
anchor
stringlengths 86
24.4k
| positive
stringlengths 174
15.6k
| negative
stringlengths 76
13.7k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
Vision is perhaps our most important sense; we use our sight every waking moment to navigate the world safely, to make decisions, and to connect with others. As such, keeping our eyes healthy is extremely important to our quality of life. In spite of this, we often neglect to get our vision tested regularly, even as we subject our eyes to many varieties of strain in our computer-saturated lives. Because visiting the optometrist can be both time-consuming and difficult to schedule, we sought to create MySight – a simple and inexpensive way to test our vision anywhere, using only a smartphone and a Google Cardboard virtual reality (VR) headset. This app also has large potential impact in developing nations, where administering eye tests cheaply using portable, readily available equipment can change many lives for the better.
## What it does
MySight is a general vision testing application that runs on any modern smartphone in concert with a Google Cardboard VR headset. It allows you to perform a variety of clinical vision tests quickly and easily, including tests for color blindness, stereo vision, visual acuity, and irregular blindspots in the visual field. Beyond informing the user about the current state of their visual health, the results of these tests can be used to recommend that the patient follow up with an optometrist for further treatment. One salient example would be if the app detects one or more especially large blindspots in the patient’s visual field, which is indicative of conditions requiring medical attention, such as glaucoma or an ischemic stroke.
## How we built it
We built MySight using the Unity gaming engine and the Google Cardboard SDK. All scripts were written in C#. Our website (whatswrongwithmyeyes.org) was generated using Angular2.
## Challenges we ran into
None of us on the team had ever used Unity before, and only two of us had even minimal exposure to the C# language in the past. As such, we needed to learn both Unity and C#.
## Accomplishments that we're proud of
We are very pleased to have produced a working version of MySight, which will run on any modern smartphone.
## What we learned
Beyond learning the basics of Unity and C#, we also learned a great deal more about how we see, and how our eyes can be tested.
## What's next for MySight
We envision MySight as a general platform for diagnosing our eyes’ health, and potentially for *improving* eye health in the future, as we plan to implement eye and vision training exercises (c.f. Ultimeyes). | ## Inspiration
Retinal degeneration affects 1 in 3000 people, slowly robbing them of vision over the course of their mid-life. The need to adjust to life without vision, often after decades of relying on it for daily life, presents a unique challenge to individuals facing genetic disease or ocular injury, one which our teammate saw firsthand in his family, and inspired our group to work on a modular, affordable solution. Current technologies which provide similar proximity awareness often cost many thousands of dollars, and require a niche replacement in the user's environment; (shoes with active proximity sensing similar to our system often cost $3-4k for a single pair of shoes). Instead, our group has worked to create a versatile module which can be attached to any shoe, walker, or wheelchair, to provide situational awareness to the thousands of people adjusting to their loss of vision.
## What it does (Higher quality demo on google drive link!: <https://drive.google.com/file/d/1o2mxJXDgxnnhsT8eL4pCnbk_yFVVWiNM/view?usp=share_link> )
The module is constantly pinging its surroundings through a combination of IR and ultrasonic sensors. These are readily visible on the prototype, with the ultrasound device looking forward, and the IR sensor looking to the outward flank. These readings are referenced, alongside measurements from an Inertial Measurement Unit (IMU), to tell when the user is nearing an obstacle. The combination of sensors allows detection of a wide gamut of materials, including those of room walls, furniture, and people. The device is powered by a 7.4v LiPo cell, which displays a charging port on the front of the module. The device has a three hour battery life, but with more compact PCB-based electronics, it could easily be doubled. While the primary use case is envisioned to be clipped onto the top surface of a shoe, the device, roughly the size of a wallet, can be attached to a wide range of mobility devices.
The internal logic uses IMU data to determine when the shoe is on the bottom of a step 'cycle', and touching the ground. The Arduino Nano MCU polls the IMU's gyroscope to check that the shoe's angular speed is close to zero, and that the module is not accelerating significantly. After the MCU has established that the shoe is on the ground, it will then compare ultrasonic and IR proximity sensor readings to see if an obstacle is within a configurable range (in our case, 75cm front, 10cm side).
If the shoe detects an obstacle, it will activate a pager motor which vibrates the wearer's shoe (or other device). The pager motor will continue vibrating until the wearer takes a step which encounters no obstacles, thus acting as a toggle flip-flop.
An RGB LED is added for our debugging of the prototype:
RED - Shoe is moving - In the middle of a step
GREEN - Shoe is at bottom of step and sees an obstacle
BLUE - Shoe is at bottom of step and sees no obstacles
While our group's concept is to package these electronics into a sleek, clip-on plastic case, for now the electronics have simply been folded into a wearable form factor for demonstration.
## How we built it
Our group used an Arduino Nano, batteries, voltage regulators, and proximity sensors from the venue, and supplied our own IMU, kapton tape, and zip ties. (yay zip ties!)
I2C code for basic communication and calibration was taken from a user's guide of the IMU sensor. Code used for logic, sensor polling, and all other functions of the shoe was custom.
All electronics were custom.
Testing was done on the circuits by first assembling the Arduino Microcontroller Unit (MCU) and sensors on a breadboard, powered by laptop. We used this setup to test our code and fine tune our sensors, so that the module would behave how we wanted. We tested and wrote the code for the ultrasonic sensor, the IR sensor, and the gyro separately, before integrating as a system.
Next, we assembled a second breadboard with LiPo cells and a 5v regulator. The two 3.7v cells are wired in series to produce a single 7.4v 2S battery, which is then regulated back down to 5v by an LM7805 regulator chip. One by one, we switched all the MCU/sensor components off of laptop power, and onto our power supply unit. Unfortunately, this took a few tries, and resulted in a lot of debugging.
. After a circuit was finalized, we moved all of the breadboard circuitry to harnessing only, then folded the harnessing and PCB components into a wearable shape for the user.
## Challenges we ran into
The largest challenge we ran into was designing the power supply circuitry, as the combined load of the sensor DAQ package exceeds amp limits on the MCU. This took a few tries (and smoked components) to get right. The rest of the build went fairly smoothly, with the other main pain points being the calibration and stabilization of the IMU readings (this simply necessitated more trials) and the complex folding of the harnessing, which took many hours to arrange into its final shape.
## Accomplishments that we're proud of
We're proud to find a good solution to balance the sensibility of the sensors. We're also proud of integrating all the parts together, supplying them with appropriate power, and assembling the final product as small as possible all in one day.
## What we learned
Power was the largest challenge, both in terms of the electrical engineering, and the product design- ensuring that enough power can be supplied for long enough, while not compromising on the wearability of the product, as it is designed to be a versatile solution for many different shoes. Currently the design has a 3 hour battery life, and is easily rechargeable through a pair of front ports. The challenges with the power system really taught us firsthand how picking the right power source for a product can determine its usability. We were also forced to consider hard questions about our product, such as if there was really a need for such a solution, and what kind of form factor would be needed for a real impact to be made. Likely the biggest thing we learned from our hackathon project was the importance of the end user, and of the impact that engineering decisions have on the daily life of people who use your solution. For example, one of our primary goals was making our solution modular and affordable. Solutions in this space already exist, but their high price and uni-functional design mean that they are unable to have the impact they could. Our modular design hopes to allow for greater flexibility, acting as a more general tool for situational awareness.
## What's next for Smart Shoe Module
Our original idea was to use a combination of miniaturized LiDAR and ultrasound, so our next steps would likely involve the integration of these higher quality sensors, as well as a switch to custom PCBs, allowing for a much more compact sensing package, which could better fit into the sleek, usable clip on design our group envisions.
Additional features might include the use of different vibration modes to signal directional obstacles and paths, and indeed expanding our group's concept of modular assistive devices to other solution types.
We would also look forward to making a more professional demo video
Current example clip of the prototype module taking measurements:(<https://youtube.com/shorts/ECUF5daD5pU?feature=share>) | ## Inspiration
Toronto being one of the busiest cities in the world, is faced with tremendous amounts of traffic, whether it is pedestrians, commuters, bikers or drivers. With this comes an increased risk of crashes, and accidents, making methods of safe travel an ever-pressing issue, not only for those in Toronto, but for all people living in Metropolitan areas. This led us to explore possible solutions to such a problem, as we believe that all accidents should be tackled proactively, emphasizing on prevention rather than attempting to better deal with the after effects. Hence, we devised an innovative solution for this problem, which at its core is utilizing machine learning to predict routes/streets that are likely to be dangerous, and advises you on which route to take wherever you want to go.
## What it does
Leveraging AI technology, RouteSafer provides safer alternatives to Google Map routes and aims to reduce automotive collisions in cities. Using machine learning algorithms such as k-nearest neighbours, RouteSafer analyzes over 20 years of collision data and uses over 11 parameters to make an intelligent estimate about the safety of a route, and ensure the user arrives safe.
## How I built it
The path to implement RouteSafer starts with developing rough architecture that shows different modules of the project being independently built and at the same time being able to interact with each other in an efficient way. We divided the project into 3 different segments of UI, Backend and AI handled by Sherley, Shane & Hanz and Tanvir respectively.
The product leverages extensive API usage for different and diverse purposes including Google map API, AWS API and Kaggle API. Technologies involve React.js for front end, Flask for web services and Python for Machine Learning along with AWS to deploy it on the cloud.
The dataset ‘KSI’ was downloaded from Kaggle and has records from 2014 to 2018 on major accidents that took place in the city of Toronto. The dataset required a good amount of preprocessing because of its inconsistency, the techniques involving OneHotEncoder, Dimensionality reduction, Filling null or None values and also data featuring. This made sure that the data is consistent for all future challenges.
The Machine Learning usage gives the project a smart way to solve our problem, the use of K-Means clustering gave our dataset the feature to extract the risk level while driving on a particular street. The Google API feature retrieves different routes and the model helps to give it a risk feature hence making your travel route even safer.
## Challenges I ran into
One of the first challenges that we ran into as a team was learning how to properly integrate the Google Maps API polyline, and accurately converting the compressed string into numerical values expressing longitudes and latitudes. We finally solved this first challenge through lots of research, and even more stackoverflow searches :)
Furthermore, another challenge we ran into was the implementation/construction of our machine learning based REST API, as there were many different parts/models that we had to "glue" together, whether it was through http POST and GET requests, or some other form of communication protocol.
We faced many challenges throughout these two days, but we were able to push through thanks to the help of the mentors and lots of caffeine!
## Accomplishments that I'm proud of
The thing that we were most proud of was the fact that we reached all of our initial expectations, and beyond with regards to the product build. At the end of the two days we were left with a deployable product, that had gone through end to end testing and was ready for production. Given the limited time for development, we were very pleased with our performance and the resulting project we built. We were especially proud when we tested the service, and found that the results matched our intuition.
## What I learned
Working on RouteSafer has helped each one of us gain soft skills and technical skills. Some of us had no prior experience with technologies on our stack and working together helped to share the knowledge like the use of React.js and Machine Learning. The guidance provided through HackThe6ix gave us all insights to the big and great world of cloud computing with two of the world's largest cloud computing service onsite at the hackathon. Apart from technical skills, leveraging the skill of team work and communication was something we all benefitted from, and something we will definitely need in the future.
## What's next for RouteSafer
Moving forward we see RouteSafer expanding to other large cities like New York, Boston, and Vancouver. Car accidents are a pressing issue in all metropolitan areas, and we want RouteSafer there to prevent them. If one day RouteSafer could be fully integrated into Google Maps, and could be provided on any global route, our goal would be achieved.
In addition, we aim to expand our coverage by using Google Places data alongside collision data collected by various police forces. Google Places data will further enhance our model and allow us to better serve our customers.
Finally, we see RouteSafer partnering with a number of large insurance companies that would like to use the service to better protect their customers, provide lower premiums, and cut costs on claims. Partnering with a large insurance company would also give RouteSafer the ability to train and vastly improve its model.
To summarize, we want RouteSafer to grow and keep drivers safe across the Globe! | partial |
## Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
## What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
## How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
## Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
## Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
## What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
## The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification. | ## Inspiration
As college students more accustomed to having meals prepared by someone else than doing so ourselves, we are not the best at keeping track of ingredients’ expiration dates. As a consequence, money is wasted and food waste is produced, thereby discounting the financially advantageous aspect of cooking and increasing the amount of food that is wasted. With this problem in mind, we built an iOS app that easily allows anyone to record and track expiration dates for groceries.
## What it does
The app, iPerish, allows users to either take a photo of a receipt or load a pre-saved picture of the receipt from their photo library. The app uses Tesseract OCR to identify and parse through the text scanned from the receipt, generating an estimated expiration date for each food item listed. It then sorts the items by their expiration dates and displays the items with their corresponding expiration dates in a tabular view, such that the user can easily keep track of food that needs to be consumed soon. Once the user has consumed or disposed of the food, they could then remove the corresponding item from the list. Furthermore, as the expiration date for an item approaches, the text is highlighted in red.
## How we built it
We used Swift, Xcode, and the Tesseract OCR API. To generate expiration dates for grocery items, we made a local database with standard expiration dates for common grocery goods.
## Challenges we ran into
We found out that one of our initial ideas had already been implemented by one of CalHacks' sponsors. After discovering this, we had to scrap the idea and restart our ideation stage.
Choosing the right API for OCR on an iOS app also required time. We tried many available APIs, including the Microsoft Cognitive Services and Google Computer Vision APIs, but they do not have iOS support (the former has a third-party SDK that unfortunately does not work, at least for OCR). We eventually decided to use Tesseract for our app.
Our team met at Cubstart; this hackathon *is* our first hackathon ever! So, while we had some challenges setting things up initially, this made the process all the more rewarding!
## Accomplishments that we're proud of
We successfully managed to learn the Tesseract OCR API and made a final, beautiful product - iPerish. Our app has a very intuitive, user-friendly UI and an elegant app icon and launch screen. We have a functional MVP, and we are proud that our idea has been successfully implemented. On top of that, we have a promising market in no small part due to the ubiquitous functionality of our app.
## What we learned
During the hackathon, we learned both hard and soft skills. We learned how to incorporate the Tesseract API and make an iOS mobile app. We also learned team building skills such as cooperating, communicating, and dividing labor to efficiently use each and every team member's assets and skill sets.
## What's next for iPerish
Machine learning can optimize iPerish greatly. For instance, it can be used to expand our current database of common expiration dates by extrapolating expiration dates for similar products (e.g. milk-based items). Machine learning can also serve to increase the accuracy of the estimates by learning the nuances in shelf life of similarly-worded products. Additionally, ML can help users identify their most frequently bought products using data from scanned receipts. The app could recommend future grocery items to users, streamlining their grocery list planning experience.
Aside from machine learning, another useful update would be a notification feature that alerts users about items that will expire soon, so that they can consume the items in question before the expiration date. | ## Inspiration
* None of my friends wanted to do an IOS application with me so I built an application to find friends to hack with
* I would like to reuse the swiping functionality in another personal project
## What it does
* Create an account
* Make a profile of skills, interests and languages
* Find matches to hack with based on profiles
* Check out my Video!
## How we built it
* Built using Swift in xCode
* Used Parse and Heroku for backend
## Challenges we ran into
* I got stuck on so many things, but luckily not for long because of..
* Stack overflow and youtube and all my hacking friends that lent me a hand!
## Accomplishments that we're proud of
* Able to finish a project in 36 hours
* Trying some of the
* No dying of caffeine overdose
## What we learned
* I had never made an IOS app before
* I had never used Heroku before
## What's next for HackMates
* Add chat capabilities
* Add UI
* Better matching algorithm | winning |
## Inspiration
The California wildfires have proven how deadly fires can be; the mere smoke from fireworks can set ablaze hundreds of acres. What starts as a few sparks can easily become the ignition for a fire capable of destroying homes and habitats. California is just one example; fires can be just as dangerous in other parts of the world, even if not as often.
Approximately 300,000 were affected by fires and 14 million people were affected by floods last year in the US alone. These numbers will continue to rise, due to issues such as climate change.
Preventative equipment and forecasting is only half of the solution; the other half is education. People should be able to navigate any situation they may encounter. However, there are inherent shortcomings in the traditional teaching approach, and our game -S.O.S. - looks to bridge that gap by mixing fun and education.
## What it does
S.O.S. is a first-person story mode game that allows the player to choose between two scenarios: a home fire, or a flooded car. Players will be presented with multiple options designed to either help get the player out of the situation unscathed or impede their escape. For example, players may choose between breaking open car windows in a flood or waiting inside for help, based on their experience and knowledge.
Through trial and error and "bulletin boards" of info gathered from national institutions, players will be able to learn about fire and flood safety. We hope to make learning safety rules fun and engaging, straying from conventional teaching methods to create an overall pleasant experience and ultimately, save lives.
## How we built it
The game was built using C#, Unity, and Blender. Some open resource models were downloaded and, if needed, textured in Blender. These models were then imported into Unity, which was then laid out using ProBuilder and ProGrids. Afterward, C# code was written using the built-in Visual Studio IDE of Unity.
## Challenges we ran into
Some challenges we ran into include learning how to use Unity and code in C# as well as texture models in Blender and Unity itself. We ran into problems such as models not having the right textures or the wrong UV maps, so one of our biggest challenges was troubleshooting all of these problems. Furthermore, the C# code proved to be a challenge, especially with buttons and the physics component of Unity. Time was the biggest challenge of all, forcing us to cut down on our initial idea.
## Accomplishments that we're proud of
There are many accomplishments we as a team are proud of in this hackathon. Overall, our group has become much more adept with 3D software and coding.
## What we learned
We expanded our knowledge of making games in Unity, coding in C#, and modeling in Blender.
## What's next for SOS; Saving Our Souls
Next, we plan to improve the appearance of our game. The maps, lighting, and animation could use some work. Furthermore, more scenarios can be added, such as a Covid-19 scenario which we had initially planned. | As a response to the ongoing wildfires devastating vast areas of Australia, our team developed a web tool which provides wildfire data visualization, prediction, and logistics handling. We had two target audiences in mind: the general public and firefighters. The homepage of Phoenix is publicly accessible and anyone can learn information about the wildfires occurring globally, along with statistics regarding weather conditions, smoke levels, and safety warnings. We have a paid membership tier for firefighting organizations, where they have access to more in-depth information, such as wildfire spread prediction.
We deployed our web app using Microsoft Azure, and used Standard Library to incorporate Airtable, which enabled us to centralize the data we pulled from various sources. We also used it to create a notification system, where we send users a text whenever the air quality warrants action such as staying indoors or wearing a P2 mask.
We have taken many approaches to improving our platform’s scalability, as we anticipate spikes of traffic during wildfire events. Our codes scalability features include reusing connections to external resources whenever possible, using asynchronous programming, and processing API calls in batch. We used Azure’s functions in order to achieve this.
Azure Notebook and Cognitive Services were used to build various machine learning models using the information we collected from the NASA, EarthData, and VIIRS APIs. The neural network had a reasonable accuracy of 0.74, but did not generalize well to niche climates such as Siberia.
Our web-app was designed using React, Python, and d3js. We kept accessibility in mind by using a high-contrast navy-blue and white colour scheme paired with clearly legible, sans-serif fonts. Future work includes incorporating a text-to-speech feature to increase accessibility, and a color-blind mode. As this was a 24-hour hackathon, we ran into a time challenge and were unable to include this feature, however, we would hope to implement this in further stages of Phoenix. | ## Inspiration
Our inspiration comes from the Telemarketing survey. We want to create a sort of "prank call" to people, especially to our friends where the call will be a super-realistic voice presenting a survey to them. At the end, we have decided to program a chatbot that will conduct a survey via phone and ask them how they feel about AI.
## What it does
Our project is a chatbot that will conduct a survey on the population of London, Ontario about their own thoughts and believes towards Artificial Intelligence. The chatbot will present a series of multiple choices questions as well as open-ended questions about the perception and knowledge of AI. The answers will be recorded and analyzed before being sent to our website, where the data will be presented. The purpose is to give a score on how well our target population knows about AI, and survive an AI apocalypse.
## How we built it
We built it using Dasha AI.
## Challenges we ran into
The challenges we run to is that the application(AI) hungs up when there is a longer delay between the question and the response of the user. The second challenge is that the AI skip the last questions and automatically exit and hungs up during the first test of our application.
## Accomplishments that we're proud of
This is the first Hackathon that most of our members have participated in. Therefore, being able to challenge ourself and to build a complex project in a span of 36 hours is the greatest achievement that we have accomplished.
## What we learned
* The basic of Dasha ai and how to use it to develop a software.
## - Fostered our skills in web design.
## What's next for Boom or Doom : The Future of AI
**Target a larger population**
## If you want to try it out for yourself:
Clone the github repo and download NodeJS and Dasha!
<https://dasha.ai/en-us>
More instructions on setting up Dasha available here. | winning |
## Inspiration
Imagine this: you are at an event with your best friends and want some great jams to play. However, you have no playlist on hand that represents this energy-filled moment. After several years of struggling to find the perfect playlist for various occasions, we finally developed a solution to meet all needs.
## What it does
Mixr solves this problem by generating custom playlists based on a short questionnaire which inquires about your current mood and environment. Using this information in combination with your Spotify listening habits, Mixr synthesizes a playlist that is perfect for the moment.
## How we built it
We utilized HTML, CSS, and JavaScript, in combination with an Express server and the Spotify API. | ## Inspiration
Taking our initial approach of web-app development and music, we wanted to make something that was useful and applicable to real life such as playing music with your friends. So, we came upon the idea of this web-app that will serve as a virtual DJ that will learn the party's favourite songs while generating an endless amount of the same type of songs that we can vote on as one to play next.
## How we built it
We used html and css for web design, firebase for database, and Java-Script with Knockout-js for data binding as well as Spotify API.
## Challenges we ran into
Learning how to deal with real-time response, finding out how use a function that changes data in Firebase so that it automatically updates the web view as well. | ## Inspiration
Fall lab and design bay cleanout leads to some pretty interesting things being put out at the free tables. In this case, we were drawn in by a motorized Audi Spyder car. And then, we saw the Neurosity Crown headsets, and an idea was born. A single late night call among team members, excited about the possibility of using a kiddy car for something bigger was all it took. Why can't we learn about cool tech and have fun while we're at it?
Spyder is a way we can control cars with our minds. Use cases include remote rescue, non able-bodied individuals, warehouse, and being extremely cool.
## What it does
Spyder uses the Neurosity Crown to take the brainwaves of an individual, train an AI model to detect and identify certain brainwave patterns, and output them as a recognizable output to humans. It's a dry brain-computer interface (BCI) which means electrodes are placed against the scalp to read the brain's electrical activity. By taking advantage of these non-invasive method of reading electrical impulses, this allows for greater accessibility to neural technology.
Collecting these impulses, we are then able to forward these commands to our Viam interface. Viam is a software platform that allows you to easily put together smart machines and robotic projects. It completely changed the way we coded this hackathon. We used it to integrate every single piece of hardware on the car. More about this below! :)
## How we built it
### Mechanical
The manual steering had to be converted to automatic. We did this in SolidWorks by creating a custom 3D printed rack and pinion steering mechanism with a motor mount that was mounted to the existing steering bracket. Custom gear sizing was used for the rack and pinion due to load-bearing constraints. This allows us to command it with a DC motor via Viam and turn the wheel of the car, while maintaining the aesthetics of the steering wheel.
### Hardware
A 12V battery is connected to a custom soldered power distribution board. This powers the car, the boards, and the steering motor. For the DC motors, they are connected to a Cytron motor controller that supplies 10A to both the drive and steering motors via pulse-width modulation (PWM).
A custom LED controller and buck converter PCB stepped down the voltage from 12V to 5V for the LED under glow lights and the Raspberry Pi 4. The Raspberry Pi 4 uses the Viam SDK (which controls all peripherals) and connects to the Neurosity Crown for vision software controlling for the motors. All the wiring is custom soldered, and many parts are custom to fit our needs.
### Software
Viam was an integral part of our software development and hardware bringup. It significantly reduced the amount of code, testing, and general pain we'd normally go through creating smart machine or robotics projects. Viam was instrumental in debugging and testing to see if our system was even viable and to quickly check for bugs. The ability to test features without writing drivers or custom code saved us a lot of time. An exciting feature was how we could take code from Viam and merge it with a Go backend which is normally very difficult to do. Being able to integrate with Go was very cool - usually have to do python (flask + SDK). Being able to use Go, we get extra backend benefits without the headache of integration!
Additional software that we used was python for the keyboard control client, testing, and validation of mechanical and electrical hardware. We also used JavaScript and node to access the Neurosity Crown, Neurosity SDK and Kinesis API to grab trained AI signals from the console. We then used websockets to port them over to the Raspberry Pi to be used in driving the car.
## Challenges we ran into
Using the Neurosity Crown was the most challenging. Training the AI model to recognize a user's brainwaves and associate them with actions didn't always work. In addition, grabbing this data for more than one action per session was not possible which made controlling the car difficult as we couldn't fully realise our dream.
Additionally, it only caught fire once - which we consider to be a personal best. If anything, we created the world's fastest smoke machine.
## Accomplishments that we're proud of
We are proud of being able to complete a full mechatronics system within our 32 hours. We iterated through the engineering design process several times, pivoting multiple times to best suit our hardware availabilities and quickly making decisions to make sure we'd finish everything on time. It's a technically challenging project - diving into learning about neurotechnology and combining it with a new platform - Viam, to create something fun and useful.
## What we learned
Cars are really cool! Turns out we can do more than we thought with a simple kid car.
Viam is really cool! We learned through their workshop that we can easily attach peripherals to boards, use and train computer vision models, and even use SLAM! We spend so much time in class writing drivers, interfaces, and code for peripherals in robotics projects, but Viam has it covered. We were really excited to have had the chance to try it out!
Neurotech is really cool! Being able to try out technology that normally isn’t available or difficult to acquire and learn something completely new was a great experience.
## What's next for Spyder
* Backflipping car + wheelies
* Fully integrating the Viam CV for human safety concerning reaction time
* Integrating Adhawk glasses and other sensors to help determine user focus and control | losing |
## Inspiration
More creators are coming online to create entertaining content for fans across the globe. On platforms like Twitch and YouTube, creators have amassed billions of dollars in revenue thanks to loyal fans who return to be part of the experiences they create.
Most of these experiences feel transactional, however: Twitch creators mostly generate revenue from donations, subscriptions, and currency like "bits," where Twitch often takes a hefty 50% of the revenue from the transaction.
Creators need something new in their toolkit. Fans want to feel like they're part of something.
## Purpose
Moments enables creators to instantly turn on livestreams that can be captured as NFTs for live fans at any moment, powered by livepeer's decentralized video infrastructure network.
>
> "That's a moment."
>
>
>
During a stream, there often comes a time when fans want to save a "clip" and share it on social media for others to see. When such a moment happens, the creator can press a button and all fans will receive a non-fungible token in their wallet as proof that they were there for it, stamped with their viewer number during the stream.
Fans can rewatch video clips of their saved moments in their Inventory page.
## Description
Moments is a decentralized streaming service that allows streamers to save and share their greatest moments with their fans as NFTs. Using Livepeer's decentralized streaming platform, anyone can become a creator. After fans connect their wallet to watch streams, creators can mass send their viewers tokens of appreciation in the form of NFTs (a short highlight clip from the stream, a unique badge etc.) Viewers can then build their collection of NFTs through their inventory. Many streamers and content creators have short viral moments that get shared amongst their fanbase. With Moments, a bond is formed with the issuance of exclusive NFTs to the viewers that supported creators at their milestones. An integrated chat offers many emotes for viewers to interact with as well. | ## Inspiration
Nowadays, the payment for knowledge has become more acceptable by the public, and people are more willing to pay to these truly insightful, cuttting edge, and well-stuctured knowledge or curriculum. However, current centalized video content production platforms (like YouTube, Udemy, etc.) take too much profits from the content producers (resaech have shown that content creators usually only receive 15% of the values their contents create) and the values generated from the video are not distributed in a timely manner. In order to tackle this unfair value distribution, we have this decentralized platform EDU.IO where the video contents will be backed by their digital assets as an NFT (copyright protection!) and fractionalized as tokens, and it creates direct connections between content creators and viewers/fans (no middlemen anymore!), maximizing the value of the contents made by creators.
## What it does
EDU.IO is a decentralized educational video streaming media platform & fractionalized NFT exchange that empowers creator economy and redefines knowledge value distribution via smart contracts.
* As an educational hub, EDU.IO is a decentralized platform of high-quality educational videos on disruptive innovations and hot topics like metaverse, 5G, IoT, etc.
* As a booster of creator economy, once a creator uploads a video (or course series), it will be mint as an NFT (with copyright protection) and fractionalizes to multiple tokens. Our platform will conduct a mini-IPO for the each content they produced - bid for fractionalized NFTs. The value of each video token is determined by the number of views over a certain time interval, and token owners (can be both creators and viewers/fans/investors) can advertise the contents they owned to increase it values, and trade these tokens to earn monkey or make other investments (more liquidity!!).
* By the end of the week, the value generated by each video NFT will be distributed via smart contracts to the copyright / fractionalized NFT owners of each video.
Overall we’re hoping to build an ecosystem with more engagement between viewers and content creators, and our three main target users are:
* 1. Instructors or Content creators: where the video contents can get copyright protection via NFT, and they can get fairer value distribution and more liquidity compare to using large centralized platforms
* 2. Fans or Content viewers: where they can directly interact and support content creators, and the fee will be sent directly to the copyright owners via smart contract.
* 3. Investors: Lower barrier of investment, where everyone can only to a fragment of a content. People can also to bid or trading as a secondary market.
## How we built it
* Frontend in HTML, CSS, SCSS, Less, React.JS
* Backend in Express.JS, Node.JS
* ELUV.IO for minting video NFTs (eth-based) and for playing quick streaming videos with high quality & low latency
* CockroachDB (a distributed SQL DB) for storing structured user information (name, email, account, password, transactions, balance, etc.)
* IPFS & Filecoin (distributed protocol & data storage) for storing video/course previews (decentralization & anti-censorship)
## Challenges we ran into
* Transition from design to code
* CockroachDB has an extensive & complicated setup, which requires other extensions and stacks (like Docker) during the set up phase which caused a lot of problems locally on different computers.
* IPFS initially had set up errors as we had no access to the given ports → we modified the original access files to access different ports to get access.
* Error in Eluv.io’s documentation, but the Eluv.io mentor was very supportive :)
* Merging process was difficult when we attempted to put all the features (Frontend, IPFS+Filecoin, CockroachDB, Eluv.io) into one ultimate full-stack project as we worked separately and locally
* Sometimes we found the documentation hard to read and understand - in a lot of problems we encountered, the doc/forum says DO this rather then RUN this, where the guidance are not specific enough and we had to spend a lot of extra time researching & debugging. Also since not a lot of people are familiar with the API therefore it was hard to find exactly issues we faced. Of course, the staff are very helpful and solved a lot of problems for us :)
## Accomplishments that we're proud of
* Our Idea! Creative, unique, revolutionary. DeFi + Education + Creator Economy
* Learned new technologies like IPFS, Filecoin, Eluv.io, CockroachDB in one day
* Successful integration of each members work into one big full-stack project
## What we learned
* More in depth knowledge of Cryptocurrency, IPFS, NFT
* Different APIs and their functionalities (strengths and weaknesses)
* How to combine different subparts with different functionalities into a single application in a project
* Learned how to communicate efficiently with team members whenever there is a misunderstanding or difference in opinion
* Make sure we know what is going on within the project through active communications so that when we detect a potential problem, we solve it right away instead of wait until it produces more problems
* Different hashing methods that are currently popular in “crypto world” such as multihash with cid, IPFS’s own hashing system, etc. All of which are beyond our only knowledge of SHA-256
* The awesomeness of NFT fragmentation, we believe it has great potential in the future
* Learned the concept of a decentralized database which is directly opposite the current data bank structure that most of the world is using
## What's next for EDU.IO
* Implement NFT Fragmentation (fractionalized tokens)
* Improve the trading and secondary market by adding more feature like more graphs
* Smart contract development in solidity for value distribution based on the fractionalized tokens people owned
* Formulation of more complete rules and regulations - The current trading prices of fractionalized tokens are based on auction transactions, and eventually we hope it can become a free secondary market (just as the stock market) | ## Inspiration
We wanted to build an app that could replicate the background blur in professional pictures
## What it does
Import a photo from the library or camera and let you select the zone you want to keep in focus
## How we built it
We used Xcode and did most of the code in Swift
## Challenges we ran into
Everything
## Accomplishments that we're proud of
Finishing
## What we learned
How to use pictures inside an iOs app
## What's next for BlurryApp
Reaching a billion users. | winning |
## Inspiration
Rewind back to the beginning of this hackathon. Our group was stuck brainstorming a wide variety of ideas, and like any young group, we were spending so much time talking and weren't able to keep track of ideas. But what if all we had to do was speak and have our ideas written down? That's when we thought of Jabber AI. Taking inspiration from sticky note applications and AI that can have conversations, we built a project that listens to your ideas, summarizes them, and takes note of them to keep you organized. All you need to do is hit start and talk!
## What it does
Meet your personal assistant Mindy, who is integrated into Jabber AI to help you brainstorm ideas about your next revolutionary project. Mindy helps you talk through your ideas, generate new possibilities, and encourage you when you are stuck. As you speak, GPT-4o processes your spoken ideas into digestible note cards, and displays them in a bento-box layout in your workspace. The workspace is interactive: you can delete note cards and start or stop conversations with Mindy while keeping your workspace untouched. Using Hume's Speech Prosody model, Jabber AI analyzes expressions in the user's voice and emphasizes notes on the screen that the user is excited about.
## How we built it
### Frontend:
Receiving the summarized notes, we display them out in their own respective note cards, adding different background colors to keep emphasis on unique qualities. We also implemented features such as deleting sticky notes to keep the notes that are important to the user. On the right sidebar, the message history allows the user to look back on responses they might've missed or to keep track of where there thought process went. We also made the notecards able to fit together and limit the gaps between them to allow the user to have a larger view of the notecards.
### Backend:
We designed our voice assistant Mindy using Hume AI's EVI configuration by utilizing prompt engineering. We constructed Mindy to have different personality traits like patience and kindness, but also specific goals like helping the user with project inspiration. We passed each user message from the voice conversation into the OpenAI API GPT 4o model, where we gave it specific prompt instructions to process the voice transcript and organize detailed, hierarchal notes. These textual notes were then fed into the front end to be put in each note card. We also utilized Hume's Speech Prosody model by analyzing expressions for the emotions interest, excitement, and surprise, and when there were excessive levels (>0.7), we enabled a special yellow note card for those ideas and created a pulsing effect for that card.
## What's next for Jabber AI
We'd like to add the idea of linking different notecards, sort of turning it into a mindmap so that the aspect of the user's "train of thinking" can be seen. Since the AI can recommend different ideas to into regarding a topic, the user could select that specific notecard, speak about topics related to it, and having the produced notecards already linked to the selected notecard.
## Who we are
Kevin Zhu: rising sophomore at MIT studying CS and Math
Garman Xu: rising sophomore at NYU interested in intersections between technology and music
Chris Franco: rising sophomore at MIT studying CS | ## Inspiration
Oftentimes when we find ourselves not understanding the content that has been taught in class and rarely remembering what exactly is being conveyed. And some of us have the habit of mismatching notes and forgetting where we put them. So to help all the ailing students, there was this idea to make an app that would give the students curated automatic content from the notes which they upload online.
## What it does
A student uploads his notes to the application. The application creates a summary of the notes, additional information on the subject of the notes, flashcards for easy remembering and quizzes to test his knowledge. There is also the option to view other student's notes (who have uploaded it in the same platform) and do all of the above with them as well. We made an interactive website that can help students digitize and share notes!
## How we built it
Google cloud vision was used to convert images into text files. We used Google cloud NLP API for the formation of questions from the plain text by identifying the entities and syntax of the notes. We also identified the most salient features of the conversation and assumed it to be the topic of interest. By doing this, we are able to scrape more detailed information on the topic using google custom search engine API. We also scrape information from Wikipedia. Then we make flashcards based on the questions and answers and also make quizzes to test the knowledge of the student. We used Django as the backend to create a web app. We also made a chatbot in google dialog-flow to inherently enable the use of google assistant skills.
## Challenges we ran into
Extending the platform to a collaborative domain was tough. Connecting the chatbot framework to the backend and sending back dynamic responses using webhook was more complicated than we expected.
Also, we had to go through multiple iterations to get our question formation framework right. We used the assumption that the main topic would be the noun at the beginning of the sentence. Also, we had to replace pronouns in order to keep track of the conversation.
## Accomplishments that we're proud of
We have only 3 members in the team and one of them has a background in electronics engineering and no experience in computer science and as we only had the idea of what we were planning to make but no idea of how we will make. We are very proud to have achieved a fully functional application at the end of this 36-hour hackathon. We learned a lot of concepts regarding UI/UX design, backend logic formation, connecting backend and frontend in Django and general software engineering techniques.
## What we learned
We learned a lot about the problems of integrations and deploying an application. We also had a lot of fun making this application because we had the motive to contribute to a large number of people in day to day life. Also, we learned about NLP, UI/UX and the importance of having a well-set plan.
## What's next for Noted
In the best-case scenario, we would want to convert this into an open-source startup and help millions of students with their studies. So that they can score good marks in their upcoming examinations. | ## Inspiration
Inspired by the challenges posed by complex and expensive tools like Cvent, we developed Eventdash: a comprehensive event platform that handles everything from start to finish. Our intuitive AI simplifies the planning process, ensuring it's both effortless and user-friendly. With Eventdash, you can easily book venues and services, track your budget from beginning to end, and rely on our agents to negotiate pricing with venues and services via email or phone.
## What it does
EventEase is an AI-powered, end-to-end event management platform. It simplifies planning by booking venues, managing budgets, and coordinating services like catering and AV. A dashboard which shows costs and progress in real-time. With EventEase, event planning becomes seamless and efficient, transforming complex tasks into a user-friendly experience.
## How we built it
We designed a modular AI platform using Langchain to orchestrate services. AWS Bedrock powered our AI/ML capabilities, while You.com enhanced our search and data retrieval. We integrated Claude, Streamlit, and Vocode for NLP, UI, and voice features, creating a comprehensive event planning solution.
## Challenges we ran into
We faced several challenges during the integration process. We encountered difficulties integrating multiple tools, particularly with some open-source solutions not aligning with our specific use cases. We are actively working to address these issues and improve the integration.
## Accomplishments that we're proud of
We're thrilled about the strides we've made with Eventdash. It's more than just an event platform; it's a game-changer. Our AI-driven system redefines event planning, making it a breeze from start to finish. From booking venues to managing services, tracking budgets, and negotiating pricing, Eventdash handles it all seamlessly. It's the culmination of our dedication to simplifying event management, and we're proud to offer it to you. **Eventdash could potentially achieve a market cap in the range of $2 billion to $5 billion just on B2B sector** the market cap could potentially be higher due to the broader reach and larger number of potential users.
## What we learned
Our project deepened our understanding of AWS Bedrock's AI/ML capabilities and Vocode's voice interaction features. We mastered the art of seamlessly integrating 6-7 diverse tools, including Langchain, You.com, Claude, and Streamlit. This experience enhanced our skills in creating cohesive AI-driven platforms for complex business processes.
## What's next for EventDash
We aim to become the DoorDash of event planning, revolutionizing the B2B world. Unlike Cvent, which offers a more traditional approach, our AI-driven platform provides personalized, efficient, and cost-effective event solutions. We'll expand our capabilities, enhancing AI-powered venue matching, automated negotiations, and real-time budget optimization. Our goal is to streamline the entire event lifecycle, making complex planning as simple as ordering food delivery. | losing |
## Inspiration
With the rise of climate change but lack in the change of public policy, the greatest danger is not only natural disasters, but it is also the public not understand what is actually causing devasting weather events throughout the world. Since public policy and getting people to change would be the best way to combat climate change, we needed to build a solution that is more targeted for an audience not moved by data, but by what affects them.
## What it does
We created a new way to present data to help change the minds of climate deniers and bring events to those who are less informed. Weather Or Not focuses more on showing strong media (videos, pictures) of **local** events rather than global events climate deniers tend to ignore. When users receive the website, the videos render based on climate events and anomalies in their area, and the videos go into a landing site which shows the cause of such events.
## How we built it
To get the local events and media for the landing page, we used both Twitter API connected to an Azure SQL database hosted within a Python flask server and Chrome's Puppeteer Web Scraper in Node.js to get 3rd-party sources such as news outlets and scraping embedded Youtube videos from such sites. We created an HTML5 template with JQuery as the frontend to render the videos. The landing page includes also a newsletter where the data is stored in Firebase's Realtime Database to help provide resources to people visiting the site who have been moved by the images to learn more about how they can help combat the effects of Climate Change.
## Challenges we ran into
The hardest part was connecting the various API's from all the applications that were created.
## Accomplishments that we're proud of
We used tools and services most of us were new to, and we managed to accomplish a complex, API calling system that can be said is common in a lot of enterprise IT system architectures within a 24 hour period!
## What we learned
We learned a lot of new tools, such as Python flask, SQL, and machine learning models with Azure.
## What's next for Weather Or Not | ## Inspiration
Diseases in monoculture farms can spread easily and significantly impact food security and farmers' lives. We aim to create a solution that uses computer vision for the early detection and mitigation of these diseases.
## What it does
Our project is a proof-of-concept for detecting plant diseases using leaf images. We have a raspberry pi with a camera that takes an image of the plant, processes it, and sends an image to our API, which uses a neural network to detect signs of disease in that image. Our end goal is to incorporate this technology onto a drone-based system that can automatically detect crop diseases and alert farmers of potential outbreaks.
## How we built it
The first layer of our implementation is a raspberry pi that connects to a camera to capture leaf images. The second layer is our neural network, which the raspberry pi accesses through an API deployed on Digital Ocean.
## Challenges we ran into
The first hurdle in our journey was training the neural network for disease detection. We overcame this with FastAI and using transfer learning to build our network on top of ResNet, a complicated and performant CNN. The second part of our challenge was interfacing our software with our hardware, which ranged from creating and deploying APIs to figuring out specific Arduino wirings.
## Accomplishments that we're proud of
We're proud of creating a working POC of a complicated idea that has the potential to make an actual impact on people's lives.
## What we learned
We learned about a lot of aspects of building and deploying technology, ranging from MLOps to electronics. Specifically, we explored Computer Vision, Backend Development, Deployment, and Microcontrollers (and all the things that come between).
## What's next for Plant Disease Analysis
The next stage is to incorporate our technology with drones to automate the process of image capture and processing. We aim to create a technology that can help farmers prevent disease outbreaks and push the world into a more sustainable direction. | ## Inspiration
Since the breakout of the pandemic, we saw a surge in people’s need for an affordable, convenient, and environmentally friendly way of transportation. In particular, the main pain points in this area include taking public transportation is risky due to the pandemic, it’s strenuous to ride a bike for long-distance commuting, increasing traffic congestion, etc.
In the post-covid time, private and renewable energy transportation will be a huge market. Compared with the cutthroat competition in the EV industry, the eBike market has been ignored to some extent, so it is the competition is not as overwhelming and the market opportunity and potential are extremely promising.
At the moment, 95% of the bikes are exported from China, and they can not provide prompt aftersales service. The next step of our idea is to integrate resources to build an efficient service system for the current Chinese exporters.
We also see great progress and a promising future for carbon credit projects and decarbonization. This is what we are trying to integrate into our APP to track people’s carbon footprint and translate it into carbon credit to encourage people to make contributions to decarbonization.
## What it does
We are building an aftersales service system to integrate the existing resources such as manufacturers in China and more than 7000 brick and mortar shops in the US.
Unique value proposition: We have a strong supply chain management ability because most of the suppliers are from China and we have a close relationship with them, in the meantime, we are about to build an assembly line in the US to provide better service to the customers. Moreover, we are working on a system to integrate cyclists and carbon emissions, this unique model can make the rides more meaningful and intriguing.
## How we built it
The ecosystem will be built for various platforms and devices. The platform will include both Android and iOS apps because both operating systems have nearly equal percentages of users in the United States.
Google Cloud Maps API:
We'll be using Google Cloud Map API for receiving map location requests continuously and plot a path map accordingly. There will be metadata requests having direction, compass degrees, acceleration, speed, and height above sea level at every API request. These data features will be used to calculate reward points.
Detecting Mock Locations:
The above features can also be mapped for checking irregularities in the data received.
For instance, if a customer tries to trick the system to gain undue favors, these data features can be used to see if the location request data received is sent by a mock location app or a real one.
For example, a mock location app won't be able to give out varying directions. Moreover, the acceleration calculated by map request can be verified against the accelerometer sensor's values.
Fraud Prevention using Machine Learning:
Our app will be able to prevent various levels of fraud by cross-referencing different users and by using Machine Learning models of usage patterns. Such patterns which will be deviant from normal usage behavior will be evident and marked.
Trusted Platform Execution:
The app will be inherently secure as we will leverage the SDK APIs of phone platforms to check the integrity level of devices. It’ll be at the security level of banking apps using advanced program isolation techniques and cryptography to secure our app from other escalated processes. Our app won't work on rooted Android phones or jail-broken iPhones
## Challenges we ran into
How to precisely calculate the conversion from Mileage to Carbon Credits, currently we are using our own way to convert these numbers, but in the future when we have a huge enough customers base and want to work on the individual carbon credits trading, this conversion calculation would be meticulous.
During this week, a challenge we had was to time difference among the teammates. Our IT brain is in China so it was quite challenging for us to properly and fully communicate and make sure the information flow well within the team during such a short time.
## Accomplishments that we're proud of
We are the only company that combines micro mobility with climate change, as well as use this way to protect the forest.
## What we learned
We have talked to many existing and potential customers and learned a lot about their behavior patterns, preferences, social media exposure and comments on the eBike products.
We have learned a lot regarding APP design, product design, business development, and business model innovation through a lot of trial and error.
We have also learned how important partnership and relationships are and we have learned to invest a lot of time and resources into cultivating this.
Above up, we learned how fun hackathons can be!
## What's next for Meego Inc
Right now we have already built up the supply chain for eBikes and the next step of our idea is to integrate resources to build an efficient service system for the current Chinese exporters. | losing |
## Hack The Valley 4
Hack the Valley 2020 project
## On The Radar
**Inspiration**
Have you ever been walking through your campus and wondered what’s happening around you, but too unmotivated to search through Facebook, the school’s website and where ever else people post about social gatherings and just want to see what’s around?
Ever see an event online and think this looks like a lot of fun, just to realize that the event has already ended, or is on a different day?
Do you usually find yourself looking for nearby events in your neighborhood while you’re bored?
Looking for a better app that could give you notifications, and have all the events in one and accessible place?
These are some of the questions that inspired us to build “On the Radar” --- a user-friendly map navigation system that allows users to discover cool, real-time events that suit their interests and passion in the nearby area.
*Now you’ll be flying over the Radar!*
**Purpose**
On the Radar is a mobile application that allows users to match users with nearby events that suit their preferences.
The user’s location is detected using the “standard autocomplete search” that tracks your current location. Then, the app will display a customized set of events that are currently in progress in the user’s area which is catered to each user.
**Challenges**
* Lack of RAM in some computers, see Android Studio (This made some of our tests and emulations slow as it is a very resource-intensive program. We resolved this by having one of our team members run a massive virtual machine)
* Google Cloud (Implementing google maps integration and google app engine to host the rest API both proved more complicated than originally imagined.)
* Android Studio (As it was the first time for the majority of us using Android Studio and app development in general, it was quite the learning curve for all of us to help contribute to the app.)
* Domain.com (Linking our domain.com name, flyingovertheradar.space, to our github pages was a little bit more tricky than anticipated, needing a particular use of CNAME dns setup.)
* Radar.io (As it was our first time using Radar.io, and the first time implementing its sdk, it took a lot of trouble shooting to get it to work as desired.)
* Mongo DB (We decided to use Mongo DB Atlas to host our backend database needs, which took a while to get configured properly.)
* JSON objects/files (These proved to be the bain of our existence and took many hours to get them to convert into a usable format.)
* Rest API (Getting the rest API to respond correctly to our http requests was quite frustrating, we had to use many different http Java libraries before we found one that worked with our project.)
* Java/xml (As some of our members had no prior experience with both Java and xml, development proved even more difficult than originally anticipated.)
* Merge Conflicts (Ah, good old merge conflicts, a lot of fun trying to figure out what code you want to keep, delete or merge at 3am)
* Sleep deprivation (Over all our team of four got collectively 24 hours of sleep over this 36 hour hackathon.)
**Process of Building**
* For the front-end, we used Android Studio to develop the user interface of the app and its interactivity. This included a login page, a registration page and our home page in which has a map and events nearby you.
* MongoDB Atlas was used for back-end, we used it to store the users’ login and personal information along with events and their details.
* This link provides you with the Github repository of “On the Radar.” <https://github.com/maxerenberg/hackthevalley4/tree/master/app/src/main/java/com/hackthevalley4/hackthevalleyiv/controller>
* We also designed a prototype using Figma to plan out how the app could potentially look like.
The prototype’s link → <https://www.figma.com/proto/iKQ5ypH54mBKbhpLZDSzPX/On-The-Radar?node-id=13%3A0&scaling=scale-down>
* We also used a framework called Bootstrap to make our website. In this project, our team uploaded the website files through Github.
The website’s code → <https://github.com/arianneghislainerull/arianneghislainerull.github.io>
The website’s link → <https://flyingovertheradar.space/#>
*Look us up at*
# <http://flyingovertheradar.space> | ## Inspiration
As first-year students, we have experienced the difficulties of navigating our way around our new home. We wanted to facilitate the transition to university by helping students learn more about their university campus.
## What it does
A social media app for students to share daily images of their campus and earn points by accurately guessing the locations of their friend's image. After guessing, students can explore the location in full with detailed maps, including within university buildings.
## How we built it
Mapped-in SDK was used to display user locations in relation to surrounding buildings and help identify different campus areas. Reactjs was used as a mobile website as the SDK was unavailable for mobile. Express and Node for backend, and MongoDB Atlas serves as the backend for flexible datatypes.
## Challenges we ran into
* Developing in an unfamiliar framework (React) after learning that Android Studio was not feasible
* Bypassing CORS permissions when accessing the user's camera
## Accomplishments that we're proud of
* Using a new SDK purposely to address an issue that was relevant to our team
* Going through the development process, and gaining a range of experiences over a short period of time
## What we learned
* Planning time effectively and redirecting our goals accordingly
* How to learn by collaborating with team members to SDK experts, as well as reading documentation.
* Our tech stack
## What's next for LooGuessr
* creating more social elements, such as a global leaderboard/tournaments to increase engagement beyond first years
* considering freemium components, such as extra guesses, 360-view, and interpersonal wagers
* showcasing 360-picture view by stitching together a video recording from the user
* addressing privacy concerns with image face blur and an option for delaying showing the image | ## Inspiration
Have you ever wished to give a memorable dining experience to your loved ones, regardless of their location? We were inspired by the desire to provide our friends and family with a taste of our favorite dining experiences, no matter where they might be.
## What it does
It lets you book and pay for a meal of someone you care about.
## How we built it
Languages:-
Javascript, html, mongoDB, Aello API
Methodologies:-
- Simple and accessible UI
- database management
- blockchain contract validation
- AI chatBot
## Challenges we ran into
1. We have to design the friendly front-end user interface for both customers and restaurant partner which of them have their own functionality. Furthermore, we needed to integrate numerous concepts into our backend system, aggregating information from various APIs and utilizing Google Cloud for the storage of user data.
2. Given the abundance of information requiring straightforward organization, we had to carefully consider how to ensure an efficient user experience.
## Accomplishments that we're proud of
We have designed the flow of product development that clearly show us the potential of idea that able to scale in the future.
## What we learned
3. System Design: Through this project, we have delved deep into the intricacies of system design. We've learned how to architect and structure systems efficiently, considering scalability, performance, and user experience. This understanding is invaluable as it forms the foundation for creating robust and user-friendly solutions.
4. Collaboration: Working as a team has taught us the significance of effective collaboration. We've realized that diverse skill sets and perspectives can lead to innovative solutions. Communication, coordination, and the ability to leverage each team member's strengths have been essential in achieving our project goals.
5. Problem-Solving: Challenges inevitably arise during any project. Our experiences have honed our problem-solving skills, enabling us to approach obstacles with creativity and resilience. We've learned to break down complex issues into manageable tasks and find solutions collaboratively.
6. Adaptability: In the ever-evolving field of technology, adaptability is crucial. We've learned to embrace new tools, technologies, and methodologies as needed to keep our project on track and ensure it remains relevant in a dynamic landscape.collaborative as a team.
## What's next for Meal Treat
We want to integrate more tools for personalization, including a chatbot that supports customers in RSVPing their spot in the restaurant. This chatbot, utilizing Google Cloud's Dialogflow, will be trained to handle scheduling tasks. Next, we also plan to use Twilio's services to communicate with our customers through text SMS. Last but not least, we expect to incorporate blockchain technology to encrypt customer information, making it easier for the restaurant to manage and enhance protection, especially given our international services. Lastly, we aim to design an ecosystem that enhances the dining experience for everyone and fosters stronger relationships through meal care. | partial |
## Away From Keyboard
## Inspiration
We wanted to create something that anyone can use AFK for chrome. Whether it be for accessibility reasons -- such as for those with disabilities that can't use the keyboard -- or for daily use when you're cooking, our aim was to make scrolling and Chrome browsing easier.
## What it does
Our app AFK (away from keyboard) helps users scroll and read, hands off. You can control the page by saying "go down/up", "open/close tab", "go back/forward", "reload/refresh", or reading the text on the page (it will autoscroll once you reach the bottom).
## How we built it
Stack overflow and lots of panicked googling -- we also used Mozilla's web speech API.
## Challenges we ran into
We had some difficulties scraping the text from sites for the reading function as well as some difficulty integrating the APIs into our extension. We started off with a completely different idea and had to pivot mid-hack. This cut down a lot of our time, and we had troubles re-organizing and gauging the situation.
However, as a team, we all worked on contributing parts to the project and, in the end we were able to create a working product despite the small road bumps we ran into.
## Accomplishments that we are proud of
As a team, we were able to learn how to make chrome extensions in 24 hours :D
## What we learned
We learned chrome extensions, using APIs in the extension and also had some side adventures with vue.js and vuetify for webapps.
## What's next for AFK
We wanted to include other functionalities like taking screen shots and taking notes with the voice. | ## Inspiration
```
We had multiple inspirations for creating Discotheque. Multiple members of our team have fond memories of virtual music festivals, silent discos, and other ways of enjoying music or other audio over the internet in a more immersive experience. In addition, Sumedh is a DJ with experience performing for thousands back at Georgia Tech, so this space seemed like a fun project to do.
```
## What it does
```
Currently, it allows a user to log in using Google OAuth and either stream music from their computer to create a channel or listen to ongoing streams.
```
## How we built it
```
We used React, with Tailwind CSS, React Bootstrap, and Twilio's Paste component library for the frontend, Firebase for user data and authentication, Twilio's Live API for the streaming, and Twilio's Serverless functions for hosting and backend. We also attempted to include the Spotify API in our application, but due to time constraints, we ended up not including this in the final application.
```
## Challenges we ran into
```
This was the first ever hackathon for half of our team, so there was a very rapid learning curve for most of the team, but I believe we were all able to learn new skills and utilize our abilities to the fullest in order to develop a successful MVP! We also struggled immensely with the Twilio Live API since it's newer and we had no experience with it before this hackathon, but we are proud of how we were able to overcome our struggles to deliver an audio application!
```
## What we learned
```
We learned how to use Twilio's Live API, Serverless hosting, and Paste component library, the Spotify API, and brushed up on our React and Firebase Auth abilities. We also learned how to persevere through seemingly insurmountable blockers.
```
## What's next for Discotheque
```
If we had more time, we wanted to work on some gamification (using Firebase and potentially some blockchain) and interactive/social features such as song requests and DJ scores. If we were to continue this, we would try to also replace the microphone input with computer audio input to have a cleaner audio mix. We would also try to ensure the legality of our service by enabling plagiarism/copyright checking and encouraging DJs to only stream music they have the rights to (or copyright-free music) similar to Twitch's recent approach. We would also like to enable DJs to play music directly from their Spotify accounts to ensure the good availability of good quality music.
``` | ## Inspiration
Ever wish you could hear your baby cry where you are in the world? Probably not, but it's great to know anyways! Did you know that babies often cry when at least one of their needs is not met? How could possibly know about baby's needs without being there watching the baby sleep?
## What it does
Our team of 3 visionaries present to you **the** innovation of the 21st century. Using just your mobile phone and an internet connection, you can now remotely receive updates on whether or not your baby is crying, and whether your baby has reached dangerously high temperatures.
## How we built it
We used AndroidStudio for building the app that receives the updates. We used Socket.io for the backend communication between the phone and the Intel Edison.
## Challenges we ran into
Attempting to make push notifications work accounted for a large portion of time spent building this prototype. In the future versions, push notifications would be included.
## Accomplishments that we're proud of
We are proud of paving the future of baby-to-mobile communications for fast footed parents around the globe.
## What we learned
As software people we are proud that we were to able to communicate with the Intel Edison.
## What's next for Baby Monitor
Push notifications. Stay tuned!! | partial |
## Our Inspiration
Designer clothing and high-fashion are extremely expensive luxuries. These clothes and dresses tend to be worn just for a few times, if at all worn more than once. A cheaper way to experience luxury clothing is not prevalent today. The fact that expensive clothing is usually worn less times by the owners can be used as a solution.
## What Almari does
**Almari** is a crowdsourced virtual wardrobe that attempts to redefine luxury clothing. Our target audience is millennials. Almari provides a web platform for high fashion products to be shared and thus better utilized. We tried to achieve two objectives:
1) An efficient way for lending/renting and borrowing high fashion clothing items. Our search criteria uses the type of event (formal, cultural, party etc.) as the method of suggesting possible clothing matches.
2) A good system of monetization for people who invested in luxury clothing, and a cheap and hassle-free experience for people who want to rent out clothes for specific events.
Almari ensures quality of the clothing items put on its store by using a UID of any clothing item.
We also have a feature for donating clothes to Salvation Army.
## How we built it
The frontend of Almari is built using the Bootstrap framework and AngularJS
The backend is built on Parse and Node.JS
## Challenges we ran into
No one knew Parse and one person had to learn it from scratch.
## Accomplishments that we're proud of
We built an API for GAP that gives an image for a product code.
Clean and professional UI/UX
## What's next for Almari
Social media integration.
Get to know the sentiment of your friends before borrowing/purchasing a dress.
Use the Postmates API for enabling exchange of clothes from anywhere to anywhere. | ## Inspiration & What it does
You're walking down the road, and see a belle rocking an exquisite one-piece. *"Damn, that would look good on me (or my wife)"*.
You go home and try to look for it: *"beautiful red dress"*. Google gives you 110,000,000 results in 0.54 seconds. Well that helped a lot. You think of checking the fashion websites, but the number of these e-commerce websites makes you refrain from spending more than a few hours. *"This is impossible..."*. You perseverance only lasts so long - you give up.
Fast forward to 2017. We've got everything from Neural Forests to Adversarial Networks.
You go home to look for it: Launch **Dream.it**
You make a chicken-sketch of the dress - you just need to get the curves right. You select the pattern on the dress, a couple of estimates about the dress. **Dream.it** synthesizes elegant dresses based on your sketch. It then gives you search results from different stores based on similar dresses, and an option to get on custom made. You love the internet. You love **Dream.it**. Its a wonderful place to make your life wonderful.
Sketch and search for anything and everything from shoes and bracelets to dresses and jeans: all at your slightest whim. **Dream.it** lets you buy existing products or get a new one custom-made to fit you.
## How we built it
**What the user sees**
**Dream.it** uses a website as the basic entry point into the service, which is run on a **linode server**. It has a chatbot interface, through which users can initially input the kind of garment they are looking for with a few details. The service gives the user examples of possible products using the **Bing Search API**.
The voice recognition for the chatbot is created using the **Bing Speech to Text API**. This is classified using a multiclassifier from **IBM Watson Natural Language Classifier** trained on custom labelled data into the clothing / accessory category. It then opens a custom drawing board for you to sketch the contours of your clothing apparel / accessories / footwear and add color to it.
Once the sketch is finalized, the image is converted to more detailed higher resolution image using [**Pixel Recursive Super Resolution**](https://arxiv.org/pdf/1702.00783.pdf).
We then use **Google's Label Detection Vision ML** and **IBM Watson's Vision** APIs to generate the most relevant tags for the final synthesized design which give additional textual details for the synthesized design.
The tags, in addition to the image itself are used to scour the web for similar dresses available for purchase
**Behind the scenes**
We used a **Deep Convolutional Generative Adversarial Network (GAN)** which runs using **Theano** and **cuDNN** on **CUDA**. This is connected to our web service through websockets. The brush strokes from the drawing pad on the website get sent to the **GAN** algorithm, which sends back the synthesized fashion design to match the user's sketch.
## Challenges we ran into
* Piping all the APIs together to create a seamless user experience. It took a long time to optimize the data (*mpeg1*) we were sending over the websocket to prevent lags and bugs.
* Running the Machine learning algorithm asynchronously on the GPU using CUDA.
* Generating a high-quality image of the synthesized design.
* Customizing **Fabric.js** to send data appropriately formatted to be processed by the machine learning algorithm.
## Accomplishments that we're proud of
* We reverse engineered the **Bing real-time Speech Recognition API** to create a Node.js library. We also added support for **partial audio frame streaming for voice recognition**.
* We applied transfer learning from Deep Convolutional Generative Adversarial Networks and implemented constraints on its gradients and weights to customize user inputs for synthesis of fashion designs.
* Creating a **Python-Node.js** stack which works asynchronously with our machine learning pipeline
## What we learned
This was a multi-faceted educational experience for all of us in different ways. Overall:
* We learnt to asynchronously run machine learning algorithms without threading issues.
* Setting up API calls and other infrastructure for the app to run on.
* Using the IBM Watson APIs for speech recognition and label detection for images.
* Setting up a website domain, web server, hosting a website, deploying code to a server, connecting using web-sockets.
* Using pip, npm; Using Node.js for development; Customizing fabric.js to send us custom data for image generation.
* Explored machine learning tools learnt how to utlize them most efficiently.
* Setting up CUDA, cuDNN, and Theano on an Ubuntu platform to use with ML algorithm.
## What's next for Dream.it
Dream.it currently is capable of generating shoes, shirts, pants, and handbags from user sketches. We'd like to expand our training set of images and language processing to support a greater variety of clothing, materials, and other accessories.
We'd like to switch to a server with GPU support to run the cuDNN-based algorithm on CUDA.
The next developmental step for Dream.it is to connect it to a 3D fabric printer which can print the designs instantly without needing the design to be sent to manufacturers. This can be supported at particular facilities in different parts of the country to enable us to be in control of the entire process. | ## Inspiration
Being second years, we all related to finding it difficult connecting with people and making support/study groups, especially due to the transition onto online learning. StudyBuddy is a way to connect you with people taking the same courses as you, in hope of forming these friend/study groups.
## What it does
Study buddy is a clever online application that enables students to learn collectively in an effective and efficient manner. Study buddy keeps records of these courses a user takes in their current study period, it searches through its database to find students taking the same course and groups nearby matches to a group study session. Collaborative education has been proven to improve student comprehension and overall content because students can turn lecture notes into their own words.
## Challenges we ran into
We didn't start working until Saturday night and ran into a time crunch. It was especially difficult getting the routes for various pages to synchronize with one another and ensure that all the pages were running smoothly. However, after persevering quite a bit we were able to make a breakthrough and figure out what we needed to do. Another issue we ran into near the submission period was trying to deploy the app on an online platform.
## What we learned
Time management is key. We definitely learned a lot about effective communication skills and that taking a proactive approach to discussions can not only boost morale for a team but also help build stronger bonds between team members. Several of us were exposed to new technologies and learned how to use them in a short period of time which is one of our key takeaways from this event.
## What's next for StudyBuddy
We may refine the app more and possibly launch it on the app/play store. Furthermore, we plan to implement more immersive features to reduce the number of third parties we would rely on by building out an in-house chat system and connect feature. Study buddy has great potential to become an MVP in a student's resource arsenal. We would like to conduct more research on the target market we aim to reach and how much of that market we will be able to capture. Finally, we would love to implement more management software to ensure that our databases are updated and managed regularly. | partial |
## Inspiration
As roommates, we found that keeping track of our weekly chore schedule and house expenses was a tedious process, more tedious than we initially figured.
Though we created a Google Doc to share among us to keep the weekly rotation in line with everyone, manually updating this became hectic and cumbersome--some of us rotated the chores clockwise, others in a zig-zag.
Collecting debts for small purchases for the house split between four other roommates was another pain point we wanted to address. We decided if we were to build technology to automate it, it must be accessible by all of us as we do not share a phone OS in common (half of us are on iPhone, the other half on Android).
## What it does
**Chores:**
Abode automatically assigns a weekly chore rotation and keeps track of expenses within a house. Only one person needs to be a part of the app for it to work--the others simply receive a text message detailing their chores for the week and reply “done” when they are finished.
If they do not finish by close to the deadline, they’ll receive another text reminding them to do their chores.
**Expenses:**
Expenses can be added and each amount owed is automatically calculated and transactions are automatically expensed to each roommates credit card using the Stripe API.
## How we built it
We started by defining user stories and simple user flow diagrams. We then designed the database where we were able to structure our user models. Mock designs were created for the iOS application and was implemented in two separate components (dashboard and the onboarding process). The front and back-end were completed separately where endpoints were defined clearly to allow for a seamless integration process thanks to Standard Library.
## Challenges we ran into
One of the significant challenges that the team faced was when the back-end database experienced technical difficulties at the tail end of the hackathon. This slowed down our ability to integrate our iOS app with our API. However, the team fought back while facing adversity and came out on top.
## Accomplishments that we're proud of
**Back-end:**
Using Standard Library we developed a comprehensive back-end for our iOS app consisting of 13 end-points, along with being able to interface via text messages using Twilio for users that do not necessarily want to download the app.
**Design:**
The team is particularly proud of the design that the application is based on. We decided to choose a relatively simplistic and modern approach through the use of a simple washed out colour palette. The team was inspired by material designs that are commonly found in many modern applications. It was imperative that the designs for each screen were consistent to ensure a seamless user experience and as a result a mock-up of design components was created prior to beginning to the project.
**Use case:**
Not only that, but our app has a real use case for us, and we look forward to iterating on our project for our own use and a potential future release.
## What we learned
This was the first time any of us had gone into a hackathon with no initial idea. There was a lot of startup-cost when fleshing out our design, and as a result a lot of back and forth between our front and back-end members. This showed us the value of good team communication as well as how valuable documentation is -- before going straight into the code.
## What's next for Abode
Abode was set out to be a solution to the gripes that we encountered on a daily basis.
Currently, we only support the core functionality - it will require some refactoring and abstractions so that we can make it extensible. We also only did manual testing of our API, so some automated test suites and unit tests are on the horizon. | ## Inspiration
We were tired of the same boring jokes that Alexa tells. In an effort to spice up her creative side, we decided to implement a machine learning model that allows her to rap instead.
## What it does
Lil 'lexa uses an LSTM machine learning model to create her own rap lyrics based on the input of the user. Users first tell Alexa their rap name, along with what rapper they would like Lil 'lexa's vocabulary to be inspired by. Models have been created for Eminem, Cardi B, Nicki Minaj, Travis Scott, and Wu-Tang Clan. After the user drops a bar themselves, Lil 'lexa will spit back her own continuation along with a beat to go with it.
## How I built it
The models were trained using TensorFlow along with the Keras API. Lyrics for each rapper were scrapped from metrolyrics.com using Selenium python package, which served as the basis for the rapper's vocabulary. Fifty-word sequences were used as training data, where the model then guesses the next best word. The web application that takes in the seed text and outputs the generated lyrics is built with Flask and is deployed using Heroku. We also use Voiceflow to create the program to be loaded onto an Alexa, which uses an API call to retrieve the generated lyrics.
## Challenges I ran into
* Formatting the user input so that it would always work with the model
* Creating a consistent vocab list for each rapper
* Voiceflow inputs being merged together or stuck
## Accomplishments that I'm proud of
* My Alexa can finally gain some street cred
## What I learned
* Using Flask and Heroku to deploy an application
* Using Voiceflow to create programs that work with Amazon Alexa and Google Assistant
* Using Tensorflow to train an LSTM model
## What's next for Lil 'lexa
* Implementing more complex models that consider sentences and rhyming
* Call and response format for a rap battle
* Wider range of background beats | ## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service. | partial |
## Inspiration
As college students, one of the biggest issues we face in our classes is finding a study group we love and are comfortable in. We created this project to solve this problem.
## What it does
Our website provides an interface for students to create and join study groups, as well as invite their friends to join their groups, and chat with other members of the group.
## How I built it
We used the Google Calendar API with a node.js / Python backend to build our website.
## Challenges I ran into
One of the biggest challenges we faced during the construction of this project was using the Google Calendar API with server-side authentication with a default email address, as opposed to requesting the user for authentication.
## Accomplishments that I'm proud of
## What I learned
## What's next for StudyGroupMe
We need to work on and improve the User Interface. Secondly, once we have access to logging in through Harvard Key, we no longer need to scrape for information, and will directly have access to class/student information on login | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | ## Inspiration
Our inspiration for developing this tool stemmed from the challenges we faced with handling large files. Whether it was struggling to process extensive datasets for model training, grappling with unwieldy CSVs during data cleaning without a concise summary, or uploading files to the cloud for basic image processing—these tasks were time-consuming and often overlooked. Editing these files manually was both labor-intensive and inefficient. This is why we decided to enhance the already impressive MASV tool with a new extension designed to streamline these processes.
## What it does
With the help of **MASV**, users are able to apply edits to large amounts of image and video files, while guaranteeing the speed, efficiency, and consistency that **MASV** provides. While focused on images and videos in this setting, the concepts are easily extended to virtually any file processing text you can imagine.
## How we built it
The web app was built and deployed with **Defang** and the file-saving system was created using **MASV** API. The image and video processing use python OpenCV library and cloud integration is done on Google Drive.
## Challenges we ran into
One of our biggest challenges was switching projects with less than 24 hours left during the hackathon. With this, it was difficult for us to catch up to the level that other teams were ahead in their projects. For this reason, we were unable to finish the project to the point that we envisioned. It lacks the fully automated features it could have with more work, but the components are there for further polishing.
## Accomplishments that we're proud of
Still managing to get a product together despite the rough start. Managed to stay persistent and not lose our desire to build something cool. Ultimately we are really proud of the idea and implementation we have put together and see it as something we can build our own workflows on top of.
## What we learned
Learned how important it can be to remain open to new ideas and to pivot quickly. If we hadn't made the quick decision to create a different project, who knows what kind of product we would have now. We're taking away this idea of flexibility and looking to apply it creatively in our future projects.
## What's next for autoM8
Completely automate the data processing pipeline. Provide more support for file formats and processing tasks, making it more applicable across domains. Integrate unique processing featues (LLM analysis, more sophisticated classification of images, etc.) | partial |
## Evaluating accents and improving pronunciation
In the digital age, it has become increasingly important to be able to communicate across cultural, national, and linguistic barriers. Although sites like DuoLingo exist to help you learn the vocabulary and sentence structure of a new language, no such site yet exists to provide detailed feedback on your pronunciation. We're taking the first steps in creating such a system by utilizing the power of deep learning.
## Idea
Baidu's DeepSpeech2 model works by combining features extracted from audio by a convolutional neural network (CNN) and contextual data from a recurrent neural network (RNN). We suspect that predictions based solely off of the CNN's features will be much more accurate for standard pronunciations or accents than for nonnative speakers, which predictions utilizing both parts of the network may be able to leverage the contextual information to mask these potential problems.
## Results
We actually discovered a bug in Baidu's PaddlePaddle API, which was reproduced by Baidu's mentors. Unfortunately, we found out at 3:00am that they couldn't find a quick way to patch the problem, so we were unable to train or test either the CNN-only or the CNN+RNN networks.
## Contributions
We still think that we have provided some interesting contributions or directions for further exploration. In particular, we feel that our idea has potential to identify both common mistakes for individuals and characteristics of accents for different countries or regions, and should be transferable to languages other than English.
We have also set up code in the GitHub repo that should be able to train the CNN-only network using the same parameters as the CNN+RNN network.
We further present Zhao's algorithm as an efficient way for tracking the substitutions, additions, and deletions between two lists of phonemes, one of which may be considered the ground truth. This provides a base-level summary for an individual's or group's results. | ## Inspiration
Our inspiration for the creation of PlanIt came from the different social circles we spend
time in. It seemed like no matter the group of people, planning an event was always
cumbersome and there were too many little factors that made it annoying.
## What it does
PlanIt allows for quick and easy construction of events. It uses Facebook and Googleplus’
APIs in order to connect people. A host chooses a date and invites people; once invited,
everyone can contribute with ideas for places, which in turn, creates a list of potential
events that are set to a vote.
The host then looks at the results and chooses an overall main event. This main event
becomes the spotlight for many features introduced by PlanIt. Some of the main features
are quite simple in its idea: Let people know when you are on the way, thereby causing
the app to track your location and instead of telling everyone your location, it lets
everybody know how far away you are from the desired destination. Another feature is the
carpool tab; people can volunteer to carpool and list their vehicle capacity, people can
sort themselves as a subpart of the driver. There are many more features that are in
play.
## How we built it
We used Microsoft Azure for cloud based server side development and Xamarin in order
to have easy cross-platform compatibility with C# as our main language.
## Challenges we ran into
Some of the challenges that we ran into were based around backend and server side
issues. We spent 3 hours trying to fix one bug and even then it still seemed to be
conflicted. All in all the frontend went by quite smoothly but the backend took some
work.
## Accomplishments that we're proud of
We were very close to quitting late into the night but we were able to take a break and
rally around a new project model in order to finish as much of it as we could. Not quitting
was probably the most notable accomplishment of the event.
## What we learned
We used two new softwares for this app. Xaramin and Microsoft Azure. We also learned
that its possible to have a semi working product with only one day of work.
## What's next for PlanIt
We were hoping to fully complete PlanIt for use within our own group of friends. If it gets
positive feedback then we could see ourselves releasing this app on the market. | ## Inspiration
We wanted to build an application that would make university students lives less stressful.
A common issue we heard about from students is navigating changes to their degree, whether it be courses, modules, or the entire degree itself. Students would have to go through multiple sources to figure out how to keep their degree on track. We thought it would be a lot more convenient to have a single website that allows you to do all this minus the stress.
## What it does
Degree Planner is a web platform that allows students to plan out their degree and evaluate their options. Students can see a dynamic chart that lays out all the necessary courses for a specific program. Degree Planner has access to all courses offered by a student's university.
## How we built it
We organized ourselves by creating user stories and assigning tasks using agile technology like Jira.
As for the frontend, we chose to use React.js, Redux, Bootstrap, and Apache E-Charts.
We used React.js because it has helped most of us produce stable code in the past, Redux for state management, Bootstrap for its grid and other built in classes, and E-Charts for data visualization.
In the backend we used Express.js, Node.js, MongoDB, and Redis. Express.js was an easy way to handle http requests to our server. Node.js was great for installing 3rd party modules for easier development. MongoDB, a NoSQL database might not be as robust as a SQL database, but we chose to use MongoDB because of Mongo Atlas, an online database that allowed all of us to share data. Redis was chosen because it was a great way to persist users after they have been authenticated.
## Challenges we ran into
We were originally going to use an open source Western API that would get information on Western's courses/programs. However, 4 hours into the hacking, the API was down. We had to switch to another school's API.
E-Charts.js is great, because it has a lot of built-in data visualization functionality, but it was challenging to customize the chart relative to our page, because of this built-in functionality. We had to make our page around the chart instead of making the chart fit our page.
## Accomplishments that we're proud of
We are proud that we managed to get a fully functioning application finished within a short time frame. We are also proud of our team members for trying their best, and helping each other out.
## What we learned
Some of members who were less familiar with frontend and more familiar with backend learned frontend tricks, while some of our members who were less familiar with backend and more familiar with frontend learned some backend architecture.
It was really great to see how people went out of their comfort zones to grow as developers.
## What's next for Degree Planner
We want to expand our website's scope to include multiple universities, including Western University. We also want to add more data visualization tools so that our site is even more user-friendly. Even though we completed a lot of features in less than 36 hours, we still wish that we had more time, because we were just starting to scratch the surface of our website's capabilities. | partial |
## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | ## Inspiration
The whiteboard or chalkboard is an essential tool in instructional settings - to learn better, students need a way to directly transport code from a non-text medium to a more workable environment.
## What it does
Enables someone to take a picture of handwritten or printed text converts it directly to code or text on your favorite text editor on your computer.
## How we built it
On the front end, we built an app using Ionic/Cordova so the user could take a picture of their code. Behind the scenes, using JavaScript, our software harnesses the power of the Google Cloud Vision API to perform intelligent character recognition (ICR) of handwritten words. Following that, we applied our own formatting algorithms to prettify the code. Finally, our server sends the formatted code to the desired computer, which opens it with the appropriate file extension in your favorite IDE. In addition, the client handles all scripting of minimization and fileOS.
## Challenges we ran into
The vision API is trained on text with correct grammar and punctuation. This makes recognition of code quite difficult, especially indentation and camel case. We were able to overcome this issue with some clever algorithms. Also, despite a general lack of JavaScript knowledge, we were able to make good use of documentation to solve our issues.
## Accomplishments that we're proud of
A beautiful spacing algorithm that recursively categorizes lines into indentation levels.
Getting the app to talk to the main server to talk to the target computer.
Scripting the client to display final result in a matter of seconds.
## What we learned
How to integrate and use the Google Cloud Vision API.
How to build and communicate across servers in JavaScript.
How to interact with native functions of a phone.
