far. We also learnt React Native, and how to train and use supervised machine learning models (which we did not have any experience in). We also worked on the business market validation such that the project that we are building is actually solving a real problem.
## What's next for Hero
Possibly introducing the idea to Government Services and getting their buy in. We may also explore other use cases that we can use Hero with | # Emotify
## Inspiration
We all cared deeply about mental health and we wanted to help those in need. 280 million people have depression in this world. However, we found out that people play a big role in treating depression - some teammates have experienced this first hand! So, we created Emotify, which brings back the memories of nostalgia and happy moments with friends.
## What it does
The application utilizes an image classification program to classify photos locally stored on one's device. The application then "brings back memories and feelings of nostalgia" by displaying photos which either match a person's mood (if positive) or inverts a person's mood (if negative). Input mood is determined by Cohere's NLP API; negatively associated moods (such as "sad") are associated with happy photos to cheer people up. The program can also be used to find images, being able to distinguish between request of individual and group photos, as well as the mood portrayed within the photo.
## How we built it
We used DeepFace api to effective predict facial emotions that sort into different emotions which are happy, sad, angry, afraid, surprise, and disgust. Each of these emotions will be token to generate the picture intelligently thanks to Cohere. Their brilliant NLP helped us to build a model that guesses what token we should feed our sorted picture generator to bring happiness and take them a trip down the memory lane to remind them of the amazing moments that they been through with their closed ones or times where they were proud of themselves. Take a step back and look back the journey they been through by using React frame work to display images that highlight their fun times. We only do two at a time for our generator because we want people to really enjoy these photos and remind what happened in these two photos (especially happy ones). Thanks to implementing a streamline pipeline, we managed to turn these pictures into objects that can return file folders that feed into the front end through getting their static images folder using the Flask api. We ask the users for their inputs, then run it through our amazing NLP that backed by Cohere to generate meaning token that produce quality photos. We trained the model in advance since it is very time consuming for the DeepFace api to go through all the photos. Of course, we have privacy in mind which thanks to Auth0, we could implement the user base system to securely protect their data and have their own privacy using the system.
## Challenges we ran into
One major challenge includes front end development. We were split on the frameworks to use (Flask? Django? React?). how the application was to be designed, the user experience workflow, and any changes we had to make to implement third party integrations (such as Auth0) and make the application look visually appealing.
## Accomplishments that we're proud of
We are very satisfied with the work that we were able to do at UofT hacks, and extremely proud of the project we created. Many of the features of this project are things that we did not have knowledge on prior to the event. So, to have been able to successfully complete everything we set out to do and more, while meeting the criteria for four of the challenges, has been very encouraging to say the least.
## What we learned
The most experienced among us has been to 2 hackathons, while it was the first for the rest of us. For that reason this learning experience has been overwhelming. Having the opportunity to work with new technologies while creating a project we are proud of within 36 hours has forced us to fill in many of the gaps in our skillset, especially with ai/ml and full stack programming.
## What's next for Emotify
We plan to further develop this application during our free time, such that we 'polish it' to our standards, and to ensure it meets our intended purpose. The developers definitely would enjoy using such an app in our daily lives to keep us going with more positive energy. Of course, winning UofTHacks is an asset. | winning |
## Inspiration
Despite being a global priority in the eyes of the United Nations, food insecurity still affects hundreds of millions of people. Even in the developed country of Canada, over 5.8 million individuals (>14% of the national population) are living in food-insecure households. These individuals are unable to access adequate quantities of nutritious foods.
## What it does
Food4All works to limit the prevalence of food insecurity by minimizing waste from food corporations. The website addresses this by serving as a link between businesses with leftover food and individuals in need. Businesses with a surplus of food are able to donate food by displaying their offering on the Food4All website. By filling out the form, businesses will have the opportunity to input the nutritional values of the food, the quantity of the food, and the location for pickup.
From a consumer’s perspective, they will be able to see nearby donations on an interactive map. By separating foods by their needs (e.g., high-protein), consumers will be able to reserve the donated food they desire. Altogether, this works to cut down unnecessary food waste by providing it to people in need.
## How we built it
We created this project using a combination of multiple languages. We used Python for the backend, specifically for setting up the login system using Flask Login. We also used Python for form submissions, where we took the input and allocated it to a JSON object which interacted with the food map. Secondly, we used Typescript (JavaScript for deployable code) and JavaScript’s Fetch API in order to interact with the Google Maps Platform. The two major APIs we used from this platform are the Places API and Maps JavaScript API. This was responsible for creating the map, the markers with information, and an accessible form system. We used HTML/CSS and JavaScript alongside Bootstrap to produce the web-design of the website. Finally, we used the QR Code API in order to get QR Code receipts for the food pickups.
## Challenges we ran into
Some of the challenges we ran into was using the Fetch API. Since none of us were familiar with asynchronous polling, specifically in JavaScript, we had to learn this to make a functioning food inventory. Additionally, learning the Google Maps Platform was a challenge due to the comprehensive documentation and our lack of prior experience. Finally, putting front-end components together with back-end components to create a cohesive website proved to be a major challenge for us.
## Accomplishments that we're proud of
Overall, we are extremely proud of the web application we created. The final website is functional and it was created to resolve a social issue we are all passionate about. Furthermore, the project we created solves a problem in a way that hasn’t been approached before. In addition to improving our teamwork skills, we are pleased to have learned new tools such as Google Maps Platform. Last but not least, we are thrilled to overcome the multiple challenges we faced throughout the process of creation.
## What we learned
In addition to learning more about food insecurity, we improved our HTML/CSS skills through developing the website. To add on, we increased our understanding of Javascript/TypeScript through the utilization of the APIs on Google Maps Platform (e.g., Maps JavaScript API and Places API). These APIs taught us valuable JavaScript skills like operating the Fetch API effectively. We also had to incorporate the Google Maps Autofill Form API and the Maps JavaScript API, which happened to be a difficult but engaging challenge for us.
## What's next for Food4All - End Food Insecurity
There are a variety of next steps of Food4All. First of all, we want to eliminate the potential misuse of reserving food. One of our key objectives is to prevent privileged individuals from taking away the donations from people in need. We plan to implement a method to verify the socioeconomic status of users. Proper implementation of this verification system would also be effective in limiting the maximum number of reservations an individual can make daily.
We also want to add a method to incentivize businesses to donate their excess food. This can be achieved by partnering with corporations and marketing their business on our webpage. By doing this, organizations who donate will be seen as charitable and good-natured by the public eye.
Lastly, we want to have a third option which would allow volunteers to act as a delivery person. This would permit them to drop off items at the consumer’s household. Volunteers, if applicable, would be able to receive volunteer hours based on delivery time. | ## Inspiration
We recognized how much time meal planning can cause, especially for busy young professionals and students who have little experience cooking. We wanted to provide an easy way to buy healthy, sustainable meals for the week, without compromising the budget or harming the environment.
## What it does
Similar to services like "Hello Fresh", this is a webapp for finding recipes and delivering the ingredients to your house. This is where the similarities end, however. Instead of shipping the ingredients to you directly, our app makes use of local grocery delivery services, such as the one provided by Loblaws. The advantages to this are two-fold: first, it helps keep the price down, as your main fee is for the groceries themselves, instead of paying large amounts in fees to a meal kit company. Second, this is more eco-friendly. Meal kit companies traditionally repackage the ingredients in house into single-use plastic packaging, before shipping it to the user, along with large coolers and ice packs which mostly are never re-used. Our app adds no additional packaging beyond that the groceries initially come in.
## How We built it
We made a web app, with the client side code written using React. The server was written in python using Flask, and was hosted on the cloud using Google App Engine. We used MongoDB Atlas, also hosted on Google Cloud.
On the server, we used the Spoonacular API to search for recipes, and Instacart for the grocery delivery.
## Challenges we ran into
The Instacart API is not publicly available, and there are no public API's for grocery delivery, so we had to reverse engineer this API to allow us to add things to the cart. The Spoonacular API was down for about 4 hours on Saturday evening, during which time we almost entirely switched over to a less functional API, before it came back online and we switched back.
## Accomplishments that we're proud of
Created a functional prototype capable of facilitating the order of recipes through Instacart. Learning new skills, like Flask, Google Cloud and for some of the team React.
## What we've learned
How to reverse engineer an API, using Python as a web server with Flask, Google Cloud, new API's, MongoDB
## What's next for Fiscal Fresh
Add additional functionality on the client side, such as browsing by popular recipes | ## Inspiration
We all feel strongly about a wide variety of issues, but often fail to support organizations fighting for causes close to us. Our inspiration for this project was this feeling: we wanted to find a way to encourage donating to nonprofits in the easiest way. What better way to do this than through something we use everyday-- email.
