
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
d029e658513f0d11a7a2183b9bb42963dd0a37cd
| 1,712 |
ipynb
|
Jupyter Notebook
|
hash.ipynb
|
y2mk1ng/Encryption-Decryption-tools
|
3526a272d18ffab3cd2acc24061ea561b0aaee70
|
[
"Unlicense"
] | null | null | null |
hash.ipynb
|
y2mk1ng/Encryption-Decryption-tools
|
3526a272d18ffab3cd2acc24061ea561b0aaee70
|
[
"Unlicense"
] | null | null | null |
hash.ipynb
|
y2mk1ng/Encryption-Decryption-tools
|
3526a272d18ffab3cd2acc24061ea561b0aaee70
|
[
"Unlicense"
] | null | null | null | 19.022222 | 59 | 0.48014 |
[
[
[
"import hashlib",
"_____no_output_____"
],
[
"m1 = hashlib.sha224()\nm1.update(b\"...\") #insert the pwd in the \"...\"\nm1.digest()",
"_____no_output_____"
],
[
"m2 = hashlib.sha256()\nm2.update(b\"...\") #insert the pwd in the \"...\"\nm2.digest()",
"_____no_output_____"
],
[
"m3 = hashlib.md5()\nm3.update(b\"...\") #insert the pwd in the \"...\"\nm3.digest()",
"_____no_output_____"
],
[
"m5 = hashlib.sha384()\nm5.update(b\"...\") #insert the pwd in the \"...\"\nm5.digest()",
"_____no_output_____"
],
[
"m6 = hashlib.sha512()\nm6.update(b\"...\") #insert the pwd in the \"...\"\nm6.digest()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02a4b38a8f93841d03b9319e8f3ca561f476adf
| 27,153 |
ipynb
|
Jupyter Notebook
|
preprocessing/ExtractTerms.ipynb
|
tychen5/IR_TextMining
|
cbe60f48f1ae3f0ae84aebfa57697e7a744000ec
|
[
"MIT"
] | 2 |
2019-01-26T04:09:40.000Z
|
2020-04-21T06:38:51.000Z
|
preprocessing/ExtractTerms.ipynb
|
tychen5/IR_TextMining
|
cbe60f48f1ae3f0ae84aebfa57697e7a744000ec
|
[
"MIT"
] | null | null | null |
preprocessing/ExtractTerms.ipynb
|
tychen5/IR_TextMining
|
cbe60f48f1ae3f0ae84aebfa57697e7a744000ec
|
[
"MIT"
] | null | null | null | 47.888889 | 769 | 0.579899 |
[
[
[
"### R06725035 陳廷易\n* Tokenization.\n* Lowercasing everything.\n* Stemming using Porter’s algorithm.\n* Stopword removal.\n* Save the result as a txt file. \n",
"_____no_output_____"
]
],
[
[
"# import keras\n# from keras.preprocessing.text import Tokenizer\n# import gensim\nimport nltk\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import wordpunct_tokenize\nfrom nltk import word_tokenize\nfrom nltk.stem.porter import *\nfrom nltk.tokenize import RegexpTokenizer\n# nltk.download('all')",
"[nltk_data] Downloading collection 'all'\n[nltk_data] | \n[nltk_data] | Downloading package abc to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package abc is already up-to-date!\n[nltk_data] | Downloading package alpino to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package alpino is already up-to-date!\n[nltk_data] | Downloading package biocreative_ppi to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package biocreative_ppi is already up-to-date!\n[nltk_data] | Downloading package brown to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package brown is already up-to-date!\n[nltk_data] | Downloading package brown_tei to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package brown_tei is already up-to-date!\n[nltk_data] | Downloading package cess_cat to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package cess_cat is already up-to-date!\n[nltk_data] | Downloading package cess_esp to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package cess_esp is already up-to-date!\n[nltk_data] | Downloading package chat80 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package chat80 is already up-to-date!\n[nltk_data] | Downloading package city_database to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package city_database is already up-to-date!\n[nltk_data] | Downloading package cmudict to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package cmudict is already up-to-date!\n[nltk_data] | Downloading package comparative_sentences to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package comparative_sentences is already up-to-\n[nltk_data] | date!\n[nltk_data] | Downloading package comtrans to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package comtrans is already up-to-date!\n[nltk_data] | Downloading package conll2000 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package conll2000 is already up-to-date!\n[nltk_data] | Downloading package conll2002 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package conll2002 is already up-to-date!\n[nltk_data] | Downloading package conll2007 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package conll2007 is already up-to-date!\n[nltk_data] | Downloading package crubadan to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package crubadan is already up-to-date!\n[nltk_data] | Downloading package dependency_treebank to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package dependency_treebank is already up-to-date!\n[nltk_data] | Downloading package dolch to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package dolch is already up-to-date!\n[nltk_data] | Downloading package europarl_raw to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package europarl_raw is already up-to-date!\n[nltk_data] | Downloading package floresta to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package floresta is already up-to-date!\n[nltk_data] | Downloading package framenet_v15 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package framenet_v15 is already up-to-date!\n[nltk_data] | Downloading package framenet_v17 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package framenet_v17 is already up-to-date!\n[nltk_data] | Downloading package gazetteers to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package gazetteers is already up-to-date!\n[nltk_data] | Downloading package genesis to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package genesis is already up-to-date!\n[nltk_data] | Downloading package gutenberg to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package gutenberg is already up-to-date!\n[nltk_data] | Downloading package ieer to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package ieer is already up-to-date!\n[nltk_data] | Downloading package inaugural to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package inaugural is already up-to-date!\n[nltk_data] | Downloading package indian to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package indian is already up-to-date!\n[nltk_data] | Downloading package jeita to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package jeita is already up-to-date!\n[nltk_data] | Downloading package kimmo to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package kimmo is already up-to-date!\n[nltk_data] | Downloading package knbc to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package knbc is already up-to-date!\n[nltk_data] | Downloading package lin_thesaurus to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package lin_thesaurus is already up-to-date!\n[nltk_data] | Downloading package mac_morpho to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package mac_morpho is already up-to-date!\n[nltk_data] | Downloading package machado to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package machado is already up-to-date!\n[nltk_data] | Downloading package masc_tagged to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package masc_tagged is already up-to-date!\n[nltk_data] | Downloading package moses_sample to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package moses_sample is already up-to-date!\n[nltk_data] | Downloading package movie_reviews to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package movie_reviews is already up-to-date!\n[nltk_data] | Downloading package names to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package names is already up-to-date!\n[nltk_data] | Downloading package nombank.1.0 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package nombank.1.0 is already up-to-date!\n[nltk_data] | Downloading package nps_chat to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package nps_chat is already up-to-date!\n[nltk_data] | Downloading package omw to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package omw is already up-to-date!\n[nltk_data] | Downloading package opinion_lexicon to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package opinion_lexicon is already up-to-date!\n[nltk_data] | Downloading package paradigms to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package paradigms is already up-to-date!\n[nltk_data] | Downloading package pil to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package pil is already up-to-date!\n[nltk_data] | Downloading package pl196x to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package pl196x is already up-to-date!\n[nltk_data] | Downloading package ppattach to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package ppattach is already up-to-date!\n[nltk_data] | Downloading package problem_reports to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package problem_reports is already up-to-date!\n[nltk_data] | Downloading package propbank to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package propbank is already up-to-date!\n[nltk_data] | Downloading package ptb to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package ptb is already up-to-date!\n[nltk_data] | Downloading package product_reviews_1 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package product_reviews_1 is already up-to-date!\n[nltk_data] | Downloading package product_reviews_2 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package product_reviews_2 is already up-to-date!\n[nltk_data] | Downloading package pros_cons to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package pros_cons is already up-to-date!\n[nltk_data] | Downloading package qc to /home/leoqaz12/nltk_data...\n[nltk_data] | Package qc is already up-to-date!\n[nltk_data] | Downloading package reuters to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package reuters is already up-to-date!\n[nltk_data] | Downloading package rte to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package rte is already up-to-date!\n[nltk_data] | Downloading package semcor to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package semcor is already up-to-date!\n[nltk_data] | Downloading package senseval to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package senseval is already up-to-date!\n[nltk_data] | Downloading package sentiwordnet to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package sentiwordnet is already up-to-date!\n[nltk_data] | Downloading package sentence_polarity to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package sentence_polarity is already up-to-date!\n[nltk_data] | Downloading package shakespeare to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package shakespeare is already up-to-date!\n[nltk_data] | Downloading package sinica_treebank to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package sinica_treebank is already up-to-date!\n[nltk_data] | Downloading package smultron to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package smultron is already up-to-date!\n[nltk_data] | Downloading package state_union to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package state_union is already up-to-date!\n[nltk_data] | Downloading package stopwords to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package stopwords is already up-to-date!\n[nltk_data] | Downloading package subjectivity to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package subjectivity is already up-to-date!\n[nltk_data] | Downloading package swadesh to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package swadesh is already up-to-date!\n[nltk_data] | Downloading package switchboard to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package switchboard is already up-to-date!\n[nltk_data] | Downloading package timit to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package timit is already up-to-date!\n[nltk_data] | Downloading package toolbox to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package toolbox is already up-to-date!\n[nltk_data] | Downloading package treebank to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package treebank is already up-to-date!\n[nltk_data] | Downloading package twitter_samples to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package twitter_samples is already up-to-date!\n[nltk_data] | Downloading package udhr to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package udhr is already up-to-date!\n[nltk_data] | Downloading package udhr2 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package udhr2 is already up-to-date!\n[nltk_data] | Downloading package unicode_samples to\n[nltk_data] | /home/leoqaz12/nltk_data...\n[nltk_data] | Package unicode_samples is already up-to-date!\n[nltk_data] | Downloading package universal_treebanks_v20 to\n[nltk_data] | /home/leoqaz12/nltk_data...\n"
]
],
[
[
"### read data",
"_____no_output_____"
]
],
[
[
"file = open('data/28.txt','r')\ntexts = file.read()\nfile.close()\ntexts",
"_____no_output_____"
]
],
[
[
"### main preprocessing",
"_____no_output_____"
]
],
[
[
"with open('data/stop_words.txt') as f:\n stop_words_list = f.read().splitlines()",
"_____no_output_____"
],
[
"ps = PorterStemmer() # Stemming\nstop_words = set(stopwords.words('english')) #Stopword\nshort = ['.', ',', '\"', \"'\", '?', '!', ':', ';', '(', ')', '[', ']', '{', '}',\n '\\'s','\\'m','\\'re','\\'ll','\\'d','n\\'t','shan\\'t']\nstop_words_list.extend(short)\nstop_words.update(stop_words_list) # remove it if you need punctuation\n\ntokens = [i for i in word_tokenize(texts.lower()) if i not in stop_words] # Tokenization.# Lowercasing\ntoken_result = ''\nfor i,token in enumerate(tokens):\n if i != len(tokens)-1: # 最後不要空白\n token_result += ps.stem(token) + ' '\n else:\n token_result += ps.stem(token)\n\n# tokens = nltk.word_tokenize(texts.lower())\n# ps.stem(token_result)\ntoken_result",
"_____no_output_____"
],
[
"\"plan\" in token_result",
"_____no_output_____"
]
],
[
[
"### Output",
"_____no_output_____"
]
],
[
[
"# output=\"\"\n# for token in tokens:\n# output+=token+' '\n# print(output)\nfile = open('result/output.txt','w')\nfile.write(token_result) #Save the result \nfile.close()\nprint(token_result)",
"yugoslav author plan arrest eleven coal miner two opposit politician suspicion sabotag connect strike action presid slobodan milosev listen bbc news world\n"
],
[
"# tokenizer = Tokenizer()\n# tokenizer.fit_on_texts(texts)\n# print(tokenizer.sequences_to_texts())",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02a60a97d18dbed3bcc727d9eee615d7820c35d
| 2,425 |
ipynb
|
Jupyter Notebook
|
19T2/2_review/functions.ipynb
|
photomz/learn-python3
|
9dba54c1ec06b9b238b70cb9c697687799616e3a
|
[
"MIT"
] | null | null | null |
19T2/2_review/functions.ipynb
|
photomz/learn-python3
|
9dba54c1ec06b9b238b70cb9c697687799616e3a
|
[
"MIT"
] | null | null | null |
19T2/2_review/functions.ipynb
|
photomz/learn-python3
|
9dba54c1ec06b9b238b70cb9c697687799616e3a
|
[
"MIT"
] | null | null | null | 20.041322 | 149 | 0.501856 |
[
[
[
"# Functions\nThink of mathematical functions...\n> 8 -------> 16\n\n> 10 ------> 20\n\n> 0.5 ------> 1\n\nThus, the function of course is `f(x) = 2x`, which is a function f that doubles whatever input. What if we could write a doubling function too?",
"_____no_output_____"
]
],
[
[
"def f(x):\n return 2*x",
"_____no_output_____"
],
[
"print(f(8))\nprint(f(10))\nprint(f(0.5))",
"_____no_output_____"
]
],
[
[
"Programmatic functions can do a lot more. For example:",
"_____no_output_____"
]
],
[
[
"def is_even(x):\n return not x % 2",
"_____no_output_____"
],
[
"print(is_even(100))\nprint(is_even(7))",
"_____no_output_____"
],
[
"def calculate_interest(principal=100,rate=0.05,year=5):\n # principal = initial amount, rate = interest rate, year = number of years\n compounded = principal\n for i in range(year):\n compounded = compounded * (1+rate)\n year = year + 1\n return compounded",
"_____no_output_____"
],
[
"print(calculate_interest())\nprint(calculate_interest(1000,0.01,100))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d02a62b1d38444a360baf54ab040a154a6409533
| 5,529 |
ipynb
|
Jupyter Notebook
|
viz/auto/3-hiveplot.ipynb
|
dhimmel/integrate
|
93feba1765fbcd76fd79e22f25121f5399629148
|
[
"CC0-1.0"
] | 23 |
2016-05-12T07:39:10.000Z
|
2022-02-15T23:52:11.000Z
|
viz/auto/3-hiveplot.ipynb
|
dhimmel/integrate
|
93feba1765fbcd76fd79e22f25121f5399629148
|
[
"CC0-1.0"
] | 16 |
2015-08-11T07:39:02.000Z
|
2019-07-04T00:42:32.000Z
|
viz/auto/3-hiveplot.ipynb
|
dhimmel/integrate
|
93feba1765fbcd76fd79e22f25121f5399629148
|
[
"CC0-1.0"
] | 13 |
2017-09-22T08:47:30.000Z
|
2021-12-29T16:17:52.000Z
| 23.133891 | 160 | 0.453608 |
[
[
[
"# Prepare dataset for hiveplot\n\nThis notebook currently just exports a subset of the nodes to a DOT file for import into [`jhive`](https://www.bcgsc.ca/wiki/display/jhive/Documentation).",
"_____no_output_____"
]
],
[
[
"import random\n\nimport pandas\nimport networkx\n\nfrom networkx.drawing.nx_pydot import write_dot",
"_____no_output_____"
],
[
"node_df = pandas.read_table('../../data/nodes.tsv')\nedge_df = pandas.read_table('../../data/edges.sif.gz')",
"_____no_output_____"
],
[
"node_df.head(2)",
"_____no_output_____"
],
[
"edge_df.head(2)",
"_____no_output_____"
],
[
"graph = networkx.MultiGraph()\n\n# No colons allowed. See https://github.com/carlos-jenkins/pydotplus/issues/3\nmake_dot_safe = lambda x: x.replace(':', '_')\n\nfor row in node_df.itertuples():\n node_id = make_dot_safe(row.id)\n graph.add_node(node_id, node_name=row.name, kind=row.kind)\n\nfor row in edge_df.itertuples():\n source = make_dot_safe(row.source)\n target = make_dot_safe(row.target)\n graph.add_edge(source, target, key=row.metaedge)\n\nlen(graph)",
"_____no_output_____"
],
[
"random.seed(0)\nnode_subset = random.sample(graph.nodes(), 1000)\ngraph_subset = graph.subgraph(node_subset)\nlen(graph_subset)",
"_____no_output_____"
],
[
"write_dot(graph_subset, 'data/hetionet-v1.0-simple.dot')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02a7597ae45b25bf0c4afceddf94638b3eda53c
| 91,394 |
ipynb
|
Jupyter Notebook
|
HW3/HW3.ipynb
|
jay-z007/Data-Science-Fundamentals
|
ffe04b4edc8bdc9115736e956577858ba8ba28a6
|
[
"Apache-2.0"
] | 1 |
2019-10-13T02:03:55.000Z
|
2019-10-13T02:03:55.000Z
|
HW3/HW3.ipynb
|
jay-z007/Data-Science-Fundamentals
|
ffe04b4edc8bdc9115736e956577858ba8ba28a6
|
[
"Apache-2.0"
] | null | null | null |
HW3/HW3.ipynb
|
jay-z007/Data-Science-Fundamentals
|
ffe04b4edc8bdc9115736e956577858ba8ba28a6
|
[
"Apache-2.0"
] | 1 |
2019-10-13T02:03:57.000Z
|
2019-10-13T02:03:57.000Z
| 35.27364 | 1,607 | 0.430105 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sb\nimport gc",
"_____no_output_____"
],
[
"prop_data = pd.read_csv(\"properties_2017.csv\")\n# prop_data",
"/usr/local/lib/python2.7/dist-packages/IPython/core/interactiveshell.py:2718: DtypeWarning: Columns (49) have mixed types. Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
],
[
"train_data = pd.read_csv(\"train_2017.csv\")\ntrain_data",
"_____no_output_____"
],
[
"# missing_val = prop_data.isnull().sum().reset_index()\n# missing_val.columns = ['column_name', 'missing_count']\n# missing_val = missing_val.loc[missing_val['missing_count']>0]\n# missing_val = missing_val.sort_values(by='missing_count')\n\n# missing_val['missing_ratio'] = missing_val[\"missing_count\"]/prop_data.shape[0]\n# missing_val = missing_val.loc[missing_val[\"missing_ratio\"]>0.6]\n# missing_val\n\n\n# ind = np.arange(missing_val.shape[0])\n# width = 0.9\n# fig, ax = plt.subplots(figsize=(12,18))\n# rects = ax.barh(ind, missing_val.missing_ratio.values, color='blue')\n# ax.set_yticks(ind)\n# ax.set_yticklabels(missing_val.column_name.values, rotation='horizontal')\n# ax.set_xlabel(\"Count of missing values\")\n# ax.set_title(\"Number of missing values in each column\")\n# plt.show()\n\n# del ind\n",
"_____no_output_____"
],
[
"# prop_data.drop(missing_val.column_name.values, axis=1, inplace=True)",
"_____no_output_____"
],
[
"prop_data",
"_____no_output_____"
],
[
"# prop_data_temp = prop_data.fillna(prop_data.mean(), )\nplt.plot(prop_data.groupby(\"regionidcounty\")[\"taxvaluedollarcnt\"].mean())\nplt.show()",
"_____no_output_____"
],
[
"original = prop_data.copy()",
"_____no_output_____"
],
[
"prop_data = original.copy()",
"_____no_output_____"
],
[
"# prop_data['actual_area'] = prop_data[['finishedfloor1squarefeet','calculatedfinishedsquarefeet','finishedsquarefeet12', 'finishedsquarefeet13',\n# 'finishedsquarefeet15', 'finishedsquarefeet50', 'finishedsquarefeet6']].max(axis=1)\n\nprop_data['actual_area'] = prop_data['calculatedfinishedsquarefeet']#.value_counts(dropna = False)\nprop_data['calculatedbathnbr'].fillna(prop_data['calculatedbathnbr'].median(),inplace = True)\nprop_data['bedroomcnt'].fillna(prop_data['bedroomcnt'].median(), inplace = True)\n\nprop_data['taxvaluedollarcnt'].fillna(prop_data[\"taxvaluedollarcnt\"].mean(), inplace=True)\n\nprop_data['actual_area'].replace(to_replace=1.0,value=np.nan,inplace=True)\nprop_data['actual_area'].fillna(prop_data['actual_area'].median(),inplace=True)\n\nprop_data['unitcnt'].fillna(1, inplace = True)\n\nprop_data['latitude'].fillna(prop_data['latitude'].median(),inplace = True)\nprop_data['longitude'].fillna(prop_data['longitude'].median(),inplace = True)\n\nprop_data['lotsizesquarefeet'].fillna(prop_data['lotsizesquarefeet'].median(), inplace = True)\n\nprop_data[\"poolcnt\"].fillna(0, inplace=True)\nprop_data[\"fireplacecnt\"].fillna(0, inplace=True)\nprop_data[\"hashottuborspa\"].fillna(0, inplace=True)\nprop_data['hashottuborspa'] = pd.to_numeric(prop_data['hashottuborspa'])\n\nprop_data[\"taxdelinquencyflag\"].fillna(-1, inplace=True)\nprop_data[\"taxdelinquencyflag\"] = prop_data[\"taxdelinquencyflag\"].map({'Y':1, -1:-1})\n\nprop_data.loc[(prop_data[\"heatingorsystemtypeid\"]==2.0) & (pd.isnull(prop_data[\"airconditioningtypeid\"])), \"airconditioningtypeid\"] = 1.0\nprop_data[\"airconditioningtypeid\"].fillna(-1, inplace=True)\n\nprop_data[\"buildingqualitytypeid\"].fillna(7, inplace=True)\n\nprop_data[\"yearbuilt\"].fillna(prop_data[\"yearbuilt\"].mean(), inplace=True)\nprop_data[\"age\"] = 2017 - prop_data[\"yearbuilt\"]\n#imputing garagecarcnt on basis of propertylandusetypeid\n#All the residential places have 1 or 2 garagecarcnt, hence using random filling for those values.\n\nprop_data.loc[(prop_data[\"propertylandusetypeid\"]==261) & (pd.isnull(prop_data[\"garagecarcnt\"])), \"garagecarcnt\"] = np.random.randint(1,3)\nprop_data.loc[(prop_data[\"propertylandusetypeid\"]==266) & (pd.isnull(prop_data[\"garagecarcnt\"])), \"garagecarcnt\"] = np.random.randint(1,3)\nprop_data[\"garagecarcnt\"].fillna(0, inplace=True)\n\nprop_data[\"taxamount\"].fillna(prop_data.taxamount.mean(), inplace=True)\n\n\nprop_data['longitude'] = prop_data['longitude'].abs()",
"_____no_output_____"
],
[
"prop_data['calculatedfinishedsquarefeet'].describe()",
"_____no_output_____"
]
],
[
[
"### Normalizing the data",
"_____no_output_____"
]
],
[
[
"\ncolsList = [\"actual_area\",\n \"poolcnt\",\n \"latitude\",\n \"longitude\",\n \"unitcnt\",\n \"lotsizesquarefeet\",\n \"bedroomcnt\",\n \"calculatedbathnbr\",\n \"hashottuborspa\",\n \"fireplacecnt\",\n \"taxvaluedollarcnt\",\n \"buildingqualitytypeid\",\n \"garagecarcnt\",\n \"age\",\n \"taxamount\"]",
"_____no_output_____"
],
[
"prop_data_ahp = prop_data[colsList]\n# prop_data_ahp",
"_____no_output_____"
],
[
"for col in prop_data_ahp.columns:\n prop_data_ahp[col] = (prop_data_ahp[col] - prop_data_ahp[col].mean())/prop_data_ahp[col].std(ddof=0)",
"/usr/local/lib/python2.7/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"# prop_data_ahp.isnull().sum()",
"_____no_output_____"
],
[
"for cols in prop_data_ahp.columns.values:\n print prop_data_ahp[cols].value_counts(dropna=False)\n",
"-0.130731 47739\n-0.199816 8968\n-0.249310 7211\n-0.323551 7111\n-0.447286 6024\n-0.364796 5956\n-0.385418 5837\n-0.406041 5436\n-0.298804 5319\n-0.220439 4743\n-0.348298 4685\n-0.292617 4658\n-0.261684 4585\n-0.302929 4520\n-0.271995 4478\n-0.274057 4281\n-0.335925 4211\n-0.459659 4166\n-0.132793 4162\n-0.397792 4148\n-0.422539 4147\n-0.150322 4029\n-0.117326 3987\n-0.496780 3926\n-0.137949 3919\n-0.352422 3888\n-0.224563 3831\n-0.076082 3799\n-0.307053 3784\n-0.168883 3690\n ... \n 6.255530 1\n 6.173555 1\n 5.930210 1\n 37.453189 1\n 10.936313 1\n 3.555018 1\n 4.396415 1\n-0.859219 1\n 5.301225 1\n 6.710255 1\n 5.229562 1\n 46.473969 1\n 10.368164 1\n 7.095379 1\n 3.632353 1\n 5.497654 1\n 7.580007 1\n 5.365670 1\n 3.451906 1\n 5.129543 1\n 4.411882 1\n 8.115676 1\n 39.548946 1\n 4.417553 1\n 6.807180 1\n 11.143053 1\n 7.860988 1\n 9.108647 1\n 2.499664 1\n 3.159067 1\nName: actual_area, Length: 12630, dtype: int64\n-0.469740 2445585\n 2.128838 539632\nName: poolcnt, dtype: int64\n 0.027779 2937\n-0.068664 859\n-1.203029 756\n 0.227560 740\n 0.700452 611\n-0.965556 568\n-0.887905 559\n 0.191816 555\n 0.692235 553\n 0.232902 541\n-1.379075 524\n-0.593808 513\n 0.226328 510\n-0.943781 504\n 0.613762 497\n 0.554599 484\n-1.238773 463\n 1.681980 455\n-0.948300 435\n-0.540323 429\n-0.177130 428\n-0.548273 424\n-0.723153 424\n-1.553897 421\n-0.724386 419\n 0.255088 416\n 0.165111 402\n-1.248634 401\n 0.611297 396\n-0.945014 395\n ... \n-0.792460 1\n-1.781087 1\n-0.116981 1\n 2.731273 1\n 0.364896 1\n 1.654765 1\n 2.764363 1\n 2.652504 1\n 1.658614 1\n 1.529635 1\n-2.704733 1\n-1.113808 1\n-1.198251 1\n 1.673393 1\n 2.347754 1\n-1.942281 1\n-1.952564 1\n 2.788509 1\n-1.251078 1\n 1.764154 1\n-1.181940 1\n-2.302825 1\n 1.751019 1\n-1.721390 1\n 0.405341 1\n-1.375559 1\n-1.770553 1\n 2.412657 1\n 1.520966 1\n 2.756364 1\nName: latitude, Length: 852718, dtype: int64\n-0.085527 2935\n 0.545319 1718\n 0.684279 1585\n 0.542424 1569\n 0.669804 1545\n 0.145809 1402\n 0.666909 1371\n 0.704544 1319\n 0.675594 1290\n 0.768234 1266\n 0.756654 1255\n 0.678489 1193\n 0.707439 1192\n 0.510579 1187\n 0.177654 1169\n 0.507684 1138\n 0.719019 1112\n-0.039471 1107\n 0.765339 1091\n 0.681384 1078\n-0.045261 1063\n 0.687174 1048\n 0.759549 1048\n 0.498999 1031\n 0.525054 1008\n 0.698754 1007\n-0.207380 1003\n 0.652434 988\n 0.307929 966\n 0.721914 965\n ... \n-1.663629 1\n 0.539561 1\n 1.032258 1\n 1.167006 1\n 1.813341 1\n-1.423735 1\n-0.706643 1\n 2.881900 1\n-1.377186 1\n 0.577607 1\n-1.512571 1\n-1.822741 1\n 1.876284 1\n-1.169508 1\n 0.722803 1\n-1.309269 1\n-1.700601 1\n 2.848760 1\n 1.539375 1\n-0.590024 1\n 2.234980 1\n 0.123243 1\n 1.000793 1\n-1.007466 1\n-1.300958 1\n-0.283968 1\n 3.112350 1\n 0.457743 1\n 2.815870 1\n-0.883366 1\nName: longitude, Length: 1043238, dtype: int64\n-0.059008 2788048\n 0.434155 115778\n 1.420482 39926\n 0.927319 39893\n 1.913645 325\n 2.406809 248\n 3.393135 136\n 2.899972 134\n 4.379462 87\n 3.886299 81\n 5.365789 45\n 4.872625 42\n 6.352115 33\n 5.858952 32\n 7.338442 30\n 11.283749 26\n 9.311096 17\n 6.845279 16\n 8.324769 15\n 7.831606 12\n 10.297422 11\n 15.229056 10\n 12.763239 9\n 8.817932 9\n 14.242729 8\n 12.270076 8\n 9.804259 7\n 10.790586 7\n 13.256402 7\n 24.105996 6\n ... \n 197.206333 1\n 56.654777 1\n 101.039479 1\n 125.697647 1\n 69.970188 1\n 47.777837 1\n 39.887223 1\n 91.176212 1\n 31.996610 1\n 37.421407 1\n 35.941917 1\n 49.257327 1\n 41.366713 1\n 148.876324 1\n 189.808882 1\n 337.264724 1\n 54.682124 1\n 37.914570 1\n 42.846203 1\n 34.955590 1\n 468.446176 1\n 437.376885 1\n 35.448753 1\n 55.668451 1\n 146.903671 1\n 67.504371 1\n 434.911068 1\n 123.724993 1\n 61.093247 1\n 31.503446 1\nName: unitcnt, Length: 154, dtype: int64\n-0.059489 284570\n-0.063685 44585\n-0.067881 17517\n-0.058650 15326\n-0.061587 11565\n-0.057391 10179\n-0.061168 6999\n-0.062426 6702\n-0.065783 6162\n-0.066202 5955\n-0.060538 5685\n-0.067042 5504\n-0.072077 5097\n-0.057396 4827\n-0.055293 4673\n-0.069979 4661\n-0.063265 4493\n-0.062846 4204\n-0.056133 4017\n-0.068720 3890\n-0.056552 3885\n-0.067461 3779\n-0.063689 3762\n-0.062636 3750\n-0.053615 3357\n-0.067877 3319\n-0.067885 3299\n-0.063181 3244\n-0.063681 3220\n-0.065363 3167\n ... \n-0.087131 1\n 0.051309 1\n 0.363920 1\n 0.122583 1\n 1.733924 1\n 0.084263 1\n 0.103895 1\n 0.017306 1\n 0.072720 1\n 0.749622 1\n 1.773566 1\n 0.826942 1\n 0.357622 1\n 0.173255 1\n 0.167759 1\n 0.541943 1\n 0.232546 1\n 0.345081 1\n 0.219338 1\n 0.387811 1\n 0.163475 1\n 0.091853 1\n 0.381819 1\n 0.363278 1\n 0.219606 1\n 0.562091 1\n 0.463503 1\n 0.039737 1\n 0.488330 1\n 0.212784 1\nName: lotsizesquarefeet, Length: 70214, dtype: int64\n-0.073386 1175702\n 0.713430 731475\n-0.860202 606782\n 1.500246 182765\n-2.433835 118705\n-1.647019 86941\n 2.287062 48915\n 3.860695 13542\n 3.073878 12763\n 4.647511 4279\n 5.434327 1702\n 7.007959 959\n 6.221143 425\n 7.794775 86\n 8.581592 69\n 10.155224 50\n 9.368408 24\n 10.942040 11\n 11.728856 9\n 13.302489 8\n 15.662937 1\n 16.449753 1\n 12.515673 1\n 17.236570 1\n 14.089305 1\nName: bedroomcnt, dtype: int64\n-0.296309 1336955\n 0.718788 633088\n-1.311405 499324\n 0.211239 208578\n 1.733884 133922\n-0.803857 45427\n 2.748981 38514\n 1.226336 31773\n 2.241432 19811\n 3.764077 16416\n 3.256529 6259\n 4.779174 6221\n 5.794270 4548\n 6.809367 1341\n 4.271625 1340\n 7.824463 496\n 5.286722 382\n 9.854656 269\n 8.839560 200\n 6.301818 110\n 10.869753 53\n 7.316915 50\n 11.884849 39\n 13.915042 25\n 12.899945 21\n 8.332011 14\n 15.945235 12\n 14.930138 8\n 17.975428 8\n 10.362204 3\n 9.347108 3\n 16.960331 3\n 29.141489 1\n 30.156586 1\n 17.467880 1\n 12.392397 1\nName: calculatedbathnbr, dtype: int64\n-0.130599 2935155\n 7.657049 50062\nName: hashottuborspa, dtype: int64\n-0.315882 2672093\n 2.260353 270019\n 4.836589 34487\n 7.412825 7716\n 9.989060 716\n 12.565296 129\n 15.141532 34\n 17.717767 15\n 22.870238 6\n 20.294003 2\nName: fireplacecnt, dtype: int64\n 1.434326e-16 34266\n-5.464493e-01 1902\n 7.974085e-03 1452\n-5.362975e-02 1371\n 6.957792e-02 1285\n 4.493639e-02 1131\n-4.346682e-03 1120\n-2.898822e-02 1117\n-1.666745e-02 1097\n-1.152336e-01 1095\n 2.029485e-02 1037\n 1.311818e-01 1036\n-2.282783e-02 1029\n 3.877600e-02 1027\n-6.595052e-02 1019\n-4.130898e-02 1010\n 1.927856e-01 975\n-7.827128e-02 964\n 2.645524e-02 938\n-1.050707e-02 937\n 3.261562e-02 934\n-8.443167e-02 927\n-3.514860e-02 913\n 1.003798e-01 897\n 5.725715e-02 890\n 9.421945e-02 885\n 8.189869e-02 874\n-1.521959e-01 873\n-1.768374e-01 871\n-1.398751e-01 864\n ... \n-1.864107e-01 1\n 6.722295e-03 1\n 2.270490e+00 1\n 9.539540e-01 1\n 6.918518e-01 1\n-1.599333e-01 1\n-2.733893e-03 1\n-4.364130e-02 1\n 2.842020e-01 1\n-2.808037e-01 1\n 1.950557e+00 1\n 1.808081e-02 1\n 1.051473e+00 1\n 7.214709e-01 1\n 2.987257e-01 1\n 4.987780e-01 1\n-2.101491e-01 1\n 8.328753e-01 1\n 2.167736e+01 1\n 2.837067e-01 1\n 1.694402e-01 1\n-3.841491e-01 1\n-7.575169e-02 1\n-5.391283e-01 1\n 4.750852e-01 1\n 2.738716e+00 1\n 7.904019e-01 1\n-5.163078e-01 1\n 7.483078e+00 1\n 2.164724e+00 1\nName: taxvaluedollarcnt, Length: 661521, dtype: int64\n 0.325565 1234066\n-0.370521 561502\n 1.021651 501925\n-1.762694 448049\n-1.066608 107053\n 1.717737 69428\n 3.109909 28488\n-2.458780 17858\n 2.413823 10629\n 3.805995 4123\n-3.850952 1776\n-3.154866 320\nName: buildingqualitytypeid, dtype: int64\n-0.353068 1632131\n 1.105037 980997\n-1.811172 340395\n 2.563141 19884\n 4.021245 8655\n 5.479350 1739\n 6.937454 587\n 8.395558 272\n 9.853663 181\n 11.311767 130\n 12.769871 83\n 14.227975 64\n 15.686080 41\n 17.144184 16\n 18.602288 14\n 20.060393 10\n 22.976601 4\n 25.892810 3\n 21.518497 3\n 27.350914 2\n 28.809018 2\n 33.183331 2\n 34.641436 1\n 24.434706 1\nName: garagecarcnt, dtype: int64\n 4.023912e-01 88555\n 6.155737e-01 76100\n 4.450277e-01 73284\n 4.876642e-01 67062\n 3.597547e-01 65723\n 1.866257e-02 64907\n 5.729372e-01 56643\n 6.129908e-02 54754\n 5.303007e-01 54378\n 7.434833e-01 52935\n 7.008467e-01 52625\n-1.047250e+00 52527\n-3.650660e-01 51429\n-2.397394e-02 49462\n 6.582102e-01 48257\n 1.039356e-01 48223\n 3.029506e-15 47833\n-6.208851e-01 47501\n 2.318451e-01 47199\n-5.356121e-01 46666\n 3.171181e-01 46509\n-9.619772e-01 44844\n-3.224295e-01 44400\n-2.797930e-01 42995\n-5.782486e-01 42674\n 1.892086e-01 41916\n-4.929756e-01 41759\n-6.635216e-01 41395\n-1.089887e+00 41213\n 1.465721e-01 40188\n ... \n 6.371503e+00 2\n 4.239677e+00 2\n 6.755231e+00 2\n 6.115684e+00 2\n 5.305590e+00 2\n 6.925777e+00 1\n 4.069131e+00 1\n 6.712595e+00 1\n 5.902501e+00 1\n 4.793952e+00 1\n 5.817228e+00 1\n 4.708679e+00 1\n 5.220317e+00 1\n 5.774592e+00 1\n 5.561409e+00 1\n 5.945138e+00 1\n 4.410223e+00 1\n 5.859865e+00 1\n 5.007134e+00 1\n 6.158320e+00 1\n 4.452860e+00 1\n 4.324950e+00 1\n 4.197041e+00 1\n 6.584685e+00 1\n 3.728039e+00 1\n 6.456776e+00 1\n 3.941222e+00 1\n 3.642766e+00 1\n 6.797868e+00 1\n 5.604045e+00 1\nName: age, Length: 184, dtype: int64\n"
]
],
[
[
"## Analytical Hierarchical Processing",
"_____no_output_____"
]
],
[
[
"rel_imp_matrix = pd.read_csv(\"rel_imp_matrix.csv\", index_col=0)\n# rel_imp_matrix",
"_____no_output_____"
],
[
"import fractions\n\n\nfor col in rel_imp_matrix.columns.values:\n temp_list = rel_imp_matrix[col].tolist()\n rel_imp_matrix[col] = [float(fractions.Fraction(x)) for x in temp_list]\n \n# data = [float(fractions.Fraction(x)) for x in data]\n# rel_imp_matrix\n",
"_____no_output_____"
],
[
"for col in rel_imp_matrix.columns.values:\n rel_imp_matrix[col] /= rel_imp_matrix[col].sum()\n \n# rel_imp_matrix",
"_____no_output_____"
],
[
"rel_imp_matrix[\"row_sum\"] = rel_imp_matrix.sum(axis=1)\n\nrel_imp_matrix[\"score\"] = rel_imp_matrix[\"row_sum\"]/rel_imp_matrix.shape[0]\n\nrel_imp_matrix.to_csv(\"final_score_matrix.csv\", index=False)\n# rel_imp_matrix",
"_____no_output_____"
],
[
"ahp_column_score = rel_imp_matrix[\"score\"]",
"_____no_output_____"
],
[
"ahp_column_score",
"_____no_output_____"
],
[
"prop_data_ahp.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2985217 entries, 0 to 2985216\nData columns (total 15 columns):\nactual_area float64\npoolcnt float64\nlatitude float64\nlongitude float64\nunitcnt float64\nlotsizesquarefeet float64\nbedroomcnt float64\ncalculatedbathnbr float64\nhashottuborspa float64\nfireplacecnt float64\ntaxvaluedollarcnt float64\nbuildingqualitytypeid float64\ngaragecarcnt float64\nage float64\ntaxamount float64\ndtypes: float64(15)\nmemory usage: 341.6 MB\n"
],
[
"prop_data_ahp.drop('sum', axis=1,inplace=True)\nprop_data_ahp.keys()",
"_____no_output_____"
]
],
[
[
"# SAW",
"_____no_output_____"
]
],
[
[
"sum_series = pd.Series(0, index=prop_data_ahp.index,dtype='float32')\n\nfor col in prop_data_ahp.columns:\n sum_series = sum_series+ prop_data_ahp[col] * ahp_column_score[col]\nprop_data_ahp[\"sum\"] = sum_series.astype('float32')",
"/usr/local/lib/python2.7/dist-packages/ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"\n"
],
[
"prop_data_ahp[\"sum\"]\n# prop_data_ahp[\"sum\"] = prop_data_ahp.sum(axis=1)\n ",
"_____no_output_____"
],
[
"prop_data_ahp[\"sum\"].describe()",
"_____no_output_____"
],
[
"prop_data_ahp.sort_values(by='sum', inplace=True)",
"/usr/local/lib/python2.7/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"prop_data_ahp.head(n=10)",
"_____no_output_____"
],
[
"prop_data_ahp.tail(n=10)",
"_____no_output_____"
],
[
"print prop_data[colsList].iloc[1252741],\"\\n\\n\"\nprint prop_data[colsList].iloc[342941]",
"actual_area 472363.0\npoolcnt 1.0\nlatitude 34061321.0\nlongitude 118342823.0\nunitcnt 478.0\nlotsizesquarefeet 7000.0\nbedroomcnt 0.0\ncalculatedbathnbr 2.0\nhashottuborspa 0.0\nfireplacecnt 0.0\ntaxvaluedollarcnt 271004605.0\nbuildingqualitytypeid 7.0\ngaragecarcnt 0.0\nage 3.0\ntaxamount 3277055.2\nName: 1252741, dtype: float64 \n\n\nactual_area 5.208250e+05\npoolcnt 0.000000e+00\nlatitude 3.406122e+07\nlongitude 1.182901e+08\nunitcnt 4.640000e+02\nlotsizesquarefeet 7.000000e+03\nbedroomcnt 0.000000e+00\ncalculatedbathnbr 2.000000e+00\nhashottuborspa 0.000000e+00\nfireplacecnt 0.000000e+00\ntaxvaluedollarcnt 2.870985e+08\nbuildingqualitytypeid 7.000000e+00\ngaragecarcnt 0.000000e+00\nage 4.000000e+00\ntaxamount 3.458861e+06\nName: 342941, dtype: float64\n"
],
[
"# #imputing airconditioningtypeid, making some NaN to 1.0 where heatingorsystemtypeid == 2\n\n# prop_data.loc[(prop_data[\"heatingorsystemtypeid\"]==2.0) & (pd.isnull(prop_data[\"airconditioningtypeid\"])), \"airconditioningtypeid\"] = 1.0\n\n# prop_data[\"airconditioningtypeid\"].fillna(-1, inplace=True)\n# print prop_data[\"airconditioningtypeid\"].value_counts()\n\n# prop_data[[\"airconditioningtypeid\", \"heatingorsystemtypeid\"]].head()\n\n# duplicate_or_not_useful_cols = pd.Series(['calculatedbathnbr', 'assessmentyear', 'fullbathcnt', \n# 'regionidneighborhood', 'propertyzoningdesc', 'censustractandblock'])#,'finishedsquarefeet12'])\n# prop_data.drop(duplicate_or_not_useful_cols, axis=1, inplace=True)\n\n# prop_data[\"buildingqualitytypeid\"].fillna(prop_data[\"buildingqualitytypeid\"].mean(), inplace=True)\n# prop_data[\"calculatedfinishedsquarefeet\"].interpolate(inplace=True)\n# prop_data[\"heatingorsystemtypeid\"].fillna(-1, inplace=True)\n# prop_data[\"lotsizesquarefeet\"].fillna(prop_data[\"lotsizesquarefeet\"].median(), inplace=True)\n# prop_data.drop([\"numberofstories\"], axis=1, inplace=True)\n# #removing propertycountylandusecode because it is not in interpretable format\n# prop_data.drop([\"propertycountylandusecode\"], axis=1, inplace=True)\n# prop_data[\"regionidcity\"].interpolate(inplace=True)\n# prop_data[\"regionidzip\"].interpolate(inplace=True)\n# prop_data[\"yearbuilt\"].fillna(prop_data[\"yearbuilt\"].mean(), inplace=True)\n\n# #impute structuretaxvaluedollarcnt, taxvaluedollarcnt, landtaxvaluedollarcnt, taxamount by interpolation\n# cols_to_interpolate = [\"structuretaxvaluedollarcnt\", \"taxvaluedollarcnt\", \"landtaxvaluedollarcnt\", \"taxamount\"]\n# for c in cols_to_interpolate:\n# prop_data[c].interpolate(inplace=True)\n\n \n# #imputing garagecarcnt on basis of propertylandusetypeid\n# #All the residential places have 1 or 2 garagecarcnt, hence using random filling for those values.\n\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==261) & (pd.isnull(prop_data[\"garagecarcnt\"])), \"garagecarcnt\"] = np.random.randint(1,3)\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==266) & (pd.isnull(prop_data[\"garagecarcnt\"])), \"garagecarcnt\"] = np.random.randint(1,3)\n\n# prop_data[\"garagecarcnt\"].fillna(-1, inplace=True)\n\n# prop_data[\"garagecarcnt\"].value_counts(dropna=False)\n\n# #imputing garagetotalsqft using the garagecarcnt\n\n# prop_data.loc[(prop_data[\"garagecarcnt\"]==-1) & (pd.isnull(prop_data[\"garagetotalsqft\"]) | (prop_data[\"garagetotalsqft\"] == 0)), \"garagetotalsqft\"] = -1\n# prop_data.loc[(prop_data[\"garagecarcnt\"]==1) & (pd.isnull(prop_data[\"garagetotalsqft\"]) | (prop_data[\"garagetotalsqft\"] == 0)), \"garagetotalsqft\"] = np.random.randint(180, 400)\n# prop_data.loc[(prop_data[\"garagecarcnt\"]==2) & (pd.isnull(prop_data[\"garagetotalsqft\"]) | (prop_data[\"garagetotalsqft\"] == 0)), \"garagetotalsqft\"] = np.random.randint(400, 720)\n# prop_data.loc[(prop_data[\"garagecarcnt\"]==3) & (pd.isnull(prop_data[\"garagetotalsqft\"]) | (prop_data[\"garagetotalsqft\"] == 0)), \"garagetotalsqft\"] = np.random.randint(720, 880)\n# prop_data.loc[(prop_data[\"garagecarcnt\"]==4) & (pd.isnull(prop_data[\"garagetotalsqft\"]) | (prop_data[\"garagetotalsqft\"] == 0)), \"garagetotalsqft\"] = np.random.randint(880, 1200)\n\n# #interpolate the remaining missing values\n# prop_data[\"garagetotalsqft\"].interpolate(inplace=True)\n\n# prop_data[\"garagetotalsqft\"].value_counts(dropna=False)\n\n\n# #imputing unitcnt using propertylandusetypeid\n \n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==261) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 1\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==266) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 1\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==269) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 1\n\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==246) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 2\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==247) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 3\n# prop_data.loc[(prop_data[\"propertylandusetypeid\"]==248) & pd.isnull(prop_data[\"unitcnt\"]), \"unitcnt\"] = 4\n\n# prop_data[\"unitcnt\"].value_counts(dropna=False)",
"_____no_output_____"
]
],
[
[
"## Distance Metric\n\nWe will be using weighted Manhattan distance as a distance metric",
"_____no_output_____"
]
],
[
[
"dist_imp_matrix = pd.read_csv(\"./dist_metric.csv\", index_col=0)\ndist_imp_matrix",
"_____no_output_____"
],
[
"import fractions\n\n\nfor col in dist_imp_matrix.columns.values:\n temp_list = dist_imp_matrix[col].tolist()\n dist_imp_matrix[col] = [float(fractions.Fraction(x)) for x in temp_list]\n ",
"_____no_output_____"
],
[
"# dist_imp_matrix",
"_____no_output_____"
],
[
"for col in dist_imp_matrix.columns.values:\n dist_imp_matrix[col] /= dist_imp_matrix[col].sum()",
"_____no_output_____"
],
[
"dist_imp_matrix[\"row_sum\"] = dist_imp_matrix.sum(axis=1)\n\ndist_imp_matrix[\"score\"] = dist_imp_matrix[\"row_sum\"]/dist_imp_matrix.shape[0]\n\ndist_imp_matrix.to_csv(\"final_score_matrix_Q2.csv\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02a886f61e87c8c50fd57b9b1c568e5c89885f4
| 11,562 |
ipynb
|
Jupyter Notebook
|
Python/Exercises/Blatt-13.ipynb
|
BuserLukas/Logic
|
cc0447554cfa75b213a10a2db37ce82c42afb91d
|
[
"MIT"
] | 13 |
2019-10-03T13:25:02.000Z
|
2021-12-26T11:49:25.000Z
|
Python/Exercises/Blatt-13.ipynb
|
BuserLukas/Logic
|
cc0447554cfa75b213a10a2db37ce82c42afb91d
|
[
"MIT"
] | 19 |
2015-01-14T15:36:24.000Z
|
2019-04-21T02:13:23.000Z
|
Python/Exercises/Blatt-13.ipynb
|
BuserLukas/Logic
|
cc0447554cfa75b213a10a2db37ce82c42afb91d
|
[
"MIT"
] | 18 |
2019-10-03T16:05:46.000Z
|
2021-12-10T19:44:15.000Z
| 31.333333 | 305 | 0.497232 |
[
[
[
"from IPython.core.display import HTML\nwith open('../style.css', 'r') as file:\n css = file.read()\nHTML(css)",
"_____no_output_____"
]
],
[
[
"# A Crypto-Arithmetic Puzzle",
"_____no_output_____"
],
[
"In this exercise we will solve the crypto-arithmetic puzzle shown in the picture below:\n<img src=\"send-more-money.png\">",
"_____no_output_____"
],
[
"The idea is that the letters \n\"$\\texttt{S}$\", \"$\\texttt{E}$\", \"$\\texttt{N}$\", \"$\\texttt{D}$\", \"$\\texttt{M}$\", \"$\\texttt{O}$\", \"$\\texttt{R}$\", \"$\\texttt{Y}$\" occurring in this puzzle\nare interpreted as variables ranging over the set of decimal digits, i.e. these variables can take values in\nthe set $\\{0,1,2,3,4,5,6,7,8,9\\}$. Then, the string \"$\\texttt{SEND}$\" is interpreted as a decimal number,\ni.e. it is interpreted as the number\n$$\\texttt{S} \\cdot 10^3 + \\texttt{E} \\cdot 10^2 + \\texttt{N} \\cdot 10^1 + \\texttt{D} \\cdot 10^0.$$\nThe strings \"$\\texttt{MORE}$ and \"$\\texttt{MONEY}$\" are interpreted similarly. To make the problem\ninteresting, the assumption is that different variables have different values. Furthermore, the\ndigits at the beginning of a number should be different from $0$. Then, we have to find values for the variables\n\"$\\texttt{S}$\", \"$\\texttt{E}$\", \"$\\texttt{N}$\", \"$\\texttt{D}$\", \"$\\texttt{M}$\", \"$\\texttt{O}$\", \"$\\texttt{R}$\", \"$\\texttt{Y}$\" such that the formula\n$$ (\\texttt{S} \\cdot 10^3 + \\texttt{E} \\cdot 10^2 + \\texttt{N} \\cdot 10 + \\texttt{D}) \n + (\\texttt{M} \\cdot 10^3 + \\texttt{O} \\cdot 10^2 + \\texttt{R} \\cdot 10 + \\texttt{E})\n = \\texttt{M} \\cdot 10^4 + \\texttt{O} \\cdot 10^3 + \\texttt{N} \\cdot 10^2 + \\texttt{E} \\cdot 10 + \\texttt{Y}\n$$\nis true. The problem with this constraint is that it involves far too many variables. As this constraint can only be\nchecked when all the variables have values assigned to them, the backtracking search would essentially\nboil down to a mere brute force search. We would have 8 variables and hence we would have to test $8^{10}$\npossible assignments. In order to do better, we have to perform the addition in the figure shown above\ncolumn by column, just as it is taught in elementary school. To be able to do this, we have to introduce <a href=\"https://en.wikipedia.org/wiki/Carry_(arithmetic)\">carry digits</a> \"$\\texttt{C1}$\", \"$\\texttt{C2}$\", \"$\\texttt{C3}$\" where $\\texttt{C1}$ is the carry produced by adding \n$\\texttt{D}$ and $\\texttt{E}$, $\\texttt{C2}$ is the carry produced by adding \n$\\texttt{N}$, $\\texttt{R}$ and $\\texttt{C1}$, and $\\texttt{C3}$ is the carry produced by adding \n$\\texttt{E}$, $\\texttt{O}$ and $\\texttt{C2}$. ",
"_____no_output_____"
]
],
[
[
"import cspSolver",
"_____no_output_____"
]
],
[
[
"For a set $V$ of variables, the function $\\texttt{allDifferent}(V)$ generates a set of formulas that express that all the variables of $V$ are different. ",
"_____no_output_____"
]
],
[
[
"def allDifferent(Variables):\n return { f'{x} != {y}' for x in Variables\n for y in Variables \n if x < y \n }",
"_____no_output_____"
],
[
"allDifferent({ 'a', 'b', 'c' })",
"_____no_output_____"
]
],
[
[
"# Pause bis 14:23",
"_____no_output_____"
]
],
[
[
"def createCSP():\n Variables = \"your code here\"\n Values = \"your code here\"\n Constraints = \"much more code here\"\n \n \n return [Variables, Values, Constraints];",
"_____no_output_____"
],
[
"puzzle = createCSP()\npuzzle",
"_____no_output_____"
],
[
"%%time\nsolution = cspSolver.solve(puzzle)\nprint(f'Time needed: {round((stop-start) * 1000)} milliseconds.')",
"_____no_output_____"
],
[
"solution",
"_____no_output_____"
],
[
"def printSolution(A):\n if A == None:\n print(\"no solution found\")\n return\n for v in { \"S\", \"E\", \"N\", \"D\", \"M\", \"O\", \"R\", \"Y\" }:\n print(f\"{v} = {A[v]}\")\n print(\"\\nThe solution of\\n\")\n print(\" S E N D\")\n print(\" + M O R E\")\n print(\" ---------\")\n print(\" M O N E Y\")\n print(\"\\nis as follows\\n\")\n print(f\" {A['S']} {A['E']} {A['N']} {A['D']}\")\n print(f\" + {A['M']} {A['O']} {A['R']} {A['E']}\")\n print(f\" ==========\")\n print(f\" {A['M']} {A['O']} {A['N']} {A['E']} {A['Y']}\")\n",
"_____no_output_____"
],
[
"printSolution(solution)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02a8e760c9c9f804b0792bdfb10e415de8f076f
| 1,746 |
ipynb
|
Jupyter Notebook
|
lessons/les02/ex.ipynb
|
alex-chin/GB_LIBS_DS
|
665f69d056fc20cba476a5459d13df5b1bfbb95a
|
[
"Unlicense"
] | null | null | null |
lessons/les02/ex.ipynb
|
alex-chin/GB_LIBS_DS
|
665f69d056fc20cba476a5459d13df5b1bfbb95a
|
[
"Unlicense"
] | null | null | null |
lessons/les02/ex.ipynb
|
alex-chin/GB_LIBS_DS
|
665f69d056fc20cba476a5459d13df5b1bfbb95a
|
[
"Unlicense"
] | null | null | null | 17.287129 | 81 | 0.453036 |
[
[
[
"import numpy as np\n",
"_____no_output_____"
],
[
"a=np.array([1,2,3,4,5])\nb=np.array([6,7,8,9,10])\na+b",
"_____no_output_____"
],
[
"b=np.array([i for i in range(30)])\nb = b.reshape(3,10)\nc = b[1:,5:]\nc",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
d02a97961440f90c91d5af9412b587126676bc4e
| 14,874 |
ipynb
|
Jupyter Notebook
|
3. NLP/AZ/Text Classification/Models_Template.ipynb
|
AmirRazaMBA/TensorFlow-Certification
|
ec0990007cff6daf36beac6d00d95c81cdf80353
|
[
"MIT"
] | 1 |
2020-11-20T14:46:45.000Z
|
2020-11-20T14:46:45.000Z
|
3. NLP/AZ/Text Classification/Models_Template.ipynb
|
AmirRazaMBA/TF_786
|
ec0990007cff6daf36beac6d00d95c81cdf80353
|
[
"MIT"
] | null | null | null |
3. NLP/AZ/Text Classification/Models_Template.ipynb
|
AmirRazaMBA/TF_786
|
ec0990007cff6daf36beac6d00d95c81cdf80353
|
[
"MIT"
] | 1 |
2021-11-17T02:40:23.000Z
|
2021-11-17T02:40:23.000Z
| 23.913183 | 125 | 0.525951 |
[
[
[
"# Solution based on Multiple Models",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport tensorflow as tf",
"_____no_output_____"
],
[
"from IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"",
"_____no_output_____"
]
],
[
[
"# Tokenize and Numerize - Make it ready",
"_____no_output_____"
]
],
[
[
"training_size = 20000",
"_____no_output_____"
],
[
"training_sentences = sentences[0:training_size]\ntesting_sentences = sentences[training_size:]\ntraining_labels = labels[0:training_size]\ntesting_labels = labels[training_size:]",
"_____no_output_____"
],
[
"vocab_size = 1000\nmax_length = 120\nembedding_dim = 16\ntrunc_type='post'\npadding_type='post'\noov_tok = \"<OOV>\"",
"_____no_output_____"
],
[
"tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)\ntokenizer.fit_on_texts(training_sentences)",
"_____no_output_____"
],
[
"word_index = tokenizer.word_index",
"_____no_output_____"
],
[
"training_sequences = tokenizer.texts_to_sequences(training_sentences)\ntraining_padded = pad_sequences(training_sequences, \n maxlen=max_length, \n padding=padding_type, \n truncating=trunc_type)",
"_____no_output_____"
],
[
"testing_sequences = tokenizer.texts_to_sequences(testing_sentences)\ntesting_padded = pad_sequences(testing_sequences, \n maxlen=max_length, \n padding=padding_type, \n truncating=trunc_type)",
"_____no_output_____"
]
],
[
[
"# Plot",
"_____no_output_____"
]
],
[
[
"def plot_graphs(history, string):\n plt.plot(history.history[string])\n plt.plot(history.history['val_'+string])\n plt.xlabel(\"Epochs\")\n plt.ylabel(string)\n plt.legend([string, 'val_'+string])\n plt.show()",
"_____no_output_____"
],
[
"plot_graphs(history, \"accuracy\")\nplot_graphs(history, \"loss\")",
"_____no_output_____"
]
],
[
[
"## Function to train and show",
"_____no_output_____"
]
],
[
[
"def fit_model_and_show_results (model, reviews):\n model.summary()\n history = model.fit(training_padded, \n training_labels_final, \n epochs=num_epochs, \n validation_data=(validation_padded, validation_labels_final))\n plot_graphs(history, \"accuracy\")\n plot_graphs(history, \"loss\")\n predict_review(model, reviews)",
"_____no_output_____"
]
],
[
[
"# ANN Embedding",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential([\n tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),\n tf.keras.layers.GlobalAveragePooling1D(), \n tf.keras.layers.Dense(1, activation='sigmoid')\n])\nmodel.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])\nmodel.summary()",
"_____no_output_____"
],
[
"num_epochs = 20\nhistory = model.fit(training_padded, training_labels_final, epochs=num_epochs, \n validation_data=(validation_padded, validation_labels_final))",
"_____no_output_____"
],
[
"plot_graphs(history, \"accuracy\")\nplot_graphs(history, \"loss\")",
"_____no_output_____"
]
],
[
[
"# CNN",
"_____no_output_____"
]
],
[
[
"num_epochs = 30",
"_____no_output_____"
],
[
"model_cnn = tf.keras.Sequential([\n tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),\n tf.keras.layers.Conv1D(16, 5, activation='relu'),\n tf.keras.layers.GlobalMaxPooling1D(),\n tf.keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"# Default learning rate for the Adam optimizer is 0.001\n# Let's slow down the learning rate by 10.\nlearning_rate = 0.0001\nmodel_cnn.compile(loss='binary_crossentropy',\n optimizer=tf.keras.optimizers.Adam(learning_rate), \n metrics=['accuracy'])",
"_____no_output_____"
],
[
"fit_model_and_show_results(model_cnn, new_reviews)",
"_____no_output_____"
]
],
[
[
"# GRU",
"_____no_output_____"
]
],
[
[
"num_epochs = 30",
"_____no_output_____"
],
[
"model_gru = tf.keras.Sequential([\n tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),\n tf.keras.layers.Bidirectional(tf.keras.layers.GRU(32)),\n tf.keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"learning_rate = 0.00003 # slower than the default learning rate\nmodel_gru.compile(loss='binary_crossentropy',\n optimizer=tf.keras.optimizers.Adam(learning_rate),\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"fit_model_and_show_results(model_gru, new_reviews)",
"_____no_output_____"
]
],
[
[
"# Bidirectional LSTM",
"_____no_output_____"
]
],
[
[
"num_epochs = 30",
"_____no_output_____"
],
[
"model_bidi_lstm = tf.keras.Sequential([\n tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),\n tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)), \n tf.keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"learning_rate = 0.00003\nmodel_bidi_lstm.compile(loss='binary_crossentropy',\n optimizer=tf.keras.optimizers.Adam(learning_rate),\n metrics=['accuracy'])\nfit_model_and_show_results(model_bidi_lstm, new_reviews)",
"_____no_output_____"
]
],
[
[
"# Multiple bidirectional LSTMs",
"_____no_output_____"
]
],
[
[
"num_epochs = 30",
"_____no_output_____"
],
[
"model_multiple_bidi_lstm = tf.keras.Sequential([\n tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),\n tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, \n return_sequences=True)),\n tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),\n tf.keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"learning_rate = 0.0003\nmodel_multiple_bidi_lstm.compile(loss='binary_crossentropy',\n optimizer=tf.keras.optimizers.Adam(learning_rate),\n metrics=['accuracy'])\nfit_model_and_show_results(model_multiple_bidi_lstm, new_reviews)",
"_____no_output_____"
]
],
[
[
"# Prediction",
"_____no_output_____"
],
[
"Define a function to prepare the new reviews for use with a model\nand then use the model to predict the sentiment of the new reviews ",
"_____no_output_____"
]
],
[
[
"def predict_review(model, reviews):\n # Create the sequences\n padding_type='post'\n sample_sequences = tokenizer.texts_to_sequences(reviews)\n reviews_padded = pad_sequences(sample_sequences, \n padding=padding_type, \n maxlen=max_length) \n \n classes = model.predict(reviews_padded)\n\n for x in range(len(reviews_padded)):\n print(reviews[x])\n print(classes[x])\n print('\\n')",
"_____no_output_____"
]
],
[
[
"## How to use examples",
"_____no_output_____"
],
[
"more_reviews = [review1, review2, review3, review4, review5, review6, review7, \n review8, review9, review10]\npredict_review(model, new_reviews)",
"_____no_output_____"
]
],
[
[
"print(\"============================\\n\",\"Embeddings only:\\n\", \"============================\")\npredict_review(model, more_reviews)",
"_____no_output_____"
],
[
"print(\"============================\\n\",\"With CNN\\n\", \"============================\")\npredict_review(model_cnn, more_reviews)",
"_____no_output_____"
],
[
"print(\"===========================\\n\",\"With bidirectional GRU\\n\", \"============================\")\npredict_review(model_gru, more_reviews)",
"_____no_output_____"
],
[
"print(\"===========================\\n\", \"With a single bidirectional LSTM:\\n\", \"===========================\")\npredict_review(model_bidi_lstm, more_reviews)",
"_____no_output_____"
],
[
"print(\"===========================\\n\", \"With multiple bidirectional LSTM:\\n\", \"==========================\")\npredict_review(model_multiple_bidi_lstm, more_reviews)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02a9ad0e801949216c0a9617ff6e9eb1238be10
| 16,841 |
ipynb
|
Jupyter Notebook
|
colabs/dv360_data_warehouse.ipynb
|
arbrown/starthinker
|
1a14664fb1a8f2a757b100363ea8958833b7754c
|
[
"Apache-2.0"
] | null | null | null |
colabs/dv360_data_warehouse.ipynb
|
arbrown/starthinker
|
1a14664fb1a8f2a757b100363ea8958833b7754c
|
[
"Apache-2.0"
] | null | null | null |
colabs/dv360_data_warehouse.ipynb
|
arbrown/starthinker
|
1a14664fb1a8f2a757b100363ea8958833b7754c
|
[
"Apache-2.0"
] | null | null | null | 41.582716 | 230 | 0.436316 |
[
[
[
"#1. Install Dependencies\nFirst install the libraries needed to execute recipes, this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"!pip install git+https://github.com/google/starthinker\n",
"_____no_output_____"
]
],
[
[
"#2. Get Cloud Project ID\nTo run this recipe [requires a Google Cloud Project](https://github.com/google/starthinker/blob/master/tutorials/cloud_project.md), this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"CLOUD_PROJECT = 'PASTE PROJECT ID HERE'\n\nprint(\"Cloud Project Set To: %s\" % CLOUD_PROJECT)\n",
"_____no_output_____"
]
],
[
[
"#3. Get Client Credentials\nTo read and write to various endpoints requires [downloading client credentials](https://github.com/google/starthinker/blob/master/tutorials/cloud_client_installed.md), this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"CLIENT_CREDENTIALS = 'PASTE CLIENT CREDENTIALS HERE'\n\nprint(\"Client Credentials Set To: %s\" % CLIENT_CREDENTIALS)\n",
"_____no_output_____"
]
],
[
[
"#4. Enter DV360 Data Warehouse Parameters\nDeploy a BigQuery dataset mirroring DV360 account structure. Foundation for solutions on top.\n 1. Wait for <b>BigQuery->->->*</b> to be created.\n 1. Every table mimics the <a href='https://developers.google.com/display-video/api/reference/rest' target='_blank'>DV360 API Endpoints</a>.\nModify the values below for your use case, can be done multiple times, then click play.\n",
"_____no_output_____"
]
],
[
[
"FIELDS = {\n 'auth_bigquery': 'service', # Credentials used for writing data.\n 'auth_dv': 'service', # Credentials used for reading data.\n 'auth_cm': 'service', # Credentials used for reading data.\n 'recipe_slug': '', # Name of Google BigQuery dataset to create.\n 'partners': [], # List of account ids to pull.\n}\n\nprint(\"Parameters Set To: %s\" % FIELDS)\n",
"_____no_output_____"
]
],
[
[
"#5. Execute DV360 Data Warehouse\nThis does NOT need to be modified unless you are changing the recipe, click play.\n",
"_____no_output_____"
]
],
[
[
"from starthinker.util.configuration import Configuration\nfrom starthinker.util.configuration import execute\nfrom starthinker.util.recipe import json_set_fields\n\nUSER_CREDENTIALS = '/content/user.json'\n\nTASKS = [\n {\n 'dataset': {\n 'description': 'Create a dataset for bigquery tables.',\n 'hour': [\n 4\n ],\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','description': 'Place where tables will be created in BigQuery.'}}\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'partners.get',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','description': 'Place where tables will be created in BigQuery.'}},\n 'legacy': False,\n 'query': 'SELECT CAST(partnerId AS STRING) partnerId FROM (SELECT DISTINCT * FROM UNNEST({partners}) AS partnerId)',\n 'parameters': {\n 'partners': {'field': {'name': 'partners','kind': 'integer_list','order': 4,'default': [],'description': 'List of account ids to pull.'}}\n }\n }\n },\n 'iterate': False,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Partners'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(partnerId AS STRING) partnerId FROM `DV360_Partners`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Advertisers'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.insertionOrders.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_InsertionOrders'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.lineItems.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_LineItems'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.campaigns.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Campaigns'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.channels.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Channels'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'advertisers.creatives.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Creatives'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'inventorySources.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Inventory_Sources'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'googleAudiences.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Google_Audiences'\n }\n }\n }\n },\n {\n 'google_api': {\n 'auth': 'user',\n 'api': 'displayvideo',\n 'version': 'v1',\n 'function': 'combinedAudiences.list',\n 'kwargs_remote': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 0,'default': '','description': 'Google BigQuery dataset to create tables in.'}},\n 'query': 'SELECT DISTINCT CAST(advertiserId AS STRING) AS advertiserId FROM `DV360_Advertisers`',\n 'legacy': False\n }\n },\n 'iterate': True,\n 'results': {\n 'bigquery': {\n 'auth': 'user',\n 'dataset': {'field': {'name': 'recipe_slug','kind': 'string','order': 4,'default': '','description': 'Name of Google BigQuery dataset to create.'}},\n 'table': 'DV360_Combined_Audiences'\n }\n }\n }\n }\n]\n\njson_set_fields(TASKS, FIELDS)\n\nexecute(Configuration(project=CLOUD_PROJECT, client=CLIENT_CREDENTIALS, user=USER_CREDENTIALS, verbose=True), TASKS, force=True)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02abd452549e2283a0198190281b6e263d22be9
| 410,419 |
ipynb
|
Jupyter Notebook
|
notebooks/PythonTutorial.ipynb
|
jagar2/BMC
|
884250645693ef828471fe1d132a093dc6df7593
|
[
"MIT"
] | 1 |
2021-08-30T04:02:59.000Z
|
2021-08-30T04:02:59.000Z
|
notebooks/PythonTutorial.ipynb
|
jagar2/BMC
|
884250645693ef828471fe1d132a093dc6df7593
|
[
"MIT"
] | null | null | null |
notebooks/PythonTutorial.ipynb
|
jagar2/BMC
|
884250645693ef828471fe1d132a093dc6df7593
|
[
"MIT"
] | 1 |
2021-08-30T04:03:02.000Z
|
2021-08-30T04:03:02.000Z
| 80.93453 | 95,157 | 0.800467 |
[
[
[
"# Tutorial on Python for scientific computing\n\nMarcos Duarte",
"_____no_output_____"
],
[
"This tutorial is a short introduction to programming and a demonstration of the basic features of Python for scientific computing. To use Python for scientific computing we need the Python program itself with its main modules and specific packages for scientific computing. [See this notebook on how to install Python for scientific computing](http://nbviewer.ipython.org/github/demotu/BMC/blob/master/notebooks/PythonInstallation.ipynb). \nOnce you get Python and the necessary packages for scientific computing ready to work, there are different ways to run Python, the main ones are:\n\n- open a terminal window in your computer and type `python` or `ipython` that the Python interpreter will start\n- run the IPython notebook and start working with Python in a browser\n- run Spyder, an interactive development environment (IDE)\n- run the IPython qtconsole, a more featured terminal\n- run IPython completely in the cloud with for example, [https://cloud.sagemath.com](https://cloud.sagemath.com) or [https://www.wakari.io](https://www.wakari.io)\n- run Python online in a website such as [https://www.pythonanywhere.com/](https://www.pythonanywhere.com/)\n- run Python using any other Python editor or IDE\n \nWe will use the IPython Notebook for this tutorial but you can run almost all the things we will see here using the other forms listed above.",
"_____no_output_____"
],
[
"## Python as a calculator\n\nOnce in the IPython notebook, if you type a simple mathematical expression and press `Shift+Enter` it will give the result of the expression:",
"_____no_output_____"
]
],
[
[
"1 + 2 - 30",
"_____no_output_____"
],
[
"4/5",
"_____no_output_____"
]
],
[
[
"If you are using Python version 2.x instead of Python 3.x, you should have got 0 as the result of 4 divided by 5, which is wrong! The problem is that for Python versions up to 2.x, the operator '/' performs division with integers and the result will also be an integer (this behavior was changed in version 3.x). \n\nIf you want the normal behavior for division, in Python 2.x you have two options: tell Python that at least one of the numbers is not an integer or import the new division operator (which is inoffensive if you are already using Python 3), let's see these two options:",
"_____no_output_____"
]
],
[
[
"4/5.",
"_____no_output_____"
],
[
"from __future__ import division",
"_____no_output_____"
],
[
"4/5",
"_____no_output_____"
]
],
[
[
"I prefer to use the import division option (from future!); if we put this statement in the beginning of a file or IPython notebook, it will work for all subsequent commands.\n\nAnother command that changed its behavior from Python 2.x to 3.x is the `print` command. \nIn Python 2.x, the print command could be used as a statement:",
"_____no_output_____"
]
],
[
[
"print 4/5",
"_____no_output_____"
]
],
[
[
"With Python 3.x, the print command bahaves as a true function and has to be called with parentheses. Let's also import this future command to Python 2.x and use it from now on:",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function",
"_____no_output_____"
],
[
"print(4/5)",
"0.8\n"
]
],
[
[
"With the `print` function, let's explore the mathematical operations available in Python:",
"_____no_output_____"
]
],
[
[
"print('1+2 = ', 1+2, '\\n', '4*5 = ', 4*5, '\\n', '6/7 = ', 6/7, '\\n', '8**2 = ', 8**2, sep='')",
"1+2 = 3\n4*5 = 20\n6/7 = 0.8571428571428571\n8**2 = 64\n"
]
],
[
[
"And if we want the square-root of a number:",
"_____no_output_____"
]
],
[
[
"sqrt(9)",
"_____no_output_____"
]
],
[
[
"We get an error message saying that the `sqrt` function if not defined. This is because `sqrt` and other mathematical functions are available with the `math` module:",
"_____no_output_____"
]
],
[
[
"import math",
"_____no_output_____"
],
[
"math.sqrt(9)",
"_____no_output_____"
],
[
"from math import sqrt",
"_____no_output_____"
],
[
"sqrt(9)",
"_____no_output_____"
]
],
[
[
"## The import function\n\nWe used the command '`import`' to be able to call certain functions. In Python functions are organized in modules and packages and they have to be imported in order to be used. \n\nA module is a file containing Python definitions (e.g., functions) and statements. Packages are a way of structuring Python’s module namespace by using “dotted module names”. For example, the module name A.B designates a submodule named B in a package named A. To be used, modules and packages have to be imported in Python with the import function. \n\nNamespace is a container for a set of identifiers (names), and allows the disambiguation of homonym identifiers residing in different namespaces. For example, with the command import math, we will have all the functions and statements defined in this module in the namespace '`math.`', for example, '`math.pi`' is the π constant and '`math.cos()`', the cosine function.",
"_____no_output_____"
],
[
"By the way, to know which Python version you are running, we can use one of the following modules:",
"_____no_output_____"
]
],
[
[
"import sys\nsys.version",
"_____no_output_____"
]
],
[
[
"And if you are in an IPython session:",
"_____no_output_____"
]
],
[
[
"from IPython import sys_info\nprint(sys_info())",
"{'commit_hash': '681fd77',\n 'commit_source': 'installation',\n 'default_encoding': 'cp1252',\n 'ipython_path': 'C:\\\\Anaconda3\\\\lib\\\\site-packages\\\\IPython',\n 'ipython_version': '2.1.0',\n 'os_name': 'nt',\n 'platform': 'Windows-7-6.1.7601-SP1',\n 'sys_executable': 'C:\\\\Anaconda3\\\\python.exe',\n 'sys_platform': 'win32',\n 'sys_version': '3.4.1 |Anaconda 2.0.1 (64-bit)| (default, May 19 2014, '\n '13:02:30) [MSC v.1600 64 bit (AMD64)]'}\n"
]
],
[
[
"The first option gives information about the Python version; the latter also includes the IPython version, operating system, etc.",
"_____no_output_____"
],
[
"## Object-oriented programming\n\nPython is designed as an object-oriented programming (OOP) language. OOP is a paradigm that represents concepts as \"objects\" that have data fields (attributes that describe the object) and associated procedures known as methods.\n\nThis means that all elements in Python are objects and they have attributes which can be acessed with the dot (.) operator after the name of the object. We already experimented with that when we imported the module `sys`, it became an object, and we acessed one of its attribute: `sys.version`.\n\nOOP as a paradigm is much more than defining objects, attributes, and methods, but for now this is enough to get going with Python.",
"_____no_output_____"
],
[
"## Python and IPython help\n\nTo get help about any Python command, use `help()`:",
"_____no_output_____"
]
],
[
[
"help(math.degrees)",
"Help on built-in function degrees in module math:\n\ndegrees(...)\n degrees(x)\n \n Convert angle x from radians to degrees.\n\n"
]
],
[
[
"Or if you are in the IPython environment, simply add '?' to the function that a window will open at the bottom of your browser with the same help content:",
"_____no_output_____"
]
],
[
[
"math.degrees?",
"_____no_output_____"
]
],
[
[
"And if you add a second '?' to the statement you get access to the original script file of the function (an advantage of an open source language), unless that function is a built-in function that does not have a script file, which is the case of the standard modules in Python (but you can access the Python source code if you want; it just does not come with the standard program for installation).\n\nSo, let's see this feature with another function:",
"_____no_output_____"
]
],
[
[
"import scipy.fftpack\nscipy.fftpack.fft??",
"_____no_output_____"
]
],
[
[
"To know all the attributes of an object, for example all the functions available in `math`, we can use the function `dir`:",
"_____no_output_____"
]
],
[
[
"print(dir(math))",
"['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'hypot', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'trunc']\n"
]
],
[
[
"### Tab completion in IPython\n\nIPython has tab completion: start typing the name of the command (object) and press `tab` to see the names of objects available with these initials letters. When the name of the object is typed followed by a dot (`math.`), pressing `tab` will show all available attribites, scroll down to the desired attribute and press `Enter` to select it.",
"_____no_output_____"
],
[
"### The four most helpful commands in IPython\n\nThese are the most helpful commands in IPython (from [IPython tutorial](http://ipython.org/ipython-doc/dev/interactive/tutorial.html)):\n\n - `?` : Introduction and overview of IPython’s features.\n - `%quickref` : Quick reference.\n - `help` : Python’s own help system.\n - `object?` : Details about ‘object’, use ‘object??’ for extra details.\n \n[See these IPython Notebooks for more on IPython and the Notebook capabilities](http://nbviewer.ipython.org/github/ipython/ipython/tree/master/examples/Notebook/).",
"_____no_output_____"
],
[
"### Comments\n\nComments in Python start with the hash character, #, and extend to the end of the physical line:",
"_____no_output_____"
]
],
[
[
"# Import the math library to access more math stuff\nimport math\nmath.pi # this is the pi constant; a useless comment since this is obvious",
"_____no_output_____"
]
],
[
[
"To insert comments spanning more than one line, use a multi-line string with a pair of matching triple-quotes: `\"\"\"` or `'''` (we will see the string data type later). A typical use of a multi-line comment is as documentation strings and are meant for anyone reading the code:",
"_____no_output_____"
]
],
[
[
"\"\"\"Documentation strings are typically written like that.\n\nA docstring is a string literal that occurs as the first statement\nin a module, function, class, or method definition.\n\n\"\"\"",
"_____no_output_____"
]
],
[
[
"A docstring like above is useless and its output as a standalone statement looks uggly in IPython Notebook, but you will see its real importance when reading and writting codes.\n\nCommenting a programming code is an important step to make the code more readable, which Python cares a lot. \nThere is a style guide for writting Python code ([PEP 8](http://www.python.org/dev/peps/pep-0008/)) with a session about [how to write comments](http://www.python.org/dev/peps/pep-0008/#comments).",
"_____no_output_____"
],
[
"### Magic functions\n\nIPython has a set of predefined ‘magic functions’ that you can call with a command line style syntax. \nThere are two kinds of magics, line-oriented and cell-oriented. \nLine magics are prefixed with the % character and work much like OS command-line calls: they get as an argument the rest of the line, where arguments are passed without parentheses or quotes. \nCell magics are prefixed with a double %%, and they are functions that get as an argument not only the rest of the line, but also the lines below it in a separate argument.",
"_____no_output_____"
],
[
"## Assignment and expressions\n\nThe equal sign ('=') is used to assign a value to a variable. Afterwards, no result is displayed before the next interactive prompt:",
"_____no_output_____"
]
],
[
[
"x = 1",
"_____no_output_____"
]
],
[
[
"Spaces between the statements are optional but it helps for readability.\n\nTo see the value of the variable, call it again or use the print function:",
"_____no_output_____"
]
],
[
[
"x",
"_____no_output_____"
],
[
"print(x)",
"1\n"
]
],
[
[
"Of course, the last assignment is that holds:",
"_____no_output_____"
]
],
[
[
"x = 2\nx = 3\nx",
"_____no_output_____"
]
],
[
[
"In mathematics '=' is the symbol for identity, but in computer programming '=' is used for assignment, it means that the right part of the expresssion is assigned to its left part. \nFor example, 'x=x+1' does not make sense in mathematics but it does in computer programming:",
"_____no_output_____"
]
],
[
[
"x = 1\nprint(x)\nx = x + 1\nprint(x)",
"1\n2\n"
]
],
[
[
"A value can be assigned to several variables simultaneously:",
"_____no_output_____"
]
],
[
[
"x = y = 4\nprint(x)\nprint(y)",
"4\n4\n"
]
],
[
[
"Several values can be assigned to several variables at once:",
"_____no_output_____"
]
],
[
[
"x, y = 5, 6\nprint(x)\nprint(y)",
"5\n6\n"
]
],
[
[
"And with that, you can do (!):",
"_____no_output_____"
]
],
[
[
"x, y = y, x\nprint(x)\nprint(y)",
"6\n5\n"
]
],
[
[
"Variables must be “defined” (assigned a value) before they can be used, or an error will occur:",
"_____no_output_____"
]
],
[
[
"x = z",
"_____no_output_____"
]
],
[
[
"## Variables and types\n\nThere are different types of built-in objects in Python (and remember that everything in Python is an object):",
"_____no_output_____"
]
],
[
[
"import types\nprint(dir(types))",
"['BuiltinFunctionType', 'BuiltinMethodType', 'CodeType', 'DynamicClassAttribute', 'FrameType', 'FunctionType', 'GeneratorType', 'GetSetDescriptorType', 'LambdaType', 'MappingProxyType', 'MemberDescriptorType', 'MethodType', 'ModuleType', 'SimpleNamespace', 'TracebackType', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_calculate_meta', 'new_class', 'prepare_class']\n"
]
],
[
[
"Let's see some of them now.",
"_____no_output_____"
],
[
"### Numbers: int, float, complex\n\nNumbers can an integer (int), float, and complex (with imaginary part). \nLet's use the function `type` to show the type of number (and later for any other object):",
"_____no_output_____"
]
],
[
[
"type(6)",
"_____no_output_____"
]
],
[
[
"A float is a non-integer number:",
"_____no_output_____"
]
],
[
[
"math.pi",
"_____no_output_____"
],
[
"type(math.pi)",
"_____no_output_____"
]
],
[
[
"Python (IPython) is showing `math.pi` with only 15 decimal cases, but internally a float is represented with higher precision. \nFloating point numbers in Python are implemented using a double (eight bytes) word; the precison and internal representation of floating point numbers are machine specific and are available in:",
"_____no_output_____"
]
],
[
[
"sys.float_info",
"_____no_output_____"
]
],
[
[
"Be aware that floating-point numbers can be trick in computers:",
"_____no_output_____"
]
],
[
[
"0.1 + 0.2",
"_____no_output_____"
],
[
"0.1 + 0.2 - 0.3",
"_____no_output_____"
]
],
[
[
"These results are not correct (and the problem is not due to Python). The error arises from the fact that floating-point numbers are represented in computer hardware as base 2 (binary) fractions and most decimal fractions cannot be represented exactly as binary fractions. As consequence, decimal floating-point numbers are only approximated by the binary floating-point numbers actually stored in the machine. [See here for more on this issue](http://docs.python.org/2/tutorial/floatingpoint.html).",
"_____no_output_____"
],
[
"A complex number has real and imaginary parts:",
"_____no_output_____"
]
],
[
[
"1+2j",
"_____no_output_____"
],
[
"print(type(1+2j))",
"<class 'complex'>\n"
]
],
[
[
"Each part of a complex number is represented as a floating-point number. We can see them using the attributes `.real` and `.imag`:",
"_____no_output_____"
]
],
[
[
"print((1+2j).real)\nprint((1+2j).imag)",
"1.0\n2.0\n"
]
],
[
[
"### Strings\n\nStrings can be enclosed in single quotes or double quotes:",
"_____no_output_____"
]
],
[
[
"s = 'string (str) is a built-in type in Python'\ns",
"_____no_output_____"
],
[
"type(s)",
"_____no_output_____"
]
],
[
[
"String enclosed with single and double quotes are equal, but it may be easier to use one instead of the other:",
"_____no_output_____"
]
],
[
[
"'string (str) is a Python's built-in type'",
"_____no_output_____"
],
[
"\"string (str) is a Python's built-in type\"",
"_____no_output_____"
]
],
[
[
"But you could have done that using the Python escape character '\\':",
"_____no_output_____"
]
],
[
[
"'string (str) is a Python\\'s built-in type'",
"_____no_output_____"
]
],
[
[
"Strings can be concatenated (glued together) with the + operator, and repeated with *:",
"_____no_output_____"
]
],
[
[
"s = 'P' + 'y' + 't' + 'h' + 'o' + 'n'\nprint(s)\nprint(s*5)",
"Python\nPythonPythonPythonPythonPython\n"
]
],
[
[
"Strings can be subscripted (indexed); like in C, the first character of a string has subscript (index) 0:",
"_____no_output_____"
]
],
[
[
"print('s[0] = ', s[0], ' (s[index], start at 0)')\nprint('s[5] = ', s[5])\nprint('s[-1] = ', s[-1], ' (last element)')\nprint('s[:] = ', s[:], ' (all elements)')\nprint('s[1:] = ', s[1:], ' (from this index (inclusive) till the last (inclusive))')\nprint('s[2:4] = ', s[2:4], ' (from first index (inclusive) till second index (exclusive))')\nprint('s[:2] = ', s[:2], ' (till this index, exclusive)')\nprint('s[:10] = ', s[:10], ' (Python handles the index if it is larger than the string length)')\nprint('s[-10:] = ', s[-10:])\nprint('s[0:5:2] = ', s[0:5:2], ' (s[ini:end:step])')\nprint('s[::2] = ', s[::2], ' (s[::step], initial and final indexes can be omitted)')\nprint('s[0:5:-1] = ', s[::-1], ' (s[::-step] reverses the string)')\nprint('s[:2] + s[2:] = ', s[:2] + s[2:], ' (because of Python indexing, this sounds natural)')",
"s[0] = P (s[index], start at 0)\ns[5] = n\ns[-1] = n (last element)\ns[:] = Python (all elements)\ns[1:] = ython (from this index (inclusive) till the last (inclusive))\ns[2:4] = th (from first index (inclusive) till second index (exclusive))\ns[:2] = Py (till this index, exclusive)\ns[:10] = Python (Python handles the index if it is larger than the string length)\ns[-10:] = Python\ns[0:5:2] = Pto (s[ini:end:step])\ns[::2] = Pto (s[::step], initial and final indexes can be omitted)\ns[0:5:-1] = nohtyP (s[::-step] reverses the string)\ns[:2] + s[2:] = Python (because of Python indexing, this sounds natural)\n"
]
],
[
[
"### len()\n\nPython has a built-in functon to get the number of itens of a sequence:",
"_____no_output_____"
]
],
[
[
"help(len)",
"Help on built-in function len in module builtins:\n\nlen(...)\n len(object)\n \n Return the number of items of a sequence or mapping.\n\n"
],
[
"s = 'Python'\nlen(s)",
"_____no_output_____"
]
],
[
[
"The function len() helps to understand how the backward indexing works in Python. \nThe index s[-i] should be understood as s[len(s) - i] rather than accessing directly the i-th element from back to front. This is why the last element of a string is s[-1]:",
"_____no_output_____"
]
],
[
[
"print('s = ', s)\nprint('len(s) = ', len(s))\nprint('len(s)-1 = ',len(s) - 1)\nprint('s[-1] = ', s[-1])\nprint('s[len(s) - 1] = ', s[len(s) - 1])",
"s = Python\nlen(s) = 6\nlen(s)-1 = 5\ns[-1] = n\ns[len(s) - 1] = n\n"
]
],
[
[
"Or, strings can be surrounded in a pair of matching triple-quotes: \"\"\" or '''. End of lines do not need to be escaped when using triple-quotes, but they will be included in the string. This is how we created a multi-line comment earlier:",
"_____no_output_____"
]
],
[
[
"\"\"\"Strings can be surrounded in a pair of matching triple-quotes: \\\"\"\" or '''.\n\nEnd of lines do not need to be escaped when using triple-quotes,\nbut they will be included in the string.\n\n\"\"\"",
"_____no_output_____"
]
],
[
[
"### Lists\n\nValues can be grouped together using different types, one of them is list, which can be written as a list of comma-separated values between square brackets. List items need not all have the same type:",
"_____no_output_____"
]
],
[
[
"x = ['spam', 'eggs', 100, 1234]\nx",
"_____no_output_____"
]
],
[
[
"Lists can be indexed and the same indexing rules we saw for strings are applied:",
"_____no_output_____"
]
],
[
[
"x[0]",
"_____no_output_____"
]
],
[
[
"The function len() works for lists:",
"_____no_output_____"
]
],
[
[
"len(x)",
"_____no_output_____"
]
],
[
[
"### Tuples\n\nA tuple consists of a number of values separated by commas, for instance:",
"_____no_output_____"
]
],
[
[
"t = ('spam', 'eggs', 100, 1234)\nt",
"_____no_output_____"
]
],
[
[
"The type tuple is why multiple assignments in a single line works; elements separated by commas (with or without surrounding parentheses) are a tuple and in an expression with an '=', the right-side tuple is attributed to the left-side tuple: ",
"_____no_output_____"
]
],
[
[
"a, b = 1, 2\nprint('a = ', a, '\\nb = ', b)",
"a = 1 \nb = 2\n"
]
],
[
[
"Is the same as:",
"_____no_output_____"
]
],
[
[
"(a, b) = (1, 2)\nprint('a = ', a, '\\nb = ', b)",
"a = 1 \nb = 2\n"
]
],
[
[
"### Sets\n\nPython also includes a data type for sets. A set is an unordered collection with no duplicate elements.",
"_____no_output_____"
]
],
[
[
"basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']\nfruit = set(basket) # create a set without duplicates\nfruit",
"_____no_output_____"
]
],
[
[
"As set is an unordered collection, it can not be indexed as lists and tuples.",
"_____no_output_____"
]
],
[
[
"set(['orange', 'pear', 'apple', 'banana'])\n'orange' in fruit # fast membership testing",
"_____no_output_____"
]
],
[
[
"### Dictionaries\n\nDictionary is a collection of elements organized keys and values. Unlike lists and tuples, which are indexed by a range of numbers, dictionaries are indexed by their keys:",
"_____no_output_____"
]
],
[
[
"tel = {'jack': 4098, 'sape': 4139}\ntel",
"_____no_output_____"
],
[
"tel['guido'] = 4127\ntel",
"_____no_output_____"
],
[
"tel['jack']",
"_____no_output_____"
],
[
"del tel['sape']\ntel['irv'] = 4127\ntel",
"_____no_output_____"
],
[
"tel.keys()",
"_____no_output_____"
],
[
"'guido' in tel",
"_____no_output_____"
]
],
[
[
"The dict() constructor builds dictionaries directly from sequences of key-value pairs:",
"_____no_output_____"
]
],
[
[
"tel = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])\ntel",
"_____no_output_____"
]
],
[
[
"## Built-in Constants\n\n- **False** : false value of the bool type\n- **True** : true value of the bool type\n- **None** : sole value of types.NoneType. None is frequently used to represent the absence of a value.",
"_____no_output_____"
],
[
"In computer science, the Boolean or logical data type is composed by two values, true and false, intended to represent the values of logic and Boolean algebra. In Python, 1 and 0 can also be used in most situations as equivalent to the Boolean values.",
"_____no_output_____"
],
[
"## Logical (Boolean) operators",
"_____no_output_____"
],
[
"### and, or, not",
"_____no_output_____"
],
[
"- **and** : logical AND operator. If both the operands are true then condition becomes true.\t (a and b) is true.\n- **or** : logical OR Operator. If any of the two operands are non zero then condition becomes true.\t (a or b) is true.\n- **not** : logical NOT Operator. Reverses the logical state of its operand. If a condition is true then logical NOT operator will make false.",
"_____no_output_____"
],
[
"### Comparisons\n\nThe following comparison operations are supported by objects in Python:\n\n- **==** : equal\n- **!=** : not equal\n- **<**\t: strictly less than\n- **<=** : less than or equal\n- **\\>** : strictly greater than\n- **\\>=** : greater than or equal\n- **is** : object identity\n- **is not** : negated object identity",
"_____no_output_____"
]
],
[
[
"True == False",
"_____no_output_____"
],
[
"not True == False",
"_____no_output_____"
],
[
"1 < 2 > 1",
"_____no_output_____"
],
[
"True != (False or True)",
"_____no_output_____"
],
[
"True != False or True",
"_____no_output_____"
]
],
[
[
"## Indentation and whitespace\n\nIn Python, statement grouping is done by indentation (this is mandatory), which are done by inserting whitespaces, not tabs. Indentation is also recommended for alignment of function calling that span more than one line for better clarity. \nWe will see examples of indentation in the next session.",
"_____no_output_____"
],
[
"## Control of flow\n\n### `if`...`elif`...`else`\n\nConditional statements (to peform something if another thing is True or False) can be implemmented using the `if` statement:\n```\nif expression:\n statement\nelif:\n statement \nelse:\n statement\n```\n`elif` (one or more) and `else` are optionals. \nThe indentation is obligatory. \nFor example:",
"_____no_output_____"
]
],
[
[
"if True:\n pass",
"_____no_output_____"
]
],
[
[
"Which does nothing useful. \n\nLet's use the `if`...`elif`...`else` statements to categorize the [body mass index](http://en.wikipedia.org/wiki/Body_mass_index) of a person:",
"_____no_output_____"
]
],
[
[
"# body mass index\nweight = 100 # kg\nheight = 1.70 # m\nbmi = weight / height**2",
"_____no_output_____"
],
[
"if bmi < 15:\n c = 'very severely underweight'\nelif 15 <= bmi < 16:\n c = 'severely underweight'\nelif 16 <= bmi < 18.5:\n c = 'underweight'\nelif 18.5 <= bmi < 25:\n c = 'normal'\nelif 25 <= bmi < 30:\n c = 'overweight'\nelif 30 <= bmi < 35:\n c = 'moderately obese'\nelif 35 <= bmi < 40:\n c = 'severely obese'\nelse:\n c = 'very severely obese'\n \nprint('For a weight of {0:.1f} kg and a height of {1:.2f} m,\\n\\\nthe body mass index (bmi) is {2:.1f} kg/m2,\\nwhich is considered {3:s}.'\\\n .format(weight, height, bmi, c))",
"For a weight of 100.0 kg and a height of 1.70 m,\nthe body mass index (bmi) is 34.6 kg/m2,\nwhich is considered moderately obese.\n"
]
],
[
[
"### for\n\nThe `for` statement iterates over a sequence to perform operations (a loop event).\n```\nfor iterating_var in sequence:\n statements\n```",
"_____no_output_____"
]
],
[
[
"for i in [3, 2, 1, 'go!']:\n print(i),",
"3\n2\n1\ngo!\n"
],
[
"for letter in 'Python':\n print(letter),",
"P\ny\nt\nh\no\nn\n"
]
],
[
[
"#### The `range()` function\n\nThe built-in function range() is useful if we need to create a sequence of numbers, for example, to iterate over this list. It generates lists containing arithmetic progressions:",
"_____no_output_____"
]
],
[
[
"help(range)",
"Help on class range in module builtins:\n\nclass range(object)\n | range(stop) -> range object\n | range(start, stop[, step]) -> range object\n | \n | Return a sequence of numbers from start to stop by step.\n | \n | Methods defined here:\n | \n | __contains__(self, key, /)\n | Return key in self.\n | \n | __eq__(self, value, /)\n | Return self==value.\n | \n | __ge__(self, value, /)\n | Return self>=value.\n | \n | __getattribute__(self, name, /)\n | Return getattr(self, name).\n | \n | __getitem__(self, key, /)\n | Return self[key].\n | \n | __gt__(self, value, /)\n | Return self>value.\n | \n | __hash__(self, /)\n | Return hash(self).\n | \n | __iter__(self, /)\n | Implement iter(self).\n | \n | __le__(self, value, /)\n | Return self<=value.\n | \n | __len__(self, /)\n | Return len(self).\n | \n | __lt__(self, value, /)\n | Return self<value.\n | \n | __ne__(self, value, /)\n | Return self!=value.\n | \n | __new__(*args, **kwargs) from builtins.type\n | Create and return a new object. See help(type) for accurate signature.\n | \n | __reduce__(...)\n | \n | __repr__(self, /)\n | Return repr(self).\n | \n | __reversed__(...)\n | Return a reverse iterator.\n | \n | count(...)\n | rangeobject.count(value) -> integer -- return number of occurrences of value\n | \n | index(...)\n | rangeobject.index(value, [start, [stop]]) -> integer -- return index of value.\n | Raise ValueError if the value is not present.\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | start\n | \n | step\n | \n | stop\n\n"
],
[
"range(10)",
"_____no_output_____"
],
[
"range(1, 10, 2)",
"_____no_output_____"
],
[
"for i in range(10):\n n2 = i**2\n print(n2),",
"0\n1\n4\n9\n16\n25\n36\n49\n64\n81\n"
]
],
[
[
"### while\n\nThe `while` statement is used for repeating sections of code in a loop until a condition is met (this different than the `for` statement which executes n times):\n```\nwhile expression:\n statement\n```\nLet's generate the Fibonacci series using a `while` loop:",
"_____no_output_____"
]
],
[
[
"# Fibonacci series: the sum of two elements defines the next\na, b = 0, 1\nwhile b < 1000:\n print(b, end=' ')\n a, b = b, a+b",
"1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 "
]
],
[
[
"## Function definition\n\nA function in a programming language is a piece of code that performs a specific task. Functions are used to reduce duplication of code making easier to reuse it and to decompose complex problems into simpler parts. The use of functions contribute to the clarity of the code.\n\nA function is created with the `def` keyword and the statements in the block of the function must be indented:",
"_____no_output_____"
]
],
[
[
"def function():\n pass",
"_____no_output_____"
]
],
[
[
"As per construction, this function does nothing when called:",
"_____no_output_____"
]
],
[
[
"function()",
"_____no_output_____"
]
],
[
[
"The general syntax of a function definition is:\n```\ndef function_name( parameters ):\n \"\"\"Function docstring.\n\n The help for the function\n\n \"\"\"\n\n function body\n\n return variables\n```\nA more useful function:",
"_____no_output_____"
]
],
[
[
"def fibo(N):\n \"\"\"Fibonacci series: the sum of two elements defines the next.\n \n The series is calculated till the input parameter N and\n returned as an ouput variable.\n \n \"\"\"\n \n a, b, c = 0, 1, []\n while b < N:\n c.append(b)\n a, b = b, a + b\n \n return c",
"_____no_output_____"
],
[
"fibo(100)",
"_____no_output_____"
],
[
"if 3 > 2:\n print('teste')",
"teste\n"
]
],
[
[
"Let's implemment the body mass index calculus and categorization as a function:",
"_____no_output_____"
]
],
[
[
"def bmi(weight, height):\n \"\"\"Body mass index calculus and categorization.\n \n Enter the weight in kg and the height in m.\n See http://en.wikipedia.org/wiki/Body_mass_index\n \n \"\"\"\n \n bmi = weight / height**2\n \n if bmi < 15:\n c = 'very severely underweight'\n elif 15 <= bmi < 16:\n c = 'severely underweight'\n elif 16 <= bmi < 18.5:\n c = 'underweight'\n elif 18.5 <= bmi < 25:\n c = 'normal'\n elif 25 <= bmi < 30:\n c = 'overweight'\n elif 30 <= bmi < 35:\n c = 'moderately obese'\n elif 35 <= bmi < 40:\n c = 'severely obese'\n else:\n c = 'very severely obese'\n \n s = 'For a weight of {0:.1f} kg and a height of {1:.2f} m,\\\n the body mass index (bmi) is {2:.1f} kg/m2,\\\n which is considered {3:s}.'\\\n .format(weight, height, bmi, c)\n \n print(s)",
"_____no_output_____"
],
[
"bmi(73, 1.70)",
"For a weight of 73.0 kg and a height of 1.70 m, the body mass index (bmi) is 25.3 kg/m2, which is considered overweight.\n"
]
],
[
[
"## Numeric data manipulation with Numpy\n\nNumpy is the fundamental package for scientific computing in Python and has a N-dimensional array package convenient to work with numerical data. With Numpy it's much easier and faster to work with numbers grouped as 1-D arrays (a vector), 2-D arrays (like a table or matrix), or higher dimensions. Let's create 1-D and 2-D arrays in Numpy:",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"x1d = np.array([1, 2, 3, 4, 5, 6])\nprint(type(x1d))\nx1d",
"<class 'numpy.ndarray'>\n"
],
[
"x2d = np.array([[1, 2, 3], [4, 5, 6]])\nx2d",
"_____no_output_____"
]
],
[
[
"len() and the Numpy functions size() and shape() give information aboout the number of elements and the structure of the Numpy array:",
"_____no_output_____"
]
],
[
[
"print('1-d array:')\nprint(x1d)\nprint('len(x1d) = ', len(x1d))\nprint('np.size(x1d) = ', np.size(x1d))\nprint('np.shape(x1d) = ', np.shape(x1d))\nprint('np.ndim(x1d) = ', np.ndim(x1d))\nprint('\\n2-d array:')\nprint(x2d)\nprint('len(x2d) = ', len(x2d))\nprint('np.size(x2d) = ', np.size(x2d))\nprint('np.shape(x2d) = ', np.shape(x2d))\nprint('np.ndim(x2d) = ', np.ndim(x2d))",
"1-d array:\n[1 2 3 4 5 6]\nlen(x1d) = 6\nnp.size(x1d) = 6\nnp.shape(x1d) = (6,)\nnp.ndim(x1d) = 1\n\n2-d array:\n[[1 2 3]\n [4 5 6]]\nlen(x2d) = 2\nnp.size(x2d) = 6\nnp.shape(x2d) = (2, 3)\nnp.ndim(x2d) = 2\n"
]
],
[
[
"Create random data",
"_____no_output_____"
]
],
[
[
"x = np.random.randn(4,3)\nx",
"_____no_output_____"
]
],
[
[
"Joining (stacking together) arrays",
"_____no_output_____"
]
],
[
[
"x = np.random.randint(0, 5, size=(2, 3))\nprint(x)\ny = np.random.randint(5, 10, size=(2, 3))\nprint(y)",
"[[0 4 0]\n [3 1 2]]\n[[6 9 6]\n [6 5 5]]\n"
],
[
"np.vstack((x,y))",
"_____no_output_____"
],
[
"np.hstack((x,y))",
"_____no_output_____"
]
],
[
[
"Create equally spaced data",
"_____no_output_____"
]
],
[
[
"np.arange(start = 1, stop = 10, step = 2)",
"_____no_output_____"
],
[
"np.linspace(start = 0, stop = 1, num = 11)",
"_____no_output_____"
]
],
[
[
"### Interpolation\n\nConsider the following data:",
"_____no_output_____"
]
],
[
[
"y = [5, 4, 10, 8, 1, 10, 2, 7, 1, 3]",
"_____no_output_____"
]
],
[
[
"Suppose we want to create data in between the given data points (interpolation); for instance, let's try to double the resolution of the data by generating twice as many data:",
"_____no_output_____"
]
],
[
[
"t = np.linspace(0, len(y), len(y)) # time vector for the original data\ntn = np.linspace(0, len(y), 2 * len(y)) # new time vector for the new time-normalized data\nyn = np.interp(tn, t, y) # new time-normalized data\nyn",
"_____no_output_____"
]
],
[
[
"The key is the Numpy `interp` function, from its help: \n\n interp(x, xp, fp, left=None, right=None) \n One-dimensional linear interpolation. \n Returns the one-dimensional piecewise linear interpolant to a function with given values at discrete data-points.\n\nA plot of the data will show what we have done:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.figure(figsize=(10,5))\nplt.plot(t, y, 'bo-', lw=2, label='original data')\nplt.plot(tn, yn, '.-', color=[1, 0, 0, .5], lw=2, label='interpolated')\nplt.legend(loc='best', framealpha=.5)\nplt.show()",
"_____no_output_____"
]
],
[
[
"For more about Numpy, see [http://wiki.scipy.org/Tentative_NumPy_Tutorial](http://wiki.scipy.org/Tentative_NumPy_Tutorial).",
"_____no_output_____"
],
[
"## Read and save files\n\nThere are two kinds of computer files: text files and binary files:\n> Text file: computer file where the content is structured as a sequence of lines of electronic text. Text files can contain plain text (letters, numbers, and symbols) but they are not limited to such. The type of content in the text file is defined by the Unicode encoding (a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems). \n>\n> Binary file: computer file where the content is encoded in binary form, a sequence of integers representing byte values.\n\nLet's see how to save and read numeric data stored in a text file:\n\n**Using plain Python**",
"_____no_output_____"
]
],
[
[
"f = open(\"newfile.txt\", \"w\") # open file for writing\nf.write(\"This is a test\\n\") # save to file\nf.write(\"And here is another line\\n\") # save to file\nf.close()\nf = open('newfile.txt', 'r') # open file for reading\nf = f.read() # read from file\nprint(f)",
"This is a test\nAnd here is another line\n\n"
],
[
"help(open)",
"Help on built-in function open in module io:\n\nopen(...)\n open(file, mode='r', buffering=-1, encoding=None,\n errors=None, newline=None, closefd=True, opener=None) -> file object\n \n Open file and return a stream. Raise IOError upon failure.\n \n file is either a text or byte string giving the name (and the path\n if the file isn't in the current working directory) of the file to\n be opened or an integer file descriptor of the file to be\n wrapped. (If a file descriptor is given, it is closed when the\n returned I/O object is closed, unless closefd is set to False.)\n \n mode is an optional string that specifies the mode in which the file\n is opened. It defaults to 'r' which means open for reading in text\n mode. Other common values are 'w' for writing (truncating the file if\n it already exists), 'x' for creating and writing to a new file, and\n 'a' for appending (which on some Unix systems, means that all writes\n append to the end of the file regardless of the current seek position).\n In text mode, if encoding is not specified the encoding used is platform\n dependent: locale.getpreferredencoding(False) is called to get the\n current locale encoding. (For reading and writing raw bytes use binary\n mode and leave encoding unspecified.) The available modes are:\n \n ========= ===============================================================\n Character Meaning\n --------- ---------------------------------------------------------------\n 'r' open for reading (default)\n 'w' open for writing, truncating the file first\n 'x' create a new file and open it for writing\n 'a' open for writing, appending to the end of the file if it exists\n 'b' binary mode\n 't' text mode (default)\n '+' open a disk file for updating (reading and writing)\n 'U' universal newline mode (deprecated)\n ========= ===============================================================\n \n The default mode is 'rt' (open for reading text). For binary random\n access, the mode 'w+b' opens and truncates the file to 0 bytes, while\n 'r+b' opens the file without truncation. The 'x' mode implies 'w' and\n raises an `FileExistsError` if the file already exists.\n \n Python distinguishes between files opened in binary and text modes,\n even when the underlying operating system doesn't. Files opened in\n binary mode (appending 'b' to the mode argument) return contents as\n bytes objects without any decoding. In text mode (the default, or when\n 't' is appended to the mode argument), the contents of the file are\n returned as strings, the bytes having been first decoded using a\n platform-dependent encoding or using the specified encoding if given.\n \n 'U' mode is deprecated and will raise an exception in future versions\n of Python. It has no effect in Python 3. Use newline to control\n universal newlines mode.\n \n buffering is an optional integer used to set the buffering policy.\n Pass 0 to switch buffering off (only allowed in binary mode), 1 to select\n line buffering (only usable in text mode), and an integer > 1 to indicate\n the size of a fixed-size chunk buffer. When no buffering argument is\n given, the default buffering policy works as follows:\n \n * Binary files are buffered in fixed-size chunks; the size of the buffer\n is chosen using a heuristic trying to determine the underlying device's\n \"block size\" and falling back on `io.DEFAULT_BUFFER_SIZE`.\n On many systems, the buffer will typically be 4096 or 8192 bytes long.\n \n * \"Interactive\" text files (files for which isatty() returns True)\n use line buffering. Other text files use the policy described above\n for binary files.\n \n encoding is the name of the encoding used to decode or encode the\n file. This should only be used in text mode. The default encoding is\n platform dependent, but any encoding supported by Python can be\n passed. See the codecs module for the list of supported encodings.\n \n errors is an optional string that specifies how encoding errors are to\n be handled---this argument should not be used in binary mode. Pass\n 'strict' to raise a ValueError exception if there is an encoding error\n (the default of None has the same effect), or pass 'ignore' to ignore\n errors. (Note that ignoring encoding errors can lead to data loss.)\n See the documentation for codecs.register or run 'help(codecs.Codec)'\n for a list of the permitted encoding error strings.\n \n newline controls how universal newlines works (it only applies to text\n mode). It can be None, '', '\\n', '\\r', and '\\r\\n'. It works as\n follows:\n \n * On input, if newline is None, universal newlines mode is\n enabled. Lines in the input can end in '\\n', '\\r', or '\\r\\n', and\n these are translated into '\\n' before being returned to the\n caller. If it is '', universal newline mode is enabled, but line\n endings are returned to the caller untranslated. If it has any of\n the other legal values, input lines are only terminated by the given\n string, and the line ending is returned to the caller untranslated.\n \n * On output, if newline is None, any '\\n' characters written are\n translated to the system default line separator, os.linesep. If\n newline is '' or '\\n', no translation takes place. If newline is any\n of the other legal values, any '\\n' characters written are translated\n to the given string.\n \n If closefd is False, the underlying file descriptor will be kept open\n when the file is closed. This does not work when a file name is given\n and must be True in that case.\n \n A custom opener can be used by passing a callable as *opener*. The\n underlying file descriptor for the file object is then obtained by\n calling *opener* with (*file*, *flags*). *opener* must return an open\n file descriptor (passing os.open as *opener* results in functionality\n similar to passing None).\n \n open() returns a file object whose type depends on the mode, and\n through which the standard file operations such as reading and writing\n are performed. When open() is used to open a file in a text mode ('w',\n 'r', 'wt', 'rt', etc.), it returns a TextIOWrapper. When used to open\n a file in a binary mode, the returned class varies: in read binary\n mode, it returns a BufferedReader; in write binary and append binary\n modes, it returns a BufferedWriter, and in read/write mode, it returns\n a BufferedRandom.\n \n It is also possible to use a string or bytearray as a file for both\n reading and writing. For strings StringIO can be used like a file\n opened in a text mode, and for bytes a BytesIO can be used like a file\n opened in a binary mode.\n\n"
]
],
[
[
"**Using Numpy**",
"_____no_output_____"
]
],
[
[
"import numpy as np\ndata = np.random.randn(3,3)\nnp.savetxt('myfile.txt', data, fmt=\"%12.6G\") # save to file\ndata = np.genfromtxt('myfile.txt', unpack=True) # read from file\ndata",
"_____no_output_____"
]
],
[
[
"## Ploting with matplotlib\n\nMatplotlib is the most-widely used packge for plotting data in Python. Let's see some examples of it.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"Use the IPython magic `%matplotlib inline` to plot a figure inline in the notebook with the rest of the text:",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook",
"C:\\Miniconda3\\lib\\site-packages\\IPython\\kernel\\__init__.py:13: ShimWarning: The `IPython.kernel` package has been deprecated. You should import from ipykernel or jupyter_client instead.\n \"You should import from ipykernel or jupyter_client instead.\", ShimWarning)\n"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"t = np.linspace(0, 0.99, 100)\nx = np.sin(2 * np.pi * 2 * t) \nn = np.random.randn(100) / 5\nplt.Figure(figsize=(12,8))\nplt.plot(t, x, label='sine', linewidth=2)\nplt.plot(t, x + n, label='noisy sine', linewidth=2)\nplt.annotate(s='$sin(4 \\pi t)$', xy=(.2, 1), fontsize=20, color=[0, 0, 1])\nplt.legend(loc='best', framealpha=.5)\nplt.xlabel('Time [s]')\nplt.ylabel('Amplitude')\nplt.title('Data plotting using matplotlib')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Use the IPython magic `%matplotlib qt` to plot a figure in a separate window (from where you will be able to change some of the figure proprerties):",
"_____no_output_____"
]
],
[
[
"%matplotlib qt",
"_____no_output_____"
],
[
"mu, sigma = 10, 2\nx = mu + sigma * np.random.randn(1000)\nfig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))\nax1.plot(x, 'ro')\nax1.set_title('Data')\nax1.grid()\n\nn, bins, patches = ax2.hist(x, 25, normed=True, facecolor='r') # histogram\nax2.set_xlabel('Bins')\nax2.set_ylabel('Probability')\nax2.set_title('Histogram')\nfig.suptitle('Another example using matplotlib', fontsize=18, y=1)\nax2.grid()\n\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"And a window with the following figure should appear:",
"_____no_output_____"
]
],
[
[
"from IPython.display import Image\nImage(url=\"./../images/plot.png\")",
"_____no_output_____"
]
],
[
[
"You can switch back and forth between inline and separate figure using the `%matplotlib` magic commands used above. There are plenty more examples with the source code in the [matplotlib gallery](http://matplotlib.org/gallery.html).",
"_____no_output_____"
]
],
[
[
"# get back the inline plot\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Signal processing with Scipy\n\nThe Scipy package has a lot of functions for signal processing, among them: Integration (scipy.integrate), Optimization (scipy.optimize), Interpolation (scipy.interpolate), Fourier Transforms (scipy.fftpack), Signal Processing (scipy.signal), Linear Algebra (scipy.linalg), and Statistics (scipy.stats). As an example, let's see how to use a low-pass Butterworth filter to attenuate high-frequency noise and how the differentiation process of a signal affects the signal-to-noise content. We will also calculate the Fourier transform of these data to look at their frequencies content.",
"_____no_output_____"
]
],
[
[
"from scipy.signal import butter, filtfilt\nimport scipy.fftpack\nfreq = 100.\nt = np.arange(0,1,.01);\nw = 2*np.pi*1 # 1 Hz\ny = np.sin(w*t)+0.1*np.sin(10*w*t)\n# Butterworth filter\nb, a = butter(4, (5/(freq/2)), btype = 'low')\ny2 = filtfilt(b, a, y)\n# 2nd derivative of the data\nydd = np.diff(y,2)*freq*freq # raw data\ny2dd = np.diff(y2,2)*freq*freq # filtered data\n# frequency content \nyfft = np.abs(scipy.fftpack.fft(y))/(y.size/2); # raw data\ny2fft = np.abs(scipy.fftpack.fft(y2))/(y.size/2); # filtered data\nfreqs = scipy.fftpack.fftfreq(y.size, 1./freq)\nyddfft = np.abs(scipy.fftpack.fft(ydd))/(ydd.size/2);\ny2ddfft = np.abs(scipy.fftpack.fft(y2dd))/(ydd.size/2);\nfreqs2 = scipy.fftpack.fftfreq(ydd.size, 1./freq)",
"_____no_output_____"
]
],
[
[
"And the plots:",
"_____no_output_____"
]
],
[
[
"fig, ((ax1,ax2),(ax3,ax4)) = plt.subplots(2, 2, figsize=(10, 4))\n\nax1.set_title('Temporal domain', fontsize=14)\nax1.plot(t, y, 'r', linewidth=2, label = 'raw data')\nax1.plot(t, y2, 'b', linewidth=2, label = 'filtered @ 5 Hz')\nax1.set_ylabel('f')\nax1.legend(frameon=False, fontsize=12)\n\nax2.set_title('Frequency domain', fontsize=14)\nax2.plot(freqs[:yfft.size/4], yfft[:yfft.size/4],'r', lw=2,label='raw data')\nax2.plot(freqs[:yfft.size/4],y2fft[:yfft.size/4],'b--',lw=2,label='filtered @ 5 Hz')\nax2.set_ylabel('FFT(f)')\nax2.legend(frameon=False, fontsize=12)\n\nax3.plot(t[:-2], ydd, 'r', linewidth=2, label = 'raw')\nax3.plot(t[:-2], y2dd, 'b', linewidth=2, label = 'filtered @ 5 Hz')\nax3.set_xlabel('Time [s]'); ax3.set_ylabel(\"f ''\")\n\nax4.plot(freqs[:yddfft.size/4], yddfft[:yddfft.size/4], 'r', lw=2, label = 'raw')\nax4.plot(freqs[:yddfft.size/4],y2ddfft[:yddfft.size/4],'b--',lw=2, label='filtered @ 5 Hz')\nax4.set_xlabel('Frequency [Hz]'); ax4.set_ylabel(\"FFT(f '')\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"For more about Scipy, see [http://docs.scipy.org/doc/scipy/reference/tutorial/](http://docs.scipy.org/doc/scipy/reference/tutorial/).",
"_____no_output_____"
],
[
"## Symbolic mathematics with Sympy\n\nSympy is a package to perform symbolic mathematics in Python. Let's see some of its features:",
"_____no_output_____"
]
],
[
[
"from IPython.display import display\nimport sympy as sym\nfrom sympy.interactive import printing\nprinting.init_printing()",
"_____no_output_____"
]
],
[
[
"Define some symbols and the create a second-order polynomial function (a.k.a., parabola):",
"_____no_output_____"
]
],
[
[
"x, y = sym.symbols('x y')\ny = x**2 - 2*x - 3\ny",
"_____no_output_____"
]
],
[
[
"Plot the parabola at some given range:",
"_____no_output_____"
]
],
[
[
"from sympy.plotting import plot\n%matplotlib inline\nplot(y, (x, -3, 5));",
"_____no_output_____"
]
],
[
[
"And the roots of the parabola are given by: ",
"_____no_output_____"
]
],
[
[
"sym.solve(y, x)",
"_____no_output_____"
]
],
[
[
"We can also do symbolic differentiation and integration:",
"_____no_output_____"
]
],
[
[
"dy = sym.diff(y, x)\ndy",
"_____no_output_____"
],
[
"sym.integrate(dy, x)",
"_____no_output_____"
]
],
[
[
"For example, let's use Sympy to represent three-dimensional rotations. Consider the problem of a coordinate system xyz rotated in relation to other coordinate system XYZ. The single rotations around each axis are illustrated by:",
"_____no_output_____"
]
],
[
[
"from IPython.display import Image\nImage(url=\"./../images/rotations.png\")",
"_____no_output_____"
]
],
[
[
"The single 3D rotation matrices around Z, Y, and X axes can be expressed in Sympy:",
"_____no_output_____"
]
],
[
[
"from IPython.core.display import Math\nfrom sympy import symbols, cos, sin, Matrix, latex\na, b, g = symbols('alpha beta gamma')\n\nRX = Matrix([[1, 0, 0], [0, cos(a), -sin(a)], [0, sin(a), cos(a)]])\ndisplay(Math(latex('\\\\mathbf{R_{X}}=') + latex(RX, mat_str = 'matrix')))\n\nRY = Matrix([[cos(b), 0, sin(b)], [0, 1, 0], [-sin(b), 0, cos(b)]])\ndisplay(Math(latex('\\\\mathbf{R_{Y}}=') + latex(RY, mat_str = 'matrix')))\n\nRZ = Matrix([[cos(g), -sin(g), 0], [sin(g), cos(g), 0], [0, 0, 1]])\ndisplay(Math(latex('\\\\mathbf{R_{Z}}=') + latex(RZ, mat_str = 'matrix')))",
"_____no_output_____"
]
],
[
[
"And using Sympy, a sequence of elementary rotations around X, Y, Z axes is given by:",
"_____no_output_____"
]
],
[
[
"RXYZ = RZ*RY*RX\ndisplay(Math(latex('\\\\mathbf{R_{XYZ}}=') + latex(RXYZ, mat_str = 'matrix')))",
"_____no_output_____"
]
],
[
[
"Suppose there is a rotation only around X ($\\alpha$) by $\\pi/2$; we can get the numerical value of the rotation matrix by substituing the angle values:",
"_____no_output_____"
]
],
[
[
"r = RXYZ.subs({a: np.pi/2, b: 0, g: 0})\nr",
"_____no_output_____"
]
],
[
[
"And we can prettify this result:",
"_____no_output_____"
]
],
[
[
"display(Math(latex(r'\\mathbf{R_{(\\alpha=\\pi/2)}}=') +\n latex(r.n(chop=True, prec=3), mat_str = 'matrix')))",
"_____no_output_____"
]
],
[
[
"For more about Sympy, see [http://docs.sympy.org/latest/tutorial/](http://docs.sympy.org/latest/tutorial/).",
"_____no_output_____"
],
[
"## Data analysis with pandas\n\n> \"[pandas](http://pandas.pydata.org/) is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python.\"\n\nTo work with labellled data, pandas has a type called DataFrame (basically, a matrix where columns and rows have may names and may be of different types) and it is also the main type of the software [R](http://www.r-project.org/). Fo ezample:",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"x = 5*['A'] + 5*['B']\nx",
"_____no_output_____"
],
[
"df = pd.DataFrame(np.random.rand(10,2), columns=['Level 1', 'Level 2'] )\ndf['Group'] = pd.Series(['A']*5 + ['B']*5)\nplot = df.boxplot(by='Group')",
"_____no_output_____"
],
[
"from pandas.tools.plotting import scatter_matrix\ndf = pd.DataFrame(np.random.randn(100, 3), columns=['A', 'B', 'C'])\nplot = scatter_matrix(df, alpha=0.5, figsize=(8, 6), diagonal='kde')",
"_____no_output_____"
]
],
[
[
"pandas is aware the data is structured and give you basic statistics considerint that and nicely formatted:",
"_____no_output_____"
]
],
[
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"For more on pandas, see this tutorial: [http://pandas.pydata.org/pandas-docs/stable/10min.html](http://pandas.pydata.org/pandas-docs/stable/10min.html).",
"_____no_output_____"
],
[
"## To learn more about Python\n\nThere is a lot of good material in the internet about Python for scientific computing, here is a small list of interesting stuff: \n\n - [How To Think Like A Computer Scientist](http://www.openbookproject.net/thinkcs/python/english2e/) or [the interactive edition](http://interactivepython.org/courselib/static/thinkcspy/index.html) (book)\n - [Python Scientific Lecture Notes](http://scipy-lectures.github.io/) (lecture notes)\n - [Lectures on scientific computing with Python](https://github.com/jrjohansson/scientific-python-lectures#lectures-on-scientific-computing-with-python) (lecture notes)\n - [IPython in depth: high-productivity interactive and parallel python](http://youtu.be/bP8ydKBCZiY) (video lectures)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d02abfc9cdccb9347a39f7c9d7a47546e5c2e5a9
| 2,768 |
ipynb
|
Jupyter Notebook
|
python/Problem4.ipynb
|
ditekunov/ProjectEuler-research
|
e8f84388045cdc1391d1e363c7b55ff4f85be708
|
[
"Unlicense"
] | 2 |
2018-05-20T08:01:42.000Z
|
2018-05-20T08:05:07.000Z
|
python/Problem4.ipynb
|
ditekunov/ProjectEuler-research
|
e8f84388045cdc1391d1e363c7b55ff4f85be708
|
[
"Unlicense"
] | null | null | null |
python/Problem4.ipynb
|
ditekunov/ProjectEuler-research
|
e8f84388045cdc1391d1e363c7b55ff4f85be708
|
[
"Unlicense"
] | null | null | null | 21.457364 | 126 | 0.501445 |
[
[
[
"Task 4: Largest palindrome product",
"_____no_output_____"
],
[
"As always, we'll try with the brute force algorithm, that has ~O(n^2) complexity, but still works pretty fast:",
"_____no_output_____"
]
],
[
[
"import time\n \nstart = time.time()\n\nmax_palindrome = 0\n\nfor i in range(100, 1000):\n for j in range(100, 1000):\n if str(i*j) == str(i*j)[::-1] and i*j > max_palindrome:\n max_palindrome = i*j\n \nfinish = time.time() - start\n\nprint(max_palindrome)\nprint(\"Time in seconds: \", finish)",
"906609\nTime in seconds: 0.7557618618011475\n"
]
],
[
[
"But we'll try to improve it.\n\nFirstly, we'll implement an obvious way to find MAX value, by running the cycle downwards.\n\nLet's record the speed to track, that the time improved.",
"_____no_output_____"
]
],
[
[
"import time\n \nstart = time.time()\n\nmax_palindrome = 0\n\nfor i in range(999, 800, -1):\n for j in range(999, 99, -1):\n if str(i*j) == str(i*j)[::-1] and i*j > max_palindrome:\n max_palindrome = i*j\n \nfinish = time.time() - start\n\nprint(max_palindrome)\nprint(finish)",
"906609\n0.17235779762268066\n"
]
],
[
[
"Unfortunately, I cannot find another way to improve the solution, so the final complexity I could obtain is just O(n^2).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02ac55f4a56668643d06b268d46f58bfb9355eb
| 12,380 |
ipynb
|
Jupyter Notebook
|
ingest.ipynb
|
rcurrie/kluster
|
dfe11a3a632ebc46427855b17bfd87bab719aa40
|
[
"Apache-2.0"
] | null | null | null |
ingest.ipynb
|
rcurrie/kluster
|
dfe11a3a632ebc46427855b17bfd87bab719aa40
|
[
"Apache-2.0"
] | null | null | null |
ingest.ipynb
|
rcurrie/kluster
|
dfe11a3a632ebc46427855b17bfd87bab719aa40
|
[
"Apache-2.0"
] | null | null | null | 32.925532 | 119 | 0.379321 |
[
[
[
"import os\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"# Install and import sourmash for kmer and minhash which includes screed for fastq access\n!pip -q install https://github.com/dib-lab/sourmash/archive/master.zip\nimport sourmash_lib\nimport screed",
"_____no_output_____"
],
[
"%%time\nif not os.path.exists(\"/data/quake/expression.hd5\"):\n expression = pd.read_csv(\"/data/quake/expression.tsv\", \n sep=\"\\t\", index_col=0).dropna().astype(np.float32).T\n expression.to_hdf(\"/data/quake/expression.hd5\", \"expression\", mode=\"w\", format=\"fixed\")\nexpression = pd.read_hdf(\"/data/quake/expression.hd5\", \"expression\")",
"CPU times: user 160 ms, sys: 40 ms, total: 200 ms\nWall time: 200 ms\n"
],
[
"expression.head()",
"_____no_output_____"
],
[
"# %%time\n# Calculate abundance directly in python\n# E = sourmash_lib.MinHash(n=500, ksize=31)\n# with screed.open(\"/data/quake/fastqs/{}_1.fastq.gz\".format(expression.index[0])) as sequence:\n# for record in sequence:\n# E.add_sequence(record.sequence[:50000], True)\n# Asumption is minhash.json was calculated via\n# sourmash compute --ksizes 31 --track-abundance --output /data/quake/minhash.json /data/quake/fastq/*_1.fastq.gz",
"_____no_output_____"
],
[
"from sourmash_lib.signature import load_signatures\n\nwith open(\"/data/quake/minhash.json\") as f:\n signatures = list(load_signatures(f))\n# signatures = [s for _, x in zip(range(10), load_signatures(f))]",
"...sig loading 465\n"
],
[
"pd.DataFrame([s.minhash.get_mins(with_abundance=True) for s in signatures[0:10]],\n index=[re.findall(r\"(.+?)_\", s.name())[0] for s in signatures[0:10]])",
"_____no_output_____"
],
[
"mins = [s.minhash.get_mins() for s in signatures[0:2]]",
"_____no_output_____"
],
[
"result = set(mins[0]).intersection(*mins)\nprint(len(result))",
"15\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02acba2b3ccea9c70da18a3a12285fdbfeef08b
| 321,893 |
ipynb
|
Jupyter Notebook
|
3_2_preliminary_statistics_project_2.ipynb
|
cnktysz/qiskit-quantum-state-classifier
|
41f63e1cea13e02dfeb7fc7721f8a218fed62678
|
[
"Apache-2.0"
] | 1 |
2021-02-13T09:14:06.000Z
|
2021-02-13T09:14:06.000Z
|
3_2_preliminary_statistics_project_2.ipynb
|
cnktysz/qiskit-quantum-state-classifier
|
41f63e1cea13e02dfeb7fc7721f8a218fed62678
|
[
"Apache-2.0"
] | 11 |
2021-01-13T14:08:47.000Z
|
2021-02-04T08:02:17.000Z
|
3_2_preliminary_statistics_project_2.ipynb
|
cnktysz/qiskit-quantum-state-classifier
|
41f63e1cea13e02dfeb7fc7721f8a218fed62678
|
[
"Apache-2.0"
] | 1 |
2021-01-23T15:52:03.000Z
|
2021-01-23T15:52:03.000Z
| 211.632479 | 134,624 | 0.847825 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport json as json\nfrom scipy import stats\nfrom statsmodels.formula.api import ols\nimport matplotlib.pyplot as plt\nfrom scipy.signal import savgol_filter",
"_____no_output_____"
],
[
"from o_plot import opl # a small local package dedicated to this project",
"_____no_output_____"
],
[
"# Prepare the data",
"_____no_output_____"
],
[
"# loading the data\nfile_name = 'Up_to_Belem_TE4AL2_data_new.json'\nf = open(file_name)\nAll_data = json.load(f)\nprint(len(All_data))",
"148\n"
]
],
[
[
"## Note for the interpretation of the curves and definition of the statistical variables\n\nThe quantum state classifier (QSC) error rates $\\widehat{r}_i$ in function of the number of experimental shots $n$ were determined for each highly entangled quantum state $\\omega_i$ in the $\\Omega$ set, with $i=1...m$.\n\nThe curves seen on the figures represents the mean of the QSC error rate $\\widehat{r}_{mean}$ over the $m$ quantum states at each $n$ value.\n\nThis Monte Carlo simulation allowed to determine a safe shot number $n_s$ such that $\\forall i\\; \\widehat{r}_i\\le \\epsilon_s$. The value of $\\epsilon_s$ was set at 0.001.\n\n$\\widehat{r}_{max}$ is the maximal value observed among all the $\\widehat{r}_i$ values for the determined number of shots $n_s$.\n\nSimilarly, from the error curves stored in the data file, was computed the safe shot number $n_t$ such that $\\widehat{r}_{mean}\\le \\epsilon_t$. The value of $\\epsilon_t$ was set at 0.0005 after verifying that all $\\widehat{r}_{mean}$ at $n_s$ were $\\le \\epsilon_s$ in the different experimental settings. \n\nCorrespondance between variables names in the text and in the data base:\n\n- $\\widehat{r}_{mean}$: error_curve\n- $n_s$: shots\n- max ($\\widehat{r}_i$) at $n_s$: shot_rate\n- $\\widehat{r}_{mean}$ at $n_s$: mns_rate\n- $n_t$: m_shots\n- $\\widehat{r}_{mean}$ at $n_t$: m_shot_rate\n\n\n",
"_____no_output_____"
]
],
[
[
"# Calculate shot number 'm_shots' for mean error rate 'm_shot_rates' <= epsilon_t\nlen_data = len(All_data)\nepsilon_t = 0.0005\nwindow = 11\nfor i in range(len_data): \n curve = np.array(All_data[i]['error_curve'])\n # filter the curve only for real devices:\n if All_data[i]['device']!=\"ideal_device\": \n curve = savgol_filter(curve,window,2) \n # find the safe shot number: \n len_c = len(curve) \n n_a = np.argmin(np.flip(curve)<=epsilon_t)+1 \n if n_a == 1:\n n_a = np.nan\n m_r = np.nan\n else:\n m_r = curve[len_c-n_a+1]\n All_data[i]['min_r_shots'] = len_c-n_a\n All_data[i]['min_r'] = m_r",
"_____no_output_____"
],
[
"# find mean error rate at n_s\nfor i in range(len_data):\n i_shot = All_data[i][\"shots\"]\n if not np.isnan(i_shot):\n j = int(i_shot)-1 \n All_data[i]['mns_rate'] = All_data[i]['error_curve'][j]\n else:\n All_data[i]['mns_rate'] = np.nan",
"_____no_output_____"
],
[
"#defining the pandas data frame for statistics excluding from here ibmqx2 data\ndf_All= pd.DataFrame(All_data,columns=['shot_rates','shots', 'device', 'fidelity',\n 'mitigation','model','id_gates',\n 'QV', 'metric','error_curve',\n 'mns_rate','min_r_shots',\n 'min_r']).query(\"device != 'ibmqx2'\")\n\n# any shot number >= 488 indicates that the curve calculation \n# was ended after reaching n = 500, hence this data correction:\ndf_All.loc[df_All.shots>=488,\"shots\"]=np.nan\n\n# add the variable neperian log of safe shot number: \ndf_All['log_shots'] = np.log(df_All['shots'])\ndf_All['log_min_r_shots'] = np.log(df_All['min_r_shots'])",
"_____no_output_____"
]
],
[
[
"### Error rates in function of chosen $\\epsilon_s$ and $\\epsilon_t$",
"_____no_output_____"
]
],
[
[
"print(\"max mean error rate at n_s over all experiments =\", round(max(df_All.mns_rate[:-2]),6))",
"max mean error rate at n_s over all experiments = 0.000515\n"
],
[
"print(\"min mean error rate at n_t over all experiments =\", round(min(df_All.min_r[:-2]),6))",
"min mean error rate at n_t over all experiments = 0.000225\n"
],
[
"print(\"max mean error rate at n_t over all experiments =\", round(max(df_All.min_r[:-2]),6))",
"max mean error rate at n_t over all experiments = 0.0005\n"
],
[
"df_All.mns_rate[:-2].plot.hist(alpha=0.5, legend = True)\ndf_All.min_r[:-2].plot.hist(alpha=0.5, legend = True)",
"_____no_output_____"
]
],
[
[
"# Statistical overview\n\nFor this section, an ordinary linear least square estimation is performed.\nThe dependent variables tested are $ln\\;n_s$ (log_shots) and $ln\\;n_t$ (log_min_r_shots)",
"_____no_output_____"
]
],
[
[
"stat_model = ols(\"log_shots ~ metric\",\n df_All.query(\"device != 'ideal_device'\")).fit()\nprint(stat_model.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: log_shots R-squared: 0.000\nModel: OLS Adj. R-squared: -0.008\nMethod: Least Squares F-statistic: 9.932e-05\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.992\nTime: 17:22:26 Log-Likelihood: -97.198\nNo. Observations: 128 AIC: 198.4\nDf Residuals: 126 BIC: 204.1\nDf Model: 1 \nCovariance Type: nonrobust \n=========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-----------------------------------------------------------------------------------------\nIntercept 3.8905 0.065 59.721 0.000 3.762 4.019\nmetric[T.sqeuclidean] -0.0009 0.092 -0.010 0.992 -0.183 0.181\n==============================================================================\nOmnibus: 50.123 Durbin-Watson: 0.999\nProb(Omnibus): 0.000 Jarque-Bera (JB): 114.723\nSkew: 1.627 Prob(JB): 1.23e-25\nKurtosis: 6.305 Cond. No. 2.62\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
],
[
"stat_model = ols(\"log_min_r_shots ~ metric\",\n df_All.query(\"device != 'ideal_device'\")).fit()\nprint(stat_model.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: log_min_r_shots R-squared: 0.000\nModel: OLS Adj. R-squared: -0.008\nMethod: Least Squares F-statistic: 0.0002891\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.986\nTime: 17:22:26 Log-Likelihood: -98.159\nNo. Observations: 128 AIC: 200.3\nDf Residuals: 126 BIC: 206.0\nDf Model: 1 \nCovariance Type: nonrobust \n=========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-----------------------------------------------------------------------------------------\nIntercept 3.6638 0.066 55.821 0.000 3.534 3.794\nmetric[T.sqeuclidean] -0.0016 0.093 -0.017 0.986 -0.185 0.182\n==============================================================================\nOmnibus: 45.986 Durbin-Watson: 0.857\nProb(Omnibus): 0.000 Jarque-Bera (JB): 98.651\nSkew: 1.517 Prob(JB): 3.79e-22\nKurtosis: 6.049 Cond. No. 2.62\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
],
[
"stat_model = ols(\"log_shots ~ model+mitigation+id_gates+fidelity+QV\",\n df_All.query(\"device != 'ideal_device' & metric == 'sqeuclidean'\")).fit()\nprint(stat_model.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: log_shots R-squared: 0.463\nModel: OLS Adj. R-squared: 0.416\nMethod: Least Squares F-statistic: 9.988\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 6.27e-07\nTime: 17:22:26 Log-Likelihood: -28.701\nNo. Observations: 64 AIC: 69.40\nDf Residuals: 58 BIC: 82.35\nDf Model: 5 \nCovariance Type: nonrobust \n======================================================================================\n coef std err t P>|t| [0.025 0.975]\n--------------------------------------------------------------------------------------\nIntercept 3.8533 2.003 1.924 0.059 -0.155 7.862\nmodel[T.ideal_sim] 0.3283 0.100 3.299 0.002 0.129 0.527\nmitigation[T.yes] -0.3640 0.100 -3.659 0.001 -0.563 -0.165\nid_gates 0.0019 0.000 4.865 0.000 0.001 0.003\nfidelity -0.0563 2.638 -0.021 0.983 -5.337 5.225\nQV -0.0078 0.013 -0.583 0.562 -0.035 0.019\n==============================================================================\nOmnibus: 27.966 Durbin-Watson: 0.977\nProb(Omnibus): 0.000 Jarque-Bera (JB): 47.697\nSkew: 1.574 Prob(JB): 4.39e-11\nKurtosis: 5.823 Cond. No. 1.21e+04\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The condition number is large, 1.21e+04. This might indicate that there are\nstrong multicollinearity or other numerical problems.\n"
],
[
"stat_model = ols(\"log_min_r_shots ~ model+mitigation+id_gates+fidelity+QV\",\n df_All.query(\"device != 'ideal_device'& metric == 'sqeuclidean'\")).fit()\nprint(stat_model.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: log_min_r_shots R-squared: 0.532\nModel: OLS Adj. R-squared: 0.491\nMethod: Least Squares F-statistic: 13.16\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 1.43e-08\nTime: 17:22:26 Log-Likelihood: -24.867\nNo. Observations: 64 AIC: 61.73\nDf Residuals: 58 BIC: 74.69\nDf Model: 5 \nCovariance Type: nonrobust \n======================================================================================\n coef std err t P>|t| [0.025 0.975]\n--------------------------------------------------------------------------------------\nIntercept 3.5234 1.886 1.868 0.067 -0.252 7.299\nmodel[T.ideal_sim] 0.2831 0.094 3.021 0.004 0.096 0.471\nmitigation[T.yes] -0.3990 0.094 -4.258 0.000 -0.587 -0.211\nid_gates 0.0022 0.000 5.893 0.000 0.001 0.003\nfidelity 0.1449 2.485 0.058 0.954 -4.829 5.119\nQV -0.0112 0.013 -0.884 0.380 -0.036 0.014\n==============================================================================\nOmnibus: 29.956 Durbin-Watson: 1.010\nProb(Omnibus): 0.000 Jarque-Bera (JB): 55.722\nSkew: 1.626 Prob(JB): 7.94e-13\nKurtosis: 6.212 Cond. No. 1.21e+04\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The condition number is large, 1.21e+04. This might indicate that there are\nstrong multicollinearity or other numerical problems.\n"
]
],
[
[
"#### Comments:\n\nFor the QSC, two different metrics were compared and at the end they gave the same output. For further analysis, the results obtained using the squared euclidean distance between distribution will be illustrated in this notebook, as it is more classical and strictly equivalent to the other classical Hellinger and Bhattacharyya distances. The Jensen-Shannon metric has however the theoretical advantage of being bayesian in nature and is therefore presented as an option for the result analysis.\n\nCurves obtained for counts corrected by measurement error mitigation (MEM) are used in this presentation. MEM significantly reduces $n_s$ and $n_t$. However, using counts distribution before MEM is presented as an option because they anticipate how the method could perform in devices with more qubits where obtaining the mitigation filter is a problem. \n\nIntroducing a delay time $\\delta t$ of 256 identity gates between state creation and measurement significantly increased $ln\\;n_s$ and $ln\\;n_t$ . \n",
"_____no_output_____"
],
[
"# Detailed statistical analysis\n\n",
"_____no_output_____"
],
[
"### Determine the options\nRunning sequentially these cells will end up with the main streaming options",
"_____no_output_____"
]
],
[
[
"# this for Jensen-Shannon metric \ns_metric = 'jensenshannon'\nsm = np.array([96+16+16+16]) # added Quito and Lima and Belem\nSAD=0\n# ! will be unselected by running the next cell",
"_____no_output_____"
],
[
"# mainstream option for metric: squared euclidean distance\n# skip this cell if you don't want this option\ns_metric = 'sqeuclidean'\nsm = np.array([97+16+16+16]) # added Quito and Lima and Belem\nSAD=2 ",
"_____no_output_____"
],
[
"# this for no mitigation\nmit = 'no'\nMIT=-4\n# ! will be unselected by running the next cell",
"_____no_output_____"
],
[
"# mainstream option: this for measurement mitigation\n# skip this cell if you don't want this option\nmit = 'yes'\nMIT=0",
"_____no_output_____"
]
],
[
[
"## 1. Compare distribution models\n",
"_____no_output_____"
]
],
[
[
"# select data according to the options\ndf_mod = df_All[df_All.mitigation == mit][df_All.metric == s_metric]",
"<ipython-input-20-af347b9ea33a>:2: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n df_mod = df_All[df_All.mitigation == mit][df_All.metric == s_metric]\n"
]
],
[
[
"### A look at $n_s$ and $n_t$",
"_____no_output_____"
]
],
[
[
"print(\"mitigation:\",mit,\" metric:\",s_metric )\ndf_mod.groupby('device')[['shots','min_r_shots']].describe(percentiles=[0.5])",
"mitigation: yes metric: sqeuclidean\n"
]
],
[
[
"### Ideal vs empirical model: no state creation - measurements delay",
"_____no_output_____"
]
],
[
[
"ADD=0+SAD+MIT\n#opl.plot_curves(All_data, np.append(sm,ADD+np.array([4,5,12,13,20,21,28,29,36,37,44,45])), \nopl.plot_curves(All_data, np.append(sm,ADD+np.array([4,5,12,13,20,21,28,29,36,37,52,53,60,61,68,69])), \n \"Monte Carlo Simulation: Theoretical PDM vs Empirical PDM - no $\\delta_t0$\",\n [\"metric\",\"mitigation\"],\n [\"device\",\"model\"], right_xlimit = 90)",
"_____no_output_____"
]
],
[
[
"#### Paired t-test and Wilcoxon test",
"_____no_output_____"
]
],
[
[
"for depvar in ['log_shots', 'log_min_r_shots']:\n#for depvar in ['shots', 'min_r_shots']:\n print(\"mitigation:\",mit,\" metric:\",s_metric, \"variable:\", depvar)\n df_dep = df_mod.query(\"id_gates == 0.0\").groupby(['model'])[depvar]\n print(df_dep.describe(percentiles=[0.5]),\"\\n\")\n # no error rate curve obtained for ibmqx2 with the ideal model, hence this exclusion:\n df_emp=df_mod.query(\"model == 'empirical' & id_gates == 0.0\")\n df_ide=df_mod.query(\"model == 'ideal_sim' & id_gates == 0.0\") #.reindex_like(df_emp,'nearest')\n # back to numpy arrays from pandas: \n print(\"paired data\")\n print(np.asarray(df_emp[depvar]))\n print(np.asarray(df_ide[depvar]),\"\\n\")\n \n print(stats.ttest_rel(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])))\n print(stats.wilcoxon(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])),\"\\n\")",
"mitigation: yes metric: sqeuclidean variable: log_shots\n count mean std min 50% max\nmodel \nempirical 8.0 3.356282 0.155304 3.218876 3.331566 3.663562\nideal_sim 8.0 3.611588 0.367515 3.295837 3.511434 4.454347 \n\npaired data\n[3.29583687 3.4657359 3.21887582 3.21887582 3.40119738 3.66356165\n 3.36729583 3.21887582]\n[3.71357207 3.49650756 3.63758616 3.29583687 3.52636052 4.4543473\n 3.40119738 3.36729583] \n\nTtest_relResult(statistic=-2.703455085610571, pvalue=0.03048624608052708)\nWilcoxonResult(statistic=0.0, pvalue=0.0078125) \n\nmitigation: yes metric: sqeuclidean variable: log_min_r_shots\n count mean std min 50% max\nmodel \nempirical 8.0 3.107878 0.155857 2.944439 3.091042 3.433987\nideal_sim 8.0 3.294950 0.332811 3.044522 3.178054 4.094345 \n\npaired data\n[3.09104245 3.17805383 2.94443898 2.94443898 3.13549422 3.4339872\n 3.09104245 3.04452244]\n[3.21887582 3.13549422 3.33220451 3.04452244 3.17805383 4.09434456\n 3.17805383 3.17805383] \n\nTtest_relResult(statistic=-2.3272474929057116, pvalue=0.052827582556702425)\nWilcoxonResult(statistic=1.5, pvalue=0.015625) \n\n"
],
[
"print(\"mitigation:\",mit,\" metric:\",s_metric, \"id_gates == 0.0 \")\nstat_model = ols(\"log_shots ~ model + device + fidelity + QV\" ,\n df_mod.query(\"id_gates == 0.0 \")).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean id_gates == 0.0 \n OLS Regression Results \n==============================================================================\nDep. Variable: log_shots R-squared: 0.818\nModel: OLS Adj. R-squared: 0.611\nMethod: Least Squares F-statistic: 3.943\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.0435\nTime: 17:22:28 Log-Likelihood: 10.577\nNo. Observations: 16 AIC: -3.154\nDf Residuals: 7 BIC: 3.799\nDf Model: 8 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.6386 0.066 24.648 0.000 1.481 1.796\nmodel[T.ideal_sim] 0.2553 0.094 2.703 0.030 0.032 0.479\ndevice[T.ibmq_belem] 0.1912 0.130 1.469 0.185 -0.117 0.499\ndevice[T.ibmq_lima] 0.5171 0.117 4.404 0.003 0.239 0.795\ndevice[T.ibmq_ourense] 0.5384 0.116 4.626 0.002 0.263 0.814\ndevice[T.ibmq_quito] 0.9596 0.130 7.367 0.000 0.652 1.268\ndevice[T.ibmq_santiago] 0.0361 0.189 0.191 0.854 -0.411 0.483\ndevice[T.ibmq_valencia] 0.3857 0.131 2.940 0.022 0.075 0.696\ndevice[T.ibmq_vigo] 0.1561 0.130 1.199 0.270 -0.152 0.464\nfidelity 1.2349 0.049 25.178 0.000 1.119 1.351\nQV 0.0185 0.007 2.709 0.030 0.002 0.035\n==============================================================================\nOmnibus: 0.291 Durbin-Watson: 2.474\nProb(Omnibus): 0.865 Jarque-Bera (JB): 0.009\nSkew: 0.000 Prob(JB): 0.996\nKurtosis: 2.887 Cond. No. 5.63e+17\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 2.02e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
],
[
"print(\"mitigation:\",mit,\" metric:\",s_metric, \"id_gates == 0.0 \" )\nstat_model = ols(\"log_min_r_shots ~ model + device + fidelity+QV\",\n df_mod.query(\"id_gates == 0.0 \")).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean id_gates == 0.0 \n OLS Regression Results \n==============================================================================\nDep. Variable: log_min_r_shots R-squared: 0.833\nModel: OLS Adj. R-squared: 0.643\nMethod: Least Squares F-statistic: 4.374\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.0335\nTime: 17:22:28 Log-Likelihood: 13.155\nNo. Observations: 16 AIC: -8.310\nDf Residuals: 7 BIC: -1.357\nDf Model: 8 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.5428 0.057 27.265 0.000 1.409 1.677\nmodel[T.ideal_sim] 0.1871 0.080 2.327 0.053 -0.003 0.377\ndevice[T.ibmq_belem] 0.2643 0.111 2.385 0.049 0.002 0.526\ndevice[T.ibmq_lima] 0.4849 0.100 4.851 0.002 0.249 0.721\ndevice[T.ibmq_ourense] 0.4523 0.099 4.565 0.003 0.218 0.687\ndevice[T.ibmq_quito] 0.9195 0.111 8.294 0.000 0.657 1.182\ndevice[T.ibmq_santiago] 0.0100 0.161 0.062 0.952 -0.371 0.391\ndevice[T.ibmq_valencia] 0.3472 0.112 3.109 0.017 0.083 0.611\ndevice[T.ibmq_vigo] 0.1480 0.111 1.335 0.224 -0.114 0.410\nfidelity 1.1633 0.042 27.862 0.000 1.065 1.262\nQV 0.0144 0.006 2.486 0.042 0.001 0.028\n==============================================================================\nOmnibus: 1.117 Durbin-Watson: 2.583\nProb(Omnibus): 0.572 Jarque-Bera (JB): 0.092\nSkew: 0.000 Prob(JB): 0.955\nKurtosis: 3.372 Cond. No. 5.63e+17\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 2.02e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
]
],
[
[
"### Ideal vs empirical model: with state creation - measurements delay of 256 id gates",
"_____no_output_____"
]
],
[
[
"ADD=72+SAD+MIT\nopl.plot_curves(All_data, np.append(sm,ADD+np.array([4,5,12,13,20,21,28,29,36,37,52,53,60,61,68,69])), \n \"No noise simulator vs empirical model - $\\epsilon=0.001$ - with delay\",\n [\"metric\",\"mitigation\"],\n [\"device\",\"model\"], right_xlimit = 90)",
"_____no_output_____"
]
],
[
[
"#### Paired t-test and Wilcoxon test",
"_____no_output_____"
]
],
[
[
"for depvar in ['log_shots', 'log_min_r_shots']:\n print(\"mitigation:\",mit,\" metric:\",s_metric, \"variable:\", depvar)\n df_dep = df_mod.query(\"id_gates == 256.0 \").groupby(['model'])[depvar]\n print(df_dep.describe(percentiles=[0.5]),\"\\n\")\n # no error rate curve obtained for ibmqx2 with the ideal model, hence their exclusion:\n df_emp=df_mod.query(\"model == 'empirical' & id_gates == 256.0 \")\n df_ide=df_mod.query(\"model == 'ideal_sim' & id_gates == 256.0\") #.reindex_like(df_emp,'nearest') \n # back to numpy arrays from pandas: \n print(\"paired data\")\n print(np.asarray(df_emp[depvar]))\n print(np.asarray(df_ide[depvar]),\"\\n\")\n \n print(stats.ttest_rel(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])))\n print(stats.wilcoxon(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])),\"\\n\")",
"mitigation: yes metric: sqeuclidean variable: log_shots\n count mean std min 50% max\nmodel \nempirical 8.0 3.804879 0.275711 3.465736 3.795426 4.276666\nideal_sim 8.0 4.057501 0.576714 3.583519 3.841932 5.323010 \n\npaired data\n[3.8286414 3.80666249 3.4657359 3.61091791 3.55534806 4.27666612\n 4.11087386 3.78418963]\n[3.71357207 3.97029191 3.58351894 3.71357207 3.68887945 5.32300998\n 4.40671925 4.06044301] \n\nTtest_relResult(statistic=-2.0745435276798316, pvalue=0.07670054021001)\nWilcoxonResult(statistic=2.0, pvalue=0.0234375) \n\nmitigation: yes metric: sqeuclidean variable: log_min_r_shots\n count mean std min 50% max\nmodel \nempirical 8.0 3.576911 0.271657 3.258097 3.540013 4.077537\nideal_sim 8.0 3.871177 0.556633 3.401197 3.702748 5.056246 \n\npaired data\n[3.49650756 3.63758616 3.25809654 3.40119738 3.33220451 4.07753744\n 3.8286414 3.58351894]\n[3.4339872 3.8501476 3.40119738 3.55534806 3.52636052 5.05624581\n 4.2341065 3.91202301] \n\nTtest_relResult(statistic=-2.693337566407444, pvalue=0.03093589687434249)\nWilcoxonResult(statistic=1.0, pvalue=0.015625) \n\n"
],
[
"print(\"mitigation:\",mit,\" metric:\",s_metric , \"id_gates == 256.0 \")\nstat_model = ols(\"log_shots ~ model + device + fidelity + QV\" ,\n df_mod.query(\"id_gates == 256.0 \")).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean id_gates == 256.0 \n OLS Regression Results \n==============================================================================\nDep. Variable: log_shots R-squared: 0.867\nModel: OLS Adj. R-squared: 0.714\nMethod: Least Squares F-statistic: 5.691\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.0167\nTime: 17:22:30 Log-Likelihood: 6.5097\nNo. Observations: 16 AIC: 4.981\nDf Residuals: 7 BIC: 11.93\nDf Model: 8 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.9043 0.086 22.215 0.000 1.702 2.107\nmodel[T.ideal_sim] 0.2526 0.122 2.075 0.077 -0.035 0.541\ndevice[T.ibmq_belem] 0.4066 0.168 2.422 0.046 0.010 0.804\ndevice[T.ibmq_lima] 0.9818 0.151 6.484 0.000 0.624 1.340\ndevice[T.ibmq_ourense] 0.2775 0.150 1.849 0.107 -0.077 0.632\ndevice[T.ibmq_quito] 1.2870 0.168 7.663 0.000 0.890 1.684\ndevice[T.ibmq_santiago] -0.1028 0.244 -0.422 0.686 -0.679 0.474\ndevice[T.ibmq_valencia] 0.0778 0.169 0.460 0.659 -0.322 0.478\ndevice[T.ibmq_vigo] 0.1471 0.168 0.876 0.410 -0.250 0.544\nfidelity 1.4365 0.063 22.713 0.000 1.287 1.586\nQV 0.0172 0.009 1.957 0.091 -0.004 0.038\n==============================================================================\nOmnibus: 4.386 Durbin-Watson: 2.947\nProb(Omnibus): 0.112 Jarque-Bera (JB): 2.231\nSkew: 0.000 Prob(JB): 0.328\nKurtosis: 4.830 Cond. No. 5.63e+17\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 2.02e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
],
[
"print(\"mitigation:\",mit,\" metric:\",s_metric, \"id_gates == 256.0 \" )\nstat_model = ols(\"log_min_r_shots ~ model + device +fidelity+QV\",\n df_mod.query(\"id_gates == 256.0 \")).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean id_gates == 256.0 \n OLS Regression Results \n==============================================================================\nDep. Variable: log_min_r_shots R-squared: 0.890\nModel: OLS Adj. R-squared: 0.764\nMethod: Least Squares F-statistic: 7.062\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 0.00913\nTime: 17:22:30 Log-Likelihood: 8.2449\nNo. Observations: 16 AIC: 1.510\nDf Residuals: 7 BIC: 8.463\nDf Model: 8 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.7754 0.077 23.083 0.000 1.594 1.957\nmodel[T.ideal_sim] 0.2943 0.109 2.693 0.031 0.036 0.553\ndevice[T.ibmq_belem] 0.3949 0.151 2.621 0.034 0.039 0.751\ndevice[T.ibmq_lima] 0.9230 0.136 6.793 0.000 0.602 1.244\ndevice[T.ibmq_ourense] 0.2576 0.135 1.913 0.097 -0.061 0.576\ndevice[T.ibmq_quito] 1.2167 0.151 8.074 0.000 0.860 1.573\ndevice[T.ibmq_santiago] -0.2650 0.219 -1.212 0.265 -0.782 0.252\ndevice[T.ibmq_valencia] 0.0412 0.152 0.271 0.794 -0.318 0.400\ndevice[T.ibmq_vigo] 0.1260 0.151 0.836 0.431 -0.230 0.482\nfidelity 1.3422 0.057 23.652 0.000 1.208 1.476\nQV 0.0187 0.008 2.376 0.049 9.25e-05 0.037\n==============================================================================\nOmnibus: 3.031 Durbin-Watson: 3.036\nProb(Omnibus): 0.220 Jarque-Bera (JB): 1.026\nSkew: 0.000 Prob(JB): 0.599\nKurtosis: 4.241 Cond. No. 5.63e+17\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 2.02e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
]
],
[
[
"### Pooling results obtained in circuit sets with and without creation-measurement delay",
"_____no_output_____"
],
[
"#### Paired t-test and Wilcoxon test",
"_____no_output_____"
]
],
[
[
"#for depvar in ['log_shots', 'log_min_r_shots']:\nfor depvar in ['log_shots', 'log_min_r_shots']:\n print(\"mitigation:\",mit,\" metric:\",s_metric, \"variable:\", depvar)\n df_dep = df_mod.groupby(['model'])[depvar]\n print(df_dep.describe(percentiles=[0.5]),\"\\n\")\n # no error rate curve obtained for ibmqx2 with the ideal model, hence this exclusion:\n df_emp=df_mod.query(\"model == 'empirical'\")\n df_ide=df_mod.query(\"model == 'ideal_sim'\") #.reindex_like(df_emp,'nearest')\n # back to numpy arrays from pandas:\n print(\"paired data\")\n print(np.asarray(df_emp[depvar]))\n print(np.asarray(df_ide[depvar]),\"\\n\")\n \n print(stats.ttest_rel(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])))\n print(stats.wilcoxon(np.asarray(df_emp[depvar]),np.asarray(df_ide[depvar])),\"\\n\")",
"mitigation: yes metric: sqeuclidean variable: log_shots\n count mean std min 50% max\nmodel \nempirical 16.0 3.580581 0.316850 3.218876 3.510542 4.276666\nideal_sim 16.0 3.834544 0.520834 3.295837 3.701226 5.323010 \n\npaired data\n[3.29583687 3.4657359 3.21887582 3.21887582 3.40119738 3.66356165\n 3.36729583 3.21887582 3.8286414 3.80666249 3.4657359 3.61091791\n 3.55534806 4.27666612 4.11087386 3.78418963]\n[3.71357207 3.49650756 3.63758616 3.29583687 3.52636052 4.4543473\n 3.40119738 3.36729583 3.71357207 3.97029191 3.58351894 3.71357207\n 3.68887945 5.32300998 4.40671925 4.06044301] \n\nTtest_relResult(statistic=-3.411743256395652, pvalue=0.0038635533717249343)\nWilcoxonResult(statistic=5.0, pvalue=0.00030517578125) \n\nmitigation: yes metric: sqeuclidean variable: log_min_r_shots\n count mean std min 50% max\nmodel \nempirical 16.0 3.342394 0.323171 2.944439 3.295151 4.077537\nideal_sim 16.0 3.583064 0.533690 3.044522 3.417592 5.056246 \n\npaired data\n[3.09104245 3.17805383 2.94443898 2.94443898 3.13549422 3.4339872\n 3.09104245 3.04452244 3.49650756 3.63758616 3.25809654 3.40119738\n 3.33220451 4.07753744 3.8286414 3.58351894]\n[3.21887582 3.13549422 3.33220451 3.04452244 3.17805383 4.09434456\n 3.17805383 3.17805383 3.4339872 3.8501476 3.40119738 3.55534806\n 3.52636052 5.05624581 4.2341065 3.91202301] \n\nTtest_relResult(statistic=-3.593874266151202, pvalue=0.0026588536103780047)\nWilcoxonResult(statistic=4.5, pvalue=0.000213623046875) \n\n"
]
],
[
[
"#### Statsmodel Ordinary Least Square (OLS) Analysis",
"_____no_output_____"
]
],
[
[
"print(\"mitigation:\",mit,\" metric:\",s_metric )\nstat_model = ols(\"log_shots ~ model + id_gates + device + fidelity + QV\" ,\n df_mod).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean\n OLS Regression Results \n==============================================================================\nDep. Variable: log_shots R-squared: 0.801\nModel: OLS Adj. R-squared: 0.720\nMethod: Least Squares F-statistic: 9.865\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 6.77e-06\nTime: 17:22:30 Log-Likelihood: 7.0023\nNo. Observations: 32 AIC: 5.995\nDf Residuals: 22 BIC: 20.65\nDf Model: 9 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.6616 0.062 26.885 0.000 1.533 1.790\nmodel[T.ideal_sim] 0.2540 0.083 3.064 0.006 0.082 0.426\ndevice[T.ibmq_belem] 0.2739 0.114 2.395 0.026 0.037 0.511\ndevice[T.ibmq_lima] 0.7090 0.103 6.860 0.000 0.495 0.923\ndevice[T.ibmq_ourense] 0.3714 0.102 3.627 0.001 0.159 0.584\ndevice[T.ibmq_quito] 1.0982 0.114 9.596 0.000 0.861 1.335\ndevice[T.ibmq_santiago] -0.0342 0.166 -0.206 0.839 -0.378 0.310\ndevice[T.ibmq_valencia] 0.2028 0.115 1.759 0.092 -0.036 0.442\ndevice[T.ibmq_vigo] 0.1266 0.114 1.107 0.280 -0.111 0.364\nid_gates 0.0017 0.000 5.395 0.000 0.001 0.002\nfidelity 1.2532 0.046 27.428 0.000 1.158 1.348\nQV 0.0166 0.006 2.776 0.011 0.004 0.029\n==============================================================================\nOmnibus: 1.314 Durbin-Watson: 1.842\nProb(Omnibus): 0.518 Jarque-Bera (JB): 0.448\nSkew: 0.203 Prob(JB): 0.799\nKurtosis: 3.413 Cond. No. 5.00e+18\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 4.22e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
],
[
"print(\"mitigation:\",mit,\" metric:\",s_metric )\nstat_model = ols(\"log_min_r_shots ~ model + id_gates + device + fidelity+QV \",\n df_mod).fit() \nprint(stat_model.summary())",
"mitigation: yes metric: sqeuclidean\n OLS Regression Results \n==============================================================================\nDep. Variable: log_min_r_shots R-squared: 0.842\nModel: OLS Adj. R-squared: 0.778\nMethod: Least Squares F-statistic: 13.08\nDate: Tue, 02 Mar 2021 Prob (F-statistic): 6.19e-07\nTime: 17:22:30 Log-Likelihood: 10.164\nNo. Observations: 32 AIC: -0.3273\nDf Residuals: 22 BIC: 14.33\nDf Model: 9 \nCovariance Type: nonrobust \n===========================================================================================\n coef std err t P>|t| [0.025 0.975]\n-------------------------------------------------------------------------------------------\nIntercept 1.5308 0.056 27.340 0.000 1.415 1.647\nmodel[T.ideal_sim] 0.2407 0.075 3.205 0.004 0.085 0.396\ndevice[T.ibmq_belem] 0.3004 0.104 2.899 0.008 0.085 0.515\ndevice[T.ibmq_lima] 0.6567 0.094 7.013 0.000 0.462 0.851\ndevice[T.ibmq_ourense] 0.3122 0.093 3.366 0.003 0.120 0.505\ndevice[T.ibmq_quito] 1.0387 0.104 10.020 0.000 0.824 1.254\ndevice[T.ibmq_santiago] -0.1285 0.150 -0.855 0.402 -0.440 0.183\ndevice[T.ibmq_valencia] 0.1604 0.104 1.536 0.139 -0.056 0.377\ndevice[T.ibmq_vigo] 0.1078 0.104 1.040 0.310 -0.107 0.323\nid_gates 0.0020 0.000 6.959 0.000 0.001 0.003\nfidelity 1.1563 0.041 27.935 0.000 1.070 1.242\nQV 0.0152 0.005 2.796 0.011 0.004 0.026\n==============================================================================\nOmnibus: 2.598 Durbin-Watson: 1.933\nProb(Omnibus): 0.273 Jarque-Bera (JB): 1.371\nSkew: 0.412 Prob(JB): 0.504\nKurtosis: 3.592 Cond. No. 5.00e+18\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The smallest eigenvalue is 4.22e-32. This might indicate that there are\nstrong multicollinearity problems or that the design matrix is singular.\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02ad73d6416b0e7d2b3c0eab95ccde0a3a09945
| 10,765 |
ipynb
|
Jupyter Notebook
|
Projects/p2_continuous-control/.ipynb_checkpoints/DDPG_with_20_Agent-checkpoint.ipynb
|
Clara-YR/Udacity-DRL
|
6736605f6cb47b7fac8ae950ea785f366758e0f1
|
[
"MIT"
] | null | null | null |
Projects/p2_continuous-control/.ipynb_checkpoints/DDPG_with_20_Agent-checkpoint.ipynb
|
Clara-YR/Udacity-DRL
|
6736605f6cb47b7fac8ae950ea785f366758e0f1
|
[
"MIT"
] | null | null | null |
Projects/p2_continuous-control/.ipynb_checkpoints/DDPG_with_20_Agent-checkpoint.ipynb
|
Clara-YR/Udacity-DRL
|
6736605f6cb47b7fac8ae950ea785f366758e0f1
|
[
"MIT"
] | null | null | null | 32.920489 | 389 | 0.54993 |
[
[
[
"# Continuous Control\n\n---\n\n## 1. Import the Necessary Packages",
"_____no_output_____"
]
],
[
[
"from unityagents import UnityEnvironment\nimport random\nimport torch\nimport numpy as np\nfrom collections import deque\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"from ddpg_agent import Agent",
"_____no_output_____"
]
],
[
[
"## 2. Instantiate the Environment and 20 Agents",
"_____no_output_____"
]
],
[
[
"# initialize the environment\nenv = UnityEnvironment(file_name='./Reacher_20.app')\n\n# get the default brain\nbrain_name = env.brain_names[0]\nbrain = env.brains[brain_name]",
"INFO:unityagents:\n'Academy' started successfully!\nUnity Academy name: Academy\n Number of Brains: 1\n Number of External Brains : 1\n Lesson number : 0\n Reset Parameters :\n\t\tgoal_speed -> 1.0\n\t\tgoal_size -> 5.0\nUnity brain name: ReacherBrain\n Number of Visual Observations (per agent): 0\n Vector Observation space type: continuous\n Vector Observation space size (per agent): 33\n Number of stacked Vector Observation: 1\n Vector Action space type: continuous\n Vector Action space size (per agent): 4\n Vector Action descriptions: , , , \n"
],
[
"# reset the environment\nenv_info = env.reset(train_mode=True)[brain_name]\n\n# number of agents\nnum_agents = len(env_info.agents)\nprint('Number of agents:', num_agents)\n\n# size of each action\naction_size = brain.vector_action_space_size\nprint('Size of each action:', action_size)\n\n# examine the state space \nstates = env_info.vector_observations\nstate_size = states.shape[1]\nprint('There are {} agents. Each observes a state with length: {}'.format(states.shape[0], state_size))\nprint('The state for the first agent looks like:', states[0])",
"Number of agents: 20\nSize of each action: 4\nThere are 20 agents. Each observes a state with length: 33\nThe state for the first agent looks like: [ 0.00000000e+00 -4.00000000e+00 0.00000000e+00 1.00000000e+00\n -0.00000000e+00 -0.00000000e+00 -4.37113883e-08 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 -1.00000000e+01 0.00000000e+00\n 1.00000000e+00 -0.00000000e+00 -0.00000000e+00 -4.37113883e-08\n 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 5.75471878e+00 -1.00000000e+00\n 5.55726624e+00 0.00000000e+00 1.00000000e+00 0.00000000e+00\n -1.68164849e-01]\n"
],
[
"# initialize agents\nagent = Agent(state_size=33, \n action_size=4, \n random_seed=2, \n num_agents=20)",
"_____no_output_____"
]
],
[
[
"## 3. Train the 20 Agents with DDPG\n\nTo amend the `ddpg` code to work for 20 agents instead of 1, here are the modifications I did in `ddpg_agent.py`:\n\n- With each step, each agent adds its experience to a replay buffer shared by all agents (line 61-61).\n- At first, the (local) actor and critic networks are updated 20 times in a row (one for each agent), using 20 different samples from the replay buffer as below:\n```\ndef step(self, states, actions, rewards, next_states, dones):\n ...\n # Learn (with each agent), if enough samples are available in memory\n if len(self.memory) > BATCH_SIZE:\n for i in range(self.num_agents):\n experiences = self.memory.sample()\n self.learn(experiences, GAMMA)\n```\n Then in order to get less aggressive with the number of updates per time step, instead of updating the actor and critic networks __20 times__ at __every timestep__, we amended the code to update the networks __10 times__ after every __20 timesteps__ (line )",