## What's next for Codify
It's feasibly to increase accuracy by using the Levenshtein distance between words. In addition, we can improve algorithms to work well with code. Finally, we can add image preprocessing (heighten image contrast, rotate accordingly) to make it more readable to the vision API. | ## Inspiration
AO3 Enhanced was inspired by the need for trashy, easily-digestible content in conjunction with thoughtful, thematic works of fiction based on popular media. It was also inspired by a crippling existentialism and a desire to escape our reality into the realm of the fictional. Take that as you will - the antidote to boredom and cause of late-night scrolling.
## What it does
Worried people behind you in lecture look over your shoulder at an importune opportunity and see the bad fanart you're frantically trying to scrolling past? AO3 Enhanced offers a feature to hide images from prying eyes, as well as to reverse the effect.
Ran into a Dead Dove: Do Not Eat fic but find yourself desperately curious? We got you - you can sneak a peek at the trigger warnings and figure out if it's a-non-kinky-person-trying-to-write-a-kinky-fic or if it's a psychotic individual coming at you with eldritch horrors.
Trying to stalk your favourite author with their bookmarks inaccessible because of the inability to filter for completion? AO3 Enhanced encourages binge-reading with no fear of unintentional cliff-hangers by adding that extra filter! Carelessly click on any fic you want without the terror of a serialized fanfiction with no end in sight!
## The Building Process and Challenges
AO3 Enhanced was built with the utmost love, much pain and a few-almost tears. After a false start with the AO3 API, we pivoted towards JavaScript and optimizing AO3 through the user interaction via browser. Once we had established our means of execution, implementation was relatively smooth: as a passion project, our ideas for features were motivated and based in personal user experience.
## Accomplishments that we're proud of
Our project offers a practical tool for a widely used platform. It is an extension useful on a personal level, one that many a friend would cherish. Our aesthetic is immaculate: the beautiful integration with the AO3 interface, the compatibility of the extension with the reading experience, and the smooth user experience - who could ask for more?
## What's next for AO3 Enhanced
Given the time constraints, we were not able to fully develop our vision for AO3 Enhanced. Future updates would include: the 'or' filter (mixing two distinct fandoms without limiting it to fics with both), an author branch network (to visualize how authors interact and which authors yield fruitful bookmarks), the ability to see the reading level and grammar of fics etc.
Where AO3 is our beloved Archive of our Own, AO3 Enhanced is made for us as well. It's made to destigmatize the fandom and encourage self-expression (although we do not condone the extremes of pro-shipping). In the same way literary critics revere Dante for his lil queer fanboy epics, we have the liberty to shameless self-indulgence: why not engage with it on the best terms we can? | winning |
## Inspiration
*Inspired by the burning hunger that resides in the stomachs of all university students, comes UBC FeedMe.*
## What it does
Scrounges UBC Facebook groups and event pages for events, gatherings, and celebrations that offer any free food or refreshments. Using a keyword searcher in the description of these events, they are filtered and posted onto the web application and sorted by date (soonest to latest).
## How We built it
*Harnessing the pain of hunger and financial crisis*
Used the MEAN stack; MongoDB, ExpressJS, Angular 2, Node.js.
Begins by using the Facebook Graph API to extract JSON objects of the events, which are filtered and formatted in a Python back-end. Valid free-food events are then stored on MongoDB; these events are then queried by the Node.js back-end which is displayed on the Angular2-built front-end.
## Challenges we ran into
*Hacking on an eternally empty stomach*
Initially chose CockroachDB; resorted to MongoDB for ease of use.
Using the Facebook Graph API to retrieve only current and future events.
Deploying; must be run locally.
## Accomplishments that we're proud of
*The hero that UBC deserves, and definitely the one it needs right now.*
(Final product functions as expected; filtered and displayed events offer free food, as desired.)
## What we learned
*How to strategically sustain yourself on only free food for the entire school year*
(How to use: PyMongo, CockroachDB, Docker, Node.js, Facebook Graph API, Angular2)
## What's next for UBC FeedMe
Automate the database updating process, integrating Google Maps, stricter filtering. | ## Inspiration for the project
I love free food at school club events.
## Goal of project
Connects Berkeley students to free food and gives them the opportunity to discover new clubs on campus. Helps people realize that though we all have many different recreational and intellectual differences, we can all connect over the human universal constant: love for free food. Also gives publicity to clubs with free food events.
## Technology behind project
The idea is that the bot has an email signed up to the mailing list of all clubs on campus, and it searches its email everyday to find all the club events of the day. It then filters out the events, storing all events that are giving out free food. Then a twitter account tweets out the events 10 minutes before the event happens, and a student can easily see which events have free food.
## Challenges we faced
Trying to make Google API and Twitter API work in harmony is still a problem we are trying to solve. How to get flyers and distribute information about the events, even if we know which events have food.
## Things we did well
Building a functional email scraping script. Building a image to text analyzer that can tell which events have free food and which do not.
## Things we learned
We learned the difficulty of combining different working parts. Especially if those different parts in different languages or use different API's. How to set up an account through Google API; I found that it was a very useful tool for many different things and serves as a very functional hub for out project. Also allows for easy data storage.
## Future of Berkeley Free Food
I hope that one day Berkeley Free Food can be a fully functioning twitter bot that can be a helpful resource to hungry Berkeley students and eventually other universities if their students want to set up their own version. | ## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service. | losing |
## Inspiration
We're 4 college freshmen that were expecting new experiences with interactive and engaging professors in college; however, COVID-19 threw a wrench in that (and a lot of other plans). As all of us are currently learning online through various video lecture platforms, we found out that these lectures sometimes move too fast or are just flat-out boring. Summaread is our solution to transform video lectures into an easy-to-digest format.
## What it does
"Summaread" automatically captures lecture content using an advanced AI NLP pipeline to automatically generate a condensed note outline. All one needs to do is provide a YouTube link to the lecture or a transcript and the corresponding outline will be rapidly generated for reading. Summaread currently generates outlines that are shortened to about 10% of the original transcript length. The outline can also be downloaded as a PDF for annotation purposes. In addition, our tool uses the Google cloud API to generate a list of Key Topics and links to Wikipedia to encourage further exploration of lecture content.
## How we built it
Our project is comprised of many interconnected components, which we detail below:
**Lecture Detection**
Our product is able to automatically detect when lecture slides change to improve the performance of the NLP model in summarizing results. This tool uses the Google Cloud Platform API to detect changes in lecture content and records timestamps accordingly.
**Text Summarization**
We use the Hugging Face summarization pipeline to automatically summarize groups of text that are between a certain number of words. This is repeated across every group of text previous generated from the Lecture Detection step.
**Post-Processing and Formatting**
Once the summarized content is generated, the text is processed into a set of coherent bullet points and split by sentences using Natural Language Processing techniques. The text is also formatted for easy reading by including “sub-bullet” points that give a further explanation into the main bullet point.
**Key Concept Suggestions**
To generate key concepts, we used the Google Cloud Platform API to scan over the condensed notes our model generates and provide wikipedia links accordingly. Some examples of Key Concepts for a COVID-19 related lecture would be medical institutions, famous researchers, and related diseases.
**Front-End**
The front end of our website was set-up with Flask and Bootstrap. This allowed us to quickly and easily integrate our Python scripts and NLP model.
## Challenges we ran into
1. Text summarization is extremely difficult -- while there are many powerful algorithms for turning articles into paragraph summaries, there is essentially nothing on shortening conversational sentences like those found in a lecture into bullet points.
2. Our NLP model is quite large, which made it difficult to host on cloud platforms
## Accomplishments that we're proud of
1) Making a multi-faceted application, with a variety of machine learning and non-machine learning techniques.
2) Working on an unsolved machine learning problem (lecture simplification)
3) Real-time text analysis to determine new elements
## What we learned
1) First time for multiple members using Flask and doing web development
2) First time using Google Cloud Platform API
3) Running deep learning models makes my laptop run very hot
## What's next for Summaread
1) Improve our summarization model through improving data pre-processing techniques and decreasing run time
2) Adding more functionality to generated outlines for better user experience
3) Allowing for users to set parameters regarding how much the lecture is condensed by | ## Inspiration
At the University of Toronto, accessibility services are always in demand of more volunteer note-takers for students who are unable to attend classes. Video lectures are not always available and most profs either don't post notes, or post very imprecise, or none-detailed notes. Without a doubt, the best way for students to learn is to attend in person, but what is the next best option? That is the problem we tried to tackle this weekend, with notepal. Other applications include large scale presentations such as corporate meetings, or use for regular students who learn better through visuals and audio rather than note-taking, etc.
## What it does
notepal is an automated note taking assistant that uses both computer vision as well as Speech-To-Text NLP to generate nicely typed LaTeX documents. We made a built-in file management system and everything syncs with the cloud upon command. We hope to provide users with a smooth, integrated experience that lasts from the moment they start notepal to the moment they see their notes on the cloud.
## Accomplishments that we're proud of
Being able to integrate so many different services, APIs, and command-line SDKs was the toughest part, but also the part we tackled really well. This was the hardest project in terms of the number of services/tools we had to integrate, but a rewarding one nevertheless.
## What's Next
* Better command/cue system to avoid having to use direct commands each time the "board" refreshes.
* Create our own word editor system so the user can easily edit the document, then export and share with friends.
## See For Your Self
Primary: <https://note-pal.com>
Backup: <https://danielkooeun.lib.id/notepal-api@dev/> | # [SwitchVR](http://getswitchvr.com)
A super cool mini game built for the Oculus Rift and the Leap Motion controller.
## Inspiration
Coming into QHacks, we didn't really have an idea for what we wanted to build so we decided to have a little fun and play with tech many of us have never used before! So we ended up grabbing the Oculus Rift and the Leap Motion and got cracking! We decided to make a fun little game inspired by the old tap-tap style games we all miss so much! And thus, SwitchVR was born!
## What it does
SwitchVR uses some of the most cutting-edge technologies and this game is not meant for just any user! When we play tap-tap games, we tend to "get in the zone" and go for that next high score. We wanted to take that experience to the next level by integrating it with virtual reality as the medium of the game. The way it works is it uses the Oculus Rift as the camera and view controller and the Leap Motion as the gesture based controller to interact with the tiles coming your way. This makes to an interesting combination that really puts you into the world of tap-tap games. Trying to break that new high score? Why not literally put yourself in the game?!
## How we built it
The game itself was built on top of the Unity gaming engine using C# as well as the Oculus Rift and Leap Motion SDKs. We split the main components amongst each other and tackled our own tasks individually and later came back to bring everything together.
In addition to the game itself, we also built a landing page to showcase our game and giving us, as the company, an identity to build our brand. Our technology stack for the website includes HTML, SASS, JavaScript, Gulp, npm, and more!
## Challenges we ran into
Many of us have never used Unity or have ever worked with any kind of VR before so there was a steep learning curve for all of us. If you've ever used Unity before, you know how it has some of its quirks. We got stumped many times trying to figure out some of the most basic functions of Unity and even though it was challenging, it was something we're proud to have experienced.
In particular, some of the challenges we came across were collision triggering, shifting lanes, reproducing targets infinitely, movement across the lanes, and adaptive difficulty as the user plays longer.
## Accomplishments that we're proud of
Our biggest accomplishment was actually pushing through all of the difficulties and finishing a project from start to finish. It's a tough thing to do in a weekend and we're really proud to have overcome it.
Our next biggest accomplishment was being able to build something using a platform we have never used before. It was a huge learning experience and we all grew so much through it!
## What we learned
We all learned so much that a paragraph wouldn't be nearly enough to highlight even a fraction of it! Things like working with VR, Augmented Reality, playing with the Oculus Rift and the Leap Motion, working around in Unity, resource design, the user experience and interface for a virtual reality game. All this only scratches the surface of the things we learned at QHacks! | winning |
## Inspiration
During the fall 2021 semester, the friend group made a fun contest to participate in: Finding the chonkiest squirrel on campus.
Now that we are back in quarantine, stuck inside all day with no motivation to do exercise, we wondered if we could make a timer like in the app [Forest](https://www.forestapp.cc/) to motivate us to work out.
Combine the two idea, and...
## Welcome to Stronk Chonk!
In this game, the user has a mission of the utmost importance: taking care of Mr Chonky, the neighbourhood squirrel!
Spending time working out in real life is converted, in the game, as time spent gathering acorns. Therefore, the more time spent working out, the more acorns are gathered, and the chonkier the squirrel will become, providing it excellent protection for the harsh Canadian winter ahead.
So work out like your life depends on it!

## How we built it
* We made the app using Android Studio
* Images were drawn in Krita
* Communications on Discord
## Challenges we ran into
36 hours is not a lot of time. Originally, the app was supposed to be a game involving a carnival high striker bell. Suffice to say: *we did not have time for this*.
And so, we implemented a basic stopwatch app on Android Studio... Which 3 of us had never used before. There were many headaches, many laughs.
The most challenging bits:
* Pausing the stopwatch: Android's Chronometer does not have a pre-existing pause function
* Layout: We wanted to make it look pretty *we did not have time to make every page pretty* (but the home page looks very neat)
* Syncing: The buttons were a mess and a half, data across different pages of the app are not synced yet
## Accomplishments that we're proud of
* Making the stopwatch work (thanks Niels!)
* Animating the squirrel
* The splash art
* The art in general (huge props to Angela and Aigiarn)
## What we learned
* Most team members used Android Studio for the first time
* This was half of the team's first hackathon
* Niels and Ojetta are now *annoyingly* familiar with Android's Chronometer function
* Niels and Angela can now navigate the Android Studio Layout functions like pros!
* All team members are now aware they might be somewhat squirrel-obsessed
## What's next for Stronk Chonk
* Syncing data across all pages
* Adding the game element: High Striker Squirrel | ## Inspiration
Save the World is a mobile app meant to promote sustainable practices, one task at a time.
## What it does
Users begin with a colorless Earth prominently displayed on their screens, along with a list of possible tasks. After completing a sustainable task, such as saying no to a straw at a restaurant, users obtain points towards their goal of saving this empty world. As points are earned and users level up, they receive lively stickers to add to their world. Suggestions for activities are given based on the time of day. They can also connect with their friends to compete for the best scores and sustainability. Both the fun stickers and friendly competition encourage heightened sustainability practices from all users!
## How I built it
Our team created an iOS app with Swift. For the backend of tasks and users, we utilized a Firebase database. To connect these two, we utilized CocoaPods.
## Challenges I ran into
Half of our team had not used iOS before this Hackathon. We worked together to get past this learning curve and all contribute to the app. Additionally, we created a setup in Xcode for the wrong type of database at first. At that point, we made a decision to change the Xcode setup instead of creating a different database. Finally, we found that it is difficult to use CocoaPods in conjunction with Github, because every computer needs to do the pod init anyway. We carefully worked through this issue along with several other merge conflicts.
## Accomplishments that I'm proud of
We are proud of our ability to work as a team even with the majority of our members having limited Xcode experience. We are also excited that we delivered a functional app with almost all of the features we had hoped to complete. We had some other project ideas at the beginning but decided they did not have a high enough challenge factor; the ambition worked out and we are excited about what we produced.
## What I learned
We learned that it is important to triage which tasks should be attempted first. We attempted to prioritize the most important app functions and leave some of the fun features for the end. It was often tempting to try to work on exciting UI or other finishing touches, but having a strong project foundation was important. We also learned to continue to work hard even when the due date seemed far away. The first several hours were just as important as the final minutes of development.
## What's next for Save the World
Save the World has some wonderful features that could be implemented after this hackathon. For instance, the social aspect could be extended to give users more points if they meet up to do a task together. There could also be be forums for sustainability blog posts from users and chat areas. Additionally, the app could recommend personal tasks for users and start to “learn” their schedule and most-completed tasks. | ## Inspiration
The three of us love lifting at the gym. We always see apps that track cardio fitness but haven't found anything that tracks lifting exercises in real-time. Often times when lifting, people tend to employ poor form leading to gym injuries which could have been avoided by being proactive.
## What it does and how we built it
Our product tracks body movements using EMG signals from a Myo armband the athlete wears. During the activity, the application provides real-time tracking of muscles used, distance specific body parts travel and information about the athlete’s posture and form. Using machine learning, we actively provide haptic feedback through the band to correct the athlete’s movements if our algorithm deems the form to be poor.
## How we built it
We trained an SVM based on employing deliberately performed proper and improper forms for exercises such as bicep curls. We read properties of the EMG signals from the Myo band and associated these with the good/poor form labels. Then, we dynamically read signals from the band during workouts and chart points in the plane where we classify their forms. If the form is bad, the band provides haptic feedback to the user indicating that they might injure themselves.
## Challenges we ran into
Interfacing with the Myo bands API was not the easiest task for us, since we ran into numerous technical difficulties. However, after we spent copious amounts of time debugging, we finally managed to get a clear stream of EMG data.
## Accomplishments that we're proud of
We made a working product by the end of the hackathon (including a fully functional machine learning model) and are extremely excited for its future applications.
## What we learned
It was our first time making a hardware hack so it was a really great experience playing around with the Myo and learning about how to interface with the hardware. We also learned a lot about signal processing.
## What's next for SpotMe
In addition to refining our algorithms and depth of insights we can provide, we definitely want to expand the breadth of activities we cover too (since we’re primarily focused on weight lifting too).
The market we want to target is sports enthusiasts who want to play like their idols. By collecting data from professional athletes, we can come up with “profiles” that the user can learn to play like. We can quantitatively and precisely assess how close the user is playing their chosen professional athlete.
For instance, we played tennis in high school and frequently had to watch videos of our favorite professionals. With this tool, you can actually learn to serve like Federer, shoot like Curry or throw a spiral like Brady. | partial |
## Inspiration
This project was heavily inspired by CANBus and its unique network arbitration method for devices on the network. However while CANBus requires a specialised circuit to be a part of the network, Monopoly Bus does not, and moreover only requires a single wire.
## What it does
Monopoly Bus allows devices to broadcast messages, commands and data onto a single wire asynchronous network without any specialized peripherals. Thus, it is built for DIYers and hobbyists and will allow them to build large device networks without any extra parts or lots of wiring.
## How we built it
The protocol uses a "virtual clock" which is essentially a timer that the GPIO uses to send or receive a value every time the timer ticks. The clock is activated once the line has been pulled down, synchronizing all nodes. Thus, the clock translates the digital signal into a stream of bits.
## Challenges we ran into
Currently the protocol is only capable of sending 1 byte in a single frame. It is also quite error prone at higher tick rates/frequencies. A major issue initially was syncing devices on the network together itself.
## Accomplishments that we're proud of
Randomness based networks have been built before (in fact the first wireless packet data network utilized randomness for network arbitration) but I am proud to have developed something unique that hobbyists could use for their projects.
## What we learned
Low level signal processing and synchronization
Network Arbitration Mechanisms
Decimal - Binary Conversions and vice versa
## What's next for Monopoly Bus!
I hope to see this project bloom into a popular open source framework. I also plan on porting this to other MCUs. | ## Inspiration
Our team always get knocks on our residence doors and we can't hear it because we are typically wearing headphones in our room. To resolve this issue, we created a wireless doorbell made for dorm rooms that give us an audible and visual notification when someone is at our door.
## What it does
A person will press the doorbell outside the room and it will tell the receiver in the room that button has been pressed. The receiver (which is built in to the clock/timer) will provide the user with a audible and visual notification. In addition, an ultrasonic sensor built into the doorbell unit will detect if objects are in front of the door for prolonged periods of time and will visually notify the user about the potential eavesdropper.
## How we built it
We used two ESP32 microcontrollers connecting over wireless Bluetooth connection to eachother to send data from the doorbell to the receiver. The doorbell consists of a standard push button, and an ultrasonic sensor that is constantly measuring for objects within a 1m distance of it. The receiver uses a 7 segment display to show the time, a buzzer to play the doorbell chime, and an LED light for the visual cue. The LED strip will start displaying flashing lights to visually notify the user when the doorbell is pressed. Simultaneously, the receiver will begin playing audio through a buzzer.
## Challenges we ran into
We quickly realized the ultrasonic sensor, likely due to its cheapness, would randomly output distances of zero when an object was in front of it. This caused our measurements to reset when trying to calculate how long someone was in front of the door. To combat this, we changed the code so that it measured data the same way, but determined the time someone is at the door by an average of multiple measurements constantly being updated one measurement at a time. This would make it so a zero would not fully reset the measurement.
Another challenge was the 8x8 LED dot matrix, as it was very difficult to use with the little ports available on the ESP32. To combat this, we changed our display device to a 7 segment number display. Though we missed out on the aesthetically pleasing design of the 8x8 LED, we got to maintain the functionality of the clock and were able to stay using the ESP32.
## Accomplishments that we're proud of
Successfully making a wireless connection between the ESP32's and being able to communicate data through them.
Creating the functioning the clock by catching data from through connecting to a wifi and using the clock from there.
Resolving the issue of the ultrasonic sensor making inaccurate measurements.
## What we learned
How to use ESP32 microcontrollers (wired and wirelessly)
How to play sound through buzzers
How to make functioning buttons and assigning them to variables
How to use the 7 segment LED display
How to grab data from a
## What's next for Dormbell
In the future we plan to integrate our system into a mobile app that will notify users on their phone when the doorbell is pressed as an added layer or notification. We also want to add one or two-way communication through the use of microphones so that the user does not even have to open the door to get information from the person if it is only verbal. Finally, we would like to increase the size of the clock and make it aesthetically pleasing. | The goal of the project was to create a hyper-casual game for players of all ages to enjoy. Two players each control a bird and make them fly around the forest, collecting fruits while dodging bombs. The cherries can in turn be used as currency to buy different bird skins, levels, or upgrades.
Player one uses the A key and player 2 uses the L key.
We built the whole game over the course of McHacks 6 2019 using Unity and C# scripts.
The game's kid-friendly aesthetic is thanks to us having hand-drawn all of the sprites and background ourselves and importing them as assets in Unity.
While not fully implemented, the addition of microtransactions is easy as players could purchase different birds/skins, backgrounds, items, additional lives, or more gamemodes.
video:
<https://drive.google.com/file/d/1EYQjmWzx42sRpG3aOB6CTT8xpv8nZHFf/view?usp=sharing> | losing |
## Inspiration
During the second wave of covid in India, I witnessed the unthinkable amount of suffering unleashed on the people. During the peak, there were around 400,000 positive cases per day that were reported, according to various media reports a significant amount of positive cases went unreported. Images of piles of dead bodies being cremated almost everywhere around the country left me in shock. Since then I wanted to make/contribute to helping as much as I could. I took this problem as an inspiration to make an effort.
Silent Hypoxia is when a patient does not feel shortness of breath, yet their oxygen level drops drastically, this is a very dangerous situation that has claimed many lives in this pandemic.
To detect Silent Hypoxia, continuous monitoring of a patient's oxygen saturation is needed, unfortunately, general oximeters available in the market are manual and must be used at frequent intervals.
This is a big problem, for one, due to the extreme shortage of healthcare workers particularly in India, individual attention to patients for measuring SPO2 every few minutes is impossible, which increases the chances of Silent Hypoxia going undetected.
The solution is, continuous monitoring of oxygen saturation, this feature, unfortunately, is not offered by common affordable oximeters, taking it as a challenge, I came up with a prototype solution.
When a person has advanced age, they are likely to experience a decrease in physical quality, one of the weaknesses (physical decline) experienced by the elderly is a weakness in their legs, which will make them more susceptible to fall. Falling is an event that causes a conscious subject to be on the ground unintentionally. Factors that cause falls are ill-informed like stroke, slippery or wet floors, holding places that are not strong or not easily held.
These days’ falls have become a major health problem, particularly in the old aged ones. According to the statistics of WHO, 646,000 fatal falls are being recorded and 37.3 million falls that are not so fatal but which needs medical treatment have occurred existing solutions include computer vision to detect if the person falls, this process is highly susceptible to lighting conditions and is very restricted when it comes to covering a wide area. For example, a camera cannot detect fall in the bathroom because there is usually no camera
## What it does
It also solves another problem, that is of network and communications, to explain, imagine there is a patient wearing the device, which uses wifi to connect to the internet and send data to dynamodb. But if the patient goes to the bathroom, for example, the wifi connection might get attenuated due to walls and physical obstructions, another situation, in developing and undeveloped countries wifi is still a luxury and very uncommon so due to these real-world conditions, depending on just wifi and Bluetooth like most smartwatches and fitness wearables do, is a bad idea and not reliable, for this reason, oxy, along with wifi also has a GSM module that connects to the internet via GPRS, the GPRS network is available almost everywhere on earth, vastly improving reliability.
## How I built it
The device continuously monitors data from the SPO2 Sensor and Inertial Measurement Unit, and sends the data to dynamo db through an API gateway and lambda function, it can either use wifi or GPRS to connect to the API, the only difference between wifi and gprs is, gprs uses AT commands to connect to an intermediate gateway because the module i had at hand does not support SSL. so Once the device detects oxygen levels dropping below a certain point or physical fall, Smartphone app sends a notification, so if a patient needs 24/7 monitoring of SPO2 levels, you don’t have to take out an oximeter and measure manually every five minutes which can be exhausting for patient and caretaker, also, in India and other similar countries, there was an extreme shortage of healthcare workers who can be physically present nearby patient all the time to measure the oxygen levels, so, through the web app, which is hosted on the Graviton EC2 instance, they can add as many devices they want to monitor remotely, and medical history for emergency purpose of every patient is one click away, this, can allow them to keep monitoring patients’ spo2 while they tend to other important tasks.
The parameters of notification on the app are customizable, you can adjust the time intervals and threshold values to trigger notifications.
The device can be powered through a battery or USB, with the microcontroller esp8266 being the brain. The device can use inbuilt wifi to connect to the internet or it can do it through GPRS and SIM800L module, it also features onboard battery charging and discharging, with overcharge and overcurrent protection. And measurement is taken through an SPO2 sensor by Melexis.
The cost of making the device prototype was around 9 USD, if mass-produced the price can come down significantly.
## Challenges I ran into
The biggest challenge was to get data from the SPO2 sensor MAX30100, although there are libraries available for it, the bad schematic design of the breakout board made it impossible to get any data. I had to physically tinker around with the tiny SMD resistors on the sensor to make sure the I2C lines of the sensor work on a logic level of 3.3V.
## Accomplishments that I'm proud of
For me, the proudest accomplishment is to have a working prototype of not only hardware but software too.
## What I learned
The most important skill I learned is to connect the microcontroller to AWS DynamoDB through Lambda Gateway, and also how not to burn your fingers while desoldering teeny-tiny SMD components, ouch! that hurt 😂.
## What's next for oxy
The hardware enclosure that houses the device is must be made clamp-like or strap-on, to make it a proper wearable device, I wanted to do it right now but I lost time trying to implement the device and app. | ## Inspiration
In the United States, every 11 seconds, a senior is treated in the emergency room for a fall. Every 19 minutes, an older adult dies from a fall, directly or indirectly. Deteriorating balance is one of the direct causes of falling in seniors. This epidemic will only increase, as the senior population will double by 2060. While we can’t prevent the effects of aging, we can slow down this process of deterioration. Our mission is to create a solution to senior falls with Smart Soles, a shoe sole insert wearable and companion mobile app that aims to improve senior health by tracking balance, tracking number of steps walked, and recommending senior-specific exercises to improve balance and overall mobility.
## What it does
Smart Soles enables seniors to improve their balance and stability by interpreting user data to generate personalized health reports and recommend senior-specific exercises. In addition, academic research has indicated that seniors are recommended to walk 7,000 to 10,000 steps/day. We aim to offer seniors an intuitive and more discrete form of tracking their steps through Smart Soles.
## How we built it
The general design of Smart Soles consists of a shoe sole that has Force Sensing Resistors (FSRs) embedded on it. These FSRs will be monitored by a microcontroller and take pressure readings to take balance and mobility metrics. This data is sent to the user’s smartphone, via a web app to Google App Engine and then to our computer for processing. Afterwards, the output data is used to generate a report whether the user has a good or bad balance.
## Challenges we ran into
**Bluetooth Connectivity**
Despite hours spent on attempting to connect the Arduino Uno and our mobile application directly via Bluetooth, we were unable to maintain a **steady connection**, even though we can transmit the data between the devices. We believe this is due to our hardware, since our HC05 module uses Bluetooth 2.0 which is quite outdated and is not compatible with iOS devices. The problem may also be that the module itself is faulty. To work around this, we can upload the data to the Google Cloud, send it to a local machine for processing, and then send it to the user’s mobile app. We would attempt to rectify this problem by upgrading our hardware to be Bluetooth 4.0 (BLE) compatible.
**Step Counting**
We intended to use a three-axis accelerometer to count the user’s steps as they wore the sole. However, due to the final form factor of the sole and its inability to fit inside a shoe, we were unable to implement this feature.
**Exercise Repository**
Due to a significant time crunch, we were unable to implement this feature. We intended to create a database of exercise videos to recommend to the user. These recommendations would also be based on the balance score of the user.
## Accomplishments that we’re proud of
We accomplished a 65% success rate with our Recurrent Neural Network model and this was our very first time using machine learning! We also successfully put together a preliminary functioning prototype that can capture the pressure distribution.
## What we learned
This hackathon was all new experience to us. We learned about:
* FSR data and signal processing
* Data transmission between devices via Bluetooth
* Machine learning
* Google App Engine
## What's next for Smart Soles
* Bluetooth 4.0 connection to smartphones
* More data points to train our machine learning model
* Quantitative balance score system | ## Inspiration
IoT devices are extremely useful; however, they come at a high price. A key example of this is a smart fridge, which can cost thousands of dollars. Although many people can't afford this type of luxury, they can still greatly benefit from it. A smart fridge can eliminate food waste by keeping an inventory of your food and its freshness. If you don't know what to do with leftover food, a smart fridge can suggest recipes that use what you have in your fridge. This can easily expand to guiding your food consumption and shopping choices.
## What it does
FridgeSight offers a cheap, practical solution for those not ready to invest in a smart fridge. It can mount on any existing fridge as a touch interface and camera. By logging what you put in, take out, and use from your fridge, FridgeSight can deliver the very same benefits that smart fridges provide. It scans barcodes of packaged products and classifies produce and other unprocessed foods. FridgeSight's companion mobile app displays your food inventory, gives shopping suggestions based on your past behavior, and offers recipes that utilize what you currently have.
## How we built it
The IoT device is powered by Android Things with a Raspberry Pi 3. A camera and touchscreen display serve as peripherals for the user. FridgeSight scans UPC barcodes in front of it with the Google Mobile Vision API and cross references them with the UPCItemdb API in order to get the product's name and image. It also can classify produce and other unpackaged products with the Google Cloud Vision API. From there, the IoT device uploads this data to its Hasura backend.
FridgeSight's mobile app is built with Expo and React Native, allowing it to dynamically display information from Hasura. Besides using the data to display inventory and log absences, it pulls from the Food2Fork API in order to suggest recipes. Together, the IoT device and mobile app have the capability to exceed the functionality of a modern smart fridge.
## Challenges we ran into
Android Things provides a flexible environment for an IoT device. However, we had difficulty with initial configuration. At the very start, we had to reflash the device with an older OS because the latest version wasn't able to connect to WiFi networks. Our setup would also experience power issues, where the camera took too much power and shut down the entire system. In order to avoid this, we had to convert from video streaming to repeated image captures. In general, there was little documentation on communicating with the Raspberry Pi camera.
## Accomplishments that we're proud of
Concurring with Android Things's philosophy, we are proud of giving accessibility to previously unaffordable IoT devices. We're also proud of integrating a multitude of APIs across different fields in order to solve this issue.
## What we learned
This was our first time programming with Android Things, Expo, Hasura, and Google Cloud - platforms that we are excited to use in the future.
## What's next for FridgeSight
We've only scratched the surface for what the FridgeSight technology is capable of. Our current system, without any hardware modifications, can notify you when food is about to expire or hasn't been touched recently. Based on your activity, it can conveniently analyze your diet and provide healthier eating suggestions. FridgeSight can also be used for cabinets and other kitchen inventories. In the future, a large FridgeSight community would be able to push the platform with crowd-trained neural networks, easily surpassing standalone IoT kitchenware. There is a lot of potential in FridgeSight, and we hope to use PennApps as a way forward. | partial |
## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | ## Inspiration
We took inspiration from the multitude of apps that help to connect those who are missing to those who are searching for their loved ones and others affected by natural disaster, especially flooding. We wanted to design a product that not only helped to locate those individuals, but also to rescue those in danger. Through the combination of these services, the process of recovering after natural disasters is streamlined and much more efficient than other solutions.
## What it does
Spotted uses a drone to capture and send real-time images of flooded areas. Spotted then extracts human shapes from these images and maps the location of each individual onto a map and assigns each victim a volunteer to cover everyone in need of help. Volunteers can see the location of victims in real time through the mobile or web app and are provided with the best routes for the recovery effort.
## How we built it
The backbone of both our mobile and web applications is HERE.com’s intelligent mapping API. The two APIs that we used were the Interactive Maps API to provide a forward-facing client for volunteers to get an understanding of how an area is affected by flood and the Routing API to connect volunteers to those in need in the most efficient route possible. We also used machine learning and image recognition to identify victims and where they are in relation to the drone. The app was written in java, and the mobile site was written with html, js, and css.
## Challenges we ran into
All of us had a little experience with web development, so we had to learn a lot because we wanted to implement a web app that was similar to the mobile app.
## Accomplishments that we're proud of
Accomplishment: We are most proud that our app can collect and stores data that is available for flood research and provide real-time assignment to volunteers in order to ensure everyone is covered in the shortest time
## What we learned
We learned a great deal about integrating different technologies including XCode, . We also learned a lot about web development and the intertwining of different languages and technologies like html, css, and javascript.
## What's next for Spotted
Future of Spotted: We think the future of Spotted is going to be bright! Certainly, it is tremendously helpful for the users, and at the same time, the program improves its own functionality as data available increases. We might implement a machine learning feature to better utilize the data and predict the situation in target areas. What's more, we believe the accuracy of this prediction function will grow exponentially as data size increases. Another important feature is that we will be developing optimization algorithms to provide a real-time most efficient solution for the volunteers. Other future development might be its involvement with specific charity groups and research groups and work on specific locations outside US. | ## What it does
Vaccinate MI (a work in progress project started at TreeHacks 2021) aims to serve as a simple informational resource for individuals confused by the vaccination process in the state of Michigan.
## How we built it
React, JavaScript, HTML, CSS
## What's next for Vaccinate MI
Adding content and a filter given an input of a user's zip code. | winning |
## Inspiration
Whenever you get takeout or coffee, using a single use container is the only option. The single use, linear economy is not sustainable and I wanted to change that with a reusable item share system.
## What it does
ShareIT is a borrowing system that can be implemented securely anywhere, without fear of losing any items. To use the machine, you use the app to request a certain number of items. Then, it will allow you to take the items which are then stored under your username in order to prevent people from not returning the items. Removing items without using the app beforehand will cause the machine to make a sound until it is put back (It's a minor security system intended to prevent theft).
## How I built it
We used some old pipe shelving and cardboard to build the machine and we've set it up with a Raspberry Pi, and many ultrasonic sensors that are used to calculate the number of objects in a certain row. It is all handmade. I burnt myself a couple of times :)
## Challenges I ran into
The challenge that hindered our performance on the project the most was making a connection between Flutter and the Raspberry Pi. The soldering was also very difficult.
## Accomplishments that we're proud of
This is quite a large system and required a lot of hardware and software. We managed to make a reasonable amount of progress, and we're proud of that.
## What we learned
How to use a Raspberry Pi. How to make the Raspberry Pi communicate to the Arduino. How to connect the Ultrasonic sensors to every micro controller. A lot about the software and hardware connection interface.
## What's next for ShareIT
We plan to create a bigger shelf with more reusable times available. For instance, collapsible take-out boxes, metal straws, reusable utensils, and reusable bags. Also, instead of using regular plastic reusable items, we could even use bioplastic reusable items. Our current shelf prototype was created to be small for demonstration purposes. We plan to have a selection of self sizes which will be bigger and more robust. The current prototype design is customizable so each business owner can easily have a custom self for their location. This is key as each location will have different demands in terms of space and consumer base. With a PCB (or even with the Raspberry Pi we have with the current prototype) we can make the ShareIT’s hardware be the smart center of the location it is in. For example, at a cafe, ShareIT’s screen and onboard computer can function as a thermostat, music player, server and even a Google Assistant. With the PCB or Raspberry Pi, there are many features we can add with ease. These features along with the boast of being “green” will make it more intriguing for businesses to adopt ShareIT especially when it will be free of cost to them. On the software side, we plan on having a major update on the app where you can find out where the closest ShareIT is along with a better U.I. On the software side of the PCB/Raspberry Pi, we plan to further improve the U.I. and optimize the program so it can process transactions faster. All in all, we have a lot in mind for improvement. | ## Inspiration
As students, we personally wanted a better way of handling group projects. There were many times where we had difficulties in dividing up work in classes, and figuring out the best time where everyone was able to meet up and collaborate.
## What it does
Unit is an iOS application that allows users to create and invite others to their teams, or Units. Within a Unit, tasks are created and posted to the main page. Individuals can voluntarily pick tasks that they want done and assign it to themselves. Users can also see available times to schedule meetings with their teammates.
## How I built it
This is an iOS application that is built on Facebook's Parse as a backend.
## Challenges I ran into
Understanding the scenario hierarchy was difficult, but very important.
## Accomplishments that I'm proud of
Our team lacked a graphic designer, so making the application look good was tough.
## What I learned
Frontend, backend. Swift as a development language. Using Parse API store and query data.
## What's next for Unit
Full integration of the 'Meetings' feature, as well as a 'Conference Mode' that will guide users through the process of dividing tasks quickly and easily. | ## Inspiration
Given the increase in mental health awareness, we wanted to focus on therapy treatment tools in order to enhance the effectiveness of therapy. Therapists rely on hand-written notes and personal memory to progress emotionally with their clients, and there is no assistive digital tool for therapists to keep track of clients’ sentiment throughout a session. Therefore, we want to equip therapists with the ability to better analyze raw data, and track patient progress over time.
## Our Team
* Vanessa Seto, Systems Design Engineering at the University of Waterloo
* Daniel Wang, CS at the University of Toronto
* Quinnan Gill, Computer Engineering at the University of Pittsburgh
* Sanchit Batra, CS at the University of Buffalo
## What it does
Inkblot is a digital tool to give therapists a second opinion, by performing sentimental analysis on a patient throughout a therapy session. It keeps track of client progress as they attend more therapy sessions, and gives therapists useful data points that aren't usually captured in typical hand-written notes.
Some key features include the ability to scrub across the entire therapy session, allowing the therapist to read the transcript, and look at specific key words associated with certain emotions. Another key feature is the progress tab, that displays past therapy sessions with easy to interpret sentiment data visualizations, to allow therapists to see the overall ups and downs in a patient's visits.
## How we built it
We built the front end using Angular and hosted the web page locally. Given a complex data set, we wanted to present our application in a simple and user-friendly manner. We created a styling and branding template for the application and designed the UI from scratch.
For the back-end we hosted a REST API built using Flask on GCP in order to easily access API's offered by GCP.
Most notably, we took advantage of Google Vision API to perform sentiment analysis and used their speech to text API to transcribe a patient's therapy session.
## Challenges we ran into
* Integrated a chart library in Angular that met our project’s complex data needs
* Working with raw data
* Audio processing and conversions for session video clips
## Accomplishments that we're proud of
* Using GCP in its full effectiveness for our use case, including technologies like Google Cloud Storage, Google Compute VM, Google Cloud Firewall / LoadBalancer, as well as both Vision API and Speech-To-Text
* Implementing the entire front-end from scratch in Angular, with the integration of real-time data
* Great UI Design :)
## What's next for Inkblot
* Database integration: Keeping user data, keeping historical data, user profiles (login)
* Twilio Integration
* HIPAA Compliancy
* Investigate blockchain technology with the help of BlockStack
* Testing the product with professional therapists | losing |
# ***One of the Top 6 Hacks at McHacks 6!***
## Inspiration
**Hasn't it happened to us all at least once that we've realized too late that our groceries have expired.** We waste goods because we don't have a way to keep track of when our items will expire. We also often forget what to buy when we reach grocery stores, or we may even write the items we want to purchase down on pieces of paper and happen to forget them when we go to the grocery store. These are cases where **GrocerySavvy comes in handy!**
## What it does
GrocerySavvy allows users to **keep track of their groceries**, with their **expiry dates**, so that they will always be aware of the groceries they have yet to use and can remember to use them before their expiry dates, which, as a result, **reduces waste of valuable goods**. If an item in the inventory list has expired, its name will turn red to clearly distinguish it from other listed goods. Similarly, an item that will expire the following day will have its name turn orange. Sorting items by expiry date and item name is also available to facilitate user experience.
In addition to providing users with grocery tracking, GrocerySavvy can **store shopping lists, even for specific stores,** so anyone that heads to the supermarket can now just pull out their phone and filter the grocery list items based on the store they are at. **Almost everyone in today's society carries their cellphone with them, wherever they go**, as opposed to handwritten notes.
**Hence, GrocerySavvy makes grocery shopping and tracking simple and practical!**
## How I built it
This app was built in *Android Studio using Java*.
## Challenges I ran into
Although last-minute circumstances caused me to be teamless, thus making the work more challenging, I did not give up and am proud of the result that I was able to achieve on my own!
## Accomplishments that I'm proud of
Overall, working on my own project for an intensive 24 hours resulted in a **useful app** that I am truly proud of.
## What I learned
The challenge of creating my own app reinforced my interest in the app development domain, improved my abilities in building mobile applications, and taught me a few aspects of Android app development that I had not discovered while coding in the past.
## What's next for GrocerySavvy
My goal is to further pursue the development of this application in hopes that it may be perhaps released one day. Features that I would like to add to GrocerySavvy in the future include: suggesting recipes based on items expiring the soonest, notifying users of expired or soon to be expired goods even while the app is closed, improving the app's UI, and, most importantly, implementing an image recognition feature to scan goods and their expiry dates using the built-in cameras on mobile devices, thereby simplifying the input of items in the app, which is currently accomplished tediously through typing relevant item details. | The goal of this app is to help consumers keep track of the expiration dates of their groceries and reduce food waste.
We began by conducting research on common pain points for grocery shoppers, such as difficulty keeping track of expiration dates and not realizing items were expired until it was too late. From there, we identified the key features the app would need to address these issues, such as the ability to easily scan barcodes and input custom expiration dates for items without barcodes.
Next, we worked together to create a user-friendly interface that made it easy for users to input and track their groceries. They also developed a feature that allows users to set reminders for when certain items were nearing their expiration date.
Overall, we weren't able to finish all the features we wanted to within the time limit but learned a lot! | ## Inspiration
Our main inspiration for the idea of the Lead Zeppelin was a result of our wanting to help people with physical disorders still be able to appreciate and play music with restricted hand movements. There are countless--hundreds upon thousands of people who suffer from various physical disorders that prevent them from moving their arms much. When it comes to playing music, this proves a major issue as very few instruments can be played without open range of movement. Because every member of our team loves playing music, with the common instrument amongst all four of us being guitar, we decided to focus on trying to solve this issue for the acoustic guitar in particular.
## What it does
The Lead Zeppelin uses mechanical systems placed above the guitar frets and sound hole that allow the user to play the instrument using only two keypads. Through this system, the user is able to play the guitar without needing to move much more than his or her fingers, effectively helping those with restricted elbow or arm movement to play the guitar.
## How we built it
There were a lot of different components put into building the Lead Zeppelin. Starting with the frets, the main point was actually the inspiration for our project's name: the use of pencils--more specifically, their erasers. Each fret on each string has a pencil eraser hovering above it, which is used to press down the string at the user's intent. The pencils are able to be pushed down through the use of servos and a few mechanisms that were custom 3D printed. Above the sound hole, two servos are mounted to the guitar to allow for horizontal and vertical movement when plucking or strumming the strings. The last hardware parts were the circuit boards and the user's keypads, for which we utilized hot glue and sodder.
## Challenges we ran into
There were many obstacles as we approached this project from all different aspects of the design to the mechanics. On the other hand, however, we expected challenges since we delved into the idea knowing it was going to be ambitious for our time constraints. One of the first challenges we confronted was short-circuiting two Raspberry Pi's that we'd intended to use, forcing us to switch over to Arduino--which was entirely unplanned for. When it came time to build, one of the main challenges that we ran into was creating the mechanism for the pressing down of the strings on the frets of the guitar. This is because not only did we have to create multiple custom CAD parts, but the scale on the guitar is also one that works in millimeters--leaving little room for error when designing, and even less so when time is taken into consideration. In addition, there were many issues with the servos not functioning properly and the batteries' voltages being too low for the high-power servos, which ended up consuming more time than was allotted for solving them.
## Accomplishments that we're proud of
The biggest accomplishment for all of us is definitely pulling the whole project together to be able to create a guitar that can potentially be used for those with physical disabilities. When we were brainstorming ideas, there was a lot of doubt about every small detail that could potentially put everything we would work for to waste. Nonetheless, the idea and goal of our project was one that we really liked and so the fact that we were able to work together to make the project work was definitely impressive.
## What we learned
One of the biggest lessons we'll keep in mind for next time is time management. We spent relatively little time in the first day working on the project, and especially considering the scale of our idea, this resulted in our necessity to stay up later and sleep less the later it got in the hackathon as we realized the magnitude of work we had left.
## What's next for Lead Zeppelin
Currently, the model of Lead Zeppelin is only on a small scale meant to demonstrate proof of concept, considering the limited amount of time we had to work. In the future, this is an automated player that would be expanded to cover all of the frets and strings over the whole guitar. Furthermore, Lead Zeppelin is a step towards an entirely self-playing, automated guitar that could follow its complete development in the design helping those with physical disabilities. | losing |
## Inspiration
Jay, one of the members of our team, has volunteered for the Suicide Helpline in Calgary for 5 years. He is personally very attached and committed to this field and is really passionate about it. The rest of the team has all been affected directly and/or indirectly by depression and suicide.
## What it does
Provide activities, motivational quotes, cute cat and dog pictures, and even provides a hot link to a suicide helpline to help individuals when they need it the most.
## How we built it
Using Android Studio and thus coding in Java.
## Challenges we ran into
Too many to list. This is our first time making an Android application, so even basics of setting up Android Studio (which took 3 hours!!) was challenging. But ultimately, we fought through it with no sleep and got a good project done!
## Accomplishments that we're proud of
Finishing our first Android Studio project!! :)
## What we learned
How to use Android Studio and work as a team.
## What's next for Smile4Real
Continue to improve the product and help tons of people if possible! | ## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration
As students who study away from home, we often find ourselves relying on public transit to get from place to place. While this was often perfectly acceptable, there was one thing we always hated about public transit: transfers. To us, the only purpose of a transfer was to make it take longer to get from point A to B, and they were a massive waste of time. On the other hand, as university students, we spend much of our time working and studying with little free time. When we did have free time, we spent most of it getting dopamine hits from our phones or computers, making it difficult for us to truly recharge our minds. This project is our attempt at resolving these issues by giving people like us something to do to slow down and relax while waiting for their next bus. In addition, by making transfers better, we hoped to increase the appeal of public transit as a whole and encourage its use over less eco-friendly transportation methods.
## What it does
Transformit allows users to enter two locations they want to travel between by transit. Then, it shows the user the route to travel along, as well as the points of interest (POI) at each transit stop/transfer.
## How we built it
Our project mainly used MapBox API to fetch desired points of interest and HERE API to fetch the transit locations based on users search results from the navigation bar. We used MapBox API and its attributes to display the POI near the transit locations retrieved from HERE API. In addition, we used the MapBox GL JS library to create most of our front-end code, including the navigation controller and the map itself. The rest of our front-end code was created with anime.js and CSS for a clean web page design.
## Challenges we ran into
We initially struggled a lot with which APIs to use in our project; many of them didn’t have everything we were looking for, and the ones that did often required payment or billing information. We settled on using both MapBox API and HERE API to cover everything we needed, but that meant we needed to grasp both MapBox API and HERE API in a short amount of time. We ran into difficulties when trying to fetch the list of coordinates from a start point to an endpoint by retrieving the coordinates from the input navigation bar. We also had a hard time with fetching information from the MapBox API because of the complicated structure of the JSON objects. In addition, many of our tools were either very niche or outdated, meaning there was very limited documentation to draw from; we had to experiment and find workarounds to do what we wanted. However, by collaboration and actively trying out different solutions, we were able to resolve our challenges, retrieve all of the data from the two APIs, and populate the information successfully to our web application interface.
## Accomplishments that we're proud of
One accomplishment is that we are resilient and encouraging to each other through this journey. Despite many difficulties and failures, we still keep a positive attitude and actively seek different approaches to resolve the problem. We are also very proud of the supportive and collaborative culture of our team. By helping each other and discussing our implementation ideas for building our application, we not only were able to incorporate innovative ideas into our application but also gained enriching experience in software development practice.
## What we learned
Our journey has been an incredible experience in exploring more API, Javascript, and Node modules to efficiently display transit routes and points of interest for users to explore during their commute journey. We started this project with very little knowledge about how to even access an API, but we managed to learn so much about using libraries, communicating and working in a team, and connecting our frontend and backend code. Even though we only had a short amount of time, the knowledge and experience we gained were invaluable.
## What's next for Transformit ⭐
Some of our next initiatives include:
-Set up a server for our application and deploy our app using Netlify
-Enhance filter functionality by adding appropriate categories of POI for users to explore along the transit route
-Optimize API performance by using more scalable API such as Google Map API
-Incorporate AI chatbot to create more personalized experiences by asking users their preference for POI | winning |
## Why Soundscape
Hacking for the hack of it. It is a great mantra, and one that we often take to heart. While there is significant value in hackathon projects that offer aid in difficult and demanding tasks, sometimes the most interesting hacks are those that exist for their own sake. Soundscape takes a novel approach to an activity that many of us love — discovering music. Instead of letting the user simply respond "yea" or "nay" to an ever increasing list of songs, Soundscape places you in midst of the action and shows you a world of music right under your feet. Users can then pursue avenues they find interesting, search for new or exciting pieces, or merely wander through a selection of dynamically curated music. With Soundscape, you have a hack-of-a-lot of power.
## Functional Overview
Soundscape is a Virtual Reality application based on the Google Daydream platform. It curates data by crawling Soundcloud and building a relationship model of songs in their repository. From there, it uses advanced graph search techniques to identify songs that are similar to each other, so that users can start with one set a long, and shift the genre and style until they find something new that they enjoy.
## Technical Overview
Soundscape is built on top of Google's yet unreleased platform for high quality mobile virtual reality—Daydream. Developing most of the application’s front end in Unity, we make use of this framework in conjunction with the existing Google Cardboard technology to help power a virtual experience that has high fidelity, low stutter, and intuitive input. The application itself is built in Unity, with custom hooks built into the Daydream infrastructure to allow for a high quality user interface.
The core functionality of Soundscape lies in our backend aggregation server which runs a node, mongodb, and express.js stack on top of Linode. This server fetches song, user, and playlist data through the SoundCloud API to generate similarity scores between songs — calculated through user comments and track favorites. This conglomerated data is then queried by the Unity application, alongside the standard SoundCloud data and audio stream. Search functionality within the app is also enabled through voice recognition powered by IBM’s Watson Developer Cloud service for speech to text. All of this works seamlessly together to power one versatile and unique music visualization and exploration app.
## Looking Forward
We are excited about Soundscape, and look forward to perfecting this for the final release of Google Daydream. Until then, we have exciting ideas about better search, and ways to incorporate other APIs | ## Inspiration
Music has become a crucial part of people's lives, and they want customized playlists to fit their mood and surroundings. This is especially true for drivers who use music entertain themselves on their journey and to stay alert.
Based off of personal experience and feedback from our peers, we realized that many drivers are dissatisfied with the repetitive selection of songs on the radio and also on the regular Spotify playlists. That's why we were inspired to create something that could tackle this problem in a creative manner.
## What It Does
Music Map curates customized playlists based on factors such as time of day, weather, driving speed, and locale, creating a set of songs that fit the drive perfectly. The songs are selected from a variety of pre-existing Spotify playlists that match the users tastes and weighted based on the driving conditions to create a unique experience each time. This allows Music Map to introduce new music to the user while staying true to their own tastes.
## How we built it
HTML/CSS, Node.js, Esri, Spotify, Google Maps APIs
## Challenges we ran into
Spotify API was challenging to work with, especially authentication.
Overlaying our own UI over the map was also a challenge.
## Accomplishments that we're proud of
Learning a lot and having something to show for it
The clean and aesthetic UI
## What we learned
For the majority of the team, this was our first Hackathon and we learned how to work together well and distribute the workload under time pressure, playing to each of our strengths. We also learned a lot about the various APIs and how to fit different pieces of code together.
## What's next for Music Map
We will be incorporating more factors into the curation of the playlists and gathering more data on the users' preferences. | ## Inspiration
In recent history, waste misplacement and ignorance has harmed countless animal, degraded our environment and health, and has costed us millions of dollars each year. Even with our current progressive education system, Canadians are still often unsure as to what their waste is categorized by. For this reason, we believe that we have a duty to show them where their waste should go, in a simple, and innovative way.
## What it does
Garb-Sort is a mobile app that allows users to find out how to dispose of their garbage at the touch of a button. By taking a picture of the garbage, Garb-Sort will tell you if it belongs in the recycling, compost, landfill or should be disposed specially.
## How we built it
On the back end, Garb-Sort passes the taken photo to Microsoft Azure’s Cognitive Services to identify the object in the photo. Garb-Sort then queries a SQL Database based on Microsoft Azure for where the recognized item should be disposed.
## Challenges we ran into
Throughout Garb-Sort’s development, we were faced with several challenges. A main feature of our app is to implement Microsoft’s Azure Computer Vision API to detect and classify objects within photos passing through our system. The challenge here was to figure out how to transfer the Computer Vision API with our SQL database that we developed on a separate platform. Implementing within Android Studio was difficult as some functions were depreciated.
## Accomplishments that we're proud of
We are proud to take a step towards improving environmental care.
## What we learned
It is hard to utilize Microsoft Azure APIs. Documentations are sparse for some languages.
## What's next for Garb Sort
In the future, we would like to add a map that details the location of waste bins so that waste disposal would require minimal effort. | partial |
## Inspiration
Athena is an author and games are fun so we put it together with distributed systems to get this madness!
## What it does
Two player choose your adventure game in which players can either split off on their own paths or continue through the story together. There are certain parts in the story where the players can reunite if they so please. The choices of one player affect the choices available to the other player. Both players try to collect points based on their paths and whoever has more points at the end wins.
## How we built it
We defined our own specification for a concurrent choose your own adventure in yaml. Our server is written in Go and uses the Gorilla toolkit and socket.io. The frontend uses bootstrap and jquery.
## Special Features
Since we defined our own custom parser for our yaml specification. New adventure games can be specified by just adding new yaml files. Additionally, all of those games will support concurrent multiplayer out of the box.
## Challenges we ran into
* STAUS
* parsing yaml in Go while maintaining a flexible yaml format
* concurrency from multiple players
* CSS is a major pain :(
* making an http handler middleware in Go for handling cookies
* connecting sockets together nicely with the cookies
## Accomplishments that we're proud of
* it works... mostly
* it was creative
* 18 different endings!!!
* the layout is as intended!
## What we learned
* coming up with good specifications is hard
* yaml is powerful, but can be a pain especially in static-typed languages like Go
* CSS layout
* CSS grid
* Media Query
* SCSS
* cookies are amazing when you get them to work!
## What's next for Such Retro Choices
* more concurrency
* support for more players
* more interactions between the players
* more flashy content for the story
* mobile version | ## Inspiration
Arriving into new places always means starting all over again, including with friends and socializing. It was one lonely night when I had the idea to do something, but didn't ask anyone thinking they would be busy. Turns out they were thinking the same way too! We needed a way to communicate effectively and gather plans based on what we are up to doing, while reconnecting with some old friends in the process.
## What it does
You log in with Facebook and the app gets your friend connections who are also registered in the app. At any point you can set up a plan you want to do, maybe going for dinner at that new place, or hiking around the mountains near town. Maybe you will spend the night home and someone might want to hop in, or even you could schedule your gaming or streaming sessions for others to join you in your plan.
Maybe you don't know exactly what you want to do. Well, the inverse is also applied, you can hop in into the app and see the plans your friends have for a specific time. Just go into their post and tell them "I'm in"
## How we built it
In order to get the open access possible in a short ammount of time we implemented this as a Web Page using the MERN stack. Mongo, Express React and Node. This helps us build and deliver fast while also retaining most of the control over the control of our app. For this project in particular we tried an interesting approach in the file ordering system, emmulating the PODS system used in some frameworks or languages like Ember. This helps us group our code by entitied and also divide the workflow efficiently.
## Challenges we ran into
Because we are using the info from Facebook we frequently run into the problem and design decision of whether to cache the information or keep it flowing to maintain it updated. We want the user data to be always fresh, but this comes at a cost of multiple repeated fetches that we don't want to push into our clients. We ended up running with a mix of both, keeping the constant queries but optimizing our flow to do the least of them as possible.
## Accomplishments that we're proud of
The system in which the user friends are gathered for social communication depends heavily on the flow of the Facebook API, this was the most difficult thing to gather, especially ensuring a smooth onboarding experience in which the user would both login seamlessly with their social network, while at the same time we make all the preparations necessary for the user model to start using the app. It's kind of like a magic trick, and we learned how to juggle our cards on this one.
## What we learned
Returning to our fresh data problem, we realized the importance of determining earlier on when to normalize or not our data, seeing the tradeoffs this bring and when to use which one. Many times we rearranged code because we saw a more efficient way to build it. Knowing this from the beginning will save a lot of time in the next hackathons.
## What's next for Jalo
Make it big!! The basic functionality is already there but we can always improve upon it. By selecting which friends are going to be the ones invited to the events, setting filters and different functionalities like a specific date for responding, etc. Improving the chat is also necessary. But after all of that, make our friends use it and continue scaling it and see what more it needs to grow! | ## Inspiration
We wanted to learn about machine learning. There are thousands of sliding doors made by Black & Decker and they're all capable of sending data about the door. With this much data, the natural thing to consider is a machine learning algorithm that can figure out ahead of time when a door is broken, and how it can be fixed. This way, we can use an app to send a technician a notification when a door is predicted to be broken. Since technicians are very expensive for large corporations, something like this can save a lot of time, and money that would otherwise be spent with the technician figuring out if a door is broken, and what's wrong with it.
## What it does
DoorHero takes attributes (eg. motor speed) from sliding doors and determines if there is a problem with the door. If it detects a problem, DoorHero will suggest a fix for the problem.
## How we built it
DoorHero uses a Tensorflow Classification Neural Network to determine fixes for doors. Since we didn't have actual sliding doors at the hackathon, we simulated data and fixes. For example, we'd assign high motor speed to one row of data, and label it as a door with a problem with the motor, or we'd assign normal attributes for a row of data and label it as a working door.
The server is built using Flask and runs on [Floydhub](https://floydhub.com). It has a Tensorflow Neural Network that was trained with the simulated data. The data is simulated in an Android app. The app generates the mock data, then sends it to the server. The server evaluates the data based on what it was trained with, adds the new data to its logs and training data, then responds with the fix it has predicted.
The android app takes the response, and displays it, along with the mock data it sent.
In short, an Android app simulates the opening and closing of a door and generates mock data about the door, which is sends everytime the door "opens", to a server using a Flask REST API. The server has a trained Tensorflow Neural Network, which evaluates the data and responds with either "No Problems" if it finds the data to be normal, or a fix suggestion if it finds that the door has an issue with it.
## Challenges we ran into
The hardest parts were:
* Simulating data (with no background in sliding doors, the concept of sliding doors sending data was pretty abstract).
* Learning how to use machine learning (turns out this isn't so easy) and implement tensorflow
* Running tensorflow on a live server.
## Accomplishments that we're proud of
## What we learned
* A lot about modern day sliding doors
* The basics of machine learning with tensorflow
* Discovered floydhub
## What we could have improve on
There are several things we could've done (and wanted to do) but either didn't have time or didn't have enough data to. ie:
* Instead of predicting a fix and returning it, the server can predict a set of potential fixes in order of likelihood, then send them to the technician who can look into each suggestion, and select the suggestion that worked. This way, the neural network could've learned a lot faster over time. (Currently, it adds the predicted fix to its training data, which would make for bad results
* Instead of having a fixed set of door "problems" for the door, we could have built the app so that in the beginning, when the neural network hasn't learned yet, it asks the technician for input after everytime the fix the door (So it can learn without data we simulated as this is what would have to happen in the normal environment)
* We could have made a much better interface for the app
* We could have added support for a wider variety of doors (eg. different models of sliding doors)
* We could have had a more secure (encrypted) data transfer method
* We could have had a larger set of attributes for the door
* We could have factored more into decisions (for example, detecting a problem if a door opens, but never closes). | losing |
## Inspiration
One of our team members is a community manager for a real estate development group that often has trouble obtaining certifications in their attempts to develop eco-friendly buildings. The trouble that they go through, leaves them demotivated because of the cost and effort, leading them to avoid the process altogether, choosing to instead develop buildings that are not good for the environment.
If there was some way that they could more easily see what tier of LEED certification they could fall into and furthermore, what they need to do to get to the NEXT tier, they would be more motivated to do so, benefiting both their building practices as well as the Earth.
## What it does
Our product is a model that takes in building specifications and is trained on LEED codes. We take your building specifications and then answer any questions you may have on your building as well as put it into bronze, silver, gold, or platinum tiering!
## How we built it
The project structure is NextJS, React, Tailwind and for the ai component we used a custom openai api contextualized using past building specs and their certification level. We also used stack ai for testing and feature analysis.
## Challenges we ran into
The most difficult part of our project was figuring out how to make the model understand what buildings fall into different tiers.
## Accomplishments that we're proud of
GETTING THIS DONE ON TIME!!
## What we learned
This is our first full stack project using ai.
## What's next for LEED Bud
We're going to bring this to builders across Berkeley for them to use! Starting of course at the company of our team member! | ## Inspiration
**DronAR** was inspired by a love of cool technology. Drones are hot right now, and the question is, why not combine it with VR? The result is an awesome product that allows for drone management to be more **visually intuitive** letting users interact with drones in ways never done before.
## What it does
**DronAR** allows users to view realtime information about their drones such as positional data and status. Using this information, users can make on the spot decisions of how to interact with their drown.
## How I built it
Unity + Vuforia for AR. Node + Socket.IO + Express + Azure for backend
## Challenges I ran into
C# is *beautiful*
## What's next for DronAR
Adding SLAM in order to make it easier to interact with the AR items. | ## Inspiration
Food wastage, that sends more than a third of our food supply to rot is also major contributor to climate change. We at “Shafoo” realizing the impact of food wastage have come up with a novel solution to tackle food mismanagement. We plan on connecting every individual in the locality in order to promote food exchange and hence prevent food wastage.
## What it does
It is a platform that allows people to exchange food for free.
We have two main functions ,
-To share: Ping your location for the food you want to share, location will be retrieved and sent to database.
-To Receive: Search the database for food available in the locality, return as blips on the map where you could gpo and collect food for consumption.
We also have a ranking system in place to keep a check on the food quality and we have special filters for people with dietary restrictions so everyone can share and receive food irrespective of their allergies.
## How We built it
we used the google map to obtain location data , and routing. We also built a database containing 3 attributes: kind of food, ping time and location
while the time of food reaches 6 hrs it will automatically disappear
## Challenges We ran into
As a UI designer faced challenges like deciding the right color scheme for the mockup,the visual hierarchy and the color contrast to go for.We were to stick to the lighter shades as we were developing a food application.We also had integrate API for Google maps in our project and also create a database to store details of the users in order to create and maintain the ranking system.So one of the major challenges was for the front end design and back end to work together to optimize the application in the best way possible.
domain integration failure
## Accomplishments that We are proud of
First We successfully implemented the google map API into our application
The map API implementation is brought out really nicely.
did HTML the first time in my project
database implementation in the application
## What We learned
We learned n number of new things through our project we learned
database implementation
Android development
UI animation
Web Development
## What's next for ShaFoo
Since we were on a time constraint in the hackathon we couldn't implement some features and we plan on doing it in the future which includes
A Proper full-fledged rating system
A more deeply integrated allergies filter.
A reward system where the donatees get coupons and also keeps a check on food quality being exchanged. | partial |
## Sales and Customer service IS HARD!
People spend thousands of dollars in Sales and Customer service to understand see what is happening with their deals and customers. 59.2% of companies have a dedicated sales enablement initiative or function. Sales managers and specialists spend thousands of hours manually examining calls for many representatives for signs of customer dissatisfaction and the capabilities of their representatives. This is extremely inefficient. Sales leaders are compelled by these concerns to expand their awareness of new threats and new opportunities to develop their own competitive advantage. These same sales leaders are also concerned with the accelerated rate of change that’s occurring in their business. In the "2017 World Class Sales Practices Study", over 70% of respondents indicated that the rate of change in “customer expectations” and “competitive activity” was increasing noticeably or significantly.
So we built Convocal.
Convocal lets sales and customer service reps monitor their communications skills via AI-powered sentiment analysis.
We leveraged powerful APIs by Google to build this platform.
NOTE: This project needs google cloud credentials to run. These credentials have not been put on the repository for security reasons. | # 🚗 InsuclaimAI: Simplifying Insurance Claims 📝
## 🌟 Inspiration
💡 After a frustrating experience with a minor fender-bender, I was faced with the overwhelming process of filing an insurance claim. Filling out endless forms, speaking to multiple customer service representatives, and waiting for assessments felt like a second job. That's when I knew that there needed to be a more streamlined process. Thus, InsuclaimAI was conceived as a solution to simplify the insurance claim maze.
## 🎓 What I Learned
### 🛠 Technologies
#### 📖 OCR (Optical Character Recognition)
* OCR technologies like OpenCV helped in scanning and reading textual information from physical insurance documents, automating the data extraction phase.
#### 🧠 Machine Learning Algorithms (CNN)
* Utilized Convolutional Neural Networks to analyze and assess damage in photographs, providing an immediate preliminary estimate for claims.
#### 🌐 API Integrations
* Integrated APIs from various insurance providers to automate the claims process. This helped in creating a centralized database for multiple types of insurance.
### 🌈 Other Skills
#### 🎨 Importance of User Experience
* Focused on intuitive design and simple navigation to make the application user-friendly.
#### 🛡️ Data Privacy Laws
* Learned about GDPR, CCPA, and other regional data privacy laws to make sure the application is compliant.
#### 📑 How Insurance Claims Work
* Acquired a deep understanding of the insurance sector, including how claims are filed, and processed, and what factors influence the approval or denial of claims.
## 🏗️ How It Was Built
### Step 1️⃣: Research & Planning
* Conducted market research and user interviews to identify pain points.
* Designed a comprehensive flowchart to map out user journeys and backend processes.
### Step 2️⃣: Tech Stack Selection
* After evaluating various programming languages and frameworks, Python, TensorFlow, and Flet (From Python) were selected as they provided the most robust and scalable solutions.
### Step 3️⃣: Development
#### 📖 OCR
* Integrated Tesseract for OCR capabilities, enabling the app to automatically fill out forms using details from uploaded insurance documents.
#### 📸 Image Analysis
* Exploited an NLP model trained on thousands of car accident photos to detect the damages on automobiles.
#### 🏗️ Backend
##### 📞 Twilio
* Integrated Twilio to facilitate voice calling with insurance agencies. This allows users to directly reach out to the Insurance Agency, making the process even more seamless.
##### ⛓️ Aleo
* Used Aleo to tokenize PDFs containing sensitive insurance information on the blockchain. This ensures the highest levels of data integrity and security. Every PDF is turned into a unique token that can be securely and transparently tracked.
##### 👁️ Verbwire
* Integrated Verbwire for advanced user authentication using FaceID. This adds an extra layer of security by authenticating users through facial recognition before they can access or modify sensitive insurance information.
#### 🖼️ Frontend
* Used Flet to create a simple yet effective user interface. Incorporated feedback mechanisms for real-time user experience improvements.
## ⛔ Challenges Faced
#### 🔒 Data Privacy
* Researching and implementing data encryption and secure authentication took longer than anticipated, given the sensitive nature of the data.
#### 🌐 API Integration
* Where available, we integrated with their REST APIs, providing a standard way to exchange data between our application and the insurance providers. This enhanced our application's ability to offer a seamless and centralized service for multiple types of insurance.
#### 🎯 Quality Assurance
* Iteratively improved OCR and image analysis components to reach a satisfactory level of accuracy. Constantly validated results with actual data.
#### 📜 Legal Concerns
* Spent time consulting with legal advisors to ensure compliance with various insurance regulations and data protection laws.
## 🚀 The Future
👁️ InsuclaimAI aims to be a comprehensive insurance claim solution. Beyond just automating the claims process, we plan on collaborating with auto repair shops, towing services, and even medical facilities in the case of personal injuries, to provide a one-stop solution for all post-accident needs. | ## Inspiration
Our team’s mission is to create a space of understanding, compassion, and curiosity through facilitating cross-cultural conversations.
At a time where a pandemic and social media algorithms keep us tightly wound in our own homes and echo chambers, we’ve made a platform to push people out of their comfort zones and into a diverse environment where they can learn more about other cultures.
Cross-cultural conversations are immensely effective at eliminating biases and fostering understanding. However, these interactions can also be challenging and awkward. We designed Perspectives to eliminate that tension by putting the focus back on similarities instead of differences. We hope that through hearing the stories of other cultures, users will be able to drop their assumptions and become more accepting of the people around them.
## What it does
Perspectives guides users through cross-cultural conversation with prompts that help facilitate understanding and reflection.
Users have the ability to create a user profile that details their cultural identity, cross-cultural interests, and personal passions. Then, through the platform’s matching system, users are connected through video with like-minded individuals of different backgrounds.
## How we built it
The main codebase for our project was the MERN stack (MongoDB, Express.js, React.js, Node.js). We used the Daily API for our video calling and RxJS to handle our async events. We spent most of our time either planning different features for our application or coding over Zoom together.
## Challenges we ran into
A big challenge we encountered was deciding on what peer-to-peer communication platform we should use for our project. At first, our project was structured to be a mobile application, but after evaluating our time and resources, we felt that we would be able to build a higher quality desktop application. We knew that video calling was a key component to our idea, and so we tested a variety of the video call technology platforms in order to determine which one would be the best fit for us.
## Accomplishments that we're proud of
With so many moving pieces and only two of us working on the project, we were so enthusiastic when our project was able to come together and run smoothly. Developing a live pairing and video call system was definitely not something either of us had experience in, and so we were ecstatic to see our functioning final product.
## What we learned
We learned that ideation is EVERYTHING. Instead of jumping straight into our first couple project ideas like we’ve done in the past, we decided to spend more time on ideating and looking for pain points in our everyday lives. For certain project ideas, we needed a long time to do research and decide whether or not they were viable, but in the end, our patience paid off. Speaking of patience, another big piece of wisdom we learned is that sleep is important! After tucking in on Friday night, we were rejuvenated and hungry to work through Saturday, where we definitely saw most of our productiveness.
## What's next for Perspectives
A definite next step for the project would be to develop a Perspectives mobile app which would increase the project’s accessibility as well as introduce a new level of convenience to cross-cultural conversation. We are also excited to develop new features like in-app speaker panel events and large community discussions which would revolutionize the way we communicate outside our comfort zones. | partial |
# About Us
Discord Team Channel: #Team-25
secretage001#6705, Null#8324, BluCloos#8986
<https://friendzr.tech/>
## Inspiration
Over the last year the world has been faced with an ever-growing pandemic. As a result, students have faced increased difficulty in finding new friends and networking for potential job offers. Based on Tinder’s UI and LinkedIn’s connect feature, we wanted to develop a web-application that would help students find new people to connect and network with in an accessible, familiar, and easy to use environment. Our hope is that people will be able Friendz to network successfully using our web-application.
## What it does
Friendzr allows users to login with their email or Google account and connect with other users. Users can record a video introduction of themselves for other users to see. When looking for connections, users can choose to connect or skip on someone’s profile. Selecting to connect allows the user to message the other party and network.
## How we built it
The front-end was built with HTML, CSS, and JS using React. On our back-end, we used Firebase for authentication, CockroachDB for storing user information, and Google Cloud to host our service.
## Challenges we ran into
Throughout the development process, our team ran into many challenges. Determining how to upload videos recorded in the app directly to the cloud was a long and strenuous process as there are few resources about this online. Early on, we discovered that the scope of our project may have been too large, and towards the end, we ended up being in a time crunch. Real-time messaging also proved incredibly difficult to implement.
## Accomplishments that we're proud of
As a team, we are proud of our easy-to-use UI. We are also proud of getting the video to record users then directly upload to the cloud. Additionally, figuring out how to authenticate users and develop a viable platform was very rewarding.
## What we learned
We learned that when collaborating on a project, it is important to communicate, and time manage. Version control is important, and code needs to be organized and planned in a well-thought manner. Video and messaging is difficult to implement, but rewarding once completed.
In addition to this, one member learned how to use HTML, CSS, JS, and react over the weekend. The other two members were able to further develop their database management skills and both front and back-end development.
## What's next for Friendzr
Moving forward, the messaging system can be further developed. Currently, the UI of the messaging service is very simple and can be improved. We plan to add more sign-in options to allow users more ways of logging in. We also want to implement AssembyAI’s API for speech to text on the profile videos so the platform can reach people who aren't as able. Friendzr functions on both mobile and web, but our team hopes to further optimize each platform. | ## Inspiration
Our inspiration for the creation of PlanIt came from the different social circles we spend
time in. It seemed like no matter the group of people, planning an event was always
cumbersome and there were too many little factors that made it annoying.
## What it does
PlanIt allows for quick and easy construction of events. It uses Facebook and Googleplus’
APIs in order to connect people. A host chooses a date and invites people; once invited,
everyone can contribute with ideas for places, which in turn, creates a list of potential
events that are set to a vote.
The host then looks at the results and chooses an overall main event. This main event
becomes the spotlight for many features introduced by PlanIt. Some of the main features
are quite simple in its idea: Let people know when you are on the way, thereby causing
the app to track your location and instead of telling everyone your location, it lets
everybody know how far away you are from the desired destination. Another feature is the
carpool tab; people can volunteer to carpool and list their vehicle capacity, people can
sort themselves as a subpart of the driver. There are many more features that are in
play.
## How we built it
We used Microsoft Azure for cloud based server side development and Xamarin in order
to have easy cross-platform compatibility with C# as our main language.
## Challenges we ran into
Some of the challenges that we ran into were based around backend and server side
issues. We spent 3 hours trying to fix one bug and even then it still seemed to be
conflicted. All in all the frontend went by quite smoothly but the backend took some
work.
## Accomplishments that we're proud of
We were very close to quitting late into the night but we were able to take a break and
rally around a new project model in order to finish as much of it as we could. Not quitting
was probably the most notable accomplishment of the event.
## What we learned
We used two new softwares for this app. Xaramin and Microsoft Azure. We also learned
that its possible to have a semi working product with only one day of work.
## What's next for PlanIt
We were hoping to fully complete PlanIt for use within our own group of friends. If it gets
positive feedback then we could see ourselves releasing this app on the market. | ## Inspiration
Our inspiration was Find My by Apple. It allows you to track your Apple devices and see them on a map giving you relevant information such as last time pinged, distance, etc.
## What it does
Picks up signals from beacons using the Eddystone protocol. Using this data, it will display the beacon's possible positions on Google Maps.
## How we built it
Node.js for the scanning of beacons, our routing and our API which is hosted on Heroku. We use React.js for the front end with Google Maps as the main component of the web app.
## Challenges we ran into
None of us had experience with mobile app development so we had to improvise with our skillset. NodeJs was our choice however we had to rely on old deprecated modules to make things work. It was tough but in the end it was worth it as we learned a lot.
Calculating the distance from the given data was also a challenge but we managed to get it quite accurately.
## Accomplishments that I'm proud of
Using hardware was an interesting as I (Olivier) have never done a hackathon project with them. I stick to web apps as it is my comfort zone but this time we have merged two together.
## What we learned
Some of us learned front-end web development and even got started with React. I've learned that hardware hacks doesn't need to be some low-level programming nightmare (which to me seemed it was).
## What's next for BeaconTracker
The Eddystone technology is deprecated and beacons are everywhere in every day life. I don't think there is a future for BeaconTracker but we have all learned much from this experience and it was definitely worth it. | partial |
## Inspiration
Essential workers are needed to fulfill tasks such as running restaurants, grocery shops, and travel services such as airports and train stations. Some of the tasks that these workers do include manual screening of customers entering trains and airports and checking if they are properly wearing masks. However, there have been frequent protest on the safety of these workers, with them being exposed to COVID-19 for prolonged periods and even potentially being harassed by those unsupportive of wearing masks. Hence, we wanted to find a solution that would prevent as many workers as possible from being exposed to danger. Additionally, we wanted to accomplish this goal while being environmentally-friendly in both our final design and process.
## What it does
This project is meant to provide an autonomous alternative to the manual inspection of masks by using computer technology to detect whether a user is wearing a mask properly, improperly, or not at all. To accomplish this, a camera records the user's face, and a trained machine learning algorithm determines whether the user is wearing a mask or not. To conserve energy and help the environment, an infrared sensor is used to detect nearby users, and shuts off the program and other hardware if no one is nearby. Depending on the result, a green LED light shines if the user is wearing a mask correctly while a red LED light shines and a buzzer sounds if it is not worn correctly. Additionally, if the user is not wearing a mask, the mask dispenser automatically activates to dispense a mask to the user's hands.
## How we built it
This project can de divided into two phases: the machine learning part and the physical hardware part. For the machine learning, we created a YOLOv5 algorithm with PyTorch to detect whether users are wearing a mask or not. To train the algorithm, a database of over 3000 pictures was used as the training data. Then, we used the computer camera to run the algorithm and categorize the resulting video feed into three categories with 0 to 100% confidence.
The physical hardware part consists of the infrared sensor prefacing the ML algorithm and the sensors and motors that act after obtaining the ML result. Both the sensors and motors were connected to a Raspberry Pi Pico microcontroller and controlled remotely through the computer. To control the sensors, MicroPython (RP2040) and Python were used to read the signal inputs, relay the signals between the Raspberry Pi and the computer, and finally perform sensor and motor outputs upon receiving results from the ML code. 3D modelled hardware was used alongside re-purposed recyclables to build the outer casings of our design.