## What it does
Project #doSomething is an email integration for a "/donate" command on Mixmax (an email enhancing tool). We then offer a variety of nonprofits to donate to, including the Best Friends Animal Society, various animal shelters, the ACLU, LGBTQ+ Initiative, ect.
## How we built it
We built this Mixmax integration with primarily JavaScript (Node.js), HTML/CSS, and lots of coffee.
## Challenges we ran into
We ran into a major issue where we found out that Chrome was blocking the integration, because we didn't have a valid security certificate on our local dev environment. We managed to eventually work around it by modifying Chrome. Another major challenge we ran into was discovering which nonprofits to add, but we quickly found a ton of worthy organizations.
## Accomplishments that we're proud of
We're proud of making a working email integration (with Mixmax) that can be used by anyone. We really hope people can use this to donate, and easily encourage their friends to donate.
## What's next for Project #doSomething
Stretch goal for the future: make it easy to match donations (and track how many donations to match) via a Mixmax integration. | winning |
## Inspiration
I, Jennifer Wong, went through many mental health hurdles and struggled to get the specific help that I needed. I was fortunate to find a relatable therapist that gave me an educational understanding of my mental health, which helped me understand my past and accept it. I was able to afford this access to mental health care and connect with a therapist similar to me, but that's not the case for many racial minorities. I saw the power of mental health education and wanted to spread it to others.
## What it does
Takes a personalized assessment of your background and mental health in order to provide a curated and self-guided educational program based on your cultural experiences.
You can journal about your reflections as you learn through watching each video. Videos are curated as an MVP, but eventually, we want to hire therapists to create these educational videos.
## How we built it
## Challenges we ran into
* We had our engineers drop the project or couldn't attend the working sessions, so there were issues with the workload. Also, there were issues with technical feasibility since knowledge on Swift was limited.
## Accomplishments that we're proud of
Proud that overall, we were able to create a fully functioning app that still achieves our mission. We were happy to get the journal tool completed, which was the most complicated.
## What we learned
We learned how to cut scope when we lost engineers on the team.
## What's next for Empathie (iOS)
We will get more customer validation about the problem and see if our idea resonates with people. We are currently getting feedback from therapists who work with people of color.
In the future, we would love to partner with schools to provide these types of self-guided services since there's a shortage of therapists, especially for underserved school districts. | ## Inspiration
**A lot of people have stressful things on their mind right now.** [According to a Boston University study, "depression symptom prevalence was more than 3-fold higher during the COVID-19 pandemic than before."](https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2770146)
Sometimes it’s hard to sleep or get a good night’s rest because of what happened that day. If you say or write everything down, it helps get it out of your mind so you’re not constantly thinking about it. Diaries take a long time to write in, and sometimes you want to talk. **Voice diaries aren't common and they are quicker and easier to use than a real diary.**
## What it does
When you're too tired to write out your thoughts at the end of the day, **you can simply talk aloud and our app will write it down for you, easy right?**
Nite Write asks you questions to get you thinking about your day. It listens to you while you speak. You can take breaks and continue speaking to the app. You can go back and look at old posts and reflect on your days!
## How we built it
* We used **Figma** to plan out the design and flow of our web app.
* We used **WebSpeech API** and **JavaScript** to hook up the speech-to-text transcription.
* We used **HTML** and **CSS** for the front-end of the web app.
* And lastly, we used **Flask** to put the entire app together.
## Challenges we ran into
Our first challenge was understanding how to use Flask both in its usage of routes, templates, and syntax. Another challenge was the lack of time and integrating the different parts of the app because we're virtual. It was difficult to coordinate and use our time efficiently since we lived all over the country in different timezones.
## Accomplishments that we're proud of
**We are proud of being able to come together virtually to address this problem we all had!**
## What we learned
We learned how to use Flask, WebSpeech API, and CSS. We also learned how to put together a demo with slides, work together virtually.
## What's next for Nite Write?
* Show summaries and trends on a person's most frequent entry topics or emotion
* Search feature that filters your diary entries based on certain words you used
* Light Mode feature
* Ability to sort entries based on topic/etc | ## What it does
Tickets is a secure, affordable, and painless system for registration and organization of in-person events. It utilizes public key cryptography to ensure the identity of visitors, while staying affordable for organizers, with no extra equipment or cost other than a cellphone. Additionally, it provides an easy method of requesting waiver and form signatures through Docusign.
## How we built it
We used Bluetooth Low Energy in order to provide easy communication between devices, PGP in order to verify the identities of both parties involved, and a variety of technologies, including Vue.js, MongoDB Stitch, and Bulma to make the final product.
## Challenges we ran into
We tried working (and struggling) with NFC and other wireless technologies before settling on Bluetooth LE as the best option for our use case. We also spent a lot of time getting familiar with MongoDB Stitch and the Docusign API.
## Accomplishments that we're proud of
We're proud of successfully creating a polished and functional product in a short period of time.
## What we learned
This was our first time using MongoDB Stitch, as well as Bluetooth Low Energy.
## What's next for Tickets
An option to allow for payments for events, as well as more input formats and data collection. | partial |
## Inspiration
All of our team members are deeply passionate about improving students' education. We focused on the underserved community of deaf or hard-of-hearing students, who communicate, understand, and think primarily in ASL. While some of these students have become accustomed to reading English in various contexts, our market research from studies conducted by Penn State University indicates that members of the community prefer to communicate and think in ASL, and think of English writing as a second language in terms of grammatical structure and syntax.
The majority of deaf people do not have what is commonly referred to as an “inner voice”; instead they often sign ASL in their heads to themselves. For this reason, deaf students are largely disadvantaged in academia, especially with regard to live attendance of lectures. As a result, we sought to design an app to translate professors’ lecture speeches to ASL in near-real time.
## What it does
Our app enables enhanced live-lecture for members of the ASL-speaking community by intelligently converting the professor's speech to a sequence of ASL videos for the user to watch during lecture. This style of real-time audio to ASL conversion has never been done before, and our app bridges the educational barrier that exists in the deaf and hard-of-hearing community.
## How we built it
We broke down the development of the app into 3 phases: converting voice to speech, converting speech to ASL videos, and connecting the two components together in an iOS application with an engaging user interface.
Building off of existing on-device speech recognition models including Pocketsphinx, Mozilla DeepSpeech, iOS Dictation, and more, we decided to combine them in an ensemble model. We employed the Google Cloud Speech to Text API to transcribe videos for ground truth, against which we compared transcription error rates for our models by phonemes, lengths, and syllabic features.
Finally, we ran our own tests to ensure that the speech-to-text API was dynamically editing previously spoken words and phrases using context of neighboring words. The ideal weights for each weight assigned to each candidate were optimized over many iterations of testing using the Weights & Biases API (along with generous amounts of freezing layers and honing in!). Through many grueling rounds and head-to-head comparisons, the iOS on-device speech recognizer shined, with its superior accuracy and performance, compared to the other two, and was assigned the highest weight by far. Based on these results, in order to improve performance, we ended up not using the other two models at all.
## Challenges we ran into
When we were designing the solution architecture, we quickly discovered there was no API or database to enable conversion of written English to ASL "gloss" (or even videos). We were therefore forced to make our own database by creating and cropping videos ourselves. While time-consuming, this ensured consistent video quality as well as speed and efficiency in loading the videos on the iOS device. It also inspired our plan to crowdsource information and database video samples from users in a way that benefits all those who opt-in to the sharing system.
One of the first difficulties we had was navigating the various different speech recognition model outputs and modifying it for continuous and lengthy voice samples. Furthermore, we had to ensure our algorithm dynamically adjusted history and performed backwards error correction, since some API's (especially Apple's iOS Dictation) dynamically alter past text when clued in on context from later words.
All of our lexical and syntactical analysis required us to meticulously design finite state machines and data structures around the results of the models and API's we used — and required significant alteration & massaging — before they became useful for our application. This was necessary due to our ambitious goal of achieving real-time ASL delivery to users.
## Accomplishments that we're proud of
As a team we were most proud of our ability to quickly learn new frameworks and use Machine Learning and Reinforcement Learning to develop an application that was scalable and modular. While we were subject to a time restriction, we ensured that our user interface was polished, and that our final app integrated several frameworks seamlessly to deliver a usable product to our target audience, *sans* bugs or errors. We pushed ourselves to learn unfamiliar skills so that our solution would be as comprehensive as we could make it. Additionally, of course, we’re proud of our ability to come together and solve a problem that could truly benefit an entire community.
