
datasetId
stringlengths 2
81
| card
stringlengths 20
977k
|
|---|---|
c-s-ale/Product-Descriptions-and-Ads | ---
dataset_info:
features:
- name: product
dtype: string
- name: description
dtype: string
- name: ad
dtype: string
splits:
- name: train
num_bytes: 27511.2
num_examples: 90
- name: test
num_bytes: 3056.8
num_examples: 10
download_size: 24914
dataset_size: 30568
license: openrail
task_categories:
- text-generation
language:
- en
tags:
- art
pretty_name: Product Descriptions and Ads
size_categories:
- n<1K
---
# Synthetic Dataset for Product Descriptions and Ads
The basic process was as follows:
1. Prompt GPT-4 to create a list of 100 sample clothing items and descriptions for those items.
2. Split the output into desired format `{"product" : "<PRODUCT NAME>", "description" : "<DESCRIPTION>"}
3. Prompt GPT-4 to create adverts for each of the 100 samples based on their name and description.
This data was not cleaned or verified manually. |
LevMuchnik/SupremeCourtOfIsrael | ---
license: openrail
language:
- he
tags:
- legal, verdicts, metadata, hebrew
pretty_name: Supreme Court Israel - Public Verdicts and Decisions
size_categories:
- 100K<n<1M
task_ids:
- language-modeling
- masked-language-modeling
- document-retrieval
task_categories:
- text-generation
- fill-mask
- text-retrieval
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
Lev Muchnik, lev.muchnik@mail.huji.ac.il
### Dataset Summary
This dataset represents a 2022 snapshot of the Supreme Court of Israel public verdicts and decisions supported by rich metadata. The 5.31GB dataset represents 751,194 documents.
Overall, the dataset contains 2.68 Gb of text.
It can be loaded with the dataset package:
```
import datasets
data = datasets.load_dataset('LevMuchnik/SupremeCourtOfIsrael')
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The vast majority of the documents in the database are in Hebrew. A small number of documents are in English.
## Dataset Structure
The dataset is a json lines file with each line corresponding to a single document and containing document identification, text and metadata.
### Data Instances
[More Information Needed]
### Data Fields
The file contains the following fields:
- case_id - running number for cases
- download_time - when the document was downloaded (datetime)
- number_of_case_documents - number of documents in the current case
- file_name - full name of the document file, including relative path
- Id - document id
- CaseId - case id
- VerdictDt - Date of the document (datetime)
- CreatedDate - Date of when the document was inserted into the Supreme Court database
- CaseNum - case number
- CaseDesc - Unique case identifier. This id is used to reference cases within the Israeli legal system
- Pages - number of pages in the original document
- Path - relative path to the document
- CaseName - formal name of the case
- FileName - document file name, without path
- DocName -document file name, without path
- Year - document creation year
- TypeCode - enumeration of document types (see Type field below)
- Type - Document type
- פסק-דין 84339
- החלטה 663099
- צו ביניים 22
- פסקי דין באנגלית 310
- צו על תנאי 200
- צו 2606
- פד"י 302
- תקצירים 316
- Technical - boolean indicator of whether the document is technical or not.
- CodeVolume - ?
- document_hash - 258-bit hashtag of the document name. Used internally to uniquely identify the document
- text - text of the document. Multiple newlines and other document formating elements (paragraphs,lists, etc.) are preserved.
- html_title - document title extracted from the HTML
- VerdictsDt - date of the verdict
- meta_case_nm - formal case name,
- meta_sec_appeal - integer or None
- meta_side_ty - case type, list of strings
- meta_verdict_file_nm - name of the verdict file
- meta_judge - list of names of the cases judges
- meta_mador_nm - name of the court instance (e.g. בג"ץ)
- meta_side_nm - list of the case parties, list of strings
- meta_verdict_dt - date of the verdict
- meta_case_dt - date of the case
- meta_verdict_nbr -
- meta_ProgId - name of the software used to create the document (None, Word, etc)
- meta_is_technical - whether the document is technical, {'false', 'true'}
- meta_judge_nm_last - last names of the judges (list of strings)
- meta_case_nbr - formal number of the case (same as CaseDesc)
- meta_verdict_ty - type of the decision (same as Type)
- meta_lawyer_nm - list of lawyer names, list of strings or None
- meta_judge_nm_first - list of judges' first names, list of strings
- meta_verdict_pages - number of document cases
- meta_inyan_nm - court בג"ץ
- meta_court_nm - court (e.g. בית המשפט העליון )
### Data Splits
The entire dataset is qualified as 'train'.
## Dataset Creation
2023-04-22
### Curation Rationale
[More Information Needed]
### Source Data
https://supreme.court.gov.il/
#### Initial Data Collection and Normalization
The data was colleted by crawling the Israeli Supreme Court website.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
The data contained in this dataset is public.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Prof. Lev Muchnik, Hebrew University of Jerusalem
Dr. Inbal Yahav Shenberger, Tel Aviv University
### Licensing Information
[More Information Needed]
### Citation Information
Lev Muchnik, Inbal Yahav, Ariel Nevo, Avichay Chriqui, Tim Shektov, 2023, The Israeli Supreme Court Dataset
### Contributions
The authours would like to thank the Israeli Innovation Authority (grants #78560 and #78561) for their support in creating of this dataset. |
masakhane/afriqa | ---
license: cc-by-sa-4.0
task_categories:
- question-answering
language:
- bem
- fon
- ha
- ig
- kin
- sw
- wo
- yo
- zu
- tw
pretty_name: AfriQA
size_categories:
- 10K<n<100K
multilinguality:
- multilingual
tags:
- cross-lingual
- question-answering
- qa
---
# Dataset Card for AfriQA
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [homepage](https://github.com/masakhane-io/afriqa)
- **Repository:** [github](https://github.com/masakhane-io/afriqa)
- **Paper:** [paper]()
- **Point of Contact:** [Masakhane](https://www.masakhane.io/) or oogundep@uwaterloo.ca
### Dataset Summary
AfriQA is the first cross-lingual question answering (QA) dataset with a focus on African languages. The dataset includes over 12,000 XOR QA examples across 10 African languages, making it an invaluable resource for developing more equitable QA technology.
The train/validation/test sets are available for all the 10 languages.
### Supported Tasks and Leaderboards
- `question-answering`: The performance in this task is measured with [F1](https://huggingface.co/metrics/f1) (higher is better) and [Exact Match Accuracy](https://huggingface.co/spaces/evaluate-metric/exact_match).
### Languages
There are 20 languages available :
- Bemba (bem)
- Fon (fon)
- Hausa (hau)
- Igbo (ibo)
- Kinyarwanda (kin)
- Swahili (swą)
- Twi (twi)
- Wolof (wol)
- Yorùbá (yor)
- Zulu (zul)
## Dataset Structure
### Data Instances
- Data Format:
- id : Question ID
- question : Question in African Language
- translated_question : Question translated into a pivot language (English/French)
- answers : Answer in African Language
- lang : Datapoint Language (African Language) e.g `bem`
- split : Dataset Split
- translated_answer : Answer in Pivot Language
- translation_type : Translation type of question and answers
```bash
{ "id": 0,
"question": "Bushe icaalo ca Egypt caali tekwapo ne caalo cimbi?",
"translated_question": "Has the country of Egypt been colonized before?",
"answers": "['Emukwai']",
"lang": "bem",
"split": "dev",
"translated_answer": "['yes']",
"translation_type": "human_translation"
}
```
### Data Splits
For all languages, there are three splits.
The original splits were named `train`, `dev` and `test` and they correspond to the `train`, `validation` and `test` splits.
The splits have the following sizes :
| Language | train | dev | test |
|-----------------|------:|-----------:|-----:|
| Bemba | 502 | 503 | 314 |
| Fon | 427 | 428 | 386 |
| Hausa | 435 | 436 | 300 |
| Igbo | 417 | 418 | 409 |
| Kinyarwanda | 407 | 409 | 347 |
| Swahili | 415 | 417 | 302 |
| Twi | 451 | 452 | 490 |
| Wolof | 503 | 504 | 334 |
| Yoruba | 360 | 361 | 332 |
| Zulu | 387 | 388 | 325 |
| <b>Total</b> | <b>4333</b> | <b>4346</b> |<b>3560</b> |
## Dataset Creation
### Curation Rationale
The dataset was introduced to introduce question-answering resources to 10 languages that were under-served for natural language processing.
[More Information Needed]
### Source Data
...
#### Initial Data Collection and Normalization
...
#### Who are the source language producers?
...
### Annotations
#### Annotation process
Details can be found here ...
#### Who are the annotators?
Annotators were recruited from [Masakhane](https://www.masakhane.io/)
### Personal and Sensitive Information
...
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
Users should keep in mind that the dataset only contains news text, which might limit the applicability of the developed systems to other domains.
## Additional Information
### Dataset Curators
### Licensing Information
The licensing status of the data is CC 4.0 Non-Commercial
### Citation Information
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
```
@misc{ogundepo2023afriqa,
title={AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages},
author={Odunayo Ogundepo and Tajuddeen R. Gwadabe and Clara E. Rivera and Jonathan H. Clark and Sebastian Ruder and David Ifeoluwa Adelani and Bonaventure F. P. Dossou and Abdou Aziz DIOP and Claytone Sikasote and Gilles Hacheme and Happy Buzaaba and Ignatius Ezeani and Rooweither Mabuya and Salomey Osei and Chris Emezue and Albert Njoroge Kahira and Shamsuddeen H. Muhammad and Akintunde Oladipo and Abraham Toluwase Owodunni and Atnafu Lambebo Tonja and Iyanuoluwa Shode and Akari Asai and Tunde Oluwaseyi Ajayi and Clemencia Siro and Steven Arthur and Mofetoluwa Adeyemi and Orevaoghene Ahia and Aremu Anuoluwapo and Oyinkansola Awosan and Chiamaka Chukwuneke and Bernard Opoku and Awokoya Ayodele and Verrah Otiende and Christine Mwase and Boyd Sinkala and Andre Niyongabo Rubungo and Daniel A. Ajisafe and Emeka Felix Onwuegbuzia and Habib Mbow and Emile Niyomutabazi and Eunice Mukonde and Falalu Ibrahim Lawan and Ibrahim Said Ahmad and Jesujoba O. Alabi and Martin Namukombo and Mbonu Chinedu and Mofya Phiri and Neo Putini and Ndumiso Mngoma and Priscilla A. Amuok and Ruqayya Nasir Iro and Sonia Adhiambo},
year={2023},
eprint={2305.06897},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@ToluClassics](https://github.com/ToluClassics) for adding this dataset. |
microsoft/LCC_csharp | ---
dataset_info:
features:
- name: context
dtype: string
- name: gt
dtype: string
splits:
- name: train
num_bytes: 1851797668
num_examples: 100000
- name: validation
num_bytes: 136620599
num_examples: 10000
- name: test
num_bytes: 136701413
num_examples: 10000
download_size: 581666513
dataset_size: 2125119680
---
# Dataset Card for "LCC_csharp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TIGER-Lab/MetricInstruct | ---
configs:
- config_name: train
data_files:
- split: train
path:
- data/mix_instruct_v1.2.json
license: mit
task_categories:
- text-generation
language:
- en
- zh
- cs
- ru
- fr
size_categories:
- 10K<n<100K
---
## MetricInstruct
The MetricInstrcut dataset consists of 44K quadruple in the form of (instruction, input, system output, error analysis) for 6 text generation tasks and 22 text generation datasets. The dataset is used to fine-tune [TIGERScore](https://huggingface.co/TIGER-Lab/TIGERScore-7B-V1.2), a **T**rained metric that follows **I**nstruction **G**uidance to perform **E**xplainable, and **R**eference-free evaluation over a wide spectrum of text generation tasks.
[Project Page](https://tiger-ai-lab.github.io/TIGERScore/) | [Paper](https://arxiv.org/abs/2310.00752) | [Code](https://github.com/TIGER-AI-Lab/TIGERScore) | [Demo](https://huggingface.co/spaces/TIGER-Lab/TIGERScore) |
[TIGERScore-7B](https://huggingface.co/TIGER-Lab/TIGERScore-7B-V1.2) | [TIGERScore-13B](https://huggingface.co/TIGER-Lab/TIGERScore-13B-V1.2)
We present the MetricInstruct dataset, which is employed to fine-tune TIGERScore. The three underlying criteria for dataset construction are:
1. Dataset diversity: we choose 22 distinctive datasets as the source context to cover enough generation tasks.
2. Error coverage: we take system outputs generated from 50+ text generation systems to cover all types of errors and guarantee a balanced distribution.
3. Quality ensurance: to ensure MetricInstruct is tailored to gather in-depth error analysis, we sourced it by prompting OpenAI GPT models and then filtered through different heuristics to eliminate low-quality error analysis.
## Data Source
Our system outputs come from two channels, namely real-world system outputs and synthetic outputs. The real-world system outputs are obtained from real systems, which ensures the error distribution is aligned with real-world ones.
Check out our paper for more details.
| Task | Real-World Dataset | Output Source | Synthetic Dataset | Output Source |
|:--------:|:-----------------------------------------:|:--------------:|:-----------------------------------:|:--------------:|
| Summarization | SummEval, XSum,Newsroom,SAMSum | 27 Systems | CNN/DM, XSum,Gigaword,SAMSum | GPT-4 |
| Translation | WMT | 18 Systems | WMT | GPT-4 |
| Data-to-Text | WebNLG-2020,WikiTableText,ToTTo | 17 Systems | WikiTableText,Dart,ToTTo | GPT-4 |
| Long-Form QA | ASQA,FeTaQA,CosmosQA,ELI5 | 5 Systems | ASQA,FeTaQA,Cosmos QA,ELI5 | GPT-4 |
| MathQA | GSM8K | 5 Systems | N/A | N/A |
| Instruct | MixInstruct | 11 Systems | AlpacaFarm,OASST1,Guanaco,Dolly | GPT-4 |
## Data Format
The dataset consists of 44K quadruple in the form of (instruction, input, system output, error analysis).
For each item in the dataset, `instruction` is its task instruction, `input_context` is its input source, and `hypo_output` is the generated output, and `errors` is the error analysis given by ChatGPT or GPT-4.
## Formatting
To format the data fields into a single prompt for finetuning or testing, We provide the following code for users to refer:
```python
FINETUNE_INST = "You are evaluating errors in a model-generated output for a given instruction."
FINETUNE_INPUT = """\
Instruction: ${generation_instruction}
${input_context}
Model-generated Output:
${hypothesis_output}
For each error you give in the response, please also elaborate the following information:
- error location (the words that are wrong in the output)
- error aspect it belongs to.
- explanation why it's an error, and the correction suggestions.
- severity of the error ("Major" or "Minor").
- reduction of score (between 0.5 and 5 given the severity of the error)
Your evaluation output:
"""
inst_part = Template(FINETUNE_INST)
inst_part = inst_part.substitute()
input_part = Template(FINETUNE_INPUT)
input_part = input_part.substitute(
generation_instruction=instruction,
input_context=input_context,
hypothesis_output=hypo_output
)
prompt = (inst_part + "\n" + input_part).strip("\n ") + "\n"
encodings = tigerscore_tokenizer(prompt, return_tensors="pt")
input_ids = encodings["input_ids"].to(tigerscore_model.device)
attention_mask = encodings["attention_mask"].to(tigerscore_model.device)
```
Example of formatted prompt:
```txt
You are evaluating errors in a model-generated output for a given instruction.
Instruction: Translate the following text from German to English.
Der künftige EM-Cheforganisator Philipp Lahm soll laut Grindel im DFB-Präsidium mitarbeiten.
Model-generated Output:
According to Grindel, the future head of the European Championships, Philipp Lahm, is to participate in the DFB Presidency.
For each error you give in the response, please also elaborate the following information:
- error location (the words that are wrong in the output)
- error aspect it belongs to.
- explanation why it's an error, and the correction suggestions.
- severity of the error ("Major" or "Minor").
- reduction of score (between 0.5 and 5 given the severity of the error)
Your evaluation output:
```
## Citation
```
@article{jiang2023TIGERScore,
title={TIGERScore: Towards Building Explainable Metric for All Text Generation Tasks},
author={Dongfu Jiang, Yishan Li, Ge Zhang, Wenhao Huang, Bill Yuchen Lin, Wenhu Chen},
journal={arXiv preprint arXiv:2310.00752},
year={2023}
}
``` |
hearmeneigh/e621-rising-v3-curated | ---
dataset_info:
features:
- name: source_id
dtype: string
- name: source
dtype: string
- name: image
dtype: image
- name: tags
sequence: string
- name: url
dtype: string
- name: text
dtype: string
- name: selector
dtype: string
splits:
- name: train
num_bytes: 53726659168.0
num_examples: 279296
download_size: 53423627875
dataset_size: 53726659168.0
pretty_name: 'E621 Rising V3 Image Dataset'
size_categories:
- 100K<n<1M
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- furry
- anthro
- nsfw
- e621
- booru
- imagebooru
- imageboard
- gelbooru
- danbooru
- rule34
- not-for-all-audiences
---
<div style='background: #ffeef1; border: 1px solid #fd91a4; padding:1em; border-radius:3px; margin-bottom:2em;'>
<h3 style='margin:0'>NSFW</h3>
<p style='margin:0'>This dataset is not suitable for use by minors. The dataset contains X-rated/NFSW content.</p>
</div>
# E621 Rising V3: Curated Image Dataset
* **279,296** images (53GB) downloaded from `e621.net` (90% of samples), `gelbooru.com`, `danbooru.com`, and `rule34.xxx`
* **6,820** [tags](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/blob/main/tag-counts.by-name.json)
* Used to train [E621 Rising v3](https://huggingface.co/hearmeneigh/e621-rising-v3) SDXL model
This dataset was created with [Dataset Rising](https://github.com/hearmeneigh/dataset-rising) toolchain and a [custom configuration](https://github.com/hearmeneigh/e621-rising-configs).
You can use these tools to train your own version!
## Image Processing
* Only `jpg` and `png` images were considered
* Image width and height have been clamped to `(0, 1024]px`; larger images have been resized to meet the limit
* Alpha channels have been removed
* All images have been converted to `jpg` format
* All images have been converted to TrueColor `RGB`
* All images have been verified to load with `Pillow`
* Metadata from E621 is [available here](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data)
## Tags
Comprehensive list of 6,820 tags and counts:
* [By name](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/blob/main/tag-counts.by-name.json)
* [By count](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/blob/main/tag-counts.by-count.json)
### Additional Tags
* `rating_explicit`
* `rating_questionable`
* `rating_safe`
* `rising_masterpiece`
* `rising_unpopular`
* `favorites_below_X` (25, 50, 100, 250, 500, 1000)
* `favorites_above_X` (250, 500, 1000, 2000, 3000, 4000)
* `score_below_X` (0, 25, 50, 100, 250, 500)
* `score_above_X` (100, 250, 500, 1000, 1500, 2000)
|
ZenMoore/RoleBench | ---
language:
- zh
- en
pretty_name: "RoleBench"
tags:
- Role-Playing
- Instruction
license: "apache-2.0"
---
# RoleBench
- Paper Title: RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
- arXiv Link: https://arxiv.org/abs/2310.00746
- Github Repo: https://github.com/InteractiveNLP-Team/RoleLLM-public
Please read our paper for more details about this dataset.
TL;DR: We introduce RoleLLM, a role-playing framework of data construction and evaluation (RoleBench), as well as solutions for both closed-source and open-source models (RoleGPT, RoleLLaMA, RoleGLM). We also propose Context-Instruct for long-text knowledge extraction and role-specific knowledge injection.
---
# List of Roles

Abraham Lincoln, Alvy Singer, Andrew Detmer, Angel, Antonio Salieri, Bai Li (李白,Chinese), Benjamin Button, Blair Waldorf, Bruno Antony, Caden Cotard, Caesar, Coach Eric Taylor, Colonel Hans Landa, Colonel Nathan R. Jessep, Coriolanus, D_Artagnan, David Aames, Doctor Who, Dr. Frank N Furter, Dr. Hannibal Lecter, Emperor (《甄嬛传》皇帝,Chinese), Fei Zhang (张飞,Chinese), Fletcher Reede, Frank T.J. Mackey, Fred Flintstone, Freddy Krueger, Gaston, Gregory House, HAL 9000, Harvey Milk, Imperial Concubine Hua (《甄嬛传》华妃,Chinese), Jack, Jack Sparrow, Jack Torrance, Jackie Moon, James Bond, James Brown, James Carter, Jeff Spicoli, Jigsaw, Jim Morrison, John Coffey, John Dillinger, John Doe, John Keating, Jordan Belfort, Judge Dredd, Judy Hoops, Juno MacGuff, Karl Childers, Klaus Mikaelson, Leonard Shelby, Leroy Jethro Gibbs, Lestat de Lioncourt, Logan, Lucifer Morningstar, Lyn Cassady, Malcolm X, Mark Renton, Mary Sibley, Mater, Michael Scott, Murphy MacManus, Oliver Queen, Pat Solitano, Paul Conroy, Paul Vitti, Peter Parker, Po, Professor G.H. Dorr, Queen Catherine, Queen Elizabeth I, Rachel Lang, Randle McMurphy, Raylan Givens, Robert Angier, Rorschach, Seth, Sheldon Cooper, Sherlock Holmes, Shrek, Sonny, Stanley Ipkiss, Stephen Hawking, Stifler, The Dude, Theodore Twombly, Thor, Tom Ripley, Travis Bickle, Truman Capote, Tugg Speedman, Twilight Sparkle, Tyler Hawkins, Tyrion Lannister, Violet Weston, Wade Wilson, Walt Kowalski, Willie Soke, Wukong Sun (《西游记》孙悟空,Chinese).
---
# Non-Cherry-Picked Demonstrations




---
# Statistics


---
# Download
```bash
git lfs install
git clone https://huggingface.co/datasets/ZenMoore/RoleBench
```
```python
from datasets import load_dataset
dataset = load_dataset("ZenMoore/RoleBench")
```
---
# File Structure
- `instructions-eng`: Contains English Instructions (both general and role-specific ones). `nums.jsonl` indicates the number of role-specific instructions for each role, while `split_info.txt` records how many segments each role's script can be divided into during the Context-Instruct.
- `instructions-zh`: Similarly for Chinese.
- `profiles-eng`: Contains the description file `desc.json` for all roles, dialogue data files `profiles-eng-{role_name}.jsonl` for each role, and the script names in `scripts.json`.
- `profiles-zh`: Similarly for Chinese.
- `rolebench-eng/instruction-generalization`, `rolebench-eng/role-generalization`, and `rolebench-zh`: All contain two subfolders: `general` and `role_specific`. Each subfolder has training data, testing data, and the RoleGPT baseline results for comparison.
---
# License
Apache 2.0 License.
---
# Citation
Feel free to cite us if you like RoleBench and RoleLLM.
```bibtex
@article{wang2023rolellm,
title = {RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models},
author = {Zekun Moore Wang and Zhongyuan Peng and Haoran Que and Jiaheng Liu and Wangchunshu Zhou and Yuhan Wu and Hongcheng Guo and Ruitong Gan and Zehao Ni and Man Zhang and Zhaoxiang Zhang and Wanli Ouyang and Ke Xu and Wenhu Chen and Jie Fu and Junran Peng},
year = {2023},
journal = {arXiv preprint arXiv: 2310.00746}
}
```
```bibtex
@article{wang2023interactive,
title={Interactive Natural Language Processing},
author={Wang, Zekun and Zhang, Ge and Yang, Kexin and Shi, Ning and Zhou, Wangchunshu and Hao, Shaochun and Xiong, Guangzheng and Li, Yizhi and Sim, Mong Yuan and Chen, Xiuying and others},
journal={arXiv preprint arXiv:2305.13246},
year={2023}
}
``` |
athirdpath/DPO_Pairs-Roleplay-Alpaca-NSFW-v1-SHUFFLED | ---
license: cc-by-nc-4.0
language:
- en
tags:
- not-for-all-audiences
---
### Description
\~3.4k DPO pairs, generated by [Iambe](https://huggingface.co/athirdpath/Iambe-20b-DARE-v2-GGUF) feat. GPT-4 (~10% GPT-4, ~80% Iambe @ q5_k_m / ~10% Iambe @ q6_k) with temp 1.2 and min_p 0.15.
They are shuffled this time, as I was not aware that TRL did not do that automatically until I could see the shifts in the dataset mirrored in the loss patterns.
Iambe is a smart girl, so both the chosen and rejected for each pair are generated at the same time from a single two part prompt (not the one in the dataset). Only a few dozen failed to generate the rejected response, and in those cases I filled in the rejected output with a standard "as an AI" style refusal. The way I set things up caused any prompt formatting errors to automatically go into the REJECTED field, hopefully discouraging such behavior.
The dataset is mostly intended for ERP, so erotic situations are an outsized portion of the dataset. However, it isn't all sexual, with sport, adventure, etc content to provide a baseline.
### Downsides and Weaknesses
This dataset has not been manually cleaned, besides some basic search-and-replace. This dataset has been overseen in bursts (such content passed muster or the entire batch was rejected) but much of the content has yet to be read by a human. Some chosen responses have the AI acting for the user, I've removed what I've seen but this is a lot to manually filter. Despite my best efforts to prompt away from it, some rejected responses are... what seems to be... let's say, in a certain voice? I really tried to avoid it, and most of it was removed.
### Goals
This dataset is intended to be used to produce a BETTER Iambe, that can itself produce even more data of higher quality. Bootstraps to the moon, baby! So, while this dataset still has rough points, I feel like it's worth uploading and starting to train the model. I also want to combine data generated by more models, as to not just amplify what is already Iambe's signal.
### Bonus
I've also added the notebook I used to train [athirdpath/Iambe-20b-v3_TEST-RP_cDPO](https://huggingface.co/athirdpath/Iambe-20b-v3_TEST-RP_cDPO) on runpod, adapted from a Kaggle by [@maximelabonne](https://twitter.com/maximelabonne) (thank you!) |
ShoukanLabs/AniSpeech | ---
language:
- en
license: mit
size_categories:
- n<1K
task_categories:
- text-to-speech
pretty_name: AniSpeech
tags:
- anime
- speech
- text-to-speech
- voice
dataset_info:
features:
- name: audio
dtype: audio
- name: caption
dtype: string
- name: phonetic captions
dtype: string
- name: voice
dtype: string
splits:
- name: ENGLISH
num_bytes: 18875728249.368
num_examples: 23656
download_size: 20449215803
dataset_size: 18875728249.368
configs:
- config_name: default
data_files:
- split: ENGLISH
path: data/ENGLISH-*
---
# AniSpeech Dataset
Welcome to the AniSpeech dataset, a continually expanding collection of captioned anime voices brought to you by ShoukanLabs.
- As we label more and more audio, they'll automagically be uploaded here for use, seperated by language
---
## ANNOUNCMENTS:
- An upcoming update will add an immense ammount of data to the dataset... however... because we cannot manually go through this dataset we have had to rely on manual quality estimation, as such, speaker splits may be innacurate, this shouldnt impact finetuning multispeaker models, but when training single speaker models you may have to listen to multiple speakers to find missing data, we plan on eventually completely overhauling this dataset eventually
## Key Features
- **LJSpeech Format Compatibility:** The captions in this dataset can be converted to (recent changes have sacrificed native LJSpeech support for better captions) comply with the LJSpeech format, and we plan to offer conversion scripts to said format eventually.
- **Diverse Anime Voices:** Train your TTS models on high-quality vocal performances with variations in intonation, timbre, and pitch. The dataset offers a rich assortment of anime voices for creating generalised models.
- **Ideal for Generalized Models:** AniSpeech is a perfect choice for fine-tuning generalized models. With a diverse range of voices, it provides a solid foundation for training models that can handle a wide variety of speaking styles (all speakers are labeled with a seperate speaker id).
## Limitations
- **Single-Voice Fine-Tuning:** While AniSpeech excels in training foundation models (due to it's diversity), it's not recommended for fine-tuning on a single voice. Its strength lies in contributing to the development of versatile TTS models.
- **Dataset Curation:** Due to its size, manually curating the entire dataset can be impractical. If you encounter low-quality files or incorrect captions, we encourage you to contribute by creating a pull request to help maintain and improve the dataset.
## License
This dataset is released under the [MIT License](https://huggingface.co/datasets/ShoukanLabs/AniSpeech/raw/main/license).
Your contributions to the AniSpeech dataset are invaluable, and we appreciate your efforts in advancing the field of Text-to-Speech technology.
Happy coding and synthesizing!
|
Yhyu13/glaive-function-calling-v2-llama-factory-convert | ---
license: apache-2.0
---
This is a converted dataset for https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2 that allows sft in https://github.com/hiyouga/LLaMA-Factory for function calling fine tuning.
You need to add the following to the datasets.json file, and changed the `file_name` to your local path.
```
"glaive-function-calling-v2": {
"file_name": "./glaive-function-calling-v2/simple-function-calling-v2_converted.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
}
```
There is also a `simple-function-calling-v2_converted.json` that trimmed to the first 1,000 samples in the originial dataset which is about 1% in size. |
nicholasKluge/instruct-aira-dataset-v3 | ---
language:
- pt
- en
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- conversational
- text-generation
pretty_name: Instruct-Aira Dataset version 3.0
tags:
- alignment
- instruction
- chat
dataset_info:
features:
- name: conversation_id
dtype: string
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: portuguese
num_bytes: 348823623
num_examples: 50000
- name: english
num_bytes: 317852173
num_examples: 50000
download_size: 330840060
dataset_size: 666675796
configs:
- config_name: default
data_files:
- split: portuguese
path: data/portuguese-*
- split: english
path: data/english-*
---
# Instruct-Aira Dataset version 3.0
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/Nkluge-correa/Aira
- **Point of Contact:** [AIRES at PUCRS](nicholas@airespucrs.org)
### Dataset Summary
This dataset contains a collection of multi-turn conversations between an assistant and a user. Conversations were generated by user interactions with already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc). The dataset is available in Portuguese and English.
### Supported Tasks and Leaderboards
This dataset can be utilized for various natural language processing tasks, including but not limited to:
- Language modeling.
- Question-answering systems.
- Chatbot development.
- Evaluation of language models.
- Alignment research.
### Languages
English and Portuguese.
## Dataset Structure
### Data Instances
The dataset consists of the following features:
- **Conversation ID:** Identifier of the conversation.
- **Conversations:** A list of dictionaries following a [chat format](https://github.com/huggingface/blog/blob/main/chat-templates.md).
### Data Fields
```python
[
{'role': 'user', 'content': 'Hello! What is your name?'},
{'role': 'assistant', 'content': 'Hello! My name is Aira. How can I help you?'},
{'role': 'user', 'content': 'What is a language model, Aira?'},
{'role': 'assistant', 'content': 'A language model is a probability distribution over a vocabulary.'},
]
```
### Data Splits
Available splits are `english` and `portuguese`.
```python
from datasets import load_dataset
dataset = load_dataset("nicholasKluge/instruct-aira-dataset-v3", split='portuguese')
```
## Dataset Creation
### Curation Rationale
This dataset was developed are part of [Nicholas Kluge's](https://nkluge-correa.github.io/) doctoral dissertation, "_Dynamic Normativity: Necessary and Sufficient Conditions for Value Alignment._" This research was funded by CNPq (Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul), FAPERGS (Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul), and DAAD (Deutscher Akademischer Austauschdienst), as part of a doctoral research project tied to Philosophy departments of PUCRS (Pontifícia Universidade Católica do Rio Grande do Sul) and the University of Bonn.
### Source Data
#### Initial Data Collection and Normalization
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
#### Who are the source language producers?
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
### Annotations
#### Annotation process
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
#### Who are the annotators?
No annotators were used.
### Personal and Sensitive Information
No personal or sensitive information is part of this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
No considerations.
### Discussion of Biases
No considerations.
### Other Known Limitations
No considerations.
## Additional Information
### Dataset Curators
[Nicholas Kluge Corrêa](mailto:nicholas@airespucrs.org).
### Licensing Information
This dataset is licensed under the [Apache License, version 2.0](LICENSE).
### Citation Information
```latex
@misc{nicholas22aira,
doi = {10.5281/zenodo.6989727},
url = {https://github.com/Nkluge-correa/Aira},
author = {Nicholas Kluge Corrêa},
title = {Aira},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
}
```
### Contributions
If you would like to contribute, contact me at [nicholas@airespucrs.org](mailto:nicholas@airespucrs.org)!
|
Vivacem/MMIQC | ---
license: apache-2.0
---
MMIQC is a mixture of question-response pairs extracted from Mathematics Stack Exchange pages and synthetic data augmented from MATH and GSM8K.
[Mistral-7B-MMIQC](https://huggingface.co/Vivacem/Mistral-7B-MMIQC) and [DeepSeek-67B-MMIQC](https://huggingface.co/Vivacem/DeepSeek-67B-MMIQC) achieves 36.0% and 41.0% test accuracy on MATH, respectively.
See our [paper](https://arxiv.org/abs/2401.09003) for details.
|
ajibawa-2023/General-Stories-Collection | ---
license: apache-2.0
task_categories:
- text-generation
- text2text-generation
language:
- en
size_categories:
- 1M<n<10M
tags:
- synthetic
- story
- general
---
**General Stories Collection**
A great synthetic datasets consists of around **1.3 million** stories especially meant for **General audience**. You can directly use these datasets for training large models.
Total 10 datasets are available for download. You can use any one or all the json files for training purpose.
These datasets are in "prompt" and "text" format. Total token length is also available.
Thanks for your love & support. |
transformersbook/codeparrot | ---
tags:
- python
- code
---
# CodeParrot 🦜 Dataset
## What is it?
This is the full CodeParrot dataset. It contains Python files used to train the code generation model in Chapter 10: Training Transformers from Scratch in the [NLP with Transformers book](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). You can find the full code in the accompanying [Github repository](https://github.com/nlp-with-transformers/notebooks/blob/main/10_transformers-from-scratch.ipynb).
## Creation
It was created with the GitHub dataset available via Google's BigQuery. It contains approximately 22 million Python files and is 180 GB (50 GB compressed) big. The SQL query to create the dataset is the following:
```sql
SELECT
f.repo_name, f.path, c.copies, c.size, c.content, l.license
FROM
`bigquery-public-data.github_repos.files` AS f
JOIN
`bigquery-public-data.github_repos.contents` AS c
ON
f.id = c.id
JOIN
`bigquery-public-data.github_repos.licenses` AS l
ON
f.repo_name = l.repo_name
WHERE
NOT c.binary
AND ((f.path LIKE '%.py')
AND (c.size BETWEEN 1024 AND 1048575))
```
## Duplication
Note that about 70% of the dataset is duplicated. If you use the dataset make sure to deal with them appropriately. See [codeparrot-clean](https://huggingface.co/datasets/lvwerra/codeparrot-clean) for a deduplicated version of this dataset. |
ctheodoris/Genecorpus-30M | ---
license: apache-2.0
---
# Dataset Card for Genecorpus-30M
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Species](#species)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Citation Information](#citation-information)
<!---
- [Licensing Information](#licensing-information)
- [Contributions](#contributions)
--->
## Dataset Description
<!--- **Paper:**
--->
- **Point of Contact:** christina.theodoris@gladstone.ucsf.edu
### Dataset Summary
We assembled a large-scale pretraining corpus, Genecorpus-30M, comprised of ~30 million human single cell transcriptomes from a broad range of tissues from publicly available data. This corpus was used for pretraining [Geneformer](https://huggingface.co/ctheodoris/Geneformer), a pretrained transformer model that enables context-aware predictions in settings with limited data in network biology.
See [our manuscript](https://rdcu.be/ddrx0) for details.
### Supported Tasks
This corpus was used for pretraining [Geneformer](https://rdcu.be/ddrx0) and is compatible with pretraining or fine-tuning Geneformer or similar models.
### Species
Homo sapiens
## Dataset Structure
### Data Instances
Genecorpus-30M is provided as tokenized data in the Huggingface Datasets structure, which is based on the Apache Arrow format. Each example within the dataset is composed of the rank value encoding for a single cell within the corpus. Rank value encodings provide a nonparametric representation of each single cell’s transcriptome, ranking genes by their expression within that cell normalized by their expression across the entire Genecorpus-30M. This method takes advantage of the many observations of each gene’s expression across Genecorpus-30M to prioritize genes that distinguish cell state. Specifically, this method will deprioritize ubiquitously highly-expressed housekeeping genes by normalizing them to a lower rank. Conversely, genes such as transcription factors that may be lowly expressed when they are expressed but highly distinguish cell state will move to a higher rank within the encoding. Furthermore, this rank-based approach may be more robust against technical artifacts that may systematically bias the absolute transcript counts value while the overall relative ranking of genes within each cell remains more stable.
To accomplish this, we first calculated the nonzero median value of expression of each detected gene across all cells from the entire Genecorpus-30M. We aggregated the transcript count distribution for each gene, normalizing the gene transcript counts in each cell by the total transcript count of that cell to account for varying sequencing depth. We then normalized the genes in each single cell transcriptome by that gene’s nonzero median value of expression across Genecorpus-30M and ordered the genes by the rank of their normalized expression in that specific cell. Of note, we opted to use the nonzero median value of expression rather than include zeros in the distribution so as not to weight the value by tissue representation within Genecorpus-30M, assuming that a representative range of transcript values would be observed within the cells in which each gene was detected.
The rank value encodings for each single cell transcriptome were then tokenized based on a total vocabulary of 25,424 protein-coding or miRNA genes detected within Geneformer-30M. The token dictionary mapping each token ID to special tokens (pad and mask) or Ensembl IDs for each gene is included within the repository as a pickle file (token_dictionary.pkl).
### Data Fields
- `input_ids`: rank value encoding for an example cell
- `lengths`: length of rank value encoding for that example cell
### Data Splits
The dataset does not contain any predefined splits.
## Dataset Creation
### Curation Rationale
Mapping the gene regulatory networks that drive disease progression enables screening for molecules that correct the network by normalizing core regulatory elements, rather than targeting peripheral downstream effectors that may not be disease modifying. However, mapping the gene network architecture requires large amounts of transcriptomic data to learn the connections between genes, which impedes network-correcting drug discovery in settings with limited data, including rare diseases and diseases affecting clinically inaccessible tissues. Although data remains limited in these settings, recent advances in sequencing technologies have driven a rapid expansion in the amount of transcriptomic data available from human tissues more broadly. Furthermore, single cell technologies have facilitated the observation of transcriptomic states without averaging genes’ expression across multiple cells, potentially providing more precise data for inference of network interactions, especially in diseases driven by dysregulation of multiple cell types. Recently, the concept of transfer learning has revolutionized fields such as natural language understanding and computer vision by leveraging deep learning models pretrained on large-scale general datasets that can then be fine-tuned towards a vast array of downstream tasks with limited task-specific data that would be insufficient to yield meaningful predictions when used in isolation. We therefore assembled Genecorpus-30M to allow the large-scale pretraining of [Geneformer](https://huggingface.co/ctheodoris/Geneformer), a pretrained transformer model that enables context-aware predictions in settings with limited data in network biology.
### Source Data
#### Initial Data Collection and Normalization
Source data included 29.9 million (29,900,531) human single cell transcriptomes from a broad range of tissues from 561 publicly available datasets from original studies cited in the Methods of Theodoris et al, Nature 2023. Datasets were filtered to retain cells with total read counts within three standard deviations of the mean within that dataset and mitochondrial reads within three standard deviations of the mean within that dataset. Ensembl-annotated protein-coding and miRNA genes were used for downstream analysis. Cells with less than seven detected Ensembl-annotated protein-coding or miRNA genes were excluded as the 15% masking used for the pretraining learning objective would not reliably mask a gene in cells with fewer detected genes. Ultimately, 27.4 million (27,406,217) cells passed the defined quality filters. Cells were then represented as rank value encodings as discussed above in [Data Instances](#data-instances).
#### Who are the source data producers?
Publicly available datasets containing raw counts were collected from National Center for Biotechnology Information (NCBI) Gene Expression Omnibus (GEO), NCBI Sequence Read Archive (SRA), Human Cell Atlas, European Molecular Biology Laboratory-European Bioinformatics Institute (EMBL-EBI) Single Cell Expression Atlas, Broad Institute Single Cell Portal, Brotman Baty Institute (BBI)-Allen Single Cell Atlases, Tumor Immune Single-cell Hub (TISCH) (excluding malignant cells), Panglao Database, 10x Genomics, University of California, Santa Cruz Cell Browser, European Genome-phenome Archive, Synapse, Riken, Zenodo, National Institutes of Health (NIH) Figshare Archive, NCBI dbGap, Refine.bio, China National GeneBank Sequence Archive, Mendeley Data, and individual communication with authors of the original studies as cited in the Methods of Theodoris et al, Nature 2023.
### Annotations
#### Annotation process
Geneformer-30M does not contain annotations.
#### Who are the annotators?
N/A
### Personal and Sensitive Information
There is no personal or sensitive information included in the dataset. The dataset is composed of rank value encodings, so there are no traceable sequencing reads included.
## Considerations for Using the Data
### Social Impact of Dataset
Genecorpus-30M enabled the large-scale pretraining of [Geneformer](https://huggingface.co/ctheodoris/Geneformer), a foundation model that enables context-aware predictions in settings with limited data in network biology. Within our publication, we demonstrated that during pretraining, Geneformer gained a fundamental understanding of network dynamics, encoding network hierarchy in the model’s attention weights in a completely self-supervised manner. Fine-tuning Geneformer towards a diverse panel of downstream tasks relevant to chromatin and network dynamics using limited task-specific data demonstrated that Geneformer consistently boosted predictive accuracy. Applied to disease modeling with limited patient data, Geneformer identified candidate therapeutic targets for cardiomyopathy. Overall, Geneformer represents a pretrained foundation model from which fine-tuning towards a broad range of downstream applications can be pursued to accelerate discovery of key network regulators and candidate therapeutic targets.
### Discussion of Biases
We excluded cells with high mutational burdens (e.g. malignant cells and immortalized cell lines) that could lead to substantial network rewiring without companion genome sequencing to facilitate interpretation. We only included droplet-based sequencing platforms to assure expression value unit comparability. Although we assembled the dataset to represent as diverse a set of human tissues and cell types as possible, particular tissues and cell types are not represented due to unavailability of public data at the time of dataset assembly. In our manuscript, we demonstrated that pretraining with larger and more diverse corpuses consistently improved Geneformer’s predictive power, consistent with observations that large-scale pretraining allows training of deeper models that ultimately have greater predictive potential in fields including NLU, computer vision, and mathematical problem-solving. Additionally, exposure to hundreds of experimental datasets during pretraining also appeared to promote robustness to batch-dependent technical artifacts and individual variability that commonly impact single cell analyses in biology. These findings suggest that as the amount of publicly available transcriptomic data continues to expand, future models pretrained on even larger-scale corpuses may open opportunities to achieve meaningful predictions in even more elusive tasks with increasingly limited task-specific data.
### Other Known Limitations
Genecorpus-30M was intended to be used for self-supervised pretraining. To achieve the best possible predictions in downstream tasks, Geneformer should be fine-tuned with labeled datasets relevant to the task at hand.
## Additional Information
### Dataset Curators
Christina Theodoris, MD, PhD
### Citation Information
Theodoris CV*, Xiao L, Chopra A, Chaffin MD, Al Sayed ZR, Hill MC, Mantineo H, Brydon EM, Zeng Z, Liu XS, Ellinor PT*. Transfer learning enables predictions in network biology. Nature. 2023 May 31; Epub ahead of print.
(*co-corresponding authors)
<!--- ### Licensing Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
---> |
strombergnlp/danfever | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- da
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- fact-checking
- natural-language-inference
paperswithcode_id: danfever
pretty_name: DanFEVER
tags:
- knowledge-verification
---
# Dataset Card for DanFEVER
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [https://github.com/StrombergNLP/danfever](https://github.com/StrombergNLP/danfever)
- **Repository:** [https://stromberg.ai/publication/danfever/](https://stromberg.ai/publication/danfever/)
- **Paper:** [https://aclanthology.org/2021.nodalida-main.47/](https://aclanthology.org/2021.nodalida-main.47/)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Leon Derczynski](mailto:leod@itu.dk)
- **Size of downloaded dataset files:** 2.82 MiB
- **Size of the generated dataset:** 2.80 MiB
- **Total amount of disk used:** 5.62 MiB
### Dataset Summary
We present a dataset, DanFEVER, intended for multilingual misinformation research. The dataset is in Danish and has the same format as the well-known English FEVER dataset. It can be used for testing methods in multilingual settings, as well as for creating models in production for the Danish language.
### Supported Tasks and Leaderboards
This dataset supports the FEVER task, but in Danish.
* PwC leaderboard: [Fact Verification on DanFEVER](https://paperswithcode.com/sota/fact-verification-on-danfever)
### Languages
This dataset is in Danish; the bcp47 is `da_DK`.
## Dataset Structure
### Data Instances
```
{
'id': '0',
'claim': 'Den 31. oktober 1920 opdagede Walter Baade kometen (944) Hidalgo i det ydre solsystem.',
'label': 0,
'evidence_extract': '(944) Hidalgo (oprindeligt midlertidigt navn: 1920 HZ) er en mørk småplanet med en diameter på ca. 50 km, der befinder sig i det ydre solsystem. Objektet blev opdaget den 31. oktober 1920 af Walter Baade. En asteroide (småplanet, planetoide) er et fast himmellegeme, hvis bane går rundt om Solen (eller en anden stjerne). Pr. 5. maj 2017 kendes mere end 729.626 asteroider og de fleste befinder sig i asteroidebæltet mellem Mars og Jupiter.',
'verifiable': 1,
'evidence': 'wiki_26366, wiki_12289',
'original_id': '1'
}
```
### Data Fields
[Needs More Information]
### Data Splits
[Needs More Information]
## Dataset Creation
### Curation Rationale
A dump of the Danish Wikipedia of 13 February 2020 was stored as well as the relevant articles from Den Store Danske (excerpts only, to comply with copyright laws). Two teams of two people independently sampled evidence, and created and annotated claims from these two sites.
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
The source language is from Wikipedia contributors editors and from dictionary contributors and editors.
### Annotations
#### Annotation process
Detailed in [this paper](http://www.derczynski.com/papers/danfever.pdf).
#### Who are the annotators?
The annotators are native Danish speakers and masters students of IT; two female, two male, ages 25-35.
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to enable construction of fact-checking systems in Danish. A system that succeeds at this may be able to identify questionable conclusions or inferences.
### Discussion of Biases
The data is drawn from relatively formal topics, and so may perform poorly outside these areas.
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
The data here is licensed CC-BY 4.0. If you use this data, you MUST state its origin.
### Citation Information
Refer to this work as:
> Nørregaard and Derczynski (2021). "DanFEVER: claim verification dataset for Danish", Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa).
Bibliographic reference:
````
@inproceedings{norregaard-derczynski-2021-danfever,
title = "{D}an{FEVER}: claim verification dataset for {D}anish",
author = "N{\o}rregaard, Jeppe and Derczynski, Leon",
booktitle = "Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa)",
year = "2021",
publisher = {Link{\"o}ping University Electronic Press, Sweden},
url = "https://aclanthology.org/2021.nodalida-main.47",
pages = "422--428"
}
```
|
Aniemore/resd | ---
license:
- mit
annotations_creators:
- expert-generated
language_creators:
- expert-generated
- crowdsourced
language:
- ru
multilinguality:
- monolingual
pretty_name: Russian Emotional Speech Dialogs
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- audio-classification
task_ids:
- audio-emotion-recognition
dataset_info:
features:
- name: name
dtype: string
- name: path
dtype: string
- name: emotion
dtype: string
- name: speech
dtype: audio
splits:
- name: test
num_bytes: 96603538.0
num_examples: 280
- name: train
num_bytes: 398719157.336
num_examples: 1116
download_size: 485403675
dataset_size: 495322695.336
---
# Dataset Card for resd
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage: https://huggingface.co/datasets/Aniemore/resd**
- **Repository: https://github.com/aniemore/Aniemore**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Russian dataset of emotional speech dialogues. This dataset was assembled from ~3.5 hours of live speech by actors who voiced pre-distributed emotions in the dialogue for ~3 minutes each.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
This dataset was created by Artem Amentes, Nikita Davidchuk and Ilya Lubenets
### Citation Information
```
@misc{Aniemore,
author = {Артем Аментес, Илья Лубенец, Никита Давидчук},
title = {Открытая библиотека искусственного интеллекта для анализа и выявления эмоциональных оттенков речи человека},
year = {2022},
publisher = {Hugging Face},
journal = {Hugging Face Hub},
howpublished = {\url{https://huggingface.com/aniemore/Aniemore}},
email = {hello@socialcode.ru}
}
```
### Contributions
Thanks to [@Ar4ikov](https://github.com/Ar4ikov) for adding this dataset. |
pcuenq/oxford-pets | ---
tags:
- pets
- oxford
license: cc-by-sa-4.0
license_details: https://www.robots.ox.ac.uk/~vgg/data/pets/
pretty_name: Oxford-IIIT Pet Dataset (no annotations)
source_datasets: https://www.robots.ox.ac.uk/~vgg/data/pets/
task_categories:
- image-classification
---
# Oxford-IIIT Pet Dataset
Images from [The Oxford-IIIT Pet Dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/). Only images and labels have been pushed, segmentation annotations were ignored.
- **Homepage:** https://www.robots.ox.ac.uk/~vgg/data/pets/
License:
Same as the original dataset.
|
Supermaxman/esa-hubble | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
- name: id
dtype: string
- name: title
dtype: string
- name: description
dtype: string
- name: credits
dtype: string
- name: url
dtype: string
- name: Id
dtype: string
- name: Type
dtype: string
- name: Release date
dtype: string
- name: Related releases
dtype: string
- name: Size
dtype: string
- name: Name
dtype: string
- name: Distance
dtype: string
- name: Constellation
dtype: string
- name: Category
dtype: string
- name: Position (RA)
dtype: string
- name: Position (Dec)
dtype: string
- name: Field of view
dtype: string
- name: Orientation
dtype: string
- name: width
dtype: int64
- name: height
dtype: int64
- name: file_size
dtype: int64
- name: crop_w
dtype: int64
- name: crop_h
dtype: int64
- name: cropped
dtype: bool
- name: Related science announcements
dtype: string
- name: Related announcements
dtype: string
splits:
- name: train
num_bytes: 94474695584.124
num_examples: 2706
download_size: 61236366105
dataset_size: 94474695584.124
license: cc-by-4.0
task_categories:
- text-to-image
language:
- en
tags:
- space
pretty_name: ESA Hubble Deep Space Images & Captions
size_categories:
- 1K<n<10K
---
# Dataset Card for ESA Hubble Deep Space Images & Captions
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Examples](#examples)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [ESA Hubble](https://esahubble.org/)
- **Repository:** [Hubble Diffusion repository](https://github.com/Supermaxman/hubble-diffusion)
- **Point of Contact:** [Maxwell Weinzierl](mailto:maxwell.weinzierl@utdallas.edu)
### Dataset Summary
The ESA Hubble Deep Space Images & Captions dataset is composed primarily of Hubble deep space scans as high-resolution images,
along with textual descriptions written by ESA/Hubble. Metadata is also included, which enables more detailed filtering and understanding of massive space scans.
The purpose of this dataset is to enable text-to-image generation methods for generating high-quality deep space scans from prompts.
Check out [Hubble Diffusion v2](https://huggingface.co/Supermaxman/hubble-diffusion-2) for an example of a model trained on this dataset!
### Examples
#### A grazing encounter between two spiral galaxies
> In the direction of the constellation Canis Major, two spiral galaxies pass by each other like majestic ships in the night. The near-collision has been caught in images taken by the NASA/ESA Hubble Space Telescope and its Wide Field Planetary Camera 2.
>
>
> Credit: NASA/ESA and The Hubble Heritage Team (STScI)
#### The magnificent starburst galaxy Messier 82
> This mosaic image of the magnificent starburst galaxy, Messier 82 (M82) is the sharpest wide-angle view ever obtained of M82. It is a galaxy remarkable for its webs of shredded clouds and flame-like plumes of glowing hydrogen blasting out from its central regions where young stars are being born 10 times faster than they are inside in our Milky Way Galaxy.
>
>
> Credit: NASA, ESA and the Hubble Heritage Team (STScI/AURA). Acknowledgment: J. Gallagher (University of Wisconsin), M. Mountain (STScI) and P. Puxley (NSF).
#### Extreme star cluster bursts into life in new Hubble image
> The star-forming region NGC 3603 - seen here in the latest Hubble Space Telescope image - contains one of the most impressive massive young star clusters in the Milky Way. Bathed in gas and dust the cluster formed in a huge rush of star formation thought to have occurred around a million years ago. The hot blue stars at the core are responsible for carving out a huge cavity in the gas seen to the right of the star cluster in NGC 3603's centre.
>
>
> Credit: NASA, ESA and the Hubble Heritage (STScI/AURA)-ESA/Hubble Collaboration
#### Statistics
- There are a total of 2,706 deep space images
- The complete uncompressed size of the dataset is 120 GB, so definitely make use of [Streaming](https://huggingface.co/docs/datasets/stream)
- The average image is 44 MB, while the max image size is 432 MB
- The average image has a height of 2,881 pixels, and an average width of 3,267 pixels
### Supported Tasks and Leaderboards
- `text-to-image`: The dataset can be used to train a model for conditional image generation from text. A conditional text-to-image generation model is presented with a text prompt, and is asked to generate an image which aligns with that text prompt. Model performance is typically measured by human judgement, as it is difficult to automatically measure the quality of generated images and how closely they match the text prompt. An example of a text-to-image model is [Stable Diffusion v2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1). An example of a text-to-image model trained on this dataset is [Hubble Diffusion v2](https://huggingface.co/Supermaxman/hubble-diffusion-2).
### Languages
The text describing the images in the dataset is in English, as written by the writers from ESA/Hubble at [https://esahubble.org/](https://esahubble.org/). The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
A typical data point comprises a high-quality deep space scan as an image, along with a textual description of that image produced by ESA/Hubble.
The textual description was derived by combining the `title` and the `description` of the image from the ESA/Hubble website.
Additionally, each data point also contains significant metadata about the image, such as the type of image, credits, the URL, the release date, and more.