## Challenges we ran into
The main challenge that the team ran into was to find a reliable method to relay signals between the Raspberry Pi Pico and the computer running the ML program. Originally, we thought that it would be possible to transfer information between the two systems through intermediary text files, but it turned out that the Pico was unable to manipulate files outside of its directory. Additionally, our subsequent idea of importing the Pico .py file into the computer failed as well. Thus, we had to implement USB serial connections to remotely modify the Pico script from within the computer.
Additionally, the wiring of the hardware components also proved to be a challenge, since caution must be exercised to prevent the project model from overheating. In many cases, this meant to use resistors when wiring the sensors and motor together with the breadboard. In essence, we had to be careful when testing our module and pay attention to any functional abnormalities and temperatures (which did happen once or twice!)
## Accomplishments that we're proud of
For many of us, we have only had experience in coding either hardware or software separately, either in classes or in other activities. Thus, the integration of the Pico Pi with the machine learning software proved to be a veritable challenge for us, since none of us were comfortable with it. With the help of mentors, we were proud of how we managed to combine our hardware and software skills together to form a coherent product with a tangible purpose. We were even more impressed of how this process was all learned and done in a short span of 24 hours.
## What we learned
From this project, we primarily learned how to integrate complex software such as machine learning and hardware together as a connected device. Since our team was new to these types of hackathons incorporating software and hardware together, building the project also proved to be a learning experience for us as a glimpse of how disciplines combining the two, such as robotics, function in real-life. Additionally, we also learned how to apply what we learned in class to real-life applications, since a good amount of information used in this project was from taught material, and it was satisfying to be able to visualize the importance of these concepts.
## What's next for AutoMask
Ideally, we would be able to introduce our physical prototype into the real world to realize our initial ambitions for this device. To successfully do so, we must first refine our algorithm bounds so that false positives and especially true negatives are minimized. Hence, a local application of our device would be our first move to obtain preliminary field results and to expand the training set as well for future calibrations. For this purpose, we could use our device for a small train station or a bus stop to test our device in a controlled manner.
Currently, AutoMask's low-fidelity prototype is only suited for a very specific type of mask dispenser. Our future goal is to make our model flexible to fit a variety of dispensers in a variety of situations. Thus, we must also refine our physical hardware to be industrially acceptable and mass producible to cover the large amount of applications this device potentially has. We want to accomplish this while maintaining our ecologically-friendly approach by continuing to use recycled and recyclable components. | ## Inspiration
The lack of good music at parties is criminal. Pretty rare to find the DJs that are not absorbed in their playlist as well. Someone had to do it, so we did it.
## What it does
It looks at the movement of the crowd using computer vision and using Spotify's data-set of over 42000 songs we find the song that makes you groove by matching the energy of the room. That is why we are the groove genie.
## How we built it
We used OpenCV to find the change in the movement, and we take the derivative of the movement over the period of the song. Change in movement is directly proportional to the energy level. From Spotify's data set, we download (no ads yay!) and play the music that best describes the way the audience is feeling.
To further optimize the song choice we keep track of the 40 songs that the audience responded to as expected. These are the songs that are reflective of superior data quality. So we choose songs that are the most similar to these songs after you have heard over 40 songs, while still matching the energy.
## Challenges we ran into
Stopping the similarity checks from overriding the movement score currently being displayed by the audience. We fixed this by changing how much value we gave to similarity.
## Accomplishments that we're proud of
Being able to detect the speed of and changes in movement using OpenCV, and the automatic player.
## What we learned
Movement detection using computer vision, data processing with Spotify's database, and integrating Youtube into the project to play songs.
## What's next for Groove Genie
A solo mode for Groove Genie, for listening to music on your own, which changes the music based on your emotional reaction. | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | losing |
## Motivation
Coding skills are in high demand and will soon become a necessary skill for nearly all industries. Jobs in STEM have grown by 79 percent since 1990, and are expected to grow an additional 13 percent by 2027, according to a 2018 Pew Research Center survey. This provides strong motivation for educators to find a way to engage students early in building their coding knowledge.
Mixed Reality may very well be the answer. A study conducted at Georgia Tech found that students who used mobile augmented reality platforms to learn coding performed better on assessments than their counterparts. Furthermore, research at Tufts University shows that tangible programming encourages high-level computational thinking. Two of our team members are instructors for an introductory programming class at the Colorado School of Mines. One team member is an interaction designer at the California College of the Art and is new to programming. Our fourth team member is a first-year computer science at the University of Maryland. Learning from each other's experiences, we aim to create the first mixed reality platform for tangible programming, which is also grounded in the reality-based interaction framework. This framework has two main principles:
1) First, interaction **takes place in the real world**, so students no longer program behind large computer monitors where they have easy access to distractions such as games, IM, and the Web.
2) Second, interaction behaves more like the real world. That is, tangible languages take advantage of **students’ knowledge of the everyday, non-computer world** to express and enforce language syntax.
Using these two concepts, we bring you MusicBlox!
## What is is
MusicBlox combines mixed reality with introductory programming lessons to create a **tangible programming experience**. In comparison to other products on the market, like the LEGO Mindstorm, our tangible programming education platform **cuts cost in the classroom** (no need to buy expensive hardware!), **increases reliability** (virtual objects will never get tear and wear), and **allows greater freedom in the design** of the tangible programming blocks (teachers can print out new card/tiles and map them to new programming concepts).
This platform is currently usable on the **Magic Leap** AR headset, but will soon be expanded to more readily available platforms like phones and tablets.
Our platform is built using the research performed by Google’s Project Bloks and operates under a similar principle of gamifying programming and using tangible programming lessons.
The platform consists of a baseboard where students must place tiles. Each of these tiles is associated with a concrete world item. For our first version, we focused on music. Thus, the tiles include a song note, a guitar, a piano, and a record. These tiles can be combined in various ways to teach programming concepts. Students must order the tiles correctly on the baseboard in order to win the various levels on the platform. For example, on level 1, a student must correctly place a music note, a piano, and a sound in order to reinforce the concept of a method. That is, an input (song note) is fed into a method (the piano) to produce an output (sound).
Thus, this platform not only provides a tangible way of thinking (students are able to interact with the tiles while visualizing augmented objects), but also makes use of everyday, non-computer world objects to express and enforce computational thinking.
## How we built it
Our initial version is deployed on the Magic Leap AR headset. There are four components to the project, which we split equally among our team members.
The first is image recognition, which Natalie worked predominantly on. This required using the Magic Leap API to locate and track various image targets (the baseboard, the tiles) and rendering augmented objects on those tracked targets.
The second component, which Nhan worked on, involved extended reality interaction. This involved both Magic Leap and Unity to determine how to interact with buttons and user interfaces in the Magic leap headset.
The third component, which Casey spearheaded, focused on integration and scene development within Unity. As the user flows through the program, there are different game scenes they encounter, which Casey designed and implemented. Furthermore, Casey ensured the seamless integration of all these scenes for a flawless user experience.
The fourth component, led by Ryan, involved project design, research, and user experience. Ryan tackled user interaction layouts to determine the best workflow for children to learn programming, concept development, and packaging of the platform.
## Challenges we ran into
We faced many challenges with the nuances of the Magic Leap platform, but we are extremely grateful to the Magic Leap mentors for providing their time and expertise over the duration of the hackathon!
## Accomplishments that We're Proud of
We are very proud of the user experience within our product. This feels like a platform that we could already begin testing with children and getting user feedback. With our design expert Ryan, we were able to package the platform to be clean, fresh, and easy to interact with.
## What We learned
Two of our team members were very unfamiliar with the Magic Leap platform, so we were able to learn a lot about mixed reality platforms that we previously did not. By implementing MusicBlox, we learned about image recognition and object manipulation within Magic Leap. Moreover, with our scene integration, we all learned more about the Unity platform and game development.
## What’s next for MusicBlox: Tangible Programming Education in Mixed Reality
This platform is currently only usable on the Magic Leap AR device. Our next big step would be to expand to more readily available platforms like phones and tablets. This would allow for more product integration within classrooms.
Furthermore, we only have one version which depends on music concepts and teaches methods and loops. We would like to expand our versions to include other everyday objects as a basis for learning abstract programming concepts. | ## Inspiration
Across the globe, a critical shortage of qualified teachers poses a significant challenge to education. The average student-to-teacher ratio in primary schools worldwide stands at an alarming **23:1!** In some regions of Africa, this ratio skyrockets to an astonishing **40:1**. [Research 1](https://data.worldbank.org/indicator/SE.PRM.ENRL.TC.ZS) and [Research 2](https://read.oecd-ilibrary.org/education/education-at-a-glance-2023_e13bef63-en#page11)
As populations continue to explode, the demand for quality education has never been higher, yet the *supply of capable teachers is dwindling*. This results in students receiving neither the attention nor the **personalized support** they desperately need from their educators.
Moreover, a staggering **20% of students** experience social anxiety when seeking help from their teachers. This anxiety can severely hinder their educational performance and overall learning experience. [Research 3](https://www.cambridge.org/core/journals/psychological-medicine/article/much-more-than-just-shyness-the-impact-of-social-anxiety-disorder-on-educational-performance-across-the-lifespan/1E0D728FDAF1049CDD77721EB84A8724)
While many educational platforms leverage generative AI to offer personalized support, we envision something even more revolutionary. Introducing **TeachXR—a fully voiced, interactive, and hyper-personalized AI** teacher that allows students to engage just like they would with a real educator, all within the immersive realm of extended reality.
*Imagine a world where every student has access to a dedicated tutor who can cater to their unique learning styles and needs. With TeachXR, we can transform education, making personalized learning accessible to all. Join us on this journey to revolutionize education and bridge the gap in teacher shortages!*
## What it does
**Introducing TeachVR: Your Interactive XR Study Assistant**
TeachVR is not just a simple voice-activated Q&A AI; it’s a **fully interactive extended reality study assistant** designed to enhance your learning experience. Here’s what it can do:
* **Intuitive Interaction**: Use natural hand gestures to circle the part of a textbook page that confuses you.
* **Focused Questions**: Ask specific questions about the selected text for summaries, explanations, or elaborations.
* **Human-like Engagement**: Interact with TeachVR just like you would with a real person, enjoying **milliseconds response times** and a human voice powered by **Vapi.ai**.
* **Multimodal Learning**: Visualize the concepts you’re asking about, aiding in deeper understanding.
* **Personalized and Private**: All interactions are tailored to your unique learning style and remain completely confidential.
### How to Ask Questions:
1. **Circle the Text**: Point your finger and circle the paragraph you want to inquire about.
2. **OK Gesture**: Use the OK gesture to crop the image and submit your question.
### TeachVR's Capabilities:
* **Summarization**: Gain a clear understanding of the paragraph's meaning. TeachVR captures both book pages to provide context.
* **Examples**: Receive relevant examples related to the paragraph.
* **Visualization**: When applicable, TeachVR can present a visual representation of the concepts discussed.
* **Unlimited Queries**: Feel free to ask anything! If it’s something your teacher can answer, TeachVR can too!
### Interactive and Dynamic:
TeachVR operates just like a human. You can even interrupt the AI if you feel it’s not addressing your needs effectively!
## How we built it
**TeachXR: A Technological Innovation in Education**
TeachXR is the culmination of advanced technologies, built on a microservice architecture. Each component focuses on delivering essential functionalities:
### 1. Gesture Detection and Image Cropping
We have developed and fine-tuned a **hand gesture detection system** that reliably identifies gestures for cropping based on **MediaPipe gesture detection**. Additionally, we created a custom **bounding box cropping algorithm** to ensure that the desired paragraphs are accurately cropped by users for further Q&A.
### 2. OCR (Word Detection)
Utilizing **Google AI OCR service**, we efficiently detect words within the cropped paragraphs, ensuring speed, accuracy, and stability. Given our priority on latency—especially when simulating interactions like pointing at a book—this approach aligns perfectly with our objectives.
### 3. Real-time Data Orchestration
Our goal is to replicate the natural interaction between a student and a teacher as closely as possible. As mentioned, latency is critical. To facilitate the transfer of image and text data, as well as real-time streaming from the OCR service to the voiced assistant, we built a robust data flow system using the **SingleStore database**. Its powerful real-time data processing and lightning-fast queries enable us to achieve sub-1-second cropping and assistant understanding for prompt question-and-answer interactions.
### 4. Voiced Assistant
To ensure a natural interaction between students and TeachXR, we leverage **Vapi**, a natural voice interaction orchestration service that enhances our feature development. By using **DeepGram** for transcription, **Google Gemini 1.5 flash model** as the AI “brain,” and **Cartesia** for a natural voice, we provide a unique and interactive experience with your virtual teacher—all within TeachXR.
## Challenges we ran into
### Challenges in Developing TeachXR
Building the architecture to keep the user-cropped image in sync with the chat on the frontend posed a significant challenge. Due to the limitations of the **Meta Quest 3**, we had to run local gesture detection directly on the headset and stream the detected image to another microservice hosted in the cloud. This required us to carefully adjust the size and details of the images while deploying a hybrid model of microservices. Ultimately, we successfully navigated these challenges.
Another difficulty was tuning our voiced assistant. The venue we were working in was quite loud, making background noise inevitable. We had to fine-tune several settings to ensure our assistant provided a smooth and natural interaction experience.
## Accomplishments that we're proud of
### Achievements
We are proud to present a complete and functional MVP! The cropped image and all related processes occur in **under 1 second**, significantly enhancing the natural interaction between the student and **TeachVR**.
## What we learned
### Developing a Great AI Application
We successfully transformed a solid idea into reality by utilizing the right tools and technologies.
There are many excellent pre-built solutions available, such as **Vapi**, which has been invaluable in helping us implement a voice interface. It provides a user-friendly and intuitive experience, complete with numerous settings and plug-and-play options for transcription, models, and voice solutions.
## What's next for TeachXR
We’re excited to think of the future of **TeachXR** holds even greater innovations! we’ll be considering\**adaptive learning algorithms*\* that tailor content in real-time based on each student’s progress and engagement.
Additionally, we will work on integrating **multi-language support** to ensure that students from diverse backgrounds can benefit from personalized education. With these enhancements, TeachXR will not only bridge the teacher shortage gap but also empower every student to thrive, no matter where they are in the world! | ## Inspiration
When going to eat out with friends or simply craving something at home, we all had the common experience of not knowing what to eat and where to go. With Food Mood we hoped to solve this problem and alleviate the pains of indecisiveness.
## What it does
Food Mood uses a questionnaire algorithm to determine what cuisine the user is most likely to enjoy based on their mood. The app then uses the user's location and the determined cuisine to search for restaurants within a 25 mile radius that fit the user's preferences. The app considers factors such as cost, customer ratings, and distance from the user to figure out the most optimal restaurant to which the user should go.
## How we built it
The app was created with Angular 8 and uses Material Design components. We use the Google Maps API to determine the user's longitude and latitude coordinates to compare with restaurants in order to find distance. It uses the Zomato API to find restaurants in the are and get various details about the restaurants, such as name, customer ratings, and restaurant highlights. We feed the data into a custom algorithm that assigns points based on the user's answers. An example question can ask "*How spicy are we feeling today?*" Spicier responses assign a rating of "2" for Asian cuisine but "0" for Sweet foods.
## Challenges we ran into
Determining the algorithm took a substantial amount of time because we had to manually assign scores to the different cuisine types that Zomato supports. Due to this we had to generalize several cuisines into larger categories (Desserts, Ice Cream, and Donuts are different cuisines but fall under the larger category "Sweets").
## Accomplishments that we're proud of
We’re proud of our planning and coordination as we worked through the project. All throughout the project, we communicated our plans and work carefully, working in tandem to produce the final result: Food Mood. And we were surprised with the accuracy with which Food Mood worked. Thinking of a certain food we wanted to eat, the algorithm correctly identified that food many times over. Our teamwork helped us create and program that we can be proud of.
## What we learned
We learned the importance of organization. Throughout the project, we kept spreadsheets and schema of what Food Mood would look like. This way, every member had the same vision and was able to work towards that goal.
## What's next for Food Mood
We hope we can work together in the future as well in order to add a wider variety of cuisines to the program. In addition, we could test the program on live people, which would give us data to better train the data, possibly with machine learning. | winning |
## Inspiration
The inspiration comes from Politik - this is a version 2.0 with significant improvements! We're passionate about politics and making sure that others can participate and more directly communicate with their politicians.
## What it does
We show you the bills your House representative has introduced, and allow you to vote on them. We've created token based auth for sign-up and login, built a backend that allows us to reformat and modify 'bill' and 'representative' objects, and done a complete redesign of the frontend to be much simpler and more user friendly. We have polished the fax route (that can fax a message embedded in a formal letter directly to your representative!) and have begun implementation of Expo push notifications!
## How we built it
We used React Native on the frontend, Node.js / Express.js on the backend, and MongoDB hosted by mLab. We created the backend almost completely from scratch and had no DB before this (just fake data pulled from a very rate limited API). We used Sketch to help us think through the redesign of the application.
## Challenges we ran into
1) Dealing with the nuances of MongoDB as we were handling an abnormally large amount of data and navigating through a bunch of promises before writing a final modified object into our Mongo collection. The mentors at the mLab booth were really helpful, giving us more creative ways to map relationships between our data.
2) Designing an intuitive, easily navigable user interface. None of us have formal design training but we realize that in politics more than anything else, the UX cannot be confusing - complicated legislation must be organized and displayed in a way that lends itself to greater understanding.
## Accomplishments that we're proud of
We're proud of the amount of functionality we were able to successfully implement in such a short period of time. The sheer amount of code we wrote was quite a bit, and considering the complexity of designing a database schema and authentication system, we're proud that we were able to even finish!
## What we learned
There is no such thing as 'too much' caffeine.
## What's next for Speak Up
Ali plans to continue this and combine it with Politik. Now that authentication and messaging your representative works - I just need to refactor the code and fully test it before releasing on the app store. | ## Inspiration
Wanting to build an FPS VR game.
## What it does
Provides ultra fun experience to all players, taking older folks back to their childhood and showing younger ones the beauty of classic arcade types!
## How we built it
Unity as the game engine
Android for the platform
socket.io for multiplayer
c# for client side code
## Challenges we ran into
We coded our own custom backend in Node.js to allow multiplayer ability in the game. It was difficult to use web sockets in the C# code to transfer game data to other players. Also, it was a challange to sync all things from player movement to shooting lazers to map data all at the same time.
## Accomplishments that we're proud of
Were able to make the game multiplayer with a custom backend
## What we learned
Unity, C#
## What's next for Space InVRders
Add other game modes, more kinds of ships, store highscores | ## Inspiration
Our inspiration for Bloom Buddy stems from the desire to create an advanced plant monitoring system that addresses the critical factors influencing plant health, such as light levels, temperature, moisture, and water levels.
## What it does
Bloom Buddy is a comprehensive plant monitoring system that effectively manages and regulates the environmental parameters surrounding a plant. The system incorporates LED lights to visually represent the condition of an environmental attribute and provides instructions for resolving any issues via an LCD display.
## How we built it
We constructed Bloom Buddy by integrating a micro-controller, Arduino IDE, and a variety of sensors, including a water level sensor, moisture sensor, temperature sensor and light sensor. The design employs LED lights for intuitive feedback on sensor conditions and an LCD display for delivering clear instructions on addressing plant-related issues.
## Challenges we ran into
Constructing the prototype posed a significant challenge for our team. We were unable to make a functioning case due to delays in 3d printing.
## Accomplishments that we're proud of
We successfully developed a fully operational hardware within the designated time frame for the competition, something we had not been able to do for prior competitions.
## What we learned
The development of Bloom Buddy provided us with valuable insights into optimizing sensor integration, ensuring precision in data monitoring, enhancing user interface design, and comprehensively understanding the operational ranges of the sensors.
## What's next for Bloom Buddy
Should we decide to proceed with the further development of Bloom Buddy, enhancements to the design could encompass expanding the scope to accommodate more plants. Additionally, we can integrating adjustable settings to cater to the unique environmental conditions required by a variety of plant species. | partial |
## Inspiration
Around 40% of the lakes in America are too polluted for aquatic life, swimming or fishing.Although children make up 10% of the world’s population, over 40% of the global burden of disease falls on them. Environmental factors contribute to more than 3 million children under age five dying every year. Pollution kills over 1 million seabirds and 100 million mammals annually. Recycling and composting alone have avoided 85 million tons of waste to be dumped in 2010. Currently in the world there are over 500 million cars, by 2030 the number will rise to 1 billion, therefore doubling pollution levels. High traffic roads possess more concentrated levels of air pollution therefore people living close to these areas have an increased risk of heart disease, cancer, asthma and bronchitis. Inhaling Air pollution takes away at least 1-2 years of a typical human life. 25% deaths in India and 65% of the deaths in Asia are resultant of air pollution. Over 80 billion aluminium cans are used every year around the world. If you throw away aluminium cans, they can stay in that can form for up to 500 years or more. People aren’t recycling as much as they should, as a result the rainforests are be cut down by approximately 100 acres per minute
On top of this, I being near the Great Lakes and Neeral being in the Bay area, we have both seen not only tremendous amounts of air pollution, but marine pollution as well as pollution in the great freshwater lakes around us. As a result, this inspired us to create this project.
## What it does
For the react native app, it connects with the Website Neeral made in order to create a comprehensive solution to this problem.
There are five main sections in the react native app:
The first section is an area where users can collaborate by creating posts in order to reach out to others to meet up and organize events in order to reduce pollution. One example of this could be a passionate environmentalist who is organizing a beach trash pick up and wishes to bring along more people. With the help of this feature, more people would be able to learn about this and participate.
The second section is a petitions section where users have the ability to support local groups or sign a petition in order to enforce change. These petitions include placing pressure on large corporations to reduce carbon emissions and so forth. This allows users to take action effectively.
The third section is the forecasts tab where the users are able to retrieve data regarding various data points in pollution. This includes the ability for the user to obtain heat maps regarding the amount of air quality, pollution and pollen in the air and retrieve recommended procedures for not only the general public but for special case scenarios using apis.
The fourth section is a tips and procedures tab for users to be able to respond to certain situations. They are able to consult this guide and find the situation that matches them in order to find the appropriate action to take. This helps the end user stay calm during situations as such happening in California with dangerously high levels of carbon.
The fifth section is an area where users are able to use Machine Learning in order to figure out whether where they are is in a place of trouble. In many instances, not many know exactly where they are especially when travelling or going somewhere unknown. With the help of Machine Learning, the user is able to place certain information regarding their surroundings and the Algorithm is able to decide whether they are in trouble. The algorithm has 90% accuracy and is quite efficient.
## How I built it
For the react native part of the application, I will break it down section by section.
For the first section, I simply used Firebase as a backend which allowed a simple, easy and fast way of retrieving and pushing data to the cloud storage. This allowed me to spend time on other features, and due to my ever growing experience with firebase, this did not take too much time. I simply added a form which pushed data to firebase and when you go to the home page it refreshes and see that the cloud was updated in real time
For the second section, I used native base in order to create my UI and found an assortment of petitions which I then linked and added images from their website in order to create the petitions tab. I then used expo-web-browser, to deep link the website in opening safari to open the link within the app.
For the third section, I used breezometer.com’s pollution api, air quality api, pollen api and heat map apis in order to create an assortment of data points, health recommendations and visual graphics to represent pollution in several ways. The apis also provided me information such as the most common pollutant and protocols for different age groups and people with certain conditions should follow. With this extensive api, there were many endpoints I wanted to add in, but not all were added due to lack of time.
For the fourth section, it is very much similar to the second section as it is an assortment of links, proofread and verified to be truthful sources, in order for the end user to have a procedure to go to for extreme emergencies. As we see horrible things happen, such as the wildfires in California, air quality becomes a serious concern for many and as a result these procedures help the user stay calm and knowledgeable.
For the fifth section, Neeral please write this one since you are the one who created it.
## Challenges I ran into
API query bugs was a big issue in formatting back the query and how to map the data back into the UI. It took some time and made us run until the end but we were still able to complete our project and goals.
## What's next for PRE-LUTE
We hope to use this in areas where there is commonly much suffering due to the extravagantly large amount of pollution, such as in Delhi where seeing is practically hard due to the amount of pollution. We hope to create a finished product and release it to the app and play stores respectively. | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | ## Inspiration
When you go out with your friends, it is essential to now your friend's location. For example, you have a meeting with your friend in SF. And you can not just call your friend to update his/her current location (maybe your friend is driving). LocationShare helps you to solve this problem.
## What it does
You can use LocationShare to allow your friends to know your current location. It will keep track the position and show in a map
## How I built it
We use HereMap API and Pubnub. The project was built by Android SDK.
## What's next for LocationShare
Add route and time predictions. | winning |
## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | # Inspiration
Traditional startup fundraising is often restricted by stringent regulations, which make it difficult for small investors and emerging founders to participate. These barriers favor established VC firms and high-networth individuals, limiting innovation and excluding a broad range of potential investors. Our goal is to break down these barriers by creating a decentralized, community-driven fundraising platform that democratizes startup investments through a Decentralized Autonomous Organization, also known as DAO.
# What It Does
To achieve this, our platform leverages blockchain technology and the DAO structure. Here’s how it works:
* **Tokenization**: We use blockchain technology to allow startups to issue digital tokens that represent company equity or utility, creating an investment proposal through the DAO.
* **Lender Participation**: Lenders join the DAO, where they use cryptocurrency, such as USDC, to review and invest in the startup proposals.
-**Startup Proposals**: Startup founders create proposals to request funding from the DAO. These proposals outline key details about the startup, its goals, and its token structure. Once submitted, DAO members review the proposal and decide whether to fund the startup based on its merits.
* **Governance-based Voting**: DAO members vote on which startups receive funding, ensuring that all investment decisions are made democratically and transparently. The voting is weighted based on the amount lent in a particular DAO.
# How We Built It
### Backend:
* **Solidity** for writing secure smart contracts to manage token issuance, investments, and voting in the DAO.
* **The Ethereum Blockchain** for decentralized investment and governance, where every transaction and vote is publicly recorded.
* **Hardhat** as our development environment for compiling, deploying, and testing the smart contracts efficiently.
* **Node.js** to handle API integrations and the interface between the blockchain and our frontend.
* **Sepolia** where the smart contracts have been deployed and connected to the web application.
### Frontend:
* **MetaMask** Integration to enable users to seamlessly connect their wallets and interact with the blockchain for transactions and voting.
* **React** and **Next.js** for building an intuitive, responsive user interface.
* **TypeScript** for type safety and better maintainability.
* **TailwindCSS** for rapid, visually appealing design.
* **Shadcn UI** for accessible and consistent component design.
# Challenges We Faced, Solutions, and Learning
### Challenge 1 - Creating a Unique Concept:
Our biggest challenge was coming up with an original, impactful idea. We explored various concepts, but many were already being implemented.
**Solution**:
After brainstorming, the idea of a DAO-driven decentralized fundraising platform emerged as the best way to democratize access to startup capital, offering a novel and innovative solution that stood out.
### Challenge 2 - DAO Governance:
Building a secure, fair, and transparent voting system within the DAO was complex, requiring deep integration with smart contracts, and we needed to ensure that all members, regardless of technical expertise, could participate easily.
**Solution**:
We developed a simple and intuitive voting interface, while implementing robust smart contracts to automate and secure the entire process. This ensured that users could engage in the decision-making process without needing to understand the underlying blockchain mechanics.
## Accomplishments that we're proud of
* **Developing a Fully Functional DAO-Driven Platform**: We successfully built a decentralized platform that allows startups to tokenize their assets and engage with a global community of investors.
* **Integration of Robust Smart Contracts for Secure Transactions**: We implemented robust smart contracts that govern token issuance, investments, and governance-based voting bhy writing extensice unit and e2e tests.
* **User-Friendly Interface**: Despite the complexities of blockchain and DAOs, we are proud of creating an intuitive and accessible user experience. This lowers the barrier for non-technical users to participate in the platform, making decentralized fundraising more inclusive.
## What we learned
* **The Importance of User Education**: As blockchain and DAOs can be intimidating for everyday users, we learned the value of simplifying the user experience and providing educational resources to help users understand the platform's functions and benefits.
* **Balancing Security with Usability**: Developing a secure voting and investment system with smart contracts was challenging, but we learned how to balance high-level security with a smooth user experience. Security doesn't have to come at the cost of usability, and this balance was key to making our platform accessible.
* **Iterative Problem Solving**: Throughout the project, we faced numerous technical challenges, particularly around integrating blockchain technology. We learned the importance of iterating on solutions and adapting quickly to overcome obstacles.
# What’s Next for DAFP
Looking ahead, we plan to:
* **Attract DAO Members**: Our immediate focus is to onboard more lenders to the DAO, building a large and diverse community that can fund a variety of startups.
* **Expand Stablecoin Options**: While USDC is our starting point, we plan to incorporate more blockchain networks to offer a wider range of stablecoin options for lenders (EURC, Tether, or Curve).
* **Compliance and Legal Framework**: Even though DAOs are decentralized, we recognize the importance of working within the law. We are actively exploring ways to ensure compliance with global regulations on securities, while maintaining the ethos of decentralized governance. | ## 💡 Inspiration
Catching us off guard with a sudden global attack, the pandemic has placed excessive pressure on our medical system. It became extremely difficult to access the optimal choice when facing medical issues. Meanwhile, the pre-assessment for medical diagnosis would usually require one to line up for 2 hours during the wait time. Our goal with Cure Connect is to provide the optimal medical resource to the patient and automate the process of pre-medical assessment in order to eliminate wait time.
## 🔍 What it does
Cure Connect is a company that is dedicated to promoting better healthcare for individuals by connecting them with the best medical institutions for their specific symptoms. The company's main focus is to help people find the right medical facility for their needs, whether it be a walk-in clinic, pharmacy, or hospital. By utilizing an advanced algorithm, Cure Connect is able to analyze a person's symptoms and provide recommendations for the most suitable medical institution. The company's goal is to reduce wait times and improve the overall healthcare experience for patients. With its user-friendly platform and easy-to-use interface, Cure Connect is making it easier for individuals to receive the medical care they need. The company is committed to providing its users with a seamless and stress-free healthcare journey.
## ⚙️ How it was built
Clubify was built with the following tools and languages:
* HTML
* CSS
* JavaScript
* Python
* React
* Django
* Google-Maps
## 🚧 Challenges we ran into
Most of the front-end development was smooth sailing. However, deploying the teach-flow was a bit troublesome, as our initial approach to the choice of technology did not work well, and half of the day's work was spent.
## ✔️ Accomplishments that we're proud of
For many of us, it was our first time working in a group environment at a hackathon and we are all proud of what we were able to build in such a short amount of time. Other accomplishments include:
* Learning how to form the connection between front-end and back-end
* Figuring out how to use google map API with front-end
* Working together collaboratively as a team, despite not knowing each other prior to the event
## 📚 What we learned
Through the implementation of Cure Connect,we learned many new concepts such as, but not limited to: how to connect React from frontend to Django in the backend; how to use React with google map API; and version control amongst the team members. The biggest takeaway from this event is the importance of collaboration and help among peers to put together a shared vision.
## 🔭 What's next for Cure Connect
At Cure Connect, we are always aiming to maximize our potential in our user interface and features, while not sacrificing the performance and purpose to deliver an efficient yet immersive experience. We have potential features to expand on in the future, such as adding a search bar with prompt guesses or implementing a more secure login for the provider side. | winning |
## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments. | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | ## Inspiration
More than 4.5 million acres of land have burned on the West Coast in the past month alone
Experts say fires will worsen in the years to come as climate change spikes temperatures and disrupts precipitation patterns
Thousands of families have been and will continue to be displaced by these disasters
## What it does
When a wildfire strikes, knowing where there are safe places to go can bring much-needed calm in times of peril
Mildfire is a tool designed to identify higher-risk areas with deep learning analysis of satellite data to keep people and their families out of danger
Users can place pins at locations of themselves or people in distress
Users can mark locations of fires in real time
Deep learning-based treetop detection to indicate areas higher-risk of forest fire
Heatmap shows safe and dangerous zones, and can facilitate smarter decision making
## How I built it
User makes a GET request w/ latitude/longitude value, which is then handled in real time, hosted on Google Cloud Functions
The request triggers a function that grabs satellite data in adjacent tiles from Google Maps Static API
Detects trees w/ RGB data from satellite imagery using deep-learning neural networks trained on existing tree canopy and vegetation data (“DeepForest”, Weinstein, et al. 2019)
Generates a heat map from longitude/latitude, flammability radius, confidence from ML model
Maps public pins, Broadcasts distress and First-Responder notifications in real-time
Simple, dynamic Web-interface
## Challenges I ran into
Completely scrapped mobile app halfway through the hack and had to change to web app.
## Accomplishments that I'm proud of
Used a lottt of GCP and learned a lot about it. Also almost finished the web app despite starting on it so late. ML model is also very accurate and useful.
## What I learned
A lot of GCP and ML and Flutter. Very fun experience overall!
## What's next for Mildfire
Finish the mobile and web app | winning |
## Inspiration
The amount of data in the world today is mind-boggling. We are generating 2.5 quintillion bytes of data every day at our current pace, but the pace is only accelerating with the growth of IoT.
We felt that the world was missing a smart find-feature for videos. To unlock heaps of important data from videos, we decided on implementing an innovative and accessible solution to give everyone the ability to access important and relevant data from videos.
## What it does
CTRL-F is a web application implementing computer vision and natural-language-processing to determine the most relevant parts of a video based on keyword search and automatically produce accurate transcripts with punctuation.
## How we built it
We leveraged the MEVN stack (MongoDB, Express.js, Vue.js, and Node.js) as our development framework, integrated multiple machine learning/artificial intelligence techniques provided by industry leaders shaped by our own neural networks and algorithms to provide the most efficient and accurate solutions.
We perform key-word matching and search result ranking with results from both speech-to-text and computer vision analysis. To produce accurate and realistic transcripts, we used natural-language-processing to produce phrases with accurate punctuation.
We used Vue to create our front-end and MongoDB to host our database. We implemented both IBM Watson's speech-to-text API and Google's Computer Vision API along with our own algorithms to perform solid key-word matching.
## Challenges we ran into
Trying to implement both Watson's API and Google's Computer Vision API proved to have many challenges. We originally wanted to host our project on Google Cloud's platform, but with many barriers that we ran into, we decided to create a RESTful API instead.
Due to the number of new technologies that we were figuring out, it caused us to face sleep deprivation. However, staying up for way longer than you're supposed to be is the best way to increase your rate of errors and bugs.
## Accomplishments that we're proud of
* Implementation of natural-language-processing to automatically determine punctuation between words.
* Utilizing both computer vision and speech-to-text technologies along with our own rank-matching system to determine the most relevant parts of the video.
## What we learned
* Learning a new development framework a few hours before a submission deadline is not the best decision to make.
* Having a set scope and specification early-on in the project was beneficial to our team.
## What's next for CTRL-F
* Expansion of the product into many other uses (professional education, automate information extraction, cooking videos, and implementations are endless)
* The launch of a new mobile application
* Implementation of a Machine Learning model to let CTRL-F learn from its correct/incorrect predictions | ## Inspiration
Knowtworthy is a startup that all three of us founded together, with the mission to make meetings awesome. We have spent this past summer at the University of Toronto’s Entrepreneurship Hatchery’s incubator executing on our vision. We’ve built a sweet platform that solves many of the issues surrounding meetings but we wanted a glimpse of the future: entirely automated meetings. So we decided to challenge ourselves and create something that the world has never seen before: sentiment analysis for meetings while transcribing and attributing all speech.
## What it does
While we focused on meetings specifically, as we built the software we realized that the applications for real-time sentiment analysis are far more varied than initially anticipated. Voice transcription and diarisation are very powerful for keeping track of what happened during a meeting but sentiment can be used anywhere from the boardroom to the classroom to a psychologist’s office.
## How I built it
We felt a web app was best suited for software like this so that it can be accessible to anyone at any time. We built the frontend on React leveraging Material UI, React-Motion, Socket IO and ChartJS. The backed was built on Node (with Express) as well as python for some computational tasks. We used GRPC, Docker and Kubernetes to launch the software, making it scalable right out of the box.
For all relevant processing, we used Google Speech-to-text, Google Diarization, Stanford Empath, SKLearn and Glove (for word-to-vec).
## Challenges I ran into
Integrating so many moving parts into one cohesive platform was a challenge to keep organized but we used trello to stay on track throughout the 36 hours.
Audio encoding was also quite challenging as we ran up against some limitations of javascript while trying to stream audio in the correct and acceptable format.
Apart from that, we didn’t encounter any major roadblocks but we were each working for almost the entire 36-hour stretch as there were a lot of features to implement.
## Accomplishments that I'm proud of
We are super proud of the fact that we were able to pull it off as we knew this was a challenging task to start and we ran into some unexpected roadblocks. There is nothing else like this software currently on the market so being first is always awesome.
## What I learned
We learned a whole lot about integration both on the frontend and the backend. We prototyped before coding, introduced animations to improve user experience, too much about computer store numbers (:p) and doing a whole lot of stuff all in real time.
## What's next for Knowtworthy Sentiment
Knowtworthy Sentiment aligns well with our startup’s vision for the future of meetings so we will continue to develop it and make it more robust before integrating it directly into our existing software. If you want to check out our stuff you can do so here: <https://knowtworthy.com/> | ## Inspiration
We sat down and thought: okay, we will come back home from CalHacks. And what's the very next action? One of us will want to go play soccer, another teammate may want to go to the bar and talk about Machine Learning with someone. And we understood there are tons of wonderful and interesting people out there (sometimes even in the closest house!), who at a certain point in time want to do the same thing as you want or a complementary one. And today, unfortunately, there is no way we can easily connect with them and find the people we need to be with exactly at the time we need it. Just because there is a barrier, just because we do not share the "friends of friends" and so on. And doing something together can be a great opportunity to get to know each other better. By the way, 22% of millennials (people just like us) reported that they do not have true friends who know them well. We want to solve this problem.
## Vision
Our platform is made for everyone regardless of any social criteria and it serves the sole purpose of making people happier by helping them spend their time in the best possible way, eliminating the feeling of loneliness. We believe, our platform can help get people out of their gadgets and bring more "real life" into our lives! We also think that many people are amazing and wonderful, but you did not get a chance to know them yet, and meeting these people any later than right now is a truly huge loss.
## What it does
It lets a host organize an event and accept/decline sign-ups for it regardless of what this event is. All the data is synchronized in real-time made possible by leveraging the enormous power of Firebase triggers and listeners. The event can be anything starting from a study group for EECS class at Berkeley at 7 up to a suite of bass, piano, and drums players for a guitarist in 30 minutes at his house! This project is **global** and will make a huge positive impact on the life of, without exaggeration, every individual. We connect people based on geolocation and not only. We make people happier and increase the quality of their time and entertainment.
## How we built it
We created a Node.js web server on Google Cloud App Engine, deployed it, connected it to a remote cloud CockroachDB cluster, where we store the history of user's searches (including the ones made with his voice, for which we used Google Cloud Speech-To-Text API). We stored events' and users' data in Firebase Real-Time Database. To make it sweet and simple, we used Expo to create the frontend (aka mobile app) and made expo app talk both to our App Engine server and Firebase serverless infrastructure. We hugely rely on the real-time functionality of Firebase. Think of huge chunks of data flying around here and there, empowering people to get the most of their time and to be happier. This is us, yeah :)
## Challenges we ran into
1. Connecting to the remote CockroachDB cluster from an App Engine. The connection string method does not work at all, so we spent some time figuring out we should use separate parameters method for this.
2. Firebase Real-time Database CRUD turned out to be more complicated than we were told it is and we expected it to be
3. Configuring Firebase Social Auth took a lot of time, because of permissions issues in Real-Time Database
4. Understanding React-Native mechanics was very challenging for all of us, but we enjoyed some of its advantages over native apps
5. There was a giant merging conflict happening at night on Saturday, that was very hard to resolve without the loss of someone's work, but we were able to manage with it
6. We were not really able to get much help on Expo and how it is different from just React Native at the beginning of the hackathon
7. Some environmental variables caused problems while working with Google Cloud's Speech-To-Text API and putting the data to CockrouchCloud cluster
## Accomplishments that we are proud of
1. We learned a lot about React-Native and Expo
2. We were able to find agreements and treated each other with respect throughout the event
3. We were able to identify the strongest parts of each teammate's skillset and delegate the tasks properly in order to save time and effort by focusing on the business logic, not technical details
4. We resolved the merging conflict that occurred
5. Finally, We made it! It's actually working! We learned so many APIs, learned cross-platform mobile, became good friends and just had a great time!
## What we learned
1. There are many ready-made solutions out there, and sometimes, if we do not find them, we can spend hours reinventing the wheel ==> a good search prior to the start is a really good practice and almost a necessity
2. Each technology has its advantages and disadvantages. It is always a trade-off
3. A decision, once made, sticks to the hackathon project until the end, since the new integrated components/libraries/frameworks have to be compatible with the existing ones
4. One person can do a good project. A team can do a life-changing product.
5. The ethics of technology is a huge question one should consider when using various tools. Always put people/users first.
## What's next for calhacks
1. Add Image recognition: let's say pointing your phone to guitar, and immediately showing you other musicians seeking for the guitarist right now close to you (as one application of this)
2. We can PROBABLY scale to the digital world too, for example, connecting gamers to play a certain game at a certain time, but this a little bit contradicts with our vision of bringing more "real" aspects to lives..
3. We want to stick to a good performance given the huge stream of new users coming soon (seriously, this is for everyone). | winning |
## Inspiration
Every musician knows that moment of confusion, that painful silence as onlookers shuffle awkward as you frantically turn the page of the sheet music in front of you. While large solo performances may have people in charge of turning pages, for larger scale ensemble works this obviously proves impractical. At this hackathon, inspired by the discussion around technology and music at the keynote speech, we wanted to develop a tool that could aid musicians.
Seeing AdHawks's MindLink demoed at the sponsor booths, ultimately give us a clear vision for our hack. MindLink, a deceptively ordinary looking pair of glasses, has the ability to track the user's gaze in three dimensions, recognizes events such as blinks and even has an external camera to display the user's view. Blown away by the possibility and opportunities this device offered, we set out to build a hands-free sheet music tool that simplifies working with digital sheet music.
## What it does
Noteation is a powerful sheet music reader and annotator. All the musician needs to do is to upload a pdf of the piece they plan to play. Noteation then displays the first page of the music and waits for eye commands to turn to the next page, providing a simple, efficient and most importantly stress-free experience for the musician as they practice and perform. Noteation also enables users to annotate on the sheet music, just as they would on printed sheet music and there are touch controls that allow the user to select, draw, scroll and flip as they please.
## How we built it
Noteation is a web app built using React and Typescript. Interfacing with the MindLink hardware was done on Python using AdHawk's SDK with Flask and CockroachDB to link the frontend with the backend.
## Challenges we ran into
One challenge we came across was deciding how to optimally allow the user to turn page using eye gestures. We tried building regression-based models using the eye-gaze data stream to predict when to turn the page and built applications using Qt to study the effectiveness of these methods. Ultimately, we decided to turn the page using right and left wink commands as this was the most reliable technique that also preserved the musicians' autonomy, allowing them to flip back and forth as needed.
Strategizing how to structure the communication between the front and backend was also a challenging problem to work on as it is important that there is low latency between receiving a command and turning the page. Our solution using Flask and CockroachDB provided us with a streamlined and efficient way to communicate the data stream as well as providing detailed logs of all events.
## Accomplishments that we're proud of
We're so proud we managed to build a functioning tool that we, for certain, believe is super useful. As musicians this is something that we've legitimately thought would be useful in the past, and granted access to pioneering technology to make that happen was super exciting. All while working with a piece of cutting-edge hardware technology that we had zero experience in using before this weekend.
## What we learned
One of the most important things we learnt this weekend were the best practices to use when collaborating on project in a time crunch. We also learnt to trust each other to deliver on our sub-tasks and helped where we could. The most exciting thing that we learnt while learning to use these cool technologies, is that the opportunities are endless in tech and the impact, limitless.
## What's next for Noteation: Music made Intuitive
Some immediate features we would like to add to Noteation is to enable users to save the pdf with their annotations and add landscape mode where the pages can be displayed two at a time. We would also really like to explore more features of MindLink and allow users to customize their control gestures. There's even possibility of expanding the feature set beyond just changing pages, especially for non-classical musicians who might have other electronic devices to potentially control. The possibilities really are endless and are super exciting to think about! | ## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## What it does
Each window in your desktop is rendered on a separate piece of paper, creating a tangible version of your everyday computer. It is fully featured desktop, with specific shortcuts for window management.
## How I built it
The hardware is combination of a projector and a webcam. The camera tracks the position of the sheets of paper, on which the projector renders the corresponding window. An OpenCV backend does the heavy lifting, calculating the appropriate translation and warping to apply.
## Challenges I ran into
The projector was initially difficulty to setup, since it has a fairly long focusing distance. Also, the engine that tracks the pieces of paper was incredibly unreliable under certain lighting conditions, which made it difficult to calibrate the device.
## Accomplishments that I'm proud of
I'm glad to have been able to produce a functional product, that could possibly be developed into a commercial one. Furthermore, I believe I've managed to put an innovative spin to one of the oldest concepts in the history of computers: the desktop.
## What I learned
I learned lots about computer vision, and especially on how to do on-the-fly image manipulation. | ## Inspiration
We were frustrated with downloading the Hack Western Android app every time it updates. We figured it would be nice if there has an open-source library so that developer can change content in real-time; therefore, users don't have to re-download the app everytime it updates.
## What it does
DynamoUI is an Open-Source Android developer library for changing a published app at Real-time. After logging in and authenticating, the client can use our simple UI to make real time changes to various app components such as the text, images, buttons, and theme at real-time. This app has immense potential for extensibility and uses such as a/b testing, data conglomeration and visualization.
## How we built it
We use Firebase for synchronizing data between Android and the Web platform, and AngularJs to make use of 3 way binding between the markup, js, and database. The mobile client constantly listens for changes on the database and makes changes accordingly through the use of our extended UI Classes.
## Challenges we ran into
Synchronizing data between AngularJS and Firebase was not always straightforward and well documented for special cases.
## Accomplishments that we are proud of
Published an Open-Source library for the use of other Android apps in real-time.
## What I learned
Making Android library, AngularJS and Firebase
## What's next for DynamoUI
Implement A/B testing so marketers can determine which versions perform better in real time. | winning |
## What Inspired Us
A good customer experience leaves a lasting impression across every stage of their journey. This is exemplified in the airline and travel industry. To give credit and show appreciation to the hardworking employees of JetBlue, we chose to scrape and analyze customer feedback on review and social media sites to both highlight their impact on customers and provide currently untracked, valuable data to build a more personalized brand that outshines its market competitors.
## What Our Project does
Our customer feedback analytics dashboard, BlueVisuals, provides JetBlue with highly visual presentations, summaries, and highlights of customers' thoughts and opinions on social media and review sites. Visuals such as word clouds and word-frequency charts highlight critical areas of focus where the customers reported having either positive or negative experiences, suggesting either areas of improvement or strengths. The users can read individual comments to review the exact situation of the customers or skim through to get a general sense of their social media interactions with their customers. Through this dashboard, we hope that the users are able to draw solid conclusions and pursue action based on those said conclusions.
Humans of JetBlue is a side product resulting from such conclusions users (such as ourselves) may draw from the dashboard that showcases the efforts and dedication of individuals working at JetBlue and their positive impacts on customers. This product highlights our inspiration for building the main dashboard and is a tool we would recommend to JetBlue.
## How we designed and built BlueVisuals and Humans of JetBlue
After establishing the goals of our project, we focused on data collection via web scraping and building the data processing pipeline using Python and Google Cloud's NLP API. After understanding our data, we drew up a website and corresponding visualizations. Then, we implemented the front end using React.
Finally, we drew conclusions from our dashboard and designed 'Humans of JetBlue' as an example usage of BlueVisuals.
## What's next for BlueVisuals and Humans of JetBlue
* collecting more data to get a more representative survey of consumer sentiment online
* building a back-end database to support data processing, storage, and organization
* expanding employee-centric
## Challenges we ran into
* Polishing scraped data and extracting important information.
* Finalizing direction and purpose of the project
* Sleeping on the floor.
## Accomplishments that we're proud of
* effectively processed, organized, and built visualizations for text data
* picking up new skills (JS, matplotlib, GCloud NLP API)
* working as a team to manage loads of work under time constraints
## What we learned
* value of teamwork in a coding environment
* technical skills | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | # Campus UBC ([Try It](https://campus.fn.lc/))
The existing "wayfinding" site for the University of British Columbia is awful, and thus a more modern replacement is needed. This is designed to be similar to the amazing internal Google app "Campus".
This allows you to easily find any room on the University of British Columbia campus as well as other points of interest such as printers, restrooms, bookable project rooms and restaurants.
There is support for rendering dynamic content directly into the search results. Currently there is direct room booking, as well as in-lining pictures of buildings.
## Technology
* Go for serving files, search, and generating map tiles on the fly.
* Front-end using Polymer and Google Maps. | partial |
Electric boogaloo lights up the fret/string combo to play for different chords, and can show you how to play songs in realtime by lighting up the banjo neck.
It's also an electronic banjo, as opposed to an electric banjo, meaning that instead of just an amplifier on regular string audio, it knows which string is being strummed and which frets are being held down, and can use those to play whatever audio files you wish, similarly to an electric keyboard. | ## Inspiration
Our main inspiration for the idea of the Lead Zeppelin was a result of our wanting to help people with physical disorders still be able to appreciate and play music with restricted hand movements. There are countless--hundreds upon thousands of people who suffer from various physical disorders that prevent them from moving their arms much. When it comes to playing music, this proves a major issue as very few instruments can be played without open range of movement. Because every member of our team loves playing music, with the common instrument amongst all four of us being guitar, we decided to focus on trying to solve this issue for the acoustic guitar in particular.
## What it does
The Lead Zeppelin uses mechanical systems placed above the guitar frets and sound hole that allow the user to play the instrument using only two keypads. Through this system, the user is able to play the guitar without needing to move much more than his or her fingers, effectively helping those with restricted elbow or arm movement to play the guitar.
## How we built it
There were a lot of different components put into building the Lead Zeppelin. Starting with the frets, the main point was actually the inspiration for our project's name: the use of pencils--more specifically, their erasers. Each fret on each string has a pencil eraser hovering above it, which is used to press down the string at the user's intent. The pencils are able to be pushed down through the use of servos and a few mechanisms that were custom 3D printed. Above the sound hole, two servos are mounted to the guitar to allow for horizontal and vertical movement when plucking or strumming the strings. The last hardware parts were the circuit boards and the user's keypads, for which we utilized hot glue and sodder.
## Challenges we ran into
There were many obstacles as we approached this project from all different aspects of the design to the mechanics. On the other hand, however, we expected challenges since we delved into the idea knowing it was going to be ambitious for our time constraints. One of the first challenges we confronted was short-circuiting two Raspberry Pi's that we'd intended to use, forcing us to switch over to Arduino--which was entirely unplanned for. When it came time to build, one of the main challenges that we ran into was creating the mechanism for the pressing down of the strings on the frets of the guitar. This is because not only did we have to create multiple custom CAD parts, but the scale on the guitar is also one that works in millimeters--leaving little room for error when designing, and even less so when time is taken into consideration. In addition, there were many issues with the servos not functioning properly and the batteries' voltages being too low for the high-power servos, which ended up consuming more time than was allotted for solving them.
## Accomplishments that we're proud of
The biggest accomplishment for all of us is definitely pulling the whole project together to be able to create a guitar that can potentially be used for those with physical disabilities. When we were brainstorming ideas, there was a lot of doubt about every small detail that could potentially put everything we would work for to waste. Nonetheless, the idea and goal of our project was one that we really liked and so the fact that we were able to work together to make the project work was definitely impressive.
## What we learned
One of the biggest lessons we'll keep in mind for next time is time management. We spent relatively little time in the first day working on the project, and especially considering the scale of our idea, this resulted in our necessity to stay up later and sleep less the later it got in the hackathon as we realized the magnitude of work we had left.
## What's next for Lead Zeppelin
Currently, the model of Lead Zeppelin is only on a small scale meant to demonstrate proof of concept, considering the limited amount of time we had to work. In the future, this is an automated player that would be expanded to cover all of the frets and strings over the whole guitar. Furthermore, Lead Zeppelin is a step towards an entirely self-playing, automated guitar that could follow its complete development in the design helping those with physical disabilities. | ## Inspiration
It takes a significant amount of effort just to schedule a hangout or a brief meeting. Current scheduling methods involve typing up when you're available, drafting tedious When2Meets, or comparing calendars. These inefficiencies add unnecessary complexity to our lives, which we can resolve through software and automation.
## What it does
IntelliMeet leverages a multitude of technologies to optimize your scheduling experience. From scraping your upcoming events and analyzing the event type and timing details, to calculating importance-scores and maximizing optimality ratings, IntelliMeet streamlines the scheduling experience in the battle of complexity in our busy lives.
## How we built it
Using the Google Calendar/Google for Developers API, we establish secure authentication processes in order to retrieve calendar and event information. After filtering/extraction of events and time-zone conversion, we employ two ways to generate importance rankings *I* for your events (1. Intel Prediction Guard-based LLM ranking based on event summary/details, 2. memoized keyword-based fast ranking for efficiency).
We then determine open time-slots in both parties' schedules that fit certain criteria like start and ending times, duration, and more. For each time slot, we calculate its "distance" *D* to other events on your schedules, which we use to generate optimality scores, in conjunction with the event importance-scores. Intuitively, we attempt to optimize the optimality scores (*min(|I|/D)*) in a way that promotes the generation of slots that raise the least conflict with your most important events (events closer to more important events are penalized). We leverage Reflex to integrate queries/hosting with our solution.
## Challenges we ran into
*Calendar API calls not accounting for timezone changes* --> solved by switching/standardizing to a new DateTime object format & by calculating UTC time differences ourselves.
*Slow LLM API calls to NeuralChat* --> developed alternate memoized version that has similar importance-score outputs as the fully LLM-relied method.
*Ways to Sort/Rank Meeting Slots* --> chose to pursue generating importance labels 2 ways and event distance labels, which contributed to overall optimality score calculations.
*Reflex Forms and Backend Scheduler*: need to configure states in async manner that allows backend scheduler to run while Reflex handles state updates.
## Accomplishments that we're proud of
Having no experience with APIs & any sort of web-dev, but learning to navigate Calendar APIs, OAuth/POST/GET requests, Intel's Prediction Guard models, Reflex's State and Forms, to pursue bringing an idea to life.
## What we learned
There's a lot of value in helping people battle complexity in their lives through scheduling. Although it was hard to prototype without API/web-dev experience, building is an excellent way to start learning.
## What's next for IntelliMeet
We'll be troubleshooting our Reflex hosting solutions in order to bring convenience to more people; you'll catch us implementing our own datasets and evaluating our own classification models for importance-ranking and time-slot-optimizing. Less scheduling frustration is something we could all use. | winning |
## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | ## Inspiration
Lectures all around the world last on average 100.68 minutes. That number goes all the way up to 216.86 minutes for art students. As students in engineering, we spend roughly 480 hours a day listening to lectures. Add an additional 480 minutes for homework (we're told to study an hour for every hour in a lecture), 120 minutes for personal breaks, 45 minutes for hygeine, not to mention tutorials, office hours, and et. cetera. Thinking about this reminded us of the triangle of sleep, grades and a social life-- and how you can only pick two. We felt that this was unfair and that there had to be a way around this. Most people approach this by attending lectures at home. But often, they just put lectures at 2x speed, or skip sections altogether. This isn't an efficient approach to studying in the slightest.
## What it does
Our web-based application takes audio files- whether it be from lectures, interviews or your favourite podcast, and takes out all the silent bits-- the parts you don't care about. That is, the intermediate walking, writing, thinking, pausing or any waiting that happens. By analyzing the waveforms, we can algorithmically select and remove parts of the audio that are quieter than the rest. This is done over our python script running behind our UI.
## How I built it
We used PHP/HTML/CSS with Bootstrap to generate the frontend, hosted on a DigitalOcean LAMP droplet with a namecheap domain. On the droplet, we have hosted an Ubuntu web server, which hosts our python file which gets run on the shell.
## Challenges I ran into
For all members in the team, it was our first time approaching all of our tasks. Going head on into something we don't know about, in a timed and stressful situation such as a hackathon was really challenging, and something we were very glad that we persevered through.
## Accomplishments that I'm proud of
Creating a final product from scratch, without the use of templates or too much guidance from tutorials is pretty rewarding. Often in the web development process, templates and guides are used to help someone learn. However, we developed all of the scripting and the UI ourselves as a team. We even went so far as to design the icons and artwork ourselves.
## What I learned
We learnt a lot about the importance of working collaboratively to create a full-stack project. Each individual in the team was assigned a different compartment of the project-- from web deployment, to scripting, to graphic design and user interface. Each role was vastly different from the next and it took a whole team to pull this together. We all gained a greater understanding of the work that goes on in large tech companies.
## What's next for lectr.me
Ideally, we'd like to develop the idea to have much more features-- perhaps introducing video, and other options. This idea was really a starting point and there's so much potential for it.
## Examples
<https://drive.google.com/drive/folders/1eUm0j95Im7Uh5GG4HwLQXreF0Lzu1TNi?usp=sharing> | ## Inspiration
In recent years, the advancement of AI technology has revolutionised the landscape of different sector. Our team is inspired by the popular ChatGPT technology and want to use it to break down the education barriers of kids, hence promoting education equality.
## What it does
KidsPedia is an online encyclopedia for children. Leveraging on the ChatGPT technology of OpenAI, KidsPedia provides simple and easy-to-understand answers with metaphors to kids’ questions. From apples to theory of relativity, KidsPedia explains them all! To enhance searching experiences, KidsPedia includes a read-out function to read out the answers to kids' questions. To fasten the search process, KidsPedia also stores search records in a database.
## How we built it
* React for building frontend user interface
* Express.js for building the backend web server
* PostgreSQL database for data persistence
* Public RESTful API of OpenAI to generate explanation of keywords
* Microsoft Azure Cognitive Services for performing the text-to-speech feature
## Challenges we ran into
* Long response time and uncertainty when calling RESTful API of OpenAI
* CORS issue when connecting frontend to backend
* Installing Docker and Docker compose to local machine
## Accomplishments that we're proud of
* Built a full stack web application that could explain concepts using easy-to-understand wordings
* Used database for caching previous response form OpenAI API, to shorten the loading time when user makes a search on KidsPedia
## What we learned
* Collaborate using Git and GitHub
* Using React hooks when building frontend
* Making HTTP requests using Postman during development stage
* Implement good design of RESTful APIs when building backend
## What's next for KidsPedia
* Develop android & iOS app version of KidsPedia so kids can use it with tablets, which is more user friendly to them compare to using a mouse and keyboard to control
* Use algorithm to suggest relevant concepts, when user search for a keyword on KidsPedia
* Enhance the UI of KidsPedia to be more attractive to kids (e.g. more colorful and animated effects) | partial |
## Inspiration
When thinking about how we could make a difference within local communities impacted by Covid-19, what came to mind are our frontline workers. Our doctors, nurses, grocery store workers, and Covid-19 testing volunteers, who have tirelessly been putting themselves and their families on the line. They are the backbone and heartbeat of our society during these past 10 months and counting. We want them to feel the appreciation and gratitude they deserve. With our app, we hope to bring moments of positivity and joy to those difficult and trying moments of our frontline workers. Thank you!
## What it does
Love 4 Heroes is a web app to support our frontline workers by expressing our gratitude for them. We want to let them know they are loved, cared for, and appreciated. In the app, a user can make a thank you card, save it, and share it with a frontline worker. A user's card is also posted to the "Warm Messages" board, a community space where you can see all the other thank-you-cards.
## How we built it
Our backend is built with Firebase. The front-end is built with Next.js, and our design framework is Tailwind CSS.
## Challenges we ran into
* Working with different time zones [12 hour time difference].
* We ran into trickiness figuring out how to save our thank you cards to a user's phone or laptop.
* Persisting likes with Firebase and Local Storage
## Accomplishments that we're proud of
* Our first Hackathon
+ We're not in the same state, but came together to be here!
+ Some of us used new technologies like Next.js, Tailwind.css, and Firebase for the first time!
+ We're happy with how the app turned out from a user's experience
+ We liked that we were able to create our own custom card designs and logos, utilizing custom made design-textiles
## What we learned
* New Technologies: Next.js, Firebase
* Managing time-zone differences
* How to convert a DOM element into a .jpeg file.
* How to make a Responsive Web App
* Coding endurance and mental focus
-Good Git workflow
## What's next for love4heroes
More cards, more love! Hopefully, we can share this with a wide community of frontline workers. | ## Inspiration
Traffic is a pain and hurdle for everyone. It costs time and money for everyone stuck within it. We wanted to empower everyone to focus on what they truly enjoy instead of having to waste their time in traffic. We found the challenge to connect autonomous vehicles and enable them to work closely with each other to make maximize traffic flow to be very interesting. We were specifically interested in aggregating real data to make decisions and evolve those over time using artificial intelligence.
## What it does
We engineered an autonomous network that minimizes the time delay for each car in the network as it moves from its source to its destination. The idea is to have 0 intersections, 0 accidents, and maximize traffic flow.
We did this by developing a simulation in P5.js and training a network of cars to interact with each other in such a way that they do not collide and still travel from their source to target destination safely. We slowly iterated on this idea by first creating the idea of incentivizing factors and negative points. This allowed the cars to learn to not collide with each other and follow the goal they're set out to do. After creating a full simulation with intersections (allowing cars to turn and drive so they stop the least number of times), we created a simulation on Unity. This simulation looked much nicer and took the values trained by our best result from our genetic AI. From the video, we can see that the generation is flawless; there are no accidents, and traffic flows seamlessly. This was the result of over hundreds of generations of training of the genetic AI. You can see our video for more information!
## How I built it
We trained an evolutionary AI on many physical parameters to optimize for no accidents and maximal speed. The allowed the AI to experiment with different weights for each factor in order to reach our goal; having the cars reach from source to destination while staying a safe distance away from all other cars.
## Challenges we ran into
Deciding which parameters to tune, removing any bias, and setting up the testing environment. To remove bias, we ended up introducing randomly generated parameters in our genetic AI and "breeding" two good outcomes. Setting up the simulation was also tricky as it involved a lot of vector math.
## Accomplishments that I'm proud of
Getting the network to communicate autonomously and work in unison to avoid accidents and maximize speed. It's really cool to see the genetic AI evolve from not being able to drive at all, to fully being autonomous in our simulation. If we wanted to apply this to the real world, we can add more parameters and have the genetic AI optimize to find the parameters needed to reach our goals in the fastest time.
## What I learned
We learned how to model and train a genetic AI. We also learned how to deal with common issues and deal with performance constraints effectively. Lastly, we learned how to decouple the components of our application to make it scalable and easier to update in the future.
## What's next for Traffix
We want to increasing the user-facing features for the mobile app and improving the data analytics platform for the city. We also want to be able to extend this to more generalized parameters so that it could be applied in more dimensions. | ## As first-year graduate students at The University of Chicago (who are ironically brand new students to CS), we faced problems with allocating our tasks properly! With students who come from many backgrounds and levels of experience, it's quite the shift to ensure you are completing your work, projects, and leaving enough time to debug your code :D
## What it does - Our product takes into account a variety of activities that the user engages in per week. These activities should be as specific as possible (i.e. Complete Java HW#3, BJJ Session #1, etc.). These tasks should be allocated an estimated time to complete, which you can then allocate across a week in a very detailed manner. Our app will track what you complete, how much you sleep, and track patterns to ensure that you are being your most productive self.
## How we built it - We used figma to envision our UI and React.js to code the MVP front-end.
## Challenges we ran into - As first year students with 0 experience in CS...and no understanding of how Hackathon's actually work, we were completely unprepared for what it takes to craft a practical solution for a common problem. We loved the experience and hope it gets easier over time!
## Accomplishments that we're proud of - Making it through both days in one piece! And sleeping on the floor without causing permanent back damage.
## What we learned - The struggles of de-bugging code at 4am, and the absolute joy of a gogurt at 5am.
## What's next for Project TimeBlock - Hopefully something more concrete and functional! | partial |
## Inspiration
Today, computer programmers all over the world have one of the highest rates of Carpal Tunnel Syndrome. Studies have shown that greater than 30% of adults experience sensory symptoms due to typing on a regular basis. This has necessitated many programmers to spend large portions of time attempting to build the optimal ergonomic setup, potentially involving adjusting chair height, ensuring your back is straight, purchasing ergonomic keyboards etc. However, the problem can still exist, and remain a significant hindrance in ones productivity. To alleviate this, we proposed the idea of removing the need for a keyboard altogether, through the use of speech to code conversions. We hope that by providing a robust and easy to use speech analyzer, programmers will no longer need to constantly use a keyboard and undergo the unfortunate consequences.
## What it does
Ava provides many features related to typing within an editor. The main feature is the ability to directly add code to an open file by simply saying the code they want to include. Another important feature is the ability to make aliases, for example psvm (Public Static Void Main), enabling use of aliases rather than saying all the words. Additional features include cursor movements, running terminal commands, and commenting/deleting specific lines. Ava can also tell you cheesy programming jokes!
## How we built it
We built a VS Code extension using JavaScript. The initial step of speech to text conversions is done by using the Google Cloud Speech to Text API. The text is then processed by our custom built natural language processing engine to understand the context and perform said commands.
## Challenges we ran into
We had initial challenges setting up the Google Cloud Speech to Text API. We had to work with not-so-good laptop microphones in a noisy environment, which often caused the API to misunderstand speech.
## Accomplishments that we're proud of
Our project involved many complicated aspects, mainly in parsing and understanding the converted text and determining the commands to run. Consequently, it was very gratifying when we saw all the features working together and as we had envisioned.
## What we learned
We learned new aspects of building VS Code extensions, creating our own natural language processing engine, and utilizing Google Cloud API.
## What's next for Ava (Amazing Virtual Assistant)
We hope to add support for more language specific features to Ava and support a larger array of editor commands. We also want Ava to have the ability to perform voice searches for programming questions and show and integrate search results into the editor. | ## Inspiration
I realized that as I work, I tend to open up a lot of tabs on Google Chrome. As I go through more and more links, I forget to clean up the old tabs, which clutters up my view and overall organization.
## What it does
I created Smarter Tabs to do all of my organization for me. Smarter Tabs is a Chrome Extension that helps track how you are using your tabs and removes the one's that have been inactive for far too long. Smarter Tabs also keeps track of all the recently deleted tabs so that if you still need the information at your fingertips, you can easily access it through the form of links. By storing these tabs that have been inactive in the form of links, you can still access them but it is less resource intensive of your browser.
## How I built it
This was actually my very first Chrome extension and I also had little experience with Javascript before so it really was an adventure. I poured through a lot of documentation about how everything goes in together and I also got help from mentors along the way, which was incredibly beneficial. This essentially tracks how long its been since a tab was last active and at the end of the timer, the tab will close, and its information will be saved.
## Challenges I ran into and What's Next
Pretty much I ran into a lot of bugs haha. I would pass variables that were the wrong type into all sorts of functions and things just broke. I spent quite a bit of time through the console debugging. It was a jarring, yet rewarding experience.
I learned a lot through this project and I feel now with the power of Google search I can figure anything out! I wish to enhance the ways that Smarter Tabs detects usage and hopefully later, as time goes by, Smarter Tabs will learn more and more from the user so that the longer they use this extension, the more capable it will be of organizing their tabs. | ## Inspiration
We wanted to find a way to use music to help users with improving their mental health. Music therapy is used to improve cognitive brain functions like memory, regulate mood, improve the quality of sleep, managing stress and it can even help with depression. What's more is that music therapy has been proven to help with physical wellbeing as well when paired with usual treatment in clinical settings. Music is also a great way to improve productivity such as listening to pink noise or white noise to aid in focus or sleep
We wanted to see if it was possible to this music to a user's music taste when given a music therapy goal, enhancing the experience of music therapy for the individual. This can be even more application in challenging times such as COVID-19 due to a decline in mental health for the general population.
This is where Music Remedy comes in: understanding the importance of music therapy and all its applications, can we *personalize this experience even further*?
## What it does
Users can log in to the app using their Spotify credentials where the app then has access to the user's Spotify data. As the users navigate through the app, they are asked to select what their goal for music therapy is.
Upon this, when the music therapy goal is chosen, the app creates a playlist for the user according to their Spotify listening history and pre-existing playlists to help them with emotional and physical health and healing. Through processing the user's taste in music, it will allow the app to create a playlist that's more favorable to the user's likes and needs while still accomplishing the goals of music therapy.
Described above allows the user to experience music therapy in a more enhanced and personalized way by ensuring that the user is listening to music to aid in their therapy while also ensuring that it is from songs and artists that they enjoy.
## How we built it
We used the Spotify API to aid with authentication and the users' music taste and history. This gave details on what artists and genres the user typically listened to and enjoyed
We built the web app representing the user interface using NodeJS paired with ExpressJS on the backend and JavaScript, HTML, CSS on the front end through the use of EJS templating, Bootstrap and jQuery.
A prototype for the mobile app representing the event participant interface was built using Figma.
## Challenges we ran into
There are definitely many areas of the Musical Remedy app that can be improved upon if we were given more time. Deciding on the idea and figuring out how much was feasible within the time given was a bit of a challenge. We tried to find the simplest way to effectively express our point across.
Additionally, this hackathon was our first introduction to the Spotify API and using user's data to generate new data for other uses.
## Accomplishments that we're proud of
We are proud of how much we learned about the Spotify API and how to use it over the course of the weekend. Additionally, learning to become more efficient in HTML, CSS and JavaScript using EJS templating is something we'd definitely use in the future with other projects.
## What we learned
We've learned how to effectively manage my time during the hackathon. We tried to work on most of my work during the peak hours of my productivity and took breaks whenever I got too overwhelmed or frustrated.
Additionally, we learned more about the Spotify API and the use of APIs in generals.
## What's next for Musical Remedy
Musical Remedy has the potential to expand its base of listeners from just Spotify users. So far, we are imaging to be able to hook up a database to store user's music preferences which would be recorded using a survey of their favourite genres, artists, etc. Additionally, we'd like to increase the number and specificity of parameters when generating recommended playlists to tailor to the specific categories (pain relief, etc.)
## Domain.Com Entry
Our domains is registered as `whatsanothernameforapplejuice-iphonechargers.tech` | losing |
## Inspiration 💡
**Due to rising real estate prices, many students are failing to find proper housing, and many landlords are failing to find good tenants**. Students looking for houses often have to hire some agent to get a nice place with a decent landlord. The same goes for house owners who need to hire agents to get good tenants. *The irony is that the agent is totally motivated by sheer commission and not by the wellbeing of any of the above two.*
Lack of communication is another issue as most of the things are conveyed by a middle person. It often leads to miscommunication between the house owner and the tenant, as they interpret the same rent agreement differently.
Expensive and time-consuming background checks of potential tenants are also prevalent, as landowners try to use every tool at their disposal to know if the person is really capable of paying rent on time, etc. Considering that current rent laws give tenants considerable power, it's very reasonable for landlords to perform background checks!
Existing online platforms can help us know which apartments are vacant in a locality, but they don't help either party know if the other person is really good! Their ranking algorithms aren't trustable with tenants. The landlords are also reluctant to use these services as they need to manually review applications from thousands of unverified individuals or even bots!
We observed that we are still using these old-age non-scalable methods to match the home seeker and homeowners willing to rent their place in this digital world! And we wish to change it with **RentEasy!**

## What it does 🤔
In this hackathon, we built a cross-platform mobile app that is trustable by both potential tenants and house owners.
The app implements a *rating system* where the students/tenants can give ratings for a house/landlord (ex: did not pay security deposit back for no reason), & the landlords can provide ratings for tenants (the house was not clean). In this way, clean tenants and honest landlords can meet each other.
This platform also helps the two stakeholders build an easily understandable contract that will establish better trust and mutual harmony. The contract is stored on an InterPlanetary File System (IPFS) and cannot be tampered by anyone.

Our application also has an end-to-end encrypted chatting module powered by @ Company. The landlords can filter through all the requests and send requests to tenants. This chatting module powers our contract generator module, where the two parties can discuss a particular agreement clause and decide whether to include it or not in the final contract.
## How we built it ️⚙️
Our beautiful and elegant mobile application was built using a cross-platform framework flutter.
We integrated the Google Maps SDK to build a map where the users can explore all the listings and used geocoding API to encode the addresses to geopoints.
We wanted our clients a sleek experience and have minimal overhead, so we exported all network heavy and resource-intensive tasks to firebase cloud functions. Our application also has a dedicated **end to end encrypted** chatting module powered by the **@-Company** SDK. The contract generator module is built with best practices and which the users can use to make a contract after having thorough private discussions. Once both parties are satisfied, we create the contract in PDF format and use Infura API to upload it to IPFS via the official [Filecoin gateway](https://www.ipfs.io/ipfs)

## Challenges we ran into 🧱
1. It was the first time we were trying to integrate the **@-company SDK** into our project. Although the SDK simplifies the end to end, we still had to explore a lot of resources and ask for assistance from representatives to get the final working build. It was very gruelling at first, but in the end, we all are really proud of having a dedicated end to end messaging module on our platform.
2. We used Firebase functions to build scalable serverless functions and used expressjs as a framework for convenience. Things were working fine locally, but our middleware functions like multer, urlencoder, and jsonencoder weren't working on the server. It took us more than 4 hours to know that "Firebase performs a lot of implicit parsing", and before these middleware functions get the data, Firebase already had removed them. As a result, we had to write the low-level encoding logic ourselves! After deploying these, the sense of satisfaction we got was immense, and now we appreciate millions of open source packages much more than ever.
## Accomplishments that we're proud of ✨
We are proud of finishing the project on time which seemed like a tough task as we started working on it quite late due to other commitments and were also able to add most of the features that we envisioned for the app during ideation. Moreover, we learned a lot about new web technologies and libraries that we could incorporate into our project to meet our unique needs. We also learned how to maintain great communication among all teammates. Each of us felt like a great addition to the team. From the backend, frontend, research, and design, we are proud of the great number of things we have built within 36 hours. And as always, working overnight was pretty fun! :)
---
## Design 🎨
We were heavily inspired by the revised version of **Iterative** design process, which not only includes visual design, but a full-fledged research cycle in which you must discover and define your problem before tackling your solution & then finally deploy it.

This time went for the minimalist **Material UI** design. We utilized design tools like Figma, Photoshop & Illustrator to prototype our designs before doing any coding. Through this, we are able to get iterative feedback so that we spend less time re-writing code.

---
# Research 📚
Research is the key to empathizing with users: we found our specific user group early and that paves the way for our whole project. Here are few of the resources that were helpful to us —
* Legal Validity Of A Rent Agreement : <https://bit.ly/3vCcZfO>
* 2020-21 Top Ten Issues Affecting Real Estate : <https://bit.ly/2XF7YXc>
* Landlord and Tenant Causes of Action: "When Things go Wrong" : <https://bit.ly/3BemMtA>
* Landlord-Tenant Law : <https://bit.ly/3ptwmGR>
* Landlord-tenant disputes arbitrable when not covered by rent control : <https://bit.ly/2Zrpf7d>
* What Happens If One Party Fails To Honour Sale Agreement? : <https://bit.ly/3nr86ST>
* When Can a Buyer Terminate a Contract in Real Estate? : <https://bit.ly/3vDexWO>
**CREDITS**
* Design Resources : Freepik, Behance
* Icons : Icons8
* Font : Semibold / Montserrat / Roboto / Recoleta
---
# Takeways
## What we learned 🙌
**Sleep is very important!** 🤐 Well, jokes apart, this was an introduction to **Web3** & **Blockchain** technologies for some of us and introduction to mobile app developent to other. We managed to improve on our teamwork by actively discussing how we are planning to build it and how to make sure we make the best of our time. We learned a lot about atsign API and end-to-end encryption and how it works in the backend. We also practiced utilizing cloud functions to automate and ease the process of development.
## What's next for RentEasy 🚀
**We would like to make it a default standard of the housing market** and consider all the legal aspects too! It would be great to see rental application system more organized in the future. We are planning to implement more additional features such as landlord's view where he/she can go through the applicants and filter them through giving the landlord more options. Furthermore we are planning to launch it near university campuses since this is where people with least housing experience live. Since the framework we used can be used for any type of operating system, it gives us the flexibility to test and learn.
**Note** — **API credentials have been revoked. If you want to run the same on your local, use your own credentials.** | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, enabling recruiters to instantly find top candidates through AI-powered conversations, ensuring the right fit, right away.
## What it does
Clients talk to our AI, explaining the type of candidate they need and any specific skills they're looking for. As they speak, the AI highlights important keywords and asks any more factors that they would need with the candidate. This data is then analyzed and parsed through our vast database of Freelancers or the best matching candidates. The AI then talks back to the recruiter, showing the top candidates based on the recruiter’s requirements. Once the recruiter picks the right candidate, they can create a smart contract that’s securely stored and managed on the blockchain for transparent payments and agreements.
## How we built it
We built starting with the Frontend using **Next.JS**, and deployed the entire application on **Terraform** for seamless scalability. For voice interaction, we integrated **Deepgram** to generate human-like voice and process recruiter inputs, which are then handled by **Fetch.ai**'s agents. These agents work in tandem: one agent interacts with **Flask** to analyze keywords from the recruiter's speech, another queries the **SingleStore** database, and the third handles communication with **Deepgram**.
Using SingleStore's real-time data analysis and Full-Text Search, we find the best candidates based on factors provided by the client. For secure transactions, we utilized **SUI** blockchain, creating an agreement object once the recruiter posts a job. When a freelancer is selected and both parties reach an agreement, the object gets updated, and escrowed funds are released upon task completion—all through Smart Contracts developed in **Move**. We also used Flask and **Express.js** to manage backend and routing efficiently.