"_____no_output_____"
]
],
[
[
"def ddpg(n_episodes=1000, max_t=300, print_every=100, \n num_agents=1):\n \"\"\"\n Params\n ======\n n_episodes (int): maximum number of training episodes\n max_t (int): maximum number of timesteps per episode\n print_every (int): episodes interval to print training scores\n num_agents (int): the number of agents\n \"\"\"\n scores_deque = deque(maxlen=print_every)\n scores = []\n \n for i_episode in range(1, n_episodes+1):\n # reset the environment\n env_info = env.reset(train_mode=True)[brain_name]\n # get the current state (for each agent)\n states = env_info.vector_observations\n # initialize the scores (for each agent) of the current episode\n scores_i = np.zeros(num_agents)\n for t in range(max_t):\n # select an action (for each agent)\n actions = agent.act(states)\n # send action to the environment\n env_info = env.step(actions)[brain_name]\n # get the next_state, reward, done (for each agent)\n next_states = env_info.vector_observations\n rewards = env_info.rewards\n dones = env_info.local_done\n # store experience and train the agent\n agent.step(states, actions, rewards, next_states, dones, \n update_every=20, update_times=10)\n # roll over state to next time step\n states = next_states\n # update the score\n scores_i += rewards\n # exit loop if episode finished\n if np.any(dones):\n break \n # save average of the most recent scores\n scores_deque.append(scores_i.mean())\n scores.append(scores_i.mean())\n \n print('\\rEpisode {}\\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)), end=\"\")\n torch.save(agent.actor_local.state_dict(), 'd')\n torch.save(agent.critic_local.state_dict(), 'checkpoint_critic.pth')\n if i_episode % print_every == 0:\n print('\\rEpisode {}\\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))\n \n return scores",
"_____no_output_____"
],
[
"scores = ddpg(n_episodes=200, max_t=1000, print_every=20, num_agents=20)\n\nfig = plt.figure()\nax = fig.add_subplot(111)\nplt.plot(np.arange(1, len(scores)+1), scores)\nplt.ylabel('Score')\nplt.xlabel('Episode #')\nplt.show()\nplt.savefig('ddpg_20_agents.png')",
"Episode 20\tAverage Score: 0.55\nEpisode 40\tAverage Score: 0.64\nEpisode 60\tAverage Score: 0.84\nEpisode 80\tAverage Score: 0.51\nEpisode 96\tAverage Score: 0.55"
],
[
"#env.close()",
"_____no_output_____"
],
[
"# load Actor-Critic policy\nagent.actor_local.state_dict() = torch.load('checkpoint_actor.pth')\nagent.critic_local.state_dict() = torch.load('checkpoint_critic.pth')\n\nscores = ddpg(n_episodes=100, max_t=300, print_every=10, num_agents=20)\n\nfig = plt.figure()\nax = fig.add_subplot(111)\nplt.plot(np.arange(1, len(scores)+1), scores)\nplt.ylabel('Score')\nplt.xlabel('Episode #')\nplt.show()\nplt.savefig('ddpg_20_agents_101to200.png')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d02ad9e24b3748683cb9b8ad60b09c81f062e549
| 60,793 |
ipynb
|
Jupyter Notebook
|
Datascience_With_Python/Machine Learning/Algorithms/Optics Clustering Algorithm/optics_clustering_algorithm.ipynb
|
vishnupriya129/winter-of-contributing
|
8632c74d0c2d55bb4fddee9d6faac30159f376e1
|
[
"MIT"
] | 1,078 |
2021-09-05T09:44:33.000Z
|
2022-03-27T01:16:02.000Z
|
Datascience_With_Python/Machine Learning/Algorithms/Optics Clustering Algorithm/optics_clustering_algorithm.ipynb
|
vishnupriya129/winter-of-contributing
|
8632c74d0c2d55bb4fddee9d6faac30159f376e1
|
[
"MIT"
] | 6,845 |
2021-09-05T12:49:50.000Z
|
2022-03-12T16:41:13.000Z
|
Datascience_With_Python/Machine Learning/Algorithms/Optics Clustering Algorithm/optics_clustering_algorithm.ipynb
|
vishnupriya129/winter-of-contributing
|
8632c74d0c2d55bb4fddee9d6faac30159f376e1
|
[
"MIT"
] | 2,629 |
2021-09-03T04:53:16.000Z
|
2022-03-20T17:45:00.000Z
| 160.403694 | 26,572 | 0.886007 |
[
[
[
"# **OPTICS Algorithm**",
"_____no_output_____"
],
[
"Ordering Points to Identify the Clustering Structure (OPTICS) is a Clustering Algorithm which locates region of high density that are seperated from one another by regions of low density.",
"_____no_output_____"
],
[
"For using this library in Python this comes under Scikit Learn Library.",
"_____no_output_____"
],
[
"## Parameters:\t\n**Reachability Distance** -It is defined with respect to another data point q(Let). The Reachability distance between a point p and q is the maximum of the Core Distance of p and the Euclidean Distance(or some other distance metric) between p and q. Note that The Reachability Distance is not defined if q is not a Core point.<br><br>\n**Core Distance** – It is the minimum value of radius required to classify a given point as a core point. If the given point is not a Core point, then it’s Core Distance is undefined.",
"_____no_output_____"
],
[
"## OPTICS Pointers\n<ol>\n <li>Produces a special order of the database with respect to its density-based clustering structure.This cluster-ordering contains info equivalent to the density-based clustering corresponding to a broad range of parameter settings.</li>\n <li>Good for both automatic and interactive cluster analysis, including finding intrinsic clustering structure</li>\n <li>Can be represented graphically or using visualization technique</li>\n</ol> \n",
"_____no_output_____"
],
[
"In this file , we will showcase how a basic OPTICS Algorithm works in Python , on a randomly created Dataset.",
"_____no_output_____"
],
[
"## Importing Libraries",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt #Used for plotting graphs\r\nfrom sklearn.datasets import make_blobs #Used for creating random dataset\r\nfrom sklearn.cluster import OPTICS #OPTICS is provided under Scikit-Learn Extra\r\nfrom sklearn.metrics import silhouette_score #silhouette score for checking accuracy\r\nimport numpy as np \r\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"## Generating Data",
"_____no_output_____"
]
],
[
[
"data, clusters = make_blobs(\r\n n_samples=800, centers=4, cluster_std=0.3, random_state=0\r\n)",
"_____no_output_____"
],
[
"# Originally created plot with data\r\nplt.scatter(data[:,0], data[:,1])\r\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Model Creation",
"_____no_output_____"
]
],
[
[
"# Creating OPTICS Model\r\noptics_model = OPTICS(min_samples=50, xi=.05, min_cluster_size=.05) \r\n#min_samples : The number of samples in a neighborhood for a point to be considered as a core point. \r\n#xi : Determines the minimum steepness on the reachability plot that constitutes a cluster boundary\r\n#min_cluster_size : Minimum number of samples in an OPTICS cluster, expressed as an absolute number or a fraction of the number of samples",
"_____no_output_____"
],
[
"pred =optics_model.fit(data) #Fitting the data",
"_____no_output_____"
],
[
"optics_labels = optics_model.labels_ #storing labels predicted by our model",
"_____no_output_____"
],
[
"no_clusters = len(np.unique(optics_labels) ) #determining the no. of unique clusters and noise our model predicted\r\nno_noise = np.sum(np.array(optics_labels) == -1, axis=0)",
"_____no_output_____"
]
],
[
[
"## Plotting our observations",
"_____no_output_____"
]
],
[
[
"print('Estimated no. of clusters: %d' % no_clusters)\r\nprint('Estimated no. of noise points: %d' % no_noise)",
"Estimated no. of clusters: 4\nEstimated no. of noise points: 0\n"
],
[
"colors = list(map(lambda x: '#aa2211' if x == 1 else '#120416', optics_labels))\r\nplt.scatter(data[:,0], data[:,1], c=colors, marker=\"o\", picker=True)\r\nplt.title(f'OPTICS clustering')\r\nplt.xlabel('Axis X[0]')\r\nplt.ylabel('Axis X[1]')\r\nplt.show()",
"_____no_output_____"
],
[
"# Generate reachability plot , this helps understand the working of our Model in OPTICS\r\nreachability = optics_model.reachability_[optics_model.ordering_]\r\nplt.plot(reachability)\r\nplt.title('Reachability plot')\r\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Accuracy of OPTICS Clustering",
"_____no_output_____"
]
],
[
[
"OPTICS_score = silhouette_score(data, optics_labels)\r\nOPTICS_score",
"_____no_output_____"
]
],
[
[
"On this randomly created dataset we got an accuracy of 84.04 %",
"_____no_output_____"
],
[
"### Hence , we can see the implementation of OPTICS Clustering Algorithm on a randomly created Dataset .As we can observe from our result . the score which we got is around 84% , which is really good for a unsupervised learning algorithm.However , this accuracy definitely comes with the additonal cost of higher computational power",
"_____no_output_____"
],
[
"## Thanks a lot!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d02adaed247be5cdea2c6bbe74a4047c33c877e7
| 659,831 |
ipynb
|
Jupyter Notebook
|
Pokemon API.ipynb
|
kosmaspanag/api_work
|
228a24a2532fb0a640897e25334b7882a00f1433
|
[
"MIT"
] | null | null | null |
Pokemon API.ipynb
|
kosmaspanag/api_work
|
228a24a2532fb0a640897e25334b7882a00f1433
|
[
"MIT"
] | null | null | null |
Pokemon API.ipynb
|
kosmaspanag/api_work
|
228a24a2532fb0a640897e25334b7882a00f1433
|
[
"MIT"
] | null | null | null | 105.539187 | 282,749 | 0.552508 |
[
[
[
"import requests",
"_____no_output_____"
],
[
"response = requests.get('https://pokeapi.co/api/v2/pokemon/snorlax')\nsnorlax = response.json()\nsnorlax['weight']",
"_____no_output_____"
],
[
"print(response.text)",
"{\"abilities\":[{\"ability\":{\"name\":\"gluttony\",\"url\":\"https://pokeapi.co/api/v2/ability/82/\"},\"is_hidden\":true,\"slot\":3},{\"ability\":{\"name\":\"thick-fat\",\"url\":\"https://pokeapi.co/api/v2/ability/47/\"},\"is_hidden\":false,\"slot\":2},{\"ability\":{\"name\":\"immunity\",\"url\":\"https://pokeapi.co/api/v2/ability/17/\"},\"is_hidden\":false,\"slot\":1}],\"base_experience\":189,\"forms\":[{\"name\":\"snorlax\",\"url\":\"https://pokeapi.co/api/v2/pokemon-form/143/\"}],\"game_indices\":[{\"game_index\":143,\"version\":{\"name\":\"white-2\",\"url\":\"https://pokeapi.co/api/v2/version/22/\"}},{\"game_index\":143,\"version\":{\"name\":\"black-2\",\"url\":\"https://pokeapi.co/api/v2/version/21/\"}},{\"game_index\":143,\"version\":{\"name\":\"white\",\"url\":\"https://pokeapi.co/api/v2/version/18/\"}},{\"game_index\":143,\"version\":{\"name\":\"black\",\"url\":\"https://pokeapi.co/api/v2/version/17/\"}},{\"game_index\":143,\"version\":{\"name\":\"soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version/16/\"}},{\"game_index\":143,\"version\":{\"name\":\"heartgold\",\"url\":\"https://pokeapi.co/api/v2/version/15/\"}},{\"game_index\":143,\"version\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version/14/\"}},{\"game_index\":143,\"version\":{\"name\":\"pearl\",\"url\":\"https://pokeapi.co/api/v2/version/13/\"}},{\"game_index\":143,\"version\":{\"name\":\"diamond\",\"url\":\"https://pokeapi.co/api/v2/version/12/\"}},{\"game_index\":143,\"version\":{\"name\":\"leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version/11/\"}},{\"game_index\":143,\"version\":{\"name\":\"firered\",\"url\":\"https://pokeapi.co/api/v2/version/10/\"}},{\"game_index\":143,\"version\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version/9/\"}},{\"game_index\":143,\"version\":{\"name\":\"sapphire\",\"url\":\"https://pokeapi.co/api/v2/version/8/\"}},{\"game_index\":143,\"version\":{\"name\":\"ruby\",\"url\":\"https://pokeapi.co/api/v2/version/7/\"}},{\"game_index\":143,\"version\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version/6/\"}},{\"game_index\":143,\"version\":{\"name\":\"silver\",\"url\":\"https://pokeapi.co/api/v2/version/5/\"}},{\"game_index\":143,\"version\":{\"name\":\"gold\",\"url\":\"https://pokeapi.co/api/v2/version/4/\"}},{\"game_index\":132,\"version\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version/3/\"}},{\"game_index\":132,\"version\":{\"name\":\"blue\",\"url\":\"https://pokeapi.co/api/v2/version/2/\"}},{\"game_index\":132,\"version\":{\"name\":\"red\",\"url\":\"https://pokeapi.co/api/v2/version/1/\"}}],\"height\":21,\"held_items\":[{\"item\":{\"name\":\"chesto-berry\",\"url\":\"https://pokeapi.co/api/v2/item/127/\"},\"version_details\":[{\"rarity\":100,\"version\":{\"name\":\"leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version/11/\"}},{\"rarity\":100,\"version\":{\"name\":\"firered\",\"url\":\"https://pokeapi.co/api/v2/version/10/\"}}]},{\"item\":{\"name\":\"leftovers\",\"url\":\"https://pokeapi.co/api/v2/item/211/\"},\"version_details\":[{\"rarity\":5,\"version\":{\"name\":\"ultra-sun\",\"url\":\"https://pokeapi.co/api/v2/version/29/\"}},{\"rarity\":5,\"version\":{\"name\":\"moon\",\"url\":\"https://pokeapi.co/api/v2/version/28/\"}},{\"rarity\":100,\"version\":{\"name\":\"y\",\"url\":\"https://pokeapi.co/api/v2/version/24/\"}},{\"rarity\":100,\"version\":{\"name\":\"x\",\"url\":\"https://pokeapi.co/api/v2/version/23/\"}},{\"rarity\":100,\"version\":{\"name\":\"white-2\",\"url\":\"https://pokeapi.co/api/v2/version/22/\"}},{\"rarity\":100,\"version\":{\"name\":\"black-2\",\"url\":\"https://pokeapi.co/api/v2/version/21/\"}},{\"rarity\":100,\"version\":{\"name\":\"white\",\"url\":\"https://pokeapi.co/api/v2/version/18/\"}},{\"rarity\":100,\"version\":{\"name\":\"black\",\"url\":\"https://pokeapi.co/api/v2/version/17/\"}},{\"rarity\":100,\"version\":{\"name\":\"soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version/16/\"}},{\"rarity\":100,\"version\":{\"name\":\"heartgold\",\"url\":\"https://pokeapi.co/api/v2/version/15/\"}},{\"rarity\":100,\"version\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version/14/\"}},{\"rarity\":100,\"version\":{\"name\":\"pearl\",\"url\":\"https://pokeapi.co/api/v2/version/13/\"}},{\"rarity\":100,\"version\":{\"name\":\"diamond\",\"url\":\"https://pokeapi.co/api/v2/version/12/\"}},{\"rarity\":100,\"version\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version/9/\"}},{\"rarity\":100,\"version\":{\"name\":\"sapphire\",\"url\":\"https://pokeapi.co/api/v2/version/8/\"}},{\"rarity\":100,\"version\":{\"name\":\"ruby\",\"url\":\"https://pokeapi.co/api/v2/version/7/\"}}]}],\"id\":143,\"is_default\":true,\"location_area_encounters\":\"https://pokeapi.co/api/v2/pokemon/143/encounters\",\"moves\":[{\"move\":{\"name\":\"mega-punch\",\"url\":\"https://pokeapi.co/api/v2/move/5/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}}]},{\"move\":{\"name\":\"pay-day\",\"url\":\"https://pokeapi.co/api/v2/move/6/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"fire-punch\",\"url\":\"https://pokeapi.co/api/v2/move/7/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"ice-punch\",\"url\":\"https://pokeapi.co/api/v2/move/8/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"thunder-punch\",\"url\":\"https://pokeapi.co/api/v2/move/9/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"whirlwind\",\"url\":\"https://pokeapi.co/api/v2/move/18/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"mega-kick\",\"url\":\"https://pokeapi.co/api/v2/move/25/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}}]},{\"move\":{\"name\":\"headbutt\",\"url\":\"https://pokeapi.co/api/v2/move/29/\"},\"version_group_details\":[{\"level_learned_at\":19,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":19,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":19,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":19,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":29,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":29,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"tackle\",\"url\":\"https://pokeapi.co/api/v2/move/33/\"},\"version_group_details\":[{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}}]},{\"move\":{\"name\":\"body-slam\",\"url\":\"https://pokeapi.co/api/v2/move/34/\"},\"version_group_details\":[{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":43,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":43,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":35,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":35,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"take-down\",\"url\":\"https://pokeapi.co/api/v2/move/36/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"double-edge\",\"url\":\"https://pokeapi.co/api/v2/move/38/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":48,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":48,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"flamethrower\",\"url\":\"https://pokeapi.co/api/v2/move/53/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}}]},{\"move\":{\"name\":\"water-gun\",\"url\":\"https://pokeapi.co/api/v2/move/55/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"surf\",\"url\":\"https://pokeapi.co/api/v2/move/57/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"ice-beam\",\"url\":\"https://pokeapi.co/api/v2/move/58/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"blizzard\",\"url\":\"https://pokeapi.co/api/v2/move/59/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"bubble-beam\",\"url\":\"https://pokeapi.co/api/v2/move/61/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"hyper-beam\",\"url\":\"https://pokeapi.co/api/v2/move/63/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":51,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":51,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":53,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":51,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":51,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":56,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":56,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"submission\",\"url\":\"https://pokeapi.co/api/v2/move/66/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"counter\",\"url\":\"https://pokeapi.co/api/v2/move/68/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"seismic-toss\",\"url\":\"https://pokeapi.co/api/v2/move/69/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}}]},{\"move\":{\"name\":\"strength\",\"url\":\"https://pokeapi.co/api/v2/move/70/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"solar-beam\",\"url\":\"https://pokeapi.co/api/v2/move/76/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"thunderbolt\",\"url\":\"https://pokeapi.co/api/v2/move/85/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"thunder\",\"url\":\"https://pokeapi.co/api/v2/move/87/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"earthquake\",\"url\":\"https://pokeapi.co/api/v2/move/89/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"fissure\",\"url\":\"https://pokeapi.co/api/v2/move/90/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"toxic\",\"url\":\"https://pokeapi.co/api/v2/move/92/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"psychic\",\"url\":\"https://pokeapi.co/api/v2/move/94/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"rage\",\"url\":\"https://pokeapi.co/api/v2/move/99/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"mimic\",\"url\":\"https://pokeapi.co/api/v2/move/102/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"double-team\",\"url\":\"https://pokeapi.co/api/v2/move/104/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"harden\",\"url\":\"https://pokeapi.co/api/v2/move/106/\"},\"version_group_details\":[{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"defense-curl\",\"url\":\"https://pokeapi.co/api/v2/move/111/\"},\"version_group_details\":[{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":10,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":10,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":10,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":10,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":4,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"reflect\",\"url\":\"https://pokeapi.co/api/v2/move/115/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"bide\",\"url\":\"https://pokeapi.co/api/v2/move/117/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"metronome\",\"url\":\"https://pokeapi.co/api/v2/move/118/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}}]},{\"move\":{\"name\":\"self-destruct\",\"url\":\"https://pokeapi.co/api/v2/move/120/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}}]},{\"move\":{\"name\":\"lick\",\"url\":\"https://pokeapi.co/api/v2/move/122/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":12,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"fire-blast\",\"url\":\"https://pokeapi.co/api/v2/move/126/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"skull-bash\",\"url\":\"https://pokeapi.co/api/v2/move/130/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"amnesia\",\"url\":\"https://pokeapi.co/api/v2/move/133/\"},\"version_group_details\":[{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":8,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":8,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":6,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":6,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":5,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":6,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":6,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":9,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"psywave\",\"url\":\"https://pokeapi.co/api/v2/move/149/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}}]},{\"move\":{\"name\":\"rest\",\"url\":\"https://pokeapi.co/api/v2/move/156/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":1,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"rock-slide\",\"url\":\"https://pokeapi.co/api/v2/move/157/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}}]},{\"move\":{\"name\":\"substitute\",\"url\":\"https://pokeapi.co/api/v2/move/164/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"yellow\",\"url\":\"https://pokeapi.co/api/v2/version-group/2/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"red-blue\",\"url\":\"https://pokeapi.co/api/v2/version-group/1/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"snore\",\"url\":\"https://pokeapi.co/api/v2/move/173/\"},\"version_group_details\":[{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":29,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"curse\",\"url\":\"https://pokeapi.co/api/v2/move/174/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"protect\",\"url\":\"https://pokeapi.co/api/v2/move/182/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"belly-drum\",\"url\":\"https://pokeapi.co/api/v2/move/187/\"},\"version_group_details\":[{\"level_learned_at\":22,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":22,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":13,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":15,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"mud-slap\",\"url\":\"https://pokeapi.co/api/v2/move/189/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}}]},{\"move\":{\"name\":\"zap-cannon\",\"url\":\"https://pokeapi.co/api/v2/move/192/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}}]},{\"move\":{\"name\":\"icy-wind\",\"url\":\"https://pokeapi.co/api/v2/move/196/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}}]},{\"move\":{\"name\":\"outrage\",\"url\":\"https://pokeapi.co/api/v2/move/200/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"sandstorm\",\"url\":\"https://pokeapi.co/api/v2/move/201/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"endure\",\"url\":\"https://pokeapi.co/api/v2/move/203/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"charm\",\"url\":\"https://pokeapi.co/api/v2/move/204/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"rollout\",\"url\":\"https://pokeapi.co/api/v2/move/205/\"},\"version_group_details\":[{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":46,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":46,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":46,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":46,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"swagger\",\"url\":\"https://pokeapi.co/api/v2/move/207/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"attract\",\"url\":\"https://pokeapi.co/api/v2/move/213/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"sleep-talk\",\"url\":\"https://pokeapi.co/api/v2/move/214/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":37,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":33,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":28,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"return\",\"url\":\"https://pokeapi.co/api/v2/move/216/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"frustration\",\"url\":\"https://pokeapi.co/api/v2/move/218/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"dynamic-punch\",\"url\":\"https://pokeapi.co/api/v2/move/223/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}}]},{\"move\":{\"name\":\"pursuit\",\"url\":\"https://pokeapi.co/api/v2/move/228/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"hidden-power\",\"url\":\"https://pokeapi.co/api/v2/move/237/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"rain-dance\",\"url\":\"https://pokeapi.co/api/v2/move/240/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"sunny-day\",\"url\":\"https://pokeapi.co/api/v2/move/241/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"crunch\",\"url\":\"https://pokeapi.co/api/v2/move/242/\"},\"version_group_details\":[{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":44,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"psych-up\",\"url\":\"https://pokeapi.co/api/v2/move/244/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}}]},{\"move\":{\"name\":\"shadow-ball\",\"url\":\"https://pokeapi.co/api/v2/move/247/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"rock-smash\",\"url\":\"https://pokeapi.co/api/v2/move/249/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"crystal\",\"url\":\"https://pokeapi.co/api/v2/version-group/4/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"gold-silver\",\"url\":\"https://pokeapi.co/api/v2/version-group/3/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"whirlpool\",\"url\":\"https://pokeapi.co/api/v2/move/250/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}}]},{\"move\":{\"name\":\"facade\",\"url\":\"https://pokeapi.co/api/v2/move/263/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"focus-punch\",\"url\":\"https://pokeapi.co/api/v2/move/264/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"superpower\",\"url\":\"https://pokeapi.co/api/v2/move/276/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"recycle\",\"url\":\"https://pokeapi.co/api/v2/move/278/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"brick-break\",\"url\":\"https://pokeapi.co/api/v2/move/280/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"yawn\",\"url\":\"https://pokeapi.co/api/v2/move/281/\"},\"version_group_details\":[{\"level_learned_at\":24,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":24,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":21,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":24,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":24,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":20,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"secret-power\",\"url\":\"https://pokeapi.co/api/v2/move/290/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"hyper-voice\",\"url\":\"https://pokeapi.co/api/v2/move/304/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"rock-tomb\",\"url\":\"https://pokeapi.co/api/v2/move/317/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"block\",\"url\":\"https://pokeapi.co/api/v2/move/335/\"},\"version_group_details\":[{\"level_learned_at\":37,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":37,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":36,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":37,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":37,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":41,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"covet\",\"url\":\"https://pokeapi.co/api/v2/move/343/\"},\"version_group_details\":[{\"level_learned_at\":42,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":42,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":45,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":42,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":42,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"shock-wave\",\"url\":\"https://pokeapi.co/api/v2/move/351/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"water-pulse\",\"url\":\"https://pokeapi.co/api/v2/move/352/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"xd\",\"url\":\"https://pokeapi.co/api/v2/version-group/13/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"colosseum\",\"url\":\"https://pokeapi.co/api/v2/version-group/12/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"firered-leafgreen\",\"url\":\"https://pokeapi.co/api/v2/version-group/7/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"emerald\",\"url\":\"https://pokeapi.co/api/v2/version-group/6/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ruby-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/5/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"natural-gift\",\"url\":\"https://pokeapi.co/api/v2/move/363/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"fling\",\"url\":\"https://pokeapi.co/api/v2/move/374/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"last-resort\",\"url\":\"https://pokeapi.co/api/v2/move/387/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"seed-bomb\",\"url\":\"https://pokeapi.co/api/v2/move/402/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"focus-blast\",\"url\":\"https://pokeapi.co/api/v2/move/411/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"giga-impact\",\"url\":\"https://pokeapi.co/api/v2/move/416/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":35,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":35,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":49,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"zen-headbutt\",\"url\":\"https://pokeapi.co/api/v2/move/428/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"rock-climb\",\"url\":\"https://pokeapi.co/api/v2/move/431/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}}]},{\"move\":{\"name\":\"gunk-shot\",\"url\":\"https://pokeapi.co/api/v2/move/441/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"iron-head\",\"url\":\"https://pokeapi.co/api/v2/move/442/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"captivate\",\"url\":\"https://pokeapi.co/api/v2/move/445/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"heartgold-soulsilver\",\"url\":\"https://pokeapi.co/api/v2/version-group/10/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"platinum\",\"url\":\"https://pokeapi.co/api/v2/version-group/9/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"diamond-pearl\",\"url\":\"https://pokeapi.co/api/v2/version-group/8/\"}}]},{\"move\":{\"name\":\"smack-down\",\"url\":\"https://pokeapi.co/api/v2/move/479/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"heavy-slam\",\"url\":\"https://pokeapi.co/api/v2/move/484/\"},\"version_group_details\":[{\"level_learned_at\":52,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":52,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":50,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"after-you\",\"url\":\"https://pokeapi.co/api/v2/move/495/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"tutor\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/3/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"round\",\"url\":\"https://pokeapi.co/api/v2/move/496/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}}]},{\"move\":{\"name\":\"chip-away\",\"url\":\"https://pokeapi.co/api/v2/move/498/\"},\"version_group_details\":[{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":25,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":17,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"incinerate\",\"url\":\"https://pokeapi.co/api/v2/move/510/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"retaliate\",\"url\":\"https://pokeapi.co/api/v2/move/514/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}}]},{\"move\":{\"name\":\"bulldoze\",\"url\":\"https://pokeapi.co/api/v2/move/523/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}}]},{\"move\":{\"name\":\"work-up\",\"url\":\"https://pokeapi.co/api/v2/move/526/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"wild-charge\",\"url\":\"https://pokeapi.co/api/v2/move/528/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-white\",\"url\":\"https://pokeapi.co/api/v2/version-group/11/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"black-2-white-2\",\"url\":\"https://pokeapi.co/api/v2/version-group/14/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"belch\",\"url\":\"https://pokeapi.co/api/v2/move/562/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"confide\",\"url\":\"https://pokeapi.co/api/v2/move/590/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}}]},{\"move\":{\"name\":\"power-up-punch\",\"url\":\"https://pokeapi.co/api/v2/move/612/\"},\"version_group_details\":[{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"x-y\",\"url\":\"https://pokeapi.co/api/v2/version-group/15/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"machine\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/4/\"},\"version_group\":{\"name\":\"omega-ruby-alpha-sapphire\",\"url\":\"https://pokeapi.co/api/v2/version-group/16/\"}},{\"level_learned_at\":0,\"move_learn_method\":{\"name\":\"egg\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/2/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]},{\"move\":{\"name\":\"high-horsepower\",\"url\":\"https://pokeapi.co/api/v2/move/667/\"},\"version_group_details\":[{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"sun-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/17/\"}},{\"level_learned_at\":57,\"move_learn_method\":{\"name\":\"level-up\",\"url\":\"https://pokeapi.co/api/v2/move-learn-method/1/\"},\"version_group\":{\"name\":\"ultra-sun-ultra-moon\",\"url\":\"https://pokeapi.co/api/v2/version-group/18/\"}}]}],\"name\":\"snorlax\",\"order\":217,\"species\":{\"name\":\"snorlax\",\"url\":\"https://pokeapi.co/api/v2/pokemon-species/143/\"},\"sprites\":{\"back_default\":\"https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/back/143.png\",\"back_female\":null,\"back_shiny\":\"https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/back/shiny/143.png\",\"back_shiny_female\":null,\"front_default\":\"https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/143.png\",\"front_female\":null,\"front_shiny\":\"https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/shiny/143.png\",\"front_shiny_female\":null},\"stats\":[{\"base_stat\":30,\"effort\":0,\"stat\":{\"name\":\"speed\",\"url\":\"https://pokeapi.co/api/v2/stat/6/\"}},{\"base_stat\":110,\"effort\":0,\"stat\":{\"name\":\"special-defense\",\"url\":\"https://pokeapi.co/api/v2/stat/5/\"}},{\"base_stat\":65,\"effort\":0,\"stat\":{\"name\":\"special-attack\",\"url\":\"https://pokeapi.co/api/v2/stat/4/\"}},{\"base_stat\":65,\"effort\":0,\"stat\":{\"name\":\"defense\",\"url\":\"https://pokeapi.co/api/v2/stat/3/\"}},{\"base_stat\":110,\"effort\":0,\"stat\":{\"name\":\"attack\",\"url\":\"https://pokeapi.co/api/v2/stat/2/\"}},{\"base_stat\":160,\"effort\":2,\"stat\":{\"name\":\"hp\",\"url\":\"https://pokeapi.co/api/v2/stat/1/\"}}],\"types\":[{\"slot\":1,\"type\":{\"name\":\"normal\",\"url\":\"https://pokeapi.co/api/v2/type/1/\"}}],\"weight\":4600}\n"
],
[
"type(data)",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"data.keys()",
"_____no_output_____"
],
[
"data['weight']",
"_____no_output_____"
],
[
"#How much havier is Snorlax than Pikachu?\nresponse = requests.get('https://pokeapi.co/api/v2/pokemon/pikachu')\npikachu = response.json()\npikachu['weight']\n",
"_____no_output_____"
],
[
"snorlax['weight'] - pikachu['weight']",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02ae1e05cc1166900401c1bc6f5ee08df591cc6
| 126,246 |
ipynb
|
Jupyter Notebook
|
square_roots_intro.ipynb
|
izzetmert/lang_calc_2017
|
88e96dc7f1aab3533922a6fc9867b3b6194b4d82
|
[
"MIT"
] | null | null | null |
square_roots_intro.ipynb
|
izzetmert/lang_calc_2017
|
88e96dc7f1aab3533922a6fc9867b3b6194b4d82
|
[
"MIT"
] | null | null | null |
square_roots_intro.ipynb
|
izzetmert/lang_calc_2017
|
88e96dc7f1aab3533922a6fc9867b3b6194b4d82
|
[
"MIT"
] | null | null | null | 87.066207 | 18,280 | 0.836771 |
[
[
[
"%matplotlib in line\nimport matplotlib.pyplot as plt",
"UsageError: unrecognized arguments: line\n"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt ",
"_____no_output_____"
]
],
[
[
"# My First Square Roots",
"_____no_output_____"
],
[
"This is my first notebook where I am going to implement the Babylonian square root algorithm in Python.\\",
"_____no_output_____"
]
],
[
[
"variable = 6\n",
"_____no_output_____"
],
[
"variable\n",
"_____no_output_____"
],
[
"a = q = 1.5",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"1.5**2",
"_____no_output_____"
],
[
"1.25**2",
"_____no_output_____"
],
[
"u*u=2",
"_____no_output_____"
],
[
"u*u = 2\n",
"_____no_output_____"
],
[
"u**2 = 2",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
],
[
"s*s=33",
"_____no_output_____"
],
[
"q = 1",
"_____no_output_____"
],
[
"q",
"_____no_output_____"
],
[
"a=[1.5]\nfor i in range (10): \n next = a [i] + 2\n a.append(next)",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"2",
"_____no_output_____"
],
[
"a[0]",
"_____no_output_____"
],
[
"a[2.3]\n",
"_____no_output_____"
],
[
"a[0]",
"_____no_output_____"
],
[
"a[5]",
"_____no_output_____"
],
[
"a[0:5]",
"_____no_output_____"
],
[
"plt.plot(a)",
"_____no_output_____"
],
[
"plt.plot(a, 'o')\nplt.title(\"My First Sequence\")",
"_____no_output_____"
],
[
"b=[1.5]\nfor i in range (10): \n next = b [i] * 2\n b.append(next)",
"_____no_output_____"
],
[
"plt. plot(b, 'o')\nplt.title (\"My Second Sequence\")",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"plt.plot(a,'--o')\nplt.plot(b, '--o')\nplt.title (\"First and Second Sequence\")",
"_____no_output_____"
],
[
"a=[3]",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"a=[3]\nfor i in range (7): \n next = a[i]+1\n a.append(next)\n",
"_____no_output_____"
],
[
"a=[3]+1\nfor i in range (7): \n next = a[i]/2\n a.append(next)",
"_____no_output_____"
],
[
"a=[3]",
"_____no_output_____"
],
[
"a[0]+1",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"a.append(next)",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"a=[3]",
"_____no_output_____"
],
[
"a[0]+1",
"_____no_output_____"
],
[
"a.append(next)",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"a=[3]",
"_____no_output_____"
],
[
"a=[3]\nfor i in range(7):\n next = a[i]*1/2\n a.append(next)",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"plt.plot(a)\nplt.title('Sequence a')\nplt.xlabel('x')\nplt.ylabel('y')",
"_____no_output_____"
],
[
"b=[1/2]\nfor i in range (7)\nnext=b[i]+ 0.5**i\nb.append(next)",
"_____no_output_____"
],
[
"b=[1/2]\nfor i in range(7):\n next = b[i]+0.5**i\n a.append(next)",
"_____no_output_____"
],
[
"b=[1/2]",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"b=[1/2]\nfor i in range(70):\n next = b[i]+0.5**i\n b.append(next)",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"plt.plot(b)\nplt.title('Sequence b')\nplt.xlabel('x')\nplt.ylabel('y')",
"_____no_output_____"
],
[
"a**2=[2]",
"_____no_output_____"
],
[
"a=[2]",
"_____no_output_____"
],
[
"root a",
"_____no_output_____"
],
[
"a=[2]",
"_____no_output_____"
],
[
"sqrt(2)",
"_____no_output_____"
],
[
"import math\nmath.sqrt(x)",
"_____no_output_____"
],
[
"sqrt = x**1/2",
"_____no_output_____"
],
[
"x=[1.5]\nfor i in range(10):\n next = (x[i]+2/x[i])/2\n x.append(next)\n",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"plt.plot(x)\nplt.title('Sequence x')\nplt.xlabel('x')\nplt.ylabel('y')",
"_____no_output_____"
],
[
"x=[10]\nfor i in range(10):\n next = (x[i]+2/x[i])/2\n x.append(next)",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"plt.plot(x)\nplt.title('Sequence x')\nplt.xlabel('x')\nplt.ylabel('y')",
"_____no_output_____"
]
],
[
[
"x**2-2=0\nx**2=2\nx=√2\n1<√2<2\n1**2=1\n2**=4\n1.5**2=2.25\n1.25**=1.5625\n1.375**2=1.890625\n1.4375**2=2.06640625\n1.40625**2=1.9775390625",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02af0ceb15a0318111b4b35fd3a755c34b94b71
| 27,434 |
ipynb
|
Jupyter Notebook
|
Mathematics/Statistics/Statistics and Probability Python Notebooks/Computational and Inferential Thinking - The Foundations of Data Science (book)/Notebooks - by chapter/9. Randomness and Probabiltities/5. Finding_Probabilities.ipynb
|
okara83/Becoming-a-Data-Scientist
|
f09a15f7f239b96b77a2f080c403b2f3e95c9650
|
[
"MIT"
] | null | null | null |
Mathematics/Statistics/Statistics and Probability Python Notebooks/Computational and Inferential Thinking - The Foundations of Data Science (book)/Notebooks - by chapter/9. Randomness and Probabiltities/5. Finding_Probabilities.ipynb
|
okara83/Becoming-a-Data-Scientist
|
f09a15f7f239b96b77a2f080c403b2f3e95c9650
|
[
"MIT"
] | null | null | null |
Mathematics/Statistics/Statistics and Probability Python Notebooks/Computational and Inferential Thinking - The Foundations of Data Science (book)/Notebooks - by chapter/9. Randomness and Probabiltities/5. Finding_Probabilities.ipynb
|
okara83/Becoming-a-Data-Scientist
|
f09a15f7f239b96b77a2f080c403b2f3e95c9650
|
[
"MIT"
] | 2 |
2022-02-09T15:41:33.000Z
|
2022-02-11T07:47:40.000Z
| 60.560706 | 11,612 | 0.721149 |
[
[
[
"from datascience import *\npath_data = '../data/'\nimport numpy as np\nimport matplotlib.pyplot as plots\nplots.style.use('fivethirtyeight')\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Finding Probabilities\nOver the centuries, there has been considerable philosophical debate about what probabilities are. Some people think that probabilities are relative frequencies; others think they are long run relative frequencies; still others think that probabilities are a subjective measure of their own personal degree of uncertainty.\n\nIn this course, most probabilities will be relative frequencies, though many will have subjective interpretations. Regardless, the ways in which probabilities are calculated and combined are consistent across the different interpretations.\n\nBy convention, probabilities are numbers between 0 and 1, or, equivalently, 0% and 100%. Impossible events have probability 0. Events that are certain have probability 1.\n\nMath is the main tool for finding probabilities exactly, though computers are useful for this purpose too. Simulation can provide excellent approximations, with high probability. In this section, we will informally develop a few simple rules that govern the calculation of probabilities. In subsequent sections we will return to simulations to approximate probabilities of complex events.\n\nWe will use the standard notation $P(\\mbox{event})$ to denote the probability that \"event\" happens, and we will use the words \"chance\" and \"probability\" interchangeably.",
"_____no_output_____"
],
[
"## When an Event Doesn't Happen\nIf the chance that event happens is 40%, then the chance that it doesn't happen is 60%. This natural calculation can be described in general as follows:\n\n$$\nP(\\mbox{an event doesn't happen}) ~=~ 1 - P(\\mbox{the event happens})\n$$",
"_____no_output_____"
],
[
"## When All Outcomes are Equally Likely\nIf you are rolling an ordinary die, a natural assumption is that all six faces are equally likely. Under this assumption, the probabilities of how one roll comes out can be easily calculated as a ratio. For example, the chance that the die shows an even number is\n\n$$\n\\frac{\\mbox{number of even faces}}{\\mbox{number of all faces}}\n~=~ \\frac{\\#\\{2, 4, 6\\}}{\\#\\{1, 2, 3, 4, 5, 6\\}}\n~=~ \\frac{3}{6}\n$$\n\nSimilarly,\n\n$$\nP(\\mbox{die shows a multiple of 3}) ~=~\n\\frac{\\#\\{3, 6\\}}{\\#\\{1, 2, 3, 4, 5, 6\\}}\n~=~ \\frac{2}{6}\n$$",
"_____no_output_____"
],
[
"In general, **if all outcomes are equally likely**,\n\n$$\nP(\\mbox{an event happens}) ~=~\n\\frac{\\#\\{\\mbox{outcomes that make the event happen}\\}}\n{\\#\\{\\mbox{all outcomes}\\}}\n$$",
"_____no_output_____"
],
[
"Not all random phenomena are as simple as one roll of a die. The two main rules of probability, developed below, allow mathematicians to find probabilities even in complex situations.",
"_____no_output_____"
],
[
"## When Two Events Must Both Happen\nSuppose you have a box that contains three tickets: one red, one blue, and one green. Suppose you draw two tickets at random without replacement; that is, you shuffle the three tickets, draw one, shuffle the remaining two, and draw another from those two. What is the chance you get the green ticket first, followed by the red one?\n\nThere are six possible pairs of colors: RB, BR, RG, GR, BG, GB (we've abbreviated the names of each color to just its first letter). All of these are equally likely by the sampling scheme, and only one of them (GR) makes the event happen. So\n\n$$\nP(\\mbox{green first, then red}) ~=~ \n\\frac{\\#\\{\\mbox{GR}\\}}{\\#\\{\\mbox{RB, BR, RG, GR, BG, GB}\\}} ~=~ \\frac{1}{6}\n$$",
"_____no_output_____"
],
[
"But there is another way of arriving at the answer, by thinking about the event in two stages. First, the green ticket has to be drawn. That has chance $1/3$, which means that the green ticket is drawn first in about $1/3$ of all repetitions of the experiment. But that doesn't complete the event. *Among the 1/3 of repetitions when green is drawn first*, the red ticket has to be drawn next. That happens in about $1/2$ of those repetitions, and so:\n\n$$\nP(\\mbox{green first, then red}) ~=~ \\frac{1}{2} ~\\mbox{of}~ \\frac{1}{3}\n~=~ \\frac{1}{6}\n$$\n\nThis calculation is usually written \"in chronological order,\" as follows.\n\n$$\nP(\\mbox{green first, then red}) ~=~ \\frac{1}{3} ~\\times~ \\frac{1}{2}\n~=~ \\frac{1}{6}\n$$",
"_____no_output_____"
],
[
"The factor of $1/2$ is called \" the conditional chance that the red ticket appears second, given that the green ticket appeared first.\"\n\nIn general, we have the **multiplication rule**:\n\n$$\nP(\\mbox{two events both happen})\n~=~ P(\\mbox{one event happens}) \\times \nP(\\mbox{the other event happens, given that the first one happened})\n$$\n\nThus, when there are two conditions – one event must happen, as well as another – the chance is *a fraction of a fraction*, which is smaller than either of the two component fractions. The more conditions that have to be satisfied, the less likely they are to all be satisfied.",
"_____no_output_____"
],
[
"## When an Event Can Happen in Two Different Ways\nSuppose instead we want the chance that one of the two tickets is green and the other red. This event doesn't specify the order in which the colors must appear. So they can appear in either order. \n\nA good way to tackle problems like this is to *partition* the event so that it can happen in exactly one of several different ways. The natural partition of \"one green and one red\" is: GR, RG. \n\nEach of GR and RG has chance $1/6$ by the calculation above. So you can calculate the chance of \"one green and one red\" by adding them up.\n\n$$\nP(\\mbox{one green and one red}) ~=~ P(\\mbox{GR}) + P(\\mbox{RG}) ~=~ \n\\frac{1}{6} + \\frac{1}{6} ~=~ \\frac{2}{6}\n$$\n\nIn general, we have the **addition rule**:\n\n$$\nP(\\mbox{an event happens}) ~=~\nP(\\mbox{first way it can happen}) + P(\\mbox{second way it can happen}) ~~~\n\\mbox{}\n$$\n\nprovided the event happens in exactly one of the two ways.\n\nThus, when an event can happen in one of two different ways, the chance that it happens is a sum of chances, and hence bigger than the chance of either of the individual ways.",
"_____no_output_____"
],
[
"The multiplication rule has a natural extension to more than two events, as we will see below. So also the addition rule has a natural extension to events that can happen in one of several different ways.\n\nWe end the section with examples that use combinations of all these rules.",
"_____no_output_____"
],
[
"## At Least One Success\nData scientists often work with random samples from populations. A question that sometimes arises is about the likelihood that a particular individual in the population is selected to be in the sample. To work out the chance, that individual is called a \"success,\" and the problem is to find the chance that the sample contains a success.\n\nTo see how such chances might be calculated, we start with a simpler setting: tossing a coin two times.\n\nIf you toss a coin twice, there are four equally likely outcomes: HH, HT, TH, and TT. We have abbreviated \"Heads\" to H and \"Tails\" to T. The chance of getting at least one head in two tosses is therefore 3/4.\n\nAnother way of coming up with this answer is to work out what happens if you *don't* get at least one head. That is when both the tosses land tails. So\n\n$$\nP(\\mbox{at least one head in two tosses}) ~=~ 1 - P(\\mbox{both tails}) ~=~ 1 - \\frac{1}{4}\n~=~ \\frac{3}{4}\n$$\n\nNotice also that \n\n$$\nP(\\mbox{both tails}) ~=~ \\frac{1}{4} ~=~ \\frac{1}{2} \\cdot \\frac{1}{2} ~=~ \\left(\\frac{1}{2}\\right)^2\n$$\nby the multiplication rule.\n\nThese two observations allow us to find the chance of at least one head in any given number of tosses. For example,\n\n$$\nP(\\mbox{at least one head in 17 tosses}) ~=~ 1 - P(\\mbox{all 17 are tails})\n~=~ 1 - \\left(\\frac{1}{2}\\right)^{17}\n$$\n\nAnd now we are in a position to find the chance that the face with six spots comes up at least once in rolls of a die. \n\nFor example,\n\n$$\nP(\\mbox{a single roll is not 6}) ~=~ 1 - P(6)\n~=~ \\frac{5}{6}\n$$\n\nTherefore,\n\n$$\nP(\\mbox{at least one 6 in two rolls}) ~=~ 1 - P(\\mbox{both rolls are not 6})\n~=~ 1 - \\left(\\frac{5}{6}\\right)^2\n$$\n\nand\n\n$$\nP(\\mbox{at least one 6 in 17 rolls})\n~=~ 1 - \\left(\\frac{5}{6}\\right)^{17}\n$$\n\nThe table below shows these probabilities as the number of rolls increases from 1 to 50.",
"_____no_output_____"
]
],
[
[
"rolls = np.arange(1, 51, 1)\nresults = Table().with_columns(\n 'Rolls', rolls,\n 'Chance of at least one 6', 1 - (5/6)**rolls\n)\nresults",
"_____no_output_____"
]
],
[
[
"The chance that a 6 appears at least once rises rapidly as the number of rolls increases.",
"_____no_output_____"
]
],
[
[
"results.scatter('Rolls')",
"_____no_output_____"
]
],
[
[
"In 50 rolls, you are almost certain to get at least one 6.",
"_____no_output_____"
]
],
[
[
"results.where('Rolls', are.equal_to(50))",
"_____no_output_____"
]
],
[
[
"Calculations like these can be used to find the chance that a particular individual is selected in a random sample. The exact calculation will depend on the sampling scheme. But what we have observed above can usually be generalized: increasing the size of the random sample increases the chance that an individual is selected.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02af2050475e2ef04e8f962b643092c6e372c26
| 45,785 |
ipynb
|
Jupyter Notebook
|
Chapter7.ipynb
|
yangzhou95/notes
|
dcf70daf5cd3817a5f0aae3ec61530f457881b38
|
[
"Apache-2.0"
] | null | null | null |
Chapter7.ipynb
|
yangzhou95/notes
|
dcf70daf5cd3817a5f0aae3ec61530f457881b38
|
[
"Apache-2.0"
] | null | null | null |
Chapter7.ipynb
|
yangzhou95/notes
|
dcf70daf5cd3817a5f0aae3ec61530f457881b38
|
[
"Apache-2.0"
] | null | null | null | 20.935071 | 451 | 0.498526 |
[
[
[
"# ",
"_____no_output_____"
],
[
"# <p style=\"color:red\">Chapter 7</p>",
"_____no_output_____"
],
[
"### 1. What makes dictionaries different from sequence type containers like lists and tuples is the way the data are stored and accessed. \n",
"_____no_output_____"
],
[
"### 2.Sequence types use numeric keys only (numbered sequentially as indexed offsets from the beginning of the sequence). Mapping types may use most other object types as keys; strings are the most common. ",
"_____no_output_____"
],
[
"### 3.Hash tabel: They store each piece of data, called a value, based on an associated data item, called a key. \n\nHash tables generally provide good performance because lookups occur fairly quickly once you have a key.",
"_____no_output_____"
],
[
"### 4. Dictionary is an unordered collection of data.\n\nThe only kind of ordering you can obtain is by taking either a dictionary’s set of keys or values. The keys() or values() method returns lists, which are sortable. You can also call items() to get a list of keys and values as tuple pairs and sort that. Dictionaries themselves have no implicit ordering because they are hashes.",
"_____no_output_____"
],
[
"### 5.create dictionary\nThe syntax of a dictionary entry is key:value. Also, dictionary entries are enclosed in braces ( { } ).",
"_____no_output_____"
],
[
"#### a.dictionary can be created by using {} with K,V pairs",
"_____no_output_____"
]
],
[
[
"adict={}",
"_____no_output_____"
],
[
"bdict={\"k\":\"v\"}",
"_____no_output_____"
],
[
"bdict",
"_____no_output_____"
]
],
[
[
"#### b. another way to create dictionary is using dict() method (factory fucntion)",
"_____no_output_____"
]
],
[
[
"fdict = dict((['x', 1], ['y', 2]))",
"_____no_output_____"
],
[
"cdict=dict([(\"k1\",2),(\"k2\",3)])",
"_____no_output_____"
]
],
[
[
"#### c.dictionaries may also be created using a very convenient built-in method for creating a “default” dictionary whose elements all have the same value (defaulting to None if not given), fromkeys():",
"_____no_output_____"
]
],
[
[
"ddict = {}.fromkeys(('x', 'y'), -1)",
"_____no_output_____"
],
[
"ddict",
"_____no_output_____"
],
[
"ddict={}.fromkeys(('x','y'),(2,3))",
"_____no_output_____"
],
[
"ddict",
"_____no_output_____"
]
],
[
[
"### 6.How to Access Values in Dictionaries\nTo traverse a dictionary (normally by key), you only need to cycle through its keys, like this:",
"_____no_output_____"
]
],
[
[
"dict2 = {'name': 'earth', 'port': 80}\nfor key in dict2.keys():\n print(\"key=%s,value=%s\" %(key,dict2[key]))",
"key=name,value=earth\nkey=port,value=80\n"
]
],
[
[
"### a.Beginning with Python 2.2, you no longer need to use the keys() method to extract a list of keys to loop over. Iterators were created to simplify access- ing of sequence-like objects such as dictionaries and files. Using just the dictionary name itself will cause an iterator over that dictionary to be used in a for loop:\n",
"_____no_output_____"
]
],
[
[
"dict2 = {'name': 'earth', 'port': 80}\nfor key in dict2:\n print(\"key=%s,value=%s\" %(key,dict2[key]))",
"key=name,value=earth\nkey=port,value=80\n"
]
],
[
[
"#### b.To access individual dictionary elements, you use the familiar square brackets along with the key to obtain its value:",
"_____no_output_____"
]
],
[
[
"dict2['name']",
"_____no_output_____"
]
],
[
[
"#### b. If we attempt to access a data item with a key that is not part of the dictio- nary, we get an error:",
"_____no_output_____"
]
],
[
[
"dict['service']",
"_____no_output_____"
]
],
[
[
"## c. The best way to check if a dic- tionary has a specific key is to use the in or not in operators ",
"_____no_output_____"
]
],
[
[
"'service' in dict2",
"_____no_output_____"
]
],
[
[
"#### d. number can be the keys for dictionary",
"_____no_output_____"
]
],
[
[
"dict3 = {3.2: 'xyz', 1: 'abc', '1': 3.14159}",
"_____no_output_____"
]
],
[
[
"#### e. Not allowing keys to change during execution makes sense keys must be hashable, so numbers and strings are fine, but lists and other dictionaries are not. ",
"_____no_output_____"
],
[
"### 7. update and add new dictionary\n\n",
"_____no_output_____"
]
],
[
[
"dict2['port'] = 6969 # update existing entry or add new entry",
"_____no_output_____"
]
],
[
[
"#### a. the string format operator (%) is specific for dictionary",
"_____no_output_____"
]
],
[
[
"print('host %(name)s is running on port %(port)d' % dict2)",
"host earth is running on port 6969\n"
],
[
"dict2",
"_____no_output_____"
]
],
[
[
"### b. You may also add the contents of an entire dictionary to another dictionary by using the update() built-in method.3",
"_____no_output_____"
],
[
"### 8. remove dictionary elements:",
"_____no_output_____"
],
[
"#### a. use the del statement to delete an entire dictionary\n",
"_____no_output_____"
]
],
[
[
"del dict2['name'] # remove entry with key 'name'",
"_____no_output_____"
],
[
"dict2.pop('port') # remove and return entry with key",
"_____no_output_____"
],
[
"adict.clear() # remove all entries in adict",
"_____no_output_____"
],
[
"del bdict # delete entire dictionary",
"_____no_output_____"
]
],
[
[
"### Note: dict() is now a type and factory function, overriding it may cause you headaches and potential bugsDo NOT create variables with built-in names like: dict, list, file, bool, str, input, or len!",
"_____no_output_____"
],
[
"### 9.Dictionaries will work with all of the standard type operators but do not support operations such as concatenation and repetition. ",
"_____no_output_____"
],
[
"#### a.Dictionary Key-Lookup Operator ( [ ] ). The key-lookup operator is used for both assigning values to and retrieving values from a dictionary",
"_____no_output_____"
]
],
[
[
"adict={\"k\":2}\nadict[\"k\"] = 3 # set value in dictionary. Dictionary Key-Lookup Operator ( [ ] )",
"_____no_output_____"
],
[
"cdict = {'fruits':1}\nddict = {'fruits':1}",
"_____no_output_____"
]
],
[
[
"## 10. dict() function\n",
"_____no_output_____"
],
[
"### a. The dict() factory function is used for creating dictionaries. If no argument is provided, then an empty dictionary is created. The fun happens when a container object is passed in as an argument to dict().",
"_____no_output_____"
],
[
"#### dict()\n* dict() -> new empty dictionary\n\n\n* dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs\n\n\n* dict(iterable) -> new dictionary initialized as if via:\n d = {}\n for k, v in iterable:\n d[k] = v\n \n \n* dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2)\n",
"_____no_output_____"
]
],
[
[
"dict()",
"_____no_output_____"
],
[
"dict({'k':1,'k2':2})",
"_____no_output_____"
],
[
"dict([(1,2),(2,3)])",
"_____no_output_____"
],
[
"dict(((1,2),(2,3)))",
"_____no_output_____"
],
[
"dict(([2,3],[3,4]))",
"_____no_output_____"
],
[
"dict(zip(('x','y'),(1,2)))",
"_____no_output_____"
]
],
[
[
"### 11. If it is a(nother) mapping object, i.e., a dictionary, then dict() will just create a new dictionary and copy the contents of the existing one. The new dictionary is actually a shallow copy of the original one and the same results can be accomplished by using a dictionary’s copy() built-in method. Because creating a new dictionary from an existing one using dict() is measurably slower than using copy(), we recommend using the latter.",
"_____no_output_____"
],
[
"### 12.it is possible to call dict() with an existing dic- tionary or keyword argument dictionary ( function operator)",
"_____no_output_____"
]
],
[
[
"dict7=dict(x=1, y=2)",
"_____no_output_____"
],
[
"dict8 = dict(x=1, y=2)",
"_____no_output_____"
],
[
"dict9 = dict(**dict8) # not a realistic example, better use copy()",
"_____no_output_____"
],
[
"dict10=dict(dict7)",
"_____no_output_____"
],
[
"dict9",
"_____no_output_____"
],
[
"dict10",
"_____no_output_____"
],
[
"dict9 = dict8.copy() # better than dict9 = dict(**dict8)",
"_____no_output_____"
]
],
[
[
"### 13.The len() BIF is flexible. It works with sequences, mapping types, and sets",
"_____no_output_____"
]
],
[
[
"dict2 = {'name': 'earth', 'port': 80}\nlen(dict2)",
"_____no_output_____"
]
],
[
[
"### 14. We can see that above, when referencing dict2, the items are listed in reverse order from which they were entered into the dictionary. ??????",
"_____no_output_____"
]
],
[
[
"dict2 = {'name': 'earth', 'port': 80}",
"_____no_output_____"
],
[
"dict2",
"_____no_output_____"
]
],
[
[
"### 15.The hash() BIF is not really meant to be used for dictionaries per se, but it can be used to determine whether an object is fit to be a dictionary key (or not).\n\n* Given an object as its argument, hash() returns the hash value of that object.\n\n\n* Numeric val- ues that are equal hash to the same value.\n\n\n* A TypeError will occur if an unhashable type is given as the argument to hash()",
"_____no_output_____"
]
],
[
[
"hash([])",
"_____no_output_____"
],
[
"dict2={}",
"_____no_output_____"
],
[
"dict2[{}]=\"foo\"",
"_____no_output_____"
]
],
[
[
"### 16. Mapping Type Built-in Methods\n\n* has_key() and its replacements in and not in\n\n\n* keys(), which returns a list of the dictionary’s keys, \n\n\n* values(), which returns a list of the dictionary’s values, and\n\n\n* items(), which returns a list of (key, value) tuple pairs. \n\n\n",
"_____no_output_____"
]
],
[
[
"dict2={\"k1\":1,\"k2\":2,\"k3\":3}",
"_____no_output_____"
],
[
"for eachKey in dict2.keys():\n print(eachKey,dict2[eachKey])",
"k1 1\nk2 2\nk3 3\n"
]
],
[
[
"#### * dict.fromkeysc (seq, val=None): create dict where all the key in seq have teh same value val",
"_____no_output_____"
]
],
[
[
"{}.fromkeys((\"k1\",\"k2\",\"3\"),None) # fromkeysc(seq, val=None)",
"_____no_output_____"
]
],
[
[
"#### * get(key,default=None): return the value corresponding to key, otherwise return None if key is not in dictionary",
"_____no_output_____"
],
[
"#### * dict.setdefault (key, default=None): Similar to get(), but sets dict[key]=default if key is not already in dict",
"_____no_output_____"
],
[
"#### * dict.setdefault(key, default=None): Add the key-value pairs of dict2 to dict",
"_____no_output_____"
],
[
"#### * keys() method to get the list of its keys, then call that list’s sort() method to get a sorted list to iterate over. sorted(), made especially for iterators, exists, which returns a sorted iterator:",
"_____no_output_____"
]
],
[
[
"for eachKey in sorted(dict2):\n print(eachKey,dict2[eachKey])",
"k1 1\nk2 2\nk3 3\n"
]
],
[
[
"#### * The update() method can be used to add the contents of one dictionary to another. Any existing entries with duplicate keys will be overridden by the new incoming entries. Nonexistent ones will be added. All entries in a dictio- nary can be removed with the clear() method.",
"_____no_output_____"
]
],
[
[
"dict2",
"_____no_output_____"
],
[
"dict3={\"k1\":\"ka\",\"kb\":\"kb\"}",
"_____no_output_____"
],
[
"dict2.update(dict3)",
"_____no_output_____"
],
[
"dict2",
"_____no_output_____"
],
[
"dict3.clear()",
"_____no_output_____"
],
[
"dict3",
"_____no_output_____"
],
[
"del dict3",
"_____no_output_____"
],
[
"dict3",
"_____no_output_____"
]
],
[
[
"#### * The copy() method simply returns a copy of a dictionary. \n\n#### * the get() method is similar to using the key-lookup operator ( [ ] ), but allows you to provide a default value returned if a key does not exist. ",
"_____no_output_____"
]
],
[
[
"dict2",
"_____no_output_____"
],
[
"dict4=dict2.copy()",
"_____no_output_____"
],
[
"dict4",
"_____no_output_____"
],
[
"dict4.get('xgag')",
"_____no_output_____"
],
[
"type(dict4.get(\"agasg\"))",
"_____no_output_____"
],
[
"type(dict4.get(\"agasg\", \"no such key\"))",
"_____no_output_____"
],
[
"dict2",
"_____no_output_____"
]
],
[
[
"#### * f the dictionary does not have the key you are seeking, you want to set a default value and then return it. That is precisely what setdefault() does",
"_____no_output_____"
]
],
[
[
"dict2.setdefault('kk','k1')",
"_____no_output_____"
],
[
"dict2",
"_____no_output_____"
]
],
[
[
"#### * Currently,thekeys(),items(),andvalues()methodsreturnlists. This can be unwieldy if such data collections are large, and the main reason why iteritems(), iterkeys(), and itervalues() were added to Python",
"_____no_output_____"
],
[
"#### * In python3, iter*() names are no longer supported. The new keys(), values(), and items() all return views",
"_____no_output_____"
],
[
"#### * When key collisions are detected (meaning duplicate keys encountered during assignment), the last (most recent) assignment wins.",
"_____no_output_____"
]
],
[
[
"dict1 = {' foo':789, 'foo': 'xyz'}\ndict1",
"_____no_output_____"
],
[
"dict1['foo']",
"_____no_output_____"
]
],
[
[
"#### * most Python objects can serve as keys; however they have to be hashable objects—mutable types such as lists and dictionaries are disallowed because they cannot be hashed\n\n\n* All immutable types are hashable\n\n\n* Numbers of the same value represent the same key. In other words, the integer 1 and the float 1.0 hash to the same value, meaning that they are identical as keys.\n\n\n* there are some mutable objects that are (barely) hashable, so they are eligible as keys, but there are very few of them. One example would be a class that has implemented the __hash__() special method. In the end, an immutable value is used anyway as __hash__() must return an integer.\n\n\n* Why must keys be hashable? The hash function used by the interpreter to calculate where to store your data is based on the value of your key. If the key was a mutable object, its value could be changed. If a key changes, the hash function will map to a different place to store the data. If that was the case, then the hash function could never reliably store or retrieve the associated value\n\n\n* : Tuples are valid keys only if they only contain immutable arguments like numbers and strings.",
"_____no_output_____"
],
[
"### 19.A set object is an unordered collection of distinct values that are hashable.",
"_____no_output_____"
],
[
"#### a.Like other container types, sets support membership testing via in and not in operators, cardinality using the len()BIF, and iteration over the set membership using for loops. However, since sets are unordered, you do not index into or slice them, and there are no keys used to access a value.",
"_____no_output_____"
],
[
"#### b.There are two different types of sets available, mutable (set) and immuta- ble (frozenset).",
"_____no_output_____"
],
[
"#### c.Note that mutable sets are not hashable and thus cannot be used as either a dictionary key or as an element of another set. ",
"_____no_output_____"
],
[
"#### d.sets module and accessed via the ImmutableSet and Set classes.",
"_____no_output_____"
],
[
"#### d. sets can be created, using their factory functions set() and frozenset():",
"_____no_output_____"
]
],
[
[
"s1=set('asgag')",
"_____no_output_____"
],
[
"s2=frozenset('sbag')",
"_____no_output_____"
],
[
"len(s1)",
"_____no_output_____"
],
[
"type(s1)",
"_____no_output_____"
],
[
"type(s2)",
"_____no_output_____"
],
[
"len(s2)",
"_____no_output_____"
]
],
[
[
"#### f. iterate over set or check if an item is a member of a set",
"_____no_output_____"
]
],
[
[
"'k' in s1",
"_____no_output_____"
]
],
[
[
"#### g. update set",
"_____no_output_____"
]
],
[
[
"s1.add('z')",
"_____no_output_____"
],
[
"s1",
"_____no_output_____"
],
[
"s1.update('abc')",
"_____no_output_____"
],
[
"s1",
"_____no_output_____"
],
[
"s1.remove('a')",
"_____no_output_____"
],
[
"s1",
"_____no_output_____"
]
],
[
[
"#### h.As mentioned before, only mutable sets can be updated. Any attempt at such operations on immutable sets is met with an exception",
"_____no_output_____"
]
],
[
[
"s2.add('c')",
"_____no_output_____"
]
],
[
[
"#### i. mixed set type operation",
"_____no_output_____"
]
],
[
[
"type(s1|s2) # set | frozenset, mix operation",
"_____no_output_____"
],
[
"s3=frozenset('agg') #frozenset",
"_____no_output_____"
],
[
"type(s2|s3)",
"_____no_output_____"
]
],
[
[
"#### j. update mutable set: (Union) Update ( |= )",
"_____no_output_____"
]
],
[
[
"s=set('abc')",
"_____no_output_____"
],
[
"s1=set(\"123\")",
"_____no_output_____"
],
[
"s |=s1",
"_____no_output_____"
],
[
"s",
"_____no_output_____"
]
],
[
[
"### k.The retention (or intersection update) operation keeps only the existing set members that are also elements of the other set. The method equivalent is intersection_update()",
"_____no_output_____"
]
],
[
[
"s=set('abc')",
"_____no_output_____"
],
[
"s1=set('ab')",
"_____no_output_____"
],
[
"s &=s1",
"_____no_output_____"
],
[
"s",
"_____no_output_____"
]
],
[
[
"### l.The difference update operation returns a set whose elements are members of the original set after removing elements that are (also) members of the other set. The method equivalent is difference_update().",
"_____no_output_____"
]
],
[
[
"s = set('cheeseshop')\ns",
"_____no_output_____"
],
[
"u = frozenset(s)\ns -= set('shop')",
"_____no_output_____"
],
[
"s",
"_____no_output_____"
]
],
[
[
"#### m.The symmetric difference update operation returns a set whose members are either elements of the original or other set but not both. The method equiva- lent is symmetric_difference_update()",
"_____no_output_____"
]
],
[
[
"s=set('cheeseshop')\ns",
"_____no_output_____"
],
[
"u=set('bookshop')\nu",
"_____no_output_____"
],
[
"s ^=u\ns",
"_____no_output_____"
],
[
"vari='abc'",
"_____no_output_____"
],
[
"set(vari) # vari must be iterable",
"_____no_output_____"
]
],
[
[
"### n.The new methods here are \n\n* add(), \n\n* remove(), \n\n* discard(), \n\n* pop(), and \n\n* clear(). \n\n* s.copy(), Copy operation: return (shallow) copy of s\n\nFor the methods that take an object, the argument must be hashable.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02af894e132fc438d9d94b4f00fbc8d4bbafcc4
| 10,902 |
ipynb
|
Jupyter Notebook
|
Stock_Algorithms/Multiple_Linear_Regression_with_Normalize_Data.ipynb
|
NTForked-ML/Deep-Learning-Machine-Learning-Stock
|
8a137972d967423c7102a33ba639bd0d5d21a0e9
|
[
"MIT"
] | 569 |
2019-02-06T16:35:19.000Z
|
2022-03-31T03:45:28.000Z
|
Stock_Algorithms/Multiple_Linear_Regression_with_Normalize_Data.ipynb
|
crazyguitar/Deep-Learning-Machine-Learning-Stock
|
99b4f30c3315806e8098327544d3d8cccfea8d65
|
[
"MIT"
] | 5 |
2021-02-27T07:03:58.000Z
|
2022-03-31T14:09:41.000Z
|
Stock_Algorithms/Multiple_Linear_Regression_with_Normalize_Data.ipynb
|
ysdede/Deep-Learning-Machine-Learning-Stock
|
2e3794efab3276b6bc389c8b38615540d4e2b144
|
[
"MIT"
] | 174 |
2019-05-23T11:46:54.000Z
|
2022-03-31T04:44:38.000Z
| 29.227882 | 116 | 0.394606 |
[
[
[
"# Multiple Linear Regression with Normalize Data",
"_____no_output_____"
]
],
[
[
"# Importing the libraries\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n\n# fix_yahoo_finance is used to fetch data \nimport fix_yahoo_finance as yf\nyf.pdr_override()",
"_____no_output_____"
],
[
"# input\nsymbol = 'AMD'\nstart = '2014-01-01'\nend = '2018-08-27'\n\n# Read data \ndataset = yf.download(symbol,start,end)\n\n# View columns \ndataset.head()",
"[*********************100%***********************] 1 of 1 downloaded\n"
],
[
"X = dataset.iloc[ : , 0:4].values\nY = np.asanyarray(dataset[['Adj Close']])",
"_____no_output_____"
],
[
"from sklearn import preprocessing\n\n# normalize the data attributes\nnormalized_X = preprocessing.normalize(X)",
"_____no_output_____"
],
[
"X = normalized_X[: , 1:]",
"_____no_output_____"
],
[
"# Splitting the dataset into the Training set and Test set\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LinearRegression\nregressor = LinearRegression()\nregressor.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"y_pred = regressor.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score\nex_var_score = explained_variance_score(Y_test, y_pred)\nm_absolute_error = mean_absolute_error(Y_test, y_pred)\nm_squared_error = mean_squared_error(Y_test, y_pred)\nr_2_score = r2_score(Y_test, y_pred)\n\nprint(\"Explained Variance Score: \"+str(ex_var_score))\nprint(\"Mean Absolute Error \"+str(m_absolute_error))\nprint(\"Mean Squared Error \"+str(m_squared_error))\nprint(\"R Squared Error \"+str(r_2_score))",
"Explained Variance Score: 0.0145762414645\nMean Absolute Error 4.3559157043\nMean Squared Error 22.546676437\nR Squared Error 0.0145752513278\n"
],
[
"print ('Coefficients: ', regressor.coef_)\nprint(\"Residual sum of squares: %.2f\"\n % np.mean((y_pred - Y_test) ** 2))\n\n# Explained variance score: 1 is perfect prediction\nprint('Variance score: %.2f' % regressor.score(X_test, y_pred))",
"Coefficients: [[-79.79361894 -53.18582378 15.74315198]]\nResidual sum of squares: 22.55\nVariance score: 1.00\n"
],
[
"print('Multiple Linear Score:', regressor.score(X_test, y_pred))",
"Multiple Linear Score: 0.0145752513278\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02af9728ce0b2572e16a58a20992aaf0c5056d3
| 19,840 |
ipynb
|
Jupyter Notebook
|
Chapter07/HandsOn-04_Transfer_with_IMDB_full_model.ipynb
|
wikibook/transfer-learning
|
6085109673b819b99f100e379ff0b3afb8f87870
|
[
"MIT"
] | 19 |
2019-08-02T07:51:40.000Z
|
2021-10-05T12:55:08.000Z
|
Chapter07/HandsOn-04_Transfer_with_IMDB_full_model.ipynb
|
0jipy/handson-Code
|
cdb71c11f42b311223e1caab4468cc85ea6031ed
|
[
"MIT"
] | 2 |
2019-10-23T07:19:25.000Z
|
2020-05-19T07:00:31.000Z
|
Chapter07/HandsOn-04_Transfer_with_IMDB_full_model.ipynb
|
0jipy/handson-Code
|
cdb71c11f42b311223e1caab4468cc85ea6031ed
|
[
"MIT"
] | 17 |
2019-11-16T22:52:16.000Z
|
2021-12-02T03:41:51.000Z
| 33.972603 | 248 | 0.544657 |
[
[
[
"# Chapter 7. 텍스트 문서의 범주화 - (4) IMDB 전체 데이터로 전이학습\n\n- 앞선 전이학습 실습과는 달리, IMDB 영화리뷰 데이터셋 전체를 사용하며 문장 수는 10개 -> 20개로 조정한다\n- IMDB 영화 리뷰 데이터를 다운로드 받아 data 디렉토리에 압축 해제한다\n - 다운로드 : http://ai.stanford.edu/~amaas/data/sentiment/\n - 저장경로 : data/aclImdb",
"_____no_output_____"
]
],
[
[
"import os\nimport config\nfrom dataloader.loader import Loader\nfrom preprocessing.utils import Preprocess, remove_empty_docs\nfrom dataloader.embeddings import GloVe\nfrom model.cnn_document_model import DocumentModel, TrainingParameters\nfrom keras.callbacks import ModelCheckpoint, EarlyStopping\nimport numpy as np",
"Using TensorFlow backend.\n"
]
],
[
[
"## 학습 파라미터 설정",
"_____no_output_____"
]
],
[
[
"# 학습된 모델을 저장할 디렉토리 생성\nif not os.path.exists(os.path.join(config.MODEL_DIR, 'imdb')):\n os.makedirs(os.path.join(config.MODEL_DIR, 'imdb'))\n\n# 학습 파라미터 설정\ntrain_params = TrainingParameters('imdb_transfer_tanh_activation', \n model_file_path = config.MODEL_DIR+ '/imdb/full_model_10.hdf5',\n model_hyper_parameters = config.MODEL_DIR+ '/imdb/full_model_10.json',\n model_train_parameters = config.MODEL_DIR+ '/imdb/full_model_10_meta.json',\n num_epochs=30,\n batch_size=128)",
"_____no_output_____"
]
],
[
[
"## IMDB 데이터셋 로드",
"_____no_output_____"
]
],
[
[
"# 다운받은 IMDB 데이터 로드: 학습셋 전체 사용\ntrain_df = Loader.load_imdb_data(directory = 'train')\n# train_df = train_df.sample(frac=0.05, random_state = train_params.seed)\nprint(f'train_df.shape : {train_df.shape}')\n\ntest_df = Loader.load_imdb_data(directory = 'test')\nprint(f'test_df.shape : {test_df.shape}')\n\n# 텍스트 데이터, 레이블 추출\ncorpus = train_df['review'].tolist()\ntarget = train_df['sentiment'].tolist()\ncorpus, target = remove_empty_docs(corpus, target)\nprint(f'corpus size : {len(corpus)}')\nprint(f'target size : {len(target)}')",
"train_df.shape : (25000, 2)\ntest_df.shape : (25000, 2)\ncorpus size : 25000\ntarget size : 25000\n"
]
],
[
[
"## 인덱스 시퀀스 생성",
"_____no_output_____"
]
],
[
[
"# 앞선 전이학습 실습과 달리, 문장 개수를 10개 -> 20개로 상향\nPreprocess.NUM_SENTENCES = 20\n\n# 학습셋을 인덱스 시퀀스로 변환\npreprocessor = Preprocess(corpus=corpus)\ncorpus_to_seq = preprocessor.fit()",
"Found 28654 unique tokens.\nAll documents processed.ocessed."
],
[
"print(f'corpus_to_seq size : {len(corpus_to_seq)}')\nprint(f'corpus_to_seq[0] size : {len(corpus_to_seq[0])}')",
"corpus_to_seq size : 25000\ncorpus_to_seq[0] size : 600\n"
],
[
"# 테스트셋을 인덱스 시퀀스로 변환\ntest_corpus = test_df['review'].tolist()\ntest_target = test_df['sentiment'].tolist()\ntest_corpus, test_target = remove_empty_docs(test_corpus, test_target)\ntest_corpus_to_seq = preprocessor.transform(test_corpus)",
"All documents processed.ocessed."
],
[
"print(f'test_corpus_to_seq size : {len(test_corpus_to_seq)}')\nprint(f'test_corpus_to_seq[0] size : {len(test_corpus_to_seq[0])}')",
"test_corpus_to_seq size : 25000\ntest_corpus_to_seq[0] size : 600\n"
],
[
"# 학습셋, 테스트셋 준비\nx_train = np.array(corpus_to_seq)\nx_test = np.array(test_corpus_to_seq)\ny_train = np.array(target)\ny_test = np.array(test_target)\n\nprint(f'x_train.shape : {x_train.shape}')\nprint(f'y_train.shape : {y_train.shape}')\nprint(f'x_test.shape : {x_test.shape}')\nprint(f'y_test.shape : {y_test.shape}')",
"x_train.shape : (25000, 600)\ny_train.shape : (25000,)\nx_test.shape : (25000, 600)\ny_test.shape : (25000,)\n"
]
],
[
[
"## GloVe 임베딩 초기화",
"_____no_output_____"
]
],
[
[
"# GloVe 임베딩 초기화 - glove.6B.50d.txt pretrained 벡터 사용\nglove = GloVe(50)\ninitial_embeddings = glove.get_embedding(preprocessor.word_index)\nprint(f'initial_embeddings.shape : {initial_embeddings.shape}')",
"Reading 50 dim GloVe vectors\nFound 400000 word vectors.\nwords not found in embeddings: 499\ninitial_embeddings.shape : (28656, 50)\n"
]
],
[
[
"## 훈련된 모델 로드\n\n- HandsOn03에서 아마존 리뷰 데이터로 학습한 CNN 모델을 로드한다.\n- DocumentModel 클래스의 load_model로 모델을 로드하고, load_model_weights로 학습된 가중치를 가져온다. \n- 그 후, GloVe.update_embeddings 함수로 GloVe 초기화 임베딩을 업데이트한다",
"_____no_output_____"
]
],
[
[
"# 모델 하이퍼파라미터 로드\nmodel_json_path = os.path.join(config.MODEL_DIR, 'amazonreviews/model_06.json')\namazon_review_model = DocumentModel.load_model(model_json_path)\n\n# 모델 가중치 로드\nmodel_hdf5_path = os.path.join(config.MODEL_DIR, 'amazonreviews/model_06.hdf5')\namazon_review_model.load_model_weights(model_hdf5_path)\n",
"Vocab Size = 43197 and the index of vocabulary words passed has 43195 words\nWARNING:tensorflow:From /Users/dhkdn9192/venv/lib/python3.7/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\nWARNING:tensorflow:From /Users/dhkdn9192/venv/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\n"
],
[
"# 모델 임베딩 레이어 추출\nlearned_embeddings = amazon_review_model.get_classification_model().get_layer('imdb_embedding').get_weights()[0]\nprint(f'learned_embeddings size : {len(learned_embeddings)}')\n\n# 기존 GloVe 모델을 학습된 임베딩 행렬로 업데이트한다\nglove.update_embeddings(preprocessor.word_index, \n np.array(learned_embeddings), \n amazon_review_model.word_index)\n\n# 업데이트된 임베딩을 얻는다\ninitial_embeddings = glove.get_embedding(preprocessor.word_index)\n",
"learned_embeddings size : 43197\n23629 words are updated out of 28654\n"
]
],
[
[
"## IMDB 전이학습 모델 생성",
"_____no_output_____"
]
],
[
[
"# 분류 모델 생성 : IMDB 리뷰 데이터를 입력받아 이진분류를 수행하는 모델 생성\nimdb_model = DocumentModel(vocab_size=preprocessor.get_vocab_size(),\n word_index = preprocessor.word_index,\n num_sentences=Preprocess.NUM_SENTENCES, \n embedding_weights=initial_embeddings,\n embedding_regularizer_l2 = 0.0,\n conv_activation = 'tanh',\n train_embedding = True, # 임베딩 레이어의 가중치 학습함\n learn_word_conv = False, # 단어 수준 conv 레이어의 가중치 학습 안 함\n learn_sent_conv = False, # 문장 수준 conv 레이어의 가중치 학습 안 함\n hidden_dims=64, \n input_dropout=0.1, \n hidden_layer_kernel_regularizer=0.01,\n final_layer_kernel_regularizer=0.01)\n\n# 가중치 업데이트 : 생성한 imdb_model 모델에서 다음의 각 레이어들의 가중치를 위에서 로드한 가중치로 갱신한다\nfor l_name in ['word_conv','sentence_conv','hidden_0', 'final']:\n new_weights = amazon_review_model.get_classification_model().get_layer(l_name).get_weights()\n imdb_model.get_classification_model().get_layer(l_name).set_weights(weights=new_weights)",
"Vocab Size = 28656 and the index of vocabulary words passed has 28654 words\n"
]
],
[
[
"## 모델 학습 및 평가",
"_____no_output_____"
]
],
[
[
"# 모델 컴파일 \nimdb_model.get_classification_model().compile(loss=\"binary_crossentropy\", \n optimizer='rmsprop',\n metrics=[\"accuracy\"])\n\n# callback (1) - 체크포인트\ncheckpointer = ModelCheckpoint(filepath=train_params.model_file_path,\n verbose=1,\n save_best_only=True,\n save_weights_only=True)\n\n# callback (2) - 조기종료\nearly_stop = EarlyStopping(patience=2)\n\n# 학습 시작\nimdb_model.get_classification_model().fit(x_train, \n y_train, \n batch_size=train_params.batch_size,\n epochs=train_params.num_epochs,\n verbose=2,\n validation_split=0.01,\n callbacks=[checkpointer])\n\n# 모델 저장\nimdb_model._save_model(train_params.model_hyper_parameters)\ntrain_params.save()",
"WARNING:tensorflow:From /Users/dhkdn9192/venv/lib/python3.7/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.cast instead.\nTrain on 24750 samples, validate on 250 samples\nEpoch 1/30\n - 40s - loss: 1.0038 - acc: 0.8686 - val_loss: 0.6622 - val_acc: 0.8560\n\nEpoch 00001: val_loss improved from inf to 0.66215, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 2/30\n - 39s - loss: 0.4992 - acc: 0.8782 - val_loss: 0.4534 - val_acc: 0.8600\n\nEpoch 00002: val_loss improved from 0.66215 to 0.45337, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 3/30\n - 39s - loss: 0.3740 - acc: 0.8825 - val_loss: 0.3998 - val_acc: 0.8600\n\nEpoch 00003: val_loss improved from 0.45337 to 0.39985, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 4/30\n - 39s - loss: 0.3271 - acc: 0.8903 - val_loss: 0.3741 - val_acc: 0.8760\n\nEpoch 00004: val_loss improved from 0.39985 to 0.37414, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 5/30\n - 39s - loss: 0.3025 - acc: 0.8960 - val_loss: 0.3723 - val_acc: 0.8680\n\nEpoch 00005: val_loss improved from 0.37414 to 0.37228, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 6/30\n - 39s - loss: 0.2845 - acc: 0.9001 - val_loss: 0.3585 - val_acc: 0.8840\n\nEpoch 00006: val_loss improved from 0.37228 to 0.35849, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 7/30\n - 39s - loss: 0.2719 - acc: 0.9044 - val_loss: 0.3591 - val_acc: 0.8760\n\nEpoch 00007: val_loss did not improve from 0.35849\nEpoch 8/30\n - 39s - loss: 0.2621 - acc: 0.9082 - val_loss: 0.3634 - val_acc: 0.8720\n\nEpoch 00008: val_loss did not improve from 0.35849\nEpoch 9/30\n - 39s - loss: 0.2536 - acc: 0.9112 - val_loss: 0.3543 - val_acc: 0.8720\n\nEpoch 00009: val_loss improved from 0.35849 to 0.35432, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 10/30\n - 39s - loss: 0.2437 - acc: 0.9183 - val_loss: 0.3536 - val_acc: 0.8760\n\nEpoch 00010: val_loss improved from 0.35432 to 0.35362, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 11/30\n - 39s - loss: 0.2362 - acc: 0.9202 - val_loss: 0.3510 - val_acc: 0.8720\n\nEpoch 00011: val_loss improved from 0.35362 to 0.35096, saving model to ./checkpoint/imdb/full_model_10.hdf5\nEpoch 12/30\n - 39s - loss: 0.2260 - acc: 0.9244 - val_loss: 0.3560 - val_acc: 0.8720\n\nEpoch 00012: val_loss did not improve from 0.35096\nEpoch 13/30\n - 39s - loss: 0.2216 - acc: 0.9270 - val_loss: 0.3514 - val_acc: 0.8760\n\nEpoch 00013: val_loss did not improve from 0.35096\nEpoch 14/30\n - 39s - loss: 0.2147 - acc: 0.9301 - val_loss: 0.3557 - val_acc: 0.8760\n\nEpoch 00014: val_loss did not improve from 0.35096\nEpoch 15/30\n - 39s - loss: 0.2066 - acc: 0.9328 - val_loss: 0.3516 - val_acc: 0.8680\n\nEpoch 00015: val_loss did not improve from 0.35096\nEpoch 16/30\n - 40s - loss: 0.2000 - acc: 0.9375 - val_loss: 0.3524 - val_acc: 0.8720\n\nEpoch 00016: val_loss did not improve from 0.35096\nEpoch 17/30\n - 42s - loss: 0.1963 - acc: 0.9386 - val_loss: 0.3600 - val_acc: 0.8800\n\nEpoch 00017: val_loss did not improve from 0.35096\nEpoch 18/30\n - 41s - loss: 0.1866 - acc: 0.9434 - val_loss: 0.3635 - val_acc: 0.8840\n\nEpoch 00018: val_loss did not improve from 0.35096\nEpoch 19/30\n - 40s - loss: 0.1821 - acc: 0.9449 - val_loss: 0.3638 - val_acc: 0.8680\n\nEpoch 00019: val_loss did not improve from 0.35096\nEpoch 20/30\n - 40s - loss: 0.1771 - acc: 0.9476 - val_loss: 0.3630 - val_acc: 0.8720\n\nEpoch 00020: val_loss did not improve from 0.35096\nEpoch 21/30\n - 40s - loss: 0.1724 - acc: 0.9499 - val_loss: 0.3765 - val_acc: 0.8760\n\nEpoch 00021: val_loss did not improve from 0.35096\nEpoch 22/30\n - 40s - loss: 0.1663 - acc: 0.9528 - val_loss: 0.3639 - val_acc: 0.8760\n\nEpoch 00022: val_loss did not improve from 0.35096\nEpoch 23/30\n - 40s - loss: 0.1613 - acc: 0.9539 - val_loss: 0.3627 - val_acc: 0.8720\n\nEpoch 00023: val_loss did not improve from 0.35096\nEpoch 24/30\n - 40s - loss: 0.1571 - acc: 0.9562 - val_loss: 0.3682 - val_acc: 0.8920\n\nEpoch 00024: val_loss did not improve from 0.35096\nEpoch 25/30\n - 41s - loss: 0.1535 - acc: 0.9581 - val_loss: 0.3757 - val_acc: 0.8760\n\nEpoch 00025: val_loss did not improve from 0.35096\nEpoch 26/30\n - 40s - loss: 0.1493 - acc: 0.9590 - val_loss: 0.3844 - val_acc: 0.8720\n\nEpoch 00026: val_loss did not improve from 0.35096\nEpoch 27/30\n - 40s - loss: 0.1465 - acc: 0.9598 - val_loss: 0.3686 - val_acc: 0.8760\n\nEpoch 00027: val_loss did not improve from 0.35096\nEpoch 28/30\n - 40s - loss: 0.1398 - acc: 0.9632 - val_loss: 0.3864 - val_acc: 0.8840\n\nEpoch 00028: val_loss did not improve from 0.35096\nEpoch 29/30\n - 40s - loss: 0.1376 - acc: 0.9644 - val_loss: 0.3744 - val_acc: 0.8880\n\nEpoch 00029: val_loss did not improve from 0.35096\nEpoch 30/30\n - 40s - loss: 0.1318 - acc: 0.9659 - val_loss: 0.3763 - val_acc: 0.8840\n\nEpoch 00030: val_loss did not improve from 0.35096\n"
],
[
"# 모델 평가\nimdb_model.get_classification_model().evaluate(x_test, \n y_test, \n batch_size=train_params.batch_size*10,\n verbose=2)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02b02c28f3416910ab509e551bf11af6ba502e1
| 3,801 |
ipynb
|
Jupyter Notebook
|
3.Statistical_NLP/2_chatbot.ipynb
|
bonigarcia/nlp-examples
|
4e7e3c06814d8fed9bd509759664a7af0a9eb8a7
|
[
"Apache-2.0"
] | 1 |
2021-01-25T07:23:56.000Z
|
2021-01-25T07:23:56.000Z
|
3.Statistical_NLP/2_chatbot.ipynb
|
bonigarcia/nlp-examples
|
4e7e3c06814d8fed9bd509759664a7af0a9eb8a7
|
[
"Apache-2.0"
] | null | null | null |
3.Statistical_NLP/2_chatbot.ipynb
|
bonigarcia/nlp-examples
|
4e7e3c06814d8fed9bd509759664a7af0a9eb8a7
|
[
"Apache-2.0"
] | null | null | null | 29.929134 | 146 | 0.485925 |
[
[
[
"**Basic chatbot**",
"_____no_output_____"
]
],
[
[
"import ast\nfrom google.colab import drive\n\nquestions = []\nanswers = []\ndrive.mount(\"/content/drive\")\n\nwith open(\"/content/drive/My Drive/data/chatbot/qa_Electronics.json\") as f:\n for line in f:\n data = ast.literal_eval(line)\n questions.append(data[\"question\"].lower())\n answers.append(data[\"answer\"].lower())",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"from sklearn.feature_extraction.text import TfidfVectorizer\nimport numpy as np\nfrom sklearn.metrics.pairwise import cosine_similarity\n\nvectorizer = TfidfVectorizer(stop_words=\"english\")\nX_questions = vectorizer.fit_transform(questions)\n\ndef conversation(user_input):\n global vectorizer, answers, X_questions\n\n X_user_input = vectorizer.transform(user_input)\n similarity_matrix = cosine_similarity(X_user_input, X_questions)\n max_similarity = np.amax(similarity_matrix)\n angle = np.rad2deg(np.arccos(max_similarity))\n\n if angle > 60:\n return \"sorry, I did not quite understand that\"\n else:\n index_max_similarity = np.argmax(similarity_matrix)\n return answers[index_max_similarity]\n\ndef main():\n usr = input(\"Please enter your username: \")\n print(\"Q&A support: Hi, welcome to Q&A support. How can I help you?\")\n while True:\n user_input = input(\"{}: \".format(usr))\n if user_input.lower() == \"bye\":\n print(\"Q&A support: bye!\")\n break\n else:\n print(\"Q&A support: \" + conversation([user_input]))",
"_____no_output_____"
],
[
"main()",
"Please enter your username: pepe\nQ&A support: Hi, welcome to Q&A support. How can I help you?\npepe: I want to buy an iPhone\nQ&A support: i am sure amazon has all types.\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d02b0af90077c6c2011e1edc5afcf3f060c3caaa
| 15,835 |
ipynb
|
Jupyter Notebook
|
Mission to mars/mission_to_mars.ipynb
|
DeLeon27/web-scraping-challenge
|
5f46fff099b4f9ba2103f240e15001ae4a58956c
|
[
"ADSL"
] | null | null | null |
Mission to mars/mission_to_mars.ipynb
|
DeLeon27/web-scraping-challenge
|
5f46fff099b4f9ba2103f240e15001ae4a58956c
|
[
"ADSL"
] | null | null | null |
Mission to mars/mission_to_mars.ipynb
|
DeLeon27/web-scraping-challenge
|
5f46fff099b4f9ba2103f240e15001ae4a58956c
|
[
"ADSL"
] | null | null | null | 31.294466 | 1,128 | 0.4982 |
[
[
[
"import pandas as pd\nfrom bs4 import BeautifulSoup as soup\nfrom splinter import Browser\nimport requests\nimport time\nfrom webdriver_manager.chrome import ChromeDriverManager\nfrom selenium import webdriver",
"_____no_output_____"
],
[
"!pip install chromedriver",
"Requirement already satisfied: chromedriver in c:\\users\\alex2\\anaconda3\\lib\\site-packages (2.24.1)\n"
],
[
"driver = webdriver.Chrome(ChromeDriverManager().install())",
"[WDM] - ====== WebDriver manager ======\n[WDM] - Current google-chrome version is 90.0.4430\n[WDM] - Get LATEST driver version for 90.0.4430\n"
],
[
"#driver = webdriver.chrome(executable_path='C:/path/to/chromedriver.exe')",
"_____no_output_____"
],
[
"#pointing to the directory where chromedriver exists\nexecutable_path = {\"executable_path\":\"C:\\\\Users\\\\alex2\\\\OneDrive\\Desktop\\chromedriver\"}\nbrowser = Browser('chrome', **executable_path, headless=False)",
"_____no_output_____"
],
[
"#url = \"https://mars.nasa.gov/news/\" ",
"_____no_output_____"
],
[
"# Mars news url\nMarsnews_url = 'https://mars.nasa.gov/news/'\nbrowser.visit(Marsnews_url)",
"_____no_output_____"
],
[
"# create beautiful soup object \nhtml = browser.html\nMarsNews_soup = soup(html, 'html.parser')",
"_____no_output_____"
],
[
"# First news Title \nNews_title = MarsNews_soup.body.find(\"div\", class_=\"content_title\").text\nNewsParagraph = MarsNews_soup.body.find(\"div\", class_=\"article_teaser_body\").text\n\nprint(f\"The title is: \\n{News_title}\")\nprint()\nprint(f\"The descriptive paragraph is: \\n{NewsParagraph}\")",
"The title is: \nMars Now\n\nThe descriptive paragraph is: \nThe small rotorcraft’s horizons were expanded on its second flight. \n"
],
[
"# JPL Mars Space Images\n## define the url and visit it with browser\n\nmars_image_url = \"https://www.jpl.nasa.gov/spaceimages/?search=&category=Mars\"\nbase_url = 'https://www.jpl.nasa.gov'\nbrowser.visit(mars_image_url)",
"_____no_output_____"
],
[
"#browser.visit(url)\n#html = browser.html\n#MarsNews_soup = soup(html, 'html.parser')\n\n#image_url = soup.find('article')['style'].replace('background-image: url(','').replace(');', '')[1:-1]\n\n# Website Url \n#main_url = \"https://www.jpl.nasa.gov\"\n\n# Concatenate website url with scrapped route\n#image_url = main_url + image_url\n\n# Display full link to featured image\n#image_url",
"_____no_output_____"
],
[
"# HTML object\nhtml=browser.html\n# Parse HTML\nMarsNews_soup = soup(html,\"html.parser\")\n# Retrieve image url\nimage_url=soup.find_all('article')\n",
"_____no_output_____"
],
[
"image_url=soup.find(\"a\", class_ = \"button fancybox\")[\"data-fancybox-href\"]\nfeatured_image_url = base_url + image_url\nprint(featured_image_url)",
"_____no_output_____"
],
[
"# Mars Facts\n\nurl = 'https://space-facts.com/mars/'\nbrowser.visit(url)\n\n# Use Pandas to \"read_html\" to parse the URL\ntables = pd.read_html(url)\n\n# Mars Facts DataFrame \nfacts_df = tables[0]\nfacts_df.columns = ['Fact', 'Value']\nfacts_df['Fact'] = facts_df['Fact'].str.replace(':', '')\nfacts_df\n\n",
"_____no_output_____"
],
[
"# Show as html table string\nfacts_df = tables[0]\nfacts_df.columns = ['Fact', 'Value']\nfacts_df['Fact'] = facts_df['Fact'].str.replace(':', '')\nfacts_df\nfacts_html = facts_df.to_html()\n\nprint(facts_html)",
"<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Fact</th>\n <th>Value</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>Equatorial Diameter</td>\n <td>6,792 km</td>\n </tr>\n <tr>\n <th>1</th>\n <td>Polar Diameter</td>\n <td>6,752 km</td>\n </tr>\n <tr>\n <th>2</th>\n <td>Mass</td>\n <td>6.39 × 10^23 kg (0.11 Earths)</td>\n </tr>\n <tr>\n <th>3</th>\n <td>Moons</td>\n <td>2 (Phobos & Deimos)</td>\n </tr>\n <tr>\n <th>4</th>\n <td>Orbit Distance</td>\n <td>227,943,824 km (1.38 AU)</td>\n </tr>\n <tr>\n <th>5</th>\n <td>Orbit Period</td>\n <td>687 days (1.9 years)</td>\n </tr>\n <tr>\n <th>6</th>\n <td>Surface Temperature</td>\n <td>-87 to -5 °C</td>\n </tr>\n <tr>\n <th>7</th>\n <td>First Record</td>\n <td>2nd millennium BC</td>\n </tr>\n <tr>\n <th>8</th>\n <td>Recorded By</td>\n <td>Egyptian astronomers</td>\n </tr>\n </tbody>\n</table>\n"
],
[
"# Mars Hemispheres\n\nhemispheres_url = \"https://astrogeology.usgs.gov/search/results?q=hemisphere+enhanced&k1=target&v1=Mars\"\nbrowser.visit(hemispheres_url)",
"_____no_output_____"
],
[
"# HTML Object\nhtml_hemispheres = browser.html\n\n# Parse HTML with Beautiful Soup\nMarsNews_soup = soup(html_hemispheres, 'html.parser')\n\n# Retreive all items that contain mars hemispheres information\nitems = soup.find_all('div', class_='item')\n\n# Create empty list for hemisphere urls \nhemisphere_image_urls = []\n\n# Store the main_ul \nhemispheres_main_url = 'https://astrogeology.usgs.gov'\n\n# Loop through the items previously stored\nfor i in items: \n # Store title\n title = i.find('h3').text\n \n # Store link that leads to full image website\n partial_img_url = i.find('a', class_='itemLink product-item')['href']\n \n # Visit the link that contains the full image website \n browser.visit(hemispheres_main_url + partial_img_url)\n \n # HTML Object of individual hemisphere information website \n partial_img_html = browser.html\n \n # Parse HTML with Beautiful Soup for every individual hemisphere information website \nMarsNews_soup = soup( partial_img_html, 'html.parser')\n \n # Retrieve full image source \nimage_url = hemispheres_main_url + soup.find('img',class_='wide-image')['src']\n \n # Append the retreived information into a list of dictionaries \nhemisphere_image_urls.append({\"title\" : title, \"img_url\" : img_url})\n \n\n# Display hemisphere_image_urls\nhemisphere_image_urls",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02b14e3027ed3c2544a20524607510934b9fd30
| 14,201 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/lgbm-optuna-cross-validate-checkpoint.ipynb
|
luigisaetta/bike-sharing-forecast
|
a76059d33aa8a6c3f0b742d4c22b14477c5653df
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/lgbm-optuna-cross-validate-checkpoint.ipynb
|
luigisaetta/bike-sharing-forecast
|
a76059d33aa8a6c3f0b742d4c22b14477c5653df
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/lgbm-optuna-cross-validate-checkpoint.ipynb
|
luigisaetta/bike-sharing-forecast
|
a76059d33aa8a6c3f0b742d4c22b14477c5653df
|
[
"MIT"
] | null | null | null | 31.142544 | 258 | 0.488416 |
[
[
[
"### Lgbm and Optuna\n* changed with cross validation",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\n# the GBM used\nmport xgboost as xgb\nimport catboost as cat\nimport lightgbm as lgb\n\nfrom sklearn.model_selection import cross_validate\nfrom sklearn.metrics import make_scorer\n\n# to encode categoricals\nfrom sklearn.preprocessing import LabelEncoder\n\n# see utils.py\nfrom utils import add_features, rmsle, train_encoders, apply_encoders \n\nimport warnings\nwarnings.filterwarnings('ignore')\n\nimport optuna",
"_____no_output_____"
],
[
"# globals and load train dataset\n\nFILE_TRAIN = \"train.csv\"",
"_____no_output_____"
],
[
"# load train dataset\ndata_orig = pd.read_csv(FILE_TRAIN)\n\n#\n# Data preparation, feature engineering\n#\n\n# add features (hour, year) extracted form timestamp\ndata_extended = add_features(data_orig)\n\n# ok, we will treat as categorical: holiday, hour, season, weather, workingday, year\nall_columns = data_extended.columns\n\n# cols to be ignored\n# atemp and temp are strongly correlated (0.98) we're taking only one\ndel_columns = ['datetime', 'casual', 'registered', 'temp']\n\nTARGET = \"count\"\ncat_cols = ['season', 'holiday','workingday', 'weather', 'hour', 'year']\nnum_cols = list(set(all_columns) - set([TARGET]) - set(del_columns) - set(cat_cols))\nfeatures = sorted(cat_cols + num_cols)\n\n# drop ignored columns\ndata_used = data_extended.drop(del_columns, axis=1)",
"_____no_output_____"
],
[
"# Code categorical columns (only season, weather, year)\nle_list = train_encoders(data_used)\n\n# coding\ndata_used = apply_encoders(data_used, le_list)\n\n# define indexes for cat_cols\n# cat boost want indexes\ncat_columns_idxs = [i for i, col in enumerate(features) if col in cat_cols]\n\n# finally we have the train dataset\nX = data_used[features].values\ny = data_used[TARGET].values",
"All columns: 14\nIgnored columns: 4\nTarget: 1\nCategorical columns: 7\nNumerical columns: 2\nAll the features 9\n"
],
[
"# general\nFOLDS = 5\nSEED = 4321\nN_TRIALS = 5\nSTUDY_NAME = \"gbm3\"",
"_____no_output_____"
],
[
"#\n# Here we define what we do using Optuna\n#\ndef objective(trial):\n \n # tuning on max_depth, n_estimators for the example\n dict_params = {\n \"num_iterations\": trial.suggest_categorical(\"num_iterations\", [3000, 4000, 5000]),\n \"learning_rate\": trial.suggest_loguniform(\"learning_rate\", low=1e-4, high=1e-2),\n \"metrics\" : [\"rmse\"],\n \"verbose\" : -1,\n }\n max_depth = trial.suggest_int(\"max_depth\", 4, 10)\n num_leaves = trial.suggest_int(\"num_leaves\", 2**(max_depth), 2**(max_depth))\n \n dict_params['max_depth'] = max_depth\n dict_params['num_leaves'] = num_leaves\n \n regr = lgb.LGBMRegressor(**dict_params)\n \n # using rmsle for scoring\n scorer = make_scorer(rmsle, greater_is_better=False)\n \n scores = cross_validate(regr, X, y, cv=FOLDS, scoring=scorer)\n \n avg_test_score = round(np.mean(scores['test_score']), 4)\n \n return avg_test_score",
"_____no_output_____"
],
[
"# launch Optuna Study\nstudy = optuna.create_study(study_name=STUDY_NAME, direction=\"maximize\")\n\nstudy.optimize(objective, n_trials=N_TRIALS)",
"\u001b[32m[I 2022-03-09 11:44:08,014]\u001b[0m A new study created in memory with name: gbm3\u001b[0m\n\u001b[32m[I 2022-03-09 11:44:53,441]\u001b[0m Trial 0 finished with value: -1.3121 and parameters: {'num_iterations': 3000, 'learning_rate': 0.00017125621912421937, 'max_depth': 8, 'num_leaves': 256}. Best is trial 0 with value: -1.3121.\u001b[0m\n\u001b[32m[I 2022-03-09 11:45:18,176]\u001b[0m Trial 1 finished with value: -1.3638 and parameters: {'num_iterations': 4000, 'learning_rate': 0.00010698031788920725, 'max_depth': 6, 'num_leaves': 64}. Best is trial 0 with value: -1.3121.\u001b[0m\n\u001b[32m[I 2022-03-09 11:45:41,954]\u001b[0m Trial 2 finished with value: -0.5258 and parameters: {'num_iterations': 5000, 'learning_rate': 0.0034648547200920796, 'max_depth': 6, 'num_leaves': 64}. Best is trial 2 with value: -0.5258.\u001b[0m\n\u001b[32m[I 2022-03-09 11:47:29,543]\u001b[0m Trial 3 finished with value: -1.2259 and parameters: {'num_iterations': 5000, 'learning_rate': 0.000141646290605655, 'max_depth': 9, 'num_leaves': 512}. Best is trial 2 with value: -0.5258.\u001b[0m\n\u001b[32m[I 2022-03-09 11:47:49,915]\u001b[0m Trial 4 finished with value: -1.3099 and parameters: {'num_iterations': 5000, 'learning_rate': 0.00011586165697773894, 'max_depth': 5, 'num_leaves': 32}. Best is trial 2 with value: -0.5258.\u001b[0m\n"
],
[
"study.best_params",
"_____no_output_____"
],
[
"# visualize trials as an ordered Pandas df\ndf = study.trials_dataframe()\n\nresult_df = df[df['state'] == 'COMPLETE'].sort_values(by=['value'], ascending=False)\n\n# best on top\nresult_df.head()",
"_____no_output_____"
]
],
[
[
"### train the model on entire train set and save",
"_____no_output_____"
]
],
[
[
"%%time\n\n# maybe I shoud add save best model (see nu_iteration in cell below)\nmodel = lgb.LGBMRegressor(**study.best_params)\n\nmodel.fit(X, y)",
"CPU times: user 18.6 s, sys: 67.9 ms, total: 18.7 s\nWall time: 4.71 s\n"
],
[
"model_file = \"lgboost.txt\"\n\nmodel.booster_.save_model(model_file, num_iteration=study.best_params['num_iterations'])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02b164239616a766821da2108845cad83753639
| 12,028 |
ipynb
|
Jupyter Notebook
|
_notebooks/2020-07-11-Tuesday-Wonderland-Fidel-Huancas.ipynb
|
jazzcoffeestuff/blog
|
7ec7c4a7b9ef565429e1db720ad43312b9a54f62
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-07-11-Tuesday-Wonderland-Fidel-Huancas.ipynb
|
jazzcoffeestuff/blog
|
7ec7c4a7b9ef565429e1db720ad43312b9a54f62
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-07-11-Tuesday-Wonderland-Fidel-Huancas.ipynb
|
jazzcoffeestuff/blog
|
7ec7c4a7b9ef565429e1db720ad43312b9a54f62
|
[
"Apache-2.0"
] | null | null | null | 126.610526 | 1,581 | 0.746758 |
[
[
[
"# \"Tuesday Wonderland and PLOT Fidel Huancas\"\n> \"In this blog post we head back to the fine folks at PLOT coffee roasting this time looking at a Peruvian competition lot. We pair this with the Esbjörn Svennson Trio classic 'Tuesday Wonderland' from 2006\"\n- toc: false\n- author: Lewis Cole (2020)\n- branch: master\n- badges: false\n- comments: false\n- categories: [Jazz, Coffee, EST, 2000s, Plot, Peru, Washed-Process, Caturra]\n- hide: false\n- search_exclude: false\n- image: https://github.com/jazzcoffeestuff/blog/raw/master/images/013-Tuesday-Wonderland/Tuesday-Wonderland.jpg",
"_____no_output_____"
],
[
"> youtube: https://youtu.be/9VF8kxFEEsA\n\nThis week we are heading back to a relatively new roaster for me: PLOT coffee roasters in Woolwich. Readers may remember a trio of their coffees featured on the page a couple of months ago which were heavily favoured. This is part of my second order from them. I'm hesitant to judge a roaster based on a single order so we will see if this one lives up to the previous coffees from them.\n\nAgain I am very impressed with the packaging, the pink and black branded packing boxes through to the \"sound wave\" style logos on the bags it is all very well done. The packaging is something I always look at when judging a roaster/coffee, it is my opinion that you make judgements about a coffee from the instant you see it and having attractive packaging adds to this. You \"first drink with your eyes\" is the expression I believe! Further good packaging to me suggests that a roaster is leaving no stone unturned, they are concerned with how their coffee is perceived at every step of the coffee drinking journey - I think this is a good indicator of attention to detail and passion, both of which are crucially important to find in a roaster.\n\nThe coffee today is called: \"Fidel Huancas - Chirinos Competition Lot\" - which is a bit of a mouthful. Fidel Huancas is the man behind the coffee, the producer who is responsible for ensuring the quality of the on site processing, growing, etc. Chirinos is the district of the province San Ignacio where the farm is located. This is in the north west corner of the country, not too far from the border with Ecuador. The term \"competition lot\" has sprung up more and more in recent years, it does not seem to be a protected term but is meant to be an indicator that the coffee is of a quality that it could be used in barita or brewing competitions.\n\nA piece of information you often find on the label of a coffee or on the roasters website is \"altitude\" or \"elevation\" - this is measured in meters above sea level (MASL) and as one would expect represents how \"high\" the coffee bushes are grown. When I was first getting into specialty coffee many many moons ago people were obsessing over altitude, people often judging whether to buy a coffee based on this metric alone. These days it appears as though the metric is not given the weight it once was, which in my opinion is a good thing. Generally speaking a coffee at a higher altitude will be favoured as being sweeter and more complex, and so some aim for higher altitude coffees as a result. Unfortunately it is not quite that simple. Higher does not necessarily mean better, what really matters (or so it seems) is the speed at which the coffee plants grow which is related to temperature. At a higher altitude generally the temperature will be lower which means the plants will grow more slowly and develop the complex flavours and sugars we are after. However we can equally find lower altitude locations that have lower temperatures and slower growing cherries which are equally delicious! \n\nUnfortunately temperature is not something that is easy to quantify, each day the temperature will fluctuate and over the course of a growing season there may be large swings. Even the \"average temperature\" nor the temperature range tell us very much at all. As such altitude has become the proxy metric used. Personally I never look at altitude at all when deciding on whether to buy or try a coffee, I have not found it a particularly useful indicator for any particular characteristic or quality. Everybody is different though, so if you find that there is a strong correlation between coffees you enjoy and the altitude they're grown at stick with it!\n\nMoving onto the tasting of this coffee. The first thing that strikes me with this coffee is the dry aroma of the beans (both whole and ground) - the smell is very intense. I'd describe it as a dried fruit sweet sort of smell laced with a delicate floral note. I usually find that the very best tasting coffees have a very intense dry aroma, it is not universally true and a great dry aroma does not always translate to a good cup but this coffee is onto a good start! As usual starting with my usual filter set up. The first thing I get hit with is apricot, this coffee has it in spades! Those that know me know that, while I'm not big on desserts, an apricot tart is one of my favourite things. This coffee reminds me a bit of that. If apricot is the head note of the coffee the heart is sweet caramel which gives some body to the coffee, perhaps apricot compote is a good descriptor given this syrupy body. As the coffee cools floral notes begin to appear and these linger in the aftertaste which is long lived and clean. Moving onto the espresso the flavour profile is much the same. I found that this coffee likes to be pulled long, about a 2.7:1 works for me. Too short and the flavours get a bit muddled and it's hard to discern individual notes. As a longer pull the flavours are defined and totally delicious! At this level the syrupy mouthfeel has all but gone but I feel this is a fair compromise. Pulling out floral notes in an espresso can be difficult, they are often dominated by the \"heavier\" notes but they manage to punch through in the aftertaste here.\n\nThis is another stand out coffee for me from the folks at PLOT. If this one is not in my shortlist for \"coffees of the year\" I have some outstanding coffees to look forward to in the last 6 months of the year!\n\nThis week's jazz is the 2006 seminal album \"Tuesday Wonderland\" by Esbjörn Svennson Trio (EST) on the ACT record label:\n\n\n\nI remember the lead up to this album being released very vividly, at the time I was a regular reader of Jazzwise magazine and it felt like every issue for the year leading up to the release (and subsequently) had an article about this album. By this point EST were already big names in the jazz world. In the late 1990s to early 2000s jazz was in a bit of a lull, by this point the whole \"fusion\" thing had lost its way and there was a movement back towards more \"traditional\" styles, however what was lacking was a young act who won international acclaim, this is where EST came in. They almost singlehandedly kept jazz alive during this period and spawned many imitators who are still playing with the \"EST sound\" today. Unusually for an album surrounded in such hype and expectation \"Tuesday Wonderland\" not only lived up to it but possibly exceeded it, which is not something you can say often.\n\nThe EST style is hard to put down in words but unmistakable once you hear it. There is a clear influence of modern European classical composers (they list Bartok in particular as an influence regularly). Esbjörn's piano style also takes inspiration from Keith Jarrett to my ear. While each member plays (primarily) on acoustic instruments they layer these with multi-track recording and run electronic effects to keep things fresh. Magnus Öström is on drum duty for the band and plays with both manic urgency as well as tender subtlty, feeling most at home playing drum and bass and techno grooves. Dan Berglund on bass brings with him the thunderous weight through the rock and heavy metal influence to preceedings. EST represents \"fusion\" in its truest sense being a melting pot of ideas. In doing this they managed to create a sound all to themselves that is not like anything that came before it.\n\nOne of my favourite pieces from the entire EST back catalogue is \"The Goldhearted Miner\" (embedded above). It is a beautiful subtle piece with a very strong melody. It is the sort of tune I could imagine being a standard if it had been released some 60 years earlier. It does not have quite the \"broad influence\" that some of the other pieces on the album have however. Perhaps their biggest hit is \"Goldwrap\":\n\n> youtube: https://youtu.be/xCuGTuDsVoY\n\nThis even had a \"proper\" music video associated with it! Back in 2006 this was essentially unheard of, I can't think of another record from the era that had that sort of reach. It shows how big the band had become, I seem to remember even seeing this appear on the music TV channels on satelite television at the time. Compared to \"The Goldhearted Miner\" this one features more prominently some of the electronic effects on the instruments and some of the EST-isms that made the band so popular.\n\nLive the band were also a force to be reckoned with. They managed to attract a young \"hip\" crowd that comprised of jazz fans, electronic music fans and rock fans alike. The crowd hanging on every single the note, and the band acting like a conductor whipping the audience up into a frenzy. There was also a running \"bit\" that Esbjörn did; the band would play 3 or 4 tunes on the bounce and then Esbjörn would try to announce what was just played to the crowd but \"forgot\" the names and the more eager members of the audience would shout out to remind him. I'm not sure if it was a genuine slip of the mind from being so deep into the moment or whether it was just a shtick, either way it certainly added a little humour to the gigs.\n\nUnfortunately Esbjörn died tragically young, at just the age of 44, in a freak scuba diving accident in 2008 only 2 years after the release of \"Tuesday Wonderland\". This was a devestating event in recent jazz history and he will be sorely missed. I was forunate enough to catch, what turned out to be, one of the last UK shows. It was truly fantastic and a totally memorable experience. Afterwards I even got to meet the band as they hung around for autographs and the like. Unfortunately camera phones of the day were still fairly rudimentary (at least the one I had) so I do not have a high-def picture but you can see me as a fresh-faced wee nipper below:\n\n\n\nTo end this post I'll leave one of the more experimental cuts from the album called: \"Brewery of Beggars\". I feel this really captures the \"melting pot\" ethos of the band and highlights the use of electronic effects and rockier sounds the band were known for.\n\n> youtube: https://youtu.be/3umiaQLwR38",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown"
]
] |
d02b1c324ce01001ca940dbbb990fd220449d85b
| 9,319 |
ipynb
|
Jupyter Notebook
|
Corpus_Making/test_excel.ipynb
|
UWPRG/BETO2020
|
55b5b329395da79047e9083232101d15af9f2c49
|
[
"MIT"
] | 4 |
2020-03-04T21:08:11.000Z
|
2020-10-28T11:28:00.000Z
|
Corpus_Making/test_excel.ipynb
|
UWPRG/BETO2020
|
55b5b329395da79047e9083232101d15af9f2c49
|
[
"MIT"
] | null | null | null |
Corpus_Making/test_excel.ipynb
|
UWPRG/BETO2020
|
55b5b329395da79047e9083232101d15af9f2c49
|
[
"MIT"
] | 6 |
2019-04-15T16:51:16.000Z
|
2019-11-13T02:45:53.000Z
| 29.678344 | 652 | 0.452731 |
[
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"data = np.array([1,2,3,4,5,6])\nname = np.array(['' for x in range(6)])\nbesio = np.array(['' for x in range(6)])\nentity = besio",
"_____no_output_____"
],
[
"columns = ['name/doi', 'data', 'BESIO', 'entity']",
"_____no_output_____"
],
[
"df = pd.DataFrame(np.array([name, data, besio, entity]).transpose(), columns=columns)",
"_____no_output_____"
],
[
"df.iloc[1,0] = 'doi'",
"_____no_output_____"
],
[
"hey = np.random.shuffle(data)",
"_____no_output_____"
],
[
"for piece in np.random.shuffle(data):\n print(piece)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"filename = 'carbon_ner_labels.xlsx'",
"_____no_output_____"
],
[
"append_df_to_excel(filename, df, startcol=0)\nappend_df_to_excel(filename, df, startcol=6)",
"_____no_output_____"
],
[
"def append_df_to_excel(filename, df, sheet_name='Sheet1', startrow=0, startcol=None,\n truncate_sheet=False, \n **to_excel_kwargs):\n \"\"\"\n Append a DataFrame [df] to existing Excel file [filename]\n into [sheet_name] Sheet.\n If [filename] doesn't exist, then this function will create it.\n\n Parameters:\n filename : File path or existing ExcelWriter\n (Example: '/path/to/file.xlsx')\n df : dataframe to save to workbook\n sheet_name : Name of sheet which will contain DataFrame.\n (default: 'Sheet1')\n startrow : upper left cell row to dump data frame.\n Per default (startrow=None) calculate the last row\n in the existing DF and write to the next row...\n \n startcol : upper left cell column to dump data frame.\n \n \n truncate_sheet : truncate (remove and recreate) [sheet_name]\n before writing DataFrame to Excel file\n to_excel_kwargs : arguments which will be passed to `DataFrame.to_excel()`\n [can be dictionary]\n\n Returns: None\n \"\"\"\n from openpyxl import load_workbook\n\n import pandas as pd\n\n # ignore [engine] parameter if it was passed\n if 'engine' in to_excel_kwargs:\n to_excel_kwargs.pop('engine')\n\n writer = pd.ExcelWriter(filename, engine='openpyxl')\n\n # Python 2.x: define [FileNotFoundError] exception if it doesn't exist \n try:\n FileNotFoundError\n except NameError:\n FileNotFoundError = IOError\n\n\n try:\n # try to open an existing workbook\n writer.book = load_workbook(filename)\n \n if startcol is None and sheet_name in writer.book.sheetnames:\n startcol = writer.book[sheet_name].max_col\n\n # truncate sheet\n if truncate_sheet and sheet_name in writer.book.sheetnames:\n # index of [sheet_name] sheet\n idx = writer.book.sheetnames.index(sheet_name)\n # remove [sheet_name]\n writer.book.remove(writer.book.worksheets[idx])\n # create an empty sheet [sheet_name] using old index\n writer.book.create_sheet(sheet_name, idx)\n\n # copy existing sheets\n writer.sheets = {ws.title:ws for ws in writer.book.worksheets}\n except FileNotFoundError:\n # file does not exist yet, we will create it\n pass\n\n \n if startcol is None:\n startcol = 0\n\n # write out the new sheet\n df.to_excel(writer, sheet_name, startrow=startrow, startcol=startcol, **to_excel_kwargs)\n\n # save the workbook\n writer.save()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02b2111c6c253e319da6bed149a8056da502b47
| 190,872 |
ipynb
|
Jupyter Notebook
|
01_Simple_Linear_Model.ipynb
|
Asciotti/TensorFlow-Tutorials
|
7f67b593473f218544db6e46518b172fdabe20ca
|
[
"MIT"
] | null | null | null |
01_Simple_Linear_Model.ipynb
|
Asciotti/TensorFlow-Tutorials
|
7f67b593473f218544db6e46518b172fdabe20ca
|
[
"MIT"
] | null | null | null |
01_Simple_Linear_Model.ipynb
|
Asciotti/TensorFlow-Tutorials
|
7f67b593473f218544db6e46518b172fdabe20ca
|
[
"MIT"
] | null | null | null | 147.277778 | 27,308 | 0.885903 |
[
[
[
"# TensorFlow Tutorial #01\n# Simple Linear Model\n\nby [Magnus Erik Hvass Pedersen](http://www.hvass-labs.org/)\n/ [GitHub](https://github.com/Hvass-Labs/TensorFlow-Tutorials) / [Videos on YouTube](https://www.youtube.com/playlist?list=PL9Hr9sNUjfsmEu1ZniY0XpHSzl5uihcXZ)",
"_____no_output_____"
],
[
"## Introduction\n\nThis tutorial demonstrates the basic workflow of using TensorFlow with a simple linear model. After loading the so-called MNIST data-set with images of hand-written digits, we define and optimize a simple mathematical model in TensorFlow. The results are then plotted and discussed.\n\nYou should be familiar with basic linear algebra, Python and the Jupyter Notebook editor. It also helps if you have a basic understanding of Machine Learning and classification.",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import LogNorm\nimport tensorflow as tf\nimport numpy as np\nfrom sklearn.metrics import confusion_matrix",
"/home/magnus/anaconda3/envs/tf-gpu/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
]
],
[
[
"This was developed using Python 3.6 (Anaconda) and TensorFlow version:",
"_____no_output_____"
]
],
[
[
"tf.__version__",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
],
[
"The MNIST data-set is about 12 MB and will be downloaded automatically if it is not located in the given path.",
"_____no_output_____"
]
],
[
[
"from mnist import MNIST\ndata = MNIST(data_dir=\"data/MNIST/\")",
"_____no_output_____"
]
],
[
[
"The MNIST data-set has now been loaded and consists of 70.000 images and class-numbers for the images. The data-set is split into 3 mutually exclusive sub-sets. We will only use the training and test-sets in this tutorial.",
"_____no_output_____"
]
],
[
[
"print(\"Size of:\")\nprint(\"- Training-set:\\t\\t{}\".format(data.num_train))\nprint(\"- Validation-set:\\t{}\".format(data.num_val))\nprint(\"- Test-set:\\t\\t{}\".format(data.num_test))",
"Size of:\n- Training-set:\t\t55000\n- Validation-set:\t5000\n- Test-set:\t\t10000\n"
]
],
[
[
"Copy some of the data-dimensions for convenience.",
"_____no_output_____"
]
],
[
[
"# The images are stored in one-dimensional arrays of this length.\nimg_size_flat = data.img_size_flat\n\n# Tuple with height and width of images used to reshape arrays.\nimg_shape = data.img_shape\n\n# Number of classes, one class for each of 10 digits.\nnum_classes = data.num_classes",
"_____no_output_____"
]
],
[
[
"### One-Hot Encoding",
"_____no_output_____"
],
[
"The output-data is loaded as both integer class-numbers and so-called One-Hot encoded arrays. This means the class-numbers have been converted from a single integer to a vector whose length equals the number of possible classes. All elements of the vector are zero except for the $i$'th element which is 1 and means the class is $i$. For example, the One-Hot encoded labels for the first 5 images in the test-set are:",
"_____no_output_____"
]
],
[
[
"data.y_test[0:5, :]",
"_____no_output_____"
]
],
[
[
"We also need the classes as integers for various comparisons and performance measures. These can be found from the One-Hot encoded arrays by taking the index of the highest element using the `np.argmax()` function. But this has already been done for us when the data-set was loaded, so we can see the class-number for the first five images in the test-set. Compare these to the One-Hot encoded arrays above.",
"_____no_output_____"
]
],
[
[
"data.y_test_cls[0:5]",
"_____no_output_____"
]
],
[
[
"### Helper-function for plotting images",
"_____no_output_____"
],
[
"Function used to plot 9 images in a 3x3 grid, and writing the true and predicted classes below each image.",
"_____no_output_____"
]
],
[
[
"def plot_images(images, cls_true, cls_pred=None):\n assert len(images) == len(cls_true) == 9\n \n # Create figure with 3x3 sub-plots.\n fig, axes = plt.subplots(3, 3)\n fig.subplots_adjust(hspace=0.3, wspace=0.3)\n\n for i, ax in enumerate(axes.flat):\n # Plot image.\n ax.imshow(images[i].reshape(img_shape), cmap='binary')\n\n # Show true and predicted classes.\n if cls_pred is None:\n xlabel = \"True: {0}\".format(cls_true[i])\n else:\n xlabel = \"True: {0}, Pred: {1}\".format(cls_true[i], cls_pred[i])\n\n ax.set_xlabel(xlabel)\n \n # Remove ticks from the plot.\n ax.set_xticks([])\n ax.set_yticks([])\n \n # Ensure the plot is shown correctly with multiple plots\n # in a single Notebook cell.\n plt.show()",
"_____no_output_____"
]
],
[
[
"### Plot a few images to see if data is correct",
"_____no_output_____"
]
],
[
[
"# Get the first images from the test-set.\nimages = data.x_test[0:9]\n\n# Get the true classes for those images.\ncls_true = data.y_test_cls[0:9]\n\n# Plot the images and labels using our helper-function above.\nplot_images(images=images, cls_true=cls_true)",
"_____no_output_____"
]
],
[
[
"## TensorFlow Graph\n\nThe entire purpose of TensorFlow is to have a so-called computational graph that can be executed much more efficiently than if the same calculations were to be performed directly in Python. TensorFlow can be more efficient than NumPy because TensorFlow knows the entire computation graph that must be executed, while NumPy only knows the computation of a single mathematical operation at a time.\n\nTensorFlow can also automatically calculate the gradients that are needed to optimize the variables of the graph so as to make the model perform better. This is because the graph is a combination of simple mathematical expressions so the gradient of the entire graph can be calculated using the chain-rule for derivatives.\n\nTensorFlow can also take advantage of multi-core CPUs as well as GPUs - and Google has even built special chips just for TensorFlow which are called TPUs (Tensor Processing Units) that are even faster than GPUs.\n\nA TensorFlow graph consists of the following parts which will be detailed below:\n\n* Placeholder variables used to feed input into the graph.\n* Model variables that are going to be optimized so as to make the model perform better.\n* The model which is essentially just a mathematical function that calculates some output given the input in the placeholder variables and the model variables.\n* A cost measure that can be used to guide the optimization of the variables.\n* An optimization method which updates the variables of the model.\n\nIn addition, the TensorFlow graph may also contain various debugging statements e.g. for logging data to be displayed using TensorBoard, which is not covered in this tutorial.",
"_____no_output_____"
],
[
"### Placeholder variables",
"_____no_output_____"
],
[
"Placeholder variables serve as the input to the graph that we may change each time we execute the graph. We call this feeding the placeholder variables and it is demonstrated further below.\n\nFirst we define the placeholder variable for the input images. This allows us to change the images that are input to the TensorFlow graph. This is a so-called tensor, which just means that it is a multi-dimensional vector or matrix. The data-type is set to `float32` and the shape is set to `[None, img_size_flat]`, where `None` means that the tensor may hold an arbitrary number of images with each image being a vector of length `img_size_flat`.",
"_____no_output_____"
]
],
[
[
"x = tf.placeholder(tf.float32, [None, img_size_flat])",
"_____no_output_____"
]
],
[
[
"Next we have the placeholder variable for the true labels associated with the images that were input in the placeholder variable `x`. The shape of this placeholder variable is `[None, num_classes]` which means it may hold an arbitrary number of labels and each label is a vector of length `num_classes` which is 10 in this case.",
"_____no_output_____"
]
],
[
[
"y_true = tf.placeholder(tf.float32, [None, num_classes])",
"_____no_output_____"
]
],
[
[
"Finally we have the placeholder variable for the true class of each image in the placeholder variable `x`. These are integers and the dimensionality of this placeholder variable is set to `[None]` which means the placeholder variable is a one-dimensional vector of arbitrary length.",
"_____no_output_____"
]
],
[
[
"y_true_cls = tf.placeholder(tf.int64, [None])",
"_____no_output_____"
]
],
[
[
"### Variables to be optimized",
"_____no_output_____"
],
[
"Apart from the placeholder variables that were defined above and which serve as feeding input data into the model, there are also some model variables that must be changed by TensorFlow so as to make the model perform better on the training data.\n\nThe first variable that must be optimized is called `weights` and is defined here as a TensorFlow variable that must be initialized with zeros and whose shape is `[img_size_flat, num_classes]`, so it is a 2-dimensional tensor (or matrix) with `img_size_flat` rows and `num_classes` columns.",
"_____no_output_____"
]
],
[
[
"weights = tf.Variable(tf.zeros([img_size_flat, num_classes]))",
"_____no_output_____"
]
],
[
[
"The second variable that must be optimized is called `biases` and is defined as a 1-dimensional tensor (or vector) of length `num_classes`.",
"_____no_output_____"
]
],
[
[
"biases = tf.Variable(tf.zeros([num_classes]))",
"_____no_output_____"
]
],
[
[
"### Model",
"_____no_output_____"
],
[
"This simple mathematical model multiplies the images in the placeholder variable `x` with the `weights` and then adds the `biases`.\n\nThe result is a matrix of shape `[num_images, num_classes]` because `x` has shape `[num_images, img_size_flat]` and `weights` has shape `[img_size_flat, num_classes]`, so the multiplication of those two matrices is a matrix with shape `[num_images, num_classes]` and then the `biases` vector is added to each row of that matrix.\n\nNote that the name `logits` is typical TensorFlow terminology, but other people may call the variable something else.",
"_____no_output_____"
]
],
[
[
"logits = tf.matmul(x, weights) + biases",
"_____no_output_____"
]
],
[
[
"Now `logits` is a matrix with `num_images` rows and `num_classes` columns, where the element of the $i$'th row and $j$'th column is an estimate of how likely the $i$'th input image is to be of the $j$'th class.\n\nHowever, these estimates are a bit rough and difficult to interpret because the numbers may be very small or large, so we want to normalize them so that each row of the `logits` matrix sums to one, and each element is limited between zero and one. This is calculated using the so-called softmax function and the result is stored in `y_pred`.",
"_____no_output_____"
]
],
[
[
"y_pred = tf.nn.softmax(logits)",
"_____no_output_____"
]
],
[
[
"The predicted class can be calculated from the `y_pred` matrix by taking the index of the largest element in each row.",
"_____no_output_____"
]
],
[
[
"y_pred_cls = tf.argmax(y_pred, axis=1)",
"_____no_output_____"
]
],
[
[
"### Cost-function to be optimized",
"_____no_output_____"
],
[
"To make the model better at classifying the input images, we must somehow change the variables for `weights` and `biases`. To do this we first need to know how well the model currently performs by comparing the predicted output of the model `y_pred` to the desired output `y_true`.\n\nThe cross-entropy is a performance measure used in classification. The cross-entropy is a continuous function that is always positive and if the predicted output of the model exactly matches the desired output then the cross-entropy equals zero. The goal of optimization is therefore to minimize the cross-entropy so it gets as close to zero as possible by changing the `weights` and `biases` of the model.\n\nTensorFlow has a built-in function for calculating the cross-entropy. Note that it uses the values of the `logits` because it also calculates the softmax internally.",
"_____no_output_____"
]
],
[
[
"cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,\n labels=y_true)",
"_____no_output_____"
]
],
[
[
"We have now calculated the cross-entropy for each of the image classifications so we have a measure of how well the model performs on each image individually. But in order to use the cross-entropy to guide the optimization of the model's variables we need a single scalar value, so we simply take the average of the cross-entropy for all the image classifications.",
"_____no_output_____"
]
],
[
[
"cost = tf.reduce_mean(cross_entropy)",
"_____no_output_____"
]
],
[
[
"### Optimization method",
"_____no_output_____"
],
[
"Now that we have a cost measure that must be minimized, we can then create an optimizer. In this case it is the basic form of Gradient Descent where the step-size is set to 0.5.\n\nNote that optimization is not performed at this point. In fact, nothing is calculated at all, we just add the optimizer-object to the TensorFlow graph for later execution.",
"_____no_output_____"
]
],
[
[
"optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(cost)",
"_____no_output_____"
]
],
[
[
"### Performance measures",
"_____no_output_____"
],
[
"We need a few more performance measures to display the progress to the user.\n\nThis is a vector of booleans whether the predicted class equals the true class of each image.",
"_____no_output_____"
]
],
[
[
"correct_prediction = tf.equal(y_pred_cls, y_true_cls)",
"_____no_output_____"
]
],
[
[
"This calculates the classification accuracy by first type-casting the vector of booleans to floats, so that False becomes 0 and True becomes 1, and then calculating the average of these numbers.",
"_____no_output_____"
]
],
[
[
"accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))",
"_____no_output_____"
]
],
[
[
"## TensorFlow Run",
"_____no_output_____"
],
[
"### Create TensorFlow session\n\nOnce the TensorFlow graph has been created, we have to create a TensorFlow session which is used to execute the graph.",
"_____no_output_____"
]
],
[
[
"session = tf.Session()",
"_____no_output_____"
]
],
[
[
"### Initialize variables\n\nThe variables for `weights` and `biases` must be initialized before we start optimizing them.",
"_____no_output_____"
]
],
[
[
"session.run(tf.global_variables_initializer())",
"_____no_output_____"
]
],
[
[
"### Helper-function to perform optimization iterations",
"_____no_output_____"
],
[
"There are 55.000 images in the training-set. It takes a long time to calculate the gradient of the model using all these images. We therefore use Stochastic Gradient Descent which only uses a small batch of images in each iteration of the optimizer.",
"_____no_output_____"
]
],
[
[
"batch_size = 100",
"_____no_output_____"
]
],
[
[
"Function for performing a number of optimization iterations so as to gradually improve the `weights` and `biases` of the model. In each iteration, a new batch of data is selected from the training-set and then TensorFlow executes the optimizer using those training samples.",
"_____no_output_____"
]
],
[
[
"def optimize(num_iterations):\n for i in range(num_iterations):\n # Get a batch of training examples.\n # x_batch now holds a batch of images and\n # y_true_batch are the true labels for those images.\n x_batch, y_true_batch, _ = data.random_batch(batch_size=batch_size)\n \n # Put the batch into a dict with the proper names\n # for placeholder variables in the TensorFlow graph.\n # Note that the placeholder for y_true_cls is not set\n # because it is not used during training.\n feed_dict_train = {x: x_batch,\n y_true: y_true_batch}\n\n # Run the optimizer using this batch of training data.\n # TensorFlow assigns the variables in feed_dict_train\n # to the placeholder variables and then runs the optimizer.\n session.run(optimizer, feed_dict=feed_dict_train)",
"_____no_output_____"
]
],
[
[
"### Helper-functions to show performance",
"_____no_output_____"
],
[
"Dict with the test-set data to be used as input to the TensorFlow graph. Note that we must use the correct names for the placeholder variables in the TensorFlow graph.",
"_____no_output_____"
]
],
[
[
"feed_dict_test = {x: data.x_test,\n y_true: data.y_test,\n y_true_cls: data.y_test_cls}",
"_____no_output_____"
]
],
[
[
"Function for printing the classification accuracy on the test-set.",
"_____no_output_____"
]
],
[
[
"def print_accuracy():\n # Use TensorFlow to compute the accuracy.\n acc = session.run(accuracy, feed_dict=feed_dict_test)\n \n # Print the accuracy.\n print(\"Accuracy on test-set: {0:.1%}\".format(acc))",
"_____no_output_____"
]
],
[
[
"Function for printing and plotting the confusion matrix using scikit-learn.",
"_____no_output_____"
]
],
[
[
"def print_confusion_matrix():\n # Get the true classifications for the test-set.\n cls_true = data.y_test_cls\n \n # Get the predicted classifications for the test-set.\n cls_pred = session.run(y_pred_cls, feed_dict=feed_dict_test)\n\n # Get the confusion matrix using sklearn.\n cm = confusion_matrix(y_true=cls_true,\n y_pred=cls_pred)\n\n # Print the confusion matrix as text.\n print(cm)\n\n # Plot the confusion matrix as an image.\n plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues, norm=LogNorm())\n\n # Make various adjustments to the plot.\n plt.tight_layout()\n plt.colorbar()\n tick_marks = np.arange(num_classes)\n plt.xticks(tick_marks, range(num_classes))\n plt.yticks(tick_marks, range(num_classes))\n plt.xlabel('Predicted')\n plt.ylabel('True')\n \n # Ensure the plot is shown correctly with multiple plots\n # in a single Notebook cell.\n plt.show()",
"_____no_output_____"
]
],
[
[
"Function for plotting examples of images from the test-set that have been mis-classified.",
"_____no_output_____"
]
],
[
[
"def plot_example_errors():\n # Use TensorFlow to get a list of boolean values\n # whether each test-image has been correctly classified,\n # and a list for the predicted class of each image.\n correct, cls_pred = session.run([correct_prediction, y_pred_cls],\n feed_dict=feed_dict_test)\n\n # Negate the boolean array.\n incorrect = (correct == False)\n \n # Get the images from the test-set that have been\n # incorrectly classified.\n images = data.x_test[incorrect]\n \n # Get the predicted classes for those images.\n cls_pred = cls_pred[incorrect]\n\n # Get the true classes for those images.\n cls_true = data.y_test_cls[incorrect]\n \n # Plot the first 9 images.\n plot_images(images=images[0:9],\n cls_true=cls_true[0:9],\n cls_pred=cls_pred[0:9])",
"_____no_output_____"
]
],
[
[
"### Helper-function to plot the model weights",
"_____no_output_____"
],
[
"Function for plotting the `weights` of the model. 10 images are plotted, one for each digit that the model is trained to recognize.",
"_____no_output_____"
]
],
[
[
"def plot_weights():\n # Get the values for the weights from the TensorFlow variable.\n w = session.run(weights)\n \n # Get the lowest and highest values for the weights.\n # This is used to correct the colour intensity across\n # the images so they can be compared with each other.\n w_min = np.min(w)\n w_max = np.max(w)\n\n # Create figure with 3x4 sub-plots,\n # where the last 2 sub-plots are unused.\n fig, axes = plt.subplots(3, 4)\n fig.subplots_adjust(hspace=0.3, wspace=0.3)\n\n for i, ax in enumerate(axes.flat):\n # Only use the weights for the first 10 sub-plots.\n if i<10:\n # Get the weights for the i'th digit and reshape it.\n # Note that w.shape == (img_size_flat, 10)\n image = w[:, i].reshape(img_shape)\n\n # Set the label for the sub-plot.\n ax.set_xlabel(\"Weights: {0}\".format(i))\n\n # Plot the image.\n ax.imshow(image, vmin=w_min, vmax=w_max, cmap='seismic')\n\n # Remove ticks from each sub-plot.\n ax.set_xticks([])\n ax.set_yticks([])\n \n # Ensure the plot is shown correctly with multiple plots\n # in a single Notebook cell.\n plt.show()",
"_____no_output_____"
]
],
[
[
"## Performance before any optimization\n\nThe accuracy on the test-set is 9.8%. This is because the model has only been initialized and not optimized at all, so it always predicts that the image shows a zero digit, as demonstrated in the plot below, and it turns out that 9.8% of the images in the test-set happens to be zero digits.",
"_____no_output_____"
]
],
[
[
"print_accuracy()",
"Accuracy on test-set: 9.8%\n"
],
[
"plot_example_errors()",
"_____no_output_____"
]
],
[
[
"## Performance after 1 optimization iteration\n\nAlready after a single optimization iteration, the model has increased its accuracy on the test-set significantly.",
"_____no_output_____"
]
],
[
[
"optimize(num_iterations=1)",
"_____no_output_____"
],
[
"print_accuracy()",
"Accuracy on test-set: 15.9%\n"
],
[
"plot_example_errors()",
"_____no_output_____"
]
],
[
[
"The weights can also be plotted as shown below. Positive weights are red and negative weights are blue. These weights can be intuitively understood as image-filters.\n\nFor example, the weights used to determine if an image shows a zero-digit have a positive reaction (red) to an image of a circle, and have a negative reaction (blue) to images with content in the centre of the circle.\n\nSimilarly, the weights used to determine if an image shows a one-digit react positively (red) to a vertical line in the centre of the image, and react negatively (blue) to images with content surrounding that line.\n\nNote that the weights mostly look like the digits they're supposed to recognize. This is because only one optimization iteration has been performed so the weights are only trained on 100 images. After training on several thousand images, the weights become more difficult to interpret because they have to recognize many variations of how digits can be written.",
"_____no_output_____"
]
],
[
[
"plot_weights()",
"_____no_output_____"
]
],
[
[
"## Performance after 10 optimization iterations",
"_____no_output_____"
]
],
[
[
"# We have already performed 1 iteration.\noptimize(num_iterations=9)",
"_____no_output_____"
],
[
"print_accuracy()",
"Accuracy on test-set: 66.2%\n"
],
[
"plot_example_errors()",
"_____no_output_____"
],
[
"plot_weights()",
"_____no_output_____"
]
],
[
[
"## Performance after 1000 optimization iterations\n\nAfter 1000 optimization iterations, the model only mis-classifies about one in ten images. As demonstrated below, some of the mis-classifications are justified because the images are very hard to determine with certainty even for humans, while others are quite obvious and should have been classified correctly by a good model. But this simple model cannot reach much better performance and more complex models are therefore needed.",
"_____no_output_____"
]
],
[
[
"# We have already performed 10 iterations.\noptimize(num_iterations=990)",
"_____no_output_____"
],
[
"print_accuracy()",
"Accuracy on test-set: 91.5%\n"
],
[
"plot_example_errors()",
"_____no_output_____"
]
],
[
[
"The model has now been trained for 1000 optimization iterations, with each iteration using 100 images from the training-set. Because of the great variety of the images, the weights have now become difficult to interpret and we may doubt whether the model truly understands how digits are composed from lines, or whether the model has just memorized many different variations of pixels.",
"_____no_output_____"
]
],
[
[
"plot_weights()",
"_____no_output_____"
]
],
[
[
"We can also print and plot the so-called confusion matrix which lets us see more details about the mis-classifications. For example, it shows that images actually depicting a 5 have sometimes been mis-classified as all other possible digits, but mostly as 6 or 8.",
"_____no_output_____"
]
],
[
[
"print_confusion_matrix()",
"[[ 956 0 3 1 1 4 11 3 1 0]\n [ 0 1114 2 2 1 2 4 2 8 0]\n [ 6 8 925 23 11 3 13 12 26 5]\n [ 3 1 19 928 0 34 2 10 5 8]\n [ 1 3 4 2 918 2 11 2 6 33]\n [ 8 3 7 36 8 781 15 6 20 8]\n [ 9 3 5 1 14 12 912 1 1 0]\n [ 2 11 24 10 6 1 0 941 1 32]\n [ 8 13 11 44 11 52 13 14 797 11]\n [ 11 7 2 14 50 10 0 30 4 881]]\n"
]
],
[
[
"We are now done using TensorFlow, so we close the session to release its resources.",
"_____no_output_____"
]
],
[
[
"# This has been commented out in case you want to modify and experiment\n# with the Notebook without having to restart it.\n# session.close()",
"_____no_output_____"
]
],
[
[
"## Exercises\n\nThese are a few suggestions for exercises that may help improve your skills with TensorFlow. It is important to get hands-on experience with TensorFlow in order to learn how to use it properly.\n\nYou may want to backup this Notebook before making any changes.\n\n* Change the learning-rate for the optimizer.\n* Change the optimizer to e.g. `AdagradOptimizer` or `AdamOptimizer`.\n* Change the batch-size to e.g. 1 or 1000.\n* How do these changes affect the performance?\n* Do you think these changes will have the same effect (if any) on other classification problems and mathematical models?\n* Do you get the exact same results if you run the Notebook multiple times without changing any parameters? Why or why not?\n* Change the function `plot_example_errors()` so it also prints the `logits` and `y_pred` values for the mis-classified examples.\n* Use `sparse_softmax_cross_entropy_with_logits` instead of `softmax_cross_entropy_with_logits`. This may require several changes to multiple places in the source-code. Discuss the advantages and disadvantages of using the two methods.\n* Remake the program yourself without looking too much at this source-code.\n* Explain to a friend how the program works.",
"_____no_output_____"
],
[
"## License (MIT)\n\nCopyright (c) 2016 by [Magnus Erik Hvass Pedersen](http://www.hvass-labs.org/)\n\nPermission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d02b257045d8d09b9c594db2f4a88592a1279106
| 36,335 |
ipynb
|
Jupyter Notebook
|
preprocessing/Untitled1.ipynb
|
SensesProject/regional-dutch
|
09d2f7fc8e550a78da93f378691c717af8223210
|
[
"0BSD"
] | null | null | null |
preprocessing/Untitled1.ipynb
|
SensesProject/regional-dutch
|
09d2f7fc8e550a78da93f378691c717af8223210
|
[
"0BSD"
] | 1 |
2020-11-30T09:33:43.000Z
|
2020-12-04T10:27:59.000Z
|
preprocessing/Untitled1.ipynb
|
SensesProject/regional-dutch
|
09d2f7fc8e550a78da93f378691c717af8223210
|
[
"0BSD"
] | null | null | null | 277.366412 | 30,836 | 0.909481 |
[
[
[
"\n\n! pip install networkx nx_altair\n\nimport altair as alt\nimport networkx as nx\nimport nx_altair as nxa\nimport pylab as plt\n\n",
"Requirement already satisfied: networkx in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (2.4)\nRequirement already satisfied: nx_altair in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (0.1.6)\nRequirement already satisfied: decorator>=4.3.0 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from networkx) (4.4.2)\nRequirement already satisfied: pandas in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from nx_altair) (1.0.3)\nRequirement already satisfied: altair in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from nx_altair) (4.1.0)\nRequirement already satisfied: numpy>=1.13.3 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from pandas->nx_altair) (1.18.3)\nRequirement already satisfied: python-dateutil>=2.6.1 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from pandas->nx_altair) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from pandas->nx_altair) (2019.3)\nRequirement already satisfied: jinja2 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from altair->nx_altair) (2.11.2)\nRequirement already satisfied: toolz in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from altair->nx_altair) (0.10.0)\nRequirement already satisfied: entrypoints in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from altair->nx_altair) (0.3)\nRequirement already satisfied: jsonschema in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from altair->nx_altair) (3.2.0)\nRequirement already satisfied: six>=1.5 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from python-dateutil>=2.6.1->pandas->nx_altair) (1.14.0)\nRequirement already satisfied: MarkupSafe>=0.23 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from jinja2->altair->nx_altair) (1.1.1)\nRequirement already satisfied: importlib-metadata; python_version < \"3.8\" in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from jsonschema->altair->nx_altair) (1.6.0)\nRequirement already satisfied: pyrsistent>=0.14.0 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from jsonschema->altair->nx_altair) (0.16.0)\nRequirement already satisfied: setuptools in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from jsonschema->altair->nx_altair) (40.8.0)\nRequirement already satisfied: attrs>=17.4.0 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from jsonschema->altair->nx_altair) (19.3.0)\nRequirement already satisfied: zipp>=0.5 in /Users/jonas/.pyenv/versions/3.7.3/lib/python3.7/site-packages (from importlib-metadata; python_version < \"3.8\"->jsonschema->altair->nx_altair) (3.1.0)\n\u001b[33mWARNING: You are using pip version 20.0.2; however, version 20.2.3 is available.\nYou should consider upgrading via the '/Users/jonas/.pyenv/versions/3.7.3/bin/python3.7 -m pip install --upgrade pip' command.\u001b[0m\n"
],
[
"G = nx.Graph()\n\nG.add_edge(\"1\", \"2\")\nG.add_edge(\"1\", \"3\")\nG.add_edge(\"2\", \"3\")\nG.add_edge(\"6\", \"3\")\nG.add_edge(\"6\", \"7\")\nG.add_edge(\"3\", \"7\")\nG.add_edge(\"8\", \"3\")\nG.add_edge(\"5\", \"2\")\nG.add_edge(\"4\", \"2\")\nG.add_edge(\"14\", \"2\")\nG.add_edge(\"4\", \"9\")\nG.add_edge(\"9\", \"5\")\nG.add_edge(\"5\", \"10\")\nG.add_edge(\"10\", \"11\")\nG.add_edge(\"11\", \"9\")\nG.add_edge(\"10\", \"13\")\nG.add_edge(\"11\", \"8\")\nG.add_edge(\"7\", \"11\")\nG.add_edge(\"12\", \"5\")\nG.add_edge(\"12\", \"7\")\nG.add_edge(\"14\", \"9\")\nG.add_edge(\"7\", \"4\")\n\nnx.draw(G, with_labels = True)\nplt.savefig('network-2.svg')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
d02b369a91cd5775e3ce0eeb2ed88e0dc781baf6
| 1,047,827 |
ipynb
|
Jupyter Notebook
|
Modelling trend life cycles in scientific research.ipynb
|
etattershall/trend-lifecycles
|
fd1b0ff57fb50808a865be9359a16c856fd37819
|
[
"MIT"
] | null | null | null |
Modelling trend life cycles in scientific research.ipynb
|
etattershall/trend-lifecycles
|
fd1b0ff57fb50808a865be9359a16c856fd37819
|
[
"MIT"
] | null | null | null |
Modelling trend life cycles in scientific research.ipynb
|
etattershall/trend-lifecycles
|
fd1b0ff57fb50808a865be9359a16c856fd37819
|
[
"MIT"
] | null | null | null | 509.148202 | 211,688 | 0.932024 |
[
[
[
"# Modelling trend life cycles in scientific research\n\n**Authors:** E. Tattershall, G. Nenadic, and R.D. Stevens\n\n**Abstract:** Scientific topics vary in popularity over time. In this paper, we model the life-cycles of 200 topics by fitting the Logistic and Gompertz models to their frequency over time in published abstracts. Unlike other work, the topics we use are algorithmically extracted from large datasets of abstracts covering computer science, particle physics, cancer research, and mental health. We find that the Gompertz model produces lower median error, leading us to conclude that it is the more appropriate model. Since the Gompertz model is asymmetric, with a steep rise followed a long tail, this implies that scientific topics follow a similar trajectory. We also explore the case of double-peaking curves and find that in some cases, topics will peak multiple times as interest resurges. Finally, when looking at the different scientific disciplines, we find that the lifespan of topics is longer in some disciplines (e.g. cancer research and mental health) than it is others, which may indicate differences in research process and culture between these disciplines. \n\n\n**Requirements**\n- Data. Data ingress is excluded from this notebook, but we alraedy have four large datasets of abstracts. The documents in these datasets have been cleaned (described in sections below) and separated by year. Anecdotally, this method works best when there are >100,000 documents in the dataset (and more is even better).\n- The other utility files in this directory, including burst_detection.py, my_stopwords.py, etc...\n\n**In this notebook** \n\n- Vectorisation\n- Burst detection\n- Clustering\n- Model fitting\n- Comparing the error of the two models\n- Calculating trend duration \n- Double peaked curves\n- Trends and fitted models in full",
"_____no_output_____"
]
],
[
[
"import os\nimport csv\nimport pandas as pd\nfrom collections import defaultdict\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import FormatStrFormatter\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.feature_extraction.text import TfidfTransformer\nimport numpy as np\nimport scipy\nfrom scipy.spatial.distance import squareform\nfrom scipy.cluster import hierarchy\nimport pickle\n\nimport burst_detection\nimport my_stopwords\nimport cleaning\nimport tools\nimport logletlab\n\nimport scipy.optimize as opt\nfrom sklearn.metrics import mean_squared_error\n\n",
"_____no_output_____"
],
[
"stop = my_stopwords.get_stopwords()\nburstiness_threshold = 0.004\ncluster_distance_threshold = 7\n\n# Burst detection internal parameters\n# These are the same as in our earlier paper [Tattershall 2020]\nparameters = {\n \"min_yearly_df\": 5,\n \"significance_threshold\": 0.0015,\n \"years_above_significance\": 3,\n \"long_ma_length\": 8,\n \"short_ma_length\": 4,\n \"signal_line_ma\": 3,\n \"significance_ma_length\": 3 \n}\n\n# Number of bursty terms to extract for each dataset. This will later be filtered down to 50 for each dataset after clustering.\nmax_bursts = 300\n\ndataset_names = ['pubmed_mh', 'arxiv_hep', 'pubmed_cancer', 'dblp_cs']\ndataset_titles = ['Computer science (dblp)', 'Particle physics (arXiv)', 'Mental health (PubMed)', 'Cancer (PubMed)']\ndatasets = {}\n\ndef reverse_cumsum(ls):\n reverse = np.zeros_like(ls)\n for i in range(len(ls)):\n if i == 0:\n reverse[i] = ls[i]\n else:\n reverse[i] = ls[i]-ls[i-1]\n \n \n if reverse[0]>reverse[1]:\n reverse[0]=reverse[1]\n \n return reverse\n\ndef detransform_fit(ypc, F, dataset_name):\n '''\n The Gompertz and Logistic curves actually model *cumulative* frequency over time, not raw frequency. \n However, raw frequency is more intuitive for graphs, so we use this function to change a cumulative \n time series into a non-cumulative one. Additionally, the models were originally fitted to scaled curves\n (such that the minumum frequency was zero and the maximum was one). This was done to make it possible to \n directly compare the error between different time series without a much more frequent term dwarfing the calculation.\n We now transform back.\n '''\n s = document_count_per_year[dataset_name]\n yf = reverse_cumsum(F*(max(ypc)-min(ypc)) + min(ypc))\n return yf\n",
"_____no_output_____"
],
[
"# Location where the cleaned data is stored\ndata_root = 'cleaned_data/'\n\n# Location where we will store the results of this notebook\nroot = 'results/'\n\nos.mkdir(root+'clusters')\nos.mkdir(root+'images')\nos.mkdir(root+'fitted_curves')\nos.mkdir(root+'vectors')\n\nfor dataset_name in dataset_names:\n os.mkdir(root+'vectors/'+dataset_name)\n os.mkdir(root+'fitted_curves/'+dataset_name)",
"_____no_output_____"
]
],
[
[
"## The data\n\nWe have four datasets:\n\n- **Computer Science (dblp_cs):** This dataset contains 2.6 million abstracts downloaded from Semantic Scholar. We select all abstracts with the dblp tag.\n- **Particle Physics (arxiv_hep):** This dataset of 0.2 million abstracts was downloaded from arXiv's public API. We extracted particle physics-reladed documents by selecting everything under the categroies hep-ex, hep-lat, hep-ph and hep-th.\n- **Mental Health (pubmed_mh):** 0.7 million abstracts downloaded from PubMed. This dataset was created by filtering on the MeSH keyword \"Mental Health\" and all its subterms.\n- **Cancer (pubmed_cancer):** 1.9 million abstracts downloaded from PubMed. This dataset was created by filtering on the MeSH keyword \"Neoplasms\" and all its subterms.\n\nThe data in each dataset has already been cleaned. We removed punctuation, set all characters to lowercase and lemmatised each word using WordNetLemmatizer. The cleaned data is stored in pickled pandas dataframes in files named 1988.p, 1989.p, 1990.p. Each dataframe has a column \"cleaned\" which contains the cleaned and lemmatized text for each document in that dataset in the given year. \n\n### How many documents are in each dataset in each year?",