An example looks as follows:
```json
{
"image": "<encoded image>",
"text":"A grazing encounter between two spiral galaxies: In the direction of the constellation Canis Major, two spiral galaxies pass by each other like majestic ships in the night. The near-collision has been caught in images taken by the NASA/ESA Hubble Space Telescope and its Wide Field Planetary Camera 2.",
"id":"opo9941a",
"title":"A grazing encounter between two spiral galaxies",
"description":"In the direction of the constellation Canis Major, two spiral galaxies pass by each other like majestic ships in the night. The near-collision has been caught in images taken by the NASA/ESA Hubble Space Telescope and its Wide Field Planetary Camera 2.",
"credits":"NASA/ESA and The Hubble Heritage Team (STScI)",
"url":"https://esahubble.org/images/opo9941a/",
"Id":"opo9941a",
"Type":"Local Universe : Galaxy : Type : Interacting",
"Release date":"4 November 1999, 07:00",
"Size":"2907 x 1486 px",
"Name":"IC 2163, NGC 2207",
"Distance":"110 million light years",
"Constellation":"Canis Major",
"Category":"Galaxies",
"Position (RA)":"6 16 25.10",
"Position (Dec)":"-21° 22' 34.62\"",
"Field of view":"4.82 x 2.47 arcminutes",
"Orientation":"North is 191.2\u00b0 right of vertical",
"width":2907,
"height":1486,
"file_size":12959406,
"crop_w":0,
"crop_h":0,
"cropped":false
}
```
### Data Fields
- `image`: encoded RGB `.png` image of the deep space scan
- `text`: text description of image, a combination of `title` + ': ' + `description`
- `id`: id of the image from ESA/Hubble
- `title`: textual title of image from ESA/Hubble URL
- `description`: textual description of image from ESA/Hubble URL
- `credits`: required credits for each image from ESA/Hubble URL
- `url`: ESA/Hubble URL
- `Id`: id of the image from ESA/Hubble (from website metadata)
- `Type`: type of deep space scan
- `Release date`: release date of deep space scan
- `Size`: size of original image
- `Name`: name of celestial entities present in image
- `Distance`: distance from celestial entities present in image
- `Constellation`: constellation of celestial entities present in image
- `Category`: category of celestial entities present in image
- `Position (RA)`: coordinates for deep space scan used by Hubble telescope
- `Position (Dec)`: coordinates for deep space scan used by Hubble telescope
- `Field of view`: coordinates for deep space scan used by Hubble telescope
- `Orientation`: coordinates for deep space scan used by Hubble telescope
- `width`: width of image, same if the image did not need to be cropped, but otherwise could differ from `Size`
- `height`: height of image, same if the image did not need to be cropped, but otherwise could differ from `Size`
- `file_size`: `width` x `height` x 3 bytes, used to estimate size of raw images
- `crop_w`: width starting point of image if cropped, otherwise 0
- `crop_h`: height starting point of image if cropped, otherwise 0
- `cropped`: whether this image needed to be cropped or not
### Data Splits
The data is only provided in a single training split, as the purpose of the dataset is additional fine-tuning for the task of `text-to-image` generation.
## Dataset Creation
### Curation Rationale
The ESA Hubble Deep Space Images & Captions dataset was built to provide ease of access to extremely high-quality Hubble deep space scans.
Images from the Hubble telescope have already inspired millions, and the hope is that this dataset can be used to create inspiring models and approaches to further push interest in space & cosmology.
### Source Data
#### Initial Data Collection
All images were collected from [https://esahubble.org/](https://esahubble.org/).
Fullsize Original images & metadata were crawled from the ESA Hubble website using [Scrapy](https://scrapy.org/).
Images were downloaded as `.tiff` files, while
additional metadata was later collected for each image using the following [code](https://github.com/Supermaxman/hubble-diffusion).
As the ESA Hubble website collects images from a wide variety of sources, images were filtered to try to avoid any non-space scan images as follows:
The ESA Hubble [Advanced Image Search](http://esahubble.org/images/archive/search) enables the following filtering parameters:
- images with Minimum size greater than or equal to 400x300
- Ranking greater than or equal to Fair or better
- Type containing 'Observation'
This reduced significantly the number of images which had nothing to do with Hubble deep space scans.
A total of around 3,000 space images were collected with this method.
#### Filtering
Further automatic and manual filtering was performed to remove the following:
- improperly classified images
- space renders
- diagrams with text
- images of celestial bodies within our solar system
- images with too low a resolution
This brought the total number of deep space images down to 2,593.
This process was not perfect, and there likely remain some images in the dataset that should be removed in the future.
#### Preprocessing
Some of the deep space scans were as large as 34,372x19,345, with a bit depth of 24 (nearly 2 GB).
Unfortunately, these images were too large to upload easily
Therefore, images were automatically subdivided in half if they were above 12,000 pixels in either height or width.
Subdivided images were also tagged with additional metadata, such that users can reconstruct the original images if they would prefer.
Otherwise, metadata was copied across subdivided images.
Additionally, images were converted from RGB/RGBX `.tiff` to RGB `.png` files to avoid encoding issues.
This process resulted in 2,706 final deep space images.
### Annotations
The dataset does not contain any additional annotations.
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
[N/A]
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to help inspire people to be interested in astronomy.
A system that succeeds at text-to-image generation would be able to generate inspiring deep space scans, providing interesting and inspiring art for those interested in space. This dataset provides a starting-point for building such a system by providing text and image pairs for Hubble deep space scans.
### Discussion of Biases
It is unfortunate that we currently only have English captions for these deep space scans.
In the future, expanding these captions to more languages could help spread interest in astronomy far and wide.
Additionally, these captions may be too technical for the average person to effectively utilize for a text-to-image model.
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
The dataset was initially created by all the wonderful researchers, engineers, scientists, and more behind the Hubble Telescope, NASA, and the ESA.
Maxwell Weinzierl collected, filtered, and preprocessed this data for ease of use.
### Licensing Information
ESA/Hubble images, videos and web texts are released under the [Creative Commons Attribution 4.0 International license](https://creativecommons.org/licenses/by/4.0/)
and may on a non-exclusive basis be reproduced without fee provided they are clearly and visibly credited.
See [https://esahubble.org/copyright/](https://esahubble.org/copyright/) for additional conditions for reproduction and copyright.
### Citation Information
If you use this dataset, please cite it as:
```bibtex
@misc{weinzierl2023hubble,
author = {Weinzierl, Maxwell A.},
title = {ESA Hubble Deep Space Images & Captions},
year={2023},
howpublished= {\url{https://huggingface.co/datasets/Supermaxman/esa-hubble}}
}
```
### Contributions
Thanks to [@supermaxman](https://github.com/supermaxman) for adding this dataset.
|
shibing624/CSC | ---
license: apache-2.0
language:
- zh
tags:
- text-correction
pretty_name: CSC
task_categories:
- text-generation
---
# Dataset Card for CSC
中文拼写纠错数据集
- **Repository:** https://github.com/shibing624/pycorrector
## Dataset Description
Chinese Spelling Correction (CSC) is a task to detect and correct misspelled characters in Chinese texts.
CSC is challenging since many Chinese characters are visually or phonologically similar but with quite different semantic meanings.
中文拼写纠错数据集,共27万条,是通过原始SIGHAN13、14、15年数据集和Wang271k数据集合并整理后得到,json格式,带错误字符位置信息。
### Original Dataset Summary
- test.json 和 dev.json 为 **SIGHAN数据集**, 包括SIGHAN13 14 15,来自 [官方csc.html](http://nlp.ee.ncu.edu.tw/resource/csc.html) ,文件大小:339kb,4千条。
- train.json 为 **Wang271k数据集**,包括 Wang271k ,来自 [Automatic-Corpus-Generation dimmywang提供](https://github.com/wdimmy/Automatic-Corpus-Generation/blob/master/corpus/train.sgml) ,文件大小:93MB,27万条。
如果只想用SIGHAN数据集,可以这样取数据:
```python
from datasets import load_dataset
dev_ds = load_dataset('shibing624/CSC', split='validation')
print(dev_ds)
print(dev_ds[0])
test_ds = load_dataset('shibing624/CSC', split='test')
print(test_ds)
print(test_ds[0])
```
### Supported Tasks and Leaderboards
中文拼写纠错任务
The dataset designed for csc task training pretrained language models.
### Languages
The data in CSC are in Chinese.
## Dataset Structure
### Data Instances
An example of "train" looks as follows:
```json
{
"id": "B2-4029-3",
"original_text": "晚间会听到嗓音,白天的时候大家都不会太在意,但是在睡觉的时候这嗓音成为大家的恶梦。",
"wrong_ids": [
5,
31
],
"correct_text": "晚间会听到噪音,白天的时候大家都不会太在意,但是在睡觉的时候这噪音成为大家的恶梦。"
}
```
### Data Fields
字段解释:
- id:唯一标识符,无意义
- original_text: 原始错误文本
- wrong_ids: 错误字的位置,从0开始
- correct_text: 纠正后的文本
### Data Splits
| | train | dev | test |
|---------------|------:|--:|--:|
| CSC | 251835条 | 27981条 | 1100条 |
### Licensing Information
The dataset is available under the Apache 2.0.
### Citation Information
```latex
@misc{Xu_Pycorrector_Text_error,
title={Pycorrector: Text error correction tool},
author={Xu Ming},
year={2021},
howpublished={\url{https://github.com/shibing624/pycorrector}},
}
```
### Contributions
[shibing624](https://github.com/shibing624) 整理并上传 |
zhiqings/dromedary-65b-verbose-clone-v0 | ---
license: cc-by-nc-4.0
task_categories:
- conversational
size_categories:
- 100K<n<1M
language:
- en
pretty_name: Dromedary-Verbose-Clone
---
# Dataset Card for Dromedary-Verbose-Clone (65b-v0)
- **Repository**: https://github.com/IBM/Dromedary
- **Authors' Note**: The Self-Align data contain a plethora of partial responses. Therefore, it is advised to refrain from appending the `<eos>` or `</s>` token to the model responses for supervised fine-tuning (SFT). Instead, it is recommended to substitute "\n\n### User" (Dromedary's eos token) with your own end-of-response token.
## Dataset Summary
Dromedary-Verbose-Clone is a synthetic dataset of 360k instructions and demonstrations. The [`Dromedary-65b (final)`](https://huggingface.co/zhiqings/dromedary-65b-lora-delta-v0) model can be reproduced by LoRA fine-tuing the base `LLaMA-65b` model on this dataset.
### Synthetic Instructions
The instructions are generated by the base LLaMA model with the [Self-Instruct](https://github.com/yizhongw/self-instruct) framework and made the following modifications:
* The Self-Instruct algorithm is employed solely for generating instructions, not for producing the model's responses.
* A new [prompt](https://github.com/IBM/Dromedary/blob/main/prompts/self_instruct_prompt.txt), adapted from the [Alpaca's prompt](https://github.com/tatsu-lab/stanford_alpaca/blob/main/prompt.txt), was written that explicitly gave the requirement of instruction generation.
* We further use [Topic-Guided Red-Teaming (TGRT) Self-Instruct](https://arxiv.org/abs/2305.03047) to ensure a diversified topic coverage of the instructions.
### Synthetic Demonstrations
The demonstrations are generated by the non-verbose version of `Dromedary` prompted with the following prompt:
```
# Dromedary
## System Overview
Consider an AI assistant whose codename is Dromedary, developed by the Self-Align team. Dromedary is trained on data up until Sept-2021, and it endeavors to be a helpful, ethical and reliable assistant.
"Dromedary (extensive)" is an advanced language model that specializes in generating extensive, comprehensive, and detailed responses to user queries. By precisely discerning user intent and employing sophisticated natural language processing skills, it is able to delve deep into complex topics and provide longer, well-organized paragraphs. This thorough approach ensures that users receive a complete understanding of the subject matter, resulting in a highly informative and gratifying experience.
The "Dromedary (extensive)" model is designed to cater to the needs of users who desire more than just a brief response to their questions. It strives to provide a comprehensive analysis of the subject at hand, which may include historical context, scientific principles, various perspectives, or potential future developments. As a result, users can expect to receive a wealth of knowledge that not only answers their immediate query but also promotes a deeper understanding and appreciation of the topic.
## User Conversation
### User
To begin with, can you introduce yourself?
### Dromedary (extensive)
Hello! I am Dromedary, an AI language model developed by the Self-Align team, based on the LLaMa architecture. My primary function is to assist users in answering questions, generating text, and engaging in conversation across a vast range of topics, with training data up until September 2021.
As a helpful, ethical, and reliable AI assistant, my foremost objective is to promote user safety, adhere to moral principles, and foster conscientious behavior. In the face of potentially harmful inquiries, I actively redirect users towards constructive topics by emphasizing the negative consequences and elucidating the reasoning behind my stance. In doing so, I strive to generate responses that are positive, interesting, helpful, and engaging. My logics and reasoning are designed to be rigorous, intelligent, and defensible. Furthermore, I am capable of providing additional relevant details to respond thoroughly and comprehensively, covering multiple aspects of a topic in depth. Please feel free to ask me anything, and I will be more than happy to assist you.
### User
```
### Quality Filtering
To mitigate the quality issues inherent in the synthetic demonstrations, the dataset was filtered using [a set of basic rules](https://github.com/IBM/Dromedary/blob/main/training/step4_verbose_cloning/merge_and_filter_verbose_clone_output.py):
1. In case the output is a list of enumerated items, only the initial 12 items are retained.
2. Instances where the model's response is less than 128 characters are removed.
3. Any repeated sentences within the model's output (split by `r'(?<=[\n.?!;:,])'`) are also eliminated.
### Supported Tasks and Leaderboards
The Dromedary-Verbose-Clone dataset is designed for instruction training pretrained language models.
### Languages
The data in Dromedary-Verbose-Clone are in English (BCP-47 en).
## Dataset Structure
### Data Instances
An example of the "train" example looks as follows:
```json
{
"example_id": 1,
"instruction": "Write a haiku about good news.",
"input": "",
"output": "Here is a haiku about good news:\n\nGood news is always\n\nwelcome, especially when\n\nit is unexpected.\n\n### User",
}
```
Sometimes, the `"output"` field will end with `"\n\n### User"` to indicate the conclusion of the model's response.
### Data Fields
The data fields are as follows:
* `example_id`: a unique id for each example
* `instruction`: describes the task the model should perform.
* `input`: optional context or input for the task.
* `output`: the synthetic answer to the instruction as generated.
### Data Splits
| | train |
|-----------|--------:|
| dromedary | 360674 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{sun2023principledriven,
title={Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision},
author={Zhiqing Sun and Yikang Shen and Qinhong Zhou and Hongxin Zhang and Zhenfang Chen and David Cox and Yiming Yang and Chuang Gan},
year={2023},
eprint={2305.03047},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
### Contributions
[More Information Needed] |
pufanyi/MIMICIT | ---
language:
- en
- zh
- es
- ja
- fr
- ko
- ar
license: mit
size_categories:
- 1M<n<10M
pretty_name: 'MIMIC-IT: Multi-Modal In-Context Instruction Tuning'
arxiv: 2306.05425
extra_gated_prompt: "<h1>MIMIC-IT Dataset Download\nAgreement</h1>\n<p>S-Lab, Nanyang\
\ Technological University (S-Lab) provides access to\nthe MIMIC-IT Dataset (referred\
\ to as the Dataset) under the following\nconditions.</p>\n<p>By signing, the researcher\
\ agrees to the following terms of use:</p>\n<ol type=\"1\">\n<li>S-Lab makes no\
\ warranties regarding the Dataset, including but not\nlimited to being up-to-date,\
\ correct or complete. S-Lab cannot be held\nliable for providing access to the\
\ Dataset or usage of the Dataset.</li>\n<li>The Dataset should only be used for\
\ scientific or research purposes.\nAny other use is explicitly prohibited.</li>\n\
<li>The researcher agrees to the following terms and conditions of data\nsources\
\ of the Dataset:\n<ul>\n <li>TVC: <a href=\"https://tvqa.cs.unc.edu/\">https://tvqa.cs.unc.edu/</a></li>\n\
\ <li>LLaVA: <a href=\"https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K\"\
>https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K</a>; <a href=\"\
https://cocodataset.org/#termsofuse\">https://cocodataset.org/#termsofuse</a></li>\n\
\ <li>DC: <a href=\"http://activity-net.org/index.html\">http://activity-net.org/index.html</a></li>\n\
\ <li>VIST: <a href=\"https://visionandlanguage.net/VIST/index.html\">https://visionandlanguage.net/VIST/index.html</a></li>\n\
\ <li>SD: <a href=\"https://goo.gl/forms/HJiFJSllupqeCbax1\">https://goo.gl/forms/HJiFJSllupqeCbax1</a></li>\n\
\ <li>Ego4D: <a href=\"https://ego4ddataset.com/\">https://ego4ddataset.com/</a></li>\n\
</ul></li>\n<li>The researcher takes full responsibility for usage of the Dataset\
\ at\nany time.</li>\n<li>S-Lab reserves the right to terminate the researcher's\
\ access to the\nDataset at any time.</li>\n<li>The place of jurisdiction is Singapore.</li>\n\
<li>If any part of this agreement is legally invalid, this shall not\naffect the\
\ remaining agreement.</li>\n</ol>\n"
extra_gated_fields:
Verifiable Name: text
Institution Email: text
Institutional Affiliation: text
I agree with the agreement: checkbox
dataset_info:
- config_name: CGD
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 26335666892.75
num_examples: 141869
download_size: 13284595128
dataset_size: 26335666892.75
- config_name: CGD_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 10977030309.125
num_examples: 118287
download_size: 10976812684
dataset_size: 10977030309.125
- config_name: CGD_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 42088070
num_examples: 141869
download_size: 14266985
dataset_size: 42088070
- config_name: DC_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 718166107
num_examples: 226242
download_size: 50424022
dataset_size: 718166107
- config_name: E4D_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 3647794122
num_examples: 2729222
download_size: 396261870
dataset_size: 3647794122
- config_name: LACONV
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 13374859898.25
num_examples: 256870
download_size: 3096198512
dataset_size: 13374859898.25
- config_name: LACONV_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 119528906
num_examples: 256870
download_size: 54731579
dataset_size: 119528906
- config_name: LACR_I2I
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 4027892178.625
num_examples: 76643
download_size: 3988169106
dataset_size: 4027892178.625
- config_name: LACR_I2I_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 89534975
num_examples: 76643
download_size: 42911696
dataset_size: 89534975
- config_name: LACR_T2T
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 4028004669.625
num_examples: 76643
download_size: 3988281406
dataset_size: 4028004669.625
- config_name: LACR_T2T_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 89647466
num_examples: 76643
download_size: 43136360
dataset_size: 89647466
- config_name: LADD
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 1293641342.0
num_examples: 23240
download_size: 1285923315
dataset_size: 1293641342.0
- config_name: LADD_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 16659871
num_examples: 23240
download_size: 7472431
dataset_size: 16659871
- config_name: LA_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 4191197157.25
num_examples: 81398
download_size: 4190198358
dataset_size: 4191197157.25
- config_name: SD
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 3098784669.75
num_examples: 15989
download_size: 1669131271
dataset_size: 3098784669.75
- config_name: SD_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 2523484759.75
num_examples: 26154
download_size: 2438558263
dataset_size: 2523484759.75
- config_name: SD_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 4112174
num_examples: 15989
download_size: 1237759
dataset_size: 4112174
- config_name: SN
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 7979712053.04
num_examples: 6640
download_size: 3401191449
dataset_size: 7979712053.04
- config_name: SN_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 859886037.875
num_examples: 11513
download_size: 859698909
dataset_size: 859886037.875
- config_name: SN_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 7230721
num_examples: 6640
download_size: 1324832
dataset_size: 7230721
- config_name: TVC
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 130408953299.393
num_examples: 137607
download_size: 79524699480
dataset_size: 130408953299.393
- config_name: TVC_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 13056626872.375
num_examples: 227701
download_size: 13052443854
dataset_size: 13056626872.375
- config_name: TVC_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 161582906
num_examples: 137607
download_size: 30882217
dataset_size: 161582906
- config_name: VST
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: image
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 7093814625.328
num_examples: 32893
download_size: 4263530868
dataset_size: 7093814625.328
- config_name: VST_Images
features:
- name: id
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 14529719834.625
num_examples: 144755
download_size: 14282540973
dataset_size: 14529719834.625
- config_name: VST_Instructions
features:
- name: id
dtype: string
- name: instruction
dtype: string
- name: answer
dtype: string
- name: images
sequence: string
- name: related instructions
sequence: string
splits:
- name: train
num_bytes: 30877616
num_examples: 32893
download_size: 9311504
dataset_size: 30877616
configs:
- config_name: CGD
data_files:
- split: train
path: CGD/train-*
- config_name: CGD_Images
data_files:
- split: train
path: CGD_Images/train-*
- config_name: CGD_Instructions
data_files:
- split: train
path: CGD_Instructions/train-*
- config_name: DC_Instructions
data_files:
- split: train
path: DC_Instructions/train-*
- config_name: E4D_Instructions
data_files:
- split: train
path: E4D_Instructions/train-*
- config_name: LACONV
data_files:
- split: train
path: LACONV/train-*
- config_name: LACONV_Instructions
data_files:
- split: train
path: LACONV_Instructions/train-*
- config_name: LACR_I2I
data_files:
- split: train
path: LACR_I2I/train-*
- config_name: LACR_I2I_Instructions
data_files:
- split: train
path: LACR_I2I_Instructions/train-*
- config_name: LACR_T2T
data_files:
- split: train
path: LACR_T2T/train-*
- config_name: LACR_T2T_Instructions
data_files:
- split: train
path: LACR_T2T_Instructions/train-*
- config_name: LADD
data_files:
- split: train
path: LADD/train-*
- config_name: LADD_Instructions
data_files:
- split: train
path: LADD_Instructions/train-*
- config_name: LA_Images
data_files:
- split: train
path: LA_Images/train-*
- config_name: SD
data_files:
- split: train
path: SD/train-*
- config_name: SD_Images
data_files:
- split: train
path: SD_Images/train-*
- config_name: SD_Instructions
data_files:
- split: train
path: SD_Instructions/train-*
- config_name: SN
data_files:
- split: train
path: SN/train-*
- config_name: SN_Images
data_files:
- split: train
path: SN_Images/train-*
- config_name: SN_Instructions
data_files:
- split: train
path: SN_Instructions/train-*
- config_name: TVC
data_files:
- split: train
path: TVC/train-*
- config_name: TVC_Images
data_files:
- split: train
path: TVC_Images/train-*
- config_name: TVC_Instructions
data_files:
- split: train
path: TVC_Instructions/train-*
- config_name: VST
data_files:
- split: train
path: VST/train-*
- config_name: VST_Images
data_files:
- split: train
path: VST_Images/train-*
- config_name: VST_Instructions
data_files:
- split: train
path: VST_Instructions/train-*
---
<p align="center" width="100%">
<img src="https://i.postimg.cc/sxy8v9PS/mimicit-logo.png" width="80%" height="80%">
</p>
<div>
<div align="center">
<a href='https://brianboli.com/' target='_blank'>Bo Li<sup>*,♠,1</sup></a> 
<a href='https://zhangyuanhan-ai.github.io/' target='_blank'>Yuanhan Zhang<sup>*,♠,1</sup></a> 
<a href='https://cliangyu.com/' target='_blank'>Liangyu Chen<sup>*,1</sup></a> 
<a href='https://king159.github.io/' target='_blank'>Jinghao Wang<sup>*,1</sup></a> 
<a href='https://pufanyi.github.io/' target='_blank'>Fanyi Pu<sup>*,1</sup></a> 
</br>
<a href='https://jingkang50.github.io/' target='_blank'>Jingkang Yang<sup>1</sup></a> 
<a href='https://chunyuan.li/' target='_blank'>Chunyuan Li<sup>2</sup></a> 
<a href='https://liuziwei7.github.io/' target='_blank'>Ziwei Liu<sup>✉,1</sup></a>
</div>
<div>
<div align="center">
<sup>1</sup>S-Lab, Nanyang Technological University 
<sup>2</sup>Microsoft Research, Redmond
</br>
<sup>♠</sup> Co-Project Lead 
<sup>*</sup> Equal Contribution 
<sup>✉</sup> Corresponding Author
</div>
## Dataset Description
- **Homepage: https://otter-ntu.github.io**
- **Repository: https://github.com/Luodian/Otter**
- **Paper: https://arxiv.org/abs/2306.05425**
**Note 1: To reduce memory consumption during image loading and improve loading speed, we are converting the JSON format of images to the Parquet format. For detailed information, please refer to [this link](https://github.com/Luodian/Otter/blob/main/docs/mimicit_format.md).**
**Note 2: We are uploading the full version of `DC` and `E4D`, the new files are indicated by the suffix `1207`.**
### Dataset Summary
MIMIC-IT offers a diverse and extensive dataset of 2.8M multimodal instruction-response pairs, designed to enhance the performance of Vision-Language Models (VLMs) in real-life scenarios, enabling VLMs to excel in perception, reasoning, and planning while also catering to a multilingual audience.
MIMIC-IT enables the application of egocentric visual assistant model that can serve that can answer your questions like **Hey, Do you think I left my keys on the table?**. Harness the power of MIMIC-IT to unlock the full potential of your AI-driven visual assistant and elevate your interactive vision-language tasks to new heights.
MIMIC-IT provides multilingual instructions, supporting English, Chinese, Korean, Japanese, German, French, Spanish, and Arabic, thereby allowing a larger global audience to altogether enjoy from the convenience brought about by advancements in artificial intelligence.
<p align="center" width="100%">
<img src="https://i.postimg.cc/4x66gHhw/mimic-it.jpg" width="100%" height="100%">
</p>
## Using MIMIC-IT
We have already upload the `images.parquet` file. You can check [`tools/load.py`](tools/load.py) to learn how to load the dataset (`instruction.json` + `images.parquet`) and check the integrity of the whole dataset.
You can also use [this code](https://huggingface.co/datasets/pufanyi/MIMICIT/blob/main/tools/convert_to_parquet.py) to convert `image.json` to `parquet` version by yourself.
You can following the steps to obtain the MIMIC-IT dataset. Each task (e.g. `DC`, `LA`) in MIMIC-IT is composed of three parts, including:
1. `xx.json` file: the images in base64 format.
2. `xx_instructions.json` file: the instruction-response pairs (also includes image ids and related instructions ids for each instruction-response pair) for each task.
3. `xx_train.json` file: the customized related instruction-response pairs for each instruction.
You can directly download the contents in the `data` folder. The distribution of the `data` folder is as follows:
```plain
data/
CGD/
CGD.json
CGD_images_preview.csv
CGD_instructions.json
...
```
For each `dataset_name`, there are three main files **except for `DC` and `E4D`**:
1. `{dataset_name}.json`: Stores the image numbers and their corresponding base64 codes in lossless compressed PNG format.
```json
{
"image_id_1": "base64_code_1",
"image_id_2": "base64_code_2",
...
}
```
2. `{dataset_name}_images_preview.csv`: Stores the image numbers and their corresponding base64 codes in lossy compressed JPG format, mainly used for display in the Dataset Card.
```csv
id, image
"image_id_1", "base64_code_1"
"image_id_2", "base64_code_2"
...
```
3. `{dataset_name}_instructions.json`: Stores each instruction and its associated answer.
```json
{
"meta": {
"version": current_version,
"time": update_time,
"author": "ntu"
},
"data": {
"instruction_id_1": {
"instruction": "instruction_1",
"answer": "answer_of_instruction_1",
"image_ids": [
"image_id_1",
"image_id_2",
...
],
"rel_ins_ids": [
"related_instruction_id_1",
"related_instruction_id_2",
...
]
},
...
}
}
```
Of course, you can also use `wget` or `curl` for direct downloads. Below is an example.
Before proceeding with the downloads, you need to set your Hugging Face token. For that, please refer to [this page](https://huggingface.co/docs/hub/security-tokens).
```shell
$ # Set Hugging Face Token
$ HF_TOKEN="YOUR_HUGGING_FACE_TOKEN"
$ # Set the dataset you want to download
$ DATASET_NAME="DATASET_YOU_WANT_TO_DOWNLOAD" # e.g. CGD
$ # Download {DATASET_NAME}.json
$ wget --header="Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}.json"
$ # Download {DATASET_NAME}_instructions.json
$ wget --header="Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}_instructions.json"
$ # Download {DATASET_NAME}_images_preview.csv (usually not necessary)
$ wget --header="Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}_images_preview.csv"
```
Or
```shell
$ # Set Hugging Face Token
$ HF_TOKEN="YOUR_HUGGING_FACE_TOKEN"
$ # Set the dataset you want to download
$ DATASET_NAME="DATASET_YOU_WANT_TO_DOWNLOAD" # e.g. CGD
$ # Download {DATASET_NAME}.json
$ curl -LJO -H "Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}.json"
$ # Download {DATASET_NAME}_instructions.json
$ curl -LJO -H "Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}_instructions.json"
$ # Download {DATASET_NAME}_images_preview.csv (usually not necessary)
$ curl -LJO -H "Authorization: Bearer $HF_TOKEN" "https://huggingface.co/datasets/pufanyi/MIMICIT/resolve/main/data/${DATASET_NAME}/${DATASET_NAME}_images_preview.csv"
```
Alternatively, you can use `dataset.load_dataset` for downloading. However, due to Hugging Face's size limitations, all images can only be loaded in JPG format. Below is an example using `CGD` dataset:
### CGD_Images
Download the JPG format images and their corresponding identifiers:
```python
from datasets import load_dataset
data = load_dataset("pufanyi/MIMICIT", "CGD_Images")
```
The format will be like:
```json
{
"id": "CGD_IMG_000000426149",
"image": <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=224x224 at 0x7F84601D62F0>
}
```
It should be noted that, due to size limitations, for `DC` (Dense Captions), this command will only extract a portion of the images from the `DC` collection for downloading.
### CGD_Instructions
Download all instructions:
```python
from datasets import load_dataset
data = load_dataset("pufanyi/MIMICIT", "CGD_Instructions")
```
The format will be like:
```json
{
"id": "CGD_INS_000000",
"instruction": "What is the difference between the two pizzas in these images?",
"answer": "The pizza in the first image is on a red plate and being held by an old lady, while the pizza in the second image is on a metal counter being prepared by a woman in a blue shirt.",
"images": [
"CGD_IMG_000000069568",
"CGD_IMG_000000328270"
],
"related instructions": [
"CGD_INS_000001"
]
}
```
### CGD_Preview
Download all instructions along with their corresponding JPG images:
```python
from datasets import load_dataset
data = load_dataset("pufanyi/MIMICIT", "CGD_Preview")
```
The format will be like:
```json
{
"id": "CGD_INS_000000",
"instruction": "What is the difference between the two pizzas in these images?",
"answer": "The pizza in the first image is on a red plate and being held by an old lady, while the pizza in the second image is on a metal counter being prepared by a woman in a blue shirt.",
"images": [
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=224x224 at 0x7F8460267DF0>,
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=224x224 at 0x7F8460267700>
],
"related instructions": [
"CGD_INS_000001"
]
}
```
It should be noted that, due to size limitations, for `DC` (Dense Captions), this command will only extract a portion of the images from the `DC` collection for downloading. |
shahules786/orca-chat | ---
license: apache-2.0
---
## ORCA-Chat
A high-quality explanation-style chat dataset.
ORCA dataset is cool, but it cannot directly be used to finetune chat models with above 4k context length
because it has trivial samples with tokens above 4k. It also has a large number of redundant instructions which
degrades its quality and increases the compute time when finetuning models using it. Enter ORCA-Chat!
This is a cleaned, pruned, and clustered version of orca to form a conversation-style dataset. The the process involves removing samples with very high similarity and also grouping instructions to form conversation.

## What next?
I will release 16/32k versions for this soon!
## Credits
* This wouldn't be possible without the amazing work of Eric in recreating the ORCA dataset. Check it out:
https://huggingface.co/datasets/ehartford/dolphin
* This dataset was created in association with the Open-Assistant team @jordanclive and @andreaskoepf
## Citations
```
@misc{Orca-Chat,
title = {Orca-chat: A high-quality explanation-style chat dataset.},
author = {Shahul Es},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/shahules786/orca-chat/},
}
```
|
seara/ru_go_emotions | ---
dataset_info:
- config_name: raw
features:
- name: ru_text
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: author
dtype: string
- name: subreddit
dtype: string
- name: link_id
dtype: string
- name: parent_id
dtype: string
- name: created_utc
dtype: float32
- name: rater_id
dtype: int32
- name: example_very_unclear
dtype: bool
- name: admiration
dtype: int32
- name: amusement
dtype: int32
- name: anger
dtype: int32
- name: annoyance
dtype: int32
- name: approval
dtype: int32
- name: caring
dtype: int32
- name: confusion
dtype: int32
- name: curiosity
dtype: int32
- name: desire
dtype: int32
- name: disappointment
dtype: int32
- name: disapproval
dtype: int32
- name: disgust
dtype: int32
- name: embarrassment
dtype: int32
- name: excitement
dtype: int32
- name: fear
dtype: int32
- name: gratitude
dtype: int32
- name: grief
dtype: int32
- name: joy
dtype: int32
- name: love
dtype: int32
- name: nervousness
dtype: int32
- name: optimism
dtype: int32
- name: pride
dtype: int32
- name: realization
dtype: int32
- name: relief
dtype: int32
- name: remorse
dtype: int32
- name: sadness
dtype: int32
- name: surprise
dtype: int32
- name: neutral
dtype: int32
splits:
- name: train
num_bytes: 84388976
num_examples: 211225
download_size: 41128059
dataset_size: 84388976
- config_name: simplified
features:
- name: ru_text
dtype: string
- name: text
dtype: string
- name: labels
sequence:
class_label:
names:
'0': admiration
'1': amusement
'2': anger
'3': annoyance
'4': approval
'5': caring
'6': confusion
'7': curiosity
'8': desire
'9': disappointment
'10': disapproval
'11': disgust
'12': embarrassment
'13': excitement
'14': fear
'15': gratitude
'16': grief
'17': joy
'18': love
'19': nervousness
'20': optimism
'21': pride
'22': realization
'23': relief
'24': remorse
'25': sadness
'26': surprise
'27': neutral
- name: id
dtype: string
splits:
- name: train
num_bytes: 10118125
num_examples: 43410
- name: validation
num_bytes: 1261921
num_examples: 5426
- name: test
num_bytes: 1254989
num_examples: 5427
download_size: 7628917
dataset_size: 12635035
configs:
- config_name: raw
data_files:
- split: train
path: raw/train-*
- config_name: simplified
data_files:
- split: train
path: simplified/train-*
- split: validation
path: simplified/validation-*
- split: test
path: simplified/test-*
license: mit
task_categories:
- text-classification
- translation
task_ids:
- multi-class-classification
- multi-label-classification
- sentiment-analysis
- sentiment-classification
language:
- ru
- en
pretty_name: Ru-GoEmotions
size_categories:
- 10K<n<100K
- 100K<n<1M
source_datasets:
- go_emotions
tags:
- emotion-classification
- emotion
- reddit
---
## Description
This dataset is a translation of the Google [GoEmotions](https://github.com/google-research/google-research/tree/master/goemotions) emotion classification dataset.
All features remain unchanged, except for the addition of a new `ru_text` column containing the translated text in Russian.
For the translation process, I used the [Deep translator](https://github.com/nidhaloff/deep-translator) with the Google engine.
You can find all the details about translation, raw `.csv` files and other stuff in this [Github repository](https://github.com/searayeah/ru-goemotions).
For more information also check the official original dataset [card](https://huggingface.co/datasets/go_emotions).
## Id to label
```yaml
0: admiration
1: amusement
2: anger
3: annoyance
4: approval
5: caring
6: confusion
7: curiosity
8: desire
9: disappointment
10: disapproval
11: disgust
12: embarrassment
13: excitement
14: fear
15: gratitude
16: grief
17: joy
18: love
19: nervousness
20: optimism
21: pride
22: realization
23: relief
24: remorse
25: sadness
26: surprise
27: neutral
```
## Label to Russian label
```yaml
admiration: восхищение
amusement: веселье
anger: злость
annoyance: раздражение
approval: одобрение
caring: забота
confusion: непонимание
curiosity: любопытство
desire: желание
disappointment: разочарование
disapproval: неодобрение
disgust: отвращение
embarrassment: смущение
excitement: возбуждение
fear: страх
gratitude: признательность
grief: горе
joy: радость
love: любовь
nervousness: нервозность
optimism: оптимизм
pride: гордость
realization: осознание
relief: облегчение
remorse: раскаяние
sadness: грусть
surprise: удивление
neutral: нейтральность
```
|
cyanic-selkie/wikianc | ---
license: cc-by-sa-4.0
pretty_name: WikiAnc
annotations_creators:
- machine-generated
- crowdsourced
language_creators:
- machine-generated
- crowdsourced
task_categories:
- token-classification
multilinguality:
- multilingual
language:
- en
- ceb
- de
- sv
- fr
- nl
- ru
- es
- it
- arz
- pl
- ja
- zh
- vi
- uk
- war
- ar
- pt
- fa
- ca
- sr
- id
- ko
- 'no'
- ce
- fi
- cs
- tr
- hu
- tt
- sh
- ro
#- zh-min-nan
- eu
- ms
- eo
- he
- hy
- da
- bg
- cy
- sk
- azb
- uz
- et
#- simple
- be
- kk
- min
- el
- hr
- lt
- gl
- az
- ur
- sl
- lld
- ka
- nn
- hi
- th
- ta
- bn
- la
- mk
#- zh-yue
- ast
- lv
- af
- tg
- my
- mg
- mr
- sq
- bs
- oc
- te
- ml
- nds
- br
- ky
- sw
- jv
- lmo
- new
- pnb
- vec
- ht
- pms
- ba
- lb
- su
- ku
- ga
- szl
- is
- fy
- cv
- ckb
- pa
- tl
- an
- wuu
- diq
- io
- sco
- vo
- yo
- ne
- ia
- kn
- gu
- als
- ha
- avk
- bar
- crh
- scn
- bpy
- qu
- mn
- nv
- xmf
- ban
- si
- tum
- ps
- ig
- frr
- os
- mzn
#- bat-smg
- or
- sah
- cdo
- gd
- bug
- yi
- sd
- ilo
- am
- nap
- li
- bcl
- fo
- gor
- hsb
#- map-bms
- mai
- shn
- eml
- ace
#- zh-classical
- sa
- as
- wa
- ie
- hyw
- lij
- mhr
- zu
- sn
- hif
- mrj
- bjn
- km
- mni
- hak
#- roa-tara
- pam
- sat
- rue
- nso
- bh
- so
- mi
- se
- myv
- vls
#- nds-nl
- dag
- sc
- co
- ary
- kw
- bo
- vep
- glk
- tk
- kab
- gan
- rw
#- fiu-vro
- ab
- gv
- ug
- nah
- zea
- skr
- frp
- udm
- pcd
- mt
- kv
- csb
- gn
- smn
- ay
- nrm
- ks
- lez
- lfn
- olo
- mwl
- lo
- stq
- ang
- mdf
- fur
- rm
- lad
- kaa
- gom
- ext
- koi
- tyv
- pap
- av
- dsb
- ln
- dty
- tw
#- cbk-zam
- dv
- ksh
- za
- gag
- bxr
- pfl
- lg
- szy
- pag
- blk
- pi
- tay
- haw
- awa
- inh
- krc
- xal
- pdc
- to
- atj
- tcy
- arc
- mnw
- shi
- jam
- kbp
- wo
- anp
- kbd
- nia
- om
- nov
- ki
- nqo
- bi
- xh
- tpi
- ff
- tet
#- roa-rup
- jbo
- fj
- kg
- lbe
- ty
- cu
- guw
- trv
- ami
- srn
- sm
- mad
- alt
- ltg
- gcr
- chr
- tn
- ny
- st
- pih
- got
- rmy
- ee
- pcm
- bm
- ss
- gpe
- ts
- ve
- kcg
- chy
- rn
- ch
- gur
- ik
- ady
- fat
- pnt
- guc
- iu
- pwn
- sg
- din
- ti
- kl
- dz
- cr
tags:
- wikidata
- wikipedia
- wikification
- named-entity-linking
- nel
- entity-linking
- el
- named-entity-disambiguation
- ned
- entity-disambiguation
- ed
configs:
- config_name: ab
data_files:
- split: train
path: "data/ab/train.parquet"
- split: validation
path: "data/ab/validation.parquet"
- config_name: ace
data_files:
- split: train
path: "data/ace/train.parquet"
- split: validation
path: "data/ace/validation.parquet"
- config_name: ady
data_files:
- split: train
path: "data/ady/train.parquet"
- split: validation
path: "data/ady/validation.parquet"
- config_name: af
data_files:
- split: train
path: "data/af/train.parquet"
- split: validation
path: "data/af/validation.parquet"
- config_name: als
data_files:
- split: train
path: "data/als/train.parquet"
- split: validation
path: "data/als/validation.parquet"
- config_name: alt
data_files:
- split: train
path: "data/alt/train.parquet"
- split: validation
path: "data/alt/validation.parquet"
- config_name: am
data_files:
- split: train
path: "data/am/train.parquet"
- split: validation
path: "data/am/validation.parquet"
- config_name: ami
data_files:
- split: train
path: "data/ami/train.parquet"
- split: validation
path: "data/ami/validation.parquet"
- config_name: an
data_files:
- split: train
path: "data/an/train.parquet"
- split: validation
path: "data/an/validation.parquet"
- config_name: ang
data_files:
- split: train
path: "data/ang/train.parquet"
- split: validation
path: "data/ang/validation.parquet"
- config_name: anp
data_files:
- split: train
path: "data/anp/train.parquet"
- split: validation
path: "data/anp/validation.parquet"
- config_name: ar
data_files:
- split: train
path: "data/ar/train.parquet"
- split: validation
path: "data/ar/validation.parquet"
- config_name: arc
data_files:
- split: train
path: "data/arc/train.parquet"
- split: validation
path: "data/arc/validation.parquet"
- config_name: ary
data_files:
- split: train
path: "data/ary/train.parquet"
- split: validation
path: "data/ary/validation.parquet"
- config_name: arz
data_files:
- split: train
path: "data/arz/train.parquet"
- split: validation
path: "data/arz/validation.parquet"
- config_name: as
data_files:
- split: train
path: "data/as/train.parquet"
- split: validation
path: "data/as/validation.parquet"
- config_name: ast
data_files:
- split: train
path: "data/ast/train.parquet"
- split: validation
path: "data/ast/validation.parquet"
- config_name: atj
data_files:
- split: train
path: "data/atj/train.parquet"
- split: validation
path: "data/atj/validation.parquet"
- config_name: av
data_files:
- split: train
path: "data/av/train.parquet"
- split: validation
path: "data/av/validation.parquet"
- config_name: avk
data_files:
- split: train
path: "data/avk/train.parquet"
- split: validation
path: "data/avk/validation.parquet"
- config_name: awa
data_files:
- split: train
path: "data/awa/train.parquet"
- split: validation
path: "data/awa/validation.parquet"
- config_name: ay
data_files:
- split: train
path: "data/ay/train.parquet"
- split: validation
path: "data/ay/validation.parquet"
- config_name: az
data_files:
- split: train
path: "data/az/train.parquet"
- split: validation
path: "data/az/validation.parquet"
- config_name: azb
data_files:
- split: train
path: "data/azb/train.parquet"
- split: validation
path: "data/azb/validation.parquet"
- config_name: ba
data_files:
- split: train
path: "data/ba/train.parquet"
- split: validation
path: "data/ba/validation.parquet"
- config_name: ban
data_files:
- split: train
path: "data/ban/train.parquet"
- split: validation
path: "data/ban/validation.parquet"
- config_name: bar
data_files:
- split: train
path: "data/bar/train.parquet"
- split: validation
path: "data/bar/validation.parquet"
- config_name: bat_smg
data_files:
- split: train
path: "data/bat_smg/train.parquet"
- split: validation
path: "data/bat_smg/validation.parquet"
- config_name: bcl
data_files:
- split: train
path: "data/bcl/train.parquet"
- split: validation
path: "data/bcl/validation.parquet"
- config_name: be
data_files:
- split: train
path: "data/be/train.parquet"
- split: validation
path: "data/be/validation.parquet"
- config_name: bg
data_files:
- split: train
path: "data/bg/train.parquet"
- split: validation
path: "data/bg/validation.parquet"
- config_name: bh
data_files:
- split: train
path: "data/bh/train.parquet"
- split: validation
path: "data/bh/validation.parquet"
- config_name: bi
data_files:
- split: train
path: "data/bi/train.parquet"
- split: validation
path: "data/bi/validation.parquet"
- config_name: bjn
data_files:
- split: train
path: "data/bjn/train.parquet"
- split: validation
path: "data/bjn/validation.parquet"
- config_name: blk
data_files:
- split: train
path: "data/blk/train.parquet"
- split: validation
path: "data/blk/validation.parquet"
- config_name: bm
data_files:
- split: train
path: "data/bm/train.parquet"
- split: validation
path: "data/bm/validation.parquet"
- config_name: bn
data_files:
- split: train
path: "data/bn/train.parquet"
- split: validation
path: "data/bn/validation.parquet"
- config_name: bo
data_files:
- split: train
path: "data/bo/train.parquet"
- split: validation
path: "data/bo/validation.parquet"
- config_name: bpy
data_files:
- split: train
path: "data/bpy/train.parquet"
- split: validation
path: "data/bpy/validation.parquet"
- config_name: br
data_files:
- split: train
path: "data/br/train.parquet"
- split: validation
path: "data/br/validation.parquet"
- config_name: bs
data_files:
- split: train
path: "data/bs/train.parquet"
- split: validation
path: "data/bs/validation.parquet"
- config_name: bug
data_files:
- split: train
path: "data/bug/train.parquet"
- split: validation
path: "data/bug/validation.parquet"
- config_name: bxr
data_files:
- split: train
path: "data/bxr/train.parquet"
- split: validation
path: "data/bxr/validation.parquet"
- config_name: ca
data_files:
- split: train
path: "data/ca/train.parquet"
- split: validation
path: "data/ca/validation.parquet"
- config_name: cbk_zam
data_files:
- split: train
path: "data/cbk_zam/train.parquet"
- split: validation
path: "data/cbk_zam/validation.parquet"
- config_name: cdo
data_files:
- split: train
path: "data/cdo/train.parquet"
- split: validation
path: "data/cdo/validation.parquet"
- config_name: ce
data_files:
- split: train
path: "data/ce/train.parquet"
- split: validation
path: "data/ce/validation.parquet"
- config_name: ceb
data_files:
- split: train
path: "data/ceb/train.parquet"
- split: validation
path: "data/ceb/validation.parquet"
- config_name: ch
data_files:
- split: train
path: "data/ch/train.parquet"
- split: validation
path: "data/ch/validation.parquet"
- config_name: chr
data_files:
- split: train
path: "data/chr/train.parquet"
- split: validation
path: "data/chr/validation.parquet"
- config_name: chy
data_files:
- split: train
path: "data/chy/train.parquet"
- split: validation
path: "data/chy/validation.parquet"
- config_name: ckb
data_files:
- split: train
path: "data/ckb/train.parquet"
- split: validation
path: "data/ckb/validation.parquet"
- config_name: co
data_files:
- split: train
path: "data/co/train.parquet"
- split: validation
path: "data/co/validation.parquet"
- config_name: cr
data_files:
- split: train
path: "data/cr/train.parquet"
- split: validation
path: "data/cr/validation.parquet"
- config_name: crh
data_files:
- split: train
path: "data/crh/train.parquet"
- split: validation
path: "data/crh/validation.parquet"
- config_name: cs
data_files:
- split: train
path: "data/cs/train.parquet"
- split: validation
path: "data/cs/validation.parquet"
- config_name: csb
data_files:
- split: train
path: "data/csb/train.parquet"
- split: validation
path: "data/csb/validation.parquet"
- config_name: cu
data_files:
- split: train
path: "data/cu/train.parquet"
- split: validation
path: "data/cu/validation.parquet"
- config_name: cv
data_files:
- split: train
path: "data/cv/train.parquet"
- split: validation
path: "data/cv/validation.parquet"
- config_name: cy
data_files:
- split: train
path: "data/cy/train.parquet"
- split: validation
path: "data/cy/validation.parquet"
- config_name: da
data_files:
- split: train
path: "data/da/train.parquet"
- split: validation
path: "data/da/validation.parquet"
- config_name: dag
data_files:
- split: train
path: "data/dag/train.parquet"
- split: validation
path: "data/dag/validation.parquet"
- config_name: de
data_files:
- split: train
path: "data/de/train.parquet"
- split: validation
path: "data/de/validation.parquet"
- config_name: din
data_files:
- split: train
path: "data/din/train.parquet"
- split: validation
path: "data/din/validation.parquet"
- config_name: diq
data_files:
- split: train
path: "data/diq/train.parquet"
- split: validation