## Challenges we ran into
We faced challenges integrating Fetch.ai agents for the first time, particularly with getting smooth communication between them. Learning Move for SUI and connecting smart contracts with the frontend also proved tricky. Setting up reliable Speech to Text was tough, as we struggled to control when voice input should stop. Despite these hurdles, we persevered and successfully developed this full stack application.
## Accomplishments that we're proud of
We’re proud to have built a fully finished application while learning and implementing new technologies here at CalHacks. Successfully integrating blockchain and AI into a cohesive solution was a major achievement, especially given how cutting-edge both are. It’s exciting to create something that leverages the potential of these rapidly emerging technologies.
## What we learned
We learned how to work with a range of new technologies, including SUI for blockchain transactions, Fetch.ai for agent communication, and SingleStore for real-time data analysis. We also gained experience with Deepgram for voice AI integration.
## What's next for FLEX
Next, we plan to implement DAOs for conflict resolution, allowing decentralized governance to handle disputes between freelancers and clients. We also aim to launch on the SUI mainnet and conduct thorough testing to ensure scalability and performance. | ## Inspiration
You can't get through college without getting sick. Between densely populated living areas and generally unhygienic college students, taking care of your own health is nearly impossible. Recently in UMD, we've had quite a few struggles with health - one student sadly passed away from an adenovirus strain.
One of our friends was also affected by this virus and needed to take a break from school for almost two months. Right before PennApps, a few of my floormates started to catch colds as well. Shouldn't there be a way to prevent this from happening?
## What it does
Chansey takes care of you. It:
* Allows users to report their symptoms
* Notifies users of higher than usual reports in the buildings they frequent (via text)
* Visualizes report data for health officials and users in a simple but detailed method
## Accomplishments that we're proud of
We build our front end completely from scratch, as well as implementing a custom login flow. We also put in a lot of time architecting our backend so that it is high in performance and scalable.
## What we learned
We learned that full stack apps are harder to make than they seem.
## What's next for Chansey
Chansey will integrate with third party APIs to provide more useful information to university students - depending on the sicknesses going around campus. We also plan on adding more useful data analysis tools, so that sources of disease can be automatically identified and remedied. In addition, we can use | winning |
## Inspiration
As post secondary students, our mental health is directly affected. Constantly being overwhelmed with large amounts of work causes us to stress over these large loads, in turn resulting in our efforts and productivity to also decrease. A common occurrence we as students continuously endure is this notion that there is a relationship and cycle between mental health and productivity; when we are unproductive, it results in us stressing, which further results in unproductivity.
## What it does
Moodivity is a web application that improves productivity for users while guiding users to be more in tune with their mental health, as well as aware of their own mental well-being.
Users can create a profile, setting daily goals for themselves, and different activities linked to the work they will be doing. They can then start their daily work, timing themselves as they do so. Once they are finished for the day, they are prompted to record an audio log to reflect on the work done in the day.
These logs are transcribed and analyzed using powerful Machine Learning models, and saved to the database so that users can reflect later on days they did better, or worse, and how their sentiment reflected that.
## How we built it
***Backend and Frontend connected through REST API***
**Frontend**
* React
+ UI framework the application was written in
* JavaScript
+ Language the frontend was written in
* Redux
+ Library used for state management in React
* Redux-Sagas
+ Library used for asynchronous requests and complex state management
**Backend**
* Django
+ Backend framework the application was written in
* Python
+ Language the backend was written in
* Django Rest Framework
+ built in library to connect backend to frontend
* Google Cloud API
+ Speech To Text API for audio transcription
+ NLP Sentiment Analysis for mood analysis of transcription
+ Google Cloud Storage to store audio files recorded by users
**Database**
* PostgreSQL
+ used for data storage of Users, Logs, Profiles, etc.
## Challenges we ran into
Creating a full-stack application from the ground up was a huge challenge. In fact, we were almost unable to accomplish this. Luckily, with lots of motivation and some mentorship, we are comfortable with naming our application *full-stack*.
Additionally, many of our issues were niche and didn't have much documentation. For example, we spent a lot of time on figuring out how to send audio through HTTP requests and manipulating the request to be interpreted by Google-Cloud's APIs.
## Accomplishments that we're proud of
Many of our team members are unfamiliar with Django let alone Python. Being able to interact with the Google-Cloud APIs is an amazing accomplishment considering where we started from.
## What we learned
* How to integrate Google-Cloud's API into a full-stack application.
* Sending audio files over HTTP and interpreting them in Python.
* Using NLP to analyze text
* Transcribing audio through powerful Machine Learning Models
## What's next for Moodivity
The Moodivity team really wanted to implement visual statistics like graphs and calendars to really drive home visual trends between productivity and mental health. In a distant future, we would love to add a mobile app to make our tool more easily accessible for day to day use. Furthermore, the idea of email push notifications can make being productive and tracking mental health even easier. | ## Inspiration
The other day when we were taking the train to get from New Jersey to New York City we started to talk about how much energy we are saving by taking the train rather than driving, and slowly we realized that a lot of people always default to driving as their only mode of transit. We realized that because of this there is a significant amount of CO2 emissions entering our atmosphere. We already have many map apps and websites out there, but none of them take eco-friendliness into account, EcoMaps on the other hand does.
## What it does
EcoMaps allows users to input an origin and destination and then gives them the most eco-friendly way to get from their origin to destination. It uses Google Maps API in order to get the directions for the 4 different ways of travel (walking, biking, public transportation, and driving). From those 4 ways of travel it then chooses what would be the most convenient and most eco friendly way to get from point A to point B. Additionally it tells users how to get to their destination. If the best form of transportation is not driving, EcoMaps tells the user how much carbon emissions they are saving, but if driving is the best form of transportation it will tell them approximately how much carbon emissions they are putting out into our atmosphere. Our website also gives users a random fun fact about going green!
## How we built it
We started this project by importing the Google Maps API into javascript and learning the basics of how the basics worked such as getting a map on screen and going to certain positions. After this, Dan was able to encode the API’s direction function by converting the text strings entered by users into latitude and longitude coordinates through a built-in function. Once the directions started working, Dan built another function which extracted the time it takes to go from one place to another based on all 4 of our different transportation options: walking, biking, driving, and using public transit. Dan then used all of the times and availability of certain methods to determine the optimal method which users should use to help reduce emissions. Obviously, walking or biking is always the optimal option for this, however, the algorithm took into account that many trips are far too long to walk or bike. In other words, it combines both logic and sustainability of our environment. While Dan worked on the backend Rumi created the user interface using Figma and then used HTML and CSS to create a website design based off of the Figma design. Once this was all done, Dan worked on ensuring that the integration of his code and Rumi’s front end display integrated properly.
## Challenges we ran into
One problem we ran into during our project was the fact that Javascript is a single-threaded language. This means that it can only process one thing at a time, which especially came into play when getting data on 4 different trips varying by travel method. This caused the problem of the code skipping certain functions as opposed to waiting and then proceeding. In order to solve this, we learned about the asynchronous option which Javascript allows for in order to await for certain functions to finish before progressing forward in the code. This process of learning included both a quick Stack Overflow question as well as some quick google scans.
Another problem that we faced was dealing with different screen sizes for our website. Throughout our testing, we were solely using devices of the same monitor size, so once we switched to testing on a larger screen all of the proportions were off. At first, we were very confused as to why this was the case, but we soon realized that it was due to our CSS being specific to only our initial screen size. We then had to go through all of our HTML and CSS and adjust the properties so that it was based on percentages of whichever screen size the user had. Although it was a painstaking process, it was worth it in our end product!
## Accomplishments that we're proud of
We are proud of coming up with a website that gives users the most eco-friendly way to travel. This will push individuals to be more conscious of their travel and what form of transportation they end up taking. This is also our second ever hackathon and we are happily surprised by the fact that we were able to make a functioning product in such a short time. EcoMaps also functions in real time meaning that it updates according to variables such as traffic, stations closing, and transit lines closing. This makes EcoMaps more useful in the real world as we all function in real time as well.
## What we learned
Throughout the creation of EcoMaps we learned a host of new skills and information. We learned just how much traveling via car actually pollutes the environment around us, and just how convenient other forms of transportation can be. On the more technical side, we learned how to use Figma to create a website design and then how to create a website with HTML, CSS, and JavaScript based on this framework. We also learned how to implement Google Maps API in our software, and just how useful it can be. Most importantly we learned how to effectively combine our expertise in frontend and backend to create our now functional website, EcoMaps!
## What's next for EcoMaps
In the future we hope to make the app take weather into account and how that may impact the different travel options that are available. Turning EcoMaps into an app that is supported by mobile devices is a major future goal of ours, as most people primarily use their phones to navigate. | ## Inspiration
Our journey with PathSense began with a deeply personal connection. Several of us have visually impaired family members, and we've witnessed firsthand the challenges they face navigating indoor spaces. We realized that while outdoor navigation has seen remarkable advancements, indoor environments remained a complex puzzle for the visually impaired.
This gap in assistive technology sparked our imagination. We saw an opportunity to harness the power of AI, computer vision, and indoor mapping to create a solution that could profoundly impact lives. We envisioned a tool that would act as a constant companion, providing real-time guidance and environmental awareness in complex indoor settings, ultimately enhancing independence and mobility for visually impaired individuals.
## What it does
PathSense, our voice-centric indoor navigation assistant, is designed to be a game-changer for visually impaired individuals. At its heart, our system aims to enhance mobility and independence by providing accessible, spoken navigation guidance in indoor spaces.
Our solution offers the following key features:
1. Voice-Controlled Interaction: Hands-free operation through intuitive voice commands.
2. Real-Time Object Detection: Continuous scanning and identification of objects and obstacles.
3. Scene Description: Verbal descriptions of the surrounding environment to build mental maps.
4. Precise Indoor Routing: Turn-by-turn navigation within buildings using indoor mapping technology.
5. Contextual Information: Relevant details about nearby points of interest.
6. Adaptive Guidance: Real-time updates based on user movement and environmental changes.
What sets PathSense apart is its adaptive nature. Our system continuously updates its guidance based on the user's movement and any changes in the environment, ensuring real-time accuracy. This dynamic approach allows for a more natural and responsive navigation experience, adapting to the user's pace and preferences as they move through complex indoor spaces.
## How we built it
In building PathSense, we embraced the challenge of integrating multiple cutting-edge technologies. Our solution is built on the following technological framework:
1. Voice Interaction: Voiceflow
* Manages conversation flow
* Interprets user intents
* Generates appropriate responses
2. Computer Vision Pipeline:
* Object Detection: Detectron
* Depth Estimation: DPT (Dense Prediction Transformer)
* Scene Analysis: GPT-4 Vision (mini)
3. Data Management: Convex database
* Stores CV data and mapping information in JSON format
4. Semantic Search: Cohere's Rerank API
* Performs semantic search on CV tags and mapping data
5. Indoor Mapping: MappedIn SDK
* Provides floor plan information
* Generates routes
6. Speech Processing:
* Speech-to-Text: Groq model (based on OpenAI's Whisper)
* Text-to-Speech: Unreal Engine
7. Video Input: Multiple TAPO cameras
* Stream 1080p video of the environment over Wi-Fi
To tie it all together, we leveraged Cohere's Rerank API for semantic search, allowing us to find the most relevant information based on user queries. For speech processing, we chose a Groq model based on OpenAI's Whisper for transcription, and Unreal Engine for speech synthesis, prioritizing low latency for real-time interaction. The result is a seamless, responsive system that processes visual information, understands user requests, and provides spoken guidance in real-time.
## Challenges we ran into
Our journey in developing PathSense was not without its hurdles. One of our biggest challenges was integrating the various complex components of our system. Combining the computer vision pipeline, Voiceflow agent, and MappedIn SDK into a cohesive, real-time system required careful planning and countless hours of debugging. We often found ourselves navigating uncharted territory, pushing the boundaries of what these technologies could do when working in concert.
Another significant challenge was balancing the diverse skills and experience levels within our team. While our diversity brought valuable perspectives, it also required us to be intentional about task allocation and communication. We had to step out of our comfort zones, often learning new technologies on the fly. This steep learning curve, coupled with the pressure of working on parallel streams while ensuring all components meshed seamlessly, tested our problem-solving skills and teamwork to the limit.
## Accomplishments that we're proud of
Looking back at our journey, we're filled with a sense of pride and accomplishment. Perhaps our greatest achievement is creating an application with genuine, life-changing potential. Knowing that PathSense could significantly improve the lives of visually impaired individuals, including our own family members, gives our work profound meaning.
We're also incredibly proud of the technical feat we've accomplished. Successfully integrating numerous complex technologies - from AI and computer vision to voice processing - into a functional system within a short timeframe was no small task. Our ability to move from concept to a working prototype that demonstrates the real-world potential of AI-driven indoor navigation assistance is a testament to our team's creativity, technical skill, and determination.
## What we learned
Our work on PathSense has been an incredible learning experience. We've gained invaluable insights into the power of interdisciplinary collaboration, seeing firsthand how diverse skills and perspectives can come together to tackle complex problems. The process taught us the importance of rapid prototyping and iterative development, especially in a high-pressure environment like a hackathon.
Perhaps most importantly, we've learned the critical importance of user-centric design in developing assistive technology. Keeping the needs and experiences of visually impaired individuals at the forefront of our design and development process not only guided our technical decisions but also gave us a deeper appreciation for the impact technology can have on people's lives.
## What's next for PathSense
As we look to the future of PathSense, we're brimming with ideas for enhancements and expansions. We're eager to partner with more venues to increase our coverage of mapped indoor spaces, making PathSense useful in a wider range of locations. We also plan to refine our object recognition capabilities, implement personalized user profiles, and explore integration with wearable devices for an even more seamless experience.
In the long term, we envision PathSense evolving into a comprehensive indoor navigation ecosystem. This includes developing community features for crowd-sourced updates, integrating augmented reality capabilities to assist sighted companions, and collaborating with smart building systems for ultra-precise indoor positioning. With each step forward, our goal remains constant: to continually improve PathSense's ability to provide independence and confidence to visually impaired individuals navigating indoor spaces. | partial |
## What it does
"ImpromPPTX" uses your computer microphone to listen while you talk. Based on what you're speaking about, it generates content to appear on your screen in a presentation in real time. It can retrieve images and graphs, as well as making relevant titles, and summarizing your words into bullet points.
## How We built it
Our project is comprised of many interconnected components, which we detail below:
#### Formatting Engine
To know how to adjust the slide content when a new bullet point or image needs to be added, we had to build a formatting engine. This engine uses flex-boxes to distribute space between text and images, and has custom Javascript to resize images based on aspect ratio and fit, and to switch between the multiple slide types (Title slide, Image only, Text only, Image and Text, Big Number) when required.
#### Voice-to-speech
We use Google’s Text To Speech API to process audio on the microphone of the laptop. Mobile Phones currently do not support the continuous audio implementation of the spec, so we process audio on the presenter’s laptop instead. The Text To Speech is captured whenever a user holds down their clicker button, and when they let go the aggregated text is sent to the server over websockets to be processed.
#### Topic Analysis
Fundamentally we needed a way to determine whether a given sentence included a request to an image or not. So we gathered a repository of sample sentences from BBC news articles for “no” examples, and manually curated a list of “yes” examples. We then used Facebook’s Deep Learning text classificiation library, FastText, to train a custom NN that could perform text classification.
#### Image Scraping
Once we have a sentence that the NN classifies as a request for an image, such as “and here you can see a picture of a golden retriever”, we use part of speech tagging and some tree theory rules to extract the subject, “golden retriever”, and scrape Bing for pictures of the golden animal. These image urls are then sent over websockets to be rendered on screen.
#### Graph Generation
Once the backend detects that the user specifically wants a graph which demonstrates their point, we employ matplotlib code to programmatically generate graphs that align with the user’s expectations. These graphs are then added to the presentation in real-time.
#### Sentence Segmentation
When we receive text back from the google text to speech api, it doesn’t naturally add periods when we pause in our speech. This can give more conventional NLP analysis (like part-of-speech analysis), some trouble because the text is grammatically incorrect. We use a sequence to sequence transformer architecture, *seq2seq*, and transfer learned a new head that was capable of classifying the borders between sentences. This was then able to add punctuation back into the text before the rest of the processing pipeline.
#### Text Title-ification
Using Part-of-speech analysis, we determine which parts of a sentence (or sentences) would best serve as a title to a new slide. We do this by searching through sentence dependency trees to find short sub-phrases (1-5 words optimally) which contain important words and verbs. If the user is signalling the clicker that it needs a new slide, this function is run on their text until a suitable sub-phrase is found. When it is, a new slide is created using that sub-phrase as a title.
#### Text Summarization
When the user is talking “normally,” and not signalling for a new slide, image, or graph, we attempt to summarize their speech into bullet points which can be displayed on screen. This summarization is performed using custom Part-of-speech analysis, which starts at verbs with many dependencies and works its way outward in the dependency tree, pruning branches of the sentence that are superfluous.
#### Mobile Clicker
Since it is really convenient to have a clicker device that you can use while moving around during your presentation, we decided to integrate it into your mobile device. After logging into the website on your phone, we send you to a clicker page that communicates with the server when you click the “New Slide” or “New Element” buttons. Pressing and holding these buttons activates the microphone on your laptop and begins to analyze the text on the server and sends the information back in real-time. This real-time communication is accomplished using WebSockets.
#### Internal Socket Communication
In addition to the websockets portion of our project, we had to use internal socket communications to do the actual text analysis. Unfortunately, the machine learning prediction could not be run within the web app itself, so we had to put it into its own process and thread and send the information over regular sockets so that the website would work. When the server receives a relevant websockets message, it creates a connection to our socket server running the machine learning model and sends information about what the user has been saying to the model. Once it receives the details back from the model, it broadcasts the new elements that need to be added to the slides and the front-end JavaScript adds the content to the slides.
## Challenges We ran into
* Text summarization is extremely difficult -- while there are many powerful algorithms for turning articles into paragraph summaries, there is essentially nothing on shortening sentences into bullet points. We ended up having to develop a custom pipeline for bullet-point generation based on Part-of-speech and dependency analysis.
* The Web Speech API is not supported across all browsers, and even though it is "supported" on Android, Android devices are incapable of continuous streaming. Because of this, we had to move the recording segment of our code from the phone to the laptop.
## Accomplishments that we're proud of
* Making a multi-faceted application, with a variety of machine learning and non-machine learning techniques.
* Working on an unsolved machine learning problem (sentence simplification)
* Connecting a mobile device to the laptop browser’s mic using WebSockets
* Real-time text analysis to determine new elements
## What's next for ImpromPPTX
* Predict what the user intends to say next
* Scraping Primary sources to automatically add citations and definitions.
* Improving text summarization with word reordering and synonym analysis. | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras18b/afouras18b.pdf). The repo for the model used as a base template can be found [here](https://github.com/afourast/deep_lip_reading).
The second source of inspiration is an existing product on the market, [Focals by North](https://www.bynorth.com/). Focals are smart glasses that aim to put the important parts of your life right in front of you through a projected heads up display. We thought it would be a great idea to build onto a platform like this through adding a camera and using artificial intelligence to gain valuable insights about what you see, which in our case, is deciphering speech from visual input. This has applications in aiding individuals who are deaf or hard-of-hearing, noisy environments where automatic speech recognition is difficult, and in conjunction with speech recognition for ultra-accurate, real-time transcripts.
## What it does
The user presses a button on the side of the glasses, which begins recording, and upon pressing the button again, recording ends. The camera is connected to a raspberry pi, which is a web enabled device. The raspberry pi uploads the recording to google cloud, and submits a post to a web server along with the file name uploaded. The web server downloads the video from google cloud, runs facial detection through a haar cascade classifier, and feeds that into a transformer network which transcribes the video. Upon finished, a front-end web application is notified through socket communication, and this results in the front-end streaming the video from google cloud as well as displaying the transcription output from the back-end server.
## How we built it
The hardware platform is a raspberry pi zero interfaced with a pi camera. A python script is run on the raspberry pi to listen for GPIO, record video, upload to google cloud, and post to the back-end server. The back-end server is implemented using Flask, a web framework in Python. The back-end server runs the processing pipeline, which utilizes TensorFlow and OpenCV. The front-end is implemented using React in JavaScript.
## Challenges we ran into
* TensorFlow proved to be difficult to integrate with the back-end server due to dependency and driver compatibility issues, forcing us to run it on CPU only, which does not yield maximum performance
* It was difficult to establish a network connection on the Raspberry Pi, which we worked around through USB-tethering with a mobile device
## Accomplishments that we're proud of
* Establishing a multi-step pipeline that features hardware, cloud storage, a back-end server, and a front-end web application
* Design of the glasses prototype
## What we learned
* How to setup a back-end web server using Flask
* How to facilitate socket communication between Flask and React
* How to setup a web server through local host tunneling using ngrok
* How to convert a video into a text prediction through 3D spatio-temporal convolutions and transformer networks
* How to interface with Google Cloud for data storage between various components such as hardware, back-end, and front-end
## What's next for Synviz
* With stronger on-board battery, 5G network connection, and a computationally stronger compute server, we believe it will be possible to achieve near real-time transcription from a video feed that can be implemented on an existing platform like North's Focals to deliver a promising business appeal | ## Inspiration
A huge issue in healthcare nowadays is the **weakened relationship between patients and physicians due to the lack of communication technologies and overload on the system**; this was our focus for this hack
Prescriptions written by doctors for retrieving medication is often not intuitive to decode for the average person as they often contain shorthand abbreviations derived from Latin. While they are mainly written an interpreted by pharmacists who receive the prescriptions, this extra step in the workflow raises areas susceptible to error. We decided to work on a solution which aims to increase the transparency for patients receiving prescriptions to strengthen patient-doctor relationships, while boosting productivity in physicians' workflows.
## What it does
RxEasy is a web application to help doctors manage and communicate their patients’ prescriptions. It uses keyboard shortcuts for doctors to generate natural language prescriptions using the shorthand they are already used to. The dashboard view allows them to manage their productivity at a glance. A mobile view is also available for patients to see their prescription information in a centralized location.
## How we built it
We used the Hypercare API and Python web scraping for the key features of the app. The Hypercare API was used to create a stronger, more clearer connection between doctor and patient. Web scraping was used to help streamline prescription writing for the doctor’s side.
We built the web app representing the doctor’s interface using Python, GraphQL on the backend and JavaScript, HTML, SCSS, and Bootstrap on the front end with VueJS as the framework. The API was connected with Hypercare and tested with Postman.
The prototypes for the mobile and desktop app representing the patient’s interface and doctor’s interface, respectively, was built using Figma.
## Challenges we ran into
One of the preliminary challenges we faced was putting our idea into a set of use cases to make a viable product. We knew what we wanted to do and how to do it, but finding the right users and stakeholders in the context of this application was a new experience for us.
Prior to this hackathon, we never used Hypercare’s API, making it relatively unfamiliar to work with, especially with its GraphQL configurations. Additionally, despite past experience with Postman, this hackathon brought a few new challenges particularly with authentication and admin access when testing with the Postman app. Additionally, VueJS was a new technology for majority of our team mates.
## Accomplishments that we're proud of
We’re particularly proud of the prototype and its design complete with its animations. This took quite a while and is an app we see actually being used by our audience base.
Additionally, the text replacement as brought about by the web scraping tools was a great accomplishment with little to no overhead. This helped our program run more efficiently and bring about new use cases for our audience.
## What we learned
We learned how to use VueJS and its uses within both the backend and front end of applications. To add on, our unfamiliarity with Hypercare’s API encouraged us to learn more about authorization and admin access when dealing with APIs and how to navigate them.
## What's next for RxEasy
NLP would be incredibly useful with reading prescriptions for users as these are not typically written in language that is easy to decipher from the get-go. Additionally, the application can be further enhanced by integrating AI to detect when a series of logged systems may indicate an adverse reaction to a drug, notifying the patient and doctor.
One thing we would like to include in a later version of this application is a built in messaging system between doctor and patient, fully compliant with PHIPAA and PIPEDA policies. This would further aid in reducing the communication gap between the two parties. | winning |
## Inspiration
As university students, we stare at screens 24/7. This exposes us to many habits unhealthy for the eyes, such as reading something too close for too long, or staring at something too bright for too long. We built the smart glasses to encourage healthy habits that reduce eye strain.
## What it does
In terms of measurements, it uses a distance sensor to compare your reading distance against a threshold, and a light sensor to compare your light exposure levels against another threshold. A buzzer buzzes when the thresholds are crossed. That prompts the user to read a warning on the web app, which informs the user what threshold has been crossed.
## How we built
In terms of hardware, we used the HC-SR04 ultrasonic sensor as the distance sensor, a photoresistor for the light sensor. They are connected to an Arduino, and their data is displayed to the Arduino's seriala terminal. For the web app, we used Javascript to read from the serial terminal and compare the data against the thresholds for healthy reading distance and light exposure levels.
## Challenges we ran into
In terms of hardware, we intended to send the sensor data to our laptops via the HC-05 Bluetooth module, but we're unable to establish a connection. For the web app, there are security protocols surrounding the use of serial terminals. We also intended to make an extension that displays warnings for the user, but many capabilities for extensions were discontinued, so we weren't able to use that.
## Accomplishments that we're proud of
We overcame the security protocols when making the Javascript read from the serial port. We also were able to build a fully functional product.
## What we learned
* Content Security Protocol (CSP) modifications
* Capabilities and limitations of extensions
* How to use Python to capture Analog Sensor Data from an Arduino Uno
## What's next for iGlasses
We can integrate computer vision to identify the object we are measuring the distance of.
We can integrate some form of wireless connection to send data from the glasses to our laptops.
We can implement the warning feature on a mobile app. In the app, we display exposure data similar to the Screen Time feature on phones.
We can sense other data useful for determining eye health. | ## Inspiration
Our inspiration for this idea came as we are becoming of age to drive and as we recognize the importance of safety on the road. We decided to address the topic of driver safety, specifically, distractions while driving, and crash detection. We are bombarded with countless distractions while driving, and as cars are at their fastest, the roads are significantly more dangerous than ever before. With these thoughts in mind, our project aims to make the roads safer for everyone, cars and pedestrians alike. We created a project that would notify and assist drivers to be focused on the road and send emergency messages when a crash is detected. Our goal is to make sure everyone on or near the road is safe and that no unnecessary accidents occur.
## What it does
The project is a live eye-tracking program that would increase overall driver safety on the road. Using the AdHawk MindLink, our program tracks the gaze of the driver and determines if the gaze has left the designated field of view, if so, causing auditory and visual notifications for the driver to re-focus on the road. The program also detects an open eye for 45 seconds or a closed eye for 45 seconds. If such conditions arise, the program recognizes it as a fatal crash by sending out a text message to emergency services. The eye tracking programming is made with python, an emergency text program with Twilio and the hardware is third-generation Arduino Uno integrated with a shield and equipped with a buzzer, LED, and programmed with C++.
## How we built it
The base of our project was inspired by AdHawk’s Mindlink glasses. Using Mindlink, we were able to extract the horizontal and vertical coordinates of the gaze. In combination with those position values, and predetermined zones (10 degrees on each side of origin), we programmed the Arduino to a buzzer and LED. For crash detection, we used an event, “Blink”, which will detect whether a blink has been made. However, if a blink is not preceded by a second one in 45 seconds, the program will recognize it as a fatal injury, triggering Twilio to send text messages to emergency services with accurate location data of the victim.
## Challenges we ran into
Throughout the hackathon, we had many minor speed bumps but our major issue was getting the accurate position values with AdHawk Mindlink. Mindlink returns vectors for indicating position which is really complicated to work with. We turned the vectors into angles (radians) and used those values to set the boundaries for what is considered distracting and considered focused.
## Accomplishments that we're proud of
An accomplishment that our team is most proud of is that our idea started as a small thought, but as we worked on the project, we were able to think about a variety of helpful features to add to our product. We went from using AdHawk's eye-tracking technology for just tracking the driver's gaze to actual safety features such as notifying drivers to be focused on the road and sending emergency messages when a crash is detected.
## What we learned
During Hack the North, we learned countless new things from how to use different programs and technologies to how to solve problems critically. We learned how to use AdHawk's eye-tracking technology by visiting their Hack the North help center website and asking questions at their venue. We learned how to use Twilio and program SMS text messages when the driver has closed/opened their eyes for more than 45 seconds. Throughout this progress, we went through a lot of trial and error, tackling one problem at a time and productively progressing through this project.
## What's next for iTrack
Several exciting ideas are planned for iTrack. Starting with Free Detection mode, currently, the driver needs to wear glasses for iTrack to work. With more time, we would be able to program and put cameras around the interior of the car and track the eye from that instead, making it less invasive. Next, we are planning to add additional sensors (accelerometer, gyroscope etc …) to the glasses to further enhance the crash detection system, which will act as additional sources of triggers for the Twilio emergency texting. Other improvements include auto-calibration, which will drastically reduce the amount of time needed to set up AdHawk Mindlink for the most accurate responses. | ## Inspiration
Ricky and I are big fans of the software culture. It's very open and free, much like the ideals of our great nation. As U.S. military veterans, we are drawn to software that liberates the oppressed and gives a voice to those unheard.
**Senate Joint Resolution 34** is awaiting ratification from the President, and if this happens, internet traffic will become a commodity. This means that Internet Service Providers (ISPs) will have the capability of using their users' browsing data for financial gain. This is a clear infringement on user privacy and is diametrically opposed to the idea of an open-internet. As such, we decided to build **chaos**, which gives a voice... many voices to the user. We feel that it's hard to listen in on a conversation in a noisy room.
## What it does
Chaos hides browsing patterns.
Chaos leverages **chaos.js**, a custom headless browser we built on top of PhantomJS and QT, to scramble incoming/outgoing requests that distorts browsing data beyond use. Further, Chaos leverages its proxy network to supply users with highly-reliable and secure HTTPS proxies on their system.
By using our own custom browser, we are able to dispatch a lightweight headless browser that mimics human-computer interaction, making its behavior indistinguishable from our user's behavior. There are two modes: **chaos** and **frenzy**. The first mode scrambles requests at an average of 50 sites per minute. The second mode scrambles requests at an average of 300 sites per minute, and stops at 9000 sites. We use a dynamically-updating list of over **26,000** approved sites in order to ensure diverse and organic browsing patterns.
## How we built it
### Development of the chaos is broken down into **3** layers we had to build
* OS X Client
* Headless browser engine (chaos.js)
* Chaos VPN/Proxy Layer
### Layer 1: OS X Client
---

The Chaos OS X Client scrambles outgoing internet traffic. This crowds IP data collection and hides browsing habits beneath layers of organic, randomized traffic.
###### OS X Client implementation
* Chaos OS X is a light-weight Swift menubar application
* Chaos OS X is built on top of **chaos.js**, a custom WebKit-driven headless-browser that revolutionizes the way that code interacts with the internet. chaos.js allows for outgoing traffic to appear **completely organic** to any external observer.
* Chaos OS X scrambles traffic and provides high-quality proxies. This is a result of our development of **chaos.js** headless browser and the **Chaos VPN/Proxy layer**.
* Chaos OS X has two primary modes:
+ **chaos**: Scrambles traffic on average of 50 sites per minute.
+ **frenzy**: Scrambles traffic on average of 500 sites per minute, stops at 9000 sites.
### Layer 2: Headless browser engine (chaos.js)
---
Chaos is built on top of the chaos.js engine that we've built, a new approach to WebKit-driven headless browsing. Chaos is **completely** indiscernible from a human user. All traffic coming from Chaos will appear as if it is actually coming from a human-user. This was, by far, the most technically challenging aspect of this hack. Here are a few of the changes we made:
##### #Step 1: Modify header ordering in the QTNetwork layer
##### Chrome headers

##### PhantomJS headers

The header order between other **WebKit** browsers come in static ordering. PhantomJS accesses **WebKit** through the **Qt networking layer**.
```
Modified: qhttpnetworkrequest.cpp
```
---
###### Step 2: Hide exposed footprints
```
Modified: examples/pagecallback.js
src/ghostdriver/request_handlers/session_request_handler.js
src/webpage.cpp
test/lib/www/*
```
---
###### Step 3: Client API implementation
* User agent randomization
* Pseudo-random bezier mouse path generation
* Speed trap reactive DOM interactions
* Dynamic view-port
* Other changes...
### Layer 3: Chaos VPN/Proxy Layer
---
The Chaos VPN back-end is made up of **two cloud systems** hosted on Linode: an OpenVPN and a server. The server deploys an Ubuntu 16.10 distro, which functions as a dynamic proxy-tester that continuously parses the Chaos Proxies to ensure performance and security standards. It then automatically removes inadequate proxies and replaces them with new ones, as well as maintaining a minimum number of proxies necessary. This ensures the Chaos Proxy database is only populated with efficient nodes.
The purpose of the OpenVPN layer is to route https traffic from the host through our VPN encryption layer and then through one of the proxies mentioned above, and finally to the destination. The VPN serves as a very safe and ethical layer that adds extra privacy for https traffic. This way, the ISP only sees traffic from the host to the VPN. Not from the VPN to the proxy, from the proxy to the destination, and all the way back. There is no connection between host and destination.
Moving forward we will implement further ways of checking and gathering safe proxies. Moreover, we've begun development on a machine learning layer which will run on the server. This will help determine which sites to scramble internet history with based on general site sentiment. This will be acomplished by running natural-language processing, sentiment analysis, and entity analytics on the sites.
## Challenges we ran into
This project was **huge**. As we peeled back layer after layer, we realized that the tools we needed simply didn't exist or weren't adequate. This required us to spend a lot of time in several different programming languages/environments in order to build the diverse elements of the platform. We also had a few blocks in terms of architecture cohesion. We wrote the platform in 6 different languages in 5 different environments, and all of the pieces had to work together *exceedingly well*. We spent a lot of time at the data layer of the respective modules, and it slowed us down considerably at times.

## Accomplishments that we're proud of
* We began by contributing to the open-source project **pak**, which allowed us to build complex build-scripts with ease. This was an early decision that helped us tremendously when dealing with `netstat`, network diagnostics and complex python/node scrape scripts.
* We're most proud of the work we did with **chaos.js**. We found that **every** headless browser that is publicly available is easily detectable. We tried PhantomJS, Selenium, Nightmare, and Casper (just to name a few), and we could expose many of them in a matter of minutes. As such, we set out to build our own layer on top of PhantomJS in order to create the first, truly undetectable headless browser.
* This was massively complex, with programming done in C++ and Javascript and nested Makefile dependencies, we found ourselves facing a giant. However, we could not afford for ISPs to be able to distinguish a pattern in the browsing data, so this technology really sits at the core of our system, alongside some other cool elements.
## What we learned
In terms of code, we learned a ton about HTTP/HTTPS and the TCP/IP protocols. We also learned first how to detect "bot" traffic on a webpage and then how to manipulate WebKit behavior to expose key behaviors that mask the code behind the IP. Neither of us had ever used Linode, and standing up two instances (a proper server and a VPN server) was an interesting experience. Fitting all of the parts together was really cool and exposed us to technology stacks on the front-end, back-end, and system level.
## What's next for chaos
More code! We're planning on deploying this as an open-source solution, which most immediately requires a build script to handle the many disparate elements of the system. Further, we plan on continued research into the deep layers of web interaction in order to find other ways of preserving anonymity and the essence of the internet for all users! | losing |
## Inspiration
For any STEM major, writing with LaTeX is a must. There's no other tool as powerful for formatting documents, but with the steep learning curve and complex commands, it's incredibly frustrating to learn. We wanted a tool that would allow people to use LaTeX without necessarily knowing LaTeX, making it even more accessible by using speech to text. This gives people more time to research as opposed to formatting their research on a hard-to-use software. This is where *teXnology* comes in.
## What it does
*teXnology* allows users to turn spoken equations into LaTeX, greatly streamlining the process of typing scientific documents. Instead of having to constantly scan the docs and looking for the proper syntax, you can read a sentence to *teXnology* which does the hard work for you. It gives you a preview of the actual LaTeX code and renders it side by side to show you what it would actually look like. It also gives users the option to render the LaTeX in Overleaf, letting them maintain their workflow.
## How we built it
We built the frontend using React and Node, using a built in React package for the speech to text. The text was converted to LaTeX using Groq's chat completion API, which we wrote in JS and set up an API for using Express.
## Challenges we ran into
There were two major challenges we faced: speech to text and PDF rendering. For speech to text we had two options. The first was using a React component, which simplified the code and showed a live transcript, but was somewhat inaccurate. The second was using Groq's whisper Open AI API, which was very accurate but couldn't generate a live transcript without constant API calls, and also needed an audio file to be sent to backend which was a huge headache. We eventually opted to use the React component, but something we definitely want to touch up in the future.
We also wanted to have a PDF rendered in the browser that would show a more accurate depiction of the final LaTeX doc. After spending hours reading through documentation changing the entire backend to Javascript (our first draft was in Python), we opted on just the Overleaf API. We realized that our solution was more focused on generating the LaTeX, and it made more sense to use an existing tool for PDF rendering rather than writing our own.
## Accomplishments that we're proud of
Since we're all first-time hackers, we're proud of making a fully functional full-stack application in the 36 hours. We had very minimal experience with web dev and learned a lot of it on the fly, so we're proud to have been able to tie it all together and make a website we're genuinely proud of. We're also very happy that we got the text to LaTeX model to work with relatively good accuracy, thanks in large to Groq. This is a tool we intend to expand on greatly in the future, so we're very happy to have established such a strong foundation.
## What we learned
We learned A LOT about full stack development. We had to work on tasks we've never done before (like backend for me), so we really rounded ourselves out We also learned a lot about prompt engineering and using an LLM for a more niche task, and were really impressed by the capabilities of Groq. Testing our speech to LaTeX forced us to learn the intricacies of LaTeX so our users don't have to. We learned how to integrate and implement API implementations, specifically speech to text, and also how to set up our own API endpoints for using the Groq model.
## What's next for teXnology
Our goal for *teXnology* is to hone in on what makes it unique--the speech to LaTeX. Rather than making our own LaTeX rendering, we want to integrate these features into an extension so users can simultaneously use \*teXnology with apps like Overleaf, using existing tools and allowing them to maintain their workflow. That said, we still want to keep the teXnology website if users prefer that, but also add a built in PDF viewer that renders the LaTeX. We're also looking into fine tuning the model for higher accuracy with more complex equations. | ## Inspiration
The genesis of this project was an extra credit opportunity in a discrete mathematics course, where the challenge was to transcribe class notes into LaTeX format. Having experienced firsthand the tediousness and time-consuming nature of manually converting these notes, I was inspired to develop a solution that could streamline this process. This project, thus, aims to bridge the gap between spoken mathematical concepts and their formal documentation in LaTeX, making the transcription process not only faster but also more accessible to students and educators alike.
## What it does
TexTalk revolutionizes mathematical documentation by seamlessly converting spoken words into LaTeX code, complete with detailed explanations and solutions. This code is then transformed into a user-friendly, accessible pdf document. The dual-output system not only streamlines document creation but also deepens comprehension by clarifying each step of the equations. Furthermore, it supports accessibility with a dictation feature that audibly reads back the document, ensuring vision-impaired users can fully engage with the content.
## How we built it
TexTalk was crafted using a modular Python approach, integrating specialized libraries for each functionality. We implemented voice capture with [PvRecorder](https://github.com/Alans44/TexTalk-/blob/main/recorder.py), then utilized speech recognition coupled with speech synthesis and custom instructions for transcription, converting speech to LaTeX. The resulting LaTeX code is rendered visually and, where applicable, solved for immediate results. AI-powered using a custom fine-tuned version of gpt4 and Toyomi Hayashi's speech synthesis through our LLM bridge module, the system generates step-by-step explanations, which are then formatted for clarity by our steps converter. The process, from recording to detailed LaTeX documents, is both efficient and user-friendly, streamlining the creation of complex mathematical documentation. Additionally, this modular approach allowed us to efficiently integrate the dictation feature because we had access to the original text formatted input which we then text-to-speech back to the user. [Steps Converter](https://github.com/Alans44/TexTalk-/blob/main/steps_converter.py) | [Voice Transcription](https://github.com/Alans44/TexTalk-/blob/main/transcript.py) | [Dictation](https://github.com/Alans44/TexTalk-/blob/main/speaker.py)
## Challenges we ran into
One of the foremost challenges was achieving high accuracy in speech recognition for mathematical terminology, which often includes highly specialized symbols and expressions. Fine-tuning and debugging the LaTeX conversion engine required a deep dive into both linguistic processing and mathematical structuring, ensuring the translation from spoken word to LaTeX code was both accurate and logically formatted. Additionally, crafting the explanation module to produce clear, step-by-step solutions demanded a strong understanding of mathematical problem-solving.
## Accomplishments that we're proud of
Successfully creating a tool that not only transcribes but also breaks down and explains mathematical equations was a great feeling. TexTalk stands as a testament to the potential of integrating technology with education, offering a novel approach to mathematical documentation. Witnessing TexTalk accurately convert complex spoken equations into LaTeX documents, complete with elucidative breakdowns, has been incredibly rewarding.
## What we learned
This project deepened our understanding of speech recognition technologies, NLP, and LaTeX formatting, highlighting the interdisciplinary nature of developing educational tools. We gained insights into the complexities of mathematical notation and the challenges of translating it from speech to structured documents. The development process also honed our skills in fine-tuning and prompt engineering, particularly in creating logic that interprets and structures mathematical content.
## What's next for TexTalk
Looking forward, we aim to enhance TexTalk's accuracy and expand its vocabulary to encompass a broader range of mathematical fields. Integrating machine learning to refine the contextual understanding of equations and exploring real-time transcription are key objectives. Additionally, we plan to develop an interactive interface that allows users to edit and refine generated LaTeX documents and explanations directly, fostering a more integrated and user-friendly experience. | ## Inspiration
Beautiful stationery and binders filled with clips, stickies, and colourful highlighting are things we miss from the past. Passing notes and memos and recognizing who it's from just from the style and handwriting, holding the sheet in your hand, and getting a little personalized note on your desk are becoming a thing of the past as the black and white of emails and messaging systems take over. Let's bring back the personality, color, and connection opportunities from memo pads in the office while taking full advantage of modern technology to make our lives easier. Best of both worlds!
## What it does
Memomi is a web application for offices to simplify organization in a busy environment while fostering small moments of connection and helping fill in the gaps on the way. Using powerful NLP technology, Memomi automatically links related memos together, suggests topical new memos to expand on missing info on, and allows you to send memos to other people in your office space.
## How we built it
We built Memomi using Figma for UI design and prototyping, React web apps for frontend development, Flask APIs for the backend logic, and Google Firebase for the database. Cohere's NLP API forms the backbone of our backend logic and is what powers Memomi's intelligent suggestions for tags, groupings, new memos, and links.
## Challenges we ran into
With such a dynamic backend with more complex data, we struggled to identify how best to organize and digitize the system. We also struggled a lot with the frontend because of the need to both edit and display data annotated at the exact needed positions based off our information. Connecting our existing backend features to the frontend was our main barrier to showing off our accomplishments.
## Accomplishments that we're proud of
We're very proud of the UI design and what we were able to implement in the frontend. We're also incredibly proud about how strong our backend is! We're able to generate and categorize meaningful tags, groupings, and links between documents and annotate text to display it.
## What we learned
We learned about different NLP topics, how to make less rigid databases, and learned a lot more about advanced react state management.
## What's next for Memomi
We would love to implement sharing memos in office spaces as well as authorization and more text editing features like markdown support. | losing |
## Inspiration
Blockchain has created new opportunities for financial empowerment and decentralized finance (DeFi), but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has been a recent wave of effort to introduce regulations for crypto, but the ease of money laundering proves to be a serious challenge for regulatory bodies like the Canadian Revenue Agency. Recognizing these dangers, we aimed to tackle this issue through BlockXism!
## What it does
BlockXism is an attempt at placing more transparency in the blockchain ecosystem, through a simple verification system. It consists of (1) a self-authenticating service, (2) a ledger of verified users, and (3) rules for how verified and unverified users interact. Users can "verify" themselves by giving proof of identity to our self-authenticating service, which stores their encrypted identity on-chain. A ledger of verified users keeps track of which addresses have been verified, without giving away personal information. Finally, users will lose verification status if they make transactions with an unverified address, preventing suspicious funds from ever entering the verified economy. Importantly, verified users will remain anonymous as long as they are in good standing. Otherwise, such as if they transact with an unverified user, a regulatory body (like the CRA) will gain permission to view their identity (as determined by a smart contract).
Through this system, we create a verified market, where suspicious funds cannot enter the verified economy while flagging suspicious activity. With the addition of a legislation piece (e.g. requiring banks and stores to be verified and only transact with verified users), BlockXism creates a safer and more regulated crypto ecosystem, while maintaining benefits like blockchain’s decentralization, absence of a middleman, and anonymity.
## How we built it
BlockXism is built on a smart contract written in Solidity, which manages the ledger. For our self-authenticating service, we incorporated Circle wallets, which we plan to integrate into a self-sovereign identification system. We simulated the chain locally using Ganache and Metamask. On the application side, we used a combination of React, Tailwind, and ethers.js for the frontend and Express and MongoDB for our backend.
## Challenges we ran into
A challenge we faced was overcoming the constraints when connecting the different tools with one another, meaning we often ran into issues with our fetch requests. For instance, we realized you can only call MetaMask from the frontend, so we had to find an alternative for the backend. Additionally, there were multiple issues with versioning in our local test chain, leading to inconsistent behaviour and some very strange bugs.
## Accomplishments that we're proud of
Since most of our team had limited exposure to blockchain prior to this hackathon, we are proud to have quickly learned about the technologies used in a crypto ecosystem. We are also proud to have built a fully working full-stack web3 MVP with many of the features we originally planned to incorporate.
## What we learned
Firstly, from researching cryptocurrency transactions and fraud prevention on the blockchain, we learned about the advantages and challenges at the intersection of blockchain and finance. We also learned how to simulate how users interact with one another blockchain, such as through peer-to-peer verification and making secure transactions using Circle wallets. Furthermore, we learned how to write smart contracts and implement them with a web application.
## What's next for BlockXism
We plan to use IPFS instead of using MongoDB to better maintain decentralization. For our self-sovereign identity service, we want to incorporate an API to recognize valid proof of ID, and potentially move the logic into another smart contract. Finally, we plan on having a chain scraper to automatically recognize unverified transactions and edit the ledger accordingly. | ## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | ## Inspiration
With the flurry of new tech developments and media tools, people have access to an incredibly large amount of news and information about the world. To assist in keeping up with current events, we built Squeeze, a web-app that takes top stories from major news outlets and summarizes + highlights keywords from the article, allowing the user to explore more headlines and find what interests them.
## What it does
Squeeze summarizes and highlights stories from top media outlets, yielding a highlighted summary but maintaining complete links to the original source. Squeeze takes in RSS feeds from major news websites, and scrapes their article contents. This data is fed into machine learning algorithms to clean and summarize their contents. Keywords are chosen using the Google Cloud natural language API. The user, upon choosing a headline of interest, are presented with a highlighted text summary, and easy-access links to the original source if they are further interested.
## How we built it
We used the Python package Feedparser to parse RSS feeds of new websites, and the package BeautifulSoup to scrape data from these feeds. Machine Learning algorithms were used to clean and summarize the scraped HTML data. Keywords in the article were chosen using the Google Cloud natural language API, and built the custom search engine using the Google Custom Search API. Front-end work was performed using Javascript + HTML.
## Challenges we ran into
There were couple of challenges that we ran into. 1) How to deploy the summarized text on the Google Cloud. 2) How to connect and visualize the scraped data through the search engine.
## Accomplishments that we're proud of
We are proud that we were able to finish the ML algorithm for text summation and how to find keywords in the text.
## What we learned
We learnt how to ML in order to clean the HTML data as well as how to find keywords in the text.
## What's next for Squeeze
To be continued | winning |
If we take a moment to stop and think of those who can't speak or hear, we will realize and be thankful for what we have. To make the lives of these differently ables people, we needed to come up with a solution and here we present you with Proximity.
Proximity uses the Myo armband for sign recognition and an active voice for speech recognition. The armband is trained on a ML model reads the signs made by human hands and interprets them, thereby, helping the speech impaired to share their ideas and communicate with people and digital assistants alike. The service is also for those who are hearing impaired, so that they can know when somebody is calling their name or giving them a task.
We're proud of successfully recognizing a few gestures and setting up a web app that understands and learns the name of a person. Apart from that we have calibrated a to-do list that can enable the hearing impaired people to actively note down tasks assigned to them.
We learned an entirely new language, Lua to set up and use the Myo Armband SDK. Apart from that we used vast array of languages, scripts, APIs, and products for different parts of the product including Python, C++, Lua, Js, NodeJs, HTML, CSS, the Azure Machine Learning Studio, and Google Firebase.
We look forward to explore the unlimited opportunities with Proximity. From training it to recognize the entire American Sign Language using the powerful computing capabilities of the Azure Machine Learning Studio to advancing our speech recognition app for it to understand more complex conversations. Proximity should integrate seamlessly into the lives of the differently abled. | ## 💡 Inspiration
>
> #hackathon-help-channel
> `<hacker>` Can a mentor help us with flask and Python? We're stuck on how to host our project.
>
>
>
How many times have you created an epic web app for a hackathon but couldn't deploy it to show publicly? At my first hackathon, my team worked hard on a Django + React app that only lived at `localhost:5000`.
Many new developers don't have the infrastructure experience and knowledge required to deploy many of the amazing web apps they create for hackathons and side projects to the cloud.
We wanted to make a tool that enables developers to share their projects through deployments without any cloud infrastructure/DevOps knowledge
(Also, as 2 interns currently working in DevOps positions, we've been learning about lots of Infrastructure as Code (IaC), Configuration as Code (CaC), and automation tools, and we wanted to create a project to apply our learning.)
## 💭 What it does
InfraBundle aims to:
1. ask a user for information about their project
2. generate appropriate IaC and CaC code configurations
3. bundle configurations with GitHub Actions workflow to simplify deployment
Then, developers commit the bundle to their project repository where deployments become as easy as pushing to your branch (literally, that's the trigger).
## 🚧 How we built it
As DevOps interns, we work with Ansible, Terraform, and CI/CD pipelines in an enterprise environment. We thought that these could help simplify the deployment process for hobbyists as well
InfraBundle uses:
* Ansible (CaC)
* Terraform (IaC)
* GitHub Actions (CI/CD)
* Python and jinja (generating CaC, IaC from templates)
* flask! (website)
## 😭 Challenges we ran into
We're relatitvely new to Terraform and Ansible and stumbled into some trouble with all the nitty-gritty aspects of setting up scripts from scratch.
In particular, we had trouble connecting an SSH key to the GitHub Action workflow for Ansible to use in each run. This led to the creation of temporary credentials that are generated in each run.
With Ansible, we had trouble creating and activating a virtual environment (see: not carefully reading [ansible.builtin.pip](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/pip_module.html) documentation on which parameters are mutually exclusive and confusing the multiple ways to pip install)
In general, hackathons are very time constrained. Unfortunately, slow pipelines do not care about your time constraints.
* hard to test locally
* cluttering commit history when debugging pipelines
## 🏆 Accomplishments that we're proud of
InfraBundle is capable of deploying itself!
In other news, we're proud of the project being something we're genuinely interested in as a way to apply our learning. Although there's more functionality we wished to implement, we learned a lot about the tools used. We also used a GitHub project board to keep track of tasks for each step of the automation.
## 📘 What we learned
Although we've deployed many times before, we learned a lot about automating the full deployment process. This involved handling data between tools and environments. We also learned to use GitHub Actions.
## ❓ What's next for InfraBundle
InfraBundle currently only works for a subset of Python web apps and the only provider is Google Cloud Platform.
With more time, we hope to:
* Add more cloud providers (AWS, Linode)
* Support more frameworks and languages (ReactJS, Express, Next.js, Gin)
* Improve support for database servers
* Improve documentation
* Modularize deploy playbook to use roles
* Integrate with GitHub and Google Cloud Platform
* Support multiple web servers | ## Inspiration
According to the Canadian Centre for Injury Prevention and Control, in Canada, an average of 4 people are killed every day as a result of impaired driving. In 2019, there were 1,346 deaths caused by impaired driving, which represents approximately 30% of all traffic-related deaths in Canada. Impaired driving is also a leading criminal cause of death in Canada and it is estimated that it costs the country around $20 billion per year. These statistics show that impaired driving is a significant problem in Canada and highlights the need for continued efforts to reduce the number of deaths and injuries caused by this preventable behavior.
## What it does
This program calculates the users blood alcohol concentration using a few input parameters to determine whether it would be safe for the user to drive their vehicle (Using Ontario's recommended blood alcohol concentraition 0.08). The program uses the users weight, sex, alcohol consumed (grams) (shots [1.5oz], wine glass [5oz], beer cup [12oz]), alcoholic beverage. The alcoholic beverage is a local database constructed using some of the most popoular drinks.
With the above parameters, we used the Widmark formula described in the following paper (<https://www.yasa.org/upload/uploadedfiles/alcohol.pdf>). The Widmark is a rough estimate of the blood alcohol concentration and shouldn't be taken as a definitive number. The Widmark formula is:
BAC=(Alcohol consumed in grams / (Body weight in grams \* r)) \* 100
## How we built it
We used ReactJS for front-end and Firebase for the backend. For the Google technology we decided to integrate the Firebase Realtime Database. We store all of the drinks on there so that whenever we reload the page or access the website on different devices, we can continue from where we left off. Your alcohol blood concentration also depends on how much time has passed since you drank the drink, so we are able to store the time and update it continuously to show more accurate results.
## Challenges we ran into
* Incorporating time into elapsed time calculations
* Use State hooks constantly delayed
* Reading data from database
## Accomplishments that we're proud of
* Our first hackathon!
## What we learned
* How to fetch data from a database.
## What's next for Alcohol Monitor
* Photo scan of drink
* More comprehensive alcohol database
* More secure database implementation
* User logins
* Mobile implementation
* BOOTSTRAP! | winning |
## Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
## What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
## How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
## ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model [link](https://arxiv.org/abs/1609.04802). SRGAN with an attention layer [link](https://arxiv.org/pdf/1812.04821.pdf). These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually *only* 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces [see here](https://arxiv.org/abs/1809.05286). We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
## Accomplishments that I'm proud of
Building it good.
## What I learned
Balanced approaches and leveraging past learning
## What's next for Crystallize
Real time stream-enhance app. | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change. | ## Inspiration
With the onset of COVID19 our education, work, and quality time with others have been moved to a virtual format increasing screen time globally. The truth is that we spend three hours and 23 minutes of our waking day staring at a screen. This has an impact on our mental and physical health. Screen time is linked to the rise in stress and anxiety. What if there was a way to prevent stress before it happens?
## What it does
Mood.io is your personal assistant for your mood! It is compatible with any web browser and webcam, so it’s easy to use. Mood.io uses machine learning to detect when you are stressed and recommends what activities to do to reduce your stress. Mood.io is the easiest way to take care of your mental health!
## How we built it
In this project we used ML libraries such as: - numpy, matplotlib and seaborn; for Deep Learning Keras; for image processing openCV and haarcascades for facial detection. We have used the FER-13 dataset for this model. So for the Convolutional Neural Networks (CNN) we have 4 layers and 2 fully connected layers and, i have imported the Adam optimizer to compute the CNN for this model. We initially set out with 48 epochs to train the model with the callback for early stopping to avoid fitting discrepancies in the model. Our final accuracy was recorded to be 69%. The model after implementing openCV's video capture function could take a live feed from the webcam and classify from the 7 trained emotions successfully.
## Challenges we ran into
It was difficult to integrate our machine learning backend with the frontend website. We had some tricky problems with our integration and had to adapt. Additionally, we had a tough time finding a proper dataset even though FER-13 was the best visible option it took a good amount of time to finalize the dataset.
## Accomplishments that we're proud of
With a group of beginners, we encountered many bugs and had to restart many times. Through that, we learned a lot about what is going on in the background of programming. We are most proud of not giving up, learning new things, and pushing this project forward.
## What we learned
For this project, we got to explore the possibilities of machine learning in a browser. We got to work on a front-end web app and tried to use various libraries, such as React and D3.js. In addition to learning about machine learning and web development, we learned about the importance of staying up to date with new technologies.
## What's next for Mood.io
We hope to be able to offer a wide range of features that will allow our users to track and analyze their mental health. We want to be able to offer a better understanding of the root causes of stress and help them manage it. Together, we can change one person's life at a time. | winning |
## \*\* Internet of Things 4 Diabetic Patient Care \*\*
## The Story Behind Our Device
One team member, from his foot doctor, heard of a story of a diabetic patient who almost lost his foot due to an untreated foot infection after stepping on a foreign object. Another team member came across a competitive shooter who had his lower leg amputated after an untreated foot ulcer resulted in gangrene.
A symptom in diabetic patients is diabetic nephropathy which results in loss of sensation in the extremities. This means a cut or a blister on a foot often goes unnoticed and untreated.
Occasionally, these small cuts or blisters don't heal properly due to poor blood circulation, which exacerbates the problem and leads to further complications. These further complications can result in serious infection and possibly amputation.
We decided to make a device that helped combat this problem. We invented IoT4DPC, a device that detects abnormal muscle activity caused by either stepping on potentially dangerous objects or caused by inflammation due to swelling.
## The technology behind it
A muscle sensor attaches to the Nucleo-L496ZG board that feeds data to a Azure IoT Hub. The IoT Hub, through Trillo, can notify the patient (or a physician, depending on the situation) via SMS that a problem has occurred, and the patient needs to get their feet checked or come in to see the doctor.
## Challenges
While the team was successful in prototyping data aquisition with an Arduino, we were unable to build a working prototype with the Nucleo board. We also came across serious hurdles with uploading any sensible data to the Azure IoTHub.
## What we did accomplish
We were able to set up an Azure IoT Hub and connect the Nucleo board to send JSON packages. We were also able to aquire test data in an excel file via the Arduino | ## Inspiration
Our inspiration comes from people who require immediate medical assistance when they are located in remote areas. The project aims to reinvent the way people in rural or remote settings, especially seniors who are unable to travel frequently, obtain medical assistance by remotely connecting them to medical resources available in their nearby cities.
## What it does
Tango is a tool to help people in remote areas (e.g. villagers, people on camping/hiking trips, etc.) to have access to direct medical assistance in case of an emergency. The user would have the device on him while hiking along with a smart watch. If the device senses a sudden fall, the vital signs of the user provided by the watch would be sent to the nearest doctor/hospital in the area. The doctor could then assist the user in a most appropriate way now that the user's vital signs are directly relayed to the doctor. In a case of no response from the user, medical assistance can be sent using his location.
## How we built it
The sensor is made out of the Particle Electron Kit, which based on input from an accelerometer and a sound sensor, asseses whether the user has fallen down or not. Signals from this sensor are sent to the doctor if the user has fallen along with data from smart watch about patient health.
## Challenges we ran into
One of our biggest challenges we ran into was taking the data from the cloud and loading it on the web page to display it.
## Accomplishments that we are proud of
It is our first experience with the Particle Electron and for some of us their first experience in a hardware project.
## What we learned
We learned how to use the Particle Election.
## What's next for Tango
Integration of the Pebble watch to send the vital signs to the doctors. | ## Inspiration
As university students, we stare at screens 24/7. This exposes us to many habits unhealthy for the eyes, such as reading something too close for too long, or staring at something too bright for too long. We built the smart glasses to encourage healthy habits that reduce eye strain.
## What it does
In terms of measurements, it uses a distance sensor to compare your reading distance against a threshold, and a light sensor to compare your light exposure levels against another threshold. A buzzer buzzes when the thresholds are crossed. That prompts the user to read a warning on the web app, which informs the user what threshold has been crossed.
## How we built
In terms of hardware, we used the HC-SR04 ultrasonic sensor as the distance sensor, a photoresistor for the light sensor. They are connected to an Arduino, and their data is displayed to the Arduino's seriala terminal. For the web app, we used Javascript to read from the serial terminal and compare the data against the thresholds for healthy reading distance and light exposure levels.
## Challenges we ran into
In terms of hardware, we intended to send the sensor data to our laptops via the HC-05 Bluetooth module, but we're unable to establish a connection. For the web app, there are security protocols surrounding the use of serial terminals. We also intended to make an extension that displays warnings for the user, but many capabilities for extensions were discontinued, so we weren't able to use that.
## Accomplishments that we're proud of
We overcame the security protocols when making the Javascript read from the serial port. We also were able to build a fully functional product.
## What we learned
* Content Security Protocol (CSP) modifications
* Capabilities and limitations of extensions
* How to use Python to capture Analog Sensor Data from an Arduino Uno
## What's next for iGlasses
We can integrate computer vision to identify the object we are measuring the distance of.
We can integrate some form of wireless connection to send data from the glasses to our laptops.
We can implement the warning feature on a mobile app. In the app, we display exposure data similar to the Screen Time feature on phones.
We can sense other data useful for determining eye health. | winning |
## Inspiration
Globally, over 92 million tons of textile waste are generated annually, contributing to overflowing landfills and environmental degradation. What's more, the fashion industry is responsible for 10% of global carbon emissions, with fast fashion being a significant contributor due to its rapid production cycles and disposal of unsold items. The inspiration behind our project, ReStyle, is rooted in the urgent need to address the environmental impact of fast fashion. Witnessing the alarming levels of clothing waste and carbon emissions prompted our team to develop a solution that empowers individuals to make sustainable choices effortlessly. We believe in reshaping the future of fashion by promoting a circular economy and encouraging responsible consumer behaviour.
## What it does
ReStyle is a revolutionary platform that leverages AI matching to transform how people buy and sell pre-loved clothing items. The platform simplifies the selling process for users, incentivizing them to resell rather than contribute to the environmental crisis of clothing ending up in landfills. Our advanced AI matching algorithm analyzes user preferences, creating tailored recommendations for buyers and ensuring a seamless connection between sellers and buyers.
## How we built it
We used React Native and Expo to build the front end, creating different screens and components for the clothing matching, camera, and user profile functionality. The backend functionality was made possible using Firebase and the OpenAI API. Each user's style preferences are saved in a Firebase Realtime Database, as are the style descriptions for each piece of clothing, and when a user takes a picture of a piece of clothing, the OpenAI API is called to generate a description for that piece of clothing, and this description is saved to the DB. When the user is on the home page, they will see the top pieces of clothing that match with their style, retrieved from the DB and the matches generated using the OpenAI API.
## Challenges we ran into
* Our entire team was new to the technologies we utilized.
* This included React Native, Expo, Firebase, OpenAI.
## Accomplishments that we're proud of
* Efficient and even work distribution between all team members
* A visually aesthetic and accurate and working application!
## What we learned
* React Native
* Expo
* Firebase
* OpenAI
## What's next for ReStyle
Continuously refine our AI matching algorithm, incorporating machine learning advancements to provide even more accurate and personalized recommendations for users, enabling users to save clothing that they are interested in. | ## Inspiration
One of our groupmates, *ahem* Jessie *ahem*, has an addiction to shopping at a fast fashion retailer which won't be named. So the team collectively came together to come up with a solution: BYEBUY. Instead of buying hauls on clothing that are cheap and don't always look good, BYEBUY uses the power of stable diffusion and your lovely selfies to show you exactly how you would look like in those pieces of clothing you've been eyeing! This solution will not only save your wallet, but will help stop the cycle of mass buying fast fashion.
## What it does
It takes a picture of you (you can upload or take a photo in-app), it takes a link of the clothing item you want to try on, and combination! BYEBUY will use our AI model to show you how you would look with those clothes on!
## How we built it
BYEBUY is a Next.js webapp that:
1. Takes in a link and uses puppeteer and cheerio to web scrape data
2. Gets react webcam takes a picture of you
3. Takes your photo + the web data and uses AI inpainting with a stable diffusion model to show you how the garments would look on you
## Challenges we ran into
**Straying from our original idea**: Our original idea was to use AR to show you in live time how clothing would look on you. However, we soon realized how challenging 3d modelling could be, especially since we wanted to use AI to turn images of clothing into 3d models...maybe another time.
**Fetching APIs and passing data around**: This was something we were all supposed to be seasoned at, but turns out, an API we used lacked documentation, so it took a lot of trial and error (and caffeine) to figure out the calls and how to pass the endpoint of one API to .
## Accomplishments that we're proud of
We are proud we came up with a solution to a problem that affects 95% of Canada's population (totally not a made up stat btw).
Just kidding, we are proud that despite being a group who was put together last minute and didn't know each other before HTV9, we worked together, talked together, laughed together, made matching bead bracelets, and created a project that we (or at least one of the members in the group) would use!
Also proud that we came up with relatively creative solutions to our problems! Like combining web scraping with AI so that users will have (almost) no limitations to the e-commerce sites they want to virtually try clothes on from!
## What we learned
* How to use Blender
* How to call an API (without docs T-T)
* How to web scrape
* Basics of stable diffusion !
* TailwindCSS
## What's next for BYEBUY
* Incorporating more e-commerce sites | ## Inspiration
Have you wondered where to travel or how to plan your trip more interesting?
Wanna make trips more adventerous ?
## What it does
Xplore is an **AI based-travel application** that allows you to experience destinations in a whole new way. It keeps your adrenaline pumping by keeping your vacation destinations undisclosed.
## How we built it
* Xplore is completely functional web application built with Html, Css, Bootstrap, Javscript and Sqlite.
* Multiple Google Cloud Api's such as Geolocation API, Maps Javascript API, Directions API were used to achieve our map functionalities.
* Web3.storage was also used for data storage service and to retrieves data on IPFS and Filecoin.
## Challenges we ran into
While integrating multiple cloud API's and API token from Web3.Strorage with our project, we discovered that it was a little complex.
## What's next for Xplore
* Mobile Application for easier access.
* Multiple language Support
* Seasonal travel suggestions. | partial |
## Inspiration
All four of us are university students and have had to study remotely due to the pandemic. Like many others, we have had to adapt to working from home and were inspired to create something to improve WFH life, and more generally life during the pandemic. The pandemic is something that has affected and continues to affect every single one of us, and we believe that it is particularly important to take breaks and look after ourselves.
It is possible that many of us will continue working remotely even after the pandemic, and in any case, life just won’t be the same as before. We need to be doing more to look after both our mental and physical health by taking regular breaks, going for walks, stretching, meditating, etc. With everything going on right now, sometimes we even need to be reminded of the simplest things, like taking a drink of water.
Enough of the serious talk! Sometimes it’s also important to have a little fun, and not take things too seriously. So we designed our webpage to be super cute, because who doesn’t like cute dinosaurs and bears? And also because, why not? It’s something a little warm n fuzzy that makes us feel good inside, and that’s a good enough reason in and of itself.
## What it does
Eventy is a website where users are able to populate empty time slots in their Google Calendar with suitable breaks like taking a drink of water, going on a walk, and doing some meditation.
## How we built it
We first divided up the work into (i) backend: research into the Google Calendar API and (ii) frontend: looking into website vs chrome extension and learning HTML. Then, we started working with the Google Calendar API to extract data surrounding the events in the user’s calendar and used this information to identify where breaks could be placed in their schedule. After that, based on the length of the time intervals between consecutive events, we scheduled breaks like drinking water, stretching, or reading. Finally, we coded the homepage of our site and connected the backend to the frontend!
## Challenges we ran into
* Deciding on a project that was realistic given our respective levels of experience, given the time constraints and the fact that we did not know each other prior to the Hackathon
* Configuring the authorization of a Google account and allowing the app to access Google Calendar data
* How to write requests to the API to read/write events
+ How would we do this in a way that ensures we’re only populating empty spots in their calendar and not overlapping with existing events?
* Deciding on a format to host our app in (website vs chrome extension)
* Figuring out how to connect the frontend of the app to the backend logic
## What we learned
We learned several new technical skills like how to collaborate on a team using Git, how to make calls to an API, and also the basics of HTML and CSS. | ## Inspiration
---
I recently read Ben Sheridan's paper on Human Centered Artificial Intelligence where he argues that Ai is best used as a tool that accelerates humans rather than trying to *replace* them. We wanted to design a "super-tool" that meaningfully augmented a user's workday. We felt that current calendar apps are a messy and convoluted mess of grids flashing lights, alarms and events all vying for the user's attention. The chief design behind Line is simple, **your workday and time is linear so why shouldn't your calendar be linear?**. Now taking this base and augmenting it with *just the right amount* of Ai.
## What it does
You get a calendar that tells you about an upcoming lunch with a person at a restaurant, gives you some information about the restaurant along with links to reviews and directions that you can choose to view. No voice-text frustration, no generative clutter.
## How we built it
We used React Js for our frontend along with a docker image for certain backend tasks and hosting a small language model for on metal event summarization **you can self host this too for an off the cloud experience**, if provided the you.com API key is used to get up to date and accurate information via the smart search query.
## Challenges we ran into
We tackled a lot of challenges particularly around the interoperability of our tech stack particularly a potential multi-database system that allows users to choose what database they wanted to use we simply ran out of time to implement this so for our demo we stuck with a firebase implementation , we also wanted to ensure that the option to host your own docker image to run some of the backend functions was present and as a result a lot of time was put into making both an appealing front and backend.
## Accomplishments that we're proud of
We're really happy to have been able to use the powerful you.com smart and research search APIs to obtain precise data! Currently even voice assistants like Siri or Google use a generative approach and if quizzed on subjects that are out of their domain of knowledge they are likely to just make things up (including reviews and addresses), which could be super annoying on a busy workday and we're glad that we've avoided this pitfall, we're also really happy at how transparent our tech stack is leaving the door open for the open source community to assist in improving our product!
## What we learned
We learnt a lot over the course of two days, everything from RAG technology to Dockerization, Huggingface spaces, react js, python and so much more!
## What's next for Line Calendar
Improvements to the UI, ability to swap out databases, connections via the google calendar API and notion APIs to import and transform calendars from other software. Better context awareness for the you.com integration. Better backend support to allow organizations to deploy and scale on their own hardware. | ## Inspiration
I've always wanted to learn to DANCE. But dance teachers cost money and I'm a bad dancer :( We made DanceBuddy so we could learn to dance :)
## What it does
It breaks down poses from a dancing video into a step-by-step tutorial. Once you hit a pose, it will move on.
We break down the movements for you into key joint movements using PoseNet. With a novel cost function developed using Umeyama's research, your dance moves are graded.
## How we built it
Python, PoseNet, opencv
## Challenges we ran into
The cost function was really hard to make. Initially it was too harsh and then it was too generous.
## Accomplishments that I'm proud of
Making the best dance tutor in the world.
## What we learned
Learned a lot about machine learning
## What's next for DanceBuddy
Hopefully we can use it with a couple of our friends | losing |
## Inspiration
Course selection is an exciting but frustrating time to be a Princeton student. While you can look at all the cool classes that the university has to offer, it is challenging to aggregate a full list of prerequisites and borderline impossible to find what courses each of them leads to in the future. We recently encountered this problem when building our schedules for next fall. The amount of searching and cross-referencing that we had to do was overwhelming, and to this day, we are not exactly sure whether our schedules are valid or if there will be hidden conflicts moving forward. So we built TigerMap to address this common issue among students.
## What it does
TigerMap compiles scraped course data from the Princeton Registrar into a traversable graph where every class comes with a clear set of prerequisites and unlocked classes. A user can search for a specific class code using a search bar and then browse through its prereqs and unlocks, going down different course paths and efficiently exploring the options available to them.
## How we built it
We used React (frontend), Python (middle tier), and a MongoDB database (backend). Prior to creating the application itself, we spent several hours scraping the Registrar's website, extracting information, and building the course graph. We then implemented the graph in Python and had it connect to a MongoDB database that stores course data like names and descriptions. The prereqs and unlocks that are found through various graph traversal algorithms, and the results are sent to the frontend to be displayed in a clear and accessible manner.
## Challenges we ran into
Data collection and processing was by far the biggest challenge for TigerMap. It was difficult to scrape the Registrar pages given that they are rendered by JavaScript, and once we had the pages downloaded, we had to go through a tedious process of extracting the necessary information and creating our course graph. The prerequisites for courses is not written in a consistent manner across the Registrar's pages, so we had to develop robust methods of extracting data. Our main concern was ensuring that we would get a graph that completely covered all of Princeton's courses and was not missing any references between classes. To accomplish this, we used classes from both the Fall and Spring 21-22 semesters, and we can proudly say that, apart from a handful of rare occurrences, we achieved full course coverage and consistency within our graph.
## Accomplishments that we're proud of
We are extremely proud of how fast and elegant our solution turned out to be. TigerMap definitely satisifes all of our objectives for the project, is user-friendly, and gives accurate results for nearly all Princeton courses. The amount of time and stress that TigerMap can save is immeasurable.
## What we learned
* Graph algorithms
* The full stack development process
* Databases
* Web-scraping
* Data cleaning and processing techniques
## What's next for TigerMap
We would like to improve our data collection pipeline, tie up some loose ends, and release TigerMap for the Princeton community to enjoy!
## Track
Education
## Discord
Leo Stepanewk - nwker#3994
Aaliyah Sayed - aaligator#1793 | **DO YOU** hate standing at the front of a line at a restaurant and not knowing what to choose? **DO YOU** want to know how restaurants are dealing with COVID-19? **DO YOU** have fat fingers and hate typing on your phone's keyboard? Then Sizzle is the perfect app for you!
## Inspiration
We wanted to create a fast way of getting important information for restaurants (COVID-19 restrictions, hours of operation, etc...). Although there are existing methods of getting the information, it isn't always kept in one place. Especially in the midst of a global epidemic, it is important to know how you can keep yourself safe. That's why we designed our app so that the COVID-19 accommodations are visible straight away. (Sort of like Shazam or Google Assistant but with a camera and restaurants instead)
## What it does
To use Sizzle, simply point it at any restaurant sign. An ML computer vision model then applies text-recognition to recognize the text. This text is then input into a Google Scraper Function, which returns information about the restaurant, including the COVID-19 accommodations.
## How it's built
We built Sizzle in Java, using the Jsoup library. The ML Computer vision model was built using Firebase. The app itself was built in Android Studio and also coded in Java. We used Figma to draft working designs for the app.
## Challenges
Our team members are from 3 different timezones, so it was challenging finding a time where we could all work together. Moreover, for many of us, this was our first time working extensively with Android Studio, so it was challenging to figure out some of the errors and syntax. Finally, the Jsoup library kept malfunctioning, so we had to find a way to implement it properly (despite how frustrating it became).
## Accomplishments
Our biggest accomplishment would probably be completing our project in the end. Despite not including all the features we initially wanted to, we were able to implement most of our ideas. We encountered a lot of roadblocks throughout our project (such as using the Jsoup library), but were able to overcome them which was also a big accomplishment for us.
## What I learned
Each of us took away something different from this experience. Some of us used Android Studio and coded in Java for the first time. Some of us went deeper into Machine Learning and experimented with something new. For others, it was their first time using the Jsoup library or even their first time attending a hackathon. We learned a lot about organization, teamwork, and coordination. We also learned more about Android Studio, Java, and Machine Learning.
## What's next?
Probably adding more information to the app such as the hours of operation, address, phone number, etc... | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | partial |
## 💫 Inspiration
It all started when I found VCR tapes of when I was born! I was simply watching the videos fascinated with how much younger everyone looked when I noticed someone unknown, present in the home videos, helping my mom!
After asking my mom, I found out there used to be a program where Nurses/Caretakers would actually make trips to their homes, teaching them how to take care of the baby, and helping them maneuver the first few months of motherhood!
And so, I became intrigued. Why haven't I heard of this before? Why does it not exist anymore? I researched at the federal, provincial and municipal levels to uncover a myriad of online resources available to first-time mothers/parents which aren't well known, and we decided, let's bring it back, better than ever!
## 👶🏻 What BabyBloom does
BabyBloom, is an all-in-one app that targets the needs of first-time mothers in Canada! It provides a simple interface to browse a variety of governmental resources, filtered based off your residential location, and a partnering service with potential caregivers and nurses to help you navigate your very first childbirth.
## 🔨 How we built it
We’re always learning and trying new things! For this app, we aimed to implement an MVC (Model, View, Controller) application structure, and focus on the user's experience and the potential for this project. We've opted for a mobile application to facilitate ease for mothers to easily access it through their phones and tablets. Design-wise, we chose a calming purple monochromatic scheme, as it is one of the main colours associated with pregnancy!
## 😰 Challenges we ran into
* Narrowing the features we intend to provide!
* Specifying the details and specs that we would feed the algorithm to choose the best caregiver for the patient.
* As the app scaled in the prototype, developing the front-end view was becoming increasingly heavier.
## 😤 Accomplishments that we're proud of
This is the first HackTheNorth for many of us, as well as the first time working with people we are unfamiliar with, so we're rather proud of how well we coordinated tasks, communicated ideas and solidified our final product! We're also pretty happy about all the various workshops and events we attended, and the amazing memories we've created.
## 🧠 What we learned
We learned…
* How to scale our idea for the prototype
* How to use AI to create connections between 2 entities
* Figma tips and Know-how to fast-track development
* An approach to modularize solutions
## 💜 What's next for BabyBloom
We can upgrade our designs to full implementation potentially using Flutter due to its cross-platform advantages, and researching the successful implementations in other countries, with their own physical hubs dedicated to mothers during and after their pregnancy! | ## Inspiration
We wanted to create a convenient, modernized journaling application with methods and components that are backed by science. Our spin on the readily available journal logging application is our take on the idea of awareness itself. What does it mean to be aware? What form or shape can mental health awareness come in? These were the key questions that we were curious about exploring, and we wanted to integrate this idea of awareness into our application. The “awareness” approach of the journal functions by providing users with the tools to track and analyze their moods and thoughts, as well as allowing them to engage with the visualizations of the journal entries to foster meaningful reflections.
## What it does
Our product provides a user-friendly platform for logging and recording journal entries and incorporates natural language processing (NLP) to conduct sentiment analysis. Users will be able to see generated insights from their journal entries, such as how their sentiments have changed over time.
## How we built it
Our front-end is powered by the ReactJS library, while our backend is powered by ExpressJS. Our sentiment analyzer was integrated with our NodeJS backend, which is also connected to a MySQL database.