"_____no_output_____"
]
],
[
[
"document_count_per_year = {}\n\nfor dataset_name in dataset_names:\n # For each dataset, we want a list of document counts for each year\n document_count_per_year[dataset_name] = []\n # The files in the directory are named 1988.p, 1989.p, 1990.p....\n files = os.listdir(data_root+dataset_name)\n min_year = np.min([int(file[0:4]) for file in files])\n max_year = np.max([int(file[0:4]) for file in files])\n \n for year in range(min_year, max_year+1):\n df = pickle.load(open(data_root+dataset_name+'/'+str(year)+'.p', \"rb\"))\n document_count_per_year[dataset_name].append(len(df))\n \npickle.dump(document_count_per_year, open(root + 'document_count_per_year.p', \"wb\"))",
"_____no_output_____"
],
[
"plt.figure(figsize=(6,3.7))\nax1=plt.subplot(111)\nplt.subplots_adjust(left=0.2, right=0.9)\nax1.set_title('Documents per year in each dataset', fontsize=11)\n\nax1.plot(np.arange(1988, 2018), document_count_per_year['dblp_cs'], 'k', label='dblp')\nax1.plot(np.arange(1994, 2018), document_count_per_year['arxiv_hep'], 'k', linestyle= '-.', label='arXiv')\nax1.plot(np.arange(1975, 2018), document_count_per_year['pubmed_mh'], 'k', linestyle= '--', label='PubMed (Mental Health)')\nax1.plot(np.arange(1975, 2018), document_count_per_year['pubmed_cancer'], 'k', linestyle= ':', label='PubMed (Cancer)')\nax1.grid()\n\n\nax1.set_xlim([1975, 2018])\nax1.set_ylabel('Documents', fontsize=10)\nax1.set_xlabel('Year', fontsize=10)\nax1.set_ylim([0,200000])\nax1.legend(fontsize=10)\n\nplt.savefig(root+'images/documents_per_year.eps', format='eps', dpi=1200)",
"_____no_output_____"
]
],
[
[
"### Create a vocabulary for each dataset\n\n- For each dataset, we find all **1-5 word terms** (after stopwords are removed). This allows us to use relatively complex phrases.\n- Since the set of all 1-5 word terms is very large and contains much noise, we filter out terms that fail to meet a **minimum threshold of \"significance\"**. For significance we require that they occur at least six times in at least one year. We find that this also gets rid of spelling erros and cuts down the size of the data.\n",
"_____no_output_____"
]
],
[
[
"for dataset_name in dataset_names:\n vocabulary = set()\n\n files = os.listdir(data_root+dataset_name)\n min_year = np.min([int(file[0:4]) for file in files])\n max_year = np.max([int(file[0:4]) for file in files])\n \n for year in range(min_year, max_year+1):\n df = pickle.load(open(data_root+dataset_name+\"/\"+str(year)+\".p\", \"rb\"))\n # Create an initial vocabulary based on the list of text files\n vectorizer = CountVectorizer(strip_accents='ascii', \n ngram_range=(1,5),\n stop_words=stop,\n min_df=6\n )\n \n # Vectorise the data in order to get the vocabulary\n vector = vectorizer.fit_transform(df['cleaned'])\n \n # Add the harvested vocabulary to the set. This removes duplicates of terms that occur in multiple years\n vocabulary = vocabulary.union(set(vectorizer.vocabulary_))\n \n # To conserve memory, delete the vector here\n del vector\n \n print('Overall vocabulary created for ', dataset_name)\n \n # We now vectorise the dataset again based on the unifying vocabulary\n vocabulary = list(vocabulary)\n vectors = []\n vectorizer = CountVectorizer(strip_accents='ascii', \n ngram_range=(1,5),\n stop_words=stop,\n vocabulary=vocabulary)\n \n for year in range(min_year, max_year+1):\n df = pickle.load(open(data_root+dataset_name+\"/\"+str(year)+\".p\", \"rb\"))\n vector = vectorizer.fit_transform(df['cleaned'])\n \n # Set all elements of the vector that are greater than 1 to 1. This is because we only care about\n # the overall document frequency of each term. If a word is used multiple times in a single document\n # it only contributes 1 to the document frequency.\n vector[vector>1] = 1\n \n # Sum the vector along its columns in order to get the total document frequency of each term in a year\n summed = np.squeeze(np.asarray(np.sum(vector, axis=0)))\n \n vectors.append(summed)\n \n # Turn the vector into a pandas dataframe\n df = pd.DataFrame(vectors, columns=vocabulary) \n\n # THE PART BELOW IS OPTIONAL\n # We found that the process works better if very similar terms are removed from the vocabulary\n # Therefore, for each 2-5 ngram, we identify all possible subterms, then attempt to calculate whether\n # the subterms are legitimate terms in their own right (i.e. they appear in documents without their\n # superterm parent). For example, the term \"long short-term memory\" is made up of the subterms\n # [\"long short\", \"short term\", \"term memory\", \"long short term\", \"short term memory\"]\n # However, when we calculate the document frequency of each subterm divided by the document frequency of \n # \"long short term memory\", we find:\n # \n # long short 1.4\n # short term 6.1\n # term memory 2.2\n # long short term 1.1\n # short term memory 1.4\n #\n # Since the term \"long short term\" occurs only very rarely outside the phrase \"long short term memory\", we \n # omit this term by setting an arbitrary threshold of 1.1. This preserves most of the subterms while removing the rarest.\n \n removed = []\n \n # for each term in the vocabulary\n for i, term in enumerate(list(df.columns)):\n # If the term is a 2-5 ngram (i.e. not a single word)\n if ' ' in term:\n # Find the overall term document frequency over the entire dataset\n term_total_document_frequency = df[term].sum()\n \n # Find all possible subterms of the term. \n subterms = tools.all_subterms(term)\n \n for subterm in subterms:\n try:\n # If the subterm is in the vocabulary, check whether it often occurs on its own\n # without the superterm being present\n subterm_total_document_frequency = df[subterm].sum()\n if subterm_total_document_frequency < term_total_document_frequency*1.1:\n removed.append([subterm, term])\n\n except:\n pass\n\n # Remove the removed terms from the dataframe\n df = df.drop(list(set([r[0] for r in removed])), axis=1)\n \n \n # END OPTIONAL PART\n \n # Store the stacked vectors for later use\n pickle.dump(df, open(root+'vectors/'+dataset_name+\"/stacked_vector.p\", \"wb\"))\n pickle.dump(list(df.columns), open(root+'vectors/'+dataset_name+\"/vocabulary.p\", \"wb\"))",
"Overall vocabulary created for arxiv_hep\n"
]
],
[
[
"### Detect bursty terms\n\nNow that we have vectors representing the document frequency of each term over time, we can use our MACD-based burst detection, as described in our earlier paper [Tattershall 2020]. ",
"_____no_output_____"
]
],
[
[
"bursts = dict()\nfor dataset_name in dataset_names:\n\n files = os.listdir(data_root+dataset_name)\n min_year = np.min([int(file[0:4]) for file in files])\n max_year = np.max([int(file[0:4]) for file in files])\n \n # Create a dataset object for the burst detection algorithm\n bd_dataset = burst_detection.Dataset(\n name = dataset_name, \n years = (min_year, max_year), \n # We divide the term-document frequency for each year by the number of documents in that year \n stacked_vectors = pickle.load(open(root+dataset_name+\"/stacked_vector.p\", \"rb\")).divide(document_count_per_year[dataset_name],axis=0)\n )\n \n # We apply the significance threshold from the burst detection methodology. This cuts the size of the dataset by \n # removing terms that occur only in one year\n bd_dataset.get_sig_stacked_vectors(parameters[\"significance_threshold\"], parameters[\"years_above_significance\"])\n bd_dataset.get_burstiness(parameters[\"short_ma_length\"], parameters[\"long_ma_length\"], parameters[\"significance_ma_length\"], parameters[\"signal_line_ma\"])\n datasets[dataset_name] = bd_dataset\n bursts[dataset_name] = tools.get_top_n_bursts(datasets[dataset_name].burstiness, max_bursts)\n \npickle.dump(bursts, open(root+'vectors/'+'bursts.p', \"wb\"))",
"_____no_output_____"
]
],
[
[
"### Calculate burst co-occurence \n\nWe now have 300 bursts per dataset. Some of these describe very similar concepts, such as \"internet of things\" and \"iot\". The purpose of this section is the merge similar terms into clusters to prevent redundancy within the dataset. We calculate the relatedness of terms using term co-occurrence within the same document (terms that appear together are grouped together).",
"_____no_output_____"
]
],
[
[
"for dataset_name in dataset_names:\n vectors = []\n vectorizer = CountVectorizer(strip_accents='ascii', \n ngram_range=(1,5),\n stop_words=stop,\n vocabulary=bursts[dataset_name])\n \n for year in range(min_year, max_year+1):\n df = pickle.load(open(data_root+dataset_name+\"/\"+str(year)+\".p\", \"rb\"))\n vector = vectorizer.fit_transform(df['cleaned'])\n \n # Set all elements of the vector that are greater than 1 to 1. This is because we only care about\n # the overall document frequency of each term. If a word is used multiple times in a single document\n # it only contributes 1 to the document frequency.\n vector[vector>1] = 1\n \n vectors.append(vector)\n \n # Calculate the cooccurrence matrix\n v = vectors[0]\n c = v.T*v\n c.setdiag(0)\n c = c.todense()\n\n cooccurrence = c\n\n for v in vectors[1:]:\n c = v.T*v\n c.setdiag(0)\n c = c.toarray()\n cooccurrence += c\n \n pickle.dump(cooccurrence, open(root+'vectors/'+dataset_name+\"/cooccurrence_matrix.p\", \"wb\"))",
"C:\\Users\\emmat\\Anaconda3\\lib\\site-packages\\scipy\\sparse\\_index.py:126: SparseEfficiencyWarning: Changing the sparsity structure of a csc_matrix is expensive. lil_matrix is more efficient.\n self._set_arrayXarray(i, j, x)\nC:\\Users\\emmat\\Anaconda3\\lib\\site-packages\\scipy\\sparse\\_index.py:126: SparseEfficiencyWarning: Changing the sparsity structure of a csc_matrix is expensive. lil_matrix is more efficient.\n self._set_arrayXarray(i, j, x)\n"
]
],
[
[
"### Use burst co-occurrence to cluster terms\n\nWe use a hierarchichal clustering method to group terms together. This is highly customisable due to threshold setting, allowing us to group more or less conservatively if required.",
"_____no_output_____"
]
],
[
[
"# Reload bursts if required by uncommenting this line\n#bursts = pickle.load(open(root+'bursts.p', \"rb\"))\n\ndataset_clusters = dict()\nfor dataset_name in dataset_names:\n #cooccurrence = pickle.load(open('Data/stacked_vectors/'+dataset_name+\"/cooccurrence_matrix.p\", \"rb\"))\n \n # Translate co-occurence into a distance\n dists = np.log(cooccurrence+1).max()- np.log(cooccurrence+1)\n\n # Remove the diagonal (squareform requires diagonals be zero)\n dists -= np.diag(np.diagonal(dists))\n\n # Put the distance matrix into the format required by hierachy.linkage\n flat_dists = squareform(dists)\n\n # Get the linkage matrix\n linkage_matrix = hierarchy.linkage(flat_dists, \"ward\")\n\n assignments = hierarchy.fcluster(linkage_matrix, t=cluster_distance_threshold, criterion='distance')\n\n clusters = defaultdict(list) \n \n for term, assign, co in zip(bursts[dataset_name], assignments, cooccurrence):\n clusters[assign].append(term)\n\n dataset_clusters[dataset_name] = list(clusters.values())",
"_____no_output_____"
],
[
"dataset_clusters['arxiv_hep'] ",
"_____no_output_____"
]
],
[
[
"### Manual choice of clusters\n\nWe now sort the clusters in order of burstiness (using the burstiness of the most bursty term in the cluster) and manually exclude clusters that include publishing artefacts such as \"elsevier science bv right reserved\". From the remainder, we select the top fifty. We do this for all four datasets, giving 200 clusters. The selected clusters are stored in the file \"200clusters.csv\".",
"_____no_output_____"
],
[
"### For each cluster, create a time series of mentions in abstracts over time\n\nWe now need to search for the clusters to pull out the frequency of appearance in abstracts over time. For the cluster [\"Internet of things\", \"IoT\"], all abstracts that mention **either** term are included (i.e. an abstract that uses \"Internet of things\" without the abbreviation \"IoT\" still counts towards the total for that year). We take document frequency, not term frequency, so the number of times the terms are mentioned in each document do not matter, so long as they are mentioned once.",
"_____no_output_____"
]
],
[
[
"raw_clusters = pd.read_csv('200clusters.csv')\ncluster_dict = defaultdict(list)\nfor dataset_name in dataset_names:\n for raw_cluster in raw_clusters[dataset_name]:\n cluster_dict[dataset_name].append(raw_cluster.split(','))\n \n\nfor dataset_name in dataset_names:\n # List all the cluster terms. This will be more than the total number of clusters.\n all_cluster_terms = sum(cluster_dict[dataset_name], [])\n\n # Get the cluster titles. This is the list of terms in each cluster\n all_cluster_titles = [','.join(cluster) for cluster in cluster_dict[dataset_name]]\n\n # Get a list of files from the directory\n files = os.listdir(data_root + dataset_name)\n\n # This is where we will store the data. The columns correspond to clusters, the rows to years\n prevalence_array = np.zeros([len(files),len(cluster_dict[dataset_name])])\n\n # Open each year file in turn\n for i, file in enumerate(files):\n print(file)\n year_data = pickle.load(open(data_root + dataset_name + '/' + file, 'rb'))\n\n # Vectorise the data for that year\n vectorizer = CountVectorizer(strip_accents='ascii', \n ngram_range=(1,5),\n stop_words=stop,\n vocabulary=all_cluster_terms\n )\n\n vector = vectorizer.fit_transform(year_data['cleaned'])\n\n\n # Get the index of each cluster term. This will allows us to map the full vocabulary \n # e.g. (60 items) back onto the original clusters (e.g. 50 items)\n for j, cluster in enumerate(cluster_dict[dataset_name]):\n indices = []\n for term in cluster:\n indices.append(all_cluster_terms.index(term))\n\n # If there are multiple terms in a cluster, sum the cluster columns together\n summed_column = np.squeeze(np.asarray(vector[:,indices].sum(axis=1).flatten()))\n # Set any element greater than one to one--we're only counting documents here, not \n # total occurrences\n summed_column[summed_column!=0] = 1\n\n # This is the total number of occurrences of the cluster per year\n prevalence_array[i, j] = np.sum(summed_column)\n\n # Save the data\n df = pd.DataFrame(data=prevalence_array, index=[f[0:4] for f in files], columns=all_cluster_titles) \n pickle.dump(df, open(root+'clusters/'+dataset_name+'.p', 'wb'))",
"1994.p\n1995.p\n1996.p\n1997.p\n1998.p\n1999.p\n2000.p\n2001.p\n2002.p\n2003.p\n2004.p\n2005.p\n2006.p\n2007.p\n2008.p\n2009.p\n2010.p\n2011.p\n2012.p\n2013.p\n2014.p\n2015.p\n2016.p\n2017.p\n"
]
],
[
[
"### Curve fitting\n\n\nThe below is a pythonic version of the Loglet Lab 4 code found at https://github.com/pheguest/logletlab4. Loglet Lab also has a web interface at https://logletlab.com/ which allows you to create amazing graphs. However, the issue with the web interface is that it is not designed for processing hundreds of time series, and in order to do this, each time series must be laboriously copy-pasted into the input box, the parameters set, and then the results saved individually. With 200 time series and multiple parameter sets, this process is quite slow! Therefore, we have adapted the code from the github repository, but the original should be seen at https://github.com/pheguest/logletlab4/blob/master/javascript/src/psmlogfunc3.js. \n",
"_____no_output_____"
]
],
[
[
"curve_header_1 = ['', 'd', 'k', 'a', 'b', 'RMS']\ncurve_header_2 = ['', 'd', 'k1', 'a1', 'b1', 'k2', 'a2', 'b2', 'RMS']\ndataset_names = ['arxiv_hep', 'pubmed_mh', 'pubmed_cancer', 'dblp_cs']\n\nfor dataset_name in dataset_names:\n print('-'*50)\n print(dataset_name.upper())\n \n for curve_type in ['logistic', 'gompertz']:\n for number_of_peaks in [1, 2]:\n with open('our_loglet_lab/'+dataset_name+'/'+curve_type+str(number_of_peaks)+'.csv', 'w', newline='') as f:\n writer = csv.writer(f)\n if number_of_peaks == 1:\n writer.writerow(curve_header_1)\n elif number_of_peaks == 2:\n writer.writerow(curve_header_2) \n\n df = pickle.load(open(root+'clusters/'+dataset_name+'.p', 'rb'))\n document_count_per_year = pickle.load(open(root+\"/document_count_per_year.p\", 'rb'))[dataset_name]\n df = df.divide(document_count_per_year, axis=0)\n\n for term in df.keys():\n y = tools.normalise_time_series(df[term].cumsum())\n x = np.array([int(i) for i in y.index])\n y = y.values\n\n\n if number_of_peaks == 1:\n logobj = logletlab.LogObj(x, y, 1)\n constraints = logletlab.estimate_constraints(x, y, 1)\n\n if curve_type == 'logistic':\n logobj = logletlab.loglet_MC_anneal_regression(logobj, constraints=constraints, number_of_loglets=1, \n curve_type='logistic', anneal_iterations=20, \n mc_iterations=1000, anneal_sample_size=100)\n else:\n logobj = logletlab.loglet_MC_anneal_regression(logobj, constraints=constraints, number_of_loglets=1, \n curve_type='gompertz', anneal_iterations=20, \n mc_iterations=1000, anneal_sample_size=100) \n\n line = [term, logobj.parameters['d'], logobj.parameters['k'][0], logobj.parameters['a'][0], logobj.parameters['b'][0], logobj.energy_best]\n\n print(curve_type, number_of_peaks, term, 'RMSE='+str(np.round(logobj.energy_best,3)))\n with open(root+'fitted_curves/'+dataset_name+'/'+curve_type+'_single.csv', 'a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(line) \n\n elif number_of_peaks == 2:\n logobj = logletlab.LogObj(x, y, 2)\n constraints = logletlab.estimate_constraints(x, y, 2)\n\n if curve_type == 'logistic':\n logobj = logletlab.loglet_MC_anneal_regression(logobj, constraints=constraints, number_of_loglets=2, \n curve_type='logistic', anneal_iterations=30, \n mc_iterations=1000, anneal_sample_size=100)\n else:\n logobj = logletlab.loglet_MC_anneal_regression(logobj, constraints=constraints, number_of_loglets=2, \n curve_type='gompertz', anneal_iterations=30, \n mc_iterations=1000, anneal_sample_size=100) \n\n line = [term, logobj.parameters['d'], \n logobj.parameters['k'][0], \n logobj.parameters['a'][0], \n logobj.parameters['b'][0], \n logobj.parameters['k'][1], \n logobj.parameters['a'][1], \n logobj.parameters['b'][1], \n logobj.energy_best]\n\n print(curve_type, number_of_peaks, term, 'RMSE='+str(np.round(logobj.energy_best,3)))\n \n with open(root+'fitted_curves/'+dataset_name+'/'+curve_type+'_double.csv', 'a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(line) ",
"--------------------------------------------------\nARXIV_HEP\nlogistic_single 1 125 gev 0.029907304762336263\nlogistic_single 1 pentaquark,pentaquarks 0.05043852824061915\nlogistic_single 1 wmap,wilkinson microwave anisotropy probe 0.0361380293123339\nlogistic_single 1 lhc run 0.020735398919035756\nlogistic_single 1 pamela 0.03204821466738317\nlogistic_single 1 lattice gauge 0.05233359007692712\nlogistic_single 1 tensor scalar ratio 0.036222971357601726\nlogistic_single 1 brane,branes 0.03141774013518978\nlogistic_single 1 atlas 0.01772382630535608\nlogistic_single 1 horava lifshitz,hovrava lifshitz 0.0410067585251185\nlogistic_single 1 lhc 0.006250825571034508\nlogistic_single 1 noncommutative,noncommutativity,non commutative,non commutativity 0.0327322808924473\nlogistic_single 1 black hole 0.020920939530327295\nlogistic_single 1 anomalous magnetic moment 0.04849255402257149\nlogistic_single 1 unparticle,unparticles 0.03351932242115829\nlogistic_single 1 superluminal 0.061748625288615105\nlogistic_single 1 m2 brane,m2 branes 0.039234821323279774\nlogistic_single 1 126 gev 0.018070446841532847\nlogistic_single 1 pp wave 0.047137089087624366\nlogistic_single 1 lambert 0.05871943152044709\nlogistic_single 1 tevatron 0.029469013159021687\nlogistic_single 1 higgs 0.034682515257204394\nlogistic_single 1 brane world 0.04485319867543418\nlogistic_single 1 extra dimension 0.03224289656019876\nlogistic_single 1 entropic 0.0366547700230139\nlogistic_single 1 kamland 0.05184286069114554\nlogistic_single 1 solar neutrino 0.02974273300483687\nlogistic_single 1 neutrino oscillation 0.04248474035767032\nlogistic_single 1 chern simon 0.027993037580545155\nlogistic_single 1 forward backward asymmetry 0.03979258482645767\nlogistic_single 1 dark energy 0.02603752198898685\nlogistic_single 1 bulk 0.029266519583018107\nlogistic_single 1 holographic 0.011123961217499157\nlogistic_single 1 international linear collider,ilc 0.04251997867004988\nlogistic_single 1 abjm 0.030827697912680977\nlogistic_single 1 babar 0.028343579032827054\nlogistic_single 1 daya bay 0.029215246675232537\nlogistic_single 1 sqrts7 tev 0.03478725079571082\nlogistic_single 1 130 gev 0.06940321757501901\nlogistic_single 1 20point3 0.041470794660599566\nlogistic_single 1 string field theory 0.03574859058388444\nlogistic_single 1 metastable vacuum 0.03939929585683627\nlogistic_single 1 gravitational wave 0.03579099579072222\nlogistic_single 1 belle 0.040482124354348815\nlogistic_single 1 diboson 0.04699497337736984\nlogistic_single 1 gamma ray excess 0.04102444964969219\nlogistic_single 1 generalized parton distribution 0.036712724912920894\nlogistic_single 1 lux 0.017863439822720473\nlogistic_single 1 higgsless 0.031371348784805776\nlogistic_single 1 planckian 0.03362768521566033\nlogistic_single 2 125 gev RMSE=0.094\nlogistic_single 2 pentaquark,pentaquarks RMSE=0.016\nlogistic_single 2 wmap,wilkinson microwave anisotropy probe RMSE=0.016\nlogistic_single 2 lhc run RMSE=0.099\nlogistic_single 2 pamela RMSE=0.067\nlogistic_single 2 lattice gauge RMSE=0.027\nlogistic_single 2 tensor scalar ratio RMSE=0.031\nlogistic_single 2 brane,branes RMSE=0.018\nlogistic_single 2 atlas RMSE=0.04\nlogistic_single 2 horava lifshitz,hovrava lifshitz RMSE=0.086\nlogistic_single 2 lhc RMSE=0.011\nlogistic_single 2 noncommutative,noncommutativity,non commutative,non commutativity RMSE=0.018\nlogistic_single 2 black hole RMSE=0.017\nlogistic_single 2 anomalous magnetic moment RMSE=0.013\nlogistic_single 2 unparticle,unparticles RMSE=0.07\nlogistic_single 2 superluminal RMSE=0.027\nlogistic_single 2 m2 brane,m2 branes RMSE=0.037\nlogistic_single 2 126 gev RMSE=0.106\nlogistic_single 2 pp wave RMSE=0.034\nlogistic_single 2 lambert RMSE=0.053\nlogistic_single 2 tevatron RMSE=0.02\nlogistic_single 2 higgs RMSE=0.017\nlogistic_single 2 brane world RMSE=0.038\nlogistic_single 2 extra dimension RMSE=0.017\nlogistic_single 2 entropic RMSE=0.04\nlogistic_single 2 kamland RMSE=0.026\nlogistic_single 2 solar neutrino RMSE=0.015\nlogistic_single 2 neutrino oscillation RMSE=0.014\nlogistic_single 2 chern simon RMSE=0.013\nlogistic_single 2 forward backward asymmetry RMSE=0.015\nlogistic_single 2 dark energy RMSE=0.009\nlogistic_single 2 bulk RMSE=0.013\nlogistic_single 2 holographic RMSE=0.019\nlogistic_single 2 international linear collider,ilc RMSE=0.025\nlogistic_single 2 abjm RMSE=0.083\nlogistic_single 2 babar RMSE=0.008\nlogistic_single 2 daya bay RMSE=0.08\nlogistic_single 2 sqrts7 tev RMSE=0.098\nlogistic_single 2 130 gev RMSE=0.023\nlogistic_single 2 20point3 RMSE=0.111\nlogistic_single 2 string field theory RMSE=0.024\nlogistic_single 2 metastable vacuum RMSE=0.04\nlogistic_single 2 gravitational wave RMSE=0.023\nlogistic_single 2 belle RMSE=0.012\nlogistic_single 2 diboson RMSE=0.048\nlogistic_single 2 gamma ray excess RMSE=0.077\nlogistic_single 2 generalized parton distribution RMSE=0.016\nlogistic_single 2 lux RMSE=0.118\nlogistic_single 2 higgsless RMSE=0.023\nlogistic_single 2 planckian RMSE=0.021\ngompertz_single 1 125 gev 0.027990893264820727\ngompertz_single 1 pentaquark,pentaquarks 0.05501721478166251\ngompertz_single 1 wmap,wilkinson microwave anisotropy probe 0.022845668269851106\ngompertz_single 1 lhc run 0.028579821827405053\ngompertz_single 1 pamela 0.045009318530154496\ngompertz_single 1 lattice gauge 0.03881798360027813\ngompertz_single 1 tensor scalar ratio 0.04165122755811488\ngompertz_single 1 brane,branes 0.015897368843519718\ngompertz_single 1 atlas 0.025302368295095044\ngompertz_single 1 horava lifshitz,hovrava lifshitz 0.03284369710043905\ngompertz_single 1 lhc 0.011982748137246894\ngompertz_single 1 noncommutative,noncommutativity,non commutative,non commutativity 0.019001965897180995\ngompertz_single 1 black hole 0.014927532025715336\ngompertz_single 1 anomalous magnetic moment 0.03815112878690011\ngompertz_single 1 unparticle,unparticles 0.04951062524644681\ngompertz_single 1 superluminal 0.06769864550310536\ngompertz_single 1 m2 brane,m2 branes 0.04913553590544861\ngompertz_single 1 126 gev 0.055558733922474034\ngompertz_single 1 pp wave 0.03301172366747924\ngompertz_single 1 lambert 0.06642398728502467\ngompertz_single 1 tevatron 0.025650416554382518\ngompertz_single 1 higgs 0.023162438641479193\ngompertz_single 1 brane world 0.02731737986487246\ngompertz_single 1 extra dimension 0.01412142348710811\ngompertz_single 1 entropic 0.04244470928862996\ngompertz_single 1 kamland 0.041561443675259296\ngompertz_single 1 solar neutrino 0.019991527081873878\ngompertz_single 1 neutrino oscillation 0.02728917506505852\ngompertz_single 1 chern simon 0.021921267236475462\ngompertz_single 1 forward backward asymmetry 0.033792375388002636\ngompertz_single 1 dark energy 0.011328325469397564\ngompertz_single 1 bulk 0.016397373612903957\ngompertz_single 1 holographic 0.013523033011049823\ngompertz_single 1 international linear collider,ilc 0.028670475081917165\ngompertz_single 1 abjm 0.01908721302892229\ngompertz_single 1 babar 0.011772702532270439\ngompertz_single 1 daya bay 0.033161025569256077\ngompertz_single 1 sqrts7 tev 0.02246390374238338\ngompertz_single 1 130 gev 0.06634184936424548\ngompertz_single 1 20point3 0.05854946662529169\ngompertz_single 1 string field theory 0.020875119663090757\ngompertz_single 1 metastable vacuum 0.05222736462207674\ngompertz_single 1 gravitational wave 0.027673653499397457\ngompertz_single 1 belle 0.02693039986623777\ngompertz_single 1 diboson 0.057996631146896745\ngompertz_single 1 gamma ray excess 0.04859899332579853\ngompertz_single 1 generalized parton distribution 0.02058799001190155\ngompertz_single 1 lux 0.013340072121053249\ngompertz_single 1 higgsless 0.02542571744624044\ngompertz_single 1 planckian 0.027723454726782445\ngompertz_single 2 125 gev RMSE=0.067\ngompertz_single 2 pentaquark,pentaquarks RMSE=0.019\ngompertz_single 2 wmap,wilkinson microwave anisotropy probe RMSE=0.021\ngompertz_single 2 lhc run RMSE=0.069\ngompertz_single 2 pamela RMSE=0.068\ngompertz_single 2 lattice gauge RMSE=0.025\ngompertz_single 2 tensor scalar ratio RMSE=0.027\ngompertz_single 2 brane,branes RMSE=0.015\ngompertz_single 2 atlas RMSE=0.018\ngompertz_single 2 horava lifshitz,hovrava lifshitz RMSE=0.065\ngompertz_single 2 lhc RMSE=0.005\ngompertz_single 2 noncommutative,noncommutativity,non commutative,non commutativity RMSE=0.018\ngompertz_single 2 black hole RMSE=0.01\n"
]
],
[
[
"## Reload the data\n\nThe preceding step is very long, and may take many hours to complete. Therefore, since we did it in chunks, we now reload the results from memory.",
"_____no_output_____"
]
],
[
[
"# Load the data back up (since the steps above store the results in files, not local memory)\ndocument_count_per_year = pickle.load(open(root+'document_count_per_year.p', \"rb\"))\n \ndatasets = {}\nfor dataset_name in dataset_names:\n datasets[dataset_name] = {}\n for curve_type in ['logistic', 'gompertz']:\n datasets[dataset_name][curve_type] = {}\n for peaks in ['single', 'double']:\n df = pd.read_csv(root+'fitted_curves/'+dataset_name+'/'+curve_type+'_'+peaks+'.csv', index_col=0)\n datasets[dataset_name][curve_type][peaks] = df",
"_____no_output_____"
]
],
[
[
"### Graph: Example single-peaked fit for XML",
"_____no_output_____"
]
],
[
[
"x = range(1988,2018)\nterm = 'xml'\n\n# Load the original time series for xml\ndf = pickle.load(open(root+'clusters/dblp_cs.p', 'rb'))\n# Divide the data for each year by the document count in each year\ny_proportional = df[term].divide(document_count_per_year['dblp_cs'])\n\n\n# Calculate Logistic and Gompertz curves from the parameters estimated earlier\ny_logistic = logletlab.calculate_series(x, \n datasets['dblp_cs']['logistic']['single']['a'][term],\n datasets['dblp_cs']['logistic']['single']['k'][term],\n datasets['dblp_cs']['logistic']['single']['b'][term],\n 'logistic'\n )\n# Since the fitting was done with a normalised version of the curve, we detransform it back into the original scale\ny_logistic = detransform_fit(y_proportional.cumsum(), y_logistic, 'dblp_cs')\n\n\ny_gompertz = logletlab.calculate_series(x, \n datasets['dblp_cs']['gompertz']['single']['a'][term],\n datasets['dblp_cs']['gompertz']['single']['k'][term],\n datasets['dblp_cs']['gompertz']['single']['b'][term],\n 'gompertz'\n )\ny_gompertz = detransform_fit(y_proportional.cumsum(), y_gompertz, 'dblp_cs')\n\n\nplt.figure(figsize=(6,3.7))\n# Multiply by 100 so that values will be percentages\nplt.plot(x, 100*y_proportional, label='Data', color='k')\nplt.plot(x, 100*y_logistic, label='Logistic', color='k', linestyle=':')\nplt.plot(x, 100*y_gompertz, label='Gompertz', color='k', linestyle='--')\nplt.legend()\nplt.grid()\nplt.title(\"Logistic and Gompertz models fitted to the data for 'XML'\", fontsize=12)\nplt.xlim([1988,2017])\nplt.ylim(0,2)\nplt.ylabel(\"Documents containing term (%)\", fontsize=11)\nplt.xlabel(\"Year\", fontsize=11)\n \nplt.savefig(root+'images/xmlexamplefit.eps', format='eps', dpi=1200)",
"_____no_output_____"
]
],
[
[
"### Table of results for Logistic vs Gompertz\n\nCompare the error of the Logistic and Gompertz models across the entire dataset of 200 trends.",
"_____no_output_____"
]
],
[
[
"def statistics(df):\n mean = df.mean()\n ci = 1.96*logistic_error.std()/np.sqrt(len(logistic_error))\n median = df.median()\n std = df.std()\n \n return [mean, mean-ci, mean+ci, median, std]\n\nlogistic_error = pd.concat([datasets['arxiv_hep']['logistic']['single']['RMS'], \n datasets['dblp_cs']['logistic']['single']['RMS'], \n datasets['pubmed_mh']['logistic']['single']['RMS'], \n datasets['pubmed_cancer']['logistic']['single']['RMS']])\n\ngompertz_error = pd.concat([datasets['arxiv_hep']['gompertz']['single']['RMS'], \n datasets['dblp_cs']['gompertz']['single']['RMS'], \n datasets['pubmed_mh']['gompertz']['single']['RMS'], \n datasets['pubmed_cancer']['gompertz']['single']['RMS']])\n\n\nprint('Logistic')\n\nmean = logistic_error.mean()\nci = 1.96*logistic_error.std()/np.sqrt(len(logistic_error))\n\nprint('Mean =', np.round(mean,3))\nprint('95% CI = [', np.round(mean-ci, 3), ',', np.round(mean+ci, 3), ']')\nprint('Median =', np.round(logistic_error.median(), 3))\nprint('STDEV =', np.round(logistic_error.std(), 3))\nprint('')\n\nprint('Gompertz')\n\nmean = gompertz_error.mean()\nci = 1.96*gompertz_error.std()/np.sqrt(len(logistic_error))\n\nprint('Mean =', np.round(mean,3))\nprint('95% CI = [', np.round(mean-ci, 3), ',', np.round(mean+ci, 3), ']')\nprint('Median =', np.round(gompertz_error.median(), 3))\nprint('STDEV =', np.round(gompertz_error.std(), 3))\n",
"Logistic\nMean = 0.029\n95% CI = [ 0.027 , 0.031 ]\nMedian = 0.029\nSTDEV = 0.014\n\nGompertz\nMean = 0.023\n95% CI = [ 0.021 , 0.026 ]\nMedian = 0.019\nSTDEV = 0.017\n"
]
],
[
[
"### Is the difference between the means significant?\n\nHere we use an independent t-test to investigate significance.",
"_____no_output_____"
]
],
[
[
"scipy.stats.ttest_ind(logistic_error, gompertz_error, axis=0, equal_var=True, nan_policy='propagate')",
"_____no_output_____"
]
],
[
[
"Yes, it is significant! However, since the data is slightly skewed, we can also test the signficance of the difference between medians using Mood's median test:",
"_____no_output_____"
]
],
[
[
"stat, p, med, tbl = scipy.stats.median_test(logistic_error, gompertz_error)\nprint(p)",
"1.1980742802127062e-08\n"
]
],
[
[
"So either way, the p-value is very low, causing us to reject the null hypothesis. This leads us to the conclusion that the **Gompertz model** is more appropriate for the task of modelling publishing activity over time.",
"_____no_output_____"
],
[
"### Box and whisker plots of Logistic and Gompertz model error",
"_____no_output_____"
]
],
[
[
"axs = pd.DataFrame({\n 'CS Logistic': datasets['dblp_cs']['logistic']['single']['RMS'],\n 'CS Gompertz': datasets['dblp_cs']['gompertz']['single']['RMS'],\n 'Physics Logistic': datasets['arxiv_hep']['logistic']['single']['RMS'],\n 'Physics Gompertz': datasets['arxiv_hep']['gompertz']['single']['RMS'],\n 'MH Logistic': datasets['pubmed_mh']['logistic']['single']['RMS'],\n 'MH Gompertz': datasets['pubmed_mh']['gompertz']['single']['RMS'],\n 'Cancer Logistic': datasets['pubmed_cancer']['logistic']['single']['RMS'],\n 'Cancer Gompertz': datasets['pubmed_cancer']['gompertz']['single']['RMS'],\n}).boxplot(figsize=(13,4), return_type='dict')\n\n[item.set_color('k') for item in axs['boxes']]\n[item.set_color('k') for item in axs['whiskers']]\n[item.set_color('k') for item in axs['medians']]\n\nplt.suptitle(\"\")\np = plt.gca()\np.set_ylabel('RMSE error')\np.set_title('Distribution of RMSE error of models fitted to the four datasets', fontsize=12)\np.set_ylim([0,0.12])",
"_____no_output_____"
]
],
[
[
"There is some variation across the datasets, although the Gompertz model is consistent in producing a lower median error than the Logistic model. It's worth noting also that the Particle Physics and Mental Health datasets are smaller than the Cancer and Computer Science ones. They also have higher error. ",
"_____no_output_____"
],
[
"### Calculation of trend duration\n\nThe Loglet Lab documentation (https://logletlab.com/loglet/documentation/index) contains a formula for the time taken for a Gompertz curve to go from 10% to 90% of its eventual maximum cumulative frequency ($\\Delta t$). Their calculation is that\n\n$\\Delta t = -\\frac{\\ln(\\ln(81))}{r}$\n\n\nHowever, our observation was that this did not remotely describe the observed span of the fitted curves. We have therefore done the derivation ourselves and found that the correct parameterisation is:\n\n$\\Delta t = \\frac{1}{\\ln(-(\\ln(0.9))-\\ln(-\\ln(0.1))}$\n\nUnfortunately, the LogletLab initial parameter guesses are tailored to this incorrect parameterisation so it is much simpler to use it when fitting the curve (and irrelevant, except when it comes to calculating curve span). Therefore we use it, then convert to the correct value using the conversion factor below:",
"_____no_output_____"
]
],
[
[
"conversion_factor = -((np.log(-np.log(0.9))-np.log(-np.log(0.1)))/np.log(np.log(81)))",
"_____no_output_____"
],
[
"spans = pd.DataFrame({\n 'Computer Science': datasets['dblp_cs']['gompertz']['single']['a']*conversion_factor,\n 'Particle Physics': datasets['arxiv_hep']['gompertz']['single']['a']*conversion_factor,\n 'Mental Health': datasets['pubmed_mh']['gompertz']['single']['a']*conversion_factor,\n 'Cancer': datasets['pubmed_cancer']['gompertz']['single']['a']*conversion_factor\n})\n\n\naxs = spans.boxplot(figsize=(7.5,3.7), return_type='dict', fontsize=11)\n\n[item.set_color('k') for item in axs['boxes']]\n[item.set_color('k') for item in axs['whiskers']]\n[item.set_color('k') for item in axs['medians']]\n\n#plt.figure(figsize=(6,3.7))\nplt.suptitle(\"\")\np = plt.gca()\np.set_ylabel('Peak width (years)', fontsize=11)\np.set_title('Distribution of peak widths by dataset (Gomperz model)', fontsize=12)\np.set_ylim([0,100])\n\nplt.savefig(root+'images/curvespans.eps', format='eps', dpi=1200)",
"_____no_output_____"
]
],
[
[
"The data is quite skewed here...something to bear in mind when testing for significance later. \n\n\n### Median trend durations in different disciplines",
"_____no_output_____"
]
],
[
[
"for i , dataset_name in enumerate(dataset_names):\n print(dataset_titles[i], '| Median trend duration =', np.round(np.median(datasets[dataset_name]['gompertz']['single']['a']*conversion_factor),1), 'years')\n",
"Computer science (dblp) | Median trend duration = 25.8 years\nParticle physics (arXiv) | Median trend duration = 15.1 years\nMental health (PubMed) | Median trend duration = 24.6 years\nCancer (PubMed) | Median trend duration = 13.4 years\n"
]
],
[
[
"### Testing for significance between disciplines\n\nThere are substantial differences between the median trend durations, with Computer Science and Particle Physics having shorter durations and the two PubMed datasets having longer ones. But are these significant? Since the data is somewhat skewed, we use Mood's median test to find p-values for the differences (Mood's median test does not require normal data).",
"_____no_output_____"
]
],
[
[
"for i in range(4):\n for j in range(i,4):\n if i == j:\n pass\n else:\n spans1 = datasets[dataset_names[i]]['gompertz']['single']['a']*conversion_factor\n spans2 = datasets[dataset_names[j]]['gompertz']['single']['a']*conversion_factor\n stat, p, med, tbl = scipy.stats.median_test(spans1, spans2)\n\n print(dataset_titles[i], 'vs', dataset_titles[j], 'p-value =', np.round(p,3))",
"Computer science (dblp) vs Particle physics (arXiv) p-value = 0.003\nComputer science (dblp) vs Mental health (PubMed) p-value = 0.841\nComputer science (dblp) vs Cancer (PubMed) p-value = 0.009\nParticle physics (arXiv) vs Mental health (PubMed) p-value = 0.072\nParticle physics (arXiv) vs Cancer (PubMed) p-value = 0.549\nMental health (PubMed) vs Cancer (PubMed) p-value = 0.028\n"
]
],
[
[
"So the p value between Particle Physics and Computer Science is not acceptable, and neither is the p-value between Mental Health and Cancer. How about between these two groups?",
"_____no_output_____"
]
],
[
[
"dblp_spans = datasets['dblp_cs']['gompertz']['single']['a']*conversion_factor\ncancer_spans = datasets['pubmed_cancer']['gompertz']['single']['a']*conversion_factor\narxiv_spans = datasets['arxiv_hep']['gompertz']['single']['a']*conversion_factor\nmh_spans = datasets['pubmed_mh']['gompertz']['single']['a']*conversion_factor\n\nstat, p, med, tbl = scipy.stats.median_test(pd.concat([arxiv_spans, dblp_spans]), pd.concat([cancer_spans, mh_spans]))\n\nprint(np.round(p,5))",
"0.00013\n"
]
],
[
[
"This difference IS significant!",
"_____no_output_____"
],
[
"### Double-peaking curves\n\nWe now move to analyse the data for double-peaked curves. For each term, we have calculated the error when two peaks are fitted, and the error when a single peak is fitted. We can compare the error in each case like so:",
"_____no_output_____"
]
],
[
[
"print('Neural networks, single peak | error =', np.round(datasets['dblp_cs']['gompertz']['single']['RMS']['neural network'],3))\nprint('Neural networks, double peak| error =', np.round(datasets['dblp_cs']['gompertz']['double']['RMS']['neural network'],3))",
"Neural networks, single peak | error = 0.031\nNeural networks, double peak| error = 0.011\n"
]
],
[
[
"Where do we see the largest reductions?",
"_____no_output_____"
]
],
[
[
"difference = datasets['dblp_cs']['gompertz']['single']['RMS']-datasets['dblp_cs']['gompertz']['double']['RMS']\nfor term in difference.index:\n if difference[term] > 0.015:\n print(term, np.round(difference[term], 3))",
"neural network 0.02\nmachine learning 0.02\nconvolutional neural network,cnn 0.085\ndiscrete mathematics 0.031\nparallel 0.024\nrecurrent 0.026\nembeddings 0.037\nlearning model 0.024\n"
]
],
[
[
"### Examples of double peaking curves\n\nSo in some cases there is an error reduction from moving from the single- to double-peaked model. What does this look like in practice?",
"_____no_output_____"
]
],
[
[
"x = range(1988,2018)\n\n# Load the original data\ndf = pickle.load(open(root+'clusters/dblp_cs.p', 'rb'))\n\n# Choose four example terms\nterms = ['big data', 'cloud', 'internet', 'neural network']\ntitles = ['a) Big Data', 'b) Cloud', 'c) Internet', 'd) Neural network']\n\n# We want to set an overall y-label. The solution(found at https://stackoverflow.com/a/27430940) is to \n# create an overall plot first, give it a y-label, then hide it by removing plot borders.\nfig, big_ax = plt.subplots(figsize=(9.0, 6.0) , nrows=1, ncols=1, sharex=True) \nbig_ax.tick_params(labelcolor=(1,1,1,0.0), top=False, bottom=False, left=False, right=False)\nbig_ax._frameon = False\nbig_ax.set_ylabel(\"Documents containing term (%)\", fontsize=11)\n\n\naxs = [0,0,0,0]\naxs[0]=fig.add_subplot(2,2,1)\naxs[1]=fig.add_subplot(2,2,2)\naxs[2]=fig.add_subplot(2,2,3)\naxs[3]=fig.add_subplot(2,2,4)\nfig.subplots_adjust(wspace=0.25, hspace=0.5, right=0.9)\n\n# Set y limits manually beforehand\nlimits = [2, 4, 6, 8]\n\n\nfor i, term in enumerate(terms):\n # Get the proportional document frequency of the term over time\n y_proportional = df[term].divide(document_count_per_year['dblp_cs'])\n \n # Multiply by 100 when plotting so that it reads as a percentage\n axs[i].plot(x, 100*y_proportional, color='k')\n \n axs[i].grid(True)\n axs[i].set_xlabel(\"Year\", fontsize=11)\n axs[i].yaxis.set_major_formatter(FormatStrFormatter('%.1f'))\n \n # Now plot single and double peaked models\n for j, curve_type in enumerate(['single', 'double']):\n if curve_type == 'single':\n y_overall = logletlab.calculate_series(x, \n datasets['dblp_cs']['gompertz'][curve_type]['a'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['k'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['b'][term],\n 'gompertz')\n \n y_overall = detransform_fit(y_proportional.cumsum(), y_overall, 'dblp_cs')\n error = datasets['dblp_cs']['gompertz'][curve_type]['RMS'][term]\n axs[i].plot(x, 100*y_overall, color='k', linestyle='--', label=\"single peak, error=\"+str(np.round(error,3)))\n\n \n else:\n y_overall, y_1, y_2 = logletlab.calculate_series_double(x, \n datasets['dblp_cs']['gompertz'][curve_type]['a1'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['k1'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['b1'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['a2'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['k2'][term],\n datasets['dblp_cs']['gompertz'][curve_type]['b2'][term],\n 'gompertz')\n y_overall = detransform_fit(y_proportional.cumsum(), y_overall, 'dblp_cs')\n error = datasets['dblp_cs']['gompertz'][curve_type]['RMS'][term]\n axs[i].plot(x, 100*y_overall, color='k', linestyle=':', label=\"double peak, error=\"+str(np.round(error,3)))\n\n\n axs[i].set_title(titles[i], fontsize=12)\n axs[i].legend( fontsize=11)\n axs[i].set_ylim([0, limits[i]])\n\n\n# We want the same number of y ticks for each axis so that it reads more neatly\naxs[2].set_yticks([0, 1.5, 3, 4.5, 6])\n\nfig.savefig(root+'images/doublepeaked.eps', format='eps', dpi=1200)\n\n",
"_____no_output_____"
]
],
[
[
"### Graphs of all four datasets\n\nIn this section we try to show as many graphs of fitted models as can reasonably fit on a page. The two functions used to make the graphs [below] are very hacky! However they work for this specific purpose.",
"_____no_output_____"
]
],
[
[
"def choose_ylimit(prevalence):\n '''\n This function works to find the most appropriate upper y limit to make the plots look good\n '''\n if max(prevalence) < 0.5:\n return 0.5\n elif max(prevalence) > 0.5 and max(prevalence) < 0.8:\n return 0.8\n elif max(prevalence) > 10 and max(prevalence) < 12:\n return 12\n elif max(prevalence) > 12 and max(prevalence) < 15:\n return 15\n elif max(prevalence) > 15 and max(prevalence) < 20:\n return 20\n else:\n return np.ceil(max(prevalence))\n \ndef prettyplot(df, dataset_name, gompertz_params, yplots, xplots, title, ylabel, xlabel, xlims, plot_titles):\n '''\n Plot a nicely formatted set of trends with their fitted models. This function is rather hacky and made\n for this specific purpose!\n '''\n fig, axs = plt.subplots(yplots, xplots)\n plt.subplots_adjust(right=1, hspace=0.5, wspace=0.25)\n plt.suptitle(title, fontsize=14)\n fig.subplots_adjust(top=0.95)\n fig.set_figheight(15)\n fig.set_figwidth(9)\n x = [int(i) for i in list(df.index)]\n\n for i, term in enumerate(df.columns[0:yplots*xplots]):\n prevalence = df[term].divide(document_count_per_year[dataset_name], axis=0)\n if plot_titles == None:\n title = term.split(',')[0]\n else:\n title = titles[i]\n \n # Now get the gompertz representation of it\n if gompertz_params['single']['RMS'][term]-gompertz_params['double']['RMS'][term] < 0.005:\n # Use the single peaked version\n y_overall = logletlab.calculate_series(x, \n gompertz_params['single']['a'][term],\n gompertz_params['single']['k'][term],\n gompertz_params['single']['b'][term],\n 'gompertz')\n y_overall = detransform_fit(prevalence.cumsum(), y_overall, dataset_name) \n \n else:\n \n y_overall, y_1, y_2 = logletlab.calculate_series_double(x, \n gompertz_params['double']['a1'][term],\n gompertz_params['double']['k1'][term],\n gompertz_params['double']['b1'][term],\n gompertz_params['double']['a2'][term],\n gompertz_params['double']['k2'][term],\n gompertz_params['double']['b2'][term],\n 'gompertz')\n y_overall = detransform_fit(prevalence.cumsum(), y_overall, dataset_name)\n \n axs[int(np.floor((i/xplots)%yplots)), i%xplots].plot(x, 100*prevalence, color='k', ls='-', label=title)\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].plot(x, 100*y_overall, color='k', ls='--', label='gompertz')\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].grid()\n\n\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].set_xlim(xlims[0], xlims[1])\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].set_ylim(0,choose_ylimit(100*prevalence))\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].set_title(title, fontsize=12)\n axs[int(np.floor((i/xplots)%yplots)), i%xplots].yaxis.set_major_formatter(FormatStrFormatter('%.1f'))\n \n if i%yplots != yplots-1:\n axs[i%yplots, int(np.floor((i/yplots)%xplots))].set_xticklabels([])\n \n\n axs[5,0].set_ylabel(ylabel, fontsize=12)\n \n",
"_____no_output_____"
],
[
"dataset_name = 'arxiv_hep'\ndf = pickle.load(open(root+'clusters/'+dataset_name+'.p', 'rb'))\n\ntitles = ['125 GeV', 'Pentaquark', 'WMAP', 'LHC Run', 'PAMELA', 'Lattice Gauge', \n 'Tensor-to-Scalar Ratio', 'Brane', 'ATLAS', 'Horava-Lifshitz', 'LHC', \n 'Noncommutative', 'Black Hole', 'Anomalous Magnetic Moment', 'Unparticle', \n 'Superluminal', 'M2 Brane', '126 GeV', 'pp-Wave', 'Lambert', 'Tevatron', 'Higgs', \n 'Brane World', 'Extra Dimension', 'Entropic', 'KamLAND', 'Solar Neutrino', \n 'Neutrino Oscillation', 'Chern Simon', 'Forward-Backward Asymmetry', 'Dark Energy', \n 'Bulk', 'Holographic', 'International Linear Collider', 'ABJM', 'BaBar']\n\nprettyplot(df, 'arxiv_hep', datasets[dataset_name]['gompertz'], 12, 3, \"Gompertz model fitted to trends in particle physics (1994-2017)\", \"Documents containing term (%)\", None, [1990,2020], titles)\n\nplt.savefig(root+'images/arxiv_hep.eps', format='eps', dpi=1200, bbox_inches='tight')",
"_____no_output_____"
],
[
"dataset_name = 'dblp_cs'\ndf = pickle.load(open(root+'clusters/'+dataset_name+'.p', 'rb'))\n\ntitles = ['Deep Learning', 'Neural Network', 'Machine Learning', 'Convolutional Neural Network', \n 'Java', 'Web', 'XML', 'Internet', 'Web Service', 'Internet of Things', 'World Wide Web', \n 'Speech', '5G', 'Discrete Mathematics', 'Parallel', 'Agent', 'Recurrent', 'SUP', 'Cloud', \n 'Big Data', 'Peer-to-peer', 'Wireless', 'Sensor Network', 'Electronic Commerce', 'ATM', 'Gene', \n 'Packet', 'Multimedia', 'Smart Grid', 'Embeddings', 'Ontology', 'Ad-hoc Network', 'Service Oriented', \n 'Web Site', 'RAC', 'Distributed Memory']\n\nprettyplot(df, 'dblp_cs', datasets[dataset_name]['gompertz'], 12, 3, 'Gompertz model fitted to trends in computer science (1988-2017)', \"Documents containing term (%)\", None, [1980,2020], titles)\nplt.savefig(root+'images/dblp_cs.eps', format='eps', dpi=1200, bbox_inches='tight')",
"_____no_output_____"
],
[
"dataset_name = 'pubmed_mh'\ndf = pickle.load(open(root+'clusters/'+dataset_name+'.p', 'rb'))\n\ntitles = titles = ['Alcoholic', 'Abeta', 'Psycinfo', 'Dexamethasone', 'Human Immunodeficiency Virus', \n 'Database', 'Alzheimers Disease', 'Amitriptyline', 'Intravenous Drug', 'Bupropion', \n 'DSM iii', 'Depression', 'Drug User', 'Apolipoprotein', 'Epsilon4 Allele', 'Rett Syndrome', \n 'Cocaine', 'Heroin', 'Panic', 'Imipramine', 'Papaverine', 'Cortisol', 'Presenilin', 'Plasma', \n 'Tricyclic', 'Epsilon Allele', 'HTLV iii', 'Learning Disability', 'DSM IV', 'DSM', \n 'Retardation', 'Aldehyde', 'Protein Precursor', 'Bulimia', 'Narcoleptic', 'Acquired Immunodeficiency Syndrome']\n\nprettyplot(df, 'pubmed_mh', datasets[dataset_name]['gompertz'], 12, 3, 'Gompertz model fitted to trends in mental health research (1975-2017)', 'Documents containing term (%)', None, [1970,2020], titles)\nplt.savefig(root+'images/pubmed_mh.eps', format='eps', dpi=1200, bbox_inches='tight')",
"_____no_output_____"
],
[
"dataset_name = 'pubmed_cancer'\ndf = pickle.load(open(root+'clusters/'+dataset_name+'.p', 'rb'))\n\ntitles = ['Immunohistochemical', 'Monoclonal Antibody', 'NF KappaB', 'Polymerase Chain Reaction', \n 'Immune Checkpoint', 'Tumor Suppressor Gene', 'Beta Catenin', 'PD-L1', 'Interleukin', \n 'Oncogene', 'Microarray', '1Alpha', 'PC12 Cell', 'Magnetic Resonance', \n 'Proliferating Cell Nuclear Antigen', 'Human T-cell Leukemia', 'Adult T-cell Leukemia', \n 'lncRNA', 'Apoptosis', 'CD4', 'Recombinant', 'Acquired Immunodeficiency Syndrome', \n 'HR', 'Meta Analysis', 'IC50', 'Immunoperoxidase', 'Blot', 'Interfering RNA', '18F', \n '(Estrogen) Receptor Alpha', 'OKT4', 'kDa', 'CA', 'OKT8', 'Imatinib', 'Helper (T-cells)']\n\nprettyplot(df, 'pubmed_cancer', datasets[dataset_name]['gompertz'], 12, 3, 'Gompertz model fitted to trends in cancer research (1988-2017)', 'Documents containing term (%)', None, [1970,2020], titles)\nplt.savefig(root+'images/pubmed_cancer.eps', format='eps', dpi=1200, bbox_inches='tight')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02b4317b45f12d4c3db95cb9942aa5da12d1614
| 328,430 |
ipynb
|
Jupyter Notebook
|
notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb
|
daiwk/grace_t
|
f83fa4f3110e4f01ea323ff918c1369533a798be
|
[
"Apache-2.0"
] | 2 |
2019-10-21T17:59:46.000Z
|
2020-07-24T15:42:37.000Z
|
notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb
|
daiwk/grace_t
|
f83fa4f3110e4f01ea323ff918c1369533a798be
|
[
"Apache-2.0"
] | null | null | null |
notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb
|
daiwk/grace_t
|
f83fa4f3110e4f01ea323ff918c1369533a798be
|
[
"Apache-2.0"
] | null | null | null | 31.157385 | 282 | 0.417897 |
[
[
[
"# CTR预估(1)\n\n资料&&代码整理by[@寒小阳](https://blog.csdn.net/han_xiaoyang)(hanxiaoyang.ml@gmail.com)\n\nreference:\n* [《广告点击率预估是怎么回事?》](https://zhuanlan.zhihu.com/p/23499698)\n* [从ctr预估问题看看f(x)设计—DNN篇](https://zhuanlan.zhihu.com/p/28202287)\n* [Atomu2014 product_nets](https://github.com/Atomu2014/product-nets)\n\n关于CTR预估的背景推荐大家看欧阳辰老师在知乎的文章[《广告点击率预估是怎么回事?》](https://zhuanlan.zhihu.com/p/23499698),感谢欧阳辰老师并在这里做一点小小的摘抄。\n\n>点击率预估是广告技术的核心算法之一,它是很多广告算法工程师喜爱的战场。一直想介绍一下点击率预估,但是涉及公式和模型理论太多,怕说不清楚,读者也不明白。所以,这段时间花了一些时间整理点击率预估的知识,希望在尽量不使用数据公式的情况下,把大道理讲清楚,给一些不愿意看公式的同学一个Cook Book。\n\n> ### 点击率预测是什么?\n\n> * 点击率预测是对每次广告的点击情况做出预测,可以判定这次为点击或不点击,也可以给出点击的概率,有时也称作pClick。\n\n> ### 点击率预测和推荐算法的不同?\n\n> * 广告中点击率预估需要给出精准的点击概率,A点击率0.3% , B点击率0.13%等,需要结合出价用于排序使用;推荐算法很多时候只需要得出一个最优的次序A>B>C即可;\n\n> ### 搜索和非搜索广告点击率预测的区别\n\n> * 搜索中有强搜索信号-“查询词(Query)”,查询词和广告内容的匹配程度很大程度影响了点击概率; 点击率也高,PC搜索能到达百分之几的点击率。\n\n> * 非搜索广告(例如展示广告,信息流广告),点击率的计算很多来源于用户的兴趣和广告特征,上下文环境;移动信息流广告的屏幕比较大,用户关注度也比较集中,好位置也能到百分之几的点击率。对于很多文章底部的广告,点击率非常低,用户关注度也不高,常常是千分之几,甚至更低;\n\n> ### 如何衡量点击率预测的准确性?\n\n> AUC是常常被用于衡量点击率预估的准确性的方法;理解AUC之前,需要理解一下Precision/Recall;对于一个分类器,我们通常将结果分为:TP,TN,FP,FN。\n> 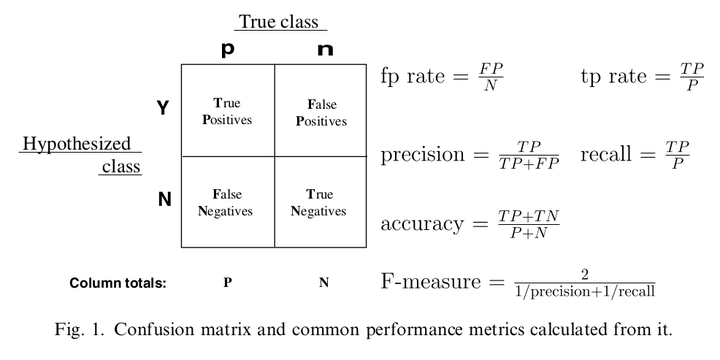\n\n\n> 本来用Precision=TP/(TP+FP),Recall=TP/P,也可以用于评估点击率算法的好坏,毕竟这是一种监督学习,每一次预测都有正确答案。但是,这种方法对于测试数据样本的依赖性非常大,稍微不同的测试数据集合,结果差异非常大。那么,既然无法使用简单的单点Precision/Recall来描述,我们可以考虑使用一系列的点来描述准确性。做法如下:\n\n> * 找到一系列的测试数据,点击率预估分别会对每个测试数据给出点击/不点击,和Confidence Score。\n\n> * 按照给出的Score进行排序,那么考虑如果将Score作为一个Thresholds的话,考虑这个时候所有数据的 TP Rate 和 FP Rate; 当Thresholds分数非常高时,例如0.9,TP数很小,NP数很大,因此TP率不会太高; \n> 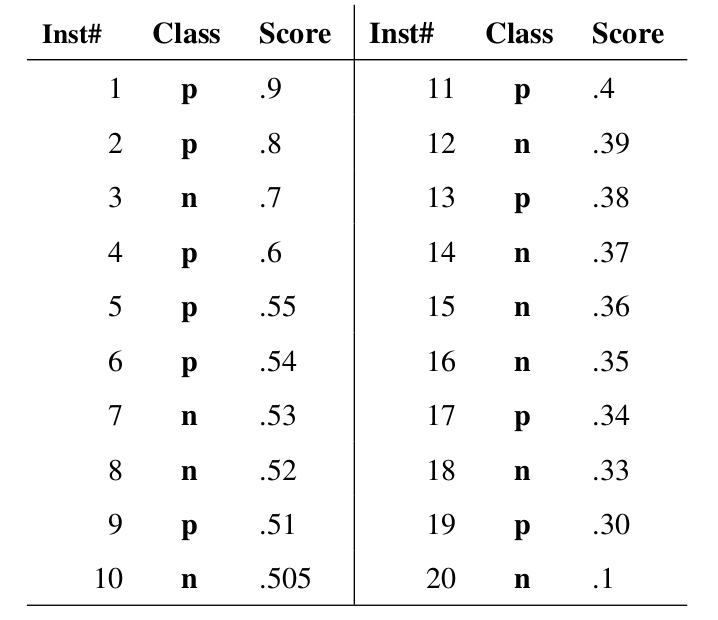\n> 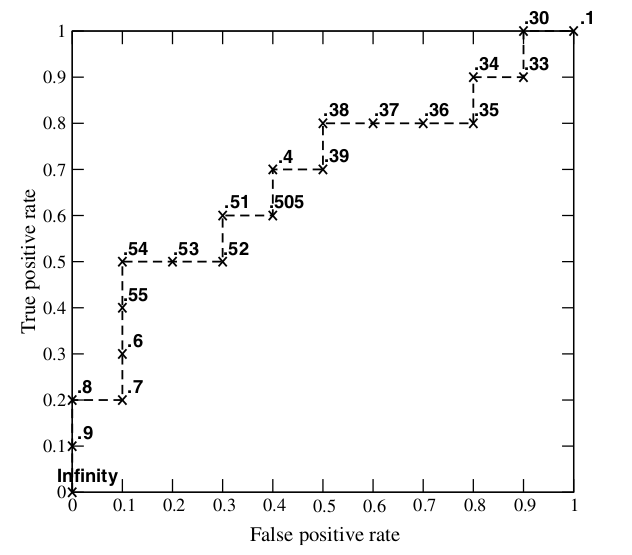\n> 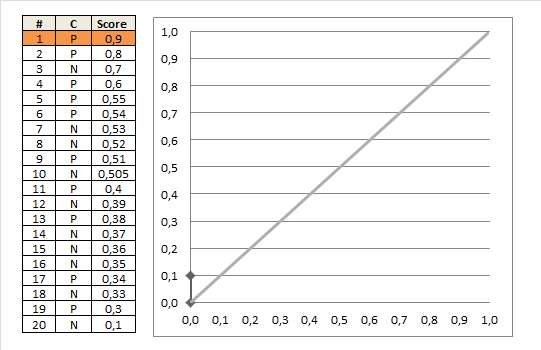\n> * 当选用不同Threshold时候,画出来的ROC曲线,以及下方AUC面积\n> * 我们计算这个曲线下面的面积就是所谓的AUC值;AUC值越大,预测约准确。\n\n\n> ### 为什么要使用AUC曲线\n\n> 既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。AUC对样本的比例变化有一定的容忍性。AUC的值通常在0.6-0.85之间。\n\n\n> ### 如何来进行点击率预测?\n\n> 点击率预测可以考虑为一个黑盒,输入一堆信号,输出点击的概率。这些信号就包括如下信号\n\n> * **广告**:历史点击率,文字,格式,图片等等\n> * **环境**:手机型号,时间媒体,位置,尺寸,曝光时间,网络IP,上网方式,代理等\n> * **用户**:基础属性(男女,年龄等),兴趣属性(游戏,旅游等),历史浏览,点击行为,电商行为\n> * **信号的粒度**:\n> `Low Level : 数据来自一些原始访问行为的记录,例如用户是否点击过Landing Page,流量IP等。这些特征可以用于粗选,模型简单,`\n> `High Level: 特征来自一些可解释的数据,例如兴趣标签,性别等`\n\n\n> * **特征编码Feature Encoding:**\n\n> `特征离散化:把连续的数字,变成离散化,例如温度值可以办成多个温度区间。`\n\n> `特征交叉: 把多个特征进行叫交叉的出的值,用于训练,这种值可以表示一些非线性的关系。例如,点击率预估中应用最多的就是广告跟用户的交叉特征、广告跟性别的交叉特征,广告跟年龄的交叉特征,广告跟手机平台的交叉特征,广告跟地域的交叉特征等等。`\n\n> * **特征选取(Feature Selection):**\n\n> `特征选择就是选择那些靠谱的Feature,去掉冗余的Feature,对于搜索广告Query和广告的匹配程度很关键;对于展示广告,广告本身的历史表现,往往是最重要的Feature。`\n\n> * **独热编码(One-Hot encoding)**\n\n```假设有三组特征,分别表示年龄,城市,设备;\n\n[\"男\", \"女\"]\n\n[\"北京\", \"上海\", \"广州\"]\n\n[\"苹果\", \"小米\", \"华为\", \"微软\"]\n\n传统变化: 对每一组特征,使用枚举类型,从0开始;\n\n[\"男“,”上海“,”小米“]=[ 0,1,1]\n\n[\"女“,”北京“,”苹果“] =[1,0,0]\n\n传统变化后的数据不是连续的,而是随机分配的,不容易应用在分类器中。\n\n 热独编码是一种经典编码,是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。\n\n[\"男“,”上海“,”小米“]=[ 1,0,0,1,0,0,1,0,0]\n\n[\"女“,”北京“,”苹果“] =[0,1,1,0,0,1,0,0,0]\n\n经过热独编码,数据会变成稀疏的,方便分类器处理。\n```\n\n> ### 点击率预估整体过程:\n\n> 三个基本过程:特征工程,模型训练,线上服务\n\n> 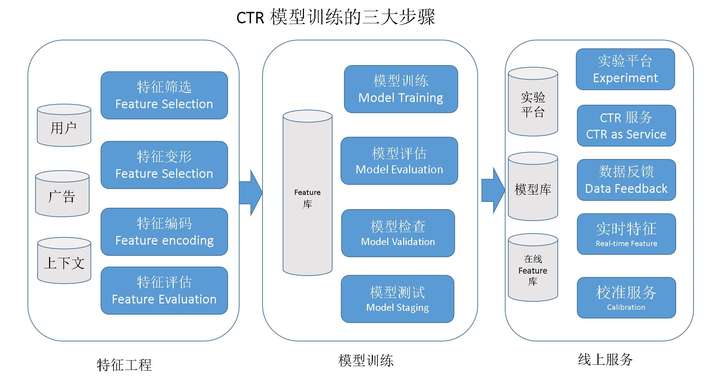\n\n> * 特征工程:准备各种特征,编码,去掉冗余特征(用PCA等)\n\n> * 模型训练:选定训练,测试等数据集,计算AUC,如果AUC有提升,通常可以在进一步在线上分流实验。\n\n> * 线上服务:线上服务,需要实时计算CTR,实时计算相关特征和利用模型计算CTR,对于不同来源的CTR,可能需要一个Calibration的服务。\n\n```",
"_____no_output_____"
],
[
"## 用tensorflow构建各种模型完成ctr预估",
"_____no_output_____"
]
],
[
[
"!head -5 ./data/train.txt",
"0 5:1 9:1 357943:1 445905:1 446144:1 446294:1 450548:1 479123:1 491626:1 491634:1 491641:1 491644:1 491648:1 491668:1 491700:1 491709:1\r\n0 5:1 9:1 403405:1 445920:1 446287:1 446293:1 452727:1 490863:1 491629:1 491637:1 491639:1 491645:1 491659:1 491668:1 491698:1 491708:1\r\n0 5:1 9:1 414259:1 445897:1 446049:1 446293:1 454694:1 491595:1 491625:1 491633:1 491639:1 491646:1 491660:1 491668:1 491674:1 491708:1\r\n0 5:1 9:1 430407:1 445892:1 446063:1 446294:1 448775:1 476818:1 491625:1 491633:1 491641:1 491644:1 491660:1 491668:1 491700:1 491709:1\r\n0 5:1 9:1 140858:1 445908:1 446177:1 446293:1 449140:1 490778:1 491626:1 491634:1 491641:1 491645:1 491648:1 491668:1 491700:1 491708:1\r\n"
],
[
"!head -10 ./data/featindex.txt",
"0:other\t0\r\n0:0\t1\r\n0:1\t2\r\n0:2\t3\r\n0:3\t4\r\n0:4\t5\r\n0:5\t6\r\n0:6\t7\r\n1:other\t8\r\n1:00\t9\r\n"
],
[
"from __future__ import print_function\nfrom __future__ import absolute_import\nfrom __future__ import division\nimport cPickle as pkl\nimport numpy as np\nimport tensorflow as tf\nfrom scipy.sparse import coo_matrix",
"_____no_output_____"
],
[
"# 读取数据,统计基本的信息,field等\nDTYPE = tf.float32\n\nFIELD_SIZES = [0] * 26\nwith open('./data/featindex.txt') as fin:\n for line in fin:\n line = line.strip().split(':')\n if len(line) > 1:\n f = int(line[0]) - 1\n FIELD_SIZES[f] += 1\nprint('field sizes:', FIELD_SIZES)\nFIELD_OFFSETS = [sum(FIELD_SIZES[:i]) for i in range(len(FIELD_SIZES))]\nINPUT_DIM = sum(FIELD_SIZES)\nOUTPUT_DIM = 1\nSTDDEV = 1e-3\nMINVAL = -1e-3\nMAXVAL = 1e-3",
"field sizes: [25, 445852, 36, 371, 4, 11328, 33995, 12, 7, 5, 4, 20, 2, 38, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8]\n"
],
[
"# 读取libsvm格式数据成稀疏矩阵形式\n# 0 5:1 9:1 140858:1 445908:1 446177:1 446293:1 449140:1 490778:1 491626:1 491634:1 491641:1 491645:1 491648:1 491668:1 491700:1 491708:1\ndef read_data(file_name):\n X = []\n D = []\n y = []\n with open(file_name) as fin:\n for line in fin:\n fields = line.strip().split()\n y_i = int(fields[0])\n X_i = [int(x.split(':')[0]) for x in fields[1:]]\n D_i = [int(x.split(':')[1]) for x in fields[1:]]\n y.append(y_i)\n X.append(X_i)\n D.append(D_i)\n y = np.reshape(np.array(y), [-1])\n X = libsvm_2_coo(zip(X, D), (len(X), INPUT_DIM)).tocsr()\n return X, y",
"_____no_output_____"
],
[
"# 数据乱序\ndef shuffle(data):\n X, y = data\n ind = np.arange(X.shape[0])\n for i in range(7):\n np.random.shuffle(ind)\n return X[ind], y[ind]",
"_____no_output_____"
],
[
"# 工具函数,libsvm格式转成coo稀疏存储格式\ndef libsvm_2_coo(libsvm_data, shape):\n coo_rows = []\n coo_cols = []\n coo_data = []\n n = 0\n for x, d in libsvm_data:\n coo_rows.extend([n] * len(x))\n coo_cols.extend(x)\n coo_data.extend(d)\n n += 1\n coo_rows = np.array(coo_rows)\n coo_cols = np.array(coo_cols)\n coo_data = np.array(coo_data)\n return coo_matrix((coo_data, (coo_rows, coo_cols)), shape=shape)",
"_____no_output_____"
],
[
"# csr转成输入格式\ndef csr_2_input(csr_mat):\n if not isinstance(csr_mat, list):\n coo_mat = csr_mat.tocoo()\n indices = np.vstack((coo_mat.row, coo_mat.col)).transpose()\n values = csr_mat.data\n shape = csr_mat.shape\n return indices, values, shape\n else:\n inputs = []\n for csr_i in csr_mat:\n inputs.append(csr_2_input(csr_i))\n return inputs",
"_____no_output_____"
],
[
"# 数据切片\ndef slice(csr_data, start=0, size=-1):\n if not isinstance(csr_data[0], list):\n if size == -1 or start + size >= csr_data[0].shape[0]:\n slc_data = csr_data[0][start:]\n slc_labels = csr_data[1][start:]\n else:\n slc_data = csr_data[0][start:start + size]\n slc_labels = csr_data[1][start:start + size]\n else:\n if size == -1 or start + size >= csr_data[0][0].shape[0]:\n slc_data = []\n for d_i in csr_data[0]:\n slc_data.append(d_i[start:])\n slc_labels = csr_data[1][start:]\n else:\n slc_data = []\n for d_i in csr_data[0]:\n slc_data.append(d_i[start:start + size])\n slc_labels = csr_data[1][start:start + size]\n return csr_2_input(slc_data), slc_labels",
"_____no_output_____"
],
[
"# 数据切分\ndef split_data(data, skip_empty=True):\n fields = []\n for i in range(len(FIELD_OFFSETS) - 1):\n start_ind = FIELD_OFFSETS[i]\n end_ind = FIELD_OFFSETS[i + 1]\n if skip_empty and start_ind == end_ind:\n continue\n field_i = data[0][:, start_ind:end_ind]\n fields.append(field_i)\n fields.append(data[0][:, FIELD_OFFSETS[-1]:])\n return fields, data[1]",
"_____no_output_____"
],
[
"# 在tensorflow中初始化各种参数变量\ndef init_var_map(init_vars, init_path=None):\n if init_path is not None:\n load_var_map = pkl.load(open(init_path, 'rb'))\n print('load variable map from', init_path, load_var_map.keys())\n var_map = {}\n for var_name, var_shape, init_method, dtype in init_vars:\n if init_method == 'zero':\n var_map[var_name] = tf.Variable(tf.zeros(var_shape, dtype=dtype), name=var_name, dtype=dtype)\n elif init_method == 'one':\n var_map[var_name] = tf.Variable(tf.ones(var_shape, dtype=dtype), name=var_name, dtype=dtype)\n elif init_method == 'normal':\n var_map[var_name] = tf.Variable(tf.random_normal(var_shape, mean=0.0, stddev=STDDEV, dtype=dtype),\n name=var_name, dtype=dtype)\n elif init_method == 'tnormal':\n var_map[var_name] = tf.Variable(tf.truncated_normal(var_shape, mean=0.0, stddev=STDDEV, dtype=dtype),\n name=var_name, dtype=dtype)\n elif init_method == 'uniform':\n var_map[var_name] = tf.Variable(tf.random_uniform(var_shape, minval=MINVAL, maxval=MAXVAL, dtype=dtype),\n name=var_name, dtype=dtype)\n elif init_method == 'xavier':\n maxval = np.sqrt(6. / np.sum(var_shape))\n minval = -maxval\n var_map[var_name] = tf.Variable(tf.random_uniform(var_shape, minval=minval, maxval=maxval, dtype=dtype),\n name=var_name, dtype=dtype)\n elif isinstance(init_method, int) or isinstance(init_method, float):\n var_map[var_name] = tf.Variable(tf.ones(var_shape, dtype=dtype) * init_method, name=var_name, dtype=dtype)\n elif init_method in load_var_map:\n if load_var_map[init_method].shape == tuple(var_shape):\n var_map[var_name] = tf.Variable(load_var_map[init_method], name=var_name, dtype=dtype)\n else:\n print('BadParam: init method', init_method, 'shape', var_shape, load_var_map[init_method].shape)\n else:\n print('BadParam: init method', init_method)\n return var_map",
"_____no_output_____"
],
[
"# 不同的激活函数选择\ndef activate(weights, activation_function):\n if activation_function == 'sigmoid':\n return tf.nn.sigmoid(weights)\n elif activation_function == 'softmax':\n return tf.nn.softmax(weights)\n elif activation_function == 'relu':\n return tf.nn.relu(weights)\n elif activation_function == 'tanh':\n return tf.nn.tanh(weights)\n elif activation_function == 'elu':\n return tf.nn.elu(weights)\n elif activation_function == 'none':\n return weights\n else:\n return weights",
"_____no_output_____"
],
[
"# 不同的优化器选择\ndef get_optimizer(opt_algo, learning_rate, loss):\n if opt_algo == 'adaldeta':\n return tf.train.AdadeltaOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'adagrad':\n return tf.train.AdagradOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'adam':\n return tf.train.AdamOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'ftrl':\n return tf.train.FtrlOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'gd':\n return tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'padagrad':\n return tf.train.ProximalAdagradOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'pgd':\n return tf.train.ProximalGradientDescentOptimizer(learning_rate).minimize(loss)\n elif opt_algo == 'rmsprop':\n return tf.train.RMSPropOptimizer(learning_rate).minimize(loss)\n else:\n return tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)",
"_____no_output_____"
],
[
"# 工具函数\n# 提示:tf.slice(input_, begin, size, name=None):按照指定的下标范围抽取连续区域的子集\n# tf.gather(params, indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集\ndef gather_2d(params, indices):\n shape = tf.shape(params)\n flat = tf.reshape(params, [-1])\n flat_idx = indices[:, 0] * shape[1] + indices[:, 1]\n flat_idx = tf.reshape(flat_idx, [-1])\n return tf.gather(flat, flat_idx)",
"_____no_output_____"
],
[
"def gather_3d(params, indices):\n shape = tf.shape(params)\n flat = tf.reshape(params, [-1])\n flat_idx = indices[:, 0] * shape[1] * shape[2] + indices[:, 1] * shape[2] + indices[:, 2]\n flat_idx = tf.reshape(flat_idx, [-1])\n return tf.gather(flat, flat_idx)",
"_____no_output_____"
],
[
"def gather_4d(params, indices):\n shape = tf.shape(params)\n flat = tf.reshape(params, [-1])\n flat_idx = indices[:, 0] * shape[1] * shape[2] * shape[3] + \\\n indices[:, 1] * shape[2] * shape[3] + indices[:, 2] * shape[3] + indices[:, 3]\n flat_idx = tf.reshape(flat_idx, [-1])\n return tf.gather(flat, flat_idx)",
"_____no_output_____"
],
[
"# 池化2d\ndef max_pool_2d(params, k):\n _, indices = tf.nn.top_k(params, k, sorted=False)\n shape = tf.shape(indices)\n r1 = tf.reshape(tf.range(shape[0]), [-1, 1])\n r1 = tf.tile(r1, [1, k])\n r1 = tf.reshape(r1, [-1, 1])\n indices = tf.concat([r1, tf.reshape(indices, [-1, 1])], 1)\n return tf.reshape(gather_2d(params, indices), [-1, k])",
"_____no_output_____"
],
[
"# 池化3d\ndef max_pool_3d(params, k):\n _, indices = tf.nn.top_k(params, k, sorted=False)\n shape = tf.shape(indices)\n r1 = tf.reshape(tf.range(shape[0]), [-1, 1])\n r2 = tf.reshape(tf.range(shape[1]), [-1, 1])\n r1 = tf.tile(r1, [1, k * shape[1]])\n r2 = tf.tile(r2, [1, k])\n r1 = tf.reshape(r1, [-1, 1])\n r2 = tf.tile(tf.reshape(r2, [-1, 1]), [shape[0], 1])\n indices = tf.concat([r1, r2, tf.reshape(indices, [-1, 1])], 1)\n return tf.reshape(gather_3d(params, indices), [-1, shape[1], k])",
"_____no_output_____"
],
[
"# 池化4d\ndef max_pool_4d(params, k):\n _, indices = tf.nn.top_k(params, k, sorted=False)\n shape = tf.shape(indices)\n r1 = tf.reshape(tf.range(shape[0]), [-1, 1])\n r2 = tf.reshape(tf.range(shape[1]), [-1, 1])\n r3 = tf.reshape(tf.range(shape[2]), [-1, 1])\n r1 = tf.tile(r1, [1, shape[1] * shape[2] * k])\n r2 = tf.tile(r2, [1, shape[2] * k])\n r3 = tf.tile(r3, [1, k])\n r1 = tf.reshape(r1, [-1, 1])\n r2 = tf.tile(tf.reshape(r2, [-1, 1]), [shape[0], 1])\n r3 = tf.tile(tf.reshape(r3, [-1, 1]), [shape[0] * shape[1], 1])\n indices = tf.concat([r1, r2, r3, tf.reshape(indices, [-1, 1])], 1)\n return tf.reshape(gather_4d(params, indices), [-1, shape[1], shape[2], k])",
"_____no_output_____"
]
],
[
[
"## 定义不同的模型",
"_____no_output_____"
]
],
[
[
"# 定义基类模型\ndtype = DTYPE\nclass Model:\n def __init__(self):\n self.sess = None\n self.X = None\n self.y = None\n self.layer_keeps = None\n self.vars = None\n self.keep_prob_train = None\n self.keep_prob_test = None\n\n # run model\n def run(self, fetches, X=None, y=None, mode='train'):\n # 通过feed_dict传入数据\n feed_dict = {}\n if type(self.X) is list:\n for i in range(len(X)):\n feed_dict[self.X[i]] = X[i]\n else:\n feed_dict[self.X] = X\n if y is not None:\n feed_dict[self.y] = y\n if self.layer_keeps is not None:\n if mode == 'train':\n feed_dict[self.layer_keeps] = self.keep_prob_train\n elif mode == 'test':\n feed_dict[self.layer_keeps] = self.keep_prob_test\n #通过session.run去执行op\n return self.sess.run(fetches, feed_dict)\n\n # 模型参数持久化\n def dump(self, model_path):\n var_map = {}\n for name, var in self.vars.iteritems():\n var_map[name] = self.run(var)\n pkl.dump(var_map, open(model_path, 'wb'))\n print('model dumped at', model_path)",
"_____no_output_____"
]
],
[
[
"### 1.LR逻辑回归\n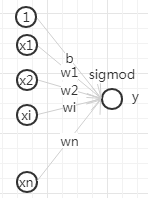\n输入输出:{X,y}<br>\n映射函数f(x):单层单节点的“DNN”, 宽而不深,sigmoid(wx+b)输出概率,需要大量的人工特征工程,非线性来源于特征处理<br>\n损失函数:logloss/... + L1/L2/...<br>\n优化方法:sgd/...<br>\n评估:logloss/auc/...<br>",
"_____no_output_____"
]
],
[
[
"class LR(Model):\n def __init__(self, input_dim=None, output_dim=1, init_path=None, opt_algo='gd', learning_rate=1e-2, l2_weight=0,\n random_seed=None):\n Model.__init__(self)\n # 声明参数\n init_vars = [('w', [input_dim, output_dim], 'xavier', dtype),\n ('b', [output_dim], 'zero', dtype)]\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n # 用稀疏的placeholder\n self.X = tf.sparse_placeholder(dtype)\n self.y = tf.placeholder(dtype)\n # init参数\n self.vars = init_var_map(init_vars, init_path)\n\n w = self.vars['w']\n b = self.vars['b']\n # sigmoid(wx+b)\n xw = tf.sparse_tensor_dense_matmul(self.X, w)\n logits = tf.reshape(xw + b, [-1])\n self.y_prob = tf.sigmoid(logits)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(labels=self.y, logits=logits)) + \\\n l2_weight * tf.nn.l2_loss(xw)\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n # GPU设定\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n # 初始化图里的参数\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn.metrics import roc_auc_score\nimport progressbar\ntrain_file = './data/train.txt'\ntest_file = './data/test.txt'\n\ninput_dim = INPUT_DIM\n\n# 读取数据\n#train_data = read_data(train_file)\n#test_data = read_data(test_file)\ntrain_data = pkl.load(open('./data/train.pkl', 'rb'))\n#train_data = shuffle(train_data)\ntest_data = pkl.load(open('./data/test.pkl', 'rb'))\n# pkl.dump(train_data, open('./data/train.pkl', 'wb'))\n# pkl.dump(test_data, open('./data/test.pkl', 'wb'))\n\n# 输出数据信息维度\nif train_data[1].ndim > 1:\n print('label must be 1-dim')\n exit(0)\nprint('read finish')\nprint('train data size:', train_data[0].shape)\nprint('test data size:', test_data[0].shape)\n\n# 训练集与测试集\ntrain_size = train_data[0].shape[0]\ntest_size = test_data[0].shape[0]\nnum_feas = len(FIELD_SIZES)\n\n# 超参数设定\nmin_round = 1\nnum_round = 200\nearly_stop_round = 5\n# train + val\nbatch_size = 1024\n\nfield_sizes = FIELD_SIZES\nfield_offsets = FIELD_OFFSETS\n\n# 逻辑回归参数设定\nlr_params = {\n 'input_dim': input_dim,\n 'opt_algo': 'gd',\n 'learning_rate': 0.1,\n 'l2_weight': 0,\n 'random_seed': 0\n}\nprint(lr_params)\nmodel = LR(**lr_params)\nprint(\"training LR...\")\ndef train(model):\n history_score = []\n # 执行num_round轮\n for i in range(num_round):\n # 主要的2个op是优化器和损失\n fetches = [model.optimizer, model.loss]\n if batch_size > 0:\n ls = []\n # 进度条工具\n bar = progressbar.ProgressBar()\n print('[%d]\\ttraining...' % i)\n for j in bar(range(int(train_size / batch_size + 1))):\n X_i, y_i = slice(train_data, j * batch_size, batch_size)\n # 训练,run op\n _, l = model.run(fetches, X_i, y_i)\n ls.append(l)\n elif batch_size == -1:\n X_i, y_i = slice(train_data)\n _, l = model.run(fetches, X_i, y_i)\n ls = [l]\n train_preds = []\n print('[%d]\\tevaluating...' % i)\n bar = progressbar.ProgressBar()\n for j in bar(range(int(train_size / 10000 + 1))):\n X_i, _ = slice(train_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n train_preds.extend(preds)\n test_preds = []\n bar = progressbar.ProgressBar()\n for j in bar(range(int(test_size / 10000 + 1))):\n X_i, _ = slice(test_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n test_preds.extend(preds)\n # 把预估的结果和真实结果拿出来计算auc\n train_score = roc_auc_score(train_data[1], train_preds)\n test_score = roc_auc_score(test_data[1], test_preds)\n # 输出auc信息\n print('[%d]\\tloss (with l2 norm):%f\\ttrain-auc: %f\\teval-auc: %f' % (i, np.mean(ls), train_score, test_score))\n history_score.append(test_score)\n # early stopping\n if i > min_round and i > early_stop_round:\n if np.argmax(history_score) == i - early_stop_round and history_score[-1] - history_score[\n -1 * early_stop_round] < 1e-5:\n print('early stop\\nbest iteration:\\n[%d]\\teval-auc: %f' % (\n np.argmax(history_score), np.max(history_score)))\n break\n\ntrain(model)",
"read finish\ntrain data size: (1742104, 491713)\ntest data size: (300928, 491713)\n{'l2_weight': 0, 'learning_rate': 0.1, 'random_seed': 0, 'input_dim': 491713, 'opt_algo': 'gd'}\n"
]
],
[
[
"### 2.FM\nFM可以视作有二次交叉的LR,为了控制参数量和充分学习,提出了user vector和item vector的概念\n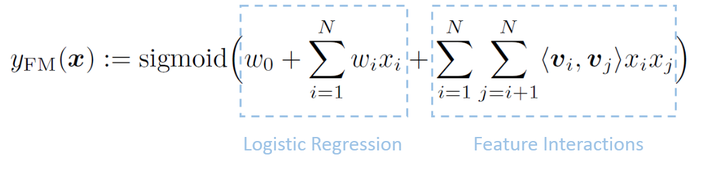\n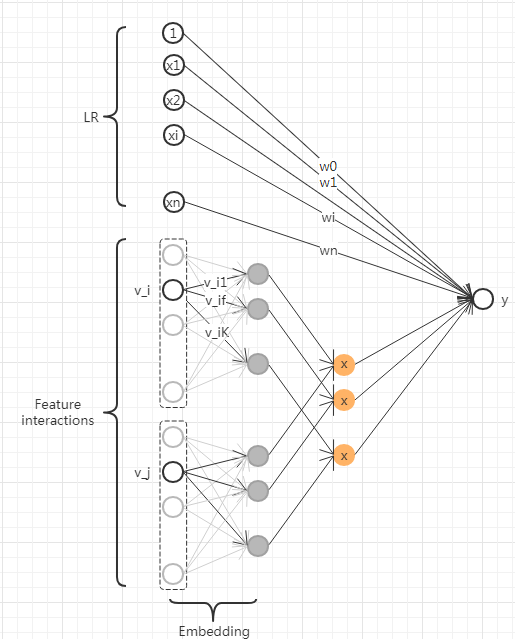",
"_____no_output_____"
]
],
[
[
"class FM(Model):\n def __init__(self, input_dim=None, output_dim=1, factor_order=10, init_path=None, opt_algo='gd', learning_rate=1e-2,\n l2_w=0, l2_v=0, random_seed=None):\n Model.__init__(self)\n # 一次、二次交叉、偏置项\n init_vars = [('w', [input_dim, output_dim], 'xavier', dtype),\n ('v', [input_dim, factor_order], 'xavier', dtype),\n ('b', [output_dim], 'zero', dtype)]\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n self.X = tf.sparse_placeholder(dtype)\n self.y = tf.placeholder(dtype)\n self.vars = init_var_map(init_vars, init_path)\n\n w = self.vars['w']\n v = self.vars['v']\n b = self.vars['b']\n \n # [(x1+x2+x3)^2 - (x1^2+x2^2+x3^2)]/2\n # 先计算所有的交叉项,再减去平方项(自己和自己相乘)\n X_square = tf.SparseTensor(self.X.indices, tf.square(self.X.values), tf.to_int64(tf.shape(self.X)))\n xv = tf.square(tf.sparse_tensor_dense_matmul(self.X, v))\n p = 0.5 * tf.reshape(\n tf.reduce_sum(xv - tf.sparse_tensor_dense_matmul(X_square, tf.square(v)), 1),\n [-1, output_dim])\n xw = tf.sparse_tensor_dense_matmul(self.X, w)\n logits = tf.reshape(xw + b + p, [-1])\n self.y_prob = tf.sigmoid(logits)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=self.y)) + \\\n l2_w * tf.nn.l2_loss(xw) + \\\n l2_v * tf.nn.l2_loss(xv)\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n\n #GPU设定\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n # 图中所有variable初始化\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn.metrics import roc_auc_score\nimport progressbar\ntrain_file = './data/train.txt'\ntest_file = './data/test.txt'\n\ninput_dim = INPUT_DIM\ntrain_data = pkl.load(open('./data/train.pkl', 'rb'))\ntrain_data = shuffle(train_data)\ntest_data = pkl.load(open('./data/test.pkl', 'rb'))\n\nif train_data[1].ndim > 1:\n print('label must be 1-dim')\n exit(0)\nprint('read finish')\nprint('train data size:', train_data[0].shape)\nprint('test data size:', test_data[0].shape)\n\n# 训练集与测试集\ntrain_size = train_data[0].shape[0]\ntest_size = test_data[0].shape[0]\nnum_feas = len(FIELD_SIZES)\n\n# 超参数设定\nmin_round = 1\nnum_round = 200\nearly_stop_round = 5\nbatch_size = 1024\n\nfield_sizes = FIELD_SIZES\nfield_offsets = FIELD_OFFSETS\n\n# FM参数设定\nfm_params = {\n 'input_dim': input_dim,\n 'factor_order': 10,\n 'opt_algo': 'gd',\n 'learning_rate': 0.1,\n 'l2_w': 0,\n 'l2_v': 0,\n}\nprint(fm_params)\nmodel = FM(**fm_params)\nprint(\"training FM...\")\n\ndef train(model):\n history_score = []\n for i in range(num_round):\n # 同样是优化器和损失两个op\n fetches = [model.optimizer, model.loss]\n if batch_size > 0:\n ls = []\n bar = progressbar.ProgressBar()\n print('[%d]\\ttraining...' % i)\n for j in bar(range(int(train_size / batch_size + 1))):\n X_i, y_i = slice(train_data, j * batch_size, batch_size)\n # 训练\n _, l = model.run(fetches, X_i, y_i)\n ls.append(l)\n elif batch_size == -1:\n X_i, y_i = slice(train_data)\n _, l = model.run(fetches, X_i, y_i)\n ls = [l]\n train_preds = []\n print('[%d]\\tevaluating...' % i)\n bar = progressbar.ProgressBar()\n for j in bar(range(int(train_size / 10000 + 1))):\n X_i, _ = slice(train_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n train_preds.extend(preds)\n test_preds = []\n bar = progressbar.ProgressBar()\n for j in bar(range(int(test_size / 10000 + 1))):\n X_i, _ = slice(test_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n test_preds.extend(preds)\n train_score = roc_auc_score(train_data[1], train_preds)\n test_score = roc_auc_score(test_data[1], test_preds)\n print('[%d]\\tloss (with l2 norm):%f\\ttrain-auc: %f\\teval-auc: %f' % (i, np.mean(ls), train_score, test_score))\n history_score.append(test_score)\n if i > min_round and i > early_stop_round:\n if np.argmax(history_score) == i - early_stop_round and history_score[-1] - history_score[\n -1 * early_stop_round] < 1e-5:\n print('early stop\\nbest iteration:\\n[%d]\\teval-auc: %f' % (\n np.argmax(history_score), np.max(history_score)))\n break\n\ntrain(model)",
"read finish\ntrain data size: (1742104, 491713)\ntest data size: (300928, 491713)\n{'l2_w': 0, 'l2_v': 0, 'factor_order': 10, 'learning_rate': 0.1, 'input_dim': 491713, 'opt_algo': 'gd'}\n"
]
],
[
[
"### FNN\nFNN的考虑是模型的capacity可以进一步提升,以对更复杂的场景建模。<br>\nFNN可以视作FM + MLP = LR + MF + MLP\n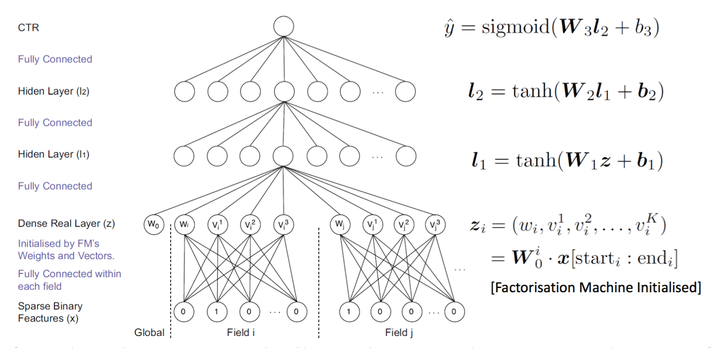",
"_____no_output_____"
]
],
[
[
"class FNN(Model):\n def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,\n embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):\n Model.__init__(self)\n init_vars = []\n num_inputs = len(field_sizes)\n for i in range(num_inputs):\n init_vars.append(('embed_%d' % i, [field_sizes[i], embed_size], 'xavier', dtype))\n node_in = num_inputs * embed_size\n for i in range(len(layer_sizes)):\n init_vars.append(('w%d' % i, [node_in, layer_sizes[i]], 'xavier', dtype))\n init_vars.append(('b%d' % i, [layer_sizes[i]], 'zero', dtype))\n node_in = layer_sizes[i]\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]\n self.y = tf.placeholder(dtype)\n self.keep_prob_train = 1 - np.array(drop_out)\n self.keep_prob_test = np.ones_like(drop_out)\n self.layer_keeps = tf.placeholder(dtype)\n self.vars = init_var_map(init_vars, init_path)\n w0 = [self.vars['embed_%d' % i] for i in range(num_inputs)]\n xw = tf.concat([tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)], 1)\n l = xw\n\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n bi = self.vars['b%d' % i]\n print(l.shape, wi.shape, bi.shape)\n l = tf.nn.dropout(\n activate(\n tf.matmul(l, wi) + bi,\n layer_acts[i]),\n self.layer_keeps[i])\n\n l = tf.squeeze(l)\n self.y_prob = tf.sigmoid(l)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))\n if layer_l2 is not None:\n self.loss += embed_l2 * tf.nn.l2_loss(xw)\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n self.loss += layer_l2[i] * tf.nn.l2_loss(wi)\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn.metrics import roc_auc_score\nimport progressbar\ntrain_file = './data/train.txt'\ntest_file = './data/test.txt'\n\ninput_dim = INPUT_DIM\ntrain_data = pkl.load(open('./data/train.pkl', 'rb'))\ntrain_data = shuffle(train_data)\ntest_data = pkl.load(open('./data/test.pkl', 'rb'))\n\nif train_data[1].ndim > 1:\n print('label must be 1-dim')\n exit(0)\nprint('read finish')\nprint('train data size:', train_data[0].shape)\nprint('test data size:', test_data[0].shape)\n\ntrain_size = train_data[0].shape[0]\ntest_size = test_data[0].shape[0]\nnum_feas = len(FIELD_SIZES)\n\nmin_round = 1\nnum_round = 200\nearly_stop_round = 5\nbatch_size = 1024\n\nfield_sizes = FIELD_SIZES\nfield_offsets = FIELD_OFFSETS\n\ntrain_data = split_data(train_data)\ntest_data = split_data(test_data)\ntmp = []\nfor x in field_sizes:\n if x > 0:\n tmp.append(x)\nfield_sizes = tmp\nprint('remove empty fields', field_sizes)\n \nfnn_params = {\n 'field_sizes': field_sizes,\n 'embed_size': 10,\n 'layer_sizes': [500, 1],\n 'layer_acts': ['relu', None],\n 'drop_out': [0, 0],\n 'opt_algo': 'gd',\n 'learning_rate': 0.1,\n 'embed_l2': 0,\n 'layer_l2': [0, 0],\n 'random_seed': 0\n}\nprint(fnn_params)\nmodel = FNN(**fnn_params)\n\ndef train(model):\n history_score = []\n for i in range(num_round):\n fetches = [model.optimizer, model.loss]\n if batch_size > 0:\n ls = []\n bar = progressbar.ProgressBar()\n print('[%d]\\ttraining...' % i)\n for j in bar(range(int(train_size / batch_size + 1))):\n X_i, y_i = slice(train_data, j * batch_size, batch_size)\n _, l = model.run(fetches, X_i, y_i)\n ls.append(l)\n elif batch_size == -1:\n X_i, y_i = slice(train_data)\n _, l = model.run(fetches, X_i, y_i)\n ls = [l]\n train_preds = []\n print('[%d]\\tevaluating...' % i)\n bar = progressbar.ProgressBar()\n for j in bar(range(int(train_size / 10000 + 1))):\n X_i, _ = slice(train_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n train_preds.extend(preds)\n test_preds = []\n bar = progressbar.ProgressBar()\n for j in bar(range(int(test_size / 10000 + 1))):\n X_i, _ = slice(test_data, j * 10000, 10000)\n preds = model.run(model.y_prob, X_i, mode='test')\n test_preds.extend(preds)\n train_score = roc_auc_score(train_data[1], train_preds)\n test_score = roc_auc_score(test_data[1], test_preds)\n print('[%d]\\tloss (with l2 norm):%f\\ttrain-auc: %f\\teval-auc: %f' % (i, np.mean(ls), train_score, test_score))\n history_score.append(test_score)\n if i > min_round and i > early_stop_round:\n if np.argmax(history_score) == i - early_stop_round and history_score[-1] - history_score[\n -1 * early_stop_round] < 1e-5:\n print('early stop\\nbest iteration:\\n[%d]\\teval-auc: %f' % (\n np.argmax(history_score), np.max(history_score)))\n break\n\ntrain(model)",
"read finish\ntrain data size: (1742104, 491713)\ntest data size: (300928, 491713)\nremove empty fields [25, 445852, 36, 371, 4, 11328, 33995, 12, 7, 5, 4, 20, 2, 38, 6, 8]\n{'field_sizes': [25, 445852, 36, 371, 4, 11328, 33995, 12, 7, 5, 4, 20, 2, 38, 6, 8], 'layer_acts': ['relu', None], 'embed_l2': 0, 'drop_out': [0, 0], 'embed_size': 10, 'random_seed': 0, 'learning_rate': 0.1, 'layer_sizes': [500, 1], 'layer_l2': [0, 0], 'opt_algo': 'gd'}\n(?, 160) (160, 500) (500,)\n(?, 500) (500, 1) (1,)\n"
]
],
[
[
"### CCPM\nreference:[ctr模型汇总](https://zhuanlan.zhihu.com/p/32523455)\n\nFM只能学习特征的二阶组合,但CNN能学习更高阶的组合,可学习的阶数和卷积的视野相关。\n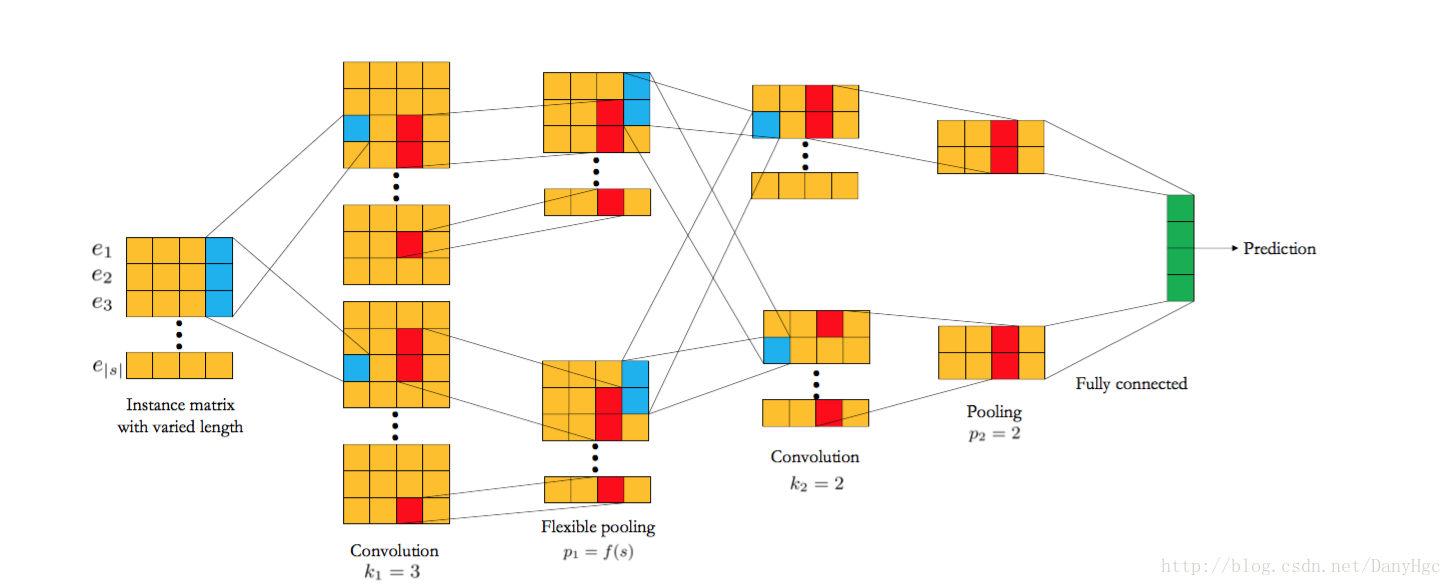\nmbedding层:e1, e2…en是某特定用户被展示的一系列广告。如果在预测广告是否会点击时不考虑历史展示广告的点击情况,则n=1。同时embedding矩阵的具体值是随着模型训练学出来的。Embedding矩阵为S,向量维度为d。\n\n卷积层:卷积参数W有d*w个,即对于矩阵S,上图每一列对应一个参数不共享的一维卷积,其视野为w,卷积共有d个,每个输出向量维度为(n+w-1),输出矩阵维度d*(n+w-1)。因为对于ctr预估而言,矩阵S每一列都对应特定的描述维度,所以需要分别处理,得到的输出矩阵的每一列就都是描述广告特定方面的特征。\n\nPooling层:flexible p-max pooling。\n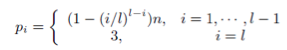\nL是模型总卷积层数,n是输入序列长度,pi就是第i层的pooling参数。这样最后一层卷积层都是输出3个最大的元素,长度固定方便后面接全连接层。同时这个指数型的参数,一开始改变比较小,几乎都是n,后面就减少得比较快。这样可以防止在模型浅层的时候就损失太多信息,众所周知深度模型在前面几层最好不要做得太简单,容易损失很多信息。文章还提到p-max pooling输出的几个最大的元素是保序的,可输入时的顺序一致,这点对于保留序列信息是重要的。\n\n激活层:tanh\n\n最后,\n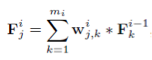\nFij是指低i层的第j个feature map。感觉是不同输入通道的卷积参数也不共享,对应输出是所有输入通道卷积的输出的求和。",
"_____no_output_____"
]
],
[
[
"class CCPM(Model):\n def __init__(self, field_sizes=None, embed_size=10, filter_sizes=None, layer_acts=None, drop_out=None,\n init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):\n Model.__init__(self)\n init_vars = []\n num_inputs = len(field_sizes)\n for i in range(num_inputs):\n init_vars.append(('embed_%d' % i, [field_sizes[i], embed_size], 'xavier', dtype))\n init_vars.append(('f1', [embed_size, filter_sizes[0], 1, 2], 'xavier', dtype))\n init_vars.append(('f2', [embed_size, filter_sizes[1], 2, 2], 'xavier', dtype))\n init_vars.append(('w1', [2 * 3 * embed_size, 1], 'xavier', dtype))\n init_vars.append(('b1', [1], 'zero', dtype))\n\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]\n self.y = tf.placeholder(dtype)\n self.keep_prob_train = 1 - np.array(drop_out)\n self.keep_prob_test = np.ones_like(drop_out)\n self.layer_keeps = tf.placeholder(dtype)\n self.vars = init_var_map(init_vars, init_path)\n w0 = [self.vars['embed_%d' % i] for i in range(num_inputs)]\n xw = tf.concat([tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)], 1)\n l = xw\n\n l = tf.transpose(tf.reshape(l, [-1, num_inputs, embed_size, 1]), [0, 2, 1, 3])\n f1 = self.vars['f1']\n l = tf.nn.conv2d(l, f1, [1, 1, 1, 1], 'SAME')\n l = tf.transpose(\n max_pool_4d(\n tf.transpose(l, [0, 1, 3, 2]),\n int(num_inputs / 2)),\n [0, 1, 3, 2])\n f2 = self.vars['f2']\n l = tf.nn.conv2d(l, f2, [1, 1, 1, 1], 'SAME')\n l = tf.transpose(\n max_pool_4d(\n tf.transpose(l, [0, 1, 3, 2]), 3),\n [0, 1, 3, 2])\n l = tf.nn.dropout(\n activate(\n tf.reshape(l, [-1, embed_size * 3 * 2]),\n layer_acts[0]),\n self.layer_keeps[0])\n w1 = self.vars['w1']\n b1 = self.vars['b1']\n l = tf.matmul(l, w1) + b1\n\n l = tf.squeeze(l)\n self.y_prob = tf.sigmoid(l)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
]
],
[
[
"### PNN\nreference:<br>\n[深度学习在CTR预估中的应用](https://zhuanlan.zhihu.com/p/35484389)\n\n可以视作FNN+product layer\n\n\nPNN和FNN的主要不同在于除了得到z向量,还增加了一个p向量,即Product向量。Product向量由每个category field的feature vector做inner product 或则 outer product 得到,作者认为这样做有助于特征交叉。另外PNN中Embeding层不再由FM生成,可以在整个网络中训练得到。\n\n对比 FNN 网络,PNN的区别在于中间多了一层 Product Layer 层。Product Layer 层由两部分组成,左边z为 embedding 层的线性部分,右边为 embedding 层的特征交叉部分。\n\n除了 Product Layer 不同,PNN 和 FNN 的 MLP 结构是一样的。这种 product 思想来源于,在 CTR 预估中,认为特征之间的关系更多是一种 and“且”的关系,而非 add\"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。\n\n根据 product 的方式不同,可以分为 inner product (IPNN) 和 outer product (OPNN),如下图所示。\n\n\n",
"_____no_output_____"
],
[
"### PNN1",
"_____no_output_____"
]
],
[
[
"class PNN1(Model):\n def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,\n embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):\n Model.__init__(self)\n init_vars = []\n num_inputs = len(field_sizes)\n for i in range(num_inputs):\n init_vars.append(('embed_%d' % i, [field_sizes[i], embed_size], 'xavier', dtype))\n num_pairs = int(num_inputs * (num_inputs - 1) / 2)\n node_in = num_inputs * embed_size + num_pairs\n # node_in = num_inputs * (embed_size + num_inputs)\n for i in range(len(layer_sizes)):\n init_vars.append(('w%d' % i, [node_in, layer_sizes[i]], 'xavier', dtype))\n init_vars.append(('b%d' % i, [layer_sizes[i]], 'zero', dtype))\n node_in = layer_sizes[i]\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]\n self.y = tf.placeholder(dtype)\n self.keep_prob_train = 1 - np.array(drop_out)\n self.keep_prob_test = np.ones_like(drop_out)\n self.layer_keeps = tf.placeholder(dtype)\n self.vars = init_var_map(init_vars, init_path)\n w0 = [self.vars['embed_%d' % i] for i in range(num_inputs)]\n xw = tf.concat([tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)], 1)\n xw3d = tf.reshape(xw, [-1, num_inputs, embed_size])\n\n row = []\n col = []\n for i in range(num_inputs-1):\n for j in range(i+1, num_inputs):\n row.append(i)\n col.append(j)\n # batch * pair * k\n p = tf.transpose(\n # pair * batch * k\n tf.gather(\n # num * batch * k\n tf.transpose(\n xw3d, [1, 0, 2]),\n row),\n [1, 0, 2])\n # batch * pair * k\n q = tf.transpose(\n tf.gather(\n tf.transpose(\n xw3d, [1, 0, 2]),\n col),\n [1, 0, 2])\n p = tf.reshape(p, [-1, num_pairs, embed_size])\n q = tf.reshape(q, [-1, num_pairs, embed_size])\n ip = tf.reshape(tf.reduce_sum(p * q, [-1]), [-1, num_pairs])\n\n # simple but redundant\n # batch * n * 1 * k, batch * 1 * n * k\n # ip = tf.reshape(\n # tf.reduce_sum(\n # tf.expand_dims(xw3d, 2) *\n # tf.expand_dims(xw3d, 1),\n # 3),\n # [-1, num_inputs**2])\n l = tf.concat([xw, ip], 1)\n\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n bi = self.vars['b%d' % i]\n l = tf.nn.dropout(\n activate(\n tf.matmul(l, wi) + bi,\n layer_acts[i]),\n self.layer_keeps[i])\n\n l = tf.squeeze(l)\n self.y_prob = tf.sigmoid(l)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))\n if layer_l2 is not None:\n self.loss += embed_l2 * tf.nn.l2_loss(xw)\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n self.loss += layer_l2[i] * tf.nn.l2_loss(wi)\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
]
],
[
[
"### PNN2",
"_____no_output_____"
]
],
[
[
"class PNN2(Model):\n def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,\n embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None,\n layer_norm=True):\n Model.__init__(self)\n init_vars = []\n num_inputs = len(field_sizes)\n for i in range(num_inputs):\n init_vars.append(('embed_%d' % i, [field_sizes[i], embed_size], 'xavier', dtype))\n num_pairs = int(num_inputs * (num_inputs - 1) / 2)\n node_in = num_inputs * embed_size + num_pairs\n init_vars.append(('kernel', [embed_size, num_pairs, embed_size], 'xavier', dtype))\n for i in range(len(layer_sizes)):\n init_vars.append(('w%d' % i, [node_in, layer_sizes[i]], 'xavier', dtype))\n init_vars.append(('b%d' % i, [layer_sizes[i]], 'zero', dtype))\n node_in = layer_sizes[i]\n self.graph = tf.Graph()\n with self.graph.as_default():\n if random_seed is not None:\n tf.set_random_seed(random_seed)\n self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]\n self.y = tf.placeholder(dtype)\n self.keep_prob_train = 1 - np.array(drop_out)\n self.keep_prob_test = np.ones_like(drop_out)\n self.layer_keeps = tf.placeholder(dtype)\n self.vars = init_var_map(init_vars, init_path)\n w0 = [self.vars['embed_%d' % i] for i in range(num_inputs)]\n xw = tf.concat([tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)], 1)\n xw3d = tf.reshape(xw, [-1, num_inputs, embed_size])\n\n row = []\n col = []\n for i in range(num_inputs - 1):\n for j in range(i + 1, num_inputs):\n row.append(i)\n col.append(j)\n # batch * pair * k\n p = tf.transpose(\n # pair * batch * k\n tf.gather(\n # num * batch * k\n tf.transpose(\n xw3d, [1, 0, 2]),\n row),\n [1, 0, 2])\n # batch * pair * k\n q = tf.transpose(\n tf.gather(\n tf.transpose(\n xw3d, [1, 0, 2]),\n col),\n [1, 0, 2])\n # b * p * k\n p = tf.reshape(p, [-1, num_pairs, embed_size])\n # b * p * k\n q = tf.reshape(q, [-1, num_pairs, embed_size])\n # k * p * k\n k = self.vars['kernel']\n\n # batch * 1 * pair * k\n p = tf.expand_dims(p, 1)\n # batch * pair\n kp = tf.reduce_sum(\n # batch * pair * k\n tf.multiply(\n # batch * pair * k\n tf.transpose(\n # batch * k * pair\n tf.reduce_sum(\n # batch * k * pair * k\n tf.multiply(\n p, k),\n -1),\n [0, 2, 1]),\n q),\n -1)\n\n #\n # if layer_norm:\n # # x_mean, x_var = tf.nn.moments(xw, [1], keep_dims=True)\n # # xw = (xw - x_mean) / tf.sqrt(x_var)\n # # x_g = tf.Variable(tf.ones([num_inputs * embed_size]), name='x_g')\n # # x_b = tf.Variable(tf.zeros([num_inputs * embed_size]), name='x_b')\n # # x_g = tf.Print(x_g, [x_g[:10], x_b])\n # # xw = xw * x_g + x_b\n # p_mean, p_var = tf.nn.moments(op, [1], keep_dims=True)\n # op = (op - p_mean) / tf.sqrt(p_var)\n # p_g = tf.Variable(tf.ones([embed_size**2]), name='p_g')\n # p_b = tf.Variable(tf.zeros([embed_size**2]), name='p_b')\n # # p_g = tf.Print(p_g, [p_g[:10], p_b])\n # op = op * p_g + p_b\n\n l = tf.concat([xw, kp], 1)\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n bi = self.vars['b%d' % i]\n l = tf.nn.dropout(\n activate(\n tf.matmul(l, wi) + bi,\n layer_acts[i]),\n self.layer_keeps[i])\n\n l = tf.squeeze(l)\n self.y_prob = tf.sigmoid(l)\n\n self.loss = tf.reduce_mean(\n tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))\n if layer_l2 is not None:\n self.loss += embed_l2 * tf.nn.l2_loss(xw)#tf.concat(w0, 0))\n for i in range(len(layer_sizes)):\n wi = self.vars['w%d' % i]\n self.loss += layer_l2[i] * tf.nn.l2_loss(wi)\n self.optimizer = get_optimizer(opt_algo, learning_rate, self.loss)\n\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n self.sess = tf.Session(config=config)\n tf.global_variables_initializer().run(session=self.sess)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02b46555fcf97821d4762bfb3a6e6d4d8e9b593
| 578,250 |
ipynb
|
Jupyter Notebook
|
indoorLocalizationModel/hierarchical_model_simplified_18ptswithdense.ipynb
|
wuh0007/masterThesis_LSTM_indoorLocalization
|
3972ebda7f59ad75a2ea7dd1cbb8af30925bf2c4
|
[
"MIT"
] | null | null | null |
indoorLocalizationModel/hierarchical_model_simplified_18ptswithdense.ipynb
|
wuh0007/masterThesis_LSTM_indoorLocalization
|
3972ebda7f59ad75a2ea7dd1cbb8af30925bf2c4
|
[
"MIT"
] | null | null | null |
indoorLocalizationModel/hierarchical_model_simplified_18ptswithdense.ipynb
|
wuh0007/masterThesis_LSTM_indoorLocalization
|
3972ebda7f59ad75a2ea7dd1cbb8af30925bf2c4
|
[
"MIT"
] | null | null | null | 87.283019 | 98,728 | 0.724391 |
[
[
[
"import pandas as pd\nimport numpy as np\n%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom os import listdir\nimport seaborn as sns\nsns.set_style(\"white\")",
"_____no_output_____"
],
[
"from keras.preprocessing import sequence\nimport tensorflow as tf\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom keras.layers import Flatten\nfrom keras.layers import Dropout\nfrom keras.callbacks import EarlyStopping\nfrom keras import optimizers\nfrom keras.regularizers import l1,l2,l1_l2\n\nfrom keras.optimizers import Adam\nfrom keras.models import load_model\nfrom keras.callbacks import ModelCheckpoint\nfrom keras.models import model_from_json",
"Using TensorFlow backend.\n"
],
[
"df_test = pd.read_csv('df_test.csv')\ndf_test",
"_____no_output_____"
],
[
"df_list = []\nfor i in range(18):\n df_split = df_test[df_test['target'] == i]\n df_split.reset_index(drop=True, inplace=True)\n df_list.append(df_split)",
"_____no_output_____"
],
[
"myorder = [0, 1, 2, 5, 4, 3, 6, 7, 8, 11, 10, 9, 12, 13, 14, 17, 16, 15]\ntest_list = [df_list[i] for i in myorder]\ntest_list[3]",
"_____no_output_____"
],
[
"df_test = pd.concat(test_list)",
"_____no_output_____"
],
[
"df_med = df_test.drop(df_test.iloc[:, :36], axis = 1) \ndf_med.drop(df_med.iloc[:, 72:108], inplace = True, axis = 1) \n\ndf_small = df_test.drop(df_test.iloc[:, :54], axis = 1) \ndf_small.drop(df_small.iloc[:, 36:90], inplace = True, axis = 1) \n\ndf_smaller = df_test.drop(df_test.iloc[:, :64], axis = 1) \ndf_smaller.drop(df_smaller.iloc[:, 18:80], inplace = True, axis = 1) ",
"_____no_output_____"
],
[
"df_smooth = df_test.T\ndf_med = df_med.T\ndf_small = df_small.T\ndf_smaller = df_smaller.T",
"_____no_output_____"
],
[
"sequences_smooth = list()\nfor i in range(df_smooth.shape[1]):\n values = df_smooth.iloc[:-1,i].values\n sequences_smooth.append(values)\ntargets_smooth = df_smooth.iloc[-1, :].values\n\nsequences_med = list()\nfor i in range(df_med.shape[1]):\n values = df_med.iloc[:-1,i].values\n sequences_med.append(values)\ntargets_med = df_med.iloc[-1, :].values\n\nsequences_small = list()\nfor i in range(df_small.shape[1]):\n values = df_small.iloc[:-1,i].values\n sequences_small.append(values)\ntargets_small = df_small.iloc[-1, :].values\n\nsequences_smaller = list()\nfor i in range(df_smaller.shape[1]):\n values = df_smaller.iloc[:-1,i].values\n sequences_smaller.append(values)\ntargets_smaller = df_smaller.iloc[-1, :].values\n\ntargets = targets_smooth",
"_____no_output_____"
],
[
"targets_smooth",
"_____no_output_____"
],
[
"from sklearn.preprocessing import LabelEncoder, OneHotEncoder\nfrom keras.utils import np_utils\n\n# encode class values as integers\nencoder = LabelEncoder()\nencoder.fit(targets)\nencoded_y = encoder.transform(targets)\n# convert integers to dummy variables (i.e. one hot encoded)\ndummy_y = np_utils.to_categorical(encoded_y)\ntargets = dummy_y",
"_____no_output_____"
],
[
"X_test_smooth, X_test_med, X_test_small, X_test_smaller, y_test = sequences_smooth, sequences_med, sequences_small, sequences_smaller, targets",
"_____no_output_____"
],
[
"# Feature Scaling\nfrom sklearn.preprocessing import StandardScaler, MinMaxScaler\nfrom sklearn.externals.joblib import dump, load\nsc1 = load('std_scaler_smooth.bin')\nX_test_smooth = sc1.transform(X_test_smooth)\n\nsc2 = load('std_scaler_med.bin')\nX_test_med = sc2.transform(X_test_med)\n\nsc3 = load('std_scaler_small.bin')\nX_test_small = sc3.transform(X_test_small)\n\nsc4 = load('std_scaler_smaller.bin')\nX_test_smaller = sc4.transform(X_test_smaller)",
"/home/hongyu/anaconda3/envs/keras/lib/python3.6/site-packages/sklearn/externals/joblib/__init__.py:15: DeprecationWarning: sklearn.externals.joblib is deprecated in 0.21 and will be removed in 0.23. Please import this functionality directly from joblib, which can be installed with: pip install joblib. If this warning is raised when loading pickled models, you may need to re-serialize those models with scikit-learn 0.21+.\n warnings.warn(msg, category=DeprecationWarning)\n"
],
[
"X_test_smooth.shape, X_test_med.shape, X_test_small.shape, X_test_smaller.shape",
"_____no_output_____"
],
[
"X_test_smooth = np.reshape(X_test_smooth, (X_test_smooth.shape[0], X_test_smooth.shape[1], 1))\nX_test_med = np.reshape(X_test_med, (X_test_med.shape[0], X_test_med.shape[1], 1))\nX_test_small = np.reshape(X_test_small, (X_test_small.shape[0], X_test_small.shape[1], 1))\nX_test_smaller = np.reshape(X_test_smaller, (X_test_smaller.shape[0], X_test_smaller.shape[1], 1))",
"_____no_output_____"
],
[
"y_test.argmax(axis=1)",
"_____no_output_____"
],
[
"class Model:\n def __init__(self, path_model, path_weight):\n self.model = self.loadmodel(path_model, path_weight)\n self.graph = tf.get_default_graph() \n \n @staticmethod\n def loadmodel(path_model, path_weight):\n json_file = open(path_model, 'r')\n loaded_model_json = json_file.read()\n json_file.close()\n model = model_from_json(loaded_model_json)\n model.load_weights(path_weight)\n return model\n\n def predict(self, X):\n with self.graph.as_default():\n return self.model.predict(X)",
"_____no_output_____"
],
[
"work_dir_model = '/home/hongyu/Documents/Spring2020/ECE_research/signal_analysis/data_18points/3_section_sliding5/MSLSTM_models/'\nwork_dir_weight = '/home/hongyu/Documents/Spring2020/ECE_research/signal_analysis/data_18points/3_section_sliding5/MSLSTM_weights/'\n\n# work_dir_model = '/home/wuh007/Desktop/signal/signal_analysis/data_18points/3_section/models_mixed/'\n# work_dir_weight = '/home/wuh007/Desktop/signal/signal_analysis/data_18points/3_section/weights_mixed/'",
"_____no_output_____"
],
[
"# model_2sec = Model(work_dir_model + 'MSLSTM_wholetotwo_model.json', work_dir_weight + 'model-015-0.976846-0.930156-0.194448-wtt.h5')\nmodel_2sec = Model(work_dir_model + 'MSLSTM_18ptswithdense_model.json', work_dir_weight + 'model-012-0.994497-0.930156-0.256649-18ptswithdense.h5')\n\n# model_TopToNine = Model(work_dir_model + 'MSLSTM_toptonine_model.json', work_dir_weight + 'MSLSTM_toptonine_weight.h5')\n# model_MiddleToSix = Model(work_dir_model + 'LSTM_MiddleToSix_model.json', work_dir_weight + 'LSTM_MiddleToSix_weight.h5')\n# model_ButtomToNine = Model(work_dir_model + 'MSLSTM_buttomtonine_model.json', work_dir_weight + 'MSLSTM_buttomtonine_weight.h5')\n\n# model_TopTopToThree = Model(work_dir_model + 'LSTM_TopTopToThree_model.json', work_dir_weight + 'LSTM_TopTopToThree_weight.h5')\n# model_TopButtomToThree = Model(work_dir_model + 'LSTM_TopButtomToThree_model.json', work_dir_weight + 'LSTM_TopButtomToThree_weight.h5')\n\n# model_MiddleTopToThree = Model(work_dir_model + 'LSTM_MiddleTopToThree_model.json', work_dir_weight + 'LSTM_MiddleTopToThree_weight.h5')\n# model_MiddleButtomToThree = Model(work_dir_model + 'LSTM_MiddleButtomToThree_model.json', work_dir_weight + 'LSTM_MiddleButtomToThree_weight.h5')\n\n# model_ButtomTopToThree = Model(work_dir_model + 'LSTM_ButtomTopToThree_model.json', work_dir_weight + 'LSTM_ButtomTopToThree_weight.h5')\n# model_ButtomButtomToThree = Model(work_dir_model + 'LSTM_ButtomButtomToThree_model.json', work_dir_weight + 'LSTM_ButtomButtomToThree_weight.h5')",
"_____no_output_____"
],
[
"y_pred_2sec = model_2sec.predict([X_test_small, X_test_med, X_test_smaller, X_test_smooth])\n# y_pred_TopToNine = model_TopToNine.predict([X_test_small, X_test_med, X_test_smaller, X_test_smooth][(y_pred_2sec.max(axis=1) > 0.00) & (y_pred_2sec.argmax(axis=1) == 0)])\n# y_pred_MiddleToSix = model_MiddleToSix.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 1)])\n# y_pred_ButtomToNine = model_ButtomToNine.predict([X_test_small, X_test_med, X_test_smaller, X_test_smooth][(y_pred_2sec.max(axis=1) > 0.00) & (y_pred_2sec.argmax(axis=1) == 1)])",
"_____no_output_____"
],
[
"# y_pred_TopTopToThree = model_TopTopToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 0)][(y_pred_TopToTwo.max(axis=1) > 0.85) & (y_pred_TopToTwo.argmax(axis=1) == 0)])\n# y_pred_TopButtomToThree = model_TopButtomToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 0)][(y_pred_TopToTwo.max(axis=1) > 0.85) & (y_pred_TopToTwo.argmax(axis=1) == 1)])\n\n# y_pred_MiddleTopToThree = model_MiddleTopToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 1)][(y_pred_MiddleToTwo.max(axis=1) > 0.85) & (y_pred_MiddleToTwo.argmax(axis=1) == 0)])\n# y_pred_MiddleButtomToThree = model_MiddleButtomToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 1)][(y_pred_MiddleToTwo.max(axis=1) > 0.85) & (y_pred_MiddleToTwo.argmax(axis=1) == 1)])\n\n# y_pred_ButtomTopToThree = model_ButtomTopToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 2)][(y_pred_ButtomToTwo.max(axis=1) > 0.85) & (y_pred_ButtomToTwo.argmax(axis=1) == 0)])\n# y_pred_ButtomButtomToThree = model_ButtomButtomToThree.predict(X_test[(y_pred_3sec.max(axis=1) > 0.85) & (y_pred_3sec.argmax(axis=1) == 2)][(y_pred_ButtomToTwo.max(axis=1) > 0.85) & (y_pred_ButtomToTwo.argmax(axis=1) == 1)])",
"_____no_output_____"
],
[
"# len(y_pred_TopToNine), len(y_pred_ButtomToNine)",
"_____no_output_____"
],
[
"# len(y_pred_TopToNine) + len(y_pred_ButtomToNine)",
"_____no_output_____"
],
[
"len(y_pred_2sec), len(y_test)",
"_____no_output_____"
],
[
"# y_pred_TopToNine.argmax(axis=1)",
"_____no_output_____"
],
[
"# y_test[(y_pred_2sec.max(axis=1) > 0.00) & (y_pred_2sec.argmax(axis=1) == 0)].argmax(axis=1)",
"_____no_output_____"
],
[
"# y_pred_ButtomToNine.argmax(axis=1)",
"_____no_output_____"
],
[
"# y_test[(y_pred_2sec.max(axis=1) > 0.00) & (y_pred_2sec.argmax(axis=1) == 2)].argmax(axis=1)",
"_____no_output_____"
],
[
"# y_pred_BTN = y_pred_ButtomToNine.argmax(axis=1)\n# y_pred_BTN[y_pred_BTN == 0] = 9\n# y_pred_BTN[y_pred_BTN == 1] = 10\n# y_pred_BTN[y_pred_BTN == 2] = 11\n# y_pred_BTN[y_pred_BTN == 3] = 12\n# y_pred_BTN[y_pred_BTN == 4] = 13\n# y_pred_BTN[y_pred_BTN == 5] = 14\n# y_pred_BTN[y_pred_BTN == 6] = 15\n# y_pred_BTN[y_pred_BTN == 7] = 16\n# y_pred_BTN[y_pred_BTN == 8] = 17\n# y_pred_BTN",
"_____no_output_____"
],
[
"# y_pred_final = np.concatenate((y_pred_TopToNine.argmax(axis=1), y_pred_BTN), axis=0)",
"_____no_output_____"
],
[
"# y_pred_final, len(y_pred_final)",
"_____no_output_____"
],
[
"# y_test_final = np.concatenate((y_test[(y_pred_3sec.max(axis=1) > 0.00) & (y_pred_3sec.argmax(axis=1) == 0)].argmax(axis=1), \n# y_test[(y_pred_3sec.max(axis=1) > 0.00) & (y_pred_3sec.argmax(axis=1) == 1)].argmax(axis=1), \n# axis=0)",
"_____no_output_____"
],
[
"y_pred_2sec",
"_____no_output_____"
],
[
"y_pred_2sec.argmax(axis=1)",
"_____no_output_____"
],
[
"y_test.argmax(axis=1)",
"_____no_output_____"
],
[
"len(y_test.argmax(axis=1))",
"_____no_output_____"
],
[
"# len(set([1,1,1]))",
"_____no_output_____"
],
[
"column_map = dict()\nrow_map = dict()\n",
"_____no_output_____"
],
[
"y_test_new = list()\nfor j in range(len(y_test.argmax(axis=1)) - 2):\n window = [y_test.argmax(axis=1)[j], \n y_test.argmax(axis=1)[j+1], \n y_test.argmax(axis=1)[j+2]]\n# print(window)\n# print(len(set(window)))\n if len(set(window)) == 1 or 2:\n for item in set(window):\n if window.count(item) > 1:\n y_test_new.append(item)\n# print(y_test_new)\n else:\n print('windows', window)\n y_test_new.append(18)",
"_____no_output_____"
],
[
"y_test_new = list()\nfor j in range(len(y_test[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)) - 2):\n window = [y_test[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j], \n y_test[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j+1], \n y_test[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j+2]]\n# print(window)\n# print(len(set(window)))\n if len(set(window)) == 1 or 2:\n for item in set(window):\n if window.count(item) > 1:\n y_test_new.append(item)\n# print(y_test_new)\n else:\n print('windows', window)\n y_test_new.append(18)\n# print(j)",
"_____no_output_____"
],
[
"len(y_test_new)",
"_____no_output_____"
],
[
"y_pred_new = list()\nfor j in range(len(y_pred_2sec.argmax(axis=1)) - 2):\n window = [y_pred_2sec.argmax(axis=1)[j], \n y_pred_2sec.argmax(axis=1)[j+1], \n y_pred_2sec.argmax(axis=1)[j+2]]\n print('windows', window)\n# print('unique elements', len(set(window)))\n if len(set(window)) == 1 or len(set(window)) == 2:\n for item in set(window):\n if window.count(item) > 1:\n y_pred_new.append(item)\n# print(y_pred_new)\n else:\n print('unique window', window)\n y_pred\n print(y_test_new[j])\n y_pred_new.append(18)\n# print('special', j)\n# print(j)",
"windows [5, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 2]\nwindows [0, 2, 0]\nwindows [2, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 5]\nwindows [0, 5, 0]\nwindows [5, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 6]\nwindows [0, 6, 0]\nwindows [6, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 11]\nwindows [0, 11, 0]\nwindows [11, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 6]\nwindows [0, 6, 11]\nunique window [0, 6, 11]\n0\nwindows [6, 11, 2]\nunique window [6, 11, 2]\n0\nwindows [11, 2, 0]\nunique window [11, 2, 0]\n0\nwindows [2, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 0]\nwindows [0, 0, 1]\nwindows [0, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 11]\nwindows [1, 11, 1]\nwindows [11, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 2]\nwindows [1, 2, 1]\nwindows [2, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 2]\nwindows [1, 2, 1]\nwindows [2, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 11]\nwindows [1, 11, 1]\nwindows [11, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 14]\nwindows [1, 14, 1]\nwindows [14, 1, 2]\nunique window [14, 1, 2]\n1\nwindows [1, 2, 1]\nwindows [2, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 11]\nwindows [1, 11, 1]\nwindows [11, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 1]\nwindows [1, 1, 2]\nwindows [1, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 1]\nwindows [2, 1, 2]\nwindows [1, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 11]\nwindows [2, 11, 2]\nwindows [11, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 0]\nwindows [2, 0, 2]\nwindows [0, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 0]\nwindows [2, 0, 2]\nwindows [0, 2, 6]\nunique window [0, 2, 6]\n2\nwindows [2, 6, 0]\nunique window [2, 6, 0]\n2\nwindows [6, 0, 2]\nunique window [6, 0, 2]\n2\nwindows [0, 2, 2]\nwindows [2, 2, 3]\nwindows [2, 3, 2]\nwindows [3, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 11]\nwindows [2, 11, 2]\nwindows [11, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 1]\nwindows [2, 1, 2]\nwindows [1, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 2]\nwindows [2, 2, 5]\nwindows [2, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 14]\nwindows [5, 14, 5]\nwindows [14, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 0]\nwindows [5, 0, 3]\nunique window [5, 0, 3]\n5\nwindows [0, 3, 5]\nunique window [0, 3, 5]\n5\nwindows [3, 5, 1]\nunique window [3, 5, 1]\n5\nwindows [5, 1, 5]\nwindows [1, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 0]\nwindows [5, 0, 5]\nwindows [0, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 0]\nwindows [5, 0, 3]\nunique window [5, 0, 3]\n5\nwindows [0, 3, 5]\nunique window [0, 3, 5]\n5\nwindows [3, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 0]\nwindows [5, 0, 5]\nwindows [0, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 2]\nwindows [5, 2, 5]\nwindows [2, 5, 3]\nunique window [2, 5, 3]\n5\nwindows [5, 3, 5]\nwindows [3, 5, 5]\nwindows [5, 5, 14]\nwindows [5, 14, 5]\nwindows [14, 5, 2]\nunique window [14, 5, 2]\n5\nwindows [5, 2, 5]\nwindows [2, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 5]\nwindows [5, 5, 4]\nwindows [5, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 10]\nwindows [4, 10, 4]\nwindows [10, 4, 4]\nwindows [4, 4, 10]\nwindows [4, 10, 4]\nwindows [10, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 8]\nwindows [4, 8, 4]\nwindows [8, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 8]\nwindows [4, 8, 4]\nwindows [8, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 8]\nwindows [4, 8, 4]\nwindows [8, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 8]\nwindows [4, 8, 4]\nwindows [8, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 11]\nwindows [4, 11, 4]\nwindows [11, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 9]\nwindows [4, 9, 4]\nwindows [9, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 4]\nwindows [4, 4, 3]\nwindows [4, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 14]\nwindows [3, 14, 3]\nwindows [14, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 5]\nwindows [3, 5, 3]\nwindows [5, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 11]\nwindows [3, 11, 3]\nwindows [11, 3, 1]\nunique window [11, 3, 1]\n3\nwindows [3, 1, 3]\nwindows [1, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 1]\nwindows [3, 1, 3]\nwindows [1, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 0]\nwindows [3, 0, 3]\nwindows [0, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 3]\nwindows [3, 3, 11]\nwindows [3, 11, 3]\nwindows [11, 3, 3]\n"
],
[
"y_pred_new = list()\nfor j in range(len(y_pred_2sec[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)) - 2):\n window = [y_pred_2sec[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j], \n y_pred_2sec[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j+1], \n y_pred_2sec[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1)[j+2]]\n# print('windows', window)\n# print('unique elements', len(set(window)))\n if len(set(window)) == 1 or len(set(window)) == 2:\n for item in set(window):\n if window.count(item) > 1:\n y_pred_new.append(item)\n# print(y_pred_new)\n else:\n print('windows', window)\n y_pred_new.append(18)\n# print('special', j)\n# print(j)",
"windows [2, 6, 0]\nwindows [6, 0, 2]\nwindows [3, 5, 1]\nwindows [2, 5, 3]\nwindows [3, 11, 6]\nwindows [12, 17, 13]\nwindows [13, 17, 12]\nwindows [17, 12, 13]\nwindows [12, 13, 17]\nwindows [13, 9, 14]\nwindows [14, 5, 9]\nwindows [5, 9, 17]\n"
],
[
"len(y_pred_new)",
"_____no_output_____"
],
[
"count = 0\nfor i in range(len(y_pred_new)):\n if y_pred_new[i] == 18:\n count += 1\ncount",
"_____no_output_____"
],
[
"count = 0\nfor i in range(len(y_pred_new)):\n if y_pred_new[i] == 18:\n count += 1\ncount",
"_____no_output_____"
],
[
"y_test_new = np.asarray(y_test_new)\ny_pred_new = np.asarray(y_pred_new)",
"_____no_output_____"
],
[
"# Creating the Confusion Matrix\nfrom sklearn.metrics import confusion_matrix\nmatrix = confusion_matrix(y_test_new, y_pred_new)\n# matrix = confusion_matrix(y_test[y_pred_2sec.max(axis=1) > 0.80].argmax(axis=1), y_pred_2sec[y_pred_2sec.max(axis=1) > 0.80].argmax(axis=1))\nmatrix",
"_____no_output_____"
],
[
"plot_confusion_matrix(matrix, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17])",
"/home/hongyu/anaconda3/envs/keras/lib/python3.6/site-packages/ipykernel_launcher.py:59: RuntimeWarning: invalid value encountered in true_divide\n"
],
[
"plot_confusion_matrix(matrix, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17])",
"/home/hongyu/anaconda3/envs/keras/lib/python3.6/site-packages/ipykernel_launcher.py:59: RuntimeWarning: invalid value encountered in true_divide\n"
],
[
"# Creating the Confusion Matrix\nfrom sklearn.metrics import confusion_matrix\n# matrix = confusion_matrix(y_pred_2sec.argmax(axis=1), y_test.argmax(axis=1))\nmatrix = confusion_matrix(y_test[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1), y_pred_2sec[y_pred_2sec.max(axis=1) > 0.70].argmax(axis=1))\nmatrix",
"_____no_output_____"
],
[
"len(y_test), len(y_test[y_pred_2sec.max(axis=1) > 0.70])",
"_____no_output_____"
],
[
"def plot_confusion_matrix(cm,\n target_names,\n title='Confusion matrix',\n cmap=None,\n normalize=True):\n \"\"\"\n given a sklearn confusion matrix (cm), make a nice plot\n\n Arguments\n ---------\n cm: confusion matrix from sklearn.metrics.confusion_matrix\n\n target_names: given classification classes such as [0, 1, 2]\n the class names, for example: ['high', 'medium', 'low']\n\n title: the text to display at the top of the matrix\n\n cmap: the gradient of the values displayed from matplotlib.pyplot.cm\n see http://matplotlib.org/examples/color/colormaps_reference.html\n plt.get_cmap('jet') or plt.cm.Blues\n\n normalize: If False, plot the raw numbers\n If True, plot the proportions\n\n Usage|\n -----\n plot_confusion_matrix(cm = cm, # confusion matrix created by\n # sklearn.metrics.confusion_matrix\n normalize = True, # show proportions\n target_names = y_labels_vals, # list of names of the classes\n title = best_estimator_name) # title of graph\n\n Citiation\n ---------\n http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html\n\n \"\"\"\n import matplotlib.pyplot as plt\n import numpy as np\n import itertools\n\n accuracy = np.trace(cm) / np.sum(cm).astype('float')\n misclass = 1 - accuracy\n\n if cmap is None:\n cmap = plt.get_cmap('Blues')\n\n plt.figure(figsize=(16, 14))\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n\n if target_names is not None:\n tick_marks = np.arange(len(target_names))\n plt.xticks(tick_marks, target_names, rotation=45)\n plt.yticks(tick_marks, target_names)\n\n if normalize:\n cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]\n\n\n thresh = cm.max() / 1.5 if normalize else cm.max() / 2\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n if normalize:\n plt.text(j, i, \"{:0.4f}\".format(cm[i, j]),\n horizontalalignment=\"center\",\n color=\"red\" if cm[i, j] > thresh else \"black\")\n else:\n plt.text(j, i, \"{:,}\".format(cm[i, j]),\n horizontalalignment=\"center\",\n color=\"red\" if cm[i, j] > thresh else \"black\")\n\n\n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label\\naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))\n plt.show()\n \n \nplot_confusion_matrix(matrix, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17])",
"_____no_output_____"
],
[
"plot_confusion_matrix(matrix, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17])",
"_____no_output_____"
],
[
"tl = np.sum(matrix[:9, :9])\ntr = np.sum(matrix[:9, 9:])\nbl = np.sum(matrix[9:, :9])\nbr = np.sum(matrix[9:, 9:])\n(tl+br)/(tl+tr+bl+br)",
"_____no_output_____"
],
[
"matrix[:9, :9]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02b483d423f953bd3b067d88f9e16c170286f13
| 62,052 |
ipynb
|
Jupyter Notebook
|
BCNcode/0_vibratioon_signal/1250/BCN/1250-015-512-x.ipynb
|
Decaili98/BCN-code-2022
|
ab0ce085cb29fbf12b6d773861953cb2cef23e20
|
[
"MulanPSL-1.0"
] | null | null | null |
BCNcode/0_vibratioon_signal/1250/BCN/1250-015-512-x.ipynb
|
Decaili98/BCN-code-2022
|
ab0ce085cb29fbf12b6d773861953cb2cef23e20
|
[
"MulanPSL-1.0"
] | null | null | null |
BCNcode/0_vibratioon_signal/1250/BCN/1250-015-512-x.ipynb
|
Decaili98/BCN-code-2022
|
ab0ce085cb29fbf12b6d773861953cb2cef23e20
|
[
"MulanPSL-1.0"
] | null | null | null | 100.570502 | 19,448 | 0.768162 |
[
[
[
"import tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom keras import initializers\nimport keras.backend as K\nimport numpy as np\nimport pandas as pd\nfrom tensorflow.keras.layers import *\nfrom keras.regularizers import l2#正则化",
"Using TensorFlow backend.\n"
],
[
"# 12-0.2\n# 13-2.4\n# 18-12.14\nimport pandas as pd\nimport numpy as np\nnormal = np.loadtxt(r'E:\\水泵代码调试\\试验数据(包括压力脉动和振动)\\2013.9.12-未发生缠绕前\\2013-9.12振动\\2013-9-12振动-1250rmin-mat\\1250rnormalvibx.txt', delimiter=',')\nchanrao = np.loadtxt(r'E:\\水泵代码调试\\试验数据(包括压力脉动和振动)\\2013.9.17-发生缠绕后\\振动\\9-18上午振动1250rmin-mat\\1250r_chanraovibx.txt', delimiter=',')\nprint(normal.shape,chanrao.shape,\"***************************************************\")\ndata_normal=normal[6:8] #提取前两行\ndata_chanrao=chanrao[6:8] #提取前两行\nprint(data_normal.shape,data_chanrao.shape)\nprint(data_normal,\"\\r\\n\",data_chanrao,\"***************************************************\")\ndata_normal=data_normal.reshape(1,-1)\ndata_chanrao=data_chanrao.reshape(1,-1)\nprint(data_normal.shape,data_chanrao.shape)\nprint(data_normal,\"\\r\\n\",data_chanrao,\"***************************************************\")",
"(22, 32768) (20, 32768) ***************************************************\n(2, 32768) (2, 32768)\n[[-0.43236 0.67967 0.051441 ... 0.59589 -0.16289 0.063553]\n [-0.020599 -1.2753 -0.56814 ... -1.4188 0.19571 0.53491 ]] \r\n [[-0.055206 -0.38574 0.42476 ... 0.81089 -1.8597 -0.1416 ]\n [-0.23825 1.8137 1.2667 ... 0.018959 -0.17037 0.48102 ]] ***************************************************\n(1, 65536) (1, 65536)\n[[-0.43236 0.67967 0.051441 ... -1.4188 0.19571 0.53491 ]] \r\n [[-0.055206 -0.38574 0.42476 ... 0.018959 -0.17037 0.48102 ]] ***************************************************\n"
],
[
"#水泵的两种故障类型信号normal正常,chanrao故障\ndata_normal=data_normal.reshape(-1, 512)#(65536,1)-(128, 515)\ndata_chanrao=data_chanrao.reshape(-1,512)\nprint(data_normal.shape,data_chanrao.shape)\n",
"(128, 512) (128, 512)\n"
],
[
"import numpy as np\ndef yuchuli(data,label):#(4:1)(51:13)\n #打乱数据顺序\n np.random.shuffle(data)\n train = data[0:102,:]\n test = data[102:128,:]\n label_train = np.array([label for i in range(0,102)])\n label_test =np.array([label for i in range(0,26)])\n return train,test ,label_train ,label_test\ndef stackkk(a,b,c,d,e,f,g,h):\n aa = np.vstack((a, e))\n bb = np.vstack((b, f))\n cc = np.hstack((c, g))\n dd = np.hstack((d, h))\n return aa,bb,cc,dd\nx_tra0,x_tes0,y_tra0,y_tes0 = yuchuli(data_normal,0)\nx_tra1,x_tes1,y_tra1,y_tes1 = yuchuli(data_chanrao,1)\ntr1,te1,yr1,ye1=stackkk(x_tra0,x_tes0,y_tra0,y_tes0 ,x_tra1,x_tes1,y_tra1,y_tes1)\n\nx_train=tr1\nx_test=te1\ny_train = yr1\ny_test = ye1\n\n#打乱数据\nstate = np.random.get_state()\nnp.random.shuffle(x_train)\nnp.random.set_state(state)\nnp.random.shuffle(y_train)\n\nstate = np.random.get_state()\nnp.random.shuffle(x_test)\nnp.random.set_state(state)\nnp.random.shuffle(y_test)\n\n\n#对训练集和测试集标准化\ndef ZscoreNormalization(x):\n \"\"\"Z-score normaliaztion\"\"\"\n x = (x - np.mean(x)) / np.std(x)\n return x\nx_train=ZscoreNormalization(x_train)\nx_test=ZscoreNormalization(x_test)\n# print(x_test[0])\n\n\n#转化为一维序列\nx_train = x_train.reshape(-1,512,1)\nx_test = x_test.reshape(-1,512,1)\nprint(x_train.shape,x_test.shape)\n\ndef to_one_hot(labels,dimension=2):\n results = np.zeros((len(labels),dimension))\n for i,label in enumerate(labels):\n results[i,label] = 1\n return results\none_hot_train_labels = to_one_hot(y_train)\none_hot_test_labels = to_one_hot(y_test)\n",
"(204, 512, 1) (52, 512, 1)\n"
],
[
"#定义挤压函数\ndef squash(vectors, axis=-1):\n \"\"\"\n 对向量的非线性激活函数\n ## vectors: some vectors to be squashed, N-dim tensor\n ## axis: the axis to squash\n :return: a Tensor with same shape as input vectors\n \"\"\"\n s_squared_norm = K.sum(K.square(vectors), axis, keepdims=True)\n scale = s_squared_norm / (1 + s_squared_norm) / K.sqrt(s_squared_norm + K.epsilon())\n return scale * vectors\n\nclass Length(layers.Layer):\n \"\"\"\n 计算向量的长度。它用于计算与margin_loss中的y_true具有相同形状的张量\n Compute the length of vectors. This is used to compute a Tensor that has the same shape with y_true in margin_loss\n inputs: shape=[dim_1, ..., dim_{n-1}, dim_n]\n output: shape=[dim_1, ..., dim_{n-1}]\n \"\"\"\n def call(self, inputs, **kwargs):\n return K.sqrt(K.sum(K.square(inputs), -1))\n\n def compute_output_shape(self, input_shape):\n return input_shape[:-1]\n \n def get_config(self):\n config = super(Length, self).get_config()\n return config\n#定义预胶囊层\ndef PrimaryCap(inputs, dim_capsule, n_channels, kernel_size, strides, padding):\n \"\"\"\n 进行普通二维卷积 `n_channels` 次, 然后将所有的胶囊重叠起来\n :param inputs: 4D tensor, shape=[None, width, height, channels]\n :param dim_capsule: the dim of the output vector of capsule\n :param n_channels: the number of types of capsules\n :return: output tensor, shape=[None, num_capsule, dim_capsule]\n \"\"\"\n output = layers.Conv2D(filters=dim_capsule*n_channels, kernel_size=kernel_size, strides=strides,\n padding=padding,name='primarycap_conv2d')(inputs)\n outputs = layers.Reshape(target_shape=[-1, dim_capsule], name='primarycap_reshape')(output)\n return layers.Lambda(squash, name='primarycap_squash')(outputs)\n\nclass DenseCapsule(layers.Layer):\n \"\"\"\n 胶囊层. 输入输出都为向量. \n ## num_capsule: 本层包含的胶囊数量\n ## dim_capsule: 输出的每一个胶囊向量的维度\n ## routings: routing 算法的迭代次数\n \"\"\"\n def __init__(self, num_capsule, dim_capsule, routings=3, kernel_initializer='glorot_uniform',**kwargs):\n super(DenseCapsule, self).__init__(**kwargs)\n self.num_capsule = num_capsule\n self.dim_capsule = dim_capsule\n self.routings = routings\n self.kernel_initializer = kernel_initializer\n\n def build(self, input_shape):\n assert len(input_shape) >= 3, '输入的 Tensor 的形状[None, input_num_capsule, input_dim_capsule]'#(None,1152,8)\n self.input_num_capsule = input_shape[1]\n self.input_dim_capsule = input_shape[2]\n\n #转换矩阵\n self.W = self.add_weight(shape=[self.num_capsule, self.input_num_capsule,\n self.dim_capsule, self.input_dim_capsule],\n initializer=self.kernel_initializer,name='W')\n self.built = True\n\n def call(self, inputs, training=None):\n # inputs.shape=[None, input_num_capsuie, input_dim_capsule]\n # inputs_expand.shape=[None, 1, input_num_capsule, input_dim_capsule]\n inputs_expand = K.expand_dims(inputs, 1)\n # 运算优化:将inputs_expand重复num_capsule 次,用于快速和W相乘\n # inputs_tiled.shape=[None, num_capsule, input_num_capsule, input_dim_capsule]\n inputs_tiled = K.tile(inputs_expand, [1, self.num_capsule, 1, 1])\n\n # 将inputs_tiled的batch中的每一条数据,计算inputs+W\n # x.shape = [num_capsule, input_num_capsule, input_dim_capsule]\n # W.shape = [num_capsule, input_num_capsule, dim_capsule, input_dim_capsule]\n # 将x和W的前两个维度看作'batch'维度,向量和矩阵相乘:\n # [input_dim_capsule] x [dim_capsule, input_dim_capsule]^T -> [dim_capsule].\n # inputs_hat.shape = [None, num_capsule, input_num_capsule, dim_capsutel\n inputs_hat = K.map_fn(lambda x: K.batch_dot(x, self.W, [2, 3]),elems=inputs_tiled)\n\n # Begin: Routing算法\n # 将系数b初始化为0.\n # b.shape = [None, self.num_capsule, self, input_num_capsule].\n b = tf.zeros(shape=[K.shape(inputs_hat)[0], self.num_capsule, self.input_num_capsule])\n \n assert self.routings > 0, 'The routings should be > 0.'\n for i in range(self.routings):\n # c.shape=[None, num_capsule, input_num_capsule]\n C = tf.nn.softmax(b ,axis=1)\n # c.shape = [None, num_capsule, input_num_capsule]\n # inputs_hat.shape = [None, num_capsule, input_num_capsule, dim_capsule]\n # 将c与inputs_hat的前两个维度看作'batch'维度,向量和矩阵相乘:\n # [input_num_capsule] x [input_num_capsule, dim_capsule] -> [dim_capsule],\n # outputs.shape= [None, num_capsule, dim_capsule]\n outputs = squash(K. batch_dot(C, inputs_hat, [2, 2])) # [None, 10, 16]\n \n if i < self.routings - 1:\n # outputs.shape = [None, num_capsule, dim_capsule]\n # inputs_hat.shape = [None, num_capsule, input_num_capsule, dim_capsule]\n # 将outputs和inρuts_hat的前两个维度看作‘batch’ 维度,向量和矩阵相乘:\n # [dim_capsule] x [imput_num_capsule, dim_capsule]^T -> [input_num_capsule]\n # b.shape = [batch_size. num_capsule, input_nom_capsule]\n# b += K.batch_dot(outputs, inputs_hat, [2, 3]) to this b += tf.matmul(self.W, x)\n b += K.batch_dot(outputs, inputs_hat, [2, 3])\n\n # End: Routing 算法\n return outputs\n\n def compute_output_shape(self, input_shape):\n return tuple([None, self.num_capsule, self.dim_capsule])\n\n def get_config(self):\n config = {\n 'num_capsule': self.num_capsule,\n 'dim_capsule': self.dim_capsule,\n 'routings': self.routings\n }\n base_config = super(DenseCapsule, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))",
"_____no_output_____"
],
[
"from tensorflow import keras\nfrom keras.regularizers import l2#正则化\nx = layers.Input(shape=[512,1, 1])\n#普通卷积层\nconv1 = layers.Conv2D(filters=16, kernel_size=(2, 1),activation='relu',padding='valid',name='conv1')(x)\n#池化层\nPOOL1 = MaxPooling2D((2,1))(conv1)\n#普通卷积层\nconv2 = layers.Conv2D(filters=32, kernel_size=(2, 1),activation='relu',padding='valid',name='conv2')(POOL1)\n#池化层\n# POOL2 = MaxPooling2D((2,1))(conv2)\n#Dropout层\nDropout=layers.Dropout(0.1)(conv2)\n\n# Layer 3: 使用“squash”激活的Conv2D层, 然后重塑 [None, num_capsule, dim_vector]\nprimarycaps = PrimaryCap(Dropout, dim_capsule=8, n_channels=12, kernel_size=(4, 1), strides=2, padding='valid')\n# Layer 4: 数字胶囊层,动态路由算法在这里工作。\ndigitcaps = DenseCapsule(num_capsule=2, dim_capsule=16, routings=3, name='digit_caps')(primarycaps)\n# Layer 5:这是一个辅助层,用它的长度代替每个胶囊。只是为了符合标签的形状。\nout_caps = Length(name='out_caps')(digitcaps)\n\nmodel = keras.Model(x, out_caps) \nmodel.summary() ",
"WARNING:tensorflow:From E:\\anaconda0\\envs\\tf2.4\\lib\\site-packages\\tensorflow\\python\\util\\deprecation.py:605: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nUse fn_output_signature instead\nModel: \"model\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) [(None, 512, 1, 1)] 0 \n_________________________________________________________________\nconv1 (Conv2D) (None, 511, 1, 16) 48 \n_________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 255, 1, 16) 0 \n_________________________________________________________________\nconv2 (Conv2D) (None, 254, 1, 32) 1056 \n_________________________________________________________________\ndropout (Dropout) (None, 254, 1, 32) 0 \n_________________________________________________________________\nprimarycap_conv2d (Conv2D) (None, 126, 1, 96) 12384 \n_________________________________________________________________\nprimarycap_reshape (Reshape) (None, 1512, 8) 0 \n_________________________________________________________________\nprimarycap_squash (Lambda) (None, 1512, 8) 0 \n_________________________________________________________________\ndigit_caps (DenseCapsule) (None, 2, 16) 387072 \n_________________________________________________________________\nout_caps (Length) (None, 2) 0 \n=================================================================\nTotal params: 400,560\nTrainable params: 400,560\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"\n#定义优化\nmodel.compile(loss='categorical_crossentropy',\n optimizer='adam',metrics=['accuracy']) ",
"_____no_output_____"
],
[
"import time\ntime_begin = time.time()\nhistory = model.fit(x_train,one_hot_train_labels,\n validation_split=0.1,\n epochs=50,batch_size=10,\n shuffle=True)\ntime_end = time.time()\ntime = time_end - time_begin\nprint('time:', time)",
"Epoch 1/50\n19/19 [==============================] - 6s 178ms/step - loss: 0.6053 - accuracy: 0.5568 - val_loss: 0.6470 - val_accuracy: 0.2857\nEpoch 2/50\n19/19 [==============================] - 1s 47ms/step - loss: 0.4966 - accuracy: 0.4679 - val_loss: 0.5733 - val_accuracy: 0.2857\nEpoch 3/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.3563 - accuracy: 0.5554 - val_loss: 0.5250 - val_accuracy: 0.2857\nEpoch 4/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.3659 - accuracy: 0.5102 - val_loss: 0.5223 - val_accuracy: 0.2857\nEpoch 5/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.3518 - accuracy: 0.5419 - val_loss: 0.5190 - val_accuracy: 0.2857\nEpoch 6/50\n19/19 [==============================] - 1s 43ms/step - loss: 0.3537 - accuracy: 0.5720 - val_loss: 0.4982 - val_accuracy: 1.0000\nEpoch 7/50\n19/19 [==============================] - 1s 47ms/step - loss: 0.2991 - accuracy: 0.9870 - val_loss: 0.0931 - val_accuracy: 1.0000\nEpoch 8/50\n19/19 [==============================] - 1s 49ms/step - loss: 0.0615 - accuracy: 1.0000 - val_loss: 0.0810 - val_accuracy: 1.0000\nEpoch 9/50\n19/19 [==============================] - 1s 46ms/step - loss: 0.0437 - accuracy: 1.0000 - val_loss: 0.0318 - val_accuracy: 1.0000\nEpoch 10/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0161 - accuracy: 1.0000 - val_loss: 0.0165 - val_accuracy: 1.0000\nEpoch 11/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0083 - accuracy: 1.0000 - val_loss: 0.0164 - val_accuracy: 1.0000\nEpoch 12/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0071 - accuracy: 1.0000 - val_loss: 0.0142 - val_accuracy: 1.0000\nEpoch 13/50\n19/19 [==============================] - 1s 66ms/step - loss: 0.0035 - accuracy: 1.0000 - val_loss: 0.0135 - val_accuracy: 1.0000\nEpoch 14/50\n19/19 [==============================] - 1s 48ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.0135 - val_accuracy: 1.0000\nEpoch 15/50\n19/19 [==============================] - 1s 50ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.0130 - val_accuracy: 1.0000\nEpoch 16/50\n19/19 [==============================] - 1s 46ms/step - loss: 0.0022 - accuracy: 1.0000 - val_loss: 0.0134 - val_accuracy: 1.0000\nEpoch 17/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.0132 - val_accuracy: 1.0000\nEpoch 18/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.0020 - accuracy: 1.0000 - val_loss: 0.0140 - val_accuracy: 1.0000\nEpoch 19/50\n19/19 [==============================] - 1s 41ms/step - loss: 0.0018 - accuracy: 1.0000 - val_loss: 0.0126 - val_accuracy: 1.0000\nEpoch 20/50\n19/19 [==============================] - 1s 43ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 0.0135 - val_accuracy: 1.0000\nEpoch 21/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.0122 - val_accuracy: 1.0000\nEpoch 22/50\n19/19 [==============================] - 1s 40ms/step - loss: 0.0018 - accuracy: 1.0000 - val_loss: 0.0127 - val_accuracy: 1.0000\nEpoch 23/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.0122 - val_accuracy: 1.0000\nEpoch 24/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.0118 - val_accuracy: 1.0000\nEpoch 25/50\n19/19 [==============================] - 1s 42ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.0152 - val_accuracy: 1.0000\nEpoch 26/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.0117 - val_accuracy: 1.0000\nEpoch 27/50\n19/19 [==============================] - 1s 49ms/step - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.0114 - val_accuracy: 1.0000\nEpoch 28/50\n19/19 [==============================] - 1s 48ms/step - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.0116 - val_accuracy: 1.0000\nEpoch 29/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.0110 - val_accuracy: 1.0000\nEpoch 30/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.0115 - val_accuracy: 1.0000\nEpoch 31/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0012 - accuracy: 1.0000 - val_loss: 0.0112 - val_accuracy: 1.0000\nEpoch 32/50\n19/19 [==============================] - 1s 46ms/step - loss: 0.0012 - accuracy: 1.0000 - val_loss: 0.0104 - val_accuracy: 1.0000\nEpoch 33/50\n19/19 [==============================] - 1s 47ms/step - loss: 0.0013 - accuracy: 1.0000 - val_loss: 0.0106 - val_accuracy: 1.0000\nEpoch 34/50\n19/19 [==============================] - 1s 43ms/step - loss: 9.9523e-04 - accuracy: 1.0000 - val_loss: 0.0110 - val_accuracy: 1.0000\nEpoch 35/50\n19/19 [==============================] - 1s 45ms/step - loss: 8.8050e-04 - accuracy: 1.0000 - val_loss: 0.0102 - val_accuracy: 1.0000\nEpoch 36/50\n19/19 [==============================] - ETA: 0s - loss: 7.9550e-04 - accuracy: 1.00 - 1s 46ms/step - loss: 8.0370e-04 - accuracy: 1.0000 - val_loss: 0.0111 - val_accuracy: 1.0000\nEpoch 37/50\n19/19 [==============================] - 1s 45ms/step - loss: 0.0010 - accuracy: 1.0000 - val_loss: 0.0102 - val_accuracy: 1.0000\nEpoch 38/50\n19/19 [==============================] - 1s 41ms/step - loss: 9.3796e-04 - accuracy: 1.0000 - val_loss: 0.0103 - val_accuracy: 1.0000\nEpoch 39/50\n19/19 [==============================] - 1s 45ms/step - loss: 8.8606e-04 - accuracy: 1.0000 - val_loss: 0.0107 - val_accuracy: 1.0000\nEpoch 40/50\n19/19 [==============================] - 1s 46ms/step - loss: 9.2422e-04 - accuracy: 1.0000 - val_loss: 0.0100 - val_accuracy: 1.0000\nEpoch 41/50\n19/19 [==============================] - 1s 44ms/step - loss: 7.4755e-04 - accuracy: 1.0000 - val_loss: 0.0102 - val_accuracy: 1.0000\nEpoch 42/50\n19/19 [==============================] - 1s 43ms/step - loss: 7.9413e-04 - accuracy: 1.0000 - val_loss: 0.0108 - val_accuracy: 1.0000\nEpoch 43/50\n19/19 [==============================] - 1s 40ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 0.0094 - val_accuracy: 1.0000\nEpoch 44/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.0014 - accuracy: 1.0000 - val_loss: 0.0085 - val_accuracy: 1.0000\nEpoch 45/50\n19/19 [==============================] - 1s 43ms/step - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.0085 - val_accuracy: 1.0000\nEpoch 46/50\n19/19 [==============================] - 1s 44ms/step - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.0101 - val_accuracy: 1.0000\nEpoch 47/50\n19/19 [==============================] - 1s 43ms/step - loss: 9.5898e-04 - accuracy: 1.0000 - val_loss: 0.0092 - val_accuracy: 1.0000\nEpoch 48/50\n19/19 [==============================] - 1s 42ms/step - loss: 8.2625e-04 - accuracy: 1.0000 - val_loss: 0.0095 - val_accuracy: 1.0000\nEpoch 49/50\n19/19 [==============================] - 1s 41ms/step - loss: 7.3787e-04 - accuracy: 1.0000 - val_loss: 0.0089 - val_accuracy: 1.0000\nEpoch 50/50\n19/19 [==============================] - 1s 41ms/step - loss: 7.8074e-04 - accuracy: 1.0000 - val_loss: 0.0094 - val_accuracy: 1.0000\ntime: 47.84789800643921\n"
],
[
"import time\ntime_begin = time.time()\nscore = model.evaluate(x_test,one_hot_test_labels, verbose=0)\nprint('Test loss:', score[0])\nprint('Test accuracy:', score[1])\n \ntime_end = time.time()\ntime = time_end - time_begin\nprint('time:', time)",
"Test loss: 0.01700088381767273\nTest accuracy: 1.0\ntime: 0.11267662048339844\n"
],
[
"#绘制acc-loss曲线\nimport matplotlib.pyplot as plt\n\nplt.plot(history.history['loss'],color='r')\nplt.plot(history.history['val_loss'],color='g')\nplt.plot(history.history['accuracy'],color='b')\nplt.plot(history.history['val_accuracy'],color='k')\nplt.title('model loss and acc')\nplt.ylabel('Accuracy')\nplt.xlabel('epoch')\nplt.legend(['train_loss', 'test_loss','train_acc', 'test_acc'], loc='center right')\n# plt.legend(['train_loss','train_acc'], loc='upper left')\n#plt.savefig('1.png')\nplt.show()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nplt.plot(history.history['loss'],color='r')\nplt.plot(history.history['accuracy'],color='b')\nplt.title('model loss and sccuracy ')\nplt.ylabel('loss/sccuracy')\nplt.xlabel('epoch')\nplt.legend(['train_loss', 'train_sccuracy'], loc='center right')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02b4b80aaa3dfd94d768155eaeaff39b544c7b4
| 596,234 |
ipynb
|
Jupyter Notebook
|
preliminary-data-visualization.ipynb
|
argha48/nyc-parking-ticket
|
0e4a898931ce6dd920faeb1e94640fdae98d2969
|
[
"MIT"
] | 3 |
2017-11-30T03:22:31.000Z
|
2021-12-12T00:11:13.000Z
|
preliminary-data-visualization.ipynb
|
argha48/nyc-parking-ticket
|
0e4a898931ce6dd920faeb1e94640fdae98d2969
|
[
"MIT"
] | null | null | null |
preliminary-data-visualization.ipynb
|
argha48/nyc-parking-ticket
|
0e4a898931ce6dd920faeb1e94640fdae98d2969
|
[
"MIT"
] | null | null | null | 347.051222 | 75,190 | 0.912472 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set(color_codes=True)\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
],
[
"import os\ndestdir = '/Users/argha/Dropbox/CS/DatSci/nyc-data'\nfiles = [ f for f in os.listdir(destdir) if os.path.isfile(os.path.join(destdir,f)) ]",
"_____no_output_____"
],
[
"files",
"_____no_output_____"
],
[
"#df2014 = pd.read_csv('/Users/argha/Dropbox/CS/DatSci/nyc-data/Parking_Violations_Issued_-_Fiscal_Year_2014.csv')\n#df2015 = pd.read_csv('/Users/argha/Dropbox/CS/DatSci/nyc-data/Parking_Violations_Issued_-_Fiscal_Year_2015.csv')\ndf2016 = pd.read_csv('/Users/argha/Dropbox/CS/DatSci/nyc-data/Parking_Violations_Issued_-_Fiscal_Year_2016.csv')\n#df2017 = pd.read_csv('/Users/argha/Dropbox/CS/DatSci/nyc-data/Parking_Violations_Issued_-_Fiscal_Year_2017.csv')\n#df2018 = pd.read_csv('/Users/argha/Dropbox/CS/DatSci/nyc-data/Parking_Violations_Issued_-_Fiscal_Year_2018.csv')",
"/Users/argha/anaconda3/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2717: DtypeWarning: Columns (17,18,20,21,22,23,29,30,31,32,34,36,38,39) have mixed types. Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
]
],
[
[
"## Take a look into the 2016 data",
"_____no_output_____"
]
],
[
[
"df2016.head(n=2)",
"_____no_output_____"
],
[
"df2016.shape",
"_____no_output_____"
]
],
[
[
"So in the 2016 dataset there are about 10.6 million entries for parking ticket, and each entry has 51 columns.\n\nLets take a look at the number of unique values for each column name...",
"_____no_output_____"
]
],
[
[
"d = {'Unique Entry': df2016.nunique(axis = 0),\n 'Nan Entry': df2016.isnull().any()}\npd.DataFrame(data = d, index = df2016.columns.values)",
"_____no_output_____"
]
],
[
[
"As it turns out, the last 11 columns in this dataset has no entry. So we can ignore those columns, while carrying out any visualization operation in this dataframe.\n\nAlso if the entry does not have a **Plate ID** it is very hard to locate those cars. Therefore I am going to drop those rows as well.",
"_____no_output_____"
]
],
[
[
"drop_column = ['No Standing or Stopping Violation', 'Hydrant Violation',\n 'Double Parking Violation', 'Latitude', 'Longitude',\n 'Community Board', 'Community Council ', 'Census Tract', 'BIN',\n 'BBL', 'NTA',\n 'Street Code1', 'Street Code2', 'Street Code3','Meter Number', 'Violation Post Code',\n 'Law Section', 'Sub Division', 'House Number', 'Street Name']\ndf2016.drop(drop_column, axis = 1, inplace = True)",
"_____no_output_____"
],
[
"drop_row = ['Plate ID']\ndf2016.dropna(axis = 0, how = 'any', subset = drop_row, inplace = True)",
"_____no_output_____"
]
],
[
[
"Check if there is anymore rows left without a **Plate ID**.",
"_____no_output_____"
]
],
[
[
"df2016['Plate ID'].isnull().any()",
"_____no_output_____"
],
[
"df2016.shape",
"_____no_output_____"
]
],
[
[
"# Create a sample data for visualization",
"_____no_output_____"
],
[
"The cleaned dataframe has 10624735 rows and 40 columns. \n\nBut this is still a lot of data points. I does not make sense to use all of them to get an idea of distribution of the data points. So for visualization I will use only 0.1% of the whole data. Assmuing that the entries are not sorted I pick my 0.1% data points from the main dataframe at random.",
"_____no_output_____"
]
],
[
[
"mini2016 = df2016.sample(frac = 0.01, replace = False)",
"_____no_output_____"
],
[
"mini2016.shape",
"_____no_output_____"
]
],
[
[
"My sample dataset has about 10K data points, which I will use for data visualization. Using the whole dataset is unnecessary and time consuming.",
"_____no_output_____"
],
[
"## Barplot of 'Registration State'",
"_____no_output_____"
]
],
[
[
"x_ticks = mini2016['Registration State'].value_counts().index\nheights = mini2016['Registration State'].value_counts()\ny_pos = np.arange(len(x_ticks))\nfig = plt.figure(figsize=(15,14)) \n# Create horizontal bars\nplt.barh(y_pos, heights)\n \n# Create names on the y-axis\nplt.yticks(y_pos, x_ticks)\n \n# Show graphic\nplt.show()\n",
"_____no_output_____"
],
[
"pd.DataFrame(mini2016['Registration State'].value_counts()/len(mini2016)).nlargest(10, columns = ['Registration State'])",
"_____no_output_____"
]
],
[
[
"You can see from the barplot above: in our sample ~77.67% cars are registered in state : **NY**. After that 9.15% cars are registered in state : **NJ**, followed by **PA**, **CT**, and **FL**.",
"_____no_output_____"
],
[
"## How the number of tickets given changes with each month?",
"_____no_output_____"
]
],
[
[
"month = []\nfor time_stamp in pd.to_datetime(mini2016['Issue Date']):\n month.append(time_stamp.month)\nm_count = pd.Series(month).value_counts()\n\nplt.figure(figsize=(12,8))\nsns.barplot(y=m_count.values, x=m_count.index, alpha=0.6)\nplt.title(\"Number of Parking Ticket Given Each Month\", fontsize=16)\nplt.xlabel(\"Month\", fontsize=16)\nplt.ylabel(\"No. of cars\", fontsize=16)\nplt.show();",
"_____no_output_____"
]
],
[
[
"So from the barplot above **March** and **October** has the highest number of tickets!",
"_____no_output_____"
],
[
"## How many parking tickets are given for each violation code?",
"_____no_output_____"
]
],
[
[
"violation_code = mini2016['Violation Code'].value_counts()\n\nplt.figure(figsize=(16,8))\nf = sns.barplot(y=violation_code.values, x=violation_code.index, alpha=0.6)\n#plt.xticks(np.arange(0,101, 10.0))\nf.set(xticks=np.arange(0,100, 5.0))\nplt.title(\"Number of Parking Tickets Given for Each Violation Code\", fontsize=16)\nplt.xlabel(\"Violation Code [ X5 ]\", fontsize=16)\nplt.ylabel(\"No. of cars\", fontsize=16)\nplt.show();",
"_____no_output_____"
]
],
[
[
"## How many parking tickets are given for each body type?",
"_____no_output_____"
]
],
[
[
"x_ticks = mini2016['Vehicle Body Type'].value_counts().index\nheights = mini2016['Vehicle Body Type'].value_counts().values\ny_pos = np.arange(len(x_ticks))\nfig = plt.figure(figsize=(15,4))\nf = sns.barplot(y=heights, x=y_pos, orient = 'v', alpha=0.6);\n# remove labels\nplt.tick_params(labelbottom='off')\nplt.ylabel('No. of cars', fontsize=16);\nplt.xlabel('Car models [Label turned off due to crowding. Too many types.]', fontsize=16);\nplt.title('Parking ticket given for different type of car body', fontsize=16);\n",
"_____no_output_____"
],
[
"df_bodytype = pd.DataFrame(mini2016['Vehicle Body Type'].value_counts() / len(mini2016)).nlargest(10, columns = ['Vehicle Body Type'])",
"_____no_output_____"
]
],
[
[
"Top 10 car body types that get the most parking tickets are listed below : ",
"_____no_output_____"
]
],
[
[
"df_bodytype",
"_____no_output_____"
],
[
"df_bodytype.sum(axis = 0)/len(mini2016)",
"_____no_output_____"
]
],
[
[
"Top 10 vehicle body type includes 93.42% of my sample dataset.",
"_____no_output_____"
],
[
"## How many parking tickets are given for each vehicle make?",
"_____no_output_____"
],
[
"Just for the sake of changing the flavor of visualization this time I will make a logplot of car no. vs make. In that case we will be able to see much smaller values in the same graph with larger values.",
"_____no_output_____"
]
],
[
[
"vehicle_make = mini2016['Vehicle Make'].value_counts()\n\nplt.figure(figsize=(16,8))\nf = sns.barplot(y=np.log(vehicle_make.values), x=vehicle_make.index, alpha=0.6)\n# remove labels\nplt.tick_params(labelbottom='off')\nplt.ylabel('log(No. of cars)', fontsize=16);\nplt.xlabel('Car make [Label turned off due to crowding. Too many companies!]', fontsize=16);\nplt.title('Parking ticket given for different type of car make', fontsize=16);\n\nplt.show();",
"_____no_output_____"
],
[
"pd.DataFrame(mini2016['Vehicle Make'].value_counts() / len(mini2016)).nlargest(10, columns = ['Vehicle Make'])",
"_____no_output_____"
]
],
[
[
"## Insight on violation time",
"_____no_output_____"
],
[
"In the raw data the **Violaation Time** is in a format, which is non-interpretable using standard **to_datatime** function in pandas. We need to change it in a useful format so that we can use the data. After formatting we may replace the old **Violation Time ** column with the new one.",
"_____no_output_____"
]
],
[
[
"timestamp = []\nfor time in mini2016['Violation Time']:\n if len(str(time)) == 5:\n time = time[:2] + ':' + time[2:]\n timestamp.append(pd.to_datetime(time, errors='coerce'))\n else:\n timestamp.append(pd.NaT)\n \n\nmini2016 = mini2016.assign(Violation_Time2 = timestamp)\nmini2016.drop(['Violation Time'], axis = 1, inplace = True)\nmini2016.rename(index=str, columns={\"Violation_Time2\": \"Violation Time\"}, inplace = True)",
"_____no_output_____"
]
],
[
[
"So in the new **Violation Time** column the data is in **Timestamp** format.",
"_____no_output_____"
]
],
[
[
"hours = [lambda x: x.hour, mini2016['Violation Time']]",
"_____no_output_____"
],
[
"# Getting the histogram\nmini2016.set_index('Violation Time', drop=False, inplace=True)\nplt.figure(figsize=(16,8))\nmini2016['Violation Time'].groupby(pd.TimeGrouper(freq='30Min')).count().plot(kind='bar');\nplt.tick_params(labelbottom='on')\nplt.ylabel('No. of cars', fontsize=16);\nplt.xlabel('Day Time', fontsize=16);\nplt.title('Parking ticket given at different time of the day', fontsize=16);\n",
"_____no_output_____"
]
],
[
[
"## Parking ticket vs county",
"_____no_output_____"
]
],
[
[
"violation_county = mini2016['Violation County'].value_counts()\n\nplt.figure(figsize=(16,8))\nf = sns.barplot(y=violation_county.values, x=violation_county.index, alpha=0.6)\n# remove labels\nplt.tick_params(labelbottom='on')\nplt.ylabel('No. of cars', fontsize=16);\nplt.xlabel('County', fontsize=16);\nplt.title('Parking ticket given in different counties', fontsize=16);",
"_____no_output_____"
]
],
[
[
"## Unregistered Vehicle?",
"_____no_output_____"
]
],
[
[
"sns.countplot(x = 'Unregistered Vehicle?', data = mini2016)",
"_____no_output_____"
],
[
"mini2016['Unregistered Vehicle?'].unique()",
"_____no_output_____"
]
],
[
[
"## Vehicle Year",
"_____no_output_____"
]
],
[
[
"pd.DataFrame(mini2016['Vehicle Year'].value_counts()).nlargest(10, columns = ['Vehicle Year'])",
"_____no_output_____"
],
[
"plt.figure(figsize=(20,8))\nsns.countplot(x = 'Vehicle Year', data = mini2016.loc[(mini2016['Vehicle Year']>1980) & (mini2016['Vehicle Year'] <= 2018)]);",
"_____no_output_____"
]
],
[
[
"## Violation In Front Of Or Opposite",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(16,8))\nsns.countplot(x = 'Violation In Front Of Or Opposite', data = mini2016);",
"_____no_output_____"
],
[
"# create data\nnames = mini2016['Violation In Front Of Or Opposite'].value_counts().index\nsize = mini2016['Violation In Front Of Or Opposite'].value_counts().values\n \n# Create a circle for the center of the plot\nmy_circle=plt.Circle( (0,0), 0.7, color='white')\nplt.figure(figsize=(8,8))\nfrom palettable.colorbrewer.qualitative import Pastel1_7\nplt.pie(size, labels=names, colors=Pastel1_7.hex_colors)\np=plt.gcf()\np.gca().add_artist(my_circle)\nplt.show()\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02b6bebce3664d764241c5971dd964f40428052
| 8,183 |
ipynb
|
Jupyter Notebook
|
legacy/arkady TF legacy/TF_2019_course2_week3_knowledge_transfer_001.ipynb
|
21kc-caracol/Acoustic_data_Image_vs_Mean
|
96801c0dd5c47859086c8b6f145a61333575d9b6
|
[
"MIT"
] | 1 |
2020-10-23T06:02:41.000Z
|
2020-10-23T06:02:41.000Z
|
legacy/arkady TF legacy/TF_2019_course2_week3_knowledge_transfer_001.ipynb
|
21kc-caracol/Acoustic_data_Image_vs_Mean
|
96801c0dd5c47859086c8b6f145a61333575d9b6
|
[
"MIT"
] | null | null | null |
legacy/arkady TF legacy/TF_2019_course2_week3_knowledge_transfer_001.ipynb
|
21kc-caracol/Acoustic_data_Image_vs_Mean
|
96801c0dd5c47859086c8b6f145a61333575d9b6
|
[
"MIT"
] | null | null | null | 35.120172 | 119 | 0.535867 |
[
[
[
"import os\n\nfrom tensorflow.keras import layers\nfrom tensorflow.keras import Model\n\nfrom tensorflow.keras.applications.inception_v3 import InceptionV3\n",
"_____no_output_____"
],
[
"#!wget --no-check-certificate \\\n# https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \\\n# -O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5\n \nroot = r'D:\\Users\\Arkady\\Verint\\Coursera_2019_Tensorflow_Specialization\\Course2_CNN_in_TF'\nlocal_weights_file = root + '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'\n\npre_trained_model = InceptionV3(input_shape = (150, 150, 3), \n include_top = False, \n weights = None)\n\npre_trained_model.load_weights(local_weights_file)\n\nfor layer in pre_trained_model.layers:\n layer.trainable = False\n \n# pre_trained_model.summary()\n\nlast_layer = pre_trained_model.get_layer('mixed7')\nprint('last layer output shape: ', last_layer.output_shape)\nlast_output = last_layer.output",
"last layer output shape: (None, 7, 7, 768)\n"
],
[
"from tensorflow.keras.optimizers import RMSprop\n\n# Flatten the output layer to 1 dimension\nx = layers.Flatten()(last_output)\n# Add a fully connected layer with 1,024 hidden units and ReLU activation\nx = layers.Dense(1024, activation='relu')(x)\n# Add a dropout rate of 0.2\nx = layers.Dropout(0.2)(x) \n# Add a final sigmoid layer for classification\nx = layers.Dense (1, activation='sigmoid')(x) \n\nmodel = Model( pre_trained_model.input, x) \n\nmodel.compile(optimizer = RMSprop(lr=0.0001), \n loss = 'binary_crossentropy', \n metrics = ['acc'])",
"_____no_output_____"
],
[
"#!wget --no-check-certificate \\\n# https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \\\n# -O /tmp/cats_and_dogs_filtered.zip\n\nfrom tensorflow.keras.preprocessing.image import ImageDataGenerator\n\nimport os\nimport zipfile\n\n#local_zip = '//tmp/cats_and_dogs_filtered.zip'\n#zip_ref = zipfile.ZipFile(local_zip, 'r')\n#zip_ref.extractall('/tmp')\n#zip_ref.close()\n\n# Define our example directories and files\nbase_dir = root + '/tmp/cats_and_dogs_filtered'\n\ntrain_dir = os.path.join( base_dir, 'train')\nvalidation_dir = os.path.join( base_dir, 'validation')\n\n\ntrain_cats_dir = os.path.join(train_dir, 'cats') # Directory with our training cat pictures\ntrain_dogs_dir = os.path.join(train_dir, 'dogs') # Directory with our training dog pictures\nvalidation_cats_dir = os.path.join(validation_dir, 'cats') # Directory with our validation cat pictures\nvalidation_dogs_dir = os.path.join(validation_dir, 'dogs')# Directory with our validation dog pictures\n\ntrain_cat_fnames = os.listdir(train_cats_dir)\ntrain_dog_fnames = os.listdir(train_dogs_dir)\n\n# Add our data-augmentation parameters to ImageDataGenerator\ntrain_datagen = ImageDataGenerator(rescale = 1./255.,\n rotation_range = 40,\n width_shift_range = 0.2,\n height_shift_range = 0.2,\n shear_range = 0.2,\n zoom_range = 0.2,\n horizontal_flip = True)\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator( rescale = 1.0/255. )\n\n# Flow training images in batches of 20 using train_datagen generator\ntrain_generator = train_datagen.flow_from_directory(train_dir,\n batch_size = 20,\n class_mode = 'binary', \n target_size = (150, 150)) \n\n# Flow validation images in batches of 20 using test_datagen generator\nvalidation_generator = test_datagen.flow_from_directory( validation_dir,\n batch_size = 20,\n class_mode = 'binary', \n target_size = (150, 150))",
"Found 2000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\n"
],
[
"history = model.fit_generator(\n train_generator,\n validation_data = validation_generator,\n steps_per_epoch = 100,\n epochs = 20,\n validation_steps = 50,\n verbose = 2)",
"Epoch 1/20\n100/100 - 371s - loss: 0.4893 - acc: 0.7690 - val_loss: 0.1920 - val_acc: 0.9360\nEpoch 2/20\n100/100 - 363s - loss: 0.3755 - acc: 0.8320 - val_loss: 0.2265 - val_acc: 0.9380\nEpoch 3/20\n100/100 - 367s - loss: 0.3416 - acc: 0.8525 - val_loss: 0.2116 - val_acc: 0.9550\nEpoch 4/20\n100/100 - 369s - loss: 0.2996 - acc: 0.8740 - val_loss: 0.2312 - val_acc: 0.9550\nEpoch 5/20\n100/100 - 369s - loss: 0.3111 - acc: 0.8770 - val_loss: 0.3894 - val_acc: 0.9320\nEpoch 6/20\n100/100 - 389s - loss: 0.2868 - acc: 0.8820 - val_loss: 0.2621 - val_acc: 0.9560\nEpoch 7/20\n100/100 - 381s - loss: 0.3061 - acc: 0.8680 - val_loss: 0.3229 - val_acc: 0.9450\nEpoch 8/20\n100/100 - 373s - loss: 0.2968 - acc: 0.8760 - val_loss: 0.3389 - val_acc: 0.9420\nEpoch 9/20\n"
],
[
"import matplotlib.pyplot as plt\nacc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'r', label='Training accuracy')\nplt.plot(epochs, val_acc, 'b', label='Validation accuracy')\nplt.title('Training and validation accuracy')\nplt.legend(loc=0)\nplt.figure()\n\n\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02b916322f11846b77152c743e24ac2bb319bac
| 33,900 |
ipynb
|
Jupyter Notebook
|
Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb
|
gantz-at-incomm/tigertoolbox
|
9ea80d39a3c5e0c77553fc851c5ee787fbf9291d
|
[
"MIT"
] | 541 |
2019-05-07T11:41:25.000Z
|
2022-03-29T17:33:19.000Z
|
Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb
|
gantz-at-incomm/tigertoolbox
|
9ea80d39a3c5e0c77553fc851c5ee787fbf9291d
|
[
"MIT"
] | 89 |
2019-05-09T14:23:52.000Z
|
2022-01-13T20:21:04.000Z
|
Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb
|
gantz-at-incomm/tigertoolbox
|
9ea80d39a3c5e0c77553fc851c5ee787fbf9291d
|
[
"MIT"
] | 338 |
2019-05-08T05:45:16.000Z
|
2022-03-28T15:35:03.000Z
| 48.085106 | 520 | 0.424218 |
[
[
[
"CER041 - Install signed Knox certificate\n========================================\n\nThis notebook installs into the Big Data Cluster the certificate signed\nusing:\n\n- [CER031 - Sign Knox certificate with generated\n CA](../cert-management/cer031-sign-knox-generated-cert.ipynb)\n\nSteps\n-----\n\n### Parameters",
"_____no_output_____"
]
],
[
[
"app_name = \"gateway\"\nscaledset_name = \"gateway/pods/gateway-0\"\ncontainer_name = \"knox\"\nprefix_keyfile_name = \"knox\"\ncommon_name = \"gateway-svc\"\n\ntest_cert_store_root = \"/var/opt/secrets/test-certificates\"",
"_____no_output_____"
]
],
[
[
"### Common functions\n\nDefine helper functions used in this notebook.",
"_____no_output_____"
]
],
[
[
"# Define `run` function for transient fault handling, suggestions on error, and scrolling updates on Windows\nimport sys\nimport os\nimport re\nimport json\nimport platform\nimport shlex\nimport shutil\nimport datetime\n\nfrom subprocess import Popen, PIPE\nfrom IPython.display import Markdown\n\nretry_hints = {}\nerror_hints = {}\ninstall_hint = {}\n\nfirst_run = True\nrules = None\n\ndef run(cmd, return_output=False, no_output=False, retry_count=0):\n \"\"\"\n Run shell command, stream stdout, print stderr and optionally return output\n \"\"\"\n MAX_RETRIES = 5\n output = \"\"\n retry = False\n\n global first_run\n global rules\n\n if first_run:\n first_run = False\n rules = load_rules()\n\n # shlex.split is required on bash and for Windows paths with spaces\n #\n cmd_actual = shlex.split(cmd)\n\n # Store this (i.e. kubectl, python etc.) to support binary context aware error_hints and retries\n #\n user_provided_exe_name = cmd_actual[0].lower()\n\n # When running python, use the python in the ADS sandbox ({sys.executable})\n #\n if cmd.startswith(\"python \"):\n cmd_actual[0] = cmd_actual[0].replace(\"python\", sys.executable)\n\n # On Mac, when ADS is not launched from terminal, LC_ALL may not be set, which causes pip installs to fail\n # with:\n #\n # UnicodeDecodeError: 'ascii' codec can't decode byte 0xc5 in position 4969: ordinal not in range(128)\n #\n # Setting it to a default value of \"en_US.UTF-8\" enables pip install to complete\n #\n if platform.system() == \"Darwin\" and \"LC_ALL\" not in os.environ:\n os.environ[\"LC_ALL\"] = \"en_US.UTF-8\"\n\n # To aid supportabilty, determine which binary file will actually be executed on the machine\n #\n which_binary = None\n\n # Special case for CURL on Windows. The version of CURL in Windows System32 does not work to\n # get JWT tokens, it returns \"(56) Failure when receiving data from the peer\". If another instance\n # of CURL exists on the machine use that one. (Unfortunately the curl.exe in System32 is almost\n # always the first curl.exe in the path, and it can't be uninstalled from System32, so here we\n # look for the 2nd installation of CURL in the path)\n if platform.system() == \"Windows\" and cmd.startswith(\"curl \"):\n path = os.getenv('PATH')\n for p in path.split(os.path.pathsep):\n p = os.path.join(p, \"curl.exe\")\n if os.path.exists(p) and os.access(p, os.X_OK):\n if p.lower().find(\"system32\") == -1:\n cmd_actual[0] = p\n which_binary = p\n break\n\n # Find the path based location (shutil.which) of the executable that will be run (and display it to aid supportability), this\n # seems to be required for .msi installs of azdata.cmd/az.cmd. (otherwise Popen returns FileNotFound) \n #\n # NOTE: Bash needs cmd to be the list of the space separated values hence shlex.split.\n #\n if which_binary == None:\n which_binary = shutil.which(cmd_actual[0])\n\n if which_binary == None:\n if user_provided_exe_name in install_hint and install_hint[user_provided_exe_name] is not None:\n display(Markdown(f'HINT: Use [{install_hint[user_provided_exe_name][0]}]({install_hint[user_provided_exe_name][1]}) to resolve this issue.'))\n\n raise FileNotFoundError(f\"Executable '{cmd_actual[0]}' not found in path (where/which)\")\n else: \n cmd_actual[0] = which_binary\n\n start_time = datetime.datetime.now().replace(microsecond=0)\n\n print(f\"START: {cmd} @ {start_time} ({datetime.datetime.utcnow().replace(microsecond=0)} UTC)\")\n print(f\" using: {which_binary} ({platform.system()} {platform.release()} on {platform.machine()})\")\n print(f\" cwd: {os.getcwd()}\")\n\n # Command-line tools such as CURL and AZDATA HDFS commands output\n # scrolling progress bars, which causes Jupyter to hang forever, to\n # workaround this, use no_output=True\n #\n\n # Work around a infinite hang when a notebook generates a non-zero return code, break out, and do not wait\n #\n wait = True \n\n try:\n if no_output:\n p = Popen(cmd_actual)\n else:\n p = Popen(cmd_actual, stdout=PIPE, stderr=PIPE, bufsize=1)\n with p.stdout:\n for line in iter(p.stdout.readline, b''):\n line = line.decode()\n if return_output:\n output = output + line\n else:\n if cmd.startswith(\"azdata notebook run\"): # Hyperlink the .ipynb file\n regex = re.compile(' \"(.*)\"\\: \"(.*)\"') \n match = regex.match(line)\n if match:\n if match.group(1).find(\"HTML\") != -1:\n display(Markdown(f' - \"{match.group(1)}\": \"{match.group(2)}\"'))\n else:\n display(Markdown(f' - \"{match.group(1)}\": \"[{match.group(2)}]({match.group(2)})\"'))\n\n wait = False\n break # otherwise infinite hang, have not worked out why yet.\n else:\n print(line, end='')\n if rules is not None:\n apply_expert_rules(line)\n\n if wait:\n p.wait()\n except FileNotFoundError as e:\n if install_hint is not None:\n display(Markdown(f'HINT: Use {install_hint} to resolve this issue.'))\n\n raise FileNotFoundError(f\"Executable '{cmd_actual[0]}' not found in path (where/which)\") from e\n\n exit_code_workaround = 0 # WORKAROUND: azdata hangs on exception from notebook on p.wait()\n\n if not no_output:\n for line in iter(p.stderr.readline, b''):\n line_decoded = line.decode()\n\n # azdata emits a single empty line to stderr when doing an hdfs cp, don't\n # print this empty \"ERR:\" as it confuses.\n #\n if line_decoded == \"\":\n continue\n \n print(f\"STDERR: {line_decoded}\", end='')\n\n if line_decoded.startswith(\"An exception has occurred\") or line_decoded.startswith(\"ERROR: An error occurred while executing the following cell\"):\n exit_code_workaround = 1\n\n if user_provided_exe_name in error_hints:\n for error_hint in error_hints[user_provided_exe_name]:\n if line_decoded.find(error_hint[0]) != -1:\n display(Markdown(f'HINT: Use [{error_hint[1]}]({error_hint[2]}) to resolve this issue.'))\n\n if rules is not None:\n apply_expert_rules(line_decoded)\n\n if user_provided_exe_name in retry_hints:\n for retry_hint in retry_hints[user_provided_exe_name]:\n if line_decoded.find(retry_hint) != -1:\n if retry_count < MAX_RETRIES:\n print(f\"RETRY: {retry_count} (due to: {retry_hint})\")\n retry_count = retry_count + 1\n output = run(cmd, return_output=return_output, retry_count=retry_count)\n\n if return_output:\n return output\n else:\n return\n\n elapsed = datetime.datetime.now().replace(microsecond=0) - start_time\n\n # WORKAROUND: We avoid infinite hang above in the `azdata notebook run` failure case, by inferring success (from stdout output), so\n # don't wait here, if success known above\n #\n if wait: \n if p.returncode != 0:\n raise SystemExit(f'Shell command:\\n\\n\\t{cmd} ({elapsed}s elapsed)\\n\\nreturned non-zero exit code: {str(p.returncode)}.\\n')\n else:\n if exit_code_workaround !=0 :\n raise SystemExit(f'Shell command:\\n\\n\\t{cmd} ({elapsed}s elapsed)\\n\\nreturned non-zero exit code: {str(exit_code_workaround)}.\\n')\n\n\n print(f'\\nSUCCESS: {elapsed}s elapsed.\\n')\n\n if return_output:\n return output\n\ndef load_json(filename):\n with open(filename, encoding=\"utf8\") as json_file:\n return json.load(json_file)\n\ndef load_rules():\n\n try:\n\n # Load this notebook as json to get access to the expert rules in the notebook metadata.\n #\n j = load_json(\"cer041-install-knox-cert.ipynb\")\n\n except:\n pass # If the user has renamed the book, we can't load ourself. NOTE: Is there a way in Jupyter, to know your own filename?\n\n else:\n if \"metadata\" in j and \\\n \"azdata\" in j[\"metadata\"] and \\\n \"expert\" in j[\"metadata\"][\"azdata\"] and \\\n \"rules\" in j[\"metadata\"][\"azdata\"][\"expert\"]:\n\n rules = j[\"metadata\"][\"azdata\"][\"expert\"][\"rules\"]\n\n rules.sort() # Sort rules, so they run in priority order (the [0] element). Lowest value first.\n\n # print (f\"EXPERT: There are {len(rules)} rules to evaluate.\")\n\n return rules\n\ndef apply_expert_rules(line):\n\n global rules\n\n for rule in rules:\n\n # rules that have 9 elements are the injected (output) rules (the ones we want). Rules\n # with only 8 elements are the source (input) rules, which are not expanded (i.e. TSG029,\n # not ../repair/tsg029-nb-name.ipynb)\n if len(rule) == 9:\n notebook = rule[1]\n cell_type = rule[2]\n output_type = rule[3] # i.e. stream or error\n output_type_name = rule[4] # i.e. ename or name \n output_type_value = rule[5] # i.e. SystemExit or stdout\n details_name = rule[6] # i.e. evalue or text \n expression = rule[7].replace(\"\\\\*\", \"*\") # Something escaped *, and put a \\ in front of it!\n\n # print(f\"EXPERT: If rule '{expression}' satisfied', run '{notebook}'.\")\n\n if re.match(expression, line, re.DOTALL):\n\n # print(\"EXPERT: MATCH: name = value: '{0}' = '{1}' matched expression '{2}', therefore HINT '{4}'\".format(output_type_name, output_type_value, expression, notebook))\n\n match_found = True\n\n display(Markdown(f'HINT: Use [{notebook}]({notebook}) to resolve this issue.'))\n\n\n\nprint('Common functions defined successfully.')\n\n# Hints for binary (transient fault) retry, (known) error and install guide\n#\nretry_hints = {'kubectl': ['A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond']}\nerror_hints = {'kubectl': [['no such host', 'TSG010 - Get configuration contexts', '../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb'], ['no such host', 'TSG011 - Restart sparkhistory server', '../repair/tsg011-restart-sparkhistory-server.ipynb'], ['No connection could be made because the target machine actively refused it', 'TSG056 - Kubectl fails with No connection could be made because the target machine actively refused it', '../repair/tsg056-kubectl-no-connection-could-be-made.ipynb']]}\ninstall_hint = {'kubectl': ['SOP036 - Install kubectl command line interface', '../install/sop036-install-kubectl.ipynb']}",
"_____no_output_____"
]
],
[
[
"### Get the Kubernetes namespace for the big data cluster\n\nGet the namespace of the big data cluster use the kubectl command line\ninterface .\n\nNOTE: If there is more than one big data cluster in the target\nKubernetes cluster, then set \\[0\\] to the correct value for the big data\ncluster.",
"_____no_output_____"
]
],
[
[
"# Place Kubernetes namespace name for BDC into 'namespace' variable\n\ntry:\n namespace = run(f'kubectl get namespace --selector=MSSQL_CLUSTER -o jsonpath={{.items[0].metadata.name}}', return_output=True)\nexcept:\n from IPython.display import Markdown\n print(f\"ERROR: Unable to find a Kubernetes namespace with label 'MSSQL_CLUSTER'. SQL Server Big Data Cluster Kubernetes namespaces contain the label 'MSSQL_CLUSTER'.\")\n display(Markdown(f'HINT: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))\n display(Markdown(f'HINT: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))\n display(Markdown(f'HINT: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))\n raise\nelse:\n print(f'The SQL Server Big Data Cluster Kubernetes namespace is: {namespace}')",
"_____no_output_____"
]
],
[
[
"### Create a temporary directory to stage files",
"_____no_output_____"
]
],
[
[
"# Create a temporary directory to hold configuration files\n\nimport tempfile\n\ntemp_dir = tempfile.mkdtemp()\n\nprint(f\"Temporary directory created: {temp_dir}\")",
"_____no_output_____"
]
],
[
[
"### Helper function to save configuration files to disk",
"_____no_output_____"
]
],
[
[
"# Define helper function 'save_file' to save configuration files to the temporary directory created above\nimport os\nimport io\n\ndef save_file(filename, contents):\n with io.open(os.path.join(temp_dir, filename), \"w\", encoding='utf8', newline='\\n') as text_file:\n text_file.write(contents)\n\n print(\"File saved: \" + os.path.join(temp_dir, filename))",
"_____no_output_____"
]
],
[
[
"### Get name of the ‘Running’ `controller` `pod`",
"_____no_output_____"
]
],
[
[
"# Place the name of the 'Running' controller pod in variable `controller`\n\ncontroller = run(f'kubectl get pod --selector=app=controller -n {namespace} -o jsonpath={{.items[0].metadata.name}} --field-selector=status.phase=Running', return_output=True)\n\nprint(f\"Controller pod name: {controller}\")",
"_____no_output_____"
]
],
[
[
"### Pod name for gateway",
"_____no_output_____"
]
],
[
[
"pod = 'gateway-0'",
"_____no_output_____"
]
],
[
[
"### Copy certifcate files from `controller` to local machine",
"_____no_output_____"
]
],
[
[
"import os\n\ncwd = os.getcwd()\nos.chdir(temp_dir) # Use chdir to workaround kubectl bug on Windows, which incorrectly processes 'c:\\' on kubectl cp cmd line \n\nrun(f'kubectl cp {controller}:{test_cert_store_root}/{app_name}/{prefix_keyfile_name}-certificate.pem {prefix_keyfile_name}-certificate.pem -c controller -n {namespace}')\nrun(f'kubectl cp {controller}:{test_cert_store_root}/{app_name}/{prefix_keyfile_name}-privatekey.pem {prefix_keyfile_name}-privatekey.pem -c controller -n {namespace}')\n\nos.chdir(cwd)",
"_____no_output_____"
]
],
[
[
"### Copy certifcate files from local machine to `controldb`",
"_____no_output_____"
]
],
[
[
"import os\n\ncwd = os.getcwd()\nos.chdir(temp_dir) # Workaround kubectl bug on Windows, can't put c:\\ on kubectl cp cmd line \n\nrun(f'kubectl cp {prefix_keyfile_name}-certificate.pem controldb-0:/var/opt/mssql/{prefix_keyfile_name}-certificate.pem -c mssql-server -n {namespace}')\nrun(f'kubectl cp {prefix_keyfile_name}-privatekey.pem controldb-0:/var/opt/mssql/{prefix_keyfile_name}-privatekey.pem -c mssql-server -n {namespace}')\n\nos.chdir(cwd)",
"_____no_output_____"
]
],
[
[
"### Get the `controller-db-rw-secret` secret\n\nGet the controller SQL symmetric key password for decryption.",
"_____no_output_____"
]
],
[
[
"import base64\n\ncontroller_db_rw_secret = run(f'kubectl get secret/controller-db-rw-secret -n {namespace} -o jsonpath={{.data.encryptionPassword}}', return_output=True)\ncontroller_db_rw_secret = base64.b64decode(controller_db_rw_secret).decode('utf-8')\n\nprint(\"controller_db_rw_secret retrieved\")",
"_____no_output_____"
]
],
[
[
"### Update the files table with the certificates through opened SQL connection",
"_____no_output_____"
]
],
[
[
"import os\n\nsql = f\"\"\"\nOPEN SYMMETRIC KEY ControllerDbSymmetricKey DECRYPTION BY PASSWORD = '{controller_db_rw_secret}'\n\nDECLARE @FileData VARBINARY(MAX), @Key uniqueidentifier;\nSELECT @Key = KEY_GUID('ControllerDbSymmetricKey');\n \nSELECT TOP 1 @FileData = doc.BulkColumn FROM OPENROWSET(BULK N'/var/opt/mssql/{prefix_keyfile_name}-certificate.pem', SINGLE_BLOB) AS doc;\nEXEC [dbo].[sp_set_file_data_encrypted] @FilePath = '/config/scaledsets/{scaledset_name}/containers/{container_name}/files/{prefix_keyfile_name}-certificate.pem',\n @Data = @FileData,\n @KeyGuid = @Key,\n @Version = '0',\n @User = '',\n @Group = '',\n @Mode = '';\n\nSELECT TOP 1 @FileData = doc.BulkColumn FROM OPENROWSET(BULK N'/var/opt/mssql/{prefix_keyfile_name}-privatekey.pem', SINGLE_BLOB) AS doc;\nEXEC [dbo].[sp_set_file_data_encrypted] @FilePath = '/config/scaledsets/{scaledset_name}/containers/{container_name}/files/{prefix_keyfile_name}-privatekey.pem',\n @Data = @FileData,\n @KeyGuid = @Key,\n @Version = '0',\n @User = '',\n @Group = '',\n @Mode = '';\n\"\"\"\n\nsave_file(\"insert_certificates.sql\", sql)\n\ncwd = os.getcwd()\nos.chdir(temp_dir) # Workaround kubectl bug on Windows, can't put c:\\ on kubectl cp cmd line \n\nrun(f'kubectl cp insert_certificates.sql controldb-0:/var/opt/mssql/insert_certificates.sql -c mssql-server -n {namespace}')\n\nrun(f\"\"\"kubectl exec controldb-0 -c mssql-server -n {namespace} -- bash -c \"SQLCMDPASSWORD=`cat /var/run/secrets/credentials/mssql-sa-password/password` /opt/mssql-tools/bin/sqlcmd -b -U sa -d controller -i /var/opt/mssql/insert_certificates.sql\" \"\"\")\n\n# Clean up\nrun(f\"\"\"kubectl exec controldb-0 -c mssql-server -n {namespace} -- bash -c \"rm /var/opt/mssql/insert_certificates.sql\" \"\"\")\nrun(f\"\"\"kubectl exec controldb-0 -c mssql-server -n {namespace} -- bash -c \"rm /var/opt/mssql/{prefix_keyfile_name}-certificate.pem\" \"\"\")\nrun(f\"\"\"kubectl exec controldb-0 -c mssql-server -n {namespace} -- bash -c \"rm /var/opt/mssql/{prefix_keyfile_name}-privatekey.pem\" \"\"\")\n\nos.chdir(cwd)",
"_____no_output_____"
]
],
[
[
"### Clear out the controller\\_db\\_rw\\_secret variable",
"_____no_output_____"
]
],
[
[
"controller_db_rw_secret= \"\"",
"_____no_output_____"
]
],
[
[
"### Clean up certificate staging area\n\nRemove the certificate files generated on disk (they have now been\nplaced in the controller database).",
"_____no_output_____"
]
],
[
[
"cmd = f\"rm -r {test_cert_store_root}/{app_name}\"\n\nrun(f'kubectl exec {controller} -c controller -n {namespace} -- bash -c \"{cmd}\"')",
"_____no_output_____"
]
],
[
[
"### Restart knox gateway service",
"_____no_output_____"
]
],
[
[
"run(f'kubectl delete pod {pod} -n {namespace}')",
"_____no_output_____"
]
],
[
[
"### Clean up temporary directory for staging configuration files",
"_____no_output_____"
]
],
[
[
"# Delete the temporary directory used to hold configuration files\n\nimport shutil\n\nshutil.rmtree(temp_dir)\n\nprint(f'Temporary directory deleted: {temp_dir}')",
"_____no_output_____"
],
[
"print('Notebook execution complete.')",
"_____no_output_____"
]
],
[
[
"Related\n-------\n\n- [CER042 - Install signed App-Proxy\n certificate](../cert-management/cer042-install-app-proxy-cert.ipynb)\n\n- [CER031 - Sign Knox certificate with generated\n CA](../cert-management/cer031-sign-knox-generated-cert.ipynb)\n\n- [CER021 - Create Knox\n certificate](../cert-management/cer021-create-knox-cert.ipynb)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d02bb8e30fc73df3be5f3068653a8291729253ed
| 5,987 |
ipynb
|
Jupyter Notebook
|
Chapter_6/Section_6.4.3.ipynb
|
godfanmiao/ML-Kaggle-Github-2022
|
19c9fd0fe5db432f43f5844e170f952eaaaeaefd
|
[
"BSD-3-Clause"
] | 8 |
2021-10-15T12:27:01.000Z
|
2022-02-21T13:50:04.000Z
|
Chapter_6/Section_6.4.3.ipynb
|
godfanmiao/ML-Kaggle-Github-2022
|
19c9fd0fe5db432f43f5844e170f952eaaaeaefd
|
[
"BSD-3-Clause"
] | null | null | null |
Chapter_6/Section_6.4.3.ipynb
|
godfanmiao/ML-Kaggle-Github-2022
|
19c9fd0fe5db432f43f5844e170f952eaaaeaefd
|
[
"BSD-3-Clause"
] | 1 |
2022-02-04T07:25:34.000Z
|
2022-02-04T07:25:34.000Z
| 27.213636 | 271 | 0.52614 |
[
[
[
"'''\n循环神经网络的PaddlePaddle实践代码。\n'''\nimport paddle\nfrom paddle import nn, optimizer, metric\n\n\n#设定超参数。\nINPUT_UNITS = 56\nTIME_STEPS = 14\nHIDDEN_SIZE = 256 \nNUM_CLASSES = 10\nEPOCHS = 5\nBATCH_SIZE = 64\nLEARNING_RATE = 1e-3\n\n\nclass RNN(paddle.nn.LSTM):\n '''\n 自定义的循环神经网络。\n '''\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n \n def forward(self, inputs):\n output, _ = super().forward(inputs)\n return output[:, -1, :]\n\n\n# 搭建循环神经网络。 \npaddle_model = nn.Sequential(\n RNN(input_size=INPUT_UNITS, hidden_size=HIDDEN_SIZE),\n nn.Linear(in_features=HIDDEN_SIZE, out_features=NUM_CLASSES),\n)\n\n# 初始化循环神经网络。\nmodel = paddle.Model(paddle_model)\n\n# 为模型训练做准备,设置优化器,损失函数和评估指标。\nmodel.prepare(optimizer=optimizer.Adam(learning_rate=LEARNING_RATE, parameters=model.parameters()),\n loss=nn.CrossEntropyLoss(),\n metrics=metric.Accuracy())",
"sysctl: unknown oid 'machdep.cpu.leaf7_features'\n"
],
[
"import pandas as pd\n\n\n#使用pandas,读取fashion_mnist的训练和测试数据文件。\ntrain_data = pd.read_csv('../datasets/fashion_mnist/fashion_mnist_train.csv')\ntest_data = pd.read_csv('../datasets/fashion_mnist/fashion_mnist_test.csv')\n\n#从训练数据中,拆解出训练特征和类别标签。\nX_train = train_data[train_data.columns[1:]]\ny_train = train_data['label']\n\n#从测试数据中,拆解出测试特征和类别标签。\nX_test = test_data[train_data.columns[1:]]\ny_test = test_data['label']",
"_____no_output_____"
],
[
"from sklearn.preprocessing import StandardScaler\n\n\n#初始化数据标准化处理器。\nss = StandardScaler()\n\n#标准化训练数据特征。\nX_train = ss.fit_transform(X_train)\n\n#标准化测试数据特征。\nX_test = ss.transform(X_test)",
"_____no_output_____"
],
[
"from paddle.io import TensorDataset\n\nX_train = X_train.reshape([-1, TIME_STEPS, INPUT_UNITS])\n\nX_train = paddle.to_tensor(X_train.astype('float32'))\n\ny_train = y_train.values\n\n#构建适用于PaddlePaddle模型训练的数据集。\ntrain_dataset = TensorDataset([X_train, y_train])\n\n# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小。\nmodel.fit(train_dataset, epochs=EPOCHS, batch_size=BATCH_SIZE, verbose=1)",
"The loss value printed in the log is the current step, and the metric is the average value of previous steps.\nEpoch 1/5\n"
],
[
"X_test = X_test.reshape([-1, TIME_STEPS, INPUT_UNITS])\n\nX_test = paddle.to_tensor(X_test.astype('float32'))\n\ny_test = y_test.values\n\n#构建适用于PaddlePaddle模型测试的数据集。\ntest_dataset = TensorDataset([X_test, y_test])\n\n#启动模型测试,指定测试数据集。\nresult = model.evaluate(test_dataset, verbose=0)\n\nprint('循环神经网络(PaddlePaddle版本)在fashion_mnist测试集上的准确率为: %.2f%%。' %(result['acc'] * 100))",
"循环神经网络(PaddlePaddle版本)在fashion_mnist测试集上的准确率为: 90.14%。\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02bc264b181a3c9b1e7e6d7c638777c966e051a
| 192,602 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb
|
sz2472/foundations-homework
|
3b33175d6b0a7d0fbdef8c5380ba87aa371b459e
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb
|
sz2472/foundations-homework
|
3b33175d6b0a7d0fbdef8c5380ba87aa371b459e
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb
|
sz2472/foundations-homework
|
3b33175d6b0a7d0fbdef8c5380ba87aa371b459e
|
[
"MIT"
] | null | null | null | 45.190521 | 2,131 | 0.447726 |
[
[
[
"import requests",
"_____no_output_____"
],
[
"!pip3 install requests",
"Requirement already satisfied (use --upgrade to upgrade): requests in /Users/sz2472/.virtualenvs/data_analysis/lib/python3.5/site-packages\r\n"
],
[
"response = requests.get(\"https://api.spotify.com/v1/search?q=Lil&type=artist&market=US&limit=50\")",
"_____no_output_____"
],
[
"print(response.text)",
"{\n \"artists\" : {\n \"href\" : \"https://api.spotify.com/v1/search?query=Lil&offset=0&limit=50&type=artist&market=US\",\n \"items\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/55Aa2cqylxrFIXC767Z865\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 2628946\n },\n \"genres\" : [ \"dirty south rap\", \"pop rap\", \"southern hip hop\", \"trap music\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/55Aa2cqylxrFIXC767Z865\",\n \"id\" : \"55Aa2cqylxrFIXC767Z865\",\n \"images\" : [ {\n \"height\" : 1239,\n \"url\" : \"https://i.scdn.co/image/cf012139c3b8681b46a66bae70558a8a336ab231\",\n \"width\" : 1000\n }, {\n \"height\" : 793,\n \"url\" : \"https://i.scdn.co/image/fffd48d60e27901f6e9ce99423f045cb2b893944\",\n \"width\" : 640\n }, {\n \"height\" : 248,\n \"url\" : \"https://i.scdn.co/image/bf03141629c202e94b206f1374a39326a9d8c6ca\",\n \"width\" : 200\n }, {\n \"height\" : 79,\n \"url\" : \"https://i.scdn.co/image/521f99f2469883b8806a69a3a2487fdd983bd621\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Wayne\",\n \"popularity\" : 86,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:55Aa2cqylxrFIXC767Z865\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6icQOAFXDZKsumw3YXyusw\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 40628\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6icQOAFXDZKsumw3YXyusw\",\n \"id\" : \"6icQOAFXDZKsumw3YXyusw\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/add25baa69fc7bfd9cfd5d87716941028c2d6736\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/3f8205117bdd028a648ad3fc925f9fb46dfa26fa\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/ccc54e2911dbc5463acb401ee61489e27d991408\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Yachty\",\n \"popularity\" : 73,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6icQOAFXDZKsumw3YXyusw\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4O15NlyKLIASxsJ0PrXPfz\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 60405\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4O15NlyKLIASxsJ0PrXPfz\",\n \"id\" : \"4O15NlyKLIASxsJ0PrXPfz\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/8c02344d1cb9069a5a2a9d1e860dc88b04088549\",\n \"width\" : 640\n }, {\n \"height\" : 320,\n \"url\" : \"https://i.scdn.co/image/28ac78387ad26048ccab0b671cbaddb30a2b52da\",\n \"width\" : 320\n }, {\n \"height\" : 160,\n \"url\" : \"https://i.scdn.co/image/6b074e198860470024e57ebbc1dda9f58088c506\",\n \"width\" : 160\n } ],\n \"name\" : \"Lil Uzi Vert\",\n \"popularity\" : 74,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4O15NlyKLIASxsJ0PrXPfz\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1tqhsYv8yBBdwANFNzHtcr\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 228488\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1tqhsYv8yBBdwANFNzHtcr\",\n \"id\" : \"1tqhsYv8yBBdwANFNzHtcr\",\n \"images\" : [ {\n \"height\" : 1000,\n \"url\" : \"https://i.scdn.co/image/a9c000526b14038b1fe69c72b0775f125bdf08af\",\n \"width\" : 1000\n }, {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/31eac6ae8bdd6909236b5fd729d17406cc794e2d\",\n \"width\" : 640\n }, {\n \"height\" : 200,\n \"url\" : \"https://i.scdn.co/image/24dcb67ddd3afc794a4b1dab4cc1a47035a0beab\",\n \"width\" : 200\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/2d2ebd85f676535129dbb7c3a4bb96e7bfd940a7\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Dicky\",\n \"popularity\" : 68,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1tqhsYv8yBBdwANFNzHtcr\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6z7xFFHxYkE9t8bwIF0Bvg\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 221080\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6z7xFFHxYkE9t8bwIF0Bvg\",\n \"id\" : \"6z7xFFHxYkE9t8bwIF0Bvg\",\n \"images\" : [ {\n \"height\" : 667,\n \"url\" : \"https://i.scdn.co/image/f89376b78fe94a1692a5768f8f3440a4397bfb17\",\n \"width\" : 1000\n }, {\n \"height\" : 427,\n \"url\" : \"https://i.scdn.co/image/fbf5353d4410a540cc74285d387d9e59d038592a\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/39995515de01dc9eb91bc9c17d5c1921e7e54a1f\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/b34f525381a78c72f423d74b76a47e1a1da9f7f8\",\n \"width\" : 64\n } ],\n \"name\" : \"Boosie Badazz\",\n \"popularity\" : 67,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6z7xFFHxYkE9t8bwIF0Bvg\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7sfl4Xt5KmfyDs2T3SVSMK\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 256611\n },\n \"genres\" : [ \"crunk\", \"dirty south rap\", \"southern hip hop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7sfl4Xt5KmfyDs2T3SVSMK\",\n \"id\" : \"7sfl4Xt5KmfyDs2T3SVSMK\",\n \"images\" : [ {\n \"height\" : 664,\n \"url\" : \"https://i.scdn.co/image/885941564eadf27b7ee86d089e87967f9e3cf612\",\n \"width\" : 1000\n }, {\n \"height\" : 425,\n \"url\" : \"https://i.scdn.co/image/b5495566665b41f3dc2560d37d043e4a3dc2ca41\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/6ea9f92a43e23eaa7ced98d8773de37229b1410d\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/ddef386b560619f296a27059874ad3fc7fd5d85d\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Jon\",\n \"popularity\" : 72,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7sfl4Xt5KmfyDs2T3SVSMK\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6L3x3if9RVimruryD9LoFb\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 64821\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6L3x3if9RVimruryD9LoFb\",\n \"id\" : \"6L3x3if9RVimruryD9LoFb\",\n \"images\" : [ {\n \"height\" : 879,\n \"url\" : \"https://i.scdn.co/image/8942e9c0745697fa8e3e75f02aa461d722a0519d\",\n \"width\" : 587\n }, {\n \"height\" : 299,\n \"url\" : \"https://i.scdn.co/image/9fa49263a60cd27888e23b6c6c10c930af48114e\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/c11e5e1e9d21cee430c1bd7c72e387422854bd6a\",\n \"width\" : 64\n } ],\n \"name\" : \"King Lil G\",\n \"popularity\" : 61,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6L3x3if9RVimruryD9LoFb\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3hcs9uc56yIGFCSy9leWe7\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 134729\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3hcs9uc56yIGFCSy9leWe7\",\n \"id\" : \"3hcs9uc56yIGFCSy9leWe7\",\n \"images\" : [ {\n \"height\" : 426,\n \"url\" : \"https://i.scdn.co/image/2b83f7df57f9098558c63047c494dea26f2da67e\",\n \"width\" : 999\n }, {\n \"height\" : 273,\n \"url\" : \"https://i.scdn.co/image/42e0d88103ed677b9a6cfa426e53428127ae903d\",\n \"width\" : 640\n }, {\n \"height\" : 85,\n \"url\" : \"https://i.scdn.co/image/b127461c288b3777fd18ffcd3523856b6063ea1e\",\n \"width\" : 199\n }, {\n \"height\" : 27,\n \"url\" : \"https://i.scdn.co/image/3674b105e3a72fbb92794029846a43dc66b2fcab\",\n \"width\" : 63\n } ],\n \"name\" : \"Lil Durk\",\n \"popularity\" : 60,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3hcs9uc56yIGFCSy9leWe7\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3ciRvbBIVz9fBoPbtSYq4x\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 17135\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3ciRvbBIVz9fBoPbtSYq4x\",\n \"id\" : \"3ciRvbBIVz9fBoPbtSYq4x\",\n \"images\" : [ {\n \"height\" : 500,\n \"url\" : \"https://i.scdn.co/image/aafc4156598fa9f8f052ec5687e648ba9120f07e\",\n \"width\" : 554\n }, {\n \"height\" : 181,\n \"url\" : \"https://i.scdn.co/image/7a9ccdaebabf83f763af6664d5d483c57332bc08\",\n \"width\" : 200\n }, {\n \"height\" : 58,\n \"url\" : \"https://i.scdn.co/image/e74083480033e85373d3deb546f16d8beedeccb3\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Jon & The East Side Boyz\",\n \"popularity\" : 60,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3ciRvbBIVz9fBoPbtSYq4x\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4uSN8Y3kgFNVULUWsZEAVW\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 44459\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4uSN8Y3kgFNVULUWsZEAVW\",\n \"id\" : \"4uSN8Y3kgFNVULUWsZEAVW\",\n \"images\" : [ {\n \"height\" : 1000,\n \"url\" : \"https://i.scdn.co/image/07c75abe717a9b704083ef38c4446abbff10fda5\",\n \"width\" : 1000\n }, {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/1903fd19c7279418c71da62aa02ce47cccf63e52\",\n \"width\" : 640\n }, {\n \"height\" : 200,\n \"url\" : \"https://i.scdn.co/image/9c37f8c40ab3594de42f1861f592f558f91d0f51\",\n \"width\" : 200\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/efba595d34603b014b125d65f7851103185158b4\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Bibby\",\n \"popularity\" : 54,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4uSN8Y3kgFNVULUWsZEAVW\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5QdEbQJ3ylBnc3gsIASAT5\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 51939\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/5QdEbQJ3ylBnc3gsIASAT5\",\n \"id\" : \"5QdEbQJ3ylBnc3gsIASAT5\",\n \"images\" : [ {\n \"height\" : 667,\n \"url\" : \"https://i.scdn.co/image/2cb955d0b6d08e1ff70cff98b332f6debf7a8e4a\",\n \"width\" : 1000\n }, {\n \"height\" : 427,\n \"url\" : \"https://i.scdn.co/image/72667af5dfd57266ba7348bbec97c246986bdbfe\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/f366a759361f875f6259ef805c76e39ff3dd754c\",\n \"width\" : 199\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/d7b0cd61112a7b8b6326c6454652685c1d1baa1c\",\n \"width\" : 64\n } ],\n \"name\" : \"G Herbo\",\n \"popularity\" : 53,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5QdEbQJ3ylBnc3gsIASAT5\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7B7TGqQe7QTVm2U6q8jzk1\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 36011\n },\n \"genres\" : [ \"chicano rap\", \"latin hip hop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7B7TGqQe7QTVm2U6q8jzk1\",\n \"id\" : \"7B7TGqQe7QTVm2U6q8jzk1\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/7b37dc3ed21b4236502d24a897ac02aa4eb9f183\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/457e18474f5cf18eae93e1435dcc5d2fb88c8efd\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/8e7c25760b9b5d6dbc58ebc30443114fdfdfb927\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Rob\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7B7TGqQe7QTVm2U6q8jzk1\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1bPxKZtCdjB1aj1csBJpdS\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 23929\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1bPxKZtCdjB1aj1csBJpdS\",\n \"id\" : \"1bPxKZtCdjB1aj1csBJpdS\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/c3f33bf2d8bc3e00d0d82fd9e2a11c0594079833\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/6535600354e3ff225b5704ab3c9b4a4033746fb1\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/ba89cf9b97304f9f07132e8bb06293170109b64b\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Reese\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1bPxKZtCdjB1aj1csBJpdS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1grI9x4Uzos1Asx8JmRW6T\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 18853\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1grI9x4Uzos1Asx8JmRW6T\",\n \"id\" : \"1grI9x4Uzos1Asx8JmRW6T\",\n \"images\" : [ {\n \"height\" : 1024,\n \"url\" : \"https://i.scdn.co/image/3e53d37d29794eccb5fc9744b962df8f2c2b1725\",\n \"width\" : 680\n }, {\n \"height\" : 964,\n \"url\" : \"https://i.scdn.co/image/82bb674230d0b08e5c82e10dfe175759581e7800\",\n \"width\" : 640\n }, {\n \"height\" : 301,\n \"url\" : \"https://i.scdn.co/image/6f26c9f3aee5c6243f2abe210ab09446df90276b\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/35fd540d7448475f46e06bc0b46f2ca106899910\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Keke\",\n \"popularity\" : 48,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1grI9x4Uzos1Asx8JmRW6T\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7352aRY2mqSxBZwzUb6LmA\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 118838\n },\n \"genres\" : [ \"hip pop\", \"pop rap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7352aRY2mqSxBZwzUb6LmA\",\n \"id\" : \"7352aRY2mqSxBZwzUb6LmA\",\n \"images\" : [ {\n \"height\" : 1500,\n \"url\" : \"https://i.scdn.co/image/bbc23f477201e3784b54516ef2ad548794947277\",\n \"width\" : 1000\n }, {\n \"height\" : 960,\n \"url\" : \"https://i.scdn.co/image/4014b68d6e33d16883c70aab0972087d38e8896d\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5d3a1e94fb0fe5cf2dfb600cd7e55e8213025968\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/6799537642674ef52cf0064aaef74cf04202c301\",\n \"width\" : 64\n } ],\n \"name\" : \"Bow Wow\",\n \"popularity\" : 57,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7352aRY2mqSxBZwzUb6LmA\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5einkgXXrjhfYCyac1FANB\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 27171\n },\n \"genres\" : [ \"crunk\", \"dirty south rap\", \"southern hip hop\", \"trap music\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5einkgXXrjhfYCyac1FANB\",\n \"id\" : \"5einkgXXrjhfYCyac1FANB\",\n \"images\" : [ {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/722a084be153a03ca1bfb0c1e7c83bd4d37db156\",\n \"width\" : 225\n }, {\n \"height\" : 267,\n \"url\" : \"https://i.scdn.co/image/9c68dc0bb9b147bd31cb13a7b1e1d95acf481a90\",\n \"width\" : 200\n }, {\n \"height\" : 85,\n \"url\" : \"https://i.scdn.co/image/96df8040ad3c03f9471139786c4ea60f3998ca81\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Scrappy\",\n \"popularity\" : 49,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5einkgXXrjhfYCyac1FANB\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/21O7WwRkik43ErKppxDKJq\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 31239\n },\n \"genres\" : [ \"juggalo\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/21O7WwRkik43ErKppxDKJq\",\n \"id\" : \"21O7WwRkik43ErKppxDKJq\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/01140761147a97db6a100c4456b531fb2d5aad82\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/0925d6476f14719b5ffd005fe0091e292c95e11e\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b232b4badce8651c11907c06ed6defcfc5616854\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Wyte\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:21O7WwRkik43ErKppxDKJq\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/74nSA5FdDOuuLw7Rn5JnuP\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 5560\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/74nSA5FdDOuuLw7Rn5JnuP\",\n \"id\" : \"74nSA5FdDOuuLw7Rn5JnuP\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/fc222056c3c65e02c96c3e94847a74ba7920757e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/052a2ef46226fa25801224fd676ba4abbb7da15a\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b3a4a57f6da39a5af2b2c56479819754caa51d35\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Blood\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:74nSA5FdDOuuLw7Rn5JnuP\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/42FaEHFfyxTdZQ5W28dXnj\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 34152\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/42FaEHFfyxTdZQ5W28dXnj\",\n \"id\" : \"42FaEHFfyxTdZQ5W28dXnj\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/89c1a0ac4f8b95c843d633493bc3657a296e3e6b\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/59654d32b34cfb51000ff26fec57ab36bf1781ae\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b3afd3776d6e3e6ed82d45b4541e8623389e347b\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Snupe\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:42FaEHFfyxTdZQ5W28dXnj\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5qK5bOC6wLtuLhG5KvU17c\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 21187\n },\n \"genres\" : [ \"hip pop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5qK5bOC6wLtuLhG5KvU17c\",\n \"id\" : \"5qK5bOC6wLtuLhG5KvU17c\",\n \"images\" : [ {\n \"height\" : 750,\n \"url\" : \"https://i.scdn.co/image/8e33c09ff1d5d91ea47254a389c36f626775275a\",\n \"width\" : 600\n }, {\n \"height\" : 250,\n \"url\" : \"https://i.scdn.co/image/991889a4147550d0421dfb80621c2e161ac7e043\",\n \"width\" : 200\n }, {\n \"height\" : 80,\n \"url\" : \"https://i.scdn.co/image/253d651a020406eb7c264304803463badabfe8cb\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Mama\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5qK5bOC6wLtuLhG5KvU17c\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4dqh62yIzDBmrMeBOLiP5F\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 244\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4dqh62yIzDBmrMeBOLiP5F\",\n \"id\" : \"4dqh62yIzDBmrMeBOLiP5F\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/5fbeb835c159b8de635ef8f5c6cc002ce138aec2\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/3002b77643ae099b657a5eca5f99a79ca064b2f7\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/73507e320c68d9890524a15f2eca9390a9fec455\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil B\",\n \"popularity\" : 44,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4dqh62yIzDBmrMeBOLiP5F\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5tth2a3v0sWwV1C7bApBdX\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 70517\n },\n \"genres\" : [ \"hip pop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5tth2a3v0sWwV1C7bApBdX\",\n \"id\" : \"5tth2a3v0sWwV1C7bApBdX\",\n \"images\" : [ {\n \"height\" : 667,\n \"url\" : \"https://i.scdn.co/image/86a3e71ffa1706d337405150ec3bb7b4e246db7b\",\n \"width\" : 1000\n }, {\n \"height\" : 427,\n \"url\" : \"https://i.scdn.co/image/aa469a2c66d8e71308dbfb3efdb116be37ccdcaa\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/a0e5359dc08b113b293b9d46715dea3ade289ba0\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/74c219f600ec1d671430515820392104a64be811\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil' Kim\",\n \"popularity\" : 62,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5tth2a3v0sWwV1C7bApBdX\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1mmlWsyPJvvxMdabcGJjRn\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 233\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1mmlWsyPJvvxMdabcGJjRn\",\n \"id\" : \"1mmlWsyPJvvxMdabcGJjRn\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/60159d868f6ceb3433cc4d9c6ad9d551c142a1ec\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/d84f042b1e6785cac700ead5797b250d0e00744d\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/98efe8330240c282b4a87fd98bf90f8c93f869cc\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Boom\",\n \"popularity\" : 43,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1mmlWsyPJvvxMdabcGJjRn\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1I5u5Umau1AgHl0ZbPL1oR\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 15624\n },\n \"genres\" : [ \"chicano rap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/1I5u5Umau1AgHl0ZbPL1oR\",\n \"id\" : \"1I5u5Umau1AgHl0ZbPL1oR\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/9a690f19d1f22f37c2d8ea2269d5d13c227059c7\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/8a8413a32bf7407d8e3c7705fb24db7b817d7804\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/06ce7932e56c32475af8927bfffcce0d76475be8\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Cuete\",\n \"popularity\" : 40,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1I5u5Umau1AgHl0ZbPL1oR\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3QnIBUOS4mUzs67rZ8r4c9\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 5360\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3QnIBUOS4mUzs67rZ8r4c9\",\n \"id\" : \"3QnIBUOS4mUzs67rZ8r4c9\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/e67d6752b4bc97f8e62e3bad2020d1a771543329\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/252344a7a2903b910fe462fb1d03e4050182d7ad\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/4481d09538ecb2554f01dec59f05dd050d1b03b9\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Phat\",\n \"popularity\" : 39,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3QnIBUOS4mUzs67rZ8r4c9\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3FNZcjyqT7F5upP99JV0oN\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 14572\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3FNZcjyqT7F5upP99JV0oN\",\n \"id\" : \"3FNZcjyqT7F5upP99JV0oN\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/f7a2070d4432472565f88e4d8e25f61de58bfde9\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/97e0127d38fd5f0b2e9c5fd593a42148f26ee8c7\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/c8c722d37914c9bd4f1b1af5b1c0e152e3e74c19\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Debbie\",\n \"popularity\" : 43,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3FNZcjyqT7F5upP99JV0oN\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/564gvOqSRcQoYAhaBpTiK2\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 14848\n },\n \"genres\" : [ \"jerk\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/564gvOqSRcQoYAhaBpTiK2\",\n \"id\" : \"564gvOqSRcQoYAhaBpTiK2\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/5280b8361231a8275ef9aeaa4e4d9a7701790eb5\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/112c7e13cf136d3389ac4e2568af3cb1a02285b7\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/0c0031c220e6536650161d837192c64168690d86\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Twist\",\n \"popularity\" : 40,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:564gvOqSRcQoYAhaBpTiK2\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5EQERGi7ffHvHsv3bnqzBn\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 2129\n },\n \"genres\" : [ \"deep trap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5EQERGi7ffHvHsv3bnqzBn\",\n \"id\" : \"5EQERGi7ffHvHsv3bnqzBn\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/b05aaee4b347f25bd1f190a47d2a04a30db96ee4\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/7cc46db0ae9aca73de9ce788ffee37711af092db\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/e39030f343a1365761a1778a873a369573fb5e11\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Trill\",\n \"popularity\" : 37,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5EQERGi7ffHvHsv3bnqzBn\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/2jXwYLNnCxNavms4mc1DYM\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 906\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/2jXwYLNnCxNavms4mc1DYM\",\n \"id\" : \"2jXwYLNnCxNavms4mc1DYM\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/c836e08658864e66d993dd082d22d6dfee7d4645\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/255d752315107f40dc7ff7d9deff7955f6ca569e\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/93902d4634605f54f6d16df88d4bd7bbf2b5ae4a\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil AJ\",\n \"popularity\" : 36,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:2jXwYLNnCxNavms4mc1DYM\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6zSBkdKFLKKggDtE3amfCk\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1384\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6zSBkdKFLKKggDtE3amfCk\",\n \"id\" : \"6zSBkdKFLKKggDtE3amfCk\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/808576eb1021286e337063e525f4ec79464be1ae\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/9e64654e7a0efcc0e83f92c183161b8563afdc9d\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/14c77d2a012121fdfb65a34f9ead19824627c787\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Lonnie\",\n \"popularity\" : 37,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6zSBkdKFLKKggDtE3amfCk\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5YZZbPdI7P7te3lW3dTpzK\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 327\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/5YZZbPdI7P7te3lW3dTpzK\",\n \"id\" : \"5YZZbPdI7P7te3lW3dTpzK\",\n \"images\" : [ {\n \"height\" : 960,\n \"url\" : \"https://i.scdn.co/image/171bcf1727e696bb7abe4af8c339654a03335c75\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/4fc43fb0bb59f30f92a4a61267b2d68a16441041\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/13157eee5b9392e4c9eddced209e32eac2540000\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Twon\",\n \"popularity\" : 37,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5YZZbPdI7P7te3lW3dTpzK\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3rWaFjgOi5mjQfllMfN3VI\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1348\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3rWaFjgOi5mjQfllMfN3VI\",\n \"id\" : \"3rWaFjgOi5mjQfllMfN3VI\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/27cd70424eb57712af1a3f02d8c065fb8248c6f7\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5df4c3e9982888cfc853591361bde30b26e4b182\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/cf681ac1c01f676cb8848fc3c1c1e91af4981940\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Goofy\",\n \"popularity\" : 35,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3rWaFjgOi5mjQfllMfN3VI\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4E9dumwOMLlTyXUp1i2WdI\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 712\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4E9dumwOMLlTyXUp1i2WdI\",\n \"id\" : \"4E9dumwOMLlTyXUp1i2WdI\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/0248b931d044d7cd9e04e985dd60e262d47bd48e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/2e0750e4f4f1b6faef4694e8cdc7be2ea7943025\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/71627015b26cd42d2d4912b0b728d26d5aa021bc\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Haiti\",\n \"popularity\" : 37,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4E9dumwOMLlTyXUp1i2WdI\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/43BqexhEx5NKF7VfeOYP9m\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1013\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/43BqexhEx5NKF7VfeOYP9m\",\n \"id\" : \"43BqexhEx5NKF7VfeOYP9m\",\n \"images\" : [ {\n \"height\" : 500,\n \"url\" : \"https://i.scdn.co/image/19b3c85c69a68790f2edef06bd2da9e51ee88a44\",\n \"width\" : 500\n }, {\n \"height\" : 200,\n \"url\" : \"https://i.scdn.co/image/ced2056dc33e8b3c318560ecdc393c5e79939927\",\n \"width\" : 200\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/08f5c3a7abf35edf216ce353f611b37d1251e2ca\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Cray\",\n \"popularity\" : 35,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:43BqexhEx5NKF7VfeOYP9m\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6tslWi0BXiDdtChermDzkU\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 4762\n },\n \"genres\" : [ \"chicano rap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/6tslWi0BXiDdtChermDzkU\",\n \"id\" : \"6tslWi0BXiDdtChermDzkU\",\n \"images\" : [ {\n \"height\" : 445,\n \"url\" : \"https://i.scdn.co/image/f3e380e2bb1706ccc3ff3136a5909b2df62fc8e6\",\n \"width\" : 999\n }, {\n \"height\" : 285,\n \"url\" : \"https://i.scdn.co/image/b422c3b95293beb367cf38901631d5537c6431b1\",\n \"width\" : 640\n }, {\n \"height\" : 89,\n \"url\" : \"https://i.scdn.co/image/c827b7877bde6b4295d708b75ec78bb493ad7245\",\n \"width\" : 200\n }, {\n \"height\" : 29,\n \"url\" : \"https://i.scdn.co/image/f9ee61c0fc0e027f2a87cb2a610637ebce8e8e4c\",\n \"width\" : 64\n } ],\n \"name\" : \"Mr. Lil One\",\n \"popularity\" : 36,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6tslWi0BXiDdtChermDzkU\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/069qBEK34YGoX7nSIT74Eg\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1770\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/069qBEK34YGoX7nSIT74Eg\",\n \"id\" : \"069qBEK34YGoX7nSIT74Eg\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/00f49af07547e77af2b67f621c8fd77be607f166\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/760852e9190609b0bf7bab4c5ba3fd14654956a3\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/390f2cc02272310ae41fb67ef92b7bf226262be6\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Flash\",\n \"popularity\" : 38,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:069qBEK34YGoX7nSIT74Eg\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/2Kv0ApBohrL213X9avMrEn\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 9512\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/2Kv0ApBohrL213X9avMrEn\",\n \"id\" : \"2Kv0ApBohrL213X9avMrEn\",\n \"images\" : [ {\n \"height\" : 1500,\n \"url\" : \"https://i.scdn.co/image/9b1581aa35fa3461ad886fe8999f3757d3292fb7\",\n \"width\" : 1000\n }, {\n \"height\" : 960,\n \"url\" : \"https://i.scdn.co/image/7105c05c8533bf8689937a1d37613db9576b73d8\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/79b367700f460ea27a3f0ad56ac2596d3f220ae1\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/9bf3f51c3475fcfa7e2cac1780c97dff19cb47c4\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Silva\",\n \"popularity\" : 43,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:2Kv0ApBohrL213X9avMrEn\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4vIlHBnzWKbmWe8ZOkT1ZT\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1153\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4vIlHBnzWKbmWe8ZOkT1ZT\",\n \"id\" : \"4vIlHBnzWKbmWe8ZOkT1ZT\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/0f0c996d27335179f4136620e95d9c3245147806\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/923c54f357bb8fbba8623cadb9f4194e90de760c\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/85d4cf1f11ec3ba3481a9414fbb5dc5801abe086\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Yase\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4vIlHBnzWKbmWe8ZOkT1ZT\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4IFVaKBbEO8Qkurg6nmoc4\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 3299\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4IFVaKBbEO8Qkurg6nmoc4\",\n \"id\" : \"4IFVaKBbEO8Qkurg6nmoc4\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/a71e6d63cee27fbf8d35783319f27517544729a6\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/6872135b1c7727339bc927f76b6502e7b0626bb4\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b9704a6bad87cf9e221824ac02f09dc8569c5fc6\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Rue\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4IFVaKBbEO8Qkurg6nmoc4\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5CY0QKsbUBpQJIE2yycsYi\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1623\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/5CY0QKsbUBpQJIE2yycsYi\",\n \"id\" : \"5CY0QKsbUBpQJIE2yycsYi\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/a1ab38ca89a4640ba1306c5f2ade50750194e5d9\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5ba8136190e12f51a128855f107afcfd446e63bd\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b2c57e0ba16bb50a92e84a1776bc6a324d858c2c\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Eddie\",\n \"popularity\" : 41,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5CY0QKsbUBpQJIE2yycsYi\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/38XiDu0kK3Z5jdHUDqBzNT\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1678\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/38XiDu0kK3Z5jdHUDqBzNT\",\n \"id\" : \"38XiDu0kK3Z5jdHUDqBzNT\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/63f06a92ecd7974e1360c1fbf318285b52208594\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/2cc112871d0755a7b08c8640d77c027dbe2fefff\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/37245d0c87fc06fd2ed5aab80207c2a70b688e9d\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Kesh\",\n \"popularity\" : 39,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:38XiDu0kK3Z5jdHUDqBzNT\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5HPsVk1MblCoa44WLJsQwN\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 5925\n },\n \"genres\" : [ \"freestyle\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5HPsVk1MblCoa44WLJsQwN\",\n \"id\" : \"5HPsVk1MblCoa44WLJsQwN\",\n \"images\" : [ {\n \"height\" : 482,\n \"url\" : \"https://i.scdn.co/image/9e2c6bb7420bdfe0675255200e6a90fbe6744514\",\n \"width\" : 720\n }, {\n \"height\" : 428,\n \"url\" : \"https://i.scdn.co/image/861aeb62673db5c88a4938462051496d54a88e14\",\n \"width\" : 639\n }, {\n \"height\" : 134,\n \"url\" : \"https://i.scdn.co/image/3bcf3420690356d33c72e6d699a6e087a2f287d4\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/b807785791281b511ee7e545825f5508648914b0\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Suzy\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5HPsVk1MblCoa44WLJsQwN\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/65npPa1U4cgobX9wU7Jgpb\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 12891\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/65npPa1U4cgobX9wU7Jgpb\",\n \"id\" : \"65npPa1U4cgobX9wU7Jgpb\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/97bfe3f9251d35d9a358d8e937d3a6365c7a674a\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/201eee225cd733022b0e78f6fbfe04861d898a84\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/80f03593b486eb3b70f9c035097d669e7704c328\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Wayne, DJ Drama\",\n \"popularity\" : 35,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:65npPa1U4cgobX9wU7Jgpb\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1cEHxCgGlEgqBc91YOcAEQ\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 16344\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1cEHxCgGlEgqBc91YOcAEQ\",\n \"id\" : \"1cEHxCgGlEgqBc91YOcAEQ\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/a7969adf46dff0c450120388bef4e760e2443a66\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/9f155a53e2c7be92a0846befc94162e84a5e02b9\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/7b434e7ce5acc91a1f1df22a4af376281e98dbbe\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Mouse\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1cEHxCgGlEgqBc91YOcAEQ\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/69swdLSkKxCQBMYJ55O2mA\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1713\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/69swdLSkKxCQBMYJ55O2mA\",\n \"id\" : \"69swdLSkKxCQBMYJ55O2mA\",\n \"images\" : [ {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/0b0c4aa534c6203577fd01f13a00807e4635851c\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/ddef4f63a39e9007bef9adab285e7c51ce345848\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil C\",\n \"popularity\" : 33,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:69swdLSkKxCQBMYJ55O2mA\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1qKzKUnuQsjB83hBZffoq0\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1834\n },\n \"genres\" : [ \"soca\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/1qKzKUnuQsjB83hBZffoq0\",\n \"id\" : \"1qKzKUnuQsjB83hBZffoq0\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/4008de208a4462c926c09d5d341638abaa734d9d\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/bd35dfb47d9719d7c94d185b55364a63d9a6e37d\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/5d11e2608b6c526ae1bc76a09b0357ac3d802bfe\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Rick\",\n \"popularity\" : 39,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1qKzKUnuQsjB83hBZffoq0\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3GH3KD2078kLPpEkN1UN26\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 1423\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3GH3KD2078kLPpEkN1UN26\",\n \"id\" : \"3GH3KD2078kLPpEkN1UN26\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/076a261d997d38ebbb55041a67bd4e00d960ce7e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/fbfc9a3a04437bba987ff1c2f4f38358b809b155\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/0b3c65e61d127766aa052b33bcddd796d06d0f28\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil June\",\n \"popularity\" : 32,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3GH3KD2078kLPpEkN1UN26\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0zn6yzsbWj3EPMgOTqfG5k\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 138\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/0zn6yzsbWj3EPMgOTqfG5k\",\n \"id\" : \"0zn6yzsbWj3EPMgOTqfG5k\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/35638d3cfbc1b763aeb111c9273e724bdef12aa4\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/ecd0a4a293cd661df2a8da127c343c46d4f7d11e\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/a9d06155df08da255a54a8dc598961b5ff5a3958\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil E\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0zn6yzsbWj3EPMgOTqfG5k\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6JUnsP7jmvYmdhbg7lTMQj\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 110\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6JUnsP7jmvYmdhbg7lTMQj\",\n \"id\" : \"6JUnsP7jmvYmdhbg7lTMQj\",\n \"images\" : [ ],\n \"name\" : \"Lil Fate\",\n \"popularity\" : 34,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6JUnsP7jmvYmdhbg7lTMQj\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 19996\n },\n \"genres\" : [ \"crunk\", \"dirty south rap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"images\" : [ {\n \"height\" : 810,\n \"url\" : \"https://i.scdn.co/image/3767913038db1bbb8e971a3f93b4eb2c86b402c1\",\n \"width\" : 1000\n }, {\n \"height\" : 519,\n \"url\" : \"https://i.scdn.co/image/dcc17914d52f5194f21ed73c2272701f940be220\",\n \"width\" : 640\n }, {\n \"height\" : 162,\n \"url\" : \"https://i.scdn.co/image/a645742d2b72d97d0abeb35eb880439f11013b1d\",\n \"width\" : 200\n }, {\n \"height\" : 52,\n \"url\" : \"https://i.scdn.co/image/d2f390e207477cdd0e2229429593f7dd99f08e54\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil' Flip\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n } ],\n \"limit\" : 50,\n \"next\" : \"https://api.spotify.com/v1/search?query=Lil&offset=50&limit=50&type=artist&market=US\",\n \"offset\" : 0,\n \"previous\" : null,\n \"total\" : 4514\n }\n}\n"
],
[
"data = response.json()",
"_____no_output_____"
],
[
"type(data)",
"_____no_output_____"
],
[
"data.keys()",
"_____no_output_____"
],
[
"\ndata['artists'].keys()",
"_____no_output_____"
],
[
"artists=data['artists']\ntype(artists['items'])",
"_____no_output_____"
],
[
"artist_info = artists['items']",
"_____no_output_____"
],
[
"for artist in artist_info:\n print(artist['name'], artist['popularity'])",
"Lil Wayne 86\nLil Yachty 73\nLil Uzi Vert 74\nLil Dicky 68\nBoosie Badazz 67\nLil Jon 72\nKing Lil G 61\nLil Durk 60\nLil Jon & The East Side Boyz 60\nLil Bibby 54\nG Herbo 53\nLil Rob 50\nLil Reese 50\nLil Keke 48\nBow Wow 57\nLil Scrappy 49\nLil Wyte 50\nLil Blood 45\nLil Snupe 45\nLil Mama 45\nLil B 44\nLil' Kim 62\nLil Boom 43\nLil Cuete 40\nLil Phat 39\nLil Debbie 43\nLil Twist 40\nLil Trill 37\nLil AJ 36\nLil Lonnie 37\nLil Twon 37\nLil Goofy 35\nLil Haiti 37\nLil Cray 35\nMr. Lil One 36\nLil Flash 38\nLil Silva 43\nLil Yase 34\nLil Rue 34\nLil Eddie 41\nLil Kesh 39\nLil Suzy 34\nLil Wayne, DJ Drama 35\nLil Mouse 34\nLil C 33\nLil Rick 39\nLil June 32\nLil E 34\nLil Fate 34\nLil' Flip 50\n"
],
[
"print(artist_info[5])",
"{'external_urls': {'spotify': 'https://open.spotify.com/artist/7sfl4Xt5KmfyDs2T3SVSMK'}, 'popularity': 72, 'followers': {'total': 256611, 'href': None}, 'id': '7sfl4Xt5KmfyDs2T3SVSMK', 'uri': 'spotify:artist:7sfl4Xt5KmfyDs2T3SVSMK', 'href': 'https://api.spotify.com/v1/artists/7sfl4Xt5KmfyDs2T3SVSMK', 'images': [{'url': 'https://i.scdn.co/image/885941564eadf27b7ee86d089e87967f9e3cf612', 'width': 1000, 'height': 664}, {'url': 'https://i.scdn.co/image/b5495566665b41f3dc2560d37d043e4a3dc2ca41', 'width': 640, 'height': 425}, {'url': 'https://i.scdn.co/image/6ea9f92a43e23eaa7ced98d8773de37229b1410d', 'width': 200, 'height': 133}, {'url': 'https://i.scdn.co/image/ddef386b560619f296a27059874ad3fc7fd5d85d', 'width': 64, 'height': 43}], 'genres': ['crunk', 'dirty south rap', 'southern hip hop'], 'name': 'Lil Jon', 'type': 'artist'}\n"
],
[
"artists=data['artists']\nartist_info = artists['items']\nseparator = \", \"\nfor artist in artist_info:\n if len(artist['genres']) == 0:\n print(\"No genres listed.\")\n else:\n print(artist['name'], \":\", separator.join(artist['genres']))",
"Lil Wayne : dirty south rap, pop rap, southern hip hop, trap music\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nLil Jon : crunk, dirty south rap, southern hip hop\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nLil Rob : chicano rap, latin hip hop\nNo genres listed.\nNo genres listed.\nBow Wow : hip pop, pop rap\nLil Scrappy : crunk, dirty south rap, southern hip hop, trap music\nLil Wyte : juggalo\nNo genres listed.\nNo genres listed.\nLil Mama : hip pop\nNo genres listed.\nLil' Kim : hip pop\nNo genres listed.\nLil Cuete : chicano rap\nNo genres listed.\nNo genres listed.\nLil Twist : jerk\nLil Trill : deep trap\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nMr. Lil One : chicano rap\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nNo genres listed.\nLil Suzy : freestyle\nNo genres listed.\nNo genres listed.\nNo genres listed.\nLil Rick : soca\nNo genres listed.\nNo genres listed.\nNo genres listed.\nLil' Flip : crunk, dirty south rap\n"
],
[
"most_popular_name = \"\"\nmost_popular_score = 0\nfor artist in artist_info:\n if artist['popularity'] > most_popular_score and artist['name'] != \"Lil Wayne\":\n most_popular_name = artist['name']\n most_popular_score = artist['popularity']\n else:\n pass\n \nprint(most_popular_name,most_popular_score)\n ",
"Lil Uzi Vert 74\n"
]
],
[
[
"print a list of Lil's that are more popular than Lil's Kim",
"_____no_output_____"
]
],
[
[
"for artist in artist_info:\n print(artist['name'])\n if artist['name']== \"Lil' Kim\":\n print(\"Found Lil Kim\")\n print(artist['popularity'])\n else:\n pass #print ",
"Lil Wayne\nLil Yachty\nLil Uzi Vert\nLil Dicky\nBoosie Badazz\nLil Jon\nKing Lil G\nLil Durk\nLil Jon & The East Side Boyz\nLil Bibby\nG Herbo\nLil Rob\nLil Reese\nLil Keke\nBow Wow\nLil Scrappy\nLil Wyte\nLil Blood\nLil Snupe\nLil Mama\nLil B\nLil' Kim\nFound Lil Kim\n62\nLil Boom\nLil Cuete\nLil Phat\nLil Debbie\nLil Twist\nLil Trill\nLil AJ\nLil Lonnie\nLil Twon\nLil Goofy\nLil Haiti\nLil Cray\nMr. Lil One\nLil Flash\nLil Silva\nLil Yase\nLil Rue\nLil Eddie\nLil Kesh\nLil Suzy\nLil Wayne, DJ Drama\nLil Mouse\nLil C\nLil Rick\nLil June\nLil E\nLil Fate\nLil' Flip\n"
],
[
"Lil_kim_popularity = 62\nmore_popular_than_Lil_kim = []\nfor artist in artist_info:\n if artist['popularity'] > Lil_kim_popularity:\n #If yes, let's add them to our list\n print(artist['name'], \"is more popular with a score of\", artist['popularity'])\n more_popular_than_Lil_kim.append(artist['name'])\n else:\n print(artist['name'], \"is less popular with a score of\", artist['popularity'])\nfor artist_name in more_popular_than_Lil_kim:\n print(artist_name)",
"Lil Wayne is more popular with a score of 86\nLil Yachty is more popular with a score of 73\nLil Uzi Vert is more popular with a score of 74\nLil Dicky is more popular with a score of 68\nBoosie Badazz is more popular with a score of 67\nLil Jon is more popular with a score of 72\nKing Lil G is less popular with a score of 61\nLil Durk is less popular with a score of 60\nLil Jon & The East Side Boyz is less popular with a score of 60\nLil Bibby is less popular with a score of 54\nG Herbo is less popular with a score of 53\nLil Rob is less popular with a score of 50\nLil Reese is less popular with a score of 50\nLil Keke is less popular with a score of 48\nBow Wow is less popular with a score of 57\nLil Scrappy is less popular with a score of 49\nLil Wyte is less popular with a score of 50\nLil Blood is less popular with a score of 45\nLil Snupe is less popular with a score of 45\nLil Mama is less popular with a score of 45\nLil B is less popular with a score of 44\nLil' Kim is less popular with a score of 62\nLil Boom is less popular with a score of 43\nLil Cuete is less popular with a score of 40\nLil Phat is less popular with a score of 39\nLil Debbie is less popular with a score of 43\nLil Twist is less popular with a score of 40\nLil Trill is less popular with a score of 37\nLil AJ is less popular with a score of 36\nLil Lonnie is less popular with a score of 37\nLil Twon is less popular with a score of 37\nLil Goofy is less popular with a score of 35\nLil Haiti is less popular with a score of 37\nLil Cray is less popular with a score of 35\nMr. Lil One is less popular with a score of 36\nLil Flash is less popular with a score of 38\nLil Silva is less popular with a score of 43\nLil Yase is less popular with a score of 34\nLil Rue is less popular with a score of 34\nLil Eddie is less popular with a score of 41\nLil Kesh is less popular with a score of 39\nLil Suzy is less popular with a score of 34\nLil Wayne, DJ Drama is less popular with a score of 35\nLil Mouse is less popular with a score of 34\nLil C is less popular with a score of 33\nLil Rick is less popular with a score of 39\nLil June is less popular with a score of 32\nLil E is less popular with a score of 34\nLil Fate is less popular with a score of 34\nLil' Flip is less popular with a score of 50\nLil Wayne\nLil Yachty\nLil Uzi Vert\nLil Dicky\nBoosie Badazz\nLil Jon\n"
]
],
[
[
"Pick two of your favorite Lils to fight it out, and use their IDs to print out their top tracks",
"_____no_output_____"
]
],
[
[
"for artist in artist_info:\n print(artist['name'], artist['id'])",
"Lil Wayne 55Aa2cqylxrFIXC767Z865\nLil Yachty 6icQOAFXDZKsumw3YXyusw\nLil Uzi Vert 4O15NlyKLIASxsJ0PrXPfz\nLil Dicky 1tqhsYv8yBBdwANFNzHtcr\nBoosie Badazz 6z7xFFHxYkE9t8bwIF0Bvg\nLil Jon 7sfl4Xt5KmfyDs2T3SVSMK\nKing Lil G 6L3x3if9RVimruryD9LoFb\nLil Durk 3hcs9uc56yIGFCSy9leWe7\nLil Jon & The East Side Boyz 3ciRvbBIVz9fBoPbtSYq4x\nLil Bibby 4uSN8Y3kgFNVULUWsZEAVW\nG Herbo 5QdEbQJ3ylBnc3gsIASAT5\nLil Rob 7B7TGqQe7QTVm2U6q8jzk1\nLil Reese 1bPxKZtCdjB1aj1csBJpdS\nLil Keke 1grI9x4Uzos1Asx8JmRW6T\nBow Wow 7352aRY2mqSxBZwzUb6LmA\nLil Scrappy 5einkgXXrjhfYCyac1FANB\nLil Wyte 21O7WwRkik43ErKppxDKJq\nLil Blood 74nSA5FdDOuuLw7Rn5JnuP\nLil Snupe 42FaEHFfyxTdZQ5W28dXnj\nLil Mama 5qK5bOC6wLtuLhG5KvU17c\nLil B 4dqh62yIzDBmrMeBOLiP5F\nLil' Kim 5tth2a3v0sWwV1C7bApBdX\nLil Boom 1mmlWsyPJvvxMdabcGJjRn\nLil Cuete 1I5u5Umau1AgHl0ZbPL1oR\nLil Phat 3QnIBUOS4mUzs67rZ8r4c9\nLil Debbie 3FNZcjyqT7F5upP99JV0oN\nLil Twist 564gvOqSRcQoYAhaBpTiK2\nLil Trill 5EQERGi7ffHvHsv3bnqzBn\nLil AJ 2jXwYLNnCxNavms4mc1DYM\nLil Lonnie 6zSBkdKFLKKggDtE3amfCk\nLil Twon 5YZZbPdI7P7te3lW3dTpzK\nLil Goofy 3rWaFjgOi5mjQfllMfN3VI\nLil Haiti 4E9dumwOMLlTyXUp1i2WdI\nLil Cray 43BqexhEx5NKF7VfeOYP9m\nMr. Lil One 6tslWi0BXiDdtChermDzkU\nLil Flash 069qBEK34YGoX7nSIT74Eg\nLil Silva 2Kv0ApBohrL213X9avMrEn\nLil Yase 4vIlHBnzWKbmWe8ZOkT1ZT\nLil Rue 4IFVaKBbEO8Qkurg6nmoc4\nLil Eddie 5CY0QKsbUBpQJIE2yycsYi\nLil Kesh 38XiDu0kK3Z5jdHUDqBzNT\nLil Suzy 5HPsVk1MblCoa44WLJsQwN\nLil Wayne, DJ Drama 65npPa1U4cgobX9wU7Jgpb\nLil Mouse 1cEHxCgGlEgqBc91YOcAEQ\nLil C 69swdLSkKxCQBMYJ55O2mA\nLil Rick 1qKzKUnuQsjB83hBZffoq0\nLil June 3GH3KD2078kLPpEkN1UN26\nLil E 0zn6yzsbWj3EPMgOTqfG5k\nLil Fate 6JUnsP7jmvYmdhbg7lTMQj\nLil' Flip 4Q5sPmM8j4SpMqL4UA1DtS\n"
],
[
"#I chose Lil Fate and Lil' Flip, first I want to figure out the top track of Lil Fate\nresponse = requests.get(\"https://api.spotify.com/v1/artists/6JUnsP7jmvYmdhbg7lTMQj/top-tracks?country=US\")",
"_____no_output_____"
],
[
"print(response.text)",
"{\n \"tracks\" : [ {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"CA\", \"MX\", \"US\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/57AbXDTvGGw2GDC6rrsH2m\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/57AbXDTvGGw2GDC6rrsH2m\",\n \"id\" : \"57AbXDTvGGw2GDC6rrsH2m\",\n \"images\" : [ {\n \"height\" : 635,\n \"url\" : \"https://i.scdn.co/image/624e4bd7bd0a5714d0bc44b30bf5667868365a9d\",\n \"width\" : 640\n }, {\n \"height\" : 297,\n \"url\" : \"https://i.scdn.co/image/f12f98e24945d6c47932878ce6eea91a7bd61f46\",\n \"width\" : 300\n }, {\n \"height\" : 63,\n \"url\" : \"https://i.scdn.co/image/21f753dee667340d202ee2a84be455f31b1c7ec6\",\n \"width\" : 64\n } ],\n \"name\" : \"Ludacris Presents...Disturbing Tha Peace (Explicit Version)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:57AbXDTvGGw2GDC6rrsH2m\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6JUnsP7jmvYmdhbg7lTMQj\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/6JUnsP7jmvYmdhbg7lTMQj\",\n \"id\" : \"6JUnsP7jmvYmdhbg7lTMQj\",\n \"name\" : \"Lil Fate\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6JUnsP7jmvYmdhbg7lTMQj\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6mXlDbi03T8wXYwWYew0Ut\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/6mXlDbi03T8wXYwWYew0Ut\",\n \"id\" : \"6mXlDbi03T8wXYwWYew0Ut\",\n \"name\" : \"Rich Boy\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6mXlDbi03T8wXYwWYew0Ut\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3ppZNqihWOzuH4A0f4KmeP\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/3ppZNqihWOzuH4A0f4KmeP\",\n \"id\" : \"3ppZNqihWOzuH4A0f4KmeP\",\n \"name\" : \"Gangsta Boo\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3ppZNqihWOzuH4A0f4KmeP\"\n } ],\n \"available_markets\" : [ \"CA\", \"MX\", \"US\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 218026,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"USUM70506893\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/60FUCHW3nR5IIftByVjBmB\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/60FUCHW3nR5IIftByVjBmB\",\n \"id\" : \"60FUCHW3nR5IIftByVjBmB\",\n \"name\" : \"Break A N**a Off\",\n \"popularity\" : 20,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/19381ff72ed3a509ed19c72138d2471ce7d377d2\",\n \"track_number\" : 7,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:60FUCHW3nR5IIftByVjBmB\"\n } ]\n}\n"
],
[
"data = response.json()",
"_____no_output_____"
],
[
"type(data)",
"_____no_output_____"
],
[
"data.keys()",
"_____no_output_____"
],
[
"type(data['tracks'])",
"_____no_output_____"
],
[
"print(data['tracks'])",
"[{'popularity': 20, 'disc_number': 1, 'album': {'external_urls': {'spotify': 'https://open.spotify.com/album/57AbXDTvGGw2GDC6rrsH2m'}, 'id': '57AbXDTvGGw2GDC6rrsH2m', 'name': 'Ludacris Presents...Disturbing Tha Peace (Explicit Version)', 'href': 'https://api.spotify.com/v1/albums/57AbXDTvGGw2GDC6rrsH2m', 'uri': 'spotify:album:57AbXDTvGGw2GDC6rrsH2m', 'images': [{'url': 'https://i.scdn.co/image/624e4bd7bd0a5714d0bc44b30bf5667868365a9d', 'width': 640, 'height': 635}, {'url': 'https://i.scdn.co/image/f12f98e24945d6c47932878ce6eea91a7bd61f46', 'width': 300, 'height': 297}, {'url': 'https://i.scdn.co/image/21f753dee667340d202ee2a84be455f31b1c7ec6', 'width': 64, 'height': 63}], 'album_type': 'album', 'available_markets': ['CA', 'MX', 'US'], 'type': 'album'}, 'uri': 'spotify:track:60FUCHW3nR5IIftByVjBmB', 'href': 'https://api.spotify.com/v1/tracks/60FUCHW3nR5IIftByVjBmB', 'external_ids': {'isrc': 'USUM70506893'}, 'explicit': True, 'type': 'track', 'external_urls': {'spotify': 'https://open.spotify.com/track/60FUCHW3nR5IIftByVjBmB'}, 'track_number': 7, 'id': '60FUCHW3nR5IIftByVjBmB', 'available_markets': ['CA', 'MX', 'US'], 'preview_url': 'https://p.scdn.co/mp3-preview/19381ff72ed3a509ed19c72138d2471ce7d377d2', 'artists': [{'external_urls': {'spotify': 'https://open.spotify.com/artist/6JUnsP7jmvYmdhbg7lTMQj'}, 'id': '6JUnsP7jmvYmdhbg7lTMQj', 'uri': 'spotify:artist:6JUnsP7jmvYmdhbg7lTMQj', 'href': 'https://api.spotify.com/v1/artists/6JUnsP7jmvYmdhbg7lTMQj', 'name': 'Lil Fate', 'type': 'artist'}, {'external_urls': {'spotify': 'https://open.spotify.com/artist/6mXlDbi03T8wXYwWYew0Ut'}, 'id': '6mXlDbi03T8wXYwWYew0Ut', 'uri': 'spotify:artist:6mXlDbi03T8wXYwWYew0Ut', 'href': 'https://api.spotify.com/v1/artists/6mXlDbi03T8wXYwWYew0Ut', 'name': 'Rich Boy', 'type': 'artist'}, {'external_urls': {'spotify': 'https://open.spotify.com/artist/3ppZNqihWOzuH4A0f4KmeP'}, 'id': '3ppZNqihWOzuH4A0f4KmeP', 'uri': 'spotify:artist:3ppZNqihWOzuH4A0f4KmeP', 'href': 'https://api.spotify.com/v1/artists/3ppZNqihWOzuH4A0f4KmeP', 'name': 'Gangsta Boo', 'type': 'artist'}], 'duration_ms': 218026, 'name': 'Break A N**a Off'}]\n"
],
[
"data['tracks'][0]",
"_____no_output_____"
],
[
"for item in data['tracks']:\n print(item['name'])\n ",
"Break A N**a Off\n"
],
[
"# now to figure out the top track of Lil' Flip #things within {} or ALL Caps means to replace them\nresponse = requests.get(\"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS/top-tracks?country=US\")",
"_____no_output_____"
],
[
"print(response.text)",
"{\n \"tracks\" : [ {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"BO\", \"BR\", \"CL\", \"CO\", \"CR\", \"DO\", \"EC\", \"SV\", \"GT\", \"HN\", \"HK\", \"MY\", \"MX\", \"NI\", \"PA\", \"PY\", \"PE\", \"PH\", \"SG\", \"TW\", \"UY\", \"US\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/548NoYLgqSBDTNIYvlpDu5\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/548NoYLgqSBDTNIYvlpDu5\",\n \"id\" : \"548NoYLgqSBDTNIYvlpDu5\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/a0a3bb94e5f7915442b5af900b0ca94013f324b9\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/0baa7b606c15c59dea157d7963b352153dc74ad6\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/9936297babae30943e0d1580e890a397533f8fce\",\n \"width\" : 64\n } ],\n \"name\" : \"U Gotta Feel Me\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:548NoYLgqSBDTNIYvlpDu5\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4tAhhPPEWcszcMjhYROUvx\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4tAhhPPEWcszcMjhYROUvx\",\n \"id\" : \"4tAhhPPEWcszcMjhYROUvx\",\n \"name\" : \"Lea\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4tAhhPPEWcszcMjhYROUvx\"\n } ],\n \"available_markets\" : [ \"AR\", \"BO\", \"BR\", \"CL\", \"CO\", \"CR\", \"DO\", \"EC\", \"SV\", \"GT\", \"HN\", \"HK\", \"MY\", \"MX\", \"NI\", \"PA\", \"PY\", \"PE\", \"PH\", \"SG\", \"TW\", \"UY\", \"US\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 225173,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"USSM10402601\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/4s0o8TJHfX9LLHa0umnOzT\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/4s0o8TJHfX9LLHa0umnOzT\",\n \"id\" : \"4s0o8TJHfX9LLHa0umnOzT\",\n \"name\" : \"Sunshine - Explicit Album Version\",\n \"popularity\" : 48,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/60b171dd286b969d956832a2dff544f70875af46\",\n \"track_number\" : 12,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:4s0o8TJHfX9LLHa0umnOzT\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"BO\", \"BR\", \"CL\", \"CO\", \"CR\", \"DO\", \"EC\", \"SV\", \"GT\", \"HN\", \"HK\", \"MY\", \"MX\", \"NI\", \"PA\", \"PY\", \"PE\", \"PH\", \"SG\", \"TW\", \"UY\", \"US\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/548NoYLgqSBDTNIYvlpDu5\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/548NoYLgqSBDTNIYvlpDu5\",\n \"id\" : \"548NoYLgqSBDTNIYvlpDu5\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/a0a3bb94e5f7915442b5af900b0ca94013f324b9\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/0baa7b606c15c59dea157d7963b352153dc74ad6\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/9936297babae30943e0d1580e890a397533f8fce\",\n \"width\" : 64\n } ],\n \"name\" : \"U Gotta Feel Me\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:548NoYLgqSBDTNIYvlpDu5\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n } ],\n \"available_markets\" : [ \"AR\", \"BO\", \"BR\", \"CL\", \"CO\", \"CR\", \"DO\", \"EC\", \"SV\", \"GT\", \"HN\", \"HK\", \"MY\", \"MX\", \"NI\", \"PA\", \"PY\", \"PE\", \"PH\", \"SG\", \"TW\", \"UY\", \"US\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 232466,\n \"explicit\" : false,\n \"external_ids\" : {\n \"isrc\" : \"USSM10412976\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/79lmvU7Qmc8QpXilbSk37z\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/79lmvU7Qmc8QpXilbSk37z\",\n \"id\" : \"79lmvU7Qmc8QpXilbSk37z\",\n \"name\" : \"Game Over\",\n \"popularity\" : 47,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/551707a49d5da4f1991fa833315e36ea706522d0\",\n \"track_number\" : 5,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:79lmvU7Qmc8QpXilbSk37z\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/5GkzesERHAJvYGw3L5r4qm\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/5GkzesERHAJvYGw3L5r4qm\",\n \"id\" : \"5GkzesERHAJvYGw3L5r4qm\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/076898ce20b70260b69aaac725fe4f9b74388332\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/977a2748d9fe44c58888e5f9177a0c83d5e38f28\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/efff45f885d2092e7fd777765a9f3e559d99291a\",\n \"width\" : 64\n } ],\n \"name\" : \"Undaground Legend (Explicit)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:5GkzesERHAJvYGw3L5r4qm\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 283733,\n \"explicit\" : false,\n \"external_ids\" : {\n \"isrc\" : \"USLR50200160\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/5FEBritagmW6iAy5wL5uXg\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/5FEBritagmW6iAy5wL5uXg\",\n \"id\" : \"5FEBritagmW6iAy5wL5uXg\",\n \"name\" : \"The Way We Ball\",\n \"popularity\" : 46,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/7cf1b05d73d9743a4a3d57d9872acadcf26716a2\",\n \"track_number\" : 6,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:5FEBritagmW6iAy5wL5uXg\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/3d6QaK8uJtUuPcZIX7dLcD\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/3d6QaK8uJtUuPcZIX7dLcD\",\n \"id\" : \"3d6QaK8uJtUuPcZIX7dLcD\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/671d3ef31ffe838ef93a5f8add2efae90dfa745e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5975a3ca58c88c5ced65fac2ec55fb481bd4813a\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/962cbf22887bc88a1ee98587a22927a721ab6872\",\n \"width\" : 64\n } ],\n \"name\" : \"Soldiers United for Cash\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:3d6QaK8uJtUuPcZIX7dLcD\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6TC6ZeVdvCuBSn32h5Msul\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/6TC6ZeVdvCuBSn32h5Msul\",\n \"id\" : \"6TC6ZeVdvCuBSn32h5Msul\",\n \"name\" : \"DJ Screw\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6TC6ZeVdvCuBSn32h5Msul\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0enCBdwJXAIvtsM97ZnHEM\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/0enCBdwJXAIvtsM97ZnHEM\",\n \"id\" : \"0enCBdwJXAIvtsM97ZnHEM\",\n \"name\" : \"Big Shasta\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0enCBdwJXAIvtsM97ZnHEM\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 321906,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"US38L0601854\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/0GoNg4tWzPFczRhguAZwnc\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/0GoNg4tWzPFczRhguAZwnc\",\n \"id\" : \"0GoNg4tWzPFczRhguAZwnc\",\n \"name\" : \"Sunny Day\",\n \"popularity\" : 39,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/c881df2ab92ac958ddac552f34545fafe97be93b\",\n \"track_number\" : 3,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:0GoNg4tWzPFczRhguAZwnc\"\n }, {\n \"album\" : {\n \"album_type\" : \"single\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/1AXC2oWg0mQEkxmvp0qMhY\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/1AXC2oWg0mQEkxmvp0qMhY\",\n \"id\" : \"1AXC2oWg0mQEkxmvp0qMhY\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/2b2a11a27eaa78de89312d163144f2cefc3cfdda\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/4d7078b0fa07008566a882f725f3100194be1936\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/876077b0d98940687d8f16c89d1729e0e6d90095\",\n \"width\" : 64\n } ],\n \"name\" : \"Sunshine / Game Over (Re-Recorded / Remastered Versions)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:1AXC2oWg0mQEkxmvp0qMhY\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 225319,\n \"explicit\" : false,\n \"external_ids\" : {\n \"isrc\" : \"USA371044317\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/5VSnk53xAO9BmquVUqGZbV\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/5VSnk53xAO9BmquVUqGZbV\",\n \"id\" : \"5VSnk53xAO9BmquVUqGZbV\",\n \"name\" : \"Sunshine (Re-Recorded / Remastered)\",\n \"popularity\" : 31,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/5929c22038a712b68d98189a2aa0e05daa749058\",\n \"track_number\" : 1,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:5VSnk53xAO9BmquVUqGZbV\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/68ojNoWMmbXgOkG3wDvK2S\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/68ojNoWMmbXgOkG3wDvK2S\",\n \"id\" : \"68ojNoWMmbXgOkG3wDvK2S\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/90bfa4c55892613e553ca3ad230952f5c06974ac\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/4d22a3e5d49669d6c989f66b367bd6ada8e0fdd3\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/47aa5c93ccb7f23a17e3a14c867459e2b8522619\",\n \"width\" : 64\n } ],\n \"name\" : \"Best of Lil Flip, Vol. 1\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:68ojNoWMmbXgOkG3wDvK2S\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4PY2b4x0BfB6srqUxCWLPo\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4PY2b4x0BfB6srqUxCWLPo\",\n \"id\" : \"4PY2b4x0BfB6srqUxCWLPo\",\n \"name\" : \"Will Lean\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4PY2b4x0BfB6srqUxCWLPo\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/2RdwBSPQiwcmiDo9kixcl8\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/2RdwBSPQiwcmiDo9kixcl8\",\n \"id\" : \"2RdwBSPQiwcmiDo9kixcl8\",\n \"name\" : \"Pharrell Williams\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:2RdwBSPQiwcmiDo9kixcl8\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7jFaoqWPhYLrKzjzlpXmUO\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/7jFaoqWPhYLrKzjzlpXmUO\",\n \"id\" : \"7jFaoqWPhYLrKzjzlpXmUO\",\n \"name\" : \"David Banner\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7jFaoqWPhYLrKzjzlpXmUO\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/45a6gCQWq61lIUDmr1tKuO\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/45a6gCQWq61lIUDmr1tKuO\",\n \"id\" : \"45a6gCQWq61lIUDmr1tKuO\",\n \"name\" : \"Bun B\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:45a6gCQWq61lIUDmr1tKuO\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0jslZSHX4gukh5miuzDJPj\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/0jslZSHX4gukh5miuzDJPj\",\n \"id\" : \"0jslZSHX4gukh5miuzDJPj\",\n \"name\" : \"Yung Redd\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0jslZSHX4gukh5miuzDJPj\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0PHPjHrN5AXFHtGOEPWH5h\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/0PHPjHrN5AXFHtGOEPWH5h\",\n \"id\" : \"0PHPjHrN5AXFHtGOEPWH5h\",\n \"name\" : \"The Clover G's\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0PHPjHrN5AXFHtGOEPWH5h\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5Jz9kKRnCRLTodCH58MyB4\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/5Jz9kKRnCRLTodCH58MyB4\",\n \"id\" : \"5Jz9kKRnCRLTodCH58MyB4\",\n \"name\" : \"Daz Dillinger\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5Jz9kKRnCRLTodCH58MyB4\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 199413,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"QMDA71468884\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/0MoRTalVQ1zPdR5HucLJrP\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/0MoRTalVQ1zPdR5HucLJrP\",\n \"id\" : \"0MoRTalVQ1zPdR5HucLJrP\",\n \"name\" : \"Sunshine\",\n \"popularity\" : 31,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/1896804fb3b5732bcb161af233c7f746849e94b7\",\n \"track_number\" : 8,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:0MoRTalVQ1zPdR5HucLJrP\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/5D6LPJOfjZq1eeD6YRamHZ\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/5D6LPJOfjZq1eeD6YRamHZ\",\n \"id\" : \"5D6LPJOfjZq1eeD6YRamHZ\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/79c0bbe8e99e834202538a12329267783ec7539e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/2ddd3497ddfb47f5f26ad8cde66fe015c4f5419a\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/4eef21614f5d3e268fc565f0084bff6f5ecc26ff\",\n \"width\" : 64\n } ],\n \"name\" : \"The Leprechaun (Original Version)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:5D6LPJOfjZq1eeD6YRamHZ\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 218213,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"USQY51030501\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/7myPmGUKJJKtASZSVaim8w\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/7myPmGUKJJKtASZSVaim8w\",\n \"id\" : \"7myPmGUKJJKtASZSVaim8w\",\n \"name\" : \"I Can Do Dat\",\n \"popularity\" : 30,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/b86b2744a54f89f399c800ff990a9dbd87eb674d\",\n \"track_number\" : 20,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:7myPmGUKJJKtASZSVaim8w\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/3d6QaK8uJtUuPcZIX7dLcD\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/3d6QaK8uJtUuPcZIX7dLcD\",\n \"id\" : \"3d6QaK8uJtUuPcZIX7dLcD\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/671d3ef31ffe838ef93a5f8add2efae90dfa745e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5975a3ca58c88c5ced65fac2ec55fb481bd4813a\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/962cbf22887bc88a1ee98587a22927a721ab6872\",\n \"width\" : 64\n } ],\n \"name\" : \"Soldiers United for Cash\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:3d6QaK8uJtUuPcZIX7dLcD\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6TC6ZeVdvCuBSn32h5Msul\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/6TC6ZeVdvCuBSn32h5Msul\",\n \"id\" : \"6TC6ZeVdvCuBSn32h5Msul\",\n \"name\" : \"DJ Screw\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6TC6ZeVdvCuBSn32h5Msul\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4LrhGO12fXPf1SCL0FTbTl\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4LrhGO12fXPf1SCL0FTbTl\",\n \"id\" : \"4LrhGO12fXPf1SCL0FTbTl\",\n \"name\" : \"H.A.W.K.\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4LrhGO12fXPf1SCL0FTbTl\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1DlbW0TOOja6uqR4CHAaeg\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/1DlbW0TOOja6uqR4CHAaeg\",\n \"id\" : \"1DlbW0TOOja6uqR4CHAaeg\",\n \"name\" : \"Grace\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1DlbW0TOOja6uqR4CHAaeg\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0SbFHrkqd2aTNDj6iX6ZC4\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/0SbFHrkqd2aTNDj6iX6ZC4\",\n \"id\" : \"0SbFHrkqd2aTNDj6iX6ZC4\",\n \"name\" : \"Ronnie Spencer\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0SbFHrkqd2aTNDj6iX6ZC4\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MY\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PH\", \"PL\", \"PT\", \"SG\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\", \"ID\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 387066,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"US38L0601853\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/2GkEMPh6RQnY8Gub6SHwMz\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/2GkEMPh6RQnY8Gub6SHwMz\",\n \"id\" : \"2GkEMPh6RQnY8Gub6SHwMz\",\n \"name\" : \"4 My Nigga Screw\",\n \"popularity\" : 29,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/82b05306c64ce7977f338a434d183637ab3adfcb\",\n \"track_number\" : 2,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:2GkEMPh6RQnY8Gub6SHwMz\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/5GkzesERHAJvYGw3L5r4qm\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/5GkzesERHAJvYGw3L5r4qm\",\n \"id\" : \"5GkzesERHAJvYGw3L5r4qm\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/076898ce20b70260b69aaac725fe4f9b74388332\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/977a2748d9fe44c58888e5f9177a0c83d5e38f28\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/efff45f885d2092e7fd777765a9f3e559d99291a\",\n \"width\" : 64\n } ],\n \"name\" : \"Undaground Legend (Explicit)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:5GkzesERHAJvYGw3L5r4qm\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/2HbHQSKQ1D7a5SIT2axDrw\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/2HbHQSKQ1D7a5SIT2axDrw\",\n \"id\" : \"2HbHQSKQ1D7a5SIT2axDrw\",\n \"name\" : \"Seville\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:2HbHQSKQ1D7a5SIT2axDrw\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 214640,\n \"explicit\" : true,\n \"external_ids\" : {\n \"isrc\" : \"USLR50200077\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/0f8MdxCsEEfEPaREwGyb9G\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/0f8MdxCsEEfEPaREwGyb9G\",\n \"id\" : \"0f8MdxCsEEfEPaREwGyb9G\",\n \"name\" : \"I Shoulda Listened - Explicit Album Version\",\n \"popularity\" : 28,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/44aa72fe6bfd25b06221f731b85c1f2f0439e799\",\n \"track_number\" : 4,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:0f8MdxCsEEfEPaREwGyb9G\"\n }, {\n \"album\" : {\n \"album_type\" : \"album\",\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/album/5GkzesERHAJvYGw3L5r4qm\"\n },\n \"href\" : \"https://api.spotify.com/v1/albums/5GkzesERHAJvYGw3L5r4qm\",\n \"id\" : \"5GkzesERHAJvYGw3L5r4qm\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/076898ce20b70260b69aaac725fe4f9b74388332\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/977a2748d9fe44c58888e5f9177a0c83d5e38f28\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/efff45f885d2092e7fd777765a9f3e559d99291a\",\n \"width\" : 64\n } ],\n \"name\" : \"Undaground Legend (Explicit)\",\n \"type\" : \"album\",\n \"uri\" : \"spotify:album:5GkzesERHAJvYGw3L5r4qm\"\n },\n \"artists\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4Q5sPmM8j4SpMqL4UA1DtS\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/4Q5sPmM8j4SpMqL4UA1DtS\",\n \"id\" : \"4Q5sPmM8j4SpMqL4UA1DtS\",\n \"name\" : \"Lil' Flip\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4Q5sPmM8j4SpMqL4UA1DtS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/0lr4HDFjHHRA6yZIr7iLcv\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/0lr4HDFjHHRA6yZIr7iLcv\",\n \"id\" : \"0lr4HDFjHHRA6yZIr7iLcv\",\n \"name\" : \"Young Redd\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:0lr4HDFjHHRA6yZIr7iLcv\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3yqkcBw5hWzsktIsaWiKHz\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/3yqkcBw5hWzsktIsaWiKHz\",\n \"id\" : \"3yqkcBw5hWzsktIsaWiKHz\",\n \"name\" : \"Lil Ron\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3yqkcBw5hWzsktIsaWiKHz\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6DV6fhUbgeRpV2dnnNwws2\"\n },\n \"href\" : \"https://api.spotify.com/v1/artists/6DV6fhUbgeRpV2dnnNwws2\",\n \"id\" : \"6DV6fhUbgeRpV2dnnNwws2\",\n \"name\" : \"Big T\",\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6DV6fhUbgeRpV2dnnNwws2\"\n } ],\n \"available_markets\" : [ \"AR\", \"AU\", \"AT\", \"BE\", \"BO\", \"BR\", \"BG\", \"CA\", \"CL\", \"CO\", \"CR\", \"CY\", \"CZ\", \"DK\", \"DO\", \"DE\", \"EC\", \"EE\", \"SV\", \"FI\", \"FR\", \"GR\", \"GT\", \"HN\", \"HK\", \"HU\", \"IS\", \"IE\", \"IT\", \"LV\", \"LT\", \"LU\", \"MT\", \"MX\", \"NL\", \"NZ\", \"NI\", \"NO\", \"PA\", \"PY\", \"PE\", \"PL\", \"PT\", \"SK\", \"ES\", \"SE\", \"CH\", \"TW\", \"TR\", \"UY\", \"US\", \"GB\", \"AD\", \"LI\", \"MC\" ],\n \"disc_number\" : 1,\n \"duration_ms\" : 269266,\n \"explicit\" : false,\n \"external_ids\" : {\n \"isrc\" : \"USLR50200074\"\n },\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/track/20SSby0PIw7HpgvFoI6ZaH\"\n },\n \"href\" : \"https://api.spotify.com/v1/tracks/20SSby0PIw7HpgvFoI6ZaH\",\n \"id\" : \"20SSby0PIw7HpgvFoI6ZaH\",\n \"name\" : \"What I Been Through\",\n \"popularity\" : 27,\n \"preview_url\" : \"https://p.scdn.co/mp3-preview/5613a5cc52e01d756df118e5a6e2f83ae6e0a98f\",\n \"track_number\" : 1,\n \"type\" : \"track\",\n \"uri\" : \"spotify:track:20SSby0PIw7HpgvFoI6ZaH\"\n } ]\n}\n"
],
[
"data = response.json()",
"_____no_output_____"
],
[
"type(data)",
"_____no_output_____"
],
[
"data.keys()",
"_____no_output_____"
],
[
"type(data['tracks'])",
"_____no_output_____"
],
[
"for item in data['tracks']:\n #type(item): dict\n #print(item.keys()), saw 'name'\n print(item['name'])",
"Sunshine - Explicit Album Version\nGame Over\nThe Way We Ball\nSunny Day\nSunshine (Re-Recorded / Remastered)\nSunshine\nI Can Do Dat\n4 My Nigga Screw\nI Shoulda Listened - Explicit Album Version\nWhat I Been Through\n"
]
],
[
[
"##Will the world explode if a musicians swears? Get an average popularity for their explicit songs vs. their non-explicit songs. How many minutes of explicit songs do they have? Non-explicit?",
"_____no_output_____"
]
],
[
[
"#for Lil' fate's top tracks\nexplicit_count = 0\nnon_explicit_count = 0\npopularity_explicit = 0\npopularity_non_explicit = 0\nminutes_explicit = 0\nminutes_non_explicit = 0\nfor track in data['tracks']:\n if track['explicit']== True:\n \n explicit_count = explicit_count + 1\n popularity_explicit = popularity_explicit + track['popularity']\n minutes_explicit = minutes_explicit + track['duration_ms']\n \n elif track['explicit']== False:\n non_explicit_count = non_explicit_count + 1\n popularity_non_explicit = popularity_non_explicit + track['popularity']\n minutes_non_explicit = minutes_non_explicit + track['duration_ms']\n\nprint(\"Lil' Flip has\", (minutes_explicit/1000)/60, \"of explicit songs\")\nprint(\"Lil' Flip has\", (minutes_non_explicit/1000)/60, \"of non-explicit songs\")\nprint(\"The average popularity of Lil' Flip explicits songs is\", popularity_explicit/explicit_count)\nprint(\"The average popularity of Lil' Flip non-explicits songs is\", popularity_non_explicit/non_explicit_count)",
"Lil' Flip has 26.10685 of explicit songs\nLil' Flip has 16.8464 of non-explicit songs\nThe average popularity of Lil' Flip explicits songs is 34.166666666666664\nThe average popularity of Lil' Flip non-explicits songs is 37.75\n"
]
],
[
[
"Since we're talking about Lils, what about Biggies? How many total \"Biggie\" artists are there? How many total \"Lil\"s? If you made 1 request every 5 seconds, how long would it take to download information on all the Lils vs the Biggies?",
"_____no_output_____"
]
],
[
[
"response = requests.get('https://api.spotify.com/v1/search?q=Lil&type=artist&market=US')\nall_lil = response.json()",
"_____no_output_____"
],
[
"print(response.text)",
"{\n \"artists\" : {\n \"href\" : \"https://api.spotify.com/v1/search?query=Lil&offset=0&limit=20&type=artist&market=US\",\n \"items\" : [ {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/55Aa2cqylxrFIXC767Z865\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 2628946\n },\n \"genres\" : [ \"dirty south rap\", \"pop rap\", \"southern hip hop\", \"trap music\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/55Aa2cqylxrFIXC767Z865\",\n \"id\" : \"55Aa2cqylxrFIXC767Z865\",\n \"images\" : [ {\n \"height\" : 1239,\n \"url\" : \"https://i.scdn.co/image/cf012139c3b8681b46a66bae70558a8a336ab231\",\n \"width\" : 1000\n }, {\n \"height\" : 793,\n \"url\" : \"https://i.scdn.co/image/fffd48d60e27901f6e9ce99423f045cb2b893944\",\n \"width\" : 640\n }, {\n \"height\" : 248,\n \"url\" : \"https://i.scdn.co/image/bf03141629c202e94b206f1374a39326a9d8c6ca\",\n \"width\" : 200\n }, {\n \"height\" : 79,\n \"url\" : \"https://i.scdn.co/image/521f99f2469883b8806a69a3a2487fdd983bd621\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Wayne\",\n \"popularity\" : 86,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:55Aa2cqylxrFIXC767Z865\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6icQOAFXDZKsumw3YXyusw\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 40628\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6icQOAFXDZKsumw3YXyusw\",\n \"id\" : \"6icQOAFXDZKsumw3YXyusw\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/add25baa69fc7bfd9cfd5d87716941028c2d6736\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/3f8205117bdd028a648ad3fc925f9fb46dfa26fa\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/ccc54e2911dbc5463acb401ee61489e27d991408\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Yachty\",\n \"popularity\" : 73,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6icQOAFXDZKsumw3YXyusw\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4O15NlyKLIASxsJ0PrXPfz\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 60405\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4O15NlyKLIASxsJ0PrXPfz\",\n \"id\" : \"4O15NlyKLIASxsJ0PrXPfz\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/8c02344d1cb9069a5a2a9d1e860dc88b04088549\",\n \"width\" : 640\n }, {\n \"height\" : 320,\n \"url\" : \"https://i.scdn.co/image/28ac78387ad26048ccab0b671cbaddb30a2b52da\",\n \"width\" : 320\n }, {\n \"height\" : 160,\n \"url\" : \"https://i.scdn.co/image/6b074e198860470024e57ebbc1dda9f58088c506\",\n \"width\" : 160\n } ],\n \"name\" : \"Lil Uzi Vert\",\n \"popularity\" : 74,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4O15NlyKLIASxsJ0PrXPfz\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1tqhsYv8yBBdwANFNzHtcr\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 228488\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1tqhsYv8yBBdwANFNzHtcr\",\n \"id\" : \"1tqhsYv8yBBdwANFNzHtcr\",\n \"images\" : [ {\n \"height\" : 1000,\n \"url\" : \"https://i.scdn.co/image/a9c000526b14038b1fe69c72b0775f125bdf08af\",\n \"width\" : 1000\n }, {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/31eac6ae8bdd6909236b5fd729d17406cc794e2d\",\n \"width\" : 640\n }, {\n \"height\" : 200,\n \"url\" : \"https://i.scdn.co/image/24dcb67ddd3afc794a4b1dab4cc1a47035a0beab\",\n \"width\" : 200\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/2d2ebd85f676535129dbb7c3a4bb96e7bfd940a7\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Dicky\",\n \"popularity\" : 68,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1tqhsYv8yBBdwANFNzHtcr\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6z7xFFHxYkE9t8bwIF0Bvg\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 221080\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6z7xFFHxYkE9t8bwIF0Bvg\",\n \"id\" : \"6z7xFFHxYkE9t8bwIF0Bvg\",\n \"images\" : [ {\n \"height\" : 667,\n \"url\" : \"https://i.scdn.co/image/f89376b78fe94a1692a5768f8f3440a4397bfb17\",\n \"width\" : 1000\n }, {\n \"height\" : 427,\n \"url\" : \"https://i.scdn.co/image/fbf5353d4410a540cc74285d387d9e59d038592a\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/39995515de01dc9eb91bc9c17d5c1921e7e54a1f\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/b34f525381a78c72f423d74b76a47e1a1da9f7f8\",\n \"width\" : 64\n } ],\n \"name\" : \"Boosie Badazz\",\n \"popularity\" : 67,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6z7xFFHxYkE9t8bwIF0Bvg\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7sfl4Xt5KmfyDs2T3SVSMK\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 256611\n },\n \"genres\" : [ \"crunk\", \"dirty south rap\", \"southern hip hop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7sfl4Xt5KmfyDs2T3SVSMK\",\n \"id\" : \"7sfl4Xt5KmfyDs2T3SVSMK\",\n \"images\" : [ {\n \"height\" : 664,\n \"url\" : \"https://i.scdn.co/image/885941564eadf27b7ee86d089e87967f9e3cf612\",\n \"width\" : 1000\n }, {\n \"height\" : 425,\n \"url\" : \"https://i.scdn.co/image/b5495566665b41f3dc2560d37d043e4a3dc2ca41\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/6ea9f92a43e23eaa7ced98d8773de37229b1410d\",\n \"width\" : 200\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/ddef386b560619f296a27059874ad3fc7fd5d85d\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Jon\",\n \"popularity\" : 72,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7sfl4Xt5KmfyDs2T3SVSMK\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/6L3x3if9RVimruryD9LoFb\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 64821\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/6L3x3if9RVimruryD9LoFb\",\n \"id\" : \"6L3x3if9RVimruryD9LoFb\",\n \"images\" : [ {\n \"height\" : 879,\n \"url\" : \"https://i.scdn.co/image/8942e9c0745697fa8e3e75f02aa461d722a0519d\",\n \"width\" : 587\n }, {\n \"height\" : 299,\n \"url\" : \"https://i.scdn.co/image/9fa49263a60cd27888e23b6c6c10c930af48114e\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/c11e5e1e9d21cee430c1bd7c72e387422854bd6a\",\n \"width\" : 64\n } ],\n \"name\" : \"King Lil G\",\n \"popularity\" : 61,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:6L3x3if9RVimruryD9LoFb\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3hcs9uc56yIGFCSy9leWe7\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 134729\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3hcs9uc56yIGFCSy9leWe7\",\n \"id\" : \"3hcs9uc56yIGFCSy9leWe7\",\n \"images\" : [ {\n \"height\" : 426,\n \"url\" : \"https://i.scdn.co/image/2b83f7df57f9098558c63047c494dea26f2da67e\",\n \"width\" : 999\n }, {\n \"height\" : 273,\n \"url\" : \"https://i.scdn.co/image/42e0d88103ed677b9a6cfa426e53428127ae903d\",\n \"width\" : 640\n }, {\n \"height\" : 85,\n \"url\" : \"https://i.scdn.co/image/b127461c288b3777fd18ffcd3523856b6063ea1e\",\n \"width\" : 199\n }, {\n \"height\" : 27,\n \"url\" : \"https://i.scdn.co/image/3674b105e3a72fbb92794029846a43dc66b2fcab\",\n \"width\" : 63\n } ],\n \"name\" : \"Lil Durk\",\n \"popularity\" : 60,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3hcs9uc56yIGFCSy9leWe7\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/3ciRvbBIVz9fBoPbtSYq4x\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 17135\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/3ciRvbBIVz9fBoPbtSYq4x\",\n \"id\" : \"3ciRvbBIVz9fBoPbtSYq4x\",\n \"images\" : [ {\n \"height\" : 500,\n \"url\" : \"https://i.scdn.co/image/aafc4156598fa9f8f052ec5687e648ba9120f07e\",\n \"width\" : 554\n }, {\n \"height\" : 181,\n \"url\" : \"https://i.scdn.co/image/7a9ccdaebabf83f763af6664d5d483c57332bc08\",\n \"width\" : 200\n }, {\n \"height\" : 58,\n \"url\" : \"https://i.scdn.co/image/e74083480033e85373d3deb546f16d8beedeccb3\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Jon & The East Side Boyz\",\n \"popularity\" : 60,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:3ciRvbBIVz9fBoPbtSYq4x\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/4uSN8Y3kgFNVULUWsZEAVW\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 44459\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/4uSN8Y3kgFNVULUWsZEAVW\",\n \"id\" : \"4uSN8Y3kgFNVULUWsZEAVW\",\n \"images\" : [ {\n \"height\" : 1000,\n \"url\" : \"https://i.scdn.co/image/07c75abe717a9b704083ef38c4446abbff10fda5\",\n \"width\" : 1000\n }, {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/1903fd19c7279418c71da62aa02ce47cccf63e52\",\n \"width\" : 640\n }, {\n \"height\" : 200,\n \"url\" : \"https://i.scdn.co/image/9c37f8c40ab3594de42f1861f592f558f91d0f51\",\n \"width\" : 200\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/efba595d34603b014b125d65f7851103185158b4\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Bibby\",\n \"popularity\" : 54,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:4uSN8Y3kgFNVULUWsZEAVW\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5QdEbQJ3ylBnc3gsIASAT5\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 51939\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/5QdEbQJ3ylBnc3gsIASAT5\",\n \"id\" : \"5QdEbQJ3ylBnc3gsIASAT5\",\n \"images\" : [ {\n \"height\" : 667,\n \"url\" : \"https://i.scdn.co/image/2cb955d0b6d08e1ff70cff98b332f6debf7a8e4a\",\n \"width\" : 1000\n }, {\n \"height\" : 427,\n \"url\" : \"https://i.scdn.co/image/72667af5dfd57266ba7348bbec97c246986bdbfe\",\n \"width\" : 640\n }, {\n \"height\" : 133,\n \"url\" : \"https://i.scdn.co/image/f366a759361f875f6259ef805c76e39ff3dd754c\",\n \"width\" : 199\n }, {\n \"height\" : 43,\n \"url\" : \"https://i.scdn.co/image/d7b0cd61112a7b8b6326c6454652685c1d1baa1c\",\n \"width\" : 64\n } ],\n \"name\" : \"G Herbo\",\n \"popularity\" : 53,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5QdEbQJ3ylBnc3gsIASAT5\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7B7TGqQe7QTVm2U6q8jzk1\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 36011\n },\n \"genres\" : [ \"chicano rap\", \"latin hip hop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7B7TGqQe7QTVm2U6q8jzk1\",\n \"id\" : \"7B7TGqQe7QTVm2U6q8jzk1\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/7b37dc3ed21b4236502d24a897ac02aa4eb9f183\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/457e18474f5cf18eae93e1435dcc5d2fb88c8efd\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/8e7c25760b9b5d6dbc58ebc30443114fdfdfb927\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Rob\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7B7TGqQe7QTVm2U6q8jzk1\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1bPxKZtCdjB1aj1csBJpdS\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 23929\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1bPxKZtCdjB1aj1csBJpdS\",\n \"id\" : \"1bPxKZtCdjB1aj1csBJpdS\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/c3f33bf2d8bc3e00d0d82fd9e2a11c0594079833\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/6535600354e3ff225b5704ab3c9b4a4033746fb1\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/ba89cf9b97304f9f07132e8bb06293170109b64b\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Reese\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1bPxKZtCdjB1aj1csBJpdS\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/1grI9x4Uzos1Asx8JmRW6T\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 18853\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/1grI9x4Uzos1Asx8JmRW6T\",\n \"id\" : \"1grI9x4Uzos1Asx8JmRW6T\",\n \"images\" : [ {\n \"height\" : 1024,\n \"url\" : \"https://i.scdn.co/image/3e53d37d29794eccb5fc9744b962df8f2c2b1725\",\n \"width\" : 680\n }, {\n \"height\" : 964,\n \"url\" : \"https://i.scdn.co/image/82bb674230d0b08e5c82e10dfe175759581e7800\",\n \"width\" : 640\n }, {\n \"height\" : 301,\n \"url\" : \"https://i.scdn.co/image/6f26c9f3aee5c6243f2abe210ab09446df90276b\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/35fd540d7448475f46e06bc0b46f2ca106899910\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Keke\",\n \"popularity\" : 48,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:1grI9x4Uzos1Asx8JmRW6T\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/7352aRY2mqSxBZwzUb6LmA\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 118838\n },\n \"genres\" : [ \"hip pop\", \"pop rap\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/7352aRY2mqSxBZwzUb6LmA\",\n \"id\" : \"7352aRY2mqSxBZwzUb6LmA\",\n \"images\" : [ {\n \"height\" : 1500,\n \"url\" : \"https://i.scdn.co/image/bbc23f477201e3784b54516ef2ad548794947277\",\n \"width\" : 1000\n }, {\n \"height\" : 960,\n \"url\" : \"https://i.scdn.co/image/4014b68d6e33d16883c70aab0972087d38e8896d\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/5d3a1e94fb0fe5cf2dfb600cd7e55e8213025968\",\n \"width\" : 200\n }, {\n \"height\" : 96,\n \"url\" : \"https://i.scdn.co/image/6799537642674ef52cf0064aaef74cf04202c301\",\n \"width\" : 64\n } ],\n \"name\" : \"Bow Wow\",\n \"popularity\" : 57,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:7352aRY2mqSxBZwzUb6LmA\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5einkgXXrjhfYCyac1FANB\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 27171\n },\n \"genres\" : [ \"crunk\", \"dirty south rap\", \"southern hip hop\", \"trap music\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5einkgXXrjhfYCyac1FANB\",\n \"id\" : \"5einkgXXrjhfYCyac1FANB\",\n \"images\" : [ {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/722a084be153a03ca1bfb0c1e7c83bd4d37db156\",\n \"width\" : 225\n }, {\n \"height\" : 267,\n \"url\" : \"https://i.scdn.co/image/9c68dc0bb9b147bd31cb13a7b1e1d95acf481a90\",\n \"width\" : 200\n }, {\n \"height\" : 85,\n \"url\" : \"https://i.scdn.co/image/96df8040ad3c03f9471139786c4ea60f3998ca81\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Scrappy\",\n \"popularity\" : 49,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5einkgXXrjhfYCyac1FANB\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/21O7WwRkik43ErKppxDKJq\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 31239\n },\n \"genres\" : [ \"juggalo\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/21O7WwRkik43ErKppxDKJq\",\n \"id\" : \"21O7WwRkik43ErKppxDKJq\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/01140761147a97db6a100c4456b531fb2d5aad82\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/0925d6476f14719b5ffd005fe0091e292c95e11e\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b232b4badce8651c11907c06ed6defcfc5616854\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Wyte\",\n \"popularity\" : 50,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:21O7WwRkik43ErKppxDKJq\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/74nSA5FdDOuuLw7Rn5JnuP\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 5560\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/74nSA5FdDOuuLw7Rn5JnuP\",\n \"id\" : \"74nSA5FdDOuuLw7Rn5JnuP\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/fc222056c3c65e02c96c3e94847a74ba7920757e\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/052a2ef46226fa25801224fd676ba4abbb7da15a\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b3a4a57f6da39a5af2b2c56479819754caa51d35\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Blood\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:74nSA5FdDOuuLw7Rn5JnuP\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/42FaEHFfyxTdZQ5W28dXnj\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 34152\n },\n \"genres\" : [ ],\n \"href\" : \"https://api.spotify.com/v1/artists/42FaEHFfyxTdZQ5W28dXnj\",\n \"id\" : \"42FaEHFfyxTdZQ5W28dXnj\",\n \"images\" : [ {\n \"height\" : 640,\n \"url\" : \"https://i.scdn.co/image/89c1a0ac4f8b95c843d633493bc3657a296e3e6b\",\n \"width\" : 640\n }, {\n \"height\" : 300,\n \"url\" : \"https://i.scdn.co/image/59654d32b34cfb51000ff26fec57ab36bf1781ae\",\n \"width\" : 300\n }, {\n \"height\" : 64,\n \"url\" : \"https://i.scdn.co/image/b3afd3776d6e3e6ed82d45b4541e8623389e347b\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Snupe\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:42FaEHFfyxTdZQ5W28dXnj\"\n }, {\n \"external_urls\" : {\n \"spotify\" : \"https://open.spotify.com/artist/5qK5bOC6wLtuLhG5KvU17c\"\n },\n \"followers\" : {\n \"href\" : null,\n \"total\" : 21187\n },\n \"genres\" : [ \"hip pop\" ],\n \"href\" : \"https://api.spotify.com/v1/artists/5qK5bOC6wLtuLhG5KvU17c\",\n \"id\" : \"5qK5bOC6wLtuLhG5KvU17c\",\n \"images\" : [ {\n \"height\" : 750,\n \"url\" : \"https://i.scdn.co/image/8e33c09ff1d5d91ea47254a389c36f626775275a\",\n \"width\" : 600\n }, {\n \"height\" : 250,\n \"url\" : \"https://i.scdn.co/image/991889a4147550d0421dfb80621c2e161ac7e043\",\n \"width\" : 200\n }, {\n \"height\" : 80,\n \"url\" : \"https://i.scdn.co/image/253d651a020406eb7c264304803463badabfe8cb\",\n \"width\" : 64\n } ],\n \"name\" : \"Lil Mama\",\n \"popularity\" : 45,\n \"type\" : \"artist\",\n \"uri\" : \"spotify:artist:5qK5bOC6wLtuLhG5KvU17c\"\n } ],\n \"limit\" : 20,\n \"next\" : \"https://api.spotify.com/v1/search?query=Lil&offset=20&limit=20&type=artist&market=US\",\n \"offset\" : 0,\n \"previous\" : null,\n \"total\" : 4514\n }\n}\n"
],
[
"all_lil.keys()",
"_____no_output_____"
],
[
"all_lil['artists'].keys()",
"_____no_output_____"
],
[
"print(all_lil['artists']['total'])",
"4514\n"
],
[
"response = requests.get('https://api.spotify.com/v1/search?q=Biggie&type=artist&market=US')\nall_biggies = response.json()\nprint(all_biggies['artists']['total'])",
"50\n"
]
],
[
[
"## how to count the genres",
"_____no_output_____"
]
],
[
[
"all_genres = []\nfor artist in artist_info:\n print(\"All genres we've heard of:\", all_genres)\n print(\"Current artist has:\", artist['genres'])\n all_genres = all_genres + artist['genres']",
"All genres we've heard of: []\nCurrent artist has: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music']\nCurrent artist has: ['crunk', 'dirty south rap', 'southern hip hop']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop']\nCurrent artist has: ['chicano rap', 'latin hip hop']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop']\nCurrent artist has: ['hip pop', 'pop rap']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap']\nCurrent artist has: ['crunk', 'dirty south rap', 'southern hip hop', 'trap music']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music']\nCurrent artist has: ['juggalo']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo']\nCurrent artist has: ['hip pop']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop']\nCurrent artist has: ['hip pop']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop']\nCurrent artist has: ['chicano rap']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap']\nCurrent artist has: ['jerk']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk']\nCurrent artist has: ['deep trap']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap']\nCurrent artist has: ['chicano rap']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap']\nCurrent artist has: ['freestyle']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle']\nCurrent artist has: ['soca']\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle', 'soca']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle', 'soca']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle', 'soca']\nCurrent artist has: []\nAll genres we've heard of: ['dirty south rap', 'pop rap', 'southern hip hop', 'trap music', 'crunk', 'dirty south rap', 'southern hip hop', 'chicano rap', 'latin hip hop', 'hip pop', 'pop rap', 'crunk', 'dirty south rap', 'southern hip hop', 'trap music', 'juggalo', 'hip pop', 'hip pop', 'chicano rap', 'jerk', 'deep trap', 'chicano rap', 'freestyle', 'soca']\nCurrent artist has: ['crunk', 'dirty south rap']\n"
],
[
"all_genres.count('dirty south rap')",
"_____no_output_____"
],
[
"## There is a library that comes with Python called Collections, inside of it is a thing called Counter\nfrom collections import Counter\n",
"_____no_output_____"
]
],
[
[
"## How to automate getting all of the results",
"_____no_output_____"
]
],
[
[
"response=requests.get('https://api.spotify.com/v1/search?q=Lil&type=artist&market=US&limit50')\nsmall_data = response.json()",
"_____no_output_____"
],
[
"data['artists']\nprint(len(data['artists']['items'])) #we only get 10 artists\nprint(data['artists']['total'])",
"_____no_output_____"
],
[
"#first page: artists 1-50, offset of 0\n# https://",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d02c0005495f89e167fba3376cb133771954a0b5
| 85,524 |
ipynb
|
Jupyter Notebook
|
samples/hierarchical_deployment/hps_e2e_demo/Continuous_Training.ipynb
|
miguelusque/hugectr_backend
|
277fb1acd78a8268f642437dd3cc49e485a8d20b
|
[
"BSD-3-Clause"
] | null | null | null |
samples/hierarchical_deployment/hps_e2e_demo/Continuous_Training.ipynb
|
miguelusque/hugectr_backend
|
277fb1acd78a8268f642437dd3cc49e485a8d20b
|
[
"BSD-3-Clause"
] | null | null | null |
samples/hierarchical_deployment/hps_e2e_demo/Continuous_Training.ipynb
|
miguelusque/hugectr_backend
|
277fb1acd78a8268f642437dd3cc49e485a8d20b
|
[
"BSD-3-Clause"
] | null | null | null | 57.903859 | 189 | 0.534517 |
[
[
[
"<img src=\"http://developer.download.nvidia.com/compute/machine-learning/frameworks/nvidia_logo.png\" style=\"width: 90px; float: right;\">\n\n# HugeCTR Continuous Training and Inference Demo (Part I)",
"_____no_output_____"
],
[
"## Overview\n\nIn HugeCTR version 3.3, we finished the whole pipeline of parameter server, including \n1. The parameter dumping interface from training to kafka.\n2. CPU cache(Redis Cluster / Hash Map / Parallel Hash Map).\n3. RocksDB as a persistence storage.\n4. Embedding cache update mechanism.\n\n\nThe purpose of this notebook is to show how to do continuous traning and inference using HugeCTR Hierarchical Parameter Server. \n\n\n## Table of Contents\n- Data Preparation\n- Data Preprocessing using Pandas\n- Wide&Deep Training Demo\n- Wide&Deep Model Inference using Python API\n- Wide&Deep Model continuous training\n- Wide&Deep Model continuous inference",
"_____no_output_____"
],
[
"## 1. Data preparation",
"_____no_output_____"
],
[
"### 1.1 Make a folder to store our data and data processing scripts:",
"_____no_output_____"
]
],
[
[
"!mkdir criteo_data\n!mkdir criteo_script",
"_____no_output_____"
]
],
[
[
"### 1.2 Download Criteo Dataset",
"_____no_output_____"
]
],
[
[
"!wget http://azuremlsampleexperiments.blob.core.windows.net/criteo/day_1.gz",
"_____no_output_____"
]
],
[
[
"**NOTE**: Replace `1` with a value from [0, 23] to use a different day.\n\nDuring preprocessing, the amount of data, which is used to speed up the preprocessing, fill missing values, and remove the feature values that are considered rare, is further reduced.",
"_____no_output_____"
],
[
"### 1.3 Write the preprocessing the script. ",
"_____no_output_____"
]
],
[
[
"%%writefile preprocess.sh\n\n#!/bin/bash\n\nif [[ $# -lt 3 ]]; then\n echo \"Usage: preprocess.sh [DATASET_NO.] [DST_DATA_DIR] [SCRIPT_TYPE] [SCRIPT_TYPE_SPECIFIC_ARGS...]\"\n exit 2\nfi\n\nDST_DATA_DIR=$2\n\necho \"Warning: existing $DST_DATA_DIR is erased\"\nrm -rf $DST_DATA_DIR\n\nif [[ $3 == \"nvt\" ]]; then\n if [[ $# -ne 6 ]]; then\n echo \"Usage: preprocess.sh [DATASET_NO.] [DST_DATA_DIR] nvt [IS_PARQUET_FORMAT] [IS_CRITEO_MODE] [IS_FEATURE_CROSSED]\"\n exit 2\n fi\n echo \"Preprocessing script: NVTabular\"\nelif [[ $3 == \"perl\" ]]; then\n if [[ $# -ne 4 ]]; then\n echo \"Usage: preprocess.sh [DATASET_NO.] [DST_DATA_DIR] perl [NUM_SLOTS]\"\n exit 2\n fi\n echo \"Preprocessing script: Perl\"\nelif [[ $3 == \"pandas\" ]]; then\n if [[ $# -lt 5 ]]; then\n echo \"Usage: preprocess.sh [DATASET_NO.] [DST_DATA_DIR] pandas [IS_DENSE_NORMALIZED] [IS_FEATURE_CROSSED] (FILE_LIST_LENGTH)\"\n exit 2\n fi\n echo \"Preprocessing script: Pandas\"\nelse\n echo \"Error: $3 is an invalid script type. Pick one from {nvt, perl, pandas}.\"\n exit 2\nfi\n\nSCRIPT_TYPE=$3\n\necho \"Getting the first few examples from the uncompressed dataset...\"\nmkdir -p $DST_DATA_DIR/train && \\\nmkdir -p $DST_DATA_DIR/val && \\\nhead -n 500000 day_$1 > $DST_DATA_DIR/day_$1_small\nif [ $? -ne 0 ]; then\n echo \"Warning: fallback to find original compressed data day_$1.gz...\"\n echo \"Decompressing day_$1.gz...\"\n gzip -d -c day_$1.gz > day_$1\n if [ $? -ne 0 ]; then\n echo \"Error: failed to decompress the file.\"\n exit 2\n fi\n head -n 500000 day_$1 > $DST_DATA_DIR/day_$1_small\n if [ $? -ne 0 ]; then\n echo \"Error: day_$1 file\"\n exit 2\n fi\nfi\n\necho \"Counting the number of samples in day_$1 dataset...\"\ntotal_count=$(wc -l $DST_DATA_DIR/day_$1_small)\ntotal_count=(${total_count})\necho \"The first $total_count examples will be used in day_$1 dataset.\"\n\necho \"Shuffling dataset...\"\nshuf $DST_DATA_DIR/day_$1_small > $DST_DATA_DIR/day_$1_shuf\n\ntrain_count=$(( total_count * 8 / 10))\nvaltest_count=$(( total_count - train_count ))\nval_count=$(( valtest_count * 5 / 10 ))\ntest_count=$(( valtest_count - val_count ))\n\nsplit_dataset()\n{\n echo \"Splitting into $train_count-sample training, $val_count-sample val, and $test_count-sample test datasets...\"\n head -n $train_count $DST_DATA_DIR/$1 > $DST_DATA_DIR/train/train.txt && \\\n tail -n $valtest_count $DST_DATA_DIR/$1 > $DST_DATA_DIR/val/valtest.txt && \\\n head -n $val_count $DST_DATA_DIR/val/valtest.txt > $DST_DATA_DIR/val/val.txt && \\\n tail -n $test_count $DST_DATA_DIR/val/valtest.txt > $DST_DATA_DIR/val/test.txt\n\n if [ $? -ne 0 ]; then\n exit 2\n fi\n}\n\necho \"Preprocessing...\"\nif [[ $SCRIPT_TYPE == \"nvt\" ]]; then\n IS_PARQUET_FORMAT=$4\n IS_CRITEO_MODE=$5\n FEATURE_CROSS_LIST_OPTION=\"\"\n if [[ ( $IS_CRITEO_MODE -eq 0 ) && ( $6 -eq 1 ) ]]; then\n FEATURE_CROSS_LIST_OPTION=\"--feature_cross_list C1_C2,C3_C4\"\n echo $FEATURE_CROSS_LIST_OPTION\n fi\n split_dataset day_$1_shuf\n python3 criteo_script/preprocess_nvt.py \\\n --data_path $DST_DATA_DIR \\\n --out_path $DST_DATA_DIR \\\n --freq_limit 6 \\\n --device_limit_frac 0.5 \\\n --device_pool_frac 0.5 \\\n --out_files_per_proc 8 \\\n --devices \"0\" \\\n --num_io_threads 2 \\\n --parquet_format=$IS_PARQUET_FORMAT \\\n --criteo_mode=$IS_CRITEO_MODE \\\n $FEATURE_CROSS_LIST_OPTION\n\nelif [[ $SCRIPT_TYPE == \"perl\" ]]; then\n NUM_SLOT=$4\n split_dataset day_$1_shuf\n perl criteo_script_legacy/preprocess.pl $DST_DATA_DIR/train/train.txt $DST_DATA_DIR/val/val.txt $DST_DATA_DIR/val/test.txt && \\\n criteo2hugectr_legacy $NUM_SLOT $DST_DATA_DIR/train/train.txt.out $DST_DATA_DIR/train/sparse_embedding $DST_DATA_DIR/file_list.txt && \\\n criteo2hugectr_legacy $NUM_SLOT $DST_DATA_DIR/val/test.txt.out $DST_DATA_DIR/val/sparse_embedding $DST_DATA_DIR/file_list_test.txt\n\nelif [[ $SCRIPT_TYPE == \"pandas\" ]]; then\n python3 criteo_script/preprocess.py \\\n --src_csv_path=$DST_DATA_DIR/day_$1_shuf \\\n --dst_csv_path=$DST_DATA_DIR/day_$1_shuf.out \\\n --normalize_dense=$4 --feature_cross=$5 && \\\n split_dataset day_$1_shuf.out\n NUM_WIDE_KEYS=\"\"\n if [[ $5 -ne 0 ]]; then\n NUM_WIDE_KEYS=2\n fi\n\n FILE_LIST_LENGTH=\"\"\n if [[ $# -gt 5 ]]; then\n FILE_LIST_LENGTH=$6\n fi\n\n criteo2hugectr $DST_DATA_DIR/train/train.txt $DST_DATA_DIR/train/sparse_embedding $DST_DATA_DIR/file_list.txt $NUM_WIDE_KEYS $FILE_LIST_LENGTH && \\\n criteo2hugectr $DST_DATA_DIR/val/test.txt $DST_DATA_DIR/val/sparse_embedding $DST_DATA_DIR/file_list_test.txt $NUM_WIDE_KEYS $FILE_LIST_LENGTH\nfi\n\nif [ $? -ne 0 ]; then\n exit 2\nfi\n\necho \"All done!\"\n",
"Overwriting preprocess.sh\n"
]
],
[
[
"**NOTE**: Here we only read the first 500000 lines of the data to do the demo.",
"_____no_output_____"
]
],
[
[
"%%writefile criteo_script/preprocess.py\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport argparse\nimport sys\nimport tempfile\n\nfrom six.moves import urllib\nimport urllib.request \n\nimport sys\nimport os\nimport math\nimport time\nimport logging\nimport concurrent.futures as cf\nfrom traceback import print_exc\n\nimport numpy as np\nimport pandas as pd\nimport sklearn.preprocessing as skp\n\nlogging.basicConfig(format='%(asctime)s %(message)s')\nlogging.root.setLevel(logging.NOTSET)\n\nNUM_INTEGER_COLUMNS = 13\nNUM_CATEGORICAL_COLUMNS = 26\nNUM_TOTAL_COLUMNS = 1 + NUM_INTEGER_COLUMNS + NUM_CATEGORICAL_COLUMNS\n\nMAX_NUM_WORKERS = NUM_TOTAL_COLUMNS\n\nINT_NAN_VALUE = np.iinfo(np.int32).min\nCAT_NAN_VALUE = '80000000'\n\ndef idx2key(idx):\n if idx == 0:\n return 'label'\n return 'I' + str(idx) if idx <= NUM_INTEGER_COLUMNS else 'C' + str(idx - NUM_INTEGER_COLUMNS)\n\ndef _fill_missing_features_and_split(chunk, series_list_dict):\n for cid, col in enumerate(chunk.columns):\n NAN_VALUE = INT_NAN_VALUE if cid <= NUM_INTEGER_COLUMNS else CAT_NAN_VALUE\n result_series = chunk[col].fillna(NAN_VALUE)\n series_list_dict[col].append(result_series)\n\ndef _merge_and_transform_series(src_series_list, col, dense_cols,\n normalize_dense):\n result_series = pd.concat(src_series_list)\n\n if col != 'label':\n unique_value_counts = result_series.value_counts()\n unique_value_counts = unique_value_counts.loc[unique_value_counts >= 6]\n unique_value_counts = set(unique_value_counts.index.values)\n NAN_VALUE = INT_NAN_VALUE if col.startswith('I') else CAT_NAN_VALUE\n result_series = result_series.apply(\n lambda x: x if x in unique_value_counts else NAN_VALUE)\n\n if col == 'label' or col in dense_cols:\n result_series = result_series.astype(np.int64)\n le = skp.LabelEncoder()\n result_series = pd.DataFrame(le.fit_transform(result_series))\n if col != 'label':\n result_series = result_series + 1\n else:\n oe = skp.OrdinalEncoder(dtype=np.int64)\n result_series = pd.DataFrame(oe.fit_transform(pd.DataFrame(result_series)))\n result_series = result_series + 1\n\n\n if normalize_dense != 0:\n if col in dense_cols:\n mms = skp.MinMaxScaler(feature_range=(0,1))\n result_series = pd.DataFrame(mms.fit_transform(result_series))\n\n result_series.columns = [col]\n\n min_max = (np.int64(result_series[col].min()), np.int64(result_series[col].max()))\n if col != 'label':\n logging.info('column {} [{}, {}]'.format(col, str(min_max[0]),str(min_max[1])))\n\n return [result_series, min_max]\n\ndef _convert_to_string(series):\n return series.astype(str)\n\ndef _merge_columns_and_feature_cross(series_list, min_max, feature_pairs,\n feature_cross):\n name_to_series = dict()\n for series in series_list:\n name_to_series[series.columns[0]] = series.iloc[:,0]\n df = pd.DataFrame(name_to_series)\n cols = [idx2key(idx) for idx in range(0, NUM_TOTAL_COLUMNS)]\n df = df.reindex(columns=cols)\n\n offset = np.int64(0)\n for col in cols:\n if col != 'label' and col.startswith('I') == False:\n df[col] += offset\n logging.info('column {} offset {}'.format(col, str(offset)))\n offset += min_max[col][1]\n\n if feature_cross != 0:\n for idx, pair in enumerate(feature_pairs):\n col0 = pair[0]\n col1 = pair[1]\n\n col1_width = int(min_max[col1][1] - min_max[col1][0] + 1)\n\n crossed_column_series = df[col0] * col1_width + df[col1]\n oe = skp.OrdinalEncoder(dtype=np.int64)\n crossed_column_series = pd.DataFrame(oe.fit_transform(pd.DataFrame(crossed_column_series)))\n crossed_column_series = crossed_column_series + 1\n\n crossed_column = col0 + '_' + col1\n df.insert(NUM_INTEGER_COLUMNS + 1 + idx, crossed_column, crossed_column_series)\n crossed_column_max_val = np.int64(df[crossed_column].max())\n logging.info('column {} [{}, {}]'.format(\n crossed_column,\n str(df[crossed_column].min()),\n str(crossed_column_max_val)))\n df[crossed_column] += offset\n logging.info('column {} offset {}'.format(crossed_column, str(offset)))\n offset += crossed_column_max_val\n\n return df\n\ndef _wait_futures_and_reset(futures):\n for future in futures:\n result = future.result()\n if result:\n print(result)\n futures = list()\n\ndef _process_chunks(executor, chunks_to_process, op, *argv):\n futures = list()\n for chunk in chunks_to_process:\n argv_list = list(argv)\n argv_list.insert(0, chunk)\n new_argv = tuple(argv_list)\n future = executor.submit(op, *new_argv)\n futures.append(future)\n _wait_futures_and_reset(futures)\n\ndef preprocess(src_txt_name, dst_txt_name, normalize_dense, feature_cross):\n cols = [idx2key(idx) for idx in range(0, NUM_TOTAL_COLUMNS)]\n series_list_dict = dict()\n\n with cf.ThreadPoolExecutor(max_workers=MAX_NUM_WORKERS) as executor:\n logging.info('read a CSV file')\n reader = pd.read_csv(src_txt_name, sep='\\t',\n names=cols,\n chunksize=131072)\n\n logging.info('_fill_missing_features_and_split')\n for col in cols:\n series_list_dict[col] = list()\n _process_chunks(executor, reader, _fill_missing_features_and_split,\n series_list_dict)\n\n with cf.ProcessPoolExecutor(max_workers=MAX_NUM_WORKERS) as executor:\n logging.info('_merge_and_transform_series')\n futures = list()\n dense_cols = [idx2key(idx+1) for idx in range(NUM_INTEGER_COLUMNS)]\n dst_series_list = list()\n min_max = dict()\n for col, src_series_list in series_list_dict.items():\n future = executor.submit(_merge_and_transform_series,\n src_series_list, col, dense_cols,\n normalize_dense)\n futures.append(future)\n\n for future in futures:\n col = None\n for idx, ret in enumerate(future.result()):\n try:\n if idx == 0:\n col = ret.columns[0]\n dst_series_list.append(ret)\n else:\n min_max[col] = ret\n except:\n print_exc()\n futures = list()\n\n logging.info('_merge_columns_and_feature_cross')\n feature_pairs = [('C1', 'C2'), ('C3', 'C4')]\n df = _merge_columns_and_feature_cross(dst_series_list, min_max, feature_pairs,\n feature_cross)\n\n \n logging.info('_convert_to_string')\n futures = dict()\n for col in cols:\n future = executor.submit(_convert_to_string, df[col])\n futures[col] = future\n if feature_cross != 0:\n for pair in feature_pairs:\n col = pair[0] + '_' + pair[1]\n future = executor.submit(_convert_to_string, df[col])\n futures[col] = future\n\n logging.info('_store_to_df')\n for col, future in futures.items():\n ret = future.result()\n try:\n df[col] = ret\n except:\n print_exc()\n futures = dict()\n\n logging.info('write to a CSV file')\n df.to_csv(dst_txt_name, sep=' ', header=False, index=False)\n\n logging.info('done!')\n\n\nif __name__ == '__main__':\n arg_parser = argparse.ArgumentParser(description='Preprocssing Criteo Dataset')\n\n arg_parser.add_argument('--src_csv_path', type=str, required=True)\n arg_parser.add_argument('--dst_csv_path', type=str, required=True)\n arg_parser.add_argument('--normalize_dense', type=int, default=1)\n arg_parser.add_argument('--feature_cross', type=int, default=1)\n\n args = arg_parser.parse_args()\n\n src_csv_path = args.src_csv_path\n dst_csv_path = args.dst_csv_path\n\n normalize_dense = args.normalize_dense\n feature_cross = args.feature_cross\n\n if os.path.exists(src_csv_path) == False:\n sys.exit('ERROR: the file \\'{}\\' doesn\\'t exist'.format(src_csv_path))\n\n if os.path.exists(dst_csv_path) == True:\n sys.exit('ERROR: the file \\'{}\\' exists'.format(dst_csv_path))\n\n preprocess(src_csv_path, dst_csv_path, normalize_dense, feature_cross)\n\n\n",
"Overwriting criteo_script/preprocess.py\n"
]
],
[
[
"### 1.4 Run the preprocess script",
"_____no_output_____"
]
],
[
[
"!bash preprocess.sh 0 criteo_data pandas 1 1 1",
"_____no_output_____"
]
],
[
[
"**IMPORTANT NOTES**: \n\nArguments may vary depend on your setting:\n- The first argument represents the dataset postfix. For instance, if `day_1` is used, the postfix is `1`.\n- The second argument, `criteo_data`, is where the preprocessed data is stored.",
"_____no_output_____"
],
[
"### 1.5 Generate data sample for inference ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\ndf = pd.read_table(\"criteo_data/train/train.txt\", header = None, sep= ' ', \\\n names = ['label'] + ['I'+str(i) for i in range(1, 14)] + \\\n ['C1_C2', 'C3_C4'] + ['C'+str(i) for i in range(1, 27)])[:5]\nleft = df.iloc[:,:14].astype(np.float32)\nright = df.iloc[:, 14:].astype(np.int64)\nmerged = pd.concat([left, right], axis = 1)\nmerged.to_csv(\"infer_data.csv\", index = False)",
"_____no_output_____"
]
],
[
[
"## 2. Start the Kafka Broker",
"_____no_output_____"
],
[
"**Please refer to the README to start the Kafka Broker properly.**",
"_____no_output_____"
],
[
"## 3. Wide&Deep Model Demo",
"_____no_output_____"
]
],
[
[
"!rm -r *model",
"_____no_output_____"
],
[
"%%writefile wdl_demo.py\nimport hugectr\nfrom mpi4py import MPI\nsolver = hugectr.CreateSolver(model_name = \"wdl\",\n max_eval_batches = 5000,\n batchsize_eval = 1024,\n batchsize = 1024,\n lr = 0.001,\n vvgpu = [[0]],\n i64_input_key = False,\n use_mixed_precision = False,\n repeat_dataset = False,\n use_cuda_graph = True,\n kafka_brockers = \"10.23.137.25:9093\") #Make sure this is consistent with your Kafka broker.)\nreader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Norm,\n source = [\"criteo_data/file_list.\"+str(i)+\".txt\" for i in range(2)],\n keyset = [\"criteo_data/file_list.\"+str(i)+\".keyset\" for i in range(2)],\n eval_source = \"criteo_data/file_list.2.txt\",\n check_type = hugectr.Check_t.Sum)\noptimizer = hugectr.CreateOptimizer(optimizer_type = hugectr.Optimizer_t.Adam)\nhc_config = hugectr.CreateHMemCache(2, 0.5, 0)\netc = hugectr.CreateETC(ps_types = [hugectr.TrainPSType_t.Staged, hugectr.TrainPSType_t.Cached],\\\n sparse_models = [\"./wdl_0_sparse_model\", \"./wdl_1_sparse_model\"],\\\n local_paths = [\"./\"], hmem_cache_configs = [hc_config])\nmodel = hugectr.Model(solver, reader, optimizer, etc)\nmodel.add(hugectr.Input(label_dim = 1, label_name = \"label\",\n dense_dim = 13, dense_name = \"dense\",\n data_reader_sparse_param_array = \n [hugectr.DataReaderSparseParam(\"wide_data\", 2, True, 1),\n hugectr.DataReaderSparseParam(\"deep_data\", 1, True, 26)]))\nmodel.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash, \n workspace_size_per_gpu_in_mb = 23,\n embedding_vec_size = 1,\n combiner = \"sum\",\n sparse_embedding_name = \"sparse_embedding0\",\n bottom_name = \"wide_data\",\n optimizer = optimizer))\nmodel.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash, \n workspace_size_per_gpu_in_mb = 358,\n embedding_vec_size = 16,\n combiner = \"sum\",\n sparse_embedding_name = \"sparse_embedding1\",\n bottom_name = \"deep_data\",\n optimizer = optimizer))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Reshape,\n bottom_names = [\"sparse_embedding1\"],\n top_names = [\"reshape1\"],\n leading_dim=416))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Reshape,\n bottom_names = [\"sparse_embedding0\"],\n top_names = [\"reshape2\"],\n leading_dim=1))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Concat,\n bottom_names = [\"reshape1\", \"dense\"], top_names = [\"concat1\"]))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.InnerProduct,\n bottom_names = [\"concat1\"],\n top_names = [\"fc1\"],\n num_output=1024))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.ReLU,\n bottom_names = [\"fc1\"],\n top_names = [\"relu1\"]))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Dropout,\n bottom_names = [\"relu1\"],\n top_names = [\"dropout1\"],\n dropout_rate=0.5))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.InnerProduct,\n bottom_names = [\"dropout1\"],\n top_names = [\"fc2\"],\n num_output=1024))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.ReLU,\n bottom_names = [\"fc2\"],\n top_names = [\"relu2\"]))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Dropout,\n bottom_names = [\"relu2\"],\n top_names = [\"dropout2\"],\n dropout_rate=0.5))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.InnerProduct,\n bottom_names = [\"dropout2\"],\n top_names = [\"fc3\"],\n num_output=1))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.Add,\n bottom_names = [\"fc3\", \"reshape2\"],\n top_names = [\"add1\"]))\nmodel.add(hugectr.DenseLayer(layer_type = hugectr.Layer_t.BinaryCrossEntropyLoss,\n bottom_names = [\"add1\", \"label\"],\n top_names = [\"loss\"]))\nmodel.compile()\nmodel.summary()\nmodel.graph_to_json(graph_config_file = \"wdl.json\")\n#model.save_params_to_files(\"wdl\")\nmodel.fit(num_epochs = 1, display = 500, eval_interval = 1000)\n\nmodel.set_source(source = [\"criteo_data/file_list.\"+str(i)+\".txt\" for i in range(3, 5)], \\\n keyset = [\"criteo_data/file_list.\"+str(i)+\".keyset\" for i in range(3, 5)], \\\n eval_source = \"criteo_data/file_list.9.txt\")\n\nmodel.save_params_to_files(\"wdl\")",
"Overwriting wdl_demo.py\n"
],
[
"!python wdl_demo.py",
"[HUGECTR][03:34:23][INFO][RANK0]: Empty embedding, trained table will be stored in ./wdl_0_sparse_model\n[HUGECTR][03:34:23][INFO][RANK0]: Empty embedding, trained table will be stored in ./wdl_1_sparse_model\nHugeCTR Version: 3.2\n====================================================Model Init=====================================================\n[HUGECTR][03:34:23][INFO][RANK0]: Initialize model: wdl\n[HUGECTR][03:34:23][INFO][RANK0]: Global seed is 337017754\n[HUGECTR][03:34:23][INFO][RANK0]: Device to NUMA mapping:\n GPU 0 -> node 0\n\n[HUGECTR][03:34:25][WARNING][RANK0]: Peer-to-peer access cannot be fully enabled.\n[HUGECTR][03:34:25][INFO][RANK0]: Start all2all warmup\n[HUGECTR][03:34:25][INFO][RANK0]: End all2all warmup\n[HUGECTR][03:34:25][INFO][RANK0]: Using All-reduce algorithm: NCCL\n[HUGECTR][03:34:25][INFO][RANK0]: Device 0: Tesla V100-SXM2-32GB\n[HUGECTR][03:34:25][DEBUG][RANK0]: Creating Kafka lifetime service.\n[HUGECTR][03:34:25][INFO][RANK0]: num of DataReader workers: 12\n[HUGECTR][03:34:25][INFO][RANK0]: max_vocabulary_size_per_gpu_=6029312\n[HUGECTR][03:34:25][INFO][RANK0]: max_vocabulary_size_per_gpu_=5865472\n[HUGECTR][03:34:25][INFO][RANK0]: Graph analysis to resolve tensor dependency\n===================================================Model Compile===================================================\n[HUGECTR][03:34:28][INFO][RANK0]: gpu0 start to init embedding\n[HUGECTR][03:34:28][INFO][RANK0]: gpu0 init embedding done\n[HUGECTR][03:34:28][INFO][RANK0]: gpu0 start to init embedding\n[HUGECTR][03:34:28][INFO][RANK0]: gpu0 init embedding done\n[HUGECTR][03:34:28][INFO][RANK0]: Enable HMEM-Based Parameter Server\n[HUGECTR][03:34:28][INFO][RANK0]: ./wdl_0_sparse_model not exist, create and train from scratch\n[HUGECTR][03:34:28][INFO][RANK0]: Enable HMemCache-Based Parameter Server\n[HUGECTR][03:34:28][INFO][RANK0]: ./wdl_1_sparse_model/key doesn't exist, created\n[HUGECTR][03:34:28][INFO][RANK0]: ./wdl_1_sparse_model/emb_vector doesn't exist, created\n[HUGECTR][03:34:28][INFO][RANK0]: ./wdl_1_sparse_model/Adam.m doesn't exist, created\n[HUGECTR][03:34:28][INFO][RANK0]: ./wdl_1_sparse_model/Adam.v doesn't exist, created\n[HUGECTR][03:34:29][INFO][RANK0]: Starting AUC NCCL warm-up\n[HUGECTR][03:34:29][INFO][RANK0]: Warm-up done\n===================================================Model Summary===================================================\nlabel Dense Sparse \nlabel dense wide_data,deep_data \n(None, 1) (None, 13) \n——————————————————————————————————————————————————————————————————————————————————————————————————————————————————\nLayer Type Input Name Output Name Output Shape \n——————————————————————————————————————————————————————————————————————————————————————————————————————————————————\nDistributedSlotSparseEmbeddingHash wide_data sparse_embedding0 (None, 1, 1) \n------------------------------------------------------------------------------------------------------------------\nDistributedSlotSparseEmbeddingHash deep_data sparse_embedding1 (None, 26, 16) \n------------------------------------------------------------------------------------------------------------------\nReshape sparse_embedding1 reshape1 (None, 416) \n------------------------------------------------------------------------------------------------------------------\nReshape sparse_embedding0 reshape2 (None, 1) \n------------------------------------------------------------------------------------------------------------------\nConcat reshape1 concat1 (None, 429) \n dense \n------------------------------------------------------------------------------------------------------------------\nInnerProduct concat1 fc1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nReLU fc1 relu1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nDropout relu1 dropout1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nInnerProduct dropout1 fc2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nReLU fc2 relu2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nDropout relu2 dropout2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nInnerProduct dropout2 fc3 (None, 1) \n------------------------------------------------------------------------------------------------------------------\nAdd fc3 add1 (None, 1) \n reshape2 \n------------------------------------------------------------------------------------------------------------------\nBinaryCrossEntropyLoss add1 loss \n label \n------------------------------------------------------------------------------------------------------------------\n[HUGECTR][03:34:29][INFO][RANK0]: Save the model graph to wdl.json successfully\n=====================================================Model Fit=====================================================\n[HUGECTR][03:34:29][INFO][RANK0]: Use embedding training cache mode with number of training sources: 2, number of epochs: 1\n[HUGECTR][03:34:29][INFO][RANK0]: Training batchsize: 1024, evaluation batchsize: 1024\n[HUGECTR][03:34:29][INFO][RANK0]: Evaluation interval: 1000, snapshot interval: 10000\n[HUGECTR][03:34:29][INFO][RANK0]: Dense network trainable: True\n[HUGECTR][03:34:29][INFO][RANK0]: Sparse embedding sparse_embedding0 trainable: True\n[HUGECTR][03:34:29][INFO][RANK0]: Sparse embedding sparse_embedding1 trainable: True\n[HUGECTR][03:34:29][INFO][RANK0]: Use mixed precision: False, scaler: 1.000000, use cuda graph: True\n[HUGECTR][03:34:29][INFO][RANK0]: lr: 0.001000, warmup_steps: 1, end_lr: 0.000000\n[HUGECTR][03:34:29][INFO][RANK0]: decay_start: 0, decay_steps: 1, decay_power: 2.000000\n[HUGECTR][03:34:29][INFO][RANK0]: Evaluation source file: criteo_data/file_list.2.txt\n[HUGECTR][03:34:29][INFO][RANK0]: --------------------Epoch 0, source file: criteo_data/file_list.0.txt--------------------\n[HUGECTR][03:34:29][INFO][RANK0]: Preparing embedding table for next pass\n[HUGECTR][03:34:29][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 0 %\n[HUGECTR][03:34:30][INFO][RANK0]: --------------------Epoch 0, source file: criteo_data/file_list.1.txt--------------------\n[HUGECTR][03:34:30][INFO][RANK0]: Preparing embedding table for next pass\n[HUGECTR][03:34:30][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 0 %\n[HUGECTR][03:34:31][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 0 %\n[HUGECTR][03:34:31][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 76.51 %\n[HUGECTR][03:34:31][INFO][RANK0]: Updating sparse model in SSD [DONE]\n[HUGECTR][03:34:32][INFO][RANK0]: Sync blocks from HMEM-Cache to SSD\n \u001b[38;2;89;255;89m ████████████████████████████████████████▏ \u001b[1m\u001b[31m100.0% \u001b[34m[ 2/ 2 | 79.0 Hz | 0s<0s] \u001b[0m\u001b[32m\u001b[0mm\n[HUGECTR][03:34:32][INFO][RANK0]: Dumping dense weights to file, successful\n[HUGECTR][03:34:32][INFO][RANK0]: Dumping dense optimizer states to file, successful\n[HUGECTR][03:34:32][INFO][RANK0]: Dumping untrainable weights to file, successful\n[HUGECTR][03:34:33][DEBUG][RANK0]: Destroying Kafka lifetime service.\n"
]
],
[
[
"## 4. WDL Inference",
"_____no_output_____"
],
[
"### 4.1 Inference using HugeCTR python API",
"_____no_output_____"
]
],
[
[
"#Create a folder for RocksDB\n!mkdir /wdl_infer\n!mkdir /wdl_infer/rocksdb",
"mkdir: cannot create directory ‘/wdl_infer’: File exists\nmkdir: cannot create directory ‘/wdl_infer/rocksdb’: File exists\n"
]
],
[
[
"**Please make sure you have started Redis cluster following the README before you start doing inference.**",
"_____no_output_____"
]
],
[
[
"%%writefile 'wdl_predict.py'\nfrom hugectr.inference import InferenceParams, CreateInferenceSession\nimport hugectr\nimport pandas as pd\nimport numpy as np\nimport sys\nfrom mpi4py import MPI\ndef wdl_inference(model_name='wdl', network_file='wdl.json', dense_file='wdl_dense_0.model', \\\n embedding_file_list=['wdl_0_sparse_model', 'wdl_1_sparse_model'], data_file='infer_data.csv',\\\n enable_cache=False, rocksdb_path=\"\"):\n CATEGORICAL_COLUMNS=[\"C1_C2\",\"C3_C4\"] + [\"C\" + str(x) for x in range(1, 27)]\n CONTINUOUS_COLUMNS=[\"I\" + str(x) for x in range(1, 14)]\n LABEL_COLUMNS = ['label']\n test_df=pd.read_csv(data_file,sep=',')\n config_file = network_file\n row_ptrs = list(range(0, 11, 2)) + list(range(0, 131))\n dense_features = list(test_df[CONTINUOUS_COLUMNS].values.flatten())\n test_df[CATEGORICAL_COLUMNS].astype(np.int64)\n embedding_columns = list((test_df[CATEGORICAL_COLUMNS]).values.flatten())\n\n redisdatabase = hugectr.inference.DistributedDatabaseParams(\n hugectr.DatabaseType_t.redis_cluster,\n address=\"127.0.0.1:7000,127.0.0.1:7001,127.0.0.1:7002\",\n initial_cache_rate=0.2)\n rocksdbdatabase = hugectr.inference.PersistentDatabaseParams(\n hugectr.DatabaseType_t.rocks_db,\n path=\"/wdl_infer/rocksdb/\")\n \n # create parameter server, embedding cache and inference session\n inference_params = InferenceParams(model_name = model_name,\n max_batchsize = 64,\n hit_rate_threshold = 0.5,\n dense_model_file = dense_file,\n sparse_model_files = embedding_file_list,\n device_id = 0,\n use_gpu_embedding_cache = enable_cache,\n cache_size_percentage = 0.9,\n i64_input_key = True,\n use_mixed_precision = False,\n volatile_db=redisdatabase,\n persistent_db=rocksdbdatabase)\n inference_session = CreateInferenceSession(config_file, inference_params)\n output = inference_session.predict(dense_features, embedding_columns, row_ptrs)\n print(\"WDL multi-embedding table inference result is {}\".format(output))\n\nwdl_inference()",
"Overwriting wdl_predict.py\n"
],
[
"!python wdl_predict.py",
"[HUGECTR][03:36:30][INFO][RANK0]: default_emb_vec_value is not specified using default: 0.000000\n[HUGECTR][03:36:30][INFO][RANK0]: default_emb_vec_value is not specified using default: 0.000000\n[HUGECTR][03:36:30][INFO][RANK0]: Creating RedisCluster backend...\n[HUGECTR][03:36:30][INFO][RANK0]: Connecting to Redis cluster via 127.0.0.1:7000 ...\n[HUGECTR][03:36:30][INFO][RANK0]: Connected to Redis database!\n[HUGECTR][03:36:30][INFO][RANK0]: Creating RocksDB backend...\n[HUGECTR][03:36:30][INFO][RANK0]: Connecting to RocksDB database...\n[HUGECTR][03:36:30][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"default\".\n[HUGECTR][03:36:30][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"hctr_et.wdl.sparse_embedding0\".\n[HUGECTR][03:36:30][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"hctr_et.wdl.sparse_embedding1\".\n[HUGECTR][03:36:31][INFO][RANK0]: Connected to RocksDB database!\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p0/v, query 0: Inserted 5565 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p1/v, query 0: Inserted 5553 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p2/v, query 0: Inserted 5572 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p3/v, query 0: Inserted 5553 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p4/v, query 0: Inserted 5485 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p5/v, query 0: Inserted 5556 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p6/v, query 0: Inserted 5584 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p7/v, query 0: Inserted 5605 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding0. Inserted 44473 / 44473 pairs.\n[HUGECTR][03:36:31][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding0; cached 44473 / 44473 embeddings in distributed database!\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 0: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 1: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 2: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 3: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 4: Inserted 4473 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding0. Inserted 44473 / 44473 pairs.\n[HUGECTR][03:36:31][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding0; cached 44473 embeddings in persistent database!\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p0/v, query 0: Inserted 6801 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p1/v, query 0: Inserted 6769 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p2/v, query 0: Inserted 6745 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p3/v, query 0: Inserted 6797 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p4/v, query 0: Inserted 6771 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p5/v, query 0: Inserted 6757 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p6/v, query 0: Inserted 6837 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p7/v, query 0: Inserted 6807 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding1. Inserted 54284 / 54284 pairs.\n[HUGECTR][03:36:31][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding1; cached 54284 / 54284 embeddings in distributed database!\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 0: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 1: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 2: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 3: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 4: Inserted 10000 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 5: Inserted 4284 pairs.\n[HUGECTR][03:36:31][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding1. Inserted 54284 / 54284 pairs.\n[HUGECTR][03:36:31][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding1; cached 54284 embeddings in persistent database!\n[HUGECTR][03:36:31][DEBUG][RANK0]: Real-time subscribers created!\n[HUGECTR][03:36:31][INFO][RANK0]: Create embedding cache in device 0.\n[HUGECTR][03:36:31][INFO][RANK0]: Use GPU embedding cache: False, cache size percentage: 0.900000\n[HUGECTR][03:36:31][INFO][RANK0]: Configured cache hit rate threshold: 0.500000\n[HUGECTR][03:36:31][INFO][RANK0]: Global seed is 2566656433\n[HUGECTR][03:36:31][INFO][RANK0]: Device to NUMA mapping:\n GPU 0 -> node 0\n\n[HUGECTR][03:36:32][WARNING][RANK0]: Peer-to-peer access cannot be fully enabled.\n[HUGECTR][03:36:32][INFO][RANK0]: Start all2all warmup\n[HUGECTR][03:36:32][INFO][RANK0]: End all2all warmup\n[HUGECTR][03:36:32][INFO][RANK0]: Model name: wdl\n[HUGECTR][03:36:32][INFO][RANK0]: Use mixed precision: False\n[HUGECTR][03:36:32][INFO][RANK0]: Use cuda graph: True\n[HUGECTR][03:36:32][INFO][RANK0]: Max batchsize: 64\n[HUGECTR][03:36:32][INFO][RANK0]: Use I64 input key: True\n[HUGECTR][03:36:32][INFO][RANK0]: start create embedding for inference\n[HUGECTR][03:36:32][INFO][RANK0]: sparse_input name wide_data\n[HUGECTR][03:36:32][INFO][RANK0]: sparse_input name deep_data\n[HUGECTR][03:36:32][INFO][RANK0]: create embedding for inference success\n[HUGECTR][03:36:32][INFO][RANK0]: Inference stage skip BinaryCrossEntropyLoss layer, replaced by Sigmoid layer\n[HUGECTR][03:36:33][INFO][RANK0]: Looking up 10 embeddings (each with 1 values)...\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p1/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p2/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p3/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p4/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p5/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p6/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p7/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding0. Fetched 10 / 10 values.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RedisCluster: 10 hits, 0 missing!\n[HUGECTR][03:36:33][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding0. Fetched 0 / 0 values.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RocksDB: 10 hits, 0 missing!\n[HUGECTR][03:36:33][INFO][RANK0]: Parameter server lookup of 10 / 10 embeddings took 656 us.\n[HUGECTR][03:36:33][INFO][RANK0]: Looking up 130 embeddings (each with 16 values)...\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p0/v, query 0: Fetched 10 keys. Hits 10.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p1/v, query 0: Fetched 16 keys. Hits 16.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p2/v, query 0: Fetched 17 keys. Hits 17.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p3/v, query 0: Fetched 16 keys. Hits 16.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p4/v, query 0: Fetched 18 keys. Hits 18.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p5/v, query 0: Fetched 14 keys. Hits 14.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p6/v, query 0: Fetched 21 keys. Hits 21.\n[HUGECTR][03:36:33][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p7/v, query 0: Fetched 18 keys. Hits 18.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding1. Fetched 130 / 130 values.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RedisCluster: 130 hits, 0 missing!\n[HUGECTR][03:36:33][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding1. Fetched 0 / 0 values.\n[HUGECTR][03:36:33][DEBUG][RANK0]: RocksDB: 130 hits, 0 missing!\n[HUGECTR][03:36:33][INFO][RANK0]: Parameter server lookup of 130 / 130 embeddings took 882 us.\nWDL multi-embedding table inference result is [0.013668588362634182, 0.008148659951984882, 0.06785331666469574, 0.007276115473359823, 0.019930679351091385]\n[HUGECTR][03:36:33][INFO][RANK0]: Disconnecting from RocksDB database...\n[HUGECTR][03:36:33][INFO][RANK0]: Disconnected from RocksDB database!\n[HUGECTR][03:36:33][INFO][RANK0]: Disconnecting from Redis database...\n[HUGECTR][03:36:33][INFO][RANK0]: Disconnected from Redis database!\n"
]
],
[
[
"### 4.2 Inference using Triton",
"_____no_output_____"
],
[
"**Please refer to the [Triton_Inference.ipynb](./Triton_Inference.ipynb) notebook to start Triton and do the inference.**",
"_____no_output_____"
],
[
"## 5. Continue Training WDL Model",
"_____no_output_____"
]
],
[
[
"%%writefile wdl_continue.py\nimport hugectr\nfrom mpi4py import MPI\nsolver = hugectr.CreateSolver(model_name = \"wdl\",\n max_eval_batches = 5000,\n batchsize_eval = 1024,\n batchsize = 1024,\n lr = 0.001,\n vvgpu = [[0]],\n i64_input_key = False,\n use_mixed_precision = False,\n repeat_dataset = False,\n use_cuda_graph = True,\n kafka_brockers = \"10.23.137.25:9093\")\nreader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Norm,\n source = [\"criteo_data/file_list.\"+str(i)+\".txt\" for i in range(6, 9)],\n keyset = [\"criteo_data/file_list.\"+str(i)+\".keyset\" for i in range(6, 9)],\n eval_source = \"criteo_data/file_list.9.txt\",\n check_type = hugectr.Check_t.Sum)\noptimizer = hugectr.CreateOptimizer(optimizer_type = hugectr.Optimizer_t.Adam)\nhc_config = hugectr.CreateHMemCache(2, 0.5, 0)\netc = hugectr.CreateETC(ps_types = [hugectr.TrainPSType_t.Staged, hugectr.TrainPSType_t.Cached],\\\n sparse_models = [\"./wdl_0_sparse_model\", \"./wdl_1_sparse_model\"],\\\n local_paths = [\"./\"], hmem_cache_configs = [hc_config])\nmodel = hugectr.Model(solver, reader, optimizer, etc)\nmodel.construct_from_json(graph_config_file = \"wdl.json\", include_dense_network = True)\nmodel.compile()\nmodel.load_dense_weights(\"wdl_dense_0_model\")\nmodel.load_dense_optimizer_states(\"dcn_opt_dense_1000.model\")\n\nmodel.summary()\nmodel.graph_to_json(graph_config_file = \"wdl.json\")\nmodel.fit(num_epochs = 1, display = 500, eval_interval = 1000)\nmodel.dump_incremental_model_2kafka()\nmodel.save_params_to_files(\"wdl_new\")",
"Overwriting wdl_continue.py\n"
],
[
"!python wdl_continue.py",
"[HUGECTR][03:37:25][INFO][RANK0]: Use existing embedding: ./wdl_0_sparse_model\n[HUGECTR][03:37:25][INFO][RANK0]: Use existing embedding: ./wdl_1_sparse_model\nHugeCTR Version: 3.2\n====================================================Model Init=====================================================\n[HUGECTR][03:37:25][INFO][RANK0]: Initialize model: wdl\n[HUGECTR][03:37:25][INFO][RANK0]: Global seed is 2083265859\n[HUGECTR][03:37:25][INFO][RANK0]: Device to NUMA mapping:\n GPU 0 -> node 0\n\n[HUGECTR][03:37:27][WARNING][RANK0]: Peer-to-peer access cannot be fully enabled.\n[HUGECTR][03:37:27][INFO][RANK0]: Start all2all warmup\n[HUGECTR][03:37:27][INFO][RANK0]: End all2all warmup\n[HUGECTR][03:37:27][INFO][RANK0]: Using All-reduce algorithm: NCCL\n[HUGECTR][03:37:27][INFO][RANK0]: Device 0: Tesla V100-SXM2-32GB\n[HUGECTR][03:37:27][DEBUG][RANK0]: Creating Kafka lifetime service.\n[HUGECTR][03:37:27][INFO][RANK0]: num of DataReader workers: 12\n[HUGECTR][03:37:27][INFO][RANK0]: max_num_frequent_categories is not specified using default: 1\n[HUGECTR][03:37:27][INFO][RANK0]: max_num_infrequent_samples is not specified using default: -1\n[HUGECTR][03:37:27][INFO][RANK0]: p_dup_max is not specified using default: 0.010000\n[HUGECTR][03:37:27][INFO][RANK0]: max_all_reduce_bandwidth is not specified using default: 130000000000.000000\n[HUGECTR][03:37:27][INFO][RANK0]: max_all_to_all_bandwidth is not specified using default: 190000000000.000000\n[HUGECTR][03:37:27][INFO][RANK0]: efficiency_bandwidth_ratio is not specified using default: 1.000000\n[HUGECTR][03:37:27][INFO][RANK0]: use_train_precompute_indices is not specified using default: 0\n[HUGECTR][03:37:27][INFO][RANK0]: use_eval_precompute_indices is not specified using default: 0\n[HUGECTR][03:37:27][INFO][RANK0]: communication_type is not specified using default: IB_NVLink\n[HUGECTR][03:37:27][INFO][RANK0]: hybrid_embedding_type is not specified using default: Distributed\n[HUGECTR][03:37:27][INFO][RANK0]: max_vocabulary_size_per_gpu_=6029312\n[HUGECTR][03:37:27][INFO][RANK0]: max_num_frequent_categories is not specified using default: 1\n[HUGECTR][03:37:27][INFO][RANK0]: max_num_infrequent_samples is not specified using default: -1\n[HUGECTR][03:37:27][INFO][RANK0]: p_dup_max is not specified using default: 0.010000\n[HUGECTR][03:37:27][INFO][RANK0]: max_all_reduce_bandwidth is not specified using default: 130000000000.000000\n[HUGECTR][03:37:27][INFO][RANK0]: max_all_to_all_bandwidth is not specified using default: 190000000000.000000\n[HUGECTR][03:37:27][INFO][RANK0]: efficiency_bandwidth_ratio is not specified using default: 1.000000\n[HUGECTR][03:37:27][INFO][RANK0]: use_train_precompute_indices is not specified using default: 0\n[HUGECTR][03:37:27][INFO][RANK0]: use_eval_precompute_indices is not specified using default: 0\n[HUGECTR][03:37:27][INFO][RANK0]: communication_type is not specified using default: IB_NVLink\n[HUGECTR][03:37:27][INFO][RANK0]: hybrid_embedding_type is not specified using default: Distributed\n[HUGECTR][03:37:27][INFO][RANK0]: max_vocabulary_size_per_gpu_=5865472\n[HUGECTR][03:37:27][INFO][RANK0]: Load the model graph from wdl.json successfully\n[HUGECTR][03:37:27][INFO][RANK0]: Graph analysis to resolve tensor dependency\n===================================================Model Compile===================================================\n[HUGECTR][03:37:30][INFO][RANK0]: gpu0 start to init embedding\n[HUGECTR][03:37:30][INFO][RANK0]: gpu0 init embedding done\n[HUGECTR][03:37:30][INFO][RANK0]: gpu0 start to init embedding\n[HUGECTR][03:37:30][INFO][RANK0]: gpu0 init embedding done\n[HUGECTR][03:37:30][INFO][RANK0]: Enable HMEM-Based Parameter Server\n[HUGECTR][03:37:30][INFO][RANK0]: Enable HMemCache-Based Parameter Server\n[HUGECTR][03:37:31][INFO][RANK0]: Starting AUC NCCL warm-up\n[HUGECTR][03:37:31][INFO][RANK0]: Warm-up done\n0. Runtime error: Cannot open dense model file /jershi/HugeCTR_gitlab/hugectr/HugeCTR/pybind/model.cpp:1983 \n\n0. Runtime error: Cannot open dense opt states file /jershi/HugeCTR_gitlab/hugectr/HugeCTR/pybind/model.cpp:1934 \n\n===================================================Model Summary===================================================\nlabel Dense Sparse \nlabel dense wide_data,deep_data \n(None, 1) (None, 13) \n——————————————————————————————————————————————————————————————————————————————————————————————————————————————————\nLayer Type Input Name Output Name Output Shape \n——————————————————————————————————————————————————————————————————————————————————————————————————————————————————\nDistributedSlotSparseEmbeddingHash wide_data sparse_embedding0 (None, 1, 1) \n------------------------------------------------------------------------------------------------------------------\nDistributedSlotSparseEmbeddingHash deep_data sparse_embedding1 (None, 26, 16) \n------------------------------------------------------------------------------------------------------------------\nReshape sparse_embedding1 reshape1 (None, 416) \n------------------------------------------------------------------------------------------------------------------\nReshape sparse_embedding0 reshape2 (None, 1) \n------------------------------------------------------------------------------------------------------------------\nConcat reshape1 concat1 (None, 429) \n dense \n------------------------------------------------------------------------------------------------------------------\nInnerProduct concat1 fc1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nReLU fc1 relu1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nDropout relu1 dropout1 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nInnerProduct dropout1 fc2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nReLU fc2 relu2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nDropout relu2 dropout2 (None, 1024) \n------------------------------------------------------------------------------------------------------------------\nInnerProduct dropout2 fc3 (None, 1) \n------------------------------------------------------------------------------------------------------------------\nAdd fc3 add1 (None, 1) \n reshape2 \n------------------------------------------------------------------------------------------------------------------\nBinaryCrossEntropyLoss add1 loss \n label \n------------------------------------------------------------------------------------------------------------------\n[HUGECTR][03:37:31][INFO][RANK0]: Save the model graph to wdl.json successfully\n=====================================================Model Fit=====================================================\n[HUGECTR][03:37:31][INFO][RANK0]: Use embedding training cache mode with number of training sources: 3, number of epochs: 1\n[HUGECTR][03:37:31][INFO][RANK0]: Training batchsize: 1024, evaluation batchsize: 1024\n[HUGECTR][03:37:31][INFO][RANK0]: Evaluation interval: 1000, snapshot interval: 10000\n[HUGECTR][03:37:31][INFO][RANK0]: Dense network trainable: True\n[HUGECTR][03:37:31][INFO][RANK0]: Sparse embedding sparse_embedding0 trainable: True\n[HUGECTR][03:37:31][INFO][RANK0]: Sparse embedding sparse_embedding1 trainable: True\n[HUGECTR][03:37:31][INFO][RANK0]: Use mixed precision: False, scaler: 1.000000, use cuda graph: True\n[HUGECTR][03:37:31][INFO][RANK0]: lr: 0.001000, warmup_steps: 1, end_lr: 0.000000\n[HUGECTR][03:37:31][INFO][RANK0]: decay_start: 0, decay_steps: 1, decay_power: 2.000000\n[HUGECTR][03:37:31][INFO][RANK0]: Evaluation source file: criteo_data/file_list.9.txt\n[HUGECTR][03:37:31][INFO][RANK0]: --------------------Epoch 0, source file: criteo_data/file_list.6.txt--------------------\n[HUGECTR][03:37:31][INFO][RANK0]: Preparing embedding table for next pass\n[HUGECTR][03:37:32][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 0 %\n[HUGECTR][03:37:32][INFO][RANK0]: --------------------Epoch 0, source file: criteo_data/file_list.7.txt--------------------\n[HUGECTR][03:37:32][INFO][RANK0]: Preparing embedding table for next pass\n[HUGECTR][03:37:32][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 90.64 %\n[HUGECTR][03:37:32][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 75.02 %\n[HUGECTR][03:37:33][INFO][RANK0]: --------------------Epoch 0, source file: criteo_data/file_list.8.txt--------------------\n[HUGECTR][03:37:33][INFO][RANK0]: Preparing embedding table for next pass\n[HUGECTR][03:37:33][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 95.81 %\n[HUGECTR][03:37:33][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 87.33 %\n[HUGECTR][03:37:34][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 85.8 %\n[HUGECTR][03:37:34][INFO][RANK0]: HMEM-Cache PS: Hit rate [load]: 86.51 %\n[HUGECTR][03:37:34][INFO][RANK0]: Get updated portion of embedding table [DONE}\n[HUGECTR][03:37:34][INFO][RANK0]: Dump incremental parameters of hctr_et.wdl.sparse_embedding0 into kafka. Embedding size is 1, num_pairs is 58853 \n[HUGECTR][03:37:34][INFO][RANK0]: Creating new Kafka topic \"hctr_et.wdl.sparse_embedding0\".\n[HUGECTR][03:37:34][INFO][RANK0]: Dump incremental parameters of hctr_et.wdl.sparse_embedding1 into kafka. Embedding size is 16, num_pairs is 58383 \n[HUGECTR][03:37:34][INFO][RANK0]: Creating new Kafka topic \"hctr_et.wdl.sparse_embedding1\".\n[HUGECTR][03:37:42][INFO][RANK0]: HMEM-Cache PS: Hit rate [dump]: 85.8 %\n[HUGECTR][03:37:42][INFO][RANK0]: Updating sparse model in SSD [DONE]\n[HUGECTR][03:37:42][INFO][RANK0]: Sync blocks from HMEM-Cache to SSD\n \u001b[38;2;89;255;89m ████████████████████████████████████████▏ \u001b[1m\u001b[31m100.0% \u001b[34m[ 2/ 2 | 62.5 Hz | 0s<0s] \u001b[0m\u001b[32m\u001b[0mm\n[HUGECTR][03:37:42][INFO][RANK0]: Dumping dense weights to file, successful\n[HUGECTR][03:37:43][INFO][RANK0]: Dumping dense optimizer states to file, successful\n[HUGECTR][03:37:43][INFO][RANK0]: Dumping untrainable weights to file, successful\n[HUGECTR][03:37:56][DEBUG][RANK0]: Destroying Kafka lifetime service.\n"
]
],
[
[
"## 6. Inference with new model",
"_____no_output_____"
],
[
"### 6.1 Continuous inference using Python API",
"_____no_output_____"
]
],
[
[
"!python wdl_predict.py",
"[HUGECTR][03:38:09][INFO][RANK0]: default_emb_vec_value is not specified using default: 0.000000\n[HUGECTR][03:38:09][INFO][RANK0]: default_emb_vec_value is not specified using default: 0.000000\n[HUGECTR][03:38:09][INFO][RANK0]: Creating RedisCluster backend...\n[HUGECTR][03:38:09][INFO][RANK0]: Connecting to Redis cluster via 127.0.0.1:7000 ...\n[HUGECTR][03:38:09][INFO][RANK0]: Connected to Redis database!\n[HUGECTR][03:38:09][INFO][RANK0]: Creating RocksDB backend...\n[HUGECTR][03:38:09][INFO][RANK0]: Connecting to RocksDB database...\n[HUGECTR][03:38:09][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"default\".\n[HUGECTR][03:38:09][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"hctr_et.wdl.sparse_embedding0\".\n[HUGECTR][03:38:09][INFO][RANK0]: RocksDB /wdl_infer/rocksdb/, found column family \"hctr_et.wdl.sparse_embedding1\".\n[HUGECTR][03:38:09][INFO][RANK0]: Connected to RocksDB database!\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p0/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p0/v, query 1: Inserted 243 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p1/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p1/v, query 1: Inserted 375 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p2/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p2/v, query 1: Inserted 329 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p3/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p3/v, query 1: Inserted 303 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p4/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p4/v, query 1: Inserted 318 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p5/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p5/v, query 1: Inserted 271 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p6/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p6/v, query 1: Inserted 310 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p7/v, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p7/v, query 1: Inserted 345 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding0. Inserted 82494 / 82494 pairs.\n[HUGECTR][03:38:09][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding0; cached 82494 / 82494 embeddings in distributed database!\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 1: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 2: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 3: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 4: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 5: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 6: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 7: Inserted 10000 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding0, query 8: Inserted 2494 pairs.\n[HUGECTR][03:38:09][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding0. Inserted 82494 / 82494 pairs.\n[HUGECTR][03:38:09][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding0; cached 82494 embeddings in persistent database!\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p0/v, query 0: Inserted 7628 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p1/v, query 0: Inserted 7631 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p2/v, query 0: Inserted 7629 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p3/v, query 0: Inserted 7628 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p4/v, query 0: Inserted 7628 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p5/v, query 0: Inserted 7629 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p6/v, query 0: Inserted 7627 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p7/v, query 0: Inserted 7635 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding1. Inserted 61035 / 61035 pairs.\n[HUGECTR][03:38:10][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding1; cached 61035 / 61035 embeddings in distributed database!\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 0: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 1: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 2: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 3: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 4: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 5: Inserted 10000 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB table hctr_et.wdl.sparse_embedding1, query 6: Inserted 1035 pairs.\n[HUGECTR][03:38:10][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding1. Inserted 61035 / 61035 pairs.\n[HUGECTR][03:38:10][INFO][RANK0]: Table: hctr_et.wdl.sparse_embedding1; cached 61035 embeddings in persistent database!\n[HUGECTR][03:38:10][DEBUG][RANK0]: Real-time subscribers created!\n[HUGECTR][03:38:10][INFO][RANK0]: Create embedding cache in device 0.\n[HUGECTR][03:38:10][INFO][RANK0]: Use GPU embedding cache: False, cache size percentage: 0.900000\n[HUGECTR][03:38:10][INFO][RANK0]: Configured cache hit rate threshold: 0.500000\n[HUGECTR][03:38:10][INFO][RANK0]: Global seed is 2362747437\n[HUGECTR][03:38:10][INFO][RANK0]: Device to NUMA mapping:\n GPU 0 -> node 0\n\n[HUGECTR][03:38:11][WARNING][RANK0]: Peer-to-peer access cannot be fully enabled.\n[HUGECTR][03:38:11][INFO][RANK0]: Start all2all warmup\n[HUGECTR][03:38:11][INFO][RANK0]: End all2all warmup\n[HUGECTR][03:38:11][INFO][RANK0]: Model name: wdl\n[HUGECTR][03:38:11][INFO][RANK0]: Use mixed precision: False\n[HUGECTR][03:38:11][INFO][RANK0]: Use cuda graph: True\n[HUGECTR][03:38:11][INFO][RANK0]: Max batchsize: 64\n[HUGECTR][03:38:11][INFO][RANK0]: Use I64 input key: True\n[HUGECTR][03:38:11][INFO][RANK0]: start create embedding for inference\n[HUGECTR][03:38:11][INFO][RANK0]: sparse_input name wide_data\n[HUGECTR][03:38:11][INFO][RANK0]: sparse_input name deep_data\n[HUGECTR][03:38:11][INFO][RANK0]: create embedding for inference success\n[HUGECTR][03:38:11][INFO][RANK0]: Inference stage skip BinaryCrossEntropyLoss layer, replaced by Sigmoid layer\n[HUGECTR][03:38:12][INFO][RANK0]: Looking up 10 embeddings (each with 1 values)...\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p1/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p2/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p3/v, query 0: Fetched 2 keys. Hits 2.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p4/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p5/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p6/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding0/p7/v, query 0: Fetched 1 keys. Hits 1.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding0. Fetched 10 / 10 values.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RedisCluster: 10 hits, 0 missing!\n[HUGECTR][03:38:12][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding0. Fetched 0 / 0 values.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RocksDB: 10 hits, 0 missing!\n[HUGECTR][03:38:12][INFO][RANK0]: Parameter server lookup of 10 / 10 embeddings took 679 us.\n[HUGECTR][03:38:12][INFO][RANK0]: Looking up 130 embeddings (each with 16 values)...\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p0/v, query 0: Fetched 10 keys. Hits 10.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p1/v, query 0: Fetched 16 keys. Hits 16.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p2/v, query 0: Fetched 17 keys. Hits 17.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p3/v, query 0: Fetched 16 keys. Hits 16.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p4/v, query 0: Fetched 18 keys. Hits 18.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p5/v, query 0: Fetched 14 keys. Hits 14.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p6/v, query 0: Fetched 21 keys. Hits 21.\n[HUGECTR][03:38:12][DEBUG][RANK0]: Redis partition hctr_et.wdl.sparse_embedding1/p7/v, query 0: Fetched 18 keys. Hits 18.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RedisCluster backend. Table: hctr_et.wdl.sparse_embedding1. Fetched 130 / 130 values.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RedisCluster: 130 hits, 0 missing!\n[HUGECTR][03:38:12][DEBUG][RANK0]: RocksDB backend. Table: hctr_et.wdl.sparse_embedding1. Fetched 0 / 0 values.\n[HUGECTR][03:38:12][DEBUG][RANK0]: RocksDB: 130 hits, 0 missing!\n[HUGECTR][03:38:12][INFO][RANK0]: Parameter server lookup of 130 / 130 embeddings took 712 us.\nWDL multi-embedding table inference result is [0.0036218352615833282, 0.000900191895198077, 0.0546233244240284, 0.0028622469399124384, 0.005312761757522821]\n[HUGECTR][03:38:12][INFO][RANK0]: Disconnecting from RocksDB database...\n[HUGECTR][03:38:12][INFO][RANK0]: Disconnected from RocksDB database!\n[HUGECTR][03:38:12][INFO][RANK0]: Disconnecting from Redis database...\n[HUGECTR][03:38:12][INFO][RANK0]: Disconnected from Redis database!\n"
]
],
[
[
"### 6.2 Continuous inference using Triton",
"_____no_output_____"
],
[
"**Please refer to the [Triton_Inference.ipynb](./Triton_Inference.ipynb) notebook to do the inference.**",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d02c0b16008ddbe84aac8e61880f19102a2eba9b
| 83,756 |
ipynb
|
Jupyter Notebook
|
Pymaceuticals/pymaceuticals_starter.ipynb
|
tomlip/Matplotlib-challenge
|
4c015c4cac7b667bb75df18dca089750734f7d14
|
[
"ADSL"
] | null | null | null |
Pymaceuticals/pymaceuticals_starter.ipynb
|
tomlip/Matplotlib-challenge
|
4c015c4cac7b667bb75df18dca089750734f7d14
|
[
"ADSL"
] | null | null | null |
Pymaceuticals/pymaceuticals_starter.ipynb
|
tomlip/Matplotlib-challenge
|
4c015c4cac7b667bb75df18dca089750734f7d14
|
[
"ADSL"
] | null | null | null | 62.457867 | 13,416 | 0.674005 |
[
[
[
"## Observations and Insights ",
"_____no_output_____"
]
],
[
[
"# Dependencies and Setup\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport scipy.stats as st\n\n# Study data files\nmouse_metadata_path = \"data/Mouse_metadata.csv\"\nstudy_results_path = \"data/Study_results.csv\"\n\n# Read the mouse data and the study results\nmouse_metadata = pd.read_csv(mouse_metadata_path)\nstudy_results = pd.read_csv(study_results_path)\n\n# Combine the data into a single dataset\nmerged_df = pd.merge(study_results, mouse_metadata, how=\"left\", on=\"Mouse ID\")\n\n# Preview of the merged dataset\nmerged_df.head()",
"_____no_output_____"
],
[
"# Checking the number of mice in the DataFrame.\nlen(merged_df[\"Mouse ID\"].value_counts())",
"_____no_output_____"
],
[
"# Getting the duplicate mice by ID number that shows up for Mouse ID and Timepoint. \nduplicate_df = merged_df[merged_df.duplicated(subset=[\"Mouse ID\", \"Timepoint\"], keep=False)]\nduplicate_df[[\"Mouse ID\", \"Timepoint\"]]",
"_____no_output_____"
],
[
"# Optional: Get all the data for the duplicate mouse ID. \nduplicate_df = merged_df.loc[merged_df[\"Mouse ID\"] == \"g989\"]\nduplicate_df",
"_____no_output_____"
],
[
"# Create a clean DataFrame by dropping the duplicate mouse by its ID.\nclean_df = merged_df.drop(duplicate_df.index)\nclean_df.head()",
"_____no_output_____"
],
[
"# Checking the number of mice in the clean DataFrame.\nlen(clean_df[\"Mouse ID\"].value_counts())",
"_____no_output_____"
]
],
[
[
"## Summary Statistics",
"_____no_output_____"
]
],
[
[
"# Generate a summary statistics table of mean, median, variance, standard deviation, and SEM of the tumor volume for each regimen\n\n# This method is the most straightforward, creating multiple series and putting them all together at the end.\n\ndrug_df = clean_df.groupby(\"Drug Regimen\")\n\n# calculating the statistics\nmean_arr = drug_df[\"Tumor Volume (mm3)\"].mean()\nmedian_arr = drug_df[\"Tumor Volume (mm3)\"].median()\nvar_arr = drug_df[\"Tumor Volume (mm3)\"].var()\nstd_arr = drug_df[\"Tumor Volume (mm3)\"].std()\nsem_arr = drug_df[\"Tumor Volume (mm3)\"].sem()\n\n# creating statistic summary dataframe\nstats_df = pd.DataFrame({\n \"Mean Tumor Volume\": mean_arr,\n \"Median Tumor Volume\": median_arr,\n \"Tumor Volume Variance\": var_arr,\n \"Tumor Volume Std. Dev.\": std_arr,\n \"Tumor Volume Std. Err.\": sem_arr\n})\n\n# show statistic summary\nstats_df",
"_____no_output_____"
],
[
"# Generate a summary statistics table of mean, median, variance, standard deviation, and SEM of the tumor volume for each regimen\n\n# This method produces everything in a single groupby function.\n\nstats2_df = clean_df.groupby(\"Drug Regimen\").agg({\"Tumor Volume (mm3)\": [\"mean\", \"median\", \"var\", \"std\", \"sem\"]})\n\nstats2_df",
"_____no_output_____"
]
],
[
[
"## Bar Plots",
"_____no_output_____"
]
],
[
[
"# Generate a bar plot showing the number of mice per time point for each treatment throughout the course of the study using pandas.\n\n#creating count dataframe\nbar_df = clean_df.groupby(\"Drug Regimen\").count()\n\n#creating bar chart dataframe\nbar_df = bar_df.sort_values(\"Timepoint\", ascending=False)\nbars_df = bar_df[\"Timepoint\"]\n\n# creating bar chart\ngraph = bars_df.plot(kind=\"bar\")\ngraph.set_ylabel(\"Number of Data Points\")",
"_____no_output_____"
],
[
"# Generate a bar plot showing the number of mice per time point for each treatment throughout the course of the study using pyplot.\n\n#creating count dataframe\nbar_df = clean_df.groupby(\"Drug Regimen\").count()\n\n#creating bar chart dataframe\nbar_df = bar_df.sort_values(\"Timepoint\", ascending=False)\nbars_df = bar_df[\"Timepoint\"]\n\nplt.bar(bar_df.index, bar_df[\"Timepoint\"])\nplt.ylabel(\"Number of Data Points\")\nplt.xticks(rotation=\"vertical\")",
"_____no_output_____"
]
],
[
[
"## Pie Plots",
"_____no_output_____"
]
],
[
[
"# Generate a pie plot showing the distribution of female versus male mice using pandas\npie_chart = mouse_metadata[\"Sex\"].value_counts()\npie_chart.plot(kind='pie', subplots=True, autopct=\"%0.1f%%\")",
"_____no_output_____"
],
[
"# Generate a pie plot showing the distribution of female versus male mice using pyplot\nf_vs_m = mouse_metadata[\"Sex\"].value_counts()\nplt.pie(f_vs_m, autopct=\"%1.1f%%\")",
"_____no_output_____"
]
],
[
[
"## Quartiles, Outliers and Boxplots",
"_____no_output_____"
]
],
[
[
"# Calculate the final tumor volume of each mouse across four of the most promising treatment regimens. Calculate the IQR and quantitatively determine if there are any potential outliers. \n\n# returning the max timepoints for Capomulin\ntemp_df = clean_df.loc[clean_df[\"Drug Regimen\"] == \"Capomulin\", :]\nmax_capo = temp_df.groupby(\"Mouse ID\").max()\n\n# returning the max timepoints for Ramicane\ntemp_df = clean_df.loc[clean_df[\"Drug Regimen\"] == \"Ramicane\", :]\nmax_rami = temp_df.groupby(\"Mouse ID\").max()\n\n# returning the max timepoints for Infubinol\ntemp_df = clean_df.loc[clean_df[\"Drug Regimen\"] == \"Infubinol\", :]\nmax_infu = temp_df.groupby(\"Mouse ID\").max()\n\n# returning the max timepoints for Ketapril\ntemp_df = clean_df.loc[clean_df[\"Drug Regimen\"] == \"Ceftamin\", :]\nmax_ceft = temp_df.groupby(\"Mouse ID\").max()\n\n# calculating IQR's\nquartiles = max_capo[\"Tumor Volume (mm3)\"].quantile([.25,.5,.75])\ncapo_iqr = quartiles[0.75] - quartiles[0.25]\nlower_bound = quartiles[0.25] - (1.5*capo_iqr)\nupper_bound = quartiles[0.75] + (1.5*capo_iqr)\ncapo_outliers = max_capo[\"Tumor Volume (mm3)\"].loc[(max_capo[\"Tumor Volume (mm3)\"] < lower_bound) | (max_capo[\"Tumor Volume (mm3)\"] > upper_bound)]\n\nquartiles = max_rami[\"Tumor Volume (mm3)\"].quantile([.25,.5,.75])\nrami_iqr = quartiles[0.75] - quartiles[0.25]\nlower_bound = quartiles[0.25] - (1.5*rami_iqr)\nupper_bound = quartiles[0.75] + (1.5*rami_iqr)\nrami_outliers = max_rami[\"Tumor Volume (mm3)\"].loc[(max_rami[\"Tumor Volume (mm3)\"] < lower_bound) | (max_rami[\"Tumor Volume (mm3)\"] > upper_bound)]\n\ninfu_quartiles = max_infu[\"Tumor Volume (mm3)\"].quantile([.25,.5,.75])\ninfu_iqr = quartiles[0.75] - infu_quartiles[0.25]\nlower_bound_infu = infu_quartiles[0.25] - (1.5*infu_iqr)\nupper_bound_infu = infu_quartiles[0.75] + (1.5*infu_iqr)\ninfu_outliers = max_infu[\"Tumor Volume (mm3)\"].loc[(max_infu[\"Tumor Volume (mm3)\"] <= lower_bound_infu) | (max_infu[\"Tumor Volume (mm3)\"] >= upper_bound_infu)]\n\n\nquartiles = max_ceft[\"Tumor Volume (mm3)\"].quantile([.25,.5,.75])\nceft_iqr = quartiles[0.75] - quartiles[0.25]\nlower_bound = quartiles[0.25] - (1.5*ceft_iqr)\nupper_bound = quartiles[0.75] + (1.5*ceft_iqr)\nceft_outliers = max_ceft[\"Tumor Volume (mm3)\"].loc[(max_ceft[\"Tumor Volume (mm3)\"] < lower_bound) | (max_ceft[\"Tumor Volume (mm3)\"] > upper_bound)]\n\nlen(infu_outliers)",
"_____no_output_____"
],
[
"# Generate a box plot of the final tumor volume of each mouse across four regimens of interest",
"_____no_output_____"
]
],
[
[
"## Line and Scatter Plots",
"_____no_output_____"
]
],
[
[
"# Generate a line plot of time point versus tumor volume for a mouse treated with Capomulin\n",
"_____no_output_____"
],
[
"# Generate a scatter plot of mouse weight versus average tumor volume for the Capomulin regimen\n\n",
"_____no_output_____"
]
],
[
[
"## Correlation and Regression",
"_____no_output_____"
]
],
[
[
"# Calculate the correlation coefficient and linear regression model \n# for mouse weight and average tumor volume for the Capomulin regimen\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02c0cfab10bd62cae98017f373041e621b3c4e9
| 20,733 |
ipynb
|
Jupyter Notebook
|
notebooks/select_enroll_test.ipynb
|
helia95/SpeakerRecognition_tutorial
|
5c00f9165fd260d50b74ab46e4d81d7cfd77ab8c
|
[
"MIT"
] | null | null | null |
notebooks/select_enroll_test.ipynb
|
helia95/SpeakerRecognition_tutorial
|
5c00f9165fd260d50b74ab46e4d81d7cfd77ab8c
|
[
"MIT"
] | null | null | null |
notebooks/select_enroll_test.ipynb
|
helia95/SpeakerRecognition_tutorial
|
5c00f9165fd260d50b74ab46e4d81d7cfd77ab8c
|
[
"MIT"
] | null | null | null | 35.932409 | 115 | 0.44176 |
[
[
[
"import os\nimport pickle\nimport glob\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"dataroot = '/cas/DeepLearn/elperu/tmp/speech_datasets/LibriSpeech/train_test_split/test/'\n\nembedding_dir = '/cas/DeepLearn/elperu/tmp/speech_datasets/LibriSpeech/embd_identification/'",
"_____no_output_____"
],
[
"spks = os.listdir(dataroot)",
"_____no_output_____"
],
[
"enroll_rows_db = []\ntest_rows_db = []\n\nfor spk in spks:\n samples = glob.glob(os.path.join(dataroot, spk, '*.p'))\n \n lengths = []\n for sample in samples:\n with open(sample, 'rb') as f:\n D = pickle.load(f)\n lengths.append(D['feat'].shape[0])\n \n # Keep the longest utterance as enroll\n enroll_idx = np.argmax(lengths)\n \n # Add to db\n for idx in range(len(samples)):\n embd_path = os.path.join(embedding_dir, spk,os.path.basename(samples[idx]).split('.')[0] + '.pth')\n if idx == enroll_idx:\n enroll_rows_db.append([embd_path, spk])\n else:\n test_rows_db.append([embd_path, spk]) \n \n \nenroll_DB = pd.DataFrame(enroll_rows_db, columns=['_path', 'spk_id'])\ntest_DB = pd.DataFrame(test_rows_db, columns=['_path', 'spk_id'])",
"_____no_output_____"
],
[
"test_DB",
"_____no_output_____"
],
[
"enroll_DB",
"_____no_output_____"
],
[
"#path_out = '/cas/DeepLearn/elperu/tmp/speech_datasets/LibriSpeech/tot_embeddings/'\n\ntest_DB.to_csv(os.path.join(embedding_dir, 'test_samples.csv'))\nenroll_DB.to_csv(os.path.join(embedding_dir, 'enroll_samples.csv'))\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02c0e445a474bf5809d50edb7a7a920c1b78302
| 909,972 |
ipynb
|
Jupyter Notebook
|
Prototypical Nets Tox21 ECFP.ipynb
|
danielvlla/Few-Shot-Learning-for-Low-Data-Drug-Discovery
|
8718bd64ff35d1c2901d07b4b2d16e1f082f0390
|
[
"MIT"
] | 1 |
2021-12-13T21:17:29.000Z
|
2021-12-13T21:17:29.000Z
|
Prototypical Nets Tox21 ECFP.ipynb
|
danielvlla/Few-Shot-Learning-for-Low-Data-Drug-Discovery
|
8718bd64ff35d1c2901d07b4b2d16e1f082f0390
|
[
"MIT"
] | null | null | null |
Prototypical Nets Tox21 ECFP.ipynb
|
danielvlla/Few-Shot-Learning-for-Low-Data-Drug-Discovery
|
8718bd64ff35d1c2901d07b4b2d16e1f082f0390
|
[
"MIT"
] | null | null | null | 909,972 | 909,972 | 0.943166 |
[
[
[
"!pip install -q condacolab\nimport condacolab\ncondacolab.install()",
"✨🍰✨ Everything looks OK!\n"
],
[
"!conda install -c chembl chembl_structure_pipeline\nimport chembl_structure_pipeline\nfrom chembl_structure_pipeline import standardizer",
"_____no_output_____"
],
[
"from IPython.display import clear_output\n\n# https://www.dgl.ai/pages/start.html\n\n# !pip install dgl\n!pip install dgl-cu111 -f https://data.dgl.ai/wheels/repo.html # FOR CUDA VERSION\n!pip install dgllife\n!pip install rdkit-pypi\n!pip install --pre deepchem\n!pip install ipython-autotime\n!pip install gputil\n!pip install psutil\n!pip install humanize\n\n%load_ext autotime\n\nclear = clear_output()",
"time: 4 ms (started: 2021-11-30 11:43:34 +00:00)\n"
],
[
"import os\nfrom os import path\nimport statistics\nimport warnings\nimport random\nimport time \nimport itertools\nimport psutil\nimport humanize\nimport GPUtil as GPU\nimport subprocess\nfrom datetime import datetime, timedelta\n\nimport matplotlib.pyplot as plt\n\nimport pandas as pd\nimport numpy as np\n\nimport tqdm\nfrom tqdm import trange, tqdm_notebook, tnrange\n\nimport deepchem as dc\nimport rdkit\nfrom rdkit import Chem\nfrom rdkit.Chem.MolStandardize import rdMolStandardize\n\nimport dgl\nfrom dgl.dataloading import GraphDataLoader\nfrom dgl.nn import GraphConv, SumPooling, MaxPooling\nimport dgl.function as fn\nimport dgllife\nfrom dgllife import utils\n\n# embedding\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.autograd import Variable\nfrom torch.optim.lr_scheduler import ReduceLROnPlateau\nfrom torch.profiler import profile, record_function, ProfilerActivity\nfrom torch.utils.tensorboard import SummaryWriter\n\n\nimport sklearn\nfrom sklearn.metrics import (auc, roc_curve, roc_auc_score, average_precision_score, \n accuracy_score, ConfusionMatrixDisplay, confusion_matrix, precision_recall_curve, \n f1_score, PrecisionRecallDisplay)\nfrom sklearn.ensemble import RandomForestClassifier\n\nwarnings.filterwarnings(\"ignore\", message=\"DGLGraph.__len__\")\n\nDGLBACKEND = 'pytorch'\n\nclear\n\ndef get_cmd_output(command):\n return subprocess.check_output(command,\n stderr=subprocess.STDOUT,\n shell=True).decode('UTF-8')",
"DGL backend not selected or invalid. Assuming PyTorch for now.\n"
]
],
[
[
"### Create Dataset",
"_____no_output_____"
]
],
[
[
"def create_dataset(df, name, bonds):\n print(f\"Creating Dataset and Saving to {drive_path}/data/{name}.pkl\")\n data = df.sample(frac=1)\n data = data.reset_index(drop=True)\n data['mol'] = data['smiles'].apply(lambda x: create_dgl_features(x, bonds))\n data.to_pickle(f\"{drive_path}/data/{name}.pkl\")\n return data\n\ndef featurize_atoms(mol):\n feats = []\n \n atom_features = utils.ConcatFeaturizer([\n utils.atom_type_one_hot,\n utils.atomic_number_one_hot,\n utils.atom_degree_one_hot,\n utils.atom_explicit_valence_one_hot,\n utils.atom_formal_charge_one_hot,\n utils.atom_num_radical_electrons_one_hot,\n utils.atom_hybridization_one_hot,\n utils.atom_is_aromatic_one_hot\n ])\n\n for atom in mol.GetAtoms():\n feats.append(atom_features(atom))\n return {'feats': torch.tensor(feats).float()}\n\ndef featurize_bonds(mol):\n feats = []\n \n bond_features = utils.ConcatFeaturizer([\n utils.bond_type_one_hot,\n utils.bond_is_conjugated_one_hot,\n utils.bond_is_in_ring_one_hot,\n utils.bond_stereo_one_hot,\n utils.bond_direction_one_hot,\n ])\n\n for bond in mol.GetBonds():\n feats.append(bond_features(bond))\n feats.append(bond_features(bond))\n return {'edge_feats': torch.tensor(feats).float()}\n\ndef create_dgl_features(smiles, bonds):\n mol = Chem.MolFromSmiles(smiles)\n mol = standardizer.standardize_mol(mol)\n \n if bonds:\n dgl_graph = utils.mol_to_bigraph(mol=mol,\n node_featurizer=featurize_atoms,\n edge_featurizer=featurize_bonds,\n canonical_atom_order=True)\n else:\n dgl_graph = utils.mol_to_bigraph(mol=mol,\n node_featurizer=featurize_atoms,\n canonical_atom_order=True)\n \n dgl_graph = dgl.add_self_loop(dgl_graph)\n \n return dgl_graph\n\ndef load_dataset(dataset, bonds=False, feat='graph', create_new=False):\n \"\"\"\n dataset values: muv, tox21, dude-gpcr\n feat values: graph, ecfp\n \"\"\"\n dataset_test_tasks = {\n 'tox21': ['SR-HSE', 'SR-MMP', 'SR-p53'],\n 'muv': ['MUV-832', 'MUV-846', 'MUV-852', 'MUV-858', 'MUV-859'],\n 'dude-gpcr': ['adrb2', 'cxcr4']\n }\n\n dataset_original = dataset\n\n if bonds:\n dataset = dataset + \"_with_bonds\"\n\n if path.exists(f\"{drive_path}/data/{dataset}_dgl.pkl\") and not create_new:\n # Load Dataset\n print(\"Reading Pickle\")\n if feat == 'graph':\n data = pd.read_pickle(f\"{drive_path}/data/{dataset}_dgl.pkl\")\n else:\n data = pd.read_pickle(f\"{drive_path}/data/{dataset}_ecfp.pkl\")\n else:\n # Create Dataset\n df = pd.read_csv(f\"{drive_path}/data/raw/{dataset_original}.csv\")\n if feat == 'graph':\n data = create_dataset(df, f\"{dataset}_dgl\", bonds)\n else:\n data = create_ecfp_dataset(df, f\"{dataset}_ecfp\")\n\n test_tasks = dataset_test_tasks.get(dataset_original)\n drop_cols = test_tasks.copy()\n drop_cols.extend(['mol_id', 'smiles', 'mol'])\n train_tasks = [x for x in list(data.columns) if x not in drop_cols]\n\n train_dfs = dict.fromkeys(train_tasks)\n for task in train_tasks:\n df = data[[task, 'mol']].dropna()\n df.columns = ['y', 'mol']\n # FOR BOND INFORMATION\n if with_bonds:\n for index, r in df.iterrows():\n if r.mol.edata['edge_feats'].shape[-1] < 17:\n df.drop(index, inplace=True)\n train_dfs[task] = df\n for key in train_dfs:\n print(key, len(train_dfs[key]))\n\n if feat == 'graph':\n feat_length = data.iloc[0].mol.ndata['feats'].shape[-1]\n print(\"Feature Length\", feat_length)\n\n if with_bonds:\n feat_length = data.iloc[0].mol.edata['edge_feats'].shape[-1]\n print(\"Feature Length\", feat_length)\n else:\n print(\"Edge Features: \", with_bonds)\n\n test_dfs = dict.fromkeys(test_tasks)\n\n for task in test_tasks:\n df = data[[task, 'mol']].dropna()\n df.columns = ['y', 'mol']\n\n # FOR BOND INFORMATION\n if with_bonds:\n for index, r in df.iterrows():\n if r.mol.edata['edge_feats'].shape[-1] < 17:\n df.drop(index, inplace=True)\n\n test_dfs[task] = df\n\n for key in test_dfs:\n print(key, len(test_dfs[key]))\n\n # return data, train_tasks, test_tasks\n return train_tasks, train_dfs, test_tasks, test_dfs",
"time: 148 ms (started: 2021-11-30 11:59:08 +00:00)\n"
]
],
[
[
"## Create Episode",
"_____no_output_____"
]
],
[
[
"def create_episode(n_support_pos, n_support_neg, n_query, data, test=False, train_balanced=True):\n \"\"\"\n n_query = per class data points\n Xy = dataframe dataset in format [['y', 'mol']]\n \"\"\"\n support = []\n query = []\n\n n_query_pos = n_query\n n_query_neg = n_query\n\n support_neg = data[data['y'] == 0].sample(n_support_neg)\n support_pos = data[data['y'] == 1].sample(n_support_pos)\n\n # organise support by class in array dimensions\n support.append(support_neg.to_numpy())\n support.append(support_pos.to_numpy())\n support = np.array(support, dtype=object)\n support_X = [rec[1] for sup_class in support for rec in sup_class]\n support_y = np.asarray([rec[0] for sup_class in support for rec in sup_class], dtype=np.float16).flatten()\n\n data = data.drop(support_neg.index)\n data = data.drop(support_pos.index)\n\n if len(data[data['y'] == 1]) < n_query:\n n_query_pos = len(data[data['y'] == 1])\n\n if test:\n # test uses all data remaining\n query_neg = data[data['y'] == 0].to_numpy()\n query_pos = data[data['y'] == 1].to_numpy()\n elif (not test) and train_balanced:\n # for balanced queries, same size as support\n query_neg = data[data['y'] == 0].sample(n_query_neg).to_numpy()\n query_pos = data[data['y'] == 1].sample(n_query_pos).to_numpy()\n elif (not test) and (not train_balanced):\n # print('test')\n query_neg = data[data['y'] == 0].sample(1).to_numpy()\n query_pos = data[data['y'] == 1].sample(1).to_numpy()\n\n query_rem = data.sample(n_query*2 - 2)\n query_neg_rem = query_rem[query_rem['y'] == 0].to_numpy()\n query_pos_rem = query_rem[query_rem['y'] == 1].to_numpy()\n\n query_neg = np.concatenate((query_neg, query_neg_rem))\n query_pos = np.concatenate((query_pos, query_pos_rem), axis=0)\n\n query_X = np.concatenate([query_neg[:, 1], query_pos[:, 1]])\n query_y = np.concatenate([query_neg[:, 0], query_pos[:, 0]])\n \n return support_X, support_y, query_X, query_y",
"time: 32.7 ms (started: 2021-11-30 11:44:01 +00:00)\n"
],
[
"# task = 'NR-AR'\n# df = data[[task, 'mol']]\n# df = df.dropna()\n# df.columns = ['y', 'mol']\n\n# support_X, support_y, query_X, query_y = create_episode(1, 1, 64, df)\n\n# support_y\n\n\n# testing\n# support = []\n# query = []\n\n# support_neg = df[df['y'] == 0].sample(2)\n# support_pos = df[df['y'] == 1].sample(2)\n\n# # organise support by class in array dimensions\n# support.append(support_neg.to_numpy())\n# support.append(support_pos.to_numpy())\n# support = np.array(support)\n# support.shape\n\n# support[:, :, 1]\n",
"time: 2.25 ms (started: 2021-11-27 16:25:20 +00:00)\n"
]
],
[
[
"## Graph Embedding",
"_____no_output_____"
]
],
[
[
"class GCN(nn.Module):\n def __init__(self, in_channels, out_channels=128):\n super(GCN, self).__init__()\n self.conv1 = GraphConv(in_channels, 64)\n self.conv2 = GraphConv(64, 128)\n self.conv3 = GraphConv(128, 64)\n self.sum_pool = SumPooling()\n self.dense = nn.Linear(64, out_channels)\n\n def forward(self, graph, in_feat):\n h = self.conv1(graph, in_feat)\n h = F.relu(h)\n graph.ndata['h'] = h \n graph.update_all(fn.copy_u('h', 'm'), fn.max('m', 'h'))\n \n h = self.conv2(graph, graph.ndata['h'])\n h = F.relu(h)\n graph.ndata['h'] = h\n graph.update_all(fn.copy_u('h', 'm'), fn.max('m', 'h'))\n\n h = self.conv3(graph, graph.ndata['h'])\n h = F.relu(h)\n graph.ndata['h'] = h\n graph.update_all(fn.copy_u('h', 'm'), fn.max('m', 'h'))\n\n output = self.sum_pool(graph, graph.ndata['h'])\n output = torch.tanh(output)\n output = self.dense(output)\n output = torch.tanh(output)\n return output",
"time: 21.9 ms (started: 2021-11-30 11:44:04 +00:00)\n"
],
[
"class Net(nn.Module):\n\n def __init__(self):\n super(Net, self).__init__()\n self.fc1 = nn.Linear(2048, 1000)\n self.fc2 = nn.Linear(1000, 500)\n self.fc3 = nn.Linear(500, 128)\n\n def forward(self, x):\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = torch.tanh(self.fc3(x))\n return x",
"time: 9.12 ms (started: 2021-11-30 11:46:53 +00:00)\n"
]
],
[
[
"## Distance Function",
"_____no_output_____"
]
],
[
[
"def euclidean_dist(x, y):\n # x: N x D\n # y: M x D\n n = x.size(0)\n m = y.size(0)\n d = x.size(1)\n assert d == y.size(1)\n\n x = x.unsqueeze(1).expand(n, m, d)\n y = y.unsqueeze(0).expand(n, m, d)\n\n return torch.pow(x - y, 2).sum(2)",
"time: 4.05 ms (started: 2021-11-30 11:44:08 +00:00)\n"
]
],
[
[
"### LSTM",
"_____no_output_____"
]
],
[
[
"def cos(x, y):\n transpose_shape = tuple(list(range(len(y.shape)))[::-1])\n\n x = x.float()\n\n denom = (\n torch.sqrt(torch.sum(torch.square(x)) *\n torch.sum(torch.square(y))) + torch.finfo(torch.float32).eps)\n\n return torch.matmul(x, torch.permute(y, transpose_shape)) / denom\n\nclass ResiLSTMEmbedding(nn.Module):\n def __init__(self, n_support, n_feat=128, max_depth=3):\n super(ResiLSTMEmbedding, self).__init__()\n\n self.max_depth = max_depth\n self.n_support = n_support\n self.n_feat = n_feat\n\n\n self.support_lstm = nn.LSTMCell(input_size=2*self.n_feat, hidden_size=self.n_feat)\n self.q_init = torch.nn.Parameter(torch.zeros((self.n_support, self.n_feat), dtype=torch.float, device=\"cuda\"))\n self.support_states_init_h = torch.nn.Parameter(torch.zeros(self.n_support, self.n_feat))\n self.support_states_init_c = torch.nn.Parameter(torch.zeros(self.n_support, self.n_feat))\n \n self.query_lstm = nn.LSTMCell(input_size=2*self.n_feat, hidden_size=self.n_feat)\n\n if torch.cuda.is_available():\n self.support_lstm = self.support_lstm.cuda()\n self.query_lstm = self.query_lstm.cuda()\n self.q_init = self.q_init.cuda()\n # self.p_init = self.p_init.cuda()\n \n def forward(self, x_support, x_query):\n self.p_init = torch.zeros((len(x_query), self.n_feat)).to(device)\n self.query_states_init_h = torch.zeros(len(x_query), self.n_feat).to(device)\n self.query_states_init_c = torch.zeros(len(x_query), self.n_feat).to(device)\n\n x_support = x_support\n x_query = x_query\n z_support = x_support\n q = self.q_init\n p = self.p_init\n support_states_h = self.support_states_init_h\n support_states_c = self.support_states_init_c\n query_states_h = self.query_states_init_h\n query_states_c = self.query_states_init_c\n\n for i in range(self.max_depth):\n sup_e = cos(z_support + q, x_support)\n sup_a = torch.nn.functional.softmax(sup_e, dim=-1)\n sup_r = torch.matmul(sup_a, x_support).float()\n\n query_e = cos(x_query + p, z_support)\n query_a = torch.nn.functional.softmax(query_e, dim=-1)\n query_r = torch.matmul(query_a, z_support).float()\n\n sup_qr = torch.cat((q, sup_r), 1)\n support_hidden, support_out = self.support_lstm(sup_qr, (support_states_h, support_states_c))\n q = support_hidden\n\n query_pr = torch.cat((p, query_r), 1)\n query_hidden, query_out = self.query_lstm(query_pr, (query_states_h, query_states_c))\n p = query_hidden\n\n z_support = sup_r\n\n return x_support + q, x_query + p",
"time: 75.5 ms (started: 2021-11-30 11:44:11 +00:00)\n"
]
],
[
[
"## Protonet\n",
"_____no_output_____"
],
[
"https://colab.research.google.com/drive/1QDYIwg2-iiUpVU8YyAh0lOgFgFPhVgvx#scrollTo=BnLOgECOKG_y",
"_____no_output_____"
]
],
[
[
"class ProtoNet(nn.Module):\n def __init__(self, with_bonds=False):\n \"\"\"\n Prototypical Network\n \"\"\"\n super(ProtoNet, self).__init__()\n\n def forward(self, X_support, X_query, n_support_pos, n_support_neg):\n\n n_support = len(X_support)\n \n # prototypes\n z_dim = X_support.size(-1) # size of the embedding - 128\n z_proto_0 = X_support[:n_support_neg].view(n_support_neg, z_dim).mean(0)\n z_proto_1 = X_support[n_support_neg:n_support].view(n_support_pos, z_dim).mean(0)\n z_proto = torch.stack((z_proto_0, z_proto_1))\n\n # queries\n z_query = X_query\n\n # compute distance\n dists = euclidean_dist(z_query, z_proto) # [128, 2]\n\n # compute probabilities\n log_p_y = nn.LogSoftmax(dim=1)(-dists) # [128, 2]\n\n return log_p_y ",
"time: 18.5 ms (started: 2021-11-30 11:44:14 +00:00)\n"
]
],
[
[
"## Training Loop\n",
"_____no_output_____"
]
],
[
[
"def train(train_tasks, train_dfs, balanced_queries, k_pos, k_neg, n_query, episodes, lr):\n writer = SummaryWriter()\n start_time = time.time()\n\n node_feat_size = 177\n embedding_size = 128\n encoder = Net()\n resi_lstm = ResiLSTMEmbedding(k_pos+k_neg)\n proto_net = ProtoNet()\n loss_fn = nn.NLLLoss()\n\n if torch.cuda.is_available(): \n encoder = encoder.cuda()\n resi_lstm = resi_lstm.cuda()\n proto_net = proto_net.cuda()\n loss_fn = loss_fn.cuda()\n\n encoder_optimizer = torch.optim.Adam(encoder.parameters(), lr = lr)\n lstm_optimizer = torch.optim.Adam(resi_lstm.parameters(), lr = lr)\n # proto_optimizer = torch.optim.Adam(proto_net.parameters(), lr = lr)\n\n # encoder_scheduler = torch.optim.lr_scheduler.StepLR(encoder_optimizer, step_size=1, gamma=0.8)\n encoder_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(encoder_optimizer, patience=300, verbose=False)\n lstm_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(lstm_optimizer, patience=300, verbose=False)\n\n # rn_scheduler = torch.optim.lr_scheduler.StepLR(rn_optimizer, step_size=1, gamma=0.8)\n # rn_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(rn_optimizer, patience=500, verbose=False)\n\n episode_num = 1\n early_stop = False\n losses = []\n\n running_loss = 0.0\n running_acc = 0.0\n running_roc = 0.0\n running_prc = 0.0\n\n # for task in shuffled_train_tasks:\n pbar = trange(episodes, desc=f\"Training\")\n # while episode_num < episodes and not early_stop:\n for episode in pbar:\n episode_loss = 0.0\n\n # SET TRAINING MODE\n encoder.train()\n resi_lstm.train()\n proto_net.train()\n\n # RANDOMISE ORDER OF TASKS PER EPISODE\n shuffled_train_tasks = random.sample(train_tasks, len(train_tasks))\n \n # LOOP OVER TASKS\n for task in shuffled_train_tasks:\n # CREATE EPISODE FOR TASK\n X = train_dfs[task]\n X_support, y_support, X_query, y_query = create_episode(k_pos, k_neg, n_query, X, False, balanced_queries)\n\n # TOTAL NUMBER OF QUERIES\n total_query = int((y_query == 0).sum() + (y_query == 1).sum())\n\n # ONE HOT QUERY TARGETS\n # query_targets = torch.from_numpy(y_query.astype('int'))\n # targets = F.one_hot(query_targets, num_classes=2)\n\n target_inds = torch.from_numpy(y_query.astype('float32')).float()\n target_inds = target_inds.unsqueeze(1).type(torch.int64)\n targets = Variable(target_inds, requires_grad=False).to(device)\n \n if torch.cuda.is_available(): \n targets=targets.cuda()\n\n n_support = k_pos + k_neg\n # flat_support = list(np.concatenate(X_support).flat)\n # X = flat_support + list(X_query)\n X = X_support + list(X_query)\n\n # CREATE EMBEDDINGS\n dataloader = torch.utils.data.DataLoader(X, batch_size=(n_support + total_query), shuffle=False, pin_memory=True)\n for graph in dataloader:\n graph = graph.to(device)\n embeddings = encoder.forward(graph)\n\n # LSTM EMBEDDINGS\n emb_support = embeddings[:n_support]\n emb_query = embeddings[n_support:]\n emb_support, emb_query = resi_lstm(emb_support, emb_query)\n \n # PROTO NETS\n logits = proto_net(emb_support, emb_query, k_pos, k_neg)\n\n # loss = loss_fn(logits, torch.max(query_targets, 1)[1])\n loss = loss_fn(logits, targets.squeeze())\n\n encoder.zero_grad()\n resi_lstm.zero_grad()\n proto_net.zero_grad()\n\n loss.backward()\n \n encoder_optimizer.step()\n lstm_optimizer.step()\n\n _, y_hat = logits.max(1)\n # class_indices = torch.max(query_targets, 1)[1]\n\n targets = targets.squeeze().cpu()\n y_hat = y_hat.squeeze().detach().cpu()\n \n roc = roc_auc_score(targets, y_hat)\n prc = average_precision_score(targets, y_hat)\n acc = accuracy_score(targets, y_hat)\n # proto_optimizer.step()\n\n # EVALUATE TRAINING LOOP ON TASK\n episode_loss += loss.item()\n running_loss += loss.item()\n running_acc += acc\n running_roc += roc\n running_prc += prc\n\n pbar.set_description(f\"Episode {episode_num} - Loss {loss.item():.6f} - Acc {acc:.4f} - LR {encoder_optimizer.param_groups[0]['lr']}\")\n pbar.refresh()\n\n losses.append(episode_loss / len(train_tasks))\n writer.add_scalar('Loss/train', episode_loss / len(train_tasks), episode_num)\n\n if encoder_optimizer.param_groups[0]['lr'] < 0.000001:\n break # EARLY STOP\n elif episode_num < episodes:\n episode_num += 1\n\n encoder_scheduler.step(loss)\n lstm_scheduler.step(loss)\n\n epoch_loss = running_loss / (episode_num*len(train_tasks))\n epoch_acc = running_acc / (episode_num*len(train_tasks))\n epoch_roc = running_roc / (episode_num*len(train_tasks))\n epoch_prc = running_prc / (episode_num*len(train_tasks))\n\n print(f'Loss: {epoch_loss:.5f} Acc: {epoch_acc:.4f} ROC: {epoch_roc:.4f} PRC: {epoch_prc:.4f}')\n\n end_time = time.time()\n train_info = {\n \"losses\": losses,\n \"duration\": str(timedelta(seconds=(end_time - start_time))),\n \"episodes\": episode_num,\n \"train_roc\": epoch_roc,\n \"train_prc\": epoch_prc\n }\n\n return encoder, resi_lstm, proto_net, train_info",
"time: 171 ms (started: 2021-11-30 11:57:42 +00:00)\n"
]
],
[
[
"## Testing Loop",
"_____no_output_____"
]
],
[
[
"def test(encoder, lstm, proto_net, test_tasks, test_dfs, k_pos, k_neg, rounds):\n encoder.eval()\n lstm.eval()\n proto_net.eval()\n\n test_info = {}\n\n with torch.no_grad():\n for task in test_tasks:\n\n Xy = test_dfs[task]\n\n running_loss = []\n running_acc = []\n running_roc = [0]\n running_prc = [0]\n\n running_preds = []\n running_targets = []\n running_actuals = []\n\n for round in trange(rounds):\n X_support, y_support, X_query, y_query = create_episode(k_pos, k_neg, n_query=0, data=Xy, test=True, train_balanced=False)\n total_query = int((y_query == 0).sum() + (y_query == 1).sum())\n \n n_support = k_pos + k_neg\n # flat_support = list(np.concatenate(X_support).flat)\n # X = flat_support + list(X_query)\n X = X_support + list(X_query)\n\n # CREATE EMBEDDINGS\n dataloader = torch.utils.data.DataLoader(X, batch_size=(n_support + total_query), shuffle=False, pin_memory=True)\n for graph in dataloader:\n graph = graph.to(device)\n embeddings = encoder.forward(graph)\n\n # LSTM EMBEDDINGS\n emb_support = embeddings[:n_support]\n emb_query = embeddings[n_support:]\n emb_support, emb_query = lstm(emb_support, emb_query)\n \n # PROTO NETS\n logits = proto_net(emb_support, emb_query, k_pos, k_neg)\n\n # PRED\n _, y_hat_actual = logits.max(1)\n y_hat = logits[:, 1]\n\n # targets = targets.squeeze().cpu()\n target_inds = torch.from_numpy(y_query.astype('float32')).float()\n target_inds = target_inds.unsqueeze(1).type(torch.int64)\n targets = Variable(target_inds, requires_grad=False)\n y_hat = y_hat.squeeze().detach().cpu()\n \n roc = roc_auc_score(targets, y_hat)\n prc = average_precision_score(targets, y_hat)\n # acc = accuracy_score(targets, y_hat)\n\n running_preds.append(y_hat)\n running_actuals.append(y_hat_actual)\n running_targets.append(targets)\n\n # running_acc.append(acc)\n running_roc.append(roc)\n running_prc.append(prc)\n\n median_index = running_roc.index(statistics.median(running_roc))\n if median_index == rounds:\n median_index = median_index - 1\n chart_preds = running_preds[median_index]\n chart_actuals = running_actuals[median_index].detach().cpu()\n chart_targets = running_targets[median_index]\n\n c_auc = roc_auc_score(chart_targets, chart_preds)\n c_fpr, c_tpr, _ = roc_curve(chart_targets, chart_preds)\n plt.plot(c_fpr, c_tpr, marker='.', label = 'AUC = %0.2f' % c_auc)\n plt.plot([0, 1], [0, 1],'r--', label='No Skill')\n # plt.plot([0, 0, 1], [0, 1, 1], 'g--', label='Perfect Classifier')\n plt.title('Receiver Operating Characteristic')\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.legend(loc = 'best')\n plt.savefig(f\"{drive_path}/{method_dir}/graphs/roc_{dataset}_{task}_ecfp_pos{n_pos}_neg{n_neg}.png\")\n plt.figure().clear()\n\n # prc_graph = PrecisionRecallDisplay.from_predictions(chart_targets, chart_preds)\n c_precision, c_recall, _ = precision_recall_curve(chart_targets, chart_preds)\n plt.title('Precision Recall Curve')\n # plt.plot([0, 1], [0, 0], 'r--', label='No Skill')\n no_skill = len(chart_targets[chart_targets==1]) / len(chart_targets)\n plt.plot([0, 1], [no_skill, no_skill], linestyle='--', label='No Skill')\n # plt.plot([0, 1, 1], [1, 1, 0], 'g--', label='Perfect Classifier')\n plt.plot(c_recall, c_precision, marker='.', label = 'AUC = %0.2f' % auc(c_recall, c_precision))\n plt.xlabel('Recall')\n plt.ylabel('Precision')\n plt.legend(loc = 'best')\n plt.savefig(f\"{drive_path}/{method_dir}/graphs/prc_{dataset}_{task}_ecfp_pos{n_pos}_neg{n_neg}.png\")\n plt.figure().clear()\n\n cm = ConfusionMatrixDisplay.from_predictions(chart_targets, chart_actuals)\n plt.title('Confusion Matrix')\n plt.savefig(f\"{drive_path}/{method_dir}/graphs/cm_{dataset}_{task}_ecfp_pos{n_pos}_neg{n_neg}.png\")\n plt.figure().clear()\n\n running_roc.pop(0) # remove the added 0\n running_prc.pop(0) # remove the added 0 \n # round_acc = f\"{statistics.mean(running_acc):.3f} \\u00B1 {statistics.stdev(running_acc):.3f}\"\n round_roc = f\"{statistics.mean(running_roc):.3f} \\u00B1 {statistics.stdev(running_roc):.3f}\"\n round_prc = f\"{statistics.mean(running_prc):.3f} \\u00B1 {statistics.stdev(running_prc):.3f}\"\n\n test_info[task] = {\n # \"acc\": round_acc,\n \"roc\": round_roc,\n \"prc\": round_prc,\n \"roc_values\": running_roc,\n \"prc_values\": running_prc\n }\n\n print(f'Test {task}')\n # print(f\"Acc: {round_acc}\")\n print(f\"ROC: {round_roc}\")\n print(f\"PRC: {round_prc}\")\n\n return targets, y_hat, test_info",
"time: 161 ms (started: 2021-11-30 11:57:33 +00:00)\n"
]
],
[
[
"## Initiate Training and Testing",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\ntime: 16.1 s (started: 2021-11-30 11:52:30 +00:00)\n"
],
[
"# PATHS\ndrive_path = \"/content/drive/MyDrive/Colab Notebooks/MSC_21\"\nmethod_dir = \"ProtoNets\"\nlog_path = f\"{drive_path}/{method_dir}/logs/\"\n\n# PARAMETERS\ndataset = 'tox21'\nwith_bonds = False \ntest_rounds = 20\nn_query = 64 # per class\nepisodes = 10000\nlr = 0.001\nbalanced_queries = True",
"time: 4.16 ms (started: 2021-11-30 11:58:12 +00:00)\n"
],
[
"#FOR DETERMINISTIC REPRODUCABILITY\nrandomseed = 12\ntorch.manual_seed(randomseed) \nnp.random.seed(randomseed)\nrandom.seed(randomseed)\ntorch.cuda.manual_seed(randomseed)\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\ntorch.backends.cudnn.is_available()\ntorch.backends.cudnn.benchmark = False # selects fastest conv algo\ntorch.backends.cudnn.deterministic = True\n\n# LOAD DATASET\n# data, train_tasks, test_tasks = load_dataset(dataset, bonds=with_bonds, create_new=False)\ntrain_tasks, train_dfs, test_tasks, test_dfs = load_dataset(dataset, bonds=with_bonds, feat='ecfp', create_new=False)",
"Reading Pickle\nNR-AR 7265\nNR-AR-LBD 6758\nNR-AhR 6549\nNR-Aromatase 5821\nNR-ER 6193\nNR-ER-LBD 6955\nNR-PPAR-gamma 6450\nSR-ARE 5832\nSR-ATAD5 7072\nSR-HSE 6467\nSR-MMP 5810\nSR-p53 6774\ntime: 217 ms (started: 2021-11-30 11:59:20 +00:00)\n"
],
[
"combinations = [\n [10, 10],\n [5, 10], \n [1, 10], \n [1, 5], \n [1, 1]\n]\n\n# worksheet = gc.open_by_url(\"https://docs.google.com/spreadsheets/d/1K15Rx4IZqiLgjUsmMq0blB-WB16MDY-ENR2j8z7S6Ss/edit#gid=0\").sheet1\n\ncols = [\n 'DATE', 'CPU', 'CPU COUNT',\t'GPU', 'GPU RAM',\t'RAM',\t'CUDA',\t\n 'REF', 'DATASET', 'ARCHITECTURE',\t\n 'SPLIT',\t'TARGET',\t'ACCURACY',\t'ROC',\t'PRC',\n 'ROC_VALUES', 'PRC_VALUES',\n 'TRAIN ROC',\t'TRAIN PRC',\t'EPISODES',\t'TRAINING TIME'\n]\n\nload_from_saved = False\n\nfor comb in combinations:\n n_pos = comb[0]\n n_neg = comb[1]\n results = pd.DataFrame(columns=cols)\n print(f\"\\nRUNNING {n_pos}+/{n_neg}-\")\n\n if load_from_saved:\n encoder = GCN(177, 128)\n lstm = ResiLSTMEmbedding(n_pos+n_neg)\n proto_net = ProtoNet()\n encoder.load_state_dict(torch.load(f\"{drive_path}/{method_dir}/{dataset}_ecfp_encoder_pos{n_pos}_neg{n_neg}.pt\"))\n lstm.load_state_dict(torch.load(f\"{drive_path}/{method_dir}/{dataset}_ecfp__lstm_pos{n_pos}_neg{n_neg}.pt\"))\n proto_net.load_state_dict(torch.load(f\"{drive_path}/{method_dir}/{dataset}_ecfp__proto_pos{n_pos}_neg{n_neg}.pt\"))\n encoder.to(device)\n lstm.to(device)\n proto_net.to(device)\n\n else:\n encoder, lstm, proto_net, train_info = train(train_tasks, train_dfs, balanced_queries, n_pos, n_neg, n_query, episodes, lr)\n\n if with_bonds:\n torch.save(encoder.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__encoder_pos{n_pos}_neg{n_neg}_bonds.pt\")\n torch.save(lstm.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__lstm_pos{n_pos}_neg{n_neg}_bonds.pt\")\n torch.save(proto_net.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__proto_pos{n_pos}_neg{n_neg}_bonds.pt\")\n else:\n torch.save(encoder.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__encoder_pos{n_pos}_neg{n_neg}.pt\")\n torch.save(lstm.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__lstm_pos{n_pos}_neg{n_neg}.pt\")\n torch.save(proto_net.state_dict(), f\"{drive_path}/{method_dir}/{dataset}_ecfp__proto_pos{n_pos}_neg{n_neg}.pt\")\n \n loss_plot = plt.plot(train_info['losses'])[0]\n loss_plot.figure.savefig(f\"{drive_path}/{method_dir}/loss_plots/{dataset}_ecfp__pos{n_pos}_neg{n_neg}.png\")\n plt.figure().clear()\n\n targets, preds, test_info = test(encoder, lstm, proto_net, test_tasks, test_dfs, n_pos, n_neg, test_rounds)\n\n dt_string = datetime.now().strftime(\"%d/%m/%Y %H:%M:%S\")\n cpu = get_cmd_output('cat /proc/cpuinfo | grep -E \"model name\"')\n cpu = cpu.split('\\n')[0].split('\\t: ')[-1]\n cpu_count = psutil.cpu_count()\n cuda_version = get_cmd_output('nvcc --version | grep -E \"Build\"')\n gpu = get_cmd_output(\"nvidia-smi -L\")\n general_ram_gb = humanize.naturalsize(psutil.virtual_memory().available)\n gpu_ram_total_mb = GPU.getGPUs()[0].memoryTotal\n\n for target in test_info:\n if load_from_saved:\n rec = pd.DataFrame([[dt_string, cpu, cpu_count, gpu, gpu_ram_total_mb, general_ram_gb, cuda_version, \"MSC\", \n dataset, {method_dir}, f\"{n_pos}+/{n_neg}-\", target, 0, test_info[target]['roc'], test_info[target]['prc'], \n test_info[target]['roc_values'], test_info[target]['prc_values'],\n 99, 99, 99, 102]], columns=cols)\n \n results = pd.concat([results, rec])\n else:\n rec = pd.DataFrame([[dt_string, cpu, cpu_count, gpu, gpu_ram_total_mb, general_ram_gb, cuda_version, \"MSC\", \n dataset, {method_dir}, f\"{n_pos}+/{n_neg}-\", target, 0, test_info[target]['roc'], test_info[target]['prc'],\n test_info[target]['roc_values'], test_info[target]['prc_values'],\n train_info[\"train_roc\"], train_info[\"train_prc\"], train_info[\"episodes\"], train_info[\"duration\"]\n ]], columns=cols)\n \n results = pd.concat([results, rec])\n\n if load_from_saved:\n results.to_csv(f\"{drive_path}/results/{dataset}_{method_dir}_ecfp_pos{n_pos}_neg{n_neg}_from_saved.csv\", index=False)\n else:\n results.to_csv(f\"{drive_path}/results/{dataset}_{method_dir}_ecfp_pos{n_pos}_neg{n_neg}.csv\", index=False)",
"\nRUNNING 10+/10-\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02c188c1a7960563347d2138f5e7f3c828f9a49
| 100,752 |
ipynb
|
Jupyter Notebook
|
public_talks/2015_11_17_nyu/3 Normalization, tokenization, tagging.ipynb
|
kylepjohnson/ipython_notebooks
|
7f77ec06a70169cc479a6f912b4888789bf28ac4
|
[
"MIT"
] | 9 |
2016-08-10T09:03:09.000Z
|
2021-01-06T21:34:20.000Z
|
public_talks/2015_11_17_nyu/3 Normalization, tokenization, tagging.ipynb
|
kylepjohnson/ipython_notebooks
|
7f77ec06a70169cc479a6f912b4888789bf28ac4
|
[
"MIT"
] | null | null | null |
public_talks/2015_11_17_nyu/3 Normalization, tokenization, tagging.ipynb
|
kylepjohnson/ipython_notebooks
|
7f77ec06a70169cc479a6f912b4888789bf28ac4
|
[
"MIT"
] | 3 |
2018-10-07T01:56:22.000Z
|
2021-01-06T21:33:28.000Z
| 52.971609 | 1,443 | 0.536754 |
[
[
[
"# Normalize text",
"_____no_output_____"
]
],
[
[
"herod_fp = '/Users/kyle/cltk_data/greek/text/tlg/plaintext/TLG0016.txt'\n\nwith open(herod_fp) as fo:\n herod_raw = fo.read()",
"_____no_output_____"
],
[
"print(herod_raw[2000:2500]) # What do we notice needs help?",
"ρίνασθαι ὡς οὐδὲ ἐκεῖνοι Ἰοῦς τῆς Ἀργείης ἔδοσάν σφι \nδίκας τῆς ἁρπαγῆς: οὐδὲ ὦν αὐτοὶ δώσειν ἐκείνοισι. Δευ- \nτέρῃ δὲ λέγουσι γενεῇ μετὰ ταῦτα Ἀλέξανδρον τὸν Πριά-\nμου ἀκηκοότα ταῦτα ἐθελῆσαί οἱ ἐκ τῆς Ἑλλάδος δι' \nἁρπαγῆς γενέσθαι γυναῖκα, ἐπιστάμενον πάντως ὅτι οὐ \nδώσει δίκας: οὐδὲ γὰρ ἐκείνους διδόναι. Οὕτω δὴ ἁρπά-\nσαντος αὐτοῦ Ἑλένην, τοῖσι Ἕλλησι δόξαι πρῶτον πέμ-\nψαντας ἀγγέλους ἀπαιτέειν τε Ἑλένην καὶ δίκας τῆς \nἁρπαγῆς αἰτέειν. Τοὺς δὲ προϊσχομένων ταῦτα προφέρειν \nσφι Μηδείης τὴν ἁρπ\n"
],
[
"from cltk.corpus.utils.formatter import tlg_plaintext_cleanup",
"_____no_output_____"
],
[
"herod_clean = tlg_plaintext_cleanup(herod_raw, rm_punctuation=True, rm_periods=False)",
"_____no_output_____"
],
[
"print(herod_clean[2000:2500])",
"έρῃ δὲ λέγουσι γενεῇ μετὰ ταῦτα Ἀλέξανδρον τὸν Πριάμου ἀκηκοότα ταῦτα ἐθελῆσαί οἱ ἐκ τῆς Ἑλλάδος δι ἁρπαγῆς γενέσθαι γυναῖκα ἐπιστάμενον πάντως ὅτι οὐ δώσει δίκας οὐδὲ γὰρ ἐκείνους διδόναι. Οὕτω δὴ ἁρπάσαντος αὐτοῦ Ἑλένην τοῖσι Ἕλλησι δόξαι πρῶτον πέμψαντας ἀγγέλους ἀπαιτέειν τε Ἑλένην καὶ δίκας τῆς ἁρπαγῆς αἰτέειν. Τοὺς δὲ προϊσχομένων ταῦτα προφέρειν σφι Μηδείης τὴν ἁρπαγήν ὡς οὐ δόντες αὐτοὶ δίκας οὐδὲ ἐκδόντες ἀπαιτεόντων βουλοίατό σφι παρ ἄλλων δίκας γίνεσθαι. Μέχρι μὲν ὦν τούτου ἁρπαγὰς μο\n"
]
],
[
[
"# Tokenize sentences",
"_____no_output_____"
]
],
[
[
"from cltk.tokenize.sentence import TokenizeSentence",
"_____no_output_____"
],
[
"tokenizer = TokenizeSentence('greek')",
"_____no_output_____"
],
[
"herod_sents = tokenizer.tokenize_sentences(herod_clean)",
"_____no_output_____"
],
[
"print(herod_sents[:5])",
"[' Ἡροδότου Θουρίου ἱστορίης ἀπόδεξις ἥδε ὡς μήτε τὰ γενόμενα ἐξ ἀνθρώπων τῷ χρόνῳ ἐξίτηλα γένηται μήτε ἔργα μεγάλα τε καὶ θωμαστά τὰ μὲν Ἕλλησι τὰ δὲ βαρβάροισι ἀποδεχθέντα ἀκλέα γένηται τά τε ἄλλα καὶ δι ἣν αἰτίην ἐπολέμησαν ἀλλήλοισι.', 'Περσέων μέν νυν οἱ λόγιοι Φοίνικας αἰτίους φασὶ γενέσθαι τῆς διαφορῆς τούτους γάρ ἀπὸ τῆς Ἐρυθρῆς καλεομένης θαλάσσης ἀπικομένους ἐπὶ τήνδε τὴν θάλασσαν καὶ οἰκήσαντας τοῦτον τὸν χῶρον τὸν καὶ νῦν οἰκέουσι αὐτίκα ναυτιλίῃσι μακρῇσι ἐπιθέσθαι ἀπαγινέοντας δὲ φορτία Αἰγύπτιά τε καὶ Ἀσσύρια τῇ τε ἄλλῃ χώρῃ ἐσαπικνέεσθαι καὶ δὴ καὶ ἐς Ἄργος τὸ δὲ Ἄργος τοῦτον τὸν χρόνον προεῖχε ἅπασι τῶν ἐν τῇ νῦν Ἑλλάδι καλεομένῃ χώρῃ.', 'Ἀπικομένους δὲ τοὺς Φοίνικας ἐς δὴ τὸ Ἄργος τοῦτο διατίθεσθαι τὸν φόρτον.', 'Πέμπτῃ δὲ ἢ ἕκτῃ ἡμέρῃ ἀπ ἧς ἀπίκοντο ἐξεμπολημένων σφι σχεδὸν πάντων ἐλθεῖν ἐπὶ τὴν θάλασσαν γυναῖκας ἄλλας τε πολλὰς καὶ δὴ καὶ τοῦ βασιλέος θυγατέρα τὸ δέ οἱ οὔνομα εἶναι κατὰ τὠυτὸ τὸ καὶ Ἕλληνες λέγουσι Ἰοῦν τὴν Ἰνάχου.', 'Ταύτας στάσας κατὰ πρύμνην τῆς νεὸς ὠνέεσθαι τῶν φορτίων τῶν σφι ἦν θυμὸς μάλιστα καὶ τοὺς Φοίνικας διακελευσαμένους ὁρμῆσαι ἐπ αὐτάς.']\n"
],
[
"for sent in herod_sents:\n print(sent)\n print()\n input()",
" Ἡροδότου Θουρίου ἱστορίης ἀπόδεξις ἥδε ὡς μήτε τὰ γενόμενα ἐξ ἀνθρώπων τῷ χρόνῳ ἐξίτηλα γένηται μήτε ἔργα μεγάλα τε καὶ θωμαστά τὰ μὲν Ἕλλησι τὰ δὲ βαρβάροισι ἀποδεχθέντα ἀκλέα γένηται τά τε ἄλλα καὶ δι ἣν αἰτίην ἐπολέμησαν ἀλλήλοισι.\n\n\nΠερσέων μέν νυν οἱ λόγιοι Φοίνικας αἰτίους φασὶ γενέσθαι τῆς διαφορῆς τούτους γάρ ἀπὸ τῆς Ἐρυθρῆς καλεομένης θαλάσσης ἀπικομένους ἐπὶ τήνδε τὴν θάλασσαν καὶ οἰκήσαντας τοῦτον τὸν χῶρον τὸν καὶ νῦν οἰκέουσι αὐτίκα ναυτιλίῃσι μακρῇσι ἐπιθέσθαι ἀπαγινέοντας δὲ φορτία Αἰγύπτιά τε καὶ Ἀσσύρια τῇ τε ἄλλῃ χώρῃ ἐσαπικνέεσθαι καὶ δὴ καὶ ἐς Ἄργος τὸ δὲ Ἄργος τοῦτον τὸν χρόνον προεῖχε ἅπασι τῶν ἐν τῇ νῦν Ἑλλάδι καλεομένῃ χώρῃ.\n\n"
]
],
[
[
"# Make word tokens",
"_____no_output_____"
]
],
[
[
"from cltk.tokenize.word import nltk_tokenize_words",
"_____no_output_____"
],
[
"for sent in herod_sents:\n words = nltk_tokenize_words(sent)\n print(words)\n input()",
"['Ἡροδότου', 'Θουρίου', 'ἱστορίης', 'ἀπόδεξις', 'ἥδε', 'ὡς', 'μήτε', 'τὰ', 'γενόμενα', 'ἐξ', 'ἀνθρώπων', 'τῷ', 'χρόνῳ', 'ἐξίτηλα', 'γένηται', 'μήτε', 'ἔργα', 'μεγάλα', 'τε', 'καὶ', 'θωμαστά', 'τὰ', 'μὲν', 'Ἕλλησι', 'τὰ', 'δὲ', 'βαρβάροισι', 'ἀποδεχθέντα', 'ἀκλέα', 'γένηται', 'τά', 'τε', 'ἄλλα', 'καὶ', 'δι', 'ἣν', 'αἰτίην', 'ἐπολέμησαν', 'ἀλλήλοισι', '.']\n\n['Περσέων', 'μέν', 'νυν', 'οἱ', 'λόγιοι', 'Φοίνικας', 'αἰτίους', 'φασὶ', 'γενέσθαι', 'τῆς', 'διαφορῆς', 'τούτους', 'γάρ', 'ἀπὸ', 'τῆς', 'Ἐρυθρῆς', 'καλεομένης', 'θαλάσσης', 'ἀπικομένους', 'ἐπὶ', 'τήνδε', 'τὴν', 'θάλασσαν', 'καὶ', 'οἰκήσαντας', 'τοῦτον', 'τὸν', 'χῶρον', 'τὸν', 'καὶ', 'νῦν', 'οἰκέουσι', 'αὐτίκα', 'ναυτιλίῃσι', 'μακρῇσι', 'ἐπιθέσθαι', 'ἀπαγινέοντας', 'δὲ', 'φορτία', 'Αἰγύπτιά', 'τε', 'καὶ', 'Ἀσσύρια', 'τῇ', 'τε', 'ἄλλῃ', 'χώρῃ', 'ἐσαπικνέεσθαι', 'καὶ', 'δὴ', 'καὶ', 'ἐς', 'Ἄργος', 'τὸ', 'δὲ', 'Ἄργος', 'τοῦτον', 'τὸν', 'χρόνον', 'προεῖχε', 'ἅπασι', 'τῶν', 'ἐν', 'τῇ', 'νῦν', 'Ἑλλάδι', 'καλεομένῃ', 'χώρῃ', '.']\n\n['Ἀπικομένους', 'δὲ', 'τοὺς', 'Φοίνικας', 'ἐς', 'δὴ', 'τὸ', 'Ἄργος', 'τοῦτο', 'διατίθεσθαι', 'τὸν', 'φόρτον', '.']\n"
]
],
[
[
"### Tokenize Latin enclitics",
"_____no_output_____"
]
],
[
[
"from cltk.corpus.utils.formatter import phi5_plaintext_cleanup\nfrom cltk.tokenize.word import WordTokenizer\n\n# 'LAT0474': 'Marcus Tullius Cicero, Cicero, Tully',\ncicero_fp = '/Users/kyle/cltk_data/latin/text/phi5/plaintext/LAT0474.TXT'\n\nwith open(cicero_fp) as fo:\n cicero_raw = fo.read()\ncicero_clean = phi5_plaintext_cleanup(cicero_raw, rm_punctuation=True, rm_periods=False) # ~5 sec",
"_____no_output_____"
],
[
"print(cicero_clean[400:600])",
"mediocria verum ita se res habet ut ego qui neque usu satis et ingenio parum possum cum patrono disertissimo comparer P. Quinctius cui tenues opes nullae facultates exiguae amicorum copiae sunt cum ad\n"
],
[
"sent_tokenizer = TokenizeSentence('latin')\ncicero_sents = tokenizer.tokenize_sentences(cicero_clean)\n\nprint(cicero_sents[:3])",
"[' Quae res in civitate duae plurimum possunt eae contra nos ambae faciunt in hoc tempore summa gratia et eloquentia quarum alteram C. Aquili vereor alteram metuo.', 'Eloquentia Q. Hortensi ne me in dicendo impediat non nihil commoveor gratia Sex.', 'Naevi ne P. Quinctio noceat id vero non mediocriter pertimesco.']\n"
],
[
"word_tokenizer = WordTokenizer('latin') # Patrick's tokenizer\n\nfor sent in cicero_sents:\n #words = nltk_tokenize_words(sent)\n sub_words = word_tokenizer.tokenize(sent)\n print(sub_words)\n \n input()",
"['Quae', 'res', 'in', 'civitate', 'duae', 'plurimum', 'possunt', 'eae', 'contra', 'nos', 'ambae', 'faciunt', 'in', 'hoc', 'tempore', 'summa', 'gratia', 'et', 'eloquentia', 'quarum', 'alteram', 'C.', 'Aquili', 'vereor', 'alteram', 'metuo.']\n\n['Eloquentia', 'Q.', 'Hortensi', 'ne', 'me', 'in', 'dicendo', 'impediat', 'non', 'nihil', 'commoveor', 'gratia', 'Sex.']\n\n['Naevi', 'ne', 'P.', 'Quinctio', 'noceat', 'id', 'vero', 'non', 'mediocriter', 'pertimesco.']\n\n['Ne', '-que', 'hoc', 'tanto', 'opere', 'querendum', 'videretur', 'haec', 'summa', 'in', 'illis', 'esse', 'si', 'in', 'nobis', 'essent', 'saltem', 'mediocria', 'verum', 'ita', 'se', 'res', 'habet', 'ut', 'ego', 'qui', 'neque', 'usu', 'satis', 'et', 'ingenio', 'parum', 'possum', 'cum', 'patrono', 'disertissimo', 'comparer', 'P.', 'Quinctius', 'cui', 'tenues', 'opes', 'nullae', 'facultates', 'exiguae', 'amicorum', 'copiae', 'sunt', 'cum', 'adversario', 'gratiosissimo', 'contendat.']\n\n['Illud', 'quoque', 'nobis', 'accedit', 'incommodum', 'quod', 'M.', 'Iunius', 'qui', 'hanc', 'causam', 'aliquotiens', 'apud', 'te', 'egit', 'homo', 'et', 'in', 'aliis', 'causis', 'exercitatus', 'et', 'in', 'hac', 'multum', 'ac', 'saepe', 'versatus', 'hoc', 'tempore', 'abest', 'nova', 'legatio', '-ne', 'impeditus', 'et', 'ad', 'me', 'ventum', 'est', 'qui', 'ut', 'summa', 'haberem', 'cetera', 'temporis', 'quidem', 'certe', 'vix', 'satis', 'habui', 'ut', 'rem', 'tantam', 'tot', 'controversiis', 'implicatam', 'possem', 'cognoscere.']\n"
]
],
[
[
"# POS Tagging",
"_____no_output_____"
]
],
[
[
"from cltk.tag.pos import POSTag\ntagger = POSTag('greek')\n\n# Heordotus again\nfor sent in herod_sents:\n tagged_text = tagger.tag_unigram(sent)\n print(tagged_text)\n input()",
"[('Ἡροδότου', None), ('Θουρίου', None), ('ἱστορίης', None), ('ἀπόδεξις', None), ('ἥδε', 'P-S---FN-'), ('ὡς', 'D--------'), ('μήτε', None), ('τὰ', 'L-P---NA-'), ('γενόμενα', None), ('ἐξ', 'R--------'), ('ἀνθρώπων', None), ('τῷ', 'P-S---MD-'), ('χρόνῳ', None), ('ἐξίτηλα', None), ('γένηται', None), ('μήτε', None), ('ἔργα', 'N-P---NA-'), ('μεγάλα', None), ('τε', 'G--------'), ('καὶ', 'C--------'), ('θωμαστά', None), ('τὰ', 'L-P---NA-'), ('μὲν', 'G--------'), ('Ἕλλησι', None), ('τὰ', 'L-P---NA-'), ('δὲ', 'G--------'), ('βαρβάροισι', None), ('ἀποδεχθέντα', None), ('ἀκλέα', None), ('γένηται', None), ('τά', None), ('τε', 'G--------'), ('ἄλλα', 'A-P---NA-'), ('καὶ', 'C--------'), ('δι', None), ('ἣν', 'P-S---FA-'), ('αἰτίην', None), ('ἐπολέμησαν', None), ('ἀλλήλοισι', None), ('.', 'U--------')]\n\n[('Περσέων', None), ('μέν', None), ('νυν', 'D--------'), ('οἱ', 'P-S---MD-'), ('λόγιοι', None), ('Φοίνικας', None), ('αἰτίους', None), ('φασὶ', 'V3PPIA---'), ('γενέσθαι', None), ('τῆς', 'L-S---FG-'), ('διαφορῆς', None), ('τούτους', None), ('γάρ', None), ('ἀπὸ', 'R--------'), ('τῆς', 'L-S---FG-'), ('Ἐρυθρῆς', None), ('καλεομένης', None), ('θαλάσσης', None), ('ἀπικομένους', None), ('ἐπὶ', 'R--------'), ('τήνδε', None), ('τὴν', 'P-S---FA-'), ('θάλασσαν', None), ('καὶ', 'C--------'), ('οἰκήσαντας', None), ('τοῦτον', 'A-S---MA-'), ('τὸν', 'P-S---MA-'), ('χῶρον', 'N-S---MA-'), ('τὸν', 'P-S---MA-'), ('καὶ', 'C--------'), ('νῦν', 'D--------'), ('οἰκέουσι', None), ('αὐτίκα', None), ('ναυτιλίῃσι', None), ('μακρῇσι', 'A-P---FD-'), ('ἐπιθέσθαι', None), ('ἀπαγινέοντας', None), ('δὲ', 'G--------'), ('φορτία', None), ('Αἰγύπτιά', None), ('τε', 'G--------'), ('καὶ', 'C--------'), ('Ἀσσύρια', None), ('τῇ', 'P-S---FD-'), ('τε', 'G--------'), ('ἄλλῃ', 'D--------'), ('χώρῃ', None), ('ἐσαπικνέεσθαι', None), ('καὶ', 'C--------'), ('δὴ', 'G--------'), ('καὶ', 'C--------'), ('ἐς', 'R--------'), ('Ἄργος', None), ('τὸ', 'L-S---NA-'), ('δὲ', 'G--------'), ('Ἄργος', None), ('τοῦτον', 'A-S---MA-'), ('τὸν', 'P-S---MA-'), ('χρόνον', None), ('προεῖχε', None), ('ἅπασι', 'A-P---MD-'), ('τῶν', 'L-P---MG-'), ('ἐν', 'R--------'), ('τῇ', 'P-S---FD-'), ('νῦν', 'D--------'), ('Ἑλλάδι', None), ('καλεομένῃ', None), ('χώρῃ', None), ('.', 'U--------')]\n\n[('Ἀπικομένους', None), ('δὲ', 'G--------'), ('τοὺς', 'P-P---MA-'), ('Φοίνικας', None), ('ἐς', 'R--------'), ('δὴ', 'G--------'), ('τὸ', 'L-S---NA-'), ('Ἄργος', None), ('τοῦτο', 'A-S---NA-'), ('διατίθεσθαι', None), ('τὸν', 'P-S---MA-'), ('φόρτον', None), ('.', 'U--------')]\n"
]
],
[
[
"# NER",
"_____no_output_____"
]
],
[
[
"## Latin -- decent, but see M, P, etc\nfrom cltk.tag import ner\n\n# Heordotus again\nfor sent in cicero_sents:\n ner_tags = ner.tag_ner('latin', input_text=sent, output_type=list)\n print(ner_tags)\n input()",
"[('Quae',), ('res',), ('in',), ('civitate',), ('duae',), ('plurimum',), ('possunt',), ('eae',), ('contra',), ('nos',), ('ambae',), ('faciunt',), ('in',), ('hoc',), ('tempore',), ('summa',), ('gratia',), ('et',), ('eloquentia',), ('quarum',), ('alteram',), ('C',), ('.',), ('Aquili', 'Entity'), ('vereor',), ('alteram',), ('metuo',), ('.',)]\n\n[('Eloquentia',), ('Q',), ('.',), ('Hortensi', 'Entity'), ('ne',), ('me',), ('in',), ('dicendo',), ('impediat',), ('non',), ('nihil',), ('commoveor',), ('gratia',), ('Sex', 'Entity'), ('.',)]\n\n[('Naevi',), ('ne',), ('P',), ('.',), ('Quinctio', 'Entity'), ('noceat',), ('id',), ('vero',), ('non',), ('mediocriter',), ('pertimesco',), ('.',)]\n\n[('Neque',), ('hoc',), ('tanto',), ('opere',), ('querendum',), ('videretur',), ('haec',), ('summa',), ('in',), ('illis',), ('esse',), ('si',), ('in',), ('nobis',), ('essent',), ('saltem',), ('mediocria',), ('verum',), ('ita',), ('se',), ('res',), ('habet',), ('ut',), ('ego',), ('qui',), ('neque',), ('usu',), ('satis',), ('et',), ('ingenio',), ('parum',), ('possum',), ('cum',), ('patrono',), ('disertissimo',), ('comparer',), ('P',), ('.',), ('Quinctius', 'Entity'), ('cui',), ('tenues',), ('opes',), ('nullae',), ('facultates',), ('exiguae',), ('amicorum',), ('copiae',), ('sunt',), ('cum',), ('adversario',), ('gratiosissimo',), ('contendat',), ('.',)]\n"
],
[
"# Greek -- not as good!\nfrom cltk.tag import ner\n\n# Heordotus again\nfor sent in herod_sents:\n ner_tags = ner.tag_ner('greek', input_text=sent, output_type=list)\n print(ner_tags)\n input()",
"[('Ἡροδότου',), ('Θουρίου',), ('ἱστορίης',), ('ἀπόδεξις',), ('ἥδε',), ('ὡς',), ('μήτε',), ('τὰ',), ('γενόμενα',), ('ἐξ',), ('ἀνθρώπων',), ('τῷ',), ('χρόνῳ',), ('ἐξίτηλα',), ('γένηται',), ('μήτε',), ('ἔργα',), ('μεγάλα',), ('τε',), ('καὶ',), ('θωμαστά',), ('τὰ',), ('μὲν',), ('Ἕλλησι', 'Entity'), ('τὰ',), ('δὲ',), ('βαρβάροισι',), ('ἀποδεχθέντα',), ('ἀκλέα',), ('γένηται',), ('τά',), ('τε',), ('ἄλλα',), ('καὶ',), ('δι',), ('ἣν',), ('αἰτίην',), ('ἐπολέμησαν',), ('ἀλλήλοισι',), ('.',)]\n\n[('Περσέων',), ('μέν',), ('νυν',), ('οἱ',), ('λόγιοι',), ('Φοίνικας',), ('αἰτίους',), ('φασὶ',), ('γενέσθαι',), ('τῆς',), ('διαφορῆς',), ('τούτους',), ('γάρ',), ('ἀπὸ',), ('τῆς',), ('Ἐρυθρῆς', 'Entity'), ('καλεομένης',), ('θαλάσσης',), ('ἀπικομένους',), ('ἐπὶ',), ('τήνδε',), ('τὴν',), ('θάλασσαν',), ('καὶ',), ('οἰκήσαντας',), ('τοῦτον',), ('τὸν',), ('χῶρον',), ('τὸν',), ('καὶ',), ('νῦν',), ('οἰκέουσι',), ('αὐτίκα',), ('ναυτιλίῃσι',), ('μακρῇσι',), ('ἐπιθέσθαι',), ('ἀπαγινέοντας',), ('δὲ',), ('φορτία',), ('Αἰγύπτιά',), ('τε',), ('καὶ',), ('Ἀσσύρια',), ('τῇ',), ('τε',), ('ἄλλῃ',), ('χώρῃ',), ('ἐσαπικνέεσθαι',), ('καὶ',), ('δὴ',), ('καὶ',), ('ἐς',), ('Ἄργος', 'Entity'), ('τὸ',), ('δὲ',), ('Ἄργος', 'Entity'), ('τοῦτον',), ('τὸν',), ('χρόνον',), ('προεῖχε',), ('ἅπασι',), ('τῶν',), ('ἐν',), ('τῇ',), ('νῦν',), ('Ἑλλάδι',), ('καλεομένῃ',), ('χώρῃ',), ('.',)]\n\n[('Ἀπικομένους',), ('δὲ',), ('τοὺς',), ('Φοίνικας',), ('ἐς',), ('δὴ',), ('τὸ',), ('Ἄργος', 'Entity'), ('τοῦτο',), ('διατίθεσθαι',), ('τὸν',), ('φόρτον',), ('.',)]\n\n[('Πέμπτῃ',), ('δὲ',), ('ἢ',), ('ἕκτῃ',), ('ἡμέρῃ',), ('ἀπ',), ('ἧς',), ('ἀπίκοντο',), ('ἐξεμπολημένων',), ('σφι',), ('σχεδὸν',), ('πάντων',), ('ἐλθεῖν',), ('ἐπὶ',), ('τὴν',), ('θάλασσαν',), ('γυναῖκας',), ('ἄλλας',), ('τε',), ('πολλὰς',), ('καὶ',), ('δὴ',), ('καὶ',), ('τοῦ',), ('βασιλέος',), ('θυγατέρα',), ('τὸ',), ('δέ',), ('οἱ',), ('οὔνομα',), ('εἶναι',), ('κατὰ',), ('τὠυτὸ',), ('τὸ',), ('καὶ',), ('Ἕλληνες', 'Entity'), ('λέγουσι',), ('Ἰοῦν', 'Entity'), ('τὴν',), ('Ἰνάχου',), ('.',)]\n\n[('Ταύτας',), ('στάσας',), ('κατὰ',), ('πρύμνην',), ('τῆς',), ('νεὸς',), ('ὠνέεσθαι',), ('τῶν',), ('φορτίων',), ('τῶν',), ('σφι',), ('ἦν',), ('θυμὸς',), ('μάλιστα',), ('καὶ',), ('τοὺς',), ('Φοίνικας',), ('διακελευσαμένους',), ('ὁρμῆσαι',), ('ἐπ',), ('αὐτάς',), ('.',)]\n\n[('Τὰς', 'Entity'), ('μὲν',), ('δὴ',), ('πλέονας',), ('τῶν',), ('γυναικῶν',), ('ἀποφυγεῖν',), ('τὴν',), ('δὲ',), ('Ἰοῦν', 'Entity'), ('σὺν',), ('ἄλλῃσι',), ('ἁρπασθῆναι',), ('ἐσβαλομένους',), ('δὲ',), ('ἐς',), ('τὴν',), ('νέα',), ('οἴχεσθαι',), ('ἀποπλέοντας',), ('ἐπ',), ('Αἰγύπτου',), ('.',)]\n"
]
],
[
[
"# Stopword filtering",
"_____no_output_____"
]
],
[
[
"from cltk.stop.greek.stops import STOPS_LIST\n#p = PunktLanguageVars()\n\nfor sent in herod_sents:\n words = nltk_tokenize_words(sent)\n print('W/ STOPS', words)\n words = [w for w in words if not w in STOPS_LIST]\n print('W/O STOPS', words)\n input()",
"W/ STOPS ['Ἡροδότου', 'Θουρίου', 'ἱστορίης', 'ἀπόδεξις', 'ἥδε', 'ὡς', 'μήτε', 'τὰ', 'γενόμενα', 'ἐξ', 'ἀνθρώπων', 'τῷ', 'χρόνῳ', 'ἐξίτηλα', 'γένηται', 'μήτε', 'ἔργα', 'μεγάλα', 'τε', 'καὶ', 'θωμαστά', 'τὰ', 'μὲν', 'Ἕλλησι', 'τὰ', 'δὲ', 'βαρβάροισι', 'ἀποδεχθέντα', 'ἀκλέα', 'γένηται', 'τά', 'τε', 'ἄλλα', 'καὶ', 'δι', 'ἣν', 'αἰτίην', 'ἐπολέμησαν', 'ἀλλήλοισι', '.']\nW/O STOPS ['Ἡροδότου', 'Θουρίου', 'ἱστορίης', 'ἀπόδεξις', 'ἥδε', 'μήτε', 'γενόμενα', 'ἀνθρώπων', 'χρόνῳ', 'ἐξίτηλα', 'γένηται', 'μήτε', 'ἔργα', 'μεγάλα', 'θωμαστά', 'Ἕλλησι', 'βαρβάροισι', 'ἀποδεχθέντα', 'ἀκλέα', 'γένηται', 'ἄλλα', 'δι', 'ἣν', 'αἰτίην', 'ἐπολέμησαν', 'ἀλλήλοισι', '.']\n\nW/ STOPS ['Περσέων', 'μέν', 'νυν', 'οἱ', 'λόγιοι', 'Φοίνικας', 'αἰτίους', 'φασὶ', 'γενέσθαι', 'τῆς', 'διαφορῆς', 'τούτους', 'γάρ', 'ἀπὸ', 'τῆς', 'Ἐρυθρῆς', 'καλεομένης', 'θαλάσσης', 'ἀπικομένους', 'ἐπὶ', 'τήνδε', 'τὴν', 'θάλασσαν', 'καὶ', 'οἰκήσαντας', 'τοῦτον', 'τὸν', 'χῶρον', 'τὸν', 'καὶ', 'νῦν', 'οἰκέουσι', 'αὐτίκα', 'ναυτιλίῃσι', 'μακρῇσι', 'ἐπιθέσθαι', 'ἀπαγινέοντας', 'δὲ', 'φορτία', 'Αἰγύπτιά', 'τε', 'καὶ', 'Ἀσσύρια', 'τῇ', 'τε', 'ἄλλῃ', 'χώρῃ', 'ἐσαπικνέεσθαι', 'καὶ', 'δὴ', 'καὶ', 'ἐς', 'Ἄργος', 'τὸ', 'δὲ', 'Ἄργος', 'τοῦτον', 'τὸν', 'χρόνον', 'προεῖχε', 'ἅπασι', 'τῶν', 'ἐν', 'τῇ', 'νῦν', 'Ἑλλάδι', 'καλεομένῃ', 'χώρῃ', '.']\nW/O STOPS ['Περσέων', 'νυν', 'λόγιοι', 'Φοίνικας', 'αἰτίους', 'φασὶ', 'γενέσθαι', 'διαφορῆς', 'τούτους', 'Ἐρυθρῆς', 'καλεομένης', 'θαλάσσης', 'ἀπικομένους', 'τήνδε', 'θάλασσαν', 'οἰκήσαντας', 'τοῦτον', 'χῶρον', 'νῦν', 'οἰκέουσι', 'αὐτίκα', 'ναυτιλίῃσι', 'μακρῇσι', 'ἐπιθέσθαι', 'ἀπαγινέοντας', 'φορτία', 'Αἰγύπτιά', 'Ἀσσύρια', 'ἄλλῃ', 'χώρῃ', 'ἐσαπικνέεσθαι', 'ἐς', 'Ἄργος', 'Ἄργος', 'τοῦτον', 'χρόνον', 'προεῖχε', 'ἅπασι', 'νῦν', 'Ἑλλάδι', 'καλεομένῃ', 'χώρῃ', '.']\n"
]
],
[
[
"# Concordance",
"_____no_output_____"
]
],
[
[
"from cltk.utils.philology import Philology\np = Philology()",
"_____no_output_____"
],
[
"herod_fp = '/Users/kyle/cltk_data/greek/text/tlg/plaintext/TLG0016.txt'\n\np.write_concordance_from_file(herod_fp, 'kyle_herod')",
"INFO:CLTK:Wrote concordance to '/Users/kyle/cltk_data/user_data/concordance_kyle_herod.txt'.\n"
]
],
[
[
"# Word count",
"_____no_output_____"
]
],
[
[
"from nltk.text import Text",
"_____no_output_____"
],
[
"words = nltk_tokenize_words(herod_clean)\nprint(words[:15])",
"['Ἡροδότου', 'Θουρίου', 'ἱστορίης', 'ἀπόδεξις', 'ἥδε', 'ὡς', 'μήτε', 'τὰ', 'γενόμενα', 'ἐξ', 'ἀνθρώπων', 'τῷ', 'χρόνῳ', 'ἐξίτηλα', 'γένηται']\n"
],
[
"t = Text(words)",
"_____no_output_____"
],
[
"vocabulary_count = t.vocab()",
"_____no_output_____"
],
[
"vocabulary_count['ἱστορίης']",
"_____no_output_____"
],
[
"vocabulary_count['μήτε']",
"_____no_output_____"
],
[
"vocabulary_count['ἀνθρώπων']",
"_____no_output_____"
]
],
[
[
"# Word frequency",
"_____no_output_____"
]
],
[
[
"from cltk.utils.frequency import Frequency",
"_____no_output_____"
],
[
"freq = Frequency()",
"_____no_output_____"
],
[
"herod_frequencies = freq.counter_from_str(herod_clean)",
"_____no_output_____"
],
[
"herod_frequencies.most_common()",
"_____no_output_____"
]
],
[
[
"# Lemmatizing",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02c2794ac77ba37b17a628ab7ea9328bbd4c8e0
| 16,561 |
ipynb
|
Jupyter Notebook
|
cars-price-dataset.ipynb
|
jaselnik/Car-Price-Predictor-Django
|
593c267196a9dd43b3155b7270291ab0b4dba70c
|
[
"MIT"
] | 1 |
2019-07-18T18:58:05.000Z
|
2019-07-18T18:58:05.000Z
|
cars-price-dataset.ipynb
|
jaselnik/Car-Price-Predictor-Django
|
593c267196a9dd43b3155b7270291ab0b4dba70c
|
[
"MIT"
] | null | null | null |
cars-price-dataset.ipynb
|
jaselnik/Car-Price-Predictor-Django
|
593c267196a9dd43b3155b7270291ab0b4dba70c
|
[
"MIT"
] | null | null | null | 30.61183 | 220 | 0.461627 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"# set the column names\ncolnames=['price', 'year_model', 'mileage', 'fuel_type', 'mark', 'model', 'fiscal_power', 'sector', 'type', 'city'] \n# read the csv file as a dataframe\ndf = pd.read_csv(\"./data/output.csv\", sep=\",\", names=colnames, header=None)\n# let's get some simple vision on our dataset\ndf.head()",
"_____no_output_____"
],
[
"# remove thos rows doesn't contain the price value\ndf = df[df.price.str.contains(\"DH\") == True]\n# remove the 'DH' caracters from the price\ndf.price = df.price.map(lambda x: x.rstrip('DH'))\n# remove the space on it\ndf.price = df.price.str.replace(\" \",\"\")\n# change it to integer value\ndf.price = pd.to_numeric(df.price, errors = 'coerce', downcast= 'integer')",
"_____no_output_____"
],
[
"# remove thos rows doesn't contain the year_model value\ndf = df[df.year_model.str.contains(\"Année-Modèle\") == True]\n# remove the 'Année-Modèle:' from the year_model\ndf.year_model = df.year_model.map(lambda x: x.lstrip('Année-Modèle:').rstrip('ou plus ancien'))\n# df.year_model = df.year_model.map(lambda x: x.lstrip('Plus de '))\n# remove those lines having the year_model not set\ndf = df[df.year_model != ' -']\ndf = df[df.year_model != '']\n# change it to integer value\ndf.year_model = pd.to_numeric(df.year_model, errors = 'coerce', downcast = 'integer')",
"_____no_output_____"
],
[
"# remove thos rows doesn't contain the year_model value\ndf = df[df.mileage.str.contains(\"Kilométrage\") == True]\n# remove the 'Kilométrage:' string from the mileage feature \ndf.mileage = df.mileage.map(lambda x: x.lstrip('Kilométrage:'))\ndf.mileage = df.mileage.map(lambda x: x.lstrip('Plus de '))\n# remove those lines having the mileage values null or '-'\ndf = df[df.mileage != '-']\n# we have only one value type that is equal to 500 000, all the other ones contain two values\nif any(df.mileage != '500 000'):\n # create two columns minim and maxim to calculate the mileage mean\n df['minim'], df['maxim'] = df.mileage.str.split('-', 1).str\n # remove spaces from the maxim & minim values \n df['maxim'] = df.maxim.str.replace(\" \",\"\")\n df['minim'] = df.minim.str.replace(\" \",\"\")\n df['maxim'] = df['maxim'].replace(np.nan, 500000)\n # calculate the mean of mileage \n df.mileage = df.apply(lambda row: (int(row.minim) + int(row.maxim)) / 2, axis=1)\n # now that the mileage is calculated so we do not need the minim and maxim values anymore\n df = df.drop(columns=['minim', 'maxim'])",
"_____no_output_____"
]
],
[
[
"#### Fuel type",
"_____no_output_____"
]
],
[
[
"# remove the 'Type de carburant:' string from the carburant_type feature\ndf.fuel_type = df.fuel_type.map(lambda x: x.lstrip('Type de carburant:'))",
"_____no_output_____"
]
],
[
[
"#### Mark & Model",
"_____no_output_____"
]
],
[
[
"# remove the 'Marque:' string from the mark feature\ndf['mark'] = df['mark'].map(lambda x: x.replace('Marque:', ''))\ndf = df[df.mark != '-']\n# remove the 'Modèle:' string from model feature \ndf['model'] = df['model'].map(lambda x: x.replace('Modèle:', ''))",
"_____no_output_____"
]
],
[
[
"#### fiscal power\n\nFor the fiscal power we can see that there is exactly 5728 rows not announced, so we will fill them by the mean of the other columns, since it is an important feature in cars price prediction so we can not drop it.",
"_____no_output_____"
]
],
[
[
"# remove the 'Puissance fiscale:' from the fiscal_power feature\ndf.fiscal_power = df.fiscal_power.map(lambda x: x.lstrip('Puissance fiscale:Plus de').rstrip(' CV'))\n# replace the - with NaN values and convert them to integer values\ndf.fiscal_power = df.fiscal_power.str.replace(\"-\",\"0\")\n# convert all fiscal_power values to numerical ones \ndf.fiscal_power = pd.to_numeric(df.fiscal_power, errors = 'coerce', downcast= 'integer')\n# now we need to fill those 0 values with the mean of all fiscal_power columns\ndf.fiscal_power = df.fiscal_power.map( lambda x : df.fiscal_power.mean() if x == 0 else x )",
"_____no_output_____"
]
],
[
[
"#### fuel type",
"_____no_output_____"
]
],
[
[
"# remove those lines having the fuel_type not set\ndf = df[df.fuel_type != '-']",
"_____no_output_____"
]
],
[
[
"#### drop unwanted columns",
"_____no_output_____"
]
],
[
[
"df = df.drop(columns=['sector', 'type'])",
"_____no_output_____"
],
[
"df = df[['price', 'year_model', 'mileage', 'fiscal_power', 'fuel_type', 'mark']]",
"_____no_output_____"
],
[
"df.to_csv('data/car_dataset.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"from car_price.wsgi import application",
"_____no_output_____"
],
[
"from api.models import Car",
"_____no_output_____"
],
[
"for x in df.values[5598:]:\n car = Car(\n price=x[0],\n year_model=x[1],\n mileage=x[2],\n fiscal_power=x[3],\n fuel_type=x[4],\n mark=x[5]\n )\n car.save()",
"_____no_output_____"
],
[
"Car.objects.all().count()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02c32eb84d03a2dabfd887c5b881b0783510c93
| 25,280 |
ipynb
|
Jupyter Notebook
|
Starter_Code/credit_risk_resampling.ipynb
|
LeoHarada/Challenge_12
|
02d5a12b232e1122186ec85e3d08e4b0ba3f383d
|
[
"MIT"
] | null | null | null |
Starter_Code/credit_risk_resampling.ipynb
|
LeoHarada/Challenge_12
|
02d5a12b232e1122186ec85e3d08e4b0ba3f383d
|
[
"MIT"
] | null | null | null |
Starter_Code/credit_risk_resampling.ipynb
|
LeoHarada/Challenge_12
|
02d5a12b232e1122186ec85e3d08e4b0ba3f383d
|
[
"MIT"
] | null | null | null | 30.167064 | 411 | 0.497468 |
[
[
[
"# Credit Risk Classification\n\nCredit risk poses a classification problem that’s inherently imbalanced. This is because healthy loans easily outnumber risky loans. In this Challenge, you’ll use various techniques to train and evaluate models with imbalanced classes. You’ll use a dataset of historical lending activity from a peer-to-peer lending services company to build a model that can identify the creditworthiness of borrowers.\n\n## Instructions:\n\nThis challenge consists of the following subsections:\n\n* Split the Data into Training and Testing Sets\n\n* Create a Logistic Regression Model with the Original Data\n\n* Predict a Logistic Regression Model with Resampled Training Data \n\n### Split the Data into Training and Testing Sets\n\nOpen the starter code notebook and then use it to complete the following steps.\n\n1. Read the `lending_data.csv` data from the `Resources` folder into a Pandas DataFrame.\n\n2. Create the labels set (`y`) from the “loan_status” column, and then create the features (`X`) DataFrame from the remaining columns.\n\n > **Note** A value of `0` in the “loan_status” column means that the loan is healthy. A value of `1` means that the loan has a high risk of defaulting. \n\n3. Check the balance of the labels variable (`y`) by using the `value_counts` function.\n\n4. Split the data into training and testing datasets by using `train_test_split`.\n\n### Create a Logistic Regression Model with the Original Data\n\nEmploy your knowledge of logistic regression to complete the following steps:\n\n1. Fit a logistic regression model by using the training data (`X_train` and `y_train`).\n\n2. Save the predictions on the testing data labels by using the testing feature data (`X_test`) and the fitted model.\n\n3. Evaluate the model’s performance by doing the following:\n\n * Calculate the accuracy score of the model.\n\n * Generate a confusion matrix.\n\n * Print the classification report.\n\n4. Answer the following question: How well does the logistic regression model predict both the `0` (healthy loan) and `1` (high-risk loan) labels?\n\n### Predict a Logistic Regression Model with Resampled Training Data\n\nDid you notice the small number of high-risk loan labels? Perhaps, a model that uses resampled data will perform better. You’ll thus resample the training data and then reevaluate the model. Specifically, you’ll use `RandomOverSampler`.\n\nTo do so, complete the following steps:\n\n1. Use the `RandomOverSampler` module from the imbalanced-learn library to resample the data. Be sure to confirm that the labels have an equal number of data points. \n\n2. Use the `LogisticRegression` classifier and the resampled data to fit the model and make predictions.\n\n3. Evaluate the model’s performance by doing the following:\n\n * Calculate the accuracy score of the model.\n\n * Generate a confusion matrix.\n\n * Print the classification report.\n \n4. Answer the following question: How well does the logistic regression model, fit with oversampled data, predict both the `0` (healthy loan) and `1` (high-risk loan) labels?\n\n### Write a Credit Risk Analysis Report\n\nFor this section, you’ll write a brief report that includes a summary and an analysis of the performance of both machine learning models that you used in this challenge. You should write this report as the `README.md` file included in your GitHub repository.\n\nStructure your report by using the report template that `Starter_Code.zip` includes, and make sure that it contains the following:\n\n1. An overview of the analysis: Explain the purpose of this analysis.\n\n\n2. The results: Using bulleted lists, describe the balanced accuracy scores and the precision and recall scores of both machine learning models.\n\n3. A summary: Summarize the results from the machine learning models. Compare the two versions of the dataset predictions. Include your recommendation for the model to use, if any, on the original vs. the resampled data. If you don’t recommend either model, justify your reasoning.",
"_____no_output_____"
]
],
[
[
"# Import the modules\nimport numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom sklearn.metrics import balanced_accuracy_score\nfrom sklearn.metrics import confusion_matrix\nfrom imblearn.metrics import classification_report_imbalanced\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"## Split the Data into Training and Testing Sets",
"_____no_output_____"
],
[
"### Step 1: Read the `lending_data.csv` data from the `Resources` folder into a Pandas DataFrame.",
"_____no_output_____"
]
],
[
[
"# Read the CSV file from the Resources folder into a Pandas DataFrame\nlending_data_df = pd.read_csv(Path(\"../Starter_Code/Resources/lending_data.csv\"))\n\n# Review the DataFrame\ndisplay(lending_data_df.head())",
"_____no_output_____"
]
],
[
[
"### Step 2: Create the labels set (`y`) from the “loan_status” column, and then create the features (`X`) DataFrame from the remaining columns.",
"_____no_output_____"
]
],
[
[
"# Separate the data into labels and features\n\n# Separate the y variable, the labels\ny = lending_data_df[\"loan_status\"]\n\n# Separate the X variable, the features\nX = lending_data_df.drop(columns=[\"loan_status\"])",
"_____no_output_____"
],
[
"# Review the y variable Series\ny.head()",
"_____no_output_____"
],
[
"# Review the X variable DataFrame\nX.head()",
"_____no_output_____"
]
],
[
[
"### Step 3: Check the balance of the labels variable (`y`) by using the `value_counts` function.",
"_____no_output_____"
]
],
[
[
"# Check the balance of our target values\ny.value_counts()",
"_____no_output_____"
]
],
[
[
"### Step 4: Split the data into training and testing datasets by using `train_test_split`.",
"_____no_output_____"
]
],
[
[
"# Import the train_test_learn module\nfrom sklearn.model_selection import train_test_split\n\n# Split the data using train_test_split\n# Assign a random_state of 1 to the function\nX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"## Create a Logistic Regression Model with the Original Data",
"_____no_output_____"
],
[
"### Step 1: Fit a logistic regression model by using the training data (`X_train` and `y_train`).",
"_____no_output_____"
]
],
[
[
"# Import the LogisticRegression module from SKLearn\nfrom sklearn.linear_model import LogisticRegression\n\n# Instantiate the Logistic Regression model\n# Assign a random_state parameter of 1 to the model\nmodel = LogisticRegression(random_state=1)\n\n# Fit the model using training data\nmodel.fit(X_train, y_train)",
"_____no_output_____"
]
],
[
[
"### Step 2: Save the predictions on the testing data labels by using the testing feature data (`X_test`) and the fitted model.",
"_____no_output_____"
]
],
[
[
"# Make a prediction using the testing data\ny_pred = model.predict(X_test)\n\ny_pred",
"_____no_output_____"
]
],
[
[
"### Step 3: Evaluate the model’s performance by doing the following:\n\n* Calculate the accuracy score of the model.\n\n* Generate a confusion matrix.\n\n* Print the classification report.",
"_____no_output_____"
]
],
[
[
"# Print the balanced_accuracy score of the model\nBAS = balanced_accuracy_score(y_test, y_pred)\nprint(BAS)",
"0.9520479254722232\n"
],
[
"# Generate a confusion matrix for the model\nprint(confusion_matrix(y_test, y_pred))",
"[[18663 102]\n [ 56 563]]\n"
],
[
"# Print the classification report for the model\nprint(classification_report_imbalanced(y_test, y_pred))",
" pre rec spe f1 geo iba sup\n\n 0 1.00 0.99 0.91 1.00 0.95 0.91 18765\n 1 0.85 0.91 0.99 0.88 0.95 0.90 619\n\navg / total 0.99 0.99 0.91 0.99 0.95 0.91 19384\n\n"
]
],
[
[
"### Step 4: Answer the following question.",
"_____no_output_____"
],
[
"**Question:** How well does the logistic regression model predict both the `0` (healthy loan) and `1` (high-risk loan) labels?\n\n**Answer:** The regression models predicts both healthy loans and high-risk loans, for the most part, accurately. We have an average 99% for our F1 score, the summary statistic for both the precision and recall of the data. Although, there is some room for improvement for healthy loans for our PPV (positive predictive value) and recall. ",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"## Predict a Logistic Regression Model with Resampled Training Data",
"_____no_output_____"
],
[
"### Step 1: Use the `RandomOverSampler` module from the imbalanced-learn library to resample the data. Be sure to confirm that the labels have an equal number of data points. ",
"_____no_output_____"
]
],
[
[
"# Import the RandomOverSampler module form imbalanced-learn\nfrom imblearn.over_sampling import RandomOverSampler\n\n# Instantiate the random oversampler model\n# # Assign a random_state parameter of 1 to the model\nrandom_oversampler = RandomOverSampler(random_state=1)\n\n# Fit the original training data to the random_oversampler model\nX_resampled, y_resampled = random_oversampler.fit_resample(X_train, y_train)",
"_____no_output_____"
],
[
"# Count the distinct values of the resampled labels data\ny_resampled.value_counts()",
"_____no_output_____"
]
],
[
[
"### Step 2: Use the `LogisticRegression` classifier and the resampled data to fit the model and make predictions.",
"_____no_output_____"
]
],
[
[
"# Instantiate the Logistic Regression model\n# Assign a random_state parameter of 1 to the model\nresampled_model = LogisticRegression(random_state=1)\n\n# Fit the model using the resampled training data\nresampled_model.fit(X_resampled, y_resampled)\n\n# Make a prediction using the testing data\ny_pred = resampled_model.predict(X_test)",
"_____no_output_____"
]
],
[
[
"### Step 3: Evaluate the model’s performance by doing the following:\n\n* Calculate the accuracy score of the model.\n\n* Generate a confusion matrix.\n\n* Print the classification report.",
"_____no_output_____"
]
],
[
[
"# Print the balanced_accuracy score of the model \nprint(balanced_accuracy_score(y_test, y_pred))",
"0.9936781215845847\n"
],
[
"# Generate a confusion matrix for the model\nconfusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"# Print the classification report for the model\nprint(classification_report_imbalanced(y_test, y_pred))",
" pre rec spe f1 geo iba sup\n\n 0 1.00 0.99 0.99 1.00 0.99 0.99 18765\n 1 0.84 0.99 0.99 0.91 0.99 0.99 619\n\navg / total 0.99 0.99 0.99 0.99 0.99 0.99 19384\n\n"
]
],
[
[
"### Step 4: Answer the following question",
"_____no_output_____"
],
[
"**Question:** How well does the logistic regression model, fit with oversampled data, predict both the `0` (healthy loan) and `1` (high-risk loan) labels?\n\n**Answer:** The logistic regression model, fit with oversampled data, predicts both the healthy loans and high-risk loans pretty accurately. We have an F1 score of 99%, which summarizes the precision and recall. Again, there's room for improvement for the high-risk loan portion in terms of precision. But for the most part, the model predicts the labels of both loans accurately.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d02c39bcf71f7debe0ac18270e29799472684cad
| 157,608 |
ipynb
|
Jupyter Notebook
|
notebooks/7-Ensemble.ipynb
|
jpjuvo/RSNA-MICCAI-Brain-Tumor-Classification
|
a8a4e9257b7475bc328870504edd18fdd9ec9d2f
|
[
"MIT"
] | 1 |
2021-10-20T19:34:27.000Z
|
2021-10-20T19:34:27.000Z
|
notebooks/7-Ensemble.ipynb
|
jpjuvo/RSNA-MICCAI-Brain-Tumor-Classification
|
a8a4e9257b7475bc328870504edd18fdd9ec9d2f
|
[
"MIT"
] | null | null | null |
notebooks/7-Ensemble.ipynb
|
jpjuvo/RSNA-MICCAI-Brain-Tumor-Classification
|
a8a4e9257b7475bc328870504edd18fdd9ec9d2f
|
[
"MIT"
] | null | null | null | 175.314794 | 58,072 | 0.867107 |
[
[
[
"import glob\nimport os\nimport random\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport cv2\nimport math\nfrom tqdm.auto import tqdm\nfrom sklearn import linear_model\nimport optuna\nimport seaborn as sns",
"_____no_output_____"
],
[
"FEAT_OOFS = [\n {\n 'model' : 'feat_lasso', \n 'fn' : '../output/2021011_segmentation_feature_model_v4/feature_model_oofs_0.csv'\n },\n {\n 'model' : 'feat_linreg', \n 'fn' : '../output/2021011_segmentation_feature_model_v4/feature_model_oofs_1.csv'\n },\n {\n 'model' : 'feat_ridge',\n 'fn' : '../output/2021011_segmentation_feature_model_v4/feature_model_oofs_2.csv',\n }\n]\n\nCNN_OOFS = [\n {\n 'model' : 'resnet50_rocstar',\n 'fn' : '../output/resnet50_bs32_ep10_rocstar_lr0.0001_ps0.8_ranger_sz256/'\n },\n {\n 'model' : 'resnet50_bce',\n 'fn' : '../output/resnet50_bs32_ep10_bce_lr0.0001_ps0.8_ranger_sz256/'\n },\n {\n 'model' : 'densenet169_rocstar',\n 'fn' : '../output/densenet169_bs32_ep10_rocstar_lr0.0001_ps0.8_ranger_sz256/'\n },\n {\n 'model' : 'resnet101_rocstar',\n 'fn' : '../output/resnet101_bs32_ep20_rocstar_lr0.0001_ps0.8_ranger_sz256/'\n },\n {\n 'model' : 'efficientnetv2_l_rocstar',\n 'fn' : '../output/tf_efficientnetv2_l_bs32_ep10_rocstar_lr0.0001_ps0.8_ranger_sz256/'\n },\n]",
"_____no_output_____"
],
[
"df = pd.read_csv('../output/20210925_segmentation_feature_model_v3/feature_model_oofs_0.csv')[\n ['BraTS21ID','MGMT_value','fold']]\ndf.head()",
"_____no_output_____"
],
[
"def read_feat_oof(fn):\n return pd.read_csv(fn).sort_values('BraTS21ID')['oof_pred'].values\n\ndef read_cnn_oof(dir_path):\n oof_fns = [os.path.join(dir_path, f'fold-{i}', 'oof.csv') for i in range(5)]\n dfs = []\n for fn in oof_fns:\n dfs.append(pd.read_csv(fn))\n df = pd.concat(dfs)\n return df.sort_values('BraTS21ID')['pred_mgmt_tta'].values\n\ndef normalize_pred_distribution(preds, min_percentile=10, max_percentile=90):\n \"\"\" Clips min and max percentiles and Z-score normalizes \"\"\"\n min_range = np.percentile(preds, min_percentile)\n max_range = np.percentile(preds, max_percentile)\n norm_preds = np.clip(preds, min_range, max_range)\n pred_std = np.std(norm_preds)\n pred_mean = np.mean(norm_preds)\n norm_preds = (norm_preds - pred_mean) / (pred_std + 1e-6)\n return norm_preds\n\ndef rescale_pred_distribution(preds):\n \"\"\" Rescales pred distribution to 0-1 range. Doesn't affect AUC \"\"\"\n return (preds - np.min(preds)) / (np.max(preds) - np.min(preds) + 1e-6)",
"_____no_output_____"
],
[
"for d in FEAT_OOFS:\n df[d['model']] = read_feat_oof(d['fn'])\nfor d in CNN_OOFS:\n df[d['model']] = read_cnn_oof(d['fn'])\n \ndf_norm = df.copy()\nfor feat in df.columns.to_list()[3:]:\n df_norm[feat] = rescale_pred_distribution(\n normalize_pred_distribution(df_norm[feat].values)\n )\n \ndf_norm.head()",
"_____no_output_____"
],
[
"df_raw = df.copy()",
"_____no_output_____"
],
[
"all_feat_names = df_norm.columns.to_list()[3:]\ncorr = df_norm[['MGMT_value'] + all_feat_names].corr()\n\n# Generate a mask for the upper triangle\nmask = np.triu(np.ones_like(corr, dtype=bool))\nplt.close('all')\nf, ax = plt.subplots(figsize=(5, 5))\ncmap = sns.diverging_palette(230, 20, as_cmap=True)\nsns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,\n square=True, linewidths=.5, cbar_kws={\"shrink\": .5})\nplt.title('OOF pred correlations')\nplt.show()",
"_____no_output_____"
],
[
"mgmt_corr_sorted = corr['MGMT_value'].sort_values()\nmgmt_corr_sorted ",
"_____no_output_____"
]
],
[
[
"## Average",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score, roc_auc_score\nfrom sklearn.preprocessing import StandardScaler",
"_____no_output_____"
],
[
"oof_preds = np.mean(df_norm[all_feat_names].to_numpy(),1)\noof_gts = df_norm['MGMT_value']\n\ncv_preds = [np.mean(df_norm[df_norm.fold==fold][all_feat_names].to_numpy(),1) for fold in range(5)]\ncv_gts = [df_norm[df_norm.fold==fold]['MGMT_value'] for fold in range(5)]",
"_____no_output_____"
],
[
"oof_acc = accuracy_score((np.array(oof_gts) > 0.5).flatten(), (np.array(oof_preds) > 0.5).flatten())\noof_auc = roc_auc_score(np.array(oof_gts).flatten().astype(np.float32), np.array(oof_preds).flatten())\n\ncv_accs = np.array([accuracy_score((np.array(cv_gt) > 0.5).flatten(), (np.array(cv_pred) > 0.5).flatten())\n for cv_gt,cv_pred in zip(cv_gts, cv_preds)])\ncv_aucs = np.array([roc_auc_score(np.array(cv_gt).flatten().astype(np.float32), np.array(cv_pred).flatten())\n for cv_gt,cv_pred in zip(cv_gts, cv_preds)])\nprint(f'OOF acc {oof_acc}, OOF auc {oof_auc}, CV AUC {np.mean(cv_aucs)} (std {np.std(cv_aucs)})')\n\nplt.close('all')\ndf_plot = pd.DataFrame({'Pred-MGMT': oof_preds, 'GT-MGMT': oof_gts})\nsns.histplot(x='Pred-MGMT', hue='GT-MGMT', data=df_plot)\nplt.title(f'Average of all models # CV AUC = {np.mean(cv_aucs):.3f} (std: {np.std(cv_aucs):.3f}), Acc. = {np.mean(cv_accs):.3f}')\nplt.show()",
"OOF acc 0.6065857885615251, OOF auc 0.6479849776108624, CV AUC 0.6484203763469425 (std 0.029397573539242678)\n"
],
[
"selected_feats = [\n 'feat_lasso',\n 'feat_ridge',\n 'feat_linreg',\n 'efficientnetv2_l_rocstar',\n 'resnet101_rocstar',\n 'densenet169_rocstar',\n] \noof_acc = accuracy_score((np.array(oof_gts) > 0.5).flatten(), (np.mean(df_norm[selected_feats].to_numpy(),1) > 0.5).flatten())\noof_auc = roc_auc_score(np.array(oof_gts).flatten().astype(np.float32), np.mean(df_norm[selected_feats].to_numpy(),1).flatten())\n\ncv_preds = [np.mean(df_norm[df_norm.fold==fold][selected_feats].to_numpy(),1) for fold in range(5)]\ncv_gts = [df_norm[df_norm.fold==fold]['MGMT_value'] for fold in range(5)]\n\ncv_accs = np.array([accuracy_score((np.array(cv_gt) > 0.5).flatten(), (np.array(cv_pred) > 0.5).flatten())\n for cv_gt,cv_pred in zip(cv_gts, cv_preds)])\ncv_aucs = np.array([roc_auc_score(np.array(cv_gt).flatten().astype(np.float32), np.array(cv_pred).flatten())\n for cv_gt,cv_pred in zip(cv_gts, cv_preds)])\nprint(f'OOF acc {oof_acc}, OOF auc {oof_auc}, CV AUC {np.mean(cv_aucs)} (std {np.std(cv_aucs)})')\n\nplt.close('all')\ndf_plot = pd.DataFrame({'Pred-MGMT': oof_preds, 'GT-MGMT': oof_gts})\nsns.histplot(x='Pred-MGMT', hue='GT-MGMT', data=df_plot)\nplt.title(f'Average of all models # CV AUC = {np.mean(cv_aucs):.3f} (std: {np.std(cv_aucs):.3f}), Acc. = {np.mean(cv_accs):.3f}')\nplt.show()",
"OOF acc 0.5944540727902946, OOF auc 0.6514516827964754, CV AUC 0.6504285580435163 (std 0.02232524533384981)\n"
]
],
[
[
"## 2nd level models",
"_____no_output_____"
]
],
[
[
"import xgboost as xgb\ndef get_data(fold, features):\n df = df_norm.dropna(inplace=False)\n scaler = StandardScaler()\n \n df_train = df[df.fold != fold]\n df_val = df[df.fold == fold]\n if len(df_val) == 0:\n df_val = df[df.fold == 0]\n \n # shuffle train\n df_train = df_train.sample(frac=1)\n \n y_train = df_train.MGMT_value.to_numpy().reshape((-1,1)).astype(np.float32)\n y_val = df_val.MGMT_value.to_numpy().reshape((-1,1)).astype(np.float32)\n \n X_train = df_train[features].to_numpy().astype(np.float32)\n X_val = df_val[features].to_numpy().astype(np.float32)\n \n scaler.fit(X_train)\n X_train = scaler.transform(X_train)\n X_val = scaler.transform(X_val)\n \n return X_train, y_train, X_val, y_val, scaler, (df_train.index.values).flatten(), (df_val.index.values).flatten()\n\ndef measure_cv_score(parameters, verbose=False, train_one_model=False, plot=False, return_oof_preds=False):\n \n val_preds = []\n val_gts = []\n val_aucs = []\n val_accs = []\n val_index_values = []\n \n for fold in range(5):\n \n if train_one_model: fold = -1\n \n X_train, y_train, X_val, y_val, scaler, train_index, val_index = get_data(fold, features=parameters['features'])\n val_index_values = val_index_values + list(val_index)\n \n if parameters['model_type'] == 'xgb':\n model = xgb.XGBRegressor(\n n_estimators=parameters['n_estimators'], \n max_depth=parameters['max_depth'], \n eta=parameters['eta'],\n subsample=parameters['subsample'], \n colsample_bytree=parameters['colsample_bytree'],\n gamma=parameters['gamma']\n )\n elif parameters['model_type'] == 'linreg':\n model = linear_model.LinearRegression()\n elif parameters['model_type'] == 'ridge':\n model = linear_model.Ridge(parameters['alpha'])\n elif parameters['model_type'] == 'bayesian':\n model = linear_model.BayesianRidge(\n n_iter = parameters['n_iter'],\n lambda_1 = parameters['lambda_1'],\n lambda_2 = parameters['lambda_2'],\n alpha_1 = parameters['alpha_1'],\n alpha_2 = parameters['alpha_2'],\n )\n elif parameters['model_type'] == 'logreg':\n model = linear_model.LogisticRegression()\n elif parameters['model_type'] == 'lassolarsic':\n model = linear_model.LassoLarsIC(\n max_iter = parameters['max_iter'],\n eps = parameters['eps']\n )\n elif parameters['model_type'] == 'perceptron':\n model = linear_model.Perceptron(\n )\n else:\n raise NotImplementedError\n \n model.fit(X_train, y_train.ravel())\n \n if train_one_model:\n return model, scaler\n \n val_pred = model.predict(X_val)\n val_preds += list(val_pred)\n val_gts += list(y_val)\n val_aucs.append(roc_auc_score(np.array(y_val).flatten().astype(np.float32), np.array(val_pred).flatten()))\n val_accs.append(accuracy_score((np.array(y_val) > 0.5).flatten(), (np.array(val_pred) > 0.5).flatten()))\n \n if return_oof_preds:\n return np.array(val_preds).flatten(), np.array(val_gts).flatten(), val_index_values\n \n oof_acc = accuracy_score((np.array(val_gts) > 0.5).flatten(), (np.array(val_preds) > 0.5).flatten())\n oof_auc = roc_auc_score(np.array(val_gts).flatten().astype(np.float32), np.array(val_preds).flatten())\n auc_std = np.std(np.array(val_aucs))\n \n if plot:\n df_plot = pd.DataFrame({'Pred-MGMT': np.array(val_preds).flatten(), 'GT-MGMT': np.array(val_gts).flatten()})\n sns.histplot(x='Pred-MGMT', hue='GT-MGMT', data=df_plot)\n plt.title(f'{parameters[\"model_type\"]} # CV AUC = {oof_auc:.3f} (std {auc_std:.3f}), Acc. = {oof_acc:.3f}')\n plt.show()\n \n if verbose:\n print(f'CV AUC = {oof_auc} (std {auc_std}), Acc. = {oof_acc}, aucs: {val_aucs}, accs: {val_accs}')\n \n # optimize lower limit of the (2x std range around mean)\n # This way, we choose the model which ranks well and performs ~equally well on all folds\n return float(oof_auc) - auc_std",
"_____no_output_____"
],
[
"default_parameters = {\n 'model_type': 'linreg',\n 'n_estimators': 100,\n 'max_depth' : 3,\n 'eta': 0.1,\n 'subsample': 0.7,\n 'colsample_bytree' : 0.8,\n 'gamma' : 1.0,\n 'alpha' : 1.0,\n 'n_iter':300,\n 'lambda_1': 1e-6, # bayesian\n 'lambda_2':1e-6, # bayesian\n 'alpha_1': 1e-6, # bayesian\n 'alpha_2': 1e-6, # bayesian\n 'max_iter': 3, #lasso\n 'eps': 1e-6, #lasso\n 'features' : all_feat_names\n}\nmeasure_cv_score(default_parameters, verbose=True)",
"CV AUC = 0.641051567239636 (std 0.016097278839270306), Acc. = 0.6204506065857885, aucs: [0.624633431085044, 0.6205278592375366, 0.6519370460048426, 0.6627272727272727, 0.6347962382445141], accs: [0.5982905982905983, 0.6324786324786325, 0.6347826086956522, 0.6347826086956522, 0.6017699115044248]\n"
],
[
"def feat_selection_linreg_objective(trial):\n kept_feats = []\n for i in range(len(all_feat_names)):\n var = trial.suggest_int(all_feat_names[i], 0,1)\n if var == 1:\n kept_feats.append(all_feat_names[i])\n parameters = default_parameters.copy()\n parameters['features'] = kept_feats\n \n return 1 - measure_cv_score(parameters, verbose=False)\n\nif 1:\n study = optuna.create_study()\n study.optimize(feat_selection_linreg_objective, n_trials=20, show_progress_bar=True)\n print(study.best_value, study.best_params)",
"\u001b[32m[I 2021-10-07 21:08:14,414]\u001b[0m A new study created in memory with name: no-name-c2d87aba-cb1a-4541-b488-f59298802bec\u001b[0m\n/home/joni/miniconda3/envs/brainclf/lib/python3.8/site-packages/optuna/progress_bar.py:47: ExperimentalWarning: Progress bar is experimental (supported from v1.2.0). The interface can change in the future.\n self._init_valid()\n"
],
[
"study.best_params",
"_____no_output_____"
],
[
"pruned_features = default_parameters.copy()\npruned_features['features'] = ['feat_lasso', 'feat_linreg', 'feat_ridge', 'efficientnetv2_l_rocstar']\nmeasure_cv_score(pruned_features, verbose=True)",
"CV AUC = 0.6597934421493572 (std 0.016749474559017194), Acc. = 0.6117850953206239, aucs: [0.6425219941348974, 0.6577712609970675, 0.6770581113801454, 0.6754545454545454, 0.6357366771159875], accs: [0.6239316239316239, 0.6324786324786325, 0.6521739130434783, 0.6, 0.5486725663716814]\n"
],
[
"random.randint(0,1)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02c56b2fa5b2ec409c0aa50363a3da1d66be5cb
| 6,027 |
ipynb
|
Jupyter Notebook
|
Introductions/LaTeX and Markdown Intro.ipynb
|
mtr3t/notebook-examples
|
936f24e87e23160c73b8b4d01a37f1040e0ceb61
|
[
"MIT"
] | null | null | null |
Introductions/LaTeX and Markdown Intro.ipynb
|
mtr3t/notebook-examples
|
936f24e87e23160c73b8b4d01a37f1040e0ceb61
|
[
"MIT"
] | null | null | null |
Introductions/LaTeX and Markdown Intro.ipynb
|
mtr3t/notebook-examples
|
936f24e87e23160c73b8b4d01a37f1040e0ceb61
|
[
"MIT"
] | null | null | null | 50.647059 | 504 | 0.631658 |
[
[
[
"## Introduction to \\LaTeX Math Mode\n\nJupyter notebooks integrate the MathJax Javascript library in order to render mathematical formulas and symbols in the same way as one would in \\LaTeX (often used to typeset textbooks, research papers, or other technical documents).\n\nFirst, we will take a look at a couple of rendered expressions and the corresponding way to render these in your notebooks, then follow-up with a few exercises which will help you become more familiar with these tools and their corresponding documentation.\n\nFor example, a common expression used in neural networks is the _weighted sum_ rendered as so:\n\n$y=\\sum_{i=1}^{N}{w_i x_i + b}$\n\nwhere the variable $y$ is calculating the sum of the elements for a vector, $x_i$, each multiplied by a corresponding weight, $w_i$. An additional scalar term, $b$, known as the _bias_ is added to the overall result as well. This expression is more commonly written as:\n\n$y=\\boldsymbol{w}\\boldsymbol{x}+b$\n\nwhere $\\boldsymbol{w}$ and $\\boldsymbol{x}$ are both vectors of length $N$. Note the subtle difference in the notation where __ _vectors_ __ are in bold italic, while _scalars_ are only in italic.\n\nThese kinds of expressions can be rendered in your notebook by creating _markdown_ cells and populating them with the proper expressions. Normally, a cell in a Jupyter notebook is for code that you would like to hand off to the interpreter, but there is a drop-down menu at the top of the current notebook which can change the mode of the current cell to either _code_, _markdown_, or _raw_. We will rarely use _raw_ cells, but the _code_ and _markdown_ types are both quite useful.\n\nTo render both of the two expressions above, you will need to create a markdown cell, and then enter the following code into the cell:\n```\n$y = \\sum_{i=1}^{N}{w_i x_i + b}$\n$y = \\boldsymbol{w}\\boldsymbol{x}+b$\n```\n\nYou should notice first that each expression is surrounded by a set of \\$ symbols. Any text that you type between two \\$ symbols is rendered using the \\LaTeX mathematics mode. \\LaTeX is a complete document preparation system that we will learn more about later in the semester. For now, the important thing to understand is that it has a special mode and markup language used to render mathematical expressions, and this markup language is supported in _markdown_ cells in Jupyter notebooks.\n\nSecond, you can see that special mathematical symbols such as a summation ($\\sum$) can be rendered using the \"sum\" escape sequence (\\\\sum) where \\\\ is the math mode escape character. There are numerous different escape sequences that can be used in math mode, each representing a common mathematical symbol or operation.\n\nThird, you can see that symbols can be attached to other symbols for rendering as sub- or super-scripts by using the _ and ^ operators, respectively. You can also use curly-braces (liberally) to group symbols together into these sub- or super-scripts and the curly-braces, themselves, will not be rendered in the equation. These delimeters only help the math mode interpreter understand which symbols you would like grouped together, and won't be displayed unless escaped.\n\nFinally, it is clear that many symbols are rendered in a way that makes intuitive sense. For example, the bias term, $b$, is simply provided with no markup. Any text __not__ escaped or otherwise marked up will be rendered as a standard scalar is rendered (italic). However, the `\\text{}` sequence can be used to render standard text when required. For example:\n\n`$a\\ \\text{plus}\\ b$`\n\n$a\\ \\text{plus}\\ b$\n\nNotice also how a backslash followed by a space will add a space between the words. Normally, when two scalars are presented, it is assumed they are being multiplied together, and are placed closely to represent this fact. However, since ext\n\nHere are a few other examples:\n\n`$\\boldsymbol{A}=\\boldsymbol{U}\\boldsymbol{\\Sigma}\\boldsymbol{V}^\\top$`\n\n$\\boldsymbol{A}=\\boldsymbol{U}\\boldsymbol{\\Sigma}\\boldsymbol{V}^\\top$ \n\n`$\\alpha \\beta \\Theta \\Omega$`\n\n$\\alpha \\beta \\Theta \\Omega$\n\n`$\\int_{-\\pi}^{\\pi} \\sin{x}\\ dx$`\n\n$\\int_{-\\pi}^{\\pi} \\sin{x}\\ dx$\n\n`$\\prod_{i=1}^{N}{(x_i+y_i)^2}$`\n\n$\\prod_{i=1}^{N}{(x_i+y_i)^2}$\n\n`$f(x)=\\frac{1}{x^2}$`\n\n$f(x)=\\frac{1}{x^2}$\n\n`$\\frac{d}{dx}f(x) = -\\frac{2}{x^3}$`\n\n$\\frac{d}{dx}f(x) = -\\frac{2}{x^3}$",
"_____no_output_____"
],
[
"Let's make a simple table, and then also show the markdown source for the table...\n\n| One | Two | Three | Four |\n| --- | --- | --- | --- |\n| 10% | Something | Else | 40% |\n| 90% | To | Do | 50% |",
"_____no_output_____"
]
],
[
[
"| One | Two | Three | Four |\n| --- | --- | --- | --- |\n| 10% | Something | Else | 40% |\n| 90% | To | Do | 50% |",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
]
] |
d02c58f05007569390a764816ead728c241dee99
| 1,544 |
ipynb
|
Jupyter Notebook
|
Notebooks/Untitled1.ipynb
|
clementmlay/Python4Bioinformatics2020
|
2ff25365464978506fd7f724c402bef748250ad5
|
[
"CC-BY-4.0"
] | null | null | null |
Notebooks/Untitled1.ipynb
|
clementmlay/Python4Bioinformatics2020
|
2ff25365464978506fd7f724c402bef748250ad5
|
[
"CC-BY-4.0"
] | null | null | null |
Notebooks/Untitled1.ipynb
|
clementmlay/Python4Bioinformatics2020
|
2ff25365464978506fd7f724c402bef748250ad5
|
[
"CC-BY-4.0"
] | null | null | null | 23.753846 | 254 | 0.53044 |
[
[
[
"import nothing",
"_____no_output_____"
],
[
"import genelist",
"_____no_output_____"
],
[
"genelist.",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
d02c6067e4a249f75ec2b0fdfeb43a527eedc8cc
| 149,925 |
ipynb
|
Jupyter Notebook
|
tests/GPy/models_basic.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | 1 |
2019-05-10T09:16:23.000Z
|
2019-05-10T09:16:23.000Z
|
tests/GPy/models_basic.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | null | null | null |
tests/GPy/models_basic.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | 1 |
2019-05-10T09:17:28.000Z
|
2019-05-10T09:17:28.000Z
| 56.725312 | 1,767 | 0.539663 |
[
[
[
"#import necessary modules, set up the plotting\nimport numpy as np\n%matplotlib inline\n%config InlineBackend.figure_format = 'svg'\nimport matplotlib;matplotlib.rcParams['figure.figsize'] = (8,6)\nfrom matplotlib import pyplot as plt\nimport GPy",
"_____no_output_____"
]
],
[
[
"# Interacting with models\n\n### November 2014, by Max Zwiessele\n#### with edits by James Hensman\n\nThe GPy model class has a set of features which are designed to make it simple to explore the parameter space of the model. By default, the scipy optimisers are used to fit GPy models (via model.optimize()), for which we provide mechanisms for ‘free’ optimisation: GPy can ensure that naturally positive parameters (such as variances) remain positive. But these mechanisms are much more powerful than simple reparameterisation, as we shall see.\n\nAlong this tutorial we’ll use a sparse GP regression model as example. This example can be in GPy.examples.regression. All of the examples included in GPy return an instance of a model class, and therefore they can be called in the following way:",
"_____no_output_____"
]
],
[
[
"m = GPy.examples.regression.sparse_GP_regression_1D(plot=False, optimize=False)",
"_____no_output_____"
]
],
[
[
"## Examining the model using print\n\nTo see the current state of the model parameters, and the model’s (marginal) likelihood just print the model\n\n print m\n\nThe first thing displayed on the screen is the log-likelihood value of the model with its current parameters. Below the log-likelihood, a table with all the model’s parameters is shown. For each parameter, the table contains the name of the parameter, the current value, and in case there are defined: constraints, ties and prior distrbutions associated.",
"_____no_output_____"
]
],
[
[
"m",
"_____no_output_____"
]
],
[
[
"In this case the kernel parameters (`bf.variance`, `bf.lengthscale`) as well as the likelihood noise parameter (`Gaussian_noise.variance`), are constrained to be positive, while the inducing inputs have no constraints associated. Also there are no ties or prior defined.\n\nYou can also print all subparts of the model, by printing the subcomponents individually; this will print the details of this particular parameter handle:",
"_____no_output_____"
]
],
[
[
"m.rbf",
"_____no_output_____"
]
],
[
[
"When you want to get a closer look into multivalue parameters, print them directly:",
"_____no_output_____"
]
],
[
[
"m.inducing_inputs",
"_____no_output_____"
],
[
"m.inducing_inputs[0] = 1",
"_____no_output_____"
]
],
[
[
"## Interacting with Parameters:\n\nThe preferred way of interacting with parameters is to act on the parameter handle itself. Interacting with parameter handles is simple. The names, printed by print m are accessible interactively and programatically. For example try to set the kernel's `lengthscale` to 0.2 and print the result:",
"_____no_output_____"
]
],
[
[
"m.rbf.lengthscale = 0.2\nprint m",
"\nName : sparse_gp\nObjective : 563.178096129\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 1.0 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 0.2 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 1.0 | +ve | \n"
]
],
[
[
"This will already have updated the model’s inner state: note how the log-likelihood has changed. YOu can immediately plot the model or see the changes in the posterior (`m.posterior`) of the model.",
"_____no_output_____"
],
[
"## Regular expressions\n\nThe model’s parameters can also be accessed through regular expressions, by ‘indexing’ the model with a regular expression, matching the parameter name. Through indexing by regular expression, you can only retrieve leafs of the hierarchy, and you can retrieve the values matched by calling `values()` on the returned object",
"_____no_output_____"
]
],
[
[
"print m['.*var']\n#print \"variances as a np.array:\", m['.*var'].values()\n#print \"np.array of rbf matches: \", m['.*rbf'].values()",
" \u001b[1mindex\u001b[0;0m | sparse_gp.rbf.variance | constraints | priors\n \u001b[1m[0] \u001b[0;0m | 1.00000000 | +ve | \n \u001b[1m-----\u001b[0;0m | sparse_gp.Gaussian_noise.variance | ----------- | ------\n \u001b[1m[0] \u001b[0;0m | 1.00000000 | +ve | \n"
]
],
[
[
"There is access to setting parameters by regular expression, as well. Here are a few examples of how to set parameters by regular expression. Note that each time the values are set, computations are done internally to compute the log likeliood of the model.",
"_____no_output_____"
]
],
[
[
"m['.*var'] = 2.\nprint m\nm['.*var'] = [2., 3.]\nprint m",
"\nName : sparse_gp\nObjective : 680.058219518\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 2.0 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 0.2 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 2.0 | +ve | \n\nName : sparse_gp\nObjective : 705.17934799\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 2.0 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 0.2 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 3.0 | +ve | \n"
]
],
[
[
"A handy trick for seeing all of the parameters of the model at once is to regular-expression match every variable:",
"_____no_output_____"
]
],
[
[
"print m['']",
" \u001b[1mindex\u001b[0;0m | sparse_gp.inducing_inputs | constraints | priors\n \u001b[1m[0 0]\u001b[0;0m | 1.00000000 | | \n \u001b[1m[1 0]\u001b[0;0m | -1.51676820 | | \n \u001b[1m[2 0]\u001b[0;0m | -2.23387110 | | \n \u001b[1m[3 0]\u001b[0;0m | 0.91816225 | | \n \u001b[1m[4 0]\u001b[0;0m | 1.33087762 | | \n \u001b[1m-----\u001b[0;0m | sparse_gp.rbf.variance | ----------- | ------\n \u001b[1m[0] \u001b[0;0m | 2.00000000 | +ve | \n \u001b[1m-----\u001b[0;0m | sparse_gp.rbf.lengthscale | ----------- | ------\n \u001b[1m[0] \u001b[0;0m | 0.20000000 | +ve | \n \u001b[1m-----\u001b[0;0m | sparse_gp.Gaussian_noise.variance | ----------- | ------\n \u001b[1m[0] \u001b[0;0m | 3.00000000 | +ve | \n"
]
],
[
[
"## Setting and fetching parameters parameter_array\n\nAnother way to interact with the model’s parameters is through the parameter_array. The Parameter array holds all the parameters of the model in one place and is editable. It can be accessed through indexing the model for example you can set all the parameters through this mechanism:",
"_____no_output_____"
]
],
[
[
"new_params = np.r_[[-4,-2,0,2,4], [.1,2], [.7]]\nprint new_params\n\nm[:] = new_params\nprint m ",
"[-4. -2. 0. 2. 4. 0.1 2. 0.7]\n\nName : sparse_gp\nObjective : 322.428807303\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 0.1 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 2.0 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 0.7 | +ve | \n"
]
],
[
[
"Parameters themselves (leafs of the hierarchy) can be indexed and used the same way as numpy arrays. First let us set a slice of the inducing_inputs:",
"_____no_output_____"
]
],
[
[
"m.inducing_inputs[2:, 0] = [1,3,5]\nprint m.inducing_inputs",
" \u001b[1mindex\u001b[0;0m | sparse_gp.inducing_inputs | constraints | priors\n \u001b[1m[0 0]\u001b[0;0m | -4.00000000 | | \n \u001b[1m[1 0]\u001b[0;0m | -2.00000000 | | \n \u001b[1m[2 0]\u001b[0;0m | 1.00000000 | | \n \u001b[1m[3 0]\u001b[0;0m | 3.00000000 | | \n \u001b[1m[4 0]\u001b[0;0m | 5.00000000 | | \n"
]
],
[
[
"Or you use the parameters as normal numpy arrays for calculations:",
"_____no_output_____"
]
],
[
[
"precision = 1./m.Gaussian_noise.variance\nprint precision",
"[ 1.42857143]\n"
]
],
[
[
"## Getting the model parameter’s gradients\n\nThe gradients of a model can shed light on understanding the (possibly hard) optimization process. The gradients of each parameter handle can be accessed through their gradient field.:",
"_____no_output_____"
]
],
[
[
"print \"all gradients of the model:\\n\", m.gradient\nprint \"\\n gradients of the rbf kernel:\\n\", m.rbf.gradient",
"all gradients of the model:\n[ 2.1054468 3.67055686 1.28382016 -0.36934978 -0.34404866\n 99.49876932 -12.83697274 -268.02492615]\n\n gradients of the rbf kernel:\n[ 99.49876932 -12.83697274]\n"
]
],
[
[
"If we optimize the model, the gradients (should be close to) zero",
"_____no_output_____"
]
],
[
[
"m.optimize()\nprint m.gradient",
"[ -4.62140715e-04 -2.13365576e-04 9.60255226e-05 4.82744982e-04\n 8.56445996e-05 -5.25465293e-06 -6.89058756e-06 -9.34850797e-02]\n"
]
],
[
[
"## Adjusting the model’s constraints\n\nWhen we initially call the example, it was optimized and hence the log-likelihood gradients were close to zero. However, since we have been changing the parameters, the gradients are far from zero now. Next we are going to show how to optimize the model setting different restrictions on the parameters.\n\nOnce a constraint has been set on a parameter, it is possible to remove it with the command unconstrain(), which can be called on any parameter handle of the model. The methods constrain() and unconstrain() return the indices which were actually unconstrained, relative to the parameter handle the method was called on. This is particularly handy for reporting which parameters where reconstrained, when reconstraining a parameter, which was already constrained:",
"_____no_output_____"
]
],
[
[
"m.rbf.variance.unconstrain()\nprint m",
"\nName : sparse_gp\nObjective : -613.999681976\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 1.6069638252 | | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 2.56942983558 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 0.00237759494452 | +ve | \n"
],
[
"m.unconstrain()\nprint m",
"\nName : sparse_gp\nObjective : -613.999681976\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 1.6069638252 | | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 2.56942983558 | | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 0.00237759494452 | | \n"
]
],
[
[
"If you want to unconstrain only a specific constraint, you can call the respective method, such as `unconstrain_fixed()` (or `unfix()`) to only unfix fixed parameters:",
"_____no_output_____"
]
],
[
[
"m.inducing_inputs[0].fix()\nm.rbf.constrain_positive()\nprint m\nm.unfix()\nprint m",
"\nName : sparse_gp\nObjective : -613.999681976\nNumber of Parameters : 8\nNumber of Optimization Parameters : 7\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | {fixed} | \n \u001b[1mrbf.variance \u001b[0;0m | 1.6069638252 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 2.56942983558 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 0.00237759494452 | | \n\nName : sparse_gp\nObjective : -613.999681976\nNumber of Parameters : 8\nNumber of Optimization Parameters : 8\nUpdates : True\nParameters:\n \u001b[1msparse_gp. \u001b[0;0m | value | constraints | priors\n \u001b[1minducing_inputs \u001b[0;0m | (5, 1) | | \n \u001b[1mrbf.variance \u001b[0;0m | 1.6069638252 | +ve | \n \u001b[1mrbf.lengthscale \u001b[0;0m | 2.56942983558 | +ve | \n \u001b[1mGaussian_noise.variance\u001b[0;0m | 0.00237759494452 | | \n"
]
],
[
[
"## Tying Parameters\n\nNot yet implemented for GPy version 0.8.0\n",
"_____no_output_____"
],
[
"## Optimizing the model\n\nOnce we have finished defining the constraints, we can now optimize the model with the function optimize.:",
"_____no_output_____"
]
],
[
[
"m.Gaussian_noise.constrain_positive()\nm.rbf.constrain_positive()\nm.optimize()",
"No handlers could be found for logger \"rbf\"\n"
]
],
[
[
"By deafult, GPy uses the lbfgsb optimizer.\n\nSome optional parameters may be discussed here.\n\n * `optimizer`: which optimizer to use, currently there are lbfgsb, fmin_tnc, scg, simplex or any unique identifier uniquely identifying an optimizer.\nThus, you can say m.optimize('bfgs') for using the `lbfgsb` optimizer\n * `messages`: if the optimizer is verbose. Each optimizer has its own way of printing, so do not be confused by differing messages of different optimizers\n * `max_iters`: Maximum number of iterations to take. Some optimizers see iterations as function calls, others as iterations of the algorithm. Please be advised to look into scipy.optimize for more instructions, if the number of iterations matter, so you can give the right parameters to optimize()\n * `gtol`: only for some optimizers. Will determine the convergence criterion, as the tolerance of gradient to finish the optimization.\n",
"_____no_output_____"
],
[
"## Plotting\nMany of GPys models have built-in plot functionality. we distringuish between plotting the posterior of the function (`m.plot_f`) and plotting the posterior over predicted data values (`m.plot`). This becomes especially important for non-Gaussian likleihoods. Here we'll plot the sparse GP model we've been working with. for more information of the meaning of the plot, please refer to the accompanying `basic_gp_regression` and `sparse_gp` noteooks.",
"_____no_output_____"
]
],
[
[
"fig = m.plot()",
" /home/nbuser/anaconda2_501/lib/python2.7/site-packages/matplotlib/figure.py:1999: UserWarning:This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.\n"
]
],
[
[
"We can even change the backend for plotting and plot the model using a different backend.",
"_____no_output_____"
]
],
[
[
"GPy.plotting.change_plotting_library('plotly')\nfig = m.plot(plot_density=True)\nGPy.plotting.show(fig, filename='gpy_sparse_gp_example')",
"This is the format of your plot grid:\n[ (1,1) x1,y1 ]\n\nAw, snap! We don't have an account for ''. Want to try again? You can authenticate with your email address or username. Sign in is not case sensitive.\n\nDon't have an account? plot.ly\n\nQuestions? support@plot.ly\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02c643b082b12d01121d875676648e53c551a2d
| 158,311 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/PredictPatientRetention-checkpoint.ipynb
|
JudoWill/ResearchNotebooks
|
35796f7ef07361eb2926c8770e623f4e9d48ab96
|
[
"MIT"
] | 1 |
2019-02-03T03:45:29.000Z
|
2019-02-03T03:45:29.000Z
|
PredictPatientRetention.ipynb
|
JudoWill/ResearchNotebooks
|
35796f7ef07361eb2926c8770e623f4e9d48ab96
|
[
"MIT"
] | null | null | null |
PredictPatientRetention.ipynb
|
JudoWill/ResearchNotebooks
|
35796f7ef07361eb2926c8770e623f4e9d48ab96
|
[
"MIT"
] | null | null | null | 224.87358 | 81,557 | 0.880924 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d02c652f71546d37a6b516ec976baceb9617e979
| 7,237 |
ipynb
|
Jupyter Notebook
|
dev/notebooks/auto_examples/plots/partial-dependence-plot.ipynb
|
scikit-optimize/scikit-optimize.github.io
|
209d20f8603b7b6663f27f058560f3e15a546d76
|
[
"BSD-3-Clause"
] | 15 |
2016-07-27T13:17:06.000Z
|
2021-08-31T14:18:07.000Z
|
0.9/_downloads/cf79556edf00662ef683d2bfac042ee0/partial-dependence-plot.ipynb
|
scikit-optimize/scikit-optimize.github.io
|
209d20f8603b7b6663f27f058560f3e15a546d76
|
[
"BSD-3-Clause"
] | 2 |
2018-05-09T15:01:09.000Z
|
2020-10-22T00:56:21.000Z
|
0.9/notebooks/auto_examples/plots/partial-dependence-plot.ipynb
|
scikit-optimize/scikit-optimize.github.io
|
209d20f8603b7b6663f27f058560f3e15a546d76
|
[
"BSD-3-Clause"
] | 6 |
2017-08-19T12:05:57.000Z
|
2021-02-16T20:54:58.000Z
| 31.881057 | 327 | 0.550919 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\n# Partial Dependence Plots\n\nSigurd Carlsen Feb 2019\nHolger Nahrstaedt 2020\n\n.. currentmodule:: skopt\n\nPlot objective now supports optional use of partial dependence as well as\ndifferent methods of defining parameter values for dependency plots.\n",
"_____no_output_____"
]
],
[
[
"print(__doc__)\nimport sys\nfrom skopt.plots import plot_objective\nfrom skopt import forest_minimize\nimport numpy as np\nnp.random.seed(123)\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## Objective function\nPlot objective now supports optional use of partial dependence as well as\ndifferent methods of defining parameter values for dependency plots\n\n",
"_____no_output_____"
]
],
[
[
"# Here we define a function that we evaluate.\ndef funny_func(x):\n s = 0\n for i in range(len(x)):\n s += (x[i] * i) ** 2\n return s",
"_____no_output_____"
]
],
[
[
"## Optimisation using decision trees\nWe run forest_minimize on the function\n\n",
"_____no_output_____"
]
],
[
[
"bounds = [(-1, 1.), ] * 3\nn_calls = 150\n\nresult = forest_minimize(funny_func, bounds, n_calls=n_calls,\n base_estimator=\"ET\",\n random_state=4)",
"_____no_output_____"
]
],
[
[
"## Partial dependence plot\nHere we see an example of using partial dependence. Even when setting\nn_points all the way down to 10 from the default of 40, this method is\nstill very slow. This is because partial dependence calculates 250 extra\npredictions for each point on the plots.\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10)",
"_____no_output_____"
]
],
[
[
"It is possible to change the location of the red dot, which normally shows\nthe position of the found minimum. We can set it 'expected_minimum',\nwhich is the minimum value of the surrogate function, obtained by a\nminimum search method.\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10, minimum='expected_minimum')",
"_____no_output_____"
]
],
[
[
"## Plot without partial dependence\nHere we plot without partial dependence. We see that it is a lot faster.\nAlso the values for the other parameters are set to the default \"result\"\nwhich is the parameter set of the best observed value so far. In the case\nof funny_func this is close to 0 for all parameters.\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, sample_source='result', n_points=10)",
"_____no_output_____"
]
],
[
[
"## Modify the shown minimum\nHere we try with setting the `minimum` parameters to something other than\n\"result\". First we try with \"expected_minimum\" which is the set of\nparameters that gives the miniumum value of the surrogate function,\nusing scipys minimum search method.\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10, sample_source='expected_minimum',\n minimum='expected_minimum')",
"_____no_output_____"
]
],
[
[
"\"expected_minimum_random\" is a naive way of finding the minimum of the\nsurrogate by only using random sampling:\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10, sample_source='expected_minimum_random',\n minimum='expected_minimum_random')",
"_____no_output_____"
]
],
[
[
"We can also specify how many initial samples are used for the two different\n\"expected_minimum\" methods. We set it to a low value in the next examples\nto showcase how it affects the minimum for the two methods.\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10, sample_source='expected_minimum_random',\n minimum='expected_minimum_random',\n n_minimum_search=10)",
"_____no_output_____"
],
[
"_ = plot_objective(result, n_points=10, sample_source=\"expected_minimum\",\n minimum='expected_minimum', n_minimum_search=2)",
"_____no_output_____"
]
],
[
[
"## Set a minimum location\nLastly we can also define these parameters ourself by parsing a list\nas the minimum argument:\n\n",
"_____no_output_____"
]
],
[
[
"_ = plot_objective(result, n_points=10, sample_source=[1, -0.5, 0.5],\n minimum=[1, -0.5, 0.5])",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02c65f2a4e26a1507eac65b3da51a5577570b3d
| 65,275 |
ipynb
|
Jupyter Notebook
|
02-Training_Models.ipynb
|
djanie1/mslearn-aml-labs
|
939ef3b8f66b5f5ebe480d360783f0ac5fb50da4
|
[
"MIT"
] | null | null | null |
02-Training_Models.ipynb
|
djanie1/mslearn-aml-labs
|
939ef3b8f66b5f5ebe480d360783f0ac5fb50da4
|
[
"MIT"
] | null | null | null |
02-Training_Models.ipynb
|
djanie1/mslearn-aml-labs
|
939ef3b8f66b5f5ebe480d360783f0ac5fb50da4
|
[
"MIT"
] | null | null | null | 50.640031 | 4,401 | 0.616791 |
[
[
[
"# Training Models\n\nThe central goal of machine learning is to train predictive models that can be used by applications. In Azure Machine Learning, you can use scripts to train models leveraging common machine learning frameworks like Scikit-Learn, Tensorflow, PyTorch, SparkML, and others. You can run these training scripts as experiments in order to track metrics and outputs - in particular, the trained models.\n\n## Before You Start\n\nBefore you start this lab, ensure that you have completed the *Create an Azure Machine Learning Workspace* and *Create a Compute Instance* tasks in [Lab 1: Getting Started with Azure Machine Learning](./labdocs/Lab01.md). Then open this notebook in Jupyter on your Compute Instance.\n\n## Connect to Your Workspace\n\nThe first thing you need to do is to connect to your workspace using the Azure ML SDK.\n\n> **Note**: If you do not have a current authenticated session with your Azure subscription, you'll be prompted to authenticate. Follow the instructions to authenticate using the code provided.",
"_____no_output_____"
]
],
[
[
"import azureml.core\nfrom azureml.core import Workspace\n\n# Load the workspace from the saved config file\nws = Workspace.from_config()\nprint('Ready to use Azure ML {} to work with {}'.format(azureml.core.VERSION, ws.name))",
"Ready to use Azure ML 1.17.0 to work with ml-sdk\n"
]
],
[
[
"## Create a Training Script\n\nYou're going to use a Python script to train a machine learning model based on the diabates data, so let's start by creating a folder for the script and data files.",
"_____no_output_____"
]
],
[
[
"import os, shutil\n\n# Create a folder for the experiment files\ntraining_folder = 'diabetes-training'\nos.makedirs(training_folder, exist_ok=True)\n\n# Copy the data file into the experiment folder\nshutil.copy('data/diabetes.csv', os.path.join(training_folder, \"diabetes.csv\"))",
"_____no_output_____"
]
],
[
[
"Now you're ready to create the training script and save it in the folder.",
"_____no_output_____"
]
],
[
[
"%%writefile $training_folder/diabetes_training.py\n# Import libraries\nfrom azureml.core import Run\nimport pandas as pd\nimport numpy as np\nimport joblib\nimport os\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import roc_curve\n\n# Get the experiment run context\nrun = Run.get_context()\n\n# load the diabetes dataset\nprint(\"Loading Data...\")\ndiabetes = pd.read_csv('diabetes.csv')\n\n# Separate features and labels\nX, y = diabetes[['Pregnancies','PlasmaGlucose','DiastolicBloodPressure','TricepsThickness','SerumInsulin','BMI','DiabetesPedigree','Age']].values, diabetes['Diabetic'].values\n\n# Split data into training set and test set\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)\n\n# Set regularization hyperparameter\nreg = 0.01\n\n# Train a logistic regression model\nprint('Training a logistic regression model with regularization rate of', reg)\nrun.log('Regularization Rate', np.float(reg))\nmodel = LogisticRegression(C=1/reg, solver=\"liblinear\").fit(X_train, y_train)\n\n# calculate accuracy\ny_hat = model.predict(X_test)\nacc = np.average(y_hat == y_test)\nprint('Accuracy:', acc)\nrun.log('Accuracy', np.float(acc))\n\n# calculate AUC\ny_scores = model.predict_proba(X_test)\nauc = roc_auc_score(y_test,y_scores[:,1])\nprint('AUC: ' + str(auc))\nrun.log('AUC', np.float(auc))\n\n# Save the trained model in the outputs folder\nos.makedirs('outputs', exist_ok=True)\njoblib.dump(value=model, filename='outputs/diabetes_model.pkl')\n\nrun.complete()",
"Overwriting diabetes-training/diabetes_training.py\n"
]
],
[
[
"## Use an Estimator to Run the Script as an Experiment\n\nYou can run experiment scripts using a **RunConfiguration** and a **ScriptRunConfig**, or you can use an **Estimator**, which abstracts both of these configurations in a single object.\n\nIn this case, we'll use a generic **Estimator** object to run the training experiment. Note that the default environment for this estimator does not include the **scikit-learn** package, so you need to explicitly add that to the configuration. The conda environment is built on-demand the first time the estimator is used, and cached for future runs that use the same configuration; so the first run will take a little longer. On subsequent runs, the cached environment can be re-used so they'll complete more quickly.",
"_____no_output_____"
]
],
[
[
"from azureml.train.estimator import Estimator\nfrom azureml.core import Experiment\n\n# Create an estimator\nestimator = Estimator(source_directory=training_folder,\n entry_script='diabetes_training.py',\n compute_target='local',\n conda_packages=['scikit-learn']\n )\n\n# Create an experiment\nexperiment_name = 'diabetes-training'\nexperiment = Experiment(workspace = ws, name = experiment_name)\n\n# Run the experiment based on the estimator\nrun = experiment.submit(config=estimator)\nrun.wait_for_completion(show_output=True)",
"WARNING - If 'script' has been provided here and a script file name has been specified in 'run_config', 'script' provided in ScriptRunConfig initialization will take precedence.\n"
]
],
[
[
"As with any experiment run, you can use the **RunDetails** widget to view information about the run and get a link to it in Azure Machine Learning studio.",
"_____no_output_____"
]
],
[
[
"from azureml.widgets import RunDetails\n\nRunDetails(run).show()",
"_____no_output_____"
]
],
[
[
"You can also retrieve the metrics and outputs from the **Run** object.",
"_____no_output_____"
]
],
[
[
"# Get logged metrics\nmetrics = run.get_metrics()\nfor key in metrics.keys():\n print(key, metrics.get(key))\nprint('\\n')\nfor file in run.get_file_names():\n print(file)",
"Regularization Rate 0.01\nAccuracy 0.774\nAUC 0.8484929598487486\n\n\nazureml-logs/60_control_log.txt\nazureml-logs/70_driver_log.txt\nlogs/azureml/8_azureml.log\noutputs/diabetes_model.pkl\n"
]
],
[
[
"## Register the Trained Model\n\nNote that the outputs of the experiment include the trained model file (**diabetes_model.pkl**). You can register this model in your Azure Machine Learning workspace, making it possible to track model versions and retrieve them later.",
"_____no_output_____"
]
],
[
[
"from azureml.core import Model\n\n# Register the model\nrun.register_model(model_path='outputs/diabetes_model.pkl', model_name='diabetes_model',\n tags={'Training context':'Estimator'},\n properties={'AUC': run.get_metrics()['AUC'], 'Accuracy': run.get_metrics()['Accuracy']})\n\n# List registered models\nfor model in Model.list(ws):\n print(model.name, 'version:', model.version)\n for tag_name in model.tags:\n tag = model.tags[tag_name]\n print ('\\t',tag_name, ':', tag)\n for prop_name in model.properties:\n prop = model.properties[prop_name]\n print ('\\t',prop_name, ':', prop)\n print('\\n')",
"diabetes_model version: 4\n\t Training context : Estimator\n\t AUC : 0.8484929598487486\n\t Accuracy : 0.774\n\n\ndiabetes_mitigated_20 version: 1\n\n\ndiabetes_mitigated_19 version: 1\n\n\ndiabetes_mitigated_18 version: 1\n\n\ndiabetes_mitigated_17 version: 1\n\n\ndiabetes_mitigated_16 version: 1\n\n\ndiabetes_mitigated_15 version: 1\n\n\ndiabetes_mitigated_14 version: 1\n\n\ndiabetes_mitigated_13 version: 1\n\n\ndiabetes_mitigated_12 version: 1\n\n\ndiabetes_mitigated_11 version: 1\n\n\ndiabetes_mitigated_10 version: 1\n\n\ndiabetes_mitigated_9 version: 1\n\n\ndiabetes_mitigated_8 version: 1\n\n\ndiabetes_mitigated_7 version: 1\n\n\ndiabetes_mitigated_6 version: 1\n\n\ndiabetes_mitigated_5 version: 1\n\n\ndiabetes_mitigated_4 version: 1\n\n\ndiabetes_mitigated_3 version: 1\n\n\ndiabetes_mitigated_2 version: 1\n\n\ndiabetes_mitigated_1 version: 1\n\n\ndiabetes_unmitigated version: 1\n\n\ndiabetes_classifier version: 1\n\n\ndiabetes_model version: 3\n\t Training context : Inline Training\n\t AUC : 0.8790686103786257\n\t Accuracy : 0.8906666666666667\n\n\ndiabetes_model version: 2\n\t Training context : Inline Training\n\t AUC : 0.888068803690671\n\t Accuracy : 0.9024444444444445\n\n\ndiabetes_model version: 1\n\t Training context : Inline Training\n\t AUC : 0.879837305338574\n\t Accuracy : 0.8923333333333333\n\n\n"
]
],
[
[
"## Create a Parameterized Training Script\n\nYou can increase the flexibility of your training experiment by adding parameters to your script, enabling you to repeat the same training experiment with different settings. In this case, you'll add a parameter for the regularization rate used by the Logistic Regression algorithm when training the model.\n\nAgain, lets start by creating a folder for the parameterized script and the training data.",
"_____no_output_____"
]
],
[
[
"import os, shutil\n\n# Create a folder for the experiment files\ntraining_folder = 'diabetes-training-params'\nos.makedirs(training_folder, exist_ok=True)\n\n# Copy the data file into the experiment folder\nshutil.copy('data/diabetes.csv', os.path.join(training_folder, \"diabetes.csv\"))",
"_____no_output_____"
]
],
[
[
"Now let's create a script containing a parameter for the regularization rate hyperparameter.",
"_____no_output_____"
]
],
[
[
"%%writefile $training_folder/diabetes_training.py\n# Import libraries\nfrom azureml.core import Run\nimport pandas as pd\nimport numpy as np\nimport joblib\nimport os\nimport argparse\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import roc_curve\n\n# Get the experiment run context\nrun = Run.get_context()\n\n# Set regularization hyperparameter\nparser = argparse.ArgumentParser()\nparser.add_argument('--reg_rate', type=float, dest='reg', default=0.01)\nargs = parser.parse_args()\nreg = args.reg\n\n# load the diabetes dataset\nprint(\"Loading Data...\")\n# load the diabetes dataset\ndiabetes = pd.read_csv('diabetes.csv')\n\n# Separate features and labels\nX, y = diabetes[['Pregnancies','PlasmaGlucose','DiastolicBloodPressure','TricepsThickness','SerumInsulin','BMI','DiabetesPedigree','Age']].values, diabetes['Diabetic'].values\n\n# Split data into training set and test set\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)\n\n# Train a logistic regression model\nprint('Training a logistic regression model with regularization rate of', reg)\nrun.log('Regularization Rate', np.float(reg))\nmodel = LogisticRegression(C=1/reg, solver=\"liblinear\").fit(X_train, y_train)\n\n# calculate accuracy\ny_hat = model.predict(X_test)\nacc = np.average(y_hat == y_test)\nprint('Accuracy:', acc)\nrun.log('Accuracy', np.float(acc))\n\n# calculate AUC\ny_scores = model.predict_proba(X_test)\nauc = roc_auc_score(y_test,y_scores[:,1])\nprint('AUC: ' + str(auc))\nrun.log('AUC', np.float(auc))\n\nos.makedirs('outputs', exist_ok=True)\njoblib.dump(value=model, filename='outputs/diabetes_model.pkl')\n\nrun.complete()",
"Writing diabetes-training-params/diabetes_training.py\n"
]
],
[
[
"## Use a Framework-Specific Estimator\n\nYou used a generic **Estimator** class to run the training script, but you can also take advantage of framework-specific estimators that include environment definitions for common machine learning frameworks. In this case, you're using Scikit-Learn, so you can use the **SKLearn** estimator. This means that you don't need to specify the **scikit-learn** package in the configuration.\n\n> **Note**: Once again, the training experiment uses a new environment; which must be created the first time it is run.",
"_____no_output_____"
]
],
[
[
"from azureml.train.sklearn import SKLearn\nfrom azureml.widgets import RunDetails\n\n# Create an estimator\nestimator = SKLearn(source_directory=training_folder,\n entry_script='diabetes_training.py',\n script_params = {'--reg_rate': 0.1},\n compute_target='local'\n )\n\n# Create an experiment\nexperiment_name = 'diabetes-training'\nexperiment = Experiment(workspace = ws, name = experiment_name)\n\n# Run the experiment\nrun = experiment.submit(config=estimator)\n\n# Show the run details while running\nRunDetails(run).show()\nrun.wait_for_completion()",
"WARNING - If 'script' has been provided here and a script file name has been specified in 'run_config', 'script' provided in ScriptRunConfig initialization will take precedence.\nWARNING - If 'arguments' has been provided here and arguments have been specified in 'run_config', 'arguments' provided in ScriptRunConfig initialization will take precedence.\n"
]
],
[
[
"Once again, you can get the metrics and outputs from the run.",
"_____no_output_____"
]
],
[
[
"# Get logged metrics\nmetrics = run.get_metrics()\nfor key in metrics.keys():\n print(key, metrics.get(key))\nprint('\\n')\nfor file in run.get_file_names():\n print(file)",
"Regularization Rate 0.1\nAccuracy 0.7736666666666666\nAUC 0.8483904671874223\n\n\nazureml-logs/60_control_log.txt\nazureml-logs/70_driver_log.txt\nlogs/azureml/8_azureml.log\noutputs/diabetes_model.pkl\n"
]
],
[
[
"## Register A New Version of the Model\n\nNow that you've trained a new model, you can register it as a new version in the workspace.",
"_____no_output_____"
]
],
[
[
"from azureml.core import Model\n\n# Register the model\nrun.register_model(model_path='outputs/diabetes_model.pkl', model_name='diabetes_model',\n tags={'Training context':'Parameterized SKLearn Estimator'},\n properties={'AUC': run.get_metrics()['AUC'], 'Accuracy': run.get_metrics()['Accuracy']})\n\n# List registered models\nfor model in Model.list(ws):\n print(model.name, 'version:', model.version)\n for tag_name in model.tags:\n tag = model.tags[tag_name]\n print ('\\t',tag_name, ':', tag)\n for prop_name in model.properties:\n prop = model.properties[prop_name]\n print ('\\t',prop_name, ':', prop)\n print('\\n')",
"diabetes_model version: 5\n\t Training context : Parameterized SKLearn Estimator\n\t AUC : 0.8483904671874223\n\t Accuracy : 0.7736666666666666\n\n\ndiabetes_model version: 4\n\t Training context : Estimator\n\t AUC : 0.8484929598487486\n\t Accuracy : 0.774\n\n\ndiabetes_mitigated_20 version: 1\n\n\ndiabetes_mitigated_19 version: 1\n\n\ndiabetes_mitigated_18 version: 1\n\n\ndiabetes_mitigated_17 version: 1\n\n\ndiabetes_mitigated_16 version: 1\n\n\ndiabetes_mitigated_15 version: 1\n\n\ndiabetes_mitigated_14 version: 1\n\n\ndiabetes_mitigated_13 version: 1\n\n\ndiabetes_mitigated_12 version: 1\n\n\ndiabetes_mitigated_11 version: 1\n\n\ndiabetes_mitigated_10 version: 1\n\n\ndiabetes_mitigated_9 version: 1\n\n\ndiabetes_mitigated_8 version: 1\n\n\ndiabetes_mitigated_7 version: 1\n\n\ndiabetes_mitigated_6 version: 1\n\n\ndiabetes_mitigated_5 version: 1\n\n\ndiabetes_mitigated_4 version: 1\n\n\ndiabetes_mitigated_3 version: 1\n\n\ndiabetes_mitigated_2 version: 1\n\n\ndiabetes_mitigated_1 version: 1\n\n\ndiabetes_unmitigated version: 1\n\n\ndiabetes_classifier version: 1\n\n\ndiabetes_model version: 3\n\t Training context : Inline Training\n\t AUC : 0.8790686103786257\n\t Accuracy : 0.8906666666666667\n\n\ndiabetes_model version: 2\n\t Training context : Inline Training\n\t AUC : 0.888068803690671\n\t Accuracy : 0.9024444444444445\n\n\ndiabetes_model version: 1\n\t Training context : Inline Training\n\t AUC : 0.879837305338574\n\t Accuracy : 0.8923333333333333\n\n\n"
]
],
[
[
"## Clean Up\n\nIf you've finished exploring, you can close this notebook and shut down your Compute Instance.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02c717d975224cd908850d1556b6b418ca49fb4
| 258,423 |
ipynb
|
Jupyter Notebook
|
examples/sampling/simple_simulations/test_class_index.ipynb
|
jumelet/path_explain
|
c0663522379b4864628962dc43daf78d826e9470
|
[
"MIT"
] | 145 |
2020-02-10T23:55:17.000Z
|
2022-03-25T18:05:57.000Z
|
examples/sampling/simple_simulations/test_class_index.ipynb
|
jumelet/path_explain
|
c0663522379b4864628962dc43daf78d826e9470
|
[
"MIT"
] | 7 |
2020-09-10T11:53:32.000Z
|
2021-11-11T17:53:23.000Z
|
examples/sampling/simple_simulations/test_class_index.ipynb
|
jumelet/path_explain
|
c0663522379b4864628962dc43daf78d826e9470
|
[
"MIT"
] | 23 |
2020-02-19T14:18:47.000Z
|
2021-12-14T01:57:44.000Z
| 96.642857 | 107,574 | 0.812915 |
[
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import tensorflow as tf\nimport numpy as np\nimport pandas as pd\nimport altair as alt\nimport shap\n\nfrom interaction_effects.marginal import MarginalExplainer\nfrom interaction_effects import utils",
"_____no_output_____"
],
[
"n = 3000\nd = 3\nbatch_size = 50\nlearning_rate = 0.02",
"_____no_output_____"
],
[
"X = np.random.randn(n, d)\ny = (np.sum(X, axis=-1) > 0.0).astype(np.float32)",
"_____no_output_____"
],
[
"model = tf.keras.Sequential()\nmodel.add(tf.keras.Input(shape=(3,), batch_size=batch_size))\nmodel.add(tf.keras.layers.Dense(2, activation=None, use_bias=True))",
"_____no_output_____"
],
[
"optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)\nmodel.compile(optimizer=optimizer,\n loss=tf.keras.losses.SparseCategoricalCrossentropy(),\n metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])",
"_____no_output_____"
],
[
"model.fit(X, y, epochs=20, verbose=2)",
"Train on 3000 samples\nEpoch 1/20\n3000/3000 - 1s - loss: 3.7362 - sparse_categorical_accuracy: 0.6037\nEpoch 2/20\n3000/3000 - 0s - loss: 0.4334 - sparse_categorical_accuracy: 0.9277\nEpoch 3/20\n3000/3000 - 0s - loss: 0.4227 - sparse_categorical_accuracy: 0.9347\nEpoch 4/20\n3000/3000 - 0s - loss: 0.4213 - sparse_categorical_accuracy: 0.9343\nEpoch 5/20\n3000/3000 - 0s - loss: 0.4208 - sparse_categorical_accuracy: 0.9340\nEpoch 6/20\n3000/3000 - 0s - loss: 0.4205 - sparse_categorical_accuracy: 0.9343\nEpoch 7/20\n3000/3000 - 0s - loss: 0.4204 - sparse_categorical_accuracy: 0.9347\nEpoch 8/20\n3000/3000 - 0s - loss: 0.4204 - sparse_categorical_accuracy: 0.9343\nEpoch 9/20\n3000/3000 - 0s - loss: 0.4204 - sparse_categorical_accuracy: 0.9350\nEpoch 10/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9347\nEpoch 11/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9350\nEpoch 12/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9350\nEpoch 13/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9350\nEpoch 14/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9347\nEpoch 15/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9347\nEpoch 16/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9353\nEpoch 17/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9353\nEpoch 18/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9353\nEpoch 19/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9353\nEpoch 20/20\n3000/3000 - 0s - loss: 0.4203 - sparse_categorical_accuracy: 0.9353\n"
],
[
"primal_explainer = MarginalExplainer(model, X[20:], nsamples=800, representation='mobius')\nprimal_effects = primal_explainer.explain(X[:20], verbose=True, index_outputs=True, labels=y[:20].astype(int))",
"100%|██████████| 20/20 [00:02<00:00, 7.58it/s]\n"
],
[
"dual_explainer = MarginalExplainer(model, X[20:], nsamples=800, representation='comobius')\ndual_effects = dual_explainer.explain(X[:20], verbose=True, index_outputs=True, labels=y[:20].astype(int))",
"100%|██████████| 20/20 [00:02<00:00, 8.71it/s]\n"
],
[
"average_explainer = MarginalExplainer(model, X[20:], nsamples=800, representation='average')\naverage_effects = average_explainer.explain(X[:20], verbose=True, index_outputs=True, labels=y[:20].astype(int))",
"100%|██████████| 20/20 [00:04<00:00, 4.70it/s]\n"
],
[
"model_func = lambda x: model(x).numpy()\nkernel_explainer = shap.SamplingExplainer(model_func, X)\nkernel_shap = kernel_explainer.shap_values(X[:20])\nkernel_shap = np.stack(kernel_shap, axis=0)",
"_____no_output_____"
],
[
"kernel_shap_true_class = kernel_shap[y[:20].astype(int), np.arange(20), :]",
"_____no_output_____"
],
[
"def unroll(x):\n ret = []\n for i in range(x.shape[-1]):\n ret.append(x[:, i])\n return np.concatenate(ret)",
"_____no_output_____"
],
[
"data_df = pd.DataFrame({\n 'Sampled Primal Effects': unroll(primal_effects),\n 'Sampled Dual Effects': unroll(dual_effects),\n 'Sampled Average Effects': unroll(average_effects),\n 'Kernel SHAP Values': unroll(kernel_shap_true_class),\n 'Feature Values': unroll(X[:20]),\n 'Feature': [int(i / 20) for i in range(20 * d)],\n 'Label': np.tile(y[:20], 3).astype(int)\n})",
"_____no_output_____"
],
[
"alt.Chart(data_df).mark_point(filled=True).encode(\n alt.X('Kernel SHAP Values:Q'),\n alt.Y(alt.repeat(\"column\"), type='quantitative')\n).properties(width=300, height=300).repeat(column=['Sampled Primal Effects', 'Sampled Dual Effects', 'Sampled Average Effects'])",
"_____no_output_____"
],
[
"melted_df = pd.melt(data_df, id_vars=['Feature Values', 'Feature', 'Label'], var_name='Effect Type', value_name='Effect Value')",
"_____no_output_____"
],
[
"alt.Chart(melted_df).mark_point(filled=True).encode(\n alt.X('Feature Values:Q'),\n alt.Y('Effect Value:Q'),\n alt.Color('Label:N')\n).properties(width=200, height=200).facet(column='Effect Type', row='Feature')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02c8cc4c82eaab3686ff69e3f0a42e3ae1a720e
| 238,414 |
ipynb
|
Jupyter Notebook
|
Stats_Live_MLR_challenge.ipynb
|
krishnavizster/Statistics
|
40051d98c45a6125f4398475309d2d65d7902e37
|
[
"MIT"
] | null | null | null |
Stats_Live_MLR_challenge.ipynb
|
krishnavizster/Statistics
|
40051d98c45a6125f4398475309d2d65d7902e37
|
[
"MIT"
] | null | null | null |
Stats_Live_MLR_challenge.ipynb
|
krishnavizster/Statistics
|
40051d98c45a6125f4398475309d2d65d7902e37
|
[
"MIT"
] | null | null | null | 176.472243 | 78,728 | 0.8928 |
[
[
[
"#CHALLENGE TASK\n#Stats Challege notebook \n#Fit multiple linear regression for the following data and check for the assumptions using python\n#X1 22 22 25 26 24 28 29 27 24 33 39 42\n#X2 15 14 18 13 12 11 11 10 5 9 7 3\n#Y 55 56 55 59 66 65 69 70 75 75 78 79",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport statsmodels.api as sm\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"\"\"\" Convert the data values into DataFrames\"\"\"\nstats_chal={\"X1\":[22, 22, 25, 26, 24, 28, 29, 27, 24, 33, 39, 42],\n \"X2\":[15, 14, 18, 13, 12, 11, 11, 10, 5, 9, 7, 3],\n \"Y\":[55, 56, 55, 59, 66, 65, 69, 70, 75, 75, 78, 79]}\ndf = pd.DataFrame(stats_chal,columns=['X1','X2','Y']) \nprint (df)",
" X1 X2 Y\n0 22 15 55\n1 22 14 56\n2 25 18 55\n3 26 13 59\n4 24 12 66\n5 28 11 65\n6 29 11 69\n7 27 10 70\n8 24 5 75\n9 33 9 75\n10 39 7 78\n11 42 3 79\n"
],
[
"\"\"\"Check for the linearity\"\"\"\nplt.scatter(df['X1'], df['Y'], color='green')\nplt.xlabel('X1 values', fontsize=14)\nplt.ylabel('Y values', fontsize=14)\nplt.grid(True)\nplt.show()\n\"\"\"its clear that indeed a linear relationship exists between the X1 values and the Y values. \nSpecifically, when X1 values go up, the Y values also goes up\"\"\"",
"_____no_output_____"
],
[
"\"\"\"Check for the linearity\"\"\"\nplt.scatter(df['X2'], df['Y'], color='blue')\nplt.xlabel('X2 values', fontsize=14)\nplt.ylabel('Y values', fontsize=14)\nplt.grid(True)\nplt.show()\n\"\"\"its clear that indeed a linear relationship exists between the X2 values and the Y values. \nSpecifically, when X2 values go up, the Y values also goes down but with a negative slope\"\"\"",
"_____no_output_____"
],
[
"\"\"\"Performing the Multiple Linear Regression\"\"\"\nX = df[['X1','X2']] # here we have 2 variables for multiple regression.\nY = df['Y']",
"_____no_output_____"
],
[
"# with statsmodels\nX = sm.add_constant(X) # adding a constant\n \nmlr_model = sm.OLS(Y, X).fit()\npredictions = mlr_model.predict(X) \n \nprint_model = mlr_model.summary()\nprint(print_model)",
" OLS Regression Results \n==============================================================================\nDep. Variable: Y R-squared: 0.894\nModel: OLS Adj. R-squared: 0.871\nMethod: Least Squares F-statistic: 38.06\nDate: Fri, 18 Mar 2022 Prob (F-statistic): 4.06e-05\nTime: 08:08:19 Log-Likelihood: -29.341\nNo. Observations: 12 AIC: 64.68\nDf Residuals: 9 BIC: 66.14\nDf Model: 2 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nconst 74.5958 8.724 8.551 0.000 54.861 94.330\nX1 0.3314 0.210 1.581 0.148 -0.143 0.806\nX2 -1.6106 0.319 -5.055 0.001 -2.331 -0.890\n==============================================================================\nOmnibus: 2.735 Durbin-Watson: 1.793\nProb(Omnibus): 0.255 Jarque-Bera (JB): 1.114\nSkew: -0.282 Prob(JB): 0.573\nKurtosis: 1.618 Cond. No. 289.\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
],
[
"\"\"\"If you plug that X1=22, X2=15 data into the regression equation, \nyou’ll get the same predicted result of Y values \"\"\"\ny = (74.5958) + (0.3314)*(22)+(-1.6106)*(15)\ny",
"_____no_output_____"
],
[
"y = (74.5958) + (0.3314)*(X1)+(-1.6106)*(X2)",
"_____no_output_____"
],
[
"predicted_values=(74.5958) + (0.3314)*(X1)+(-1.6106)*(X2)\npredicted_values",
"_____no_output_____"
],
[
"X = df[['X1','X2']].values\nX",
"_____no_output_____"
],
[
"sns.regplot(data=df,x=\"X\",y=\"Y\",color=\"green\") #OLS",
"_____no_output_____"
],
[
"y=df[\"Y\"]\ny",
"_____no_output_____"
],
[
"X = df[['X1','X2']]\nX",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)",
"_____no_output_____"
],
[
"X_train.head()",
"_____no_output_____"
],
[
"len(X_train)",
"_____no_output_____"
],
[
"len(X_test)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"model =LinearRegression()",
"_____no_output_____"
],
[
"model.fit(X_train,y_train) ",
"_____no_output_____"
],
[
"test_model=model.predict(X_test)",
"_____no_output_____"
],
[
"test_model",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error,mean_absolute_error",
"_____no_output_____"
],
[
"import seaborn as sns\nsns.histplot(data=df,x=\"X1\",bins=20)",
"_____no_output_____"
],
[
"import seaborn as sns\nsns.histplot(data=df,x=\"X2\",bins=20)",
"_____no_output_____"
],
[
"mean_absolute_error(y_test,test_model)",
"_____no_output_____"
],
[
"mean_squared_error(y_test,test_model)",
"_____no_output_____"
],
[
"np.sqrt(mean_squared_error(y_test,test_model))",
"_____no_output_____"
],
[
"sns.scatterplot(x=\"X\",y=\"y\",data=df)#scatter plot\nplt.plot(potential_spend,predicted_sales,color=\"green\")",
"_____no_output_____"
],
[
"# with sklearn\nfrom sklearn import linear_model\nml_regr = linear_model.LinearRegression()\nml_regr.fit(X, Y)\n\nprint('Intercept: \\n', ml_regr.intercept_)\nprint('Coefficients: \\n', ml_regr.coef_)",
"Intercept: \n 74.59582972285749\nCoefficients: \n [ 0. 0.33138486 -1.61056402]\n"
]
],
[
[
"#CHECKING FOR LINEAR REGRESSION ASSUMPTIONS \n\n1.Linear Relationship \nAims at finding linear relationship between the independent and dependent variables \n\nTEST\nA simple visual way of determining this is through the use of scatter plot\n\n2.Variables follow a normal Distribution\nThis assumption ensures that for each value of independent variable, the dependent variable is a random variable following a normal distribution and its mean lies on the regression line. \n\nTEST\nOne of the ways to visually test for this assumption is through the use of the Quantile-Quantile plot(Q-Q_Plot)\n",
"_____no_output_____"
]
],
[
[
"#Multicollinearity test \ncorr =df.corr()\nprint(corr)",
" X1 X2 Y\nX1 1.000000 -0.696592 0.770767\nX2 -0.696592 1.000000 -0.930008\nY 0.770767 -0.930008 1.000000\n"
],
[
"#Linearity and Normality Test \nimport seaborn as sns \nsns.set(style=\"ticks\", color_codes=True, font_scale=2)\ng=sns.pairplot(df, height=3, diag_kind=\"hist\",kind=\"reg\")\ng.fig.suptitle(\"Scatter Plot\",y=1.08) \n",
"_____no_output_____"
],
[
"X_test = sm.add_constant(X_test)\nX_test",
"_____no_output_____"
],
[
"y_pred=mlr_model.predict(X_test)",
"_____no_output_____"
],
[
"residual = y_test - y_pred",
"_____no_output_____"
],
[
"#No Multicolinearity\nfrom statsmodels.stats.outliers_influence import variance_inflation_factor\nvif = [variance_inflation_factor(X_train.values, i) for i in range(X_train.shape[1])]",
"_____no_output_____"
],
[
"pd.DataFrame({'vif': vif[0:]}, index=X_train.columns).T\n\"\"\"Little or no multicollinearity \nThis assumption aims to test correlation between independent variables.\nIf multicollinearity exists between them (i.e independent variables are highly correlated), they are no longer independent.\nTEST\nCorrelation Analysis (others are variance inflation factor (VIF)) and condition Index\nIf you find any values in which the absolute value of their correlation is >=0.8, the multicollinearity \nAssumption is being broken.\n\"\"\"",
"_____no_output_____"
],
[
"#Normailty of Residual\nsns.distplot(residual)",
"C:\\Users\\USER\\anaconda3\\lib\\site-packages\\seaborn\\distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"import scipy as sp\nfig, ax = plt.subplots(figsize=(6,2.5))\n_, (__, ___, r) = sp.stats.probplot(residual, plot=ax, fit=True)",
"_____no_output_____"
],
[
"np.mean(residual)",
"_____no_output_____"
],
[
"#Normality of error / residue \nimport scipy.stats as stats \nfig, ax=plt.subplots(figsize=(10,6))\nstats.probplot(residual, dist=\"norm\",plot=plt)\nplt.show \n",
"_____no_output_____"
],
[
"#Homoscedasticity\nfig, ax = plt.subplots(figsize=(6,2.5))\n_ = ax.scatter(y_pred, residual)\nplt.title(\"Homoscedasticity\")\n\"\"\"Data is homoscedastic \nThe linear regression analysis makes is homoscedasticity (i.e the error terms along the regression line are equal)\nThis analysis is also applied to the residuals of your linear regression model. \n\nTEST\nHomoscedasticity can be easily tested with a Scatterplot of the residuals. \n\"\"\"",
"_____no_output_____"
],
[
"#No autocorrelation of residuals\nimport statsmodels.tsa.api as smt\nacf = smt.graphics.plot_acf(residual, lags=3 , alpha=0.05)\nacf.show()\n\"\"\"Little or No Autocorrelation \nThis next assumption is much like our previous one, except it applies to the residuals of your linear regression model. \nLinear regression analysis requires that there is little or no autocorrelation in the data.\nTEST\nYou can test the liner regression model for autocorrelation with Durbin-Watson test(d), \nwhile d can assume values between 0 and 4 ,values around 2 indicates no autocorrelation. As a rule of thumb values of 1.5\n\"\"\"",
"_____no_output_____"
]
],
[
[
"#Conclusion\nHere performd multiple linear regression in Python using both \nsklearn and statsmodels in this both models the coefficient values are same. \nwe got consistent results by applying both sklearn and statsmodels.\n\n#Multicollinearity test : If the VIF value of greater than 10 signifies that heavy Multicollinearity in the dataset,\n a value less than 5 for a given feature specifies that there is a little relatioship that feature holds with \n other feature.\n In this case the VIF score are 4.085853 with independet having vey weak VIF score within them, \n so the assumption of Multicollinearity holds True in our given schemes of things. \n \n#Normailty of Residual\nResidual is the differenec berween y_test & y_pred, if you check the plot for Normal distrubution , \nthe plot is near Normal distrubution but its not entirely Normal distrubution and centered near to zero,\nwhich one of the assumptions of Normal distrubution. \nOne more way to validate Normal distrubution is Q-Q Plot, Here I can see that the theoritical values fall on same line, \ni.e most of the values near the line, this shows clear that the overall distribution is near Normal distrubution. \nhere we can observe the mean value 0.87 it inferes that genereaal this not enough good value, meanschnege cureve towards right.\ni.e to ge normal distribution the value of mean should be zero or near to zero. so our assumption is True. \n\n#Homoscedasticity or Constant variance \nHere we need to observe the visuvalization, overall distribution is randomly sampled, \ndoes it kind of inrecare with increase in residual values, here my predections on X-axis, \noverall residuals on Y-axis,i find that there is no pattern based on the predection and residual \nvalues, and move cenetred arond zero value.so our assumption is True. \n\n#No autocorrelation of residuals\nHere there shoulb be absolutely no correleation of the residual value is with any of its \nlagged verstions which is called as autocorrelation, I observed in tha plot the residuals itself have a heavy correlation, \nif you observe the most of auto correlated values non of the values corss the threashold of beying significant,\nso the blue color signified here shows the significance level of the autocorrelation which it should cross \nin orderd to be significant in termd of auto correlation , so here there no value cross the blue bounndary ,\nso this linear regression model followign the assumptios of the linear regression. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02c8fc5af1e43815a335f1ab29f7df590827e57
| 1,071 |
ipynb
|
Jupyter Notebook
|
imports.ipynb
|
franzihe/Radiosonde
|
a9456679ac3cdb73f95a638e025343754c026aea
|
[
"MIT"
] | null | null | null |
imports.ipynb
|
franzihe/Radiosonde
|
a9456679ac3cdb73f95a638e025343754c026aea
|
[
"MIT"
] | null | null | null |
imports.ipynb
|
franzihe/Radiosonde
|
a9456679ac3cdb73f95a638e025343754c026aea
|
[
"MIT"
] | null | null | null | 20.596154 | 40 | 0.563959 |
[
[
[
"import os\nimport numpy as np\nimport urllib3\nfrom bs4 import BeautifulSoup\nimport pandas as pd\nimport xarray as xr\nfrom metpy.units import units\nfrom metpy.plots import SkewT\nimport metpy.calc as mpcalc\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom datetime import datetime\n\nimport functions as fct",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
d02c9a15d39c7fcee66b7e5cae1ccc9fc7fd61f3
| 75,084 |
ipynb
|
Jupyter Notebook
|
rigmq/util/prepare_audio_stims_debug.ipynb
|
zekearneodo/rigmq
|
35414c7b97c0a4e2e13020cb96bec63d4493bab0
|
[
"MIT"
] | 1 |
2019-04-03T23:32:26.000Z
|
2019-04-03T23:32:26.000Z
|
rigmq/util/prepare_audio_stims_debug.ipynb
|
zekearneodo/rigmq
|
35414c7b97c0a4e2e13020cb96bec63d4493bab0
|
[
"MIT"
] | null | null | null |
rigmq/util/prepare_audio_stims_debug.ipynb
|
zekearneodo/rigmq
|
35414c7b97c0a4e2e13020cb96bec63d4493bab0
|
[
"MIT"
] | null | null | null | 194.015504 | 17,860 | 0.91042 |
[
[
[
"### Prepare stimuli in stereo with sync tone in the L channel\nTo syncrhonize the recording systems, each stimulus file goes in stereo, the L channel has the stimulus, and the R channel has a pure tone (500-5Khz).\nThis is done here, with the help of the rigmq.util.stimprep module\nIt uses (or creates) a dictionary of {stim_file: tone_freq} which is stored as a .json file for offline processing.",
"_____no_output_____"
]
],
[
[
"import socket\nimport os\nimport sys\nimport logging\nimport warnings\nimport numpy as np\nimport glob\n\nfrom rigmq.util import stimprep as sp\n\n# setup the logger\nlogger = logging.getLogger()\nhandler = logging.StreamHandler()\nformatter = logging.Formatter(\n '%(asctime)s %(name)-12s %(levelname)-8s %(message)s')\nhandler.setFormatter(formatter)\nlogger.addHandler(handler)\nlogger.setLevel(logging.INFO)\n\n# Check wich computer to decide where the things are mounted\ncomp_name=socket.gethostname()\nlogger.info('Computer: ' + comp_name)\n\n",
"2019-06-27 16:29:30,841 root INFO Computer: lookfar\n"
],
[
"exp_folder = os.path.abspath('/Users/zeke/experiment/birds')\nbird = 'g3v3'\nsess = 'acute_0'\nstim_sf = 48000 # sampling frequency of the stimulus system\n\nstim_folder = os.path.join(exp_folder, bird, 'SongData', sess)\nglob.glob(os.path.join(stim_folder, '*.wav'))",
"_____no_output_____"
],
[
"from scipy.io import wavfile\nfrom scipy.signal import resample\n\n\na_file = glob.glob(os.path.join(stim_folder, '*.wav'))[0]\nin_sf, data = wavfile.read(a_file)",
"_____no_output_____"
],
[
"%matplotlib inline\nfrom matplotlib import pyplot as plt\nplt.plot(data)",
"_____no_output_____"
],
[
"data.dtype",
"_____no_output_____"
],
[
"np.iinfo(data.dtype).min",
"_____no_output_____"
],
[
"def normalize(x: np.array, max_amp: np.float=0.9)-> np.array:\n y = x.astype(np.float)\n y = y - np.mean(y)\n y = y / np.max(np.abs(y)) # if it is still of-centered, scale to avoid clipping in the widest varyng sign\n return y * max_amp\n\ndata_float = normalize(data)\nplt.plot(data_float)",
"_____no_output_____"
],
[
"def int_range(x: np.array, dtype: np.dtype):\n min_int = np.iinfo(dtype).min\n max_int = np.iinfo(dtype).max\n\n if min_int==0: # for unsigned types shift everything\n x = x + np.min(x)\n y = x * max_int\n return y.astype(dtype)\n\ndata_int = int_range(data_float, data.dtype)\nplt.plot(data_int)",
"_____no_output_____"
],
[
"data_tagged = sp.make_stereo_stim(a_file, 48000, tag_freq=1000)",
"2019-06-27 16:29:31,994 rigmq.util.stimprep INFO Will resample from 40414 to 60621 sampes\n"
],
[
"plt.plot(data_tagged[:480,1])",
"_____no_output_____"
],
[
"### Define stim_tags\nThere is a dictionary of {wav_file: tag_frequency} can be done by hand when there are few stimuli",
"_____no_output_____"
],
[
"stim_tags_dict = {'bos': 1000,\n 'bos-lo': 2000,\n 'bos-rev': 3000}\n\nstims_list = list(stim_tags_dict.keys())\nsp.create_sbc_stim(stims_list, stim_folder, stim_sf, stim_tag_dict=stim_tags_dict)\n",
"2019-06-27 16:36:59,810 rigmq.util.stimprep INFO Processing /Users/zeke/experiment/birds/g3v3/SongData/acute_0/bos.wav\n2019-06-27 16:36:59,813 rigmq.util.stimprep INFO tag_freq = 1000\n2019-06-27 16:36:59,815 rigmq.util.stimprep INFO Will resample from 40414 to 60621 sampes\n2019-06-27 16:36:59,831 rigmq.util.stimprep INFO Saved to /Users/zeke/experiment/birds/g3v3/SongData/acute_0/sbc_stim/bos_tag.wav\n2019-06-27 16:36:59,832 rigmq.util.stimprep INFO Processing /Users/zeke/experiment/birds/g3v3/SongData/acute_0/bos-lo.wav\n2019-06-27 16:36:59,833 rigmq.util.stimprep INFO tag_freq = 2000\n2019-06-27 16:36:59,835 rigmq.util.stimprep INFO Will resample from 43906 to 65859 sampes\n2019-06-27 16:36:59,876 rigmq.util.stimprep INFO Saved to /Users/zeke/experiment/birds/g3v3/SongData/acute_0/sbc_stim/bos-lo_tag.wav\n2019-06-27 16:36:59,876 rigmq.util.stimprep INFO Processing /Users/zeke/experiment/birds/g3v3/SongData/acute_0/bos-rev.wav\n2019-06-27 16:36:59,877 rigmq.util.stimprep INFO tag_freq = 3000\n2019-06-27 16:36:59,879 rigmq.util.stimprep INFO Will resample from 40414 to 60621 sampes\n2019-06-27 16:36:59,893 rigmq.util.stimprep INFO Saved to /Users/zeke/experiment/birds/g3v3/SongData/acute_0/sbc_stim/bos-rev_tag.wav\n2019-06-27 16:36:59,895 rigmq.util.stimprep INFO Saved tags .json file to /Users/zeke/experiment/birds/g3v3/SongData/acute_0/sbc_stim/stim_tags.json\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02c9b0cf7da6c9b63ccfe35f5ec5a680a44b7dc
| 49,422 |
ipynb
|
Jupyter Notebook
|
Scaling and Normalization.ipynb
|
dbl007/python-cheat-sheet
|
2537fc452857efbf2da7e0d1c3d24229d0adb02c
|
[
"MIT"
] | 7 |
2020-07-01T02:29:47.000Z
|
2021-08-12T01:38:22.000Z
|
Scaling and Normalization.ipynb
|
dbl007/python-cheat-sheet
|
2537fc452857efbf2da7e0d1c3d24229d0adb02c
|
[
"MIT"
] | null | null | null |
Scaling and Normalization.ipynb
|
dbl007/python-cheat-sheet
|
2537fc452857efbf2da7e0d1c3d24229d0adb02c
|
[
"MIT"
] | 2 |
2020-07-30T03:00:49.000Z
|
2022-02-23T04:14:13.000Z
| 85.65338 | 9,324 | 0.790539 |
[
[
[
"# Scaling and Normalization",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler\nfrom scipy.cluster.vq import whiten",
"_____no_output_____"
]
],
[
[
"Terminology (from [this post](https://towardsdatascience.com/scale-standardize-or-normalize-with-scikit-learn-6ccc7d176a02)):\n \n* Scale generally means to change the range of the values. The shape of the distribution doesn’t change. Think about how a scale model of a building has the same proportions as the original, just smaller. That’s why we say it is drawn to scale. The range is often set at 0 to 1.\n* Standardize generally means changing the values so that the distribution standard deviation from the mean equals one. It outputs something very close to a normal distribution. Scaling is often implied.\n* Normalize can be used to mean either of the above things (and more!). I suggest you avoid the term normalize, because it has many definitions and is prone to creating confusion.\n\nvia [Machine Learning Mastery](https://machinelearningmastery.com/standardscaler-and-minmaxscaler-transforms-in-python/):\n\n* If the distribution of the quantity is normal, then it should be standardized, otherwise, the data should be normalized.",
"_____no_output_____"
]
],
[
[
"house_prices = pd.read_csv(\"data/house-prices.csv\")\nhouse_prices[\"AgeWhenSold\"] = house_prices[\"YrSold\"] - house_prices[\"YearBuilt\"]\nhouse_prices.head()",
"_____no_output_____"
]
],
[
[
"## Unscaled Housing Prices Age When Sold",
"_____no_output_____"
]
],
[
[
"sns.displot(house_prices[\"AgeWhenSold\"])\nplt.xticks(rotation=90)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## StandardScaler\n\nNote that DataFrame.var and DataFrame.std default to using 1 degree of freedom (ddof=1) but StandardScaler is using numpy's versions which default to ddof=0. That's why when printing the variance and standard deviation of the original data frame, we're specifying ddof=0. ddof=1 is known as Bessel's correction.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame({\n 'col1': [1, 2, 3],\n 'col2': [10, 20, 30],\n 'col3': [0, 20, 22]\n})\nprint(\"Original:\\n\")\nprint(df)\nprint(\"\\nColumn means:\\n\")\nprint(df.mean())\nprint(\"\\nOriginal variance:\\n\")\nprint(df.var(ddof=0))\nprint(\"\\nOriginal standard deviations:\\n\")\nprint(df.std(ddof=0))\n\nscaler = StandardScaler()\ndf1 = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)\nprint(\"\\nAfter scaling:\\n\")\nprint(df1)\nprint(\"\\nColumn means:\\n\")\nprint(round(df1.mean(), 3))\nprint(\"\\nVariance:\\n\")\nprint(df1.var(ddof=0))\nprint(\"\\nStandard deviations:\\n\")\nprint(df1.std(ddof=0))\n\nprint(\"\\nExample calculation for col2:\")\nprint(\"z = (x - mean) / std\")\nprint(\"z = (10 - 20) / 8.164966 = -1.224745\")",
"Original:\n\n col1 col2 col3\n0 1 10 0\n1 2 20 20\n2 3 30 22\n\nColumn means:\n\ncol1 2.0\ncol2 20.0\ncol3 14.0\ndtype: float64\n\nOriginal variance:\n\ncol1 0.666667\ncol2 66.666667\ncol3 98.666667\ndtype: float64\n\nOriginal standard deviations:\n\ncol1 0.816497\ncol2 8.164966\ncol3 9.933110\ndtype: float64\n\nAfter scaling:\n\n col1 col2 col3\n0 -1.224745 -1.224745 -1.409428\n1 0.000000 0.000000 0.604040\n2 1.224745 1.224745 0.805387\n\nColumn means:\n\ncol1 0.0\ncol2 0.0\ncol3 0.0\ndtype: float64\n\nVariance:\n\ncol1 1.0\ncol2 1.0\ncol3 1.0\ndtype: float64\n\nStandard deviations:\n\ncol1 1.0\ncol2 1.0\ncol3 1.0\ndtype: float64\n\nExample calculation for col2:\nz = (x - mean) / std\nz = (10 - 20) / 8.164966 = -1.224745\n"
]
],
[
[
"### Standard Scaler with Age When Sold",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\nage_when_sold_scaled = scaler.fit_transform(house_prices[\"AgeWhenSold\"].values.reshape(-1, 1))\nsns.displot(age_when_sold_scaled)\nplt.xticks(rotation=90)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Whiten\n\n```\nx_new = x / std(x)\n```",
"_____no_output_____"
]
],
[
[
"data = [5, 1, 3, 3, 2, 3, 8, 1, 2, 2, 3, 5]\nprint(\"Original:\", data)\nprint(\"\\nStd Dev:\", np.std(data))\n\nscaled = whiten(data)\nprint(\"\\nScaled with Whiten:\", scaled)\n\nscaled_manual = data / np.std(data)\nprint(\"\\nScaled Manuallly:\", scaled_manual)",
"Original: [5, 1, 3, 3, 2, 3, 8, 1, 2, 2, 3, 5]\n\nStd Dev: 1.9075871903765997\n\nScaled with Whiten: [2.62111217 0.52422243 1.5726673 1.5726673 1.04844487 1.5726673\n 4.19377947 0.52422243 1.04844487 1.04844487 1.5726673 2.62111217]\n\nScaled Manuallly: [2.62111217 0.52422243 1.5726673 1.5726673 1.04844487 1.5726673\n 4.19377947 0.52422243 1.04844487 1.04844487 1.5726673 2.62111217]\n"
]
],
[
[
"## MinMax\n\nScales to a value between 0 and 1.\n\nMore suspectible to influence by outliers.",
"_____no_output_____"
],
[
"### Housing Prices Age When Sold",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\nage_when_sold_scaled = scaler.fit_transform(house_prices[\"AgeWhenSold\"].values.reshape(-1, 1))\nsns.displot(age_when_sold_scaled)\nplt.xticks(rotation=90)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Robust Scaler",
"_____no_output_____"
]
],
[
[
"scaler = RobustScaler()\nage_when_sold_scaled = scaler.fit_transform(house_prices[\"AgeWhenSold\"].values.reshape(-1, 1))\nsns.displot(age_when_sold_scaled)\nplt.xticks(rotation=90)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02c9b4eee9a3971bb9111039b70a8c5c2a140d9
| 294,490 |
ipynb
|
Jupyter Notebook
|
prelim-model/2D TVD - Pa profile.ipynb
|
UBC-MOAD/pa-th-simple
|
bafb8dc6d281556f01233a32342a53bad8af392c
|
[
"Apache-2.0"
] | null | null | null |
prelim-model/2D TVD - Pa profile.ipynb
|
UBC-MOAD/pa-th-simple
|
bafb8dc6d281556f01233a32342a53bad8af392c
|
[
"Apache-2.0"
] | null | null | null |
prelim-model/2D TVD - Pa profile.ipynb
|
UBC-MOAD/pa-th-simple
|
bafb8dc6d281556f01233a32342a53bad8af392c
|
[
"Apache-2.0"
] | null | null | null | 127.484848 | 22,433 | 0.840877 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d02cb374729f3dd4572d27770f515498220dddf9
| 5,103 |
ipynb
|
Jupyter Notebook
|
notebooks/Exploring Json.ipynb
|
BillmanH/exoplanets
|
92656bf8c917c6e07d91f82a7cd0b75679ffa680
|
[
"MIT"
] | 14 |
2021-03-03T19:27:46.000Z
|
2022-03-21T16:24:45.000Z
|
notebooks/Exploring Json.ipynb
|
BillmanH/exoplanets
|
92656bf8c917c6e07d91f82a7cd0b75679ffa680
|
[
"MIT"
] | 6 |
2021-08-14T17:17:58.000Z
|
2021-09-28T14:34:56.000Z
|
notebooks/Exploring Json.ipynb
|
BillmanH/exoplanets
|
92656bf8c917c6e07d91f82a7cd0b75679ffa680
|
[
"MIT"
] | null | null | null | 39.867188 | 2,330 | 0.576524 |
[
[
[
"# Parsing out Cosmos Data JSON",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport yaml\n",
"_____no_output_____"
],
[
"import os\nos.listdir('../data')",
"_____no_output_____"
]
],
[
[
"## Loading local data\r\nI ran a query in the Cosmos DB Explorer and then load it in a json file. ",
"_____no_output_____"
]
],
[
[
"res = yaml.safe_load(open('../data/example nodes.json'))\r\nres[1]",
"_____no_output_____"
]
],
[
[
"Now I just need to parse out the orbiting edges",
"_____no_output_____"
]
],
[
[
"[{\"source\":i['objid'][0],\"target\":i['orbitsId'][0],\"label\":\"orbits\"} for i in res]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02cb658d805c3fc35eae623b651bc96001dd640
| 114,188 |
ipynb
|
Jupyter Notebook
|
Ex06Advanced/3_ExtremeValueAnalysis/.ipynb_checkpoints/swe_ws1920_6_3_advanced_topics_on_extreme_value_analysis-checkpoint.ipynb
|
mpentek/StructuralWindEngineering
|
97e88f8446ab29934d0c2128ec3ab33793efb48e
|
[
"BSD-3-Clause"
] | 1 |
2021-04-14T11:12:52.000Z
|
2021-04-14T11:12:52.000Z
|
Ex06Advanced/3_ExtremeValueAnalysis/.ipynb_checkpoints/swe_ws1920_6_3_advanced_topics_on_extreme_value_analysis-checkpoint.ipynb
|
mpentek/StructuralWindEngineering
|
97e88f8446ab29934d0c2128ec3ab33793efb48e
|
[
"BSD-3-Clause"
] | null | null | null |
Ex06Advanced/3_ExtremeValueAnalysis/.ipynb_checkpoints/swe_ws1920_6_3_advanced_topics_on_extreme_value_analysis-checkpoint.ipynb
|
mpentek/StructuralWindEngineering
|
97e88f8446ab29934d0c2128ec3ab33793efb48e
|
[
"BSD-3-Clause"
] | 1 |
2022-03-15T12:00:53.000Z
|
2022-03-15T12:00:53.000Z
| 284.049751 | 37,820 | 0.925369 |
[
[
[
"# Tutorial 6.3. Advanced Topics on Extreme Value Analysis",
"_____no_output_____"
],
[
"### Description: Some advanced topics on Extreme Value Analysis are presented.\n\n#### Students are advised to complete the exercises. ",
"_____no_output_____"
],
[
"Project: Structural Wind Engineering WS19-20 \n Chair of Structural Analysis @ TUM - R. Wüchner, M. Péntek\n \nAuthor: anoop.kodakkal@tum.de, mate.pentek@tum.de\n\nCreated on: 24.12.2019\n\nLast update: 08.01.2020",
"_____no_output_____"
],
[
"##### Contents:\n\n 1. Prediction of the extreme value of a time series - MaxMin Estimation \n 2. Lieblein's BLUE method\n \nThe worksheet is based on the knowledge base and scripts provided by [NIST](https://www.itl.nist.gov/div898/winds/overview.htm) as well as work available from [Christopher Howlett](https://github.com/chowlet5) from UWO. ",
"_____no_output_____"
]
],
[
[
"# import\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom scipy.stats import gumbel_r as gumbel\nfrom ipywidgets import interactive\n#external files \nfrom peakpressure import maxminest\nfrom blue4pressure import *\nimport custom_utilities as c_utils",
"_____no_output_____"
]
],
[
[
"## 1. Prediction of the extreme value of a time series - MaxMin Estimation\n",
"_____no_output_____"
],
[
"#### This method is based on [the procedure (and sample Matlab file](https://www.itl.nist.gov/div898/winds/peakest_files/peakest.htm) by Sadek, F. and Simiu, E. (2002). \"Peak non-gaussian wind effects for database-assisted low-rise building design.\" Journal of Engineering Mechanics, 128(5), 530-539. Please find it [here](https://www.itl.nist.gov/div898/winds/pdf_files/b02030.pdf).\n\nThe method uses\n* gamma distribution for estimating the peaks corresponding to the longer tail of time series \n* normal distribution for estimating the peaks corresponding to the shorter tail of time series\nThe distribution of the peaks is then estimated by using the standard translation processes approach.\n",
"_____no_output_____"
],
[
"#### implementation details : \n\nINPUT ARGUMENTS:\n\nEach row of *record* is a time series.\nThe optional input argument *dur_ratio* allows peaks to be estimated for\na duration that differs from the duration of the record itself:\n *dur_ratio* = [duration for peak estimation]/[duration of record]\n (If unspecified, a value of 1 is used.)\n\nOUTPUT ARGUMENTS:\n\n* *max_est* gives the expected maximum values of each row of *record*\n* *min_est* gives the expected minimum values of each row of *record*\n* *max_std* gives the standard deviations of the maximum value for each row of *record*\n* *min_std* gives the standard deviations of the minimum value for each row of *record*\n",
"_____no_output_____"
],
[
"#### Let us test the method for a given time series ",
"_____no_output_____"
]
],
[
[
"# using as sample input some pre-generated generalized extreme value random series\ngiven_series = np.loadtxt('test_data_gevrnd.dat', skiprows=0, usecols = (0,))\n\n# print results\ndur_ratio = 1\nresult = maxminest(given_series, dur_ratio)\nmaxv = result[0][0][0]\nminv = result[1][0][0]\nprint('estimation of maximum value ', np.around(maxv,3))\nprint('estimation of minimum value ', np.around(minv,3))\n",
"estimation of maximum value 2.24\nestimation of minimum value -0.675\n"
],
[
"plt.figure(num=1, figsize=(8, 6))\nx_series = np.arange(0.0, len(given_series), 1.0)\nplt.plot(x_series, given_series)\nplt.ylabel('Amplitude')\nplt.xlabel('Time [s]')\nplt.hlines([maxv, minv], x_series[0], x_series[-1])\nplt.title('Predicted extrema')\nplt.grid(True)\nplt.show()\n\n",
"_____no_output_____"
]
],
[
[
"#### Let us plot the pdf and cdf ",
"_____no_output_____"
]
],
[
[
"[pdf_x, pdf_y] = c_utils.get_pdf(given_series)\necdf_y = c_utils.get_ecdf(pdf_x, pdf_y)\nplt.figure(num=2, figsize=(16, 6))\nplt.subplot(1,2,1)\nplt.plot(pdf_x, pdf_y)\nplt.ylabel('PDF(Amplitude)')\nplt.grid(True)\n\nplt.subplot(1,2,2)\nplt.plot(pdf_x, ecdf_y)\nplt.vlines([maxv, minv], 0, 1)\nplt.ylabel('CDF(Amplitude)')\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 2. Lieblein's BLUE method",
"_____no_output_____"
],
[
"From a time series of pressure coefficients, *blue4pressure.py* estimates\nextremes of positive and negative pressures based on Lieblein's BLUE \n(Best Linear Unbiased Estimate) method applied to n epochs. \nExtremes are estimated for 1 and dur epochs for probabilities of non-exceedance \nP1 and P2 of the Gumbel distribution fitted to the epochal peaks.\n*n* = integer, dur need not be an integer.\nWritten by Dat Duthinh 8_25_2015, 2_2_2016, 2_6_2017.\n\nFor further reference check out the material provided by [NIST](https://www.itl.nist.gov/div898/winds/gumbel_blue/gumbblue.htm).\n\n\nReference: \n\n1) Julius Lieblein \"Efficient Methods of Extreme-Value\nMethodology\" NBSIR 74-602 OCT 1974 for n = 4:16\n\n2) Nicholas John Cook \"The designer's guide to wind loading of\nbuilding structures\" part 1, British Research Establishment 1985 Table C3\npp. 321-323 for n = 17:24. Extension to n=100 by Adam Pintar Feb 12 2016.\n\n3) INTERNATIONAL STANDARD, ISO 4354 (2009-06-01), 2nd edition, “Wind \nactions on structures,” Annex D (informative) “Aerodynamic pressure and \nforce coefficients,” Geneva, Switzerland, p. 22 ",
"_____no_output_____"
],
[
"#### implementation details : \n\nINPUT ARGUMENTS\n\n* *cp* = vector of time history of pressure coefficients\n* *n* = number of epochs (integer)of cp data, 4 <= n <= 100\n* *dur* = number of epochs for estimation of extremes. Default dur = n dur need not be an integer\n* *P1, P2* = probabilities of non-exceedance of extremes in EV1 (Gumbel), P1 defaults to 0.80 (ISO)and P2 to 0.5704 (mean) for the Gumbel distribution . \n\nOUTPUT ARGUMENTS\n\n* *suffix max* for + peaks, min for - peaks of pressure coeff.\n* *p1_max* (p1_min)= extreme value of positive (negative) peaks with probability of non-exceedance P1 for 1 epoch\n* *p2_max* (p2_min)= extreme value of positive (negative) peaks with probability of exceedance P2 for 1 epoch\n* *p1_rmax* (p1_rmin)= extreme value of positive (negative) peaks with probability of non-exceedance P1 for dur epochs\n* *p2_rmax* (p2_rmin)= extreme value of positive (negative) peaks with probability of non-exceedance P2 for for dur epochs\n* *cp_max* (cp_min)= vector of n positive (negative) epochal peaks\n* *u_max, b_max* (u_min, b_min) = location and scale parameters of EV1 (Gumbel) for positive (negative) peaks",
"_____no_output_____"
]
],
[
[
"# n = number of epochs (integer)of cp data, 4 <= n <= 100\nn=4\n# P1, P2 = probabilities of non-exceedance of extremes in EV1 (Gumbel).\nP1=0.80\nP2=0.5704 # this corresponds to the mean of gumbel distribution \n# dur = number of epochs for estimation of extremes. Default dur = n\n# dur need not be an integer\ndur=1\n\n# Call function\nresult = blue4pressure(given_series, n, P1, P2, dur)\np1_max = result[0][0]\np2_max = result[1][0]\numax = result[4][0] # location parameters\nb_max = result[5][0] # sclae parameters \np1_min = result[7][0]\np2_min = result[8][0]\numin = result[11][0] # location parameters \nb_min = result[12][0] # scale parameters ",
"_____no_output_____"
],
[
"# print results\n## maximum \nprint('estimation of maximum value with probability of non excedence of p1', np.around(p1_max,3))\nprint('estimation of maximum value with probability of non excedence of p2', np.around(p2_max,3))\n## minimum \nprint('estimation of minimum value with probability of non excedence of p1', np.around(p1_min,3))\nprint('estimation of minimum value with probability of non excedence of p2', np.around(p2_min,3))",
"estimation of maximum value with probability of non excedence of p1 2.055\nestimation of maximum value with probability of non excedence of p2 1.908\nestimation of minimum value with probability of non excedence of p1 -0.582\nestimation of minimum value with probability of non excedence of p2 -0.547\n"
]
],
[
[
"#### Let us plot the pdf and cdf for the maximum values",
"_____no_output_____"
]
],
[
[
"max_pdf_x = np.linspace(1, 3, 100)\nmax_pdf_y = gumbel.pdf(max_pdf_x, umax, b_max)\nmax_ecdf_y = c_utils.get_ecdf(max_pdf_x, max_pdf_y)\n\nplt.figure(num=3, figsize=(16, 6))\nplt.subplot(1,2,1)\n# PDF generated as a fitted curve using generalized extreme distribution\nplt.plot(max_pdf_x, max_pdf_y, label = 'PDF from the fitted Gumbel')\nplt.xlabel('Max values')\nplt.ylabel('PDF(Amplitude)')\nplt.title('PDF of Maxima')\nplt.grid(True)\nplt.legend()\nplt.subplot(1,2,2)\nplt.plot(max_pdf_x, max_ecdf_y)\nplt.vlines([p1_max, p2_max], 0, 1)\nplt.ylabel('CDF(Amplitude)')\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Try plotting these for the minimum values. Discuss among groups the advanced extreme value evaluation methods.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02cbadb3e53def35658cf102fda5533bb079e29
| 84,857 |
ipynb
|
Jupyter Notebook
|
assignment2/TensorFlow.ipynb
|
LOTEAT/CS231n
|
b840b37848b262dc14d8f200b4656e859bb2c81e
|
[
"MIT"
] | null | null | null |
assignment2/TensorFlow.ipynb
|
LOTEAT/CS231n
|
b840b37848b262dc14d8f200b4656e859bb2c81e
|
[
"MIT"
] | null | null | null |
assignment2/TensorFlow.ipynb
|
LOTEAT/CS231n
|
b840b37848b262dc14d8f200b4656e859bb2c81e
|
[
"MIT"
] | null | null | null | 50.360237 | 1,999 | 0.584183 |
[
[
[
"# What's this TensorFlow business?\n\nYou've written a lot of code in this assignment to provide a whole host of neural network functionality. Dropout, Batch Norm, and 2D convolutions are some of the workhorses of deep learning in computer vision. You've also worked hard to make your code efficient and vectorized.\n\nFor the last part of this assignment, though, we're going to leave behind your beautiful codebase and instead migrate to one of two popular deep learning frameworks: in this instance, TensorFlow (or PyTorch, if you choose to work with that notebook).",
"_____no_output_____"
],
[
"#### What is it?\nTensorFlow is a system for executing computational graphs over Tensor objects, with native support for performing backpropogation for its Variables. In it, we work with Tensors which are n-dimensional arrays analogous to the numpy ndarray.\n\n#### Why?\n\n* Our code will now run on GPUs! Much faster training. Writing your own modules to run on GPUs is beyond the scope of this class, unfortunately.\n* We want you to be ready to use one of these frameworks for your project so you can experiment more efficiently than if you were writing every feature you want to use by hand. \n* We want you to stand on the shoulders of giants! TensorFlow and PyTorch are both excellent frameworks that will make your lives a lot easier, and now that you understand their guts, you are free to use them :) \n* We want you to be exposed to the sort of deep learning code you might run into in academia or industry. ",
"_____no_output_____"
],
[
"## How will I learn TensorFlow?\n\nTensorFlow has many excellent tutorials available, including those from [Google themselves](https://www.tensorflow.org/get_started/get_started).\n\nOtherwise, this notebook will walk you through much of what you need to do to train models in TensorFlow. See the end of the notebook for some links to helpful tutorials if you want to learn more or need further clarification on topics that aren't fully explained here.\n\n**NOTE: This notebook is meant to teach you the latest version of Tensorflow which is as of this homework version `2.2.0-rc3`. Most examples on the web today are still in 1.x, so be careful not to confuse the two when looking up documentation**.\n\n## Install Tensorflow 2.0 (ONLY IF YOU ARE WORKING LOCALLY)\n\n1. Have the latest version of Anaconda installed on your machine.\n2. Create a new conda environment starting from Python 3.7. In this setup example, we'll call it `tf_20_env`.\n3. Run the command: `source activate tf_20_env`\n4. Then pip install TF 2.0 as described here: https://www.tensorflow.org/install",
"_____no_output_____"
],
[
"# Table of Contents\n\nThis notebook has 5 parts. We will walk through TensorFlow at **three different levels of abstraction**, which should help you better understand it and prepare you for working on your project.\n\n1. Part I, Preparation: load the CIFAR-10 dataset.\n2. Part II, Barebone TensorFlow: **Abstraction Level 1**, we will work directly with low-level TensorFlow graphs. \n3. Part III, Keras Model API: **Abstraction Level 2**, we will use `tf.keras.Model` to define arbitrary neural network architecture. \n4. Part IV, Keras Sequential + Functional API: **Abstraction Level 3**, we will use `tf.keras.Sequential` to define a linear feed-forward network very conveniently, and then explore the functional libraries for building unique and uncommon models that require more flexibility.\n5. Part V, CIFAR-10 open-ended challenge: please implement your own network to get as high accuracy as possible on CIFAR-10. You can experiment with any layer, optimizer, hyperparameters or other advanced features. \n\nWe will discuss Keras in more detail later in the notebook.\n\nHere is a table of comparison:\n\n| API | Flexibility | Convenience |\n|---------------|-------------|-------------|\n| Barebone | High | Low |\n| `tf.keras.Model` | High | Medium |\n| `tf.keras.Sequential` | Low | High |",
"_____no_output_____"
],
[
"# Part I: Preparation\n\nFirst, we load the CIFAR-10 dataset. This might take a few minutes to download the first time you run it, but after that the files should be cached on disk and loading should be faster.\n\nIn previous parts of the assignment we used CS231N-specific code to download and read the CIFAR-10 dataset; however the `tf.keras.datasets` package in TensorFlow provides prebuilt utility functions for loading many common datasets.\n\nFor the purposes of this assignment we will still write our own code to preprocess the data and iterate through it in minibatches. The `tf.data` package in TensorFlow provides tools for automating this process, but working with this package adds extra complication and is beyond the scope of this notebook. However using `tf.data` can be much more efficient than the simple approach used in this notebook, so you should consider using it for your project.",
"_____no_output_____"
]
],
[
[
"import os\nimport tensorflow as tf\nimport numpy as np\nimport math\nimport timeit\nimport matplotlib.pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
],
[
"def load_cifar10(num_training=49000, num_validation=1000, num_test=10000):\n \"\"\"\n Fetch the CIFAR-10 dataset from the web and perform preprocessing to prepare\n it for the two-layer neural net classifier. These are the same steps as\n we used for the SVM, but condensed to a single function.\n \"\"\"\n # Load the raw CIFAR-10 dataset and use appropriate data types and shapes\n cifar10 = tf.keras.datasets.cifar10.load_data()\n (X_train, y_train), (X_test, y_test) = cifar10\n X_train = np.asarray(X_train, dtype=np.float32)\n y_train = np.asarray(y_train, dtype=np.int32).flatten()\n X_test = np.asarray(X_test, dtype=np.float32)\n y_test = np.asarray(y_test, dtype=np.int32).flatten()\n\n # Subsample the data\n mask = range(num_training, num_training + num_validation)\n X_val = X_train[mask]\n y_val = y_train[mask]\n mask = range(num_training)\n X_train = X_train[mask]\n y_train = y_train[mask]\n mask = range(num_test)\n X_test = X_test[mask]\n y_test = y_test[mask]\n\n # Normalize the data: subtract the mean pixel and divide by std\n mean_pixel = X_train.mean(axis=(0, 1, 2), keepdims=True)\n std_pixel = X_train.std(axis=(0, 1, 2), keepdims=True)\n X_train = (X_train - mean_pixel) / std_pixel\n X_val = (X_val - mean_pixel) / std_pixel\n X_test = (X_test - mean_pixel) / std_pixel\n\n return X_train, y_train, X_val, y_val, X_test, y_test\n\n# If there are errors with SSL downloading involving self-signed certificates,\n# it may be that your Python version was recently installed on the current machine.\n# See: https://github.com/tensorflow/tensorflow/issues/10779\n# To fix, run the command: /Applications/Python\\ 3.7/Install\\ Certificates.command\n# ...replacing paths as necessary.\n\n# Invoke the above function to get our data.\nNHW = (0, 1, 2)\nX_train, y_train, X_val, y_val, X_test, y_test = load_cifar10()\nprint('Train data shape: ', X_train.shape)\nprint('Train labels shape: ', y_train.shape, y_train.dtype)\nprint('Validation data shape: ', X_val.shape)\nprint('Validation labels shape: ', y_val.shape)\nprint('Test data shape: ', X_test.shape)\nprint('Test labels shape: ', y_test.shape)",
"Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz\n170500096/170498071 [==============================] - 36s 0us/step\nTrain data shape: (49000, 32, 32, 3)\nTrain labels shape: (49000,) int32\nValidation data shape: (1000, 32, 32, 3)\nValidation labels shape: (1000,)\nTest data shape: (10000, 32, 32, 3)\nTest labels shape: (10000,)\n"
],
[
"class Dataset(object):\n def __init__(self, X, y, batch_size, shuffle=False):\n \"\"\"\n Construct a Dataset object to iterate over data X and labels y\n \n Inputs:\n - X: Numpy array of data, of any shape\n - y: Numpy array of labels, of any shape but with y.shape[0] == X.shape[0]\n - batch_size: Integer giving number of elements per minibatch\n - shuffle: (optional) Boolean, whether to shuffle the data on each epoch\n \"\"\"\n assert X.shape[0] == y.shape[0], 'Got different numbers of data and labels'\n self.X, self.y = X, y\n self.batch_size, self.shuffle = batch_size, shuffle\n\n def __iter__(self):\n N, B = self.X.shape[0], self.batch_size\n idxs = np.arange(N)\n if self.shuffle:\n np.random.shuffle(idxs)\n return iter((self.X[i:i+B], self.y[i:i+B]) for i in range(0, N, B))\n\n\ntrain_dset = Dataset(X_train, y_train, batch_size=64, shuffle=True)\nval_dset = Dataset(X_val, y_val, batch_size=64, shuffle=False)\ntest_dset = Dataset(X_test, y_test, batch_size=64)",
"_____no_output_____"
],
[
"# We can iterate through a dataset like this:\nfor t, (x, y) in enumerate(train_dset):\n print(t, x.shape, y.shape)\n if t > 5: break",
"0 (64, 32, 32, 3) (64,)\n1 (64, 32, 32, 3) (64,)\n2 (64, 32, 32, 3) (64,)\n3 (64, 32, 32, 3) (64,)\n4 (64, 32, 32, 3) (64,)\n5 (64, 32, 32, 3) (64,)\n6 (64, 32, 32, 3) (64,)\n"
]
],
[
[
"You can optionally **use GPU by setting the flag to True below**.\n\n## Colab Users\n\nIf you are using Colab, you need to manually switch to a GPU device. You can do this by clicking `Runtime -> Change runtime type` and selecting `GPU` under `Hardware Accelerator`. Note that you have to rerun the cells from the top since the kernel gets restarted upon switching runtimes.",
"_____no_output_____"
]
],
[
[
"# Set up some global variables\nUSE_GPU = True\n\nif USE_GPU:\n device = '/device:GPU:0'\nelse:\n device = '/cpu:0'\n\n# Constant to control how often we print when training models\nprint_every = 100\n\nprint('Using device: ', device)",
"Using device: /device:GPU:0\n"
]
],
[
[
"# Part II: Barebones TensorFlow\nTensorFlow ships with various high-level APIs which make it very convenient to define and train neural networks; we will cover some of these constructs in Part III and Part IV of this notebook. In this section we will start by building a model with basic TensorFlow constructs to help you better understand what's going on under the hood of the higher-level APIs.\n\n**\"Barebones Tensorflow\" is important to understanding the building blocks of TensorFlow, but much of it involves concepts from TensorFlow 1.x.** We will be working with legacy modules such as `tf.Variable`.\n\nTherefore, please read and understand the differences between legacy (1.x) TF and the new (2.0) TF.\n\n### Historical background on TensorFlow 1.x\n\nTensorFlow 1.x is primarily a framework for working with **static computational graphs**. Nodes in the computational graph are Tensors which will hold n-dimensional arrays when the graph is run; edges in the graph represent functions that will operate on Tensors when the graph is run to actually perform useful computation.\n\nBefore Tensorflow 2.0, we had to configure the graph into two phases. There are plenty of tutorials online that explain this two-step process. The process generally looks like the following for TF 1.x:\n1. **Build a computational graph that describes the computation that you want to perform**. This stage doesn't actually perform any computation; it just builds up a symbolic representation of your computation. This stage will typically define one or more `placeholder` objects that represent inputs to the computational graph.\n2. **Run the computational graph many times.** Each time the graph is run (e.g. for one gradient descent step) you will specify which parts of the graph you want to compute, and pass a `feed_dict` dictionary that will give concrete values to any `placeholder`s in the graph.\n\n### The new paradigm in Tensorflow 2.0\nNow, with Tensorflow 2.0, we can simply adopt a functional form that is more Pythonic and similar in spirit to PyTorch and direct Numpy operation. Instead of the 2-step paradigm with computation graphs, making it (among other things) easier to debug TF code. You can read more details at https://www.tensorflow.org/guide/eager.\n\nThe main difference between the TF 1.x and 2.0 approach is that the 2.0 approach doesn't make use of `tf.Session`, `tf.run`, `placeholder`, `feed_dict`. To get more details of what's different between the two version and how to convert between the two, check out the official migration guide: https://www.tensorflow.org/alpha/guide/migration_guide\n\nLater, in the rest of this notebook we'll focus on this new, simpler approach.",
"_____no_output_____"
],
[
"### TensorFlow warmup: Flatten Function\n\nWe can see this in action by defining a simple `flatten` function that will reshape image data for use in a fully-connected network.\n\nIn TensorFlow, data for convolutional feature maps is typically stored in a Tensor of shape N x H x W x C where:\n\n- N is the number of datapoints (minibatch size)\n- H is the height of the feature map\n- W is the width of the feature map\n- C is the number of channels in the feature map\n\nThis is the right way to represent the data when we are doing something like a 2D convolution, that needs spatial understanding of where the intermediate features are relative to each other. When we use fully connected affine layers to process the image, however, we want each datapoint to be represented by a single vector -- it's no longer useful to segregate the different channels, rows, and columns of the data. So, we use a \"flatten\" operation to collapse the `H x W x C` values per representation into a single long vector. \n\nNotice the `tf.reshape` call has the target shape as `(N, -1)`, meaning it will reshape/keep the first dimension to be N, and then infer as necessary what the second dimension is in the output, so we can collapse the remaining dimensions from the input properly.\n\n**NOTE**: TensorFlow and PyTorch differ on the default Tensor layout; TensorFlow uses N x H x W x C but PyTorch uses N x C x H x W.",
"_____no_output_____"
]
],
[
[
"def flatten(x):\n \"\"\" \n Input:\n - TensorFlow Tensor of shape (N, D1, ..., DM)\n \n Output:\n - TensorFlow Tensor of shape (N, D1 * ... * DM)\n \"\"\"\n N = tf.shape(x)[0]\n return tf.reshape(x, (N, -1))",
"_____no_output_____"
],
[
"def test_flatten():\n # Construct concrete values of the input data x using numpy\n x_np = np.arange(24).reshape((2, 3, 4))\n print('x_np:\\n', x_np, '\\n')\n # Compute a concrete output value.\n x_flat_np = flatten(x_np)\n print('x_flat_np:\\n', x_flat_np, '\\n')\n\ntest_flatten()",
"x_np:\n [[[ 0 1 2 3]\n [ 4 5 6 7]\n [ 8 9 10 11]]\n\n [[12 13 14 15]\n [16 17 18 19]\n [20 21 22 23]]] \n\nx_flat_np:\n tf.Tensor(\n[[ 0 1 2 3 4 5 6 7 8 9 10 11]\n [12 13 14 15 16 17 18 19 20 21 22 23]], shape=(2, 12), dtype=int32) \n\n"
]
],
[
[
"### Barebones TensorFlow: Define a Two-Layer Network\nWe will now implement our first neural network with TensorFlow: a fully-connected ReLU network with two hidden layers and no biases on the CIFAR10 dataset. For now we will use only low-level TensorFlow operators to define the network; later we will see how to use the higher-level abstractions provided by `tf.keras` to simplify the process.\n\nWe will define the forward pass of the network in the function `two_layer_fc`; this will accept TensorFlow Tensors for the inputs and weights of the network, and return a TensorFlow Tensor for the scores. \n\nAfter defining the network architecture in the `two_layer_fc` function, we will test the implementation by checking the shape of the output.\n\n**It's important that you read and understand this implementation.**",
"_____no_output_____"
]
],
[
[
"def two_layer_fc(x, params):\n \"\"\"\n A fully-connected neural network; the architecture is:\n fully-connected layer -> ReLU -> fully connected layer.\n Note that we only need to define the forward pass here; TensorFlow will take\n care of computing the gradients for us.\n \n The input to the network will be a minibatch of data, of shape\n (N, d1, ..., dM) where d1 * ... * dM = D. The hidden layer will have H units,\n and the output layer will produce scores for C classes.\n\n Inputs:\n - x: A TensorFlow Tensor of shape (N, d1, ..., dM) giving a minibatch of\n input data.\n - params: A list [w1, w2] of TensorFlow Tensors giving weights for the\n network, where w1 has shape (D, H) and w2 has shape (H, C).\n \n Returns:\n - scores: A TensorFlow Tensor of shape (N, C) giving classification scores\n for the input data x.\n \"\"\"\n w1, w2 = params # Unpack the parameters\n x = flatten(x) # Flatten the input; now x has shape (N, D)\n h = tf.nn.relu(tf.matmul(x, w1)) # Hidden layer: h has shape (N, H)\n scores = tf.matmul(h, w2) # Compute scores of shape (N, C)\n return scores",
"_____no_output_____"
],
[
"def two_layer_fc_test():\n hidden_layer_size = 42\n\n # Scoping our TF operations under a tf.device context manager \n # lets us tell TensorFlow where we want these Tensors to be\n # multiplied and/or operated on, e.g. on a CPU or a GPU.\n with tf.device(device): \n x = tf.zeros((64, 32, 32, 3))\n w1 = tf.zeros((32 * 32 * 3, hidden_layer_size))\n w2 = tf.zeros((hidden_layer_size, 10))\n\n # Call our two_layer_fc function for the forward pass of the network.\n scores = two_layer_fc(x, [w1, w2])\n\n print(scores.shape)\n\ntwo_layer_fc_test()",
"(64, 10)\n"
]
],
[
[
"### Barebones TensorFlow: Three-Layer ConvNet\nHere you will complete the implementation of the function `three_layer_convnet` which will perform the forward pass of a three-layer convolutional network. The network should have the following architecture:\n\n1. A convolutional layer (with bias) with `channel_1` filters, each with shape `KW1 x KH1`, and zero-padding of two\n2. ReLU nonlinearity\n3. A convolutional layer (with bias) with `channel_2` filters, each with shape `KW2 x KH2`, and zero-padding of one\n4. ReLU nonlinearity\n5. Fully-connected layer with bias, producing scores for `C` classes.\n\n**HINT**: For convolutions: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/nn/conv2d; be careful with padding!\n\n**HINT**: For biases: https://www.tensorflow.org/performance/xla/broadcasting",
"_____no_output_____"
]
],
[
[
"def three_layer_convnet(x, params):\n \"\"\"\n A three-layer convolutional network with the architecture described above.\n \n Inputs:\n - x: A TensorFlow Tensor of shape (N, H, W, 3) giving a minibatch of images\n - params: A list of TensorFlow Tensors giving the weights and biases for the\n network; should contain the following:\n - conv_w1: TensorFlow Tensor of shape (KH1, KW1, 3, channel_1) giving\n weights for the first convolutional layer.\n - conv_b1: TensorFlow Tensor of shape (channel_1,) giving biases for the\n first convolutional layer.\n - conv_w2: TensorFlow Tensor of shape (KH2, KW2, channel_1, channel_2)\n giving weights for the second convolutional layer\n - conv_b2: TensorFlow Tensor of shape (channel_2,) giving biases for the\n second convolutional layer.\n - fc_w: TensorFlow Tensor giving weights for the fully-connected layer.\n Can you figure out what the shape should be?\n - fc_b: TensorFlow Tensor giving biases for the fully-connected layer.\n Can you figure out what the shape should be?\n \"\"\"\n conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b = params\n scores = None\n ############################################################################\n # TODO: Implement the forward pass for the three-layer ConvNet. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n paddings = tf.constant([[0,0], [2,2], [2,2], [0,0]])\n x = tf.pad(x, paddings, 'CONSTANT')\n conv1 = tf.nn.conv2d(x, conv_w1, strides=[1,1,1,1], padding=\"VALID\")+conv_b1\n relu1 = tf.nn.relu(conv1)\n \n paddings = tf.constant([[0,0], [1,1], [1,1], [0,0]])\n conv1 = tf.pad(conv1, paddings, 'CONSTANT')\n conv2 = tf.nn.conv2d(conv1, conv_w2, strides=[1,1,1,1], padding=\"VALID\")+conv_b2\n relu2 = tf.nn.relu(conv2)\n \n relu2 = flatten(relu2)\n scores = tf.matmul(relu2, fc_w) + fc_b\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return scores",
"_____no_output_____"
]
],
[
[
"After defing the forward pass of the three-layer ConvNet above, run the following cell to test your implementation. Like the two-layer network, we run the graph on a batch of zeros just to make sure the function doesn't crash, and produces outputs of the correct shape.\n\nWhen you run this function, `scores_np` should have shape `(64, 10)`.",
"_____no_output_____"
]
],
[
[
"def three_layer_convnet_test():\n \n with tf.device(device):\n x = tf.zeros((64, 32, 32, 3))\n conv_w1 = tf.zeros((5, 5, 3, 6))\n conv_b1 = tf.zeros((6,))\n conv_w2 = tf.zeros((3, 3, 6, 9))\n conv_b2 = tf.zeros((9,))\n fc_w = tf.zeros((32 * 32 * 9, 10))\n fc_b = tf.zeros((10,))\n params = [conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b]\n scores = three_layer_convnet(x, params)\n\n # Inputs to convolutional layers are 4-dimensional arrays with shape\n # [batch_size, height, width, channels]\n print('scores_np has shape: ', scores.shape)\n\nthree_layer_convnet_test()",
"scores_np has shape: (64, 10)\n"
]
],
[
[
"### Barebones TensorFlow: Training Step\n\nWe now define the `training_step` function performs a single training step. This will take three basic steps:\n\n1. Compute the loss\n2. Compute the gradient of the loss with respect to all network weights\n3. Make a weight update step using (stochastic) gradient descent.\n\n\nWe need to use a few new TensorFlow functions to do all of this:\n- For computing the cross-entropy loss we'll use `tf.nn.sparse_softmax_cross_entropy_with_logits`: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/nn/sparse_softmax_cross_entropy_with_logits\n\n- For averaging the loss across a minibatch of data we'll use `tf.reduce_mean`:\nhttps://www.tensorflow.org/versions/r2.0/api_docs/python/tf/reduce_mean\n\n- For computing gradients of the loss with respect to the weights we'll use `tf.GradientTape` (useful for Eager execution): https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/GradientTape\n\n- We'll mutate the weight values stored in a TensorFlow Tensor using `tf.assign_sub` (\"sub\" is for subtraction): https://www.tensorflow.org/api_docs/python/tf/assign_sub \n",
"_____no_output_____"
]
],
[
[
"def training_step(model_fn, x, y, params, learning_rate):\n with tf.GradientTape() as tape:\n scores = model_fn(x, params) # Forward pass of the model\n loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=scores)\n total_loss = tf.reduce_mean(loss)\n grad_params = tape.gradient(total_loss, params)\n\n # Make a vanilla gradient descent step on all of the model parameters\n # Manually update the weights using assign_sub()\n for w, grad_w in zip(params, grad_params):\n w.assign_sub(learning_rate * grad_w)\n \n return total_loss",
"_____no_output_____"
],
[
"def train_part2(model_fn, init_fn, learning_rate):\n \"\"\"\n Train a model on CIFAR-10.\n \n Inputs:\n - model_fn: A Python function that performs the forward pass of the model\n using TensorFlow; it should have the following signature:\n scores = model_fn(x, params) where x is a TensorFlow Tensor giving a\n minibatch of image data, params is a list of TensorFlow Tensors holding\n the model weights, and scores is a TensorFlow Tensor of shape (N, C)\n giving scores for all elements of x.\n - init_fn: A Python function that initializes the parameters of the model.\n It should have the signature params = init_fn() where params is a list\n of TensorFlow Tensors holding the (randomly initialized) weights of the\n model.\n - learning_rate: Python float giving the learning rate to use for SGD.\n \"\"\"\n \n \n params = init_fn() # Initialize the model parameters \n \n for t, (x_np, y_np) in enumerate(train_dset):\n # Run the graph on a batch of training data.\n loss = training_step(model_fn, x_np, y_np, params, learning_rate)\n \n # Periodically print the loss and check accuracy on the val set.\n if t % print_every == 0:\n print('Iteration %d, loss = %.4f' % (t, loss))\n check_accuracy(val_dset, x_np, model_fn, params)",
"_____no_output_____"
],
[
"def check_accuracy(dset, x, model_fn, params):\n \"\"\"\n Check accuracy on a classification model, e.g. for validation.\n \n Inputs:\n - dset: A Dataset object against which to check accuracy\n - x: A TensorFlow placeholder Tensor where input images should be fed\n - model_fn: the Model we will be calling to make predictions on x\n - params: parameters for the model_fn to work with\n \n Returns: Nothing, but prints the accuracy of the model\n \"\"\"\n num_correct, num_samples = 0, 0\n for x_batch, y_batch in dset:\n scores_np = model_fn(x_batch, params).numpy()\n y_pred = scores_np.argmax(axis=1)\n num_samples += x_batch.shape[0]\n num_correct += (y_pred == y_batch).sum()\n acc = float(num_correct) / num_samples\n print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))",
"_____no_output_____"
]
],
[
[
"### Barebones TensorFlow: Initialization\nWe'll use the following utility method to initialize the weight matrices for our models using Kaiming's normalization method.\n\n[1] He et al, *Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification\n*, ICCV 2015, https://arxiv.org/abs/1502.01852",
"_____no_output_____"
]
],
[
[
"def create_matrix_with_kaiming_normal(shape):\n if len(shape) == 2:\n fan_in, fan_out = shape[0], shape[1]\n elif len(shape) == 4:\n fan_in, fan_out = np.prod(shape[:3]), shape[3]\n return tf.keras.backend.random_normal(shape) * np.sqrt(2.0 / fan_in)",
"_____no_output_____"
]
],
[
[
"### Barebones TensorFlow: Train a Two-Layer Network\nWe are finally ready to use all of the pieces defined above to train a two-layer fully-connected network on CIFAR-10.\n\nWe just need to define a function to initialize the weights of the model, and call `train_part2`.\n\nDefining the weights of the network introduces another important piece of TensorFlow API: `tf.Variable`. A TensorFlow Variable is a Tensor whose value is stored in the graph and persists across runs of the computational graph; however unlike constants defined with `tf.zeros` or `tf.random_normal`, the values of a Variable can be mutated as the graph runs; these mutations will persist across graph runs. Learnable parameters of the network are usually stored in Variables.\n\nYou don't need to tune any hyperparameters, but you should achieve validation accuracies above 40% after one epoch of training.",
"_____no_output_____"
]
],
[
[
"def two_layer_fc_init():\n \"\"\"\n Initialize the weights of a two-layer network, for use with the\n two_layer_network function defined above. \n You can use the `create_matrix_with_kaiming_normal` helper!\n \n Inputs: None\n \n Returns: A list of:\n - w1: TensorFlow tf.Variable giving the weights for the first layer\n - w2: TensorFlow tf.Variable giving the weights for the second layer\n \"\"\"\n hidden_layer_size = 4000\n w1 = tf.Variable(create_matrix_with_kaiming_normal((3 * 32 * 32, 4000)))\n w2 = tf.Variable(create_matrix_with_kaiming_normal((4000, 10)))\n return [w1, w2]\n\nlearning_rate = 1e-2\ntrain_part2(two_layer_fc, two_layer_fc_init, learning_rate)",
"Iteration 0, loss = 3.0406\nGot 146 / 1000 correct (14.60%)\nIteration 100, loss = 2.0258\nGot 377 / 1000 correct (37.70%)\nIteration 200, loss = 1.4799\nGot 399 / 1000 correct (39.90%)\nIteration 300, loss = 1.8364\nGot 361 / 1000 correct (36.10%)\nIteration 400, loss = 1.8527\nGot 415 / 1000 correct (41.50%)\nIteration 500, loss = 1.8608\nGot 434 / 1000 correct (43.40%)\nIteration 600, loss = 1.8009\nGot 432 / 1000 correct (43.20%)\nIteration 700, loss = 1.9825\nGot 445 / 1000 correct (44.50%)\n"
]
],
[
[
"### Barebones TensorFlow: Train a three-layer ConvNet\nWe will now use TensorFlow to train a three-layer ConvNet on CIFAR-10.\n\nYou need to implement the `three_layer_convnet_init` function. Recall that the architecture of the network is:\n\n1. Convolutional layer (with bias) with 32 5x5 filters, with zero-padding 2\n2. ReLU\n3. Convolutional layer (with bias) with 16 3x3 filters, with zero-padding 1\n4. ReLU\n5. Fully-connected layer (with bias) to compute scores for 10 classes\n\nYou don't need to do any hyperparameter tuning, but you should see validation accuracies above 43% after one epoch of training.",
"_____no_output_____"
]
],
[
[
"def three_layer_convnet_init():\n \"\"\"\n Initialize the weights of a Three-Layer ConvNet, for use with the\n three_layer_convnet function defined above.\n You can use the `create_matrix_with_kaiming_normal` helper!\n \n Inputs: None\n \n Returns a list containing:\n - conv_w1: TensorFlow tf.Variable giving weights for the first conv layer\n - conv_b1: TensorFlow tf.Variable giving biases for the first conv layer\n - conv_w2: TensorFlow tf.Variable giving weights for the second conv layer\n - conv_b2: TensorFlow tf.Variable giving biases for the second conv layer\n - fc_w: TensorFlow tf.Variable giving weights for the fully-connected layer\n - fc_b: TensorFlow tf.Variable giving biases for the fully-connected layer\n \"\"\"\n params = None\n ############################################################################\n # TODO: Initialize the parameters of the three-layer network. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n conv_w1 = tf.Variable(kaiming_normal([5, 5, 3, 32]))\n conv_b1 = tf.Variable(np.zeros([32]), dtype=tf.float32)\n conv_w2 = tf.Variable(kaiming_normal([3, 3, 32, 16]))\n conv_b2 = tf.Variable(np.zeros([16]), dtype=tf.float32)\n fc_w = tf.Variable(kaiming_normal([32*32*16,10]))\n fc_b = tf.Variable(np.zeros([10]), dtype=tf.float32)\n params = (conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b)\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return params\n\nlearning_rate = 3e-3\ntrain_part2(three_layer_convnet, three_layer_convnet_init, learning_rate)",
"_____no_output_____"
]
],
[
[
"# Part III: Keras Model Subclassing API\n\nImplementing a neural network using the low-level TensorFlow API is a good way to understand how TensorFlow works, but it's a little inconvenient - we had to manually keep track of all Tensors holding learnable parameters. This was fine for a small network, but could quickly become unweildy for a large complex model.\n\nFortunately TensorFlow 2.0 provides higher-level APIs such as `tf.keras` which make it easy to build models out of modular, object-oriented layers. Further, TensorFlow 2.0 uses eager execution that evaluates operations immediately, without explicitly constructing any computational graphs. This makes it easy to write and debug models, and reduces the boilerplate code.\n\nIn this part of the notebook we will define neural network models using the `tf.keras.Model` API. To implement your own model, you need to do the following:\n\n1. Define a new class which subclasses `tf.keras.Model`. Give your class an intuitive name that describes it, like `TwoLayerFC` or `ThreeLayerConvNet`.\n2. In the initializer `__init__()` for your new class, define all the layers you need as class attributes. The `tf.keras.layers` package provides many common neural-network layers, like `tf.keras.layers.Dense` for fully-connected layers and `tf.keras.layers.Conv2D` for convolutional layers. Under the hood, these layers will construct `Variable` Tensors for any learnable parameters. **Warning**: Don't forget to call `super(YourModelName, self).__init__()` as the first line in your initializer!\n3. Implement the `call()` method for your class; this implements the forward pass of your model, and defines the *connectivity* of your network. Layers defined in `__init__()` implement `__call__()` so they can be used as function objects that transform input Tensors into output Tensors. Don't define any new layers in `call()`; any layers you want to use in the forward pass should be defined in `__init__()`.\n\nAfter you define your `tf.keras.Model` subclass, you can instantiate it and use it like the model functions from Part II.\n\n### Keras Model Subclassing API: Two-Layer Network\n\nHere is a concrete example of using the `tf.keras.Model` API to define a two-layer network. There are a few new bits of API to be aware of here:\n\nWe use an `Initializer` object to set up the initial values of the learnable parameters of the layers; in particular `tf.initializers.VarianceScaling` gives behavior similar to the Kaiming initialization method we used in Part II. You can read more about it here: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/initializers/VarianceScaling\n\nWe construct `tf.keras.layers.Dense` objects to represent the two fully-connected layers of the model. In addition to multiplying their input by a weight matrix and adding a bias vector, these layer can also apply a nonlinearity for you. For the first layer we specify a ReLU activation function by passing `activation='relu'` to the constructor; the second layer uses softmax activation function. Finally, we use `tf.keras.layers.Flatten` to flatten the output from the previous fully-connected layer.",
"_____no_output_____"
]
],
[
[
"class TwoLayerFC(tf.keras.Model):\n def __init__(self, hidden_size, num_classes):\n super(TwoLayerFC, self).__init__() \n initializer = tf.initializers.VarianceScaling(scale=2.0)\n self.fc1 = tf.keras.layers.Dense(hidden_size, activation='relu',\n kernel_initializer=initializer)\n self.fc2 = tf.keras.layers.Dense(num_classes, activation='softmax',\n kernel_initializer=initializer)\n self.flatten = tf.keras.layers.Flatten()\n \n def call(self, x, training=False):\n x = self.flatten(x)\n x = self.fc1(x)\n x = self.fc2(x)\n return x\n\n\ndef test_TwoLayerFC():\n \"\"\" A small unit test to exercise the TwoLayerFC model above. \"\"\"\n input_size, hidden_size, num_classes = 50, 42, 10\n x = tf.zeros((64, input_size))\n model = TwoLayerFC(hidden_size, num_classes)\n with tf.device(device):\n scores = model(x)\n print(scores.shape)\n \ntest_TwoLayerFC()",
"_____no_output_____"
]
],
[
[
"### Keras Model Subclassing API: Three-Layer ConvNet\nNow it's your turn to implement a three-layer ConvNet using the `tf.keras.Model` API. Your model should have the same architecture used in Part II:\n\n1. Convolutional layer with 5 x 5 kernels, with zero-padding of 2\n2. ReLU nonlinearity\n3. Convolutional layer with 3 x 3 kernels, with zero-padding of 1\n4. ReLU nonlinearity\n5. Fully-connected layer to give class scores\n6. Softmax nonlinearity\n\nYou should initialize the weights of your network using the same initialization method as was used in the two-layer network above.\n\n**Hint**: Refer to the documentation for `tf.keras.layers.Conv2D` and `tf.keras.layers.Dense`:\n\nhttps://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Conv2D\n\nhttps://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dense",
"_____no_output_____"
]
],
[
[
"class ThreeLayerConvNet(tf.keras.Model):\n def __init__(self, channel_1, channel_2, num_classes):\n super(ThreeLayerConvNet, self).__init__()\n ########################################################################\n # TODO: Implement the __init__ method for a three-layer ConvNet. You #\n # should instantiate layer objects to be used in the forward pass. #\n ########################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n initializer = tf.variance_scaling_initializer(scale=2.0)\n self.conv1 = tf.layers.Conv2D(channel_1, [5,5], [1,1], padding='valid',\n kernel_initializer=initializer,\n activation=tf.nn.relu)\n self.conv2 = tf.layers.Conv2D(channel_2, [3,3], [1,1], padding='valid',\n kernel_initializer=initializer,\n activation=tf.nn.relu)\n self.fc = tf.layers.Dense(num_classes, kernel_initializer=initializer)\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ########################################################################\n # END OF YOUR CODE #\n ########################################################################\n \n def call(self, x, training=False):\n scores = None\n ########################################################################\n # TODO: Implement the forward pass for a three-layer ConvNet. You #\n # should use the layer objects defined in the __init__ method. #\n ########################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n padding = tf.constant([[0,0],[2,2],[2,2],[0,0]])\n x = tf.pad(x, padding, 'CONSTANT')\n x = self.conv1(x)\n padding = tf.constant([[0,0],[1,1],[1,1],[0,0]])\n x = tf.pad(x, padding, 'CONSTANT')\n x = self.conv2(x)\n x = tf.layers.flatten(x)\n scores = self.fc(x)\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ########################################################################\n # END OF YOUR CODE #\n ######################################################################## \n return scores",
"_____no_output_____"
]
],
[
[
"Once you complete the implementation of the `ThreeLayerConvNet` above you can run the following to ensure that your implementation does not crash and produces outputs of the expected shape.",
"_____no_output_____"
]
],
[
[
"def test_ThreeLayerConvNet(): \n channel_1, channel_2, num_classes = 12, 8, 10\n model = ThreeLayerConvNet(channel_1, channel_2, num_classes)\n with tf.device(device):\n x = tf.zeros((64, 3, 32, 32))\n scores = model(x)\n print(scores.shape)\n\ntest_ThreeLayerConvNet()",
"_____no_output_____"
]
],
[
[
"### Keras Model Subclassing API: Eager Training\n\nWhile keras models have a builtin training loop (using the `model.fit`), sometimes you need more customization. Here's an example, of a training loop implemented with eager execution.\n\nIn particular, notice `tf.GradientTape`. Automatic differentiation is used in the backend for implementing backpropagation in frameworks like TensorFlow. During eager execution, `tf.GradientTape` is used to trace operations for computing gradients later. A particular `tf.GradientTape` can only compute one gradient; subsequent calls to tape will throw a runtime error. \n\nTensorFlow 2.0 ships with easy-to-use built-in metrics under `tf.keras.metrics` module. Each metric is an object, and we can use `update_state()` to add observations and `reset_state()` to clear all observations. We can get the current result of a metric by calling `result()` on the metric object.",
"_____no_output_____"
]
],
[
[
"def train_part34(model_init_fn, optimizer_init_fn, num_epochs=1, is_training=False):\n \"\"\"\n Simple training loop for use with models defined using tf.keras. It trains\n a model for one epoch on the CIFAR-10 training set and periodically checks\n accuracy on the CIFAR-10 validation set.\n \n Inputs:\n - model_init_fn: A function that takes no parameters; when called it\n constructs the model we want to train: model = model_init_fn()\n - optimizer_init_fn: A function which takes no parameters; when called it\n constructs the Optimizer object we will use to optimize the model:\n optimizer = optimizer_init_fn()\n - num_epochs: The number of epochs to train for\n \n Returns: Nothing, but prints progress during trainingn\n \"\"\" \n with tf.device(device):\n\n # Compute the loss like we did in Part II\n loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()\n \n model = model_init_fn()\n optimizer = optimizer_init_fn()\n \n train_loss = tf.keras.metrics.Mean(name='train_loss')\n train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')\n \n val_loss = tf.keras.metrics.Mean(name='val_loss')\n val_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='val_accuracy')\n \n t = 0\n for epoch in range(num_epochs):\n \n # Reset the metrics - https://www.tensorflow.org/alpha/guide/migration_guide#new-style_metrics\n train_loss.reset_states()\n train_accuracy.reset_states()\n \n for x_np, y_np in train_dset:\n with tf.GradientTape() as tape:\n \n # Use the model function to build the forward pass.\n scores = model(x_np, training=is_training)\n loss = loss_fn(y_np, scores)\n \n gradients = tape.gradient(loss, model.trainable_variables)\n optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n \n # Update the metrics\n train_loss.update_state(loss)\n train_accuracy.update_state(y_np, scores)\n \n if t % print_every == 0:\n val_loss.reset_states()\n val_accuracy.reset_states()\n for test_x, test_y in val_dset:\n # During validation at end of epoch, training set to False\n prediction = model(test_x, training=False)\n t_loss = loss_fn(test_y, prediction)\n\n val_loss.update_state(t_loss)\n val_accuracy.update_state(test_y, prediction)\n \n template = 'Iteration {}, Epoch {}, Loss: {}, Accuracy: {}, Val Loss: {}, Val Accuracy: {}'\n print (template.format(t, epoch+1,\n train_loss.result(),\n train_accuracy.result()*100,\n val_loss.result(),\n val_accuracy.result()*100))\n t += 1",
"_____no_output_____"
]
],
[
[
"### Keras Model Subclassing API: Train a Two-Layer Network\nWe can now use the tools defined above to train a two-layer network on CIFAR-10. We define the `model_init_fn` and `optimizer_init_fn` that construct the model and optimizer respectively when called. Here we want to train the model using stochastic gradient descent with no momentum, so we construct a `tf.keras.optimizers.SGD` function; you can [read about it here](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/optimizers/SGD).\n\nYou don't need to tune any hyperparameters here, but you should achieve validation accuracies above 40% after one epoch of training.",
"_____no_output_____"
]
],
[
[
"hidden_size, num_classes = 4000, 10\nlearning_rate = 1e-2\n\ndef model_init_fn():\n return TwoLayerFC(hidden_size, num_classes)\n\ndef optimizer_init_fn():\n return tf.keras.optimizers.SGD(learning_rate=learning_rate)\n\ntrain_part34(model_init_fn, optimizer_init_fn)",
"_____no_output_____"
]
],
[
[
"### Keras Model Subclassing API: Train a Three-Layer ConvNet\nHere you should use the tools we've defined above to train a three-layer ConvNet on CIFAR-10. Your ConvNet should use 32 filters in the first convolutional layer and 16 filters in the second layer.\n\nTo train the model you should use gradient descent with Nesterov momentum 0.9. \n\n**HINT**: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/optimizers/SGD\n\nYou don't need to perform any hyperparameter tuning, but you should achieve validation accuracies above 50% after training for one epoch.",
"_____no_output_____"
]
],
[
[
"learning_rate = 3e-3\nchannel_1, channel_2, num_classes = 32, 16, 10\n\ndef model_init_fn():\n model = None\n ############################################################################\n # TODO: Complete the implementation of model_fn. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return model\n\ndef optimizer_init_fn():\n optimizer = None\n ############################################################################\n # TODO: Complete the implementation of model_fn. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return optimizer\n\ntrain_part34(model_init_fn, optimizer_init_fn)",
"_____no_output_____"
]
],
[
[
"# Part IV: Keras Sequential API\nIn Part III we introduced the `tf.keras.Model` API, which allows you to define models with any number of learnable layers and with arbitrary connectivity between layers.\n\nHowever for many models you don't need such flexibility - a lot of models can be expressed as a sequential stack of layers, with the output of each layer fed to the next layer as input. If your model fits this pattern, then there is an even easier way to define your model: using `tf.keras.Sequential`. You don't need to write any custom classes; you simply call the `tf.keras.Sequential` constructor with a list containing a sequence of layer objects.\n\nOne complication with `tf.keras.Sequential` is that you must define the shape of the input to the model by passing a value to the `input_shape` of the first layer in your model.\n\n### Keras Sequential API: Two-Layer Network\nIn this subsection, we will rewrite the two-layer fully-connected network using `tf.keras.Sequential`, and train it using the training loop defined above.\n\nYou don't need to perform any hyperparameter tuning here, but you should see validation accuracies above 40% after training for one epoch.",
"_____no_output_____"
]
],
[
[
"learning_rate = 1e-2\n\ndef model_init_fn():\n input_shape = (32, 32, 3)\n hidden_layer_size, num_classes = 4000, 10\n initializer = tf.initializers.VarianceScaling(scale=2.0)\n layers = [\n tf.keras.layers.Flatten(input_shape=input_shape),\n tf.keras.layers.Dense(hidden_layer_size, activation='relu',\n kernel_initializer=initializer),\n tf.keras.layers.Dense(num_classes, activation='softmax', \n kernel_initializer=initializer),\n ]\n model = tf.keras.Sequential(layers)\n return model\n\ndef optimizer_init_fn():\n return tf.keras.optimizers.SGD(learning_rate=learning_rate) \n\ntrain_part34(model_init_fn, optimizer_init_fn)",
"_____no_output_____"
]
],
[
[
"### Abstracting Away the Training Loop\nIn the previous examples, we used a customised training loop to train models (e.g. `train_part34`). Writing your own training loop is only required if you need more flexibility and control during training your model. Alternately, you can also use built-in APIs like `tf.keras.Model.fit()` and `tf.keras.Model.evaluate` to train and evaluate a model. Also remember to configure your model for training by calling `tf.keras.Model.compile.\n\nYou don't need to perform any hyperparameter tuning here, but you should see validation and test accuracies above 42% after training for one epoch.",
"_____no_output_____"
]
],
[
[
"model = model_init_fn()\nmodel.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate),\n loss='sparse_categorical_crossentropy',\n metrics=[tf.keras.metrics.sparse_categorical_accuracy])\nmodel.fit(X_train, y_train, batch_size=64, epochs=1, validation_data=(X_val, y_val))\nmodel.evaluate(X_test, y_test)",
"_____no_output_____"
]
],
[
[
"### Keras Sequential API: Three-Layer ConvNet\nHere you should use `tf.keras.Sequential` to reimplement the same three-layer ConvNet architecture used in Part II and Part III. As a reminder, your model should have the following architecture:\n\n1. Convolutional layer with 32 5x5 kernels, using zero padding of 2\n2. ReLU nonlinearity\n3. Convolutional layer with 16 3x3 kernels, using zero padding of 1\n4. ReLU nonlinearity\n5. Fully-connected layer giving class scores\n6. Softmax nonlinearity\n\nYou should initialize the weights of the model using a `tf.initializers.VarianceScaling` as above.\n\nYou should train the model using Nesterov momentum 0.9.\n\nYou don't need to perform any hyperparameter search, but you should achieve accuracy above 45% after training for one epoch.",
"_____no_output_____"
]
],
[
[
"def model_init_fn():\n model = None\n ############################################################################\n # TODO: Construct a three-layer ConvNet using tf.keras.Sequential. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return model\n\nlearning_rate = 5e-4\ndef optimizer_init_fn():\n optimizer = None\n ############################################################################\n # TODO: Complete the implementation of model_fn. #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return optimizer\n\ntrain_part34(model_init_fn, optimizer_init_fn)",
"_____no_output_____"
]
],
[
[
"We will also train this model with the built-in training loop APIs provided by TensorFlow.",
"_____no_output_____"
]
],
[
[
"model = model_init_fn()\nmodel.compile(optimizer='sgd',\n loss='sparse_categorical_crossentropy',\n metrics=[tf.keras.metrics.sparse_categorical_accuracy])\nmodel.fit(X_train, y_train, batch_size=64, epochs=1, validation_data=(X_val, y_val))\nmodel.evaluate(X_test, y_test)",
"_____no_output_____"
]
],
[
[
"## Part IV: Functional API\n### Demonstration with a Two-Layer Network \n\nIn the previous section, we saw how we can use `tf.keras.Sequential` to stack layers to quickly build simple models. But this comes at the cost of losing flexibility.\n\nOften we will have to write complex models that have non-sequential data flows: a layer can have **multiple inputs and/or outputs**, such as stacking the output of 2 previous layers together to feed as input to a third! (Some examples are residual connections and dense blocks.)\n\nIn such cases, we can use Keras functional API to write models with complex topologies such as:\n\n 1. Multi-input models\n 2. Multi-output models\n 3. Models with shared layers (the same layer called several times)\n 4. Models with non-sequential data flows (e.g. residual connections)\n\nWriting a model with Functional API requires us to create a `tf.keras.Model` instance and explicitly write input tensors and output tensors for this model. ",
"_____no_output_____"
]
],
[
[
"def two_layer_fc_functional(input_shape, hidden_size, num_classes): \n initializer = tf.initializers.VarianceScaling(scale=2.0)\n inputs = tf.keras.Input(shape=input_shape)\n flattened_inputs = tf.keras.layers.Flatten()(inputs)\n fc1_output = tf.keras.layers.Dense(hidden_size, activation='relu',\n kernel_initializer=initializer)(flattened_inputs)\n scores = tf.keras.layers.Dense(num_classes, activation='softmax',\n kernel_initializer=initializer)(fc1_output)\n\n # Instantiate the model given inputs and outputs.\n model = tf.keras.Model(inputs=inputs, outputs=scores)\n return model\n\ndef test_two_layer_fc_functional():\n \"\"\" A small unit test to exercise the TwoLayerFC model above. \"\"\"\n input_size, hidden_size, num_classes = 50, 42, 10\n input_shape = (50,)\n \n x = tf.zeros((64, input_size))\n model = two_layer_fc_functional(input_shape, hidden_size, num_classes)\n \n with tf.device(device):\n scores = model(x)\n print(scores.shape)\n \ntest_two_layer_fc_functional()",
"_____no_output_____"
]
],
[
[
"### Keras Functional API: Train a Two-Layer Network\nYou can now train this two-layer network constructed using the functional API.\n\nYou don't need to perform any hyperparameter tuning here, but you should see validation accuracies above 40% after training for one epoch.",
"_____no_output_____"
]
],
[
[
"input_shape = (32, 32, 3)\nhidden_size, num_classes = 4000, 10\nlearning_rate = 1e-2\n\ndef model_init_fn():\n return two_layer_fc_functional(input_shape, hidden_size, num_classes)\n\ndef optimizer_init_fn():\n return tf.keras.optimizers.SGD(learning_rate=learning_rate)\n\ntrain_part34(model_init_fn, optimizer_init_fn)",
"_____no_output_____"
]
],
[
[
"# Part V: CIFAR-10 open-ended challenge\n\nIn this section you can experiment with whatever ConvNet architecture you'd like on CIFAR-10.\n\nYou should experiment with architectures, hyperparameters, loss functions, regularization, or anything else you can think of to train a model that achieves **at least 70%** accuracy on the **validation** set within 10 epochs. You can use the built-in train function, the `train_part34` function from above, or implement your own training loop.\n\nDescribe what you did at the end of the notebook.\n\n### Some things you can try:\n- **Filter size**: Above we used 5x5 and 3x3; is this optimal?\n- **Number of filters**: Above we used 16 and 32 filters. Would more or fewer do better?\n- **Pooling**: We didn't use any pooling above. Would this improve the model?\n- **Normalization**: Would your model be improved with batch normalization, layer normalization, group normalization, or some other normalization strategy?\n- **Network architecture**: The ConvNet above has only three layers of trainable parameters. Would a deeper model do better?\n- **Global average pooling**: Instead of flattening after the final convolutional layer, would global average pooling do better? This strategy is used for example in Google's Inception network and in Residual Networks.\n- **Regularization**: Would some kind of regularization improve performance? Maybe weight decay or dropout?\n\n### NOTE: Batch Normalization / Dropout\nIf you are using Batch Normalization and Dropout, remember to pass `is_training=True` if you use the `train_part34()` function. BatchNorm and Dropout layers have different behaviors at training and inference time. `training` is a specific keyword argument reserved for this purpose in any `tf.keras.Model`'s `call()` function. Read more about this here : https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/BatchNormalization#methods\nhttps://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dropout#methods\n\n### Tips for training\nFor each network architecture that you try, you should tune the learning rate and other hyperparameters. When doing this there are a couple important things to keep in mind: \n\n- If the parameters are working well, you should see improvement within a few hundred iterations\n- Remember the coarse-to-fine approach for hyperparameter tuning: start by testing a large range of hyperparameters for just a few training iterations to find the combinations of parameters that are working at all.\n- Once you have found some sets of parameters that seem to work, search more finely around these parameters. You may need to train for more epochs.\n- You should use the validation set for hyperparameter search, and save your test set for evaluating your architecture on the best parameters as selected by the validation set.\n\n### Going above and beyond\nIf you are feeling adventurous there are many other features you can implement to try and improve your performance. You are **not required** to implement any of these, but don't miss the fun if you have time!\n\n- Alternative optimizers: you can try Adam, Adagrad, RMSprop, etc.\n- Alternative activation functions such as leaky ReLU, parametric ReLU, ELU, or MaxOut.\n- Model ensembles\n- Data augmentation\n- New Architectures\n - [ResNets](https://arxiv.org/abs/1512.03385) where the input from the previous layer is added to the output.\n - [DenseNets](https://arxiv.org/abs/1608.06993) where inputs into previous layers are concatenated together.\n - [This blog has an in-depth overview](https://chatbotslife.com/resnets-highwaynets-and-densenets-oh-my-9bb15918ee32)\n \n### Have fun and happy training! ",
"_____no_output_____"
]
],
[
[
"class CustomConvNet(tf.keras.Model):\n def __init__(self):\n super(CustomConvNet, self).__init__()\n ############################################################################\n # TODO: Construct a model that performs well on CIFAR-10 #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n \n def call(self, input_tensor, training=False):\n ############################################################################\n # TODO: Construct a model that performs well on CIFAR-10 #\n ############################################################################\n # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n\n pass\n\n # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****\n ############################################################################\n # END OF YOUR CODE #\n ############################################################################\n return x\n\n\nprint_every = 700\nnum_epochs = 10\n\nmodel = CustomConvNet()\n\ndef model_init_fn():\n return CustomConvNet()\n\ndef optimizer_init_fn():\n learning_rate = 1e-3\n return tf.keras.optimizers.Adam(learning_rate) \n\ntrain_part34(model_init_fn, optimizer_init_fn, num_epochs=num_epochs, is_training=True)",
"_____no_output_____"
]
],
[
[
"## Describe what you did \n\nIn the cell below you should write an explanation of what you did, any additional features that you implemented, and/or any graphs that you made in the process of training and evaluating your network.",
"_____no_output_____"
],
[
"TODO: Tell us what you did",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d02cd2fbfe58b8aaf8119cc1ae63e757a28349cd
| 4,444 |
ipynb
|
Jupyter Notebook
|
series2/week1/week1_class2.ipynb
|
s-ahuja/AI-Saturday
|
17a4c1eeeb480f1a1ff29c1828ea60f30703965a
|
[
"Apache-2.0"
] | null | null | null |
series2/week1/week1_class2.ipynb
|
s-ahuja/AI-Saturday
|
17a4c1eeeb480f1a1ff29c1828ea60f30703965a
|
[
"Apache-2.0"
] | null | null | null |
series2/week1/week1_class2.ipynb
|
s-ahuja/AI-Saturday
|
17a4c1eeeb480f1a1ff29c1828ea60f30703965a
|
[
"Apache-2.0"
] | null | null | null | 18.594142 | 82 | 0.478173 |
[
[
[
"## paperspace\n## tmux - multiple screens\n## tensor = array",
"_____no_output_____"
]
],
[
[
"## nomenclature\n# error/loss = target - calculated",
"_____no_output_____"
],
[
"# non linear - activation functions",
"_____no_output_____"
]
],
[
[
"# Slide 24, Slide 25 of neuralNetwork.pptx",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"#Slide 25\nweights_1 = np.array([[0.71,0.112],[0.355,0.856],[0.268,0.468]])\nx = np.array([1,1])\nprint(weights)\nprint(x)",
"[[0.71 0.112]\n [0.355 0.856]\n [0.268 0.468]]\n[1 1]\n"
],
[
"y_linear_1 = np.dot(weights,x)\nprint(y_linear_1)",
"[0.822 1.211 0.736]\n"
],
[
"import math\ndef sigmoid(x):\n return 1 / (1 + math.exp(-x))\nfn_sigmoid = np.vectorize(sigmoid)",
"_____no_output_____"
],
[
"y_nonlinear_1 = fn_sigmoid(y_linear_1)\nprint(y_nonlinear_1)",
"[0.69466072 0.77047584 0.67612055]\n"
],
[
"weights2 = np.array([0.116,0.329,0.708]) # 1x3",
"_____no_output_____"
],
[
"y_linear_2 = np.dot(weights2,y_nonlinear_1)\nprint(y_linear_2)",
"0.8127605425998854\n"
],
[
"y_nonlinear_2 = fn_sigmoid(y_linear_2)\nprint(y_nonlinear_2)",
"0.6926974470214398\n"
]
],
[
[
"# Slide 26",
"_____no_output_____"
]
],
[
[
"import math\n\nweights_list = []\nweights_list.append(np.array([[0.71,0.112],[0.355,0.856],[0.268,0.468]]))\nweights_list.append(np.array([0.116,0.329,0.708]))\ninput_x = np.array([1,1])\n\ndef sigmoid(x):\n return 1 / (1 + math.exp(-x))\n\nfn_sigmoid = np.vectorize(sigmoid)\n\ndef calc(weight,x):\n y_linear = np.dot(weight,x)\n y_nonlinear = fn_sigmoid(y_linear)\n return y_nonlinear\n\nfor weight in weights_list:\n y = calc(weight,input_x)\n input_x = y\n\nprint (y)",
"0.6926974470214398\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02cf188ce96e2455469aaa75b7f7cbaef77b071
| 18,598 |
ipynb
|
Jupyter Notebook
|
Week 2 - A Crash Course In Python Part 2/Collections.ipynb
|
2series/Analytics-And-Python
|
38cc6b17e0c946da6360a63025979d9bffddedfa
|
[
"MIT"
] | null | null | null |
Week 2 - A Crash Course In Python Part 2/Collections.ipynb
|
2series/Analytics-And-Python
|
38cc6b17e0c946da6360a63025979d9bffddedfa
|
[
"MIT"
] | null | null | null |
Week 2 - A Crash Course In Python Part 2/Collections.ipynb
|
2series/Analytics-And-Python
|
38cc6b17e0c946da6360a63025979d9bffddedfa
|
[
"MIT"
] | null | null | null | 20.084233 | 902 | 0.464297 |
[
[
[
"<h1>Lists</h1>\n<li>Sequential, Ordered Collection\n",
"_____no_output_____"
],
[
"<h2>Creating lists</h2>",
"_____no_output_____"
]
],
[
[
"x = [4,2,6,3] #Create a list with values\ny = list() # Create an empty list\ny = [] #Create an empty list\nprint(x)\nprint(y)",
"[4, 2, 6, 3]\n[]\n"
]
],
[
[
"<h3>Adding items to a list</h3>\n",
"_____no_output_____"
]
],
[
[
"x=list()\nprint(x)\nx.append('One') #Adds 'One' to the back of the empty list\nprint(x)\nx.append('Two') #Adds 'Two' to the back of the list ['One']\nprint(x)",
"[]\n['One']\n['One', 'Two']\n"
],
[
"x.insert(0,'Half') #Inserts 'Half' at location 0. Items will shift to make roomw\nprint(x)",
"['Half', 'One', 'Two']\n"
],
[
"x=list()\nx.extend([1,2,3]) #Unpacks the list and adds each item to the back of the list\nprint(x)",
"[1, 2, 3]\n"
]
],
[
[
"<h3>Indexing and slicing</h3>",
"_____no_output_____"
]
],
[
[
"x=[1,7,2,5,3,5,67,32]\nprint(len(x))\nprint(x[3])\nprint(x[2:5])\nprint(x[-1])\nprint(x[::-1])",
"8\n5\n[2, 5, 3]\n32\n[32, 67, 5, 3, 5, 2, 7, 1]\n"
]
],
[
[
"<h3>Removing items from a list</h3>",
"_____no_output_____"
]
],
[
[
"x=[1,7,2,5,3,5,67,32]\nx.pop() #Removes the last element from a list\nprint(x)\nx.pop(3) #Removes element at item 3 from a list\nprint(x)\nx.remove(7) #Removes the first 7 from the list\nprint(x)",
"[1, 7, 2, 5, 3, 5, 67]\n[1, 7, 2, 3, 5, 67]\n[1, 2, 3, 5, 67]\n"
]
],
[
[
"<h3>Anything you want to remove must be in the list or the location must be inside the list</h3>",
"_____no_output_____"
]
],
[
[
"x.remove(20)",
"_____no_output_____"
]
],
[
[
"<h2>Mutablility of lists</h2>",
"_____no_output_____"
]
],
[
[
"y=['a','b']\nx = [1,y,3]\nprint(x)\nprint(y)\ny[1] = 4\nprint(y)",
"[1, ['a', 'b'], 3]\n['a', 'b']\n['a', 4]\n"
],
[
"print(x)",
"[1, ['a', 4], 3]\n"
],
[
"x=\"Hello\"\nprint(x,id(x))\nx+=\" You!\"\nprint(x,id(x)) #x is not the same object it was\ny=[\"Hello\"]\nprint(y,id(y))\ny+=[\"You!\"] \nprint(y,id(y)) #y is still the same object. Lists are mutable. Strings are immutable\n",
"Hello 1833079418136\nHello You! 1833080396016\n['Hello'] 1833078976456\n['Hello', 'You!'] 1833078976456\n"
],
[
"def eggs(item,total=0):\n total+=item\n return total\n\n\ndef spam(elem,some_list=[]):\n some_list.append(elem)\n return some_list\n",
"_____no_output_____"
],
[
"print(eggs(1))\nprint(eggs(2))\n\nprint(spam(1))\nprint(spam(2))",
"1\n2\n[1]\n[1, 2]\n"
]
],
[
[
"<h1>Iteration</h1>",
"_____no_output_____"
],
[
"<h2>Range iteration</h2>",
"_____no_output_____"
]
],
[
[
"#The for loop creates a new variable (e.g., index below)\n#range(len(x)) generates values from 0 to len(x) \nx=[1,7,2,5,3,5,67,32]\nfor index in range(len(x)):\n print(x[index])",
"1\n7\n2\n5\n3\n5\n67\n32\n"
],
[
"list(range(len(x)))",
"_____no_output_____"
]
],
[
[
"<h3>List element iteration</h3>",
"_____no_output_____"
]
],
[
[
"x=[1,7,2,5,3,5,67,32]\n#The for draws elements - sequentially - from the list x and uses the variable \"element\" to store values\nfor element in x: \n print(element)",
"1\n7\n2\n5\n3\n5\n67\n32\n"
]
],
[
[
"<h3>Practice problem</h3>",
"_____no_output_____"
],
[
"Write a function search_list that searches a list of tuple pairs and returns the value associated with the first element of the pair",
"_____no_output_____"
]
],
[
[
"def search_list(list_of_tuples,value):\n #Write the function here\n for t in prices:\n if t[0] == value:\n return t[1]",
"_____no_output_____"
],
[
"prices = [('AAPL',96.43),('IONS',39.28),('GS',159.53)]\nticker = 'IONS'\nprint(search_list(prices,ticker))",
"39.28\n"
]
],
[
[
"<h1>Dictionaries</h1>",
"_____no_output_____"
]
],
[
[
"mktcaps = {'AAPL':538.7,'GOOG':68.7,'IONS':4.6}\n",
"_____no_output_____"
],
[
"mktcaps['AAPL'] #Returns the value associated with the key \"AAPL\"",
"_____no_output_____"
],
[
"mktcaps['GS'] #Error because GS is not in mktcaps",
"_____no_output_____"
],
[
"mktcaps.get('GS') #Returns None because GS is not in mktcaps",
"_____no_output_____"
],
[
"mktcaps['GS'] = 88.65 #Adds GS to the dictionary\nprint(mktcaps) ",
"{'AAPL': 538.7, 'GOOG': 68.7, 'IONS': 4.6, 'GS': 88.65}\n"
],
[
"del(mktcaps['GOOG']) #Removes GOOG from mktcaps\nprint(mktcaps)",
"{'AAPL': 538.7, 'IONS': 4.6, 'GS': 88.65}\n"
],
[
"mktcaps.keys() #Returns all the keys",
"_____no_output_____"
],
[
"mktcaps.values() #Returns all the values",
"_____no_output_____"
],
[
"list1 = [1, 2, 3, 4, 5, 6, 7]",
"_____no_output_____"
],
[
"list1[0]",
"_____no_output_____"
],
[
"list1[:2]",
"_____no_output_____"
],
[
"list1[:-2]",
"_____no_output_____"
],
[
"list1[3:5]",
"_____no_output_____"
],
[
"data = [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]\nprint(data[1][0][0])",
"5\n"
],
[
"numbers = [1, 2, 3, 4] \nnumbers.append([5, 6, 7, 8])\nprint(len(numbers))",
"5\n"
],
[
"list1 = [1, 2, 3, 4, 5, 6, 7]\n\nprint(list1[0])\nprint(list1[:2])\nprint(list1[:-2])\nprint(list1[3:5])",
"1\n[1, 2]\n[1, 2, 3, 4, 5]\n[4, 5]\n"
],
[
"dict1 = {\"john\":40, \"peter\":45} \ndict2 = {\"john\":466, \"peter\":45}\ndict1 > dict2",
"_____no_output_____"
],
[
"dict1 = {\"a\":1, \"b\":2}# to delete the entry for \"a\":1, use ________.\n#d.delete(\"a\":1)\n#dict1.delete(\"a\")\n#del dict1(\"a\":1)\ndel dict1[\"a\"]\ndict1",
"_____no_output_____"
],
[
"s = {1, 2, 4, 3}# which of the following will result in an exception (error)? Multiple options may be correct.\n\n#print(s[3])\nprint(max(s))\nprint(len(s))\n#s[3] = 45",
"4\n4\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02cf1a0df0828c2590dcb5c7d502169dfc85b42
| 25,334 |
ipynb
|
Jupyter Notebook
|
notebooks/01_jma_Main.ipynb
|
javiermas/BCNAirQualityDatathon
|
88e0d487046a3d4b76f7757c7def2350d86766ab
|
[
"MIT"
] | null | null | null |
notebooks/01_jma_Main.ipynb
|
javiermas/BCNAirQualityDatathon
|
88e0d487046a3d4b76f7757c7def2350d86766ab
|
[
"MIT"
] | null | null | null |
notebooks/01_jma_Main.ipynb
|
javiermas/BCNAirQualityDatathon
|
88e0d487046a3d4b76f7757c7def2350d86766ab
|
[
"MIT"
] | null | null | null | 32.272611 | 101 | 0.355609 |
[
[
[
"%load_ext autoreload\n%autoreload 2\nimport pandas as pd\nimport numpy as np\nfrom datetime import timedelta\nfrom airquality.data.prepare_data import create_model_matrix, create_ts_df",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"'''\nheaders_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/headers_mod.csv'\nheaders_obs = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/headers_obs.csv'\nstations_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/stations.csv'\n'''\ntargets_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/raw/targets.csv'\nobs_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/all_obs.csv'\nmodels_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/all_models.csv'\nsubmission_path = '/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/submissions/'",
"_____no_output_____"
],
[
"def read_obs(path='/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/processed/all_obs.csv'):\n data = pd.read_csv(obs_path).rename(columns={\n 'AirQualityStationEoICode':'station',\n 'DatetimeBegin': 'datetime',\n 'Concentration': 'concentration'\n})\n data['datetime'] = pd.to_datetime(data['datetime'])\n data = data.sort_values(['station', 'datetime']).reset_index(drop=True)\n data = create_ts_df(data, 'datetime')\n data['date'] = data['datetime'].dt.date\n return data",
"_____no_output_____"
],
[
"data = pd.read_csv(obs_path).rename(columns={\n 'AirQualityStationEoICode':'station',\n 'DatetimeBegin': 'datetime',\n 'Concentration': 'concentration'\n})\ndata['datetime'] = pd.to_datetime(data['datetime'])\ndata = data.sort_values(['station', 'datetime']).reset_index(drop=True)\ndata = create_ts_df(data, 'datetime')\ndata['date'] = data['datetime'].dt.date\ndata.head()",
"_____no_output_____"
],
[
"def read_targets(path='/Users/b.yc0006/Cloud/BCNAirQualityDatathon/data/raw/targets.csv'):\n target = pd.read_csv(targets_path).rename(columns={\n 'target':'concentration',\n })\n target['date'] = pd.to_datetime(target['date'])\n target = target.sort_values(['station', 'date']).reset_index(drop=True)\n target = create_ts_df(target, 'date')\n return target",
"_____no_output_____"
],
[
"data.loc[data['date'] == ((target['date'][0] - timedelta(days=1)).date())]",
"_____no_output_____"
],
[
"for date in target['date']:\n test = data.loc[data['date'] < date]\n trainX, trainY = train.drop(target_cols, axis=1), train[target_cols]\n gt = target.loc[target['date'] == date]\n LSTM_K.predict()\n \n",
"_____no_output_____"
],
[
"target['date']",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02cf67b81a5540b4e80f13d23fbe98dfea6e4ee
| 886 |
ipynb
|
Jupyter Notebook
|
doc/source/tutorial/MNIST.ipynb
|
IronySuzumiya/pytorx
|
32995481b5092a46cdbacd2feb79fba2f5292664
|
[
"Apache-2.0"
] | 20 |
2019-10-14T07:00:28.000Z
|
2022-03-30T07:24:56.000Z
|
doc/source/tutorial/MNIST.ipynb
|
IronySuzumiya/pytorx
|
32995481b5092a46cdbacd2feb79fba2f5292664
|
[
"Apache-2.0"
] | 2 |
2021-08-31T12:43:34.000Z
|
2021-10-03T06:27:51.000Z
|
doc/source/tutorial/MNIST.ipynb
|
IronySuzumiya/pytorx
|
32995481b5092a46cdbacd2feb79fba2f5292664
|
[
"Apache-2.0"
] | 15 |
2019-09-10T13:00:25.000Z
|
2021-12-06T08:07:04.000Z
| 18.851064 | 154 | 0.551919 |
[
[
[
"# hello\n",
"_____no_output_____"
],
[
"This tutorial will give a toy example of using the PytorX library to conduct the neural network mapping on crossbar arrays to perform computation.\n",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown"
]
] |
d02d0029bad697b3958428cc561b083ba2b4ded3
| 587,536 |
ipynb
|
Jupyter Notebook
|
topocode2.ipynb
|
pangeo-data/pangeo-rema
|
271e573ca977001a1978c936b00c139b8262e865
|
[
"Apache-2.0"
] | null | null | null |
topocode2.ipynb
|
pangeo-data/pangeo-rema
|
271e573ca977001a1978c936b00c139b8262e865
|
[
"Apache-2.0"
] | 5 |
2019-03-19T14:00:31.000Z
|
2019-09-16T15:03:10.000Z
|
topocode2.ipynb
|
rabernat/pangeo-rema
|
271e573ca977001a1978c936b00c139b8262e865
|
[
"Apache-2.0"
] | 1 |
2020-01-23T18:00:43.000Z
|
2020-01-23T18:00:43.000Z
| 799.368707 | 259,844 | 0.950914 |
[
[
[
"import shapefile\nimport numpy as np\nimport xarray as xr\nfrom shapely.geometry import mapping as mappy\nfrom shapely.geometry import Polygon\nimport cartopy.crs as ccrs\nimport cartopy\nimport os, sys\nimport pandas as pd\nimport richdem as rd\nimport skimage\nfrom matplotlib import pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"from skimage import measure\nfrom skimage import util\nfrom skimage import morphology\nimport numpy as np\nimport scipy\nfrom scipy.ndimage import gaussian_filter\nfrom skimage import data\nfrom skimage import img_as_float\nfrom skimage.morphology import reconstruction",
"_____no_output_____"
],
[
"tiffname = '38_49_8m_dem.tif'\nmetadata = '38_49_8m_dem_meta.txt'\nDEM = rd.rdarray(xr.open_rasterio(tiffname),no_data = -9999)\nDEMflat = DEM.squeeze()\nDEMfig = rd.rdShow(DEMflat[6249:-1,6249:-1], ignore_colours=[0], axes=False, cmap='jet', figsize=(8,5.5))",
"_____no_output_____"
],
[
"geoDEM = xr.open_rasterio(tiffname)\ngeoDEM",
"_____no_output_____"
],
[
"from pyproj import Proj, transform\n\ninProj = Proj(init= geoDEM.crs)\noutProj = Proj(init='epsg:4326') #Plate Carree\nx2,y2 = transform(inProj,outProj,list(geoDEM.x),list(geoDEM.y))\nlat, lon = np.meshgrid(y2,x2)\nlatmesh = np.array([[lat],]*len(lat))\nlonmesh = np.array([[lon],]*len(lat)).transpose()",
"_____no_output_____"
],
[
"DEMflat_ss = DEMflat[6249:-1,6249:-1]",
"_____no_output_____"
],
[
"import time\nstart=time.time()\n#DEM40 = skimage.transform.resize(DEMflat_ss, (DEMflat_ss.shape[0] / 5, DEMflat_ss.shape[1] / 5),\n #anti_aliasing=True)\n#DEM40 = rd.rdarray(DEM40,no_data = -9999 )\nDEMf = rd.FillDepressions(DEMflat)\nlakes = DEMf-DEMflat\nend = time.time()\nprint(end-start)",
"Warning! No geotransform defined. Choosing a standard one! (Top left cell's top let corner at <0,0>; cells are 1x1.)\n36.27514839172363\n"
],
[
"fig_diff = rd.rdShow(lakes, ignore_colours=[0], axes=False, cmap='jet', figsize=(8,5.5))",
"_____no_output_____"
]
],
[
[
"## Julian's Code",
"_____no_output_____"
]
],
[
[
"start = time.time()\n# 5m meter lakes\nDEM40 = skimage.transform.resize(DEMflat, (DEMflat.shape[0] / 10, DEMflat.shape[1] / 10),\n anti_aliasing=True)\nDEM_inv = skimage.util.invert(DEM40)\nDEMinv_gaus = gaussian_filter(DEM_inv,1)\nmarker = np.copy(DEMinv_gaus)\nmarker[1:-1, 1:-1] = -9999\n\nInan = np.argwhere(np.isnan(DEMinv_gaus))\nInan_mask = np.isnan(DEMinv_gaus)\nInan_mask_not = np.logical_not(Inan_mask)\nif((np.array(Inan)).size>0):\n I = skimage.morphology.binary_dilation(Inan_mask,np.ones(3)) & Inan_mask_not\n marker[I] = DEMinv_gaus[I]\n \nmask = DEMinv_gaus\ndemfs = reconstruction(marker, mask, method='dilation') \n\nD = DEMinv_gaus-demfs\nindex = list(Inan_mask_not)\n\n\nmaxdepth = 40\nwhile np.any(D[index]>maxdepth):\n lakemask = D>0\n label_lakemask = measure.label(lakemask)\n STATS = measure.regionprops(label_lakemask,D)\n\n for r in np.arange(0,len(STATS)):\n if(STATS[r].max_intensity < maxdepth):\n pass\n else:\n poly_x = STATS[r].coords[:,0]\n poly_y = STATS[r].coords[:,1]\n poly = D[poly_x, poly_y]\n ix = poly.argmax()\n #ix = ix[1]\n marker[STATS[r].coords[ix][0],STATS[r].coords[ix][1]] = DEMinv_gaus[STATS[r].coords[ix][0],STATS[r].coords[ix][1]]\n demfs = reconstruction(marker,DEMinv_gaus, method='dilation');\n D = DEMinv_gaus-demfs;\n\ndemfs = skimage.util.invert(demfs)\ndemfs[Inan_mask] = np.nan\nend = time.time()",
"_____no_output_____"
],
[
"print(end-start)",
"4.819223403930664\n"
],
[
"fig, ax = plt.subplots(ncols = 2, figsize=(10,5))\nlakes2 = demfs-DEM40\njjscodefig = ax[0].imshow(lakes2, cmap='jet')\njjscodefig.set_clim(0,8)\nplt.colorbar(jjscodefig)\n\nbasecodefig = ax[1].imshow(lakes, cmap='jet')\nbasecodefig.set_clim(0,8)\n",
"_____no_output_____"
],
[
"#difference between methods\nlakediff = lakes-lakes2\nfig, ax = plt.subplots( figsize=(10,10))\nplt.imshow(lakediff)\nplt.colorbar()\nplt.clim(-5,5)",
"_____no_output_____"
]
],
[
[
"Lake Properties",
"_____no_output_____"
]
],
[
[
"lakemask = lakes>0\nlabel_lakes = measure.label(lakemask)\nLakeProps = measure.regionprops(label_lakes,lakes)",
"_____no_output_____"
],
[
"numLakes = len(LakeProps)\nArea = np.zeros((numLakes,1))\nOrientation= np.zeros((numLakes,1))\nVolume = np.zeros((numLakes,1))\nMax_Depth = np.zeros((numLakes,1))\nMean_Depth = np.zeros((numLakes,1))\nMin_Depth = np.zeros((numLakes,1))\nPerimeter = np.zeros((numLakes,1))\nPPscore = np.zeros((numLakes,1))\nDVscore = np.zeros((numLakes,1))\nCentroid = np.zeros((numLakes,2))\n",
"_____no_output_____"
],
[
"for lake in np.arange(0,numLakes):\n Area[lake] = LakeProps[lake].area*8**2\n Orientation[lake] = LakeProps[lake].orientation\n Volume[lake] = LakeProps[lake].intensity_image.sum()*8**2\n Max_Depth[lake] = LakeProps[lake].max_intensity\n Mean_Depth[lake] = LakeProps[lake].mean_intensity\n Min_Depth[lake] = LakeProps[lake].min_intensity\n Perimeter[lake] = LakeProps[lake].perimeter*8\n PPscore[lake] = (4*3.14*Area[lake])/(Perimeter[lake]**2)\n DVscore[lake] = 3*Mean_Depth[lake]/Max_Depth[lake]\n Centroid[lake] = LakeProps[lake].centroid",
"C:\\Users\\Julian Spergel\\Anaconda3\\envs\\geo_scipy\\lib\\site-packages\\ipykernel_launcher.py:9: RuntimeWarning: divide by zero encountered in true_divide\n if __name__ == '__main__':\n"
],
[
"plt.scatter(Area, Max_Depth)\nplt.xlim(0,1e5)\nplt.ylim(0,5)",
"_____no_output_____"
]
],
[
[
"## Elevation Data",
"_____no_output_____"
]
],
[
[
"ElevationProps = measure.regionprops(label_lakes,DEM40)",
"_____no_output_____"
],
[
"numLakes = len(LakeProps)\nMax_Elev = np.zeros((numLakes,1))\nMean_Elev = np.zeros((numLakes,1))\nMin_Elev = np.zeros((numLakes,1))\nfor lake in np.arange(0,numLakes):\n Max_Elev[lake] =ElevationProps[lake].max_intensity\n Mean_Elev[lake] = ElevationProps[lake].mean_intensity\n Min_Elev[lake] = ElevationProps[lake].min_intensity",
"_____no_output_____"
]
],
[
[
"## Full Tiles",
"_____no_output_____"
]
],
[
[
"xlength = DEMflat.shape[0]\nylength = DEMflat.shape[1]\nquarter_tile = np.empty([int(xlength/2),int(ylength/2),4])\n\ninProj = Proj(init= geoDEM.crs)\noutProj = Proj(init='epsg:4326') #Plate Carree\nlon,lat = transform(inProj,outProj,list(geoDEM.x),list(geoDEM.y))\n\n\nquarter_tile[:,:,0] = DEMflat[0:int(xlength/2), 0:int(ylength/2)]\nquarter_tile[:,:,1] = DEMflat[int(xlength/2):xlength,0:int(ylength/2)]\nquarter_tile[:,:,2] = DEMflat[0:int(xlength/2),int(ylength/2):ylength]\nquarter_tile[:,:,3] = DEMflat[int(xlength/2):xlength,int(ylength/2):ylength]\n\n#coordinates_lat = np.empty([int(xlength/2),4])\n#coordinates_lon = np.empty([int(ylength/2),4])\n\n#coordinates_lon[:,0] = lon[0:int(xlength/2)]\n#coordinates_lon[:,1] = lon[int(xlength/2):xlength]\n#coordinates_lon[:,2] = lon[0:int(xlength/2)]\n#coordinates_lon[:,3] = lon[int(xlength/2):xlength]\n#coordinates_lat[:,0] = lat[0:int(ylength/2)]\n#coordinates_lat[:,1] = lat[0:int(ylength/2)]\n#coordinates_lat[:,2] = lat[int(ylength/2):ylength]\n#coordinates_lat[:,3] = lat[int(ylength/2):ylength]\n",
"_____no_output_____"
],
[
"numLakes_total = 0\nArea_total = []\nOrientation_total= []\nVolume_total = []\nMax_Depth_total = []\nMean_Depth_total = []\nMin_Depth_total = []\nPerimeter_total = []\nPPscore_total = []\nDVscore_total = []\nMax_Elev_total = []\nMean_Elev_total = []\nMin_Elev_total = []\nCentroidlat_total = []\nCentroidlon_total = []\n\nfor tile in np.arange(0,3):\n \n DEM40 = skimage.transform.resize(quarter_tile[:,:,tile], (quarter_tile[:,:,tile].shape[0] / 5, \n quarter_tile[:,:,tile].shape[1] / 5), anti_aliasing=True)\n DEM40 = rd.rdarray(DEM40,no_data = -9999 )\n DEMf = rd.FillDepressions(DEM40)\n lakes = DEMf-DEM40\n\n\n lakemask = lakes>0\n label_lakes = measure.label(lakemask)\n LakeProps = measure.regionprops(label_lakes,lakes)\n ElevationProps = measure.regionprops(label_lakes,DEM40)\n numLakes = len(LakeProps)\n Area = np.zeros((numLakes,1))\n Orientation= np.zeros((numLakes,1))\n Volume = np.zeros((numLakes,1))\n Max_Depth = np.zeros((numLakes,1))\n Mean_Depth = np.zeros((numLakes,1))\n Min_Depth = np.zeros((numLakes,1))\n Perimeter = np.zeros((numLakes,1))\n PPscore = np.zeros((numLakes,1))\n DVscore = np.zeros((numLakes,1))\n Centroidlon = np.zeros((numLakes,1))\n Centroidlat = np.zeros((numLakes,1))\n \n for lake in np.arange(0,numLakes):\n Area[lake] = LakeProps[lake].area*8**2\n Orientation[lake] = LakeProps[lake].orientation\n Volume[lake] = LakeProps[lake].intensity_image.sum()*8**2\n Max_Depth[lake] = LakeProps[lake].max_intensity\n Mean_Depth[lake] = LakeProps[lake].mean_intensity\n Min_Depth[lake] = LakeProps[lake].min_intensity\n Perimeter[lake] = LakeProps[lake].perimeter*8\n PPscore[lake] = (4*3.14*Area[lake])/(Perimeter[lake]**2)\n DVscore[lake] = 3*Mean_Depth[lake]/Max_Depth[lake]\n Max_Elev[lake] =ElevationProps[lake].max_intensity\n Mean_Elev[lake] = ElevationProps[lake].mean_intensity\n Min_Elev[lake] = ElevationProps[lake].min_intensity\n Centroidlat[lake] = coordinates_lat[int(round(LakeProps[lake].centroid[0])),tile]\n Centroidlon[lake] = coordinates_lon[int(round(LakeProps[lake].centroid[1])),tile]\n\n \n numLakes_total = numLakes_total+numLakes\n Area_total = np.append(Area_total,Area)\n Orientation_total= np.append(Orientation_total,Orientation)\n Volume_total = np.append(Volume_total,Volume)\n Max_Depth_total =np.append(Max_Depth_total,Max_Depth)\n Mean_Depth_total = np.append(Mean_Depth_total,Mean_Depth)\n Min_Depth_total = np.append(Min_Depth_total,Min_Depth)\n Perimeter_total = np.append(Perimeter_total,Perimeter)\n PPscore_total = np.append(PPscore_total,PPscore)\n DVscore_total = np.append(DVscore_total,DVscore)\n Max_Elev_total = np.append(Max_Elev_total,Max_Elev)\n Mean_Elev_total = np.append(Mean_Elev_total,Mean_Elev)\n Min_Elev_total = np.append(Min_Elev_total,Min_Elev)\n Centroidlat_total = np.append(Centroidlat_total,Centroidlat)\n Centroidlon_total = np.append(Centroidlon_total, Centroidlon)",
"C:\\Users\\Julian Spergel\\Anaconda3\\envs\\geo_scipy\\lib\\site-packages\\skimage\\transform\\_warps.py:105: UserWarning: The default mode, 'constant', will be changed to 'reflect' in skimage 0.15.\n warn(\"The default mode, 'constant', will be changed to 'reflect' in \"\n"
],
[
"coordinates_lat[int(round(LakeProps[1].centroid[0])),1]",
"_____no_output_____"
],
[
"plt.scatter(Centroidlat_total,Centroidlon_total)",
"_____no_output_____"
],
[
"len(lon)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d02d1b0a5ae75885d2eb4d0df89d40c14a42b62a
| 15,280 |
ipynb
|
Jupyter Notebook
|
fundamentals/src/notebooks/040_pipelines.ipynb
|
konabuta/fta-azure-machine-learning
|
70da95e7a4c9b3e42db61bb0f69eda8e07c28eee
|
[
"MIT"
] | null | null | null |
fundamentals/src/notebooks/040_pipelines.ipynb
|
konabuta/fta-azure-machine-learning
|
70da95e7a4c9b3e42db61bb0f69eda8e07c28eee
|
[
"MIT"
] | null | null | null |
fundamentals/src/notebooks/040_pipelines.ipynb
|
konabuta/fta-azure-machine-learning
|
70da95e7a4c9b3e42db61bb0f69eda8e07c28eee
|
[
"MIT"
] | null | null | null | 24.845528 | 106 | 0.445353 |
[
[
[
"# Authoring repeatable processes aka AzureML pipelines",
"_____no_output_____"
]
],
[
[
"from azureml.core import Workspace\n\nws = Workspace.from_config()\ndataset = ws.datasets[\"diabetes-tabular\"]\ncompute_target = ws.compute_targets[\"cpu-cluster\"]",
"_____no_output_____"
],
[
"from azureml.core import RunConfiguration\n\n# To simplify we are going to use a big demo environment instead\n# of creating our own specialized environment. We will also use\n# the same environment for all steps, but this is not needed.\nrunconfig = RunConfiguration()\nrunconfig.environment = ws.environments[\"AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu\"]",
"_____no_output_____"
]
],
[
[
"## Step 1 - Convert data into LightGBM dataset",
"_____no_output_____"
]
],
[
[
"from azureml.pipeline.core import PipelineData\n\nstep01_output = PipelineData(\n \"training_data\", datastore=ws.get_default_datastore(), is_directory=True\n)",
"_____no_output_____"
],
[
"from azureml.pipeline.core import PipelineParameter\nfrom azureml.data.dataset_consumption_config import DatasetConsumptionConfig\n\nds_pipeline_param = PipelineParameter(name=\"dataset\", default_value=dataset)\nstep01_input_dataset = DatasetConsumptionConfig(\"input_dataset\", ds_pipeline_param)",
"_____no_output_____"
],
[
"from azureml.pipeline.steps import PythonScriptStep\n\nstep_01 = PythonScriptStep(\n \"step01_data_prep.py\",\n source_directory=\"040_scripts\",\n arguments=[\"--dataset-id\", step01_input_dataset, \"--output-path\", step01_output],\n name=\"Prepare data\",\n runconfig=runconfig,\n compute_target=compute_target,\n inputs=[step01_input_dataset],\n outputs=[step01_output],\n allow_reuse=True,\n)",
"_____no_output_____"
]
],
[
[
"## Step 2 - Train the LightGBM model",
"_____no_output_____"
]
],
[
[
"from azureml.pipeline.core import PipelineParameter\n\nlearning_rate_param = PipelineParameter(name=\"learning_rate\", default_value=0.05)",
"_____no_output_____"
],
[
"step02_output = PipelineData(\n \"model_output\", datastore=ws.get_default_datastore(), is_directory=True\n)",
"_____no_output_____"
],
[
"step_02 = PythonScriptStep(\n \"step02_train.py\",\n source_directory=\"040_scripts\",\n arguments=[\n \"--learning-rate\",\n learning_rate_param,\n \"--input-path\",\n step01_output,\n \"--output-path\",\n step02_output,\n ],\n name=\"Train model\",\n runconfig=runconfig,\n compute_target=compute_target,\n inputs=[step01_output],\n outputs=[step02_output],\n)",
"_____no_output_____"
]
],
[
[
"## Step 3 - Register model",
"_____no_output_____"
]
],
[
[
"step_03 = PythonScriptStep(\n \"step03_register.py\",\n source_directory=\"040_scripts\",\n arguments=[\n \"--input-path\",\n step02_output,\n \"--dataset-id\",\n step01_input_dataset,\n ],\n name=\"Register model\",\n runconfig=runconfig,\n compute_target=compute_target,\n inputs=[step01_input_dataset, step02_output],\n)",
"_____no_output_____"
]
],
[
[
"## Create pipeline",
"_____no_output_____"
]
],
[
[
"from azureml.pipeline.core import Pipeline\n\npipeline = Pipeline(workspace=ws, steps=[step_01, step_02, step_03])",
"_____no_output_____"
]
],
[
[
"## Trigger pipeline through SDK",
"_____no_output_____"
]
],
[
[
"from azureml.core import Experiment\n\n# Using the SDK\nexperiment = Experiment(ws, \"pipeline-run\")\npipeline_run = experiment.submit(pipeline, pipeline_parameters={\"learning_rate\": 0.5})\npipeline_run.wait_for_completion()",
"_____no_output_____"
]
],
[
[
"## Register pipeline to reuse",
"_____no_output_____"
]
],
[
[
"published_pipeline = pipeline.publish(\n \"Training pipeline\", description=\"A pipeline to train a LightGBM model\"\n)",
"_____no_output_____"
]
],
[
[
"## Trigger published pipeline through REST",
"_____no_output_____"
]
],
[
[
"from azureml.core.authentication import InteractiveLoginAuthentication\n\nauth = InteractiveLoginAuthentication()\naad_token = auth.get_authentication_header()",
"_____no_output_____"
],
[
"import requests\n\nresponse = requests.post(\n published_pipeline.endpoint,\n headers=aad_token,\n json={\n \"ExperimentName\": \"pipeline-run\",\n \"ParameterAssignments\": {\"learning_rate\": 0.02},\n },\n)\n\nprint(\n f\"Made a POST request to {published_pipeline.endpoint} and got {response.status_code}.\"\n)\nprint(f\"The portal url for the run is {response.json()['RunUrl']}\")",
"_____no_output_____"
]
],
[
[
"## Scheduling a pipeline",
"_____no_output_____"
]
],
[
[
"from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule\nfrom datetime import datetime\n\nrecurrence = ScheduleRecurrence(\n frequency=\"Month\", interval=1, start_time=datetime.now()\n)\n\nschedule = Schedule.create(\n workspace=ws,\n name=\"pipeline-schedule\",\n pipeline_id=published_pipeline.id,\n experiment_name=\"pipeline-schedule-run\",\n recurrence=recurrence,\n wait_for_provisioning=True,\n description=\"Schedule to retrain model\",\n)\n\nprint(\"Created schedule with id: {}\".format(schedule.id))",
"_____no_output_____"
],
[
"from azureml.pipeline.core.schedule import Schedule\n\n# Disable schedule\nschedules = Schedule.list(ws, active_only=True)\nprint(\"Your workspace has the following schedules set up:\")\nfor schedule in schedules:\n print(f\"Disabling {schedule.id} (Published pipeline: {schedule.pipeline_id}\")\n schedule.disable(wait_for_provisioning=True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02d1b8258688297dd5f45d601777cca6f0d0880
| 41,285 |
ipynb
|
Jupyter Notebook
|
Exercise3/Exercise3/local_feature_matching.ipynb
|
danikhani/CV1-2020
|
80b77776763dbd30f68bc2966e51e7ad592a0373
|
[
"MIT"
] | null | null | null |
Exercise3/Exercise3/local_feature_matching.ipynb
|
danikhani/CV1-2020
|
80b77776763dbd30f68bc2966e51e7ad592a0373
|
[
"MIT"
] | null | null | null |
Exercise3/Exercise3/local_feature_matching.ipynb
|
danikhani/CV1-2020
|
80b77776763dbd30f68bc2966e51e7ad592a0373
|
[
"MIT"
] | null | null | null | 40.916749 | 507 | 0.60172 |
[
[
[
"# Local Feature Matching\n\nBy the end of this exercise, you will be able to transform images of a flat (planar) object, or images taken from the same point into a common reference frame. This is at the core of applications such as panorama stitching.\n\nA quick overview:\n\n1. We will start with histogram representations for images (or image regions).\n2. Then we will detect robust keypoints in images and use simple histogram descriptors to describe the neighborhood of each keypoint.\n3. After this we will compare descriptors from different images using a distance function and establish matching points.\n4. Using these matching points we will estimate the homography transformation between two images of a planar object (wall with graffiti) and use this to warp one image to look like the other.",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport imageio\nimport cv2\nimport math\nfrom scipy import ndimage\nfrom attrdict import AttrDict\nfrom mpl_toolkits.mplot3d import Axes3D\n\n# Many useful functions\ndef plot_multiple(images, titles=None, colormap='gray',\n max_columns=np.inf, imwidth=4, imheight=4, share_axes=False):\n \"\"\"Plot multiple images as subplots on a grid.\"\"\"\n if titles is None:\n titles = [''] *len(images)\n assert len(images) == len(titles)\n n_images = len(images)\n n_cols = min(max_columns, n_images)\n n_rows = int(np.ceil(n_images / n_cols))\n fig, axes = plt.subplots(\n n_rows, n_cols, figsize=(n_cols * imwidth, n_rows * imheight),\n squeeze=False, sharex=share_axes, sharey=share_axes)\n\n axes = axes.flat\n # Hide subplots without content\n for ax in axes[n_images:]:\n ax.axis('off')\n \n if not isinstance(colormap, (list,tuple)):\n colormaps = [colormap]*n_images\n else:\n colormaps = colormap\n\n for ax, image, title, cmap in zip(axes, images, titles, colormaps):\n ax.imshow(image, cmap=cmap)\n ax.set_title(title)\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n \n fig.tight_layout()\n \ndef load_image(f_name):\n return imageio.imread(f_name, as_gray=True).astype(np.float32)/255\n\ndef convolve_with_two(image, kernel1, kernel2):\n \"\"\"Apply two filters, one after the other.\"\"\"\n image = ndimage.convolve(image, kernel1)\n image = ndimage.convolve(image, kernel2) \n return image\n\ndef gauss(x, sigma):\n return 1 / np.sqrt(2 * np.pi) / sigma * np.exp(- x**2 / 2 / sigma**2)\n\ndef gaussdx(x, sigma):\n return (-1 / np.sqrt(2 * np.pi) / sigma**3 * x *\n np.exp(- x**2 / 2 / sigma**2))\n\ndef gauss_derivs(image, sigma):\n kernel_radius = np.ceil(3.0 * sigma)\n x = np.arange(-kernel_radius, kernel_radius + 1)[np.newaxis]\n G = gauss(x, sigma)\n D = gaussdx(x, sigma)\n image_dx = convolve_with_two(image, D, G.T)\n image_dy = convolve_with_two(image, G, D.T)\n return image_dx, image_dy\n\ndef gauss_filter(image, sigma):\n kernel_radius = np.ceil(3.0 * sigma)\n x = np.arange(-kernel_radius, kernel_radius + 1)[np.newaxis]\n G = gauss(x, sigma)\n return convolve_with_two(image, G, G.T)\n\ndef gauss_second_derivs(image, sigma):\n kernel_radius = np.ceil(3.0 * sigma)\n x = np.arange(-kernel_radius, kernel_radius + 1)[np.newaxis]\n G = gauss(x, sigma)\n D = gaussdx(x, sigma)\n \n image_dx, image_dy = gauss_derivs(image, sigma)\n image_dxx = convolve_with_two(image_dx, D, G.T)\n image_dyy = convolve_with_two(image_dy, G, D.T)\n image_dxy = convolve_with_two(image_dx, G, D.T)\n return image_dxx, image_dxy, image_dyy\n\ndef map_range(x, start, end):\n \"\"\"Maps values `x` that are within the range [start, end) to the range [0, 1)\n Values smaller than `start` become 0, values larger than `end` become\n slightly smaller than 1.\"\"\"\n return np.clip((x-start)/(end-start), 0, 1-1e-10)\n\ndef draw_keypoints(image, points):\n image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)\n radius = image.shape[1]//100+1\n for x, y in points:\n cv2.circle(image, (int(x), int(y)), radius, (1, 0, 0), thickness=2) \n return image\n\ndef draw_point_matches(im1, im2, point_matches):\n result = np.concatenate([im1, im2], axis=1)\n result = (result.astype(float)*0.6).astype(np.uint8)\n im1_width = im1.shape[1]\n for x1, y1, x2, y2 in point_matches:\n cv2.line(result, (x1, y1), (im1_width+x2, y2), \n color=(0,255,255), thickness=2, lineType=cv2.LINE_AA)\n return result",
"_____no_output_____"
],
[
"%%html\n<!-- This adds heading numbers to each section header -->\n<style>\nbody {counter-reset: section;}\nh2:before {counter-increment: section;\n content: counter(section) \" \";}\n</style>",
"_____no_output_____"
]
],
[
[
"## Histograms in 1D\n\nIf we have a grayscale image, creating a histogram of the gray values tells us how frequently each gray value appears in the image, at a certain discretization level, which is controlled by the number of bins.\n\nImplement `compute_1d_histogram(im, n_bins)`. Given an grayscale image `im` with shape `[height, width]` and the number of bins `n_bins`, return a `histogram` array that contains the number of values falling into each bin. Assume that the values (of the image) are in the range \\[0,1), so the specified number of bins should cover the range from 0 to 1. Normalize the resulting histogram to sum to 1.",
"_____no_output_____"
]
],
[
[
"def compute_1d_histogram(im, n_bins):\n histogram = np.zeros(n_bins)\n # YOUR CODE HERE\n raise NotImplementedError()\n return histogram\n\nfig, axes = plt.subplots(1,4, figsize=(10,2), constrained_layout=True)\nbin_counts = [2, 25, 256]\ngray_img = imageio.imread('terrain.png', as_gray=True\n ).astype(np.float32)/256\n\naxes[0].set_title('Image')\naxes[0].imshow(gray_img, cmap='gray')\nfor ax, n_bins in zip(axes[1:], bin_counts):\n ax.set_title(f'1D histogram with {n_bins} bins')\n bin_size = 1/n_bins\n x_axis = np.linspace(0, 1, n_bins, endpoint=False)+bin_size/2\n hist = compute_1d_histogram(gray_img, n_bins)\n ax.bar(x_axis, hist, bin_size)",
"_____no_output_____"
]
],
[
[
"What is the effect of the different bin counts?",
"_____no_output_____"
],
[
"YOUR ANSWER HERE",
"_____no_output_____"
],
[
"## Histograms in 3D\n\nIf the pixel values are more than one-dimensional (e.g. three-dimensional RGB, for red, green and blue color channels), we can build a multi-dimensional histogram. In the R, G, B example this will tell us how frequently each *combination* of R, G, B values occurs. (Note that this contains more information than simply building 3 one-dimensional histograms, each for R, G and B, separately. Why?)\n\nImplement a new function `compute_3d_histogram(im, n_bins)`, which takes as input an array of shape `[height, width, 3]` and returns a histogram of shape `[n_bins, n_bins, n_bins]`. Again, assume that the range of values is \\[0,1) and normalize the histogram at the end.\n\nVisualize the RGB histograms of the images `sunset.png` and `terrain.png` using the provided code and describe what you see. We cannot use a bar chart in 3D. Instead, in the position of each 3D bin (\"voxel\"), we have a sphere, whose volume is proportional to the histogram's value in that bin. The color of the sphere is simply the RGB color that the bin represents. Which number of bins gives the best impression of the color distribution?",
"_____no_output_____"
]
],
[
[
"def compute_3d_histogram(im, n_bins):\n histogram = np.zeros([n_bins, n_bins, n_bins], dtype=np.float32)\n\n # YOUR CODE HERE\n raise NotImplementedError()\n \n return histogram\n\ndef plot_3d_histogram(ax, data, axis_names='xyz'):\n \"\"\"Plot a 3D histogram. We plot a sphere for each bin,\n with volume proportional to the bin content.\"\"\"\n r,g,b = np.meshgrid(*[np.linspace(0,1, dim) for dim in data.shape], indexing='ij')\n colors = np.stack([r,g,b], axis=-1).reshape(-1, 3)\n marker_sizes = 300 * data**(1/3)\n ax.scatter(r.flat, g.flat, b.flat, s=marker_sizes.flat, c=colors, alpha=0.5)\n ax.set_xlabel(axis_names[0])\n ax.set_ylabel(axis_names[1])\n ax.set_zlabel(axis_names[2])\n\npaths = ['sunset.png', 'terrain.png']\nimages = [imageio.imread(p) for p in paths]\nplot_multiple(images, paths)\n\nfig, axes = plt.subplots(1, 2, figsize=(8, 4), subplot_kw={'projection': '3d'})\nfor path, ax in zip(paths, axes):\n im = imageio.imread(path).astype(np.float32)/256\n hist = compute_3d_histogram(im, n_bins=16) # <--- FIDDLE WITH N_BINS HERE\n plot_3d_histogram(ax, hist, 'RGB') \nfig.tight_layout()",
"_____no_output_____"
]
],
[
[
"## Histograms in 2D\n\nNow modify your code to work in 2D. This can be useful, for example, for a gradient image that stores two values for each pixel: the vertical and horizontal derivative. Again, assume the values are in the range \\[0,1).\n\nSince gradients can be negative, we need to pick a relevant range of values an map them linearly to the range of \\[0,1) before applying `compute_2d_histogram`. This is implemented by the function `map_range` provided at the beginning of the notebook.\n\nIn 2D we can plot the histogram as an image. For better visibility of small values, we plot the logarithm of each bin value. Yellowish colors mean high values. The center is (0,0). Can you explain why each histogram looks the way it does for the test images?",
"_____no_output_____"
]
],
[
[
"def compute_2d_histogram(im, n_bins):\n histogram = np.zeros([n_bins, n_bins], dtype=np.float32)\n\n # YOUR CODE HERE\n raise NotImplementedError()\n return histogram\n\ndef compute_gradient_histogram(rgb_im, n_bins):\n # Convert to grayscale\n gray_im = cv2.cvtColor(im, cv2.COLOR_RGB2GRAY).astype(float)\n # Compute Gaussian derivatives\n dx, dy = gauss_derivs(gray_im, sigma=2.0)\n # Map the derivatives between -10 and 10 to be between 0 and 1\n dx = map_range(dx, start=-10, end=10)\n dy = map_range(dy, start=-10, end=10)\n # Stack the two derivative images along a new\n # axis at the end (-1 means \"last\")\n gradients = np.stack([dy, dx], axis=-1)\n return dx, dy, compute_2d_histogram(gradients, n_bins=16)\n\npaths = ['model/obj4__0.png', 'model/obj42__0.png']\nimages, titles = [], []\n\nfor path in paths:\n im = imageio.imread(path)\n dx, dy, hist = compute_gradient_histogram(im, n_bins=16)\n images += [im, dx, dy, np.log(hist+1e-3)]\n titles += [path, 'dx', 'dy', 'Histogram (log)']\n \nplot_multiple(images, titles, max_columns=4, imwidth=2,\n imheight=2, colormap='viridis')",
"_____no_output_____"
]
],
[
[
"Similar to the function `compute_gradient_histogram` above, we can build a \"Mag/Lap\" histogram from the gradient magnitudes and the Laplacians at each pixel. Refer back to the first exercise to refresh your knowledge of the Laplacian. Implement this in `compute_maglap_histogram`!\n\nMake sure to map the relevant range of the gradient magnitude and Laplacian values to \\[0,1) using `map_range()`. For the magnitude you can assume that the values will mostly lie in the range \\[0, 15) and the Laplacian in the range \\[-5, 5).",
"_____no_output_____"
]
],
[
[
"def compute_maglap_histogram(rgb_im, n_bins):\n # Convert to grayscale\n gray_im = cv2.cvtColor(rgb_im, cv2.COLOR_RGB2GRAY).astype(float)\n # Compute Gaussian derivatives\n sigma = 2\n kernel_radius = np.ceil(3.0 * sigma)\n x = np.arange(-kernel_radius, kernel_radius + 1)[np.newaxis]\n G = gauss(x, sigma)\n D = gaussdx(x, sigma)\n dx = convolve_with_two(gray_im, D, G.T)\n dy = convolve_with_two(gray_im, G, D.T)\n \n # Compute second derivatives\n dxx = convolve_with_two(dx, D, G.T)\n dyy = convolve_with_two(dy, G, D.T)\n\n # Compute gradient magnitude and Laplacian\n # YOUR CODE HERE\n raise NotImplementedError()\n \n mag_lap = np.stack([mag, lap], axis=-1)\n return mag, lap, compute_2d_histogram(mag_lap, n_bins=16)\n\npaths = [f'model/obj{i}__0.png' for i in [20, 37, 36, 55]]\nimages, titles = [], []\n\nfor path in paths:\n im = imageio.imread(path)\n mag, lap, hist = compute_maglap_histogram(im, n_bins=16)\n images += [im, mag, lap, np.log(hist+1e-3)]\n titles += [path, 'Gradient magn.', 'Laplacian', 'Histogram (log)']\n \nplot_multiple(images, titles, imwidth=2, imheight=2,\n max_columns=4, colormap='viridis')",
"_____no_output_____"
]
],
[
[
"## Comparing Histograms\n\nThe above histograms looked different, but to quantify this objectively, we need a **distance measure**. The Euclidean distance is a common one.\nImplement the function `euclidean_distance`, which takes two histograms $P$ and $Q$ as input and returns their Euclidean distance:\n\n$$\n\\textit{dist}_{\\textit{Euclidean}}(P, Q) = \\sqrt{\\sum_{i=1}^{D}{(P_i - Q_i)^2}}\n$$\n\nAnother commonly used distance for histograms is the so-called chi-squared ($\\chi^2$) distance, commonly defined as:\n\n$$\n\\chi^2(P, Q) = \\frac{1}{2} \\sum_{i=1}^{D}\\frac{(P_i - Q_i)^2}{P_i + Q_i + \\epsilon}\n$$\n\nWhere we can use a small value $\\epsilon$ is used to avoid division by zero.\nImplement it as `chi_square_distance`. The inputs `hist1` and `hist2` are histogram vectors containing the bin values. Remember to use numpy array functions (such as `np.sum()`) instead of looping over each element in Python (looping is slow).",
"_____no_output_____"
]
],
[
[
"def euclidean_distance(hist1, hist2):\n # YOUR CODE HERE\n raise NotImplementedError()\n \ndef chi_square_distance(hist1, hist2, eps=1e-3):\n # YOUR CODE HERE\n raise NotImplementedError()",
"_____no_output_____"
]
],
[
[
"Now let's take the image `obj1__0.png` as reference and let's compare it to `obj91__0.png` and `obj94__0.png`, using an RGB histogram, both with Euclidean and chi-square distance. Can you interpret the results?\n\nYou can also try other images from the \"model\" folder.",
"_____no_output_____"
]
],
[
[
"im1 = imageio.imread('model/obj1__0.png')\nim2 = imageio.imread('model/obj91__0.png')\nim3 = imageio.imread('model/obj94__0.png')\nn_bins = 8\nh1 = compute_3d_histogram(im1/256, n_bins)\nh2 = compute_3d_histogram(im2/256, n_bins)\nh3 = compute_3d_histogram(im3/256, n_bins)\n\neucl_dist1 = euclidean_distance(h1, h2)\nchisq_dist1 = chi_square_distance(h1, h2)\neucl_dist2 = euclidean_distance(h1, h3)\nchisq_dist2 = chi_square_distance(h1, h3)\n\ntitles = ['Reference image',\n f'Eucl: {eucl_dist1:.3f}, ChiSq: {chisq_dist1:.3f}',\n f'Eucl: {eucl_dist2:.3f}, ChiSq: {chisq_dist2:.3f}']\nplot_multiple([im1, im2, im3], titles, imheight=3)",
"_____no_output_____"
]
],
[
[
"# Keypoint Detection\n\nNow we turn to finding keypoints in images.\n\n## Harris Detector\n\nThe Harris detector searches for points, around which the second-moment matrix $M$ of the gradient vector has two large eigenvalues (This $M$ is denoted by $C$ in the Grauman & Leibe script). This matrix $M$ can be written as:\n\n$$\nM(\\sigma, \\tilde{\\sigma}) = G(\\tilde{\\sigma}) \\star \\left[\\begin{matrix} I_x^2(\\sigma) & I_x(\\sigma) \\cdot I_y(\\sigma) \\cr I_x(\\sigma)\\cdot I_y(\\sigma) & I_y^2(\\sigma) \\end{matrix}\\right]\n$$\n\nNote that the matrix $M$ is computed for each pixel (we omitted the $x, y$ dependency in this formula for clarity). In the above notation the 4 elements of the second-moment matrix are considered as full 2D \"images\" (signals) and each of these 4 \"images\" are convolved with the Gaussian $G(\\tilde{\\sigma})$ independently. We have two sigmas $\\sigma$ and $\\tilde{\\sigma}$ here for two different uses of Gaussian blurring:\n\n * first for computing the derivatives themselves (as derivatives-of-Gaussian) with $\\sigma$, and\n * then another Gaussian with $\\tilde{\\sigma}$ that operates on \"images\" containing the *products* of the derivatives (such as $I_x^2(\\sigma)$) in order to collect summary statistics from a window around each point.\n\nInstead of explicitly computing the eigenvalues $\\lambda_1$ and $\\lambda_2$ of $M$, the following equivalences are used:\n\n$$\n\\det(M) = \\lambda_1 \\lambda_2 = (G(\\tilde{\\sigma}) \\star I_x^2)\\cdot (G(\\tilde{\\sigma}) \\star I_y^2) - (G(\\tilde{\\sigma}) \\star (I_x\\cdot I_y))^2\n$$\n\n$$\n\\mathrm{trace}(M) = \\lambda_1 + \\lambda_2 = G(\\tilde{\\sigma}) \\star I_x^2 + G(\\tilde{\\sigma}) \\star I_y^2\n$$\n\nThe Harris criterion is then:\n\n$$\n\\det(M) - \\alpha \\cdot \\mathrm{trace}^2(M) > t\n$$\n\nIn practice, the parameters are usually set as $\\tilde{\\sigma} = 2 \\sigma, \\alpha=0.06$.\nRead more in Section 3.2.1.2 of the Grauman & Leibe script (grauman-leibe-ch3-local-features.pdf in the Moodle).\n\n----\n\nWrite a function `harris_score(im, opts)` which:\n - computes the values of $M$ **for each pixel** of the grayscale image `im`\n - calculates the trace and the determinant at each pixel\n - combines them to the Harris response and returns the resulting image\n\nTo handle the large number of configurable parameters in this exercise, we will store them in an `opts` object. Use `opts.sigma1` for $\\sigma$, `opts.sigma2` for $\\tilde{\\sigma}$ and `opts.alpha` for $\\alpha$.\n\nFurthermore, implement `nms(scores)` to perform non-maximum suppression of the response image.\n\nThen look at `score_map_to_keypoints(scores, opts)`. It takes a score map and returns an array of shape `[number_of_corners, 2]`, with each row being the $(x,y)$ coordinates of a found keypoint. We use `opts.score_threshold` as the threshold for considering a point to be a keypoint. (This is quite similar to how we found detections from score maps in the sliding-window detection exercise.)",
"_____no_output_____"
]
],
[
[
"def harris_scores(im, opts):\n dx, dy = gauss_derivs(im, opts.sigma1)\n \n # YOUR CODE HERE\n raise NotImplementedError()\n return scores\n\ndef nms(scores):\n \"\"\"Non-maximum suppression\"\"\"\n # YOUR CODE HERE\n raise NotImplementedError()\n return scores_out\n\ndef score_map_to_keypoints(scores, opts):\n corner_ys, corner_xs = (scores > opts.score_threshold).nonzero()\n return np.stack([corner_xs, corner_ys], axis=1)",
"_____no_output_____"
]
],
[
[
"Now check the score maps and keypoints:",
"_____no_output_____"
]
],
[
[
"opts = AttrDict()\nopts.sigma1=2\nopts.sigma2=opts.sigma1*2\nopts.alpha=0.06\nopts.score_threshold=1e-8\n\npaths = ['checkboard.jpg', 'graf.png', 'gantrycrane.png']\nimages = []\ntitles = []\nfor path in paths:\n image = load_image(path)\n \n score_map = harris_scores(image, opts)\n score_map_nms = nms(score_map)\n keypoints = score_map_to_keypoints(score_map_nms, opts)\n keypoint_image = draw_keypoints(image, keypoints)\n\n images += [score_map, keypoint_image]\n titles += ['Harris response scores', 'Harris keypoints']\nplot_multiple(images, titles, max_columns=2, colormap='viridis')",
"_____no_output_____"
]
],
[
[
"## Hessian Detector\nThe Hessian detector operates on the second-derivative matrix $H$ (called the “Hessian” matrix)\n\n$$\nH = \\left[\\begin{matrix}I_{xx}(\\sigma) & I_{xy}(\\sigma) \\cr I_{xy}(\\sigma) & I_{yy}(\\sigma)\\end{matrix}\\right] \\tag{6}\n$$\n\nNote that these are *second* derivatives, while the Harris detector computes *products* of *first* derivatives! The score is computed as follows:\n\n$$\n\\sigma^4 \\det(H) = \\sigma^4 (I_{xx}I_{yy} - I^2_{xy}) > t \\tag{7}\n$$\n\nYou can read more in Section 3.2.1.1 of the Grauman & Leibe script (grauman-leibe-ch3-local-features.pdf in the Moodle).\n\n-----\n\nWrite a function `hessian_scores(im, opts)`, which:\n - computes the four entries of the $H$ matrix for each pixel of a given image, \n - calculates the determinant of $H$ to get the response image\n\nUse `opts.sigma1` for computing the Gaussian second derivatives.",
"_____no_output_____"
]
],
[
[
"def hessian_scores(im, opts):\n height, width = im.shape\n # YOUR CODE HERE\n raise NotImplementedError()\n return scores",
"_____no_output_____"
],
[
"opts = AttrDict()\nopts.sigma1=3\nopts.score_threshold=5e-4\n\npaths = ['checkboard.jpg', 'graf.png', 'gantrycrane.png']\nimages = []\ntitles = []\nfor path in paths:\n image = load_image(path)\n score_map = hessian_scores(image, opts)\n score_map_nms = nms(score_map)\n keypoints = score_map_to_keypoints(score_map_nms, opts)\n keypoint_image = draw_keypoints(image, keypoints)\n images += [score_map, keypoint_image]\n titles += ['Hessian scores', 'Hessian keypoints']\n \nplot_multiple(images, titles, max_columns=2, colormap='viridis')",
"_____no_output_____"
]
],
[
[
"## Region Descriptor Matching\n\nNow that we can detect robust keypoints, we can try to match them across different images of the same object. For this we need a way to compare the neighborhood of a keypoint found in one image with the neighborhood of a keypoint found in another. If the neighborhoods are similar, then the keypoints may represent the same physical point on the object.\n\nTo compare two neighborhoods, we compute a **descriptor** vector for the image window around each keypoint and then compare these descriptors using a **distance function**.\n\nInspect the following `compute_rgb_descriptors` function that takes a window around each point in `points` and computes a 3D RGB histogram and returns these as row vectors in a `descriptors` array.\n\nNow write the function `compute_maglap_descriptors`, which works very similarly to `compute_rgb_descriptors`, but computes two-dimensional gradient-magnitude/Laplacian histograms. (Compute the gradient magnitude and the Laplacian for the full image first. See also the beginning of this exercise.) Pay attention to the scale of the gradient-magnitude values.",
"_____no_output_____"
]
],
[
[
"def compute_rgb_descriptors(rgb_im, points, opts):\n \"\"\"For each (x,y) point in `points` calculate the 3D RGB histogram \n descriptor and stack these into a matrix \n of shape [num_points, descriptor_length]\n \"\"\"\n win_half = opts.descriptor_window_halfsize\n descriptors = []\n rgb_im_01 = rgb_im.astype(np.float32)/256\n\n for (x, y) in points:\n y_start = max(0, y-win_half)\n y_end = y+win_half+1\n x_start = max(0, x-win_half)\n x_end = x+win_half+1\n window = rgb_im_01[y_start:y_end, x_start:x_end]\n histogram = compute_3d_histogram(window, opts.n_histogram_bins)\n descriptors.append(histogram.reshape(-1))\n\n return np.array(descriptors)\n\ndef compute_maglap_descriptors(rgb_im, points, opts):\n \"\"\"For each (x,y) point in `points` calculate the magnitude-Laplacian\n 2D histogram descriptor and stack these into a matrix of\n shape [num_points, descriptor_length]\n \"\"\"\n \n # Compute the gradient magnitude and Laplacian for each pixel first\n gray_im = cv2.cvtColor(rgb_im, cv2.COLOR_RGB2GRAY).astype(float)\n kernel_radius = np.ceil(3.0 * opts.sigma1)\n x = np.arange(-kernel_radius, kernel_radius + 1)[np.newaxis]\n G = gauss(x, opts.sigma1)\n D = gaussdx(x, opts.sigma1)\n dx = convolve_with_two(gray_im, D, G.T)\n dy = convolve_with_two(gray_im, G, D.T)\n dxx = convolve_with_two(dx, D, G.T)\n dyy = convolve_with_two(dy, G, D.T)\n \n # YOUR CODE HERE\n raise NotImplementedError()\n return np.array(descriptors)",
"_____no_output_____"
]
],
[
[
"Now let's implement the distance computation between descriptors. Look at `compute_euclidean_distances`. It takes descriptors that were computed for keypoints found in two different images and returns the pairwise distances between all point pairs.\n\nImplement `compute_chi_square_distances` in a similar manner.",
"_____no_output_____"
]
],
[
[
"def compute_euclidean_distances(descriptors1, descriptors2):\n distances = np.empty((len(descriptors1), len(descriptors2)))\n for i, desc1 in enumerate(descriptors1):\n distances[i] = np.linalg.norm(descriptors2-desc1, axis=-1)\n return distances\n\ndef compute_chi_square_distances(descriptors1, descriptors2):\n distances = np.empty((len(descriptors1), len(descriptors2)))\n # YOUR CODE HERE\n raise NotImplementedError()\n return distances",
"_____no_output_____"
]
],
[
[
"Given the distances, a simple way to produce point matches is to take each descriptor extracted from a keypoint of the first image, and find the keypoint in the second image with the nearest descriptor. The full pipeline from images to point matches is implemented below in the function `find_point_matches(im1, im2, opts)`.\n\nExperiment with different parameter settings. Which keypoint detector, region descriptor and distance function works best?",
"_____no_output_____"
]
],
[
[
"def find_point_matches(im1, im2, opts):\n # Process first image\n im1_gray = cv2.cvtColor(im1, cv2.COLOR_RGB2GRAY).astype(float)/255\n score_map1 = nms(opts.score_func(im1_gray, opts))\n points1 = score_map_to_keypoints(score_map1, opts)\n descriptors1 = opts.descriptor_func(im1, points1, opts)\n\n # Process second image independently of first\n im2_gray = cv2.cvtColor(im2, cv2.COLOR_RGB2GRAY).astype(float)/255\n score_map2 = nms(opts.score_func(im2_gray, opts))\n points2 = score_map_to_keypoints(score_map2, opts)\n descriptors2 = opts.descriptor_func(im2, points2, opts)\n \n # Compute descriptor distances\n distances = opts.distance_func(descriptors1, descriptors2)\n \n # Find the nearest neighbor of each descriptor from the first image\n # among descriptors of the second image\n closest_ids = np.argmin(distances, axis=1)\n closest_dists = np.min(distances, axis=1)\n \n # Sort the point pairs in increasing order of distance\n # (most similar ones first)\n ids1 = np.argsort(closest_dists)\n ids2 = closest_ids[ids1]\n points1 = points1[ids1]\n points2 = points2[ids2]\n \n # Stack the point matches into rows of (x1, y1, x2, y2) values\n point_matches = np.concatenate([points1, points2], axis=1)\n return point_matches\n\n# Try changing these values in different ways and see if you can explain\n# why the result changes the way it does.\nopts = AttrDict()\nopts.sigma1=2\nopts.sigma2=opts.sigma1*2\nopts.alpha=0.06\nopts.score_threshold=1e-8\nopts.descriptor_window_halfsize = 20\nopts.n_histogram_bins = 16\nopts.score_func = harris_scores\nopts.descriptor_func = compute_maglap_descriptors\nopts.distance_func = compute_chi_square_distances\n\n# Or try these:\n#opts.sigma1=3\n#opts.n_histogram_bins = 8\n#opts.score_threshold=5e-4\n#opts.score_func = hessian_scores\n#opts.descriptor_func = compute_rgb_descriptors\n#opts.distance_func = compute_euclidean_distances\n\nim1 = imageio.imread('graff5/img1.jpg')\nim2 = imageio.imread('graff5/img2.jpg')\n\npoint_matches = find_point_matches(im1, im2, opts)\nmatch_image = draw_point_matches(im1, im2, point_matches[:50])\nplot_multiple([match_image], imwidth=16, imheight=8)",
"_____no_output_____"
]
],
[
[
"## Homography Estimation\n\nNow that we have these pairs of matching points (also called point correspondences), what can we do with them? In the above case, the wall is planar (flat) and the camera was moved towards the left to take the second image compared to the first image. Therefore, the way that points on the wall are transformed across these two images can be modeled as a **homography**. Homographies can model two distinct effects:\n\n * transformation across images of **any scene** taken from the **exact same camera position** (center of projection)\n * transformation across images of a **planar object** taken from **any camera position**.\n \nWe are dealing with the second case in these graffiti images. Therefore if our point matches are correct, there should be a homography that transforms image points in the first image to the corresponding points in the second image. Recap the algorithm from the lecture for finding this homography (it's called the **Direct Linear Transformation**, DLT). There is a 2 page description of it in the Grauman & Leibe script (grauman-leibe-ch5-geometric-verification.pdf in the Moodle) in Section 5.1.3.\n\n----\n\nNow let's actually put this into practice. Implement `estimate_homography(point_matches)`, which returns a 3x3 homography matrix that transforms points of the first image to points of the second image.\nThe steps are:\n\n 1. Build the matrix $A$ from the point matches according to Eq. 5.7 from the script.\n 2. Apply SVD using `np.linalg.svd(A)`. It returns $U,d,V^T$. Note that the last return value is not $V$ but $V^T$.\n 3. Compute $\\mathbf{h}$ from $V$ according to Eq. 5.9 or 5.10\n 4. Reshape $\\mathbf{h}$ to the 3x3 matrix $H$ and return it.\n \nThe input `point_matches` contains as many rows as there are point matches (correspondences) and each row has 4 elements: $x, y, x', y'$.",
"_____no_output_____"
]
],
[
[
"def estimate_homography(point_matches):\n n_matches = len(point_matches)\n A = np.empty((n_matches*2, 9))\n for i, (x1, y1, x2, y2) in enumerate(point_matches):\n # YOUR CODE HERE\n raise NotImplementedError()\n return H",
"_____no_output_____"
]
],
[
[
"The `point_matches` have already been sorted in the `find_point_matches` function according to the descriptor distances, so the more accurate pairs will be near the beginning. We can use the top $k$, e.g. $k=10$ pairs in the homography estimation and have a reasonably accurate estimate. What $k$ give the best result? What happens if you use too many? Why?\n\nWe can use `cv2.warpPerspective` to warp the first image to the reference frame of the second. Does the result look good?\n\nCan you interpret the entries of the resulting $H$ matrix and are the numbers as you would expect them for these images?\n\nYou can also try other image from the `graff5` folder or the `NewYork` folder.",
"_____no_output_____"
]
],
[
[
"# See what happens if you change top_k below\ntop_k = 10\nH = estimate_homography(point_matches[:top_k])\n\nH_string = np.array_str(H, precision=5, suppress_small=True)\nprint('The estimated homography matrix H is\\n', H_string)\n\nim1_warped = cv2.warpPerspective(im1, H, (im2.shape[1], im2.shape[0]))\nabsdiff = np.abs(im2.astype(np.float32)-im1_warped.astype(np.float32))/255\nplot_multiple([im1, im2, im1_warped, absdiff],\n ['First image', 'Second image', \n 'Warped first image', 'Absolute difference'],\n max_columns=2, colormap='viridis')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02d2469f89df85a688b94b19325a89f2108b58c
| 14,800 |
ipynb
|
Jupyter Notebook
|
2/trainGPR.ipynb
|
aghaeijo/Prediction-of-the-equivalent-sandgrain-height
|
cc249653c72ba3d8eea011a81e53ab2d3c62c747
|
[
"MIT"
] | 1 |
2021-06-17T08:45:46.000Z
|
2021-06-17T08:45:46.000Z
|
2/trainGPR.ipynb
|
aghaeijo/Prediction-of-the-equivalent-sandgrain-height
|
cc249653c72ba3d8eea011a81e53ab2d3c62c747
|
[
"MIT"
] | 1 |
2021-04-16T01:38:06.000Z
|
2021-04-16T01:38:06.000Z
|
2/trainGPR.ipynb
|
aghaeijo/Prediction-of-the-equivalent-sandgrain-height
|
cc249653c72ba3d8eea011a81e53ab2d3c62c747
|
[
"MIT"
] | 3 |
2021-06-17T08:45:50.000Z
|
2022-03-23T21:47:33.000Z
| 30.833333 | 111 | 0.473041 |
[
[
[
"# Load necessary modules and libraries\n\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.model_selection import learning_curve\nfrom sklearn.neural_network import MLPRegressor\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.gaussian_process import GaussianProcessRegressor\nfrom sklearn.gaussian_process.kernels import RBF, RationalQuadratic, Matern, ExpSineSquared,DotProduct\n\nimport pickle\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"# Load the data\n\n\nGeometry1 = pd.read_csv('Surface_features.csv',header=0, usecols=(4,8,9,10,11,12,14))\nGeometry = pd.read_csv('Surface_features.csv',header=0, usecols=(4,6,7,8,9,10,11,12)).values\n\nRa_ch = pd.read_csv('Surface_features.csv',header=0,usecols=(5,)).values\nRa_ch = Ra_ch[:,0]\nks = pd.read_csv('Surface_features.csv',header=0,usecols=(13,)).values\nks = ks[:,0]\n\n\n\nGeometry1[\"ks\"]= np.divide(ks,Ra_ch)\nGeometry1[\"krms_ch\"]= np.divide(Geometry1[\"krms_ch\"],Ra_ch)\n\n\nGeometry1.rename({'krms_ch': '$k_{rms}/R_a$',\n 'pro_ch': '$P_o$',\n 'ESx_ch': '$E_x$',\n 'ESz_ch': '$E_z$',\n 'sk_ch': '$S_k$',\n 'ku_ch': '$K_u$',\n 'ks': '$k_s/R_a$',\n 'label': 'Label',\n }, axis='columns', errors=\"raise\",inplace = True)\n",
"_____no_output_____"
],
[
"# Plot raw data\n\nplt.rc('text', usetex=True)\n\nsns.set(context='paper',\n style='ticks', \n palette='deep',\n font='sans-serif', \n font_scale=3, color_codes=True, rc=None)\n\n\ng = sns.pairplot(Geometry1,diag_kind=\"kde\", #palette=\"seismic\", \n hue='Label',\n plot_kws=dict(s=70,facecolor=\"w\", edgecolor=\"w\", linewidth=1),\n diag_kws=dict(linewidth=1.5))\ng.map_upper(sns.kdeplot)\ng.map_lower(sns.scatterplot, s=50,)\n\nplt.savefig('pair.pdf', dpi=None, facecolor='w', edgecolor='w',\n orientation='portrait', papertype=None, format=None,\n transparent=False, bbox_inches=None, pad_inches=0.1,\n frameon=None, metadata=None)\n\n",
"_____no_output_____"
],
[
"# Data reconfiguration, to be used in ML\n\nX = Geometry\ny = np.divide(ks,Ra_ch)\n\n\nX[:,0] = np.divide(X[:,0],Ra_ch)\nX[:,2] = np.abs(X[:,2])\n\n\n# Generate secondary features and append them to the original dataset\n\nn,m = X.shape \nX0 = np.ones((n,1))\nX1 = np.ones((n,1))\nX2 = np.ones((n,1))\nX3 = np.ones((n,1))\nX4 = np.ones((n,1))\nX5 = np.ones((n,1))\nX6 = np.ones((n,1))\nX7 = np.ones((n,1))\nX8 = np.ones((n,1))\nX9 = np.ones((n,1))\n\n\n\n\nX1[:,0] = np.transpose(X[:,4]*X[:,5])\nX2[:,0] = np.transpose(X[:,4]*X[:,6])\nX3[:,0] = np.transpose(X[:,4]*X[:,7])\nX4[:,0] = np.transpose(X[:,5]*X[:,6])\nX5[:,0] = np.transpose(X[:,5]*X[:,7])\nX6[:,0] = np.transpose(X[:,6]*X[:,7])\nX7[:,0] = np.transpose(X[:,4]*X[:,4])\nX8[:,0] = np.transpose(X[:,5]*X[:,5])\nX9[:,0] = np.transpose(X[:,6]*X[:,6])\n\n\n\n\nX = np.hstack((X,X1))\nX = np.hstack((X,X2))\nX = np.hstack((X,X3))\nX = np.hstack((X,X4))\nX = np.hstack((X,X5))\nX = np.hstack((X,X6))\nX = np.hstack((X,X7))\nX = np.hstack((X,X8))\nX = np.hstack((X,X9))\n\n\n",
"_____no_output_____"
],
[
"# Best linear estimation\n\n\nreg = LinearRegression().fit(X, y)\nreg.score(X, y)\nyn=reg.predict(X)\nprint(\"Mean err: %f\" % np.mean(100.*abs(yn-y)/(y)))\nprint(\"Max err: %f\" % max(100.*abs(yn-y)/(y)))\n\n\n\n",
"_____no_output_____"
],
[
"# Define two files that store the best ML prediction based on either L1 or L_\\infty norms\n\n\nfilename1 = 'GPR_Linf.sav'\nfilename2 = 'GPR_L1.sav'\n\n\n\n",
"_____no_output_____"
],
[
"# Perform ML training --- it may take some time. \n# Adjust ranges for by4 for faster (but potentially less accurate) results.\n\n\n\n\nminy1=100\nminy2=100\nby4=0.\nwhile by4<10000.:\n by4=by4+1\n kernel1 = RBF(10, (1e-3, 1e2))\n kernel2 = RBF(5, (1e-3, 1e2))\n kernel3 = RationalQuadratic(length_scale=1.0, alpha=0.1)\n kernel4 = Matern(length_scale=1.0, length_scale_bounds=(1e-05, 100000.0), nu=4.5)\n kernel5 = ExpSineSquared(length_scale=2.0, \n periodicity=3.0, \n length_scale_bounds=(1e-05, 100000.0), \n periodicity_bounds=(1e-05, 100000.0))\n kernel6 = DotProduct()\n \n gpr = GaussianProcessRegressor(kernel=kernel1, n_restarts_optimizer=1000)\n gpr = GaussianProcessRegressor(kernel=kernel3, n_restarts_optimizer=1000,alpha=.1)\n \n \n \n print(\"by4: %f\" % by4)\n\n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)\n gpr.fit(X_train, y_train)\n yn, sigma = gpr.predict(X, return_std=True)\n \n #print(\"Max err: %f\" % max(100.*abs(yn-y)/y))\n #print(\"Mean err: %f\" % np.mean(100.*abs(yn-y)/y))\n \n if miny1>max(100.*abs(yn-y)/y):\n pickle.dump(gpr, open(filename1, 'wb'))\n miny1=max(100.*abs(yn-y)/y)\n print(\"Miny1: %f\" % miny1)\n \n if miny2>np.mean(100.*abs(yn-y)/y):\n pickle.dump(gpr, open(filename2, 'wb'))\n miny2=np.mean(100.*abs(yn-y)/y)\n print(\"Miny2: %f\" % miny2)\n \n\n \n \nprint(\"by4: %f\" % by4)\n\n",
"_____no_output_____"
],
[
"# Load either file1 or file2 to extract the results\n\nloaded_model = pickle.load(open(filename2, 'rb'))\nloaded_model.get_params()\n",
"_____no_output_____"
],
[
"\nyn, sigma = loaded_model.predict(X,return_std=True)\nprint(\"PREDICTED k_s/R_a= \")\nprint(yn)\nprint(\"Max err: %f\" % max(100.*abs(yn-y)/(y)))\nprint(\"mean err: %f\" % np.mean(100.*abs(yn-y)/(y))) \n\n\nError=pd.DataFrame()\nError[\"$k_s/Ra$\"]= y\nError[\"$k_{sp}/Ra$\"]= yn\nError[\"$error(\\%)$\"]= (100.*(yn-y)/(y))\nError[\"Label\"]= Geometry1[\"Label\"]\n\nprint(Error)",
"_____no_output_____"
],
[
"# Plot the results\n\n\nplt.rc('text', usetex=True)\n\nsns.set(context='paper',\n style='ticks', \n palette='deep',\n font='sans-serif', \n font_scale=2, color_codes=True, rc=None)\n\ng = sns.pairplot(Error,diag_kind=\"kde\", hue='Label',\n aspect=1.,\n plot_kws=dict(s=50,facecolor=\"w\", edgecolor=\"w\", linewidth=1.),\n diag_kws=dict(linewidth=1.5,kernel='gau'))\n\ng.map_upper(sns.kdeplot)\ng.map_lower(sns.scatterplot, s=50,legend='full')\ng.axes[-2,0].plot(range(15), range(15),'k--', linewidth= 1.7)\n\n\nfor i in range(0,3):\n for ax in g.axes[:,i]:\n ax.spines['top'].set_visible(True)\n ax.spines['right'].set_visible(True)\n\n\n\n\nplt.savefig('GPR_result.pdf', dpi=None, facecolor='w', edgecolor='w',\n orientation='portrait', papertype=None, format=None,\n transparent=False, bbox_inches=None, pad_inches=0.1,\n frameon=None, metadata=None)\n\n",
"_____no_output_____"
],
[
"# Plot confidence interval\n\nsns.set(context='notebook',\n style='ticks', \n palette='seismic',\n font='sans-serif', \n font_scale=5, color_codes=True, rc=None)\nplt.rc('text', usetex=True)\nfig = plt.figure(figsize=(50,55))\n\nplt.subplot(411)\nXm=X[np.argsort(X[:,0])]\nXm=Xm[:,0]\nym=y[np.argsort(X[:,0])]\nymp=yn[np.argsort(X[:,0])]\nsigmap=sigma[np.argsort(X[:,0])]\n\nplt.plot(Xm, ym, 'r.', markersize=26)\nplt.plot(Xm, ymp, 'b-',linewidth=6)\nplt.fill(np.concatenate([Xm, Xm[::-1]]),\n np.concatenate([ymp - 1.900 * sigmap,\n (ymp + 1.900 * sigmap)[::-1]]),\n alpha=.5, fc='b', ec='None')\nplt.xlabel('$k_{rms}/R_a$')\nplt.ylabel('$k_s/R_a$')\nplt.grid(alpha=0.15)\n#plt.legend(loc='best')\n\n\nplt.subplot(412)\nXm=X[np.argsort(X[:,4])]\nXm=Xm[:,4]\nym=y[np.argsort(X[:,4])]\nymp=yn[np.argsort(X[:,4])]\nsigmap=sigma[np.argsort(X[:,4])]\n\nplt.plot(Xm, ym, 'r.', markersize=26)\nplt.plot(Xm, ymp, 'b-',linewidth=6)\nplt.fill(np.concatenate([Xm, Xm[::-1]]),\n np.concatenate([ymp - 1.900 * sigmap,\n (ymp + 1.900 * sigmap)[::-1]]),\n alpha=.5, fc='b', ec='None')\nplt.xlabel('$E_x$')\nplt.ylabel('$k_s/R_a$')\nplt.grid(alpha=0.15)\n\n\nplt.subplot(413)\nXm=X[np.argsort(X[:,3])]\nXm=Xm[:,3]\nym=y[np.argsort(X[:,3])]\nymp=yn[np.argsort(X[:,3])]\nsigmap=sigma[np.argsort(X[:,3])]\n\nplt.plot(Xm, ym, 'r.', markersize=26)\nplt.plot(Xm, ymp, 'b-',linewidth=6)\nplt.fill(np.concatenate([Xm, Xm[::-1]]),\n np.concatenate([ymp - 1.900 * sigmap,\n (ymp + 1.900 * sigmap)[::-1]]),\n alpha=.5, fc='b', ec='None')\nplt.xlabel('$P_o$')\nplt.ylabel('$k_s/R_a$')\nplt.grid(alpha=0.15)\n\nplt.subplot(414)\nXm=X[np.argsort(X[:,6])]\nXm=Xm[:,6]\nym=y[np.argsort(X[:,6])]\nymp=yn[np.argsort(X[:,6])]\nsigmap=sigma[np.argsort(X[:,6])]\n\nplt.plot(Xm, ym, 'r.', markersize=26, label='$k_s/R_a$')\nplt.plot(Xm, ymp, 'b-', linewidth=6,label='$k_{sp}/R_a$')\nplt.fill(np.concatenate([Xm, Xm[::-1]]),\n np.concatenate([ymp - 1.900 * sigmap,\n (ymp + 1.900 * sigmap)[::-1]]),\n alpha=.5, fc='b', ec='None', label='$90\\%$ $CI$')\nplt.xlabel('$S_k$')\nplt.ylabel('$k_s/R_a$')\nplt.grid(alpha=0.15)\nplt.legend(loc='best')\n\n\nplt.savefig('GPR_CI.pdf', dpi=None, facecolor='w', edgecolor='w',\n orientation='portrait', papertype=None, format=None,\n transparent=False, bbox_inches=None, pad_inches=0.1,\n frameon=None, metadata=None)\n\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02d2db32294a41daa16763dc601b39ae4cf9e57
| 5,781 |
ipynb
|
Jupyter Notebook
|
report/QueuesReport.ipynb
|
FactomProject/factomd-bench
|
177adc773303d78dae5a96d578c507da0d1755ac
|
[
"MIT"
] | null | null | null |
report/QueuesReport.ipynb
|
FactomProject/factomd-bench
|
177adc773303d78dae5a96d578c507da0d1755ac
|
[
"MIT"
] | null | null | null |
report/QueuesReport.ipynb
|
FactomProject/factomd-bench
|
177adc773303d78dae5a96d578c507da0d1755ac
|
[
"MIT"
] | null | null | null | 27.014019 | 178 | 0.442311 |
[
[
[
"import psycopg2 as pg\nimport pandas.io.sql as psql\nimport pandas as pd\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"_query = \"\"\"\nSELECT\n trim('\"' FROM block::text )::int as block,\n trim('\"' FROM min::text )::int as min,\n s.holding,\n s.acks,\n s.msgqueue,\n s.inmsgqueue,\n s.apiqueue,\n s.ackqueue,\n s.timermsg,\n ts::text::time,\n s.run\nFROM (SELECT\n --mt | \"LIST_SIZES Holding: %v, Acks: %v, MsgQueue: %v, InMsgQueue: %v, APIQueue: %v, AckQueue: %v, TimerMsg: %v \"\n run,\n e->'log'->'height' as block,\n e->'log'->'min' as min,\n e->'log'->'event'->0 as holding,\n e->'log'->'event'->1 as acks,\n e->'log'->'event'->2 as msgqueue,\n e->'log'->'event'->3 as inmsgqueue,\n e->'log'->'event'->4 as apiqueue,\n e->'log'->'event'->5 as ackqueue,\n e->'log'->'event'->6 as timermsg,\n e->'log'->'event'->7 as fmt,\n e->'ts' as ts\n --e as l\nFROM\n logs\n) as s\n\nWHERE\n s.fmt::varchar like '%LIST_SIZES%'\n\"\"\"\n\n_order = \"\"\"\nORDER BY ts;\n\"\"\"\n\n\ndef query(i):\n return _query + ' AND run = %s ' % i + _order\n\nconnection = pg.connect(\"host='localdb' dbname=load user=load password='load'\")\n",
"_____no_output_____"
],
[
"log_runs = pd.read_sql_query('SELECT * from log_runs;', con=connection)\nlog_runs",
"_____no_output_____"
],
[
"import plotly.plotly as py\nimport plotly.graph_objs as go\n\ndata = []\nfor i, n in log_runs['label'].items():\n r = log_runs['id'][i]\n df = pd.read_sql_query(query(r), con=connection)\n #data.append(\n # go.Scatter(x=df['ts'], y=df['holding'], name=n.replace('test_','')+'holding')\n #)\n data.append(\n go.Scatter(x=df['ts'], y=df['inmsgqueue'], name=n.replace('test_','')+'inmsg')\n )\n\npy.iplot(data, filename='WIP-queues')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
d02d3823593ba041b92c33fece73233079ed3a28
| 23,078 |
ipynb
|
Jupyter Notebook
|
notebooks/004_fingerprints/999_fetch_sitealign_features.ipynb
|
volkamerlab/kissim_app
|
83ba9af39ec38f0dcae7c7c65dc5a31c3ee367d4
|
[
"MIT"
] | 6 |
2021-02-19T20:01:57.000Z
|
2022-02-03T04:25:25.000Z
|
notebooks/004_fingerprints/999_fetch_sitealign_features.ipynb
|
volkamerlab/kissim_app
|
83ba9af39ec38f0dcae7c7c65dc5a31c3ee367d4
|
[
"MIT"
] | 39 |
2020-12-16T09:19:13.000Z
|
2021-12-11T09:17:01.000Z
|
notebooks/004_fingerprints/999_fetch_sitealign_features.ipynb
|
volkamerlab/kissim_app
|
83ba9af39ec38f0dcae7c7c65dc5a31c3ee367d4
|
[
"MIT"
] | 1 |
2022-02-03T04:25:26.000Z
|
2022-02-03T04:25:26.000Z
| 29.511509 | 378 | 0.353713 |
[
[
[
"# SiteAlign features\n\nWe read the SiteAlign features from the respective [paper](https://onlinelibrary.wiley.com/doi/full/10.1002/prot.21858) and [SI table](https://onlinelibrary.wiley.com/action/downloadSupplement?doi=10.1002%2Fprot.21858&file=prot21858-SupplementaryTable.pdf) to verify `kissim`'s implementation of the SiteAlign definitions:",
"_____no_output_____"
]
],
[
[
"from kissim.definitions import SITEALIGN_FEATURES",
"_____no_output_____"
],
[
"SITEALIGN_FEATURES",
"_____no_output_____"
]
],
[
[
"## Size",
"_____no_output_____"
],
[
"SiteAlign's size definitions:\n\n> Natural amino acids have been classified into three groups according to the number of heavy atoms (<4 heavy atoms: Ala, Cys, Gly, Pro, Ser, Thr, Val; 4–6 heavy atoms: Asn, Asp, Gln, Glu, His, Ile, Leu, Lys, Met; >6 heavy atoms: Arg, Phe, Trp, Tyr) and three values (“1,” “2,” “3”) are outputted according to the group to which the current residues belong to (Table I)\n\nhttps://onlinelibrary.wiley.com/doi/full/10.1002/prot.21858",
"_____no_output_____"
],
[
"### Parse text from SiteAlign paper",
"_____no_output_____"
]
],
[
[
"size = {\n 1.0: \"Ala, Cys, Gly, Pro, Ser, Thr, Val\".split(\", \"),\n 2.0: \"Asn, Asp, Gln, Glu, His, Ile, Leu, Lys, Met\".split(\", \"),\n 3.0: \"Arg, Phe, Trp, Tyr\".split(\", \"),\n}",
"_____no_output_____"
]
],
[
[
"### `kissim` definitions correct?",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom IPython.display import display, HTML\n\n# Format SiteAlign data\nsize_list = []\nfor value, amino_acids in size.items():\n values = [(amino_acid.upper(), value) for amino_acid in amino_acids]\n size_list = size_list + values\nsize_series = (\n pd.DataFrame(size_list, columns=[\"amino_acid\", \"size\"])\n .sort_values(\"amino_acid\")\n .set_index(\"amino_acid\")\n .squeeze()\n)\n\n# KiSSim implementation of SiteAlign features correct?\ndiff = size_series == SITEALIGN_FEATURES[\"size\"]\nif not diff.all():\n raise ValueError(\n f\"KiSSim implementation of SiteAlign features is incorrect!!!\\n\"\n f\"{display(HTML(diff.to_html()))}\"\n )\nelse:\n print(\"KiSSim implementation of SiteAlign features is correct :)\")",
"KiSSim implementation of SiteAlign features is correct :)\n"
]
],
[
[
"## HBA, HBD, charge, aromatic, aliphatic",
"_____no_output_____"
],
[
"### Parse table from SiteAlign SI",
"_____no_output_____"
]
],
[
[
"sitealign_table = \"\"\"\nAla 0 0 0 1 0\nArg 3 0 +1 0 0\nAsn 1 1 0 0 0\nAsp 0 2 -1 0 0\nCys 1 0 0 1 0\nGly 0 0 0 0 0\nGln 1 1 0 0 0\nGlu 0 2 -1 0 0\nHis/Hid/Hie 1 1 0 0 1\nHip 2 0 1 0 0\nIle 0 0 0 1 0\nLeu 0 0 0 1 0\nLys 1 0 +1 0 0\nMet 0 0 0 1 0\nPhe 0 0 0 0 1\nPro 0 0 0 1 0\nSer 1 1 0 0 0\nThr 1 1 0 1 0\nTrp 1 0 0 0 1\nTyr 1 1 0 0 1\nVal 0 0 0 1 0\n\"\"\"\nsitealign_table = [i.split() for i in sitealign_table.split(\"\\n\")[1:-1]]\nsitealign_dict = {i[0]: i[1:] for i in sitealign_table}\nsitealign_df = pd.DataFrame.from_dict(sitealign_dict).transpose()\nsitealign_df.columns = [\"hbd\", \"hba\", \"charge\", \"aliphatic\", \"aromatic\"]\nsitealign_df = sitealign_df[[\"hbd\", \"hba\", \"charge\", \"aromatic\", \"aliphatic\"]]\nsitealign_df = sitealign_df.rename(index={\"His/Hid/Hie\": \"His\"})\nsitealign_df = sitealign_df.drop(\"Hip\", axis=0)\nsitealign_df = sitealign_df.astype(\"float\")\nsitealign_df.index = [i.upper() for i in sitealign_df.index]\nsitealign_df = sitealign_df.sort_index()\nsitealign_df",
"_____no_output_____"
]
],
[
[
"### `kissim` definitions correct?",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, HTML\n\ndiff = sitealign_df == SITEALIGN_FEATURES.drop(\"size\", axis=1).sort_index()\nif not diff.all().all():\n raise ValueError(\n f\"KiSSim implementation of SiteAlign features is incorrect!!!\\n\"\n f\"{display(HTML(diff.to_html()))}\"\n )\nelse:\n print(\"KiSSim implementation of SiteAlign features is correct :)\")",
"KiSSim implementation of SiteAlign features is correct :)\n"
]
],
[
[
"## Table style",
"_____no_output_____"
]
],
[
[
"from Bio.Data.IUPACData import protein_letters_3to1\n\nfor feature_name in SITEALIGN_FEATURES.columns:\n print(feature_name)\n for name, group in SITEALIGN_FEATURES.groupby(feature_name):\n amino_acids = {protein_letters_3to1[i.capitalize()] for i in group.index}\n amino_acids = sorted(amino_acids)\n print(f\"{name:<7}{' '.join(amino_acids)}\")\n print()",
"size\n1.0 A C G P S T V\n2.0 D E H I K L M N Q\n3.0 F R W Y\n\nhbd\n0.0 A D E F G I L M P V\n1.0 C H K N Q S T W Y\n3.0 R\n\nhba\n0.0 A C F G I K L M P R V W\n1.0 H N Q S T Y\n2.0 D E\n\ncharge\n-1.0 D E\n0.0 A C F G H I L M N P Q S T V W Y\n1.0 K R\n\naromatic\n0.0 A C D E G I K L M N P Q R S T V\n1.0 F H W Y\n\naliphatic\n0.0 D E F G H K N Q R S W Y\n1.0 A C I L M P T V\n\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d02d3cba361439fcb466b45432e194ac62fc8da8
| 10,389 |
ipynb
|
Jupyter Notebook
|
_notebooks/2022-2-1-NYSE-data-analysis.ipynb
|
saaleh2/ALHODAIF-Portfolio
|
913437ee7e05f3e4cac90ba4eef7ff202c313e3c
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2022-2-1-NYSE-data-analysis.ipynb
|
saaleh2/ALHODAIF-Portfolio
|
913437ee7e05f3e4cac90ba4eef7ff202c313e3c
|
[
"Apache-2.0"
] | 1 |
2022-01-10T07:29:45.000Z
|
2022-01-10T07:30:18.000Z
|
_notebooks/2022-2-1-NYSE-data-analysis.ipynb
|
saaleh2/ALHODAIF-Portfolio
|
913437ee7e05f3e4cac90ba4eef7ff202c313e3c
|
[
"Apache-2.0"
] | null | null | null | 38.764925 | 589 | 0.632111 |
[
[
[
"# \"Building Excel dashboard using NYSE data\"\n> \"A project for my Udacity certificate in business analysis\"\n\n- toc: false\n- branch: master\n- badges: false\n- hide_github_badge: true\n- comments: true\n- categories: [Excel, Dashboards]\n- image: images/dashboard_icon.webp\n- hide: false\n- search_exclude: false\n- metadata_key1: Excel\n- metadata_key2: Dashboards",
"_____no_output_____"
],
[
"This project is from my Udacityies' \"Business Analysis\" nanodegree last year. Udacity has famously known for thair project-based courses. Meaning that candidates can only get thair certificate if they apply what they have learned in real-life projects. Candidates' projects get checked by experts to evaluate their work and make sure they have fulfilled Udacityies' requirements. \n\nThis project uses the NYSE dataset for over 450 companies. It includes companies' financials data for four years, period date, sector, and industry. \nHere's a look at the dataset head:",
"_____no_output_____"
],
[
"<iframe width=\"900\" height=\"281\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=dataset_head&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"To pass this project I've been asked to attain two requirements: \n- Find insights from the data and tell a story about it through a presentation.\n- Build a dynamic financial dashboard in excel.\n\n## Find insights in the data \n\nThe dataset includes financial data from 2012 to 2016. The first thing that came to my mind of that period is when the oil price hit 120$ in 2012 and then fell in 2015. \nI was wondering how the airline industry did during that period. Why airline? because during that time I was studying in China and I've noticed that airline ticket prices were getting more and more expensive. So I wanted to see if there's a correlation between ticket prices and oil prices to confirm my hypothesis. In general, if oil prices go up or down it affects many aspects of the global economy, some sectors benefit from high prices but most of them benefit from lower prices. my question was **\"how was airline companies' financial performance during that period?\"** \nMy assumption was that high oil prices will increase the cost of airline operations, which therefore increases the price of tickets. High ticket prices lead to lower demand and therefore lower profits.\n\n### Extracting EBIT from data\n\nThe main benchmarks I used to answer my question are **total revenue** and **EBIT** (earnings before interest and tax). There are other factors that could tell you about companies' performance, but these two are good for my question. We don't have EBIT in the dataset, But luckily we have the raw data to extract **EBIT**. \nTo do that, First I found the ``Gross Profit`` by subtracting ``Cost of Goods Sold`` from ``Total Revenue`` then we get **EBIT** by subtracting ``Sales, General and Admin`` from ``Gross Profit``. \nLastly, I used the wonderful pivot table tool, to get ***average, median,***, and ***standard deviation*** of the two benchmarks mentioned earlier. Using them all together will give us more accurate insight. \n\nHere's the result on excel: \n\n- Average EBIT & revenue \n ",
"_____no_output_____"
],
[
"<iframe width=\"900\" height=\"615\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=average_EBIT&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"---\n  \n- Median EBIT\n ",
"_____no_output_____"
],
[
"<iframe width=\"900\" height=\"480\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=median_EBIT&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"--- \n  \n- EBIT standard deviation\n ",
"_____no_output_____"
],
[
"<iframe width=\"900\" height=\"462\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=STD_EBIT&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"---\n  \n\nHere are my insights in clean slides: \n{% include info.html text=\"Use the full-screen button in the lower right corner.\" %}",
"_____no_output_____"
],
[
"<iframe src=\"https://onedrive.live.com/embed?cid=946CEB56A706EBDB&resid=946CEB56A706EBDB%219681&authkey=AHt-YAA_ZHUa-YI&em=2\" width=\"900\" height=\"480\" frameborder=\"0\" scrolling=\"no\"></iframe>",
"_____no_output_____"
],
[
"--- \n\n\n## Building dynamic dashboard in Excel\n\nUdacity required me to build two dynamic dashboards: \n+ P/L (Profit and loss) dashboard.\n+ Forecast analysis dashboard with three case scenarios. \n\nA dynamic dashboard means that the user can choose the company symbol and read P/L or predictions for any company individually. The prediction dashboard predicts how a company would perform in the next two years. \n\n### P/L statment dashboard \n \nThis dashboard is simple, I just brought the data from the dataset sheet into each cell using `INDEX` and `MATCH` functions and used `Ctrl`+`Shift`+`Enter` to turn it into an array formula. \nTry it yourself: \n  ",
"_____no_output_____"
],
[
"<iframe width=\"900\" height=\"370\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=profit_loss_dashboard&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"  \n## Forecast dashboard \n\nThis dashboard is different. Here I'm required to build a dynamic dashboard that can show each company forecast with: \n- Three scenarios: *week*, *base*, and *strong* scenario.\n- Operating scenarios\n \nFirst, I created the ratios table like **Gross margin** and **Revenue growth** percentages because assumptions will be extracted from past years' ratios. Then under that table, I created the *operating scenario* table (sensitivity analysis). I could've implemented this table in the final formula but this will not allow the users to read ratios when they need it.\nFinally, I built the assumption table with past data as a final result.\nIn all tables, I used `INDEX`, `OFFSET`, and `MATCH` but in a boolean way. This is an example of a formula from one of the cells: ",
"_____no_output_____"
],
[
"```\n{=INDEX(total_revenue,MATCH(1,($F$5=symbols)*(G$8=years),0))}\n```",
"_____no_output_____"
],
[
"  \nThis is the forecasting dashboard, give it a try.\n  \n<iframe width=\"900\" height=\"813\" frameborder=\"0\" scrolling=\"no\" src=\"https://onedrive.live.com/embed?resid=946CEB56A706EBDB%219613&authkey=%21AJt2pyGN0wVXNN4&em=2&wdAllowInteractivity=False&Item=forecast_dashboard&wdHideGridlines=True&wdInConfigurator=True\"></iframe>",
"_____no_output_____"
],
[
"  \n  \nIf you would like to play with the file yourself [Click here](https://1drv.ms/x/s!AtvrBqdW62yUyw1J0gD7Z5hDorfQ?e=mmCYL1) to open the full file on OneDrive. \nIf you have any question please contact me on my [LinkedIn](https://www.linkedin.com/in/saleh-alhodaif) or [Twitter](https://twitter.com/salehalhodaif2)",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d02d3fefdc4ee0a2dd54e20010727f768e317d5a
| 8,081 |
ipynb
|
Jupyter Notebook
|
ads_classification_sklearn.ipynb
|
jaywoong/test_machinelearning
|
fa6a204133fda5382db433d3b4149a4c794e5ba7
|
[
"Apache-2.0"
] | null | null | null |
ads_classification_sklearn.ipynb
|
jaywoong/test_machinelearning
|
fa6a204133fda5382db433d3b4149a4c794e5ba7
|
[
"Apache-2.0"
] | null | null | null |
ads_classification_sklearn.ipynb
|
jaywoong/test_machinelearning
|
fa6a204133fda5382db433d3b4149a4c794e5ba7
|
[
"Apache-2.0"
] | null | null | null | 22.323204 | 287 | 0.466403 |
[
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"pd_data = pd.read_excel('./files/advertising.xls')\npd_data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 10 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Daily Time Spent on Site 1000 non-null float64 \n 1 Age 1000 non-null int64 \n 2 Area Income 1000 non-null float64 \n 3 Daily Internet Usage 1000 non-null float64 \n 4 Ad Topic Line 1000 non-null object \n 5 City 1000 non-null object \n 6 Male 1000 non-null int64 \n 7 Country 1000 non-null object \n 8 Timestamp 1000 non-null datetime64[ns]\n 9 Clicked on Ad 1000 non-null int64 \ndtypes: datetime64[ns](1), float64(3), int64(3), object(3)\nmemory usage: 78.2+ KB\n"
],
[
"x = pd_data[['Daily Time Spent on Site','Age','Area Income','Daily Internet Usage','Male']]\ny = pd_data[['Clicked on Ad']]\nx.shape, y.shape",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"x_train, x_test, y_train, y_test = train_test_split(x,y)\nx_train.shape, x_test.shape, y_train.shape, y_test.shape",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression",
"_____no_output_____"
],
[
"log = LogisticRegression() ",
"_____no_output_____"
],
[
"log.fit(x_train, y_train)",
"c:\\users\\jeaung-lee\\appdata\\local\\programs\\python\\python39\\lib\\site-packages\\sklearn\\utils\\validation.py:63: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n return f(*args, **kwargs)\n"
],
[
"log.coef_, log.intercept_",
"_____no_output_____"
],
[
"log.predict_proba(x_train[100:104])",
"_____no_output_____"
],
[
"log.predict(x_train[100:104])",
"_____no_output_____"
],
[
"from sklearn import metrics",
"_____no_output_____"
],
[
"y_pred = log.predict(x_train)\ny_pred.shape, y_train.shape",
"_____no_output_____"
],
[
"print(metrics.classification_report(y_train, y_pred))",
" precision recall f1-score support\n\n 0 0.88 0.94 0.91 387\n 1 0.93 0.86 0.89 363\n\n accuracy 0.90 750\n macro avg 0.90 0.90 0.90 750\nweighted avg 0.90 0.90 0.90 750\n\n"
],
[
"metrics.confusion_matrix(y_train, y_pred)",
"_____no_output_____"
],
[
"import pickle",
"_____no_output_____"
],
[
"pickle.dump(log, open('./saves/log.pkl', 'wb'))",
"_____no_output_____"
],
[
"log_load = pickle.load(open('./saves/log.pkl', 'rb'))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02d5af63757f56a166455a26890c226ffb090f5
| 15,055 |
ipynb
|
Jupyter Notebook
|
notebooks/preprocessing/02_matrix.ipynb
|
sgg10/games_seeker
|
c9b7723586e79baffb5dc9f6ddb88f541da416a7
|
[
"MIT"
] | null | null | null |
notebooks/preprocessing/02_matrix.ipynb
|
sgg10/games_seeker
|
c9b7723586e79baffb5dc9f6ddb88f541da416a7
|
[
"MIT"
] | null | null | null |
notebooks/preprocessing/02_matrix.ipynb
|
sgg10/games_seeker
|
c9b7723586e79baffb5dc9f6ddb88f541da416a7
|
[
"MIT"
] | null | null | null | 46.180982 | 3,231 | 0.680438 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d02d6f1a8db2b9af61f9c599fcb3423749691989
| 7,616 |
ipynb
|
Jupyter Notebook
|
notebooks/depTFIDFModel-Test.ipynb
|
BigBossAnwer/STS-Pipeline
|
952d2c577dd4b8a66c99b80a24589a98e20c2e60
|
[
"MIT"
] | null | null | null |
notebooks/depTFIDFModel-Test.ipynb
|
BigBossAnwer/STS-Pipeline
|
952d2c577dd4b8a66c99b80a24589a98e20c2e60
|
[
"MIT"
] | null | null | null |
notebooks/depTFIDFModel-Test.ipynb
|
BigBossAnwer/STS-Pipeline
|
952d2c577dd4b8a66c99b80a24589a98e20c2e60
|
[
"MIT"
] | null | null | null | 27.395683 | 90 | 0.407957 |
[
[
[
"%cd ..",
"/media/Windows/Users/white/Documents/UTD/Fall19/NLP.6320.501/Project/STS-Project\n"
],
[
"import numpy as np\nimport pandas as pd\n\nfrom sts_wrldom.corpusReader import read_data\nfrom sts_wrldom.enrichPipe import preprocess_raw\nfrom sts_wrldom.depTFIDFModel import depFit_Predict\nfrom sts_wrldom.utils import write_results",
"_____no_output_____"
],
[
"%%time\ntest = read_data([\"test\"])\ntest_docs = preprocess_raw(test)\ntest_predics = depFit_Predict(test_docs)",
"Reading test-set from: data/test-set.txt\nTest DF shape: (750, 3)\nTest Pairs Omitted: 0 = 750 - 750\n\nEnriching data from dataframe...\nS1 parse failures: 0\nS2 parse failures: 0\n\nCPU times: user 7.91 s, sys: 191 ms, total: 8.1 s\nWall time: 8.07 s\n"
],
[
"test[\"prediction\"] = [int(elem) for elem in np.round(test_predics)]\n\nres = test[[\"id\", \"prediction\"]]\nwrite_results(res, \"test\", \"depPredic\")",
"_____no_output_____"
],
[
"test.head(5)",
"_____no_output_____"
],
[
"res.head(5)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02d89ba9d61ccaf8480a0915fc0f0622feb6c57
| 944 |
ipynb
|
Jupyter Notebook
|
01_Babynames.ipynb
|
cathimeister/spiced-w1-babynames
|
c1157d045f1f2b7d3a4eb5fd804da894e1ed56b6
|
[
"MIT"
] | 1 |
2019-03-01T08:50:08.000Z
|
2019-03-01T08:50:08.000Z
|
01_Babynames.ipynb
|
cathimeister/spiced-w1-babynames
|
c1157d045f1f2b7d3a4eb5fd804da894e1ed56b6
|
[
"MIT"
] | null | null | null |
01_Babynames.ipynb
|
cathimeister/spiced-w1-babynames
|
c1157d045f1f2b7d3a4eb5fd804da894e1ed56b6
|
[
"MIT"
] | null | null | null | 17.481481 | 98 | 0.523305 |
[
[
[
"# Analyzing Baby Names",
"_____no_output_____"
],
[
"### 1. Read and write data",
"_____no_output_____"
],
[
"Read the file yob2000.txt, print the first 10 entries and write the data to a different file",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
]
] |
d02d8cd0c7085f43f47b5b3b16aa0b2e14154572
| 446,520 |
ipynb
|
Jupyter Notebook
|
gan-fashion-mnist/notebook.ipynb
|
Tiendil/public-jupyter-notebooks
|
1681ca44d5805608cd3782ca1d793b6bad44f57b
|
[
"BSD-3-Clause"
] | null | null | null |
gan-fashion-mnist/notebook.ipynb
|
Tiendil/public-jupyter-notebooks
|
1681ca44d5805608cd3782ca1d793b6bad44f57b
|
[
"BSD-3-Clause"
] | 1 |
2021-07-24T13:15:23.000Z
|
2021-07-24T13:15:23.000Z
|
gan-fashion-mnist/notebook.ipynb
|
Tiendil/public-jupyter-notebooks
|
1681ca44d5805608cd3782ca1d793b6bad44f57b
|
[
"BSD-3-Clause"
] | null | null | null | 361.262136 | 193,180 | 0.924386 |
[
[
[
"# Fashion MNIST Generative Adversarial Network (GAN)",
"_____no_output_____"
],
[
"[Мой блог](https://tiendil.org)\n\n[Пост об этом notebook](https://tiendil.org/generative-adversarial-network-implementation)\n\n[Все публичные notebooks](https://github.com/Tiendil/public-jupyter-notebooks)\n\nУчебная реализация [GAN](https://en.wikipedia.org/wiki/Generative_adversarial_network) на данных [Fashion MNIST](https://github.com/zalandoresearch/fashion-mnist).\n\nНа основе следующих материалов:\n\n- https://machinelearningmastery.com/practical-guide-to-gan-failure-modes/\n- https://www.tensorflow.org/tutorials/generative/dcgan\n- https://keras.io/examples/generative/dcgan_overriding_train_step/\n\nСходу у меня не получилось нагуглись «красивое» решение. Поэтому тут будет композиция разных уроков. На мой взгляд, получилось более идиоматично.\n\nПро GAN лучше почитать по ссылке выше. Краткая суть:\n\n- Тренируются две сети: generator & discriminator.\n- Генератор учится создавать картинки из шума.\n- Дискриминатор учится отличать поддельные картинки от настоящих.\n- Ошибка дискриминатора определяется качеством предсказания фейковости изображения.\n- Ошибка генератора определяется качеством обмана дискриминатора. \n\nПодробнее про ошибки будет далее.\n\nЕсли правильно подобрать топологии сетей и параметры обучения, то в итоге генератор научается создавать картинки неотличимые от оригинальных. ??????. Profit.",
"_____no_output_____"
],
[
"## Подготовка",
"_____no_output_____"
],
[
"Notebook запускался в кастомизированном docker контейнере.\n\nПодробнее про мои злоключения с настройкой tensorflow + CUDA можно почитать в блоге: [нельзя просто так взять и запустить DL](https://tiendil.org/you-cant-just-take-and-run-dl).\n\nОфициальная документация о [запуске tensorflow через docker](https://www.tensorflow.org/install/docker).\n\nDockerfile: \n\n```\nFROM tensorflow/tensorflow:2.5.0-gpu-jupyter\n\nRUN apt-get update && apt-get install -y graphviz\n\nRUN pip install --upgrade pip\n\nCOPY requirements.txt ./\n\nRUN pip install -r ./requirements.txt\n\n```\n\nrequirements.txt:\n```\npandas==1.1.5\nkaggle==1.5.12\npydot==1.4.2 # requeired by tensorflow to visualize models\nlivelossplot==0.5.4 # required to plot loss while training\nalbumentations==1.0.3 # augument image data\njupyter-beeper==1.0.3\n```",
"_____no_output_____"
],
[
"## Инициализация",
"_____no_output_____"
],
[
"Уже без комментариев, подробнее рассказано в [предыдущих notebooks](https://github.com/Tiendil/public-jupyter-notebooks).",
"_____no_output_____"
]
],
[
[
"import os\nimport random\nimport logging\nimport datetime\n\nimport PIL\nimport PIL.Image\n\nimport jupyter_beeper\n\nfrom IPython.display import display, Markdown, Image\nimport ipywidgets as ipw\n\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'\n\nimport numpy as np\nimport pandas as pd\n\nimport tensorflow as tf\n\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\n\nimport matplotlib.pyplot as plt\n\nfrom livelossplot import PlotLossesKerasTF\n\nimport cv2 \n\nlogging.getLogger().setLevel(logging.WARNING)\n\ntf.get_logger().setLevel(logging.WARNING)\ntf.autograph.set_verbosity(1)\n\nold_settings = np.seterr('raise')\n\ngpus = tf.config.list_physical_devices(\"GPU\")\n\ndisplay(Markdown(f'Num GPUs Available: {len(gpus)}'))\n\nif not gpus:\n raise RuntimeError('No GPUs found, learning process will be too slow. In Google Colab set runtime type — GPU.')\n \ndisplay(Markdown(f'Eager mode: {tf.executing_eagerly()}'))\n\ntf.config.experimental.set_memory_growth(gpus[0], True)",
"_____no_output_____"
],
[
"SEED = 1\n\nrandom.seed(SEED)\nnp.random.seed(SEED)\ntf.random.set_seed(SEED)\n\ntf.keras.backend.clear_session()\n\nRNG = np.random.default_rng()",
"_____no_output_____"
]
],
[
[
"## Вспомогательные функции",
"_____no_output_____"
],
[
"Можно пролистать. Смотрите при необходимости.",
"_____no_output_____"
]
],
[
[
"def split_dataset(data, *parts, cache):\n data_size = data.cardinality()\n assert data_size == sum(parts), \\\n f\"dataset size must be equal to sum of parts: {data_size} != sum{parts}\"\n \n result = []\n \n for part in parts:\n data_part = data.take(part)\n \n if cache:\n data_part = data_part.cache()\n \n result.append(data_part)\n \n data = data.skip(part)\n \n return result\n\n\ndef normalizer(minimum, maximum): \n def normalize_dataset(x):\n return (x - minimum) / (maximum - minimum)\n return normalize_dataset\n\n\ndef display_model(model, name):\n filename = f'/tmp/tmp_model_schema_{name}.png'\n \n keras.utils.plot_model(model, \n show_shapes=True, \n show_layer_names=True, \n show_dtype=True,\n expand_nested=True,\n to_file=filename)\n display(Image(filename))\n \n\nclass LayersNameGenerator:\n __slots__ = ('prefix', 'number')\n \n _version = 0\n \n def __init__(self, prefix):\n self.prefix = prefix\n self.number = 0\n \n self.__class__._version += 1\n \n def __call__(self, type_name, name=None):\n self.number += 1\n \n if name is None:\n name = str(self.number)\n \n return f'{self.prefix}.{self._version}-{type_name}.{name}' \n \n\ndef display_examples(examples_number=1, \n data_number=1, \n image_getter=None, \n label_getter='',\n figsize=(16, 16),\n subplot=None,\n cmap=plt.get_cmap('gray')):\n\n if image_getter is None:\n raise ValueError('image_getter must be an image or a collable')\n \n if not callable(image_getter):\n image_value = image_getter\n image_getter = lambda j: image_value\n \n if not callable(label_getter):\n label_value = label_getter\n label_getter = lambda j: label_value\n\n examples_number = min(examples_number, data_number)\n \n if subplot is None:\n subplot = (1, examples_number)\n \n plt.figure(figsize=figsize)\n \n if examples_number < data_number:\n choices = RNG.choice(data_number, examples_number, replace=False)\n else:\n choices = list(range(data_number))\n \n for i, j in enumerate(choices):\n plt.subplot(*subplot, i+1)\n plt.imshow(image_getter(j), cmap=cmap)\n plt.title(label_getter(j))\n\n plt.show()\n \n \ndef display_memory_stats():\n stats = tf.config.experimental.get_memory_info('GPU:0')\n message = f'''\n current: {stats[\"current\"]/1024/1024}Mb\n peak: {stats[\"peak\"]/1024/1024}Mb\n '''\n display(Markdown(message))\n \n \ndef make_report(history, main, metrics): \n groups = {'main': {}}\n \n for key in history.history.keys():\n if key in ('loss', 'val_loss', 'accuracy', 'val_accuracy'):\n if key.startswith('val_'):\n metric = key\n else:\n metric = f'train_{key}'\n \n groups['main'][metric] = history.history[key][-1]\n continue\n \n if not any(key.endswith(f'_{metric}') for metric in metrics):\n continue\n \n group, metric = key.rsplit('_', 1)\n \n validation = False\n \n if group.startswith('val_'):\n group = group[4:]\n validation = True\n \n if group not in groups:\n groups[group] = {}\n \n if validation:\n metric = f'val_{metric}'\n else:\n metric = f'train_{metric}'\n \n groups[group][metric] = history.history[key][-1]\n \n lines = []\n \n for group, group_metrics in groups.items():\n lines.append(f'**{group}:**')\n lines.append(f'```')\n \n for name, value in sorted(group_metrics.items()):\n if name in ('accuracy', 'val_accuracy', 'train_accuracy'):\n lines.append(f' {name}: {value:.4%} ({value})')\n else:\n lines.append(f' {name}: {value}')\n \n lines.append(f'```')\n \n train_loss = groups[main]['train_loss']\n val_loss = groups[main].get('val_loss')\n val_accuracy = groups[main].get('val_accuracy')\n \n history.history[key][-1]\n \n if val_loss is None:\n description = f'train_loss: {train_loss:.4};'\n else:\n description = f'train_loss: {train_loss:.4}; val_loss: {val_loss:.4}; val_acc: {val_accuracy:.4%}'\n \n lines.append(f'**description:** {description}')\n \n return '\\n\\n'.join(lines), description\n\n\ndef crope_layer(input, expected_shape, names):\n raw_shape = input.get_shape()\n \n if raw_shape == (None, *expected_shape):\n outputs = input\n else:\n dy = raw_shape[1] - expected_shape[0]\n dx = raw_shape[2] - expected_shape[1]\n \n x1 = dx // 2\n x2 = dx - x1\n \n y1 = dy // 2\n y2 = dy - y1\n \n outputs = layers.Cropping2D(cropping=((y1, y2), (x1, x2)), \n name=names('Cropping2D'))(input)\n \n return outputs\n\n\ndef neurons_in_shape(shape):\n input_n = 1\n \n for n in shape:\n if n is not None:\n input_n *= n\n \n return input_n\n\n\ndef form_images_map(h, w, images, channels, scale=1):\n map_image = np.empty((SPRITE_SIZE*h, SPRITE_SIZE*w, channels), dtype=np.float32)\n \n for i in range(h):\n y_1 = i * SPRITE_SIZE\n \n for j in range(w):\n sprite = images[i*w+j] \n \n x_1 = j * SPRITE_SIZE\n\n map_image[y_1:y_1+SPRITE_SIZE, x_1:x_1+SPRITE_SIZE, :] = sprite\n \n if channels == 1:\n mode = 'L'\n map_image = np.squeeze(map_image)\n elif channels == 3:\n mode = 'RGB'\n else:\n raise ValueError(f'Unexpected channels value {channels}')\n \n if scale != 1:\n width, height = w * SPRITE_SIZE, h * SPRITE_SIZE\n map_image = cv2.resize(map_image, dsize=(width * scale, height * scale), interpolation=cv2.INTER_NEAREST)\n \n image = PIL.Image.fromarray((map_image * 255).astype(np.int8), mode)\n \n return image",
"_____no_output_____"
]
],
[
[
"## Получение данных",
"_____no_output_____"
]
],
[
[
"# получаем картинки одежды средствами TensorFlow\n(TRAIN_IMAGES, TRAIN_LABELS), (TEST_IMAGES, TEST_LABELS) = tf.keras.datasets.fashion_mnist.load_data()",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz\n32768/29515 [=================================] - 0s 1us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz\n26427392/26421880 [==============================] - 1s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz\n8192/5148 [===============================================] - 0s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz\n4423680/4422102 [==============================] - 0s 0us/step\n"
],
[
"# константы, описывающие данные\n\nCHANNELS = 1\nSPRITE_SIZE = 28\nSPRITE_SHAPE = (SPRITE_SIZE, SPRITE_SIZE, CHANNELS)",
"_____no_output_____"
],
[
"# Подготавливаем данные. Для GAN нам нужны только картинки.\n\ndef transform(images):\n images = (images / 255.0).astype(np.float32)\n images = np.expand_dims(images, axis=-1)\n return images\n\n\ndef filter_by_class(images, labels, classes):\n _images = tf.data.Dataset.from_tensor_slices(transform(images))\n _labels = tf.data.Dataset.from_tensor_slices(labels)\n \n d = tf.data.Dataset.zip((_images, _labels))\n d = d.filter(lambda i, l: tf.reduce_any(tf.equal(classes, l)))\n d = d.map(lambda i, l: i)\n \n return d\n\n\n# Обучаться будем только на изображениях обуви:\n#\n# - сеть будет учиться быстрее;\n# - результат будет лучше;\n# - будет проще, интереснее играться с работой обученной сети.\n#\n# Впрочем, эта реализация нормально учится и на всех изображениях.\n\n_classes = tf.constant((5, 7, 9), tf.uint8)\n\n_train = filter_by_class(TRAIN_IMAGES, TRAIN_LABELS, _classes)\n_test = filter_by_class(TEST_IMAGES, TEST_LABELS, _classes)\n\nDATA = _train.concatenate(_test).cache()\n\n# В некоторых местах нам потребуется знать размер обучающей выборки.\n# Получать его таким образом — плохое решение, но на таких объёмах данных оно работает.\nDATA_NUMBER = len(list(DATA))\n\ndisplay(Markdown(f'full data shape: {DATA}'))\n\n# Визуально проверяем, что отобрали нужные классы\ndata = [image for image in DATA.take(100).as_numpy_iterator()]\nform_images_map(5, 20, data, scale=1, channels=CHANNELS)",
"_____no_output_____"
]
],
[
[
"## Конструируем модель",
"_____no_output_____"
],
[
"По-сути, GAN — это три сети:\n\n- Generator.\n- Discriminator.\n- GAN — объединение двух предыдущих.\n\nСам GAN можно не оформлять отдельной сетью, достаточно правильно описать взаимодействие генератора и дискриминатора при обучения. Но, поскольку они учатся совместно, как одно целое, я вижу логичным работать с ними как с единой сетью.\n\nПоэтому мы отдельно создадим генератор с дискриминатором, после чего опишем класс сети, объединяющий их в единое целое.",
"_____no_output_____"
],
[
"### Обучение GAN",
"_____no_output_____"
],
[
"Обучение генератора и дискриминатора, само собой, происходит на основе функций ошибок. Функции каждой сети оценивают качество бинарной классификации входных данных, на фейковые и реальные. Обычно для этого используют [Binary Crossentropy](https://www.tensorflow.org/api_docs/python/tf/keras/losses/BinaryCrossentropy).\n\nДискриминатор на вход получает часть реальных изображений и часть созданных генератором. Поскольку класс каждого изображения мы знаем, мы можем легко определить ошибку дискриминатора.\n\nОшибку же генератора посчитать немного сложнее — качество его работы определяется дискриминатором. Чем хуже результат выдаёт дискриминатор на картинках генератора, тем лучше работает генератор. Поэтому мы скармиливаем дискриминатору созданные изображения с отметкой того, что они реальные (относятся к классу реальных), ошибка дискриминатора на таких данных и будет ошибкой генератора.",
"_____no_output_____"
],
[
"### Синхронизация сетей",
"_____no_output_____"
],
[
"Если генератор и дискриминатор будут учиться с разной скоростью или иметь разный потенциал выучиваемости, то они не смогут обучаться синхронно. Либо генератор превзойдёт дискриминатор и будет душить его тривиальными фейками, либо дискриминатор найдёт элементарный способ отличать подделки, который генератор не сможет обойти. \n\nПоэтому очень рекомендую при экспериментах с GAN сначала запускать что-нибудь очень простое, но работающее. И только после этого усложнять и экспериментировать. Не будьте как я :-)\n\nЭти же соображения предполагают визуализацию результатов обучения сети. **Убедитесь, что она корректно работает перед экспериментами.** Иначе можете как я сутки отлаживать работающую сеть с неработающей визуализацией.",
"_____no_output_____"
],
[
"### Метрики",
"_____no_output_____"
],
[
"У нас есть две конкурирующие сети, которые учатся на результатах работы друг друга. Такое обучение, потенциально, может происходить бесконечно. \n\nПоэтому сходу не ясно какой критерий остановки использовать и на какие метрики смотреть, чтобы анализировать ход обучения.\n\nНа сколько я понял, по крайней мере для простых случаев качество обучения GAN оценивают визуально: видит человек косяки на выходе генератора или не видит. Альтернативой может быть либо использование другой, предобученной сети, либо метаанализ метрик. Ни в ту ни в другую сторону я не смотрел.\n\nКасательно анализа самих метрик, есть одна эвристика, которую можно применить сразу в двух местах. \n\nПоскольку сети конкурируют, обучаются совместно и на одних данных, мы можем ожидать, что их ошибки будут стабильны. Утрируя, если генератор и дискриминатор обучаются с одинаковой скоростью из одного состояния, то их ошибки не должны изменяться, так как на любое улучшение генератора последует соответствующее улучшение дискриминатора и наоборот.\n\nОтсюда можно вывести метаметрики, которые позволяют оценить стабильность обучения GAN:\n\n- Отношение ошибки генератора к ошибке диксриминатора должно колебаться около единицы. Конечно, если их функции ошибок совпадают.\n- Отношение ошибки дискриминатора на реальных данных к ошибке дискриминатора на фейковых данных должно колебаться около единицы.\n\nЕсли любое из этих отношений сильно отклоняется от единицы, значит GAN обучается неравномерно и могут возникнуть проблемы. В то же время необходимо помнить, что нейронные сети — сложная штука, и отклонения могут быть. Иногда даже большие. Главное чтобы GAN восстанавливался после них.",
"_____no_output_____"
]
],
[
[
"def construct_discriminator():\n \n names = LayersNameGenerator('discriminator')\n \n inputs = keras.Input(shape=SPRITE_SHAPE, name=names('Input'))\n \n branch = inputs\n \n n = 64\n \n branch = layers.Conv2D(n, 4, 2, padding='same', name=names('Conv2D'))(branch)\n branch = layers.LeakyReLU(alpha=0.2, name=names('LeakyReLU'))(branch)\n \n branch = layers.Conv2D(n, 4, 2, padding='same', name=names('Conv2D'))(branch)\n branch = layers.LeakyReLU(alpha=0.2, name=names('LeakyReLU'))(branch)\n \n branch = layers.Flatten(name=names('Flatten'))(branch)\n \n branch = layers.Dense(1, activation=\"sigmoid\", name=names('Dense'))(branch)\n \n outputs = branch\n \n return keras.Model(inputs=inputs, outputs=outputs, name='Discimiantor')\n\n\ndef construct_generator(code_n):\n \n names = LayersNameGenerator('generator')\n \n inputs = keras.Input(shape=(code_n,), name=names('Input')) \n \n branch = inputs\n \n n = 128\n \n branch = layers.Dense(7 * 7 * n, activation='elu', name=names('Dense'))(branch)\n \n branch = layers.Reshape((7, 7, n), name=names('Reshape'))(branch)\n \n branch = layers.Conv2DTranspose(n, 4, 2, activation='relu', padding='same', name=names('Conv2DTranspose'))(branch)\n \n branch = layers.Conv2DTranspose(n, 4, 2, activation='relu', padding='same', name=names('Conv2DTranspose'))(branch)\n \n branch = layers.Conv2D(CHANNELS, 7, activation=\"sigmoid\", padding='same', name=names('Conv2D'))(branch)\n \n outputs = branch\n\n \n return keras.Model(inputs=inputs, outputs=outputs, name='Generator')\n\n\n# Вспомогательный класс для сбора метрик GAN.\n# Кроме трёх базовых метрик:\n# - ошибка дискриминатора на реальных данных;\n# - ошибка дискриминатора на фейковых данных;\n# - ошибка генератора;\n# Поддерживает две производные метрики:\n# - отношение ошибок дискриминатора на реальных и фейковых данных;\n# - отношение ошибок дискриминатора на фековых данных и генератора.\nclass GANMetrics:\n \n def __init__(self):\n self._define('discriminator_real_loss')\n self._define('discriminator_fake_loss')\n self._define('generator_loss')\n \n self._define('discriminator_real_vs_fake_loss')\n self._define('discriminator_vs_generator_loss')\n \n def _define(self, name):\n setattr(self, name, keras.metrics.Mean(name=name))\n \n def update_state(self, d_real_loss, d_fake_loss, g_loss):\n self.discriminator_real_loss.update_state(d_real_loss)\n self.discriminator_fake_loss.update_state(d_fake_loss)\n self.generator_loss.update_state(g_loss)\n \n self.discriminator_real_vs_fake_loss.update_state(tf.math.divide_no_nan(d_real_loss, d_fake_loss))\n self.discriminator_vs_generator_loss.update_state(tf.math.divide_no_nan(d_fake_loss, g_loss))\n \n def result(self):\n return {\"discriminator_real_loss\": self.discriminator_real_loss.result(),\n \"discriminator_fake_loss\": self.discriminator_fake_loss.result(),\n \"generator_loss\": self.generator_loss.result(),\n \n \"discriminator_real_vs_fake_loss\": self.discriminator_real_vs_fake_loss.result(),\n \"discriminator_vs_generator_loss\": self.discriminator_vs_generator_loss.result()}\n \n def list(self):\n return [self.discriminator_real_loss,\n self.discriminator_fake_loss,\n self.generator_loss,\n self.discriminator_real_vs_fake_loss,\n self.discriminator_vs_generator_loss]\n \n # Группы графиков для livelossplot\n def plotlosses_groups(self):\n return {'discriminator loss': ['discriminator_real_loss', 'discriminator_fake_loss'],\n 'generator loss': ['generator_loss'],\n 'relations': ['discriminator_real_vs_fake_loss', 'discriminator_vs_generator_loss']}\n \n # Короткие имена для графиков livelossplot\n def plotlosses_group_patterns(self):\n return ((r'^(discriminator_real_loss)(.*)', 'real'),\n (r'^(discriminator_fake_loss)(.*)', 'fake'),\n (r'^(generator_loss)(.*)', 'loss'),\n (r'^(discriminator_real_vs_fake_loss)(.*)', 'real / fake'),\n (r'^(discriminator_vs_generator_loss)(.*)', 'disciminator / generator'),)\n \n\n# Класс сети, объединяющей генератор и дискриминатор в GAN.\n# Делаем отдельный класс, так как нам необходимо переопределить шаг обучения.\n# Плюс, оформление в виде класса позволяет проще визуализировать сеть.\nclass GAN(keras.Model):\n def __init__(self, discriminator, generator, latent_dim, **kwargs):\n \n inputs = layers.Input(shape=latent_dim)\n \n super().__init__(inputs=inputs, \n outputs=discriminator(generator(inputs)), \n **kwargs)\n \n self.discriminator = discriminator\n self.generator = generator\n \n self.latent_dim = latent_dim\n \n self.batch_size = None\n self.real_labels = None\n self.fake_labels = None\n\n def compile(self, batch_size):\n super().compile()\n self.custom_metrics = GANMetrics()\n \n self.batch_size = batch_size\n \n self.real_labels = tf.ones((self.batch_size, 1))\n self.fake_labels = tf.zeros((self.batch_size, 1))\n\n @property\n def metrics(self):\n return self.custom_metrics.list()\n \n def latent_vector(self, n):\n return tf.random.normal(shape=(n, self.latent_dim)) \n \n # Самый интересный метод — шаг обучения GAN.\n # В куче примеров генератор и дискриминатор учатся отдельно и даже на разных данных.\n # Такой лобовой подход имеет право на жизнь, но он точно не оптимален. \n # Он приводит к генерации большого количества лишних данных и просто к лишним операциям над памятью.\n # Поэтому мы будем учить обе сети в один проход.\n @tf.function \n def train_step(self, real_images): \n # Генерируем шум для генератора, количество примеров берём равным количеству входных данных.\n random_latent_vectors = self.latent_vector(self.batch_size)\n \n # Генератор и дискриминатор должны учиться на разных операциях.\n # Поэтому самостоятельно записываем операции для расчёта градиентов.\n # Указываем persistent=True. TensorFlow по-умолчанию чистит GradientTape после расчёта первого градиаента,\n # а нам надо рассчитывать два — по градиенту на сеть.\n try:\n with tf.GradientTape(persistent=True) as tape:\n # генерируем поддельные картинки\n fake_images = self.generator(random_latent_vectors)\n \n # оцениваем их дискриминатором\n fake_predictions = self.discriminator(fake_images)\n \n # рассчитываем ошибку генератора, предполагая что сгенерированные картинки реальны\n g_loss = self.discriminator.compiled_loss(self.real_labels, fake_predictions)\n \n # рассчитываем ошибку дискриминатора на фейковых картинках, зная, что они фейковые\n d_f_loss = self.discriminator.compiled_loss(self.fake_labels, fake_predictions)\n \n # получаем предсказания дискриминатора для реальных картинок\n real_predictions = self.discriminator(real_images)\n \n # рассчитываем ошибку дискриминатора для реальных картинок\n d_r_loss = self.discriminator.compiled_loss(self.real_labels, real_predictions) \n \n # считаем градиент генератора и делаем шаг оптимизации\n grads = tape.gradient(g_loss, self.generator.trainable_weights)\n self.generator.optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))\n \n # считаем градиент дискриминатора и делаем шаг оптимизации\n grads = tape.gradient((d_r_loss, d_f_loss), self.discriminator.trainable_weights) \n self.discriminator.optimizer.apply_gradients(zip(grads, self.discriminator.trainable_weights))\n \n # обновляем метрики\n self.custom_metrics.update_state(d_r_loss, d_f_loss, g_loss)\n \n finally:\n # Удаляем лог градиента\n del tape \n\n return self.custom_metrics.result()\n\n\n# Количество входов шума для генератора.\n# 10 — очень малое значение! Я взял его, чтобы после обучения сети было проще с ней экспериментировать.\n# По-хорошему, это значение надо установить в 100 или больше.\n# Само собой, при большом количестве шума, сложно будет целенаправлено манипулировать сетью.\n# Обойти эту проблему можно с использованием дополнительной autoencoder сети, \n# которая учится «сжимать» данные до множества признаков.\n# Подход с autoencoder мне видится логичным и потому, что GAN использует входные данные всё-таки как шум,\n# а не как признаки. В то же время autoencoder ориентирован на выделение признаков.\nCODE_N = 10\n\n# Создаём генератор, дискриминатор и объединяем их в GAN.\n# Обратите внимание на кастомные параметры оптимизаторов. \n# Стандартные параметры TensorFlow плохо подходят для обучения GAN.\n\ndiscriminator = construct_discriminator()\ndiscriminator.compile(optimizer=keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5), \n loss=keras.losses.BinaryCrossentropy())\n\ngenerator = construct_generator(CODE_N)\ngenerator.compile(optimizer=keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5), \n loss=keras.losses.BinaryCrossentropy())\n \ngan = GAN(discriminator=discriminator, generator=generator, latent_dim=CODE_N, name='GAN')\n\ndisplay_model(gan, 'GAN')",
"_____no_output_____"
],
[
"# Проверяем, что модель в принципе что-то считает\ncheck_input = tf.constant(RNG.random((1, CODE_N)), shape=(1, CODE_N))\n\ngenerator_output = gan.generator(check_input)\n\ndisplay(Markdown(f'Generator output'))\n\ndisplay_examples(image_getter=generator_output[0],\n figsize=(3, 3))\n\ndiscriminator_output = gan.discriminator(generator_output)\n\ndisplay(Markdown(f'Discriminator output: {discriminator_output}'))",
"_____no_output_____"
],
[
"# Проверяем, что визуализатор работает на реальных данных\ndata = [image for image in DATA.take(9).as_numpy_iterator()]\nform_images_map(3, 3, data, scale=1, channels=CHANNELS)",
"_____no_output_____"
],
[
"# Определяем собственный callback для model.fit, который будет:\n# - отображать работу генератора каждую эпоху;\n# - сохранять картинки на файловую систему.\nclass GANMonitor(keras.callbacks.Callback):\n def __init__(self, w, h, images_directory, scale):\n self.w = w \n self.h = h\n self.images_directory = images_directory\n self.scale = scale\n\n def on_epoch_end(self, epoch, logs=None):\n n = self.w * self.h\n \n random_latent_vectors = self.model.latent_vector(n) \n \n generated_images = self.model.generator(random_latent_vectors).numpy()\n \n pil_world = form_images_map(self.h, self.w, generated_images, channels=CHANNELS, scale=self.scale)\n \n pil_world.save(f\"{IMAGES_DIRECTORY}/generated_img_%04d.png\" % (epoch,))\n \n display(pil_world)",
"_____no_output_____"
],
[
"# Задаём параметры обучения\n\n# Сколько раз цикл обучения пройдёт по всем обучающим данным.\n# Установите на свой вкус, 100 должно хватить, чтобу увидеть результат\nEPOCHS = 100\nBATCH_SIZE = 128\n\ndisplay(Markdown(f'batch size: {BATCH_SIZE}'))\ndisplay(Markdown(f'epochs: {EPOCHS}'))",
"_____no_output_____"
],
[
"%%time\n\n# каталог с результатами работы генератора\nIMAGES_DIRECTORY = 'generated-images'\n\n# создаём каталог с картинками и чистим его, если он заполнен\n!mkdir -p $IMAGES_DIRECTORY\n!rm $IMAGES_DIRECTORY/*\n\n# Явно формируем dataset для скармливания сети во время обучения.\n# Разбиваем на куски и говорим готовить их заранее.\ndata_for_train = DATA.shuffle(DATA_NUMBER).batch(BATCH_SIZE, drop_remainder=True).prefetch(buffer_size=10)\n\n# Подготавливаем модель. \ngan.compile(batch_size=BATCH_SIZE)\n\n# Запускаем обучение.\n# Для PlotLossesKerasTF указываем дополнительную конфигурацию графиков.\n# Для GANMonitor указываем параметры визуализации.\nhistory = gan.fit(data_for_train,\n epochs=EPOCHS,\n callbacks=[PlotLossesKerasTF(from_step=-50,\n groups=gan.custom_metrics.plotlosses_groups(),\n group_patterns=gan.custom_metrics.plotlosses_group_patterns(),\n outputs=['MatplotlibPlot']),\n GANMonitor(h=3, \n w=10, \n images_directory=IMAGES_DIRECTORY, \n scale=1)])",
"_____no_output_____"
],
[
"# Гудим противным звуком, чтобы сообщить об окончании обучения\njupyter_beeper.Beeper().beep(frequency=330, secs=3, blocking=True)",
"_____no_output_____"
],
[
"# Поиграем с результатом\n\nstart_index = random.randint(0, DATA_NUMBER-1)\n\ndef zero_input():\n return tf.zeros((CODE_N,))\n\nstart_vector = gan.latent_vector(1)[0]\n\ninteract_args = {f'v_{i}': ipw.FloatSlider(min=-3.0, max=3.0, step=0.01, value=start_vector[i])\n for i in range(CODE_N)}\n\n\n@ipw.interact(**interact_args)\ndef generate_sprite(**kwargs):\n vector = zero_input().numpy()\n \n for i in range(CODE_N):\n vector[i] = kwargs[f'v_{i}']\n \n vector = vector.reshape((1, CODE_N))\n \n sprite = gan.generator(vector)[0].numpy()\n \n scale = 1\n \n sprite = cv2.resize(sprite, dsize=(SPRITE_SIZE*scale, SPRITE_SIZE*scale), interpolation=cv2.INTER_NEAREST)\n \n return PIL.Image.fromarray((sprite * 255).astype(np.uint8))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02d946411668ff61da1ba509cd880d8be727b19
| 2,321 |
ipynb
|
Jupyter Notebook
|
test/dist-correct/exam_40/test-exam.ipynb
|
chrispyles/jexam
|
ebe83b170f51c5820e0c93955824c3798922f097
|
[
"BSD-3-Clause"
] | 1 |
2020-07-25T02:36:38.000Z
|
2020-07-25T02:36:38.000Z
|
test/dist-correct/exam_40/test-exam.ipynb
|
chrispyles/jexam
|
ebe83b170f51c5820e0c93955824c3798922f097
|
[
"BSD-3-Clause"
] | null | null | null |
test/dist-correct/exam_40/test-exam.ipynb
|
chrispyles/jexam
|
ebe83b170f51c5820e0c93955824c3798922f097
|
[
"BSD-3-Clause"
] | null | null | null | 18.132813 | 251 | 0.494614 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d02da62b648b970370ef8a950afca72de2aa1271
| 28,688 |
ipynb
|
Jupyter Notebook
|
auto_mmd_vmd_run_v1_02.ipynb
|
CrazyReason/mmd_auto_motion_colab
|
ba7b2f85d11b453c14c28bf3258b63f4950d1045
|
[
"CC0-1.0"
] | 6 |
2020-04-01T16:08:24.000Z
|
2022-03-11T05:08:35.000Z
|
auto_mmd_vmd_run_v1_02.ipynb
|
CrazyReason/mmd_auto_motion_colab
|
ba7b2f85d11b453c14c28bf3258b63f4950d1045
|
[
"CC0-1.0"
] | null | null | null |
auto_mmd_vmd_run_v1_02.ipynb
|
CrazyReason/mmd_auto_motion_colab
|
ba7b2f85d11b453c14c28bf3258b63f4950d1045
|
[
"CC0-1.0"
] | 2 |
2020-06-12T16:03:10.000Z
|
2021-09-11T05:45:00.000Z
| 42.188235 | 405 | 0.501115 |
[
[
[
"#@markdown ■■■■■■■■■■■■■■■■■■\n\n#@markdown 初始化openpose\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\n#设置版本为1.x\n%tensorflow_version 1.x\nimport tensorflow as tf\ntf.__version__\n\n! nvcc --version\n! nvidia-smi\n\n! pip install PyQt5\n\nimport time\n\ninit_start_time = time.time()\n\n\n#安装 cmake\n\n#https://drive.google.com/file/d/1lAXs5X7qMnKQE48I0JqSob4FX1t6-mED/view?usp=sharing\n \nfile_id = \"1lAXs5X7qMnKQE48I0JqSob4FX1t6-mED\"\nfile_name = \"cmake-3.13.4.zip\"\n! cd ./ && curl -sc ./cookie \"https://drive.google.com/uc?export=download&id=$file_id\" > /dev/null\ncode = \"$(awk '/_warning_/ {print $NF}' ./cookie)\" \n! cd ./ && curl -Lb ./cookie \"https://drive.google.com/uc?export=download&confirm=$code&id=$file_id\" -o \"$file_name\"\n! cd ./ && unzip cmake-3.13.4.zip\n \n! cd cmake-3.13.4 && ./configure && make && sudo make install\n\n\n# 依赖库安装 \n\n! sudo apt install caffe-cuda\n\n! sudo apt-get --assume-yes update\n! sudo apt-get --assume-yes install build-essential\n# OpenCV\n! sudo apt-get --assume-yes install libopencv-dev\n# General dependencies\n! sudo apt-get --assume-yes install libatlas-base-dev libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler\n! sudo apt-get --assume-yes install --no-install-recommends libboost-all-dev\n# Remaining dependencies, 14.04\n! sudo apt-get --assume-yes install libgflags-dev libgoogle-glog-dev liblmdb-dev\n# Python3 libs\n! sudo apt-get --assume-yes install python3-setuptools python3-dev build-essential\n! sudo apt-get --assume-yes install python3-pip\n! sudo -H pip3 install --upgrade numpy protobuf opencv-python\n# OpenCL Generic\n! sudo apt-get --assume-yes install opencl-headers ocl-icd-opencl-dev\n! sudo apt-get --assume-yes install libviennacl-dev\n\n\n # Openpose安装\nver_openpose = \"v1.6.0\"\n \n# Openpose の clone\n! git clone --depth 1 -b \"$ver_openpose\" https://github.com/CMU-Perceptual-Computing-Lab/openpose.git \n# ! git clone --depth 1 https://github.com/CMU-Perceptual-Computing-Lab/openpose.git \n \n# Openpose の モデルデータDL\n! cd openpose/models && ./getModels.sh\n\n#编译Openpose\n! cd openpose && rm -r build || true && mkdir build && cd build && cmake .. && make -j`nproc` # example demo usage\n\n# 执行示例确认\n! cd /content/openpose && ./build/examples/openpose/openpose.bin --video examples/media/video.avi --write_json ./output/ --display 0 --write_video ./output/openpose.avi\n\n\n\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\n#@markdown 其他软件初始化\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\n\n\n\nver_tag = \"ver1.02.01\"\n\n# FCRN-DepthPrediction-vmd clone\n! git clone --depth 1 -b \"$ver_tag\" https://github.com/miu200521358/FCRN-DepthPrediction-vmd.git\n\n# FCRN-DepthPrediction-vmd 识别深度模型下载\n\n# 建立模型数据文件夹\n! mkdir -p ./FCRN-DepthPrediction-vmd/tensorflow/data\n\n# 下载模型数据并解压\n! cd ./FCRN-DepthPrediction-vmd/tensorflow/data && wget -c \"http://campar.in.tum.de/files/rupprecht/depthpred/NYU_FCRN-checkpoint.zip\" && unzip NYU_FCRN-checkpoint.zip\n\n# 3d-pose-baseline-vmd clone\n! git clone --depth 1 -b \"$ver_tag\" https://github.com/miu200521358/3d-pose-baseline-vmd.git\n\n# 3d-pose-baseline-vmd Human3.6M 模型数据DL\n\n# 建立Human3.6M模型数据文件夹\n! mkdir -p ./3d-pose-baseline-vmd/data/h36m\n\n# 下载Human3.6M模型数据并解压\nfile_id = \"1W5WoWpCcJvGm4CHoUhfIB0dgXBDCEHHq\"\nfile_name = \"h36m.zip\"\n! cd ./ && curl -sc ./cookie \"https://drive.google.com/uc?export=download&id=$file_id\" > /dev/null\ncode = \"$(awk '/_warning_/ {print $NF}' ./cookie)\" \n! cd ./ && curl -Lb ./cookie \"https://drive.google.com/uc?export=download&confirm=$code&id=$file_id\" -o \"$file_name\"\n! cd ./ && unzip h36m.zip\n! mv ./h36m ./3d-pose-baseline-vmd/data/\n\n# 3d-pose-baseline-vmd 训练数据\n\n# 3d-pose-baseline学习数据文件夹\n! mkdir -p ./3d-pose-baseline-vmd/experiments\n\n# 下载3d-pose-baseline训练后的数据\nfile_id = \"1v7ccpms3ZR8ExWWwVfcSpjMsGscDYH7_\"\nfile_name = \"experiments.zip\"\n! cd ./3d-pose-baseline-vmd && curl -sc ./cookie \"https://drive.google.com/uc?export=download&id=$file_id\" > /dev/null\ncode = \"$(awk '/_warning_/ {print $NF}' ./cookie)\" \n! cd ./3d-pose-baseline-vmd && curl -Lb ./cookie \"https://drive.google.com/uc?export=download&confirm=$code&id=$file_id\" -o \"$file_name\"\n! cd ./3d-pose-baseline-vmd && unzip experiments.zip\n\n\n# VMD-3d-pose-baseline-multi clone\n\n! git clone --depth 1 -b \"$ver_tag\" https://github.com/miu200521358/VMD-3d-pose-baseline-multi.git\n\n# 安装VMD-3d-pose-baseline-multi 依赖库\n\n! sudo apt-get install python3-pyqt5 \n! sudo apt-get install pyqt5-dev-tools\n! sudo apt-get install qttools5-dev-tools\n\n#安装编码器\n! sudo apt-get install mkvtoolnix\n\ninit_elapsed_time = (time.time() - init_start_time) / 60\n\n! echo \"■■■■■■■■■■■■■■■■■■■■■■■■\"\n! echo \"■■所有初始化均已完成\"\n! echo \"■■\"\n! echo \"■■处理时间:\" \"$init_elapsed_time\" \"分\"\n! echo \"■■■■■■■■■■■■■■■■■■■■■■■■\"\n\n! echo \"Openpose执行结果\"\n\n! ls -l /content/openpose/output\n\n\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\n#@markdown 执行函数初始化\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\n\nimport os\nimport cv2\nimport datetime\n\n\nimport time\nimport datetime\nimport cv2\nimport shutil\nimport glob\n\nfrom google.colab import files\n\nstatic_number_people_max = 1 \nstatic_frame_first = 0 \nstatic_end_frame_no = -1 \nstatic_reverse_specific = \"\" \nstatic_order_specific = \"\" \nstatic_born_model_csv = \"born/animasa_miku_born.csv\"\nstatic_is_ik = 1 \nstatic_heel_position = 0.0 \nstatic_center_z_scale = 1\nstatic_smooth_times = 1\nstatic_threshold_pos = 0.5 \nstatic_threshold_rot = 3 \n\nstatic_src_input_video = \"\"\nstatic_input_video = \"\"\n\n#执行文件夹\nopenpose_path = \"/content/openpose\"\n\n#输出文件夹\nbase_path = \"/content/output\"\noutput_json = \"/content/output/json\"\noutput_openpose_avi = \"/content/output/openpose.avi\"\n\n\n\nnow_str = \"\"\ndepth_dir_path = \"\"\ndrive_dir_path = \"\"\n\ndef video_hander( input_video):\n global base_path\n print(\"视频名称: \", os.path.basename(input_video))\n print(\"视频大小: \", os.path.getsize(input_video))\n\n\n video = cv2.VideoCapture(input_video)\n # 宽\n W = video.get(cv2.CAP_PROP_FRAME_WIDTH)\n # 高\n H = video.get(cv2.CAP_PROP_FRAME_HEIGHT)\n # 总帧数\n count = video.get(cv2.CAP_PROP_FRAME_COUNT)\n # fps\n fps = video.get(cv2.CAP_PROP_FPS)\n\n print(\"宽: {0}, 高: {1}, 总帧数: {2}, fps: {3}\".format(W, H, count, fps))\n\n\n\n width = 1280\n height = 720\n\n if W != 1280 or (fps != 30 and fps != 60):\n print(\"重新编码,因为大小或fps不在范围: \"+ input_video)\n \n # 縮尺\n scale = width / W\n \n # 高さ\n height = int(H * scale)\n\n # 出力ファイルパス\n out_name = 'recode_{0}.mp4'.format(\"{0:%Y%m%d_%H%M%S}\".format(datetime.datetime.now()))\n out_path = '{0}/{1}'.format(base_path, out_name)\n \n # try:\n # fourcc = cv2.VideoWriter_fourcc(*\"MP4V\")\n # out = cv2.VideoWriter(out_path, fourcc, 30.0, (width, height), True)\n # # 入力ファイル\n # cap = cv2.VideoCapture(input_video)\n\n # while(cap.isOpened()):\n # # 動画から1枚キャプチャして読み込む\n # flag, frame = cap.read() # Capture frame-by-frame\n\n # # 動画が終わっていたら終了\n # if flag == False:\n # break\n\n # # 縮小\n # output_frame = cv2.resize(frame, (width, height))\n\n # # 出力\n # out.write(output_frame)\n\n # # 終わったら開放\n # out.release()\n # except Exception as e:\n # print(\"重新编码失败\", e)\n\n # cap.release()\n # cv2.destroyAllWindows()\n\n # ! mkvmerge --default-duration 0:30fps --fix-bitstream-timing-information 0 \"$input_video\" -o temp-video.mkv\n # ! ffmpeg -i temp-video.mkv -c:v copy side_video.mkv\n # ! ffmpeg -i side_video.mkv -vf scale=1280:720 \"$out_path\"\n\n ! ffmpeg -i \"$input_video\" -qscale 0 -r 30 -y -vf scale=1280:720 \"$out_path\"\n \n print('MMD重新生成MP4文件成功', out_path)\n input_video_name = out_name\n\n # 入力動画ファイル再設定\n input_video = base_path + \"/\"+ input_video_name\n \n video = cv2.VideoCapture(input_video)\n # 幅\n W = video.get(cv2.CAP_PROP_FRAME_WIDTH)\n # 高さ\n H = video.get(cv2.CAP_PROP_FRAME_HEIGHT)\n # 総フレーム数\n count = video.get(cv2.CAP_PROP_FRAME_COUNT)\n # fps\n fps = video.get(cv2.CAP_PROP_FPS)\n\n print(\"【重新生成】宽: {0}, 高: {1}, 总帧数: {2}, fps: {3}, 名字: {4}\".format(W, H, count, fps,input_video_name))\n return input_video\n\n\ndef run_openpose(input_video,number_people_max,frame_first):\n #建立临时文件夹\n\n ! mkdir -p \"$output_json\"\n #开始执行\n ! cd \"$openpose_path\" && ./build/examples/openpose/openpose.bin --video \"$input_video\" --display 0 --model_pose COCO --write_json \"$output_json\" --write_video \"$output_openpose_avi\" --frame_first \"$frame_first\" --number_people_max \"$number_people_max\"\n\ndef run_fcrn_depth(input_video,end_frame_no,reverse_specific,order_specific):\n global now_str,depth_dir_path,drive_dir_path\n now_str = \"{0:%Y%m%d_%H%M%S}\".format(datetime.datetime.now())\n ! cd FCRN-DepthPrediction-vmd && python tensorflow/predict_video.py --model_path tensorflow/data/NYU_FCRN.ckpt --video_path \"$input_video\" --json_path \"$output_json\" --interval 10 --reverse_specific \"$reverse_specific\" --order_specific \"$order_specific\" --verbose 1 --now \"$now_str\" --avi_output \"yes\" --number_people_max \"$number_people_max\" --end_frame_no \"$end_frame_no\"\n # 深度結果コピー\n depth_dir_path = output_json + \"_\" + now_str + \"_depth\"\n drive_dir_path = base_path + \"/\" + now_str \n\n ! mkdir -p \"$drive_dir_path\"\n\n if os.path.exists( depth_dir_path + \"/error.txt\"):\n \n # 发生错误\n ! cp \"$depth_dir_path\"/error.txt \"$drive_dir_path\"\n\n ! echo \"■■■■■■■■■■■■■■■■■■■■■■■■\"\n ! echo \"■■由于发生错误,处理被中断。\"\n ! echo \"■■\"\n ! echo \"■■■■■■■■■■■■■■■■■■■■■■■■\"\n\n ! echo \"$drive_dir_path\" \"请检查 error.txt 的内容。\"\n else:\n \n ! cp \"$depth_dir_path\"/*.avi \"$drive_dir_path\"\n ! cp \"$depth_dir_path\"/message.log \"$drive_dir_path\"\n ! cp \"$depth_dir_path\"/reverse_specific.txt \"$drive_dir_path\"\n ! cp \"$depth_dir_path\"/order_specific.txt \"$drive_dir_path\"\n\n for i in range(1, number_people_max+1):\n ! echo ------------------------------------------\n ! echo 3d-pose-baseline-vmd [\"$i\"]\n ! echo ------------------------------------------\n\n target_name = \"_\" + now_str + \"_idx0\" + str(i)\n target_dir = output_json + target_name\n\n !cd ./3d-pose-baseline-vmd && python src/openpose_3dpose_sandbox_vmd.py --camera_frame --residual --batch_norm --dropout 0.5 --max_norm --evaluateActionWise --use_sh --epochs 200 --load 4874200 --gif_fps 30 --verbose 1 --openpose \"$target_dir\" --person_idx 1 \n\ndef run_3d_to_vmd(number_people_max,born_model_csv,is_ik,heel_position,center_z_scale,smooth_times,threshold_pos,threshold_rot):\n global now_str,depth_dir_path,drive_dir_path\n for i in range(1, number_people_max+1):\n target_name = \"_\" + now_str + \"_idx0\" + str(i)\n target_dir = output_json + target_name\n for f in glob.glob(target_dir +\"/*.vmd\"):\n ! rm \"$f\"\n ! cd ./VMD-3d-pose-baseline-multi && python applications/pos2vmd_multi.py -v 2 -t \"$target_dir\" -b \"$born_model_csv\" -c 30 -z \"$center_z_scale\" -s \"$smooth_times\" -p \"$threshold_pos\" -r \"$threshold_rot\" -k \"$is_ik\" -e \"$heel_position\"\n\n # INDEX別結果コピー\n idx_dir_path = drive_dir_path + \"/idx0\" + str(i)\n ! mkdir -p \"$idx_dir_path\"\n \n # 日本語対策でpythonコピー\n for f in glob.glob(target_dir +\"/*.vmd\"):\n shutil.copy(f, idx_dir_path)\n print(f)\n files.download(f)\n \n ! cp \"$target_dir\"/pos.txt \"$idx_dir_path\"\n ! cp \"$target_dir\"/start_frame.txt \"$idx_dir_path\"\n\n\n\ndef run_mmd(input_video,number_people_max,frame_first,end_frame_no,reverse_specific,order_specific,born_model_csv,is_ik,heel_position,center_z_scale,smooth_times,threshold_pos,threshold_rot):\n\n global static_input_video,static_number_people_max ,static_frame_first ,static_end_frame_no,static_reverse_specific ,static_order_specific,static_born_model_csv \n global static_is_ik,static_heel_position ,static_center_z_scale ,static_smooth_times ,static_threshold_pos ,static_threshold_rot \n global base_path,static_src_input_video\n\n start_time = time.time()\n\n video_check= False\n openpose_check = False\n Fcrn_depth_check = False\n pose_to_vmd_check = False\n\n#源文件对比\n if static_src_input_video != input_video:\n video_check = True\n openpose_check = True\n Fcrn_depth_check = True\n pose_to_vmd_check = True\n\n if (static_number_people_max != number_people_max) or (static_frame_first != frame_first):\n openpose_check = True\n Fcrn_depth_check = True\n pose_to_vmd_check = True\n\n if (static_end_frame_no != end_frame_no) or (static_reverse_specific != reverse_specific) or (static_order_specific != order_specific):\n Fcrn_depth_check = True\n pose_to_vmd_check = True\n\n if (static_born_model_csv != born_model_csv) or (static_is_ik != is_ik) or (static_heel_position != heel_position) or (static_center_z_scale != center_z_scale) or \\\n (static_smooth_times != smooth_times) or (static_threshold_pos != threshold_pos) or (static_threshold_rot != threshold_rot):\n pose_to_vmd_check = True\n\n #因为视频源文件重置,所以如果无修改需要重命名文件\n if video_check:\n ! rm -rf \"$base_path\"\n ! mkdir -p \"$base_path\"\n static_src_input_video = input_video\n input_video = video_hander(input_video)\n static_input_video = input_video\n else:\n input_video = static_input_video\n\n if openpose_check:\n run_openpose(input_video,number_people_max,frame_first)\n static_number_people_max = number_people_max\n static_frame_first = frame_first\n\n if Fcrn_depth_check:\n run_fcrn_depth(input_video,end_frame_no,reverse_specific,order_specific)\n static_end_frame_no = end_frame_no\n static_reverse_specific = reverse_specific\n static_order_specific = order_specific\n\n if pose_to_vmd_check:\n run_3d_to_vmd(number_people_max,born_model_csv,is_ik,heel_position,center_z_scale,smooth_times,threshold_pos,threshold_rot)\n static_born_model_csv = born_model_csv \n static_is_ik = is_ik\n static_heel_position = heel_position\n static_center_z_scale = center_z_scale\n static_smooth_times = smooth_times\n static_threshold_pos = threshold_pos\n static_threshold_rot = threshold_rot\n\n\n elapsed_time = (time.time() - start_time) / 60\n print( \"■■■■■■■■■■■■■■■■■■■■■■■■\")\n print( \"■■所有处理完成\")\n print( \"■■\")\n print( \"■■处理時間:\" + str(elapsed_time)+ \"分\")\n print( \"■■■■■■■■■■■■■■■■■■■■■■■■\")\n print( \"\")\n print( \"MMD自动跟踪执行结果\")\n print( base_path)\n ! ls -l \"$base_path\"\n",
"_____no_output_____"
],
[
"#@markdown ■■■■■■■■■■■■■■■■■■\n\n#@markdown GO GO GO GO 执行本单元格,上传视频\n\n#@markdown ■■■■■■■■■■■■■■■■■■\n\nfrom google.colab import files\n\n\n\n#@markdown --- \n\n#@markdown ### 输入视频名称\n#@markdown 可以选择手动拖入视频到文件中(比较快),然后输入视频文件名,或者直接运行,不输入文件名直接本地上传\ninput_video = \"\" #@param {type: \"string\"}\n\nif input_video == \"\":\n uploaded = files.upload()\n\n for fn in uploaded.keys():\n print('User uploaded file \"{name}\" with length {length} bytes'.format(\n name=fn, length=len(uploaded[fn])))\n input_video = fn\n input_video = \"/content/\" + input_video \n\nprint(\"本次执行的转化视频文件名为: \"+input_video)",
"_____no_output_____"
],
[
"#@markdown 输入用于跟踪图像的参数并执行单元。\n\n#@markdown --- \n\n#@markdown ### 【O】视频中的最大人数\n#@markdown 请输入您希望从视频中获得的人数。\n#@markdown 请与视频中人数尽量保持一致\nnumber_people_max = 1#@param {type: \"number\"}\n\n#@markdown --- \n\n#@markdown ### 【O】要从第几帧开始分析\n#@markdown 输入帧号以开始分析。(从0开始)\n#@markdown 请指定在视频中显示所有人的第一帧,默认为0即可,除非你需要跳过某些片段(例如片头)。\nframe_first = 0 #@param {type: \"number\"}\n\n\n#@markdown ---\n\n#@markdown ### 【F】要从第几帧结束\n#@markdown 请输入要从哪一帧结束\n#@markdown (从0开始)在“FCRN-DepthPrediction-vmd”中调整反向或顺序时,可以完成过程并查看结果,默认为-1 表示执行到最后\nend_frame_no = -1 #@param {type: \"number\"}\n\n#@markdown --- \n\n#@markdown ### 【F】反转数据表\n#@markdown 指定由Openpose反转的帧号(从0开始),人员INDEX顺序和反转的内容。\n#@markdown 按照Openpose在 0F 识别的顺序,将INDEX分配为0,1,...。\n\n#@markdown 格式: [{帧号}: 用于指定反转的人INDEX, {反转内容}]\n#@markdown {反转内容}: R: 整体身体反转, U:上半身反转, L: 下半身反转, N: 无反转\n\n#@markdown 例如:[10:1,R] 整个人在第10帧中反转第一个人。在message.log中会记录以上述格式输出内容\n\n\n#@markdown 因此请参考与[10:1,R][30:0,U],中一样,可以在括号中指定多个项目 ps(不要带有中文标点符号))\nreverse_specific = \"\" #@param {type: \"string\"}\n\n#@markdown --- \n\n#@markdown ### 【F】输出颜色(仅参考,如果多人时,某个人序号跟别人交换或者错误,可以用此项修改)\n#@markdown 请在多人轨迹中的交点之后指定人索引顺序。如果要跟踪一个人,可以将其留为空白。\n#@markdown 按照Openpose在0F时识别的顺序分配0、1和INDEX。格式:[<帧号>:第几个人的索引,第几个人的索引,…]示例)[10:1,0]…第帧10是从左数第1人按第0个人的顺序对其进行排序。\n#@markdown message.log包含以上述格式输出的顺序,因此请参考它。可以在括号中指定多个项目,例如[10:1,0] [30:0,1]。在output_XXX.avi中,按照估计顺序为人们分配了颜色。身体的右半部分为红色,左半部分为以下颜色。\n#@markdown 0:绿色,1:蓝色,2:白色,3:黄色,4:桃红色,5:浅蓝色,6:深绿色,7:深蓝色,8:灰色,9:深黄色,10:深桃红色,11:深浅蓝色\norder_specific = \"\" #@param {type: \"string\"}\n\n#@markdown --- \n\n#@markdown ### 【V】骨骼结构CSV文件\n#@markdown 选择或输入跟踪目标模型的骨骼结构CSV文件的路径。请将csv文件上传到Google云端硬盘的“ autotrace”文件夹。\n#@markdown 您可以选择 \"Animasa-Miku\" 和 \"Animasa-Miku semi-standard\", 也可以输入任何模型的骨骼结构CSV文件\n#@markdown 如果要输入任何模型骨骼结构CSV文件, 请将csv文件上传到Google云端硬盘的 \"autotrace\" 文件夹下\n#@markdown 然后请输入「/gdrive/My Drive/autotrace/[csv file name]」\nborn_model_csv = \"born/\\u3042\\u306B\\u307E\\u3055\\u5F0F\\u30DF\\u30AF\\u6E96\\u6A19\\u6E96\\u30DC\\u30FC\\u30F3.csv\" #@param [\"born/animasa_miku_born.csv\", \"born/animasa_miku_semi_standard_born.csv\"] {allow-input: true}\n\n\n#@markdown --- \n\n#@markdown ### 【V】是否使用IK输出\n#@markdown 选择以IK输出,yes或no \n#@markdown 如果输入no,则以输出FK\nik_flag = \"yes\" #@param ['yes', 'no']\nis_ik = 1 if ik_flag == \"yes\" else 0\n\n#@markdown ---\n\n#@markdown ### 【V】脚与地面位置校正\n#@markdown 请输入数值的鞋跟的Y轴校正值(可以为小数)\n#@markdown 输入负值会接近地面,输入正值会远离地面。\n#@markdown 尽管会自动在某种程度上自动校正,但如果无法校正,请进行设置。\nheel_position = 0.0 #@param {type: \"number\"}\n\n#@markdown ---\n\n#@markdown ### 【V】Z中心放大倍率\n#@markdown 以将放大倍数应用到Z轴中心移动(可以是小数)\n#@markdown 值越小,中心Z移动的宽度越小\n#@markdown 输入0时,不进行Z轴中心移动。\ncenter_z_scale = 2#@param {type: \"number\"}\n\n#@markdown ---\n\n#@markdown ### 【V】平滑频率\n#@markdown 指定运动的平滑频率\n#@markdown 请仅输入1或更大的整数\n#@markdown 频率越大,频率越平滑。(行为幅度会变小)\nsmooth_times = 1#@param {type: \"number\"}\n\n#@markdown ---\n\n#@markdown ### 【V】移动稀疏量 (低于该阀值的运动宽度,不会进行输出,防抖动)\n#@markdown 用数值(允许小数)指定用于稀疏移动(IK /中心)的移动量\n#@markdown 如果在指定范围内有移动,则将稀疏。如果移动抽取量设置为0,则不执行抽取。\n#@markdown 当移动稀疏量设置为0时,不进行稀疏。\nthreshold_pos = 0.3 #@param {type: \"number\"}\n\n#@markdown ---\n\n#@markdown ### 【V】旋转稀疏角 (低于该阀值的运动角度,则不会进行输出)\n#@markdown 指定用于稀疏旋转键的角度(0到180度的十进制数)\n#@markdown 如果在指定角度范围内有旋转,则稀疏旋转键。\nthreshold_rot = 3#@param {type: \"number\"}\n\n\n\nprint(\" 【O】Maximum number of people in the video: \"+str(number_people_max))\nprint(\" 【O】Frame number to start analysis: \"+str(frame_first))\nprint(\" 【F】Frame number to finish analysis: \"+str(end_frame_no))\nprint(\" 【F】Reverse specification list: \"+str(reverse_specific))\nprint(\" 【F】Ordered list: \"+str(order_specific))\nprint(\" 【V】Bone structure CSV file: \"+str(born_model_csv))\nprint(\" 【V】Whether to output with IK: \"+str(ik_flag))\nprint(\" 【V】Heel position correction: \"+str(heel_position))\nprint(\" 【V】Center Z moving magnification: \"+str(center_z_scale))\nprint(\" 【V】Smoothing frequency: \"+str(smooth_times))\nprint(\" 【V】Movement key thinning amount: \"+str(threshold_pos))\nprint(\" 【V】Rotating Key Culling Angle: \"+str(threshold_rot))\n\n\nprint(\"\")\nprint(\"If the above is correct, please proceed to the next.\")\n\n\n#input_video = \"/content/openpose/examples/media/video.avi\"\n\nrun_mmd(input_video,number_people_max,frame_first,end_frame_no,reverse_specific,order_specific,born_model_csv,is_ik,heel_position,center_z_scale,smooth_times,threshold_pos,threshold_rot)\n\n\n",
"_____no_output_____"
]
],
[
[
"# License许可",
"_____no_output_____"
],
[
"发布和分发MMD自动跟踪的结果时,请确保检查许可证。Unity也是如此。\n\n如果您能列出您的许可证,我将不胜感激。\n[MMD运动跟踪自动化套件许可证](https://ch.nicovideo.jp/miu200521358/blomaga/ar1686913)\n\n原作者:Twitter miu200521358\n\n修改与优化:B站 妖风瑟瑟\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d02da98d663e0fe3a5f19a337dd44c913316bebd
| 421,197 |
ipynb
|
Jupyter Notebook
|
nbs/dl1/00_notebook_tutorial.ipynb
|
jwdinius/course-v3
|
188214a51ce1f92bb348ebe7b2fd85b1b61fbe02
|
[
"Apache-2.0"
] | null | null | null |
nbs/dl1/00_notebook_tutorial.ipynb
|
jwdinius/course-v3
|
188214a51ce1f92bb348ebe7b2fd85b1b61fbe02
|
[
"Apache-2.0"
] | null | null | null |
nbs/dl1/00_notebook_tutorial.ipynb
|
jwdinius/course-v3
|
188214a51ce1f92bb348ebe7b2fd85b1b61fbe02
|
[
"Apache-2.0"
] | null | null | null | 519.355117 | 387,208 | 0.945185 |
[
[
[
"**Important note:** You should always work on a duplicate of the course notebook. On the page you used to open this, tick the box next to the name of the notebook and click duplicate to easily create a new version of this notebook.\n\nYou will get errors each time you try to update your course repository if you don't do this, and your changes will end up being erased by the original course version.",
"_____no_output_____"
],
[
"# Welcome to Jupyter Notebooks!",
"_____no_output_____"
],
[
"If you want to learn how to use this tool you've come to the right place. This article will teach you all you need to know to use Jupyter Notebooks effectively. You only need to go through Section 1 to learn the basics and you can go into Section 2 if you want to further increase your productivity.",
"_____no_output_____"
],
[
"You might be reading this tutorial in a web page (maybe Github or the course's webpage). We strongly suggest to read this tutorial in a (yes, you guessed it) Jupyter Notebook. This way you will be able to actually *try* the different commands we will introduce here.",
"_____no_output_____"
],
[
"## Section 1: Need to Know",
"_____no_output_____"
],
[
"### Introduction",
"_____no_output_____"
],
[
"Let's build up from the basics, what is a Jupyter Notebook? Well, you are reading one. It is a document made of cells. You can write like I am writing now (markdown cells) or you can perform calculations in Python (code cells) and run them like this:",
"_____no_output_____"
]
],
[
[
"1+1",
"_____no_output_____"
]
],
[
[
"Cool huh? This combination of prose and code makes Jupyter Notebook ideal for experimentation: we can see the rationale for each experiment, the code and the results in one comprehensive document. In fast.ai, each lesson is documented in a notebook and you can later use that notebook to experiment yourself. \n\nOther renowned institutions in academy and industry use Jupyter Notebook: Google, Microsoft, IBM, Bloomberg, Berkeley and NASA among others. Even Nobel-winning economists [use Jupyter Notebooks](https://paulromer.net/jupyter-mathematica-and-the-future-of-the-research-paper/) for their experiments and some suggest that Jupyter Notebooks will be the [new format for research papers](https://www.theatlantic.com/science/archive/2018/04/the-scientific-paper-is-obsolete/556676/).",
"_____no_output_____"
],
[
"### Writing",
"_____no_output_____"
],
[
"A type of cell in which you can write like this is called _Markdown_. [_Markdown_](https://en.wikipedia.org/wiki/Markdown) is a very popular markup language. To specify that a cell is _Markdown_ you need to click in the drop-down menu in the toolbar and select _Markdown_.",
"_____no_output_____"
],
[
"Click on the the '+' button on the left and select _Markdown_ from the toolbar.",
"_____no_output_____"
],
[
"Now you can type your first _Markdown_ cell. Write 'My first markdown cell' and press run.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"You should see something like this:",
"_____no_output_____"
],
[
"My first markdown cell",
"_____no_output_____"
],
[
"Now try making your first _Code_ cell: follow the same steps as before but don't change the cell type (when you add a cell its default type is _Code_). Type something like 3/2. You should see '1.5' as output.",
"_____no_output_____"
]
],
[
[
"3/2",
"_____no_output_____"
]
],
[
[
"### Modes",
"_____no_output_____"
],
[
"If you made a mistake in your *Markdown* cell and you have already ran it, you will notice that you cannot edit it just by clicking on it. This is because you are in **Command Mode**. Jupyter Notebooks have two distinct modes:\n\n1. **Edit Mode**: Allows you to edit a cell's content.\n\n2. **Command Mode**: Allows you to edit the notebook as a whole and use keyboard shortcuts but not edit a cell's content. \n\nYou can toggle between these two by either pressing <kbd>ESC</kbd> and <kbd>Enter</kbd> or clicking outside a cell or inside it (you need to double click if its a Markdown cell). You can always know which mode you're on since the current cell has a green border if in **Edit Mode** and a blue border in **Command Mode**. Try it!",
"_____no_output_____"
],
[
"### Other Important Considerations",
"_____no_output_____"
],
[
"1. Your notebook is autosaved every 120 seconds. If you want to manually save it you can just press the save button on the upper left corner or press <kbd>s</kbd> in **Command Mode**.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"2. To know if your kernel is computing or not you can check the dot in your upper right corner. If the dot is full, it means that the kernel is working. If not, it is idle. You can place the mouse on it and see the state of the kernel be displayed.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"3. There are a couple of shortcuts you must know about which we use **all** the time (always in **Command Mode**). These are:\n\n<kbd>Shift</kbd>+<kbd>Enter</kbd>: Runs the code or markdown on a cell\n\n<kbd>Up Arrow</kbd>+<kbd>Down Arrow</kbd>: Toggle across cells\n\n<kbd>b</kbd>: Create new cell\n\n<kbd>0</kbd>+<kbd>0</kbd>: Reset Kernel\n\nYou can find more shortcuts in the Shortcuts section below.",
"_____no_output_____"
],
[
"4. You may need to use a terminal in a Jupyter Notebook environment (for example to git pull on a repository). That is very easy to do, just press 'New' in your Home directory and 'Terminal'. Don't know how to use the Terminal? We made a tutorial for that as well. You can find it [here](https://course.fast.ai/terminal_tutorial.html).",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"That's it. This is all you need to know to use Jupyter Notebooks. That said, we have more tips and tricks below ↓↓↓",
"_____no_output_____"
],
[
"## Section 2: Going deeper",
"_____no_output_____"
],
[
"### Markdown formatting",
"_____no_output_____"
],
[
"#### Italics, Bold, Strikethrough, Inline, Blockquotes and Links",
"_____no_output_____"
],
[
"The five most important concepts to format your code appropriately when using markdown are:\n \n1. *Italics*: Surround your text with '\\_' or '\\*'\n2. **Bold**: Surround your text with '\\__' or '\\**'\n3. `inline`: Surround your text with '\\`'\n4. > blockquote: Place '\\>' before your text.\n5. [Links](https://course.fast.ai/): Surround the text you want to link with '\\[\\]' and place the link adjacent to the text, surrounded with '()'\n",
"_____no_output_____"
],
[
"#### Headings",
"_____no_output_____"
],
[
"Notice that including a hashtag before the text in a markdown cell makes the text a heading. The number of hashtags you include will determine the priority of the header ('#' is level one, '##' is level two, '###' is level three and '####' is level four). We will add three new cells with the '+' button on the left to see how every level of heading looks.",
"_____no_output_____"
],
[
"Double click on some headings and find out what level they are!",
"_____no_output_____"
],
[
"#### Lists",
"_____no_output_____"
],
[
"There are three types of lists in markdown.",
"_____no_output_____"
],
[
"Ordered list:\n\n1. Step 1\n 2. Step 1B\n3. Step 3",
"_____no_output_____"
],
[
"Unordered list\n\n* learning rate\n* cycle length\n* weight decay",
"_____no_output_____"
],
[
"Task list\n\n- [x] Learn Jupyter Notebooks\n - [x] Writing\n - [x] Modes\n - [x] Other Considerations\n- [ ] Change the world",
"_____no_output_____"
],
[
"Double click on each to see how they are built! ",
"_____no_output_____"
],
[
"### Code Capabilities",
"_____no_output_____"
],
[
"**Code** cells are different than **Markdown** cells in that they have an output cell. This means that we can _keep_ the results of our code within the notebook and share them. Let's say we want to show a graph that explains the result of an experiment. We can just run the necessary cells and save the notebook. The output will be there when we open it again! Try it out by running the next four cells.",
"_____no_output_____"
]
],
[
[
"# Import necessary libraries\nfrom fastai.vision import * \nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"from PIL import Image",
"_____no_output_____"
],
[
"a = 1\nb = a + 1\nc = b + a + 1\nd = c + b + a + 1\na, b, c ,d",
"_____no_output_____"
],
[
"plt.plot([a,b,c,d])\nplt.show()",
"_____no_output_____"
]
],
[
[
"We can also print images while experimenting. I am watching you.",
"_____no_output_____"
]
],
[
[
"Image.open('images/notebook_tutorial/cat_example.jpg')",
"_____no_output_____"
]
],
[
[
"### Running the app locally",
"_____no_output_____"
],
[
"You may be running Jupyter Notebook from an interactive coding environment like Gradient, Sagemaker or Salamander. You can also run a Jupyter Notebook server from your local computer. What's more, if you have installed Anaconda you don't even need to install Jupyter (if not, just `pip install jupyter`).\n\nYou just need to run `jupyter notebook` in your terminal. Remember to run it from a folder that contains all the folders/files you will want to access. You will be able to open, view and edit files located within the directory in which you run this command but not files in parent directories.\n\nIf a browser tab does not open automatically once you run the command, you should CTRL+CLICK the link starting with 'https://localhost:' and this will open a new tab in your default browser.",
"_____no_output_____"
],
[
"### Creating a notebook",
"_____no_output_____"
],
[
"Click on 'New' in the upper left corner and 'Python 3' in the drop-down list (we are going to use a [Python kernel](https://github.com/ipython/ipython) for all our experiments).\n\n\n\nNote: You will sometimes hear people talking about the Notebook 'kernel'. The 'kernel' is just the Python engine that performs the computations for you. ",
"_____no_output_____"
],
[
"### Shortcuts and tricks",
"_____no_output_____"
],
[
"#### Command Mode Shortcuts",
"_____no_output_____"
],
[
"There are a couple of useful keyboard shortcuts in `Command Mode` that you can leverage to make Jupyter Notebook faster to use. Remember that to switch back and forth between `Command Mode` and `Edit Mode` with <kbd>Esc</kbd> and <kbd>Enter</kbd>.",
"_____no_output_____"
],
[
"<kbd>m</kbd>: Convert cell to Markdown",
"_____no_output_____"
],
[
"<kbd>y</kbd>: Convert cell to Code",
"_____no_output_____"
],
[
"<kbd>D</kbd>+<kbd>D</kbd>: Delete cell",
"_____no_output_____"
],
[
"<kbd>o</kbd>: Toggle between hide or show output",
"_____no_output_____"
],
[
"<kbd>Shift</kbd>+<kbd>Arrow up/Arrow down</kbd>: Selects multiple cells. Once you have selected them you can operate on them like a batch (run, copy, paste etc).",
"_____no_output_____"
],
[
"<kbd>Shift</kbd>+<kbd>M</kbd>: Merge selected cells.",
"_____no_output_____"
],
[
"<kbd>Shift</kbd>+<kbd>Tab</kbd>: [press once] Tells you which parameters to pass on a function\n<kbd>Shift</kbd>+<kbd>Tab</kbd>: [press three times] Gives additional information on the method",
"_____no_output_____"
],
[
"#### Cell Tricks",
"_____no_output_____"
]
],
[
[
"from fastai import*\nfrom fastai.vision import *",
"_____no_output_____"
]
],
[
[
"There are also some tricks that you can code into a cell.",
"_____no_output_____"
],
[
"`?function-name`: Shows the definition and docstring for that function",
"_____no_output_____"
]
],
[
[
"?ImageDataBunch",
"_____no_output_____"
]
],
[
[
"`??function-name`: Shows the source code for that function",
"_____no_output_____"
]
],
[
[
"??ImageDataBunch",
"_____no_output_____"
]
],
[
[
"`doc(function-name)`: Shows the definition, docstring **and links to the documentation** of the function\n(only works with fastai library imported)",
"_____no_output_____"
]
],
[
[
"doc(ImageDataBunch)",
"_____no_output_____"
]
],
[
[
"#### Line Magics",
"_____no_output_____"
],
[
"Line magics are functions that you can run on cells and take as an argument the rest of the line from where they are called. You call them by placing a '%' sign before the command. The most useful ones are:",
"_____no_output_____"
],
[
"`%matplotlib inline`: This command ensures that all matplotlib plots will be plotted in the output cell within the notebook and will be kept in the notebook when saved.",
"_____no_output_____"
],
[
"`%reload_ext autoreload`, `%autoreload 2`: Reload all modules before executing a new line. If a module is edited, it is not necessary to rerun the import commands, the modules will be reloaded automatically.",
"_____no_output_____"
],
[
"These three commands are always called together at the beginning of every notebook.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%reload_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"`%timeit`: Runs a line a ten thousand times and displays the average time it took to run it.",
"_____no_output_____"
]
],
[
[
"%timeit [i+1 for i in range(1000)]",
"39.6 µs ± 543 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n"
]
],
[
[
"`%debug`: Allows to inspect a function which is showing an error using the [Python debugger](https://docs.python.org/3/library/pdb.html).",
"_____no_output_____"
]
],
[
[
"for i in range(1000):\n a = i+1\n b = 'string'\n c = b+1",
"_____no_output_____"
],
[
"%debug",
"> \u001b[0;32m<ipython-input-15-8d78ff778454>\u001b[0m(4)\u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m 1 \u001b[0;31m\u001b[0;32mfor\u001b[0m \u001b[0mi\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m1000\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 2 \u001b[0;31m \u001b[0ma\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mi\u001b[0m\u001b[0;34m+\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 3 \u001b[0;31m \u001b[0mb\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'string'\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m----> 4 \u001b[0;31m \u001b[0mc\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mb\u001b[0m\u001b[0;34m+\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\nipdb> print(a)\n1\nipdb> print(b)\nstring\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02dd3b19800f54efc24c25461799fe88bd339f0
| 375,897 |
ipynb
|
Jupyter Notebook
|
P1.ipynb
|
MohamedHeshamMustafa/CarND-LaneLines-P1
|
e609a998b6feaa433072d33c85026dd42faed090
|
[
"MIT"
] | null | null | null |
P1.ipynb
|
MohamedHeshamMustafa/CarND-LaneLines-P1
|
e609a998b6feaa433072d33c85026dd42faed090
|
[
"MIT"
] | null | null | null |
P1.ipynb
|
MohamedHeshamMustafa/CarND-LaneLines-P1
|
e609a998b6feaa433072d33c85026dd42faed090
|
[
"MIT"
] | null | null | null | 367.805284 | 115,036 | 0.928842 |
[
[
[
"# Self-Driving Car Engineer Nanodegree\n\n\n## Project: **Finding Lane Lines on the Road** \n***\nIn this project, you will use the tools you learned about in the lesson to identify lane lines on the road. You can develop your pipeline on a series of individual images, and later apply the result to a video stream (really just a series of images). Check out the video clip \"raw-lines-example.mp4\" (also contained in this repository) to see what the output should look like after using the helper functions below. \n\nOnce you have a result that looks roughly like \"raw-lines-example.mp4\", you'll need to get creative and try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video \"P1_example.mp4\". Ultimately, you would like to draw just one line for the left side of the lane, and one for the right.\n\nIn addition to implementing code, there is a brief writeup to complete. The writeup should be completed in a separate file, which can be either a markdown file or a pdf document. There is a [write up template](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) that can be used to guide the writing process. Completing both the code in the Ipython notebook and the writeup template will cover all of the [rubric points](https://review.udacity.com/#!/rubrics/322/view) for this project.\n\n---\nLet's have a look at our first image called 'test_images/solidWhiteRight.jpg'. Run the 2 cells below (hit Shift-Enter or the \"play\" button above) to display the image.\n\n**Note: If, at any point, you encounter frozen display windows or other confounding issues, you can always start again with a clean slate by going to the \"Kernel\" menu above and selecting \"Restart & Clear Output\".**\n\n---",
"_____no_output_____"
],
[
"**The tools you have are color selection, region of interest selection, grayscaling, Gaussian smoothing, Canny Edge Detection and Hough Tranform line detection. You are also free to explore and try other techniques that were not presented in the lesson. Your goal is piece together a pipeline to detect the line segments in the image, then average/extrapolate them and draw them onto the image for display (as below). Once you have a working pipeline, try it out on the video stream below.**\n\n---\n\n<figure>\n <img src=\"examples/line-segments-example.jpg\" width=\"380\" alt=\"Combined Image\" />\n <figcaption>\n <p></p> \n <p style=\"text-align: center;\"> Your output should look something like this (above) after detecting line segments using the helper functions below </p> \n </figcaption>\n</figure>\n <p></p> \n<figure>\n <img src=\"examples/laneLines_thirdPass.jpg\" width=\"380\" alt=\"Combined Image\" />\n <figcaption>\n <p></p> \n <p style=\"text-align: center;\"> Your goal is to connect/average/extrapolate line segments to get output like this</p> \n </figcaption>\n</figure>",
"_____no_output_____"
],
[
"**Run the cell below to import some packages. If you get an `import error` for a package you've already installed, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.** ",
"_____no_output_____"
],
[
"## Import Packages",
"_____no_output_____"
]
],
[
[
"#importing some useful packages\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\nimport numpy as np\nimport cv2\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Read in an Image",
"_____no_output_____"
]
],
[
[
"#reading in an image\nimage = mpimg.imread('test_images/solidWhiteRight.jpg')\n\n#printing out some stats and plotting\nprint('This image is:', type(image), 'with dimensions:', image.shape)\nplt.imshow(image) # if you wanted to show a single color channel image called 'gray', for example, call as plt.imshow(gray, cmap='gray')",
"This image is: <class 'numpy.ndarray'> with dimensions: (540, 960, 3)\n"
]
],
[
[
"## Ideas for Lane Detection Pipeline",
"_____no_output_____"
],
[
"**Some OpenCV functions (beyond those introduced in the lesson) that might be useful for this project are:**\n\n`cv2.inRange()` for color selection \n`cv2.fillPoly()` for regions selection \n`cv2.line()` to draw lines on an image given endpoints \n`cv2.addWeighted()` to coadd / overlay two images\n`cv2.cvtColor()` to grayscale or change color\n`cv2.imwrite()` to output images to file \n`cv2.bitwise_and()` to apply a mask to an image\n\n**Check out the OpenCV documentation to learn about these and discover even more awesome functionality!**",
"_____no_output_____"
],
[
"## Helper Functions",
"_____no_output_____"
],
[
"Below are some helper functions to help get you started. They should look familiar from the lesson!",
"_____no_output_____"
]
],
[
[
"import math\n\ndef grayscale(img):\n \"\"\"Applies the Grayscale transform\n This will return an image with only one color channel\n but NOTE: to see the returned image as grayscale\n (assuming your grayscaled image is called 'gray')\n you should call plt.imshow(gray, cmap='gray')\"\"\"\n return cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)\n # Or use BGR2GRAY if you read an image with cv2.imread()\n # return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n \ndef canny(img, low_threshold, high_threshold):\n \"\"\"Applies the Canny transform\"\"\"\n return cv2.Canny(img, low_threshold, high_threshold)\n\ndef gaussian_blur(img, kernel_size):\n \"\"\"Applies a Gaussian Noise kernel\"\"\"\n return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)\n\ndef region_of_interest(img, vertices):\n \"\"\"\n Applies an image mask.\n \n Only keeps the region of the image defined by the polygon\n formed from `vertices`. The rest of the image is set to black.\n `vertices` should be a numpy array of integer points.\n \"\"\"\n #defining a blank mask to start with\n mask = np.zeros_like(img) \n \n #defining a 3 channel or 1 channel color to fill the mask with depending on the input image\n if len(img.shape) > 2:\n channel_count = img.shape[2] # i.e. 3 or 4 depending on your image\n ignore_mask_color = (255,) * channel_count\n else:\n ignore_mask_color = 255\n \n #filling pixels inside the polygon defined by \"vertices\" with the fill color \n cv2.fillPoly(mask, vertices, ignore_mask_color)\n \n #returning the image only where mask pixels are nonzero\n masked_image = cv2.bitwise_and(img, mask)\n return masked_image\n\n\ndef draw_lines(img, lines, color=[255, 0, 0], thickness=8):\n \"\"\"\n NOTE: this is the function you might want to use as a starting point once you want to \n average/extrapolate the line segments you detect to map out the full\n extent of the lane (going from the result shown in raw-lines-example.mp4\n to that shown in P1_example.mp4). \n \n Think about things like separating line segments by their \n slope ((y2-y1)/(x2-x1)) to decide which segments are part of the left\n line vs. the right line. Then, you can average the position of each of \n the lines and extrapolate to the top and bottom of the lane.\n \n This function draws `lines` with `color` and `thickness`. \n Lines are drawn on the image inplace (mutates the image).\n If you want to make the lines semi-transparent, think about combining\n this function with the weighted_img() function below\n \"\"\"\n negative_slopes = []\n positive_slopes = []\n \n negetive_intercepts = []\n positive_intercepts = []\n \n left_line_x = []\n left_line_y = []\n \n right_line_x = []\n right_line_y = []\n \n y_max = img.shape[0]\n y_min = img.shape[0]\n \n #Drawing Lines \n for line in lines:\n for x1,y1,x2,y2 in line:\n current_slope = (y2-y1)/(x2-x1)\n \n if current_slope < 0.0 and current_slope > -math.inf:\n negative_slopes.append(current_slope) # left line\n left_line_x.append(x1)\n left_line_x.append(x2)\n left_line_y.append(y1)\n left_line_y.append(y2)\n negetive_intercepts.append(y1 -current_slope*x1)\n \n if current_slope > 0.0 and current_slope < math.inf:\n positive_slopes.append(current_slope) # right line\n right_line_x.append(x1)\n right_line_x.append(x2)\n right_line_y.append(y1)\n right_line_y.append(y2)\n positive_intercepts.append(y1 - current_slope*x1)\n \n y_min = min(y_min, y1, y2)\n \n y_min += 20 # add small threshold\n \n if len(positive_slopes) > 0 and len(right_line_x) > 0 and len(right_line_y) > 0:\n ave_positive_slope = sum(positive_slopes) / len(positive_slopes)\n ave_right_line_x = sum(right_line_x) / len(right_line_x)\n ave_right_line_y = sum(right_line_y ) / len(right_line_y)\n intercept = sum(positive_intercepts) / len(positive_intercepts) \n x_min=int((y_min-intercept)/ave_positive_slope) \n x_max = int((y_max - intercept)/ ave_positive_slope)\n cv2.line(img, (x_min, y_min), (x_max, y_max), color, thickness)\n\n if len(negative_slopes) > 0 and len(left_line_x) > 0 and len(left_line_y) > 0:\n ave_negative_slope = sum(negative_slopes) / len(negative_slopes)\n ave_left_line_x = sum(left_line_x) / len(left_line_x)\n ave_left_line_y = sum(left_line_y ) / len(left_line_y)\n intercept = sum(negetive_intercepts) / len(negetive_intercepts)\n x_min = int((y_min-intercept)/ave_negative_slope) \n x_max = int((y_max - intercept)/ ave_negative_slope)\n cv2.line(img, (x_min, y_min), (x_max, y_max), color, thickness)\n \ndef hough_lines(img, rho, theta, threshold, min_line_len, max_line_gap):\n \"\"\"\n `img` should be the output of a Canny transform.\n \n Returns an image with hough lines drawn.\n \"\"\"\n lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap)\n line_img = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8)\n draw_lines(line_img, lines)\n return line_img\n\n# Python 3 has support for cool math symbols.\n\ndef weighted_img(img, initial_img, α=0.8, β=1., γ=0.):\n \"\"\"\n `img` is the output of the hough_lines(), An image with lines drawn on it.\n Should be a blank image (all black) with lines drawn on it.\n \n `initial_img` should be the image before any processing.\n \n The result image is computed as follows:\n \n initial_img * α + img * β + γ\n NOTE: initial_img and img must be the same shape!\n \"\"\"\n return cv2.addWeighted(initial_img, α, img, β, γ)",
"_____no_output_____"
]
],
[
[
"## Test Images\n\nBuild your pipeline to work on the images in the directory \"test_images\" \n**You should make sure your pipeline works well on these images before you try the videos.**",
"_____no_output_____"
]
],
[
[
"import os\nos.listdir(\"test_images/\")",
"_____no_output_____"
]
],
[
[
"## Build a Lane Finding Pipeline\n\n",
"_____no_output_____"
],
[
"Build the pipeline and run your solution on all test_images. Make copies into the `test_images_output` directory, and you can use the images in your writeup report.\n\nTry tuning the various parameters, especially the low and high Canny thresholds as well as the Hough lines parameters.",
"_____no_output_____"
]
],
[
[
"# TODO: Build your pipeline that will draw lane lines on the test_images\n# then save them to the test_images_output directory.\n\n##1) We Have To read our Image in a grey scale fromat\nInput_Image = mpimg.imread('test_images/solidWhiteCurve.jpg')\nInput_Grey_Img = grayscale(Input_Image)\nplt.imshow(Input_Grey_Img, cmap='gray')\nplt.title('Image in Grey Scale Format')",
"_____no_output_____"
],
[
"##2) Apply Canny Detection with a low threshold 1 : 3 to high threshold\n## we do further smoothing before applying canny algorithm\nKernel_size = 3 #always put an odd number (3, 5, 7, ..)\nimg_Smoothed = gaussian_blur(Input_Grey_Img, Kernel_size)\nHigh_threshold = 150\nLow_threshold = 75\nimga_fter_Canny = canny(img_Smoothed, Low_threshold, High_threshold)\nplt.imshow(imga_fter_Canny, cmap='gray')\nplt.title('Image after Applying Canny')",
"_____no_output_____"
],
[
"##3) Determine Region of interest to detect Lane lines in Image\n## Set Verticies Parameter to determine regoin of interest first\n\n#Vertices : Left_bottom, Right_bottom, Apex (Area of interest)\nvertices = np.array([[(0,image.shape[0]),(470, 320), (500, 320), (image.shape[1],image.shape[0])]], dtype=np.int32)\nMasked_Image = region_of_interest(imga_fter_Canny, vertices)\nplt.imshow(Masked_Image,cmap='gray')\nplt.title('Massked Image')",
"_____no_output_____"
],
[
"##4)using hough transfrom to find lines\n# Define the Hough transform parameters\n# Make a blank the same size as our image to draw on\nrho = 2\ntheta = np.pi/180\nthreshold = 15\nmin_line_length = 40\nmax_line_gap = 20\n\nlines = hough_lines(Masked_Image, rho, theta, threshold, min_line_length, max_line_gap)\nplt.imshow(lines,cmap='gray')\nplt.title('lines Image')\n",
"_____no_output_____"
],
[
"##5) Draw Lines on the real Image\nFinal_out = weighted_img(lines, Input_Image, α=0.8, β=1., γ=0.)\nplt.imshow(Final_out)\nplt.title('Final Image with lane detected')",
"_____no_output_____"
]
],
[
[
"## Test on Videos\n\nYou know what's cooler than drawing lanes over images? Drawing lanes over video!\n\nWe can test our solution on two provided videos:\n\n`solidWhiteRight.mp4`\n\n`solidYellowLeft.mp4`\n\n**Note: if you get an import error when you run the next cell, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.**\n\n**If you get an error that looks like this:**\n```\nNeedDownloadError: Need ffmpeg exe. \nYou can download it by calling: \nimageio.plugins.ffmpeg.download()\n```\n**Follow the instructions in the error message and check out [this forum post](https://discussions.udacity.com/t/project-error-of-test-on-videos/274082) for more troubleshooting tips across operating systems.**",
"_____no_output_____"
]
],
[
[
"# Import everything needed to edit/save/watch video clips\nfrom moviepy.editor import VideoFileClip\nfrom IPython.display import HTML",
"_____no_output_____"
],
[
"def process_image(image):\n # NOTE: The output you return should be a color image (3 channel) for processing video below\n # TODO: put your pipeline here,\n # you should return the final output (image where lines are drawn on lanes)\n ##1) We Have To read our Image in a grey scale fromat\n Input_Grey_Img = grayscale(image)\n ##2) Apply Canny Detection with a low threshold 1 : 3 to high threshold\n ## we do further smoothing before applying canny algorithm\n Kernel_size = 3 #always put an odd number (3, 5, 7, ..)\n img_Smoothed = gaussian_blur(Input_Grey_Img, Kernel_size)\n High_threshold = 150\n Low_threshold = 50\n imga_fter_Canny = canny(img_Smoothed, Low_threshold, High_threshold)\n ##3) Determine Region of interest to detect Lane lines in Image\n ## Set Verticies Parameter to determine regoin of interest first\n #Vertices : Left_bottom, Right_bottom, Apex (Area of interest)\n vertices = np.array([[(0,image.shape[0]),\n (470, 320),\n (500, 320),\n (image.shape[1],\n image.shape[0])]],\n dtype=np.int32)\n\n Masked_Image = region_of_interest(imga_fter_Canny, vertices)\n ##4)using hough transfrom to find lines\n # Define the Hough transform parameters\n # Make a blank the same size as our image to draw on\n rho = 2\n theta = np.pi/180\n threshold = 55\n min_line_length = 100\n max_line_gap = 150\n lines = hough_lines(Masked_Image, rho, theta, threshold, min_line_length, max_line_gap)\n ##5)Draw Lines on the real Image\n result = weighted_img(lines, image, α=0.8, β=1., γ=0.)\n\n return result",
"_____no_output_____"
]
],
[
[
"Let's try the one with the solid white lane on the right first ...",
"_____no_output_____"
]
],
[
[
"white_output = 'test_videos_output/solidWhiteRight.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n##clip1 = VideoFileClip(\"test_videos/solidWhiteRight.mp4\").subclip(0,5)\nclip1 = VideoFileClip(\"test_videos/solidWhiteRight.mp4\")\nwhite_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!\n%time white_clip.write_videofile(white_output, audio=False)",
"t: 10%|▉ | 21/221 [00:00<00:00, 209.97it/s, now=None]"
]
],
[
[
"Play the video inline, or if you prefer find the video in your filesystem (should be in the same directory) and play it in your video player of choice.",
"_____no_output_____"
]
],
[
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(white_output))",
"_____no_output_____"
]
],
[
[
"## Improve the draw_lines() function\n\n**At this point, if you were successful with making the pipeline and tuning parameters, you probably have the Hough line segments drawn onto the road, but what about identifying the full extent of the lane and marking it clearly as in the example video (P1_example.mp4)? Think about defining a line to run the full length of the visible lane based on the line segments you identified with the Hough Transform. As mentioned previously, try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video \"P1_example.mp4\".**\n\n**Go back and modify your draw_lines function accordingly and try re-running your pipeline. The new output should draw a single, solid line over the left lane line and a single, solid line over the right lane line. The lines should start from the bottom of the image and extend out to the top of the region of interest.**",
"_____no_output_____"
],
[
"Now for the one with the solid yellow lane on the left. This one's more tricky!",
"_____no_output_____"
]
],
[
[
"yellow_output = 'test_videos_output/solidYellowLeft.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n##clip2 = VideoFileClip('test_videos/solidYellowLeft.mp4').subclip(0,5)\nclip2 = VideoFileClip('test_videos/solidYellowLeft.mp4')\nyellow_clip = clip2.fl_image(process_image)\n%time yellow_clip.write_videofile(yellow_output, audio=False)",
"\rt: 0%| | 0/681 [00:00<?, ?it/s, now=None]"
],
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(yellow_output))",
"_____no_output_____"
]
],
[
[
"## Writeup and Submission\n\nIf you're satisfied with your video outputs, it's time to make the report writeup in a pdf or markdown file. Once you have this Ipython notebook ready along with the writeup, it's time to submit for review! Here is a [link](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) to the writeup template file.\n",
"_____no_output_____"
],
[
"## Optional Challenge\n\nTry your lane finding pipeline on the video below. Does it still work? Can you figure out a way to make it more robust? If you're up for the challenge, modify your pipeline so it works with this video and submit it along with the rest of your project!",
"_____no_output_____"
]
],
[
[
"def process_image1(image):\n # NOTE: The output you return should be a color image (3 channel) for processing video below\n # TODO: put your pipeline here,\n # you should return the final output (image where lines are drawn on lanes)\n ##1) We Have To read our Image in a grey scale fromat\n Input_Grey_Img = grayscale(image)\n ##2) Apply Canny Detection with a low threshold 1 : 3 to high threshold\n ## we do further smoothing before applying canny algorithm\n Kernel_size = 3 #always put an odd number (3, 5, 7, ..)\n img_Smoothed = gaussian_blur(Input_Grey_Img, Kernel_size)\n High_threshold = 150\n Low_threshold = 50\n imga_fter_Canny = canny(img_Smoothed, Low_threshold, High_threshold)\n ##3) Determine Region of interest to detect Lane lines in Image\n ## Set Verticies Parameter to determine regoin of interest first\n vertices = np.array([[(226, 680),\n (614,436),\n (714,436),\n (1093,634)]])\n Masked_Image = region_of_interest(imga_fter_Canny, vertices)\n ##4)using hough transfrom to find lines\n # Define the Hough transform parameters\n # Make a blank the same size as our image to draw on\n rho = 2\n theta = np.pi/180\n threshold = 55\n min_line_length = 100\n max_line_gap = 150\n lines = hough_lines(Masked_Image, rho, theta, threshold, min_line_length, max_line_gap)\n ##5)Draw Lines on the real Image\n result = weighted_img(lines, image, α=0.8, β=1., γ=0.)\n\n return result",
"_____no_output_____"
],
[
"challenge_output = 'test_videos_output/challenge.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n##clip3 = VideoFileClip('test_videos/challenge.mp4').subclip(0,5)\nclip3 = VideoFileClip('test_videos/challenge.mp4')\nchallenge_clip = clip3.fl_image(process_image1)\n%time challenge_clip.write_videofile(challenge_output, audio=False)",
"\rt: 0%| | 0/251 [00:00<?, ?it/s, now=None]"
],
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(challenge_output))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
d02de5b7e03a9cbed136420152b0319ff2c7ff72
| 845,027 |
ipynb
|
Jupyter Notebook
|
Week4/AdvML_week4_ex2.ipynb
|
mikkokotola/AdvancedMachineLearning
|
574e82d4104ac04f1cb9889beb5be7d122bd0d01
|
[
"MIT"
] | 1 |
2020-03-18T08:51:44.000Z
|
2020-03-18T08:51:44.000Z
|
Week4/AdvML_week4_ex2.ipynb
|
mikkokotola/AdvancedMachineLearning
|
574e82d4104ac04f1cb9889beb5be7d122bd0d01
|
[
"MIT"
] | null | null | null |
Week4/AdvML_week4_ex2.ipynb
|
mikkokotola/AdvancedMachineLearning
|
574e82d4104ac04f1cb9889beb5be7d122bd0d01
|
[
"MIT"
] | null | null | null | 2,600.083077 | 256,780 | 0.961881 |
[
[
[
"## Advanced Course in Machine Learning\n## Week 4\n## Exercise 2 / Probabilistic PCA\n\nimport numpy as np\nimport scipy\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport matplotlib.animation as animation\nfrom numpy import linalg as LA\n\nsns.set_style(\"darkgrid\")",
"_____no_output_____"
],
[
"def build_dataset(N, D, K, sigma=1):\n x = np.zeros((D, N))\n z = np.random.normal(0.0, 1.0, size=(K, N))\n # Create a w with random values\n w = np.random.normal(0.0, sigma**2, size=(D, K))\n \n mean = np.dot(w, z)\n \n for d in range(D):\n for n in range(N):\n x[d, n] = np.random.normal(mean[d, n], sigma**2)\n\n print(\"True principal axes:\")\n print(w)\n return x, mean, w, z\n\nN = 5000 # number of data points\nD = 2 # data dimensionality\nK = 1 # latent dimensionality\nsigma = 1.0\n\nx, mean, w, z = build_dataset(N, D, K, sigma)",
"True principal axes:\n[[-0.60928742]\n [ 0.06539077]]\n"
],
[
"print(z)",
"[[ 0.15935665 -0.89767049 -1.66636704 ... -0.66798166 1.62407392\n -0.52317225]]\n"
],
[
"print(w)",
"[[-0.60928742]\n [ 0.06539077]]\n"
],
[
"plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k')\nsns.scatterplot(z[0, :], 0, alpha=0.5, label='z')\norigin = [0], [0] # origin point\n\nplt.xlabel('x')\nplt.ylabel('y')\nplt.legend(loc='lower right')\nplt.title('Probabilistic PCA, generated z')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k')\nsns.scatterplot(z[0, :], 0, alpha=0.5, label='z')\nsns.scatterplot(mean[0, :], mean[1, :], color='red', alpha=0.5, label='Wz')\norigin = [0], [0] # origin point\n#Plot the principal axis\nplt.quiver(*origin, w[0,0], w[1,0], color=['g'], scale=1, label='W')\n\nplt.xlabel('x')\nplt.ylabel('y')\nplt.legend(loc='upper right')\nplt.title('Probabilistic PCA, generated z')\nplt.show()",
"_____no_output_____"
],
[
"print(x)",
"[[ 2.54607646 -2.29734781 0.48287155 ... 0.03014842 -1.04560512\n -0.64827475]\n [-0.1049034 -0.56708834 0.16910261 ... -0.65630482 -0.21093167\n -2.17181129]]\n"
],
[
"plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k')\nsns.scatterplot(x[0, :], x[1, :], color='orange', alpha=0.5)\n#plt.axis([-5, 5, -5, 5])\nplt.xlabel('x')\nplt.ylabel('y')\n#Plot the principal axis\nplt.quiver(*origin, w[0,0], w[1,0], color=['g'], scale=10, label='W')\n\n#Plot probability density contours\nsns.kdeplot(x[0, :], x[1, :], n_levels=3, color='purple')\n\nplt.title('Probabilistic PCA, generated x')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k')\n\nsns.scatterplot(x[0, :], x[1, :], color='orange', alpha=0.5, label='X')\nsns.scatterplot(z[0, :], 0, alpha=0.5, label='z')\nsns.scatterplot(mean[0, :], mean[1, :], color='red', alpha=0.5, label='Wz')\n\norigin = [0], [0] # origin point\n#Plot the principal axis\nplt.quiver(*origin, w[0,0], w[1,0], color=['g'], scale=10, label='W')\n\nplt.xlabel('x')\nplt.ylabel('y')\nplt.legend(loc='lower right')\nplt.title('Probabilistic PCA')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k')\n\nsns.scatterplot(x[0, :], x[1, :], color='orange', alpha=0.5, label='X')\nsns.scatterplot(z[0, :], 0, alpha=0.5, label='z')\nsns.scatterplot(mean[0, :], mean[1, :], color='red', alpha=0.5, label='Wz')\n\norigin = [0], [0] # origin point\n#Plot the principal axis\nplt.quiver(*origin, w[0,0], w[1,0], color=['g'], scale=10, label='W')\n\n#Plot probability density contours\nsns.kdeplot(x[0, :], x[1, :], n_levels=6, color='purple')\n\nplt.xlabel('x')\nplt.ylabel('y')\nplt.legend(loc='lower right')\nplt.title('Probabilistic PCA')\nplt.show()",
"_____no_output_____"
]
],
[
[
"def main():\n fig = plt.figure()\n scat = plt.scatter(mean[0, :], color='red', alpha=0.5, label='Wz')\n\n ani = animation.FuncAnimation(fig, update_plot, frames=xrange(N),\n fargs=(scat))\n plt.show()\n\ndef update_plot(i, scat):\n scat.set_array(data[i])\n return scat,\n\nmain()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02deeaec567b87ef29c33226a3114420f0f8583
| 25,904 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Labelling-checkpoint.ipynb
|
Pramadita/Analisis-Sentimen-Bansos-Random-Forest
|
ae1b80acd8597905c0d542fcff4628ba558d9b83
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Labelling-checkpoint.ipynb
|
Pramadita/Analisis-Sentimen-Bansos-Random-Forest
|
ae1b80acd8597905c0d542fcff4628ba558d9b83
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Labelling-checkpoint.ipynb
|
Pramadita/Analisis-Sentimen-Bansos-Random-Forest
|
ae1b80acd8597905c0d542fcff4628ba558d9b83
|
[
"MIT"
] | null | null | null | 43.979626 | 1,649 | 0.491044 |
[
[
[
"import tweepy\nfrom textblob import TextBlob #NLP bahasa inggris\nimport re\nimport pandas as pd",
"_____no_output_____"
],
[
"data = pd.read_csv('Dataset/All-Pra & Pasca ND Clean for translate 5.csv',sep=\";\")#nama file data\ndata = data.astype({'Tweet' : 'string'})\ndata = data.astype({'Terjemah' : 'string'})\ndata.dtypes",
"_____no_output_____"
],
[
"def load_data():\n data = pd.read_csv('Dataset/All-Pra & Pasca ND Clean for translate 5.csv',sep=\";\")#nama file data\n return data",
"_____no_output_____"
],
[
"tweet_df = load_data()\ntweet_df.head()",
"_____no_output_____"
],
[
"df = pd.DataFrame(tweet_df[['Tanggal', 'Banyak Retweet', 'Tweet', 'Terjemah']])\ndf",
"_____no_output_____"
],
[
"def getSubjectivity(text): \n return TextBlob(text).sentiment.subjectivity\n\ndef getPolarity(text):\n return TextBlob(text).sentiment.polarity\n\ndf['Subjectivity'] = df['Terjemah'].apply(getSubjectivity)\ndf['Polarity'] = df['Terjemah'].apply(getPolarity)\n\ndf",
"_____no_output_____"
],
[
"def getSentiment(score):\n if score < 0 :\n return '0'\n elif score == 0 :\n return '1'\n else :\n return '2'\n# Apply the function\ndf['Sentiment'] = df['Polarity'].apply(getSentiment)\n#lets take a look\ndf",
"_____no_output_____"
],
[
"for index, row in df.iterrows():\n id_blob = df.iloc[index]['Tweets']\n translation = TextBlob(id_blob)\n if translation.detect_language() != 'en' :\n en_blob = translation.translate(to=u'en')\n else :\n en_blob = translation\n df.at[index,str('Tweets_Translated')] = str(en_blob)\n# Lets take a look\ndf.head()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02dff2150000ff2339051356625cb9998b1d557
| 1,497 |
ipynb
|
Jupyter Notebook
|
if-condition.ipynb
|
cj-asimov12/python_ds
|
b063e1047addc337af451566d93e3851615b4ef2
|
[
"MIT"
] | null | null | null |
if-condition.ipynb
|
cj-asimov12/python_ds
|
b063e1047addc337af451566d93e3851615b4ef2
|
[
"MIT"
] | null | null | null |
if-condition.ipynb
|
cj-asimov12/python_ds
|
b063e1047addc337af451566d93e3851615b4ef2
|
[
"MIT"
] | null | null | null | 19.96 | 108 | 0.492986 |
[
[
[
"\"\"\"\n1. Input the values of a and b as 10 and 20 respectively. Now check if a is greater or b is greater\nusing if condition. Think about all the edge cases, and print the statements accordingly.\n\"\"\"",
"_____no_output_____"
],
[
"a = 10\nb = 20",
"_____no_output_____"
],
[
"if a > b or b < a:\n print(\"a is greater than b.\")\n\nelif b > a or a < b:\n print(\"b is greater than a.\")\n \nelse:\n print(\"Both a and b are equal to eachother.\")",
"b is greater than a.\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
d02e0174c5e9cfcba31b3d3461129920fca9d203
| 252,516 |
ipynb
|
Jupyter Notebook
|
Week2/Bayes Classifier.ipynb
|
yumengdong/GANs
|
973291b913cbc8c8764670f70c2b6fc5682f9a6b
|
[
"MIT"
] | null | null | null |
Week2/Bayes Classifier.ipynb
|
yumengdong/GANs
|
973291b913cbc8c8764670f70c2b6fc5682f9a6b
|
[
"MIT"
] | null | null | null |
Week2/Bayes Classifier.ipynb
|
yumengdong/GANs
|
973291b913cbc8c8764670f70c2b6fc5682f9a6b
|
[
"MIT"
] | null | null | null | 329.655352 | 11,672 | 0.93261 |
[
[
[
"# Bayes Classifier",
"_____no_output_____"
]
],
[
[
"import util\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.stats import multivariate_normal as mvn\n\n%matplotlib inline",
"_____no_output_____"
],
[
"def clamp_sample(x):\n x = np.minimum(x, 1)\n x = np.maximum(x, 0)\n return x",
"_____no_output_____"
],
[
"class BayesClassifier:\n def fit(self, X, Y):\n # assume classes are numbered 0...K-1\n self.K = len(set(Y))\n\n self.gaussians = []\n self.p_y = np.zeros(self.K)\n for k in range(self.K):\n Xk = X[Y == k]\n self.p_y[k] = len(Xk)\n mean = Xk.mean(axis=0) # describe gaussian\n cov = np.cov(Xk.T) # describe gaussian\n g = {'m': mean, 'c': cov}\n self.gaussians.append(g)\n # normalize p(y)\n self.p_y /= self.p_y.sum()\n\n def sample_given_y(self, y):\n g = self.gaussians[y]\n return clamp_sample( mvn.rvs(mean=g['m'], cov=g['c']) )\n\n def sample(self):\n y = np.random.choice(self.K, p=self.p_y)\n return clamp_sample( self.sample_given_y(y) )",
"_____no_output_____"
],
[
"X, Y = util.get_mnist()\nclf = BayesClassifier()\nclf.fit(X, Y)",
"Reading in and transforming data...\n"
],
[
"for k in range(clf.K):\n# show one sample for each class\n# also show the mean image learned from Gaussian Bayes Classifier\n\n sample = clf.sample_given_y(k).reshape(28, 28)\n mean = clf.gaussians[k]['m'].reshape(28, 28)\n\n plt.subplot(1,2,1)\n plt.imshow(sample, cmap='gray')\n plt.title(\"Sample\")\n plt.subplot(1,2,2)\n plt.imshow(mean, cmap='gray')\n plt.title(\"Mean\")\n plt.show()",
"_____no_output_____"
]
],
[
[
"# Bayes Classifier with Gaussian Mixture Models",
"_____no_output_____"
]
],
[
[
"from sklearn.mixture import BayesianGaussianMixture",
"_____no_output_____"
],
[
"class BayesClassifier:\n def fit(self, X, Y):\n # assume classes are numbered 0...K-1\n self.K = len(set(Y))\n\n self.gaussians = []\n self.p_y = np.zeros(self.K)\n for k in range(self.K):\n print(\"Fitting gmm\", k)\n Xk = X[Y == k]\n self.p_y[k] = len(Xk)\n gmm = BayesianGaussianMixture(10) # number of clusters\n gmm.fit(Xk)\n self.gaussians.append(gmm)\n # normalize p(y)\n self.p_y /= self.p_y.sum()\n\n def sample_given_y(self, y):\n gmm = self.gaussians[y]\n sample = gmm.sample()\n # note: sample returns a tuple containing 2 things:\n # 1) the sample\n # 2) which cluster it came from\n # we'll use (2) to obtain the means so we can plot\n # them like we did in the previous script\n # we cheat by looking at \"non-public\" params in\n # the sklearn source code\n mean = gmm.means_[sample[1]]\n return clamp_sample( sample[0].reshape(28, 28) ), mean.reshape(28, 28)\n\n def sample(self):\n y = np.random.choice(self.K, p=self.p_y)\n return clamp_sample( self.sample_given_y(y) )",
"_____no_output_____"
],
[
"clf = BayesClassifier()\nclf.fit(X, Y)",
"Fitting gmm 0\nFitting gmm 1\nFitting gmm 2\nFitting gmm 3\nFitting gmm 4\nFitting gmm 5\nFitting gmm 6\nFitting gmm 7\nFitting gmm 8\nFitting gmm 9\n"
],
[
"for k in range(clf.K):\n# show one sample for each class\n# also show the mean image learned\n\n sample, mean = clf.sample_given_y(k)\n\n plt.subplot(1,2,1)\n plt.imshow(sample, cmap='gray')\n plt.title(\"Sample\")\n plt.subplot(1,2,2)\n plt.imshow(mean, cmap='gray')\n plt.title(\"Mean\")\n plt.show()",
"_____no_output_____"
],
[
"# generate a random sample\nsample, mean = clf.sample()\nplt.subplot(1,2,1)\nplt.imshow(sample, cmap='gray')\nplt.title(\"Random Sample from Random Class\")\nplt.subplot(1,2,2)\nplt.imshow(mean, cmap='gray')\nplt.title(\"Corresponding Cluster Mean\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Neural Network and Autoencoder",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf",
"_____no_output_____"
],
[
"class Autoencoder:\n def __init__(self, D, M):\n # represents a batch of training data\n self.X = tf.placeholder(tf.float32, shape=(None, D))\n\n # input -> hidden\n self.W = tf.Variable(tf.random_normal(shape=(D, M)) * np.sqrt(2.0 / M))\n self.b = tf.Variable(np.zeros(M).astype(np.float32))\n\n # hidden -> output\n self.V = tf.Variable(tf.random_normal(shape=(M, D)) * np.sqrt(2.0 / D))\n self.c = tf.Variable(np.zeros(D).astype(np.float32))\n\n # construct the reconstruction\n self.Z = tf.nn.relu(tf.matmul(self.X, self.W) + self.b)\n logits = tf.matmul(self.Z, self.V) + self.c\n self.X_hat = tf.nn.sigmoid(logits)\n\n # compute the cost\n self.cost = tf.reduce_sum(\n tf.nn.sigmoid_cross_entropy_with_logits(\n labels=self.X,\n logits=logits\n )\n )\n\n # make the trainer\n self.train_op = tf.train.RMSPropOptimizer(learning_rate=0.001).minimize(self.cost)\n\n # set up session and variables for later\n self.init_op = tf.global_variables_initializer()\n self.sess = tf.InteractiveSession()\n self.sess.run(self.init_op)\n \n def fit(self, X, epochs=30, batch_sz=64):\n costs = []\n n_batches = len(X) // batch_sz\n print(\"n_batches:\", n_batches)\n for i in range(epochs):\n if i % 5 == 0:\n print(\"epoch:\", i)\n np.random.shuffle(X)\n for j in range(n_batches):\n batch = X[j*batch_sz:(j+1)*batch_sz]\n _, c, = self.sess.run((self.train_op, self.cost), feed_dict={self.X: batch})\n c /= batch_sz # just debugging\n costs.append(c)\n if (j % 100 == 0) and (i % 5 == 0):\n print(\"iter: %d, cost: %.3f\" % (j, c))\n plt.plot(costs)\n plt.show()\n \n def predict(self, X):\n return self.sess.run(self.X_hat, feed_dict={self.X: X})",
"_____no_output_____"
],
[
"model = Autoencoder(784, 300)\nmodel.fit(X)",
"n_batches: 656\nepoch: 0\niter: 0, cost: 556.776\niter: 100, cost: 116.676\niter: 200, cost: 92.653\niter: 300, cost: 79.293\niter: 400, cost: 71.079\niter: 500, cost: 66.773\niter: 600, cost: 63.363\nepoch: 5\niter: 0, cost: 53.079\niter: 100, cost: 55.792\niter: 200, cost: 58.212\niter: 300, cost: 50.718\niter: 400, cost: 55.812\niter: 500, cost: 52.909\niter: 600, cost: 55.598\nepoch: 10\niter: 0, cost: 52.137\niter: 100, cost: 52.782\niter: 200, cost: 52.657\niter: 300, cost: 52.161\niter: 400, cost: 52.250\niter: 500, cost: 51.924\niter: 600, cost: 52.588\nepoch: 15\niter: 0, cost: 50.259\niter: 100, cost: 52.758\niter: 200, cost: 52.034\niter: 300, cost: 51.771\niter: 400, cost: 51.935\niter: 500, cost: 51.255\niter: 600, cost: 51.129\nepoch: 20\niter: 0, cost: 52.164\niter: 100, cost: 52.326\niter: 200, cost: 51.630\niter: 300, cost: 52.303\niter: 400, cost: 51.917\niter: 500, cost: 51.300\niter: 600, cost: 51.685\nepoch: 25\niter: 0, cost: 51.437\niter: 100, cost: 53.558\niter: 200, cost: 50.846\niter: 300, cost: 53.695\niter: 400, cost: 49.608\niter: 500, cost: 50.895\niter: 600, cost: 51.706\n"
],
[
"done = False\nwhile not done:\n i = np.random.choice(len(X))\n x = X[i]\n im = model.predict([x]).reshape(28, 28)\n plt.subplot(1,2,1)\n plt.imshow(x.reshape(28, 28), cmap='gray')\n plt.title(\"Original\")\n plt.subplot(1,2,2)\n plt.imshow(im, cmap='gray')\n plt.title(\"Reconstruction\")\n plt.show()\n\n ans = input(\"Generate another?\")\n if ans and ans[0] in ('n' or 'N'):\n done = True",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d02e05fedc1cab9bbf7a51c221ec1408ef71f57a
| 103,876 |
ipynb
|
Jupyter Notebook
|
notebooks/KMeans_40_22800_v2.ipynb
|
KYHyeon/captcha-solver
|
08567b25017339aeec8c51a4f420104f9abb8f9a
|
[
"MIT"
] | 1 |
2020-12-15T12:52:51.000Z
|
2020-12-15T12:52:51.000Z
|
notebooks/KMeans_40_22800_v2.ipynb
|
KYHyeon/captcha-solver
|
08567b25017339aeec8c51a4f420104f9abb8f9a
|
[
"MIT"
] | null | null | null |
notebooks/KMeans_40_22800_v2.ipynb
|
KYHyeon/captcha-solver
|
08567b25017339aeec8c51a4f420104f9abb8f9a
|
[
"MIT"
] | null | null | null | 219.610994 | 47,292 | 0.903057 |
[
[
[
"%matplotlib inline\nimport pandas as pd\nimport cv2\nimport numpy as np\nfrom matplotlib import pyplot as plt\n",
"_____no_output_____"
],
[
"\ndf = pd.read_csv(\"data/22800_SELECT_t___FROM_data_data_t.csv\",header=None,index_col=0)\ndf = df.rename(columns={0:\"no\", 1: \"CAPTDATA\", 2: \"CAPTIMAGE\",3: \"timestamp\"})",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 22800 entries, 1 to 22815\nData columns (total 3 columns):\nCAPTDATA 22800 non-null object\nCAPTIMAGE 22800 non-null object\ntimestamp 22800 non-null object\ndtypes: object(3)\nmemory usage: 712.5+ KB\n"
],
[
"df.sample(5)",
"_____no_output_____"
],
[
"def alpha_to_gray(img):\n alpha_channel = img[:, :, 3]\n _, mask = cv2.threshold(alpha_channel, 128, 255, cv2.THRESH_BINARY) # binarize mask\n color = img[:, :, :3]\n img = cv2.bitwise_not(cv2.bitwise_not(color, mask=mask))\n return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)",
"_____no_output_____"
],
[
"def preprocess(data):\n data = bytes.fromhex(data[2:])\n img = cv2.imdecode( np.asarray(bytearray(data), dtype=np.uint8), cv2.IMREAD_UNCHANGED )\n img = alpha_to_gray(img)\n kernel = np.ones((3, 3), np.uint8)\n img = cv2.dilate(img, kernel, iterations=1)\n img = cv2.medianBlur(img, 3)\n kernel = np.ones((4, 4), np.uint8)\n img = cv2.erode(img, kernel, iterations=1)\n# plt.imshow(img)\n return img",
"_____no_output_____"
],
[
"df[\"IMAGE\"] = df[\"CAPTIMAGE\"].apply(preprocess)",
"_____no_output_____"
],
[
"def bounding(gray):\n# data = bytes.fromhex(df[\"CAPTIMAGE\"][1][2:])\n# image = cv2.imdecode( np.asarray(bytearray(data), dtype=np.uint8), cv2.IMREAD_UNCHANGED )\n\n# alpha_channel = image[:, :, 3]\n# _, mask = cv2.threshold(alpha_channel, 128, 255, cv2.THRESH_BINARY) # binarize mask\n# color = image[:, :, :3]\n# src = cv2.bitwise_not(cv2.bitwise_not(color, mask=mask))\n\n ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)\n binary = cv2.bitwise_not(binary)\n\n contours, hierachy = cv2.findContours(binary, cv2.RETR_EXTERNAL , cv2.CHAIN_APPROX_NONE)\n\n ans = []\n for h, tcnt in enumerate(contours):\n x,y,w,h = cv2.boundingRect(tcnt)\n if h < 25:\n continue\n if 40 < w < 100: # 2개가 붙어 있는 경우\n ans.append([x,y,w//2,h])\n ans.append([x+(w//2),y,w//2,h])\n continue\n if 100 <= w < 170:\n ans.append([x,y,w//3,h])\n ans.append([x+(w//3),y,w//3,h])\n ans.append([x+(2*w//3),y,w//3,h])\n# cv2.rectangle(src,(x,y),(x+w,y+h),(255,0,0),1)\n ans.append([x,y,w,h])\n return ans\n # cv2.destroyAllWindows()",
"_____no_output_____"
],
[
"df[\"bounding\"] = df[\"IMAGE\"].apply(bounding)",
"_____no_output_____"
],
[
"def draw_bounding(idx):\n CAPTIMAGE = df[\"CAPTIMAGE\"][idx]\n bounding = df[\"bounding\"][idx]\n \n data = bytes.fromhex(CAPTIMAGE[2:])\n image = cv2.imdecode( np.asarray(bytearray(data), dtype=np.uint8), cv2.IMREAD_UNCHANGED )\n\n alpha_channel = image[:, :, 3]\n _, mask = cv2.threshold(alpha_channel, 128, 255, cv2.THRESH_BINARY) # binarize mask\n color = image[:, :, :3]\n src = cv2.bitwise_not(cv2.bitwise_not(color, mask=mask))\n\n for x,y,w,h in bounding:\n# print(x,y,w,h)\n cv2.rectangle(src,(x,y),(x+w,y+h),(255,0,0),1)\n return src",
"_____no_output_____"
],
[
"import random\n\nnrows = 4\nncols = 4\nfig, axes = plt.subplots(nrows=nrows, ncols=ncols)\nfig.set_size_inches((16, 6)) \nfor i in range(nrows):\n for j in range(ncols):\n idx = random.randrange(20,22800)\n axes[i][j].set_title(str(idx))\n axes[i][j].imshow(draw_bounding(idx))\nfig.tight_layout()\nplt.savefig('sample.png')\nplt.show()",
"_____no_output_____"
],
[
"charImg = []\nfor idx in df.index:\n IMAGE = df[\"IMAGE\"][idx]\n bounding = df[\"bounding\"][idx]\n \n for x,y,w,h in bounding:\n newImg = IMAGE[y:y+h,x:x+w]\n newImg = cv2.resize(newImg, dsize=(41, 38), interpolation=cv2.INTER_NEAREST)\n charImg.append(newImg/255.0)\n",
"_____no_output_____"
],
[
"# cast to numpy arrays\ntrainingImages = np.asarray(charImg)\n\n# reshape img array to vector\ndef reshape_image(img):\n return np.reshape(img,len(img)*len(img[0]))\n\nimg_reshape = np.zeros((len(trainingImages),len(trainingImages[0])*len(trainingImages[0][0])))\n\nfor i in range(0,len(trainingImages)):\n img_reshape[i] = reshape_image(trainingImages[i])",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\n\nimport matplotlib.pyplot as plt\n\nimport seaborn as sns\n\n\n\n# create model and prediction\n\nmodel = KMeans(n_clusters=40,algorithm='auto')\n\nmodel.fit(img_reshape)\n\npredict = pd.DataFrame(model.predict(img_reshape))\n\npredict.columns=['predict']",
"_____no_output_____"
],
[
"import pickle\npickle.dump(model, open(\"KMeans_40_22800.pkl\", \"wb\"))",
"_____no_output_____"
],
[
"import pickle\nmodel = pickle.load(open(\"KMeans_40_22800.pkl\", \"rb\"))\n\npredict = pd.DataFrame(model.predict(img_reshape))\n\npredict.columns=['predict']\n",
"_____no_output_____"
],
[
"import random\nfrom tqdm import tqdm\n\nr = pd.concat([pd.DataFrame(img_reshape),predict],axis=1)\n\n!rm -rf res_40\n!mkdir res_40\n\nnrows = 4\nncols = 10\nfig, axes = plt.subplots(nrows=nrows, ncols=ncols)\nfig.set_size_inches((16, 6))\n\nfor j in tqdm(range(40)):\n i = 0\n nSample = min(nrows * ncols,len(r[r[\"predict\"] == j]))\n for idx in r[r[\"predict\"] == j].sample(nSample).index:\n axes[i // ncols][i % ncols].set_title(str(idx))\n axes[i // ncols][i % ncols].imshow(trainingImages[idx])\n i+=1\n fig.tight_layout()\n plt.savefig('res_40/sample_' + str(j) + '.png')",
"100%|██████████| 40/40 [01:16<00:00, 1.92s/it]\n"
]
],
[
[
"98 95 92 222 255",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d02e2a93b98d19e8fbab3ad65f4a92b0365af9ee
| 6,436 |
ipynb
|
Jupyter Notebook
|
Data Augumentation/extract_imgs.ipynb
|
vcaptainv/SinGan-Data-Augumentation
|
09b0ef180bebb0ed31ab3dfd7e29a3d4ba684f97
|
[
"MIT"
] | null | null | null |
Data Augumentation/extract_imgs.ipynb
|
vcaptainv/SinGan-Data-Augumentation
|
09b0ef180bebb0ed31ab3dfd7e29a3d4ba684f97
|
[
"MIT"
] | null | null | null |
Data Augumentation/extract_imgs.ipynb
|
vcaptainv/SinGan-Data-Augumentation
|
09b0ef180bebb0ed31ab3dfd7e29a3d4ba684f97
|
[
"MIT"
] | null | null | null | 26.377049 | 112 | 0.511187 |
[
[
[
"import torch\nimport torchvision\nimport torchvision.transforms as transforms",
"_____no_output_____"
],
[
"transform = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n\ntrainset = torchvision.datasets.CIFAR10(root='./data', train=True,\n download=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=4,\n shuffle=True, num_workers=2)\n\ntestset = torchvision.datasets.CIFAR10(root='./data', train=False,\n download=True, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=4,\n shuffle=False, num_workers=2)\n\nclasses = ('plane', 'car', 'bird', 'cat',\n 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')",
"Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz\n"
],
[
"import mxnet as mx\nimport numpy as np\nimport pickle\nimport cv2\n\ndef extractImagesAndLabels(file):\n f = open(file, 'rb')\n dict = pickle.load(f, encoding='latin1')\n images = dict['data']\n images = np.reshape(images, (10000, 3, 32, 32))\n labels = dict['labels']\n imagearray = mx.nd.array(images)\n labelarray = mx.nd.array(labels)\n return imagearray, labelarray\n\ndef extractCategories(file):\n f = open(file, 'rb')\n dict = pickle.load(f, encoding='latin1')\n return dict['label_names']\n\ndef saveCifarImage(array, path, file):\n # array is 3x32x32. cv2 needs 32x32x3\n array = array.asnumpy().transpose(1,2,0)\n # array is RGB. cv2 needs BGR\n array = cv2.cvtColor(array, cv2.COLOR_RGB2BGR)\n # save to PNG file\n return cv2.imwrite(path+file+\".png\", array)",
"_____no_output_____"
],
[
"classes = {}\nimgarray, lblarray = extractImagesAndLabels(\"data/cifar-10-batches-py/data_batch_2\")\n#print(imgarray)\n#print(lblarray)",
"_____no_output_____"
],
[
"categories = extractCategories(\"./data/cifar-10-batches-py/batches.meta\")\nprint(categories)",
"['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']\n"
],
[
"for name in categories:\n classes[name] = []\n\nfor i in range(len(imgarray)):\n category = lblarray[i].asnumpy()\n category = (int)(category[0])\n category_name = categories[category]\n classes[category_name].append(imgarray[i])",
"_____no_output_____"
],
[
"print(classes.keys())\ntotal = 0\nfor name in classes.keys():\n length = len(classes[name])\n print(length)\n total += length\nprint(total)",
"dict_keys(['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'])\n984\n1007\n1010\n995\n1010\n988\n1008\n1026\n987\n985\n10000\n"
],
[
"path = \"cifar10-classes-batch2/\"\nfor name in classes.keys():\n folder = path+name+\"/\"\n print(folder)\n for i in range(len(classes[name])):\n saveCifarImage(classes[name][i], folder, (str)(i))",
"cifar10-classes-batch2/airplane/\ncifar10-classes-batch2/automobile/\ncifar10-classes-batch2/bird/\ncifar10-classes-batch2/cat/\ncifar10-classes-batch2/deer/\ncifar10-classes-batch2/dog/\ncifar10-classes-batch2/frog/\ncifar10-classes-batch2/horse/\ncifar10-classes-batch2/ship/\ncifar10-classes-batch2/truck/\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e381b652a29699932c288945e75b813f9f5de
| 5,907 |
ipynb
|
Jupyter Notebook
|
Big_Data_Integration_and_Processing/SoccerTweetAnalysis.ipynb
|
P7h/Coursera__Big_Data_Integration_and_Processing
|
41a7f4bf548932ece71b15343c8fec4b4fcda5c9
|
[
"Apache-2.0"
] | 3 |
2017-03-18T20:41:20.000Z
|
2019-05-03T18:22:01.000Z
|
Big_Data_Integration_and_Processing/SoccerTweetAnalysis.ipynb
|
P7h/Coursera__Big_Data_Integration_and_Processing
|
41a7f4bf548932ece71b15343c8fec4b4fcda5c9
|
[
"Apache-2.0"
] | null | null | null |
Big_Data_Integration_and_Processing/SoccerTweetAnalysis.ipynb
|
P7h/Coursera__Big_Data_Integration_and_Processing
|
41a7f4bf548932ece71b15343c8fec4b4fcda5c9
|
[
"Apache-2.0"
] | 3 |
2017-04-08T07:37:20.000Z
|
2020-07-10T15:43:48.000Z
| 23.347826 | 126 | 0.559506 |
[
[
[
"# Import and create a new SQLContext \nfrom pyspark.sql import SQLContext\nsqlContext = SQLContext(sc)",
"_____no_output_____"
],
[
"# Read the country CSV file into an RDD.\ncountry_lines = sc.textFile('file:///home/ubuntu/work/notebooks/UCSD/big-data-3/final-project/country-list.csv')",
"_____no_output_____"
],
[
"country_lines.collect()",
"_____no_output_____"
],
[
"# Convert each line into a pair of words\ncountry_lines.map(lambda a: a.split(\",\")).collect()",
"_____no_output_____"
],
[
"# Convert each pair of words into a tuple\ncountry_tuples = country_lines.map(lambda a: (a.split(\",\")[0].lower(), a.split(\",\")[1]))",
"_____no_output_____"
],
[
"# Create the DataFrame, look at schema and contents\ncountryDF = sqlContext.createDataFrame(country_tuples, [\"country\", \"code\"])\ncountryDF.printSchema()\ncountryDF.take(3)",
"_____no_output_____"
],
[
"# Read tweets CSV file into RDD of lines\ntweets = sc.textFile('file:///home/ubuntu/work/notebooks/UCSD/big-data-3/final-project/tweets.csv')\ntweets.count()",
"_____no_output_____"
],
[
"# Clean the data: some tweets are empty. Remove the empty tweets using filter() \nfiltered_tweets = tweets.filter(lambda a: len(a) > 0)\nfiltered_tweets.count()",
"_____no_output_____"
],
[
"# Perform WordCount on the cleaned tweet texts. (note: this is several lines.)\nword_counts = filtered_tweets.flatMap(lambda a: a.split(\" \")) \\\n .map(lambda word: (word.lower(), 1)) \\\n .reduceByKey(lambda a, b: a + b)",
"_____no_output_____"
],
[
"from pyspark.sql import HiveContext\nfrom pyspark.sql.types import *\n\n# sc is an existing SparkContext.\nsqlContext = HiveContext(sc)\n\nschemaString = \"word count\"\n\nfields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]\nschema = StructType(fields)\n\n# Create the DataFrame of tweet word counts\ntweetsDF = sqlContext.createDataFrame(word_counts, schema)\ntweetsDF.printSchema()\ntweetsDF.count()",
"_____no_output_____"
],
[
"# Join the country and tweet DataFrames (on the appropriate column)\njoined = countryDF.join(tweetsDF, countryDF.country == tweetsDF.word)\njoined.take(5)\njoined.show()",
"_____no_output_____"
],
[
"# Question 1: number of distinct countries mentioned\ndistinct_countries = joined.select(\"country\").distinct()\ndistinct_countries.show(100)",
"_____no_output_____"
],
[
"# Question 2: number of countries mentioned in tweets.\nfrom pyspark.sql.functions import sum\nfrom pyspark.sql import SparkSession\nfrom pyspark.sql import Row\n\ncountries_count = joined.groupBy(\"country\")\njoined.createOrReplaceTempView(\"records\")\nspark.sql(\"SELECT country, count(*) count1 FROM records group by country order by count1 desc, country asc\").show(100)",
"_____no_output_____"
],
[
"# Table 1: top three countries and their counts.\nfrom pyspark.sql.functions import desc\nfrom pyspark.sql.functions import col\n\ntop_3 = joined.sort(col(\"count\").desc())\ntop_3.show()",
"_____no_output_____"
],
[
"# Table 2: counts for Wales, Iceland, and Japan.\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e40362f3f38a0cdcc8b61d62a6feb685f15c1
| 273,192 |
ipynb
|
Jupyter Notebook
|
In-Class Projects/Project 8 - Working with OLS.ipynb
|
zacharyejohnson/ECON411
|
b547a18f49480c10517166be5da3225c071ee9cf
|
[
"MIT"
] | null | null | null |
In-Class Projects/Project 8 - Working with OLS.ipynb
|
zacharyejohnson/ECON411
|
b547a18f49480c10517166be5da3225c071ee9cf
|
[
"MIT"
] | null | null | null |
In-Class Projects/Project 8 - Working with OLS.ipynb
|
zacharyejohnson/ECON411
|
b547a18f49480c10517166be5da3225c071ee9cf
|
[
"MIT"
] | null | null | null | 95.354974 | 44,480 | 0.719454 |
[
[
[
"# Our data exists as vectors in matrixes \nLinear algeabra helps us manipulate data to eventually find the smallest sum squared errors of our data which will give us our beta value for our regression model ",
"_____no_output_____"
]
],
[
[
"import numpy as np\n# create array to be transformed into vectors\nx1 = np.array([1,2,1])\nx2 = np.array([4,1,5])\nx3 = np.array([6,8,6])\nprint(\"Array 1:\", x1, sep=\"\\n\")\nprint(\"Array 2:\", x2, sep=\"\\n\")\nprint(\"Array 3:\", x3, sep=\"\\n\")",
"Array 1:\n[1 2 1]\nArray 2:\n[4 1 5]\nArray 3:\n[6 8 6]\n"
]
],
[
[
"Next, transform these arrays into row vectors using matrix().",
"_____no_output_____"
]
],
[
[
"x1 = np.matrix(x1)\nx2 = np.matrix(x2)\nx3 = np.matrix(x3)",
"_____no_output_____"
]
],
[
[
"use np.concatenate() to combine the rows ",
"_____no_output_____"
]
],
[
[
"X = np.concatenate((x1, x2, x3), axis = 0)\nX",
"_____no_output_____"
]
],
[
[
"X.getI method gets inverse of matrix",
"_____no_output_____"
]
],
[
[
"X_inverse = X.getI()\nX_inverse = np.round(X_inverse, 2)\nX_inverse",
"_____no_output_____"
]
],
[
[
"# Regression function - Pulling necessary data\n\nWe now know the necessary operations for inverting matrices and minimizing squared residuals. We can import real data and begin to analyze how variables influence one another. \n\nTo start, we will use the Fraser economic freedom data. ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport statsmodels.api as sm\nimport numpy as np",
"_____no_output_____"
],
[
"data = pd.read_csv('fraserDataWithRGDPPC.csv', \n index_col = [0,1],\n parse_dates = True)",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"years = np.array(sorted(list(set(data.index.get_level_values(\"Year\")))))\nyears = pd.date_range(years[0], years[-2], freq = \"AS\")\ncountries = sorted(list(set(data.index.get_level_values(\"ISO_Code\"))))\nindex_names = list(data.index.names)\nmulti_index = pd.MultiIndex.from_product([countries, years[:-1]], names = data.index.names)\ndata = data.reindex(multi_index)\n\ndata[\"RGDP Per Capita Lag\"] = data.groupby(\"ISO_Code\")[\"RGDP Per Capita\"].shift()",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"data.dropna(axis = 0).loc['GBR']",
"_____no_output_____"
]
],
[
[
"# Running Regression Model: \n\n",
"_____no_output_____"
]
],
[
[
"y_vars = ['RGDP Per Capita']\nx_vars = [\n 'Size of Government', 'Legal System & Property Rights', 'Sound Money',\n 'Freedom to trade internationally', 'Regulation'\n]\nreg_vars = y_vars + x_vars\nreg_data = data[reg_vars].dropna()\nreg_data.corr().round(2)",
"_____no_output_____"
],
[
"reg_data.describe().round(2)",
"_____no_output_____"
],
[
"y = reg_data[y_vars]\nx = reg_data[x_vars]\nx['Constant'] = 1\nresults = sm.OLS(y, x).fit()",
"_____no_output_____"
],
[
"results.summary()",
"_____no_output_____"
],
[
"\npredictor = results.predict()\nreg_data[y_vars[0] + \" Predictor\"] = predictor\nreg_data.loc[\"GBR\", [y_vars[0], y_vars[0] + \" Predictor\"]].plot()",
"_____no_output_____"
]
],
[
[
"# OLS Statistics \n\nWe have calculated beta values for each independent variable, meaning that we estimated the average effect of a change in each independent variable upon the dependent variable. While this is useful, we have not yet measured the statistical significance of these estimations; neither have we determined the explanatory power of our particular regression.\n\nOur regression has estimated predicted values for our dependent variable given the values of the independent variables for each observation. Together, these estimations for an array of predicted values that we will refer to as $y ̂ $. We will refer to individual predicted values as ($y_i$) ̂. We will also refer to the mean value of observations of our dependent variable as $y ̅ $ and individual observed values of our dependent variable as $y_i$. These values will be use to estimate the sum of squares due to regression ($SSR$), sum of squared errors ($SSE$), and the total sum of squares ($SST$). By comparing the estimated $y$ values, the observed $y$ values, and the mean of $y$, we will estimate the standard error for each coefficient and other values that estimate convey the significance of the estimation.\n\nWe define these values as follows:\n\n$SSR = \\sum_{i=0}^{n} (y ̂ _{i} - y ̅ )^2$\n\n$SSE = \\sum_{i=0}^{n} (y_{i} - y ̂ _{i})^2$\n\n$SST = \\sum_{i=0}^{n} (y_{i} - y ̅ _{i})^2$\n\nIt happens that the sum of the squared distances between the estimated values and mean of observed values and the squared distances between the observed and estimated values add up to the sum of the squared distances between the observed values and the mean of observed values. We indicate this as:\n\n$SST = SSR + SSE$\n\nThe script below will estimate these statistics. It calls the sum_square_stats method from the which is passed in the calculate_regression_stats method.",
"_____no_output_____"
]
],
[
[
"y_name = y_vars[0]\ny_hat = reg_data[y_name + \" Predictor\"]\ny_mean = reg_data[y_name].mean()\ny = reg_data[y_name]\ny_hat, y_mean, y",
"_____no_output_____"
],
[
"reg_data[\"Residuals\"] = y_hat.sub(y_mean)\nreg_data[\"Squared Residuals\"] = reg_data[\"Residuals\"].pow(2)\nreg_data[\"Squared Errors\"] = (y.sub(y_hat)) ** 2\nreg_data[\"Squared Totals\"] = (y.sub(y_mean)) ** 2\n",
"_____no_output_____"
],
[
"SSR = reg_data[\"Squared Residuals\"].sum()\nSSE = reg_data[\"Squared Errors\"].sum()\nSST = reg_data[\"Squared Totals\"].sum()\n\nSSR, SSE, SST",
"_____no_output_____"
],
[
"n = results.nobs\nk = len(results.params)\nestimator_variance = SSE / (n-k)\nn, k, estimator_variance",
"_____no_output_____"
],
[
"cov_matrix = results.cov_params()\ncov_matrix",
"_____no_output_____"
]
],
[
[
"## Calculate t-stats",
"_____no_output_____"
]
],
[
[
"parameters = {}\nfor x_var in cov_matrix.keys():\n parameters[x_var] = {}\n parameters[x_var][\"Beta\"] = results.params[x_var]\n parameters[x_var][\"Standard Error\"] = cov_matrix.loc[x_var, x_var]**(1 / 2)\n parameters[x_var][\"t_stats\"] = parameters[x_var][\"Beta\"] / parameters[\n x_var][\"Standard Error\"]\n\npd.DataFrame(parameters).T",
"_____no_output_____"
],
[
"r2 = SSR / SST\nr2",
"_____no_output_____"
],
[
"results.summary()",
"_____no_output_____"
]
],
[
[
"# Plot Residuals",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nplt.rcParams.update({\"font.size\": 26})\nfig, ax = plt.subplots(figsize=(12, 8))\nreg_data[[\"Residuals\"]].plot.hist(bins=100, ax=ax)\nplt.xticks(rotation=60)",
"_____no_output_____"
]
],
[
[
"slightly skewed left. Need to log the data in order to normally distrbute it ",
"_____no_output_____"
],
[
"# Regression using rates ",
"_____no_output_____"
]
],
[
[
"reg_data = data\nreg_data[\"RGDP Per Capita\"] = data.groupby(\"ISO_Code\")[\"RGDP Per Capita\"].pct_change() \nreg_data[\"RGDP Per Capita Lag\"] = reg_data[\"RGDP Per Capita\"].shift() \nreg_data = reg_data.replace([np.inf, -np.inf], np.nan).dropna(axis = 0, how = \"any\")\nreg_data.loc[\"USA\"]",
"_____no_output_____"
],
[
"reg_data.corr().round(2)",
"_____no_output_____"
],
[
"y_var = [\"RGDP Per Capita\"]\nx_vars = [\"Size of Government\", \n \"Legal System & Property Rights\", \n \"Sound Money\",\n \"Freedom to trade internationally\",\n \"Regulation\",\n \"RGDP Per Capita Lag\"]\n\ny = reg_data[y_var]\nX = reg_data[x_vars]\nx[\"Constant\"] = 1\nresults = sm.OLS(y, X).fit()\nreg_data[\"Predictor\"] = results.predict()",
"<ipython-input-72-457cdf0f1736>:11: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n x[\"Constant\"] = 1\n"
],
[
"results.summary()",
"_____no_output_____"
],
[
"reg_data[\"Residuals\"] = results.resid\nfig, ax = plt.subplots(figsize = (12,8))\n\nreg_data[[\"Residuals\"]].plot.hist(bins = 100, ax = ax)",
"_____no_output_____"
],
[
"betaEstimates = results.params\ntStats = results.tvalues\npValues = results.pvalues\nstdErrors = results.bse\n\nresultsDict = {\"Beta Estimates\" : betaEstimates,\n \"t-stats\":tStats,\n \"p-values\":pValues,\n \"Standard Errors\":stdErrors}\nresultsDF = pd.DataFrame(resultsDict)\nresultsDF.round(3)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize = (14,10))\nreg_data.plot.scatter(x = y_var[0],\n y = \"Predictor\", \n s = 30, ax = ax)\nplt.xticks(rotation=90)\nplt.show()\nplt.close()\n\nfig, ax = plt.subplots(figsize = (14,10))\nreg_data.plot.scatter(x = y_var[0],\n y = \"Residuals\", \n s = 30, ax = ax)\nax.axhline(0, ls = \"--\", color = \"k\")\nplt.xticks(rotation=90)\nplt.show()\nplt.close()\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e42512a8fcf9c32683903115fd4e520cf82b9
| 467,271 |
ipynb
|
Jupyter Notebook
|
examples/tutorial/patched.ipynb
|
natbusa/datalabframework
|
77f1249f55c76f20f2ef6253c0af2f1943f36226
|
[
"MIT"
] | 21 |
2018-09-01T05:50:54.000Z
|
2019-06-17T08:39:18.000Z
|
examples/tutorial/patched.ipynb
|
natbusa/datafaucet
|
77f1249f55c76f20f2ef6253c0af2f1943f36226
|
[
"MIT"
] | 9 |
2018-09-06T12:02:58.000Z
|
2019-04-15T16:52:52.000Z
|
examples/tutorial/patched.ipynb
|
natbusa/datalabframework
|
77f1249f55c76f20f2ef6253c0af2f1943f36226
|
[
"MIT"
] | 18 |
2017-06-27T22:00:36.000Z
|
2019-07-03T09:45:39.000Z
| 145.839888 | 156,651 | 0.699337 |
[
[
[
"# Datafaucet\n\nDatafaucet is a productivity framework for ETL, ML application. Simplifying some of the common activities which are typical in Data pipeline such as project scaffolding, data ingesting, start schema generation, forecasting etc.",
"_____no_output_____"
]
],
[
[
"import datafaucet as dfc",
"_____no_output_____"
]
],
[
[
"## Loading and Saving Data",
"_____no_output_____"
]
],
[
[
"dfc.project.load()",
"created SparkEngine\nInit engine \"spark\"\nConfiguring packages:\n - com.microsoft.sqlserver:mssql-jdbc:6.4.0.jre8\n - mysql:mysql-connector-java:8.0.12\n - org.apache.hadoop:hadoop-aws:3.1.1\n - org.postgresql:postgresql:42.2.5\nConfiguring conf:\n - spark.hadoop.fs.s3a.access.key : ****** (redacted)\n - spark.hadoop.fs.s3a.endpoint : http://minio:9000\n - spark.hadoop.fs.s3a.impl : org.apache.hadoop.fs.s3a.S3AFileSystem\n - spark.hadoop.fs.s3a.path.style.access : true\n - spark.hadoop.fs.s3a.secret.key : ****** (redacted)\nConnecting to spark master: local[*]\nEngine context spark:2.4.1 successfully started\n"
],
[
"query = \"\"\"\n SELECT \n p.payment_date,\n p.amount,\n p.rental_id,\n p.staff_id,\n c.*\n FROM payment p \n INNER JOIN customer c \n ON p.customer_id = c.customer_id;\n \"\"\"\n\ndf = dfc.load(query, 'pagila')",
"_____no_output_____"
]
],
[
[
"#### Select cols",
"_____no_output_____"
]
],
[
[
"df.cols.find('id').columns",
"_____no_output_____"
],
[
"df.cols.find(by_type='string').columns",
"_____no_output_____"
],
[
"df.cols.find(by_func=lambda x: x.startswith('st')).columns",
"_____no_output_____"
],
[
"df.cols.find('^st').columns",
"_____no_output_____"
]
],
[
[
"#### Collect data, oriented by rows or cols",
"_____no_output_____"
]
],
[
[
"df.cols.find(by_type='numeric').rows.collect(3)",
"_____no_output_____"
],
[
"df.cols.find(by_type='string').collect(3)",
"_____no_output_____"
],
[
"df.cols.find('name', 'date').data.collect(3)",
"_____no_output_____"
]
],
[
[
"#### Get just one row or column",
"_____no_output_____"
]
],
[
[
"df.cols.find('active', 'amount', 'name').one()",
"_____no_output_____"
],
[
"df.cols.find('active', 'amount', 'name').rows.one()",
"_____no_output_____"
]
],
[
[
"#### Grid view",
"_____no_output_____"
]
],
[
[
"df.cols.find('amount', 'id', 'name').data.grid(5)",
"_____no_output_____"
]
],
[
[
"#### Data Exploration",
"_____no_output_____"
]
],
[
[
"df.cols.find('amount', 'id', 'name').data.facets()",
"_____no_output_____"
]
],
[
[
"#### Rename columns",
"_____no_output_____"
]
],
[
[
"df.cols.find(by_type='timestamp').rename('new_', '***').columns",
"_____no_output_____"
],
[
"# to do\n# df.cols.rename(transform=['unidecode', 'alnum', 'alpha', 'num', 'lower', 'trim', 'squeeze', 'slice', tr(\"abc\", \"_\", mode='')'])\n# df.cols.rename(transform=['unidecode', 'alnum', 'lower', 'trim(\"_\")', 'squeeze(\"_\")'])",
"_____no_output_____"
],
[
"# as a dictionary\nmapping = {\n 'staff_id': 'foo', \n 'first_name': 'bar',\n 'email': 'qux',\n 'active':'active'\n}\n\n# or as a list of 2-tuples\nmapping = [\n ('staff_id','foo'),\n ('first_name','bar'),\n 'active'\n]\n\ndict(zip(df.columns, df.cols.rename('new_', '***', mapping).columns))",
"_____no_output_____"
]
],
[
[
"#### Drop multiple columns",
"_____no_output_____"
]
],
[
[
"df.cols.find('id').drop().rows.collect(3)",
"_____no_output_____"
]
],
[
[
"#### Apply to multiple columns",
"_____no_output_____"
]
],
[
[
"from pyspark.sql import functions as F\n\n(df\n .cols.find(by_type='string').lower()\n .cols.get('email').split('@')\n .cols.get('email').expand(2)\n .cols.find('name', 'email')\n .rows.collect(3)\n)",
"_____no_output_____"
]
],
[
[
"### Aggregations",
"_____no_output_____"
]
],
[
[
"from datafaucet.spark import aggregations as A",
"_____no_output_____"
],
[
"df.cols.find('amount', '^st.*id', 'first_name').agg(A.all).cols.collect(10)",
"_____no_output_____"
]
],
[
[
"##### group by a set of columns",
"_____no_output_____"
]
],
[
[
"df.cols.find('amount').groupby('staff_id', 'store_id').agg(A.all).cols.collect(4)",
"_____no_output_____"
]
],
[
[
"#### Aggregate specific metrics ",
"_____no_output_____"
]
],
[
[
"# by function\ndf.cols.get('amount', 'active').groupby('customer_id').agg({'count':F.count, 'sum': F.sum}).rows.collect(10)\n\n# or by alias\ndf.cols.get('amount', 'active').groupby('customer_id').agg('count','sum').rows.collect(10)\n\n# or a mix of the two\ndf.cols.get('amount', 'active').groupby('customer_id').agg('count',{'sum': F.sum}).rows.collect(10)",
"_____no_output_____"
]
],
[
[
"#### Featurize specific metrics in a single row",
"_____no_output_____"
]
],
[
[
"(df\n .cols.get('amount', 'active')\n .groupby('customer_id', 'store_id')\n .featurize({'count':A.count, 'sum':A.sum, 'avg':A.avg})\n .rows.collect(10)\n)\n\n# todo:\n# different features per different column",
"_____no_output_____"
]
],
[
[
"#### Plot dataset statistics",
"_____no_output_____"
]
],
[
[
"df.data.summary()",
"_____no_output_____"
],
[
"from bokeh.io import output_notebook\noutput_notebook()",
"_____no_output_____"
],
[
"from bokeh.plotting import figure, show, output_file\n\np = figure(plot_width=400, plot_height=400)\np.hbar(y=[1, 2, 3], height=0.5, left=0,\n right=[1.2, 2.5, 3.7], color=\"navy\")\n\nshow(p)",
"_____no_output_____"
],
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\nsns.set(style=\"whitegrid\")\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(6, 6))\n\n# Load the example car crash dataset\ncrashes = sns.load_dataset(\"car_crashes\").sort_values(\"total\", ascending=False)[:10]\n\n# Plot the total crashes\nsns.set_color_codes(\"pastel\")\nsns.barplot(x=\"total\", y=\"abbrev\", data=crashes,\n label=\"Total\", color=\"b\")\n\n# Plot the crashes where alcohol was involved\nsns.set_color_codes(\"muted\")\nsns.barplot(x=\"alcohol\", y=\"abbrev\", data=crashes,\n label=\"Alcohol-involved\", color=\"b\")\n\n# Add a legend and informative axis label\nax.legend(ncol=2, loc=\"lower right\", frameon=True)\nax.set(xlim=(0, 24), ylabel=\"\",\n xlabel=\"Automobile collisions per billion miles\")\nsns.despine(left=True, bottom=True)",
"_____no_output_____"
],
[
"import numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nsns.set(style=\"white\", palette=\"muted\", color_codes=True)\n\n# Generate a random univariate dataset\nrs = np.random.RandomState(10)\nd = rs.normal(size=100)\n\n# Plot a simple histogram with binsize determined automatically\nsns.distplot(d, hist=True, kde=True, rug=True, color=\"b\");",
"/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
],
[
"import seaborn as sns\nsns.set(style=\"ticks\")\n\ndf = sns.load_dataset(\"iris\")\nsns.pairplot(df, hue=\"species\")",
"/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
],
[
"from IPython.display import HTML\n\nHTML('''\n <!-- Bootstrap CSS -->\n <link rel=\"stylesheet\" href=\"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css\" crossorigin=\"anonymous\">\n<div class=\"container-fluid\">\n<div class=\"jumbotron\">\n <h1 class=\"display-4\">Hello, world!</h1>\n <p class=\"lead\">This is a simple hero unit, a simple jumbotron-style component for calling extra attention to featured content or information.</p>\n <hr class=\"my-4\">\n <p>It uses utility classes for typography and spacing to space content out within the larger container.</p>\n <a class=\"btn btn-primary btn-lg\" href=\"#\" role=\"button\">Learn more</a>\n</div>\n<button type=\"button\" class=\"btn btn-secondary\" data-toggle=\"tooltip\" data-placement=\"top\" title=\"Tooltip on top\">\n Tooltip on top\n</button>\n<button type=\"button\" class=\"btn btn-secondary\" data-toggle=\"tooltip\" data-placement=\"right\" title=\"Tooltip on right\">\n Tooltip on right\n</button>\n<button type=\"button\" class=\"btn btn-secondary\" data-toggle=\"tooltip\" data-placement=\"bottom\" title=\"Tooltip on bottom\">\n Tooltip on bottom\n</button>\n<button type=\"button\" class=\"btn btn-secondary\" data-toggle=\"tooltip\" data-placement=\"left\" title=\"Tooltip on left\">\n Tooltip on left\n</button>\n<table class=\"table\">\n <thead>\n <tr>\n <th scope=\"col\">#</th>\n <th scope=\"col\">First</th>\n <th scope=\"col\">Last</th>\n <th scope=\"col\">Handle</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th scope=\"row\">1</th>\n <td>Mark</td>\n <td>Otto</td>\n <td>@mdo</td>\n </tr>\n <tr>\n <th scope=\"row\">2</th>\n <td>Jacob</td>\n <td>Thornton</td>\n <td>@fat</td>\n </tr>\n <tr>\n <th scope=\"row\">3</th>\n <td>Larry</td>\n <td>the Bird</td>\n <td>@twitter</td>\n </tr>\n </tbody>\n</table>\n<span class=\"badge badge-primary\">Primary</span>\n<span class=\"badge badge-secondary\">Secondary</span>\n<span class=\"badge badge-success\">Success</span>\n<span class=\"badge badge-danger\">Danger</span>\n<span class=\"badge badge-warning\">Warning</span>\n<span class=\"badge badge-info\">Info</span>\n<span class=\"badge badge-light\">Light</span>\n<span class=\"badge badge-dark\">Dark</span>\n<table class=\"table table-sm\" style=\"text-align:left\">\n <thead>\n <tr>\n <th scope=\"col\">#</th>\n <th scope=\"col\">First</th>\n <th scope=\"col\">Last</th>\n <th scope=\"col\">Handle</th>\n <th scope=\"col\">bar</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th scope=\"row\">1</th>\n <td>Mark</td>\n <td>Otto</td>\n <td>@mdo</td>\n <td class=\"text-left\"><span class=\"badge badge-primary\" style=\"width: 75%\">Primary</span></td>\n </tr>\n <tr>\n <th scope=\"row\">2</th>\n <td>Jacob</td>\n <td>Thornton</td>\n <td>@fat</td>\n <td class=\"text-left\"><span class=\"badge badge-secondary\" style=\"width: 25%\">Primary</span></td>\n </tr>\n <tr>\n <th scope=\"row\">3</th>\n <td colspan=\"2\">Larry the Bird</td>\n <td>@twitter</td>\n <td class=\"text-left\"><span class=\"badge badge-warning\" style=\"width: 55%\">Primary</span></td>\n</div>\n </tr>\n </tbody>\n</table>\n</div>''')",
"_____no_output_____"
],
[
"tbl = '''\n<table class=\"table table-sm\">\n <thead>\n <tr>\n <th scope=\"col\">#</th>\n <th scope=\"col\">First</th>\n <th scope=\"col\">Last</th>\n <th scope=\"col\">Handle</th>\n <th scope=\"col\">bar</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th scope=\"row\">1</th>\n <td>Mark</td>\n <td>Otto</td>\n <td>@mdo</td>\n <td class=\"text-left\"><span class=\"badge badge-primary\" style=\"width: 75%\">75%</span></td>\n </tr>\n <tr>\n <th scope=\"row\">2</th>\n <td>Jacob</td>\n <td>Thornton</td>\n <td>@fat</td>\n <td class=\"text-left\"><span class=\"badge badge-secondary\" style=\"width: 25%\" title=\"Tooltip on top\">25%</span></td>\n </tr>\n <tr>\n <th scope=\"row\">3</th>\n <td colspan=\"2\">Larry the Bird</td>\n <td>@twitter</td>\n <td class=\"text-left\"><span class=\"badge badge-warning\" style=\"width: 0%\">0%</span></td>\n </tr>\n </tbody>\n</table>\n'''\ndrp = '''\n<div class=\"dropdown\">\n <button class=\"btn btn-secondary dropdown-toggle\" type=\"button\" id=\"dropdownMenuButton\" data-toggle=\"dropdown\" aria-haspopup=\"true\" aria-expanded=\"false\">\n Dropdown button\n </button>\n <div class=\"dropdown-menu\" aria-labelledby=\"dropdownMenuButton\">\n <a class=\"dropdown-item\" href=\"#\">Action</a>\n <a class=\"dropdown-item\" href=\"#\">Another action</a>\n <a class=\"dropdown-item\" href=\"#\">Something else here</a>\n </div>\n</div>'''\n\ntabs = f'''\n<nav>\n <div class=\"nav nav-tabs\" id=\"nav-tab\" role=\"tablist\">\n <a class=\"nav-item nav-link active\" id=\"nav-home-tab\" data-toggle=\"tab\" href=\"#nav-home\" role=\"tab\" aria-controls=\"nav-home\" aria-selected=\"true\">Home</a>\n <a class=\"nav-item nav-link\" id=\"nav-profile-tab\" data-toggle=\"tab\" href=\"#nav-profile\" role=\"tab\" aria-controls=\"nav-profile\" aria-selected=\"false\">Profile</a>\n <a class=\"nav-item nav-link\" id=\"nav-contact-tab\" data-toggle=\"tab\" href=\"#nav-contact\" role=\"tab\" aria-controls=\"nav-contact\" aria-selected=\"false\">Contact</a>\n </div>\n</nav>\n<div class=\"tab-content\" id=\"nav-tabContent\">\n <div class=\"tab-pane fade show active\" id=\"nav-home\" role=\"tabpanel\" aria-labelledby=\"nav-home-tab\">..jjj.</div>\n <div class=\"tab-pane fade\" id=\"nav-profile\" role=\"tabpanel\" aria-labelledby=\"nav-profile-tab\">..kkk.</div>\n <div class=\"tab-pane fade\" id=\"nav-contact\" role=\"tabpanel\" aria-labelledby=\"nav-contact-tab\">{tbl}</div>\n</div>\n'''\n\nfrom IPython.display import HTML\n\nHTML(f'''\n <!-- Bootstrap CSS -->\n <link rel=\"stylesheet\" href=\"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css\" crossorigin=\"anonymous\">\n <div class=\"container-fluid\">\n <div class=\"row\">\n <div class=\"col\">\n {drp}\n </div>\n <div class=\"col\">\n \n {tabs}\n \n </div>\n <div class=\"col\">\n {tbl}\n </div> \n </div>\n </div>\n <script src=\"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.bundle.min.js\" crossorigin=\"anonymous\" >\n''')",
"_____no_output_____"
],
[
"from IPython.display import HTML\n\nHTML(f'''\n <!-- Bootstrap CSS -->\n <link rel=\"stylesheet\" href=\"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css\" crossorigin=\"anonymous\">\n <script src=\"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.bundle.min.js\" crossorigin=\"anonymous\" >\n''')",
"_____no_output_____"
],
[
"d =df.cols.find('id', 'name').sample(10)\nd.columns",
"_____no_output_____"
],
[
"tbl_head = '''\n <thead>\n <tr>\n'''\ntbl_head += '\\n'.join([' <th scope=\"col\">'+str(x)+'</th>' for x in d.columns])\n\ntbl_head +='''\n </tr>\n </thead>\n'''\n\nprint(tbl_head)\n\ntbl_body = '''\n<tbody>\n <tr>\n <th scope=\"row\">1</th>\n <td>Mark</td>\n <td>Otto</td>\n <td>@mdo</td>\n <td class=\"text-left\"><span class=\"badge badge-primary\" style=\"width: 75%\">75%</span></td>\n </tr>\n <tr>\n <th scope=\"row\">2</th>\n <td>Jacob</td>\n <td>Thornton</td>\n <td>@fat</td>\n <td class=\"text-left\"><span class=\"badge badge-secondary\" style=\"width: 25%\" title=\"Tooltip on top\">25%</span></td>\n </tr>\n <tr>\n <th scope=\"row\">3</th>\n <td colspan=\"2\">Larry the Bird</td>\n <td>@twitter</td>\n <td class=\"text-left\"><span class=\"badge badge-warning\" style=\"width: 0%\">0%</span></td>\n </tr>\n </tbody>\n</table>\n'''\n\nHTML(f'''\n <!-- Bootstrap CSS -->\n <div class=\"container-fluid\">\n <div class=\"row\">\n <div class=\"col\">\n <table class=\"table table-sm\">\n {tbl_head}\n {tbl_body}\n </table>\n </div> \n </div>\n </div>\n''')",
"\n <thead>\n <tr>\n <th scope=\"col\">rental_id</th>\n <th scope=\"col\">staff_id</th>\n <th scope=\"col\">customer_id</th>\n <th scope=\"col\">store_id</th>\n <th scope=\"col\">address_id</th>\n <th scope=\"col\">first_name</th>\n <th scope=\"col\">last_name</th>\n </tr>\n </thead>\n\n"
],
[
"# .rows.sample()\n# .cols.select('name', 'id', 'amount')\\\n# .cols.apply(F.lower, 'name')\\\n# .cols.apply(F.floor, 'amount', output_prefix='_')\\\n# .cols.drop('^amount$')\\\n# .cols.rename()\n# .cols.unicode()\n.grid()",
"_____no_output_____"
],
[
"df = df.cols.select('name')\ndf = df.rows.overwrite([('Nhập mật', 'khẩu')])\ndf.columns\n# .rows.overwrite(['Nhập mật', 'khẩu'])\\\n# .cols.apply(F.lower)\\\n# .grid()\n# #withColumn('pippo', F.lower(F.col('first_name'))).grid()",
"_____no_output_____"
],
[
"import pandas as pd\n\ndf = pd.DataFrame({'lab':['A', 'B', 'C'], 'val':[10, 30, 20]})\ndf.plot.bar(x='lab', y='val', rot=0);",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e5067791542b8e09c6e4fdb8bc70a91921a78
| 5,250 |
ipynb
|
Jupyter Notebook
|
notebooks/model_decision_making.ipynb
|
larahabashy/capstone-diabetes
|
021e5c18ebf366e953444eea15833036b62b42d0
|
[
"MIT"
] | null | null | null |
notebooks/model_decision_making.ipynb
|
larahabashy/capstone-diabetes
|
021e5c18ebf366e953444eea15833036b62b42d0
|
[
"MIT"
] | null | null | null |
notebooks/model_decision_making.ipynb
|
larahabashy/capstone-diabetes
|
021e5c18ebf366e953444eea15833036b62b42d0
|
[
"MIT"
] | null | null | null | 39.179104 | 579 | 0.673905 |
[
[
[
"## Deciding on a Model Using Manual Analysis with Gradio\n\nThis notebook documents some of the steps taken to choose the final model for deployment. ",
"_____no_output_____"
],
[
"For this project, we played around with four different models to see which performed best for our dataset. Our initial literature search showcased four different models that are popular for transfer learning including:\n\n1. Densenet\n2. Resnet\n3. Vgg16\n4. Inception\n\nAfter conducting extensive runs to choose the [best image transformations](https://github.com/UBC-MDS/capstone-gdrl-lipo/blob/master/notebooks/manual-albumentation.ipynb) and doing hyperparameter tuning on the individual [models](https://github.com/UBC-MDS/capstone-gdrl-lipo/tree/master/notebooks), we used these optimized models to do a manual analysis of images to compare the models. We build a [local internal decision making tool app using gradio](https://github.com/UBC-MDS/capstone-gdrl-lipo/tree/master/notebooks/gradio_demo.ipynb) to analyze specific test cases. ",
"_____no_output_____"
],
[
"## Reviewing Specific Images",
"_____no_output_____"
],
[
"Below are some screenshots from the gradio app of some negative and positive images that the model has never seen. Six negative images and five positives images were chosen for a manual review in hopes to pick out ways to see how the model would do on examples that are visually hard for the human eye to identify and label correctly. All models were able to catch negative examples relatively well. Densenet stood out was able to capture 4 out of the 6 images well compared to the rest of the models with very high confidence. ",
"_____no_output_____"
],
[
"### Negative Image Example",
"_____no_output_____"
],
[
"We chose a difficult negative image example that features a circular ball that to the eye appears to be lipohypertrophy but it is not. We can see that although all models predict negative, Densenet is the most confident in its prediction.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"## Positive Image Example",
"_____no_output_____"
],
[
"Identifying positives was hard for all models and the below figure shows an example where all model struggled. It makes sense that all the models are struggling as we don't have a very large dataset (~300 total images with a 62:38 split for negative:positive) and it's hard to tell visually where the lipohypertrophy is present or not. However, we noticed that even when Densenet is wrong, it is less confident in its prediction. This is ideal as our capstone partner has identified that the model should be less confident in its prediction when its wrong.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"## Conclusion and Next Steps",
"_____no_output_____"
],
[
"From this manual visualization excercise, we were able to narrow down our model choice to Densenet. According to the recall and accuracy, this model has the highest score, so even when it is wrong, it is not as confident in its prediction. Lastly, due to resource limitation on the deployment of this application, DenseNet is also the smallest app. So, the next steps were to optimize the Densenet model to further improve the scores. Two steps taken were:\n\n1. Increase the pos_weight argument of the optimizer so that there is a greater loss on positive examples. See the exploration [here](https://github.com/UBC-MDS/capstone-gdrl-lipo/blob/master/notebooks/pos-weight-exploration.ipynb).\n2. Play around with the dropout rate in the model architechture. See the exploration [here](https://github.com/UBC-MDS/capstone-gdrl-lipo/blob/master/notebooks/densemodels-ax-dropout-layers.ipynb).",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d02e76b9c6da2b8e677d432034b1b411b68629a1
| 575,966 |
ipynb
|
Jupyter Notebook
|
Indexer_for_Santa.ipynb
|
taniokah/where-is-santa-
|
caa511ebccd3ab6921c01710c23cf47d45f2f125
|
[
"MIT"
] | null | null | null |
Indexer_for_Santa.ipynb
|
taniokah/where-is-santa-
|
caa511ebccd3ab6921c01710c23cf47d45f2f125
|
[
"MIT"
] | null | null | null |
Indexer_for_Santa.ipynb
|
taniokah/where-is-santa-
|
caa511ebccd3ab6921c01710c23cf47d45f2f125
|
[
"MIT"
] | null | null | null | 803.299861 | 406,890 | 0.930975 |
[
[
[
"<a href=\"https://colab.research.google.com/github/taniokah/where-is-santa/blob/master/Indexer_for_Santa.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Indexer for Santa\n\nScript score queryedit \nhttps://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-script-score-query.html#vector-functions\n\nELASTICSEARCHで分散表現を使った類似文書検索 \nhttps://yag-ays.github.io/project/elasticsearch-similarity-search/\n\nImage Search for ICDAR WML 2019 \nhttps://github.com/taniokah/icdar-wml-2019/blob/master/Image%20Search%20for%20ICDAR%20WML%202019.ipynb",
"_____no_output_____"
]
],
[
[
"# Crawling Santa images.\n\n!pip install icrawler\n\n!rm -rf google_images/*\n!rm -rf bing_images/*\n!rm -rf baidu_images/*\n\nfrom icrawler.builtin import BaiduImageCrawler, BingImageCrawler, GoogleImageCrawler\n\ncrawler = GoogleImageCrawler(storage={\"root_dir\": \"google_images\"}, downloader_threads=4)\ncrawler.crawl(keyword=\"Santa\", offset=0, max_num=1000)\n\n#bing_crawler = BingImageCrawler(storage={'root_dir': 'bing_images'}, downloader_threads=4)\n#bing_crawler.crawl(keyword='Santa', filters=None, offset=0, max_num=1000)\n\n#baidu_crawler = BaiduImageCrawler(storage={'root_dir': 'baidu_images'})\n#baidu_crawler.crawl(keyword='Santa', offset=0, max_num=1000)",
"_____no_output_____"
],
[
"!wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-linux-x86_64.tar.gz -q\n!tar -xzf elasticsearch-7.5.1-linux-x86_64.tar.gz\n\n!chown -R daemon:daemon elasticsearch-7.5.1/\n#!elasticsearch-7.5.1/bin/elasticsearch",
"_____no_output_____"
],
[
"import os\nfrom subprocess import Popen, PIPE, STDOUT\nes_server = Popen(['elasticsearch-7.5.1/bin/elasticsearch'], \n stdout=PIPE, stderr=STDOUT,\n preexec_fn=lambda: os.setuid(1) # as daemon\n )\n\n!ps aux | grep elastic\n!sleep 30\n!curl -X GET \"localhost:9200/\"",
"daemon 2344 62.0 7.3 1522012 974744 ? Sl 12:56 0:00 /content/elasticsearch-7.5.1/jdk/bin/java -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dio.netty.allocator.numDirectArenas=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.locale.providers=COMPAT -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Djava.io.tmpdir=/tmp/elasticsearch-7715959795961183513 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=logs/hs_err_pid%p.log -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m -XX:MaxDirectMemorySize=536870912 -Des.path.home=/content/elasticsearch-7.5.1 -Des.path.conf=/content/elasticsearch-7.5.1/config -Des.distribution.flavor=default -Des.distribution.type=tar -Des.bundled_jdk=true -cp /content/elasticsearch-7.5.1/lib/* org.elasticsearch.bootstrap.Elasticsearch\nroot 2425 0.0 0.0 39192 6420 ? S 12:56 0:00 /bin/bash -c ps aux | grep elastic\nroot 2427 0.0 0.0 39192 2708 ? R 12:56 0:00 /bin/bash -c ps aux | grep elastic\n{\n \"name\" : \"3296e1eea1ef\",\n \"cluster_name\" : \"elasticsearch\",\n \"cluster_uuid\" : \"HT7T_r6OSMSf6lqs2oq3Eg\",\n \"version\" : {\n \"number\" : \"7.5.1\",\n \"build_flavor\" : \"default\",\n \"build_type\" : \"tar\",\n \"build_hash\" : \"3ae9ac9a93c95bd0cdc054951cf95d88e1e18d96\",\n \"build_date\" : \"2019-12-16T22:57:37.835892Z\",\n \"build_snapshot\" : false,\n \"lucene_version\" : \"8.3.0\",\n \"minimum_wire_compatibility_version\" : \"6.8.0\",\n \"minimum_index_compatibility_version\" : \"6.0.0-beta1\"\n },\n \"tagline\" : \"You Know, for Search\"\n}\n"
],
[
"!pip install elasticsearch\n\nfrom datetime import datetime\nfrom elasticsearch import Elasticsearch\nes = Elasticsearch(timeout=60)\n\ndoc = {\n 'author': 'Santa Claus',\n 'text': 'Where is Santa Claus?',\n 'timestamp': datetime.now(),\n}\nres = es.index(index=\"test-index\", doc_type='tweet', id=1, body=doc)\nprint(res['result'])\n\nres = es.get(index=\"test-index\", doc_type='tweet', id=1)\nprint(res['_source'])\n\nes.indices.refresh(index=\"test-index\")\n\nres = es.search(index=\"test-index\", body={\"query\": {\"match_all\": {}}})\nprint(\"Got %d Hits:\" % res['hits']['total']['value'])\nfor hit in res['hits']['hits']:\n print(\"%(timestamp)s %(author)s: %(text)s\" % hit[\"_source\"])",
"Requirement already satisfied: elasticsearch in /usr/local/lib/python3.6/dist-packages (7.1.0)\nRequirement already satisfied: urllib3>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from elasticsearch) (1.24.3)\n"
],
[
"# Load libraries\nfrom keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions\nfrom keras.preprocessing import image\nfrom PIL import Image\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport sys\n\nmodel = VGG16(weights='imagenet')",
"_____no_output_____"
],
[
"def predict(filename, featuresize, scale=1.0):\n img = image.load_img(filename, target_size=(224, 224))\n return predictimg(img, featuresize, scale=1.0)\n\ndef predictpart(filename, featuresize, scale=1.0, size=1):\n im = Image.open(filename)\n width, height = im.size\n im = im.resize((width * size, height * size))\n im_list = np.asarray(im)\n # partition\n out_img = []\n if size > 1: \n v_split = size\n h_split = size\n [out_img.extend(np.hsplit(h_img, h_split)) for h_img in np.vsplit(im_list, v_split)]\n else:\n out_img.append(im_list)\n reslist = []\n for offset in range(size * size):\n img = Image.fromarray(out_img[offset])\n reslist.append(predictimg(img, featuresize, scale))\n return reslist\n\ndef predictimg(img, featuresize, scale=1.0):\n width, height = img.size\n img = img.resize((int(width * scale), int(height * scale)))\n img = img.resize((224, 224))\n x = image.img_to_array(img)\n x = np.expand_dims(x, axis=0)\n preds = model.predict(preprocess_input(x))\n results = decode_predictions(preds, top=featuresize)[0]\n return results\n\ndef showimg(filename, title, i, scale=1.0, col=2, row=5):\n im = Image.open(filename)\n width, height = im.size\n im = im.resize((int(width * scale), int(height * scale)))\n im = im.resize((width, height))\n im_list = np.asarray(im)\n plt.subplot(col, row, i)\n plt.title(title)\n plt.axis(\"off\")\n plt.imshow(im_list)\n \ndef showpartimg(filename, title, i, size, scale=1.0, col=2, row=5):\n im = Image.open(filename)\n width, height = im.size\n im = im.resize((int(width * scale), int(height * scale)))\n #im = im.resize((width, height))\n im = im.resize((width * size, height * size))\n im_list = np.asarray(im)\n # partition\n out_img = []\n if size > 1: \n v_split = size\n h_split = size\n [out_img.extend(np.hsplit(h_img, h_split)) for h_img in np.vsplit(im_list, v_split)]\n else:\n out_img.append(im_list)\n # draw image\n for offset in range(size * size):\n im_list = out_img[offset]\n pos = i + offset\n print(str(col) + ' ' + str(row) + ' ' + str(pos))\n plt.subplot(col, row, pos)\n plt.title(title)\n plt.axis(\"off\")\n plt.imshow(im_list)\n out_img[offset] = Image.fromarray(im_list)\n return out_img",
"_____no_output_____"
],
[
"# Predict an image\nscale = 1.0\nfilename = \"google_images/000046.jpg\"\nplt.figure(figsize=(20, 10))\n\n#showimg(filename, \"query\", i+1, scale)\nimgs = showpartimg(filename, \"query\", 1, 1, scale)\nplt.show()\n\nfor img in imgs:\n reslist = predictpart(filename, 10, scale)\n for results in reslist:\n for result in results:\n print(result)\n print()",
"2 5 1\n"
],
[
"def createindex(indexname):\n if es.indices.exists(index=indexname):\n es.indices.delete(index=indexname)\n es.indices.create(index=indexname, body={\n \"settings\": {\n \"index.mapping.total_fields.limit\": 10000,\n }\n })\n\n mapping = {\n \"image\": {\n \"properties\": {\n \"f\": {\n \"type\": \"text\"\n },\n 's': {\n \"type\": \"sparse_vector\"\n }\n }\n }\n }\n es.indices.put_mapping(index=indexname, doc_type='image', body=mapping, include_type_name=True)\n\nwnidmap = {}\n\ndef loadimages(directory):\n imagefiles = []\n for file in os.listdir(directory):\n if file.rfind('.jpg') < 0:\n continue\n filepath = os.path.join(directory, file)\n imagefiles.append(filepath)\n return imagefiles\n\ndef indexfiles(indexname, directory, featuresize=10, docsize=1000):\n imagefiles = loadimages(directory)\n for i in range(len(imagefiles)):\n if i >= docsize:\n return\n filename = imagefiles[i]\n indexfile(indexname, filename, i, featuresize)\n sys.stdout.write(\"\\r%d\" % (i + 1))\n sys.stdout.flush()\n es.indices.refresh(index=indexname) \n\ndef indexfile(indexname, filename, i, featuresize):\n global wnidmap\n\n rounddown = 16\n doc = {'f': filename, 's':{}}\n results = predict(filename, featuresize) \n\n #print(len(results))\n synset = doc['s']\n for result in results:\n score = float(str(result[2]))\n wnid = result[0]\n id = 0\n if wnid in wnidmap.keys():\n id = wnidmap[wnid]\n else:\n id = len(wnidmap)\n wnidmap[wnid] = id\n synset[str(id)] = score\n\n #print(doc)\n #count = es.count(index=indexname, doc_type='image')['count']\n count = i\n res = es.index(index=indexname, doc_type='image', id=count, body=doc)",
"_____no_output_____"
],
[
"createindex(\"santa-search\")\n\ndirectory = \"google_images/\"\nindexfiles(\"santa-search\", directory, 100, 1000)\n#directory = \"bing_images/\"\n#indexfiles(\"santa-search\", directory, 100, 1000)\n#directory = \"baidu_images/\"\n#indexfiles(\"santa-search\", directory, 100, 1000)",
"_____no_output_____"
],
[
"res = es.search(index=\"santa-search\", request_timeout=60, body={\"query\": {\"match_all\": {}}})\nprint(\"Got \" + str(res['hits']['total']) + \" Hits:\" )\nfor hit in res['hits']['hits']:\n print(hit[\"_source\"])\n #print(\"%(timestamp)s %(author)s: %(text)s\" % hit[\"_source\"])",
"2019-12-28 12:24:41,606 - INFO - elasticsearch - GET http://localhost:9200/santa-search/_search [status:200 request:0.013s]\n"
],
[
"def searchimg(indexname, filename, num=10, topk=10, scoretype='dot', scale=1.0, partition=1):\n plt.figure(figsize=(20, 10))\n \n imgs = showpartimg(filename, \"query\", 1, partition, scale)\n plt.show()\n\n reslist = []\n for img in imgs:\n results = predictimg(img, num, scale)\n for result in results:\n print(result)\n print()\n res = search(indexname, results, num, topk, scoretype)\n reslist.append(res)\n return reslist\n\ndef search(indexname, synsets, num, topk, scoretype='dot', disp=True):\n if scoretype == 'vcos':\n inline = {}\n for synset in synsets:\n score = synset[2]\n if score <= 0.0:\n continue\n wnid = synset[0]\n if wnid not in wnidmap.keys():\n continue\n id = wnidmap[wnid]\n inline[str(id)] = float(score)\n if inline == {}: \n print(\"Got \" + str(0) + \" Hits:\")\n return\n #print('wnidmap = ' + str(wnidmap))\n #print('inline = ' + str(inline))\n\n b = {\n \"size\": topk,\n \"query\": {\n \"script_score\": {\n \"query\": {\"match_all\": {}}, \n \"script\": {\n \"source\": \"cosineSimilaritySparse(params.s, doc['s']) + 0.01\", \n \"params\": {\n 's': {}\n }\n }\n }\n }}\n b['query']['script_score']['script']['params']['s'] = inline\n res = es.search(index=indexname, body=b)\n #print(str(b))\n\n if disp==True:\n print(\"Got \" + str(res['hits']['total']['value']) + \" Hits:\")\n topres = res['hits']['hits'][0:topk]\n for hit in topres:\n print(str(hit[\"_id\"]) + \" \" + str(hit[\"_source\"][\"f\"]) + \" \" + str(hit[\"_score\"]))\n plt.figure(figsize=(20, 10))\n\n for i in range(len(topres)):\n hit = topres[i]\n row = 5\n col = int(topk / 5)\n if i >= 25:\n break\n showimg(hit[\"_source\"][\"f\"], hit[\"_id\"], i+1, col, row)\n plt.show()\n \n return res\n",
"_____no_output_____"
],
[
"filename = \"google_images/000001.jpg\"\n_ = searchimg('santa-search', filename, 10, 10, 'vcos', 1.0, 1)",
"2 5 1\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e86dfe1a1305e5def4677e1a3fb7ced06a822
| 39,024 |
ipynb
|
Jupyter Notebook
|
multi_epoch-max-duration-Autumnal.ipynb
|
Niu-LIU/Canopus
|
751967cfcbc0047b714152e14586cabf9c359ad9
|
[
"BSD-2-Clause"
] | null | null | null |
multi_epoch-max-duration-Autumnal.ipynb
|
Niu-LIU/Canopus
|
751967cfcbc0047b714152e14586cabf9c359ad9
|
[
"BSD-2-Clause"
] | null | null | null |
multi_epoch-max-duration-Autumnal.ipynb
|
Niu-LIU/Canopus
|
751967cfcbc0047b714152e14586cabf9c359ad9
|
[
"BSD-2-Clause"
] | null | null | null | 152.4375 | 29,404 | 0.872668 |
[
[
[
"===================================================================\n\nDetermine the observable time of the Canopus on the Vernal and Autumnal equinox among -2000 B.C.E. ~ 0 B.C.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom astropy.visualization import astropy_mpl_style\nplt.style.use(astropy_mpl_style)\n\nimport astropy.units as u\nfrom astropy.time import Time\nfrom astropy.coordinates import SkyCoord, EarthLocation, AltAz, ICRS",
"_____no_output_____"
]
],
[
[
"The observing period is the whole year of -2000 B.C.E. ~ 0 B.C.\nTo represent the epoch before the common era, I use the Julian date.",
"_____no_output_____"
]
],
[
[
"We can see that if we transformate the dates into UTC, they don't exactly respond to March 21 or September 23.\nThis is normal since UTC is used only after 1960-01-01.\nIn my opinion, this won't affect our results.",
"_____no_output_____"
]
],
[
[
"I calculate the altitude and azimuth of Sun and Canopus among 4:00~8:00 in autumnal equinox and 16:00~20:00 in vernal equinox for every year.",
"_____no_output_____"
]
],
[
[
"def observable_duration(obs_time):\n \"\"\"\n \"\"\"\n\n # Assume we have an observer in Tai Mountain.\n taishan = EarthLocation(lat=36.2*u.deg, lon=117.1*u.deg, height=1500*u.m)\n\n utcoffset = +8 * u.hour # Daylight Time\n midnight = obs_time - utcoffset\n\n # Position of the Canopus with the proper motion correction at the beginning of the year.\n # This effect is very small.\n dt_jyear = obs_time.jyear - 2000.0\n ra = 95.98787790 * u.deg + 19.93 * u.mas * dt_jyear\n dec = -52.69571787 * u.deg + 23.24 * u.mas * dt_jyear\n hip30438 = SkyCoord(ra=ra, dec=dec, frame=\"icrs\")\n\n delta_midnight = np.arange(0, 24, 1./30) * u.hour # Interval of 2 minutes\n obser_time = midnight + delta_midnight\n\n local_frame = AltAz(obstime=obser_time,\n location=taishan)\n hip30438altazs = hip30438.transform_to(local_frame)\n\n # position of Sun\n from astropy.coordinates import get_sun\n sunaltazs = get_sun(obser_time).transform_to(local_frame)\n\n mask = (sunaltazs.alt < -0*u.deg) & (hip30438altazs.alt > 0)\n observable_time = delta_midnight[mask]\n \n # observable_time\n if len(observable_time):\n beg_time = observable_time.min().to('hr').value\n end_time = observable_time.max().to('hr').value\n else:\n beg_time, end_time = 0, 0 \n\n return beg_time, end_time",
"_____no_output_____"
],
[
"year_arr = np.arange(0, 2000, 1)\n\n# Number of days for every year\ndate_nb = np.ones_like(year_arr)\ndate_nb = np.where(year_arr % 4 == 0, 366, 365)\ndate_nb = np.where((year_arr % 100 == 0) & (\n year_arr % 400 != 0), 365, date_nb)\n\ntotal_date_nb = np.zeros_like(year_arr)\nfor i in range(year_arr.size):\n total_date_nb[i] = np.sum(date_nb[:i+1])\n\n# Autumnal equinox of every year\nobs_time_aut = Time(\"0000-09-23 00:00:00\") - total_date_nb * u.day\n\n\n# Calculate the observable time of everyday\nbeg_time = np.zeros_like(obs_time_aut)\nend_time = np.zeros_like(obs_time_aut)\nobs_dur = np.zeros_like(obs_time_aut) # Observable duration\n\nfor i, obs_timei in enumerate(obs_time_aut):\n # we calculate the 30 days before and after the equinox\n delta_date = np.arange(-5, 5, 1) * u.day\n obs_time0 = obs_timei + delta_date\n\n beg_time_aut = np.zeros_like(obs_time0)\n end_time_aut = np.zeros_like(obs_time0)\n\n for j, obs_time0j in enumerate(obs_time0):\n # Vernal equninox\n beg_time_aut[j], end_time_aut[j] = observable_duration(obs_time0j)\n \n obs_dur_aut = end_time_aut - beg_time_aut\n \n obs_dur[i] = np.max(obs_dur_aut)\n beg_time[i] = beg_time_aut[obs_dur_aut == obs_dur[i]][0]\n end_time[i] = end_time_aut[obs_dur_aut == obs_dur[i]][0]",
"WARNING: ErfaWarning: ERFA function \"dtf2d\" yielded 1 of \"dubious year (Note 6)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"utctai\" yielded 1 of \"dubious year (Note 3)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 2000 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 10 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 1 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 720 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"utctai\" yielded 720 of \"dubious year (Note 3)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"epv00\" yielded 720 of \"warning: date outsidethe range 1900-2100 AD\" [astropy._erfa.core]\nWARNING: Tried to get polar motions for times before IERS data is valid. Defaulting to polar motion from the 50-yr mean for those. This may affect precision at the 10s of arcsec level [astropy.coordinates.builtin_frames.utils]\nWARNING: ErfaWarning: ERFA function \"apio13\" yielded 720 of \"dubious year (Note 2)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"utctai\" yielded 720 of \"dubious year (Note 3)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 720 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"epv00\" yielded 720 of \"warning: date outsidethe range 1900-2100 AD\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"utcut1\" yielded 720 of \"dubious year (Note 3)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"utctai\" yielded 1 of \"dubious year (Note 3)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 1 of \"dubious year (Note 4)\" [astropy._erfa.core]\nWARNING: ErfaWarning: ERFA function \"taiutc\" yielded 10 of \"dubious year (Note 4)\" [astropy._erfa.core]\n"
]
],
[
[
"I assume that the Canopus can be observed by the local observer only when the observable duration in one day is longer than 10 minitues.\nWith such an assumption, I determine the observable period of the Canopus.",
"_____no_output_____"
]
],
[
[
"# Save data\nnp.save(\"multi_epoch-max-duration-Autumnal-output\", [obs_time_aut.jyear, obs_dur])\n\n# For Autumnal equinox\n# mask = (obs_dur >= 1./6)\nmask = (obs_dur >= 1.0/60)\nobservable_date = obs_time_aut[mask]",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(12, 8))\nax.plot(observable_date.jyear, obs_dur[mask],\n \"r.\", ms=3, label=\"Autumnal\")\n\n# ax.fill_between(obs_time.jyear, 0, 24,\n# (obs_dur1 >= 1./6) & (obs_dur2 >= 1./6), color=\"0.8\", zorder=0)\n\nax.set_xlabel(\"Year\", fontsize=15)\nax.set_xlim([-2000, 0])\nax.set_xticks(np.arange(-2000, 1, 100))\n\nax.set_ylim([0, 2.0])\nax.set_ylabel(\"Time (hour)\", fontsize=15)\nax.set_title(\"Observable duration of Canopus among $-2000$ B.C.E and 0\")\n\nax.legend(fontsize=15)\n\nfig.tight_layout()\nplt.savefig(\"multi_epoch-max-duration-Autumnal.eps\", dpi=100)\nplt.savefig(\"multi_epoch-max-duration-Autumnal.png\", dpi=100)",
"_____no_output_____"
]
]
] |
[
"raw",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"raw"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d02e8d9fe1fec1cd4e7a63a672c330803538ff40
| 4,843 |
ipynb
|
Jupyter Notebook
|
scripts/human_eval/prepare_qualitative_block.ipynb
|
edorado93/Writing-editing-Network
|
9898666d5be2c0d2bd84903af3a0e6fa93823953
|
[
"MIT"
] | 1 |
2020-08-28T00:43:26.000Z
|
2020-08-28T00:43:26.000Z
|
scripts/human_eval/prepare_qualitative_block.ipynb
|
edorado93/Writing-editing-Network
|
9898666d5be2c0d2bd84903af3a0e6fa93823953
|
[
"MIT"
] | 1 |
2018-07-09T05:53:23.000Z
|
2018-07-27T18:00:24.000Z
|
scripts/human_eval/prepare_qualitative_block.ipynb
|
edorado93/Writing-editing-Network
|
9898666d5be2c0d2bd84903af3a0e6fa93823953
|
[
"MIT"
] | 1 |
2018-06-29T02:04:46.000Z
|
2018-06-29T02:04:46.000Z
| 25.223958 | 132 | 0.512699 |
[
[
[
"import json\nimport random\nfrom eval import Evaluate\nimport torch\neval_f = Evaluate()",
"_____no_output_____"
],
[
"def get_original_samples(path, is_unk):\n abstracts = {}\n with open(path) as f:\n for line in f:\n j = json.loads(line.strip())\n if not is_unk:\n abstracts[j[\"title\"]] = j[\"abstract\"]\n else:\n abstracts[j[\"abstract\"]] = j[\"title\"]\n return abstracts ",
"_____no_output_____"
],
[
"def get_generated_samples(path):\n abstracts = {}\n with open(path) as f:\n for line in f:\n j = json.loads(line.strip())\n abstracts[j[\"original\"]] = j[\"generated\"]\n return abstracts ",
"_____no_output_____"
],
[
"def get_abstract_metrics(gen, org):\n ref = {0 : [org]}\n cand = {0 : gen}\n final_scores = eval_f.evaluate(live=True, cand=cand, ref=ref)\n return final_scores",
"_____no_output_____"
],
[
"original_abstracts = get_original_samples(\"acl-dataset/acl_original.txt\", is_unk=False)\noriginal_unk = get_original_samples(\"acl-dataset/acl-UNK-abstracts.txt\", is_unk=True)\ngenerated = get_generated_samples(\"acl-dataset/WEPGen/ACL-WE-Topics-Structure-IntraAttention-Polishing-BLEU-4=2.733333.txt\")",
"_____no_output_____"
],
[
"ratings = []\nc = 0\nfor key in generated.keys():\n original_abs_UNK = key\n title = original_unk[original_abs_UNK]\n org = original_abstracts[title]\n gen = generated[key]\n metrics = get_abstract_metrics(gen, org)\n ratings.append((title, org, gen, metrics.values()))\n c += 1\n \n if c % 200 == 0:\n print(\"Done {}\".format(c))",
"Done 200\nDone 400\nDone 600\nDone 800\nDone 1000\n"
],
[
"bleu_samples = sorted(ratings, reverse=True, key=lambda x: sum(list(x[-1])[:4]))[:100]\nmeteor_samples = sorted(ratings, reverse=True, key=lambda x: list(x[-1])[4])[:100]\nrouge_samples = sorted(ratings, reverse=True, key=lambda x: list(x[-1])[5])[:100]\ncombined_samples = sorted(ratings, reverse=True, key=lambda x: sum(x[-1]))[:100]\n\nbleu_set = set([b[:3] for b in bleu_samples])\nmeteor_set = set([b[:3] for b in meteor_samples])\nrouge_set = set([b[:3] for b in rouge_samples])\ncombined_set = set([b[:3] for b in combined_samples])\n\nA = bleu_set.intersection(meteor_set)\nB = A.intersection(rouge_set)\nfinal_set = list(B.intersection(combined_set))\nlen(final_set)",
"_____no_output_____"
],
[
"qualitative = {}\ni = 0\nfor title, _, generated in final_set:\n qualitative[i] = (title, generated)\n i += 1",
"_____no_output_____"
],
[
"with open(\"acl-dataset/Qualitative/W.txt\", \"w\") as f:\n f.write(json.dumps(qualitative))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02e90203b3be535b0c087275b3cc4a630b30007
| 87,301 |
ipynb
|
Jupyter Notebook
|
notebooks/test_sunpy_1.0.0.ipynb
|
MSKirk/MachineLearning
|
14e19244441aeef1f28e24e3b3f63b659b80087e
|
[
"BSD-3-Clause"
] | 1 |
2020-06-28T15:29:43.000Z
|
2020-06-28T15:29:43.000Z
|
notebooks/test_sunpy_1.0.0.ipynb
|
MSKirk/MachineLearning
|
14e19244441aeef1f28e24e3b3f63b659b80087e
|
[
"BSD-3-Clause"
] | 1 |
2019-05-24T19:28:12.000Z
|
2019-05-24T19:28:12.000Z
|
notebooks/test_sunpy_1.0.0.ipynb
|
MSKirk/MachineLearning
|
14e19244441aeef1f28e24e3b3f63b659b80087e
|
[
"BSD-3-Clause"
] | null | null | null | 450.005155 | 70,860 | 0.949004 |
[
[
[
"import matplotlib.pyplot as plt\nimport astropy.units as u\n\nimport sunpy.map\nimport sunpy.data.sample\nimport numpy as np",
"_____no_output_____"
],
[
"aia_map = sunpy.map.Map(sunpy.data.sample.AIA_171_IMAGE)",
"_____no_output_____"
],
[
"aia_map.data.dtype",
"_____no_output_____"
],
[
"aia_map.plot()",
"_____no_output_____"
],
[
"mask = np.ones_like(aia_map.data)\nmask[0,0] = 0\nmask[0,1] = 0\naia_map.data[0,0]\naia_map.data[0,1]",
"_____no_output_____"
],
[
"aia_map.mask = mask\naia_map.plot()",
"_____no_output_____"
],
[
"aia_map = sunpy.map.Map('/Users/rattie/Data/SDO/AIA/aia.lev1_euv_12s.2012-08-31T000012Z.171.image_lev1.fits')",
"_____no_output_____"
],
[
"aia_map.data.dtype",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02eac645b6d9edef9812d6d2d1cea240f6ab7e7
| 27,457 |
ipynb
|
Jupyter Notebook
|
CMC/.ipynb_checkpoints/BCR_CMC_test-checkpoint.ipynb
|
wtwt5237/Benisse
|
2c7e569ff7f1d15d883576dd9487612e5ed1077f
|
[
"MIT"
] | null | null | null |
CMC/.ipynb_checkpoints/BCR_CMC_test-checkpoint.ipynb
|
wtwt5237/Benisse
|
2c7e569ff7f1d15d883576dd9487612e5ed1077f
|
[
"MIT"
] | null | null | null |
CMC/.ipynb_checkpoints/BCR_CMC_test-checkpoint.ipynb
|
wtwt5237/Benisse
|
2c7e569ff7f1d15d883576dd9487612e5ed1077f
|
[
"MIT"
] | null | null | null | 67.132029 | 1,514 | 0.647157 |
[
[
[
"import sys\nimport os\nimport time\nimport torch\nimport torch.backends.cudnn as cudnn\nimport argparse\nimport socket\nimport pandas as pd\nimport csv\nimport numpy as np\nimport pickle\nimport re\nfrom model_util import MyAlexNetCMC\nfrom contrast_util import NCEAverage,AverageMeter,NCESoftmaxLoss\nfrom torch.utils.data.sampler import SubsetRandomSampler\nfrom data_pre import load_BCRdata,aamapping,datasetMap_nt,ntmapping\nfrom data_util import Dataset\nfrom random import sample,seed\nfrom sklearn.metrics import roc_curve,auc",
"_____no_output_____"
],
[
"class opttest(object):\n def __init__(self,path1,path2,path3,num,num2):\n self.input_data=path1\n self.atchley_factors=path2\n self.resume=path3\n self.encode_dim=num\n self.pad_length=num2\nopt=opttest('/home2/s421955/projects/scBCR/data/cleaned_BCRmltrain/IEDB.csv',\n '/home2/s421955/projects/scBCR/data/Atchley_factors.csv',\n '/home2/s421955/projects/scBCR/data/model_BCRmltrain',\n 40,\n 130)",
"_____no_output_____"
],
[
"test=load_BCRdata(opt)\ntest['strlen']=test['cdr3_nt'].str.len()\ntest=test[test['strlen']<=130]\ntest.index=range(0,test.shape[0])",
"Reading file:\n0\n"
],
[
"import os\nfiledir=opt.input_data\nif filedir.find('.csv')>(-1):\n datasets=[filedir]\nelse:\n datasets=[os.path.join(dp, f) for dp, dn, fn in os.walk(os.path.expanduser(filedir)) for f in fn]\nprint(datasets)\nfor index,file in enumerate(datasets):\n if index % 10==0:\n print('Reading file:')\n print(index)\n f=pd.read_csv(file,header=0)",
"['/home2/s421955/projects/scBCR/data/cleaned_BCRmltrain/IEDB.csv']\nReading file:\n0\n"
],
[
"test.shape\ntest['cdr3_nt'][0]",
"_____no_output_____"
],
[
"aa_dict=dict()\nwith open(opt.atchley_factors,'r') as aa:\n aa_reader=csv.reader(aa)\n next(aa_reader, None)\n for rows in aa_reader:\n aa_name=rows[0]\n aa_factor=rows[1:len(rows)]\n aa_dict[aa_name]=np.asarray(aa_factor,dtype='float')",
"_____no_output_____"
],
[
"cdr_test,vdj_test,cdr3_seq_test=datasetMap_nt(test,aa_dict,opt.encode_dim,opt.pad_length)",
"Converting row:\n0\n"
],
[
"#cdr = open('/home2/s421955/projects/scBCR/data/model_BCRmltrain/cdr_test.pkl',\"wb\")\n#pickle.dump(cdr_test,cdr)\n#cdr.close()\n#vdj = open('/home2/s421955/projects/scBCR/data/model_BCRmltrain/nt_test.pkl',\"wb\")\n#pickle.dump(vdj_testtest,vdj)\n#vdj.close()",
"_____no_output_____"
],
[
"#After data prep\n# cdr = open('/home2/s421955/projects/scBCR/data/model_BCRmltrain/cdr_10ktest.pkl', 'rb')\n# cdr_test = pickle.load(cdr)\n# cdr.close()\n#cdr_test={ind:cdr_test[ind][0:40,:] for ind in list(cdr_test.keys())}\n\n# vdj = open('/home2/s421955/projects/scBCR/data/model_BCRmltrain/nt_10ktest.pkl', 'rb')\n# vdj_test = pickle.load(vdj)\n# vdj.close()",
"_____no_output_____"
],
[
"#Load data\nbatch_size = 64\nrandom_seed= 123\ntest_indices = list(set(vdj_test.keys()))\ncdr_shape = cdr_test[list(cdr_test.keys())[0]].shape[0]\ntest_set = Dataset(test_indices,cdr_test,vdj_test,cdr3_seq_test)\ntest_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, \n shuffle=False, sampler=None,batch_sampler=None,num_workers=1)",
"_____no_output_____"
],
[
"#Load model\ndevice = \"cuda: 0\"\nepoch=59\nfeat_dim=20\nin_feature=130\nn_out_features=feat_dim\nnce_k = 1\nnce_t = 0.2\nnce_m = 0.9\nn_vdj = vdj_test[list(vdj_test.keys())[0]].size()[0]\nn_data = len(test_indices)\nlr = 0.001\nmomentum = 0.9\nweight_decay = 0.0001\ngradient_clip = 5\n\nstate=torch.load(opt.resume+\"/trained_model.pt\")\ntest_model=MyAlexNetCMC(in_feature=in_feature,feat_dim=feat_dim,freeze=True).cuda()\ncontrast = NCEAverage(n_out_features, n_data, nce_k, nce_t, nce_m).cuda()\ncriterion_cdr = NCESoftmaxLoss().cuda()\ncriterion_vdj = NCESoftmaxLoss().cuda()\noptimizer = torch.optim.SGD(test_model.parameters(),\n lr=lr,\n momentum=momentum,\n weight_decay=weight_decay)\ntest_model.load_state_dict(state['model'])\noptimizer.load_state_dict(state['optimizer'])",
"_____no_output_____"
],
[
"def predict(test_loader, model, contrast,criterion_cdr,criterion_vdj):\n acc=dict()\n roc_score=dict()\n model.eval()\n contrast.eval()\n with torch.no_grad():\n for idx, (data, index) in enumerate(test_loader):\n index = index.to(device)\n for _ in list(data.keys())[0:2]:\n data[_] = data[_].float().to(device)\n feat_cdr,feat_vdj,cdr3_seq = model(data)\n if idx==0:\n feature_array=pd.DataFrame(feat_cdr.cpu().numpy())\n feature_array['index']=cdr3_seq\n else:\n feature_array_tmp=pd.DataFrame(feat_cdr.cpu().numpy())\n feature_array_tmp['index']=cdr3_seq\n feature_array=feature_array.append(feature_array_tmp)\n out_cdr, out_vdj = contrast(feat_cdr, feat_vdj, index)\n loss_cdr=criterion_cdr(out_cdr)\n loss_vdj=criterion_vdj(out_vdj)\n loss=loss_cdr+loss_vdj\n print('Batch {0}: test loss {1:.3f}'.format(idx,loss))\n out_cdr=out_cdr.squeeze()\n out_vdj=out_vdj.squeeze()\n acc_cdr=torch.argmax(out_cdr,dim=1)\n acc_vdj=torch.argmax(out_vdj,dim=1)\n acc_vdj=acc_vdj.squeeze()\n if idx==0:\n acc['cdr']=acc_cdr\n acc['vdj']=acc_vdj\n roc_score['cdr']=out_cdr.flatten()\n roc_score['vdj']=out_vdj.flatten()\n else:\n acc['cdr']=torch.cat((acc['cdr'],acc_cdr),0)\n acc['vdj']=torch.cat((acc['vdj'],acc_vdj),0)\n roc_score['cdr']=torch.cat((roc_score['cdr'],out_cdr.flatten()),0)\n roc_score['vdj']=torch.cat((roc_score['vdj'],out_vdj.flatten()),0)\n return feature_array,acc,roc_score,loss",
"_____no_output_____"
],
[
"feature_array,acc,roc_score,test_loss=predict(test_loader,test_model,contrast,criterion_cdr,criterion_vdj)\nacc['cdr']=acc['cdr'].cpu().numpy()\nacc['vdj']=acc['vdj'].cpu().numpy()\nprint('cdr accuracy:\\n')\nprint(len(np.where(acc['cdr']==0)[0])/len(acc['cdr']))\nprint('nt accuracy:\\n')\nprint(len(np.where(acc['vdj']==0)[0])/len(acc['vdj']))\nfeature_array.to_csv('/home2/s421955/projects/scBCR/data/test_BCRmltrain/testoutput.csv',sep=',')",
"Batch 0: test loss 6.552\nBatch 1: test loss 8.563\nBatch 2: test loss 8.143\nBatch 3: test loss 10.190\nBatch 4: test loss 10.953\nBatch 5: test loss 9.737\nBatch 6: test loss 12.805\nBatch 7: test loss 9.460\nBatch 8: test loss 11.596\nBatch 9: test loss 12.835\nBatch 10: test loss 15.701\nBatch 11: test loss 16.419\nBatch 12: test loss 12.937\nBatch 13: test loss 16.237\nBatch 14: test loss 16.806\nBatch 15: test loss 16.813\nBatch 16: test loss 18.835\nBatch 17: test loss 15.745\nBatch 18: test loss 19.446\nBatch 19: test loss 19.645\nBatch 20: test loss 22.615\nBatch 21: test loss 21.380\nBatch 22: test loss 23.783\nBatch 23: test loss 29.294\ncdr accuracy:\n\n0.31108144192256343\nnt accuracy:\n\n0.30507343124165553\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02ed16e59e5c19b70bbc3aa815cbdfc8577bbc4
| 25,301 |
ipynb
|
Jupyter Notebook
|
content/en/docs/components/pipelines/sdk/build-pipeline.ipynb
|
droctothorpe/website
|
cb78f24d663f50aa13ef1846962ac6d3cba20b7c
|
[
"CC-BY-4.0"
] | null | null | null |
content/en/docs/components/pipelines/sdk/build-pipeline.ipynb
|
droctothorpe/website
|
cb78f24d663f50aa13ef1846962ac6d3cba20b7c
|
[
"CC-BY-4.0"
] | null | null | null |
content/en/docs/components/pipelines/sdk/build-pipeline.ipynb
|
droctothorpe/website
|
cb78f24d663f50aa13ef1846962ac6d3cba20b7c
|
[
"CC-BY-4.0"
] | null | null | null | 40.808065 | 191 | 0.640726 |
[
[
[
"# Build a Pipeline\n> A tutorial on building pipelines to orchestrate your ML workflow\n\n\nA Kubeflow pipeline is a portable and scalable definition of a machine learning\n(ML) workflow. Each step in your ML workflow, such as preparing data or\ntraining a model, is an instance of a pipeline component. This document\nprovides an overview of pipeline concepts and best practices, and instructions\ndescribing how to build an ML pipeline.\n\n## Before you begin\n\n1. Run the following command to install the Kubeflow Pipelines SDK. If you run this command in a Jupyter\n notebook, restart the kernel after installing the SDK. ",
"_____no_output_____"
]
],
[
[
"!pip install kfp --upgrade",
"_____no_output_____"
]
],
[
[
"2. Import the `kfp` and `kfp.components` packages.",
"_____no_output_____"
]
],
[
[
"import kfp\nimport kfp.components as comp",
"_____no_output_____"
]
],
[
[
"## Understanding pipelines\n\nA Kubeflow pipeline is a portable and scalable definition of an ML workflow,\nbased on containers. A pipeline is composed of a set of input parameters and a\nlist of the steps in this workflow. Each step in a pipeline is an instance of a\ncomponent, which is represented as an instance of \n[`ContainerOp`][container-op].\n\nYou can use pipelines to:\n\n* Orchestrate repeatable ML workflows.\n* Accelerate experimentation by running a workflow with different sets of\n hyperparameters.\n\n### Understanding pipeline components\n\nA pipeline component is a containerized application that performs one step in a\npipeline's workflow. Pipeline components are defined in\n[component specifications][component-spec], which define the following:\n\n* The component's interface, its inputs and outputs.\n* The component's implementation, the container image and the command to\n execute.\n* The component's metadata, such as the name and description of the\n component.\n\nYou can build components by [defining a component specification for a\ncontainerized application][component-dev], or you can [use the Kubeflow\nPipelines SDK to generate a component specification for a Python\nfunction][python-function-component]. You can also [reuse prebuilt components\nin your pipeline][prebuilt-components]. \n\n### Understanding the pipeline graph\n\nEach step in your pipeline's workflow is an instance of a component. When\nyou define your pipeline, you specify the source of each step's inputs. Step\ninputs can be set from the pipeline's input arguments, constants, or step\ninputs can depend on the outputs of other steps in this pipeline. Kubeflow\nPipelines uses these dependencies to define your pipeline's workflow as\na graph.\n\nFor example, consider a pipeline with the following steps: ingest data,\ngenerate statistics, preprocess data, and train a model. The following\ndescribes the data dependencies between each step.\n\n* **Ingest data**: This step loads data from an external source which is\n specified using a pipeline argument, and it outputs a dataset. Since\n this step does not depend on the output of any other steps, this step\n can run first.\n* **Generate statistics**: This step uses the ingested dataset to generate\n and output a set of statistics. Since this step depends on the dataset\n produced by the ingest data step, it must run after the ingest data step.\n* **Preprocess data**: This step preprocesses the ingested dataset and\n transforms the data into a preprocessed dataset. Since this step depends\n on the dataset produced by the ingest data step, it must run after the\n ingest data step.\n* **Train a model**: This step trains a model using the preprocessed dataset,\n the generated statistics, and pipeline parameters, such as the learning\n rate. Since this step depends on the preprocessed data and the generated\n statistics, it must run after both the preprocess data and generate\n statistics steps are complete.\n\nSince the generate statistics and preprocess data steps both depend on the\ningested data, the generate statistics and preprocess data steps can run in\nparallel. All other steps are executed once their data dependencies are\navailable.\n\n## Designing your pipeline\n\nWhen designing your pipeline, think about how to split your ML workflow into\npipeline components. The process of splitting an ML workflow into pipeline\ncomponents is similar to the process of splitting a monolithic script into\ntestable functions. The following rules can help you define the components\nthat you need to build your pipeline.\n\n* Components should have a single responsibility. Having a single\n responsibility makes it easier to test and reuse a component. For example,\n if you have a component that loads data you can reuse that for similar\n tasks that load data. If you have a component that loads and transforms\n a dataset, the component can be less useful since you can use it only when\n you need to load and transform that dataset. \n\n* Reuse components when possible. Kubeflow Pipelines provides [components for\n common pipeline tasks and for access to cloud\n services][prebuilt-components].\n\n* Consider what you need to know to debug your pipeline and research the\n lineage of the models that your pipeline produces. Kubeflow Pipelines\n stores the inputs and outputs of each pipeline step. By interrogating the\n artifacts produced by a pipeline run, you can better understand the\n variations in model quality between runs or track down bugs in your\n workflow.\n\nIn general, you should design your components with composability in mind. \n\nPipelines are composed of component instances, also called steps. Steps can\ndefine their inputs as depending on the output of another step. The\ndependencies between steps define the pipeline workflow graph.\n\n### Building pipeline components\n\nKubeflow pipeline components are containerized applications that perform a\nstep in your ML workflow. Here are the ways that you can define pipeline\ncomponents:\n\n* If you have a containerized application that you want to use as a\n pipeline component, create a component specification to define this\n container image as a pipeline component.\n \n This option provides the flexibility to include code written in any\n language in your pipeline, so long as you can package the application\n as a container image. Learn more about [building pipeline\n components][component-dev].\n\n* If your component code can be expressed as a Python function, [evaluate if\n your component can be built as a Python function-based\n component][python-function-component]. The Kubeflow Pipelines SDK makes it\n easier to build lightweight Python function-based components by saving you\n the effort of creating a component specification.\n\nWhenever possible, [reuse prebuilt components][prebuilt-components] to save\nyourself the effort of building custom components.\n\nThe example in this guide demonstrates how to build a pipeline that uses a\nPython function-based component and reuses a prebuilt component.\n\n### Understanding how data is passed between components\n\nWhen Kubeflow Pipelines runs a component, a container image is started in a\nKubernetes Pod and your component’s inputs are passed in as command-line\narguments. When your component has finished, the component's outputs are\nreturned as files.\n\nIn your component's specification, you define the components inputs and outputs\nand how the inputs and output paths are passed to your program as command-line\narguments. You can pass small inputs, such as short strings or numbers, to your\ncomponent by value. Large inputs, such as datasets, must be passed to your\ncomponent as file paths. Outputs are written to the paths that Kubeflow\nPipelines provides.\n\nPython function-based components make it easier to build pipeline components\nby building the component specification for you. Python function-based\ncomponents also handle the complexity of passing inputs into your component\nand passing your function’s outputs back to your pipeline.\n\nLearn more about how [Python function-based components handle inputs and\noutputs][python-function-component-data-passing]. \n\n## Getting started building a pipeline\n\nThe following sections demonstrate how to get started building a Kubeflow\npipeline by walking through the process of converting a Python script into\na pipeline.\n\n### Design your pipeline\n\nThe following steps walk through some of the design decisions you may face\nwhen designing a pipeline.\n\n1. Evaluate the process. In the following example, a Python function downloads\n a zipped tar file (`.tar.gz`) that contains several CSV files, from a\n public website. The function extracts the CSV files and then merges them\n into a single file.\n\n[container-op]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.dsl.html#kfp.dsl.ContainerOp\n[component-spec]: https://www.kubeflow.org/docs/components/pipelines/reference/component-spec/\n[python-function-component]: https://www.kubeflow.org/docs/components/pipelines/sdk/python-function-components/\n[component-dev]: https://www.kubeflow.org/docs/components/pipelines/sdk/component-development/\n[python-function-component-data-passing]: https://www.kubeflow.org/docs/components/pipelines/sdk/python-function-components/#understanding-how-data-is-passed-between-components\n[prebuilt-components]: https://www.kubeflow.org/docs/examples/shared-resources/",
"_____no_output_____"
]
],
[
[
"import glob\nimport pandas as pd\nimport tarfile\nimport urllib.request\n \ndef download_and_merge_csv(url: str, output_csv: str):\n with urllib.request.urlopen(url) as res:\n tarfile.open(fileobj=res, mode=\"r|gz\").extractall('data')\n df = pd.concat(\n [pd.read_csv(csv_file, header=None) \n for csv_file in glob.glob('data/*.csv')])\n df.to_csv(output_csv, index=False, header=False)",
"_____no_output_____"
]
],
[
[
"2. Run the following Python command to test the function. ",
"_____no_output_____"
]
],
[
[
"download_and_merge_csv(\n url='https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz', \n output_csv='merged_data.csv')",
"_____no_output_____"
]
],
[
[
"3. Run the following to print the first few rows of the\n merged CSV file.",
"_____no_output_____"
]
],
[
[
"!head merged_data.csv",
"_____no_output_____"
]
],
[
[
"4. Design your pipeline. For example, consider the following pipeline designs.\n\n * Implement the pipeline using a single step. In this case, the pipeline\n contains one component that works similarly to the example function.\n This is a straightforward function, and implementing a single-step\n pipeline is a reasonable approach in this case.\n \n The down side of this approach is that the zipped tar file would not be\n an artifact of your pipeline runs. Not having this artifact available \n could make it harder to debug this component in production.\n \n * Implement this as a two-step pipeline. The first step downloads a file\n from a website. The second step extracts the CSV files from a zipped\n tar file and merges them into a single file. \n \n This approach has a few benefits:\n \n * You can reuse the [Web Download component][web-download-component]\n to implement the first step.\n * Each step has a single responsibility, which makes the components\n easier to reuse.\n * The zipped tar file is an artifact of the first pipeline step.\n This means that you can examine this artifact when debugging\n pipelines that use this component.\n \n This example implements a two-step pipeline.\n\n### Build your pipeline components\n\n \n1. Build your pipeline components. This example modifies the initial script to\n extract the contents of a zipped tar file, merge the CSV files that were\n contained in the zipped tar file, and return the merged CSV file.\n \n This example builds a Python function-based component. You can also package\n your component's code as a Docker container image and define the component\n using a ComponentSpec.\n \n In this case, the following modifications were required to the original\n function.\n\n * The file download logic was removed. The path to the zipped tar file\n is passed as an argument to this function.\n * The import statements were moved inside of the function. Python\n function-based components require standalone Python functions. This\n means that any required import statements must be defined within the\n function, and any helper functions must be defined within the function.\n Learn more about [building Python function-based\n components][python-function-components].\n * The function's arguments are decorated with the\n [`kfp.components.InputPath`][input-path] and the\n [`kfp.components.OutputPath`][output-path] annotations. These\n annotations let Kubeflow Pipelines know to provide the path to the\n zipped tar file and to create a path where your function stores the\n merged CSV file. \n \n The following example shows the updated `merge_csv` function.\n\n[web-download-component]: https://github.com/kubeflow/pipelines/blob/master/components/web/Download/component.yaml\n[python-function-components]: https://www.kubeflow.org/docs/components/pipelines/sdk/python-function-components/\n[input-path]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.components.html?highlight=inputpath#kfp.components.InputPath\n[output-path]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.components.html?highlight=outputpath#kfp.components.OutputPath",
"_____no_output_____"
]
],
[
[
"def merge_csv(file_path: comp.InputPath('Tarball'),\n output_csv: comp.OutputPath('CSV')):\n import glob\n import pandas as pd\n import tarfile\n\n tarfile.open(name=file_path, mode=\"r|gz\").extractall('data')\n df = pd.concat(\n [pd.read_csv(csv_file, header=None) \n for csv_file in glob.glob('data/*.csv')])\n df.to_csv(output_csv, index=False, header=False)",
"_____no_output_____"
]
],
[
[
"2. Use [`kfp.components.create_component_from_func`][create_component_from_func]\n to return a factory function that you can use to create pipeline steps.\n This example also specifies the base container image to run this function\n in, the path to save the component specification to, and a list of PyPI\n packages that need to be installed in the container at runtime.\n\n[create_component_from_func]: (https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.components.html#kfp.components.create_component_from_func\n[container-op]: https://kubeflow-pipelines.readthedocs.io/en/stable/source/kfp.dsl.html#kfp.dsl.ContainerOp",
"_____no_output_____"
]
],
[
[
"create_step_merge_csv = kfp.components.create_component_from_func(\n func=merge_csv,\n output_component_file='component.yaml', # This is optional. It saves the component spec for future use.\n base_image='python:3.7',\n packages_to_install=['pandas==1.1.4'])",
"_____no_output_____"
]
],
[
[
"### Build your pipeline\n\n1. Use [`kfp.components.load_component_from_url`][load_component_from_url]\n to load the component specification YAML for any components that you are\n reusing in this pipeline.\n\n[load_component_from_url]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.components.html?highlight=load_component_from_url#kfp.components.load_component_from_url",
"_____no_output_____"
]
],
[
[
"web_downloader_op = kfp.components.load_component_from_url(\n 'https://raw.githubusercontent.com/kubeflow/pipelines/master/components/contrib/web/Download/component.yaml')",
"_____no_output_____"
]
],
[
[
"2. Define your pipeline as a Python function. \n\n Your pipeline function's arguments define your pipeline's parameters. Use\n pipeline parameters to experiment with different hyperparameters, such as\n the learning rate used to train a model, or pass run-level inputs, such as\n the path to an input file, into a pipeline run.\n \n Use the factory functions created by\n `kfp.components.create_component_from_func` and\n `kfp.components.load_component_from_url` to create your pipeline's tasks. \n The inputs to the component factory functions can be pipeline parameters,\n the outputs of other tasks, or a constant value. In this case, the\n `web_downloader_task` task uses the `url` pipeline parameter, and the\n `merge_csv_task` uses the `data` output of the `web_downloader_task`.\n ",
"_____no_output_____"
]
],
[
[
"# Define a pipeline and create a task from a component:\ndef my_pipeline(url):\n web_downloader_task = web_downloader_op(url=url)\n merge_csv_task = create_step_merge_csv(file=web_downloader_task.outputs['data'])\n # The outputs of the merge_csv_task can be referenced using the\n # merge_csv_task.outputs dictionary: merge_csv_task.outputs['output_csv']",
"_____no_output_____"
]
],
[
[
"### Compile and run your pipeline\n\nAfter defining the pipeline in Python as described in the preceding section, use one of the following options to compile the pipeline and submit it to the Kubeflow Pipelines service.\n\n#### Option 1: Compile and then upload in UI\n\n1. Run the following to compile your pipeline and save it as `pipeline.yaml`. \n",
"_____no_output_____"
]
],
[
[
"kfp.compiler.Compiler().compile(\n pipeline_func=my_pipeline,\n package_path='pipeline.yaml')",
"_____no_output_____"
]
],
[
[
"2. Upload and run your `pipeline.yaml` using the Kubeflow Pipelines user interface.\nSee the guide to [getting started with the UI][quickstart].\n\n[quickstart]: https://www.kubeflow.org/docs/components/pipelines/overview/quickstart",
"_____no_output_____"
],
[
"#### Option 2: run the pipeline using Kubeflow Pipelines SDK client\n\n1. Create an instance of the [`kfp.Client` class][kfp-client] following steps in [connecting to Kubeflow Pipelines using the SDK client][connect-api].\n\n[kfp-client]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.client.html#kfp.Client\n[connect-api]: https://www.kubeflow.org/docs/components/pipelines/sdk/connect-api",
"_____no_output_____"
]
],
[
[
"client = kfp.Client() # change arguments accordingly",
"_____no_output_____"
]
],
[
[
"2. Run the pipeline using the `kfp.Client` instance:",
"_____no_output_____"
]
],
[
[
"client.create_run_from_pipeline_func(\n my_pipeline,\n arguments={\n 'url': 'https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz'\n })",
"_____no_output_____"
]
],
[
[
"\n## Next steps\n\n* Learn about advanced pipeline features, such as [authoring recursive\n components][recursion] and [using conditional execution in a\n pipeline][conditional].\n* Learn how to [manipulate Kubernetes resources in a\n pipeline][k8s-resources] (Experimental).\n\n[conditional]: https://github.com/kubeflow/pipelines/blob/master/samples/tutorials/DSL%20-%20Control%20structures/DSL%20-%20Control%20structures.py\n[recursion]: https://www.kubeflow.org/docs/components/pipelines/sdk/dsl-recursion/\n[k8s-resources]: https://www.kubeflow.org/docs/components/pipelines/sdk/manipulate-resources/",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02edbaeaac510d581d7c5092d9f32d163498dd6
| 40,113 |
ipynb
|
Jupyter Notebook
|
tutorials/old_generation_notebooks/colab/6- Sarcasm Classifiers (TF-IDF).ipynb
|
fcivardi/spark-nlp-workshop
|
aedb1f5d93577c81bc3dd0da5e46e02586941541
|
[
"Apache-2.0"
] | 687 |
2018-09-07T03:45:39.000Z
|
2022-03-20T17:11:20.000Z
|
tutorials/old_generation_notebooks/colab/6- Sarcasm Classifiers (TF-IDF).ipynb
|
fcivardi/spark-nlp-workshop
|
aedb1f5d93577c81bc3dd0da5e46e02586941541
|
[
"Apache-2.0"
] | 89 |
2018-09-18T02:04:42.000Z
|
2022-02-24T18:22:27.000Z
|
tutorials/old_generation_notebooks/colab/6- Sarcasm Classifiers (TF-IDF).ipynb
|
fcivardi/spark-nlp-workshop
|
aedb1f5d93577c81bc3dd0da5e46e02586941541
|
[
"Apache-2.0"
] | 407 |
2018-09-07T03:45:44.000Z
|
2022-03-20T05:12:25.000Z
| 35.592724 | 418 | 0.466881 |
[
[
[
"",
"_____no_output_____"
],
[
"https://www.kaggle.com/danofer/sarcasm\n<div class=\"markdown-converter__text--rendered\"><h3>Context</h3>\n\n<p>This dataset contains 1.3 million Sarcastic comments from the Internet commentary website Reddit. The dataset was generated by scraping comments from Reddit (not by me :)) containing the <code>\\s</code> ( sarcasm) tag. This tag is often used by Redditors to indicate that their comment is in jest and not meant to be taken seriously, and is generally a reliable indicator of sarcastic comment content.</p>\n\n<h3>Content</h3>\n\n<p>Data has balanced and imbalanced (i.e true distribution) versions. (True ratio is about 1:100). The\ncorpus has 1.3 million sarcastic statements, along with what they responded to as well as many non-sarcastic comments from the same source.</p>\n\n<p>Labelled comments are in the <code>train-balanced-sarcasm.csv</code> file.</p>\n\n<h3>Acknowledgements</h3>\n\n<p>The data was gathered by: Mikhail Khodak and Nikunj Saunshi and Kiran Vodrahalli for their article \"<a href=\"https://arxiv.org/abs/1704.05579\" rel=\"nofollow\">A Large Self-Annotated Corpus for Sarcasm</a>\". The data is hosted <a href=\"http://nlp.cs.princeton.edu/SARC/0.0/\" rel=\"nofollow\">here</a>.</p>\n\n<p>Citation:</p>\n\n<pre><code>@unpublished{SARC,\n authors={Mikhail Khodak and Nikunj Saunshi and Kiran Vodrahalli},\n title={A Large Self-Annotated Corpus for Sarcasm},\n url={https://arxiv.org/abs/1704.05579},\n year=2017\n}\n</code></pre>\n\n<p><a href=\"http://nlp.cs.princeton.edu/SARC/0.0/readme.txt\" rel=\"nofollow\">Annotation of files in the original dataset: readme.txt</a>.</p>\n\n<h3>Inspiration</h3>\n\n<ul>\n<li>Predicting sarcasm and relevant NLP features (e.g. subjective determinant, racism, conditionals, sentiment heavy words, \"Internet Slang\" and specific phrases). </li>\n<li>Sarcasm vs Sentiment</li>\n<li>Unusual linguistic features such as caps, italics, or elongated words. e.g., \"Yeahhh, I'm sure THAT is the right answer\".</li>\n<li>Topics that people tend to react to sarcastically</li>\n</ul></div>",
"_____no_output_____"
]
],
[
[
"import os\n\n# Install java\n! apt-get update -qq\n! apt-get install -y openjdk-8-jdk-headless -qq > /dev/null\n\nos.environ[\"JAVA_HOME\"] = \"/usr/lib/jvm/java-8-openjdk-amd64\"\nos.environ[\"PATH\"] = os.environ[\"JAVA_HOME\"] + \"/bin:\" + os.environ[\"PATH\"]\n! java -version\n\n# Install pyspark\n! pip install --ignore-installed pyspark==2.4.4\n\n# Install Spark NLP\n! pip install --ignore-installed spark-nlp",
"_____no_output_____"
],
[
"import sys\nimport time\nimport sparknlp\n\nfrom pyspark.sql import SparkSession\npackages = [\n 'JohnSnowLabs:spark-nlp: 2.5.5'\n]\nspark = SparkSession \\\n .builder \\\n .appName(\"ML SQL session\") \\\n .config('spark.jars.packages', ','.join(packages)) \\\n .config('spark.executor.instances','2') \\\n .config(\"spark.executor.memory\", \"2g\") \\\n .config(\"spark.driver.memory\",\"16g\") \\\n .getOrCreate()",
"_____no_output_____"
],
[
"print(\"Spark NLP version: \", sparknlp.version())\nprint(\"Apache Spark version: \", spark.version)",
"Spark NLP version: 2.4.2\nApache Spark version: 2.4.4\n"
],
[
"! wget -N https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sarcasm/train-balanced-sarcasm.csv -P /tmp",
"--2020-02-11 19:18:09-- https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sarcasm/train-balanced-sarcasm.csv\nLoaded CA certificate '/etc/ssl/certs/ca-certificates.crt'\nResolving s3.amazonaws.com (s3.amazonaws.com)... 52.216.237.229\nConnecting to s3.amazonaws.com (s3.amazonaws.com)|52.216.237.229|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 255268960 (243M) [text/csv]\nSaving to: ‘/tmp/train-balanced-sarcasm.csv’\n\ntrain-balanced-sarc 100%[===================>] 243,44M 5,01MB/s in 33s \n\n2020-02-11 19:18:43 (7,46 MB/s) - ‘/tmp/train-balanced-sarcasm.csv’ saved [255268960/255268960]\n\n"
],
[
"from pyspark.sql import SQLContext\n\nsql = SQLContext(spark)\n\ntrainBalancedSarcasmDF = spark.read.option(\"header\", True).option(\"inferSchema\", True).csv(\"/tmp/train-balanced-sarcasm.csv\")\ntrainBalancedSarcasmDF.printSchema()\n\n# Let's create a temp view (table) for our SQL queries\ntrainBalancedSarcasmDF.createOrReplaceTempView('data')\n\nsql.sql('SELECT COUNT(*) FROM data').collect()",
"root\n |-- label: integer (nullable = true)\n |-- comment: string (nullable = true)\n |-- author: string (nullable = true)\n |-- subreddit: string (nullable = true)\n |-- score: string (nullable = true)\n |-- ups: string (nullable = true)\n |-- downs: string (nullable = true)\n |-- date: string (nullable = true)\n |-- created_utc: string (nullable = true)\n |-- parent_comment: string (nullable = true)\n\n"
],
[
"sql.sql('select * from data limit 20').show()",
"+-----+--------------------+------------------+------------------+-----+---+-----+-------+-------------------+--------------------+\n|label| comment| author| subreddit|score|ups|downs| date| created_utc| parent_comment|\n+-----+--------------------+------------------+------------------+-----+---+-----+-------+-------------------+--------------------+\n| 0| NC and NH.| Trumpbart| politics| 2| -1| -1|2016-10|2016-10-16 23:55:23|Yeah, I get that ...|\n| 0|You do know west ...| Shbshb906| nba| -4| -1| -1|2016-11|2016-11-01 00:24:10|The blazers and M...|\n| 0|They were underdo...| Creepeth| nfl| 3| 3| 0|2016-09|2016-09-22 21:45:37|They're favored t...|\n| 0|\"This meme isn't ...| icebrotha|BlackPeopleTwitter| -8| -1| -1|2016-10|2016-10-18 21:03:47|deadass don't kil...|\n| 0|I could use one o...| cush2push|MaddenUltimateTeam| 6| -1| -1|2016-12|2016-12-30 17:00:13|Yep can confirm I...|\n| 0|I don't pay atten...| only7inches| AskReddit| 0| 0| 0|2016-09|2016-09-02 10:35:08|do you find arian...|\n| 0|Trick or treating...| only7inches| AskReddit| 1| -1| -1|2016-10|2016-10-23 21:43:03|What's your weird...|\n| 0|Blade Mastery+Mas...| P0k3rm4s7| FFBraveExvius| 2| -1| -1|2016-10|2016-10-13 21:13:55|Probably Sephirot...|\n| 0|You don't have to...| SoupToPots| pcmasterrace| 1| -1| -1|2016-10|2016-10-27 19:11:06|What to upgrade? ...|\n| 0|I would love to s...| chihawks| Lollapalooza| 2| -1| -1|2016-11|2016-11-21 23:39:12|Probably count Ka...|\n| 0|I think a signifi...|ThisIsNotKimJongUn| politics| 92| 92| 0|2016-09|2016-09-20 17:53:52|I bet if that mon...|\n| 0|Damn I was hoping...| Kvetch__22| baseball| 14| -1| -1|2016-10|2016-10-28 09:07:50|James Shields Wil...|\n| 0|They have an agenda.| Readbooks6| exmormon| 4| -1| -1|2016-10|2016-10-15 01:14:03|There's no time t...|\n| 0| Great idea!| pieman2005| fantasyfootball| 1| -1| -1|2016-10|2016-10-06 23:27:53|Team Specific Thr...|\n| 0|Ayy bb wassup, it...| Jakethejoker| NYGiants| 29| 29| 0|2016-09|2016-09-19 18:46:58|Ill give you a hi...|\n| 0| what the fuck| Pishwi| AskReddit| 22| -1| -1|2016-11|2016-11-04 20:10:33|Star Wars, easy. ...|\n| 0| noted.| kozmo1313| NewOrleans| 2| -1| -1|2016-12|2016-12-20 21:59:45| You're adorable.|\n| 0|because it's what...| kozmo1313| politics| 15| -1| -1|2016-12|2016-12-26 20:10:45|He actually acts ...|\n| 0|why you fail me, ...| kozmo1313| HillaryForPrison| 1| 1| 0|2016-09|2016-09-18 13:02:45|Clinton struggles...|\n| 0|Pre-Flashpoint Cl...| BreakingGarrick| superman| 2| 2| 0|2016-09|2016-09-16 02:34:04|Is that the Older...|\n+-----+--------------------+------------------+------------------+-----+---+-----+-------+-------------------+--------------------+\n\n"
],
[
"sql.sql('select label,count(*) as cnt from data group by label order by cnt desc').show()",
"+-----+------+\n|label| cnt|\n+-----+------+\n| 0|505413|\n| 1|505413|\n+-----+------+\n\n"
],
[
"sql.sql('select count(*) from data where comment is null').collect()",
"_____no_output_____"
],
[
"df = sql.sql('select label,concat(parent_comment,\"\\n\",comment) as comment from data where comment is not null and parent_comment is not null limit 100000')\nprint(type(df))\ndf.printSchema()\ndf.show()",
"<class 'pyspark.sql.dataframe.DataFrame'>\nroot\n |-- label: integer (nullable = true)\n |-- comment: string (nullable = true)\n\n+-----+--------------------+\n|label| comment|\n+-----+--------------------+\n| 0|Yeah, I get that ...|\n| 0|The blazers and M...|\n| 0|They're favored t...|\n| 0|deadass don't kil...|\n| 0|Yep can confirm I...|\n| 0|do you find arian...|\n| 0|What's your weird...|\n| 0|Probably Sephirot...|\n| 0|What to upgrade? ...|\n| 0|Probably count Ka...|\n| 0|I bet if that mon...|\n| 0|James Shields Wil...|\n| 0|There's no time t...|\n| 0|Team Specific Thr...|\n| 0|Ill give you a hi...|\n| 0|Star Wars, easy. ...|\n| 0|You're adorable.\n...|\n| 0|He actually acts ...|\n| 0|Clinton struggles...|\n| 0|Is that the Older...|\n+-----+--------------------+\nonly showing top 20 rows\n\n"
],
[
"from sparknlp.annotator import *\nfrom sparknlp.common import *\nfrom sparknlp.base import *\n\nfrom pyspark.ml import Pipeline\n\n\ndocument_assembler = DocumentAssembler() \\\n .setInputCol(\"comment\") \\\n .setOutputCol(\"document\")\n \nsentence_detector = SentenceDetector() \\\n .setInputCols([\"document\"]) \\\n .setOutputCol(\"sentence\") \\\n .setUseAbbreviations(True)\n \ntokenizer = Tokenizer() \\\n .setInputCols([\"sentence\"]) \\\n .setOutputCol(\"token\")\n\nstemmer = Stemmer() \\\n .setInputCols([\"token\"]) \\\n .setOutputCol(\"stem\")\n \nnormalizer = Normalizer() \\\n .setInputCols([\"stem\"]) \\\n .setOutputCol(\"normalized\")\n\nfinisher = Finisher() \\\n .setInputCols([\"normalized\"]) \\\n .setOutputCols([\"ntokens\"]) \\\n .setOutputAsArray(True) \\\n .setCleanAnnotations(True)\n\nnlp_pipeline = Pipeline(stages=[document_assembler, sentence_detector, tokenizer, stemmer, normalizer, finisher])\nnlp_model = nlp_pipeline.fit(df)\nprocessed = nlp_model.transform(df).persist()\nprocessed.count()\nprocessed.show()",
"+-----+--------------------+--------------------+\n|label| comment| ntokens|\n+-----+--------------------+--------------------+\n| 0|Yeah, I get that ...|[yeah, i, get, th...|\n| 0|The blazers and M...|[the, blazer, and...|\n| 0|They're favored t...|[theyr, favor, to...|\n| 0|deadass don't kil...|[deadass, dont, k...|\n| 0|Yep can confirm I...|[yep, can, confir...|\n| 0|do you find arian...|[do, you, find, a...|\n| 0|What's your weird...|[what, your, weir...|\n| 0|Probably Sephirot...|[probabl, sephiro...|\n| 0|What to upgrade? ...|[what, to, upgrad...|\n| 0|Probably count Ka...|[probabl, count, ...|\n| 0|I bet if that mon...|[i, bet, if, that...|\n| 0|James Shields Wil...|[jame, shield, wi...|\n| 0|There's no time t...|[there, no, time,...|\n| 0|Team Specific Thr...|[team, specif, th...|\n| 0|Ill give you a hi...|[ill, give, you, ...|\n| 0|Star Wars, easy. ...|[star, war, easi,...|\n| 0|You're adorable.\n...| [your, ador, note]|\n| 0|He actually acts ...|[he, actual, act,...|\n| 0|Clinton struggles...|[clinton, struggl...|\n| 0|Is that the Older...|[i, that, the, ol...|\n+-----+--------------------+--------------------+\nonly showing top 20 rows\n\n"
],
[
"train, test = processed.randomSplit(weights=[0.7, 0.3], seed=123)\nprint(train.count())\nprint(test.count())",
"70136\n29864\n"
],
[
"from pyspark.ml import feature as spark_ft\n\nstopWords = spark_ft.StopWordsRemover.loadDefaultStopWords('english')\nsw_remover = spark_ft.StopWordsRemover(inputCol='ntokens', outputCol='clean_tokens', stopWords=stopWords)\ntf = spark_ft.CountVectorizer(vocabSize=500, inputCol='clean_tokens', outputCol='tf')\nidf = spark_ft.IDF(minDocFreq=5, inputCol='tf', outputCol='idf')\n\nfeature_pipeline = Pipeline(stages=[sw_remover, tf, idf])\nfeature_model = feature_pipeline.fit(train)\n\ntrain_featurized = feature_model.transform(train).persist()\ntrain_featurized.count()\ntrain_featurized.show()",
"+-----+--------------------+--------------------+--------------------+--------------------+--------------------+\n|label| comment| ntokens| clean_tokens| tf| idf|\n+-----+--------------------+--------------------+--------------------+--------------------+--------------------+\n| 0| !\nGoes| [goe]| [goe]| (500,[375],[1.0])|(500,[375],[4.866...|\n| 0|!completed\n!compl...| [complet, complet]| [complet, complet]| (500,[227],[2.0])|(500,[227],[8.875...|\n| 0|\"\"\" \"\"Very Right ...|[veri, right, win...|[veri, right, win...|(500,[1,7,31,77,9...|(500,[1,7,31,77,9...|\n| 0|\"\"\" Perhaps you n...|[perhap, you, ne,...|[perhap, ne, stro...| (500,[34],[1.0])|(500,[34],[3.1336...|\n| 0|\"\"\" This covering...|[thi, cover, not,...|[thi, cover, onli...|(500,[0,6,14,18,2...|(500,[0,6,14,18,2...|\n| 0|\"\"\"*Kirk\nI am sin...|[kirk, i, am, sin...|[kirk, singl, gue...|(500,[31,168,348]...|(500,[31,168,348]...|\n| 0|\"\"\"*looks at hand...|[look, at, hand, ...|[look, hand, doe,...|(500,[22,58,211,2...|(500,[22,58,211,2...|\n| 0|\"\"\"+100\"\" indicat...|[+, indic, come, ...|[+, indic, come, ...|(500,[5,9,18,57,9...|(500,[5,9,18,57,9...|\n| 0|\"\"\".$witty_remark...|[wittyremark, shi...|[wittyremark, shi...| (500,[],[])| (500,[],[])|\n| 0|\"\"\"... and Fancy ...|[and, fanci, feas...|[fanci, feast, so...| (500,[1],[1.0])|(500,[1],[1.87740...|\n| 0|\"\"\"...and then th...|[and, then, the, ...|[entir, food, cou...|(500,[14,31,64,19...|(500,[14,31,64,19...|\n| 0|\"\"\"...newtons.\"\" ...|[newton, which, i...|[newton, dont, ge...|(500,[0,5,6,208],...|(500,[0,5,6,208],...|\n| 0|\"\"\"100 level and ...|[level, and, k, e...|[level, k, easfc,...|(500,[0,1,27,56,8...|(500,[0,1,27,56,8...|\n| 0|\"\"\"8 operators.\"\"...|[oper, well, i, m...|[oper, well, mean...|(500,[5,24,51,66,...|(500,[5,24,51,66,...|\n| 0|\"\"\"@wikileaks - A...|[wikileak, americ...|[wikileak, americ...| (500,[300],[1.0])|(500,[300],[4.703...|\n| 0|\"\"\"A Cyborg... Ni...|[a, cyborg, ninja...|[cyborg, ninja, n...| (500,[],[])| (500,[],[])|\n| 0|\"\"\"A Victoria's S...|[a, victoria, sec...|[victoria, secret...|(500,[2,139,173,2...|(500,[2,139,173,2...|\n| 0|\"\"\"A basic aspect...|[a, basic, aspect...|[basic, aspect, f...|(500,[0,1,2,3,10,...|(500,[0,1,2,3,10,...|\n| 0|\"\"\"A sense of pur...|[a, sens, of, pur...|[sens, purpos, sh...|(500,[131,133,326...|(500,[131,133,326...|\n| 0|\"\"\"Agreed. I thin...|[agr, i, think, w...|[agr, think, issu...|(500,[0,1,7,9,29,...|(500,[0,1,7,9,29,...|\n+-----+--------------------+--------------------+--------------------+--------------------+--------------------+\nonly showing top 20 rows\n\n"
],
[
"train_featurized.groupBy(\"label\").count().show()\ntrain_featurized.printSchema()",
"+-----+-----+\n|label|count|\n+-----+-----+\n| 0|40466|\n| 1|29670|\n+-----+-----+\n\nroot\n |-- label: integer (nullable = true)\n |-- comment: string (nullable = true)\n |-- ntokens: array (nullable = true)\n | |-- element: string (containsNull = true)\n |-- clean_tokens: array (nullable = true)\n | |-- element: string (containsNull = true)\n |-- tf: vector (nullable = true)\n |-- idf: vector (nullable = true)\n\n"
],
[
"from pyspark.ml import classification as spark_cls\n\nrf = spark_cls. RandomForestClassifier(labelCol=\"label\", featuresCol=\"idf\", numTrees=100)\n\nmodel = rf.fit(train_featurized)",
"_____no_output_____"
],
[
"test_featurized = feature_model.transform(test)\npreds = model.transform(test_featurized)\npreds.show()",
"+-----+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n|label| comment| ntokens| clean_tokens| tf| idf| rawPrediction| probability|prediction|\n+-----+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n| 0|!RemindMe 1 week\n...|[remindm, week, r...|[remindm, week, r...|(500,[56,132],[1....|(500,[56,132],[3....|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|!Remindme 2 weeks...|[remindm, week, r...|[remindm, week, r...| (500,[132],[2.0])|(500,[132],[8.254...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|!SH!TPOST!: All t...|[shtpost, all, th...|[shtpost, poor, u...|(500,[286,476],[1...|(500,[286,476],[4...|[58.6927668196978...|[0.58692766819697...| 0.0|\n| 0|\"\"\"**FUCK** Cloud...|[fuck, cloud, lin...|[fuck, cloud, lin...|(500,[30,35],[1.0...|(500,[30,35],[3.0...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"*Komrad\n\"*\"\"Th...|[komrad, those, w...|[komrad, prousa, ...| (500,[308],[1.0])|(500,[308],[4.833...|[57.9747819444301...|[0.57974781944430...| 0.0|\n| 0|\"\"\"... thanks to ...|[thank, to, a, pa...|[thank, parad, tr...|(500,[18,31,81,14...|(500,[18,31,81,14...|[57.8971892730668...|[0.57897189273066...| 0.0|\n| 0|\"\"\"...FUCK IS THA...|[fuck, i, tha, de...|[fuck, tha, death...|(500,[3,11,29,30,...|(500,[3,11,29,30,...|[58.8662918135306...|[0.58866291813530...| 0.0|\n| 0|\"\"\"...I'm Going T...|[im, go, to, end,...|[im, go, end, dre...|(500,[8,11,119],[...|(500,[8,11,119],[...|[59.1473600893163...|[0.59147360089316...| 0.0|\n| 0|\"\"\"A SMALL FUCKIN...|[a, small, fuck, ...|[small, fuck, hol...|(500,[30,31,57,42...|(500,[30,31,57,42...|[57.9152715153977...|[0.57915271515397...| 0.0|\n| 0|\"\"\"A new brick wa...|[a, new, brick, w...|[new, brick, wall...|(500,[3,32,43,124...|(500,[3,32,43,124...|[58.7612174551342...|[0.58761217455134...| 0.0|\n| 0|\"\"\"Add dabbing to...|[add, dab, to, mi...|[add, dab, minecr...| (500,[358],[1.0])|(500,[358],[4.866...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"All according ...|[all, accord, to,...|[accord, keikaku,...|(500,[51,350],[1....|(500,[51,350],[3....|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"An unmet playe...|[an, unmet, playe...|[unmet, player, h...|(500,[0,1,7,8,14,...|(500,[0,1,7,8,14,...|[58.3304632923714...|[0.58330463292371...| 0.0|\n| 0|\"\"\"And bacon. Lot...|[and, bacon, lot,...|[bacon, lot, lot,...|(500,[6,74,82,483...|(500,[6,74,82,483...|[58.9443340184272...|[0.58944334018427...| 0.0|\n| 0|\"\"\"And later... S...|[and, later, some...|[later, someth, f...|(500,[54,73,120,1...|(500,[54,73,120,1...|[58.9578427385407...|[0.58957842738540...| 0.0|\n| 0|\"\"\"And please tel...|[and, pleas, tell...|[pleas, tell, mom...|(500,[0,43,94,116...|(500,[0,43,94,116...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"Angry Birds?\"\"...|[angri, bird, u, ...|[angri, bird, u, ...|(500,[12,43,44,28...|(500,[12,43,44,28...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"Any objections...|[ani, object, fuc...|[ani, object, fuc...|(500,[1,30,33,34,...|(500,[1,30,33,34,...|[58.6845929081117...|[0.58684592908111...| 0.0|\n| 0|\"\"\"Anyway here's ...|[anywai, here, st...|[anywai, stairwai...| (500,[361],[1.0])|(500,[361],[4.817...|[58.8715006890861...|[0.58871500689086...| 0.0|\n| 0|\"\"\"Aren't you a C...|[arent, you, a, c...|[arent, christian...|(500,[123,207],[1...|(500,[123,207],[3...|[59.0632707665339...|[0.59063270766533...| 0.0|\n+-----+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\nonly showing top 20 rows\n\n"
],
[
"pred_df = preds.select('comment', 'label', 'prediction').toPandas()",
"_____no_output_____"
],
[
"pred_df.head()",
"_____no_output_____"
],
[
"import pandas as pd\nfrom sklearn import metrics as skmetrics\npd.DataFrame(\n data=skmetrics.confusion_matrix(pred_df['label'], pred_df['prediction']),\n columns=['pred ' + l for l in ['0','1']],\n index=['true ' + l for l in ['0','1']]\n)",
"_____no_output_____"
],
[
"print(skmetrics.classification_report(pred_df['label'], pred_df['prediction'], \n target_names=['0','1']))",
" precision recall f1-score support\n\n 0 0.59 0.99 0.74 17224\n 1 0.83 0.04 0.08 12640\n\n accuracy 0.59 29864\n macro avg 0.71 0.52 0.41 29864\nweighted avg 0.69 0.59 0.46 29864\n\n"
],
[
"spark.stop()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02ee05735d8bcfae1cbbf3c750efa51cc3d91eb
| 205,856 |
ipynb
|
Jupyter Notebook
|
HW_03_LSTM.ipynb
|
RamSaw/NLP
|
01d135b14430c178ca61341e22b7dadd07662625
|
[
"MIT"
] | null | null | null |
HW_03_LSTM.ipynb
|
RamSaw/NLP
|
01d135b14430c178ca61341e22b7dadd07662625
|
[
"MIT"
] | null | null | null |
HW_03_LSTM.ipynb
|
RamSaw/NLP
|
01d135b14430c178ca61341e22b7dadd07662625
|
[
"MIT"
] | null | null | null | 260.577215 | 167,157 | 0.925438 |
[
[
[
"<a href=\"https://colab.research.google.com/github/RamSaw/NLP/blob/master/HW_03_LSTM.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import re\nfrom collections import defaultdict\nfrom tqdm import tnrange, tqdm_notebook\nimport random\nfrom tqdm.auto import tqdm\nimport os\nfrom sklearn.model_selection import train_test_split\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torch.utils.data.dataset import Dataset\nfrom torch.nn.utils.rnn import pad_sequence\nfrom nltk.stem.snowball import SnowballStemmer",
"_____no_output_____"
],
[
"def make_reproducible(seed, make_cuda_reproducible):\n random.seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n if make_cuda_reproducible:\n torch.backends.cudnn.deterministic = True\n torch.backends.cudnn.benchmark = False\n\nSEED = 2341\nmake_reproducible(SEED, False)\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\nprint(device)",
"cuda\n"
],
[
"def indices_from_sentence(words):\n cur_id = 0\n result = []\n for word in words:\n result.append((cur_id, len(word)))\n cur_id += len(word)\n return result\n\nprint(indices_from_sentence(['word1', 'a', ',', 'word2']))\nprint(indices_from_sentence(re.split('(\\W)', 'Барак Обама принимает в Белом доме своего французского коллегу Николя Саркози.')))",
"[(0, 5), (5, 1), (6, 1), (7, 5)]\n[(0, 5), (5, 1), (6, 5), (11, 1), (12, 9), (21, 1), (22, 1), (23, 1), (24, 5), (29, 1), (30, 4), (34, 1), (35, 6), (41, 1), (42, 12), (54, 1), (55, 7), (62, 1), (63, 6), (69, 1), (70, 7), (77, 1), (78, 0)]\n"
],
[
"test_words = re.split('(\\W)', 'Скотланд-Ярд{ORG} вызвал на допрос Руперта{PERSON} Мердока{PERSON}')\ntest_words_clean = re.split('(\\W)', 'Скотланд-Ярд вызвал на допрос Руперта Мердока')\nprint(test_words)\nprint(indices_from_sentence(test_words_clean))",
"['Скотланд', '-', 'Ярд', '{', 'ORG', '}', '', ' ', 'вызвал', ' ', 'на', ' ', 'допрос', ' ', 'Руперта', '{', 'PERSON', '}', '', ' ', 'Мердока', '{', 'PERSON', '}', '']\n[(0, 8), (8, 1), (9, 3), (12, 1), (13, 6), (19, 1), (20, 2), (22, 1), (23, 6), (29, 1), (30, 7), (37, 1), (38, 7)]\n"
],
[
"def extract_tags(words):\n i = 0\n res_tags = []\n res_source = []\n cur_id = 0\n while i < len(words):\n if words[i] == '{':\n res_tags.append((cur_id - len(words[i - 1]), len(words[i - 1]), words[i + 1]))\n i += 2\n else:\n res_source.append(words[i])\n cur_id += len(words[i])\n i += 1\n return res_tags, res_source\n\nextract_tags(test_words)",
"_____no_output_____"
],
[
"def combine_datasets():\n with open('train_nes.txt', 'r') as train_nes, \\\n open('train_sentences.txt', 'r') as train_sentences, \\\n open('train_sentences_enhanced.txt', 'r') as train_sentences_enhanced, \\\n open('combined_sentences.txt', 'w') as combined_sentences, \\\n open('combined_nes.txt', 'w') as combined_nes:\n combined_nes.write(train_nes.read())\n combined_sentences.write(train_sentences.read())\n for line in train_sentences_enhanced:\n words = re.split('(\\W)', line)\n res_tags, res_source = extract_tags(words)\n res_tags_flatten = []\n for tag in res_tags:\n res_tags_flatten.append(str(tag[0]))\n res_tags_flatten.append(str(tag[1]))\n res_tags_flatten.append(tag[2])\n res_tags_flatten.append('EOL')\n combined_nes.write(' '.join(res_tags_flatten) + '\\n')\n combined_sentences.write(''.join(res_source))\n\ncombine_datasets()",
"_____no_output_____"
],
[
"def read_training_data():\n with open('train_nes.txt', 'r') as combined_nes, open('train_sentences.txt', 'r') as combined_sentences:\n X, y = [], []\n for line in combined_sentences:\n X.append(re.split('(\\W)', line))\n for i, line in enumerate(combined_nes):\n words = line.split()[:-1]\n tags_in_line = []\n i = 0\n while i < len(words):\n tags_in_line.append((int(words[i]), int(words[i + 1]), words[i + 2]))\n i += 3\n y.append(tags_in_line)\n return X, y",
"_____no_output_____"
],
[
"X, y = read_training_data()\nprint(X[0])\nprint(y[0])\nprint(X[-1])\nprint(y[-1])",
"['Выступления', ' ', 'в', ' ', 'ресторанах', ' ', 'и', ' ', 'кабаках', ' ', '', '—', '', ' ', 'между', ' ', 'горячим', ' ', 'и', ' ', 'десертом', ';', '', ' ', 'в', ' ', 'мюзик', '-', 'холлах', ' ', 'и', ' ', 'фешенебельных', ' ', 'отелях', ' ', '', '—', '', ' ', 'для', ' ', 'королей', ' ', 'Густава', ' ', 'Шведского', ',', '', ' ', 'Альфонса', ' ', 'Испанского', ',', '', ' ', 'принца', ' ', 'Уэльского', ',', '', ' ', 'для', ' ', 'Вандербильтов', ' ', 'и', ' ', 'Ротшильдов', '.', '', '\\n', '']\n[(115, 7, 'PERSON'), (123, 9, 'PERSON'), (134, 8, 'PERSON'), (143, 10, 'PERSON'), (162, 9, 'PERSON')]\n['Республиканское', ' ', 'большинство', ' ', 'взяло', ' ', 'под', ' ', 'контроль', ' ', 'Палату', ' ', 'представителей', '.', '', '\\n', '']\n[(47, 6, 'ORG'), (54, 14, 'ORG')]\n"
],
[
"stemmer = SnowballStemmer(\"russian\")\ndef preprocess(word):\n return stemmer.stem(word.lower())\n\ndef build_vocab(data):\n vocab = defaultdict(lambda: 0)\n\n for sent in data:\n for word in sent:\n stemmed = preprocess(word)\n if stemmed not in vocab:\n vocab[stemmed] = len(vocab) + 1\n\n return vocab",
"_____no_output_____"
],
[
"VOCAB = build_vocab(X)\nPAD_VALUE = len(VOCAB) + 1\nprint(len(VOCAB))",
"7669\n"
],
[
"def get_positions(sent):\n pos = []\n idx = 0\n for word in sent:\n cur_l = len(word)\n pos.append((idx, cur_l))\n idx += cur_l\n return pos",
"_____no_output_____"
],
[
"def pad_dataset(dataset, vocab):\n num_dataset = [torch.tensor([vocab[preprocess(word)] for word in sent]) for sent in dataset]\n return pad_sequence(num_dataset, batch_first=True, padding_value=PAD_VALUE)\nX_padded = pad_dataset(X, VOCAB)",
"_____no_output_____"
],
[
"def pos_dataset(dataset):\n return [get_positions(sent) for sent in dataset]\nX_pos = pos_dataset(X)",
"_____no_output_____"
],
[
"def pair_X_Y(X_padded, X_pos, Y):\n dataset = []\n tag_to_int = {\n 'NONE': 0,\n 'PERSON': 1,\n 'ORG': 2\n }\n for sent, pos, tags in zip(X_padded, X_pos, Y):\n y = []\n pos_i = 0\n tag_i = 0\n\n for word in sent:\n if pos_i < len(pos) and tag_i < len(tags) and pos[pos_i][0] == tags[tag_i][0]:\n y.append(tag_to_int[tags[tag_i][2]])\n tag_i += 1\n else:\n y.append(tag_to_int['NONE'])\n pos_i += 1\n \n dataset.append([sent.numpy(), y])\n\n return np.array(dataset)",
"_____no_output_____"
],
[
"pairs_dataset = pair_X_Y(X_padded, X_pos, y)\nprint(pairs_dataset.shape)",
"(4906, 2, 169)\n"
],
[
"TRAIN_X_Y, VAL_X_Y = train_test_split(pairs_dataset, test_size=0.1, random_state=SEED)",
"_____no_output_____"
],
[
"class Model(nn.Module):\n def __init__(self, embedding_dim, hidden_dim, vocab_size):\n super(Model, self).__init__()\n self.emb = nn.Embedding(vocab_size, embedding_dim)\n self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=2, bidirectional=False, batch_first=True)\n self.fc2 = nn.Linear(hidden_dim, 3)\n \n def forward(self, batch):\n emb = self.emb(batch)\n out, _ = self.lstm(emb)\n tag_hidden = self.fc2(out)\n tag_probs = F.log_softmax(tag_hidden, dim=-1)\n return tag_probs",
"_____no_output_____"
],
[
"def train(model, train, val, epoch_cnt, batch_size):\n train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True)\n val_loader = torch.utils.data.DataLoader(val, batch_size=batch_size)\n loss_function = nn.NLLLoss()\n optimizer = optim.Adam(model.parameters(), lr=5e-4)\n train_loss_values = []\n val_loss_values = []\n \n for epoch in tnrange(epoch_cnt, desc='Epoch'):\n for batch_data in train_loader:\n x, y = batch_data[:, 0].to(device), batch_data[:, 1].to(device)\n optimizer.zero_grad()\n output = model(x.long())\n output = output.view(-1, 3)\n y = y.reshape(-1)\n loss = loss_function(output, y.long())\n train_loss_values.append(loss)\n loss.backward()\n nn.utils.clip_grad_norm_(model.parameters(), 5)\n optimizer.step()\n\n with torch.no_grad():\n loss_values = []\n for batch_data in val_loader:\n x, y = batch_data[:, 0].to(device), batch_data[:, 1].to(device)\n output = model(x.long())\n output = output.view(-1, 3)\n y = y.reshape(-1)\n loss = loss_function(output, y.long())\n loss_values.append(loss.item())\n val_loss_values.append(np.mean(np.array(loss_values)))\n\n return train_loss_values, val_loss_values",
"_____no_output_____"
],
[
"embed = 128\nhidden_dim = 256\nvocab_size = len(VOCAB) + 1\nepoch_cnt = 290\nbatch_size = 512",
"_____no_output_____"
],
[
"model = Model(embed, hidden_dim, vocab_size)\nmodel = model.float()\nmodel = model.to(device)",
"_____no_output_____"
],
[
"train_loss_values, val_loss_values =\\\n train(model, TRAIN_X_Y, VAL_X_Y, epoch_cnt, batch_size)",
"_____no_output_____"
],
[
"plt.plot(train_loss_values, label='train')\nplt.plot(np.arange(0, len(train_loss_values), len(train_loss_values) / epoch_cnt), val_loss_values, label='validation')\nplt.legend()\nplt.title(\"Loss values\")\nplt.show()",
"_____no_output_____"
],
[
"def read_test():\n test_filename = \"test.txt\"\n lines = []\n with open(test_filename, 'r') as test_file:\n for line in test_file:\n lines.append(re.split('(\\W)', line))\n return lines\nTEST = read_test()\nprint(TEST[0])",
"['И', ' ', 'лишь', ' ', 'в', ' ', '1994', ' ', 'г', '.', '', ' ', 'по', ' ', 'просьбе', ' ', 'руководителя', ' ', 'Баховской', ' ', 'Академии', ' ', 'в', ' ', 'Штутгарте', ' ', 'Хельмута', ' ', 'Риллинга', ' ', 'Эдисон', ' ', 'Денисов', ' ', 'завершил', ' ', 'партитуру', ' ', 'и', ' ', 'вдохнул', ' ', 'новую', ' ', 'жизнь', ' ', 'в', ' ', 'творение', ' ', 'немецкого', ' ', 'мастера', ' ', '', '—', '', ' ', 'опера', ' ', 'была', ' ', 'возвращена', ' ', 'из', ' ', 'забвения', ' ', 'подобно', ' ', 'тому', ',', '', ' ', 'как', ' ', 'был', ' ', 'воскрешен', ' ', 'ее', ' ', 'главный', ' ', 'герой', '.', '', '\\n', '']\n"
],
[
"def produce_test_results():\n test_padded = pad_dataset(TEST, VOCAB)\n test_pos = pos_dataset(TEST)\n with torch.no_grad():\n test_loader = torch.utils.data.DataLoader(test_padded, batch_size=batch_size)\n ans = None\n \n for batch_data in test_loader:\n x = batch_data.to(device)\n output = model(x.long())\n _, ansx = output.max(dim=-1)\n ansx = ansx.cpu().numpy()\n if ans is None:\n ans = ansx\n else:\n ans = np.append(ans, ansx, axis=0)\n out_filename = \"out.txt\"\n int_to_tag = {1:\"PERSON\" , 2:\"ORG\"}\n with open(out_filename, \"w\") as out:\n for sent, pos, tags in zip(test_padded, test_pos, ans):\n for i in range(len(pos)):\n if tags[i] in int_to_tag:\n out.write(\"%d %d %s \" % (pos[i][0], pos[i][1], int_to_tag[tags[i]]))\n out.write(\"EOL\\n\")\n \nproduce_test_results()",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d02ee3805d264f9350212b9368ff767af4041eb3
| 4,902 |
ipynb
|
Jupyter Notebook
|
ejercicios/D1_E2_callbacks_SOLUCION.ipynb
|
lcmencia/penguin-tf-workshop
|
b4491c6a587fe80c15f98527b13b91822f760e6b
|
[
"MIT"
] | 10 |
2020-01-17T23:20:33.000Z
|
2020-03-30T20:13:55.000Z
|
ejercicios/D1_E2_callbacks_SOLUCION.ipynb
|
lcmencia/penguin-tf-workshop
|
b4491c6a587fe80c15f98527b13b91822f760e6b
|
[
"MIT"
] | null | null | null |
ejercicios/D1_E2_callbacks_SOLUCION.ipynb
|
lcmencia/penguin-tf-workshop
|
b4491c6a587fe80c15f98527b13b91822f760e6b
|
[
"MIT"
] | 6 |
2020-01-21T22:35:53.000Z
|
2020-01-28T15:47:44.000Z
| 26.074468 | 249 | 0.573643 |
[
[
[
"# Fashion MNIST con terminación temprana\n\nUsando el modelo del ejercicio anterior, en este notebooks aprenderás a crear tu callback y terminar tempranamente el entrenamiento de tu modelo.\n\n# Ejercicio 1 - importar tensorflow\n\nprimero que nada, importa las bibliotecas que consideres necesarias\n\n\n",
"_____no_output_____"
]
],
[
[
"%tensorflow_version 2.x\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"# Ejercicio 2 - crear el callback\n\nEscribe un callback que resulte en la terminación temprana del entrenamiento cuando el modelo llegue a más de 80% de precisión. Imprime un mensaje en la consola explicando el motivo de la terminación temprana y el número de *epoch* al usuario.",
"_____no_output_____"
]
],
[
[
"class CallbackPenguin(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if logs.get('accuracy') > 0.85:\n print('\\nEl modelo ha llegado a 85% de precisión, terminando entrenamiento en el epoch', epoch + 1)\n self.model.stop_training = True",
"_____no_output_____"
]
],
[
[
"# Ejercicio 3 - cargar el *dataset*\n\nCarga el *dataset* de Fashion MNIST y normaliza las imágenes del dataset (recuerda que se deben normalizar tanto las imágenes del *training set* y las del *testing set*)",
"_____no_output_____"
]
],
[
[
"(train_imgs, train_labels), (test_imgs, test_labels) = tf.keras.datasets.fashion_mnist.load_data()\ntrain_imgs = train_imgs/255.0\ntest_imgs = test_imgs/255.0",
"_____no_output_____"
]
],
[
[
"# Ejercicio 4 - crear el modelo\n\nRecrea el modelo del ejercicio anterior, y compila el modelo.",
"_____no_output_____"
]
],
[
[
"# crear el modelo\nmodel = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)), \n tf.keras.layers.Dense(100, activation=tf.nn.relu), \n tf.keras.layers.Dense(10, activation=tf.nn.softmax)])\n# compilar el modelo\nmodel.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"# Ejercicio 4 - entrenar el modelo\n\nEntrena el modelo usando el comando `fit` y el callback que escribiste en el ejercicio 2.",
"_____no_output_____"
]
],
[
[
"callback_penguin = CallbackPenguin()\nmodel.fit(train_imgs, train_labels, epochs=50, callbacks=[callback_penguin])",
"_____no_output_____"
]
],
[
[
"Felicitaciones! \n\nSi terminaste estos ejercicios, te darás cuenta que más o menos 15 líneas de código son suficientes para implementar un clasificador de imágenes, incluyendo su entrenamiento con la opción de terminar tempranamente!\n\nEsto finaliza el primer día del workshop.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d02eeaee296e0064e63be51986016ee77e52ba77
| 96,902 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb
|
danelle1126/web-scraping-challenge
|
8937448f5a0b6e57ee89099395c64d6787197f5e
|
[
"ADSL"
] | null | null | null |
.ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb
|
danelle1126/web-scraping-challenge
|
8937448f5a0b6e57ee89099395c64d6787197f5e
|
[
"ADSL"
] | null | null | null |
.ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb
|
danelle1126/web-scraping-challenge
|
8937448f5a0b6e57ee89099395c64d6787197f5e
|
[
"ADSL"
] | null | null | null | 38.514308 | 1,076 | 0.423407 |
[
[
[
"# Import Splinter, BeautifulSoup, and Pandas\nfrom splinter import Browser\nfrom bs4 import BeautifulSoup as soup\nimport pandas as pd\nfrom webdriver_manager.chrome import ChromeDriverManager",
"_____no_output_____"
],
[
"# Set up Splinter\nexecutable_path = {'executable_path': ChromeDriverManager().install()}\nbrowser = Browser('chrome', **executable_path, headless=False)",
"\n\n====== WebDriver manager ======\nCurrent google-chrome version is 96.0.4664\nGet LATEST chromedriver version for 96.0.4664 google-chrome\nDriver [C:\\Users\\jaw_m\\.wdm\\drivers\\chromedriver\\win32\\96.0.4664.45\\chromedriver.exe] found in cache\n"
]
],
[
[
"## Visit the NASA mars news site",
"_____no_output_____"
]
],
[
[
"# Visit the Mars news site\nurl = 'https://redplanetscience.com/'\nbrowser.visit(url)\n\n# Optional delay for loading the page\nbrowser.is_element_present_by_css('div.list_text', wait_time=1)",
"_____no_output_____"
],
[
"# Convert the browser html to a soup object\nhtml = browser.html\nnews_soup = soup(html, 'html.parser')\n\nslide_elem = news_soup.select_one('div.list_text')",
"_____no_output_____"
],
[
"print(news_soup.prettify())",
"<html>\n <head>\n <meta charset=\"utf-8\"/>\n <meta content=\"width=device-width, initial-scale=1\" name=\"viewport\"/>\n <link crossorigin=\"anonymous\" href=\"https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css\" integrity=\"sha384-giJF6kkoqNQ00vy+HMDP7azOuL0xtbfIcaT9wjKHr8RbDVddVHyTfAAsrekwKmP1\" rel=\"stylesheet\"/>\n <link href=\"css/font.css\" rel=\"stylesheet\" type=\"text/css\"/>\n <link href=\"css/app.css\" rel=\"stylesheet\" type=\"text/css\"/>\n <link crossorigin=\"anonymous\" href=\"https://pro.fontawesome.com/releases/v5.10.0/css/all.css\" integrity=\"sha384-AYmEC3Yw5cVb3ZcuHtOA93w35dYTsvhLPVnYs9eStHfGJvOvKxVfELGroGkvsg+p\" rel=\"stylesheet\"/>\n <title>\n News - Mars Exploration Program\n </title>\n </head>\n <body>\n <div class=\"col-md-12\">\n <div class=\"row\">\n <nav class=\"navbar navbar-expand-lg navbar-light fixed-top\">\n <div class=\"container-fluid\">\n <a class=\"navbar-brand\" href=\"#\">\n <img src=\"image/nasa.png\" width=\"80\"/>\n <span class=\"logo\">\n MARS Planet Science\n </span>\n <span class=\"logo1\">\n Exploration Program\n </span>\n </a>\n <button aria-controls=\"navbarNav\" aria-expanded=\"false\" aria-label=\"Toggle navigation\" class=\"navbar-toggler\" data-bs-target=\"#navbarNav\" data-bs-toggle=\"collapse\" type=\"button\">\n <span class=\"navbar-toggler-icon\">\n </span>\n </button>\n <div class=\"collapse navbar-collapse justify-content-end\" id=\"navbarNav\">\n <ul class=\"navbar-nav\">\n <li class=\"nav-item\">\n <a aria-current=\"page\" class=\"nav-link active\" href=\"#\">\n The Red Planet\n </a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"#\">\n The Program\n </a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"#\">\n News & Events\n </a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"#\">\n Multimedia\n </a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"#\">\n Missions\n </a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"#\">\n More\n </a>\n </li>\n <li class=\"nav-item nav_search\">\n <a class=\"nav-link\" href=\"#\">\n </a>\n </li>\n </ul>\n </div>\n </div>\n </nav>\n <section class=\"search\">\n <div class=\"container\">\n <h1>\n News\n </h1>\n <div class=\"col-md-12 filter\">\n <div class=\"row\">\n <div class=\"col-md-3 search_binder\">\n <input class=\"search_field\" name=\"search\" type=\"text\"/>\n <input class=\"search_submit\" name=\"search\" type=\"text\"/>\n </div>\n <div class=\"col-md-3\">\n <select aria-label=\"Default select example\" class=\"form-select\" id=\"year\">\n <option selected=\"\">\n Latest\n </option>\n <option>\n 2020\n </option>\n <option>\n 2019\n </option>\n </select>\n </div>\n <div class=\"col-md-3\">\n <select aria-label=\"Default select example\" class=\"form-select\" id=\"cat\">\n <option selected=\"\">\n All Categories\n </option>\n <option>\n Feature Stories\n </option>\n <option>\n Status Reports\n </option>\n <option>\n Press Releases\n </option>\n </select>\n </div>\n <div class=\"col-md-3\">\n </div>\n </div>\n </div>\n </div>\n </section>\n <section class=\"image_and_description_container\">\n <div class=\"container\" id=\"news\">\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8736_PIA24043-Rover-and-Helicopter-320x240.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 16, 2021\n </div>\n <div class=\"content_title\">\n NASA's Ingenuity Mars Helicopter Recharges Its Batteries in Flight\n </div>\n <div class=\"article_teaser_body\">\n Headed to the Red Planet with the Perseverance rover, the pioneering helicopter is powered up for the first time in interplanetary space as part of a systems check.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8699_helicopter-delivery-system-320.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 15, 2021\n </div>\n <div class=\"content_title\">\n How NASA's Mars Helicopter Will Reach the Red Planet's Surface\n </div>\n <div class=\"article_teaser_body\">\n The small craft will seek to prove that powered, controlled flight is possible on another planet. But just getting it onto the surface of Mars will take a whole lot of ingenuity.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8770_PIA24047-320.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 13, 2021\n </div>\n <div class=\"content_title\">\n NASA's Perseverance Rover Will Peer Beneath Mars' Surface\n </div>\n <div class=\"article_teaser_body\">\n The agency's newest rover will use the first ground-penetrating radar instrument on the Martian surface to help search for signs of past microbial life.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8548_mars_seasonal_oxygen_gale_crater-320x240.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 12, 2021\n </div>\n <div class=\"content_title\">\n With Mars Methane Mystery Unsolved, Curiosity Serves Scientists a New One: Oxygen\n </div>\n <div class=\"article_teaser_body\">\n For the first time in the history of space exploration, scientists have measured the seasonal changes in the gases that fill the air directly above the surface of Gale Crater on Mars.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8719_launch-at-home-320.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 5, 2021\n </div>\n <div class=\"content_title\">\n NASA Invites Public to Share Excitement of Mars 2020 Perseverance Rover Launch\n </div>\n <div class=\"article_teaser_body\">\n There are lots of ways to participate in the historic event, which is targeted for July 30.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8609_list_image.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n December 4, 2021\n </div>\n <div class=\"content_title\">\n NASA's Mars Reconnaissance Orbiter Undergoes Memory Update\n </div>\n <div class=\"article_teaser_body\">\n Other orbiters will continue relaying data from Mars surface missions for a two-week period.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8660_24934_3-courtesyRupanifamily-320x240.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 30, 2021\n </div>\n <div class=\"content_title\">\n Q&A with the Student Who Named Ingenuity, NASA's Mars Helicopter\n </div>\n <div class=\"article_teaser_body\">\n As a longtime fan of space exploration, Vaneeza Rupani appreciates the creativity and collaboration involved with trying to fly on another planet.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8606_list_image.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 30, 2021\n </div>\n <div class=\"content_title\">\n NASA Prepares for Moon and Mars With New Addition to Its Deep Space Network\n </div>\n <div class=\"article_teaser_body\">\n Robotic spacecraft will be able to communicate with the dish using radio waves and lasers.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8630_PIA23768-320x240.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 26, 2021\n </div>\n <div class=\"content_title\">\n NASA's Mars Perseverance Rover Gets Its Sample Handling System\n </div>\n <div class=\"article_teaser_body\">\n The system will be collecting and storing Martian rock and soil. Its installation marks another milestone in the march toward the July launch period.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8408_22206_PIA22655-th.gif\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 25, 2021\n </div>\n <div class=\"content_title\">\n The MarCO Mission Comes to an End\n </div>\n <div class=\"article_teaser_body\">\n The pair of briefcase-sized satellites made history when they sailed past Mars in 2019.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8695_24732_PIA23499-226.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 24, 2021\n </div>\n <div class=\"content_title\">\n The Launch Is Approaching for NASA's Next Mars Rover, Perseverance\n </div>\n <div class=\"article_teaser_body\">\n The Red Planet's surface has been visited by eight NASA spacecraft. The ninth will be the first that includes a roundtrip ticket in its flight plan.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8522_PIA21261-320x240.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 22, 2021\n </div>\n <div class=\"content_title\">\n NASA's Curiosity Rover Finds an Ancient Oasis on Mars\n </div>\n <div class=\"article_teaser_body\">\n New evidence suggests salty, shallow ponds once dotted a Martian crater — a sign of the planet's drying climate.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8687_PIA23893-Odyssey-Phobos-320.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 22, 2021\n </div>\n <div class=\"content_title\">\n Three New Views of Mars' Moon Phobos\n </div>\n <div class=\"article_teaser_body\">\n Taken with the infrared camera aboard NASA's Odyssey orbiter, they reveal temperature variations on the small moon as it drifts into and out of Mars’ shadow.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8817_PIA23180_320.gif\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 19, 2021\n </div>\n <div class=\"content_title\">\n 3 Things We've Learned From NASA's Mars InSight\n </div>\n <div class=\"article_teaser_body\">\n Scientists are finding new mysteries since the geophysics mission landed two years ago.\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-md-12\">\n <hr/>\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"list_image\">\n <img src=\"https://mars.nasa.gov/system/news_items/list_view_images/8794_PIA23496-320.jpg\"/>\n </div>\n </div>\n <div class=\"col-md-8\">\n <div class=\"list_text\">\n <div class=\"list_date\">\n November 17, 2021\n </div>\n <div class=\"content_title\">\n Independent Review Indicates NASA Prepared for Mars Sample Return Campaign\n </div>\n <div class=\"article_teaser_body\">\n NASA released an independent review report Tuesday indicating the agency is well positioned for its Mars Sample Return campaign to bring pristine samples from Mars to Earth for scientific study.\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n <hr class=\"container\" style=\"margin: 25px auto;width: 83%;\"/>\n <button class=\"btn disable\" id=\"more\" onclick=\"populateContent()\">\n More\n </button>\n </section>\n <section class=\"last_news\">\n <div class=\"container\">\n <div class=\"row\">\n <div class=\"col-12\">\n <h2>\n You Might Also Like\n </h2>\n </div>\n <!-- <a class=\" prev\" href=\"#carouselExampleIndicators2\" role=\"button\" data-slide=\"prev\">\n <i class=\"fas fa-angle-left\"></i>\n </a>\n <a class=\" next\" href=\"#carouselExampleIndicators2\" role=\"button\" data-slide=\"next\">\n <i class=\"fas fa-angle-right\"></i>\n </a> -->\n <div class=\"col-12\">\n <div class=\"carousel slide\" data-ride=\"carousel\" id=\"carouselExampleIndicators2\">\n <div class=\"carousel-inner\">\n <div class=\"carousel-item active\">\n <div class=\"row\">\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://mars.nasa.gov/system/news_items/main_images/8716_PIA23499-16.jpg\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n NASA to Broadcast Mars 2020 Perseverance Launch, Prelaunch Activities\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://mars.nasa.gov/system/news_items/main_images/8716_PIA23499-16.jpg\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n The Launch Is Approaching for NASA's Next Mars Rover, Perseverance\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://mars.nasa.gov/system/news_items/main_images/8692_PIA23920-web.jpg\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n NASA to Hold Mars 2020 Perseverance Rover Launch Briefing\n </p>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"carousel-item\">\n <div class=\"row\">\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1532771098148-525cefe10c23?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=3f317c1f7a16116dec454fbc267dd8e4\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1532715088550-62f09305f765?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=ebadb044b374504ef8e81bdec4d0e840\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1506197603052-3cc9c3a201bd?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=0754ab085804ae8a3b562548e6b4aa2e\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"carousel-item\">\n <div class=\"row\">\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1507525428034-b723cf961d3e?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=ee8417f0ea2a50d53a12665820b54e23\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1532777946373-b6783242f211?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=8ac55cf3a68785643998730839663129\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4 mb-3\">\n <div class=\"card\">\n <img alt=\"100%x280\" class=\"img-fluid\" src=\"https://images.unsplash.com/photo-1532763303805-529d595877c5?ixlib=rb-0.3.5&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjMyMDc0fQ&s=5ee4fd5d19b40f93eadb21871757eda6\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n With supporting text below as a natural lead-in to additional content.\n </p>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </section>\n <section class=\"footer\">\n <div class=\"container\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-3\">\n <h5>\n The Red Planet\n </h5>\n <ul>\n <li>\n Dashboard\n </li>\n <li>\n Science Goals\n </li>\n <li>\n The Planet\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h5>\n The Program\n </h5>\n <ul>\n <li>\n Mission Statement\n </li>\n <li>\n About the Program\n </li>\n <li>\n Organization Why Mars?\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h5>\n Multimedia\n </h5>\n <ul>\n <li>\n Images\n </li>\n <li>\n Videos\n </li>\n <li>\n More Resources\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h5>\n Missions\n </h5>\n <ul>\n <li>\n Past\n </li>\n <li>\n Present\n </li>\n <li>\n Future\n </li>\n </ul>\n </div>\n </div>\n </div>\n </div>\n </section>\n <script src=\"https://code.jquery.com/jquery-1.12.4.min.js\" type=\"text/javascript\">\n </script>\n <script src=\"https://cdn.jsdelivr.net/npm/@popperjs/core@2.5.4/dist/umd/popper.min.js\">\n </script>\n <script src=\"https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/js/bootstrap.min.js\">\n </script>\n <script src=\"js/app.js\">\n </script>\n </div>\n </div>\n </body>\n</html>\n"
],
[
"slide_elem = news_soup.body.find('div', class_=\"content_title\")",
"_____no_output_____"
],
[
"#display the current title content\n",
"_____no_output_____"
],
[
"news_title = slide_elem.find('div', class_=\"content_title\").get_text()\nnews_title",
"_____no_output_____"
],
[
"# Use the parent element to find the first a tag and save it as `news_title`\n\nnews_title",
"_____no_output_____"
],
[
"news_p = slide_elem.find('div', class_=\"article_teaser_body\").get_text()\nnews_p",
"_____no_output_____"
],
[
"# Use the parent element to find the paragraph text\n\nnews_p",
"_____no_output_____"
]
],
[
[
"## JPL Space Images Featured Image",
"_____no_output_____"
]
],
[
[
"# Visit URL\nurl = 'https://spaceimages-mars.com'\nbrowser.visit(url)",
"_____no_output_____"
],
[
"# Find and click the full image button\nfull_image_link = browser.find_by_tag('button')[1]\nfull_image_link.click()",
"_____no_output_____"
],
[
"# Parse the resulting html with soup\nhtml = browser.html\nimg_soup = soup(html, 'html.parser')",
"_____no_output_____"
],
[
"print(img_soup.prettify())",
"<html class=\"fancybox-margin fancybox-lock\">\n <head>\n <meta charset=\"utf-8\"/>\n <meta content=\"width=device-width, initial-scale=1\" name=\"viewport\"/>\n <link href=\"https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css\" rel=\"stylesheet\"/>\n <!-- <link rel=\"stylesheet\" type=\"text/css\" href=\"css/font.css\"> -->\n <link href=\"css/app.css\" rel=\"stylesheet\" type=\"text/css\"/>\n <link href=\"https://stackpath.bootstrapcdn.com/font-awesome/4.7.0/css/font-awesome.min.css\" rel=\"stylesheet\" type=\"text/css\"/>\n <title>\n Space Image\n </title>\n <style type=\"text/css\">\n .fancybox-margin{margin-right:17px;}\n </style>\n </head>\n <body>\n <div class=\"header\">\n <nav class=\"navbar navbar-expand-lg\">\n <a class=\"navbar-brand\" href=\"#\">\n <img id=\"logo\" src=\"image/nasa.png\"/>\n <span class=\"logo\">\n Jet Propulsion Laboratory\n </span>\n <span class=\"logo1\">\n California Institute of Technology\n </span>\n </a>\n <button aria-controls=\"navbarNav\" aria-expanded=\"false\" aria-label=\"Toggle navigation\" class=\"navbar-toggler\" data-target=\"#navbarNav\" data-toggle=\"collapse\" type=\"button\">\n <span class=\"navbar-toggler-icon\">\n </span>\n </button>\n <div class=\"collapse navbar-collapse justify-content-end\" id=\"navbarNav\">\n <ul class=\"navbar-nav\">\n <li class=\"nav-item active\">\n <a class=\"nav-link\" href=\"#\">\n <i aria-hidden=\"true\" class=\"fa fa-bars\">\n </i>\n MENU\n <i aria-hidden=\"true\" class=\"fa fa-search\">\n </i>\n </a>\n </li>\n </ul>\n </div>\n </nav>\n <div class=\"floating_text_area\">\n <h2 class=\"brand_title\">\n FEATURED IMAGE\n </h2>\n <h1 class=\"media_feature_title\">\n Dusty Space Cloud\n </h1>\n <br/>\n <a class=\"showimg fancybox-thumbs\" href=\"image/featured/mars1.jpg\" target=\"_blank\">\n <button class=\"btn btn-outline-light\">\n FULL IMAGE\n </button>\n </a>\n </div>\n <img class=\"headerimage fade-in\" src=\"image/featured/mars1.jpg\"/>\n </div>\n <div class=\"search sticky\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-6\">\n <input name=\"Search\" placeholder=\"Search\" type=\"text\"/>\n </div>\n <div class=\"col-md-6\">\n <select aria-label=\"Default select example\" class=\"form-select\" id=\"options\">\n <option onchange=\"0\" selected=\"\">\n Mars\n </option>\n <!-- <option data-filter=\"sun\" class=\"button\">Mars</option> -->\n <option class=\"button\" data-filter=\"Sun\">\n Sun\n </option>\n <option class=\"button\" data-filter=\"earth\">\n Earth\n </option>\n <option class=\"button\" data-filter=\"ida\">\n Ida\n </option>\n <option class=\"button\" data-filter=\"jupiter\">\n Jupiter\n </option>\n <option class=\"button\" data-filter=\"venus\">\n Venus\n </option>\n </select>\n </div>\n </div>\n </div>\n </div>\n <div class=\"container mt-5\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-6\">\n <h1>\n Images\n </h1>\n </div>\n <div class=\"col-md-6\" id=\"icon\">\n <div class=\"icon2\">\n </div>\n <div class=\"icon1\">\n </div>\n </div>\n </div>\n </div>\n <!-- first div -->\n <div class=\"div1\" id=\"filter\">\n <div class=\"thmbgroup\">\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae7.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Icaria Fossae7\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Proctor Crater Dunes 7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Proctor Crater Dunes 7.jpg\"/>\n <p class=\"thumbcontent\">\n December 31, 2020\n <br/>\n Proctor Crater Dunes\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae7.jpg\"/>\n <p class=\"thumbcontent\">\n December 31, 2020\n <br/>\n Icaria Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Proctor Crater Dunes 7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Proctor Crater Dunes 7.jpg\"/>\n <p class=\"thumbcontent\">\n December 29, 2020\n <br/>\n Proctor Crater Dunes\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Proctor Crater Dunes 7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Proctor Crater Dunes 7.jpg\"/>\n <p class=\"thumbcontent\">\n December 28, 2020\n <br/>\n roctor Crater Dunes\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae7.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae7.jpg\"/>\n <p class=\"thumbcontent\">\n December 22, 2020\n <br/>\n Icaria Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae.jpg\"/>\n <p class=\"thumbcontent\">\n December 21, 2020\n <br/>\n Icaria Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Ariadnes Colles4.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Ariadnes Colles4.jpg\"/>\n <p class=\"thumbcontent\">\n December 18, 2020\n <br/>\n Ariadnes Colles\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Niger Vallis.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Niger Vallis.jpg\"/>\n <p class=\"thumbcontent\">\n December 17, 2020\n <br/>\n Niger Vallis\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Proctor Crater Dunes.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Proctor Crater Dunes.jpg\"/>\n <p class=\"thumbcontent\">\n December 16, 2020\n <br/>\n Proctor Crater Dunes\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Niger Vallis.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Niger Vallis.jpg\"/>\n <p class=\"thumbcontent\">\n December 15, 2020\n <br/>\n Niger Vallis\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Daedalia Planum.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Daedalia Planum.jpg\"/>\n <p class=\"thumbcontent\">\n December 11, 2020\n <br/>\n Daedalia Planum\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Sirenum Fossae.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Sirenum Fossae.jpg\"/>\n <p class=\"thumbcontent\">\n November,11, 2020\n <br/>\n Sirenum Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Ariadnes Colles4.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Ariadnes Colles4.jpg\"/>\n <p class=\"thumbcontent\">\n November,13, 2020\n <br/>\n Ariadnes Colles\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/South Polar Cap.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/South Polar Cap.jpg\"/>\n <p class=\"thumbcontent\">\n November,14, 2020\n <br/>\n South Polar Cap\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Daedalia Planum.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Daedalia Planum.jpg\"/>\n <p class=\"thumbcontent\">\n November,17, 2020\n <br/>\n Daedalia Planum\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Ariadnes Colles3.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Ariadnes Colles3.jpg\"/>\n <p class=\"thumbcontent\">\n November,11, 2020\n <br/>\n Ariadnes Colles\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Atlantis Chaos.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Atlantis Chaos.jpg\"/>\n <p class=\"thumbcontent\">\n November,09, 2020\n <br/>\n Atlantis Chaos\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Daedalia Planum.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Daedalia Planum.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Daedalia Planum\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Icaria Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Niger Vallis.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Niger Vallis.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Niger Vallis\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Proctor Crater Dunes.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Proctor Crater Dunes.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Proctor Crater Dunes\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Reull Vallis.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Reull Vallis.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Reull Vallis\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Ariadnes Colles3.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Ariadnes Colles3.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Ariadnes Colles\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Sirenum Fossae.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Sirenum Fossae.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Sirenum Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/South Polar Cap.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/South Polar Cap.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n South Polar Cap\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Niger Vallis.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Niger Vallis.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Niger Vallis\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Daedalia Planum.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Daedalia Planum.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Daedalia Planum\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Icaria Fossae.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Icaria Fossae.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Icaria Fossae\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Ariadnes Colles4.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Ariadnes Colles4.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Ariadnes Colles\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/South Polar Cap.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/South Polar Cap.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n South Polar Cap\n </p>\n </div>\n </a>\n <a class=\"fancybox-thumbs\" data-fancybox-group=\"thumb\" href=\"image/mars/Daedalia Planum.jpg\">\n <div class=\"thmb\">\n <img alt=\"\" class=\"thumbimg\" src=\"image/mars/Daedalia Planum.jpg\"/>\n <p class=\"thumbcontent\">\n January 1, 2020\n <br/>\n Daedalia Planum\n </p>\n </div>\n </a>\n </div>\n </div>\n <!-- first div ends -->\n <!-- second div starts -->\n <div class=\"col-md-12 grid-margin\" id=\"column\">\n <ul class=\"post-list\">\n <li class=\"post-heading\">\n </li>\n </ul>\n </div>\n <!-- second div starts -->\n </div>\n <div class=\"first imgcontainer mt-3\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-3\">\n <img id=\"pic\" src=\"\"/>\n </div>\n </div>\n </div>\n </div>\n <!-- end -->\n <div class=\"module_gallery container\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-6\">\n <div class=\"card\">\n <img alt=\"Card image cap\" class=\"card-img-top\" src=\"https://www.jpl.nasa.gov/assets/images/content/tmp/images/jpl_photojournal(3x1).jpg\"/>\n <div class=\"card-body\">\n <h5 class=\"card-title\">\n JPL Photojournal\n </h5>\n <p class=\"card-text\">\n Access to the full library of publicly released images from various Solar System exploration programs\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-6\">\n <div class=\"card\">\n <img alt=\"Card image cap\" class=\"card-img-top\" src=\"https://www.jpl.nasa.gov/assets/images/content/tmp/images/nasa_images(3x1).jpg\"/>\n <div class=\"card-body\">\n <h5 class=\"card-title\">\n Great images in NASA\n </h5>\n <p class=\"card-text\">\n A selection of the best-known images from a half-century of exploration and discovery\n </p>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"multi_teaser\">\n <div class=\"container\">\n <h1>\n You Might Also Like\n </h1>\n <div class=\"col-md-12 mt-5\">\n <div class=\"row\">\n <div class=\"col-md-4\">\n <div class=\"card\">\n <img alt=\"Card image cap\" class=\"card-img-top\" src=\"https://imagecache.jpl.nasa.gov/images/640x350/C1-PIA24304---CatScanMars-16-640x350.gif\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n Access to the full library of publicly released images from various Solar System exploration programs\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4\">\n <div class=\"card\">\n <img alt=\"Card image cap\" class=\"card-img-top\" src=\"https://imagecache.jpl.nasa.gov/images/640x350/PIA23491-16-640x350.jpg\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n Access to the full library of publicly released images from various Solar System exploration programs\n </p>\n </div>\n </div>\n </div>\n <div class=\"col-md-4\">\n <div class=\"card\">\n <img alt=\"Card image cap\" class=\"card-img-top\" src=\"https://imagecache.jpl.nasa.gov/images/640x350/C1-PIA23180-16-640x350.gif\"/>\n <div class=\"card-body\">\n <p class=\"card-text\">\n Access to the full library of publicly released images from various Solar System exploration programs\n </p>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"footer\">\n <div class=\"container\">\n <div class=\"col-md-12\">\n <div class=\"row\">\n <div class=\"col-md-3\">\n <h4>\n About JPL\n </h4>\n <ul>\n <li>\n About JPL\n </li>\n <li>\n JPL Vision\n </li>\n <li>\n Executive Council\n </li>\n <li>\n History\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h4>\n Education\n </h4>\n <ul>\n <li>\n Intern\n </li>\n <li>\n Learn\n </li>\n <li>\n Teach\n </li>\n <li>\n News\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h4>\n Our Sites\n </h4>\n <ul>\n <li>\n Asteroid Watch\n </li>\n <li>\n Basics of Spaceflight\n </li>\n <li>\n Cassini - Mission to Saturn\n </li>\n <li>\n Climate Kids\n </li>\n </ul>\n </div>\n <div class=\"col-md-3\">\n <h4>\n Galleries\n </h4>\n <ul>\n <li>\n JPL Space Images\n </li>\n <li>\n Videos\n </li>\n <li>\n Infographics\n </li>\n <li>\n Photojournal\n </li>\n </ul>\n </div>\n </div>\n </div>\n </div>\n </div>\n <!--<div class=\"showFullimage\">\n\t<button class=\"btn btn-outline-light hideimage\" onclick=hideimage()> Close</button>\n\t<img class=\"fullimage fade-in\" src=\"\">\n</div>-->\n <!-- <script src=\"js/jquery.easeScroll.js\"></script> -->\n <script src=\"js/jquery-3.5.1.min.js\">\n </script>\n <!-- <script src=\"js/jquery-3.2.1.slim.min.js\"></script> -->\n <script src=\"js/demo.js\">\n </script>\n <!-- <script src=\"js/app.js\"></script> -->\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js\">\n </script>\n <script src=\"https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js\">\n </script>\n <script src=\"js/fancyBox/jquery.fancybox.pack.js?v=2.1.5\" type=\"text/javascript\">\n </script>\n <link href=\"js/fancyBox/jquery.fancybox.css?v=2.1.5\" media=\"screen\" rel=\"stylesheet\" type=\"text/css\"/>\n <link href=\"js/fancyBox/helpers/jquery.fancybox-thumbs.css?v=1.0.7\" rel=\"stylesheet\" type=\"text/css\"/>\n <script src=\"js/fancyBox/helpers/jquery.fancybox-thumbs.js?v=1.0.7\" type=\"text/javascript\">\n </script>\n <div class=\"fancybox-overlay fancybox-overlay-fixed\" style=\"width: auto; height: auto; display: block;\">\n <div class=\"fancybox-wrap fancybox-desktop fancybox-type-image fancybox-opened\" style=\"width: 670px; height: auto; position: absolute; top: 253px; left: 121px; opacity: 1; overflow: visible;\" tabindex=\"-1\">\n <div class=\"fancybox-skin\" style=\"padding: 15px; width: auto; height: auto;\">\n <div class=\"fancybox-outer\">\n <div class=\"fancybox-inner\" style=\"overflow: visible; width: 640px; height: 350px;\">\n <img alt=\"\" class=\"fancybox-image\" src=\"image/featured/mars1.jpg\"/>\n </div>\n </div>\n <a class=\"fancybox-item fancybox-close\" href=\"javascript:;\" title=\"Close\">\n </a>\n </div>\n </div>\n </div>\n </body>\n</html>\n"
],
[
"img_url_rel = img_soup.find('img',class_='fancybox-image').get('src')\nimg_url_rel",
"_____no_output_____"
],
[
"# find the relative image url\n\nimg_url_rel",
"_____no_output_____"
],
[
"img_url = f'https://spaceimages-mars.com/{img_url_rel}'\nimg_url",
"_____no_output_____"
],
[
"# Use the base url to create an absolute url\n\nimg_url",
"_____no_output_____"
]
],
[
[
"## Mars Facts",
"_____no_output_____"
]
],
[
[
"url = 'https://galaxyfacts-mars.com'\nbrowser.visit(url)\nhtml = browser.html\nfacts_soup = soup(html, 'html.parser')",
"_____no_output_____"
],
[
"html = browser.html\nfacts_soup = soup(html, 'html.parser')",
"_____no_output_____"
],
[
"tables = pd.read_html(url)\ntables",
"_____no_output_____"
],
[
"df = tables[0]\ndf.head()",
"_____no_output_____"
],
[
"# Use `pd.read_html` to pull the data from the Mars-Earth Comparison section\n# hint use index 0 to find the table\n\ndf.head()",
"_____no_output_____"
],
[
"df.columns = ['Description','Mars','Earth']\ndf = df.iloc[1:]\ndf.set_index('Description',inplace=True)\ndf",
"_____no_output_____"
],
[
"\ndf",
"_____no_output_____"
],
[
"df.to_html()",
"_____no_output_____"
],
[
"df.to_html()",
"_____no_output_____"
]
],
[
[
"## Hemispheres",
"_____no_output_____"
]
],
[
[
"url = 'https://marshemispheres.com/'\nbrowser.visit(url)",
"_____no_output_____"
],
[
"html = browser.html\nhems_soup = soup(html, 'html.parser')",
"_____no_output_____"
],
[
"print(hems_soup.prettify())",
"<html lang=\"en\">\n <head>\n <meta content=\"text/html; charset=utf-8\" http-equiv=\"Content-Type\"/>\n <link href=\"css/jquery-ui.css\" rel=\"stylesheet\" type=\"text/css\"/>\n <title>\n Astropedia Search Results | GUSS Astrogeology Science Center\n </title>\n <meta content=\"GUSS Astrogeology Science Center Astropedia search results.\" name=\"description\"/>\n <meta content=\"GUSS,Astrogeology Science Center,Cartography,Geology,Space,Geological Survey,Mapping\" name=\"keywords\"/>\n <meta content=\"IE=edge\" http-equiv=\"X-UA-Compatible\"/>\n <meta content=\"width=device-width, initial-scale=1, maximum-scale=1\" name=\"viewport\"/>\n <link href=\"css/main.css\" media=\"screen\" rel=\"stylesheet\"/>\n <link href=\"css/print.css\" media=\"print\" rel=\"stylesheet\"/>\n <link href=\"#\" rel=\"icon\" type=\"image/x-ico\"/>\n </head>\n <body id=\"results\">\n <header>\n <a href=\"#\" style=\"float:right;margin-top:10px;\" target=\"_blank\">\n <img alt=\"USGS: Science for a Changing World\" class=\"logo\" height=\"60\" src=\"images/usgs_logo_main_2x.png\"/>\n </a>\n <a href=\"#\" style=\"float:right;margin-top:5px;margin-right:20px;\" target=\"_blank\">\n <img alt=\"NASA\" class=\"logo\" height=\"65\" src=\"images/nasa-logo-web-med.png\"/>\n </a>\n </header>\n <div class=\"wrapper\">\n <div class=\"container\">\n <div class=\"widget block bar\">\n <a href=\"https://astrogeology.usgs.gov/search\" style=\"float:right;text-decoration:none;\">\n <img alt=\"Astropedia\" src=\"images/astropedia-logo-main.png\" style=\"width:200px;border:none;float:right;\"/>\n <div style=\"clear:both;font-size:.8em;float:right;color:#888;\">\n Lunar and Planetary Cartographic Catalog\n </div>\n </a>\n <div style=\"float:left;height:60px;\">\n </div>\n </div>\n <div class=\"full-content\">\n <section class=\"block\" id=\"results-accordian\">\n <div class=\"result-list\" data-section=\"product\" id=\"product-section\">\n <div class=\"accordian\">\n <h2>\n Products\n </h2>\n <span class=\"count\">\n 4 Results\n </span>\n <span class=\"collapse\">\n Collapse\n </span>\n </div>\n <div class=\"collapsible results\">\n <div class=\"item\">\n <a class=\"itemLink product-item\" href=\"cerberus.html\">\n <img alt=\"Cerberus Hemisphere Enhanced thumbnail\" class=\"thumb\" src=\"images/39d3266553462198bd2fbc4d18fbed17_cerberus_enhanced.tif_thumb.png\"/>\n </a>\n <div class=\"description\">\n <a class=\"itemLink product-item\" href=\"cerberus.html\">\n <h3>\n Cerberus Hemisphere Enhanced\n </h3>\n </a>\n <span class=\"subtitle\" style=\"float:left\">\n image/tiff 21 MB\n </span>\n <span class=\"pubDate\" style=\"float:right\">\n </span>\n <br/>\n <p>\n Mosaic of the Cerberus hemisphere of Mars projected into point perspective, a view similar to that which one would see from a spacecraft. This mosaic is composed of 104 Viking Orbiter images acquired…\n </p>\n </div>\n <!-- end description -->\n </div>\n <div class=\"item\">\n <a class=\"itemLink product-item\" href=\"schiaparelli.html\">\n <img alt=\"Schiaparelli Hemisphere Enhanced thumbnail\" class=\"thumb\" src=\"images/08eac6e22c07fb1fe72223a79252de20_schiaparelli_enhanced.tif_thumb.png\"/>\n </a>\n <div class=\"description\">\n <a class=\"itemLink product-item\" href=\"schiaparelli.html\">\n <h3>\n Schiaparelli Hemisphere Enhanced\n </h3>\n </a>\n <span class=\"subtitle\" style=\"float:left\">\n image/tiff 35 MB\n </span>\n <span class=\"pubDate\" style=\"float:right\">\n </span>\n <br/>\n <p>\n Mosaic of the Schiaparelli hemisphere of Mars projected into point perspective, a view similar to that which one would see from a spacecraft. The images were acquired in 1980 during early northern…\n </p>\n </div>\n <!-- end description -->\n </div>\n <div class=\"item\">\n <a class=\"itemLink product-item\" href=\"syrtis.html\">\n <img alt=\"Syrtis Major Hemisphere Enhanced thumbnail\" class=\"thumb\" src=\"images/55a0a1e2796313fdeafb17c35925e8ac_syrtis_major_enhanced.tif_thumb.png\"/>\n </a>\n <div class=\"description\">\n <a class=\"itemLink product-item\" href=\"syrtis.html\">\n <h3>\n Syrtis Major Hemisphere Enhanced\n </h3>\n </a>\n <span class=\"subtitle\" style=\"float:left\">\n image/tiff 25 MB\n </span>\n <span class=\"pubDate\" style=\"float:right\">\n </span>\n <br/>\n <p>\n Mosaic of the Syrtis Major hemisphere of Mars projected into point perspective, a view similar to that which one would see from a spacecraft. This mosaic is composed of about 100 red and violet…\n </p>\n </div>\n <!-- end description -->\n </div>\n <div class=\"item\">\n <a class=\"itemLink product-item\" href=\"valles.html\">\n <img alt=\"Valles Marineris Hemisphere Enhanced thumbnail\" class=\"thumb\" src=\"images/4e59980c1c57f89c680c0e1ccabbeff1_valles_marineris_enhanced.tif_thumb.png\"/>\n </a>\n <div class=\"description\">\n <a class=\"itemLink product-item\" href=\"valles.html\">\n <h3>\n Valles Marineris Hemisphere Enhanced\n </h3>\n </a>\n <span class=\"subtitle\" style=\"float:left\">\n image/tiff 27 MB\n </span>\n <span class=\"pubDate\" style=\"float:right\">\n </span>\n <br/>\n <p>\n Mosaic of the Valles Marineris hemisphere of Mars projected into point perspective, a view similar to that which one would see from a spacecraft. The distance is 2500 kilometers from the surface of…\n </p>\n </div>\n <!-- end description -->\n </div>\n </div>\n <!-- end this-section -->\n </div>\n </section>\n </div>\n <div class=\"navigation clear\" style=\"display: none;\">\n <a class=\"itemLink product-item\" href=\"#\" onclick=\"showMain()\">\n <h3>\n Back\n </h3>\n </a>\n </div>\n </div>\n <footer>\n <div class=\"left\">\n <a href=\"#\">\n Search\n </a>\n |\n <a href=\"#\">\n About\n </a>\n |\n <a href=\"#\">\n Contact\n </a>\n </div>\n <div class=\"right\">\n <a href=\"#\">\n GUSS Science Center\n </a>\n </div>\n </footer>\n </div>\n <div class=\"page-background\" style=\"\n background:url('./images/mars.jpg');\n filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(\n src='./images/mars.jpg', sizingMethod='scale');\n \">\n </div>\n <script type=\"text/javascript\">\n var baseUrl = \"\";\n </script>\n <script src=\"js/jquery.min.js\" type=\"text/javascript\">\n </script>\n <script src=\"js/jquery-ui.min.js\" type=\"text/javascript\">\n </script>\n <script src=\"js/general.js\" type=\"text/javascript\">\n </script>\n </body>\n</html>\n"
],
[
"# Create a list to hold the images and titles.\nhemisphere_image_urls = []\n\n# Get a list of all of the hemispheres\nlinks = browser.find_by_css('a.product-item img')\n\n# Next, loop through those links, click the link, find the sample anchor, return the href\nfor i in range(len(links)):\n\n hemisphereInfo = {}\n\n # We have to find the elements on each loop to avoid a stale element exception\n browser.find_by_css('a.product-item img')[i].click()\n \n # Next, we find the Sample image anchor tag and extract the href\n sample = browser.links.find_by_text('Sample').first\n hemisphereInfo['img_url'] = sample['href']\n \n # Get Hemisphere title \n titleA = browser.find_by_css('h2.title').text\n hemisphereInfo['title'] = titleA.rpartition(' Enhanced')[0] \n\n # Append hemisphere object to list\n hemisphere_image_urls.append(hemisphereInfo)\n\n # Finally, we navigate backwards\n browser.back()\n \nhemisphere_image_urls",
"_____no_output_____"
],
[
"hemisphere_image_urls",
"_____no_output_____"
],
[
"browser.quit()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.