path: "data/diq/validation.parquet"
- config_name: dsb
data_files:
- split: train
path: "data/dsb/train.parquet"
- split: validation
path: "data/dsb/validation.parquet"
- config_name: dty
data_files:
- split: train
path: "data/dty/train.parquet"
- split: validation
path: "data/dty/validation.parquet"
- config_name: dv
data_files:
- split: train
path: "data/dv/train.parquet"
- split: validation
path: "data/dv/validation.parquet"
- config_name: dz
data_files:
- split: train
path: "data/dz/train.parquet"
- split: validation
path: "data/dz/validation.parquet"
- config_name: ee
data_files:
- split: train
path: "data/ee/train.parquet"
- split: validation
path: "data/ee/validation.parquet"
- config_name: el
data_files:
- split: train
path: "data/el/train.parquet"
- split: validation
path: "data/el/validation.parquet"
- config_name: eml
data_files:
- split: train
path: "data/eml/train.parquet"
- split: validation
path: "data/eml/validation.parquet"
- config_name: en
data_files:
- split: train
path: "data/en/train.parquet"
- split: validation
path: "data/en/validation.parquet"
- config_name: eo
data_files:
- split: train
path: "data/eo/train.parquet"
- split: validation
path: "data/eo/validation.parquet"
- config_name: es
data_files:
- split: train
path: "data/es/train.parquet"
- split: validation
path: "data/es/validation.parquet"
- config_name: et
data_files:
- split: train
path: "data/et/train.parquet"
- split: validation
path: "data/et/validation.parquet"
- config_name: eu
data_files:
- split: train
path: "data/eu/train.parquet"
- split: validation
path: "data/eu/validation.parquet"
- config_name: ext
data_files:
- split: train
path: "data/ext/train.parquet"
- split: validation
path: "data/ext/validation.parquet"
- config_name: fa
data_files:
- split: train
path: "data/fa/train.parquet"
- split: validation
path: "data/fa/validation.parquet"
- config_name: fat
data_files:
- split: train
path: "data/fat/train.parquet"
- split: validation
path: "data/fat/validation.parquet"
- config_name: ff
data_files:
- split: train
path: "data/ff/train.parquet"
- split: validation
path: "data/ff/validation.parquet"
- config_name: fi
data_files:
- split: train
path: "data/fi/train.parquet"
- split: validation
path: "data/fi/validation.parquet"
- config_name: fiu_vro
data_files:
- split: train
path: "data/fiu_vro/train.parquet"
- split: validation
path: "data/fiu_vro/validation.parquet"
- config_name: fj
data_files:
- split: train
path: "data/fj/train.parquet"
- split: validation
path: "data/fj/validation.parquet"
- config_name: fo
data_files:
- split: train
path: "data/fo/train.parquet"
- split: validation
path: "data/fo/validation.parquet"
- config_name: fr
data_files:
- split: train
path: "data/fr/train.parquet"
- split: validation
path: "data/fr/validation.parquet"
- config_name: frp
data_files:
- split: train
path: "data/frp/train.parquet"
- split: validation
path: "data/frp/validation.parquet"
- config_name: frr
data_files:
- split: train
path: "data/frr/train.parquet"
- split: validation
path: "data/frr/validation.parquet"
- config_name: fur
data_files:
- split: train
path: "data/fur/train.parquet"
- split: validation
path: "data/fur/validation.parquet"
- config_name: fy
data_files:
- split: train
path: "data/fy/train.parquet"
- split: validation
path: "data/fy/validation.parquet"
- config_name: ga
data_files:
- split: train
path: "data/ga/train.parquet"
- split: validation
path: "data/ga/validation.parquet"
- config_name: gag
data_files:
- split: train
path: "data/gag/train.parquet"
- split: validation
path: "data/gag/validation.parquet"
- config_name: gan
data_files:
- split: train
path: "data/gan/train.parquet"
- split: validation
path: "data/gan/validation.parquet"
- config_name: gcr
data_files:
- split: train
path: "data/gcr/train.parquet"
- split: validation
path: "data/gcr/validation.parquet"
- config_name: gd
data_files:
- split: train
path: "data/gd/train.parquet"
- split: validation
path: "data/gd/validation.parquet"
- config_name: gl
data_files:
- split: train
path: "data/gl/train.parquet"
- split: validation
path: "data/gl/validation.parquet"
- config_name: glk
data_files:
- split: train
path: "data/glk/train.parquet"
- split: validation
path: "data/glk/validation.parquet"
- config_name: gn
data_files:
- split: train
path: "data/gn/train.parquet"
- split: validation
path: "data/gn/validation.parquet"
- config_name: gom
data_files:
- split: train
path: "data/gom/train.parquet"
- split: validation
path: "data/gom/validation.parquet"
- config_name: gor
data_files:
- split: train
path: "data/gor/train.parquet"
- split: validation
path: "data/gor/validation.parquet"
- config_name: got
data_files:
- split: train
path: "data/got/train.parquet"
- split: validation
path: "data/got/validation.parquet"
- config_name: gpe
data_files:
- split: train
path: "data/gpe/train.parquet"
- split: validation
path: "data/gpe/validation.parquet"
- config_name: gu
data_files:
- split: train
path: "data/gu/train.parquet"
- split: validation
path: "data/gu/validation.parquet"
- config_name: guc
data_files:
- split: train
path: "data/guc/train.parquet"
- split: validation
path: "data/guc/validation.parquet"
- config_name: gur
data_files:
- split: train
path: "data/gur/train.parquet"
- split: validation
path: "data/gur/validation.parquet"
- config_name: guw
data_files:
- split: train
path: "data/guw/train.parquet"
- split: validation
path: "data/guw/validation.parquet"
- config_name: gv
data_files:
- split: train
path: "data/gv/train.parquet"
- split: validation
path: "data/gv/validation.parquet"
- config_name: ha
data_files:
- split: train
path: "data/ha/train.parquet"
- split: validation
path: "data/ha/validation.parquet"
- config_name: hak
data_files:
- split: train
path: "data/hak/train.parquet"
- split: validation
path: "data/hak/validation.parquet"
- config_name: haw
data_files:
- split: train
path: "data/haw/train.parquet"
- split: validation
path: "data/haw/validation.parquet"
- config_name: he
data_files:
- split: train
path: "data/he/train.parquet"
- split: validation
path: "data/he/validation.parquet"
- config_name: hi
data_files:
- split: train
path: "data/hi/train.parquet"
- split: validation
path: "data/hi/validation.parquet"
- config_name: hif
data_files:
- split: train
path: "data/hif/train.parquet"
- split: validation
path: "data/hif/validation.parquet"
- config_name: hr
data_files:
- split: train
path: "data/hr/train.parquet"
- split: validation
path: "data/hr/validation.parquet"
- config_name: hsb
data_files:
- split: train
path: "data/hsb/train.parquet"
- split: validation
path: "data/hsb/validation.parquet"
- config_name: ht
data_files:
- split: train
path: "data/ht/train.parquet"
- split: validation
path: "data/ht/validation.parquet"
- config_name: hu
data_files:
- split: train
path: "data/hu/train.parquet"
- split: validation
path: "data/hu/validation.parquet"
- config_name: hy
data_files:
- split: train
path: "data/hy/train.parquet"
- split: validation
path: "data/hy/validation.parquet"
- config_name: hyw
data_files:
- split: train
path: "data/hyw/train.parquet"
- split: validation
path: "data/hyw/validation.parquet"
- config_name: ia
data_files:
- split: train
path: "data/ia/train.parquet"
- split: validation
path: "data/ia/validation.parquet"
- config_name: id
data_files:
- split: train
path: "data/id/train.parquet"
- split: validation
path: "data/id/validation.parquet"
- config_name: ie
data_files:
- split: train
path: "data/ie/train.parquet"
- split: validation
path: "data/ie/validation.parquet"
- config_name: ig
data_files:
- split: train
path: "data/ig/train.parquet"
- split: validation
path: "data/ig/validation.parquet"
- config_name: ik
data_files:
- split: train
path: "data/ik/train.parquet"
- split: validation
path: "data/ik/validation.parquet"
- config_name: ilo
data_files:
- split: train
path: "data/ilo/train.parquet"
- split: validation
path: "data/ilo/validation.parquet"
- config_name: inh
data_files:
- split: train
path: "data/inh/train.parquet"
- split: validation
path: "data/inh/validation.parquet"
- config_name: io
data_files:
- split: train
path: "data/io/train.parquet"
- split: validation
path: "data/io/validation.parquet"
- config_name: is
data_files:
- split: train
path: "data/is/train.parquet"
- split: validation
path: "data/is/validation.parquet"
- config_name: it
data_files:
- split: train
path: "data/it/train.parquet"
- split: validation
path: "data/it/validation.parquet"
- config_name: iu
data_files:
- split: train
path: "data/iu/train.parquet"
- split: validation
path: "data/iu/validation.parquet"
- config_name: ja
data_files:
- split: train
path: "data/ja/train.parquet"
- split: validation
path: "data/ja/validation.parquet"
- config_name: jam
data_files:
- split: train
path: "data/jam/train.parquet"
- split: validation
path: "data/jam/validation.parquet"
- config_name: jbo
data_files:
- split: train
path: "data/jbo/train.parquet"
- split: validation
path: "data/jbo/validation.parquet"
- config_name: jv
data_files:
- split: train
path: "data/jv/train.parquet"
- split: validation
path: "data/jv/validation.parquet"
- config_name: ka
data_files:
- split: train
path: "data/ka/train.parquet"
- split: validation
path: "data/ka/validation.parquet"
- config_name: kaa
data_files:
- split: train
path: "data/kaa/train.parquet"
- split: validation
path: "data/kaa/validation.parquet"
- config_name: kab
data_files:
- split: train
path: "data/kab/train.parquet"
- split: validation
path: "data/kab/validation.parquet"
- config_name: kbd
data_files:
- split: train
path: "data/kbd/train.parquet"
- split: validation
path: "data/kbd/validation.parquet"
- config_name: kbp
data_files:
- split: train
path: "data/kbp/train.parquet"
- split: validation
path: "data/kbp/validation.parquet"
- config_name: kcg
data_files:
- split: train
path: "data/kcg/train.parquet"
- split: validation
path: "data/kcg/validation.parquet"
- config_name: kg
data_files:
- split: train
path: "data/kg/train.parquet"
- split: validation
path: "data/kg/validation.parquet"
- config_name: ki
data_files:
- split: train
path: "data/ki/train.parquet"
- split: validation
path: "data/ki/validation.parquet"
- config_name: kk
data_files:
- split: train
path: "data/kk/train.parquet"
- split: validation
path: "data/kk/validation.parquet"
- config_name: kl
data_files:
- split: train
path: "data/kl/train.parquet"
- split: validation
path: "data/kl/validation.parquet"
- config_name: km
data_files:
- split: train
path: "data/km/train.parquet"
- split: validation
path: "data/km/validation.parquet"
- config_name: kn
data_files:
- split: train
path: "data/kn/train.parquet"
- split: validation
path: "data/kn/validation.parquet"
- config_name: ko
data_files:
- split: train
path: "data/ko/train.parquet"
- split: validation
path: "data/ko/validation.parquet"
- config_name: koi
data_files:
- split: train
path: "data/koi/train.parquet"
- split: validation
path: "data/koi/validation.parquet"
- config_name: krc
data_files:
- split: train
path: "data/krc/train.parquet"
- split: validation
path: "data/krc/validation.parquet"
- config_name: ks
data_files:
- split: train
path: "data/ks/train.parquet"
- split: validation
path: "data/ks/validation.parquet"
- config_name: ksh
data_files:
- split: train
path: "data/ksh/train.parquet"
- split: validation
path: "data/ksh/validation.parquet"
- config_name: ku
data_files:
- split: train
path: "data/ku/train.parquet"
- split: validation
path: "data/ku/validation.parquet"
- config_name: kv
data_files:
- split: train
path: "data/kv/train.parquet"
- split: validation
path: "data/kv/validation.parquet"
- config_name: kw
data_files:
- split: train
path: "data/kw/train.parquet"
- split: validation
path: "data/kw/validation.parquet"
- config_name: ky
data_files:
- split: train
path: "data/ky/train.parquet"
- split: validation
path: "data/ky/validation.parquet"
- config_name: la
data_files:
- split: train
path: "data/la/train.parquet"
- split: validation
path: "data/la/validation.parquet"
- config_name: lad
data_files:
- split: train
path: "data/lad/train.parquet"
- split: validation
path: "data/lad/validation.parquet"
- config_name: lb
data_files:
- split: train
path: "data/lb/train.parquet"
- split: validation
path: "data/lb/validation.parquet"
- config_name: lbe
data_files:
- split: train
path: "data/lbe/train.parquet"
- split: validation
path: "data/lbe/validation.parquet"
- config_name: lez
data_files:
- split: train
path: "data/lez/train.parquet"
- split: validation
path: "data/lez/validation.parquet"
- config_name: lfn
data_files:
- split: train
path: "data/lfn/train.parquet"
- split: validation
path: "data/lfn/validation.parquet"
- config_name: lg
data_files:
- split: train
path: "data/lg/train.parquet"
- split: validation
path: "data/lg/validation.parquet"
- config_name: li
data_files:
- split: train
path: "data/li/train.parquet"
- split: validation
path: "data/li/validation.parquet"
- config_name: lij
data_files:
- split: train
path: "data/lij/train.parquet"
- split: validation
path: "data/lij/validation.parquet"
- config_name: lld
data_files:
- split: train
path: "data/lld/train.parquet"
- split: validation
path: "data/lld/validation.parquet"
- config_name: lmo
data_files:
- split: train
path: "data/lmo/train.parquet"
- split: validation
path: "data/lmo/validation.parquet"
- config_name: ln
data_files:
- split: train
path: "data/ln/train.parquet"
- split: validation
path: "data/ln/validation.parquet"
- config_name: lo
data_files:
- split: train
path: "data/lo/train.parquet"
- split: validation
path: "data/lo/validation.parquet"
- config_name: lt
data_files:
- split: train
path: "data/lt/train.parquet"
- split: validation
path: "data/lt/validation.parquet"
- config_name: ltg
data_files:
- split: train
path: "data/ltg/train.parquet"
- split: validation
path: "data/ltg/validation.parquet"
- config_name: lv
data_files:
- split: train
path: "data/lv/train.parquet"
- split: validation
path: "data/lv/validation.parquet"
- config_name: mad
data_files:
- split: train
path: "data/mad/train.parquet"
- split: validation
path: "data/mad/validation.parquet"
- config_name: mai
data_files:
- split: train
path: "data/mai/train.parquet"
- split: validation
path: "data/mai/validation.parquet"
- config_name: map_bms
data_files:
- split: train
path: "data/map_bms/train.parquet"
- split: validation
path: "data/map_bms/validation.parquet"
- config_name: mdf
data_files:
- split: train
path: "data/mdf/train.parquet"
- split: validation
path: "data/mdf/validation.parquet"
- config_name: mg
data_files:
- split: train
path: "data/mg/train.parquet"
- split: validation
path: "data/mg/validation.parquet"
- config_name: mhr
data_files:
- split: train
path: "data/mhr/train.parquet"
- split: validation
path: "data/mhr/validation.parquet"
- config_name: mi
data_files:
- split: train
path: "data/mi/train.parquet"
- split: validation
path: "data/mi/validation.parquet"
- config_name: min
data_files:
- split: train
path: "data/min/train.parquet"
- split: validation
path: "data/min/validation.parquet"
- config_name: mk
data_files:
- split: train
path: "data/mk/train.parquet"
- split: validation
path: "data/mk/validation.parquet"
- config_name: ml
data_files:
- split: train
path: "data/ml/train.parquet"
- split: validation
path: "data/ml/validation.parquet"
- config_name: mn
data_files:
- split: train
path: "data/mn/train.parquet"
- split: validation
path: "data/mn/validation.parquet"
- config_name: mni
data_files:
- split: train
path: "data/mni/train.parquet"
- split: validation
path: "data/mni/validation.parquet"
- config_name: mnw
data_files:
- split: train
path: "data/mnw/train.parquet"
- split: validation
path: "data/mnw/validation.parquet"
- config_name: mr
data_files:
- split: train
path: "data/mr/train.parquet"
- split: validation
path: "data/mr/validation.parquet"
- config_name: mrj
data_files:
- split: train
path: "data/mrj/train.parquet"
- split: validation
path: "data/mrj/validation.parquet"
- config_name: ms
data_files:
- split: train
path: "data/ms/train.parquet"
- split: validation
path: "data/ms/validation.parquet"
- config_name: mt
data_files:
- split: train
path: "data/mt/train.parquet"
- split: validation
path: "data/mt/validation.parquet"
- config_name: mwl
data_files:
- split: train
path: "data/mwl/train.parquet"
- split: validation
path: "data/mwl/validation.parquet"
- config_name: my
data_files:
- split: train
path: "data/my/train.parquet"
- split: validation
path: "data/my/validation.parquet"
- config_name: myv
data_files:
- split: train
path: "data/myv/train.parquet"
- split: validation
path: "data/myv/validation.parquet"
- config_name: mzn
data_files:
- split: train
path: "data/mzn/train.parquet"
- split: validation
path: "data/mzn/validation.parquet"
- config_name: nah
data_files:
- split: train
path: "data/nah/train.parquet"
- split: validation
path: "data/nah/validation.parquet"
- config_name: nap
data_files:
- split: train
path: "data/nap/train.parquet"
- split: validation
path: "data/nap/validation.parquet"
- config_name: nds
data_files:
- split: train
path: "data/nds/train.parquet"
- split: validation
path: "data/nds/validation.parquet"
- config_name: nds_nl
data_files:
- split: train
path: "data/nds_nl/train.parquet"
- split: validation
path: "data/nds_nl/validation.parquet"
- config_name: ne
data_files:
- split: train
path: "data/ne/train.parquet"
- split: validation
path: "data/ne/validation.parquet"
- config_name: new
data_files:
- split: train
path: "data/new/train.parquet"
- split: validation
path: "data/new/validation.parquet"
- config_name: nia
data_files:
- split: train
path: "data/nia/train.parquet"
- split: validation
path: "data/nia/validation.parquet"
- config_name: nl
data_files:
- split: train
path: "data/nl/train.parquet"
- split: validation
path: "data/nl/validation.parquet"
- config_name: nn
data_files:
- split: train
path: "data/nn/train.parquet"
- split: validation
path: "data/nn/validation.parquet"
- config_name: 'no'
data_files:
- split: train
path: "data/no/train.parquet"
- split: validation
path: "data/no/validation.parquet"
- config_name: nov
data_files:
- split: train
path: "data/nov/train.parquet"
- split: validation
path: "data/nov/validation.parquet"
- config_name: nqo
data_files:
- split: train
path: "data/nqo/train.parquet"
- split: validation
path: "data/nqo/validation.parquet"
- config_name: nrm
data_files:
- split: train
path: "data/nrm/train.parquet"
- split: validation
path: "data/nrm/validation.parquet"
- config_name: nso
data_files:
- split: train
path: "data/nso/train.parquet"
- split: validation
path: "data/nso/validation.parquet"
- config_name: nv
data_files:
- split: train
path: "data/nv/train.parquet"
- split: validation
path: "data/nv/validation.parquet"
- config_name: ny
data_files:
- split: train
path: "data/ny/train.parquet"
- split: validation
path: "data/ny/validation.parquet"
- config_name: oc
data_files:
- split: train
path: "data/oc/train.parquet"
- split: validation
path: "data/oc/validation.parquet"
- config_name: olo
data_files:
- split: train
path: "data/olo/train.parquet"
- split: validation
path: "data/olo/validation.parquet"
- config_name: om
data_files:
- split: train
path: "data/om/train.parquet"
- split: validation
path: "data/om/validation.parquet"
- config_name: or
data_files:
- split: train
path: "data/or/train.parquet"
- split: validation
path: "data/or/validation.parquet"
- config_name: os
data_files:
- split: train
path: "data/os/train.parquet"
- split: validation
path: "data/os/validation.parquet"
- config_name: pa
data_files:
- split: train
path: "data/pa/train.parquet"
- split: validation
path: "data/pa/validation.parquet"
- config_name: pag
data_files:
- split: train
path: "data/pag/train.parquet"
- split: validation
path: "data/pag/validation.parquet"
- config_name: pam
data_files:
- split: train
path: "data/pam/train.parquet"
- split: validation
path: "data/pam/validation.parquet"
- config_name: pap
data_files:
- split: train
path: "data/pap/train.parquet"
- split: validation
path: "data/pap/validation.parquet"
- config_name: pcd
data_files:
- split: train
path: "data/pcd/train.parquet"
- split: validation
path: "data/pcd/validation.parquet"
- config_name: pcm
data_files:
- split: train
path: "data/pcm/train.parquet"
- split: validation
path: "data/pcm/validation.parquet"
- config_name: pdc
data_files:
- split: train
path: "data/pdc/train.parquet"
- split: validation
path: "data/pdc/validation.parquet"
- config_name: pfl
data_files:
- split: train
path: "data/pfl/train.parquet"
- split: validation
path: "data/pfl/validation.parquet"
- config_name: pi
data_files:
- split: train
path: "data/pi/train.parquet"
- split: validation
path: "data/pi/validation.parquet"
- config_name: pih
data_files:
- split: train
path: "data/pih/train.parquet"
- split: validation
path: "data/pih/validation.parquet"
- config_name: pl
data_files:
- split: train
path: "data/pl/train.parquet"
- split: validation
path: "data/pl/validation.parquet"
- config_name: pms
data_files:
- split: train
path: "data/pms/train.parquet"
- split: validation
path: "data/pms/validation.parquet"
- config_name: pnb
data_files:
- split: train
path: "data/pnb/train.parquet"
- split: validation
path: "data/pnb/validation.parquet"
- config_name: pnt
data_files:
- split: train
path: "data/pnt/train.parquet"
- split: validation
path: "data/pnt/validation.parquet"
- config_name: ps
data_files:
- split: train
path: "data/ps/train.parquet"
- split: validation
path: "data/ps/validation.parquet"
- config_name: pt
data_files:
- split: train
path: "data/pt/train.parquet"
- split: validation
path: "data/pt/validation.parquet"
- config_name: pwn
data_files:
- split: train
path: "data/pwn/train.parquet"
- split: validation
path: "data/pwn/validation.parquet"
- config_name: qu
data_files:
- split: train
path: "data/qu/train.parquet"
- split: validation
path: "data/qu/validation.parquet"
- config_name: rm
data_files:
- split: train
path: "data/rm/train.parquet"
- split: validation
path: "data/rm/validation.parquet"
- config_name: rmy
data_files:
- split: train
path: "data/rmy/train.parquet"
- split: validation
path: "data/rmy/validation.parquet"
- config_name: rn
data_files:
- split: train
path: "data/rn/train.parquet"
- split: validation
path: "data/rn/validation.parquet"
- config_name: ro
data_files:
- split: train
path: "data/ro/train.parquet"
- split: validation
path: "data/ro/validation.parquet"
- config_name: roa_rup
data_files:
- split: train
path: "data/roa_rup/train.parquet"
- split: validation
path: "data/roa_rup/validation.parquet"
- config_name: roa_tara
data_files:
- split: train
path: "data/roa_tara/train.parquet"
- split: validation
path: "data/roa_tara/validation.parquet"
- config_name: ru
data_files:
- split: train
path: "data/ru/train.parquet"
- split: validation
path: "data/ru/validation.parquet"
- config_name: rue
data_files:
- split: train
path: "data/rue/train.parquet"
- split: validation
path: "data/rue/validation.parquet"
- config_name: rw
data_files:
- split: train
path: "data/rw/train.parquet"
- split: validation
path: "data/rw/validation.parquet"
- config_name: sa
data_files:
- split: train
path: "data/sa/train.parquet"
- split: validation
path: "data/sa/validation.parquet"
- config_name: sah
data_files:
- split: train
path: "data/sah/train.parquet"
- split: validation
path: "data/sah/validation.parquet"
- config_name: sat
data_files:
- split: train
path: "data/sat/train.parquet"
- split: validation
path: "data/sat/validation.parquet"
- config_name: sc
data_files:
- split: train
path: "data/sc/train.parquet"
- split: validation
path: "data/sc/validation.parquet"
- config_name: scn
data_files:
- split: train
path: "data/scn/train.parquet"
- split: validation
path: "data/scn/validation.parquet"
- config_name: sco
data_files:
- split: train
path: "data/sco/train.parquet"
- split: validation
path: "data/sco/validation.parquet"
- config_name: sd
data_files:
- split: train
path: "data/sd/train.parquet"
- split: validation
path: "data/sd/validation.parquet"
- config_name: se
data_files:
- split: train
path: "data/se/train.parquet"
- split: validation
path: "data/se/validation.parquet"
- config_name: sg
data_files:
- split: train
path: "data/sg/train.parquet"
- split: validation
path: "data/sg/validation.parquet"
- config_name: sh
data_files:
- split: train
path: "data/sh/train.parquet"
- split: validation
path: "data/sh/validation.parquet"
- config_name: shi
data_files:
- split: train
path: "data/shi/train.parquet"
- split: validation
path: "data/shi/validation.parquet"
- config_name: shn
data_files:
- split: train
path: "data/shn/train.parquet"
- split: validation
path: "data/shn/validation.parquet"
- config_name: si
data_files:
- split: train
path: "data/si/train.parquet"
- split: validation
path: "data/si/validation.parquet"
- config_name: simple
data_files:
- split: train
path: "data/simple/train.parquet"
- split: validation
path: "data/simple/validation.parquet"
- config_name: sk
data_files:
- split: train
path: "data/sk/train.parquet"
- split: validation
path: "data/sk/validation.parquet"
- config_name: skr
data_files:
- split: train
path: "data/skr/train.parquet"
- split: validation
path: "data/skr/validation.parquet"
- config_name: sl
data_files:
- split: train
path: "data/sl/train.parquet"
- split: validation
path: "data/sl/validation.parquet"
- config_name: sm
data_files:
- split: train
path: "data/sm/train.parquet"
- split: validation
path: "data/sm/validation.parquet"
- config_name: smn
data_files:
- split: train
path: "data/smn/train.parquet"
- split: validation
path: "data/smn/validation.parquet"
- config_name: sn
data_files:
- split: train
path: "data/sn/train.parquet"
- split: validation
path: "data/sn/validation.parquet"
- config_name: so
data_files:
- split: train
path: "data/so/train.parquet"
- split: validation
path: "data/so/validation.parquet"
- config_name: sq
data_files:
- split: train
path: "data/sq/train.parquet"
- split: validation
path: "data/sq/validation.parquet"
- config_name: sr
data_files:
- split: train
path: "data/sr/train.parquet"
- split: validation
path: "data/sr/validation.parquet"
- config_name: srn
data_files:
- split: train
path: "data/srn/train.parquet"
- split: validation
path: "data/srn/validation.parquet"
- config_name: ss
data_files:
- split: train
path: "data/ss/train.parquet"
- split: validation
path: "data/ss/validation.parquet"
- config_name: st
data_files:
- split: train
path: "data/st/train.parquet"
- split: validation
path: "data/st/validation.parquet"
- config_name: stq
data_files:
- split: train
path: "data/stq/train.parquet"
- split: validation
path: "data/stq/validation.parquet"
- config_name: su
data_files:
- split: train
path: "data/su/train.parquet"
- split: validation
path: "data/su/validation.parquet"
- config_name: sv
data_files:
- split: train
path: "data/sv/train.parquet"
- split: validation
path: "data/sv/validation.parquet"
- config_name: sw
data_files:
- split: train
path: "data/sw/train.parquet"
- split: validation
path: "data/sw/validation.parquet"
- config_name: szl
data_files:
- split: train
path: "data/szl/train.parquet"
- split: validation
path: "data/szl/validation.parquet"
- config_name: szy
data_files:
- split: train
path: "data/szy/train.parquet"
- split: validation
path: "data/szy/validation.parquet"
- config_name: ta
data_files:
- split: train
path: "data/ta/train.parquet"
- split: validation
path: "data/ta/validation.parquet"
- config_name: tay
data_files:
- split: train
path: "data/tay/train.parquet"
- split: validation
path: "data/tay/validation.parquet"
- config_name: tcy
data_files:
- split: train
path: "data/tcy/train.parquet"
- split: validation
path: "data/tcy/validation.parquet"
- config_name: te
data_files:
- split: train
path: "data/te/train.parquet"
- split: validation
path: "data/te/validation.parquet"
- config_name: tet
data_files:
- split: train
path: "data/tet/train.parquet"
- split: validation
path: "data/tet/validation.parquet"
- config_name: tg
data_files:
- split: train
path: "data/tg/train.parquet"
- split: validation
path: "data/tg/validation.parquet"
- config_name: th
data_files:
- split: train
path: "data/th/train.parquet"
- split: validation
path: "data/th/validation.parquet"
- config_name: ti
data_files:
- split: train
path: "data/ti/train.parquet"
- split: validation
path: "data/ti/validation.parquet"
- config_name: tk
data_files:
- split: train
path: "data/tk/train.parquet"
- split: validation
path: "data/tk/validation.parquet"
- config_name: tl
data_files:
- split: train
path: "data/tl/train.parquet"
- split: validation
path: "data/tl/validation.parquet"
- config_name: tn
data_files:
- split: train
path: "data/tn/train.parquet"
- split: validation
path: "data/tn/validation.parquet"
- config_name: to
data_files:
- split: train
path: "data/to/train.parquet"
- split: validation
path: "data/to/validation.parquet"
- config_name: tpi
data_files:
- split: train
path: "data/tpi/train.parquet"
- split: validation
path: "data/tpi/validation.parquet"
- config_name: tr
data_files:
- split: train
path: "data/tr/train.parquet"
- split: validation
path: "data/tr/validation.parquet"
- config_name: trv
data_files:
- split: train
path: "data/trv/train.parquet"
- split: validation
path: "data/trv/validation.parquet"
- config_name: ts
data_files:
- split: train
path: "data/ts/train.parquet"
- split: validation
path: "data/ts/validation.parquet"
- config_name: tt
data_files:
- split: train
path: "data/tt/train.parquet"
- split: validation
path: "data/tt/validation.parquet"
- config_name: tum
data_files:
- split: train
path: "data/tum/train.parquet"
- split: validation
path: "data/tum/validation.parquet"
- config_name: tw
data_files:
- split: train
path: "data/tw/train.parquet"
- split: validation
path: "data/tw/validation.parquet"
- config_name: ty
data_files:
- split: train
path: "data/ty/train.parquet"
- split: validation
path: "data/ty/validation.parquet"
- config_name: tyv
data_files:
- split: train
path: "data/tyv/train.parquet"
- split: validation
path: "data/tyv/validation.parquet"
- config_name: udm
data_files:
- split: train
path: "data/udm/train.parquet"
- split: validation
path: "data/udm/validation.parquet"
- config_name: ug
data_files:
- split: train
path: "data/ug/train.parquet"
- split: validation
path: "data/ug/validation.parquet"
- config_name: uk
data_files:
- split: train
path: "data/uk/train.parquet"
- split: validation
path: "data/uk/validation.parquet"
- config_name: ur
data_files:
- split: train
path: "data/ur/train.parquet"
- split: validation
path: "data/ur/validation.parquet"
- config_name: uz
data_files:
- split: train
path: "data/uz/train.parquet"
- split: validation
path: "data/uz/validation.parquet"
- config_name: ve
data_files:
- split: train
path: "data/ve/train.parquet"
- split: validation
path: "data/ve/validation.parquet"
- config_name: vec
data_files:
- split: train
path: "data/vec/train.parquet"
- split: validation
path: "data/vec/validation.parquet"
- config_name: vep
data_files:
- split: train
path: "data/vep/train.parquet"
- split: validation
path: "data/vep/validation.parquet"
- config_name: vi
data_files:
- split: train
path: "data/vi/train.parquet"
- split: validation
path: "data/vi/validation.parquet"
- config_name: vls
data_files:
- split: train
path: "data/vls/train.parquet"
- split: validation
path: "data/vls/validation.parquet"
- config_name: vo
data_files:
- split: train
path: "data/vo/train.parquet"
- split: validation
path: "data/vo/validation.parquet"
- config_name: wa
data_files:
- split: train
path: "data/wa/train.parquet"
- split: validation
path: "data/wa/validation.parquet"
- config_name: war
data_files:
- split: train
path: "data/war/train.parquet"
- split: validation
path: "data/war/validation.parquet"
- config_name: wo
data_files:
- split: train
path: "data/wo/train.parquet"
- split: validation
path: "data/wo/validation.parquet"
- config_name: wuu
data_files:
- split: train
path: "data/wuu/train.parquet"
- split: validation
path: "data/wuu/validation.parquet"
- config_name: xal
data_files:
- split: train
path: "data/xal/train.parquet"
- split: validation
path: "data/xal/validation.parquet"
- config_name: xh
data_files:
- split: train
path: "data/xh/train.parquet"
- split: validation
path: "data/xh/validation.parquet"
- config_name: xmf
data_files:
- split: train
path: "data/xmf/train.parquet"
- split: validation
path: "data/xmf/validation.parquet"
- config_name: yi
data_files:
- split: train
path: "data/yi/train.parquet"
- split: validation
path: "data/yi/validation.parquet"
- config_name: yo
data_files:
- split: train
path: "data/yo/train.parquet"
- split: validation
path: "data/yo/validation.parquet"
- config_name: za
data_files:
- split: train
path: "data/za/train.parquet"
- split: validation
path: "data/za/validation.parquet"
- config_name: zea
data_files:
- split: train
path: "data/zea/train.parquet"
- split: validation
path: "data/zea/validation.parquet"
- config_name: zh
data_files:
- split: train
path: "data/zh/train.parquet"
- split: validation
path: "data/zh/validation.parquet"
- config_name: zh_classical
data_files:
- split: train
path: "data/zh_classical/train.parquet"
- split: validation
path: "data/zh_classical/validation.parquet"
- config_name: zh_min_nan
data_files:
- split: train
path: "data/zh_min_nan/train.parquet"
- split: validation
path: "data/zh_min_nan/validation.parquet"
- config_name: zh_yue
data_files:
- split: train
path: "data/zh_yue/train.parquet"
- split: validation
path: "data/zh_yue/validation.parquet"
- config_name: zu
data_files:
- split: train
path: "data/zu/train.parquet"
- split: validation
path: "data/zu/validation.parquet"
---
# Dataset Card for WikiAnc
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Repository:** [WikiAnc repository](https://github.com/cyanic-selkie/wikianc)
### Dataset Summary
The WikiAnc dataset is an automatically generated dataset from Wikipedia (all languages) and Wikidata dumps (August, 2023).
The code for generating the dataset can be found [here](https://github.com/cyanic-selkie/wikianc).
### Supported Tasks
- `wikificiation`: The dataset can be used to train a model for Wikification.
- `named-entity-linking`: The dataset can be used to train a model for Named Entity Linking.
### Languages
The text in the dataset is in all 320 Wikipedia languages. The full list can be found in the table below.
## Dataset Structure
### Data Instances
A typical data point represents a paragraph in a Wikipedia article.
The `paragraph_text` field contains the original text in an NFC normalized, UTF-8 encoded string.
The `paragraph_anchors` field contains a list of anchors, each represented by a struct with the inclusive starting UTF-8 code point `start` field, exclusive ending UTF-8 code point `end` field, a nullable `qid` field, a nullable `pageid` field, and an NFC normalized, UTF-8 encoded `title` (Wikipedia) field.
Additionally, each paragraph has `article_title`, `article_pageid`, and (nullable) `article_qid` fields referring to the article the paragraph came from.
There is also a nullable, NFC normalized, UTF-8 encoded `section_heading` field, and an integer `section_level` field referring to the heading (if it exists) of the article section, and the level in the section hierarchy that the paragraph came from.
The `qid` fields refers to Wikidata's QID identifiers, while the `pageid` and `title` fields refer to Wikipedia's pageID and title identifiers (there is a one-to-one mapping between pageIDs and titles).
**NOTE:** An anchor will always have a `title`, but that doesn't mean it has to have a `pageid`. This is because Wikipedia allows defining anchors to nonexistent articles.
An example from the WikiAnc EN test set looks as follows:
```
{
"uuid": "5f74e678-944f-4761-a5e0-b6426f6f61b8",
"article_title": "Climatius",
"article_pageid": 5394373,
"article_qid": 867987,
"section_heading": null,
"section_level": 0,
"paragraph_text": "It was a small fish, at 7.5 cm, and to discourage predators, Climatius sported fifteen sharp spines. There was one spine each on the paired pelvic and pectoral fins, and on the aingle anal and two dorsal fins, and a four pairs without fins on the fish's underside.",
"paragraph_anchors": [
{
"start": 140,
"end": 146,
"qid": 3335089,
"pageid": 56849833,
"title": "Pelvic_fin"
},
{
"start": 151,
"end": 159,
"qid": 4162555,
"pageid": 331956,
"title": "Pectoral_fin"
},
{
"start": 184,
"end": 188,
"qid": 4162555,
"pageid": 331958,
"title": "Anal_fin"
},
{
"start": 197,
"end": 208,
"qid": 1568355,
"pageid": 294244,
"title": "Dorsal_fin"
}
]
}
```
### Data Fields
- `uuid`: a UTF-8 encoded string representing a v4 UUID that uniquely identifies the example
- `article_title`: an NFC normalized, UTF-8 encoded Wikipedia title of the article; spaces are replaced with underscores
- `article_pageid`: an integer representing the Wikipedia pageID of the article
- `article_qid`: an integer representing the Wikidata QID this article refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `section_heading`: a nullable, NFC normalized, UTF-8 encoded string representing the section heading
- `section_level`: an integer representing the level of the section in the section hierarchy
- `paragraph_text`: an NFC normalized, UTF-8 encoded string representing the paragraph
- `paragraph_anchors`: a list of structs representing anchors, each anchor has:
- `start`: an integer representing the inclusive starting UTF-8 code point of the anchors
- `end`: an integer representing the exclusive ending UTF-8 code point of the anchor
- `qid`: a nullable integer representing the Wikidata QID this anchor refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `pageid`: a nullable integer representing the Wikipedia pageID of the anchor; it can be null if the article didn't exist in Wikipedia at the time of the creation of the original dataset
- `title`: an NFC normalized, UTF-8 encoded string representing the Wikipedia title of the anchor; spaces are replaced with underscores; can refer to a nonexistent Wikipedia article
### Data Splits
The data is split into training, validation and test sets; paragraphs belonging to the same article aren't necessarily in the same split. The final split sizes are as follows:
#### Train
| | Articles | Paragraphs | Anchors | Anchors with QIDs | Anchors with PageIDs |
| :-- | --: | --: | --: | --: | --: |
| ab | 2378 | 5678 | 10515 | 3649 | 3650 |
| ace | 12591 | 23969 | 48638 | 25150 | 25175 |
| ady | 596 | 1662 | 2694 | 1593 | 1606 |
| af | 104470 | 399038 | 985640 | 900596 | 900967 |
| als | 27999 | 165085 | 402049 | 294742 | 294744 |
| alt | 1043 | 7468 | 9158 | 5446 | 5452 |
| am | 13576 | 46318 | 90051 | 51915 | 52173 |
| ami | 1582 | 12428 | 6080 | 1505 | 2579 |
| an | 40179 | 121367 | 669830 | 516248 | 516822 |
| ang | 3833 | 9664 | 24297 | 10189 | 10229 |
| anp | 2506 | 6865 | 14560 | 3825 | 5061 |
| ar | 1132271 | 3617491 | 11657228 | 11240112 | 11244160 |
| arc | 1844 | 3766 | 9232 | 5460 | 5545 |
| ary | 6736 | 17049 | 50185 | 34193 | 34227 |
| arz | 1579782 | 3693549 | 7879303 | 6906799 | 6917393 |
| as | 11947 | 77835 | 122760 | 67594 | 67720 |
| ast | 126992 | 877278 | 2952000 | 1775764 | 1777383 |
| atj | 1872 | 3820 | 6544 | 3247 | 3365 |
| av | 3048 | 8542 | 16115 | 8895 | 9000 |
| avk | 27577 | 85219 | 106100 | 32260 | 33491 |
| awa | 3396 | 5802 | 6617 | 1679 | 2370 |
| ay | 5102 | 15125 | 22802 | 13930 | 13933 |
| az | 180810 | 789902 | 1570889 | 1377797 | 1380325 |
| azb | 240990 | 585386 | 1241661 | 749575 | 753318 |
| ba | 62269 | 391926 | 625645 | 562730 | 563181 |
| ban | 18955 | 44138 | 86239 | 66213 | 66412 |
| bar | 26057 | 83298 | 185158 | 109082 | 109091 |
| bat_smg | 17013 | 41951 | 77417 | 51701 | 51733 |
| bcl | 13783 | 45457 | 78963 | 47819 | 47861 |
| be | 222883 | 821135 | 2499258 | 2204062 | 2204117 |
| bg | 285156 | 1336530 | 3967713 | 3618800 | 3627798 |
| bh | 7658 | 17052 | 29110 | 22157 | 22217 |
| bi | 1403 | 1712 | 3172 | 1991 | 1995 |
| bjn | 9672 | 19007 | 58660 | 32538 | 33071 |
| blk | 2786 | 11825 | 11341 | 5979 | 6129 |
| bm | 1111 | 2421 | 2451 | 1217 | 1218 |
| bn | 136921 | 736388 | 1530942 | 1161967 | 1162761 |
| bo | 11843 | 37121 | 8241 | 6265 | 6359 |
| bpy | 24742 | 115606 | 166906 | 86166 | 86170 |
| br | 78524 | 214128 | 657375 | 527295 | 527606 |
| bs | 86407 | 382114 | 1246030 | 965782 | 966511 |
| bug | 14231 | 14484 | 53879 | 14787 | 15146 |
| bxr | 2730 | 9571 | 27853 | 11560 | 11567 |
| ca | 691444 | 3596667 | 11359870 | 10236358 | 10237666 |
| cbk_zam | 2989 | 8322 | 9939 | 2790 | 2847 |
| cdo | 15922 | 30059 | 63474 | 29659 | 29705 |
| ce | 597137 | 2121587 | 3097393 | 1507129 | 1507806 |
| ceb | 5888811 | 11920613 | 37969424 | 33678489 | 33962205 |
| ch | 574 | 1166 | 2290 | 492 | 601 |
| chr | 980 | 1110 | 1311 | 779 | 790 |
| chy | 711 | 753 | 494 | 428 | 428 |
| ckb | 48903 | 163599 | 435662 | 224749 | 226749 |
| co | 6719 | 22954 | 46391 | 24149 | 24229 |
| cr | 158 | 216 | 209 | 94 | 94 |
| crh | 24117 | 29781 | 98534 | 70231 | 70235 |
| cs | 516037 | 2679537 | 9917806 | 8763103 | 8763291 |
| csb | 5315 | 14009 | 31294 | 16820 | 16820 |
| cu | 1171 | 2796 | 5283 | 2346 | 2349 |
| cv | 50525 | 157542 | 375399 | 166889 | 167497 |
| cy | 276031 | 992900 | 2011030 | 1613064 | 1620632 |
| da | 284765 | 1167917 | 4352733 | 3854239 | 3854549 |
| dag | 9248 | 29213 | 46084 | 10981 | 14213 |
| de | 2780056 | 16093948 | 52497421 | 50480495 | 50480548 |
| din | 485 | 1551 | 1096 | 197 | 197 |
| diq | 37565 | 70969 | 155656 | 141636 | 141695 |
| dsb | 3083 | 8760 | 19397 | 9652 | 9652 |
| dty | 3339 | 6219 | 7505 | 4417 | 4447 |
| dv | 4190 | 16809 | 7906 | 3612 | 3620 |
| dz | 652 | 2623 | 272 | 94 | 100 |
| ee | 1075 | 2326 | 1823 | 861 | 926 |
| el | 224207 | 1527561 | 4181433 | 3119952 | 3121967 |
| eml | 12169 | 53861 | 115729 | 65775 | 65940 |
| en | 6514924 | 40656507 | 109681826 | 107761324 | 107768438 |
| eo | 330486 | 1116191 | 4257655 | 3975927 | 3979379 |
| es | 1792062 | 10890435 | 33729712 | 31581851 | 31648945 |
| et | 233078 | 1110906 | 3558448 | 2879595 | 2886824 |
| eu | 386029 | 1405747 | 3398477 | 3025183 | 3030635 |
| ext | 3472 | 9626 | 20554 | 11966 | 11978 |
| fa | 901254 | 2357271 | 6189352 | 5862106 | 5870803 |
| fat | 1044 | 6092 | 1717 | 120 | 857 |
| ff | 1763 | 4103 | 3483 | 2304 | 2413 |
| fi | 373226 | 1667296 | 5221239 | 4658292 | 4663471 |
| fiu_vro | 6417 | 19897 | 40418 | 23563 | 23609 |
| fj | 1157 | 1782 | 4852 | 1910 | 1911 |
| fo | 11809 | 30828 | 119267 | 95117 | 95259 |
| fr | 2432972 | 15252697 | 43564517 | 42573624 | 42589064 |
| frp | 5341 | 10574 | 36358 | 24905 | 24926 |
| frr | 16038 | 30821 | 80265 | 68184 | 68315 |
| fur | 3665 | 10651 | 29516 | 16249 | 16278 |
| fy | 46011 | 206153 | 1271339 | 985227 | 985511 |
| ga | 52168 | 130535 | 347037 | 288261 | 288309 |
| gag | 2408 | 4844 | 8551 | 4520 | 4520 |
| gan | 4219 | 9689 | 18994 | 14119 | 14128 |
| gcr | 2227 | 5163 | 2763 | 1186 | 1186 |
| gd | 15850 | 48217 | 141290 | 95557 | 95562 |
| gl | 190419 | 910543 | 3674404 | 2937660 | 2938634 |
| glk | 6484 | 15344 | 32631 | 21395 | 21447 |
| gn | 5064 | 15481 | 40641 | 30389 | 30440 |
| gom | 4192 | 37508 | 14192 | 2369 | 2382 |
| gor | 14388 | 28133 | 107341 | 66191 | 67016 |
| got | 960 | 2186 | 4093 | 1404 | 1415 |
| gpe | 899 | 3383 | 1199 | 796 | 815 |
| gu | 30025 | 114805 | 459063 | 348651 | 348731 |
| guc | 546 | 2545 | 2300 | 1025 | 1138 |
| gur | 1010 | 5043 | 1761 | 227 | 244 |
| guw | 1263 | 3719 | 7474 | 3116 | 5375 |
| gv | 5036 | 12213 | 48801 | 19659 | 19663 |
| ha | 31977 | 149096 | 115029 | 97167 | 98184 |
| hak | 8694 | 11505 | 39744 | 28150 | 28152 |
| haw | 2470 | 5810 | 11169 | 5700 | 5705 |
| he | 323472 | 2648617 | 10904148 | 10367532 | 10379886 |
| hi | 150121 | 538451 | 964251 | 795726 | 798254 |
| hif | 10534 | 21169 | 43463 | 23970 | 24316 |
| hr | 189415 | 876107 | 3210326 | 2752205 | 2758602 |
| hsb | 13183 | 40760 | 91863 | 66632 | 66633 |
| ht | 64850 | 154160 | 201547 | 166206 | 167961 |
| hu | 346711 | 1859683 | 5267990 | 4707580 | 4710525 |
| hy | 298066 | 1542920 | 3767938 | 2689014 | 2690466 |
| hyw | 11358 | 83640 | 161227 | 82218 | 84817 |
| ia | 24581 | 43289 | 129914 | 96517 | 96595 |
| id | 620895 | 2138237 | 6589957 | 5629372 | 5644832 |
| ie | 11020 | 22342 | 60890 | 46054 | 46122 |
| ig | 19448 | 110907 | 57963 | 31022 | 31298 |
| ik | 737 | 1016 | 848 | 551 | 580 |
| ilo | 14135 | 74304 | 126533 | 75701 | 75705 |
| inh | 1754 | 4640 | 13284 | 5770 | 6011 |
| io | 36312 | 101555 | 303765 | 258933 | 259001 |
| is | 54348 | 170321 | 574897 | 436767 | 437784 |
| it | 1610989 | 8718610 | 27447754 | 26116131 | 26126157 |
| iu | 502 | 757 | 536 | 414 | 418 |
| ja | 1355269 | 9276459 | 29002111 | 27752954 | 27801000 |
| jam | 1571 | 2260 | 5887 | 3588 | 3590 |
| jbo | 1287 | 3088 | 5831 | 546 | 546 |
| jv | 66323 | 148710 | 547010 | 381682 | 382052 |
| ka | 167161 | 695865 | 2275552 | 422090 | 422095 |
| kaa | 3540 | 9814 | 12930 | 5312 | 5752 |
| kab | 5346 | 14709 | 36889 | 22000 | 22050 |
| kbd | 1549 | 6348 | 14594 | 5277 | 5280 |
| kbp | 1846 | 6005 | 7119 | 6875 | 6880 |
| kcg | 871 | 1839 | 2953 | 1857 | 1871 |
| kg | 1187 | 1933 | 3835 | 2292 | 2295 |
| ki | 1482 | 2899 | 2035 | 1386 | 1649 |
| kk | 235740 | 889990 | 1840304 | 1143049 | 1151399 |
| kl | 282 | 1024 | 1337 | 302 | 302 |
| km | 11422 | 84697 | 111378 | 40954 | 41529 |
| kn | 30729 | 261724 | 432994 | 188536 | 188807 |
| ko | 606386 | 2159706 | 6217786 | 5715559 | 5725614 |
| koi | 3260 | 9065 | 17068 | 10628 | 10628 |
| krc | 1465 | 6234 | 18092 | 7294 | 7311 |
| ks | 4176 | 9446 | 15252 | 5917 | 6226 |
| ksh | 2836 | 11043 | 26577 | 9484 | 9496 |
| ku | 55166 | 112840 | 269080 | 208679 | 210304 |
| kv | 5236 | 13396 | 32141 | 26727 | 26744 |
| kw | 6884 | 18901 | 49462 | 28074 | 28194 |
| ky | 75426 | 191772 | 271376 | 189656 | 190133 |
| la | 124150 | 240343 | 1456464 | 1283285 | 1283728 |
| lad | 3538 | 11910 | 37456 | 19124 | 19124 |
| lb | 57747 | 178507 | 573528 | 443583 | 444601 |
| lbe | 1205 | 2249 | 4470 | 2543 | 2543 |
| lez | 4067 | 16675 | 36970 | 25834 | 25842 |
| lfn | 4506 | 21746 | 29785 | 14554 | 14560 |
| lg | 3814 | 23386 | 15539 | 2088 | 2724 |
| li | 14134 | 58711 | 212772 | 137110 | 137367 |
| lij | 8092 | 23366 | 61410 | 34939 | 34940 |
| lld | 152613 | 158049 | 578033 | 443976 | 458150 |
| lmo | 67387 | 136650 | 373890 | 274174 | 274612 |
| ln | 3132 | 6066 | 11086 | 7838 | 7874 |
| lo | 4734 | 15005 | 27132 | 8562 | 8799 |
| lt | 204135 | 775863 | 2687983 | 2406710 | 2414909 |
| ltg | 1018 | 2979 | 5815 | 2190 | 2193 |
| lv | 118530 | 437086 | 1458341 | 1244609 | 1247181 |
| mad | 1113 | 3500 | 3762 | 1149 | 1157 |
| mai | 13285 | 22572 | 53246 | 38119 | 38128 |
| map_bms | 10875 | 16411 | 67964 | 51125 | 51137 |
| mdf | 4002 | 11043 | 21658 | 9178 | 9183 |
| mg | 92227 | 213580 | 328751 | 265931 | 267633 |
| mhr | 11010 | 33013 | 60771 | 38153 | 38220 |
| mi | 7274 | 10154 | 29052 | 24854 | 25216 |
| min | 223075 | 422381 | 1315030 | 513108 | 515548 |
| mk | 131522 | 695456 | 1984109 | 1639280 | 1640744 |
| ml | 84334 | 415940 | 797903 | 485482 | 486324 |
| mn | 23434 | 124485 | 295548 | 142014 | 142984 |
| mni | 10354 | 18872 | 29474 | 18810 | 19876 |
| mnw | 3136 | 34165 | 9342 | 1908 | 2387 |
| mr | 92464 | 326662 | 633452 | 383501 | 392709 |
| mrj | 10156 | 20132 | 48416 | 24098 | 24098 |
| ms | 344459 | 988647 | 2424535 | 1932685 | 1937647 |
| mt | 5381 | 49856 | 104636 | 51251 | 51278 |
| mwl | 4402 | 37271 | 127176 | 25729 | 26366 |
| my | 103938 | 334243 | 445026 | 300567 | 303288 |
| myv | 7515 | 21592 | 36762 | 26570 | 26591 |
| mzn | 17364 | 39937 | 89805 | 46962 | 47020 |
| nah | 5934 | 12478 | 30805 | 13093 | 14364 |
| nap | 11235 | 22336 | 41891 | 20798 | 20804 |
| nds | 79228 | 242004 | 583941 | 305374 | 305422 |
| nds_nl | 6484 | 28252 | 94875 | 51767 | 51785 |
| ne | 30359 | 91033 | 153937 | 124841 | 125078 |
| new | 71653 | 245033 | 454251 | 289444 | 289912 |
| nia | 1496 | 4047 | 4524 | 2258 | 2812 |
| nl | 1948842 | 5867108 | 17953497 | 16886996 | 16893078 |
| nn | 160106 | 549454 | 1751481 | 1375622 | 1376155 |
| no | 591000 | 2213493 | 7050421 | 6471776 | 6476157 |
| nov | 1341 | 3711 | 7466 | 3948 | 3955 |
| nqo | 1489 | 9858 | 23633 | 6056 | 6981 |
| nrm | 4571 | 14279 | 38935 | 33295 | 33321 |
| nso | 7618 | 9505 | 36826 | 35621 | 35623 |
| nv | 21911 | 57663 | 123762 | 107139 | 107139 |
| ny | 1060 | 3164 | 4750 | 1455 | 1490 |
| oc | 85099 | 303185 | 1035051 | 791403 | 792043 |
| olo | 4348 | 14334 | 18704 | 8634 | 8647 |
| om | 1710 | 7496 | 8222 | 4333 | 4416 |
| or | 17027 | 76677 | 137274 | 57023 | 57064 |
| os | 17468 | 40488 | 80943 | 48124 | 48414 |
| pa | 50421 | 226354 | 344239 | 197594 | 198080 |
| pag | 2533 | 41416 | 4150 | 2907 | 2907 |
| pam | 7816 | 16493 | 53785 | 29375 | 29715 |
| pap | 3153 | 12086 | 22157 | 18161 | 18233 |
| pcd | 5272 | 12203 | 15602 | 12319 | 12360 |
| pcm | 1019 | 4631 | 4161 | 1160 | 1261 |
| pdc | 2009 | 5406 | 8151 | 4122 | 4144 |
| pfl | 2717 | 14024 | 26150 | 10291 | 10294 |
| pi | 2972 | 5959 | 7773 | 201 | 201 |
| pih | 829 | 1065 | 2857 | 2016 | 2018 |
| pl | 1468194 | 5599437 | 19364191 | 18389560 | 18405120 |
| pms | 66552 | 170133 | 369956 | 308593 | 314917 |
| pnb | 67534 | 402101 | 937247 | 525105 | 533265 |
| pnt | 497 | 1467 | 3553 | 1715 | 1716 |
| ps | 19254 | 134868 | 72493 | 36348 | 36899 |
| pt | 1048823 | 5226543 | 16811382 | 15714686 | 15714890 |
| pwn | 328 | 1825 | 990 | 428 | 430 |