## Challenges we ran into
Creating this app idea under such a short period of time proved to be more challenge than we anticipated. Our product was meant to comprise of more features that helped the journaling aspect of the app as well as the mood tracking aspect of the app. We had planned on showcasing an aggregation of the user's mood over different time periods, for instance, daily, weekly, monthly, etc. And on top of that, we had initially planned on deploying our web app on a remote hosting server but due to the time constraint, we had decided to reduce our proof-of-concept to the most essential cores features for our idea.
## Accomplishments that we're proud of
Designing and building such an amazing web app has been a wonderful experience. To think that we created a web app that could potentially be used by individuals all over the world and could help them keep track of their mental health has been such a proud moment. It really embraces the essence of a hackathon in its entirety. And this accomplishment has been a moment that our team can proud of. The animation video is an added bonus, visual presentations have a way of captivating an audience.
## What we learned
By going through the whole cycle of app development, we learned how one single part does not comprise the whole. What we mean is that designing an app is more than just coding it, the real work starts in showcasing the idea to others. In addition to that, we learned the importance of a clear roadmap for approaching issues (for example, coming up with an idea) and that complicated problems do not require complicated solutions, for instance, our app in simplicity allows for users to engage in a journal activity and to keep track of their moods over time. And most importantly, we learned how the simplest of ideas can be the most useful if they are thought right.
## What's next for Mood for Thought
Making a mobile app could have been better, given that it would align with our goals of making journaling as easy as possible. Users could also retain a degree of functionality offline. This could have also enabled a notification feature that would encourage healthy habits.
More sophisticated machine learning would have the potential to greatly improve the functionality of our app. Right now, simply determining either positive/negative sentiment could be a bit vague.
Adding recommendations on good journaling practices could have been an excellent addition to the project. These recommendations could be based on further sentiment analysis via NLP. | # Stegano
## End-to-end steganalysis and steganography tool
#### Demo at <https://stanleyzheng.tech>
Please see the video before reading documentation, as the video is more brief: <https://youtu.be/47eLlklIG-Q>
A technicality, GitHub user RonanAlmeida ghosted our group after committing react template code, which has been removed in its entirety.
### What is steganalysis and steganography?
Steganography is the practice of concealing a message within a file, usually an image. It can be done one of 3 ways, JMiPOD, UNIWARD, or UERD. These are beyond the scope of this hackathon, but each algorithm must have its own unique bruteforce tools and methods, contributing to the massive compute required to crack it.
Steganoanalysis is the opposite of steganography; either detecting or breaking/decoding steganographs. Think of it like cryptanalysis and cryptography.
### Inspiration
We read an article about the use of steganography in Al Qaeda, notably by Osama Bin Laden[1]. The concept was interesting. The advantage of steganography over cryptography alone is that the intended secret message does not attract attention to itself as an object of scrutiny. Plainly visible encrypted messages, no matter how unbreakable they are, arouse interest.
Another curious case was its use by Russian spies, who communicated in plain sight through images uploaded to public websites hiding steganographed messages.[2]
Finally, we were utterly shocked by how difficult these steganographs were to decode - 2 images sent to the FBI claiming to hold a plan to bomb 11 airliners took a year to decode. [3] We thought to each other, "If this is such a widespread and powerful technique, why are there so few modern solutions?"
Therefore, we were inspired to do this project to deploy a model to streamline steganalysis; also to educate others on stegography and steganalysis, two underappreciated areas.
### What it does
Our app is split into 3 parts. Firstly, we provide users a way to encode their images with a steganography technique called least significant bit, or LSB. It's a quick and simple way to encode a message into an image.
This is followed by our decoder, which decodes PNG's downloaded from our LSB steganograph encoder. In this image, our decoder can be seen decoding a previoustly steganographed image:

Finally, we have a model (learn more about the model itself in the section below) which classifies an image into 4 categories: unstegographed, MiPOD, UNIWARD, or UERD. You can input an image into the encoder, then save it, and input the encoded and original images into the model, and they will be distinguished from each other. In this image, we are inferencing our model on the image we decoded earlier, and it is correctly identified as stegographed.

### How I built it (very technical machine learning)
We used data from a previous Kaggle competition, [ALASKA2 Image Steganalysis](https://www.kaggle.com/c/alaska2-image-steganalysis). This dataset presented a large problem in its massive size, of 305 000 512x512 images, or about 30gb. I first tried training on it with my local GPU alone, but at over 40 hours for an Efficientnet b3 model, it wasn't within our timeline for this hackathon. I ended up running this model on dual Tesla V100's with mixed precision, bringing the training time to about 10 hours. We then inferred on the train set and distilled a second model, an Efficientnet b1 (a smaller, faster model). This was trained on the RTX3090.
The entire training pipeline was built with PyTorch and optimized with a number of small optimizations and tricks I used in previous Kaggle competitions.
Top solutions in the Kaggle competition use techniques that marginally increase score while hugely increasing inference time, such as test time augmentation (TTA) or ensembling. In the interest of scalibility and low latency, we used neither of these. These are by no means the most optimized hyperparameters, but with only a single fold, we didn't have good enough cross validation, or enough time, to tune them more. Considering we achieved 95% of the performance of the State of the Art with a tiny fraction of the compute power needed due to our use of mixed precision and lack of TTA and ensembling, I'm very proud.
One aspect of this entire pipeline I found very interesting was the metric. The metric is a weighted area under receiver operating characteristic (AUROC, often abbreviated as AUC), biased towards the true positive rate and against the false positive rate. This way, as few unstegographed images are mislabelled as possible.
### What I learned
I learned about a ton of resources I would have never learned otherwise. I've used GCP for cloud GPU instances, but never for hosting, and was super suprised by the utility; I will definitely be using it more in the future.
I also learned about stenography and steganalysis; these were fields I knew very little about, but was very interested in, and this hackathon proved to be the perfect place to learn more and implement ideas.
### What's next for Stegano - end-to-end steganlaysis tool
We put a ton of time into the Steganalysis aspect of our project, expecting there to be a simple steganography library in python to be easy to use. We found 2 libraries, one of which had not been updated for 5 years; ultimantely we chose stegano[4], the namesake for our project. We'd love to create our own module, adding more algorithms for steganography and incorporating audio data and models.
Scaling to larger models is also something we would love to do - Efficientnet b1 offered us the best mix of performance and speed at this time, but further research into the new NFNet models or others could yeild significant performance uplifts on the modelling side, but many GPU hours are needed.
## References
1. <https://www.wired.com/2001/02/bin-laden-steganography-master/>
2. <https://www.wired.com/2010/06/alleged-spies-hid-secret-messages-on-public-websites/>
3. <https://www.giac.org/paper/gsec/3494/steganography-age-terrorism/102620>
4. <https://pypi.org/project/stegano/> | losing |
## Inspiration
The idea for AI Packaging sprouted from the trending topic of AI Art, paired with the relatively few business use cases currently active in the market. As such, we are thinking about how to get AI Art benefitting people and business owners alike.
We then had the idea of helping small business (e-commerce) owners and individuals to design their packages based on the keywords/ideas they're looking for.
## What it does
By using our website, a user can place a search using keywords, and our Open AI API will be used to design the packaging pattern for the user based on the input.
We have a list of packing styles that allow users to choose from, shopping bags, wrapping paper, boxes, and more!
The special thing about using our website design is that the images and patterns are AI-generated that are completely unique to the users' query, allowing the users to get completely individual designs on the packages for their business.
Once the user has chosen the packing style and made the purchase, we will ship the products to them.
## How we built it
We used Figma for brainstorming and wireframes. Using Open AI for the AI Art where they provided public API.
For the final website, we used Velo by Wix to design the front end.
## Challenges we ran into
We were having a hard time embedding the Open AI API into Wix since it was the first hackathon for most of us, and we learned almost everything we ended up using from scratch for this hackathon.
## Accomplishments that we're proud of
We are proud of building a functional website and implementing our idea into a real business use case.
## What we learned
We have learned how to work as a team with different backgrounds and gained a plethora of understanding when it comes to website design, API embedding, and 3D vector design.
## What's next for AI Packaging
The next step is to do some tests with real customers, allowing us to observe how they interact with the website, to make changes for a better UX experience. | ## Inspiration
Every restaurant ever has the most concise and minimalistic menus. We always found ourselves having to manually research the food and drinks provided, as the only thing we see is text. We wanted a way to automate this process to make it more friendly and less bloated, and we believed we could provide clean user friendly solution that provides ultimately what you need to make your decision on what to eat.
## What It Does
What the F--- is That? takes a camera input source focused on text and on a simple tap, an image is captured. Optical Character Recognition is applied on the image and is then parsed into a readable format. What happens next is that it will analyze the text, image search of the product and provide nutritional information of the various food and beverages.
## How We Built It
It uses a camera on a device to take a picture of the text, and then we applied an Optical Character Recognition API on it and parse it into a string, and the Bing Image Search API to searches for results in parallel with an API that retrieves nutritional info on the scanned item, which is then displayed in a sleek user interface.
## Challenges We Ran Into
Optical Character Recognition is insanely tough to implement, so finding an API that did it proficiently was a challenge. We tried multiple API's but ultimately we decided on the one that suited our needs.
## Accomplishments That We're Proud Of
We are proud not only of the motivation to create this product, but how quickly we were able to implement core functionality, within a single weekend.
## What We Learned
We realized that we have the potential to make and expand our product into the wider market, and take our innovation to the next level.
## The Future
Our goals towards the future is to use this in the wider market. We realized we made something that is extensible and dynamic enough so that we would be able to analyze things in pseudo-augmented reality wherein we would be able to live display information beside it in real-time. At the Hackathon we realized that we would be to extend our software to live Optical Character Recognition tracking within Augmented Reality environments such as Microsoft Hololens, which could be used for simple user functionality, but as a new innovative way to express ad space. | ## Inspiration
Recently we have noticed an influx in elaborate spam calls, email, and texts. Although for a native English and technologically literate person in Canada, these phishing attempts are a mere inconvenience, to susceptible individuals falling for these attempts may result in heavy personal or financial loss. We aim to reduce this using our hack.
We created PhishBlock to address the disparity in financial opportunities faced by minorities and vulnerable groups like the elderly, visually impaired, those with limited technological literacy, and ESL individuals. These groups are disproportionately targeted by financial scams. The PhishBlock app is specifically designed to help these individuals identify and avoid scams. By providing them with the tools to protect themselves, the app aims to level the playing field and reduce their risk of losing savings, ultimately giving them the same financial opportunities as others.
## What it does
PhishBlock is a web application that leverages LLMs to parse and analyze email messages and recorded calls.
## How we built it
We leveraged the following technologies to create a pipeline classify potentially malicious email from safe ones.
Gmail API: Integrated reading a user’s email.
Cloud Tech: Enabled voice recognition, data processing and training models.
Google Cloud Enterprise (Vertex AI): Leveraged for secure cloud infrastructure.
GPT: Employed for natural language understanding and generation.
numPy, Pandas: Data collection and cleaning
Scikit-learn: Applied for efficient model training
## Challenges we ran into
None of our team members had worked with google’s authentication process and the gmail api, so much of saturday was devoted to hashing out technical difficulties with these things. On the AI side, data collection is an important step in training and fine tuning. Assuring the quality of the data was essential
## Accomplishments that we're proud of
We are proud of coming together as a group and creating a demo to a project in such a short time frame
## What we learned
The hackathon was just one day, but we realized we could get much more done than we initially intended. Our goal seemed tall when we planned it on Friday, but by Saturday night all the functionality we imagined had fallen into place. On the technical side, we didn’t use any frontend frameworks and built interactivity the classic way and it was incredibly challenging. However, we discovered a lot about what we’re capable of under extreme time pressures!
## What's next for PhishBlock
We used closed source OpenAI API to fine tune a GPT 3.5 Model. This has obvious privacy concerns, but as a proof of concept it demonstrate the ability of LLMs to detect phishing attempts. With more computing power open source models can be used. | losing |
# Hungr.ai Hungr.ai Hippos
Our HackWestern IV project which makes hungry hungry hippo even cooler.
## Milestones


## Inspiration
Metaphysically speaking, we didn't find the idea, it found us.
## What it does
A multiplayer game which allows player to play against AI(s) (one for each hippo) while controlling the physical hippos in the real world.
## How we built it
Once, we knew we wanted to do something fun with hungry hungry hippos, we acquired the game through Kijiji #CanadianFeels. We deconstructed the game to understand the mechanics of it and made a rough plan to use servos controlled through Raspberry Pi 3 to move the hippos. We decided to keep most of our processing on a laptop to not burden the Pi. Pi served as a end point serving video stream through **web sockets**. **Multithreading** (in Python) allowed us to control each servo/hippo individually through the laptop with Pi always listening for commands. **Flask** framework help us tie in the React.js frontend with Python servers and backends.
## Challenges we ran into
Oh dear god, where do we begin?
* The servos we expected to be delivered to us by Amazon were delayed and due to the weekend we never got them :( Fortunately, we brought almost enough backup servos
* Multithreading in python!!
* Our newly bought PiCamera was busted :( Fortunately, we found someone to lend us their's.
* CNN !!
* Working with Pi without a screen (it doesn't allow you to ssh into it over a public wifi. We had to use ethernet cable to find a workaround)
## Accomplishments that we're proud of
Again, oh dear god, where do we begin?
* The hardware platform (with complementing software backend) looks so elegant and pretty
* The front-end tied the whole thing really well (elegantly simplying the complexity behind the hood)
* The feed from the Picamera to the laptop was so good, much better than we expected.
## What we learned
And again, oh dear god, where do we begin?
* Working with Flask (great if you wanna work with python and js)
* Multithreading in Python
* Working with websockets (and, in general, data transmission between Pi and Laptop over ethernet/network)
## What's next for Hungr.ai
* A Dance Dance Revolution starring our hippo stars (a.k.a Veggie Potamus, Hungry Hippo, Bottomless Potamus and Sweetie Potamus)
* Train our AI/ML models even more/ Try new models
## How do we feel?
In a nutshell, we had a very beneficial spectrum of skills. We believe that the project couldn't have been completed if any of the members weren't present. The learning curve was challenging, but with time and focus, we were able to learn the required skills to carry this project. | ## Inspiration
This game was inspired by the classical game of connect four, in which one inserts disks into a vertical board to try to get four in a row. As big fans of the game, our team sought to improve it by adding new features.
## What it does
The game is played like a regular game of connect four, except each player may choose to use their turn to rotate the board left or right and let gravity force the pieces to fall downwards. This seemingly innocent change to connect four adds many new layers of strategy and fun to what was already a strategic and fun game.
We developed two products: an iOS app, and a web app, to run the game. In addition, both the iOS and web apps feature the abilities of:
1) Play local "pass and play" multiplayer
2) Play against multiple different AIs we crafted, each of differing skill levels
3) Play live online games against random opponents, including those on different devices!
## How we built it
The iOS app was built in Swift and the web app was written with Javascript's canvas. The bulk of the backend, which is crucial for both our online multiplayer and our AIs, came from Firebase's services.
## Challenges we ran into
None of us are particularly artistic, so getting a visually pleasant UI wasn't exactly easy...
## Accomplishments that we're proud of
We are most proud of our ability to successfully run an online cross-platform multiplayer, which we could not have possibly done without the help of Firebase and its servers and APIs. We are also proud of the AIs we developed, which so far tend to beat us almost every time.
## What we learned
Most of us had very little experience working with backend servers, so Firebase provided us with a lovely introduction to allowing our applications to flourish on my butt.
## What's next for Gravity Four
Let's get Gravity Four onto even more types of devices and into the app store! | ## Inspiration
We really are passionate about hardware, however many hackers in the community, especially those studying software-focused degrees, miss out on the experience of working on projects involving hardware and experience in vertical integration.
To remedy this, we came up with modware. Modware provides the toolkit for software-focused developers to branch out into hardware and/or to add some verticality to their current software stack with easy to integrate hardware interactions and displays.
## What it does
The modware toolkit is a baseboard that interfaces with different common hardware modules through magnetic power and data connection lines as they are placed onto the baseboard.
Once modules are placed on the board and are detected, the user then has three options with the modules: to create a "wired" connection between an input type module (LCD Screen) and an output type module (knob), to push a POST request to any user-provided URL, or to request a GET request to pull information from any user-provided URL.
These three functionalities together allow a software-focused developer to create their own hardware interactions without ever touching the tedious aspects of hardware (easy hardware prototyping), to use different modules to interact with software applications they have already built (easy hardware interface prototyping), and to use different modules to create a physical representation of events/data from software applications they have already built (easy hardware interface prototyping).
## How we built it
Modware is a very large project with a very big stack: ranging from a fullstack web application with a server and database, to a desktop application performing graph traversal optimization algorithms, all the way down to sending I2C signals and reading analog voltage.
We had to handle the communication protocols between all the levels of modware very carefully. One of the interesting points of communication is using neodymium magnets to conduct power and data for all of the modules to a central microcontroller. Location data is also kept track of as well using a 9-stage voltage divider, a series circuit going through all 9 locations on the modware baseboard.
All of the data gathered at the central microcontroller is then sent to a local database over wifi to be accessed by the desktop application. Here the desktop application uses case analysis to solve the NP-hard problem of creating optimal wire connections, with proper geometry and distance rendering, as new connections are created, destroyed, and modified by the user. The desktop application also handles all of the API communications logic.
The local database is also synced with a database up in the cloud on Heroku, which uses the gathered information to wrap up APIs in order for the modware hardware to be able to communicate with any software that a user may write both in providing data as well as receiving data.
## Challenges we ran into
The neodymium magnets that we used were plated in nickel, a highly conductive material. However magnets will lose their magnetism when exposed to high heat and neodymium magnets are no different. So we had to extremely careful to solder everything correctly on the first try as to not waste the magnetism in our magnets. These magnets also proved very difficult to actually get a solid data and power and voltage reader electricity across due to minute differences in laser cut holes, glue residues, etc. We had to make both hardware and software changes to make sure that the connections behaved ideally.
## Accomplishments that we're proud of
We are proud that we were able to build and integrate such a huge end-to-end project. We also ended up with a fairly robust magnetic interface system by the end of the project, allowing for single or double sized modules of both input and output types to easily interact with the central microcontroller.
## What's next for ModWare
More modules! | partial |
Duet's music generation revolutionizes how we approach music therapy. We capture real-time brainwave data using Emotiv EEG technology, translating it into dynamic, personalized soundscapes live. Our platform, backed by machine learning, classifies emotional states and generates adaptive music that evolves with your mind. We are all intrinsically creative, but some—whether language or developmental barriers—struggle to convey it. We’re not just creating music; we’re using the intersection of art, neuroscience, and technology to let your inner mind shine.
## About the project
**Inspiration**
Duet revolutionizes the way children with developmental disabilities—approximately 1 in 10 in the United States—express their creativity through music by harnessing EEG technology to translate brainwaves into personalized musical experiences.
Daniel and Justin have extensive experience teaching music to children, but working with those who have developmental disabilities presents unique challenges:
1. Identifying and adapting resources for non-verbal and special needs students.
2. Integrating music therapy principles into lessons to foster creativity.
3. Encouraging improvisation to facilitate emotional expression.
4. Navigating the complexities of individual accessibility needs.
Unfortunately, many children are left without the tools they need to communicate and express themselves creatively. That's where Duet comes in. By utilizing EEG technology, we aim to transform the way these children interact with music, giving them a voice and a means to share their feelings.
At Duet, we are committed to making music an inclusive experience for all, ensuring that every child—and anyone who struggles to express themselves—has the opportunity to convey their true creative self!
**What it does:**
1. Wear an EEG
2. Experience your brain waves as music! Focus and relaxation levels will change how fast/exciting vs. slow/relaxing the music is.
**How we built it:**
We started off by experimenting with Emotiv’s EEGs — devices that feed a stream of brain wave activity in real time! After trying it out on ourselves, the CalHacks stuffed bear, and the Ariana Grande cutout in the movie theater, we dove into coding. We built the backend in Python, leveraging the Cortex library that allowed us to communicate with the EEGs. For our database, we decided on SingleStore for its low latency, real-time applications, since our goal was to ultimately be able to process and display the brain wave information live on our frontend.
Traditional live music is done procedurally, with rules manually fixed by the developer to decide what to generate. On the other hand, existing AI music generators often generate sounds through diffusion-like models and pre-set prompts. However, we wanted to take a completely new approach — what if we could have an AI be a live “composer”, where it decided based on the previous few seconds of live emotional data, a list of available instruments it can select to “play”, and what it previously generated to compose the next few seconds of music? This way, we could have live AI music generation (which, to our knowledge, does not exist yet). Powered by Google’s Gemini LLM, we crafted a prompt that would do just that — and it turned out to be not too shabby!
To play our AI-generated scores live, we used Sonic Pi, a Ruby-based library that specializes in live music generation (think DJing in code). We fed this and our brain wave data to a frontend built in Next.js to display the brain waves from the EEG and sound spectrum from our audio that highlight the correlation between them.
**Challenges:**
Our biggest challenge was coming up with a way to generate live music with AI. We originally thought it was impossible and that the tech wasn’t “there” yet — we couldn’t find anything online about it, and even spent hours thinking about how to pivot to another idea that we could use our EEGs with.
However, we eventually pushed through and came up with a completely new method of doing live AI music generation that, to our knowledge, doesn’t exist anywhere else! It was most of our first times working with this type of hardware, and we ran into many issues with getting it to connect properly to our computers — but in the end, we got everything to run smoothly, so it was a huge feat for us to make it all work!
**What’s next for Duet?**
Music therapy is on the rise – and Duet aims to harness this momentum by integrating EEG technology to facilitate emotional expression through music. With a projected growth rate of 15.59% in the music therapy sector, our mission is to empower kids and individuals through personalized musical experiences. We plan to implement our programs in schools across the states, providing students with a unique platform to express their emotions creatively. By partnering with EEG companies, we’ll ensure access to the latest technology, enhancing the therapeutic impact of our programs. Duet gives everyone a voice to express emotions and ideas that transcend words, and we are committed to making this future a reality!
**Built with:**
* Emotiv EEG headset
* SingleStore real-time database
* Python
* Google Gemini
* Sonic Pi (Ruby library)
* Next.js | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
The media we consume daily has an impact on our thinking, behavior, and emotions. If you’ve fallen into a pattern of regularly watching or listening to the news, the majority of what you’re consuming is likely about the coronavirus (COVID-19) crisis.
And while staying up to date on local and national news, especially as it relates to mandates and health updates, is critical during this time, experts say over-consumption of the news can take a toll on your physical, emotional, and mental health.
## What it does
The app first greets users with a screen prompting them to either sign up for an account or sign in to a pre-existing account. With the usual authentication formalities out of the way the app gets straight to business as our server scrapes oodles of articles from the internet and filters out the good from the bad, before displaying the user with a smorgasbord of good news.
## How we built it
We have used flutter to create our android based application and used firebase as a database. ExpressJS as a backend web framework. With the help of RapidAPI, we are getting lists of top headline news.
## Challenges we ran into
Initially, we tried to include Google Cloud-Based Sentiment Analysis of each news. However, we thought to try some new technology. Since the majority of our team members were new to machine learning, we were facing too many challenges to even get started with. Issues with lack of examples available. So we again limited our app to show customized positive news. We wanted to add more features during the hacking period but due to time constraints, we had to limit.
## Accomplishments that we're proud of
Completely Working android based applications and integrated with backend having the contribution of each and every member of the team.
## What we learned
We have learned to fetch and upload data to firebase's real-time database through the flutter application. We learned the value of Team Contribution and Team Work which is the ultimate key to the success of the project. Using Text-based Sentiment Analysis to analyze and rank news on the basis of positivity through Cloud Natural Language Processing.
## What's next for Hopeful
1. More Customized Feed
2. Update Profile Section
3. Like and Reply to comments | winning |
## Inspiration
It’s no secret that the COVID-19 pandemic ruined most of our social lives. ARoom presents an opportunity to boost your morale by supporting you to converse with your immediate neighbors and strangers in a COVID safe environment.
## What it does
Our app is designed to help you bring your video chat experience to the next level. By connecting to your webcam and microphone, ARoom allows you to chat with people living near you virtually. Coupled with an augmented reality system, our application also allows you to view 3D models and images for more interactivity and fun. Want to chat with new people? Open the map offered by ARoom to discover the other rooms available around you and join one to start chatting!
## How we built it
The front-end was created with Svelte, HTML, CSS, and JavaScript. We used Node.js and Express.js to design the backend, constructing our own voice chat API from scratch. We used VS Code’s Live Share plugin to collaborate, as many of us worked on the same files at the same time. We used the A-Frame web framework to implement Augmented Reality and the Leaflet JavaScript library to add a map to the project.
## Challenges we ran into
From the start, Svelte and A-Frame were brand new frameworks for every member of the team, so we had to devote a significant portion of time just to learn them. Implementing many of our desired features was a challenge, as our knowledge of the programs simply wasn’t comprehensive enough in the beginning. We encountered our first major problem when trying to implement the AR interactions with 3D models in A-Frame. We couldn’t track the objects on camera without using markers, and adding our most desired feature, interactions with users was simply out of the question. We tried to use MediaPipe to detect the hand’s movements to manipulate the positions of the objects, but after spending all of Friday night working on it we were unsuccessful and ended up changing the trajectory of our project.
Our next challenge materialized when we attempted to add a map to our function. We wanted the map to display nearby rooms, and allow users to join any open room within a certain radius. We had difficulties pulling the location of the rooms from other files, as we didn’t understand how Svelte deals with abstraction. We were unable to implement the search radius due to the time limit, but we managed to add our other desired features after an entire day and night of work.
We encountered various other difficulties as well, including updating the rooms when new users join, creating and populating icons on the map, and configuring the DNS for our domain.
## Accomplishments that we're proud of
Our team is extremely proud of our product, and the effort we’ve put into it. It was ¾ of our members’ first hackathon, and we worked extremely hard to build a complete web application. Although we ran into many challenges, we are extremely happy that we either overcame or found a way to work around every single one. Our product isn’t what we initially set out to create, but we are nonetheless delighted at its usefulness, and the benefit it could bring to society, especially to people whose mental health is suffering due to the pandemic. We are also very proud of our voice chat API, which we built from scratch.
## What we learned
Each member of our group has learned a fair bit over the last 36 hours. Using new frameworks, plugins, and other miscellaneous development tools allowed us to acquire heaps of technical knowledge, but we also learned plenty about more soft topics, like hackathons and collaboration. From having to change the direction of our project nearly 24 hours into the event, we learned that it’s important to clearly define objectives at the beginning of an event. We learned that communication and proper documentation is essential, as it can take hours to complete the simplest task when it involves integrating multiple files that several different people have worked on. Using Svelte, Leaflet, GitHub, and Node.js solidified many of our hard skills, but the most important lessons learned were of the other variety.
## What's next for ARoom
Now that we have a finished, complete, usable product, we would like to add several features that were forced to remain in the backlog this weekend. We plan on changing the map to show a much more general location for each room, for safety reasons. We will also prevent users from joining rooms more than an arbitrary distance away from their current location, to promote a more of a friendly neighborhood vibe on the platform. Adding a video and text chat, integrating Google’s Translation API, and creating a settings page are also on the horizon. | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | We're fortunate enough to have access to medication but in developing countries, not everyone has the same privilege that we do. Two of the four members of our group have physical medical conditions that they must take medication for. One of our members has the most common congenital heart disease, Tetrology of Fallot, and the other has Type 1 Diabetes. We want to make medication more accessible for those dealing with these common conditions and for the people with countless other needs that require medication.
Our project uses facial recognition to dispense medication.
We began by programming our GUI for the dispenser, setting up Azure, and setting up the webcam. We had one member buy parts for the prototype and then he spent the next day building it. We started working on the facial recognition, merging the webcam, GUI, and the facial recognition into one program. We spent the last couple hours setting up the motor controllers to finalize the project.
We ran into many challenges along the way. Our Telus LTE-M IoT Starter Kit was incompatible with Azure, so after many hours of attempting to make it work, we had to give up and find another way to store the facial recognition data. We started making the GUI in Python with Tkinter but after a couple hours, decided to use another module as it would be easier and look more visually appealing.
Our team is very proud that we were able to complete our facial recognition program and prototype for the dispenser.
We learned how to use the Raspberry Pi, Arduino, Stepper controllers, breadboards. We set up a virtual machine, an IoT hub, and image processing.
In the future we hope to polish our prototype and actually use Azure in the program. | partial |
## Inspiration
While there are plenty of language-learning apps out there that provide resources to help language-learners learn/practice reading and writing, speaking a new language is a difficult yet incredibly applicable aspect of learning a new language that can often be overlooked by learning resources. Additionally, when considering speaking a new language, we realized there can often a big gap between native and non-native speakers of a language because their use of correct grammar/pronunciation, so we were inspired to create a resource to help bridge this gap.
## What it does
Our program allows users to record their conversations either with others or directly into the program and outputs both the user's speech and a version of their speech that corrects grammar/word choice, allowing them to learn where their grammar went wrong, if at all.
## How we built it
First, we built a voice recorder using Google voice recognition APIs. Then, we created a speech-to-text converter and then created a series of grammar checks that filtered the input text and modifies it into a grammatically correct version of itself. Then, we constructed a GUI that outputs both of these texts and compares them one on top of the other.
## Challenges we ran into
It was difficult to get a combination of grammar checks that were actually effective in correcting grammar. There were also a lot of challenges along the way with combining the different components of the program, installing different packages, and creating the GUI.
## Accomplishments that we're proud of
We're proud of creating something from scratch with relatively little coding experience, especially in Python. Also, neither of us knew how to create a GUI, so we learned the entire process of creating an interface in the span of a day.
## What we learned
We learned a lot about how to navigate packages in Python, grammar check models, and how to create a GUI. Also, as my (Sabrina) first hackathon, I learned the process of creating a project from start to finish, including brainstorming ideas and layers upon layers of failure and modification.
## What's next for SpeechLearn
Our program has a long way to go, as we want to implement it for all languages, and implement a pronunciation-checker. We also can modify the GUI for a more aesthetic interactive experience, and the final vision would be to create a phone app after combining all of these moving parts. | ## Inspiration
Software engineering and development have been among the most dynamically changing fields over the years. Our voice is one of our most powerful tools, and one which we often take for granted - we share ideas and inspiration and can communicate instantly on a global scale. However, according to recent statistics, 3 out of 1000 children are born with a detectable level of hearing loss in one or both ears. While many developers have pursued methods of converting sign language to English, we identified a need for increased accessibility in the opposite way. In an effort to propel forth the innovators of tomorrow, we wanted to develop a learning tool for children with hearing impairments to accelerate their ability to find their own voice.
## What it does
Our Sign Language Trainer is primarily designed to teach children sign language by introducing them to the ASL alphabet with simple words and effective visuals. Additionally, the application implements voice-to-text to provide feedback on word pronunciation to allow children with a hearing impairment to practice speaking from a young age.
## How we built it
The program was built using node.js as well as HTML. We also made a version of the web app for Android using Java.
## Challenges we ran into
The majority of our team was not familiar with HTML nor node.js, which caused many roadblocks during the majority of the hack. Throughout the competition, although we had an idea of what we wanted to accomplish, our plans continued to change as we learned new things about the available software. The main challenge that we dealt with was the large amount of learning involved with creating a website from scratch as we kept running into new problems that we had never seen before. We also had to overcome issues with hosting the domain using Firebase.
## Accomplishments that we proud of
While also our largest challenge, the amount of content we had to learn about web development was our favorite accomplishment. We were really happy to have completed a product from scratch with almost no prior knowledge of the tools we used to build it. The addition of creating a phone app for our project was the cherry on top.
## What I learned
1. Learned about node.js, HTML, and CSS
2. The ability to understand and structure code through analysis and documentation
3. How to cooperate as a team and brainstorm effectively
4. GitHub was new for some members of the team, but by the end, we were all using it like a pro
5. How to implement android applications with android studio
6. How to fully develop our own website
## What's next for floraisigne
If we were to continue this project, we would try and add additional hardware to exponentially increase the accuracy of the solution. We would also implement a neural network system to allow the product to convert sign language into English Language. | ### Overview
Resililink is a node-based mesh network leveraging LoRa technology to facilitate communication in disaster-prone regions where traditional infrastructure, such as cell towers and internet services, is unavailable. The system is designed to operate in low-power environments and cover long distances, ensuring that essential communication can still occur when it is most needed. A key feature of this network is the integration of a "super" node equipped with satellite connectivity (via Skylo), which serves as the bridge between local nodes and a centralized server. The server processes the data and sends SMS notifications through Twilio to the intended recipients. Importantly, the system provides acknowledgment back to the originating node, confirming successful delivery of the message. This solution is aimed at enabling individuals to notify loved ones or emergency responders during critical times, such as natural disasters, when conventional communication channels are down.
### Project Inspiration
The inspiration for Resililink came from personal experiences of communication outages during hurricanes. In each instance, we found ourselves cut off from vital resources like the internet, making it impossible to check on family members, friends, or receive updates on the situation. These moments of helplessness highlighted the urgent need for a resilient communication network that could function even when the usual infrastructure fails.
### System Capabilities
Resililink is designed to be resilient, easy to deploy, and scalable, with several key features:
* **Ease of Deployment**: The network is fast to set up, making it particularly useful in emergency situations.
* **Dual Connectivity**: It allows communication both across the internet and in peer-to-peer fashion over long ranges, ensuring continuous data flow even in remote areas.
* **Cost-Efficiency**: The nodes are inexpensive to produce, as each consists of a single LoRa radio and an ESP32 microcontroller, keeping hardware costs to a minimum.
### Development Approach
The development of Resililink involved creating a custom communication protocol based on Protocol Buffers (protobufs) to efficiently manage data exchange. The core hardware components include LoRa radios, which provide long-range communication, and Skylo satellite connectivity, enabling nodes to transmit data to the internet using the MQTT protocol.
On the backend, a server hosted on Microsoft Azure handles the incoming MQTT messages, decrypts them, and forwards the relevant information to appropriate APIs, such as Twilio, for further processing and notification delivery. This seamless integration of satellite technology and cloud infrastructure ensures the reliability and scalability of the system.
### Key Challenges
Several challenges arose during the development process. One of the most significant issues was the lack of clear documentation for the AT commands on the Mutura evaluation board, which made it difficult to implement some of the core functionalities. Additionally, given the low-level nature of the project, debugging was particularly challenging, requiring in-depth tracing of system operations to identify and resolve issues. Another constraint was the limited packet size of 256 bytes, necessitating careful optimization to ensure efficient use of every byte of data transmitted.
### Achievements
Despite these challenges, we successfully developed a fully functional network, complete with a working demonstration. The system proved capable of delivering messages over long distances with low power consumption, validating the concept and laying the groundwork for future enhancements.
### Lessons Learned
Through this project, we gained a deeper understanding of computer networking, particularly in the context of low-power, long-range communication technologies like LoRa. The experience also provided valuable insights into the complexities of integrating satellite communication with terrestrial mesh networks.
### Future Plans for Resililink
Looking ahead, we plan to explore ways to scale the network, focusing on enhancing its reliability and expanding its reach to serve larger geographic areas. We are also interested in further refining the underlying protocol and exploring new applications for Resililink beyond disaster recovery scenarios, such as in rural connectivity or industrial IoT use cases. | losing |
Fujifusion is our group's submission for Hack MIT 2018. It is a data-driven application for predicting corporate credit ratings.
## Problem
Scholars and regulators generally agree that credit rating agency failures were at the center of the 2007-08 global financial crisis.
## Solution
\*Train a machine learning model to automate the prediction of corporate credit ratings.
\*Compare vendor ratings with predicted ratings to identify discrepancies.
\*Present this information in a cross-platform application for RBC’s traders and clients.
## Data
Data obtained from RBC Capital Markets consists of 20 features recorded for 27 companies at multiple points in time for a total of 524 samples. Available at <https://github.com/em3057/RBC_CM>
## Analysis
We took two approaches to analyzing the data: a supervised approach to predict corporate credit ratings and an unsupervised approach to try to cluster companies into scoring groups.
## Product
We present a cross-platform application built using Ionic that works with Android, iOS, and PCs. Our platform allows users to view their investments, our predicted credit rating for each company, a vendor rating for each company, and visual cues to outline discrepancies. They can buy and sell stock through our app, while also exploring other companies they would potentially be interested in investing in. | ## Inspiration
To any financial institution, the most valuable asset to increase revenue, remain competitive and drive innovation, is aggregated **market** and **client** **data**. However, a lot of data and information is left behind due to lack of *structure*.
So we asked ourselves, *what is a source of unstructured data in the financial industry that would provide novel client insight and color to market research*?. We chose to focus on phone call audio between a salesperson and client on an investment banking level. This source of unstructured data is more often then not, completely gone after a call is ended, leaving valuable information completely underutilized.
## What it does
**Structerall** is a web application that translates phone call recordings to structured data for client querying, portfolio switching/management and novel client insight. **Structerall** displays text dialogue transcription from a phone call and sentiment analysis specific to each trade idea proposed in the call.
Instead of loosing valuable client information, **Structerall** will aggregate this data, allowing the institution to leverage this underutilized data.
## How we built it
We worked with RevSpeech to transcribe call audio to text dialogue. From here, we connected to Microsoft Azure to conduct sentiment analysis on the trade ideas discussed, and displayed this analysis on our web app, deployed on Azure.
## Challenges we ran into
We had some trouble deploying our application on Azure. This was definitely a slow point for getting a minimum viable product on the table. Another challenge we faced was learning the domain to fit our product to, and what format/structure of data may be useful to our proposed end users.
## Accomplishments that we're proud of
We created a proof of concept solution to an issue that occurs across a multitude of domains; structuring call audio for data aggregation.
## What we learned
We learnt a lot about deploying web apps, server configurations, natural language processing and how to effectively delegate tasks among a team with diverse skill sets.
## What's next for Structurall
We also developed some machine learning algorithms/predictive analytics to model credit ratings of financial instruments. We built out a neural network to predict credit ratings of financial instruments and clustering techniques to map credit ratings independent of s\_and\_p and moodys. We unfortunately were not able to showcase this model but look forward to investigating this idea in the future. | ## Inspiration
I will have the opportunity to participate in biology field research in Peru, so I thought I'd come up with a solution to a relevant problem there related to ML. I learned that researchers spend months labeling camera trap data from wildlife reserves before they can perform analysis on it. This means that they will be at least a few seasons late to respond to any changes in animal populations, biodiversity, etc. that may be caused by spontaneous changes in the climate.
## What it does
With data that I previously got from an Operation Wallacea Reserve in Peru, I trained a Faster-RCNN object detection model fine tuned with the iNaturalist Faster-RCNN on 32 classes of animals that are commonly seen in the Peruvian Amazon, achieving a high degree of accuracy on prevalent species.
## How I built it
I learned the Tensorflow Object Detection api from scratch and implemented the infrastructure to train my specific model. The data model was trained on a paperspace ML-in-a-box machine over approx. 10k steps, achieving a final average loss of < 0.5 (Though I have a strong feeling that it overfit)
## Accomplishments that I'm proud of
The model actually works
## What I learned
-tensorflow is very finnicky and there is not a truly straightforward plug-and-play object detection model training method.
-How data is setup for model training.
-linux is harder to use than windows but much less vague.
## What's next for The Project
In the future, perfected versions of this model could be incorporated into scalable software that would improve over time and improve quality of life for biologists conducting field research. | winning |
## Inspiration
As students who have lived through both the paper and digital forms of notes, there were many aspects of note-taking from our childhoods that we had missed out on with the newer applications for notes. To relive these nostalgic experiences, we created a note-taking application that reenacts the efficiency and simplicity of note-taking with sticky-notes. In addition, we added a modern twist of using AI through Cohere's AI API to help generate notes to help assist students with efficient note taking.
## What it does
Sticky acts similarly to other note-taking apps where users can upload pdf files of their textbook or lectures notes and make highlighted annotations along with sticky notes that can be AI generated to help assist with the student's note-taking skills.
## How we built it
The program is built with html, css, and javascript. The main pages were programmed using html and styled with css files. In addition, all interactive elements were programmed using common javascript. Initially, we were planning on using Taipy for our UI, but since we wanted more freedom in customization of interactive elements we decided to do our own UI through javascript.
## Challenges we ran into
Some of the challenges we went into were figuring out what framework we should use for this project. Different frameworks had their own benefits but ultimately due to time we decided to create an html web-app using javascript and css to add interactive elements. In addition, this was our first project where we implemented an API for our hackathon, so there were times where most time was spent on debugging. Finally, the biggest challenge was figuring out how we could annotate a PDF, or at least give users the experience of annotating a PDF with sticky notes. :)
## Accomplishments that we're proud of
We're most proud of how much new information we learned from this hackathon. Our idea had big potential to be expanded onto other programs and we continuously worked to solve any problems that occurred during the hackathon. (NEVER GIVE UP !!! )
## What we learned
We learned many new skills that are found in front-end programming, in addition to decision-making when it comes to design ideas. Initially, we had many ideas for our program and we wanted to explore as many libraries as possible. However, throughout the implementation, we recognized that throughout the design process of the app, not everything will always be compatible which caused us to use our decision-making skills to prioritize the use of some libraries over others.
## What's next for Sticky
In the future we hope to add export options for students to download use these annotated notes for other purposes. Additionally, we hope to also add an option for students to upload their own notes and compare it with lecture or textbook notes they made have to further improve their note-taking skills. :D | ## What Inspired Us
The main goal of this project was to learn more about machine learning and its practical applications. Having little to no experience on machine learning between team members, we decided to go simple and build a classification model based on existing neural nets. After settling on machine learning, we were inspired to tackle classification problems that were simple but relevant. One of the many shared nitpicks between team members was the sheer amount of clutter in terms of the camera roll on a person's phone. Countless scanned homeworks, memes, and screenshots blotted out more personal photos of family and friends. We wanted to make something that would quickly be able to filter out and delete irrelevant information
## What it does
The app scans through a users camera roll and sends it to a server that categorizes and then determines if it should be kept. The user can see a summary of their photos and filter out unwanted photos based on categories.
## How we built it
The app was built using Swift. The classification model is a transfer learning model built using Tensorflow. It relies on the pre-trained MobileNetV2 with the top layer removed. The top layer is then trained using a new dataset with more specific categories. The app will upload the images to the flask server, which will use the classification model to predict the category of the photo. This information is sent to the app, which shows the user which categories
## Challenges we ran into
We wanted to work with React Native, but we were unable to integrate it with the camera roll. Additionally, we wanted the app to be run locally, but had difficulties using tensorflow lite and porting the learning model to mobile. We chose to go with a flask server as an alternative. Another challenge was the time pressure of training the neural net. We ended up training the model on approximately ~100,000 images, which was reduced from our dataset of about ~300,000 images. Additionally, we reduced the number of epochs to reduce time spent training, and did not fine tune our model to adjust the initial weights of the MobileNetV2 neural net.
## Accomplishments that we're proud of
The neural network was surprisingly accurate, ~97% accuracy, though we trained it using a limited number of categories.
## What we learned
We learned the basics of neural networks and how to integrate neural networks with mobile apps. Additionally, we (Akshit) learned about developing in Swift and Flask.
## What's next for Cleanr
Our next goal is to work on the UI and improve the apps functionality. | ## Inspiration
Inspired by leap motion applications
## What it does
User can their gesture to control motor, speaker, and led matrix.
## How we built it
Use arduino to control motor, speaker, led matrix and use Bluetooth to connect with computer that is connected to Oculus and leap-motion.
## Challenges we ran into
Put augmented reality overlay onto the things that we want to control.
## Accomplishments that we're proud of
Successfully controlled their components using gestures.
## What we learned
How to make use of Oculus and Leap-motion.
## What's next for Augmented Reality Control Experience (ARCX)
People with disabilities can use this technology to control their technologies such as turning on lights and playing music. | losing |
### Inspiration
The way research is funded is harmful to science — researchers seeking science funding can be big losers in the equality and diversity game. We need a fresh ethos to change this.
### What it does
Connexsci is a grant funding platform that generates exposure to undervalued and independent research through graph-based analytics. We've built a proprietary graph representation across 250k research papers that allows for indexing central nodes with highest value-driving research. Our grant marketplace allows users to leverage these graph analytics and make informed decisions on scientific public funding, a power which is currently concentrated in a select few government organizations. Additionally, we employ quadratic funding, a fundraising model that democratizes impact of contributions that has seen mainstream success through <https://gitcoin.co/>.
### How we built it
To gain unique insights on graph representations of research papers, we leveraged Cohere's NLP suite. More specifically, we used Cohere's generate functionality for entity extraction and fine-tuned their small language model with our custom research paper dataset for text embeddings. We created self-supervised training examples where we fine-tuned Cohere's model using extracted key topics given abstracts using entity extraction. These training examples were then used to fine-tune a small language model for our text embeddings.
Node prediction was achieved via a mix of document-wise cosine similarity, and other adjacency matrices that held rich information regarding authors, journals, and domains.
For our funding model, we created a modified version of the Quadratic Funding model. Unlike the typical quadratic funding systems, if the subsidy pool is not big enough to make the full required payment to every project, we can divide the subsidies proportionately by whatever constant makes the total add up to the subsidy pool's budget. For a given scenario, for example, a project dominated the leaderboard with an absolute advantage. The team then gives away up to 50% of their matching pool distribution so that every other project can have a share from the round, and after that we can see an increase of submissions.
The model is then implemented to our Bounty platform where organizers/investors can set a "goal" or bounty for a certain group/topic to be encouraged to research in a specific area of academia. In turn, this allows more researchers of unpopular topics to be noticed by society, as well as allow for advancements in the unpopular fields.
### Challenges we ran into
The entire dataset broke down in the middle of the night! Cohere also gave trouble with semantic search, making it hard to train our exploration model.
### Accomplishments that we're proud of
Parsing 250K+ publications and breaking it down to the top 150 most influential models. Parsing all ML outputs on to a dynamic knowledge graph. Building an explorable knowledge graph that interacts with the bounty backend.
### What's next for Connex
Integrating models directly on the page, instead of through smaller microservices. | Ever wonder where that video clip came from? Probably some show or movie you've never watched. Well with RU Recognized, you can do a reverse video search to find out what show or movie it's from.
## Inspiration
We live in a world rife with movie and tv show references, and not being able to identify these references is a sign of ignorance in our society. More importantly, the feeling of not being able to remember what movie or show that one really funny clip was from can get really frustrating. We wanted to enale every single human on this planet to be able to seek out and enjoy video based content easily but also efficiently. So, we decided to make **Shazam, but for video clips!**
## What it does
RU Recognized takes a user submitted video and uses state of the art algorithms to find the best match for that clip. Once a likely movie or tv show is found, the user is notified and can happily consume the much desired content!
## How we built it
We took on a **3 pronged approach** to tackle this herculean task:
1. Using **AWS Rekognition's** celebrity detection capabilities, potential celebs are spotted in the user submitted video. These identifications have a harsh confidence value cut off to ensure only the best matching algorithm.
2. We scrape the video using **AWS' Optical Character Recognition** (OCR) capabilities to find any identifying text that could help in identification.
3. **Google Cloud's** Speech to Text API allows us to extract the audio into readable plaintext. This info is threaded through Google Cloud Custom Search to find a large unstructured datadump.
To parse and exract useful information from this amourphous data, we also maintained a self-curated, specialized, custom made dataset made from various data banks, including **Kaggle's** actor info, as well as IMDB's incredibly expansive database.
Furthermore, due to the uncertain nature of the recognition API's, we used **clever tricks** such as cross referencing celebrities seen together, and only detecting those that had IMDB links.
Correlating the information extracted from the video with the known variables stored in our database, we are able to make an educated guess at origins of the submitted clip.
## Challenges we ran into
Challenges are an obstacle that our team is used to, and they only serve to make us stronger. That being said, some of the (very frustrating) challenges we ran into while trying to make RU Recognized a good product were:
1. As with a lot of new AI/ML algorithms on the cloud, we struggles alot with getting our accuracy rates up for identified celebrity faces. Since AWS Rekognition is trained on images of celebrities from everyday life, being able to identify a heavily costumed/made-up actor is a massive challenge.
2. Cross-connecting across various cloud platforms such as AWS and GCP lead to some really specific and hard to debug authorization problems.
3. We faced a lot of obscure problems when trying to use AWS to automatically detect the celebrities in the video, without manually breaking it up into frames. This proved to be an obstacle we weren't able to surmount, and we decided to sample the frames at a constant rate and detect people frame by frame.
4. Dataset cleaning took hours upon hours of work and dedicated picking apart. IMDB datasets were too large to parse completely and ended up costing us hours of our time, so we decided to make our own datasets from this and other datasets.
## Accomplishments that we're proud of
Getting the frame by frame analysis to (somewhat) accurately churn out celebrities and being able to connect a ton of clever identification mechanisms was a very rewarding experience. We were effectively able to create an algorithm that uses 3 to 4 different approaches to, in a way, 'peer review' each option, and eliminate incorrect ones.
## What I learned
* Data cleaning is ver very very cumbersome and time intensive
* Not all AI/ML algorithms are magically accurate
## What's next for RU Recognized
Hopefully integrate all this work into an app, that is user friendly and way more accurate, with the entire IMDB database to reference. | ## Inspiration
Our inspiration for this project came from newfound research stating the capabilities of models to perform the work of data engineers and provide accurate tools for analysis. We realized that such work is impactful in various sectors, including finance, climate change, medical devices, and much more. We decided to test our solution on various datasets to see the potential in its impact.
## What it does
A lot of things will let you know soon
## How we built it
For our project, we developed a sophisticated query pipeline that integrates a chatbot interface with a SQL database. This setup enables users to make database queries effortlessly through natural language inputs. We utilized SQLAlchemy to handle the database connection and ORM functionalities, ensuring smooth interaction with the SQL database. To bridge the gap between user queries and database commands, we employed LangChain, which translates the natural language inputs from the chatbot into SQL queries. To further enhance the query pipeline, we integrated Llama Index, which facilitates sequential reasoning, allowing the chatbot to handle more complex queries that require step-by-step logic. Additionally, we added a dynamic dashboard feature using Plotly. This dashboard allows users to visualize query results in an interactive and visually appealing manner, providing insightful data representations. This seamless integration of chatbot querying, sequential reasoning, and data visualization makes our system robust, user-friendly, and highly efficient for data access and analysis.
## Challenges we ran into
Participating in the hackathon was a highly rewarding yet challenging experience. One primary obstacle was integrating a large language model (LLM) and chatbot functionality into our project. We faced compatibility issues with our back-end server and third-party APIs, and encountered unexpected bugs when training the AI model with specific datasets. Quick troubleshooting was necessary under tight deadlines.
Another challenge was maintaining effective communication within our remote team. Coordinating efforts and ensuring everyone was aligned led to occasional misunderstandings and delays. Despite these hurdles, the hackathon taught us invaluable lessons in problem-solving, collaboration, and time management, preparing us better for future AI-driven projects.
## Accomplishments that we're proud of
We successfully employed sequential reasoning within the LLM, enabling it to not only infer the next steps but also to accurately follow the appropriate chain of actions that a data analyst would take. This advanced capability ensures that complex queries are handled with precision, mirroring the logical progression a professional analyst would utilize. Additionally, our integration of SQLAlchemy streamlined the connection and ORM functionalities with our SQL database, while LangChain effectively translated natural language inputs from the chatbot into accurate SQL queries. We further enhanced the user experience by implementing a dynamic dashboard with Plotly, allowing for interactive and visually appealing data visualizations. These accomplishments culminated in a robust, user-friendly system that excels in both data access and analysis.
## What we learned
We learned the skills in integrating various APIs along with the sequential process of actually being a data engineer and analyst through the implementation of our agent pipeline.
## What's next for Stratify
For our next steps, we plan to add full UI integration to enhance the user experience, making our system even more intuitive and accessible. We aim to expand our data capabilities by incorporating datasets from various other industries, broadening the scope and applicability of our project. Additionally, we will focus on further testing to ensure the robustness and reliability of our system. This will involve rigorous validation and optimization to fine-tune the performance and accuracy of our query pipeline, chatbot interface, and visualization dashboard. By pursuing these enhancements, we strive to make our platform a comprehensive, versatile, and highly reliable tool for data analysis and visualization across different domains. | winning |
## Inspiration
Sexual assault survivors are in tremendously difficult situations after being assaulted, having to sacrifice privacy and anonymity to receive basic medical, legal, and emotional support. And understanding how to proceed with one's life after being assaulted is challenging due to how scattered information on resources for these victims is for different communities, whether the victim is on an American college campus, in a foreign country, or any number of other situations. Instead of building a single solution or organizing one set of resources to help sexual assault victims everywhere, we believe a simple, community-driven solution to this problem lies in Echo.
## What it does
Using Blockstack, Echo facilitates anonymized communication among sexual assault victims, legal and medical help, and local authorities to foster a supportive online community for victims. Members of this community can share their stories, advice, and support for each other knowing that they truly own their data and it is anonymous to other users, using Blockstack. Victims may also anonymously report incidents of assault on the platform as they happen, and these reports are shared with local authorities if a particular individual has been reported as an offender on the platform several times by multiple users. This incident data is also used to geographically map where in small communities sexual assault happens, to provide users of the app information on safe walking routes.
## How we built it
A crucial part to feeling safe as a sexual harassment survivor stems from the ability to stay anonymous in interactions with others. Our backend is built with this key foundation in mind. We used Blockstack’s Radiks server to create a decentralized application that would keep all user’s data local to that user. By encrypting their information when storing the data, we ensure user privacy and mitigate all risks to sacrificing user data. The user owns their own data. We integrated Radiks into our Node and Express backend server and used this technology to manage our database for our app.
On the frontend, we wanted to create an experience that was eager to welcome users to a safe community and to share an abundance of information to empower victims to take action. To do this, we built the frontend from React and Redux, and styling with SASS. We use blockstack’s Radiks API to gather anonymous messages in the Support Room feature. We used Twilio’s message forwarding API to ensure that victims could very easily start anonymous conversations with professionals such as healthcare providers, mental health therapists, lawyers, and other administrators who could empower them. We created an admin dashboard for police officials to supervise communities, equipped with Esri’s maps that plot where the sexual assaults happen so they can patrol areas more often. On the other pages, we aggregate online resources and research into an easy guide to provide victims the ability to take action easily. We used Azure in our backend cloud hosting with Blockstack.
## Challenges we ran into
We ran into issues of time, as we had ambitious goals for our multi-functional platform. Generally, we faced the learning curve of using Blockstack’s APIs and integrating that into our application. We also ran into issues with React Router as the Express routes were being overwritten by our frontend routes.
## Accomplishments that we're proud of
We had very little experience developing blockchain apps before and this gave us hands-on experience with a use-case we feel is really important.
## What we learned
We learned about decentralized data apps and the importance of keeping user data private. We learned about blockchain’s application beyond just cryptocurrency.
## What's next for Echo
Our hope is to get feedback from people impacted by sexual assault on how well our app can foster community, and factor this feedback into a next version of the application. We also want to build out shadowbanning, a feature to block abusive content from spammers on the app, using a trust system between users. | ## Inspiration
Our inspiration came from a common story that we have been seeing on the news lately - the wildfires that are impacting people on a nationwide scale. These natural disasters strike at uncertain times, and we don't know if we are necessarily going to be in the danger zone or not. So, we decided to ease the tensions that occur during these high-stress situations by acting as the middle persons.
## What it does
At RescueNet, we have two types of people with using our service - either subscribers or homeowners. The subscriber pays RescueNet monthly or annually at a rate which is cheaper than insurance! Our infrastructure mainly targets people who live in natural disaster-prone areas. In the event such a disaster happens, the homeowners will provide temporary housing and will receive a stipend after the temporary guests move away. We also provide driving services for people to escape their emergency situations.
## How we built it
We divided our work into the clientside and the backend. Diving into the clientside, we bootstrapped our project using Vite.js for faster loadtimes. Apart from that, React.js was used along with React Router to link the pages and organize the file structure accordingly. Tailwind CSS was employed to simplify styling along with Material Tailwind, where its pre-built UI components were used in the about page.
Our backend server is made using Node.js and Express.js, and it connects to a MongoDB Atlas database making use of a JavaScript ORM - Mongoose. We make use of city data from WikiData, geographic locations from GeoDB API, text messaging functionality of Twilio, and crypto payment handling of Circle.
## Challenges we ran into
Some challenges we ran into initially is to make the entire web app responsive across devices while still keeping our styles to be rendered. At the end, we figured out a great way of displaying it in a mobile setting while including a proper navbar as well. In addition, we ran into trouble working with the Circle API for the first time. Since we've never worked with cryptocurrency before, we didn't understand some of the implications of the code we wrote, and that made it difficult to continue with Circle.
## Accomplishments that we're proud of
An accomplishment we are proud of is rendering the user dashboard along with the form component, which allowed the user to either enlist as a subscriber or homeowner. The info received from this component would later be parsed into the dashboard would be available for show.
We are also proud of how we integrated Twilio's SMS messaging services into the backend algorithm for matching subscribers with homeowners. This algorithm used information queried from our database, accessed from WikiData, and returned from various API calls to make an "optimal" matching based on distance and convenience, and it was nice to see this concept work in real life by texting those who were matched.
## What we learned
We learned many things such as how to use React Router in linking to pages in an easy way. Also, leaving breadcrumbs in our Main.jsx allowed us to manually navigate to such pages when we didn't necessarily had anything set up in our web app. We also learned how to use many backend tools like Twilio and Circle.
## What's next for RescueNet
What's next for RescueNet includes many things. We are planning on completing the payment model using Circle API, including implementing automatic monthly charges and the ability to unsubscribe. Additionally, we plan on marketing to a few customers nationwide, this will allow us to conceptualize and iterate on our ideas till they are well polished. It will also help in scaling things to include countries such as the U.S.A and Mexico. | ## Inspiration
We got the idea for this app after one of our teammates shared that during her summer internship in China, she could not find basic over the counter medication that she needed. She knew the brand name of the medication in English, however, she was unfamiliar with the local pharmaceutical brands and she could not read Chinese.
## Links
* [FYIs for your Spanish pharmacy visit](http://nolongernative.com/visiting-spanish-pharmacy/)
* [Comparison of the safety information on drug labels in three developed countries: The USA, UK and Canada](https://www.sciencedirect.com/science/article/pii/S1319016417301433)
* [How to Make Sure You Travel with Medication Legally](https://www.nytimes.com/2018/01/19/travel/how-to-make-sure-you-travel-with-medication-legally.html)
## What it does
This mobile app allows users traveling to different countries to find the medication they need. They can input the brand name in the language/country they know and get the name of the same compound in the country they are traveling to. The app provides a list of popular brand names for that type of product, along with images to help the user find the medicine at a pharmacy.
## How we built it
We used Beautiful Soup to scrape Drugs.com to create a database of 20 most popular active ingredients in over the counter medication. We included in our database the name of the compound in 6 different languages/countries, as well as the associated brand names in the 6 different countries.
We stored our database on MongoDB Atlas and used Stitch to connect it to our React Native front-end.
Our Android app was built with Android Studio and connected to the MongoDB Atlas database via the Stitch driver.
## Challenges we ran into
We had some trouble connecting our React Native app to the MongoDB database since most of our team members had little experience with these platforms. We revised the schema for our data multiple times in order to find the optimal way of representing fields that have multiple values.
## Accomplishments that we're proud of
We're proud of how far we got considering how little experience we had. We learned a lot from this Hackathon and we are very proud of what we created. We think that healthcare and finding proper medication is one of the most important things in life, and there is a lack of informative apps for getting proper healthcare abroad, so we're proud that we came up with a potential solution to help travellers worldwide take care of their health.
## What we learned
We learned a lot of React Native and MongoDB while working on this project. We also learned what the most popular over the counter medications are and what they're called in different countries.
## What's next for SuperMed
We hope to continue working on our MERN skills in the future so that we can expand SuperMed to include even more data from a variety of different websites. We hope to also collect language translation data and use ML/AI to automatically translate drug labels into different languages. This would provide even more assistance to travelers around the world. | partial |
## Inspiration
researching at hackathons is really tiring, so we wanted to spice up our screens with some color
## What it does
users have the option to change their webpage into four different colors
## How we built it
using JS & HTML,
## Challenges we ran into
we did not know how to use Javascript. we were planning to use Python but had to switch it last minute
we also never created a chrome extension before
## Accomplishments that we're proud of
completing our first hackathon
## What we learned
How to use JS, and how to work/code efficiently
## What's next for Four Colors
Hopefully allow for a wider range of colors and more user input, like letting users enter their own colors. We also want to allow users to be more specific with what they wanna personalize | ## Inspiration
Every student has experienced the difficulties that arise with a sudden transition to an online learning medium. With a multitude of assignments, midterms, extra-curriculars, etc, time is of the essence. We strived to create a solution that enables any individual to be able to focus on their productivity through the power of automation.
## What it does
**ProSistant** is an easy-to-download Google Chrome extension that will be available to any individual through the Google Chrome Webstore. This productivity assistant's main purpose is to ensure that the student is able to stay on track throughout the week by reducing the stress of having to remember deadlines and tasks while promoting a positive working environment.
## How we built it
Through Google Chrome's developer mode, we unpacked a load package that consisted of all of our HTML, CSS and JavaScript files. HTML was used to give the content of the extension its structure, CSS a presentation language created to style the appearance of content—using, for example, fonts or colours. JavaScript was the functionality workhorse of the extension, powered and enhanced by Google's developer extension API.
## Challenges we ran into
Although the development of the HTML and CSS code went relatively smoothly, the user interface that was working perfectly through the HTML interface failed to build when the Chrome extension was loaded. This was a major setback in the design process as there were many contradicting sources about the way to fix this. However, through repeated experimentation and fully diversifying in the behaviour of JavaScript, we were able to overcome this obstacle and build a Chrome extension that encompassed the interface that we wished for the user to interact with.
## Accomplishments that we're proud of
All three of us were new to web development, and we were able to maintain a positive working environment while demonstrating our ability to pick up on new techniques in a fast and efficient manner. We are proud of our ability to implement unique features that we are confident will be of service for any student through the use of programming languages that, coming into this weekend, were foreign to us.
## What we learned
We fully emersed ourselves in the hackathon environment and learned to trust one another when it came to implementing unique features that would eventually come together for the final product. We learned how to optimize HTML and CSS code to make visually appealing interfaces, and essential JavaScript code to increase user interactivity.
## What's next for ProSistant
The potential for **ProSistant** is abundant. Our team will continue to roll out newer versions to implement even more productivity-related features and further improve the user interface. | ## Inspiration
We created this app to address a problem that our creators were facing: waking up in the morning. As students, the stakes of oversleeping can be very high. Missing a lecture or an exam can set you back days or greatly detriment your grade. It's too easy to sleep past your alarm. Even if you set multiple, we can simply turn all those off knowing that there is no human intention behind each alarm. It's almost as if we've forgotten that we're supposed to get up after our alarm goes off! In our experience, what really jars you awake in the morning is another person telling you to get up. Now, suddenly there is consequence and direct intention behind each call to wake up. Wake simulates this in an interactive alarm experience.
## What it does
Users sync their alarm up with their trusted peers to form a pact each morning to make sure that each member of the group wakes up at their designated time. One user sets an alarm code with a common wakeup time associated with this alarm code. The user's peers can use this alarm code to join their alarm group. Everybody in the alarm group will experience the same alarm in the morning. After each user hits the button when they wake up, they are sent to a soundboard interface, where they can hit buttons to send try to wake those that are still sleeping with real time sound effects. Each time one user in the server hits a sound effect button, that sound registers on every device, including their own device to provide auditory feedback that they have indeed successfully sent a sound effect. Ultimately, users exit the soundboard to leave the live alarm server and go back to the home screen of the app. They can finally start their day!
## How we built it
We built this app using React Native as a frontend, Node.js as the server, and Supabase as the database. We created files for the different screens that users will interact with in the front end, namely the home screen, goodnight screen, wakeup screen, and the soundboard. The home screen is where they set an alarm code or join using someone else's alarm code. The "goodnight screen" is what screen the app will be on while the user sleeps. When the app is on, it displays the current time, when the alarm is set to go off, who else is in the alarm server, and a warm message, "Goodnight, sleep tight!". Each one of these screens went through its own UX design process. We also used Socket.io to establish connections between those in the same alarm group. When a user sends a sound effect, it would go to the server which would be sent to all the users in the group. As for the backend, we used Supabase as a database to store the users, alarm codes, current time, and the wake up times. We connected the front and back end and the app came together. All of this was tested on our own phones using Expo.
## Challenges we ran into
We ran into many difficult challenges during the development process. It was all of our first times using React Native, so there was a little bit of a learning curve in the beginning. Furthermore, incorporating Sockets with the project proved to be very difficult because it required a lot of planning and experimenting with the server/client relationships. The alarm ringing also proved to be surprisingly difficult to implement. If the alarm was left to ring, the "goodnight screen" would continue ringing and would not terminate. Many of React Native's tools like setInterval didn't seem to solve the problem. This was a problematic and reoccurring issue. Secondly, the database in Supabase was also quite difficult and time consuming to connect, but in the end, once we set it up, using it simply entailed brief SQL queries. Thirdly, setting up the front end proved quite confusing and problematic, especially when it came to adding alarm codes to the database.
## Accomplishments that we're proud of
We are super proud of the work that we’ve done developing this mobile application. The interface is minimalist yet attention- grabbing when it needs to be, namely when the alarm goes off. Then, the hours of debugging, although frustrating, was very satisfying once we finally got the app running. Additionally, we greatly improved our understanding of mobile app developement. Finally, the app is also just amusing and fun to use! It’s a cool concept!
## What we learned
As mentioned before, we greatly improved our understanding of React Native, as for most of our group, this was the first time using it for a major project. We learned how to use Supabase and socket. Additionally, we improved our general Javascript and user experience design skills as well.
## What's next for Wakey
We would like to put this app on the iOS App Store and the Android Play Store, which would take more extensive and detailed testing, especially as for how the app will run in the background. Additionally, we would like to add some other features, like a leaderboard for who gets up most immediately after their alarm gets off, who sends the most sound effects, and perhaps other ways to rank the members of each alarm server. We would also like to add customizable sound effects, where users can record themselves or upload recordings that they can add to their soundboards. | losing |
## Inspiration
This project was inspired by providing a solution to the problem of users with medical constraints. There are users who have mobility limitations which causes them to have difficulty leaving their homes. PrescriptionCare allows them to order prescriptions online and have them delivered to their homes on a monthly or a weekly basis.
## What it does
PrescriptionCare is a web app that allows users to order medical prescriptions online. Users can fill out a form and upload an image of their prescription in order to have their medication delivered to their homes. This app has a monthly subscription feature since most medications is renewed after 30 days, but also allows users to sign up for weekly subscriptions.
## How we built it
We designed PrescriptionCare using Figma, and built it using Wix.
## Challenges we ran into
We ran into several challenges, mainly due to our inexperience with hackathons and the programs and languages we used along the way. Initially, we wanted to create the website using HTML, CSS, and JavaScript, however, we didn't end up going down that path, as it ended up being a bit too complicated because we were all beginners. We ended up choosing to use Wix due to its ease of use and excellent template selection to give us a solid base to build PrescriptionCare off of. We also ran into issues with an iOS app we tried to develop to complement the website, mainly due to learning Swift and SwiftUI, which is not very beginner friendly.
## Accomplishments that we're proud of
Managing to create a website in just a few hours and being able to work with a great team. Some the members of this team also had to learn new software in just a few hours which was also a challenge, but this experience is a good one and we'll be much more prepared for our next hackathon.
We are proud to have experimented with two new tools thanks to this application. We were able to draft a website through Wix and create an app through xCode and SwiftUI. Another accomplishment is that our team consists of first-time hackers, so we are proud to have started the journey of hacking and cannot wait to see what is waiting for us in the future.
## What we learned
We learned how to use the Wix website builder for the first time and also how to collaborate together as a team. We don't really know each other and happened to meet at the competition and will probably work together at another hackathon in the future.
We learned a positive mindset is another important asset to bring into a hackathon. At first, we felt intimidated by hackathons, but we are thankful to have learned that hackathons can be fun and a priceless learning experience.
## What's next for PrescriptionCare
It would be nice to be able to create a mobile app so that users can get updates and notifications when their medication arrives. We could create a tracking system that keeps track of the medication you take and estimates when the user finishes their medication.
PrescriptionCare will continue to expand and develop its services to reach more audience. We hope to bring more medication and subscription plans for post-secondary students who live away from home, at-home caretakers, and more, and we aim to bring access to medicine to everyone. Our next goal is to continue developing our website and mobile app (both android and IOS), as well as collect data of pharmaceutical drugs and their usage. We hope to make our app a more diverse, and inclusive app, with a wide variety of medication and delivery methods. | ## Inspiration
As students, we’ve all heard it from friends, read it on social media or even experienced it ourselves: students in need of mental health support will book counselling appointments, only to be waitlisted for the foreseeable future without knowing alternatives. Or worse, they get overwhelmed by the process of finding a suitable mental health service for their needs, give up and deal with their struggles alone.
The search for the right mental health service can be daunting but it doesn’t need to be!
## What it does
MindfulU centralizes information on mental health services offered by UBC, SFU, and other organizations. It assists students in finding, learning about, and using mental health resources through features like a chatbot, meditation mode, and an interactive services map.
## How we built it
Before building, we designed the UI of the website first with Figma to visualize how the website should look like.
The website is built with React and Twilio API for its core feature to connect users with the Twilio chatbot to connect them with the correct helpline. We also utilized many npm libraries to ensure the website has a smooth look to it.
Lastly, we deployed the website using Vercel.
## Challenges We ran into
We had a problem in making the website responsive for the smaller screens. As this is a hackathon, we were focusing on trying to implement the designs and critical features for laptop screen size.
## Accomplishments that we're proud of
We are proud that we had the time to implement the core features that we wanted, especially implementing all the designs from Figma into React components and ensuring it fits in a laptop screen size.
## What we learned
We learned that it's not only the tech stack and implementation of the project that matters but also the purpose and message that the project is trying to convey.
## What's next for MindfulU
We want to make the website more responsive towards any screen size to ensure every user can access it from any device. | # eleos
## Inspiration
In times of hardships, generosity is needed in order to overcome barriers, and with technology connecting the world, helping someone should be simple. Though technology is readily available, information regarding different not-for-profits can be less apparent, as someone may be interested in a cause, but unsure which of the many organizations they should donate to. Additionally, some people may want to help others, but are unable due to current financial situations, and thus feels powerless and inferior. Therefore, there lies a need for a convenient manner to utilize the innate compassion that we possess as a society.
## What it
Eleos is a website that compiles a list of not-for-profits that partakes in this service, allows not-for-profits to show all the work they’ve accomplished and wish to accomplish in a more transparent manner, and allows users to watch ads/complete surveys in exchange to donating to their interested causes. This takes advantage of current Google ads and various survey platforms, as companies are always looking to promote and analyze their branding and are willing to pay in exchange for this information.
## How I built it
This was built using Google Firebase and Firestore to store user’s data, Google Maps and Radar.io to locate not-for-profits in close proximity, HTML, CSS, and JavaScript for front end design of the website. Challenges that occurred during this process include having to learn new software development tools that required lots of experimental processes.
## Accomplishments that I'm proud of
We are proud that we have built a website that gives everyone the opportunity to help others and the environment by lending just a few moments of their time. We are proud that we were able to integrate different software that we were not familiar with to create a cohesive product.
## What's next?
Next steps for Eleos include pairing the system with the Google ads and survey systems and establishing bonds with not-for-profits to create a comprehensive list of different organizations currently available and the work they do. | partial |
### Inspiration
A general liking of watching Twitch streams led me to try and make this. When a streamer gets too big, it can be hard to keep track of questions, reactions, subscriber notifications, and more. This application is meant to help streamline the process of broadcaster and chat interaction.
### What it should do
It would gather data from Twitch chat in real time, analyze and catagorize them, and display the results on a web page that gets updated in real time.
### What it actually does
Barely simulates a Twitch chatbot typing into the chat.
### How I built it
I used Nodejs and Reactjs for my framework. Another community developed API called tmi.js connects the Twitch chat to my code. So far, I have programmed the .js to output rudimentary messages in chat.
### Challenges I ran into
For one thing, I have zero prior experience working with JS and APIs, so I had to start from the ground up. Every step of the way, I ran into problems, searched for solutions, and got stuck again.
### Accomplishments that I'm proud of
The fact that I made something that does something is quite amazing. Although it isn't even a minimum viable product, it's still something.
### What I learned
I have learned so much about APIs.
### What's next for Better Twich Chat Info
To conceive the actual goal I want to achieve. | ## Inspiration
During the multiple COVID lockdowns last year, our team and many other people experienced a severe lack of human interaction. Doing our best to socially distance while having some fun we decided to play online board games but ran into problems trying to figure out how to communicate while playing. Certain solutions required a lot of setup and were overly complicated so we decided to streamline the process by creating Chat Hero!
---
## What it does
Chat Hero is a chrome extension that allows users to join virtual rooms with friends or strangers where you can interact with one another by text while playing online board games. The purpose of this implementation is to allow for easy communication and interaction on any website so you can play games together or hang out while watching a movie.
---
## How we built it
Chat Hero has two main components, The extension/web component as well as the database component; both components are an integral aspect in the function of the app. The extension uses HTML5 and CSS3 to create an appealing and simple user interface that anyone can use. The database component features a MySQL database along with a couple of Php files so that the web app can converse with the backend database.
We started with the web component and created a visually appealing and easy to use user interface with HTML and CSS. WE then used the Php code to fetch and upload data to our database to add the chat function to our app.
---
## Challenges we ran into
We ran into A LOT of challenges while making this app. Given the fact that our team was not too familiar with SQL and databases we found it very hard to get our database set up and running. We began using CockroachDB however after hours of trying we kept getting issue while trying to run our database and so we resulted in some alternate options. The database software that ended up working for us was MySQL.
Another issue we ran into was how to link a chrome extension with different html and Php files that we were working on. Although our team has had previous experience with web development none of us had any experience with chrome extensions so this was a very challenging task to figure out. However after a lot of research, team work and error messages, we figured out how to implement a chrome extension for our project
---
## Accomplishments that we're proud of
We're really proud of learning HTML, PHP and utilizing MySQL. These are skills we have never learned before and using them to make our first ever chrome extension, in our first hackathon, is a memory we will cherish forever.
---
## What we learned
The main thing we learning during this project was that you should never stop trying to solve your problems no matter how hard it is. There were many times that we all wanted to give up after we would fail over and over again. There were times when it seemed that none of the code we tried would ever work. However we kept a positive attitude and encouraged each other to keep going and at the end of it all it was extremely worth it. On top of that we also learned and got familiar with many web development interfaces which is a huge skill to have in the field of computer science
---
## What's next for Chat Hero
We hope to continue developing the Chat Hero project. Our vision for the immediate future is to allow users to share what's on their screens and further down the line add games you can play together right from Chat Hero! | ## Inspiration
Our team firmly believes that a hackathon is the perfect opportunity to learn technical skills while having fun. Especially because of the hardware focus that MakeUofT provides, we decided to create a game! This electrifying project places two players' minds to the test, working together to solve various puzzles. Taking heavy inspiration from the hit videogame, "Keep Talking and Nobody Explodes", what better way to engage the players than have then defuse a bomb!
## What it does
The MakeUofT 2024 Explosive Game includes 4 modules that must be disarmed, each module is discrete and can be disarmed in any order. The modules the explosive includes are a "cut the wire" game where the wires must be cut in the correct order, a "press the button" module where different actions must be taken depending the given text and LED colour, an 8 by 8 "invisible maze" where players must cooperate in order to navigate to the end, and finally a needy module which requires players to stay vigilant and ensure that the bomb does not leak too much "electronic discharge".
## How we built it
**The Explosive**
The explosive defuser simulation is a modular game crafted using four distinct modules, built using the Qualcomm Arduino Due Kit, LED matrices, Keypads, Mini OLEDs, and various microcontroller components. The structure of the explosive device is assembled using foam board and 3D printed plates.
**The Code**
Our explosive defuser simulation tool is programmed entirely within the Arduino IDE. We utilized the Adafruit BusIO, Adafruit GFX Library, Adafruit SSD1306, Membrane Switch Module, and MAX7219 LED Dot Matrix Module libraries. Built separately, our modules were integrated under a unified framework, showcasing a fun-to-play defusal simulation.
Using the Grove LCD RGB Backlight Library, we programmed the screens for our explosive defuser simulation modules (Capacitor Discharge and the Button). This library was used in addition for startup time measurements, facilitating timing-based events, and communicating with displays and sensors that occurred through the I2C protocol.
The MAT7219 IC is a serial input/output common-cathode display driver that interfaces microprocessors to 64 individual LEDs. Using the MAX7219 LED Dot Matrix Module we were able to optimize our maze module controlling all 64 LEDs individually using only 3 pins. Using the Keypad library and the Membrane Switch Module we used the keypad as a matrix keypad to control the movement of the LEDs on the 8 by 8 matrix. This module further optimizes the maze hardware, minimizing the required wiring, and improves signal communication.
## Challenges we ran into
Participating in the biggest hardware hackathon in Canada, using all the various hardware components provided such as the keypads or OLED displays posed challenged in terms of wiring and compatibility with the parent code. This forced us to adapt to utilize components that better suited our needs as well as being flexible with the hardware provided.
Each of our members designed a module for the puzzle, requiring coordination of the functionalities within the Arduino framework while maintaining modularity and reusability of our code and pins. Therefore optimizing software and hardware was necessary to have an efficient resource usage, a challenge throughout the development process.
Another issue we faced when dealing with a hardware hack was the noise caused by the system, to counteract this we had to come up with unique solutions mentioned below:
## Accomplishments that we're proud of
During the Makeathon we often faced the issue of buttons creating noise, and often times the noise it would create would disrupt the entire system. To counteract this issue we had to discover creative solutions that did not use buttons to get around the noise. For example, instead of using four buttons to determine the movement of the defuser in the maze, our teammate Brian discovered a way to implement the keypad as the movement controller, which both controlled noise in the system and minimized the number of pins we required for the module.
## What we learned
* Familiarity with the functionalities of new Arduino components like the "Micro-OLED Display," "8 by 8 LED matrix," and "Keypad" is gained through the development of individual modules.
* Efficient time management is essential for successfully completing the design. Establishing a precise timeline for the workflow aids in maintaining organization and ensuring successful development.
* Enhancing overall group performance is achieved by assigning individual tasks.
## What's next for Keep Hacking and Nobody Codes
* Ensure the elimination of any unwanted noises in the wiring between the main board and game modules.
* Expand the range of modules by developing additional games such as "Morse-Code Game," "Memory Game," and others to offer more variety for players.
* Release the game to a wider audience, allowing more people to enjoy and play it. | losing |
## What it does
Our site allows a user to take a picture of their outfit and receive AI-generated feedback on their style, color palette, and cohesiveness. While we are not your typical education tool, we think that dressing well has a massive boost on your confidence, your presence, and your ability to talk about yourself! Our goal is to give everyone a chance to be their most styling self.
In addition to hyping up the best of your outfit, we recommend relevant pieces to incorporate into your style as you explore defining your visual voice. Discovering fashion should be exciting, not intimidating -- and with the help of LLM's, **Drip or Drown** does exactly that!
## How we built it
During the course of the weekend, we experimented with many different approaches but ultimately settled on the following architecture ([click here for full res](https://i.ibb.co/8rBwgqB/architecture2.png)):
. Here's some of the salient elements:
1. Depth Perception
When an image is uploaded, we use computer vision to remove noise. We use the MIDAS depth perception model to separate the background from the foreground, create a separate image only of the person and their fit!
2. Visual Transformation Model (Q&A):
We used the ViLT QnA model to query the de-noised image about attributes about the outfit — extracting information about what they're wearing and details in a recursive fashion.
3. In-Context Learning Fashion Critique Model
Finally, we use Large Language Models to generate in-depth feedback for your fit using our description. We also use a model to rate it on a scale of 1-10 and another to categorize it into one of many "aura"s, so that you can have a well-rounded understanding of your own style!
## Challenges we ran into
1. Figuring out deployment was particularly hard. Given the many moving parts, our project is hosted on multiple platforms that all interact with each other.
2. Using non-production research models like ViLT meant that our performance for the API calls was quite abysmal, and we had to get pretty clever about parallelization and early-stopping algorithms within our call structure.
3. We spent a lot of time adding juice to the project! Making it fun to use was a big goal of ours, which was often easier said than done :)
## Accomplishments that we're proud of
1. The UI! We think it looks pretty great – one of our teammates mocked it all up in Figma, and then we spent most of Sunday night making components together. We really wanted to make our project fun to use, and I think we accomplished that.
2. Using Multi-modal AI! It's one of the biggest unsolved problems in AI right now. How do you use multiple forms of input — image *and* text — together? I think we came up with a pretty clever solution that works quite well, and is pretty interpretable as well!
## What we learned
1. A lot about many technologies! Like Flask, PythonAnywhere, AWS, Heroku, Vercel, generating particles, CSS, Visual Transformer models, GPT fine-tuning, image progressing, classification algorithms, and more! This project spans many different domains, and it was pretty fun to pick up skills along the way.
2. The need for patience! For the longest time, we would have "blocker" bugs that would prevent us from deploying or developing further. We pushed ahead, and every time we handled those, the emergent abilities of the system surprised us as well.
3. And of course, that having fun once in a while is important. We did some of our best work when we were all singing to pop songs together at 11PM.
## What's next for Drip or Drown
1. Improving suggestion quality: We think we can push this even further! While our current image -> text algorithm is clever, we think we could make it even smarter by using a shared embedding space between images and text. This could capture attributes of the image our QnA model could not!
2. Follow-ups and conversation: We'd love for you to be able to ask the model questions about your fit! "Why does a white belt work better?" "What do you think about this leather jacket with that shirt?"
3. Suggestions! Finally, from all the feedback, we'd love for the model to be able to suggest fits as well. "You'd look great in a green croptop for this casual event!" We hope that Drip is the AI assistant to help you achieve your most fashionable self. | ## Inspiration 🛍️
In this moving world where different fashions and styles are becoming more accessible to more people, it's easy to shop online for things you think are going to look good on you. Only for you to buy and try it on, where you realize you ended up with a $50 disappointment. People want to dress to impress but oftentimes end up missing the mark as the clothes simply don't fit. With fast-fashion on a rise, [**74%**](https://www.prnewswire.com/news-releases/buyers-remorse-due-to-online-shopping-has-affected-seventy-four-percent-of-americans-according-to-survey-commissioned-by-slickdeals-301511257.html) of consumers have regretted buying online, accumulating to nearly [500 million kilograms](https://uwaterloo.ca/news/new-research-could-divert-billion-pounds-clothes-and-other#:%7E:text=Canadians%20trash%20about%20a%20billion,most%20of%20it%20from%20landfills.) a year. Our invention hopes to stop the trash from where it orginally comes from, the decision to purchase a garment or not.
## What it does 👗
Using AI our website will let you try out any outfit you want simply with an image of the clothes you want and a photo of you before you buy it. After selection, it will generate a photo of you in the clothes, replacing the clothes you were currently wearing. If you like the photos, you can create an account to save your photos and revist them another time.
Companies will be able to use our API to implement our program into their own e-commerce website creating a more personalized shopping experience. These better experiences will increase customer engagement and sales conversion rate, lower shopping cart abandonment rates, and help companies reach their environmental targets by helping customers choose the right clothes.
## How we built it 🛠️
* **Model Development:** SegmentBody, IP-Adapter
* **Front-End:** React, Tailwind CSS
* **Back-End:** Express, MongoDB, Auth0
* **Additional Tools:** Figma, Postman, Google Colab
For the model itself, we segmented the photo into pieces to create a mask and used generative AI to change the image at a selected segment with an image prompt. To segment the photo, we used [SegmentBody](https://github.com/TonyAssi/Segment-Body/tree/main) to separate the background with the foreground body, removing the face and hands in progress (as to not apply a style on unclothed features).
We then use the [IP-Adapter](https://huggingface.co/docs/diffusers/using-diffusers/ip_adapter?tasks=Inpainting) pipeline, which allows us to prompt the image generation with an image (the new clothes) instead of text by [inpainting](https://huggingface.co/docs/diffusers/using-diffusers/inpaint) the mask. We apply the image generation to our mask with a few negative and positive prompts to then
the IP-Adapter pipeline to do inpainting which generates a new image on our selected segment of the photo.
```
final_image = ipadapter_pipeline(
prompt="photorealistic, natural body, realistic skin, natural skin",
negative_prompt="ugly, bad quality, bad anatomy, deformed body, deformed hands, deformed feet, deformed face, deformed clothing, deformed skin, bad skin, leggings, tights, stockings",
image=image,
mask_image=mask_img,
ip_adapter_image=ip_image,
strength=0.99,
guidance_scale=7.5,
num_inference_steps=100,
).images[0]
```
[Source](https://huggingface.co/blog/tonyassi/virtual-try-on-ip-adapter)
To create a visually appealing user experience, mockups were designed, reviewed, and reiterated on Figma. We used React and Tailwind CSS for the front-end. React allowed us to build a dynamic and responsive interface, ensuring that users can easily upload photos, select garments, and view the generated images in real-time. Tailwind CSS enabled us to quickly prototype and implement a minimalist design that is both functional and aesthetically pleasing. This approach allowed for rapid iteration and customization, ensuring the interface is intuitive and aligns with modern web design trends.
We also integrated features such as image uploads, user account management, and API interactions with the backend. The backend was built using Express and MongoDB to efficiently handle server requests and data storage. Postman was used for testing and documenting API endpoints, while Auth0 provided secure user authentication.
## Challenges we ran into 🚧
Creating an AI from scratch that can both identify and replace clothes in a convincing manner was time-consuming and difficult to train. To get one that tops any of the ones made by researchers who have spent months working on a model is a challenge that in and of itself and not one which is truly feasible by any team within a 36 hour time frame. However, we still managed to get a working model that with some fine-tuning and more time would be feasible to implement and learnt a lot about making one through this experience.
Better models = More computations and based on our limited budget we weren't able to get a high-end subscription to run the programs limiting our overall quality of machines.
Additionally, with how ubiquitous AI is nowadays it's often easy to forget how complicated softwares can be to implement together. We ran into a major error with deprecated libraries, causing us to have to use an older version of Python in addition to purchasing compute on Google Colab to get the model working in the first place. This issue left us with a new appreciation to how thankless the job of being an upkeeper of used packages
Our challenges were not only virtual limitations, but also physical ones. One of our team members could not access wifi for the whole event, leading to friction with intergrating their work with the rest of the team's. This lead to re-assignment of tasks to different members, causing our team to have to push themselves out of their comfort zones to learn something new.
## Accomplishments that we're proud of 🎉
We’re really proud of the design, which successfully achieves a minimalist and modern vibe.
We're happy about getting diffusion to work and actually being able to generate images based on our prompts (at least at the notebook level), this being the first time doing any work with diffusion (or with ML and AI of this type)
## What we learned 📚
Many of us weren't great at design, but through collaboration with other teammates we learnt a lot into what makes good design, especially in the modern age.
## What's next for FittingRoom 🔮
Most consumers don't purchase clothes soley by how they look behind a white background, but instead how they look on models. That poses an issue to our program as it's unable to recognize clothes on other people. We plan to solve this by creating an AI to recognzie clothes worn by people in photos and output a image of the plain clothes. If not enough information is provided by a singular photo, users can supplement the rest with context-filling (like in Adobe) or use multiple photos.
Additionally, it's often hard to find similarly like-minded people with the same unique style. FittingRoom will implement a system where you can find people with similar taste in clothing, giving you recommendations based off what others have tried on and enjoyed with similar styles as you (similar to the Spotify recommendation system). | ## Inspiration
We are all software/game devs excited by new and unexplored game experiences. We originally came to PennApps thinking of building an Amazon shopping experience in VR, but eventaully pivoted to Project Em - a concept we all found mroe engaging. Our swtich was motivated by the same force that is driving us to create and improve Project Em - the desire to venture into unexplored territory, and combine technologies not often used together.
## What it does
Project Em is a puzzle exploration game driven by Amazon's Alexa API - players control their character with the canonical keyboard and mouse controls, but cannot accomplish anything relevant in the game without talking to a mysterious, unknown benefactor who calls out at the beginning of the game.
## How we built it
We used a combination of C++, Pyhon, and lots of shell scripting to create our project. The client-side game code runs on Unreal Engine 4, and is a combination of C++ classes and Blueprint (Epic's visual programming language) scripts. Those scripts and classes communicate an intermediary server running Python/Flask, which in turn communicates with the Alexa API. There were many challenges in communicating RESTfully out of a game engine (see below for more here), so the two-legged approach lent itself well to focusing on game logic as much as possible. Sacha and Akshay worked mostly on the Python, TCP socket, and REST communication platform, while Max and Trung worked mainly on the game, assets, and scripts.
The biggest challenge we faced was networking. Unreal Engine doesn't naively support running a webserver inside a game, so we had to think outside of the box when it came to networked communication.
The first major hurdle was to find a way to communicate from Alexa to Unreal - we needed to be able to communicate back the natural language parsing abilities of the Amazon API to the game. So, we created a complex system of runnable threads and sockets inside of UE4 to pipe in data (see challenges section for more info on the difficulties here). Next, we created a corresponding client socket creation mechanism on the intermediary Python server to connect into the game engine. Finally, we created a basic registration system where game clients can register their publicly exposed IPs and Ports to Python.
The second step was to communicate between Alexa and Python. We utilitzed [Flask-Ask](https://flask-ask.readthedocs.io/en/latest/) to abstract away most of the communication difficulties,. Next, we used [VaRest](https://github.com/ufna/VaRest), a plugin for handing JSON inside of unreal, to communicate from the game directly to Alexa.
The third and final step was to create a compelling and visually telling narrative for the player to follow. Though we can't describe too much of that in text, we'd love you to give the game a try :)
## Challenges we ran into
The challenges we ran into divided roughly into three sections:
* **Threading**: This was an obvious problem from the start. Game engines rely on a single main "UI" thread to be unblocked and free to process for the entirety of the game's life-cycle. Running a socket that blocks for input is a concept in direct conflict with that idiom. So, we dove into the FSocket documentation in UE4 (which, according to Trung, hasn't been touched since Unreal Tournament 2...) - needless to say it was difficult. The end solution was a combination of both FSocket and FRunnable that could block and certain steps in the socket process without interrupting the game's main thread. Lots of stuff like this happened:
```
while (StopTaskCounter.GetValue() == 0)
{
socket->HasPendingConnection(foo);
while (!foo && StopTaskCounter.GetValue() == 0)
{
Sleep(1);
socket->HasPendingConnection(foo);
}
// at this point there is a client waiting
clientSocket = socket->Accept(TEXT("Connected to client.:"));
if (clientSocket == NULL) continue;
while (StopTaskCounter.GetValue() == 0)
{
Sleep(1);
if (!clientSocket->HasPendingData(pendingDataSize)) continue;
buf.Init(0, pendingDataSize);
clientSocket->Recv(buf.GetData(), buf.Num(), bytesRead);
if (bytesRead < 1) {
UE_LOG(LogTemp, Error, TEXT("Socket did not receive enough data: %d"), bytesRead);
return 1;
}
int32 command = (buf[0] - '0');
// call custom event with number here
alexaEvent->Broadcast(command);
clientSocket->Close();
break; // go back to wait state
}
}
```
Notice a few things here: we are constantly checking for a stop call from the main thread so we can terminate safely, we are sleeping to not block on Accept and Recv, and we are calling a custom event broadcast so that the actual game logic can run on the main thread when it needs to.
The second point of contention in threading was the Python server. Flask doesn't natively support any kind of global-to-request variables. So, the canonical approach of opening a socket once and sending info through it over time would not work, regardless of how hard we tried. The solution, as you can see from the above C++ snippet, was to repeatedly open and close a socket to the game on each Alexa call. This ended up causing a TON of problems in debugging (see below for difficulties there) and lost us a bit of time.
* **Network Protocols**: Of all things to deal with in terms of networks, we spent he largest amount of time solving the problems for which we had the least control. Two bad things happened: heroku rate limited us pretty early on with the most heavily used URLs (i.e. the Alexa responders). This prompted two possible solutions: migrate to DigitalOcean, or constantly remake Heroku dynos. We did both :). DigitalOcean proved to be more difficult than normal because the Alexa API only works with HTTPS addresses, and we didn't want to go through the hassle of using LetsEncrypt with Flask/Gunicorn/Nginx. Yikes. Switching heroku dynos it was.
The other problem we had was with timeouts. Depending on how we scheduled socket commands relative to REST requests, we would occasionally time out on Alexa's end. This was easier to solve than the rate limiting.
* **Level Design**: Our levels were carefully crafted to cater to the dual player relationship. Each room and lighting balance was tailored so that the player wouldn't feel totally lost, but at the same time, would need to rely heavily on Em for guidance and path planning.
## Accomplishments that we're proud of
The single largest thing we've come together in solving has been the integration of standard web protocols into a game engine. Apart from matchmaking and data transmission between players (which are both handled internally by the engine), most HTTP based communication is undocumented or simply not implemented in engines. We are very proud of the solution we've come up with to accomplish true bidirectional communication, and can't wait to see it implemented in other projects. We see a lot of potential in other AAA games to use voice control as not only an additional input method for players, but a way to catalyze gameplay with a personal connection.
On a more technical note, we are all so happy that...
THE DAMN SOCKETS ACTUALLY WORK YO
## Future Plans
We'd hope to incorporate the toolchain we've created for Project Em as a public GItHub repo and Unreal plugin for other game devs to use. We can't wait to see what other creative minds will come up with!
### Thanks
Much <3 from all of us, Sacha (CIS '17), Akshay (CGGT '17), Trung (CGGT '17), and Max (ROBO '16). Find us on github and say hello anytime. | losing |
## Inspiration
This project is inspired by the experience of one of our group member’s transportation issues during his time living in Newfoundland. The cell reception is terrible and the only available mode of transport is a taxi (aside from public buses) which is extremely expensive. Additionally, we were also inspired by our personal experience of running out of data during a trip which caused us great inconvenience (forcing us to walk around in order to look for free wifi) and delayed our journey.
## What it does
RideText is a provider of software for mobility services that simplifies the booking process and improves the accessibility of transportation services (such as taxis and private car services) for lower-income individuals and people living in areas with subpar cell reception. This is possible due to RideText’s 0% commission ride service which will in turn reduce costs for customers by 20 - 25% (average commission fees charged by existing mobility providers such as Uber and Lyft). RideText utilizes a very basic messaging service (SMS) present in every cell phone which will in turn provide a very accessible transportation service to people in rural areas and those living in areas with subpar cell reception. The use of SMS to book a ride is made possible with the integration of Twilio (a software company providing programmable communication tools to make and receive text messages using its web service APIs) in RideText’s system.
## How we built it
The front-end of the system is built using an app design & development tool FlutterFlow. Using FlutterFlow we were able to quickly produce prototypes for the UI design for RideText’s driver application. We also incorporated Firebase for secured authentication and google maps to help our drivers navigate through their journeys.
The backend of the system is built using node js and express framework. It integrates with Twilio API using a webhook to handle SMS sent by customers. It integrates Google Maps API, using Buf for secured and quick query handling, to compute the closest car to the customer. Then it feeds the incoming data to the driver's app using REST API.
## Challenges we ran into
At the start of the project, none of our team was experienced in the use of FlutterFlow as a development tool or Twilio’s APIs. However, after thorough research (and many stack overflow and youtube searches) we managed to figure out how to implement both technologies into our project. The main challenges of this project were mostly due to the use of new technologies.
## Accomplishments that we're proud of
We are extremely proud that despite our geographic and timezone difference, we were able to collaborate and learn about new technologies effectively. This is especially impressive as we have a few members who are brand new to software engineering work.
## What we learned
Through this hackathon project, we’ve learned the basics and some advanced techniques used when designing a UI with the design tool Flutter flow and its integration with firebase. Additionally, we learned how to store user data in firestore real-time database using collection and fields, helping us perform basic CRUD functions related to user data.
Through the implementation of GoogleMaps API using Buf, we learned a lot about protocol buffer and about its advantages over rest API and JSON structure. Though we weren’t able to complete implemented google maps functions due to the restricted timeframe, we were able to learn a lot about Buf Schema Registry (BSR) and its build method to implement the needed google maps API. Learning how systems can be automated simply using SMS services like Twilio was interesting as well.
## What's next for RideText
Our next goal for RideText is to explore its viability in the current marketplace (North America). From our initial research before starting this project, we have discovered that no other company provides the same services we are proposing. Due to the lack of competition and market opportunity, we’ve decided to continue developing this project after this hackathon. | ## 🌟 **Inspiration**
We were inspired by the story of our founder's grandfather, who suffered a stroke several years ago. Although he initially seemed to recover, his physical and mental abilities have rapidly declined since then. This deeply personal experience motivated us to develop a solution that can offer others facing similar challenges a more positive and hopeful outcome.
## 🩺 **What it Does**
Phoenix Health seamlessly integrates with patients' existing medical records and MRI/CT scans. By obtaining permission from both the patient and the doctor, our service analyzes the latest MRI or CT scans and compares them to pre-stroke scans. This analysis facilitates the creation of a personalized, sustainable, and effective recovery strategy. Phoenix Health continues to monitor the patient's progress, allowing for real-time adjustments to the recovery plan as needed.
## 🛠 **How We Built It**
Phoenix Health is a full-stack application designed for web use. We built this platform with **React** and **TypeScript**, ensuring a robust and scalable user experience.
## ⚡ **Challenges We Ran Into**
We faced numerous challenges throughout the development process, including technical hurdles, integration issues, and ensuring the security and privacy of patient data. These challenges led to many late nights and early mornings, but we persevered.
## 🎉 **Accomplishments That We're Proud Of**
We are incredibly proud of the functional and intuitive platform we have created. Our system's ability to seamlessly integrate with medical records and provide valuable insights for stroke recovery is a testament to our hard work and dedication.
## 📚 **What We Learned**
During this hackathon, we honed our skills in **React** and **TypeScript**, and learned how to effectively interact with large language models. We also gained valuable experience in crafting prompts to extract meaningful data from these models, enhancing the functionality of Phoenix Health.
## 🚀 **What's Next for Phoenix Health**
Looking ahead, we aim to collaborate with medical professionals, researchers, and healthcare providers to further refine and expand our platform. Our goal is to continue offering an empowering, secure, and beneficial tool for stroke recovery and beyond. | ## Inspiration
It may have been the last day before an important exam, the first day at your job, or the start of your ambitious journey of learning a new language, where you were frustrated at the lack of engaging programming tutorials. It was impossible to get their "basics" down, as well as stay focused due to the struggle of navigating through the different tutorials trying to find the perfect one to solve your problems.
Well, that's what led us to create Code Warriors. Code Warriors is a platform focused on encouraging the younger and older audience to learn how to code. Video games and programming are brought together to offer an engaging and fun way to learn how to code. Not only are you having fun, but you're constantly gaining new and meaningful skills!
## What it does
Code warriors provides a gaming website where you can hone your skills in all the coding languages it provides, all while levelling up your character and following the storyline! As you follow Asmodeus the Python into the jungle of Pythania to find the lost amulet, you get to develop your skills in python by solving puzzles that incorporate data types, if statements, for loops, operators, and more. Once you finish each mission/storyline, you unlock new items, characters, XP, and coins which can help buy new storylines/coding languages to learn! In conclusion, Code Warriors offers a fun time that will make you forget you were even coding in the first place!
## How we built it
We built code warriors by splitting our team into two to focus on two specific points of the project.
The first team was the UI/UX team, which was tasked with creating the design of the website in Figma. This was important as we needed a team that could make our thoughts come to life in a short time, and design them nicely to make the website aesthetically pleasing.
The second team was the frontend team, which was tasked with using react to create the final product, the website. They take what the UI/UX team has created, and add the logic and function behind it to serve as a real product. The UI/UX team shortly joined them after their initial task was completed, as their task takes less time to complete.
## Challenges we ran into
The main challenge we faced was learning how to code with React. All of us had either basic/no experience with the language, so applying it to create code warriors was difficult. The main difficulties associated with this were organizing everything correctly, setting up the react-router to link pages, as well as setting up the compiler.
## Accomplishments that we're proud of
The first accomplishment we were proud of was setting up the login page. It takes only registered usernames and passwords, and will not let you login in without them. We are also proud of the gamified look we gave the website, as it gives the impression that the user is playing a game. Lastly, we are proud of having the compiler embedded in the website as it allows for a lot more user interaction and function to the website.
## What we learned
We learnt a lot about react, node, CSS, javascript, and tailwind. A lot of the syntax was new to us, as well as the applications of a lot of formatting options, such as padding, margins, and more. We learnt how to integrate tailwind with react, and how a lot of frontend programming works.
We also learnt how to efficiently split tasks as a team. We were lucky enough to see that our initial split up of the group into two teams worked, which is why we know that we can continue to use this strategy for future competitions, projects, and more.
## What's next for Code Warriors
What's next for code warriors is to add more lessons, integrate a full story behind the game, add more animations to give more of a game feel to it, as well as expand into different coding languages! The potential for code warriors is unlimited, and we can improve almost every aspect and expand the platform to proving a multitude of learning opportunities all while having an enjoyable experience.
## Important Info for the Figma Link
**When opening the link, go into the simulation and press z to fit screen and then go full screen to experience true user interaction** | losing |
# Doctors Within Borders
### A crowdsourcing app that improves first response time to emergencies by connecting city 911 dispatchers with certified civilians
## 1. The Challenge
In Toronto, ambulances get to the patient in 9 minutes 90% of the time. We all know
that the first few minutes after an emergency occurs are critical, and the difference of
just a few minutes could mean the difference between life and death.
Doctors Within Borders aims to get the closest responder within 5 minutes of
the patient to arrive on scene so as to give the patient the help needed earlier.
## 2. Main Features
### a. Web view: The Dispatcher
The dispatcher takes down information about an ongoing emergency from a 911 call, and dispatches a Doctor with the help of our dashboard.
### b. Mobile view: The Doctor
A Doctor is a certified individual who is registered with Doctors Within Borders. Each Doctor is identified by their unique code.
The Doctor can choose when they are on duty.
On-duty Doctors are notified whenever a new emergency occurs that is both within a reasonable distance and the Doctor's certified skill level.
## 3. The Technology
The app uses *Flask* to run a server, which communicates between the web app and the mobile app. The server supports an API which is used by the web and mobile app to get information on doctor positions, identify emergencies, and dispatch doctors. The web app was created in *Angular 2* with *Bootstrap 4*. The mobile app was created with *Ionic 3*.
Created by Asic Chen, Christine KC Cheng, Andrey Boris Khesin and Dmitry Ten. | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | ## Inspiration
We wanted to make something create something interesting for our first time using Android-Studio.
## What it does
By sending a late text, you'll never miss that happy birthday wish or that important event reminder.
## How we built it
By researching online, we discovered how to send texts utilizing android-studio.
## Challenges we ran into
Originally, we decided to create an android-wear heat attack detection app. This app consisted of 3 main areas. The heart rate sensor, the text features and a quiz that can diagnose high risk patients for a heart attack. We were unable to utilize the android-wear's heart rate sensor in the allotted time, as a result, we pivoted to a delayed text messaging service.
## Accomplishments that we're proud of
We're proud of our ability to pivot an ambitious idea into something that was feasible, and we're also proud of stepping outside of our comfort zones and opting to program into an IDE we are unfamiliar with.
## What we learned
Android studios development, working with the IDE in Android wear as well as SMS.
## What's next for MSG2GO
We hope to update the app with aestheically pleasing visuals. As well as a personal account associated with the app's features. | winning |
### Problem and Challenge
Achieving 100% financial inclusion where all have access to financial services still remains a difficult challenge. Particularly, a huge percentage of the unbanked adults comprise of women [1]. There are various barriers worldwide that prevent women from accessing formal financial services, including lower levels of income, lack of financial literacy, time and mobility constraints as well as cultural constraints and an overall lack of gender parity [1]. With this problem present, our team wanted to take on Scotiabank's challenge to build a FinTech tool/hack for females.
### Our Inspiration
Inspired by LinkedIn, Ten Thousands Coffee, and Forte Foundation, we wanted to build a platform that combines networking opportunities, mentorship programs, and learning resources of personal finance management and investment opportunities to empower women in managing their own finance; thereby increasing financial inclusion of females.
## What it does
The three main pillars of Elevate consists of safe community, continuous learning, and mentor support with features including personal financial tracking.
### Continuous Learning
Based on the participant's interests, the platform will suggest suitable learning tracks that are available on the current platform. The participant will be able to keep track of their learning progress and apply the lessons learned in real life, for example, tracking their personal financial activity.
### Safe Community
The Forum will allow participants to post questions from their learning tracks, current financial news, or discuss any relevant financial topics. Upon signing up, mentors and mentees should abide by the guidelines for respectful and appropriate interactions between parties. Account will be taken off if any events occur.
### Mentor Support
Elevate pairs the participant with a mentor that has expertise in the area that the mentor wishes to learn more about. The participant can schedule sessions with the mentor to discuss financial topics that they are insecure about, or discuss questions they have about their lessons learned on the Elevate platform.
### Personal Financial Activity Tracking
Elevate participants will be able to track their financial expenses. They would receive notifications and analytics results to help them achieve their financial goals.
## How we built it
Before we started implementing, we prototyped the workflow with Webflow.
We then built the platform as a web application using html, CSS, JavaScript, and collaborated real-time using git.
## Challenges we ran into
* There are a lot of features to incorporate. However we were able to demonstrate the core concepts of our project - to make financing more inclusive.
## Accomplishments that we're proud of
* The idea of incorporating several features into one platform.
* Deployed a demo web application.
* The sophisticated design of the interface and flow of navigation.
## What we learned
We learned about the gender parity in finance, and how technology can remove the barriers and create a strong and supportive community for all to understand the important role that finance plays in their lives.
## What's next for Elevate
* Partner with financial institutions to create and curate a list of credible learning tracks/resources for mentees
* Recruit financial experts as mentees to help enable the program
* Add credit/debit cards onto the system to make financial tracking easier. Security issues should be addressed.
* Strengthen and implement the backend of the platform to include:
Instant messaging, admin page to monitor participants
## Resources and Citation
[1] 2020. REMOVING THE BARRIERS TO WOMEN’S FINANCIAL INCLUSION. [ebook] Toronto: Toronto Centre. Available at: <https://res.torontocentre.org/guidedocs/Barriers%20to%20Womens%20Financial%20Inclusion.pdf>. | ## Inspiration
Ever felt a shock by thinking where did your monthly salary or pocket money go by the end of a month? When Did you spend it? Where did you spend all of it? and Why did you spend it? How to save and not make that same mistake again?
There has been endless progress and technical advancements in how we deal with day to day financial dealings be it through Apple Pay, PayPal, or now cryptocurrencies and also financial instruments that are crucial to create one’s wealth through investing in stocks, bonds, etc. But all of these amazing tools are catering to a very small demographic of people. 68% of the world population still stands to be financially illiterate. Most schools do not discuss personal finance in their curriculum. To enable these high end technologies to help reach a larger audience we need to work on the ground level and attack the fundamental blocks around finance in people’s mindset.
We want to use technology to elevate the world's consciousness around their personal finance.
## What it does
Where’s my money, is an app that simply takes in financial jargon and simplifies it for you, giving you a taste of managing your money without affording real losses so that you can make wiser decisions in real life.
It is a financial literacy app that teaches you A-Z about managing and creating wealth in a layman's and gamified manner. You start as a person who earns $1000 dollars monthly, as you complete each module you are hit with a set of questions which makes you ponder about how you can deal with different situations. After completing each module you are rewarded with some bonus money which then can be used in our stock exchange simulator. You complete courses, earn money, and build virtual wealth.
Each quiz captures different data as to how your overview towards finance is. Is it inclining towards savings or more towards spending.
## How we built it
The project was not simple at all, keeping in mind the various components of the app we first started by creating a fundamental architecture to as to how the our app would be functioning - shorturl.at/cdlxE
Then we took it to Figma where we brainstormed and completed design flows for our prototype -
Then we started working on the App-
**Frontend**
* React.
**Backend**
* Authentication: Auth0
* Storing user-data (courses completed by user, info of stocks purchased etc.): Firebase
* Stock Price Changes: Based on Real time prices using a free tier API (Alpha vantage/Polygon
## Challenges we ran into
The time constraint was our biggest challenge. The project was very backend-heavy and it was a big challenge to incorporate all the backend logic.
## What we learned
We researched about the condition of financial literacy in people, which helped us to make a better product. We also learnt about APIs like Alpha Vantage that provide real-time stock data.
## What's next for Where’s my money?
We are looking to complete the backend of the app to make it fully functional. Also looking forward to adding more course modules for more topics like crypto, taxes, insurance, mutual funds etc.
Domain Name: learnfinancewitheaseusing.tech (Learn-finance-with-ease-using-tech) | ## **Inspiration**
Ever have an idea for a project brewing in your head, but you're not sure where to start? Our vision for **IdeaCrowd** is to allow you to jumpstart your project by connecting you with others with shared interests and similar project ideas! You can explore through a collection of current and previous projects for inspiration, and connect with other creators with ease.
## What it does
#### My Profile
IdeaCrowd is a three step process to jumpstart your project idea.
1. *Find your narrative*: You fill in a prompt with as many words as you can to describe your project in the Ideation Box, which uses Open AI's GPT-3 to distill the essence of your idea into relevant keywords for our matching algorithm.. From here, you complete your profile to describe your skillset, interests, and accomplishments to help match you with other creators.
2. Draw inspiration\_: After the initial prompt, you can explore past and current projects by creators of similar interests, and connect with them through IdeaCrowd to draw some inspiration and develop your idea.
3. *Check these out*: IdeaCrowd will get you started with product management tools, and a shared workspace that lets you focus on your project, and connecting with other creators and potential collaborators.
#### Explore!
* *Featured*: Our curated list of projects that are relevant to current/ recent events, social cause, eco-conscious, mental health awareness
* *Trending*: A list of the projects that are hot, most viewed or most "favorite"
* *Inspire*: A list of projects based on the user's selection of categories, and projects that are similar to the user's own project (if applicable)
* User can click on the project and view it (if it is public), "favorite" it, and contact the project owner to see if there's a collaboration opportunity (this is where the Friends and Chat functionality would come in handy)
#### New Project
1. *Ideation Box*: Freely write and describe your idea: what you want to do, what you intend to accomplish, who is the target audience, is this a private or collaborative project
2. *Tags*: Select a few categories that might fit with your project
3. *Check these out*: Based on the selected tags, and keywords processed from the **Ideation Box** by openAI, a short list of current and past projects that are similar to the *new* Project
#### Project Workspace
This page allows you to initiate your project. Basic tools will be provided to help guide you through the process of implementing the project, such as Budget Calculator, ToDo list, Calendar, Notebook, Sketchpad, Text Editor etc.
## How we built it
#### **Backend**
We used Python, CockroachDB, Firebase, Docker
#### **Frontend**
We used React, HTML/CSS
## Challenges we ran into
* Connecting frontend and backend was a huge hurdle
* Creating a Docker image for the Flask application because we chose to use CockroachDB which uses some PostgreSQL driver and it did some funky stuff (We will have spend the rest of the weekend deleting those "failed" images. Grrrrrrrr, I'm more familiar with MongoDB).
## Accomplishments that we're proud of
* Submitting something (better than nothing haha)
* We actually have a working Docker image of the Flask app (CockroachDB T-Shirt here I come)
* We have some decent UI (although we had hope that it would look more like the ones we have on Figma).
* The Flask app is a 400-line file (what a weekend)
* We have a working sidebar
## What we learned
* Dev Ops and deploying applications **ARE NOT TRIVIAL TASKS**
* Time is very limited
* Balancing ambition and simplicity
* Many, many, many new software
## What's next for IdeaCrowd
#### Implementing the rest of the tools we had planned for
* OpenAI: Keywords for the Ideation Box
* Creating the Explore page
* Creating the Project Workspace Page
* Proper Sign-in Authentication
* Connecting the pages together
#### Commercial Potential
* The basic project initiation, browsing for inspiration, networking/ chat are free and accessible to the public
* Subscription Plan: *IdeaCrowd Pro* will provide more advanced tools to help develop your project
* Promotional: Project Development tools can be advertised (eg Asana)
# #Social cause #WebApp #CockroachDB #GoogleCloud #Mental Health #Ideation #Creativity #Ambitious | winning |
## Inspiration
When struggling to learn HTML, and basic web development. The tools provided by browsers like google chrome were hidden making hard to learn of its existence. As an avid gamer, we thought that it would be a great idea to create a game involving the inspect element tool provided by browsers so that more people could learn of this nifty feature, and start their own hacks.
## What it does
The project is a series of small puzzle games that are reliant on the user to modify the webpage DOM to be able to complete. When the user reaches the objective, they are automatically redirected to the next puzzle to solve.
## How we built it
We used a game engine called craftyjs to run the game as DOM elements. These elements could be deleted and an event would be triggered so that we could handle any DOM changes.
## Challenges we ran into
Catching DOM changes from inspect element is incredibly difficult. Working with craftyjs which is in version 0.7.1 and not released therefore some built-ins e.g. collision detection, is not fully supported. Handling various events such as adding and deleting elements instead of recursively creating a ton of things recursively.
## Accomplishments that we're proud of
EVERYTHING
## What we learned
Javascript was not designed to run as a game engine with DOM elements, and modifying anything has been a struggle. We learned that canvases are black boxes and are impossible to interact with through DOM manipulation.
## What's next for We haven't thought that far yet
You give us too much credit.
But we have thought that far. We would love to do more with the inspect element tool, and in the future, if we could get support from one of the major browsers, we would love to add more puzzles based on tools provided by the inspect element option. | ## Inspiration
After seeing the breakout success that was Pokemon Go, my partner and I were motivated to create our own game that was heavily tied to physical locations in the real-world.
## What it does
Our game is supported on every device that has a modern web browser, absolutely no installation required. You walk around the real world, fighting your way through procedurally generated dungeons that are tied to physical locations. If you find that a dungeon is too hard, you can pair up with some friends and tackle it together.
Unlike Niantic, who monetized Pokemon Go using micro-transactions, we plan to monetize the game by allowing local businesses to to bid on enhancements to their location in the game-world. For example, a local coffee shop could offer an in-game bonus to players who purchase a coffee at their location.
By offloading the cost of the game onto businesses instead of players we hope to create a less "stressful" game, meaning players will spend more time having fun and less time worrying about when they'll need to cough up more money to keep playing.
## How We built it
The stack for our game is built entirely around the Node.js ecosystem: express, socket.io, gulp, webpack, and more. For easy horizontal scaling, we make use of Heroku to manage and run our servers. Computationally intensive one-off tasks (such as image resizing) are offloaded onto AWS Lambda to help keep server costs down.
To improve the speed at which our website and game assets load all static files are routed through MaxCDN, a continent delivery network with over 19 datacenters around the world. For security, all requests to any of our servers are routed through CloudFlare, a service which helps to keep websites safe using traffic filtering and other techniques.
Finally, our public facing website makes use of Mithril MVC, an incredibly fast and light one-page-app framework. Using Mithril allows us to keep our website incredibly responsive and performant. | # HackMIT2019
For Speech to Text, in the python\_examples folder, run:
pip install -r requirements.txt
## Backstory
For our project, we were inspired by one of our team member's difficulty in learning Spanish. Reading a language you don't understand can be difficult. Mispronunciation is a common side effect of reading words you don't understand - how can you remember something if you don't know what it means. For our project, we wanted to make a tool for people to input sentences they want to learn to read aloud and then practice them with the computer's assistance.
## Structure of the Tool
In order to use our tool, the learner must first input any sentence they want to practice reading. Then they press "start speaking" and read back their sentence to the computer. The computer will then highlight the words they got wrong and provide an image and the correct pronunciation of the word they got wrong. This way, the combination of audio, visual, and semantics will aid in a true understanding of they are saying.
## Main Tools Used
Our webapp is a combination of HTML, Flask, and python code using several different APIs. For the speech-to-text portion of our app, we utilized REV.ai's streaming API. For the image search of incorrect words, we used Bing's image search API. Finally, to get the correct pronunciation, we used IBM's text-to-speech API. | winning |
## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part detection model to track movements that correspond to controls for classic games that are ran through an online browser. The user can choose from a variety of classic games such as temple run, super mario, and play them with their body movements.
## How we built it
* The first step was setting up opencv and importing the a body part tracking model from google mediapipe
* Next, based off the position and angles between the landmarks, we created classification functions that detected specific movements such as when an arm or leg was raised or the user jumped.
* Then we correlated these movement identifications to keybinds on the computer. For example when the user raises their right arm it corresponds to the right arrow key
* We then embedded some online games of our choice into our front and and when the user makes a certain movement which corresponds to a certain key, the respective action would happen
* Finally, we created a visually appealing and interactive frontend/loading page where the user can select which game they want to play
## Challenges we ran into
A large challenge we ran into was embedding the video output window into the front end. We tried passing it through an API and it worked with a basic plane video, however the difficulties arose when we tried to pass the video with the body tracking model overlay on it
## Accomplishments that we're proud of
We are proud of the fact that we are able to have a functioning product in the sense that multiple games can be controlled with body part commands of our specification. Thanks to threading optimization there is little latency between user input and video output which was a fear when starting the project.
## What we learned
We learned that it is possible to embed other websites (such as simple games) into our own local HTML sites.
We learned how to map landmark node positions into meaningful movement classifications considering positions, and angles.
We learned how to resize, move, and give priority to external windows such as the video output window
We learned how to run python files from JavaScript to make automated calls to further processes
## What's next for AR.cade
The next steps for AR.cade are to implement a more accurate body tracking model in order to track more precise parameters. This would allow us to scale our product to more modern games that require more user inputs such as Fortnite or Minecraft. | ## Inspiration
There is a growing number of people sharing gardens in Montreal. As a lot of people share apartment buildings, it is indeed more convenient to share gardens than to have their own.
## What it does
With that in mind, we decided to create a smart garden platform that is meant to make sharing gardens as fast, intuitive, and community friendly as possible.
## How I built it
We use a plethora of sensors that are connected to a Raspberry Pi. Sensors range from temperature to light-sensitivity, with one sensor even detecting humidity levels. Through this, we're able to collect data from the sensors and post it on a google sheet, using the Google Drive API.
Once the data is posted on the google sheet, we use a python script to retrieve the 3 latest values and make an average of those values. This allows us to detect a change and send a flag to other parts of our algorithm.
For the user, it is very simple. They simply have to text a number dedicated to a certain garden. This will allow them to create an account and to receive alerts if a plant needs attention.
This part is done through the Twilio API and python scripts that are triggered when the user sends an SMS to the dedicated cell-phone number.
We even thought about implementing credit and verification systems that allow active users to gain points over time. These points are earned once the user decides to take action in the garden after receiving a notification from the Twilio API. The points can be redeemed through the app via Interac transfer or by simply keeping the plant once it is fully grown. In order to verify that the user actually takes action in the garden, we use a visual recognition software that runs the Azure API. Through a very simple system of QR codes, the user can scan its QR code to verify his identity. | ## Inspiration
I've been studying and working from home ever since the pandemic began. I realized my PC has been getting really hot over time, due to the nature of the software applications I'm using. Instead of buying a PC cooler, I decided to build one!
## What it does
It's a cooler for your computer, cooling it down as it starts to heat up. If you have an Arduino lying around, it can easily be built within a few dollars. An added bonus is its energy efficiency - a temperature sensor consistently checks the PC temperature and accordingly regulates the fan speed, allowing you to work knowing you're taking care of your PC while not wasting energy / electricity unnecessarily.
## How we built it
A DC motor (capable of connecting up to 2 DC motors with the L293D chip used) was used with fan blades serving as the fan that cools the PC. An L293D chip is used to control the DC motor direction (blowing cool air towards the PC). Using PWM, the DC motor speed is controlled. An Arduino Uno was used to deploy the code and run this apparatus, while a Temp/Humidity sensor was used to measure the temperature of the PC. The code checks the temperature every 5 seconds and automatically changes the fan speed accordingly. And the optimal PC temperature I set was between 20 - 25 degrees C.
## Challenges we ran into
Time was definitely a major challenge - balancing this with work and term courses was definitely the biggest challenge (going into an in-person hackathon automatically carves out a set time to work on this, but with the pandemic, it was definitely a challenge to ensure I carved out enough time to complete this project).
Another challenge presented itself during testing - to ensure that the PC cooler worked properly (changing fan speed when the temperature changed), it was a small challenge getting the air to heat up to 30 degrees C and back down to 20 degrees C to ensure all the edge case conditions were met. I got around this by using a heat gun and a much larger fan to ensure the code worked optimally!
## Accomplishments that we're proud of
Proud of the fact that this was accomplished in the short time I had between work and study. Getting all the individual pieces to fit together and actually build something useful (this problem presented itself during the pandemic and it's something I've been meaning to make for quite some time) that I will actually use is quite rewarding!
## What we learned
Learnt that a PC cooler that is also quite energy-efficient that can be built at the fraction of the market cost - quite a rewarding experience!
## What's next for PCool
I'll be adding a Red and Green LED to visually display whether the PC is hot or cold (for the user).
I would like to use an Arduino Nano instead (due to the smaller form factor) and solder all these connections onto a perf board, so I can easily put this into a mechanical enclosure I plan to either 3D print or make out of materials found around the house.
I was in the middle of adding a function that increases and decreases the fan speed gradually, as opposed to an immediate jump (this will probably take about 30 min to implement and test with the project to ensure it works well).
I would also like to find a better motor that can run off 5V and still deliver quality air flow, so I can plug this device into my computer, allowing it to be powered by my PC just like a real cooler! | winning |
## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it! | ## Inspiration
An article that was published last month by the CBC talked about CRA phone scams.
The article said that “Thousands of Canadians had been scammed over the past several years, at an estimated cost of more than $10 million dollars, falling prey to the dozens of call centers using the same scheme.”
We realized that we had to protect consumers and those not as informed.
## The app
We created a mobile app that warns users about incoming SMS or Phone fraud from scam numbers.
The mobile app as well offers a playback function so users can learn what scam calls sound like.
Alongside the mobile app we built a website that provides information on scamming and allows users to query to see if a number is a scam number.
## How it works
The PBX server gets an incoming phone call or SMS from a scamming bot and records/saves the information. Afterwards the data is fed into a trained classifier so that it can be determined as scam or not scam. If the sender was a scammer, they're entered into the Postgresql database to later be queried over HTTP. The extensions from here are endless. API's, User applications, Blacklisting etc . . .
## Challenges we ran into
At first, we were going to build a react native application. However, Apple does not support the retrieval of incoming call phone numbers so we defaulted to a android application instead. FreePBX runs PHP 5 which is either deprecated or near deprecation. We as well originally tried to use Postgresql for FreePBX but had to use MySQL instead. PBX call recording was not achieved unfortunately.
## Accomplishments that we're proud of
* Setting up FreePBX
* Finished Website
* Finished App
* Broadcast Receiver
## What we learned
* FreePBX
* NGINX
* Android Media Player
## What's next for Tenty
* Full SMS support
* Distributed PBX network to increase data input
* API for Financial Institutions, and or those affiliated with what is being scammed. Allowing them to protect their customers.
* Assisting Governments in catching scammers. | ## Inspiration
We were inspired by two key challenges: the widespread anxiety around presentations among students and the unique difficulties faced by people with hearing disabilities in developing effective presentation skills. Recognizing that 75% of students fear presentations and that individuals with hearing impairments struggle to self-correct their speech patterns, we saw an opportunity to create an inclusive tool that empowers both groups to overcome these challenges.
## What it does
VoiceEdge AI is an AI-powered speech skills coach tailored for high school and college students, as well as individuals with hearing disabilities. It provides:
* Real-time feedback on speech patterns, rhythm, intonation, body language, and content delivery
* Personalized coaching to improve storytelling and persuasive skills
* Real-time practice sessions with your role model
* Visual cues and haptic feedback for users with hearing disabilities
* A safe, judgment-free environment for practice and skill development
* Adaptive learning that caters to different presentation scenarios and user needs
* Mindfulness techniques to help reduce stress and anxiety and build confidence for presentations
## How we built it
Test the API on the backend. Local computer we tested out the unit tests and
Semantic used the whisper API. Acoustic used the Praat.
## Challenges we ran into
We ran into problems with our computers not having the specified libraries, often running into ModuleNotFound errors. When trying to import HumeVoiceClient from the Hume library, we run into this problem. We solved this by using Google Colab instead of our local machines. By doing so, we were able to collaborate with one another on the project and work harmoniously. Debugging these issues meant that we had to spend time looking into forums and documentation. In addition, we also had problems with our access codes. We sought help by going into the Slack channels and using the redeem codes that they provided in the chat. By redeeming the free credits, we were able to focus on building the project and not having to worry about the billing.
## Accomplishments that we're proud of
Democratizing Role Models: Leveraged AI to make learning from role models accessible and widespread, reducing the scarcity of real-life mentors.
AI for Good: Integrated mindfulness techniques to help users manage stress and anxiety, enhancing their presentation skills.
Advanced Feedback: Utilized Hume's speech recognition and large language models (LLMs) like OpenAI and AWS Claude to provide clear, actionable feedback, making it easier for students to improve their skills.
## What's next for VoiceEdge AI
1. Streamline Product (1 Month):
2. Transition to a fully online platform with real-time feedback capabilities
3. Optimize system performance to reduce latency for a smoother user experience
4. User Research & NPO Collaboration (3 Months):
5. Conduct comprehensive user behavior analysis by recruiting diverse students
6. Partner with non-profit organizations to engage with hearing-impaired users
7. Test and refine business models based on feedback from NPO collaborations
8. Ecosystem & Feature Expansion (6 Months):
9. Develop an inclusive, engaging ecosystem featuring interactive avatars (e.g., teddy bears) to create a more welcoming practice environment
10. Introduce new modules for networking skills and small talk practice
11. Expand the platform's capabilities to cater to a wider range of communication scenarios
12. Continuous Improvement:
13. Regularly update our AI models based on user data and feedback
14. Enhance accessibility features for users with hearing disabilities
15. Explore partnerships with educational institutions to integrate VoiceEdge AI into curricula
16. Community Building:
17. Create a supportive user community for peer feedback and shared experiences
18. Organize virtual events and workshops to foster engagement and skill development
19. Research and Development:
20. Invest in ongoing research to improve AI coaching capabilities
21. Explore emerging technologies to enhance the user experience and effectiveness of the platform | winning |
## Inspiration
Many students have learning disabilities that negatively impact their education. After doing some research, we learned that there were nearly 150,000 students in Ontario alone!
UofT offers note-taking services to students that are registered with accessibility services, but the service relies on the quality and availability of fellow student volunteers. After learning about Cohere, we realized that we could create a product that could more reliably provide this support to students.
## What it does
Scribes aims to address these issues by providing a service that simplifies and enhances accessibility in the note-taking process. The web app was built with accessibility as the main priority, delivered through high contrast, readable fonts and clear hierarchies.
To start saving lecture sessions, the user can simply sign up for free with their school email! Scribes allows students to record live lectures on either their phone or laptop, and then receive a live transcript that can be highlighted and commented on in real-time. Once class is done, the annotated transcript is summarized by Cohere's advanced NLP algorithms to provide an easily digestible overview of the session material.
The student is also presented with definitions and additional context to better understand key terms and difficult concepts. The recorded sessions and personalized notes are always accessible through the student's tailored dashboard, where they can organize their study material through the selection of tags and folders.
## How we built it
*Designers:*
* Conducted research to gain a better understanding of our target demographic, their pain points, and our general project scope.
* Produced wireframes to map out the user experience.
* Gathered visual inspiration and applied our own design system toward creating a final design for the web app.
*Devs:*
* Used Python and AssemblyAI API to convert audio files into text transcription
* Used Cohere to summarize text, and adjusted hyperparameters in order to generate accurate and succinct summarizations of the input text
* Used Flask to create a backend API to send data from the frontend to the backend and to retrieve data from the Cohere API
*Team:*
* Brainstormed potential project ideas and features specific to this flow.
* Shared ideas and portions of the project to combine into one overall project.
## Challenges we ran into
* Troubleshooting with code: some of our earlier approaches required components that were out of date/no longer hosted, and we had to adjust by shifting the input type
* The short timeframe was a barrier preventing us from implementing stylized front-end code. To make the most out of our time, we designed the interface on Figma, developed the back-end to transcribe the sessions, and created a simple front-end document to showcase the functionality and potential methods of integration.
* Figuring out which platform and which technologies to use such that our project would be reflective of our original idea, easy and fast to develop, and also extensible for future improvements
## Accomplishments that we're proud of
Over the course of 36 hours, we’ve managed to work together and create an effective business pitch, a Figma prototype for our web app, and a working website that transcribes and summarizes audio files.
## What we learned
Our team members learned a great deal this weekend, including: creating pitches, working in a tight timeframe, networking, learning about good accessibility practices in design when designing for those with learning needs, how to work with and train advanced machine learning models, python dependencies, working with APIs and Virtual Environments.
## What's next for Scribes
If provided with more time, we plan to implement other features — such as automatically generated cue cards, a bot to answer questions regarding session content, and collaborative notes. As we prioritize accessibility and ease-of-use, we would also conduct usability testing to continue ensuring that our users are at the forefront of our product.
To cover these additional goals, we may apply to receive funding dedicated to accessibility, such as the Government of Canada’s Enabling Education Fund. We could also partner with news platforms, wiki catalogs, and other informational websites to receive more funding and bridge the gap in accessing more knowledge online. We believe that everyone is equally deserving of receiving proper access to education and the necessary support it takes to help them make the most of it. | ## Inspiration
The inspiration for this app comes from the recent natural disasters and terror events that have been occurring around the United States and the globe. From our personal experience, when traveling to foreign places, there is always a sense of fear as it is difficult to get information on what is going on and where. We also realized that it is difficult to keep loved ones posted constantly and consistently on your safety status during these trips as well.
## What it does
Safescape intelligently analyzes real-time new's articles and classifies them as a "non-safe" or "safe" event and notifies users in the respective locations if the article is deemed "non-safe." The app provides emergency contact information and a map of escape routes for the location that you are in. The app has a report button that sends a text to local emergency personnel and notifies users in the vicinity that an emergency is happening. In the event of an emergency, the app also allows the users the options to contact loved one's in a quick and easy manner.
## How we built it
Our backend is a Flask server. We used Google Cloud Platform to intelligently analyze news articles. Microsoft search to pull news articles. Wrld Maps to display a map for the users. Sparkpost API to send out a notification to the users affected. UnifyId to authenticate users.
## Challenges we ran into
We ran into several challenges including getting the Unifyid SDK to work as well as working with the API's in general.
## Accomplishments that we're proud of
We're proud of sticking through with our app even when nothing was working and figuring out how to get all the API's to run properly. Also proud of our designs and the functionalities we were able to get working in our project.
## What we learned
We learned a ton this hackathon. From integrating API's to sending notifications, most everything required looking into something that we haven't worked with before.
## What's next for Safescape
There are a ton of functionalities that are half implemented or implemented not as well as we would like. We would love to add real escape routes based on the venue that the user is at and other stretch features such as alerting the police and potentially identifying whether there is danger based on the movement of the individuals around you. | ## Inspiration
Many visually impaired individuals face challenges due to their dependence on others. They lack the ability to do things on their own and often miss out on the simple pleasures of life. We wanted to create an app that helps the visually impaired fully experience life -- on their own terms.
## What it does
"Sight" is essentially a navigation app for the blind. It uses image recognition and ultrasonic sensors attached to an Arduino in order to help visually impaired people to "see" around them. It also provides audio-based directions to the user.
## How we built it
Our team first designed visual and audio based interfaces with a visually-impaired audience in mind. We then 3D-printed an iPhone case which was designed to hold an Arduino board/ultrasonic sensor. Then, our team developed an image recognition model using Apple's CoreML. Lastly, the model was implemented in the iOS application and any remaining flaws were removed.
## Challenges we ran into
The main issue our team ran into regarded implementing our ML models in the final iOS application. We had a TensorFlow model already trained, however, our team was not able to use this model in the final application.
## Accomplishments that we're proud of
Although our team was not able to use the TensorFlow model as initially planned, we were able to come up with an alternate solution that worked. Our team is proud that we were able to come up with a working app that has potential to impact the modern world.
## What we learned
Our team primarily learned how to complement iOS development and ML models and how Arduino/iOS compatibility functions.
## What's next for Sight
Moving forward, our team needs to improve Sight's image-recognition software. We created our own dataset since we lacked the computing power to use larger, more official datasets. We used CoreML's pre-trained MobileNet model. Although the model works to an extent, the safety of the blind individual is paramount and improving the image-recognition software directly benefits the safety of the user. | partial |
## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | ## Inspiration
This project was a response to the events that occurred during Hurricane Harvey in Houston last year, wildfires in California, and the events that occurred during the monsoon in India this past year. 911 call centers are extremely inefficient in providing actual aid to people due to the unreliability of tracking cell phones. We are also informing people of the risk factors in certain areas so that they will be more knowledgeable when making decisions for travel, their futures, and taking preventative measures.
## What it does
Supermaritan provides a platform for people who are in danger and affected by disasters to send out "distress signals" specifying how severe their damage is and the specific type of issue they have. We store their location in a database and present it live on react-native-map API. This allows local authorities to easily locate people, evaluate how badly they need help, and decide what type of help they need. Dispatchers will thus be able to quickly and efficiently aid victims. More importantly, the live map feature allows local users to see live incidents on their map and gives them the ability to help out if possible, allowing for greater interaction within a community. Once a victim has been successfully aided, they will have the option to resolve their issue and store it in our database to aid our analytics.
Using information from previous disaster incidents, we can also provide information about the safety of certain areas. Taking the previous incidents within a certain range of latitudinal and longitudinal coordinates, we can calculate what type of incident (whether it be floods, earthquakes, fire, injuries, etc.) is most common in the area. Additionally, by taking a weighted average based on the severity of previous resolved incidents of all types, we can generate a risk factor that provides a way to gauge how safe the range a user is in based off the most dangerous range within our database.
## How we built it
We used react-native, MongoDB, Javascript, NodeJS, and the Google Cloud Platform, and various open source libraries to help build our hack.
## Challenges we ran into
Ejecting react-native from Expo took a very long time and prevented one of the members in our group who was working on the client-side of our app from working. This led to us having a lot more work for us to divide amongst ourselves once it finally ejected.
Getting acquainted with react-native in general was difficult. It was fairly new to all of us and some of the libraries we used did not have documentation, which required us to learn from their source code.
## Accomplishments that we're proud of
Implementing the Heat Map analytics feature was something we are happy we were able to do because it is a nice way of presenting the information regarding disaster incidents and alerting samaritans and authorities. We were also proud that we were able to navigate and interpret new APIs to fit the purposes of our app. Generating successful scripts to test our app and debug any issues was also something we were proud of and that helped us get past many challenges.
## What we learned
We learned that while some frameworks have their advantages (for example, React can create projects at a fast pace using built-in components), many times, they have glaring drawbacks and limitations which may make another, more 'complicated' framework, a better choice in the long run.
## What's next for Supermaritan
In the future, we hope to provide more metrics and analytics regarding safety and disaster issues for certain areas. Showing disaster trends overtime and displaying risk factors for each individual incident type is something we definitely are going to do in the future. | ## Inspiration
Lighting sets an appropriate atmosphere and heightens an audience's understanding of a theatrical performance. However, rehearsing and experimenting with lighting is costly and time consuming. That is why we created a virtual lighting lab that is universally accessible, affordable, and fun! :)
## What it does
There are two major components for LIT.
1) The LIT lighting lab provides a real-time rendering of the stage to the user in response to any change made to light's color, intensity, and the camera perspective.The user can toggle light helpers. The spotlight palette is pre-populated with LEE's filter colors [link](http://www.leefilters.com/lighting/colour-list.html) for users to experiment with, and they may also save the cue configuration and download the scene's images for future reference. The user can zoom by scrolling, rotate by dragging, and pan by holding middle mouse button and dragging.
2) The LIT VR Viewer puts users in the stages they designed. It uses device orientation so users can use a cardboard to look around the stage. By saying "cue," users can transition to a scene with different lighting and perspective. Demonstration of cue: [link](https://youtu.be/muywi8lxq9Q).
## How we built it
We used three.js to set up our 3d environment. Using jQuery, we linked our Material Design Lite (MDL) UI components to the spotlight objects so users could modify the color, intensity, and light helpers. We used Python's Beautiful Soup to scrape LEE's color filters. We used JavaScript to enable cues that can be saved and allow the user to download photos of the stage.We also created a VR mode by hyperlinking to the stage fullscreen and using device orientation to respond to the user's movements. Anyanng's voice recognition API allowed the user to cue through scenes in VR Mode.
## Challenges we ran into
Threejs had many deprecated methods.
It was my first time programming in JavaScript, and I didn't realize the ordering of scripts and function calls mattered. That led to unexpected challenges because the logic in the code was correct but it still didn't compile. We weren't sure if the renderer couldn't handle too many lights, the virtual model was too big, or there was an issue with the code. We started over using Threejs's WebVR scripts. However, the user had to enable the site's WebVR, which would have made LIT less accessible. We were able to configure VR using device orientation and stereo effect by editing and reorganizing the code.
## Accomplishments that we're proud of
Intuitive Design
VR mode / Voice Cues
## What we learned
This was my first time programming in Javascript, Python, and HTML. I learned how to program a 3d environment and interactive GUI, scrape information, and enable VR and voice recognition using these programs.
## What's next for LIT
This prototype is based on Penn's PAC shop: [link](http://pacshop.org/). This is a demonstration of LightWeb, the light simulation we based our program on: [link](https://youtu.be/ZSxVUmhcKLA). We look forward to adding more features such as different types of spotlights and allowing the user to change the location of the cameras. | winning |
## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up with a healthy social media network, where you directly interact with other people that are going through similar problems as you so you can work together. Not only the network itself comes with tools to cultivate healthy relationships, from **sentiment analysis** to **detailed data visualization** of how much time you spend and how many people you talk to!
## What does it even do
It starts simply by pressing a button, we use **Google OATH** to take your username, email, and image. From that, we create a webpage for each user with spots for detailed analytics on how you speak to others. From there you have two options:
**1)** You can join private discussions based around the mood that you're currently in, here you can interact completely as yourself as it is anonymous. As well if you don't like the person they dont have any way of contacting you and you can just refresh away!
**2)** You can join group discussions about hobbies that you might have and meet interesting people that you can then send private messages too! All the discussions are also being supervised to make sure that no one is being picked on using our machine learning algorithms
## The Fun Part
Here's the fun part. The backend was a combination of **Node**, **Firebase**, **Fetch** and **Socket.io**. The ML model was hosted on **Node**, and was passed into **Socket.io**. Through over 700 lines of **Javascript** code, we were able to create multiple chat rooms and lots of different analytics.
One thing that was really annoying was storing data on both the **Firebase** and locally on **Node Js** so that we could do analytics while also sending messages at a fast rate!
There are tons of other things that we did, but as you can tell my **handwriting sucks....** So please instead watch the youtube video that we created!
## What we learned
We learned how important and powerful social communication can be. We realized that being able to talk to others, especially under a tough time during a pandemic, can make a huge positive social impact on both ourselves and others. Even when check-in with the team, we felt much better knowing that there is someone to support us. We hope to provide the same key values in Companion! | ## Inspiration
On social media, most of the things that come up are success stories. We've seen a lot of our friends complain that there are platforms where people keep bragging about what they've been achieving in life, but not a single one showing their failures.
We realized that there's a need for a platform where people can share their failure episodes for open and free discussion. So we have now decided to take matters in our own hands and are creating Failed-In to break the taboo around failures! On Failed-in, you realize - "You're NOT alone!"
## What it does
* It is a no-judgment platform to learn to celebrate failure tales.
* Enabled User to add failure episodes (anonymously/non-anonymously), allowing others to react and comment.
* Each episode on the platform has #tags associated with it, which helps filter out the episodes easily. A user's recommendation is based on the #tags with which they usually interact
* Implemented sentiment analysis to predict the sentiment score of a user from the episodes and comments posted.
* We have a motivational bot to lighten the user's mood.
* Allowed the users to report the episodes and comments for
+ NSFW images (integrated ML check to detect nudity)
+ Abusive language (integrated ML check to classify texts)
+ Spam (Checking the previous activity and finding similarities)
+ Flaunting success (Manual checks)
## How we built it
* We used Node for building REST API and MongoDb as database.
* For the client side we used flutter.
* Also we used tensorflowjs library and its built in models for NSFW, abusive text checks and sentiment analysis.
## Challenges we ran into
* While brainstorming on this particular idea, we weren't sure how to present it not to be misunderstood. Mental health issues from failure are serious, and using Failed-In, we wanted to break the taboo around discussing failures.
* It was the first time we tried using Flutter-beta instead of React with MongoDB and node. It took a little longer than usual to integrate the server-side with the client-side.
* Finding the versions of tensorflow and other libraries which could integrate with the remaining code.
## Accomplishments that we're proud of
* During the 36 hour time we were able to ideate and build a prototype for the same.
* From fixing bugs to resolving merge conflicts the whole experience is worth remembering.
## What we learned
* Team collaboration
* how to remain calm and patient during the 36 hours
* Remain up on caffeine.
## What's next for Failed-In
* Improve the model of sentiment analysis to get more accurate results so we can understand the users and recommend them famous failure to success stories using web scraping.
* Create separate discussion rooms for each #tag, facilitating users to communicate and discuss their failures.
* Also provide the option to follow/unfollow a user. | ## Inspiration
As the quarantine has dragged on, more than a few of us discovered the unfortunate ability of time to act like a gas, escaping the neatly ordered confines of hours and days. In fact, nearly 40% of Canadians say they experienced a mental health decline due to COVID. In order to combat this, we sought to create an assistant to help people find some structure in their lives to maintain and improve mental health.
## What it does
Wilson’s aim is to keep your head above water during this global pandemic. He’s named after the volleyball that Tom Hanks talks to in the film Cast Away because he fulfills that same purpose. He keeps track of the friends you want to talk to, and the habits you want to keep. Wilson pushes you to stay in continual contact with each of these friends, and to pursue the habits that keep you mentally strong. He rotates through all your friends and habits, and urges you to contact different ones. On top of that, Wilson has an extensive voice script that makes him feel alive. He might say something sarcastic or even crack a joke, so watch out!
## How we built it
We used a web program called Voiceflow, which assists the rapid and collaborative design of voice applications for Google Assistant. We chose this medium because we wanted to make it as easy as possible for people to access and use - anyone with Google Assistant can easily access the assistant, with no downloads or additional signups. The application was constructed using Voiceflow code blocks, along with custom javascript code to add additional functionalities not fulfilled by Voiceflow. It was deployed using the Google Actions Console.
## Challenges we ran into
We faced many challenges while working on Wilson.
Our biggest challenge as a team was learning to use Voiceflow. It took quite a bit of time to learn and then be able to develop a solid plan for the project since Voiceflow was a new tool to everyone on the team.
The next challenge was testing our product on Google Assistant. We ran into issues that we did not have on Voiceflow. Substantial amount of time was spent running tests, identifying the causes of the issue and finding resolutions to these issues.
An unexpected issue we encountered was deploying Wilson onto Google Assistant. We did not take into consideration that to publish for public use that it must be reviewed by the Google Team during our planning, so this would not be done in time during the judging process. We found a workaround which is to deploy as an Alpha option where only particular individuals can use it but we encountered issues on the site when completing this as well.
## Accomplishments that we're proud of
Overall, we are very proud of what we were able to accomplish in such a short time. Our team has very little experience with hackathons, and were able to work very well together, despite our different disciplines and levels of education. Moreover, we learned a lot - none of us had used the google voice platform nor the Voiceflow emulator, and despite this we were able to deploy a well-functioning product.
## What we learned
The main difficulty we faced was the different ways that the Voiceflow emulator and Google emulator runs the code. Most of our debugging was done directly on the Voiceflow platform, but there were numerous issues when we tested the system with the Google Actions Console Simulator. In the future, we know it is critical to test the system on the intended deployment platform.
## What's next for WilsonHACKS
Due to the time constraints, we were not able to completely flesh out all of our ideas.
We wanted to make WIlson be more dynamic when responding to the user to simulate a person-to-person interaction. In the future, we would like to generate more natural responses for Wilson to say and be able take in free-form responses from the user.
Moreover, we would have liked to be able to specify the frequency at which the user would like to be reminded of a specific habit or to talk to a certain person.
Another idea we could not complete was to keep track of the user’s progress in completing their habits and contacting their friends. In implementing this tracking system, we can extract various data to help the user by developing personalized suggestions or reminders that assist them in achieving their goals.
Our next Major step for Wilson would be to track the users mood, as well as their “mental health” level. Based on this, we could specify different activities to complete or even suggest contacting professional help if required.
Another next step is to deploy Wilson for public use so that any individual that has Google Assistant can use Wilson. | partial |
## Inspiration
Our good friend's uncle was involved in a nearly-fatal injury. This led to him becoming deaf-blind at a very young age, without many ways to communicate with others. To help people like our friend's uncle, we decided to create HapticSpeak, a communication tool that transcends traditional barriers. As we have witnessed the challenges faced by deaf-blind individuals first hand, we were determined to bring help to these people.
## What it does
Our project HapticSpeak can take a users voice, and then converts the voice to text. The text is then converted to morse code. At this point, the morse code is sent to an arduino using the bluetooth module, where the arduino will decode the morse code into it's haptic feedback equivalents, allowing for the deafblind indivudals to understand what the user's said.
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for HapticSpeak | ## Inspiration
Over **15% of American adults**, over **37 million** people, are either **deaf** or have trouble hearing according to the National Institutes of Health. One in eight people have hearing loss in both ears, and not being able to hear or freely express your thoughts to the rest of the world can put deaf people in isolation. However, only 250 - 500 million adults in America are said to know ASL. We strongly believe that no one's disability should hold them back from expressing themself to the world, and so we decided to build Sign Sync, **an end-to-end, real-time communication app**, to **bridge the language barrier** between a **deaf** and a **non-deaf** person. Using Natural Language Processing to analyze spoken text and Computer Vision models to translate sign language to English, and vice versa, our app brings us closer to a more inclusive and understanding world.
## What it does
Our app connects a deaf person who speaks American Sign Language into their device's camera to a non-deaf person who then listens through a text-to-speech output. The non-deaf person can respond by recording their voice and having their sentences translated directly into sign language visuals for the deaf person to see and understand. After seeing the sign language visuals, the deaf person can respond to the camera to continue the conversation.
We believe real-time communication is the key to having a fluid conversation, and thus we use automatic speech-to-text and text-to-speech translations. Our app is a web app designed for desktop and mobile devices for instant communication, and we use a clean and easy-to-read interface that ensures a deaf person can follow along without missing out on any parts of the conversation in the chat box.
## How we built it
For our project, precision and user-friendliness were at the forefront of our considerations. We were determined to achieve two critical objectives:
1. Precision in Real-Time Object Detection: Our foremost goal was to develop an exceptionally accurate model capable of real-time object detection. We understood the urgency of efficient item recognition and the pivotal role it played in our image detection model.
2. Seamless Website Navigation: Equally essential was ensuring that our website offered a seamless and intuitive user experience. We prioritized designing an interface that anyone could effortlessly navigate, eliminating any potential obstacles for our users.
* Frontend Development with Vue.js: To rapidly prototype a user interface that seamlessly adapts to both desktop and mobile devices, we turned to Vue.js. Its flexibility and speed in UI development were instrumental in shaping our user experience.
* Backend Powered by Flask: For the robust foundation of our API and backend framework, Flask was our framework of choice. It provided the means to create endpoints that our frontend leverages to retrieve essential data.
* Speech-to-Text Transformation: To enable the transformation of spoken language into text, we integrated the webkitSpeechRecognition library. This technology forms the backbone of our speech recognition system, facilitating communication with our app.
* NLTK for Language Preprocessing: Recognizing that sign language possesses distinct grammar, punctuation, and syntax compared to spoken English, we turned to the NLTK library. This aided us in preprocessing spoken sentences, ensuring they were converted into a format comprehensible by sign language users.
* Translating Hand Motions to Sign Language: A pivotal aspect of our project involved translating the intricate hand and arm movements of sign language into a visual form. To accomplish this, we employed a MobileNetV2 convolutional neural network. Trained meticulously to identify individual characters using the device's camera, our model achieves an impressive accuracy rate of 97%. It proficiently classifies video stream frames into one of the 26 letters of the sign language alphabet or one of the three punctuation marks used in sign language. The result is the coherent output of multiple characters, skillfully pieced together to form complete sentences
## Challenges we ran into
Since we used multiple AI models, it was tough for us to integrate them seamlessly with our Vue frontend. Since we are also using the webcam through the website, it was a massive challenge to seamlessly use video footage, run realtime object detection and classification on it and show the results on the webpage simultaneously. We also had to find as many opensource datasets for ASL as possible, which was definitely a challenge, since with a short budget and time we could not get all the words in ASL, and thus, had to resort to spelling words out letter by letter. We also had trouble figuring out how to do real time computer vision on a stream of hand gestures of ASL.
## Accomplishments that we're proud of
We are really proud to be working on a project that can have a profound impact on the lives of deaf individuals and contribute to greater accessibility and inclusivity. Some accomplishments that we are proud of are:
* Accessibility and Inclusivity: Our app is a significant step towards improving accessibility for the deaf community.
* Innovative Technology: Developing a system that seamlessly translates sign language involves cutting-edge technologies such as computer vision, natural language processing, and speech recognition. Mastering these technologies and making them work harmoniously in our app is a major achievement.
* User-Centered Design: Crafting an app that's user-friendly and intuitive for both deaf and hearing users has been a priority.
* Speech Recognition: Our success in implementing speech recognition technology is a source of pride.
* Multiple AI Models: We also loved merging natural language processing and computer vision in the same application.
## What we learned
We learned a lot about how accessibility works for individuals that are from the deaf community. Our research led us to a lot of new information and we found ways to include that into our project. We also learned a lot about Natural Language Processing, Computer Vision, and CNN's. We learned new technologies this weekend. As a team of individuals with different skillsets, we were also able to collaborate and learn to focus on our individual strengths while working on a project.
## What's next?
We have a ton of ideas planned for Sign Sync next!
* Translate between languages other than English
* Translate between other sign languages, not just ASL
* Native mobile app with no internet access required for more seamless usage
* Usage of more sophisticated datasets that can recognize words and not just letters
* Use a video image to demonstrate the sign language component, instead of static images | ## Inspiration
The main problem we are focusing is the inability of differently abled people to communicate with normal people or other differently abled people. Now, we are here with the combined Hardware and Software solution which is called **“EME”**, after analysing some problems. And, try to make the next generation Support Device for differently abled people. (Deaf, mute & Blind)
## What it does
There is a Hardware project which consists of a Hand Gesture Recognition and Smart Blind Stick. Smart Blind Stick for “Blind People”, in this when object comes near to 1 m than less, then, buzzer beeping with increasing in beep frequency as object comes closer, through way they get an Alert.
Hand Gesture Recognition for “Dumb People (or mute people)”, because they have their own sign language but normal people don’t know the sign language which is used for intercommunication between mute people. This system will be useful to solve this problem and help them to make their interaction easily with the people. They can communicate hassle-free by using this device & with the help of our app EME, we converted gesture pattern into text to Speech.
In our app, there so many specifications-
1. Speech to Text (for Deaf people, to understand other people communication)
2. Text to Speech (for Dumb people with bluetooth connectivity)
3. Text to Speech (for Normally use)
## How we built it
In the Hardware of this project, Smart Blind Stick for “Blind People” using Adruino, Ultrasonic Sensor HC-SR04, IR Sensor & Buzzer to give alert and Hand Gesture Recognition for “Dumb People” using Arduino, Bluetooth HC 05, LDR Sensors & our app EME, through we convert gesture pattern into text to Speech.
We build our app on Flutter which is a hybrid platform using dart language. Because Flutter apps can run on ios and android devices. Then, Text to Speech with bluetooth connection and Speech to Text were implemented with our skills.
## Challenges we ran into
Due to lockdown, we don’t have much hardware components. So, we try to figure out this with Arduino Uno and Bluetooth in specific time duration. Also, make an app with such functioning is new to us.
## Accomplishments that we're proud of
Working of Hand Gesture recognition is so efficiently and accurately. Also, make a this device very cheap around 13 USD. ( There some sensors in market whose cost around 30 USD each then for four fingers 120 USD with other components additional cost also)
And, converted Text to Speech & Speech to Text successfully.
## What we learned
Learned a lot about that without having much components, how to make efficient project in hardware in specific time and also, learned about the new sensors.
Moreover, built a more functioning mobile app.
## What's next for EME
In terms of enhancing the project, we can introduce Obstacle alert Helmet for Blind People using circular rotate sensor like a radar and with the help of Gyrometer in hand gesture, we can increase the limits of signs means able for whole sentence instead of common words.
In terms of marketing the product, we would like to initially target differently abled people center of our region. | partial |
## Inspiration
The EPA estimates that although 75% of American waste is recyclable, only 30% gets recycled. Our team was inspired to create RecyclAIble by the simple fact that although most people are not trying to hurt the environment, many unknowingly throw away recyclable items in the trash. Additionally, the sheer amount of restrictions related to what items can or cannot be recycled might dissuade potential recyclers from making this decision. Ultimately, this is detrimental since it can lead to more trash simply being discarded and ending up in natural lands and landfills rather than being recycled and sustainably treated or converted into new materials. As such, RecyclAIble fulfills the task of identifying recycling objects with a machine learning-based computer vision software, saving recyclers the uncertainty of not knowing whether they can safely dispose of an object or not. Its easy-to-use web interface lets users track their recycling habits and overall statistics like the number of items disposed of, allowing users to see and share a tangible representation of their contributions to sustainability, offering an additional source of motivation to recycle.
## What it does
RecyclAIble is an AI-powered mechanical waste bin that separates trash and recycling. It employs a camera to capture items placed on an oscillating lid and, with the assistance of a motor, tilts the lid in the direction of one compartment or another depending on whether the AI model determines the object as recyclable or not. Once the object slides into the compartment, the lid will re-align itself and prepare for proceeding waste. Ultimately, RecyclAIBle autonomously helps people recycle as much as they can and waste less without them doing anything different.
## How we built it
The RecyclAIble hardware was constructed using cardboard, a Raspberry Pi 3 B+, an ultrasonic sensor, a Servo motor, and a Logitech plug-in USB web camera, and Raspberry PI. Whenever the ultrasonic sensor detects an object placed on the surface of the lid, the camera takes an image of the object, converts it into base64 and sends it to a backend Flask server. The server receives this data, decodes the base64 back into an image file, and inputs it into a Tensorflow convolutional neural network to identify whether the object seen is recyclable or not. This data is then stored in an SQLite database and returned back to the hardware. Based on the AI model's analysis, the Servo motor in the Raspberry Pi flips the lip one way or the other, allowing the waste item to slide into its respective compartment. Additionally, a reactive, mobile-friendly web GUI was designed using Next.js, Tailwind.css, and React. This interface provides the user with insight into their current recycling statistics and how they compare to the nationwide averages of recycling.
## Challenges we ran into
The prototype model had to be assembled, measured, and adjusted very precisely to avoid colliding components, unnecessary friction, and instability. It was difficult to get the lid to be spun by a single Servo motor and getting the Logitech camera to be propped up to get a top view. Additionally, it was very difficult to get the hardware to successfully send the encoded base64 image to the server and for the server to decode it back into an image. We also faced challenges figuring out how to publicly host the server before deciding to use ngrok. Additionally, the dataset for training the AI demanded a significant amount of storage, resources and research. Finally, establishing a connection from the frontend website to the backend server required immense troubleshooting and inspect-element hunting for missing headers. While these challenges were both time-consuming and frustrating, we were able to work together and learn about numerous tools and techniques to overcome these barriers on our way to creating RecyclAIble.
## Accomplishments that we're proud of
We all enjoyed the bittersweet experience of discovering bugs, editing troublesome code, and staying up overnight working to overcome the various challenges we faced. We are proud to have successfully made a working prototype using various tools and technologies new to us. Ultimately, our efforts and determination culminated in a functional, complete product we are all very proud of and excited to present. Lastly, we are proud to have created something that could have a major impact on the world and help clean our environment clean.
## What we learned
First and foremost, we learned just how big of a problem under-recycling was in America and throughout the world, and how important recycling is to Throughout the process of creating RecyclAIble, we had to do a lot of research on the technologies we wanted to use, the hardware we needed to employ and manipulate, and the actual processes, institutions, and statistics related to the process of recycling. The hackathon has motivated us to learn a lot more about our respective technologies - whether it be new errors, or desired functions, new concepts and ideas had to be introduced to make the tech work. Additionally, we educated ourselves on the importance of sustainability and recycling as well to better understand the purpose of the project and our goals.
## What's next for RecyclAIble
RecycleAIble has a lot of potential as far as development goes. RecyclAIble's AI can be improved with further generations of images of more varied items of trash, enabling it to be more accurate and versatile in determining which items to recycle and which to trash. Additionally, new features can be incorporated into the hardware and website to allow for more functionality, like dates, tracking features, trends, and the weights of trash, that expand on the existing information and capabilities offered. And we’re already thinking of ways to make this device better, from a more robust AI to the inclusion of much more sophisticated hardware/sensors. Overall, RecyclAIble has the potential to revolutionize the process of recycling and help sustain our environment for generations to come. | ## Inspiration
An Article, about 86 per cent of Canada's plastic waste ends up in landfill, a big part due to Bad Sorting. We thought it shouldn't be impossible to build a prototype for a Smart bin.
## What it does
The Smart bin is able, using Object detection, to sort Plastic, Glass, Metal, and Paper
We see all around Canada the trash bins split into different types of trash. It sometimes becomes frustrating and this inspired us to built a solution that doesn't require us to think about the kind of trash being thrown
The Waste Wizard takes any kind of trash you want to throw, uses machine learning to detect what kind of bin it should be disposed in, and drops it in the proper disposal bin
## How we built it\
Using Recyclable Cardboard, used dc motors, and 3d printed parts.
## Challenges we ran into
We had to train our Model for the ground up, even getting all the data
## Accomplishments that we're proud of
We managed to get the whole infrastructure build and all the motor and sensors working.
## What we learned
How to create and train model, 3d print gears, use sensors
## What's next for Waste Wizard
A Smart bin able to sort the 7 types of plastic | ## Inspiration 🎞️
imy draws inspiration from the universal human desire to revisit and share cherished memories. We were particularly inspired by the simplicity and addictive nature of the iconic Flappy Bird game, as well as the nostalgic appeal of an 8-bit design style. Our goal was to blend the engaging mechanics of a beloved game with the warmth of reminiscing on the good old days.
## What it does 📷
imy is a gamified social media application that revitalizes the charm and nostalgia of the past. Users not only relive some of their favourite memories, but are also able to reconnect with old friends, reminded of the countless hours of fun that they've spent together.
Upload photos in response to daily memory prompts like "A time you learned a new skill," or "Your first photo with a best friend," as well as prompts from different times/periods in your life. Posts can be liked by friends, with each like increasing the user's score. The app features a Flappy Bird-themed leaderboard, displaying leaders and encouraging friendly competition. Additionally, users can customize their profiles with really cute avatars!
## How we built it 💻
We built imy as a native mobile application with React Native and Expo Go. For the backend, we used Node.js, Express, and MongoDB. We chose this stack because of our team's relative familiarity with JavaScript and frontend development, and our team's interest in learning some backend and mobile development. This stack allowed us to learn both skills without having to learn new languages, and also deploy a cool app that we could run natively on our phones!
## Challenges we ran into ⏳
One of the biggest challenges we ran into was learning the intricacies of React Native and backend development; we had originally thought that React Native wouldn't be too difficult to pick up, because of our previous experience with React. Although the languages are similar, we ran into some bugs that took us quite some time to resolve! Bugs, bugs, bugs were the pests of the weekend, as we spent hours trying to figure out why images weren't uploading to the backend, or why profile icons kept returning NaN. It didn't help that Railway (where we hosted our backend) had a site-wide crash during that debugging session :(
Additionally, we wanted to use Auth0 for our authentication, but we found out after much too long that it did not work with Expo Go.
Stepping out of our comfort zones forced us to think on our feet and be constantly learning over the last 36 hours, but it was definitely worth it in the end!
## Accomplishments that we're proud of 📽️
As a team comprised of all beginner hackers, we're super proud that we were able to come up with a cool idea and push ourselves to complete it within 36 hours! UofTHacks was two of our team members' first hackathon, and our most experienced member has only been to 2 hackathons herself.
In terms of the final product, we're really happy with the retro-style design and our creative, nostalgia-themed idea. We worked really hard this weekend, and we learned so much!
## What we learned 💿
We learned how to deploy a backend, make a native app, and merge conflicts (there were a *lot* of them, and not just in git!). We learned what we're capable of doing in just 36 hours, and had lots of fun in the process.
## What's next for imy 📱
We love the idea behind imy and it's definitely a project that we'll continue working on post UoftHacks! There's lots of code refactoring and little features that we'd love to add, and we think the cute frontend design has a lot of promise. We're extremely excited for the future of imy, and we hope to make it even better soon. | winning |
## Inspiration
The inspiration for the project was thinking back to playing contact sports. Sometimes players would receive head injuries and not undergo a proper concussion examination; a concussion could then go undetected - possibly resulting in cognitive issues in the future.
## What it does
The project is a web page that has a concussion diagnosis algorithm and a concussion diagnosis form. The web page can open the camera window - allowing the user to record video of their pupils. This video undergoes analysis by the concussion algorithm. This compares the radii of the patient's pupils over time. With this data, a concussion diagnosis can be provided. After analysis, a concussion form is provided to the patient to further confirm the diagnosis.
## How we built it
We built the project using openCV in python. The web browser was developed using JavaScript in WIX and the communication between the openCV algorithm and the browser is done using flask.
## Challenges we ran into
We ran into a challenge with sending data between flask and our hosted file. The file would refresh before receiving the flask data causing us to be unable to use our calculated concussion variable.
## Accomplishments that we're proud of
We are proud of developing a functional front end and a functional algorithm. We are also proud that we were able to use OpenCV to locate pupils and read their sizes.
## What we learned
We learned how to work with openCV, Wix, flask, and js. Although some of these skills are still very rudimentary, we have a foundation using frameworks and languages we had never used before.
## What's next for ConcussionMD
Next, we will try to improve our flask back end to ensure users can upload their own videos, as right now this functionality is not fully implemented. We will also try to implement an option for users who were found concussed to see hospitals near their location to go to. | ## Inspiration
According to a 2015 study in the American Journal of Infection Control, people touch their faces more than 20 times an hour on average. More concerningly, about 44% of the time involves contact with mucous membranes (e.g. eyes, nose, mouth).
With the onset of the COVID-19 pandemic ravaging our population (with more than 300 million current cases according to the WHO), it's vital that we take preventative steps wherever possible to curb the spread of the virus. Health care professionals are urging us to refrain from touching these mucous membranes of ours as these parts of our face essentially act as pathways to the throat and lungs.
## What it does
Our multi-platform application (a python application, and a hardware wearable) acts to make users aware of the frequency they are touching their faces in order for them to consciously avoid doing so in the future. The web app and python script work by detecting whenever the user's hands reach the vicinity of the user's face and tallies the total number of touches over a span of time. It presents the user with their rate of face touches, images of them touching their faces, and compares their rate with a **global average**!
## How we built it
The base of the application (the hands tracking) was built using OpenCV and tkinter to create an intuitive interface for users. The database integration used CockroachDB to persist user login records and their face touching counts. The website was developed in React to showcase our products. The wearable schematic was written up using Fritzing and the code developed on Arduino IDE. By means of a tilt switch, the onboard microcontroller can detect when a user's hand is in an upright position, which typically only occurs when the hand is reaching up to touch the face. The device alerts the wearer via the buzzing of a vibratory motor/buzzer and the flashing of an LED. The emotion detection analysis component was built using the Google Cloud Vision API.
## Challenges we ran into
After deciding to use opencv and deep vision to determine with live footage if a user was touching their face, we came to the unfortunate conclusion that there isn't a lot of high quality trained algorithms for detecting hands, given the variability of what a hand looks like (open, closed, pointed, etc.).
In addition to this, the CockroachDB documentation was out of date/inconsistent which caused the actual implementation to differ from the documentation examples and a lot of debugging.
## Accomplishments that we're proud of
Despite developing on three different OSes we managed to get our application to work on every platform. We are also proud of the multifaceted nature of our product which covers a variety of use cases. Despite being two projects we still managed to finish on time.
To work around the original idea of detecting overlap between hands detected and faces, we opted to detect for eyes visible and determine whether an eye was covered due to hand contact.
## What we learned
We learned how to use CockroachDB and how it differs from other DBMSes we have used in the past, such as MongoDB and MySQL.
We learned about deep vision, how to utilize opencv with python to detect certain elements from a live web camera, and how intricate the process for generating Haar-cascade models are.
## What's next for Hands Off
Our next steps would be to increase the accuracy of Hands Off to account for specific edge cases (ex. touching hair/glasses/etc.) to ensure false touches aren't reported. As well, to make the application more accessible to users, we would want to port the application to a web app so that it is easily accessible to everyone. Our use of CockroachDB will help with scaling in the future. With our newfound familliarity with opencv, we would like to train our own models to have a more precise and accurate deep vision algorithm that is much better suited to our project's goals. | ## Inspiration
While we were back in school, before the COVID-19 pandemic, there was one prominent problem in our classes. While many platforms existed for teacher-to-student and student-to-teacher communication, there was nowhere for students to communicate with each other and help each other out. In fact, some of our classmates tried to solve this problem by creating group chats for classes on apps like Instagram and Snapchat. However, a large concern with such a solution is that these social media apps are inherently distracting, we didn't join these group chats myself because we were concerned that they would be detrimental to my education; chats were often going off-topic, or even inappropriate content being posted.
A platform encouraging classmates to help each other out would greatly enrich the learning experience for everyone. As schools began to close down due to COVID-19, this problem became even more pertinent as it prevented struggling students from getting the help they needed through after-school study sessions, peer tutoring sessions, and the like. Even though these meet-ups might still be possible, they are a lot harder to organize and execute, causing many struggling students to be left with insufficient help and few ways to get it.
## What it does
To solve these issues, we created DigiClass, a platform that encourages student-to-student interaction in an optimal and incentivizing manner. Currently, there are three main parts to DigiClass, a discussion page, a question page, and a room page. In the discussion page, students can discuss with one another in real-time for short and simple things, such as the textbook pages for homework, or if there was a test the next day. For more detailed questions relating to the current subject or lesson, students would use the questions panel. It's based on a similar system to StackExchange, where students can ask questions and the most upvoted ones bubble to the top. This way, teachers and other students are able to get a good overview of the most common questions about a certain subject or lesson, and instead of the inefficient method of having the teacher answer every student's question separately through email, every student can benefit from this question page and teachers also don't need to repeatedly answer individual questions.
In addition, we understand that teachers don't always have enough time or resources to help every student and answer every question. That's why we made it possible for students to also answer one another's questions. Answers to questions can also be upvoted, and each question can also be approved by the teacher for official confirmation. This way, instead of teachers spending their time writing out answers to every question, their workload is now reduced to simply reviewing the answers and correcting them as necessary. By answering other students' questions, students can gain "reputation", which can be used to give them higher priorities in other features for the app. For example, when students send teachers private questions or messages, instead of being sorted by the time sent, they are instead sorted based on the reputation of the students. This way, students will have an incentive to gain reputation as they will be able to receive quicker and more prioritized responses from teachers to their questions and emails.
The last page is a room page, where students can connect with one another through video chat. Instead of forcing students to download other distracting applications such as Instagram or Discord for video calling, Digiclass comes with a video call feature for students to directly connect to one another. This video calling feature can be used in a variety of ways, ranging from one-on-one help, a quiet virtual study session, or as a place to communicate with one another about their results for a quiz or a test, This page also provides more than just a place to video chat, as it also provides integrations with other educational apps. Here, you can see that we've integrated with Tabulo, a digital whiteboard that greatly facilitates visual teaching, as you can draw from your phone onto the computer instead of struggling with a mouse. We made it so that when you upload a picture through DigiClass and open it via Tabulo, it will automatically create a room for you with the picture you used in the background so that you can immediately share your room with others and start helping or receiving help with minimal friction. This could be helpful in a variety of situations—not just when you have a worksheet that you need help on. By using this integration, you can allow others to write on the same worksheet as you, so they can correct your steps and also write out the correct steps in real-time.
DigiClass also features a mobile application so that you won't miss a message, and can chat with friends on the go.
## How we built it
We used a lot of different technologies to turn DigiClass into reality. The front-end of the application is built with Vue.js and Quasar Framework, which gives the app a standard and beautiful layout with Material Design. The backend server is a Node.js server using Express and uses PostgreSQL for accounts, and Redis and Socket.io for real-time publishing and subscriptions to the client. The video calling feature is built with WebRTC, PeerJS and vanilla JavaScript.
## Challenges we ran into
As we were using somewhat uncommon technologies, we had to install PostgreSQL and Redis, which wasn't as easy as we expected, especially on Windows. We spent a lot of time debugging and tracking down errors related to the installation of these tools. In addition, a lot of these technologies were new, such as WebRTC and the combination of Redis + Socket.io, and so we spent a lot more time debugging these unfamiliar and uncommon bugs we were encountering.
## Accomplishments that we're proud of
As we started approaching the submission deadline, we began to pick up the pace and development was quickly underway. However, as we sped up the process, many more bugs came up and cross-OS compatibility was becoming more and more of an issue. Thankfully, we were able to solve them very quickly due to our experience of working with previous bugs and being able to resolve them quickly. We are also proud of how we were able to troubleshoot, integrate and learn so many different tools in such a short amount of time.
## What's next for DigiClass
Of course, as all of this was built in only 36 hours, we believe that DigiClass has a ton of potential in the future to be a standard app in all virtual and physical classrooms, as it can unlock the hidden value in providing an easily accessible platform for students to assist one another. | partial |
## Inspiration
Recently, one of our team members, Trevor, got his credit card information stolen and we realized how much of an issue scam calls are in today's world. We want nobody to go through the same experience. So we created ScamSlam!
## What it does
ScamSlam is a mobile app that you can sign up for which gives you a new phone number. This phone number is then linked to the user's actual phone number. This allows for the calls to be forwarded to the user after being scanned.
When an incoming call is received, ScamSlam streams the call data to intelligent machine learning models which transcribe and predict in real time the likelihood the call is a scam. If a scam is detected ScamSlam SLAMs the call to protect the end user. After the SLAM the end user is notified that a scam was detected and the call was ended.
## How we built it
Twilio was used to generate a unique phone number for each user and intercept the call. Node.js, Google app engine and Google Cloud Speech-to-Text api were used to get the phone call data of the hacker. IBM Watson machine learning classifier was used to train on the spam/not spam data set of emails. React native was used to build the iOS app.
## Challenges we ran into
It was quite a challenge to integrate the machine learning model with the active phone call to get real time results. It was also challenging to make the phone call disconnect on its own once the call was classified as spam.
## Accomplishments that we're proud of
We were able resolve our challenges and build a fully functioning app! It was fun to integrate the backend and the frontend together.
## What we learned
How to stream and process data in real time, deploying to Google Cloud, how to train machine learning models in the cloud.
## What's next for ScamSlam
Integrate ScamSlam technology with Twilio Elastic SIP trunking to allow anyone to port their existing number into a VOIP network and be protected from telephone scams. Additionally, continue to improve our scam detection models. | ## Inspiration
With the rise of information pertaining health, specifically mental health, we felt that it would be important and wise to create a program that directs a user to next steps based on their health state.
## What it does
A website with health related information contains a bot which based on user input, guides the user on what they can do based on their health to get help, combat their issues and overcome them. This is done by directing the user to loved ones, health care, the emergency room and emergency hotlines.
## How we built it
We used python to make our bot, and HTML and CSS to create our website. The two were made separately, and then the python bot was added through an online IDE.
## Challenges we ran into
In our python bot, we made it so that based on user input feelings, a smiley face image representing the corresponding emotion would pop up. Unfortunately, when added to the website, this code ran into errors, and needed to be removed.
## Accomplishments that we're proud of
We are proud that we pushed our limits, being unfamiliar with these branches of python and front end website design of CSS and HTML. Creating the site, and though it didn't work, the python graphics was a proud moment for the two of us.
## What we learned
We learned that code from multiple different languages and languages can be embedded into one, and work together. We also came across the design work process, that required brainstorming, planning, scrapping ideas and having to toggle and troubleshoot. It showed us that creating solutions to problems in real life would be no easy task.
## What's next for Baldeep and Krish's project
We will continue to better the look and graphics of the website, increase the intelligence of our bot, make the error that didn't allow the bot's images to be produced on the website work and make the usability of the program easier for the user to be drawn in and want to evaluate their own health. | *Everything in this project was completed during TreeHacks.*
*By the way, we've included lots of hidden fishy puns in our writeup! Comment how many you find!*
## TL; DR
* Illegal overfishing is a massive issue (**>200 billion fish**/year), disrupting global ecosystems and placing hundreds of species at risk of extinction.
* Satellite imagery can detect fishing ships but there's little positive data to train a good ML model.
* To get synthetic data: we fine-tuned Stable Diffusion on **1/1000ths of the data** of a typical GAN (and 10x training speed) on images of satellite pictures of ships and achieved comparable quality to SOTA. We only used **68** original images!
* We trained a neural network using our real and synthetic data that detected ships with **96%** accuracy.
* Built a global map and hotspot dashboard that lets governments view realtime satellite images, analyze suspicious activity hotspots, & take action.
* Created a custom polygon renderer on top of ArcGIS
* Our novel Stable Diffusion data augmentation method has potential for many other low-data applications.
Got you hooked? Keep reading!
## Let's get reel...
Did you know global fish supply has **decreased by [49%](https://www.scientificamerican.com/article/ocean-fish-numbers-cut-in-half-since-1970/)** since 1970?
While topics like deforestation and melting ice dominate sustainability headlines, overfishing is a seriously overlooked issue. After thoroughly researching sustainability, we realized that this was an important but under-addressed challenge.
We were shocked to learn that **[90%](https://datatopics.worldbank.org/sdgatlas/archive/2017/SDG-14-life-below-water.html) of fisheries are over-exploited** or collapsing. What's more, around [1 trillion](https://www.forbes.com/sites/michaelpellmanrowland/2017/07/24/seafood-sustainability-facts/?sh=2a46f1794bbf) (1,000,000,000,000) fish are caught yearly.
Hailing from San Diego, Boston, and other cities known for seafood, we were shocked to hear about this problem. Research indicates that despite many verbal commitments to fish sustainably, **one in five fish is illegally caught**. What a load of carp!
### People are shellfish...
Around the world, governments and NGOs have been trying to reel in overfishing, but economic incentives and self-interest mean that many ships continue to exploit resources secretly. It's hard to detect small ships on the world's 140 million square miles of ocean.
## What we're shipping
In short (we won't keep you on the hook): we used custom Stable Diffusion to create realistic synthetic image data of ships and trained a convolutional neural networks (CNNs) to detect and locate ships from satellite imagery. We also built a **data visualization platform** for stakeholders to monitor overfishing. To enhance this platform, we **identified several hotspots of suspicious dark vessel activity** by digging into 55,000+ AIS radar records.
While people have tried to build AI models to detect overfishing before, accuracy was poor due to high class imbalance. There are few positive examples of ships on water compared to the infinite negative examples of patches of water without ships. Researchers have used GANs to generate synthetic data for other purposes. However, it takes around **50,000** sample images to train a decent GAN. The largest satellite ship dataset only has ~2,000 samples.
We realized that Stable Diffusion (SD), a popular text-to-image AI model, could be repurposed to generate unlimited synthetic image data of ships based on relatively few inputs. We were able to achieve highly realistic synthetic images using **only 68** original images.
## How we shipped it
First, we read scientific literature and news articles about overfishing, methods to detect overfishing, and object detection models (and limitations). We identified a specific challenge: class imbalance in satellite imagery.
Next, we split into teams. Molly and Soham worked on the front-end, developing a geographical analysis portal with React and creating a custom polygon renderer on top of existing geospatial libraries. Andrew and Sayak worked on curating satellite imagery from a variety of datasets, performing classical image transformations (rotations, flips, crops), fine-tuning Stable Diffusion models and GANs (to compare quality), and finally using a combo of real and synthetic data to train an CNN. Andrew also worked on design, graphics, and AIS data analysis. We explored Leap ML and Runway fine-tuning methods.
## Challenges we tackled
Building Earth visualization portals are always quite challenging, but we could never have predicted the waves we would face. Among animations, rotations, longitude, latitude, country and ocean lines, and the most-feared WebGL, we had a lot to learn. For ocean lines, we made an API call to a submarine transmissions library and recorded features to feed into a JSON. Inspired by the beautiful animated globes of Stripe's and CoPilot's landing pages alike, we challengingly but succeedingly wrote our own.
Additionally, the synthesis between globe to 3D map was difficult, as it required building a new scroll effect compatible with the globe. These challenges, although significant at the time, were ultimately surmountable, as we navigated through their waters unforgivingly. This enabled the series of accomplishments that ensued.
It was challenging to build a visual data analysis layer on top of the ArcGIS library. The library was extremely granular, requiring us to assimilate the meshes of each individual polygon to display. To overcome this, we built our own component-based layer that enabled us to draw on top of a preexisting map.
## Making waves (accomplishments)
Text-to-image models are really cool but have failed to find that many real-world use cases besides art and profile pics. We identified and validated a relevant application for Stable Diffusion that has far-reaching effects for agricultural, industry, medicine, defense, and more.
We also made a sleek and refined web portal to display our results, in just a short amount of time. We also trained a CNN to detect ships using the real and synthetic data that achieved 96% accuracy.
## What we learned
### How to tackle overfishing:
We learned a lot about existing methods to combat overfishing that we didn't know about. We really became more educated on ocean sustainability practices and the pressing nature of the situation. We schooled ourselves on AIS, satellite imagery, dark vessels, and other relevant topics.
### Don't cast a wide net. And don't go overboard.
Originally, we were super ambitious with what we wanted to do, such as implementing Monte Carlo particle tracking algorithms to build probabilistic models of ship trajectories. We realized that we should really focus on a couple of ideas at max because of time constraints.
### Divide and conquer
We also realized that splitting into sub-teams of two to work on specific tasks and being clear about responsibilities made things go very smoothly.
### Geographic data visualization
Building platforms that enable interactions with maps and location data.
## What's on the horizon (implications + next steps)
Our Stable Diffusion data augmentation protocol has implications for few-shot learning of any object for agricultural, defense, medical and other applications. For instance, you could use our method to generate synthetic lung CT-Scan data to train cancer detection models or fine-tune a model to detect a specific diseased fruit not covered by existing general-purpose models.
We plan to create an API that allows anyone to upload a few photos of a specific object. We will build a large synthetic image dataset based off of those objects and train a plug-and-play CNN API that performs object location, classification, and counting.
While general purpose object detection models like YOLO work well for popular and broad categories like "bike" or "dog", they aren't feasible for specific detection purposes. For instance, if you are a farmer trying to use computer vision to detect diseased lychees. Or a medical researcher trying to detect cancerous cells from a microscope slide. Our method allows anyone to obtain an accurate task-specific object detection model. Because one-size-fits-all doesn't cut it.
We're excited to turn the tide with our fin-tech!
*How many fish/ocean-related puns did you find?* | losing |
## Inspiration
Every year roughly 25% of recyclable material is not able to be recycled due to contamination. We set out to reduce the amount of things that are needlessly sent to the landfill by reducing how much people put the wrong things into recycling bins (i.e. no coffee cups).
## What it does
This project is a lid for a recycling bin that uses sensors, microcontrollers, servos, and ML/AI to determine if something should be recycled or not and physically does it.
To do this it follows the following process:
1. Waits for object to be placed on lid
2. Take picture of object using webcam
3. Does image processing to normalize image
4. Sends image to Tensorflow model
5. Model predicts material type and confidence ratings
6. If material isn't recyclable, it sends a *YEET* signal and if it is it sends a *drop* signal to the Arduino
7. Arduino performs the motion sent to it it (aka. slaps it *Happy Gilmore* style or drops it)
8. System resets and waits to run again
## How we built it
We used an Arduino Uno with an Ultrasonic sensor to detect the proximity of an object, and once it meets the threshold, the Arduino sends information to the pre-trained TensorFlow ML Model to detect whether the object is recyclable or not. Once the processing is complete, information is sent from the Python script to the Arduino to determine whether to yeet or drop the object in the recycling bin.
## Challenges we ran into
A main challenge we ran into was integrating both the individual hardware and software components together, as it was difficult to send information from the Arduino to the Python scripts we wanted to run. Additionally, we debugged a lot in terms of the servo not working and many issues when working with the ML model.
## Accomplishments that we're proud of
We are proud of successfully integrating both software and hardware components together to create a whole project. Additionally, it was all of our first times experimenting with new technology such as TensorFlow/Machine Learning, and working with an Arduino.
## What we learned
* TensorFlow
* Arduino Development
* Jupyter
* Debugging
## What's next for Happy RecycleMore
Currently the model tries to predict everything in the picture which leads to inaccuracies since it detects things in the backgrounds like people's clothes which aren't recyclable causing it to yeet the object when it should drop it. To fix this we'd like to only use the object in the centre of the image in the prediction model or reorient the camera to not be able to see anything else. | ## Inspiration
Let's start by taking a look at some statistics on waste from Ontario and Canada. In Canada, only nine percent of plastics are recycled, while the rest is sent to landfills. More locally, in Ontario, over 3.6 million metric tonnes of plastic ended up as garbage due to tainted recycling bins. Tainted recycling bins occur when someone disposes of their waste into the wrong bin, causing the entire bin to be sent to the landfill. Mark Badger, executive vice-president of Canada Fibers, which runs 12 plants that sort about 60 percent of the curbside recycling collected in Ontario has said that one in three pounds of what people put into blue bins should not be there. This is a major problem, as it is causing our greenhouse gas emissions to grow exponentially. However, if we can reverse this, not only will emissions lower, but according to Deloitte, around 42,000 new jobs will be created. Now let's turn our focus locally. The City of Kingston is seeking input on the implementation of new waste strategies to reach its goal of diverting 65 percent of household waste from landfill by 2025. This project is now in its public engagement phase. That’s where we come in.
## What it does
Cycle AI is an app that uses machine learning to classify certain articles of trash/recyclables to incentivize awareness of what a user throws away. You simply pull out your phone, snap a shot of whatever it is that you want to dispose of and Cycle AI will inform you where to throw it out as well as what it is that you are throwing out. On top of that, there are achievements for doing things such as using the app to sort your recycling every day for a certain amount of days. You keep track of your achievements and daily usage through a personal account.
## How We built it
In a team of four, we separated into three groups. For the most part, two of us focused on the front end with Kivy, one on UI design, and one on the backend with TensorFlow. From these groups, we divided into subsections that held certain responsibilities like gathering data to train the neural network. This was done by using photos taken from waste picked out of, relatively unsorted, waste bins around Goodwin Hall at Queen's University. 200 photos were taken for each subcategory, amounting to quite a bit of data by the end of it. The data was used to train the neural network backend. The front end was all programmed on Python using Kivy. After the frontend and backend were completed, a connection was created between them to seamlessly feed data from end to end. This allows a user of the application to take a photo of whatever it is they want to be sorted, having the photo feed to the neural network, and then returned to the front end with a displayed message. The user can also create an account with a username and password, for which they can use to store their number of scans as well as achievements.
## Challenges We ran into
The two hardest challenges we had to overcome as a group was the need to build an adequate dataset as well as learning the framework Kivy. In our first attempt at gathering a dataset, the images we got online turned out to be too noisy when grouped together. This caused the neural network to become overfit, relying on patterns to heavily. We decided to fix this by gathering our own data. I wen around Goodwin Hall and went into the bins to gather "data". After washing my hands thoroughly, I took ~175 photos of each category to train the neural network with real data. This seemed to work well, overcoming that challenge. The second challenge I, as well as my team, ran into was our little familiarity with Kivy. For the most part, we had all just began learning Kivy the day of QHacks. This posed to be quite a time-consuming problem, but we simply pushed through it to get the hang of it.
## 24 Hour Time Lapse
**Bellow is a 24 hour time-lapse of my team and I work. The naps on the tables weren't the most comfortable.**
<https://www.youtube.com/watch?v=oyCeM9XfFmY&t=49s> | ## Inspiration
We were inspired to create such a project since we are all big fans of 2D content, yet have no way of actually animating 2D movies. Hence, the idea for StoryMation was born!
## What it does
Given a text prompt, our platform converts it into a fully-featured 2D animation, complete with music, lots of action, and amazing-looking sprites! And the best part? This isn't achieved by calling some image generation API to generate a video for our movie; instead, we call on such APIs to create lots of 2D sprites per scene, and then leverage the power of LLMs (CoHere) to move those sprites around in a fluid and dynamic matter!
## How we built it
On the frontend we used React and Tailwind, whereas on the backend we used Node JS and Express. However, for the actual movie generation, we used a massive, complex pipeline of AI-APIs. We first use Cohere to split the provided story plot into a set of scenes. We then use another Cohere API call to generate a list of characters, and a lot of their attributes, such as their type, description (for image gen), and most importantly, Actions. Each "Action" consists of a transformation (translation/rotation) in some way, and by interpolating between different "Actions" for each character, we can integrate them seamlessly into a 2D animation.
This framework for moving, rotating and scaling ALL sprites using LLMs like Cohere is what makes this project truly stand out. Had we used an Image Generation API like SDXL to simply generate a set of frames for our "video", we would have ended up with a janky stop-motion video. However, we used Cohere in a creative way, to decide where and when each character should move, scale, rotate, etc. thus ending up with a very smooth and human-like final 2D animation.
## Challenges we ran into
Since our project is very heavily reliant on BETA parts of Cohere for many parts of its pipeline, getting Cohere to fit everything into the strict JSON prompts we had provided, despite the fine-tuning, was often quite difficult.
## Accomplishments that we're proud of
In the end, we were able to accomplish what we wanted! | winning |
## Inspiration
We wanted to use Magnet's real-time messaging framework to make something cool that's not exactly messaging. We thought of recreating the popular Agar.io game, but with a twist.
## What it does
We use geolocation to plot the user's position as a circle on a map, and as they walk around and collect smaller, randomly generated dots, they get larger in size.
When they see another player that is smaller than them, they can try to consume the other user by walking near them.
## How I built it
We took advantage of Magnet's real-time publish-subscribe messaging framework to create smooth and interactive gameplay.
## Challenges I ran into
We had first decided to build this with the new react-native for android, which was only a week old. We quickly found out that wouldn't work, as many features were not implemented yet. We pivoted to react, and ran into another problem.
Commercial geolocation is not very reliable, and it destroyed the smooth aspect we were trying to achieve. Player's would jump around sporadically due to GPS inaccuracies, and movement would lag due to latency.
In addition, since we were not developing for native android we had to use Magnet's RESTful API which was not fully implemented for our needs. We should have researched that more before we decided on this project.
## Accomplishments that I'm proud of
Though we were pretty discouraged after seeing all our hard work squashed by something in space we couldn't fix, we still managed to hack together a cool prototype. We implemented some guards to reduce GPS errors, and increased our render frequency to make it seem smoother.
## What I learned
We learned that the technologies you choose to develop around is very important, and can either benefit or hinder you. For us, react-native for android and GPS delayed our progress greatly, and in hindsight we should have forseen that they were causing.
## What's next for Agar
We will take our skills and passion elsewhere for now, but Agar.me will always be remembered. | ## Inspiration 🌟
Creative writing is hard. Like really REALLY hard. Trying to come up with a fresh story can seem very intimidating, and if given a blank page, most people would probably just ponder endlessly... "where do I even start???"
## What it does 📕
Introducing **TaleTeller**, an interactive gamified experience designed to help young storytellers create their own unique short stories. It utilizes a "mad libs" style game format where players input five words to inspire the start of their story. The AI will incorporate these words into the narrative, guiding the direction of the tale. Players continue the tale by filling in blanks with words of their choice, actively shaping the story as it unfolds. It's an engaging experience that encourages creativity and fosters a love for storytelling.
## How we built it 🔧
TaleTeller utilizes the Unity Game Engine for its immersive storytelling experience. The AI responses are powered by OpenAI's GPT4-Turbo API while story images are created using OpenAI's DALL-E. The aesthetic UI of the project includes a mix of open course and custom 2D assets.
## Challenges we ran into 🏁
One of the main challenges we faced was fine-tuning the AI to generate cohesive and engaging storylines based on the player's input (prompt engineering is harder than it seems!). We also had a lot of trouble trying to integrate DALL-E within Unity, but after much blood, sweat, and tears, we got the job done :)
## Accomplishments that we're proud of 👏
* Having tons of fun creating fully fledged stories with the AI
* Getting both GPT and DALL-E to work in Unity (it actually took forever...)
* Our ✨ *gorgeous* ✨ UI
## What we learned 🔍
* How to prompt engineer GPT to give us consistent responses
* How to integrate APIs in Unity
* C# is Tony's mortal enemy
## What's next for TaleTeller 📈
Training an AI Text-to-Speech to read out the story in the voice of Morgan Freeman 😂 | Can you save a life?
## Inspiration
For the past several years heart disease has remained the second leading cause of death in Canada. Many know how to prevent it, but many don’t know how to deal with cardiac events that have the potential to end your life. What if you can change this?
## What it does
Can You Save Me simulates three different conversational actions showcasing cardiac events at some of their deadliest moments. It’s your job to make decisions to save the person in question from either a stroke, sudden cardiac arrest, or a heart attack. Can You Save Me puts emphasis on the symptomatic differences between men and women during specific cardiac events. Are you up for it?
## How we built it
We created the conversational action with Voiceflow. While the website was created with HTML, CSS, Javascript, and Bootstrap. Additionally, the backend of the website, which counts the number of simulated lives our users saved, uses Node.js and Google sheets.
## Challenges we ran into
There were several challenges our team ran into, however, we managed to overcome each of them. Initially, we used React.js but it deemed too complex and time consuming given our time-sensitive constraints. We switched over to Javascript, HTML, CSS, and Bootstrap instead for the frontend of the website.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to come together as complete strangers and produce a product that is educational and can empower people to save lives. We managed our time efficiently and divided our work fairly according to our strengths.
## What we learned
Our team learned many technical skills such as how to use React.js, Node.js, Voiceflow and how to deploy actions on Google Assistant. Due to the nature of this project, we completed extensive research on cardiovascular health using resources from Statstics Canada, the Standing Committee on Health, the University of Ottawa Heart Institute, The Heart & Stroke Foundation, American Journal of Cardiology, American Heart Association and Harvard Health.
## What's next for Can You Save Me
We're interested in adding more storylines and variables to enrich our users' experience and learning. We are considering adding a play again action to improve our Voice Assistant and encourage iterations. | losing |
## Inspiration
US export is a Trillion $ industry, with roughly $800+ Billion market share of Organic Food Exports.
Surprisingly, the functions of such a large scale industry are still massively manual (pen and paper ordering) between Suppliers, Exporters, Distributors & Retail Stores (mom-n-pop shops).
It is time to not only automate the process but also tackle some other pressing problems like
* counter the markups by middle-men/distributors
* reduce turn-around time in fulfilling orders
* insights into buying behaviors of customers
## What it does
A set of responsive web pages for suppliers, distributors and small mom-n-pop shops have been set up to automate the entire flow of information as export/import orders are processed and fulfilled.
* An intuitive "pool purchasing" option allows smaller retail stores to directly place order with international suppliers, totally bypassing the markups of the local distributors.
* Finally, analytics on order data provide insights into the purchasing behavior of the end-customers. This plays a critical role in reducing the current time to fulfill orders as suppliers can anticipate demand and pre-stock international ports.
## Challenges we ran into
* Understanding the depth of the problem statement and coming up with a shrink-wrapped solution for the same.
* Serving the app over HTTPS
* Using camera to read barcode in a web browser
## Accomplishments that we're proud of
* Design Thinking session with a probable customer (they have made an offer to purchase our system post the hackathon).
* Setting up a full-stack solution in 36 hours :)
## What we learned
The importance of co-innovation with the end-customer.
## What's next for trade-O-bundle
Setup the entire platform to scale well and handle the expected data-loads of international trade. | ## Inspiration
One of our teammates works part time in Cineplex and at the end of the day, he told us that all their extra food was just throw out.This got us thinking, why throw the food out when you can you earn revenue and some end of the day sales for people in the local proxmity that are looking for something to eat.
## What it does
Out web-app will give a chance for the restaurant to publish the food item which they are selling with a photo of the food. Meanwhile, users have the chance to see everything in real-time and order food directly from the platform. The web-app also identifies the items in the food, nutrient facts, and health benefitis, pro's and con's of the food item and displays it directly to the user. The web-app also provides a secure transaction method which can be used to pay for the food. The food by the restaurant would be sold at a discounted price.
## How I built it
The page was fully made by HTML, CSS, JavaScript and jQuery. There would be both a login and signup for both the restaurants wanting to sell and also for the participants wanting to buy the food.Once signed up for the app, the entry would get stored into Azure and would request for access to the Android Pay app which will allow the users to use Android Pay to pay for the food. When the food is ordered, we use the Clarifai API which allows the users can see the ingredients, health benefits, nutrient facts, pro's and con's of the food item on their dashboard and the photo of the app. This would all come together once the food is delivered by the restaurant.
## Challenges I ran into
Challenges we ran into were getting our database working as none of us have past experiences using Azure. The biggest challenge we ran into was our first two ideas but after talking to sponsors we found out that they were too limiting meaning we had to let go of the ideas and keep coming up with new ones. We started hacking late afternoon on Saturday which cut our time to finish the entire thing.
## Accomplishments that I'm proud of
We are really proud of getting the entire website up and running properly within the 20 hours as we started late enough with database problems that we were at the point of giving up on Sunday morning. Additionally we were very proud of getting our Clarifai API working as none of us had past experenices with Clarifai.
## What I learned
The most important thing we learned out of this hackathon was to start with a concrete idea early on as if this was done for this weekend, our idea could've included a lot more functions. This would benefit both our users and consumers.
## What's next for LassMeal
Our biggest next leap would be modifying the delivery portion of the food item. Instead of the restaurant delivering the food, users that sign up for the food service, also have a chance to become a deliverer. If they are within the distance of the restaurant and going back in the prxomity of the user's home, they would be able to pick up food for the user and deliver it and earn a percentage of the entire order. This would mean both the users and restaurants are earning money now for food that was once losing them money as they were throwing it out.Another additoin would be taking our Android Mockups and transferring them into a app meaning now both the users and restaurants have a way to buy/publish food via a mobile device. | ## Inspiration
Reading long articles suck. We were too lazy to do that. Why not have an app that would summarize the long boring content for us? Why not take just take a pic of the page and let the app summarize it for us ?
## What it does
Snaplify searches your images. It could tell you exactly what your image is, top 10 things you could do with that. Not just this. It reads the text within your image and summarizes it for you. Cool isn't it ?
## How I built it
We harnessed the power of alchemy api to help us understand what actually the image is. Then we ask bing to tell us the top things you could do with the it. If the image has any text we use Microsoft's Project Oxford to extract the text. We then apply some Natural Language Processing (NLP) on it to give us a brief summary. For the server we used Node.js and ionic at the client side.
## Challenges I ran into
* Angular is great. But like any other Javascript framework it doesn't have the built in ability to make synchronous HTTP calls to the server. That's when we had to make promises to our function by deferring the one already executed.
* Drafting down a summary from huge text using NLP was difficult. The use of underscore.js helped simplify some of the things for us.
## Accomplishments that I'm proud of
* Within 36 hours we have an app that could give us a summary of the long boring article we always hate reading.
## What I learned
* Microsoft API's are excellent. They have nearly accurate results and can be used more wisely.
* You should always keep your promises (even with your functions :P)
## What's next for Snaplify
* The current summary using NLP could be made much more better.
* SnapCash: A cool new way to transfer money to your friend by just taking picture of the cash.
* Product search in ecommerce using images. | partial |
## Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
## What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
## How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
## ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model [link](https://arxiv.org/abs/1609.04802). SRGAN with an attention layer [link](https://arxiv.org/pdf/1812.04821.pdf). These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually *only* 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces [see here](https://arxiv.org/abs/1809.05286). We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
## Accomplishments that I'm proud of
Building it good.
## What I learned
Balanced approaches and leveraging past learning
## What's next for Crystallize
Real time stream-enhance app. | ## The Gist
We combine state-of-the-art LLM/GPT detection methods with image diffusion models to accurately detect AI-generated video with 92% accuracy.
## Inspiration
As image and video generation models become more powerful, they pose a strong threat to traditional media norms of trust and truth. OpenAI's SORA model released in the last week produces extremely realistic video to fit any prompt, and opens up pathways for malicious actors to spread unprecedented misinformation regarding elections, war, etc.
## What it does
BinoSoRAs is a novel system designed to authenticate the origin of videos through advanced frame interpolation and deep learning techniques. This methodology is an extension of the state-of-the-art Binoculars framework by Hans et al. (January 2024), which employs dual LLMs to differentiate human-generated text from machine-generated counterparts based on the concept of textual "surprise".
BinoSoRAs extends on this idea in the video domain by utilizing **Fréchet Inception Distance (FID)** to compare the original input video against a model-generated video. FID is a common metric which measures the quality and diversity of images using an Inception v3 convolutional neural network. We create model-generated video by feeding the suspect input video into a **Fast Frame Interpolation (FLAVR)** model, which interpolates every 8 frames given start and end reference frames. We show that this interpolated video is more similar (i.e. "less surprising") to authentic video than artificial content when compared using FID.
The resulting FID + FLAVR two-model combination is an effective framework for detecting video generation such as that from OpenAI's SoRA. This innovative application enables a root-level analysis of video content, offering a robust mechanism for distinguishing between human-generated and machine-generated videos. Specifically, by using the Inception v3 and FLAVR models, we are able to look deeper into shared training data commonalities present in generated video.
## How we built it
Rather than simply analyzing the outputs of generative models, a common approach for detecting AI content, our methodology leverages patterns and weaknesses that are inherent to the common training data necessary to make these models in the first place. Our approach builds on the **Binoculars** framework developed by Hans et al. (Jan 2024), which is a highly accurate method of detecting LLM-generated tokens. Their state-of-the-art LLM text detector makes use of two assumptions: simply "looking" at text of unknown origin is not enough to classify it as human- or machine-generated, because a generator aims to make differences undetectable. Additionally, *models are more similar to each other than they are to any human*, in part because they are trained on extremely similar massive datasets. The natural conclusion is that an observer model will find human text to be very *perplex* and surprising, while an observer model will find generated text to be exactly what it expects.
We used Fréchet Inception Distance between the unknown video and interpolated generated video as a metric to determine if video is generated or real. FID uses the Inception score, which calculates how well the top-performing classifier Inception v3 classifies an image as one of 1,000 objects. After calculating the Inception score for every frame in the unknown video and the interpolated video, FID calculates the Fréchet distance between these Gaussian distributions, which is a high-dimensional measure of similarity between two curves. FID has been previously shown to correlate extremely well with human recognition of images as well as increase as expected with visual degradation of images.
We also used the open-source model **FLAVR** (Flow-Agnostic Video Representations for Fast Frame Interpolation), which is capable of single shot multi-frame prediction and reasoning about non-linear motion trajectories. With fine-tuning, this effectively served as our generator model, which created the comparison video necessary to the final FID metric.
With a FID-threshold-distance of 52.87, the true negative rate (Real videos correctly identified as real) was found to be 78.5%, and the false positive rate (Real videos incorrectly identified as fake) was found to be 21.4%. This computes to an accuracy of 91.67%.
## Challenges we ran into
One significant challenge was developing a framework for translating the Binoculars metric (Hans et al.), designed for detecting tokens generated by large-language models, into a practical score for judging AI-generated video content. Ultimately, we settled on our current framework of utilizing an observer and generator model to get an FID-based score; this method allows us to effectively determine the quality of movement between consecutive video frames through leveraging the distance between image feature vectors to classify suspect images.
## Accomplishments that we're proud of
We're extremely proud of our final product: BinoSoRAs is a framework that is not only effective, but also highly adaptive to the difficult challenge of detecting AI-generated videos. This type of content will only continue to proliferate the internet as text-to-video models such as OpenAI's SoRA get released to the public: in a time when anyone can fake videos effectively with minimal effort, these kinds of detection solutions and tools are more important than ever, *especially in an election year*.
BinoSoRAs represents a significant advancement in video authenticity analysis, combining the strengths of FLAVR's flow-free frame interpolation with the analytical precision of FID. By adapting the Binoculars framework's methodology to the visual domain, it sets a new standard for detecting machine-generated content, offering valuable insights for content verification and digital forensics. The system's efficiency, scalability, and effectiveness underscore its potential to address the evolving challenges of digital content authentication in an increasingly automated world.
## What we learned
This was the first-ever hackathon for all of us, and we all learned many valuable lessons about generative AI models and detection metrics such as Binoculars and Fréchet Inception Distance. Some team members also got new exposure to data mining and analysis (through data-handling libraries like NumPy, PyTorch, and Tensorflow), in addition to general knowledge about processing video data via OpenCV.
Arguably more importantly, we got to experience what it's like working in a team and iterating quickly on new research ideas. The process of vectoring and understanding how to de-risk our most uncertain research questions was invaluable, and we are proud of our teamwork and determination that ultimately culminated in a successful project.
## What's next for BinoSoRAs
BinoSoRAs is an exciting framework that has obvious and immediate real-world applications, in addition to more potential research avenues to explore. The aim is to create a highly-accurate model that can eventually be integrated into web applications and news articles to give immediate and accurate warnings/feedback of AI-generated content. This can mitigate the risk of misinformation in a time where anyone with basic computer skills can spread malicious content, and our hope is that we can build on this idea to prove our belief that despite its misuse, AI is a fundamental force for good. | ## Inspiration
Currently, there is an exponential growth of obesity in the world, leading to devastating consequences such as an increased rate of diabetes and heart diseases. All three of our team members are extremely passionate about nutrition issues and wish to educate others and promote healthy active living.
## What it does
This iOS app allows users to take pictures of meals that they eat and understand their daily nutrition intake. For each food that is imaged, the amount of calories, carbohydrates, fats and proteins are shown, contributing to the daily percentage on the nutrition tab. In the exercise tab, the users are able to see how much physical activities they need to do to burn off their calories, accounting for their age and weight differences. The data that is collected easily syncs with the iPhone built-in health app.
## How we built it
We built the iOS app in Swift programming language in Xcode. For the computer vision of the machine learning component, we used CoreML, and more specifically its Resnet 50 Model. We also implemented API calls to Edamam to receive nutrition details on each food item.
## Challenges we ran into
Two of our three team members have never used Swift before - it is definitely a challenge writing in an unfamiliar coding language. It was also challenging calling different APIs and integrating them back in Xcode, as the CoreML documentation is unclear.
## Accomplishments that we're proud of
We are proud of learning an entirely new programming language and building a substantial amount of a well-functioning app within 36 hours.
## What's next for NutriFitness
Building our own machine learning model and getting more accurate image descriptions. | winning |
## Inspiration
How do you define a sandwich? According to your definition is hotdog a sandwich? Well, according to Merriam Webster it is and so are sliders and many other food items that you might or might not consider sandwiches yourself (check out the link for more details- <https://www.merriam-webster.com/words-at-play/to-chew-on-10-kinds-of-sandwiches/sloppy-joe>)!
Expanding on this concept, this project aims to explore the classification of sandwiches and the boundaries to the definition.
## What it does
The Webapp determines whether an image classifies as a sandwich.
## How we built it
We downloaded 10,000 images from Google Images and 20,000 images from the Food101 dataset to train a binary classification algorithm on sandwiches using SqueezeNet Network in DeepLearning4J.
## Challenges we ran into
We had to switch from using Tensorflow and Python to using DeepLearning4J and Java because we wanted to do everything in memory of the server of the Webapp but the backend of the Webapp is in Java.
## What's next for Sandwichinator | ## Inspiration
Sign Language is what majority of the people who are part of the deaf and mute community use as a part of their daily conversing. **Not everyone knows sign language** and hence this necessitates the need for a tool to help others understand Sign. This basically emphasizes the possibility for the deaf and mute to be **solely independent** and not in need of translators when they have to address or even have a normal conversation with those who do not understand sign language.
## What it does
The platform basically takes in input via a camera of a hand gesture and tells you which alphabet does the letter stand for. It is based on the American Sign Language conventions and can recognize all the alphabets given the conditions are met which are derived from it's training data.
## How we built it
The backend was done using Python-Flask, Tailwind CSS was used for frontend development along with HTML and JS. For the AI part , Microsoft Azure Custom Vision service was used. The custom vision service can be used to train and deploy models with high availability and efficiency.
I used the ASL image dataset from Kaggle where 190 random images from the entire ASL was taken and used to train the model for each alphabet. Hence a total of 190\*26 images were used to train the Azure Custom Vision Model.
The application has been separately deployed on Azure WebApp service with GitHub Actions auto redeploying on new commit using a simple CI workflow.
## Challenges we ran into
1. Securing the critical keys in the code before pushing to github
2. Bottleneck on model efficiency when it comes to the use of real time data.
3. Azure Limitations on 5000 images per Custom Vision Project.
## Accomplishments that we're proud of
1. Making a model that successfully classified the ASL test data from Kaggle.
2. More deep understanding of Azure technologies and cloud.
## What we learned
1. Frontend Development with Tailwind CSS
2. Integrating Azure Services into Python Flask
3. Deployment on Azure
## What's next for Sign-To-Text
1. More efficient model.
2. Real-Time sign to text conversion followed by a text-to-voice converter.
3. Sign-To-Voice Converter | ## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service. | losing |
## Inspiration
Our inspiration came from the desire to address the issue of food waste and to help those in need. We decided to create an online platform that connects people with surplus food to those who need to address the problem of food insecurity and food waste, which is a significant environmental and economic problem. We also hoped to highlight the importance of community-based solutions, where individuals and organizations can come together to make a positive impact. We believed in the power of technology and how it can be used to create innovative solutions to social issues.
## What it does
Users can create posts about their surplus perishable food (along with expiration date+time) and other users can find those posts to contact the poster and come pick up the food. We thought about it as analogous to Facebook Marketplace but focused on surplus food.
## How we built it
We used React + Vite for the frontend and Express + Node.js for the backend. For infrastructure, we used Cloudflare Pages for the frontend and Microsoft Azure App Service for backend.
## Security Practices
#### Strict repository access permissions
(Some of these were lifted temporarily to quickly make changes while working with the tight deadline in a hackathon environment):
* Pull Request with at least 1 review required for merging to the main branch so that one of our team members' machines getting compromised doesn't affect our service.
* Reviews on pull requests must be after the latest commit is pushed to the branch to avoid making malicious changes after a review
* Status checks (build + successful deployment) must pass before merging to the main branch to avoid erroneous commits in the main branch
* PR branches must be up to date with the main branch to merge to make sure there are no incompatibilities with the latest commit causing issues in the main branch
* All conversations on the PR must be marked as resolved to make sure any concerns (including security) concerns someone may have expressed have been dealt with before merging
* Admins of the repository are not allowed to bypass any of these rules to avoid accidental downtime or malicious commits due to the admin's machine being compromised
#### Infrastructure
* Use Cloudflare's CDN (able to mitigate the largest DDoS attacks in the world) to deploy our static files for the frontend
* Set up SPF, DMARC and DKIM records on our domain so that someone spoofing our domain in emails doesn't work
* Use Microsoft Azure's App Service for CI/CD to have a standard automated procedure for deployments and avoid mistakes as well as avoid the responsibility of having to keep up with OS security updates since Microsoft would do that regularly for us
* We worked on using DNSSEC for our domain to avoid DNS-related attacks but domain.com (the hackathon sponsor) requires contacting their support to enable it. For my other projects, I implement it by adding a DS record on the registrar's end using the nameserver-provided credentials
* Set up logging on Microsoft Azure
#### Other
* Use environment variables to avoid disclosing any secret credentials
* Signed up with Github dependabot alerts to receive updates about any security vulnerabilities in our dependencies
* We were in the process of implementing an Authentication service using an open-source service called Supabase to let users sign in using multiple OAuth methods and implement 2FA with TOTP (instead of SMS)
* For all the password fields required for our database and Azure service, we used Bitwarden password generator to generate 20-character random passwords as well as used 2FA with TOTP to login to all services that support it
* Used SSL for all communication between our resources
## Challenges we ran into
* Getting the Google Maps API to work
* Weird errors deploying on Azure
* Spending too much time trying to make CockroachDB work. It seemed to require certificates for connection even for testing. It seemed like their docs for using sequalize with their DB were not updated since this requirement was put into place.
## Accomplishments that we're proud of
Winning the security award by CSE!
## What we learned
We learned to not underestimate the amount of work required and do better planning next time.
Meanwhile, maybe go to fewer activities though they are super fun and engaging! Don't take us wrong as we did not regret doing them! XD
## What's next for Food Share
Food Share is built within a limited time. Some implementations that couldn't be included in time:
* Location of available food on the interactive map
* More filters for the search for available food
* Accounts and authentication method
* Implement Microsoft Azure live chat called Azure Web PubSub
* Cleaner UI | ## Inspiration
Ever join a project only to be overwhelmed by all of the open tickets? Not sure which tasks you should take on to increase the teams overall productivity? As students, we know the struggle. We also know that this does not end when school ends and in many different work environments you may encounter the same situations.
## What it does
tAIket allows project managers to invite collaborators to a project. Once the user joins the project, tAIket will analyze their resume for both soft skills and hard skills. Once the users resume has been analyzed, tAIket will provide the user a list of tickets sorted in order of what it has determined that user would be the best at. From here, the user can accept the task, work on it, and mark it as complete! This helps increase productivity as it will match users with tasks that they should be able to complete with relative ease.
## How we built it
Our initial prototype of the UI was designed using Figma. The frontend was then developed using the Vue framework. The backend was done in Python via the Flask framework. The database we used to store users, projects, and tickets was Redis.
## Challenges we ran into
We ran into a few challenges throughout the course of the project. Figuring out how to parse a PDF, using fuzzy searching and cosine similarity analysis to help identify the users skills were a few of our main challenges. Additionally working out how to use Redis was another challenge we faced. Thanks to the help from the wonderful mentors and some online resources (documentation, etc.), we were able to work through these problems. We also had some difficulty working out how to make our site look nice and clean. We ended up looking at many different sites to help us identify some key ideas in overall web design.
## Accomplishments that we're proud of
Overall, we have much that we can be proud of from this project. For one, implementing fuzzy searching and cosine similarity analysis is something we are happy to have achieved. Additionally, knowing how long the process to create a UI should normally take, especially when considering user centered design, we are proud of the UI that we were able to create in the time that we did have.
## What we learned
Each team member has a different skillset and knowledge level. For some of us, this was a great opportunity to learn a new framework while for others this was a great opportunity to challenge and expand our existing knowledge. This was the first time that we have used Redis and we found it was fairly easy to understand how to use it. We also had the chance to explore natural language processing models with fuzzy search and our cosine similarity analysis.
## What's next for tAIket
In the future, we would like to add the ability to assign a task to all members of a project. Some tasks in projects *must* be completed by all members so we believe that this functionality would be useful. Additionally, the ability for "regular" users to "suggest" a task. We believe that this functionality would be useful as sometimes a user may notice something that is broken or needs to be completed but the project manager has not noticed it. Finally, something else that we would work on in the future would be the implementation of the features located in the sidebar of the screen where the tasks are displayed. | ## Inspiration:
The inspiration for Kisan Mitra came from the realization that Indian farmers face a number of challenges in accessing information that can help them improve their productivity and incomes. These challenges include:
```
Limited reach of extension services
Lack of awareness of government schemes
Difficulty understanding complex information
Language barriers
```
Kisan Mitra is designed to address these challenges by providing farmers with timely and accurate information in a user-friendly and accessible manner.
## What it does :
Kisan Mitra is a chatbot that can answer farmers' questions on a wide range of topics, including:
```
Government schemes and eligibility criteria
Farming techniques and best practices
Crop selection and pest management
Irrigation and water management
Market prices and weather conditions
```
Kisan Mitra can also provide farmers with links to additional resources, such as government websites and agricultural research papers.
## How we built it:
Kisan Mitra is built using the PaLM API, which is a large language model from Google AI. PaLM is trained on a massive dataset of text and code, which allows it to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Kisan Mitra is also integrated with a number of government databases and agricultural knowledge bases. This ensures that the information that Kisan Mitra provides is accurate and up-to-date.
## Challenges we ran into:
One of the biggest challenges we faced in developing Kisan Mitra was making it accessible to farmers of all levels of literacy and technical expertise. We wanted to create a chatbot that was easy to use and understand, even for farmers who have never used a smartphone before.
Another challenge was ensuring that Kisan Mitra could provide accurate and up-to-date information on a wide range of topics. We worked closely with government agencies and agricultural experts to develop a knowledge base that is comprehensive and reliable.
## Accomplishments that we're proud of:
We are proud of the fact that Kisan Mitra is a first-of-its-kind chatbot that is designed to address the specific needs of Indian farmers. We are also proud of the fact that Kisan Mitra is user-friendly and accessible to farmers of all levels of literacy and technical expertise.
## What we learned:
We learned a lot while developing Kisan Mitra. We learned about the challenges that Indian farmers face in accessing information, and we learned how to develop a chatbot that is both user-friendly and informative. We also learned about the importance of working closely with domain experts to ensure that the information that we provide is accurate and up-to-date.
## What's next for Kisan Mitra:
We are committed to continuing to develop and improve Kisan Mitra. We plan to add new features and functionality, and we plan to expand the knowledge base to cover more topics. We also plan to work with more government agencies and agricultural experts to ensure that Kisan Mitra is the best possible resource for Indian farmers.
We hope that Kisan Mitra will make a positive impact on the lives of Indian farmers by helping them to improve their productivity and incomes. | partial |
## Inspiration
Our inspiration for the project stems from our experience with elderly and visually impaired people, and understanding that there is an imminent need for a solution that integrates AI to bring a new level of convenience and safety to modern day navigation tools.
## What it does
IntelliCane firstly employs an ultrasonic sensor to identify any object, person, or thing within a 2 meter range and when that happens, a piezo buzzer alarm alerts the user. Simultaneously, a camera identifies the object infront of the user and provides them with voice feedback identifying what is infront of them.
## How we built it
The project firstly employs an ultrasonic sensor to identify an object, person or thing close by. Then the piezo buzzer is turned on and alerts the user. Then the Picamera that is on the raspberrypi 5 identifies the object. We have employed a CNN algorithm to train the data and improve the accuracy of identifying the objects. From there this data is transferred to a text-to-speech function which provides voice feedback describing the object infront of them. The project was built on YOLO V8 platform.
## Challenges we ran into
We ran into multiple problems during our project. For instance, we initially tried to used tensorflow, however due to the incompatibility of our version of python with the raspberrypi 5, we switched to the YOLO V8 Platform.
## Accomplishments that we're proud of
There are many accomplishments we are proud of, such as successfully creating an the ultrasonic-piezo buzzer system for the arduino, and successfully mounting everything onto the PVC Pipe. However, we are most proud of developing a CNN algorithm that accurately identifies objects and provides voice feedback identifying the object that is infront of the user.
## What we learned
We learned more about developing ML algorithms and became more proficient with the raspberrypi IDE.
## What's next for IntelliCane
Next steps for IntelliCane include integrating GPS modules and Bluetooth modules to add another level of convenience to navigation tools. | ## Inspiration
On the bus ride to another hackathon, one of our teammates was trying to get some sleep, but was having trouble because of how complex and loud the sound of people in the bus was. This led to the idea that in sufficiently noisy environment, hearing could be just as descriptive and rich as seeing. Therefore to better enable people with visual impairments to be able to navigate and understand their environment, we created a piece of software that is able to describe and create an auditory map of ones environment.
## What it does
In a sentence, it uses machine vision to give individuals a kind of echo location. More specifically, one simply needs to hold their cell phone up, and the software will work to guide them using a 3D auditory map. The video feed is streamed over to a server where our modified version of the yolo9000 classification convolutional neural network identifies and localizes the objects of interest within the image. It will then return the position and name of each object back to ones phone. It also uses the Watson IBM api to further augment its readings by validating what objects are actually in the scene, and whether or not they have been misclassified.
From here, we make it seem as though each object essentially says its own name, so that individual can essentially create a spacial map of their environment just through audio cues. The sounds get quieter the further away the objects are, and the ratio of sounds between the left and right are also varied as the object moves around the use. The phone are records its orientation, and remembers where past objects were for a few seconds afterwards, even if it is no longer seeing them.
However, we also thought about where in everyday life you would want extra detail, and one aspect that stood out to us was faces. Generally, people use specific details on and individual's face to recognize them, so using microsoft's face recognition api, we added a feature that will allow our system to identify and follow friend and family by name. All one has to do is set up their face as a recognizable face, and they are now their own identifiable feature in one's personal system.
## What's next for SoundSight
This system could easily be further augmented with voice recognition and processing software that would allow for feedback that would allow for a much more natural experience. It could also be paired with a simple infrared imaging camera to be used to navigate during the night time, making it universally usable. A final idea for future improvement could be to further enhance the machine vision of the system, thereby maximizing its overall effectiveness | ## Inspiration
Our team firmly believes that a hackathon is the perfect opportunity to learn technical skills while having fun. Especially because of the hardware focus that MakeUofT provides, we decided to create a game! This electrifying project places two players' minds to the test, working together to solve various puzzles. Taking heavy inspiration from the hit videogame, "Keep Talking and Nobody Explodes", what better way to engage the players than have then defuse a bomb!
## What it does
The MakeUofT 2024 Explosive Game includes 4 modules that must be disarmed, each module is discrete and can be disarmed in any order. The modules the explosive includes are a "cut the wire" game where the wires must be cut in the correct order, a "press the button" module where different actions must be taken depending the given text and LED colour, an 8 by 8 "invisible maze" where players must cooperate in order to navigate to the end, and finally a needy module which requires players to stay vigilant and ensure that the bomb does not leak too much "electronic discharge".
## How we built it
**The Explosive**
The explosive defuser simulation is a modular game crafted using four distinct modules, built using the Qualcomm Arduino Due Kit, LED matrices, Keypads, Mini OLEDs, and various microcontroller components. The structure of the explosive device is assembled using foam board and 3D printed plates.
**The Code**
Our explosive defuser simulation tool is programmed entirely within the Arduino IDE. We utilized the Adafruit BusIO, Adafruit GFX Library, Adafruit SSD1306, Membrane Switch Module, and MAX7219 LED Dot Matrix Module libraries. Built separately, our modules were integrated under a unified framework, showcasing a fun-to-play defusal simulation.
Using the Grove LCD RGB Backlight Library, we programmed the screens for our explosive defuser simulation modules (Capacitor Discharge and the Button). This library was used in addition for startup time measurements, facilitating timing-based events, and communicating with displays and sensors that occurred through the I2C protocol.
The MAT7219 IC is a serial input/output common-cathode display driver that interfaces microprocessors to 64 individual LEDs. Using the MAX7219 LED Dot Matrix Module we were able to optimize our maze module controlling all 64 LEDs individually using only 3 pins. Using the Keypad library and the Membrane Switch Module we used the keypad as a matrix keypad to control the movement of the LEDs on the 8 by 8 matrix. This module further optimizes the maze hardware, minimizing the required wiring, and improves signal communication.
## Challenges we ran into
Participating in the biggest hardware hackathon in Canada, using all the various hardware components provided such as the keypads or OLED displays posed challenged in terms of wiring and compatibility with the parent code. This forced us to adapt to utilize components that better suited our needs as well as being flexible with the hardware provided.
Each of our members designed a module for the puzzle, requiring coordination of the functionalities within the Arduino framework while maintaining modularity and reusability of our code and pins. Therefore optimizing software and hardware was necessary to have an efficient resource usage, a challenge throughout the development process.
Another issue we faced when dealing with a hardware hack was the noise caused by the system, to counteract this we had to come up with unique solutions mentioned below:
## Accomplishments that we're proud of
During the Makeathon we often faced the issue of buttons creating noise, and often times the noise it would create would disrupt the entire system. To counteract this issue we had to discover creative solutions that did not use buttons to get around the noise. For example, instead of using four buttons to determine the movement of the defuser in the maze, our teammate Brian discovered a way to implement the keypad as the movement controller, which both controlled noise in the system and minimized the number of pins we required for the module.
## What we learned
* Familiarity with the functionalities of new Arduino components like the "Micro-OLED Display," "8 by 8 LED matrix," and "Keypad" is gained through the development of individual modules.
* Efficient time management is essential for successfully completing the design. Establishing a precise timeline for the workflow aids in maintaining organization and ensuring successful development.
* Enhancing overall group performance is achieved by assigning individual tasks.
## What's next for Keep Hacking and Nobody Codes
* Ensure the elimination of any unwanted noises in the wiring between the main board and game modules.
* Expand the range of modules by developing additional games such as "Morse-Code Game," "Memory Game," and others to offer more variety for players.
* Release the game to a wider audience, allowing more people to enjoy and play it. | partial |
# Recipe Finder - Project for NWHacks 2020
## The Problem
About 1/3 of food produced in the world is lost or wasted in the year. There are many reasons for this, including not being able to cook with said food, not having time to cook this food or cooking food that does not taste good. Albeit this, food waste is a serious problem that wastes money, wastes time and harms the environment.
## Our Solution
Our web app, Recipe Nest is a chat bot deployed on Slack, the Web, through calls. (Messenger and Google Assistant are currently awaiting approval). Users simply enter in all the filters they would like their recipe to contain and Recipe Nest finds a recipe conforming to the users' requests! We believe that making this application as accessible as possible reflects our goal of making it easy to get started with cooking at home and not wasting food!
## How we did it
We used Python, Flask, for the backend. Our chat bot was built with Google Cloud's Dialogflow in which we personally trained to be able to take user input. The front end was built with CSS, HTML, and Bootstrap.
## Going forward
We hope to add user logins via Firebase. We would then add features such as 1. Saving food in your fridge 2. Having the app remind you of this food 3. Allow the user to save recipes that they like. Additionally, we would like to add more filters, such as nutrition, cost, and excluding certain foods, and finally, create a better UI/UX experience for the user. | ## Inspiration
CookHack was inspired by the fact that students in university are always struggling with the responsibility of cooking their next healthy and nutritious meal. However, most of the time, we as students are always too busy to decide and learn how to cook basic meals, and we resort to the easy route and start ordering Uber Eats or Skip the Dishes. Now, the goal with CookHack was to eliminate the mental resistance and make the process of cooking healthy and delicious meals at home as streamlined as possible while sharing the process online.
## What it does
CookHack, in a nutshell, is a full-stack web application that provides users with the ability to log in to a personalized account to browse a catalog of 50 different recipes from our database and receive simple step-by-step instructions on how to cook delicious homemade dishes. CookHack also provides the ability for users to add the ingredients that they have readily available and start cooking recipes with those associated ingredients. Lastly, CookHack encourages the idea of interconnection by sharing their cooking experiences online by allowing users to post updates and blog forums about their cooking adventures.
## How we built it
The web application was built using the following tech stack: React, MongoDB, Firebase, and Flask. The frontend was developed with React to make the site fast and performant for the web application and allow for dynamic data to be passed to and from the backend server built with Flask. Flask connects to MongoDB to store our recipe documents on the backend, and Flask essentially serves as the delivery system for the recipes between MongoDB and React. For our authentication, Firebase was used to implement user authentication using Firebase Auth, and Firestore was used for storing and updating documents about the blog/forum posts on the site. Lastly, the Hammer of the Gods API was connected to the frontend, allowing us to use machine learning image detection.
## Challenges we ran into
* Lack of knowledge with Flask and how it works together with react.
* Implementing the user ingredients and sending back available recipes
* Had issues with the backend
* Developing the review page
* Implementing HoTG API
## Accomplishments that we're proud of
* The frontend UI and UX design for the site
* How to use Flask and React together
* The successful transfer of data flow between frontend, backend, and the database
* How to create a "forum" page in react
* The implementation of Hammer of the Gods API
* The overall functionality of the project
## What we learned
* How to setup Flask backend server
* How to use Figma and do UI and UX design
* How to implement Hammer of the Gods API
* How to make a RESTFUL API
* How to create a forum page
* How to create a login system
* How to implement Firebase Auth
* How to implement Firestore
* How to use MongoDB
## What's next for CookHack
* Fix any nit-picky things on each web page
* Make sure all the functionality works reliably
* Write error checking code to prevent the site from crashing due to unloaded data
* Add animations to the frontend UI
* Allow users to have more interconnections by allowing others to share their own recipes to the database
* Make sure all the images have the same size proportions | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | partial |
## Inspiration
At Princeton, there are lots of opportunities available to students. However, sometimes these opportunities are missed because people do not know about them. We wanted to integrate the information available on certificates and on extracurriculars, so students have one place to look for all the information.
## What it does
It includes a list of all the different certificates offered and the extracurricular activities at Princeton that are most related to this particular field.
## How we built it
We coded using html.
## Challenges we ran into
This was our first time programming in html, so there was a learning curve with figuring out the new syntax and methods.
## What's next for Activities and Academics United
We need to improve the presentation and add a search function so that users can search for information they find interesting.
Please open the certificate.html file first because this is our main directory. The other files are sub-directories. | ## Inspiration
We were inspired by the PSRJ also known as the Princeton Student for Reproductive Justice as they handed out contraceptives to students, anonymously. So we wanted to create a website that facilities the access of reproductive healthcare products to Princeton students.
## What it does
Our website allows students to order reproductive health products, anonymously, and then sends these orders to students that can deliver these products in association with student groups such as PSRJ. The colorful, welcoming design is meant to make the students feel more comfortable and less intimidated by these products that can sometimes seem not very accessible to them.
## How we built it
We built the backend using Flask and connected it to a MySQL database that contains user, order, and delivery information. We then used Streamlit for the frontend meaning that most of our project was in Python which is the language we are the most familiar with. We leveraged certain libraries such as SQLAlchemy to help us produce our website. We also focused heavily on the ui/design and used css to style our website into a fun, bright website.
## Challenges we ran into
One main challenge was the planning as this was our first hackathon. We could have definitely been more efficient with our time management and also set specific goals that we wanted to accomplish within a certain timeframe. We also struggled to use streamlit and other technologies that some of us were not very familiar with.
## Accomplishments that we're proud of
We are proud of creating a product that can greatly benefit the student community and that can contribute towards breaking down the stigma surrounding healthcare products. We strive to empower college students and allow them to be comfortable with themselves.
## What we learned
We learned the importance of proper planning and also establishing team roles in order to improve efficiency. We also learned more about individuals technologies and also more general knowledge through all the very well structured workshops that made for excellent learning opportunities.
## What's next for Princeton Care Package
Scalability and uploading the website to the cloud so that our product can reach a wider audience beyond just Princeton. | ## Inspiration
A deep and unreasonable love of xylophones
## What it does
An air xylophone right in your browser!
Play such classic songs as twinkle twinkle little star, ba ba rainbow sheep and the alphabet song or come up with the next club banger in free play.
We also added an air guitar mode where you can play any classic 4 chord song such as Wonderwall
## How we built it
We built a static website using React which utilised Posenet from TensorflowJS to track the users hand positions and translate these to specific xylophone keys.
We then extended this by creating Xylophone Hero, a fun game that lets you play your favourite tunes without requiring any physical instruments.
## Challenges we ran into
Fine tuning the machine learning model to provide a good balance of speed and accuracy
## Accomplishments that we're proud of
I can get 100% on Never Gonna Give You Up on XylophoneHero (I've practised since the video)
## What we learned
We learnt about fine tuning neural nets to achieve maximum performance for real time rendering in the browser.
## What's next for XylophoneHero
We would like to:
* Add further instruments including a ~~guitar~~ and drum set in both freeplay and hero modes
* Allow for dynamic tuning of Posenet based on individual hardware configurations
* Add new and exciting songs to Xylophone
* Add a multiplayer jam mode | losing |
## Inspiration
Trump's statements include some of the most outrageous things said recently, so we wanted to see whether someone could distinguish between a fake statement and something Trump would say.
## What it does
We generated statements using markov chains (<https://en.wikipedia.org/wiki/Markov_chain>) that are based off of the things trump actually says. To show how difficult it is to distinguish between the machine generated text and the real stuff he says, we made a web app to test whether someone could determine which was the machine generated text (Drumpf) and which was the real Trump speech.
## How we built it
python+regex for parsing Trump's statementsurrent tools you use to find & apply to jobs?
html/css/js frontend
azure and aws for backend/hosting
## Challenges we ran into
Machine learning is hard. We tried to use recurrent neural networks at first for speech but realized we didn't have a large enough data set, so we switched to markov chains which don't need as much training data, but also have less variance in what is generated.
We actually spent a bit of time getting <https://github.com/jcjohnson/torch-rnn> up and running, but then figured out it was actually pretty bad as we had a pretty small data set (<100kB at that point)
Eventually got to 200kB and we were half-satisfied with the results, so we took the good ones and put it up on our web app.
## Accomplishments that we're proud of
First hackathon we've done where our front end looks good in addition to having a decent backend.
regex was interesting.
## What we learned
bootstrap/javascript/python to generate markov chains
## What's next for MakeTrumpTrumpAgain
scrape trump's twitter and add it
get enough data to use a neural network
dynamically generate drumpf statements
If you want to read all the machine generated text that we deemed acceptable to release to the public, open up your javascript console, open up main.js. Line 4599 is where the hilarity starts. | ## Inspiration
I'm lazy and voice recognition / nlp continues to blow my mind with its accuracy.
## What it does
Using Voice recognition and Natural Language Processing you can talk to your browser and it will do your bidding, no hands required!
I also built in "Demonstration" so if ever the AI doesn't do what you want you can give it a sample command and the Demonstrate what to click on / type while the bot watches! All of these training demonstrations get added to a centralized database so that everyone together makes the bot smarter!
## How I built it
Chrome Extension, Nuance APIs MIX.NLU and Voice Recognition, Angular JS, Firebase
## Challenges I ran into
Nuance API took a little while to figure out, also sending inputs into the browser on the right elements is tricky.
## Accomplishments that I'm proud of
Making is all work together and in such a short time! :D
## What I learned
## What's next for AI-Browser
I want to take the time to properly implement the training portion | ## Inspiration
With everything going on nowadays, people are starting to feel less connected. While we are focused on physical illnesses during these times, we tend to forget to take care of our mental health. Our team wanted to make a game that would show a bit about how hard it is to live with depression to give a chance for people to have fun while learn more about mental health. We wanted to start conversations about mental health and allow people to connect.
## What it does
The mobile game, ‘Hope’ portrays the life of a girl who is going through depression, difficulties are solved through mini-games, while her daily life is being portrayed through animations and comic strips.
## How we built it
We used Unity to create this game, and we used Procreate to create all of the assets.
## Challenges we ran into
Some members of our team were new to programming, and they learned a lot of new skills like C# programming and navigating Unity. Also, we had a lot of assets to draw in such a short amount of time.
## Accomplishments that we're proud of
We are proud that we made a complete game with great purpose in such a short time.
## What we learned
Through the development of this game/project, we learnt various new skills regarding the use of unity and C#.
## What's next for Hope
We hope to continue adding more mini-games to showcase more aspects of mental health and depression. We may create other versions of the game focusing on different aspects of mental health.
APK download link: <https://github.com/SallyLim/Hope/releases/download/v1.0/hope.apk> | partial |
## Inspiration
Learning about some environmental impact of the retail industry led us to wonder about what companies have aimed for in terms of sustainability goals. The textile industry is notorious for its carbon and water footprints with statistics widely available. How does a company promote sustainability? Do people know and support about these movements?
With many movements by certain retail companies to have more sustainable clothes and supply-chain processes, we wanted people to know and support these sustainability movements, all through an interactive and fun UI :)
## What it does
We built an application to help users select suitable outfit pairings that meet environmental standards. The user is prompted to upload a picture of a piece of clothing they currently own. Based on this data, we generate potential outfit pairings from a database of environmentally friendly retailers. Users are shown prices, means of purchase, reasons the company is sustainable, as well as an environmental rating.
## How we built it
**Backend**: Google Vision API, MySQL, AWS, Python with Heroku and Flask deployment
Using the Google Vision API, we learn of the features (labels, company, type of clothes and colour) from pictures of clothes. With these features, we use Python to interact with our MySQL database of clothes to both select a recommended outfit and additional recommended clothes for other potential outfit combinations.
To generate more accurate label results, we additionally perform a Keras (with Tensorflow backend) image segmentation to crop out the background, allowing the Google Vision API to extract more accurate features.
**Frontend**: JavaScript, React, Firebase
We built the front-end with React, using Firebase to handle user authentications and act as a content delivery network.
## Challenges we ran into
The most challenging part of the project was learning to use the Google Vision API, and deploying the API on Heroku with all its dependencies.
## Accomplishments that we're proud of
Intuitive and clean UI for users that allows ease of mix and matching while raising awareness of sustainability within the retail industry, and of course, the integration and deployment of our technology stack.
## What we learned
After viewing some misfit outfit recommendations, such as a jacket with shorts, had we added a "seasonal" label, and furthermore a "dress code" label (by perhaps, integrating transfer learning to label the images), we could have given better outfit recommendations. This made us realize importance of brainstorming and planning.
## What's next for Fabrical
Deploy more sophisticated clothes matching algorithms, saving the user's outfits into a closet, in addition to recording the user's age, and their preferences as they like / dislike new outfit combinations; incorporate larger database, more metrics, and integrate the machine learning matching / cropping techniques. | #### HackPrinceton - Clean Tech Category: **Tetra** ♻️
## Inspiration ✨♻️
We were inspired to create this project after reading ongoing [**news**](https://www.businessoffashion.com/articles/luxury/luxury-brands-burn-unsold-goods-what-should-they-do-instead) about famous luxury clothing brands yearly burning their unsold inventories. It was very surprising to learn about the number of high-quality goods these brands have burned when they could have recycled them or kept a better track of their supply chain in order to prevent the result. These brands also have more resources (which is why they are luxury brands) yet this problem keeps persisting which partly roots from a bigger issue of current supply chains not being sustainable enough to help brands improve their practices.
## What it does ⚡⚙️
**Tetra** is a sustainable supply chain management system that helps clothing brands have clear transparency into each stage of their supply chain while also helping them recycle more of their unsold inventory.
## How we built it 🖥️🌿
Tetra's technical backbone uses blockchain for business using Ethereum and Web3.js. This allows each product in the inventory to have a unique ID that can be traced and tracked to see which stages in the supply chain it has gone through (example: shipping stage, factory, supply). It will also show what types of materials this product is made out of. If this item is unsold, admins can send the item to a recycling facility. Once a product gets recycled, users of Tetra can also trace the history of the different parts that made up that product got recycled into.
### Some of the completed user stories are:
* As an admin, I am able to track which product to recycle
* As an admin, I am able to add a new product to the chain
* As an admin, I am able to add or ship new materials (that are parts of the product) to the chain
* As a customer, I am able to see a history/timeline of where the materials of a product have been recycled to
## Challenges we ran into 🤕
Since this was our first time working with Ethereum as a blockchain platform, and with writing Solidity smart contracts, we had to learn a lot of concepts as a team before we were able to fully grasp what the blockchain architecture would look like and how we were to structure the web app to get it talking the blockchain! 🔗
## Accomplishments that we're proud of 🦚
We are very proud of writing working smart contracts in solidity. We are happy with the progress we made and are stoked about the design and UI/UX of the web app. We are also proud to have tackled such a major issue - one that brings the earth closer to its destruction. 🌍
## What we learned 🏫
For this hackathon, we switched roles on the tech stack. So Ana and Tayeeb built out the backend while Krishna worked on the frontend. It was Anastasiya's first time working on the backend, and she is happy to have learned so much about Web Servers, and REST APIs. We all enjoyed diving into the world of blockchain and managing to create an MVP in one weekend. We also learned how to pitch and market our project.
## What's next for Tetra 🚀
We hope to make the MVP into an actual beta version that can be shipped out to various retail brands that can make use of a supply chain, and we hope that by using Tetra, we can help make a difference in the world!
## Contributors 👨🏻💻👩🏻💻
1. Tayeeb Hasan - [github](https://github.com/flozender)
2. Krishna - [github](https://github.com/JethroGibbsN)
3. Anastasiya Uraleva - [github](https://github.com/APiligrim) | ## Inspiration
Determined to create a project that was able to make impactful change, we sat and discussed together as a group our own lived experiences, thoughts, and opinions. We quickly realized the way that the lack of thorough sexual education in our adolescence greatly impacted each of us as we made the transition to university. Furthermore, we began to really see how this kind of information wasn't readily available to female-identifying individuals (and others who would benefit from this information) in an accessible and digestible manner. We chose to name our idea 'Illuminate' as we are bringing light to a very important topic that has been in the dark for so long.
## What it does
This application is a safe space for women (and others who would benefit from this information) to learn more about themselves and their health regarding their sexuality and relationships. It covers everything from menstruation to contraceptives to consent. The app also includes a space for women to ask questions, find which products are best for them and their lifestyles, and a way to find their local sexual health clinics. Not only does this application shed light on a taboo subject but empowers individuals to make smart decisions regarding their bodies.
## How we built it
Illuminate was built using Flutter as our mobile framework in order to be able to support iOS and Android.
We learned the fundamentals of the dart language to fully take advantage of Flutter's fast development and created a functioning prototype of our application.
## Challenges we ran into
As individuals who have never used either Flutter or Android Studio, the learning curve was quite steep. We were unable to even create anything for a long time as we struggled quite a bit with the basics. However, with lots of time, research, and learning, we quickly built up our skills and were able to carry out the rest of our project.
## Accomplishments that we're proud of
In all honesty, we are so proud of ourselves for being able to learn as much as we did about Flutter in the time that we had. We really came together as a team and created something we are all genuinely really proud of. This will definitely be the first of many stepping stones in what Illuminate will do!
## What we learned
Despite this being our first time, by the end of all of this we learned how to successfully use Android Studio, Flutter, and how to create a mobile application!
## What's next for Illuminate
In the future, we hope to add an interactive map component that will be able to show users where their local sexual health clinics are using a GPS system. | partial |
## Inspiration
Berkeley is a competitive school and many course offerings are well known for their academic rigor. in order to plan their class schedules, Berkeley students regularly rely on unit values of the courses to estimate the weekly time commitment they require. The Academic Senate defines one unit as three hours of work per week. Therefore, most major requirement courses are of 3 or 4 units, equivalent to 9 or 12 hours per week. However, almost every Berkeley student knows that this is usually an underestimate. Alumni and even the professors admit that most courses take way more time to do well in it than what is implied in unit values. Popular classes such as CS 61A even draw criticism due to students end up spending more than 12 hours per week to complete the required lectures, homework, labs, projects, and exam practice. **We don't think there is anything wrong with making a course demanding, but a lack of information on how much time is really needed hinders students' ability to make informed decisions on what classes to take.** Right now, students usually rely on words to gauge a class' workload: they will ask their friends and upperclassmen who have taken the course. This approach is not perfect, however, because each people may perceive difficulty a bit differently and sometimes it's hard to find someone who has actually taken the class. Therefore, we decide to create a RateMyProfessor-style website so that students can rate and view courses' workload information in one stop.
## What it does
CalRate is a platform that can enable students to rate a course's real workload and time commitment based on their personal experience during the semester. Their ratings will be used to calculate the average rating of a course which represents the average opinion on how much time the course actually takes each week. Students can search the database during the enrollment period, allowing them to make better-informed decisions on which course to take and how many units to enroll.
## How we built it
We use the Anvil web app builder as our main tool. We create a Data Table to store the average course ratings and then we use Python to implement a searching tool to enable users to search the data table for the courses of interest. We also use Python to implement the data updating algorithm so that the average rating of a course can be correctly updated when someone submits a new rating, and a new course entry will be created when someone rates a new course.
## Challenges we ran into
We are somewhat unfamiliar with the Anvil environment when starting out, so it takes us some time and effort to learn how to use this tool. In the end, we are able to overcome this difficulty by closely reading the documentation and searching for answers on forums.
## Accomplishments that we're proud of
After we finish the app, we are most proud of the fact that this working web app can actually go out there and help our fellow Berkeley students, especially those with less personal connections and social resources. With proper advertisement, we believe this platform can really help students make more reasonable plans about their upcoming semester, knowing what to expect from each course they choose.
## What we learned
During the process of completing this project, there are many valuable takeaways. Most importantly, this project provides an opportunity for us to learn how to use the web app building tool Anvil, which, as part of our software engineering skillsets, can benefit us in future studies or work. Also, we learn the
## What's next for CalRate
Next, we want to start by making this platform available and known among Berkeley students. As a crowdsourcing app, its success also relies on more people using it. We will start out by inviting our friends to try out and provide ratings for the courses they have taken. This will give us valuable feedback and allow us to further polish the UI and functionalities. This will also generate initial data so that when it is online for all students to use, they will already find it useful. In the long run, we also hope to integrate this with another functionality: sharing course resources. Some classes have instructor-provided extra resources - notes, Youtube videos, books, to help those students that find course materials insufficient, but many others don't. We want to build a platform that allows students that have taken the course to take the lead and share resources they find helpful. Together with this, we believe CalRate can further support our fellow Berkeley students in completing a successful college career. | ## Inspiration
Lectures all around the world last on average 100.68 minutes. That number goes all the way up to 216.86 minutes for art students. As students in engineering, we spend roughly 480 hours a day listening to lectures. Add an additional 480 minutes for homework (we're told to study an hour for every hour in a lecture), 120 minutes for personal breaks, 45 minutes for hygeine, not to mention tutorials, office hours, and et. cetera. Thinking about this reminded us of the triangle of sleep, grades and a social life-- and how you can only pick two. We felt that this was unfair and that there had to be a way around this. Most people approach this by attending lectures at home. But often, they just put lectures at 2x speed, or skip sections altogether. This isn't an efficient approach to studying in the slightest.
## What it does
Our web-based application takes audio files- whether it be from lectures, interviews or your favourite podcast, and takes out all the silent bits-- the parts you don't care about. That is, the intermediate walking, writing, thinking, pausing or any waiting that happens. By analyzing the waveforms, we can algorithmically select and remove parts of the audio that are quieter than the rest. This is done over our python script running behind our UI.
## How I built it
We used PHP/HTML/CSS with Bootstrap to generate the frontend, hosted on a DigitalOcean LAMP droplet with a namecheap domain. On the droplet, we have hosted an Ubuntu web server, which hosts our python file which gets run on the shell.
## Challenges I ran into
For all members in the team, it was our first time approaching all of our tasks. Going head on into something we don't know about, in a timed and stressful situation such as a hackathon was really challenging, and something we were very glad that we persevered through.
## Accomplishments that I'm proud of
Creating a final product from scratch, without the use of templates or too much guidance from tutorials is pretty rewarding. Often in the web development process, templates and guides are used to help someone learn. However, we developed all of the scripting and the UI ourselves as a team. We even went so far as to design the icons and artwork ourselves.
## What I learned
We learnt a lot about the importance of working collaboratively to create a full-stack project. Each individual in the team was assigned a different compartment of the project-- from web deployment, to scripting, to graphic design and user interface. Each role was vastly different from the next and it took a whole team to pull this together. We all gained a greater understanding of the work that goes on in large tech companies.
## What's next for lectr.me
Ideally, we'd like to develop the idea to have much more features-- perhaps introducing video, and other options. This idea was really a starting point and there's so much potential for it.
## Examples
<https://drive.google.com/drive/folders/1eUm0j95Im7Uh5GG4HwLQXreF0Lzu1TNi?usp=sharing> | ## Inspiration
Today we live in a world that is all online with the pandemic forcing us at home. Due to this, our team and the people around us were forced to rely on video conference apps for school and work. Although these apps function well, there was always something missing and we were faced with new problems we weren't used to facing. Personally, forgetting to mute my mic when going to the door to yell at my dog, accidentally disturbing the entire video conference. For others, it was a lack of accessibility tools that made the experience more difficult. Then for some, simply scared of something embarrassing happening during class while it is being recorded to be posted and seen on repeat! We knew something had to be done to fix these issues.
## What it does
Our app essentially takes over your webcam to give the user more control of what it does and when it does. The goal of the project is to add all the missing features that we wished were available during all our past video conferences.
Features:
Webcam:
1 - Detect when user is away
This feature will automatically blur the webcam feed when a User walks away from the computer to ensure the user's privacy
2- Detect when user is sleeping
We all fear falling asleep on a video call and being recorded by others, our app will detect if the user is sleeping and will automatically blur the webcam feed.
3- Only show registered user
Our app allows the user to train a simple AI face recognition model in order to only allow the webcam feed to show if they are present. This is ideal to prevent ones children from accidentally walking in front of the camera and putting on a show for all to see :)
4- Display Custom Unavailable Image
Rather than blur the frame, we give the option to choose a custom image to pass to the webcam feed when we want to block the camera
Audio:
1- Mute Microphone when video is off
This option allows users to additionally have the app mute their microphone when the app changes the video feed to block the camera.
Accessibility:
1- ASL Subtitle
Using another AI model, our app will translate your ASL into text allowing mute people another channel of communication
2- Audio Transcriber
This option will automatically transcribe all you say to your webcam feed for anyone to read.
Concentration Tracker:
1- Tracks the user's concentration level throughout their session making them aware of the time they waste, giving them the chance to change the bad habbits.
## How we built it
The core of our app was built with Python using OpenCV to manipulate the image feed. The AI's used to detect the different visual situations are a mix of haar\_cascades from OpenCV and deep learning models that we built on Google Colab using TensorFlow and Keras.
The UI of our app was created using Electron with React.js and TypeScript using a variety of different libraries to help support our app. The two parts of the application communicate together using WebSockets from socket.io as well as synchronized python thread.
## Challenges we ran into
Dam where to start haha...
Firstly, Python is not a language any of us are too familiar with, so from the start, we knew we had a challenge ahead. Our first main problem was figuring out how to highjack the webcam video feed and to pass the feed on to be used by any video conference app, rather than make our app for a specific one.
The next challenge we faced was mainly figuring out a method of communication between our front end and our python. With none of us having too much experience in either Electron or in Python, we might have spent a bit too much time on Stack Overflow, but in the end, we figured out how to leverage socket.io to allow for continuous communication between the two apps.
Another major challenge was making the core features of our application communicate with each other. Since the major parts (speech-to-text, camera feed, camera processing, socket.io, etc) were mainly running on blocking threads, we had to figure out how to properly do multi-threading in an environment we weren't familiar with. This caused a lot of issues during the development, but we ended up having a pretty good understanding near the end and got everything working together.
## Accomplishments that we're proud of
Our team is really proud of the product we have made and have already begun proudly showing it to all of our friends!
Considering we all have an intense passion for AI, we are super proud of our project from a technical standpoint, finally getting the chance to work with it. Overall, we are extremely proud of our product and genuinely plan to better optimize it in order to use within our courses and work conference, as it is really a tool we need in our everyday lives.
## What we learned
From a technical point of view, our team has learnt an incredible amount the past few days. Each of us tackled problems using technologies we have never used before that we can now proudly say we understand how to use. For me, Jonathan, I mainly learnt how to work with OpenCV, following a 4-hour long tutorial learning the inner workings of the library and how to apply it to our project. For Quan, it was mainly creating a structure that would allow for our Electron app and python program communicate together without killing the performance. Finally, Zhi worked for the first time with the Google API in order to get our speech to text working, he also learned a lot of python and about multi-threadingbin Python to set everything up together. Together, we all had to learn the basics of AI in order to implement the various models used within our application and to finally attempt (not a perfect model by any means) to create one ourselves.
## What's next for Boom. The Meeting Enhancer
This hackathon is only the start for Boom as our team is exploding with ideas!!! We have a few ideas on where to bring the project next. Firstly, we would want to finish polishing the existing features in the app. Then we would love to make a market place that allows people to choose from any kind of trained AI to determine when to block the webcam feed. This would allow for limitless creativity from us and anyone who would want to contribute!!!! | partial |
## 1. Inspiration
The *SmartCaliper* is a fresh approach to caliper design disrupting a stagnant market. We designed the SmartCaliper after seeing firsthand in the industry the limitations that modern calipers have; hence we present a fresh vision for a technology that can reduce error and increase productivity for engineers and hobbyists. The SmartCaliper allows for measurement data to be digitally transferred from the caliper to the computer. Additionally, we offer a novel software package that integrates the SmartCaliper to not only analyze the part tolerances against its 3D model, but to also facilitate the computer-aided-designing (CAD) process .
To demonstrate the application in industry for the SmartCaliper, one of our team members offers two first-hand experiences from an aerospace company and mech engineering company. First in aerospace, working with satellite hardware, there are a number of precision parts which all require their dimensions to be verified. During the assembly process, there was a case of one of the parts not fitting correctly. Consequently, an engineer and I began taking measurements of the part that could be causing the fit to deviate from the tolerance specification in the clean chamber. These measurements are often recorded from the caliper’s screen then written onto a piece of paper, usually a notebook. This is then brought to a computer and compared. What is bizarre about this is the use of paper since it is counter-intuitive to record measurements from a digital caliper onto a piece of paper only to then check with a digital CAD model. This creates a source of error when recording the measurements and leaves no concrete log of the measurements for later use, unless they are digitized from the notebook. In this case, SmartCalipers would have streamlined this process since it seamlessly transfers caliper data to Blender with our custom addon installed, which enables the user to annotate and record the tolerance information directly into the 3D Wavefront OBJ file itself. When the annotations need to be accessed again in the future, the Blender addon is also capable of loading in and editing them.
The second example is from working with tight tolerance parts in a local mechanical engineering company. Similar to the one off components for space, large production run parts often require dimensions to be verified and fits checked for parts. There do exist numerous cases where commercial off-the-shelf (COTS) parts are purchased without drawings or with inaccurate drawings. As a result, when the engineers have to turn those parts into 3D models, they often have to measure each dimension with their calipers and manually type those dimensions into the CAD software. Despite the fact that engineers had access to high-end Mitutoyo calipers that have the capability of sending data to computers over a serial link, engineers still often do not use the data transferring feature. This is because the software that handles the data transfer and its integration with the CAD environment is unintuitive and overall clunky to use, which fails to expedite the 3D modeling process. SmartCaliper aims to resolve these existing issues by taking the form factor of an inexpensive upgrade kit that can be installed on any digital caliper. Our software integration is also extremely user-friendly since it only requires the user to press one button to send the data to the desired textbox in any CAD software.
Overall, the caliper industry has not pushed to innovate on their technologies, hence having no pressure from competitors. Ultimately, the goal of the SmartCaliper is to improve the workflow of calipers in the modern digital age and push manufacturers to innovate again.
## 2. Market Application
The caliper market has largely been able to avoid massive change for the past decade, which translates to limited compatibility with the digitally driven engineering workflow of today. If an engineer wants to directly log measurements from their caliper in a digital format, their only option is to hope they have an exposed data link connector and the required cable. They then need to wire this into their computer and use a clunky software that will allow them to log the measurements.
The smart caliper serves to offer a simple alternative that is low in cost for both engineers and hobbyists, improving the overall caliper experience without attempting to reinvent the wheel. Today, almost every digital caliper has data link ports, which are enclosed within the caliper. We plan to sell conversion kits for many of the major caliper manufacturers such as Mitutoyo, Neiko, Starret, and more. This kit would consist of the circuit, shown in the technical summary, miniaturized into a small PCB along with a simple plastic case that mounts to the rear of the caliper body as well as a cable that hooks into the caliper's data port. We also offer our intuitive software package to anyone who purchases this kit.
Since this solution consists of very few simple parts, it would be easy to scale production and move to market with the technology seen in this hackathon. The end product would be very affordable for less than the price of most calipers due to the elegance of the design.
## 3. Technical Summary
## 3.1 Hardware
Almost every digital caliper on the market today has a connection port on the PCB that is used to stream measurement data to the computer over a special USB adapter cable. These cables are often upwards of $100 and strangely, most of those calipers do not even make the port available, opting to use it for conducting quality-control and calibration during production.
The first step of the project was to acquire a suitable caliper, we chose to use one we had on hand, which was the Neiko 01407A. This caliper proved to have a connection port tucked away under the body and required a Dremel to cut a slot for wires to be attached. These 3 wires were soldered to the caliper’s GND, Clock, and Data lines. This was then run to two transistors, which handled the 1.5v to 3.3v logic level conversion from the caliper to microcontroller respectively.
The microcontroller chosen was an ESP32 breakout module since it would allow for the high clock rate required to parse the data from the calipers and enable wireless data transfer. A pushbutton was also added to allow the user to choose when a measurement should be recorded without having to touch the computer.
## 3.2 Firmware
Using an oscilloscope, the clock and data lines were probed to determine how the information was encoded. We discovered that every ~40ms, the caliper would send three bytes to the computer. Each bit was marked with the falling edge of the clock line. The first 16 bits were the measurement bits (LSB to MSB), followed by three high bits, then one bit to encode the sign, followed by four remaining high bits. An interrupt was used to detect the edge of the clock pulse and handle recording the values. An additional interrupt was used to detect the user button press and send the measurement via either serial or wirelessly, depending on how the system is configured.
## 3.3 Software Package
To maximize the potential of the SmartCaliper, we created a software package that focuses on enhancing the two main uses of a caliper:
*Function 1:* Measuring dimensions of a part for the purpose of creating its 3D model
*Function 2:* Measuring dimensions of a manufactured part to compare its dimensions with its 3D model
**3.3.1 Function 1:**
When one desires to create a 3D CAD model of a physical part, the most tedious process is probably measuring its dimensions with a caliper and then manually entering those dimensions into a CAD software. To streamline the dimensioning part of the CAD process, we created a functionality in our software package that allows the user to send the caliper measurement directly to the CAD software at the press of a button. We have also tested our program in a plethora of the most popular CAD softwares, including SOLIDWORKS, Fusion360, and CATIA. However, this program was designed to work with virtually every CAD software.
This program is accomplished using the multiprocessing module of Python as the software enables parallelism for two functions. The first function is responsible for running the user-specified CAD software. The second function continuously runs a while loop that checks for data sent from the caliper using the pySerial module; when a data packet is detected, it decodes the data and enters the correct caliper measurement into a textbox that the user clicks on in the CAD software. The program enters the measurement into the CAD software by using the pynput module, which mimics specified keystrokes.
**3.3.2 Function 2:**
After a part is manufactured, it is common practice to use a caliper to measure the dimensions of that part to determine its tolerance and errors introduced during the manufacturing process. In order to determine the part’s tolerance, it is required to compare the manufactured part with its original 3D CAD model. To make this process faster and more intuitive, our software package includes a functionality that enables the user to input the measured dimensions and make any annotations directly onto the 3D CAD model. The user is able to view the original 3D CAD model in our software, then click on any two vertices/faces of the 3D model to generate a dimension the user wants to comment on. The software then stores any user-inputted comments, computes and logs the intended original dimension, and prompts the user to enter the part’s actual measured dimension. Similar to Function 1, the user simply needs to click one button on the SmartCaliper to transfer the measure dimension into the software without the need to type. The user can make as many of these annotations as they desire and all of that information is saved directly as comments in the 3D CAD model. By doing so, the user can use the software to load the 3D CAD model along with all of the saved annotations if the user wants to edit or append new annotations in the future. To accomplish this, we used Blender as the main viewport environment. This is because Blender is an open source CAD software that has a lot of documentation for custom AddOn development. Its native support of Python, through the Blender 2.83.0 Python API, allowed us to integrate the program developed in Function 1 into our codebase. The code contains three files: an initialization file, a panel class file, and an operator class file. The initialization file is responsible for instantiating instances of all the classes. The panel class file is responsible for the class definitions of all the custom GUI that our AddOn implements. The operator class file contains the functionality to actually execute all the desired actions (e.g. measuring the Euclidean distance between two selected vertices/faces, loading/saving annotations to the header of the .obj file, etc.).
## 4. Next Steps for *SmartCaliper*
There are numerous hardware and software improvements we have in mind for the next stage of this project.
**4.1 Hardware:**
1. The current SmartCaliper circuit is built on a breadboard, which is only meant for prototyping purposes. We are planning to condense the current breadboard circuit into a PCB that can be mounted to the rear of calipers. This can then be sold as a kit for digital calipers that will allow people to modify their existing calipers easily.
2. The SmartCaliper currently uses a micro USB wire to transmit the measurement data via serial. However, our original intent for using an ESP32 module was to be able to transmit the data wirelessly via WiFi, but we simply did not have time to implement that during the hackathon. Therefore, we plan to enable wireless communication between the computer and the caliper.
**4.2 Software:**
1. An immediate next step would be to add a GUI for the launch menu to enhance the user experience. We could also convert all the Python files into one executable file.
2. An interesting idea we want to explore is add a “fix” feature that corrects the 3D model in real time based on the errors between the theoretical dimension and the measured dimension. In Blender, the user can very easily manipulate the mesh, which means we could automate that process with a click of a button.
3. We want to implement an ML online learning algorithm that allows the user to feed the error percentage value into the model every time the user adds an annotation. Overtime, the online learning algorithm will establish a more and more accurate model that predicts the errors before the part is manufactured. This model will also be catered towards each user since it will only be receiving data from each user alone. Since each user’s manufacturing environment will be different (for instance, different users have different quality of 3D printers), it is therefore highly beneficial to have models that adapt to the user’s individual environment.
4. When a discrepancy has been measured between the CAD model and the manufactured model, there are many ways the digital model can be fixed to account for this. For instance, the user could either just simply translate the vertex, translate the entire polygon of which the vertex is a part, or even translate several of the surrounding polygons. A Deep Neural Network could be used to learn how the user prefers to correct the CAD model in order to automate this feature as well. Recently, there have been promising results seen with using General Adversarial Networks to CAD 3D models, and this is another type of model that could be considered as well.
5. When two vertices or faces are selected, we want to be able to change the imported obj file into X-ray mode and display a line indicating the distance being calculated. This would make the software even more user-friendly. As well, when the user selects an annotation, we want to display a coloured line on the imported 3D object to exhibit the measurement contained in the annotation. | ## Inspiration
The other day, I heard my mom, a math tutor, tell her students "I wish you were here so I could give you some chocolate prizes!" We wanted to bring this incentive program back, even among COVID, so that students can have a more engaging learning experience.
## What it does
The student will complete a math worksheet and use the Raspberry Pi to take a picture of their completed work. The program then sends it to Google Cloud Vision API to extract equations. Our algorithms will then automatically mark the worksheet, annotate the jpg with Pure Image, and upload it to our website. The student then gains money based on the score that they received. For example, if they received a 80% on the worksheet, they will get 80 cents. Once the student has earned enough money, they can choose to buy a chocolate, where the program will check to ensure they have enough funds, and if so, will dispense it for them.
## How we built it
We used a Raspberry Pi to take pictures of worksheets, Google Cloud Vision API to extract text, and Pure Image to annotate the worksheet. The dispenser uses the Raspberry Pi and Lego to dispense the Mars Bars.
## Challenges we ran into
We ran into the problem that if the writing in the image was crooked, it would not detect the numbers on the same line. To fix this, we opted for line paper instead of blank paper which helped us to write straight.
## Accomplishments that we're proud of
We are proud of getting the Raspberry Pi and motor working as this was the first time using one. We are also proud of the gear ratio where we connected small gears to big gears ensuring high torque to enable us to move candy. We also had a lot of fun building the lego.
## What we learned
We learned how to use the Raspberry Pi, the Pi camera, and the stepper motor. We also learned how to integrate backend functions with Google Cloud Vision API
## What's next for Sugar Marker
We are hoping to build an app to allow students to take pictures, view their work, and purchase candy all from their phone. | ## Inspiration
There are many productivity apps that each serve a single function, like blocking unwanted websites or tracking tasks. We wanted to create an all in one extension that you could use to manage all of your productivity needs
## What it does
Our extension has a pomodoro timer, a task manager, site blocking and general notes. Site blocking and general notes are not finished yet though
## How we built it
We created a chrome extension by essentially creating a mini-website and using a manifest file to get browsers to open it as a local extension instead
## Challenges we ran into
One of the challenges that we ran into was turning the design into a working website. Since we were all new to using HTML and CSS, trying to make the website look as nice as the initial design was a huge challenge.
## Accomplishments that we're proud of
We were able to get the final extension to look good while being functional, even though it doesn't look like the initial designs | partial |
## Inspiration
We have to wait 4-5 years to elect an official or person in power who may potentially not achieve anything meaningful during his time. This simple addition to Envel puts the power and ownership of the community back into their hands. A single dollar may not achieve much, but a million one dollars will.
## What it does
Provides an option for Envel users to donate residue cash from daily budget to a local charity
## How we built it
Our concept design was built through photoshop and premiere pro. Photoshop allowed us to easily manipulate and experiment with potential UI elements. Then we brought life to our static ideas by animating them in premiere pro. This allowed us to experience the possible user experience.
## Challenges we ran into
Designing an attractive and alluring interface was our primary challenge. Incentivizing users to participate in activities charitable in nature is inherently difficult. As a result, we ran through many designs until we felt like the entire process was as frictionless and as inviting as possible.
## Accomplishments that we're proud of
Our team was able to conceptualize an application function and effectively materialize the concepts within our very strict time constraints.
## What we learned
What businesses do is not single faceted. With the current ever-evolving industry, businesses must adapt and grasp these facets in order to survive.
## What's next for The power of the dollar
Currently, our Design concept is still only a concept. Our next step would be to work with backend developers to actually program our design to the application and tackle any potential problems that we may encounter. | ## Inspiration
With the recent Corona Virus outbreak, we noticed a major issue in charitable donations of equipment/supplies ending up in the wrong hands or are lost in transit. How can donors know their support is really reaching those in need? At the same time, those in need would benefit from a way of customizing what they require, almost like a purchasing experience.
With these two needs in mind, we created Promise. A charity donation platform to ensure the right aid is provided to the right place.
## What it does
Promise has two components. First, a donation request view to submitting aid requests and confirm aids was received. Second, a donor world map view of where donation requests are coming from.
The request view allows aid workers, doctors, and responders to specificity the quantity/type of aid required (for our demo we've chosen quantity of syringes, medicine, and face masks as examples) after verifying their identity by taking a picture with their government IDs. We verify identities through Microsoft Azure's face verification service. Once a request is submitted, it and all previous requests will be visible in the donor world view.
The donor world view provides a Google Map overlay for potential donors to look at all current donation requests as pins. Donors can select these pins, see their details and make the choice to make a donation. Upon donating, donors are presented with a QR code that would be applied to the aid's packaging.
Once the aid has been received by the requesting individual(s), they would scan the QR code, confirm it has been received or notify the donor there's been an issue with the item/loss of items. The comments of the recipient are visible to the donor on the same pin.
## How we built it
Frontend: React
Backend: Flask, Node
DB: MySQL, Firebase Realtime DB
Hosting: Firebase, Oracle Cloud
Storage: Firebase
API: Google Maps, Azure Face Detection, Azure Face Verification
Design: Figma, Sketch
## Challenges we ran into
Some of the APIs we used had outdated documentation.
Finding a good of ensuring information flow (the correct request was referred to each time) for both the donor and recipient.
## Accomplishments that we're proud of
We utilized a good number of new technologies and created a solid project in the end which we believe has great potential for good.
We've built a platform that is design-led, and that we believe works well in practice, for both end-users and the overall experience.
## What we learned
Utilizing React states in a way that benefits a multi-page web app
Building facial recognition authentication with MS Azure
## What's next for Promise
Improve detail of information provided by a recipient on QR scan. Give donors a statistical view of how much aid is being received so both donors and recipients can better action going forward.
Add location-based package tracking similar to Amazon/Arrival by Shopify for transparency | ## Inspiration
We wanted to build something interactive and fun, so we combined our interests in art, technology, and health to create Fricasso!
## What it does
Control a digital painting through dance! As you move your arms around, the Fitbit will recognize certain gestures to change the color of your paintbrush, direction of stroke, etc.
## How we built it
Fitbit beams information to a common server. Server sends out commands to dynamic web page and Matrix LED board. | winning |
## Background
Being a team of four first year computer science students who are all participating in a Hackathon for their first times, we had no idea what to expect going in. Our only goals in mind were to make friends, learn things, and get some stickers.
## The Journey
For a solid few hours after the hacking started, we had no idea what we were going to make. We ended up singling out 3 ideas, a microwave time calculating app, an idea/teamwork posting app, and a Github for everything app. After calm and peaceful discussions, we decided upon the microwave app, because the idea of using computer vision was just too cool to pass up.
With that, we went straight to work. After a few hours of blood, sweat, and yes, a few tears, we finally got a basic website up and running. At big problem we had was figuring out how to calculate the microwave time accurately, since we couldn't find any data on the microwave time of each food. Our solution for now was to group foods into different categories and just return the time based on what category it was in.
After attending the lecture on the Microsoft bot service, we integrated the technology into our app to create a reheat bot. Instead of just being a web app, users could now send an image through messenger to the bot and get the time that they should microwave the food for. The bot was quite a challenge, since none of us had used Microsoft Azure before and none of us knew C# neither. Somehow, we managed to finish the bot in the end.
Around 3 AM, when we were all half dead, we came up with the solution to implement basic machine learning into our app to get more accurate times. Instead of just getting the time data from a static server file, the data would now modify itself depending on user feedback. With this implementation, the microwave times of each food item would be crowd sourced instead of just defaulting on some preset value, thus making it more accurate.
## The Conclusion
After 125 commits, we finally brought the project to an end. Find the Github repository [here](https://github.com/jackzheng06/microwave-time). We used Clarifai for image recognition and Microsoft Azure to host our back end as well as our chat bot.
Reheat is a web application that takes a picture of food and determines how long it should be microwaved for. The website is mobile friendly, and there is a messenger chat bot for those who don't want to use the website. The app uses basic machine learning with user feedback to adjust the microwave times of each food item. Reheat is the future of microwaves, perfectly heated food is just one click away! | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts and add the items into the database representing your fridge. Using the items you have in your fridge, our app will be able to recommend recipes for dishes for you to make.
## How We Built It
On the back-end, we have a Flask server that receives the image from the front-end through ngrok and then sends the image of the receipt to Google Cloud Vision to get the text extracted. We then post-process the data we receive to filter out any unwanted noise in the data.
On the front-end, our app is built using react-native, using axios to query from the recipe API, and then stores data into Firebase.
## Challenges We Ran Into
Some of the challenges we ran into included deploying our Flask to Google App Engine, and styling in react. We found that it was not possible to write into Google App Engine storage, instead we had to write into Firestore and have that interact with Google App Engine.
On the frontend, we had trouble designing the UI to be responsive across platforms, especially since we were relatively inexperienced with React Native development. We also had trouble finding a recipe API that suited our needs and had sufficient documentation. | ## Inspiration
The Google Map API has features that display the crowdedness of locations. But it does not provide an efficient way to explore the alternative trip plans, nor does it take into account regional COVID cases. We hope this tool provides a safe and quick way to minimize COVID exposure for people who need to make essential trips.
Despite our best efforts to stay safe, essential travel comes with risk. This includes trips to the grocery store, convenience store trips, and more. When carrying out these everyday tasks, we need a way to stay safe as possible. What better way to do this than proactively? Effective trip planning can massively decrease risk of COVID exposure, so we developed a tool to do this automatically.
## What it does
By providing your location and a desired destination, AVOID-19 determines the risk of your entire trip, from the moment you step out of your house to the moment you return. This risk is represented by a risk score, which will be calculated based on the number of people you are expected to encounter on your trip, and the risk of exposure from each encounter. The number of people you are expected to encounter will be calculated using both population density and transit information, alongside how many people are anticipated to be at your destination. The risk of exposure from each encounter will be calculated using the number of active infections in your area and your proximity to known public exposure sites.
Taking this risk score into account, AVOID-19 provides alternative destinations if the risk is high, and tips for your travel like times at which your location is least busy. By following this advice, you are able to minimize the risk of your essential travel.
## How we built it
Front-end
* React.js, Next.js, Vercel
Back-end
* Firebase
* Folium, OSMnx, Google Maps API, BestTime API
Data Source
* Canadian Census Data:
Census Subdivision Boundaries
Census Subdivision Population
* BC COVID-19 Public Exposures (web-scraping using Python BeautifulSoup)
* BC COVID-19 Dashboard (manually collected regional cases)
## Challenges we ran into
* Designing the layout from scratch; small layout issues like flexbox took a lot of time
* When trying to build the choropleth map we had to download the census data from the Canadian government and struggled for a while to convert the projection that the boundary file uses
## What we learned
* Time-management and team-coordination is crucial to the outcome
## What's next
* Incorporating more data with finer granularity
* Improve the COVID risk calculation to incorporate: cases per capita, transit/location crowdedness, etc.
* Integrate an intelligent trip recommender | partial |
## Inspiration
We were going to build a themed application to time portal you back to various points in the internet's history that we loved, but we found out prototyping with retro looking components is tough. Building each component takes a long time, and even longer to code. We started by automating parts of this process, kept going, and ended up focusing all our efforts on automating component construction from simple Figma prototypes.
## What it does
Give the plugin a Figma frame that has a component roughly sketched out in it. Our code will parse the frame and output JSX that matches the input frame. We use semantic detection with Cohere classify on the button labels combined with deterministic algorithms on the width, height, etc. to determine whether a box is a button, input field, etc. It's like magic! Try it!
## How we built it
Under the hood, the plugin is a transpiler for high level Figma designs.
Similar to a C compiler compiling C code to binary, our plugin uses an abstract syntax tree like approach to parse Figma designs into html code.
Figma stores all it's components (buttons, text, frames, input fields, etc) in nodes.. Nodes store properties about the component or type of element, such as height, width, absolute positions, fills, and also it's children nodes, other components that live within the parent component. Consequently, these nodes form a tree.
Our algorithm starts at the root node (root of the tree), and traverses downwards. Pushing-up the generated html from the leaf nodes to the root.
The base case is if the component was 'basic', one that can be represented with two or less html tags. These are our leaf nodes. Examples include buttons, body texts, headings, and input fields. To recognize whether a node was a basic component, we leveraged the power of LLM.
We parsed the information stored in node given to us by Figma into English sentences, then used it to train/fine tune our classification model provided by co:here. We decided to use an ML to do this since it is more flexible to unique and new designs. For example, we were easily able to create 8 different designs of a destructive button, and it would be time-consuming relative to the length of this hackathon to come up with a deterministic algorithm. We also opted to parse the information into English sentences instead of just feeding the model raw figma node information since the LLM would have a hard time understanding data that didn't resemble a human language.
At each node level in the tree, we grouped the children nodes based on a visual hierarchy. Humans do this all the time, if things are closer together, they're probably related, and we naturally group them. We achieved a similar effect by calculating the spacing between each component, then greedily grouped them based on spacing size. Components with spacings that were within a tolerance percentage of each other were grouped under one html
. We also determined the alignments (cross-axis, main-axis), of these grouped children to handle designs with different combinations of orientations. Finally, the function is recursed on their children, and their converted code is pushed back up to the parent to be composited, until the root contains the code for the design. Our recursive algorithm made it so our plugin was flexible to the countless designs possible in Figma.
## Challenges we ran into
We ran into three main challenges. One was calculating the spacing. Since while it was easy to just apply an algorithm to merge two components at a time (similar to mergesort), it would produce too many nested divs, and wouldn't really be useful for developers to use the created component. So we came up with our greedy algorithm. However, due to our perhaps mistaken focus on efficiency, we decided to implement a more difficult O(n) algorithm to determine spacing, where n is the number of children. This sapped a lot of time away, which could have been used for other tasks and supporting more elements.
The second main challenge was with ML. We were actually using Cohere Classify wrongly, not taking semantics into account and trying to feed it raw numerical data. We eventually settled on using ML for what it was good at - semantic analysis of the label, while using deterministic algorithms to take other factors into account. Huge thanks to the Cohere team for helping us during the hackathon! Especially Sylvie - you were super helpful!
We also ran into issues with theming on our demo website. To show how extensible and flexible theming could be on our components, we offered three themes - windows XP, 7, and a modern web layout. We were originally only planning to write out the code for windows XP, but extending the component systems to take themes into account was a refactor that took quite a while, and detracted from our plugin algorithm refinement.
## Accomplishments that we're proud of
We honestly didn't think this would work as well as it does. We've never built a compiler before, and from learning off blog posts about parsing abstract syntax trees to implementing and debugging highly asychronous tree algorithms, I'm proud of us for learning so much and building something that is genuinely useful for us on a daily basis.
## What we learned
Leetcode tree problems actually are useful, huh.
## What's next for wayback
More elements! We can only currently detect buttons, text form inputs, text elments, and pictures. We want to support forms too, and automatically insert the controlling componengs (eg. useState) where necessary. | ## Inspiration
We, as passionate tinkerers, understand the struggles that come with making a project come to life (especially for begineers). **80% of U.S. workers agree that learning new skills is important, but only 56% are actually learning something new**. From not knowing how electrical components should be wired, to not knowing what a particular component does, and what is the correct procedure to effectively assemble a creation, TinkerFlow is here to help you ease this process, all in one interface.
## What it does
-> Image identification/classification or text input of available electronic components
-> Powered by Cohere and Groq LLM, generates wiring scheme and detailed instructions (with personality!) to complete an interesting project that is possible with electronics available
-> Using React Flow, we developed our own library (as other existing softwares were depreciated) that generates electrical schematics to make the fine, precise and potentially tedious work of wiring projects easier.
-> Display generated text of instructions to complete project
## How we built it
We allowed the user to upload a photo, have it get sent to the backend (handled by Flask), used Python and Google Vision AI to do image classification and identify with 80% accuracy the component.
To provide our users with a high quality and creative response, we used a central LLM to find projects that could be created based on inputted components, and from there generate instructions, schematics, and codes for the user to use to create their project. For this central LLM, we offer two options: Cohere and Groq. Our default model is the Cohere LLM, which using its integrated RAG and preamble capability offers superior accuracy and a custom personality for our responses, providing more fun and engagement for the user. Our second option Groq though providing a lesser quality of a response, provides fast process times, a short coming of Cohere. Both of these LLM's are based on large meticulously defined prompts (characterizing from the output structure to the method of listing wires), which produce the results that are necessary in generating the final results seen by the user.
In order to provide the user with different forms of information, we decide to present electrical schematics on the webpage. However during the development due to many circumstances, our group had to use simple JavaScript libraries to create its functionality.
## Challenges we ran into
* LLM misbehaving: The biggest challenge in the incorporation of the Cohere LLM was the ability to generate consistent results through the prompts used to generate the results needed for all of the information provided about the project proposed. The solution to this was to include a very specifically defined prompts with examples to reduce the amount of errors generated by the LLM.
* Not able to find a predefined electrical schematics library to use to generate electrical schematics diagrams, there we had start from scratch and create our own schematic drawer based on basic js library.
## Accomplishments that we're proud of
Create electrical schematics using basic js library.
Create consistent outputting LLM's for multiple fields.
## What we learned
Ability to overcome troubles - consistently innovating for solutions, even if there may not have been an easy route (ex. existing library) to use - our schematic diagrams were custom made!
## What's next for TinkerFlow
Aiming for faster LLM processing speed.
Update the user interface of the website, especially for the electrical schematic graph generation.
Implement the export of code files, to allow for even more information being provided to the user for their project. | ## Inspiration
Everybody eats and in college if you are taking difficult classes it is often challenging to hold a job. Therefore as college students we have no income during the year. Our inspiration came as we have moved off campus this year to live in apartments with full kitchens but the lack of funds to make complete meals at a reasonable price. So along came the thought that we couldn't be the only ones with this issue, so..."what if we made an app where all of us could connect via a social media platform and share and post our meals with the price range attached to it so that we don't have to come up with good cost effective meals on our own".
## What it does
Our app connects college students, or anyone that is looking for a great way to find good cost effective meals and doesn't want to come up with the meals on their own, by allowing everyone to share their meals and create an abundant database of food.
## How we built it
We used android studio to create the application and tested the app using the built in emulator to see how the app was coming along when viewed on the phone. Specifically we used an MVVM design to interweave the functionality with the graphical display of the app.
## Challenges we ran into
The backend that we were familiar with ended up not working well for us, so we had to transition over to another backend holder called back4app. We also were challenged with the user personal view and being able to save the users data all the time.
## Accomplishments that we're proud of
We are proud of all the work that we put into the application in a very short amount of time, and learning how to work with a new backend during the same time so that everything worked as intended. We are proud of the process and organization we had throughout the project, beginning with a wire frame and building our way up part by part until the finished project.
## What we learned
We learned how to work with drop down menus to hold multiple values of possible data for the user to choose from. And for one of our group members learned how to work with app development on the full size scale.
## What's next for Forkollege
In version 2.0 we plan on implementing a better settings page that allows the user to change their password, we also plan on fixing the for you page specifically for each recipe displayed we were not able to come up with a way to showcase the number of $ sign's and instead opted for using stars again. As an outside user this is a little confusing, so updating this aspect is of the most importance. | winning |
## Inspiration
For physical therapy patients, doing your home exercise program is a crucial part of therapy and recovery. These exercises improve the body and allow patients to remain pain-free without having to pay for costly repeat visits. However, doing these exercises incorrectly can hinder progress and put you back in the doctor’s office.
## What it does
PocketPT uses deep learning technologies to detect and correct patient's form in a broad range of Physical Therapy exercises.
## How we built it
We used the NVIDIA Jetson-Nano computer and a Logitech webcam to build a deep learning model. We trained the model on over 100 images in order to detect the accuracy of Physical Therapy postures.
## Challenges we ran into
Since our group was using new technology, we struggled at first with setting up the hardware and figuring out how to train the deep learning model.
## Accomplishments that we're proud of
We are proud that we created a working deep learning model despite no prior experience with hardware hacking or machine learning.
## What we learned
We learned the principles of deep learning, hardware, and IoT. We learned how to use the NVIDIA Jetson Nano computer for use in various disciplines.
## What's next for PocketPT
In the future, we want to expand to include more Physical Therapy postures. We also want to implement our product for use on Apple Watch and FitBit, which would allow a more seamless workout experience for users. | ## Inspiration
Peripheral nerve compression syndromes such as carpal tunnel syndrome affect approximately 1 out of every 6 adults. They are commonly caused by repetitive stress and with the recent trend of working at home due to the pandemic it has become a mounting issue more individuals will need to address. There exist several different types of exercises to help prevent these syndromes, in fact studies show that 71.2% of patients who did not perform these exercises had to later undergo surgery due to their condition. It should also be noted that doing these exercises wrong could cause permanent injury to the hand as well.
## What it does
That is why we decided to create the “Helping Hand”, providing exercises for a user to perform and using a machine learning model to recognize each successful try. We implemented flex sensors and an IMU on a glove to track the movement and position of the user's hand. An interactive GUI was created in Python to prompt users to perform certain hand exercises. A real time classifier is then run once the user begins the gesture to identify whether they were able to successfully recreate it. Through the application, we can track the progression of the user's hand mobility and appropriately recommend exercises to target the areas where they are lacking most.
## How we built it
The flex sensors were mounted on the glove using custom-designed 3D printed holders. We used an Arduino Uno to collect all the information from the 5 flex sensors and the IMU. The Arduino Uno interfaced with our computer via a USB cable. We created a machine learning model with the use of TensorFlow and Python to classify hand gestures in real time. The user was able to interact with our program with a simple GUI made in Python.
## Challenges we ran into
Hooking up 5 flex sensors and an IMU to one power supply initially caused some power issues causing the IMU not to function/give inaccurate readings. We were able to rectify the problem and add pull-up resistors as necessary. There were also various issues with the data collection such as gyroscopic drift in the IMU readings. Another challenge was the need to effectively collect large datasets for the model which prompted us to create clever Python scripts to facilitate this process.
## Accomplishments that we're proud of
Accomplishments we are proud of include, designing and 3D printing custom holders for the flex sensors and integrating both the IMU and flex sensors to collect data simultaneously on the glove. It was also our first time collecting real datasets and using TensorFlow to train a machine learning classifier model.
## What we learned
We learned how to collect real-time data from sensors and create various scripts to process the data. We also learned how to set up a machine learning model including parsing the data, splitting data into training and testing sets, and validating the model.
## What's next for Helping Hand
There are many improvements for Helping Hand. We would like to make Helping Hand wireless, by using an Arduino Nano which has Bluetooth capabilities as well as compatibility with Tensorflow lite. This would mean that all the classification would happen right on the device! Also, by uploading the data from the glove to a central database, it can be easily shared with your doctor.
We would also like to create an app so that the user can conveniently perform these exercises anywhere, anytime.
Lastly, we would like to implement an accuracy score of each gesture rather than a binary pass/fail (i.e. display a reading of how well you are able to bend your fingers/rotate your wrist when performing a particular gesture). This would allow us to more appropriately identify the weaknesses within the hand. | ## Inspiration
**Substandard** food at a **5-star** rated restaurants? We feel you! Yelp or TripAdvisor do not tell the whole story - the ratings you see on these websites say very little about how particular dishes at a restaurant taste like. Therefore, we are here to satisfy your cravings for REAL good dishes.
## What it does
Our app collects user ratings based on specific dishes rather than vague, general experiences about a restaurant. Therefore, our recommendations tell you exactly where GOOD DISHES are. It also allows you to subscribe to interest groups based on your favorite dishes and ensures that you do not miss out on good restaurants and good reviewers.
## How we built it
We developed an Android application with Google Firebase API.
## Challenges we ran into
Learning new stuff in such a short time.
## Accomplishments that we're proud of
We're gonna have a working app!!
## What we learned
UI/UX Design, Frontend Development, Firebase API
## What's next for Culinect
Continuing development especially in regards to supporting communities and location support | winning |
## Inspiration
The need for driver monitoring in autonomous vehicle research has greatly improved computer vision and Human Activity Recognition (HAR). We realized that there was huge opportunity for computer vision in another area of life where focus and concentration are the primary concern: work productivity.
## What it does
Tiger Mom uses computer vision to monitor both your screen and your behavior. You leave it on while you study and it will track your screen activity, your physical behavior, and even your ambient surroundings. Its revolutionary approach to sensing allows it to quantitatively learn and suggest actionable insights such as optimal work intervals, exact breakdowns of how time is spent on different distractions, how your productivity responds to the ambient volume/brightness of your surroundings, and can even catch and interrupt you if it notices you dozing off or getting distracted for too long.
## How I built it
Tiger Mom's backend is built entirely with Python, with all computation taking place locally.
The computer vision uses DLib to identify facial landmarks on your face, and then solves the PnP problem to compute the pose of your head (direction your head is facing). It also tracks the aspect of the your eyes to detect how open/closed they are. These two facts are used to detect if you are looking away (implying distraction) or if you are drowsy. OpenCV is used to parse video input from the webcam, process images, and display them with visuals overlaid. Numpy and scipy were used for all mathematical computations/analysis.
Screen-based application tracking is done by parsing the title of your active window and cross-checking against known applications (and in the case of the web browser, different websites too). The software tracks a dictionary of applications mapped to timers to track the total amount of time you spend on each one individually.
Ambient noise and ambient light is derived by applying mathematical transforms on input periodically gathered from the microphone and webcam.
Every 10 seconds, the application tracker sends its values to the front-end in JSON format,
Tiger Mom's front-end is built entirely on React and JavaScript. Graphs were made with CanvasJS.
## Challenges I ran into
For Human Activity Recognition, I originally used a Haar cascade on keras/tensorflow to detect distraction. However, the neural network I found online had been trained on a dataset that I suspect did not include many Asian subjects, so they were not very accurate when detecting my eyes. I thought this was hilarious. This and the fact that Haar cascades also have a tendency to perform more poorly on subjects with darker skin colors led me to pursue another solution which wound up being DLib.
## Accomplishments that I'm proud of
* Running an accurate facial pose estimator with excellent visualizations.
* Demonstrating an original and unique use of computer-vision beyond driver monitoring.
* Developing a tool that genuinely creates value for you, and helps you understand and reduce bad study habits.
## What I learned
Like. Alot.
## What's next for Tiger Mom
The next immediate step that I wanted to touch was key logging! Analyzing words-per-minute would have been an excellent additional data point. And following that I would have loved to incorporate some sentiment analysis into the computer vision to track your mood throughout your study session. One fun idea to combine these two things as suggested by a mentor, Andreas Putz, was to analyze the sound of your typing with the microphone. For software engineers especially, panic and emotion translate very distinctively to the sound of their typing.
But what makes Tiger Mom special (but also a pain) is the sheer breadth of possible insights that can be derived from the data it is capable of sensing. For example, if users were to tag what subjects they were studying, the data could be used to analyze and suggest what sort of work they were passionate/skilled in. Or if location data were to be considered, then Tiger Mom could recommend what are your best places to study at based on ambient noise and light data of previous visits.
These personalized insights could be produced with some clever machine learning on data aggregated over time. Tiger Mom is capable of quantitatively analyzing things like what times of day you specifically are productive, to exact percentages and times. I would have loved to dive into the ML algorithms and set up some learning mechanisms but I did not have enough time to even build a proof of concept. | ## Inspiration
2020 has definitely been the year of chess. Between 2020 locking everyone indoors, and Netflix's Queen Gambit raking in 62 million viewers, everyone is either talking about chess, or watching others play chess.
## What it does
**Have you ever wanted to see chess through the eyes of chess prodigy Beth Harmon?** Where prodigies and beginners meet, BethtChess is an innovative software that takes any picture of a chessboard and instantly returns the next best move given the situation of the game. Not only does it create an experience to help improve your own chess skills and strategies, but you can now analyze chessboards in real-time while watching your favourite streamers on Twitch.
## How we built it
IN A NUTSHELL:
1. Take picture of the chessboard
2. Turn position into text (by extracting the FEN code of it by using some machine learning model)
3. Run code through chess engine (we send the FEN code to stockfish (chess engine))
4. Chess engine will return next best move to us
5. Display results to the user
Some of our inspiration came from Apple's Camera app's ability to identify the URL of QR codes in an instant -- without even having to take a picture.
**Front-end Technology**
* Figma - Used for prototyping the front end
* ReactJS - Used for making the website
* HTML5 + CSS3 + Fomantic-UI
* React-webcam
* Styled-components
* Framer-motion
**Back-end Technology**
* OpenCV - Convert image to an ortho-rectified chess board
* Kaggle - Data set which has 100,000 chess board images
* Keras - Deep Learning (DL) model to predict FEN string
* Stockfish.js - The most powerful chess engine
* NodeJS - To link front-end, DL model and Stockfish
**User Interface**
Figma was the main tool we used to design a prototype for the UI/UX page. Here's the link to our prototype: [<https://www.figma.com/proto/Vejv1dzQyZ2ZGOMoFw5w2L/BethtChess?node-id=4%3A2&scaling=min-zoom>]
**Website**
React.js and node.js were mainly used to create the website for our project (as it is a web app).
**Predicting next best move using FEN stream**
To predict the next best move, Node.js (express module) was used and stockfish.js was used to communicate with the most powerful chess engine so that we could receive information from the API to deliver to our user.
We also trained the Deep Learning model with **Keras** and predicted the FEN string for the image taken from the webcam after image processing using **OpenCV**.
## Challenges we ran into
Whether if it's 8pm, 12am, 4am, it doesn't matter to us. Literally. Each of us live in a different timezone and a large challenge was working around these differences. But that's okay. We stayed resilient, optimistic, and determined to finish our project off with a bang!
**Learning Curves**
It's pretty safe to say that all of us had to learn SOMETHING on the fly. Machine learning, image recognition, computing languages, navigating through Github, are only some of the huge learning curves we had to overcome. Not to mention, splitting the work and especially connecting all components together was a challenge that we had to work extra hard to achieve.
Here's what Melody has to say about her personal learning curve:
*At first, it felt like I didn't know ANYTHING. Literally nothing. I had some Python and Java experience but now I realize there's a whole other world out there full of possibilities, opportunities, etc. What the heck is an API? What's this? What's that? What are you doing right now? What is my job? What can I do to help? The infinite loop of questions kept on racing through my head. Honestly, though, the only thing that got me through all this was my extremely supportive team!!! They were extremely understanding, supportive, and kind and I couldn't have asked for a better team. Also, they're so smart??? They know so much!!*
## Accomplishments that we're proud of
Only one hour into the hackathon (while we were still trying to work out our idea), one of our members already had a huge component of the project (a website + active camera component + "capture image" button) as a rough draft. Definitely, a pleasant surprise for all of us, and we're very proud of how far we've gotten together in terms of learning, developing, and bonding!
As it was most of our members' first hackathon ever, we didn't know what to expect by the end of the hackathon. But, we managed to deliver a practically **fully working application** that connected all components that we originally planned. Obviously, there is still lots of room for improvement, but we are super proud of what we achieved in these twenty-four hours, as well as how it looks and feels.
## What we learned
Our team consisted of students from high school all the way to recent graduates and our levels of knowledge vastly differed. Although almost all of our team consisted of newbies to hackathons, we didn't let that stop us from creating the coolest chess-analyzing platform on the web. Learning curves were huge for some of us: APIs, Javascript, node.js, react.js, Github, etc. were some of the few concepts we had to wrap our head around and learn on the fly. While more experienced members explored their limits by understanding how the stockfish.js engine works with APIs, how to run Python and node.js simultaneously, and how the two communicate in real-time.
Because each of our members lives in a different time zone (including one across the world), adapting to each other's schedules was crucial to our team's success and efficiency. But, we stayed positive and worked hard through dusk and dawn together to achieve goals, complete tasks, and collaborate on Github.
## What's next for BethtChess?
Maybe we'll turn it into an app available for iOS and Android mobile devices? Maybe we'll get rid of the "capture photo" so that before you even realize, it has already returned the next best move? Maybe we'll make it read out the instructions for those with impaired vision so that they know where to place the next piece? You'll just have to wait and see :) | ## ✨ Inspiration
Quarantining is hard, and during the pandemic, symptoms of anxiety and depression are shown to be at their peak 😔[[source]](https://www.kff.org/coronavirus-covid-19/issue-brief/the-implications-of-covid-19-for-mental-health-and-substance-use/). To combat the negative effects of isolation and social anxiety [[source]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7306546/), we wanted to provide a platform for people to seek out others with similar interests. To reduce any friction between new users (who may experience anxiety or just be shy!), we developed an AI recommendation system that can suggest virtual, quarantine-safe activities, such as Spotify listening parties🎵, food delivery suggestions 🍔, or movie streaming 🎥 at the comfort of one’s own home.
## 🧐 What it Friendle?
Quarantining alone is hard😥. Choosing fun things to do together is even harder 😰.
After signing up for Friendle, users can create a deck showing their interests in food, games, movies, and music. Friendle matches similar users together and puts together some hangout ideas for those matched. 🤝💖 I
## 🧑💻 How we built Friendle?
To start off, our designer created a low-fidelity mockup in Figma to get a good sense of what the app would look like. We wanted it to have a friendly and inviting look to it, with simple actions as well. Our designer also created all the vector illustrations to give the app a cohesive appearance. Later on, our designer created a high-fidelity mockup for the front-end developer to follow.
The frontend was built using react native.
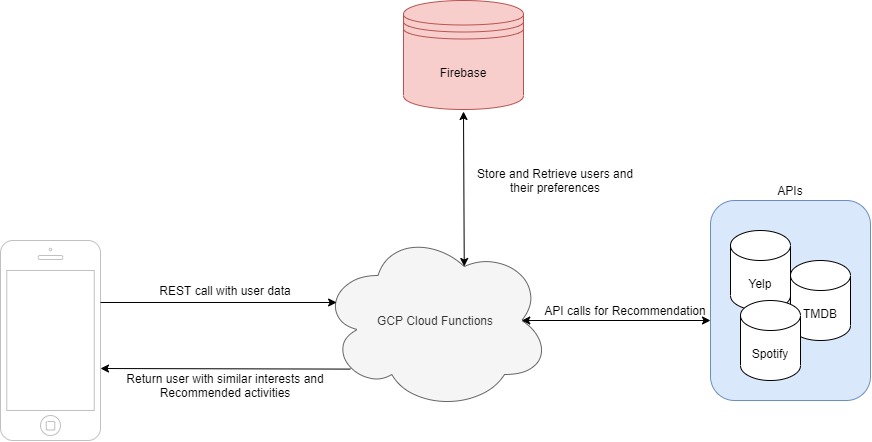
We split our backend tasks into two main parts: 1) API development for DB accesses and 3rd-party API support and 2) similarity computation, storage, and matchmaking. Both the APIs and the batch computation app use Firestore to persist data.
### ☁️ Google Cloud
For the API development, we used Google Cloud Platform Cloud Functions with the API Gateway to manage our APIs. The serverless architecture allows our service to automatically scale up to handle high load and scale down when there is little load to save costs. Our Cloud Functions run on Python 3, and access the Spotify, Yelp, and TMDB APIs for recommendation queries. We also have a NoSQL schema to store our users' data in Firebase.
### 🖥 Distributed Computer
The similarity computation and matching algorithm is powered by a node.js app which leverages the Distributed Computer for parallel computing. We encode the user's preferences and Meyers-Briggs type into a feature vector, then compare similarity using cosine similarity. The cosine similarity algorithm is a good candidate for parallelizing since each computation is independent of the results of others.
We experimented with different strategies to batch up our data prior to slicing & job creation to balance the trade-off between individual job compute speed and scheduling delays. By selecting a proper batch size, we were able to reduce our overall computation speed by around 70% (varies based on the status of the DC network, distribution scheduling, etc).
## 😢 Challenges we ran into
* We had to be flexible with modifying our API contracts as we discovered more about 3rd-party APIs and our front-end designs became more fleshed out.
* We spent a lot of time designing for features and scalability problems that we would not necessarily face in a Hackathon setting. We also faced some challenges with deploying our service to the cloud.
* Parallelizing load with DCP
## 🏆 Accomplishments that we're proud of
* Creating a platform where people can connect with one another, alleviating the stress of quarantine and social isolation
* Smooth and fluid UI with slick transitions
* Learning about and implementing a serverless back-end allowed for quick setup and iterating changes.
* Designing and Creating a functional REST API from scratch - You can make a POST request to our test endpoint (with your own interests) to get recommended quarantine activities anywhere, anytime 😊
e.g.
`curl -d '{"username":"turbo","location":"toronto,ca","mbti":"entp","music":["kpop"],"movies":["action"],"food":["sushi"]}' -H 'Content-Type: application/json' ' https://recgate-1g9rdgr6.uc.gateway.dev/rec'`
## 🚀 What we learned
* Balancing the trade-off between computational cost and scheduling delay for parallel computing can be a fun problem :)
* Moving server-based architecture (Flask) to Serverless in the cloud ☁
* How to design and deploy APIs and structure good schema for our developers and users
## ⏩ What's next for Friendle
* Make a web-app for desktop users 😎
* Improve matching algorithms and architecture
* Adding a messaging component to the app | partial |
## Inspiration
There are approximately **10 million** Americans who suffer from visual impairment, and over **5 million Americans** suffer from Alzheimer's dementia. This weekend our team decided to help those who were not as fortunate. We wanted to utilize technology to create a positive impact on their quality of life.
## What it does
We utilized a smartphone camera to analyze the surrounding and warn visually impaired people about obstacles that were in their way. Additionally, we took it a step further and used the **Azure Face API** to detect the faces of people that the user interacted with and we stored their name and facial attributes that can be recalled later. An Alzheimer's patient can utilize the face recognition software to remind the patient of who the person is, and when they last saw him.
## How we built it
We built our app around **Azure's APIs**, we created a **Custom Vision** network that identified different objects and learned from the data that we collected from the hacking space. The UI of the iOS app was created to be simple and useful for the visually impaired, so that they could operate it without having to look at it.
## Challenges we ran into
Through the process of coding and developing our idea we ran into several technical difficulties. Our first challenge was to design a simple UI, so that the visually impaired people could effectively use it without getting confused. The next challenge we ran into was attempting to grab visual feed from the camera, and running them fast enough through the Azure services to get a quick response. Another challenging task that we had to accomplish was to create and train our own neural network with relevant data.
## Accomplishments that we're proud of
We are proud of several accomplishments throughout our app. First, we are especially proud of setting up a clean UI with two gestures, and voice control with speech recognition for the visually impaired. Additionally, we are proud of having set up our own neural network, that was capable of identifying faces and objects.
## What we learned
We learned how to implement **Azure Custom Vision and Azure Face APIs** into **iOS**, and we learned how to use a live camera feed to grab frames and analyze them. Additionally, not all of us had worked with a neural network before, making it interesting for the rest of us to learn about neural networking.
## What's next for BlindSpot
In the future, we want to make the app hands-free for the visually impaired, by developing it for headsets like the Microsoft HoloLens, Google Glass, or any other wearable camera device. | ## Inspiration
Old school bosses don't want want to see you slacking off and always expect you to be all movie hacker in the terminal 24/7. As professional slackers, we also need our fair share of coffee and snacks. We initially wanted to create a terminal app to order Starbucks and deliver it to the E7 front desk. Then bribe a volunteer to bring it up using directions from Mappedin. It turned out that it's quite hard to reverse engineer Starbucks. Thus, we tried UberEats, which was even worse. After exploring bubble tea, cafes, and even Lazeez, we decided to order pizza instead. Because if we're suffering, might as well suffer in a food coma.
## What it does
Skip the Walk brings food right to your table with the help of volunteers. In exchange for not taking a single step, volunteers are paid in what we like to call bribes. These can be the swag hackers received, food, money,
## How we built it
We used commander.js to create the command-line interface, Next.js to run MappedIn, and Vercel to host our API endpoints and frontend. We integrated a few Slack APIs to create the Slack bot. To actually order the pizzas, we employed Terraform.
## Challenges we ran into
Our initial idea was to order coffee through a command line, but we soon realized there weren’t suitable APIs for that. When we tried manually sending POST requests to Starbucks’ website, we ran into reCaptcha issues. After examining many companies’ websites and nearly ordering three pizzas from Domino’s by accident, we found ourselves back at square one—three times. By the time we settled on our final project, we had only nine hours left.
## Accomplishments that we're proud of
Despite these challenges, we’re proud that we managed to get a proof of concept up and running with a CLI, backend API, frontend map, and a Slack bot in less than nine hours. This achievement highlights our ability to adapt quickly and work efficiently under pressure.
## What we learned
Through this experience, we learned that planning is crucial, especially when working within the tight timeframe of a hackathon. Flexibility and quick decision-making are essential when initial plans don’t work out, and being able to pivot effectively can make all the difference.
## Terraform
We used Terraform this weekend for ordering Domino's. We had many close calls and actually did accidentally order once, but luckily we got that cancelled. We created a Node.JS app that we created Terraform files for to run. We also used Terraform to order Domino's using template .tf files. Finally, we used TF to deploy our map on Render. We always thought it funny to use infrastructure as code to do something other than pure infrastructure. Gotta eat too!
## Mappedin
Mappedin was an impressive tool to work with. Its documentation was clear and easy to follow, and the product itself was highly polished. We leveraged its room labeling and pathfinding capabilities to help volunteers efficiently deliver pizzas to hungry hackers with accuracy and ease.
## What's next for Skip the Walk
We plan to enhance the CLI features by adding options such as reordering, randomizing orders, and providing tips for volunteers. These improvements aim to enrich the user experience and make the platform more engaging for both hackers and volunteers. | # Echo Chef
### TreeHacks 2016 @ Stanford
#### <http://echochef.net/>
Ever wanted a hands-free way to follow recipes while you cook?
Echo Chef can guide you through recipes interactively, think of it as your personal assistant in the kitchen.
Just add your favorite recipes to our web interface and they'll be available on your Amazon Echo!
Ask for step by step instructions, preheat temperatures, and more!
In addition to Echo Chef's use in the kitchen, we track your data and deliver it to you in an easily digestible way.
From your completion time of each recipe, to your most often used ingredients.
#### Features:
* Data Analytics and Visualization
* Amazon Alexa Skill Kit using the Amazon Echo
* AWS and DynamoDB
* Qualtrics API
* Responsive Site
#### Team
* Brandon Cen
* Cherrie Wang
* Elizabeth Chu
* Izzy Benavente | partial |
## Inspiration
In today’s day and age, there are countless datasets available containing valuable information about any given location. This includes analytics based on urban infrastructures (dangerous intersections), traffic, and many more. Using these datasets and recent data analytics techniques, a modernized approach can be taken to support insurance companies with ideas to calculate effective and accurate premiums for their clients. So, we created Surely Insured, a platform that leverages this data and supports the car insurance industry. With the help and support from administrations and businesses, our platform can help many insurance companies by providing a modernized approach to make better decisions for pricing car insurance premiums.
## What it does
Surely Insured provides car insurance companies with a data-driven edge on calculating premiums for their clients.
Given a location, Surely Insured provides a whole suite of information that the insurance company can use to make better decisions on insurance premium pricing. More specifically, it provides possible factors or reasons for why your client's insurance premium should be higher or lower.
Moreover, Surely Insured serves three main purposes:
* Create a modernized approach to present traffic incidents and severity scores
* Provide analytics to help create effective insurance premiums
* Use the Google Maps Platform Geocoding API, Google Maps Platform Maps JavaScript API, and various Geotab Ignition datasets to extract valuable data for the analytics.
## How we built it
* We built the web app using React as the front-end framework and Flask as the back-end framework.
* We used the Google Maps Platform Maps Javascript API to dynamically display the map.
* We used the Google Maps Platform Geocoding API to get the latitude and longitude given the inputted address.
* We used three different Geotab Ignition datasets (HazardousDrivingAreas, IdlingAreas, ServiceCenterMetrics) to calculate metrics (with Pandas) based on the customer's location.
## Challenges we ran into
* Integrating the Google Maps Platform JavaScript API and Google Maps Platform Geocoding API with the front-end was a challenge.
* There were a lot of features to incorporate in this project, given the time constraints. However, we were able to accomplish the primary purpose of our project, which was to provide car insurance companies an effective method to calculate premiums for their clients.
* Not being able to communicate face to face meant we had to rely on digital apps, which made it difficult to brainstorm concepts and ideas. This was exceptionally challenging when we had to work together to discuss potential changes or help debug issues.
* Brainstorming a way to combine multiple API prizes in an ambitious manner was quite a creative exercise and our idea had gone through multiple iterations until it was refined.
## Accomplishments that we're proud of
We're proud that our implementation of the Google Maps Platform APIs works as we intended. We're also proud of having the front-end and back-end working simultaneously and the overall accomplishment of successfully incorporating multiple features into one platform.
## What we learned
* We learned how to use the Google Maps Platform Map JavaScript API and Geocoding API.
* Some of us improved our understanding of how to use Git for large team projects.
## What's next for Surely Insured
* We want to integrate other data sets to Surely Insured. For example, in addition to hazardous driving areas, we could also use weather patterns to assess whether insurance premiums should be high or low. \* Another possible feature is to give the user a quantitative price quote based on location in addition to traditional factors such as age and gender. | ## Inspiration
One of the biggest problems during this COVID-19 pandemic and these awful times in general is that thousands of people are filing for property and casualty insurance. As a result, insurance companies are receiving an influx of insurance claims, causing longer processing times. These delays not only hurt the company, but also negatively impact the people who filed the claims, as the payout could be essential.
We wanted to tackle these problems with our website, Smooth Claiminal. Our platform uses natural language algorithms to speed up the insurance claiming process. With the help and support from governments and businesses, our platform can save many lives during the current pandemic crisis, while easing the burdens on the employees working at insurance companies or banks.
## What it does
Smooth Claiminal serves three main purposes:
* Provides an analytics dashboard for insurance companies
* Uses AI to extract insights from long insurance claims
* Secures data from the claim using blockchain
The analytics dashboard provides insurance companies with information about the previously processed claims, as well as the overall company performance. The upload tab allows for a simplified claim submittal process, as they can be submitted digitally as a PDF or DOCX file.
Once the claim is submitted, our algorithm first scans the text for typos using the Bing Spell Check API by Microsoft Azure. Then, it intelligently summarizes the claim by creating a subset that only contains the most important and relevant information. The text is also passed through a natural language processing algorithm powered by Google Cloud. Our algorithm then parses and refines the information to extract insights such as names, dates, addresses, quotes, etc., and predict the type of insurance claim being processed (i.e. home, health, auto, dental).
Internally, the claim is also assigned a sentiment score, ranging from 0 (very unhappy) to 1 (very happy). The sentimental analysis is powered by GCP, and allows insurance companies to prioritize claims accordingly.
Finally, the claim submissions are stored in a blockchain database built with IPFS and OrbitDB. Our peer to peer network is fast, efficient, and maximizes data integrity through distribution. We also guarantee reliability, as it will remain functional even if the central server crashes.
## How we built it
* Website built with HTML, CSS, and JS for front end, with a Python and Flask back end
* Blockchain database built with IPFS and OrbitDB
* NLP algorithm built with Google Cloud's NL API, Microsoft Azure's Spell Check API, Gensim, and our own Python algorithms
## Challenges we ran into
* Setting up the front end was tough! We had lots of errors from misplaced files and missing dependencies, and resolving these took a lot more time than expected
* Our original BigchainDB was too resource-intensive and didn't work on Windows, so we had to scrap the idea and switch to OrbitDB, which was completely new to all of us
* Not being able to communicate face to face meant we had to rely on digital channels - this was exceptionally challenging when we had to work together to debug any issues
## Accomplishments that we're proud of
* Getting it to work! Most, if not all the technologies were new to us, so we're extremely proud and grateful to have a working NLP algorithm which accurately extracts insights and a working blockchain database. Oh yeah, and all in 36 hours!
* Finishing everything on time! Building our hack and filming the video remotely were daunting tasks, but we were able to work efficiently through everybody's combined efforts
## What we learned
* For some of us, it was our first time using Python as a back end language, so we learned a lot about how it can be used to handle API requests and leverage AI tools
* We explored a new APIs, frameworks, and technologies (like GCP, Azure, and OrbitDB)
## What's next for Smooth Claiminal
* We'd love to expand the number of classifiers for insurance claims, and perhaps increase the accuracy by training a new model with more data
* We also hope to improve the accuracy of the claim summarization and insights extraction
* Adding OCR so we can extract text from images of claims as well
* Expanding this application to more than just insurance claims! We see a diverse use case for Smooth Claiminal, especially for any industry where long applications are still the norm! We're also hoping to build a consumer version of this application, which could help to simplify long documents like terms and conditions, or privacy policies. | # Fake Bananas
Fake news detection made simple and scalable for real people.
## Getting Started
I would strongly recommend a `conda` environment in order to easily install our older version of TensorFlow. We used `TensorFlow 0.12.1` for backwards compatibility with previous work in the field.
Newer versions of TensorFlow may work, but certainly not 'out of the box'.
```
# download and install anaconda
# python 3.5 is required for this version of TensorFlow
conda create --name FakeBananas python=3.5
NumPy==1.11.3
scikit-learn==0.18.1
TensorFlow==0.12.1
# note: older versions of TF (like 0.10) require less modification to use than newer ones
Pandas
eventregistry
watson_developer_cloud # IBM api signup required
py-ms-cognitive # microsoft
```
## How this works
Our fake news detection is based on the concept of ***stance detection***. Fake news is tough to identify. Many 'facts' are highly complex and difficult to check, or exist on a 'continuum of truth' or are compound sentences with fact and fiction overlapping. The best way to attack this problem is not through fact checking, but by comparing how reputable sources feel about a claim.
1. Users input a claim like *"The Afghanistan war was bad for the world"*
2. Our program will search the thousands of global and local news sources for their 'stance' on that topic.
3. We run sources through our Reputability Algorithm. If lots of reputable sources all agree with your claim, then it's probably true!
4. Then we cite our sources so our users can click through and read more about that topic!
### News Sources
After combing through numerous newspaper and natural language processing APIs, I discovered that the best way to find related articles is by searching for keywords. The challenge was implementing a natural language processing algorithm that extracted the most relevant keywords that were searchable, and to extract just the right number of keywords. Many algorithms were simply summarizers, and would return well over 50 keywords, which would be too many to search with. On top of that, many algorithms were resource exhaustive and would sometimes take up to a minute to parse a given text.
In the end, I implemented both Microsoft’s Azure and IBM’s Watson to process, parse, and extract keywords given the URL to a news article or a claim. I passed the extracted keywords to Event Registry’s incredible database of almost 200 million articles to find as many related articles as possible.
With more time, I would love to implement Event Registry’s data visualization capabilities which include generating tag clouds and graphs showing top news publishers given a topic.
-@Henry
### Determining Reputation
Using a large set of default sources with hard coded reputability, our database of sources continues to become more accurate with each web scraping by adding new sources and articles. To ensure this makes our algorithm better, the weights of each source are adjusted according to how much each new article agrees or disagrees with sources determined to be reputable. In the future, we would love to implement deep learning to further advance this ‘learning’ aspect of our reputability, but the current system more than supplies a proof of concept.
-@Josh
### Stance Detection
To determine if a claim is true or false, we go out and see where sources which are known to be reputable stand on that issue. We do this by leaning on established machine learning principles used for 'stance detection.' So we:
1. Ask the user to input a claim (which holds a 'stance') on a topic. A claim might be "ISIS has developed the technology to fire missiles at the International Space Station."
2. We search databases, and scrape web pages, to find other articles on that issue.
3. Then run our 'stance detection' machine learning algorithm to determine if reputable sources generally agree or generally disagree with that claim. *If many reputable sources all agree with a claim, then it's probably true!*
Our stance detection is run by (Google's Tensorflow)[<https://www.tensorflow.org/>] and our model is built off of the work of the fantastic people at University College London's (UCL) (Machine Reading group)[<http://mr.cs.ucl.ac.uk/>]. -@Kastan
### Frontend/backend info
Our backend is written on a Flask python server which connects to our front-end written in JavaScript.
## Other (worse) methods
##### 1. 'Fake News Style' Detection
Some teams try to train machine learning models on sets of 'fake' articles and sets of 'real' articles. This method is terrible because fake news can appear in well written articles and vice versa! Style is not equal to content and we care about finding true content.
##### 2. Fact checking
Some teams try to granularly check the truth of each fact in an article. This is interesting, and may ultimately be a part of some future fake news detection system, but today this method is not feasible. The truth of facts exists on a continuum and relies heavily on the nuance of individual words and their connotations. The nuances of human language are difficult to parse into true/false dichotomies.
1. Human language is nuanced. Determining a single statement as true or false
2. No databases of what's true or false
3. Many facts in a single article existing on all sides of the truth spectrum -- is that article true or false?
##### 2. 'Fake News Style' Detection
Some teams try to train machine learning models on sets of 'fake' articles and sets of 'real' articles. This method is terrible because fake news can appear in well written articles and vice versa! Style is not equal to content and we care about finding true content.
## Team Members
* (Kastan Day)[<https://github.com/KastanDay>]
* (Josh Frier)[<https://github.com/jfreier1>]
* (Henry Han)[<https://github.com/hanksterhan>]
* (Jason Jin)[<https://github.com/likeaj6>]
### Acknowledgements
(fakenewschallenge.com)[fakenewschallenge.com] provided great inspiration for our project and guiding principles for tackling the task.
The University of College London's short paper on the topic:
```
@article{riedel2017fnc,
author = {Benjamin Riedel and Isabelle Augenstein and George Spithourakis and Sebastian Riedel},
title = {A simple but tough-to-beat baseline for the {F}ake {N}ews {C}hallenge stance detection task},
journal = {CoRR},
volume = {abs/1707.03264},
year = {2017},
url = {http://arxiv.org/abs/1707.03264}
}
``` | partial |