## What we learned
We learned how to brainstorm ideas effectively and in a team, create ideas collaboratively, and parallelize tasks for maximum efficiency. We exercised our literature research and market research skills to recognize that there was a gap we could fill in the ASL community. We also integrated ML techniques into our design and solution process, carefully selecting analysis methods to evaluate candidate options before proceeding on a rigorously defined footing. Finally, we strove to continually analyze data to inform future design decisions and train our models.
## What's next for Sign-ify
We want to expand our app to be more robust and extensible. Currently, the greatest limitation of our application is the limited database of ASL words that we recorded videos for. In the future, one of our biggest priorities is to dynamically generate animation so that we will have a larger and more accurate database. We want to improve our speech to text API with more training data so that it becomes more accurate in educational settings.
Publishing the app on the iOS app store will provide the most effective distribution channel and allow members of the deaf and hard-of-hearing community easy access to our app.
We are very excited by the prospects of this solution and will continue to update the software to achieve our goal of enhancing the educational experience for users with auditory impairments.
## Citations:
Google Cloud Platform API
Penn State. "Sign language users read words and see signs simultaneously." ScienceDaily. ScienceDaily, 24 March 2011 [[www.sciencedaily.com/releases/2011/03/110322105438.htm](http://www.sciencedaily.com/releases/2011/03/110322105438.htm)]. | ## Inspiration
Since the outbreak of COVID-19, while the rest of the world has moved online, ASL speakers faced even greater inequities making it difficult for so many of them to communicate. However, this has to come to an end. In the pursuit of finding accessibility, I created a tool to empower ASL speakers to speak freely with the help of AI.
## What it does
Uses a webcam to translate ASL speech to text.
## How we built it
Used Mediapipe to generate points on hands, then use those points to get training data set.
I used Jupyter Notebook to run OpenCV and Mediapipe. Upon running our data in Mediapipe, we were able to get a skeleton map of the body with 22 points for each hand. These points can be mapped in 3-dimension as it contains X, Y, and Z axis. We processed these features (22 points x 3) by saving them into a spreadsheet. Then we divided the spreadsheet into training and testing data.
Using the training set, we were able to create 6 Machine learning models:
* Gradient Boost Classifier
* XGBoost Classifier
* Support Vector Machine
* Logistic Regression
* Ridge Classifier
* Random Forest Classifier
## Challenges we ran into
* Had to do solo work due to issues with the team
* Time management
* Project management
* Lack of data
## Accomplishments that we're proud of
Proud of pivoting my original idea and completing this epic hackathon. Also proud of making a useful tool
## What we learned
* Time management
* Project management
## What's next for Voice4Everyone
* More training of data - more classifications
* Phone app + Chrome Extension
* Reverse translation: Converting English Text to ASL
* Cleaner UI
* Add support for the entire ASL dictionary and other sign languages | ## The Gist
We combine state-of-the-art LLM/GPT detection methods with image diffusion models to accurately detect AI-generated video with 92% accuracy.
## Inspiration
As image and video generation models become more powerful, they pose a strong threat to traditional media norms of trust and truth. OpenAI's SORA model released in the last week produces extremely realistic video to fit any prompt, and opens up pathways for malicious actors to spread unprecedented misinformation regarding elections, war, etc.
## What it does
BinoSoRAs is a novel system designed to authenticate the origin of videos through advanced frame interpolation and deep learning techniques. This methodology is an extension of the state-of-the-art Binoculars framework by Hans et al. (January 2024), which employs dual LLMs to differentiate human-generated text from machine-generated counterparts based on the concept of textual "surprise".
BinoSoRAs extends on this idea in the video domain by utilizing **Fréchet Inception Distance (FID)** to compare the original input video against a model-generated video. FID is a common metric which measures the quality and diversity of images using an Inception v3 convolutional neural network. We create model-generated video by feeding the suspect input video into a **Fast Frame Interpolation (FLAVR)** model, which interpolates every 8 frames given start and end reference frames. We show that this interpolated video is more similar (i.e. "less surprising") to authentic video than artificial content when compared using FID.
The resulting FID + FLAVR two-model combination is an effective framework for detecting video generation such as that from OpenAI's SoRA. This innovative application enables a root-level analysis of video content, offering a robust mechanism for distinguishing between human-generated and machine-generated videos. Specifically, by using the Inception v3 and FLAVR models, we are able to look deeper into shared training data commonalities present in generated video.
## How we built it
Rather than simply analyzing the outputs of generative models, a common approach for detecting AI content, our methodology leverages patterns and weaknesses that are inherent to the common training data necessary to make these models in the first place. Our approach builds on the **Binoculars** framework developed by Hans et al. (Jan 2024), which is a highly accurate method of detecting LLM-generated tokens. Their state-of-the-art LLM text detector makes use of two assumptions: simply "looking" at text of unknown origin is not enough to classify it as human- or machine-generated, because a generator aims to make differences undetectable. Additionally, *models are more similar to each other than they are to any human*, in part because they are trained on extremely similar massive datasets. The natural conclusion is that an observer model will find human text to be very *perplex* and surprising, while an observer model will find generated text to be exactly what it expects.
We used Fréchet Inception Distance between the unknown video and interpolated generated video as a metric to determine if video is generated or real. FID uses the Inception score, which calculates how well the top-performing classifier Inception v3 classifies an image as one of 1,000 objects. After calculating the Inception score for every frame in the unknown video and the interpolated video, FID calculates the Fréchet distance between these Gaussian distributions, which is a high-dimensional measure of similarity between two curves. FID has been previously shown to correlate extremely well with human recognition of images as well as increase as expected with visual degradation of images.
We also used the open-source model **FLAVR** (Flow-Agnostic Video Representations for Fast Frame Interpolation), which is capable of single shot multi-frame prediction and reasoning about non-linear motion trajectories. With fine-tuning, this effectively served as our generator model, which created the comparison video necessary to the final FID metric.
With a FID-threshold-distance of 52.87, the true negative rate (Real videos correctly identified as real) was found to be 78.5%, and the false positive rate (Real videos incorrectly identified as fake) was found to be 21.4%. This computes to an accuracy of 91.67%.
## Challenges we ran into
One significant challenge was developing a framework for translating the Binoculars metric (Hans et al.), designed for detecting tokens generated by large-language models, into a practical score for judging AI-generated video content. Ultimately, we settled on our current framework of utilizing an observer and generator model to get an FID-based score; this method allows us to effectively determine the quality of movement between consecutive video frames through leveraging the distance between image feature vectors to classify suspect images.
## Accomplishments that we're proud of
We're extremely proud of our final product: BinoSoRAs is a framework that is not only effective, but also highly adaptive to the difficult challenge of detecting AI-generated videos. This type of content will only continue to proliferate the internet as text-to-video models such as OpenAI's SoRA get released to the public: in a time when anyone can fake videos effectively with minimal effort, these kinds of detection solutions and tools are more important than ever, *especially in an election year*.
BinoSoRAs represents a significant advancement in video authenticity analysis, combining the strengths of FLAVR's flow-free frame interpolation with the analytical precision of FID. By adapting the Binoculars framework's methodology to the visual domain, it sets a new standard for detecting machine-generated content, offering valuable insights for content verification and digital forensics. The system's efficiency, scalability, and effectiveness underscore its potential to address the evolving challenges of digital content authentication in an increasingly automated world.
## What we learned
This was the first-ever hackathon for all of us, and we all learned many valuable lessons about generative AI models and detection metrics such as Binoculars and Fréchet Inception Distance. Some team members also got new exposure to data mining and analysis (through data-handling libraries like NumPy, PyTorch, and Tensorflow), in addition to general knowledge about processing video data via OpenCV.
Arguably more importantly, we got to experience what it's like working in a team and iterating quickly on new research ideas. The process of vectoring and understanding how to de-risk our most uncertain research questions was invaluable, and we are proud of our teamwork and determination that ultimately culminated in a successful project.
## What's next for BinoSoRAs
BinoSoRAs is an exciting framework that has obvious and immediate real-world applications, in addition to more potential research avenues to explore. The aim is to create a highly-accurate model that can eventually be integrated into web applications and news articles to give immediate and accurate warnings/feedback of AI-generated content. This can mitigate the risk of misinformation in a time where anyone with basic computer skills can spread malicious content, and our hope is that we can build on this idea to prove our belief that despite its misuse, AI is a fundamental force for good. | partial |
## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward. | ## Inspiration
A couple of weeks ago, 3 of us met up at a new Italian restaurant and we started going over the menu. It became very clear to us that there were a lot of options, but also a lot of them didn't match our dietary requirements. And so, we though of Easy Eats, a solution that analyzes the menu for you, to show you what options are available to you without the dissapointment.
## What it does
You first start by signing up to our service through the web app, set your preferences and link your phone number. Then, any time you're out (or even if you're deciding on a place to go) just pull up the Easy Eats contact and send a picture of the menu via text - No internet required!