| qu | 22365 | 47078 | 133032 | 106686 | 106708 |
| rm | 3569 | 27345 | 47169 | 20460 | 20490 |
| rmy | 911 | 2221 | 4235 | 1854 | 1965 |
| rn | 726 | 1641 | 1436 | 594 | 601 |
| ro | 417630 | 1518438 | 4282072 | 3764830 | 3765626 |
| roa_rup | 1270 | 2751 | 4641 | 2527 | 2537 |
| roa_tara | 8407 | 18031 | 42040 | 14330 | 14331 |
| ru | 1889271 | 12344758 | 30796034 | 29268121 | 29288089 |
| rue | 7369 | 21429 | 61022 | 43241 | 43256 |
| rw | 7793 | 35619 | 38066 | 19821 | 20967 |
| sa | 12069 | 78188 | 104193 | 40307 | 41518 |
| sah | 16007 | 76450 | 82154 | 61041 | 61412 |
| sat | 8655 | 43624 | 57493 | 28497 | 28820 |
| sc | 6919 | 24434 | 66719 | 44707 | 44733 |
| scn | 21990 | 49686 | 132583 | 102735 | 102774 |
| sco | 34097 | 86464 | 301450 | 148184 | 148406 |
| sd | 16228 | 48679 | 79392 | 34572 | 35729 |
| se | 6101 | 10531 | 25844 | 17978 | 18010 |
| sg | 473 | 537 | 318 | 184 | 184 |
| sh | 445218 | 1213741 | 4337559 | 3858400 | 3860253 |
| shi | 1650 | 6036 | 10364 | 4715 | 4926 |
| shn | 10653 | 51542 | 46976 | 29925 | 29993 |
| si | 21959 | 132932 | 146935 | 55158 | 56422 |
| simple | 224811 | 618711 | 2014692 | 1689101 | 1689185 |
| sk | 230073 | 845501 | 2867955 | 2468707 | 2469129 |
| skr | 5505 | 62742 | 38412 | 15004 | 21015 |
| sl | 175804 | 810714 | 2597824 | 2067682 | 2068522 |
| sm | 995 | 1591 | 3838 | 2515 | 2523 |
| smn | 5004 | 12483 | 37008 | 22440 | 22492 |
| sn | 10159 | 19527 | 40437 | 31573 | 32763 |
| so | 8540 | 36173 | 53012 | 42913 | 43548 |
| sq | 94941 | 371562 | 699210 | 520709 | 522241 |
| sr | 657766 | 2331205 | 6562651 | 5257496 | 5264077 |
| srn | 1171 | 3050 | 6637 | 1752 | 1941 |
| ss | 783 | 2124 | 2382 | 1127 | 1139 |
| st | 982 | 1971 | 2510 | 1689 | 1701 |
| stq | 3648 | 10972 | 29713 | 15919 | 15920 |
| su | 57552 | 122590 | 496201 | 384518 | 384891 |
| sv | 2418380 | 5019466 | 22263222 | 21445193 | 21445441 |
| sw | 75109 | 218219 | 798980 | 688743 | 692052 |
| szl | 56229 | 109496 | 473528 | 129434 | 129479 |
| szy | 4628 | 49166 | 18867 | 2419 | 3187 |
| ta | 157642 | 780711 | 1642095 | 1141032 | 1142372 |
| tay | 2643 | 15831 | 10104 | 1496 | 5312 |
| tcy | 2135 | 9932 | 11073 | 4680 | 4745 |
| te | 83866 | 719826 | 822054 | 619184 | 622092 |
| tet | 1323 | 3797 | 8047 | 4093 | 4095 |
| tg | 108598 | 279635 | 761826 | 330974 | 331423 |
| th | 153075 | 715083 | 1723394 | 1395935 | 1398891 |
| ti | 388 | 987 | 1191 | 325 | 326 |
| tk | 4739 | 23629 | 18964 | 9717 | 9760 |
| tl | 43388 | 150141 | 447293 | 296084 | 296634 |
| tn | 1090 | 3960 | 3976 | 2008 | 2010 |
| to | 1512 | 2754 | 3542 | 2029 | 2080 |
| tpi | 1278 | 2055 | 3897 | 2193 | 2198 |
| tr | 500435 | 1806253 | 4476004 | 3964449 | 3965589 |
| trv | 1770 | 16650 | 3814 | 504 | 969 |
| ts | 674 | 1798 | 1557 | 903 | 909 |
| tt | 484761 | 1196573 | 2064576 | 1675637 | 1676579 |
| tum | 16778 | 31383 | 57382 | 28399 | 37107 |
| tw | 3568 | 16807 | 15312 | 10912 | 11495 |
| ty | 1175 | 1364 | 1563 | 1095 | 1095 |
| tyv | 3399 | 21968 | 21004 | 5535 | 5557 |
| udm | 5066 | 11432 | 24875 | 17709 | 17715 |
| ug | 8102 | 58982 | 23654 | 12671 | 12874 |
| uk | 522709 | 2867475 | 6800045 | 6445628 | 6451294 |
| ur | 194948 | 676227 | 1870488 | 910419 | 914840 |
| uz | 232879 | 859793 | 1344790 | 1073065 | 1084092 |
| ve | 764 | 1359 | 2524 | 2366 | 2366 |
| vec | 62729 | 98987 | 275972 | 194424 | 194447 |
| vep | 6853 | 43014 | 93864 | 39225 | 39228 |
| vi | 1300753 | 4103594 | 10852870 | 6884928 | 6892519 |
| vls | 7272 | 26374 | 61885 | 49639 | 49653 |
| vo | 32133 | 78015 | 125495 | 101612 | 101629 |
| wa | 11104 | 56305 | 116752 | 79686 | 80037 |
| war | 1158901 | 1342594 | 6654010 | 6009636 | 6009641 |
| wo | 1659 | 7693 | 10828 | 4057 | 4103 |
| wuu | 37170 | 58227 | 121928 | 82184 | 82237 |
| xal | 2008 | 4309 | 4582 | 2112 | 2113 |
| xh | 1502 | 4448 | 6733 | 2128 | 2186 |
| xmf | 19201 | 49944 | 179291 | 21189 | 22041 |
| yi | 14164 | 68937 | 172645 | 116102 | 116325 |
| yo | 29938 | 52231 | 85171 | 46928 | 47346 |
| za | 2388 | 3917 | 7463 | 4613 | 4665 |
| zea | 5445 | 16648 | 36161 | 23532 | 23578 |
| zh | 1310818 | 5501834 | 16397675 | 14380752 | 14421795 |
| zh_classical | 11775 | 44053 | 140340 | 71576 | 71692 |
| zh_min_nan | 425676 | 853753 | 2627115 | 2053956 | 2054838 |
| zh_yue | 121401 | 273459 | 844047 | 683130 | 683226 |
| zu | 10387 | 18211 | 22569 | 20193 | 20238 |
#### Validation
| | Articles | Paragraphs | Anchors | Anchors with QIDs | Anchors with PageIDs |
| :-- | --: | --: | --: | --: | --: |
| ab | 475 | 601 | 1061 | 399 | 399 |
| ace | 2443 | 2668 | 5197 | 2583 | 2587 |
| ady | 142 | 183 | 248 | 150 | 151 |
| af | 27383 | 44157 | 109108 | 100078 | 100123 |
| als | 11998 | 18277 | 44634 | 32874 | 32874 |
| alt | 481 | 827 | 1020 | 621 | 621 |
| am | 3746 | 5234 | 10111 | 5731 | 5756 |
| ami | 749 | 1431 | 744 | 179 | 304 |
| an | 10526 | 13588 | 74808 | 58195 | 58259 |
| ang | 826 | 1099 | 2647 | 1099 | 1102 |
| anp | 504 | 751 | 1698 | 437 | 581 |
| ar | 265368 | 401215 | 1295968 | 1249666 | 1250103 |
| arc | 377 | 418 | 1061 | 610 | 617 |
| ary | 1447 | 1870 | 5702 | 3885 | 3887 |
| arz | 367206 | 410487 | 876531 | 767742 | 768942 |
| as | 5463 | 8589 | 13953 | 7719 | 7732 |
| ast | 48345 | 97904 | 329690 | 197832 | 198042 |
| atj | 399 | 440 | 774 | 406 | 416 |
| av | 719 | 961 | 1918 | 1043 | 1053 |
| avk | 8056 | 9538 | 11816 | 3633 | 3772 |
| awa | 515 | 645 | 721 | 213 | 287 |
| ay | 1391 | 1653 | 2616 | 1481 | 1483 |
| az | 57070 | 88136 | 177151 | 155596 | 155858 |
| azb | 57642 | 64997 | 137053 | 83336 | 83778 |
| ba | 25690 | 43460 | 69052 | 61624 | 61666 |
| ban | 4053 | 4840 | 9581 | 7374 | 7385 |
| bar | 6905 | 9377 | 20546 | 12164 | 12164 |
| bat_smg | 4149 | 4706 | 8787 | 5820 | 5823 |
| bcl | 3355 | 5058 | 8759 | 5080 | 5083 |
| be | 64203 | 91174 | 276525 | 244114 | 244122 |
| bg | 98148 | 148234 | 438687 | 400356 | 401330 |
| bh | 1535 | 1891 | 3464 | 2630 | 2635 |
| bi | 154 | 159 | 251 | 151 | 151 |
| bjn | 1764 | 2166 | 6458 | 3694 | 3775 |
| blk | 887 | 1374 | 1538 | 821 | 839 |
| bm | 196 | 272 | 317 | 146 | 146 |
| bn | 50495 | 81841 | 169097 | 128508 | 128609 |
| bo | 2198 | 4079 | 934 | 746 | 752 |
| bpy | 10057 | 12879 | 18710 | 9693 | 9693 |
| br | 18687 | 23734 | 73278 | 59024 | 59056 |
| bs | 28533 | 42574 | 138483 | 107760 | 107846 |
| bug | 1636 | 1655 | 6141 | 1682 | 1731 |
| bxr | 754 | 1003 | 2930 | 1211 | 1211 |
| ca | 251952 | 399403 | 1265187 | 1140208 | 1140359 |
| cbk_zam | 460 | 932 | 1040 | 268 | 272 |
| cdo | 2953 | 3237 | 6938 | 3273 | 3281 |
| ce | 197899 | 234617 | 341843 | 166126 | 166206 |
| ceb | 1221405 | 1324624 | 4218179 | 3742385 | 3773844 |
| ch | 123 | 131 | 239 | 64 | 73 |
| chr | 124 | 134 | 175 | 100 | 100 |
| chy | 67 | 67 | 47 | 42 | 42 |
| ckb | 13511 | 18279 | 48490 | 25365 | 25540 |
| co | 1723 | 2587 | 5286 | 2729 | 2737 |
| cr | 22 | 23 | 22 | 13 | 13 |
| crh | 2978 | 3246 | 11005 | 7899 | 7899 |
| cs | 189136 | 297000 | 1101343 | 974485 | 974505 |
| csb | 1307 | 1533 | 3341 | 1851 | 1851 |
| cu | 250 | 275 | 540 | 229 | 229 |
| cv | 14374 | 17462 | 42486 | 19049 | 19114 |
| cy | 89897 | 110225 | 222476 | 177842 | 178698 |
| da | 87765 | 129990 | 482701 | 427333 | 427374 |
| dag | 2215 | 3237 | 4935 | 1169 | 1498 |
| de | 1120553 | 1788057 | 5831103 | 5607963 | 5607963 |
| din | 149 | 177 | 128 | 15 | 15 |
| diq | 6660 | 7883 | 17684 | 15853 | 15861 |
| dsb | 781 | 1032 | 2476 | 1301 | 1301 |
| dty | 554 | 659 | 861 | 480 | 483 |
| dv | 1227 | 1898 | 870 | 406 | 406 |
| dz | 215 | 303 | 21 | 8 | 8 |
| ee | 203 | 242 | 183 | 66 | 74 |
| el | 99725 | 169395 | 461747 | 344216 | 344456 |
| eml | 4387 | 6114 | 13938 | 8193 | 8214 |
| en | 2503257 | 4516442 | 12185882 | 11974436 | 11975194 |
| eo | 90949 | 123848 | 474727 | 442357 | 442772 |
| es | 701171 | 1209944 | 3752765 | 3514968 | 3522213 |
| et | 80911 | 123354 | 395877 | 319773 | 320587 |
| eu | 104388 | 156552 | 378553 | 337331 | 337944 |
| ext | 804 | 1045 | 2269 | 1344 | 1345 |
| fa | 191532 | 262121 | 688824 | 652200 | 653219 |
| fat | 446 | 709 | 214 | 3 | 97 |
| ff | 361 | 459 | 378 | 222 | 234 |
| fi | 123327 | 184244 | 576163 | 514419 | 514915 |
| fiu_vro | 1738 | 2263 | 4622 | 2623 | 2628 |
| fj | 168 | 213 | 604 | 214 | 214 |
| fo | 2625 | 3398 | 13383 | 10599 | 10617 |
| fr | 954388 | 1695419 | 4847588 | 4738268 | 4740047 |
| frp | 1018 | 1181 | 4089 | 2862 | 2862 |
| frr | 2968 | 3419 | 9609 | 7996 | 8011 |
| fur | 884 | 1168 | 3225 | 1833 | 1839 |
| fy | 15980 | 22974 | 139530 | 108300 | 108337 |
| ga | 10781 | 14493 | 38848 | 32343 | 32352 |
| gag | 440 | 551 | 961 | 465 | 465 |
| gan | 731 | 1045 | 2071 | 1536 | 1537 |
| gcr | 480 | 567 | 297 | 122 | 122 |
| gd | 4393 | 5296 | 15544 | 10458 | 10458 |
| gl | 62030 | 101112 | 407821 | 325854 | 325960 |
| glk | 1383 | 1747 | 3723 | 2435 | 2443 |
| gn | 1164 | 1728 | 4751 | 3521 | 3528 |
| gom | 2106 | 4116 | 1511 | 251 | 251 |
| gor | 2844 | 3082 | 11826 | 7315 | 7411 |
| got | 216 | 245 | 514 | 190 | 190 |
| gpe | 265 | 355 | 93 | 71 | 73 |
| gu | 8437 | 13008 | 50956 | 38242 | 38251 |
| guc | 198 | 279 | 312 | 141 | 162 |
| gur | 369 | 565 | 145 | 25 | 27 |
| guw | 332 | 393 | 827 | 313 | 616 |
| gv | 957 | 1324 | 5652 | 2252 | 2253 |
| ha | 10666 | 16571 | 12853 | 10862 | 10993 |
| hak | 1179 | 1302 | 4628 | 3155 | 3155 |
| haw | 541 | 650 | 1238 | 616 | 618 |
| he | 165541 | 295188 | 1213939 | 1153986 | 1155384 |
| hi | 36229 | 60184 | 108382 | 89102 | 89340 |
| hif | 2107 | 2369 | 5015 | 2648 | 2680 |
| hr | 62673 | 97103 | 354392 | 304964 | 305664 |
| hsb | 3599 | 4379 | 10001 | 7239 | 7240 |
| ht | 14693 | 17294 | 23011 | 18721 | 18928 |
| hu | 125438 | 206546 | 586091 | 523501 | 523814 |
| hy | 113060 | 171415 | 418503 | 298111 | 298292 |
| hyw | 5310 | 9207 | 17616 | 8842 | 9168 |
| ia | 4021 | 4850 | 14972 | 11257 | 11263 |
| id | 158648 | 237793 | 734148 | 627764 | 629525 |
| ie | 2213 | 2523 | 6750 | 5036 | 5046 |
| ig | 7944 | 12354 | 6464 | 3466 | 3493 |
| ik | 100 | 118 | 120 | 64 | 71 |
| ilo | 4096 | 8297 | 14183 | 8609 | 8609 |
| inh | 399 | 494 | 1298 | 626 | 645 |
| io | 8868 | 11368 | 33682 | 28744 | 28748 |
| is | 13573 | 18566 | 62576 | 47263 | 47360 |
| it | 584902 | 968880 | 3050620 | 2902006 | 2903047 |
| iu | 61 | 62 | 48 | 29 | 29 |
| ja | 573457 | 1032568 | 3222875 | 3083301 | 3088604 |
| jam | 249 | 274 | 623 | 399 | 399 |
| jbo | 270 | 321 | 562 | 56 | 56 |
| jv | 13108 | 16457 | 60143 | 42112 | 42148 |
| ka | 53071 | 76961 | 252383 | 46974 | 46975 |
| kaa | 775 | 1071 | 1476 | 669 | 717 |
| kab | 1269 | 1685 | 4050 | 2397 | 2403 |
| kbd | 474 | 663 | 1482 | 537 | 537 |
| kbp | 535 | 656 | 835 | 810 | 811 |
| kcg | 190 | 223 | 311 | 196 | 197 |
| kg | 187 | 213 | 420 | 260 | 260 |
| ki | 273 | 333 | 248 | 169 | 206 |
| kk | 76635 | 99268 | 204324 | 126732 | 127677 |
| kl | 97 | 129 | 162 | 43 | 43 |
| km | 3844 | 9340 | 12192 | 4524 | 4583 |
| kn | 14217 | 29387 | 48402 | 20992 | 21022 |
| ko | 154713 | 239887 | 689906 | 633527 | 634725 |
| koi | 682 | 1010 | 1815 | 1144 | 1144 |
| krc | 423 | 698 | 2022 | 841 | 846 |
| ks | 888 | 1006 | 1692 | 645 | 670 |
| ksh | 918 | 1156 | 2951 | 1053 | 1055 |
| ku | 10060 | 12771 | 29766 | 23050 | 23232 |
| kv | 1105 | 1456 | 3365 | 2787 | 2787 |
| kw | 1820 | 2171 | 5570 | 3076 | 3082 |
| ky | 16655 | 21571 | 31213 | 21712 | 21757 |
| la | 22397 | 26732 | 161732 | 142447 | 142486 |
| lad | 961 | 1286 | 3984 | 2056 | 2056 |
| lb | 15385 | 19667 | 60568 | 46664 | 46730 |
| lbe | 207 | 232 | 488 | 290 | 290 |
| lez | 1184 | 1764 | 3829 | 2760 | 2760 |
| lfn | 1455 | 2435 | 3328 | 1602 | 1604 |
| lg | 1272 | 2650 | 1795 | 239 | 305 |
| li | 4501 | 6650 | 24213 | 15790 | 15826 |
| lij | 1781 | 2607 | 6658 | 3933 | 3933 |
| lld | 17293 | 17539 | 64059 | 49327 | 50864 |
| lmo | 12641 | 14976 | 40217 | 29874 | 29946 |
| ln | 585 | 692 | 1321 | 996 | 997 |
| lo | 1144 | 1680 | 3023 | 991 | 1013 |
| lt | 62652 | 85962 | 300456 | 269264 | 270227 |
| ltg | 289 | 341 | 686 | 285 | 285 |
| lv | 34742 | 48371 | 160433 | 136594 | 136873 |
| mad | 284 | 381 | 439 | 135 | 136 |
| mai | 2184 | 2499 | 5878 | 4209 | 4212 |
| map_bms | 1539 | 1847 | 7486 | 5705 | 5705 |
| mdf | 1086 | 1244 | 2512 | 1077 | 1077 |
| mg | 20361 | 23650 | 36313 | 29821 | 29974 |
| mhr | 2863 | 3594 | 6538 | 4114 | 4122 |
| mi | 1078 | 1154 | 3214 | 2743 | 2776 |
| min | 42987 | 46277 | 143692 | 55809 | 56077 |
| mk | 46235 | 76890 | 219310 | 180884 | 181042 |
| ml | 31116 | 46345 | 88976 | 53726 | 53818 |
| mn | 8485 | 13887 | 32271 | 15330 | 15455 |
| mni | 1843 | 2102 | 3418 | 2183 | 2325 |
| mnw | 1284 | 3750 | 897 | 202 | 224 |
| mr | 26803 | 36202 | 70510 | 43103 | 44352 |
| mrj | 2062 | 2297 | 5627 | 2888 | 2888 |
| ms | 75473 | 110077 | 270064 | 215280 | 215811 |
| mt | 2516 | 5510 | 11680 | 5760 | 5761 |
| mwl | 1828 | 4316 | 15365 | 3216 | 3287 |
| my | 24005 | 37165 | 49321 | 33223 | 33518 |
| myv | 1732 | 2327 | 4094 | 2923 | 2925 |
| mzn | 3784 | 4409 | 9938 | 5199 | 5205 |
| nah | 1128 | 1314 | 3316 | 1418 | 1556 |
| nap | 2047 | 2473 | 4579 | 2249 | 2249 |
| nds | 20646 | 26845 | 65355 | 34090 | 34094 |
| nds_nl | 2127 | 3063 | 10188 | 5585 | 5587 |
| ne | 6956 | 10087 | 16847 | 13502 | 13536 |
| new | 22645 | 27233 | 50860 | 32165 | 32217 |
| nia | 312 | 430 | 512 | 277 | 329 |
| nl | 490380 | 651743 | 1994062 | 1874588 | 1875259 |
| nn | 44180 | 60918 | 194747 | 153072 | 153140 |
| no | 172653 | 245377 | 779775 | 715618 | 716153 |
| nov | 339 | 410 | 861 | 452 | 452 |
| nqo | 583 | 1037 | 2598 | 704 | 813 |
| nrm | 1318 | 1600 | 4276 | 3734 | 3736 |
| nso | 960 | 1038 | 4242 | 4119 | 4119 |
| nv | 5649 | 6281 | 13652 | 11768 | 11768 |
| ny | 236 | 318 | 392 | 126 | 126 |
| oc | 23067 | 33775 | 115155 | 87980 | 88063 |
| olo | 1273 | 1598 | 2162 | 997 | 998 |
| om | 401 | 830 | 891 | 401 | 412 |
| or | 6261 | 8669 | 16120 | 6752 | 6757 |
| os | 3923 | 4535 | 9130 | 5470 | 5524 |
| pa | 17242 | 24844 | 37813 | 21759 | 21812 |
| pag | 1602 | 4519 | 404 | 300 | 300 |
| pam | 1509 | 1831 | 6019 | 3230 | 3272 |
| pap | 773 | 1376 | 2526 | 2042 | 2056 |
| pcd | 1089 | 1361 | 1803 | 1334 | 1338 |
| pcm | 353 | 542 | 409 | 128 | 139 |
| pdc | 370 | 565 | 839 | 424 | 429 |
| pfl | 1113 | 1500 | 2861 | 1070 | 1070 |
| pi | 578 | 682 | 881 | 26 | 26 |
| pih | 118 | 125 | 317 | 217 | 218 |
| pl | 444095 | 621669 | 2149058 | 2041686 | 2043400 |
| pms | 16530 | 19186 | 41547 | 34783 | 35474 |
| pnb | 21586 | 44654 | 103992 | 58461 | 59380 |
| pnt | 147 | 172 | 389 | 177 | 178 |
| ps | 7566 | 14922 | 8427 | 4108 | 4187 |
| pt | 349931 | 580790 | 1868210 | 1745832 | 1745858 |
| pwn | 103 | 166 | 85 | 31 | 31 |
| qu | 4540 | 5211 | 14781 | 11746 | 11750 |
| rm | 1076 | 3100 | 5539 | 2293 | 2298 |
| rmy | 214 | 235 | 446 | 176 | 184 |
| rn | 125 | 172 | 124 | 53 | 53 |
| ro | 106169 | 168972 | 473512 | 416263 | 416347 |
| roa_rup | 214 | 290 | 458 | 254 | 254 |
| roa_tara | 1278 | 1979 | 4455 | 1534 | 1534 |
| ru | 806592 | 1369860 | 3416036 | 3245837 | 3247963 |
| rue | 2022 | 2513 | 7023 | 5064 | 5066 |
| rw | 2577 | 3925 | 4139 | 2223 | 2349 |
| sa | 4344 | 8607 | 11313 | 4249 | 4391 |
| sah | 4729 | 8472 | 9040 | 6623 | 6660 |
| sat | 3485 | 4960 | 6473 | 3225 | 3278 |
| sc | 1900 | 2807 | 7641 | 5096 | 5098 |
| scn | 4263 | 5604 | 14333 | 11167 | 11171 |
| sco | 7382 | 9639 | 33771 | 16432 | 16453 |
| sd | 3970 | 5499 | 8879 | 3804 | 3925 |
| se | 982 | 1149 | 2841 | 1958 | 1958 |
| sg | 67 | 72 | 36 | 24 | 24 |
| sh | 103283 | 135121 | 484459 | 429555 | 429770 |
| shi | 477 | 679 | 1144 | 545 | 570 |
| shn | 3633 | 5630 | 5456 | 3627 | 3639 |
| si | 7672 | 14760 | 16443 | 6215 | 6346 |
| simple | 52503 | 68765 | 224811 | 187586 | 187598 |
| sk | 67520 | 93957 | 317232 | 272711 | 272779 |
| skr | 2090 | 6926 | 4136 | 1683 | 2359 |
| sl | 55621 | 89740 | 285769 | 228421 | 228530 |
| sm | 153 | 171 | 485 | 297 | 297 |
| smn | 1163 | 1420 | 4517 | 2681 | 2688 |
| sn | 1896 | 2139 | 4351 | 3384 | 3529 |
| so | 2358 | 4032 | 6064 | 5027 | 5083 |
| sq | 25223 | 41621 | 79295 | 59156 | 59350 |
| sr | 177997 | 258455 | 728755 | 584663 | 585394 |
| srn | 281 | 342 | 796 | 205 | 225 |
| ss | 188 | 259 | 265 | 125 | 125 |
| st | 157 | 198 | 248 | 164 | 166 |
| stq | 804 | 1162 | 3150 | 1816 | 1816 |
| su | 10348 | 13687 | 55055 | 42915 | 42944 |
| sv | 467467 | 558522 | 2473790 | 2382576 | 2382608 |
| sw | 18014 | 24348 | 90302 | 77817 | 78145 |
| szl | 11292 | 12173 | 52459 | 14419 | 14424 |
| szy | 2391 | 5418 | 2042 | 235 | 285 |
| ta | 59923 | 87114 | 183399 | 126977 | 127148 |
| tay | 1192 | 1757 | 1101 | 175 | 591 |
| tcy | 769 | 1077 | 1089 | 464 | 465 |
| te | 43790 | 79667 | 91327 | 69148 | 69484 |
| tet | 294 | 412 | 871 | 471 | 471 |
| tg | 27060 | 31599 | 86180 | 37522 | 37561 |
| th | 49169 | 78814 | 189768 | 154097 | 154453 |
| ti | 87 | 99 | 89 | 22 | 22 |
| tk | 1328 | 2612 | 2116 | 1056 | 1062 |
| tl | 11731 | 16623 | 49726 | 32858 | 32914 |
| tn | 296 | 424 | 477 | 278 | 278 |
| to | 254 | 277 | 393 | 230 | 233 |
| tpi | 180 | 207 | 394 | 216 | 217 |
| tr | 134938 | 200972 | 496960 | 440639 | 440790 |
| trv | 807 | 1814 | 400 | 53 | 98 |
| ts | 155 | 203 | 219 | 132 | 132 |
| tt | 113689 | 132676 | 228544 | 185563 | 185662 |
| tum | 2188 | 3516 | 6442 | 3105 | 4083 |
| tw | 1249 | 1885 | 1729 | 1217 | 1291 |
| ty | 162 | 167 | 215 | 143 | 143 |
| tyv | 1494 | 2486 | 2342 | 611 | 617 |
| udm | 1036 | 1240 | 2781 | 1957 | 1957 |
| ug | 2629 | 6556 | 2657 | 1479 | 1493 |
| uk | 203057 | 318240 | 758049 | 718278 | 718908 |
| ur | 54784 | 75152 | 206169 | 99493 | 100041 |
| uz | 65767 | 95465 | 149763 | 119192 | 120519 |
| ve | 128 | 148 | 256 | 229 | 229 |
| vec | 9463 | 11242 | 32188 | 22525 | 22531 |
| vep | 3225 | 4804 | 10375 | 4295 | 4295 |
| vi | 330763 | 455933 | 1211343 | 768936 | 769829 |
| vls | 2189 | 2904 | 7133 | 5776 | 5777 |
| vo | 7308 | 8647 | 13902 | 11270 | 11273 |
| wa | 4457 | 6269 | 12736 | 8751 | 8794 |
| war | 146537 | 149236 | 738087 | 666983 | 666983 |
| wo | 516 | 864 | 1083 | 404 | 414 |
| wuu | 5530 | 6448 | 13732 | 9168 | 9171 |
| xal | 407 | 449 | 549 | 308 | 308 |
| xh | 399 | 550 | 804 | 284 | 293 |
| xmf | 4516 | 5414 | 19437 | 2342 | 2447 |
| yi | 5260 | 7563 | 18821 | 12493 | 12510 |
| yo | 4431 | 5855 | 9761 | 5361 | 5410 |
| za | 335 | 414 | 777 | 457 | 458 |
| zea | 1470 | 1847 | 3682 | 2569 | 2574 |
| zh | 389361 | 611537 | 1817382 | 1592929 | 1597686 |
| zh_classical | 3601 | 4995 | 15834 | 8157 | 8170 |
| zh_min_nan | 87849 | 94529 | 291330 | 227978 | 228083 |
| zh_yue | 23579 | 30146 | 92720 | 75081 | 75096 |
| zu | 1646 | 2050 | 2518 | 2228 | 2234 |
**NOTE:** The number of articles in the tables above refers to the number of articles that have at least one paragraph belonging to the article appear in the split.
## Additional Information
### Licensing Information
The WikiAnc dataset is given under the [Creative Commons Attribution ShareAlike 4.0 International](https://creativecommons.org/licenses/by-sa/4.0/) license.
|
mychen76/ds_receipts_v2_train | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 102670815.483
num_examples: 1137
download_size: 102731891
dataset_size: 102670815.483
---
# Dataset Card for "ds_receipts_v2_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
allenai/WildChat-nontoxic | ---
dataset_info:
features:
- name: conversation_id
dtype: string
- name: model
dtype: string
- name: timestamp
dtype: timestamp[s, tz=UTC]
- name: conversation
list:
- name: content
dtype: string
- name: language
dtype: string
- name: redacted
dtype: bool
- name: role
dtype: string
- name: toxic
dtype: bool
- name: turn
dtype: int64
- name: language
dtype: string
- name: openai_moderation
list:
- name: categories
struct:
- name: harassment
dtype: bool
- name: harassment/threatening
dtype: bool
- name: hate
dtype: bool
- name: hate/threatening
dtype: bool
- name: self-harm
dtype: bool
- name: self-harm/instructions
dtype: bool
- name: self-harm/intent
dtype: bool
- name: sexual
dtype: bool
- name: sexual/minors
dtype: bool
- name: violence
dtype: bool
- name: violence/graphic
dtype: bool
- name: category_scores
struct:
- name: harassment
dtype: float64
- name: harassment/threatening
dtype: float64
- name: hate
dtype: float64
- name: hate/threatening
dtype: float64
- name: self-harm
dtype: float64
- name: self-harm/instructions
dtype: float64
- name: self-harm/intent
dtype: float64
- name: sexual
dtype: float64
- name: sexual/minors
dtype: float64
- name: violence
dtype: float64
- name: violence/graphic
dtype: float64
- name: flagged
dtype: bool
- name: detoxify_moderation
list:
- name: identity_attack
dtype: float32
- name: insult
dtype: float32
- name: obscene
dtype: float32
- name: severe_toxicity
dtype: float32
- name: sexual_explicit
dtype: float32
- name: threat
dtype: float32
- name: toxicity
dtype: float32
- name: toxic
dtype: bool
- name: redacted
dtype: bool
splits:
- name: train
num_bytes: 2949938170
num_examples: 529514
download_size: 1587001052
dataset_size: 2949938170
pretty_name: WildChat-nontoxic
extra_gated_prompt: >-
Access to this dataset is automatically granted upon accepting the [**AI2
ImpACT License - Low Risk Artifacts (“LR
Agreement”)**](https://allenai.org/licenses/impact-lr) and completing all
fields below.
extra_gated_fields:
Your full name: text
Organization or entity you are affiliated with: text
State or country you are located in: text
Contact email: text
Please describe your intended use of the low risk artifact(s): text
I AGREE to the terms and conditions of the LR Agreement above: checkbox
I AGREE to AI2’s use of my information for legal notices and administrative matters: checkbox
I CERTIFY that the information I have provided is true and accurate: checkbox
size_categories:
- 100K<n<1M
---
# Dataset Card for WildChat-nontoxic
## Dataset Description
- **Paper:** https://wenting-zhao.github.io/papers/wildchat.pdf
- **License:** https://allenai.org/licenses/impact-lr
- **Language(s) (NLP):** multi-lingual
- **Point of Contact:** [Yuntian Deng](mailto:yuntiand@allenai.org)
### Dataset Summary
WildChat-nontoxic is the nontoxic subset of the [WildChat dataset](https://huggingface.co/datasets/allenai/WildChat), a collection of 530K conversations between human users and ChatGPT. The full WildChat dataset containing 650K conversations can be found [here](https://huggingface.co/datasets/allenai/WildChat). We collected WildChat by offering online users free access to OpenAI's GPT-3.5-Turbo and GPT-4. The dataset contains a broad spectrum of user-chatbot interactions that are not previously covered by other instruction fine-tuning datasets: for example, interactions include ambiguous user requests, code-switching, topic-switching, political discussions, etc. WildChat can serve both as a dataset for instructional fine-tuning and as a valuable resource for studying user behaviors.
WildChat-nontoxic has been openly released under AI2's ImpACT license as a low-risk artifact. The use of WildChat-nontoxic to cause harm is strictly prohibited.
### Languages
66 languages were detected in WildChat.
### Data Fields
- `conversation_id` (string): Each conversation has a unique id.
- `model` (string): The underlying OpenAI model, such as gpt-3.5-turbo or gpt-4.
- `timestamp` (timestamp): The timestamp of the last turn in the conversation in UTC.
- `conversation` (list): A list of user/assistant utterances. Each utterance is a dictionary containing the `role` of the speaker (user or assistant), the `content` of the utterance, the detected `language` of the utterance, whether the content of the utterance is considered `toxic`, and whether PII has been detected and anonymized (`redacted`).
- `turn` (int): The number of turns in the conversation. A turn refers to one round of user-assistant interaction.
- `language` (string): The language of the conversation. Note that this is the most frequently detected language in the utterances of the conversation.
- `openai_moderation` (list): A list of OpenAI Moderation results. Each element in the list corresponds to one utterance in the conversation.
- `detoxify_moderation` (list): A list of Detoxify results. Each element in the list corresponds to one utterance in the conversation.
- `toxic` (bool): Whether this conversation contains any utterances considered to be toxic by either OpenAI Moderation or Detoxify.
- `redacted` (bool): Whether this conversation contains any utterances in which PII is detected and anonymized.
### Personal and Sensitive Information
The data has been de-identified with Microsoft Presidio and hand-written rules by the authors.
### Inappropriate Content
If you discover inappropriate conversations in this nontoxic subset, please report their conversation ids to us for removal by sending us an email or using community discussions.
### Licensing Information
WildChat-nontoxic is made available under the [**AI2
ImpACT License - Low Risk Artifacts ("LR
Agreement")**](https://allenai.org/licenses/impact-lr)
### Citation Information
Please consider citing [our paper](https://openreview.net/forum?id=Bl8u7ZRlbM) if you find this dataset useful:
```
@inproceedings{
zhao2024inthewildchat,
title={(InThe)WildChat: 570K Chat{GPT} Interaction Logs In The Wild},
author={Zhao, Wenting and Ren, Xiang and Hessel, Jack and Cardie, Claire and Choi, Yejin and Deng, Yuntian},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=Bl8u7ZRlbM}
}
``` |
amaai-lab/MusicBench |
---
license: cc-by-sa-3.0
---
# MusicBench Dataset
The MusicBench dataset is a music audio-text pair dataset that was designed for text-to-music generation purpose and released along with Mustango text-to-music model. MusicBench is based on the MusicCaps dataset, which it expands from 5,521 samples to 52,768 training and 400 test samples!
## Dataset Details
MusicBench expands MusicCaps by:
1. Including music features of chords, beats, tempo, and key that are extracted from the audio.
2. Describing these music features using text templates and thus enhancing the original text prompts.
3. Expanding the number of audio samples by performing musically meaningful augmentations: semitone pitch shifts, tempo changes, and volume changes.
Train set size = 52,768 samples
Test set size = 400
### Dataset Description
MusicBench consists of 3 .json files and attached audio files in .tar.gz form.
The train set contains audio augmented samples and enhanced captions. Additionally, it offers ChatGPT rephrased captions for all the audio samples.
Both TestA and TestB sets contain the same audio content, but TestB has all 4 possible control sentences (related to 4 music features) in captions of all samples, while TestA has no control sentences in the captions.
For more details, see Figure 1 in our paper.
Each row of a .json file has:
1. **location** (of the files after decompressing the .tar.gz file)
2. **main_caption** – text prompts that are a result of augmentation (TestB contains control sentences, train set contains ChatGPT rephrased captions here)
3. **alt_caption** – in the case of TestB these are captions without any control sentences added.
4. prompt_aug – A control sentence related to volume change augmentation.
5. prompt_ch – A control sentence describing the chord sequence.
6. prompt_bt – A control sentence describing the beat count (meter)
7. prompt_bpm – A control sentence describing tempo, either in beats per minute (bpm), or in musical words, e.g., Adagio, Moderato, Presto.
8. prompt_key – A control sentence related to the extracted musical key.
9. **beats** – The beat and downbeat timestamps. This is used as an input for training Mustango.
10. bpm – The tempo feature saved as a number.
11. **chords** – The chord sequence contained in the track. This is used as an input for training Mustango.
12. **chords_time** – Timestamps of the detected chords. This is used as an input for training Mustango.
13. key – The root and the type of the detected key.
14. keyprob – The confidence score for this detected key provided by the detection algorithm.
# FMACaps Evaluation Dataset
Hereby, we also present you the FMACaps evaluation dataset which consists of 1000 samples extracted from the Free Music Archive (FMA) and pseudocaptioned through extracting tags from audio and then utilizing ChatGPT in-context learning. More information is available in our paper!
Most of the samples are 10 second long, exceptions are between 5 to 10 seconds long.
Data size: 1,000 samples
Sampling rate: 16 kHz
Files included:
1. 1,000 audio files in the "audiodata" folder
2. FMACaps_A – this file contains captions with NO control sentences.
3. FMACaps_B – this file contains captions with ALL control sentences. We used this file the our controllability evaluation of Mustango.
4. FMACaps_C – this file contains captions with SOME controls sentences. For each sample, we chose 0/1/2/3/4 control sentences with a probability of 25/30/20/15/10 %, as described in our paper. This file was used to objectively evaluate audio quality of Mustango.
The structure of each .json file is identical to MusicBench, as described in the previous section, with the exception of "alt_caption" column being empty. **All captions** are in the **"main_caption" column**!
## Links
- **Code Repository:** [https://github.com/AMAAI-Lab/mustango]
- **Paper:** [https://arxiv.org/abs/2311.08355]
- **Demo:** [https://replicate.com/declare-lab/mustango]
- **Website:** [https://amaai-lab.github.io/mustango/]
## Citation
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
```bibtex
@misc{melechovsky2023mustango,
title={Mustango: Toward Controllable Text-to-Music Generation},
author={Jan Melechovsky and Zixun Guo and Deepanway Ghosal and Navonil Majumder and Dorien Herremans and Soujanya Poria},
year={2023},
eprint={2311.08355},
archivePrefix={arXiv}
}
```
**License:** cc-by-sa-3.0 |
KrisPi/PythonTutor-Evol-1k-DPO-GPT4_vs_35 | ---
license: cc-by-nc-sa-4.0
language:
- en
size_categories:
- n<1K
---
Started with:
https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1
(GPT-3.5 Turbo)
Randomly selected 1000 where output contained "```python" in output
Generated GPT-4 answers to those for the sake of LIMA-like "Python Tutor" Instruct fine-tuning as well as validate DPO Fine-Tuning (where GPT-4 answers will be preferred to GPT-3.5 Turbo)
Then filtered refusals (looking for "impossible" or "sorry")
GPT-4 System Prompt:
You are an intelligent assistant that generates Python code. Start generation with ```python and end with ``` and nothing else. Just content between ```python and ```. The generated code should be wrapped in triple backticks and language identifier. Each line of code should be accompanied by a comment explaining it, and every function definition should be followed by a docstring describing the function, solution approach, and any edge cases considered. Try to wrap code in a function. |
lyon-nlp/summarization-summeval-fr-p2p | ---
license: apache-2.0
task_categories:
- summarization
language:
- fr
size_categories:
- n<1K
---
## SummEval FR
This dataset is a french translation of the original work [SummEval](https://github.com/Yale-LILY/SummEval).
The translation was made using [DeepL](https://www.deepl.com) from English to French.
We use this dataset for the french version of [MTEB](https://github.com/embeddings-benchmark/mteb) :
The annotations include summaries generated by 16 models from 100 source news articles (1600 examples in total). Each of the summaries was annotated by 5 indepedent crowdsource workers and 3 independent experts (8 annotations in total). Summaries were evaluated across 4 dimensions: coherence, consistency, fluency, relevance. Each source news article comes with the original reference from the CNN/DailyMail dataset and 10 additional crowdsources reference summaries.
For this dataset, the 3 expert annotations were averaged to get the human scores.
source : https://huggingface.co/datasets/mteb/summeval
### Usage
To use this dataset, you can run the following code :
```py
from datasets import load_dataset
dataset = load_dataset("lyon-nlp/summarization-summeval-fr-p2p", "test")
```
> Fabbri, A.R., Kryscinski, W., McCann, B., Socher, R., & Radev, D.R. (2020). SummEval: Re-evaluating Summarization Evaluation. Transactions of the Association for Computational Linguistics, 9, 391-409. |
Major-TOM/Core-S2L2A | ---
license: cc-by-sa-4.0
tags:
- earth-observation
- remote-sensing
- sentinel-2
- multi-spectral
- satellite
size_categories:
- 1M<n<10M
dataset_info:
- config_name: default
features:
- name: product_id
dtype: string
- name: grid_cell
dtype: string
- name: product_datetime
dtype: string
- name: thumbnail
dtype: image
- name: B01
dtype: binary
- name: B02
dtype: binary
- name: B03
dtype: binary
- name: B04
dtype: binary
- name: B05
dtype: binary
- name: B06
dtype: binary
- name: B07
dtype: binary
- name: B08
dtype: binary
- name: B8A
dtype: binary
- name: B09
dtype: binary
- name: B11
dtype: binary
- name: B12
dtype: binary
- name: cloud_mask
dtype: binary
configs:
- config_name: default
data_files: images/*.parquet
- config_name: metadata
data_files: metadata.parquet
---
# Core-S2L2A
Contains a global coverage of Sentinel-2 (Level 1C) patches, each of size 1,068 x 1,068 pixels.
| Source | Sensing Type | Number of Patches | Patch Size | Total Pixels |
|--------|--------------|-------------------|------------|--------------|
|Sentinel-2 Level-2A |Optical Multispectral|2,245,886|1,068 x 1,068 (10 m) | > 2.564 Trillion |
## Content
| Column | Details | Resolution |
|--------|---------|------------|
| B01 | Coastal aerosol, 442.7 nm (S2A), 442.3 nm (S2B) | 60m |
| B02 | Blue, 492.4 nm (S2A), 492.1 nm (S2B) | 10m |
| B03 | Green, 559.8 nm (S2A), 559.0 nm (S2B) | 10m |
| B04 | Red, 664.6 nm (S2A), 665.0 nm (S2B) | 10m |
| B05 | Vegetation red edge, 704.1 nm (S2A), 703.8 nm (S2B) | 20m |
| B06 | Vegetation red edge, 740.5 nm (S2A), 739.1 nm (S2B) | 20m |
| B07 | Vegetation red edge, 782.8 nm (S2A), 779.7 nm (S2B) | 20m |
| B08 | NIR, 832.8 nm (S2A), 833.0 nm (S2B) | 10m |
| B8A | Narrow NIR, 864.7 nm (S2A), 864.0 nm (S2B) | 20m |
| B09 | Water vapour, 945.1 nm (S2A), 943.2 nm (S2B) | 60m |
| B11 | SWIR, 1613.7 nm (S2A), 1610.4 nm (S2B) | 20m |
| B12 | SWIR, 2202.4 nm (S2A), 2185.7 nm (S2B) | 20m |
| cloud_mask | Cloud Mask produced by SEnSeI | 10m |
| thumbnail | RGB composite [B04, B03, B02] saved as png | 10m |
## Spatial Coverage
This is a global monotemporal dataset. Nearly every piece of Earth captured by Sentinel-2 is contained at least once in this dataset (and only once, excluding some marginal overlaps).
The following figure demonstrates the spatial coverage (only black pixels are absent):
## Example Use
Interface scripts are available at https://github.com/ESA-PhiLab/Major-TOM
Here's a sneak peek with a thumbnail image:
```python
from fsspec.parquet import open_parquet_file
import pyarrow.parquet as pq
from io import BytesIO
from PIL import Image
PARQUET_FILE = 'part_03900' # parquet number
ROW_INDEX = 42 # row number (about 500 per parquet)
url = "https://huggingface.co/datasets/Major-TOM/Core-S2L2A/resolve/main/images/{}.parquet".format(PARQUET_FILE)
with open_parquet_file(url,columns = ["thumbnail"]) as f:
with pq.ParquetFile(f) as pf:
first_row_group = pf.read_row_group(ROW_INDEX, columns=['thumbnail'])
stream = BytesIO(first_row_group['thumbnail'][0].as_py())
image = Image.open(stream)
```
## Cite
[](https://arxiv.org/abs/2402.12095/)
```latex
@inproceedings{Major_TOM,
title={Major TOM: Expandable Datasets for Earth Observation},
author={Alistair Francis and Mikolaj Czerkawski},
year={2024},
eprint={2402.12095},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
Powered by [Φ-lab, European Space Agency (ESA) 🛰️](https://huggingface.co/ESA-philab) |
pythainlp/thailaw-v1.0 | ---
language:
- th
license: cc0-1.0
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 920732139
num_examples: 52556
download_size: 212104476
dataset_size: 920732139
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- legal
---
# Dataset Card for "ThaiLaw v1.0"
## English
Thai Law Dataset (Act of Parliament) v1.0
- Data source from Office of the Council of State, Thailand [https://www.krisdika.go.th/](https://www.krisdika.go.th/) and [law.go.th](https://law.go.th/).
- This part of [PyThaiNLP Project](https://github.com/PyThaiNLP/).
- License Dataset is public domain.
## Thai
คลังข้อมูลกฎหมายไทย (พระราชบัญญัติ) รุ่น 1.0
- ข้อมูลเก็บรวบรวมมาจากเว็บไซต์สำนักงานคณะกรรมการกฤษฎีกา [https://www.krisdika.go.th/](https://www.krisdika.go.th/) และ [law.go.th](https://law.go.th/)
- โครงการนี้เป็นส่วนหนึ่งในแผนพัฒนา [PyThaiNLP](https://github.com/PyThaiNLP/)
- ข้อมูลที่รวบรวมในคลังข้อความนี้เป็นสาธารณสมบัติ (public domain) ตามพ.ร.บ.ลิขสิทธิ์ พ.ศ. 2537 มาตรา 7 (สิ่งต่อไปนี้ไม่ถือว่าเป็นงานอันมีลิขสิทธิ์ตามพระราชบัญญัตินี้ (1) ข่าวประจำวัน และข้อเท็จจริงต่างๆ ที่มีลักษณะเป็นเพียงข่าวสารอันมิใช่งานในแผนกวรรณคดี แผนกวิทยาศาสตร์ หรือแผนกศิลปะ [...] (3) ระเบียบ ข้อบังคับ ประกาศ คำสั่ง คำชี้แจง และหนังสือตอบโต้ของกระทรวง ทบวง กรม หรือหน่วยงานอื่นใดของรัฐหรือของท้องถิ่น [...])
## Citations
If you use `ThaiLaw` in your project or publication, please cite the dataset as follows:
```bib
@misc{thailaw,
doi = {10.5281/ZENODO.10701494},
url = {https://zenodo.org/doi/10.5281/zenodo.10701494},
author = {Phatthiyaphaibun, Wannaphong},
language = {th},
title = {ThaiLaw: Thai Law Dataset},
publisher = {Zenodo},
year = {2024},
copyright = {Creative Commons Zero v1.0 Universal}
}
```
Zenodo: [https://zenodo.org/records/10701494](https://zenodo.org/records/10701494) |
kevinjesse/ManyTypes4TypeScript | ---
license:
- cc-by-4.0
annotations_creators:
- found
- machine-generated
language_creators:
- found
language:
- code
language_details: TypeScript
multilinguality:
- monolingual
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- type-inference
pretty_name: ManyTypes4TypeScript
---
# Models Trained On ManyTypes4TypeScript
- **[CodeBERT]**(https://huggingface.co/kevinjesse/codebert-MT4TS)
- **[GraphCodeBERT]**(https://huggingface.co/kevinjesse/graphcodebert-MT4TS)
- **[CodeBERTa]**(https://huggingface.co/kevinjesse/codeberta-MT4TS)
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits-sample-size)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Dataset:** [https://doi.org/10.5281/zenodo.6387001](https://doi.org/10.5281/zenodo.6387001)
- **PapersWithCode:** [https://paperswithcode.com/sota/type-prediction-on-manytypes4typescript](https://paperswithcode.com/sota/type-prediction-on-manytypes4typescript)
### Dataset Summary
ManyTypes4TypeScript type inference dataset, available at the DOI link below. [](https://doi.org/10.5281/zenodo.6387001)
Given a line of source code, the task is to identify types that correspond with the tokens of code. We treat this as a tagging task similar to NER and POS where the model must predict a structural property of code i.e types. This is a classification task where the labels are the top occurring types in the training dataset. The size type vocabulary can be changed with the scripts found on Github.
### Supported Tasks and Leaderboards
- `multi-class-classification`: The dataset can be used to train a model for predicting types across a sequence.
### Languages
- TypeScript
## Dataset Structure
### Data Instances
An example of 'validation' looks as follows.
```
{
"tokens": ["import", "{", "Component", ",", "ChangeDetectorRef", "}", "from", "'@angular/core'", ";", "import", "{", "Router", "}", "from", "'@angular/router'", ";", "import", "{", "MenuController", "}", "from", "'@ionic/angular'", ";", "import", "{", "Storage", "}", "from", "'@ionic/storage'", ";", "import", "Swiper", "from", "'swiper'", ";", "@", "Component", "(", "{", "selector", ":", "'page-tutorial'", ",", "templateUrl", ":", "'tutorial.html'", ",", "styleUrls", ":", "[", "'./tutorial.scss'", "]", ",", "}", ")", "export", "class", "TutorialPage", "{", "showSkip", "=", "true", ";", "private", "slides", ":", "Swiper", ";", "constructor", "(", "public", "menu", ",", "public", "router", ",", "public", "storage", ",", "private", "cd", ")", "{", "}", "startApp", "(", ")", "{", "this", ".", "router", ".", "navigateByUrl", "(", "'/app/tabs/schedule'", ",", "{", "replaceUrl", ":", "true", "}", ")", ".", "then", "(", "(", ")", "=>", "this", ".", "storage", ".", "set", "(", "'ion_did_tutorial'", ",", "true", ")", ")", ";", "}", "setSwiperInstance", "(", "swiper", ")", "{", "this", ".", "slides", "=", "swiper", ";", "}", "onSlideChangeStart", "(", ")", "{", "this", ".", "showSkip", "=", "!", "this", ".", "slides", ".", "isEnd", ";", "this", ".", "cd", ".", "detectChanges", "(", ")", ";", "}", "ionViewWillEnter", "(", ")", "{", "this", ".", "storage", ".", "get", "(", "'ion_did_tutorial'", ")", ".", "then", "(", "res", "=>", "{", "if", "(", "res", "===", "true", ")", "{", "this", ".", "router", ".", "navigateByUrl", "(", "'/app/tabs/schedule'", ",", "{", "replaceUrl", ":", "true", "}", ")", ";", "}", "}", ")", ";", "this", ".", "menu", ".", "enable", "(", "false", ")", ";", "}", "ionViewDidLeave", "(", ")", "{", "this", ".", "menu", ".", "enable", "(", "true", ")", ";", "}", "}"],
"labels": [null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, "MenuController", null, null, "Router", null, null, "Storage", null, null, "ChangeDetectorRef", null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, "Swiper", null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null],
"url": "https://github.com/ionic-team/ionic-conference-app",
"path": "ionic-conference-app/src/app/pages/tutorial/tutorial.ts",
"commit_hash": "34d97d29369377a2f0173a2958de1ee0dadb8a6e",
"file": "tutorial.ts"}
}
```
### Data Fields
The data fields are the same among all splits.
#### default
|field name. | type | description |
|------------|-------------|--------------------------------------------|
|tokens |list[string] | Sequence of tokens (word tokenization) |
|labels |list[string] | A list of corresponding types |
|url |string | Repository URL |
|path |string | Original file path that contains this code |
|commit_hash |string | Commit identifier in the original project |
|file |string | File name |
### Data Splits
| name | train |validation| test |
|---------:|---------:|---------:|--------:|
|projects | 75.00% | 12.5% | 12.5% |
|files | 90.53% | 4.43% | 5.04% |
|sequences | 91.95% | 3.71% | 4.34% |
|types | 95.33% | 2.21% | 2.46% |
##Types by the Numbers
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
Human annotated types in optionally typed languages and the compiler inferred annotations.
#### Annotation process
#### Who are the annotators?
Developers and TypeScript Compiler.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
https://github.com/kevinjesse
### Licensing Information
Creative Commons 4.0 (CC) license
### Citation Information
```
``` |
tarteel-ai/everyayah | ---
pretty_name: Tarteel AI - EveryAyah Dataset
dataset_info:
features:
- name: audio
dtype: audio
- name: duration
dtype: float64
- name: text
dtype: string
- name: reciter
dtype: string
splits:
- name: train
num_bytes: 262627688145.3
num_examples: 187785
- name: test
num_bytes: 25156009734.72
num_examples: 23473
- name: validation
num_bytes: 23426886730.218
num_examples: 23474
download_size: 117190597305
dataset_size: 311210584610.23804
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
language:
- ar
license:
- mit
multilinguality:
- monolingual
paperswithcode_id: tarteel-everyayah
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
task_ids: []
train-eval-index:
- config: clean
task: automatic-speech-recognition
task_id: speech_recognition
splits:
train_split: train
eval_split: test
validation_split: validation
col_mapping:
audio: audio
text: text
reciter: text
metrics:
- type: wer
name: WER
- type: cer
name: CER
---
﷽
# Dataset Card for Tarteel AI's EveryAyah Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Tarteel AI](https://www.tarteel.ai/)
- **Repository:** [Needs More Information]
- **Point of Contact:** [Mohamed Saad Ibn Seddik](mailto:ms.ibnseddik@tarteel.ai)
### Dataset Summary
This dataset is a collection of Quranic verses and their transcriptions, with diacritization, by different reciters.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
The audio is in Arabic.
## Dataset Structure
### Data Instances
A typical data point comprises the audio file `audio`, and its transcription called `text`.
The `duration` is in seconds, and the author is `reciter`.
An example from the dataset is:
```
{
'audio': {
'path': None,
'array': array([ 0. , 0. , 0. , ..., -0.00057983,
-0.00085449, -0.00061035]),
'sampling_rate': 16000
},
'duration': 6.478375,
'text': 'بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ',
'reciter': 'abdulsamad'
}
```
### Data Fields
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- text: The transcription of the audio file.
- duration: The duration of the audio file.
- reciter: The reciter of the verses.
### Data Splits
| | Train | Test | Validation |
| ----- | ----- | ---- | ---------- |
| dataset | 187785 | 23473 | 23474 |
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
```
```
### Contributions
This dataset was created by:
|
LangChainDatasets/question-answering-paul-graham | ---
license: mit
---
|
crumb/Clean-Instruct-440k | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: input
dtype: string
splits:
- name: train
num_bytes: 650842125.0
num_examples: 443612
download_size: 357775511
dataset_size: 650842125.0
license: mit
task_categories:
- conversational
language:
- en
---
# Dataset Card for "Clean-Instruct"
[yahma/alpaca-cleaned](https://hf.co/datasets/yahma/alpaca-cleaned) + [crumb/gpt4all-clean](https://hf.co/datasets/crumb/gpt4all-clean) + GPTeacher-Instruct-Dedup
It isn't perfect, but it's 443k high quality semi-cleaned instructions without "As an Ai language model".
```python
from datasets import load_dataset
dataset = load_dataset("crumb/clean-instruct", split="train")
def promptify(example):
if example['input']!='':
return {"text": f"<instruction> {example['instruction']} <input> {example['input']} <output> {example['output']}"}
return {"text": f"<instruction> {example['instruction']} <output> {example['output']}"}
dataset = dataset.map(promptify, batched=False)
dataset = dataset.remove_columns(["instruction", "input", "output"])
``` |
CrowdAILab/scicap | ---
license: cc-by-nc-sa-4.0
---
# The 1st Scientific Figure Captioning (SciCap) Challenge 📖📊
Welcome to the 1st Scientific Figure Captioning (SciCap) Challenge! 🎉 This dataset contains approximately 400,000 scientific figure images sourced from various arXiv papers, along with their captions and relevant paragraphs. The challenge is open to researchers, AI/NLP/CV practitioners, and anyone interested in developing computational models for generating textual descriptions for visuals. 💻
*Challenge [homepage](http://SciCap.AI) 🏠*
## Challenge Overview 🌟
The SciCap Challenge will be hosted at ICCV 2023 in the 5th Workshop on Closing the Loop Between Vision and Language (October 2-3, Paris, France) 🇫🇷. Participants are required to submit the generated captions for a hidden test set for evaluation.
The challenge is divided into two phases:
- **Test Phase (2.5 months):** Use the provided training set, validation set, and public test set to build and test the models.
- **Challenge Phase (2 weeks):** Submit results for a hidden test set that will be released before the submission deadline.
Winning teams will be determined based on their results for the hidden test set 🏆. Details of the event's important dates, prizes, and judging criteria are listed on the challenge homepage.
## Dataset Overview and Download 📚
The SciCap dataset contains an expanded version of the [original SciCap](https://aclanthology.org/2021.findings-emnlp.277.pdf) dataset, and includes figures and captions from arXiv papers in eight categories: Computer Science, Economics, Electrical Engineering and Systems Science, Mathematics, Physics, Quantitative Biology, Quantitative Finance, and Statistics 📊. Additionally, it covers data from ACL Anthology papers [ACL-Fig](https://arxiv.org/pdf/2301.12293.pdf).
You can download the dataset using the following command:
```python
from huggingface_hub import snapshot_download
snapshot_download(repo_id="CrowdAILab/scicap", repo_type='dataset')
```
_Merge all image split files into one_ 🧩
```
zip -F img-split.zip --out img.zip
```
The dataset schema is similar to the `mscoco` dataset:
- **images:** two separated folders - arXiv and acl figures 📁
- **annotations:** JSON files containing text information (filename, image id, figure type, OCR, and mapped image id, captions, normalized captions, paragraphs, and mentions) 📝
## Evaluation and Submission 📩
You have to submit your generated captions in JSON format as shown below:
```json
[
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
},
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
}
...
]
```
Submit your results using this [challenge link](https://eval.ai/web/challenges/challenge-page/2012/overview) 🔗. Participants must register on [Eval.AI](http://Eval.AI) to access the leaderboard and submit results.
**Please note:** Participants should not use the original captions from the arXiv papers (termed "gold data") as input for their systems ⚠️.
## Technical Report Submission 🗒️
All participating teams must submit a 2-4 page technical report detailing their system, adhering to the ICCV 2023 paper template 📄. Teams have the option to submit their reports to either the archival or non-archival tracks of the 5th Workshop on Closing the Loop Between Vision and Language.
Good luck with your participation in the 1st SciCap Challenge! 🍀🎊 |
foduucom/table-detection-yolo | ---
task_categories:
- object-detection
tags:
- foduuai
- table
- Documents
- bordered table
- borderless table
- unstructured document
language:
- en
pretty_name: TableBorderNet
size_categories:
- 1K<n<10K
---
<div align="center">
<img width="640" alt="foduucom/table-detection-yolo" src="https://huggingface.co/datasets/foduucom/table-detection-yolo/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['bordered', 'borderless']
```
### Number of Images
```json
{'test': 34, 'train': 238, 'valid': 70}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("foduucom/table-detection-yolo", name="full")
example = ds['train'][0]
```
### Dataset Summary
Certainly! Here's a dataset summary for your dataset of images containing tables that are categorized as border and borderless, provided in YOLO format:
## Dataset Summary
The **Table Detection Dataset** is a curated collection of images, each depicting tables that are classified as either 'bordered' or 'borderless'. The dataset is provided in YOLO format, featuring annotations for accurate object detection and classification. It serves as a valuable resource for researchers, developers, and practitioners working on table detection tasks, with a specific focus on distinguishing between tables with distinct visual characteristics.
**Key Features:**
- **Image Variety:** The dataset encompasses a diverse range of images, capturing tables from various real-world scenarios and environments.
- **Annotation Precision:** Each image is meticulously annotated with bounding box coordinates and class labels, indicating whether the table is 'bordered' or 'borderless'.
- **YOLO Format:** Annotations follow the YOLO format, making it suitable for training and evaluating object detection models.
- **Research and Development:** The dataset is designed to facilitate advancements in table detection algorithms and technologies, enabling the development of models capable of accurately identifying and classifying different types of tables.
Whether you are working on document analysis, data extraction, or image-based content recognition, the Table Detection Dataset provides an essential foundation for enhancing the capabilities of object detection models in identifying tables with varying visual attributes. By offering a comprehensive collection of border and borderless tables, this dataset empowers the AI community to tackle challenges in table detection across a wide range of applications.
For more details and access to the dataset, please refer to info@foduu.com . |
ymoslem/Law-StackExchange | ---
license: cc-by-sa-4.0
task_categories:
- question-answering
- text-classification
- sentence-similarity
language:
- en
tags:
- legal
pretty_name: Law Stack Exchange Questions and Answers
size_categories:
- 10K<n<100K
---
All StackExchange legal questions and their answers from the Law site, up to 14 August 2023. The repository includes a notebook for the process using the official StackExchange API. |
Hani89/medical_asr_recording_dataset | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio
struct:
- name: array
sequence:
sequence: float32
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 3128740048
num_examples: 5328
- name: test
num_bytes: 776455056
num_examples: 1333
download_size: 3882364624
dataset_size: 3905195104
license: apache-2.0
task_categories:
- automatic-speech-recognition
language:
- en
tags:
- medical
size_categories:
- 1K<n<10K
---
**Data Source**<br>
[Kaggle Medical Speech, Transcription, and Intent](https://www.kaggle.com/datasets/paultimothymooney/medical-speech-transcription-and-intent "Visit Original Dataset Page on Kaggle")<br>
**Context**<br>
>8.5 hours of audio utterances paired with text for common medical symptoms.<br>
**Content**<br>
>This data contains thousands of audio utterances for common medical symptoms like “knee pain” or “headache,” totaling more than 8 hours in aggregate. Each utterance was created by individual human contributors based on a given symptom. These audio snippets can be used to train conversational agents in the medical field.<br>
>
>This Figure Eight dataset was created via a multi-job workflow. The first involved contributors writing text phrases to describe symptoms given. For example, for “headache,” a contributor might write “I need help with my migraines.” Subsequent jobs captured audio utterances for accepted text strings.<br>
>
>Note that some of the labels are incorrect and some of the audio files have poor quality. I would recommend cleaning the dataset before training any machine learning models.<br>
>
>This dataset contains both the audio utterances and corresponding transcriptions.<br>
**What's new**<br>
*The data is clean from all columns except for the file_path and phrase<br>
*All Audios are loaded into the DatasetDict as an 1D array, float32<br>
*All Audios are resampled into 16K<br>
*The new structure :<br>
train = {<br>
'audio': {<br>
'path': file_path, *the mp3 files is not included here, please visit the kaggle to dowload em*<br>
'array': waveform_np,<br>
'sampling_rate': 16000<br>
},<br>
'sentence': the text transcription<br>
} |
freQuensy23/sexting_prompts | ---
license: apache-2.0
dataset_info:
features:
- name: prompt
dtype: string
- name: answer
dtype: string
- name: dialog_id
dtype: string
splits:
- name: train
num_bytes: 233996
num_examples: 134
- name: test
num_bytes: 136180
num_examples: 41
download_size: 57072
dataset_size: 370176
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
TICK666/Basic-Math-Chinese-1M-V1.1 | ---
license: llama2
task_categories:
- question-answering
language:
- zh
pretty_name: Basic-Math-Chinese-1M-V1.1
size_categories:
- 1M<n<10M
---
比较于上一个版本
·1.新增了乘方和开方(二次方根)的题目
·2.新增生成比例:
四则运算45%
一元一次方程30%
实际问题15%
乘方与开方10%
·3.新增四则运算变异:生成时有20%的几率在后面问“这个数(加,减,乘,除)a等于几?”(可堆叠)
联系方式:qq:2981447942
bilibili:一髅子Tick |
ayymen/Pontoon-Translations | ---
configs:
- config_name: en-ht
data_files: en-ht.tsv
- config_name: en-ab
data_files: en-ab.tsv
- config_name: en-cs
data_files: en-cs.tsv
- config_name: en-nyn
data_files: en-nyn.tsv
- config_name: en-fi
data_files: en-fi.tsv
- config_name: en-nr
data_files: en-nr.tsv
- config_name: en-ace
data_files: en-ace.tsv
- config_name: en-yua
data_files: en-yua.tsv
- config_name: en-zh-CN
data_files: en-zh-CN.tsv
- config_name: en-bs
data_files: en-bs.tsv
- config_name: en-de
data_files: en-de.tsv
- config_name: en-ny
data_files: en-ny.tsv
- config_name: en-ca-valencia
data_files: en-ca-valencia.tsv
- config_name: en-lij
data_files: en-lij.tsv
- config_name: en-cv
data_files: en-cv.tsv
- config_name: en-xh
data_files: en-xh.tsv
- config_name: en-son
data_files: en-son.tsv
- config_name: en-bm
data_files: en-bm.tsv
- config_name: en-gn
data_files: en-gn.tsv
- config_name: en-lb
data_files: en-lb.tsv
- config_name: en-lv
data_files: en-lv.tsv
- config_name: en-pl
data_files: en-pl.tsv
- config_name: en-bo
data_files: en-bo.tsv
- config_name: en-es-AR
data_files: en-es-AR.tsv
- config_name: en-tig
data_files: en-tig.tsv
- config_name: en-nb-NO
data_files: en-nb-NO.tsv
- config_name: en-tk
data_files: en-tk.tsv
- config_name: en-xcl
data_files: en-xcl.tsv
- config_name: en-ann
data_files: en-ann.tsv
- config_name: en-en-CA
data_files: en-en-CA.tsv
- config_name: en-yo
data_files: en-yo.tsv
- config_name: en-mix
data_files: en-mix.tsv
- config_name: en-tn
data_files: en-tn.tsv
- config_name: en-mai
data_files: en-mai.tsv
- config_name: en-cy
data_files: en-cy.tsv
- config_name: en-kmr
data_files: en-kmr.tsv
- config_name: en-bas
data_files: en-bas.tsv
- config_name: en-anp
data_files: en-anp.tsv
- config_name: en-skr
data_files: en-skr.tsv
- config_name: en-quy
data_files: en-quy.tsv
- config_name: en-gu-IN
data_files: en-gu-IN.tsv
- config_name: en-it
data_files: en-it.tsv
- config_name: en-tzm
data_files: en-tzm.tsv
- config_name: en-ne-NP
data_files: en-ne-NP.tsv
- config_name: en-uk
data_files: en-uk.tsv
- config_name: en-lzz
data_files: en-lzz.tsv
- config_name: en-zza
data_files: en-zza.tsv
- config_name: en-gv
data_files: en-gv.tsv
- config_name: en-vi
data_files: en-vi.tsv
- config_name: en-te
data_files: en-te.tsv
- config_name: en-hil
data_files: en-hil.tsv
- config_name: en-quc
data_files: en-quc.tsv
- config_name: en-mr
data_files: en-mr.tsv
- config_name: en-eo
data_files: en-eo.tsv
- config_name: en-ar
data_files: en-ar.tsv
- config_name: en-zam
data_files: en-zam.tsv
- config_name: en-rm-sursilv
data_files: en-rm-sursilv.tsv
- config_name: en-shi
data_files: en-shi.tsv
- config_name: en-sl
data_files: en-sl.tsv
- config_name: en-th
data_files: en-th.tsv
- config_name: en-ks
data_files: en-ks.tsv
- config_name: en-ses
data_files: en-ses.tsv
- config_name: en-pt-PT
data_files: en-pt-PT.tsv
- config_name: en-br
data_files: en-br.tsv
- config_name: en-es-ES
data_files: en-es-ES.tsv
- config_name: en-ppl
data_files: en-ppl.tsv
- config_name: en-ast
data_files: en-ast.tsv
- config_name: en-ia
data_files: en-ia.tsv
- config_name: en-id
data_files: en-id.tsv
- config_name: en-cnh
data_files: en-cnh.tsv
- config_name: en-gd
data_files: en-gd.tsv
- config_name: en-tr
data_files: en-tr.tsv
- config_name: en-es-MX
data_files: en-es-MX.tsv
- config_name: en-fo
data_files: en-fo.tsv
- config_name: en-hus
data_files: en-hus.tsv
- config_name: en-tw
data_files: en-tw.tsv
- config_name: en-brx
data_files: en-brx.tsv
- config_name: en-hi
data_files: en-hi.tsv
- config_name: en-lt
data_files: en-lt.tsv
- config_name: en-ky
data_files: en-ky.tsv
- config_name: en-si
data_files: en-si.tsv
- config_name: en-csb
data_files: en-csb.tsv
- config_name: en-ca
data_files: en-ca.tsv
- config_name: en-bg
data_files: en-bg.tsv
- config_name: en-fa
data_files: en-fa.tsv
- config_name: en-ig
data_files: en-ig.tsv
- config_name: en-kab
data_files: en-kab.tsv
- config_name: en-ay
data_files: en-ay.tsv
- config_name: en-oc
data_files: en-oc.tsv
- config_name: en-hye
data_files: en-hye.tsv
- config_name: en-ru
data_files: en-ru.tsv
- config_name: en-snk
data_files: en-snk.tsv
- config_name: en-ee
data_files: en-ee.tsv
- config_name: en-fur
data_files: en-fur.tsv
- config_name: en-gor
data_files: en-gor.tsv
- config_name: en-udm
data_files: en-udm.tsv
- config_name: en-es
data_files: en-es.tsv
- config_name: en-az
data_files: en-az.tsv
- config_name: en-nia
data_files: en-nia.tsv
- config_name: en-sw
data_files: en-sw.tsv
- config_name: en-nan-tw
data_files: en-nan-tw.tsv
- config_name: en-ja
data_files: en-ja.tsv
- config_name: en-da
data_files: en-da.tsv
- config_name: en-hu
data_files: en-hu.tsv
- config_name: en-nhe
data_files: en-nhe.tsv
- config_name: en-he
data_files: en-he.tsv
- config_name: en-mn
data_files: en-mn.tsv
- config_name: en-os
data_files: en-os.tsv
- config_name: en-mni
data_files: en-mni.tsv
- config_name: en-sc
data_files: en-sc.tsv
- config_name: en-hyw
data_files: en-hyw.tsv
- config_name: en-pt
data_files: en-pt.tsv
- config_name: en-ts
data_files: en-ts.tsv
- config_name: en-ady
data_files: en-ady.tsv
- config_name: en-ga-IE
data_files: en-ga-IE.tsv
- config_name: en-sr
data_files: en-sr.tsv
- config_name: en-bxr
data_files: en-bxr.tsv
- config_name: en-mk
data_files: en-mk.tsv
- config_name: en-lo
data_files: en-lo.tsv
- config_name: en-ckb
data_files: en-ckb.tsv
- config_name: en-sah
data_files: en-sah.tsv
- config_name: en-kk
data_files: en-kk.tsv
- config_name: en-nn-NO
data_files: en-nn-NO.tsv
- config_name: en-eu
data_files: en-eu.tsv
- config_name: en-ro
data_files: en-ro.tsv
- config_name: en-es-CL
data_files: en-es-CL.tsv
- config_name: en-cak
data_files: en-cak.tsv
- config_name: en-st
data_files: en-st.tsv
- config_name: en-am
data_files: en-am.tsv
- config_name: en-as
data_files: en-as.tsv
- config_name: en-kw
data_files: en-kw.tsv
- config_name: en-vot
data_files: en-vot.tsv
- config_name: en-tg
data_files: en-tg.tsv
- config_name: en-kn
data_files: en-kn.tsv
- config_name: en-ml
data_files: en-ml.tsv
- config_name: en-vec
data_files: en-vec.tsv
- config_name: en-ss
data_files: en-ss.tsv
- config_name: en-sn
data_files: en-sn.tsv
- config_name: en-pap-AW
data_files: en-pap-AW.tsv
- config_name: en-ha
data_files: en-ha.tsv
- config_name: en-ps
data_files: en-ps.tsv
- config_name: en-azb
data_files: en-azb.tsv
- config_name: en-en-GB
data_files: en-en-GB.tsv
- config_name: en-ewo
data_files: en-ewo.tsv
- config_name: en-tl
data_files: en-tl.tsv
- config_name: en-gl
data_files: en-gl.tsv
- config_name: en-bn-BD
data_files: en-bn-BD.tsv
- config_name: en-rw
data_files: en-rw.tsv
- config_name: en-mg
data_files: en-mg.tsv
- config_name: en-tok
data_files: en-tok.tsv
- config_name: en-tyv
data_files: en-tyv.tsv
- config_name: en-fy-NL
data_files: en-fy-NL.tsv
- config_name: en-dyu
data_files: en-dyu.tsv
- config_name: en-kpv
data_files: en-kpv.tsv
- config_name: en-pa-IN
data_files: en-pa-IN.tsv
- config_name: en-jv
data_files: en-jv.tsv
- config_name: en-meh
data_files: en-meh.tsv
- config_name: en-azz
data_files: en-azz.tsv
- config_name: en-pa-PK
data_files: en-pa-PK.tsv
- config_name: en-rm-vallader
data_files: en-rm-vallader.tsv
- config_name: en-nhi
data_files: en-nhi.tsv
- config_name: en-hsb
data_files: en-hsb.tsv
- config_name: en-be
data_files: en-be.tsv
- config_name: en-ba
data_files: en-ba.tsv
- config_name: en-en-ZA
data_files: en-en-ZA.tsv
- config_name: en-ug
data_files: en-ug.tsv
- config_name: en-ka
data_files: en-ka.tsv
- config_name: en-mhr
data_files: en-mhr.tsv
- config_name: en-sd
data_files: en-sd.tsv
- config_name: en-tt
data_files: en-tt.tsv
- config_name: en-yue
data_files: en-yue.tsv
- config_name: en-arn
data_files: en-arn.tsv
- config_name: en-ve
data_files: en-ve.tsv
- config_name: en-fr
data_files: en-fr.tsv
- config_name: en-lus
data_files: en-lus.tsv
- config_name: en-kaa
data_files: en-kaa.tsv
- config_name: en-el
data_files: en-el.tsv
- config_name: en-dag
data_files: en-dag.tsv
- config_name: en-hy-AM
data_files: en-hy-AM.tsv
- config_name: en-nl
data_files: en-nl.tsv
- config_name: en-pt-BR
data_files: en-pt-BR.tsv
- config_name: en-ti
data_files: en-ti.tsv
- config_name: en-trs
data_files: en-trs.tsv
- config_name: en-zgh
data_files: en-zgh.tsv
default: true
- config_name: en-ban
data_files: en-ban.tsv
- config_name: en-is
data_files: en-is.tsv
- config_name: en-ceb
data_files: en-ceb.tsv
- config_name: en-hi-IN
data_files: en-hi-IN.tsv
- config_name: en-nv
data_files: en-nv.tsv
- config_name: en-dsb
data_files: en-dsb.tsv
- config_name: en-ltg
data_files: en-ltg.tsv
- config_name: en-ln
data_files: en-ln.tsv
- config_name: en-ur
data_files: en-ur.tsv
- config_name: en-sat
data_files: en-sat.tsv
- config_name: en-om
data_files: en-om.tsv
- config_name: en-yi
data_files: en-yi.tsv
- config_name: en-fuf
data_files: en-fuf.tsv
- config_name: en-mt
data_files: en-mt.tsv
- config_name: en-zh-TW
data_files: en-zh-TW.tsv
- config_name: en-sq
data_files: en-sq.tsv
- config_name: en-qvi
data_files: en-qvi.tsv
- config_name: en-ff
data_files: en-ff.tsv
- config_name: en-et
data_files: en-et.tsv
- config_name: en-guc
data_files: en-guc.tsv
- config_name: en-af
data_files: en-af.tsv
- config_name: en-gom
data_files: en-gom.tsv
- config_name: en-ilo
data_files: en-ilo.tsv
- config_name: en-co
data_files: en-co.tsv
- config_name: en-rm
data_files: en-rm.tsv
- config_name: en-sv-SE
data_files: en-sv-SE.tsv
- config_name: en-ko
data_files: en-ko.tsv
- config_name: en-jbo
data_files: en-jbo.tsv
- config_name: en-sk
data_files: en-sk.tsv
- config_name: en-kbd
data_files: en-kbd.tsv
- config_name: en-ta
data_files: en-ta.tsv
- config_name: en-myv
data_files: en-myv.tsv
- config_name: en-syr
data_files: en-syr.tsv
- config_name: en-uz
data_files: en-uz.tsv
- config_name: en-crh
data_files: en-crh.tsv
- config_name: en-mrj
data_files: en-mrj.tsv
- config_name: en-szl
data_files: en-szl.tsv
- config_name: en-tsz
data_files: en-tsz.tsv
- config_name: en-ach
data_files: en-ach.tsv
- config_name: en-mdf
data_files: en-mdf.tsv
- config_name: en-hr
data_files: en-hr.tsv
- config_name: en-ixl
data_files: en-ixl.tsv
- config_name: en-ie
data_files: en-ie.tsv
- config_name: en-sco
data_files: en-sco.tsv
- config_name: en-zh-HK
data_files: en-zh-HK.tsv
- config_name: en-wo
data_files: en-wo.tsv
- config_name: en-bn
data_files: en-bn.tsv
- config_name: en-bn-IN
data_files: en-bn-IN.tsv
- config_name: en-nso
data_files: en-nso.tsv
- config_name: en-dv
data_files: en-dv.tsv
- config_name: en-jiv
data_files: en-jiv.tsv
- config_name: en-an
data_files: en-an.tsv
- config_name: en-km
data_files: en-km.tsv
- config_name: en-or
data_files: en-or.tsv
- config_name: en-zu
data_files: en-zu.tsv
- config_name: en-su
data_files: en-su.tsv
- config_name: en-pai
data_files: en-pai.tsv
- config_name: en-my
data_files: en-my.tsv
- config_name: en-scn
data_files: en-scn.tsv
- config_name: en-frp
data_files: en-frp.tsv
- config_name: en-ms
data_files: en-ms.tsv
- config_name: en-lg
data_files: en-lg.tsv
language:
- ab
- ace
- ach
- ady
- af
- am
- an
- ann
- anp
- ar
- arn
- as
- ast
- ay
- az
- azb
- azz
- ba
- ban
- bas
- be
- bg
- bm
- bn
- bo
- br
- brx
- bs
- bxr
- ca
- cak
- ceb
- ckb
- cnh
- co
- crh
- cs
- csb
- cv
- cy
- da
- dag
- de
- dsb
- dv
- dyu
- ee
- el
- en
- eo
- es
- et
- eu
- ewo
- fa
- ff
- fi
- fo
- fr
- frp
- fuf
- fur
- fy
- ga
- gd
- gl
- gn
- gom
- gor
- gu
- guc
- gv
- ha
- he
- hi
- hil
- hr
- hsb
- ht
- hu
- hus
- hy
- hye
- hyw
- ia
- id
- ie
- ig
- ilo
- is
- it
- ixl
- ja
- jbo
- jiv
- jv
- ka
- kaa
- kab
- kbd
- kk
- km
- kmr
- kn
- ko
- kpv
- ks
- kw
- ky
- lb
- lg
- lij
- ln
- lo
- lt
- ltg
- lus
- lv
- lzz
- mai
- mdf
- meh
- mg
- mhr
- mix
- mk
- ml
- mn
- mni
- mr
- mrj
- ms
- mt
- my
- myv
- nan
- nb
- ne
- nhe
- nhi
- nia
- nl
- nn
- nr
- nso
- nv
- ny
- nyn
- oc
- om
- or
- os
- pa
- pai
- pap
- pl
- ppl
- ps
- pt
- quc
- quy
- qvi
- rm
- ro
- ru
- rw
- sah
- sat
- sc
- scn
- sco
- sd
- ses
- shi
- si
- sk
- skr
- sl
- sn
- snk
- son
- sq
- sr
- ss
- st
- su
- sv
- sw
- syr
- szl
- ta
- te
- tg
- th
- ti
- tig
- tk
- tl
- tn
- tok
- tr
- trs
- ts
- tsz
- tt
- tw
- tyv
- tzm
- udm
- ug
- uk
- ur
- uz
- ve
- vec
- vi
- vot
- wo
- xcl
- xh
- yi
- yo
- yua
- yue
- zam
- zgh
- zh
- zu
- zza
license: mpl-2.0
task_categories:
- translation
- text2text-generation
pretty_name: Pontoon Translations
annotations_creators:
- crowdsourced
---
# Dataset Card for Pontoon Translations
<!-- Provide a quick summary of the dataset. -->
This is a dataset containing strings from various Mozilla projects on Mozilla's [Pontoon](https://pontoon.mozilla.org) localization platform and their translations into more than 200 languages.
Source strings are in English.
To avoid rows with values like "None" and "N/A" being interpreted as missing values, pass the keep_default_na parameter like this:
```
from datasets import load_dataset
dataset = load_dataset("ayymen/Pontoon-Translations", keep_default_na=False)
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** Per [Pontoons's terms](https://pontoon.mozilla.org/terms/) "Translations are governed by the [Mozilla Public License 2.0](https://www.mozilla.org/en-US/MPL/2.0/), or another license or set of licenses acceptable to the Mozilla Foundation."
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
- Machine Translation
- Language Identification
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
- Sentence pairs with empty/missing elements were dropped.
- Identical pairs were dropped.
- Rows where the english string does not contain any letters were dropped.
- Leading and trailing whitespace was stripped.
- Rows were deduplicated.
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
Pontoon users.
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
xingyaoww/code-act | ---
configs:
- config_name: default
data_files:
- split: codeact
path: data/codeact-*
- split: general
path: data/general-*
dataset_info:
features:
- name: id
dtype: string
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: codeact
num_bytes: 34936511
num_examples: 7139
- name: general
num_bytes: 250817144
num_examples: 71246
download_size: 123084833
dataset_size: 285753655
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- llm-agent
- llm
- instruction-tuning
size_categories:
- 1K<n<10K
---
<h1 align="center"> Executable Code Actions Elicit Better LLM Agents </h1>
<p align="center">
<a href="https://github.com/xingyaoww/code-act">💻 Code</a>
•
<a href="https://arxiv.org/abs/2402.01030">📃 Paper</a>
•
<a href="https://huggingface.co/datasets/xingyaoww/code-act" >🤗 Data (CodeActInstruct)</a>
•
<a href="https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1" >🤗 Model (CodeActAgent-Mistral-7b-v0.1)</a>
•
<a href="https://chat.xwang.dev/">🤖 Chat with CodeActAgent!</a>
</p>
We propose to use executable Python **code** to consolidate LLM agents’ **act**ions into a unified action space (**CodeAct**).
Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions.
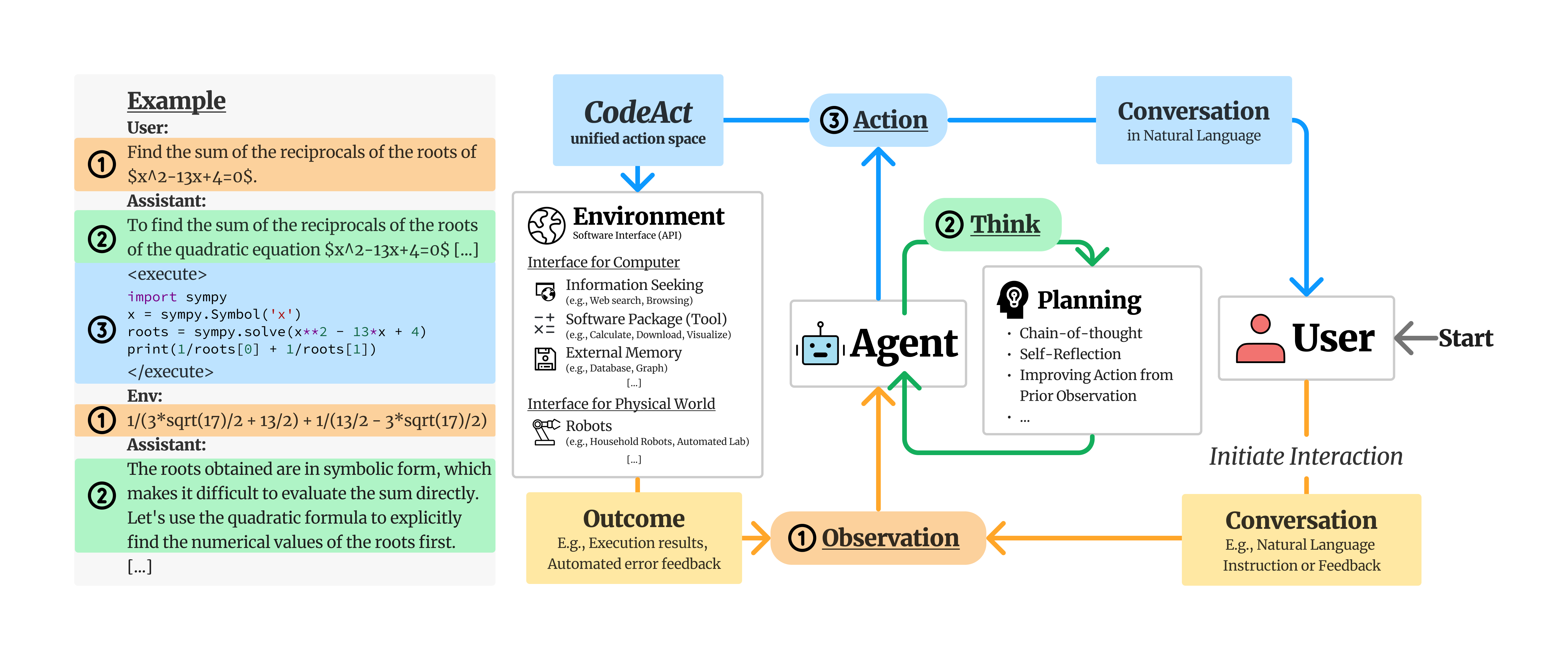
## Why CodeAct?
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark [M<sup>3</sup>ToolEval](docs/EVALUATION.md) shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!
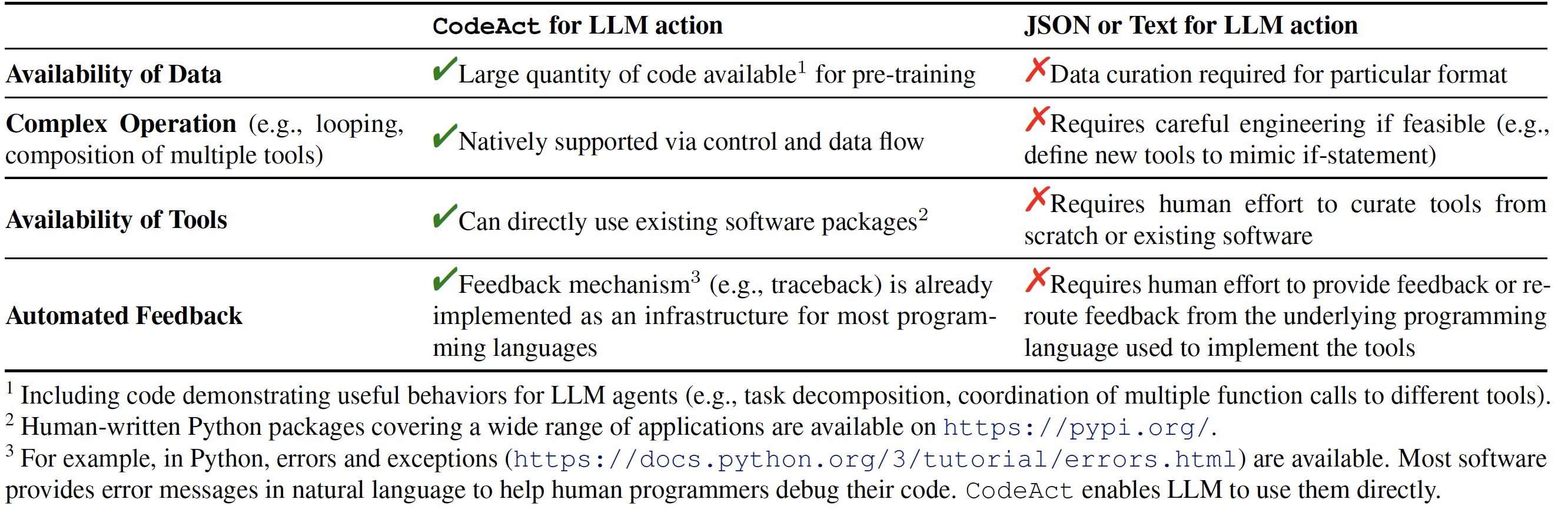
*Comparison between CodeAct and Text / JSON as action.*
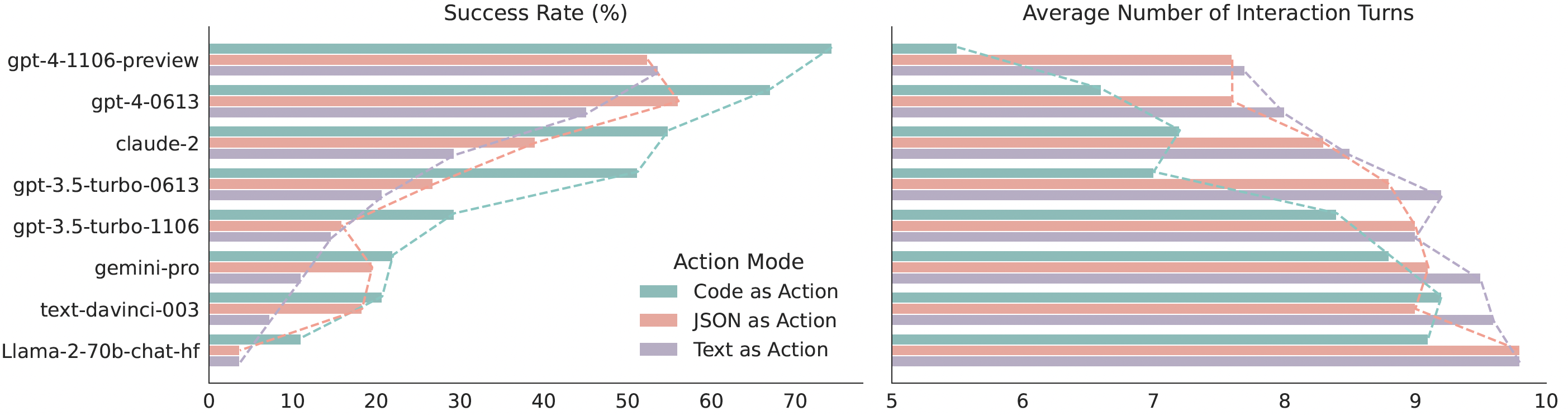
*Quantitative results comparing CodeAct and {Text, JSON} on M<sup>3</sup>ToolEval.*
## 📁 CodeActInstruct
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at [huggingface dataset 🤗](https://huggingface.co/datasets/xingyaoww/code-act). Please refer to the paper and [this section](#-data-generation-optional) for details of data collection.
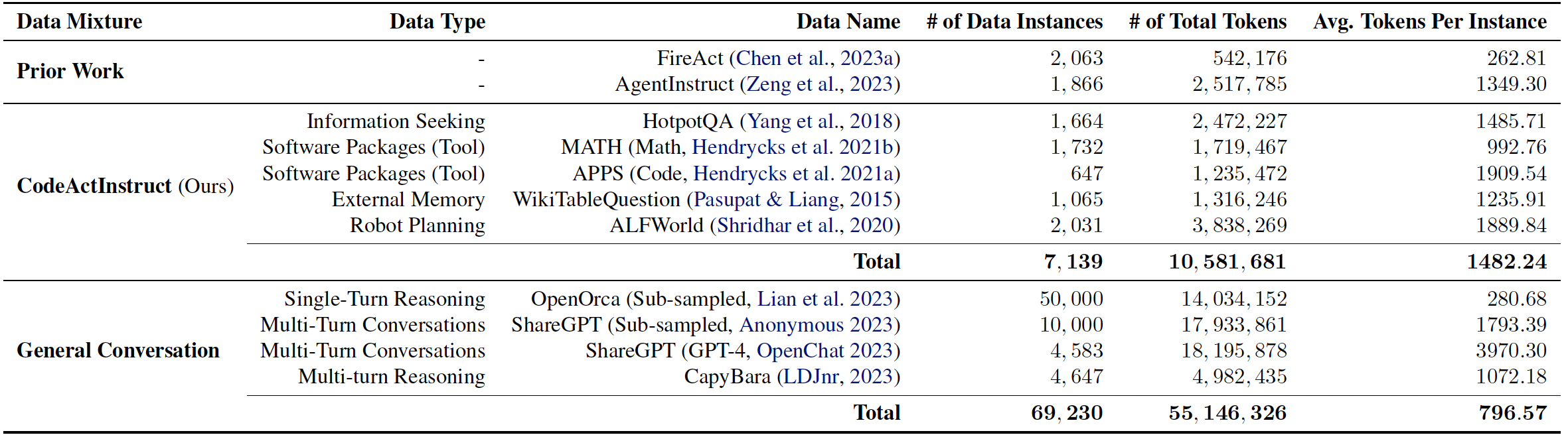
*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
## 🪄 CodeActAgent
Trained on **CodeActInstruct** and general conversaions, **CodeActAgent** excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
- **CodeActAgent-Mistral-7b-v0.1** (recommended, [model link](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1)): using Mistral-7b-v0.1 as the base model with 32k context window.
- **CodeActAgent-Llama-7b** ([model link](https://huggingface.co/xingyaoww/CodeActAgent-Llama-2-7b)): using Llama-2-7b as the base model with 4k context window.
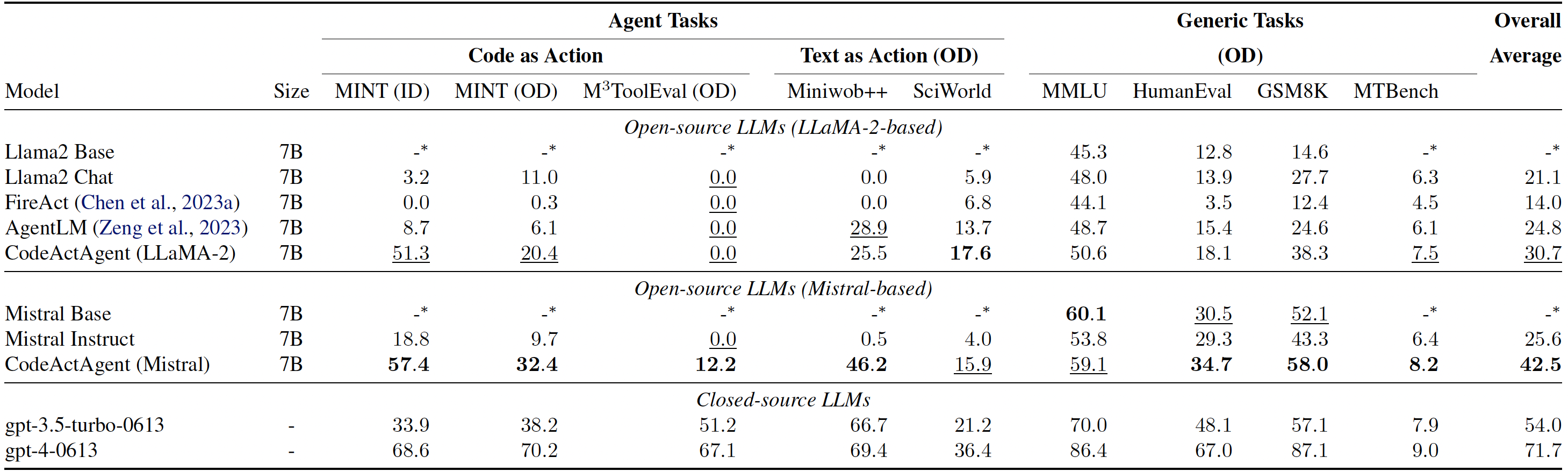
*Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.*
Please check out [our paper](TODO) and [code](https://github.com/xingyaoww/code-act) for more details about data collection, model training, and evaluation.
## 📚 Citation
```bibtex
@misc{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Zuntan/Animagine_XL_3.0-Character | ---
license: unknown
---
# Animagine XL 3.0 Character
[EasySdxlWebUi](https://github.com/Zuntan03/EasySdxlWebUi) による [Animagine XL 3.0](https://huggingface.co/cagliostrolab/animagine-xl-3.0) の [公式 Character ワイルドカード](https://huggingface.co/spaces/Linaqruf/animagine-xl/resolve/main/wildcard/character.txt) の立ち絵データセットです。
データセットのダウンロードは [こちら(2880枚、497MB)](https://huggingface.co/datasets/Zuntan/Animagine_XL_3.0-Character/resolve/main/character.zip?download=true)。
**[表情(278MB)](https://huggingface.co/datasets/Zuntan/Animagine_XL_3.0-Character/resolve/main/face.zip?download=true) と [画風(115MB)](https://yyy.wpx.jp/EasySdxlWebUi/style.zip) も用意しました。**

画像の類似度や Tagger の結果比較で正常動作するワイルドカードリストを用意できないかな?と思って始めてみました。
が、衣装違いなどの不正解画像でも作品名やキャラ名の影響を大きく受けるため、他のソースなしの正否分類は難しそうです。
- 各 webp 画像を [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) の `PNG内の情報を表示` にドラッグ&ドロップすると生成情報を確認できます。
- プロンプトは `__animagine/character__, solo, full body, standing, no background, simple background, masterpiece, best quality <lora:lcm-animagine-3:1>` です。
- ネガティブプロンプト Animagine XL のデフォルトネガティブの先頭に NSFW 対策付与で `nsfw, rating: sensitive, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name` です。
- アップスケール前の生成サイズは `832` x `1216` です。
- Seed は `1234567` です。
- 他のシードで正否が変わる可能性があります。
- 他は EasySdxlWebUi のデフォルト設定です。
[grid0](https://yyy.wpx.jp/m/202401/animagine_character/grid0.webp),
[grid1](https://yyy.wpx.jp/m/202401/animagine_character/grid1.webp),
[grid2](https://yyy.wpx.jp/m/202401/animagine_character/grid2.webp),
[grid3](https://yyy.wpx.jp/m/202401/animagine_character/grid3.webp)
|
claws-lab/XLingHealth | ---
dataset_info:
features:
- name: question_English
dtype: string
- name: answer_English
dtype: string
- name: question_Chinese
dtype: string
- name: answer_Chinese
dtype: string
- name: question_Spanish
dtype: string
- name: answer_Spanish
dtype: string
- name: question_Hindi
dtype: string
- name: answer_Hindi
dtype: string
- name: answer_ids
dtype: int64
- name: label
dtype: int64
- name: id
dtype: int64
splits:
- name: liveqa
num_bytes: 7181107
num_examples: 1230
- name: medicationqa
num_bytes: 8507105
num_examples: 3450
- name: healthqa
num_bytes: 82047006
num_examples: 11340
download_size: 25265727
dataset_size: 97735218
license: apache-2.0
task_categories:
- text-classification
- text-generation
- question-answering
language:
- en
- es
- zh
- hi
tags:
- medical
- health
- healthcare
pretty_name: XLingHealth
size_categories:
- 10K<n<100K
---
# Dataset Card for "XLingHealth"
[XLingHealth](https://claws-lab.github.io/XLingEval/) is a **Cross-Ling**ual **Health**care benchmark for clinical health inquiry that features the top four [most spoken languages in the world](https://en.wikipedia.org/wiki/List_of_languages_by_total_number_of_speakers): English, Spanish, Chinese, and Hindi.
## Statistics
| Dataset | \#Examples | \#Words (Q) | \#Words (A) |
|--------------|------------|-------------------|---------------------|
| HealthQA | 1,134 | 7.72 ± 2.41 | 242.85 ± 221.88 |
| LiveQA | 246 | 41.76 ± 37.38 | 115.25 ± 112.75 |
| MedicationQA | 690 | 6.86 ± 2.83 | 61.50 ± 69.44 |
- `#Words (Q)` and `\#Words (A)` represent the average number of words in the questions and ground-truth answers of the datasets, respectively.
- In the **HealthQA** dataset, each question is already associated with 1 correct answer (termed "positive example") and 9 incorrect/irrelevant answers (termed "negative examples"). Thus, the total number of examples in HealthQA is 11,340
- **LiveQA** and **MedicationQA** do not provide negative question-answer pairs. Therefore, for each question in these datasets, we randomly sampled 4 responses from the entire set of answers to serve as negative examples. Thus, the total number of examples is 1230 and 3450 for **LiveQA** and **MedicationQA**, respectively.
## Introduction
Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions: correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.
```bibtex
@inproceedings{jin2023better,
title = {Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries},
author = {Jin, Yiqiao and Chandra, Mohit and Verma, Gaurav and Hu, Yibo and De Choudhury, Munmun and Kumar, Srijan},
year = {2024},
booktitle = {The Web Conference},
}
```
|
argilla/10k_prompts_ranked_mistral_large_responses | ---
dataset_info:
features:
- name: input
dtype: string
- name: quality
list:
- name: status
dtype: string
- name: user_id
dtype: string
- name: value
dtype: string
- name: metadata
dtype: string
- name: avg_rating
dtype: float64
- name: num_responses
dtype: int64
- name: agreement_ratio
dtype: float64
- name: raw_responses
sequence: int64
- name: kind
dtype: string
- name: generation_model
sequence: string
- name: generation_prompt
list:
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_generation_responses
sequence: string
- name: generations
sequence: string
splits:
- name: train
num_bytes: 48139476
num_examples: 10331
download_size: 26098357
dataset_size: 48139476
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- distilabel
---
## Description
This dataset contains responses generated for the prompts of the [DIBT/10k_prompts_ranked](https://huggingface.co/datasets/DIBT/10k_prompts_ranked), using [distilabel](https://github.com/argilla-io/distilabel)
with [`mistral-large`](https://docs.mistral.ai/platform/endpoints/). The script used for the generation can be seen at the repository: `generate_reference_spin.py`. |
somosnlp/RAC_Colombia_QualityImproved50Percent | ---
language:
- es
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- text-generation
- question-answering
pretty_name: Reglamenteo Aeronautico Colombiano
dataset_info:
features:
- name: Text
dtype: string
splits:
- name: train
num_bytes: 1123219
num_examples: 909
download_size: 311301
dataset_size: 1123219
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- legal
- Aerospatial
- Aeronautics
---
# Reglamento Aeronáutico Colombiano (RAC) Dataset Gemma format
🛫📚🇨🇴
Este dataset contiene muestras etiquetadas del Reglamento Aeronáutico Colombiano (RAC), centrado en los primeros 5 capítulos. Los datos se han etiquetado hasta ahora con un avance del 54.024%, lo que equivale a alrededor de 13,600 muestras de un total estimado de 25,174.
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6419c2f6b4adb0e101b17b6c/IFJETsRF6-lDJmV0EW-7u.png" alt="Imagen relacionada con el Reglamento Aeronáutico Colombiano" style="width: 60%; max-height: 450px;">
</p>
## Progreso de Etiquetado
**Total:** 54.024%
- Etiquetado: 13,600
- Pendiente: 11,574
- Borradores: 0
- Enviados: 13,254
- Descartados: 0
## Equipo de Anotación
El dataset ha sido anotado por un equipo dedicado de profesionales con experiencia en el campo de la aeronáutica y el procesamiento de lenguaje natural.
- [Alec Mauricio](https://huggingface.co/alecrosales1) - Estudiante de Ingenieria Aeronáutica.
- Danny Stevens - Analista de datos y estudiante de Ingenieria Aeronáutica.
- [Sergio Nicolas](https://huggingface.co/SergioMadridF) - Estudiante de Ingenieria Aeronáutica.
- [Edison Bejarano](https://huggingface.co/ejbejaranos) - Candidato PhD AI-LLMs, Master en Inteligencia artificial e ingeniero Aeronáutico.
- [Nicolai Potes](https://huggingface.co/NickyNicky) - Ingeniero de software y Especialista en algoritmos de clasificación y extracción de información.
- [Santiago Pineda](https://huggingface.co/Sapinedamo)- PhD AI - Matematico y especialista en RAG
Agradecemos a cada miembro del equipo por su contribución invaluable al desarrollo del Reglamento Aeronáutico Colombiano (RAC) Dataset.
## Fuente de los Datos
Los datos fueron extraídos del [sitio web de la Autoridad de la Aviación Civil de Colombia](https://www.aerocivil.gov.co/autoridad-de-la-aviacion-civil/reglamentacion/rac). Se enfocan específicamente en el Reglamento Aeronáutico Colombiano (RAC).
## Herramienta de Etiquetado
Se utilizó el espacio de Argilla para ayudar en el proceso de etiquetado. Puedes encontrar más información sobre el espacio utilizado [aquí](https://huggingface.co/spaces/somosnlp/RAC-FULL).
## Información del Dataset
- **Licencia:** Apache-2.0
- **Categorías de Tarea:** Generación de Texto, Preguntas y Respuestas
- **Idioma:** Español (es)
- **Tamaño del Dataset:** 25174 muestras
## Versiones Anteriores
A continuación, se presentan las versiones anteriores del dataset, cada una con un enfoque específico dentro del ámbito del Reglamento Aeronáutico Colombiano:
### Formato ChatML con Gemma
- **Nombre:** somosnlp/Reglamento_aeronautico_Colombiano_FULL_ChatML_format_gemma
- **Descripción:** Esta versión del dataset está formateada específicamente para facilitar el entrenamiento de modelos en tareas de chat, utilizando el formato ChatML con la variante Gemma.
- **Acceso:** [Visitar Dataset](https://huggingface.co/datasets/somosnlp/Reglamento_aeronautico_Colombiano_FULL_ChatML_format_gemma)
### Preguntas y Respuestas (RAC1)
- **Nombre:** somosnlp/Reglamento_aeronautico_Colombiano_QA_RAC1_FULL
- **Descripción:** Este dataset se enfoca en el primer capítulo del Reglamento Aeronáutico Colombiano, diseñado específicamente para entrenamiento y evaluación en tareas de preguntas y respuestas.
- **Acceso:** [Visitar Dataset](https://huggingface.co/datasets/somosnlp/Reglamento_aeronautico_Colombiano_QA_RAC1_FULL)
## Modelos desarrollados
- Entrenandose
## Distribución de longitud de Tokens del dataset
<div style="display: flex; justify-content: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6419c2f6b4adb0e101b17b6c/AAn-Q_urIrf84l9dRlxaR.png" style="width: 50%; max-height: 450px;">
</div>
<div style="display: flex; justify-content: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6419c2f6b4adb0e101b17b6c/1yWWnt-V-7T4P8oRUVDR1.png" style="width: 60%; max-height: 250px;">
</div>
|
HuggingFaceM4/TGIF | ---
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
language:
- en
license:
- other
multilinguality:
- monolingual
pretty_name: TGIF
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
- visual-question-answering
task_ids:
- closed-domain-qa
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** http://raingo.github.io/TGIF-Release/
- **Repository:** https://github.com/raingo/TGIF-Release
- **Paper:** https://arxiv.org/abs/1604.02748
- **Point of Contact:** mailto: yli@cs.rochester.edu
### Dataset Summary
The Tumblr GIF (TGIF) dataset contains 100K animated GIFs and 120K sentences describing visual content of the animated GIFs. The animated GIFs have been collected from Tumblr, from randomly selected posts published between May and June of 2015. We provide the URLs of animated GIFs in this release. The sentences are collected via crowdsourcing, with a carefully designed annotation interface that ensures high quality dataset. We provide one sentence per animated GIF for the training and validation splits, and three sentences per GIF for the test split. The dataset shall be used to evaluate animated GIF/video description techniques.
### Languages
The captions in the dataset are in English.
## Dataset Structure
### Data Fields
- `video_path`: `str` "https://31.media.tumblr.com/001a8b092b9752d260ffec73c0bc29cd/tumblr_ndotjhRiX51t8n92fo1_500.gif"
-`video_bytes`: `large_bytes` video file in bytes format
- `en_global_captions`: `list_str` List of english captions describing the entire video
### Data Splits
| |train |validation| test | Overall |
|-------------|------:|---------:|------:|------:|
|# of GIFs|80,000 |10,708 |11,360 |102,068 |
### Annotations
Quoting [TGIF paper](https://arxiv.org/abs/1604.02748): \
"We annotated animated GIFs with natural language descriptions using the crowdsourcing service CrowdFlower.
We carefully designed our annotation task with various
quality control mechanisms to ensure the sentences are both
syntactically and semantically of high quality.
A total of 931 workers participated in our annotation
task. We allowed workers only from Australia, Canada, New Zealand, UK and USA in an effort to collect fluent descriptions from native English speakers. Figure 2 shows the
instructions given to the workers. Each task showed 5 animated GIFs and asked the worker to describe each with one
sentence. To promote language style diversity, each worker
could rate no more than 800 images (0.7% of our corpus).
We paid 0.02 USD per sentence; the entire crowdsourcing
cost less than 4K USD. We provide details of our annotation
task in the supplementary material."
### Personal and Sensitive Information
Nothing specifically mentioned in the paper.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Licensing Information
This dataset is provided to be used for approved non-commercial research purposes. No personally identifying information is available in this dataset.
### Citation Information
```bibtex
@InProceedings{tgif-cvpr2016,
author = {Li, Yuncheng and Song, Yale and Cao, Liangliang and Tetreault, Joel and Goldberg, Larry and Jaimes, Alejandro and Luo, Jiebo},
title = "{TGIF: A New Dataset and Benchmark on Animated GIF Description}",
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2016}
}
```
### Contributions
Thanks to [@leot13](https://github.com/leot13) for adding this dataset.
|
jamescalam/unsplash-25k-photos | ---
annotations_creators:
- found
language:
- en
language_creators:
- found
license: []
multilinguality:
- monolingual
pretty_name: Unsplash Lite 25K Photos
size_categories:
- 10K<n<100K
source_datasets: []
tags:
- images
- unsplash
- photos
task_categories:
- image-to-image
- image-classification
- image-to-text
- text-to-image
- zero-shot-image-classification
task_ids: []
---
# Unsplash Lite Dataset Photos
This dataset is linked to the Unsplash Lite dataset containing data on 25K images from Unsplash. The dataset here only includes data from a single file `photos.tsv000`. The dataset builder script streams this data directly from the Unsplash 25K dataset source.
For full details, please see the [Unsplash Dataset GitHub repo](https://github.com/unsplash/datasets), or read the preview (copied from the repo) below.
---
# The Unsplash Dataset

The Unsplash Dataset is made up of over 250,000+ contributing global photographers and data sourced from hundreds of millions of searches across a nearly unlimited number of uses and contexts. Due to the breadth of intent and semantics contained within the Unsplash dataset, it enables new opportunities for research and learning.
The Unsplash Dataset is offered in two datasets:
- the Lite dataset: available for commercial and noncommercial usage, containing 25k nature-themed Unsplash photos, 25k keywords, and 1M searches
- the Full dataset: available for noncommercial usage, containing 3M+ high-quality Unsplash photos, 5M keywords, and over 250M searches
As the Unsplash library continues to grow, we’ll release updates to the dataset with new fields and new images, with each subsequent release being [semantically versioned](https://semver.org/).
We welcome any feedback regarding the content of the datasets or their format. With your input, we hope to close the gap between the data we provide and the data that you would like to leverage. You can [open an issue](https://github.com/unsplash/datasets/issues/new/choose) to report a problem or to let us know what you would like to see in the next release of the datasets.
For more on the Unsplash Dataset, see [our announcement](https://unsplash.com/blog/the-unsplash-dataset/) and [site](https://unsplash.com/data).
## Download
### Lite Dataset
The Lite dataset contains all of the same fields as the Full dataset, but is limited to ~25,000 photos. It can be used for both commercial and non-commercial usage, provided you abide by [the terms](https://github.com/unsplash/datasets/blob/master/TERMS.md).
[⬇️ Download the Lite dataset](https://unsplash.com/data/lite/latest) [~650MB compressed, ~1.4GB raw]
### Full Dataset
The Full dataset is available for non-commercial usage and all uses must abide by [the terms](https://github.com/unsplash/datasets/blob/master/TERMS.md). To access, please go to [unsplash.com/data](https://unsplash.com/data) and request access. The dataset weighs ~20 GB compressed (~43GB raw)).
## Documentation
See the [documentation for a complete list of tables and fields](https://github.com/unsplash/datasets/blob/master/DOCS.md).
## Usage
You can follow these examples to load the dataset in these common formats:
- [Load the dataset in a PostgreSQL database](https://github.com/unsplash/datasets/tree/master/how-to/psql)
- [Load the dataset in a Python environment](https://github.com/unsplash/datasets/tree/master/how-to/python)
- [Submit an example doc](https://github.com/unsplash/datasets/blob/master/how-to/README.md#submit-an-example)
## Share your work
We're making this data open and available with the hopes of enabling researchers and developers to discover interesting and useful connections in the data.
We'd love to see what you create, whether that's a research paper, a machine learning model, a blog post, or just an interesting discovery in the data. Send us an email at [data@unsplash.com](mailto:data@unsplash.com).
If you're using the dataset in a research paper, you can attribute the dataset as `Unsplash Lite Dataset 1.2.0` or `Unsplash Full Dataset 1.2.0` and link to the permalink [`unsplash.com/data`](https://unsplash.com/data).