Easy Eats then does the hard work of going through the menu and comparing the items with your preferences, and highlights options that it thinks you would like, dislike and love!
It then returns the menu to you, and saves you time when deciding your next meal.
Even if you don't have any dietary restricitons, by sharing your preferences Easy Eats will learn what foods you like and suggest better meals and restaurants.
## How we built it
The heart of Easy Eats lies on the Google Cloud Platform (GCP), and the soul is offered by Twilio.
The user interacts with Twilio's APIs by sending and recieving messages, Twilio also initiates some of the API calls that are directed to GCP through Twilio's serverless functions. The user can also interact with Easy Eats through Twilio's chat function or REST APIs that connect to the front end.
In the background, Easy Eats uses Firestore to store user information, and Cloud Storage buckets to store all images+links sent to the platform. From there the images/PDFs are parsed using either the OCR engine or Vision AI API (OCR works better with PDFs whereas Vision AI is more accurate when used on images). Then, the data is passed through the NLP engine (customized for food) to find synonym for popular dietary restrictions (such as Pork byproducts: Salami, Ham, ...).
Finally, App Engine glues everything together by hosting the frontend and the backend on its servers.
## Challenges we ran into
This was the first hackathon for a couple of us, but also the first time for any of us to use Twilio. That proved a little hard to work with as we misunderstood the difference between Twilio Serverless Functions and the Twilio SDK for use on an express server. We ended up getting lost in the wrong documentation, scratching our heads for hours until we were able to fix the API calls.
Further, with so many moving parts a few of the integrations were very difficult to work with, especially when having to re-download + reupload files, taking valuable time from the end user.
## Accomplishments that we're proud of
Overall we built a solid system that connects Twilio, GCP, a back end, Front end and a database and provides a seamless experience. There is no dependency on the user either, they just send a text message from any device and the system does the work.
It's also special to us as we personally found it hard to find good restaurants that match our dietary restrictions, it also made us realize just how many foods have different names that one would normally google.
## What's next for Easy Eats
We plan on continuing development by suggesting local restaurants that are well suited for the end user. This would also allow us to monetize the platform by giving paid-priority to some restaurants.
There's also a lot to be improved in terms of code efficiency (I think we have O(n4) in one of the functions ahah...) to make this a smoother experience.
Easy Eats will change restaurant dining as we know it. Easy Eats will expand its services and continue to make life easier for people, looking to provide local suggestions based on your preference. | ## Inspiration
We were inspired mainly by Buzzfeed's personality quiz, and we wanted to see if we could use more open-ended prompts powered by Openai's api.
## What it does
Aistrology is a personality quiz which takes your personality traits and outputs your personality based on what you provided.
## How we built it
We built it using Typescript/React/Vite/TailwindCSS for the front end; javascript and open ai's API for the backend.
## Challenges we ran into
Our main challenges were centering divs and selecting the correct elements in CSS.
## Accomplishments that we're proud of
Finishing on time and having a working website that looks okay.
## What we learned
We learned how to work on both front-end and back-end simultaneously, and then integrated them together at the end.
## What's next for Aistrology
Perhaps make the questions show up one at a time in a carousel style. | winning |
## Inspiration
Currently, Zoom only offers live closed captioning when a human transcriber manually transcribes a meeting. We believe that users would benefit greatly from closed captions in *every* meeting, so we created Cloud Caption.
## What it does
Cloud Caption receives live system audio from a Zoom meeting or other video conference platform and translate this audio in real time to closed captioning that is displayed in a floating window. This window can be positioned on top of the Zoom meeting and it is translucent, so it will never get in the way.
## How we built it
Cloud Caption uses the Google Cloud Speech-to-Text API to automatically transcribe the audio streamed from Zoom or another video conferencing app.
## Challenges we ran into
We went through a few iterations before we were able to get Cloud Caption working. First, we started with a browser-based app that would embed Zoom, but we discovered that the Google Cloud framework isn't compatible in browser-based environments. We then pivoted to an Electron-based desktop app, but the experimental web APIs that we needed did not work. Finally, we implemented a Python-based desktop app that uses a third-party program like [Loopback](https://rogueamoeba.com/loopback/) to route the audio.
## Accomplishments that we're proud of
We are proud of our ability to think and adapt quickly and collaborate efficiently during this remote event. We're also proud that our app is a genuinely useful accessibility tool for anyone who is deaf or hard-of-hearing, encouraging all students and learners to collaborate in real time despite any personal challenges they may face. Cloud Caption is also useful for students who aren't auditory learners and prefer to learn information by reading.
Finally, we're proud of the relative ease-of-use of the application. Users only need to have Loopback (or another audio-routing program) installed on their computer in order to receive real time video speech-to-text transcription, instead of being forced to wait and re-watch a video conference later with closed captioning embedded.
## What we learned
Our team learned that specifying, controlling, and linking audio input and output sources can be an incredibly difficult task with poor support from browser and framework vendors. We also came to appreciate the values of building with accessibility as a major goal throughout the design and development process. Accessibility can often be overlooked in applications and projects of every size, so all of us have learned to prioritize developing with inclusivity in mind for our projects moving forward.
## What's next for Cloud Caption
Our next step is to integrate audio routing so that users won't need a third-party program. We would also like to explore further applications of our closed captioning application in other business or corporate uses cases for HR or training purposes, especially targeting those users who may be deaf or hard-of-hearing. | ## Coinbase Analytics
**Sign in with your Coinbase account, and get helpful analytics specific to your investment.**
See in depth returns, and a simple profit and cost analysis for Bitcoin, Ethereum, and Litecoin.
Hoping to help everyone that uses and will use Coinbase to purchase cryptocurrency. | ## Inspiration
TerraRium was born from our desire to make staying fit fun and adventurous. In a world where most of us spend too much time sitting, we wanted to create something that would inspire people to get up and move by turning exercise into an exciting game.
## What it does
TerraRium is an app that transforms your daily activities into an exciting virtual adventure. It's like having a personal fitness game. As you move and stay active, your in-game character reflects your real-life health and energy levels.
## How we built it
To create TerraRium, we used the power of modern technology. We built it with tools like Next.js and Node.js, and we used Firebase for handling user data and authentication. We also connected to the Terra API to gather health, sleep, and activity data and a little bit of Math Magic in our algorithm for calculations.
## Challenges we ran into
We faced some challenges along the way. One of them was dealing with limitations in accessing character data. We also had to figure out the best way to calculate points and levels based on your health data. We worked hard to find the right balance, so the game isn't too easy or too tough.
For instance this code block:
```
const updateStats = async (data, uid) => {
const docRef = doc(db, "pets", uid)
const docSnap = await getDoc(docRef);
const currentStats = docSnap.data()
const calories = Math.trunc(Number(data.calories_data.net_activity_calories))
currentStats['energy'] = Math.min(Math.round(currentStats['energy'] + (calories * 0.1)), 100)
if ((currentStats['xp'] + calories) >= Math.round(Math.pow(currentStats['level'], 3) * 20)) {
currentStats['strength'] = Math.round(currentStats['strength'] * 1.0080) + 3
currentStats['endurance'] = Math.round(currentStats['endurance'] * 1.025)
currentStats['stamina'] = Math.round(Math.log(Math.pow(currentStats['level'], 5)) * 3) + 1
currentStats['level'] += 1
}
currentStats['xp'] += calories
updateDoc(docRef, currentStats);
}
```
## Accomplishments that we're proud of
One of our proudest achievements is bringing TerraRium to life. We've created an app that makes fitness more enjoyable and engaging. We successfully integrated various technologies and received positive feedback from users who feel fitter and happier.
## What we learned
Through this journey, we've learned that making fitness fun is key to motivating people to stay active. We've also gained valuable insights into using health data to create an exciting game.
## What's next for TerraRium
The journey continues! In the future, we plan to refine TerraRium based on user feedback. We're also exploring opportunities to expand to other platforms. We plan to refine TerraRium based on user insights and expand its reach to iOS and beyond. Our goal is to keep inspiring people to lead healthier lives while having a great time. | partial |
## Inspiration
With new developments in AI and growing considerations about both how we will introduce education technology to the classroom, and how we will refine computer science education, it begs the question of how to design with students in mind. As a computer science major who is studying child policy research, I care immensely about working towards equity in education, and more specifically computer science education.
Having worked in various public school systems, as a mentor and volunteer, as an intern at an educational technology startup, and as a fellow developing curricula with public school teachers, I have interacted with many important parties: students, teachers, parents, families, and board members. When it comes to computer science curriculum and development, there can be a disconnect between policy and practice. It is easy to throw some tools at a teacher, or some frameworks. The hard part is understanding what teachers and students need, and how we can also make the "black box" of algorithms and computing more transparent.
At Duke, I am learning about and focusing on "Open-Design" which is "an equity-focused innovation methodology that foregrounds active inclusivity, transparency, and collaboration." When applied to curriculum development and lesson planning, this means that "open design enables students and teachers to develop critical, creative, and courageous thinking skills and habits of mind necessary for a participatory and self-determined life."
## What it does
This web application, EthiCode, serves as a way to support and guide teachers in learning about Open-Design and integrating ethical considerations into computer science curriculum development. The first page discusses the guiding values of open-design. Underneath, to emulate the understand phase, there is a chatbot where teachers can send in inquiries they have about ethics, equity, gender and computing, open-design, and more. This bot was given context from a database of over 1000 rows of academic and relevant texts. The goal of developing this Retrieval-Augmented Generation (RAG) system was to "optimize the output of the large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response."
The second page, the create page, is where educators can upload both their favorite lesson plan and their county standards. This information goes into a secure database. Then, the output would be lesson plan ideas for the teachers that keep in mind the county standards, previous lessons that their students liked, all while aligning with an ethics-centered framework.
## How we built it
I used Reflex to create the frontend and backend of my app, all based in python. I used InterSystems IRIS for the database, which allowed me to use embedding models, translate my text to vectors, store these vectors in IRIS, and then query text. To gather the text, I used a pdf parsing function in python to translate academic articles to text files.
At a high level, the flow is
User query → relevant data → feed it to the LLM as context. Following recommendations from InterSystems, I used LLAMA index to develop this RAG system. I also did some fine-tuning to calibrate some of the responses.
## Challenges we ran into
It was very difficult connecting the front and backend, figuring out what models to use, actually being able to run things without using all my RAM, and synthesizing my idea. Picking up a new framework was also difficult but incredibly rewarding.
## Accomplishments that we're proud of
I am proud that some of my functionality is working. I enjoyed training the models and seeing the different outputs based on the retrieved context.
## What we learned
I learned a lot about RAG and using NLP and LLMs for development. I felt like my idea was very ambitious because I did not have much prior experience with this field. I really learned a lot about Reflex and would definitely use it in the future. I learned more about vector search, API calls, and front-end development.
## What's next for EthiCode
I hope to flesh out the features that I mentioned. | ## Inspiration
Problems we as students encounter. We thought of the problem "What would help me in my school life and work ethic?"
## What it does
Still fairly empty and holds a bunch of dummy data. However it would,
-Scrape the Web for similar assignment questions for the course
-Chat with a tutor one-on-one to gain knowledge for courses
-Store all your assignments and past projects in the database interface
-Uses classmate finder to look for the next student with traits you like for your next project
## How we built it
-Html, CSS, JavaScript, possibly MongoDB
## Challenges we ran into
-Creating functions for main pages
## Accomplishments that we're proud of
-Holding the idea and creating a simple but nice design
## What we learned
-Use your time wisely or else you lose it
## What's next for Helping Hand Student Program
-Implementing the other features not yet uploaded and working currently | ## Inspiration
In the fast-paced world of networking and professional growth, connecting with students, peers, mentors, and like-minded individuals is essential. However, the need to manually jot down notes in Excel or the risk of missing out on valuable follow-up opportunities can be a real hindrance.
## What it does
Coffee Copilot transcribes, summarizes, and suggests talking points for your conversations, eliminating manual note-taking and maximizing networking efficiency. Also able to take forms with genesys.
## How we built it
**Backend**:
* Python + FastAPI was used to serve CRUD requests
* Cohere was used for both text summarization and text generation using their latest Coral model
* CockroachDB was used to store user and conversation data
* AssemblyAI was used for speech-to-text transcription and speaker diarization (i.e. identifying who is talking)
**Frontend**:
* We used Next.js for its frontend capabilities
## Challenges we ran into
We ran into a few of the classic problems - going in circles about what idea we wanted to implement, biting off more than we can chew with scope creep and some technical challenges that **seem** like they should be simple (such as sending an audio file as a blob to our backend 😒).
## Accomplishments that we're proud of
A huge last minute push to get us over the finish line.
## What we learned
We learned some new technologies like working with LLMs at the API level, navigating heavily asynchronous tasks and using event-driven patterns like webhooks. Aside of technologies, we learned how to disagree but move forwards, when to cut our losses and how to leverage each others strengths!
## What's next for Coffee Copilot
There's quite a few things on the horizon to look forwards to:
* Adding sentiment analysis
* Allow the user to augment the summary and the prompts that get generated
* Fleshing out the user structure and platform (adding authentication, onboarding more users)
* Using smart glasses to take pictures and recognize previous people you've met before | losing |
## Inspiration
While a member of my team was conducting research at UCSF, he noticed a family partaking in a beautiful, albeit archaic, practice. They gave their grandfather access to a google doc, where each family member would write down the memories that they have with him. Nearly every day, the grandfather would scroll through the doc and look at the memories that him and his family wanted him to remember.
## What it does
Much like the Google Doc does, our site stores memories inputted by either the main account holder themself, or other people who have access to the account, perhaps through a shared family email. From there, the memories show up on the users feed and are tagged with the emotion they indicate. Someone with Alzheimers can easily search through their memories to find what they are looking for. In addition, our Chatbot feature trained on their memories also allows users to easily talk to the app directly, asking what they are looking for.
## How we built it
Next.js, React, Node.js, Tailwind, etc.
## Challenges we ran into
It was difficult implementing our chatbot in a way where it is automatically update with data that our user inputs into the site. Moreover, we were working with React for the first time and faced many challenges trying to build out and integrate the different technologies into our website including setting up MongoDB, Flask, and different APIs.
## Accomplishments that we're proud of
Getting this done! Our site is polished and carries out our desired functions well!
## What we learned
As beginners, we were introduced to full-stack development!
## What's next for Scrapbook
We'd like to introduce Scrapbook to medical professionals at UCSF and see their thoughts on it. | ## 🤔 Problem Statement
* 55 million people worldwide struggle to engage with their past memories effectively (World Health Organization) and 40% of us will experience some form of memory loss (Alzhiemer's Society of Canada). This widespread struggle with nostalgia emphasizes the critical need for user-friendly solutions. Utilizing modern technology to support reminiscence therapy and enhance cognitive stimulation in this population is essential.
## 💡 Inspiration
* Alarming statistics from organizations like the Alzheimer's Society of Canada and the World Health Organization motivated us.
* Desire to create a solution to assist individuals experiencing memory loss and dementia.
* Urge to build a machine learning and computer vision project to test our skillsets.
## 🤖 What it does
* DementiaBuddy offers personalized support for individuals with dementia symptoms.
* Integrates machine learning, computer vision, and natural language processing technologies.
* Facilitates face recognition, memory recording, transcription, summarization, and conversation.
* Helps users stay grounded, recall memories, and manage symptoms effectively.
## 🧠 How we built it
* Backend developed using Python libraries including OpenCV, TensorFlow, and PyTorch.
* Integration with Supabase for data storage.
* Utilization of Cohere Summarize API for text summarization.
* Frontend built with Next.js, incorporating Voiceflow for chatbot functionality.
## 🧩 Challenges we ran into
* Limited team size with only two initial members.
* Late addition of two teammates on Saturday.
* Required efficient communication, task prioritization, and adaptability, especially with such unique circumstances for our team.
* Lack of experience in combining all these foreign sponsorship technology, as well as limited frontend and fullstack abilities.
## 🏆 Accomplishments that we're proud of
* Successful development of a functional prototype within the given timeframe.
* Implementation of key features including face recognition and memory recording.
* Integration of components into a cohesive system.
## 💻 What we learned
* Enhanced skills in machine learning, computer vision, and natural language processing.
* Improved project management, teamwork, and problem-solving abilities.
* Deepened understanding of dementia care and human-centered design principles.
## 🚀 What's next for DementiaBuddy
* Refining face recognition algorithm for improved accuracy and scalability.
* Expanding memory recording capabilities.
* Enhancing chatbot's conversational abilities.
* Collaborating with healthcare professionals for validation and tailoring to diverse needs.
## 📈 Why DementiaBuddy?
Asides from being considered for the Top 3 prizes, we worked really hard so that DementiaBuddy could be considered to win multiple sponsorship awards at this hackathon, including the Best Build with Co:Here, RBC's Retro-Revolution: Bridging Eras with Innovation Prize, Best Use of Auth0, Best Use of StarkNet, & Best .tech Domain Name. Our project stands out because we've successfully integrated multiple cutting-edge technologies to create a user-friendly and accessible platform for those with memory ailments. Here's how we've met each challenge:
* 💫 Best Build with Co:Here: Dementia Buddy should win the Best Build with Cohere award because it uses Cohere's Summarizing API to make remembering easier for people with memory issues. By summarizing long memories into shorter versions, it helps users connect with their past experiences better. This simple and effective use of Cohere's technology shows how well the project is made and how it focuses on helping users.
* 💫 RBC's Retro-Revolution - Bridging Eras with Innovation Prize: Dementia Buddy seamlessly combines nostalgia with modern technology, perfectly fitting the criteria of the RBC Bridging Eras prize. By updating the traditional photobook with dynamic video memories, it transforms the reminiscence experience, especially for individuals dealing with dementia and memory issues. Through leveraging advanced digital media tools, Dementia Buddy not only preserves cherished memories but also deepens emotional connections to the past. This innovative approach revitalizes traditional memory preservation methods, offering a valuable resource for stimulating cognitive function and improving overall well-being.
* 💫 Best Use of Auth0: We succesfully used Auth0's API within our Next.js frontend to help users login and ensure that our web app maintains a personalized experience for users.
* 💫 Best .tech Domain Name: AMachineLearningProjectToHelpYouTakeATripDownMemoryLane.tech, I can't think of a better domain name. It perfectly describes our project. | ## Inspiration
The opioid crisis is a widespread danger, affecting millions of Americans every year. In 2016 alone, 2.1 million people had an opioid use disorder, resulting in over 40,000 deaths. After researching what had been done to tackle this problem, we came upon many pill dispensers currently on the market. However, we failed to see how they addressed the core of the problem - most were simply reminder systems with no way to regulate the quantity of medication being taken, ineffective to prevent drug overdose. As for the secure solutions, they cost somewhere between $200 to $600, well out of most people’s price ranges. Thus, we set out to prototype our own secure, simple, affordable, and end-to-end pipeline to address this problem, developing a robust medication reminder and dispensing system that not only makes it easy to follow the doctor’s orders, but also difficult to disobey.
## What it does
This product has three components: the web app, the mobile app, and the physical device. The web end is built for doctors to register patients, easily schedule dates and timing for their medications, and specify the medication name and dosage. Any changes the doctor makes are automatically synced with the patient’s mobile app. Through the app, patients can view their prescriptions and contact their doctor with the touch of one button, and they are instantly notified when they are due for prescriptions. Once they click on on an unlocked medication, the app communicates with LocPill to dispense the precise dosage. LocPill uses a system of gears and motors to do so, and it remains locked to prevent the patient from attempting to open the box to gain access to more medication than in the dosage; however, doctors and pharmacists will be able to open the box.
## How we built it
The LocPill prototype was designed on Rhino and 3-D printed. Each of the gears in the system was laser cut, and the gears were connected to a servo that was controlled by an Adafruit Bluefruit BLE Arduino programmed in C.
The web end was coded in HTML, CSS, Javascript, and PHP. The iOS app was coded in Swift using Xcode with mainly the UIKit framework with the help of the LBTA cocoa pod. Both front ends were supported using a Firebase backend database and email:password authentication.
## Challenges we ran into
Nothing is gained without a challenge; many of the skills this project required were things we had little to no experience with. From the modeling in the RP lab to the back end communication between our website and app, everything was a new challenge with a lesson to be gained from. During the final hours of the last day, while assembling our final product, we mistakenly positioned a gear in the incorrect area. Unfortunately, by the time we realized this, the super glue holding the gear in place had dried. Hence began our 4am trip to Fresh Grocer Sunday morning to acquire acetone, an active ingredient in nail polish remover. Although we returned drenched and shivering after running back in shorts and flip-flops during a storm, the satisfaction we felt upon seeing our final project correctly assembled was unmatched.
## Accomplishments that we're proud of
Our team is most proud of successfully creating and prototyping an object with the potential for positive social impact. Within a very short time, we accomplished much of our ambitious goal: to build a project that spanned 4 platforms over the course of two days: two front ends (mobile and web), a backend, and a physical mechanism. In terms of just codebase, the iOS app has over 2600 lines of code, and in total, we assembled around 5k lines of code. We completed and printed a prototype of our design and tested it with actual motors, confirming that our design’s specs were accurate as per the initial model.
## What we learned
Working on LocPill at PennApps gave us a unique chance to learn by doing. Laser cutting, Solidworks Design, 3D printing, setting up Arduino/iOS bluetooth connections, Arduino coding, database matching between front ends: these are just the tip of the iceberg in terms of the skills we picked up during the last 36 hours by diving into challenges rather than relying on a textbook or being formally taught concepts. While the skills we picked up were extremely valuable, our ultimate takeaway from this project is the confidence that we could pave the path in front of us even if we couldn’t always see the light ahead.
## What's next for LocPill
While we built a successful prototype during PennApps, we hope to formalize our design further before taking the idea to the Rothberg Catalyzer in October, where we plan to launch this product. During the first half of 2019, we plan to submit this product at more entrepreneurship competitions and reach out to healthcare organizations. During the second half of 2019, we plan to raise VC funding and acquire our first deals with healthcare providers. In short, this idea only begins at PennApps; it has a long future ahead of it. | partial |
A long time ago (last month) in a galaxy far far away (literally my room) I was up studying late for exams and decided to order some hot wings. With my food being the only source of joy that night you can imaging how devastated I was to find out that they were stolen from the front lobby of my building! That's when the idea struck to create a secure means of ordering food without the stress of someone else stealing it.
## What it does
Locker as a service is a full hardware and software solution that intermediates a the food exchange between seller and buyer. Buyers can order food from our mobile app, the seller receives this notification on their end of the app, fills the box with its contents, and locks the box. The buyer is notified that the order is ready and using face biometrics receives permission to open the box and safely. The order can specify whether the food needs to be refrigerated or heated and the box's temperature is adjusted accordingly. Sounds also play at key moments in the exchange such as putting in a cold or hot item as well as opening the box.
## How we built it
The box is made out of cardboard and uses a stepper motor to open and close the main door, LED's are in the top of the box to indicate it's content status and temperature. A raspberry pi controls these devices and is also connected to a Bluetooth speaker which is also inside of the box playing the sounds. The frontend was developed using Flutter and IOS simulator. Commands from the front end are sent to Firebase which is a realtime cloud database which can be connected to the raspberry pi to send all of the physical commands. Since the raspberry pi has internet and Bluetooth access, it can run wirelessly (with the exception of power to the pi)
## Challenges we ran into
A large challenge we ran into was having the raspberry-pi run it's code wirelessly. Initially we needed to connect to VNC Viewer to via ethernet to get a GUI. Only after we developed all the python code to control the hardware seamlessly could we disconnect the VNC viewer and let the script run autonomously. Another challenge we ran into was getting the IoS simulated app to run on a real iphone, this required several several YouTube tutorials and debugging could we get it to work.
## Accomplishments that we're proud of
We are proud that we were able to connect both the front end (flutter) and backend (raspberry pi) to the firebase database, it was very satisfying to do so.
## What we learned
Some team members learned about mobile development for the first time while others learned about control systems (we had to track filled state, open state, and led colour for 6 stages of the cycle)
## What's next for LaaS | ## Inspiration
The failure of a certain project using Leap Motion API motivated us to learn it and use it successfully this time.
## What it does
Our hack records a motion password desired by the user. Then, when the user wishes to open the safe, they repeat the hand motion that is then analyzed and compared to the set password. If it passes the analysis check, the safe unlocks.
## How we built it
We built a cardboard model of our safe and motion input devices using Leap Motion and Arduino technology. To create the lock, we utilized Arduino stepper motors.
## Challenges we ran into
Learning the Leap Motion API and debugging was the toughest challenge to our group. Hot glue dangers and complications also impeded our progress.
## Accomplishments that we're proud of
All of our hardware and software worked to some degree of success. However, we recognize that there is room for improvement and if given the chance to develop this further, we would take it.
## What we learned
Leap Motion API is more difficult than expected and communicating with python programs and Arduino programs is simpler than expected.
## What's next for Toaster Secure
-Wireless Connections
-Sturdier Building Materials
-User-friendly interface | ## Inspiration
When challenged by TreeHacks🌲 to think of a way to promote sustainability, we thought there was no better way to bring awareness to car pollution than by "converting" your car's daily commute into **trees**🌲. Everyone on the team has lived in So Cal, so we are all too familiar with long commutes by car and we wondered just how many trees 🌲 it would take to balance out our daily commutes.
## What it does
When you first visit the website, you are greeted with a lush forest to serve as a reminder of what's at stake🌲. Then you enter your car's make, model, and year in that order. Suggestions drop-down to show what options we have in our database. For the best results, use the suggestions. After doing so, you then input your daily commute distance and hit calculate. On the next screen, you will then see the amount of CO2 your car releases during your commute and the number of trees that are needed to counteract the pollution. If your car is electric, you will see no trees, which is good for the environment, but bad if you like tree pictures🌲. From there you can then choose to calculate again.
## How we built it
First, we did some research and found an Excel sheet with car emissions published by the US EPA. From there we implemented the *routes*🌲 to our different pages by using React Router. After converting the Excel spreadsheets to JSON, we then created search boxes with suggestions by using Regex expressions on the JSON. After some quick maths, we then were able to display the amount of CO2 your daily commute releases using the grams of CO2 per mile value we have in our database for your car. We then converted this number to trees based on a website that said an average tree can absorb 48 pounds of CO2 per year. Finally, we made everything look better using CSS and Bootstrap.
## Challenges we ran into
One of the challenges was navigating through our JSON file structure but after a bunch of console.log statements, we finally figured it out. Another difficulty was aligning the search bar, but once we discovered flexbox everything was much easier. We also had difficulty getting a variable number of trees to display, but we eventually figured it out using flexbox and a variable-length array.🌲
## Accomplishments that we're proud of
We're honestly very proud that we actually completed what we put our minds to, considering this is the first hackathon for most of our team. 🌲We're also excited about how what we developed has the potential to bring to the attention of others the sheer number of trees that are needed to absorb a car's CO2! 🌲🌲
## What we learned
Our biggest takeaway from this project is the realization that a lot more trees are needed to counteract car pollution than we initially thought🌲. Besides that, we also learned a lot about React and Bootstrap, while delving deeper into CSS and JavaScript.
## What's next for Emissions Calculator
Going forwards, we would like to improve our search functionality. Another feature we would have liked to add is the ability to calculate your daily commute distance from your starting point and destination. In the future, we would also like to integrate with fitness apps to promoting exercise by rewarding mitigating CO2 emissions.🌲🌲 | winning |
## Inspiration
We take our inspiration from our everyday lives. As avid travellers, we often run into places with foreign languages and need help with translations. As avid learners, we're always eager to add more words to our bank of knowledge. As children of immigrant parents, we know how difficult it is to grasp a new language and how comforting it is to hear the voice in your native tongue. LingoVision was born with these inspirations and these inspirations were born from our experiences.
## What it does
LingoVision uses AdHawk MindLink's eye-tracking glasses to capture foreign words or sentences as pictures when given a signal (double blink). Those sentences are played back in an audio translation (either using an earpiece, or out loud with a speaker) in your preferred language of choice. Additionally, LingoVision stores all of the old photos and translations for future review and study.
## How we built it
We used the AdHawk MindLink eye-tracking classes to map the user's point of view, and detect where exactly in that space they're focusing on. From there, we used Google's Cloud Vision API to perform OCR and construct bounding boxes around text. We developed a custom algorithm to infer what text the user is most likely looking at, based on the vector projected from the glasses, and the available bounding boxes from CV analysis.
After that, we pipe the text output into the DeepL translator API to a language of the users choice. Finally, the output is sent to Google's text to speech service to be delivered to the user.
We use Firebase Cloud Firestore to keep track of global settings, such as output language, and also a log of translation events for future reference.
## Challenges we ran into
* Getting the eye-tracker to be properly calibrated (it was always a bit off than our view)
* Using a Mac, when the officially supported platforms are Windows and Linux (yay virtualization!)
## Accomplishments that we're proud of
* Hearing the first audio playback of a translation was exciting
* Seeing the system work completely hands free while walking around the event venue was super cool!
## What we learned
* we learned about how to work within the limitations of the eye tracker
## What's next for LingoVision
One of the next steps in our plan for LingoVision is to develop a dictionary for individual words. Since we're all about encouraging learning, we want to our users to see definitions of individual words and add them in a dictionary.
Another goal is to eliminate the need to be tethered to a computer. Computers are the currently used due to ease of development and software constraints. If a user is able to simply use eye tracking glasses with their cell phone, usability would improve significantly. | ## Inspiration
**75% of adults over the age of 50** take prescription medication on a regular basis. Of these people, **over half** do not take their medication as prescribed - either taking them too early (causing toxic effects) or taking them too late (non-therapeutic). This type of medication non-adherence causes adverse drug reactions which is costing the Canadian government over **$8 billion** in hospitalization fees every year. Further, the current process of prescription between physicians and patients is extremely time-consuming and lacks transparency and accountability. There's a huge opportunity for a product to help facilitate the **medication adherence and refill process** between these two parties to not only reduce the effects of non-adherence but also to help save tremendous amounts of tax-paying dollars.
## What it does
**EZPill** is a platform that consists of a **web application** (for physicians) and a **mobile app** (for patients). Doctors first create a prescription in the web app by filling in information including the medication name and indications such as dosage quantity, dosage timing, total quantity, etc. This prescription generates a unique prescription ID and is translated into a QR code that practitioners can print and attach to their physical prescriptions. The patient then has two choices: 1) to either create an account on **EZPill** and scan the QR code (which automatically loads all prescription data to their account and connects with the web app), or 2) choose to not use EZPill (prescription will not be tied to the patient). This choice of data assignment method not only provides a mechanism for easy onboarding to **EZPill**, but makes sure that the privacy of the patients’ data is not compromised by not tying the prescription data to any patient **UNTIL** the patient consents by scanning the QR code and agreeing to the terms and conditions.
Once the patient has signed up, the mobile app acts as a simple **tracking tool** while the medicines are consumed, but also serves as a quick **communication tool** to quickly reach physicians to either request a refill or to schedule the next check-up once all the medication has been consumed.
## How we built it
We split our team into 4 roles: API, Mobile, Web, and UI/UX Design.
* **API**: A Golang Web Server on an Alpine Linux Docker image. The Docker image is built from a laptop and pushed to DockerHub; our **Azure App Service** deployment can then pull it and update the deployment. This process was automated with use of Makefiles and the **Azure** (az) **CLI** (Command Line Interface). The db implementation is a wrapper around MongoDB (**Azure CosmosDB**).
* **Mobile Client**: A client targeted exclusively at patients, written in swift for iOS.
* **Web Client**: A client targeted exclusively at healthcare providers, written in HTML & JavaScript. The Web Client is also hosted on **Azure**.
* **UI/UX Design**: Userflow was first mapped with the entire team's input. The wireframes were then created using Adobe XD in parallel with development, and the icons were vectorized using Gravit Designer to build a custom assets inventory.
## Challenges we ran into
* Using AJAX to build dynamically rendering websites
## Accomplishments that we're proud of
* Built an efficient privacy-conscious QR sign-up flow
* Wrote a custom MongoDB driver in Go to use Azure's CosmosDB
* Recognized the needs of our two customers and tailored the delivery of the platform to their needs
## What we learned
* We learned the concept of "Collections" and "Documents" in the Mongo(NoSQL)DB
## What's next for EZPill
There are a few startups in Toronto (such as MedMe, Livi, etc.) that are trying to solve this same problem through a pure hardware solution using a physical pill dispenser. We hope to **collaborate** with them by providing the software solution in addition to their hardware solution to create a more **complete product**. | ## Inspiration
Ever find yourself occupied reading lengthy Terms & Conditions on websites, or worse agreeing to those conditions without reading them through?! Is there a better way?
Our project aims to solve this mundane, everyday nuisance through the use of intuitive (and eventually standardized) symbols.
## What it does
Essentially, our application consists of a chrome extension (used in lieu of embedded HTML snippets, which would be used in practice however we don't have appropriate permissions from any websites to embed our code yet), which is activated on websites that are heuristically determined to contain either a privacy policy or terms of service. Then the extension embeds a small modal over the left corner of the website summarizing the lengthy legal document so that readers can understand the gist of the jargon without going through 5 years of law school.
This summarization works through Google's AutoML service, which is fed in line by line every sentence of the legal document. For each line, the NLP program will classify it according to our internal classifications, such as “Third-party data sharing”, “Irrelevant Jargon” etc.
For the purpose of our MVP demo, our extension combines these tags and gives the website a description of 3 categories which we have determined to be the most important to users; What data is the website collecting? Who has access to this data? If a user can create or upload intellectual property on a given website, who owns it?
## How we built it
ReactJS, GrommetUI, GCP's AutoML / Entity & Classification models, keyword-search, [pre-scraped data for NLP](http://tosdr.org/), mock embeddable HTML snippets (chrome extension used in lieu), Domain.com, GitHub Pages,
## Challenges we ran into
We weren't able to find enough data to train the AutoML model, and given the lack of labeled data available on platforms like Kaggle for the purposes of our project, we, unfortunately, had to rely on some biased labels (i.e. hand-labeled tags).
Also, since we can't currently reach out to website owners such as Google/Facebook (as this hackathon takes place outside of normal business hours), we did not have any websites try out our embeddable button feature, and hence we had to show our demo using a Chrome extension instead.
## Accomplishments that we're proud of
**Making a boring task like reading jargon much more intuitive and much less painful.**
**Website deployed.**
**Pulled an all-nighter.**
## What we learned
Among the things we explored, we were most excited to learn about the different Google Cloud APIs and building embeddable HTML snippets as well as Chrome extensions!
## What's next for <https://explici.tech>
We'd like to onboard companies to make the switch to a more intuitive and clear version of their policies rather than opting to use complex, inconvenient, and mundane jargon. | winning |
## Inspiration
As the council jotted down their ideas, the search for a project to better our lives came to an end when the idea of garbage sorting came to us. It's not uncommon that people tend to misplace daily objects, and these little misplays and blunders add up quickly in an environment where people tend to give little thought to what they dispose of.
Our methodology against these cringe habits calls for **Sort the 6ix**, an application made to identify and sort an object with your phone camera. With some very convoluted **object detection magic** and **API calling**, the application will take an image, presumably of the debris you're looking to dispose of, and categorize it, while providing applicable instructions for safe item disposal.
## How we built it
With the help of Expo, the app was built with React Native. We used **Google Cloud's Vision AI** to help **detect and classify** our object by producing a list of labels. The response labels and weights are passed to our **Flask backend** to identify where the objects should be disposed, using the Open Toronto's Waste Wizard **dataset** to help classify where each object should be disposed, as well as additional instructions for cleaning items or dealing with hazardous waste.
## Challenges we ran into
A big roadblock in our project was finding a sufficient image detection model, as the trash dataset (double entendre) we used had a lot of detailed objects, and the object detection models we used were not working or not expansive enough for the dataset. A decent portion of our time spent was looking for a model that would suit our requirements, to which we took the compromise of Google Cloud's Vision AI.
There were also issues with dependencies that caused some headaches for for group, as well as the dataset as using a lot of html formatting which we had trouble working with.
## Accomplishments that we're proud of
We were proud that we were able to get the app working and the object detection. We successfully navigated Google Cloud's API for the first time and implemented it into the comfort of your phone camera.
We also used another Artificial Intelligence model from Hugging Face, called all-MiniLM-L6-v2. We utilized this for semantic search to better help **contextualize** the camera output, through the models ability to graph sentences & paragraphs to a **384 dimensional dense vector space**, and **comparing** it to the most relevant trash categories that are given from the dataset.
## What we learned
During the 36 hours, we learned how to make and deal with **APIs**, we learned how to use **object recognition models \*\*and properly apply them onto our application, as well as implementing that into \*\*semantic search** to give the result using a comprehensive .json dataset, and **calling relevant information** from said dataset.
And most importantly, we learned that react native wasn't the play for choosing a frontend language.
## What's next for Sort the 6ix
The time constraint failed to give us the capability to implement this product physically, and we plan to implement this into a physical product, that can actively scan for objects to quickly output visual feedback. This then can be mounted directly onto garbage grabbers in Toronto, to better help people identify and clean up items to maximize their environmental impact on a whim. | ## Inspiration
Incorrectly sorted garbage is costing Canada's recycling programs millions of dollars per year. Furthermore, Canada is struggling to meet the standard for the amount of contamination in recyclables set by China (0.5%), the world's biggest importer of recyclable materials. All of these are costing Canada's economy a huge amount of resources which can be instead used for developing other services such as healthcare and transportation systems.
## What it does
It is called "ZeroWaste", an **interactive and engaging educational app** which aims to **motivate** people to recycle correctly. It has a few different features:
* Input real time pictures and categorize them into correct trash sorting labels
* Approximate contents in the trash
* Waste tracker
* Socially interactive Facebook Messenger game
## How we built it
The backend image classification is based on Microsoft Azure's Cognitive Services Custom Vision API. The front end is built using JavaScript, HTML5, Angular JS.
## Challenges we ran into
We have no experience in front end developing such as JavaScript, Angular JS. It took us a lot of time to pick up these different languages within short period of time. Also, Azure's Cognitive Services API doesn't not recognize HTTP request in Python and it's c# library is still in development with many failing library functions, so we had to consider alternative ways to make HTTP request.
## Accomplishments that we're proud of
* Learning how to use Azure's machine learning portal
* Building a HTTP request that connects Azure portal to facebook messenger
* A workable prototype which helps sustainability
## What we learned
* We learned web development and UI design.
* We learned to use the Microsoft's Azure Cognitive Services to leverage the power of AI to build something socially meaningful.
* We learned how to produce a workable prototype under pressure and sleep deprived :).
## What's next for Zero waste
* We want to be able to calculate the weight and size of object being categorized to determine how much waste is thrown out.
* Improve ML model's precision by training on images with noisy backgrounds
* Image tagging functionality where we can categorize different garbages in a single image
* Image segmentation functionality where we can recover only the object of interest | ## Inspiration
For this hackathon, we wanted to build something that could have a positive impact on its users. We've all been to university ourselves, and we understood the toll, stress took on our minds. Demand for mental health services among youth across universities has increased dramatically in recent years. A Ryerson study of 15 universities across Canada show that all but one university increased their budget for mental health services. The average increase has been 35 per cent. A major survey of over 25,000 Ontario university students done by the American college health association found that there was a 50% increase in anxiety, a 47% increase in depression, and an 86 percent increase in substance abuse since 2009.
This can be attributed to the increasingly competitive job market that doesn’t guarantee you a job if you have a degree, increasing student debt and housing costs, and a weakening Canadian middle class and economy. It can also be contributed to social media, where youth are becoming increasingly digitally connected to environments like instagram. People on instagram only share the best, the funniest, and most charming aspects of their lives, while leaving the boring beige stuff like the daily grind out of it. This indirectly perpetuates the false narrative that everything you experience in life should be easy, when in fact, life has its ups and downs.
## What it does
One good way of dealing with overwhelming emotion is to express yourself. Journaling is an often overlooked but very helpful tool because it can help you manage your anxiety by helping you prioritize your problems, fears, and concerns. It can also help you recognize those triggers and learn better ways to control them. This brings us to our application, which firstly lets users privately journal online. We implemented the IBM watson API to automatically analyze the journal entries. Users can receive automated tonal and personality data which can depict if they’re feeling depressed or anxious. It is also key to note that medical practitioners only have access to the results, and not the journal entries themselves. This is powerful because it takes away a common anxiety felt by patients, who are reluctant to take the first step in healing themselves because they may not feel comfortable sharing personal and intimate details up front.
MyndJournal allows users to log on to our site and express themselves freely, exactly like they were writing a journal. The difference being, every entry in a persons journal is sent to IBM Watson's natural language processing tone analyzing API's, which generates a data driven image of the persons mindset. The results of the API are then rendered into a chart to be displayed to medical practitioners. This way, all the users personal details/secrets remain completely confidential and can provide enough data to counsellors to allow them to take action if needed.
## How we built it
On back end, all user information is stored in a PostgreSQL users table. Additionally all journal entry information is stored in a results table. This aggregate data can later be used to detect trends in university lifecycles.
An EJS viewing template engine is used to render the front end.
After user authentication, a journal entry prompt when submitted is sent to the back end to be fed asynchronously into all IBM water language processing API's. The results from which are then stored in the results table, with associated with a user\_id, (one to many relationship).
Data is pulled from the database to be serialized and displayed intuitively on the front end.
All data is persisted.
## Challenges we ran into
Rendering the data into a chart that was both visually appealing and provided clear insights.
Storing all API results in the database and creating join tables to pull data out.
## Accomplishments that we're proud of
Building a entire web application within 24 hours. Data is persisted in the database!
## What we learned
IBM Watson API's
ChartJS
Difference between the full tech stack and how everything works together
## What's next for MyndJournal
A key feature we wanted to add for the web app for it to automatically book appointments with appropriate medical practitioners (like nutritionists or therapists) if the tonal and personality results returned negative. This would streamline the appointment making process and make it easier for people to have access and gain referrals. Another feature we would have liked to add was for universities to be able to access information into what courses or programs are causing the most problems for the most students so that policymakers, counsellors, and people in authoritative positions could make proper decisions and allocate resources accordingly.
Funding please | losing |
## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | Tabasco is a humanitarian project aimed to help victims of disasters. It is designed to process aerial-view images from drones and search autonomously for human faces, allowing more victims to be rescued and decreasing workload on rescue dispatchers.
Tabasco was built using Microsoft's Bing API and HP's Haven OnDemand Face Detection API. | winning |