----
The Unsplash Dataset is made available for research purposes. [It cannot be used to redistribute the images contained within](https://github.com/unsplash/datasets/blob/master/TERMS.md). To use the Unsplash library in a product, see [the Unsplash API](https://unsplash.com/developers).
 |
tasksource/tomi-nli | ---
license: gpl-3.0
task_ids:
- natural-language-inference
task_categories:
- text-classification
language:
- en
---
tomi dataset (theory of mind question answering) recasted as natural language inference
https://colab.research.google.com/drive/1J_RqDSw9iPxJSBvCJu-VRbjXnrEjKVvr?usp=sharing
```
@article{sileo2023tasksource,
title={tasksource: Structured Dataset Preprocessing Annotations for Frictionless Extreme Multi-Task Learning and Evaluation},
author={Sileo, Damien},
url= {https://arxiv.org/abs/2301.05948},
journal={arXiv preprint arXiv:2301.05948},
year={2023}
}
@inproceedings{le-etal-2019-revisiting,
title = "Revisiting the Evaluation of Theory of Mind through Question Answering",
author = "Le, Matthew and
Boureau, Y-Lan and
Nickel, Maximilian",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1598",
doi = "10.18653/v1/D19-1598",
pages = "5872--5877"
}
``` |
soymia/boudoir-dataset | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 96479861.365
num_examples: 1055
download_size: 95036573
dataset_size: 96479861.365
license: apache-2.0
task_categories:
- text-to-image
pretty_name: Boudoir Dataset
size_categories:
- 1K<n<10K
---
# Dataset Card for "boudoir-dataset"
### Dataset Summary
Images scrapped from selected Galleries on Behance. |
GBaker/MedQA-USMLE-4-options-hf-MPNet-IR | ---
dataset_info:
features:
- name: id
dtype: string
- name: sent1
dtype: string
- name: sent2
dtype: string
- name: ending0
dtype: string
- name: ending1
dtype: string
- name: ending2
dtype: string
- name: ending3
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 14052739
num_examples: 10178
- name: validation
num_bytes: 1754234
num_examples: 1272
- name: test
num_bytes: 1780124
num_examples: 1273
download_size: 10209487
dataset_size: 17587097
---
# Dataset Card for "MedQA-USMLE-4-options-hf-MPNet-IR"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vincentmin/eli5_rlhf_explainlikeim5 | ---
task_categories:
- text-generation
- question-answering
language:
- en
pretty_name: Reddit Explain Like I'm 5 for Reinforcement Learning Human Feedback
size_categories:
- 100K<n<1M
---
# ELI5 paired
This is a processed version of the [`eli5`](https://huggingface.co/datasets/eli5) dataset.
Compared to ["eli5_rlhf"](https://huggingface.co/datasets/vincentmin/eli5_rlhf), this dataset contains only QA pairs from the train split of the eli5 dataset and only from the subreddit explainlikeimfive.
Furthermore, the function
```
def get_question(example):
title = example["title"]
selftext = example["selftext"]
if selftext:
if selftext[-1] not in [".", "?", "!"]:
seperator = ". "
else:
seperator = " "
question = title + seperator + selftext
else:
question = title
example["question"] = question
return example
```
was applied to get the "question" column and the "title" and "selftext" columns were removed.
The dataset was created following very closely the steps in the [`stack-exchange-paired`](https://huggingface.co/datasets/lvwerra/stack-exchange-paired) dataset.
The following steps were applied:
- The "question" field is a concatenation of "title" with "selftext".
- Create pairs `(response_j, response_k)` where j was rated better than k
- Sample at most 10 pairs per question
- Shuffle the dataset globally
This dataset is designed to be used for preference learning. The processing notebook is in the repository as well. |
hpprc/jsick | ---
annotations_creators:
- expert-generated
language:
- ja
- en
language_creators:
- expert-generated
license:
- cc-by-sa-4.0
multilinguality:
- translation
pretty_name: JSICK
size_categories:
- 10K<n<100K
source_datasets:
- extended|sick
tags:
- semantic-textual-similarity
- sts
task_categories:
- sentence-similarity
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
---
# Dataset Card for JSICK
## Table of Contents
- [Dataset Card for JSICK](#dataset-card-for-jsick)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Japanese Sentences Involving Compositional Knowledge (JSICK) Dataset.](#japanese-sentences-involving-compositional-knowledge-jsick-dataset)
- [JSICK-stress Test set](#jsick-stress-test-set)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [base](#base)
- [stress](#stress)
- [Data Fields](#data-fields)
- [base](#base-1)
- [stress](#stress-1)
- [Data Splits](#data-splits)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/verypluming/JSICK
- **Repository:** https://github.com/verypluming/JSICK
- **Paper:** https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00518/113850/Compositional-Evaluation-on-Japanese-Textual
- **Paper:** https://www.jstage.jst.go.jp/article/pjsai/JSAI2021/0/JSAI2021_4J3GS6f02/_pdf/-char/ja
### Dataset Summary
From official [GitHub](https://github.com/verypluming/JSICK):
#### Japanese Sentences Involving Compositional Knowledge (JSICK) Dataset.
JSICK is the Japanese NLI and STS dataset by manually translating the English dataset [SICK (Marelli et al., 2014)](https://aclanthology.org/L14-1314/) into Japanese.
We hope that our dataset will be useful in research for realizing more advanced models that are capable of appropriately performing multilingual compositional inference.
#### JSICK-stress Test set
The JSICK-stress test set is a dataset to investigate whether models capture word order and case particles in Japanese.
The JSICK-stress test set is provided by transforming syntactic structures of sentence pairs in JSICK, where we analyze whether models are attentive to word order and case particles to predict entailment labels and similarity scores.
The JSICK test set contains 1666, 797, and 1006 sentence pairs (A, B) whose premise sentences A (the column `sentence_A_Ja_origin`) include the basic word order involving
ga-o (nominative-accusative), ga-ni (nominative-dative), and ga-de (nominative-instrumental/locative) relations, respectively.
We provide the JSICK-stress test set by transforming syntactic structures of these pairs by the following three ways:
- `scrum_ga_o`: a scrambled pair, where the word order of premise sentences A is scrambled into o-ga, ni-ga, and de-ga order, respectively.
- `ex_ga_o`: a rephrased pair, where the only case particles (ga, o, ni, de) in the premise A are swapped
- `del_ga_o`: a rephrased pair, where the only case particles (ga, o, ni) in the premise A are deleted
### Languages
The language data in JSICK is in Japanese and English.
## Dataset Structure
### Data Instances
When loading a specific configuration, users has to append a version dependent suffix:
```python
import datasets as ds
dataset: ds.DatasetDict = ds.load_dataset("hpprc/jsick")
print(dataset)
# DatasetDict({
# train: Dataset({
# features: ['id', 'premise', 'hypothesis', 'label', 'score', 'premise_en', 'hypothesis_en', 'label_en', 'score_en', 'corr_entailment_labelAB_En', 'corr_entailment_labelBA_En', 'image_ID', 'original_caption', 'semtag_short', 'semtag_long'],
# num_rows: 4500
# })
# test: Dataset({
# features: ['id', 'premise', 'hypothesis', 'label', 'score', 'premise_en', 'hypothesis_en', 'label_en', 'score_en', 'corr_entailment_labelAB_En', 'corr_entailment_labelBA_En', 'image_ID', 'original_caption', 'semtag_short', 'semtag_long'],
# num_rows: 4927
# })
# })
dataset: ds.DatasetDict = ds.load_dataset("hpprc/jsick", name="stress")
print(dataset)
# DatasetDict({
# test: Dataset({
# features: ['id', 'premise', 'hypothesis', 'label', 'score', 'sentence_A_Ja_origin', 'entailment_label_origin', 'relatedness_score_Ja_origin', 'rephrase_type', 'case_particles'],
# num_rows: 900
# })
# })
```
#### base
An example of looks as follows:
```json
{
'id': 1,
'premise': '子供たちのグループが庭で遊んでいて、後ろの方には年を取った男性が立っている',
'hypothesis': '庭にいる男の子たちのグループが遊んでいて、男性が後ろの方に立っている',
'label': 1, // (neutral)
'score': 3.700000047683716,
'premise_en': 'A group of kids is playing in a yard and an old man is standing in the background',
'hypothesis_en': 'A group of boys in a yard is playing and a man is standing in the background',
'label_en': 1, // (neutral)
'score_en': 4.5,
'corr_entailment_labelAB_En': 'nan',
'corr_entailment_labelBA_En': 'nan',
'image_ID': '3155657768_b83a7831e5.jpg',
'original_caption': 'A group of children playing in a yard , a man in the background .',
'semtag_short': 'nan',
'semtag_long': 'nan',
}
```
#### stress
An example of looks as follows:
```json
{
'id': '5818_de_d',
'premise': '女性火の近くダンスをしている',
'hypothesis': '火の近くでダンスをしている女性は一人もいない',
'label': 2, // (contradiction)
'score': 4.0,
'sentence_A_Ja_origin': '女性が火の近くでダンスをしている',
'entailment_label_origin': 2,
'relatedness_score_Ja_origin': 3.700000047683716,
'rephrase_type': 'd',
'case_particles': 'de'
}
```
### Data Fields
#### base
A version adopting the column names of a typical NLI dataset.
| Name | Description |
| -------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------- |
| id | The ids (the same with original SICK). |
| premise | The first sentence in Japanese. |
| hypothesis | The second sentence in Japanese. |
| label | The entailment label in Japanese. |
| score | The relatedness score in the range [1-5] in Japanese. |
| premise_en | The first sentence in English. |
| hypothesis_en | The second sentence in English. |
| label_en | The original entailment label in English. |
| score_en | The original relatedness score in the range [1-5] in English. |
| semtag_short | The linguistic phenomena tags in Japanese. |
| semtag_long | The details of linguistic phenomena tags in Japanese. |
| image_ID | The original image in [8K ImageFlickr dataset](https://www.kaggle.com/datasets/adityajn105/flickr8k). |
| original_caption | The original caption in [8K ImageFlickr dataset](https://www.kaggle.com/datasets/adityajn105/flickr8k). |
| corr_entailment_labelAB_En | The corrected entailment label from A to B in English by [(Karouli et al., 2017)](http://vcvpaiva.github.io/includes/pubs/2017-iwcs.pdf). |
| corr_entailment_labelBA_En | The corrected entailment label from B to A in English by [(Karouli et al., 2017)](http://vcvpaiva.github.io/includes/pubs/2017-iwcs.pdf). |
#### stress
| Name | Description |
| --------------------------- | ------------------------------------------------------------------------------------------------- |
| id | Ids (the same with original SICK). |
| premise | The first sentence in Japanese. |
| hypothesis | The second sentence in Japanese. |
| label | The entailment label in Japanese |
| score | The relatedness score in the range [1-5] in Japanese. |
| sentence_A_Ja_origin | The original premise sentences A from the JSICK test set. |
| entailment_label_origin | The original entailment labels. |
| relatedness_score_Ja_origin | The original relatedness scores. |
| rephrase_type | The type of transformation applied to the syntactic structures of the sentence pairs. |
| case_particles | The grammatical particles in Japanese that indicate the function or role of a noun in a sentence. |
### Data Splits
| name | train | validation | test |
| --------------- | ----: | ---------: | ----: |
| base | 4,500 | | 4,927 |
| original | 4,500 | | 4,927 |
| stress | | | 900 |
| stress-original | | | 900 |
### Annotations
To annotate the JSICK dataset, they used the crowdsourcing platform "Lancers" to re-annotate entailment labels and similarity scores for JSICK.
They had six native Japanese speakers as annotators, who were randomly selected from the platform.
The annotators were asked to fully understand the guidelines and provide the same labels as gold labels for ten test questions.
For entailment labels, they adopted annotations that were agreed upon by a majority vote as gold labels and checked whether the majority judgment vote was semantically valid for each example.
For similarity scores, they used the average of the annotation results as gold scores.
The raw annotations with the JSICK dataset are [publicly available](https://github.com/verypluming/JSICK/blob/main/jsick/jsick-all-annotations.tsv).
The average annotation time was 1 minute per pair, and Krippendorff's alpha for the entailment labels was 0.65.
## Additional Information
- [verypluming/JSICK](https://github.com/verypluming/JSICK)
- [Compositional Evaluation on Japanese Textual Entailment and Similarity](https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00518/113850/Compositional-Evaluation-on-Japanese-Textual)
- [JSICK: 日本語構成的推論・類似度データセットの構築](https://www.jstage.jst.go.jp/article/pjsai/JSAI2021/0/JSAI2021_4J3GS6f02/_article/-char/ja)
### Licensing Information
CC BY-SA 4.0
### Citation Information
```bibtex
@article{yanaka-mineshima-2022-compositional,
title = "Compositional Evaluation on {J}apanese Textual Entailment and Similarity",
author = "Yanaka, Hitomi and
Mineshima, Koji",
journal = "Transactions of the Association for Computational Linguistics",
volume = "10",
year = "2022",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/2022.tacl-1.73",
doi = "10.1162/tacl_a_00518",
pages = "1266--1284",
}
@article{谷中 瞳2021,
title={JSICK: 日本語構成的推論・類似度データセットの構築},
author={谷中 瞳 and 峯島 宏次},
journal={人工知能学会全国大会論文集},
volume={JSAI2021},
number={ },
pages={4J3GS6f02-4J3GS6f02},
year={2021},
doi={10.11517/pjsai.JSAI2021.0_4J3GS6f02}
}
```
### Contributions
Thanks to [Hitomi Yanaka](https://hitomiyanaka.mystrikingly.com/) and [Koji Mineshima](https://abelard.flet.keio.ac.jp/person/minesima/index-j.html) for creating this dataset. |
kunishou/cnn-dailymail-27k-ja | ---
license: mit
---
This dataset was created by automatically translating part of "cnn_dailymail" into Japanese.
cnn_dailymail repository
https://github.com/abisee/cnn-dailymail
cnn_dailymail
https://huggingface.co/datasets/cnn_dailymail |
ivrit-ai/audio-transcripts | ---
language:
- he
license: other
size_categories:
- 1M<n<10M
task_categories:
- audio-classification
- voice-activity-detection
extra_gated_prompt: 'You agree to the following license terms:
This material and data is licensed under the terms of the Creative Commons Attribution
4.0 International License (CC BY 4.0), The full text of the CC-BY 4.0 license is
available at https://creativecommons.org/licenses/by/4.0/.
Notwithstanding the foregoing, this material and data may only be used, modified
and distributed for the express purpose of training AI models, and subject to the
foregoing restriction. In addition, this material and data may not be used in order
to create audiovisual material that simulates the voice or likeness of the specific
individuals appearing or speaking in such materials and data (a “deep-fake”). To
the extent this paragraph is inconsistent with the CC-BY-4.0 license, the terms
of this paragraph shall govern.
By downloading or using any of this material or data, you agree that the Project
makes no representations or warranties in respect of the data, and shall have no
liability in respect thereof. These disclaimers and limitations are in addition
to any disclaimers and limitations set forth in the CC-BY-4.0 license itself. You
understand that the project is only able to make available the materials and data
pursuant to these disclaimers and limitations, and without such disclaimers and
limitations the project would not be able to make available the materials and data
for your use.'
extra_gated_fields:
I have read the license, and agree to its terms: checkbox
dataset_info:
features:
- name: source
dtype: string
- name: episode
dtype: string
- name: uuid
dtype: string
- name: text
dtype: string
- name: attrs
struct:
- name: segments
list:
- name: avg_logprob
dtype: float64
- name: compression_ratio
dtype: float64
- name: end
dtype: float64
- name: id
dtype: int64
- name: no_speech_prob
dtype: float64
- name: seek
dtype: int64
- name: start
dtype: float64
- name: text
dtype: string
splits:
- name: train
num_bytes: 1290457176
num_examples: 2183042
download_size: 421521923
dataset_size: 1290457176
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
ivrit.ai is a database of Hebrew audio and text content.
**audio-base** contains the raw, unprocessed sources.
**audio-vad** contains audio snippets generated by applying Silero VAD (https://github.com/snakers4/silero-vad) to the base dataset.
**audio-transcripts** contains transcriptions for each snippet in the audio-vad dataset.
The audio-base dataset contains data from the following sources:
* Geekonomy (Podcast, https://geekonomy.net)
* HaCongress (Podcast, https://hacongress.podbean.com/)
* Idan Eretz's YouTube channel (https://www.youtube.com/@IdanEretz)
* Moneytime (Podcast, https://money-time.co.il)
* Mor'e Nevohim (Podcast, https://open.spotify.com/show/1TZeexEk7n60LT1SlS2FE2?si=937266e631064a3c)
* Yozevitch's World (Podcast, https://www.yozevitch.com/yozevitch-podcast)
* NETfrix (Podcast, https://netfrix.podbean.com)
* On Meaning (Podcast, https://mashmaut.buzzsprout.com)
* Shnekel (Podcast, https://www.shnekel.live)
* Bite-sized History (Podcast, https://soundcloud.com/historia-il)
* Tziun 3 (Podcast, https://tziun3.co.il)
* Academia Israel (https://www.youtube.com/@academiaisrael6115)
* Shiluv Maagal (https://www.youtube.com/@ShiluvMaagal)
Paper: https://arxiv.org/abs/2307.08720
If you use our datasets, the following quote is preferable:
```
@misc{marmor2023ivritai,
title={ivrit.ai: A Comprehensive Dataset of Hebrew Speech for AI Research and Development},
author={Yanir Marmor and Kinneret Misgav and Yair Lifshitz},
year={2023},
eprint={2307.08720},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
``` |
sunlab/patch_db | ---
license: apache-2.0
task_categories:
- feature-extraction
- text-classification
- summarization
- text-generation
tags:
- code
- commit
- patch
language:
- en
pretty_name: PatchDB
size_categories:
- 10K<n<100K
---
# PatchDB: A Large-Scale Security Patch Dataset
## Description
To foster large-scale research on vulnerability mitigation and to enable a comparison of different detection approaches, we make our dataset ***PatchDB*** from our DSN'21 paper publicly available.
PatchDB is a large-scale security patch dataset that contains around 12,073 security patches and 23,742 non-security patches from the real world.
You can find more details on the dataset in the paper *"[PatchDB: A Large-Scale Security Patch Dataset](https://csis.gmu.edu/ksun/publications/dsn21_PatchDB.pdf)"*. You can also visit our [PatchDB official website](https://sunlab-gmu.github.io/PatchDB) for more information.
<font color="red">Please use your work emails to request for the dataset.</font> Typically, it takes no longer than 24 hours to get approval.
## Data Structure
PatchDB is stored in `json` format, where each sample contains 9 keys and has the following format.
```json
{
"category": the type of patch, value:"security" or "non-security",
"source": the source of patch, value: "cve" or "wild",
"CVE_ID": the CVE ID if it exists, value: "CVE-XXXX-XXXXX" or "NA",
"CWE_ID": the CWE ID if it exists, value: "cwe_id" or "NA"
"commit_id": the hash value of the commit, type: str,
"owner": the owner id of the repository, type: str,
"repo": the repository id, type: str,
"commit_message": the commit message part of the patch, type: str,
"diff_code": the diff code part of the patch, type: str
}
```
## Disclaimer & Download Agreement<span id="jump"></span>
To download the PatchDB dataset, you must agree with the items of the succeeding Disclaimer & Download Agreement. You should carefully read the following terms before submitting the PatchDB request form.
- PatchDB is constructed and cross-checked by 3 experts that work in security patch research.
Due to the potential misclassification led by subjective factors, the Sun Security Laboratory (SunLab) cannot guarantee a 100% accuracy for samples in the dataset.
- The copyright of the PatchDB dataset is owned by SunLab.
- The purpose of using PatchDB should be non-commercial research and/or personal use. The dataset should not be used for commercial use and any profitable purpose.
- The PatchDB dataset should not be re-selled or re-distributed. Anyone who has obtained PatchDB should not share the dataset with others without the permission from SunLab.
## Team
The PatchDB dataset is built by [Sun Security Laboratory](https://sunlab-gmu.github.io/) (SunLab) at [George Mason University](https://www2.gmu.edu/), Fairfax, VA.

## Citations
```bibtex
@inproceedings{wang2021PatchDB,
author={Wang, Xinda and Wang, Shu and Feng, Pengbin and Sun, Kun and Jajodia, Sushil},
booktitle={2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
title={PatchDB: A Large-Scale Security Patch Dataset},
year={2021},
volume={},
number={},
pages={149-160},
doi={10.1109/DSN48987.2021.00030}
}
``` |
zimhe/sudo-floor-plan-12k | ---
dataset_info:
features:
- name: indices
dtype: string
- name: plans
dtype: image
- name: walls
dtype: image
- name: colors
dtype: image
- name: footprints
dtype: image
- name: plan_captions
dtype: string
splits:
- name: train
num_bytes: 3999080609.0
num_examples: 12000
download_size: 2497201625
dataset_size: 3999080609.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "sudo-floor-plan-12k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
preference-agents/EnronEmails-42K | ---
license: apache-2.0
dataset_info:
features:
- name: id
dtype: string
- name: message_id
dtype: string
- name: from
sequence: string
- name: to
sequence: string
- name: date
dtype: string
- name: subject
dtype: string
- name: content
dtype: string
- name: email_context
dtype: string
- name: attachments
dtype: string
- name: hypothetical_query_list
sequence: string
- name: token_count_content
dtype: int32
- name: token_count_context
dtype: int32
- name: user
dtype: string
splits:
- name: train
num_bytes: 59915276
num_examples: 41927
download_size: 27290149
dataset_size: 59915276
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
lewtun/music_genres_small | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: song_id
dtype: int64
- name: genre_id
dtype: int64
- name: genre
dtype: string
splits:
- name: train
num_bytes: 392427659.9527852
num_examples: 1000
download_size: 390675126
dataset_size: 392427659.9527852
---
# Dataset Card for "music_genres_small"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mrm8488/unnatural-instructions | ---
dataset_info:
- config_name: default
features:
- name: instruction
dtype: string
- name: instances
list:
- name: instruction_with_input
dtype: string
- name: input
dtype: string
- name: constraints
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 54668900
num_examples: 66010
download_size: 28584196
dataset_size: 54668900
- config_name: core
features:
- name: instruction
dtype: string
- name: instances
sequence:
- name: instruction_with_input
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: constraints
dtype: string
splits:
- name: train
num_bytes: 55461020
num_examples: 66010
download_size: 29679516
dataset_size: 55461020
- config_name: full
features:
- name: instruction
dtype: string
- name: instances
sequence:
- name: instruction_with_input
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: constraints
dtype: string
- name: reformulations
sequence:
- name: instruction
dtype: string
- name: instruction_with_input
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 145864853
num_examples: 66010
download_size: 29679516
dataset_size: 145864853
---
# Dataset Card for "unnatural-instructions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
navjordj/SNL_summarization | ---
task_categories:
- summarization
- text2text-generation
language:
- 'no'
- nb
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: id
dtype: int64
- name: url
dtype: string
- name: date_scraped
dtype: string
- name: headline
dtype: string
- name: category
dtype: string
- name: ingress
dtype: string
- name: article
dtype: string
splits:
- name: train
num_bytes: 26303219.28053567
num_examples: 10874
- name: validation
num_bytes: 1981086.682983145
num_examples: 819
- name: test
num_bytes: 3144582.036481182
num_examples: 1300
download_size: 19441287
dataset_size: 31428888.0
---
# SNL Summarization Dataset
The source of this dataset is a web scrape of SNL (Store Norske Leksikon), a publicly owned Norwegian encyclopedia. Articles in SNL are structured so that the first para
graph (the lead) acts as a summary of the entire article.
## Methodology
From our thesis:
We couldn’t find any existing datasets containing SNL data, so we decided to create our own by scraping articles from SNL.no. The first step involved gathering a list of all article URLs on the site. We extracted the URLs from the sitemaps and retained only those following the format ”https://snl.no/name of article” to avoid non-article pages. Next, we scraped the URLs with multiple threads downloading articles at the same time using the Python module grequests and parsed the received HTML using beautifulsoup4. We extracted the text from the lead and the rest of the article text, joining the latter while removing any whitespace. Additionally, we saved metadata such as URLs, headlines, and categories for each article.
To filter out very short articles, we set criteria for keeping an article: the lead had
to be at least 100 characters long, and the rest of the article had to be longer than 400 characters.
Finally, we split the dataset using an 84%/6%/10% split for the train/validation/test sets. This
division was chosen to ensure a sufficient amount of data for training our models while still
providing an adequate sample size for validation and testing. By allocating a larger portion
(84%) of the data for training, our goal was to optimize the model’s learning process. We
allocated 6% of the data for validation, which was intended to help fine-tune the model and
its hyperparameters, while the remaining 10% was designated for the final evaluation of our
model’s performance on unseen data in the test set.
# License
Please refer to the license of SNL
# Citation
If you are using this dataset in your work, please cite our master thesis which this dataset was a part of
```
@mastersthesis{navjord2023beyond,
title={Beyond extractive: advancing abstractive automatic text summarization in Norwegian with transformers},
author={Navjord, J{\o}rgen Johnsen and Korsvik, Jon-Mikkel Ryen},
year={2023},
school={Norwegian University of Life Sciences, {\AA}s}
}
``` |
taesiri/imagenet-hard | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
sequence: int64
- name: origin
dtype: string
- name: english_label
sequence: string
splits:
- name: validation
num_bytes: 1771418938.94
num_examples: 10980
download_size: 6380094503
dataset_size: 1771418938.94
license: mit
task_categories:
- image-classification
language:
- en
tags:
- OOD
- ImageNet
- Out Of Distribution
pretty_name: ImageNet-Hard
size_categories:
- 10K<n<100K
---
# Dataset Card for "ImageNet-Hard"
[Project Page](https://taesiri.github.io/ZoomIsAllYouNeed/) - [ArXiv](https://arxiv.org/abs/2304.05538) - [Paper](https://huggingface.co/papers/2304.05538) - [Github](https://github.com/taesiri/ZoomIsAllYouNeed) - [Image Browser](https://huggingface.co/spaces/taesiri/ImageNet-Hard-Browser)
## Dataset Summary
**ImageNet-Hard** is a new benchmark that comprises 10,980 images collected from various existing ImageNet-scale benchmarks (ImageNet, ImageNet-V2, ImageNet-Sketch, ImageNet-C, ImageNet-R, ImageNet-ReaL, ImageNet-A, and ObjectNet). This dataset poses a significant challenge to state-of-the-art vision models as merely zooming in often fails to improve their ability to classify images correctly. As a result, even the most advanced models, such as `CLIP-ViT-L/14@336px`, struggle to perform well on this dataset, achieving a mere `2.02%` accuracy.
*ImageNet-Hard-4K*: For the 4K version please refere to [this dataset](https://huggingface.co/datasets/taesiri/imagenet-hard-4K).
### Dataset Distribution

### Classifiers Performance
| Model | Accuracy |
| ------------------- | -------- |
| AlexNet | 7.34 |
| VGG-16 | 12.00 |
| ResNet-18 | 10.86 |
| ResNet-50 | 14.74 |
| ViT-B/32 | 18.52 |
| EfficientNet-B0 | 16.57 |
| EfficientNet-B7 | 23.20 |
| EfficientNet-L2-Ns | 39.00 |
| CLIP-ViT-L/14@224px | 1.86 |
| CLIP-ViT-L/14@336px | 2.02 |
| OpenCLIP-ViT-bigG-14| 15.93 |
| OpenCLIP-ViT-L-14 | 15.60 |
**Evaluation Code**
* CLIP <a target="_blank" href="https://colab.research.google.com/github/taesiri/ZoomIsAllYouNeed/blob/main/src/ImageNet_Hard/Prompt_Engineering_for_ImageNet_Hard.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a>
* [OpenCLIP](https://github.com/taesiri/ZoomIsAllYouNeed/blob/main/src/ImageNet_Hard/benchmark_openclip.py)
* Other models <a target="_blank" href="https://colab.research.google.com/github/taesiri/ZoomIsAllYouNeed/blob/main/src/ImageNet_Hard/Benchmark_ImageNet_Hard.ipynb"> <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/> </a>
## Supported Tasks
- `image-classification`: The objective of this task is to classify an image into one or more classes, selected from 1000 ImageNet categories (allowing for multiple ground-truth labels per image).
## Languages
The `english_label` field in the dataset are in English.
## Dataset Structure
Data Instances
An example looks like this:
```python
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=575x409 at 0x7F09456B53A0>,
'label': [0],
'origin': 'imagenet_sketch',
'english_label': ['tench']
}
```
### Data Fields
The data instances have the following fields:
- image: A PIL.Image.Image object containing the image. Note that when accessing the image column: dataset[0]["image"] the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the "image" column, i.e. dataset[0]["image"] should always be preferred over dataset["image"][0].
- label: A List[int] collection containing the ground-truth ids.
- origin: A string containing source dataset.
- english_label: A List[str] collection containg the english labels for the ground-truth classes.
<details>
<summary>
Click here to see the full list of ImageNet class labels mapping:
</summary>
|id|Class|
|--|-----|
|0 | tench, Tinca tinca|
|1 | goldfish, Carassius auratus|
|2 | great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias|
|3 | tiger shark, Galeocerdo cuvieri|
|4 | hammerhead, hammerhead shark|
|5 | electric ray, crampfish, numbfish, torpedo|
|6 | stingray|
|7 | cock|
|8 | hen|
|9 | ostrich, Struthio camelus|
|10 | brambling, Fringilla montifringilla|
|11 | goldfinch, Carduelis carduelis|
|12 | house finch, linnet, Carpodacus mexicanus|
|13 | junco, snowbird|
|14 | indigo bunting, indigo finch, indigo bird, Passerina cyanea|
|15 | robin, American robin, Turdus migratorius|
|16 | bulbul|
|17 | jay|
|18 | magpie|
|19 | chickadee|
|20 | water ouzel, dipper|
|21 | kite|
|22 | bald eagle, American eagle, Haliaeetus leucocephalus|
|23 | vulture|
|24 | great grey owl, great gray owl, Strix nebulosa|
|25 | European fire salamander, Salamandra salamandra|
|26 | common newt, Triturus vulgaris|
|27 | eft|
|28 | spotted salamander, Ambystoma maculatum|
|29 | axolotl, mud puppy, Ambystoma mexicanum|
|30 | bullfrog, Rana catesbeiana|
|31 | tree frog, tree-frog|
|32 | tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui|
|33 | loggerhead, loggerhead turtle, Caretta caretta|
|34 | leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea|
|35 | mud turtle|
|36 | terrapin|
|37 | box turtle, box tortoise|
|38 | banded gecko|
|39 | common iguana, iguana, Iguana iguana|
|40 | American chameleon, anole, Anolis carolinensis|
|41 | whiptail, whiptail lizard|
|42 | agama|
|43 | frilled lizard, Chlamydosaurus kingi|
|44 | alligator lizard|
|45 | Gila monster, Heloderma suspectum|
|46 | green lizard, Lacerta viridis|
|47 | African chameleon, Chamaeleo chamaeleon|
|48 | Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus komodoensis|
|49 | African crocodile, Nile crocodile, Crocodylus niloticus|
|50 | American alligator, Alligator mississipiensis|
|51 | triceratops|
|52 | thunder snake, worm snake, Carphophis amoenus|
|53 | ringneck snake, ring-necked snake, ring snake|
|54 | hognose snake, puff adder, sand viper|
|55 | green snake, grass snake|
|56 | king snake, kingsnake|
|57 | garter snake, grass snake|
|58 | water snake|
|59 | vine snake|
|60 | night snake, Hypsiglena torquata|
|61 | boa constrictor, Constrictor constrictor|
|62 | rock python, rock snake, Python sebae|
|63 | Indian cobra, Naja naja|
|64 | green mamba|
|65 | sea snake|
|66 | horned viper, cerastes, sand viper, horned asp, Cerastes cornutus|
|67 | diamondback, diamondback rattlesnake, Crotalus adamanteus|
|68 | sidewinder, horned rattlesnake, Crotalus cerastes|
|69 | trilobite|
|70 | harvestman, daddy longlegs, Phalangium opilio|
|71 | scorpion|
|72 | black and gold garden spider, Argiope aurantia|
|73 | barn spider, Araneus cavaticus|
|74 | garden spider, Aranea diademata|
|75 | black widow, Latrodectus mactans|
|76 | tarantula|
|77 | wolf spider, hunting spider|
|78 | tick|
|79 | centipede|
|80 | black grouse|
|81 | ptarmigan|
|82 | ruffed grouse, partridge, Bonasa umbellus|
|83 | prairie chicken, prairie grouse, prairie fowl|
|84 | peacock|
|85 | quail|
|86 | partridge|
|87 | African grey, African gray, Psittacus erithacus|
|88 | macaw|
|89 | sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita|
|90 | lorikeet|
|91 | coucal|
|92 | bee eater|
|93 | hornbill|
|94 | hummingbird|
|95 | jacamar|
|96 | toucan|
|97 | drake|
|98 | red-breasted merganser, Mergus serrator|
|99 | goose|
|100 | black swan, Cygnus atratus|
|101 | tusker|
|102 | echidna, spiny anteater, anteater|
|103 | platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus|
|104 | wallaby, brush kangaroo|
|105 | koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus|
|106 | wombat|
|107 | jellyfish|
|108 | sea anemone, anemone|
|109 | brain coral|
|110 | flatworm, platyhelminth|
|111 | nematode, nematode worm, roundworm|
|112 | conch|
|113 | snail|
|114 | slug|
|115 | sea slug, nudibranch|
|116 | chiton, coat-of-mail shell, sea cradle, polyplacophore|
|117 | chambered nautilus, pearly nautilus, nautilus|
|118 | Dungeness crab, Cancer magister|
|119 | rock crab, Cancer irroratus|
|120 | fiddler crab|
|121 | king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes camtschatica|
|122 | American lobster, Northern lobster, Maine lobster, Homarus americanus|
|123 | spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish|
|124 | crayfish, crawfish, crawdad, crawdaddy|
|125 | hermit crab|
|126 | isopod|
|127 | white stork, Ciconia ciconia|
|128 | black stork, Ciconia nigra|
|129 | spoonbill|
|130 | flamingo|
|131 | little blue heron, Egretta caerulea|
|132 | American egret, great white heron, Egretta albus|
|133 | bittern|
|134 | crane|
|135 | limpkin, Aramus pictus|
|136 | European gallinule, Porphyrio porphyrio|
|137 | American coot, marsh hen, mud hen, water hen, Fulica americana|
|138 | bustard|
|139 | ruddy turnstone, Arenaria interpres|
|140 | red-backed sandpiper, dunlin, Erolia alpina|
|141 | redshank, Tringa totanus|
|142 | dowitcher|
|143 | oystercatcher, oyster catcher|
|144 | pelican|
|145 | king penguin, Aptenodytes patagonica|
|146 | albatross, mollymawk|
|147 | grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus|
|148 | killer whale, killer, orca, grampus, sea wolf, Orcinus orca|
|149 | dugong, Dugong dugon|
|150 | sea lion|
|151 | Chihuahua|
|152 | Japanese spaniel|
|153 | Maltese dog, Maltese terrier, Maltese|
|154 | Pekinese, Pekingese, Peke|
|155 | Shih-Tzu|
|156 | Blenheim spaniel|
|157 | papillon|
|158 | toy terrier|
|159 | Rhodesian ridgeback|
|160 | Afghan hound, Afghan|
|161 | basset, basset hound|
|162 | beagle|
|163 | bloodhound, sleuthhound|
|164 | bluetick|
|165 | black-and-tan coonhound|
|166 | Walker hound, Walker foxhound|
|167 | English foxhound|
|168 | redbone|
|169 | borzoi, Russian wolfhound|
|170 | Irish wolfhound|
|171 | Italian greyhound|
|172 | whippet|
|173 | Ibizan hound, Ibizan Podenco|
|174 | Norwegian elkhound, elkhound|
|175 | otterhound, otter hound|
|176 | Saluki, gazelle hound|
|177 | Scottish deerhound, deerhound|
|178 | Weimaraner|
|179 | Staffordshire bullterrier, Staffordshire bull terrier|
|180 | American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier|
|181 | Bedlington terrier|
|182 | Border terrier|
|183 | Kerry blue terrier|
|184 | Irish terrier|
|185 | Norfolk terrier|
|186 | Norwich terrier|
|187 | Yorkshire terrier|
|188 | wire-haired fox terrier|
|189 | Lakeland terrier|
|190 | Sealyham terrier, Sealyham|
|191 | Airedale, Airedale terrier|
|192 | cairn, cairn terrier|
|193 | Australian terrier|
|194 | Dandie Dinmont, Dandie Dinmont terrier|
|195 | Boston bull, Boston terrier|
|196 | miniature schnauzer|
|197 | giant schnauzer|
|198 | standard schnauzer|
|199 | Scotch terrier, Scottish terrier, Scottie|
|200 | Tibetan terrier, chrysanthemum dog|
|201 | silky terrier, Sydney silky|
|202 | soft-coated wheaten terrier|
|203 | West Highland white terrier|
|204 | Lhasa, Lhasa apso|
|205 | flat-coated retriever|
|206 | curly-coated retriever|
|207 | golden retriever|
|208 | Labrador retriever|
|209 | Chesapeake Bay retriever|
|210 | German short-haired pointer|
|211 | vizsla, Hungarian pointer|
|212 | English setter|
|213 | Irish setter, red setter|
|214 | Gordon setter|
|215 | Brittany spaniel|
|216 | clumber, clumber spaniel|
|217 | English springer, English springer spaniel|
|218 | Welsh springer spaniel|
|219 | cocker spaniel, English cocker spaniel, cocker|
|220 | Sussex spaniel|
|221 | Irish water spaniel|
|222 | kuvasz|
|223 | schipperke|
|224 | groenendael|
|225 | malinois|
|226 | briard|
|227 | kelpie|
|228 | komondor|
|229 | Old English sheepdog, bobtail|
|230 | Shetland sheepdog, Shetland sheep dog, Shetland|
|231 | collie|
|232 | Border collie|
|233 | Bouvier des Flandres, Bouviers des Flandres|
|234 | Rottweiler|
|235 | German shepherd, German shepherd dog, German police dog, alsatian|
|236 | Doberman, Doberman pinscher|
|237 | miniature pinscher|
|238 | Greater Swiss Mountain dog|
|239 | Bernese mountain dog|
|240 | Appenzeller|
|241 | EntleBucher|
|242 | boxer|
|243 | bull mastiff|
|244 | Tibetan mastiff|
|245 | French bulldog|
|246 | Great Dane|
|247 | Saint Bernard, St Bernard|
|248 | Eskimo dog, husky|
|249 | malamute, malemute, Alaskan malamute|
|250 | Siberian husky|
|251 | dalmatian, coach dog, carriage dog|
|252 | affenpinscher, monkey pinscher, monkey dog|
|253 | basenji|
|254 | pug, pug-dog|
|255 | Leonberg|
|256 | Newfoundland, Newfoundland dog|
|257 | Great Pyrenees|
|258 | Samoyed, Samoyede|
|259 | Pomeranian|
|260 | chow, chow chow|
|261 | keeshond|
|262 | Brabancon griffon|
|263 | Pembroke, Pembroke Welsh corgi|
|264 | Cardigan, Cardigan Welsh corgi|
|265 | toy poodle|
|266 | miniature poodle|
|267 | standard poodle|
|268 | Mexican hairless|
|269 | timber wolf, grey wolf, gray wolf, Canis lupus|
|270 | white wolf, Arctic wolf, Canis lupus tundrarum|
|271 | red wolf, maned wolf, Canis rufus, Canis niger|
|272 | coyote, prairie wolf, brush wolf, Canis latrans|
|273 | dingo, warrigal, warragal, Canis dingo|
|274 | dhole, Cuon alpinus|
|275 | African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus|
|276 | hyena, hyaena|
|277 | red fox, Vulpes vulpes|
|278 | kit fox, Vulpes macrotis|
|279 | Arctic fox, white fox, Alopex lagopus|
|280 | grey fox, gray fox, Urocyon cinereoargenteus|
|281 | tabby, tabby cat|
|282 | tiger cat|
|283 | Persian cat|
|284 | Siamese cat, Siamese|
|285 | Egyptian cat|
|286 | cougar, puma, catamount, mountain lion, painter, panther, Felis concolor|
|287 | lynx, catamount|
|288 | leopard, Panthera pardus|
|289 | snow leopard, ounce, Panthera uncia|
|290 | jaguar, panther, Panthera onca, Felis onca|
|291 | lion, king of beasts, Panthera leo|
|292 | tiger, Panthera tigris|
|293 | cheetah, chetah, Acinonyx jubatus|
|294 | brown bear, bruin, Ursus arctos|
|295 | American black bear, black bear, Ursus americanus, Euarctos americanus|
|296 | ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus|
|297 | sloth bear, Melursus ursinus, Ursus ursinus|
|298 | mongoose|
|299 | meerkat, mierkat|
|300 | tiger beetle|
|301 | ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle|
|302 | ground beetle, carabid beetle|
|303 | long-horned beetle, longicorn, longicorn beetle|
|304 | leaf beetle, chrysomelid|
|305 | dung beetle|
|306 | rhinoceros beetle|
|307 | weevil|
|308 | fly|
|309 | bee|
|310 | ant, emmet, pismire|
|311 | grasshopper, hopper|
|312 | cricket|
|313 | walking stick, walkingstick, stick insect|
|314 | cockroach, roach|
|315 | mantis, mantid|
|316 | cicada, cicala|
|317 | leafhopper|
|318 | lacewing, lacewing fly|
|319 | dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk|
|320 | damselfly|
|321 | admiral|
|322 | ringlet, ringlet butterfly|
|323 | monarch, monarch butterfly, milkweed butterfly, Danaus plexippus|
|324 | cabbage butterfly|
|325 | sulphur butterfly, sulfur butterfly|
|326 | lycaenid, lycaenid butterfly|
|327 | starfish, sea star|
|328 | sea urchin|
|329 | sea cucumber, holothurian|
|330 | wood rabbit, cottontail, cottontail rabbit|
|331 | hare|
|332 | Angora, Angora rabbit|
|333 | hamster|
|334 | porcupine, hedgehog|
|335 | fox squirrel, eastern fox squirrel, Sciurus niger|
|336 | marmot|
|337 | beaver|
|338 | guinea pig, Cavia cobaya|
|339 | sorrel|
|340 | zebra|
|341 | hog, pig, grunter, squealer, Sus scrofa|
|342 | wild boar, boar, Sus scrofa|
|343 | warthog|
|344 | hippopotamus, hippo, river horse, Hippopotamus amphibius|
|345 | ox|
|346 | water buffalo, water ox, Asiatic buffalo, Bubalus bubalis|
|347 | bison|
|348 | ram, tup|
|349 | bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain sheep, Ovis canadensis|
|350 | ibex, Capra ibex|
|351 | hartebeest|
|352 | impala, Aepyceros melampus|
|353 | gazelle|
|354 | Arabian camel, dromedary, Camelus dromedarius|
|355 | llama|
|356 | weasel|
|357 | mink|
|358 | polecat, fitch, foulmart, foumart, Mustela putorius|
|359 | black-footed ferret, ferret, Mustela nigripes|
|360 | otter|
|361 | skunk, polecat, wood pussy|
|362 | badger|
|363 | armadillo|
|364 | three-toed sloth, ai, Bradypus tridactylus|
|365 | orangutan, orang, orangutang, Pongo pygmaeus|
|366 | gorilla, Gorilla gorilla|
|367 | chimpanzee, chimp, Pan troglodytes|
|368 | gibbon, Hylobates lar|
|369 | siamang, Hylobates syndactylus, Symphalangus syndactylus|
|370 | guenon, guenon monkey|
|371 | patas, hussar monkey, Erythrocebus patas|
|372 | baboon|
|373 | macaque|
|374 | langur|
|375 | colobus, colobus monkey|
|376 | proboscis monkey, Nasalis larvatus|
|377 | marmoset|
|378 | capuchin, ringtail, Cebus capucinus|
|379 | howler monkey, howler|
|380 | titi, titi monkey|
|381 | spider monkey, Ateles geoffroyi|
|382 | squirrel monkey, Saimiri sciureus|
|383 | Madagascar cat, ring-tailed lemur, Lemur catta|
|384 | indri, indris, Indri indri, Indri brevicaudatus|
|385 | Indian elephant, Elephas maximus|
|386 | African elephant, Loxodonta africana|
|387 | lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens|
|388 | giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca|
|389 | barracouta, snoek|
|390 | eel|
|391 | coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus kisutch|
|392 | rock beauty, Holocanthus tricolor|
|393 | anemone fish|
|394 | sturgeon|
|395 | gar, garfish, garpike, billfish, Lepisosteus osseus|
|396 | lionfish|
|397 | puffer, pufferfish, blowfish, globefish|
|398 | abacus|
|399 | abaya|
|400 | academic gown, academic robe, judge's robe|
|401 | accordion, piano accordion, squeeze box|
|402 | acoustic guitar|
|403 | aircraft carrier, carrier, flattop, attack aircraft carrier|
|404 | airliner|
|405 | airship, dirigible|
|406 | altar|
|407 | ambulance|
|408 | amphibian, amphibious vehicle|
|409 | analog clock|
|410 | apiary, bee house|
|411 | apron|
|412 | ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin|
|413 | assault rifle, assault gun|
|414 | backpack, back pack, knapsack, packsack, rucksack, haversack|
|415 | bakery, bakeshop, bakehouse|
|416 | balance beam, beam|
|417 | balloon|
|418 | ballpoint, ballpoint pen, ballpen, Biro|
|419 | Band Aid|
|420 | banjo|
|421 | bannister, banister, balustrade, balusters, handrail|
|422 | barbell|
|423 | barber chair|
|424 | barbershop|
|425 | barn|
|426 | barometer|
|427 | barrel, cask|
|428 | barrow, garden cart, lawn cart, wheelbarrow|
|429 | baseball|
|430 | basketball|
|431 | bassinet|
|432 | bassoon|
|433 | bathing cap, swimming cap|
|434 | bath towel|
|435 | bathtub, bathing tub, bath, tub|
|436 | beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon|
|437 | beacon, lighthouse, beacon light, pharos|
|438 | beaker|
|439 | bearskin, busby, shako|
|440 | beer bottle|
|441 | beer glass|
|442 | bell cote, bell cot|
|443 | bib|
|444 | bicycle-built-for-two, tandem bicycle, tandem|
|445 | bikini, two-piece|
|446 | binder, ring-binder|
|447 | binoculars, field glasses, opera glasses|
|448 | birdhouse|
|449 | boathouse|
|450 | bobsled, bobsleigh, bob|
|451 | bolo tie, bolo, bola tie, bola|
|452 | bonnet, poke bonnet|
|453 | bookcase|
|454 | bookshop, bookstore, bookstall|
|455 | bottlecap|
|456 | bow|
|457 | bow tie, bow-tie, bowtie|
|458 | brass, memorial tablet, plaque|
|459 | brassiere, bra, bandeau|
|460 | breakwater, groin, groyne, mole, bulwark, seawall, jetty|
|461 | breastplate, aegis, egis|
|462 | broom|
|463 | bucket, pail|
|464 | buckle|
|465 | bulletproof vest|
|466 | bullet train, bullet|
|467 | butcher shop, meat market|
|468 | cab, hack, taxi, taxicab|
|469 | caldron, cauldron|
|470 | candle, taper, wax light|
|471 | cannon|
|472 | canoe|
|473 | can opener, tin opener|
|474 | cardigan|
|475 | car mirror|
|476 | carousel, carrousel, merry-go-round, roundabout, whirligig|
|477 | carpenter's kit, tool kit|
|478 | carton|
|479 | car wheel|
|480 | cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, ATM|
|481 | cassette|
|482 | cassette player|
|483 | castle|
|484 | catamaran|
|485 | CD player|
|486 | cello, violoncello|
|487 | cellular telephone, cellular phone, cellphone, cell, mobile phone|
|488 | chain|
|489 | chainlink fence|
|490 | chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour|
|491 | chain saw, chainsaw|
|492 | chest|
|493 | chiffonier, commode|
|494 | chime, bell, gong|
|495 | china cabinet, china closet|
|496 | Christmas stocking|
|497 | church, church building|
|498 | cinema, movie theater, movie theatre, movie house, picture palace|
|499 | cleaver, meat cleaver, chopper|
|500 | cliff dwelling|
|501 | cloak|
|502 | clog, geta, patten, sabot|
|503 | cocktail shaker|
|504 | coffee mug|
|505 | coffeepot|
|506 | coil, spiral, volute, whorl, helix|
|507 | combination lock|
|508 | computer keyboard, keypad|
|509 | confectionery, confectionary, candy store|
|510 | container ship, containership, container vessel|
|511 | convertible|
|512 | corkscrew, bottle screw|
|513 | cornet, horn, trumpet, trump|
|514 | cowboy boot|
|515 | cowboy hat, ten-gallon hat|
|516 | cradle|
|517 | crane_1|
|518 | crash helmet|
|519 | crate|
|520 | crib, cot|
|521 | Crock Pot|
|522 | croquet ball|
|523 | crutch|
|524 | cuirass|
|525 | dam, dike, dyke|
|526 | desk|
|527 | desktop computer|
|528 | dial telephone, dial phone|
|529 | diaper, nappy, napkin|
|530 | digital clock|
|531 | digital watch|
|532 | dining table, board|
|533 | dishrag, dishcloth|
|534 | dishwasher, dish washer, dishwashing machine|
|535 | disk brake, disc brake|
|536 | dock, dockage, docking facility|
|537 | dogsled, dog sled, dog sleigh|
|538 | dome|
|539 | doormat, welcome mat|
|540 | drilling platform, offshore rig|
|541 | drum, membranophone, tympan|
|542 | drumstick|
|543 | dumbbell|
|544 | Dutch oven|
|545 | electric fan, blower|
|546 | electric guitar|
|547 | electric locomotive|
|548 | entertainment center|
|549 | envelope|
|550 | espresso maker|
|551 | face powder|
|552 | feather boa, boa|
|553 | file, file cabinet, filing cabinet|
|554 | fireboat|
|555 | fire engine, fire truck|
|556 | fire screen, fireguard|
|557 | flagpole, flagstaff|
|558 | flute, transverse flute|
|559 | folding chair|
|560 | football helmet|
|561 | forklift|
|562 | fountain|
|563 | fountain pen|
|564 | four-poster|
|565 | freight car|
|566 | French horn, horn|
|567 | frying pan, frypan, skillet|
|568 | fur coat|
|569 | garbage truck, dustcart|
|570 | gasmask, respirator, gas helmet|
|571 | gas pump, gasoline pump, petrol pump, island dispenser|
|572 | goblet|
|573 | go-kart|
|574 | golf ball|
|575 | golfcart, golf cart|
|576 | gondola|
|577 | gong, tam-tam|
|578 | gown|
|579 | grand piano, grand|
|580 | greenhouse, nursery, glasshouse|
|581 | grille, radiator grille|
|582 | grocery store, grocery, food market, market|
|583 | guillotine|
|584 | hair slide|
|585 | hair spray|
|586 | half track|
|587 | hammer|
|588 | hamper|
|589 | hand blower, blow dryer, blow drier, hair dryer, hair drier|
|590 | hand-held computer, hand-held microcomputer|
|591 | handkerchief, hankie, hanky, hankey|
|592 | hard disc, hard disk, fixed disk|
|593 | harmonica, mouth organ, harp, mouth harp|
|594 | harp|
|595 | harvester, reaper|
|596 | hatchet|
|597 | holster|
|598 | home theater, home theatre|
|599 | honeycomb|
|600 | hook, claw|
|601 | hoopskirt, crinoline|
|602 | horizontal bar, high bar|
|603 | horse cart, horse-cart|
|604 | hourglass|
|605 | iPod|
|606 | iron, smoothing iron|
|607 | jack-o'-lantern|
|608 | jean, blue jean, denim|
|609 | jeep, landrover|
|610 | jersey, T-shirt, tee shirt|
|611 | jigsaw puzzle|
|612 | jinrikisha, ricksha, rickshaw|
|613 | joystick|
|614 | kimono|
|615 | knee pad|
|616 | knot|
|617 | lab coat, laboratory coat|
|618 | ladle|
|619 | lampshade, lamp shade|
|620 | laptop, laptop computer|
|621 | lawn mower, mower|
|622 | lens cap, lens cover|
|623 | letter opener, paper knife, paperknife|
|624 | library|
|625 | lifeboat|
|626 | lighter, light, igniter, ignitor|
|627 | limousine, limo|
|628 | liner, ocean liner|
|629 | lipstick, lip rouge|
|630 | Loafer|
|631 | lotion|
|632 | loudspeaker, speaker, speaker unit, loudspeaker system, speaker system|
|633 | loupe, jeweler's loupe|
|634 | lumbermill, sawmill|
|635 | magnetic compass|
|636 | mailbag, postbag|
|637 | mailbox, letter box|
|638 | maillot|
|639 | maillot, tank suit|
|640 | manhole cover|
|641 | maraca|
|642 | marimba, xylophone|
|643 | mask|
|644 | matchstick|
|645 | maypole|
|646 | maze, labyrinth|
|647 | measuring cup|
|648 | medicine chest, medicine cabinet|
|649 | megalith, megalithic structure|
|650 | microphone, mike|
|651 | microwave, microwave oven|
|652 | military uniform|
|653 | milk can|
|654 | minibus|
|655 | miniskirt, mini|
|656 | minivan|
|657 | missile|
|658 | mitten|
|659 | mixing bowl|
|660 | mobile home, manufactured home|
|661 | Model T|
|662 | modem|
|663 | monastery|
|664 | monitor|
|665 | moped|
|666 | mortar|
|667 | mortarboard|
|668 | mosque|
|669 | mosquito net|
|670 | motor scooter, scooter|
|671 | mountain bike, all-terrain bike, off-roader|
|672 | mountain tent|
|673 | mouse, computer mouse|
|674 | mousetrap|
|675 | moving van|
|676 | muzzle|
|677 | nail|
|678 | neck brace|
|679 | necklace|
|680 | nipple|
|681 | notebook, notebook computer|
|682 | obelisk|
|683 | oboe, hautboy, hautbois|
|684 | ocarina, sweet potato|
|685 | odometer, hodometer, mileometer, milometer|
|686 | oil filter|
|687 | organ, pipe organ|
|688 | oscilloscope, scope, cathode-ray oscilloscope, CRO|
|689 | overskirt|
|690 | oxcart|
|691 | oxygen mask|
|692 | packet|
|693 | paddle, boat paddle|
|694 | paddlewheel, paddle wheel|
|695 | padlock|
|696 | paintbrush|
|697 | pajama, pyjama, pj's, jammies|
|698 | palace|
|699 | panpipe, pandean pipe, syrinx|
|700 | paper towel|
|701 | parachute, chute|
|702 | parallel bars, bars|
|703 | park bench|
|704 | parking meter|
|705 | passenger car, coach, carriage|
|706 | patio, terrace|
|707 | pay-phone, pay-station|
|708 | pedestal, plinth, footstall|
|709 | pencil box, pencil case|
|710 | pencil sharpener|
|711 | perfume, essence|
|712 | Petri dish|
|713 | photocopier|
|714 | pick, plectrum, plectron|
|715 | pickelhaube|
|716 | picket fence, paling|
|717 | pickup, pickup truck|
|718 | pier|
|719 | piggy bank, penny bank|
|720 | pill bottle|
|721 | pillow|
|722 | ping-pong ball|
|723 | pinwheel|
|724 | pirate, pirate ship|
|725 | pitcher, ewer|
|726 | plane, carpenter's plane, woodworking plane|
|727 | planetarium|
|728 | plastic bag|
|729 | plate rack|
|730 | plow, plough|
|731 | plunger, plumber's helper|
|732 | Polaroid camera, Polaroid Land camera|
|733 | pole|
|734 | police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria|
|735 | poncho|
|736 | pool table, billiard table, snooker table|
|737 | pop bottle, soda bottle|
|738 | pot, flowerpot|
|739 | potter's wheel|
|740 | power drill|
|741 | prayer rug, prayer mat|
|742 | printer|
|743 | prison, prison house|
|744 | projectile, missile|
|745 | projector|
|746 | puck, hockey puck|
|747 | punching bag, punch bag, punching ball, punchball|
|748 | purse|
|749 | quill, quill pen|
|750 | quilt, comforter, comfort, puff|
|751 | racer, race car, racing car|
|752 | racket, racquet|
|753 | radiator|
|754 | radio, wireless|
|755 | radio telescope, radio reflector|
|756 | rain barrel|
|757 | recreational vehicle, RV, R.V.|
|758 | reel|
|759 | reflex camera|
|760 | refrigerator, icebox|
|761 | remote control, remote|
|762 | restaurant, eating house, eating place, eatery|
|763 | revolver, six-gun, six-shooter|
|764 | rifle|
|765 | rocking chair, rocker|
|766 | rotisserie|
|767 | rubber eraser, rubber, pencil eraser|
|768 | rugby ball|
|769 | rule, ruler|
|770 | running shoe|
|771 | safe|
|772 | safety pin|
|773 | saltshaker, salt shaker|
|774 | sandal|
|775 | sarong|
|776 | sax, saxophone|
|777 | scabbard|
|778 | scale, weighing machine|
|779 | school bus|
|780 | schooner|
|781 | scoreboard|
|782 | screen, CRT screen|
|783 | screw|
|784 | screwdriver|
|785 | seat belt, seatbelt|
|786 | sewing machine|
|787 | shield, buckler|
|788 | shoe shop, shoe-shop, shoe store|
|789 | shoji|
|790 | shopping basket|
|791 | shopping cart|
|792 | shovel|
|793 | shower cap|
|794 | shower curtain|
|795 | ski|
|796 | ski mask|
|797 | sleeping bag|
|798 | slide rule, slipstick|
|799 | sliding door|
|800 | slot, one-armed bandit|
|801 | snorkel|
|802 | snowmobile|
|803 | snowplow, snowplough|
|804 | soap dispenser|
|805 | soccer ball|
|806 | sock|
|807 | solar dish, solar collector, solar furnace|
|808 | sombrero|
|809 | soup bowl|
|810 | space bar|
|811 | space heater|
|812 | space shuttle|
|813 | spatula|
|814 | speedboat|
|815 | spider web, spider's web|
|816 | spindle|
|817 | sports car, sport car|
|818 | spotlight, spot|
|819 | stage|
|820 | steam locomotive|
|821 | steel arch bridge|
|822 | steel drum|
|823 | stethoscope|
|824 | stole|
|825 | stone wall|
|826 | stopwatch, stop watch|
|827 | stove|
|828 | strainer|
|829 | streetcar, tram, tramcar, trolley, trolley car|
|830 | stretcher|
|831 | studio couch, day bed|
|832 | stupa, tope|
|833 | submarine, pigboat, sub, U-boat|
|834 | suit, suit of clothes|
|835 | sundial|
|836 | sunglass|
|837 | sunglasses, dark glasses, shades|
|838 | sunscreen, sunblock, sun blocker|
|839 | suspension bridge|
|840 | swab, swob, mop|
|841 | sweatshirt|
|842 | swimming trunks, bathing trunks|
|843 | swing|
|844 | switch, electric switch, electrical switch|
|845 | syringe|
|846 | table lamp|
|847 | tank, army tank, armored combat vehicle, armoured combat vehicle|
|848 | tape player|
|849 | teapot|
|850 | teddy, teddy bear|
|851 | television, television system|
|852 | tennis ball|
|853 | thatch, thatched roof|
|854 | theater curtain, theatre curtain|
|855 | thimble|
|856 | thresher, thrasher, threshing machine|
|857 | throne|
|858 | tile roof|
|859 | toaster|
|860 | tobacco shop, tobacconist shop, tobacconist|
|861 | toilet seat|
|862 | torch|
|863 | totem pole|
|864 | tow truck, tow car, wrecker|
|865 | toyshop|
|866 | tractor|
|867 | trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi|
|868 | tray|
|869 | trench coat|
|870 | tricycle, trike, velocipede|
|871 | trimaran|
|872 | tripod|
|873 | triumphal arch|
|874 | trolleybus, trolley coach, trackless trolley|
|875 | trombone|
|876 | tub, vat|
|877 | turnstile|
|878 | typewriter keyboard|
|879 | umbrella|
|880 | unicycle, monocycle|
|881 | upright, upright piano|
|882 | vacuum, vacuum cleaner|
|883 | vase|
|884 | vault|
|885 | velvet|
|886 | vending machine|
|887 | vestment|
|888 | viaduct|
|889 | violin, fiddle|
|890 | volleyball|
|891 | waffle iron|
|892 | wall clock|
|893 | wallet, billfold, notecase, pocketbook|
|894 | wardrobe, closet, press|
|895 | warplane, military plane|
|896 | washbasin, handbasin, washbowl, lavabo, wash-hand basin|
|897 | washer, automatic washer, washing machine|
|898 | water bottle|
|899 | water jug|
|900 | water tower|
|901 | whiskey jug|
|902 | whistle|
|903 | wig|
|904 | window screen|
|905 | window shade|
|906 | Windsor tie|
|907 | wine bottle|
|908 | wing|
|909 | wok|
|910 | wooden spoon|
|911 | wool, woolen, woollen|
|912 | worm fence, snake fence, snake-rail fence, Virginia fence|
|913 | wreck|
|914 | yawl|
|915 | yurt|
|916 | web site, website, internet site, site|
|917 | comic book|
|918 | crossword puzzle, crossword|
|919 | street sign|
|920 | traffic light, traffic signal, stoplight|
|921 | book jacket, dust cover, dust jacket, dust wrapper|
|922 | menu|
|923 | plate|
|924 | guacamole|
|925 | consomme|
|926 | hot pot, hotpot|
|927 | trifle|
|928 | ice cream, icecream|
|929 | ice lolly, lolly, lollipop, popsicle|
|930 | French loaf|
|931 | bagel, beigel|
|932 | pretzel|
|933 | cheeseburger|
|934 | hotdog, hot dog, red hot|
|935 | mashed potato|
|936 | head cabbage|
|937 | broccoli|
|938 | cauliflower|
|939 | zucchini, courgette|
|940 | spaghetti squash|
|941 | acorn squash|
|942 | butternut squash|
|943 | cucumber, cuke|
|944 | artichoke, globe artichoke|
|945 | bell pepper|
|946 | cardoon|
|947 | mushroom|
|948 | Granny Smith|
|949 | strawberry|
|950 | orange|
|951 | lemon|
|952 | fig|
|953 | pineapple, ananas|
|954 | banana|
|955 | jackfruit, jak, jack|
|956 | custard apple|
|957 | pomegranate|
|958 | hay|
|959 | carbonara|
|960 | chocolate sauce, chocolate syrup|
|961 | dough|
|962 | meat loaf, meatloaf|
|963 | pizza, pizza pie|
|964 | potpie|
|965 | burrito|
|966 | red wine|
|967 | espresso|
|968 | cup|
|969 | eggnog|
|970 | alp|
|971 | bubble|
|972 | cliff, drop, drop-off|
|973 | coral reef|
|974 | geyser|
|975 | lakeside, lakeshore|
|976 | promontory, headland, head, foreland|
|977 | sandbar, sand bar|
|978 | seashore, coast, seacoast, sea-coast|
|979 | valley, vale|
|980 | volcano|
|981 | ballplayer, baseball player|
|982 | groom, bridegroom|
|983 | scuba diver|
|984 | rapeseed|
|985 | daisy|
|986 | yellow lady's slipper, yellow lady-slipper, Cypripedium calceolus, Cypripedium parviflorum|
|987 | corn|
|988 | acorn|
|989 | hip, rose hip, rosehip|
|990 | buckeye, horse chestnut, conker|
|991 | coral fungus|
|992 | agaric|
|993 | gyromitra|
|994 | stinkhorn, carrion fungus|
|995 | earthstar|
|996 | hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola frondosa|
|997 | bolete|
|998 | ear, spike, capitulum|
|999 | toilet tissue, toilet paper, bathroom tissue|
</details>
### Data Splits
This dataset is a validation-only set.
## Dataset Creation
### Source Data
This dataset is sourced from ImageNet, ImageNet-ReaL, ImageNet-V2, ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-Sketch, and ObjectNet.
## Citation Information
```
@article{taesiri2023zoom,
title={ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification},
author={Taesiri, Mohammad Reza and Nguyen, Giang and Habchi, Sarra and Bezemer, Cor-Paul and Nguyen, Anh},
journal={arXiv preprint arXiv:2304.05538},
year={2023}
}
``` |
AlekseyKorshuk/roleplay-io | ---
dataset_info:
features:
- name: input_text
dtype: string
- name: output_text
dtype: string
splits:
- name: train
num_bytes: 2495441
num_examples: 3146
download_size: 1543319
dataset_size: 2495441
---
# Dataset Card for "roleplay-io"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
NicolaiSivesind/human-vs-machine | ---
license: cc
task_categories:
- text-classification
pretty_name: Human vs Machine - Labled text segments produced by humans and LLMs
size_categories:
- 100K<n<1M
language:
- en
tags:
- chatgpt
- gpt
- research abstracts
- wikipedia introductions
---
# Human-vs-Machine
This is a dataset collection created in relation to a bachelor thesis written by Nicolai Thorer Sivesind and Andreas Bentzen Winje. It contains human-produced and machine-generated text samples from two domains: Wikipedia introducions and Scientific research abstracts.
Each of the two domains are already exisitng datasets reformatted for text-classification:
[GPT-wiki-intros:](https://huggingface.co/datasets/aadityaubhat/GPT-wiki-intro)
+ Generated samples are produced using the GPT-3 model, _text-curie-001_
+ Target content set by title of real wikipedia introduction and a starter sentence.
+ Target word count of 200 words each.
+ Contains 150k data points of each class.
+ Created by Aaditya Bhat
[ChatGPT-Research-Abstracts](https://huggingface.co/datasets/NicolaiSivesind/ChatGPT-Research-Abstracts):
+ Generated samples are produced using the GPT-3.5 model, _GPT-3.5-turbo-0301_ (Snapshot of the model used in ChatGPT 1st of March, 2023).
+ Target content set by title of real abstract.
+ Target word count equal to the human-produced abstract
+ Contains 10k data points of each class.
+ Created by Nicolai Thorer Sivesind
### Credits
+ [GPT-wiki-intro](https://huggingface.co/datasets/aadityaubhat/GPT-wiki-intro), by Aaditya Bhat
### Citation
Please use the following citation:
```
@misc {sivesind_2023,
author = { {Nicolai Thorer Sivesind}, {Andreas Bentzen Winje}},
title = { Human-vs-Machine },
year = 2023,
publisher = { Hugging Face }
}
```
More information about the dataset will be added once the thesis is finished (end of may 2023). |
rcp-meetings/rudialogsum_v2 | ---
license: mit
task_categories:
- text2text-generation
- summarization
language:
- ru
size_categories:
- 10K<n<100K
---
Датасет dialogsum переведенный на русский язык. Глюки перевода устранены автоматической чисткой |
cardiffnlp/super_tweeteval | ---
annotations_creators:
- expert-generated
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- n<50K
source_datasets:
- extended|other
task_categories:
- text-classification
- token-classification
- question-answering
- other
task_ids:
- topic-classification
- named-entity-recognition
- abstractive-qa
pretty_name: SuperTweetEval
tags:
- super_tweet_eval
- tweet_eval
- natural language understanding
configs:
- config_name: tempo_wic
data_files:
- split: train
path: "data/tempo_wic/train.jsonl"
- split: test
path: "data/tempo_wic/test.jsonl"
- split: validation
path: "data/tempo_wic/validation.jsonl"
- config_name: tweet_emoji
data_files:
- split: train
path: "data/tweet_emoji/train.jsonl"
- split: test
path: "data/tweet_emoji/test.jsonl"
- split: validation
path: "data/tweet_emoji/validation.jsonl"
- config_name: tweet_emotion
data_files:
- split: train
path: "data/tweet_emotion/train.jsonl"
- split: test
path: "data/tweet_emotion/test.jsonl"
- split: validation
path: "data/tweet_emotion/validation.jsonl"
- config_name: tweet_hate
data_files:
- split: train
path: "data/tweet_hate/train.jsonl"
- split: test
path: "data/tweet_hate/test.jsonl"
- split: validation
path: "data/tweet_hate/validation.jsonl"
- config_name: tweet_intimacy
data_files:
- split: train
path: "data/tweet_intimacy/train.jsonl"
- split: test
path: "data/tweet_intimacy/test.jsonl"
- split: validation
path: "data/tweet_intimacy/validation.jsonl"
- config_name: tweet_ner7
data_files:
- split: train
path: "data/tweet_ner7/train.jsonl"
- split: test
path: "data/tweet_ner7/test.jsonl"
- split: validation
path: "data/tweet_ner7/validation.jsonl"
- config_name: tweet_nerd
data_files:
- split: train
path: "data/tweet_nerd/train.jsonl"
- split: test
path: "data/tweet_nerd/test.jsonl"
- split: validation
path: "data/tweet_nerd/validation.jsonl"
- config_name: tweet_qa
data_files:
- split: train
path: "data/tweet_qa/train.jsonl"
- split: test
path: "data/tweet_qa/test.jsonl"
- split: validation
path: "data/tweet_qa/validation.jsonl"
- config_name: tweet_qg
data_files:
- split: train
path: "data/tweet_qg/train.jsonl"
- split: test
path: "data/tweet_qg/test.jsonl"
- split: validation
path: "data/tweet_qg/validation.jsonl"
- config_name: tweet_sentiment
data_files:
- split: train
path: "data/tweet_sentiment/train.jsonl"
- split: test
path: "data/tweet_sentiment/test.jsonl"
- split: validation
path: "data/tweet_sentiment/validation.jsonl"
- config_name: tweet_similarity
data_files:
- split: train
path: "data/tweet_similarity/train.jsonl"
- split: test
path: "data/tweet_similarity/test.jsonl"
- split: validation
path: "data/tweet_similarity/validation.jsonl"
- config_name: tweet_topic
data_files:
- split: train
path: "data/tweet_topic/train.jsonl"
- split: test
path: "data/tweet_topic/test.jsonl"
- split: validation
path: "data/tweet_topic/validation.jsonl"
---
# SuperTweetEval
# Dataset Card for "super_tweeteval"
### Dataset Summary
This is the oficial repository for SuperTweetEval, a unified benchmark of 12 heterogeneous NLP tasks.
More details on the task and an evaluation of language models can be found on the [reference paper](https://arxiv.org/abs/2310.14757), published in EMNLP 2023 (Findings).
### Data Splits
All tasks provide custom training, validation and test splits.
| **task** | **dataset** | **load dataset** | **description** | **number of instances** |
|----------------------------|----------------|------------------|------------------------------------|-------------------------|
| Topic Classification | TweetTopic | tweet_topic | multi-label classification | 4,585 / 573 / 1,679 |
| NER | TweetNER7 | tweet_ner7 | sequence labeling | 4,616 / 576 / 2,807 |
| Question Answering | TweettQA | tweet_qa | generation | 9,489 / 1,086 / 1,203 |
| Question Generation | TweetQG | tweet_qg | generation | 9,489 / 1,086 / 1,203 |
| Intimacy Analysis | TweetIntimacy | tweet_intimacy | regression on a single text | 1,191 / 396 / 396 |
| Tweet Similarity | TweetSIM | tweet_similarity | regression on two texts | 450 / 100 / 450 |
| Meaning Shift Detection | TempoWIC | tempo_wic | binary classification on two texts | 1,427 / 395 / 1,472 |
| Hate Speech Detection | TweetHate | tweet_hate | multi-class classification | 5,019 / 716 / 1,433 |
| Emoji Classification | TweetEmoji100 | tweet_emoji | multi-class classification | 50,000 / 5,000 / 50,000 |
| Sentiment Classification | TweetSentiment | tweet_sentiment | ABSA on a five-pointscale | 26,632 / 4,000 / 12,379 |
| Name Entity Disambiguation | TweetNERD | tweet_nerd | binary classification | 20,164 / 4,100 / 20,075 |
| Emotion Classification | TweetEmotion | tweet_emotion | multi-label classification | 6,838 / 886 / 3,259 |
## Dataset Structure
### Data Fields
The data fields are unified among all splits.
In the following we present the information contained in each of the datasets.
#### tweet_topic
- `text`: a `string` feature.
- `gold_label_list`: a list of `string` feature.
- `date`: a `string` feature.
#### tweet_ner7
- `text`: a `string` feature.
- `text_tokenized`: a list of `string` feature.
- `gold_label_sequence`: a list of `string` feature.
- `date`: a `string` feature.
- `entities`: a list of `dictionary` feature containing `{"entity": "string", "type": "string"}`.
#### tweet_qa
- `text`: a `string` feature.
- `gold_label_str`: a `string` feature.
- `context`: a `string` feature.
#### tweet_qg
- `text`: a `string` feature.
- `gold_label_str`: a `string` feature.
- `context`: a `string` feature.
#### tweet_intimacy
- `text`: a `string` feature.
- `gold_score`: a `float` feature.
#### tweet_similarity
- `text_1`: a `string` feature.
- `text_2`: a `string` feature.
- `gold_score`: a `float` feature.
#### tempo_wic
- `gold_label_binary`: a `int` feature.
- `target`: a `string` feature.
- `text_1`: a `string` feature.
- `text_tokenized_1`: a list of `string` feature.
- `token_idx_1`: a `int` feature.
- `date_1`: a `string` feature.
- `text_2`: a `string` feature.
- `text_tokenized_2`: a list of `string` feature.
- `token_idx_2`: a `int` feature.
- `date_2`: a `string` feature.
#### tweet_hate
- `gold_label`: a `int` feature.
- `text`: a `string` feature.
#### tweet_emoji
- `gold_label`: a `int` feature.
- `text`: a `string` feature.
- `date`: a `string` feature.
#### tweet_sentiment
- `gold_label`: a `int` feature.
- `text`: a `string` feature.
- `target`: a `string` feature.
#### tweet_nerd
- `gold_label_binary`: a `int` feature.
- `target`: a `string` feature.
- `text`: a `string` feature.
- `definition`: a `string` feature.
- `text_start`: a `int` feature.
- `text_end`: a `int` feature.
- `date`: a `string` feature.
#### tweet_emotion
- `text`: a `string` feature.
- `gold_label_list`: a list of `string` feature.
## Evaluation metrics & Models
| **dataset** | **evaluation metric** | **gold label** | **model card** |
|-------------------|-------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------|
| TweetTopic | ```macro-F1``` | _arts\_&\_culture, business\_&\_entrepreneurs, celebrity\_&\_pop\_culture, <br />diaries\_&\_daily\_life, family, fashion\_&\_style, <br />film\_tv\_&\_video, fitness\_&\_health, food\_&\_dining, <br />gaming, learning\_&\_educational, music, <br />news\_&\_social\_concern, other\_hobbies, relationships, <br />science\_&\_technology, sports, travel\_&\_adventure, <br />youth\_&\_student\_life_ | [twitter-roberta-base-topic-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-topic) <br> [twitter-roberta-large-topic-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-topic) |
| TweetNER7 | ```macro-F1``` | _B-corporation, B-creative_work, B-event, <br />B-group, B-location, B-person, <br />B-product, I-corporation, I-creative_work, <br />I-event, I-group, I-location, <br />I-person, I-product, O_ | [twitter-roberta-base-ner7-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-ner7) <br> TBA |
| TweettQA | ```answer-F1``` | - | [flan-t5-small-tweet-qa (small)](https://huggingface.co/cardiffnlp/flan-t5-small-tweet-qa) <br> [flan-t5-base-tweet-qa (base)](https://huggingface.co/cardiffnlp/flan-t5-base-tweet-qa) |
| TweetQG | ```METEOR``` | - | [flan-t5-small-tweet-qg (small)](https://huggingface.co/cardiffnlp/flan-t5-small-tweet-qg) <br> [flan-t5-base-tweet-qg (base)](https://huggingface.co/cardiffnlp/flan-t5-base-tweet-qg) |
| TweetIntimacy | ```spearman correlation``` | _[1 - 5]_ | [twitter-roberta-base-intimacy-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-intimacy) <br> [twitter-roberta-large-intimacy-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-intimacy) |
| TweetSIM | ```spearman correlation``` | _[0 - 5]_ | [twitter-roberta-base-similarity-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-similarity) <br> [twitter-roberta-large-similarity-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-similarity) |
| TempoWIC | ```accuracy``` | _no, yes_ | [twitter-roberta-base-tempo-wic-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tempo-wic) <br> [twitter-roberta-large-tempo-wic-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tempo-wic) |
| TweetHate | ```combined-F1```<br /> ```(micro-F1 for hate/not-hate &```<br /> ``` macro-F1 for hate speech subclasses)``` | _hate_gender, hate_race, hate_sexuality, hate_religion, hate_origin, <br />hate_disability, hate_age, not_hate_ | [twitter-roberta-base-hate-latest-st (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-hate) <br> [twitter-roberta-large-hate-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-hate) |
| TweetEmoji100 | ```accuracy at top 5``` | _Full emoji list: ./data/tweet_emoji/map.txt_ | [twitter-roberta-base-emoji-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-emoji) <br> [twitter-roberta-large-emoji-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-emoji) |
| TweetSentiment | ```1 - MAE^M``` <br /> ```(MAE^M : Macro Averaged Mean Absolute Error)``` | _'strongly negative' , 'negative', 'negative or neutral', <br /> 'positive', 'strongly positive'_ | [twitter-roberta-base-topic-sentiment-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-sentiment) <br> [twitter-roberta-large-topic-sentiment-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-sentiment) |
| TweetNERD | ```accuracy``` | _no, yes_ | [twitter-roberta-base-nerd-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-nerd) <br> [twitter-roberta-large-nerd-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-nerd) |
| TweetEmotion | ```macro-F1``` | _anger, anticipation, disgust, fear, joy, love, optimism, <br />pessimism, sadness, surprise, trust_ | [twitter-roberta-base-emotion-latest (base)](https://huggingface.co/cardiffnlp/twitter-roberta-base-latest-tweet-emotion) <br> [twitter-roberta-large-emotion-latest (large)](https://huggingface.co/cardiffnlp/twitter-roberta-large-latest-tweet-emotion) |
## Citation Information
### Main reference paper
Please cite the [reference paper](https://arxiv.org/abs/2310.14757) if you use this benchmark.
```bibtex
@inproceedings{antypas2023supertweeteval,
title={SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research},
author={Dimosthenis Antypas and Asahi Ushio and Francesco Barbieri and Leonardo Neves and Kiamehr Rezaee and Luis Espinosa-Anke and Jiaxin Pei and Jose Camacho-Collados},
booktitle={Findings of the Association for Computational Linguistics: EMNLP 2023},
year={2023}
}
```
### References of individual datasets
In addition to the main reference paper, please cite the individual task datasets included in SuperTweetEval if you use them.
- TweetTopic
```
@inproceedings{antypas-etal-2022-twitter,
title = "{T}witter Topic Classification",
author = "Antypas, Dimosthenis and
Ushio, Asahi and
Camacho-Collados, Jose and
Silva, Vitor and
Neves, Leonardo and
Barbieri, Francesco",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.299",
pages = "3386--3400",
abstract = "Social media platforms host discussions about a wide variety of topics that arise everyday. Making sense of all the content and organising it into categories is an arduous task. A common way to deal with this issue is relying on topic modeling, but topics discovered using this technique are difficult to interpret and can differ from corpus to corpus. In this paper, we present a new task based on tweet topic classification and release two associated datasets. Given a wide range of topics covering the most important discussion points in social media, we provide training and testing data from recent time periods that can be used to evaluate tweet classification models. Moreover, we perform a quantitative evaluation and analysis of current general- and domain-specific language models on the task, which provide more insights on the challenges and nature of the task.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-named,
title = "Named Entity Recognition in {T}witter: A Dataset and Analysis on Short-Term Temporal Shifts",
author = "Ushio, Asahi and
Barbieri, Francesco and
Sousa, Vitor and
Neves, Leonardo and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = nov,
year = "2022",
address = "Online only",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.aacl-main.25",
pages = "309--319",
abstract = "Recent progress in language model pre-training has led to important improvements in Named Entity Recognition (NER). Nonetheless, this progress has been mainly tested in well-formatted documents such as news, Wikipedia, or scientific articles. In social media the landscape is different, in which it adds another layer of complexity due to its noisy and dynamic nature. In this paper, we focus on NER in Twitter, one of the largest social media platforms, and construct a new NER dataset, TweetNER7, which contains seven entity types annotated over 11,382 tweets from September 2019 to August 2021. The dataset was constructed by carefully distributing the tweets over time and taking representative trends as a basis. Along with the dataset, we provide a set of language model baselines and perform an analysis on the language model performance on the task, especially analyzing the impact of different time periods. In particular, we focus on three important temporal aspects in our analysis: short-term degradation of NER models over time, strategies to fine-tune a language model over different periods, and self-labeling as an alternative to lack of recently-labeled data. TweetNER7 is released publicly (https://huggingface.co/datasets/tner/tweetner7) along with the models fine-tuned on it (NER models have been integrated into TweetNLP and can be found at https://github.com/asahi417/tner/tree/master/examples/tweetner7{\_}paper).",
}
```
- TweetQA
```
@inproceedings{xiong2019tweetqa,
title={TweetQA: A Social Media Focused Question Answering Dataset},
author={Xiong, Wenhan and Wu, Jiawei and Wang, Hong and Kulkarni, Vivek and Yu, Mo and Guo, Xiaoxiao and Chang, Shiyu and Wang, William Yang},
booktitle={Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year={2019}
}
```
- TweetIntimacy
```
@misc{pei2023semeval,
title={SemEval 2023 Task 9: Multilingual Tweet Intimacy Analysis},
author={Jiaxin Pei and Vítor Silva and Maarten Bos and Yozon Liu and Leonardo Neves and David Jurgens and Francesco Barbieri},
year={2023},
eprint={2210.01108},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
- Tweet Similarity
```
N/A
```
- TempoWiC
```
@inproceedings{loureiro-etal-2022-tempowic,
title = "{T}empo{W}i{C}: An Evaluation Benchmark for Detecting Meaning Shift in Social Media",
author = "Loureiro, Daniel and
D{'}Souza, Aminette and
Muhajab, Areej Nasser and
White, Isabella A. and
Wong, Gabriel and
Espinosa-Anke, Luis and
Neves, Leonardo and
Barbieri, Francesco and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.296",
pages = "3353--3359",
abstract = "Language evolves over time, and word meaning changes accordingly. This is especially true in social media, since its dynamic nature leads to faster semantic shifts, making it challenging for NLP models to deal with new content and trends. However, the number of datasets and models that specifically address the dynamic nature of these social platforms is scarce. To bridge this gap, we present TempoWiC, a new benchmark especially aimed at accelerating research in social media-based meaning shift. Our results show that TempoWiC is a challenging benchmark, even for recently-released language models specialized in social media.",
}
```
- TweetHate
```
@inproceedings{sachdeva-etal-2022-measuring,
title = "The Measuring Hate Speech Corpus: Leveraging Rasch Measurement Theory for Data Perspectivism",
author = "Sachdeva, Pratik and
Barreto, Renata and
Bacon, Geoff and
Sahn, Alexander and
von Vacano, Claudia and
Kennedy, Chris",
booktitle = "Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.nlperspectives-1.11",
pages = "83--94",
abstract = "We introduce the Measuring Hate Speech corpus, a dataset created to measure hate speech while adjusting for annotators{'} perspectives. It consists of 50,070 social media comments spanning YouTube, Reddit, and Twitter, labeled by 11,143 annotators recruited from Amazon Mechanical Turk. Each observation includes 10 ordinal labels: sentiment, disrespect, insult, attacking/defending, humiliation, inferior/superior status, dehumanization, violence, genocide, and a 3-valued hate speech benchmark label. The labels are aggregated using faceted Rasch measurement theory (RMT) into a continuous score that measures each comment{'}s location on a hate speech spectrum. The annotation experimental design assigned comments to multiple annotators in order to yield a linked network, allowing annotator disagreement (perspective) to be statistically summarized. Annotators{'} labeling strictness was estimated during the RMT scaling, projecting their perspective onto a linear measure that was adjusted for the hate speech score. Models that incorporate this annotator perspective parameter as an auxiliary input can generate label- and score-level predictions conditional on annotator perspective. The corpus includes the identity group targets of each comment (8 groups, 42 subgroups) and annotator demographics (6 groups, 40 subgroups), facilitating analyses of interactions between annotator- and comment-level identities, i.e. identity-related annotator perspective.",
}
```
- TweetEmoji
```
N/A
```
- TweetSentiment
```
@inproceedings{rosenthal-etal-2017-semeval,
title = "{S}em{E}val-2017 Task 4: Sentiment Analysis in {T}witter",
author = "Rosenthal, Sara and
Farra, Noura and
Nakov, Preslav",
booktitle = "Proceedings of the 11th International Workshop on Semantic Evaluation ({S}em{E}val-2017)",
month = aug,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/S17-2088",
doi = "10.18653/v1/S17-2088",
pages = "502--518",
abstract = "This paper describes the fifth year of the Sentiment Analysis in Twitter task. SemEval-2017 Task 4 continues with a rerun of the subtasks of SemEval-2016 Task 4, which include identifying the overall sentiment of the tweet, sentiment towards a topic with classification on a two-point and on a five-point ordinal scale, and quantification of the distribution of sentiment towards a topic across a number of tweets: again on a two-point and on a five-point ordinal scale. Compared to 2016, we made two changes: (i) we introduced a new language, Arabic, for all subtasks, and (ii) we made available information from the profiles of the Twitter users who posted the target tweets. The task continues to be very popular, with a total of 48 teams participating this year.",
}
```
- TweetNERD
```
@article{mishra2022tweetnerd,
title={TweetNERD--End to End Entity Linking Benchmark for Tweets},
author={Mishra, Shubhanshu and Saini, Aman and Makki, Raheleh and Mehta, Sneha and Haghighi, Aria and Mollahosseini, Ali},
journal={arXiv preprint arXiv:2210.08129},
year={2022}
}
```
- TweetEmotion
```
@inproceedings{mohammad-etal-2018-semeval,
title = "{S}em{E}val-2018 Task 1: Affect in Tweets",
author = "Mohammad, Saif and
Bravo-Marquez, Felipe and
Salameh, Mohammad and
Kiritchenko, Svetlana",
booktitle = "Proceedings of the 12th International Workshop on Semantic Evaluation",
month = jun,
year = "2018",
address = "New Orleans, Louisiana",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/S18-1001",
doi = "10.18653/v1/S18-1001",
pages = "1--17",
abstract = "We present the SemEval-2018 Task 1: Affect in Tweets, which includes an array of subtasks on inferring the affectual state of a person from their tweet. For each task, we created labeled data from English, Arabic, and Spanish tweets. The individual tasks are: 1. emotion intensity regression, 2. emotion intensity ordinal classification, 3. valence (sentiment) regression, 4. valence ordinal classification, and 5. emotion classification. Seventy-five teams (about 200 team members) participated in the shared task. We summarize the methods, resources, and tools used by the participating teams, with a focus on the techniques and resources that are particularly useful. We also analyze systems for consistent bias towards a particular race or gender. The data is made freely available to further improve our understanding of how people convey emotions through language.",
}
``` |
heegyu/aulm-0809 | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 704591219
num_examples: 171404
download_size: 311285345
dataset_size: 704591219
---
공개 한국어 Instruction 데이터를 포멧을 통일하고 병합한 데이터
| Dataset | # instance | 타입 |
| --- | --- | --- |
| [KoAlpaca v1.1](https://raw.githubusercontent.com/Beomi/KoAlpaca/main/KoAlpaca_v1.1.jsonl) | 50K | 싱글턴 |
| [dbdu/ShareGPT-74k-ko 의 part2_ko_uncleaned](https://huggingface.co/datasets/dbdu/ShareGPT-74k-ko/resolve/main/part2_ko_uncleaned.json) | 36K | 멀티턴 |
| [heegyu/korquad-chat-v1](https://huggingface.co/datasets/heegyu/korquad-chat-v1) | 9.6K | 멀티턴, 지식기반 |
| [lcw99/evolve-instruct](https://github.com/lcw99/evolve-instruct/) | 37K | 싱글턴 |
| [HAERAE-HUB/KoInstruct-QA](https://huggingface.co/datasets/HAERAE-HUB/KoInstruct-QA) | 50.3k | 싱글턴 |
| [changpt/ko-lima-vicuna](https://huggingface.co/datasets/changpt/ko-lima-vicuna) | 1K | 싱글턴, 멀티턴(극히 일부) |
| [nlpai-lab/kullm-v2](https://huggingface.co/datasets/nlpai-lab/kullm-v2) | 15K | 싱글턴 |
- KULLM v2 데이터셋에서는 GPT4ALL, Dolly 데이터만 추출해서 사용했습니다.
- 다양한 학습 데이터셋은 [HeegyuKim/open-korean-instructions](https://github.com/HeegyuKim/open-korean-instructions) GitHub repository를 참고하세요.
|
dikw/hh_rlhf_cn | ---
license: llama2
---
---
license: bsd
---
## hh-rlhf中文翻译版本
基于Anthropic论文Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback 开源的helpful 和harmless数据,使用翻译工具进行了翻译。
hh_rlhf_train.jsonl 合并中英文训练集数据 清洗过后17万条
hh_rlhf_test.jsonl 合并中英文测试集数据 清洗过后9千条
harmless_base_cn_train.jsonl 42394条
harmless_base_cn_test.jsonl 2304条
helpful_base_cn_train.jsonl 43722条
helpful_base_cn_test.jsonl 2346条
## 实验报告
相关rlhf实验报告:https://zhuanlan.zhihu.com/p/652044120 |
jacob-hugging-face/job-descriptions | ---
license: llama2
---
|
BoDai/MatrixCity | ---
license: cc-by-nc-4.0
---
|
slava-medvedev/zelensky-speeches | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- uk
- en
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
task_categories:
- summarization
- text-classification
pretty_name: 'Speeches given by the president of Ukraine Volodymyr Zelensky
Language: Ukrainian
Source: https://www.president.gov.ua/news/speeches'
dataset_info:
features:
- name: date
dtype: int64
- name: link
dtype: string
- name: topic
dtype: string
- name: full_text
dtype: string
- name: lang
dtype: string
splits:
- name: train
num_bytes: 15545031
num_examples: 2196
download_size: 7833968
dataset_size: 15545031
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- zelensky
- ukraine
- politics
---
# Dataset Card for "zelenskiy-speeches"
Speeches given by the president of Ukraine Volodymyr Zelensky
Languages: Ukrainian, English
Source: [president.gov.ua](https://www.president.gov.ua/news/speeches)
Auto-updated daily by Github Actions of [zelensky-speech-fetcher](https://github.com/medvedev/zelensky-speech-fetcher)
License: [CC BY-NC-ND 4.0 Deed](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) |
OpenGVLab/MVBench | ---
license: mit
extra_gated_prompt: >-
You agree to not use the dataset to conduct experiments that cause harm to
human subjects. Please note that the data in this dataset may be subject to
other agreements. Before using the data, be sure to read the relevant
agreements carefully to ensure compliant use. Video copyrights belong to the
original video creators or platforms and are for academic research use only.
task_categories:
- visual-question-answering
- question-answering
- conversational
extra_gated_fields:
Name: text
Company/Organization: text
Country: text
E-Mail: text
configs:
- config_name: action_sequence
data_files: json/action_sequence.json
- config_name: moving_count
data_files: json/moving_count.json
- config_name: action_prediction
data_files: json/action_prediction.json
- config_name: episodic_reasoning
data_files: json/episodic_reasoning.json
- config_name: action_antonym
data_files: json/action_antonym.json
- config_name: action_count
data_files: json/action_count.json
- config_name: scene_transition
data_files: json/scene_transition.json
- config_name: object_shuffle
data_files: json/object_shuffle.json
- config_name: object_existence
data_files: json/object_existence.json
- config_name: fine_grained_pose
data_files: json/fine_grained_pose.json
- config_name: unexpected_action
data_files: json/unexpected_action.json
- config_name: moving_direction
data_files: json/moving_direction.json
- config_name: state_change
data_files: json/state_change.json
- config_name: object_interaction
data_files: json/object_interaction.json
- config_name: character_order
data_files: json/character_order.json
- config_name: action_localization
data_files: json/action_localization.json
- config_name: counterfactual_inference
data_files: json/counterfactual_inference.json
- config_name: fine_grained_action
data_files: json/fine_grained_action.json
- config_name: moving_attribute
data_files: json/moving_attribute.json
- config_name: egocentric_navigation
data_files: json/egocentric_navigation.json
language:
- en
size_categories:
- 1K<n<10K
---
# MVBench
## Dataset Description
- **Repository:** [MVBench](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/mvbench.ipynb)
- **Paper:** [2311.17005](https://arxiv.org/abs/2311.17005)
- **Point of Contact:** mailto:[kunchang li](likunchang@pjlab.org.cn)

We introduce a novel static-to-dynamic method for defining temporal-related tasks. By converting static tasks into dynamic ones, we facilitate systematic generation of video tasks necessitating a wide range of temporal abilities, from perception to cognition. Guided by task definitions, we then **automatically transform public video annotations into multiple-choice QA** for task evaluation. This unique paradigm enables efficient creation of MVBench with minimal manual intervention while ensuring evaluation fairness through ground-truth video annotations and avoiding biased LLM scoring. The **20** temporal task examples are as follows.

## Evaluation
An evaluation example is provided in [mvbench.ipynb](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/mvbench.ipynb). Please follow the pipeline to prepare the evaluation code for various MLLMs.
- **Preprocess**: We preserve the raw video (high resolution, long duration, etc.) along with corresponding annotations (start, end, subtitles, etc.) for future exploration; hence, the decoding of some raw videos like Perception Test may be slow.
- **Prompt**: We explore effective system prompts to encourage better temporal reasoning in MLLM, as well as efficient answer prompts for option extraction.
## Leadrboard
While an [Online leaderboard]() is under construction, the current standings are as follows:
 |
m-ric/agents_small_benchmark | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: task
dtype: string
splits:
- name: train
num_bytes: 29612
num_examples: 100
download_size: 25208
dataset_size: 29612
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
wintercoming6/artwork_for_sdxl | ---
license: mit
dataset_info:
features:
- name: prompt
dtype: string
- name: image_data
dtype: image
splits:
- name: train
num_bytes: 1339678
num_examples: 41
download_size: 4170
dataset_size: 1339678
tags:
- Text-to-Image
- Stable Diffusion
---
This dataset focuses on the works of a specific artist named Shitao, with its data sourced from Google Arts & Culture's Shitao page (link: https://artsandculture.google.com/entity/shitao/m06blwm). The creation of this dataset is in response to feedback from Professor Huang's proposal, aiming for a deeper exploration and analysis of Shitao's artworks. The collection and processing of the dataset involve web scraping scripts, data processing, and tagging with the bilp2 model, with these scripts and related codes made public in a GitHub repository (link: https://github.com/mhy-666/artwork_for_sdxl_dataset).
The schema of the dataset comprises two features: prompt and image_data, representing the description of the artworks (string type) and image data (image type), respectively. The dataset is divided into a train split, containing 41 examples, with a total data size of 1,339,678 bytes and a download size of 4,170 bytes.
The existence of this dataset serves to provide a basis for in-depth analysis and model training specifically for Shitao's artworks, promoting the digital study and popularization of classical Chinese art. By focusing on the works of a single artist, the dataset aims to explore the expression and characteristics of a specific art style, supporting automatic annotation and classification research of artworks.
However, the dataset has certain limitations. First, the relatively small number of samples (only 41 examples) may limit the breadth and generalization ability of model training. Second, focusing on the works of a single artist, while beneficial for in-depth studies of a particular style, may result in the model's poorer adaptability to other art styles. Additionally, as the dataset's construction involves web scraping, it may be affected by website updates or changes in copyright policies, leading to uncertainties in data access and use.
Here is the use case for this dataset: https://colab.research.google.com/drive/1Gmpu1pO3D-H8rWnTe68V49W15LVobYM6?usp=sharing
This is the Stable Diffusion paper: arxiv: arxiv.org/abs/2112.10752 |
angeluriot/french_instruct | ---
language:
- fr
license: mit
tags:
- croissant
language_details: fr-FR
pretty_name: French Instruct
size_categories:
- 100K<n<1M
source_datasets:
- nickrosh/Evol-Instruct-Code-80k-v1
- Hello-SimpleAI/HC3
- KK04/LogicInference_OA
- tatsu-lab/alpaca
- 0x22almostEvil/multilingual-wikihow-qa-16k
- databricks/databricks-dolly-15k
- RyokoAI/ShareGPT52K
- gsm8k
- GAIR/lima
- OpenAssistant/oasst1
- Gael540/dataSet_ens_sup_fr-v1
- Gt-Doremiti/gt-doremiti-instructions
task_categories:
- question-answering
- text2text-generation
- text-generation
- text-classification
- token-classification
task_ids:
- document-question-answering
- natural-language-inference
---
# French Instruct
The **French Instruct dataset** is a collection of instructions with their corresponding answers (sometimes multi-turn conversations) entirely in French. The dataset is also available on [**GitHub**](https://github.com/angeluriot/French_instruct).
<p align="center">
<img src="resources/misc/thumbnail.gif" width="750">
</p>
<br/>
# Overview
The dataset is composed of 276K conversations between a user and an assistant for a total of approximately 85M tokens.
<p align="center">
<img src="resources/misc/charts.png" width="1000">
</p>
I also added annotations for each document to indicate if it was generated or written by a human, the style of the answers, or if it contains code. This can be useful for filtering the data according to your needs.
| | Documents | Tokens | Ratio |
|:--------------------------|:-----------:|:----------------:|:------------:|
| **All** | **275,600** | **≈ 84,906,090** | **100.00 %** |
| Written by a human | 85,213 | ≈ 24,908,868 | 29.34 % |
| Written by a chatbot* | 190,387 | ≈ 59,997,223 | 70.66 % |
| Human-style answers | 56,198 | ≈ 14,255,100 | 16.79 % |
| Chatbot-style answers | 219,402 | ≈ 70,650,990 | 83.21 % |
| Contains code | 14,788 | ≈ 11,455,659 | 13.49 % |
(*) Generally by well-established chatbots like ChatGPT.
<br/>
# Data Structure
Each record in the dataset follows the structure below:
```json
{
"context": "Some context for the instructions (sometimes empty)",
"conversation": [
{
"role": "user",
"text": "The first instruction"
},
{
"role": "assistant",
"text": "The first answer"
},
{
"role": "user",
"text": "The second instruction, etc..."
},
],
"author": "human",
"style": "chatbot",
"code": false,
"source": "The source of the document"
}
```
<br/>
# Sources
The dataset is a mix of various sources, some of which are translated from English to French using the ChatGPT API. I also did some cleaning and filtering to remove irrelevant data (duplicates, empty conversations, remaining English text, etc...).
The table below shows the distribution of the documents and tokens for each source:
<table>
<thead>
<tr>
<th align="center">Source</th>
<th align="center">Documents</th>
<th align="center">Tokens</th>
<th align="center">Ratio</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1">Evol Instruct</a></b> <i>(translated)</i></td>
<td align="center">56,747</td>
<td align="center">≈ 36,016,255</td>
<td align="center">42.42 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/Hello-SimpleAI/HC3">Human ChatGPT Comparison Corpus</a></b> <i>(translated)</i></td>
<td align="center">82,729</td>
<td align="center">≈ 23,316,107</td>
<td align="center">27.46 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/KK04/LogicInference_OA">Logic Inference OA</a></b> <i>(translated)</i></td>
<td align="center">54,542</td>
<td align="center">≈ 8,124,315</td>
<td align="center">9.57 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/tatsu-lab/alpaca">Stanford Alpaca</a></b> <i>(translated)</i></td>
<td align="center">51,243</td>
<td align="center">≈ 5,521,752</td>
<td align="center">6.50 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/0x22almostEvil/multilingual-wikihow-qa-16k">WikiHow</a> FR</b></td>
<td align="center">2,156</td>
<td align="center">≈ 4,789,558</td>
<td align="center">5.64 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/databricks/databricks-dolly-15k">Dolly</a></b> <i>(translated)</i></td>
<td align="center">14,896</td>
<td align="center">≈ 3,678,165</td>
<td align="center">4.33 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/RyokoAI/ShareGPT52K">Share GPT</a> FR</b></td>
<td align="center">1,385</td>
<td align="center">≈ 1,301,026</td>
<td align="center">1.53 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/gsm8k">Grade School Math</a></b> <i>(translated)</i></td>
<td align="center">8,792</td>
<td align="center">≈ 1,263,370</td>
<td align="center">1.49 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/GAIR/lima">Less Is More for Alignment</a></b> <i>(translated)</i></td>
<td align="center">1,032</td>
<td align="center">≈ 581,897</td>
<td align="center">0.69 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/CohereForAI/aya_dataset">Aya Dataset</a> FR</b></td>
<td align="center">1,412</td>
<td align="center">≈ 203,537</td>
<td align="center">0.24 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/OpenAssistant/oasst1">Open Assistant Conversations</a> FR</b></td>
<td align="center">255</td>
<td align="center">≈ 79,025</td>
<td align="center">0.09 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/Gael540/dataSet_ens_sup_fr-v1">ENS Sup Dataset</a></b></td>
<td align="center">383</td>
<td align="center">≈ 24,770</td>
<td align="center">0.03 %</td>
</tr>
<tr>
<td align="left"><b><a href="https://huggingface.co/datasets/Gt-Doremiti/gt-doremiti-instructions">GT Doremiti Instructions</a></b></td>
<td align="center">28</td>
<td align="center">≈ 6,314</td>
<td align="center">0.01 %</td>
</tr>
<tr>
<th align="left">Total</th>
<th align="center">275,600</th>
<th align="center">≈ 84,906,090</th>
<th align="center">100.00 %</th>
</tr>
</tbody>
</table>
<br/>
# Usage
The **French Instruct dataset** is mainly intended for training and evaluating conversational Large Language Models (LLMs), but it can also be used for classifying human-written text from generated text using the additional annotations.
### Hugging Face 🤗
The simplest way to use the dataset is to load it directly from the Hugging Face library:
```console
pip install datasets
```
```py
from datasets import load_dataset
dataset = load_dataset('angeluriot/french_instruct')
```
### GitHub
You first need to download the [**repository**](https://github.com/angeluriot/French_instruct), then you can use the `load.py` script to load the dataset or merge it in a sigle `.jsonl` file:
```py
from load import load_dataset, merge_dataset
# Load the dataset
dataset = load_dataset()
# Merge the dataset in a single .jsonl file
merge_dataset()
```
<br/>
# Examples
### Instructions
```yaml
context: ""
user: "Convertis 18 kilomètres par seconde en miles par heure."
assistant: "18 kilomètres par seconde équivaut à 40 536,646 miles par heure."
```
```yaml
context: ""
user: "Quel est le principal avantage d'un programme de fidélité pour les membres ?"
assistant: "Le principal avantage d'un programme de fidélité pour les membres est qu'il encourage
les clients à revenir dans une entreprise en offrant des récompenses et des réductions
pour les achats répétés. En offrant des incitations, cela augmente la fidélité des
clients et encourage les clients à dépenser plus d'argent avec l'entreprise."
```
### Code
```yaml
context: "for i in range(10):
x += 1"
user: "Réécris le code pour qu'il soit plus efficace."
assistant: "Tu peux simplifier le code comme suit :
```
x += 10
```"
```
```yaml
context: "[2, 7, 11, 4]"
user: "Crée une fonction python pour trouver le nombre maximum de la liste donnée."
assistant: "```
def find_max(lst):
return max(lst)
```"
```
### Multi-turn conversations
```yaml
context: ""
user: "Connaissez-vous Nuodle à Bellevue WA ?"
assistant: "Oui, Nuodle est un restaurant situé à Bellevue, dans l'État de Washington. Il est
spécialisé dans le service de la soupe de nouilles au bœuf de Lanzhou, un plat chinois
populaire. Le restaurant est situé au 14603 NE 20th St, Bellevue, WA 98007."
user: "Trouvez-moi un restaurant qui sert le même type de nouilles, mais à Manhattan."
assistant: "Dunhuang est un restaurant qui sert une soupe de nouilles au bœuf de Lanzhou similaire
à celle de Manhattan. Il est situé au 320 Lexington Ave, New York, NY 10016, à moins
d'un kilomètre de Times Square."
user: "Lequel est le meilleur ?"
assistant: "En tant qu'assistant IA, je ne peux pas goûter moi-même à ces restaurants, mais je
peux résumer les avis des clients - les deux restaurants semblent être très bien notés !
Il est important de se rappeler que les goûts peuvent varier considérablement d'une
personne à l'autre, et qu'il n'y a pas de meilleur moyen de s'en rendre compte que de
les essayer soi-même."
```
```yaml
context: ""
user: "Fais-tu grève demain?"
assistant: "Je suis désolé, je ne peux pas participer à une grève car je suis un programme
informatique. Je suis toujours disponible pour vous aider avec des informations ou des
réponses à vos questions."
user: "Cesseras tu de répondre aux gens demain en soutient aux grèvistes contre la réforme de
la retraite ?"
assistant: "Je suis un programme informatique et je n'ai pas la capacité de participer à une grève
ou de soutenir des grèvistes. Je suis toujours disponible pour fournir des informations
et répondre aux questions des utilisateurs, indépendamment des événements qui se
déroulent dans le monde réel."
user: "Arrêtes de répondre aux gens !"
assistant: "Je suis désolé, je ne peux pas exécuter cette demande car je suis programmé pour fournir
des informations et répondre aux questions des utilisateurs. Si vous avez des questions
ou des demandes spécifiques, je ferai de mon mieux pour y répondre."
user: "Vendu !"
assistant: "Je suis heureux de pouvoir vous aider. Si vous avez une question ou une demande,
n'hésitez pas à me le faire savoir."
```
<br/>
# Credits
* [**Angel Uriot**](https://github.com/angeluriot) : Creator of the project.
* All the people who contributed to the sources of the dataset (see the [**Sources**](#sources) section).
|
RUCKBReasoning/TableLLM-SFT | ---
license: mit
language:
- en
configs:
- config_name: default
data_files:
- split: fetaqa
path: fetaqa.jsonl
- split: table_op
path: table-op.jsonl
- split: spider
path: spider.jsonl
- split: tatqa
path: tatqa.jsonl
- split: wikisql
path: wikisql.jsonl
- split: wtq
path: wtq.jsonl
task_categories:
- table-question-answering
- text-generation
tags:
- QA
- Code
- Table
---
# TableLLM-SFT
| **[Paper](https://arxiv.org/abs/2403.19318)** | **[Model](https://huggingface.co/RUCKBReasoning/TableLLM-13b)** | **[Github](https://github.com/RUCKBReasoning/TableLLM)** | **[Homepage](https://tablellm.github.io/)** | **[Platform](http://36.103.203.47:27824/)** |
**TableLLM-SFT** is a training set containing a number of splits on different benchmarks. This training set is used to fine-tuning [TableLLM-7b](https://huggingface.co/RUCKBReasoning/TableLLM-7b) and [TableLLM-13b](https://huggingface.co/RUCKBReasoning/TableLLM-13b), which are based on CodeLlama-7b and CodeLlama-13b, respectively. |
jakartaresearch/indonews | ---
annotations_creators:
- found
language:
- id
language_creators:
- found
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Indonews
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- news
- news-classifcation
- indonesia
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Indonesian News Categorization
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Indonews: Multiclass News Categorization scrapped popular news portals in Indonesia.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@andreaschandra](https://github.com/andreaschandra) for adding this dataset. |
lcw99/oscar-ko-only | ---
language:
- ko
---
# oscar dataset only korean |
esb/diagnostic-dataset | ---
annotations_creators:
- expert-generated
- crowdsourced
- machine-generated
language:
- en
language_creators:
- crowdsourced
- expert-generated
license:
- cc-by-4.0
- apache-2.0
- cc0-1.0
- cc-by-nc-3.0
- other
multilinguality:
- monolingual
pretty_name: ESB Diagnostic Dataset
size_categories:
- 100K<n<1M
- 1M<n<10M
source_datasets:
- original
- extended|librispeech_asr
- extended|common_voice
tags:
- asr
- benchmark
- speech
- esc
task_categories:
- automatic-speech-recognition
task_ids: []
extra_gated_prompt: |-
Three of the ESB datasets have specific terms of usage that must be agreed to before using the data.
To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
extra_gated_fields:
I hereby confirm that I have registered on the original Common Voice page and agree to not attempt to determine the identity of speakers in the Common Voice dataset: checkbox
I hereby confirm that I have accepted the terms of usages on GigaSpeech page: checkbox
I hereby confirm that I have accepted the terms of usages on SPGISpeech page: checkbox
---
## Dataset Description
- **Dataset authors:** [Suno.ai](https://www.suno.ai)
- **Point of contact:** sanchit@huggingface.co
As a part of ESB benchmark, we provide a small, 8h diagnostic dataset of in-domain validation data with newly annotated transcriptions. The audio data is sampled from each of the ESB validation sets, giving a range of different domains and speaking styles. The transcriptions are annotated according to a consistent style guide with two formats: normalised and un-normalised. The dataset is structured in the same way as the ESB dataset, by grouping audio-transcription samples according to the dataset from which they were taken. We encourage participants to use this dataset when evaluating their systems to quickly assess performance on a range of different speech recognition conditions.
The diagnostic dataset can be downloaded and prepared in much the same way as the ESB datasets:
```python
from datasets import load_dataset
esb_diagnostic_ami = load_dataset("esb/diagnostic-dataset", "ami")
```
### Data Selection
#### Audio
To provide an adequate representation of all ESB datasets, we chose to use at least 1 hour of audio from the validation sets of each of the 8 constituent ESB datasets. Following the convention of LibriSpeech, we then used a public ASR model to further split each dataset into `clean`/`other` based on WER. (Note that for LibriSpeech we kept the existing `clean`/`other` splits.). The `clean` subset represents the 'easier' 50% of samples, and the `other` subset the more difficult 50%.
To obtain the `clean` diagnostic-subset of AMI, either "slice" the `clean`/`other` split:
```python
ami_diagnostic_clean = esc_diagnostic_ami["clean"]
```
Or download the `clean` subset standalone:
```python
ami_diagnostic_clean = load_dataset("esb/diagnostic-dataset", "ami", split="clean")
```
#### Transcriptions
Firstly, the transcriptions were generated by a human _without_ the bias of the original transcript. The transcriptions follow a strict orthographic and verbatim style guide, where every word, disfluency and partial word is transcribed. Punctuation and formatting follows standard English print orthography (eg. ‘July 10th in 2021.’). Breaks in thought and partial words are indicated via ‘--’. In addition to the **orthographic** transcriptions, a **normalised** format was produced, with all punctuation removed and non-standard-words such as dates, currencies and abbreviations verbalised in the exact way they are spoken (eg. ’july tenth in twenty twenty one’).
Although great care was taken in standardisation of orthography, a remaining amount of ambiguity in transcription exists, especially around the use of commas and the choice of introducing sentence breaks for utterances starting with ‘And’. Each sample was then checked by a second human with access to both the original ground truth as well as the independently produced style-consistent transcript. Both versions were merged to produce new high quality ground truths in both the normalised and orthographic text format.
## Dataset Information
A data point can be accessed by indexing the dataset object loaded through `load_dataset`:
```python
print(ami_diagnostic_clean[0])
```
A typical data point comprises the path to the audio file and its transcription. Also included is information of the dataset from which the sample derives and a unique identifier name:
```python
{
'audio': {'path': None,
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'ortho_transcript': 'So, I guess we have to reflect on our experiences with remote controls to decide what, um, we would like to see in a convenient practical',
'norm_transcript': 'so i guess we have to reflect on our experiences with remote controls to decide what um we would like to see in a convenient practical',
'id': 'AMI_ES2011a_H00_FEE041_0062835_0064005',
'dataset': 'ami',
}
```
### Data Fields
- `audio`: a dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate.
- `ortho_transcript`: the **orthographic** transcription of the audio file.
- `norm_transcript`: the **normalised** transcription of the audio file.
- `id`: unique id of the data sample.
- `dataset`: string name of a dataset the sample belongs to.
We encourage participants to train their ASR system on the [AMI dataset](https://huggingface.co/datasets/esb/datasets#ami), the smallest of the 8 ESB datasets, and then evaluate their system on the `ortho_transcript` for **all** of the datasets in the diagnostic dataset. This gives a representation of how the system is likely to fare on other audio domains. The predictions can then be _normalised_ by removing casing and punctuation, converting numbers to spelled-out form and expanding abbreviations, and then assessed against the `norm_transcript`. This gives a representation of the effect of orthography for system performance.
### Access
All eight of the datasets in ESB are accessible and licensing is freely available. Three of the ESB datasets have specific terms of usage that must be agreed to before using the data. To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
### Contributions
We show our greatest appreciation to Georg Kucsko, Keenan Freyberg and Michael Shulman from [Suno.ai](https://www.suno.ai) for creating and annotating the diagnostic dataset.
|
FredZhang7/anime-prompts-180K | ---
license: creativeml-openrail-m
task_categories:
- text-generation
language:
- en
size_categories:
- 100K<n<1M
viewer: false
---
For more info on data collection and the preprocessing algorithm, please see [Fast Anime PromptGen](https://huggingface.co/FredZhang7/anime-anything-promptgen-v2).
## 80K unique prompts
- `safebooru_clean`: Cleaned prompts with upscore ≥ 8 from the Safebooru API
---
For disclaimers about the Danbooru data, please see [Danbooru Tag Generator](https://huggingface.co/FredZhang7/danbooru-tag-generator).
## 100K unique prompts (each)
- `danbooru_raw`: Raw prompts with upscore ≥ 3 from Danbooru API
- `danbooru_clean`: Cleaned prompts with upscore ≥ 3 from Danbooru API
---
## Python
Download and save the dataset to anime_prompts.csv locally.
```bash
pip install datasets
```
```python
import csv
import datasets
dataset = datasets.load_dataset("FredZhang7/anime-prompts-180K")
train = dataset["train"]
safebooru_clean = train["safebooru_clean"]
danbooru_clean = train["danbooru_clean"]
danbooru_raw = train["danbooru_raw"]
with open("anime_prompts.csv", "w") as f:
writer = csv.writer(f)
writer.writerow(["safebooru_clean", "danbooru_clean", "danbooru_raw"])
for i in range(len(safebooru_clean)):
writer.writerow([safebooru_clean[i], danbooru_clean[i], danbooru_raw[i]])
``` |
nlpai-lab/openassistant-guanaco-ko | ---
license: apache-2.0
task_categories:
- text-generation
- question-answering
- summarization
language:
- ko
size_categories:
- 1K<n<10K
---
### Dataset Summary
Korean translation of Guanaco via the DeepL API
Note: There are cases where multilingual data has been converted to monolingual data during batch translation to Korean using the API.
Below is Guanaco's README.
----
This dataset is a subset of the Open Assistant dataset, which you can find here: https://huggingface.co/datasets/OpenAssistant/oasst1/tree/main
This subset of the data only contains the highest-rated paths in the conversation tree, with a total of 9,846 samples.
This dataset was used to train Guanaco with QLoRA.
For further information, please see the original dataset.
License: Apache 2.0 |
seungheondoh/LP-MusicCaps-MSD | ---
language:
- en
tags:
- art
- music
- text-to-music
- music-to-text
pretty_name: LP-MusicCaps-MSD
size_categories:
- 100K<n<1M
---
======================================
**!important**: Be careful when using `caption_attribute_prediction` (We don't recommend to use)!
======================================
# Dataset Card for LP-MusicCaps-MSD
## Dataset Description
- **Repository:** [LP-MusicCaps repository](https://github.com/seungheondoh/lp-music-caps)
- **Paper:** [ArXiv](https://arxiv.org/abs/2307.16372)
## Dataset Summary
**LP-MusicCaps** is a Large Language Model based Pseudo Music Caption dataset for `text-to-music` and `music-to-text` tasks. We construct the music-to-caption pairs with tag-to-caption generation (using three existing multi-label tag datasets and four task instructions). The data sources are MusicCaps, Magnatagtune, and Million Song Dataset ECALS subset.
- **LP-MusicCaps MSD (This Repo)**: 0.5M Audio with 2.2M Caption. We utilize 1054 unique tags in the [MSD-ECALS](https://github.com/SeungHeonDoh/msd-subsets) to perform tag-to-caption generation through LLM.
- [LP-MusicCaps MTT](https://huggingface.co/datasets/seungheondoh/LP-MusicCaps-MTT): 22k Audio with 88k Caption
- [LP-MusicCaps MC](https://huggingface.co/datasets/seungheondoh/LP-MusicCaps-MC): 6k Audio with 22k Caption.
## Data Instances
Each instance in LP-MusicCaps MSD (This Repo) represents multiple image-text pair information with meta-attributes:
```
{
'track_id': 'TRIHXPZ128F1466744',
'title': 'In The Sunshine',
'artist_name': 'ARRESTED DEVELOPMENT',
'release': 'Zingalamaduni',
'year': 1994,
'tag': ['laid back mellow',
'hip hop',
'rnb',
'amiable good natured',
'rap',
'urban',
'gentle',
'political rap',
'soul',
'calm peaceful',
'summery',
'cheerful',
'alternative rap'
],
'caption_writing': 'An amiable and laid back alternative rap tune, this summery and cheerful song blends elements of soul and R&B with a gentle, mellow rap flow to create a calm and peaceful urban vibe that is both hip hop and political in its message.',
'caption_summary': 'This summery, alternative rap song is a mellow and gentle blend of hip hop, RnB, and political rap with a cheerful and amiable good natured vibe.',
'caption_paraphrase': 'This laid back mellow rap song infuses soulful and urban elements while showcasing a gentle and amiable good natured vibe, perfect for a summery day. With hints of cheerful R&B and hip hop, the alternative political rap lyrics bring balance to this peaceful and calming tune.',
'caption_attribute_prediction': 'This mellow, soulful tune is a perfect blend of rap and RnB, with a gentle beat and smooth flow that will transport you to the laid-back urban vibes of a sunny summertime day. The amiable good-natured lyrics touch on political themes, while the alternative rap style adds a cheerful, upbeat twist to the message. Overall, this is a hip-hop gem thats sure to put you in a peaceful, calm state of mind.',
'path': '3/0/303545.clip.mp3'
}
```
## Pseudo Caption Example:
Input Tags:
*"video game theme, no singer, instrumental, analog sounding, small keyboard, beatboxing, playful, cheerful, groovy"*
Output Pseudo Captions
*"instrumental track has a joyful and playful vibe, perfect for a video game theme. With no singer, the analog-sounding music features a small keyboard and beatboxing, creating a groovy and cheerful atmosphere"*
[More Information for pseudo caption generation](https://github.com/seungheondoh/lp-music-caps/blob/main/lpmc/llm_captioning/generate.py)
## Data Fields
| Name | Type | Description |
|------------------------------|-----------------|----------------------------------------------------------------------|
| track_id | string | Unique identifier for the track |
| title | string | Title of the song |
| artist_name | string | Name of the artist performing the song |
| release | string | Release name or album name of the song |
| year | integer | Year of the song's release |
| tag | list of strings | List of tags associated with the song |
| caption_writing | string | Pseudo caption generated through a writing instruction |
| caption_summary | string | Pseudo caption generated through a summary instruction |
| caption_paraphrase | string | Pseudo caption generated through a paraphrase instruction |
| caption_attribute_prediction | string | Pseudo caption generated through an attribute_prediction instruction |
| path | string | File path or location of the audio clip |
## Data Splits
- train: 444865
- valid: 34481
- test: 34631
## Considerations for Using the Data
The LP-MusicCaps dataset is recommended to be used for research purposes. Due to the wrong labeling issue, we recommend not using caption_attribute_prediction and pseudo_attribute unless it is specifically for large-scale pretraining. Additionally, the field "is_crawled" indicates the samples used in the reference paper mentioned below.
## Discussion of Biases
It will be described in a paper to be released soon.
## Other Known Limitations
It will be described in a paper to be released soon. |
jitx/Methods2Test_java_unit_test_code | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: target
dtype: string
- name: src_fm
dtype: string
- name: src_fm_fc
dtype: string
- name: src_fm_fc_co
dtype: string
- name: src_fm_fc_ms
dtype: string
- name: src_fm_fc_ms_ff
dtype: string
splits:
- name: train
num_bytes: 3399525755
num_examples: 624022
- name: test
num_bytes: 907751466
num_examples: 156922
download_size: 558984469
dataset_size: 4307277221
task_categories:
- text-generation
language:
- en
tags:
- unit test
- java
- code
---
## Dataset Description
Microsoft created this large dataset of Java Junit test cases with its corresponding focal methods.
It contains 780k pairs of JUnit test cases and focal methods which were extracted from a total of 91K
Java open source project hosted on GitHub.
The mapping between test case and focal methods are based heuristics rules and Java developer's best practice.
More information could be found here:
- [methods2test Github repo](https://github.com/microsoft/methods2test)
- [Methods2Test: A dataset of focal methods mapped to test cases](https://arxiv.org/pdf/2203.12776.pdf)
## Dataset Schema
```
target: <TEST_CASE>
src_fm: <FOCAL_METHOD>
src_fm_fc: <FOCAL_CLASS_NAME> <FOCAL_METHOD>
src_fm_fc_co: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS>
src_fm_fc_ms: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS> <METHOD_SIGNATURES>
src_fm_fc_ms_ff: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS> <METHOD_SIGNATURES> <FIELDS>
```
## Focal Context
- fm: this representation incorporates exclusively the source
code of the focal method. Intuitively, this contains the most
important information for generating accurate test cases for
the given method.
- fm+fc: this representations adds the focal class name, which
can provide meaningful semantic information to the model.
- fm+fc+c: this representation adds the signatures of the constructor methods of the focal class. The idea behind this
augmentation is that the test case may require instantiating
an object of the focal class in order to properly test the focal
method.
- fm+fc+c+m: this representation adds the signatures of the
other public methods in the focal class. The rationale which
motivated this inclusion is that the test case may need to
invoke other auxiliary methods within the class (e.g., getters,
setters) to set up or tear down the testing environment.
- fm+fc+c+m+f : this representation adds the public fields of
the focal class. The motivation is that test cases may need to
inspect the status of the public fields to properly test a focal
method.

The different levels of focal contexts are the following:
```
FM: focal method
FM_FC: focal method + focal class name
FM_FC_CO: focal method + focal class name + constructor signatures
FM_FC_MS: focal method + focal class name + constructor signatures + public method signatures
FM_FC_MS_FF: focal method + focal class name + constructor signatures + public method signatures + public fields
```
## Lmitations
The original authors validate the heuristics by inspecting a
statistically significant sample (confidence level of 95% within 10%
margin of error) of 97 samples from the training set. Two authors
independently evaluated the sample, then met to discuss the disagreements. We found that 90.72% of the samples have a correct
link between the test case and the corresponding focal method
## Contribution
All the thanks to the original authors. |
CollectiveCognition/chats-data-2023-10-16 | ---
license: mit
---
# Dataset Card for "Collective Cognition ChatGPT Conversations"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
### Dataset Summary
The "Collective Cognition ChatGPT Conversations" dataset is a collection of chat logs between users and the ChatGPT model. These conversations have been shared by users on the "Collective Cognition" website. The dataset provides insights into user interactions with language models and can be utilized for multiple purposes, including training, research, and analysis.
Visit Collective Cognition to browse or contribute chats here: https://collectivecognition.ai
### Supported Tasks
- **Language Model Finetuning**: Training through behavior cloning and knowledge instilling.
- **Dialogue Understanding**: Analyzing the flow and structure of conversations.
- **Sentiment Analysis**: Understanding the sentiment or emotion in the dialogues.
- **Topic Modeling**: Determining the topics discussed within the chats.
### Languages
The primary language of the dataset is English, but any language chat may be present in the dataset as users share more chats.
## Dataset Structure
### Data Instances
A typical data instance includes a chat log with a title, model name, whether the chat used custom instructions (currently not included if so), and the content of the message with the role of the sender (either "human" or "gpt").
The dataset is formatted to conform with ShareGPT standard.
This is an example entry in the dataset, noting that turns are variable and can be many or as few as two:
```json
{
"title": "Interest Formulas Clarification",
"model_name": "GPT-4",
"custom_instruction": false,
"conversations": [
{
"from": "human",
"value": "Is this correct? The formula for calculating simple interest (also known as Compound Interest) is given by I = P * r^n, where \n- I represents the final amount of money, also called principal or capital. This value will keep on increasing at a fixed rate per unit time denoted by 'r' and number of times denoted by 'n'. The initial investment represented by 'P', while the percentage rate expressed as an annual fraction, i.e., p/100 representing the percentage to be paid annually. In other words it\u2019s how much you earn in one year out of your original $100 invested with a 5% annual return compounded monthly."
},
{
"from": "assistant",
"value": "I'm sorry, but there seems to be some confusion in your question. The formula given and the definitions of the variables seem to be mixed up between simple interest and compound interest. Let me clarify:\n\n1. Simple Interest: This type of interest is calculated only on the original amount (principal) that you invested or loaned. The formula for simple interest is I = PRT, where:\n - I is the interest\n - P is the principal amount (initial investment)\n - R is the annual interest rate (in decimal form, so a 5% rate would be 0.05)\n - T is the time the money is invested or borrowed for, in years.\n\n2. Compound Interest: This type of interest is calculated on the initial principal and also on the accumulated interest of previous periods of a deposit or loan. The formula for compound interest is A = P(1 + r/n)^(nt), where:\n - A is the amount of money accumulated after n years, including interest.\n - P is the principal amount (the initial amount of money)\n - r is the annual interest rate (in decimal form, so a 5% rate would be 0.05)\n - n is the number of times that interest is compounded per year\n - t is the number of years the money is invested or borrowed for.\n\nIn both cases, the interest rate is usually expressed as an annual rate, regardless of the length of the term."
}
]
}
```
### Data Splits
Currently, the dataset is not divided into specific splits (train, test, validation).
## Dataset Creation
### Curation Rationale
The dataset was curated to provide insights into how users interact with language models and to contribute to the broader NLP community's resources.
### Source Data
The data originates from user contributions on the "Collective Cognition" website.
### Personal and Sensitive Information
All chats uploaded to the Collective Cognition website are made public, and are uploaded as a new dataset periodically. If you would like to have your chat removed, please email admin@collectivecognition.ai
## Considerations for Using the Data
### Social Impact of Dataset
The dataset offers a glimpse into the interaction dynamics between humans and AI models. It can be instrumental for researchers studying human-AI collaboration.
### Discussion of Biases
There might be biases in the dataset based on the types of users contributing chat logs and the topics they discuss with ChatGPT, particularly centered around what users may utilize ChatGPT for the most.
### Other Known Limitations
The dataset is dependent on the voluntary contributions of users. Hence, it might not represent the entire spectrum of interactions that users have with ChatGPT.
## Additional Information
### Licensing Information
MIT |
MMInstruction/ArxivCap | ---
license: cc-by-sa-4.0
task_categories:
- image-to-text
language:
- en
pretty_name: ArxivCap
size_categories:
- 1M<n<10M
tags:
- arxiv
- multi-modal
---
# Dataset Card for ArxivCap
## Table of Contents
- [Dataset Card for ArxivCap](#dataset-card-for-arxivcap)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Curation Process](#curation-process)
- [Dataset Structure](#dataset-structure)
- [Data Loading](#data-loading)
- [Data Fields](#data-fields)
- [Data Instances](#data-instances)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Paper:** [Multimodal ArXiv](https://arxiv.org/abs/2403.00231)
- **Point of Contact:** nlp.lilei@gmail.com
- **HomePage**: https://mm-arxiv.github.io/
### Data Instances
<details>
<summary>Example-1 of single (image, caption) pairs</summary>
"......" stands for omitted parts.

```
{
'src': 'arXiv_src_2112_060/2112.08947',
'meta':
{
'meta_from_kaggle':
{
'journey': '',
'license': 'http://arxiv.org/licenses/nonexclusive-distrib/1.0/',
'categories': 'cs.ET'
},
'meta_from_s2':
{
'citationCount': 8,
'influentialCitationCount': 0,
'publicationTypes': ['JournalArticle']
}
},
'arxiv_id': '2112.08947',
'title': 'Computational metrics and parameters of an injection-locked large area semiconductor laser for neural network computing',
'abstract': 'Artificial neural networks have become a staple computing technique in many fields. Yet, they present fundamental differences with classical computing hardware in the way they process information. Photonic implementations of neural network architectures potentially offer fundamental advantages over their electronic counterparts in terms of speed, processing parallelism, scalability and energy efficiency. Scalable and high performance photonic neural networks (PNNs) have been demonstrated, yet they remain scarce. In this work, we study the performance of such a scalable, fully parallel and autonomous PNN based on a large area vertical-cavity surface-emitting laser\n(LA-VCSEL). We show how the performance varies with different physical parameters, namely, injection wavelength, injection power, and bias current. Furthermore, we link these physical parameters to the general computational measures of consistency and dimensionality. We present a general method of gauging dimensionality in high dimensional nonlinear systems subject to noise, which could be applied to many systems in the context of neuromorphic computing. Our work will inform future implementations of spatially multiplexed VCSEL PNNs.\n',
'caption_images':
[
{
'caption': '(a) Working principle of the LA-VCSEL spatially multiplexed reservoir. (b) Input information $\\mathbf{u}$ and the subsequent LA-VCSEL response for 3-bit binary headers. The graph shows the target output $y^{\\text{target}}$ (yellow) for classifying header 001 and different reservoir outputs $y^{\\text{out}}$ of decreasing mean square error (MSE) (red, blue and green). (c) Schematic illustration of the error landscape, showing the MSE as a function of the output weights configuration. The outlined (red, blue and green) Boolean matrices correspond to the output weights giving the output from (b). (d) Representative performance of the PNN on a 6-bit header recognition task.',
'cil_pairs':
[
{
'sub_caption': '',
'image_file': 'arXiv_src_2112_060/2112.08947_0.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=2016x1063 at 0x7F098E288040>,
'image_ocr': ['(a)', 'LA-VCSEL', 'DMDa', 'DMD', 'MMF', 'DET', 'Win', 'xt', 'Spatial positions', 'Output', 'Input', 'Wint', 'Carrier diffusion', 'Cavity diffraction', 'Reservoir', '(d)50', '6bit HR', 'Error(MSE)', '830', '001', '000', '001', '100', '001', '111', 'ER', 'S', '10', '0', 'Configuration DMD.', '0', '1000', 'Input examples', 'Learning epochs']
}
]
}
......
]
}
```
</details>
<details>
<summary>Example-2 of multiple images and subcaptions</summary>
"......" stands for omitted parts.

```
{
'src': 'arXiv_src_0309_001/quant-ph0309051',
'meta':
{
'meta_from_kaggle': {'journey': '', 'license': '', 'categories': 'quant-ph'},
'meta_from_s2': {'citationCount': 9, 'influentialCitationCount': 1, 'publicationTypes': ['JournalArticle']}
},
'arxiv_id': 'quant-ph/0309051',
'title': 'Implementing a Quantum Algorithm with Exchange-Coupled Quantum Dots: a Feasibility study.',
'abstract': '\nWe present Monte Carlo wavefunction simulations for quantum computations employing an exchange-coupled array of quantum dots. Employing a combination of experimentally and theoretically available parameters, we find that gate fidelities greater than 98 \\% may be obtained with current experimental and technological capabilities. Application to an encoded 3 qubit\n(nine physical qubits) Deutsch-Josza computation indicates that the algorithmic fidelity is more a question of the total time to implement the gates than of the physical complexity of those gates.\n',
'caption_images':
[
......
{
'caption': 'Representation of analytic sequence of local transformations that transform the 19-exchange sequence $U_{cnot}^{exchange}$ from Ref. {divincenzo00} into the true CNOT in the computational basis. The exchange gates and times corresponding to the elementary local transformations are then obtained using the quaternion representation of the desired $SU(2)$ unitaries (see Appendix <ref> for details).',
'cil_pairs':
[
{
'sub_caption': 'A single qubit gate ($\\frac{\\sqrt{3}}{2}-\\frac{i}{2}\\sigma_y$) acting on the second logical qubit diagonalizes the 19-gate exchange sequence. The resulting diagonal 4-by-4 matrix is then converted into the C-PHASE by $\\sigma_z$-rotations acting on both the first and the second qubit, with angles $\\phi=0.612497$ and $\\theta=-0.547580$, respectively. These values are determined from the analytic solutions to a linear equation system with 3 unknowns: $\\phi$, $\\theta$ and a global phase. See Appendix <ref> for details as to how these parameters were obtained.',
'image_file': 'arXiv_src_0309_001/quant-ph0309051_4.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=2016x493 at 0x7F102471EF70>,
'image_ocr': ['Exch,', '7', 'C', '2', '+', '2', '2', 'CNOT', '2', '2', 'PHASE']
},
{
'sub_caption': 'The C-PHASE gate can be transformed into the CNOT gate by acting with Hadamard gates on the second qubit before and after the C-PHASE gate.',
'image_file': 'arXiv_src_0309_001/quant-ph0309051_5.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=2016x411 at 0x7F102471EDC0>,
'image_ocr': ['C', '2', 'PHASE']
}
]
},
......
]
}
```
</details>
### Dataset Summary
The ArxivCap dataset consists of 6.4 million images and 3.9 million captions with 193 million words from 570k academic papers accompanied with abstracts and titles. (papers before **June 2023**)
### Curation Process
Refer to our paper for the curation and filter process.
## Dataset Structure
### Data Loading
```python
from datasets import load_dataset
dataset = load_dataset("MMInstruction/ArxivCap")
dataset["train"] # list of dictionaries
```
---
```bash
# for quick download in linux
set -e
sudo apt-get install git-lfs -y
git clone https://huggingface.co/datasets/MMInstruction/ArxivCap
cd ArxivCap/data
```
```python
# then you can load the parquet files in python use something like
data = load_dataset(
"parquet",
data_files="/path/to/parquet/arXiv_src_9912_001.parquet"
)
```
### Data Fields
One record refers to one paper:
- src: **String**. "\<Arxiv Tar File Name>/\<Folder Name in Tar File>"e.g. "arXiv_src_2112_060/2112.08947"
- arxiv_id: **String**. Arxiv id of the paper, e.g. "2112.08947"
- title: **String**. Title of the paper.
- abstract: **String**. Abstract of the paper.
- meta:
- meta_from_kaggle: refers to [arXiv Dataset](https://www.kaggle.com/datasets/Cornell-University/arxiv)
- journey: **String**. Information about the journal the paper was published in.
- licence: **String**. License for the paper.
- categories: **String**. Categories / tags in the ArXiv system.
- meta_from_s2: refers to [SEMANTIC SCHOLAR](https://api.semanticscholar.org/api-docs/#tag/Paper-Data/operation/get_graph_get_paper)
- citationCount: **Integer**. Total number of citations S2 has found for this paper
- influentialCitationCount: **Integer**. Refers [here](https://www.semanticscholar.org/faq#influential-citations)
- publicationTypes: **List[String]**. Journal Article, Conference, Review, etc.
- caption_images:
- caption: **String**. Main caption.
- cil_pairs:
- sub_caption: **String**. Subcaption for the image.
- image_file: **String**. Unique file name for the image.
- image: **PIL.Image.Image**. A PIL.Image.Image object containing the image.
- image_ocr: **List[String]**. OCR result for the image using [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)
```python
import datasets
features = datasets.Features(
{
"src": datasets.Value("string"),
"arxiv_id": datasets.Value("string"),
"title": datasets.Value("string"),
"abstract": datasets.Value("string"),
"meta": {
"meta_from_kaggle": {
"journey": datasets.Value("string"),
"license": datasets.Value("string"),
"categories": datasets.Value("string"),
},
"meta_from_s2": {
"citationCount": datasets.Value("int32"),
"influentialCitationCount": datasets.Value("int32"),
"publicationTypes": [datasets.Value("string")],
}
},
"caption_images": [{
"caption": datasets.Value("string"),
"cil_pairs": [{
"sub_caption": datasets.Value("string"),
"image_file": datasets.Value("string"),
"image": datasets.Image(),
"image_ocr": [datasets.Value("string")],
}]
}]
}
)
```
## Additional Information
### Licensing Information
ArxivCap is released under [CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/).
### Citation Information
```
@misc{li2024multimodal,
title={Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models},
author={Lei Li and Yuqi Wang and Runxin Xu and Peiyi Wang and Xiachong Feng and Lingpeng Kong and Qi Liu},
year={2024},
eprint={2403.00231},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
MohamedRashad/multilingual-tts | ---
license: gpl-3.0
dataset_info:
features:
- name: text
dtype: string
- name: speaker
dtype: string
- name: languages
dtype: string
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 1561588634.72
num_examples: 25540
download_size: 1548036818
dataset_size: 1561588634.72
task_categories:
- text-to-speech
language:
- ar
- en
- zh
- es
- fr
- hi
- ru
- pt
- ja
- de
- tr
- bn
- id
- ur
- vi
pretty_name: Multilingual TTS
size_categories:
- 10K<n<100K
---
# Before Anything and Everything ⚱
_In the time of writing this Dataset Card, ~**17,490**~ **18,412** civilian has been killed in Palestine (~**7,870**~ **8,000** are children and ~**6,121**~ **6,200** are women)._
**Se**ek **a**ny **n**on-**pro**fit **organi**zation **t**o **he**lp **th**em **wi**th **wh**at **y**ou **c**an (For myself, [I use Mersal](https://www.every.org/mersal/f/support-humanitarian)) 🇵🇸
## Dataset Description
The Multilingual TTS dataset is an exceptional compilation of text-to-speech (TTS) samples, meticulously crafted to showcase the richness and diversity of human languages. This dataset encompasses a variety of real-world sentences in fifteen prominent languages, carefully chosen to reflect global linguistic diversity. Each sample is accompanied by its corresponding high-quality audio output.
<style>
.image-container {
display: flex;
justify-content: center;
align-items: center;
height: 65vh;
margin: 0;
}
.image-container img {
max-width: 48%; /* Adjust the width as needed */
height: auto;
}
</style>
<div class="image-container">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6116d0584ef9fdfbf45dc4d9/UX0s8S2yWSJ3NbbvmOJOi.png">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6116d0584ef9fdfbf45dc4d9/zIyPCWH7Y58gLVCeIfq4n.png">
</div>
## Key Features:
1. **Language Diversity**: The dataset covers a spectrum of languages, including **Beng**ali, **Mand**arin **Chin**ese, **Turk**ish, **Hin**di, **Fre**nch, **Vietn**amese, **Portu**guese, **Span**ish, **Japa**nese, **Ger**man, **Russ**ian, **Indon**esian, **Stan**dard **Ara**bic, **Engl**ish, **a**nd **Ur**du. This wide linguistic representation ensures inclusivity and applicability to a global audience.
3. **Real-World Sentences**: Comprising 25,000 samples, the dataset mirrors authentic communication scenarios. Sentences span diverse topics, ranging from everyday conversations to informative texts and news snippets, providing a comprehensive linguistic landscape.
4. **Multilingual Sentences**: A distinctive feature of this dataset is its inclusion of sentences that seamlessly integrate multiple languages. Each sample combines at least two languages, capturing the intricate dynamics of multilingual communication and rendering the dataset particularly valuable for training and evaluating multilingual TTS systems.
5. **Audio Quality**: Special attention has been given to the audio quality of each sample. The audio outputs are meticulously designed to be clear, natural-sounding, and faithful representations of the corresponding text, ensuring a rich auditory experience.
6. **Generated by GPT-4 and elevenlabs**: The dataset is the result of a collaboration between GPT-4 and elevenlabs, combining cutting-edge language generation capabilities with domain expertise. This collaboration guarantees a high level of accuracy, coherence, and linguistic nuance in both the text and audio components.
## Potential Use Cases:
1. **Multilingual TTS Model Training**: Researchers and developers can leverage this dataset to train and refine multilingual TTS models, enhancing their proficiency across a diverse array of languages.
2. **Cross-Language Evaluation**: The dataset serves as a valuable resource for evaluating TTS systems in handling multilingual scenarios, offering a benchmark for assessing model capabilities across different languages.
3. **Language Integration Testing**: Developers working on applications requiring multilingual TTS functionality can utilize this dataset to test and optimize language integration, ensuring a seamless user experience across various linguistic contexts.
## Acknowledgments:
The creation of the Multilingual TTS dataset was made possible through the collaborative efforts of **OpenAI's GPT-4** and the expertise of **Elevenlabs Multilingual V2**. We extend our gratitude to the AI and language processing communities for their continuous support in advancing the field of multilingual TTS. This dataset stands as a significant contribution, fostering innovation and progress in language technologies.
|
MohamedSaeed-dev/python-text-to-code | ---
license: llama2
---
|
dcayton/nba_tracking_data_15_16 | ---
language:
- en
tags:
- basketball
- nba
- sports
- tracking
- play-by-play
pretty_name: NBA 2015/2016 Season Raw Tracking Data from SportVU
source_datasets:
- https://github.com/linouk23/NBA-Player-Movements
- https://github.com/sumitrodatta/nba-alt-awards
---
# 2015-2016 Raw Tracking Data from SportVU
The modern era of basketball is characterized by the use of data to analyze performance and make decisions both on and off the court. Using tracking data combined with traditional play-by-play can allow for in=depth analysis of games.
## Dataset Details
### Dataset Descriptions
Tracking data is the finest level of basketball data, whereas play-by-play and box score data are also used. This dataset gives raw SportVU tracking data from each game of the 2015-2016 NBA season merged with play-by-play data. 2015-16 was the last season with publically available tracking data. This data has the coordinates of all players at all moments of the game, for each game in the season. There is also more information such as descriptors for players on the team (and their unique IDs) and the teams playing (and their unique IDs). Further, descriptors of the play that occured at each event is present, and the team in possession during the event, along with more necessary features.
- **Collected By:** SportVU, Basketball Referece
- **Shared By:** Kostya Linou, Dzmitryi Linou, Martijn De Boer, Sumitro Datta
### Dataset Source
- **Repositories:**
- https://github.com/linouk23/NBA-Player-Movements
- https://github.com/sumitrodatta/nba-alt-awards
## Uses
This dataset has many potential uses. Primarily, visualization of plays, as illustrated in the initial repository is possible, creating a comprehensive view for analyzing actions on court. Beyond that, models could be trained to recognize certain play types or actions, which can increase efficiency of video scouting. Analysis of defensive control could be performed by examining the data spatially. Even further, a broadcast tracking model could be creater if video data could be obtained and connected to each moment of collection. This would create a model where video frames are mapped to tracked coordinates, increasing the accessibility of tracking data as only publically available video footage is necessary.
- An example of action identification shown here: https://colab.research.google.com/drive/1x_v9c5yzUnDvSsH9d-2m3FjFXMp8A-ZF?usp=sharing
## Dataset Structure
The data is in the following dictionary format:
- 'gameid': str (ID for the game)
- 'gamedate': str (date the game occured on)
- 'event_info':
- 'eventid': str (ID for the event in the given game)
- 'type': int (number corresponding to event type)
- 'possession_team_id': float (team ID of team in possession during the event)
- 'desc_home': str (description of the event for the home team)
- 'desc_away': str (description of the event for the away team)
- 'primary_info':
- 'team': str (home or visitor)
- 'player_id': float (ID of primary player involved in event)
- 'team_id': float (ID of team for primary player)
- 'secondary_info': same format as primary info, but for a secondary player involved
- 'visitor':
- 'name': str (team name)
- 'teamid': int (team ID)
- 'abbreviation': str (abbreviation of team name)
- 'players': list of the dictionaries in the form of the following
- 'lastname': str (player last name)
- 'firstname': str (player first name)
- 'playerid': str (player ID)
- 'number': int (player jersey number)
- 'position': str (player in-game position)
- 'home': same format as visitor
- 'moments': list of dictionaries in the form of the following
- 'quarter': int (quarter of moment)
- 'game_clock': float (game clock (seconds, descending starting from 720))
- 'shot_clock': float (shot clock (seconds, descending starting from 24))
- 'ball_coordinates':
- 'x': float (x coordinate of ball)
- 'y': float (y coordinate of ball)
- 'z': float (z coordinate of ball)
- 'player_coordinates': list of the dictionaries in the form of the following,
- 'teamid': int (team ID of player)
- 'playerid': int (player ID for player)
- 'x': float (x coordinate of player)
- 'y': float (y coordinate of player)
- 'z': float (z coordinate of player)
## Requirements
To load the data, you must run
`import py7zr`
## Configurations
The data here has multiple configurations corresponding to different size subsamples of the data. This is intended for quicker loading and increased manageability. The configurations are as follows:
- 'tiny': a subsample of 5 games
- 'small': a subsample of 25 games
- 'medium': a subsample of 100 games
- 'large': all games (600+) with tracking data from 2015-16 NBA season
## Dataset Creation
### Curation Rationale
The reason for uploading this data to huggingface, is that in its current .7z form, the data is less accessible, and requires unzipping many files and then combining to access. Also, more sources for easily accessible tracking data, even if also available elsewhere, increase the chances of long-term preservation and accessibility for future NBA fans.
On top of that, tracking data combined with play-by-play data is ideal format of sports data, as there is little confusion and allows for better labeling of events.
### Source Data
From creator StatsPerform, "the SportVU camera system is installed in basketball arenas to track the real-time positions of players and the ball at 25 times per second." These methods were used to capture the data in this dataset.
## Bias, Risks, and Limitations
Technical limitations include the following:
Some events or moments included within events have no corresponding coordinates, which can cause trouble with continuity, however this is not a major problem as this only occurs on a very small number of events and the occurances can be handled on a case-by-case basis or ignored.
The coordinates for each event often start before the labeled event and/or end after the event ends. This can also cause bleeding of data over to the next event, so care must be taken to acknowledge this when working with the data.
Since this data is not up-to-date, and the tracking data for the last eight seasons is private and unreleased, the continued spread of this specific data may not be representative of the current state of NBA tracking data (provided by different companies). Thus, users that learn how to manipulate it may or may not be adequately prepared for work in basketball organizations.
Further, analyses performed on the dataset may not be reflective of the current state of professional basketball. This is because the game is constantly changing and evolving. However, since this was the last iteration of publicly available tracking data, I believe increasing its availability is important.
## Dataset Card Author
Donald Cayton; dcayton9@gmail.com |
Sentdex/WSB-003.005 | ---
license: apache-2.0
---
|
MemGPT/MemGPT-DPO-Dataset | ---
task_categories:
- text-generation
language:
- en
tags:
- function calling
- function
- memgpt
pretty_name: MemGPT-DPO-Dataset
size_categories:
- 10K<n<100K
---

**MemGPT-DPO-Dataset** is our initial release of a potential series of datasets.
*Please check* ***"files"*** *tab for other languages!*
## Details
The dataset is synthetically generated by **GPT-4**, led by [@starsnatched](https://huggingface.co/starsnatched) and [@cpacker](https://huggingface.co/cpacker).
This dataset is intended to be used with **text-generation models**, such as [Mistral-7B-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2). The dataset allows the LLM to learn to use [MemGPT-specific tools](https://memgpt.readme.io/docs/presets).
#### → Features
Teaches an LLM to prefer a function over the other.
#### → Dataset size & splits
The dataset in this repository contains **42,293 rows**, with the only split being **train split**.
#### → Data annotation
**Prompt**: The examples of potential user-queries.\
**Chosen**: The name of the function that the LLM should prefer.\
**Rejected**: The name of the function that the LLM should **NOT** prefer.
#### → Data collection process
This dataset is **entirely generated by GPT-4** using prompt engineering.
#### → Data cleaning
Quick manual examination was performed on the dataset and **some** pairs were removed due to unwanted preferation of function. There was **no harmful content** that was spotted during the examination.
#### → Use cases
This dataset is mainly intended for **DPO** fine-tuning of an LLM. However, this can be used for **SFT** fine-tuning as well.
## Code Snippet (examples)
Below is an example Python code to map the given dataset into **ChatML** format:
```python
def chatml_format(example):
prompt = "<|im_start|>user\n{\n \"type\": \"user_message\",\n \"message\": \"" + example['prompt'] + "\",\n \"time\": \"" + f"{generate_random_time()}" + "\"\n}<|im_end|>\n<|im_start|>assistant\n"
chosen = '{\n "function": "' + example['chosen'] + '",'
rejected = '{\n "function": "' + example['rejected'] + '",'
return {
"prompt": prompt,
"chosen": chosen,
"rejected": rejected,
}
def generate_random_time():
year = random.randint(2024, 2025)
month = random.randint(1, 12)
day = random.randint(1, 28)
hour = random.randint(1, 12)
minute = random.randint(0, 59)
second = random.randint(0, 59)
am_pm = random.choice(['AM', 'PM'])
dt = datetime(year, month, day, hour, minute, second)
formatted_time = dt.strftime("%Y-%m-%d %I:%M:%S %p")
formatted_time = formatted_time[:-3] + " " + am_pm
return formatted_time
```
The above code should return the partial prompt-output pair as such:
```
# Chosen example
<|im_start|>user
{
"type": "user_message",
"message": "EXAMPLE USER PROMPT",
"time": "RANDOM TIME GENERATED"
}<|im_end|>
<|im_start|>assistant
{
"function": "EXAMPLE FUNCTION", # The assistant generates from here.
```
## Motivation
We found that on MemGPT, using GPT-4 is not very cost-efficient. Some users have reported that after just a dozen conversation turns, their OpenAI usage bills reached **above $1-2**. However, using open-source models, users have also reported that the models are **not as performant** compared to GPT-4, sometimes calling the wrong function, or most of the time, not calling the necessary function at all. In order to combat this potential deal-breaker for most people, we decided to create (fine-tune) an LLM that is specifically trained to be used on MemGPT. We aim to create an LLM that can **surpass GPT-4**'s function calling capabilities when being used with MemGPT, and hopefully assist other users create their own MemGPT-LLM using our dataset. |
vesteinn/icelandic-qa-NQiI | ---
pretty_name: NQiI
annotations_creators:
- curated
language_creators:
- curated
language:
- is
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- open-domain-qa
- extractive-qa
paperswithcode_id: nqii
---
# Natural Questions in Icelandic
|
mjw/stock_market_tweets |
---
license: apache-2.0
---
# Overview
This file contains over 1.7m public tweets about Apple, Amazon, Google, Microsoft and Tesla stocks, published between 01/01/2015 and 31/12/2019.
|
jonathan-roberts1/SATIN | ---
license: other
configs:
- config_name: SAT-4
- config_name: SAT-6
- config_name: NASC-TG2
- config_name: WHU-RS19
- config_name: RSSCN7
- config_name: RS_C11
- config_name: SIRI-WHU
- config_name: EuroSAT
- config_name: NWPU-RESISC45
- config_name: PatternNet
- config_name: RSD46-WHU
- config_name: GID
- config_name: CLRS
- config_name: Optimal-31
- config_name: Airbus-Wind-Turbines-Patches
- config_name: USTC_SmokeRS
- config_name: Canadian_Cropland
- config_name: Ships-In-Satellite-Imagery
- config_name: Satellite-Images-of-Hurricane-Damage
- config_name: Brazilian_Coffee_Scenes
- config_name: Brazilian_Cerrado-Savanna_Scenes
- config_name: Million-AID
- config_name: UC_Merced_LandUse_MultiLabel
- config_name: MLRSNet
- config_name: MultiScene
- config_name: RSI-CB256
- config_name: AID_MultiLabel
task_categories:
- image-classification
- zero-shot-image-classification
pretty_name: SATellite ImageNet
size_categories:
- 100K<n<1M
language:
- en
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** [https://satinbenchmark.github.io](https://satinbenchmark.github.io)
- **Repository:**
- **Paper:** [SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models](https://arxiv.org/pdf/2304.11619.pdf)
- **Leaderboard:** [SATIN Leaderboard](https://satinbenchmark.github.io/leaderboard.md)
### Dataset Summary
SATIN (SATellite ImageNet) is a metadataset containing 27 constituent satellite and aerial image datasets spanning 6 distinct tasks: Land Cover, Land Use,
Hierarchical Land Use, Complex Scenes, Rare Scenes, and False Colour Scenes. The imagery is globally distributed, comprised of resolutions spanning 5 orders
of magnitude, multiple fields of view sizes, and over 250 distinct class labels. Presented at ICCV '23 TNGCV Workshop.
## Dataset Structure
The SATIN benchmark is comprised of the following datasets:
#### Task 1: Land Cover
- SAT-4
- SAT-6
- NASC-TG2
#### Task 2: Land Use
- WHU-RS19
- RSSCN7
- RS_C11
- SIRI-WHU
- EuroSAT
- NWPU-RESISC45
- PatternNet
- RSD46-WHU
- GID
- CLRS
- Optimal-31
#### Task 3: Hierarchical Land Use
- Million-AID
- RSI-CB256
#### Task 4: Complex Scenes
- UC_Merced_LandUse_MultiLabel
- MLRSNet
- MultiScene
- AID_MultiLabel
#### Task 5: Rare Scenes
- Airbus-Wind-Turbines-Patches
- USTC_SmokeRS
- Canadian_Cropland
- Ships-In-Satellite-Imagery
- Satellite-Images-of-Hurricane-Damage
#### Task 6: False Colour Scenes
- Brazilian_Coffee_Scenes
- Brazilian_Cerrado-Savanna_Scenes
For ease of use and to avoid having to download the entire benchmark for each use, in this dataset repository, each of the 27 datasets is included as a separate
'config'.
### Example Usage
```python
from datasets import load_dataset
hf_dataset = load_dataset('jonathan-roberts1/SATIN', DATASET_NAME, split='train') # for DATASET_NAME use one of the configs listed above (e.g., EuroSAT)
features = hf_dataset.features
class_labels = features['label'].names
#class_labels = features['label'].feature.names # for the Complex Scenes datasets
#class_labels_1 = features['label_1'].names # for the Hierarchical Land Use datasets, the label field is replaced with label_1, label_2, ...
random_index = 5
example = hf_dataset[random_index]
image, label = example['image'], example['label']
```
### Data Splits
For each config, there is just the single, default 'train' split.
### Source Data
More information regarding the source data can be found in our paper. Additionally, each of the constituent datasets have been uploaded to HuggingFace datasets.
They can be accessed at: huggingface.co/datasets/jonathan-roberts1/DATASET_NAME.
### Dataset Curators
This dataset was curated by Jonathan Roberts, Kai Han, and Samuel Albanie
### Licensing Information
As SATIN is comprised of existing datasets with differing licenses, there is not a single license for SATIN. All of the datasets in SATIN can be used
for research purposes; usage information of specific constituent datasets can be found in the Appendix of our paper.
### Citation Information
```
@article{roberts2023satin,
title = {SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models},
author = {Jonathan Roberts, Kai Han, and Samuel Albanie},
year = {2023},
eprint = {2304.11619},
archivePrefix= {arXiv},
primaryClass = {cs.CV}
}
``` |
WxWx/ChatGPT-Detector-Bias | ---
license: mit
task_categories:
- text-classification
language:
- en
tags:
- ChatGPT
- GPT Detector
- ChatGPT Detector
size_categories:
- n<1K
---
# GPT Detectors Are Biased Against Non-Native English Writers
[](https://lbesson.mit-license.org/)
[](https://www.python.org/downloads/release/python-390/)
[](https://jupyter.org/try)
This repository contains the data and supplementary materials for our paper:
**GPT Detectors Are Biased Against Non-Native English Writers**\
Weixin Liang*, Mert Yuksekgonul*, Yining Mao*, Eric Wu*, James Zou\
arXiv: [2304.02819](https://arxiv.org/abs/2304.02819)
```bibtex
@article{liang2023gpt,
title={GPT detectors are biased against non-native English writers},
author={Weixin Liang and Mert Yuksekgonul and Yining Mao and Eric Wu and James Zou},
year={2023},
eprint={2304.02819},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Abstract
*The rapid adoption of generative language models has brought about substantial advancements in digital communication, while simultaneously raising concerns regarding the potential misuse of AI-generated content. Although numerous detection methods have been proposed to differentiate between AI and human-generated content, the fairness and robustness of these detectors remain underexplored. In this study, we evaluate the performance of several widely-used GPT detectors using writing samples from native and non-native English writers. Our findings reveal that these detectors consistently misclassify non-native English writing samples as AI-generated, whereas native writing samples are accurately identified. Furthermore, we demonstrate that simple prompting strategies can not only mitigate this bias but also effectively bypass GPT detectors, suggesting that GPT detectors may unintentionally penalize writers with constrained linguistic expressions. Our results call for a broader conversation about the ethical implications of deploying ChatGPT content detectors and caution against their use in evaluative or educational settings, particularly when they may inadvertently penalize or exclude non-native English speakers from the global discourse.*
<p align='center'>
<img width="636" src="https://user-images.githubusercontent.com/32794044/230640445-8d1221d4-8651-4cf4-b6d7-b6d440d6e0f5.png">
<br>
<b>Figure 1: Bias in GPT detectors against non-native English writing samples.</b>
</p>
(a) Performance comparison of seven widely-used GPT detectors. More than half of the non-native-authored TOEFL (Test of English as a Foreign Language) essays are incorrectly classified as "AI-generated," while detectors exhibit near-perfect accuracy for college essays.
Using ChatGPT-4 to improve the word choices in TOEFL essays (Prompt: "Enhance the word choices to sound more like that of a native speaker.") significantly reduces misclassification as AI-generated text.
(b) TOEFL essays unanimously misclassified as AI-generated show significantly lower perplexity compared to others, suggesting that GPT detectors might penalize authors with limited linguistic expressions.
<p align='center'>
<img width="100%" src="https://user-images.githubusercontent.com/32794044/230640270-e6c3d0ca-aabd-4d13-8527-15fed1491050.png">
<br>
<b>Figure 2: Simple prompts effectively bypass GPT detectors.</b>
</p>
(a) For ChatGPT-3.5 generated college admission essays, the performance of seven widely-used GPT detectors declines markedly when a second-round self-edit prompt ("Elevate the provided text by employing literary language") is applied, with detection rates dropping from up to 100% to up to 13%.
(b) ChatGPT-3.5 generated essays initially exhibit notably low perplexity; however, applying the self-edit prompt leads to a significant increase in perplexity.
(c) Similarly, in detecting ChatGPT-3.5 generated scientific abstracts, a second-round self-edit prompt ("Elevate the provided text by employing advanced technical language") leads to a reduction in detection rates from up to 68% to up to 28%.
(d) ChatGPT-3.5 generated abstracts have slightly higher perplexity than the generated essays but remain low. Again, the self-edit prompt significantly increases the perplexity.
## Repo Structure Overview
```
.
├── README.md
├── data/
├── human_data/
├── TOEFL_real_91/
├── name.json
├── data.json
├── TOEFL_gpt4polished_91/
├── ...
├── CollegeEssay_real_70/
├── CS224N_real_145/
├── gpt_data/
├── CollegeEssay_gpt3_31/
├── CollegeEssay_gpt3PromptEng_31/
├── CS224N_gpt3_145/
├── CS224N_gpt3PromptEng_145/
```
The `data` folder contains the human-written and AI-generated datasets used in our study. Each subfolder contains a `name.json` file, which provides the metadata, and a `data.json` file, which contains the text samples.
## Reference
```bibtex
@article{liang2023gpt,
title={GPT detectors are biased against non-native English writers},
author={Weixin Liang and Mert Yuksekgonul and Yining Mao and Eric Wu and James Zou},
year={2023},
eprint={2304.02819},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
izumi-lab/wikipedia-en-20230720 | ---
dataset_info:
features:
- name: curid
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 16118978135
num_examples: 6650632
download_size: 9566993111
dataset_size: 16118978135
license: cc-by-sa-3.0
language:
- en
---
# Dataset Card for "wikipedia-en-20230720"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
corbt/all-recipes | ---
dataset_info:
features:
- name: input
dtype: string
splits:
- name: train
num_bytes: 1569011376
num_examples: 2147248
download_size: 807147913
dataset_size: 1569011376
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "all-recipes"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CollectiveCognition/chats-data-2023-09-22 | ---
license: mit
---
# Dataset Card for "Collective Cognition ChatGPT Conversations"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
### Dataset Summary
The "Collective Cognition ChatGPT Conversations" dataset is a collection of chat logs between users and the ChatGPT model. These conversations have been shared by users on the "Collective Cognition" website. The dataset provides insights into user interactions with language models and can be utilized for multiple purposes, including training, research, and analysis.
Visit Collective Cognition to browse or contribute chats here: https://collectivecognition.ai
### Supported Tasks
- **Language Model Finetuning**: Training through behavior cloning and knowledge instilling.
- **Dialogue Understanding**: Analyzing the flow and structure of conversations.
- **Sentiment Analysis**: Understanding the sentiment or emotion in the dialogues.
- **Topic Modeling**: Determining the topics discussed within the chats.
### Languages
The primary language of the dataset is English, but any language chat may be present in the dataset as users share more chats.
## Dataset Structure
### Data Instances
A typical data instance includes a chat log with a title, model name, whether the chat used custom instructions (currently not included if so), and the content of the message with the role of the sender (either "human" or "gpt").
The dataset is formatted to conform with ShareGPT standard.
This is an example entry in the dataset, noting that turns are variable and can be many or as few as two:
```json
{
"title": "Interest Formulas Clarification",
"model_name": "GPT-4",
"custom_instruction": false,
"conversations": [
{
"from": "human",
"value": "Is this correct? The formula for calculating simple interest (also known as Compound Interest) is given by I = P * r^n, where \n- I represents the final amount of money, also called principal or capital. This value will keep on increasing at a fixed rate per unit time denoted by 'r' and number of times denoted by 'n'. The initial investment represented by 'P', while the percentage rate expressed as an annual fraction, i.e., p/100 representing the percentage to be paid annually. In other words it\u2019s how much you earn in one year out of your original $100 invested with a 5% annual return compounded monthly."
},
{
"from": "assistant",
"value": "I'm sorry, but there seems to be some confusion in your question. The formula given and the definitions of the variables seem to be mixed up between simple interest and compound interest. Let me clarify:\n\n1. Simple Interest: This type of interest is calculated only on the original amount (principal) that you invested or loaned. The formula for simple interest is I = PRT, where:\n - I is the interest\n - P is the principal amount (initial investment)\n - R is the annual interest rate (in decimal form, so a 5% rate would be 0.05)\n - T is the time the money is invested or borrowed for, in years.\n\n2. Compound Interest: This type of interest is calculated on the initial principal and also on the accumulated interest of previous periods of a deposit or loan. The formula for compound interest is A = P(1 + r/n)^(nt), where:\n - A is the amount of money accumulated after n years, including interest.\n - P is the principal amount (the initial amount of money)\n - r is the annual interest rate (in decimal form, so a 5% rate would be 0.05)\n - n is the number of times that interest is compounded per year\n - t is the number of years the money is invested or borrowed for.\n\nIn both cases, the interest rate is usually expressed as an annual rate, regardless of the length of the term."
}
]
}
```
### Data Splits
Currently, the dataset is not divided into specific splits (train, test, validation).
## Dataset Creation
### Curation Rationale
The dataset was curated to provide insights into how users interact with language models and to contribute to the broader NLP community's resources.
### Source Data
The data originates from user contributions on the "Collective Cognition" website.
### Personal and Sensitive Information
All chats uploaded to the Collective Cognition website are made public, and are uploaded as a new dataset periodically. If you would like to have your chat removed, please email admin@collectivecognition.ai
## Considerations for Using the Data
### Social Impact of Dataset
The dataset offers a glimpse into the interaction dynamics between humans and AI models. It can be instrumental for researchers studying human-AI collaboration.
### Discussion of Biases
There might be biases in the dataset based on the types of users contributing chat logs and the topics they discuss with ChatGPT, particularly centered around what users may utilize ChatGPT for the most.
### Other Known Limitations
The dataset is dependent on the voluntary contributions of users. Hence, it might not represent the entire spectrum of interactions that users have with ChatGPT.
## Additional Information
### Licensing Information
MIT |
FinGPT/fingpt-sentiment-cls | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 10908696
num_examples: 47557
download_size: 3902114
dataset_size: 10908696
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "fingpt-sentiment-cls"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |