
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
d0044c78dfeb344d9e2261c200df73fb277d0a73
| 5,408 |
ipynb
|
Jupyter Notebook
|
docs/source/resources/faq.ipynb
|
flowersw/compose
|
d51a397988f4a9b78a489260b541d02d59a4d290
|
[
"BSD-3-Clause"
] | 181 |
2020-11-05T08:18:48.000Z
|
2022-03-31T16:35:48.000Z
|
docs/source/resources/faq.ipynb
|
evgeni-nikolaev/compose
|
cd59d7146b93ba413627648ca14010f3ed59c62a
|
[
"BSD-3-Clause"
] | 147 |
2019-08-14T18:45:44.000Z
|
2020-11-04T15:44:04.000Z
|
docs/source/resources/faq.ipynb
|
evgeni-nikolaev/compose
|
cd59d7146b93ba413627648ca14010f3ed59c62a
|
[
"BSD-3-Clause"
] | 21 |
2020-11-07T03:00:17.000Z
|
2022-03-15T01:27:30.000Z
| 74.082192 | 740 | 0.72966 |
[
[
[
"# FAQ\n\n## I have heard of autoML and automated feature engineering, how is this different?\n\nAutoML targets solving the problem once the labels or targets one wants to predict are well defined and available. Feature engineering focuses on generating features, given a dataset, labels, and targets. Both assume that the target a user wants to predict is already defined and computed. In most real world scenarios, this is something a data scientist has to do: define an outcome to predict and create labeled training examples. We structured this process and called it prediction engineering (a play on an already well defined process feature engineering). This library provides an easy way for a user to define the target outcome and generate training examples automatically from relational, temporal, multi entity datasets.\n\n## I have used Featuretools for competing in KAGGLE, how can I use Compose?\n\nIn most KAGGLE competitions the target to predict is already defined. In many cases, they follow the same way to represent training examples as us—“label times” (see here and here). Compose is a step prior to where KAGGLE starts. Indeed, it is a step that KAGGLE or the company sponsoring the competition might have to do or would have done before publishing the competition.\n\n## Why have I not encountered the need for Compose yet?\n\nIn many cases, setting up prediction problem is done independently before even getting started on the machine learning. This has resulted in a very skewed availability of datasets with already defined prediction problems and labels. A number of times it also results in a data scientist not knowing how the label was defined. In opening up this part of the process, we are enabling data scientists to more flexibly define problems, explore more problems and solve problems to maximize the end goal - ROI.\n\n## I already have “Label times” file, do I need Compose?\n\nIf you already have label times you don’t need LabelMaker and search. However, you could use the label transforms functionality of Compose to apply lead and threshold, as well as balance labels.\n\n## What is the best use of Compose?\n\nSince we have automated feature engineering and autoML, the best recommended use for Compose is to closely couple *LabelMaker* and *Search* functionality of Compose with the rest of the machine learning pipeline. Certain parameters used in *Search*, and *LabelMaker* and *label transforms* can be tuned alongside machine learning model.\n\n## Where can I read about your technical approach in detail?\n\nYou can read about prediction engineering, the way we defined the search algorithm and technical details in this peer reviewed paper published in IEEE international conference on data science and advanced analytics. If you’re interested, you can also watch a video here. Please note that some of our thinking and terminology has evolved as we built this library and applied Compose to different industrial scale problems.\n\n## Do you think Compose should be part of a data scientist’s toolkit?\n\nYes. As we mentioned above, extracting value out of your data is dependent on how you set the prediction problem. Currently, data scientists do not iterate through the setting up of the prediction problem because there is no structured way of doing it or algorithms and library to help do it. We believe that prediction engineering should be taken even more seriously than any other part of actually solving a problem.\n\n## How can I contribute labeling functions, or use cases?\n\nWe are happy for anyone who can provide interesting labeling functions. To contribute an interesting new use case and labeling function, we request you create a representative synthetic data set, a labeling function and the parameters for label maker. Once you have these three, you can write a brief explanation about the use case and do a pull request.\n\n## I have a transaction file with the label as the last column, what are my label times?\n\nYour label times is the . However, when such a data set is given one should ask for how that label was generated. It could be one of very many cases: a human could have assigned it based on their assessment/analysis, it could have been automatically generated by a system, or it could have been computed using some data. If it is the third case one should ask for the function that computed the label or rewrite it. If it is (1), one should note that the ref_time would be slightly after the transaction timestamp.",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
d0044d40317d574effd51923c16969f45e56b098
| 16,676 |
ipynb
|
Jupyter Notebook
|
practice-note/week_02/W02-2_advanced-text-mining_python-data-structure.ipynb
|
fingeredman/advanced-text-mining
|
68d2e7ee203363dd11da548e3ba92a5101b134fd
|
[
"Apache-2.0"
] | 15 |
2020-10-05T05:31:40.000Z
|
2022-03-19T01:50:03.000Z
|
practice-note/week_02/W02-2_advanced-text-mining_python-data-structure.ipynb
|
fingeredman/machine-learning-with-python
|
751168d68e2a10974716dcb700d287ff56cd0b8f
|
[
"Apache-2.0"
] | null | null | null |
practice-note/week_02/W02-2_advanced-text-mining_python-data-structure.ipynb
|
fingeredman/machine-learning-with-python
|
751168d68e2a10974716dcb700d287ff56cd0b8f
|
[
"Apache-2.0"
] | 1 |
2021-05-22T04:15:12.000Z
|
2021-05-22T04:15:12.000Z
| 22 | 110 | 0.448969 |
[
[
[
"# ADVANCED TEXT MINING\n\n- 본 자료는 텍스트 마이닝을 활용한 연구 및 강의를 위한 목적으로 제작되었습니다.\n- 본 자료를 강의 목적으로 활용하고자 하시는 경우 꼭 아래 메일주소로 연락주세요.\n- 본 자료에 대한 허가되지 않은 배포를 금지합니다.\n- 강의, 저작권, 출판, 특허, 공동저자에 관련해서는 문의 바랍니다.\n- **Contact : ADMIN(admin@teanaps.com)**\n\n---",
"_____no_output_____"
],
[
"## WEEK 02-2. Python 자료구조 이해하기\n- 텍스트 데이터를 다루기 위한 Python 자료구조에 대해 다룹니다.\n\n---",
"_____no_output_____"
],
[
"### 1. 리스트(LIST) 자료구조 이해하기\n\n---",
"_____no_output_____"
],
[
"#### 1.1. 리스트(LIST): 값 또는 자료구조를 저장할 수 있는 구조를 선언합니다.\n\n---",
"_____no_output_____"
]
],
[
[
"# 1) 리스트를 생성합니다.\nnew_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\nprint(new_list)",
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n"
],
[
"# 2) 리스트의 마지막 원소 뒤에 새로운 원소를 추가합니다.\nnew_list.append(100)\nprint(new_list)",
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 100]\n"
],
[
"# 3) 더하기 연산자를 활용해 두 리스트를 결합합니다.\nnew_list = new_list + [101, 102]\nprint(new_list)",
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 100, 101, 102]\n"
],
[
"# 4-1) 리스트에 존재하는 특정 원소 중 일치하는 가장 앞의 원소를 삭제합니다.\nnew_list.remove(3)\nprint(new_list)",
"[0, 1, 2, 4, 5, 6, 7, 8, 9, 100, 101, 102]\n"
],
[
"# 4-2) 리스트에 존재하는 N 번째 원소를 삭제합니다.\ndel new_list[3]\nprint(new_list)",
"[0, 1, 2, 5, 6, 7, 8, 9, 100, 101, 102]\n"
],
[
"# 5) 리스트에 존재하는 N 번째 원소의 값을 변경합니다.\nnew_list[0] = 105\nprint(new_list)",
"[105, 1, 2, 5, 6, 7, 8, 9, 100, 101, 102]\n"
],
[
"# 6) 리스트에 존재하는 모든 원소를 오름차순으로 정렬합니다.\nnew_list.sort()\n#new_list.sort(reverse=False)\nprint(new_list)",
"[1, 2, 5, 6, 7, 8, 9, 100, 101, 102, 105]\n"
],
[
"# 7) 리스트에 존재하는 모든 원소를 내림차순으로 정렬합니다.\nnew_list.sort(reverse=True)\nprint(new_list)",
"[105, 102, 101, 100, 9, 8, 7, 6, 5, 2, 1]\n"
],
[
"# 8) 리스트에 존재하는 모든 원소의 순서를 거꾸로 변경합니다.\nnew_list.reverse()\nprint(new_list)",
"[1, 2, 5, 6, 7, 8, 9, 100, 101, 102, 105]\n"
],
[
"# 9) 리스트에 존재하는 모든 원소의 개수를 불러옵니다.\nlength = len(new_list)\nprint(new_list)",
"[1, 2, 5, 6, 7, 8, 9, 100, 101, 102, 105]\n"
],
[
"# 10-1) 리스트에 특정 원소에 존재하는지 여부를 in 연산자를 통해 확인합니다.\nprint(100 in new_list)",
"True\n"
],
[
"# 10-2) 리스트에 특정 원소에 존재하지 않는지 여부를 not in 연산자를 통해 확인합니다.\nprint(100 not in new_list)",
"False\n"
]
],
[
[
"#### 1.2. 리스트(LIST) 인덱싱: 리스트에 존재하는 특정 원소를 불러옵니다.\n\n---",
"_____no_output_____"
]
],
[
[
"new_list = [0, 1, 2, 3, 4, 5, 6, 7, \"hjvjg\", 9]",
"_____no_output_____"
],
[
"# 1) 리스트에 존재하는 N 번째 원소를 불러옵니다.\nprint(\"0번째 원소 :\", new_list[0])\nprint(\"1번째 원소 :\", new_list[1])\nprint(\"4번째 원소 :\", new_list[4])",
"0번째 원소 : 0\n1번째 원소 : 1\n4번째 원소 : 4\n"
],
[
"# 2) 리스트에 존재하는 N번째 부터 M-1번째 원소를 리스트 형식으로 불러옵니다.\nprint(\"0~3번째 원소 :\", new_list[0:3])\nprint(\"4~9번째 원소 :\", new_list[4:9])\nprint(\"2~3번째 원소 :\", new_list[2:3])",
"0~3번째 원소 : [0, 1, 2]\n4~9번째 원소 : [4, 5, 6, 7, 8]\n2~3번째 원소 : [2]\n"
],
[
"# 3) 리스트에 존재하는 N번째 부터 모든 원소를 리스트 형식으로 불러옵니다.\nprint(\"3번째 부터 모든 원소 :\", new_list[3:])\nprint(\"5번째 부터 모든 원소 :\", new_list[5:])\nprint(\"9번째 부터 모든 원소 :\", new_list[9:])",
"3번째 부터 모든 원소 : [3, 4, 5, 6, 7, 8, 9]\n5번째 부터 모든 원소 : [5, 6, 7, 8, 9]\n9번째 부터 모든 원소 : [9]\n"
],
[
"# 4) 리스트에 존재하는 N번째 이전의 모든 원소를 리스트 형식으로 불러옵니다.\nprint(\"1번째 이전의 모든 원소 :\", new_list[:1])\nprint(\"7번째 이전의 모든 원소 :\", new_list[:7])\nprint(\"9번째 이전의 모든 원소 :\", new_list[:9])",
"1번째 이전의 모든 원소 : [0]\n7번째 이전의 모든 원소 : [0, 1, 2, 3, 4, 5, 6]\n9번째 이전의 모든 원소 : [0, 1, 2, 3, 4, 5, 6, 7, 8]\n"
],
[
"# 5) 리스트 인덱싱에 사용되는 정수 N의 부호가 음수인 경우, 마지막 원소부터 |N|-1번째 원소를 의미합니다.\nprint(\"끝에서 |-1|-1번째 이전의 모든 원소 :\", new_list[:-1])\nprint(\"끝에서 |-1|-1번째 부터 모든 원소 :\", new_list[-1:])\nprint(\"끝에서 |-2|-1번째 이전의 모든 원소 :\", new_list[:-2])\nprint(\"끝에서 |-2|-1번째 부터 모든 원소 :\", new_list[-2:])",
"끝에서 |-1|-1번째 이전의 모든 원소 : [0, 1, 2, 3, 4, 5, 6, 7, 8]\n끝에서 |-1|-1번째 부터 모든 원소 : [9]\n끝에서 |-2|-1번째 이전의 모든 원소 : [0, 1, 2, 3, 4, 5, 6, 7]\n끝에서 |-2|-1번째 부터 모든 원소 : [8, 9]\n"
]
],
[
[
"#### 1.3. 다차원 리스트(LIST): 리스트의 원소에 다양한 값 또는 자료구조를 저장할 수 있습니다.\n\n---",
"_____no_output_____"
]
],
[
[
"# 1-1) 리스트의 원소에는 유형(TYPE)의 값 또는 자료구조를 섞어서 저장할 수 있습니다.\nnew_list = [\"텍스트\", 0, 1.9, [1, 2, 3, 4], {\"서울\": 1, \"부산\": 2, \"대구\": 3}]\nprint(new_list)",
"['텍스트', 0, 1.9, [1, 2, 3, 4], {'서울': 1, '부산': 2, '대구': 3}]\n"
],
[
"# 1-2) 리스트의 각 원소의 유형(TYPE)을 type(변수) 함수를 활용해 확인합니다.\nprint(\"Type of new_list[0] :\", type(new_list[0]))\nprint(\"Type of new_list[1] :\", type(new_list[1]))\nprint(\"Type of new_list[2] :\", type(new_list[2]))\nprint(\"Type of new_list[3] :\", type(new_list[3]))\nprint(\"Type of new_list[4] :\", type(new_list[4]))",
"Type of new_list[0] : <class 'str'>\nType of new_list[1] : <class 'int'>\nType of new_list[2] : <class 'float'>\nType of new_list[3] : <class 'list'>\nType of new_list[4] : <class 'dict'>\n"
],
[
"# 2) 리스트 원소에 리스트를 여러개 추가하여 다차원 리스트(NxM)를 생성할 수 있습니다.\nnew_list = [[0, 1, 2], [2, 3, 7], [9, 6, 8], [4, 5, 1]]\nprint(\"new_list :\", new_list)\nprint(\"new_list[0] :\", new_list[0])\nprint(\"new_list[1] :\", new_list[1])\nprint(\"new_list[2] :\", new_list[2])\nprint(\"new_list[3] :\", new_list[3])",
"new_list : [[0, 1, 2], [2, 3, 7], [9, 6, 8], [4, 5, 1]]\nnew_list[0] : [0, 1, 2]\nnew_list[1] : [2, 3, 7]\nnew_list[2] : [9, 6, 8]\nnew_list[3] : [4, 5, 1]\n"
],
[
"# 3-1) 다차원 리스트(NxM)를 정렬하는 경우 기본적으로 각 리스트의 첫번째 원소를 기준으로 정렬합니다.\nnew_list.sort()\nprint(\"new_list :\", new_list)\nprint(\"new_list[0] :\", new_list[0])\nprint(\"new_list[1] :\", new_list[1])\nprint(\"new_list[2] :\", new_list[2])\nprint(\"new_list[3] :\", new_list[3])",
"new_list : [[0, 1, 2], [2, 3, 7], [4, 5, 1], [9, 6, 8]]\nnew_list[0] : [0, 1, 2]\nnew_list[1] : [2, 3, 7]\nnew_list[2] : [4, 5, 1]\nnew_list[3] : [9, 6, 8]\n"
],
[
"# 3-2) 다차원 리스트(NxM)를 각 리스트의 N 번째 원소를 기준으로 정렬합니다.\nnew_list.sort(key=lambda elem: elem[2])\nprint(\"new_list :\", new_list)\nprint(\"new_list[0] :\", new_list[0])\nprint(\"new_list[1] :\", new_list[1])\nprint(\"new_list[2] :\", new_list[2])\nprint(\"new_list[3] :\", new_list[3])",
"new_list : [[4, 5, 1], [0, 1, 2], [2, 3, 7], [9, 6, 8]]\nnew_list[0] : [4, 5, 1]\nnew_list[1] : [0, 1, 2]\nnew_list[2] : [2, 3, 7]\nnew_list[3] : [9, 6, 8]\n"
]
],
[
[
"### 2. 딕셔너리(DICTIONARY) 자료구조 이해하기\n\n---",
"_____no_output_____"
],
[
"#### 2.1. 딕셔너리(DICTIONARY): 값 또는 자료구조를 저장할 수 있는 구조를 선언합니다.\n\n---",
"_____no_output_____"
]
],
[
[
"# 1) 딕셔너리를 생성합니다.\nnew_dict = {\"마케팅팀\": 98, \"개발팀\": 78, \"데이터분석팀\": 83, \"운영팀\": 33}\nprint(new_dict)",
"{'마케팅팀': 98, '개발팀': 78, '데이터분석팀': 83, '운영팀': 33}\n"
],
[
"# 2) 딕셔너리의 각 원소는 KEY:VALUE 쌍의 구조를 가지며, KEY 값에 대응되는 VALUE를 불러옵니다.\nprint(new_dict[\"마케팅팀\"])",
"98\n"
],
[
"# 3-1) 딕셔너리에 새로운 KEY:VALUE 쌍의 원소를 추가합니다.\nnew_dict[\"미화팀\"] = 55\nprint(new_dict)",
"{'마케팅팀': 98, '개발팀': 78, '데이터분석팀': 83, '운영팀': 33, '미화팀': 55}\n"
],
[
"# 3-2) 딕셔너리에 저장된 각 원소의 KEY 값은 유일해야하기 때문에, 중복된 KEY 값이 추가되는 경우 VALUE는 덮어쓰기 됩니다.\nnew_dict[\"데이터분석팀\"] = 100\nprint(new_dict)",
"{'마케팅팀': 98, '개발팀': 78, '데이터분석팀': 100, '운영팀': 33, '미화팀': 55}\n"
],
[
"# 4) 딕셔너리에 다양한 유형(TYPE)의 값 또는 자료구조를 VALUE로 사용할 수 있습니다.\nnew_dict[\"데이터분석팀\"] = {\"등급\": \"A\"}\nnew_dict[\"운영팀\"] = [\"A\"]\nnew_dict[\"개발팀\"] = \"재평가\"\nnew_dict[0] = \"오타\"\nprint(new_dict)",
"{'마케팅팀': 98, '개발팀': '재평가', '데이터분석팀': {'등급': 'A'}, '운영팀': ['A'], '미화팀': 55, 0: '오타'}\n"
]
],
[
[
"#### 2.2. 딕셔너리(DICTIONARY) 인덱싱: 딕셔너리에 존재하는 원소를 리스트 형태로 불러옵니다.\n\n---",
"_____no_output_____"
]
],
[
[
"# 1-1) 다양한 함수를 활용해 딕셔너리를 인덱싱 가능한 구조로 불러옵니다.\nnew_dict = {\"마케팅팀\": 98, \"개발팀\": 78, \"데이터분석팀\": 83, \"운영팀\": 33}\nprint(\"KEY List of new_dict :\", new_dict.keys())\nprint(\"VALUE List of new_dict :\", new_dict.values())\nprint(\"(KEY, VALUE) List of new_dict :\", new_dict.items())",
"KEY List of new_dict : dict_keys(['마케팅팀', '개발팀', '데이터분석팀', '운영팀'])\nVALUE List of new_dict : dict_values([98, 78, 83, 33])\n(KEY, VALUE) List of new_dict : dict_items([('마케팅팀', 98), ('개발팀', 78), ('데이터분석팀', 83), ('운영팀', 33)])\n"
],
[
"for i, j in new_dict.items():\n print(i, j)",
"마케팅팀 98\n개발팀 78\n데이터분석팀 83\n운영팀 33\n"
],
[
"# 1-2) 불러온 자료구조를 실제 리스트 자료구조로 변환합니다.\nprint(\"KEY List of new_dict :\", list(new_dict.keys()))\nprint(\"VALUE List of new_dict :\", list(new_dict.values()))\nprint(\"(KEY, VALUE) List of new_dict :\", list(new_dict.items()))",
"KEY List of new_dict : ['마케팅팀', '개발팀', '데이터분석팀', '운영팀']\nVALUE List of new_dict : [98, 78, 83, 33]\n(KEY, VALUE) List of new_dict : [('마케팅팀', 98), ('개발팀', 78), ('데이터분석팀', 83), ('운영팀', 33)]\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0046b58d763006925def508fcf35d8395053a5b
| 1,649 |
ipynb
|
Jupyter Notebook
|
Euler 148 - Exploring Pascal's triangle.ipynb
|
Radcliffe/project-euler
|
5eb0c56e2bd523f3dc5329adb2fbbaf657e7fa38
|
[
"MIT"
] | 6 |
2016-05-11T18:55:35.000Z
|
2019-12-27T21:38:43.000Z
|
Euler 148 - Exploring Pascal's triangle.ipynb
|
Radcliffe/project-euler
|
5eb0c56e2bd523f3dc5329adb2fbbaf657e7fa38
|
[
"MIT"
] | null | null | null |
Euler 148 - Exploring Pascal's triangle.ipynb
|
Radcliffe/project-euler
|
5eb0c56e2bd523f3dc5329adb2fbbaf657e7fa38
|
[
"MIT"
] | null | null | null | 20.873418 | 85 | 0.486962 |
[
[
[
"Euler Problem 148\n=================\n\n\nWe can easily verify that none of the entries in the first seven rows of\nPascal's triangle are divisible by 7:\n\nHowever, if we check the first one hundred rows, we will find that only 2361\nof the 5050 entries are not divisible by 7.\n\nFind the number of entries which are not divisible by 7 in the first one\nbillion (10^9) rows of Pascal's triangle.",
"_____no_output_____"
]
],
[
[
"def f(n):\n if n == 0:\n return 1\n return (1+(n%7))*f(n//7)\n\ndef F(n):\n if n == 0:\n return 0\n r = n % 7\n return 28*F(n//7) + r*(r+1)//2*f(n//7)\n\nprint(F(10**9))",
"2129970655314432\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
d0046e00b43dff9aa070653367ac580eabe2fccb
| 27,489 |
ipynb
|
Jupyter Notebook
|
Coursera Deeplearning Specialization/c2wk1c - Gradient+Checking+v1.ipynb
|
hamil168/Data-Science-Misc
|
dd91e4336b6a48a30265a86f8b816658639a17e9
|
[
"BSD-2-Clause"
] | null | null | null |
Coursera Deeplearning Specialization/c2wk1c - Gradient+Checking+v1.ipynb
|
hamil168/Data-Science-Misc
|
dd91e4336b6a48a30265a86f8b816658639a17e9
|
[
"BSD-2-Clause"
] | 1 |
2018-07-12T02:49:02.000Z
|
2018-07-12T02:49:02.000Z
|
Coursera Deeplearning Specialization/c2wk1c - Gradient+Checking+v1.ipynb
|
hamil168/Learning-Data-Science
|
dd91e4336b6a48a30265a86f8b816658639a17e9
|
[
"BSD-2-Clause"
] | null | null | null | 41.840183 | 399 | 0.549965 |
[
[
[
"# Gradient Checking\n\nWelcome to the final assignment for this week! In this assignment you will learn to implement and use gradient checking. \n\nYou are part of a team working to make mobile payments available globally, and are asked to build a deep learning model to detect fraud--whenever someone makes a payment, you want to see if the payment might be fraudulent, such as if the user's account has been taken over by a hacker. \n\nBut backpropagation is quite challenging to implement, and sometimes has bugs. Because this is a mission-critical application, your company's CEO wants to be really certain that your implementation of backpropagation is correct. Your CEO says, \"Give me a proof that your backpropagation is actually working!\" To give this reassurance, you are going to use \"gradient checking\".\n\nLet's do it!",
"_____no_output_____"
]
],
[
[
"# Packages\nimport numpy as np\nfrom testCases import *\nfrom gc_utils import sigmoid, relu, dictionary_to_vector, vector_to_dictionary, gradients_to_vector",
"_____no_output_____"
]
],
[
[
"## 1) How does gradient checking work?\n\nBackpropagation computes the gradients $\\frac{\\partial J}{\\partial \\theta}$, where $\\theta$ denotes the parameters of the model. $J$ is computed using forward propagation and your loss function.\n\nBecause forward propagation is relatively easy to implement, you're confident you got that right, and so you're almost 100% sure that you're computing the cost $J$ correctly. Thus, you can use your code for computing $J$ to verify the code for computing $\\frac{\\partial J}{\\partial \\theta}$. \n\nLet's look back at the definition of a derivative (or gradient):\n$$ \\frac{\\partial J}{\\partial \\theta} = \\lim_{\\varepsilon \\to 0} \\frac{J(\\theta + \\varepsilon) - J(\\theta - \\varepsilon)}{2 \\varepsilon} \\tag{1}$$\n\nIf you're not familiar with the \"$\\displaystyle \\lim_{\\varepsilon \\to 0}$\" notation, it's just a way of saying \"when $\\varepsilon$ is really really small.\"\n\nWe know the following:\n\n- $\\frac{\\partial J}{\\partial \\theta}$ is what you want to make sure you're computing correctly. \n- You can compute $J(\\theta + \\varepsilon)$ and $J(\\theta - \\varepsilon)$ (in the case that $\\theta$ is a real number), since you're confident your implementation for $J$ is correct. \n\nLets use equation (1) and a small value for $\\varepsilon$ to convince your CEO that your code for computing $\\frac{\\partial J}{\\partial \\theta}$ is correct!",
"_____no_output_____"
],
[
"## 2) 1-dimensional gradient checking\n\nConsider a 1D linear function $J(\\theta) = \\theta x$. The model contains only a single real-valued parameter $\\theta$, and takes $x$ as input.\n\nYou will implement code to compute $J(.)$ and its derivative $\\frac{\\partial J}{\\partial \\theta}$. You will then use gradient checking to make sure your derivative computation for $J$ is correct. \n\n<img src=\"images/1Dgrad_kiank.png\" style=\"width:600px;height:250px;\">\n<caption><center> <u> **Figure 1** </u>: **1D linear model**<br> </center></caption>\n\nThe diagram above shows the key computation steps: First start with $x$, then evaluate the function $J(x)$ (\"forward propagation\"). Then compute the derivative $\\frac{\\partial J}{\\partial \\theta}$ (\"backward propagation\"). \n\n**Exercise**: implement \"forward propagation\" and \"backward propagation\" for this simple function. I.e., compute both $J(.)$ (\"forward propagation\") and its derivative with respect to $\\theta$ (\"backward propagation\"), in two separate functions. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation\n\ndef forward_propagation(x, theta):\n \"\"\"\n Implement the linear forward propagation (compute J) presented in Figure 1 (J(theta) = theta * x)\n \n Arguments:\n x -- a real-valued input\n theta -- our parameter, a real number as well\n \n Returns:\n J -- the value of function J, computed using the formula J(theta) = theta * x\n \"\"\"\n \n ### START CODE HERE ### (approx. 1 line)\n J = theta * x\n ### END CODE HERE ###\n \n return J",
"_____no_output_____"
],
[
"x, theta = 2, 4\nJ = forward_propagation(x, theta)\nprint (\"J = \" + str(J))",
"J = 8\n"
]
],
[
[
"**Expected Output**:\n\n<table style=>\n <tr>\n <td> ** J ** </td>\n <td> 8</td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"**Exercise**: Now, implement the backward propagation step (derivative computation) of Figure 1. That is, compute the derivative of $J(\\theta) = \\theta x$ with respect to $\\theta$. To save you from doing the calculus, you should get $dtheta = \\frac { \\partial J }{ \\partial \\theta} = x$.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: backward_propagation\n\ndef backward_propagation(x, theta):\n \"\"\"\n Computes the derivative of J with respect to theta (see Figure 1).\n \n Arguments:\n x -- a real-valued input\n theta -- our parameter, a real number as well\n \n Returns:\n dtheta -- the gradient of the cost with respect to theta\n \"\"\"\n \n ### START CODE HERE ### (approx. 1 line)\n dtheta = x\n ### END CODE HERE ###\n \n return dtheta",
"_____no_output_____"
],
[
"x, theta = 2, 4\ndtheta = backward_propagation(x, theta)\nprint (\"dtheta = \" + str(dtheta))",
"dtheta = 2\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td> ** dtheta ** </td>\n <td> 2 </td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"**Exercise**: To show that the `backward_propagation()` function is correctly computing the gradient $\\frac{\\partial J}{\\partial \\theta}$, let's implement gradient checking.\n\n**Instructions**:\n- First compute \"gradapprox\" using the formula above (1) and a small value of $\\varepsilon$. Here are the Steps to follow:\n 1. $\\theta^{+} = \\theta + \\varepsilon$\n 2. $\\theta^{-} = \\theta - \\varepsilon$\n 3. $J^{+} = J(\\theta^{+})$\n 4. $J^{-} = J(\\theta^{-})$\n 5. $gradapprox = \\frac{J^{+} - J^{-}}{2 \\varepsilon}$\n- Then compute the gradient using backward propagation, and store the result in a variable \"grad\"\n- Finally, compute the relative difference between \"gradapprox\" and the \"grad\" using the following formula:\n$$ difference = \\frac {\\mid\\mid grad - gradapprox \\mid\\mid_2}{\\mid\\mid grad \\mid\\mid_2 + \\mid\\mid gradapprox \\mid\\mid_2} \\tag{2}$$\nYou will need 3 Steps to compute this formula:\n - 1'. compute the numerator using np.linalg.norm(...)\n - 2'. compute the denominator. You will need to call np.linalg.norm(...) twice.\n - 3'. divide them.\n- If this difference is small (say less than $10^{-7}$), you can be quite confident that you have computed your gradient correctly. Otherwise, there may be a mistake in the gradient computation. \n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: gradient_check\n\ndef gradient_check(x, theta, epsilon = 1e-7):\n \"\"\"\n Implement the backward propagation presented in Figure 1.\n \n Arguments:\n x -- a real-valued input\n theta -- our parameter, a real number as well\n epsilon -- tiny shift to the input to compute approximated gradient with formula(1)\n \n Returns:\n difference -- difference (2) between the approximated gradient and the backward propagation gradient\n \"\"\"\n \n # Compute gradapprox using left side of formula (1). epsilon is small enough, you don't need to worry about the limit.\n ### START CODE HERE ### (approx. 5 lines)\n thetaplus = theta + epsilon # Step 1\n thetaminus = theta - epsilon # Step 2\n J_plus = thetaplus * x # Step 3\n J_minus = thetaminus * x # Step 4\n gradapprox = (J_plus - J_minus) / (2 * epsilon) # Step 5\n ### END CODE HERE ###\n \n # Check if gradapprox is close enough to the output of backward_propagation()\n ### START CODE HERE ### (approx. 1 line)\n grad = backward_propagation(x, theta)\n ### END CODE HERE ###\n \n ### START CODE HERE ### (approx. 1 line)\n numerator = np.linalg.norm(grad - gradapprox) # Step 1'\n denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2'\n difference = numerator / denominator # Step 3'\n ### END CODE HERE ###\n\n if difference < 1e-7:\n print (\"The gradient is correct!\")\n else:\n print (\"The gradient is wrong!\")\n\n return difference",
"_____no_output_____"
],
[
"x, theta = 2, 4\ndifference = gradient_check(x, theta)\nprint(\"difference = \" + str(difference))",
"The gradient is correct!\ndifference = 2.91933588329e-10\n"
]
],
[
[
"**Expected Output**:\nThe gradient is correct!\n<table>\n <tr>\n <td> ** difference ** </td>\n <td> 2.9193358103083e-10 </td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"Congrats, the difference is smaller than the $10^{-7}$ threshold. So you can have high confidence that you've correctly computed the gradient in `backward_propagation()`. \n\nNow, in the more general case, your cost function $J$ has more than a single 1D input. When you are training a neural network, $\\theta$ actually consists of multiple matrices $W^{[l]}$ and biases $b^{[l]}$! It is important to know how to do a gradient check with higher-dimensional inputs. Let's do it!",
"_____no_output_____"
],
[
"## 3) N-dimensional gradient checking",
"_____no_output_____"
],
[
"The following figure describes the forward and backward propagation of your fraud detection model.\n\n<img src=\"images/NDgrad_kiank.png\" style=\"width:600px;height:400px;\">\n<caption><center> <u> **Figure 2** </u>: **deep neural network**<br>*LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID*</center></caption>\n\nLet's look at your implementations for forward propagation and backward propagation. ",
"_____no_output_____"
]
],
[
[
"def forward_propagation_n(X, Y, parameters):\n \"\"\"\n Implements the forward propagation (and computes the cost) presented in Figure 3.\n \n Arguments:\n X -- training set for m examples\n Y -- labels for m examples \n parameters -- python dictionary containing your parameters \"W1\", \"b1\", \"W2\", \"b2\", \"W3\", \"b3\":\n W1 -- weight matrix of shape (5, 4)\n b1 -- bias vector of shape (5, 1)\n W2 -- weight matrix of shape (3, 5)\n b2 -- bias vector of shape (3, 1)\n W3 -- weight matrix of shape (1, 3)\n b3 -- bias vector of shape (1, 1)\n \n Returns:\n cost -- the cost function (logistic cost for one example)\n \"\"\"\n \n # retrieve parameters\n m = X.shape[1]\n W1 = parameters[\"W1\"]\n b1 = parameters[\"b1\"]\n W2 = parameters[\"W2\"]\n b2 = parameters[\"b2\"]\n W3 = parameters[\"W3\"]\n b3 = parameters[\"b3\"]\n\n # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID\n Z1 = np.dot(W1, X) + b1\n A1 = relu(Z1)\n Z2 = np.dot(W2, A1) + b2\n A2 = relu(Z2)\n Z3 = np.dot(W3, A2) + b3\n A3 = sigmoid(Z3)\n\n # Cost\n logprobs = np.multiply(-np.log(A3),Y) + np.multiply(-np.log(1 - A3), 1 - Y)\n cost = 1./m * np.sum(logprobs)\n \n cache = (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3)\n \n return cost, cache",
"_____no_output_____"
]
],
[
[
"Now, run backward propagation.",
"_____no_output_____"
]
],
[
[
"def backward_propagation_n(X, Y, cache):\n \"\"\"\n Implement the backward propagation presented in figure 2.\n \n Arguments:\n X -- input datapoint, of shape (input size, 1)\n Y -- true \"label\"\n cache -- cache output from forward_propagation_n()\n \n Returns:\n gradients -- A dictionary with the gradients of the cost with respect to each parameter, activation and pre-activation variables.\n \"\"\"\n \n m = X.shape[1]\n (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache\n \n dZ3 = (A3 - Y) # / (A3 * (1 - A3)) WHY ISN'T dZ3 more complicated\n dW3 = 1./m * np.dot(dZ3, A2.T)\n db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)\n \n dA2 = np.dot(W3.T, dZ3)\n dZ2 = np.multiply(dA2, np.int64(A2 > 0))\n dW2 = 1./m * np.dot(dZ2, A1.T) #2* before the end of assignment made us look for errors up here\n db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)\n \n dA1 = np.dot(W2.T, dZ2)\n dZ1 = np.multiply(dA1, np.int64(A1 > 0))\n dW1 = 1./m * np.dot(dZ1, X.T)\n db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True) # 4 / m before the end of assn made us look for errors up here\n \n gradients = {\"dZ3\": dZ3, \"dW3\": dW3, \"db3\": db3,\n \"dA2\": dA2, \"dZ2\": dZ2, \"dW2\": dW2, \"db2\": db2,\n \"dA1\": dA1, \"dZ1\": dZ1, \"dW1\": dW1, \"db1\": db1}\n \n return gradients",
"_____no_output_____"
]
],
[
[
"You obtained some results on the fraud detection test set but you are not 100% sure of your model. Nobody's perfect! Let's implement gradient checking to verify if your gradients are correct.",
"_____no_output_____"
],
[
"**How does gradient checking work?**.\n\nAs in 1) and 2), you want to compare \"gradapprox\" to the gradient computed by backpropagation. The formula is still:\n\n$$ \\frac{\\partial J}{\\partial \\theta} = \\lim_{\\varepsilon \\to 0} \\frac{J(\\theta + \\varepsilon) - J(\\theta - \\varepsilon)}{2 \\varepsilon} \\tag{1}$$\n\nHowever, $\\theta$ is not a scalar anymore. It is a dictionary called \"parameters\". We implemented a function \"`dictionary_to_vector()`\" for you. It converts the \"parameters\" dictionary into a vector called \"values\", obtained by reshaping all parameters (W1, b1, W2, b2, W3, b3) into vectors and concatenating them.\n\nThe inverse function is \"`vector_to_dictionary`\" which outputs back the \"parameters\" dictionary.\n\n<img src=\"images/dictionary_to_vector.png\" style=\"width:600px;height:400px;\">\n<caption><center> <u> **Figure 2** </u>: **dictionary_to_vector() and vector_to_dictionary()**<br> You will need these functions in gradient_check_n()</center></caption>\n\nWe have also converted the \"gradients\" dictionary into a vector \"grad\" using gradients_to_vector(). You don't need to worry about that.\n\n**Exercise**: Implement gradient_check_n().\n\n**Instructions**: Here is pseudo-code that will help you implement the gradient check.\n\nFor each i in num_parameters:\n- To compute `J_plus[i]`:\n 1. Set $\\theta^{+}$ to `np.copy(parameters_values)`\n 2. Set $\\theta^{+}_i$ to $\\theta^{+}_i + \\varepsilon$\n 3. Calculate $J^{+}_i$ using to `forward_propagation_n(x, y, vector_to_dictionary(`$\\theta^{+}$ `))`. \n- To compute `J_minus[i]`: do the same thing with $\\theta^{-}$\n- Compute $gradapprox[i] = \\frac{J^{+}_i - J^{-}_i}{2 \\varepsilon}$\n\nThus, you get a vector gradapprox, where gradapprox[i] is an approximation of the gradient with respect to `parameter_values[i]`. You can now compare this gradapprox vector to the gradients vector from backpropagation. Just like for the 1D case (Steps 1', 2', 3'), compute: \n$$ difference = \\frac {\\| grad - gradapprox \\|_2}{\\| grad \\|_2 + \\| gradapprox \\|_2 } \\tag{3}$$",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: gradient_check_n\n\ndef gradient_check_n(parameters, gradients, X, Y, epsilon = 1e-7):\n \"\"\"\n Checks if backward_propagation_n computes correctly the gradient of the cost output by forward_propagation_n\n \n Arguments:\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", \"W2\", \"b2\", \"W3\", \"b3\":\n grad -- output of backward_propagation_n, contains gradients of the cost with respect to the parameters. \n x -- input datapoint, of shape (input size, 1)\n y -- true \"label\"\n epsilon -- tiny shift to the input to compute approximated gradient with formula(1)\n \n Returns:\n difference -- difference (2) between the approximated gradient and the backward propagation gradient\n \"\"\"\n \n # Set-up variables\n parameters_values, _ = dictionary_to_vector(parameters)\n grad = gradients_to_vector(gradients)\n num_parameters = parameters_values.shape[0]\n J_plus = np.zeros((num_parameters, 1))\n J_minus = np.zeros((num_parameters, 1))\n gradapprox = np.zeros((num_parameters, 1))\n \n # Compute gradapprox\n for i in range(num_parameters):\n \n # Compute J_plus[i]. Inputs: \"parameters_values, epsilon\". Output = \"J_plus[i]\".\n # \"_\" is used because the function you have to outputs two parameters but we only care about the first one\n ### START CODE HERE ### (approx. 3 lines)\n thetaplus = np.copy(parameters_values) # Step 1\n #print(thetaplus[i][0])\n thetaplus[i,0] = thetaplus[i,0] + epsilon\n #thetaplus[i][0] = thetaplus[i][0] + epsilon # Step 2\n J_plus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaplus)) # Step 3\n ### END CODE HERE ###\n \n # Compute J_minus[i]. Inputs: \"parameters_values, epsilon\". Output = \"J_minus[i]\".\n ### START CODE HERE ### (approx. 3 lines)\n thetaminus = np.copy(parameters_values) # Step 1\n thetaminus[i,0] = thetaplus[i,0] - epsilon\n #thetaminus[i][0] = thetaplus[i][0] - epsilon # Step 2 \n J_minus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaminus)) # Step 3\n ### END CODE HERE ###\n \n # Compute gradapprox[i]\n ### START CODE HERE ### (approx. 1 line)\n gradapprox[i] = (J_plus[i] - J_minus[i]) / (epsilon) #Why isn't the 2 eeps in here? need this to be correct.\n #gradapprox[i] = (J_plus[i] - J_minus[i]) / (2. * epsilon) #How is should be!\n ### END CODE HERE ###\n\n # Compare gradapprox to backward propagation gradients by computing difference.\n ### START CODE HERE ### (approx. 1 line)\n numerator = np.linalg.norm(grad - gradapprox) # Step 1'\n denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2'\n difference = numerator / denominator # Step 3'\n ### END CODE HERE ###\n\n if difference > 2e-7:\n print (\"\\033[93m\" + \"There is a mistake in the backward propagation! difference = \" + str(difference) + \"\\033[0m\")\n else:\n print (\"\\033[92m\" + \"Your backward propagation works perfectly fine! difference = \" + str(difference) + \"\\033[0m\")\n\n #print(gradapprox)\n \n return difference",
"_____no_output_____"
],
[
"X, Y, parameters = gradient_check_n_test_case()\n\ncost, cache = forward_propagation_n(X, Y, parameters)\ngradients = backward_propagation_n(X, Y, cache)\ndifference = gradient_check_n(parameters, gradients, X, Y)",
"\u001b[92mYour backward propagation works perfectly fine! difference = 1.69916980932e-07\u001b[0m\n"
]
],
[
[
"**Expected output**:\n\n<table>\n <tr>\n <td> ** There is a mistake in the backward propagation!** </td>\n <td> difference = 0.285093156781 </td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"It seems that there were errors in the `backward_propagation_n` code we gave you! Good that you've implemented the gradient check. Go back to `backward_propagation` and try to find/correct the errors *(Hint: check dW2 and db1)*. Rerun the gradient check when you think you've fixed it. Remember you'll need to re-execute the cell defining `backward_propagation_n()` if you modify the code. \n\nCan you get gradient check to declare your derivative computation correct? Even though this part of the assignment isn't graded, we strongly urge you to try to find the bug and re-run gradient check until you're convinced backprop is now correctly implemented. \n\n**Note** \n- Gradient Checking is slow! Approximating the gradient with $\\frac{\\partial J}{\\partial \\theta} \\approx \\frac{J(\\theta + \\varepsilon) - J(\\theta - \\varepsilon)}{2 \\varepsilon}$ is computationally costly. For this reason, we don't run gradient checking at every iteration during training. Just a few times to check if the gradient is correct. \n- Gradient Checking, at least as we've presented it, doesn't work with dropout. You would usually run the gradient check algorithm without dropout to make sure your backprop is correct, then add dropout. \n\nCongrats, you can be confident that your deep learning model for fraud detection is working correctly! You can even use this to convince your CEO. :) \n\n<font color='blue'>\n**What you should remember from this notebook**:\n- Gradient checking verifies closeness between the gradients from backpropagation and the numerical approximation of the gradient (computed using forward propagation).\n- Gradient checking is slow, so we don't run it in every iteration of training. You would usually run it only to make sure your code is correct, then turn it off and use backprop for the actual learning process. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d0047c49fd8ebbf2787bef955db3213467bdf770
| 533,153 |
ipynb
|
Jupyter Notebook
|
Scale, Standardize, or Normalize with scikit-learn.ipynb
|
2IS239-Data-Analytics/Code_along4
|
9deeee0b028235d0e618e0d3b4fe2b93b3ee2209
|
[
"Apache-2.0"
] | null | null | null |
Scale, Standardize, or Normalize with scikit-learn.ipynb
|
2IS239-Data-Analytics/Code_along4
|
9deeee0b028235d0e618e0d3b4fe2b93b3ee2209
|
[
"Apache-2.0"
] | null | null | null |
Scale, Standardize, or Normalize with scikit-learn.ipynb
|
2IS239-Data-Analytics/Code_along4
|
9deeee0b028235d0e618e0d3b4fe2b93b3ee2209
|
[
"Apache-2.0"
] | null | null | null | 423.810016 | 139,308 | 0.939507 |
[
[
[
"# Code along 4\n\n## Scale, Standardize, or Normalize with scikit-learn\n### När ska man använda MinMaxScaler, RobustScaler, StandardScaler, och Normalizer\n### Attribution: Jeff Hale",
"_____no_output_____"
],
[
"### Varför är det ofta nödvändigt att genomföra så kallad variable transformation/feature scaling det vill säga, standardisera, normalisera eller på andra sätt ändra skalan på data vid dataaalys?\n\nSom jag gått igenom på föreläsningen om data wrangling kan data behöva formateras (variable transformation) för att förbättra prestandan hos många algoritmer för dataanalys. En typ av formaterinng av data, som går att göra på många olika sätt, är så kallad skalning av attribut (feature scaling). Det kan finnas flera anledningar till att data kan behöv skalas, några exempel är:\n\n* Exempelvis neurala nätverk, regressionsalgoritmer och K-nearest neighbors fungerar inte lika bra om inte de attribut (features) som algoritmen använder befinner sig i relativt lika skalor. \n\n* Vissa av metoderna för att skala, standardisera och normalisera kan också minska den negativa påverkan outliers kan ha i vissa algoritmer.\n\n* Ibland är det också av vikt att ha data som är normalfördelat (standardiserat) \n\n*Med skala menas inte den skala som hänsyftas på exempelvis kartor där det brukar anges att skalan är 1:50 000 vilket tolkas som att varje avstånd på kartan är 50 000 ggr kortare än i verkligheten.* \n",
"_____no_output_____"
]
],
[
[
"#Importerar de bibliotek vi behöver\nimport numpy as np \nimport pandas as pd \nfrom sklearn import preprocessing\n\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport warnings\n\nwarnings.filterwarnings('ignore')\n#Denna kod sätter upp hur matplotlib ska visa grafer och plotar\n%matplotlib inline\nmatplotlib.style.use('ggplot')\n\n#Generera lite input \n#(den som är extremt intresserad kan läsa följande, intressanta och roliga förklaring kring varför random.seed egentligen är pseudorandom)\n#https://www.sharpsightlabs.com/blog/numpy-random-seed/\nnp.random.seed(34)",
"_____no_output_____"
]
],
[
[
"# Original Distributions \n\nData som det kan se ut i original, alltså när det samlats in, innan någon pre-processing har genomförts.\n\nFör att ha data att använda i övningarna skapar nedanstående kod ett antal randomiserade spridningar av data",
"_____no_output_____"
]
],
[
[
"#skapa kolumner med olika fördelningar \ndf = pd.DataFrame({ \n 'beta': np.random.beta(5, 1, 1000) * 60, # beta\n 'exponential': np.random.exponential(10, 1000), # exponential\n 'normal_p': np.random.normal(10, 2, 1000), # normal platykurtic\n 'normal_l': np.random.normal(10, 10, 1000), # normal leptokurtic\n})\n\n# make bimodal distribution\nfirst_half = np.random.normal(20, 3, 500) \nsecond_half = np.random.normal(-20, 3, 500) \nbimodal = np.concatenate([first_half, second_half])\n\ndf['bimodal'] = bimodal\n\n# create list of column names to use later\ncol_names = list(df.columns)",
"_____no_output_____"
]
],
[
[
"## Uppgift 1: \n\na. Plotta de kurvor som skapats i ovanstående cell i en och samma koordinatsystem med hjälp av [seaborn biblioteket](https://seaborn.pydata.org/api.html#distribution-api).\n\n>Se till att det är tydligt vilken kurva som representerar vilken distribution.\n>\n>Koden för själva koordinatsystemet är given, fortsätt koda i samma cell\n>\n>HINT! alla fem är distribution plots",
"_____no_output_____"
]
],
[
[
"# plot original distribution plot\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('Original Distributions')\n\n#De fem kurvorna\nsns.kdeplot(df['beta'], ax=ax1)\nsns.kdeplot(df['exponential'], ax=ax1)\nsns.kdeplot(df['normal_p'], ax=ax1)\nsns.kdeplot(df['normal_l'], ax=ax1)\nsns.kdeplot(df['bimodal'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"b. Visa de fem första raderna i den dataframe som innehåller alla distributioner.",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
]
],
[
[
"c. För samtliga fem attribut, beräkna:\n\n* medel\n* median\n\nVad för bra metod kan användas för att få ett antal statistiska mått på en dataframe? Hämta denna information med denna metod.",
"_____no_output_____"
]
],
[
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"d. I pandas kan du plotta din dataframe på några olika sätt. Gör en plot för att ta reda på hur skalan på de olika attibuten ser ut, befinner sig alla fem i ungefär samma skala?\n",
"_____no_output_____"
]
],
[
[
"df.plot()",
"_____no_output_____"
]
],
[
[
"* Samtliga värden ligger inom liknande intervall",
"_____no_output_____"
],
[
"e. Vad händer om följande kolumn med randomiserade värden läggs till?",
"_____no_output_____"
]
],
[
[
"new_column = np.random.normal(1000000, 10000, (1000,1))\ndf['new_column'] = new_column\ncol_names.append('new_column')\ndf['new_column'].plot(kind='kde')",
"_____no_output_____"
],
[
"# plot våra originalvärden tillsammans med det nya värdet\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('Original Distributions')\n\nsns.kdeplot(df['beta'], ax=ax1)\nsns.kdeplot(df['exponential'], ax=ax1)\nsns.kdeplot(df['normal_p'], ax=ax1)\nsns.kdeplot(df['normal_l'], ax=ax1)\nsns.kdeplot(df['bimodal'], ax=ax1);\nsns.kdeplot(df['new_column'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"Hur gick det?",
"_____no_output_____"
],
[
"Testar några olika sätt att skala dataframes..",
"_____no_output_____"
],
[
"### MinMaxScaler\n\nMinMaxScaler subtraherar varje värde i en kolumn med medelvärdet av den kolumnen och dividerar sedan med antalet värden. ",
"_____no_output_____"
]
],
[
[
"mm_scaler = preprocessing.MinMaxScaler()\ndf_mm = mm_scaler.fit_transform(df)\n\ndf_mm = pd.DataFrame(df_mm, columns=col_names)\n\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('After MinMaxScaler')\n\nsns.kdeplot(df_mm['beta'], ax=ax1)\nsns.kdeplot(df_mm['exponential'], ax=ax1)\nsns.kdeplot(df_mm['normal_p'], ax=ax1)\nsns.kdeplot(df_mm['normal_l'], ax=ax1)\nsns.kdeplot(df_mm['bimodal'], ax=ax1)\nsns.kdeplot(df_mm['new_column'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"Vad har hänt med värdena?",
"_____no_output_____"
]
],
[
[
"df_mm['beta'].min()",
"_____no_output_____"
],
[
"df_mm['beta'].max()",
"_____no_output_____"
]
],
[
[
"Vi jämför med min och maxvärde för varje kolumn innan vi normaliserade vår dataframe",
"_____no_output_____"
]
],
[
[
"mins = [df[col].min() for col in df.columns]\nmins",
"_____no_output_____"
],
[
"maxs = [df[col].max() for col in df.columns]\nmaxs",
"_____no_output_____"
]
],
[
[
"Let's check the minimums and maximums for each column after MinMaxScaler.",
"_____no_output_____"
]
],
[
[
"mins = [df_mm[col].min() for col in df_mm.columns]\nmins",
"_____no_output_____"
],
[
"maxs = [df_mm[col].max() for col in df_mm.columns]\nmaxs",
"_____no_output_____"
]
],
[
[
"Vad har hänt?",
"_____no_output_____"
],
[
"### RobustScaler\n\nRobustScaler subtraherar med medianen för kolumnen och dividerar med kvartilavståndet (skillnaden mellan största 25% och minsta 25%) ",
"_____no_output_____"
]
],
[
[
"r_scaler = preprocessing.RobustScaler()\ndf_r = r_scaler.fit_transform(df)\n\ndf_r = pd.DataFrame(df_r, columns=col_names)\n\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('After RobustScaler')\n\nsns.kdeplot(df_r['beta'], ax=ax1)\nsns.kdeplot(df_r['exponential'], ax=ax1)\nsns.kdeplot(df_r['normal_p'], ax=ax1)\nsns.kdeplot(df_r['normal_l'], ax=ax1)\nsns.kdeplot(df_r['bimodal'], ax=ax1)\nsns.kdeplot(df_r['new_column'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"Vi kollar igen min och max efteråt (OBS; jämför med originalet högst upp innan vi startar olika skalningsmetoder).",
"_____no_output_____"
]
],
[
[
"mins = [df_r[col].min() for col in df_r.columns]\nmins",
"_____no_output_____"
],
[
"maxs = [df_r[col].max() for col in df_r.columns]\nmaxs",
"_____no_output_____"
]
],
[
[
"Vad har hänt?",
"_____no_output_____"
],
[
"### StandardScaler\n\nStandardScaler skalar varje kolumn till att ha 0 som medelvärde och standardavvikelsen 1 ",
"_____no_output_____"
]
],
[
[
"s_scaler = preprocessing.StandardScaler()\ndf_s = s_scaler.fit_transform(df)\n\ndf_s = pd.DataFrame(df_s, columns=col_names)\n\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('After StandardScaler')\n\nsns.kdeplot(df_s['beta'], ax=ax1)\nsns.kdeplot(df_s['exponential'], ax=ax1)\nsns.kdeplot(df_s['normal_p'], ax=ax1)\nsns.kdeplot(df_s['normal_l'], ax=ax1)\nsns.kdeplot(df_s['bimodal'], ax=ax1)\nsns.kdeplot(df_s['new_column'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"Vi kontrollerar min och max efter skalningen återigen",
"_____no_output_____"
]
],
[
[
"mins = [df_s[col].min() for col in df_s.columns]\nmins",
"_____no_output_____"
],
[
"maxs = [df_s[col].max() for col in df_s.columns]\nmaxs",
"_____no_output_____"
]
],
[
[
"Vad har hänt? I jämförelse med de två innan?",
"_____no_output_____"
],
[
"# Normalizer\n\nNormaliser transformerar rader istället för kolumner genom att (default) beräkna den Euclidiska normen som är roten ur summan av roten ur samtliga värden. Kallas för l2.",
"_____no_output_____"
]
],
[
[
"n_scaler = preprocessing.Normalizer()\ndf_n = n_scaler.fit_transform(df)\n\ndf_n = pd.DataFrame(df_n, columns=col_names)\n\nfig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))\nax1.set_title('After Normalizer')\n\nsns.kdeplot(df_n['beta'], ax=ax1)\nsns.kdeplot(df_n['exponential'], ax=ax1)\nsns.kdeplot(df_n['normal_p'], ax=ax1)\nsns.kdeplot(df_n['normal_l'], ax=ax1)\nsns.kdeplot(df_n['bimodal'], ax=ax1)\nsns.kdeplot(df_n['new_column'], ax=ax1);",
"_____no_output_____"
]
],
[
[
"Min och max efter skalning",
"_____no_output_____"
]
],
[
[
"mins = [df_n[col].min() for col in df_n.columns]\nmins",
"_____no_output_____"
],
[
"maxs = [df_n[col].max() for col in df_n.columns]\nmaxs",
"_____no_output_____"
]
],
[
[
"Vad har hänt?",
"_____no_output_____"
],
[
"Nu tar vi en titt på alla olika sätt att skala tillsammans, dock skippar vi normalizern då det är väldigt ovanligt att man vill skala om rader.",
"_____no_output_____"
],
[
"### Kombinerad plot",
"_____no_output_____"
]
],
[
[
"#Själva figuren\nfig, (ax0, ax1, ax2, ax3) = plt.subplots(ncols=4, figsize=(20, 8))\n\n\nax0.set_title('Original Distributions')\n\nsns.kdeplot(df['beta'], ax=ax0)\nsns.kdeplot(df['exponential'], ax=ax0)\nsns.kdeplot(df['normal_p'], ax=ax0)\nsns.kdeplot(df['normal_l'], ax=ax0)\nsns.kdeplot(df['bimodal'], ax=ax0)\nsns.kdeplot(df['new_column'], ax=ax0);\n\n\nax1.set_title('After MinMaxScaler')\n\nsns.kdeplot(df_mm['beta'], ax=ax1)\nsns.kdeplot(df_mm['exponential'], ax=ax1)\nsns.kdeplot(df_mm['normal_p'], ax=ax1)\nsns.kdeplot(df_mm['normal_l'], ax=ax1)\nsns.kdeplot(df_mm['bimodal'], ax=ax1)\nsns.kdeplot(df_mm['new_column'], ax=ax1);\n\n\nax2.set_title('After RobustScaler')\n\nsns.kdeplot(df_r['beta'], ax=ax2)\nsns.kdeplot(df_r['exponential'], ax=ax2)\nsns.kdeplot(df_r['normal_p'], ax=ax2)\nsns.kdeplot(df_r['normal_l'], ax=ax2)\nsns.kdeplot(df_r['bimodal'], ax=ax2)\nsns.kdeplot(df_r['new_column'], ax=ax2);\n\n\nax3.set_title('After StandardScaler')\n\nsns.kdeplot(df_s['beta'], ax=ax3)\nsns.kdeplot(df_s['exponential'], ax=ax3)\nsns.kdeplot(df_s['normal_p'], ax=ax3)\nsns.kdeplot(df_s['normal_l'], ax=ax3)\nsns.kdeplot(df_s['bimodal'], ax=ax3)\nsns.kdeplot(df_s['new_column'], ax=ax3);",
"_____no_output_____"
]
],
[
[
"Efter samtliga transformationer är värdena på en mer lika skala. MinMax hade varit att föredra här eftersom den ger minst förskjutning av värdena i förhållande till varandra. Det är samma avstånd som i originalet, de andra två skalningsmetoderna ändrar avstånden mellan värdena vilket kommer påverka modellens korrekthet. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d00494fcaaa891443dd92cb39c1647b9a3baed33
| 504,504 |
ipynb
|
Jupyter Notebook
|
seek-chains-2.ipynb
|
gkovacs/invideo-quizzes-analysis-las2016
|
6ec8686ef0d3ffa5e994f8dec41590fea87e9539
|
[
"MIT"
] | null | null | null |
seek-chains-2.ipynb
|
gkovacs/invideo-quizzes-analysis-las2016
|
6ec8686ef0d3ffa5e994f8dec41590fea87e9539
|
[
"MIT"
] | null | null | null |
seek-chains-2.ipynb
|
gkovacs/invideo-quizzes-analysis-las2016
|
6ec8686ef0d3ffa5e994f8dec41590fea87e9539
|
[
"MIT"
] | null | null | null | 219.444976 | 21,961 | 0.841607 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d004994ec179a32e18cdaaac9f901ff5485ebbd3
| 72,060 |
ipynb
|
Jupyter Notebook
|
docs/source/examples/tutorial-02-diffusion-1D-solvers-FTCS.ipynb
|
vxsharma-14/DIFFUS
|
d70633890b8fb2e7b3dde918eb13b263f7a035ef
|
[
"MIT"
] | 14 |
2021-01-28T06:52:15.000Z
|
2021-03-05T01:34:30.000Z
|
docs/source/examples/tutorial-02-diffusion-1D-solvers-FTCS.ipynb
|
vxsharma-14/project-NAnPack
|
fad644ec9a614605f84562745a317e5512db1d58
|
[
"MIT"
] | 2 |
2021-01-22T22:55:08.000Z
|
2021-01-22T22:56:13.000Z
|
docs/source/examples/tutorial-02-diffusion-1D-solvers-FTCS.ipynb
|
vxsharma-14/DIFFUS
|
d70633890b8fb2e7b3dde918eb13b263f7a035ef
|
[
"MIT"
] | 2 |
2021-01-28T06:52:17.000Z
|
2021-01-30T12:35:52.000Z
| 143.545817 | 44,816 | 0.862559 |
[
[
[
"# Tutorial 2. Solving a 1D diffusion equation",
"_____no_output_____"
]
],
[
[
"\n# Document Author: Dr. Vishal Sharma\n# Author email: sharma_vishal14@hotmail.com\n# License: MIT\n# This tutorial is applicable for NAnPack version 1.0.0-alpha4 ",
"_____no_output_____"
]
],
[
[
"### I. Background\n\nThe objective of this tutorial is to present the step-by-step solution of a 1D diffusion equation using NAnPack such that users can follow the instructions to learn using this package. The numerical solution is obtained using the Forward Time Central Spacing (FTCS) method. The detailed description of the FTCS method is presented in Section IV of this tutorial.\n\n### II. Case Description\n\nWe will be solving a classical probkem of a suddenly accelerated plate in fluid mechanicas which has the known exact solution. In this problem, the fluid is\nbounded between two parallel plates. The upper plate remains stationary and the lower plate is suddenly accelerated in *y*-direction at velocity $U_o$. It is\nrequired to find the velocity profile between the plates for the given initial and boundary conditions.\n\n(For the sake of simplicity in setting up numerical variables, let's assume that the *x*-axis is pointed in the upward direction and *y*-axis is pointed along the horizontal direction as shown in the schematic below:",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**Initial conditions**\n$$u(t=0.0, 0.0<x\\leq H) = 0.0 \\;m/s$$\n$$u(t=0.0, x=0.0) = 40.0 \\;m/s$$\n\n**Boundary conditions**\n$$u(t\\geq0.0, x=0.0) = 40.0 \\;m/s$$\n$$u(t\\geq0.0, x=H) = 0.0 \\;m/s$$\n\nViscosity of fluid, $\\;\\;\\nu = 2.17*10^{-4} \\;m^2/s$ \nDistance between plates, $\\;\\;H = 0.04 \\;m$ \nGrid step size, $\\;\\;dx = 0.001 \\;m$ \nSimulation time, $\\;\\;T = 1.08 \\;sec$\n\nSpecify the required simulation inputs based on our setup in the configuration file provided with this package. You may choose to save the configuration file with any other filename. I have saved the configuration file in the \"input\" folder of my project directory such that the relative path is `./input/config.ini`. ",
"_____no_output_____"
],
[
"### III. Governing Equation\n\nThe governing equation for the given application is the simplified for the the Navies-Stokes equation which is given as:\n\n$$\\frac{\\partial u} {\\partial t} = \\nu\\frac{\\partial^2 u}{\\partial x^2}$$\n\nThis is the diffusion equation model and is classified as the parabolic PDE.\n\n### IV. FTCS method\n\nThe forward time central spacing approximation equation in 1D is presented here. This is a time explicit method which means that one unknown is calculated using the known neighbouring values from the previous time step. Here *i* represents grid point location, *n*+1 is the future time step, and *n* is the current time step.\n\n$$u_{i}^{n+1} = u_{i}^{n} + \\frac{\\nu\\Delta t}{(\\Delta x)^2}(u_{i+1}^{n} - 2u_{i}^{n} + u_{i-1}^{n})$$\n\nThe order of this approximation is $[(\\Delta t), (\\Delta x)^2]$\n\nThe diffusion number is given as $d_{x} = \\nu\\frac{\\Delta t}{(\\Delta x)^2}$ and for one-dimensional applications the stability criteria is $d_{x}\\leq\\frac{1}{2}$ \n\nThe solution presented here is obtained using a diffusion number = 0.5 (CFL = 0.5 in configuration file). Time step size will be computed using the expression of diffusion number. Beginners are encouraged to try diffusion numbers greater than 0.5 as an exercise after running this script.\n\nUsers are encouraged to read my blogs on numerical methods - [link here](https://www.linkedin.com/in/vishalsharmaofficial/detail/recent-activity/posts/).\n",
"_____no_output_____"
],
[
"### V. Script Development\n\n*Please note that this code script is provided in file `./examples/tutorial-02-diffusion-1D-solvers-FTCS.py`.*\n\nAs per the Python established coding guidelines [PEP 8](https://www.python.org/dev/peps/pep-0008/#imports), all package imports must be done at the top part of the script in the following sequence -- \n1. import standard library\n2. import third party modules\n3. import local application/library specific\n\nAccordingly, in our code we will importing the following required modules (in alphabetical order). If you are using Jupyter notebook, hit `Shift + Enter` on each cell after typing the code.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nfrom nanpack.benchmark import ParallelPlateFlow\nimport nanpack.preprocess as pre\nfrom nanpack.grid import RectangularGrid\nfrom nanpack.parabolicsolvers import FTCS\nimport nanpack.postprocess as post",
"_____no_output_____"
]
],
[
[
"As the first step in simulation, we have to tell our script to read the inputs and assign those inputs to the variables/objects that we will use in our entire code. For this purpose, there is a class `RunConfig` in `nanpack.preprocess` module. We will call this class and assign an object (instance) to it so that we can use its member variables. The `RunConfig` class is written in such a manner that its methods get executed as soon as it's instance is created. The users must provide the configuration file path as a parameter to `RunConfig` class.",
"_____no_output_____"
]
],
[
[
"FileName = \"path/to/project/input/config.ini\" # specify the correct file path\ncfg = pre.RunConfig(FileName) # cfg is an instance of RunConfig class which can be used to access class variables. You may choose any variable in place of cfg.",
"*******************************************************\n*******************************************************\nStarting configuration.\n\nSearching for simulation configuration file in path:\n\"D:/MyProjects/projectroot/nanpack/input/config.ini\"\nSUCCESS: Configuration file parsing.\nChecking whether all sections are included in config file.\nChecking section SETUP: Completed.\nChecking section DOMAIN: Completed.\nChecking section MESH: Completed.\nChecking section IC: Completed.\nChecking section BC: Completed.\nChecking section CONST: Completed.\nChecking section STOP: Completed.\nChecking section OUTPUT: Completed.\nChecking numerical setup.\nUser inputs in SETUP section check: Completed.\nAccessing domain geometry configuration: Completed\nAccessing meshing configuration: Completed.\nCalculating grid size: Completed.\nAssigning COLD-START initial conditions to the dependent term.\nInitialization: Completed.\nAccessing boundary condition settings: Completed\nAccessing constant data: Completed.\nCalculating time step size for the simulation: Completed.\nCalculating maximum iterations/steps for the simulation: Completed.\nAccessing simulation stop settings: Completed.\nAccessing settings for storing outputs: Completed.\n\n**********************************************************\nCASE DESCRIPTION SUDDENLY ACC. PLATE\nSOLVER STATE TRANSIENT\nMODEL EQUATION DIFFUSION\nDOMAIN DIMENSION 1D\n LENGTH 0.04\nGRID STEP SIZE\n dX 0.001\nTIME STEP 0.002\nGRID POINTS\n along X 41\nDIFFUSION CONST. 2.1700e-04\nDIFFUSION NUMBER 0.5\nTOTAL SIMULATION TIME 1.08\nNUMBER OF TIME STEPS 468\nSTART CONDITION COLD-START\n**********************************************************\nSUCEESS: Configuration completed.\n\n"
]
],
[
[
"You will obtain several configuration messages on your output screen so that you can verify that your inputs are correct and that the configuration is successfully completed. Next step is the assignment of initial conditions and the boundary conditions. For assigning boundary conditions, I have created a function `BC()` which we will be calling in the next cell. I have included this function at the bottom of this tutorial for your reference. It is to be noted that U is the dependent variable that was initialized when we executed the configuration, and thus we will be using `cfg.U` to access the initialized U. In a similar manner, all the inputs provided in the configuration file can be obtained by using configuration class object `cfg.` as the prefix to the variable names. Users are allowed to use any object of their choice.\n\n*If you are using Jupyter Notebook, the function BC must be executed before referencing to it, otherwise, you will get an error. Jump to the bottom of this notebook where you see code cell # 1 containing the `BC()` function*",
"_____no_output_____"
]
],
[
[
"# Assign initial conditions\ncfg.U[0] = 40.0\ncfg.U[1:] = 0.0\n\n# Assign boundary conditions\nU = BC(cfg.U)",
"_____no_output_____"
]
],
[
[
"Next, we will be calculating location of all grid points within the domain using the function `RectangularGrid()` and save values into X. We will also require to calculate diffusion number in X direction. In nanpack, the program treats the diffusion number = CFL for 1D applications that we entered in the configuration file, and therefore this step may be skipped, however, it is not the same in two-dimensional applications and therefore to stay consistent and to avoid confusion we will be using the function `DiffusionNumbers()` to compute the term `diffX`. ",
"_____no_output_____"
]
],
[
[
"X, _ = RectangularGrid(cfg.dX, cfg.iMax)",
"Uniform rectangular grid generation in cartesian coordinate system: Completed.\n"
],
[
"diffX,_ = pre.DiffusionNumbers(cfg.Dimension, cfg.diff, cfg.dT, cfg.dX)",
"Calculating diffusion numbers: Completed.\n"
]
],
[
[
"Next, we will initialize some local variables before start the time stepping:",
"_____no_output_____"
]
],
[
[
"Error = 1.0 # variable to keep track of error\nn = 0 # variable to advance in time",
"_____no_output_____"
]
],
[
[
"Start time loop using while loop such that if one of the condition returns False, the time stepping will be stopped. For explanation of each line, see the comments. Please note the identation of the codes within the while loop. Take extra care with indentation as Python is very particular about it.",
"_____no_output_____"
]
],
[
[
"while n <= cfg.nMax and Error > cfg.ConvCrit: # start loop\n Error = 0.0 # reset error to 0.0 at the beginning of each step\n n += 1 # advance the value of n at each step\n Uold = U.copy() # store solution at time level, n\n U = FTCS(Uold, diffX) # solve for U using FTCS method at time level n+1\n Error = post.AbsoluteError(U, Uold) # calculate errors\n U = BC(U) # Update BC\n post.MonitorConvergence(cfg, n, Error) # Use this function to monitor convergence\n post.WriteSolutionToFile(U, n, cfg.nWrite, cfg.nMax,\\\n cfg.OutFileName, cfg.dX) # Write output to file\n post.WriteConvHistToFile(cfg, n, Error) # Write convergence log to history file",
" ITER ERROR\n ---- -----\n 10 4.92187500\n 20 3.52394104\n 30 2.88928896\n 40 2.50741375\n 50 2.24550338\n 60 2.05156084\n 70 1.90048503\n 80 1.77844060\n 90 1.67704721\n 100 1.59085792\n 110 1.51614304\n 120 1.45025226\n 130 1.39125374\n 140 1.33771501\n 150 1.28856146\n 160 1.24298016\n 170 1.20035213\n 180 1.16020337\n 190 1.12216882\n 200 1.08596559\n 210 1.05137298\n 220 1.01821734\n 230 0.98636083\n 240 0.95569280\n 250 0.92612336\n 260 0.89757851\n 270 0.86999638\n 280 0.84332454\n 290 0.81751777\n 300 0.79253655\n 310 0.76834575\n 320 0.74491380\n 330 0.72221190\n 340 0.70021355\n 350 0.67889409\n 360 0.65823042\n 370 0.63820074\n 380 0.61878436\n 390 0.59996158\n 400 0.58171354\n 410 0.56402217\n 420 0.54687008\n 430 0.53024053\n 440 0.51411737\n 450 0.49848501\n 460 0.48332837\n\nSTATUS: SOLUTION OBTAINED AT\nTIME LEVEL= 1.08 s.\nTIME STEPS= 468\n\nWriting convergence log file: Completed.\nFiles saved:\n\"D:/MyProjects/projectroot/nanpack/output/HISTftcs1D.dat\".\n"
]
],
[
[
"In the above convergence monitor, it is worth noting that the solution error is gradually moving towards zero which is what we need to confirm stability in the solution. If the solution becomes unstable, the errors will rise, probably upto the point where your code will crash. As you know that the solution obtained is a time-dependent solution and therefore, we didn't allow the code to run until the convergence is observed. If a steady-state solution is desired, change the STATE key in the configuration file equals to \"STEADY\" and specify a much larger value of nMax key, say nMax = 5000. This is left as an exercise for the users to obtain a stead-state solution. Also, try running the solution with the larger grid step size, $\\Delta x$ or a larger time step size, $\\Delta t$.\n\nAfter the time stepping is completed, save the final results to the output files.",
"_____no_output_____"
]
],
[
[
"# Write output to file\npost.WriteSolutionToFile(U, n, cfg.nWrite, cfg.nMax,\n cfg.OutFileName, cfg.dX)\n# Write convergence history log to a file\npost.WriteConvHistToFile(cfg, n, Error)",
"_____no_output_____"
]
],
[
[
"Verify that the files are saved in the target directory.\nNow let us obtain analytical solution of this flow that will help us in validating our codes.",
"_____no_output_____"
]
],
[
[
"# Obtain analytical solution\nUana = ParallelPlateFlow(40.0, X, cfg.diff, cfg.totTime, 20)",
"_____no_output_____"
]
],
[
[
"Next, we will validate our results by plotting the results using the matplotlib package that we have imported above. Type the following lines of codes:",
"_____no_output_____"
]
],
[
[
"plt.rc(\"font\", family=\"serif\", size=8) # Assign fonts in the plot\nfig, ax = plt.subplots(dpi=150) # Create axis for plotting\nplt.plot(U, X, \">-.b\", linewidth=0.5, label=\"FTCS\",\\\n markersize=5, markevery=5) # Plot data with required labels and markers, customize the plot however you may like\nplt.plot(Uana, X, \"o:r\", linewidth=0.5, label=\"Analytical\",\\\n markersize=5, markevery=5) # Plot analytical solution on the same plot\nplt.xlabel('Velocity (m/s)') # X-axis labelling\nplt.ylabel('Plate distance (m)') # Y-axis labelling\nplt.title(f\"Velocity profile\\nat t={cfg.totTime} sec\", fontsize=8) # Plot title\nplt.legend()\nplt.show() # Show plot- this command is very important",
"_____no_output_____"
]
],
[
[
"Function for the boundary conditions.",
"_____no_output_____"
]
],
[
[
"def BC(U):\n \"\"\"Return the dependent variable with the updated values at the boundaries.\"\"\"\n U[0] = 40.0\n U[-1] = 0.0\n\n return U",
"_____no_output_____"
]
],
[
[
"Congratulations, you have completed the first coding tutoria using nanpack package and verified that your codes produced correct results. If you solve some other similar diffusion-1D model example, share it with the nanpack community. I will be excited to see your projects.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d004aae7a5fd2d625ea028f9d9f2c844e6d27abf
| 50,057 |
ipynb
|
Jupyter Notebook
|
article_materials/fig1_catastrophic_forgetting.ipynb
|
authoranonymous321/soft_mt_adaptation
|
5d2d7f569e0113a81b65dcc7634fcc2ee489bd68
|
[
"MIT"
] | null | null | null |
article_materials/fig1_catastrophic_forgetting.ipynb
|
authoranonymous321/soft_mt_adaptation
|
5d2d7f569e0113a81b65dcc7634fcc2ee489bd68
|
[
"MIT"
] | null | null | null |
article_materials/fig1_catastrophic_forgetting.ipynb
|
authoranonymous321/soft_mt_adaptation
|
5d2d7f569e0113a81b65dcc7634fcc2ee489bd68
|
[
"MIT"
] | null | null | null | 410.303279 | 44,567 | 0.915037 |
[
[
[
"import pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nall_domains = [\"Bible\", \"Opensub\", \"Wiki\"]\n\ncomet_json_output = \"eval_X_sequence2sequence_bleu_gen_chart_data.json\"\n\ndf = pd.read_json(\"data/fig1/%s\" % comet_json_output)\n\nper_domain_records = pd.read_json(\"data/fig1/%s\" % comet_json_output, orient=\"columns\", typ=\"series\")",
"_____no_output_____"
],
[
"domain_dfs = []\n\nwindow_size = 5\n\nfor domain_record in per_domain_records:\n domain_df = pd.DataFrame(domain_record)\n plot_name = next(domain for domain in all_domains if domain in domain_df[\"name\"].iloc[0])\n\n reference_value = domain_df[\"y\"].iloc[0]\n\n domain_df[plot_name] = domain_df[\"y\"]\n domain_df[\"Update step\"] = domain_df.x\n domain_df = domain_df.set_index(\"Update step\", drop=True)\n domain_df = domain_df[plot_name]\n\n smoothed = domain_df.rolling(window=window_size, center=True).mean()\n normalised = smoothed / reference_value\n domain_df[pd.isna(normalised)] = 1\n domain_df[~pd.isna(normalised)] = normalised[~pd.isna(normalised)]\n\n domain_df = domain_df.iloc[:-(window_size // 2 + 1)]\n\n domain_dfs.append(domain_df)\n\nall_df = pd.concat(domain_dfs, axis=1)\nall_df",
"_____no_output_____"
],
[
"all_df.plot(grid=True, colormap=\"Paired\", figsize=(12, 6), marker=\"o\")\nplt.tight_layout()\nplt.savefig(\"MLE_forgetting.png\", format=\"png\", dpi=300)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
d004c9d8d890da363355e68aa808f5cf45a4c71d
| 16,693 |
ipynb
|
Jupyter Notebook
|
Markdown 101-class.ipynb
|
uc-data-services/elag2016-jupyter-jumpstart
|
b15ec9c72e6fc33ecd046da0afddb9ee9e521426
|
[
"CC0-1.0"
] | null | null | null |
Markdown 101-class.ipynb
|
uc-data-services/elag2016-jupyter-jumpstart
|
b15ec9c72e6fc33ecd046da0afddb9ee9e521426
|
[
"CC0-1.0"
] | null | null | null |
Markdown 101-class.ipynb
|
uc-data-services/elag2016-jupyter-jumpstart
|
b15ec9c72e6fc33ecd046da0afddb9ee9e521426
|
[
"CC0-1.0"
] | null | null | null | 24.548529 | 245 | 0.503205 |
[
[
[
"# lesson goals",
"_____no_output_____"
],
[
"* Intro to markdown, plain text-based syntax for formatting docs\n* markdown is integrated into the jupyter notebook",
"_____no_output_____"
],
[
"## What is markdown?",
"_____no_output_____"
],
[
"* developed in 2004 by John Gruber\n - a way of formatting text\n \n - a perl utility for converting markdown into html\n\n**plain text files** have many advantages of other formats\n1. they are readable on virt. all devices\n2. withstood the test of time (legacy word processing formats)\n\nby using markdown you'll be able to produce files that are legible in plain text and ready to be styled in other platforms\n\nexample: \n\n* blogging engines, static site generators, sites like (github) support markdown & will render markdown into html\n* tools like pandoc convert files into and out of markdown",
"_____no_output_____"
],
[
"markdown files are saved in extention `.md` and can be opened in text editors like textedit, notepad, sublime text, or vim",
"_____no_output_____"
],
[
"#### Headings",
"_____no_output_____"
],
[
"Four levels of heading are avaiable in Markdown, and are indicated by the number of `#` preceding the heading text. Paste the following examples into a code box.",
"_____no_output_____"
],
[
"```\n# First level heading\n## Second level heading\n### Third level heading\n#### Fourth level heading\n```",
"_____no_output_____"
],
[
"# First level heading\n## Second level heading\n### Third level heading\n#### Fourth level heading",
"_____no_output_____"
],
[
"First and second level headings may also be entered as follows:\n\n```\nFirst level heading\n=======\n\nSecond level heading\n----------\n```",
"_____no_output_____"
],
[
"First level heading\n=======\n\nSecond level heading\n----------",
"_____no_output_____"
],
[
"#### Paragraphs & Line Breaks\n\nTry typing the following sentence into the textbox:\n\n```\nWelcome to the Jupyter Jumpstart.\n\nToday we'll be learning about Markdown syntax.\nThis sentence is separated by a single line break from the preceding one.\n```",
"_____no_output_____"
],
[
"Welcome to the Jupyter Jumpstart.\n\nToday we'll be learning about Markdown syntax.\nThis sentence is separated by a single line break from the preceding one.",
"_____no_output_____"
],
[
"NOTE: \n\n* Paragraphs must be separated by an empty line\n* leave an empty line between `syntax` and `This`\n* some implementations of Markdown, single line breaks must also be indicated with two empty spaces at the end of each line\n",
"_____no_output_____"
],
[
"#### Adding Emphasis",
"_____no_output_____"
],
[
"* Text can be italicized by wrapping the word in `*` or `_` symbols\n* bold text is written by wrapping the word in `**` or `_`",
"_____no_output_____"
],
[
"Try adding emphasis to a sentence using these methods:\n\n```\nI am **very** excited about the _Jupyter Jumpstart_ workshop.\n```",
"_____no_output_____"
],
[
"I am **very** excited about the _Jupyter Jumpstart_ workshop.",
"_____no_output_____"
],
[
"\n#### Making Lists",
"_____no_output_____"
],
[
"Markdown includes support for ordered and unordered lists. Try typing the following list into the textbox:\n\n```\nShopping List\n----------\n* Fruits\n * Apples\n * Oranges\n * Grapes\n* Dairy\n * Milk\n * Cheese\n```\n\nIndenting the `*` will allow you to created nested items.\n",
"_____no_output_____"
],
[
"Shopping List\n----------\n* Fruits\n * Apples\n - hellow\n * Oranges\n * Grapes\n* Dairy\n * Milk\n * Cheese",
"_____no_output_____"
],
[
"**Ordered lists** are written by numbering each line. Once again, the goal of Markdown is to produce documents that are both legible as plain text and able to be transformed into other formats. \n\n```\nTo-do list\n----------\n1. Finish Markdown tutorial\n2. Go to grocery store\n3. Prepare lunch\n```",
"_____no_output_____"
],
[
"To-do list\n----------\n1. Finish Markdown tutorial\n2. Go to grocery store\n3. Going for drinks\n3. Prepare lunch",
"_____no_output_____"
],
[
"#### Code Snippets",
"_____no_output_____"
],
[
"* Represent code by wrapping snippets in back-tick characters like `````\n* for example `` `<br />` ``\n* whole blocks of code are written by typing three backtick characters before and after each block\n\nTry typing the following text into the textbox:\n\n ```html\n <html>\n <head>\n <title>Website Title</title>\n </head>\n <body>\n </body>\n </html>\n ```",
"_____no_output_____"
],
[
"```html\n<html>\n <head>\n <title>Website Title</title>\n </head>\n <body>\n </body>\n</html>\n```",
"_____no_output_____"
],
[
"**specific languages** \n\nin jupyter you can specify specific lanauages for code syntax hylighting\n\nexample:\n\n```python\n\nfor item in collection:\n print(item)\n```\n\nnote how the keywords in python are highlighted",
"_____no_output_____"
],
[
"```python\n\nfor item in collection:\n print(item)\n```",
"_____no_output_____"
],
[
"\n#### Blockquotes\n\nAdding a `>` before any paragraph will render it as a blockquote element.\n\nTry typing the following text into the textbox:\n\n```\n> Hello, I am a paragraph of text enclosed in a blockquote. Notice how I am offset from the left margin. \n```",
"_____no_output_____"
],
[
"> Hello, I am a paragraph of text enclosed in a blockquote. Notice how I am offset from the left margin.",
"_____no_output_____"
],
[
"#### Links\n\n* Inline links are written by enclosing the link text in square brackets first, then including the URL and optional alt-text in round brackets\n\n`For more tutorials, please visit the [Programming Historian](http://programminghistorian.org/ \"Programming Historian main page\").`\n",
"_____no_output_____"
],
[
"[Programming Historian](http://programminghistorian.org/ \"Programming Historian main page\")",
"_____no_output_____"
],
[
"#### Images\n\nImages can be referenced using `!`, followed by some alt-text in square brackets, followed by the image URL and an optional title. These will not be displayed in your plain text document, but would be embedded into a rendered HTML page.\n\n``",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"#### Horizontal Rules\n\nHorizontal rules are produced when three or more `-`, `*` or `_` are included on a line by themselves, regardless of the number of spaces between them. All of the following combinations will render horizontal rules:\n\n```\n___\n* * *\n- - - - - -\n```",
"_____no_output_____"
],
[
"___\n* * *\n- - - - - -",
"_____no_output_____"
],
[
"#### Tables \n\n* use pipes `|` to separate columns and hyphens `-` between your headings and the rest of the table content \n* pipes are only strictly necessary between columns, you may use them on either side of your table for a more polished look \n* cells can contain any length of content, and it is not necessary for pipes to be vertically aligned with each other.\n\nMake the below into a table in the notebook:\n\n```\n| Heading 1 | Heading 2 | Heading 3 |\n| --------- | --------- | --------- |\n| Row 1, column 1 | Row 1, column 2 | Row 1, column 3|\n| Row 2, column 1 | Row 2, column 2 | Row 2, column 3|\n| Row 3, column 1 | Row 3, column 2 | Row 3, column 3|\n```",
"_____no_output_____"
],
[
"| Heading 1 | Heading 2 | Heading 3 |\n| --------- | --------- | --------- |\n| Row 1, column 1 | Row 1, column 2 | Row 1, column 3|\n| Row 2, column 1 | Row 2, column 2 | Row 2, column 3|\n| Row 3, column 1 | Row 3, column 2 | Row 3, column 3|",
"_____no_output_____"
],
[
"\nTo specify the alignment of each column, colons `:` can be added to the header row as follows. Create the table in the notebook.\n\n```\n| Left-aligned | Centered | Right-aligned |\n| :-------- | :-------: | --------: |\n| Apples | Red | 5000 |\n| Bananas | Yellow | 75 |\n```\n",
"_____no_output_____"
],
[
"| Left-aligned | Centered | Right-aligned |\n| :-------- | :-------: | --------: |\n| Apples | Red | 5000 |\n| Bananas | Yellow | 75 |",
"_____no_output_____"
]
],
[
[
"from IPython import display",
"_____no_output_____"
],
[
"display.YouTubeVideo('Rc4JQWowG5I')",
"_____no_output_____"
],
[
"whos",
"Variable Type Data/Info\n------------------------------\ndisplay module <module 'IPython.display'<...>ages/IPython/display.py'>\n"
],
[
"display.YouTubeVideo??",
"_____no_output_____"
],
[
"help(display.YouTubeVideo)",
"Help on class YouTubeVideo in module IPython.lib.display:\n\nclass YouTubeVideo(IFrame)\n | Class for embedding a YouTube Video in an IPython session, based on its video id.\n | \n | e.g. to embed the video from https://www.youtube.com/watch?v=foo , you would\n | do::\n | \n | vid = YouTubeVideo(\"foo\")\n | display(vid)\n | \n | To start from 30 seconds::\n | \n | vid = YouTubeVideo(\"abc\", start=30)\n | display(vid)\n | \n | To calculate seconds from time as hours, minutes, seconds use\n | :class:`datetime.timedelta`::\n | \n | start=int(timedelta(hours=1, minutes=46, seconds=40).total_seconds())\n | \n | Other parameters can be provided as documented at\n | https://developers.google.com/youtube/player_parameters#parameter-subheader\n | \n | Method resolution order:\n | YouTubeVideo\n | IFrame\n | builtins.object\n | \n | Methods defined here:\n | \n | __init__(self, id, width=400, height=300, **kwargs)\n | Initialize self. See help(type(self)) for accurate signature.\n | \n | ----------------------------------------------------------------------\n | Data descriptors inherited from IFrame:\n | \n | __dict__\n | dictionary for instance variables (if defined)\n | \n | __weakref__\n | list of weak references to the object (if defined)\n | \n | ----------------------------------------------------------------------\n | Data and other attributes inherited from IFrame:\n | \n | iframe = '\\n <iframe\\n width=\"{width}\"\\n ... ...\n\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d004cda46481a52b658f55ff71ca3eeced2be7d4
| 8,931 |
ipynb
|
Jupyter Notebook
|
gym-train/classification/fruits/model_optimization.ipynb
|
GrzegorzKrug/GymTrain
|
0731c45a61f9b727e9d91e3d082d6bae90f9bd8b
|
[
"Apache-2.0"
] | 2 |
2020-08-13T08:22:11.000Z
|
2021-01-20T05:35:12.000Z
|
gym-train/classification/fruits/model_optimization.ipynb
|
GrzegorzKrug/GymTrain
|
0731c45a61f9b727e9d91e3d082d6bae90f9bd8b
|
[
"Apache-2.0"
] | 3 |
2021-06-08T21:16:44.000Z
|
2022-03-12T00:22:56.000Z
|
gym-train/classification/fruits/model_optimization.ipynb
|
GrzegorzKrug/GymTrain
|
0731c45a61f9b727e9d91e3d082d6bae90f9bd8b
|
[
"Apache-2.0"
] | null | null | null | 31.670213 | 121 | 0.453701 |
[
[
[
"import tensorflow as tf\nfrom tensorflow.keras.callbacks import TensorBoard\n\nimport os\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport random\nimport cv2\nimport time\n\n\ntraining_path = \"fruits-360_dataset/Training\"\ntest_path = \"fruits-360_dataset/Test\"\n\ntry:\n STATS = np.load(\"stats.npy\", allow_pickle=True)\nexcept FileNotFoundError as fnf:\n print(\"Not found stats file.\")\n STATS = []\n\n# Parameters \nGRAY_SCALE = False\nFRUITS = os.listdir(training_path)\nrandom.shuffle(FRUITS)\n\ntrain_load = 0.1\ntest_load = 0.3\n\n",
"_____no_output_____"
],
[
"def load_data(directory_path, load_factor=None):\n data = []\n labels = []\n \n \n for fruit_name in FRUITS:\n class_num = FRUITS.index(fruit_name) \n \n path = os.path.join(directory_path, fruit_name)\n \n for img in os.listdir(path):\n if load_factor and np.random.random() > load_factor: # skip image\n continue\n \n img_path = os.path.join(path, img) \n if GRAY_SCALE:\n image = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)\n else:\n image = cv2.imread(img_path)\n image = image[:, :, [2, 1, 0]]\n \n image = image / 255.0\n image = np.array(image, dtype=np.single) # Reduce precision and memory consumption\n \n data.append([image, class_num])\n\n random.shuffle(data)\n \n X = []\n y = []\n \n \n for image, label in data:\n X.append(image)\n y.append(label)\n \n X = np.array(X)\n y = np.array(y)\n \n if GRAY_SCALE:\n print(\"Reshaping gray scale\")\n X = X.reshape(-1, X.shape[1], X.shape[2], 1)\n \n return X, y ",
"_____no_output_____"
],
[
"X_training, y_training = load_data(training_path, load_factor=train_load)\nprint(\"Created training array\") \nprint(f\"X shape: {X_training.shape}\")\nprint(f\"y shape: {y_training.shape}\")",
"_____no_output_____"
],
[
"X_test, y_test = load_data(test_path, load_factor=test_load)\n\nprint(\"Created test arrays\") \nprint(f\"X shape: {X_test.shape}\")\nprint(f\"y shape: {y_test.shape}\")",
"_____no_output_____"
],
[
"class AfterTwoEpochStop(tf.keras.callbacks.Callback):\n def __init__(self, acc_threshold, loss_threshold):\n# super(AfterTwoEpochStop, self).__init__()\n self.acc_threshold = acc_threshold\n self.loss_threshold = loss_threshold\n self.checked = False\n print(\"Init\")\n\n def on_epoch_end(self, epoch, logs=None): \n acc = logs[\"accuracy\"] \n loss = logs[\"loss\"]\n if acc >= self.acc_threshold and loss <= self.loss_threshold:\n if self.checked:\n self.model.stop_training = True\n else:\n self.checked = True\n else:\n self.checked = False\n\nstop = AfterTwoEpochStop(acc_threshold=0.98, loss_threshold=0.05) ",
"_____no_output_____"
],
[
"# Limit gpu memory usage\n\nconfig = tf.compat.v1.ConfigProto()\nconfig.gpu_options.allow_growth = False\nconfig.gpu_options.per_process_gpu_memory_fraction = 0.4\nsession = tf.compat.v1.Session(config=config)\n",
"_____no_output_____"
],
[
"from tensorflow.keras.layers import Dense, Flatten, Conv2D, Conv3D, MaxPooling2D, MaxPooling3D, Activation, Dropout",
"_____no_output_____"
],
[
"dense_layers = [2]\ndense_size = [32, 64]\nconv_layers = [1, 2, 3]\nconv_size = [32, 64]\nconv_shape = [2, 5]\n\npic_shape = X_training.shape[1:]\nlabel_count = len(FRUITS)\n\n\nrun_num = 0\ntotal = len(dense_layers)*len(dense_size)*len(conv_layers)*len(conv_size)*len(conv_shape)\nfor dl in dense_layers:\n for ds in dense_size:\n for cl in conv_layers:\n for cs in conv_size: \n for csh in conv_shape: \n run_num += 1\n with tf.compat.v1.Session(config=config) as sess:\n \n NAME = f\"{cl}xConv({cs:>03})_shape{csh}-{dl}xDense({ds:>03})-{time.time():10.0f}\"\n \n\n tensorboard = TensorBoard(log_dir=f'logs-optimize/{NAME}')\n model = None\n model = tf.keras.models.Sequential()\n\n model.add(Conv2D(cs, (csh, csh), activation='relu', input_shape=pic_shape))\n model.add(MaxPooling2D())\n\n for i in range(cl-1):\n model.add(Conv2D(cs, (csh, csh), activation='relu'))\n model.add(MaxPooling2D())\n\n model.add(Flatten())\n\n for x in range(dl):\n model.add(Dense(ds, activation='relu'))\n\n model.add(Dense(label_count, activation='softmax'))\n\n model.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\n history = model.fit(X_training, y_training, \n batch_size=25, epochs=10,\n validation_data=(X_test, y_test), \n callbacks=[tensorboard, stop])\n\n loss = history.history['loss']\n accuracy = history.history['accuracy']\n\n val_loss = history.history['val_loss']\n val_accuracy = history.history['val_accuracy']\n\n print(f\"{(run_num/total)*100:<5.1f}% - {NAME} Results: \")\n # print(f\"Test Accuracy: {val_accuracy[-1]:>2.4f}\")\n # print(f\"Test loss: {val_loss[-1]:>2.4f}\")\n ",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d004e6b2cb8ff4088530ed57b8d96cf23441342f
| 169,520 |
ipynb
|
Jupyter Notebook
|
Dev/BTC-USD/Codes/07 XgBoost Performance Results .ipynb
|
Sidhus234/WQU-Capstone-Project-2021
|
d92cf80e06e8f919e1404c1e93200d2e92847c71
|
[
"MIT"
] | 6 |
2021-04-11T09:18:15.000Z
|
2022-03-29T15:42:40.000Z
|
Dev/BTC-USD/Codes/07 XgBoost Performance Results .ipynb
|
Sidhus234/WQU-Capstone-Project-2021
|
d92cf80e06e8f919e1404c1e93200d2e92847c71
|
[
"MIT"
] | null | null | null |
Dev/BTC-USD/Codes/07 XgBoost Performance Results .ipynb
|
Sidhus234/WQU-Capstone-Project-2021
|
d92cf80e06e8f919e1404c1e93200d2e92847c71
|
[
"MIT"
] | 2 |
2022-02-24T06:06:50.000Z
|
2022-03-31T13:12:46.000Z
| 134.007905 | 35,816 | 0.842839 |
[
[
[
"# <span style=\"color:Maroon\">Trade Strategy",
"_____no_output_____"
],
[
"__Summary:__ <span style=\"color:Blue\">In this code we shall test the results of given model",
"_____no_output_____"
]
],
[
[
"# Import required libraries\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport os\nnp.random.seed(0)",
"_____no_output_____"
],
[
"import warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"# User defined names\nindex = \"BTC-USD\"\nfilename_whole = \"whole_dataset\"+index+\"_xgboost_model.csv\"\nfilename_trending = \"Trending_dataset\"+index+\"_xgboost_model.csv\"\nfilename_meanreverting = \"MeanReverting_dataset\"+index+\"_xgboost_model.csv\"\ndate_col = \"Date\"\nRf = 0.01 #Risk free rate of return",
"_____no_output_____"
],
[
"# Get current working directory\nmycwd = os.getcwd()\nprint(mycwd)",
"C:\\Users\\sidhu\\Downloads\\Course 10 Capstone Project\\Trading Strategy Development\\Dev\\BTC-USD\\Codes\n"
],
[
"# Change to data directory\nos.chdir(\"..\")\nos.chdir(str(os.getcwd()) + \"\\\\Data\")",
"_____no_output_____"
],
[
"# Read the datasets\ndf_whole = pd.read_csv(filename_whole, index_col=date_col)\ndf_trending = pd.read_csv(filename_trending, index_col=date_col)\ndf_meanreverting = pd.read_csv(filename_meanreverting, index_col=date_col)\n# Convert index to datetime\ndf_whole.index = pd.to_datetime(df_whole.index)\ndf_trending.index = pd.to_datetime(df_trending.index)\ndf_meanreverting.index = pd.to_datetime(df_meanreverting.index)",
"_____no_output_____"
],
[
"# Head for whole dataset\ndf_whole.head()",
"_____no_output_____"
],
[
"df_whole.shape",
"_____no_output_____"
],
[
"# Head for Trending dataset\ndf_trending.head()",
"_____no_output_____"
],
[
"df_trending.shape",
"_____no_output_____"
],
[
"# Head for Mean Reverting dataset\ndf_meanreverting.head()",
"_____no_output_____"
],
[
"df_meanreverting.shape",
"_____no_output_____"
],
[
"# Merge results from both models to one\ndf_model = df_trending.append(df_meanreverting)\ndf_model.sort_index(inplace=True)\ndf_model.head()",
"_____no_output_____"
],
[
"df_model.shape",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
],
[
"## <span style=\"color:Maroon\">Functions",
"_____no_output_____"
]
],
[
[
"def initialize(df):\n days, Action1, Action2, current_status, Money, Shares = ([] for i in range(6))\n Open_price = list(df['Open'])\n Close_price = list(df['Adj Close'])\n Predicted = list(df['Predicted'])\n Action1.append(Predicted[0])\n Action2.append(0)\n current_status.append(Predicted[0])\n if(Predicted[0] != 0):\n days.append(1)\n if(Predicted[0] == 1):\n Money.append(0)\n else:\n Money.append(200)\n Shares.append(Predicted[0] * (100/Open_price[0]))\n else:\n days.append(0)\n Money.append(100)\n Shares.append(0)\n return days, Action1, Action2, current_status, Predicted, Money, Shares, Open_price, Close_price",
"_____no_output_____"
],
[
"def Action_SA_SA(days, Action1, Action2, current_status, i):\n if(current_status[i-1] != 0):\n days.append(1)\n else:\n days.append(0)\n current_status.append(current_status[i-1])\n Action1.append(0)\n Action2.append(0)\n return days, Action1, Action2, current_status",
"_____no_output_____"
],
[
"def Action_ZE_NZE(days, Action1, Action2, current_status, i):\n if(days[i-1] < 5):\n days.append(days[i-1] + 1)\n Action1.append(0)\n Action2.append(0)\n current_status.append(current_status[i-1])\n else:\n days.append(0)\n Action1.append(current_status[i-1] * (-1))\n Action2.append(0)\n current_status.append(0)\n return days, Action1, Action2, current_status",
"_____no_output_____"
],
[
"def Action_NZE_ZE(days, Action1, Action2, current_status, Predicted, i):\n current_status.append(Predicted[i])\n Action1.append(Predicted[i])\n Action2.append(0)\n days.append(days[i-1] + 1)\n return days, Action1, Action2, current_status",
"_____no_output_____"
],
[
"def Action_NZE_NZE(days, Action1, Action2, current_status, Predicted, i):\n current_status.append(Predicted[i])\n Action1.append(Predicted[i])\n Action2.append(Predicted[i])\n days.append(1)\n return days, Action1, Action2, current_status",
"_____no_output_____"
],
[
"def get_df(df, Action1, Action2, days, current_status, Money, Shares):\n df['Action1'] = Action1\n df['Action2'] = Action2\n df['days'] = days\n df['current_status'] = current_status\n df['Money'] = Money\n df['Shares'] = Shares\n return df",
"_____no_output_____"
],
[
"def Get_TradeSignal(Predicted, days, Action1, Action2, current_status):\n # Loop over 1 to N\n for i in range(1, len(Predicted)):\n # When model predicts no action..\n if(Predicted[i] == 0):\n if(current_status[i-1] != 0):\n days, Action1, Action2, current_status = Action_ZE_NZE(days, Action1, Action2, current_status, i)\n else:\n days, Action1, Action2, current_status = Action_SA_SA(days, Action1, Action2, current_status, i)\n # When Model predicts sell\n elif(Predicted[i] == -1):\n if(current_status[i-1] == -1):\n days, Action1, Action2, current_status = Action_SA_SA(days, Action1, Action2, current_status, i)\n elif(current_status[i-1] == 0):\n days, Action1, Action2, current_status = Action_NZE_ZE(days, Action1, Action2, current_status, Predicted,\n i)\n else:\n days, Action1, Action2, current_status = Action_NZE_NZE(days, Action1, Action2, current_status, Predicted,\n i)\n # When model predicts Buy\n elif(Predicted[i] == 1):\n if(current_status[i-1] == 1):\n days, Action1, Action2, current_status = Action_SA_SA(days, Action1, Action2, current_status, i)\n elif(current_status[i-1] == 0):\n days, Action1, Action2, current_status = Action_NZE_ZE(days, Action1, Action2, current_status, Predicted,\n i)\n else:\n days, Action1, Action2, current_status = Action_NZE_NZE(days, Action1, Action2, current_status, Predicted,\n i)\n return days, Action1, Action2, current_status",
"_____no_output_____"
],
[
"def Get_FinancialSignal(Open_price, Action1, Action2, Money, Shares, Close_price):\n for i in range(1, len(Open_price)):\n if(Action1[i] == 0):\n Money.append(Money[i-1])\n Shares.append(Shares[i-1])\n else:\n if(Action2[i] == 0):\n # Enter new position\n if(Shares[i-1] == 0):\n Shares.append(Action1[i] * (Money[i-1]/Open_price[i]))\n Money.append(Money[i-1] - Action1[i] * Money[i-1])\n # Exit the current position\n else:\n Shares.append(0)\n Money.append(Money[i-1] - Action1[i] * np.abs(Shares[i-1]) * Open_price[i])\n else:\n Money.append(Money[i-1] -1 *Action1[i] *np.abs(Shares[i-1]) * Open_price[i])\n Shares.append(Action2[i] * (Money[i]/Open_price[i]))\n Money[i] = Money[i] - 1 * Action2[i] * np.abs(Shares[i]) * Open_price[i]\n return Money, Shares",
"_____no_output_____"
],
[
"def Get_TradeData(df):\n # Initialize the variables\n days,Action1,Action2,current_status,Predicted,Money,Shares,Open_price,Close_price = initialize(df)\n # Get Buy/Sell trade signal\n days, Action1, Action2, current_status = Get_TradeSignal(Predicted, days, Action1, Action2, current_status)\n Money, Shares = Get_FinancialSignal(Open_price, Action1, Action2, Money, Shares, Close_price)\n df = get_df(df, Action1, Action2, days, current_status, Money, Shares)\n df['CurrentVal'] = df['Money'] + df['current_status'] * np.abs(df['Shares']) * df['Adj Close']\n return df",
"_____no_output_____"
],
[
"def Print_Fromated_PL(active_days, number_of_trades, drawdown, annual_returns, std_dev, sharpe_ratio, year):\n \"\"\"\n Prints the metrics\n \"\"\"\n print(\"++++++++++++++++++++++++++++++++++++++++++++++++++++\")\n print(\" Year: {0}\".format(year))\n print(\" Number of Trades Executed: {0}\".format(number_of_trades))\n print(\"Number of days with Active Position: {}\".format(active_days))\n print(\" Annual Return: {:.6f} %\".format(annual_returns*100))\n print(\" Sharpe Ratio: {:.2f}\".format(sharpe_ratio))\n print(\" Maximum Drawdown (Daily basis): {:.2f} %\".format(drawdown*100))\n print(\"----------------------------------------------------\")\n return",
"_____no_output_____"
],
[
"def Get_results_PL_metrics(df, Rf, year):\n df['tmp'] = np.where(df['current_status'] == 0, 0, 1)\n active_days = df['tmp'].sum()\n number_of_trades = np.abs(df['Action1']).sum()+np.abs(df['Action2']).sum()\n df['tmp_max'] = df['CurrentVal'].rolling(window=20).max()\n df['tmp_min'] = df['CurrentVal'].rolling(window=20).min()\n df['tmp'] = np.where(df['tmp_max'] > 0, (df['tmp_max'] - df['tmp_min'])/df['tmp_max'], 0)\n drawdown = df['tmp'].max()\n annual_returns = (df['CurrentVal'].iloc[-1]/100 - 1)\n std_dev = df['CurrentVal'].pct_change(1).std()\n sharpe_ratio = (annual_returns - Rf)/std_dev\n Print_Fromated_PL(active_days, number_of_trades, drawdown, annual_returns, std_dev, sharpe_ratio, year)\n return ",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
]
],
[
[
"# Change to Images directory\nos.chdir(\"..\")\nos.chdir(str(os.getcwd()) + \"\\\\Images\")",
"_____no_output_____"
]
],
[
[
"## <span style=\"color:Maroon\">Whole Dataset",
"_____no_output_____"
]
],
[
[
"df_whole_train = df_whole[df_whole[\"Sample\"] == \"Train\"]\ndf_whole_test = df_whole[df_whole[\"Sample\"] == \"Test\"]\ndf_whole_test_2019 = df_whole_test[df_whole_test.index.year == 2019]\ndf_whole_test_2020 = df_whole_test[df_whole_test.index.year == 2020]",
"_____no_output_____"
],
[
"output_train_whole = Get_TradeData(df_whole_train)\noutput_test_whole = Get_TradeData(df_whole_test)\noutput_test_whole_2019 = Get_TradeData(df_whole_test_2019)\noutput_test_whole_2020 = Get_TradeData(df_whole_test_2020)\noutput_train_whole[\"BuyandHold\"] = (100 * output_train_whole[\"Adj Close\"])/(output_train_whole.iloc[0][\"Adj Close\"])\noutput_test_whole[\"BuyandHold\"] = (100*output_test_whole[\"Adj Close\"])/(output_test_whole.iloc[0][\"Adj Close\"])\noutput_test_whole_2019[\"BuyandHold\"] = (100 * output_test_whole_2019[\"Adj Close\"])/(output_test_whole_2019.iloc[0]\n [\"Adj Close\"])\noutput_test_whole_2020[\"BuyandHold\"] = (100 * output_test_whole_2020[\"Adj Close\"])/(output_test_whole_2020.iloc[0]\n [\"Adj Close\"])",
"_____no_output_____"
],
[
"Get_results_PL_metrics(output_test_whole_2019, Rf, 2019)",
"++++++++++++++++++++++++++++++++++++++++++++++++++++\n Year: 2019\n Number of Trades Executed: 41\nNumber of days with Active Position: 195\n Annual Return: -35.317809 %\n Sharpe Ratio: -12.08\n Maximum Drawdown (Daily basis): 48.25 %\n----------------------------------------------------\n"
],
[
"Get_results_PL_metrics(output_test_whole_2020, Rf, 2020)",
"++++++++++++++++++++++++++++++++++++++++++++++++++++\n Year: 2020\n Number of Trades Executed: 19\nNumber of days with Active Position: 241\n Annual Return: -71.655759 %\n Sharpe Ratio: -25.96\n Maximum Drawdown (Daily basis): 36.34 %\n----------------------------------------------------\n"
],
[
"# Scatter plot to save fig\nplt.figure(figsize=(10,5))\nplt.plot(output_train_whole[\"CurrentVal\"], 'b-', label=\"Value (Model)\")\nplt.plot(output_train_whole[\"BuyandHold\"], 'r--', alpha=0.5, label=\"Buy and Hold\")\nplt.xlabel(\"Date\", fontsize=12)\nplt.ylabel(\"Value\", fontsize=12)\nplt.legend()\nplt.title(\"Train Sample \"+ str(index) + \" Xgboost Whole Dataset\", fontsize=16)\nplt.savefig(\"Train Sample Whole Dataset Xgboost Model\" + str(index) +'.png')\nplt.show()\nplt.close()",
"_____no_output_____"
],
[
"# Scatter plot to save fig\nplt.figure(figsize=(10,5))\nplt.plot(output_test_whole[\"CurrentVal\"], 'b-', label=\"Value (Model)\")\nplt.plot(output_test_whole[\"BuyandHold\"], 'r--', alpha=0.5, label=\"Buy and Hold\")\nplt.xlabel(\"Date\", fontsize=12)\nplt.ylabel(\"Value\", fontsize=12)\nplt.legend()\nplt.title(\"Test Sample \"+ str(index) + \" Xgboost Whole Dataset\", fontsize=16)\nplt.savefig(\"Test Sample Whole Dataset XgBoost Model\" + str(index) +'.png')\nplt.show()\nplt.close()",
"_____no_output_____"
]
],
[
[
"__Comments:__ <span style=\"color:Blue\"> Based on the performance of model on Train Sample, the model has definitely learnt the patter, instead of over-fitting. But the performance of model in Test Sample is very poor",
"_____no_output_____"
],
[
"## <span style=\"color:Maroon\">Segment Model",
"_____no_output_____"
]
],
[
[
"df_model_train = df_model[df_model[\"Sample\"] == \"Train\"]\ndf_model_test = df_model[df_model[\"Sample\"] == \"Test\"]\ndf_model_test_2019 = df_model_test[df_model_test.index.year == 2019]\ndf_model_test_2020 = df_model_test[df_model_test.index.year == 2020]",
"_____no_output_____"
],
[
"output_train_model = Get_TradeData(df_model_train)\noutput_test_model = Get_TradeData(df_model_test)\noutput_test_model_2019 = Get_TradeData(df_model_test_2019)\noutput_test_model_2020 = Get_TradeData(df_model_test_2020)\noutput_train_model[\"BuyandHold\"] = (100 * output_train_model[\"Adj Close\"])/(output_train_model.iloc[0][\"Adj Close\"])\noutput_test_model[\"BuyandHold\"] = (100 * output_test_model[\"Adj Close\"])/(output_test_model.iloc[0][\"Adj Close\"])\noutput_test_model_2019[\"BuyandHold\"] = (100 * output_test_model_2019[\"Adj Close\"])/(output_test_model_2019.iloc[0]\n [\"Adj Close\"])\noutput_test_model_2020[\"BuyandHold\"] = (100 * output_test_model_2020[\"Adj Close\"])/(output_test_model_2020.iloc[0]\n [\"Adj Close\"])",
"_____no_output_____"
],
[
"Get_results_PL_metrics(output_test_model_2019, Rf, 2019)",
"++++++++++++++++++++++++++++++++++++++++++++++++++++\n Year: 2019\n Number of Trades Executed: 67\nNumber of days with Active Position: 260\n Annual Return: -84.807315 %\n Sharpe Ratio: -27.22\n Maximum Drawdown (Daily basis): 55.32 %\n----------------------------------------------------\n"
],
[
"Get_results_PL_metrics(output_test_model_2020, Rf, 2020)",
"++++++++++++++++++++++++++++++++++++++++++++++++++++\n Year: 2020\n Number of Trades Executed: 38\nNumber of days with Active Position: 216\n Annual Return: -75.886205 %\n Sharpe Ratio: -31.92\n Maximum Drawdown (Daily basis): 29.73 %\n----------------------------------------------------\n"
],
[
"# Scatter plot to save fig\nplt.figure(figsize=(10,5))\nplt.plot(output_train_model[\"CurrentVal\"], 'b-', label=\"Value (Model)\")\nplt.plot(output_train_model[\"BuyandHold\"], 'r--', alpha=0.5, label=\"Buy and Hold\")\nplt.xlabel(\"Date\", fontsize=12)\nplt.ylabel(\"Value\", fontsize=12)\nplt.legend()\nplt.title(\"Train Sample Hurst Segment XgBoost Models \"+ str(index), fontsize=16)\nplt.savefig(\"Train Sample Hurst Segment XgBoost Models\" + str(index) +'.png')\nplt.show()\nplt.close()",
"_____no_output_____"
],
[
"# Scatter plot to save fig\nplt.figure(figsize=(10,5))\nplt.plot(output_test_model[\"CurrentVal\"], 'b-', label=\"Value (Model)\")\nplt.plot(output_test_model[\"BuyandHold\"], 'r--', alpha=0.5, label=\"Buy and Hold\")\nplt.xlabel(\"Date\", fontsize=12)\nplt.ylabel(\"Value\", fontsize=12)\nplt.legend()\nplt.title(\"Test Sample Hurst Segment XgBoost Models\" + str(index), fontsize=16)\nplt.savefig(\"Test Sample Hurst Segment XgBoost Models\" + str(index) +'.png')\nplt.show()\nplt.close()",
"_____no_output_____"
]
],
[
[
"__Comments:__ <span style=\"color:Blue\"> Based on the performance of model on Train Sample, the model has definitely learnt the patter, instead of over-fitting. The model does perform well in Test sample (Not compared to Buy and Hold strategy) compared to single model. Hurst Exponent based segmentation has definately added value to the model",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d004ed9107e709482458a0fef17879fccede4cda
| 13,447 |
ipynb
|
Jupyter Notebook
|
Object Tracking and Localization/Representing State and Motion/Interacting with a Car Object/Interacting with a Car Object.ipynb
|
brand909/Computer-Vision
|
18e5bda880e40f0a355d1df8520770df5bb1ed6b
|
[
"MIT"
] | null | null | null |
Object Tracking and Localization/Representing State and Motion/Interacting with a Car Object/Interacting with a Car Object.ipynb
|
brand909/Computer-Vision
|
18e5bda880e40f0a355d1df8520770df5bb1ed6b
|
[
"MIT"
] | 4 |
2021-03-19T02:34:33.000Z
|
2022-03-11T23:56:20.000Z
|
Object Tracking and Localization/Representing State and Motion/Interacting with a Car Object/Interacting with a Car Object.ipynb
|
brand909/Computer-Vision
|
18e5bda880e40f0a355d1df8520770df5bb1ed6b
|
[
"MIT"
] | null | null | null | 66.569307 | 4,408 | 0.818398 |
[
[
[
"# Interacting with a Car Object",
"_____no_output_____"
],
[
"In this notebook, you've been given some of the starting code for creating and interacting with a car object.\n\nYour tasks are to:\n1. Become familiar with this code. \n - Know how to create a car object, and how to move and turn that car.\n2. Constantly visualize.\n - To make sure your code is working as expected, frequently call `display_world()` to see the result!\n3. **Make the car move in a 4x4 square path.** \n - If you understand the move and turn functions, you should be able to tell a car to move in a square path. This task is a **TODO** at the end of this notebook.\n\nFeel free to change the values of initial variables and add functions as you see fit!\n\nAnd remember, to run a cell in the notebook, press `Shift+Enter`.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport car\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### Define the initial variables",
"_____no_output_____"
]
],
[
[
"# Create a 2D world of 0's\nheight = 4\nwidth = 6\nworld = np.zeros((height, width))\n\n# Define the initial car state\ninitial_position = [0, 0] # [y, x] (top-left corner)\nvelocity = [0, 1] # [vy, vx] (moving to the right)\n",
"_____no_output_____"
]
],
[
[
"### Create a car object",
"_____no_output_____"
]
],
[
[
"# Create a car object with these initial params\ncarla = car.Car(initial_position, velocity, world)\n\nprint('Carla\\'s initial state is: ' + str(carla.state))",
"Carla's initial state is: [[0, 0], [0, 1]]\n"
]
],
[
[
"### Move and track state",
"_____no_output_____"
]
],
[
[
"# Move in the direction of the initial velocity\ncarla.move()\n\n# Track the change in state\nprint('Carla\\'s state is: ' + str(carla.state))\n\n# Display the world\ncarla.display_world()",
"Carla's state is: [[0, 1], [0, 1]]\n"
]
],
[
[
"## TODO: Move in a square path\n\nUsing the `move()` and `turn_left()` functions, make carla traverse a 4x4 square path.\n\nThe output should look like:\n<img src=\"files/4x4_path.png\" style=\"width: 30%;\">",
"_____no_output_____"
]
],
[
[
"## TODO: Make carla traverse a 4x4 square path\n## Display the result\ncarla.move()\ncarla.display_world()",
"_____no_output_____"
]
],
[
[
"There is also one potential solution included by clicking on the \"Jupyter\" in the top left of this notebook, and going into the solution notebook.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d004ee756174906959a292e24c1b89118f42e842
| 85,004 |
ipynb
|
Jupyter Notebook
|
Chapter21/chapter21.ipynb
|
sr006608/Artificial-Intelligence-with-Python-Second-Edition
|
dacfe5cde6812d222668ca78260fb30df7feb55f
|
[
"MIT"
] | 41 |
2020-02-03T13:44:47.000Z
|
2022-02-20T06:37:08.000Z
|
Chapter21/chapter21.ipynb
|
itsshaikaslam/Artificial-Intelligence-with-Python-Second-Edition
|
4bd545232dfc2611a7819e1051d66f93d244e547
|
[
"MIT"
] | 3 |
2020-05-12T03:19:47.000Z
|
2020-07-25T13:27:26.000Z
|
Chapter21/chapter21.ipynb
|
itsshaikaslam/Artificial-Intelligence-with-Python-Second-Edition
|
4bd545232dfc2611a7819e1051d66f93d244e547
|
[
"MIT"
] | 45 |
2019-12-24T18:14:57.000Z
|
2022-02-20T03:56:49.000Z
| 200.009412 | 41,176 | 0.874006 |
[
[
[
"import numpy as np\nimport math\nimport matplotlib.pyplot as plt\ninput_data = np.array([math.cos(x) for x in np.arange(200)])\nplt.plot(input_data[:50])\nplt.show",
"_____no_output_____"
],
[
"X = []\nY = []\n\nsize = 50\nnumber_of_records = len(input_data) - size\nfor i in range(number_of_records - 50):\n X.append(input_data[i:i+size])\n Y.append(input_data[i+size])\nX = np.array(X)\nX = np.expand_dims(X, axis=2)\nY = np.array(Y)\nY = np.expand_dims(Y, axis=1)",
"_____no_output_____"
],
[
"X.shape, Y.shape",
"_____no_output_____"
],
[
"X_valid = []\nY_valid = []\nfor i in range(number_of_records - 50, number_of_records):\n X_valid.append(input_data[i:i+size])\n Y_valid.append(input_data[i+size])\nX_valid = np.array(X_valid)\nX_valid = np.expand_dims(X_valid, axis=2)\nY_valid = np.array(Y_valid)\nY_valid = np.expand_dims(Y_valid, axis=1)",
"_____no_output_____"
],
[
"learning_rate = 0.0001\nnumber_of_epochs = 5\nsequence_length = 50\nhidden_layer_size = 100\noutput_layer_size = 1\nback_prop_truncate = 5\nmin_clip_value = -10\nmax_clip_value = 10",
"_____no_output_____"
],
[
"W1 = np.random.uniform(0, 1, (hidden_layer_size, sequence_length))\nW2 = np.random.uniform(0, 1, (hidden_layer_size, hidden_layer_size))\nW3 = np.random.uniform(0, 1, (output_layer_size, hidden_layer_size))",
"_____no_output_____"
],
[
"def sigmoid(x):\n return 1 / (1 + np.exp(-x))",
"_____no_output_____"
],
[
"for epoch in range(number_of_epochs):\n # check loss on train\n loss = 0.0\n \n # do a forward pass to get prediction\n for i in range(Y.shape[0]):\n x, y = X[i], Y[i]\n prev_act = np.zeros((hidden_layer_size, 1))\n for t in range(sequence_length):\n new_input = np.zeros(x.shape)\n new_input[t] = x[t]\n mul_w1 = np.dot(W1, new_input)\n mul_w2 = np.dot(W2, prev_act)\n add = mul_w2 + mul_w1\n act = sigmoid(add)\n mul_w3 = np.dot(W3, act)\n prev_act = act\n\n # calculate error \n loss_per_record = (y - mul_w3)**2 / 2\n loss += loss_per_record\n loss = loss / float(y.shape[0])\n \n # check loss on validation\n val_loss = 0.0\n for i in range(Y_valid.shape[0]):\n x, y = X_valid[i], Y_valid[i]\n prev_act = np.zeros((hidden_layer_size, 1))\n for t in range(sequence_length):\n new_input = np.zeros(x.shape)\n new_input[t] = x[t]\n mul_w1 = np.dot(W1, new_input)\n mul_w2 = np.dot(W2, prev_act)\n add = mul_w2 + mul_w1\n act = sigmoid(add)\n mul_w3 = np.dot(W3, act)\n prev_act = act\n\n loss_per_record = (y - mul_w3)**2 / 2\n val_loss += loss_per_record\n val_loss = val_loss / float(y.shape[0])\n\n print('Epoch: ', epoch + 1, ', Loss: ', loss, ', Val Loss: ', val_loss)\n \n # train model\n for i in range(Y.shape[0]):\n x, y = X[i], Y[i]\n \n layers = []\n prev_act = np.zeros((hidden_layer_size, 1))\n dW1 = np.zeros(W1.shape)\n dW3 = np.zeros(W3.shape)\n dW2 = np.zeros(W2.shape)\n \n dW1_t = np.zeros(W1.shape)\n dW3_t = np.zeros(W3.shape)\n dW2_t = np.zeros(W2.shape)\n \n dW1_i = np.zeros(W1.shape)\n dW2_i = np.zeros(W2.shape)\n \n # forward pass\n for t in range(sequence_length):\n new_input = np.zeros(x.shape)\n new_input[t] = x[t]\n mul_w1 = np.dot(W1, new_input)\n mul_w2 = np.dot(W2, prev_act)\n add = mul_w2 + mul_w1\n act = sigmoid(add)\n mul_w3 = np.dot(W3, act)\n layers.append({'act':act, 'prev_act':prev_act})\n prev_act = act\n\n # derivative of pred\n dmul_w3 = (mul_w3 - y)\n \n # backward pass\n for t in range(sequence_length):\n dW3_t = np.dot(dmul_w3, np.transpose(layers[t]['act']))\n dsv = np.dot(np.transpose(W3), dmul_w3)\n \n ds = dsv\n dadd = add * (1 - add) * ds\n \n dmul_w2 = dadd * np.ones_like(mul_w2)\n\n dprev_act = np.dot(np.transpose(W2), dmul_w2)\n\n\n for i in range(t-1, max(-1, t-back_prop_truncate-1), -1):\n ds = dsv + dprev_act\n dadd = add * (1 - add) * ds\n\n dmul_w2 = dadd * np.ones_like(mul_w2)\n dmul_w1 = dadd * np.ones_like(mul_w1)\n\n dW2_i = np.dot(W2, layers[t]['prev_act'])\n dprev_act = np.dot(np.transpose(W2), dmul_w2)\n\n new_input = np.zeros(x.shape)\n new_input[t] = x[t]\n dW1_i = np.dot(W1, new_input)\n dx = np.dot(np.transpose(W1), dmul_w1)\n\n dW1_t += dW1_i\n dW2_t += dW2_i\n \n dW3 += dW3_t\n dW1 += dW1_t\n dW2 += dW2_t\n \n if dW1.max() > max_clip_value:\n dW1[dW1 > max_clip_value] = max_clip_value\n if dW3.max() > max_clip_value:\n dW3[dW3 > max_clip_value] = max_clip_value\n if dW2.max() > max_clip_value:\n dW2[dW2 > max_clip_value] = max_clip_value\n \n \n if dW1.min() < min_clip_value:\n dW1[dW1 < min_clip_value] = min_clip_value\n if dW3.min() < min_clip_value:\n dW3[dW3 < min_clip_value] = min_clip_value\n if dW2.min() < min_clip_value:\n dW2[dW2 < min_clip_value] = min_clip_value\n \n # update\n W1 -= learning_rate * dW1\n W3 -= learning_rate * dW3\n W2 -= learning_rate * dW2",
"Epoch: 1 , Loss: [[129321.80142656]] , Val Loss: [[64655.76954217]]\nEpoch: 2 , Loss: [[83469.71575242]] , Val Loss: [[41730.74354188]]\nEpoch: 3 , Loss: [[47617.6300782]] , Val Loss: [[23805.71754155]]\nEpoch: 4 , Loss: [[21765.54373458]] , Val Loss: [[10880.69120694]]\nEpoch: 5 , Loss: [[5911.30616237]] , Val Loss: [[2954.59044314]]\n"
],
[
"preds = []\nfor i in range(Y_valid.shape[0]):\n x, y = X_valid[i], Y_valid[i]\n prev_act = np.zeros((hidden_layer_size, 1))\n # For each time step...\n for t in range(sequence_length):\n mul_w1 = np.dot(W1, x)\n mul_w2 = np.dot(W2, prev_act)\n add = mul_w2 + mul_w1\n act = sigmoid(add)\n mul_w3 = np.dot(W3, act)\n prev_act = act\n\n preds.append(mul_w3)\n \npreds = np.array(preds)\n\nplt.plot(preds[:, 0, 0], 'g')\nplt.plot(Y_valid[:, 0], 'r')\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error\nmath.sqrt(mean_squared_error(Y_valid[:, 0], preds[:, 0, 0]))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d004f4d0720e6a2ce20d417f1577e1dfe5d64758
| 172,375 |
ipynb
|
Jupyter Notebook
|
Monte-Carlo-integration.ipynb
|
00inboxtest/Stats-Maths-with-Python
|
1417888aca0cfadf3ca5a61dedc27d7c7dadd094
|
[
"MIT"
] | 540 |
2019-01-23T15:58:49.000Z
|
2022-03-31T15:53:06.000Z
|
Monte-Carlo-integration.ipynb
|
rajsingh7/Stats-Maths-with-Python
|
1417888aca0cfadf3ca5a61dedc27d7c7dadd094
|
[
"MIT"
] | 1 |
2020-12-15T07:57:46.000Z
|
2020-12-15T07:57:46.000Z
|
Monte-Carlo-integration.ipynb
|
rajsingh7/Stats-Maths-with-Python
|
1417888aca0cfadf3ca5a61dedc27d7c7dadd094
|
[
"MIT"
] | 291 |
2019-02-25T03:03:48.000Z
|
2022-03-15T06:46:15.000Z
| 289.705882 | 39,752 | 0.926283 |
[
[
[
"# Monte Carlo Integration with Python\n\n## Dr. Tirthajyoti Sarkar ([LinkedIn](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/), [Github](https://github.com/tirthajyoti)), Fremont, CA, July 2020\n\n---",
"_____no_output_____"
],
[
"### Disclaimer\n\nThe inspiration for this demo/notebook stemmed from [Georgia Tech's Online Masters in Analytics (OMSA) program](https://www.gatech.edu/academics/degrees/masters/analytics-online-degree-oms-analytics) study material. I am proud to pursue this excellent Online MS program. You can also check the details [here](http://catalog.gatech.edu/programs/analytics-ms/#onlinetext).",
"_____no_output_____"
],
[
"## What is Monte Carlo integration?\n\n### A casino trick for mathematics\n\n\n\nMonte Carlo, is in fact, the name of the world-famous casino located in the eponymous district of the city-state (also called a Principality) of Monaco, on the world-famous French Riviera.\n\nIt turns out that the casino inspired the minds of famous scientists to devise an intriguing mathematical technique for solving complex problems in statistics, numerical computing, system simulation.\n\n### Modern origin (to make 'The Bomb')\n\n\n\nOne of the first and most famous uses of this technique was during the Manhattan Project when the chain-reaction dynamics in highly enriched uranium presented an unimaginably complex theoretical calculation to the scientists. Even the genius minds like John Von Neumann, Stanislaw Ulam, Nicholas Metropolis could not tackle it in the traditional way. They, therefore, turned to the wonderful world of random numbers and let these probabilistic quantities tame the originally intractable calculations.\n\nAmazingly, these random variables could solve the computing problem, which stymied the sure-footed deterministic approach. The elements of uncertainty actually won.\n\nJust like uncertainty and randomness rule in the world of Monte Carlo games. That was the inspiration for this particular moniker.\n\n### Today\n\nToday, it is a technique used in a wide swath of fields,\n- risk analysis, financial engineering, \n- supply chain logistics, \n- statistical learning and modeling,\n- computer graphics, image processing, game design,\n- large system simulations, \n- computational physics, astronomy, etc.\n\nFor all its successes and fame, the basic idea is deceptively simple and easy to demonstrate. We demonstrate it in this article with a simple set of Python code.",
"_____no_output_____"
],
[
"## The code and the demo",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.integrate import quad",
"_____no_output_____"
]
],
[
[
"### A simple function which is difficult to integrate analytically\n\nWhile the general Monte Carlo simulation technique is much broader in scope, we focus particularly on the Monte Carlo integration technique here.\n\nIt is nothing but a numerical method for computing complex definite integrals, which lack closed-form analytical solutions.\n\nSay, we want to calculate,\n\n$$\\int_{0}^{4}\\sqrt[4]{15x^3+21x^2+41x+3}.e^{-0.5x} dx$$",
"_____no_output_____"
]
],
[
[
"def f1(x):\n return (15*x**3+21*x**2+41*x+3)**(1/4) * (np.exp(-0.5*x))",
"_____no_output_____"
]
],
[
[
"### Plot",
"_____no_output_____"
]
],
[
[
"x = np.arange(0,4.1,0.1)\ny = f1(x)",
"_____no_output_____"
],
[
"plt.figure(figsize=(8,4))\nplt.title(\"Plot of the function: $\\sqrt[4]{15x^3+21x^2+41x+3}.e^{-0.5x}$\",\n fontsize=18)\nplt.plot(x,y,'-',c='k',lw=2)\nplt.grid(True)\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Riemann sums?\n\nThere are many such techniques under the general category of [Riemann sum](https://medium.com/r/?url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FRiemann_sum). The idea is just to divide the area under the curve into small rectangular or trapezoidal pieces, approximate them by the simple geometrical calculations, and sum those components up.\n\nFor a simple illustration, I show such a scheme with only 5 equispaced intervals.\n\nFor the programmer friends, in fact, there is a [ready-made function in the Scipy package](https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.quad.html#scipy.integrate.quad) which can do this computation fast and accurately.",
"_____no_output_____"
]
],
[
[
"rect = np.linspace(0,4,5)\n\nplt.figure(figsize=(8,4))\nplt.title(\"Area under the curve: With Riemann sum\",\n fontsize=18)\nplt.plot(x,y,'-',c='k',lw=2)\nplt.fill_between(x,y1=y,y2=0,color='orange',alpha=0.6)\nfor i in range(5):\n plt.vlines(x=rect[i],ymin=0,ymax=2,color='blue')\nplt.grid(True)\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### What if I go random?\n\nWhat if I told you that I do not need to pick the intervals so uniformly, and, in fact, I can go completely probabilistic, and pick 100% random intervals to compute the same integral?\n\nCrazy talk? My choice of samples could look like this…",
"_____no_output_____"
]
],
[
[
"rand_lines = 4*np.random.uniform(size=5)\n\nplt.figure(figsize=(8,4))\nplt.title(\"With 5 random sampling intervals\",\n fontsize=18)\nplt.plot(x,y,'-',c='k',lw=2)\nplt.fill_between(x,y1=y,y2=0,color='orange',alpha=0.6)\nfor i in range(5):\n plt.vlines(x=rand_lines[i],ymin=0,ymax=2,color='blue')\nplt.grid(True)\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Or, this?",
"_____no_output_____"
]
],
[
[
"rand_lines = 4*np.random.uniform(size=5)\n\nplt.figure(figsize=(8,4))\nplt.title(\"With 5 random sampling intervals\",\n fontsize=18)\nplt.plot(x,y,'-',c='k',lw=2)\nplt.fill_between(x,y1=y,y2=0,color='orange',alpha=0.6)\nfor i in range(5):\n plt.vlines(x=rand_lines[i],ymin=0,ymax=2,color='blue')\nplt.grid(True)\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### It just works!\n\nWe don't have the time or scope to prove the theory behind it, but it can be shown that with a reasonably high number of random sampling, we can, in fact, compute the integral with sufficiently high accuracy!\n\nWe just choose random numbers (between the limits), evaluate the function at those points, add them up, and scale it by a known factor. We are done.\n\nOK. What are we waiting for? Let's demonstrate this claim with some simple Python code.",
"_____no_output_____"
],
[
"### A simple version",
"_____no_output_____"
]
],
[
[
"def monte_carlo(func,\n a=0,\n b=1,\n n=1000):\n \"\"\"\n Monte Carlo integration\n \"\"\"\n \n u = np.random.uniform(size=n)\n #plt.hist(u)\n u_func = func(a+(b-a)*u)\n s = ((b-a)/n)*u_func.sum()\n \n return s",
"_____no_output_____"
]
],
[
[
"### Another version with 10-spaced sampling",
"_____no_output_____"
]
],
[
[
"def monte_carlo_uniform(func,\n a=0,\n b=1,\n n=1000):\n \"\"\"\n Monte Carlo integration with more uniform spread (forced)\n \"\"\"\n subsets = np.arange(0,n+1,n/10)\n steps = n/10\n u = np.zeros(n)\n for i in range(10):\n start = int(subsets[i])\n end = int(subsets[i+1])\n u[start:end] = np.random.uniform(low=i/10,high=(i+1)/10,size=end-start)\n np.random.shuffle(u)\n #plt.hist(u)\n #u = np.random.uniform(size=n)\n u_func = func(a+(b-a)*u)\n s = ((b-a)/n)*u_func.sum()\n \n return s",
"_____no_output_____"
],
[
"inte = monte_carlo_uniform(f1,a=0,b=4,n=100)\nprint(inte)",
"5.73321706375046\n"
]
],
[
[
"### How good is the calculation anyway?\nThis integral cannot be calculated analytically. So, we need to benchmark the accuracy of the Monte Carlo method against another numerical integration technique anyway. We chose the Scipy `integrate.quad()` function for that.\n\nNow, you may also be thinking - **what happens to the accuracy as the sampling density changes**. This choice clearly impacts the computation speed - we need to add less number of quantities if we choose a reduced sampling density.\n\nTherefore, we simulated the same integral for a range of sampling density and plotted the result on top of the gold standard - the Scipy function represented as the horizontal line in the plot below,",
"_____no_output_____"
]
],
[
[
"inte_lst = []\nfor i in range(100,2100,50):\n inte = monte_carlo_uniform(f1,a=0,b=4,n=i)\n inte_lst.append(inte)\n\nresult,_ = quad(f1,a=0,b=4)\n\nplt.figure(figsize=(8,4))\nplt.plot([i for i in range(100,2100,50)],inte_lst,color='blue')\nplt.hlines(y=result,xmin=0,xmax=2100,linestyle='--',lw=3)\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.xlabel(\"Sample density for Monte Carlo\",fontsize=15)\nplt.ylabel(\"Integration result\",fontsize=15)\nplt.grid(True)\nplt.legend(['Monte Carlo integration','Scipy function'],fontsize=15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Not bad at all...\nTherefore, we observe some small perturbations in the low sample density phase, but they smooth out nicely as the sample density increases. In any case, the absolute error is extremely small compared to the value returned by the Scipy function - on the order of 0.02%.\n\nThe Monte Carlo trick works fantastically!",
"_____no_output_____"
],
[
"### Speed of the Monte Carlo method\n\nIn this particular example, the Monte Carlo calculations are running twice as fast as the Scipy integration method!\n\nWhile this kind of speed advantage depends on many factors, we can be assured that the Monte Carlo technique is not a slouch when it comes to the matter of computation efficiency.",
"_____no_output_____"
]
],
[
[
"%%timeit -n100 -r100\ninte = monte_carlo_uniform(f1,a=0,b=4,n=500)",
"107 µs ± 6.57 µs per loop (mean ± std. dev. of 100 runs, 100 loops each)\n"
]
],
[
[
"### Speed of the Scipy function",
"_____no_output_____"
]
],
[
[
"%%timeit -n100 -r100\nquad(f1,a=0,b=4)",
"216 µs ± 5.31 µs per loop (mean ± std. dev. of 100 runs, 100 loops each)\n"
]
],
[
[
"### Repeat\n\nFor a probabilistic technique like Monte Carlo integration, it goes without saying that mathematicians and scientists almost never stop at just one run but repeat the calculations for a number of times and take the average.\n\nHere is a distribution plot from a 10,000 run experiment. As you can see, the plot almost resembles a Gaussian Normal distribution and this fact can be utilized to not only get the average value but also construct confidence intervals around that result.",
"_____no_output_____"
]
],
[
[
"inte_lst = []\nfor i in range(10000):\n inte = monte_carlo_uniform(f1,a=0,b=4,n=500)\n inte_lst.append(inte)\n\nplt.figure(figsize=(8,4))\nplt.title(\"Distribution of the Monte Carlo runs\",\n fontsize=18)\nplt.hist(inte_lst,bins=50,color='orange',edgecolor='k')\nplt.xticks(fontsize=14)\nplt.yticks(fontsize=14)\nplt.xlabel(\"Integration result\",fontsize=15)\nplt.ylabel(\"Density\",fontsize=15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Particularly suitable for high-dimensional integrals\n\nAlthough for our simple illustration (and for pedagogical purpose), we stick to a single-variable integral, the same idea can easily be extended to high-dimensional integrals with multiple variables.\n\nAnd it is in this higher dimension that the Monte Carlo method particularly shines as compared to Riemann sum based approaches. The sample density can be optimized in a much more favorable manner for the Monte Carlo method to make it much faster without compromising the accuracy.\n\nIn mathematical terms, the convergence rate of the method is independent of the number of dimensions. In machine learning speak, the Monte Carlo method is the best friend you have to beat the curse of dimensionality when it comes to complex integral calculations.",
"_____no_output_____"
],
[
"---\n\n## Summary\nWe introduced the concept of Monte Carlo integration and illustrated how it differs from the conventional numerical integration methods. We also showed a simple set of Python codes to evaluate a one-dimensional function and assess the accuracy and speed of the techniques.\n\nThe broader class of Monte Carlo simulation techniques is more exciting and is used in a ubiquitous manner in fields related to artificial intelligence, data science, and statistical modeling.\n\nFor example, the famous Alpha Go program from DeepMind used a Monte Carlo search technique to be computationally efficient in the high-dimensional space of the game Go. Numerous such examples can be found in practice.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0050ba97a3c6270642be8771aa3dbce740b0597
| 13,066 |
ipynb
|
Jupyter Notebook
|
_posts/scikit/randomly-generated-multilabel-dataset/randomly-generated-multilabel-dataset.ipynb
|
bmb804/documentation
|
57826d25e0afea7fff6a8da9abab8be2f7a4b48c
|
[
"CC-BY-3.0"
] | 2 |
2019-06-24T23:55:53.000Z
|
2019-07-08T12:22:56.000Z
|
_posts/scikit/randomly-generated-multilabel-dataset/randomly-generated-multilabel-dataset.ipynb
|
bmb804/documentation
|
57826d25e0afea7fff6a8da9abab8be2f7a4b48c
|
[
"CC-BY-3.0"
] | 15 |
2020-06-30T21:21:30.000Z
|
2021-08-02T21:16:33.000Z
|
_posts/scikit/randomly-generated-multilabel-dataset/randomly-generated-multilabel-dataset.ipynb
|
bmb804/documentation
|
57826d25e0afea7fff6a8da9abab8be2f7a4b48c
|
[
"CC-BY-3.0"
] | 1 |
2019-11-10T04:01:48.000Z
|
2019-11-10T04:01:48.000Z
| 34.026042 | 400 | 0.535129 |
[
[
[
"This illustrates the datasets.make_multilabel_classification dataset generator. Each sample consists of counts of two features (up to 50 in total), which are differently distributed in each of two classes.\n\nPoints are labeled as follows, where Y means the class is present:\n\n| 1 \t| 2 \t| 3 \t| Color \t|\n|---\t|---\t|---\t|--------\t|\n| Y \t| N \t| N \t| Red \t|\n| N \t| Y \t| N \t| Blue \t|\n| N \t| N \t| Y \t| Yellow \t|\n| Y \t| Y \t| N \t| Purple \t|\n| Y \t| N \t| Y \t| Orange \t|\n| Y \t| Y \t| N \t| Green \t|\n| Y \t| Y \t| Y \t| Brown \t|\n\nA big circle marks the expected sample for each class; its size reflects the probability of selecting that class label.\n\nThe left and right examples highlight the n_labels parameter: more of the samples in the right plot have 2 or 3 labels.\n\nNote that this two-dimensional example is very degenerate: generally the number of features would be much greater than the “document length”, while here we have much larger documents than vocabulary. Similarly, with n_classes > n_features, it is much less likely that a feature distinguishes a particular class.",
"_____no_output_____"
],
[
"#### New to Plotly?\nPlotly's Python library is free and open source! [Get started](https://plot.ly/python/getting-started/) by downloading the client and [reading the primer](https://plot.ly/python/getting-started/).\n<br>You can set up Plotly to work in [online](https://plot.ly/python/getting-started/#initialization-for-online-plotting) or [offline](https://plot.ly/python/getting-started/#initialization-for-offline-plotting) mode, or in [jupyter notebooks](https://plot.ly/python/getting-started/#start-plotting-online).\n<br>We also have a quick-reference [cheatsheet](https://images.plot.ly/plotly-documentation/images/python_cheat_sheet.pdf) (new!) to help you get started!",
"_____no_output_____"
],
[
"### Version",
"_____no_output_____"
]
],
[
[
"import sklearn\nsklearn.__version__",
"_____no_output_____"
]
],
[
[
"### Imports",
"_____no_output_____"
],
[
"This tutorial imports [make_ml_clf](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_multilabel_classification.html#sklearn.datasets.make_multilabel_classification).",
"_____no_output_____"
]
],
[
[
"import plotly.plotly as py\nimport plotly.graph_objs as go\n\nfrom __future__ import print_function\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom sklearn.datasets import make_multilabel_classification as make_ml_clf",
"_____no_output_____"
]
],
[
[
"### Calculations",
"_____no_output_____"
]
],
[
[
"\nCOLORS = np.array(['!',\n '#FF3333', # red\n '#0198E1', # blue\n '#BF5FFF', # purple\n '#FCD116', # yellow\n '#FF7216', # orange\n '#4DBD33', # green\n '#87421F' # brown\n ])\n\n# Use same random seed for multiple calls to make_multilabel_classification to\n# ensure same distributions\nRANDOM_SEED = np.random.randint(2 ** 10)\n\ndef plot_2d(n_labels=1, n_classes=3, length=50):\n X, Y, p_c, p_w_c = make_ml_clf(n_samples=150, n_features=2,\n n_classes=n_classes, n_labels=n_labels,\n length=length, allow_unlabeled=False,\n return_distributions=True,\n random_state=RANDOM_SEED)\n\n trace1 = go.Scatter(x=X[:, 0], y=X[:, 1], \n mode='markers',\n showlegend=False,\n marker=dict(size=8,\n color=COLORS.take((Y * [1, 2, 4]).sum(axis=1)))\n )\n trace2 = go.Scatter(x=p_w_c[0] * length, y=p_w_c[1] * length,\n mode='markers',\n showlegend=False,\n marker=dict(color=COLORS.take([1, 2, 4]),\n size=14,\n line=dict(width=1, color='black'))\n )\n \n data = [trace1, trace2]\n return data, p_c, p_w_c\n",
"_____no_output_____"
]
],
[
[
"### Plot Results",
"_____no_output_____"
],
[
"n_labels=1",
"_____no_output_____"
]
],
[
[
"data, p_c, p_w_c = plot_2d(n_labels=1)\n\nlayout=go.Layout(title='n_labels=1, length=50',\n xaxis=dict(title='Feature 0 count',\n showgrid=False),\n yaxis=dict(title='Feature 1 count',\n showgrid=False),\n )\n\nfig = go.Figure(data=data, layout=layout)\npy.iplot(fig)",
"_____no_output_____"
]
],
[
[
"n_labels=3",
"_____no_output_____"
]
],
[
[
"data = plot_2d(n_labels=3)\n\nlayout=go.Layout(title='n_labels=3, length=50',\n xaxis=dict(title='Feature 0 count',\n showgrid=False),\n yaxis=dict(title='Feature 1 count',\n showgrid=False),\n )\n\nfig = go.Figure(data=data[0], layout=layout)\npy.iplot(fig)",
"_____no_output_____"
],
[
"print('The data was generated from (random_state=%d):' % RANDOM_SEED)\nprint('Class', 'P(C)', 'P(w0|C)', 'P(w1|C)', sep='\\t')\nfor k, p, p_w in zip(['red', 'blue', 'yellow'], p_c, p_w_c.T):\n print('%s\\t%0.2f\\t%0.2f\\t%0.2f' % (k, p, p_w[0], p_w[1]))",
"The data was generated from (random_state=701):\nClass\tP(C)\tP(w0|C)\tP(w1|C)\nred\t0.11\t0.66\t0.34\nblue\t0.59\t0.52\t0.48\nyellow\t0.30\t0.66\t0.34\n"
],
[
"\nfrom IPython.display import display, HTML\n\ndisplay(HTML('<link href=\"//fonts.googleapis.com/css?family=Open+Sans:600,400,300,200|Inconsolata|Ubuntu+Mono:400,700\" rel=\"stylesheet\" type=\"text/css\" />'))\ndisplay(HTML('<link rel=\"stylesheet\" type=\"text/css\" href=\"http://help.plot.ly/documentation/all_static/css/ipython-notebook-custom.css\">'))\n\n! pip install git+https://github.com/plotly/publisher.git --upgrade\nimport publisher\npublisher.publish(\n 'randomly-generated-multilabel-dataset.ipynb', 'scikit-learn/plot-random-multilabel-dataset/', 'Randomly Generated Multilabel Dataset | plotly',\n ' ',\n title = 'Randomly Generated Multilabel Dataset| plotly',\n name = 'Randomly Generated Multilabel Dataset',\n has_thumbnail='true', thumbnail='thumbnail/multilabel-dataset.jpg', \n language='scikit-learn', page_type='example_index',\n display_as='dataset', order=4,\n ipynb= '~Diksha_Gabha/2909')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d005101d0da75ccc0be0c964312a884a9a7e5960
| 358,203 |
ipynb
|
Jupyter Notebook
|
build_models_04.ipynb
|
dispink/CaCO3_NWP
|
2865a1f933afc7fe3241c08a9c85369782d6a073
|
[
"MIT"
] | null | null | null |
build_models_04.ipynb
|
dispink/CaCO3_NWP
|
2865a1f933afc7fe3241c08a9c85369782d6a073
|
[
"MIT"
] | null | null | null |
build_models_04.ipynb
|
dispink/CaCO3_NWP
|
2865a1f933afc7fe3241c08a9c85369782d6a073
|
[
"MIT"
] | null | null | null | 598.001669 | 57,924 | 0.945464 |
[
[
[
"Log the concentrations to and learn the models for CaCO3 again to avoid 0 happen in the prediction.",
"_____no_output_____"
]
],
[
[
"import numpy as np \nimport pandas as pd\nimport dask.dataframe as dd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nplt.style.use('ggplot')\n#plt.style.use('seaborn-whitegrid')\nplt.style.use('seaborn-colorblind')\nplt.rcParams['figure.dpi'] = 300\nplt.rcParams['savefig.dpi'] = 300\nplt.rcParams['savefig.bbox'] = 'tight'\n\nimport datetime\ndate = datetime.datetime.now().strftime('%Y%m%d')\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Launch deployment",
"_____no_output_____"
]
],
[
[
"from dask.distributed import Client\nfrom dask_jobqueue import SLURMCluster\ncluster = SLURMCluster(\n project=\"aslee@10.110.16.5\",\n queue='main',\n cores=40, \n memory='10 GB',\n walltime=\"00:10:00\",\n log_directory='job_logs'\n)",
"_____no_output_____"
],
[
"client.close()\ncluster.close()",
"_____no_output_____"
],
[
"client = Client(cluster)\ncluster.scale(100)\n#cluster.adapt(maximum=100)",
"_____no_output_____"
],
[
"client",
"_____no_output_____"
]
],
[
[
"# Build model for CaCO3",
"_____no_output_____"
]
],
[
[
"from dask_ml.model_selection import train_test_split\nmerge_df = dd.read_csv('data/spe+bulk_dataset_20201008.csv')\nX = merge_df.iloc[:, 1: -5].to_dask_array(lengths=True)\nX = X / X.sum(axis = 1, keepdims = True)\ny = merge_df['CaCO3%'].to_dask_array(lengths=True)\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, shuffle = True, random_state = 24)",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
]
],
[
[
"## Grid search\nWe know the relationship between the spectra and bulk measurements might not be linear; and based on the pilot_test.ipynb, the SVR algorithm with NMF transformation provides the better cv score. So we focus on grid search with NMF transformation (4, 5, 6, 7, 8 components based on the PCA result) and SVR. First, we try to build the model on the transformed (ln) y, and evaluate the score on the y transformed back to the original space by using TransformedTargetRegressor. However, it might be something wrong with the parallelism in dask, so we have to do the workflow manually. Transformed (np.log) y_train during training, use the model to predict X_test, transform (np.exp) y_predict back to original space, and evaluate the score. ",
"_____no_output_____"
]
],
[
[
"from dask_ml.model_selection import GridSearchCV\nfrom sklearn.decomposition import NMF\nfrom sklearn.svm import SVR\nfrom sklearn.pipeline import make_pipeline\nfrom sklearn.compose import TransformedTargetRegressor\n\npipe = make_pipeline(NMF(max_iter = 2000, random_state = 24), SVR())\nparams = {\n 'nmf__n_components': [4, 5, 6, 7, 8],\n 'svr__C': np.logspace(0, 7, 8),\n 'svr__gamma': np.logspace(-5, 0, 6)\n}\ngrid = GridSearchCV(pipe, param_grid = params, cv = 10, n_jobs = -1) \n\ngrid.fit(X_train, np.log(y_train))\n\nprint('The best cv score: {:.3f}'.format(grid.best_score_)) \n#print('The test score: {:.3f}'.format(grid.best_estimator_.score(X_test, y_test)))\nprint('The best model\\'s parameters: {}'.format(grid.best_estimator_))",
"The best cv score: 0.875\nThe best model's parameters: Pipeline(steps=[('nmf', NMF(max_iter=2000, n_components=6, random_state=24)),\n ('svr', SVR(C=1000000.0, gamma=1.0))])\n"
],
[
"y_predict = np.exp(grid.best_estimator_.predict(X_test))\ny_ttest = np.array(y_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nfrom sklearn.metrics import mean_absolute_error\nfrom sklearn.metrics import max_error\n\nprint('Scores in the test set:')\nprint('R2 = {:.3f} .'.format(r2_score(y_ttest, y_predict)))\nprint('The mean absolute error is {:.3f} (%, concetration).'.format(mean_absolute_error(y_ttest, y_predict)))\nprint('The max. residual error is {:.3f} (%, concetration).'.format(max_error(y_ttest, y_predict)))",
"Scores in the test set:\nR2 = 0.902 .\nThe mean absolute error is 6.198 (%, concetration).\nThe max. residual error is 37.643 (%, concetration).\n"
],
[
"plt.plot(range(len(y_predict)), y_ttest, alpha=0.6, label='Measurement')\nplt.plot(range(len(y_predict)), y_predict, label='Prediction (R$^2$={:.2f})'.format(r2_score(y_ttest, y_predict)))\n#plt.text(12, -7, r'R$^2$={:.2f}, mean ab. error={:.2f}, max. ab. error={:.2f}'.format(grid.best_score_, mean_absolute_error(y_ttest, y_predict), max_error(y_ttest, y_predict)))\nplt.ylabel('CaCO$_3$ concentration (%)')\nplt.xlabel('Sample no.')\nplt.legend(loc = 'upper right')\nplt.savefig('results/caco3_predictions_nmr+svr_{}.png'.format(date))",
"_____no_output_____"
]
],
[
[
"### Visualization",
"_____no_output_____"
]
],
[
[
"#result_df = pd.DataFrame(grid.cv_results_)\n#result_df.to_csv('results/caco3_grid_nmf+svr_{}.csv'.format(date))\nresult_df = pd.read_csv('results/caco3_grid_nmf+svr_20201013.csv', index_col = 0)\n#result_df = result_df[result_df.mean_test_score > -1].reset_index(drop = True)",
"_____no_output_____"
],
[
"from mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\n\nfor n_components in [4, 5, 6, 7, 8]:\n data = result_df[result_df.param_nmf__n_components == n_components].reset_index(drop = True)\n fig = plt.figure(figsize = (7.3,5))\n ax = fig.gca(projection='3d')\n xx = data.param_svr__gamma.astype(float)\n yy = data.param_svr__C.astype(float)\n zz = data.mean_test_score.astype(float)\n max_index = np.argmax(zz)\n\n surf = ax.plot_trisurf(np.log10(xx), np.log10(yy), zz, cmap=cm.Greens, linewidth=0.1)\n ax.scatter3D(np.log10(xx), np.log10(yy), zz, c = 'orange', s = 5)\n # mark the best score\n ax.scatter3D(np.log10(xx), np.log10(yy), zz, c = 'w', s = 5, alpha = 1)\n text = '{} components\\n$\\gamma :{:.1f}$, C: {:.1e},\\nscore:{:.3f}'.format(n_components, xx[max_index], yy[max_index], zz[max_index])\n ax.text(np.log10(xx[max_index])-3, np.log10(yy[max_index]), 1,text, fontsize=12)\n \n ax.set_zlim(-.6, 1.2)\n ax.set_zticks(np.linspace(-.5, 1, 4))\n ax.set_xlabel('$log(\\gamma)$')\n ax.set_ylabel('log(C)')\n ax.set_zlabel('CV score')\n #fig.colorbar(surf, shrink=0.5, aspect=5)\n fig.savefig('results/caco3_grid_{}nmr+svr_3D_{}.png'.format(n_components, date))",
"_____no_output_____"
],
[
"n_components = [4, 5, 6, 7, 8]\nscores = []\nfor n in n_components:\n data = result_df[result_df.param_nmf__n_components == n].reset_index(drop = True)\n rank_min = data.rank_test_score.min()\n scores = np.hstack((scores, data.loc[data.rank_test_score == rank_min, 'mean_test_score'].values))\n \nplt.plot(n_components, scores, marker='o')\nplt.xticks(n_components)\nplt.yticks(np.linspace(0.86, 0.875, 4))\nplt.xlabel('Amount of components')\nplt.ylabel('Best CV score')\nplt.savefig('results/caco3_scores_components_{}.png'.format(date))",
"_____no_output_____"
],
[
"from joblib import dump, load\n#model = load('models/tc_nmf+svr_model_20201012.joblib')\ndump(grid.best_estimator_, 'models/caco3_nmf+svr_model_{}.joblib'.format(date)) ",
"_____no_output_____"
]
],
[
[
"# Check prediction",
"_____no_output_____"
]
],
[
[
"spe_df = pd.read_csv('data/spe_dataset_20201008.csv', index_col = 0)\nX = spe_df.iloc[:, :2048].values\nX = X / X.sum(axis = 1, keepdims = True)",
"_____no_output_____"
],
[
"y_caco3 = np.exp(grid.best_estimator_.predict(X))",
"_____no_output_____"
],
[
"len(y_caco3[y_caco3 < 0])",
"_____no_output_____"
],
[
"len(y_caco3[y_caco3 > 100])",
"_____no_output_____"
],
[
"len(y_caco3[y_caco3 > 100])/len(y_caco3)",
"_____no_output_____"
]
],
[
[
"Yes, the negative-prediction issue is solved. Only 0.1 % of the predictions over 100. The previous model has 96% accuracy in the test set (build_models_01.ipynb), but has 8.5 % unrealistic predictions (prediction_01.ipynb). The enhanced model has lower score in the test set, 90%, but only has 0.1 % unrealistic predictions. Overall, the enhanced model here is better.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0051ee10734d6012f2fbf587cf5d73238fc8a8d
| 165,681 |
ipynb
|
Jupyter Notebook
|
07-Kalman-Filter-Math.ipynb
|
esvhd/Kalman-and-Bayesian-Filters-in-Python
|
55d73b21de01ee4278cef1ab5b32405917f96287
|
[
"CC-BY-4.0"
] | 2 |
2020-12-27T13:20:04.000Z
|
2021-05-16T00:35:29.000Z
|
07-Kalman-Filter-Math.ipynb
|
gokhanettin/Kalman-and-Bayesian-Filters-in-Python
|
55d73b21de01ee4278cef1ab5b32405917f96287
|
[
"CC-BY-4.0"
] | null | null | null |
07-Kalman-Filter-Math.ipynb
|
gokhanettin/Kalman-and-Bayesian-Filters-in-Python
|
55d73b21de01ee4278cef1ab5b32405917f96287
|
[
"CC-BY-4.0"
] | 2 |
2019-12-13T03:24:27.000Z
|
2022-02-20T08:03:29.000Z
| 93.131535 | 24,754 | 0.76707 |
[
[
[
"[Table of Contents](http://nbviewer.ipython.org/github/rlabbe/Kalman-and-Bayesian-Filters-in-Python/blob/master/table_of_contents.ipynb)",
"_____no_output_____"
],
[
"# Kalman Filter Math",
"_____no_output_____"
]
],
[
[
"#format the book\n%matplotlib inline\nfrom __future__ import division, print_function\nfrom book_format import load_style\nload_style()",
"_____no_output_____"
]
],
[
[
"If you've gotten this far I hope that you are thinking that the Kalman filter's fearsome reputation is somewhat undeserved. Sure, I hand waved some equations away, but I hope implementation has been fairly straightforward for you. The underlying concept is quite straightforward - take two measurements, or a measurement and a prediction, and choose the output to be somewhere between the two. If you believe the measurement more your guess will be closer to the measurement, and if you believe the prediction is more accurate your guess will lie closer to it. That's not rocket science (little joke - it is exactly this math that got Apollo to the moon and back!). \n\nTo be honest I have been choosing my problems carefully. For an arbitrary problem designing the Kalman filter matrices can be extremely difficult. I haven't been *too tricky*, though. Equations like Newton's equations of motion can be trivially computed for Kalman filter applications, and they make up the bulk of the kind of problems that we want to solve. \n\nI have illustrated the concepts with code and reasoning, not math. But there are topics that do require more mathematics than I have used so far. This chapter presents the math that you will need for the rest of the book.",
"_____no_output_____"
],
[
"## Modeling a Dynamic System\n\nA *dynamic system* is a physical system whose state (position, temperature, etc) evolves over time. Calculus is the math of changing values, so we use differential equations to model dynamic systems. Some systems cannot be modeled with differential equations, but we will not encounter those in this book.\n\nModeling dynamic systems is properly the topic of several college courses. To an extent there is no substitute for a few semesters of ordinary and partial differential equations followed by a graduate course in control system theory. If you are a hobbyist, or trying to solve one very specific filtering problem at work you probably do not have the time and/or inclination to devote a year or more to that education.\n\nFortunately, I can present enough of the theory to allow us to create the system equations for many different Kalman filters. My goal is to get you to the stage where you can read a publication and understand it well enough to implement the algorithms. The background math is deep, but in practice we end up using a few simple techniques. \n\nThis is the longest section of pure math in this book. You will need to master everything in this section to understand the Extended Kalman filter (EKF), the most common nonlinear filter. I do cover more modern filters that do not require as much of this math. You can choose to skim now, and come back to this if you decide to learn the EKF.\n\nWe need to start by understanding the underlying equations and assumptions that the Kalman filter uses. We are trying to model real world phenomena, so what do we have to consider?\n\nEach physical system has a process. For example, a car traveling at a certain velocity goes so far in a fixed amount of time, and its velocity varies as a function of its acceleration. We describe that behavior with the well known Newtonian equations that we learned in high school.\n\n$$\n\\begin{aligned}\nv&=at\\\\\nx &= \\frac{1}{2}at^2 + v_0t + x_0\n\\end{aligned}\n$$\n\nOnce we learned calculus we saw them in this form:\n\n$$ \\mathbf v = \\frac{d \\mathbf x}{d t}, \n\\quad \\mathbf a = \\frac{d \\mathbf v}{d t} = \\frac{d^2 \\mathbf x}{d t^2}\n$$\n\nA typical automobile tracking problem would have you compute the distance traveled given a constant velocity or acceleration, as we did in previous chapters. But, of course we know this is not all that is happening. No car travels on a perfect road. There are bumps, wind drag, and hills that raise and lower the speed. The suspension is a mechanical system with friction and imperfect springs.\n\nPerfectly modeling a system is impossible except for the most trivial problems. We are forced to make a simplification. At any time $t$ we say that the true state (such as the position of our car) is the predicted value from the imperfect model plus some unknown *process noise*:\n\n$$\nx(t) = x_{pred}(t) + noise(t)\n$$\n\nThis is not meant to imply that $noise(t)$ is a function that we can derive analytically. It is merely a statement of fact - we can always describe the true value as the predicted value plus the process noise. \"Noise\" does not imply random events. If we are tracking a thrown ball in the atmosphere, and our model assumes the ball is in a vacuum, then the effect of air drag is process noise in this context.\n\nIn the next section we will learn techniques to convert a set of higher order differential equations into a set of first-order differential equations. After the conversion the model of the system without noise is:\n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax}$$\n\n$\\mathbf A$ is known as the *systems dynamics matrix* as it describes the dynamics of the system. Now we need to model the noise. We will call that $\\mathbf w$, and add it to the equation. \n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax} + \\mathbf w$$\n\n$\\mathbf w$ may strike you as a poor choice for the name, but you will soon see that the Kalman filter assumes *white* noise.\n\nFinally, we need to consider any inputs into the system. We assume an input $\\mathbf u$, and that there exists a linear model that defines how that input changes the system. For example, pressing the accelerator in your car makes it accelerate, and gravity causes balls to fall. Both are contol inputs. We will need a matrix $\\mathbf B$ to convert $u$ into the effect on the system. We add that into our equation:\n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax} + \\mathbf{Bu} + \\mathbf{w}$$\n\nAnd that's it. That is one of the equations that Dr. Kalman set out to solve, and he found an optimal estimator if we assume certain properties of $\\mathbf w$.",
"_____no_output_____"
],
[
"## State-Space Representation of Dynamic Systems",
"_____no_output_____"
],
[
"We've derived the equation\n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax}+ \\mathbf{Bu} + \\mathbf{w}$$\n\nHowever, we are not interested in the derivative of $\\mathbf x$, but in $\\mathbf x$ itself. Ignoring the noise for a moment, we want an equation that recusively finds the value of $\\mathbf x$ at time $t_k$ in terms of $\\mathbf x$ at time $t_{k-1}$:\n\n$$\\mathbf x(t_k) = \\mathbf F(\\Delta t)\\mathbf x(t_{k-1}) + \\mathbf B(t_k) + \\mathbf u (t_k)$$\n\nConvention allows us to write $\\mathbf x(t_k)$ as $\\mathbf x_k$, which means the \nthe value of $\\mathbf x$ at the k$^{th}$ value of $t$.\n\n$$\\mathbf x_k = \\mathbf{Fx}_{k-1} + \\mathbf B_k\\mathbf u_k$$\n\n$\\mathbf F$ is the familiar *state transition matrix*, named due to its ability to transition the state's value between discrete time steps. It is very similar to the system dynamics matrix $\\mathbf A$. The difference is that $\\mathbf A$ models a set of linear differential equations, and is continuous. $\\mathbf F$ is discrete, and represents a set of linear equations (not differential equations) which transitions $\\mathbf x_{k-1}$ to $\\mathbf x_k$ over a discrete time step $\\Delta t$. \n\nFinding this matrix is often quite difficult. The equation $\\dot x = v$ is the simplest possible differential equation and we trivially integrate it as:\n\n$$ \\int\\limits_{x_{k-1}}^{x_k} \\mathrm{d}x = \\int\\limits_{0}^{\\Delta t} v\\, \\mathrm{d}t $$\n$$x_k-x_0 = v \\Delta t$$\n$$x_k = v \\Delta t + x_0$$\n\nThis equation is *recursive*: we compute the value of $x$ at time $t$ based on its value at time $t-1$. This recursive form enables us to represent the system (process model) in the form required by the Kalman filter:\n\n$$\\begin{aligned}\n\\mathbf x_k &= \\mathbf{Fx}_{k-1} \\\\\n&= \\begin{bmatrix} 1 & \\Delta t \\\\ 0 & 1\\end{bmatrix}\n\\begin{bmatrix}x_{k-1} \\\\ \\dot x_{k-1}\\end{bmatrix}\n\\end{aligned}$$\n\nWe can do that only because $\\dot x = v$ is simplest differential equation possible. Almost all other in physical systems result in more complicated differential equation which do not yield to this approach. \n\n*State-space* methods became popular around the time of the Apollo missions, largely due to the work of Dr. Kalman. The idea is simple. Model a system with a set of $n^{th}$-order differential equations. Convert them into an equivalent set of first-order differential equations. Put them into the vector-matrix form used in the previous section: $\\dot{\\mathbf x} = \\mathbf{Ax} + \\mathbf{Bu}$. Once in this form we use of of several techniques to convert these linear differential equations into the recursive equation:\n\n$$ \\mathbf x_k = \\mathbf{Fx}_{k-1} + \\mathbf B_k\\mathbf u_k$$\n\nSome books call the state transition matrix the *fundamental matrix*. Many use $\\mathbf \\Phi$ instead of $\\mathbf F$. Sources based heavily on control theory tend to use these forms.\n\nThese are called *state-space* methods because we are expressing the solution of the differential equations in terms of the system state. ",
"_____no_output_____"
],
[
"### Forming First Order Equations from Higher Order Equations\n\nMany models of physical systems require second or higher order differential equations with control input $u$:\n\n$$a_n \\frac{d^ny}{dt^n} + a_{n-1} \\frac{d^{n-1}y}{dt^{n-1}} + \\dots + a_2 \\frac{d^2y}{dt^2} + a_1 \\frac{dy}{dt} + a_0 = u$$\n\nState-space methods require first-order equations. Any higher order system of equations can be reduced to first-order by defining extra variables for the derivatives and then solving. \n\n\nLet's do an example. Given the system $\\ddot{x} - 6\\dot x + 9x = u$ find the equivalent first order equations. I've used the dot notation for the time derivatives for clarity.\n\nThe first step is to isolate the highest order term onto one side of the equation.\n\n$$\\ddot{x} = 6\\dot x - 9x + u$$\n\nWe define two new variables:\n\n$$\\begin{aligned} x_1(u) &= x \\\\\nx_2(u) &= \\dot x\n\\end{aligned}$$\n\nNow we will substitute these into the original equation and solve. The solution yields a set of first-order equations in terms of these new variables. It is conventional to drop the $(u)$ for notational convenience.\n\nWe know that $\\dot x_1 = x_2$ and that $\\dot x_2 = \\ddot{x}$. Therefore\n\n$$\\begin{aligned}\n\\dot x_2 &= \\ddot{x} \\\\\n &= 6\\dot x - 9x + t\\\\\n &= 6x_2-9x_1 + t\n\\end{aligned}$$\n\nTherefore our first-order system of equations is\n\n$$\\begin{aligned}\\dot x_1 &= x_2 \\\\\n\\dot x_2 &= 6x_2-9x_1 + t\\end{aligned}$$\n\nIf you practice this a bit you will become adept at it. Isolate the highest term, define a new variable and its derivatives, and then substitute.",
"_____no_output_____"
],
[
"### First Order Differential Equations In State-Space Form\n\nSubstituting the newly defined variables from the previous section:\n\n$$\\frac{dx_1}{dt} = x_2,\\, \n\\frac{dx_2}{dt} = x_3, \\, ..., \\, \n\\frac{dx_{n-1}}{dt} = x_n$$\n\ninto the first order equations yields: \n\n$$\\frac{dx_n}{dt} = \\frac{1}{a_n}\\sum\\limits_{i=0}^{n-1}a_ix_{i+1} + \\frac{1}{a_n}u\n$$\n\n\nUsing vector-matrix notation we have:\n\n$$\\begin{bmatrix}\\frac{dx_1}{dt} \\\\ \\frac{dx_2}{dt} \\\\ \\vdots \\\\ \\frac{dx_n}{dt}\\end{bmatrix} = \n\\begin{bmatrix}\\dot x_1 \\\\ \\dot x_2 \\\\ \\vdots \\\\ \\dot x_n\\end{bmatrix}=\n\\begin{bmatrix}0 & 1 & 0 &\\cdots & 0 \\\\\n0 & 0 & 1 & \\cdots & 0 \\\\\n\\vdots & \\vdots & \\vdots & \\ddots & \\vdots \\\\\n-\\frac{a_0}{a_n} & -\\frac{a_1}{a_n} & -\\frac{a_2}{a_n} & \\cdots & -\\frac{a_{n-1}}{a_n}\\end{bmatrix}\n\\begin{bmatrix}x_1 \\\\ x_2 \\\\ \\vdots \\\\ x_n\\end{bmatrix} + \n\\begin{bmatrix}0 \\\\ 0 \\\\ \\vdots \\\\ \\frac{1}{a_n}\\end{bmatrix}u$$\n\nwhich we then write as $\\dot{\\mathbf x} = \\mathbf{Ax} + \\mathbf{B}u$.",
"_____no_output_____"
],
[
"### Finding the Fundamental Matrix for Time Invariant Systems\n\nWe express the system equations in state-space form with\n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax}$$\n\nwhere $\\mathbf A$ is the system dynamics matrix, and want to find the *fundamental matrix* $\\mathbf F$ that propagates the state $\\mathbf x$ over the interval $\\Delta t$ with the equation\n\n$$\\begin{aligned}\n\\mathbf x(t_k) = \\mathbf F(\\Delta t)\\mathbf x(t_{k-1})\\end{aligned}$$\n\nIn other words, $\\mathbf A$ is a set of continuous differential equations, and we need $\\mathbf F$ to be a set of discrete linear equations that computes the change in $\\mathbf A$ over a discrete time step.\n\nIt is conventional to drop the $t_k$ and $(\\Delta t)$ and use the notation\n\n$$\\mathbf x_k = \\mathbf {Fx}_{k-1}$$\n\nBroadly speaking there are three common ways to find this matrix for Kalman filters. The technique most often used is the matrix exponential. Linear Time Invariant Theory, also known as LTI System Theory, is a second technique. Finally, there are numerical techniques. You may know of others, but these three are what you will most likely encounter in the Kalman filter literature and praxis.",
"_____no_output_____"
],
[
"### The Matrix Exponential\n\nThe solution to the equation $\\frac{dx}{dt} = kx$ can be found by:\n\n$$\\begin{gathered}\\frac{dx}{dt} = kx \\\\\n\\frac{dx}{x} = k\\, dt \\\\\n\\int \\frac{1}{x}\\, dx = \\int k\\, dt \\\\\n\\log x = kt + c \\\\\nx = e^{kt+c} \\\\\nx = e^ce^{kt} \\\\\nx = c_0e^{kt}\\end{gathered}$$\n\nUsing similar math, the solution to the first-order equation \n\n$$\\dot{\\mathbf x} = \\mathbf{Ax} ,\\, \\, \\, \\mathbf x(0) = \\mathbf x_0$$\n\nwhere $\\mathbf A$ is a constant matrix, is\n\n$$\\mathbf x = e^{\\mathbf At}\\mathbf x_0$$\n\nSubstituting $F = e^{\\mathbf At}$, we can write \n\n$$\\mathbf x_k = \\mathbf F\\mathbf x_{k-1}$$\n\nwhich is the form we are looking for! We have reduced the problem of finding the fundamental matrix to one of finding the value for $e^{\\mathbf At}$.\n\n$e^{\\mathbf At}$ is known as the [matrix exponential](https://en.wikipedia.org/wiki/Matrix_exponential). It can be computed with this power series:\n\n$$e^{\\mathbf At} = \\mathbf{I} + \\mathbf{A}t + \\frac{(\\mathbf{A}t)^2}{2!} + \\frac{(\\mathbf{A}t)^3}{3!} + ... $$\n\nThat series is found by doing a Taylor series expansion of $e^{\\mathbf At}$, which I will not cover here.\n\nLet's use this to find the solution to Newton's equations. Using $v$ as an substitution for $\\dot x$, and assuming constant velocity we get the linear matrix-vector form \n\n$$\\begin{bmatrix}\\dot x \\\\ \\dot v\\end{bmatrix} =\\begin{bmatrix}0&1\\\\0&0\\end{bmatrix} \\begin{bmatrix}x \\\\ v\\end{bmatrix}$$\n\nThis is a first order differential equation, so we can set $\\mathbf{A}=\\begin{bmatrix}0&1\\\\0&0\\end{bmatrix}$ and solve the following equation. I have substituted the interval $\\Delta t$ for $t$ to emphasize that the fundamental matrix is discrete:\n\n$$\\mathbf F = e^{\\mathbf A\\Delta t} = \\mathbf{I} + \\mathbf A\\Delta t + \\frac{(\\mathbf A\\Delta t)^2}{2!} + \\frac{(\\mathbf A\\Delta t)^3}{3!} + ... $$\n\nIf you perform the multiplication you will find that $\\mathbf{A}^2=\\begin{bmatrix}0&0\\\\0&0\\end{bmatrix}$, which means that all higher powers of $\\mathbf{A}$ are also $\\mathbf{0}$. Thus we get an exact answer without an infinite number of terms:\n\n$$\n\\begin{aligned}\n\\mathbf F &=\\mathbf{I} + \\mathbf A \\Delta t + \\mathbf{0} \\\\\n&= \\begin{bmatrix}1&0\\\\0&1\\end{bmatrix} + \\begin{bmatrix}0&1\\\\0&0\\end{bmatrix}\\Delta t\\\\\n&= \\begin{bmatrix}1&\\Delta t\\\\0&1\\end{bmatrix}\n\\end{aligned}$$\n\nWe plug this into $\\mathbf x_k= \\mathbf{Fx}_{k-1}$ to get\n\n$$\n\\begin{aligned}\nx_k &=\\begin{bmatrix}1&\\Delta t\\\\0&1\\end{bmatrix}x_{k-1}\n\\end{aligned}$$\n\nYou will recognize this as the matrix we derived analytically for the constant velocity Kalman filter in the **Multivariate Kalman Filter** chapter.\n\nSciPy's linalg module includes a routine `expm()` to compute the matrix exponential. It does not use the Taylor series method, but the [Padé Approximation](https://en.wikipedia.org/wiki/Pad%C3%A9_approximant). There are many (at least 19) methods to computed the matrix exponential, and all suffer from numerical difficulties[1]. But you should be aware of the problems, especially when $\\mathbf A$ is large. If you search for \"pade approximation matrix exponential\" you will find many publications devoted to this problem. \n\nIn practice this may not be of concern to you as for the Kalman filter we normally just take the first two terms of the Taylor series. But don't assume my treatment of the problem is complete and run off and try to use this technique for other problem without doing a numerical analysis of the performance of this technique. Interestingly, one of the favored ways of solving $e^{\\mathbf At}$ is to use a generalized ode solver. In other words, they do the opposite of what we do - turn $\\mathbf A$ into a set of differential equations, and then solve that set using numerical techniques! \n\nHere is an example of using `expm()` to solve $e^{\\mathbf At}$.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom scipy.linalg import expm\n\ndt = 0.1\nA = np.array([[0, 1], \n [0, 0]])\nexpm(A*dt)",
"_____no_output_____"
]
],
[
[
"### Time Invariance\n\nIf the behavior of the system depends on time we can say that a dynamic system is described by the first-order differential equation\n\n$$ g(t) = \\dot x$$\n\nHowever, if the system is *time invariant* the equation is of the form:\n\n$$ f(x) = \\dot x$$\n\nWhat does *time invariant* mean? Consider a home stereo. If you input a signal $x$ into it at time $t$, it will output some signal $f(x)$. If you instead perform the input at time $t + \\Delta t$ the output signal will be the same $f(x)$, shifted in time.\n\nA counter-example is $x(t) = \\sin(t)$, with the system $f(x) = t\\, x(t) = t \\sin(t)$. This is not time invariant; the value will be different at different times due to the multiplication by t. An aircraft is not time invariant. If you make a control input to the aircraft at a later time its behavior will be different because it will have burned fuel and thus lost weight. Lower weight results in different behavior.\n\nWe can solve these equations by integrating each side. I demonstrated integrating the time invariant system $v = \\dot x$ above. However, integrating the time invariant equation $\\dot x = f(x)$ is not so straightforward. Using the *separation of variables* techniques we divide by $f(x)$ and move the $dt$ term to the right so we can integrate each side:\n\n$$\\begin{gathered}\n\\frac{dx}{dt} = f(x) \\\\\n\\int^x_{x_0} \\frac{1}{f(x)} dx = \\int^t_{t_0} dt\n\\end{gathered}$$\n\nIf we let $F(x) = \\int \\frac{1}{f(x)} dx$ we get\n\n$$F(x) - F(x_0) = t-t_0$$\n\nWe then solve for x with\n\n$$\\begin{gathered}\nF(x) = t - t_0 + F(x_0) \\\\\nx = F^{-1}[t-t_0 + F(x_0)]\n\\end{gathered}$$\n\nIn other words, we need to find the inverse of $F$. This is not trivial, and a significant amount of coursework in a STEM education is devoted to finding tricky, analytic solutions to this problem. \n\nHowever, they are tricks, and many simple forms of $f(x)$ either have no closed form solution or pose extreme difficulties. Instead, the practicing engineer turns to state-space methods to find approximate solutions.\n\nThe advantage of the matrix exponential is that we can use it for any arbitrary set of differential equations which are *time invariant*. However, we often use this technique even when the equations are not time invariant. As an aircraft flies it burns fuel and loses weight. However, the weight loss over one second is negligible, and so the system is nearly linear over that time step. Our answers will still be reasonably accurate so long as the time step is short.",
"_____no_output_____"
],
[
"#### Example: Mass-Spring-Damper Model\n\nSuppose we wanted to track the motion of a weight on a spring and connected to a damper, such as an automobile's suspension. The equation for the motion with $m$ being the mass, $k$ the spring constant, and $c$ the damping force, under some input $u$ is \n\n$$m\\frac{d^2x}{dt^2} + c\\frac{dx}{dt} +kx = u$$\n\nFor notational convenience I will write that as\n\n$$m\\ddot x + c\\dot x + kx = u$$\n\nI can turn this into a system of first order equations by setting $x_1(t)=x(t)$, and then substituting as follows:\n\n$$\\begin{aligned}\nx_1 &= x \\\\\nx_2 &= \\dot x_1 \\\\\n\\dot x_2 &= \\dot x_1 = \\ddot x\n\\end{aligned}$$\n\nAs is common I dropped the $(t)$ for notational convenience. This gives the equation\n\n$$m\\dot x_2 + c x_2 +kx_1 = u$$\n\nSolving for $\\dot x_2$ we get a first order equation:\n\n$$\\dot x_2 = -\\frac{c}{m}x_2 - \\frac{k}{m}x_1 + \\frac{1}{m}u$$\n\nWe put this into matrix form:\n\n$$\\begin{bmatrix} \\dot x_1 \\\\ \\dot x_2 \\end{bmatrix} = \n\\begin{bmatrix}0 & 1 \\\\ -k/m & -c/m \\end{bmatrix}\n\\begin{bmatrix} x_1 \\\\ x_2 \\end{bmatrix} + \n\\begin{bmatrix} 0 \\\\ 1/m \\end{bmatrix}u$$\n\nNow we use the matrix exponential to find the state transition matrix:\n\n$$\\Phi(t) = e^{\\mathbf At} = \\mathbf{I} + \\mathbf At + \\frac{(\\mathbf At)^2}{2!} + \\frac{(\\mathbf At)^3}{3!} + ... $$\n\nThe first two terms give us\n\n$$\\mathbf F = \\begin{bmatrix}1 & t \\\\ -(k/m) t & 1-(c/m) t \\end{bmatrix}$$\n\nThis may or may not give you enough precision. You can easily check this by computing $\\frac{(\\mathbf At)^2}{2!}$ for your constants and seeing how much this matrix contributes to the results.",
"_____no_output_____"
],
[
"### Linear Time Invariant Theory\n\n[*Linear Time Invariant Theory*](https://en.wikipedia.org/wiki/LTI_system_theory), also known as LTI System Theory, gives us a way to find $\\Phi$ using the inverse Laplace transform. You are either nodding your head now, or completely lost. I will not be using the Laplace transform in this book. LTI system theory tells us that \n\n$$ \\Phi(t) = \\mathcal{L}^{-1}[(s\\mathbf{I} - \\mathbf{F})^{-1}]$$\n\nI have no intention of going into this other than to say that the Laplace transform $\\mathcal{L}$ converts a signal into a space $s$ that excludes time, but finding a solution to the equation above is non-trivial. If you are interested, the Wikipedia article on LTI system theory provides an introduction. I mention LTI because you will find some literature using it to design the Kalman filter matrices for difficult problems. ",
"_____no_output_____"
],
[
"### Numerical Solutions\n\nFinally, there are numerical techniques to find $\\mathbf F$. As filters get larger finding analytical solutions becomes very tedious (though packages like SymPy make it easier). C. F. van Loan [2] has developed a technique that finds both $\\Phi$ and $\\mathbf Q$ numerically. Given the continuous model\n\n$$ \\dot x = Ax + Gw$$\n\nwhere $w$ is the unity white noise, van Loan's method computes both $\\mathbf F_k$ and $\\mathbf Q_k$.\n \nI have implemented van Loan's method in `FilterPy`. You may use it as follows:\n\n```python\nfrom filterpy.common import van_loan_discretization\n\nA = np.array([[0., 1.], [-1., 0.]])\nG = np.array([[0.], [2.]]) # white noise scaling\nF, Q = van_loan_discretization(A, G, dt=0.1)\n```\n \nIn the section *Numeric Integration of Differential Equations* I present alternative methods which are very commonly used in Kalman filtering.",
"_____no_output_____"
],
[
"## Design of the Process Noise Matrix\n\nIn general the design of the $\\mathbf Q$ matrix is among the most difficult aspects of Kalman filter design. This is due to several factors. First, the math requires a good foundation in signal theory. Second, we are trying to model the noise in something for which we have little information. Consider trying to model the process noise for a thrown baseball. We can model it as a sphere moving through the air, but that leaves many unknown factors - the wind, ball rotation and spin decay, the coefficient of drag of a ball with stitches, the effects of wind and air density, and so on. We develop the equations for an exact mathematical solution for a given process model, but since the process model is incomplete the result for $\\mathbf Q$ will also be incomplete. This has a lot of ramifications for the behavior of the Kalman filter. If $\\mathbf Q$ is too small then the filter will be overconfident in its prediction model and will diverge from the actual solution. If $\\mathbf Q$ is too large than the filter will be unduly influenced by the noise in the measurements and perform sub-optimally. In practice we spend a lot of time running simulations and evaluating collected data to try to select an appropriate value for $\\mathbf Q$. But let's start by looking at the math.\n\n\nLet's assume a kinematic system - some system that can be modeled using Newton's equations of motion. We can make a few different assumptions about this process. \n\nWe have been using a process model of\n\n$$ \\dot{\\mathbf x} = \\mathbf{Ax} + \\mathbf{Bu} + \\mathbf{w}$$\n\nwhere $\\mathbf{w}$ is the process noise. Kinematic systems are *continuous* - their inputs and outputs can vary at any arbitrary point in time. However, our Kalman filters are *discrete* (there are continuous forms for Kalman filters, but we do not cover them in this book). We sample the system at regular intervals. Therefore we must find the discrete representation for the noise term in the equation above. This depends on what assumptions we make about the behavior of the noise. We will consider two different models for the noise.",
"_____no_output_____"
],
[
"### Continuous White Noise Model",
"_____no_output_____"
],
[
"We model kinematic systems using Newton's equations. We have either used position and velocity, or position, velocity, and acceleration as the models for our systems. There is nothing stopping us from going further - we can model jerk, jounce, snap, and so on. We don't do that normally because adding terms beyond the dynamics of the real system degrades the estimate. \n\nLet's say that we need to model the position, velocity, and acceleration. We can then assume that acceleration is constant for each discrete time step. Of course, there is process noise in the system and so the acceleration is not actually constant. The tracked object will alter the acceleration over time due to external, unmodeled forces. In this section we will assume that the acceleration changes by a continuous time zero-mean white noise $w(t)$. In other words, we are assuming that the small changes in velocity average to 0 over time (zero-mean). \n\nSince the noise is changing continuously we will need to integrate to get the discrete noise for the discretization interval that we have chosen. We will not prove it here, but the equation for the discretization of the noise is\n\n$$\\mathbf Q = \\int_0^{\\Delta t} \\mathbf F(t)\\mathbf{Q_c}\\mathbf F^\\mathsf{T}(t) dt$$\n\nwhere $\\mathbf{Q_c}$ is the continuous noise. This gives us\n\n$$\\Phi = \\begin{bmatrix}1 & \\Delta t & {\\Delta t}^2/2 \\\\ 0 & 1 & \\Delta t\\\\ 0& 0& 1\\end{bmatrix}$$\n\nfor the fundamental matrix, and\n\n$$\\mathbf{Q_c} = \\begin{bmatrix}0&0&0\\\\0&0&0\\\\0&0&1\\end{bmatrix} \\Phi_s$$\n\nfor the continuous process noise matrix, where $\\Phi_s$ is the spectral density of the white noise.\n\nWe could carry out these computations ourselves, but I prefer using SymPy to solve the equation.\n\n$$\\mathbf{Q_c} = \\begin{bmatrix}0&0&0\\\\0&0&0\\\\0&0&1\\end{bmatrix} \\Phi_s$$\n\n",
"_____no_output_____"
]
],
[
[
"import sympy\nfrom sympy import (init_printing, Matrix,MatMul, \n integrate, symbols)\n\ninit_printing(use_latex='mathjax')\ndt, phi = symbols('\\Delta{t} \\Phi_s')\nF_k = Matrix([[1, dt, dt**2/2],\n [0, 1, dt],\n [0, 0, 1]])\nQ_c = Matrix([[0, 0, 0],\n [0, 0, 0],\n [0, 0, 1]])*phi\n\nQ=sympy.integrate(F_k * Q_c * F_k.T, (dt, 0, dt))\n\n# factor phi out of the matrix to make it more readable\nQ = Q / phi\nsympy.MatMul(Q, phi)",
"_____no_output_____"
]
],
[
[
"For completeness, let us compute the equations for the 0th order and 1st order equations.",
"_____no_output_____"
]
],
[
[
"F_k = sympy.Matrix([[1]])\nQ_c = sympy.Matrix([[phi]])\n\nprint('0th order discrete process noise')\nsympy.integrate(F_k*Q_c*F_k.T,(dt, 0, dt))",
"0th order discrete process noise\n"
],
[
"F_k = sympy.Matrix([[1, dt],\n [0, 1]])\nQ_c = sympy.Matrix([[0, 0],\n [0, 1]])*phi\n\nQ = sympy.integrate(F_k * Q_c * F_k.T, (dt, 0, dt))\n\nprint('1st order discrete process noise')\n# factor phi out of the matrix to make it more readable\nQ = Q / phi\nsympy.MatMul(Q, phi)",
"1st order discrete process noise\n"
]
],
[
[
"### Piecewise White Noise Model\n\nAnother model for the noise assumes that the that highest order term (say, acceleration) is constant for the duration of each time period, but differs for each time period, and each of these is uncorrelated between time periods. In other words there is a discontinuous jump in acceleration at each time step. This is subtly different than the model above, where we assumed that the last term had a continuously varying noisy signal applied to it. \n\nWe will model this as\n\n$$f(x)=Fx+\\Gamma w$$\n\nwhere $\\Gamma$ is the *noise gain* of the system, and $w$ is the constant piecewise acceleration (or velocity, or jerk, etc). \n\nLet's start by looking at a first order system. In this case we have the state transition function\n\n$$\\mathbf{F} = \\begin{bmatrix}1&\\Delta t \\\\ 0& 1\\end{bmatrix}$$\n\nIn one time period, the change in velocity will be $w(t)\\Delta t$, and the change in position will be $w(t)\\Delta t^2/2$, giving us\n\n$$\\Gamma = \\begin{bmatrix}\\frac{1}{2}\\Delta t^2 \\\\ \\Delta t\\end{bmatrix}$$\n\nThe covariance of the process noise is then\n\n$$Q = \\mathbb E[\\Gamma w(t) w(t) \\Gamma^\\mathsf{T}] = \\Gamma\\sigma^2_v\\Gamma^\\mathsf{T}$$.\n\nWe can compute that with SymPy as follows",
"_____no_output_____"
]
],
[
[
"var=symbols('sigma^2_v')\nv = Matrix([[dt**2 / 2], [dt]])\n\nQ = v * var * v.T\n\n# factor variance out of the matrix to make it more readable\nQ = Q / var\nsympy.MatMul(Q, var)",
"_____no_output_____"
]
],
[
[
"The second order system proceeds with the same math.\n\n\n$$\\mathbf{F} = \\begin{bmatrix}1 & \\Delta t & {\\Delta t}^2/2 \\\\ 0 & 1 & \\Delta t\\\\ 0& 0& 1\\end{bmatrix}$$\n\nHere we will assume that the white noise is a discrete time Wiener process. This gives us\n\n$$\\Gamma = \\begin{bmatrix}\\frac{1}{2}\\Delta t^2 \\\\ \\Delta t\\\\ 1\\end{bmatrix}$$\n\nThere is no 'truth' to this model, it is just convenient and provides good results. For example, we could assume that the noise is applied to the jerk at the cost of a more complicated equation. \n\nThe covariance of the process noise is then\n\n$$Q = \\mathbb E[\\Gamma w(t) w(t) \\Gamma^\\mathsf{T}] = \\Gamma\\sigma^2_v\\Gamma^\\mathsf{T}$$.\n\nWe can compute that with SymPy as follows",
"_____no_output_____"
]
],
[
[
"var=symbols('sigma^2_v')\nv = Matrix([[dt**2 / 2], [dt], [1]])\n\nQ = v * var * v.T\n\n# factor variance out of the matrix to make it more readable\nQ = Q / var\nsympy.MatMul(Q, var)",
"_____no_output_____"
]
],
[
[
"We cannot say that this model is more or less correct than the continuous model - both are approximations to what is happening to the actual object. Only experience and experiments can guide you to the appropriate model. In practice you will usually find that either model provides reasonable results, but typically one will perform better than the other.\n\nThe advantage of the second model is that we can model the noise in terms of $\\sigma^2$ which we can describe in terms of the motion and the amount of error we expect. The first model requires us to specify the spectral density, which is not very intuitive, but it handles varying time samples much more easily since the noise is integrated across the time period. However, these are not fixed rules - use whichever model (or a model of your own devising) based on testing how the filter performs and/or your knowledge of the behavior of the physical model.\n\nA good rule of thumb is to set $\\sigma$ somewhere from $\\frac{1}{2}\\Delta a$ to $\\Delta a$, where $\\Delta a$ is the maximum amount that the acceleration will change between sample periods. In practice we pick a number, run simulations on data, and choose a value that works well.",
"_____no_output_____"
],
[
"### Using FilterPy to Compute Q\n\nFilterPy offers several routines to compute the $\\mathbf Q$ matrix. The function `Q_continuous_white_noise()` computes $\\mathbf Q$ for a given value for $\\Delta t$ and the spectral density.",
"_____no_output_____"
]
],
[
[
"from filterpy.common import Q_continuous_white_noise\nfrom filterpy.common import Q_discrete_white_noise\n\nQ = Q_continuous_white_noise(dim=2, dt=1, spectral_density=1)\nprint(Q)",
"[[ 0.333 0.5]\n [ 0.5 1.0]]\n"
],
[
"Q = Q_continuous_white_noise(dim=3, dt=1, spectral_density=1)\nprint(Q)",
"[[ 0.05 0.125 0.167]\n [ 0.125 0.333 0.5]\n [ 0.167 0.5 1.0]]\n"
]
],
[
[
"The function `Q_discrete_white_noise()` computes $\\mathbf Q$ assuming a piecewise model for the noise.",
"_____no_output_____"
]
],
[
[
"Q = Q_discrete_white_noise(2, var=1.)\nprint(Q)",
"[[ 0.25 0.5]\n [ 0.5 1.0]]\n"
],
[
"Q = Q_discrete_white_noise(3, var=1.)\nprint(Q)",
"[[ 0.25 0.5 0.5]\n [ 0.5 1.0 1.0]\n [ 0.5 1.0 1.0]]\n"
]
],
[
[
"### Simplification of Q\n\nMany treatments use a much simpler form for $\\mathbf Q$, setting it to zero except for a noise term in the lower rightmost element. Is this justified? Well, consider the value of $\\mathbf Q$ for a small $\\Delta t$",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nnp.set_printoptions(precision=8)\nQ = Q_continuous_white_noise(\n dim=3, dt=0.05, spectral_density=1)\nprint(Q)\nnp.set_printoptions(precision=3)",
"[[ 0.00000002 0.00000078 0.00002083]\n [ 0.00000078 0.00004167 0.00125 ]\n [ 0.00002083 0.00125 0.05 ]]\n"
]
],
[
[
"We can see that most of the terms are very small. Recall that the only equation using this matrix is\n\n$$ \\mathbf P=\\mathbf{FPF}^\\mathsf{T} + \\mathbf Q$$\n\nIf the values for $\\mathbf Q$ are small relative to $\\mathbf P$\nthan it will be contributing almost nothing to the computation of $\\mathbf P$. Setting $\\mathbf Q$ to the zero matrix except for the lower right term\n\n$$\\mathbf Q=\\begin{bmatrix}0&0&0\\\\0&0&0\\\\0&0&\\sigma^2\\end{bmatrix}$$\n\nwhile not correct, is often a useful approximation. If you do this you will have to perform quite a few studies to guarantee that your filter works in a variety of situations. \n\nIf you do this, 'lower right term' means the most rapidly changing term for each variable. If the state is $x=\\begin{bmatrix}x & \\dot x & \\ddot{x} & y & \\dot{y} & \\ddot{y}\\end{bmatrix}^\\mathsf{T}$ Then Q will be 6x6; the elements for both $\\ddot{x}$ and $\\ddot{y}$ will have to be set to non-zero in $\\mathbf Q$.",
"_____no_output_____"
],
[
"## Numeric Integration of Differential Equations",
"_____no_output_____"
],
[
"We've been exposed to several numerical techniques to solve linear differential equations. These include state-space methods, the Laplace transform, and van Loan's method. \n\nThese work well for linear ordinary differential equations (ODEs), but do not work well for nonlinear equations. For example, consider trying to predict the position of a rapidly turning car. Cars maneuver by turning the front wheels. This makes them pivot around their rear axle as it moves forward. Therefore the path will be continuously varying and a linear prediction will necessarily produce an incorrect value. If the change in the system is small enough relative to $\\Delta t$ this can often produce adequate results, but that will rarely be the case with the nonlinear Kalman filters we will be studying in subsequent chapters. \n\nFor these reasons we need to know how to numerically integrate ODEs. This can be a vast topic that requires several books. If you need to explore this topic in depth *Computational Physics in Python* by Dr. Eric Ayars is excellent, and available for free here:\n\nhttp://phys.csuchico.edu/ayars/312/Handouts/comp-phys-python.pdf\n\nHowever, I will cover a few simple techniques which will work for a majority of the problems you encounter.\n",
"_____no_output_____"
],
[
"### Euler's Method\n\nLet's say we have the initial condition problem of \n\n$$\\begin{gathered}\ny' = y, \\\\ y(0) = 1\n\\end{gathered}$$\n\nWe happen to know the exact answer is $y=e^t$ because we solved it earlier, but for an arbitrary ODE we will not know the exact solution. In general all we know is the derivative of the equation, which is equal to the slope. We also know the initial value: at $t=0$, $y=1$. If we know these two pieces of information we can predict the value at $y(t=1)$ using the slope at $t=0$ and the value of $y(0)$. I've plotted this below.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nt = np.linspace(-1, 1, 10)\nplt.plot(t, np.exp(t))\nt = np.linspace(-1, 1, 2)\nplt.plot(t,t+1, ls='--', c='k');",
"_____no_output_____"
]
],
[
[
"You can see that the slope is very close to the curve at $t=0.1$, but far from it\nat $t=1$. But let's continue with a step size of 1 for a moment. We can see that at $t=1$ the estimated value of $y$ is 2. Now we can compute the value at $t=2$ by taking the slope of the curve at $t=1$ and adding it to our initial estimate. The slope is computed with $y'=y$, so the slope is 2.",
"_____no_output_____"
]
],
[
[
"import code.book_plots as book_plots\n\nt = np.linspace(-1, 2, 20)\nplt.plot(t, np.exp(t))\nt = np.linspace(0, 1, 2)\nplt.plot([1, 2, 4], ls='--', c='k')\nbook_plots.set_labels(x='x', y='y');",
"_____no_output_____"
]
],
[
[
"Here we see the next estimate for y is 4. The errors are getting large quickly, and you might be unimpressed. But 1 is a very large step size. Let's put this algorithm in code, and verify that it works by using a small step size.",
"_____no_output_____"
]
],
[
[
"def euler(t, tmax, y, dx, step=1.):\n ys = []\n while t < tmax:\n y = y + step*dx(t, y)\n ys.append(y)\n t +=step \n return ys",
"_____no_output_____"
],
[
"def dx(t, y): return y\n\nprint(euler(0, 1, 1, dx, step=1.)[-1])\nprint(euler(0, 2, 1, dx, step=1.)[-1])",
"2.0\n4.0\n"
]
],
[
[
"This looks correct. So now let's plot the result of a much smaller step size.",
"_____no_output_____"
]
],
[
[
"ys = euler(0, 4, 1, dx, step=0.00001)\nplt.subplot(1,2,1)\nplt.title('Computed')\nplt.plot(np.linspace(0, 4, len(ys)),ys)\nplt.subplot(1,2,2)\nt = np.linspace(0, 4, 20)\nplt.title('Exact')\nplt.plot(t, np.exp(t));",
"_____no_output_____"
],
[
"print('exact answer=', np.exp(4))\nprint('euler answer=', ys[-1])\nprint('difference =', np.exp(4) - ys[-1])\nprint('iterations =', len(ys))",
"exact answer= 54.5981500331\neuler answer= 54.59705808834125\ndifference = 0.00109194480299\niterations = 400000\n"
]
],
[
[
"Here we see that the error is reasonably small, but it took a very large number of iterations to get three digits of precision. In practice Euler's method is too slow for most problems, and we use more sophisticated methods.\n\nBefore we go on, let's formally derive Euler's method, as it is the basis for the more advanced Runge Kutta methods used in the next section. In fact, Euler's method is the simplest form of Runge Kutta.\n\n\nHere are the first 3 terms of the Euler expansion of $y$. An infinite expansion would give an exact answer, so $O(h^4)$ denotes the error due to the finite expansion.\n\n$$y(t_0 + h) = y(t_0) + h y'(t_0) + \\frac{1}{2!}h^2 y''(t_0) + \\frac{1}{3!}h^3 y'''(t_0) + O(h^4)$$\n\nHere we can see that Euler's method is using the first two terms of the Taylor expansion. Each subsequent term is smaller than the previous terms, so we are assured that the estimate will not be too far off from the correct value. ",
"_____no_output_____"
],
[
"### Runge Kutta Methods",
"_____no_output_____"
],
[
"\nRunge Kutta is the workhorse of numerical integration. There are a vast number of methods in the literature. In practice, using the Runge Kutta algorithm that I present here will solve most any problem you will face. It offers a very good balance of speed, precision, and stability, and it is the 'go to' numerical integration method unless you have a very good reason to choose something different.\n\nLet's dive in. We start with some differential equation\n\n$$\\ddot{y} = \\frac{d}{dt}\\dot{y}$$.\n\nWe can substitute the derivative of y with a function f, like so\n\n$$\\ddot{y} = \\frac{d}{dt}f(y,t)$$.",
"_____no_output_____"
],
[
"Deriving these equations is outside the scope of this book, but the Runge Kutta RK4 method is defined with these equations.\n\n$$y(t+\\Delta t) = y(t) + \\frac{1}{6}(k_1 + 2k_2 + 2k_3 + k_4) + O(\\Delta t^4)$$\n\n$$\\begin{aligned}\nk_1 &= f(y,t)\\Delta t \\\\\nk_2 &= f(y+\\frac{1}{2}k_1, t+\\frac{1}{2}\\Delta t)\\Delta t \\\\\nk_3 &= f(y+\\frac{1}{2}k_2, t+\\frac{1}{2}\\Delta t)\\Delta t \\\\\nk_4 &= f(y+k_3, t+\\Delta t)\\Delta t\n\\end{aligned}\n$$\n\nHere is the corresponding code:",
"_____no_output_____"
]
],
[
[
"def runge_kutta4(y, x, dx, f):\n \"\"\"computes 4th order Runge-Kutta for dy/dx.\n y is the initial value for y\n x is the initial value for x\n dx is the difference in x (e.g. the time step)\n f is a callable function (y, x) that you supply \n to compute dy/dx for the specified values.\n \"\"\"\n \n k1 = dx * f(y, x)\n k2 = dx * f(y + 0.5*k1, x + 0.5*dx)\n k3 = dx * f(y + 0.5*k2, x + 0.5*dx)\n k4 = dx * f(y + k3, x + dx)\n \n return y + (k1 + 2*k2 + 2*k3 + k4) / 6.",
"_____no_output_____"
]
],
[
[
"Let's use this for a simple example. Let\n\n$$\\dot{y} = t\\sqrt{y(t)}$$\n\nwith the initial values\n\n$$\\begin{aligned}t_0 &= 0\\\\y_0 &= y(t_0) = 1\\end{aligned}$$",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nt = 0.\ny = 1.\ndt = .1\n\nys, ts = [], []\n\ndef func(y,t):\n return t*math.sqrt(y)\n\nwhile t <= 10:\n y = runge_kutta4(y, t, dt, func)\n t += dt\n ys.append(y)\n ts.append(t)\n\nexact = [(t**2 + 4)**2 / 16. for t in ts]\nplt.plot(ts, ys)\nplt.plot(ts, exact)\n\nerror = np.array(exact) - np.array(ys)\nprint(\"max error {}\".format(max(error)))",
"max error 5.206970035942504e-05\n"
]
],
[
[
"## Bayesian Filtering\n\nStarting in the Discrete Bayes chapter I used a Bayesian formulation for filtering. Suppose we are tracking an object. We define its *state* at a specific time as its position, velocity, and so on. For example, we might write the state at time $t$ as $\\mathbf x_t = \\begin{bmatrix}x_t &\\dot x_t \\end{bmatrix}^\\mathsf T$. \n\nWhen we take a measurement of the object we are measuring the state or part of it. Sensors are noisy, so the measurement is corrupted with noise. Clearly though, the measurement is determined by the state. That is, a change in state may change the measurement, but a change in measurement will not change the state.\n\nIn filtering our goal is to compute an optimal estimate for a set of states $\\mathbf x_{0:t}$ from time 0 to time $t$. If we knew $\\mathbf x_{0:t}$ then it would be trivial to compute a set of measurements $\\mathbf z_{0:t}$ corresponding to those states. However, we receive a set of measurements $\\mathbf z_{0:t}$, and want to compute the corresponding states $\\mathbf x_{0:t}$. This is called *statistical inversion* because we are trying to compute the input from the output. \n\nInversion is a difficult problem because there is typically no unique solution. For a given set of states $\\mathbf x_{0:t}$ there is only one possible set of measurements (plus noise), but for a given set of measurements there are many different sets of states that could have led to those measurements. \n\nRecall Bayes Theorem:\n\n$$P(x \\mid z) = \\frac{P(z \\mid x)P(x)}{P(z)}$$\n\nwhere $P(z \\mid x)$ is the *likelihood* of the measurement $z$, $P(x)$ is the *prior* based on our process model, and $P(z)$ is a normalization constant. $P(x \\mid z)$ is the *posterior*, or the distribution after incorporating the measurement $z$, also called the *evidence*.\n\nThis is a *statistical inversion* as it goes from $P(z \\mid x)$ to $P(x \\mid z)$. The solution to our filtering problem can be expressed as:\n\n$$P(\\mathbf x_{0:t} \\mid \\mathbf z_{0:t}) = \\frac{P(\\mathbf z_{0:t} \\mid \\mathbf x_{0:t})P(\\mathbf x_{0:t})}{P(\\mathbf z_{0:t})}$$\n\nThat is all well and good until the next measurement $\\mathbf z_{t+1}$ comes in, at which point we need to recompute the entire expression for the range $0:t+1$. \n\n\nIn practice this is intractable because we are trying to compute the posterior distribution $P(\\mathbf x_{0:t} \\mid \\mathbf z_{0:t})$ for the state over the full range of time steps. But do we really care about the probability distribution at the third step (say) when we just received the tenth measurement? Not usually. So we relax our requirements and only compute the distributions for the current time step.\n\nThe first simplification is we describe our process (e.g., the motion model for a moving object) as a *Markov chain*. That is, we say that the current state is solely dependent on the previous state and a transition probability $P(\\mathbf x_k \\mid \\mathbf x_{k-1})$, which is just the probability of going from the last state to the current one. We write:\n\n$$\\mathbf x_k \\sim P(\\mathbf x_k \\mid \\mathbf x_{k-1})$$\n\nThe next simplification we make is do define the *measurement model* as depending on the current state $\\mathbf x_k$ with the conditional probability of the measurement given the current state: $P(\\mathbf z_t \\mid \\mathbf x_x)$. We write:\n\n$$\\mathbf z_k \\sim P(\\mathbf z_t \\mid \\mathbf x_x)$$\n\nWe have a recurrance now, so we need an initial condition to terminate it. Therefore we say that the initial distribution is the probablity of the state $\\mathbf x_0$:\n\n$$\\mathbf x_0 \\sim P(\\mathbf x_0)$$\n\n\nThese terms are plugged into Bayes equation. If we have the state $\\mathbf x_0$ and the first measurement we can estimate $P(\\mathbf x_1 | \\mathbf z_1)$. The motion model creates the prior $P(\\mathbf x_2 \\mid \\mathbf x_1)$. We feed this back into Bayes theorem to compute $P(\\mathbf x_2 | \\mathbf z_2)$. We continue this predictor-corrector algorithm, recursively computing the state and distribution at time $t$ based solely on the state and distribution at time $t-1$ and the measurement at time $t$.\n\nThe details of the mathematics for this computation varies based on the problem. The **Discrete Bayes** and **Univariate Kalman Filter** chapters gave two different formulations which you should have been able to reason through. The univariate Kalman filter assumes that for a scalar state both the noise and process are linear model are affected by zero-mean, uncorrelated Gaussian noise. \n\nThe Multivariate Kalman filter make the same assumption but for states and measurements that are vectors, not scalars. Dr. Kalman was able to prove that if these assumptions hold true then the Kalman filter is *optimal* in a least squares sense. Colloquially this means there is no way to derive more information from the noise. In the remainder of the book I will present filters that relax the constraints on linearity and Gaussian noise.\n\nBefore I go on, a few more words about statistical inversion. As Calvetti and Somersalo write in *Introduction to Bayesian Scientific Computing*, \"we adopt the Bayesian point of view: *randomness simply means lack of information*.\"[3] Our state parametize physical phenomena that we could in principle measure or compute: velocity, air drag, and so on. We lack enough information to compute or measure their value, so we opt to consider them as random variables. Strictly speaking they are not random, thus this is a subjective position. \n\nThey devote a full chapter to this topic. I can spare a paragraph. Bayesian filters are possible because we ascribe statistical properties to unknown parameters. In the case of the Kalman filter we have closed-form solutions to find an optimal estimate. Other filters, such as the discrete Bayes filter or the particle filter which we cover in a later chapter, model the probability in a more ad-hoc, non-optimal manner. The power of our technique comes from treating lack of information as a random variable, describing that random variable as a probability distribution, and then using Bayes Theorem to solve the statistical inference problem.",
"_____no_output_____"
],
[
"## Converting Kalman Filter to a g-h Filter\n\nI've stated that the Kalman filter is a form of the g-h filter. It just takes some algebra to prove it. It's more straightforward to do with the one dimensional case, so I will do that. Recall \n\n$$\n\\mu_{x}=\\frac{\\sigma_1^2 \\mu_2 + \\sigma_2^2 \\mu_1} {\\sigma_1^2 + \\sigma_2^2}\n$$\n\nwhich I will make more friendly for our eyes as:\n\n$$\n\\mu_{x}=\\frac{ya + xb} {a+b}\n$$\n\nWe can easily put this into the g-h form with the following algebra\n\n$$\n\\begin{aligned}\n\\mu_{x}&=(x-x) + \\frac{ya + xb} {a+b} \\\\\n\\mu_{x}&=x-\\frac{a+b}{a+b}x + \\frac{ya + xb} {a+b} \\\\ \n\\mu_{x}&=x +\\frac{-x(a+b) + xb+ya}{a+b} \\\\\n\\mu_{x}&=x+ \\frac{-xa+ya}{a+b} \\\\\n\\mu_{x}&=x+ \\frac{a}{a+b}(y-x)\\\\\n\\end{aligned}\n$$\n\nWe are almost done, but recall that the variance of estimate is given by \n\n$$\\begin{aligned}\n\\sigma_{x}^2 &= \\frac{1}{\\frac{1}{\\sigma_1^2} + \\frac{1}{\\sigma_2^2}} \\\\\n&= \\frac{1}{\\frac{1}{a} + \\frac{1}{b}}\n\\end{aligned}$$\n\nWe can incorporate that term into our equation above by observing that\n\n$$ \n\\begin{aligned}\n\\frac{a}{a+b} &= \\frac{a/a}{(a+b)/a} = \\frac{1}{(a+b)/a} \\\\\n &= \\frac{1}{1 + \\frac{b}{a}} = \\frac{1}{\\frac{b}{b} + \\frac{b}{a}} \\\\\n &= \\frac{1}{b}\\frac{1}{\\frac{1}{b} + \\frac{1}{a}} \\\\\n &= \\frac{\\sigma^2_{x'}}{b}\n \\end{aligned}\n$$\n\nWe can tie all of this together with\n\n$$\n\\begin{aligned}\n\\mu_{x}&=x+ \\frac{a}{a+b}(y-x) \\\\\n&= x + \\frac{\\sigma^2_{x'}}{b}(y-x) \\\\\n&= x + g_n(y-x)\n\\end{aligned}\n$$\n\nwhere\n\n$$g_n = \\frac{\\sigma^2_{x}}{\\sigma^2_{y}}$$\n\nThe end result is multiplying the residual of the two measurements by a constant and adding to our previous value, which is the $g$ equation for the g-h filter. $g$ is the variance of the new estimate divided by the variance of the measurement. Of course in this case $g$ is not a constant as it varies with each time step as the variance changes. We can also derive the formula for $h$ in the same way. It is not a particularly illuminating derivation and I will skip it. The end result is\n\n$$h_n = \\frac{COV (x,\\dot x)}{\\sigma^2_{y}}$$\n\nThe takeaway point is that $g$ and $h$ are specified fully by the variance and covariances of the measurement and predictions at time $n$. In other words, we are picking a point between the measurement and prediction by a scale factor determined by the quality of each of those two inputs.",
"_____no_output_____"
],
[
"## References",
"_____no_output_____"
],
[
" * [1] C.B. Molwer and C.F. Van Loan \"Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later,\", *SIAM Review 45, 3-49*. 2003.\n\n\n * [2] C.F. van Loan, \"Computing Integrals Involving the Matrix Exponential,\" IEEE *Transactions Automatic Control*, June 1978.\n \n \n * [3] Calvetti, D and Somersalo E, \"Introduction to Bayesian Scientific Computing: Ten Lectures on Subjective Computing,\", *Springer*, 2007.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d00546fe967f543f1d15d40fc6662207773e44af
| 148,643 |
ipynb
|
Jupyter Notebook
|
Discrete_Fourier_Transform.ipynb
|
server73/numpy_excercises
|
4145f5fe8193f1110a7e83360aa6ae455cf87491
|
[
"MIT"
] | 1 |
2020-06-13T15:22:50.000Z
|
2020-06-13T15:22:50.000Z
|
7_Discrete_Fourier_Transform.ipynb
|
DANNALI35/numpy_exercises
|
a41546bc5cdfe947a6ffb7eb8969be38624bf3e3
|
[
"MIT"
] | 1 |
2021-05-10T09:14:01.000Z
|
2021-05-10T09:14:01.000Z
|
book/numpy/code/7_Discrete_Fourier_Transform.ipynb
|
tanpv/mdawp
|
8859e413f1510d0859899f3ee2789ea324c7eb75
|
[
"MIT"
] | 2 |
2018-12-26T22:17:37.000Z
|
2019-02-06T18:27:07.000Z
| 363.430318 | 140,530 | 0.92856 |
[
[
[
"from __future__ import print_function\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"from datetime import date\ndate.today()",
"_____no_output_____"
],
[
"author = \"kyubyong. https://github.com/Kyubyong/numpy_exercises\"",
"_____no_output_____"
],
[
"np.__version__",
"_____no_output_____"
]
],
[
[
"### Complex Numbers",
"_____no_output_____"
],
[
"Q1. Return the angle of `a` in radian.",
"_____no_output_____"
]
],
[
[
"a = 1+1j\noutput = ...\nprint(output)",
"0.785398163397\n"
]
],
[
[
"Q2. Return the real part and imaginary part of `a`.",
"_____no_output_____"
]
],
[
[
"a = np.array([1+2j, 3+4j, 5+6j])\nreal = ...\nimag = ...\nprint(\"real part=\", real)\nprint(\"imaginary part=\", imag)",
"real part= [ 1. 3. 5.]\nimaginary part= [ 2. 4. 6.]\n"
]
],
[
[
"Q3. Replace the real part of a with `9`, the imaginary part with `[5, 7, 9]`.",
"_____no_output_____"
]
],
[
[
"a = np.array([1+2j, 3+4j, 5+6j])\n...\n...\nprint(a)",
"[ 9.+5.j 9.+7.j 9.+9.j]\n"
]
],
[
[
"Q4. Return the complex conjugate of `a`.",
"_____no_output_____"
]
],
[
[
"a = 1+2j\noutput = ...\nprint(output)",
"(1-2j)\n"
]
],
[
[
"### Discrete Fourier Transform",
"_____no_output_____"
],
[
"Q5. Compuete the one-dimensional DFT of `a`.",
"_____no_output_____"
]
],
[
[
"a = np.exp(2j * np.pi * np.arange(8))\noutput = ...\nprint(output)\n",
"[ 8.00000000e+00 -6.85802208e-15j 2.36524713e-15 +9.79717439e-16j\n 9.79717439e-16 +9.79717439e-16j 4.05812251e-16 +9.79717439e-16j\n 0.00000000e+00 +9.79717439e-16j -4.05812251e-16 +9.79717439e-16j\n -9.79717439e-16 +9.79717439e-16j -2.36524713e-15 +9.79717439e-16j]\n"
]
],
[
[
"Q6. Compute the one-dimensional inverse DFT of the `output` in the above question.",
"_____no_output_____"
]
],
[
[
"print(\"a=\", a)\ninversed = ...\nprint(\"inversed=\", a)",
"a= [ 1. +0.00000000e+00j 1. -2.44929360e-16j 1. -4.89858720e-16j\n 1. -7.34788079e-16j 1. -9.79717439e-16j 1. -1.22464680e-15j\n 1. -1.46957616e-15j 1. -1.71450552e-15j]\ninversed= [ 1. +0.00000000e+00j 1. -2.44929360e-16j 1. -4.89858720e-16j\n 1. -7.34788079e-16j 1. -9.79717439e-16j 1. -1.22464680e-15j\n 1. -1.46957616e-15j 1. -1.71450552e-15j]\n"
]
],
[
[
"Q7. Compute the one-dimensional discrete Fourier Transform for real input `a`.",
"_____no_output_____"
]
],
[
[
"a = [0, 1, 0, 0]\noutput = ...\nprint(output)\nassert output.size==len(a)//2+1 if len(a)%2==0 else (len(a)+1)//2\n\n# cf.\noutput2 = np.fft.fft(a)\nprint(output2)",
"[ 1.+0.j 0.-1.j -1.+0.j]\n[ 1.+0.j 0.-1.j -1.+0.j 0.+1.j]\n"
]
],
[
[
"Q8. Compute the one-dimensional inverse DFT of the output in the above question.",
"_____no_output_____"
]
],
[
[
"inversed = ...\nprint(\"inversed=\", a)",
"inversed= [0, 1, 0, 0]\n"
]
],
[
[
"Q9. Return the DFT sample frequencies of `a`.",
"_____no_output_____"
]
],
[
[
"signal = np.array([-2, 8, 6, 4, 1, 0, 3, 5], dtype=np.float32)\nfourier = np.fft.fft(signal)\nn = signal.size\nfreq = ...\nprint(freq)",
"[ 0. 0.125 0.25 0.375 -0.5 -0.375 -0.25 -0.125]\n"
]
],
[
[
"### Window Functions",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(19, 10))\n\n# Hamming window\nwindow = np.hamming(51)\nplt.plot(np.bartlett(51), label=\"Bartlett window\")\nplt.plot(np.blackman(51), label=\"Blackman window\")\nplt.plot(np.hamming(51), label=\"Hamming window\")\nplt.plot(np.hanning(51), label=\"Hanning window\")\nplt.plot(np.kaiser(51, 14), label=\"Kaiser window\")\nplt.xlabel(\"sample\")\nplt.ylabel(\"amplitude\")\nplt.legend()\nplt.grid()\n\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0056c14aacfd979374c63e1878432a523a4cd27
| 13,048 |
ipynb
|
Jupyter Notebook
|
spec/helpers/test-notebook.ipynb
|
willwhitney/atom-ipython
|
6410bd61a7f267f693f5503e39fcc26eaef1fa0b
|
[
"MIT"
] | 3,839 |
2016-02-16T11:32:56.000Z
|
2022-03-30T20:57:42.000Z
|
spec/helpers/test-notebook.ipynb
|
willwhitney/atom-ipython
|
6410bd61a7f267f693f5503e39fcc26eaef1fa0b
|
[
"MIT"
] | 1,694 |
2016-02-12T04:16:06.000Z
|
2022-03-23T19:56:21.000Z
|
spec/helpers/test-notebook.ipynb
|
willwhitney/atom-ipython
|
6410bd61a7f267f693f5503e39fcc26eaef1fa0b
|
[
"MIT"
] | 413 |
2016-02-16T00:20:28.000Z
|
2022-03-31T18:30:49.000Z
| 37.386819 | 69 | 0.320892 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"pd.util.testing.makeDataFrame()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
d0058f095320f925c3d67f8ad0cb4cfdba9856ae
| 59,159 |
ipynb
|
Jupyter Notebook
|
data/ReadDataset.ipynb
|
mattianeroni/fleet-assignment-problem
|
dd739e5aa50c06504d70778a0cc88b482fcad97f
|
[
"MIT"
] | null | null | null |
data/ReadDataset.ipynb
|
mattianeroni/fleet-assignment-problem
|
dd739e5aa50c06504d70778a0cc88b482fcad97f
|
[
"MIT"
] | null | null | null |
data/ReadDataset.ipynb
|
mattianeroni/fleet-assignment-problem
|
dd739e5aa50c06504d70778a0cc88b482fcad97f
|
[
"MIT"
] | null | null | null | 54.726179 | 9,148 | 0.564901 |
[
[
[
"import numpy as np\nimport pandas as pd \nimport statistics\nimport matplotlib.pyplot as plt \nimport itertools",
"_____no_output_____"
],
[
"avail = pd.read_csv(\"FleetAreaConstraints.csv\", index_col=0).to_numpy()",
"_____no_output_____"
],
[
"n_postcodes, n_fleets = avail.shape\n\navail_assignments = np.array([itertools.cycle( np.where(avail[i] == 1)[0] ) for i in range(n_postcodes)])\nsolution = np.random.randint(0, n_fleets, size=(n_postcodes))\n\nsolution",
"_____no_output_____"
],
[
"mut_probs = np.random.rand(n_postcodes)",
"_____no_output_____"
],
[
"solution = np.where(mut_probs < 0.3, next(avail_assignments), solution)",
"_____no_output_____"
],
[
"x = np.array([1,4,90])\ny = np.array([2,2,2])\n\nnp.minimum(x, y)",
"_____no_output_____"
],
[
"demand = pd.read_csv(\"Demand.csv\", index_col=0).to_numpy()",
"_____no_output_____"
],
[
"demand.shape",
"_____no_output_____"
],
[
"(avail * demand).shape",
"_____no_output_____"
],
[
"#pd.read_csv(\"Fleets.csv\", index_col=0)#.to_numpy()",
"_____no_output_____"
],
[
"prods = pd.read_csv(\"ParcelsPerH.csv\", index_col=0).to_numpy()\nprods",
"_____no_output_____"
],
[
"np.around((avail * demand).astype(\"float32\") / prods, 2)",
"_____no_output_____"
],
[
"df = pd.read_csv(\"Delayed.csv\", index_col=0)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df * 0.5",
"_____no_output_____"
],
[
"delays = np.unique(np.reshape(matrix, matrix.size))",
"_____no_output_____"
],
[
"delays = np.sort(delays)[::-1]\ndelays",
"_____no_output_____"
],
[
"plt.plot(delays)",
"_____no_output_____"
],
[
"plt.plot(delays * 0.5)",
"_____no_output_____"
],
[
"x = np.asarray([[1, 0], \n [0, 0],\n [1, 0]])\ny = np.array([3,4,5])\n#y.resize((3,1))\n",
"_____no_output_____"
],
[
"x.shape, y.shape",
"_____no_output_____"
],
[
"(x.T * y).T",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0059a7a7e0cc39f55367f4202bb4d80df2461c3
| 6,193 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/atomic/windows/credential_access/SDWIN-201018225619.ipynb
|
Korving-F/Security-Datasets
|
5b98c5f0cbba6a0d138b72da2c9b7519d8d857a2
|
[
"MIT"
] | null | null | null |
docs/notebooks/atomic/windows/credential_access/SDWIN-201018225619.ipynb
|
Korving-F/Security-Datasets
|
5b98c5f0cbba6a0d138b72da2c9b7519d8d857a2
|
[
"MIT"
] | null | null | null |
docs/notebooks/atomic/windows/credential_access/SDWIN-201018225619.ipynb
|
Korving-F/Security-Datasets
|
5b98c5f0cbba6a0d138b72da2c9b7519d8d857a2
|
[
"MIT"
] | null | null | null | 29.350711 | 356 | 0.536735 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d0059cddfa777644c6e83e092ad4076b4b860a78
| 364,143 |
ipynb
|
Jupyter Notebook
|
Multiple-linear-regression.ipynb
|
memphis-iis/datawhys-intern-solutions-2020
|
78558f2201e75b38692c2d95a310a796c49eb86e
|
[
"Apache-2.0"
] | null | null | null |
Multiple-linear-regression.ipynb
|
memphis-iis/datawhys-intern-solutions-2020
|
78558f2201e75b38692c2d95a310a796c49eb86e
|
[
"Apache-2.0"
] | null | null | null |
Multiple-linear-regression.ipynb
|
memphis-iis/datawhys-intern-solutions-2020
|
78558f2201e75b38692c2d95a310a796c49eb86e
|
[
"Apache-2.0"
] | null | null | null | 61.210792 | 72,534 | 0.635201 |
[
[
[
"# Multiple linear regression \n\nIn many data sets there may be several predictor variables that have an effect on a response variable.\n In fact, the *interaction* between variables may also be used to predict response.\n When we incorporate these additional predictor variables into the analysis the model is called *multiple regression* .\n The multiple regression model builds on the simple linear regression model by adding additional predictors with corresponding parameters.\n\n## Multiple Regression Model\nLet's suppose we are interested in determining what factors might influence a baby's birth weight.\n In our data set we have information on birth weight, our response, and predictors: mother’s age, weight and height and gestation period.\n A *main effects model* includes each of the possible predictors but no interactions.\n Suppose we name these features as in the chart below.\n \n| Variable | Description |\n|----------|:-------------------|\n| BW | baby birth weight |\n| MA | mother's age |\n| MW | mother's weight |\n| MH | mother's height |\n| GP | gestation period |",
"_____no_output_____"
],
[
"Then the theoretical main effects multiple regression model is \n\n$$BW = \\beta_0 + \\beta_1 MA + \\beta_2 MW + \\beta_3 MH + \\beta_4 GP+ \\epsilon.$$ \n\nNow we have five parameters to estimate from the data, $\\beta_0, \\beta_1, \\beta_2, \\beta_3$ and $\\beta_4$.\n The random error term, $\\epsilon$ has the same interpretation as in simple linear regression and is assumed to come from a normal distribution with mean equal to zero and variance equal to $\\sigma^2$.\n Note that multiple regression also includes the polynomial models discussed in the simple linear regression notebook.\n \nOne of the most important things to notice about the equation above is that each variable makes a contribution **independently** of the other variables.\nThis is sometimes called **additivity**: the effects of predictor variable are added together to get the total effect on `BW`.",
"_____no_output_____"
],
[
"## Interaction Effects\n\nSuppose in the example, through exploratory data analysis, we discover that younger mothers with long gestational times tend to have heavier babies, but older mother with short gestational times tend to have lighter babies.\n This could indicate an interaction effect on the response.\n When there is an interaction effect, the effects of the variables involved are not additive.\n \n Different numbers of variables can be involved in an interaction.\n When two features are involved in the interaction it is called a *two-way interaction* .\n There are three-way and higher interactions possible as well, but they are less common in practice.\n The *full model* includes main effects and all interactions.\n For the example given here there are 6 two-way interactions possible between the variables, 4 possible three-way, and 1 four-way interaction in the full model.\n \n Often in practice we fit the full model to check for significant interaction effects.\n If there are no interactions that are significantly different from zero, we can drop the interaction terms and fit the main effects model to see which of those effects are significant.\n If interaction effects are significant (important in predicting the behavior of the response) then we will interpret the effects of the model in terms of the interaction.\n \n<!-- NOTE: not sure if correction for multiple comparisons is outside the scope here; I would in general not recommend to students that they test all possible interactions unless they had a theoretical reason to, or unless they were doinging something exploratory and then would collect new data to test any interaction found. -->",
"_____no_output_____"
],
[
"## Feature Selection\n\nSuppose we run a full model for the four variables in our example and none of the interaction terms are significant.\n We then run a main effects model and we get parameter estimates as shown in the table below.\n \n| Coefficients | Estimate | Std. Error | p-value |\n|--------------|----------|------------|---------|\n| Intercept | 36.69 | 5.97 | 1.44e-6 |\n| MA | 0.36 | 1.00 | 0.7197 |\n| MW | 3.02 | 0.85 | 0.0014 |\n| MH | -0.02 | 0.01 | 0.1792 |\n| GP | -0.81 | 0.66 | 0.2311 |",
"_____no_output_____"
],
[
"Recall that the p-value is the probability of getting the estimate that we got from the data or something more extreme (further from zero).\n Small p-values (typically less than 0.05) indicate the associated parameter is different from zero, implying that the associated covariate is important to predict response.\n In our birth weight example, we see the p-value for the intercept is very low $1.44 \\times 10^{-6}$ and so the intercept is not at zero.\n The mother's weight (MW) has p-value 0.0014 which is very small, indicating that mother's weight has an important (significant) impact on her baby's birth weight.\n The p-value from all other Wald tests are large: 0.7197, 0.1792, and 0.2311, so we know none of these variables are important when predicting the birth weight.\n \n We can modify the coefficient of determination to account for having more than one predictor in the model, called the *adjusted R-square* .\n R-square has the property that as you add more terms, it will always increase.\n The adjustment for more terms takes this into consideration.\n For this data the adjusted R-square is 0.8208, indicating a reasonably good fit.\n\n Different combinations of the variables included in the model may give better or worse fits to the data.\n We can use several methods to select the \"best\" model for the data.\n One example is called *forward selection* .\n This method begins with an empty model (intercept only) and adds variables to the model one by one until the full main effects model is reached.\n In each forward step, you add the one variable that gives the best improvement to the fit.\n There is also *backward selection* where you start with the full model and then drop the least important variables one at a time until you are left with the intercept only.\n If there are not too many features, you can also look at all possible models.\n Typically these models are compared using the AIC (Akaike information criterion) which measures the relative quality of models.\n Given a set of models, the preferred model is the one with the minimum AIC value.\n \nPreviously we talked about splitting the data into training and test sets.\nIn statistics, this is not common, and the models are trained with all the data.\nThis is because statistics is generally more interested in the effect of a particular variable *across the entire dataset* than it is about using that variable to make a prediction about a particular datapoint.\nBecause of this, we typically have concerns about how well linear regression will work with new data, i.e. will it have the same $r^2$ for new data or a lower $r^2$?\nBoth forward and backward selection potentially enhance this problem because they tune the model to the data even more closely by removing variables that aren't \"important.\"\nYou should always be very careful with such variable selection methods and their implications for model generalization.\n\n<!-- NOTE: sklearn does not seem to support forward/backward https://datascience.stackexchange.com/questions/937/does-scikit-learn-have-forward-selection-stepwise-regression-algorithm ; what it does support is sufficient different/complicated that it doesn't seem useful to try to introduce it now ; this is an example where the give text would fit R perfectly but be dififcult for python -->",
"_____no_output_____"
],
[
"# Categorical Variables\n\nIn the birth weight example, there is also information available about the mother's activity level during her pregnancy.\n Values for this categorical variable are: low, moderate, and high.\n How can we incorporate these into the model? \n Since they are not numeric, we have to create *dummy variables* that are numeric to use.\n A dummy variable represents the presence or absence of a level of the categorical variable by a 1 and the absence by a zero.\n Fortunately, most software packages that do multiple regression do this for us automatically.\n \nOften, one of the levels of the categorical variable is considered the \"baseline\" and the contributions to the response of the other levels are in relation to baseline.\nLet's look at the data again. \n In the table below, the mother's age is dropped and the mother's activity level (MAL) is included.\n \n | Coefficients | Estimate | Std. Error | p-value |\n|--------------|----------|------------|----------|\n| Intercept | 31.35 | 4.65 | 3.68e-07 |\n| MW | 2.74 | 0.82 | 0.0026 |\n| MH | -0.04 | 0.02 | 0.0420 |\n| GP | 1.11 | 1.03 | 0.2917 |\n| MALmoderate | -2.97 | 1.44 | 0.049 |\n| MALhigh | -1.45 | 2.69 | 0.5946 |\n ",
"_____no_output_____"
],
[
"For the categorical variable MAL, MAL low has been chosen as the base line.\n The other two levels have parameter estimates that we can use to determine which are significantly different from the low level.\n This makes sense because all mothers will at least have low activity level, and the two additional dummy variables `MALhigh` and `MALmoderate` just get added on top of that.\n \n We can see that MAL moderate level is significantly different from the low level (p-value < 0.05).\n The parameter estimate for the moderate level of MAL is -2.97.\n This can be interpreted as: being in the moderately active group decreases birth weight by 2.97 units compared to babies in the low activity group.\n We also see that for babies with mothers in the high activity group, their birth weights are not different from birth weights in the low group, since the p-value is not low (0.5946 > 0.05) and so this term does not have a significant effect on the response (birth weight).\n \n This example highlights a phenomenon that often happens in multiple regression.\n When we drop the variable MA (mother's age) from the model and the categorical variable is included, both MW (mother's weight) and MH (mother's height) are both important predictors of birth weight (p-values 0.0026 and 0.0420 respectively).\n This is why it is important to perform some systematic model selection (forward or backward or all possible) to find an optimum set of features.\n \n# Diagnostics\n\nAs in the simple linear regression case, we can use the residuals to check the fit of the model.\n Recall that the residuals are the observed response minus the predicted response.\n \n - Plot the residuals against each independent variable to check whether higher order terms are needed \n - Plot the residuals versus the predicted values to check whether the variance is constant \n - Plot a qq-plot of the residuals to check for normality \n ",
"_____no_output_____"
],
[
"# Multicollinearity\n\nMulticollinearity occurs when two variables or features are linearly related, i.e.\n they have very strong correlation between them (close to -1 or 1).\n Practically this means that some of the independent variables are measuring the same thing and are not needed.\n In the extreme case (close to -1 or 1), the estimates of the parameters of the model cannot be obtained.\n This is because there is no unique solution for OLS when multicolinearity occurs.\n As a result, multicollinearity makes conclusions about which features should be used questionable.",
"_____no_output_____"
],
[
"## Example: Trees\n\nLet's take a look at a dataset we've seen before `trees` but with an additional tree type added `plum`:\n\n| Variable | Type | Description |\n|----------|-------|:-------------------------------------------------------|\n| Girth | Ratio | Tree diameter (rather than girth, actually) in inches |\n| Height | Ratio | Height in ft |\n| Volume | Ratio | Volume of timber in cubic ft |\n| Type | Nominal | The type of tree, cherry or plum |\n\nMuch of what we'll do is the same as with simple linear regression, except:\n\n- Converting categorical variables into dummy variables\n- Different multiple predictors\n- Interactions\n\n### Load data\n\nStart with the imports:\n\n- `import pandas as pd`",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"Vd-20qkN(WN5nJAUj;?4\">pd</variable></variables><block type=\"importAs\" id=\"ji{aK+A5l`eBa?Q1/|Pf\" x=\"128\" y=\"319\"><field name=\"libraryName\">pandas</field><field name=\"libraryAlias\" id=\"Vd-20qkN(WN5nJAUj;?4\">pd</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Load the dataframe:\n \n- Create variable `dataframe`\n- Set it to `with pd do read_csv using \"datasets/trees2.csv\"`\n- `dataframe` (to display)",
"_____no_output_____"
]
],
[
[
"dataframe = pd.read_csv('datasets/trees2.csv')\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable><variable id=\"Vd-20qkN(WN5nJAUj;?4\">pd</variable></variables><block type=\"variables_set\" id=\"9aUm-oG6/!Z54ivA^qkm\" x=\"2\" y=\"351\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"g.yE$oK%3]$!k91|6U|I\"><field name=\"VAR\" id=\"Vd-20qkN(WN5nJAUj;?4\">pd</field><field name=\"MEMBER\">read_csv</field><data>pd:read_csv</data><value name=\"INPUT\"><block type=\"text\" id=\"fBBU[Z}QCipaz#y=F$!p\"><field name=\"TEXT\">datasets/trees2.csv</field></block></value></block></value></block><block type=\"variables_get\" id=\"pVVu/utZDzpFy(h9Q-+Z\" x=\"6\" y=\"425\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"We know that later on, we'd like to use `Type` as a predictor, so we need to convert it into a dummy variable.\n\nHowever, we'd also like to keep `Type` as a column for our plot labels. \nThere are several ways to do this, but probably the easiest is to save `Type` and then put it back in the dataframe.\n\nIt will make sense as we go:\n\n- Create variable `treeType`\n- Set it to `dataframe[` list containing `\"Type\"` `]` (use {dictVariable}[] from LISTS)\n- `treeType` (to display)",
"_____no_output_____"
]
],
[
[
"treeType = dataframe[['Type']]\n\ntreeType\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"hr*VLs~Y+rz.qsB5%AkC\">treeType</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"n?M6{W!2xggQx@X7_00@\" x=\"0\" y=\"391\"><field name=\"VAR\" id=\"hr*VLs~Y+rz.qsB5%AkC\">treeType</field><value name=\"VALUE\"><block type=\"indexer\" id=\"3_O9X7-U(%IcMj/dcLIo\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"?V*^3XN6]-U+o1C:Vzq$\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"^a?w!r[mo5(HVwiC0q=4\"><field name=\"TEXT\">Type</field></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"Lvbr[Vv2??Mx*R}-s{,0\" x=\"8\" y=\"470\"><field name=\"VAR\" id=\"hr*VLs~Y+rz.qsB5%AkC\">treeType</field></block></xml>",
"_____no_output_____"
]
],
[
[
"To do the dummy conversion:\n \n- Set `dataframe` to `with pd do get_dummies using` a list containing\n - `dataframe`\n - freestyle `drop_first=True`\n- `dataframe` (to display)",
"_____no_output_____"
]
],
[
[
"dataframe = pd.get_dummies(dataframe, drop_first=True)\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable><variable id=\"Vd-20qkN(WN5nJAUj;?4\">pd</variable></variables><block type=\"variables_set\" id=\"f~Vi_+$-EAjHP]f_eV;K\" x=\"55\" y=\"193\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"|n$+[JUtgfsvt4?c:yr_\"><field name=\"VAR\" id=\"Vd-20qkN(WN5nJAUj;?4\">pd</field><field name=\"MEMBER\">get_dummies</field><data>pd:get_dummies</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"?P;X;R^dn$yjWHW=i7u2\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"variables_get\" id=\"Bbsj2h*vF?=ou`pb%n59\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></value><value name=\"ADD1\"><block type=\"dummyOutputCodeBlock\" id=\"bMU2}K@krqBgj]d/*N%r\"><field name=\"CODE\">drop_first=True</field></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"2cWY4Drg[bFmM~E#v`]o\" x=\"73\" y=\"293\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Notice that `cherry` is now the base level, so `Type_plum` is in `0` where `cherry` was before and `1` where `plum` was before.\n\nTo put `Type` back in, use `assign`:\n\n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `Type=treeType`\n- `dataframe` (to display)",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(Type=treeType)\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"asM(PJ)BfN(o4N+9wUt$\" x=\"-18\" y=\"225\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\";29VMd-(]?GAtxBc4RYY\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"~HSVpyu|XuF_=bZz[e./\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"dummyOutputCodeBlock\" id=\"0yKT_^W!N#JL!5%=T_+J\"><field name=\"CODE\">Type=treeType</field></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"U)2!3yg#Q,f=4ImV=Pl.\" x=\"-3\" y=\"288\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"This is nice - we have our dummy code for modeling but also the nice original lable in `Type` so we don't get confused.",
"_____no_output_____"
],
[
"### Explore data\n\nLet's start with some *overall* descriptive statistics:\n\n- `with dataframe do describe using`",
"_____no_output_____"
]
],
[
[
"dataframe.describe()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"varDoMethod\" id=\"?LJ($9e@x-B.Y,`==|to\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">describe</field><data>dataframe:describe</data></block></xml>",
"_____no_output_____"
]
],
[
[
"This is nice, but we suspect there might be some differences between cherry trees and plum trees that this doesn't show.\n\nWe can `describe` each group as well:\n\n- Create variable `groups`\n- Set it to `with dataframe do groupby using \"Type\"`",
"_____no_output_____"
]
],
[
[
"groups = dataframe.groupby('Type')\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"0zfUO$}u$G4I(G1e~N#r\">groups</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"kr80`.2l6nJi|eO*fce[\" x=\"44\" y=\"230\"><field name=\"VAR\" id=\"0zfUO$}u$G4I(G1e~N#r\">groups</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"x-nB@sYwAL|7o-0;9DUU\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">groupby</field><data>dataframe:groupby</data><value name=\"INPUT\"><block type=\"text\" id=\"Lby0o8dWqy8ta:56K|bn\"><field name=\"TEXT\">Type</field></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"Now `describe` groups:\n\n- `with groups do describe using`",
"_____no_output_____"
]
],
[
[
"groups.describe()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"0zfUO$}u$G4I(G1e~N#r\">groups</variable></variables><block type=\"varDoMethod\" id=\"]q4DcYnB3HUf/GehIu+T\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"0zfUO$}u$G4I(G1e~N#r\">groups</field><field name=\"MEMBER\">describe</field><data>groups:describe</data></block></xml>",
"_____no_output_____"
]
],
[
[
"Notice this results table has been rotated compared to the normal `describe`.\nThe rows are our two tree types, and the columns are **stacked columns** where the header (e.g. `Girth`) applies to everything below it and to the left (it is not centered).\n\nFrom this we see that the `Girth` is about the same across trees, the `Height` is 13ft different on average, and `Volume` is 5ft different on average.",
"_____no_output_____"
],
[
"Let's do a plot.\nWe can sneak all the variables into a 2D scatterplot with some clever annotations.\n\nFirst the import:\n\n- `import plotly.express as px`",
"_____no_output_____"
]
],
[
[
"import plotly.express as px\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"k#w4n=KvP~*sLy*OW|Jl\">px</variable></variables><block type=\"importAs\" id=\"kPF|afHe60B:rsCmJI2O\" x=\"128\" y=\"178\"><field name=\"libraryName\">plotly.express</field><field name=\"libraryAlias\" id=\"k#w4n=KvP~*sLy*OW|Jl\">px</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Create the scatterplot:\n\n- Create variable `fig`\n- Set it to `with px do scatter using` a list containing\n - `dataframe`\n - freestyle `x=\"Height\"`\n - freestyle `y=\"Volume\"`\n - freestyle `color=\"Type\"`\n - freestyle `size=\"Girth\"`",
"_____no_output_____"
]
],
[
[
"fig = px.scatter(dataframe, x=\"Height\", y=\"Volume\", color=\"Type\", size=\"Girth\")\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable><variable id=\"k#w4n=KvP~*sLy*OW|Jl\">px</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"/1x?=CLW;i70@$T5LPN/\" x=\"48\" y=\"337\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"O07?sQIdula@ap]/9Ogq\"><field name=\"VAR\" id=\"k#w4n=KvP~*sLy*OW|Jl\">px</field><field name=\"MEMBER\">scatter</field><data>px:scatter</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"~tHtb;Nbw/OP6#7pB9wX\"><mutation items=\"5\"></mutation><value name=\"ADD0\"><block type=\"variables_get\" id=\"UE)!btph,4mdjsf[F37|\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></value><value name=\"ADD1\"><block type=\"dummyOutputCodeBlock\" id=\"~L)yq!Jze#v9R[^p;2{O\"><field name=\"CODE\">x=\"Height\"</field></block></value><value name=\"ADD2\"><block type=\"dummyOutputCodeBlock\" id=\"yu5^$n1zXY3)#RcRx:~;\"><field name=\"CODE\">y=\"Volume\"</field></block></value><value name=\"ADD3\"><block type=\"dummyOutputCodeBlock\" id=\"aCZ,k0LzStF1D(+SB2%A\"><field name=\"CODE\">color=\"Type\"</field></block></value><value name=\"ADD4\"><block type=\"dummyOutputCodeBlock\" id=\"4yv:pfYUrA=V0bO}PLcX\"><field name=\"CODE\">size=\"Girth\"</field></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"And show the figure:\n\n- `with fig do show using`",
"_____no_output_____"
]
],
[
[
"fig.show()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable></variables><block type=\"varDoMethod\" id=\"SV]QMDs*p(4s=2tPrl4a\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><field name=\"MEMBER\">show</field><data>fig:show</data></block></xml>",
"_____no_output_____"
]
],
[
[
"### Modeling 1\n\nLast time we looked at `trees`, we used `Height` to predict `Volume`.\nWith multiple linear regression, we can use more that one variable.\nLet's start with using `Girth` and `Height` to predict `Volume`.\n\nBut first, the imports:\n\n- `import sklearn.linear_model as sklearn`\n- `import numpy as np`",
"_____no_output_____"
]
],
[
[
"import sklearn.linear_model as linear_model\nimport numpy as np\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"!+Hi;Yx;ZB!EQYU8ItpO\">linear_model</variable><variable id=\"YynR+H75hTgW`vKfMxOx\">np</variable></variables><block type=\"importAs\" id=\"m;0Uju49an!8G3YKn4cP\" x=\"93\" y=\"288\"><field name=\"libraryName\">sklearn.linear_model</field><field name=\"libraryAlias\" id=\"!+Hi;Yx;ZB!EQYU8ItpO\">linear_model</field><next><block type=\"importAs\" id=\"^iL#`T{6G3.Uxfj*r`Cv\"><field name=\"libraryName\">numpy</field><field name=\"libraryAlias\" id=\"YynR+H75hTgW`vKfMxOx\">np</field></block></next></block></xml>",
"_____no_output_____"
]
],
[
[
"Create the model:\n\n- Create variable `lm` (for linear model)\n- Set it to `with sklearn create LinearRegression using`",
"_____no_output_____"
]
],
[
[
"lm = linear_model.LinearRegression()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable><variable id=\"!+Hi;Yx;ZB!EQYU8ItpO\">linear_model</variable></variables><block type=\"variables_set\" id=\"!H`J#y,K:4I.h#,HPeK{\" x=\"127\" y=\"346\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><value name=\"VALUE\"><block type=\"varCreateObject\" id=\"h:O3ZfE(*c[Hz3sF=$Mm\"><field name=\"VAR\" id=\"!+Hi;Yx;ZB!EQYU8ItpO\">linear_model</field><field name=\"MEMBER\">LinearRegression</field><data>linear_model:LinearRegression</data></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"Train the model using all the data:\n\n- `with lm do fit using` a list containing\n - `dataframe [ ]` (use {dictVariable} from LISTS) containing a list containing\n - `\"Girth\"` (this is $X_1$)\n - `\"Height\"` (this is $X_2$)\n - `dataframe [ ]` containing a list containing\n - `\"Volume\"` (this is $Y$)",
"_____no_output_____"
]
],
[
[
"lm.fit(dataframe[['Girth', 'Height']], dataframe[['Volume']])\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"varDoMethod\" id=\"W6(0}aPsJ;vA9C3A!:G@\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">fit</field><data>lm:</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"|pmNlB*$t`wI~M5-Nu5]\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\".|%fa!U;=I@;!6$?B7Id\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"o5szXy4*HmKGA;-.~H?H\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"{*5MFGJL4(x-JLsuD9qv\"><field name=\"TEXT\">Girth</field></block></value><value name=\"ADD1\"><block type=\"text\" id=\"#cqoT/|u(kuI^=VOHoB@\"><field name=\"TEXT\">Height</field></block></value></block></value></block></value><value name=\"ADD1\"><block type=\"indexer\" id=\"o.R`*;zvaP%^K2/_t`6*\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"[WAkSKWMcU+j3zS)uzVG\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"w0w/T-Wh/df/waYll,rv\"><field name=\"TEXT\">Volume</field></block></value></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"Go ahead and get the $r^2$ ; you can just copy the blocks from the last cell and change `fit` to `score`.",
"_____no_output_____"
]
],
[
[
"lm.score(dataframe[['Girth', 'Height']], dataframe[['Volume']])\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"varDoMethod\" id=\"W6(0}aPsJ;vA9C3A!:G@\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">score</field><data>lm:score</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"|pmNlB*$t`wI~M5-Nu5]\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\".|%fa!U;=I@;!6$?B7Id\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"o5szXy4*HmKGA;-.~H?H\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"{*5MFGJL4(x-JLsuD9qv\"><field name=\"TEXT\">Girth</field></block></value><value name=\"ADD1\"><block type=\"text\" id=\"#cqoT/|u(kuI^=VOHoB@\"><field name=\"TEXT\">Height</field></block></value></block></value></block></value><value name=\"ADD1\"><block type=\"indexer\" id=\"o.R`*;zvaP%^K2/_t`6*\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"[WAkSKWMcU+j3zS)uzVG\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"w0w/T-Wh/df/waYll,rv\"><field name=\"TEXT\">Volume</field></block></value></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"Based on that $r^2$, we'd think we have a really good model, right?",
"_____no_output_____"
],
[
"### Diagnostics 1\n\nTo check the model, the first thing we need to do is get the predictions from the model. \nOnce we have the predictions, we can `assign` them to a column in the `dataframe`:\n\n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `predictions1=` *followed by*\n - `with lm do predict using` a list containing\n - `dataframe [ ]` containing a list containing\n - `\"Girth\"`\n - `\"Height\"`\n- `dataframe` (to display)\n\n**This makes a very long block, so you probably want to create all the blocks and then connect them in reverse order.**",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(predictions1= (lm.predict(dataframe[['Girth', 'Height']])))\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable></variables><block type=\"variables_set\" id=\"rn0LHF%t,0JD5-!Ov?-U\" x=\"-21\" y=\"228\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"ou+aFod:USt{s9i+emN}\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"Llv.8Hqls5S/.2ZpnF=D\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"valueOutputCodeBlock\" id=\"UFqs+Ox{QF6j*LkUvNvu\"><field name=\"CODE\">predictions1=</field><value name=\"INPUT\"><block type=\"varDoMethod\" id=\"(2l5d}m6K9#ZC6_^/JXe\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">predict</field><data>lm:predict</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"bm@2N5t#Fx`yDxjg~:Nw\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\"WQaaM]1BPY=1wxWQsv:$\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"Asy|RX,d{QfgBQmjI{@@\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"+5PTgD[9U~pl`q#YlA^!\"><field name=\"TEXT\">Girth</field></block></value><value name=\"ADD1\"><block type=\"text\" id=\"{vo.7:W51MOg?Ef(L-Rn\"><field name=\"TEXT\">Height</field></block></value></block></value></block></value></block></value></block></value></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"+]Ia}Q|FmU.bu*zJ1qHs\" x=\"-13\" y=\"339\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Similarly, we want to add the residuals to `dataframe`:\n \n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `residuals1=` *followed by* `dataframe [ \"Volume\" ] - dataframe [ \"predictions1\" ]`\n\n- `dataframe` (to display)\n\n**Hint: use {dictVariable}[] and the + block from MATH**",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(residuals1= (dataframe['Volume'] - dataframe['predictions1']))\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"rn0LHF%t,0JD5-!Ov?-U\" x=\"-28\" y=\"224\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"(2l5d}m6K9#ZC6_^/JXe\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"bm@2N5t#Fx`yDxjg~:Nw\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"valueOutputCodeBlock\" id=\"^$QWpb1hPzxWt/?~mZBX\"><field name=\"CODE\">residuals1=</field><value name=\"INPUT\"><block type=\"math_arithmetic\" id=\"=szmSC[EoihfyX_5cH6v\"><field name=\"OP\">MINUS</field><value name=\"A\"><shadow type=\"math_number\" id=\"E[2Ss)z+r1pVe~OSDMne\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"WQaaM]1BPY=1wxWQsv:$\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"+5PTgD[9U~pl`q#YlA^!\"><field name=\"TEXT\">Volume</field></block></value></block></value><value name=\"B\"><shadow type=\"math_number\" id=\"Z%,Q(P8VED{wb;Q#^bM4\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"b.`x=!iTEC%|-VGV[Hu5\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"g`tk1*Psq~biS1z%3c`q\"><field name=\"TEXT\">predictions1</field></block></value></block></value></block></value></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"+]Ia}Q|FmU.bu*zJ1qHs\" x=\"-13\" y=\"339\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Now let's do some plots!\n\nLet's check linearity and equal variance:\n\n- Linearity means the residuals will be close to zero\n- Equal variance means residuals will be evenly away from zero\n\n- Set `fig` to `with px do scatter using` a list containing\n - `dataframe`\n - freestyle `x=\"predictions1\"`\n - freestyle `y=\"residuals1\"`",
"_____no_output_____"
]
],
[
[
"fig = px.scatter(dataframe, x=\"predictions1\", y=\"residuals1\")\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable><variable id=\"k#w4n=KvP~*sLy*OW|Jl\">px</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"/1x?=CLW;i70@$T5LPN/\" x=\"48\" y=\"337\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"O07?sQIdula@ap]/9Ogq\"><field name=\"VAR\" id=\"k#w4n=KvP~*sLy*OW|Jl\">px</field><field name=\"MEMBER\">scatter</field><data>px:scatter</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"~tHtb;Nbw/OP6#7pB9wX\"><mutation items=\"3\"></mutation><value name=\"ADD0\"><block type=\"variables_get\" id=\"UE)!btph,4mdjsf[F37|\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></value><value name=\"ADD1\"><block type=\"dummyOutputCodeBlock\" id=\"~L)yq!Jze#v9R[^p;2{O\"><field name=\"CODE\">x=\"predictions1\"</field></block></value><value name=\"ADD2\"><block type=\"dummyOutputCodeBlock\" id=\"yu5^$n1zXY3)#RcRx:~;\"><field name=\"CODE\">y=\"residuals1\"</field></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"And show it:\n\n- `with fig do show using`",
"_____no_output_____"
]
],
[
[
"fig.show()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable></variables><block type=\"varDoMethod\" id=\"SV]QMDs*p(4s=2tPrl4a\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><field name=\"MEMBER\">show</field><data>fig:show</data></block></xml>",
"_____no_output_____"
]
],
[
[
"We see something very, very wrong here: a \"U\" shape from left to right.\nThis means our residuals are positive for low predictions, go negative for mid predictions, and go positive again for high predictions.\nThe only way this can happen is if something is quadratic (squared) in the phenomenon we're trying to model.",
"_____no_output_____"
],
[
"### Modeling 2\n\nStep back for a moment and consider what we are trying to do.\nWe are trying to predict volume from other measurements of the tree.\nWhat is the formula for volume?\n\n$$V = \\pi r^2 h$$\n\nSince this is the mathematical definition, we don't expect any differences for `plum` vs. `cherry`.\n\nWhat are our variables?\n\n- `Volume`\n- `Girth` (diameter, which is twice $r$)\n- `Height`\n\nIn other words, we basically have everything in the formula.\nLet's create a new column that is closer to what we want, `Girth` * `Girth` * `Height`:\n\n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `GGH=` *followed by* `dataframe [ \"Girth\" ] * dataframe [ \"Girth\" ] * dataframe [ \"Height\" ]`\n\n- `dataframe` (to display)",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(GGH= (dataframe['Girth'] * (dataframe['Girth'] * dataframe['Height'])))\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"rn0LHF%t,0JD5-!Ov?-U\" x=\"-28\" y=\"224\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"(2l5d}m6K9#ZC6_^/JXe\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"bm@2N5t#Fx`yDxjg~:Nw\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"valueOutputCodeBlock\" id=\"^$QWpb1hPzxWt/?~mZBX\"><field name=\"CODE\">GGH=</field><value name=\"INPUT\"><block type=\"math_arithmetic\" id=\"5RK=q#[GZz]1)F{}r5DR\"><field name=\"OP\">MULTIPLY</field><value name=\"A\"><shadow type=\"math_number\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"Xh!r5Y0#k:n+aqBjuvad\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"|4#UlYaNe-aeV+s$,Wn]\"><field name=\"TEXT\">Girth</field></block></value></block></value><value name=\"B\"><shadow type=\"math_number\" id=\";S0XthTRZu#Q.w|qt88k\"><field name=\"NUM\">1</field></shadow><block type=\"math_arithmetic\" id=\"=szmSC[EoihfyX_5cH6v\"><field name=\"OP\">MULTIPLY</field><value name=\"A\"><shadow type=\"math_number\" id=\"E[2Ss)z+r1pVe~OSDMne\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"WQaaM]1BPY=1wxWQsv:$\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"+5PTgD[9U~pl`q#YlA^!\"><field name=\"TEXT\">Girth</field></block></value></block></value><value name=\"B\"><shadow type=\"math_number\" id=\"Z%,Q(P8VED{wb;Q#^bM4\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"b.`x=!iTEC%|-VGV[Hu5\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"g`tk1*Psq~biS1z%3c`q\"><field name=\"TEXT\">Height</field></block></value></block></value></block></value></block></value></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"+]Ia}Q|FmU.bu*zJ1qHs\" x=\"-13\" y=\"339\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"As you might have noticed, `GGH` is an interaction. \nOften when we have interactions, we include the variables that the interactions are made off (also known as **main effects**).\nHowever, in this case, that doesn't make sense because we know the interaction is close to the definition of `Volume`.\n\nSo let's fit a new model using just `GGH`, save it's predictions and residuals, and plot it's predicted vs. residual diagnostic plot.\n\nFirst, fit the model:\n\n- `with lm do fit using` a list containing\n - `dataframe [ ]` containing a list containing\n - `\"GGH\"`\n - `dataframe [ ]` containing a list containing\n - `\"Volume\"` ",
"_____no_output_____"
]
],
[
[
"lm.fit(dataframe[['GGH']], dataframe[['Volume']])\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"varDoMethod\" id=\"W6(0}aPsJ;vA9C3A!:G@\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">fit</field><data>lm:</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"|pmNlB*$t`wI~M5-Nu5]\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\".|%fa!U;=I@;!6$?B7Id\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"o5szXy4*HmKGA;-.~H?H\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"{*5MFGJL4(x-JLsuD9qv\"><field name=\"TEXT\">GGH</field></block></value></block></value></block></value><value name=\"ADD1\"><block type=\"indexer\" id=\"o.R`*;zvaP%^K2/_t`6*\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"[WAkSKWMcU+j3zS)uzVG\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"w0w/T-Wh/df/waYll,rv\"><field name=\"TEXT\">Volume</field></block></value></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"### Diagnostics 2\n\nSave the predictions:\n\n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `predictions2=` *followed by*\n - `with lm do predict using` a list containing\n - `dataframe [ ]` containing a list containing\n - `\"GGH\"`\n- `dataframe` (to display)",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(predictions2= (lm.predict(dataframe[['GGH']])))\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable></variables><block type=\"variables_set\" id=\"rn0LHF%t,0JD5-!Ov?-U\" x=\"-21\" y=\"228\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"ou+aFod:USt{s9i+emN}\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"Llv.8Hqls5S/.2ZpnF=D\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"valueOutputCodeBlock\" id=\"UFqs+Ox{QF6j*LkUvNvu\"><field name=\"CODE\">predictions2=</field><value name=\"INPUT\"><block type=\"varDoMethod\" id=\"(2l5d}m6K9#ZC6_^/JXe\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">predict</field><data>lm:predict</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"bm@2N5t#Fx`yDxjg~:Nw\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\"WQaaM]1BPY=1wxWQsv:$\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"rugUT!#.Lk(@nt!}4hC;\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"4nD6,I;gq.Y.D%v3$kFX\"><field name=\"TEXT\">GGH</field></block></value></block></value></block></value></block></value></block></value></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"+]Ia}Q|FmU.bu*zJ1qHs\" x=\"-13\" y=\"339\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"Save the residuals:\n \n- Set `dataframe` to `with dataframe do assign using` a list containing\n - freestyle `residuals2=` *followed by* `dataframe [ \"Volume\" ] - dataframe [ \"predictions2\" ]`\n\n- `dataframe` (to display)\n",
"_____no_output_____"
]
],
[
[
"dataframe = dataframe.assign(residuals2= (dataframe['Volume'] - dataframe['predictions2']))\n\ndataframe\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"rn0LHF%t,0JD5-!Ov?-U\" x=\"-28\" y=\"224\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"(2l5d}m6K9#ZC6_^/JXe\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><field name=\"MEMBER\">assign</field><data>dataframe:assign</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"bm@2N5t#Fx`yDxjg~:Nw\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"valueOutputCodeBlock\" id=\"^$QWpb1hPzxWt/?~mZBX\"><field name=\"CODE\">residuals2=</field><value name=\"INPUT\"><block type=\"math_arithmetic\" id=\"=szmSC[EoihfyX_5cH6v\"><field name=\"OP\">MINUS</field><value name=\"A\"><shadow type=\"math_number\" id=\"E[2Ss)z+r1pVe~OSDMne\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"WQaaM]1BPY=1wxWQsv:$\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"+5PTgD[9U~pl`q#YlA^!\"><field name=\"TEXT\">Volume</field></block></value></block></value><value name=\"B\"><shadow type=\"math_number\" id=\"Z%,Q(P8VED{wb;Q#^bM4\"><field name=\"NUM\">1</field></shadow><block type=\"indexer\" id=\"b.`x=!iTEC%|-VGV[Hu5\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"text\" id=\"g`tk1*Psq~biS1z%3c`q\"><field name=\"TEXT\">predictions2</field></block></value></block></value></block></value></block></value></block></value></block></value></block><block type=\"variables_get\" id=\"+]Ia}Q|FmU.bu*zJ1qHs\" x=\"-13\" y=\"339\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></xml>",
"_____no_output_____"
]
],
[
[
"And now plot the predicted vs residuals to check linearity and equal variance:\n\n- Set `fig` to `with px do scatter using` a list containing\n - `dataframe`\n - freestyle `x=\"predictions2\"`\n - freestyle `y=\"residuals2\"`",
"_____no_output_____"
]
],
[
[
"fig = px.scatter(dataframe, x=\"predictions2\", y=\"residuals2\")\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable><variable id=\"k#w4n=KvP~*sLy*OW|Jl\">px</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"variables_set\" id=\"/1x?=CLW;i70@$T5LPN/\" x=\"48\" y=\"337\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><value name=\"VALUE\"><block type=\"varDoMethod\" id=\"O07?sQIdula@ap]/9Ogq\"><field name=\"VAR\" id=\"k#w4n=KvP~*sLy*OW|Jl\">px</field><field name=\"MEMBER\">scatter</field><data>px:scatter</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"~tHtb;Nbw/OP6#7pB9wX\"><mutation items=\"3\"></mutation><value name=\"ADD0\"><block type=\"variables_get\" id=\"UE)!btph,4mdjsf[F37|\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field></block></value><value name=\"ADD1\"><block type=\"dummyOutputCodeBlock\" id=\"~L)yq!Jze#v9R[^p;2{O\"><field name=\"CODE\">x=\"predictions2\"</field></block></value><value name=\"ADD2\"><block type=\"dummyOutputCodeBlock\" id=\"yu5^$n1zXY3)#RcRx:~;\"><field name=\"CODE\">y=\"residuals2\"</field></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"And show it:\n\n- `with fig do show using`",
"_____no_output_____"
]
],
[
[
"fig.show()\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</variable></variables><block type=\"varDoMethod\" id=\"SV]QMDs*p(4s=2tPrl4a\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"w|!1_/S4wRKF4S1`6Xg+\">fig</field><field name=\"MEMBER\">show</field><data>fig:show</data></block></xml>",
"_____no_output_____"
]
],
[
[
"This is a pretty good plot.\nMost of the residuals are close to zero, and what residuals aren't are fairly evenly spread.\nWe want to see an evenly spaced band above and below 0 as we scan from left to right, and we do.\n\nWith this new model, calculate $r^2$:",
"_____no_output_____"
]
],
[
[
"lm.score(dataframe[['GGH']], dataframe[['Volume']])\n\n#<xml xmlns=\"https://developers.google.com/blockly/xml\"><variables><variable id=\"F]q147x/*m|PMfPQU-lZ\">lm</variable><variable id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</variable></variables><block type=\"varDoMethod\" id=\"W6(0}aPsJ;vA9C3A!:G@\" x=\"8\" y=\"188\"><field name=\"VAR\" id=\"F]q147x/*m|PMfPQU-lZ\">lm</field><field name=\"MEMBER\">score</field><data>lm:score</data><value name=\"INPUT\"><block type=\"lists_create_with\" id=\"|pmNlB*$t`wI~M5-Nu5]\"><mutation items=\"2\"></mutation><value name=\"ADD0\"><block type=\"indexer\" id=\".|%fa!U;=I@;!6$?B7Id\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"o5szXy4*HmKGA;-.~H?H\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"{*5MFGJL4(x-JLsuD9qv\"><field name=\"TEXT\">GGH</field></block></value></block></value></block></value><value name=\"ADD1\"><block type=\"indexer\" id=\"o.R`*;zvaP%^K2/_t`6*\"><field name=\"VAR\" id=\"B5p-Xul6IZ.0%nd96oa%\">dataframe</field><value name=\"INDEX\"><block type=\"lists_create_with\" id=\"[WAkSKWMcU+j3zS)uzVG\"><mutation items=\"1\"></mutation><value name=\"ADD0\"><block type=\"text\" id=\"w0w/T-Wh/df/waYll,rv\"><field name=\"TEXT\">Volume</field></block></value></block></value></block></value></block></value></block></xml>",
"_____no_output_____"
]
],
[
[
"We went from .956 to .989 by putting the right variables in the interaction.\n\n## Submit your work\n\nWhen you have finished the notebook, please download it, log in to [OKpy](https://okpy.org/) using \"Student Login\", and submit it there.\n\nThen let your instructor know on Slack.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d005a700f846c72effe6df946baa776cd5849336
| 5,496 |
ipynb
|
Jupyter Notebook
|
06-Gradient-Descent/08-Debug-Gradient/08-Debug-Gradient.ipynb
|
mtianyan/Mtianyan-Play-with-Machine-Learning-Algorithms
|
445b5930564f85ba2bccc18ee51fa7f68ef34ddd
|
[
"Apache-2.0"
] | 7 |
2019-03-24T09:36:14.000Z
|
2021-04-17T06:28:15.000Z
|
06-Gradient-Descent/08-Debug-Gradient/08-Debug-Gradient.ipynb
|
mtianyan/Play_with_Machine_Learning
|
445b5930564f85ba2bccc18ee51fa7f68ef34ddd
|
[
"Apache-2.0"
] | null | null | null |
06-Gradient-Descent/08-Debug-Gradient/08-Debug-Gradient.ipynb
|
mtianyan/Play_with_Machine_Learning
|
445b5930564f85ba2bccc18ee51fa7f68ef34ddd
|
[
"Apache-2.0"
] | 4 |
2020-02-11T15:25:27.000Z
|
2021-04-17T06:28:17.000Z
| 21.302326 | 91 | 0.461972 |
[
[
[
"## 关于梯度的计算调试",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"np.random.seed(666)\nX = np.random.random(size=(1000, 10))\n\ntrue_theta = np.arange(1, 12, dtype=float)\nX_b = np.hstack([np.ones((len(X), 1)), X])\ny = X_b.dot(true_theta) + np.random.normal(size=1000)",
"_____no_output_____"
],
[
"true_theta",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"def J(theta, X_b, y):\n try:\n return np.sum((y - X_b.dot(theta))**2) / len(X_b)\n except:\n return float('inf')",
"_____no_output_____"
],
[
"def dJ_math(theta, X_b, y):\n return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)",
"_____no_output_____"
],
[
"def dJ_debug(theta, X_b, y, epsilon=0.01):\n res = np.empty(len(theta))\n for i in range(len(theta)):\n theta_1 = theta.copy()\n theta_1[i] += epsilon\n theta_2 = theta.copy()\n theta_2[i] -= epsilon\n res[i] = (J(theta_1, X_b, y) - J(theta_2, X_b, y)) / (2 * epsilon)\n return res",
"_____no_output_____"
],
[
"def gradient_descent(dJ, X_b, y, initial_theta, eta, n_iters = 1e4, epsilon=1e-8):\n \n theta = initial_theta\n cur_iter = 0\n\n while cur_iter < n_iters:\n gradient = dJ(theta, X_b, y)\n last_theta = theta\n theta = theta - eta * gradient\n if(abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):\n break\n \n cur_iter += 1\n\n return theta",
"_____no_output_____"
],
[
"X_b = np.hstack([np.ones((len(X), 1)), X])\ninitial_theta = np.zeros(X_b.shape[1])\neta = 0.01\n\n%time theta = gradient_descent(dJ_debug, X_b, y, initial_theta, eta)\ntheta",
"CPU times: user 13.8 s, sys: 283 ms, total: 14.1 s\nWall time: 7.6 s\n"
],
[
"%time theta = gradient_descent(dJ_math, X_b, y, initial_theta, eta)\ntheta",
"CPU times: user 1.57 s, sys: 30.6 ms, total: 1.6 s\nWall time: 856 ms\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d005ad7d7dbbba3023d9ca060dc703d300154ef6
| 3,828 |
ipynb
|
Jupyter Notebook
|
inauguralproject/inauguralproject.ipynb
|
henrikkyndal/projects-2020-slangerne
|
7d031b9c505957ba3cb40bc0dec743f1c0c07115
|
[
"MIT"
] | 1 |
2020-03-11T13:51:30.000Z
|
2020-03-11T13:51:30.000Z
|
inauguralproject/inauguralproject.ipynb
|
henrikkyndal/projects-2020-slangerne
|
7d031b9c505957ba3cb40bc0dec743f1c0c07115
|
[
"MIT"
] | 3 |
2020-04-14T14:00:38.000Z
|
2020-05-08T11:15:58.000Z
|
inauguralproject/inauguralproject.ipynb
|
NumEconCopenhagen/projects-2020-needagroup
|
f7acdebcefacf9dd7c54b996f884a321c331fa5f
|
[
"MIT"
] | 1 |
2020-05-08T07:18:58.000Z
|
2020-05-08T07:18:58.000Z
| 18.056604 | 170 | 0.507315 |
[
[
[
"# Inaugural Project",
"_____no_output_____"
],
[
"> **Note the following:** \n> 1. This is an example of how to structure your **inaugural project**.\n> 1. Remember the general advice on structuring and commenting your code from [lecture 5](https://numeconcopenhagen.netlify.com/lectures/Workflow_and_debugging).\n> 1. Remember this [guide](https://www.markdownguide.org/basic-syntax/) on markdown and (a bit of) latex.\n> 1. Turn on automatic numbering by clicking on the small icon on top of the table of contents in the left sidebar.\n> 1. The `inauguralproject.py` file includes a function which can be used multiple times in this notebook.",
"_____no_output_____"
],
[
"Imports and set magics:",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# autoreload modules when code is run\n%load_ext autoreload\n%autoreload 2\n\n# local modules\nimport inauguralproject",
"_____no_output_____"
]
],
[
[
"# Question 1",
"_____no_output_____"
],
[
"BRIEFLY EXPLAIN HOW YOU SOLVE THE MODEL.",
"_____no_output_____"
]
],
[
[
"# code for solving the model (remember documentation and comments)\n\na = np.array([1,2,3])\nb = inauguralproject.square(a)\nprint(b)",
"[1 4 9]\n"
]
],
[
[
"# Question 2",
"_____no_output_____"
],
[
"ADD ANSWER.",
"_____no_output_____"
]
],
[
[
"# code",
"_____no_output_____"
]
],
[
[
"# Question 3",
"_____no_output_____"
],
[
"ADD ANSWER.",
"_____no_output_____"
]
],
[
[
"# code",
"_____no_output_____"
]
],
[
[
"# Question 4",
"_____no_output_____"
],
[
"ADD ANSWER.",
"_____no_output_____"
]
],
[
[
"# code",
"_____no_output_____"
]
],
[
[
"# Question 5",
"_____no_output_____"
],
[
"ADD ANSWER.",
"_____no_output_____"
]
],
[
[
"# code",
"_____no_output_____"
]
],
[
[
"# Conclusion",
"_____no_output_____"
],
[
"ADD CONCISE CONLUSION.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d005ae1bbf1201cd5d9f22011e9275a8121cbe32
| 215,774 |
ipynb
|
Jupyter Notebook
|
Intro_to_GANs_Exercises.ipynb
|
agoila/gan_mnist
|
70340bf0ec4ac3a879b6961360b493ad7d9fc17c
|
[
"Apache-2.0"
] | null | null | null |
Intro_to_GANs_Exercises.ipynb
|
agoila/gan_mnist
|
70340bf0ec4ac3a879b6961360b493ad7d9fc17c
|
[
"Apache-2.0"
] | null | null | null |
Intro_to_GANs_Exercises.ipynb
|
agoila/gan_mnist
|
70340bf0ec4ac3a879b6961360b493ad7d9fc17c
|
[
"Apache-2.0"
] | null | null | null | 274.521628 | 89,596 | 0.896498 |
[
[
[
"# Generative Adversarial Network\n\nIn this notebook, we'll be building a generative adversarial network (GAN) trained on the MNIST dataset. From this, we'll be able to generate new handwritten digits!\n\nGANs were [first reported on](https://arxiv.org/abs/1406.2661) in 2014 from Ian Goodfellow and others in Yoshua Bengio's lab. Since then, GANs have exploded in popularity. Here are a few examples to check out:\n\n* [Pix2Pix](https://affinelayer.com/pixsrv/) \n* [CycleGAN](https://github.com/junyanz/CycleGAN)\n* [A whole list](https://github.com/wiseodd/generative-models)\n\nThe idea behind GANs is that you have two networks, a generator $G$ and a discriminator $D$, competing against each other. The generator makes fake data to pass to the discriminator. The discriminator also sees real data and predicts if the data it's received is real or fake. The generator is trained to fool the discriminator, it wants to output data that looks _as close as possible_ to real data. And the discriminator is trained to figure out which data is real and which is fake. What ends up happening is that the generator learns to make data that is indistiguishable from real data to the discriminator.\n\n\n\nThe general structure of a GAN is shown in the diagram above, using MNIST images as data. The latent sample is a random vector the generator uses to contruct it's fake images. As the generator learns through training, it figures out how to map these random vectors to recognizable images that can fool the discriminator.\n\nThe output of the discriminator is a sigmoid function, where 0 indicates a fake image and 1 indicates an real image. If you're interested only in generating new images, you can throw out the discriminator after training. Now, let's see how we build this thing in TensorFlow.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport pickle as pkl\nimport numpy as np\nimport tensorflow as tf\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"from tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets('MNIST_data')",
"Extracting MNIST_data\\train-images-idx3-ubyte.gz\nExtracting MNIST_data\\train-labels-idx1-ubyte.gz\nExtracting MNIST_data\\t10k-images-idx3-ubyte.gz\nExtracting MNIST_data\\t10k-labels-idx1-ubyte.gz\n"
]
],
[
[
"## Model Inputs\n\nFirst we need to create the inputs for our graph. We need two inputs, one for the discriminator and one for the generator. Here we'll call the discriminator input `inputs_real` and the generator input `inputs_z`. We'll assign them the appropriate sizes for each of the networks.\n\n>**Exercise:** Finish the `model_inputs` function below. Create the placeholders for `inputs_real` and `inputs_z` using the input sizes `real_dim` and `z_dim` respectively.",
"_____no_output_____"
]
],
[
[
"def model_inputs(real_dim, z_dim):\n inputs_real = tf.placeholder(tf.float32, (None, real_dim), name=\"discriminator_inputs\")\n inputs_z = tf.placeholder(tf.float32, (None, z_dim), name=\"generator_inputs\")\n \n return inputs_real, inputs_z",
"_____no_output_____"
]
],
[
[
"## Generator network\n\n\n\nHere we'll build the generator network. To make this network a universal function approximator, we'll need at least one hidden layer. We should use a leaky ReLU to allow gradients to flow backwards through the layer unimpeded. A leaky ReLU is like a normal ReLU, except that there is a small non-zero output for negative input values.\n\n#### Variable Scope\nHere we need to use `tf.variable_scope` for two reasons. Firstly, we're going to make sure all the variable names start with `generator`. Similarly, we'll prepend `discriminator` to the discriminator variables. This will help out later when we're training the separate networks.\n\nWe could just use `tf.name_scope` to set the names, but we also want to reuse these networks with different inputs. For the generator, we're going to train it, but also _sample from it_ as we're training and after training. The discriminator will need to share variables between the fake and real input images. So, we can use the `reuse` keyword for `tf.variable_scope` to tell TensorFlow to reuse the variables instead of creating new ones if we build the graph again.\n\nTo use `tf.variable_scope`, you use a `with` statement:\n```python\nwith tf.variable_scope('scope_name', reuse=False):\n # code here\n```\n\nHere's more from [the TensorFlow documentation](https://www.tensorflow.org/programmers_guide/variable_scope#the_problem) to get another look at using `tf.variable_scope`.\n\n#### Leaky ReLU\nTensorFlow doesn't provide an operation for leaky ReLUs, so we'll need to make one . For this you can just take the outputs from a linear fully connected layer and pass them to `tf.maximum`. Typically, a parameter `alpha` sets the magnitude of the output for negative values. So, the output for negative input (`x`) values is `alpha*x`, and the output for positive `x` is `x`:\n$$\nf(x) = max(\\alpha * x, x)\n$$\n\n#### Tanh Output\nThe generator has been found to perform the best with $tanh$ for the generator output. This means that we'll have to rescale the MNIST images to be between -1 and 1, instead of 0 and 1.\n\n>**Exercise:** Implement the generator network in the function below. You'll need to return the tanh output. Make sure to wrap your code in a variable scope, with 'generator' as the scope name, and pass the `reuse` keyword argument from the function to `tf.variable_scope`.",
"_____no_output_____"
]
],
[
[
"def generator(z, out_dim, n_units=128, reuse=False, alpha=0.01):\n ''' Build the generator network.\n \n Arguments\n ---------\n z : Input tensor for the generator\n out_dim : Shape of the generator output\n n_units : Number of units in hidden layer\n reuse : Reuse the variables with tf.variable_scope\n alpha : leak parameter for leaky ReLU\n \n Returns\n -------\n out: \n '''\n with tf.variable_scope(\"generator\", reuse=reuse):\n # Hidden layer\n h1 = tf.layers.dense(z, n_units, activation=None)\n # Leaky ReLU\n h1 = tf.maximum(alpha * h1, h1)\n \n # Logits and tanh output\n logits = tf.layers.dense(h1, out_dim, activation=None)\n out = tf.tanh(logits)\n \n return out",
"_____no_output_____"
]
],
[
[
"## Discriminator\n\nThe discriminator network is almost exactly the same as the generator network, except that we're using a sigmoid output layer.\n\n>**Exercise:** Implement the discriminator network in the function below. Same as above, you'll need to return both the logits and the sigmoid output. Make sure to wrap your code in a variable scope, with 'discriminator' as the scope name, and pass the `reuse` keyword argument from the function arguments to `tf.variable_scope`.",
"_____no_output_____"
]
],
[
[
"def discriminator(x, n_units=128, reuse=False, alpha=0.01):\n ''' Build the discriminator network.\n \n Arguments\n ---------\n x : Input tensor for the discriminator\n n_units: Number of units in hidden layer\n reuse : Reuse the variables with tf.variable_scope\n alpha : leak parameter for leaky ReLU\n \n Returns\n -------\n out, logits: \n '''\n with tf.variable_scope(\"discriminator\", reuse=reuse):\n # Hidden layer\n h1 = tf.layers.dense(x, n_units, activation=None)\n # Leaky ReLU\n h1 = tf.maximum(alpha * h1, h1)\n \n logits = tf.layers.dense(h1, 1, activation=None)\n out = tf.sigmoid(logits)\n \n return out, logits",
"_____no_output_____"
]
],
[
[
"## Hyperparameters",
"_____no_output_____"
]
],
[
[
"# Size of input image to discriminator\ninput_size = 784 # 28x28 MNIST images flattened\n# Size of latent vector to generator\nz_size = 100\n# Sizes of hidden layers in generator and discriminator\ng_hidden_size = 128\nd_hidden_size = 128\n# Leak factor for leaky ReLU\nalpha = 0.01\n# Label smoothing \nsmooth = 0.1",
"_____no_output_____"
]
],
[
[
"## Build network\n\nNow we're building the network from the functions defined above.\n\nFirst is to get our inputs, `input_real, input_z` from `model_inputs` using the sizes of the input and z.\n\nThen, we'll create the generator, `generator(input_z, input_size)`. This builds the generator with the appropriate input and output sizes.\n\nThen the discriminators. We'll build two of them, one for real data and one for fake data. Since we want the weights to be the same for both real and fake data, we need to reuse the variables. For the fake data, we're getting it from the generator as `g_model`. So the real data discriminator is `discriminator(input_real)` while the fake discriminator is `discriminator(g_model, reuse=True)`.\n\n>**Exercise:** Build the network from the functions you defined earlier.",
"_____no_output_____"
]
],
[
[
"tf.reset_default_graph()\n# Create our input placeholders\ninput_real, input_z = model_inputs(input_size, z_size)\n\n# Generator network here\ng_model = generator(input_z, input_size, n_units=g_hidden_size, alpha=alpha)\n# g_model is the generator output\n\n# Disriminator network here\nd_model_real, d_logits_real = discriminator(input_real, n_units=d_hidden_size, alpha=alpha)\nd_model_fake, d_logits_fake = discriminator(g_model, n_units=d_hidden_size, reuse=True, alpha=alpha)",
"_____no_output_____"
]
],
[
[
"## Discriminator and Generator Losses\n\nNow we need to calculate the losses, which is a little tricky. For the discriminator, the total loss is the sum of the losses for real and fake images, `d_loss = d_loss_real + d_loss_fake`. The losses will by sigmoid cross-entropies, which we can get with `tf.nn.sigmoid_cross_entropy_with_logits`. We'll also wrap that in `tf.reduce_mean` to get the mean for all the images in the batch. So the losses will look something like \n\n```python\ntf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))\n```\n\nFor the real image logits, we'll use `d_logits_real` which we got from the discriminator in the cell above. For the labels, we want them to be all ones, since these are all real images. To help the discriminator generalize better, the labels are reduced a bit from 1.0 to 0.9, for example, using the parameter `smooth`. This is known as label smoothing, typically used with classifiers to improve performance. In TensorFlow, it looks something like `labels = tf.ones_like(tensor) * (1 - smooth)`\n\nThe discriminator loss for the fake data is similar. The logits are `d_logits_fake`, which we got from passing the generator output to the discriminator. These fake logits are used with labels of all zeros. Remember that we want the discriminator to output 1 for real images and 0 for fake images, so we need to set up the losses to reflect that.\n\nFinally, the generator losses are using `d_logits_fake`, the fake image logits. But, now the labels are all ones. The generator is trying to fool the discriminator, so it wants to discriminator to output ones for fake images.\n\n>**Exercise:** Calculate the losses for the discriminator and the generator. There are two discriminator losses, one for real images and one for fake images. For the real image loss, use the real logits and (smoothed) labels of ones. For the fake image loss, use the fake logits with labels of all zeros. The total discriminator loss is the sum of those two losses. Finally, the generator loss again uses the fake logits from the discriminator, but this time the labels are all ones because the generator wants to fool the discriminator.",
"_____no_output_____"
]
],
[
[
"# Calculate losses\nd_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, \\\n labels=tf.ones_like(d_logits_real) * (1 - smooth)))\n\nd_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, \\\n labels=tf.zeros_like(d_logits_real)))\n\nd_loss = d_loss_real + d_loss_fake\n\ng_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, \\\n labels=tf.ones_like(d_logits_fake)))",
"_____no_output_____"
]
],
[
[
"## Optimizers\n\nWe want to update the generator and discriminator variables separately. So we need to get the variables for each part and build optimizers for the two parts. To get all the trainable variables, we use `tf.trainable_variables()`. This creates a list of all the variables we've defined in our graph.\n\nFor the generator optimizer, we only want to generator variables. Our past selves were nice and used a variable scope to start all of our generator variable names with `generator`. So, we just need to iterate through the list from `tf.trainable_variables()` and keep variables that start with `generator`. Each variable object has an attribute `name` which holds the name of the variable as a string (`var.name == 'weights_0'` for instance). \n\nWe can do something similar with the discriminator. All the variables in the discriminator start with `discriminator`.\n\nThen, in the optimizer we pass the variable lists to the `var_list` keyword argument of the `minimize` method. This tells the optimizer to only update the listed variables. Something like `tf.train.AdamOptimizer().minimize(loss, var_list=var_list)` will only train the variables in `var_list`.\n\n>**Exercise: ** Below, implement the optimizers for the generator and discriminator. First you'll need to get a list of trainable variables, then split that list into two lists, one for the generator variables and another for the discriminator variables. Finally, using `AdamOptimizer`, create an optimizer for each network that update the network variables separately.",
"_____no_output_____"
]
],
[
[
"# Optimizers\nlearning_rate = 0.002\n\n# Get the trainable_variables, split into G and D parts\nt_vars = tf.trainable_variables()\ng_vars = [var for var in t_vars if var.name.startswith('generator')]\nd_vars = [var for var in t_vars if var.name.startswith('discriminator')]\n\nd_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars)\ng_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"batch_size = 100\nepochs = 100\nsamples = []\nlosses = []\nsaver = tf.train.Saver(var_list = g_vars)\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for e in range(epochs):\n for ii in range(mnist.train.num_examples//batch_size):\n batch = mnist.train.next_batch(batch_size)\n \n # Get images, reshape and rescale to pass to D\n batch_images = batch[0].reshape((batch_size, 784))\n batch_images = batch_images*2 - 1\n \n # Sample random noise for G\n batch_z = np.random.uniform(-1, 1, size=(batch_size, z_size))\n \n # Run optimizers\n _ = sess.run(d_train_opt, feed_dict={input_real: batch_images, input_z: batch_z})\n _ = sess.run(g_train_opt, feed_dict={input_z: batch_z})\n \n # At the end of each epoch, get the losses and print them out\n train_loss_d = sess.run(d_loss, {input_z: batch_z, input_real: batch_images})\n train_loss_g = g_loss.eval({input_z: batch_z})\n \n print(\"Epoch {}/{}...\".format(e+1, epochs),\n \"Discriminator Loss: {:.4f}...\".format(train_loss_d),\n \"Generator Loss: {:.4f}\".format(train_loss_g)) \n # Save losses to view after training\n losses.append((train_loss_d, train_loss_g))\n \n # Sample from generator as we're training for viewing afterwards\n sample_z = np.random.uniform(-1, 1, size=(16, z_size))\n gen_samples = sess.run(\n generator(input_z, input_size, n_units=g_hidden_size, reuse=True, alpha=alpha),\n feed_dict={input_z: sample_z})\n samples.append(gen_samples)\n saver.save(sess, './checkpoints/generator.ckpt')\n\n# Save training generator samples\nwith open('train_samples.pkl', 'wb') as f:\n pkl.dump(samples, f)",
"Epoch 1/100... Discriminator Loss: 0.3678... Generator Loss: 3.5897\nEpoch 2/100... Discriminator Loss: 0.3645... Generator Loss: 3.6309\nEpoch 3/100... Discriminator Loss: 0.4357... Generator Loss: 3.4136\nEpoch 4/100... Discriminator Loss: 0.7224... Generator Loss: 6.2652\nEpoch 5/100... Discriminator Loss: 0.6075... Generator Loss: 4.3486\nEpoch 6/100... Discriminator Loss: 0.7519... Generator Loss: 4.1813\nEpoch 7/100... Discriminator Loss: 0.9000... Generator Loss: 2.0781\nEpoch 8/100... Discriminator Loss: 1.3756... Generator Loss: 1.5895\nEpoch 9/100... Discriminator Loss: 0.9456... Generator Loss: 2.2028\nEpoch 10/100... Discriminator Loss: 1.0948... Generator Loss: 2.3228\nEpoch 11/100... Discriminator Loss: 1.0107... Generator Loss: 1.9952\nEpoch 12/100... Discriminator Loss: 1.0860... Generator Loss: 1.6382\nEpoch 13/100... Discriminator Loss: 1.1476... Generator Loss: 2.2547\nEpoch 14/100... Discriminator Loss: 1.1930... Generator Loss: 2.0586\nEpoch 15/100... Discriminator Loss: 0.7046... Generator Loss: 2.6142\nEpoch 16/100... Discriminator Loss: 1.4536... Generator Loss: 1.9014\nEpoch 17/100... Discriminator Loss: 0.9945... Generator Loss: 1.8042\nEpoch 18/100... Discriminator Loss: 0.9138... Generator Loss: 2.2109\nEpoch 19/100... Discriminator Loss: 1.9424... Generator Loss: 1.3089\nEpoch 20/100... Discriminator Loss: 1.1435... Generator Loss: 2.6712\nEpoch 21/100... Discriminator Loss: 1.1042... Generator Loss: 1.9536\nEpoch 22/100... Discriminator Loss: 1.0478... Generator Loss: 1.8048\nEpoch 23/100... Discriminator Loss: 1.0245... Generator Loss: 1.7871\nEpoch 24/100... Discriminator Loss: 1.1023... Generator Loss: 1.3868\nEpoch 25/100... Discriminator Loss: 1.0755... Generator Loss: 1.6908\nEpoch 26/100... Discriminator Loss: 0.9878... Generator Loss: 1.5943\nEpoch 27/100... Discriminator Loss: 1.0857... Generator Loss: 1.3091\nEpoch 28/100... Discriminator Loss: 1.3463... Generator Loss: 1.0437\nEpoch 29/100... Discriminator Loss: 1.1604... Generator Loss: 1.5717\nEpoch 30/100... Discriminator Loss: 0.8951... Generator Loss: 2.0207\nEpoch 31/100... Discriminator Loss: 0.7005... Generator Loss: 2.6086\nEpoch 32/100... Discriminator Loss: 0.8702... Generator Loss: 3.1350\nEpoch 33/100... Discriminator Loss: 0.8715... Generator Loss: 2.2553\nEpoch 34/100... Discriminator Loss: 0.9684... Generator Loss: 2.1891\nEpoch 35/100... Discriminator Loss: 1.1734... Generator Loss: 2.2908\nEpoch 36/100... Discriminator Loss: 1.0828... Generator Loss: 1.7820\nEpoch 37/100... Discriminator Loss: 1.0500... Generator Loss: 2.0008\nEpoch 38/100... Discriminator Loss: 1.0380... Generator Loss: 1.8724\nEpoch 39/100... Discriminator Loss: 0.9818... Generator Loss: 2.2052\nEpoch 40/100... Discriminator Loss: 0.7781... Generator Loss: 2.0690\nEpoch 41/100... Discriminator Loss: 0.9980... Generator Loss: 2.0535\nEpoch 42/100... Discriminator Loss: 0.9168... Generator Loss: 1.9688\nEpoch 43/100... Discriminator Loss: 0.8056... Generator Loss: 2.1651\nEpoch 44/100... Discriminator Loss: 0.9269... Generator Loss: 2.4960\nEpoch 45/100... Discriminator Loss: 0.8217... Generator Loss: 2.0567\nEpoch 46/100... Discriminator Loss: 0.8549... Generator Loss: 2.3850\nEpoch 47/100... Discriminator Loss: 0.7160... Generator Loss: 2.2929\nEpoch 48/100... Discriminator Loss: 0.8896... Generator Loss: 2.0800\nEpoch 49/100... Discriminator Loss: 1.0880... Generator Loss: 1.6579\nEpoch 50/100... Discriminator Loss: 1.0534... Generator Loss: 2.2300\nEpoch 51/100... Discriminator Loss: 0.9481... Generator Loss: 2.1894\nEpoch 52/100... Discriminator Loss: 0.9767... Generator Loss: 2.1380\nEpoch 53/100... Discriminator Loss: 1.1231... Generator Loss: 1.8526\nEpoch 54/100... Discriminator Loss: 0.9081... Generator Loss: 1.9529\nEpoch 55/100... Discriminator Loss: 1.0239... Generator Loss: 2.2693\nEpoch 56/100... Discriminator Loss: 1.0482... Generator Loss: 1.7395\nEpoch 57/100... Discriminator Loss: 0.9157... Generator Loss: 1.8313\nEpoch 58/100... Discriminator Loss: 0.8839... Generator Loss: 2.2156\nEpoch 59/100... Discriminator Loss: 0.9230... Generator Loss: 1.8060\nEpoch 60/100... Discriminator Loss: 0.9655... Generator Loss: 2.0184\nEpoch 61/100... Discriminator Loss: 0.9161... Generator Loss: 1.9261\nEpoch 62/100... Discriminator Loss: 0.8266... Generator Loss: 2.0038\nEpoch 63/100... Discriminator Loss: 0.8978... Generator Loss: 2.2338\nEpoch 64/100... Discriminator Loss: 1.0432... Generator Loss: 1.6098\nEpoch 65/100... Discriminator Loss: 1.1114... Generator Loss: 1.4504\nEpoch 66/100... Discriminator Loss: 0.9215... Generator Loss: 1.7533\nEpoch 67/100... Discriminator Loss: 0.9408... Generator Loss: 1.9942\nEpoch 68/100... Discriminator Loss: 1.1266... Generator Loss: 1.8851\nEpoch 69/100... Discriminator Loss: 1.1030... Generator Loss: 1.5994\nEpoch 70/100... Discriminator Loss: 0.8640... Generator Loss: 2.1240\nEpoch 71/100... Discriminator Loss: 0.9544... Generator Loss: 2.0405\nEpoch 72/100... Discriminator Loss: 0.9874... Generator Loss: 1.6178\nEpoch 73/100... Discriminator Loss: 0.9185... Generator Loss: 2.0491\nEpoch 74/100... Discriminator Loss: 1.1316... Generator Loss: 1.4504\nEpoch 75/100... Discriminator Loss: 0.9773... Generator Loss: 1.5728\nEpoch 76/100... Discriminator Loss: 0.9489... Generator Loss: 1.8277\nEpoch 77/100... Discriminator Loss: 1.1911... Generator Loss: 1.6216\nEpoch 78/100... Discriminator Loss: 1.0081... Generator Loss: 2.2352\nEpoch 79/100... Discriminator Loss: 0.9159... Generator Loss: 1.9558\nEpoch 80/100... Discriminator Loss: 1.0335... Generator Loss: 1.7723\nEpoch 81/100... Discriminator Loss: 1.1103... Generator Loss: 1.7102\nEpoch 82/100... Discriminator Loss: 0.9083... Generator Loss: 2.1996\nEpoch 83/100... Discriminator Loss: 1.0865... Generator Loss: 1.8519\nEpoch 84/100... Discriminator Loss: 0.9847... Generator Loss: 1.6953\nEpoch 85/100... Discriminator Loss: 0.8754... Generator Loss: 2.0061\nEpoch 86/100... Discriminator Loss: 1.0773... Generator Loss: 1.7892\nEpoch 87/100... Discriminator Loss: 0.8109... Generator Loss: 1.9592\nEpoch 88/100... Discriminator Loss: 0.9158... Generator Loss: 2.1380\nEpoch 89/100... Discriminator Loss: 0.8513... Generator Loss: 2.1318\nEpoch 90/100... Discriminator Loss: 0.8617... Generator Loss: 2.1592\nEpoch 91/100... Discriminator Loss: 0.9953... Generator Loss: 1.7510\nEpoch 92/100... Discriminator Loss: 0.9552... Generator Loss: 2.0343\nEpoch 93/100... Discriminator Loss: 0.8665... Generator Loss: 1.7532\nEpoch 94/100... Discriminator Loss: 0.8872... Generator Loss: 1.5990\nEpoch 95/100... Discriminator Loss: 1.1236... Generator Loss: 1.5481\nEpoch 96/100... Discriminator Loss: 0.8847... Generator Loss: 2.2585\nEpoch 97/100... Discriminator Loss: 0.9323... Generator Loss: 1.6943\nEpoch 98/100... Discriminator Loss: 1.1218... Generator Loss: 1.4691\nEpoch 99/100... Discriminator Loss: 0.9928... Generator Loss: 2.0241\nEpoch 100/100... Discriminator Loss: 0.9447... Generator Loss: 2.0391\n"
]
],
[
[
"## Training loss\n\nHere we'll check out the training losses for the generator and discriminator.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nlosses = np.array(losses)\nplt.plot(losses.T[0], label='Discriminator')\nplt.plot(losses.T[1], label='Generator')\nplt.title(\"Training Losses\")\nplt.legend()",
"_____no_output_____"
]
],
[
[
"## Generator samples from training\n\nHere we can view samples of images from the generator. First we'll look at images taken while training.",
"_____no_output_____"
]
],
[
[
"def view_samples(epoch, samples):\n fig, axes = plt.subplots(figsize=(7,7), nrows=4, ncols=4, sharey=True, sharex=True)\n for ax, img in zip(axes.flatten(), samples[epoch]):\n ax.xaxis.set_visible(False)\n ax.yaxis.set_visible(False)\n im = ax.imshow(img.reshape((28,28)), cmap='Greys_r')\n \n return fig, axes",
"_____no_output_____"
],
[
"# Load samples from generator taken while training\nwith open('train_samples.pkl', 'rb') as f:\n samples = pkl.load(f)",
"_____no_output_____"
]
],
[
[
"These are samples from the final training epoch. You can see the generator is able to reproduce numbers like 5, 7, 3, 0, 9. Since this is just a sample, it isn't representative of the full range of images this generator can make.",
"_____no_output_____"
]
],
[
[
"_ = view_samples(-1, samples)",
"_____no_output_____"
]
],
[
[
"Below I'm showing the generated images as the network was training, every 10 epochs. With bonus optical illusion!",
"_____no_output_____"
]
],
[
[
"rows, cols = 10, 6\nfig, axes = plt.subplots(figsize=(7,12), nrows=rows, ncols=cols, sharex=True, sharey=True)\n\nfor sample, ax_row in zip(samples[::int(len(samples)/rows)], axes):\n for img, ax in zip(sample[::int(len(sample)/cols)], ax_row):\n ax.imshow(img.reshape((28,28)), cmap='Greys_r')\n ax.xaxis.set_visible(False)\n ax.yaxis.set_visible(False)",
"_____no_output_____"
]
],
[
[
"It starts out as all noise. Then it learns to make only the center white and the rest black. You can start to see some number like structures appear out of the noise. Looks like 1, 9, and 8 show up first. Then, it learns 5 and 3.",
"_____no_output_____"
],
[
"## Sampling from the generator\n\nWe can also get completely new images from the generator by using the checkpoint we saved after training. We just need to pass in a new latent vector $z$ and we'll get new samples!",
"_____no_output_____"
]
],
[
[
"saver = tf.train.Saver(var_list=g_vars)\nwith tf.Session() as sess:\n saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))\n sample_z = np.random.uniform(-1, 1, size=(16, z_size))\n gen_samples = sess.run(\n generator(input_z, input_size, n_units=g_hidden_size, reuse=True, alpha=alpha),\n feed_dict={input_z: sample_z})\nview_samples(0, [gen_samples])",
"INFO:tensorflow:Restoring parameters from checkpoints\\generator.ckpt\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
d005d7a236bac735a6f30b47f48338d02e9cfad1
| 28,766 |
ipynb
|
Jupyter Notebook
|
PXL_DIGITAL_JAAR_2/Data Advanced/Bestanden/notebooks_data/Machine Learning Exercises/Own solutions/Machine_Learning_1_Classification.ipynb
|
Limoentaart/PXL_IT_JAAR_1
|
fe8440145a4cb75b66aaaa8e74a92cac0d58dcc8
|
[
"MIT"
] | null | null | null |
PXL_DIGITAL_JAAR_2/Data Advanced/Bestanden/notebooks_data/Machine Learning Exercises/Own solutions/Machine_Learning_1_Classification.ipynb
|
Limoentaart/PXL_IT_JAAR_1
|
fe8440145a4cb75b66aaaa8e74a92cac0d58dcc8
|
[
"MIT"
] | null | null | null |
PXL_DIGITAL_JAAR_2/Data Advanced/Bestanden/notebooks_data/Machine Learning Exercises/Own solutions/Machine_Learning_1_Classification.ipynb
|
Limoentaart/PXL_IT_JAAR_1
|
fe8440145a4cb75b66aaaa8e74a92cac0d58dcc8
|
[
"MIT"
] | 1 |
2020-10-30T10:02:44.000Z
|
2020-10-30T10:02:44.000Z
| 29.353061 | 394 | 0.511194 |
[
[
[
"# Intro to Machine Learning with Classification",
"_____no_output_____"
],
[
"## Contents\n1. **Loading** iris dataset\n2. Splitting into **train**- and **test**-set\n3. Creating a **model** and training it\n4. **Predicting** test set\n5. **Evaluating** the result\n6. Selecting **features**",
"_____no_output_____"
],
[
"This notebook will introduce you to Machine Learning and classification, using our most valued Python data science toolkit: [ScikitLearn](http://scikit-learn.org/).\n\nClassification will allow you to automatically classify data, based on the classification of previous data. The algorithm determines automatically which features it will use to classify, so the programmer does not have to think of this anymore (although it helps).\n\nFirst, we will transform a dataset into a set of features with labels that the algorithm can use. Then we will predict labels and validate them. Last we will select features manually and see if we can make the prediction better.\n\nLet's start with some imports.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom sklearn import datasets",
"_____no_output_____"
]
],
[
[
"## 1. Loading iris dataset",
"_____no_output_____"
],
[
"We load the dataset from the datasets module in sklearn.",
"_____no_output_____"
]
],
[
[
"iris = datasets.load_iris()",
"_____no_output_____"
]
],
[
[
"This dataset contains information about iris flowers. Every entry describes a flower, more specifically its \n- sepal length\n- sepal width\n- petal length\n- petal width\n\nSo every entry has four columns.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"We can visualise the data with Pandas, a Python library to handle dataframes. This gives us a pretty table to see what our data looks like.\n\nWe will not cover Pandas in this notebook, so don't worry about this piece of code.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\ndf = pd.DataFrame(data=iris.data, columns=iris.feature_names)\ndf[\"target\"] = iris.target\ndf.sample(n=10) # show 10 random rows",
"_____no_output_____"
]
],
[
[
"There are 3 different species of irises in the dataset. Every species has 50 samples, so there are 150 entries in total.\n\nWe can confirm this by checking the \"data\"-element of the iris variable. The \"data\"-element is a 2D-array that contains all our entries. We can use the python function `.shape` to check its dimensions.",
"_____no_output_____"
]
],
[
[
"iris.data.shape",
"_____no_output_____"
]
],
[
[
"To get an example of the data, we can print the first ten rows:",
"_____no_output_____"
]
],
[
[
"print(iris.data[0:10, :]) # 0:10 gets rows 0-10, : gets all the columns",
"[[5.1 3.5 1.4 0.2]\n [4.9 3. 1.4 0.2]\n [4.7 3.2 1.3 0.2]\n [4.6 3.1 1.5 0.2]\n [5. 3.6 1.4 0.2]\n [5.4 3.9 1.7 0.4]\n [4.6 3.4 1.4 0.3]\n [5. 3.4 1.5 0.2]\n [4.4 2.9 1.4 0.2]\n [4.9 3.1 1.5 0.1]]\n"
]
],
[
[
"The labels that we're looking for are in the \"target\"-element of the iris variable. This 1D-array contains the iris species for each of the entries.",
"_____no_output_____"
]
],
[
[
"iris.target.shape",
"_____no_output_____"
]
],
[
[
"Let's have a look at the target values:",
"_____no_output_____"
]
],
[
[
"print(iris.target)",
"[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1\n 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2\n 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2\n 2 2]\n"
]
],
[
[
"There are three categories so each entry will be classified as 0, 1 or 2. To get the names of the corresponding species we can print `target_names`.",
"_____no_output_____"
]
],
[
[
"print(iris.target_names)",
"['setosa' 'versicolor' 'virginica']\n"
]
],
[
[
"The iris variable is a dataset from sklearn and also contains a description of itself. We already provided the information you need to know about the data, but if you want to check, you can print the `.DESCR` method of the iris dataset.",
"_____no_output_____"
]
],
[
[
"print(iris.DESCR)",
".. _iris_dataset:\n\nIris plants dataset\n--------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n \n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ====================\n Min Max Mean SD Class Correlation\n ============== ==== ==== ======= ===== ====================\n sepal length: 4.3 7.9 5.84 0.83 0.7826\n sepal width: 2.0 4.4 3.05 0.43 -0.4194\n petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n ============== ==== ==== ======= ===== ====================\n\n :Missing Attribute Values: None\n :Class Distribution: 33.3% for each of 3 classes.\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)\n :Date: July, 1988\n\nThe famous Iris database, first used by Sir R.A. Fisher. The dataset is taken\nfrom Fisher's paper. Note that it's the same as in R, but not as in the UCI\nMachine Learning Repository, which has two wrong data points.\n\nThis is perhaps the best known database to be found in the\npattern recognition literature. Fisher's paper is a classic in the field and\nis referenced frequently to this day. (See Duda & Hart, for example.) The\ndata set contains 3 classes of 50 instances each, where each class refers to a\ntype of iris plant. One class is linearly separable from the other 2; the\nlatter are NOT linearly separable from each other.\n\n.. topic:: References\n\n - Fisher, R.A. \"The use of multiple measurements in taxonomic problems\"\n Annual Eugenics, 7, Part II, 179-188 (1936); also in \"Contributions to\n Mathematical Statistics\" (John Wiley, NY, 1950).\n - Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.\n (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.\n - Dasarathy, B.V. (1980) \"Nosing Around the Neighborhood: A New System\n Structure and Classification Rule for Recognition in Partially Exposed\n Environments\". IEEE Transactions on Pattern Analysis and Machine\n Intelligence, Vol. PAMI-2, No. 1, 67-71.\n - Gates, G.W. (1972) \"The Reduced Nearest Neighbor Rule\". IEEE Transactions\n on Information Theory, May 1972, 431-433.\n - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al\"s AUTOCLASS II\n conceptual clustering system finds 3 classes in the data.\n - Many, many more ...\n"
]
],
[
[
"Now we have a good idea what our data looks like.\n\nOur task now is to solve a **supervised** learning problem: Predict the species of an iris using the measurements that serve as our so-called **features**.",
"_____no_output_____"
]
],
[
[
"# First, we store the features we use and the labels we want to predict into two different variables\nX = iris.data\ny = iris.target",
"_____no_output_____"
]
],
[
[
"## 2. Splitting into train- and test-set",
"_____no_output_____"
],
[
"We want to evaluate our model on data with labels that our model has not seen yet. This will give us an idea on how well the model can predict new data, and makes sure we are not [overfitting](https://en.wikipedia.org/wiki/Overfitting). If we would test and train on the same data, we would just learn this dataset really really well, but not be able to tell anything about other data.\n\nSo we split our dataset into a train- and test-set. Sklearn has a function to do this: `train_test_split`. Have a look at the [documentation](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html) of this function and see if you can split `iris.data` and `iris.target` into train- and test-sets with a test-size of 33%.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n??train_test_split",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.33, stratify=iris.target)# TODO: split iris.data and iris.target into test and train",
"_____no_output_____"
]
],
[
[
"We can now check the size of the resulting arrays. The shapes should be `(100, 4)`, `(100,)`, `(50, 4)` and `(50,)`.",
"_____no_output_____"
]
],
[
[
"print(\"X_train shape: {}, y_train shape: {}\".format(X_train.shape, y_train.shape))\nprint(\"X_test shape: {} , y_test shape: {}\".format(X_test.shape, y_test.shape))",
"X_train shape: (100, 4), y_train shape: (100,)\nX_test shape: (50, 4) , y_test shape: (50,)\n"
]
],
[
[
"## 3. Creating a model and training it",
"_____no_output_____"
],
[
"Now we will give the data to a model. We will use a Decision Tree Classifier model for this.\n\nThis model will create a decision tree based on the X_train and y_train values and include decisions like this:",
"_____no_output_____"
],
[
"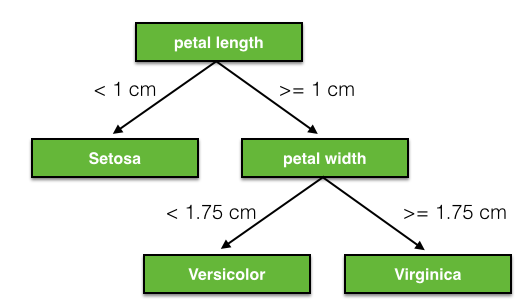",
"_____no_output_____"
],
[
"Find the Decision Tree Classifier in sklearn and call its constructor. It might be useful to set the random_state parameter to 0, otherwise a different tree will be generated each time you run the code.",
"_____no_output_____"
]
],
[
[
"from sklearn import tree",
"_____no_output_____"
],
[
"model = tree.DecisionTreeClassifier(random_state=0)# TODO: create a decision tree classifier",
"_____no_output_____"
]
],
[
[
"The model is still empty and doesn't know anything. Train (fit) it with our train-data, so that it learns things about our iris-dataset.",
"_____no_output_____"
]
],
[
[
"model = model.fit(X_train, y_train)# TODO: fit the train-data to the model",
"_____no_output_____"
]
],
[
[
"## 4. Predicting test set",
"_____no_output_____"
],
[
"We now have a model that contains a decision tree. This decision tree knows how to turn our X_train values into y_train values. We will now let it run on our X_test values and have a look at the result.\n\nWe don't want to overwrite our actual y_test values, so we store the predicted y_test values as y_pred.",
"_____no_output_____"
]
],
[
[
"y_pred = model.predict(X_test)# TODO: predict y_pred from X_test",
"_____no_output_____"
]
],
[
[
"## 5. Evaluating the result",
"_____no_output_____"
],
[
"We now have y_test (the real values for X_test) and y_pred. We can print these values and compare them, to get an idea of how good the model predicted the data.",
"_____no_output_____"
]
],
[
[
"print(y_test)\nprint(\"-\"*75) # print a line\nprint(y_pred)",
"[0 2 0 2 2 1 1 0 1 1 2 0 2 0 2 1 2 0 0 1 0 2 2 1 1 1 2 0 1 2 2 0 1 0 0 1 1\n 2 2 0 1 1 1 0 2 0 1 0 0 2]\n---------------------------------------------------------------------------\n[0 2 0 2 1 1 1 0 1 1 2 0 2 0 2 1 2 0 0 1 0 2 2 1 1 1 2 0 2 2 2 0 1 0 0 2 1\n 2 2 0 1 1 1 0 2 0 1 0 0 2]\n"
]
],
[
[
"If we look at the values closely, we can discover that all but two values are predicted correctly. However, it is bothersome to compare the numbers one by one. There are only thirty of them, but what if there were one hundred? We will need an easier method to compare our results.\n\nLuckily, this can also be found in sklearn. Google for sklearn's accuracy score and compare our y_test and y_pred. This will give us the percentage of entries that was predicted correctly.",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\n\naccuracy = metrics.accuracy_score(y_test, y_pred) # TODO: calculate accuracy score of y_test and y_pred\nprint(accuracy)",
"0.94\n"
]
],
[
[
"That's pretty good, isn't it?\n\nTo understand what our classifier actually did, have a look at the following picture:",
"_____no_output_____"
],
[
"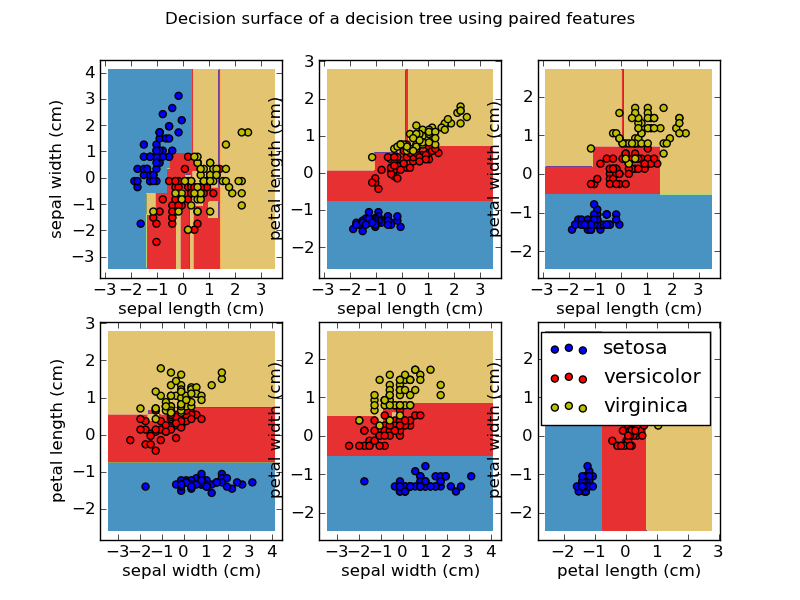",
"_____no_output_____"
],
[
"We see the distribution of all our features, compared with each other. Some have very clear distinctions between two categories, so our decision tree probably used those to make predictions about our data.",
"_____no_output_____"
],
[
"## 6. Selecting features",
"_____no_output_____"
],
[
"In our dataset, there are four features to describe the flowers. Using these four features, we got a pretty high accuracy to predict the species. But maybe some of our features were not necessary. Maybe some did not improve our prediction, or even made it worse.\n\nIt's worth a try to see if a subset of features is better at predicting the labels than all features.\n\nWe still have our X_train, X_test, y_train and y_test variables. We will try removing a few columns from X_train and X_test and recalculate our accuracy.\n\nFirst, create a feature selector that will select the 2 features X_train that best describe y_train.\n\n(Hint: look at the imports)",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_selection import SelectKBest, chi2\n\nselector = SelectKBest(chi2, k=2) # TODO: create a selector for the 2 best features and fit X_train and y_train to it",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.33, random_state=42)",
"_____no_output_____"
],
[
"selector = selector.fit(X_train, y_train)",
"_____no_output_____"
]
],
[
[
"We can check which features our selector selected, using the following function:",
"_____no_output_____"
]
],
[
[
"print(selector.get_support())",
"[False False True True]\n"
]
],
[
[
"It gives us an array of True and False values that represent the columns of the original X_train. The values that are marked by True are considered the most informative by the selector. Let's use the selector to select (transform) these features from the X_train values.",
"_____no_output_____"
]
],
[
[
"X_train_new = selector.transform(X_train) # TODO: use selector to transform X_train",
"_____no_output_____"
]
],
[
[
"The dimensions of X_train have now changed:",
"_____no_output_____"
]
],
[
[
"X_train_new.shape",
"_____no_output_____"
]
],
[
[
"If we want to use these values in our model, we will need to adjust X_test as well. We would get in trouble later if X_train has only 2 columns and X_test has 4. So perform the same selection on X_test.",
"_____no_output_____"
]
],
[
[
"X_test_new = selector.transform(X_test) # TODO: use selector to transform X_test",
"_____no_output_____"
],
[
"X_test_new.shape",
"_____no_output_____"
]
],
[
[
"Now we can repeat the earlier steps: create a model, fit the data to it and predict our y_test values.",
"_____no_output_____"
]
],
[
[
"model = tree.DecisionTreeClassifier(random_state=0) # TODO: create model as before\nmodel = model.fit(X_train_new, y_train) # TODO: fit model as before, but use X_train_new\ny_pred = model.predict(X_test_new) # TODO: predict values as before, but use X_test_new",
"_____no_output_____"
]
],
[
[
"Let's have a look at the accuracy score of our new prediction. ",
"_____no_output_____"
]
],
[
[
"accuracy = metrics.accuracy_score(y_test, y_pred) # TODO: calculate accuracy score of y_test and y_pred\nprint(accuracy) # TODO: calculate accuracy score as before",
"1.0\n"
]
],
[
[
"So our new prediction, using only two of the four features, is better than the one using all information. The two features we used are petal length and petal width. These say more about the species of the flowers than the sepal length and sepal width.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d005e19497f1764c944efc4d0d2eac7825816def
| 23,990 |
ipynb
|
Jupyter Notebook
|
Link Dataset Cleaning.ipynb
|
geridashja/phishing-links-detection
|
5fe88b2c4070de8586a094d27f9661dc0e412437
|
[
"MIT"
] | null | null | null |
Link Dataset Cleaning.ipynb
|
geridashja/phishing-links-detection
|
5fe88b2c4070de8586a094d27f9661dc0e412437
|
[
"MIT"
] | null | null | null |
Link Dataset Cleaning.ipynb
|
geridashja/phishing-links-detection
|
5fe88b2c4070de8586a094d27f9661dc0e412437
|
[
"MIT"
] | null | null | null | 29.435583 | 93 | 0.365069 |
[
[
[
"###### This Dataset was taken online",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"dataset = pd.read_csv('url_dataset.csv')",
"_____no_output_____"
],
[
"#deleting all columns except url\ndataset.drop(dataset.columns.difference(['URL']), 1, inplace=True)",
"_____no_output_____"
],
[
"dataset.head(5)",
"_____no_output_____"
],
[
"dataset.to_csv('cleaned_link_dataset.csv')",
"_____no_output_____"
],
[
"#split protocol from the other part of link\ncleaned_dataset = pd.read_csv('cleaned_link_dataset.csv')\nprotocol = cleaned_dataset['URL'].str.split('://',expand=True)",
"_____no_output_____"
],
[
"#renaming columns\nprotocol.head()",
"_____no_output_____"
],
[
"protocol.rename(columns={0: 'protocol'}, inplace= True)",
"_____no_output_____"
],
[
"protocol.head()",
"_____no_output_____"
],
[
"#dividing domain name from the address of the link and create a new column with it\ndomain = protocol[1].str.split('/', 1,expand=True)",
"_____no_output_____"
],
[
"domain.head()",
"_____no_output_____"
],
[
"domain.rename(columns ={0:'domain', 1:'address'}, inplace= True)",
"_____no_output_____"
],
[
"domain.head()",
"_____no_output_____"
],
[
"protocol.head()",
"_____no_output_____"
],
[
"#joining datasets together in one dataframe using pd.concat\nfull_dataset = pd.concat([protocol['protocol'],domain],axis=1)",
"_____no_output_____"
],
[
"full_dataset.head(5)",
"_____no_output_____"
],
[
"full_dataset.to_csv('full_cleaned.csv')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d005e551d56e5106908bd13696457adae6aa60fd
| 15,059 |
ipynb
|
Jupyter Notebook
|
nbs/06-metriques-et-evaluation-des-modeles-de-regression/06-TP.ipynb
|
tiombo/TP12
|
e0062fcb2b4eb2a6b1c7cff5e23add48a9b6f79a
|
[
"MIT"
] | null | null | null |
nbs/06-metriques-et-evaluation-des-modeles-de-regression/06-TP.ipynb
|
tiombo/TP12
|
e0062fcb2b4eb2a6b1c7cff5e23add48a9b6f79a
|
[
"MIT"
] | 3 |
2020-10-27T22:29:01.000Z
|
2021-08-23T20:42:41.000Z
|
nbs/06-metriques-et-evaluation-des-modeles-de-regression/06-TP.ipynb
|
tiombo/Projet-Final
|
0964e042599bb41d2c523a3f05075775449b7d14
|
[
"MIT"
] | null | null | null | 25.01495 | 267 | 0.493326 |
[
[
[
"420-A52-SF - Algorithmes d'apprentissage supervisé - Hiver 2020 - Spécialisation technique en Intelligence Artificielle - Mikaël Swawola, M.Sc.\n<br/>\n\n<br/>\n**Objectif:** cette séance de travaux pratique est consacrée à la mise en oeuvre de l'ensemble des connaissances acquises jusqu'alors sur un nouveau jeu de données, *NBA*",
"_____no_output_____"
]
],
[
[
"%reload_ext autoreload\n%autoreload 2\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### 0 - Chargement des bibliothèques",
"_____no_output_____"
]
],
[
[
"# Manipulation de données\nimport numpy as np\nimport pandas as pd\n\n# Visualisation de données\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"# Configuration de la visualisation\nsns.set(style=\"darkgrid\", rc={'figure.figsize':(11.7,8.27)})",
"_____no_output_____"
]
],
[
[
"### 1 - Lecture du jeu de données *NBA*",
"_____no_output_____"
],
[
"**Lire le fichier `NBA_train.csv`**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nNBA = None",
"_____no_output_____"
]
],
[
[
"**Afficher les dix premières lignes de la trame de données**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nNone",
"_____no_output_____"
]
],
[
[
"Ci-dessous, la description des différentes variables explicatives du jeu de données\n</br>\n\n| Variable | Description |\n| ------------- |:-------------------------------------------------------------:|\n| SeasonEnd | Année de fin de la saison |\n| Team | Nom de l'équipe |\n| Playoffs | Indique si l'équipe est allée en playoffs |\n| W | Nombre de victoires au cours de la saison régulière |\n| PTS | Nombre de points obtenus (saison régulière) |\n| oppPTS | Nombre de points obtenus pas les opposants (saison régulière) |\n| FG | Nombre de Field Goals réussis |\n| FGA | Nombre de tentatives de Field Goals |\n| 2P | Nombre de 2-pointers réussis |\n| 2PA | Nombre de tentatives de 2-pointers |\n| 3P | Nombre de 3-pointers réussis |\n| 3PA | Nombre de tentatives de 3-pointers |\n| FT | Nombre de Free throws réussis |\n| FTA | Nombre de tentatives de Free throws |\n| ORB | Nombre de rebonds offensifs |\n| DRB | Nombre de rebonds défensifs |\n| AST | Nombre de passes décisives (assists) |\n| STL | Nombre d'interceptions (steals) |\n| BLK | Nombre de contres (blocks) |\n| TOV | Nombre de turnovers |\n",
"_____no_output_____"
],
[
"### 1 - Régression linéaire simple",
"_____no_output_____"
],
[
"Nous allons dans un premier temps effectuer la prédiction du nombre de victoires au cours de la saison régulière en fonction de la différence de points obtenus pas l'équipe et par ses opposants\n<br/><br/>\nNous commencons donc par un peu d'**ingénierie de données**. Une nouvelle variable explicative correspondant à la différence de points obtenus pas l'équipe et par ses opposants est crée",
"_____no_output_____"
],
[
"**Créer un nouvelle variable PTSdiff, représentant la différence entre PTS et oppPTS**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nNone",
"_____no_output_____"
]
],
[
[
"**Stocker le nombre de lignes du jeu de donnée (nombre d'exemples d'entraînement) dans la variable `m`**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nm = None",
"_____no_output_____"
]
],
[
[
"**Stocker le nombre de victoires au cours de la saison dans la variable `y`. Il s'agira de la variable que l'on cherche à prédire**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ny = None",
"_____no_output_____"
]
],
[
[
"**Créer la matrice des prédicteurs `X`.** Indice: `X` doit avoir 2 colonnes...",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 3 lignes\nX = None",
"_____no_output_____"
]
],
[
[
"**Vérifier la dimension de la matrice des prédicteurs `X`. Quelle est la dimension de `X` ?**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nNone",
"_____no_output_____"
]
],
[
[
"**Créer le modèle de référence (baseline)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ny_baseline = None",
"_____no_output_____"
]
],
[
[
"**À l'aide de l'équation normale, trouver les paramètres optimaux du modèle de régression linéaire simple**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ntheta = None",
"_____no_output_____"
]
],
[
[
"**Calculer la somme des carrées des erreurs (SSE)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nSSE = None",
"_____no_output_____"
]
],
[
[
"**Calculer la racine carrée de l'erreur quadratique moyenne (RMSE)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nRMSE = None",
"_____no_output_____"
]
],
[
[
"**Calculer le coefficient de détermination $R^2$**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1-2 lignes\nR2 = None",
"_____no_output_____"
]
],
[
[
"**Affichage des résultats**",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.scatter(x1, y,label=\"Data points\")\nreg_x = np.linspace(-1000,1000,50)\nreg_y = theta[0] + np.linspace(-1000,1000,50)* theta[1]\nax.plot(reg_x, np.repeat(y_baseline,50), color='#777777', label=\"Baseline\", lw=2)\nax.plot(reg_x, reg_y, color=\"g\", lw=2, label=\"Modèle\")\nax.set_xlabel(\"Différence de points\", fontsize=16)\nax.set_ylabel(\"Nombre de victoires\", fontsize=16)\nax.legend(loc='upper left', fontsize=16)",
"_____no_output_____"
]
],
[
[
"### 3 - Régression linéaire multiple",
"_____no_output_____"
],
[
"Nous allons maintenant tenter de prédire le nombre de points obtenus par une équipe donnée au cours de la saison régulière en fonction des autres variables explicatives disponibles. Nous allons mettre en oeuvre plusieurs modèles de régression linéaire multiple",
"_____no_output_____"
],
[
"**Stocker le nombre de points marqués au cours de la saison dans la variable `y`. Il s'agira de la varible que l'on cherche à prédire**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ny = None",
"_____no_output_____"
]
],
[
[
"**Créer la matrice des prédicteurs `X` à partir des variables `2PA` et `3PA`**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 3 lignes\nX = None",
"_____no_output_____"
]
],
[
[
"**Vérifier la dimension de la matrice des prédicteurs `X`. Quelle est la dimension de `X` ?**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nNone",
"_____no_output_____"
]
],
[
[
"**Créer le modèle de référence (baseline)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ny_baseline = None",
"_____no_output_____"
]
],
[
[
"**À l'aide de l'équation normale, trouver les paramètres optimaux du modèle de régression linéaire**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\ntheta = None",
"_____no_output_____"
]
],
[
[
"**Calculer la somme des carrées des erreurs (SSE)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nSSE = None",
"_____no_output_____"
]
],
[
[
"**Calculer la racine carrée de l'erreur quadratique moyenne (RMSE)**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1 ligne\nRMSE = None",
"_____no_output_____"
]
],
[
[
"**Calculer le coefficient de détermination $R^2$**",
"_____no_output_____"
]
],
[
[
"# Compléter le code ci-dessous ~ 1-2 lignes\nR2 = None",
"_____no_output_____"
]
],
[
[
"### 3 - Ajouter les variables explicatives FTA et AST",
"_____no_output_____"
],
[
"**Recommencer les étapes ci-dessus en incluant les variables FTA et AST**",
"_____no_output_____"
]
],
[
[
"None",
"_____no_output_____"
]
],
[
[
"### 4 - Ajouter les variables explicatives ORB et STL",
"_____no_output_____"
],
[
"**Recommencer les étapes ci-dessus en incluant les variables ORB et STL**",
"_____no_output_____"
]
],
[
[
"None",
"_____no_output_____"
]
],
[
[
"### 5 - Ajouter les variables explicatives DRB et BLK",
"_____no_output_____"
],
[
"**Recommencer les étapes ci-dessus en incluant les variables DRB et BLK**",
"_____no_output_____"
]
],
[
[
"None",
"_____no_output_____"
]
],
[
[
"### 6 - Optionnel - Regression polynomiale",
"_____no_output_____"
],
[
"Ajouter des variables explicatives de type polynomiales",
"_____no_output_____"
],
[
"### Fin du TP",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d005e6c15dc164d20c9748d23c0bc6763018c336
| 61,918 |
ipynb
|
Jupyter Notebook
|
Multi_Perceptor_VQGAN_+_CLIP_[Public].ipynb
|
keirwilliamsxyz/keirxyz
|
abd824f25def58a873b08f8ba305ccec404c66f8
|
[
"MIT"
] | null | null | null |
Multi_Perceptor_VQGAN_+_CLIP_[Public].ipynb
|
keirwilliamsxyz/keirxyz
|
abd824f25def58a873b08f8ba305ccec404c66f8
|
[
"MIT"
] | null | null | null |
Multi_Perceptor_VQGAN_+_CLIP_[Public].ipynb
|
keirwilliamsxyz/keirxyz
|
abd824f25def58a873b08f8ba305ccec404c66f8
|
[
"MIT"
] | null | null | null | 46.554887 | 310 | 0.503359 |
[
[
[
"<a href=\"https://colab.research.google.com/github/keirwilliamsxyz/keirxyz/blob/main/Multi_Perceptor_VQGAN_%2B_CLIP_%5BPublic%5D.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Multi-Perceptor VQGAN + CLIP (v.3.2021.11.29)\nby [@remi_durant](https://twitter.com/remi_durant)\n\n\nLots drawn from or inspired by other colabs, chief among them is [@jbusted1](https://twitter.com/jbusted1)'s MSE regularized VQGAN + Clip, and [@RiversHaveWings](https://twitter.com/RiversHaveWings) VQGAN + Clip with Z+Quantize. Standing on the shoulders of giants. \n\n\n- Multi-clip mode sends the same cutouts to whatever clip models you want. If they have different perceptor resolutions, the cuts are generated at each required size, replaying the same augments across both scales\n- Alternate random noise generation options to use as start point (perlin, pyramid, or vqgan random z tokens)\n- MSE Loss doesn't apply if you have no init_image until after reaching the first epoch.\n- MSE epoch targets z.tensor, not z.average, to allow for more creativity\n- Grayscale augment added for better structure\n- Padding fix for perspective and affine augments to not always be black barred\n- Automatic disable of cudnn for A100\n\n",
"_____no_output_____"
]
],
[
[
"#@title First check what GPU you got and make sure it's a good one. \n#@markdown - Tier List: (K80 < T4 < P100 < V100 < A100)\nfrom subprocess import getoutput\n!nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader",
"_____no_output_____"
]
],
[
[
"# Setup",
"_____no_output_____"
]
],
[
[
"#@title memory footprint support libraries/code\n\n!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi\n!pip install gputil\n!pip install psutil\n!pip install humanize\n\nimport psutil\nimport humanize\nimport os\nimport GPUtil as GPU\n",
"_____no_output_____"
],
[
"#@title Print GPU details\n\n!nvidia-smi\n\nGPUs = GPU.getGPUs()\n# XXX: only one GPU on Colab and isn’t guaranteed\ngpu = GPUs[0]\ndef printm():\n process = psutil.Process(os.getpid())\n print(\"Gen RAM Free: \" + humanize.naturalsize(psutil.virtual_memory().available), \" | Proc size: \" + humanize.naturalsize(process.memory_info().rss))\n print(\"GPU RAM Free: {0:.0f}MB | Used: {1:.0f}MB | Util {2:3.0f}% | Total {3:.0f}MB\".format(gpu.memoryFree, gpu.memoryUsed, gpu.memoryUtil*100, gpu.memoryTotal))\nprintm()\n",
"_____no_output_____"
],
[
"#@title Install Dependencies\n\n# Fix for A100 issues\n!pip install tensorflow==1.15.2\n\n# Install normal dependencies\n!git clone https://github.com/openai/CLIP\n!git clone https://github.com/CompVis/taming-transformers\n!pip install ftfy regex tqdm omegaconf pytorch-lightning\n!pip install kornia\n!pip install einops\n!pip install transformers",
"_____no_output_____"
],
[
"#@title Load libraries and variables\nimport argparse\nimport math\nfrom pathlib import Path\nimport sys\n\nsys.path.append('./taming-transformers')\n\nfrom IPython import display\nfrom omegaconf import OmegaConf\nfrom PIL import Image\nfrom taming.models import cond_transformer, vqgan\nimport torch\nfrom torch import nn, optim\nfrom torch.nn import functional as F\nfrom torchvision import transforms\nfrom torchvision.transforms import functional as TF\nfrom tqdm.notebook import tqdm\nimport numpy as np\nimport os.path\nfrom os import path\nfrom urllib.request import Request, urlopen\n \nfrom CLIP import clip\nimport kornia\nimport kornia.augmentation as K\nfrom torch.utils.checkpoint import checkpoint\n\nfrom matplotlib import pyplot as plt\nfrom fastprogress.fastprogress import master_bar, progress_bar\nimport random\nimport gc\n\nimport re\nfrom datetime import datetime\n\nfrom base64 import b64encode\n\nimport warnings\n\nwarnings.filterwarnings('ignore')\ntorch.set_printoptions( sci_mode=False )\n\ndef noise_gen(shape, octaves=5):\n n, c, h, w = shape\n noise = torch.zeros([n, c, 1, 1])\n max_octaves = min(octaves, math.log(h)/math.log(2), math.log(w)/math.log(2))\n for i in reversed(range(max_octaves)):\n h_cur, w_cur = h // 2**i, w // 2**i\n noise = F.interpolate(noise, (h_cur, w_cur), mode='bicubic', align_corners=False)\n noise += torch.randn([n, c, h_cur, w_cur]) / 5\n return noise\n\n\ndef sinc(x):\n return torch.where(x != 0, torch.sin(math.pi * x) / (math.pi * x), x.new_ones([]))\n\n\ndef lanczos(x, a):\n cond = torch.logical_and(-a < x, x < a)\n out = torch.where(cond, sinc(x) * sinc(x/a), x.new_zeros([]))\n return out / out.sum()\n\n\ndef ramp(ratio, width):\n n = math.ceil(width / ratio + 1)\n out = torch.empty([n])\n cur = 0\n for i in range(out.shape[0]):\n out[i] = cur\n cur += ratio\n return torch.cat([-out[1:].flip([0]), out])[1:-1]\n\n\ndef resample(input, size, align_corners=True):\n n, c, h, w = input.shape\n dh, dw = size\n\n input = input.view([n * c, 1, h, w])\n\n if dh < h:\n kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)\n pad_h = (kernel_h.shape[0] - 1) // 2\n input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')\n input = F.conv2d(input, kernel_h[None, None, :, None])\n\n if dw < w:\n kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)\n pad_w = (kernel_w.shape[0] - 1) // 2\n input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')\n input = F.conv2d(input, kernel_w[None, None, None, :])\n\n input = input.view([n, c, h, w])\n return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)\n \n\n# def replace_grad(fake, real):\n# return fake.detach() - real.detach() + real\n\n\nclass ReplaceGrad(torch.autograd.Function):\n @staticmethod\n def forward(ctx, x_forward, x_backward):\n ctx.shape = x_backward.shape\n return x_forward\n\n @staticmethod\n def backward(ctx, grad_in):\n return None, grad_in.sum_to_size(ctx.shape)\n\n\nclass ClampWithGrad(torch.autograd.Function):\n @staticmethod\n def forward(ctx, input, min, max):\n ctx.min = min\n ctx.max = max\n ctx.save_for_backward(input)\n return input.clamp(min, max)\n\n @staticmethod\n def backward(ctx, grad_in):\n input, = ctx.saved_tensors\n return grad_in * (grad_in * (input - input.clamp(ctx.min, ctx.max)) >= 0), None, None\n\nreplace_grad = ReplaceGrad.apply\n\nclamp_with_grad = ClampWithGrad.apply\n# clamp_with_grad = torch.clamp\n\ndef vector_quantize(x, codebook):\n d = x.pow(2).sum(dim=-1, keepdim=True) + codebook.pow(2).sum(dim=1) - 2 * x @ codebook.T\n indices = d.argmin(-1)\n x_q = F.one_hot(indices, codebook.shape[0]).to(d.dtype) @ codebook\n return replace_grad(x_q, x)\n\n\nclass Prompt(nn.Module):\n def __init__(self, embed, weight=1., stop=float('-inf')):\n super().__init__()\n self.register_buffer('embed', embed)\n self.register_buffer('weight', torch.as_tensor(weight))\n self.register_buffer('stop', torch.as_tensor(stop))\n\n def forward(self, input):\n \n input_normed = F.normalize(input.unsqueeze(1), dim=2)#(input / input.norm(dim=-1, keepdim=True)).unsqueeze(1)# \n embed_normed = F.normalize((self.embed).unsqueeze(0), dim=2)#(self.embed / self.embed.norm(dim=-1, keepdim=True)).unsqueeze(0)#\n\n dists = input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)\n dists = dists * self.weight.sign()\n \n return self.weight.abs() * replace_grad(dists, torch.maximum(dists, self.stop)).mean()\n\n\ndef parse_prompt(prompt):\n vals = prompt.rsplit(':', 2)\n vals = vals + ['', '1', '-inf'][len(vals):]\n return vals[0], float(vals[1]), float(vals[2])\n\ndef one_sided_clip_loss(input, target, labels=None, logit_scale=100):\n input_normed = F.normalize(input, dim=-1)\n target_normed = F.normalize(target, dim=-1)\n logits = input_normed @ target_normed.T * logit_scale\n if labels is None:\n labels = torch.arange(len(input), device=logits.device)\n return F.cross_entropy(logits, labels)\n\nclass MakeCutouts(nn.Module):\n def __init__(self, cut_size, cutn, cut_pow=1.):\n super().__init__()\n self.cut_size = cut_size\n self.cutn = cutn\n self.cut_pow = cut_pow\n\n self.av_pool = nn.AdaptiveAvgPool2d((self.cut_size, self.cut_size))\n self.max_pool = nn.AdaptiveMaxPool2d((self.cut_size, self.cut_size))\n\n def set_cut_pow(self, cut_pow):\n self.cut_pow = cut_pow\n\n def forward(self, input):\n sideY, sideX = input.shape[2:4]\n max_size = min(sideX, sideY)\n min_size = min(sideX, sideY, self.cut_size)\n cutouts = []\n cutouts_full = []\n \n min_size_width = min(sideX, sideY)\n lower_bound = float(self.cut_size/min_size_width)\n \n for ii in range(self.cutn):\n size = int(min_size_width*torch.zeros(1,).normal_(mean=.8, std=.3).clip(lower_bound, 1.)) # replace .5 with a result for 224 the default large size is .95\n \n offsetx = torch.randint(0, sideX - size + 1, ())\n offsety = torch.randint(0, sideY - size + 1, ())\n cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]\n cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))\n\n cutouts = torch.cat(cutouts, dim=0)\n\n return clamp_with_grad(cutouts, 0, 1)\n\n\ndef load_vqgan_model(config_path, checkpoint_path):\n config = OmegaConf.load(config_path)\n if config.model.target == 'taming.models.vqgan.VQModel':\n model = vqgan.VQModel(**config.model.params)\n model.eval().requires_grad_(False)\n model.init_from_ckpt(checkpoint_path)\n elif config.model.target == 'taming.models.cond_transformer.Net2NetTransformer':\n parent_model = cond_transformer.Net2NetTransformer(**config.model.params)\n parent_model.eval().requires_grad_(False)\n parent_model.init_from_ckpt(checkpoint_path)\n model = parent_model.first_stage_model\n elif config.model.target == 'taming.models.vqgan.GumbelVQ':\n model = vqgan.GumbelVQ(**config.model.params)\n model.eval().requires_grad_(False)\n model.init_from_ckpt(checkpoint_path)\n else:\n raise ValueError(f'unknown model type: {config.model.target}')\n del model.loss\n return model\n\ndef resize_image(image, out_size):\n ratio = image.size[0] / image.size[1]\n area = min(image.size[0] * image.size[1], out_size[0] * out_size[1])\n size = round((area * ratio)**0.5), round((area / ratio)**0.5)\n return image.resize(size, Image.LANCZOS)\n\nclass GaussianBlur2d(nn.Module):\n def __init__(self, sigma, window=0, mode='reflect', value=0):\n super().__init__()\n self.mode = mode\n self.value = value\n if not window:\n window = max(math.ceil((sigma * 6 + 1) / 2) * 2 - 1, 3)\n if sigma:\n kernel = torch.exp(-(torch.arange(window) - window // 2)**2 / 2 / sigma**2)\n kernel /= kernel.sum()\n else:\n kernel = torch.ones([1])\n self.register_buffer('kernel', kernel)\n\n def forward(self, input):\n n, c, h, w = input.shape\n input = input.view([n * c, 1, h, w])\n start_pad = (self.kernel.shape[0] - 1) // 2\n end_pad = self.kernel.shape[0] // 2\n input = F.pad(input, (start_pad, end_pad, start_pad, end_pad), self.mode, self.value)\n input = F.conv2d(input, self.kernel[None, None, None, :])\n input = F.conv2d(input, self.kernel[None, None, :, None])\n return input.view([n, c, h, w])\n\nclass EMATensor(nn.Module):\n \"\"\"implmeneted by Katherine Crowson\"\"\"\n def __init__(self, tensor, decay):\n super().__init__()\n self.tensor = nn.Parameter(tensor)\n self.register_buffer('biased', torch.zeros_like(tensor))\n self.register_buffer('average', torch.zeros_like(tensor))\n self.decay = decay\n self.register_buffer('accum', torch.tensor(1.))\n self.update()\n \n @torch.no_grad()\n def update(self):\n if not self.training:\n raise RuntimeError('update() should only be called during training')\n\n self.accum *= self.decay\n self.biased.mul_(self.decay)\n self.biased.add_((1 - self.decay) * self.tensor)\n self.average.copy_(self.biased)\n self.average.div_(1 - self.accum)\n\n def forward(self):\n if self.training:\n return self.tensor\n return self.average\n \nimport io\nimport base64\ndef image_to_data_url(img, ext): \n img_byte_arr = io.BytesIO()\n img.save(img_byte_arr, format=ext)\n img_byte_arr = img_byte_arr.getvalue()\n # ext = filename.split('.')[-1]\n prefix = f'data:image/{ext};base64,'\n return prefix + base64.b64encode(img_byte_arr).decode('utf-8')\n \n\ndef update_random( seed, purpose ):\n if seed == -1:\n seed = random.seed()\n seed = random.randrange(1,99999)\n \n print( f'Using seed {seed} for {purpose}')\n random.seed(seed)\n torch.manual_seed(seed)\n np.random.seed(seed)\n\n return seed\n\ndef clear_memory():\n gc.collect()\n torch.cuda.empty_cache()",
"_____no_output_____"
],
[
"#@title Setup for A100\ndevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\n\nif gpu.name.startswith('A100'):\n torch.backends.cudnn.enabled = False\n print('Finished setup for A100')\n ",
"_____no_output_____"
],
[
"#@title Loss Module Definitions\nfrom typing import cast, Dict, Optional\nfrom kornia.augmentation.base import IntensityAugmentationBase2D\n\nclass FixPadding(nn.Module):\n \n def __init__(self, module=None, threshold=1e-12, noise_frac=0.00 ):\n super().__init__()\n\n self.threshold = threshold\n self.noise_frac = noise_frac\n\n self.module = module\n\n def forward(self,input):\n\n dims = input.shape\n\n if self.module is not None:\n input = self.module(input + self.threshold)\n\n light = input.new_empty(dims[0],1,1,1).uniform_(0.,2.)\n\n mixed = input.view(*dims[:2],-1).sum(dim=1,keepdim=True)\n\n black = mixed < self.threshold\n black = black.view(-1,1,*dims[2:4]).type(torch.float)\n black = kornia.filters.box_blur( black, (5,5) ).clip(0,0.1)/0.1\n\n mean = input.view(*dims[:2],-1).sum(dim=2) / mixed.count_nonzero(dim=2)\n mean = ( mean[:,:,None,None] * light ).clip(0,1)\n\n fill = mean.expand(*dims)\n if 0 < self.noise_frac:\n rng = torch.get_rng_state()\n fill = fill + torch.randn_like(mean) * self.noise_frac\n torch.set_rng_state(rng)\n \n if self.module is not None:\n input = input - self.threshold\n\n return torch.lerp(input,fill,black)\n\n\nclass MyRandomNoise(IntensityAugmentationBase2D):\n def __init__(\n self,\n frac: float = 0.1,\n return_transform: bool = False,\n same_on_batch: bool = False,\n p: float = 0.5,\n ) -> None:\n super().__init__(p=p, return_transform=return_transform, same_on_batch=same_on_batch, p_batch=1.0)\n self.frac = frac\n\n def __repr__(self) -> str:\n return self.__class__.__name__ + f\"({super().__repr__()})\"\n\n def generate_parameters(self, shape: torch.Size) -> Dict[str, torch.Tensor]:\n noise = torch.FloatTensor(1).uniform_(0,self.frac)\n \n # generate pixel data without throwing off determinism of augs\n rng = torch.get_rng_state()\n noise = noise * torch.randn(shape)\n torch.set_rng_state(rng)\n\n return dict(noise=noise)\n\n def apply_transform(\n self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None\n ) -> torch.Tensor:\n return input + params['noise'].to(input.device)\n\nclass MakeCutouts2(nn.Module):\n def __init__(self, cut_size, cutn):\n super().__init__()\n self.cut_size = cut_size\n self.cutn = cutn\n\n def forward(self, input):\n sideY, sideX = input.shape[2:4]\n max_size = min(sideX, sideY)\n min_size = min(sideX, sideY, self.cut_size)\n cutouts = []\n cutouts_full = []\n \n min_size_width = min(sideX, sideY)\n lower_bound = float(self.cut_size/min_size_width)\n \n for ii in range(self.cutn):\n size = int(min_size_width*torch.zeros(1,).normal_(mean=.8, std=.3).clip(lower_bound, 1.)) # replace .5 with a result for 224 the default large size is .95\n \n offsetx = torch.randint(0, sideX - size + 1, ())\n offsety = torch.randint(0, sideY - size + 1, ())\n cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]\n cutouts.append(cutout)\n \n return cutouts\n\n\nclass MultiClipLoss(nn.Module):\n def __init__(self, clip_models, text_prompt, normalize_prompt_weights, cutn, cut_pow=1., clip_weight=1., use_old_augs=False, simulate_old_cuts=False ):\n super().__init__()\n\n self.use_old_augs = use_old_augs\n self.simulate_old_cuts = simulate_old_cuts \n\n # Load Clip\n self.perceptors = []\n for cm in clip_models:\n c = clip.load(cm[0], jit=False)[0].eval().requires_grad_(False).to(device)\n self.perceptors.append( { 'res': c.visual.input_resolution, 'perceptor': c, 'weight': cm[1], 'prompts':[] } ) \n self.perceptors.sort(key=lambda e: e['res'], reverse=True)\n \n # Make Cutouts\n self.cut_sizes = list(set([p['res'] for p in self.perceptors]))\n self.cut_sizes.sort( reverse=True )\n \n self.make_cuts = MakeCutouts2(self.cut_sizes[-1], cutn)\n\n # Get Prompt Embedings\n texts = [phrase.strip() for phrase in text_prompt.split(\"|\")]\n if text_prompt == ['']:\n texts = []\n\n self.pMs = []\n\n prompts_weight_sum = 0\n parsed_prompts = []\n for prompt in texts:\n txt, weight, stop = parse_prompt(prompt)\n parsed_prompts.append( [txt,weight,stop] )\n prompts_weight_sum += max( weight, 0 )\n\n for prompt in parsed_prompts:\n txt, weight, stop = prompt\n clip_token = clip.tokenize(txt).to(device)\n\n if normalize_prompt_weights and 0 < prompts_weight_sum:\n weight /= prompts_weight_sum\n\n for p in self.perceptors:\n embed = p['perceptor'].encode_text(clip_token).float()\n embed_normed = F.normalize(embed.unsqueeze(0), dim=2)\n p['prompts'].append({'embed_normed':embed_normed,'weight':torch.as_tensor(weight, device=device),'stop':torch.as_tensor(stop, device=device)})\n \n # Prep Augments\n self.noise_fac = 0.1\n self.normalize = transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],\n std=[0.26862954, 0.26130258, 0.27577711]) \n \n self.augs = nn.Sequential(\n K.RandomHorizontalFlip(p=0.5),\n K.RandomSharpness(0.3,p=0.1),\n FixPadding( nn.Sequential(\n K.RandomAffine(degrees=30, translate=0.1, p=0.8, padding_mode='zeros'), # padding_mode=2\n K.RandomPerspective(0.2,p=0.4, ),\n )),\n K.ColorJitter(hue=0.01, saturation=0.01, p=0.7),\n K.RandomGrayscale(p=0.15), \n MyRandomNoise(frac=self.noise_fac,p=1.),\n )\n\n self.clip_weight = clip_weight\n\n def prepare_cuts(self,img):\n cutouts = self.make_cuts(img)\n cutouts_out = []\n \n rng = torch.get_rng_state()\n\n for sz in self.cut_sizes:\n cuts = [resample(c, (sz,sz)) for c in cutouts]\n cuts = torch.cat(cuts, dim=0)\n cuts = clamp_with_grad(cuts,0,1)\n\n torch.set_rng_state(rng)\n cuts = self.augs(cuts)\n cuts = self.normalize(cuts)\n\n cutouts_out.append(cuts)\n\n return cutouts_out\n\n def forward( self, i, img ):\n cutouts = self.prepare_cuts( img )\n loss = []\n \n current_cuts = None\n currentres = 0\n \n for p in self.perceptors:\n if currentres != p['res']:\n currentres = p['res']\n current_cuts = cutouts[self.cut_sizes.index( currentres )]\n\n iii = p['perceptor'].encode_image(current_cuts).float()\n input_normed = F.normalize(iii.unsqueeze(1), dim=2)\n for prompt in p['prompts']:\n dists = input_normed.sub(prompt['embed_normed']).norm(dim=2).div(2).arcsin().pow(2).mul(2)\n dists = dists * prompt['weight'].sign()\n l = prompt['weight'].abs() * replace_grad(dists, torch.maximum(dists, prompt['stop'])).mean()\n loss.append(l * p['weight'])\n\n return loss\n\nclass MSEDecayLoss(nn.Module):\n def __init__(self, init_weight, mse_decay_rate, mse_epoches, mse_quantize ):\n super().__init__()\n \n self.init_weight = init_weight\n self.has_init_image = False\n self.mse_decay = init_weight / mse_epoches if init_weight else 0 \n self.mse_decay_rate = mse_decay_rate\n self.mse_weight = init_weight\n self.mse_epoches = mse_epoches\n self.mse_quantize = mse_quantize\n\n @torch.no_grad()\n def set_target( self, z_tensor, model ):\n z_tensor = z_tensor.detach().clone()\n if self.mse_quantize:\n z_tensor = vector_quantize(z_tensor.movedim(1, 3), model.quantize.embedding.weight).movedim(3, 1)#z.average\n self.z_orig = z_tensor\n \n def forward( self, i, z ):\n if self.is_active(i):\n return F.mse_loss(z, self.z_orig) * self.mse_weight / 2\n return 0\n \n def is_active(self, i):\n if not self.init_weight:\n return False\n if i <= self.mse_decay_rate and not self.has_init_image:\n return False\n return True\n\n @torch.no_grad()\n def step( self, i ):\n\n if i % self.mse_decay_rate == 0 and i != 0 and i < self.mse_decay_rate * self.mse_epoches:\n \n if self.mse_weight - self.mse_decay > 0 and self.mse_weight - self.mse_decay >= self.mse_decay:\n self.mse_weight -= self.mse_decay\n else:\n self.mse_weight = 0\n print(f\"updated mse weight: {self.mse_weight}\")\n\n return True\n\n return False\n \nclass TVLoss(nn.Module):\n def forward(self, input):\n input = F.pad(input, (0, 1, 0, 1), 'replicate')\n x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]\n y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]\n diff = x_diff**2 + y_diff**2 + 1e-8\n return diff.mean(dim=1).sqrt().mean()\n",
"_____no_output_____"
],
[
"#@title Random Inits\n\nimport torch\nimport math\n\ndef rand_perlin_2d(shape, res, fade = lambda t: 6*t**5 - 15*t**4 + 10*t**3):\n delta = (res[0] / shape[0], res[1] / shape[1])\n d = (shape[0] // res[0], shape[1] // res[1])\n \n grid = torch.stack(torch.meshgrid(torch.arange(0, res[0], delta[0]), torch.arange(0, res[1], delta[1])), dim = -1) % 1\n angles = 2*math.pi*torch.rand(res[0]+1, res[1]+1)\n gradients = torch.stack((torch.cos(angles), torch.sin(angles)), dim = -1)\n \n tile_grads = lambda slice1, slice2: gradients[slice1[0]:slice1[1], slice2[0]:slice2[1]].repeat_interleave(d[0], 0).repeat_interleave(d[1], 1)\n dot = lambda grad, shift: (torch.stack((grid[:shape[0],:shape[1],0] + shift[0], grid[:shape[0],:shape[1], 1] + shift[1] ), dim = -1) * grad[:shape[0], :shape[1]]).sum(dim = -1)\n \n n00 = dot(tile_grads([0, -1], [0, -1]), [0, 0])\n n10 = dot(tile_grads([1, None], [0, -1]), [-1, 0])\n n01 = dot(tile_grads([0, -1],[1, None]), [0, -1])\n n11 = dot(tile_grads([1, None], [1, None]), [-1,-1])\n t = fade(grid[:shape[0], :shape[1]])\n return math.sqrt(2) * torch.lerp(torch.lerp(n00, n10, t[..., 0]), torch.lerp(n01, n11, t[..., 0]), t[..., 1])\n\ndef rand_perlin_2d_octaves( desired_shape, octaves=1, persistence=0.5):\n shape = torch.tensor(desired_shape)\n shape = 2 ** torch.ceil( torch.log2( shape ) )\n shape = shape.type(torch.int)\n\n max_octaves = int(min(octaves,math.log(shape[0])/math.log(2), math.log(shape[1])/math.log(2)))\n res = torch.floor( shape / 2 ** max_octaves).type(torch.int)\n\n noise = torch.zeros(list(shape))\n frequency = 1\n amplitude = 1\n for _ in range(max_octaves):\n noise += amplitude * rand_perlin_2d(shape, (frequency*res[0], frequency*res[1]))\n frequency *= 2\n amplitude *= persistence\n \n return noise[:desired_shape[0],:desired_shape[1]]\n\ndef rand_perlin_rgb( desired_shape, amp=0.1, octaves=6 ):\n r = rand_perlin_2d_octaves( desired_shape, octaves )\n g = rand_perlin_2d_octaves( desired_shape, octaves )\n b = rand_perlin_2d_octaves( desired_shape, octaves )\n rgb = ( torch.stack((r,g,b)) * amp + 1 ) * 0.5\n return rgb.unsqueeze(0).clip(0,1).to(device)\n\n\ndef pyramid_noise_gen(shape, octaves=5, decay=1.):\n n, c, h, w = shape\n noise = torch.zeros([n, c, 1, 1])\n max_octaves = int(min(math.log(h)/math.log(2), math.log(w)/math.log(2)))\n if octaves is not None and 0 < octaves:\n max_octaves = min(octaves,max_octaves)\n for i in reversed(range(max_octaves)):\n h_cur, w_cur = h // 2**i, w // 2**i\n noise = F.interpolate(noise, (h_cur, w_cur), mode='bicubic', align_corners=False)\n noise += ( torch.randn([n, c, h_cur, w_cur]) / max_octaves ) * decay**( max_octaves - (i+1) )\n return noise\n\ndef rand_z(model, toksX, toksY):\n e_dim = model.quantize.e_dim\n n_toks = model.quantize.n_e\n z_min = model.quantize.embedding.weight.min(dim=0).values[None, :, None, None]\n z_max = model.quantize.embedding.weight.max(dim=0).values[None, :, None, None]\n\n one_hot = F.one_hot(torch.randint(n_toks, [toksY * toksX], device=device), n_toks).float()\n z = one_hot @ model.quantize.embedding.weight\n z = z.view([-1, toksY, toksX, e_dim]).permute(0, 3, 1, 2)\n\n return z\n\n\ndef make_rand_init( mode, model, perlin_octaves, perlin_weight, pyramid_octaves, pyramid_decay, toksX, toksY, f ):\n\n if mode == 'VQGAN ZRand':\n return rand_z(model, toksX, toksY)\n elif mode == 'Perlin Noise':\n rand_init = rand_perlin_rgb((toksY * f, toksX * f), perlin_weight, perlin_octaves )\n z, *_ = model.encode(rand_init * 2 - 1)\n return z\n elif mode == 'Pyramid Noise':\n rand_init = pyramid_noise_gen( (1,3,toksY * f, toksX * f), pyramid_octaves, pyramid_decay).to(device)\n rand_init = ( rand_init * 0.5 + 0.5 ).clip(0,1)\n z, *_ = model.encode(rand_init * 2 - 1)\n return z\n \n",
"_____no_output_____"
]
],
[
[
"# Make some Art!",
"_____no_output_____"
]
],
[
[
"#@title Set VQGAN Model Save Location\n#@markdown It's a lot faster to load model files from google drive than to download them every time you want to use this notebook.\nsave_vqgan_models_to_drive = True #@param {type: 'boolean'}\ndownload_all = False \nvqgan_path_on_google_drive = \"/content/drive/MyDrive/Art/Models/VQGAN/\" #@param {type: 'string'}\nvqgan_path_on_google_drive += \"/\" if not vqgan_path_on_google_drive.endswith('/') else \"\"\n\n#@markdown Should all the images during the run be saved to google drive?\nsave_output_to_drive = True #@param {type:'boolean'}\noutput_path_on_google_drive = \"/content/drive/MyDrive/Art/\" #@param {type: 'string'}\noutput_path_on_google_drive += \"/\" if not output_path_on_google_drive.endswith('/') else \"\"\n\n#@markdown When saving the images, how much should be included in the name?\ninclude_full_prompt_in_filename = False #@param {type:'boolean'}\nshortname_limit = 50 #@param {type: 'number'}\nfilename_limit = 250\n\nif save_vqgan_models_to_drive or save_output_to_drive:\n from google.colab import drive \n drive.mount('/content/drive')\n\nvqgan_model_path = \"/content/\"\nif save_vqgan_models_to_drive:\n vqgan_model_path = vqgan_path_on_google_drive\n !mkdir -p \"$vqgan_path_on_google_drive\"\n\nsave_output_path = \"/content/art/\"\nif save_output_to_drive:\n save_output_path = output_path_on_google_drive\n!mkdir -p \"$save_output_path\"\n\nmodel_download={\n \"vqgan_imagenet_f16_1024\":\n [[\"vqgan_imagenet_f16_1024.yaml\", \"https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1\"],\n [\"vqgan_imagenet_f16_1024.ckpt\", \"https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fckpts%2Flast.ckpt&dl=1\"]],\n \"vqgan_imagenet_f16_16384\": \n [[\"vqgan_imagenet_f16_16384.yaml\", \"https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1\"],\n [\"vqgan_imagenet_f16_16384.ckpt\", \"https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fckpts%2Flast.ckpt&dl=1\"]],\n \"vqgan_openimages_f8_8192\":\n [[\"vqgan_openimages_f8_8192.yaml\", \"https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1\"],\n [\"vqgan_openimages_f8_8192.ckpt\", \"https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/files/?p=%2Fckpts%2Flast.ckpt&dl=1\"]],\n \"coco\":\n [[\"coco_first_stage.yaml\", \"http://batbot.tv/ai/models/vqgan/coco_first_stage.yaml\"],\n [\"coco_first_stage.ckpt\", \"http://batbot.tv/ai/models/vqgan/coco_first_stage.ckpt\"]],\n \"faceshq\":\n [[\"faceshq.yaml\", \"https://drive.google.com/uc?export=download&id=1fHwGx_hnBtC8nsq7hesJvs-Klv-P0gzT\"],\n [\"faceshq.ckpt\", \"https://app.koofr.net/content/links/a04deec9-0c59-4673-8b37-3d696fe63a5d/files/get/last.ckpt?path=%2F2020-11-13T21-41-45_faceshq_transformer%2Fcheckpoints%2Flast.ckpt\"]],\n \"wikiart_1024\":\n [[\"wikiart_1024.yaml\", \"http://batbot.tv/ai/models/vqgan/WikiArt_augmented_Steps_7mil_finetuned_1mil.yaml\"],\n [\"wikiart_1024.ckpt\", \"http://batbot.tv/ai/models/vqgan/WikiArt_augmented_Steps_7mil_finetuned_1mil.ckpt\"]],\n \"wikiart_16384\":\n [[\"wikiart_16384.yaml\", \"http://eaidata.bmk.sh/data/Wikiart_16384/wikiart_f16_16384_8145600.yaml\"],\n [\"wikiart_16384.ckpt\", \"http://eaidata.bmk.sh/data/Wikiart_16384/wikiart_f16_16384_8145600.ckpt\"]],\n \"sflckr\":\n [[\"sflckr.yaml\", \"https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/files/?p=%2Fconfigs%2F2020-11-09T13-31-51-project.yaml&dl=1\"],\n [\"sflckr.ckpt\", \"https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/files/?p=%2Fcheckpoints%2Flast.ckpt&dl=1\"]],\n }\n\nloaded_model = None\nloaded_model_name = None\ndef dl_vqgan_model(image_model):\n for curl_opt in model_download[image_model]:\n modelpath = f'{vqgan_model_path}{curl_opt[0]}'\n if not path.exists(modelpath):\n print(f'downloading {curl_opt[0]} to {modelpath}')\n !curl -L -o {modelpath} '{curl_opt[1]}'\n else:\n print(f'found existing {curl_opt[0]}')\n\ndef get_vqgan_model(image_model):\n global loaded_model\n global loaded_model_name\n if loaded_model is None or loaded_model_name != image_model:\n dl_vqgan_model(image_model)\n \n print(f'loading {image_model} vqgan checkpoint')\n\n \n vqgan_config= vqgan_model_path + model_download[image_model][0][0]\n vqgan_checkpoint= vqgan_model_path + model_download[image_model][1][0]\n print('vqgan_config',vqgan_config)\n print('vqgan_checkpoint',vqgan_checkpoint)\n\n model = load_vqgan_model(vqgan_config, vqgan_checkpoint).to(device)\n if image_model == 'vqgan_openimages_f8_8192':\n model.quantize.e_dim = 256\n model.quantize.n_e = model.quantize.n_embed\n model.quantize.embedding = model.quantize.embed\n\n loaded_model = model\n loaded_model_name = image_model\n\n return loaded_model\n\ndef slugify(value):\n value = str(value)\n value = re.sub(r':([-\\d.]+)', ' [\\\\1]', value)\n value = re.sub(r'[|]','; ',value)\n value = re.sub(r'[<>:\"/\\\\|?*]', ' ', value)\n return value\n\ndef get_filename(text, seed, i, ext):\n if ( not include_full_prompt_in_filename ):\n text = re.split(r'[|:;]',text, 1)[0][:shortname_limit]\n text = slugify(text)\n\n now = datetime.now()\n t = now.strftime(\"%y%m%d%H%M\")\n if i is not None:\n data = f'; r{seed} i{i} {t}{ext}'\n else:\n data = f'; r{seed} {t}{ext}'\n\n return text[:filename_limit-len(data)] + data\n\ndef save_output(pil, text, seed, i):\n fname = get_filename(text,seed,i,'.png')\n pil.save(save_output_path + fname)\n\nif save_vqgan_models_to_drive and download_all:\n for model in model_download.keys():\n dl_vqgan_model(model)\n",
"_____no_output_____"
],
[
"#@title Set Display Rate\n#@markdown If `use_automatic_display_schedule` is enabled, the image will be output frequently at first, and then more spread out as time goes on. Turn this off if you want to specify the display rate yourself.\nuse_automatic_display_schedule = False #@param {type:'boolean'}\ndisplay_every = 5 #@param {type:'number'}\n\ndef should_checkin(i):\n if i == max_iter: \n return True \n\n if not use_automatic_display_schedule:\n return i % display_every == 0\n\n schedule = [[100,25],[500,50],[1000,100],[2000,200]]\n for s in schedule:\n if i <= s[0]:\n return i % s[1] == 0\n return i % 500 == 0\n",
"_____no_output_____"
]
],
[
[
"Before generating, the rest of the setup steps must first be executed by pressing **`Runtime > Run All`**. This only needs to be done once.",
"_____no_output_____"
]
],
[
[
"#@title Do the Run\n\n#@markdown What do you want to see?\ntext_prompt = 'made of buildings:200 | Ethiopian flags:40 | pollution:30 | 4k:20 | Unreal engine:20 | V-ray:20 | Cryengine:20 | Ray tracing:20 | Photorealistic:20 | Hyper-realistic:20'#@param {type:'string'}\ngen_seed = -1#@param {type:'number'}\n#@markdown - If you want to keep starting from the same point, set `gen_seed` to a positive number. `-1` will make it random every time. \ninit_image = '/content/d.png'#@param {type:'string'}\nwidth = 300#@param {type:'number'}\nheight = 300#@param {type:'number'}\nmax_iter = 2000#@param {type:'number'}\n\n\n#@markdown There are different ways of generating the random starting point, when not using an init image. These influence how the image turns out. The default VQGAN ZRand is good, but some models and subjects may do better with perlin or pyramid noise.\nrand_init_mode = 'VQGAN ZRand'#@param [ \"VQGAN ZRand\", \"Perlin Noise\", \"Pyramid Noise\"]\nperlin_octaves = 7#@param {type:\"slider\", min:1, max:8, step:1}\nperlin_weight = 0.22#@param {type:\"slider\", min:0, max:1, step:0.01}\npyramid_octaves = 5#@param {type:\"slider\", min:1, max:8, step:1}\npyramid_decay = 0.99#@param {type:\"slider\", min:0, max:1, step:0.01}\nema_val = 0.99\n\n#@markdown How many slices of the image should be sent to CLIP each iteration to score? Higher numbers are better, but cost more memory. If you are running into memory issues try lowering this value.\ncut_n = 64 #@param {type:'number'}\n\n#@markdown One clip model is good. Two is better? You may need to reduce the number of cuts to support having more than one CLIP model. CLIP is what scores the image against your prompt and each model has slightly different ideas of what things are.\n#@markdown - `ViT-B/32` is fast and good and what most people use to begin with\n\nclip_model = 'ViT-B/32' #@param [\"ViT-B/16\", \"ViT-B/32\", \"RN50x16\", \"RN50x4\"]\nclip_model2 ='ViT-B/16' #@param [\"None\",\"ViT-B/16\", \"ViT-B/32\", \"RN50x16\", \"RN50x4\"]\nif clip_model2 == \"None\":\n clip_model2 = None \nclip1_weight = 0.5 #@param {type:\"slider\", min:0, max:1, step:0.01}\n\n#@markdown Picking a different VQGAN model will impact how an image generates. Think of this as giving the generator a different set of brushes and paints to work with. CLIP is still the \"eyes\" and is judging the image against your prompt but using different brushes will make a different image.\n#@markdown - `vqgan_imagenet_f16_16384` is the default and what most people use\nvqgan_model = 'vqgan_imagenet_f16_16384'#@param [ \"vqgan_imagenet_f16_1024\", \"vqgan_imagenet_f16_16384\", \"vqgan_openimages_f8_8192\", \"coco\", \"faceshq\",\"wikiart_1024\", \"wikiart_16384\", \"sflckr\"]\n\n#@markdown Learning rates greatly impact how quickly an image can generate, or if an image can generate at all. The first learning rate is only for the first 50 iterations. The epoch rate is what is used after reaching the first mse epoch. \n#@markdown You can try lowering the epoch rate while raising the initial learning rate and see what happens\nlearning_rate = 0.9#@param {type:'number'}\nlearning_rate_epoch = 0.2#@param {type:'number'}\n#@markdown How much should we try to match the init image, or if no init image how much should we resist change after reaching the first epoch?\nmse_weight = 1.8#@param {type:'number'}\n#@markdown Adding some TV may make the image blurrier but also helps to get rid of noise. A good value to try might be 0.1.\ntv_weight = 0.0 #@param {type:'number'}\n#@markdown Should the total weight of the text prompts stay in the same range, relative to other loss functions?\nnormalize_prompt_weights = True #@param {type:'boolean'}\n\n#@markdown Enabling the EMA tensor will cause the image to be slower to generate but may help it be more cohesive.\n#@markdown This can also help keep the final image closer to the init image, if you are providing one.\nuse_ema_tensor = False #@param {type:'boolean'}\n\n#@markdown If you want to generate a video of the run, you need to save the frames as you go. The more frequently you save, the longer the video but the slower it will take to generate.\nsave_art_output = True #@param {type:'boolean'}\nsave_frames_for_video = False #@param {type:'boolean'}\nsave_frequency_for_video = 3 #@param {type:'number'}\n\n\n#@markdown ----\n#@markdown I'd love to see what you can make with my notebook. Tweet me your art [@remi_durant](https://twitter.com/remi_durant)!\n\noutput_as_png = True\n\nprint('Using device:', device)\nprint('using prompts: ', text_prompt)\n\nclear_memory()\n\n!rm -r steps\n!mkdir -p steps\n\nmodel = get_vqgan_model( vqgan_model )\n\nif clip_model2:\n clip_models = [[clip_model, clip1_weight], [clip_model2, 1. - clip1_weight]]\nelse:\n clip_models = [[clip_model, 1.0]]\nprint(clip_models)\n\nclip_loss = MultiClipLoss( clip_models, text_prompt, normalize_prompt_weights=normalize_prompt_weights, cutn=cut_n)\n\nseed = update_random( gen_seed, 'image generation')\n \n# Make Z Init\nz = 0\n\nf = 2**(model.decoder.num_resolutions - 1)\ntoksX, toksY = math.ceil( width / f), math.ceil( height / f)\n\nprint(f'Outputing size: [{toksX*f}x{toksY*f}]')\n\nhas_init_image = (init_image != \"\")\nif has_init_image:\n if 'http' in init_image:\n req = Request(init_image, headers={'User-Agent': 'Mozilla/5.0'})\n img = Image.open(urlopen(req))\n else:\n img = Image.open(init_image)\n\n pil_image = img.convert('RGB')\n pil_image = pil_image.resize((toksX * f, toksY * f), Image.LANCZOS)\n pil_image = TF.to_tensor(pil_image)\n #if args.use_noise:\n # pil_image = pil_image + args.use_noise * torch.randn_like(pil_image) \n z, *_ = model.encode(pil_image.to(device).unsqueeze(0) * 2 - 1)\n del pil_image\n del img\n\nelse:\n z = make_rand_init( rand_init_mode, model, perlin_octaves, perlin_weight, pyramid_octaves, pyramid_decay, toksX, toksY, f )\n \nz = EMATensor(z, ema_val)\n\nopt = optim.Adam( z.parameters(), lr=learning_rate, weight_decay=0.00000000)\n\nmse_loss = MSEDecayLoss( mse_weight, mse_decay_rate=50, mse_epoches=5, mse_quantize=True )\nmse_loss.set_target( z.tensor, model )\nmse_loss.has_init_image = has_init_image\n\ntv_loss = TVLoss() \n\n\nlosses = []\nmb = master_bar(range(1))\ngnames = ['losses']\n\nmb.names=gnames\nmb.graph_fig, axs = plt.subplots(1, 1) # For custom display\nmb.graph_ax = axs\nmb.graph_out = display.display(mb.graph_fig, display_id=True)\n\n## optimizer loop\n\ndef synth(z, quantize=True, scramble=True):\n z_q = 0\n if quantize:\n z_q = vector_quantize(z.movedim(1, 3), model.quantize.embedding.weight).movedim(3, 1)\n else:\n z_q = z.model\n\n out = clamp_with_grad(model.decode(z_q).add(1).div(2), 0, 1)\n\n return out\n\n@torch.no_grad()\ndef checkin(i, z, out_pil, losses):\n losses_str = ', '.join(f'{loss.item():g}' for loss in losses)\n tqdm.write(f'i: {i}, loss: {sum(losses).item():g}, losses: {losses_str}')\n\n display_format='png' if output_as_png else 'jpg'\n pil_data = image_to_data_url(out_pil, display_format)\n \n display.display(display.HTML(f'<img src=\"{pil_data}\" />'))\n\ndef should_save_for_video(i):\n return save_frames_for_video and i % save_frequency_for_video\n\ndef train(i):\n global opt\n global z \n opt.zero_grad( set_to_none = True )\n\n out = checkpoint( synth, z.tensor )\n\n lossAll = []\n lossAll += clip_loss( i,out )\n\n if 0 < mse_weight:\n msel = mse_loss(i,z.tensor)\n if 0 < msel:\n lossAll.append(msel)\n \n if 0 < tv_weight:\n lossAll.append(tv_loss(out)*tv_weight)\n \n loss = sum(lossAll)\n loss.backward()\n\n if should_checkin(i) or should_save_for_video(i):\n with torch.no_grad():\n if use_ema_tensor:\n out = synth( z.average )\n\n pil = TF.to_pil_image(out[0].cpu())\n\n if should_checkin(i):\n checkin(i, z, pil, lossAll)\n if save_art_output:\n save_output(pil, text_prompt, seed, i)\n \n if should_save_for_video(i):\n pil.save(f'steps/step{i//save_frequency_for_video:04}.png')\n \n # update graph\n losses.append(loss)\n x = range(len(losses))\n mb.update_graph( [[x,losses]] )\n\n opt.step()\n if use_ema_tensor:\n z.update()\n\ni = 0\ntry:\n with tqdm() as pbar:\n while True and i <= max_iter:\n \n if i % 200 == 0:\n clear_memory()\n\n train(i)\n\n with torch.no_grad():\n if mse_loss.step(i):\n print('Reseting optimizer at mse epoch')\n\n if mse_loss.has_init_image and use_ema_tensor:\n mse_loss.set_target(z.average,model)\n else:\n mse_loss.set_target(z.tensor,model)\n \n # Make sure not to spike loss when mse_loss turns on\n if not mse_loss.is_active(i):\n z.tensor = nn.Parameter(mse_loss.z_orig.clone())\n z.tensor.requires_grad = True\n\n if use_ema_tensor:\n z = EMATensor(z.average, ema_val)\n else:\n z = EMATensor(z.tensor, ema_val)\n\n opt = optim.Adam(z.parameters(), lr=learning_rate_epoch, weight_decay=0.00000000)\n\n i += 1\n pbar.update()\n\nexcept KeyboardInterrupt:\n pass\n",
"_____no_output_____"
],
[
"#@title Make a Video of Your Last Run!\n#@markdown If you want to make a video, you must first enable `save_frames_for_video` during the run. Setting a higher frequency will make a longer video, and a higher framerate will make a shorter video.\n\nfps = 24 #@param{type:'number'}\n\n!mkdir -p \"/content/video/\"\nvname = \"/content/video/\"+get_filename(text_prompt,seed,None,'.mp4')\n\n!ffmpeg -y -v 1 -framerate $fps -i steps/step%04d.png -r $fps -vcodec libx264 -crf 32 -pix_fmt yuv420p \"$vname\"\nif save_output_to_drive:\n !cp \"$vname\" \"$output_path_on_google_drive\"\n\nmp4 = open(vname,'rb').read()\ndata_url = \"data:video/mp4;base64,\" + b64encode(mp4).decode()\ndisplay.display( display.HTML(f'<video controls><source src=\"{data_url}\" type=\"video/mp4\"></video>') )",
"_____no_output_____"
]
],
[
[
"# Extra Resources\n\nYou may want to check out some of my other projects as well to get more insight into how the different parts of VQGAN+CLIP work together to generate an image:\n\n- Art Styles and Movements, as perceived by VQGAN+CLIP\n - [VQGAN Imagenet16k + ViT-B/32](https://imgur.com/gallery/BZzXLHY)\n - [VQGAN Imagenet16k + ViT-B/16](https://imgur.com/gallery/w14XZFd)\n - [VQGAN Imagenet16k + RN50x16](https://imgur.com/gallery/Kd0WYfo)\n - [VQGAN Imagenet16k + RN50x4](https://imgur.com/gallery/PNd7zYp)\n- [How CLIP \"sees\"](https://twitter.com/remi_durant/status/1460607677801897990?s=20)\n\nThere is also this great prompt exploration from @kingdomakrillic which showcases a lot of the words you can add to your prompt to push CLIP towards certain styles:\n- [CLIP + VQGAN Keyword Comparison](https://imgur.com/a/SnSIQRu)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d005eda3f68cb84605e3bccea8168ff44a21d4b1
| 42,916 |
ipynb
|
Jupyter Notebook
|
notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | 1 |
2021-11-02T07:05:50.000Z
|
2021-11-02T07:05:50.000Z
|
notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | null | null | null |
notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | null | null | null | 37.844797 | 477 | 0.541546 |
[
[
[
"# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Vertex Pipelines: Lightweight Python function-based components, and component I/O\n\n<table align=\"left\">\n <td>\n <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Colab logo\"> Run in Colab\n </a>\n </td>\n <td>\n <a href=\"https://github.com/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\">\n View on GitHub\n </a>\n </td>\n <td>\n <a href=\"https://console.cloud.google.com/ai/platform/notebooks/deploy-notebook?download_url=https://github.com/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/lightweight_functions_component_io_kfp.ipynb\">\n Open in Google Cloud Notebooks\n </a>\n </td>\n</table>\n<br/><br/><br/>",
"_____no_output_____"
],
[
"## Overview\n\nThis notebooks shows how to use [the Kubeflow Pipelines (KFP) SDK](https://www.kubeflow.org/docs/components/pipelines/) to build [Vertex Pipelines](https://cloud.google.com/vertex-ai/docs/pipelines) that use lightweight Python function based components, as well as supporting component I/O using the KFP SDK.",
"_____no_output_____"
],
[
"### Objective\n\nIn this tutorial, you use the KFP SDK to build lightweight Python function-based components.\n\nThe steps performed include:\n\n- Build Python function-based components.\n- Pass *Artifacts* and *parameters* between components, both by path reference and by value.\n- Use the `kfp.dsl.importer` method.",
"_____no_output_____"
],
[
"### KFP Python function-based components\n\nA Kubeflow pipeline component is a self-contained set of code that performs one step in your ML workflow. A pipeline component is composed of:\n\n* The component code, which implements the logic needed to perform a step in your ML workflow.\n* A component specification, which defines the following:\n * The component’s metadata, its name and description.\n * The component’s interface, the component’s inputs and outputs.\n* The component’s implementation, the Docker container image to run, how to pass inputs to your component code, and how to get the component’s outputs.\n\nLightweight Python function-based components make it easier to iterate quickly by letting you build your component code as a Python function and generating the component specification for you. This notebook shows how to create Python function-based components for use in [Vertex Pipelines](https://cloud.google.com/vertex-ai/docs/pipelines).\n\nPython function-based components use the Kubeflow Pipelines SDK to handle the complexity of passing inputs into your component and passing your function’s outputs back to your pipeline.\n\nThere are two categories of inputs/outputs supported in Python function-based components: *artifacts* and *parameters*.\n\n* Parameters are passed to your component by value and typically contain `int`, `float`, `bool`, or small `string` values.\n* Artifacts are passed to your component as a *reference* to a path, to which you can write a file or a subdirectory structure. In addition to the artifact’s data, you can also read and write the artifact’s metadata. This lets you record arbitrary key-value pairs for an artifact such as the accuracy of a trained model, and use metadata in downstream components – for example, you could use metadata to decide if a model is accurate enough to deploy for predictions.",
"_____no_output_____"
],
[
"### Costs\n\nThis tutorial uses billable components of Google Cloud:\n\n* Vertex AI\n* Cloud Storage\n\nLearn about [Vertex AI\npricing](https://cloud.google.com/vertex-ai/pricing) and [Cloud Storage\npricing](https://cloud.google.com/storage/pricing), and use the [Pricing\nCalculator](https://cloud.google.com/products/calculator/)\nto generate a cost estimate based on your projected usage.",
"_____no_output_____"
],
[
"### Set up your local development environment\n\nIf you are using Colab or Google Cloud Notebook, your environment already meets all the requirements to run this notebook. You can skip this step.\n\nOtherwise, make sure your environment meets this notebook's requirements. You need the following:\n\n- The Cloud Storage SDK\n- Git\n- Python 3\n- virtualenv\n- Jupyter notebook running in a virtual environment with Python 3\n\nThe Cloud Storage guide to [Setting up a Python development environment](https://cloud.google.com/python/setup) and the [Jupyter installation guide](https://jupyter.org/install) provide detailed instructions for meeting these requirements. The following steps provide a condensed set of instructions:\n\n1. [Install and initialize the SDK](https://cloud.google.com/sdk/docs/).\n\n2. [Install Python 3](https://cloud.google.com/python/setup#installing_python).\n\n3. [Install virtualenv](Ihttps://cloud.google.com/python/setup#installing_and_using_virtualenv) and create a virtual environment that uses Python 3.\n\n4. Activate that environment and run `pip3 install Jupyter` in a terminal shell to install Jupyter.\n\n5. Run `jupyter notebook` on the command line in a terminal shell to launch Jupyter.\n\n6. Open this notebook in the Jupyter Notebook Dashboard.\n",
"_____no_output_____"
],
[
"## Installation\n\nInstall the latest version of Vertex SDK for Python.",
"_____no_output_____"
]
],
[
[
"import os\n\n# Google Cloud Notebook\nif os.path.exists(\"/opt/deeplearning/metadata/env_version\"):\n USER_FLAG = \"--user\"\nelse:\n USER_FLAG = \"\"\n\n! pip3 install --upgrade google-cloud-aiplatform $USER_FLAG",
"_____no_output_____"
]
],
[
[
"Install the latest GA version of *google-cloud-storage* library as well.",
"_____no_output_____"
]
],
[
[
"! pip3 install -U google-cloud-storage $USER_FLAG",
"_____no_output_____"
]
],
[
[
"Install the latest GA version of *google-cloud-pipeline-components* library as well.",
"_____no_output_____"
]
],
[
[
"! pip3 install $USER kfp google-cloud-pipeline-components --upgrade",
"_____no_output_____"
]
],
[
[
"### Restart the kernel\n\nOnce you've installed the additional packages, you need to restart the notebook kernel so it can find the packages.",
"_____no_output_____"
]
],
[
[
"import os\n\nif not os.getenv(\"IS_TESTING\"):\n # Automatically restart kernel after installs\n import IPython\n\n app = IPython.Application.instance()\n app.kernel.do_shutdown(True)",
"_____no_output_____"
]
],
[
[
"Check the versions of the packages you installed. The KFP SDK version should be >=1.6.",
"_____no_output_____"
]
],
[
[
"! python3 -c \"import kfp; print('KFP SDK version: {}'.format(kfp.__version__))\"\n! python3 -c \"import google_cloud_pipeline_components; print('google_cloud_pipeline_components version: {}'.format(google_cloud_pipeline_components.__version__))\"",
"_____no_output_____"
]
],
[
[
"## Before you begin\n\n### GPU runtime\n\nThis tutorial does not require a GPU runtime.\n\n### Set up your Google Cloud project\n\n**The following steps are required, regardless of your notebook environment.**\n\n1. [Select or create a Google Cloud project](https://console.cloud.google.com/cloud-resource-manager). When you first create an account, you get a $300 free credit towards your compute/storage costs.\n\n2. [Make sure that billing is enabled for your project.](https://cloud.google.com/billing/docs/how-to/modify-project)\n\n3. [Enable the Vertex AI APIs, Compute Engine APIs, and Cloud Storage.](https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component,storage-component.googleapis.com)\n\n4. [The Google Cloud SDK](https://cloud.google.com/sdk) is already installed in Google Cloud Notebook.\n\n5. Enter your project ID in the cell below. Then run the cell to make sure the\nCloud SDK uses the right project for all the commands in this notebook.\n\n**Note**: Jupyter runs lines prefixed with `!` as shell commands, and it interpolates Python variables prefixed with `$`.",
"_____no_output_____"
]
],
[
[
"PROJECT_ID = \"[your-project-id]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if PROJECT_ID == \"\" or PROJECT_ID is None or PROJECT_ID == \"[your-project-id]\":\n # Get your GCP project id from gcloud\n shell_output = ! gcloud config list --format 'value(core.project)' 2>/dev/null\n PROJECT_ID = shell_output[0]\n print(\"Project ID:\", PROJECT_ID)",
"_____no_output_____"
],
[
"! gcloud config set project $PROJECT_ID",
"_____no_output_____"
]
],
[
[
"#### Region\n\nYou can also change the `REGION` variable, which is used for operations\nthroughout the rest of this notebook. Below are regions supported for Vertex AI. We recommend that you choose the region closest to you.\n\n- Americas: `us-central1`\n- Europe: `europe-west4`\n- Asia Pacific: `asia-east1`\n\nYou may not use a multi-regional bucket for training with Vertex AI. Not all regions provide support for all Vertex AI services.\n\nLearn more about [Vertex AI regions](https://cloud.google.com/vertex-ai/docs/general/locations)",
"_____no_output_____"
]
],
[
[
"REGION = \"us-central1\" # @param {type: \"string\"}",
"_____no_output_____"
]
],
[
[
"#### Timestamp\n\nIf you are in a live tutorial session, you might be using a shared test account or project. To avoid name collisions between users on resources created, you create a timestamp for each instance session, and append the timestamp onto the name of resources you create in this tutorial.",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\n\nTIMESTAMP = datetime.now().strftime(\"%Y%m%d%H%M%S\")",
"_____no_output_____"
]
],
[
[
"### Authenticate your Google Cloud account\n\n**If you are using Google Cloud Notebook**, your environment is already authenticated. Skip this step.\n\n**If you are using Colab**, run the cell below and follow the instructions when prompted to authenticate your account via oAuth.\n\n**Otherwise**, follow these steps:\n\nIn the Cloud Console, go to the [Create service account key](https://console.cloud.google.com/apis/credentials/serviceaccountkey) page.\n\n**Click Create service account**.\n\nIn the **Service account name** field, enter a name, and click **Create**.\n\nIn the **Grant this service account access to project** section, click the Role drop-down list. Type \"Vertex\" into the filter box, and select **Vertex Administrator**. Type \"Storage Object Admin\" into the filter box, and select **Storage Object Admin**.\n\nClick Create. A JSON file that contains your key downloads to your local environment.\n\nEnter the path to your service account key as the GOOGLE_APPLICATION_CREDENTIALS variable in the cell below and run the cell.",
"_____no_output_____"
]
],
[
[
"# If you are running this notebook in Colab, run this cell and follow the\n# instructions to authenticate your GCP account. This provides access to your\n# Cloud Storage bucket and lets you submit training jobs and prediction\n# requests.\n\nimport os\nimport sys\n\n# If on Google Cloud Notebook, then don't execute this code\nif not os.path.exists(\"/opt/deeplearning/metadata/env_version\"):\n if \"google.colab\" in sys.modules:\n from google.colab import auth as google_auth\n\n google_auth.authenticate_user()\n\n # If you are running this notebook locally, replace the string below with the\n # path to your service account key and run this cell to authenticate your GCP\n # account.\n elif not os.getenv(\"IS_TESTING\"):\n %env GOOGLE_APPLICATION_CREDENTIALS ''",
"_____no_output_____"
]
],
[
[
"### Create a Cloud Storage bucket\n\n**The following steps are required, regardless of your notebook environment.**\n\nWhen you initialize the Vertex SDK for Python, you specify a Cloud Storage staging bucket. The staging bucket is where all the data associated with your dataset and model resources are retained across sessions.\n\nSet the name of your Cloud Storage bucket below. Bucket names must be globally unique across all Google Cloud projects, including those outside of your organization.",
"_____no_output_____"
]
],
[
[
"BUCKET_NAME = \"gs://[your-bucket-name]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if BUCKET_NAME == \"\" or BUCKET_NAME is None or BUCKET_NAME == \"gs://[your-bucket-name]\":\n BUCKET_NAME = \"gs://\" + PROJECT_ID + \"aip-\" + TIMESTAMP",
"_____no_output_____"
]
],
[
[
"**Only if your bucket doesn't already exist**: Run the following cell to create your Cloud Storage bucket.",
"_____no_output_____"
]
],
[
[
"! gsutil mb -l $REGION $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"Finally, validate access to your Cloud Storage bucket by examining its contents:",
"_____no_output_____"
]
],
[
[
"! gsutil ls -al $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"#### Service Account\n\n**If you don't know your service account**, try to get your service account using `gcloud` command by executing the second cell below.",
"_____no_output_____"
]
],
[
[
"SERVICE_ACCOUNT = \"[your-service-account]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if (\n SERVICE_ACCOUNT == \"\"\n or SERVICE_ACCOUNT is None\n or SERVICE_ACCOUNT == \"[your-service-account]\"\n):\n # Get your GCP project id from gcloud\n shell_output = !gcloud auth list 2>/dev/null\n SERVICE_ACCOUNT = shell_output[2].strip()\n print(\"Service Account:\", SERVICE_ACCOUNT)",
"_____no_output_____"
]
],
[
[
"#### Set service account access for Vertex Pipelines\n\nRun the following commands to grant your service account access to read and write pipeline artifacts in the bucket that you created in the previous step -- you only need to run these once per service account.",
"_____no_output_____"
]
],
[
[
"! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.objectCreator $BUCKET_NAME\n\n! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.objectViewer $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"### Set up variables\n\nNext, set up some variables used throughout the tutorial.\n### Import libraries and define constants",
"_____no_output_____"
]
],
[
[
"import google.cloud.aiplatform as aip",
"_____no_output_____"
]
],
[
[
"#### Vertex Pipelines constants\n\nSetup up the following constants for Vertex Pipelines:",
"_____no_output_____"
]
],
[
[
"PIPELINE_ROOT = \"{}/pipeline_root/shakespeare\".format(BUCKET_NAME)",
"_____no_output_____"
]
],
[
[
"Additional imports.",
"_____no_output_____"
]
],
[
[
"from typing import NamedTuple\n\nimport kfp\nfrom kfp.v2 import dsl\nfrom kfp.v2.dsl import (Artifact, Dataset, Input, InputPath, Model, Output,\n OutputPath, component)",
"_____no_output_____"
]
],
[
[
"## Initialize Vertex SDK for Python\n\nInitialize the Vertex SDK for Python for your project and corresponding bucket.",
"_____no_output_____"
]
],
[
[
"aip.init(project=PROJECT_ID, staging_bucket=BUCKET_NAME)",
"_____no_output_____"
]
],
[
[
"### Define Python function-based pipeline components\n\nIn this tutorial, you define function-based components that consume parameters and produce (typed) Artifacts and parameters. Functions can produce Artifacts in three ways:\n\n* Accept an output local path using `OutputPath`\n* Accept an `OutputArtifact` which gives the function a handle to the output artifact's metadata\n* Return an `Artifact` (or `Dataset`, `Model`, `Metrics`, etc) in a `NamedTuple`\n\nThese options for producing Artifacts are demonstrated.\n\n#### Define preprocess component\n\nThe first component definition, `preprocess`, shows a component that outputs two `Dataset` Artifacts, as well as an output parameter. (For this example, the datasets don't reflect real data).\n\nFor the parameter output, you would typically use the approach shown here, using the `OutputPath` type, for \"larger\" data.\nFor \"small data\", like a short string, it might be more convenient to use the `NamedTuple` function output as shown in the second component instead.",
"_____no_output_____"
]
],
[
[
"@component\ndef preprocess(\n # An input parameter of type string.\n message: str,\n # Use Output to get a metadata-rich handle to the output artifact\n # of type `Dataset`.\n output_dataset_one: Output[Dataset],\n # A locally accessible filepath for another output artifact of type\n # `Dataset`.\n output_dataset_two_path: OutputPath(\"Dataset\"),\n # A locally accessible filepath for an output parameter of type string.\n output_parameter_path: OutputPath(str),\n):\n \"\"\"'Mock' preprocessing step.\n Writes out the passed in message to the output \"Dataset\"s and the output message.\n \"\"\"\n output_dataset_one.metadata[\"hello\"] = \"there\"\n # Use OutputArtifact.path to access a local file path for writing.\n # One can also use OutputArtifact.uri to access the actual URI file path.\n with open(output_dataset_one.path, \"w\") as f:\n f.write(message)\n\n # OutputPath is used to just pass the local file path of the output artifact\n # to the function.\n with open(output_dataset_two_path, \"w\") as f:\n f.write(message)\n\n with open(output_parameter_path, \"w\") as f:\n f.write(message)",
"_____no_output_____"
]
],
[
[
"#### Define train component\n\nThe second component definition, `train`, defines as input both an `InputPath` of type `Dataset`, and an `InputArtifact` of type `Dataset` (as well as other parameter inputs). It uses the `NamedTuple` format for function output. As shown, these outputs can be Artifacts as well as parameters.\n\nAdditionally, this component writes some metrics metadata to the `model` output Artifact. This information is displayed in the Cloud Console user interface when the pipeline runs.",
"_____no_output_____"
]
],
[
[
"@component(\n base_image=\"python:3.9\", # Use a different base image.\n)\ndef train(\n # An input parameter of type string.\n message: str,\n # Use InputPath to get a locally accessible path for the input artifact\n # of type `Dataset`.\n dataset_one_path: InputPath(\"Dataset\"),\n # Use InputArtifact to get a metadata-rich handle to the input artifact\n # of type `Dataset`.\n dataset_two: Input[Dataset],\n # Output artifact of type Model.\n imported_dataset: Input[Dataset],\n model: Output[Model],\n # An input parameter of type int with a default value.\n num_steps: int = 3,\n # Use NamedTuple to return either artifacts or parameters.\n # When returning artifacts like this, return the contents of\n # the artifact. The assumption here is that this return value\n # fits in memory.\n) -> NamedTuple(\n \"Outputs\",\n [\n (\"output_message\", str), # Return parameter.\n (\"generic_artifact\", Artifact), # Return generic Artifact.\n ],\n):\n \"\"\"'Mock' Training step.\n Combines the contents of dataset_one and dataset_two into the\n output Model.\n Constructs a new output_message consisting of message repeated num_steps times.\n \"\"\"\n\n # Directly access the passed in GCS URI as a local file (uses GCSFuse).\n with open(dataset_one_path, \"r\") as input_file:\n dataset_one_contents = input_file.read()\n\n # dataset_two is an Artifact handle. Use dataset_two.path to get a\n # local file path (uses GCSFuse).\n # Alternately, use dataset_two.uri to access the GCS URI directly.\n with open(dataset_two.path, \"r\") as input_file:\n dataset_two_contents = input_file.read()\n\n with open(model.path, \"w\") as f:\n f.write(\"My Model\")\n\n with open(imported_dataset.path, \"r\") as f:\n data = f.read()\n print(\"Imported Dataset:\", data)\n\n # Use model.get() to get a Model artifact, which has a .metadata dictionary\n # to store arbitrary metadata for the output artifact. This metadata will be\n # recorded in Managed Metadata and can be queried later. It will also show up\n # in the UI.\n model.metadata[\"accuracy\"] = 0.9\n model.metadata[\"framework\"] = \"Tensorflow\"\n model.metadata[\"time_to_train_in_seconds\"] = 257\n\n artifact_contents = \"{}\\n{}\".format(dataset_one_contents, dataset_two_contents)\n output_message = \" \".join([message for _ in range(num_steps)])\n return (output_message, artifact_contents)",
"_____no_output_____"
]
],
[
[
"#### Define read_artifact_input component\n\nFinally, you define a small component that takes as input the `generic_artifact` returned by the `train` component function, and reads and prints the Artifact's contents.",
"_____no_output_____"
]
],
[
[
"@component\ndef read_artifact_input(\n generic: Input[Artifact],\n):\n with open(generic.path, \"r\") as input_file:\n generic_contents = input_file.read()\n print(f\"generic contents: {generic_contents}\")",
"_____no_output_____"
]
],
[
[
"### Define a pipeline that uses your components and the Importer\n\nNext, define a pipeline that uses the components that were built in the previous section, and also shows the use of the `kfp.dsl.importer`.\n\nThis example uses the `importer` to create, in this case, a `Dataset` artifact from an existing URI.\n\nNote that the `train_task` step takes as inputs three of the outputs of the `preprocess_task` step, as well as the output of the `importer` step.\nIn the \"train\" inputs we refer to the `preprocess` `output_parameter`, which gives us the output string directly.\n\nThe `read_task` step takes as input the `train_task` `generic_artifact` output.",
"_____no_output_____"
]
],
[
[
"@dsl.pipeline(\n # Default pipeline root. You can override it when submitting the pipeline.\n pipeline_root=PIPELINE_ROOT,\n # A name for the pipeline. Use to determine the pipeline Context.\n name=\"metadata-pipeline-v2\",\n)\ndef pipeline(message: str):\n importer = kfp.dsl.importer(\n artifact_uri=\"gs://ml-pipeline-playground/shakespeare1.txt\",\n artifact_class=Dataset,\n reimport=False,\n )\n preprocess_task = preprocess(message=message)\n train_task = train(\n dataset_one_path=preprocess_task.outputs[\"output_dataset_one\"],\n dataset_two=preprocess_task.outputs[\"output_dataset_two_path\"],\n imported_dataset=importer.output,\n message=preprocess_task.outputs[\"output_parameter_path\"],\n num_steps=5,\n )\n read_task = read_artifact_input( # noqa: F841\n train_task.outputs[\"generic_artifact\"]\n )",
"_____no_output_____"
]
],
[
[
"## Compile the pipeline\n\nNext, compile the pipeline.",
"_____no_output_____"
]
],
[
[
"from kfp.v2 import compiler # noqa: F811\n\ncompiler.Compiler().compile(\n pipeline_func=pipeline, package_path=\"lightweight_pipeline.json\".replace(\" \", \"_\")\n)",
"_____no_output_____"
]
],
[
[
"## Run the pipeline\n\nNext, run the pipeline.",
"_____no_output_____"
]
],
[
[
"DISPLAY_NAME = \"shakespeare_\" + TIMESTAMP\n\njob = aip.PipelineJob(\n display_name=DISPLAY_NAME,\n template_path=\"lightweight_pipeline.json\".replace(\" \", \"_\"),\n pipeline_root=PIPELINE_ROOT,\n parameter_values={\"message\": \"Hello, World\"},\n)\n\njob.run()",
"_____no_output_____"
]
],
[
[
"Click on the generated link to see your run in the Cloud Console.\n\n<!-- It should look something like this as it is running:\n\n<a href=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" target=\"_blank\"><img src=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" width=\"40%\"/></a> -->\n\nIn the UI, many of the pipeline DAG nodes will expand or collapse when you click on them. Here is a partially-expanded view of the DAG (click image to see larger version).\n\n<a href=\"https://storage.googleapis.com/amy-jo/images/mp/artifact_io2.png\" target=\"_blank\"><img src=\"https://storage.googleapis.com/amy-jo/images/mp/artifact_io2.png\" width=\"95%\"/></a>",
"_____no_output_____"
],
[
"# Cleaning up\n\nTo clean up all Google Cloud resources used in this project, you can [delete the Google Cloud\nproject](https://cloud.google.com/resource-manager/docs/creating-managing-projects#shutting_down_projects) you used for the tutorial.\n\nOtherwise, you can delete the individual resources you created in this tutorial -- *Note:* this is auto-generated and not all resources may be applicable for this tutorial:\n\n- Dataset\n- Pipeline\n- Model\n- Endpoint\n- Batch Job\n- Custom Job\n- Hyperparameter Tuning Job\n- Cloud Storage Bucket",
"_____no_output_____"
]
],
[
[
"delete_dataset = True\ndelete_pipeline = True\ndelete_model = True\ndelete_endpoint = True\ndelete_batchjob = True\ndelete_customjob = True\ndelete_hptjob = True\ndelete_bucket = True\n\ntry:\n if delete_model and \"DISPLAY_NAME\" in globals():\n models = aip.Model.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n model = models[0]\n aip.Model.delete(model)\n print(\"Deleted model:\", model)\nexcept Exception as e:\n print(e)\n\ntry:\n if delete_endpoint and \"DISPLAY_NAME\" in globals():\n endpoints = aip.Endpoint.list(\n filter=f\"display_name={DISPLAY_NAME}_endpoint\", order_by=\"create_time\"\n )\n endpoint = endpoints[0]\n endpoint.undeploy_all()\n aip.Endpoint.delete(endpoint.resource_name)\n print(\"Deleted endpoint:\", endpoint)\nexcept Exception as e:\n print(e)\n\nif delete_dataset and \"DISPLAY_NAME\" in globals():\n if \"text\" == \"tabular\":\n try:\n datasets = aip.TabularDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.TabularDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"text\" == \"image\":\n try:\n datasets = aip.ImageDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.ImageDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"text\" == \"text\":\n try:\n datasets = aip.TextDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.TextDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"text\" == \"video\":\n try:\n datasets = aip.VideoDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.VideoDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\ntry:\n if delete_pipeline and \"DISPLAY_NAME\" in globals():\n pipelines = aip.PipelineJob.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n pipeline = pipelines[0]\n aip.PipelineJob.delete(pipeline.resource_name)\n print(\"Deleted pipeline:\", pipeline)\nexcept Exception as e:\n print(e)\n\nif delete_bucket and \"BUCKET_NAME\" in globals():\n ! gsutil rm -r $BUCKET_NAME",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
d00607c3ca92283c32594ae0efdd24b559e1939a
| 19,669 |
ipynb
|
Jupyter Notebook
|
for-scripters/Python/wikiPathways-and-py4cytoscape.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null |
for-scripters/Python/wikiPathways-and-py4cytoscape.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null |
for-scripters/Python/wikiPathways-and-py4cytoscape.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null | 31.023659 | 418 | 0.515532 |
[
[
[
"# WikiPathways and py4cytoscape\n## Yihang Xin and Alex Pico\n## 2020-11-10",
"_____no_output_____"
],
[
"WikiPathways is a well-known repository for biological pathways that provides unique tools to the research community for content creation, editing and utilization [@Pico2008].\n\nPython is an interpreted, high-level and general-purpose programming language.\n\npy4cytoscape leverages the WikiPathways API to communicate between Python and WikiPathways, allowing any pathway to be queried, interrogated and downloaded in both data and image formats. Queries are typically performed based on “Xrefs”, standardized identifiers for genes, proteins and metabolites. Once you can identified a pathway, you can use the WPID (WikiPathways identifier) to make additional queries.\n\npy4cytoscape leverages the CyREST API to provide a number of functions related to network visualization and analysis. \n",
"_____no_output_____"
],
[
"# Installation\nThe following chunk of code installs the `py4cytoscape` module.",
"_____no_output_____"
]
],
[
[
"%%capture\n!python3 -m pip install python-igraph requests pandas networkx\n!python3 -m pip install py4cytoscape",
"_____no_output_____"
]
],
[
[
"# Prerequisites\n## In addition to this package (py4cytoscape latest version 0.0.7), you will need:\n\n* Latest version of Cytoscape, which can be downloaded from https://cytoscape.org/download.html. Simply follow the installation instructions on screen.\n* Complete installation wizard\n* Launch Cytoscape\n\nFor this vignette, you’ll also need the WikiPathways app to access the WikiPathways database from within Cytoscape. \n\nInstall the WikiPathways app from http://apps.cytoscape.org/apps/wikipathways\n\nInstall the filetransfer app from https://apps.cytoscape.org/apps/filetransfer\n\nYou can also install app inside Python notebook by running \"py4cytoscape.install_app('Your App')\"",
"_____no_output_____"
],
[
"# Import the required package",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport requests\nimport pandas as pd\nfrom lxml import etree as ET\nfrom collections import OrderedDict\nimport py4cytoscape as p4c",
"_____no_output_____"
],
[
"# Check Version\np4c.cytoscape_version_info()",
"_____no_output_____"
]
],
[
[
"# Working together\nOk, with all of these components loaded and launched, you can now perform some nifty sequences. For example, search for a pathway based on a keyword search and then load it into Cytoscape.",
"_____no_output_____"
]
],
[
[
"def find_pathways_by_text(query, species):\n base_iri = 'http://webservice.wikipathways.org/'\n request_params = {'query':query, 'species':species}\n response = requests.get(base_iri + 'findPathwaysByText', params=request_params)\n return response",
"_____no_output_____"
],
[
"response = find_pathways_by_text(\"colon cancer\", \"Homo sapiens\")",
"_____no_output_____"
],
[
"def find_pathway_dataframe(response):\n data = response.text\n dom = ET.fromstring(data)\n pathways = []\n NAMESPACES = {'ns1':'http://www.wso2.org/php/xsd','ns2':'http://www.wikipathways.org/webservice/'}\n for node in dom.findall('ns1:result', NAMESPACES):\n pathway_using_api_terms = {}\n for child in node:\n pathway_using_api_terms[ET.QName(child).localname] = child.text\n pathways.append(pathway_using_api_terms)\n id_list = []\n score_list = []\n url_list = []\n name_list = []\n species_list = []\n revision_list = []\n for p in pathways:\n id_list.append(p[\"id\"])\n score_list.append(p[\"score\"])\n url_list.append(p[\"url\"])\n name_list.append(p[\"name\"])\n species_list.append(p[\"species\"])\n revision_list.append(p[\"revision\"])\n df = pd.DataFrame(list(zip(id_list,score_list,url_list,name_list,species_list,revision_list)), columns =['id', 'score','url','name','species','revision'])\n return df",
"_____no_output_____"
],
[
"df = find_pathway_dataframe(response)\ndf.head(10)",
"_____no_output_____"
]
],
[
[
"We have a list of human pathways that mention “Colon Cancer”. The results include lots of information, so let’s get a unique list of just the WPIDs.",
"_____no_output_____"
]
],
[
[
"unique_id = list(OrderedDict.fromkeys(df[\"id\"]))\nunique_id[0]",
"_____no_output_____"
]
],
[
[
"Let’s import the first one of these into Cytoscape!",
"_____no_output_____"
]
],
[
[
"cmd_list = ['wikipathways','import-as-pathway','id=\"',unique_id[0],'\"']\ncmd = \" \".join(cmd_list)\np4c.commands.commands_get(cmd) ",
"_____no_output_____"
]
],
[
[
"Once in Cytoscape, you can load data, apply visual style mappings, perform analyses, and export images and data formats. See py4cytoscape package for details.",
"_____no_output_____"
],
[
"# From networks to pathways\nIf you are already with with networks and data in Cytoscape, you may end up focusing on one or few particular genes, proteins or metabolites, and want to query WikiPathways.\n\nFor example, let’s open a sample network from Cytoscape and identify the gene with the largest number of connections, i.e., node degree.\n\nNote: this next chunk will overwrite your current session. Save if you want to keep anything.",
"_____no_output_____"
]
],
[
[
"p4c.session.open_session()",
"Opening sampleData/sessions/Yeast Perturbation.cys...\n"
],
[
"net_data = p4c.tables.get_table_columns(columns=['name','degree.layout','COMMON'])",
"_____no_output_____"
],
[
"max_gene = net_data[net_data[\"degree.layout\"] == net_data[\"degree.layout\"].max()]\nmax_gene",
"_____no_output_____"
]
],
[
[
"Great. It looks like MCM1 has the larget number of connections (18) in this network. Let’s use it’s identifier (YMR043W) to query WikiPathways to learn more about the gene and its biological role, and load it into Cytoscape.\n\nPro-tip: We need to know the datasource that provides a given identifier. In this case, it’s sort of tricky: Ensembl provides these Yeast ORF identifiers for this organism rather than they typical format. So, we’ll include the ‘En’ system code. See other vignettes for more details.",
"_____no_output_____"
]
],
[
[
"def find_pathways_by_xref(ids, codes):\n base_iri = 'http://webservice.wikipathways.org/'\n request_params = {'ids':ids, 'codes':codes}\n response = requests.get(base_iri + 'findPathwaysByXref', params=request_params)\n return response",
"_____no_output_____"
],
[
"response = find_pathways_by_xref('YMR043W','En')\nmcm1_pathways = find_pathway_dataframe(response)",
"_____no_output_____"
],
[
"unique_id = list(OrderedDict.fromkeys(mcm1_pathways[\"id\"]))\nunique_id = \"\".join(unique_id)\nunique_id",
"_____no_output_____"
],
[
"cmd_list = ['wikipathways','import-as-pathway','id=\"',unique_id,'\"']\ncmd = \" \".join(cmd_list)\np4c.commands.commands_get(cmd) ",
"_____no_output_____"
]
],
[
[
"And we can easily select the MCM1 node by name in the newly imported pathway to help see where exactly it plays its role.\n\n",
"_____no_output_____"
]
],
[
[
"p4c.network_selection.select_nodes(['Mcm1'], by_col='name')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0060aefec8bd4f713e809c4fcaa49d2a0098c4e
| 330,875 |
ipynb
|
Jupyter Notebook
|
02-plotting-with-matplotlib.ipynb
|
theed-ml/notebooks
|
30cbea30b2c91526293794c6151063f0af993359
|
[
"Apache-2.0"
] | null | null | null |
02-plotting-with-matplotlib.ipynb
|
theed-ml/notebooks
|
30cbea30b2c91526293794c6151063f0af993359
|
[
"Apache-2.0"
] | null | null | null |
02-plotting-with-matplotlib.ipynb
|
theed-ml/notebooks
|
30cbea30b2c91526293794c6151063f0af993359
|
[
"Apache-2.0"
] | null | null | null | 420.96056 | 43,288 | 0.93571 |
[
[
[
"# Plotting with Matplotlib",
"_____no_output_____"
],
[
"## What is `matplotlib`?\n\n* `matplotlib` is a 2D plotting library for Python\n* It provides quick way to visualize data from Python\n* It comes with a set plots\n* We can import its functions through the command\n\n```Python\nimport matplotlib.pyplot as plt\n```",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Basic plots\n\nYour goal is to plot the cosine and the sine functions on the same plot, using the default `matplotlib` settings.",
"_____no_output_____"
],
[
"### Generating the data",
"_____no_output_____"
]
],
[
[
"x = np.linspace(-np.pi, np.pi, 256, endpoint=True)\nc, s = np.cos(x), np.sin(x)",
"_____no_output_____"
]
],
[
[
"where, \n * x is a vector with 256 values ranging from $-\\pi$ to $\\pi$ included\n * c and s are vectors with the cosine and the sine values of X",
"_____no_output_____"
]
],
[
[
"plt.plot(x, c)\nplt.plot(x, s)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Rather than creating a plot with default size, we want to specify:\n* the size of the figure\n* the colors and type of the lines\n* the limits of the axes",
"_____no_output_____"
]
],
[
[
"# Create a figure of size 8x6 inches, 80 dots per inch\nplt.figure(figsize=(8, 6), dpi=80)\n\n# Create a new subplot from a grid of 1x1\nplt.subplot(1, 1, 1)\n\n# Plot cosine with a blue continuous line of width 1 (pixels)\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\n\n# Plot sine with a green dotted line of width 1 (pixels)\nplt.plot(x, s, color=\"green\", linewidth=1.0, linestyle=\"dotted\")\n\n# Set x limits\nplt.xlim(-4.0, 4)\n\n# Set x ticks\nplt.xticks(np.linspace(-4, 4, 9, endpoint=True))\n\n# Set y limits\nplt.ylim(-1.0, 1.0)\n\n# Set y ticks\nplt.yticks(np.linspace(-1, 1, 5, endpoint=True))",
"_____no_output_____"
]
],
[
[
"### Changing colors and line widths\n\n* We can to: \n - make the figure more horizontal\n - change the color of the lines to blue and red\n - have slighty thicker lines",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\")",
"_____no_output_____"
]
],
[
[
"### Setting limits\n\nNow, we want to space the axes to see all the data points",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)",
"_____no_output_____"
]
],
[
[
"### Setting ticks\n\nCurrent ticks are not ideal because they do not show the interesting values ($+/-\\pi$, $+/-\\pi/2$) for sine and cosine.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi])\nplt.yticks([-1, 0, +1])",
"_____no_output_____"
]
],
[
[
"### Setting tick labels\n\n* Ticks are correctly placed but their labels are not very explicit\n* We can guess that 3.142 is $\\pi$, but it would be better to make it explicit\n* When we set tick values, we can also provide a corresponding label in the second argument list\n* We can use $\\LaTeX$ when defining the labels",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], \n ['$-\\pi$', '$-\\pi/2$', '$0$', '$+\\pi/2$', '$+\\pi$'])\nplt.yticks([-1, 0, +1], ['$-1$', '$0$', '$+1$'])",
"_____no_output_____"
]
],
[
[
"### Moving spines\n\n* **Spines** are the lines connecting the axis tick marks and noting the boundaries of the data area.\n* Spines can be placed at arbitrary positions\n* Until now, they are on the border of the axis \n* We want to have them in the middle\n* There are four of them: top, bottom, left, right\n* Therefore, the top and the right will be discarded by setting their color to `none` \n* The bottom and the left ones will be moved to coordinate 0 in data space coordinates",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], ['$-\\pi$', '$-\\pi/2$', '$0$', '$+\\pi/2$', '$+\\pi$'])\nplt.yticks([-1, 0, +1], ['$-1$', '$0$', '$+1$'])\n\nax = plt.gca() # 'get current axis'\n\n# discard top and right spines\nax.spines['top'].set_color('none')\nax.spines['right'].set_color('none')\n\nax.xaxis.set_ticks_position('bottom')\nax.spines['bottom'].set_position(('data',0))\n\nax.yaxis.set_ticks_position('left')\nax.spines['left'].set_position(('data',0))",
"_____no_output_____"
]
],
[
[
"### Adding a legend \n\n* Let us include a legend in the upper right of the plot ",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\",\n label=\"cosine\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\", \n label=\"sine\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], ['$-\\pi$', '$-\\pi/2$', '$0$', '$+\\pi/2$', '$+\\pi$'])\nplt.yticks([-1, 0, +1], ['$-1$', '$0$', '$+1$'])\n\nax = plt.gca() # 'get current axis'\n\n# discard top and right spines\nax.spines['top'].set_color('none')\nax.spines['right'].set_color('none')\n\nax.xaxis.set_ticks_position('bottom')\nax.spines['bottom'].set_position(('data',0))\n\nax.yaxis.set_ticks_position('left')\nax.spines['left'].set_position(('data',0))\n\nplt.legend(loc='upper right')",
"_____no_output_____"
]
],
[
[
"### Annotate some points\n\n* The `annotate` command allows us to include annotation in the plot\n* For instance, to annotate the value $\\frac{2\\pi}{3}$ of both the sine and the cosine, we have to:\n 1. draw a marker on the curve as well as a straight dotted line\n 2. use the annotate command to display some text with an arrow",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\", label=\"cosine\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\", label=\"sine\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], ['$-\\pi$', '$-\\pi/2$', '$0$', '$+\\pi/2$', '$+\\pi$'])\nplt.yticks([-1, 0, +1], ['$-1$', '$0$', '$+1$'])\n\nt = 2 * np.pi / 3\nplt.plot([t, t], [0, np.cos(t)], color='blue', linewidth=2.5, linestyle=\"--\")\nplt.scatter([t, ], [np.cos(t), ], 50, color='blue')\n\nplt.annotate(r'$cos(\\frac{2\\pi}{3})=-\\frac{1}{2}$',\n xy=(t, np.cos(t)), xycoords='data',\n xytext=(-90, -50), textcoords='offset points',\n fontsize=16,\n arrowprops=dict(arrowstyle=\"->\",\n connectionstyle=\"arc3,rad=.2\"))\n\nplt.plot([t, t],[0, np.sin(t)], color='red', linewidth=2.5,\n linestyle=\"--\")\nplt.scatter([t, ],[np.sin(t), ], 50, color='red')\n\nplt.annotate(r'$sin(\\frac{2\\pi}{3})=\\frac{\\sqrt{3}}{2}$',\n xy=(t, np.sin(t)), xycoords='data',\n xytext=(+10, +30), textcoords='offset points', fontsize=16,\n arrowprops=dict(arrowstyle=\"->\", connectionstyle=\"arc3,rad=.2\"))\n\nax = plt.gca() # 'get current axis'\n\n# discard top and right spines\nax.spines['top'].set_color('none')\nax.spines['right'].set_color('none')\n\nax.xaxis.set_ticks_position('bottom')\nax.spines['bottom'].set_position(('data',0))\n\nax.yaxis.set_ticks_position('left')\nax.spines['left'].set_position(('data',0))\n\nplt.legend(loc='upper left')",
"_____no_output_____"
]
],
[
[
"* The tick labels are now hardly visible because of the blue and red lines\n* We can make them bigger and we can also adjust their properties to be rendered on a semi-transparent white background\n* This will allow us to see both the data and the label",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 6), dpi=80)\n\nplt.plot(x, c, color=\"blue\", linewidth=2.5, linestyle=\"-\", label=\"cosine\")\nplt.plot(x, s, color=\"red\", linewidth=2.5, linestyle=\"solid\", label=\"sine\")\n\nplt.xlim(x.min() * 1.1, x.max() * 1.1)\nplt.ylim(c.min() * 1.1, c.max() * 1.1)\n\nplt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], ['$-\\pi$', '$-\\pi/2$', '$0$', '$+\\pi/2$', '$+\\pi$'])\nplt.yticks([-1, 0, +1], ['$-1$', '$0$', '$+1$'])\n\nt = 2 * np.pi / 3\nplt.plot([t, t], [0, np.cos(t)], color='blue', linewidth=2.5, linestyle=\"--\")\nplt.scatter([t, ], [np.cos(t), ], 50, color='blue')\n\nplt.annotate(r'$cos(\\frac{2\\pi}{3})=-\\frac{1}{2}$',\n xy=(t, np.cos(t)), xycoords='data',\n xytext=(-90, -50), textcoords='offset points', fontsize=16,\n arrowprops=dict(arrowstyle=\"->\", connectionstyle=\"arc3,rad=.2\"))\n\nplt.plot([t, t],[0, np.sin(t)], color='red', linewidth=2.5, linestyle=\"--\")\nplt.scatter([t, ],[np.sin(t), ], 50, color='red')\n\nplt.annotate(r'$sin(\\frac{2\\pi}{3})=\\frac{\\sqrt{3}}{2}$',\n xy=(t, np.sin(t)), xycoords='data',\n xytext=(+10, +30), textcoords='offset points', fontsize=16,\n arrowprops=dict(arrowstyle=\"->\", connectionstyle=\"arc3,rad=.2\"))\n\nax = plt.gca() # 'get current axis'\n\n# discard top and right spines\nax.spines['top'].set_color('none')\nax.spines['right'].set_color('none')\n\nax.xaxis.set_ticks_position('bottom')\nax.spines['bottom'].set_position(('data',0))\n\nax.yaxis.set_ticks_position('left')\nax.spines['left'].set_position(('data',0))\n\nplt.legend(loc='upper left')\n\nfor label in ax.get_xticklabels() + ax.get_yticklabels():\n label.set_fontsize(16)\n label.set_bbox(dict(facecolor='white', edgecolor='None', alpha=0.65))",
"_____no_output_____"
]
],
[
[
"### Scatter plots",
"_____no_output_____"
]
],
[
[
"n = 1024\n\nx = np.random.normal(0, 1, n)\ny = np.random.normal(0, 1, n)\nt = np.arctan2(y, x)\n\nplt.axes([0.025, 0.025, 0.95, 0.95])\nplt.scatter(x, y, s=75, c=t, alpha=.5)\n\nplt.xlim(-1.5, 1.5)\nplt.xticks(())\nplt.ylim(-1.5, 1.5)\nplt.yticks(())\n\nax = plt.gca()\n\nax.spines['top'].set_color('none')\nax.spines['right'].set_color('none')\nax.spines['bottom'].set_color('none')\nax.spines['left'].set_color('none')",
"_____no_output_____"
]
],
[
[
"### Bar plots\n\n* Creates two bar plots overlying the same axis\n* Include the value of each bar",
"_____no_output_____"
]
],
[
[
"n = 12\n\nxs = np.arange(n)\ny1 = (1 - xs / float(n)) * np.random.uniform(0.5, 1.0, n)\ny2 = (1 - xs / float(n)) * np.random.uniform(0.5, 1.0, n)\n\nplt.axes([0.025, 0.025, 0.95, 0.95])\n\nplt.bar(xs, +y1, facecolor='#9999ff', edgecolor='white')\nplt.bar(xs, -y2, facecolor='#ff9999', edgecolor='white')\n\nfor x, y in zip(xs, y1):\n plt.text(x + 0.4, y + 0.05, '%.2f' % y, ha='center', va= 'bottom')\n\nfor x, y in zip(xs, y2):\n plt.text(x + 0.4, -y - 0.05, '%.2f' % y, ha='center', va= 'top')\n\nplt.xlim(-.5, n)\nplt.xticks(())\nplt.ylim(-1.25, 1.25)\nplt.yticks(())",
"_____no_output_____"
],
[
"## Images",
"_____no_output_____"
],
[
"image = np.random.rand(30, 30)\nplt.imshow(image, cmap=plt.cm.hot) \nplt.colorbar() ",
"_____no_output_____"
],
[
"years, months, sales = np.loadtxt('data/carsales.csv', delimiter=',', skiprows=1, dtype=int, unpack=True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d0060c38f454c33a410f864d7da3ad98e52bdf8f
| 10,278 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/12-4_review-checkpoint.ipynb
|
willdoucet/Classwork
|
25c45cc4f582f679483c662afb709a495b1a6a95
|
[
"MIT"
] | 1 |
2018-12-02T21:58:07.000Z
|
2018-12-02T21:58:07.000Z
|
.ipynb_checkpoints/12-4_review-checkpoint.ipynb
|
willdoucet/Classwork
|
25c45cc4f582f679483c662afb709a495b1a6a95
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/12-4_review-checkpoint.ipynb
|
willdoucet/Classwork
|
25c45cc4f582f679483c662afb709a495b1a6a95
|
[
"MIT"
] | 1 |
2018-11-15T03:31:42.000Z
|
2018-11-15T03:31:42.000Z
| 28.789916 | 136 | 0.499319 |
[
[
[
"# Classes\n\nFor more information on the magic methods of pytho classes, consult the docs: https://docs.python.org/3/reference/datamodel.html\n",
"_____no_output_____"
]
],
[
[
"class DumbClass:\n \"\"\" This class is just meant to demonstrate the magic __repr__ method\n \"\"\"\n \n def __repr__(self):\n \"\"\" I'm giving this method a docstring\n \"\"\"\n return(\"I'm representing an instance of my dumbclass\")\n\ndc = DumbClass()\nprint(dc)\ndc",
"_____no_output_____"
],
[
"help(DumbClass)",
"_____no_output_____"
],
[
"class Stack:\n \"\"\" A simple class implimenting some common features of Stack\n objects\n \"\"\"\n \n def __init__(self, iterable=None):\n \"\"\" Initializes Stack objects. If an iterable is provided,\n add elements from the iterable to this Stack until the\n iterable is exhausted\n \"\"\"\n self.head = None\n self.size = 0\n if(iterable is not None):\n for item in iterable:\n self.add(item)\n \n def add(self, item):\n \"\"\" Add an element to the top of the stack. This method will\n modify self and return self.\n \"\"\"\n self.head = (item, self.head)\n self.size += 1\n return self\n \n def pop(self):\n \"\"\" remove the top item from the stack and return it\n \"\"\"\n if(len(self) > 0):\n ret = self.head[0]\n self.head = self.head[1]\n self.size -= 1\n return ret\n return None\n \n def __contains__(self, item):\n \"\"\" Returns True if item is in self\n \"\"\"\n for i in self:\n if(i == item):\n return True\n return False\n \n def __len__(self):\n \"\"\" Returns the number of items in self\n \"\"\"\n return self.size\n \n def __iter__(self):\n \"\"\" prepares this stack for iteration and returns self\n \"\"\"\n self.curr = self.head\n return self\n \n def __next__(self):\n \"\"\" Returns items from the stack from top to bottom\n \"\"\"\n if(not hasattr(self, 'curr')):\n iter(self)\n if(self.curr is None):\n raise StopIteration\n else:\n ret = self.curr[0]\n self.curr = self.curr[1]\n return ret\n \n def __reversed__(self):\n \"\"\" returns a copy of self with the stack turned upside\n down\n \"\"\"\n return Stack(self)\n \n \n def __add__(self, other):\n \"\"\" Put self on top of other\n \"\"\"\n ret = Stack(reversed(other))\n for item in reversed(self):\n ret.add(item)\n return ret\n \n def __repr__(self):\n \"\"\" Represent self as a string\n \"\"\"\n return f'Stack({str(list(self))})'",
"_____no_output_____"
],
[
"# Create a stack object and test some methods\nx = Stack([3, 2])\nprint(x)\n\n# adds an element to the top of the stack\nprint('\\nLets add 1 to the stack')\nx.add(1)\nprint(x)\n\n# Removes the top most element\nprint('\\nLets remove an item from the top of the stack')\nitem = x.pop()\nprint(item)\nprint(x)\n\n# Removes the top most element\nprint('\\nlets remove another item')\nitem = x.pop()\nprint(item)\nprint(x)",
"_____no_output_____"
],
[
"x = Stack([4,5,6])\n# Because I implimented the __contains__ method,\n# I can check if items are in stack objects\nprint(f'Does my stack contain 2? {2 in x}')\nprint(f'Does my stack contain 4? {4 in x}')\n# Because I implimented the __len__ method,\n# I can check how many items are in stack objects\nprint(f'How many elements are in my stack? {len(x)}')",
"_____no_output_____"
],
[
"# because my stack class has an __iter__ and __next__ methods\n# I can iterate over stack objects\nx = Stack([7,3,4])\nprint(f\"Lets iterate over my stack : {x}\")\nfor item in x:\n print(item)\n# Because my stack class has a __reversed__ method,\n# I can easily reverse a stack object\nprint(f'I am flipping my stack upside down : {reversed(x)}')",
"_____no_output_____"
],
[
"# Because I implimented the __add__ method,\n# I can add stacks together\nx = Stack([4,5,6])\ny = Stack([1,2,3])\nprint(\"I have two stacks\")\nprint(f'x : {x}')\nprint(f'y : {y}')\nprint(\"Let's add them together\")\nprint(f'x + y = {x + y}')\nfor item in (x + y):\n print(item)",
"_____no_output_____"
]
],
[
[
"# Using the SqlAlchemy ORM\nFor more information, check out the documentation : https://docs.sqlalchemy.org/en/latest/orm/tutorial.html",
"_____no_output_____"
]
],
[
[
"from sqlalchemy import create_engine\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy import Column, Integer, String, Float, ForeignKey\nfrom sqlalchemy.orm import Session, relationship\nimport pymysql\npymysql.install_as_MySQLdb()",
"_____no_output_____"
],
[
"# Sets an object to utilize the default declarative base in SQL Alchemy\nBase = declarative_base()\n\n\n# Lets define the owners table/class\nclass Owners(Base):\n __tablename__ = 'owners'\n id = Column(Integer, primary_key=True)\n name = Column(String(255))\n phone_number = Column(String(255))\n pets = relationship(\"Pets\", back_populates=\"owner\")\n\n def __repr__(self):\n return f\"<Owners(id={self.id}, name='{self.name}', phone_number='{self.phone_number}')>\"\n\n\n# Lets define the pets table/class\nclass Pets(Base):\n __tablename__ = 'pets'\n id = Column(Integer, primary_key=True)\n name = Column(String(255))\n owner_id = Column(Integer, ForeignKey('owners.id'))\n owner = relationship(\"Owners\", back_populates=\"pets\")\n \n def __repr__(self):\n return f\"<Pets(id={self.id}, name='{self.name}', owner_id={self.owner_id})>\"",
"_____no_output_____"
],
[
"# Lets connect to my database\n# engine = create_engine(\"sqlite:///pets.sqlite\")\nengine = create_engine(\"mysql://root@localhost/review_db\")\n# conn = engine.connect()\nBase.metadata.create_all(engine)\nsession = Session(bind=engine)",
"_____no_output_____"
],
[
"# Lets create me\nme = Owners(name='Kenton', phone_number='867-5309')\nsession.add(me)\nsession.commit()\n# Now lets add my dog\nmy_dog = Pets(name='Saxon', owner_id=me.id)\nsession.add(my_dog)\nsession.commit()",
"_____no_output_____"
],
[
"# We can query the tables using the session object from earlier\n# Lets just get all the data\nall_owners = list(session.query(Owners))\nall_pets = list(session.query(Pets))\nprint(all_owners)\nprint(all_pets)",
"_____no_output_____"
],
[
"me = all_owners[0]\nrio = all_pets[0]\n# Because we are using an ORM and have defined relations,\n# we can easily and intuitively access related data\nprint(me.pets)\nprint(rio.owner)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0060f78a0065e196f0e917675f438f188b87e01
| 573,947 |
ipynb
|
Jupyter Notebook
|
Main/MSM_real.ipynb
|
mathiassunesen/Speciale_retirement
|
9db901a3791b9b75f228d1cec6c180e917be93e8
|
[
"MIT"
] | 1 |
2020-01-14T22:19:42.000Z
|
2020-01-14T22:19:42.000Z
|
Main/MSM_real.ipynb
|
mathiassunesen/Speciale_retirement
|
9db901a3791b9b75f228d1cec6c180e917be93e8
|
[
"MIT"
] | null | null | null |
Main/MSM_real.ipynb
|
mathiassunesen/Speciale_retirement
|
9db901a3791b9b75f228d1cec6c180e917be93e8
|
[
"MIT"
] | 1 |
2020-01-14T22:19:46.000Z
|
2020-01-14T22:19:46.000Z
| 523.67427 | 37,860 | 0.937524 |
[
[
[
"# Estimation on real data using MSM",
"_____no_output_____"
]
],
[
[
"from consav import runtools\nruntools.write_numba_config(disable=0,threads=4)\n\n%matplotlib inline\n%load_ext autoreload\n%autoreload 2\n\n# Local modules\nfrom Model import RetirementClass\nimport figs\nimport SimulatedMinimumDistance as SMD\n\n# Global modules\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### Data",
"_____no_output_____"
]
],
[
[
"data = pd.read_excel('SASdata/moments.xlsx')\nmom_data = data['mom'].to_numpy()\nse = data['se'].to_numpy()\nobs = data['obs'].to_numpy()\nse = se/np.sqrt(obs)\nse[se>0] = 1/se[se>0]\nfactor = np.ones(len(se))\nfactor[-15:] = 4\nW = np.eye(len(se))*se*factor\ncov = pd.read_excel('SASdata/Cov.xlsx')\nOmega = cov*obs\nNobs = np.median(obs)",
"_____no_output_____"
]
],
[
[
"### Set up estimation",
"_____no_output_____"
]
],
[
[
"single_kwargs = {'simN': int(1e5), 'simT': 68-53+1}\nCouple = RetirementClass(couple=True, single_kwargs=single_kwargs, \n simN=int(1e5), simT=68-53+1)\nCouple.solve()\nCouple.simulate()",
"_____no_output_____"
],
[
"def mom_fun(Couple):\n return SMD.MomFun(Couple)",
"_____no_output_____"
],
[
"est_par = [\"alpha_0_male\", \"alpha_0_female\", \"sigma_eta\", \"pareto_w\", \"phi_0_male\"]\nsmd = SMD.SimulatedMinimumDistance(Couple,mom_data,mom_fun,est_par=est_par)",
"_____no_output_____"
]
],
[
[
"### Estimate",
"_____no_output_____"
]
],
[
[
"theta0 = SMD.start(9,bounds=[(0,1), (0,1), (0.2,0.8), (0.2,0.8), (0,2)])",
"_____no_output_____"
],
[
"theta0",
"_____no_output_____"
],
[
"smd.MultiStart(theta0,W)\ntheta = smd.est",
"1 estimation:\nsuccess: True | feval: 294 | time: 68.7 min | obj: 16.905881405720866\nstart par: [0.878, 0.939, 0.494, 0.501, 1.482]\npar: [0.5510516 0.52007452 0.69700755 0.83112885 0.21190369]\n\n2 estimation:\nsuccess: True | feval: 349 | time: 80.5 min | obj: 18.743042219364817\nstart par: [0.977, 0.97, 0.23, 0.493, 0.119]\npar: [ 0.56730198 0.49988837 0.61304702 0.7803967 -0.04185609]\n\n3 estimation:\nsuccess: True | feval: 294 | time: 70.3 min | obj: 32.16736516479271\nstart par: [0.075, 0.755, 0.446, 0.641, 1.784]\npar: [0.32828476 0.66112227 0.95527434 1.46132755 3.54434154]\n\n4 estimation:\nsuccess: True | feval: 237 | time: 57.1 min | obj: 16.929741033852547\nstart par: [0.422, 0.416, 0.587, 0.292, 0.241]\npar: [0.55256372 0.52567413 0.69690618 0.81814051 0.18685789]\n\n5 estimation:\nsuccess: True | feval: 374 | time: 89.6 min | obj: 25.487253110929686\nstart par: [0.932, 0.964, 0.682, 0.351, 1.553]\npar: [0.62460141 0.70705836 1.2125916 0.82666782 0.30013556]\n\n6 estimation:\nsuccess: True | feval: 467 | time: 111.4 min | obj: 16.935676607261676\nstart par: [0.885, 0.083, 0.46, 0.651, 1.52]\npar: [0.55760544 0.51807476 0.69169474 0.82546804 0.20394115]\n\n7 estimation:\nsuccess: True | feval: 275 | time: 65.5 min | obj: 17.07506485725594\nstart par: [0.404, 0.689, 0.531, 0.61, 1.184]\npar: [0.56587079 0.5336313 0.74874107 0.82307253 0.23745914]\n\n8 estimation:\nsuccess: True | feval: 251 | time: 57.7 min | obj: 64.85828596422479\nstart par: [0.019, 0.665, 0.645, 0.521, 1.796]\npar: [-2.05313707e-03 6.54563983e-01 1.06581689e+00 7.73913398e-01\n 3.64039665e+00]\n\n9 estimation:\nsuccess: True | feval: 264 | time: 65.0 min | obj: 17.945645692500133\nstart par: [0.555, 0.039, 0.415, 0.692, 0.001]\npar: [0.57775562 0.52468374 0.68575121 0.79668983 0.00911142]\n\nfinal estimation:\nsuccess: True | feval: 158 | obj: 16.904319627758227\ntotal estimation time: 11.7 hours\nstart par: [0.5510516 0.52007452 0.69700755 0.83112885 0.21190369]\npar: [0.55104885 0.52006874 0.69700671 0.83110603 0.21188706]\n\n"
],
[
"smd.MultiStart(theta0,W)\ntheta = smd.est",
"Iteration: 50 (11.08 minutes)\n alpha_0_male=0.5044 alpha_0_female=0.4625 sigma_eta=0.8192 pareto_w=0.7542 phi_0_male=0.1227 -> 21.6723\nIteration: 100 (11.19 minutes)\n alpha_0_male=0.5703 alpha_0_female=0.5002 sigma_eta=0.7629 pareto_w=0.7459 phi_0_male=0.1575 -> 17.7938\nIteration: 150 (10.73 minutes)\n alpha_0_male=0.5546 alpha_0_female=0.5131 sigma_eta=0.6877 pareto_w=0.8166 phi_0_male=0.1905 -> 16.9717\nIteration: 200 (10.94 minutes)\n alpha_0_male=0.5526 alpha_0_female=0.5128 sigma_eta=0.6891 pareto_w=0.8133 phi_0_male=0.1875 -> 16.9319\n1 estimation:\nsuccess: True | feval: 248 | time: 54.8 min | obj: 16.927585558076142\nstart par: [0.551, 0.576, 0.596, 0.5, 1.241]\npar: [0.55258074 0.51274232 0.68921531 0.81324937 0.18777072]\n\nIteration: 250 (11.3 minutes)\n alpha_0_male=0.6206 alpha_0_female=0.5880 sigma_eta=0.4200 pareto_w=0.4980 phi_0_male=0.5590 -> 57.7093\nIteration: 300 (11.24 minutes)\n alpha_0_male=0.5428 alpha_0_female=0.4145 sigma_eta=0.6379 pareto_w=0.5308 phi_0_male=0.3868 -> 22.4315\nIteration: 350 (10.62 minutes)\n alpha_0_male=0.5777 alpha_0_female=0.5323 sigma_eta=0.7206 pareto_w=0.6119 phi_0_male=0.1712 -> 19.5532\nIteration: 400 (10.7 minutes)\n alpha_0_male=0.5412 alpha_0_female=0.4850 sigma_eta=0.6265 pareto_w=0.7680 phi_0_male=0.1276 -> 17.5896\nIteration: 450 (11.15 minutes)\n alpha_0_male=0.5727 alpha_0_female=0.5056 sigma_eta=0.6590 pareto_w=0.7641 phi_0_male=0.1026 -> 17.3178\nIteration: 500 (11.37 minutes)\n alpha_0_male=0.5724 alpha_0_female=0.5112 sigma_eta=0.6671 pareto_w=0.7618 phi_0_male=0.1020 -> 17.2860\n2 estimation:\nsuccess: True | feval: 300 | time: 66.3 min | obj: 17.27324442907804\nstart par: [0.591, 0.588, 0.42, 0.498, 0.559]\npar: [0.57229758 0.5114954 0.66670532 0.7624101 0.1016371 ]\n\nIteration: 550 (11.27 minutes)\n alpha_0_male=0.2415 alpha_0_female=0.5020 sigma_eta=0.5640 pareto_w=0.5470 phi_0_male=1.3920 -> 52.9243\nIteration: 600 (11.18 minutes)\n alpha_0_male=0.3956 alpha_0_female=0.4874 sigma_eta=0.6780 pareto_w=0.6912 phi_0_male=0.2409 -> 26.3473\nIteration: 650 (11.25 minutes)\n alpha_0_male=0.4919 alpha_0_female=0.5041 sigma_eta=0.6219 pareto_w=0.7558 phi_0_male=0.2084 -> 18.6088\nIteration: 700 (11.42 minutes)\n alpha_0_male=0.5489 alpha_0_female=0.4931 sigma_eta=0.6267 pareto_w=0.7717 phi_0_male=0.1391 -> 17.4406\nIteration: 750 (10.88 minutes)\n alpha_0_male=0.5477 alpha_0_female=0.4897 sigma_eta=0.6247 pareto_w=0.7747 phi_0_male=0.1398 -> 17.4092\nIteration: 800 (10.64 minutes)\n alpha_0_male=0.5478 alpha_0_female=0.4898 sigma_eta=0.6248 pareto_w=0.7747 phi_0_male=0.1394 -> 17.3802\n3 estimation:\nsuccess: True | feval: 253 | time: 56.0 min | obj: 17.38030688438767\nstart par: [0.23, 0.502, 0.564, 0.547, 1.392]\npar: [0.54777719 0.4897951 0.62477554 0.77474538 0.13940557]\n\nIteration: 850 (10.52 minutes)\n alpha_0_male=0.6309 alpha_0_female=0.4741 sigma_eta=0.8748 pareto_w=0.7275 phi_0_male=0.3000 -> 20.2731\nIteration: 900 (10.65 minutes)\n alpha_0_male=0.5417 alpha_0_female=0.5320 sigma_eta=0.7344 pareto_w=0.8562 phi_0_male=0.3055 -> 17.2592\nIteration: 950 (10.64 minutes)\n alpha_0_male=0.5331 alpha_0_female=0.5218 sigma_eta=0.7226 pareto_w=0.8497 phi_0_male=0.2874 -> 17.1254\nIteration: 1000 (10.59 minutes)\n alpha_0_male=0.5359 alpha_0_female=0.5206 sigma_eta=0.7271 pareto_w=0.8505 phi_0_male=0.2736 -> 17.1173\nIteration: 1050 (10.68 minutes)\n alpha_0_male=0.5358 alpha_0_female=0.5207 sigma_eta=0.7268 pareto_w=0.8501 phi_0_male=0.2741 -> 17.0704\n4 estimation:\nsuccess: True | feval: 260 | time: 55.2 min | obj: 17.069749122995066\nstart par: [0.369, 0.367, 0.658, 0.431, 0.62]\npar: [0.53580109 0.52075601 0.72683222 0.85007036 0.27418587]\n\nIteration: 1100 (10.73 minutes)\n alpha_0_male=0.5503 alpha_0_female=0.5148 sigma_eta=0.6911 pareto_w=0.8155 phi_0_male=0.1885 -> 16.9585\nIteration: 1150 (10.81 minutes)\n alpha_0_male=0.5525 alpha_0_female=0.5129 sigma_eta=0.6894 pareto_w=0.8134 phi_0_male=0.1879 -> 16.9468\nIteration: 1200 (10.89 minutes)\n alpha_0_male=0.5525 alpha_0_female=0.5128 sigma_eta=0.6893 pareto_w=0.8134 phi_0_male=0.1879 -> 16.9224\nfinal estimation:\nsuccess: True | feval: 142 | obj: 16.922410852892398\ntotal estimation time: 4.4 hours\nstart par: [0.55258074 0.51274232 0.68921531 0.81324937 0.18777072]\npar: [0.5524854 0.51284598 0.68929759 0.81336732 0.18791813]\n\n"
]
],
[
[
"### Save parameters",
"_____no_output_____"
]
],
[
[
"est_par.append('phi_0_female')\nthetaN = list(theta)\nthetaN.append(Couple.par.phi_0_male)\nSMD.save_est(est_par,thetaN,name='baseline2')",
"_____no_output_____"
]
],
[
[
"### Standard errors",
"_____no_output_____"
]
],
[
[
"est_par = [\"alpha_0_male\", \"alpha_0_female\", \"sigma_eta\", \"pareto_w\", \"phi_0_male\"]\nsmd = SMD.SimulatedMinimumDistance(Couple,mom_data,mom_fun,est_par=est_par)",
"_____no_output_____"
],
[
"theta = list(SMD.load_est('baseline2').values())\ntheta = theta[:5]\nsmd.obj_fun(theta,W)",
"_____no_output_____"
],
[
"np.round(theta,3)",
"_____no_output_____"
],
[
"Nobs = np.quantile(obs,0.25)\nsmd.std_error(theta,Omega,W,Nobs,Couple.par.simN*2/Nobs)",
"_____no_output_____"
],
[
"# Nobs = lower quartile\nnp.round(smd.std,3)",
"_____no_output_____"
],
[
"# Nobs = lower quartile\nnp.round(smd.std,3)",
"_____no_output_____"
],
[
"Nobs = np.quantile(obs,0.25)\nsmd.std_error(theta,Omega,W,Nobs,Couple.par.simN*2/Nobs)",
"_____no_output_____"
],
[
"# Nobs = median\nnp.round(smd.std,3)",
"_____no_output_____"
]
],
[
[
"### Model fit",
"_____no_output_____"
]
],
[
[
"smd.obj_fun(theta,W)",
"_____no_output_____"
],
[
"jmom = pd.read_excel('SASdata/joint_moments_ad.xlsx')",
"_____no_output_____"
],
[
"for i in range(-2,3):\n data = jmom[jmom.Age_diff==i]['ssh'].to_numpy()\n plt.bar(np.arange(-7,8), data, label='Data')\n plt.plot(np.arange(-7,8),SMD.joint_moments_ad(Couple,i),'k--', label='Predicted')\n #plt.ylim(0,0.4)\n plt.legend()\n plt.show()",
"_____no_output_____"
],
[
"figs.MyPlot(figs.model_fit_marg(smd,0,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenSingle2.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenSingle2.png')\nfigs.MyPlot(figs.model_fit_marg(smd,0,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenCouple2.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenCouple2.png')\nfigs.model_fit_joint(smd).savefig('figs/ModelFit/Joint2')",
"_____no_output_____"
],
[
"theta[4] = 1\nsmd.obj_fun(theta,W)\ndist1 = smd.mom_sim[44:]\ntheta[4] = 2\nsmd.obj_fun(theta,W)\ndist2 = smd.mom_sim[44:]\ntheta[4] = 3\nsmd.obj_fun(theta,W)\ndist3 = smd.mom_sim[44:]\ndist_data = mom_data[44:]",
"_____no_output_____"
],
[
"figs.model_fit_joint_many(dist_data,dist1,dist2,dist3).savefig('figs/ModelFit/JointMany2')",
"_____no_output_____"
]
],
[
[
"### Sensitivity",
"_____no_output_____"
]
],
[
[
"est_par_tex = [r'$\\alpha^m$', r'$\\alpha^f$', r'$\\sigma$', r'$\\lambda$', r'$\\phi$']\nfixed_par = ['R', 'rho', 'beta', 'gamma', 'v',\n 'priv_pension_male', 'priv_pension_female', 'g_adjust', 'pi_adjust_m', 'pi_adjust_f']\nfixed_par_tex = [r'$R$', r'$\\rho$', r'$\\beta$', r'$\\gamma$', r'$v$',\n r'$PPW^m$', r'$PPW^f$', r'$g$', r'$\\pi^m$', r'$\\pi^f$']",
"_____no_output_____"
],
[
"smd.recompute=True\nsmd.sensitivity(theta,W,fixed_par)\nfigs.sens_fig_tab(smd.sens2[:,:5],smd.sens2e[:,:5],theta,\n est_par_tex,fixed_par_tex[:5]).savefig('figs/ModelFit/CouplePref2.png')\nfigs.sens_fig_tab(smd.sens2[:,5:],smd.sens2e[:,5:],theta,\n est_par_tex,fixed_par_tex[5:]).savefig('figs/modelFit/CoupleCali2.png')",
"_____no_output_____"
],
[
"smd.recompute=True\nsmd.sensitivity(theta,W,fixed_par)\nfigs.sens_fig_tab(smd.sens2[:,:5],smd.sens2e[:,:5],theta,\n est_par_tex,fixed_par_tex[:5]).savefig('figs/ModelFit/CouplePref.png')\nfigs.sens_fig_tab(smd.sens2[:,5:],smd.sens2e[:,5:],theta,\n est_par_tex,fixed_par_tex[5:]).savefig('figs/modelFit/CoupleCali.png')",
"_____no_output_____"
]
],
[
[
"### Recalibrate model (phi=0)",
"_____no_output_____"
]
],
[
[
"Couple.par.phi_0_male = 0\nCouple.par.phi_0_female = 0",
"_____no_output_____"
],
[
"est_par = [\"alpha_0_male\", \"alpha_0_female\", \"sigma_eta\", \"pareto_w\"]\nsmd = SMD.SimulatedMinimumDistance(Couple,mom_data,mom_fun,est_par=est_par)",
"_____no_output_____"
],
[
"theta0 = SMD.start(4,bounds=[(0,1), (0,1), (0.2,0.8), (0.2,0.8)])",
"_____no_output_____"
],
[
"smd.MultiStart(theta0,W)\ntheta = smd.est",
"1 estimation:\nsuccess: True | feval: 220 | time: 48.2 min | obj: 18.075899540131683\nstart par: [0.878, 0.939, 0.494, 0.501]\npar: [0.57538856 0.53292983 0.66919452 0.78768373]\n\n2 estimation:\nsuccess: True | feval: 268 | time: 59.8 min | obj: 18.06436034188825\nstart par: [0.741, 0.977, 0.782, 0.23]\npar: [0.57877531 0.52225649 0.67987012 0.77814082]\n\n3 estimation:\nsuccess: True | feval: 263 | time: 59.3 min | obj: 18.025100144784872\nstart par: [0.489, 0.059, 0.245, 0.653]\npar: [0.57954467 0.52886497 0.68641805 0.78896568]\n\n4 estimation:\nsuccess: True | feval: 193 | time: 44.8 min | obj: 18.05028603223897\nstart par: [0.409, 0.736, 0.735, 0.453]\npar: [0.58045624 0.52222793 0.67634017 0.78087117]\n\nfinal estimation:\nsuccess: True | feval: 146 | obj: 18.02470109022947\ntotal estimation time: 4.1 hours\nstart par: [0.57954467 0.52886497 0.68641805 0.78896568]\npar: [0.57954205 0.52886806 0.68643258 0.7889642 ]\n\n"
],
[
"est_par.append(\"phi_0_male\")\nest_par.append(\"phi_0_female\")\ntheta = list(theta)\ntheta.append(Couple.par.phi_0_male)\ntheta.append(Couple.par.phi_0_male)\nSMD.save_est(est_par,theta,name='phi0')",
"_____no_output_____"
],
[
"smd.obj_fun(theta,W)\nfigs.MyPlot(figs.model_fit_marg(smd,0,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenSingle_phi0.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenSingle_phi0.png')\nfigs.MyPlot(figs.model_fit_marg(smd,0,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenCouple_phi0.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenCoupleW_phi0.png')\nfigs.model_fit_joint(smd).savefig('figs/ModelFit/Joint_phi0')",
"_____no_output_____"
]
],
[
[
"### Recalibrate model (phi high)",
"_____no_output_____"
]
],
[
[
"Couple.par.phi_0_male = 1.187\nCouple.par.phi_0_female = 1.671\nCouple.par.pareto_w = 0.8",
"_____no_output_____"
],
[
"est_par = [\"alpha_0_male\", \"alpha_0_female\", \"sigma_eta\"]\nsmd = SMD.SimulatedMinimumDistance(Couple,mom_data,mom_fun,est_par=est_par)",
"_____no_output_____"
],
[
"theta0 = SMD.start(4,bounds=[(0.2,0.6), (0.2,0.6), (0.4,0.8)])",
"_____no_output_____"
],
[
"theta0",
"_____no_output_____"
],
[
"smd.MultiStart(theta0,W)\ntheta = smd.est",
"1 estimation:\nsuccess: True | feval: 112 | time: 25.5 min | obj: 31.24196829478647\nstart par: [0.551, 0.576, 0.596]\npar: [0.39309581 0.44701373 0.78087338]\n\n"
],
[
"est_par.append(\"phi_0_male\")\nest_par.append(\"phi_0_female\")\ntheta = list(theta)\ntheta.append(Couple.par.phi_0_male)\ntheta.append(Couple.par.phi_0_male)\nSMD.save_est(est_par,theta,name='phi_high')",
"_____no_output_____"
],
[
"smd.obj_fun(theta,W)\nfigs.MyPlot(figs.model_fit_marg(smd,0,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenSingle_phi_high.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,0),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenSingle_phi_high.png')\nfigs.MyPlot(figs.model_fit_marg(smd,0,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargWomenCouple_phi_high.png')\nfigs.MyPlot(figs.model_fit_marg(smd,1,1),ylim=[-0.01,0.4],linewidth=3).savefig('figs/ModelFit/MargMenCoupleW_phi_high.png')\nfigs.model_fit_joint(smd).savefig('figs/ModelFit/Joint_phi_high')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0061144f90dea9a660d01eda4cfc23a4eb094cb
| 740,345 |
ipynb
|
Jupyter Notebook
|
Exemplos_DR/Exercicios_DimensionalReduction.ipynb
|
UERJ-FISICA/ML4PPGF_UERJ
|
60f456568d2168056b0c9a1574950bce56955fd9
|
[
"MIT"
] | 3 |
2019-08-12T18:05:18.000Z
|
2021-02-09T01:04:11.000Z
|
Exemplos_DR/Exercicios_DimensionalReduction.ipynb
|
UERJ-FISICA/ML4PPGF_UERJ
|
60f456568d2168056b0c9a1574950bce56955fd9
|
[
"MIT"
] | 1 |
2020-02-11T16:32:07.000Z
|
2020-02-11T16:32:07.000Z
|
Exemplos_DR/Exercicios_DimensionalReduction.ipynb
|
UERJ-FISICA/ML4PPGF_UERJ
|
60f456568d2168056b0c9a1574950bce56955fd9
|
[
"MIT"
] | 18 |
2019-08-12T18:05:20.000Z
|
2022-01-19T19:30:15.000Z
| 874.079103 | 207,436 | 0.93674 |
[
[
[
"<a href=\"https://colab.research.google.com/github/clemencia/ML4PPGF_UERJ/blob/master/Exemplos_DR/Exercicios_DimensionalReduction.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"#Mais Exercícios de Redução de Dimensionalidade",
"_____no_output_____"
],
[
"Baseado no livro \"Python Data Science Handbook\" de Jake VanderPlas\nhttps://jakevdp.github.io/PythonDataScienceHandbook/\n\nUsando os dados de rostos do scikit-learn, utilizar as tecnicas de aprendizado de variedade para comparação.",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import fetch_lfw_people\nfaces = fetch_lfw_people(min_faces_per_person=30)\nfaces.data.shape",
"_____no_output_____"
]
],
[
[
"A base de dados tem 2300 imagens de rostos com 2914 pixels cada (47x62)\n\nVamos visualizar as primeiras 32 dessas imagens",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom numpy import random\nfrom matplotlib import pyplot as plt\n\n%matplotlib inline\n\nfig, ax = plt.subplots(5, 8, subplot_kw=dict(xticks=[], yticks=[]))\nfor i, axi in enumerate(ax.flat):\n axi.imshow(faces.images[i], cmap='gray')",
"_____no_output_____"
]
],
[
[
"Podemos ver se com redução de dimensionalidade é possível entender algumas das caraterísticas das imagens. \n",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import PCA\n\n\nmodel0 = PCA(n_components=0.95)\nX_pca=model0.fit_transform(faces.data)\n\nplt.plot(np.cumsum(model0.explained_variance_ratio_))\nplt.xlabel('n components')\nplt.ylabel('cumulative variance')\nplt.grid(True)\nprint(\"Numero de componentes para 95% de variância preservada:\",model0.n_components_)",
"Numero de componentes para 95% de variância preservada: 171\n"
]
],
[
[
"Quer dizer que para ter 95% de variância preservada na dimensionalidade reduzida precisamos mais de 170 dimensões. \n\nAs novas \"coordenadas\" podem ser vistas em quadros de 9x19 pixels",
"_____no_output_____"
]
],
[
[
"\ndef plot_faces(instances, **options):\n fig, ax = plt.subplots(5, 8, subplot_kw=dict(xticks=[], yticks=[]))\n sizex = 9\n sizey = 19\n images = [instance.reshape(sizex,sizey) for instance in instances]\n \n \n for i,axi in enumerate(ax.flat):\n axi.imshow(images[i], cmap = \"gray\", **options)\n axi.axis(\"off\")\n \n",
"_____no_output_____"
]
],
[
[
"Vamos visualizar a compressão dessas imagens",
"_____no_output_____"
]
],
[
[
"plot_faces(X_pca,aspect=\"auto\")",
"_____no_output_____"
]
],
[
[
"A opção ```svd_solver=randomized``` faz o PCA achar as $d$ componentes principais mais rápido quando $d \\ll n$, mas o $d$ é fixo. Tem alguma vantagem usar para compressão das imagens de rosto? Teste!",
"_____no_output_____"
],
[
"## Aplicar Isomap para vizualizar em 2D",
"_____no_output_____"
]
],
[
[
"from sklearn.manifold import Isomap\niso = Isomap(n_components=2)\nX_iso = iso.fit_transform(faces.data)\nX_iso.shape",
"_____no_output_____"
],
[
"from matplotlib import offsetbox\n\n \ndef plot_projection(data,proj,images=None,ax=None,thumb_frac=0.5,cmap=\"gray\"):\n ax = ax or plt.gca()\n \n ax.plot(proj[:, 0], proj[:, 1], '.k')\n \n if images is not None:\n min_dist_2 = (thumb_frac * max(proj.max(0) - proj.min(0))) ** 2\n shown_images = np.array([2 * proj.max(0)])\n for i in range(data.shape[0]):\n dist = np.sum((proj[i] - shown_images) ** 2, 1)\n if np.min(dist) < min_dist_2:\n # don't show points that are too close\n continue\n shown_images = np.vstack([shown_images, proj[i]])\n imagebox = offsetbox.AnnotationBbox(\n offsetbox.OffsetImage(images[i], cmap=cmap),\n proj[i])\n ax.add_artist(imagebox)\n \ndef plot_components(data, model, images=None, ax=None,\n thumb_frac=0.05,cmap=\"gray\"):\n \n \n proj = model.fit_transform(data)\n plot_projection(data,proj,images,ax,thumb_frac,cmap)\n ",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(10, 10))\nplot_projection(faces.data,X_iso,images=faces.images[:, ::2, ::2],thumb_frac=0.07)\nax.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"As imagens mais a direita são mais escuras que as da direita (seja iluminação ou cor da pele), as imagens mais embaixo estão orientadas com o rosto à esquerda e as de cima com o rosto à direita.\n\n\n## Exercícios: \n1. Aplicar LLE à base de dados dos rostos e visualizar em mapa 2D, em particular a versão \"modificada\" ([link](https://scikit-learn.org/stable/modules/manifold.html#modified-locally-linear-embedding))\n2. Aplicar t-SNE à base de dados dos rostos e visualizar em mapa 2D\n3. Escolher mais uma implementação de aprendizado de variedade do Scikit-Learn ([link](https://scikit-learn.org/stable/modules/manifold.html)) e aplicar ao mesmo conjunto. (*Hessian, LTSA, Spectral*)\n\nQual funciona melhor? Adicione contador de tempo para comparar a duração de cada ajuste.\n\n\n ",
"_____no_output_____"
],
[
"## Kernel PCA e sequências \n\nVamos ver novamente o exemplo do rocambole \n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom numpy import random\nfrom matplotlib import pyplot as plt\n\n%matplotlib inline\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom sklearn.datasets import make_swiss_roll\nX, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)\n\naxes = [-11.5, 14, -2, 23, -12, 15]\n\nfig = plt.figure(figsize=(12, 10))\nax = fig.add_subplot(111, projection='3d')\n\nax.scatter(X[:, 0], X[:, 1], X[:, 2], c=t, cmap=\"plasma\")\nax.view_init(10, -70)\nax.set_xlabel(\"$x_1$\", fontsize=18)\nax.set_ylabel(\"$x_2$\", fontsize=18)\nax.set_zlabel(\"$x_3$\", fontsize=18)\nax.set_xlim(axes[0:2])\nax.set_ylim(axes[2:4])\nax.set_zlim(axes[4:6])\n\n\n",
"_____no_output_____"
]
],
[
[
"Como foi no caso do SVM, pode se aplicar uma transformação de *kernel*, para ter um novo espaço de *features* onde pode ser aplicado o PCA. Embaixo o exemplo de PCA com kernel linear (equiv. a aplicar o PCA), RBF (*radial basis function*) e *sigmoide* (i.e. logístico).",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import KernelPCA\n\nlin_pca = KernelPCA(n_components = 2, kernel=\"linear\", fit_inverse_transform=True)\nrbf_pca = KernelPCA(n_components = 2, kernel=\"rbf\", gamma=0.0433, fit_inverse_transform=True)\nsig_pca = KernelPCA(n_components = 2, kernel=\"sigmoid\", gamma=0.001, coef0=1, fit_inverse_transform=True)\n\n\nplt.figure(figsize=(11, 4))\nfor subplot, pca, title in ((131, lin_pca, \"Linear kernel\"), (132, rbf_pca, \"RBF kernel, $\\gamma=0.04$\"), (133, sig_pca, \"Sigmoid kernel, $\\gamma=10^{-3}, r=1$\")):\n X_reduced = pca.fit_transform(X)\n if subplot == 132:\n X_reduced_rbf = X_reduced\n \n plt.subplot(subplot)\n\n plt.title(title, fontsize=14)\n plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=t, cmap=plt.cm.hot)\n plt.xlabel(\"$z_1$\", fontsize=18)\n if subplot == 131:\n plt.ylabel(\"$z_2$\", fontsize=18, rotation=0)\n plt.grid(True)\n \n",
"/usr/local/lib/python3.6/dist-packages/sklearn/utils/extmath.py:516: RuntimeWarning: invalid value encountered in multiply\n v *= signs[:, np.newaxis]\n/usr/local/lib/python3.6/dist-packages/sklearn/utils/extmath.py:516: RuntimeWarning: invalid value encountered in multiply\n v *= signs[:, np.newaxis]\n"
]
],
[
[
"## Selecionar um Kernel e Otimizar Hiperparâmetros\n\nComo estos são algoritmos não supervisionados, no existe uma forma \"obvia\" de determinar a sua performance. \n\nPorém a redução de dimensionalidade muitas vezes é um passo preparatório para uma outra tarefa de aprendizado supervisionado. Nesse caso é possível usar o ```GridSearchCV``` para avaliar a melhor performance no passo seguinte, com um ```Pipeline```. A classificação será em base ao valor do ```t``` com limite arbitrário de 6.9.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.pipeline import Pipeline\n\ny = t>6.9\n\nclf = Pipeline([\n (\"kpca\", KernelPCA(n_components=2)),\n (\"log_reg\", LogisticRegression(solver=\"liblinear\"))\n ])\n\nparam_grid = [{\n \"kpca__gamma\": np.linspace(0.03, 0.05, 10),\n \"kpca__kernel\": [\"rbf\", \"sigmoid\"]\n }]\n\ngrid_search = GridSearchCV(clf, param_grid, cv=3)\ngrid_search.fit(X, y)",
"_____no_output_____"
],
[
"print(grid_search.best_params_)",
"{'kpca__gamma': 0.043333333333333335, 'kpca__kernel': 'rbf'}\n"
]
],
[
[
"### Exercício :\n\nVarie o valor do corte em ```t``` e veja tem faz alguma diferência para o kernel e hiperparámetros ideais.",
"_____no_output_____"
],
[
"### Inverter a transformação e erro de Reconstrução \n\nOutra opção seria escolher o kernel e hiperparâmetros que tem o menor erro de reconstrução. \n\nO seguinte código, com opção ```fit_inverse_transform=True```, vai fazer junto com o kPCA um modelo de regressão com as instancias projetadas (```X_reduced```) de treino e as originais (```X```) de target. O resultado do ```inverse_transform``` será uma tentativa de reconstrução no espaço original .",
"_____no_output_____"
]
],
[
[
"rbf_pca = KernelPCA(n_components = 2, kernel=\"rbf\", gamma=13./300.,\n fit_inverse_transform=True)\nX_reduced = rbf_pca.fit_transform(X)\nX_preimage = rbf_pca.inverse_transform(X_reduced)\nX_preimage.shape",
"_____no_output_____"
],
[
"axes = [-11.5, 14, -2, 23, -12, 15]\n\nfig = plt.figure(figsize=(12, 10))\nax = fig.add_subplot(111, projection='3d')\n\nax.scatter(X_preimage[:, 0], X_preimage[:, 1], X_preimage[:, 2], c=t, cmap=\"plasma\")\nax.view_init(10, -70)\nax.set_xlabel(\"$x_1$\", fontsize=18)\nax.set_ylabel(\"$x_2$\", fontsize=18)\nax.set_zlabel(\"$x_3$\", fontsize=18)\nax.set_xlim(axes[0:2])\nax.set_ylim(axes[2:4])\nax.set_zlim(axes[4:6])\n",
"_____no_output_____"
]
],
[
[
"Então é possível computar o \"erro\" entre o dataset reconstruido e o original (MSE).",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_squared_error as mse\n\nprint(mse(X,X_preimage))",
"32.79523578725337\n"
]
],
[
[
"## Exercício :\n Usar *grid search* com validação no valor do MSE para achar o kernel e hiperparámetros que minimizam este erro, para o exemplo do rocambole. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0064846d9fd7e8a42ab97e8230da87582bfe2ef
| 885,428 |
ipynb
|
Jupyter Notebook
|
TEMA-2/Clase12_EjemplosDeAplicaciones.ipynb
|
kitziafigueroa/SPF-2019-II
|
7c27ffe068a94a6140ba98ad8dffe2b3a2369df4
|
[
"MIT"
] | null | null | null |
TEMA-2/Clase12_EjemplosDeAplicaciones.ipynb
|
kitziafigueroa/SPF-2019-II
|
7c27ffe068a94a6140ba98ad8dffe2b3a2369df4
|
[
"MIT"
] | 1 |
2019-11-22T00:32:07.000Z
|
2019-11-22T00:32:07.000Z
|
TEMA-2/Clase12_EjemplosDeAplicaciones.ipynb
|
kitziafigueroa/SPF-2019-II
|
7c27ffe068a94a6140ba98ad8dffe2b3a2369df4
|
[
"MIT"
] | null | null | null | 2,432.494505 | 177,020 | 0.960874 |
[
[
[
"## Ejemplos aplicaciones de las distribuciones de probabilidad",
"_____no_output_____"
],
[
"## Ejemplo Binomial\n\nUn modelo de precio de opciones, el cual intente modelar el precio de un activo $S(t)$ en forma simplificada, en vez de usar ecuaciones diferenciales estocásticas. De acuerdo a este modelo simplificado, dado el precio del activo actual $S(0)=S_0$, el precio después de un paso de tiempo $\\delta t$, denotado por $S(\\delta t)$, puede ser ya sea $S_u=uS_0$ o $S_d=dS_0$, con probabilidades $p_u$ y $p_d$, respectivamente. Los subíndices $u$ y $p$ pueden ser interpretados como 'subida' y 'bajada', además consideramos cambios multiplicativos. Ahora imagine que el proces $S(t)$ es observado hasta el tiempo $T=n\\cdot \\delta t$ y que las subidas y bajadas del precio son independientes en todo el tiempo. Como hay $n$ pasos, el valor mas grande de $S(T)$ alcanzado es $S_0u^n$ y el valor más pequeño es $S_0d^n$. Note que valores intermedios serán de la forma $S_0u^md^{n-m}$ donde $m$ es el número de saltos de subidas realizadas por el activo y $n-m$ el número bajadas del activo. Observe que es irrelevante la secuencia exacta de subidas y bajadas del precio para determinar el precio final, es decir como los cambios multiplicativos conmutan: $S_0ud=S_0du$. Un simple modelo como el acá propuesto, puede representarse mediante un modelo binomial y se puede representar de la siguiente forma:\n\n\nTal modelo es un poco conveniente para simples opciones de dimensión baja debido a que **(el diagrama puede crecer exponencialmente)**, cuando las recombinaciones mantienen una complejidad baja. Con este modelo podíamos intentar responder \n - Cúal es la probabilidad que $S(T)=S_0u^md^{(n-m)}$?\n - **Hablar como construir el modelo binomial** \n - $n,m,p \\longrightarrow X\\sim Bin(n,p)$\n - PMF $\\rightarrow P(X=m)={n \\choose m}p^m(1-p)^{n-m}$\n - Dibuje la Densidad de probabilidad para $n=30, p_1=0.2,p_2=0.4$",
"_____no_output_____"
]
],
[
[
"# Importamos librerías a trabajar en todas las simulaciones\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport scipy.stats as st # Librería estadística\nfrom math import factorial as fac # Importo la operación factorial\nfrom scipy.special import comb # Importamos la función combinatoria\n\n%matplotlib inline",
"_____no_output_____"
],
[
"# Parámetros de la distribución \nn = 30; p1=0.2; p2 = 0.4\n\nm = np.arange(0,n)\nn = n*np.ones(len(m))\n# Distribución binomial creada\nP = lambda p,n,m:comb(n,m)*p**m*(1-p)**(n-m)\n\n# Distribución binomial del paquete de estadística\nP2 = st.binom(n,p1).pmf(m)\n\n# Comparación de función creada con función de python\nplt.plot(P(p1,n,m),'o-',label='Función creada')\nplt.stem(P2,'r--',label='Función de librería estadística')\nplt.legend()\nplt.title('Comparación de funciones')\nplt.show()\n\n# Grafica de pmf para el problema de costo de activos\nplt.plot(P(p1,n,m),'o-.b',label='$p_1 = 0.2$')\nplt.plot(st.binom(n,p2).pmf(m),'gv--',label='$p_2 = 0.4$')\nplt.legend()\nplt.title('Gráfica de pmf para el problema de costo de activos')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Ejercicio\n<font color='red'>Problema referencia: Introduction to Operations Research,(Chap.10.1, pag.471 and 1118)\n> Descargar ejercicio de el siguiente link\n> https://drive.google.com/file/d/19GvzgEmYUNXrZqlmppRyW5t0p8WfUeIf/view?usp=sharing\n\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**Pessimistic case**\n",
"_____no_output_____"
],
[
"**Possibilities: Most likely**\n",
"_____no_output_____"
],
[
"**Optimistic case**\n",
"_____no_output_____"
],
[
"## **Approximations**\n\n1. **Simplifying Approximation 1:** Assume that the mean critical path will turn out to be the longest path through the project network.\n2. **Simplifying Approximation 2:** Assume that the durations of the activities on the mean critical path are statistically independent\n\n$$\\mu_p \\longrightarrow \\text{Use the approximation 1}$$\n$$\\sigma_p \\longrightarrow \\text{Use the approximation 1,2}$$",
"_____no_output_____"
],
[
"**Choosing the mean critical path**\n",
"_____no_output_____"
],
[
"3. **Simplifying Approximation 3:** Assume that the form of the probability distribution of project duration is a `normal distribution`. By using simplifying approximations 1 and 2, one version of the central limit theorem justifies this assumption as being a reasonable approximation if the number of activities on the mean critical path is not too small (say, at least 5). The approximation becomes better as this number of activities increases.",
"_____no_output_____"
],
[
"### Casos de estudio\nSe tiene entonces la variable aleatoria $T$ la cual representa la duración del proyecto en semanas con media $\\mu_p$ y varianza $\\sigma_p^2$ y $d$ representa la fecha límite de entrega del proyecto, la cual es de 47 semanas.\n1. Suponer que $T$ distribuye normal y responder cual es la probabilidad $P(T\\leq d)$.",
"_____no_output_____"
]
],
[
[
"######### Caso de estudio 1 ################\nup = 44; sigma = np.sqrt(9); d = 47\nP = st.norm(up,sigma).cdf(d)\nprint('P(T<=d)=',P)\nP2 = st.beta",
"P(T<=d)= 0.8413447460685429\n"
]
],
[
[
">## <font color = 'red'> Tarea\n>1.Suponer que $T$ distribuye beta donde la media es $\\mu_p$ y varianza $\\sigma_p^2$ y responder cual es la probabilidad $P(T\\leq d)$.\n \n\n> **Ayuda**: - Aprender a utlizar el solucionador de ecuaciones no lineales https://stackoverflow.com/questions/19843116/passing-arguments-to-fsolve\n- Leer el help d\n\n>2.Suponer que $T$ distribuye triangular donde el valor mas probable es $\\mu_p$ el valor pesimista es $p=49$ y el valor optimista es $o=40$ y responder cual es la probabilidad $P(T\\leq d)$.\n\n>3.Una vez respondido los dos numerales anteriores, suponer que cada actividad es dependiente y su dependencia es mostrada en la figura donde se nombran los procesos, además considere que la distribución de cada actividad distribuye beta. Partiendo de la dependencia de las actividades, generar 10000 escenarios diferentes para cada actividad y utilizar montecarlo para responder ¿Cuál es la probabilidad $P(T\\leq d)$. Comparar con el resultado obtenido 1 y comentar las diferencias (CONCLUIR)\n\n>4.Repetir el literal 3 pero en este caso usando una distribución triangular.\n\n> **Nota:** en el archivo PDF que les puse al principio de esta clase, hay una posible solución que les puede ayudar a la hora de hacer su suposiciones y su programación.\n\n## Parámetros de entrega\nSe habilitará un enlace en Canvas donde deben de subir su cuaderno de python con la solución dada. La fecha límite de recepción será el jueves 10 de octubre a las 11:55 pm.",
"_____no_output_____"
],
[
"<script>\n $(document).ready(function(){\n $('div.prompt').hide();\n $('div.back-to-top').hide();\n $('nav#menubar').hide();\n $('.breadcrumb').hide();\n $('.hidden-print').hide();\n });\n</script>\n\n<footer id=\"attribution\" style=\"float:right; color:#808080; background:#fff;\">\nCreated with Jupyter by Oscar David Jaramillo Zuluaga\n</footer>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0064936273975eb4da949453e9d2b3ffdc6b71b
| 548,404 |
ipynb
|
Jupyter Notebook
|
module3-databackedassertions/Sanjay_Krishna_LS_DS_113_Making_Data_backed_Assertions_Assignment.ipynb
|
sanjaykmenon/DS-Unit-1-Sprint-1-Dealing-With-Data
|
2d405c116b8caac952900bdf3282f9014596d27e
|
[
"MIT"
] | null | null | null |
module3-databackedassertions/Sanjay_Krishna_LS_DS_113_Making_Data_backed_Assertions_Assignment.ipynb
|
sanjaykmenon/DS-Unit-1-Sprint-1-Dealing-With-Data
|
2d405c116b8caac952900bdf3282f9014596d27e
|
[
"MIT"
] | null | null | null |
module3-databackedassertions/Sanjay_Krishna_LS_DS_113_Making_Data_backed_Assertions_Assignment.ipynb
|
sanjaykmenon/DS-Unit-1-Sprint-1-Dealing-With-Data
|
2d405c116b8caac952900bdf3282f9014596d27e
|
[
"MIT"
] | null | null | null | 197.409647 | 438,344 | 0.819824 |
[
[
[
"<a href=\"https://colab.research.google.com/github/sanjaykmenon/DS-Unit-1-Sprint-1-Dealing-With-Data/blob/master/module3-databackedassertions/Sanjay_Krishna_LS_DS_113_Making_Data_backed_Assertions_Assignment.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Lambda School Data Science - Making Data-backed Assertions\n\nThis is, for many, the main point of data science - to create and support reasoned arguments based on evidence. It's not a topic to master in a day, but it is worth some focused time thinking about and structuring your approach to it.",
"_____no_output_____"
],
[
"## Assignment - what's going on here?\n\nConsider the data in `persons.csv` (already prepared for you, in the repo for the week). It has four columns - a unique id, followed by age (in years), weight (in lbs), and exercise time (in minutes/week) of 1200 (hypothetical) people.\n\nTry to figure out which variables are possibly related to each other, and which may be confounding relationships.\n\nTry and isolate the main relationships and then communicate them using crosstabs and graphs. Share any cool graphs that you make with the rest of the class in Slack!",
"_____no_output_____"
]
],
[
[
"# TODO - your code here\n# Use what we did live in lecture as an example\n\n# HINT - you can find the raw URL on GitHub and potentially use that\n# to load the data with read_csv, or you can upload it yourself\n\nimport pandas as pd\n\ndf = pd.read_csv('https://raw.githubusercontent.com/LambdaSchool/DS-Unit-1-Sprint-1-Dealing-With-Data/master/module3-databackedassertions/persons.csv')\ndf.head()",
"_____no_output_____"
],
[
"df.columns = ['unique_id', 'age','weight','exercise_time']\ndf.head()\ndf.dtypes\n#df.reset_index()",
"_____no_output_____"
],
[
"exercise_bins = pd.cut(df['exercise_time'],10)\n\npd.crosstab(exercise_bins, df['age'], normalize = 'columns')\n\n",
"_____no_output_____"
],
[
"pd.crosstab(exercise_bins, df['weight'], normalize='columns')",
"_____no_output_____"
],
[
"weight_bins = pd.cut(df['weight'], 5)\n\npd.crosstab(weight_bins, df['age'], normalize='columns')",
"_____no_output_____"
]
],
[
[
"## Can't seem to find a relationship because there is too much data to analyze here. I think I will try plotting this to see if i can get a better understanding.",
"_____no_output_____"
]
],
[
[
"import seaborn as sns\n\nsns.pairplot(df)",
"_____no_output_____"
]
],
[
[
"## Using seaborn pairplot to plot relationships between each variable to each other, it seems there is a relationship between weights & exercise time where the lower your weigh the more exercie time you have.",
"_____no_output_____"
],
[
"### Assignment questions\n\nAfter you've worked on some code, answer the following questions in this text block:\n\n1. What are the variable types in the data?\n2. What are the relationships between the variables?\n3. Which relationships are \"real\", and which spurious?\n",
"_____no_output_____"
],
[
"1. All are continuous data\n\n2. There is a relationship between weight and exercise time, where it seems people who exercise for more time have a lower weight. Similarly there is relationship between age and exercise time where people who are in the group of 60-80 exercise less.\n\n3. The relationship between exercise time and weight can be spurious because usually people who exercise more weigh less and as a result this a causal factor. The other factors seem more realistic such as the age and exercise time, since older people tend to not have the physical capacity to exercise longer generally.",
"_____no_output_____"
],
[
"## Stretch goals and resources\n\nFollowing are *optional* things for you to take a look at. Focus on the above assignment first, and make sure to commit and push your changes to GitHub.\n\n- [Spurious Correlations](http://tylervigen.com/spurious-correlations)\n- [NIH on controlling for confounding variables](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4017459/)\n\nStretch goals:\n\n- Produce your own plot inspired by the Spurious Correlation visualizations (and consider writing a blog post about it - both the content and how you made it)\n- Pick one of the techniques that NIH highlights for confounding variables - we'll be going into many of them later, but see if you can find which Python modules may help (hint - check scikit-learn)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0065750b7c2fd05a9be14d2533c40539e67df55
| 34,869 |
ipynb
|
Jupyter Notebook
|
docs/jax-101/05.1-pytrees.ipynb
|
slowy07/jax
|
1db53b11755a86d69238b4e999ad011d1142e23c
|
[
"ECL-2.0",
"Apache-2.0"
] | 1 |
2021-06-29T17:37:27.000Z
|
2021-06-29T17:37:27.000Z
|
docs/jax-101/05.1-pytrees.ipynb
|
slowy07/jax
|
1db53b11755a86d69238b4e999ad011d1142e23c
|
[
"ECL-2.0",
"Apache-2.0"
] | 2 |
2022-01-31T13:20:35.000Z
|
2022-02-14T13:20:49.000Z
|
docs/jax-101/05.1-pytrees.ipynb
|
slowy07/jax
|
1db53b11755a86d69238b4e999ad011d1142e23c
|
[
"ECL-2.0",
"Apache-2.0"
] | null | null | null | 46.062087 | 12,144 | 0.698873 |
[
[
[
"# Working with Pytrees\n\n[](https://colab.research.google.com/github/google/jax/blob/main/docs/jax-101/05.1-pytrees.ipynb)\n\n*Author: Vladimir Mikulik*\n\nOften, we want to operate on objects that look like dicts of arrays, or lists of lists of dicts, or other nested structures. In JAX, we refer to these as *pytrees*, but you can sometimes see them called *nests*, or just *trees*.\n\nJAX has built-in support for such objects, both in its library functions as well as through the use of functions from [`jax.tree_utils`](https://jax.readthedocs.io/en/latest/jax.tree_util.html) (with the most common ones also available as `jax.tree_*`). This section will explain how to use them, give some useful snippets and point out common gotchas.",
"_____no_output_____"
],
[
"## What is a pytree?\n\nAs defined in the [JAX pytree docs](https://jax.readthedocs.io/en/latest/pytrees.html):\n\n> a pytree is a container of leaf elements and/or more pytrees. Containers include lists, tuples, and dicts. A leaf element is anything that’s not a pytree, e.g. an array. In other words, a pytree is just a possibly-nested standard or user-registered Python container. If nested, note that the container types do not need to match. A single “leaf”, i.e. a non-container object, is also considered a pytree.\n\nSome example pytrees:",
"_____no_output_____"
]
],
[
[
"import jax\nimport jax.numpy as jnp\n\nexample_trees = [\n [1, 'a', object()],\n (1, (2, 3), ()),\n [1, {'k1': 2, 'k2': (3, 4)}, 5],\n {'a': 2, 'b': (2, 3)},\n jnp.array([1, 2, 3]),\n]\n\n# Let's see how many leaves they have:\nfor pytree in example_trees:\n leaves = jax.tree_leaves(pytree)\n print(f\"{repr(pytree):<45} has {len(leaves)} leaves: {leaves}\")",
"[1, 'a', <object object at 0x7fded60bb8c0>] has 3 leaves: [1, 'a', <object object at 0x7fded60bb8c0>]\n(1, (2, 3), ()) has 3 leaves: [1, 2, 3]\n[1, {'k1': 2, 'k2': (3, 4)}, 5] has 5 leaves: [1, 2, 3, 4, 5]\n{'a': 2, 'b': (2, 3)} has 3 leaves: [2, 2, 3]\nDeviceArray([1, 2, 3], dtype=int32) has 1 leaves: [DeviceArray([1, 2, 3], dtype=int32)]\n"
]
],
[
[
"We've also introduced our first `jax.tree_*` function, which allowed us to extract the flattened leaves from the trees.",
"_____no_output_____"
],
[
"## Why pytrees?\n\nIn machine learning, some places where you commonly find pytrees are:\n* Model parameters\n* Dataset entries\n* RL agent observations\n\nThey also often arise naturally when working in bulk with datasets (e.g., lists of lists of dicts).",
"_____no_output_____"
],
[
"## Common pytree functions\nThe most commonly used pytree functions are `jax.tree_map` and `jax.tree_multimap`. They work analogously to Python's native `map`, but on entire pytrees.\n\nFor functions with one argument, use `jax.tree_map`:",
"_____no_output_____"
]
],
[
[
"list_of_lists = [\n [1, 2, 3],\n [1, 2],\n [1, 2, 3, 4]\n]\n\njax.tree_map(lambda x: x*2, list_of_lists)",
"_____no_output_____"
]
],
[
[
"To use functions with more than one argument, use `jax.tree_multimap`:",
"_____no_output_____"
]
],
[
[
"another_list_of_lists = list_of_lists\njax.tree_multimap(lambda x, y: x+y, list_of_lists, another_list_of_lists)",
"_____no_output_____"
]
],
[
[
"For `tree_multimap`, the structure of the inputs must exactly match. That is, lists must have the same number of elements, dicts must have the same keys, etc.",
"_____no_output_____"
],
[
"## Example: ML model parameters\n\nA simple example of training an MLP displays some ways in which pytree operations come in useful:",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef init_mlp_params(layer_widths):\n params = []\n for n_in, n_out in zip(layer_widths[:-1], layer_widths[1:]):\n params.append(\n dict(weights=np.random.normal(size=(n_in, n_out)) * np.sqrt(2/n_in),\n biases=np.ones(shape=(n_out,))\n )\n )\n return params\n\nparams = init_mlp_params([1, 128, 128, 1])",
"_____no_output_____"
]
],
[
[
"We can use `jax.tree_map` to check that the shapes of our parameters are what we expect:",
"_____no_output_____"
]
],
[
[
"jax.tree_map(lambda x: x.shape, params)",
"_____no_output_____"
]
],
[
[
"Now, let's train our MLP:",
"_____no_output_____"
]
],
[
[
"def forward(params, x):\n *hidden, last = params\n for layer in hidden:\n x = jax.nn.relu(x @ layer['weights'] + layer['biases'])\n return x @ last['weights'] + last['biases']\n\ndef loss_fn(params, x, y):\n return jnp.mean((forward(params, x) - y) ** 2)\n\nLEARNING_RATE = 0.0001\n\n@jax.jit\ndef update(params, x, y):\n\n grads = jax.grad(loss_fn)(params, x, y)\n # Note that `grads` is a pytree with the same structure as `params`.\n # `jax.grad` is one of the many JAX functions that has\n # built-in support for pytrees.\n\n # This is handy, because we can apply the SGD update using tree utils:\n return jax.tree_multimap(\n lambda p, g: p - LEARNING_RATE * g, params, grads\n )",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nxs = np.random.normal(size=(128, 1))\nys = xs ** 2\n\nfor _ in range(1000):\n params = update(params, xs, ys)\n\nplt.scatter(xs, ys)\nplt.scatter(xs, forward(params, xs), label='Model prediction')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"## Custom pytree nodes\n\nSo far, we've only been considering pytrees of lists, tuples, and dicts; everything else is considered a leaf. Therefore, if you define my own container class, it will be considered a leaf, even if it has trees inside it:",
"_____no_output_____"
]
],
[
[
"class MyContainer:\n \"\"\"A named container.\"\"\"\n\n def __init__(self, name: str, a: int, b: int, c: int):\n self.name = name\n self.a = a\n self.b = b\n self.c = c",
"_____no_output_____"
],
[
"jax.tree_leaves([\n MyContainer('Alice', 1, 2, 3),\n MyContainer('Bob', 4, 5, 6)\n])",
"_____no_output_____"
]
],
[
[
"Accordingly, if we try to use a tree map expecting our leaves to be the elements inside the container, we will get an error:",
"_____no_output_____"
]
],
[
[
"jax.tree_map(lambda x: x + 1, [\n MyContainer('Alice', 1, 2, 3),\n MyContainer('Bob', 4, 5, 6)\n])",
"_____no_output_____"
]
],
[
[
"To solve this, we need to register our container with JAX by telling it how to flatten and unflatten it:",
"_____no_output_____"
]
],
[
[
"from typing import Tuple, Iterable\n\ndef flatten_MyContainer(container) -> Tuple[Iterable[int], str]:\n \"\"\"Returns an iterable over container contents, and aux data.\"\"\"\n flat_contents = [container.a, container.b, container.c]\n\n # we don't want the name to appear as a child, so it is auxiliary data.\n # auxiliary data is usually a description of the structure of a node,\n # e.g., the keys of a dict -- anything that isn't a node's children.\n aux_data = container.name\n return flat_contents, aux_data\n\ndef unflatten_MyContainer(\n aux_data: str, flat_contents: Iterable[int]) -> MyContainer:\n \"\"\"Converts aux data and the flat contents into a MyContainer.\"\"\"\n return MyContainer(aux_data, *flat_contents)\n\njax.tree_util.register_pytree_node(\n MyContainer, flatten_MyContainer, unflatten_MyContainer)\n\njax.tree_leaves([\n MyContainer('Alice', 1, 2, 3),\n MyContainer('Bob', 4, 5, 6)\n])",
"_____no_output_____"
]
],
[
[
"Modern Python comes equipped with helpful tools to make defining containers easier. Some of these will work with JAX out-of-the-box, but others require more care. For instance:",
"_____no_output_____"
]
],
[
[
"from typing import NamedTuple, Any\n\nclass MyOtherContainer(NamedTuple):\n name: str\n a: Any\n b: Any\n c: Any\n\n# Since `tuple` is already registered with JAX, and NamedTuple is a subclass,\n# this will work out-of-the-box:\njax.tree_leaves([\n MyOtherContainer('Alice', 1, 2, 3),\n MyOtherContainer('Bob', 4, 5, 6)\n])",
"_____no_output_____"
]
],
[
[
"Notice that the `name` field now appears as a leaf, as all tuple elements are children. That's the price we pay for not having to register the class the hard way.",
"_____no_output_____"
],
[
"## Common pytree gotchas and patterns",
"_____no_output_____"
],
[
"### Gotchas\n#### Mistaking nodes for leaves\nA common problem to look out for is accidentally introducing tree nodes instead of leaves:",
"_____no_output_____"
]
],
[
[
"a_tree = [jnp.zeros((2, 3)), jnp.zeros((3, 4))]\n\n# Try to make another tree with ones instead of zeros\nshapes = jax.tree_map(lambda x: x.shape, a_tree)\njax.tree_map(jnp.ones, shapes)",
"_____no_output_____"
]
],
[
[
"What happened is that the `shape` of an array is a tuple, which is a pytree node, with its elements as leaves. Thus, in the map, instead of calling `jnp.ones` on e.g. `(2, 3)`, it's called on `2` and `3`.\n\nThe solution will depend on the specifics, but there are two broadly applicable options:\n* rewrite the code to avoid the intermediate `tree_map`.\n* convert the tuple into an `np.array` or `jnp.array`, which makes the entire\nsequence a leaf.",
"_____no_output_____"
],
[
"#### Handling of None\n`jax.tree_utils` treats `None` as a node without children, not as a leaf:",
"_____no_output_____"
]
],
[
[
"jax.tree_leaves([None, None, None])",
"_____no_output_____"
]
],
[
[
"### Patterns\n#### Transposing trees\n\nIf you would like to transpose a pytree, i.e. turn a list of trees into a tree of lists, you can do so using `jax.tree_multimap`:",
"_____no_output_____"
]
],
[
[
"def tree_transpose(list_of_trees):\n \"\"\"Convert a list of trees of identical structure into a single tree of lists.\"\"\"\n return jax.tree_multimap(lambda *xs: list(xs), *list_of_trees)\n\n\n# Convert a dataset from row-major to column-major:\nepisode_steps = [dict(t=1, obs=3), dict(t=2, obs=4)]\ntree_transpose(episode_steps)",
"_____no_output_____"
]
],
[
[
"For more complicated transposes, JAX provides `jax.tree_transpose`, which is more verbose, but allows you specify the structure of the inner and outer Pytree for more flexibility:",
"_____no_output_____"
]
],
[
[
"jax.tree_transpose(\n outer_treedef = jax.tree_structure([0 for e in episode_steps]),\n inner_treedef = jax.tree_structure(episode_steps[0]),\n pytree_to_transpose = episode_steps\n)",
"_____no_output_____"
]
],
[
[
"## More Information\n\nFor more information on pytrees in JAX and the operations that are available, see the [Pytrees](https://jax.readthedocs.io/en/latest/pytrees.html) section in the JAX documentation.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d00659470ea295f8d7a213e865e48807e4d8d945
| 53,588 |
ipynb
|
Jupyter Notebook
|
pycorrector_threshold_1.1.ipynb
|
JohnParken/iigroup
|
1292833208dff74eaeeeeb760d20557ca6ecc933
|
[
"Apache-2.0"
] | null | null | null |
pycorrector_threshold_1.1.ipynb
|
JohnParken/iigroup
|
1292833208dff74eaeeeeb760d20557ca6ecc933
|
[
"Apache-2.0"
] | null | null | null |
pycorrector_threshold_1.1.ipynb
|
JohnParken/iigroup
|
1292833208dff74eaeeeeb760d20557ca6ecc933
|
[
"Apache-2.0"
] | null | null | null | 54.020161 | 1,242 | 0.535306 |
[
[
[
"<a href=\"https://colab.research.google.com/github/JohnParken/iigroup/blob/master/pycorrector_threshold_1.1.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"### 准备工作",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
],
[
"import os\nos.chdir('/content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs')",
"_____no_output_____"
],
[
"!pip install -r requirements.txt\n!pip install pyltp",
"Requirement already satisfied: jieba in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 1)) (0.39)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 2)) (1.3.3)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 3)) (0.21.3)\nCollecting pypinyin\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/24/b9/ade53a5211136b51b046c16466de9e31e2543e25691582fe088d37b7f64f/pypinyin-0.36.0-py2.py3-none-any.whl (779kB)\n\u001b[K |████████████████████████████████| 788kB 9.4MB/s \n\u001b[?25hCollecting kenlm==0.0.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/57/54/0cc492b8d7aceb17a9164c6e6b9c9afc2c73706bb39324e8f6fa02f7134a/kenlm-0.tar.gz (1.4MB)\n\u001b[K |████████████████████████████████| 1.5MB 56.9MB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.13.3 in /usr/local/lib/python3.6/dist-packages (from scipy->-r requirements.txt (line 2)) (1.17.4)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->-r requirements.txt (line 3)) (0.14.1)\nBuilding wheels for collected packages: kenlm\n Building wheel for kenlm (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for kenlm: filename=kenlm-0.0.0-cp36-cp36m-linux_x86_64.whl size=2272626 sha256=bf25aded9932d27ae899a16b432a6b6d95cd4692d114b118b0dd572c7d1b666c\n Stored in directory: /root/.cache/pip/wheels/e9/cf/f4/1a1aab56f87f4132667a7a47045a750384f19d646099ab4858\nSuccessfully built kenlm\nInstalling collected packages: pypinyin, kenlm\nSuccessfully installed kenlm-0.0.0 pypinyin-0.36.0\nCollecting pyltp\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/aa/72/2d88c54618cf4d8916832950374a6f265e12289fa9870aeb340800a28a62/pyltp-0.2.1.tar.gz (5.3MB)\n\u001b[K |████████████████████████████████| 5.3MB 7.5MB/s \n\u001b[?25hBuilding wheels for collected packages: pyltp\n Building wheel for pyltp (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pyltp: filename=pyltp-0.2.1-cp36-cp36m-linux_x86_64.whl size=31968153 sha256=8751928b2aa1bd084f6780b3208e8d2ac667eb0f872fe988c9a89bad6dc5f600\n Stored in directory: /root/.cache/pip/wheels/fc/3a/35/b11293efb2c77c0e7b6fa574271d51cddd9abd1f634535343c\nSuccessfully built pyltp\nInstalling collected packages: pyltp\nSuccessfully installed pyltp-0.2.1\n"
],
[
"import pycorrector",
"_____no_output_____"
]
],
[
[
"### 测试结果",
"_____no_output_____"
]
],
[
[
"sent, detail = pycorrector.correct('我是你的眼')",
"[ DEBUG 20191215 04:05:36 corrector:110] Loaded same pinyin file: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/same_pinyin.txt, same stroke file: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/same_stroke.txt, spend: 1.865 s.\n[ DEBUG 20191215 04:05:40 detector:70] Loaded language model: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/kenlm/people_chars_lm.klm, spend: 3.7385997772216797 s\n[ DEBUG 20191215 04:05:42 detector:77] Loaded word freq file: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/word_freq.txt, size: 583280, spend: 2.7575013637542725 s\n[ DEBUG 20191215 04:05:43 detector:82] Loaded confusion file: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/custom_confusion.txt, size: 1767, spend: 0.3202035427093506 s\n[ DEBUG 20191215 04:05:44 detector:96] Loaded custom word file: /content/drive/My Drive/Colab Notebooks/PyTorch/data/pycorrector-words/pycorrector-master-new-abs/pycorrector/data/custom_confusion.txt, size: 59779, spend: 1.8662502765655518 s\n[ INFO 20191215 04:05:46 detector:100] Loaded dict ok, spend: 10.387823343276978 s\n"
],
[
"print(sent,detail)",
"我是你的眼 []\n"
],
[
"sentences = [\n '他们都很饿了,需要一些食物来充饥',\n '关于外交事务,我们必须十分谨慎才可以的',\n '他们都很饿了,需要一些事物来充饥',\n '关于外交事物,我们必须十分谨慎才可以的',\n '关于外交食务,我们必须十分谨慎才可以的',\n '这些方法是非常实用的',\n '这些方法是非常食用的',\n '高老师的植物是什么你知道吗',\n '高老师的值务是什么你知道吗',\n '高老师的职务是什么你知道马',\n '你的行为让我们赶到非常震惊',\n '你的行为让我们感到非常震惊',\n '他的医生都将在遗憾当中度过',\n '目前的形势对我们非常有力',\n '权力和义务是对等的,我们在行使权利的同时,也必须履行相关的义五',\n '权力和义务是对等的,我们在行使权力的同时',\n '权利和义务是对等的',\n '新讲生产建设兵团',\n '坐位新时代的接班人'\n '物理取闹',\n '我们不太敢说话了已经',\n '此函数其实就是将环境变量座位在path参数里面做替换,如果环境变量不存在,就原样返回。'\n\n]\n\nfor sentence in sentences:\n sent, detail = pycorrector.correct(sentence)\n print(sent, detail)\n print('\\n')",
"[('他们', 0, 2), ('都', 2, 3), ('很', 3, 4), ('饿', 4, 5), ('了', 5, 6), (',', 6, 7), ('需要', 7, 9), ('一些', 9, 11), ('食物', 11, 13), ('来', 13, 14), ('充饥', 14, 16)]\nngram: n=2\n[-3.2085440158843994, -5.418898582458496, -4.664351463317871, -6.906415939331055, -5.395123481750488, -5.325242042541504, -5.845865249633789, -6.048429489135742, -6.460465431213379, -6.186435699462891, -7.609062671661377, -8.022212982177734]\nngram: n=3\n[-5.090388774871826, -5.090388774871826, -6.518762588500977, -8.749101638793945, -7.788795471191406, -7.5064496994018555, -8.573263168334961, -8.662345886230469, -9.289972305297852, -9.06784439086914, -11.140613555908203, -10.439553260803223, -10.439553260803223]\nmed_abs_deviation: 0.5478081703186035\ny_score: [2.63819223 1.43925824 0.42762948 0. 0.52279728 0.20478823\n 0.38382137 0.6745 1.22555036 1.81501632 2.66159165]\nmedian: [-7.08277599]\nscores: [-4.94011734 -5.91385468 -6.73546847 -7.08277599 -6.6581761 -6.91645328\n -7.39450391 -7.63058416 -8.07813032 -8.55687646 -9.24443893]\nmaybe_err: ['食物', 8, 9, 'char']\nmaybe_err: ['来', 9, 10, 'char']\nmaybe_err: ['充饥', 10, 11, 'char']\n他们都很饿了,需时物一充即食物来充饥 [['食物', '时物', 8, 9], ['充饥', '充即', 10, 11]]\n\n\n[('关于', 0, 2), ('外交', 2, 4), ('事务', 4, 6), (',', 6, 7), ('我们', 7, 9), ('必须', 9, 11), ('十分', 11, 13), ('谨慎', 13, 15), ('才', 15, 16), ('可以', 16, 18), ('的', 18, 19)]\nngram: n=2\n[-3.050492286682129, -7.701910972595215, -6.242913246154785, -6.866119384765625, -5.359715938568115, -6.163232326507568, -7.367890357971191, -6.525017738342285, -8.21739387512207, -5.210103988647461, -5.497365951538086, -4.90977668762207]\nngram: n=3\n[-6.10285758972168, -6.10285758972168, -9.94007682800293, -8.959914207458496, -9.552006721496582, -7.43984317779541, -10.261677742004395, -10.424861907958984, -10.460886001586914, -10.168984413146973, -7.879795551300049, -9.49227237701416, -9.49227237701416]\nmed_abs_deviation: 0.41716365019480506\ny_score: [2.06034913 0. 0.59162991 0.43913363 0.37245575 0.6745\n 1.63484645 1.95325208 0.73589959 0.62460491 0.92836197]\nmedian: [-7.65334749]\nscores: [-6.37906615 -7.65334749 -8.01925778 -7.38175285 -7.42299167 -8.07051114\n -8.66446463 -8.86139162 -8.10848546 -7.26704288 -7.07917571]\nmaybe_err: ['十分', 6, 7, 'char']\nmaybe_err: ['谨慎', 7, 8, 'char']\n关于外交事务失分仅慎们必须十分谨慎才可以的 [['十分', '失分', 6, 7], ['谨慎', '仅慎', 7, 8]]\n\n\n[('他们', 0, 2), ('都', 2, 3), ('很', 3, 4), ('饿', 4, 5), ('了', 5, 6), (',', 6, 7), ('需要', 7, 9), ('一些', 9, 11), ('事物', 11, 13), ('来', 13, 14), ('充饥', 14, 16)]\nngram: n=2\n[-3.2085440158843994, -5.418898582458496, -4.664351463317871, -6.906415939331055, -5.395123481750488, -5.325242042541504, -5.845865249633789, -6.048429489135742, -7.34495210647583, -8.187288284301758, -7.609062671661377, -8.022212982177734]\nngram: n=3\n[-5.090388774871826, -5.090388774871826, -6.518762588500977, -8.749101638793945, -7.788795471191406, -7.5064496994018555, -8.573263168334961, -8.662345886230469, -10.174459457397461, -10.841046333312988, -12.81308364868164, -10.439553260803223, -10.439553260803223]\nmed_abs_deviation: 1.1689213116963701\ny_score: [1.23637344 0.6745 0.20040607 0. 0.2450059 0.09597281\n 0.26493792 0.69928721 1.40701421 1.4706084 1.40818304]\nmedian: [-7.08277599]\nscores: [-4.94011734 -5.91385468 -6.73546847 -7.08277599 -6.6581761 -6.91645328\n -7.54191844 -8.29465401 -9.52115834 -9.63136828 -9.52318394]\nmaybe_err: ['事物', 8, 9, 'char']\nmaybe_err: ['来', 9, 10, 'char']\nmaybe_err: ['充饥', 10, 11, 'char']\n他们都很饿了,需事无一充其事物来充饥 [['事物', '事无', 8, 9], ['充饥', '充其', 10, 11]]\n\n\n[('关于', 0, 2), ('外交', 2, 4), ('事物', 4, 6), (',', 6, 7), ('我们', 7, 9), ('必须', 9, 11), ('十分', 11, 13), ('谨慎', 13, 15), ('才', 15, 16), ('可以', 16, 18), ('的', 18, 19)]\nngram: n=2\n[-3.050492286682129, -7.701910972595215, -9.457276344299316, -7.2831268310546875, -5.359715938568115, -6.163232326507568, -7.367890357971191, -6.525017738342285, -8.21739387512207, -5.210103988647461, -5.497365951538086, -4.90977668762207]\nngram: n=3\n[-6.10285758972168, -6.10285758972168, -13.154439926147461, -11.874530792236328, -9.969014167785645, -7.43984317779541, -10.261677742004395, -10.424861907958984, -10.460886001586914, -10.168984413146973, -7.879795551300049, -9.49227237701416, -9.49227237701416]\nmed_abs_deviation: 0.7908804814020769\ny_score: [0.9856504 1.20074345 1.66099373 0.02493363 0.49296108 0.\n 0.50655142 0.6745 0.03238628 0.68523545 0.84545739]\nmedian: [-8.07051114]\nscores: [ -6.91479333 -9.47843488 -10.01809827 -8.04127538 -7.49249291\n -8.07051114 -8.66446463 -8.86139162 -8.10848546 -7.26704288\n -7.07917571]\nmaybe_err: ['外交', 1, 2, 'char']\nmaybe_err: ['事物', 2, 3, 'char']\n关外焦氏物交事物,我们必须十分谨慎才可以的 [['外交', '外焦', 1, 2], ['事物', '氏物', 2, 3]]\n\n\ncut_words: \n[('关于', 0, 2), ('外交', 2, 4), ('食务', 4, 6), (',', 6, 7), ('我们', 7, 9), ('必须', 9, 11), ('十分', 11, 13), ('谨慎', 13, 15), ('才', 15, 16), ('可以', 16, 18), ('的', 18, 19)]\nngram: n=2\n[-3.050492286682129, -7.701910972595215, -11.190844535827637, -9.44794750213623, -5.359715938568115, -6.163232326507568, -7.367890357971191, -6.525017738342285, -8.21739387512207, -5.210103988647461, -5.497365951538086, -4.90977668762207]\nngram: n=3\n[-6.10285758972168, -6.10285758972168, -14.888008117675781, -14.039351463317871, -11.95915699005127, -7.43984317779541, -10.261677742004395, -10.424861907958984, -10.460886001586914, -10.168984413146973, -7.879795551300049, -9.49227237701416, -9.49227237701416]\nmed_abs_deviation: 0.8414425849914551\ny_score: [0.72525849 1.96638218 3.09868887 0.93505707 0.22789642 0.0304402\n 0.44567266 0.60352924 0. 0.6745 0.82509424]\nmedian: [-8.10848546]\nscores: [ -7.20372136 -10.56155841 -11.97411744 -9.27497447 -7.82418338\n -8.07051114 -8.66446463 -8.86139162 -8.10848546 -7.26704288\n -7.07917571]\nmaybe_err: ['外交', 1, 2, 'char']\nmaybe_err: ['食务', 2, 3, 'char']\n关外焦试务交试务,我们必须十分谨慎才可以的 [['外交', '外焦', 1, 2], ['食务', '试务', 2, 3], ['食务', '试务', 4, 6]]\n\n\n[('这些', 0, 2), ('方法', 2, 4), ('是', 4, 5), ('非常', 5, 7), ('实用', 7, 9), ('的', 9, 10)]\nngram: n=2\n[-2.9876956939697266, -6.867339134216309, -5.548357009887695, -5.092251300811768, -6.260161399841309, -5.2522478103637695, -4.90977668762207]\nngram: n=3\n[-6.694278717041016, -6.694278717041016, -8.818385124206543, -8.583428382873535, -8.434252738952637, -6.460238456726074, -8.519281387329102, -8.519281387329102]\nmed_abs_deviation: 0.2545950611432395\ny_score: [1.59177657 0.93837236 0.53097205 0.03882287 0.03882287 0.81802795]\nmedian: [-6.76574375]\nscores: [-6.1649158 -7.11993941 -6.96616312 -6.75108977 -6.78039773 -6.456973 ]\n这些方法是非常实用的 []\n\n\n[('这些', 0, 2), ('方法', 2, 4), ('是', 4, 5), ('非常', 5, 7), ('食用', 7, 9), ('的', 9, 10)]\nngram: n=2\n[-2.9876956939697266, -6.867339134216309, -5.548357009887695, -5.092251300811768, -8.108214378356934, -5.325277328491211, -4.90977668762207]\nngram: n=3\n[-6.694278717041016, -6.694278717041016, -8.818385124206543, -8.583428382873535, -10.282306671142578, -9.311288833618164, -8.729578018188477, -8.729578018188477]\nmed_abs_deviation: 0.48789137601852417\ny_score: [1.4269127 0.1066118 0.1066118 1.10492119 1.21913446 0.24407881]\nmedian: [-7.19705576]\nscores: [-6.1649158 -7.11993941 -7.27417211 -7.99628707 -8.07890185 -7.02050432]\nmaybe_err: ['非常', 3, 4, 'char']\nmaybe_err: ['食用', 4, 5, 'char']\n这些方非长是用非常食用的 [['非常', '非长', 3, 4], ['食用', '是用', 4, 5]]\n\n\n[('高', 0, 1), ('老师', 1, 3), ('的', 3, 4), ('植物', 4, 6), ('是', 6, 7), ('什么', 7, 9), ('你', 9, 10), ('知道', 10, 12), ('吗', 12, 13)]\nngram: n=2\n[-3.5867576599121094, -6.95546817779541, -4.949565887451172, -5.875271797180176, -6.52583646774292, -4.761568546295166, -6.828787803649902, -5.650130271911621, -5.661978721618652, -5.170923709869385]\nngram: n=3\n[-7.516331672668457, -7.516331672668457, -8.474910736083984, -9.268739700317383, -8.36678409576416, -8.958122253417969, -8.822084426879883, -9.309122085571289, -6.1620001792907715, -8.10757064819336, -8.10757064819336]\nmed_abs_deviation: 0.24387991428375244\ny_score: [1.70121811 0.04883747 0.30602196 1.00658985 0.03065992 0.6745\n 0. 1.13611832 2.02131059]\nmedian: [-7.1685973]\nscores: [-6.55348547 -7.18625553 -7.05794851 -7.53255141 -7.17968305 -7.41247722\n -7.1685973 -6.7578094 -6.43774919]\n高老师的植物是什么你知道吗 []\n\n\ncut_words: \n[('高', 0, 1), ('老师', 1, 3), ('的', 3, 4), ('值务', 4, 6), ('是', 6, 7), ('什么', 7, 9), ('你', 9, 10), ('知道', 10, 12), ('吗', 12, 13)]\nngram: n=2\n[-3.5867576599121094, -6.95546817779541, -4.949565887451172, -9.382380485534668, -9.103401184082031, -4.761568546295166, -6.828787803649902, -5.650130271911621, -5.661978721618652, -5.170923709869385]\nngram: n=3\n[-7.516331672668457, -7.516331672668457, -8.474910736083984, -12.775847434997559, -11.886341094970703, -11.36100959777832, -8.822084426879883, -9.309122085571289, -6.1620001792907715, -8.10757064819336, -8.10757064819336]\nmed_abs_deviation: 1.0403747955958051\ny_score: [0.7891971 0. 0.86555344 1.85066582 0.6745 0.02734952\n 0.39040531 0.65672898 0.86423171]\nmedian: [-7.77077349]\nscores: [ -6.55348547 -7.77077349 -9.10583647 -10.62531177 -8.81114829\n -7.81295844 -7.1685973 -6.7578094 -6.43774919]\nmaybe_err: ['值务', 3, 4, 'char']\n高老师之务之务是什么你知道吗 [['值务', '之务', 3, 4], ['值务', '之务', 4, 6]]\n\n\n[('高', 0, 1), ('老师', 1, 3), ('的', 3, 4), ('职务', 4, 6), ('是', 6, 7), ('什么', 7, 9), ('你', 9, 10), ('知道', 10, 12), ('马', 12, 13)]\nngram: n=2\n[-3.5867576599121094, -6.95546817779541, -4.949565887451172, -5.560400009155273, -6.402518272399902, -4.761568546295166, -6.828787803649902, -5.650130271911621, -8.077543258666992, -6.342696189880371]\nngram: n=3\n[-7.516331672668457, -7.516331672668457, -8.474910736083984, -8.953866958618164, -7.117727279663086, -8.958152770996094, -8.822084426879883, -9.309122085571289, -10.476810455322266, -10.630916595458984, -10.630916595458984]\nmed_abs_deviation: 0.44377843538920025\ny_score: [0.92542097 0.04343475 0.6745 0. 0.33691927 0.38017055\n 1.10250433 2.03520912 2.63320046]\nmedian: [-7.16235407]\nscores: [-6.55348547 -7.13377674 -6.71857564 -7.16235407 -6.94068245 -7.4124823\n -7.88773235 -8.50139324 -8.8948338 ]\nmaybe_err: ['你', 6, 7, 'char']\nmaybe_err: ['知道', 7, 8, 'char']\nmaybe_err: ['马', 8, 9, 'char']\n高老师的职务是指道骂你知道马 [['知道', '指道', 7, 8], ['马', '骂', 8, 9]]\n\n\n[('你', 0, 1), ('的', 1, 2), ('行为', 2, 4), ('让', 4, 5), ('我们', 5, 7), ('赶到', 7, 9), ('非常', 9, 11), ('震惊', 11, 13)]\nngram: n=2\n[-2.0952072143554688, -4.555307388305664, -4.642626762390137, -6.130861282348633, -4.983797073364258, -7.352697372436523, -7.873891830444336, -6.127691745758057, -6.726749420166016]\nngram: n=3\n[-3.207780361175537, -3.207780361175537, -6.979850769042969, -7.035740852355957, -8.14639663696289, -9.491897583007812, -11.670570373535156, -10.582359313964844, -6.806113243103027, -6.806113243103027]\nmed_abs_deviation: 1.0877295335133863\ny_score: [1.96777584 1.17724368 0.42258866 0.1100792 0.5583445 1.25813706\n 0.7906555 0.1100792 ]\nmedian: [-7.06852251]\nscores: [-3.89519723 -5.17004553 -6.38703672 -6.89100377 -7.96893438 -9.09745185\n -8.34356972 -7.24604126]\nmaybe_err: ['赶到', 5, 6, 'char']\n你的行为让赶至们赶到非常震惊 [['赶到', '赶至', 5, 6]]\n\n\n[('你', 0, 1), ('的', 1, 2), ('行为', 2, 4), ('让', 4, 5), ('我们', 5, 7), ('感到', 7, 9), ('非常', 9, 11), ('震惊', 11, 13)]\nngram: n=2\n[-2.0952072143554688, -4.555307388305664, -4.642626762390137, -6.130861282348633, -4.983797073364258, -6.644998550415039, -5.245226860046387, -6.127691745758057, -6.726749420166016]\nngram: n=3\n[-3.207780361175537, -3.207780361175537, -6.979850769042969, -7.035740852355957, -8.14639663696289, -7.294723033905029, -7.49325704574585, -7.124472618103027, -6.806113243103027, -6.806113243103027]\nmed_abs_deviation: 0.1778402328491211\ny_score: [9.76302518 4.92786968 0.31215061 0.2103787 0.98708058 0.58898341\n 0.2103787 0.76001659]\nmedian: [-6.46933907]\nscores: [-3.89519723 -5.17004553 -6.38703672 -6.52480801 -6.72959503 -6.6246318\n -6.41387014 -6.66972681]\n你的行为让我们感到非常震惊 []\n\n\n[('他', 0, 1), ('的', 1, 2), ('医生', 2, 4), ('都', 4, 5), ('将', 5, 6), ('在', 6, 7), ('遗憾', 7, 9), ('当中', 9, 11), ('度过', 11, 13)]\nngram: n=2\n[-2.4090709686279297, -4.423801898956299, -5.471065521240234, -5.9832048416137695, -4.63366174697876, -4.27167272567749, -7.480583667755127, -8.875551223754883, -8.777113914489746, -7.0591840744018555]\nngram: n=3\n[-3.7044668197631836, -3.7044668197631836, -8.563815116882324, -7.541207790374756, -8.117171287536621, -5.731840133666992, -9.846197128295898, -11.941191673278809, -13.709709167480469, -11.545108795166016, -11.545108795166016]\nmed_abs_deviation: 1.125301480293274\ny_score: [1.51662318 0.6745 0. 0.4083958 0.43460023 0.37402381\n 1.86089154 2.22489479 1.91314613]\nmedian: [-6.90059996]\nscores: [ -4.37034301 -5.77529848 -6.90059996 -6.21925318 -6.17553504\n -7.52460225 -10.00521672 -10.61250122 -10.09239562]\nmaybe_err: ['遗憾', 6, 7, 'char']\nmaybe_err: ['当中', 7, 8, 'char']\nmaybe_err: ['度过', 8, 9, 'char']\n他的医生都将以憾遗都过当中度过 [['遗憾', '以憾', 6, 7], ['度过', '都过', 8, 9]]\n\n\n[('目前', 0, 2), ('的', 2, 3), ('形势', 3, 5), ('对', 5, 6), ('我们', 6, 8), ('非常', 8, 10), ('有力', 10, 12)]\nngram: n=2\n[-2.3610503673553467, -4.943981170654297, -5.557995319366455, -6.957886695861816, -5.192829608917236, -6.353403091430664, -7.5294013023376465, -6.784845352172852]\nngram: n=3\n[-4.504214286804199, -4.504214286804199, -7.833000183105469, -9.01765251159668, -9.504611015319824, -8.642641067504883, -10.75419807434082, -10.082660675048828, -10.082660675048828]\nmed_abs_deviation: 0.8187878926595049\ny_score: [2.41531947 1.13724668 0.03595688 0. 0.11393136 0.6745\n 0.96106281]\nmedian: [-7.56516318]\nscores: [-4.63316268 -6.18463862 -7.52151446 -7.56516318 -7.70346653 -8.38395107\n -8.7318149 ]\n目前的形势对我们非常有力 []\n\n\ncut_words: \ncut_words: \n[('权力', 0, 2), ('和', 2, 3), ('义务', 3, 5), ('是', 5, 6), ('对等', 6, 8), ('的', 8, 9), (',', 9, 10), ('我们', 10, 12), ('在', 12, 13), ('行使', 13, 15), ('权利', 15, 17), ('的', 17, 18), ('同时', 18, 20), (',', 20, 21), ('也', 21, 22), ('必须', 22, 24), ('履行', 24, 26), ('相关', 26, 28), ('的', 28, 29), ('义五', 29, 31)]\nngram: n=2\n[-4.37300443649292, -6.0308122634887695, -6.386775493621826, -7.048316955566406, -8.320059776306152, -5.903896808624268, -5.199775695800781, -5.359715938568115, -5.341310977935791, -6.909099578857422, -6.23046350479126, -5.3515167236328125, -4.509489059448242, -6.630192756652832, -4.818633556365967, -5.530858993530273, -7.080272674560547, -6.197956085205078, -4.534612655639648, -9.382380485534668, -8.904118537902832]\nngram: n=3\n[-6.573680877685547, -6.573680877685547, -10.594644546508789, -9.784056663513184, -13.039094924926758, -8.99142074584961, -9.424959182739258, -7.983367919921875, -7.195198059082031, -10.18882942199707, -8.975001335144043, -7.2957587242126465, -8.215274810791016, -6.430002212524414, -8.102603912353516, -8.171028137207031, -9.31860637664795, -9.254379272460938, -7.701275825500488, -12.386096954345703, -11.687058448791504, -11.687058448791504]\nmed_abs_deviation: 0.7180008292198181\ny_score: [0.89868935 0.07689711 1.328145 1.53116843 1.20617383 0.31820586\n 0.72724141 0.57440296 0.05526576 0.16929949 0.50550173 1.30814654\n 0.88151807 0.81584206 0.62175859 0.08972756 0.17284899 0.05526576\n 1.18402107 2.83426475]\nmedian: [-7.51460415]\nscores: [ -6.55795523 -7.59646062 -8.9284058 -9.14452291 -8.79856829\n -7.1758761 -6.74046044 -6.90315596 -7.45577411 -7.69482235\n -6.97650087 -6.12209074 -6.57623394 -6.64614562 -6.85274621\n -7.61011855 -7.69860077 -7.57343419 -8.77498682 -10.5316604 ]\nmaybe_err: ['义务', 2, 3, 'char']\nmaybe_err: ['是', 3, 4, 'char']\nmaybe_err: ['对等', 4, 5, 'char']\nmaybe_err: ['的', 18, 19, 'char']\nmaybe_err: ['义五', 19, 20, 'char']\n权力义武义守等是对等的,我们在行使权利的同以五,也必须履行相关的一五 [['义务', '义武', 2, 3], ['对等', '守等', 4, 5], ['义五', '以五', 19, 20], ['义五', '一五', 29, 31]]\n\n\ncut_words: \n[('权力', 0, 2), ('和', 2, 3), ('义务', 3, 5), ('是', 5, 6), ('对等', 6, 8), ('的', 8, 9), (',', 9, 10), ('我们', 10, 12), ('在', 12, 13), ('行使', 13, 15), ('权力', 15, 17), ('的', 17, 18), ('同时', 18, 20)]\nngram: n=2\n[-4.37300443649292, -6.0308122634887695, -6.386775493621826, -7.048316955566406, -8.320059776306152, -5.903896808624268, -5.199775695800781, -5.359715938568115, -5.341310977935791, -6.909099578857422, -5.651635646820068, -5.195062637329102, -4.509489059448242, -6.352172374725342]\nngram: n=3\n[-6.573680877685547, -6.573680877685547, -10.594644546508789, -9.784056663513184, -13.039094924926758, -8.99142074584961, -9.424959182739258, -7.983367919921875, -7.195198059082031, -10.18882942199707, -7.820140838623047, -5.863378524780273, -8.186124801635742, -8.364859580993652, -8.364859580993652]\nmed_abs_deviation: 0.4775520165761309\ny_score: [0.79229705 0.6745 2.5557548 2.8610011 2.37237079 0.08046155\n 0.53452458 0.30473153 0.20393635 0. 1.07667194 1.35173937\n 0.3543071 ]\nmedian: [-7.1189086]\nscores: [-6.55795523 -7.59646062 -8.9284058 -9.14452291 -8.79856829 -7.1758761\n -6.74046044 -6.90315596 -7.26329736 -7.1189086 -6.35661527 -6.16186508\n -6.86805602]\nmaybe_err: ['义务', 2, 3, 'char']\nmaybe_err: ['是', 3, 4, 'char']\nmaybe_err: ['对等', 4, 5, 'char']\n权力义武义守等是对等的,我们在行使权力的同时 [['义务', '义武', 2, 3], ['对等', '守等', 4, 5]]\n\n\ncut_words: \n[('权利', 0, 2), ('和', 2, 3), ('义务', 3, 5), ('是', 5, 6), ('对等', 6, 8), ('的', 8, 9)]\nngram: n=2\n[-5.426438331604004, -5.823465824127197, -6.386775493621826, -7.048316955566406, -8.320059776306152, -5.903896808624268, -4.90977668762207]\nngram: n=3\n[-6.919649600982666, -6.919649600982666, -6.214104652404785, -9.784056663513184, -13.039094924926758, -8.99142074584961, -9.134960174560547, -9.134960174560547]\nmed_abs_deviation: 0.9390198191006984\ny_score: [1.12625152 0.61088013 0.34167502 1.02133765 0.73811987 0.34167502]\nmedian: [-7.72264552]\nscores: [-6.15471001 -6.87219548 -8.19831582 -9.14452291 -8.75023512 -7.24697522]\n权利和义务是对等的 []\n\n\n[('新', 0, 1), ('讲', 1, 2), ('生产', 2, 4), ('建设', 4, 6), ('兵团', 6, 8)]\nngram: n=2\n[-3.0517780780792236, -7.551418304443359, -7.9017534255981445, -6.074876308441162, -7.295460224151611, -7.080999374389648]\nngram: n=3\n[-7.756345748901367, -7.756345748901367, -11.65687370300293, -10.411882400512695, -6.108068943023682, -10.44609546661377, -10.44609546661377]\nmed_abs_deviation: 0.25723294417063514\ny_score: [2.39951291 1.94034206 0.25208367 0.6745 0. ]\nmedian: [-8.09415821]\nscores: [-7.17905996 -8.83414324 -8.19029494 -7.83692527 -8.09415821]\nmaybe_err: ['讲', 1, 2, 'char']\n新强生产建设兵团 [['讲', '强', 1, 2]]\n\n\n[('坐位', 0, 2), ('新', 2, 3), ('时代', 3, 5), ('的', 5, 6), ('接班人', 6, 9), ('物理', 9, 11), ('取闹', 11, 13)]\nngram: n=2\n[-6.747719764709473, -9.164161682128906, -7.018512725830078, -4.766091346740723, -6.6565985679626465, -10.101886749267578, -11.431344985961914, -8.904118537902832]\nngram: n=3\n[-10.260345458984375, -10.260345458984375, -12.915098190307617, -8.43337345123291, -9.926911354064941, -11.915477752685547, -16.982120513916016, -13.73602294921875, -13.73602294921875]\nmed_abs_deviation: 1.3918870290120466\ny_score: [0. 0.11475043 0.6745 0.79908035 0.53778831 1.42388698\n 1.4258167 ]\nmedian: [-9.55060188]\nscores: [ -9.55060188 -9.31380479 -8.15871485 -7.90163291 -10.66037293\n -12.48891147 -12.49289362]\nmaybe_err: ['物理', 5, 6, 'char']\nmaybe_err: ['取闹', 6, 7, 'char']\n座位新时代物里去闹班人物理取闹 [['坐位', '座位', 0, 2], ['物理', '物里', 5, 6], ['取闹', '去闹', 6, 7]]\n\n\n[('我们', 0, 2), ('不', 2, 3), ('太', 3, 4), ('敢', 4, 5), ('说话', 5, 7), ('了', 7, 8), ('已经', 8, 10)]\nngram: n=2\n[-2.622403860092163, -5.762763977050781, -4.652327060699463, -7.548602104187012, -7.889505386352539, -5.700841903686523, -5.977187156677246, -5.885366439819336]\nngram: n=3\n[-4.361483573913574, -4.361483573913574, -7.9327192306518555, -6.799012184143066, -11.193404197692871, -8.891648292541504, -9.989688873291016, -9.188436508178711, -9.188436508178711]\nmed_abs_deviation: 0.7424014409383126\ny_score: [2.47627802 1.64611444 0.2059789 0.6745 0.73795175 0.\n 0.08685246]\nmedian: [-7.59780288]\nscores: [-4.87223969 -5.78597526 -7.37108823 -8.34020432 -8.41004372 -7.59780288\n -7.69339871]\n我们不太敢说话了已经 []\n\n\n[('此', 0, 1), ('函数', 1, 3), ('其实', 3, 5), ('就', 5, 6), ('是', 6, 7), ('将', 7, 8), ('环境', 8, 10), ('变量', 10, 12), ('座位', 12, 14), ('在', 14, 15), ('path', 15, 19), ('参数', 19, 21), ('里面', 21, 23), ('做', 23, 24), ('替换', 24, 26), (',', 26, 27), ('如果', 27, 29), ('环境', 29, 31), ('变量', 31, 33), ('不', 33, 34), ('存在', 34, 36), (',', 36, 37), ('就', 37, 38), ('原样', 38, 40), ('返回', 40, 42), ('。', 42, 43)]\nngram: n=2\n[-3.188654661178589, -10.135616302490234, -9.938329696655273, -6.042247772216797, -5.905479907989502, -5.266623020172119, -6.801047325134277, -9.70965576171875, -10.202875137329102, -6.995171546936035, -9.665081024169922, -11.482141494750977, -8.909974098205566, -6.503015518188477, -7.575140953063965, -8.029123306274414, -5.349051475524902, -7.7674407958984375, -9.70965576171875, -8.578041076660156, -5.115281105041504, -6.570872783660889, -5.113883972167969, -8.801565170288086, -9.633380889892578, -5.4418253898620605, -2.8844380378723145]\nngram: n=3\n[-10.25171184539795, -10.25171184539795, -14.15152359008789, -12.095661163330078, -9.515466690063477, -8.966397285461426, -9.581117630004883, -13.09030532836914, -14.426555633544922, -12.797473907470703, -14.434349060058594, -14.547782897949219, -15.509414672851562, -11.681863784790039, -11.053136825561523, -10.821532249450684, -10.529668807983398, -9.45646858215332, -13.882020950317383, -12.80172061920166, -10.917584419250488, -8.571220397949219, -9.0109281539917, -11.435738563537598, -13.041593551635742, -11.06408977508545, -5.741176605224609, -5.741176605224609]\nmed_abs_deviation: 1.1547281940778102\ny_score: [0.05849936 1.10667059 0.4372399 0.65646676 1.01453053 0.53572824\n 0.64465274 1.45454486 1.1889958 1.12226359 2.04151251 1.66328054\n 0.59596306 0.05534376 0.05534376 0.42517318 0.16543783 0.69253324\n 0.95314976 0.2347912 0.89694443 0.84670441 0.08575049 0.77411399\n 0.27089366 1.96716213]\nmedian: [-9.20704182]\nscores: [ -9.10689229 -11.10163593 -9.95558627 -8.08318611 -7.47018933\n -8.28988763 -10.3106722 -11.69718854 -11.24257477 -11.12833079\n -12.7020634 -12.05453912 -10.22731662 -9.11229459 -9.30178905\n -8.4791553 -8.92381612 -10.3926425 -10.83881187 -8.80508478\n -7.67149397 -7.75750371 -9.060239 -10.53230683 -8.74327823\n -5.83930635]\nmaybe_err: ['函数', 1, 2, 'char']\nmaybe_err: ['变量', 7, 8, 'char']\nmaybe_err: ['座位', 8, 9, 'char']\nmaybe_err: ['在', 9, 10, 'char']\nmaybe_err: ['参数', 11, 12, 'char']\n此和数数其实就是变凉座为境变餐数座位在path参数里面做替换,如果环境变量不存在,就原样返回。 [['函数', '和数', 1, 2], ['变量', '变凉', 7, 8], ['座位', '座为', 8, 9], ['参数', '餐数', 11, 12]]\n\n\n"
],
[
"sent = '这些方法是非常食用的'\nsent, detail = pycorrector.correct(sent)\nprint(sent,detail)",
"[('这些', 0, 2), ('方法', 2, 4), ('是', 4, 5), ('非常', 5, 7), ('食用', 7, 9), ('的', 9, 10)]\nngram: n=2\n[-2.9876956939697266, -6.867339134216309, -5.548357009887695, -5.092251300811768, -8.108214378356934, -5.325277328491211, -4.90977668762207]\nngram: n=3\n[-6.694278717041016, -6.694278717041016, -8.818385124206543, -8.583428382873535, -10.282306671142578, -9.311288833618164, -8.729578018188477, -8.729578018188477]\nmed_abs_deviation: 0.48789137601852417\ny_score: [1.4269127 0.1066118 0.1066118 1.10492119 1.21913446 0.24407881]\nmedian: [-7.19705576]\nscores: [-6.1649158 -7.11993941 -7.27417211 -7.99628707 -8.07890185 -7.02050432]\nmaybe_err: ['非常', 3, 4, 'char']\nmaybe_err: ['食用', 4, 5, 'char']\n这些方非长是用非常食用的 [['非常', '非长', 3, 4], ['食用', '是用', 4, 5]]\n"
],
[
"sent = '这些方法是非常实用的'\nsent, detail = pycorrector.correct(sent)\nprint(sent,detail)",
"[('这些', 0, 2), ('方法', 2, 4), ('是', 4, 5), ('非常', 5, 7), ('实用', 7, 9), ('的', 9, 10)]\nngram: n=2\n[-2.9876956939697266, -6.867339134216309, -5.548357009887695, -5.092251300811768, -6.260161399841309, -5.2522478103637695, -4.90977668762207]\nngram: n=3\n[-6.694278717041016, -6.694278717041016, -8.818385124206543, -8.583428382873535, -8.434252738952637, -6.460238456726074, -8.519281387329102, -8.519281387329102]\nmed_abs_deviation: 0.2545950611432395\ny_score: [1.59177657 0.93837236 0.53097205 0.03882287 0.03882287 0.81802795]\nmedian: [-6.76574375]\nscores: [-6.1649158 -7.11993941 -6.96616312 -6.75108977 -6.78039773 -6.456973 ]\n这些方法是非常实用的 []\n"
],
[
"sent = '关于外交事物,我们必须十分谨慎才可以的'\nsent, detail = pycorrector.correct(sent)\nprint(sent,detail)",
"[('关于', 0, 2), ('外交', 2, 4), ('事物', 4, 6), (',', 6, 7), ('我们', 7, 9), ('必须', 9, 11), ('十分', 11, 13), ('谨慎', 13, 15), ('才', 15, 16), ('可以', 16, 18), ('的', 18, 19)]\nngram: n=2\n[-3.050492286682129, -7.701910972595215, -9.457276344299316, -7.2831268310546875, -5.359715938568115, -6.163232326507568, -7.367890357971191, -6.525017738342285, -8.21739387512207, -5.210103988647461, -5.497365951538086, -4.90977668762207]\nngram: n=3\n[-6.10285758972168, -6.10285758972168, -13.154439926147461, -11.874530792236328, -9.969014167785645, -7.43984317779541, -10.261677742004395, -10.424861907958984, -10.460886001586914, -10.168984413146973, -7.879795551300049, -9.49227237701416, -9.49227237701416]\nmed_abs_deviation: 0.7908804814020769\ny_score: [0.9856504 1.20074345 1.66099373 0.02493363 0.49296108 0.\n 0.50655142 0.6745 0.03238628 0.68523545 0.84545739]\nmedian: [-8.07051114]\nscores: [ -6.91479333 -9.47843488 -10.01809827 -8.04127538 -7.49249291\n -8.07051114 -8.66446463 -8.86139162 -8.10848546 -7.26704288\n -7.07917571]\nmaybe_err: ['外交', 1, 2, 'char']\nmaybe_err: ['事物', 2, 3, 'char']\n关外焦氏物交事物,我们必须十分谨慎才可以的 [['外交', '外焦', 1, 2], ['事物', '氏物', 2, 3]]\n"
],
[
"sent = '关于外交事务,我们必须十分谨慎才可以的'\nsent, detail = pycorrector.correct(sent)\nprint(sent,detail)",
"[('关于', 0, 2), ('外交', 2, 4), ('事务', 4, 6), (',', 6, 7), ('我们', 7, 9), ('必须', 9, 11), ('十分', 11, 13), ('谨慎', 13, 15), ('才', 15, 16), ('可以', 16, 18), ('的', 18, 19)]\nngram: n=2\n[-3.050492286682129, -7.701910972595215, -6.242913246154785, -6.866119384765625, -5.359715938568115, -6.163232326507568, -7.367890357971191, -6.525017738342285, -8.21739387512207, -5.210103988647461, -5.497365951538086, -4.90977668762207]\nngram: n=3\n[-6.10285758972168, -6.10285758972168, -9.94007682800293, -8.959914207458496, -9.552006721496582, -7.43984317779541, -10.261677742004395, -10.424861907958984, -10.460886001586914, -10.168984413146973, -7.879795551300049, -9.49227237701416, -9.49227237701416]\nmed_abs_deviation: 0.41716365019480506\ny_score: [2.06034913 0. 0.59162991 0.43913363 0.37245575 0.6745\n 1.63484645 1.95325208 0.73589959 0.62460491 0.92836197]\nmedian: [-7.65334749]\nscores: [-6.37906615 -7.65334749 -8.01925778 -7.38175285 -7.42299167 -8.07051114\n -8.66446463 -8.86139162 -8.10848546 -7.26704288 -7.07917571]\nmaybe_err: ['十分', 6, 7, 'char']\nmaybe_err: ['谨慎', 7, 8, 'char']\n关于外交事务失分仅慎们必须十分谨慎才可以的 [['十分', '失分', 6, 7], ['谨慎', '仅慎', 7, 8]]\n"
]
],
[
[
"### 纠错调试(与结果无关)",
"_____no_output_____"
]
],
[
[
"import jieba\nwords = '权力和义务是对等的'\nword = jieba.cut(words)\nprint(' '.join(word))",
"权力 和义 务是 对 等 的\n"
],
[
"!pip install pyltp",
"Requirement already satisfied: pyltp in /usr/local/lib/python3.6/dist-packages (0.2.1)\n"
],
[
"import os\nfrom pyltp import Segmentor\nLTP_DATA_DIR='/content/drive/My Drive/Colab Notebooks/PyTorch/data/ltp_data_v3.4.0'\ncws_model_path=os.path.join(LTP_DATA_DIR,'cws.model')\nsegmentor=Segmentor()\nsegmentor.load(cws_model_path)\nwords=segmentor.segment('权力和义务是对等的')\nprint(type(words))\nprint(' '.join(words))\nwords_list = ' '.join(words).split(' ')\n# segmentor.release()\ntoken = list(yield_tuple(words_list))\n\ndef yield_tuple(words_list):\n start = 0\n for w in words_list:\n width = len(w)\n yield(w, start, start + width)\n start += width",
"<class 'pyltp.VectorOfString'>\n权力 和 义务 是 对等 的\n"
],
[
"words=segmentor.segment('<s>这些方法是非常实用的</s>')\nprint(type(words))\nprint(' '.join(words))\n# segmentor.release()",
"_____no_output_____"
],
[
"words=segmentor.segment('这些方法是非常实用的')\nprint(type(words))\nprint(' '.join(words))\n# segmentor.release()",
"_____no_output_____"
],
[
"for i in range(0):\n print(\"hello\")",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d00688ffc3aa9adbbffceb99df8924ab14e9b267
| 7,955 |
ipynb
|
Jupyter Notebook
|
weekly_quiz/Week_5_Quiz-paj2117.ipynb
|
perrindesign/data-science-class
|
54045e89cb366bf2c589610e419e3bc46349708a
|
[
"CC0-1.0"
] | null | null | null |
weekly_quiz/Week_5_Quiz-paj2117.ipynb
|
perrindesign/data-science-class
|
54045e89cb366bf2c589610e419e3bc46349708a
|
[
"CC0-1.0"
] | null | null | null |
weekly_quiz/Week_5_Quiz-paj2117.ipynb
|
perrindesign/data-science-class
|
54045e89cb366bf2c589610e419e3bc46349708a
|
[
"CC0-1.0"
] | null | null | null | 28.309609 | 223 | 0.551477 |
[
[
[
"# Week 5 Quiz\n\n## Perrin Anto - paj2117",
"_____no_output_____"
]
],
[
[
"# import the datasets module from sklearn\nfrom sklearn import datasets",
"_____no_output_____"
],
[
"# use datasets.load_boston() to load the Boston housing dataset\nboston = datasets.load_boston()",
"_____no_output_____"
],
[
"# print the description of the dataset in boston.DESCR\nprint(boston.DESCR)",
".. _boston_dataset:\n\nBoston house prices dataset\n---------------------------\n\n**Data Set Characteristics:** \n\n :Number of Instances: 506 \n\n :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.\n\n :Attribute Information (in order):\n - CRIM per capita crime rate by town\n - ZN proportion of residential land zoned for lots over 25,000 sq.ft.\n - INDUS proportion of non-retail business acres per town\n - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)\n - NOX nitric oxides concentration (parts per 10 million)\n - RM average number of rooms per dwelling\n - AGE proportion of owner-occupied units built prior to 1940\n - DIS weighted distances to five Boston employment centres\n - RAD index of accessibility to radial highways\n - TAX full-value property-tax rate per $10,000\n - PTRATIO pupil-teacher ratio by town\n - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town\n - LSTAT % lower status of the population\n - MEDV Median value of owner-occupied homes in $1000's\n\n :Missing Attribute Values: None\n\n :Creator: Harrison, D. and Rubinfeld, D.L.\n\nThis is a copy of UCI ML housing dataset.\nhttps://archive.ics.uci.edu/ml/machine-learning-databases/housing/\n\n\nThis dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.\n\nThe Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic\nprices and the demand for clean air', J. Environ. Economics & Management,\nvol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics\n...', Wiley, 1980. N.B. Various transformations are used in the table on\npages 244-261 of the latter.\n\nThe Boston house-price data has been used in many machine learning papers that address regression\nproblems. \n \n.. topic:: References\n\n - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.\n - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.\n\n"
],
[
"# copy the dataset features from boston.data to X\nX = boston.data",
"_____no_output_____"
],
[
"# copy the dataset labels from boston.target to y\ny = boston.target",
"_____no_output_____"
],
[
"# import the LinearRegression model from sklearn.linear_model\nfrom sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"# initialize a linear regression model as lr with the default arguments\nlr = LinearRegression()",
"_____no_output_____"
],
[
"# fit the lr model using the entire set of X features and y labels\nlr.fit(X,y)",
"_____no_output_____"
],
[
"# score the lr model on entire set of X features and y labels\nlr.score(X,y)",
"_____no_output_____"
],
[
"# import the DecisionTreeRegressor from sklearn.tree\nfrom sklearn.tree import DecisionTreeRegressor",
"_____no_output_____"
],
[
"# initialize a decision tree model as dt with the default arguments\ndt = DecisionTreeRegressor()",
"_____no_output_____"
],
[
"# fit the dt model using the entire set of X features and y labels\ndt.fit(X,y)",
"_____no_output_____"
],
[
"# score the dt model on the entire set of X features and y labels\ndt.score(X,y)",
"_____no_output_____"
]
],
[
[
"**What are we doing wrong here?!<br>\nWhy shouldn't we trust these scores to tell us how the models with generalize?**\nWe never split the data set into training and testing subsets. These scores are based on the same data that was used to train the model, as seen by the perfect score on the decision tree regressor! \n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d00692aeb8d98ddf758beec50f7ea6ce69e05b06
| 909 |
ipynb
|
Jupyter Notebook
|
5. OS with Python/Codes/5. Bulk Directories Creation/OS Library - Bulk Directories Creation.ipynb
|
AshishJangra27/Data-Science-Live-Course-GeeksForGeeks
|
4fefa9c855dd515a974ee4c0d9a41886e3c0c1f8
|
[
"Apache-2.0"
] | 1 |
2021-11-24T16:41:00.000Z
|
2021-11-24T16:41:00.000Z
|
5. OS with Python/Codes/5. Bulk Directories Creation/OS Library - Bulk Directories Creation.ipynb
|
AshishJangra27/Data-Science-Live-Course-GeeksForGeeks
|
4fefa9c855dd515a974ee4c0d9a41886e3c0c1f8
|
[
"Apache-2.0"
] | null | null | null |
5. OS with Python/Codes/5. Bulk Directories Creation/OS Library - Bulk Directories Creation.ipynb
|
AshishJangra27/Data-Science-Live-Course-GeeksForGeeks
|
4fefa9c855dd515a974ee4c0d9a41886e3c0c1f8
|
[
"Apache-2.0"
] | null | null | null | 17.150943 | 48 | 0.466447 |
[
[
[
"import os",
"_____no_output_____"
],
[
"n = 'GFG'\n\nos.mkdir(n)\n\nfor i in range(1000):\n \n name = n +'/'+ n + \" \" + str(i+1)\n os.mkdir(name)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
d0069e2a36204df8606dc23f8e75ef7c3b8b2179
| 51,222 |
ipynb
|
Jupyter Notebook
|
Code/demographics_Lat_Long.ipynb
|
rabest265/GunViolence
|
dbe51d40fb959f624d482619549f6e21a80409d3
|
[
"CNRI-Python",
"OML"
] | null | null | null |
Code/demographics_Lat_Long.ipynb
|
rabest265/GunViolence
|
dbe51d40fb959f624d482619549f6e21a80409d3
|
[
"CNRI-Python",
"OML"
] | null | null | null |
Code/demographics_Lat_Long.ipynb
|
rabest265/GunViolence
|
dbe51d40fb959f624d482619549f6e21a80409d3
|
[
"CNRI-Python",
"OML"
] | null | null | null | 26.040671 | 116 | 0.439831 |
[
[
[
"#API calls to Google Maps for Lat & Long",
"_____no_output_____"
],
[
"# Dependencies\nimport requests\nimport json\nfrom config import gkey\nimport os\nimport csv\nimport pandas as pd\nimport numpy as np\n",
"_____no_output_____"
],
[
"# Load CSV file\ncsv_path = os.path.join('..',\"output\", \"demographics.csv\")\n\n# Read Purchasing File and store into Pandas data frame\ncities_df = pd.read_csv(csv_path, encoding = \"ISO-8859-1\")\ncities_df.head()",
"_____no_output_____"
],
[
"params = {\"key\": gkey}\n\n# Loop through the cities_df that do not have lat & long and run a lat/long search for each city\n\nfor index, row in cities_df.iterrows():\n if(pd.isnull(row['Lat'])):\n \n base_url = \"https://maps.googleapis.com/maps/api/geocode/json\"\n\n city = row['city_name']\n state = row['State']\n citystate=city + \", \"+ state\n print (citystate)\n \n # update address key value\n params['address'] = f\"{city},{state}\"\n\n # make request\n cities_lat_lng = requests.get(base_url, params=params)\n\n # print the cities_lat_lng url, avoid doing for public github repos in order to avoid exposing key\n # print(cities_lat_lng.url)\n\n # convert to json\n cities_lat_lng = cities_lat_lng.json()\n\n cities_df.loc[index, \"Lat\"] = cities_lat_lng[\"results\"][0][\"geometry\"][\"location\"][\"lat\"]\n cities_df.loc[index, \"Lng\"] = cities_lat_lng[\"results\"][0][\"geometry\"][\"location\"][\"lng\"]\n\n# Visualize to confirm lat lng appear\ncities_df.head()",
"Quincy, WA\nRaft Island, WA\nRainier, WA\nRavensdale, WA\nRaymond, WA\nReardan, WA\nRedmond, WA\nRenton, WA\nRepublic, WA\nRichland, WA\nRidgefield, WA\nRitzville, WA\nRiverbend, WA\nRiver Road, WA\nRiverside, WA\nRochester, WA\nRockford, WA\nRock Island, WA\nRockport, WA\nRocky Point, WA\nRonald, WA\nRoosevelt, WA\nRosalia, WA\nRosburg, WA\nRosedale, WA\nRoslyn, WA\nRoy, WA\nRoyal City, WA\nRuston, WA\nRyderwood, WA\nSt. John, WA\nSalmon Creek, WA\nSammamish, WA\nSantiago, WA\nSatsop, WA\nSeabeck, WA\nSeaTac, WA\nSeattle, WA\nSedro-Woolley, WA\nSekiu, WA\nSelah, WA\nSequim, WA\nShadow Lake, WA\nShelton, WA\nShoreline, WA\nSilvana, WA\nSilverdale, WA\nSilver Firs, WA\nSisco Heights, WA\nSkamokawa Valley, WA\nSkokomish, WA\nSkykomish, WA\nSnohomish, WA\nSnoqualmie, WA\nSnoqualmie Pass, WA\nSoap Lake, WA\nSouth Bend, WA\nSouth Cle Elum, WA\nSouth Creek, WA\nSouth Hill, WA\nSouth Prairie, WA\nSouth Wenatchee, WA\nSouthworth, WA\nSpanaway, WA\nSpangle, WA\nSpokane, WA\nSpokane Valley, WA\nSprague, WA\nSpringdale, WA\nStansberry Lake, WA\nStanwood, WA\nStarbuck, WA\nStartup, WA\nSteilacoom, WA\nSteptoe, WA\nStevenson, WA\nSudden Valley, WA\nSultan, WA\nSumas, WA\nSummit, WA\nSummit View, WA\nSummitview, WA\nSumner, WA\nSunday Lake, WA\nSunnyside, WA\nSunnyslope, WA\nSuquamish, WA\nSwede Heaven, WA\nTacoma, WA\nTaholah, WA\nTampico, WA\nTanglewilde, WA\nTanner, WA\nTekoa, WA\nTenino, WA\nTerrace Heights, WA\nThorp, WA\nThree Lakes, WA\nTieton, WA\nTokeland, WA\nToledo, WA\nTonasket, WA\nToppenish, WA\nTorboy, WA\nTouchet, WA\nTown and Country, WA\nTracyton, WA\nTrout Lake, WA\nTukwila, WA\nTumwater, WA\nTwin Lakes, WA\nTwisp, WA\nUnion, WA\nUnion Gap, WA\nUnion Hill-Novelty Hill, WA\nUniontown, WA\nUniversity Place, WA\nUpper Elochoman, WA\nVader, WA\nValley, WA\nVancouver, WA\nVantage, WA\nVashon, WA\nVaughn, WA\nVenersborg, WA\nVerlot, WA\nWaitsburg, WA\nWalla Walla, WA\nWalla Walla East, WA\nWaller, WA\nWallula, WA\nWalnut Grove, WA\nWapato, WA\nWarden, WA\nWarm Beach, WA\nWashougal, WA\nWashtucna, WA\nWaterville, WA\nWauna, WA\nWaverly, WA\nWenatchee, WA\nWest Clarkston-Highland, WA\nWest Pasco, WA\nWestport, WA\nWest Richland, WA\nWest Side Highway, WA\nWhidbey Island Station, WA\nWhite Center, WA\nWhite Salmon, WA\nWhite Swan, WA\nWilbur, WA\nWilderness Rim, WA\nWilkeson, WA\nWillapa, WA\nWilson Creek, WA\nWinlock, WA\nWinthrop, WA\nWishram, WA\nWollochet, WA\nWoodinville, WA\nWoodland, WA\nWoods Creek, WA\nWoodway, WA\nYacolt, WA\nYakima, WA\nYarrow Point, WA\nYelm, WA\nZillah, WA\nAccoville, WV\nAddison, WV\nAlbright, WV\nAlderson, WV\nAlum Creek, WV\nAmherstdale, WV\nAnawalt, WV\nAnmoore, WV\nAnsted, WV\nApple Grove, WV\nArbovale, WV\nAthens, WV\nAuburn, WV\nAurora, WV\nBancroft, WV\nBarboursville, WV\nBarrackville, WV\nBartley, WV\nBartow, WV\nBath, WV\nBayard, WV\nBeards Fork, WV\nBeaver, WV\nBeckley, WV\nBeech Bottom, WV\nBelington, WV\nBelle, WV\nBelmont, WV\nBelva, WV\nBenwood, WV\nBergoo, WV\nBerwind, WV\nBethany, WV\nBethlehem, WV\nBeverly, WV\nBig Chimney, WV\nBig Creek, WV\nBig Sandy, WV\nBirch River, WV\nBlacksville, WV\nBlennerhassett, WV\nBluefield, WV\nBluewell, WV\nBoaz, WV\nBolivar, WV\nBolt, WV\nBoomer, WV\nBowden, WV\nBradley, WV\nBradshaw, WV\nBramwell, WV\nBrandonville, WV\nBrandywine, WV\nBrenton, WV\nBridgeport, WV\nBrookhaven, WV\nBruceton Mills, WV\nBruno, WV\nBrush Fork, WV\nBuckhannon, WV\nBud, WV\nBuffalo, WV\nBurlington, WV\nBurnsville, WV\nCairo, WV\nCamden-on-Gauley, WV\nCameron, WV\nCapon Bridge, WV\nCarolina, WV\nCarpendale, WV\nCass, WV\nCassville, WV\nCedar Grove, WV\nCentury, WV\nCeredo, WV\nChapmanville, WV\nCharleston, WV\nCharles Town, WV\nCharlton Heights, WV\nChattaroy, WV\nChauncey, WV\nCheat Lake, WV\nChelyan, WV\nChesapeake, WV\nChester, WV\nClarksburg, WV\nClay, WV\nClearview, WV\nClendenin, WV\nCoal City, WV\nCoal Fork, WV\nComfort, WV\nCorinne, WV\nCovel, WV\nCowen, WV\nCrab Orchard, WV\nCraigsville, WV\nCross Lanes, WV\nCrum, WV\nCrumpler, WV\nCucumber, WV\nCulloden, WV\nDailey, WV\nDaniels, WV\nDanville, WV\nDavis, WV\nDavy, WV\nDeep Water, WV\nDelbarton, WV\nDespard, WV\nDixie, WV\nDunbar, WV\nDurbin, WV\nEast Bank, WV\nEast Dailey, WV\nEccles, WV\nEleanor, WV\nElizabeth, WV\nElk Garden, WV\nElkins, WV\nElkview, WV\nEllenboro, WV\nEnterprise, WV\nFairlea, WV\nFairmont, WV\nFairview, WV\nFalling Spring, WV\nFalling Waters, WV\nFalls View, WV\nFarmington, WV\nFayetteville, WV\nFenwick, WV\nFlatwoods, WV\nFlemington, WV\nFollansbee, WV\nFort Ashby, WV\nFort Gay, WV\nFrank, WV\nFranklin, WV\nFriendly, WV\nGallipolis Ferry, WV\nGalloway, WV\nGary, WV\nGassaway, WV\nGauley Bridge, WV\nGhent, WV\nGilbert, WV\nGilbert Creek, WV\nGlasgow, WV\nGlen Dale, WV\nGlen Ferris, WV\nGlen Fork, WV\nGlen Jean, WV\nGlenville, WV\nGlen White, WV\nGrafton, WV\nGrantsville, WV\nGrant Town, WV\nGranville, WV\nGreat Cacapon, WV\nGreen Bank, WV\nGreen Spring, WV\nGreenview, WV\nGypsy, WV\nHambleton, WV\nHamlin, WV\nHandley, WV\nHarman, WV\nHarpers Ferry, WV\nHarrisville, WV\nHartford City, WV\nHarts, WV\nHedgesville, WV\nHelen, WV\nHelvetia, WV\nHenderson, WV\nHendricks, WV\nHenlawson, WV\nHepzibah, WV\nHico, WV\nHillsboro, WV\nHilltop, WV\nHinton, WV\nHolden, WV\nHometown, WV\nHooverson Heights, WV\nHundred, WV\nHuntersville, WV\nHuntington, WV\nHurricane, WV\nHuttonsville, WV\nIaeger, WV\nIdamay, WV\nInwood, WV\nItmann, WV\nJacksonburg, WV\nJane Lew, WV\nJefferson, WV\nJunior, WV\nJustice, WV\nKenova, WV\nKermit, WV\nKeyser, WV\nKeystone, WV\nKimball, WV\nKimberly, WV\nKincaid, WV\nKingwood, WV\nKistler, WV\nKopperston, WV\nLashmeet, WV\nLavalette, WV\nLeon, WV\nLesage, WV\nLester, WV\nLewisburg, WV\nLittleton, WV\nLogan, WV\nLost Creek, WV\nLubeck, WV\nLumberport, WV\nMabscott, WV\nMacArthur, WV\nMcConnell, WV\nMcMechen, WV\nMadison, WV\nMallory, WV\nMan, WV\nMannington, WV\nMarlinton, WV\nMarmet, WV\nMartinsburg, WV\nMason, WV\nMasontown, WV\nMatewan, WV\nMatheny, WV\nMatoaka, WV\nMaybeury, WV\nMeadow Bridge, WV\nMiddlebourne, WV\nMiddleway, WV\nMill Creek, WV\nMilton, WV\nMinden, WV\nMineralwells, WV\nMitchell Heights, WV\nMonaville, WV\nMonongah, WV\nMontcalm, WV\nMontgomery, WV\nMontrose, WV\nMoorefield, WV\nMorgantown, WV\nMoundsville, WV\nMount Carbon, WV\nMount Gay-Shamrock, WV\nMount Hope, WV\nMullens, WV\nNeibert, WV\nNettie, WV\nNewburg, WV\nNew Cumberland, WV\nNewell, WV\nNew Haven, WV\nNew Martinsville, WV\nNew Richmond, WV\nNitro, WV\nNorthfork, WV\nNorth Hills, WV\nNutter Fort, WV\nOak Hill, WV\nOakvale, WV\nOceana, WV\nOmar, WV\nPaden City, WV\nPage, WV\nPageton, WV\nParcoal, WV\nParkersburg, WV\nParsons, WV\nPaw Paw, WV\nPax, WV\nPea Ridge, WV\nPennsboro, WV\nPentress, WV\nPetersburg, WV\nPeterstown, WV\nPhilippi, WV\nPickens, WV\nPiedmont, WV\nPinch, WV\nPine Grove, WV\nPineville, WV\nPiney View, WV\nPleasant Valley, WV\nPoca, WV\nPoint Pleasant, WV\nPowellton, WV\nPratt, WV\nPrichard, WV\nPrince, WV\nPrinceton, WV\nProsperity, WV\nPullman, WV\nQuinwood, WV\nRachel, WV\nRacine, WV\nRainelle, WV\nRand, WV\nRanson, WV\nRavenswood, WV\nRaysal, WV\nReader, WV\nRed Jacket, WV\nReedsville, WV\nReedy, WV\nRhodell, WV\nRichwood, WV\nRidgeley, WV\nRipley, WV\nRivesville, WV\nRobinette, WV\nRoderfield, WV\nRomney, WV\nRonceverte, WV\nRossmore, WV\nRowlesburg, WV\nRupert, WV\nSt. Albans, WV\nSt. George, WV\nSt. Marys, WV\nSalem, WV\nSalt Rock, WV\nSand Fork, WV\nSarah Ann, WV\nScarbro, WV\nShady Spring, WV\nShannondale, WV\nShenandoah Junction, WV\nShepherdstown, WV\nShinnston, WV\nShrewsbury, WV\nSissonville, WV\nSistersville, WV\nSmithers, WV\nSmithfield, WV\nSophia, WV\nSouth Charleston, WV\nSpelter, WV\nSpencer, WV\nSpringfield, WV\nStanaford, WV\nStar City, WV\nStollings, WV\nStonewood, WV\nSummersville, WV\nSutton, WV\nSwitzer, WV\nSylvester, WV\nTeays Valley, WV\nTerra Alta, WV\nThomas, WV\nThurmond, WV\nTioga, WV\nTornado, WV\nTriadelphia, WV\nTunnelton, WV\nTwilight, WV\nUnion, WV\nValley Bend, WV\nValley Grove, WV\nValley Head, WV\nVan, WV\nVerdunville, WV\nVienna, WV\nVivian, WV\nWallace, WV\nWar, WV\nWardensville, WV\nWashington, WV\nWaverly, WV\nWayne, WV\nWeirton, WV\nWelch, WV\nWellsburg, WV\nWest Hamlin, WV\nWest Liberty, WV\nWest Logan, WV\nWest Milford, WV\nWeston, WV\nWestover, WV\nWest Union, WV\nWheeling, WV\nWhite Hall, WV\nWhite Sulphur Springs, WV\nWhitesville, WV\nWhitmer, WV\nWiley Ford, WV\nWilliamson, WV\nWilliamstown, WV\nWindsor Heights, WV\nWinfield, WV\nWolf Summit, WV\nWomelsdorf, WV\nWorthington, WV\nAbbotsford, WI\nAbrams, WI\nAdams, WI\nAdell, WI\nAlbany, WI\nAlgoma, WI\nAllenton, WI\nAllouez, WI\nAlma, WI\nAlma Center, WI\nAlmena, WI\nAlmond, WI\nAltoona, WI\nAmberg, WI\nAmery, WI\nAmherst, WI\nAmherst Junction, WI\nAngelica, WI\nAniwa, WI\nAntigo, WI\nAppleton, WI\nArcadia, WI\nArena, WI\nArgonne, WI\nArgyle, WI\nArkansaw, WI\nArkdale, WI\nArlington, WI\nArpin, WI\n"
],
[
"cities_df.head() \ncities_df.to_csv(\"../Output/cities.csv\", index=False, header=True)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
d006bca3f1ef84afd38cb7505b3e72d7ae4175e8
| 74,088 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/TwitchAPIMining-checkpoint.ipynb
|
yash5OG/GamingVizs-PriyaYash
|
7c6ea4ac86c9825e3cfd59a39a7dc84adbebf27e
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/TwitchAPIMining-checkpoint.ipynb
|
yash5OG/GamingVizs-PriyaYash
|
7c6ea4ac86c9825e3cfd59a39a7dc84adbebf27e
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/TwitchAPIMining-checkpoint.ipynb
|
yash5OG/GamingVizs-PriyaYash
|
7c6ea4ac86c9825e3cfd59a39a7dc84adbebf27e
|
[
"MIT"
] | null | null | null | 41.045983 | 738 | 0.456592 |
[
[
[
"import matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nimport requests\nimport time\nfrom scipy.stats import linregress\nimport psycopg2\nfrom sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, Float\nfrom api_keys import client_id\nfrom twitch import TwitchClient\nfrom pprint import pprint",
"_____no_output_____"
],
[
"csvpath = './Priya_Notebooks/Website/static/csv/'",
"_____no_output_____"
],
[
"client = TwitchClient(client_id= f'{client_id}')",
"_____no_output_____"
],
[
"#getting live streams data\n\nlive_streams = client.streams.get_live_streams(limit = 100)\npprint(live_streams[0])\n\n#lsdf = pd.DataFrame.from_dict(live_streams[0].channel, orient = 'index')\n\n\n\n\n\n\n\n\n",
"{'average_fps': 60,\n 'broadcast_platform': 'live',\n 'channel': {'broadcaster_language': 'en',\n 'broadcaster_software': '',\n 'broadcaster_type': '',\n 'created_at': datetime.datetime(2014, 3, 20, 22, 28, 22, 813998),\n 'description': 'Youtube.com/AdinRoss '\n 'Twitter.com/adinross',\n 'display_name': 'AdinRoss',\n 'followers': 2854562,\n 'game': 'Just Chatting',\n 'id': 59299632,\n 'language': 'en',\n 'logo': 'https://static-cdn.jtvnw.net/jtv_user_pictures/10c197cb-295f-4d40-8a6c-26a0a5da22ee-profile_image-300x300.png',\n 'mature': False,\n 'name': 'adinross',\n 'partner': True,\n 'privacy_options_enabled': False,\n 'private_video': False,\n 'profile_banner': 'https://static-cdn.jtvnw.net/jtv_user_pictures/ab24c36c-51f8-4872-a8db-335b9e3318dd-profile_banner-480.jpeg',\n 'profile_banner_background_color': '#000000',\n 'status': 'ADIN X LIL TECCA X SILKY X ANNOYING SPECIAL',\n 'updated_at': datetime.datetime(2021, 4, 24, 1, 55, 34, 458449),\n 'url': 'https://www.twitch.tv/adinross',\n 'video_banner': 'https://static-cdn.jtvnw.net/jtv_user_pictures/e569badb-3df1-4fd3-bc5f-1c26942dcc0b-channel_offline_image-1920x1080.png',\n 'views': 14257157},\n 'community_id': '',\n 'community_ids': [],\n 'created_at': datetime.datetime(2021, 4, 24, 1, 59, 9),\n 'delay': 0,\n 'game': 'Just Chatting',\n 'id': 41554516509,\n 'is_playlist': False,\n 'preview': {'large': 'https://static-cdn.jtvnw.net/previews-ttv/live_user_adinross-640x360.jpg',\n 'medium': 'https://static-cdn.jtvnw.net/previews-ttv/live_user_adinross-320x180.jpg',\n 'small': 'https://static-cdn.jtvnw.net/previews-ttv/live_user_adinross-80x45.jpg',\n 'template': 'https://static-cdn.jtvnw.net/previews-ttv/live_user_adinross-{width}x{height}.jpg'},\n 'stream_type': 'live',\n 'video_height': 1080,\n 'viewers': 130093}\n"
],
[
"lsdf = pd.DataFrame.from_dict(live_streams[0].channel, orient = 'index')\n#live_streams[0].values()\nlsdf.transpose()",
"_____no_output_____"
],
[
"channels = []\ngame_name = []\nviewers = []\n\nchannel_created_at = []\nchannel_followers = []\nchannel_id = []\nchannel_display_name = []\nchannel_game = []\nchannel_lan = []\nchannel_mature = []\nchannel_partner = []\nchannel_views = []\nchannel_description = []\nfor game in live_streams: \n channel_created_at.append(game.channel.created_at)\n channel_followers.append(game.channel.followers)\n channel_game.append(game.channel.game)\n channel_lan.append(game.channel.language)\n channel_mature.append(game.channel.mature)\n channel_partner.append(game.channel.partner)\n channel_views.append(game.channel.views)\n channel_description.append(game.channel.description)\n channel_id.append(game.channel.id)\n channel_display_name.append(game.channel.display_name)\n viewers.append(game.viewers)\n \ntoplivestreams = pd.DataFrame({\n \"channel_id\":channel_id,\n \"channel_display_name\":channel_display_name,\n \"channel_description\" : channel_description,\n \"channel_created_at\" : channel_created_at,\n \"channel_followers\" : channel_followers,\n \"channel_game\" : channel_game,\n \"channel_lan\" : channel_lan,\n \"channel_mature\" : channel_mature,\n \"channel_partner\" : channel_partner,\n \"channel_views\" : channel_views,\n \"stream_viewers\" : viewers})\n\ntoplivestreams.head(5+1)\n",
"_____no_output_____"
],
[
"toplivestreams.to_csv(csvpath+'toplivestreams.csv', index = False, header = True)",
"_____no_output_____"
],
[
"df = pd.Panel(live_streams[0])",
"_____no_output_____"
],
[
"top_videos = client.videos.get_top(limit = 100)\npprint(top_videos[1])",
"{'animated_preview_url': 'https://dgeft87wbj63p.cloudfront.net/46989779e4766b5fef0b_auronplay_41807275580_1618754838/storyboards/992088534-strip-0.jpg',\n 'broadcast_id': 41807275580,\n 'broadcast_type': 'archive',\n 'channel': {'broadcaster_language': 'es',\n 'broadcaster_software': 'unknown_rtmp',\n 'broadcaster_type': 'partner',\n 'created_at': datetime.datetime(2019, 9, 3, 14, 2, 49, 15250),\n 'description': 'feliz pero no mucho ',\n 'display_name': 'auronplay',\n 'followers': 8236862,\n 'game': 'Grand Theft Auto V',\n 'id': 459331509,\n 'language': 'es',\n 'logo': 'https://static-cdn.jtvnw.net/jtv_user_pictures/ec898e4a-e0df-4dc0-a99d-7540c6dbe1e8-profile_image-300x300.png',\n 'mature': True,\n 'name': 'auronplay',\n 'partner': True,\n 'privacy_options_enabled': False,\n 'private_video': False,\n 'profile_banner': 'https://static-cdn.jtvnw.net/jtv_user_pictures/57457a3e-dc8a-4f46-9fca-64b89b069dba-profile_banner-480.png',\n 'profile_banner_background_color': '',\n 'status': 'MARBELLA VICE #8 || Empezamos a tener mucho material..',\n 'updated_at': datetime.datetime(2021, 4, 24, 2, 58, 11, 780159),\n 'url': 'https://www.twitch.tv/auronplay',\n 'video_banner': 'https://static-cdn.jtvnw.net/jtv_user_pictures/a6d0e655-da35-420a-b763-9f1f3b67d621-channel_offline_image-1920x1080.jpeg',\n 'views': 126233055},\n 'created_at': datetime.datetime(2021, 4, 18, 14, 7, 28),\n 'delete_at': '2021-06-17T14:07:28Z',\n 'description': None,\n 'description_html': None,\n 'fps': {'160p30': 29.994347271474453,\n '360p30': 29.994347271474453,\n '480p30': 29.994347271474453,\n '720p30': 29.994347271474453,\n '720p60': 59.988497446417334,\n 'chunked': 59.988497446417334},\n 'game': 'Charlando',\n 'id': 'v992088534',\n 'increment_view_count_url': 'https://countess.twitch.tv/ping.gif?u=%7B%22id%22%3A%22992088534%22%2C%22type%22%3A%22vod%22%7D',\n 'language': 'es',\n 'length': 15220,\n 'preview': {'large': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-640x360.jpg',\n 'medium': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-320x180.jpg',\n 'small': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-80x45.jpg',\n 'template': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-{width}x{height}.jpg'},\n 'published_at': datetime.datetime(2021, 4, 18, 14, 7, 28),\n 'recorded_at': '2021-04-18T14:07:28Z',\n 'resolutions': {'160p30': '284x160',\n '360p30': '640x360',\n '480p30': '852x480',\n '720p30': '1280x720',\n '720p60': '1280x720',\n 'chunked': '1920x1080'},\n 'restriction': '',\n 'seek_previews_url': 'https://dgeft87wbj63p.cloudfront.net/46989779e4766b5fef0b_auronplay_41807275580_1618754838/storyboards/992088534-info.json',\n 'status': 'recorded',\n 'tag_list': '',\n 'thumbnails': {'large': [{'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-640x360.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb1-640x360.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb2-640x360.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb3-640x360.jpg'}],\n 'medium': [{'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-320x180.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb1-320x180.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb2-320x180.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb3-320x180.jpg'}],\n 'small': [{'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-80x45.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb1-80x45.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb2-80x45.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb3-80x45.jpg'}],\n 'template': [{'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb0-{width}x{height}.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb1-{width}x{height}.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb2-{width}x{height}.jpg'},\n {'type': 'generated',\n 'url': 'https://static-cdn.jtvnw.net/cf_vods/dgeft87wbj63p/46989779e4766b5fef0b_auronplay_41807275580_1618754838//thumb/thumb3-{width}x{height}.jpg'}]},\n 'title': 'MARBELLA VICE #5 || En busca de un gran botín 🤡',\n 'url': 'https://www.twitch.tv/videos/992088534',\n 'viewable': 'public',\n 'viewable_at': None,\n 'views': 3926790}\n"
],
[
"channels1 = []\ngame_name1 = []\nviews1 = []\nvid_length = []\nvid_title = []\nvid_total_views = []\n\nchannel_created_at1 = []\nchannel_followers1 = []\nchannel_id1 = []\nchannel_display_name1 = []\nchannel_game1 = []\nchannel_lan1 = []\nchannel_mature1 = []\nchannel_partner1 = []\nchannel_views1 = []\nchannel_description1 = []\nfor game in top_videos: \n channel_created_at1.append(game.channel.created_at)\n channel_followers1.append(game.channel.followers)\n channel_game1.append(game.channel.game)\n channel_lan1.append(game.channel.language)\n channel_mature1.append(game.channel.mature)\n channel_partner1.append(game.channel.partner)\n channel_views1.append(game.channel.views)\n channel_description1.append(game.channel.description)\n channel_id1.append(game.channel.id)\n channel_display_name1.append(game.channel.display_name)\n views1.append(game.views)\n vid_length.append(game.length)\n vid_title.append(game.title)\n vid_total_views.append(round(((game.views*game.length)/(60*60)),2))\n \ntopvideos = pd.DataFrame({\n \"vid_title\":vid_title,\n \"vid_length\":vid_length,\n \"video_views\" : views1,\n \"total_view_time-calc-hours\":vid_total_views,\n \"channel_id\":channel_id,\n \"channel_display_name\":channel_display_name1,\n \"channel_description\" : channel_description1,\n \"channel_created_at\" : channel_created_at1,\n \"channel_followers\" : channel_followers1,\n \"channel_game\" : channel_game1,\n \"channel_lan\" : channel_lan1,\n \"channel_mature\" : channel_mature1,\n \"channel_partner\" : channel_partner1,\n \"channel_views\" : channel_views1,\n \n \n })\n\ntopvideos.head(5+1)",
"_____no_output_____"
],
[
"topvideos.to_csv(csvpath+'topvideos.csv', index = False, header = True)",
"_____no_output_____"
],
[
"toplivestreams.channel_game.value_counts()",
"_____no_output_____"
],
[
"topvideos.channel_game.value_counts()",
"_____no_output_____"
],
[
"gamesummary = client.stream.get_summary(toplivestreamgames[0])",
"_____no_output_____"
],
[
"topvidchan = topvideos.channel_display_name.unique()",
"_____no_output_____"
],
[
"topstreamchan = toplivestreams.channel_display_name.unique()",
"_____no_output_____"
],
[
"topchan = set(topvidchan).intersection(topstreamchan)\ntopchan",
"_____no_output_____"
],
[
"serverlocations = []\nfor server in servers:\n serverlocations.append(server.name)\nserverlocations",
"_____no_output_____"
],
[
"servers = client.ingests.get_server_list()\npprint(servers)",
"[{'availability': 1.0,\n 'default': False,\n 'id': 1,\n 'name': 'Europe: Germany, Frankfurt (2)',\n 'url_template': 'rtmp://fra02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 2,\n 'name': 'NA: Mexico, Queretaro (1)',\n 'url_template': 'rtmp://qro01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 3,\n 'name': 'Asia: Japan, Tokyo (1)',\n 'url_template': 'rtmp://tyo01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 4,\n 'name': 'Asia: India, Chennai',\n 'url_template': 'rtmp://maa01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 5,\n 'name': 'US Central: Dallas, TX',\n 'url_template': 'rtmp://dfw.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 6,\n 'name': 'Asia: Thailand, Bangkok',\n 'url_template': 'rtmp://bkk.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 7,\n 'name': 'US East: Chicago, IL (2)',\n 'url_template': 'rtmp://ord02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 8,\n 'name': 'Asia: Singapore',\n 'url_template': 'rtmp://sin.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 9,\n 'name': 'Europe: Finland, Helsinki',\n 'url_template': 'rtmp://hel.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 10,\n 'name': 'Europe: Norway, Oslo',\n 'url_template': 'rtmp://osl.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 11,\n 'name': 'Australia: Sydney (2)',\n 'url_template': 'rtmp://syd02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 12,\n 'name': 'US West: Salt Lake City, UT',\n 'url_template': 'rtmp://slc.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 13,\n 'name': 'Europe: Sweden, Stockholm',\n 'url_template': 'rtmp://arn.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 14,\n 'name': 'US West: Seattle, WA',\n 'url_template': 'rtmp://sea.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 15,\n 'name': 'NA: Canada, Quebec',\n 'url_template': 'rtmp://ymq.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 16,\n 'name': 'Asia: Taiwan, Taipei (1)',\n 'url_template': 'rtmp://tpe01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 17,\n 'name': 'US East: Miami, FL',\n 'url_template': 'rtmp://mia.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 18,\n 'name': 'South America: Brazil, Sao Paulo',\n 'url_template': 'rtmp://sao.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 19,\n 'name': 'Europe: Germany, Düsseldorf (1)',\n 'url_template': 'rtmp://dus01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 20,\n 'name': 'Asia: Japan, Tokyo (3)',\n 'url_template': 'rtmp://tyo03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 21,\n 'name': 'Europe: UK, London (3)',\n 'url_template': 'rtmp://lhr03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 22,\n 'name': 'US West: Los Angeles, CA',\n 'url_template': 'rtmp://lax.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 23,\n 'name': 'NA: Mexico, Queretaro (2)',\n 'url_template': 'rtmp://qro02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 24,\n 'name': 'Asia: Hong Kong',\n 'url_template': 'rtmp://hkg.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 25,\n 'name': 'Europe: France, Marseille',\n 'url_template': 'rtmp://mrs.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 26,\n 'name': 'US East: Ashburn, VA (3)',\n 'url_template': 'rtmp://iad03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 27,\n 'name': 'US East: Ashburn, VA (5)',\n 'url_template': 'rtmp://iad05.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 28,\n 'name': 'US West: Phoenix, AZ',\n 'url_template': 'rtmp://phx.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 29,\n 'name': 'Europe: Netherlands, Amsterdam (3)',\n 'url_template': 'rtmp://ams03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 30,\n 'name': 'US East: Atlanta, GA',\n 'url_template': 'rtmp://atl.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 31,\n 'name': 'Asia: South Korea, Seoul (3)',\n 'url_template': 'rtmp://sel03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': True,\n 'id': 32,\n 'name': 'US West: San Francisco, CA',\n 'url_template': 'rtmp://sfo.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 33,\n 'name': 'Europe: Czech Republic, Prague',\n 'url_template': 'rtmp://prg.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 34,\n 'name': 'Australia: Sydney (1)',\n 'url_template': 'rtmp://syd01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 35,\n 'name': 'US East: New York, NY',\n 'url_template': 'rtmp://jfk.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 36,\n 'name': 'US Central: Denver, CO',\n 'url_template': 'rtmp://den.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 37,\n 'name': 'Europe: Spain, Madrid',\n 'url_template': 'rtmp://mad.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 38,\n 'name': 'US West: San Jose, CA (2)',\n 'url_template': 'rtmp://sjc02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 39,\n 'name': 'Asia: South Korea, Seoul (1)',\n 'url_template': 'rtmp://sel01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 40,\n 'name': 'US West: San Jose, CA (5)',\n 'url_template': 'rtmp://sjc05.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 41,\n 'name': 'Asia: India, Mumbai',\n 'url_template': 'rtmp://bom01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 42,\n 'name': 'Asia: Taiwan, Taipei (3)',\n 'url_template': 'rtmp://tpe03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 43,\n 'name': 'Europe: Italy, Milan',\n 'url_template': 'rtmp://mil.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 44,\n 'name': 'US Central: Houston, TX',\n 'url_template': 'rtmp://hou.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 45,\n 'name': 'Europe: Denmark, Copenhagen',\n 'url_template': 'rtmp://cph.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 46,\n 'name': 'Europe: Germany, Frankfurt (5)',\n 'url_template': 'rtmp://fra05.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 47,\n 'name': 'US West: Portland, OR',\n 'url_template': 'rtmp://pdx.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 48,\n 'name': 'Europe: UK, London (4)',\n 'url_template': 'rtmp://lhr04.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 49,\n 'name': 'NA: Canada, Toronto',\n 'url_template': 'rtmp://yto.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 50,\n 'name': 'Europe: France, Paris',\n 'url_template': 'rtmp://cdg.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 51,\n 'name': 'Europe: Poland, Warsaw',\n 'url_template': 'rtmp://waw.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 52,\n 'name': 'Europe: Netherlands, Amsterdam (2)',\n 'url_template': 'rtmp://ams02.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 53,\n 'name': 'Europe: Germany, Berlin',\n 'url_template': 'rtmp://ber.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 54,\n 'name': 'US East: Chicago, IL (3)',\n 'url_template': 'rtmp://ord03.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 55,\n 'name': 'South America: Brazil, Fortaleza (1)',\n 'url_template': 'rtmp://for01.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 56,\n 'name': 'South America: Brazil, Rio de Janeiro',\n 'url_template': 'rtmp://rio.contribute.live-video.net/app/{stream_key}'},\n {'availability': 1.0,\n 'default': False,\n 'id': 57,\n 'name': 'Europe: Austria, Vienna',\n 'url_template': 'rtmp://vie.contribute.live-video.net/app/{stream_key}'}]\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d006c191a3722901ed436191ade8964dd32d5b88
| 136,534 |
ipynb
|
Jupyter Notebook
|
opencv_class_2.ipynb
|
hrnn/image-processing-practice
|
015e2c75314b410263e379a3d93577aa05cac572
|
[
"MIT"
] | null | null | null |
opencv_class_2.ipynb
|
hrnn/image-processing-practice
|
015e2c75314b410263e379a3d93577aa05cac572
|
[
"MIT"
] | null | null | null |
opencv_class_2.ipynb
|
hrnn/image-processing-practice
|
015e2c75314b410263e379a3d93577aa05cac572
|
[
"MIT"
] | null | null | null | 433.44127 | 37,422 | 0.93628 |
[
[
[
"<a href=\"https://colab.research.google.com/github/hrnn/image-processing-practice/blob/main/opencv_class_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/gdrive')",
"Mounted at /gdrive\n"
],
[
"import cv2\nimport numpy as np\nfrom google.colab.patches import cv2_imshow",
"_____no_output_____"
],
[
"circles = cv2.imread('/gdrive/My Drive/Colab Notebooks/opencv/circles.png')\ncv2_imshow(circles)",
"_____no_output_____"
],
[
"blue_channel = circles[:,:,0]\ngreen_channel = circles[:,:,1]\nred_channel = circles[:,:,2]\ncv2_imshow(blue_channel)",
"_____no_output_____"
],
[
"gray = cv2.cvtColor(circles, cv2.COLOR_BGR2GRAY)\ncv2_imshow(gray)",
"_____no_output_____"
],
[
"blue = cv2.subtract(blue_channel, gray)\ncv2_imshow(blue)",
"_____no_output_____"
],
[
"ret, threshold = cv2.threshold(blue, 110, 255, cv2.THRESH_BINARY)\ncv2_imshow(threshold)",
"_____no_output_____"
],
[
"#HSV\n\nblue_array = np.uint8([[[255, 0, 0]]])\nhsv_blue_array = cv2.cvtColor(blue_array, cv2.COLOR_BGR2HSV)\nprint(hsv_blue_array)",
"[[[120 255 255]]]\n"
],
[
"img = cv2.imread('/gdrive/My Drive/Colab Notebooks/opencv/circles.png', 1)\nhsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)\n\ncv2_imshow(img)\n",
"_____no_output_____"
],
[
"#blue color range\n\nblue_low = np.array([110,50,50])\nblue_high = np.array([130,255,255])\n\nmask = cv2.inRange(hsv, blue_low, blue_high)\n\ncv2_imshow(mask)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d006dd4fb1fa91a4542a16f2efa522b4932bf8ac
| 8,661 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/CNN2Head_test-checkpoint.ipynb
|
Hsintien-Ng/multi-task-learning
|
29c0407241ba8d74ddc9139b3c98b545363270fb
|
[
"MIT"
] | 156 |
2017-12-07T10:33:53.000Z
|
2022-03-23T17:13:05.000Z
|
.ipynb_checkpoints/CNN2Head_test-checkpoint.ipynb
|
Hsintien-Ng/multi-task-learning
|
29c0407241ba8d74ddc9139b3c98b545363270fb
|
[
"MIT"
] | 4 |
2018-05-25T08:53:33.000Z
|
2020-05-13T09:22:07.000Z
|
.ipynb_checkpoints/CNN2Head_test-checkpoint.ipynb
|
Hsintien-Ng/multi-task-learning
|
29c0407241ba8d74ddc9139b3c98b545363270fb
|
[
"MIT"
] | 54 |
2018-05-30T03:01:44.000Z
|
2022-03-30T07:03:08.000Z
| 42.455882 | 281 | 0.46057 |
[
[
[
"import CNN2Head_input\nimport tensorflow as tf\nimport numpy as np\n\nSAVE_FOLDER = '/home/ubuntu/coding/cnn/multi-task-learning/save/current'\n\n_, smile_test_data = CNN2Head_input.getSmileImage()\n_, gender_test_data = CNN2Head_input.getGenderImage()\n_, age_test_data = CNN2Head_input.getAgeImage()",
"/home/ubuntu/anaconda3/envs/tensorflow_p36/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6\n return f(*args, **kwds)\n"
],
[
"def eval_smile_gender_age_test(nbof_crop):\n nbof_smile = len(smile_test_data)\n nbof_gender = len(gender_test_data)\n nbof_age = len(age_test_data)\n\n nbof_true_smile = 0\n nbof_true_gender = 0\n nbof_true_age = 0\n\n sess = tf.InteractiveSession()\n saver = tf.train.import_meta_graph(SAVE_FOLDER + '/model.ckpt.meta')\n saver.restore(sess, SAVE_FOLDER + \"/model.ckpt\")\n \n x_smile = tf.get_collection('x_smile')[0]\n x_gender = tf.get_collection('x_gender')[0]\n x_age = tf.get_collection('x_age')[0]\n \n keep_prob_smile_fc1 = tf.get_collection('keep_prob_smile_fc1')[0]\n keep_prob_gender_fc1 = tf.get_collection('keep_prob_gender_fc1')[0]\n keep_prob_age_fc1 = tf.get_collection('keep_prob_age_fc1')[0]\n \n keep_prob_smile_fc2 = tf.get_collection('keep_prob_smile_fc2')[0]\n keep_prob_gender_fc2 = tf.get_collection('keep_prob_emotion_fc2')[0]\n keep_prob_age_fc2 = tf.get_collection('keep_prob_age_fc2')[0]\n \n y_smile_conv = tf.get_collection('y_smile_conv')[0]\n y_gender_conv = tf.get_collection('y_gender_conv')[0]\n y_age_conv = tf.get_collection('y_age_conv')[0]\n \n is_training = tf.get_collection('is_training')[0]\n\n for i in range(nbof_smile): \n smile = np.zeros([1,48,48,1])\n smile[0] = smile_test_data[i % 1000][0]\n smile_label = smile_test_data[i % 1000][1]\n \n gender = np.zeros([1,48,48,1])\n gender[0] = gender_test_data[i % 1000][0]\n gender_label = gender_test_data[i % 1000][1]\n \n age = np.zeros([1,48,48,1])\n age[0] = age_test_data[i % 1000][0]\n age_label = age_test_data[i % 1000][1]\n \n y_smile_pred = np.zeros([2])\n y_gender_pred = np.zeros([2])\n y_age_pred = np.zeros([4])\n\n for _ in range(nbof_crop):\n x_smile_ = CNN2Head_input.random_crop(smile, (48, 48), 10)\n x_gender_ = CNN2Head_input.random_crop(gender,(48, 48), 10)\n x_age_ = CNN2Head_input.random_crop(age,(48, 48), 10)\n \n y1 = y_smile_conv.eval(feed_dict={x_smile: x_smile_,\n x_gender: x_gender_,\n x_age: x_age_,\n keep_prob_smile_fc1: 1,\n keep_prob_smile_fc2: 1,\n keep_prob_gender_fc1: 1,\n keep_prob_gender_fc2: 1,\n keep_prob_age_fc1: 1,\n keep_prob_age_fc2: 1,\n is_training: False})\n y2 = y_gender_conv.eval(feed_dict={x_smile: x_smile_,\n x_gender: x_gender_,\n x_age: x_age_,\n keep_prob_smile_fc1: 1,\n keep_prob_smile_fc2: 1,\n keep_prob_gender_fc1: 1,\n keep_prob_gender_fc2: 1,\n keep_prob_age_fc1: 1,\n keep_prob_age_fc2: 1,\n is_training: False})\n y3 = y_age_conv.eval(feed_dict={x_smile: x_smile_,\n x_gender: x_gender_,\n x_age: x_age_,\n keep_prob_smile_fc1: 1,\n keep_prob_smile_fc2: 1,\n keep_prob_gender_fc1: 1,\n keep_prob_gender_fc2: 1,\n keep_prob_age_fc1: 1,\n keep_prob_age_fc2: 1,\n is_training: False})\n \n y_smile_pred += y1[0]\n y_gender_pred += y2[0]\n y_age_pred += y3[0]\n\n predict_smile = np.argmax(y_smile_pred)\n predict_gender = np.argmax(y_gender_pred)\n predict_age = np.argmax(y_age_pred)\n\n if (predict_smile == smile_label) & (i < 1000):\n nbof_true_smile += 1\n if (predict_gender == gender_label):\n nbof_true_gender += 1\n if (predict_age == age_label):\n nbof_true_age += 1\n \n return nbof_true_smile * 100.0 / nbof_smile, nbof_true_gender * 100.0 / nbof_gender, nbof_true_age * 100.0 / nbof_age\n\n\ndef evaluate(nbof_crop):\n print('Testing phase...............................')\n smile_acc, gender_acc, age_acc = eval_smile_gender_age_test(nbof_crop)\n print('Smile test accuracy: ',str(smile_acc))\n print('Gender test accuracy: ', str(gender_acc))\n print('Age test accuracy: ', str(age_acc))\n\nevaluate(10)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
d006dda302e2c351f39058fc5655e8bf4e4f6bd3
| 2,898 |
ipynb
|
Jupyter Notebook
|
Keras/Keras-0102EN Functional API.ipynb
|
reddyprasade/Deep-Learning
|
35fea69af72f94f6ad62a0f308de7bd515c27e7a
|
[
"MIT"
] | 15 |
2020-01-23T12:01:22.000Z
|
2022-03-29T21:07:41.000Z
|
Introduction to Keras/Keras-0102EN Functional API.ipynb
|
reddyprasade/Deep-Learning-with-Tensorflow-2.x
|
bc01fd270037df09b4c8f3d6bb0b512819d7e92c
|
[
"Apache-2.0"
] | null | null | null |
Introduction to Keras/Keras-0102EN Functional API.ipynb
|
reddyprasade/Deep-Learning-with-Tensorflow-2.x
|
bc01fd270037df09b4c8f3d6bb0b512819d7e92c
|
[
"Apache-2.0"
] | 10 |
2020-02-12T02:52:04.000Z
|
2021-07-04T07:38:39.000Z
| 31.16129 | 158 | 0.594203 |
[
[
[
"## **Functional API:**\n * The Functional API, which is an easy-to-use.\n * This Funcational API can use in fully-featured API that supports arbitrary model architectures.\n * For most people and most use cases, this is what you should be using. This is the Keras \"industry strength\" model.",
"_____no_output_____"
],
[
"|**Model architectures**|**User DataSet**|**Application**|\n|-------------------|------------|----------|\n|RNN (Recurrent neural networks)| Voice,Image,Text|Speech recognition, handwriting recognition,Translations |\n|LSTM/GRU networks|Text, Image|Natural language text compression, handwriting recognition, speech recognition, gesture recognition, image captioning|\n|CNN|Image Text(light)|Image recognition, video analysis, natural language processing|\n|DBN|image, Text|Image recognition, information retrieval, natural language understanding, failure prediction|\n|DSN|Audio|Information retrieval, continuous speech recognition|",
"_____no_output_____"
],
[
"* The Keras functional API is a way to create models that are more flexible than the `tf.keras.Sequential` API.\n* The functional API can handle models with non-linear topology, shared layers, and even multiple inputs(Feature) or outputs(Target) Classifications.\n* The main idea is that a deep learning model is usually a directed acyclic graph (DAG) of layer.\n* So the functional API is a way to build graphs of layers.\n",
"_____no_output_____"
]
],
[
[
"### Consider the following model:\n\n# Image size of 28*28\n(input:784-dimensional Vector)\n |\n[Dense:(64 unit relu activation)]\n\n | \n\n[Dense:(64 unit relu activation)] \n |\n\n[Dense:(10 unit relu activation)]\n |\n\n(output Should be 10 Class (Target))",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers",
"_____no_output_____"
]
]
] |
[
"markdown",
"raw",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"code"
]
] |
d006dea018227d56a1acf5485a6cad514c478f77
| 4,536 |
ipynb
|
Jupyter Notebook
|
aws/python/AWS boto3 ec2 various test.ipynb
|
honux77/practice
|
f92481740190b20ef352135c392c8a9bea58dcc7
|
[
"MIT"
] | 152 |
2015-01-12T07:40:53.000Z
|
2022-03-20T15:51:35.000Z
|
aws/python/AWS boto3 ec2 various test.ipynb
|
Brielle-Choi/practice
|
f92481740190b20ef352135c392c8a9bea58dcc7
|
[
"MIT"
] | 11 |
2015-01-12T07:45:54.000Z
|
2021-09-02T02:46:52.000Z
|
aws/python/AWS boto3 ec2 various test.ipynb
|
Brielle-Choi/practice
|
f92481740190b20ef352135c392c8a9bea58dcc7
|
[
"MIT"
] | 32 |
2015-01-12T09:10:04.000Z
|
2022-03-02T09:18:17.000Z
| 18.666667 | 100 | 0.475088 |
[
[
[
"# client 생성",
"_____no_output_____"
]
],
[
[
"import boto3",
"_____no_output_____"
],
[
"ec2 = boto3.resource('ec2') #high level client",
"_____no_output_____"
],
[
"instances = ec2.instances.all()",
"_____no_output_____"
],
[
"for i in instances:\n print(i)",
"ec2.Instance(id='i-0cda56764352ef50e')\nec2.Instance(id='i-0e0c4fa77f5a678b2')\nec2.Instance(id='i-07e52d2fbc2ebd266')\nec2.Instance(id='i-0d022de22510a69b7')\nec2.Instance(id='i-0e701a6507dbae898')\n"
],
[
"i1 = ec2.Instance(id='i-0cda56764352ef50e')",
"_____no_output_____"
],
[
"tag = i1.tags\nprint(tag)",
"[{'Key': 'Environment', 'Value': 'production'}, {'Key': 'Name', 'Value': 'june-prod-NAT'}]\n"
],
[
"next((t['Value'] for t in i1.tags if t['Key'] == 'Name'), None)",
"_____no_output_____"
],
[
"b = next((t['Value'] for t in i1.tags if t['Key'] == 'dd'), None)\nprint(b)",
"None\n"
],
[
"def findTag(instance, key, value):\n tags = instance.tags\n if tags is None:\n return False \n tag_value = next((t['Value'] for t in tags if t['Key'] == key), None)\n return tag_value == value ",
"_____no_output_____"
],
[
"findTag(i1,'Name', value='tt')",
"_____no_output_____"
],
[
"findTag(i1,'Name', value='june-prod-NAT')",
"_____no_output_____"
],
[
"findTag(i1,'d', value='june-prod-NAT')",
"_____no_output_____"
],
[
"for i in instances:\n print(i.instance_id, findTag(i, 'Stop', 'auto'))",
"i-0cda56764352ef50e False\ni-0e0c4fa77f5a678b2 True\ni-07e52d2fbc2ebd266 False\ni-0d022de22510a69b7 False\ni-0e701a6507dbae898 False\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d006df31dca86f926642626e7756c5843c5ecff7
| 175,126 |
ipynb
|
Jupyter Notebook
|
faers_multiclass_data_pipeline_1_18_2021.ipynb
|
briangriner/OSTF-FAERS
|
4af97c85d43950704bfb7f1695873e1809f6f43c
|
[
"MIT"
] | null | null | null |
faers_multiclass_data_pipeline_1_18_2021.ipynb
|
briangriner/OSTF-FAERS
|
4af97c85d43950704bfb7f1695873e1809f6f43c
|
[
"MIT"
] | null | null | null |
faers_multiclass_data_pipeline_1_18_2021.ipynb
|
briangriner/OSTF-FAERS
|
4af97c85d43950704bfb7f1695873e1809f6f43c
|
[
"MIT"
] | 1 |
2021-02-18T03:34:54.000Z
|
2021-02-18T03:34:54.000Z
| 82.919508 | 25,464 | 0.690554 |
[
[
[
"#import libraries\n\nimport numpy as np\nimport pandas as pd\nprint('The pandas version is {}.'.format(pd.__version__))\nfrom pandas import read_csv\nfrom random import random\n\nimport sklearn\nprint('The scikit-learn version is {}.'.format(sklearn.__version__))\nfrom sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV\nfrom sklearn.preprocessing import StandardScaler, LabelBinarizer, MultiLabelBinarizer\nfrom sklearn.linear_model import Lasso, Ridge\nfrom sklearn.metrics import mean_squared_error, make_scorer, accuracy_score, confusion_matrix\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neural_network import MLPClassifier\nfrom sklearn.svm import LinearSVC\n#from sklearn.inspection import permutation_importance, partial_dependence - ONLY AVAIL IN LATER VER\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import PercentFormatter\nfrom mpl_toolkits.mplot3d import Axes3D\nimport seaborn as sns\nsns.set()\n%matplotlib inline\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"The pandas version is 1.2.0.\nThe scikit-learn version is 0.24.0.\n"
]
],
[
[
"## Methodology\n\n### Objective\n**Use FAERS data on drug safety to identify possible risk factors associated with patient mortality and other serious adverse events associated with approved used of a drug or drug class** \n\n### Data\n**_Outcome table_** \n1. Start with outcome_c table to define unit of analysis (primaryid)\n2. Reshape outcome_c to one row per primaryid\n3. Outcomes grouped into 3 categories: a. death, b. serious, c. other \n4. Multiclass model target format: each outcome grp coded into separate columns\n\n**_Demo table_**\n1. Drop fields not used in model input to reduce table size (preferably before import to notebook)\n2. Check if demo table one row per primaryid (if NOT then need to reshape / clean - TBD)\n\n**_Model input and targets_**\n1. Merge clean demo table with reshaped multilabel outcome targets (rows: primaryid, cols: outcome grps)\n2. Inspect merged file to check for anomalies (outliers, bad data, ...)\n\n### Model\n**_Multilabel Classifier_**\n1. Since each primaryid has multiple outcomes coded in the outcome_c table, the ML model should predict the probability of each possible outcome.\n2. In scikit-learn lib most/all classifiers can predict multilabel outcomes by coding target outputs into array\n\n### Results\nTBD\n\n### Insights\nTBD",
"_____no_output_____"
],
[
"## Data Pipeline: Outcome Table ",
"_____no_output_____"
]
],
[
[
"# read outcome_c.csv & drop unnecessary fields\ninfile = '../input/Outc20Q1.csv'\ncols_in = ['primaryid','outc_cod']\ndf = pd.read_csv(infile, usecols=cols_in)\nprint(df.head(),'\\n')\nprint(f'Total number of rows: {len(df):,}\\n')\nprint(f'Unique number of primaryids: {df.primaryid.nunique():,}')",
" primaryid outc_cod\n0 100046942 OT\n1 100048206 HO\n2 100048206 OT\n3 100048622 OT\n4 100051352 OT \n\nTotal number of rows: 335,470\n\nUnique number of primaryids: 260,715\n"
],
[
"# distribution of outcomes\nfrom collections import Counter\no_cnt = Counter(df['outc_cod'])\nprint('Distribution of Adverse Event Outcomes in FAERS 2020 Q1')\nfor k, v in o_cnt.items():\n print(f'{k}: {v:>8,}')\n\nprint(72*'-')\nprint(f'Most common outcome is {o_cnt.most_common(1)[0][0]} with {o_cnt.most_common(1)[0][1]:,} in 2020Q1')",
"Distribution of Adverse Event Outcomes in FAERS 2020 Q1\nOT: 168,410\nHO: 105,542\nDE: 40,221\nLT: 12,416\nDS: 6,925\nCA: 1,598\nRI: 358\n------------------------------------------------------------------------\nMost common outcome is OT with 168,410 in 2020Q1\n"
],
[
"# DO NOT GROUP OUTCOMES FOR MULTILABEL - MUST BE 0 (-1) OR 1 FOR EACH CLASS\n\n### create outcome groups: death:'DE', serious: ['LT','HO','DS','CA',RI], other: 'OT'\n\n# - USE TO CREATE OUTCOME GROUPS: key(original code) : value(new code)\n# map grp dict to outc_cod \n\n'''\noutc_to_grp = {'DE':'death',\n 'LT':'serious',\n 'HO':'serious',\n 'DS':'serious',\n 'CA':'serious',\n 'RI':'serious',\n 'OT':'other'}\ndf['oc_cat'] = df['outc_cod'].map(outc_to_grp)\nprint(df.head(),'\\n')'''\n\nprint('Distribution of AE Outcomes')\nprint(df['outc_cod'].value_counts()/len(df['outc_cod']),'\\n')\nprint(df['outc_cod'].value_counts().plot(kind='pie'))\n# outcome grps\nprint(df['outc_cod'].value_counts()/len(df['outc_cod']),'\\n')",
"Distribution of AE Outcomes\nOT 0.502012\nHO 0.314609\nDE 0.119894\nLT 0.037011\nDS 0.020643\nCA 0.004763\nRI 0.001067\nName: outc_cod, dtype: float64 \n\nAxesSubplot(0.260833,0.125;0.503333x0.755)\nOT 0.502012\nHO 0.314609\nDE 0.119894\nLT 0.037011\nDS 0.020643\nCA 0.004763\nRI 0.001067\nName: outc_cod, dtype: float64 \n\n"
],
[
"# one-hot encoding of outcome grp\n\n# step1: pandas automatic dummy var coding\ncat_cols = ['outc_cod'] #, 'oc_cat']\ndf1 = pd.get_dummies(df, prefix_sep=\"__\", columns=cat_cols)\n \nprint('Outcome codes and groups')\nprint(f'Total number of rows: {len(df1):,}')\nprint(f'Unique number of primaryids: {df1.primaryid.nunique():,}\\n')\nprint(df1.columns,'\\n')\nprint(df1.head())\nprint(df1.tail())",
"Outcome codes and groups\nTotal number of rows: 335,470\nUnique number of primaryids: 260,715\n\nIndex(['primaryid', 'outc_cod__CA', 'outc_cod__DE', 'outc_cod__DS',\n 'outc_cod__HO', 'outc_cod__LT', 'outc_cod__OT', 'outc_cod__RI'],\n dtype='object') \n\n primaryid outc_cod__CA outc_cod__DE outc_cod__DS outc_cod__HO \\\n0 100046942 0 0 0 0 \n1 100048206 0 0 0 1 \n2 100048206 0 0 0 0 \n3 100048622 0 0 0 0 \n4 100051352 0 0 0 0 \n\n outc_cod__LT outc_cod__OT outc_cod__RI \n0 0 1 0 \n1 0 0 0 \n2 0 1 0 \n3 0 1 0 \n4 0 1 0 \n primaryid outc_cod__CA outc_cod__DE outc_cod__DS outc_cod__HO \\\n335465 99974543 0 0 0 0 \n335466 99975132 0 0 0 0 \n335467 99977523 0 0 0 0 \n335468 99978615 0 0 0 0 \n335469 99998112 0 0 0 0 \n\n outc_cod__LT outc_cod__OT outc_cod__RI \n335465 0 1 0 \n335466 0 1 0 \n335467 0 1 0 \n335468 0 1 0 \n335469 0 1 0 \n"
],
[
"# step 2: create multilabel outcomes by primaryid with groupby\n\noutc_lst = ['outc_cod__CA','outc_cod__DE','outc_cod__DS','outc_cod__HO','outc_cod__LT',\n 'outc_cod__OT','outc_cod__RI']\n#oc_lst = ['oc_cat__death','oc_cat__other','oc_cat__serious']\n\ndf2 = df1.groupby(['primaryid'])[outc_lst].sum().reset_index() \ndf2['n_outc'] = df2[outc_lst].sum(axis='columns') # cnt total outcomes by primaryid\nprint(df2.columns)\nprint('-'*72)\nprint('Outcome codes in Multilabel format')\nprint(f'Total number of rows: {len(df2):,}')\nprint(f'Unique number of primaryids: {df2.primaryid.nunique():,}\\n')\nprint(df2.head())\n#print(df2.tail())\nprint(df2[outc_lst].corr())\nprint(df2.describe().T,'\\n')\n\n# plot distribution of outcome groups\n'''\ncolor = {'boxes':'DarkGreen', 'whiskers':'DarkOrange', 'medians':'DarkBlue', 'caps':'Gray'}\nprint(df2[outc_lst].plot.bar()) #color=color, sym='r+'))'''",
"Index(['primaryid', 'outc_cod__CA', 'outc_cod__DE', 'outc_cod__DS',\n 'outc_cod__HO', 'outc_cod__LT', 'outc_cod__OT', 'outc_cod__RI',\n 'n_outc'],\n dtype='object')\n------------------------------------------------------------------------\nOutcome codes in Multilabel format\nTotal number of rows: 260,715\nUnique number of primaryids: 260,715\n\n primaryid outc_cod__CA outc_cod__DE outc_cod__DS outc_cod__HO \\\n0 39651443 0 0 0 0 \n1 39703652 0 0 0 1 \n2 39928752 0 0 0 1 \n3 40142274 0 0 0 0 \n4 40158544 0 0 0 0 \n\n outc_cod__LT outc_cod__OT outc_cod__RI n_outc \n0 0 1 0 1 \n1 0 1 0 2 \n2 0 0 0 1 \n3 0 1 0 1 \n4 0 1 0 1 \n outc_cod__CA outc_cod__DE outc_cod__DS outc_cod__HO \\\noutc_cod__CA 1.000000 -0.016262 0.008727 -0.045043 \noutc_cod__DE -0.016262 1.000000 -0.050937 -0.122620 \noutc_cod__DS 0.008727 -0.050937 1.000000 -0.034083 \noutc_cod__HO -0.045043 -0.122620 -0.034083 1.000000 \noutc_cod__LT -0.006254 -0.004410 0.055467 0.092932 \noutc_cod__OT 0.001517 -0.258372 -0.060765 -0.476639 \noutc_cod__RI -0.002912 -0.014690 0.026727 0.002548 \n\n outc_cod__LT outc_cod__OT outc_cod__RI \noutc_cod__CA -0.006254 0.001517 -0.002912 \noutc_cod__DE -0.004410 -0.258372 -0.014690 \noutc_cod__DS 0.055467 -0.060765 0.026727 \noutc_cod__HO 0.092932 -0.476639 0.002548 \noutc_cod__LT 1.000000 -0.058607 0.047153 \noutc_cod__OT -0.058607 1.000000 -0.031677 \noutc_cod__RI 0.047153 -0.031677 1.000000 \n count mean std min 25% \\\nprimaryid 260715.0 1.905476e+08 1.567929e+08 39651443.0 172318487.0 \noutc_cod__CA 260715.0 6.129298e-03 7.804969e-02 0.0 0.0 \noutc_cod__DE 260715.0 1.542719e-01 3.612099e-01 0.0 0.0 \noutc_cod__DS 260715.0 2.656157e-02 1.607985e-01 0.0 0.0 \noutc_cod__HO 260715.0 4.048175e-01 4.908576e-01 0.0 0.0 \noutc_cod__LT 260715.0 4.762288e-02 2.129674e-01 0.0 0.0 \noutc_cod__OT 260715.0 6.459544e-01 4.782240e-01 0.0 0.0 \noutc_cod__RI 260715.0 1.373147e-03 3.703062e-02 0.0 0.0 \nn_outc 260715.0 1.286731e+00 5.546336e-01 1.0 1.0 \n\n 50% 75% max \nprimaryid 173619571.0 174849461.0 1.741600e+09 \noutc_cod__CA 0.0 0.0 1.000000e+00 \noutc_cod__DE 0.0 0.0 1.000000e+00 \noutc_cod__DS 0.0 0.0 1.000000e+00 \noutc_cod__HO 0.0 1.0 1.000000e+00 \noutc_cod__LT 0.0 0.0 1.000000e+00 \noutc_cod__OT 1.0 1.0 1.000000e+00 \noutc_cod__RI 0.0 0.0 1.000000e+00 \nn_outc 1.0 1.0 6.000000e+00 \n\n"
],
[
"# check primaryid from outcomes table with many outcomes\n\n# print(df2[df2['n_outc'] >= 6]) \n# checked in both outcomes and demo - multiple primaryids in outcome but only one primaryid in demo\n# appears to be okay to use",
"_____no_output_____"
],
[
"# compare primaryids above in outcomes table to same in demo table\n\n#pid_lst = [171962202,173902932,174119951,175773511,176085111]\n#[print(df_demo[df_demo['primaryid'] == p]) for p in pid_lst] # one row in demo per primaryid - looks ok to join",
"_____no_output_____"
],
[
"# save multilabel data to csv\ndf2.to_csv('../input/outc_cod-multilabel.csv')",
"_____no_output_____"
]
],
[
[
"## Data Pipeline - Demo Table",
"_____no_output_____"
]
],
[
[
"# step 0: read demo.csv & check fields for missing values\ninfile = '../input/DEMO20Q1.csv'\n#%timeit df_demo = pd.read_csv(infile) # 1 loop, best of 5: 5.19 s per loop\ndf_demo = pd.read_csv(infile)\nprint(df_demo.columns,'\\n')\nprint(f'Percent missing by column:\\n{(pd.isnull(df_demo).sum()/len(df_demo))*100}')",
"Index(['primaryid', 'caseid', 'caseversion', 'i_f_code', 'event.dt1', 'mfr_dt',\n 'init_fda_dt', 'fda_dt', 'rept_cod', 'auth_num', 'mfr_num', 'mfr_sndr',\n 'lit_ref', 'age', 'age_cod', 'age_grp', 'sex', 'e_sub', 'wt', 'wt_cod',\n 'rept.dt1', 'to_mfr', 'occp_cod', 'reporter_country', 'occr_country'],\n dtype='object') \n\nPercent missing by column:\nprimaryid 0.000000\ncaseid 0.000000\ncaseversion 0.000000\ni_f_code 0.000000\nevent.dt1 50.425676\nmfr_dt 5.891247\ninit_fda_dt 0.000000\nfda_dt 0.000000\nrept_cod 0.000000\nauth_num 94.114401\nmfr_num 5.889943\nmfr_sndr 0.000000\nlit_ref 94.064002\nage 41.312371\nage_cod 41.309547\nage_grp 89.348007\nsex 10.358072\ne_sub 0.000000\nwt 80.314646\nwt_cod 80.314646\nrept.dt1 0.047140\nto_mfr 94.109188\noccp_cod 4.056464\nreporter_country 0.000000\noccr_country 0.001738\ndtype: float64\n"
],
[
"# step 1: exclude fields with large percent missing on read to preserve memory\n\nkeep_cols = ['primaryid', 'caseversion', 'i_f_code', 'event.dt1', 'mfr_dt', 'init_fda_dt', 'fda_dt', \n 'rept_cod', 'mfr_num', 'mfr_sndr', 'age', 'age_cod', 'age_grp','sex', 'e_sub', 'wt', 'wt_cod', \n 'rept.dt1', 'occp_cod', 'reporter_country', 'occr_country']\n\n# removed cols: ['auth_num','lit_ref','to_mfr']\n\ninfile = '../input/DEMO20Q1.csv'\n#%timeit df_demo = pd.read_csv(infile, usecols=keep_cols) # 1 loop, best of 5: 4.5 s per loop\ndf_demo = pd.read_csv(infile, usecols=keep_cols)\ndf_demo.set_index('primaryid', drop=False)\nprint(df_demo.head(),'\\n')\nprint(f'Total number of rows: {len(df_demo):,}\\n')\nprint(f'Percent missing by column:\\n{(pd.isnull(df_demo).sum()/len(df_demo))*100}')",
" primaryid caseversion i_f_code event.dt1 mfr_dt init_fda_dt \\\n0 100046942 2 F NaN 2020-01-08 2014-03-12 \n1 100048206 6 F NaN 2020-03-05 2014-03-12 \n2 100048622 2 F 2005-12-30 2020-03-12 2014-03-12 \n3 100051352 2 F 2006-09-22 2020-02-20 2014-03-12 \n4 100051382 2 F 1999-01-01 2020-01-08 2014-03-12 \n\n fda_dt rept_cod mfr_num mfr_sndr ... age_cod \\\n0 2020-01-10 EXP US-PFIZER INC-2014065112 PFIZER ... NaN \n1 2020-03-09 EXP US-PFIZER INC-2014029927 PFIZER ... YR \n2 2020-03-16 EXP US-PFIZER INC-2014066653 PFIZER ... YR \n3 2020-02-24 EXP US-PFIZER INC-2014072143 PFIZER ... YR \n4 2020-01-10 EXP US-PFIZER INC-2014071938 PFIZER ... YR \n\n age_grp sex e_sub wt wt_cod rept.dt1 occp_cod reporter_country \\\n0 NaN F Y 81.0 KG 2020-01-10 LW US \n1 NaN F Y NaN NaN 2020-03-09 MD US \n2 NaN F Y NaN NaN 2020-03-16 LW US \n3 NaN F Y NaN NaN 2020-02-24 LW US \n4 NaN F Y 83.0 KG 2020-01-10 LW US \n\n occr_country \n0 US \n1 US \n2 US \n3 US \n4 US \n\n[5 rows x 21 columns] \n\nTotal number of rows: 460,327\n\nPercent missing by column:\nprimaryid 0.000000\ncaseversion 0.000000\ni_f_code 0.000000\nevent.dt1 50.425676\nmfr_dt 5.891247\ninit_fda_dt 0.000000\nfda_dt 0.000000\nrept_cod 0.000000\nmfr_num 5.889943\nmfr_sndr 0.000000\nage 41.312371\nage_cod 41.309547\nage_grp 89.348007\nsex 10.358072\ne_sub 0.000000\nwt 80.314646\nwt_cod 80.314646\nrept.dt1 0.047140\noccp_cod 4.056464\nreporter_country 0.000000\noccr_country 0.001738\ndtype: float64\n"
],
[
"# step 2: merge demo and multilabel outcomes on primaryid\n\ndf_demo_outc = pd.merge(df_demo, df2, on='primaryid')\nprint('Demo - Multilabel outcome Merge','\\n')\nprint(df_demo_outc.head(),'\\n')\nprint(f'Total number of rows: {len(df_demo_outc):,}\\n')\nprint(f'Unique number of primaryids: {df_demo_outc.primaryid.nunique():,}','\\n')\nprint(f'Percent missing by column:\\n{(pd.isnull(df_demo_outc).sum()/len(df_demo_outc))*100}')",
"Demo - Multilabel outcome Merge \n\n primaryid caseversion i_f_code event.dt1 mfr_dt init_fda_dt \\\n0 100046942 2 F NaN 2020-01-08 2014-03-12 \n1 100048206 6 F NaN 2020-03-05 2014-03-12 \n2 100048622 2 F 2005-12-30 2020-03-12 2014-03-12 \n3 100051352 2 F 2006-09-22 2020-02-20 2014-03-12 \n4 100051382 2 F 1999-01-01 2020-01-08 2014-03-12 \n\n fda_dt rept_cod mfr_num mfr_sndr ... \\\n0 2020-01-10 EXP US-PFIZER INC-2014065112 PFIZER ... \n1 2020-03-09 EXP US-PFIZER INC-2014029927 PFIZER ... \n2 2020-03-16 EXP US-PFIZER INC-2014066653 PFIZER ... \n3 2020-02-24 EXP US-PFIZER INC-2014072143 PFIZER ... \n4 2020-01-10 EXP US-PFIZER INC-2014071938 PFIZER ... \n\n reporter_country occr_country outc_cod__CA outc_cod__DE outc_cod__DS \\\n0 US US 0 0 0 \n1 US US 0 0 0 \n2 US US 0 0 0 \n3 US US 0 0 0 \n4 US US 0 0 0 \n\n outc_cod__HO outc_cod__LT outc_cod__OT outc_cod__RI n_outc \n0 0 0 1 0 1 \n1 1 0 1 0 2 \n2 0 0 1 0 1 \n3 0 0 1 0 1 \n4 0 0 1 0 1 \n\n[5 rows x 29 columns] \n\nTotal number of rows: 260,715\n\nUnique number of primaryids: 260,715 \n\nPercent missing by column:\nprimaryid 0.000000\ncaseversion 0.000000\ni_f_code 0.000000\nevent.dt1 45.019657\nmfr_dt 4.475769\ninit_fda_dt 0.000000\nfda_dt 0.000000\nrept_cod 0.000000\nmfr_num 4.473851\nmfr_sndr 0.000000\nage 33.273881\nage_cod 33.269279\nage_grp 89.183975\nsex 9.671097\ne_sub 0.000000\nwt 74.717220\nwt_cod 74.717220\nrept.dt1 0.055616\noccp_cod 2.708321\nreporter_country 0.000000\noccr_country 0.001918\noutc_cod__CA 0.000000\noutc_cod__DE 0.000000\noutc_cod__DS 0.000000\noutc_cod__HO 0.000000\noutc_cod__LT 0.000000\noutc_cod__OT 0.000000\noutc_cod__RI 0.000000\nn_outc 0.000000\ndtype: float64\n"
],
[
"# step 3: calculate wt_lbs and check\n\nprint(df_demo_outc.wt_cod.value_counts()) \nprint(df_demo_outc.groupby('wt_cod')['wt'].describe())\n# convert kg to lbs\ndf_demo_outc['wt_lbs'] = np.where(df_demo_outc['wt_cod']=='KG',df_demo_outc['wt']*2.204623,df_demo_outc['wt'])\nprint(df_demo_outc[['age','wt_lbs']].describe())\nprint(df_demo_outc[['age','wt_lbs']].corr())\nprint(sns.regplot('age','wt_lbs',data=df_demo_outc))",
"KG 65844\nLBS 72\nName: wt_cod, dtype: int64\n count mean std min 25% 50% 75% max\nwt_cod \nKG 65844.0 73.377305 26.078758 0.0 59.00 72.00 86.26 720.18\nLBS 72.0 171.151389 60.316181 17.0 128.75 165.75 195.25 361.00\n age wt_lbs\ncount 173965.000000 65916.000000\nmean 237.044055 161.779543\nstd 2050.336650 57.497343\nmin -3.000000 0.000000\n25% 43.000000 130.072757\n50% 60.000000 158.732856\n75% 72.000000 190.170780\nmax 41879.000000 1587.725392\n age wt_lbs\nage 1.000000 0.042254\nwt_lbs 0.042254 1.000000\nAxesSubplot(0.125,0.125;0.775x0.755)\n"
]
],
[
[
"### Insight: No correlation between wt and age + age range looks wrong. Check age distributions",
"_____no_output_____"
]
],
[
[
"# step 4: check age fields\n\n# age_grp\nprint('age_grp')\nprint(df_demo_outc.age_grp.value_counts(),'\\n') \n# age_cod\nprint('age_cod')\nprint(df_demo_outc.age_cod.value_counts(),'\\n')\n# age\nprint('age')\nprint(df_demo_outc.groupby(['age_grp','age_cod'])['age'].describe()) ",
"age_grp\nA 17048\nE 8674\nN 1004\nC 626\nT 503\nI 344\nName: age_grp, dtype: int64 \n\nage_cod\nYR 168732\nDY 2289\nMON 1434\nDEC 1377\nWK 134\nHR 11\nName: age_cod, dtype: int64 \n\nage\n count mean std min 25% 50% 75% \\\nage_grp age_cod \nA DEC 73.0 4.424658 1.311464 2.0 3.00 5.0 6.00 \n MON 1.0 19.000000 NaN 19.0 19.00 19.0 19.00 \n YR 10548.0 46.204115 12.832555 14.0 36.00 49.0 57.00 \nC MON 4.0 29.500000 5.196152 24.0 26.25 29.0 32.25 \n YR 315.0 6.726984 3.043486 2.0 4.00 7.0 9.00 \nE DEC 65.0 7.830769 0.893890 7.0 7.00 8.0 8.00 \n YR 6096.0 74.605315 7.153633 44.0 69.00 73.0 79.00 \nI DY 1.0 1.000000 NaN 1.0 1.00 1.0 1.00 \n MON 63.0 9.190476 5.535391 1.0 5.00 9.0 11.50 \n WK 4.0 14.250000 14.705441 4.0 6.25 8.5 16.50 \n YR 12.0 1.166667 0.389249 1.0 1.00 1.0 1.00 \nN DY 61.0 1.540984 3.423321 0.0 0.00 0.0 1.00 \n HR 1.0 1.000000 NaN 1.0 1.00 1.0 1.00 \n MON 14.0 13.857143 11.400790 3.0 5.25 9.5 17.00 \n YR 6.0 0.166667 0.408248 0.0 0.00 0.0 0.00 \nT YR 388.0 14.938144 1.631818 12.0 14.00 15.0 16.00 \n\n max \nage_grp age_cod \nA DEC 6.0 \n MON 19.0 \n YR 82.0 \nC MON 36.0 \n YR 13.0 \nE DEC 10.0 \n YR 103.0 \nI DY 1.0 \n MON 23.0 \n WK 36.0 \n YR 2.0 \nN DY 16.0 \n HR 1.0 \n MON 34.0 \n YR 1.0 \nT YR 19.0 \n"
]
],
[
[
"### age_grp, age_cod, age: Distributions by age group & code look reasonable. Create age in yrs. \n\nage_grp\n* N - Neonate\n* I - Infant\n* C - Child\n* T - Adolescent (teen?)\n* A - Adult\n* E - Elderly\n\nage_cod\n* DEC - decade (yrs = 10*DEC)\n* YR - year (yrs = 1*YR)\n* MON - month (yrs = MON/12)\n* WK - week (yrs = WK/52)\n* DY - day (yrs = DY/365.25)\n* HR - hour (yrs = HR/(365.25*24)) or code to zero",
"_____no_output_____"
]
],
[
[
"# step 5: calculate age_yrs and check corr with wt_lbs\n\ndf_demo_outc['age_yrs'] = np.where(df_demo_outc['age_cod']=='DEC',df_demo_outc['age']*10,\n np.where(df_demo_outc['age_cod']=='MON',df_demo_outc['age']/12,\n np.where(df_demo_outc['age_cod']=='WK',df_demo_outc['age']/52,\n np.where(df_demo_outc['age_cod']=='DY',df_demo_outc['age']/365.25,\n np.where(df_demo_outc['age_cod']=='DEC',df_demo_outc['age']/8766,\n df_demo_outc['age'])))))\n\n# age_yrs\nprint('age_yrs')\nprint(df_demo_outc.groupby(['age_grp','age_cod'])['age_yrs'].describe()) \nprint(df_demo_outc[['age','age_yrs']].describe())\nprint(df_demo_outc[['wt_lbs','age_yrs']].corr())\nprint(sns.regplot('wt_lbs','age_yrs',data=df_demo_outc))",
"age_yrs\n count mean std min 25% \\\nage_grp age_cod \nA DEC 73.0 44.246575 13.114645 20.000000 30.000000 \n MON 1.0 1.583333 NaN 1.583333 1.583333 \n YR 10548.0 46.204115 12.832555 14.000000 36.000000 \nC MON 4.0 2.458333 0.433013 2.000000 2.187500 \n YR 315.0 6.726984 3.043486 2.000000 4.000000 \nE DEC 65.0 78.307692 8.938895 70.000000 70.000000 \n YR 6096.0 74.605315 7.153633 44.000000 69.000000 \nI DY 1.0 0.002738 NaN 0.002738 0.002738 \n MON 63.0 0.765873 0.461283 0.083333 0.416667 \n WK 4.0 0.274038 0.282797 0.076923 0.120192 \n YR 12.0 1.166667 0.389249 1.000000 1.000000 \nN DY 61.0 0.004219 0.009373 0.000000 0.000000 \n HR 1.0 1.000000 NaN 1.000000 1.000000 \n MON 14.0 1.154762 0.950066 0.250000 0.437500 \n YR 6.0 0.166667 0.408248 0.000000 0.000000 \nT YR 388.0 14.938144 1.631818 12.000000 14.000000 \n\n 50% 75% max \nage_grp age_cod \nA DEC 50.000000 60.000000 60.000000 \n MON 1.583333 1.583333 1.583333 \n YR 49.000000 57.000000 82.000000 \nC MON 2.416667 2.687500 3.000000 \n YR 7.000000 9.000000 13.000000 \nE DEC 80.000000 80.000000 100.000000 \n YR 73.000000 79.000000 103.000000 \nI DY 0.002738 0.002738 0.002738 \n MON 0.750000 0.958333 1.916667 \n WK 0.163462 0.317308 0.692308 \n YR 1.000000 1.000000 2.000000 \nN DY 0.000000 0.002738 0.043806 \n HR 1.000000 1.000000 1.000000 \n MON 0.791667 1.416667 2.833333 \n YR 0.000000 0.000000 1.000000 \nT YR 15.000000 16.000000 19.000000 \n age age_yrs\ncount 173965.000000 173965.000000\nmean 237.044055 55.906426\nstd 2050.336650 20.714407\nmin -3.000000 -3.000000\n25% 43.000000 43.000000\n50% 60.000000 60.000000\n75% 72.000000 71.000000\nmax 41879.000000 120.000000\n wt_lbs age_yrs\nwt_lbs 1.000000 0.229312\nage_yrs 0.229312 1.000000\nAxesSubplot(0.125,0.125;0.775x0.755)\n"
]
],
[
[
"### Halis checked and wt in 400-800 range (and max wt of 1,400 lbs) is correct",
"_____no_output_____"
]
],
[
[
"# review data where wt_lbs > 800 lbs?\nprint(df_demo_outc[df_demo_outc['wt_lbs'] > 800])",
" primaryid caseversion i_f_code event.dt1 mfr_dt init_fda_dt \\\n39797 169193346 6 F 2019-09-24 2020-01-16 2019-10-15 \n121172 173344201 1 I NaN 2020-01-15 2020-01-28 \n\n fda_dt rept_cod mfr_num \\\n39797 2020-01-16 EXP JP-BRISTOL-MYERS SQUIBB COMPANY-BMS-2019-097328 \n121172 2020-01-28 EXP US-LUPIN PHARMACEUTICALS INC.-2020-00387 \n\n mfr_sndr ... rept.dt1 occp_cod reporter_country \\\n39797 BRISTOL MYERS SQUIBB ... 2020-01-16 MD JP \n121172 LUPIN ... 2020-01-28 HP US \n\n occr_country death other serious n_outc wt_lbs age_yrs \n39797 JP 1 1 2 4 1418.674901 58.0 \n121172 US 1 1 2 4 1587.725392 NaN \n\n[2 rows x 27 columns]\n"
],
[
"# step 6: Number of AE's reported in 2020Q1 by manufacturer\n\nprint('Number of patients with adverse events by manufacturer reported in 2020Q1 from DEMO table:')\nprint(df_demo_outc.mfr_sndr.value_counts()) ",
"Number of patients with adverse events by manufacturer reported in 2020Q1 from DEMO table:\nPFIZER 35415\nNOVARTIS 35022\nFDA-CTU 27113\nGALDERMA 26005\nABBVIE 23892\nJOHNSON AND JOHNSON 21011\nCELGENE 16846\nROCHE 16543\nMYLAN 14987\nSANOFI AVENTIS 14526\nAMGEN 13995\nBRISTOL MYERS SQUIBB 13050\nTEVA 12774\nGLAXOSMITHKLINE 10212\nASTRAZENECA 9396\nELI LILLY AND CO 8441\nBAYER 7870\nALLERGAN 7727\nAUROBINDO 7699\nMERCK 6750\nBIOGEN 6432\nTAKEDA 4742\nBOEHRINGER INGELHEIM 4442\nUCB 4411\nGILEAD 4360\nACTELION 4256\nSHIRE 4217\nRANBAXY 3919\nACORDA 3289\nBAUSCH AND LOMB 3082\n ... \nMANNKIND 1\nMETHAPHARM 1\nTARGET 1\nEVUS PHARMACEUTICALS 1\nHERCON 1\nHANGZHOU MINSHENG BINJIANG PHARMA 1\nTECHNOMED 1\nAVONDALE PHARMACEUTICALS 1\nTAMARANG PHARMACEUTICALS 1\nMLV PHARMA 1\nPROGENICS PHARMACEUTICALS 1\nVGYAAN PHARMACEUTICALS 1\nACCESS 1\nAVELLA SPECIALTY - COMPOUNDING 1\nNAPO PHARMACEUTICALS 1\nNIELSEN BIOSCIENCES 1\nMEDINATURA 1\nBLUE EARTH DIAGNOSTICS 1\nBIOLOGICAL E. 1\nZEALAND PHARMACEUTICALS 1\nCATALENT PHARMA 1\nALLERMED LABORATORIES 1\nIRONSHORE PHARMA 1\nSTI PHARMA 1\nHALOZYME 1\nPHARMACEUTICS INTERNATIONAL 1\nPHARMAXIS 1\nAIR PRODUCTS 1\nKNIGHT THERAPEUTICS 1\nPHARMACEUTICAL ASSOC 1\nName: mfr_sndr, Length: 504, dtype: int64\n"
],
[
"# step 7: save updated file to csv\n\nprint(df_demo_outc.columns)\n# save merged demo & multilabel data to csv\ndf_demo_outc.to_csv('../input/demo-outc_cod-multilabel-wt_lbs-age_yrs.csv')",
"Index(['primaryid', 'caseversion', 'i_f_code', 'event.dt1', 'mfr_dt',\n 'init_fda_dt', 'fda_dt', 'rept_cod', 'mfr_num', 'mfr_sndr', 'age',\n 'age_cod', 'age_grp', 'sex', 'e_sub', 'wt', 'wt_cod', 'rept.dt1',\n 'occp_cod', 'reporter_country', 'occr_country', 'outc_cod__CA',\n 'outc_cod__DE', 'outc_cod__DS', 'outc_cod__HO', 'outc_cod__LT',\n 'outc_cod__OT', 'outc_cod__RI', 'n_outc', 'wt_lbs', 'age_yrs'],\n dtype='object')\n"
]
],
[
[
"## ML Pipeline: Preprocessing",
"_____no_output_____"
]
],
[
[
"# step 0: check cat vars for one-hot coding\n\ncat_lst = ['i_f_code','rept_cod','sex','occp_cod']\n[print(df_demo_outc[x].value_counts(),'\\n') for x in cat_lst]\nprint(df_demo_outc[cat_lst].describe(),'\\n') # sex, occp_cod have missing values",
"I 164918\nF 95797\nName: i_f_code, dtype: int64 \n\nEXP 222818\nPER 26229\nDIR 11664\n5DAY 3\n30DAY 1\nName: rept_cod, dtype: int64 \n\nF 135630\nM 99851\nUNK 20\nName: sex, dtype: int64 \n\nCN 88471\nMD 72708\nHP 70916\nPH 17819\nLW 3740\nName: occp_cod, dtype: int64 \n\n i_f_code rept_cod sex occp_cod\ncount 260715 260715 235501 253654\nunique 2 5 3 5\ntop I EXP F CN\nfreq 164918 222818 135630 88471 \n\n"
],
[
"# step 1: create one-hot dummies for multilabel outcomes\n\ncat_cols = ['i_f_code', 'rept_cod', 'occp_cod', 'sex']\ndf = pd.get_dummies(df_demo_outc, prefix_sep=\"__\", columns=cat_cols, drop_first=True)\nprint(df.columns)\nprint(df.describe().T)\nprint(df.head())",
"Index(['primaryid', 'caseversion', 'event.dt1', 'mfr_dt', 'init_fda_dt',\n 'fda_dt', 'mfr_num', 'mfr_sndr', 'age', 'age_cod', 'age_grp', 'e_sub',\n 'wt', 'wt_cod', 'rept.dt1', 'reporter_country', 'occr_country',\n 'outc_cod__CA', 'outc_cod__DE', 'outc_cod__DS', 'outc_cod__HO',\n 'outc_cod__LT', 'outc_cod__OT', 'outc_cod__RI', 'n_outc', 'wt_lbs',\n 'age_yrs', 'i_f_code__I', 'rept_cod__5DAY', 'rept_cod__DIR',\n 'rept_cod__EXP', 'rept_cod__PER', 'occp_cod__HP', 'occp_cod__LW',\n 'occp_cod__MD', 'occp_cod__PH', 'sex__M', 'sex__UNK'],\n dtype='object')\n count mean std min \\\nprimaryid 260715.0 1.905476e+08 1.567929e+08 39651443.0 \ncaseversion 260715.0 1.950620e+00 2.538483e+00 1.0 \nage 173965.0 2.370441e+02 2.050337e+03 -3.0 \nwt 65916.0 7.348410e+01 2.633834e+01 0.0 \noutc_cod__CA 260715.0 6.129298e-03 7.804969e-02 0.0 \noutc_cod__DE 260715.0 1.542719e-01 3.612099e-01 0.0 \noutc_cod__DS 260715.0 2.656157e-02 1.607985e-01 0.0 \noutc_cod__HO 260715.0 4.048175e-01 4.908576e-01 0.0 \noutc_cod__LT 260715.0 4.762288e-02 2.129674e-01 0.0 \noutc_cod__OT 260715.0 6.459544e-01 4.782240e-01 0.0 \noutc_cod__RI 260715.0 1.373147e-03 3.703062e-02 0.0 \nn_outc 260715.0 1.286731e+00 5.546336e-01 1.0 \nwt_lbs 65916.0 1.617795e+02 5.749734e+01 0.0 \nage_yrs 173965.0 5.590643e+01 2.071441e+01 -3.0 \ni_f_code__I 260715.0 6.325605e-01 4.821085e-01 0.0 \nrept_cod__5DAY 260715.0 1.150682e-05 3.392157e-03 0.0 \nrept_cod__DIR 260715.0 4.473851e-02 2.067296e-01 0.0 \nrept_cod__EXP 260715.0 8.546420e-01 3.524621e-01 0.0 \nrept_cod__PER 260715.0 1.006041e-01 3.008044e-01 0.0 \noccp_cod__HP 260715.0 2.720058e-01 4.449937e-01 0.0 \noccp_cod__LW 260715.0 1.434517e-02 1.189094e-01 0.0 \noccp_cod__MD 260715.0 2.788792e-01 4.484489e-01 0.0 \noccp_cod__PH 260715.0 6.834666e-02 2.523403e-01 0.0 \nsex__M 260715.0 3.829891e-01 4.861166e-01 0.0 \nsex__UNK 260715.0 7.671212e-05 8.758226e-03 0.0 \n\n 25% 50% 75% max \nprimaryid 1.723185e+08 1.736196e+08 1.748495e+08 1.741600e+09 \ncaseversion 1.000000e+00 1.000000e+00 2.000000e+00 9.200000e+01 \nage 4.300000e+01 6.000000e+01 7.200000e+01 4.187900e+04 \nwt 5.900000e+01 7.200000e+01 8.640000e+01 7.201800e+02 \noutc_cod__CA 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__DE 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__DS 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__HO 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noutc_cod__LT 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__OT 0.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \noutc_cod__RI 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nn_outc 1.000000e+00 1.000000e+00 1.000000e+00 6.000000e+00 \nwt_lbs 1.300728e+02 1.587329e+02 1.901708e+02 1.587725e+03 \nage_yrs 4.300000e+01 6.000000e+01 7.100000e+01 1.200000e+02 \ni_f_code__I 0.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \nrept_cod__5DAY 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nrept_cod__DIR 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nrept_cod__EXP 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \nrept_cod__PER 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noccp_cod__HP 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noccp_cod__LW 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noccp_cod__MD 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noccp_cod__PH 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nsex__M 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \nsex__UNK 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \n primaryid caseversion event.dt1 mfr_dt init_fda_dt fda_dt \\\n0 100046942 2 NaN 2020-01-08 2014-03-12 2020-01-10 \n1 100048206 6 NaN 2020-03-05 2014-03-12 2020-03-09 \n2 100048622 2 2005-12-30 2020-03-12 2014-03-12 2020-03-16 \n3 100051352 2 2006-09-22 2020-02-20 2014-03-12 2020-02-24 \n4 100051382 2 1999-01-01 2020-01-08 2014-03-12 2020-01-10 \n\n mfr_num mfr_sndr age age_cod ... rept_cod__5DAY \\\n0 US-PFIZER INC-2014065112 PFIZER NaN NaN ... 0 \n1 US-PFIZER INC-2014029927 PFIZER 68.0 YR ... 0 \n2 US-PFIZER INC-2014066653 PFIZER 57.0 YR ... 0 \n3 US-PFIZER INC-2014072143 PFIZER 51.0 YR ... 0 \n4 US-PFIZER INC-2014071938 PFIZER 50.0 YR ... 0 \n\n rept_cod__DIR rept_cod__EXP rept_cod__PER occp_cod__HP occp_cod__LW \\\n0 0 1 0 0 1 \n1 0 1 0 0 0 \n2 0 1 0 0 1 \n3 0 1 0 0 1 \n4 0 1 0 0 1 \n\n occp_cod__MD occp_cod__PH sex__M sex__UNK \n0 0 0 0 0 \n1 1 0 0 0 \n2 0 0 0 0 \n3 0 0 0 0 \n4 0 0 0 0 \n\n[5 rows x 38 columns]\n"
]
],
[
[
"## check sklearn for imputation options",
"_____no_output_____"
]
],
[
[
"# step 2: use means to impute the missing values of the features with missing records\n\n# calculate percent missing\nprint(df.columns,'\\n')\nprint(f'Percent missing by column:\\n{(pd.isnull(df).sum()/len(df))*100}')\n\nnum_inputs = ['n_outc', 'wt_lbs', 'age_yrs']\ncat_inputs = ['n_outc', 'wt_lbs', 'age_yrs', 'i_f_code__I', 'rept_cod__5DAY', \n 'rept_cod__DIR', 'rept_cod__EXP', 'rept_cod__PER', 'occp_cod__HP', \n 'occp_cod__LW', 'occp_cod__MD', 'occp_cod__PH', 'sex__M', 'sex__UNK']\n\ninputs = num_inputs + cat_inputs\nprint(inputs)\n\ntarget_labels = ['oc_cat__death', 'oc_cat__other', 'oc_cat__serious']\n\n# calculate means\nmeans = df[inputs].mean()\nprint(means.shape, means)",
"Index(['primaryid', 'caseid', 'caseversion', 'event.dt1', 'mfr_dt',\n 'init_fda_dt', 'fda_dt', 'auth_num', 'mfr_num', 'mfr_sndr', 'lit_ref',\n 'age', 'age_cod', 'age_grp', 'e_sub', 'wt', 'wt_cod', 'rept.dt1',\n 'to_mfr', 'reporter_country', 'occr_country', 'outc_cod__CA',\n 'outc_cod__DE', 'outc_cod__DS', 'outc_cod__HO', 'outc_cod__LT',\n 'outc_cod__OT', 'outc_cod__RI', 'oc_cat__death', 'oc_cat__other',\n 'oc_cat__serious', 'n_outc', 'wt_lbs', 'age_yrs', 'i_f_code__I',\n 'rept_cod__5DAY', 'rept_cod__DIR', 'rept_cod__EXP', 'rept_cod__PER',\n 'occp_cod__HP', 'occp_cod__LW', 'occp_cod__MD', 'occp_cod__PH',\n 'sex__M', 'sex__UNK'],\n dtype='object') \n\nPercent missing by column:\nprimaryid 0.000000\ncaseid 0.000000\ncaseversion 0.000000\nevent.dt1 45.019657\nmfr_dt 4.475769\ninit_fda_dt 0.000000\nfda_dt 0.000000\nauth_num 90.010164\nmfr_num 4.473851\nmfr_sndr 0.000000\nlit_ref 90.137890\nage 33.273881\nage_cod 33.269279\nage_grp 89.183975\ne_sub 0.000000\nwt 74.717220\nwt_cod 74.717220\nrept.dt1 0.055616\nto_mfr 95.524615\nreporter_country 0.000000\noccr_country 0.001918\noutc_cod__CA 0.000000\noutc_cod__DE 0.000000\noutc_cod__DS 0.000000\noutc_cod__HO 0.000000\noutc_cod__LT 0.000000\noutc_cod__OT 0.000000\noutc_cod__RI 0.000000\noc_cat__death 0.000000\noc_cat__other 0.000000\noc_cat__serious 0.000000\nn_outc 0.000000\nwt_lbs 74.717220\nage_yrs 33.273881\ni_f_code__I 0.000000\nrept_cod__5DAY 0.000000\nrept_cod__DIR 0.000000\nrept_cod__EXP 0.000000\nrept_cod__PER 0.000000\noccp_cod__HP 0.000000\noccp_cod__LW 0.000000\noccp_cod__MD 0.000000\noccp_cod__PH 0.000000\nsex__M 0.000000\nsex__UNK 0.000000\ndtype: float64\n['n_outc', 'wt_lbs', 'age_yrs', 'n_outc', 'wt_lbs', 'age_yrs', 'i_f_code__I', 'rept_cod__5DAY', 'rept_cod__DIR', 'rept_cod__EXP', 'rept_cod__PER', 'occp_cod__HP', 'occp_cod__LW', 'occp_cod__MD', 'occp_cod__PH', 'sex__M', 'sex__UNK']\n(17,) n_outc 1.286731\nwt_lbs 161.779543\nage_yrs 55.906426\nn_outc 1.286731\nwt_lbs 161.779543\nage_yrs 55.906426\ni_f_code__I 0.632560\nrept_cod__5DAY 0.000012\nrept_cod__DIR 0.044739\nrept_cod__EXP 0.854642\nrept_cod__PER 0.100604\noccp_cod__HP 0.272006\noccp_cod__LW 0.014345\noccp_cod__MD 0.278879\noccp_cod__PH 0.068347\nsex__M 0.382989\nsex__UNK 0.000077\ndtype: float64\n"
],
[
"# mean fill NA\n'''\nwt_lbs 161.779543\nage_yrs 55.906426\n'''\ndf['wt_lbs_mean'] = np.where(pd.isnull(df['wt_lbs']),161.779543,df['wt_lbs']) \ndf['age_yrs_mean'] = np.where(pd.isnull(df['age_yrs']),55.906426,df['age_yrs']) \nprint('mean fill NA - wt_lbs & age_yrs')\nprint(df.describe().T)\nprint(df.columns)",
"mean fill NA - wt_lbs & age_yrs\n count mean std min \\\nprimaryid 260715.0 1.905476e+08 1.567929e+08 39651443.0 \ncaseid 260715.0 1.704415e+07 1.077987e+06 3965144.0 \ncaseversion 260715.0 1.950620e+00 2.538483e+00 1.0 \nage 173965.0 2.370441e+02 2.050337e+03 -3.0 \nwt 65916.0 7.348410e+01 2.633834e+01 0.0 \noutc_cod__CA 260715.0 6.129298e-03 7.804969e-02 0.0 \noutc_cod__DE 260715.0 1.542719e-01 3.612099e-01 0.0 \noutc_cod__DS 260715.0 2.656157e-02 1.607985e-01 0.0 \noutc_cod__HO 260715.0 4.048175e-01 4.908576e-01 0.0 \noutc_cod__LT 260715.0 4.762288e-02 2.129674e-01 0.0 \noutc_cod__OT 260715.0 6.459544e-01 4.782240e-01 0.0 \noutc_cod__RI 260715.0 1.373147e-03 3.703062e-02 0.0 \noc_cat__death 260715.0 1.542719e-01 3.612099e-01 0.0 \noc_cat__other 260715.0 6.459544e-01 4.782240e-01 0.0 \noc_cat__serious 260715.0 4.865044e-01 5.789312e-01 0.0 \nn_outc 260715.0 1.286731e+00 5.546336e-01 1.0 \nwt_lbs 65916.0 1.617795e+02 5.749734e+01 0.0 \nage_yrs 173965.0 5.590643e+01 2.071441e+01 -3.0 \ni_f_code__I 260715.0 6.325605e-01 4.821085e-01 0.0 \nrept_cod__5DAY 260715.0 1.150682e-05 3.392157e-03 0.0 \nrept_cod__DIR 260715.0 4.473851e-02 2.067296e-01 0.0 \nrept_cod__EXP 260715.0 8.546420e-01 3.524621e-01 0.0 \nrept_cod__PER 260715.0 1.006041e-01 3.008044e-01 0.0 \noccp_cod__HP 260715.0 2.720058e-01 4.449937e-01 0.0 \noccp_cod__LW 260715.0 1.434517e-02 1.189094e-01 0.0 \noccp_cod__MD 260715.0 2.788792e-01 4.484489e-01 0.0 \noccp_cod__PH 260715.0 6.834666e-02 2.523403e-01 0.0 \nsex__M 260715.0 3.829891e-01 4.861166e-01 0.0 \nsex__UNK 260715.0 7.671212e-05 8.758226e-03 0.0 \nwt_lbs_mean 260715.0 1.617795e+02 2.891064e+01 0.0 \nage_yrs_mean 260715.0 5.590643e+01 1.692077e+01 -3.0 \n\n 25% 50% 75% max \nprimaryid 1.723185e+08 1.736196e+08 1.748495e+08 1.741600e+09 \ncaseid 1.722399e+07 1.735384e+07 1.747773e+07 1.762916e+07 \ncaseversion 1.000000e+00 1.000000e+00 2.000000e+00 9.200000e+01 \nage 4.300000e+01 6.000000e+01 7.200000e+01 4.187900e+04 \nwt 5.900000e+01 7.200000e+01 8.640000e+01 7.201800e+02 \noutc_cod__CA 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__DE 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__DS 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__HO 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noutc_cod__LT 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noutc_cod__OT 0.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \noutc_cod__RI 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noc_cat__death 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noc_cat__other 0.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \noc_cat__serious 0.000000e+00 0.000000e+00 1.000000e+00 4.000000e+00 \nn_outc 1.000000e+00 1.000000e+00 1.000000e+00 6.000000e+00 \nwt_lbs 1.300728e+02 1.587329e+02 1.901708e+02 1.587725e+03 \nage_yrs 4.300000e+01 6.000000e+01 7.100000e+01 1.200000e+02 \ni_f_code__I 0.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \nrept_cod__5DAY 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nrept_cod__DIR 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nrept_cod__EXP 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 \nrept_cod__PER 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noccp_cod__HP 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noccp_cod__LW 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \noccp_cod__MD 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \noccp_cod__PH 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nsex__M 0.000000e+00 0.000000e+00 1.000000e+00 1.000000e+00 \nsex__UNK 0.000000e+00 0.000000e+00 0.000000e+00 1.000000e+00 \nwt_lbs_mean 1.617795e+02 1.617795e+02 1.617795e+02 1.587725e+03 \nage_yrs_mean 5.300000e+01 5.590643e+01 6.557974e+01 1.200000e+02 \nIndex(['primaryid', 'caseid', 'caseversion', 'event.dt1', 'mfr_dt',\n 'init_fda_dt', 'fda_dt', 'auth_num', 'mfr_num', 'mfr_sndr', 'lit_ref',\n 'age', 'age_cod', 'age_grp', 'e_sub', 'wt', 'wt_cod', 'rept.dt1',\n 'to_mfr', 'reporter_country', 'occr_country', 'outc_cod__CA',\n 'outc_cod__DE', 'outc_cod__DS', 'outc_cod__HO', 'outc_cod__LT',\n 'outc_cod__OT', 'outc_cod__RI', 'oc_cat__death', 'oc_cat__other',\n 'oc_cat__serious', 'n_outc', 'wt_lbs', 'age_yrs', 'i_f_code__I',\n 'rept_cod__5DAY', 'rept_cod__DIR', 'rept_cod__EXP', 'rept_cod__PER',\n 'occp_cod__HP', 'occp_cod__LW', 'occp_cod__MD', 'occp_cod__PH',\n 'sex__M', 'sex__UNK', 'wt_lbs_mean', 'age_yrs_mean'],\n dtype='object')\n"
],
[
"### standarize features \n\ndrop_cols = ['primaryid', 'caseid', 'caseversion', 'event.dt1', 'mfr_dt',\n 'init_fda_dt', 'fda_dt', 'auth_num', 'mfr_num', 'mfr_sndr', 'lit_ref',\n 'age', 'age_cod', 'age_grp', 'e_sub', 'wt', 'wt_cod', 'rept.dt1',\n 'to_mfr', 'reporter_country', 'occr_country', 'outc_cod__CA',\n 'outc_cod__DE', 'outc_cod__DS', 'outc_cod__HO', 'outc_cod__LT',\n 'outc_cod__OT', 'outc_cod__RI', 'oc_cat__death', 'oc_cat__other',\n 'oc_cat__serious', 'wt_lbs', 'age_yrs']\n\ninputs_mean = ['n_outc', 'wt_lbs_mean', 'age_yrs_mean', 'i_f_code__I', 'rept_cod__5DAY',\n 'rept_cod__DIR', 'rept_cod__EXP', 'rept_cod__PER', 'occp_cod__HP', \n 'occp_cod__LW', 'occp_cod__MD', 'occp_cod__PH', 'sex__M']\n\nX = df.drop(columns=drop_cols)\nprint(X.columns)\n\nXscaled = StandardScaler().fit_transform(X)\nprint(Xscaled.shape)\n\n#X = pd.DataFrame(scaled, columns=inputs_mean) #.reset_index()\n#print(X.describe().T,'\\n')\n\n#y_multilabel = np.c_[df['CA'], df['DE'], df['DS'], df['HO'], df['LT'], df['OT'], df['RI']]\ny_multilabel = np.c_[df['oc_cat__death'], df['oc_cat__other'], df['oc_cat__serious']]\nprint(y_multilabel.shape)",
"Index(['n_outc', 'i_f_code__I', 'rept_cod__5DAY', 'rept_cod__DIR',\n 'rept_cod__EXP', 'rept_cod__PER', 'occp_cod__HP', 'occp_cod__LW',\n 'occp_cod__MD', 'occp_cod__PH', 'sex__M', 'sex__UNK', 'wt_lbs_mean',\n 'age_yrs_mean'],\n dtype='object')\n(260715, 14)\n(260715, 3)\n"
],
[
"# test multilabel classifier\nknn_clf = KNeighborsClassifier()\nknn_clf.fit(Xscaled,y_multilabel)",
"_____no_output_____"
],
[
"knn_clf.score(Xscaled,y_multilabel)",
"_____no_output_____"
],
[
"# review sklean api - hamming_loss, jaccard_similarity_score, f1_score\nfrom sklearn.metrics import hamming_loss, jaccard_similarity_score\npred_knn_multilabel = knn_clf.pred(Xscaled)\nf1_score(y_multilabel, pred_knn_multilabel, average='macro')",
"_____no_output_____"
]
],
[
[
"# STOPPED HERE - 1.13.2021",
"_____no_output_____"
],
[
"## ML Pipeline: Model Selection",
"_____no_output_____"
]
],
[
[
"### define functions for evaluating each of 8 types of supervised learning algorithms\n\ndef evaluate_model(predictors, targets, model, param_dict, passes=500):\n \n seed = int(round(random()*1000,0))\n print(seed)\n \n # specify minimum test MSE, best hyperparameter set\n test_err = []\n min_test_err = 1e10\n best_hyperparams = {}\n # specify MSE predicted from the full dataset by the optimal model of each type with the best hyperparameter set\n #full_y_err = None\n full_err_mintesterr = None\n full_err = []\n # specify the final model returned\n ret_model = None\n \n # define MSE as the statistic to determine goodness-of-fit - the smaller the better\n scorer = make_scorer(mean_squared_error, greater_is_better=False)\n \n # split the data to a training-testing pair randomly by passes = n times\n for i in range(passes):\n print('Pass {}/{} for model {}'.format(i + 1, passes, model))\n X_train, X_test, y_train, y_test = train_test_split(predictors, targets, test_size=0.3, random_state=(i+1)*seed )\n \n # 3-fold CV on a training set, and returns an optimal_model with the best_params_ fit\n default_model = model()\n model_gs = GridSearchCV(default_model, param_dict, cv=3, n_jobs=-1, verbose=0, scoring=scorer) # n_jobs=16,\n model_gs.fit(X_train, y_train)\n optimal_model = model(**model_gs.best_params_)\n optimal_model.fit(X_train, y_train)\n \n # use the optimal_model generated above to test in the testing set and yield an MSE\n y_pred = optimal_model.predict(X_test)\n err = mean_squared_error(y_test, y_pred)\n test_err.extend([err]) \n \n # use the optimal_model generated above to be applied to the full data set and predict y to yield an MSE\n full_y_pred=optimal_model.predict(predictors)\n full_y_err = mean_squared_error(full_y_pred, y)\n full_err.extend([full_y_err]) \n \n # look for the smallest MSE yield from the testing set, \n # so the optimal model that meantimes yields the smallest MSE from the testing set can be considered as the final model of the type\n #print('MSE for {}: {}'.format(model, err))\n if err < min_test_err:\n min_test_err = err\n best_hyperparams = model_gs.best_params_\n \n full_err_mintesterr = full_y_err\n\n # return the final model of the type\n ret_model = optimal_model\n \n test_err_dist = pd.DataFrame(test_err, columns=[\"test_err\"]).describe()\n full_err_dist = pd.DataFrame(full_err, columns=[\"full_err\"]).describe()\n \n print('Model {} with hyperparams {} yielded \\n\\ttest error {} with distribution \\n{} \\n\\\n toverall error {} with distribution \\n{}'. \\\n format(model, best_hyperparams, min_test_err, test_err_dist, full_err_mintesterr,full_err_dist))\n return ret_model",
"_____no_output_____"
],
[
"#%lsmagic",
"_____no_output_____"
],
[
"# Random Forest\n#%%timeit \nrf = evaluate_model(X,y, RandomForestClassifier, \n {'n_estimators': [200, 400, 800,1000],\n 'max_depth': [2, 3, 4, 5], \n 'min_samples_leaf': [2,3],\n 'min_samples_split': [2, 3, 4],\n 'max_features' : ['auto', 'sqrt', 'log2']}, passes=1) # 250)",
"988\nPass 1/1 for model <class 'sklearn.ensemble.forest.RandomForestClassifier'>\n"
]
],
[
[
"# STOPPED HERE - 1.12.2021\n## TODOs:\n1. Multicore processing: Setup Dask for multicore processing in Jupyter Notebook\n2. Distributed computing: Check Dask Distributed for local cluster setup",
"_____no_output_____"
]
],
[
[
"from joblib import dump, load\n\ndump(rf, 'binary_rf.obj') # rf_model",
"_____no_output_____"
],
[
"features2 = pd.DataFrame(data=rf.feature_importances_, index=data.columns)\nfeatures2.sort_values(by=0,ascending=False, inplace=True)\nprint(features2[:50])",
"_____no_output_____"
],
[
"import seaborn as sns\n\nax_rf = sns.barplot(x=features2.index, y=features2.iloc[:,0], order=features2.index)\nax_rf.set_ylabel('Feature importance')\nfig_rf = ax_rf.get_figure()",
"_____no_output_____"
],
[
"rf_top_features=features2.index[:2].tolist()\nprint(rf_top_features)",
"_____no_output_____"
],
[
"pdp, axes = partial_dependence(rf, X= data, features=[(0, 1)], grid_resolution=20)",
"_____no_output_____"
],
[
"fig = plt.figure()\nax = Axes3D(fig)\n\nXX, YY = np.meshgrid(axes[0], axes[1])\nZ = pdp[0].T\n\nsurf = ax.plot_surface(XX, YY, Z, rstride=1, cstride=1,\n cmap=plt.cm.BuPu, edgecolor='k')\n#ax.set_xlabel('% Severe Housing \\nCost Burden', fontsize=12)\n#ax.set_ylabel('% Veteran', fontsize=15)\nax.set_xlabel('% mortality diff', fontsize=12)\nax.set_ylabel('% severe housing \\ncost burden', fontsize=15)\nax.set_zlabel('Partial dependence', fontsize=15)\nax.view_init(elev=22, azim=330)\nplt.colorbar(surf)\nplt.suptitle('Partial Dependence of Top 2 Features \\nRandom Forest', fontsize=15)\nplt.subplots_adjust(top=0.9)\nplt.show()",
"_____no_output_____"
],
[
"print(features2.index[range(14)])\ndatafeatures2 = pd.concat([states,y,data[features2.index[range(38)]]],axis=1)\ndatafeatures2.head(10)",
"_____no_output_____"
],
[
"from sklearn.inspection import permutation_importance\n\n# feature names \nfeature_names = list(features2.columns)\n# model - rf\nmodel = load('binary_rf.obj')\n# calculate permutation importance - all data - final model\nperm_imp_all = permutation_importance(model, data, y, n_repeats=10, random_state=42)\n\nprint('Permutation Importances - mean')\nprint(perm_imp_all.importances_mean)\n\n\n\n'''\n# create dict of feature names and importances\nfimp_dict_all = dict(zip(feature_names,perm_imp_all.importances_mean))\n\n# feature importance - all\nprint('Permutation Importance for All Data')\nprint(fimp_dict_all)\n# plot importances - all\ny_pos = np.arange(len(feature_names))\nplt.barh(y_pos, fimp_dict_all.importances_mean, align='center', alpha=0.5)\nplt.yticks(y_pos, feature_names)\nplt.xlabel('Permutation Importance - All')\nplt.title('Feature Importance - All Data')\nplt.show()\n'''",
"_____no_output_____"
],
[
"dataused = pd.concat([states,y,data],axis=1)\nprint(dataused.shape)\nprint(dataused.head(10))",
"_____no_output_____"
],
[
"#from joblib import dump, load\n\ndump(perm_imp_all, 'perm_imp_rf.obj')",
"_____no_output_____"
],
[
"dataused.to_excel(r'dataused_cj08292020_v2.xlsx',index=None, header=True)",
"_____no_output_____"
]
],
[
[
"### END BG RF ANALYSIS - 8.31.2020",
"_____no_output_____"
],
[
"### OTHER MODELS NOT RUN",
"_____no_output_____"
]
],
[
[
"# LASSO \n \nlasso = evaluate_model(data, Lasso, {'alpha': np.arange(0, 1.1, 0.001), \n 'normalize': [True],\n 'tol' : [1e-3, 1e-4, 1e-5],\n 'max_iter': [1000, 4000, 7000]}, passes=250)",
"_____no_output_____"
],
[
"# Ridge regression\n\nridge = evaluate_model(data, Ridge, {'alpha': np.arange(0, 1.1, 0.05), \n 'normalize': [True], \n 'tol' : [1e-3, 1e-4, 1e-5],\n 'max_iter': [1000, 4000, 7000]}, passes=250)",
"_____no_output_____"
],
[
"# K-nearest neighborhood\n\nknn = evaluate_model(data, KNeighborsRegressor, {'n_neighbors': np.arange(1, 8),\n 'algorithm': ['ball_tree','kd_tree','brute']}, passes=250)",
"_____no_output_____"
],
[
"# Gradient Boosting Machine\n\ngbm = evaluate_model(data, GradientBoostingRegressor, {'learning_rate': [0.1, 0.05, 0.02, 0.01], \n 'n_estimators': [100, 200, 400, 800, 1000],\n 'min_samples_leaf': [2,3],\n 'max_depth': [2, 3, 4, 5],\n 'max_features': ['auto', 'sqrt', 'log2']}, passes=250)",
"_____no_output_____"
],
[
"# CART: classification and regression tree\n\ncart = evaluate_model(data, DecisionTreeRegressor, {'splitter': ['best', 'random'], \n 'criterion': ['mse', 'friedman_mse', 'mae'],\n 'max_depth': [2, 3, 4, 5],\n 'min_samples_leaf': [2,3],\n 'max_features' : ['auto', 'sqrt', 'log2']}, passes=250)",
"_____no_output_____"
],
[
"# Neural network: multi-layer perceptron\n\nnnmlp = evaluate_model(data, MLPRegressor, {'hidden_layer_sizes': [(50,)*3, (50,)*5, (50,)*10, (50,)*30, (50,)*50],\n 'activation': ['identity','logistic','tanh','relu']}, passes=250)",
"_____no_output_____"
],
[
"# Support Vector Machine: a linear function is an efficient model to work with\n\nsvm = evaluate_model(data, LinearSVR, {'tol': [1e-3, 1e-4, 1e-5],\n 'C' : np.arange(0.1,3,0.1),\n 'loss': ['epsilon_insensitive','squared_epsilon_insensitive'],\n 'max_iter': [1000, 2000, 4000]}, passes=250)",
"_____no_output_____"
],
[
"features1 = pd.DataFrame(data=gbm.feature_importances_, index=data.columns)\nfeatures1.sort_values(by=0,ascending=False, inplace=True)\nprint(features1[:40])",
"_____no_output_____"
],
[
"print(features1.index[range(38)])\ndatafeatures1 = pd.concat([states,y,data[features1.index[range(38)]]],axis=1)\ndatafeatures1.head(10)",
"_____no_output_____"
],
[
"import seaborn as sns\n\nax_gbm = sns.barplot(x=features1.index, y=features1.iloc[:,0], order=features1.index)\nax_gbm.set_ylabel('Feature importance')\nfig_gbm = ax_gbm.get_figure()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d006eb44ccb81f14b30beea80c5951c6832aa07e
| 14,001 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/tutorial/simulation.ipynb
|
Alalalalaki/pyblp
|
793cc0b7549e9aea720453c5949b6366e894a4e5
|
[
"MIT"
] | 1 |
2020-09-09T13:44:02.000Z
|
2020-09-09T13:44:02.000Z
|
docs/notebooks/tutorial/simulation.ipynb
|
yirsung/pyblp
|
cd3f79ddef51da8104df128399d6e981bf34f3bf
|
[
"MIT"
] | null | null | null |
docs/notebooks/tutorial/simulation.ipynb
|
yirsung/pyblp
|
cd3f79ddef51da8104df128399d6e981bf34f3bf
|
[
"MIT"
] | null | null | null | 33.737349 | 534 | 0.472823 |
[
[
[
"# Problem Simulation Tutorial",
"_____no_output_____"
]
],
[
[
"import pyblp\nimport numpy as np\nimport pandas as pd\n\npyblp.options.digits = 2\npyblp.options.verbose = False\npyblp.__version__",
"_____no_output_____"
]
],
[
[
"Before configuring and solving a problem with real data, it may be a good idea to perform Monte Carlo analysis on simulated data to verify that it is possible to accurately estimate model parameters. For example, before configuring and solving the example problems in the prior tutorials, it may have been a good idea to simulate data according to the assumed models of supply and demand. During such Monte Carlo anaysis, the data would only be used to determine sample sizes and perhaps to choose reasonable true parameters.\n\nSimulations are configured with the :class:`Simulation` class, which requires many of the same inputs as :class:`Problem`. The two main differences are:\n\n1. Variables in formulations that cannot be loaded from `product_data` or `agent_data` will be drawn from independent uniform distributions.\n2. True parameters and the distribution of unobserved product characteristics are specified.\n\nFirst, we'll use :func:`build_id_data` to build market and firm IDs for a model in which there are $T = 50$ markets, and in each market $t$, a total of $J_t = 20$ products produced by $F = 10$ firms.",
"_____no_output_____"
]
],
[
[
"id_data = pyblp.build_id_data(T=50, J=20, F=10)",
"_____no_output_____"
]
],
[
[
"Next, we'll create an :class:`Integration` configuration to build agent data according to a Gauss-Hermite product rule that exactly integrates polynomials of degree $2 \\times 9 - 1 = 17$ or less.",
"_____no_output_____"
]
],
[
[
"integration = pyblp.Integration('product', 9)\nintegration",
"_____no_output_____"
]
],
[
[
"We'll then pass these data to :class:`Simulation`. We'll use :class:`Formulation` configurations to create an $X_1$ that consists of a constant, prices, and an exogenous characteristic; an $X_2$ that consists only of the same exogenous characteristic; and an $X_3$ that consists of the common exogenous characteristic and a cost-shifter.",
"_____no_output_____"
]
],
[
[
"simulation = pyblp.Simulation(\n product_formulations=(\n pyblp.Formulation('1 + prices + x'),\n pyblp.Formulation('0 + x'),\n pyblp.Formulation('0 + x + z')\n ),\n beta=[1, -2, 2],\n sigma=1,\n gamma=[1, 4],\n product_data=id_data,\n integration=integration,\n seed=0\n)\nsimulation",
"_____no_output_____"
]
],
[
[
"When :class:`Simulation` is initialized, it constructs :attr:`Simulation.agent_data` and simulates :attr:`Simulation.product_data`.\n\nThe :class:`Simulation` can be further configured with other arguments that determine how unobserved product characteristics are simulated and how marginal costs are specified.\n\nAt this stage, simulated variables are not consistent with true parameters, so we still need to solve the simulation with :meth:`Simulation.replace_endogenous`. This method replaced simulated prices and market shares with values that are consistent with the true parameters. Just like :meth:`ProblemResults.compute_prices`, to do so it iterates over the $\\zeta$-markup equation from :ref:`references:Morrow and Skerlos (2011)`.",
"_____no_output_____"
]
],
[
[
"simulation_results = simulation.replace_endogenous()\nsimulation_results",
"_____no_output_____"
]
],
[
[
"Now, we can try to recover the true parameters by creating and solving a :class:`Problem`. \n\nThe convenience method :meth:`SimulationResults.to_problem` constructs some basic \"sums of characteristics\" BLP instruments that are functions of all exogenous numerical variables in the problem. In this example, excluded demand-side instruments are the cost-shifter `z` and traditional BLP instruments constructed from `x`. Excluded supply-side instruments are traditional BLP instruments constructed from `x` and `z`.",
"_____no_output_____"
]
],
[
[
"problem = simulation_results.to_problem()\nproblem",
"_____no_output_____"
]
],
[
[
"We'll choose starting values that are half the true parameters so that the optimization routine has to do some work. Note that since we're jointly estimating the supply side, we need to provide an initial value for the linear coefficient on prices because this parameter cannot be concentrated out of the problem (unlike linear coefficients on exogenous characteristics).",
"_____no_output_____"
]
],
[
[
"results = problem.solve(\n sigma=0.5 * simulation.sigma, \n pi=0.5 * simulation.pi,\n beta=[None, 0.5 * simulation.beta[1], None],\n optimization=pyblp.Optimization('l-bfgs-b', {'gtol': 1e-5})\n)\nresults",
"_____no_output_____"
]
],
[
[
"The parameters seem to have been estimated reasonably well.",
"_____no_output_____"
]
],
[
[
"np.c_[simulation.beta, results.beta]",
"_____no_output_____"
],
[
"np.c_[simulation.gamma, results.gamma]",
"_____no_output_____"
],
[
"np.c_[simulation.sigma, results.sigma]",
"_____no_output_____"
]
],
[
[
"In addition to checking that the configuration for a model based on actual data makes sense, the :class:`Simulation` class can also be a helpful tool for better understanding under what general conditions BLP models can be accurately estimated. Simulations are also used extensively in pyblp's test suite.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
d006f785b40a30c99d8568e1f4c8588eca78c1f2
| 93,125 |
ipynb
|
Jupyter Notebook
|
assignment1/softmax.ipynb
|
rahul1990gupta/bcs231n
|
5b28c277ef365722a435d33004a8b88a92894176
|
[
"MIT"
] | null | null | null |
assignment1/softmax.ipynb
|
rahul1990gupta/bcs231n
|
5b28c277ef365722a435d33004a8b88a92894176
|
[
"MIT"
] | null | null | null |
assignment1/softmax.ipynb
|
rahul1990gupta/bcs231n
|
5b28c277ef365722a435d33004a8b88a92894176
|
[
"MIT"
] | null | null | null | 166.890681 | 70,222 | 0.863871 |
[
[
[
"# Softmax exercise\n\n*Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the [assignments page](http://vision.stanford.edu/teaching/cs231n/assignments.html) on the course website.*\n\nThis exercise is analogous to the SVM exercise. You will:\n\n- implement a fully-vectorized **loss function** for the Softmax classifier\n- implement the fully-vectorized expression for its **analytic gradient**\n- **check your implementation** with numerical gradient\n- use a validation set to **tune the learning rate and regularization** strength\n- **optimize** the loss function with **SGD**\n- **visualize** the final learned weights\n",
"_____no_output_____"
]
],
[
[
"import random\nimport numpy as np\nfrom cs231n.data_utils import load_CIFAR10\nimport matplotlib.pyplot as plt\n\nfrom __future__ import print_function\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n# for auto-reloading extenrnal modules\n# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000, num_dev=500):\n \"\"\"\n Load the CIFAR-10 dataset from disk and perform preprocessing to prepare\n it for the linear classifier. These are the same steps as we used for the\n SVM, but condensed to a single function. \n \"\"\"\n # Load the raw CIFAR-10 data\n cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'\n X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)\n \n # subsample the data\n mask = list(range(num_training, num_training + num_validation))\n X_val = X_train[mask]\n y_val = y_train[mask]\n mask = list(range(num_training))\n X_train = X_train[mask]\n y_train = y_train[mask]\n mask = list(range(num_test))\n X_test = X_test[mask]\n y_test = y_test[mask]\n mask = np.random.choice(num_training, num_dev, replace=False)\n X_dev = X_train[mask]\n y_dev = y_train[mask]\n \n # Preprocessing: reshape the image data into rows\n X_train = np.reshape(X_train, (X_train.shape[0], -1))\n X_val = np.reshape(X_val, (X_val.shape[0], -1))\n X_test = np.reshape(X_test, (X_test.shape[0], -1))\n X_dev = np.reshape(X_dev, (X_dev.shape[0], -1))\n \n # Normalize the data: subtract the mean image\n mean_image = np.mean(X_train, axis = 0)\n X_train -= mean_image\n X_val -= mean_image\n X_test -= mean_image\n X_dev -= mean_image\n \n # add bias dimension and transform into columns\n X_train = np.hstack([X_train, np.ones((X_train.shape[0], 1))])\n X_val = np.hstack([X_val, np.ones((X_val.shape[0], 1))])\n X_test = np.hstack([X_test, np.ones((X_test.shape[0], 1))])\n X_dev = np.hstack([X_dev, np.ones((X_dev.shape[0], 1))])\n \n return X_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev\n\n\n# Invoke the above function to get our data.\nX_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev = get_CIFAR10_data()\nprint('Train data shape: ', X_train.shape)\nprint('Train labels shape: ', y_train.shape)\nprint('Validation data shape: ', X_val.shape)\nprint('Validation labels shape: ', y_val.shape)\nprint('Test data shape: ', X_test.shape)\nprint('Test labels shape: ', y_test.shape)\nprint('dev data shape: ', X_dev.shape)\nprint('dev labels shape: ', y_dev.shape)",
"Train data shape: (49000, 3073)\nTrain labels shape: (49000,)\nValidation data shape: (1000, 3073)\nValidation labels shape: (1000,)\nTest data shape: (1000, 3073)\nTest labels shape: (1000,)\ndev data shape: (500, 3073)\ndev labels shape: (500,)\n"
]
],
[
[
"## Softmax Classifier\n\nYour code for this section will all be written inside **cs231n/classifiers/softmax.py**. \n",
"_____no_output_____"
]
],
[
[
"# First implement the naive softmax loss function with nested loops.\n# Open the file cs231n/classifiers/softmax.py and implement the\n# softmax_loss_naive function.\n\nfrom cs231n.classifiers.softmax import softmax_loss_naive\nimport time\n\n# Generate a random softmax weight matrix and use it to compute the loss.\nW = np.random.randn(3073, 10) * 0.0001\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)\n\n# As a rough sanity check, our loss should be something close to -log(0.1).\nprint('loss: %f' % loss)\nprint('sanity check: %f' % (-np.log(0.1)))",
"loss: 2.339283\nsanity check: 2.302585\n"
]
],
[
[
"## Inline Question 1:\nWhy do we expect our loss to be close to -log(0.1)? Explain briefly.**\n\n**Your answer:** *Because it's a random classifier. Since there are 10 classes and a random classifier will correctly classify with 10% probability.*\n",
"_____no_output_____"
]
],
[
[
"# Complete the implementation of softmax_loss_naive and implement a (naive)\n# version of the gradient that uses nested loops.\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)\n\n# As we did for the SVM, use numeric gradient checking as a debugging tool.\n# The numeric gradient should be close to the analytic gradient.\nfrom cs231n.gradient_check import grad_check_sparse\nf = lambda w: softmax_loss_naive(w, X_dev, y_dev, 0.0)[0]\ngrad_numerical = grad_check_sparse(f, W, grad, 10)\n\n# similar to SVM case, do another gradient check with regularization\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 5e1)\nf = lambda w: softmax_loss_naive(w, X_dev, y_dev, 5e1)[0]\ngrad_numerical = grad_check_sparse(f, W, grad, 10)",
"numerical: -2.711457 analytic: -2.711456, relative error: 1.378904e-08\nnumerical: 0.499281 analytic: 0.499281, relative error: 6.386435e-08\nnumerical: 1.700688 analytic: 1.700688, relative error: 2.252673e-08\nnumerical: 0.142741 analytic: 0.142741, relative error: 1.846926e-08\nnumerical: 0.074467 analytic: 0.074467, relative error: 8.832638e-08\nnumerical: -1.280084 analytic: -1.280084, relative error: 1.226021e-08\nnumerical: 1.174501 analytic: 1.174500, relative error: 1.471364e-08\nnumerical: -0.663582 analytic: -0.663582, relative error: 5.688584e-10\nnumerical: 0.549119 analytic: 0.549119, relative error: 2.846142e-08\nnumerical: 2.033137 analytic: 2.033137, relative error: 3.581406e-08\nnumerical: 3.344238 analytic: 3.344238, relative error: 9.808289e-10\nnumerical: -0.702850 analytic: -0.702850, relative error: 9.306586e-09\nnumerical: -0.114013 analytic: -0.114013, relative error: 4.003082e-07\nnumerical: 0.153676 analytic: 0.153676, relative error: 3.841183e-07\nnumerical: 1.383883 analytic: 1.383883, relative error: 9.866454e-09\nnumerical: 0.308772 analytic: 0.308772, relative error: 3.430377e-08\nnumerical: 2.630956 analytic: 2.630956, relative error: 8.988423e-09\nnumerical: -4.731367 analytic: -4.731367, relative error: 3.080379e-09\nnumerical: 1.834523 analytic: 1.834523, relative error: 5.437608e-08\nnumerical: 1.457681 analytic: 1.457681, relative error: 1.494485e-08\n"
],
[
"# Now that we have a naive implementation of the softmax loss function and its gradient,\n# implement a vectorized version in softmax_loss_vectorized.\n# The two versions should compute the same results, but the vectorized version should be\n# much faster.\ntic = time.time()\nloss_naive, grad_naive = softmax_loss_naive(W, X_dev, y_dev, 0.000005)\ntoc = time.time()\nprint('naive loss: %e computed in %fs' % (loss_naive, toc - tic))\n\nfrom cs231n.classifiers.softmax import softmax_loss_vectorized\ntic = time.time()\nloss_vectorized, grad_vectorized = softmax_loss_vectorized(W, X_dev, y_dev, 0.000005)\ntoc = time.time()\nprint('vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))\n\n# As we did for the SVM, we use the Frobenius norm to compare the two versions\n# of the gradient.\ngrad_difference = np.linalg.norm(grad_naive - grad_vectorized, ord='fro')\nprint('Loss difference: %f' % np.abs(loss_naive - loss_vectorized))\nprint('Gradient difference: %f' % grad_difference)",
"naive loss: 2.339283e+00 computed in 0.129017s\nvectorized loss: 2.339283e+00 computed in 0.010606s\nLoss difference: 0.000000\nGradient difference: 0.000000\n"
],
[
"# Use the validation set to tune hyperparameters (regularization strength and\n# learning rate). You should experiment with different ranges for the learning\n# rates and regularization strengths; if you are careful you should be able to\n# get a classification accuracy of over 0.35 on the validation set.\nfrom cs231n.classifiers import Softmax\nresults = {}\nbest_val = -1\nbest_softmax = None\nlearning_rates = [5e-6, 1e-7, 5e-7]\nregularization_strengths = [1e3, 2.5e4, 5e4]\n\n################################################################################\n# TODO: #\n# Use the validation set to set the learning rate and regularization strength. #\n# This should be identical to the validation that you did for the SVM; save #\n# the best trained softmax classifer in best_softmax. #\n################################################################################\nfor lr in learning_rates:\n for reg in regularization_strengths:\n softmax = Softmax()\n loss_hist = softmax.train(X_train, y_train, learning_rate=lr, reg=reg,\n num_iters=1500, verbose=True)\n y_train_pred = softmax.predict(X_train)\n y_val_pred = softmax.predict(X_val)\n training_accuracy = np.mean(y_train == y_train_pred)\n validation_accuracy = np.mean(y_val == y_val_pred)\n #append in results\n results[(lr,reg)] = (training_accuracy, validation_accuracy)\n if validation_accuracy > best_val:\n best_val = validation_accuracy\n best_softmax = softmax\n################################################################################\n# END OF YOUR CODE #\n################################################################################\n \n# Print out results.\nfor lr, reg in sorted(results):\n train_accuracy, val_accuracy = results[(lr, reg)]\n print('lr %e reg %e train accuracy: %f val accuracy: %f' % (\n lr, reg, train_accuracy, val_accuracy))\n \nprint('best validation accuracy achieved during cross-validation: %f' % best_val)",
"iteration 0 / 1500: loss 37.026239\niteration 100 / 1500: loss 5.972171\niteration 200 / 1500: loss 2.290215\niteration 300 / 1500: loss 1.933894\niteration 400 / 1500: loss 1.864538\niteration 500 / 1500: loss 1.879764\niteration 600 / 1500: loss 2.087135\niteration 700 / 1500: loss 2.089950\niteration 800 / 1500: loss 1.919125\niteration 900 / 1500: loss 1.826578\niteration 1000 / 1500: loss 2.092291\niteration 1100 / 1500: loss 1.961465\niteration 1200 / 1500: loss 1.801198\niteration 1300 / 1500: loss 2.069641\niteration 1400 / 1500: loss 1.960803\niteration 0 / 1500: loss 765.967498\niteration 100 / 1500: loss 2.400515\niteration 200 / 1500: loss 2.404887\niteration 300 / 1500: loss 2.382598\niteration 400 / 1500: loss 2.577466\niteration 500 / 1500: loss 2.439970\niteration 600 / 1500: loss 3.102152\niteration 700 / 1500: loss 2.993507\niteration 800 / 1500: loss 2.248262\niteration 900 / 1500: loss 2.465928\niteration 1000 / 1500: loss 2.241201\niteration 1100 / 1500: loss 2.359386\niteration 1200 / 1500: loss 2.571714\niteration 1300 / 1500: loss 2.675238\niteration 1400 / 1500: loss 2.426348\niteration 0 / 1500: loss 1525.213020\niteration 100 / 1500: loss 3.456369\niteration 200 / 1500: loss 3.592648\niteration 300 / 1500: loss 2.973572\niteration 400 / 1500: loss 4.084492\niteration 500 / 1500: loss 3.959729\niteration 600 / 1500: loss 4.814919\niteration 700 / 1500: loss 3.836402\niteration 800 / 1500: loss 2.843925\niteration 900 / 1500: loss 2.762622\niteration 1000 / 1500: loss 4.012991\niteration 1100 / 1500: loss 3.247986\niteration 1200 / 1500: loss 3.392535\niteration 1300 / 1500: loss 4.217185\niteration 1400 / 1500: loss 3.209385\niteration 0 / 1500: loss 36.643778\niteration 100 / 1500: loss 33.695385\niteration 200 / 1500: loss 31.995589\niteration 300 / 1500: loss 30.459135\niteration 400 / 1500: loss 29.400728\niteration 500 / 1500: loss 28.152498\niteration 600 / 1500: loss 27.065654\niteration 700 / 1500: loss 26.150816\niteration 800 / 1500: loss 24.746647\niteration 900 / 1500: loss 23.860600\niteration 1000 / 1500: loss 22.896428\niteration 1100 / 1500: loss 22.198605\niteration 1200 / 1500: loss 21.237286\niteration 1300 / 1500: loss 20.307297\niteration 1400 / 1500: loss 19.718855\niteration 0 / 1500: loss 769.296404\niteration 100 / 1500: loss 282.221971\niteration 200 / 1500: loss 104.500143\niteration 300 / 1500: loss 39.584606\niteration 400 / 1500: loss 15.808951\niteration 500 / 1500: loss 7.108806\niteration 600 / 1500: loss 3.964666\niteration 700 / 1500: loss 2.750583\niteration 800 / 1500: loss 2.340610\niteration 900 / 1500: loss 2.184483\niteration 1000 / 1500: loss 2.093044\niteration 1100 / 1500: loss 2.090062\niteration 1200 / 1500: loss 2.061139\niteration 1300 / 1500: loss 2.033618\niteration 1400 / 1500: loss 2.019729\niteration 0 / 1500: loss 1548.628992\niteration 100 / 1500: loss 208.713030\niteration 200 / 1500: loss 29.682393\niteration 300 / 1500: loss 5.837030\niteration 400 / 1500: loss 2.637671\niteration 500 / 1500: loss 2.185459\niteration 600 / 1500: loss 2.167637\niteration 700 / 1500: loss 2.119912\niteration 800 / 1500: loss 2.111120\niteration 900 / 1500: loss 2.208620\niteration 1000 / 1500: loss 2.137508\niteration 1100 / 1500: loss 2.135539\niteration 1200 / 1500: loss 2.126507\niteration 1300 / 1500: loss 2.166721\niteration 1400 / 1500: loss 2.170068\niteration 0 / 1500: loss 36.631196\niteration 100 / 1500: loss 28.093018\niteration 200 / 1500: loss 23.074229\niteration 300 / 1500: loss 18.971843\niteration 400 / 1500: loss 15.550396\niteration 500 / 1500: loss 13.267168\niteration 600 / 1500: loss 10.987813\niteration 700 / 1500: loss 9.255770\niteration 800 / 1500: loss 7.999631\niteration 900 / 1500: loss 6.782824\niteration 1000 / 1500: loss 5.915609\niteration 1100 / 1500: loss 5.200583\niteration 1200 / 1500: loss 4.571346\niteration 1300 / 1500: loss 4.085386\niteration 1400 / 1500: loss 3.688506\niteration 0 / 1500: loss 772.002240\niteration 100 / 1500: loss 6.891738\niteration 200 / 1500: loss 2.180575\niteration 300 / 1500: loss 2.058586\niteration 400 / 1500: loss 2.097293\niteration 500 / 1500: loss 2.087843\niteration 600 / 1500: loss 2.057644\niteration 700 / 1500: loss 2.156801\niteration 800 / 1500: loss 2.046076\niteration 900 / 1500: loss 2.086162\niteration 1000 / 1500: loss 2.085515\niteration 1100 / 1500: loss 2.099258\niteration 1200 / 1500: loss 2.101244\niteration 1300 / 1500: loss 2.138095\niteration 1400 / 1500: loss 2.051729\niteration 0 / 1500: loss 1536.115777\niteration 100 / 1500: loss 2.184413\niteration 200 / 1500: loss 2.134691\niteration 300 / 1500: loss 2.148602\niteration 400 / 1500: loss 2.169638\niteration 500 / 1500: loss 2.124173\niteration 600 / 1500: loss 2.128369\niteration 700 / 1500: loss 2.136320\niteration 800 / 1500: loss 2.150777\niteration 900 / 1500: loss 2.121623\niteration 1000 / 1500: loss 2.145394\niteration 1100 / 1500: loss 2.121273\niteration 1200 / 1500: loss 2.163069\niteration 1300 / 1500: loss 2.125183\niteration 1400 / 1500: loss 2.149066\nlr 1.000000e-07 reg 1.000000e+03 train accuracy: 0.257367 val accuracy: 0.257000\nlr 1.000000e-07 reg 2.500000e+04 train accuracy: 0.329224 val accuracy: 0.347000\nlr 1.000000e-07 reg 5.000000e+04 train accuracy: 0.312510 val accuracy: 0.327000\nlr 5.000000e-07 reg 1.000000e+03 train accuracy: 0.385102 val accuracy: 0.389000\nlr 5.000000e-07 reg 2.500000e+04 train accuracy: 0.313265 val accuracy: 0.332000\nlr 5.000000e-07 reg 5.000000e+04 train accuracy: 0.292510 val accuracy: 0.301000\nlr 5.000000e-06 reg 1.000000e+03 train accuracy: 0.361918 val accuracy: 0.361000\nlr 5.000000e-06 reg 2.500000e+04 train accuracy: 0.223714 val accuracy: 0.220000\nlr 5.000000e-06 reg 5.000000e+04 train accuracy: 0.117837 val accuracy: 0.131000\nbest validation accuracy achieved during cross-validation: 0.389000\n"
],
[
"# evaluate on test set\n# Evaluate the best softmax on test set\ny_test_pred = best_softmax.predict(X_test)\ntest_accuracy = np.mean(y_test == y_test_pred)\nprint('softmax on raw pixels final test set accuracy: %f' % (test_accuracy, ))",
"softmax on raw pixels final test set accuracy: 0.365000\n"
],
[
"# Visualize the learned weights for each class\nw = best_softmax.W[:-1,:] # strip out the bias\nw = w.reshape(32, 32, 3, 10)\n\nw_min, w_max = np.min(w), np.max(w)\n\nclasses = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']\nfor i in range(10):\n plt.subplot(2, 5, i + 1)\n \n # Rescale the weights to be between 0 and 255\n wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)\n plt.imshow(wimg.astype('uint8'))\n plt.axis('off')\n plt.title(classes[i])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d006f9dd70db6f42d8eec37425474bcb4b6542ec
| 861,992 |
ipynb
|
Jupyter Notebook
|
index.ipynb
|
Massachute/TS
|
75b7ecddf34dc2305c439bd078428d3a086dca59
|
[
"Apache-2.0"
] | 96 |
2020-02-28T17:25:47.000Z
|
2022-01-19T09:34:15.000Z
|
index.ipynb
|
Massachute/TS
|
75b7ecddf34dc2305c439bd078428d3a086dca59
|
[
"Apache-2.0"
] | 9 |
2020-03-11T12:09:29.000Z
|
2022-02-26T06:30:59.000Z
|
index.ipynb
|
Massachute/TS
|
75b7ecddf34dc2305c439bd078428d3a086dca59
|
[
"Apache-2.0"
] | 13 |
2020-03-03T08:51:23.000Z
|
2022-03-18T03:55:31.000Z
| 429.492775 | 148,582 | 0.909256 |
[
[
[
"<a href=\"https://colab.research.google.com/github/ai-fast-track/timeseries/blob/master/nbs/index.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# `timeseries` package for fastai v2\n\n> **`timeseries`** is a Timeseries Classification and Regression package for fastai v2.\n> It mimics the fastai v2 vision module (fastai2.vision).\n\n> This notebook is a tutorial that shows, and trains an end-to-end a timeseries dataset. \n\n> The dataset example is the NATOPS dataset (see description here beow).\n\n> First, 4 different methods of creation on how to create timeseries dataloaders are presented. \n\n> Then, we train a model based on [Inception Time] (https://arxiv.org/pdf/1909.04939.pdf) architecture \n",
"_____no_output_____"
],
[
"## Credit\n> timeseries for fastai v2 was inspired by by Ignacio's Oguiza timeseriesAI (https://github.com/timeseriesAI/timeseriesAI.git).\n\n> Inception Time model definition is a modified version of [Ignacio Oguiza] (https://github.com/timeseriesAI/timeseriesAI/blob/master/torchtimeseries/models/InceptionTime.py) and [Thomas Capelle] (https://github.com/tcapelle/TimeSeries_fastai/blob/master/inception.py) implementaions",
"_____no_output_____"
],
[
"## Installing **`timeseries`** on local machine as an editable package\n\n1- Only if you have not already installed `fastai v2` \nInstall [fastai2](https://dev.fast.ai/#Installing) by following the steps described there.\n\n2- Install timeseries package by following the instructions here below:\n\n```\ngit clone https://github.com/ai-fast-track/timeseries.git\ncd timeseries\npip install -e .\n```",
"_____no_output_____"
],
[
"# pip installing **`timeseries`** from repo either locally or in Google Colab - Start Here",
"_____no_output_____"
],
[
"## Installing fastai v2",
"_____no_output_____"
]
],
[
[
"!pip install git+https://github.com/fastai/fastai2.git",
"Collecting git+https://github.com/fastai/fastai2.git\n Cloning https://github.com/fastai/fastai2.git to /tmp/pip-req-build-icognque\n Running command git clone -q https://github.com/fastai/fastai2.git /tmp/pip-req-build-icognque\nCollecting fastcore\n Downloading https://files.pythonhosted.org/packages/5d/e4/62d66b9530a777af12049d20592854eb21a826b7cf6fee96f04bd8cdcbba/fastcore-0.1.12-py3-none-any.whl\nRequirement already satisfied: torch>=1.3.0 in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (1.4.0)\nRequirement already satisfied: torchvision>=0.5 in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (0.5.0)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (3.1.3)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (0.25.3)\nRequirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (2.21.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (3.13)\nRequirement already satisfied: fastprogress>=0.1.22 in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (0.2.2)\nRequirement already satisfied: pillow in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (6.2.2)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (0.22.1)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (1.4.1)\nRequirement already satisfied: spacy in /usr/local/lib/python3.6/dist-packages (from fastai2==0.0.11) (2.1.9)\nRequirement already satisfied: dataclasses>='0.7'; python_version < \"3.7\" in /usr/local/lib/python3.6/dist-packages (from fastcore->fastai2==0.0.11) (0.7)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from fastcore->fastai2==0.0.11) (1.17.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from torchvision>=0.5->fastai2==0.0.11) (1.12.0)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->fastai2==0.0.11) (0.10.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->fastai2==0.0.11) (2.6.1)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->fastai2==0.0.11) (2.4.6)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->fastai2==0.0.11) (1.1.0)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas->fastai2==0.0.11) (2018.9)\nRequirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2==0.0.11) (1.24.3)\nRequirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2==0.0.11) (2.8)\nRequirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2==0.0.11) (3.0.4)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2==0.0.11) (2019.11.28)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->fastai2==0.0.11) (0.14.1)\nRequirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (2.0.3)\nRequirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (1.0.2)\nRequirement already satisfied: preshed<2.1.0,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (2.0.1)\nRequirement already satisfied: plac<1.0.0,>=0.9.6 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (0.9.6)\nRequirement already satisfied: wasabi<1.1.0,>=0.2.0 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (0.6.0)\nRequirement already satisfied: srsly<1.1.0,>=0.0.6 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (1.0.1)\nRequirement already satisfied: thinc<7.1.0,>=7.0.8 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (7.0.8)\nRequirement already satisfied: blis<0.3.0,>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2==0.0.11) (0.2.4)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from kiwisolver>=1.0.1->matplotlib->fastai2==0.0.11) (45.1.0)\nRequirement already satisfied: tqdm<5.0.0,>=4.10.0 in /usr/local/lib/python3.6/dist-packages (from thinc<7.1.0,>=7.0.8->spacy->fastai2==0.0.11) (4.28.1)\nBuilding wheels for collected packages: fastai2\n Building wheel for fastai2 (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for fastai2: filename=fastai2-0.0.11-cp36-none-any.whl size=179392 sha256=69eaf43720cb7cce9ee55b2819763266646b3804b779da3bb5729a15741b766e\n Stored in directory: /tmp/pip-ephem-wheel-cache-ihi2rkgx/wheels/38/fd/31/ec7df01a47c0c9fafe85a1af76b59a86caf47ec649710affa8\nSuccessfully built fastai2\nInstalling collected packages: fastcore, fastai2\nSuccessfully installed fastai2-0.0.11 fastcore-0.1.12\n"
]
],
[
[
"## Installing `timeseries` package from github",
"_____no_output_____"
]
],
[
[
"!pip install git+https://github.com/ai-fast-track/timeseries.git",
"Collecting git+https://github.com/ai-fast-track/timeseries.git\n Cloning https://github.com/ai-fast-track/timeseries.git to /tmp/pip-req-build-2010puda\n Running command git clone -q https://github.com/ai-fast-track/timeseries.git /tmp/pip-req-build-2010puda\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from timeseries==0.0.2) (3.1.3)\nRequirement already satisfied: fastai2 in /usr/local/lib/python3.6/dist-packages (from timeseries==0.0.2) (0.0.11)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->timeseries==0.0.2) (2.4.6)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->timeseries==0.0.2) (2.6.1)\nRequirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from matplotlib->timeseries==0.0.2) (1.17.5)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->timeseries==0.0.2) (0.10.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->timeseries==0.0.2) (1.1.0)\nRequirement already satisfied: pillow in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (6.2.2)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (0.25.3)\nRequirement already satisfied: spacy in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (2.1.9)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (1.4.1)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (0.22.1)\nRequirement already satisfied: fastprogress>=0.1.22 in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (0.2.2)\nRequirement already satisfied: torchvision>=0.5 in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (0.5.0)\nRequirement already satisfied: torch>=1.3.0 in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (1.4.0)\nRequirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (2.21.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (3.13)\nRequirement already satisfied: fastcore in /usr/local/lib/python3.6/dist-packages (from fastai2->timeseries==0.0.2) (0.1.12)\nRequirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.1->matplotlib->timeseries==0.0.2) (1.12.0)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from kiwisolver>=1.0.1->matplotlib->timeseries==0.0.2) (45.1.0)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas->fastai2->timeseries==0.0.2) (2018.9)\nRequirement already satisfied: srsly<1.1.0,>=0.0.6 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (1.0.1)\nRequirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (1.0.2)\nRequirement already satisfied: thinc<7.1.0,>=7.0.8 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (7.0.8)\nRequirement already satisfied: plac<1.0.0,>=0.9.6 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (0.9.6)\nRequirement already satisfied: preshed<2.1.0,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (2.0.1)\nRequirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (2.0.3)\nRequirement already satisfied: blis<0.3.0,>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (0.2.4)\nRequirement already satisfied: wasabi<1.1.0,>=0.2.0 in /usr/local/lib/python3.6/dist-packages (from spacy->fastai2->timeseries==0.0.2) (0.6.0)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->fastai2->timeseries==0.0.2) (0.14.1)\nRequirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2->timeseries==0.0.2) (2.8)\nRequirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2->timeseries==0.0.2) (3.0.4)\nRequirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2->timeseries==0.0.2) (1.24.3)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->fastai2->timeseries==0.0.2) (2019.11.28)\nRequirement already satisfied: dataclasses>='0.7'; python_version < \"3.7\" in /usr/local/lib/python3.6/dist-packages (from fastcore->fastai2->timeseries==0.0.2) (0.7)\nRequirement already satisfied: tqdm<5.0.0,>=4.10.0 in /usr/local/lib/python3.6/dist-packages (from thinc<7.1.0,>=7.0.8->spacy->fastai2->timeseries==0.0.2) (4.28.1)\nBuilding wheels for collected packages: timeseries\n Building wheel for timeseries (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for timeseries: filename=timeseries-0.0.2-cp36-none-any.whl size=349967 sha256=5c4dc9e779bf83f095cdb40069fe8c488f541b8154daaad64ab1b3f9d8fe380f\n Stored in directory: /tmp/pip-ephem-wheel-cache-dgali9hg/wheels/35/01/01/4fdd69c029e9537c05914ee49520e9d36edaa9b2636f089bfc\nSuccessfully built timeseries\nInstalling collected packages: timeseries\nSuccessfully installed timeseries-0.0.2\n"
]
],
[
[
"# *pip Installing - End Here*",
"_____no_output_____"
],
[
"# `Usage`",
"_____no_output_____"
]
],
[
[
"%reload_ext autoreload\n%autoreload 2\n%matplotlib inline",
"_____no_output_____"
],
[
"from fastai2.basics import *",
"_____no_output_____"
],
[
"# hide\n# Only for Windows users because symlink to `timeseries` folder is not recognized by Windows\nimport sys\nsys.path.append(\"..\")",
"_____no_output_____"
],
[
"from timeseries.all import *",
"_____no_output_____"
]
],
[
[
"# Tutorial on timeseries package for fastai v2",
"_____no_output_____"
],
[
"## Example : NATOS dataset",
"_____no_output_____"
],
[
"<img src=\"https://github.com/ai-fast-track/timeseries/blob/master/images/NATOPS.jpg?raw=1\">",
"_____no_output_____"
],
[
"## Right Arm vs Left Arm (3: 'Not clear' Command (see picture here above))\n<br>\n<img src=\"https://github.com/ai-fast-track/timeseries/blob/master/images/ts-right-arm.png?raw=1\"><img src=\"https://github.com/ai-fast-track/timeseries/blob/master/images/ts-left-arm.png?raw=1\">",
"_____no_output_____"
],
[
"## Description\nThe data is generated by sensors on the hands, elbows, wrists and thumbs. The data are the x,y,z coordinates for each of the eight locations. The order of the data is as follows:\n\n## Channels (24)\n\n0.\tHand tip left, X coordinate\n1.\tHand tip left, Y coordinate\n2.\tHand tip left, Z coordinate\n3.\tHand tip right, X coordinate\n4.\tHand tip right, Y coordinate\n5.\tHand tip right, Z coordinate\n6.\tElbow left, X coordinate\n7.\tElbow left, Y coordinate\n8.\tElbow left, Z coordinate\n9.\tElbow right, X coordinate\n10.\tElbow right, Y coordinate\n11.\tElbow right, Z coordinate\n12.\tWrist left, X coordinate\n13.\tWrist left, Y coordinate\n14.\tWrist left, Z coordinate\n15.\tWrist right, X coordinate\n16.\tWrist right, Y coordinate\n17.\tWrist right, Z coordinate\n18.\tThumb left, X coordinate\n19.\tThumb left, Y coordinate\n20.\tThumb left, Z coordinate\n21.\tThumb right, X coordinate\n22.\tThumb right, Y coordinate\n23.\tThumb right, Z coordinate\n\n## Classes (6)\nThe six classes are separate actions, with the following meaning:\n \n1: I have command \n2: All clear \n3: Not clear \n4: Spread wings \n5: Fold wings \n6: Lock wings",
"_____no_output_____"
],
[
"## Download data using `download_unzip_data_UCR(dsname=dsname)` method",
"_____no_output_____"
]
],
[
[
"dsname = 'NATOPS' #'NATOPS', 'LSST', 'Wine', 'Epilepsy', 'HandMovementDirection'",
"_____no_output_____"
],
[
"# url = 'http://www.timeseriesclassification.com/Downloads/NATOPS.zip'\npath = unzip_data(URLs_TS.NATOPS)\npath",
"_____no_output_____"
]
],
[
[
"## Why do I have to concatenate train and test data?\nBoth Train and Train dataset contains 180 samples each. We concatenate them in order to have one big dataset and then split into train and valid dataset using our own split percentage (20%, 30%, or whatever number you see fit)",
"_____no_output_____"
]
],
[
[
"fname_train = f'{dsname}_TRAIN.arff'\nfname_test = f'{dsname}_TEST.arff'\nfnames = [path/fname_train, path/fname_test]\nfnames",
"_____no_output_____"
],
[
"data = TSData.from_arff(fnames)\nprint(data)",
"TSData:\n Datasets names (concatenated): ['NATOPS_TRAIN', 'NATOPS_TEST']\n Filenames: [Path('/root/.fastai/data/NATOPS/NATOPS_TRAIN.arff'), Path('/root/.fastai/data/NATOPS/NATOPS_TEST.arff')]\n Data shape: (360, 24, 51)\n Targets shape: (360,)\n Nb Samples: 360\n Nb Channels: 24\n Sequence Length: 51\n"
],
[
"items = data.get_items()",
"_____no_output_____"
],
[
"idx = 1\nx1, y1 = data.x[idx], data.y[idx]\ny1",
"_____no_output_____"
],
[
"\n# You can select any channel to display buy supplying a list of channels and pass it to `chs` argument\n# LEFT ARM\n# show_timeseries(x1, title=y1, chs=[0,1,2,6,7,8,12,13,14,18,19,20])\n",
"_____no_output_____"
],
[
"# RIGHT ARM\n# show_timeseries(x1, title=y1, chs=[3,4,5,9,10,11,15,16,17,21,22,23])",
"_____no_output_____"
],
[
"# ?show_timeseries(x1, title=y1, chs=range(0,24,3)) # Only the x axis coordinates\n",
"_____no_output_____"
],
[
"seed = 42\nsplits = RandomSplitter(seed=seed)(range_of(items)) #by default 80% for train split and 20% for valid split are chosen \nsplits",
"_____no_output_____"
]
],
[
[
"# Using `Datasets` class",
"_____no_output_____"
],
[
"## Creating a Datasets object",
"_____no_output_____"
]
],
[
[
"tfms = [[ItemGetter(0), ToTensorTS()], [ItemGetter(1), Categorize()]]\n\n# Create a dataset\nds = Datasets(items, tfms, splits=splits)",
"_____no_output_____"
],
[
"ax = show_at(ds, 2, figsize=(1,1))",
"3.0\n"
]
],
[
[
"# Create a `Dataloader` objects",
"_____no_output_____"
],
[
"## 1st method : using `Datasets` object",
"_____no_output_____"
]
],
[
[
"bs = 128 \n# Normalize at batch time\ntfm_norm = Normalize(scale_subtype = 'per_sample_per_channel', scale_range=(0, 1)) # per_sample , per_sample_per_channel\n# tfm_norm = Standardize(scale_subtype = 'per_sample')\nbatch_tfms = [tfm_norm]\n\ndls1 = ds.dataloaders(bs=bs, val_bs=bs * 2, after_batch=batch_tfms, num_workers=0, device=default_device()) ",
"_____no_output_____"
],
[
"dls1.show_batch(max_n=9, chs=range(0,12,3))",
"_____no_output_____"
]
],
[
[
"# Using `DataBlock` class",
"_____no_output_____"
],
[
"## 2nd method : using `DataBlock` and `DataBlock.get_items()` ",
"_____no_output_____"
]
],
[
[
"getters = [ItemGetter(0), ItemGetter(1)] \ntsdb = DataBlock(blocks=(TSBlock, CategoryBlock),\n get_items=get_ts_items,\n getters=getters,\n splitter=RandomSplitter(seed=seed),\n batch_tfms = batch_tfms)",
"_____no_output_____"
],
[
"tsdb.summary(fnames)",
"Setting-up type transforms pipelines\nCollecting items from [Path('/root/.fastai/data/NATOPS/NATOPS_TRAIN.arff'), Path('/root/.fastai/data/NATOPS/NATOPS_TEST.arff')]\nFound 360 items\n2 datasets of sizes 288,72\nSetting up Pipeline: itemgetter -> ToTensorTS\nSetting up Pipeline: itemgetter -> Categorize\n\nBuilding one sample\n Pipeline: itemgetter -> ToTensorTS\n starting from\n ([[-0.540579 -0.54101 -0.540603 ... -0.56305 -0.566314 -0.553712]\n [-1.539567 -1.540042 -1.538992 ... -1.532014 -1.534645 -1.536015]\n [-0.608539 -0.604609 -0.607679 ... -0.593769 -0.592854 -0.599014]\n ...\n [ 0.454542 0.449924 0.453195 ... 0.480281 0.45537 0.457275]\n [-1.411445 -1.363464 -1.390869 ... -1.468123 -1.368706 -1.386574]\n [-0.473406 -0.453322 -0.463813 ... -0.440582 -0.427211 -0.435581]], 2.0)\n applying itemgetter gives\n [[-0.540579 -0.54101 -0.540603 ... -0.56305 -0.566314 -0.553712]\n [-1.539567 -1.540042 -1.538992 ... -1.532014 -1.534645 -1.536015]\n [-0.608539 -0.604609 -0.607679 ... -0.593769 -0.592854 -0.599014]\n ...\n [ 0.454542 0.449924 0.453195 ... 0.480281 0.45537 0.457275]\n [-1.411445 -1.363464 -1.390869 ... -1.468123 -1.368706 -1.386574]\n [-0.473406 -0.453322 -0.463813 ... -0.440582 -0.427211 -0.435581]]\n applying ToTensorTS gives\n TensorTS of size 24x51\n Pipeline: itemgetter -> Categorize\n starting from\n ([[-0.540579 -0.54101 -0.540603 ... -0.56305 -0.566314 -0.553712]\n [-1.539567 -1.540042 -1.538992 ... -1.532014 -1.534645 -1.536015]\n [-0.608539 -0.604609 -0.607679 ... -0.593769 -0.592854 -0.599014]\n ...\n [ 0.454542 0.449924 0.453195 ... 0.480281 0.45537 0.457275]\n [-1.411445 -1.363464 -1.390869 ... -1.468123 -1.368706 -1.386574]\n [-0.473406 -0.453322 -0.463813 ... -0.440582 -0.427211 -0.435581]], 2.0)\n applying itemgetter gives\n 2.0\n applying Categorize gives\n TensorCategory(1)\n\nFinal sample: (TensorTS([[-0.5406, -0.5410, -0.5406, ..., -0.5630, -0.5663, -0.5537],\n [-1.5396, -1.5400, -1.5390, ..., -1.5320, -1.5346, -1.5360],\n [-0.6085, -0.6046, -0.6077, ..., -0.5938, -0.5929, -0.5990],\n ...,\n [ 0.4545, 0.4499, 0.4532, ..., 0.4803, 0.4554, 0.4573],\n [-1.4114, -1.3635, -1.3909, ..., -1.4681, -1.3687, -1.3866],\n [-0.4734, -0.4533, -0.4638, ..., -0.4406, -0.4272, -0.4356]]), TensorCategory(1))\n\n\nSetting up after_item: Pipeline: ToTensor\nSetting up before_batch: Pipeline: \nSetting up after_batch: Pipeline: Normalize\n\nBuilding one batch\nApplying item_tfms to the first sample:\n Pipeline: ToTensor\n starting from\n (TensorTS of size 24x51, TensorCategory(1))\n applying ToTensor gives\n (TensorTS of size 24x51, TensorCategory(1))\n\nAdding the next 3 samples\n\nNo before_batch transform to apply\n\nCollating items in a batch\n\nApplying batch_tfms to the batch built\n Pipeline: Normalize\n starting from\n (TensorTS of size 4x24x51, TensorCategory([1, 5, 4, 5], device='cuda:0'))\n applying Normalize gives\n (TensorTS of size 4x24x51, TensorCategory([1, 5, 4, 5], device='cuda:0'))\n"
],
[
"# num_workers=0 is Microsoft Windows\ndls2 = tsdb.dataloaders(fnames, num_workers=0, device=default_device())",
"_____no_output_____"
],
[
"dls2.show_batch(max_n=9, chs=range(0,12,3))",
"_____no_output_____"
]
],
[
[
"## 3rd method : using `DataBlock` and passing `items` object to the `DataBlock.dataloaders()`",
"_____no_output_____"
]
],
[
[
"getters = [ItemGetter(0), ItemGetter(1)] \ntsdb = DataBlock(blocks=(TSBlock, CategoryBlock),\n getters=getters,\n splitter=RandomSplitter(seed=seed))",
"_____no_output_____"
],
[
"dls3 = tsdb.dataloaders(data.get_items(), batch_tfms=batch_tfms, num_workers=0, device=default_device())",
"_____no_output_____"
],
[
"dls3.show_batch(max_n=9, chs=range(0,12,3))",
"_____no_output_____"
]
],
[
[
"## 4th method : using `TSDataLoaders` class and `TSDataLoaders.from_files()`",
"_____no_output_____"
]
],
[
[
"dls4 = TSDataLoaders.from_files(fnames, batch_tfms=batch_tfms, num_workers=0, device=default_device())",
"_____no_output_____"
],
[
"dls4.show_batch(max_n=9, chs=range(0,12,3))",
"_____no_output_____"
]
],
[
[
"# Train Model",
"_____no_output_____"
]
],
[
[
"# Number of channels (i.e. dimensions in ARFF and TS files jargon)\nc_in = get_n_channels(dls2.train) # data.n_channels\n# Number of classes\nc_out= dls2.c \nc_in,c_out",
"_____no_output_____"
]
],
[
[
"## Create model",
"_____no_output_____"
]
],
[
[
"model = inception_time(c_in, c_out).to(device=default_device())\nmodel",
"_____no_output_____"
]
],
[
[
"## Create Learner object",
"_____no_output_____"
]
],
[
[
"#Learner\nopt_func = partial(Adam, lr=3e-3, wd=0.01) \nloss_func = LabelSmoothingCrossEntropy() \nlearn = Learner(dls2, model, opt_func=opt_func, loss_func=loss_func, metrics=accuracy)\n\nprint(learn.summary())",
"Sequential (Input shape: ['64 x 24 x 51'])\n================================================================\nLayer (type) Output Shape Param # Trainable \n================================================================\nConv1d 64 x 32 x 51 29,952 True \n________________________________________________________________\nConv1d 64 x 32 x 51 14,592 True \n________________________________________________________________\nConv1d 64 x 32 x 51 6,912 True \n________________________________________________________________\nMaxPool1d 64 x 24 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 768 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,128 True \n________________________________________________________________\nConv1d 64 x 32 x 51 39,936 True \n________________________________________________________________\nConv1d 64 x 32 x 51 19,456 True \n________________________________________________________________\nConv1d 64 x 32 x 51 9,216 True \n________________________________________________________________\nMaxPool1d 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,096 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,128 True \n________________________________________________________________\nConv1d 64 x 32 x 51 39,936 True \n________________________________________________________________\nConv1d 64 x 32 x 51 19,456 True \n________________________________________________________________\nConv1d 64 x 32 x 51 9,216 True \n________________________________________________________________\nMaxPool1d 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,096 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 128 x 51 16,384 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nConv1d 64 x 32 x 51 4,128 True \n________________________________________________________________\nConv1d 64 x 32 x 51 39,936 True \n________________________________________________________________\nConv1d 64 x 32 x 51 19,456 True \n________________________________________________________________\nConv1d 64 x 32 x 51 9,216 True \n________________________________________________________________\nMaxPool1d 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,096 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,128 True \n________________________________________________________________\nConv1d 64 x 32 x 51 39,936 True \n________________________________________________________________\nConv1d 64 x 32 x 51 19,456 True \n________________________________________________________________\nConv1d 64 x 32 x 51 9,216 True \n________________________________________________________________\nMaxPool1d 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,096 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,128 True \n________________________________________________________________\nConv1d 64 x 32 x 51 39,936 True \n________________________________________________________________\nConv1d 64 x 32 x 51 19,456 True \n________________________________________________________________\nConv1d 64 x 32 x 51 9,216 True \n________________________________________________________________\nMaxPool1d 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 32 x 51 4,096 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nReLU 64 x 128 x 51 0 False \n________________________________________________________________\nConv1d 64 x 128 x 51 16,384 True \n________________________________________________________________\nBatchNorm1d 64 x 128 x 51 256 True \n________________________________________________________________\nAdaptiveAvgPool1d 64 x 128 x 1 0 False \n________________________________________________________________\nAdaptiveMaxPool1d 64 x 128 x 1 0 False \n________________________________________________________________\nFlatten 64 x 256 0 False \n________________________________________________________________\nLinear 64 x 6 1,542 True \n________________________________________________________________\n\nTotal params: 472,742\nTotal trainable params: 472,742\nTotal non-trainable params: 0\n\nOptimizer used: functools.partial(<function Adam at 0x7fb6eb402e18>, lr=0.003, wd=0.01)\nLoss function: LabelSmoothingCrossEntropy()\n\nCallbacks:\n - TrainEvalCallback\n - Recorder\n - ProgressCallback\n"
]
],
[
[
"## LR find ",
"_____no_output_____"
]
],
[
[
"lr_min, lr_steep = learn.lr_find()\nlr_min, lr_steep",
"_____no_output_____"
]
],
[
[
"## Train",
"_____no_output_____"
]
],
[
[
"#lr_max=1e-3\nepochs=30; lr_max=lr_steep; pct_start=.7; moms=(0.95,0.85,0.95); wd=1e-2\nlearn.fit_one_cycle(epochs, lr_max=lr_max, pct_start=pct_start, moms=moms, wd=wd)\n# learn.fit_one_cycle(epochs=20, lr_max=lr_steep)",
"_____no_output_____"
]
],
[
[
"## Plot loss function",
"_____no_output_____"
]
],
[
[
"learn.recorder.plot_loss()",
"_____no_output_____"
]
],
[
[
"## Show results",
"_____no_output_____"
]
],
[
[
"learn.show_results(max_n=9, chs=range(0,12,3))",
"_____no_output_____"
],
[
"#hide\nfrom nbdev.export import notebook2script\n# notebook2script()\nnotebook2script(fname='index.ipynb')\n",
"Converted index.ipynb.\n"
],
[
"# #hide\n# from nbdev.export2html import _notebook2html\n# # notebook2script()\n# _notebook2html(fname='index.ipynb')",
"_____no_output_____"
]
],
[
[
"# Fin",
"_____no_output_____"
],
[
"<img src=\"https://github.com/ai-fast-track/timeseries/blob/master/images/tree.jpg?raw=1\" width=\"1440\" height=\"840\" alt=\"\"/>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d0070a5db66bb3f35199c4050cdf9f6046680184
| 457,893 |
ipynb
|
Jupyter Notebook
|
Cement_prediction_.ipynb
|
mouctarbalde/concrete-strength-prediction
|
629a2435e7f3fd3563db3ed8fdca7184e7b557cb
|
[
"MIT"
] | null | null | null |
Cement_prediction_.ipynb
|
mouctarbalde/concrete-strength-prediction
|
629a2435e7f3fd3563db3ed8fdca7184e7b557cb
|
[
"MIT"
] | null | null | null |
Cement_prediction_.ipynb
|
mouctarbalde/concrete-strength-prediction
|
629a2435e7f3fd3563db3ed8fdca7184e7b557cb
|
[
"MIT"
] | null | null | null | 207.755445 | 69,957 | 0.86565 |
[
[
[
"<a href=\"https://colab.research.google.com/github/mouctarbalde/concrete-strength-prediction/blob/main/Cement_prediction_.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.metrics import mean_absolute_error\nfrom sklearn.metrics import r2_score\nfrom sklearn.preprocessing import RobustScaler\nfrom sklearn.linear_model import Lasso\nfrom sklearn.ensemble import GradientBoostingRegressor\nfrom sklearn.ensemble import StackingRegressor\nimport warnings\nimport random\nseed = 42\nrandom.seed(seed)\nimport numpy as np\nnp.random.seed(seed)\nwarnings.filterwarnings('ignore')\nplt.style.use('ggplot')",
"_____no_output_____"
],
[
"df = pd.read_csv('https://raw.githubusercontent.com/mouctarbalde/concrete-strength-prediction/main/Train.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"columns_name = df.columns.to_list()\ncolumns_name =['Cement',\n 'Blast_Furnace_Slag',\n 'Fly_Ash',\n 'Water',\n 'Superplasticizer',\n 'Coarse Aggregate',\n 'Fine Aggregate',\n 'Age_day',\n 'Concrete_compressive_strength']\ndf.columns = columns_name\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1030 entries, 0 to 1029\nData columns (total 9 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Cement 1030 non-null float64\n 1 Blast_Furnace_Slag 1030 non-null float64\n 2 Fly_Ash 1030 non-null float64\n 3 Water 1030 non-null float64\n 4 Superplasticizer 1030 non-null float64\n 5 Coarse Aggregate 1030 non-null float64\n 6 Fine Aggregate 1030 non-null float64\n 7 Age_day 1030 non-null int64 \n 8 Concrete_compressive_strength 1030 non-null float64\ndtypes: float64(8), int64(1)\nmemory usage: 72.5 KB\n"
],
[
"df.shape",
"_____no_output_____"
],
[
"import missingno as ms\nms.matrix(df)",
"_____no_output_____"
],
[
"df.isna().sum()",
"_____no_output_____"
],
[
"df.describe().T",
"_____no_output_____"
],
[
"df.corr()['Concrete_compressive_strength'].sort_values().plot(kind='barh')\nplt.title(\"Correlation based on the target variable.\")\nplt.show()",
"_____no_output_____"
],
[
"sns.heatmap(df.corr(),annot=True)",
"_____no_output_____"
],
[
"sns.boxplot(x='Water', y = 'Cement',data=df)",
"_____no_output_____"
],
[
"plt.figure(figsize=(15,9))\ndf.boxplot()\n",
"_____no_output_____"
],
[
"sns.regplot(x='Water', y = 'Cement',data=df)",
"_____no_output_____"
]
],
[
[
"As we can see from the above cell there is not correlation between **water** and our target variable.",
"_____no_output_____"
]
],
[
[
"sns.boxplot(x='Age_day', y = 'Cement',data=df)",
"_____no_output_____"
],
[
"sns.regplot(x='Age_day', y = 'Cement',data=df)",
"_____no_output_____"
],
[
"X = df.drop('Concrete_compressive_strength',axis=1)\ny = df.Concrete_compressive_strength",
"_____no_output_____"
],
[
"X.head()",
"_____no_output_____"
],
[
"y.head()",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=.2, random_state=seed)",
"_____no_output_____"
],
[
"X_train.shape ,y_train.shape",
"_____no_output_____"
]
],
[
[
"In our case we notice from our analysis the presence of outliers although they are not many we are going to use Robustscaler from sklearn to scale the data.\n\nRobust scaler is going to remove the median and put variance to 1 it will also transform the data by removing outliers(24%-75%) is considered.",
"_____no_output_____"
]
],
[
[
"scale = RobustScaler()\n\n# note we have to fit_transform only on the training data. On your test data you only have to transform.\nX_train = scale.fit_transform(X_train)\nX_test = scale.transform(X_test)",
"_____no_output_____"
],
[
"X_train",
"_____no_output_____"
]
],
[
[
"# Model creation",
"_____no_output_____"
],
[
"### Linear Regression",
"_____no_output_____"
]
],
[
[
"lr = LinearRegression()\nlr.fit(X_train,y_train)",
"_____no_output_____"
],
[
"pred_lr = lr.predict(X_test)\npred_lr[:10]",
"_____no_output_____"
],
[
"mae_lr = mean_absolute_error(y_test,pred_lr)\nr2_lr = r2_score(y_test,pred_lr)\nprint(f'Mean absolute error of linear regression is {mae_lr}')\nprint(f'R2 score of Linear Regression is {r2_lr}')",
"Mean absolute error of linear regression is 7.745559243921439\nR2 score of Linear Regression is 0.6275531792314843\n"
]
],
[
[
"**Graph for linear regression** the below graph is showing the relationship between the actual and the predicted values.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.scatter(pred_lr, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
]
],
[
[
"### Decision tree Regression",
"_____no_output_____"
]
],
[
[
"dt = DecisionTreeRegressor(criterion='mae')\ndt.fit(X_train,y_train)\n\npred_dt = dt.predict(X_test)\n\nmae_dt = mean_absolute_error(y_test,pred_dt)\nr2_dt = r2_score(y_test,pred_dt)\nprint(f'Mean absolute error of linear regression is {mae_dt}')\nprint(f'R2 score of Decision tree regressor is {r2_dt}')",
"Mean absolute error of linear regression is 5.170145631067961\nR2 score of Decision tree regressor is 0.7424150392589254\n"
],
[
"fig, ax = plt.subplots()\nplt.title('Linear relationship for decison tree')\nax.scatter(pred_dt, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
]
],
[
[
"### Random Forest Regression",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestRegressor",
"_____no_output_____"
],
[
"rf = RandomForestRegressor()\nrf.fit(X_train, y_train)\n\n# prediction\npred_rf = rf.predict(X_test)\n\nmae_rf = mean_absolute_error(y_test,pred_rf)\nr2_rf = r2_score(y_test,pred_rf)\n\nprint(f'Mean absolute error of Random forst regression is {mae_rf}')\nprint(f'R2 score of Random forst regressor is {r2_rf}')",
"Mean absolute error of Random forst regression is 3.736345008668516\nR2 score of Random forst regressor is 0.8846424240028741\n"
],
[
"fig, ax = plt.subplots()\nplt.title('Linear relationship for random forest regressor')\nax.scatter(pred_rf, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
]
],
[
[
"# Lasso Regression",
"_____no_output_____"
]
],
[
[
"laso = Lasso()\nlaso.fit(X_train, y_train)\npred_laso = laso.predict(X_test)\n\nmae_laso = mean_absolute_error(y_test, pred_laso)\nr2_laso = r2_score(y_test, pred_laso)\n\nprint(f'Mean absolute error of Random forst regression is {mae_laso}')\nprint(f'R2 score of Random forst regressor is {r2_laso}')",
"Mean absolute error of Random forst regression is 8.792670141747196\nR2 score of Random forst regressor is 0.5562659499743227\n"
],
[
"fig, ax = plt.subplots()\nplt.title('Linear relationship for Lasso regressor')\nax.scatter(pred_laso, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
],
[
"gb = GradientBoostingRegressor()\ngb.fit(X_train, y_train)\n\npred_gb = gb.predict(X_test)\n\nmae_gb = mean_absolute_error(y_test, pred_gb)\nr2_gb = r2_score(y_test, pred_gb)\n\nprint(f'Mean absolute error of Random forst regression is {mae_gb}')\nprint(f'R2 score of Random forst regressor is {r2_gb}')",
"Mean absolute error of Random forst regression is 4.1289993674027725\nR2 score of Random forst regressor is 0.8835272597908818\n"
],
[
"fig, ax = plt.subplots()\nplt.title('Linear relationship for Lasso regressor')\nax.scatter(pred_gb, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
]
],
[
[
"# Stacking Regressor:\ncombining multiple regression model and choosing the final model. in our case we used kfold cross validation to make sure that the model is not overfitting.",
"_____no_output_____"
]
],
[
[
"estimators = [('lr',LinearRegression()), ('gb',GradientBoostingRegressor()),\\\n ('dt',DecisionTreeRegressor()), ('laso',Lasso())]",
"_____no_output_____"
],
[
"from sklearn.model_selection import KFold\n\nkf = KFold(n_splits=10,shuffle=True, random_state=seed)\nstacking = StackingRegressor(estimators=estimators, final_estimator=RandomForestRegressor(random_state=seed), cv=kf)\n\nstacking.fit(X_train, y_train)\n\npred_stack = stacking.predict(X_test)\n\nmae_stack = mean_absolute_error(y_test, pred_stack)\nr2_stack = r2_score(y_test, pred_stack)\n\nprint(f'Mean absolute error of Random forst regression is {mae_stack}')\nprint(f'R2 score of Random forst regressor is {r2_stack}')\n",
"Mean absolute error of Random forst regression is 4.196688430420712\nR2 score of Random forst regressor is 0.8748435628075502\n"
],
[
"fig, ax = plt.subplots()\nplt.title('Linear relationship for Stacking regressor')\nax.scatter(pred_stack, y_test)\nax.plot([y_test.min(), y_test.max()],[y_test.min(), y_test.max()], color = 'red', marker = \"*\", markersize = 10)",
"_____no_output_____"
],
[
"result = pd.DataFrame({'Model':['Linear Regression','Decison tree','Random Forest', 'Lasso',\\\n 'Gradient Boosting Regressor', 'Stacking Regressor'],\n\n 'MAE':[mae_lr, mae_dt, mae_rf, mae_laso, mae_gb, mae_stack],\n 'R2 score':[r2_lr, r2_dt, r2_rf, r2_laso, r2_gb, r2_stack]\n })\nresult",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0070a7158041c12fcf45c5e88d0fe58de803274
| 115,065 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/xspec_models.ipynb
|
ke-fang/3ML
|
5f3208d878c8c3bd712c8db618b426138baceaa1
|
[
"BSD-3-Clause"
] | 1 |
2021-01-26T14:21:26.000Z
|
2021-01-26T14:21:26.000Z
|
docs/notebooks/xspec_models.ipynb
|
ke-fang/3ML
|
5f3208d878c8c3bd712c8db618b426138baceaa1
|
[
"BSD-3-Clause"
] | null | null | null |
docs/notebooks/xspec_models.ipynb
|
ke-fang/3ML
|
5f3208d878c8c3bd712c8db618b426138baceaa1
|
[
"BSD-3-Clause"
] | null | null | null | 89.614486 | 69,235 | 0.776048 |
[
[
[
"## Working with XSPEC models\n\nOne of the most powerful aspects of **XSPEC** is a huge modeling community. While in 3ML, we are focused on building a powerful and modular data analysis tool, we cannot neglect the need for many of the models thahat already exist in **XSPEC** and thus provide support for them via **astromodels** directly in 3ML. \n\nFor details on installing **astromodels** with **XSPEC** support, visit the 3ML or **astromodels** installation page. \n\n\nLet's explore how we can use **XSPEC** spectral models in 3ML. ",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook\nimport matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"We do not load the models by default as this takes some time and 3ML should load quickly. However, if you need the **XSPEC** models, they are imported from astromodels like this:",
"_____no_output_____"
]
],
[
[
"from astromodels.xspec.factory import *",
"Loading xspec models...done\n"
]
],
[
[
"The models are indexed with *XS_* before the typical **XSPEC** model names.",
"_____no_output_____"
]
],
[
[
"plaw = XS_powerlaw()\nphabs = XS_phabs()\nphabs\n",
"_____no_output_____"
]
],
[
[
"The spectral models behave just as any other **astromodels** spectral model and can be used in combination with other **astromodels** spectral models.",
"_____no_output_____"
]
],
[
[
"from astromodels import Powerlaw\n\nam_plaw = Powerlaw()\n\nplaw_with_abs = am_plaw*phabs\n\n\nfig, ax =plt.subplots()\n\nenergy_grid = np.linspace(.1,10.,1000)\n\nax.loglog(energy_grid,plaw_with_abs(energy_grid))\nax.set_xlabel('energy')\nax.set_ylabel('flux')\n",
"_____no_output_____"
]
],
[
[
"## XSPEC Settings\n\nMany **XSPEC** models depend on external abundances, cross-sections, and cosmological parameters. We provide an interface to control these directly.\n\nSimply import the **XSPEC** settings like so:",
"_____no_output_____"
]
],
[
[
"from astromodels.xspec.xspec_settings import *",
"_____no_output_____"
]
],
[
[
"Calling the functions without arguments simply returns their current settings",
"_____no_output_____"
]
],
[
[
"xspec_abund()",
"_____no_output_____"
],
[
"xspec_xsect()",
"_____no_output_____"
],
[
"xspec_cosmo()",
"_____no_output_____"
]
],
[
[
"To change the settings for abundance and cross-section, provide strings with the normal **XSPEC** naming conventions.",
"_____no_output_____"
]
],
[
[
"xspec_abund('wilm')\nxspec_abund()",
"_____no_output_____"
],
[
"xspec_xsect('bcmc')\nxspec_xsect()",
"_____no_output_____"
]
],
[
[
"To alter the cosmological parameters, one passes either the parameters that should be changed, or all three:",
"_____no_output_____"
]
],
[
[
"xspec_cosmo(H0=68.)\nxspec_cosmo()",
"_____no_output_____"
],
[
"xspec_cosmo(H0=68.,q0=.1,lambda_0=70.)\nxspec_cosmo()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0071f914b6dd3e24ed1342001ddd8df0d508802
| 23,351 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Extended Kalman Filter-checkpoint.ipynb
|
ai-robotics-kr/sensor_fusion_study
|
e9e69686bad99ae56c039d4f4df2290f9a866e7c
|
[
"Apache-2.0"
] | 51 |
2020-05-09T08:03:55.000Z
|
2021-12-17T10:42:26.000Z
|
.ipynb_checkpoints/Extended Kalman Filter-checkpoint.ipynb
|
ai-robotics-kr/sensor_fusion_study
|
e9e69686bad99ae56c039d4f4df2290f9a866e7c
|
[
"Apache-2.0"
] | null | null | null |
.ipynb_checkpoints/Extended Kalman Filter-checkpoint.ipynb
|
ai-robotics-kr/sensor_fusion_study
|
e9e69686bad99ae56c039d4f4df2290f9a866e7c
|
[
"Apache-2.0"
] | 3 |
2020-10-14T02:14:11.000Z
|
2020-11-17T15:50:13.000Z
| 38.469522 | 1,243 | 0.492484 |
[
[
[
"# The Extended Kalman Filter\n\n선형 칼만 필터 (Linear Kalman Filter)에 대한 이론을 바탕으로 비선형 문제에 칼만 필터를 적용해 보겠습니다. 확장칼만필터 (EKF)는 예측단계와 추정단계의 데이터를 비선형으로 가정하고 현재의 추정값에 대해 시스템을 선형화 한뒤 선형 칼만 필터를 사용하는 기법입니다.\n\n비선형 문제에 적용되는 성능이 더 좋은 알고리즘들 (UKF, H_infinity)이 있지만 EKF 는 아직도 널리 사용되서 관련성이 높습니다.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n# HTML(\"\"\"\n# <style>\n# .output_png {\n# display: table-cell;\n# text-align: center;\n# vertical-align: middle;\n# }\n# </style>\n# \"\"\")",
"_____no_output_____"
]
],
[
[
"## Linearizing the Kalman Filter\n\n### Non-linear models\n칼만 필터는 시스템이 선형일것이라는 가정을 하기 때문에 비선형 문제에는 직접적으로 사용하지 못합니다. 비선형성은 두가지 원인에서 기인될수 있는데 첫째는 프로세스 모델의 비선형성 그리고 둘째 측정 모델의 비선형성입니다. 예를 들어, 떨어지는 물체의 가속도는 속도의 제곱에 비례하는 공기저항에 의해 결정되기 때문에 비선형적인 프로세스 모델을 가지고, 레이더로 목표물의 범위와 방위 (bearing) 를 측정할때 비선형함수인 삼각함수를 사용하여 표적의 위치를 계산하기 때문에 비선형적인 측정 모델을 가지게 됩니다.\n\n비선형문제에 기존의 칼만필터 방정식을 적용하지 못하는 이유는 비선형함수에 정규분포 (Gaussian)를 입력하면 아래와 같이 Gaussian 이 아닌 분포를 가지게 되기 때문입니다. ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport scipy.stats as stats\nimport matplotlib.pyplot as plt\n\nmu, sigma = 0, 0.1\ngaussian = stats.norm.pdf(x, mu, sigma)\n\nx = np.linspace(mu - 3*sigma, mu + 3*sigma, 10000)\n\ndef nonlinearFunction(x):\n return np.sin(x)\n\ndef linearFunction(x):\n return 0.5*x\n\nnonlinearOutput = nonlinearFunction(gaussian)\nlinearOutput = linearFunction(gaussian)\n\n# print(x) \n \nplt.plot(x, gaussian, label = 'Gaussian Input')\nplt.plot(x, linearOutput, label = 'Linear Output')\nplt.plot(x, nonlinearOutput, label = 'Nonlinear Output')\n\nplt.grid(linestyle='dotted', linewidth=0.8)\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### System Equations\n선형 칼만 필터의 경우 프로세스 및 측정 모델은 다음과 같이 나타낼수 있습니다.\n\n$$\\begin{aligned}\\dot{\\mathbf x} &= \\mathbf{Ax} + w_x\\\\\n\\mathbf z &= \\mathbf{Hx} + w_z\n\\end{aligned}$$\n\n이때 $\\mathbf A$ 는 (연속시간에서) 시스템의 역학을 묘사하는 dynamic matrix 입니다. 위의 식을 이산화(discretize)시키면 아래와 같이 나타내줄 수 있습니다. \n\n$$\\begin{aligned}\\bar{\\mathbf x}_k &= \\mathbf{F} \\mathbf{x}_{k-1} \\\\\n\\bar{\\mathbf z} &= \\mathbf{H} \\mathbf{x}_{k-1}\n\\end{aligned}$$\n\n이때 $\\mathbf F$ 는 이산시간 $\\Delta t$ 에 걸쳐 $\\mathbf x_{k-1}$을 $\\mathbf x_{k}$ 로 전환하는 상태변환행렬 또는 상태전달함수 (state transition matrix) 이고, 위에서의 $w_x$ 와 $w_z$는 각각 프로세스 노이즈 공분산 행렬 $\\mathbf Q$ 과 측정 노이즈 공분산 행렬 $\\mathbf R$ 에 포함됩니다.\n\n선형 시스템에서의 $\\mathbf F \\mathbf x- \\mathbf B \\mathbf u$ 와 $\\mathbf H \\mathbf x$ 는 비선형 시스템에서 함수 $f(\\mathbf x, \\mathbf u)$ 와 $h(\\mathbf x)$ 로 대체됩니다.\n\n$$\\begin{aligned}\\dot{\\mathbf x} &= f(\\mathbf x, \\mathbf u) + w_x\\\\\n\\mathbf z &= h(\\mathbf x) + w_z\n\\end{aligned}$$",
"_____no_output_____"
],
[
"### Linearisation\n선형화란 말그대로 하나의 시점에 대하여 비선형함수에 가장 가까운 선 (선형시스템) 을 찾는것이라고 볼수 있습니다. 여러가지 방법으로 선형화를 할수 있겠지만 흔히 일차 테일러 급수를 사용합니다. ($ c_0$ 과 $c_1 x$)\n\n$$f(x) = \\sum_{k=0}^\\infty c_k x^k = c_0 + c_1 x + c_2 x^2 + \\dotsb$$\n$$c_k = \\frac{f^{\\left(k\\right)}(0)}{k!} = \\frac{1}{k!} \\cdot \\frac{d^k f}{dx^k}\\bigg|_0 $$\n\n행렬의 미분값을 Jacobian 이라고 하는데 이를 통해서 위와 같이 $\\mathbf F$ 와 $\\mathbf H$ 를 나타낼 수 있습니다.\n\n$$\n\\begin{aligned}\n\\mathbf F \n= {\\frac{\\partial{f(\\mathbf x_t, \\mathbf u_t)}}{\\partial{\\mathbf x}}}\\biggr|_{{\\mathbf x_t},{\\mathbf u_t}} \\;\\;\\;\\;\n\\mathbf H = \\frac{\\partial{h(\\bar{\\mathbf x}_t)}}{\\partial{\\bar{\\mathbf x}}}\\biggr|_{\\bar{\\mathbf x}_t} \n\\end{aligned}\n$$\n\n$$\\mathbf F = \\frac{\\partial f(\\mathbf x, \\mathbf u)}{\\partial x} =\\begin{bmatrix}\n\\frac{\\partial f_1}{\\partial x_1} & \\frac{\\partial f_1}{\\partial x_2} & \\dots & \\frac{\\partial f_1}{\\partial x_n}\\\\\n\\frac{\\partial f_2}{\\partial x_1} & \\frac{\\partial f_2}{\\partial x_2} & \\dots & \\frac{\\partial f_2}{\\partial x_n} \\\\\n\\\\ \\vdots & \\vdots & \\ddots & \\vdots\n\\\\\n\\frac{\\partial f_n}{\\partial x_1} & \\frac{\\partial f_n}{\\partial x_2} & \\dots & \\frac{\\partial f_n}{\\partial x_n}\n\\end{bmatrix}\n$$\n\nLinear Kalman Filter 와 Extended Kalman Filter 의 식들을 아래와 같이 비교할수 있습니다.\n\n$$\\begin{array}{l|l}\n\\text{Linear Kalman filter} & \\text{EKF} \\\\\n\\hline \n& \\boxed{\\mathbf F = {\\frac{\\partial{f(\\mathbf x_t, \\mathbf u_t)}}{\\partial{\\mathbf x}}}\\biggr|_{{\\mathbf x_t},{\\mathbf u_t}}} \\\\\n\\mathbf{\\bar x} = \\mathbf{Fx} + \\mathbf{Bu} & \\boxed{\\mathbf{\\bar x} = f(\\mathbf x, \\mathbf u)} \\\\\n\\mathbf{\\bar P} = \\mathbf{FPF}^\\mathsf{T}+\\mathbf Q & \\mathbf{\\bar P} = \\mathbf{FPF}^\\mathsf{T}+\\mathbf Q \\\\\n\\hline\n& \\boxed{\\mathbf H = \\frac{\\partial{h(\\bar{\\mathbf x}_t)}}{\\partial{\\bar{\\mathbf x}}}\\biggr|_{\\bar{\\mathbf x}_t}} \\\\\n\\textbf{y} = \\mathbf z - \\mathbf{H \\bar{x}} & \\textbf{y} = \\mathbf z - \\boxed{h(\\bar{x})}\\\\\n\\mathbf{K} = \\mathbf{\\bar{P}H}^\\mathsf{T} (\\mathbf{H\\bar{P}H}^\\mathsf{T} + \\mathbf R)^{-1} & \\mathbf{K} = \\mathbf{\\bar{P}H}^\\mathsf{T} (\\mathbf{H\\bar{P}H}^\\mathsf{T} + \\mathbf R)^{-1} \\\\\n\\mathbf x=\\mathbf{\\bar{x}} +\\mathbf{K\\textbf{y}} & \\mathbf x=\\mathbf{\\bar{x}} +\\mathbf{K\\textbf{y}} \\\\\n\\mathbf P= (\\mathbf{I}-\\mathbf{KH})\\mathbf{\\bar{P}} & \\mathbf P= (\\mathbf{I}-\\mathbf{KH})\\mathbf{\\bar{P}}\n\\end{array}$$\n\n$\\mathbf F \\mathbf x_{k-1}$ 을 사용하여 $\\mathbf x_{k}$의 값을 추정할수 있겠지만, 선형화 과정에서 오차가 생길수 있기 때문에 Euler 또는 Runge Kutta 수치 적분 (numerical integration) 을 통해서 사전추정값 $\\mathbf{\\bar{x}}$ 를 구합니다. 같은 이유로 $\\mathbf y$ (innovation vector 또는 잔차(residual)) 를 구할때도 $\\mathbf H \\mathbf x$ 대신에 수치적인 방법으로 계산하게 됩니다.",
"_____no_output_____"
],
[
"## Example: Robot Localization\n\n### Prediction Model (예측모델)\nEKF를 4륜 로봇에 적용시켜 보겠습니다. 간단한 bicycle steering model 을 통해 아래의 시스템 모델을 나타낼 수 있습니다.",
"_____no_output_____"
]
],
[
[
"import kf_book.ekf_internal as ekf_internal\nekf_internal.plot_bicycle()",
"_____no_output_____"
]
],
[
[
"$$\\begin{aligned} \n\\beta &= \\frac d w \\tan(\\alpha) \\\\\n\\bar x_k &= x_{k-1} - R\\sin(\\theta) + R\\sin(\\theta + \\beta) \\\\\n\\bar y_k &= y_{k-1} + R\\cos(\\theta) - R\\cos(\\theta + \\beta) \\\\\n\\bar \\theta_k &= \\theta_{k-1} + \\beta\n\\end{aligned}\n$$",
"_____no_output_____"
],
[
"위의 식들을 토대로 상태벡터를 $\\mathbf{x}=[x, y, \\theta]^T$ 그리고 입력벡터를 $\\mathbf{u}=[v, \\alpha]^T$ 라고 정의 해주면 아래와 같이 $f(\\mathbf x, \\mathbf u)$ 나타내줄수 있고 $f$ 의 Jacobian $\\mathbf F$를 미분하여 아래의 행렬을 구해줄수 있습니다.\n\n$$\\bar x = f(x, u) + \\mathcal{N}(0, Q)$$\n\n$$f = \\begin{bmatrix}x\\\\y\\\\\\theta\\end{bmatrix} + \n\\begin{bmatrix}- R\\sin(\\theta) + R\\sin(\\theta + \\beta) \\\\\nR\\cos(\\theta) - R\\cos(\\theta + \\beta) \\\\\n\\beta\\end{bmatrix}$$\n\n$$\\mathbf F = \\frac{\\partial f(\\mathbf x, \\mathbf u)}{\\partial \\mathbf x} = \\begin{bmatrix}\n1 & 0 & -R\\cos(\\theta) + R\\cos(\\theta+\\beta) \\\\\n0 & 1 & -R\\sin(\\theta) + R\\sin(\\theta+\\beta) \\\\\n0 & 0 & 1\n\\end{bmatrix}$$",
"_____no_output_____"
],
[
"$\\bar{\\mathbf P}$ 을 구하기 위해 입력($\\mathbf u$)에서 비롯되는 프로세스 노이즈 $\\mathbf Q$ 를 아래와 같이 정의합니다.\n\n$$\\mathbf{M} = \\begin{bmatrix}\\sigma_{vel}^2 & 0 \\\\ 0 & \\sigma_\\alpha^2\\end{bmatrix}\n\\;\\;\\;\\;\n\\mathbf{V} = \\frac{\\partial f(x, u)}{\\partial u} \\begin{bmatrix}\n\\frac{\\partial f_1}{\\partial v} & \\frac{\\partial f_1}{\\partial \\alpha} \\\\\n\\frac{\\partial f_2}{\\partial v} & \\frac{\\partial f_2}{\\partial \\alpha} \\\\\n\\frac{\\partial f_3}{\\partial v} & \\frac{\\partial f_3}{\\partial \\alpha}\n\\end{bmatrix}$$\n\n$$\\mathbf{\\bar P} =\\mathbf{FPF}^{\\mathsf T} + \\mathbf{VMV}^{\\mathsf T}$$\n",
"_____no_output_____"
]
],
[
[
"import sympy\nfrom sympy.abc import alpha, x, y, v, w, R, theta\nfrom sympy import symbols, Matrix\nsympy.init_printing(use_latex=\"mathjax\", fontsize='16pt')\ntime = symbols('t')\nd = v*time\nbeta = (d/w)*sympy.tan(alpha)\nr = w/sympy.tan(alpha)\n\nfxu = Matrix([[x-r*sympy.sin(theta) + r*sympy.sin(theta+beta)],\n [y+r*sympy.cos(theta)- r*sympy.cos(theta+beta)],\n [theta+beta]])\nF = fxu.jacobian(Matrix([x, y, theta]))\nF",
"_____no_output_____"
],
[
"# reduce common expressions\nB, R = symbols('beta, R')\nF = F.subs((d/w)*sympy.tan(alpha), B)\nF.subs(w/sympy.tan(alpha), R)",
"_____no_output_____"
],
[
"V = fxu.jacobian(Matrix([v, alpha]))\nV = V.subs(sympy.tan(alpha)/w, 1/R) \nV = V.subs(time*v/R, B)\nV = V.subs(time*v, 'd')\nV",
"_____no_output_____"
]
],
[
[
"### Measurement Model (측정모델)\n\n레이더로 범위$(r)$와 방위($\\phi$)를 측정할때 다음과 같은 센서모델을 사용합니다. 이때 $\\mathbf p$ 는 landmark의 위치를 나타내줍니다.\n\n$$r = \\sqrt{(p_x - x)^2 + (p_y - y)^2}\n\\;\\;\\;\\;\n\\phi = \\arctan(\\frac{p_y - y}{p_x - x}) - \\theta\n$$\n\n$$\\begin{aligned}\n\\mathbf z& = h(\\bar{\\mathbf x}, \\mathbf p) &+ \\mathcal{N}(0, R)\\\\\n&= \\begin{bmatrix}\n\\sqrt{(p_x - x)^2 + (p_y - y)^2} \\\\\n\\arctan(\\frac{p_y - y}{p_x - x}) - \\theta \n\\end{bmatrix} &+ \\mathcal{N}(0, R)\n\\end{aligned}$$\n\n$h$ 의 Jacobian $\\mathbf H$를 미분하여 아래의 행렬을 구해줄수 있습니다.\n$$\\mathbf H = \\frac{\\partial h(\\mathbf x, \\mathbf u)}{\\partial \\mathbf x} =\n\\left[\\begin{matrix}\\frac{- p_{x} + x}{\\sqrt{\\left(p_{x} - x\\right)^{2} + \\left(p_{y} - y\\right)^{2}}} & \\frac{- p_{y} + y}{\\sqrt{\\left(p_{x} - x\\right)^{2} + \\left(p_{y} - y\\right)^{2}}} & 0\\\\- \\frac{- p_{y} + y}{\\left(p_{x} - x\\right)^{2} + \\left(p_{y} - y\\right)^{2}} & - \\frac{p_{x} - x}{\\left(p_{x} - x\\right)^{2} + \\left(p_{y} - y\\right)^{2}} & -1\\end{matrix}\\right]\n$$",
"_____no_output_____"
]
],
[
[
"import sympy\nfrom sympy.abc import alpha, x, y, v, w, R, theta\n\npx, py = sympy.symbols('p_x, p_y')\nz = sympy.Matrix([[sympy.sqrt((px-x)**2 + (py-y)**2)],\n [sympy.atan2(py-y, px-x) - theta]])\nz.jacobian(sympy.Matrix([x, y, theta]))\n\n# print(sympy.latex(z.jacobian(sympy.Matrix([x, y, theta])))",
"_____no_output_____"
],
[
"from math import sqrt\n\ndef H_of(x, landmark_pos):\n \"\"\" compute Jacobian of H matrix where h(x) computes \n the range and bearing to a landmark for state x \"\"\"\n\n px = landmark_pos[0]\n py = landmark_pos[1]\n hyp = (px - x[0, 0])**2 + (py - x[1, 0])**2\n dist = sqrt(hyp)\n\n H = array(\n [[-(px - x[0, 0]) / dist, -(py - x[1, 0]) / dist, 0],\n [ (py - x[1, 0]) / hyp, -(px - x[0, 0]) / hyp, -1]])\n return H",
"_____no_output_____"
],
[
"from math import atan2\n\ndef Hx(x, landmark_pos):\n \"\"\" takes a state variable and returns the measurement\n that would correspond to that state.\n \"\"\"\n px = landmark_pos[0]\n py = landmark_pos[1]\n dist = sqrt((px - x[0, 0])**2 + (py - x[1, 0])**2)\n\n Hx = array([[dist],\n [atan2(py - x[1, 0], px - x[0, 0]) - x[2, 0]]])\n return Hx",
"_____no_output_____"
]
],
[
[
"측정 노이즈는 다음과 같이 나타내줍니다.\n$$\\mathbf R=\\begin{bmatrix}\\sigma_{range}^2 & 0 \\\\ 0 & \\sigma_{bearing}^2\\end{bmatrix}$$",
"_____no_output_____"
],
[
"### Implementation\n\n`FilterPy` 의 `ExtendedKalmanFilter` class 를 활용해서 EKF 를 구현해보도록 하겠습니다.",
"_____no_output_____"
]
],
[
[
"from filterpy.kalman import ExtendedKalmanFilter as EKF\nfrom numpy import array, sqrt, random\nimport sympy\n\nclass RobotEKF(EKF):\n def __init__(self, dt, wheelbase, std_vel, std_steer):\n EKF.__init__(self, 3, 2, 2)\n self.dt = dt\n self.wheelbase = wheelbase\n self.std_vel = std_vel\n self.std_steer = std_steer\n\n a, x, y, v, w, theta, time = sympy.symbols(\n 'a, x, y, v, w, theta, t')\n d = v*time\n beta = (d/w)*sympy.tan(a)\n r = w/sympy.tan(a)\n \n self.fxu = sympy.Matrix(\n [[x-r*sympy.sin(theta)+r*sympy.sin(theta+beta)],\n [y+r*sympy.cos(theta)-r*sympy.cos(theta+beta)],\n [theta+beta]])\n\n self.F_j = self.fxu.jacobian(sympy.Matrix([x, y, theta]))\n self.V_j = self.fxu.jacobian(sympy.Matrix([v, a]))\n\n # save dictionary and it's variables for later use\n self.subs = {x: 0, y: 0, v:0, a:0, \n time:dt, w:wheelbase, theta:0}\n self.x_x, self.x_y, = x, y \n self.v, self.a, self.theta = v, a, theta\n\n def predict(self, u):\n self.x = self.move(self.x, u, self.dt)\n\n self.subs[self.theta] = self.x[2, 0]\n self.subs[self.v] = u[0]\n self.subs[self.a] = u[1]\n\n F = array(self.F_j.evalf(subs=self.subs)).astype(float)\n V = array(self.V_j.evalf(subs=self.subs)).astype(float)\n\n # covariance of motion noise in control space\n M = array([[self.std_vel*u[0]**2, 0], \n [0, self.std_steer**2]])\n\n self.P = F @ self.P @ F.T + V @ M @ V.T\n\n def move(self, x, u, dt):\n hdg = x[2, 0]\n vel = u[0]\n steering_angle = u[1]\n dist = vel * dt\n\n if abs(steering_angle) > 0.001: # is robot turning?\n beta = (dist / self.wheelbase) * tan(steering_angle)\n r = self.wheelbase / tan(steering_angle) # radius\n\n dx = np.array([[-r*sin(hdg) + r*sin(hdg + beta)], \n [r*cos(hdg) - r*cos(hdg + beta)], \n [beta]])\n else: # moving in straight line\n dx = np.array([[dist*cos(hdg)], \n [dist*sin(hdg)], \n [0]])\n return x + dx",
"_____no_output_____"
]
],
[
[
"정확한 잔차값 $y$을 구하기 방위값이 $0 \\leq \\phi \\leq 2\\pi$ 이도록 고쳐줍니다.",
"_____no_output_____"
]
],
[
[
"def residual(a, b):\n \"\"\" compute residual (a-b) between measurements containing \n [range, bearing]. Bearing is normalized to [-pi, pi)\"\"\"\n y = a - b\n y[1] = y[1] % (2 * np.pi) # force in range [0, 2 pi)\n if y[1] > np.pi: # move to [-pi, pi)\n y[1] -= 2 * np.pi\n return y",
"_____no_output_____"
],
[
"from filterpy.stats import plot_covariance_ellipse\nfrom math import sqrt, tan, cos, sin, atan2\nimport matplotlib.pyplot as plt\n\ndt = 1.0\n\ndef z_landmark(lmark, sim_pos, std_rng, std_brg):\n x, y = sim_pos[0, 0], sim_pos[1, 0]\n d = np.sqrt((lmark[0] - x)**2 + (lmark[1] - y)**2) \n a = atan2(lmark[1] - y, lmark[0] - x) - sim_pos[2, 0]\n z = np.array([[d + random.randn()*std_rng],\n [a + random.randn()*std_brg]])\n return z\n\ndef ekf_update(ekf, z, landmark):\n ekf.update(z, HJacobian = H_of, Hx = Hx, \n residual=residual,\n args=(landmark), hx_args=(landmark))\n \n \ndef run_localization(landmarks, std_vel, std_steer, \n std_range, std_bearing,\n step=10, ellipse_step=20, ylim=None):\n ekf = RobotEKF(dt, wheelbase=0.5, std_vel=std_vel, \n std_steer=std_steer)\n ekf.x = array([[2, 6, .3]]).T # x, y, steer angle\n ekf.P = np.diag([.1, .1, .1])\n ekf.R = np.diag([std_range**2, std_bearing**2])\n\n sim_pos = ekf.x.copy() # simulated position\n # steering command (vel, steering angle radians)\n u = array([1.1, .01]) \n\n plt.figure()\n plt.scatter(landmarks[:, 0], landmarks[:, 1],\n marker='s', s=60)\n \n track = []\n for i in range(200):\n sim_pos = ekf.move(sim_pos, u, dt/10.) # simulate robot\n track.append(sim_pos)\n\n if i % step == 0:\n ekf.predict(u=u)\n\n if i % ellipse_step == 0:\n plot_covariance_ellipse(\n (ekf.x[0,0], ekf.x[1,0]), ekf.P[0:2, 0:2], \n std=6, facecolor='k', alpha=0.3)\n\n x, y = sim_pos[0, 0], sim_pos[1, 0]\n for lmark in landmarks:\n z = z_landmark(lmark, sim_pos,\n std_range, std_bearing)\n ekf_update(ekf, z, lmark)\n\n if i % ellipse_step == 0:\n plot_covariance_ellipse(\n (ekf.x[0,0], ekf.x[1,0]), ekf.P[0:2, 0:2],\n std=6, facecolor='g', alpha=0.8)\n track = np.array(track)\n plt.plot(track[:, 0], track[:,1], color='k', lw=2)\n plt.axis('equal')\n plt.title(\"EKF Robot localization\")\n if ylim is not None: plt.ylim(*ylim)\n plt.show()\n return ekf",
"_____no_output_____"
],
[
"landmarks = array([[5, 10], [10, 5], [15, 15]])\n\nekf = run_localization(\n landmarks, std_vel=0.1, std_steer=np.radians(1),\n std_range=0.3, std_bearing=0.1)\nprint('Final P:', ekf.P.diagonal())",
"_____no_output_____"
]
],
[
[
"## References\n\n* Roger R Labbe, Kalman and Bayesian Filters in Python\n(https://github.com/rlabbe/Kalman-and-Bayesian-Filters-in-Python/blob/master/11-Extended-Kalman-Filters.ipynb)\n* https://blog.naver.com/jewdsa813/222200570774",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0072b459910b42f77f44d3ec64e412af0de6cbc
| 607,551 |
ipynb
|
Jupyter Notebook
|
notebooks/fake_simulations/Visualize_warped_learning.ipynb
|
MaryZolfaghar/WCSLS
|
fcb3bfd11c19bb90690ec772f91bbd107832d636
|
[
"Apache-2.0"
] | null | null | null |
notebooks/fake_simulations/Visualize_warped_learning.ipynb
|
MaryZolfaghar/WCSLS
|
fcb3bfd11c19bb90690ec772f91bbd107832d636
|
[
"Apache-2.0"
] | null | null | null |
notebooks/fake_simulations/Visualize_warped_learning.ipynb
|
MaryZolfaghar/WCSLS
|
fcb3bfd11c19bb90690ec772f91bbd107832d636
|
[
"Apache-2.0"
] | null | null | null | 369.331915 | 38,229 | 0.939501 |
[
[
[
"# Method for visualizing warping over training steps",
"_____no_output_____"
]
],
[
[
"import os\nimport imageio\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"np.random.seed(0)",
"_____no_output_____"
]
],
[
[
"### Construct warping matrix",
"_____no_output_____"
]
],
[
[
"g = 1.02 # scaling parameter\n\n# Matrix for rotating 45 degrees\nrotate = np.array([[np.cos(np.pi/4), -np.sin(np.pi/4)],\n [np.sin(np.pi/4), np.cos(np.pi/4)]])\n\n# Matrix for scaling along x coordinate\nscale_x = np.array([[g, 0],\n [0, 1]])\n\n# Matrix for scaling along y coordinate\nscale_y = np.array([[1, 0],\n [0, g]])\n\n# Matrix for unrotating (-45 degrees)\nunrotate = np.array([[np.cos(-np.pi/4), -np.sin(-np.pi/4)],\n [np.sin(-np.pi/4), np.cos(-np.pi/4)]])\n\n# Warping matrix\nwarp = rotate @ scale_x @ unrotate\n\n# Unwarping matrix\nunwarp = rotate @ scale_y @ unrotate",
"_____no_output_____"
]
],
[
[
"### Warp grid slowly over time",
"_____no_output_____"
]
],
[
[
"# Construct 4x4 grid\ns = 1 # initial scale\nlocs = [[x,y] for x in range(4) for y in range(4)]\ngrid = s*np.array(locs)",
"_____no_output_____"
],
[
"# Matrix to collect data\nn_steps = 50\nwarp_data = np.zeros([n_steps, 16, 2])\n\n# Initial timestep has no warping\nwarp_data[0,:,:] = grid\n\n# Warp slowly over time\nfor i in range(1,n_steps):\n grid = grid @ warp\n warp_data[i,:,:] = grid\n ",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1,3, figsize=(15, 5), sharex=True, sharey=True)\nax[0].scatter(warp_data[0,:,0], warp_data[0,:,1])\nax[0].set_title(\"Warping: step 0\")\nax[1].scatter(warp_data[n_steps//2,:,0], warp_data[n_steps//2,:,1])\nax[1].set_title(\"Warping: Step {}\".format(n_steps//2))\nax[2].scatter(warp_data[n_steps-1,:,0], warp_data[n_steps-1,:,1])\nax[2].set_title(\"Warping: Step {}\".format(n_steps-1))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Unwarp grid slowly over time",
"_____no_output_____"
]
],
[
[
"# Matrix to collect data\nunwarp_data = np.zeros([n_steps, 16, 2])\n\n# Start with warped grid\nunwarp_data[0,:,:] = grid\n\n# Unwarp slowly over time\nfor i in range(1,n_steps):\n grid = grid @ unwarp\n unwarp_data[i,:,:] = grid",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1,3, figsize=(15, 5), sharex=True, sharey=True)\nax[0].scatter(unwarp_data[0,:,0], unwarp_data[0,:,1])\nax[0].set_title(\"Unwarping: Step 0\")\n# ax[0].set_ylim([-0.02, 0.05])\n# ax[0].set_xlim([-0.02, 0.05])\nax[1].scatter(unwarp_data[n_steps//2,:,0], unwarp_data[n_steps//2,:,1])\nax[1].set_title(\"Unwarping: Step {}\".format(n_steps//2))\nax[2].scatter(unwarp_data[n_steps-1,:,0], unwarp_data[n_steps-1,:,1])\nax[2].set_title(\"Unwarping: Step {}\".format(n_steps-1))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### High-dimensional vectors with random projection matrix",
"_____no_output_____"
]
],
[
[
"# data = [warp_data, unwarp_data]\ndata = np.concatenate([warp_data, unwarp_data], axis=0)\n\n# Random projection matrix\nhidden_dim = 32\nrandom_mat = np.random.randn(2, hidden_dim)\ndata = data @ random_mat\n\n# Add noise to each time step\nsigma = 0.2\nnoise = sigma*np.random.randn(2*n_steps, 16, hidden_dim)\ndata = data + noise\n",
"_____no_output_____"
]
],
[
[
"### Parameterize scatterplot with average \"congruent\" and \"incongruent\" distances",
"_____no_output_____"
]
],
[
[
"loc2idx = {i:(loc[0],loc[1]) for i,loc in enumerate(locs)}\nidx2loc = {v:k for k,v in loc2idx.items()}",
"_____no_output_____"
]
],
[
[
"Function for computing distance matrix",
"_____no_output_____"
]
],
[
[
"def get_distances(M):\n n,m = M.shape\n D = np.zeros([n,n])\n for i in range(n):\n for j in range(n):\n D[i,j] = np.linalg.norm(M[i,:] - M[j,:])\n return D",
"_____no_output_____"
],
[
"D = get_distances(data[0])\nplt.imshow(D)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Construct same-rank groups for \"congruent\" and \"incongruent\" diagonals",
"_____no_output_____"
]
],
[
[
"c_rank = np.array([loc[0] + loc[1] for loc in locs]) # rank along \"congruent\" diagonal\ni_rank = np.array([3 + loc[0] - loc[1] for loc in locs]) # rank along \"incongruent\" diagonal\n\nG_idxs = [] # same-rank group for \"congruent\" diagonal\nH_idxs = [] # same-rank group for \"incongruent\" diagonal\nfor i in range(7): # total number of ranks (0 through 6)\n G_set = [j for j in range(len(c_rank)) if c_rank[j] == i]\n H_set = [j for j in range(len(i_rank)) if i_rank[j] == i]\n G_idxs.append(G_set)\n H_idxs.append(H_set)",
"_____no_output_____"
]
],
[
[
"Function for estimating $ \\alpha $ and $ \\beta $",
"_____no_output_____"
],
[
"$$ \\bar{x_i} = \\sum_{x \\in G_i} \\frac{1}{n} x $$\n\n$$ \\alpha_{i, i+1} = || \\bar{x}_i - \\bar{x}_{i+1} || $$\n\n$$ \\bar{y_i} = \\sum_{y \\in H_i} \\frac{1}{n} y $$\n\n$$ \\beta_{i, i+1} = || \\bar{y}_i - \\bar{y}_{i+1} || $$\n",
"_____no_output_____"
]
],
[
[
"def get_parameters(M):\n # M: [16, hidden_dim]\n alpha = []\n beta = []\n for i in range(6): # total number of parameters (01,12,23,34,45,56)\n # alpha_{i, i+1}\n x_bar_i = np.mean(M[G_idxs[i],:], axis=0)\n x_bar_ip1 = np.mean(M[G_idxs[i+1],:], axis=0)\n x_dist = np.linalg.norm(x_bar_i - x_bar_ip1)\n alpha.append(x_dist)\n \n # beta_{i, i+1}\n y_bar_i = np.mean(M[H_idxs[i],:], axis=0)\n y_bar_ip1 = np.mean(M[H_idxs[i+1],:], axis=0)\n y_dist = np.linalg.norm(y_bar_i - y_bar_ip1)\n beta.append(y_dist)\n \n return alpha, beta",
"_____no_output_____"
],
[
"alpha_data = []\nbeta_data = []\nfor t in range(len(data)):\n alpha, beta = get_parameters(data[t])\n alpha_data.append(alpha)\n beta_data.append(beta)",
"_____no_output_____"
],
[
"plt.plot(alpha_data, color='tab:blue')\nplt.plot(beta_data, color='tab:orange')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Use parameters to plot idealized 2D representations",
"_____no_output_____"
]
],
[
[
"idx2g = {}\nfor idx in range(16):\n for g, group in enumerate(G_idxs):\n if idx in group:\n idx2g[idx] = g\n\nidx2h = {}\nfor idx in range(16):\n for h, group in enumerate(H_idxs):\n if idx in group:\n idx2h[idx] = h",
"_____no_output_____"
],
[
"def generate_grid(alpha, beta):\n cum_alpha = np.zeros(7)\n cum_beta = np.zeros(7)\n cum_alpha[1:] = np.cumsum(alpha)\n cum_beta[1:] = np.cumsum(beta)\n \n # Get x and y coordinate in rotated basis\n X = np.zeros([16, 2])\n for idx in range(16):\n g = idx2g[idx] # G group\n h = idx2h[idx] # H group\n X[idx,0] = cum_alpha[g] # x coordinate\n X[idx,1] = cum_beta[h] # y coordinate\n \n # Unrotate\n unrotate = np.array([[np.cos(-np.pi/4), -np.sin(-np.pi/4)],\n [np.sin(-np.pi/4), np.cos(-np.pi/4)]])\n X = X @ unrotate\n \n # Mean-center\n X = X - np.mean(X, axis=0, keepdims=True)\n \n return X",
"_____no_output_____"
],
[
"X = generate_grid(alpha, beta)",
"_____no_output_____"
]
],
[
[
"Get reconstructed grid for each time step",
"_____no_output_____"
]
],
[
[
"reconstruction = np.zeros([data.shape[0], data.shape[1], 2])\nfor t,M in enumerate(data):\n alpha, beta = get_parameters(M)\n X = generate_grid(alpha, beta)\n reconstruction[t,:,:] = X",
"_____no_output_____"
],
[
"t = 50\nplt.scatter(reconstruction[t,:,0], reconstruction[t,:,1])\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Make .gif",
"_____no_output_____"
]
],
[
[
"plt.scatter(M[:,0], M[:,1])",
"_____no_output_____"
],
[
"reconstruction.shape",
"_____no_output_____"
],
[
"xmin = np.min(reconstruction[:,:,0])\nxmax = np.max(reconstruction[:,:,0])\nymin = np.min(reconstruction[:,:,1])\nymax = np.max(reconstruction[:,:,1])\nfor t,M in enumerate(reconstruction):\n plt.scatter(M[:,0], M[:,1])\n plt.title(\"Reconstructed grid\")\n plt.xlim([xmin-1.5, xmax+1.5])\n plt.ylim([ymin-1.5, ymax+1.5])\n plt.xticks([])\n plt.yticks([])\n plt.tight_layout()\n plt.savefig('reconstruction_test_{}.png'.format(t), dpi=100)\n plt.show()",
"_____no_output_____"
],
[
"filenames = ['reconstruction_test_{}.png'.format(i) for i in range(2*n_steps)]",
"_____no_output_____"
],
[
"with imageio.get_writer('reconstruction_test.gif', mode='I') as writer:\n for filename in filenames:\n image = imageio.imread(filename)\n writer.append_data(image)\n\n# remove files\nfor filename in filenames:\n os.remove(filename)",
"_____no_output_____"
]
],
[
[
"<img src=\"reconstruction_test.gif\" width=\"750\" align=\"center\">",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0072d86ebf28cd6cb2fda57162630222b7aa57c
| 6,072 |
ipynb
|
Jupyter Notebook
|
dft_workflow/run_slabs/rerun_magmoms/rerun_magmoms.ipynb
|
raulf2012/PROJ_IrOx_OER
|
56883d6f5b62e67703fe40899e2e68b3f5de143b
|
[
"MIT"
] | 1 |
2022-03-21T04:43:47.000Z
|
2022-03-21T04:43:47.000Z
|
dft_workflow/run_slabs/rerun_magmoms/rerun_magmoms.ipynb
|
raulf2012/PROJ_IrOx_OER
|
56883d6f5b62e67703fe40899e2e68b3f5de143b
|
[
"MIT"
] | null | null | null |
dft_workflow/run_slabs/rerun_magmoms/rerun_magmoms.ipynb
|
raulf2012/PROJ_IrOx_OER
|
56883d6f5b62e67703fe40899e2e68b3f5de143b
|
[
"MIT"
] | 1 |
2021-02-13T12:55:02.000Z
|
2021-02-13T12:55:02.000Z
| 27.726027 | 99 | 0.39361 |
[
[
[
"# Rerun jobs to achieve better magmom matching\n---\n\nWill take most magnetic slab of OER set and apply those magmoms to the other slabs",
"_____no_output_____"
],
[
"### Import Modules",
"_____no_output_____"
]
],
[
[
"import os\nprint(os.getcwd())\nimport sys\n\n# #########################################################\nfrom methods import get_df_features_targets\nfrom methods import get_df_magmoms",
"/mnt/f/Dropbox/01_norskov/00_git_repos/PROJ_IrOx_OER/dft_workflow/run_slabs/rerun_magmoms\n"
]
],
[
[
"### Read Data",
"_____no_output_____"
]
],
[
[
"df_features_targets = get_df_features_targets()\n\ndf_magmoms = get_df_magmoms()\ndf_magmoms = df_magmoms.set_index(\"job_id\")",
"_____no_output_____"
],
[
"for name_i, row_i in df_features_targets.iterrows():\n tmp = 42\n\n# #####################################################\njob_id_o_i = row_i[(\"data\", \"job_id_o\", \"\", )]\njob_id_oh_i = row_i[(\"data\", \"job_id_oh\", \"\", )]\njob_id_bare_i = row_i[(\"data\", \"job_id_bare\", \"\", )]\n# #####################################################\n\njob_ids = [job_id_o_i, job_id_oh_i, job_id_bare_i]",
"_____no_output_____"
],
[
"df_magmoms.loc[job_ids]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0072ff42b238cf6606a6f7363ad87218c0b4ac3
| 23,026 |
ipynb
|
Jupyter Notebook
|
answers/08_class_documentation.ipynb
|
CCPBioSim/python_and_data_workshop
|
6fb543d48c1d18401e830851f05046b9aa9249cc
|
[
"MIT"
] | 3 |
2019-09-23T14:29:34.000Z
|
2022-01-06T09:53:09.000Z
|
answers/08_class_documentation.ipynb
|
CCPBioSim/python_and_data_workshop
|
6fb543d48c1d18401e830851f05046b9aa9249cc
|
[
"MIT"
] | null | null | null |
answers/08_class_documentation.ipynb
|
CCPBioSim/python_and_data_workshop
|
6fb543d48c1d18401e830851f05046b9aa9249cc
|
[
"MIT"
] | 3 |
2018-04-04T13:26:20.000Z
|
2018-04-25T11:00:24.000Z
| 29.558408 | 1,048 | 0.503561 |
[
[
[
"# Documenting Classes\n\nIt is almost as easy to document a class as it is to document a function. Simply add docstrings to all of the classes functions, and also below the class name itself. For example, here is a simple documented class",
"_____no_output_____"
]
],
[
[
"class Demo:\n \"\"\"This class demonstrates how to document a class.\n \n This class is just a demonstration, and does nothing.\n \n However the principles of documentation are still valid!\n \"\"\"\n \n def __init__(self, name):\n \"\"\"You should document the constructor, saying what it expects to \n create a valid class. In this case\n \n name -- the name of an object of this class\n \"\"\"\n self._name = name\n \n def getName(self):\n \"\"\"You should then document all of the member functions, just as\n you do for normal functions. In this case, returns\n the name of the object\n \"\"\"\n return self._name",
"_____no_output_____"
],
[
"d = Demo(\"cat\")",
"_____no_output_____"
],
[
"help(d)",
"Help on Demo in module __main__ object:\n\nclass Demo(builtins.object)\n | This class demonstrates how to document a class.\n | \n | This class is just a demonstration, and does nothing.\n | \n | However the principles of documentation are still valid!\n | \n | Methods defined here:\n | \n | __init__(self, name)\n | You should document the constructor, saying what it expects to \n | create a valid class. In this case\n | \n | name -- the name of an object of this class\n | \n | getName(self)\n | You should then document all of the member functions, just as\n | you do for normal functions. In this case, returns\n | the name of the object\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | __dict__\n | dictionary for instance variables (if defined)\n | \n | __weakref__\n | list of weak references to the object (if defined)\n\n"
]
],
[
[
"Often, when you write a class, you want to hide member data or member functions so that they are only visible within an object of the class. For example, above, the `self._name` member data should be hidden, as it should only be used by the object.\n\nYou control the visibility of member functions or member data using an underscore. If the member function or member data name starts with an underscore, then it is hidden. Otherwise, the member data or function is visible.\n\nFor example, we can hide the `getName` function by renaming it to `_getName`",
"_____no_output_____"
]
],
[
[
"class Demo:\n \"\"\"This class demonstrates how to document a class.\n \n This class is just a demonstration, and does nothing.\n \n However the principles of documentation are still valid!\n \"\"\"\n \n def __init__(self, name):\n \"\"\"You should document the constructor, saying what it expects to \n create a valid class. In this case\n \n name -- the name of an object of this class\n \"\"\"\n self._name = name\n \n def _getName(self):\n \"\"\"You should then document all of the member functions, just as\n you do for normal functions. In this case, returns\n the name of the object\n \"\"\"\n return self._name",
"_____no_output_____"
],
[
"d = Demo(\"cat\")",
"_____no_output_____"
],
[
"help(d)",
"Help on Demo in module __main__ object:\n\nclass Demo(builtins.object)\n | This class demonstrates how to document a class.\n | \n | This class is just a demonstration, and does nothing.\n | \n | However the principles of documentation are still valid!\n | \n | Methods defined here:\n | \n | __init__(self, name)\n | You should document the constructor, saying what it expects to \n | create a valid class. In this case\n | \n | name -- the name of an object of this class\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | __dict__\n | dictionary for instance variables (if defined)\n | \n | __weakref__\n | list of weak references to the object (if defined)\n\n"
]
],
[
[
"Member functions or data that are hidden are called \"private\". Member functions or data that are visible are called \"public\". You should document all public member functions of a class, as these are visible and designed to be used by other people. It is helpful, although not required, to document all of the private member functions of a class, as these will only really be called by you. However, in years to come, you will thank yourself if you still documented them... ;-)\n\nWhile it is possible to make member data public, it is not advised. It is much better to get and set values of member data using public member functions. This makes it easier for you to add checks to ensure that the data is consistent and being used in the right way. For example, compare these two classes that represent a person, and hold their height.",
"_____no_output_____"
]
],
[
[
"class Person1:\n \"\"\"Class that holds a person's height\"\"\"\n def __init__(self):\n \"\"\"Construct a person who has zero height\"\"\"\n self.height = 0",
"_____no_output_____"
],
[
"class Person2:\n \"\"\"Class that holds a person's height\"\"\"\n def __init__(self):\n \"\"\"Construct a person who has zero height\"\"\"\n self._height = 0\n \n def setHeight(self, height):\n \"\"\"Set the person's height to 'height', returning whether or \n not the height was set successfully\n \"\"\"\n if height < 0 or height > 300:\n print(\"This is an invalid height! %s\" % height)\n return False\n else:\n self._height = height\n return True\n \n def getHeight(self):\n \"\"\"Return the person's height\"\"\"\n return self._height",
"_____no_output_____"
]
],
[
[
"The first example is quicker to write, but it does little to protect itself against a user who attempts to use the class badly.",
"_____no_output_____"
]
],
[
[
"p = Person1()",
"_____no_output_____"
],
[
"p.height = -50",
"_____no_output_____"
],
[
"p.height",
"_____no_output_____"
],
[
"p.height = \"cat\"",
"_____no_output_____"
],
[
"p.height",
"_____no_output_____"
]
],
[
[
"The second example takes more lines of code, but these lines are valuable as they check that the user is using the class correctly. These checks, when combined with good documentation, ensure that your classes can be safely used by others, and that incorrect use will not create difficult-to-find bugs.",
"_____no_output_____"
]
],
[
[
"p = Person2()",
"_____no_output_____"
],
[
"p.setHeight(-50)",
"This is an invalid height! -50\n"
],
[
"p.getHeight()",
"_____no_output_____"
],
[
"p.setHeight(\"cat\")",
"_____no_output_____"
],
[
"p.getHeight()",
"_____no_output_____"
]
],
[
[
"# Exercise\n\n## Exercise 1\n\nBelow is the completed `GuessGame` class from the previous lesson. Add documentation to this class.",
"_____no_output_____"
]
],
[
[
"class GuessGame:\n \"\"\"\n This class provides a simple guessing game. You create an object\n of the class with its own secret, with the aim that a user\n then needs to try to guess what the secret is.\n \"\"\"\n def __init__(self, secret, max_guesses=5):\n \"\"\"Create a new guess game\n \n secret -- the secret that must be guessed\n max_guesses -- the maximum number of guesses allowed by the user\n \"\"\"\n self._secret = secret\n self._nguesses = 0\n self._max_guesses = max_guesses\n \n def guess(self, value):\n \"\"\"Try to guess the secret. This will print out to the screen whether\n or not the secret has been guessed.\n \n value -- the user-supplied guess\n \"\"\"\n if (self.nGuesses() >= self.maxGuesses()):\n print(\"Sorry, you have run out of guesses\")\n elif (value == self._secret):\n print(\"Well done - you have guessed my secret\")\n else:\n self._nguesses += 1\n print(\"Try again...\")\n \n def nGuesses(self):\n \"\"\"Return the number of incorrect guesses made so far\"\"\"\n return self._nguesses\n \n def maxGuesses(self):\n \"\"\"Return the maximum number of incorrect guesses allowed\"\"\"\n return self._max_guesses",
"_____no_output_____"
],
[
"help(GuessGame)",
"Help on class GuessGame in module __main__:\n\nclass GuessGame(builtins.object)\n | This class provides a simple guessing game. You create an object\n | of the class with its own secret, with the aim that a user\n | then needs to try to guess what the secret is.\n | \n | Methods defined here:\n | \n | __init__(self, secret, max_guesses=5)\n | Create a new guess game\n | \n | secret -- the secret that must be guessed\n | max_guesses -- the maximum number of guesses allowed by the user\n | \n | guess(self, value)\n | Try to guess the secret. This will print out to the screen whether\n | or not the secret has been guessed.\n | \n | value -- the user-supplied guess\n | \n | maxGuesses(self)\n | Return the maximum number of incorrect guesses allowed\n | \n | nGuesses(self)\n | Return the number of incorrect guesses made so far\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | __dict__\n | dictionary for instance variables (if defined)\n | \n | __weakref__\n | list of weak references to the object (if defined)\n\n"
]
],
[
[
"## Exercise 2\n\nBelow is a poorly-written class that uses public member data to store the name and age of a Person. Edit this class so that the member data is made private. Add `get` and `set` functions that allow you to safely get and set the name and age.",
"_____no_output_____"
]
],
[
[
"class Person:\n \"\"\"Class the represents a Person, holding their name and age\"\"\"\n def __init__(self, name=\"unknown\", age=0):\n \"\"\"Construct a person with unknown name and an age of 0\"\"\"\n self.setName(name)\n self.setAge(age)\n \n def setName(self, name):\n \"\"\"Set the person's name to 'name'\"\"\"\n self._name = str(name) # str ensures the name is a string\n \n def getName(self):\n \"\"\"Return the person's name\"\"\"\n return self._name\n \n def setAge(self, age):\n \"\"\"Set the person's age. This must be a number between 0 and 130\"\"\"\n if (age < 0 or age > 130):\n print(\"Cannot set the age to an invalid value: %s\" % age)\n \n self._age = age\n \n def getAge(self):\n \"\"\"Return the person's age\"\"\"\n return self._age",
"_____no_output_____"
],
[
"p = Person(name=\"Peter Parker\", age=21)",
"_____no_output_____"
],
[
"p.getName()",
"_____no_output_____"
],
[
"p.getAge()",
"_____no_output_____"
]
],
[
[
"## Exercise 3\n\nAdd a private member function called `_splitName` to your `Person` class that breaks the name into a surname and first name. Add new functions called `getFirstName` and `getSurname` that use this function to return the first name and surname of the person.",
"_____no_output_____"
]
],
[
[
"class Person:\n \"\"\"Class the represents a Person, holding their name and age\"\"\"\n def __init__(self, name=\"unknown\", age=0):\n \"\"\"Construct a person with unknown name and an age of 0\"\"\"\n self.setName(name)\n self.setAge(age)\n \n def setName(self, name):\n \"\"\"Set the person's name to 'name'\"\"\"\n self._name = str(name) # str ensures the name is a string\n \n def getName(self):\n \"\"\"Return the person's name\"\"\"\n return self._name\n \n def setAge(self, age):\n \"\"\"Set the person's age. This must be a number between 0 and 130\"\"\"\n if (age < 0 or age > 130):\n print(\"Cannot set the age to an invalid value: %s\" % age)\n \n self._age = age\n \n def getAge(self):\n \"\"\"Return the person's age\"\"\"\n return self._age\n \n def _splitName(self):\n \"\"\"Private function that splits the name into parts\"\"\"\n return self._name.split(\" \")\n \n def getFirstName(self):\n \"\"\"Return the first name of the person\"\"\"\n return self._splitName()[0]\n \n def getSurname(self):\n \"\"\"Return the surname of the person\"\"\"\n return self._splitName()[-1]",
"_____no_output_____"
],
[
"p = Person(name=\"Peter Parker\", age=21)",
"_____no_output_____"
],
[
"p.getFirstName()",
"_____no_output_____"
],
[
"p.getSurname()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d007316e368062b9c3a3479d0281de295d785ea8
| 702 |
ipynb
|
Jupyter Notebook
|
lecture/Lesson 05/Untitled.ipynb
|
shaheen19/Adv_Py_Scripting_for_GIS_Course
|
d5e3109c47b55d10a7b8c90e5eac837f659af200
|
[
"Apache-2.0"
] | 7 |
2020-01-22T14:22:57.000Z
|
2021-12-22T11:33:40.000Z
|
lecture/Lesson 05/Untitled.ipynb
|
achapkowski/Adv_Py_Scripting_for_GIS_Course
|
d5e3109c47b55d10a7b8c90e5eac837f659af200
|
[
"Apache-2.0"
] | null | null | null |
lecture/Lesson 05/Untitled.ipynb
|
achapkowski/Adv_Py_Scripting_for_GIS_Course
|
d5e3109c47b55d10a7b8c90e5eac837f659af200
|
[
"Apache-2.0"
] | 2 |
2020-04-22T11:33:01.000Z
|
2021-01-04T21:16:04.000Z
| 16.325581 | 34 | 0.498575 |
[
[
[
"# Lesson 05 \n\n## Time Enabled Data\n\n",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
d0073f5be7c29d38349a8b0c0f78236e4b3d1895
| 1,618 |
ipynb
|
Jupyter Notebook
|
notebooks/extract_blocks.ipynb
|
naveen-chalasani/natural-language-processing-and-anomaly-detection
|
6c6ea44f1966f7abe37c452d84dd24cffd572e1e
|
[
"MIT"
] | 2 |
2021-12-03T11:00:21.000Z
|
2022-02-22T03:12:16.000Z
|
notebooks/extract_blocks.ipynb
|
naveen-chalasani/natural-language-processing-and-anomaly-detection
|
6c6ea44f1966f7abe37c452d84dd24cffd572e1e
|
[
"MIT"
] | null | null | null |
notebooks/extract_blocks.ipynb
|
naveen-chalasani/natural-language-processing-and-anomaly-detection
|
6c6ea44f1966f7abe37c452d84dd24cffd572e1e
|
[
"MIT"
] | null | null | null | 19.493976 | 88 | 0.504326 |
[
[
[
"import re\nimport pandas as pd\nfrom collections import OrderedDict",
"_____no_output_____"
],
[
"block_info = OrderedDict()\nindex = 1\n\nwith open(\"HDFS_2k.log\") as infile:\n for line in infile:\n block_ids_in_row = re.findall(r'(blk_-?\\d+)', line)\n block_info[index] = block_ids_in_row[0]\n index += 1\n",
"_____no_output_____"
],
[
"block_info[1]",
"_____no_output_____"
],
[
"df = pd.DataFrame.from_dict(block_info, orient = 'index', columns=['block_id'])\ndf.to_csv(\"blocks.csv\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
d00741055dc800ea60b86da8dd05cb6e0b604bae
| 1,023,042 |
ipynb
|
Jupyter Notebook
|
ECE365/genomics/Genomics_Lab4/ECE365-Genomics-Lab4-Spring21.ipynb
|
debugevent90901/courseArchive
|
1585c9a0f4a1884c143973dcdf416514eb30aded
|
[
"MIT"
] | null | null | null |
ECE365/genomics/Genomics_Lab4/ECE365-Genomics-Lab4-Spring21.ipynb
|
debugevent90901/courseArchive
|
1585c9a0f4a1884c143973dcdf416514eb30aded
|
[
"MIT"
] | null | null | null |
ECE365/genomics/Genomics_Lab4/ECE365-Genomics-Lab4-Spring21.ipynb
|
debugevent90901/courseArchive
|
1585c9a0f4a1884c143973dcdf416514eb30aded
|
[
"MIT"
] | null | null | null | 1,344.339028 | 602,447 | 0.711366 |
[
[
[
"# Lab 4: EM Algorithm and Single-Cell RNA-seq Data",
"_____no_output_____"
],
[
"### Name: Your Name Here (Your netid here)",
"_____no_output_____"
],
[
"### Due April 2, 2021 11:59 PM",
"_____no_output_____"
],
[
"#### Preamble (Don't change this)",
"_____no_output_____"
],
[
"## Important Instructions - \n\n1. Please implement all the *graded functions* in main.py file. Do not change function names in main.py.\n2. Please read the description of every graded function very carefully. The description clearly states what is the expectation of each graded function. \n3. After some graded functions, there is a cell which you can run and see if the expected output matches the output you are getting. \n4. The expected output provided is just a way for you to assess the correctness of your code. The code will be tested on several other cases as well.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"%run main.py",
"_____no_output_____"
],
[
"module = Lab4()",
"_____no_output_____"
]
],
[
[
"## Part 1 : Expectation-Maximization (EM) algorithm for transcript quantification",
"_____no_output_____"
],
[
"## Introduction\n\nThe EM algorithm is a very helpful tool to compute maximum likelihood estimates of parameters in models that have some latent (hidden) variables.\nIn the case of the transcript quantification problem, the model parameters we want to estimate are the transcript relative abundances $\\rho_1,...,\\rho_K$.\nThe latent variables are the read-to-transcript indicator variables $Z_{ik}$, which indicate whether the $i$th read comes from the $k$th transcript (in which case $Z_{ik}=1$.\n\nIn this part of the lab, you will be given the read alignment data.\nFor each read and transcript pair, it tells you whether the read can be mapped (i.e., aligned) to that transcript.\nUsing the EM algorithm, you will estimate the relative abundances of the trascripts.\n",
"_____no_output_____"
],
[
"### Reading read transcript data - We have 30000 reads and 30 transcripts",
"_____no_output_____"
]
],
[
[
"n_reads=30000\nn_transcripts=30\nread_mapping=[]\nwith open(\"read_mapping_data.txt\",'r') as file :\n lines_reads=file.readlines()\nfor line in lines_reads :\n read_mapping.append([int(x) for x in line.split(\",\")])",
"_____no_output_____"
],
[
"read_mapping[:10]",
"_____no_output_____"
]
],
[
[
"Rather than giving you a giant binary matrix, we encoded the read mapping data in a more concise way. read_mapping is a list of lists. The $i$th list contains the indices of the transcripts that the $i$th read maps to.",
"_____no_output_____"
],
[
"### Reading true abundances and transcript lengths",
"_____no_output_____"
]
],
[
[
"with open(\"transcript_true_abundances.txt\",'r') as file :\n lines_gt=file.readlines()\nground_truth=[float(x) for x in lines_gt[0].split(\",\")]\n\nwith open(\"transcript_lengths.txt\",'r') as file :\n lines_gt=file.readlines()\ntr_lengths=[float(x) for x in lines_gt[0].split(\",\")]",
"_____no_output_____"
],
[
"ground_truth[:5]",
"_____no_output_____"
],
[
"tr_lengths[:5]",
"_____no_output_____"
]
],
[
[
"## Graded Function 1 : expectation_maximization (10 marks) \n\nPurpose : To implement the EM algorithm to obtain abundance estimates for each transcript.\n\nE-step : In this step, we calculate the fraction of read that is assigned to each transcript (i.e., the estimate of $Z_{ik}$). For read $i$ and transicript $k$, this is calculated by dividing the current abundance estimate of transcript $k$ by the sum of abundance estimates of all transcripts that read $i$ maps to.\n\nM-step : In this step, we update the abundance estimate of each transcript based on the fraction of all reads that is currently assigned to the transcript. First we compute the average fraction of all reads assigned to the transcript. Then, (if transcripts are of different lengths) we divide the result by the transcript length.\nFinally, we normalize all abundance estimates so that they add up to 1.\n\nInputs - read_mapping (which is a list of lists where each sublist contains the transcripts to which a particular read belongs to. The length of this list is equal to the number of reads, i.e. 30000; tr_lengths (a list containing the length of the 30 transcripts, in order); n_iterations (the number of EM iterations to be performed)\n\nOutput - a list of lists where each sublist contains the abundance estimates for a transcript across all iterations. The length of each sublist should be equal to the number of iterations plus one (for the initialization) and the total number of sublists should be equal to the number of transcripts.",
"_____no_output_____"
]
],
[
[
"history=module.expectation_maximization(read_mapping,tr_lengths,20)\nprint(len(history))\nprint(len(history[0]))\nprint(history[0][-5:])\nprint(history[1][-5:])\nprint(history[2][-5:])",
"30\n21\n[0.033769639494636614, 0.03381298624783303, 0.03384568373972949, 0.0338703482393148, 0.03388895326082054]\n[0.0020082674603036053, 0.0019649207071071456, 0.0019322232152109925, 0.0019075587156241912, 0.0018889536941198502]\n[0.0660581789629968, 0.06606927656035864, 0.0660765012689558, 0.06608120466668756, 0.0660842666518177]\n"
]
],
[
[
"## Expected Output - \n\n30\n\n21\n\n[0.033769639494636614, 0.03381298624783303, 0.03384568373972948, 0.0338703482393148, 0.03388895326082054]\n\n[0.0020082674603036053, 0.0019649207071071456, 0.0019322232152109925, 0.0019075587156241912, 0.0018889536941198502]\n\n[0.0660581789629968, 0.06606927656035864, 0.06607650126895578, 0.06608120466668756, 0.0660842666518177]\n",
"_____no_output_____"
],
[
"You can use the following function to visualize how the estimated relative abundances are converging with the number of iterations of the algorithm.",
"_____no_output_____"
]
],
[
[
"def visualize_em(history,n_iterations) :\n #start code here\n fig, ax = plt.subplots(figsize=(8,6))\n for j in range(n_transcripts): \n ax.plot([i for i in range(n_iterations+1)],[history[j][i] - ground_truth[j] for i in range(n_iterations+1)],marker='o')\n #end code here",
"_____no_output_____"
],
[
"visualize_em(history,20)",
"_____no_output_____"
]
],
[
[
"## Part 2 : Exploring Single-Cell RNA-seq data",
"_____no_output_____"
],
[
"In a study published in 2015, Zeisel et al. used single-cell RNA-seq data to explore the cell diversity in the mouse brain. \nWe will explore the data used for their study.\nYou can read more about it [here](https://science.sciencemag.org/content/347/6226/1138).",
"_____no_output_____"
]
],
[
[
"#reading single-cell RNA-seq data\nlines_genes=[]\nwith open(\"Zeisel_expr.txt\",'r') as file :\n lines_genes=file.readlines()",
"_____no_output_____"
],
[
"lines_genes[0][:300]",
"_____no_output_____"
]
],
[
[
"Each line in the file Zeisel_expr.txt corresponds to one gene.\nThe columns correspond to different cells (notice that this is the opposite of how we looked at this matrix in class).\nThe entries of this matrix correspond to the number of reads mapping to a given gene in the corresponding cell.",
"_____no_output_____"
]
],
[
[
"# reading true labels for each cell\nwith open(\"Zeisel_labels.txt\",'r') as file :\n true_labels = file.read().splitlines()",
"_____no_output_____"
]
],
[
[
"The study also provides us with true labels for each of the cells.\nFor each of the cells, the vector true_labels contains the name of the cell type.\nThere are nine different cell types in this dataset.",
"_____no_output_____"
]
],
[
[
"set(true_labels)",
"_____no_output_____"
]
],
[
[
"## Graded Function 2 : prepare_data (10 marks) :\n\nPurpose - To create a dataframe where each row corresponds to a specific cell and each column corresponds to the expressions levels of a particular gene across all cells. \nYou should name the columns as \"Gene_1\", \"Gene_2\", and so on.\n\nWe will iterate through all the lines in lines_genes list created above, add 1 to each value and take log.\n\nEach line will correspond to 1 column in the dataframe\n\nOutput - gene expression dataframe\n\n### Note - All the values in the output dataframe should be rounded off to 5 digits after the decimal",
"_____no_output_____"
]
],
[
[
"data_df=module.prepare_data(lines_genes)\nprint(data_df.shape)\nprint(data_df.iloc[0:3,:5])",
"(3005, 19972)\n Gene_0 Gene_1 Gene_2 Gene_3 Gene_4\n0 0.0 1.38629 1.38629 0.0 0.69315\n1 0.0 0.69315 0.69315 0.0 0.69315\n2 0.0 0.00000 1.94591 0.0 0.69315\n"
],
[
"print(data_df.columns)",
"Index(['Gene_0', 'Gene_1', 'Gene_2', 'Gene_3', 'Gene_4', 'Gene_5', 'Gene_6',\n 'Gene_7', 'Gene_8', 'Gene_9',\n ...\n 'Gene_19962', 'Gene_19963', 'Gene_19964', 'Gene_19965', 'Gene_19966',\n 'Gene_19967', 'Gene_19968', 'Gene_19969', 'Gene_19970', 'Gene_19971'],\n dtype='object', length=19972)\n"
]
],
[
[
"## Expected Output :\n\n``(3005, 19972)``\n\n`` Gene_0 Gene_1 Gene_2 Gene_3 Gene_4``\n \n``0 0.0 1.38629 1.38629 0.0 0.69315``\n\n``1 0.0 0.69315 0.69315 0.0 0.69315``\n\n``2 0.0 0.00000 1.94591 0.0 0.69315``",
"_____no_output_____"
],
[
"## Graded Function 3 : identify_less_expressive_genes (10 marks)\n\nPurpose : To identify genes (columns) that are expressed in less than 25 cells. We will create a list of all gene columns that have values greater than 0 for less than 25 cells.\n\nInput - gene expression dataframe\n\nOutput - list of column names which are expressed in less than 25 cells",
"_____no_output_____"
]
],
[
[
"drop_columns = module.identify_less_expressive_genes(data_df)\nprint(len(drop_columns))\nprint(drop_columns[:10])",
"5120\nIndex(['Gene_28', 'Gene_126', 'Gene_145', 'Gene_146', 'Gene_151', 'Gene_152',\n 'Gene_167', 'Gene_168', 'Gene_170', 'Gene_173'],\n dtype='object')\n"
]
],
[
[
"## Expected Output : \n\n``5120`` \n\n``['Gene_28', 'Gene_126', 'Gene_145', 'Gene_146', 'Gene_151', 'Gene_152', 'Gene_167', 'Gene_168', 'Gene_170', 'Gene_173']``",
"_____no_output_____"
],
[
"### Filtering less expressive genes\n\nWe will now create a new dataframe in which genes which are expressed in less than 25 cells will not be present",
"_____no_output_____"
]
],
[
[
"df_new = data_df.drop(drop_columns, axis=1)",
"_____no_output_____"
],
[
"df_new.head()",
"_____no_output_____"
]
],
[
[
"## Graded Function 4 : perform_pca (10 marks)\n\nPupose - Perform Principal Component Analysis on the new dataframe and take the top 50 principal components\n\nInput - df_new\n\nOutput - numpy array containing the top 50 principal components of the data.\n\n### Note - All the values in the output should be rounded off to 5 digits after the decimal\n\n### Note - Please use random_state=365 for the PCA object you will create",
"_____no_output_____"
]
],
[
[
"pca_data=module.perform_pca(df_new)\nprint(pca_data.shape)\nprint(type(pca_data))\nprint(pca_data[0:3,:5])",
"(3005, 50)\n<class 'numpy.ndarray'>\n[[26.97148 -2.7244 0.62163 25.90148 -6.24736]\n [26.49135 -1.58774 -4.79315 24.01094 -7.25618]\n [47.82664 5.06799 2.15177 30.24367 -3.38878]]\n"
]
],
[
[
"## Expected Output : \n\n``(3005, 50)``\n\n``<class 'numpy.ndarray'>``\n\n``[[26.97148 -2.7244 0.62163 25.90148 -6.24736]``\n\n`` [26.49135 -1.58774 -4.79315 24.01094 -7.25618]``\n \n`` [47.82664 5.06799 2.15177 30.24367 -3.38878]]``",
"_____no_output_____"
],
[
"## (Non-graded) Function 5 : perform_tsne\n\nPupose - Perform t-SNE on the pca_data and obtain 2 t-SNE components\n\nWe will use TSNE class of the sklearn.manifold package. Use random_state=1000 and perplexity=50\n\nDocumenation can be found here - https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html\n\nInput - pca_data\n\nOutput - numpy array containing the top 2 tsne components of the data.\n\n**Note: This function will not be graded because of the random nature of t-SNE.**",
"_____no_output_____"
]
],
[
[
"tsne_data50 = module.perform_tsne(pca_data)\nprint(tsne_data50.shape)\nprint(tsne_data50[:3,:])",
"(3005, 2)\n[[ 19.031317 -45.3434 ]\n [ 19.188553 -44.945473]\n [ 17.369982 -47.997364]]\n"
]
],
[
[
"## Expected Output :\n\n(These numbers can deviate a bit depending on your sklearn)\n\n``(3005, 2)``\n\n``[[ 15.069608 -47.535984]``\n\n`` [ 15.251476 -47.172073]``\n \n`` [ 13.3932 -49.909657]]``",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(12,8))\nsns.scatterplot(tsne_data50[:,0], tsne_data50[:,1], hue=true_labels)\nplt.show()",
"/usr/local/lib/python3.9/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n warnings.warn(\n"
]
],
[
[
"Notice that the different cell types form clusters (which can be easily visualized on the t-SNE space).\nZeisel et al. performed clustering on this data in order to identify and label the different cell types.\n\nYou can try using clustering methods (such as k-means and GMM) to cluster the single-cell RNA-seq data of Zeisel at al. and see if your results agree with theirs!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d007591ef701271b1c7fc0da5fa3ee77c30208d2
| 8,119 |
ipynb
|
Jupyter Notebook
|
Week 2/Week 2 Tasks.ipynb
|
jihoonkang0829/Codable_FA20
|
f68627520abe408d13878b8cf0419fc8e23f96b6
|
[
"MIT"
] | null | null | null |
Week 2/Week 2 Tasks.ipynb
|
jihoonkang0829/Codable_FA20
|
f68627520abe408d13878b8cf0419fc8e23f96b6
|
[
"MIT"
] | null | null | null |
Week 2/Week 2 Tasks.ipynb
|
jihoonkang0829/Codable_FA20
|
f68627520abe408d13878b8cf0419fc8e23f96b6
|
[
"MIT"
] | 1 |
2021-08-29T06:46:00.000Z
|
2021-08-29T06:46:00.000Z
| 29.310469 | 313 | 0.570883 |
[
[
[
"# Week 2 Tasks",
"_____no_output_____"
],
[
"During this week's meeting, we have discussed about if/else statements, Loops and Lists. This notebook file will guide you through reviewing the topics discussed and assisting you to be familiarized with the concepts discussed.",
"_____no_output_____"
],
[
"## Let's first create a list",
"_____no_output_____"
]
],
[
[
"# Create a list that stores the multiples of 5, from 0 to 50 (inclusive)\n# initialize the list using list comprehension!\n# Set the list name to be 'l'\n# TODO: Make the cell return 'True'\n# Hint: Do you remember that you can apply arithmetic operators in the list comprehension?\n\n# Your code goes below here\n\n\n\n# Do not modify below\nl == [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]",
"_____no_output_____"
]
],
[
[
"If you are eager to learn more about list comprehension, you can look up here -> https://www.programiz.com/python-programming/list-comprehension. You will find out how you can initialize `l` without using arithmetic operators, but using conditionals (if/else).\n\nNow, simply run the cell below, and observe how `l` has changed.",
"_____no_output_____"
]
],
[
[
"l[0] = 3\nprint(l)",
"_____no_output_____"
],
[
"l[5]",
"_____no_output_____"
]
],
[
[
"As seen above, you can overwrite each elements of the list.\n\nUsing this fact, complete the task written below.",
"_____no_output_____"
],
[
"## If/elif/else practice",
"_____no_output_____"
]
],
[
[
"# Write a for loop such that:\n# For each elements in the list l,\n# If the element is divisible by 6, divide the element by 6\n# Else if the element is divisible by 3, divide the element by 3 and then add 4\n# Else if the element is divisible by 2, subtract 10.\n# Else, square the element\n# TODO: Make the cell return 'True'\n\nl = [3, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]\n\n# Your code goes below here\n\n\n\n \n\n# Do not modify below\nl = [int(i) for i in l]\nl == [5, 25, 0, 9, 10, 625, 5, 1225, 30, 19, 40]",
"_____no_output_____"
]
],
[
[
"## Limitations of a ternary operator",
"_____no_output_____"
]
],
[
[
"# Write a for loop that counts the number of odd number elements in the list \n# and the number of even number elements in the list\n# These should be stored in the variables 'odd_count' and 'even_count', which are declared below.\n# Try to use the ternary operator inside the for loop and inspect why it does not work\n# TODO: Make the cell return 'True'\n\nl = [5, 25, 0, 9, 10, 625, 5, 1225, 30, 19, 40]\nodd_count, even_count = 0, 0\n\n# Your code goes below here\n\n\n \n \n \n \n \n# Do not modify below\nprint(\"There are 7 odd numbers in the list.\") if odd_count == 7 else print(\"Your odd_count is not correct.\")\nprint(\"There are 4 even numbers in the list.\") if even_count == 4 else print(\"Your even_count is not correct.\")\nprint(odd_count == 7 and even_count == 4 and odd_count + even_count == len(l))",
"_____no_output_____"
]
],
[
[
"If you have tried using the ternary operator in the cell above, you would have found that the cell fails to compile because of a syntax error. This is because you can only write *expressions* in ternary operators, specifically **the last segment of the three segments in the operator**, not *statements*.\n\nIn other words, since your code (which last part of it would have been something like `odd_count += 1` or `even_count += 1`) is a *statement*, the code is syntactically incorrect.\n\nTo learn more about *expressions* and *statements*, please refer to this webpage -> https://runestone.academy/runestone/books/published/thinkcspy/SimplePythonData/StatementsandExpressions.html\n\nThus, a code like `a += 1 if <CONDITION> else b += 1` is syntactically wrong as `b += 1` is a *statement*, and we cannot use the ternary operator to achieve something like this.\n\nIn fact, ternary operators are usually used like this: `a += 1 if <CONDITION> else 0`.\n\nThe code above behaves exactly the same as this: `if <CONDITION>: a += 1 else: a = 0`. \n\nDoes this give better understanding about why statements cannot be used in ternary operators? If not, feel free to do more research on your own, or open up a discussion during the next team meeting!\n",
"_____no_output_____"
],
[
"## While loop and boolean practice",
"_____no_output_____"
]
],
[
[
"# Write a while loop that finds an index of the element in 'l' which first exceeds 1000.\n# The index found should be stored in the variable 'large_index'\n# If there are no element in 'l' that exceeds 1000, 'large_index' must store -1\n# Use the declared 'large_not_found' as the condition for the while loop\n# Use the declared 'index' to iterate through 'l'\n# Do not use 'break'\n# TODO: Make the cell return 'True'\n\nl = [5, 25, 0, 9, 10, 625, 5, 1225, 30, 19, 1001]\n\n\nlarge_not_found = True\nindex = 0\nlarge_index = 0\n\n# Your code goes below here\n\n\n\n# Do not modify below\nprint(large_index == 7)",
"_____no_output_____"
]
],
[
[
"## Finding the minimum element",
"_____no_output_____"
]
],
[
[
"# For this task, you can use either for loop or while loop, depending on your preference\n# Find the smallest element in 'l' and store it in the declared variable 'min_value'\n# 'min_value' is initialized as a big number\n# Do not use min()\n# TODO: Make the cell return 'True'\n\nimport sys\nmin_value = sys.maxsize\nmin_index = 0\n# Your code goes below here\n\n \n\n\n# Do not modify below\nprint(min_value == 0)",
"_____no_output_____"
],
[
"import os\nos.getpid()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0075ca9e1223c88d75907cdc916dc1c1d2b49f6
| 13,987 |
ipynb
|
Jupyter Notebook
|
slurm-working-dir/SLURM-launcher.ipynb
|
aQaLeiden/QuantumDigitalCooling
|
5d19128750faca1eb62954789c5d939ec9acfadf
|
[
"Apache-2.0"
] | null | null | null |
slurm-working-dir/SLURM-launcher.ipynb
|
aQaLeiden/QuantumDigitalCooling
|
5d19128750faca1eb62954789c5d939ec9acfadf
|
[
"Apache-2.0"
] | null | null | null |
slurm-working-dir/SLURM-launcher.ipynb
|
aQaLeiden/QuantumDigitalCooling
|
5d19128750faca1eb62954789c5d939ec9acfadf
|
[
"Apache-2.0"
] | null | null | null | 26.641905 | 193 | 0.490455 |
[
[
[
"# launch scripts through SLURM \n\nThe script in the cell below submits SLURM jobs running the requested `script`, with all parameters specified in `param_iterators` and the folder where to dump data as last parameter. \n\nThe generated SBATCH scipts (`.job` files) are saved in the `jobs` folder and then submitted.\nOutput and error dumps are saved in the `out` folder.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport os\nfrom itertools import product\n\n\n#######################\n### User parameters ###\n#######################\n\nscript = \"TFIM-bangbang-WF.py\" # name of the script to be run\ndata_subdir = \"TFIM/bangbang/WF\" # subdirectory of ´data´ where to save results\njobname_template = \"BBWF-L{}JvB{}nit{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(16, 21), # L\n [0.2, 1, 5], # JvB\n [None], # nit\n [200] # n_samples\n)\n\ntime = \"4-00:00\" # format days-hh:mm\nmem = \"4GB\" # can use postfixes (MB, GB, ...)\npartition = \"compIntel\"\n\n# insert here additional lines that should be run before the script \n# (source bash scripts, load modules, activate environment, etc.) \nadditional_lines = [\n 'source ~/.bashrc\\n'\n]\n\n\n#####################################\n### Create folders, files and run ###\n#####################################\n\ncurrent_dir = os.getcwd()\nscript = os.path.join(*os.path.split(current_dir)[:-1], 'scripts', script)\ndata_supdir = os.path.join(*os.path.split(current_dir)[:-1], 'data')\ndata_dir = os.path.join(data_supdir, data_subdir)\njob_dir = 'jobs'\nout_dir = 'out'\n\nos.makedirs(job_dir, exist_ok=True)\nos.makedirs(out_dir, exist_ok=True)\nos.makedirs(data_dir, exist_ok=True)\n\nfor params in product(*param_iterators):\n \n # ******** for BangBang ********\n # redefine nit = L if it is None\n if params[2] is None:\n params = list(params)\n params[2] = params[0]\n # ****************************** \n \n job_name = jobname_template.format(*params)\n job_file = os.path.join(job_dir, job_name+'.job')\n \n with open(job_file, 'wt') as fh:\n fh.writelines(\n [\"#!/bin/bash\\n\",\n f\"#SBATCH --job-name={job_name}\\n\",\n f\"#SBATCH --output={os.path.join(out_dir, job_name+'.out')}\\n\",\n f\"#SBATCH --error={os.path.join(out_dir, job_name+'.err')}\\n\",\n f\"#SBATCH --time={time}\\n\",\n f\"#SBATCH --mem={mem}\\n\",\n f\"#SBATCH --partition={partition}\\n\",\n f\"#SBATCH --mail-type=NONE\\n\",\n ] + additional_lines + [\n f\"python -u {script} {' '.join(str(par) for par in params)} {data_dir}\\n\"]\n )\n\n os.system(\"sbatch %s\" %job_file)",
"_____no_output_____"
],
[
"complex(1).__sizeof__() * 2**(2*15) / 1E9",
"_____no_output_____"
]
],
[
[
"# History of parameters that have been run",
"_____no_output_____"
],
[
"## TFIM LogSweep",
"_____no_output_____"
],
[
"### density matrix ",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-DM.py\"\ndata_subdir = \"TFIM/logsweep/DM\"",
"_____no_output_____"
],
[
"param_iterators = (\n [2], # L\n [0.2, 1, 5], # JvB\n np.arange(2, 50) # K\n)",
"_____no_output_____"
],
[
"param_iterators = (\n [7], # L\n [0.2, 1, 5], # JvB\n np.arange(2, 50) # K\n)",
"_____no_output_____"
],
[
"param_iterators = (\n np.arange(2, 11), # L\n [0.2, 1, 5], # JvB\n [2, 5, 10, 20, 40] # K\n)",
"_____no_output_____"
]
],
[
[
"### Iterative, density matrix",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-DM-iterative.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/DM/iterative\" # subdirectory of ´data´ where to save results\njobname_template = \"ItLS-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n [2, 7], # L\n [0.2, 1, 5], # JvB\n np.arange(2, 50) # K\n)",
"_____no_output_____"
]
],
[
[
"### WF + Monte Carlo",
"_____no_output_____"
],
[
"#### old version of the script \nthe old version suffered from unnormalized final states due to numerical error",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-WF.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/WF-raw\" # subdirectory of ´data´ where to save results\njobname_template = \"WF-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2, 15), # L\n [0.2, 1, 5], # JvB\n [2, 3, 5, 10, 20, 40], # K\n [100] # n_samples\n)",
"_____no_output_____"
]
],
[
[
"#### new version of the script \nWhere normalization is forced",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-WF.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/WF\" # subdirectory of ´data´ where to save results\njobname_template = \"WF-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2, 10), # L\n [0.2, 1, 5], # JvB\n [2, 3, 5, 10], # K\n [100] # n_samples\n)\n\ntime = \"3-00:00\" # format days-hh:mm\nmem = \"1GB\" # can use postfixes (MB, GB, ...)\npartition = \"compIntel\"",
"_____no_output_____"
],
[
"script = \"TFIM-logsweep-WF.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/WF\" # subdirectory of ´data´ where to save results\njobname_template = \"WF-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(10, 14), # L\n [0.2, 1, 5], # JvB\n [2, 3, 5, 10], # K\n [100] # n_samples\n)\n\ntime = \"3-00:00\" # format days-hh:mm\nmem = \"20GB\" # can use postfixes (MB, GB, ...)\npartition = \"compIntel\"",
"_____no_output_____"
]
],
[
[
"### iterative, WF + Monte Carlo",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-WF-iterative.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/WF/iterative\" # subdirectory of ´data´ where to save results\njobname_template = \"WFiter-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2, 14), # L\n [0.2, 1, 5], # JvB\n [5, 10], # K\n [100] # n_samples\n)\n\ntime = \"3-00:00\" # format days-hh:mm\nmem = \"20GB\" # can use postfixes (MB, GB, ...)\npartition = \"ibIntel\"",
"_____no_output_____"
]
],
[
[
"### continuous DM",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-continuous-DM.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/continuous/DM\" # subdirectory of ´data´ where to save results\njobname_template = \"Rh-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2,7), # L\n [0.2, 1, 5], # JvB\n [2, 3, 5, 10, 20, 40] # K\n)",
"_____no_output_____"
],
[
"param_iterators = (\n [7], # L\n [0.2, 1, 5], # JvB\n np.arange(2, 50) # K\n)",
"_____no_output_____"
],
[
"param_iterators = (\n np.arange(8, 15), # L\n [0.2, 1, 5], # JvB\n [2,3,5,10,20,40] # K\n)",
"_____no_output_____"
]
],
[
[
"### continuous WF",
"_____no_output_____"
]
],
[
[
"script = \"TFIM-logsweep-continuous-WF.py\" # name of the script to be run\ndata_subdir = \"TFIM/logsweep/continuous/WF\" # subdirectory of ´data´ where to save results\njobname_template = \"CWF-L{}JvB{}K{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2, 12), # L\n [0.2, 1, 5], # JvB\n [2, 3, 5, 10, 20, 40], # K\n [100] # n_samples\n)\n\ntime = \"3-00:00\" # format days-hh:mm\nmem = \"1GB\" # can use postfixes (MB, GB, ...)\npartition = \"ibIntel\"",
"_____no_output_____"
],
[
"param_iterators = (\n [13, 14], # L\n [0.2, 1, 5], # JvB\n [2, 10], # K\n [100] # n_samples\n)\n\ntime = \"3-00:00\" # format days-hh:mm\nmem = \"100GB\" # can use postfixes (MB, GB, ...)\npartition = \"ibIntel\"",
"_____no_output_____"
]
],
[
[
"## TFIM bang-bang ",
"_____no_output_____"
]
],
[
[
"data_subdir = \"TFIM/bangbang/WF\" # subdirectory of ´data´ where to save results\njobname_template = \"BBWF-L{}JvB{}nit{}\" # job name will be created from this, inserting parameter values\n\nparam_iterators = (\n np.arange(2, 21), # L\n [0.2, 1, 5], # JvB\n [None], # nit\n [200] # n_samples\n)\n\ntime = \"4-00:00\" # format days-hh:mm\nmem = \"4GB\" # can use postfixes (MB, GB, ...)\npartition = \"compIntel\"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d00766559dfc1abf4dcc87f71b4177b52d3c3f60
| 108,086 |
ipynb
|
Jupyter Notebook
|
module1-define-ml-problems/Unit_2_Sprint_3_Module_1_LESSON.ipynb
|
Vanagand/DS-Unit-2-Applied-Modeling
|
386ac08648f3a96f4bf8291a139fd929aaa67d05
|
[
"MIT"
] | null | null | null |
module1-define-ml-problems/Unit_2_Sprint_3_Module_1_LESSON.ipynb
|
Vanagand/DS-Unit-2-Applied-Modeling
|
386ac08648f3a96f4bf8291a139fd929aaa67d05
|
[
"MIT"
] | null | null | null |
module1-define-ml-problems/Unit_2_Sprint_3_Module_1_LESSON.ipynb
|
Vanagand/DS-Unit-2-Applied-Modeling
|
386ac08648f3a96f4bf8291a139fd929aaa67d05
|
[
"MIT"
] | null | null | null | 48.490803 | 14,878 | 0.553337 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Vanagand/DS-Unit-2-Applied-Modeling/blob/master/module1-define-ml-problems/Unit_2_Sprint_3_Module_1_LESSON.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"\nLambda School Data Science\n\n*Unit 2, Sprint 3, Module 1*\n\n---\n\n",
"_____no_output_____"
],
[
"# Define ML problems\n- Choose a target to predict, and check its distribution\n- Avoid leakage of information from test to train or from target to features\n- Choose an appropriate evaluation metric\n",
"_____no_output_____"
],
[
"### Setup\n",
"_____no_output_____"
]
],
[
[
"%%capture\nimport sys\n\n# If you're on Colab:\nif 'google.colab' in sys.modules:\n DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Applied-Modeling/master/data/'\n !pip install category_encoders==2.*\n\n# If you're working locally:\nelse:\n DATA_PATH = '../data/'",
"_____no_output_____"
]
],
[
[
"# Choose a target to predict, and check its distribution",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"This is the data science process at a high level:\n\n<img src=\"https://image.slidesharecdn.com/becomingadatascientistadvice-pydatadc-shared-161012184823/95/becoming-a-data-scientist-advice-from-my-podcast-guests-55-638.jpg?cb=1476298295\">\n\n—Renee Teate, [Becoming a Data Scientist, PyData DC 2016 Talk](https://www.becomingadatascientist.com/2016/10/11/pydata-dc-2016-talk/)",
"_____no_output_____"
],
[
"We've focused on the 2nd arrow in the diagram, by training predictive models. Now let's zoom out and focus on the 1st arrow: defining problems, by translating business questions into code/data questions.",
"_____no_output_____"
],
[
"Last sprint, you did a Kaggle Challenge. It’s a great way to practice model validation and other technical skills. But that's just part of the modeling process. [Kaggle gets critiqued](https://speakerdeck.com/szilard/machine-learning-software-in-practice-quo-vadis-invited-talk-kdd-conference-applied-data-science-track-august-2017-halifax-canada?slide=119) because some things are done for you: Like [**defining the problem!**](https://www.linkedin.com/pulse/data-science-taught-universities-here-why-maciej-wasiak/) In today’s module, you’ll begin to practice this objective, with your dataset you’ve chosen for your personal portfolio project.\n\nWhen defining a supervised machine learning problem, one of the first steps is choosing a target to predict.",
"_____no_output_____"
],
[
"Which column in your tabular dataset will you predict?\n\nIs your problem regression or classification? You have options. Sometimes it’s not straightforward, as we'll see below.\n\n- Discrete, ordinal, low cardinality target: Can be regression or multi-class classification.\n- (In)equality comparison: Converts regression or multi-class classification to binary classification.\n- Predicted probability: Seems to [blur](https://brohrer.github.io/five_questions_data_science_answers.html) the line between classification and regression.",
"_____no_output_____"
],
[
"## Follow Along",
"_____no_output_____"
],
[
"Let's reuse the [Burrito reviews dataset.](https://nbviewer.jupyter.org/github/LambdaSchool/DS-Unit-2-Linear-Models/blob/master/module4-logistic-regression/LS_DS_214_assignment.ipynb) 🌯\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\npd.options.display.max_columns = None\ndf = pd.read_csv(DATA_PATH+'burritos/burritos.csv')",
"_____no_output_____"
]
],
[
[
"### Choose your target \n\nWhich column in your tabular dataset will you predict?\n",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
],
[
"df['overall'].describe()\n\n",
"_____no_output_____"
],
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nsns.distplot(df['overall'])",
"_____no_output_____"
],
[
"df['Great'] = df['overall'] >= 4\n",
"_____no_output_____"
],
[
"df['Great']",
"_____no_output_____"
]
],
[
[
"### How is your target distributed?\n\nFor a classification problem, determine: How many classes? Are the classes imbalanced?",
"_____no_output_____"
]
],
[
[
"y = df['Great']\ny.unique()",
"_____no_output_____"
],
[
"y.value_counts(normalize=True)",
"_____no_output_____"
],
[
"sns.countplot(y)",
"_____no_output_____"
],
[
"y.value_counts(normalize=True).plot(kind=\"bar\")\n\n",
"_____no_output_____"
],
[
"# Stretch: how to fix imbalanced classes\n#. upsampling: randomly re-sample from the minority class to increase the sample in the minority class\n#. downsampling: random re-sampling from the majority class to decrease the sample in the majority class\n\n# Why does it matter if we have imbalanced classes?\n# 1:1000 tested positive:tested negative\n# 99.99% accuracy\n# ",
"_____no_output_____"
]
],
[
[
"# Avoid leakage of information from test to train or from target to features",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"Overfitting is our enemy in applied machine learning, and leakage is often the cause.\n\n> Make sure your training features do not contain data from the “future” (aka time traveling). While this might be easy and obvious in some cases, it can get tricky. … If your test metric becomes really good all of the sudden, ask yourself what you might be doing wrong. Chances are you are time travelling or overfitting in some way. — [Xavier Amatriain](https://www.quora.com/What-are-some-best-practices-for-training-machine-learning-models/answer/Xavier-Amatriain)\n\nChoose train, validate, and test sets. Are some observations outliers? Will you exclude them? Will you do a random split or a time-based split? You can (re)read [How (and why) to create a good validation set](https://www.fast.ai/2017/11/13/validation-sets/).",
"_____no_output_____"
],
[
"## Follow Along",
"_____no_output_____"
],
[
"First, begin to **explore and clean your data.**",
"_____no_output_____"
]
],
[
[
"df['Burrito'].nunique()",
"_____no_output_____"
],
[
"df['Burrito'].unique()",
"_____no_output_____"
],
[
"# Combine Burrito categories\ndf['Burrito_rename'] = df['Burrito'].str.lower()\n\n# All burrito types that contain 'California' are grouped into the same\n#. category. Similar logic applied to asada, surf, and carnitas.\n\n# 'California Surf and Turf'\ncalifornia = df['Burrito'].str.contains('california')\nasada = df['Burrito'].str.contains('asada')\nsurf = df['Burrito'].str.contains('surf')\ncarnitas = df['Burrito'].str.contains('carnitas')\n\ndf.loc[california, 'Burrito_rename'] = 'California'\ndf.loc[asada, 'Burrito_rename'] = 'Asada'\ndf.loc[surf, 'Burrito_rename'] = 'Surf & Turf'\ndf.loc[carnitas, 'Burrito_rename'] = 'Carnitas'\n\n# If the burrito is not captured in one of the above categories, it is put in the \n# 'Other' category.\ndf.loc[~california & ~asada & ~surf & ~carnitas, 'Burrito_rename'] = 'Other'\n\ndf[['Burrito', 'Burrito_rename']]",
"_____no_output_____"
],
[
"df = df.drop(columns=['Notes', 'Location', 'Reviewer', 'Address', 'URL', 'Neighborhood'])",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 423 entries, 0 to 422\nData columns (total 61 columns):\nBurrito 423 non-null object\nDate 423 non-null object\nYelp 87 non-null float64\nGoogle 87 non-null float64\nChips 26 non-null object\nCost 416 non-null float64\nHunger 420 non-null float64\nMass (g) 22 non-null float64\nDensity (g/mL) 22 non-null float64\nLength 284 non-null float64\nCircum 282 non-null float64\nVolume 282 non-null float64\nTortilla 423 non-null float64\nTemp 403 non-null float64\nMeat 409 non-null float64\nFillings 420 non-null float64\nMeat:filling 414 non-null float64\nUniformity 421 non-null float64\nSalsa 398 non-null float64\nSynergy 421 non-null float64\nWrap 420 non-null float64\noverall 421 non-null float64\nRec 233 non-null object\nUnreliable 33 non-null object\nNonSD 7 non-null object\nBeef 180 non-null object\nPico 159 non-null object\nGuac 155 non-null object\nCheese 160 non-null object\nFries 128 non-null object\nSour cream 92 non-null object\nPork 51 non-null object\nChicken 21 non-null object\nShrimp 21 non-null object\nFish 6 non-null object\nRice 36 non-null object\nBeans 35 non-null object\nLettuce 11 non-null object\nTomato 7 non-null object\nBell peper 7 non-null object\nCarrots 1 non-null object\nCabbage 8 non-null object\nSauce 38 non-null object\nSalsa.1 7 non-null object\nCilantro 15 non-null object\nOnion 17 non-null object\nTaquito 4 non-null object\nPineapple 7 non-null object\nHam 2 non-null object\nChile relleno 4 non-null object\nNopales 4 non-null object\nLobster 1 non-null object\nQueso 0 non-null float64\nEgg 5 non-null object\nMushroom 3 non-null object\nBacon 3 non-null object\nSushi 2 non-null object\nAvocado 13 non-null object\nCorn 3 non-null object\nZucchini 1 non-null object\nGreat 423 non-null bool\ndtypes: bool(1), float64(20), object(40)\nmemory usage: 198.8+ KB\n"
],
[
"df.isna().sum().sort_values()",
"_____no_output_____"
],
[
"df = df.fillna('Missing')\n",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 423 entries, 0 to 422\nData columns (total 61 columns):\nBurrito 423 non-null object\nDate 423 non-null object\nYelp 423 non-null object\nGoogle 423 non-null object\nChips 423 non-null object\nCost 423 non-null object\nHunger 423 non-null object\nMass (g) 423 non-null object\nDensity (g/mL) 423 non-null object\nLength 423 non-null object\nCircum 423 non-null object\nVolume 423 non-null object\nTortilla 423 non-null float64\nTemp 423 non-null object\nMeat 423 non-null object\nFillings 423 non-null object\nMeat:filling 423 non-null object\nUniformity 423 non-null object\nSalsa 423 non-null object\nSynergy 423 non-null object\nWrap 423 non-null object\noverall 423 non-null object\nRec 423 non-null object\nUnreliable 423 non-null object\nNonSD 423 non-null object\nBeef 423 non-null object\nPico 423 non-null object\nGuac 423 non-null object\nCheese 423 non-null object\nFries 423 non-null object\nSour cream 423 non-null object\nPork 423 non-null object\nChicken 423 non-null object\nShrimp 423 non-null object\nFish 423 non-null object\nRice 423 non-null object\nBeans 423 non-null object\nLettuce 423 non-null object\nTomato 423 non-null object\nBell peper 423 non-null object\nCarrots 423 non-null object\nCabbage 423 non-null object\nSauce 423 non-null object\nSalsa.1 423 non-null object\nCilantro 423 non-null object\nOnion 423 non-null object\nTaquito 423 non-null object\nPineapple 423 non-null object\nHam 423 non-null object\nChile relleno 423 non-null object\nNopales 423 non-null object\nLobster 423 non-null object\nQueso 423 non-null object\nEgg 423 non-null object\nMushroom 423 non-null object\nBacon 423 non-null object\nSushi 423 non-null object\nAvocado 423 non-null object\nCorn 423 non-null object\nZucchini 423 non-null object\nGreat 423 non-null bool\ndtypes: bool(1), float64(1), object(59)\nmemory usage: 198.8+ KB\n"
]
],
[
[
"Next, do a **time-based split:**\n\n- Train on reviews from 2016 & earlier. \n- Validate on 2017. \n- Test on 2018 & later.",
"_____no_output_____"
]
],
[
[
"df['Date'] = pd.to_datetime(df['Date'])\n",
"_____no_output_____"
],
[
"# create a subset of data for anything less than or equal to the year 2016, equal\n#. to 2017 for validation, and test set to include >= 2018\ntrain = df[df['Date'].dt.year <= 2016]\nval = df[df['Date'].dt.year == 2017]\ntest = df[df['Date'].dt.year >= 2018]\n",
"_____no_output_____"
],
[
"train.shape, val.shape, test.shape",
"_____no_output_____"
]
],
[
[
"Begin to choose which features, if any, to exclude. **Would some features “leak” future information?**\n\nWhat happens if we _DON’T_ drop features with leakage?",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"# Try a shallow decision tree as a fast, first model\n\nimport category_encoders as ce\nfrom sklearn.pipeline import make_pipeline\nfrom sklearn.tree import DecisionTreeClassifier\n\ntarget = 'Great'\nfeatures = train.columns.drop([target, 'Date', 'Data'])\nX_train = train[features]\ny_train = train[target]\nX_val = val[features]\ny_val = val[target]\n\npipeline = make_pipeline(\n ce.OrdinalEncoder(), \n DecisionTreeClassifier()\n)\n\npipeline.fit(X_train, y_train)\nprint('Validation Accuracy', pipeline.score(X_val, y_val))",
"_____no_output_____"
]
],
[
[
"Drop the column with “leakage”.",
"_____no_output_____"
]
],
[
[
"target = 'Great'\nfeatures = train.columns.drop([target, 'Date', 'Data', 'overall'])\nX_train = train[features]\ny_train = train[target]\nX_val = val[features]\ny_val = val[target]\n\npipeline = make_pipeline(\n ce.OrdinalEncoder(), \n DecisionTreeClassifier()\n)\n\npipeline.fit(X_train, y_train)\nprint('Validation Accuracy', pipeline.score(X_val, y_val))",
"_____no_output_____"
]
],
[
[
"# Choose an appropriate evaluation metric",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"How will you evaluate success for your predictive model? You must choose an appropriate evaluation metric, depending on the context and constraints of your problem.\n\n**Classification & regression metrics are different!**\n\n- Don’t use _regression_ metrics to evaluate _classification_ tasks.\n- Don’t use _classification_ metrics to evaluate _regression_ tasks.\n\n[Scikit-learn has lists of popular metrics.](https://scikit-learn.org/stable/modules/model_evaluation.html#common-cases-predefined-values)",
"_____no_output_____"
],
[
"## Follow Along",
"_____no_output_____"
],
[
"For classification problems: \n\nAs a rough rule of thumb, if your majority class frequency is >= 50% and < 70% then you can just use accuracy if you want. Outside that range, accuracy could be misleading — so what evaluation metric will you choose, in addition to or instead of accuracy? For example:\n\n- Precision?\n- Recall?\n- ROC AUC?\n",
"_____no_output_____"
]
],
[
[
"# 1:3 -> 25%, 75% \n\ny.value_counts(normalize=True)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"### Precision & Recall\n\nLet's review Precision & Recall. What do these metrics mean, in scenarios like these?\n\n- Predict great burritos\n- Predict fraudulent transactions\n- Recommend Spotify songs\n\n[Are false positives or false negatives more costly? Can you optimize for dollars?](https://alexgude.com/blog/machine-learning-metrics-interview/)",
"_____no_output_____"
]
],
[
[
"# High precision -> few false positives.\n# High recall -> few false negatives.\n\n# In lay terms, how would we translate our problem with burritos:\n#. high precision- 'Great burrito'. If we make a prediction of a great burrito,\n#. it probably IS a great burrito.\n\n# Which metric would you emphasize if you were choosing a burrito place to take your first date to?\n#. Precision.\n\n# Which metric would -> feeling adventurous?\n# . Recall.\n\n# Predict Fraud:\n\n# True negative: normal transaction\n# True positive: we caught fraud!\n# False Positive: normal transaction that is blocked -> annoyed customer! (low precision)\n# False Negative: fraudulent transaction that was allowed -> lost money (low recall)\n\n\n\n",
"_____no_output_____"
]
],
[
[
"### ROC AUC \n\nLet's also review ROC AUC (Receiver Operating Characteristic, Area Under the Curve).\n\n[Wikipedia explains,](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) \"A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. **The ROC curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings.**\"\n\nROC AUC is the area under the ROC curve. [It can be interpreted](https://stats.stackexchange.com/questions/132777/what-does-auc-stand-for-and-what-is-it) as \"the expectation that a uniformly drawn random positive is ranked before a uniformly drawn random negative.\" \n\nROC AUC measures **how well a classifier ranks predicted probabilities.** So, when you get your classifier’s ROC AUC score, you need to **use predicted probabilities, not discrete predictions.**\n\nROC AUC ranges **from 0 to 1.** Higher is better. A naive majority class **baseline** will have an ROC AUC score of **0.5**, regardless of class (im)balance.\n\n#### Scikit-Learn docs\n- [User Guide: Receiver operating characteristic (ROC)](https://scikit-learn.org/stable/modules/model_evaluation.html#receiver-operating-characteristic-roc)\n- [sklearn.metrics.roc_curve](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html)\n- [sklearn.metrics.roc_auc_score](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html)\n\n#### More links\n- [StatQuest video](https://youtu.be/4jRBRDbJemM)\n- [Data School article / video](https://www.dataschool.io/roc-curves-and-auc-explained/)\n- [The philosophical argument for using ROC curves](https://lukeoakdenrayner.wordpress.com/2018/01/07/the-philosophical-argument-for-using-roc-curves/)\n",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import roc_auc_score\ny_pred_proba = pipeline.predict_proba(X_val)[:, -1]\nroc_auc_score(y_val, y_pred_proba)",
"_____no_output_____"
],
[
"from sklearn.metrics import roc_curve\nfpr, tpr, thresholds = roc_curve(y_val, y_pred_proba)\n(fpr, tpr, thresholds)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nplt.scatter(fpr, tpr)\nplt.plot(fpr, tpr)\nplt.title('ROC curve')\nplt.xlabel('False Positive Rate')\nplt.ylabel('True Positive Rate')",
"_____no_output_____"
]
],
[
[
"### Imbalanced classes\n\nDo you have highly imbalanced classes?\n\nIf so, you can try ideas from [Learning from Imbalanced Classes](https://www.svds.com/tbt-learning-imbalanced-classes/):\n\n- “Adjust the class weight (misclassification costs)” — most scikit-learn classifiers have a `class_balance` parameter.\n- “Adjust the decision threshold” — we did this last module. Read [Visualizing Machine Learning Thresholds to Make Better Business Decisions](https://blog.insightdatascience.com/visualizing-machine-learning-thresholds-to-make-better-business-decisions-4ab07f823415).\n- “Oversample the minority class, undersample the majority class, or synthesize new minority classes” — try the the [imbalanced-learn](https://github.com/scikit-learn-contrib/imbalanced-learn) library as a stretch goal.",
"_____no_output_____"
],
[
"# BONUS: Regression example 🏘️\n",
"_____no_output_____"
]
],
[
[
"# Read our NYC apartment rental listing dataset\ndf = pd.read_csv(DATA_PATH+'apartments/renthop-nyc.csv')",
"_____no_output_____"
]
],
[
[
"### Choose your target\n\nWhich column in your tabular dataset will you predict?\n",
"_____no_output_____"
]
],
[
[
"y = df['price']",
"_____no_output_____"
]
],
[
[
"### How is your target distributed?\n\nFor a regression problem, determine: Is the target right-skewed?\n",
"_____no_output_____"
]
],
[
[
"# Yes, the target is right-skewed\nimport seaborn as sns\nsns.distplot(y);",
"_____no_output_____"
],
[
"y.describe()",
"_____no_output_____"
]
],
[
[
"### Are some observations outliers? \n\nWill you exclude\nthem?\n",
"_____no_output_____"
]
],
[
[
"# Yes! There are outliers\n# Some prices are so high or low it doesn't really make sense.\n# Some locations aren't even in New York City\n\n# Remove the most extreme 1% prices, \n# the most extreme .1% latitudes, &\n# the most extreme .1% longitudes\nimport numpy as np\ndf = df[(df['price'] >= np.percentile(df['price'], 0.5)) & \n (df['price'] <= np.percentile(df['price'], 99.5)) & \n (df['latitude'] >= np.percentile(df['latitude'], 0.05)) & \n (df['latitude'] < np.percentile(df['latitude'], 99.95)) &\n (df['longitude'] >= np.percentile(df['longitude'], 0.05)) & \n (df['longitude'] <= np.percentile(df['longitude'], 99.95))]",
"_____no_output_____"
],
[
"# The distribution has improved, but is still right-skewed\ny = df['price']\nsns.distplot(y);",
"_____no_output_____"
],
[
"y.describe()",
"_____no_output_____"
]
],
[
[
"### Log-Transform\n\nIf the target is right-skewed, you may want to “log transform” the target.\n\n\n> Transforming the target variable (using the mathematical log function) into a tighter, more uniform space makes life easier for any [regression] model.\n>\n> The only problem is that, while easy to execute, understanding why taking the log of the target variable works and how it affects the training/testing process is intellectually challenging. You can skip this section for now, if you like, but just remember that this technique exists and check back here if needed in the future.\n>\n> Optimally, the distribution of prices would be a narrow “bell curve” distribution without a tail. This would make predictions based upon average prices more accurate. We need a mathematical operation that transforms the widely-distributed target prices into a new space. The “price in dollars space” has a long right tail because of outliers and we want to squeeze that space into a new space that is normally distributed. More specifically, we need to shrink large values a lot and smaller values a little. That magic operation is called the logarithm or log for short. \n>\n> To make actual predictions, we have to take the exp of model predictions to get prices in dollars instead of log dollars. \n>\n>— Terence Parr & Jeremy Howard, [The Mechanics of Machine Learning, Chapter 5.5](https://mlbook.explained.ai/prep.html#logtarget)\n\n[Numpy has exponents and logarithms](https://docs.scipy.org/doc/numpy/reference/routines.math.html#exponents-and-logarithms). Your Python code could look like this:\n\n```python\nimport numpy as np\ny_train_log = np.log1p(y_train)\nmodel.fit(X_train, y_train_log)\ny_pred_log = model.predict(X_val)\ny_pred = np.expm1(y_pred_log)\nprint(mean_absolute_error(y_val, y_pred))\n```",
"_____no_output_____"
]
],
[
[
"import numpy as np\ny_log = np.log1p(y)\nsns.distplot(y_log)",
"_____no_output_____"
],
[
"sns.distplot(y)\nplt.title('Original target, in the unit of US dollars');",
"_____no_output_____"
],
[
"y_log = np.log1p(y)\nsns.distplot(y_log)\nplt.title('Log-transformed target, in log-dollars');",
"_____no_output_____"
],
[
"y_untransformed = np.expm1(y_log)\nsns.distplot(y_untransformed)\nplt.title('Back to the original units');",
"_____no_output_____"
]
],
[
[
"## Challenge\n\nYou will use your portfolio project dataset for all assignments this sprint. (If you haven't found a dataset yet, do that today. [Review requirements for your portfolio project](https://lambdaschool.github.io/ds/unit2) and choose your dataset.)\n\nComplete these tasks for your project, and document your decisions.\n\n- Choose your target. Which column in your tabular dataset will you predict?\n- Is your problem regression or classification?\n- How is your target distributed?\n - Classification: How many classes? Are the classes imbalanced?\n - Regression: Is the target right-skewed? If so, you may want to log transform the target.\n- Choose your evaluation metric(s).\n - Classification: Is your majority class frequency >= 50% and < 70% ? If so, you can just use accuracy if you want. Outside that range, accuracy could be misleading. What evaluation metric will you choose, in addition to or instead of accuracy?\n - Regression: Will you use mean absolute error, root mean squared error, R^2, or other regression metrics?\n- Choose which observations you will use to train, validate, and test your model.\n - Are some observations outliers? Will you exclude them?\n - Will you do a random split or a time-based split?\n- Begin to clean and explore your data.\n- Begin to choose which features, if any, to exclude. Would some features \"leak\" future information?\n\nSome students worry, ***what if my model isn't “good”?*** Then, [produce a detailed tribute to your wrongness. That is science!](https://twitter.com/nathanwpyle/status/1176860147223867393)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0076c2b0c480bad47b84d9651401b8cb1757eb3
| 9,685 |
ipynb
|
Jupyter Notebook
|
boards/ZCU111/rfsoc_sam/notebooks/voila_rfsoc_spectrum_analyzer.ipynb
|
dnorthcote/rfsoc_sam
|
1b22f5204f545b8f6a13b2f0f585c9d8c6c40d52
|
[
"BSD-3-Clause"
] | 39 |
2020-02-22T00:40:51.000Z
|
2022-03-30T00:39:45.000Z
|
boards/ZCU111/rfsoc_sam/notebooks/voila_rfsoc_spectrum_analyzer.ipynb
|
dnorthcote/rfsoc_sam
|
1b22f5204f545b8f6a13b2f0f585c9d8c6c40d52
|
[
"BSD-3-Clause"
] | 7 |
2021-01-19T18:46:19.000Z
|
2022-03-10T10:25:43.000Z
|
boards/ZCU111/rfsoc_sam/notebooks/voila_rfsoc_spectrum_analyzer.ipynb
|
dnorthcote/rfsoc_sam
|
1b22f5204f545b8f6a13b2f0f585c9d8c6c40d52
|
[
"BSD-3-Clause"
] | 19 |
2020-02-25T10:42:51.000Z
|
2021-12-15T06:40:41.000Z
| 31.343042 | 561 | 0.586267 |
[
[
[
"<img src=\"images/strathsdr_banner.png\" align=\"left\">",
"_____no_output_____"
],
[
"# An RFSoC Spectrum Analyzer Dashboard with Voila\n----\n\n<div class=\"alert alert-box alert-info\">\nPlease use Jupyter Labs http://board_ip_address/lab for this notebook.\n</div>\n\nThe RFSoC Spectrum Analyzer is an open source tool developed by the [University of Strathclyde](https://github.com/strath-sdr/rfsoc_sam). This notebook is specifically for Voila dashboards. If you would like to see an overview of the Spectrum Analyser, see this [notebook](rfsoc_spectrum_analysis.ipynb) instead.\n\n## Table of Contents\n* [Introduction](#introduction)\n* [Running this Demonstration](#running-this-demonstration)\n* [The Voila Procedure](#the-voila-procedure)\n * [Import Libraries](#import-libraries)\n * [Initialise Overlay](#initialise-overlay)\n * [Dashboard Display](#dashboard-display)\n* [Conclusion](#conclusion)\n\n## References\n* [Xilinx, Inc, \"USP RF Data Converter: LogiCORE IP Product Guide\", PG269, v2.3, June 2020](https://www.xilinx.com/support/documentation/ip_documentation/usp_rf_data_converter/v2_3/pg269-rf-data-converter.pdf)\n\n## Revision History\n* **v1.0** | 16/02/2021 | Voila spectrum analyzer demonstration\n* **v1.1** | 22/10/2021 | Voila update notes in 'running this demonstration' section\n\n## Introduction <a class=\"anchor\" id=\"introduction\"></a>\nYou ZCU111 platform and XM500 development board is capable of quad-channel spectral analysis. The RFSoC Spectrum Analyser Module (rfsoc-sam) enables hardware accelerated analysis of signals received from the RF Analogue-to-Digital Converters (RF ADCs). This notebook is specifically for running the Spectrum Analyser using Voila dashboards. Follow the instructions outlined in [Running this Demonstration](#running-this-demonstration) to learn more.\n\n### Hardware Setup <a class=\"anchor\" id=\"hardware-setup\"></a>\nYour ZCU111 development board can host four Spectrum Analyzer Modules. To setup your board for this demonstration, you can connect each channel in loopback as shown in [Figure 1](#fig-1), or connect an antenna to one of the ADC channels.\n\nDon't worry if you don't have an antenna. The default loopback configuration will still be very interesting and is connected as follows:\n* Channel 0: DAC4 (Tile 229 Block 0) to ADC0 (Tile 224 Block 0)\n* Channel 1: DAC5 (Tile 229 Block 1) to ADC1 (Tile 224 Block 1)\n* Channel 2: DAC6 (Tile 229 Block 2) to ADC2 (Tile 225 Block 0)\n* Channel 3: DAC7 (Tile 229 Block 3) to ADC3 (Tile 225 Block 1)\n\nThere has been several XM500 board revisions, and some contain different silkscreen and labels for the ADCs and DACs. Use the image below for further guidance and pay attention to the associated Tile and Block.\n\n<a class=\"anchor\" id=\"fig-1\"></a>\n<figure>\n<img src='images/zcu111_setup.png' height='50%' width='50%'/>\n <figcaption><b>Figure 1: ZCU111 and XM500 development board setup in loopback mode.</b></figcaption>\n</figure>\n\nIf you have chosen to use an antenna, **do not** attach your antenna to any SMA interfaces labelled DAC.\n\n<div class=\"alert alert-box alert-danger\">\n<b>Caution:</b>\n In this demonstration, we generate tones using the RFSoC development board. Your device should be setup in loopback mode. You should understand that the RFSoC platform can also transmit RF signals wirelessly. Remember that unlicensed wireless transmission of RF signals may be illegal in your geographical location. Radio signals may also interfere with nearby devices, such as pacemakers and emergency radio equipment. Note that it is also illegal to intercept and decode particular RF signals. If you are unsure, please seek professional support.\n</div>\n\n----\n\n## Running this Demonstration <a class=\"anchor\" id=\"running-this-demonstration\"></a>\nVoila can be used to execute the Spectrum Analyzer Module, while ignoring all of the markdown and code cells typically found in a normal Jupyter notebook. The Voila dashboard can be launched following the instructions below:\n\n* Click on the \"Open with Voila Gridstack in a new browser tab\" button at the top of the screen:\n\n<figure>\n<img src='images/open_voila.png' height='50%' width='50%'/>\n</figure>\n\nAfter the new tab opens the kernel will start and the notebook will run. Only the Spectrum Analyzer will be displayed. The initialisation process takes around 1 minute.\n\n## The Voila Procedure <a class=\"anchor\" id=\"the-voila-procedure\"></a>\nBelow are the code cells that will be ran when Voila is called. The procedure is fairly straight forward. Load the rfsoc-sam library, initialise the overlay, and display the spectrum analyzer. All you have to ensure is that the above command is executed in the terminal and you have launched a browser tab using the given address. You do not need to run these code cells individually to create the voila dashboard.\n\n### Import Libraries",
"_____no_output_____"
]
],
[
[
"from rfsoc_sam.overlay import Overlay",
"_____no_output_____"
]
],
[
[
"### Initialise Overlay",
"_____no_output_____"
]
],
[
[
"sam = Overlay(init_rf_clks = True)",
"_____no_output_____"
]
],
[
[
"### Dashboard Display",
"_____no_output_____"
]
],
[
[
"sam.spectrum_analyzer_application()",
"_____no_output_____"
]
],
[
[
"## Conclusion\nThis notebook has presented a hardware accelerated Spectrum Analyzer Module for the ZCU111 development board. The demonstration used Voila to enable rapid dashboarding for visualisation and control.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0077e24f0c874bff46f8ed4181b4ba9e225fd38
| 307,367 |
ipynb
|
Jupyter Notebook
|
Task/Week 3 Visualization/Week 3 Day 3.ipynb
|
mazharrasyad/Data-Science-SanberCode
|
3a6a770d5d0f4453b76cae0c4c9b642f7abed24c
|
[
"MIT"
] | 3 |
2021-05-26T19:07:32.000Z
|
2021-06-25T03:42:18.000Z
|
Task/Week 3 Visualization/Week 3 Day 3.ipynb
|
mazharrasyad/Data-Science-SanberCode
|
3a6a770d5d0f4453b76cae0c4c9b642f7abed24c
|
[
"MIT"
] | null | null | null |
Task/Week 3 Visualization/Week 3 Day 3.ipynb
|
mazharrasyad/Data-Science-SanberCode
|
3a6a770d5d0f4453b76cae0c4c9b642f7abed24c
|
[
"MIT"
] | null | null | null | 2,458.936 | 250,048 | 0.965198 |
[
[
[
"import matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"<h2>No 1 : Multiple Subplots</h2>\n\nDengan data di bawah ini buatlah visualisasi seperti expected output :",
"_____no_output_____"
]
],
[
[
"x = np.linspace(2*-np.pi, 2*np.pi, 200)\ntan = np.tan(x)/10\ncos = np.cos(x)\nsin = np.sin(x)",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"<h2>No 2 : Nested Axis</h2>\n\nDengan data di bawah ini, buatlah visualisasi seperti expected output :",
"_____no_output_____"
]
],
[
[
"x = np.linspace(2*-np.pi, 2*np.pi, 100)\ny = np.cos(x)\ny2 = np.cos(x**2)\ny3 = np.cos(x**3)\ny4 = np.cos(x**4)\ny5 = np.cos(x**5)",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d00797710b505ac5f918a0be79803260f72e8ef6
| 264,847 |
ipynb
|
Jupyter Notebook
|
docs/Examples - I.ipynb
|
ryanaloomis/eddy
|
bd65a6df43ee12e5df49bdd84d798470089a1d63
|
[
"MIT"
] | null | null | null |
docs/Examples - I.ipynb
|
ryanaloomis/eddy
|
bd65a6df43ee12e5df49bdd84d798470089a1d63
|
[
"MIT"
] | null | null | null |
docs/Examples - I.ipynb
|
ryanaloomis/eddy
|
bd65a6df43ee12e5df49bdd84d798470089a1d63
|
[
"MIT"
] | null | null | null | 618.801402 | 47,992 | 0.936337 |
[
[
[
"# Examples I - Inferring $v_{\\rm rot}$ By Minimizing the Line Width\n\nThis Notebook intends to demonstrate the method used in [Teague et al. (2018a)](https://ui.adsabs.harvard.edu/#abs/2018ApJ...860L..12T) to infer the rotation velocity as a function of radius in the disk of HD 163296. The following [Notebook](Examples%20-%20II.ipynb) demonstrates the updated method presented in Teague et al. (2018b) which relaxes many of the assumptions used in this Notebook.\n\n## Methodology\n\nFor this method to work we make the assumption that the disk is azimuthally symmetric (note that this does not mean that the emission we observe in symmetric, but only that the underlying disk structure is). Therefore, if we were to observe the line profile at different azimuthal angles for a given radius, they should all have the same shape. What will be different is the line centre due to the line-of-sight component of the rotation,\n\n$$v_0 = v_{\\rm LSR} + v_{\\rm rot} \\cdot \\cos \\theta$$ \n\nwhere $i$ is the inclination of the disk, $\\theta$ is the azimuthal angle measured from the red-shifted major axis and $v_{\\rm LSR}$ is the systemic velocity. Note that this azimuthal angle is not the same as position angle and must be calculated accounting for the 3D structure of the disk.\n\nIt has already been shown by assuming a rotation velocity, for example from fitting a first moment map, each spectrum can be shifted back to the systemic velocity and then stacked in azimuth to boost the signal-to-noise of these lines (see [Yen et al. (2016)](https://ui.adsabs.harvard.edu/#abs/2016ApJ...832..204Y) for a thorough discussion on this and [Teague et al. (2016)](https://ui.adsabs.harvard.edu/#abs/2016A&A...592A..49T) and [Matrà et al. (2017)](https://ui.adsabs.harvard.edu/#abs/2017ApJ...842....9M) for applications of this).\n\n---\n\n\n\nIn the above image, the left hand plot shows the typical Keplerian rotation pattern, taking into account a flared emission surface. Dotted lines show contours of constant azimuthal angle $\\theta$ and radius $r$. Three spectra, shown on the right in black, are extracted at the dot locations. By shifting the velocity axis of each of this by $-v_{\\rm rot} \\cdot \\cos \\theta$ they are aligned along the systemic velocity, $v_{\\rm LSR}$, and able to be stacked (shown in gray).\n\n---\n\nHowever, this only works correctly if we know the rotation velocity. If an incorrect velocity is used to deproject the spectra then the line centres will be scattered around the systemic velocity. When these lines are stacked, the resulting profile will be broader with a smaller amplitude. We can therefore assert that the correct velocity used to derproject the spectra is the one which _minimises the width of the stacked line profile_. One could make a similar argument about the line peak, however with noisy data this is a less strict constraint as this relies on one channel (the one containing the line peak) rather than the entire line profile ([Yen et al. (2018)](www.google.com), who use a similar method, use the signal-to-noise of the stacked line weighted by a Gaussian fit as their quality of fit measure).\n\n## Python Implementation\n\nThis approach is relatively simple to code up with Python. We consider the case of very high signal-to-noise data, however it also works well with low signal-to-noise data, as we describe below. All the functions are part of the `eddy.ensemble` class which will be discussed in more detail below.\n\nWe start with an annulus of spectra which we have extracted from our data, along with their azimuthal angles and the velocity axis of the observations. We can generate model spectra through the `eddy.modelling` functions. We model an annulus of 20 spectra with a peak brightness temperature of 40K, a linewidth of 350m/s and and RMS noise of 2K. What's returned is an `ensemble` instance which containts all the deprojecting functions.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom eddy.annulus import ensemble\nfrom eddy.modelling import gaussian_ensemble",
"_____no_output_____"
],
[
"annulus = gaussian_ensemble(vrot=1500., Tb=40., dV=350., rms=2.0, N=20, plot=True, return_ensemble=True)",
"_____no_output_____"
]
],
[
[
"We first want to shift all the points to the systemic velocity (here at 0m/s). To do this we use the `deproject_spectra()` function which takes the rotation as its only argument. It returns the new velocity of each pixel in the annulus and it's value. Lets first deproject with the correct rotation velocity of 1500m/s to check we recover the intrinsic line profile.",
"_____no_output_____"
]
],
[
[
"velocity, brightness = annulus.deprojected_spectra(1500.)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nfig, ax = plt.subplots()\nax.errorbar(velocity, brightness, fmt='.k', ms=4)\nax.set_xlim(velocity[0], velocity[-1])\nax.set_xlabel(r'Velocity')\nax.set_ylabel(r'Intensity')",
"_____no_output_____"
]
],
[
[
"This highlights which this method can achieve such a high precision on determinations of the rotation velocity. Because we shift back all the spectra by a non-quantised amount, we end up sampling the intrinsic profile at a much higher rate (by a factor of the number of beams we have in our annulus).\n\nWe can compare this with the spectrum which is resampled backed down to the original velocity resolution using the `deprojected_spectrum()` functions.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nvelocity, brightness = annulus.deprojected_spectrum(1500.)\nax.errorbar(velocity, brightness, fmt='.k', ms=4)\nax.set_xlim(velocity[0], velocity[-1])\nax.set_xlabel(r'Velocity')\nax.set_ylabel(r'Intensity')",
"_____no_output_____"
]
],
[
[
"Now, if we projected the spectra with the incorrect velocity, we can see that the stacked spectrum becomes broader. Note also that this is symmetric about the correct velocity meaning this is a convex problem making minimization much easier.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nfig, ax = plt.subplots()\n\nfor vrot in np.arange(1100, 2100, 200):\n velocity, brightness = annulus.deprojected_spectrum(vrot)\n ax.plot(velocity, brightness, label='%d m/s' % vrot)\n ax.legend(markerfirst=False)\n ax.set_xlim(-1000, 1000)\n ax.set_xlabel(r'Velocity')\n ax.set_ylabel(r'Intensity')",
"_____no_output_____"
]
],
[
[
"We can measure the width of the stacked lines by fitting a Gaussian using the `get_deprojected_width()` function.",
"_____no_output_____"
]
],
[
[
"vrots = np.linspace(1300, 1700, 150)\nwidths = np.array([annulus.get_deprojected_width(vrot) for vrot in vrots])\n\nfig, ax = plt.subplots()\nax.plot(vrots, widths, label='Deprojected Widths')\nax.axvline(1500., ls=':', color='k', label='Truth')\nax.set_xlabel(r'Rotation Velocity (m/s)')\nax.set_ylabel(r'Width of Stacked Line (m/s)')\nax.legend(markerfirst=False)",
"_____no_output_____"
]
],
[
[
"This shows that if we find the rotation velocity which minimizes the width of the stacked line we should have a pretty good idea of the rotation velocity is. The `get_vrot_dV()` function packges this all up, using the `bounded` method to search for the minimum width within a range of 0.7 to 1.3 times an initial guess. This guess can be provided (for instance if you have an idea of what the Keplerian rotation should be), otherwise it will try to guess it from the spectra based on the peaks of the spectra which are most shifted.",
"_____no_output_____"
]
],
[
[
"vfit = annulus.get_vrot_dV()\n\nprint(\"The linewidth is minimized for a rotation velocity of %.1f m/s\" % vfit)",
"The linewidth is minimized for a rotation velocity of 1502.1 m/s\n"
]
],
[
[
"The power of this method is also that the fitting is performed on the stacked spectrum meaning that in the noisy regions at the edges of the disk we stack over so many independent beams that we still get a reasonable line profile to fit.\n\nLets try with a signal-to-noise ratio of 4.",
"_____no_output_____"
]
],
[
[
"annulus = gaussian_ensemble(vrot=1500., Tb=40., dV=350., rms=10.0, N=20, plot=True, return_ensemble=True)\n\nfig, ax = plt.subplots()\nvelocity, brightness = annulus.deprojected_spectrum(1500.)\nax.step(velocity, brightness, color='k', where='mid', label='Shifted')\nax.legend(markerfirst=False)\nax.set_xlim(velocity[0], velocity[-1])\nax.set_xlabel(r'Velocity')\nax.set_ylabel(r'Intensity')\n\nvfit = annulus.get_vrot_dV()\nprint(\"The linewidth is minimized for a rotation velocity of %.1f m/s\" % vfit)",
"The linewidth is minimized for a rotation velocity of 1491.9 m/s\n"
]
],
[
[
"The final advtange of this method is that it is exceptionally quick. The convex nature of the problem means that a minimum width is readily found and so it can be applied very quickly, even with a large number of spectra. With 200 indiviudal beams:",
"_____no_output_____"
]
],
[
[
"annulus = gaussian_ensemble(vrot=1500., Tb=40., dV=350., rms=10.0, N=200, plot=True, return_ensemble=True)",
"_____no_output_____"
],
[
"%timeit annulus.get_vrot_dV()",
"10 loops, best of 3: 102 ms per loop\n"
]
],
[
[
"This method, however, does not provide a good measure of the uncertainty on the inferred rotation velocity. Furthermore, it makes the implicit assumption that the intrinsic line profile is Gaussian which for optically thick lines is not the case. In the next [Notebook](Examples%20-%20II.ipynb) we use Gaussian Processes to model the stacked line profile and search for the smoothest model.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d007ba8e0c34cc3cee955a135b927142e98d59c0
| 13,668 |
ipynb
|
Jupyter Notebook
|
Fred API.ipynb
|
Anandkarthick/API_Stuff
|
e4338545e184880009b1ad8b12728926e0f8b602
|
[
"MIT"
] | null | null | null |
Fred API.ipynb
|
Anandkarthick/API_Stuff
|
e4338545e184880009b1ad8b12728926e0f8b602
|
[
"MIT"
] | null | null | null |
Fred API.ipynb
|
Anandkarthick/API_Stuff
|
e4338545e184880009b1ad8b12728926e0f8b602
|
[
"MIT"
] | null | null | null | 31.56582 | 209 | 0.514779 |
[
[
[
"## Data Extraction and load from FRED API.. ",
"_____no_output_____"
]
],
[
[
"## Import packages for the process... \n\nimport requests\nimport pickle\nimport os\nimport mysql.connector\nimport time",
"_____no_output_____"
]
],
[
[
"### Using pickle to wrap the database credentials and Fred API keys ",
"_____no_output_____"
]
],
[
[
"if not os.path.exists('fred_api_secret.pk1'):\n fred_key = {}\n fred_key['api_key'] = ''\n with open ('fred_api_secret.pk1','wb') as f:\n pickle.dump(fred_key,f)\nelse:\n fred_key=pickle.load(open('fred_api_secret.pk1','rb'))",
"_____no_output_____"
],
[
"if not os.path.exists('fred_sql.pk1'):\n fred_sql = {}\n fred_sql['user'] = ''\n fred_sql['password'] = ''\n fred_sql['database'] = ''\n with open ('fred_sql.pk1','wb') as f:\n pickle.dump(fred_sql,f)\nelse:\n fred_sql=pickle.load(open('fred_sql.pk1','rb'))",
"_____no_output_____"
]
],
[
[
"#### testing database connection.\n\nWe have a lookup table containing the FRED series along with the value. Let's export the connection parameters and test the connection by running a select query against the lookup table. \n",
"_____no_output_____"
]
],
[
[
"cn = mysql.connector.connect(user=fred_sql['user'], password=fred_sql['password'],\n host='127.0.0.1',\n database=fred_sql['database'])\ncursor = cn.cursor()\n\nquery = (\"SELECT frd_cd,frd_val FROM frd_lkp\")\ncursor.execute(query)\n\nfor (frd_cd,frd_val) in cursor:\n sr_list.append(frd_cd)\n print(frd_cd +' - '+ frd_val)\n\ncn.close()",
"UMCSENT - University of Michigan Consumer Sentiment Index\nGDPC1 - Real Gross Domestic Product\nUNRATE - US Civilian Unemployment Rate\n"
]
],
[
[
"## Helper functions.. \n\nWe are doing this exercise with minimal modelling. Hence, just one target table to store the observations for all series. \n\nLet's create few helper functions to make this process easier. \n\n db_max_count - We are adding surrogate key to the table to make general querying operations and loads easier. COALESCE is used, to get a valid value from the database. \n\n db_srs_count - Since we are using just one target table, we are adding the series name as part of the data. this function will help us with the count for each series present in the table. \n\n fred_req - Helper function that sends the request to FRED API and returns the response back.. \n",
"_____no_output_____"
]
],
[
[
"def db_max_count():\n cn = mysql.connector.connect(user=fred_sql['user'], password=fred_sql['password'],\n host='127.0.0.1',\n database=fred_sql['database'])\n cursor = cn.cursor()\n dbquery = (\"SELECT COALESCE(max(idfrd_srs),0) FROM frd_srs_data\")\n cursor.execute(dbquery)\n \n for ct in cursor:\n if ct is not None:\n return ct[0]\n cn.close()",
"_____no_output_____"
],
[
"def db_srs_count():\n cn = mysql.connector.connect(user=fred_sql['user'], password=fred_sql['password'],\n host='127.0.0.1',\n database=fred_sql['database'])\n cursor = cn.cursor()\n dbquery = (\"SELECT frd_srs, count(*) FROM frd_srs_data group by frd_srs\")\n cursor.execute(dbquery)\n \n for ct in cursor:\n print(ct)\n cn.close()",
"_____no_output_____"
],
[
"def fred_req(series):\n time.sleep(10)\n response = requests.get('https://api.stlouisfed.org/fred/series/observations?series_id='+series+'&api_key='+fred_key['api_key']+'&file_type=json')\n result = response.json()\n return result",
"_____no_output_____"
]
],
[
[
"## Main functions.. \n\nWe are creating main functions to support the process. Here are the steps \n\n 1) Get the data from FRED API. (helper function created above)\n 2) Validate and transform the observations data from API.\n 3) Create tuples according to the table structure. \n 4) Load the tuples into the relational database\n \nfred_data for Step 2 & Step 3. Function dbload for Step 4. ",
"_____no_output_____"
]
],
[
[
"def dbload(tuple_list):\n try:\n \n cn = mysql.connector.connect(user=fred_sql['user'], password=fred_sql['password'],\n host='127.0.0.1',\n database=fred_sql['database'])\n cursor = cn.cursor()\n\n insert_query = (\"INSERT INTO frd_srs_data\"\n \"(idfrd_srs,frd_srs,frd_srs_val_dt,frd_srs_val,frd_srs_val_yr,frd_srs_val_mth,frd_srs_val_dy,frd_srs_strt_dt,frd_srs_end_dt)\"\n \"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)\")\n\n print(\"*** Database Connection Initialized, buckle up the seat belts..\")\n \n # Data load.. \n for i in range(len(tuple_list)):\n data_val=tuple_list[i]\n cursor.execute(insert_query, data_val)\n\n cn.commit()\n \n ## Intended timeout before starting the next interation of load.. \n time.sleep(5)\n \n \n print(\"\\n *** Data load successful.. \")\n db_srs_count()\n \n # Closing database connection... \n cn.close\n except mysql.connector.Error as err:\n cn.close\n print(\"Something went wrong: {}\".format(err))",
"_____no_output_____"
],
[
"def fred_data(series):\n print(\"\\n\")\n print(\"** Getting data for the series: \" + series)\n \n counter=db_max_count()\n # Calling function to get the data from FRED API for the series.\n fred_result = fred_req(series)\n \n print(\"** Number of observations extracted -\" '{:d}'.format(fred_result['count']))\n \n # transforming observations and preparing for data load.\n print(\"** Preparing data for load for series -\",series)\n temp_lst = fred_result['observations']\n tlist = []\n\n # from the incoming data, let's create tuple of values for data load. \n for val in range(len(temp_lst)):\n temp_dict = temp_lst[val]\n for key,val in temp_dict.items():\n if key=='date':\n dt_lst = val.split(\"-\")\n yr = dt_lst[0]\n mth = dt_lst[1]\n dtt = dt_lst[2]\n if key=='value':\n if len(val.strip())>1:\n out_val = val\n else:\n out_val = 0.00\n counter+=1\n tup = (counter,series,temp_dict['date'],out_val,yr,mth,dtt,temp_dict['realtime_start'],temp_dict['realtime_end'])\n tlist.append(tup)\n print(\"** Data is ready for the load.. Loading \" '{:d}'.format(len(tlist)))\n dbload(tlist)",
"_____no_output_____"
]
],
[
[
"### Starting point... \n\nSo, we have all functions created based on few assumptions (that data is all good with very minimal or no issues). ",
"_____no_output_____"
]
],
[
[
"sr_list = ['UMCSENT', 'GDPC1', 'UNRATE']\n\nfor series in sr_list:\n fred_data(series)",
"\n\n** Getting data for the series: UMCSENT\n** Number of observations extracted -574\n** Preparing data for load for series - UMCSENT\n** Data is ready for the load.. Loading 574\n*** Database Connection Initialized, buckle up the seat belts..\n\n *** Data load successful.. \n('UMCSENT', 574)\n\n\n** Getting data for the series: GDPC1\n** Number of observations extracted -284\n** Preparing data for load for series - GDPC1\n** Data is ready for the load.. Loading 284\n*** Database Connection Initialized, buckle up the seat belts..\n\n *** Data load successful.. \n('GDPC1', 284)\n('UMCSENT', 574)\n\n\n** Getting data for the series: UNRATE\n** Number of observations extracted -842\n** Preparing data for load for series - UNRATE\n** Data is ready for the load.. Loading 842\n*** Database Connection Initialized, buckle up the seat belts..\n\n *** Data load successful.. \n('GDPC1', 284)\n('UMCSENT', 574)\n('UNRATE', 842)\n"
],
[
" cn = mysql.connector.connect(user=fred_sql['user'], password=fred_sql['password'],\n host='127.0.0.1',\n database=fred_sql['database'])\n cursor = cn.cursor()\n quizquery = (\"SELECT frd_srs_val_yr , avg(frd_srs_val) as avg_unrate FROM fred.frd_srs_data WHERE frd_srs='UNRATE' AND frd_srs_val_yr BETWEEN 1980 AND 2015 GROUP BY frd_srs_val_yr ORDER BY 1\")\n cursor.execute(quizquery)\n \n for qz in cursor:\n print(qz)",
"(1980, 7.175000000000001)\n(1981, 7.616666666666667)\n(1982, 9.708333333333332)\n(1983, 9.6)\n(1984, 7.508333333333334)\n(1985, 7.191666666666666)\n(1986, 7.0)\n(1987, 6.175000000000001)\n(1988, 5.491666666666666)\n(1989, 5.258333333333333)\n(1990, 5.616666666666666)\n(1991, 6.849999999999999)\n(1992, 7.491666666666667)\n(1993, 6.908333333333332)\n(1994, 6.1000000000000005)\n(1995, 5.591666666666668)\n(1996, 5.408333333333334)\n(1997, 4.941666666666666)\n(1998, 4.5)\n(1999, 4.216666666666668)\n(2000, 3.9666666666666663)\n(2001, 4.741666666666666)\n(2002, 5.783333333333334)\n(2003, 5.991666666666667)\n(2004, 5.541666666666667)\n(2005, 5.083333333333333)\n(2006, 4.608333333333333)\n(2007, 4.616666666666667)\n(2008, 5.8)\n(2009, 9.283333333333333)\n(2010, 9.608333333333333)\n(2011, 8.933333333333334)\n(2012, 8.075000000000001)\n(2013, 7.358333333333334)\n(2014, 6.175000000000001)\n(2015, 5.266666666666667)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d007d2448d75b4d919c00275a6952ecf5be83743
| 5,365 |
ipynb
|
Jupyter Notebook
|
examples/protyping/icom/006-convert-to-mechanical.ipynb
|
lipteck/pymedphys
|
6e8e2b5db8173eafa6006481ceeca4f4341789e0
|
[
"Apache-2.0"
] | 2 |
2020-02-04T03:21:20.000Z
|
2020-04-11T14:17:53.000Z
|
prototyping/icom/006-convert-to-mechanical.ipynb
|
SimonBiggs/pymedphys
|
83f02eac6549ac155c6963e0a8d1f9284359b652
|
[
"Apache-2.0"
] | 6 |
2020-10-06T15:36:46.000Z
|
2022-02-27T05:15:17.000Z
|
prototyping/icom/006-convert-to-mechanical.ipynb
|
SimonBiggs/pymedphys
|
83f02eac6549ac155c6963e0a8d1f9284359b652
|
[
"Apache-2.0"
] | 1 |
2020-12-20T14:14:00.000Z
|
2020-12-20T14:14:00.000Z
| 25.917874 | 107 | 0.517801 |
[
[
[
"import pathlib\nimport lzma\nimport re\nimport os\nimport datetime\nimport copy\n\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"# Makes it so any changes in pymedphys is automatically\n# propagated into the notebook without needing a kernel reset.\nfrom IPython.lib.deepreload import reload\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import pymedphys._utilities.filesystem\nfrom prototyping import *",
"_____no_output_____"
],
[
"root = pathlib.Path(r'\\\\physics-server\\iComLogFiles\\patients')\ncompressed_files = sorted(list(root.glob('**/*.xz')))\n# compressed_files",
"_____no_output_____"
],
[
"mechanical_output = root.parent.joinpath('mechanical/4299/20200116.csv')\nmechanical_output.parent.mkdir(exist_ok=True)",
"_____no_output_____"
],
[
"data = b\"\"\n\nfor path in compressed_files:\n with lzma.open(path, 'r') as f:\n data += f.read()",
"_____no_output_____"
],
[
"data_points = get_data_points(data)",
"_____no_output_____"
],
[
"mechanical_data = {}\nfor data_point in data_points:\n _, result = strict_extract(data_point)\n machine_id = result['Machine ID']\n \n try:\n machine_record = mechanical_data[machine_id]\n except KeyError:\n machine_record = {}\n mechanical_data[machine_id] = machine_record\n \n timestamp = result['Timestamp']\n try:\n timestamp_record = machine_record[timestamp]\n except KeyError:\n timestamp_record = {}\n machine_record[timestamp] = timestamp_record\n \n counter = result['Counter']\n \n mlc = result['MLCX']\n mlc_a = mlc[0::2]\n mlc_b = mlc[1::2]\n width_at_cra = np.mean(mlc_b[39:41] - mlc_a[39:41])\n jaw = result['ASYMY']\n length = np.sum(jaw)\n \n timestamp_record[counter] = {\n 'Energy': result['Energy'],\n 'Monitor Units': result['Total MU'],\n 'Gantry': result['Gantry'],\n 'Collimator': result['Collimator'],\n 'Table Column': result['Table Column'],\n 'Table Isocentric': result['Table Isocentric'],\n 'Table Vertical': result['Table Vertical'],\n 'Table Longitudinal': result['Table Longitudinal'],\n 'Table Lateral': result['Table Lateral'],\n 'MLC distance at CRA': width_at_cra,\n 'Jaw distance': length \n }",
"_____no_output_____"
],
[
"# pd.Timestamp('2020-01-16T17:08:45')",
"_____no_output_____"
],
[
"table_record = pd.DataFrame(\n columns=[\n 'Timestamp', 'Counter', 'Energy', 'Monitor Units', 'Gantry', 'Collimator', 'Table Column',\n 'Table Isocentric', 'Table Vertical', 'Table Longitudinal',\n 'Table Lateral', 'MLC distance at CRA', 'Jaw distance'\n ]\n)",
"_____no_output_____"
],
[
"for timestamp, timestamp_record in mechanical_data[4299].items():\n for counter, record in timestamp_record.items():\n table_record = table_record.append({\n **{\n 'Timestamp': pd.Timestamp(timestamp),\n 'Counter': counter\n },\n **record\n }, ignore_index=True)",
"_____no_output_____"
],
[
"table_record.to_csv(mechanical_output, index=False)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d007d3bedeb7954bde79b6d4922b7ca8211f95d0
| 84,217 |
ipynb
|
Jupyter Notebook
|
arize/examples/tutorials/Arize_Tutorials/SHAP/Surrogate_Model_Feature_Importance.ipynb
|
Arize-ai/client_python
|
b80afbcafd243c693791bbb77f534eb6def731f1
|
[
"BSD-3-Clause"
] | 12 |
2020-03-31T17:42:45.000Z
|
2022-03-31T07:30:24.000Z
|
arize/examples/tutorials/Arize_Tutorials/SHAP/Surrogate_Model_Feature_Importance.ipynb
|
Arize-ai/client_python
|
b80afbcafd243c693791bbb77f534eb6def731f1
|
[
"BSD-3-Clause"
] | 22 |
2021-08-18T20:16:09.000Z
|
2022-03-24T22:50:21.000Z
|
arize/examples/tutorials/Arize_Tutorials/SHAP/Surrogate_Model_Feature_Importance.ipynb
|
Arize-ai/client_python
|
b80afbcafd243c693791bbb77f534eb6def731f1
|
[
"BSD-3-Clause"
] | 2 |
2021-08-18T18:39:54.000Z
|
2021-08-30T23:14:59.000Z
| 35.639865 | 449 | 0.390467 |
[
[
[
"<img src=\"https://storage.googleapis.com/arize-assets/arize-logo-white.jpg\" width=\"200\"/>\n\n# Arize Tutorial: Surrogate Model Feature Importance\n\nA surrogate model is an interpretable model trained on predicting the predictions of a black box model. The goal is to approximate the predictions of the black box model as closely as possible and generate feature importance values from the interpretable surrogate model. The benefit of this approach is that it does not require knowledge of the inner workings of the black box model.\n\nIn this tutorial we use the `MimcExplainer` from the `interpret_community` library to generate feature importance values from a surrogate model using only the prediction outputs from a black box model. Both [classification](#classification) and [regression](#regression) examples are provided below and feature importance values are logged to Arize using the Pandas [logger](https://docs.arize.com/arize/api-reference/python-sdk/arize.pandas).",
"_____no_output_____"
],
[
"# Install and import the `interpret_community` library",
"_____no_output_____"
]
],
[
[
"!pip install -q interpret==0.2.7 interpret-community==0.22.0\nfrom interpret_community.mimic.mimic_explainer import (\n MimicExplainer,\n LGBMExplainableModel,\n)",
"_____no_output_____"
]
],
[
[
"<a name=\"classification\"></a>\n# Classification Example\n### Generate example\nIn this example we'll use a support vector machine (SVM) as our black box model. Only the prediction outputs of the SVM model is needed to train the surrogate model, and feature importances are generated from the surrogate model and sent to Arize.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.datasets import load_breast_cancer\nfrom sklearn.svm import SVC\n\nbc = load_breast_cancer()\n\nfeature_names = bc.feature_names\ntarget_names = bc.target_names\ndata, target = bc.data, bc.target\n\ndf = pd.DataFrame(data, columns=feature_names)\n\nmodel = SVC(probability=True).fit(df, target)\n\nprediction_label = pd.Series(map(lambda v: target_names[v], model.predict(df)))\nprediction_score = pd.Series(map(lambda v: v[1], model.predict_proba(df)))\nactual_label = pd.Series(map(lambda v: target_names[v], target))\nactual_score = pd.Series(target)",
"_____no_output_____"
]
],
[
[
"### Generate feature importance values\nNote that the model itself is not used here. Only its prediction outputs are used.",
"_____no_output_____"
]
],
[
[
"def model_func(_):\n return np.array(list(map(lambda p: [1 - p, p], prediction_score)))\n\n\nexplainer = MimicExplainer(\n model_func,\n df,\n LGBMExplainableModel,\n augment_data=False,\n is_function=True,\n)\n\nfeature_importance_values = pd.DataFrame(\n explainer.explain_local(df).local_importance_values, columns=feature_names\n)\n\nfeature_importance_values",
"_____no_output_____"
]
],
[
[
"### Send data to Arize\nSet up Arize client. We'll be using the Pandas Logger. First copy the Arize `API_KEY` and `ORG_KEY` from your admin page linked below!\n\n[](https://app.arize.com/admin)",
"_____no_output_____"
]
],
[
[
"!pip install -q arize\nfrom arize.pandas.logger import Client, Schema\nfrom arize.utils.types import ModelTypes, Environments\n\nORGANIZATION_KEY = \"ORGANIZATION_KEY\"\nAPI_KEY = \"API_KEY\"\n\narize_client = Client(organization_key=ORGANIZATION_KEY, api_key=API_KEY)\n\nif ORGANIZATION_KEY == \"ORGANIZATION_KEY\" or API_KEY == \"API_KEY\":\n raise ValueError(\"❌ NEED TO CHANGE ORGANIZATION AND/OR API_KEY\")\nelse:\n print(\"✅ Import and Setup Arize Client Done! Now we can start using Arize!\")",
"_____no_output_____"
]
],
[
[
"Helper functions to simulate prediction IDs and timestamps.",
"_____no_output_____"
]
],
[
[
"import uuid\nfrom datetime import datetime, timedelta\n\n# Prediction ID is required for logging any dataset\ndef generate_prediction_ids(df):\n return pd.Series((str(uuid.uuid4()) for _ in range(len(df))), index=df.index)\n\n\n# OPTIONAL: We can directly specify when inferences were made\ndef simulate_production_timestamps(df, days=30):\n t = datetime.now()\n current_t, earlier_t = t.timestamp(), (t - timedelta(days=days)).timestamp()\n return pd.Series(np.linspace(earlier_t, current_t, num=len(df)), index=df.index)",
"_____no_output_____"
]
],
[
[
"Assemble Pandas DataFrame as a production dataset with prediction IDs and timestamps.",
"_____no_output_____"
]
],
[
[
"feature_importance_values_column_names_mapping = {\n f\"{feat}\": f\"{feat} (feature importance)\" for feat in feature_names\n}\n\nproduction_dataset = pd.concat(\n [\n pd.DataFrame(\n {\n \"prediction_id\": generate_prediction_ids(df),\n \"prediction_ts\": simulate_production_timestamps(df),\n \"prediction_label\": prediction_label,\n \"actual_label\": actual_label,\n \"prediction_score\": prediction_score,\n \"actual_score\": actual_score,\n }\n ),\n df,\n feature_importance_values.rename(\n columns=feature_importance_values_column_names_mapping\n ),\n ],\n axis=1,\n)\n\nproduction_dataset",
"_____no_output_____"
]
],
[
[
"Send dataframe to Arize",
"_____no_output_____"
]
],
[
[
"# Define a Schema() object for Arize to pick up data from the correct columns for logging\nproduction_schema = Schema(\n prediction_id_column_name=\"prediction_id\", # REQUIRED\n timestamp_column_name=\"prediction_ts\",\n prediction_label_column_name=\"prediction_label\",\n prediction_score_column_name=\"prediction_score\",\n actual_label_column_name=\"actual_label\",\n actual_score_column_name=\"actual_score\",\n feature_column_names=feature_names,\n shap_values_column_names=feature_importance_values_column_names_mapping,\n)\n\n# arize_client.log returns a Response object from Python's requests module\nresponse = arize_client.log(\n dataframe=production_dataset,\n schema=production_schema,\n model_id=\"surrogate_model_example_classification\",\n model_type=ModelTypes.SCORE_CATEGORICAL,\n environment=Environments.PRODUCTION,\n)\n\n# If successful, the server will return a status_code of 200\nif response.status_code != 200:\n print(\n f\"❌ logging failed with response code {response.status_code}, {response.text}\"\n )\nelse:\n print(\n f\"✅ You have successfully logged {len(production_dataset)} data points to Arize!\"\n )",
"_____no_output_____"
]
],
[
[
"<a name=\"regression\"></a>\n# Regression Example\n### Generate example\nIn this example we'll use a support vector machine (SVM) as our black box model. Only the prediction outputs of the SVM model is needed to train the surrogate model, and feature importances are generated from the surrogate model and sent to Arize.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.datasets import fetch_california_housing\n\nhousing = fetch_california_housing()\n\n# Use only 1,000 data point for a speedier example\ndata_reg = housing.data[:1000]\ntarget_reg = housing.target[:1000]\nfeature_names_reg = housing.feature_names\n\ndf_reg = pd.DataFrame(data_reg, columns=feature_names_reg)\n\nfrom sklearn.svm import SVR\n\nmodel_reg = SVR().fit(df_reg, target_reg)\n\nprediction_label_reg = pd.Series(model_reg.predict(df_reg))\nactual_label_reg = pd.Series(target_reg)",
"_____no_output_____"
]
],
[
[
"### Generate feature importance values\nNote that the model itself is not used here. Only its prediction outputs are used.",
"_____no_output_____"
]
],
[
[
"def model_func_reg(_):\n return np.array(prediction_label_reg)\n\n\nexplainer_reg = MimicExplainer(\n model_func_reg,\n df_reg,\n LGBMExplainableModel,\n augment_data=False,\n is_function=True,\n)\n\nfeature_importance_values_reg = pd.DataFrame(\n explainer_reg.explain_local(df_reg).local_importance_values,\n columns=feature_names_reg,\n)\n\nfeature_importance_values_reg",
"_____no_output_____"
]
],
[
[
"Assemble Pandas DataFrame as a production dataset with prediction IDs and timestamps.",
"_____no_output_____"
]
],
[
[
"feature_importance_values_column_names_mapping_reg = {\n f\"{feat}\": f\"{feat} (feature importance)\" for feat in feature_names_reg\n}\n\nproduction_dataset_reg = pd.concat(\n [\n pd.DataFrame(\n {\n \"prediction_id\": generate_prediction_ids(df_reg),\n \"prediction_ts\": simulate_production_timestamps(df_reg),\n \"prediction_label\": prediction_label_reg,\n \"actual_label\": actual_label_reg,\n }\n ),\n df_reg,\n feature_importance_values_reg.rename(\n columns=feature_importance_values_column_names_mapping_reg\n ),\n ],\n axis=1,\n)\n\nproduction_dataset_reg",
"_____no_output_____"
]
],
[
[
"Send DataFrame to Arize.",
"_____no_output_____"
]
],
[
[
"# Define a Schema() object for Arize to pick up data from the correct columns for logging\nproduction_schema_reg = Schema(\n prediction_id_column_name=\"prediction_id\", # REQUIRED\n timestamp_column_name=\"prediction_ts\",\n prediction_label_column_name=\"prediction_label\",\n actual_label_column_name=\"actual_label\",\n feature_column_names=feature_names_reg,\n shap_values_column_names=feature_importance_values_column_names_mapping_reg,\n)\n\n# arize_client.log returns a Response object from Python's requests module\nresponse_reg = arize_client.log(\n dataframe=production_dataset_reg,\n schema=production_schema_reg,\n model_id=\"surrogate_model_example_regression\",\n model_type=ModelTypes.NUMERIC,\n environment=Environments.PRODUCTION,\n)\n\n# If successful, the server will return a status_code of 200\nif response_reg.status_code != 200:\n print(\n f\"❌ logging failed with response code {response_reg.status_code}, {response_reg.text}\"\n )\nelse:\n print(\n f\"✅ You have successfully logged {len(production_dataset_reg)} data points to Arize!\"\n )",
"_____no_output_____"
]
],
[
[
"## Conclusion\nYou now know how to seamlessly log surrogate model feature importance values onto the Arize platform. Go to [Arize](https://app.arize.com/) in order to analyze and monitor the logged SHAP values.",
"_____no_output_____"
],
[
"### Overview\nArize is an end-to-end ML observability and model monitoring platform. The platform is designed to help ML engineers and data science practitioners surface and fix issues with ML models in production faster with:\n- Automated ML monitoring and model monitoring\n- Workflows to troubleshoot model performance\n- Real-time visualizations for model performance monitoring, data quality monitoring, and drift monitoring\n- Model prediction cohort analysis\n- Pre-deployment model validation\n- Integrated model explainability\n\n### Website\nVisit Us At: https://arize.com/model-monitoring/\n\n### Additional Resources\n- [What is ML observability?](https://arize.com/what-is-ml-observability/)\n- [Playbook to model monitoring in production](https://arize.com/the-playbook-to-monitor-your-models-performance-in-production/)\n- [Using statistical distance metrics for ML monitoring and observability](https://arize.com/using-statistical-distance-metrics-for-machine-learning-observability/)\n- [ML infrastructure tools for data preparation](https://arize.com/ml-infrastructure-tools-for-data-preparation/)\n- [ML infrastructure tools for model building](https://arize.com/ml-infrastructure-tools-for-model-building/)\n- [ML infrastructure tools for production](https://arize.com/ml-infrastructure-tools-for-production-part-1/)\n- [ML infrastructure tools for model deployment and model serving](https://arize.com/ml-infrastructure-tools-for-production-part-2-model-deployment-and-serving/)\n- [ML infrastructure tools for ML monitoring and observability](https://arize.com/ml-infrastructure-tools-ml-observability/)\n\nVisit the [Arize Blog](https://arize.com/blog) and [Resource Center](https://arize.com/resource-hub/) for more resources on ML observability and model monitoring.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d007e8f76ba85927adb654b8c6e8a33ebedd6820
| 83,863 |
ipynb
|
Jupyter Notebook
|
Gentrification Paper.ipynb
|
JanineW/Quantitative-Economics
|
54577eb68c3e7c373e7376433a8750c34374cf9d
|
[
"MIT"
] | null | null | null |
Gentrification Paper.ipynb
|
JanineW/Quantitative-Economics
|
54577eb68c3e7c373e7376433a8750c34374cf9d
|
[
"MIT"
] | null | null | null |
Gentrification Paper.ipynb
|
JanineW/Quantitative-Economics
|
54577eb68c3e7c373e7376433a8750c34374cf9d
|
[
"MIT"
] | null | null | null | 67.305778 | 45,636 | 0.688242 |
[
[
[
"import pandas as pd\nimport os\nimport json\nimport requests\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"Seattle = pd.read_csv(\"Seattle.csv\")",
"_____no_output_____"
],
[
"Seattle",
"_____no_output_____"
],
[
"Seattle['15num'] = Seattle['2015Number'].str.replace(\",\", \"\").astype(float)",
"_____no_output_____"
],
[
"Seattle['00num'] = Seattle['2000Number'].str.replace(\",\", \"\").astype(float)",
"_____no_output_____"
],
[
"Seattle",
"_____no_output_____"
],
[
"Seattle['diff'] = Seattle['15num']-Seattle['00num']",
"_____no_output_____"
],
[
"Seattle['change'] = (Seattle['15num']-Seattle['00num'])/Seattle['00num']",
"_____no_output_____"
],
[
"Seattle",
"_____no_output_____"
],
[
"df = pd.DataFrame({'Industry': Seattle['INDUSTRY'], 'Change': Seattle['diff']})",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.ix[7, 'Industry'] = \"Finance, Insurance, and Real Estate\"",
"/Users/janinewei/anaconda/lib/python3.5/site-packages/ipykernel/__main__.py:1: DeprecationWarning: \n.ix is deprecated. Please use\n.loc for label based indexing or\n.iloc for positional indexing\n\nSee the documentation here:\nhttp://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated\n if __name__ == '__main__':\n"
],
[
"df.ix[0, 'Industry']",
"_____no_output_____"
],
[
"df.ix[0, 'Industry'] = \"Agriculture\"",
"_____no_output_____"
],
[
"df.ix[9, 'Industry'] = \"Educational,Healthcare and Social Assistance\"",
"_____no_output_____"
],
[
"df.ix[10, 'Industry'] = \"Arts, Recreation and Food Services\"",
"_____no_output_____"
],
[
"df.ix[8, 'Industry'] = \"Professional, Scientific and management\"",
"_____no_output_____"
],
[
"plt.rcdefaults()\nfig, ax = plt.subplots()",
"_____no_output_____"
],
[
"df['Change']",
"_____no_output_____"
],
[
"people = ('Tom', 'Dick', 'Harry', 'Slim', 'Jim')\ny_pos = np.arange(len(people))\nerror = np.random.rand(len(people))",
"_____no_output_____"
],
[
"Industry = df['Industry']",
"_____no_output_____"
],
[
"y_pos = np.arange(len(Industry))",
"_____no_output_____"
],
[
"performance = df['Change']",
"_____no_output_____"
],
[
"error = np.random.rand(len(Industry))",
"_____no_output_____"
],
[
"ax.barh(y_pos, performance, xerr=error, align='center',color='green', ecolor='black')",
"_____no_output_____"
],
[
"plt.style.use('ggplot')",
"_____no_output_____"
],
[
"ax.set_yticks(y_pos)\nax.set_yticklabels(Industry, fontsize=8)\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Change')\nax.get_yaxis().set_tick_params(which='both', direction='in')\nax.get_xaxis().set_tick_params(which='both', direction='in')",
"_____no_output_____"
],
[
"plt.show()",
"_____no_output_____"
],
[
"import cenpy as c\nimport pandas",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d007eac027308b4022540e5578bbd9eacb13b6c1
| 2,413 |
ipynb
|
Jupyter Notebook
|
01_pandas_basics/10_pandas_plotting.ipynb
|
markumreed/data_management_sp_2021
|
d61a0caf4ff23c08136401d8a46f7c9ad2f8c922
|
[
"MIT"
] | 1 |
2022-01-14T00:11:10.000Z
|
2022-01-14T00:11:10.000Z
|
01_pandas_basics/10_pandas_plotting.ipynb
|
markumreed/data_management_sp_2021
|
d61a0caf4ff23c08136401d8a46f7c9ad2f8c922
|
[
"MIT"
] | null | null | null |
01_pandas_basics/10_pandas_plotting.ipynb
|
markumreed/data_management_sp_2021
|
d61a0caf4ff23c08136401d8a46f7c9ad2f8c922
|
[
"MIT"
] | 2 |
2022-01-05T03:25:38.000Z
|
2022-03-12T09:08:21.000Z
| 16.992958 | 99 | 0.457107 |
[
[
[
"# Plotting",
"_____no_output_____"
]
],
[
[
"ts = pd.Series(np.random.randn(1000),\n index=pd.date_range('1/1/2000', periods=1000))\n",
"_____no_output_____"
],
[
"ts = ts.cumsum()",
"_____no_output_____"
],
[
"ts.plot();",
"_____no_output_____"
]
],
[
[
"On a DataFrame, the plot() method is a convenience to plot all of the columns with labels:\n\n",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index,\n columns=['A', 'B', 'C', 'D'])\n",
"_____no_output_____"
],
[
"df = df.cumsum()",
"_____no_output_____"
],
[
"df.plot();",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d007f555603cad3f841e6fe7b71e76809911ab6d
| 7,639 |
ipynb
|
Jupyter Notebook
|
03_modeling/01_TF-IDF.ipynb
|
yunah0515/dss7_Personal_Project
|
67483ed7c6d968769a993ea5843e1db8c1f05e06
|
[
"MIT"
] | 2 |
2018-09-28T12:17:20.000Z
|
2019-11-02T11:58:21.000Z
|
03_modeling/01_TF-IDF.ipynb
|
yunah0515/Sentiment_Analysis_for_Cosmetic_Reviews
|
67483ed7c6d968769a993ea5843e1db8c1f05e06
|
[
"MIT"
] | null | null | null |
03_modeling/01_TF-IDF.ipynb
|
yunah0515/Sentiment_Analysis_for_Cosmetic_Reviews
|
67483ed7c6d968769a993ea5843e1db8c1f05e06
|
[
"MIT"
] | null | null | null | 30.313492 | 421 | 0.530043 |
[
[
[
"import pandas as pd\nimport nltk",
"_____no_output_____"
],
[
"cosmetic = pd.read_csv('../dataset/cosmetics_reviews_final.csv')\nreviews = cosmetic['review']\nreviews[:10]",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train, X_test = train_test_split(reviews, test_size=.2, random_state =0)",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import TfidfTransformer\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.pipeline import Pipeline\nfrom nltk.corpus import words\n\nvectorizer = CountVectorizer(analyzer = 'word', \n lowercase = True,\n tokenizer = None,\n preprocessor = None,\n min_df = 2, # 토큰이 나타날 최소 문서 개수로 오타나 자주 나오지 않는 특수한 전문용어 제거에 좋다. \n ngram_range=(1, 3),\n vocabulary = set(words.words()), # nltk의 words를 사용하거나 문서 자체의 사전을 만들거나 선택한다. \n max_features = 90000\n )\nvectorizer",
"_____no_output_____"
],
[
"pipeline = Pipeline([\n ('vect', vectorizer),\n ('tfidf', TfidfTransformer(smooth_idf = False)),\n]) \npipeline",
"_____no_output_____"
],
[
"%time X_train_tfidf_vector = pipeline.fit_transform(X_train)",
"CPU times: user 1.46 s, sys: 37.7 ms, total: 1.49 s\nWall time: 1.52 s\n"
],
[
"%time X_test_tfidf_vector = pipeline.fit_transform(X_test)",
"CPU times: user 637 ms, sys: 24.6 ms, total: 662 ms\nWall time: 659 ms\n"
],
[
"X_train_tfidf_vector",
"_____no_output_____"
],
[
"from sklearn.ensemble import RandomForestClassifier\n\n# 랜덤포레스트 분류기를 사용\nforest = RandomForestClassifier(\n n_estimators = 100, n_jobs = -1, random_state=2018)\nforest",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0081543cca00a9b0f323739dd679db92a0a5553
| 969,006 |
ipynb
|
Jupyter Notebook
|
DL_Example.ipynb
|
MingSheng92/AE_denoise
|
d437c7cf06c62cec38f4b630e03cfdb17e779ee8
|
[
"MIT"
] | null | null | null |
DL_Example.ipynb
|
MingSheng92/AE_denoise
|
d437c7cf06c62cec38f4b630e03cfdb17e779ee8
|
[
"MIT"
] | null | null | null |
DL_Example.ipynb
|
MingSheng92/AE_denoise
|
d437c7cf06c62cec38f4b630e03cfdb17e779ee8
|
[
"MIT"
] | null | null | null | 1,583.343137 | 328,200 | 0.944568 |
[
[
[
"<a href=\"https://colab.research.google.com/github/MingSheng92/AE_denoise/blob/master/DL_Example.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"!pip show tensorflow",
"Name: tensorflow\nVersion: 1.15.0\nSummary: TensorFlow is an open source machine learning framework for everyone.\nHome-page: https://www.tensorflow.org/\nAuthor: Google Inc.\nAuthor-email: packages@tensorflow.org\nLicense: Apache 2.0\nLocation: /usr/local/lib/python3.6/dist-packages\nRequires: google-pasta, termcolor, protobuf, absl-py, tensorflow-estimator, grpcio, wrapt, six, keras-preprocessing, opt-einsum, gast, tensorboard, numpy, keras-applications, astor, wheel\nRequired-by: stable-baselines, magenta, fancyimpute\n"
],
[
"!git clone https://github.com/MingSheng92/AE_denoise.git",
"Cloning into 'AE_denoise'...\nremote: Enumerating objects: 48, done.\u001b[K\nremote: Counting objects: 100% (48/48), done.\u001b[K\nremote: Compressing objects: 100% (40/40), done.\u001b[K\nremote: Total 48 (delta 17), reused 0 (delta 0), pack-reused 0\u001b[K\nUnpacking objects: 100% (48/48), done.\n"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
],
[
"%load /content/AE_denoise/scripts/utility.py\n%load /content/AE_denoise/scripts/Denoise_NN.py\n\nfrom AE_denoise.scripts.utility import load_data, faceGrid, ResultGrid, subsample, AddNoiseToMatrix, noisy\nfrom AE_denoise.scripts.Denoise_NN import PSNRLoss, createModel\n\nimport numpy as np \nimport matplotlib.pyplot as plt\nfrom sklearn.model_selection import train_test_split",
"Using TensorFlow backend.\n"
],
[
"img_data, label, img_size = load_data('/content/drive/My Drive/FaceDataset/CroppedYaleB', 0)\n#img_data, label, img_size = load_data('/content/drive/My Drive/FaceDataset/ORL', 0)",
"_____no_output_____"
],
[
"img_size",
"_____no_output_____"
],
[
"x_train, x_test, y_train, y_test = train_test_split(img_data.T, label, test_size=0.1, random_state=111)\nx_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.1, random_state=111)\n\nprint(\"Total number of training samples: \", x_train.shape)\nprint(\"Total number of training samples: \", x_val.shape)\nprint(\"Total number of validation samples: \", x_test.shape)",
"Total number of training samples: (1962, 28224)\nTotal number of training samples: (218, 28224)\nTotal number of validation samples: (243, 28224)\n"
],
[
"x_train = x_train.astype('float32') / 255.0\nx_val = x_val.astype('float32') / 255.0\nx_test = x_test.astype('float32') / 255.0\n\n#x_train = x_train.reshape(-1, img_size[0], img_size[1], 1)\n#x_val = x_val.reshape(-1, img_size[0], img_size[1], 1)\nx_train = np.reshape(x_train, (len(x_train), img_size[0], img_size[1], 1))\nx_val = np.reshape(x_val, (len(x_val), img_size[0], img_size[1], 1))\nx_test = np.reshape(x_test, (len(x_test), img_size[0], img_size[1], 1)) ",
"_____no_output_____"
],
[
"# add noise to the face images\nnoise_factor = 0.3\nx_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape) \nx_val_noisy = x_val + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_val.shape) \nx_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape) \n\nx_train_noisy = np.clip(x_train_noisy, 0., 1.)\nx_val_noisy = np.clip(x_val_noisy, 0., 1.)\nx_test_noisy = np.clip(x_test_noisy, 0., 1.)",
"_____no_output_____"
],
[
"faceGrid(10, x_train, img_size, 64)",
"_____no_output_____"
],
[
"faceGrid(10, x_train_noisy, img_size, 64)",
"_____no_output_____"
],
[
"model = createModel(img_size)",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"model_15\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_15 (InputLayer) (None, 168, 168, 1) 0 \n_________________________________________________________________\nconv2d_52 (Conv2D) (None, 168, 168, 64) 1664 \n_________________________________________________________________\nconv2d_53 (Conv2D) (None, 168, 168, 64) 102464 \n_________________________________________________________________\nconv2d_54 (Conv2D) (None, 168, 168, 64) 102464 \n_________________________________________________________________\ndropout_5 (Dropout) (None, 168, 168, 64) 0 \n_________________________________________________________________\nbatch_normalization_35 (Batc (None, 168, 168, 64) 256 \n_________________________________________________________________\nconv2d_55 (Conv2D) (None, 168, 168, 32) 18464 \n_________________________________________________________________\nconv2d_56 (Conv2D) (None, 168, 168, 32) 9248 \n_________________________________________________________________\ndropout_6 (Dropout) (None, 168, 168, 32) 0 \n_________________________________________________________________\nbatch_normalization_36 (Batc (None, 168, 168, 32) 128 \n_________________________________________________________________\ndropout_7 (Dropout) (None, 168, 168, 32) 0 \n_________________________________________________________________\nconv2d_transpose_38 (Conv2DT (None, 168, 168, 32) 9248 \n_________________________________________________________________\nconv2d_transpose_39 (Conv2DT (None, 168, 168, 32) 9248 \n_________________________________________________________________\ndropout_8 (Dropout) (None, 168, 168, 32) 0 \n_________________________________________________________________\nbatch_normalization_37 (Batc (None, 168, 168, 32) 128 \n_________________________________________________________________\nconv2d_transpose_40 (Conv2DT (None, 168, 168, 64) 51264 \n_________________________________________________________________\nconv2d_transpose_41 (Conv2DT (None, 168, 168, 64) 102464 \n_________________________________________________________________\nconv2d_transpose_42 (Conv2DT (None, 168, 168, 64) 102464 \n_________________________________________________________________\ndropout_9 (Dropout) (None, 168, 168, 64) 0 \n_________________________________________________________________\nbatch_normalization_38 (Batc (None, 168, 168, 64) 256 \n_________________________________________________________________\nconv2d_57 (Conv2D) (None, 168, 168, 1) 65 \n=================================================================\nTotal params: 509,825\nTrainable params: 509,441\nNon-trainable params: 384\n_________________________________________________________________\n"
],
[
"model.fit(x_train_noisy, x_train,\n epochs=15,\n batch_size=64,\n validation_data=(x_val_noisy, x_val))",
"Train on 1962 samples, validate on 218 samples\nEpoch 1/15\n1962/1962 [==============================] - 23s 12ms/step - loss: 0.0238 - PSNRLoss: 17.4902 - val_loss: 0.0526 - val_PSNRLoss: 12.7983\nEpoch 2/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0066 - PSNRLoss: 21.8847 - val_loss: 0.0737 - val_PSNRLoss: 11.3278\nEpoch 3/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0050 - PSNRLoss: 23.0366 - val_loss: 0.0123 - val_PSNRLoss: 19.0879\nEpoch 4/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0043 - PSNRLoss: 23.7915 - val_loss: 0.0052 - val_PSNRLoss: 22.8809\nEpoch 5/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0038 - PSNRLoss: 24.3160 - val_loss: 0.0054 - val_PSNRLoss: 22.6885\nEpoch 6/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0040 - PSNRLoss: 24.0530 - val_loss: 0.0253 - val_PSNRLoss: 15.9726\nEpoch 7/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0033 - PSNRLoss: 24.7992 - val_loss: 0.0074 - val_PSNRLoss: 21.3257\nEpoch 8/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0034 - PSNRLoss: 24.7213 - val_loss: 0.0118 - val_PSNRLoss: 19.2935\nEpoch 9/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0030 - PSNRLoss: 25.2877 - val_loss: 0.0048 - val_PSNRLoss: 23.1611\nEpoch 10/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0032 - PSNRLoss: 24.9987 - val_loss: 0.0061 - val_PSNRLoss: 22.1570\nEpoch 11/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0032 - PSNRLoss: 25.0257 - val_loss: 0.0041 - val_PSNRLoss: 23.8727\nEpoch 12/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0035 - PSNRLoss: 24.6498 - val_loss: 0.0037 - val_PSNRLoss: 24.2844\nEpoch 13/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0031 - PSNRLoss: 25.1227 - val_loss: 0.0036 - val_PSNRLoss: 24.4544\nEpoch 14/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0030 - PSNRLoss: 25.3048 - val_loss: 0.0056 - val_PSNRLoss: 22.4946\nEpoch 15/15\n1962/1962 [==============================] - 19s 10ms/step - loss: 0.0026 - PSNRLoss: 25.8603 - val_loss: 0.0043 - val_PSNRLoss: 23.6579\n"
],
[
"denoise_prediction = model.predict(x_test_noisy)",
"_____no_output_____"
],
[
"faceGrid(10, x_test, img_size, 5)",
"_____no_output_____"
],
[
"faceGrid(10, x_test_noisy, img_size, 5)",
"_____no_output_____"
],
[
"faceGrid(10, denoise_prediction, img_size, 5)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0082314df8938d1910b02e0e2b66d5dc6601185
| 19,415 |
ipynb
|
Jupyter Notebook
|
docs/content/perceptron/Rosenblatt.ipynb
|
yiyulanghuan/deeplearning
|
e9153ed04f771a4941543b05ef2a43512fadedb1
|
[
"MIT"
] | 1 |
2020-02-19T17:31:34.000Z
|
2020-02-19T17:31:34.000Z
|
docs/content/perceptron/Rosenblatt.ipynb
|
yiyulanghuan/deeplearning
|
e9153ed04f771a4941543b05ef2a43512fadedb1
|
[
"MIT"
] | 2 |
2021-05-20T12:16:47.000Z
|
2021-09-28T00:17:13.000Z
|
docs/content/perceptron/Rosenblatt.ipynb
|
yiyulanghuan/deeplearning
|
e9153ed04f771a4941543b05ef2a43512fadedb1
|
[
"MIT"
] | null | null | null | 29.596037 | 297 | 0.543343 |
[
[
[
"<center><h1> The RosenBlatt Perceptron </h1></center>\n<center> An exemple on the MNIST database </center>",
"_____no_output_____"
],
[
"# Import",
"_____no_output_____"
]
],
[
[
"from tensorflow.examples.tutorials.mnist import input_data\nimport tensorflow as tf\nmnist_data = input_data.read_data_sets('MNIST_data', one_hot=True)",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n"
]
],
[
[
"# Model Parameters",
"_____no_output_____"
]
],
[
[
"input_size = 784\nno_classes = 10\nbatch_size = 100\ntotal_batches = 200",
"_____no_output_____"
],
[
"x_input = tf.placeholder(tf.float32, shape=[None, input_size])\ny_input = tf.placeholder(tf.float32, shape=[None, no_classes])\nweights = tf.Variable(tf.random_normal([input_size, no_classes]))\nbias = tf.Variable(tf.random_normal([no_classes]))",
"_____no_output_____"
],
[
"logits = tf.matmul(x_input, weights) + bias\n\nsoftmax_cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_input,\nlogits=logits)\nloss_operation = tf.reduce_mean(softmax_cross_entropy)\noptimiser = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(loss_operation)\n",
"_____no_output_____"
]
],
[
[
"# Run the model",
"_____no_output_____"
]
],
[
[
"session = tf.Session()\nsession.run(tf.global_variables_initializer())\n\nfor batch_no in range(total_batches):\n \n amnist_batch = mnist_data.train.next_batch(batch_size)\n _, loss_value = session.run([optimiser, loss_operation], feed_dict={\n x_input: mnist_batch[0],\n y_input: mnist_batch[1]})\n print(loss_value)\n\n predictions = tf.argmax(logits, 1)\n correct_predictions = tf.equal(predictions, tf.argmax(y_input, 1))\n accuracy_operation = tf.reduce_mean(tf.cast(correct_predictions,tf.float32))\n test_images, test_labels = mnist_data.test.images, mnist_data.test.labels\n accuracy_value = session.run(accuracy_operation, feed_dict={\n x_input: test_images,\n y_input: test_labels})\n \n print('Accuracy : ', accuracy_value)\n\nsession.close()",
"/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n/anaconda3/lib/python3.6/site-packages/requests/__init__.py:80: RequestsDependencyWarning: urllib3 (1.21.1) or chardet (2.3.0) doesn't match a supported version!\n RequestsDependencyWarning)\n"
]
],
[
[
"We reach an accuracy of around 81%.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d008264976cef15bd9ab3ad046872c9f14899aa6
| 4,401 |
ipynb
|
Jupyter Notebook
|
two_layer_net_nn.ipynb
|
asapypy/mokumokuTorch
|
ec59877b407a3f0ac1a9627ea5609698f2979278
|
[
"MIT"
] | null | null | null |
two_layer_net_nn.ipynb
|
asapypy/mokumokuTorch
|
ec59877b407a3f0ac1a9627ea5609698f2979278
|
[
"MIT"
] | null | null | null |
two_layer_net_nn.ipynb
|
asapypy/mokumokuTorch
|
ec59877b407a3f0ac1a9627ea5609698f2979278
|
[
"MIT"
] | null | null | null | 33.340909 | 92 | 0.598728 |
[
[
[
"!pwd",
"/Users/asakawa/study/2018pytorch_lecture\r\n"
],
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\nPyTorch: nn\n-----------\n\nA fully-connected ReLU network with one hidden layer, trained to predict y from x\nby minimizing squared Euclidean distance.\n\nThis implementation uses the nn package from PyTorch to build the network.\nPyTorch autograd makes it easy to define computational graphs and take gradients,\nbut raw autograd can be a bit too low-level for defining complex neural networks;\nthis is where the nn package can help. The nn package defines a set of Modules,\nwhich you can think of as a neural network layer that has produces output from\ninput and may have some trainable weights.\n\n",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch.autograd import Variable\n\n# N is batch size; D_in is input dimension;\n# H is hidden dimension; D_out is output dimension.\nN, D_in, H, D_out = 64, 1000, 100, 10\n\n# Create random Tensors to hold inputs and outputs, and wrap them in Variables.\nx = Variable(torch.randn(N, D_in))\ny = Variable(torch.randn(N, D_out), requires_grad=False)\n\n# Use the nn package to define our model as a sequence of layers. nn.Sequential\n# is a Module which contains other Modules, and applies them in sequence to\n# produce its output. Each Linear Module computes output from input using a\n# linear function, and holds internal Variables for its weight and bias.\nmodel = torch.nn.Sequential(\n torch.nn.Linear(D_in, H),\n torch.nn.ReLU(),\n torch.nn.Linear(H, D_out),\n)\n\n# The nn package also contains definitions of popular loss functions; in this\n# case we will use Mean Squared Error (MSE) as our loss function.\nloss_fn = torch.nn.MSELoss(size_average=False)\n\nlearning_rate = 1e-4\nfor t in range(500):\n # Forward pass: compute predicted y by passing x to the model. Module objects\n # override the __call__ operator so you can call them like functions. When\n # doing so you pass a Variable of input data to the Module and it produces\n # a Variable of output data.\n y_pred = model(x)\n\n # Compute and print loss. We pass Variables containing the predicted and true\n # values of y, and the loss function returns a Variable containing the\n # loss.\n loss = loss_fn(y_pred, y)\n print(t, loss.data[0])\n\n # Zero the gradients before running the backward pass.\n model.zero_grad()\n\n # Backward pass: compute gradient of the loss with respect to all the learnable\n # parameters of the model. Internally, the parameters of each Module are stored\n # in Variables with requires_grad=True, so this call will compute gradients for\n # all learnable parameters in the model.\n loss.backward()\n\n # Update the weights using gradient descent. Each parameter is a Variable, so\n # we can access its data and gradients like we did before.\n for param in model.parameters():\n param.data -= learning_rate * param.grad.data",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d00845ee1714ba38c387f2a218dc4aed544ce488
| 11,973 |
ipynb
|
Jupyter Notebook
|
#2 Introduction to Numpy/Python-Data-Types.ipynb
|
Sphincz/dsml
|
a292fd717fc01980c08f4ea23fde910d37fbd1cb
|
[
"MIT"
] | null | null | null |
#2 Introduction to Numpy/Python-Data-Types.ipynb
|
Sphincz/dsml
|
a292fd717fc01980c08f4ea23fde910d37fbd1cb
|
[
"MIT"
] | null | null | null |
#2 Introduction to Numpy/Python-Data-Types.ipynb
|
Sphincz/dsml
|
a292fd717fc01980c08f4ea23fde910d37fbd1cb
|
[
"MIT"
] | null | null | null | 19.034976 | 361 | 0.473231 |
[
[
[
"# Understanding Data Types in Python",
"_____no_output_____"
],
[
"Effective data-driven science and computation requires understanding how data is stored and manipulated. This section outlines and contrasts how arrays of data are handled in the Python language itself, and how NumPy improves on this. Understanding this difference is fundamental to understanding much of the material throughout the rest of the course.\n\nPython is simple to use. While a statically-typed language like C or Java requires each variable to be explicitly declared, a dynamically-typed language like Python skips this specification.\n\nIn C, the data types of each variable are explicitly declared, while in Python the types are dynamically inferred.\nThis means, for example, that we can assign any kind of data to any variable:",
"_____no_output_____"
]
],
[
[
"x = 4\nx = \"four\"",
"_____no_output_____"
]
],
[
[
"This sort of flexibility is one piece that makes Python and other dynamically-typed languages convenient and easy to use. ",
"_____no_output_____"
],
[
"## 1.1. Data Types",
"_____no_output_____"
],
[
"We have several data types in python:\n* None\n* Numeric (int, float, complex, bool)\n* List\n* Tuple\n* Set \n* String\n* Range\n* Dictionary (Map)",
"_____no_output_____"
]
],
[
[
"# NoneType\na = None\ntype(a)",
"_____no_output_____"
],
[
"# int\na = 1+1\nprint(a)\ntype(a)",
"2\n"
],
[
"# complex\nc = 1.5 + 0.5j \ntype(c)",
"_____no_output_____"
],
[
"c.real",
"_____no_output_____"
],
[
"c.imag",
"_____no_output_____"
],
[
"# boolean\nd = 2 > 3\nprint(d)\ntype(d)",
"False\n"
]
],
[
[
"## Python Lists",
"_____no_output_____"
],
[
"Let's consider now what happens when we use a Python data structure that holds many Python objects. The standard mutable multi-element container in Python is the list. We can create a list of integers as follows:",
"_____no_output_____"
]
],
[
[
"L = list(range(10))\nL",
"_____no_output_____"
],
[
"type(L[0])",
"_____no_output_____"
]
],
[
[
"Or, similarly, a list of strings:",
"_____no_output_____"
]
],
[
[
"L2 = [str(c) for c in L]\nL2",
"_____no_output_____"
],
[
"type(L2[0])",
"_____no_output_____"
]
],
[
[
"Because of Python's dynamic typing, we can even create heterogeneous lists:",
"_____no_output_____"
]
],
[
[
"L3 = [True, \"2\", 3.0, 4]\n[type(item) for item in L3]",
"_____no_output_____"
]
],
[
[
"## Python Dictionaries",
"_____no_output_____"
]
],
[
[
"keys = [1, 2, 3, 4, 5]\nvalues = ['monday', 'tuesday', 'wendsday', 'friday']\n\ndictionary = dict(zip(keys, values))\ndictionary",
"_____no_output_____"
],
[
"dictionary.get(1)",
"_____no_output_____"
],
[
"dictionary[1]",
"_____no_output_____"
]
],
[
[
"## Fixed-Type Arrays in Python",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"First, we can use np.array to create arrays from Python lists:",
"_____no_output_____"
]
],
[
[
"# integer array:\nnp.array([1, 4, 2, 5, 3])",
"_____no_output_____"
]
],
[
[
"Unlike python lists, NumPy is constrained to arrays that all contain the same type. \n\nIf we want to explicitly set the data type of the resulting array, we can use the dtype keyword:\n\n",
"_____no_output_____"
]
],
[
[
"np.array([1, 2, 3, 4], dtype='float32')",
"_____no_output_____"
]
],
[
[
"### Creating Arrays from Scratch",
"_____no_output_____"
],
[
"Especially for larger arrays, it is more efficient to create arrays from scratch using routines built into NumPy. Here are several examples:",
"_____no_output_____"
]
],
[
[
"# Create a length-10 integer array filled with zeros\nnp.zeros(10, dtype=int)",
"_____no_output_____"
],
[
"# Create a 3x5 floating-point array filled with ones\nnp.ones((3, 5), dtype=float)",
"_____no_output_____"
],
[
"# Create a 3x5 array filled with 3.14\nnp.full((3, 5), 3.14)",
"_____no_output_____"
],
[
"# Create an array filled with a linear sequence\nnp.arange(1, 10)",
"_____no_output_____"
],
[
"# Starting at 0, ending at 20, stepping by 2\n# (this is similar to the built-in range() function)\n\nnp.arange(0, 20, 2)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0084f3f12d22ba093ecfff4fab55863b5870d49
| 2,023 |
ipynb
|
Jupyter Notebook
|
turtle_graphics.ipynb
|
lukaszplk/turtle_graphics
|
d7801344756d465c478e7b2090c7d8c68458040c
|
[
"MIT"
] | null | null | null |
turtle_graphics.ipynb
|
lukaszplk/turtle_graphics
|
d7801344756d465c478e7b2090c7d8c68458040c
|
[
"MIT"
] | null | null | null |
turtle_graphics.ipynb
|
lukaszplk/turtle_graphics
|
d7801344756d465c478e7b2090c7d8c68458040c
|
[
"MIT"
] | null | null | null | 23.523256 | 52 | 0.471577 |
[
[
[
"import turtle as t\ndef rectangle(horizontal, vertical, color):\n t.pendown()\n t.pensize(1)\n t.color(color)\n t.begin_fill()\n for counter in range(1, 3):\n t.forward(horizontal)\n t.right(90)\n t.forward(vertical)\n t.right(90)\n t.end_fill()\n t.penup()\n\nt.penup()\nt.speed('slow')\nt.bgcolor('Dodger blue')\n# feet\nt.goto(-100, -150)\nrectangle(50, 20, 'blue')\nt.goto(-30, -150)\nrectangle(50, 20, 'blue')\n# legs\nt.goto(-25, -50)\nrectangle(15, 100, 'grey')\nt.goto(-55, -50)\nrectangle(-15, 100, 'grey')\n# body\nt.goto(-90, 100)\nrectangle(100, 150, 'red')\n# arms\nt.goto(-150, 70)\nrectangle(60, 15, 'grey')\nt.goto(-150, 110)\nrectangle(15, 40, 'grey')\nt.goto(10, 70)\nrectangle(60, 15, 'grey')\nt.goto(55, 110)\nrectangle(15, 40, 'grey')\n# neck\nt.goto(-50, 120)\nrectangle(15, 20, 'grey')\n# head\nt.goto(-85, 170)\nrectangle(80, 50, 'red')\n# eyes\nt.goto(-60, 160)\nrectangle(30, 10, 'white')\nt.goto(-55, 155)\nrectangle(5, 5, 'black')\nt.goto(-40, 155)\nrectangle(5, 5, 'black')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
d008572d49a989cd99e3483d1d71124fda222b87
| 9,370 |
ipynb
|
Jupyter Notebook
|
notebooks/layers/pooling/GlobalMaxPooling1D.ipynb
|
HimariO/keras-js
|
e914a21733ea3a1ed49e3e71331b1c5e860a9eb7
|
[
"MIT"
] | 5,330 |
2016-10-01T02:04:36.000Z
|
2022-03-28T18:32:10.000Z
|
notebooks/layers/pooling/GlobalMaxPooling1D.ipynb
|
HimariO/keras-js
|
e914a21733ea3a1ed49e3e71331b1c5e860a9eb7
|
[
"MIT"
] | 126 |
2016-10-14T04:49:22.000Z
|
2022-02-23T14:24:47.000Z
|
notebooks/layers/pooling/GlobalMaxPooling1D.ipynb
|
HimariO/keras-js
|
e914a21733ea3a1ed49e3e71331b1c5e860a9eb7
|
[
"MIT"
] | 615 |
2016-10-14T00:48:57.000Z
|
2021-12-31T05:43:54.000Z
| 33.109541 | 1,485 | 0.562753 |
[
[
[
"import numpy as np\nfrom keras.models import Model\nfrom keras.layers import Input\nfrom keras.layers.pooling import GlobalMaxPooling1D\nfrom keras import backend as K\nimport json\nfrom collections import OrderedDict",
"Using TensorFlow backend.\n"
],
[
"def format_decimal(arr, places=6):\n return [round(x * 10**places) / 10**places for x in arr]",
"_____no_output_____"
],
[
"DATA = OrderedDict()",
"_____no_output_____"
]
],
[
[
"### GlobalMaxPooling1D",
"_____no_output_____"
],
[
"**[pooling.GlobalMaxPooling1D.0] input 6x6**",
"_____no_output_____"
]
],
[
[
"data_in_shape = (6, 6)\nL = GlobalMaxPooling1D()\n\nlayer_0 = Input(shape=data_in_shape)\nlayer_1 = L(layer_0)\nmodel = Model(inputs=layer_0, outputs=layer_1)\n\n# set weights to random (use seed for reproducibility)\nnp.random.seed(260)\ndata_in = 2 * np.random.random(data_in_shape) - 1\nresult = model.predict(np.array([data_in]))\ndata_out_shape = result[0].shape\ndata_in_formatted = format_decimal(data_in.ravel().tolist())\ndata_out_formatted = format_decimal(result[0].ravel().tolist())\nprint('')\nprint('in shape:', data_in_shape)\nprint('in:', data_in_formatted)\nprint('out shape:', data_out_shape)\nprint('out:', data_out_formatted)\n\nDATA['pooling.GlobalMaxPooling1D.0'] = {\n 'input': {'data': data_in_formatted, 'shape': data_in_shape},\n 'expected': {'data': data_out_formatted, 'shape': data_out_shape}\n}",
"\nin shape: (6, 6)\nin: [-0.806777, -0.564841, -0.481331, 0.559626, 0.274958, -0.659222, -0.178541, 0.689453, -0.028873, 0.053859, -0.446394, -0.53406, 0.776897, -0.700858, -0.802179, -0.616515, 0.718677, 0.303042, -0.080606, -0.850593, -0.795971, 0.860487, -0.90685, 0.89858, 0.617251, 0.334305, -0.351137, -0.642574, 0.108974, -0.993964, 0.051085, -0.372012, 0.843766, 0.088025, -0.598662, 0.789035]\nout shape: (6,)\nout: [0.776897, 0.689453, 0.843766, 0.860487, 0.718677, 0.89858]\n"
]
],
[
[
"**[pooling.GlobalMaxPooling1D.1] input 3x7**",
"_____no_output_____"
]
],
[
[
"data_in_shape = (3, 7)\nL = GlobalMaxPooling1D()\n\nlayer_0 = Input(shape=data_in_shape)\nlayer_1 = L(layer_0)\nmodel = Model(inputs=layer_0, outputs=layer_1)\n\n# set weights to random (use seed for reproducibility)\nnp.random.seed(261)\ndata_in = 2 * np.random.random(data_in_shape) - 1\nresult = model.predict(np.array([data_in]))\ndata_out_shape = result[0].shape\ndata_in_formatted = format_decimal(data_in.ravel().tolist())\ndata_out_formatted = format_decimal(result[0].ravel().tolist())\nprint('')\nprint('in shape:', data_in_shape)\nprint('in:', data_in_formatted)\nprint('out shape:', data_out_shape)\nprint('out:', data_out_formatted)\n\nDATA['pooling.GlobalMaxPooling1D.1'] = {\n 'input': {'data': data_in_formatted, 'shape': data_in_shape},\n 'expected': {'data': data_out_formatted, 'shape': data_out_shape}\n}",
"\nin shape: (3, 7)\nin: [0.601872, -0.028379, 0.654213, 0.217731, -0.864161, 0.422013, 0.888312, -0.714141, -0.184753, 0.224845, -0.221123, -0.847943, -0.511334, -0.871723, -0.597589, -0.889034, -0.544887, -0.004798, 0.406639, -0.35285, 0.648562]\nout shape: (7,)\nout: [0.601872, -0.028379, 0.654213, 0.217731, 0.406639, 0.422013, 0.888312]\n"
]
],
[
[
"**[pooling.GlobalMaxPooling1D.2] input 8x4**",
"_____no_output_____"
]
],
[
[
"data_in_shape = (8, 4)\nL = GlobalMaxPooling1D()\n\nlayer_0 = Input(shape=data_in_shape)\nlayer_1 = L(layer_0)\nmodel = Model(inputs=layer_0, outputs=layer_1)\n\n# set weights to random (use seed for reproducibility)\nnp.random.seed(262)\ndata_in = 2 * np.random.random(data_in_shape) - 1\nresult = model.predict(np.array([data_in]))\ndata_out_shape = result[0].shape\ndata_in_formatted = format_decimal(data_in.ravel().tolist())\ndata_out_formatted = format_decimal(result[0].ravel().tolist())\nprint('')\nprint('in shape:', data_in_shape)\nprint('in:', data_in_formatted)\nprint('out shape:', data_out_shape)\nprint('out:', data_out_formatted)\n\nDATA['pooling.GlobalMaxPooling1D.2'] = {\n 'input': {'data': data_in_formatted, 'shape': data_in_shape},\n 'expected': {'data': data_out_formatted, 'shape': data_out_shape}\n}",
"\nin shape: (8, 4)\nin: [-0.215694, 0.441215, 0.116911, 0.53299, 0.883562, -0.535525, -0.869764, -0.596287, 0.576428, -0.689083, -0.132924, -0.129935, -0.17672, -0.29097, 0.590914, 0.992098, 0.908965, -0.170202, 0.640203, 0.178644, 0.866749, -0.545566, -0.827072, 0.420342, -0.076191, 0.207686, -0.908472, -0.795307, -0.948319, 0.683682, -0.563278, -0.82135]\nout shape: (4,)\nout: [0.908965, 0.683682, 0.640203, 0.992098]\n"
]
],
[
[
"### export for Keras.js tests",
"_____no_output_____"
]
],
[
[
"import os\n\nfilename = '../../../test/data/layers/pooling/GlobalMaxPooling1D.json'\nif not os.path.exists(os.path.dirname(filename)):\n os.makedirs(os.path.dirname(filename))\nwith open(filename, 'w') as f:\n json.dump(DATA, f)",
"_____no_output_____"
],
[
"print(json.dumps(DATA))",
"{\"pooling.GlobalMaxPooling1D.0\": {\"input\": {\"data\": [-0.806777, -0.564841, -0.481331, 0.559626, 0.274958, -0.659222, -0.178541, 0.689453, -0.028873, 0.053859, -0.446394, -0.53406, 0.776897, -0.700858, -0.802179, -0.616515, 0.718677, 0.303042, -0.080606, -0.850593, -0.795971, 0.860487, -0.90685, 0.89858, 0.617251, 0.334305, -0.351137, -0.642574, 0.108974, -0.993964, 0.051085, -0.372012, 0.843766, 0.088025, -0.598662, 0.789035], \"shape\": [6, 6]}, \"expected\": {\"data\": [0.776897, 0.689453, 0.843766, 0.860487, 0.718677, 0.89858], \"shape\": [6]}}, \"pooling.GlobalMaxPooling1D.1\": {\"input\": {\"data\": [0.601872, -0.028379, 0.654213, 0.217731, -0.864161, 0.422013, 0.888312, -0.714141, -0.184753, 0.224845, -0.221123, -0.847943, -0.511334, -0.871723, -0.597589, -0.889034, -0.544887, -0.004798, 0.406639, -0.35285, 0.648562], \"shape\": [3, 7]}, \"expected\": {\"data\": [0.601872, -0.028379, 0.654213, 0.217731, 0.406639, 0.422013, 0.888312], \"shape\": [7]}}, \"pooling.GlobalMaxPooling1D.2\": {\"input\": {\"data\": [-0.215694, 0.441215, 0.116911, 0.53299, 0.883562, -0.535525, -0.869764, -0.596287, 0.576428, -0.689083, -0.132924, -0.129935, -0.17672, -0.29097, 0.590914, 0.992098, 0.908965, -0.170202, 0.640203, 0.178644, 0.866749, -0.545566, -0.827072, 0.420342, -0.076191, 0.207686, -0.908472, -0.795307, -0.948319, 0.683682, -0.563278, -0.82135], \"shape\": [8, 4]}, \"expected\": {\"data\": [0.908965, 0.683682, 0.640203, 0.992098], \"shape\": [4]}}}\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0087f950cb5e968ff12e8a7cc56ec5964348674
| 5,328 |
ipynb
|
Jupyter Notebook
|
_notebooks/2021-05-24-Understanding-Various-Genetic-Analyses.ipynb
|
EucharistKun/Research_Blog
|
e16fc2f747fc207d48486b2a8ad39e85f7315449
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2021-05-24-Understanding-Various-Genetic-Analyses.ipynb
|
EucharistKun/Research_Blog
|
e16fc2f747fc207d48486b2a8ad39e85f7315449
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2021-05-24-Understanding-Various-Genetic-Analyses.ipynb
|
EucharistKun/Research_Blog
|
e16fc2f747fc207d48486b2a8ad39e85f7315449
|
[
"Apache-2.0"
] | null | null | null | 64.192771 | 1,104 | 0.722035 |
[
[
[
"# GWAS, PheWAS, and Mendelian Randomization\n> Understanding Methods of Genetic Analysis\n\n- categories: [jupyter]",
"_____no_output_____"
],
[
"## GWAS\n\nGenome Wide Association Studies (GWAS) look for genetic variants across the genome in a large amount of individuals to see if any variants are associated with a specific trait such as height or disease. GWA studies typically look at single nucleotide polymorphisms (SNPs), which are germline substitutions of a single nucleotide at a specific position in the genome, meaning that these are heritable differences in the human population. A GWAS is performed by taking DNA samples from many individuals and using SNP arrays to read the different genetic variants. If a particular variant is more present in people with a specific trait, the SNP is associated with the disease. Results from a GWAS are typically shown in a Manhattan plot displaying which loci on the various chromosomes are more associated with a specific trait. In the picture below taken from Wikipedia, each dot represents a SNP, and \"this example is taken from a GWA study investigating microcirculation, so the tops indicates genetic variants that more often are found in individuals with constrictions in small blood vessels.\"",
"_____no_output_____"
],
[
"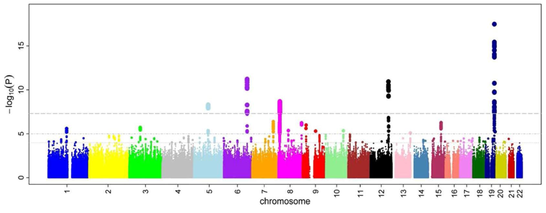",
"_____no_output_____"
],
[
"A GWAS is a non-candidate-driven approach, in that a GWAS investigate the whole genome and not specific genes. As a result, a GWAS can tell the user which genes are associated with the disease but cannot describe any causal relations between the genes identified and the trait/disease being studied. ",
"_____no_output_____"
],
[
"### Methodology\n \nTypically, two general populations are used for a GWAS, a case group with a certain disease and a control group without the disease. The individuals in the population are genotyped for the majority of known SNPs in the human genome, which surpass a million. The allele frequences at each SNP are calculated, and an odds ratio is generated in order to compare the case and control populations. An odds ratio is \"the ratio of the odds of A in the presence of B and the odds of A in the absence of B\", or in the case of a GWAS, it is \"the odds of case for individuals having a specific allele and the odds of case for individuals who do not have that same allele\". \n\nFor example, at a certain SNP, there are two main alleles, T and C. The amount of individuals in the case group having allele T is represented by A, or 4500, and the amount of individuals in the control group having allele T is represented by B, or 2000. Then the number of individuals in the case group having allele C is represented by X, or 3000, and the individuals in the control group having allele C is represented by Y, or 3500. The odds ratio for allele T is calculated as (A/B) / (X/Y) or (4500/2000) / (3000,3500). \n\nIf the allele frequency is much higher in the case group than in the control group, the odds ratio will be greater than one. Furthermore, a chi-squared test is used to calculate a p-value for the significance of the generated odds ratios. For a GWAS, typically a p-value < 5x10^-8 is required for an odds ratio to be meaningful.\n\nFurthermore, factors such as ethnicity, geography, sex, and age must be taken into consideration and controlled for as they could confound the results.",
"_____no_output_____"
],
[
"### Imputation\n\nAnother key facet used in many studies involves imputation, or the statistical inference of unobserved genetic sequences. Since it is time-consuming and costly to do genome wide sequencing on a large population, only key areas of the genome are typically sequenced and a large portion of the genome is statistically inferred through large scale genome datasets such as the HapMap or 1000 Genomes Project. Imputation is achieved by combining the GWAS data with the reference panel of haplotypes (HapMap/1000 Genomes Project) and inferring other SNPs in the genome through shared haplotypes among individuals over short sequences. For example, if we know that a patient with an A allele at base 10 always has a G allele at base 135, we can impute this information for the entire population. This method increases the number of SNPs that can be tested for association in a GWAS as well as the power of the GWAS. ",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d008a7e3d13a544213ad0342c4ce2c4188e51bc1
| 319,005 |
ipynb
|
Jupyter Notebook
|
notebooks/eda/ntlk_ch02.ipynb
|
metinsenturk/semantic-analysis
|
9dd673ed249b4c0f24b8b9d5eb7349a9fdfd7f4f
|
[
"MIT"
] | null | null | null |
notebooks/eda/ntlk_ch02.ipynb
|
metinsenturk/semantic-analysis
|
9dd673ed249b4c0f24b8b9d5eb7349a9fdfd7f4f
|
[
"MIT"
] | null | null | null |
notebooks/eda/ntlk_ch02.ipynb
|
metinsenturk/semantic-analysis
|
9dd673ed249b4c0f24b8b9d5eb7349a9fdfd7f4f
|
[
"MIT"
] | 1 |
2019-10-23T16:16:28.000Z
|
2019-10-23T16:16:28.000Z
| 47.877082 | 44,908 | 0.631394 |
[
[
[
"import nltk\nfrom nltk import *",
"_____no_output_____"
],
[
"emma = nltk.Text(nltk.corpus.gutenberg.words('austen-emma.txt'))",
"_____no_output_____"
],
[
"len(emma)",
"_____no_output_____"
],
[
"emma.concordance(\"surprise\")",
"Displaying 1 of 1 matches:\n, that Emma could not but feel some surprise , and a little displeasure , on hea\n"
],
[
"from nltk.corpus import gutenberg\nprint(gutenberg.fileids())\nemma = gutenberg.words(\"austen-emma.txt\")",
"['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']\n"
],
[
"type(gutenberg)",
"_____no_output_____"
],
[
"for fileid in gutenberg.fileids():\n n_chars = len(gutenberg.raw(fileid))\n n_words = len(gutenberg.words(fileid))\n n_sents = len(gutenberg.sents(fileid))\n n_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))\n print(f\"chr: {n_chars} wor: {n_words} sen: {n_sents} voc: {n_vocab} {fileid}\")\n print(round(n_chars/n_words), round(n_words/n_sents), round(n_words/n_vocab), fileid)",
"chr: 887071 wor: 192427 sen: 7752 voc: 7344 austen-emma.txt\n5 25 26 austen-emma.txt\nchr: 466292 wor: 98171 sen: 3747 voc: 5835 austen-persuasion.txt\n5 26 17 austen-persuasion.txt\nchr: 673022 wor: 141576 sen: 4999 voc: 6403 austen-sense.txt\n5 28 22 austen-sense.txt\nchr: 4332554 wor: 1010654 sen: 30103 voc: 12767 bible-kjv.txt\n4 34 79 bible-kjv.txt\nchr: 38153 wor: 8354 sen: 438 voc: 1535 blake-poems.txt\n5 19 5 blake-poems.txt\nchr: 249439 wor: 55563 sen: 2863 voc: 3940 bryant-stories.txt\n4 19 14 bryant-stories.txt\nchr: 84663 wor: 18963 sen: 1054 voc: 1559 burgess-busterbrown.txt\n4 18 12 burgess-busterbrown.txt\nchr: 144395 wor: 34110 sen: 1703 voc: 2636 carroll-alice.txt\n4 20 13 carroll-alice.txt\nchr: 457450 wor: 96996 sen: 4779 voc: 8335 chesterton-ball.txt\n5 20 12 chesterton-ball.txt\nchr: 406629 wor: 86063 sen: 3806 voc: 7794 chesterton-brown.txt\n5 23 11 chesterton-brown.txt\nchr: 320525 wor: 69213 sen: 3742 voc: 6349 chesterton-thursday.txt\n5 18 11 chesterton-thursday.txt\nchr: 935158 wor: 210663 sen: 10230 voc: 8447 edgeworth-parents.txt\n4 21 25 edgeworth-parents.txt\nchr: 1242990 wor: 260819 sen: 10059 voc: 17231 melville-moby_dick.txt\n5 26 15 melville-moby_dick.txt\nchr: 468220 wor: 96825 sen: 1851 voc: 9021 milton-paradise.txt\n5 52 11 milton-paradise.txt\nchr: 112310 wor: 25833 sen: 2163 voc: 3032 shakespeare-caesar.txt\n4 12 9 shakespeare-caesar.txt\nchr: 162881 wor: 37360 sen: 3106 voc: 4716 shakespeare-hamlet.txt\n4 12 8 shakespeare-hamlet.txt\nchr: 100351 wor: 23140 sen: 1907 voc: 3464 shakespeare-macbeth.txt\n4 12 7 shakespeare-macbeth.txt\nchr: 711215 wor: 154883 sen: 4250 voc: 12452 whitman-leaves.txt\n5 36 12 whitman-leaves.txt\n"
],
[
"machbeth = gutenberg.sents(\"shakespeare-macbeth.txt\")\nls = max(len(w) for w in machbeth)\n[s for s in machbeth if len(s) == ls]",
"_____no_output_____"
],
[
"from nltk.corpus import webtext\nfor fileid in webtext.fileids():\n print(fileid, len(webtext.raw(fileid)), webtext.raw(fileid)[:20])",
"firefox.txt 564601 Cookie Manager: \"Don\ngrail.txt 65003 SCENE 1: [wind] [clo\noverheard.txt 830118 White guy: So, do yo\npirates.txt 95368 PIRATES OF THE CARRI\nsingles.txt 21302 25 SEXY MALE, seeks \nwine.txt 149772 Lovely delicate, fra\n"
],
[
"from nltk.corpus import brown\nbrown.categories()",
"_____no_output_____"
],
[
"brown.words(categories=[\"lore\", \"reviews\"])",
"_____no_output_____"
],
[
"brown.words(fileids=['cg22'])",
"_____no_output_____"
],
[
"brown.sents(categories=['news', 'editorial', 'reviews']) ",
"_____no_output_____"
],
[
"from nltk.corpus import reuters\nprint(reuters.fileids()[:10])\nprint(reuters.categories()[:10])",
"['test/14826', 'test/14828', 'test/14829', 'test/14832', 'test/14833', 'test/14839', 'test/14840', 'test/14841', 'test/14842', 'test/14843']\n['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa', 'coconut', 'coconut-oil', 'coffee']\n"
],
[
"reuters.categories('training/9865')",
"_____no_output_____"
],
[
"reuters.categories(['training/9865', 'training/9880'])",
"_____no_output_____"
],
[
"reuters.fileids('barley')\nreuters.fileids(['barley', 'corn'])",
"_____no_output_____"
],
[
"reuters.words('training/9865')[:14]",
"_____no_output_____"
],
[
"from nltk.corpus import inaugural\ninaugural.fileids()\nprint([fileid[:4] for fileid in inaugural.fileids()])\nimport matplotlib.pyplot as plt\n\ny = [int(fileid[:4]) for fileid in inaugural.fileids()]\nx = range(0, len(y))\nplt.plot(y)",
"['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', '1825', '1829', '1833', '1837', '1841', '1845', '1849', '1853', '1857', '1861', '1865', '1869', '1873', '1877', '1881', '1885', '1889', '1893', '1897', '1901', '1905', '1909', '1913', '1917', '1921', '1925', '1929', '1933', '1937', '1941', '1945', '1949', '1953', '1957', '1961', '1965', '1969', '1973', '1977', '1981', '1985', '1989', '1993', '1997', '2001', '2005', '2009']\n"
],
[
"cfd = nltk.ConditionalFreqDist(\n (target, fileid[:4]) for fileid in inaugural.fileids() \\\n for w in inaugural.words(fileid) \\\n for target in [\"america\", \"citizen\"] if w.lower().startswith(target)\n)\ncfd.plot()",
"_____no_output_____"
],
[
"from nltk.corpus import udhr\n\nlanguages = ['Chickasaw', 'English', 'German_Deutsch', 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']\ncfd = nltk.ConditionalFreqDist( \n (lang, len(word)) \\\n for lang in languages \\\n for word in udhr.words(lang + '-Latin1')\n)\ncfd.plot(cumulative=True)",
"_____no_output_____"
],
[
"cfd.tabulate(conditions=['English', 'German_Deutsch'], samples=range(10), cumulative=True)",
" 0 1 2 3 4 5 6 7 8 9 \n English 0 185 525 883 997 1166 1283 1440 1558 1638 \nGerman_Deutsch 0 171 263 614 717 894 1013 1110 1213 1275 \n"
],
[
"turkish_raw = udhr.raw(\"Turkish_Turkce-Turkish\")\nnltk.FreqDist(turkish_raw).plot()",
"_____no_output_____"
],
[
"inaugural.readme()",
"_____no_output_____"
],
[
"from nltk.corpus import brown\ncfd = nltk.ConditionalFreqDist(\n (genre, word)\\\n for genre in brown.categories() \\\n for word in brown.words(categories=genre)\n)",
"_____no_output_____"
],
[
"cfd.items()",
"_____no_output_____"
],
[
"days = [\"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\", \"Sunday\"]\ncfd.tabulate(samples=days)",
" Monday Tuesday Wednesday Thursday Friday Saturday Sunday \n adventure 1 0 0 0 0 0 0 \n belles_lettres 0 1 1 2 2 0 4 \n editorial 1 0 1 1 0 3 4 \n fiction 0 2 1 2 1 3 3 \n government 3 1 0 1 0 4 9 \n hobbies 1 0 0 1 3 0 2 \n humor 1 0 0 0 0 3 0 \n learned 0 4 3 1 3 1 1 \n lore 0 1 1 1 2 2 5 \n mystery 5 2 1 1 2 2 4 \n news 54 43 22 20 41 33 51 \n religion 0 0 0 0 2 0 8 \n reviews 0 1 2 2 1 12 4 \n romance 2 3 3 1 3 4 5 \nscience_fiction 0 0 0 0 0 0 1 \n"
],
[
"genre_word = [\n (genre, word)\\\n for genre in [\"news\", \"romance\"] \\\n for word in brown.words(categories=genre)\n]\nlen(genre_word)",
"_____no_output_____"
],
[
"genre_word[:4]",
"_____no_output_____"
],
[
"cfd = nltk.ConditionalFreqDist(genre_word)",
"_____no_output_____"
],
[
"cfd.conditions()",
"_____no_output_____"
],
[
"cfd[\"romance\"].most_common()",
"_____no_output_____"
],
[
"sent = ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven',\n... 'and', 'the', 'earth', '.']\nlist(nltk.bigrams(sent))",
"_____no_output_____"
],
[
"def generate_model(cfdist, word, num=15):\n for i in range(num):\n print(word, end=' ')\n word = cfdist[word].max()\n\ntext = nltk.corpus.genesis.words('english-kjv.txt')\nbigrams = nltk.bigrams(text)\ncfd = nltk.ConditionalFreqDist(bigrams)\ncfd['living']",
"_____no_output_____"
],
[
"generate_model(cfd, \"living\")",
"living creature that he said , and the land of the land of the land "
],
[
"cfd['creature']",
"_____no_output_____"
],
[
"from nltk.book import *",
"_____no_output_____"
],
[
"list(nltk.bigrams(text))",
"_____no_output_____"
],
[
"vocal = sorted(set(text))",
"_____no_output_____"
],
[
"text",
"_____no_output_____"
],
[
"def unusual_words(text):\n text_vocab = set(w.lower() for w in text if w.isalpha())\n english_vocab = set(w.lower() for w in nltk.corpus.words.words())\n unusual = text_vocab - english_vocab\n return sorted(unusual)",
"_____no_output_____"
],
[
"unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))",
"_____no_output_____"
],
[
"unusual_words(nltk.corpus.nps_chat.words())",
"_____no_output_____"
],
[
"def frac_stopwords(text):\n stopwords = nltk.corpus.stopwords.words('english')\n content = [w for w in text if w.lower() not in stopwords]\n return len(content) / len(text)\nfrac_stopwords(text)\nfrac_stopwords(nltk.corpus.reuters.words())",
"_____no_output_____"
],
[
"puzzle_letters = nltk.FreqDist('egivrvonl')\nobligatory = 'r'\nwordlist = nltk.corpus.words.words()",
"_____no_output_____"
],
[
"[w for w in wordlist \n if len(w) >= 6 and \n obligatory in w and \n nltk.FreqDist(w) <= puzzle_letters\n]",
"_____no_output_____"
],
[
"nltk.FreqDist('sdfsd') <= puzzle_letters",
"_____no_output_____"
],
[
"names = nltk.corpus.names\nmale_names, female_names = names.words('male.txt'), names.words('female.txt')\n[w for w in male_names if w in female_names]",
"_____no_output_____"
],
[
"from nltk import ConditionalFreqDist\ncfd = ConditionalFreqDist(\n (fileid, name[-1])\n for fileid in names.fileids()\n for name in names.words(fileid)\n)\ncfd.plot()",
"_____no_output_____"
],
[
"entries = nltk.corpus.cmudict.entries()\nfor entry in entries[42371:42380]:\n print(entry)",
"('fir', ['F', 'ER1'])\n('fire', ['F', 'AY1', 'ER0'])\n('fire', ['F', 'AY1', 'R'])\n('firearm', ['F', 'AY1', 'ER0', 'AA2', 'R', 'M'])\n('firearm', ['F', 'AY1', 'R', 'AA2', 'R', 'M'])\n('firearms', ['F', 'AY1', 'ER0', 'AA2', 'R', 'M', 'Z'])\n('firearms', ['F', 'AY1', 'R', 'AA2', 'R', 'M', 'Z'])\n('fireball', ['F', 'AY1', 'ER0', 'B', 'AO2', 'L'])\n('fireball', ['F', 'AY1', 'R', 'B', 'AO2', 'L'])\n"
],
[
"for word, pron in entries: \n if len(pron) == 3: \n ph1, ph2, ph3 = pron\n if ph1 == 'P' and ph3 == 'N':\n print(word, ph2, end=' ')",
"paign EY1 pain EY1 paine EY1 pan AE1 pane EY1 pawn AO1 payne EY1 peine IY1 pen EH1 penh EH1 penn EH1 pin IH1 pine AY1 pinn IH1 pon AA1 poon UW1 pun AH1 pyne AY1 "
],
[
"syllable = ['N', 'IH0', 'K', 'S']\n[word for word, pron in entries if pron[-4:] == syllable]",
"_____no_output_____"
],
[
"prondict = nltk.corpus.cmudict.dict()\nprondict['fire']",
"_____no_output_____"
],
[
"from nltk.corpus import swadesh\nswadesh.fileids()\nswadesh.words('en')",
"_____no_output_____"
],
[
"fr2en = swadesh.entries(['fr', 'en'])\ntranslate = dict(fr2en)\ntranslate['chien']\ntranslate['jeter']",
"_____no_output_____"
],
[
"languages = ['en', 'de', 'nl', 'es', 'fr', 'pt', 'la']\nfor i in [139, 140, 141, 142]:\n print(swadesh.entries(languages)[i])",
"('say', 'sagen', 'zeggen', 'decir', 'dire', 'dizer', 'dicere')\n('sing', 'singen', 'zingen', 'cantar', 'chanter', 'cantar', 'canere')\n('play', 'spielen', 'spelen', 'jugar', 'jouer', 'jogar, brincar', 'ludere')\n('float', 'schweben', 'zweven', 'flotar', 'flotter', 'flutuar, boiar', 'fluctuare')\n"
],
[
"from nltk.corpus import wordnet as wn\nwn.synsets('motorcar')",
"_____no_output_____"
],
[
"wn.synset('car.n.01').lemma_names()",
"_____no_output_____"
],
[
"wn.synset('car.n.01').definition()",
"_____no_output_____"
],
[
"wn.synset('car.n.01').examples()",
"_____no_output_____"
],
[
"wn.lemma('car.n.01.automobile')",
"_____no_output_____"
],
[
"wn.lemma('car.n.01.automobile').synset()",
"_____no_output_____"
],
[
"wn.synsets('car')",
"_____no_output_____"
],
[
"for synset in wn.synsets('car'):\n print(synset.lemma_names())",
"['car', 'auto', 'automobile', 'machine', 'motorcar']\n['car', 'railcar', 'railway_car', 'railroad_car']\n['car', 'gondola']\n['car', 'elevator_car']\n['cable_car', 'car']\n"
],
[
"wn.lemmas('car')",
"_____no_output_____"
],
[
"for synset in wn.synsets('dish'):\n print(synset.lemma_names())\n print(synset.definition())",
"['dish']\na piece of dishware normally used as a container for holding or serving food\n['dish']\na particular item of prepared food\n['dish', 'dishful']\nthe quantity that a dish will hold\n['smasher', 'stunner', 'knockout', 'beauty', 'ravisher', 'sweetheart', 'peach', 'lulu', 'looker', 'mantrap', 'dish']\na very attractive or seductive looking woman\n['dish', 'dish_aerial', 'dish_antenna', 'saucer']\ndirectional antenna consisting of a parabolic reflector for microwave or radio frequency radiation\n['cup_of_tea', 'bag', 'dish']\nan activity that you like or at which you are superior\n['serve', 'serve_up', 'dish_out', 'dish_up', 'dish']\nprovide (usually but not necessarily food)\n['dish']\nmake concave; shape like a dish\n"
],
[
"typmtrcr = wn.synset('car.n.01').hyponyms()[0].hyponyms()",
"_____no_output_____"
],
[
"sorted(lemma.name() for synset in typmtrcr for lemma in synset.lemmas())",
"_____no_output_____"
],
[
"motorcar = wn.synset('car.n.01')\nmotorcar.hypernyms()",
"_____no_output_____"
],
[
"paths = motorcar.hypernym_paths()\n[synset.name() for synset in paths[0]]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d008b78daee5bcdf6322ef68f1f17bddcd199edb
| 109,909 |
ipynb
|
Jupyter Notebook
|
notebooks/water_quality.ipynb
|
Skydipper/CNN-tests
|
43c80bc1871b13c64035e07cda64a744575e61e7
|
[
"MIT"
] | 7 |
2020-02-10T17:23:42.000Z
|
2022-03-30T16:09:07.000Z
|
notebooks/water_quality.ipynb
|
Skydipper/CNN-tests
|
43c80bc1871b13c64035e07cda64a744575e61e7
|
[
"MIT"
] | 1 |
2020-02-10T16:56:20.000Z
|
2020-02-10T17:00:20.000Z
|
notebooks/water_quality.ipynb
|
Skydipper/CNN-tests
|
43c80bc1871b13c64035e07cda64a744575e61e7
|
[
"MIT"
] | 3 |
2020-09-03T23:10:48.000Z
|
2021-08-01T08:35:48.000Z
| 48.546378 | 14,436 | 0.663876 |
[
[
[
"# Water quality\n## Setup software libraries",
"_____no_output_____"
]
],
[
[
"# Import and initialize the Earth Engine library.\nimport ee\nee.Initialize()\nee.__version__",
"_____no_output_____"
],
[
"# Folium setup.\nimport folium\nprint(folium.__version__)",
"0.8.3\n"
],
[
"# Skydipper library.\nimport Skydipper\nprint(Skydipper.__version__)",
"0.1.7\n"
],
[
"import matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport functools\nimport json\nimport uuid\nimport os\nfrom pprint import pprint\nimport env\nimport time",
"_____no_output_____"
],
[
"import ee_collection_specifics",
"_____no_output_____"
]
],
[
[
"## Composite image\n**Variables**",
"_____no_output_____"
]
],
[
[
"collection = 'Lake-Water-Quality-100m'\ninit_date = '2019-01-21'\nend_date = '2019-01-31'",
"_____no_output_____"
],
[
"# Define the URL format used for Earth Engine generated map tiles.\nEE_TILES = 'https://earthengine.googleapis.com/map/{mapid}/{{z}}/{{x}}/{{y}}?token={token}'\n\ncomposite = ee_collection_specifics.Composite(collection)(init_date, end_date)\nmapid = composite.getMapId(ee_collection_specifics.vizz_params_rgb(collection))\n\ntiles_url = EE_TILES.format(**mapid)\n\nmap = folium.Map(location=[39.31, 0.302])\nfolium.TileLayer(\ntiles=tiles_url,\nattr='Google Earth Engine',\noverlay=True,\nname=str(ee_collection_specifics.ee_bands_rgb(collection))).add_to(map)\n \nmap.add_child(folium.LayerControl())\nmap",
"_____no_output_____"
]
],
[
[
"***\n## Geostore\n\nWe select the areas from which we will export the training data.\n\n**Variables**",
"_____no_output_____"
]
],
[
[
"def polygons_to_multipoligon(polygons):\n multipoligon = []\n MultiPoligon = {}\n for polygon in polygons.get('features'):\n multipoligon.append(polygon.get('geometry').get('coordinates'))\n \n MultiPoligon = {\n \"type\": \"FeatureCollection\",\n \"features\": [\n {\n \"type\": \"Feature\",\n \"properties\": {},\n \"geometry\": {\n \"type\": \"MultiPolygon\",\n \"coordinates\": multipoligon\n }\n }\n ]\n }\n \n return MultiPoligon",
"_____no_output_____"
],
[
"#trainPolygons = {\"type\":\"FeatureCollection\",\"features\":[{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-0.45043945312499994,39.142842478062505],[0.06042480468749999,39.142842478062505],[0.06042480468749999,39.55064761909318],[-0.45043945312499994,39.55064761909318],[-0.45043945312499994,39.142842478062505]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-0.2911376953125,38.659777730712534],[0.2581787109375,38.659777730712534],[0.2581787109375,39.10022600175347],[-0.2911376953125,39.10022600175347],[-0.2911376953125,38.659777730712534]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-0.3350830078125,39.56758783088905],[0.22521972656249997,39.56758783088905],[0.22521972656249997,39.757879992021756],[-0.3350830078125,39.757879992021756],[-0.3350830078125,39.56758783088905]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[0.07965087890625,39.21310328979648],[0.23345947265625,39.21310328979648],[0.23345947265625,39.54852980171147],[0.07965087890625,39.54852980171147],[0.07965087890625,39.21310328979648]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-1.0931396484375,35.7286770448517],[-0.736083984375,35.7286770448517],[-0.736083984375,35.94243575255426],[-1.0931396484375,35.94243575255426],[-1.0931396484375,35.7286770448517]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-1.7303466796874998,35.16931803601131],[-1.4666748046875,35.16931803601131],[-1.4666748046875,35.74205383068037],[-1.7303466796874998,35.74205383068037],[-1.7303466796874998,35.16931803601131]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-1.42822265625,35.285984736065764],[-1.131591796875,35.285984736065764],[-1.131591796875,35.782170703266075],[-1.42822265625,35.782170703266075],[-1.42822265625,35.285984736065764]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-1.8127441406249998,35.831174956246535],[-1.219482421875,35.831174956246535],[-1.219482421875,36.04465753921525],[-1.8127441406249998,36.04465753921525],[-1.8127441406249998,35.831174956246535]]]}}]}\ntrainPolygons = {\"type\":\"FeatureCollection\",\"features\":[{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-0.406494140625,38.64476310916202],[0.27740478515625,38.64476310916202],[0.27740478515625,39.74521015328692],[-0.406494140625,39.74521015328692],[-0.406494140625,38.64476310916202]]]}},{\"type\":\"Feature\",\"properties\":{},\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[-1.70013427734375,35.15135442846945],[-0.703125,35.15135442846945],[-0.703125,35.94688293218141],[-1.70013427734375,35.94688293218141],[-1.70013427734375,35.15135442846945]]]}}]}\ntrainPolys = polygons_to_multipoligon(trainPolygons)\n\nevalPolys = None",
"_____no_output_____"
],
[
"nTrain = len(trainPolys.get('features')[0].get('geometry').get('coordinates'))\nprint('Number of training polygons:', nTrain)\n\nif evalPolys:\n nEval = len(evalPolys.get('features')[0].get('geometry').get('coordinates'))\n print('Number of training polygons:', nEval)",
"Number of training polygons: 2\n"
]
],
[
[
"**Display Polygons**",
"_____no_output_____"
]
],
[
[
"# Define the URL format used for Earth Engine generated map tiles.\nEE_TILES = 'https://earthengine.googleapis.com/map/{mapid}/{{z}}/{{x}}/{{y}}?token={token}'\n\ncomposite = ee_collection_specifics.Composite(collection)(init_date, end_date)\nmapid = composite.getMapId(ee_collection_specifics.vizz_params_rgb(collection))\n\ntiles_url = EE_TILES.format(**mapid)\n\nmap = folium.Map(location=[39.31, 0.302], zoom_start=6)\nfolium.TileLayer(\ntiles=tiles_url,\nattr='Google Earth Engine',\noverlay=True,\nname=str(ee_collection_specifics.ee_bands_rgb(collection))).add_to(map)\n \n\n# Convert the GeoJSONs to feature collections\ntrainFeatures = ee.FeatureCollection(trainPolys.get('features'))\nif evalPolys:\n evalFeatures = ee.FeatureCollection(evalPolys.get('features'))\n \npolyImage = ee.Image(0).byte().paint(trainFeatures, 1)\nif evalPolys:\n polyImage = ee.Image(0).byte().paint(trainFeatures, 1).paint(evalFeatures, 2)\npolyImage = polyImage.updateMask(polyImage)\n\nmapid = polyImage.getMapId({'min': 1, 'max': 2, 'palette': ['red', 'blue']})\nfolium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name='training polygons',\n ).add_to(map)\n\nmap.add_child(folium.LayerControl())\nmap",
"_____no_output_____"
]
],
[
[
"***\n## Data pre-processing\n\nWe normalize the composite images to have values from 0 to 1.\n\n**Variables**",
"_____no_output_____"
]
],
[
[
"input_dataset = 'Sentinel-2-Top-of-Atmosphere-Reflectance'\noutput_dataset = 'Lake-Water-Quality-100m'\ninit_date = '2019-01-21'\nend_date = '2019-01-31'\nscale = 100 #scale in meters\ncollections = [input_dataset, output_dataset]",
"_____no_output_____"
]
],
[
[
"**Normalize images**",
"_____no_output_____"
]
],
[
[
"def min_max_values(image, collection, scale, polygons=None):\n \n normThreshold = ee_collection_specifics.ee_bands_normThreshold(collection)\n \n num = 2\n lon = np.linspace(-180, 180, num)\n lat = np.linspace(-90, 90, num)\n \n features = []\n for i in range(len(lon)-1):\n for j in range(len(lat)-1):\n features.append(ee.Feature(ee.Geometry.Rectangle(lon[i], lat[j], lon[i+1], lat[j+1])))\n \n if not polygons:\n polygons = ee.FeatureCollection(features)\n \n regReducer = {\n 'geometry': polygons,\n 'reducer': ee.Reducer.minMax(),\n 'maxPixels': 1e10,\n 'bestEffort': True,\n 'scale':scale,\n 'tileScale': 10\n \n }\n \n values = image.reduceRegion(**regReducer).getInfo()\n print(values)\n \n # Avoid outliers by taking into account only the normThreshold% of the data points.\n regReducer = {\n 'geometry': polygons, \n 'reducer': ee.Reducer.histogram(),\n 'maxPixels': 1e10,\n 'bestEffort': True,\n 'scale':scale,\n 'tileScale': 10\n \n }\n \n hist = image.reduceRegion(**regReducer).getInfo()\n\n for band in list(normThreshold.keys()):\n if normThreshold[band] != 100:\n count = np.array(hist.get(band).get('histogram'))\n x = np.array(hist.get(band).get('bucketMeans'))\n \n cumulative_per = np.cumsum(count/count.sum()*100)\n \n values[band+'_max'] = x[np.where(cumulative_per < normThreshold[band])][-1]\n \n return values\n\ndef normalize_ee_images(image, collection, values):\n \n Bands = ee_collection_specifics.ee_bands(collection)\n \n # Normalize [0, 1] ee images\n for i, band in enumerate(Bands):\n if i == 0:\n image_new = image.select(band).clamp(values[band+'_min'], values[band+'_max'])\\\n .subtract(values[band+'_min'])\\\n .divide(values[band+'_max']-values[band+'_min'])\n else:\n image_new = image_new.addBands(image.select(band).clamp(values[band+'_min'], values[band+'_max'])\\\n .subtract(values[band+'_min'])\\\n .divide(values[band+'_max']-values[band+'_min']))\n \n return image_new",
"_____no_output_____"
],
[
"%%time\n\nimages = []\nfor collection in collections:\n # Create composite\n image = ee_collection_specifics.Composite(collection)(init_date, end_date)\n \n bands = ee_collection_specifics.ee_bands(collection)\n image = image.select(bands)\n \n #Create composite\n if ee_collection_specifics.normalize(collection):\n # Get min man values for each band\n values = min_max_values(image, collection, scale, polygons=trainFeatures)\n print(values)\n \n # Normalize images\n image = normalize_ee_images(image, collection, values)\n else:\n values = {}\n \n images.append(image)",
"{'B11_max': 10857.5, 'B11_min': 7.0, 'B12_max': 10691.0, 'B12_min': 1.0, 'B1_max': 6806.0, 'B1_min': 983.0, 'B2_max': 6406.0, 'B2_min': 685.0, 'B3_max': 6182.0, 'B3_min': 412.0, 'B4_max': 7485.5, 'B4_min': 229.0, 'B5_max': 8444.0, 'B5_min': 186.0, 'B6_max': 9923.0, 'B6_min': 153.0, 'B7_max': 11409.0, 'B7_min': 128.0, 'B8A_max': 12957.0, 'B8A_min': 84.0, 'B8_max': 7822.0, 'B8_min': 104.0, 'ndvi_max': 0.8359633027522936, 'ndvi_min': -0.6463519313304721, 'ndwi_max': 0.7134948096885814, 'ndwi_min': -0.8102189781021898}\n{'B11_max': 10857.5, 'B11_min': 7.0, 'B12_max': 10691.0, 'B12_min': 1.0, 'B1_max': 1330.4577965925364, 'B1_min': 983.0, 'B2_max': 1039.5402534802865, 'B2_min': 685.0, 'B3_max': 879.698114934553, 'B3_min': 412.0, 'B4_max': 751.6494664084341, 'B4_min': 229.0, 'B5_max': 1119.607360754671, 'B5_min': 186.0, 'B6_max': 1823.92697289679, 'B6_min': 153.0, 'B7_max': 2079.961473786427, 'B7_min': 128.0, 'B8A_max': 2207.831974029281, 'B8A_min': 84.0, 'B8_max': 2031.6418424876374, 'B8_min': 104.0, 'ndvi_max': 0.8359633027522936, 'ndvi_min': -0.6463519313304721, 'ndwi_max': 0.7134948096885814, 'ndwi_min': -0.8102189781021898}\nCPU times: user 45.8 ms, sys: 4.96 ms, total: 50.7 ms\nWall time: 9.69 s\n"
]
],
[
[
"**Display composite**",
"_____no_output_____"
]
],
[
[
"# Define the URL format used for Earth Engine generated map tiles.\nEE_TILES = 'https://earthengine.googleapis.com/map/{mapid}/{{z}}/{{x}}/{{y}}?token={token}'\nmap = folium.Map(location=[39.31, 0.302], zoom_start=6)\nfor n, collection in enumerate(collections):\n for params in ee_collection_specifics.vizz_params(collection):\n mapid = images[n].getMapId(params)\n folium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name=str(params['bands']),\n ).add_to(map)\n \n# Convert the GeoJSONs to feature collections\ntrainFeatures = ee.FeatureCollection(trainPolys.get('features'))\nif evalPolys:\n evalFeatures = ee.FeatureCollection(evalPolys.get('features'))\n \npolyImage = ee.Image(0).byte().paint(trainFeatures, 1)\nif evalPolys:\n polyImage = ee.Image(0).byte().paint(trainFeatures, 1).paint(evalFeatures, 2)\npolyImage = polyImage.updateMask(polyImage)\n\nmapid = polyImage.getMapId({'min': 1, 'max': 2, 'palette': ['red', 'blue']})\nfolium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name='training polygons',\n ).add_to(map)\n\nmap.add_child(folium.LayerControl())\nmap",
"_____no_output_____"
]
],
[
[
"***\n## Create TFRecords for training\n### Export pixels\n**Variables**",
"_____no_output_____"
]
],
[
[
"input_bands = ['B2','B3','B4','B5','ndvi','ndwi']\noutput_bands = ['turbidity_blended_mean']\nbands = [input_bands, output_bands]\n\ndataset_name = 'Sentinel2_WaterQuality'\nbase_names = ['training_pixels', 'eval_pixels']\nbucket = env.bucket_name\nfolder = 'cnn-models/'+dataset_name+'/data'",
"_____no_output_____"
]
],
[
[
"**Select the bands**",
"_____no_output_____"
]
],
[
[
"# Select the bands we want\nc = images[0].select(bands[0])\\\n.addBands(images[1].select(bands[1]))\n\npprint(c.getInfo())",
"{'bands': [{'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.0,\n 'min': 0.0,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'B2'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.0,\n 'min': 0.0,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'B3'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.0,\n 'min': 0.0,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'B4'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.0,\n 'min': 0.0,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'B5'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.000000004087453,\n 'min': -1.449649135231728e-09,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'ndvi'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [1.0, 0.0, 0.0, 0.0, 1.0, 0.0],\n 'data_type': {'max': 1.0000000181106892,\n 'min': -7.70938799632259e-09,\n 'precision': 'double',\n 'type': 'PixelType'},\n 'id': 'ndwi'},\n {'crs': 'EPSG:4326',\n 'crs_transform': [0.000898311174991017,\n 0.0,\n -10.06198347107437,\n 0.0,\n -0.000898311174991017,\n 43.89328063241106],\n 'data_type': {'precision': 'float', 'type': 'PixelType'},\n 'dimensions': [15043, 10004],\n 'id': 'turbidity_blended_mean'}],\n 'type': 'Image'}\n"
]
],
[
[
"**Sample pixels**",
"_____no_output_____"
]
],
[
[
"sr = c.sample(region = trainFeatures, scale = scale, numPixels=20000, tileScale=4, seed=999)\n\n# Add random column\nsr = sr.randomColumn(seed=999)\n\n# Partition the sample approximately 70-30.\ntrain_dataset = sr.filter(ee.Filter.lt('random', 0.7))\neval_dataset = sr.filter(ee.Filter.gte('random', 0.7))",
"_____no_output_____"
],
[
"# Print the first couple points to verify.\npprint({'training': train_dataset.first().getInfo()})\npprint({'testing': eval_dataset.first().getInfo()})",
"{'training': {'geometry': None,\n 'id': '6',\n 'properties': {'B2': 0.8574484759229273,\n 'B3': 0.3634823288175725,\n 'B4': 0.12149634522036754,\n 'B5': 0.05248459048179677,\n 'ndvi': 0.18857628593212067,\n 'ndwi': 0.12332980645053383,\n 'random': 0.2613394930887267,\n 'turbidity_blended_mean': 0.24297301471233368},\n 'type': 'Feature'}}\n{'testing': {'geometry': None,\n 'id': '9',\n 'properties': {'B2': 0.8447559820359103,\n 'B3': 0.36455139449056534,\n 'B4': 0.11097303972883964,\n 'B5': 0.049271248207401044,\n 'ndvi': 0.18537677513643622,\n 'ndwi': 0.11719150831907015,\n 'random': 0.7072425790569007,\n 'turbidity_blended_mean': 0.2145373672246933},\n 'type': 'Feature'}}\n"
],
[
"# Print the first couple points to verify.\nfrom pprint import pprint\ntrain_size=train_dataset.size().getInfo()\neval_size=eval_dataset.size().getInfo()\n\npprint({'training': train_size})\npprint({'testing': eval_size})",
"{'training': 8091}\n{'testing': 3508}\n"
]
],
[
[
"**Export the training and validation data**",
"_____no_output_____"
]
],
[
[
"def export_TFRecords_pixels(datasets, base_names, bucket, folder, selectors):\n # Export all the training/evaluation data \n \n filePaths = []\n for n, dataset in enumerate(datasets):\n \n filePaths.append(bucket+ '/' + folder + '/' + base_names[n])\n \n # Create the tasks.\n task = ee.batch.Export.table.toCloudStorage(\n collection = dataset,\n description = 'Export '+base_names[n],\n fileNamePrefix = folder + '/' + base_names[n],\n bucket = bucket,\n fileFormat = 'TFRecord',\n selectors = selectors)\n \n task.start()\n \n return filePaths",
"_____no_output_____"
],
[
"datasets = [train_dataset, eval_dataset]\nselectors = input_bands + output_bands\n\n# Export training/evaluation data\nfilePaths = export_TFRecords_pixels(datasets, base_names, bucket, folder, selectors)",
"_____no_output_____"
]
],
[
[
"***\n## Inspect data\n### Inspect pixels\nLoad the data exported from Earth Engine into a tf.data.Dataset. \n\n**Helper functions**",
"_____no_output_____"
]
],
[
[
"# Tensorflow setup.\nimport tensorflow as tf\n\nif tf.__version__ == '1.15.0':\n tf.enable_eager_execution()\nprint(tf.__version__)",
"1.15.0\n"
],
[
"def parse_function(proto):\n \"\"\"The parsing function.\n Read a serialized example into the structure defined by FEATURES_DICT.\n Args:\n example_proto: a serialized Example.\n Returns: \n A tuple of the predictors dictionary and the labels.\n \"\"\"\n \n # Define your tfrecord \n features = input_bands + output_bands\n \n # Specify the size and shape of patches expected by the model.\n columns = [\n tf.io.FixedLenFeature(shape=[1,1], dtype=tf.float32) for k in features\n ]\n \n features_dict = dict(zip(features, columns))\n \n # Load one example\n parsed_features = tf.io.parse_single_example(proto, features_dict)\n \n # Convert a dictionary of tensors to a tuple of (inputs, outputs)\n inputsList = [parsed_features.get(key) for key in features]\n stacked = tf.stack(inputsList, axis=0)\n \n # Convert the tensors into a stack in HWC shape\n stacked = tf.transpose(stacked, [1, 2, 0])\n \n return stacked[:,:,:len(input_bands)], stacked[:,:,len(input_bands):]\n\ndef get_dataset(glob, buffer_size, batch_size):\n \"\"\"Get the dataset\n Returns: \n A tf.data.Dataset of training data.\n \"\"\"\n glob = tf.compat.v1.io.gfile.glob(glob)\n \n dataset = tf.data.TFRecordDataset(glob, compression_type='GZIP')\n dataset = dataset.map(parse_function, num_parallel_calls=5)\n \n dataset = dataset.shuffle(buffer_size).batch(batch_size).repeat()\n return dataset",
"_____no_output_____"
]
],
[
[
"**Variables**",
"_____no_output_____"
]
],
[
[
"buffer_size = 100\nbatch_size = 4",
"_____no_output_____"
]
],
[
[
"**Dataset**",
"_____no_output_____"
]
],
[
[
"glob = 'gs://' + bucket + '/' + folder + '/' + base_names[0] + '*'\ndataset = get_dataset(glob, buffer_size, batch_size)\ndataset",
"_____no_output_____"
]
],
[
[
"**Check the first record**",
"_____no_output_____"
]
],
[
[
"arr = iter(dataset.take(1)).next()\ninput_arr = arr[0].numpy()\nprint(input_arr.shape)\noutput_arr = arr[1].numpy()\nprint(output_arr.shape)",
"(4, 1, 1, 6)\n(4, 1, 1, 1)\n"
]
],
[
[
"***\n## Training the model locally\n**Variables**",
"_____no_output_____"
]
],
[
[
"job_dir = 'gs://' + bucket + '/' + 'cnn-models/'+ dataset_name +'/trainer'\nlogs_dir = job_dir + '/logs'\nmodel_dir = job_dir + '/model'\nshuffle_size = 2000\nbatch_size = 4\nepochs=50\ntrain_size=train_size\neval_size=eval_size\noutput_activation=''",
"_____no_output_____"
]
],
[
[
"**Training/evaluation data**\n\nThe following is code to load training/evaluation data.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\ndef parse_function(proto):\n \"\"\"The parsing function.\n Read a serialized example into the structure defined by FEATURES_DICT.\n Args:\n example_proto: a serialized Example.\n Returns: \n A tuple of the predictors dictionary and the labels.\n \"\"\"\n \n # Define your tfrecord \n features = input_bands + output_bands\n \n # Specify the size and shape of patches expected by the model.\n columns = [\n tf.io.FixedLenFeature(shape=[1,1], dtype=tf.float32) for k in features\n ]\n \n features_dict = dict(zip(features, columns))\n \n # Load one example\n parsed_features = tf.io.parse_single_example(proto, features_dict)\n \n # Convert a dictionary of tensors to a tuple of (inputs, outputs)\n inputsList = [parsed_features.get(key) for key in features]\n stacked = tf.stack(inputsList, axis=0)\n \n # Convert the tensors into a stack in HWC shape\n stacked = tf.transpose(stacked)\n \n return stacked[:,:,:len(input_bands)], stacked[:,:,len(input_bands):]\n\ndef get_dataset(glob):\n \"\"\"Get the dataset\n Returns: \n A tf.data.Dataset of training data.\n \"\"\"\n glob = tf.compat.v1.io.gfile.glob(glob)\n \n dataset = tf.data.TFRecordDataset(glob, compression_type='GZIP')\n dataset = dataset.map(parse_function, num_parallel_calls=5)\n \n return dataset\n\n\ndef get_training_dataset():\n \"\"\"Get the preprocessed training dataset\n Returns: \n A tf.data.Dataset of training data.\n \"\"\"\n glob = 'gs://' + bucket + '/' + folder + '/' + base_names[0] + '*'\n dataset = get_dataset(glob)\n dataset = dataset.shuffle(shuffle_size).batch(batch_size).repeat()\n return dataset\n\ndef get_evaluation_dataset():\n \"\"\"Get the preprocessed evaluation dataset\n Returns: \n A tf.data.Dataset of evaluation data.\n \"\"\"\n glob = 'gs://' + bucket + '/' + folder + '/' + base_names[1] + '*'\n dataset = get_dataset(glob)\n dataset = dataset.batch(1).repeat()\n return dataset",
"_____no_output_____"
]
],
[
[
"**Model**",
"_____no_output_____"
]
],
[
[
"from tensorflow.python.keras import Model # Keras model module\nfrom tensorflow.python.keras.layers import Input, Dense, Dropout, Activation \n\ndef create_keras_model(inputShape, nClasses, output_activation='linear'):\n \n inputs = Input(shape=inputShape, name='vector')\n \n x = Dense(32, input_shape=inputShape, activation='relu')(inputs)\n x = Dropout(0.5)(x)\n x = Dense(128, activation='relu')(x)\n x = Dropout(0.5)(x)\n x = Dense(nClasses)(x)\n \n outputs = Activation(output_activation, name= 'output')(x)\n \n model = Model(inputs=inputs, outputs=outputs, name='sequential')\n \n return model",
"_____no_output_____"
]
],
[
[
"**Training task**\n\nThe following will get the training and evaluation data, train the model and save it when it's done in a Cloud Storage bucket.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport time\nimport os\n \ndef train_and_evaluate():\n \"\"\"Trains and evaluates the Keras model.\n\n Uses the Keras model defined in model.py and trains on data loaded and\n preprocessed in util.py. Saves the trained model in TensorFlow SavedModel\n format to the path defined in part by the --job-dir argument.\n \"\"\"\n\n # Create the Keras Model\n if not output_activation:\n keras_model = create_keras_model(inputShape = (None, None, len(input_bands)), nClasses = len(output_bands))\n else:\n keras_model = create_keras_model(inputShape = (None, None, len(input_bands)), nClasses = len(output_bands), output_activation = output_activation)\n\n # Compile Keras model\n keras_model.compile(loss='mse', optimizer='adam', metrics=['mse'])\n\n\n # Pass a tfrecord\n training_dataset = get_training_dataset()\n evaluation_dataset = get_evaluation_dataset()\n \n # Setup TensorBoard callback.\n tensorboard_cb = tf.keras.callbacks.TensorBoard(logs_dir)\n\n # Train model\n keras_model.fit(\n x=training_dataset,\n steps_per_epoch=int(train_size / batch_size),\n epochs=epochs,\n validation_data=evaluation_dataset,\n validation_steps=int(eval_size / batch_size),\n verbose=1,\n callbacks=[tensorboard_cb])\n \n tf.keras.models.save_model(keras_model, filepath=os.path.join(model_dir, str(int(time.time()))), save_format=\"tf\")\n \n return keras_model",
"_____no_output_____"
],
[
"model = train_and_evaluate()",
"Train for 2022 steps, validate for 877 steps\nEpoch 1/50\n 1/2022 [..............................] - ETA: 36:44 - loss: 0.0110 - mean_squared_error: 0.0110WARNING:tensorflow:Method (on_train_batch_end) is slow compared to the batch update (3.539397). Check your callbacks.\n2022/2022 [==============================] - 15s 7ms/step - loss: 83.2001 - mean_squared_error: 83.2309 - val_loss: 64.3992 - val_mean_squared_error: 64.3992\nEpoch 2/50\n2022/2022 [==============================] - 28s 14ms/step - loss: 78.7397 - mean_squared_error: 78.7687 - val_loss: 59.1074 - val_mean_squared_error: 59.1074\nEpoch 3/50\n2022/2022 [==============================] - 10s 5ms/step - loss: 78.1049 - mean_squared_error: 78.1339 - val_loss: 54.7844 - val_mean_squared_error: 54.7844\nEpoch 4/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 64.1067 - mean_squared_error: 64.1305 - val_loss: 52.8855 - val_mean_squared_error: 52.8855\nEpoch 5/50\n2022/2022 [==============================] - 12s 6ms/step - loss: 65.9322 - mean_squared_error: 65.9566 - val_loss: 49.9769 - val_mean_squared_error: 49.9769\nEpoch 6/50\n2022/2022 [==============================] - 7s 3ms/step - loss: 64.9093 - mean_squared_error: 64.9334 - val_loss: 46.0060 - val_mean_squared_error: 46.0060\nEpoch 7/50\n2022/2022 [==============================] - 7s 3ms/step - loss: 59.9277 - mean_squared_error: 59.9500 - val_loss: 45.4808 - val_mean_squared_error: 45.4808\nEpoch 8/50\n2022/2022 [==============================] - 11s 6ms/step - loss: 60.2654 - mean_squared_error: 60.2877 - val_loss: 43.2340 - val_mean_squared_error: 43.2340\nEpoch 9/50\n2022/2022 [==============================] - 7s 4ms/step - loss: 61.9468 - mean_squared_error: 61.9697 - val_loss: 43.2755 - val_mean_squared_error: 43.2755\nEpoch 10/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 60.1263 - mean_squared_error: 60.1486 - val_loss: 44.4449 - val_mean_squared_error: 44.4449\nEpoch 11/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 68.2141 - mean_squared_error: 68.2394 - val_loss: 40.8561 - val_mean_squared_error: 40.8561\nEpoch 12/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 55.4871 - mean_squared_error: 55.5077 - val_loss: 41.8557 - val_mean_squared_error: 41.8557\nEpoch 13/50\n2022/2022 [==============================] - 18s 9ms/step - loss: 58.3074 - mean_squared_error: 58.3290 - val_loss: 41.2392 - val_mean_squared_error: 41.2392\nEpoch 14/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 62.9377 - mean_squared_error: 62.9610 - val_loss: 39.4673 - val_mean_squared_error: 39.4673\nEpoch 15/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 52.0152 - mean_squared_error: 52.0330 - val_loss: 32.8405 - val_mean_squared_error: 32.8405\nEpoch 16/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 55.8185 - mean_squared_error: 55.8392 - val_loss: 34.5340 - val_mean_squared_error: 34.5340\nEpoch 17/50\n2022/2022 [==============================] - 9s 5ms/step - loss: 58.6639 - mean_squared_error: 58.6857 - val_loss: 37.0712 - val_mean_squared_error: 37.0712\nEpoch 18/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 61.4281 - mean_squared_error: 54.1492 - val_loss: 34.6674 - val_mean_squared_error: 34.6674\nEpoch 19/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 56.6472 - mean_squared_error: 56.6683 - val_loss: 31.4451 - val_mean_squared_error: 31.4451\nEpoch 20/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 52.6858 - mean_squared_error: 52.7053 - val_loss: 30.1258 - val_mean_squared_error: 30.1258\nEpoch 21/50\n2022/2022 [==============================] - 7s 3ms/step - loss: 53.4791 - mean_squared_error: 53.4989 - val_loss: 32.4835 - val_mean_squared_error: 32.4835\nEpoch 22/50\n2022/2022 [==============================] - 10s 5ms/step - loss: 52.6867 - mean_squared_error: 51.6206 - val_loss: 33.0613 - val_mean_squared_error: 33.0613\nEpoch 23/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 51.0708 - mean_squared_error: 51.0897 - val_loss: 28.4322 - val_mean_squared_error: 28.4322\nEpoch 24/50\n2022/2022 [==============================] - 5s 2ms/step - loss: 48.4817 - mean_squared_error: 48.4997 - val_loss: 26.6276 - val_mean_squared_error: 26.6276\nEpoch 25/50\n2022/2022 [==============================] - 15s 7ms/step - loss: 40.9348 - mean_squared_error: 40.9500 - val_loss: 23.2825 - val_mean_squared_error: 23.2825\nEpoch 26/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 48.1200 - mean_squared_error: 48.1378 - val_loss: 22.9047 - val_mean_squared_error: 22.9047\nEpoch 27/50\n2022/2022 [==============================] - 13s 6ms/step - loss: 38.1358 - mean_squared_error: 38.1500 - val_loss: 22.1093 - val_mean_squared_error: 22.1093\nEpoch 28/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 41.3039 - mean_squared_error: 41.3192 - val_loss: 20.6742 - val_mean_squared_error: 20.6742\nEpoch 29/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 55.5983 - mean_squared_error: 55.6182 - val_loss: 22.4796 - val_mean_squared_error: 22.4796\nEpoch 30/50\n2022/2022 [==============================] - 5s 3ms/step - loss: 47.1700 - mean_squared_error: 47.1874 - val_loss: 18.7321 - val_mean_squared_error: 18.7321\nEpoch 31/50\n2022/2022 [==============================] - 13s 7ms/step - loss: 37.0061 - mean_squared_error: 37.0198 - val_loss: 18.1387 - val_mean_squared_error: 18.1387\nEpoch 32/50\n2022/2022 [==============================] - 5s 3ms/step - loss: 38.3234 - mean_squared_error: 38.3376 - val_loss: 17.2121 - val_mean_squared_error: 17.2121\nEpoch 33/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 35.8868 - mean_squared_error: 35.9001 - val_loss: 13.4702 - val_mean_squared_error: 13.4702\nEpoch 34/50\n2022/2022 [==============================] - 7s 4ms/step - loss: 39.1125 - mean_squared_error: 39.1271 - val_loss: 14.8563 - val_mean_squared_error: 14.8563\nEpoch 35/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 35.0492 - mean_squared_error: 35.0621 - val_loss: 7.9853 - val_mean_squared_error: 7.9853\nEpoch 36/50\n2022/2022 [==============================] - 9s 4ms/step - loss: 32.7854 - mean_squared_error: 32.7975 - val_loss: 5.5603 - val_mean_squared_error: 5.5603\nEpoch 37/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 28.6975 - mean_squared_error: 28.7081 - val_loss: 9.9096 - val_mean_squared_error: 9.9096\nEpoch 38/50\n2022/2022 [==============================] - 5s 3ms/step - loss: 32.4937 - mean_squared_error: 32.5058 - val_loss: 8.3113 - val_mean_squared_error: 8.3113\nEpoch 39/50\n2022/2022 [==============================] - 10s 5ms/step - loss: 28.3869 - mean_squared_error: 28.3974 - val_loss: 15.2752 - val_mean_squared_error: 15.2752\nEpoch 40/50\n2022/2022 [==============================] - 7s 3ms/step - loss: 31.6952 - mean_squared_error: 31.7070 - val_loss: 6.0550 - val_mean_squared_error: 6.0550\nEpoch 41/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 24.0169 - mean_squared_error: 24.0259 - val_loss: 6.6364 - val_mean_squared_error: 6.6364\nEpoch 42/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 28.1696 - mean_squared_error: 28.1800 - val_loss: 3.9832 - val_mean_squared_error: 3.9832\nEpoch 43/50\n2022/2022 [==============================] - 9s 5ms/step - loss: 27.9051 - mean_squared_error: 27.9154 - val_loss: 6.5917 - val_mean_squared_error: 6.5917\nEpoch 44/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 36.0532 - mean_squared_error: 36.0665 - val_loss: 9.1431 - val_mean_squared_error: 9.1431\nEpoch 45/50\n2022/2022 [==============================] - 7s 3ms/step - loss: 34.9575 - mean_squared_error: 34.9704 - val_loss: 2.6993 - val_mean_squared_error: 2.6993\nEpoch 46/50\n2022/2022 [==============================] - 10s 5ms/step - loss: 23.5416 - mean_squared_error: 23.5503 - val_loss: 11.6222 - val_mean_squared_error: 11.6222\nEpoch 47/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 31.2373 - mean_squared_error: 31.2488 - val_loss: 3.7480 - val_mean_squared_error: 3.7480\nEpoch 48/50\n2022/2022 [==============================] - 8s 4ms/step - loss: 25.8300 - mean_squared_error: 25.8396 - val_loss: 2.2407 - val_mean_squared_error: 2.2407\nEpoch 49/50\n2022/2022 [==============================] - 6s 3ms/step - loss: 25.2008 - mean_squared_error: 25.2070 - val_loss: 2.5820 - val_mean_squared_error: 2.5820\nEpoch 50/50\n2022/2022 [==============================] - 5s 2ms/step - loss: 26.1330 - mean_squared_error: 26.1426 - val_loss: 4.6872 - val_mean_squared_error: 4.6872\nINFO:tensorflow:Assets written to: gs://skydipper_materials/cnn-models/Sentinel2_WaterQuality/trainer/model/1580817124/assets\n"
]
],
[
[
"**Evaluate model**",
"_____no_output_____"
]
],
[
[
"evaluation_dataset = get_evaluation_dataset()\nmodel.evaluate(evaluation_dataset, steps=int(eval_size / batch_size))",
"877/877 [==============================] - 1s 1ms/step - loss: 4.6872 - mean_squared_error: 4.6872\n"
]
],
[
[
"### Read pretrained model",
"_____no_output_____"
]
],
[
[
"job_dir = 'gs://' + env.bucket_name + '/' + 'cnn-models/' + dataset_name + '/trainer'\nmodel_dir = job_dir + '/model'\nPROJECT_ID = env.project_id",
"_____no_output_____"
],
[
"# Pick the directory with the latest timestamp, in case you've trained multiple times\nexported_model_dirs = ! gsutil ls {model_dir}\nsaved_model_path = exported_model_dirs[-1]",
"_____no_output_____"
],
[
"model = tf.keras.models.load_model(saved_model_path)",
"_____no_output_____"
]
],
[
[
"***\n## Predict in Earth Engine\n\n### Prepare the model for making predictions in Earth Engine\n\nBefore we can use the model in Earth Engine, it needs to be hosted by AI Platform. But before we can host the model on AI Platform we need to *EEify* (a new word!) it. The EEification process merely appends some extra operations to the input and outputs of the model in order to accomdate the interchange format between pixels from Earth Engine (float32) and inputs to AI Platform (base64). (See [this doc](https://cloud.google.com/ml-engine/docs/online-predict#binary_data_in_prediction_input) for details.) \n\n**`earthengine model prepare`**\n\nThe EEification process is handled for you using the Earth Engine command `earthengine model prepare`. To use that command, we need to specify the input and output model directories and the name of the input and output nodes in the TensorFlow computation graph. We can do all that programmatically:",
"_____no_output_____"
]
],
[
[
"dataset_name = 'Sentinel2_WaterQuality'\njob_dir = 'gs://' + env.bucket_name + '/' + 'cnn-models/' + dataset_name + '/trainer'\nmodel_dir = job_dir + '/model'\nproject_id = env.project_id",
"_____no_output_____"
],
[
"# Pick the directory with the latest timestamp, in case you've trained multiple times\nexported_model_dirs = ! gsutil ls {model_dir}\nsaved_model_path = exported_model_dirs[-1]\n\nfolder_name = saved_model_path.split('/')[-2]",
"_____no_output_____"
],
[
"from tensorflow.python.tools import saved_model_utils\n\nmeta_graph_def = saved_model_utils.get_meta_graph_def(saved_model_path, 'serve')\ninputs = meta_graph_def.signature_def['serving_default'].inputs\noutputs = meta_graph_def.signature_def['serving_default'].outputs\n\n# Just get the first thing(s) from the serving signature def. i.e. this\n# model only has a single input and a single output.\ninput_name = None\nfor k,v in inputs.items():\n input_name = v.name\n break\n\noutput_name = None\nfor k,v in outputs.items():\n output_name = v.name\n break\n\n# Make a dictionary that maps Earth Engine outputs and inputs to \n# AI Platform inputs and outputs, respectively.\nimport json\ninput_dict = \"'\" + json.dumps({input_name: \"array\"}) + \"'\"\noutput_dict = \"'\" + json.dumps({output_name: \"prediction\"}) + \"'\"\n\n# Put the EEified model next to the trained model directory.\nEEIFIED_DIR = job_dir + '/eeified/' + folder_name\n\n# You need to set the project before using the model prepare command.\n!earthengine set_project {PROJECT_ID}\n!earthengine model prepare --source_dir {saved_model_path} --dest_dir {EEIFIED_DIR} --input {input_dict} --output {output_dict}",
"Running command using Cloud API. Set --no-use_cloud_api to go back to using the API\n\nSuccessfully saved project id\nRunning command using Cloud API. Set --no-use_cloud_api to go back to using the API\n\nSuccess: model at 'gs://skydipper_materials/cnn-models/Sentinel2_WaterQuality/trainer/eeified/1580824709' is ready to be hosted in AI Platform.\n"
]
],
[
[
"### Deployed the model to AI Platform",
"_____no_output_____"
]
],
[
[
"from googleapiclient import discovery\nfrom googleapiclient import errors",
"_____no_output_____"
]
],
[
[
"**Authenticate your GCP account**\n\nEnter the path to your service account key as the\n`GOOGLE_APPLICATION_CREDENTIALS` variable in the cell below and run the cell.",
"_____no_output_____"
]
],
[
[
"%env GOOGLE_APPLICATION_CREDENTIALS {env.privatekey_path}",
"env: GOOGLE_APPLICATION_CREDENTIALS=/Users/ikersanchez/Vizzuality/Keys/Skydipper/skydipper-196010-a4ce18e66917.json\n"
],
[
"model_name = 'water_quality_test'\nversion_name = 'v' + folder_name\nproject_id = env.project_id",
"_____no_output_____"
]
],
[
[
"**Create model**",
"_____no_output_____"
]
],
[
[
"print('Creating model: ' + model_name)\n\n# Store your full project ID in a variable in the format the API needs.\nproject = 'projects/{}'.format(project_id)\n\n# Build a representation of the Cloud ML API.\nml = discovery.build('ml', 'v1')\n\n# Create a dictionary with the fields from the request body.\nrequest_dict = {'name': model_name,\n 'description': ''}\n\n# Create a request to call projects.models.create.\nrequest = ml.projects().models().create(\n parent=project, body=request_dict)\n\n# Make the call.\ntry:\n response = request.execute()\n print(response)\nexcept errors.HttpError as err:\n # Something went wrong, print out some information.\n print('There was an error creating the model. Check the details:')\n print(err._get_reason())",
"Creating model: water_quality_test\nThere was an error creating the model. Check the details:\nField: model.name Error: A model with the same name already exists.\n"
]
],
[
[
"**Create version**",
"_____no_output_____"
]
],
[
[
"ml = discovery.build('ml', 'v1')\nrequest_dict = {\n 'name': version_name,\n 'deploymentUri': EEIFIED_DIR,\n 'runtimeVersion': '1.14',\n 'pythonVersion': '3.5',\n 'framework': 'TENSORFLOW',\n 'autoScaling': {\n \"minNodes\": 10\n },\n 'machineType': 'mls1-c4-m2'\n}\nrequest = ml.projects().models().versions().create(\n parent=f'projects/{project_id}/models/{model_name}',\n body=request_dict\n)\n\n# Make the call.\ntry:\n response = request.execute()\n print(response)\nexcept errors.HttpError as err:\n # Something went wrong, print out some information.\n print('There was an error creating the model. Check the details:')\n print(err._get_reason())",
"{'name': 'projects/skydipper-196010/operations/create_water_quality_test_v1580824709-1580824821325', 'metadata': {'@type': 'type.googleapis.com/google.cloud.ml.v1.OperationMetadata', 'createTime': '2020-02-04T14:00:22Z', 'operationType': 'CREATE_VERSION', 'modelName': 'projects/skydipper-196010/models/water_quality_test', 'version': {'name': 'projects/skydipper-196010/models/water_quality_test/versions/v1580824709', 'deploymentUri': 'gs://skydipper_materials/cnn-models/Sentinel2_WaterQuality/trainer/eeified/1580824709', 'createTime': '2020-02-04T14:00:21Z', 'runtimeVersion': '1.14', 'autoScaling': {'minNodes': 10}, 'etag': 'NbCwe2E94o0=', 'framework': 'TENSORFLOW', 'machineType': 'mls1-c4-m2', 'pythonVersion': '3.5'}}}\n"
]
],
[
[
"**Check deployment status**",
"_____no_output_____"
]
],
[
[
"def check_status_deployment(model_name, version_name):\n desc = !gcloud ai-platform versions describe {version_name} --model={model_name}\n return desc.grep('state:')[0].split(':')[1].strip() ",
"_____no_output_____"
],
[
"print(check_status_deployment(model_name, version_name))",
"READY\n"
]
],
[
[
"### Load the trained model and use it for prediction in Earth Engine\n**Variables**",
"_____no_output_____"
]
],
[
[
"# polygon where we want to display de predictions\ngeometry = {\n \"type\": \"FeatureCollection\",\n \"features\": [\n {\n \"type\": \"Feature\",\n \"properties\": {},\n \"geometry\": {\n \"type\": \"Polygon\",\n \"coordinates\": [\n [\n [\n -2.63671875,\n 34.56085936708384\n ],\n [\n -1.2084960937499998,\n 34.56085936708384\n ],\n [\n -1.2084960937499998,\n 36.146746777814364\n ],\n [\n -2.63671875,\n 36.146746777814364\n ],\n [\n -2.63671875,\n 34.56085936708384\n ]\n ]\n ]\n }\n }\n ]\n}",
"_____no_output_____"
]
],
[
[
"**Input image**\n\nSelect bands and convert them into float",
"_____no_output_____"
]
],
[
[
"image = images[0].select(bands[0]).float()",
"_____no_output_____"
]
],
[
[
"**Output image**",
"_____no_output_____"
]
],
[
[
"# Load the trained model and use it for prediction.\nmodel = ee.Model.fromAiPlatformPredictor(\n projectName = project_id,\n modelName = model_name,\n version = version_name,\n inputTileSize = [1, 1],\n inputOverlapSize = [0, 0],\n proj = ee.Projection('EPSG:4326').atScale(scale),\n fixInputProj = True,\n outputBands = {'prediction': {\n 'type': ee.PixelType.float(),\n 'dimensions': 1,\n } \n }\n)\npredictions = model.predictImage(image.toArray()).arrayFlatten([bands[1]])\npredictions.getInfo()",
"_____no_output_____"
]
],
[
[
"Clip the prediction area with the polygon",
"_____no_output_____"
]
],
[
[
"# Clip the prediction area with the polygon\npolygon = ee.Geometry.Polygon(geometry.get('features')[0].get('geometry').get('coordinates'))\npredictions = predictions.clip(polygon)\n\n# Get centroid\ncentroid = polygon.centroid().getInfo().get('coordinates')[::-1]",
"_____no_output_____"
]
],
[
[
"**Display**\n\nUse folium to visualize the input imagery and the predictions.",
"_____no_output_____"
]
],
[
[
"# Define the URL format used for Earth Engine generated map tiles.\nEE_TILES = 'https://earthengine.googleapis.com/map/{mapid}/{{z}}/{{x}}/{{y}}?token={token}'\n\nmapid = image.getMapId({'bands': ['B4', 'B3', 'B2'], 'min': 0, 'max': 1})\nmap = folium.Map(location=centroid, zoom_start=8)\nfolium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name='median composite',\n ).add_to(map)\n\nparams = ee_collection_specifics.vizz_params(collections[1])[0]\nmapid = images[1].getMapId(params)\nfolium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name=str(params['bands']),\n ).add_to(map)\n\nfor band in bands[1]:\n mapid = predictions.getMapId({'bands': [band], 'min': 0, 'max': 1})\n \n folium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name=band,\n ).add_to(map)\n \nmap.add_child(folium.LayerControl())\nmap",
"_____no_output_____"
]
],
[
[
"***",
"_____no_output_____"
],
[
"## Make predictions of an image outside Earth Engine\n### Export the imagery\n\nWe export the imagery using TFRecord format. ",
"_____no_output_____"
],
[
"**Variables**",
"_____no_output_____"
]
],
[
[
"#Input image\nimage = images[0].select(bands[0])\n\ndataset_name = 'Sentinel2_WaterQuality'\nfile_name = 'image_pixel'\nbucket = env.bucket_name\nfolder = 'cnn-models/'+dataset_name+'/data'\n\n# polygon where we want to display de predictions\ngeometry = {\n \"type\": \"FeatureCollection\",\n \"features\": [\n {\n \"type\": \"Feature\",\n \"properties\": {},\n \"geometry\": {\n \"type\": \"Polygon\",\n \"coordinates\": [\n [\n [\n -2.63671875,\n 34.56085936708384\n ],\n [\n -1.2084960937499998,\n 34.56085936708384\n ],\n [\n -1.2084960937499998,\n 36.146746777814364\n ],\n [\n -2.63671875,\n 36.146746777814364\n ],\n [\n -2.63671875,\n 34.56085936708384\n ]\n ]\n ]\n }\n }\n ]\n}",
"_____no_output_____"
],
[
"# Specify patch and file dimensions.\nimageExportFormatOptions = {\n 'patchDimensions': [256, 256],\n 'maxFileSize': 104857600,\n 'compressed': True\n}\n\n# Setup the task.\nimageTask = ee.batch.Export.image.toCloudStorage(\n image=image,\n description='Image Export',\n fileNamePrefix=folder + '/' + file_name,\n bucket=bucket,\n scale=scale,\n fileFormat='TFRecord',\n region=geometry.get('features')[0].get('geometry').get('coordinates'),\n formatOptions=imageExportFormatOptions,\n)\n\n# Start the task.\nimageTask.start()",
"_____no_output_____"
]
],
[
[
"**Read the JSON mixer file**\n\nThe mixer contains metadata and georeferencing information for the exported patches, each of which is in a different file. Read the mixer to get some information needed for prediction.",
"_____no_output_____"
]
],
[
[
"json_file = f'gs://{bucket}' + '/' + folder + '/' + file_name +'.json'\n\n# Load the contents of the mixer file to a JSON object.\njson_text = !gsutil cat {json_file}\n\n# Get a single string w/ newlines from the IPython.utils.text.SList\nmixer = json.loads(json_text.nlstr)\npprint(mixer)",
"_____no_output_____"
]
],
[
[
"**Read the image files into a dataset**\n\nThe input needs to be preprocessed differently than the training and testing. Mainly, this is because the pixels are written into records as patches, we need to read the patches in as one big tensor (one patch for each band), then flatten them into lots of little tensors.",
"_____no_output_____"
]
],
[
[
"# Get relevant info from the JSON mixer file.\nPATCH_WIDTH = mixer['patchDimensions'][0]\nPATCH_HEIGHT = mixer['patchDimensions'][1]\nPATCHES = mixer['totalPatches']\nPATCH_DIMENSIONS_FLAT = [PATCH_WIDTH * PATCH_HEIGHT, 1]\nfeatures = bands[0]\n\nglob = f'gs://{bucket}' + '/' + folder + '/' + file_name +'.tfrecord.gz'\n\n# Note that the tensors are in the shape of a patch, one patch for each band.\nimage_columns = [\n tf.FixedLenFeature(shape=PATCH_DIMENSIONS_FLAT, dtype=tf.float32) for k in features\n]\n\n# Parsing dictionary.\nfeatures_dict = dict(zip(bands[0], image_columns))\n\ndef parse_image(proto):\n return tf.io.parse_single_example(proto, features_dict)\n\nimage_dataset = tf.data.TFRecordDataset(glob, compression_type='GZIP')\n\nimage_dataset = image_dataset.map(parse_image, num_parallel_calls=5)\n\n# Break our long tensors into many little ones.\nimage_dataset = image_dataset.flat_map(\n lambda features: tf.data.Dataset.from_tensor_slices(features)\n)\n \n# Turn the dictionary in each record into a tuple without a label.\nimage_dataset = image_dataset.map(\n lambda dataDict: (tf.transpose(list(dataDict.values())), )\n)\n\n# Turn each patch into a batch.\nimage_dataset = image_dataset.batch(PATCH_WIDTH * PATCH_HEIGHT)\n\nimage_dataset",
"_____no_output_____"
]
],
[
[
"**Check the first record**",
"_____no_output_____"
]
],
[
[
"arr = iter(image_dataset.take(1)).next()\ninput_arr = arr[0].numpy()\nprint(input_arr.shape)",
"_____no_output_____"
]
],
[
[
"**Display the input channels**",
"_____no_output_____"
]
],
[
[
"def display_channels(data, nChannels, titles = False):\n if nChannels == 1:\n plt.figure(figsize=(5,5))\n plt.imshow(data[:,:,0])\n if titles:\n plt.title(titles[0])\n else:\n fig, axs = plt.subplots(nrows=1, ncols=nChannels, figsize=(5*nChannels,5))\n for i in range(nChannels):\n ax = axs[i]\n ax.imshow(data[:,:,i])\n if titles:\n ax.set_title(titles[i])",
"_____no_output_____"
],
[
"input_arr = input_arr.reshape((PATCH_WIDTH, PATCH_HEIGHT, len(bands[0])))\ninput_arr.shape",
"_____no_output_____"
],
[
"display_channels(input_arr, input_arr.shape[2], titles=bands[0])",
"_____no_output_____"
]
],
[
[
"### Generate predictions for the image pixels\n\nTo get predictions in each pixel, run the image dataset through the trained model using model.predict(). Print the first prediction to see that the output is a list of the three class probabilities for each pixel. Running all predictions might take a while.",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(image_dataset, steps=PATCHES, verbose=1)",
"_____no_output_____"
],
[
"output_arr = predictions.reshape((PATCHES, PATCH_WIDTH, PATCH_HEIGHT, len(bands[1])))\noutput_arr.shape",
"_____no_output_____"
],
[
"display_channels(output_arr[9,:,:,:], output_arr.shape[3], titles=bands[1])",
"_____no_output_____"
]
],
[
[
"### Write the predictions to a TFRecord file\n\nWe need to write the pixels into the file as patches in the same order they came out. The records are written as serialized `tf.train.Example` protos. ",
"_____no_output_____"
]
],
[
[
"dataset_name = 'Sentinel2_WaterQuality'\nbucket = env.bucket_name\nfolder = 'cnn-models/'+dataset_name+'/data'\n\noutput_file = 'gs://' + bucket + '/' + folder + '/predicted_image_pixel.TFRecord'\nprint('Writing to file ' + output_file)",
"_____no_output_____"
],
[
"# Instantiate the writer.\nwriter = tf.io.TFRecordWriter(output_file)\n\npatch = [[]]\nnPatch = 1\nfor prediction in predictions:\n patch[0].append(prediction[0][0])\n # Once we've seen a patches-worth of class_ids...\n if (len(patch[0]) == PATCH_WIDTH * PATCH_HEIGHT):\n print('Done with patch ' + str(nPatch) + ' of ' + str(PATCHES))\n # Create an example\n example = tf.train.Example(\n features=tf.train.Features(\n feature={\n 'prediction': tf.train.Feature(\n float_list=tf.train.FloatList(\n value=patch[0]))\n }\n )\n )\n # Write the example to the file and clear our patch array so it's ready for\n # another batch of class ids\n writer.write(example.SerializeToString())\n patch = [[]]\n nPatch += 1\n\nwriter.close()",
"_____no_output_____"
]
],
[
[
"**Verify the existence of the predictions file**",
"_____no_output_____"
]
],
[
[
"!gsutil ls -l {output_file}",
"_____no_output_____"
]
],
[
[
"### Upload the predicted image to an Earth Engine asset",
"_____no_output_____"
]
],
[
[
"asset_id = 'projects/vizzuality/skydipper-water-quality/predicted-image' \nprint('Writing to ' + asset_id)",
"_____no_output_____"
],
[
"# Start the upload.\n!earthengine upload image --asset_id={asset_id} {output_file} {json_file}",
"_____no_output_____"
]
],
[
[
"### View the predicted image",
"_____no_output_____"
]
],
[
[
"# Get centroid\npolygon = ee.Geometry.Polygon(geometry.get('features')[0].get('geometry').get('coordinates'))\n\ncentroid = polygon.centroid().getInfo().get('coordinates')[::-1]",
"_____no_output_____"
],
[
"EE_TILES = 'https://earthengine.googleapis.com/map/{mapid}/{{z}}/{{x}}/{{y}}?token={token}'\n\nmap = folium.Map(location=centroid, zoom_start=8)\nfor n, collection in enumerate(collections):\n params = ee_collection_specifics.vizz_params(collection)[0]\n mapid = images[n].getMapId(params)\n folium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name=str(params['bands']),\n ).add_to(map)\n \n \n# Read predicted Image\npredicted_image = ee.Image(asset_id)\n \nmapid = predicted_image.getMapId({'bands': ['prediction'], 'min': 0, 'max': 1})\nfolium.TileLayer(\n tiles=EE_TILES.format(**mapid),\n attr='Google Earth Engine',\n overlay=True,\n name='predicted image',\n ).add_to(map)\n \nmap.add_child(folium.LayerControl())\nmap",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d008cb6b2b088c8592a337a76cdb6927ef7a8352
| 40,816 |
ipynb
|
Jupyter Notebook
|
0_1_calculate_area_centroid.ipynb
|
edesz/chicago-bikeshare
|
8a51dac660defc618c4174131ac287047854b0c0
|
[
"MIT"
] | null | null | null |
0_1_calculate_area_centroid.ipynb
|
edesz/chicago-bikeshare
|
8a51dac660defc618c4174131ac287047854b0c0
|
[
"MIT"
] | 15 |
2021-06-01T22:49:59.000Z
|
2021-12-31T18:13:35.000Z
|
0_1_calculate_area_centroid.ipynb
|
edesz/chicago-bikeshare
|
8a51dac660defc618c4174131ac287047854b0c0
|
[
"MIT"
] | null | null | null | 48.075383 | 445 | 0.531017 |
[
[
[
"# Calculating Area and Center Coordinates of a Polygon",
"_____no_output_____"
]
],
[
[
"%load_ext lab_black\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import geopandas as gpd\nimport pandas as pd",
"_____no_output_____"
],
[
"%aimport src.utils\nfrom src.utils import show_df",
"_____no_output_____"
]
],
[
[
"<a id=\"toc\"></a>\n\n## [Table of Contents](#table-of-contents)\n0. [About](#about)\n1. [User Inputs](#user-inputs)\n2. [Load Chicago Community Areas GeoData](#load-chicago-community-areas-geodata)\n3. [Calculate Area of each Community Area](#calculate-area-of-each-community-area)\n4. [Calculate Coordinates of Midpoint of each Community Area](#calculate-coordinates-of-midpoint-of-each-community-area)",
"_____no_output_____"
],
[
"<a id=\"about\"></a>\n\n## 0. [About](#about)",
"_____no_output_____"
],
[
"We'll explore calculations of the area and central coordinates of polygons from geospatial data using the Python [`geopandas` library](https://pypi.org/project/geopandas/).",
"_____no_output_____"
],
[
"<a id=\"user-inputs\"></a>\n\n## 1. [User Inputs](#user-inputs)",
"_____no_output_____"
]
],
[
[
"ca_url = \"https://data.cityofchicago.org/api/geospatial/cauq-8yn6?method=export&format=GeoJSON\"\n\nconvert_sqm_to_sqft = 10.7639",
"_____no_output_____"
]
],
[
[
"<a id=\"load-chicago-community-areas-geodata\"></a>\n\n## 2. [Load Chicago Community Areas GeoData](#load-chicago-community-areas-geodata)",
"_____no_output_____"
],
[
"Load the boundaries geodata for the [Chicago community areas](https://data.cityofchicago.org/Facilities-Geographic-Boundaries/Boundaries-Community-Areas-current-/cauq-8yn6)",
"_____no_output_____"
]
],
[
[
"%%time\ngdf_ca = gpd.read_file(ca_url)\nprint(gdf_ca.crs)\ngdf_ca.head(2)",
"epsg:4326\nCPU times: user 209 ms, sys: 11.7 ms, total: 221 ms\nWall time: 1.1 s\n"
]
],
[
[
"<a id=\"calculate-area-of-each-community-area\"></a>\n\n## 3. [Calculate Area of each Community Area](#calculate-area-of-each-community-area)",
"_____no_output_____"
],
[
"To get the area, we need to\n- project the geometry into a Cylindrical Equal-Area (CEA) format, an equal area projection, with that preserves area ([1](https://learn.arcgis.com/en/projects/choose-the-right-projection/))\n- calculate the area by calling the `.area()` method on the `GeoDataFrame`\n - this will give area in square meters\n- [convert area from square meters to square feet](https://www.metric-conversions.org/area/square-meters-to-square-feet.htm)\n - through trial and error, it was found that this is the unit in which the Chicago community areas geodata gives the area (see the `shape_area` column)",
"_____no_output_____"
]
],
[
[
"%%time\ngdf_ca[\"cea_area_square_feet\"] = gdf_ca.to_crs({\"proj\": \"cea\"}).area * convert_sqm_to_sqft\ngdf_ca[\"diff_sq_feet\"] = gdf_ca[\"shape_area\"].astype(float) - gdf_ca[\"cea_area_square_feet\"]\ngdf_ca[\"diff_pct\"] = gdf_ca[\"diff_sq_feet\"] / gdf_ca[\"shape_area\"].astype(float) * 100\nshow_df(gdf_ca.drop(columns=[\"geometry\"]))\ndisplay(gdf_ca[[\"diff_sq_feet\", \"diff_pct\"]].describe())",
"_____no_output_____"
]
],
[
[
"**Observations**\n1. It is reassuring that the CEA projection has given us areas in square feet that are within less than 0.01 percent of the areas provided with the Chicago community areas dataset. We'll use this approach to calculate shape areas.",
"_____no_output_____"
],
[
"<a id=\"calculate-coordinates-of-midpoint-of-each-community-area\"></a>\n\n## 4. [Calculate Coordinates of Midpoint of each Community Area](#calculate-coordinates-of-midpoint-of-each-community-area)",
"_____no_output_____"
],
[
"In order to get the centroid of a geometry, it is [recommended to first project to the CEA CRS (equal area CRS) before computing the centroid](https://gis.stackexchange.com/a/401815/135483). [Other used CRS values include 3395, 32663 or 4087](https://gis.stackexchange.com/a/390563/135483). Once the geometry is projected, we can calculate the centroid coordinates calling the `.centroid()` method on the `GeoDataFrame`'s `geometry` column",
"_____no_output_____"
]
],
[
[
"%%time\ncentroid_cea = gdf_ca[\"geometry\"].to_crs(\"+proj=cea\").centroid.to_crs(gdf_ca.crs)\ncentroid_3395 = gdf_ca[\"geometry\"].to_crs(epsg=3395).centroid.to_crs(gdf_ca.crs)\ncentroid_32663 = gdf_ca[\"geometry\"].to_crs(epsg=32663).centroid.to_crs(gdf_ca.crs)\ncentroid_4087 = gdf_ca[\"geometry\"].to_crs(epsg=4087).centroid.to_crs(gdf_ca.crs)\ncentroid_6345 = gdf_ca[\"geometry\"].to_crs(epsg=6345).centroid.to_crs(gdf_ca.crs)\ndf_centroid_coords = pd.DataFrame()\nfor c, centroid_coords in zip(\n [\"cea\", 3395, 32663, 4087, 6345],\n [centroid_cea, centroid_3395, centroid_32663, centroid_4087, centroid_6345],\n):\n df_centroid_coords[f\"lat_{c}\"] = centroid_coords.y\n df_centroid_coords[f\"lon_{c}\"] = centroid_coords.x\nshow_df(df_centroid_coords)",
"_____no_output_____"
]
],
[
[
"**Observations**\n1. For our case, centroids computed using all projections give nearly identical co-ordinates. This is likely since each of the city's community areas cover a very small area on the surface of the Earth. Further reading will be required to understand the close agreement between these centroid locations found using the different projections. For subsequent calculation of the centroids, we'll use the equal area projection.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d008d1f1deac6e6d0f4d8b5613c235d714d1c0de
| 255,525 |
ipynb
|
Jupyter Notebook
|
experiments/tuned_1v2/oracle.run1_limited/trials/8/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tuned_1v2/oracle.run1_limited/trials/8/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tuned_1v2/oracle.run1_limited/trials/8/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null | 87.990702 | 73,968 | 0.777427 |
[
[
[
"# PTN Template\nThis notebook serves as a template for single dataset PTN experiments \nIt can be run on its own by setting STANDALONE to True (do a find for \"STANDALONE\" to see where) \nBut it is intended to be executed as part of a *papermill.py script. See any of the \nexperimentes with a papermill script to get started with that workflow. ",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n \nimport os, json, sys, time, random\nimport numpy as np\nimport torch\nfrom torch.optim import Adam\nfrom easydict import EasyDict\nimport matplotlib.pyplot as plt\n\nfrom steves_models.steves_ptn import Steves_Prototypical_Network\n\nfrom steves_utils.lazy_iterable_wrapper import Lazy_Iterable_Wrapper\nfrom steves_utils.iterable_aggregator import Iterable_Aggregator\nfrom steves_utils.ptn_train_eval_test_jig import PTN_Train_Eval_Test_Jig\nfrom steves_utils.torch_sequential_builder import build_sequential\nfrom steves_utils.torch_utils import get_dataset_metrics, ptn_confusion_by_domain_over_dataloader\nfrom steves_utils.utils_v2 import (per_domain_accuracy_from_confusion, get_datasets_base_path)\nfrom steves_utils.PTN.utils import independent_accuracy_assesment\n\nfrom steves_utils.stratified_dataset.episodic_accessor import Episodic_Accessor_Factory\n\nfrom steves_utils.ptn_do_report import (\n get_loss_curve,\n get_results_table,\n get_parameters_table,\n get_domain_accuracies,\n)\n\nfrom steves_utils.transforms import get_chained_transform",
"_____no_output_____"
]
],
[
[
"# Required Parameters\nThese are allowed parameters, not defaults\nEach of these values need to be present in the injected parameters (the notebook will raise an exception if they are not present)\n\nPapermill uses the cell tag \"parameters\" to inject the real parameters below this cell.\nEnable tags to see what I mean",
"_____no_output_____"
]
],
[
[
"required_parameters = {\n \"experiment_name\",\n \"lr\",\n \"device\",\n \"seed\",\n \"dataset_seed\",\n \"labels_source\",\n \"labels_target\",\n \"domains_source\",\n \"domains_target\",\n \"num_examples_per_domain_per_label_source\",\n \"num_examples_per_domain_per_label_target\",\n \"n_shot\",\n \"n_way\",\n \"n_query\",\n \"train_k_factor\",\n \"val_k_factor\",\n \"test_k_factor\",\n \"n_epoch\",\n \"patience\",\n \"criteria_for_best\",\n \"x_transforms_source\",\n \"x_transforms_target\",\n \"episode_transforms_source\",\n \"episode_transforms_target\",\n \"pickle_name\",\n \"x_net\",\n \"NUM_LOGS_PER_EPOCH\",\n \"BEST_MODEL_PATH\",\n \"torch_default_dtype\"\n}",
"_____no_output_____"
],
[
"\n\nstandalone_parameters = {}\nstandalone_parameters[\"experiment_name\"] = \"STANDALONE PTN\"\nstandalone_parameters[\"lr\"] = 0.0001\nstandalone_parameters[\"device\"] = \"cuda\"\n\nstandalone_parameters[\"seed\"] = 1337\nstandalone_parameters[\"dataset_seed\"] = 1337\n\n\nstandalone_parameters[\"num_examples_per_domain_per_label_source\"]=100\nstandalone_parameters[\"num_examples_per_domain_per_label_target\"]=100\n\nstandalone_parameters[\"n_shot\"] = 3\nstandalone_parameters[\"n_query\"] = 2\nstandalone_parameters[\"train_k_factor\"] = 1\nstandalone_parameters[\"val_k_factor\"] = 2\nstandalone_parameters[\"test_k_factor\"] = 2\n\n\nstandalone_parameters[\"n_epoch\"] = 100\n\nstandalone_parameters[\"patience\"] = 10\nstandalone_parameters[\"criteria_for_best\"] = \"target_accuracy\"\n\nstandalone_parameters[\"x_transforms_source\"] = [\"unit_power\"]\nstandalone_parameters[\"x_transforms_target\"] = [\"unit_power\"]\nstandalone_parameters[\"episode_transforms_source\"] = []\nstandalone_parameters[\"episode_transforms_target\"] = []\n\nstandalone_parameters[\"torch_default_dtype\"] = \"torch.float32\" \n\n\n\nstandalone_parameters[\"x_net\"] = [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\":[-1, 1, 2, 256]}},\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":1, \"out_channels\":256, \"kernel_size\":(1,7), \"bias\":False, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":256, \"out_channels\":80, \"kernel_size\":(2,7), \"bias\":True, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 80*256, \"out_features\": 256}}, # 80 units per IQ pair\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n]\n\n# Parameters relevant to results\n# These parameters will basically never need to change\nstandalone_parameters[\"NUM_LOGS_PER_EPOCH\"] = 10\nstandalone_parameters[\"BEST_MODEL_PATH\"] = \"./best_model.pth\"\n\n# uncomment for CORES dataset\nfrom steves_utils.CORES.utils import (\n ALL_NODES,\n ALL_NODES_MINIMUM_1000_EXAMPLES,\n ALL_DAYS\n)\n\n\nstandalone_parameters[\"labels_source\"] = ALL_NODES\nstandalone_parameters[\"labels_target\"] = ALL_NODES\n\nstandalone_parameters[\"domains_source\"] = [1]\nstandalone_parameters[\"domains_target\"] = [2,3,4,5]\n\nstandalone_parameters[\"pickle_name\"] = \"cores.stratified_ds.2022A.pkl\"\n\n\n# Uncomment these for ORACLE dataset\n# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n# standalone_parameters[\"labels_source\"] = ALL_SERIAL_NUMBERS\n# standalone_parameters[\"labels_target\"] = ALL_SERIAL_NUMBERS\n# standalone_parameters[\"domains_source\"] = [8,20, 38,50]\n# standalone_parameters[\"domains_target\"] = [14, 26, 32, 44, 56]\n# standalone_parameters[\"pickle_name\"] = \"oracle.frame_indexed.stratified_ds.2022A.pkl\"\n# standalone_parameters[\"num_examples_per_domain_per_label_source\"]=1000\n# standalone_parameters[\"num_examples_per_domain_per_label_target\"]=1000\n\n# Uncomment these for Metahan dataset\n# standalone_parameters[\"labels_source\"] = list(range(19))\n# standalone_parameters[\"labels_target\"] = list(range(19))\n# standalone_parameters[\"domains_source\"] = [0]\n# standalone_parameters[\"domains_target\"] = [1]\n# standalone_parameters[\"pickle_name\"] = \"metehan.stratified_ds.2022A.pkl\"\n# standalone_parameters[\"n_way\"] = len(standalone_parameters[\"labels_source\"])\n# standalone_parameters[\"num_examples_per_domain_per_label_source\"]=200\n# standalone_parameters[\"num_examples_per_domain_per_label_target\"]=100\n\n\nstandalone_parameters[\"n_way\"] = len(standalone_parameters[\"labels_source\"])",
"_____no_output_____"
],
[
"# Parameters\nparameters = {\n \"experiment_name\": \"tuned_1v2:oracle.run1_limited\",\n \"device\": \"cuda\",\n \"lr\": 0.0001,\n \"labels_source\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"labels_target\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"episode_transforms_source\": [],\n \"episode_transforms_target\": [],\n \"domains_source\": [8, 32, 50],\n \"domains_target\": [14, 20, 26, 38, 44],\n \"num_examples_per_domain_per_label_source\": 2000,\n \"num_examples_per_domain_per_label_target\": 2000,\n \"n_shot\": 3,\n \"n_way\": 16,\n \"n_query\": 2,\n \"train_k_factor\": 3,\n \"val_k_factor\": 2,\n \"test_k_factor\": 2,\n \"torch_default_dtype\": \"torch.float32\",\n \"n_epoch\": 50,\n \"patience\": 3,\n \"criteria_for_best\": \"target_accuracy\",\n \"x_net\": [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\": [-1, 1, 2, 256]}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 1,\n \"out_channels\": 256,\n \"kernel_size\": [1, 7],\n \"bias\": False,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 256}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 256,\n \"out_channels\": 80,\n \"kernel_size\": [2, 7],\n \"bias\": True,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 20480, \"out_features\": 256}},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\": 256}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n ],\n \"NUM_LOGS_PER_EPOCH\": 10,\n \"BEST_MODEL_PATH\": \"./best_model.pth\",\n \"pickle_name\": \"oracle.Run1_10kExamples_stratified_ds.2022A.pkl\",\n \"x_transforms_source\": [\"unit_power\"],\n \"x_transforms_target\": [\"unit_power\"],\n \"dataset_seed\": 1337,\n \"seed\": 1337,\n}\n",
"_____no_output_____"
],
[
"# Set this to True if you want to run this template directly\nSTANDALONE = False\nif STANDALONE:\n print(\"parameters not injected, running with standalone_parameters\")\n parameters = standalone_parameters\n\nif not 'parameters' in locals() and not 'parameters' in globals():\n raise Exception(\"Parameter injection failed\")\n\n#Use an easy dict for all the parameters\np = EasyDict(parameters)\n\nsupplied_keys = set(p.keys())\n\nif supplied_keys != required_parameters:\n print(\"Parameters are incorrect\")\n if len(supplied_keys - required_parameters)>0: print(\"Shouldn't have:\", str(supplied_keys - required_parameters))\n if len(required_parameters - supplied_keys)>0: print(\"Need to have:\", str(required_parameters - supplied_keys))\n raise RuntimeError(\"Parameters are incorrect\")\n\n",
"_____no_output_____"
],
[
"###################################\n# Set the RNGs and make it all deterministic\n###################################\nnp.random.seed(p.seed)\nrandom.seed(p.seed)\ntorch.manual_seed(p.seed)\n\ntorch.use_deterministic_algorithms(True) ",
"_____no_output_____"
],
[
"###########################################\n# The stratified datasets honor this\n###########################################\ntorch.set_default_dtype(eval(p.torch_default_dtype))",
"_____no_output_____"
],
[
"###################################\n# Build the network(s)\n# Note: It's critical to do this AFTER setting the RNG\n# (This is due to the randomized initial weights)\n###################################\nx_net = build_sequential(p.x_net)",
"_____no_output_____"
],
[
"start_time_secs = time.time()",
"_____no_output_____"
],
[
"###################################\n# Build the dataset\n###################################\n\nif p.x_transforms_source == []: x_transform_source = None\nelse: x_transform_source = get_chained_transform(p.x_transforms_source) \n\nif p.x_transforms_target == []: x_transform_target = None\nelse: x_transform_target = get_chained_transform(p.x_transforms_target)\n\nif p.episode_transforms_source == []: episode_transform_source = None\nelse: raise Exception(\"episode_transform_source not implemented\")\n\nif p.episode_transforms_target == []: episode_transform_target = None\nelse: raise Exception(\"episode_transform_target not implemented\")\n\n\neaf_source = Episodic_Accessor_Factory(\n labels=p.labels_source,\n domains=p.domains_source,\n num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_source,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),\n x_transform_func=x_transform_source,\n example_transform_func=episode_transform_source,\n \n)\ntrain_original_source, val_original_source, test_original_source = eaf_source.get_train(), eaf_source.get_val(), eaf_source.get_test()\n\n\neaf_target = Episodic_Accessor_Factory(\n labels=p.labels_target,\n domains=p.domains_target,\n num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_target,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),\n x_transform_func=x_transform_target,\n example_transform_func=episode_transform_target,\n)\ntrain_original_target, val_original_target, test_original_target = eaf_target.get_train(), eaf_target.get_val(), eaf_target.get_test()\n\n\ntransform_lambda = lambda ex: ex[1] # Original is (<domain>, <episode>) so we strip down to episode only\n\ntrain_processed_source = Lazy_Iterable_Wrapper(train_original_source, transform_lambda)\nval_processed_source = Lazy_Iterable_Wrapper(val_original_source, transform_lambda)\ntest_processed_source = Lazy_Iterable_Wrapper(test_original_source, transform_lambda)\n\ntrain_processed_target = Lazy_Iterable_Wrapper(train_original_target, transform_lambda)\nval_processed_target = Lazy_Iterable_Wrapper(val_original_target, transform_lambda)\ntest_processed_target = Lazy_Iterable_Wrapper(test_original_target, transform_lambda)\n\ndatasets = EasyDict({\n \"source\": {\n \"original\": {\"train\":train_original_source, \"val\":val_original_source, \"test\":test_original_source},\n \"processed\": {\"train\":train_processed_source, \"val\":val_processed_source, \"test\":test_processed_source}\n },\n \"target\": {\n \"original\": {\"train\":train_original_target, \"val\":val_original_target, \"test\":test_original_target},\n \"processed\": {\"train\":train_processed_target, \"val\":val_processed_target, \"test\":test_processed_target}\n },\n})",
"_____no_output_____"
],
[
"# Some quick unit tests on the data\nfrom steves_utils.transforms import get_average_power, get_average_magnitude\n\nq_x, q_y, s_x, s_y, truth = next(iter(train_processed_source))\n\nassert q_x.dtype == eval(p.torch_default_dtype)\nassert s_x.dtype == eval(p.torch_default_dtype)\n\nprint(\"Visually inspect these to see if they line up with expected values given the transforms\")\nprint('x_transforms_source', p.x_transforms_source)\nprint('x_transforms_target', p.x_transforms_target)\nprint(\"Average magnitude, source:\", get_average_magnitude(q_x[0].numpy()))\nprint(\"Average power, source:\", get_average_power(q_x[0].numpy()))\n\nq_x, q_y, s_x, s_y, truth = next(iter(train_processed_target))\nprint(\"Average magnitude, target:\", get_average_magnitude(q_x[0].numpy()))\nprint(\"Average power, target:\", get_average_power(q_x[0].numpy()))\n",
"Visually inspect these to see if they line up with expected values given the transforms\nx_transforms_source ['unit_power']\nx_transforms_target ['unit_power']\nAverage magnitude, source: 0.8852737\nAverage power, source: 1.0\n"
],
[
"###################################\n# Build the model\n###################################\nmodel = Steves_Prototypical_Network(x_net, device=p.device, x_shape=(2,256))\noptimizer = Adam(params=model.parameters(), lr=p.lr)",
"(2, 256)\n"
],
[
"###################################\n# train\n###################################\njig = PTN_Train_Eval_Test_Jig(model, p.BEST_MODEL_PATH, p.device)\n\njig.train(\n train_iterable=datasets.source.processed.train,\n source_val_iterable=datasets.source.processed.val,\n target_val_iterable=datasets.target.processed.val,\n num_epochs=p.n_epoch,\n num_logs_per_epoch=p.NUM_LOGS_PER_EPOCH,\n patience=p.patience,\n optimizer=optimizer,\n criteria_for_best=p.criteria_for_best,\n)",
"epoch: 1, [batch: 1 / 2520], examples_per_second: 127.0495, train_label_loss: 2.7531, \n"
],
[
"total_experiment_time_secs = time.time() - start_time_secs",
"_____no_output_____"
],
[
"###################################\n# Evaluate the model\n###################################\nsource_test_label_accuracy, source_test_label_loss = jig.test(datasets.source.processed.test)\ntarget_test_label_accuracy, target_test_label_loss = jig.test(datasets.target.processed.test)\n\nsource_val_label_accuracy, source_val_label_loss = jig.test(datasets.source.processed.val)\ntarget_val_label_accuracy, target_val_label_loss = jig.test(datasets.target.processed.val)\n\nhistory = jig.get_history()\n\ntotal_epochs_trained = len(history[\"epoch_indices\"])\n\nval_dl = Iterable_Aggregator((datasets.source.original.val,datasets.target.original.val))\n\nconfusion = ptn_confusion_by_domain_over_dataloader(model, p.device, val_dl)\nper_domain_accuracy = per_domain_accuracy_from_confusion(confusion)\n\n# Add a key to per_domain_accuracy for if it was a source domain\nfor domain, accuracy in per_domain_accuracy.items():\n per_domain_accuracy[domain] = {\n \"accuracy\": accuracy,\n \"source?\": domain in p.domains_source\n }\n\n# Do an independent accuracy assesment JUST TO BE SURE!\n# _source_test_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.test, p.device)\n# _target_test_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.test, p.device)\n# _source_val_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.val, p.device)\n# _target_val_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.val, p.device)\n\n# assert(_source_test_label_accuracy == source_test_label_accuracy)\n# assert(_target_test_label_accuracy == target_test_label_accuracy)\n# assert(_source_val_label_accuracy == source_val_label_accuracy)\n# assert(_target_val_label_accuracy == target_val_label_accuracy)\n\nexperiment = {\n \"experiment_name\": p.experiment_name,\n \"parameters\": dict(p),\n \"results\": {\n \"source_test_label_accuracy\": source_test_label_accuracy,\n \"source_test_label_loss\": source_test_label_loss,\n \"target_test_label_accuracy\": target_test_label_accuracy,\n \"target_test_label_loss\": target_test_label_loss,\n \"source_val_label_accuracy\": source_val_label_accuracy,\n \"source_val_label_loss\": source_val_label_loss,\n \"target_val_label_accuracy\": target_val_label_accuracy,\n \"target_val_label_loss\": target_val_label_loss,\n \"total_epochs_trained\": total_epochs_trained,\n \"total_experiment_time_secs\": total_experiment_time_secs,\n \"confusion\": confusion,\n \"per_domain_accuracy\": per_domain_accuracy,\n },\n \"history\": history,\n \"dataset_metrics\": get_dataset_metrics(datasets, \"ptn\"),\n}",
"_____no_output_____"
],
[
"ax = get_loss_curve(experiment)\nplt.show()",
"_____no_output_____"
],
[
"get_results_table(experiment)",
"_____no_output_____"
],
[
"get_domain_accuracies(experiment)",
"_____no_output_____"
],
[
"print(\"Source Test Label Accuracy:\", experiment[\"results\"][\"source_test_label_accuracy\"], \"Target Test Label Accuracy:\", experiment[\"results\"][\"target_test_label_accuracy\"])\nprint(\"Source Val Label Accuracy:\", experiment[\"results\"][\"source_val_label_accuracy\"], \"Target Val Label Accuracy:\", experiment[\"results\"][\"target_val_label_accuracy\"])",
"Source Test Label Accuracy: 0.5891493055555556 Target Test Label Accuracy: 0.5005729166666667\nSource Val Label Accuracy: 0.5872395833333334 Target Val Label Accuracy: 0.4978125\n"
],
[
"json.dumps(experiment)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d00926b0038948ab4fa4402a8f7c72e0003439db
| 39,906 |
ipynb
|
Jupyter Notebook
|
Deep.Learning/5.Generative-Adversial-Networks/2.Deep-Convolutional-Gan/Batch_Normalization_Exercises.ipynb
|
Scrier/udacity
|
1326441aa2104a641b555676ec2429d8b6eb539f
|
[
"MIT"
] | 1 |
2021-09-08T02:55:34.000Z
|
2021-09-08T02:55:34.000Z
|
Deep.Learning/5.Generative-Adversial-Networks/2.Deep-Convolutional-Gan/Batch_Normalization_Exercises.ipynb
|
Scrier/udacity
|
1326441aa2104a641b555676ec2429d8b6eb539f
|
[
"MIT"
] | 1 |
2018-01-14T16:34:49.000Z
|
2018-01-14T16:34:49.000Z
|
Deep.Learning/5.Generative-Adversial-Networks/2.Deep-Convolutional-Gan/Batch_Normalization_Exercises.ipynb
|
Scrier/udacity
|
1326441aa2104a641b555676ec2429d8b6eb539f
|
[
"MIT"
] | null | null | null | 50.386364 | 586 | 0.60437 |
[
[
[
"# Batch Normalization – Practice",
"_____no_output_____"
],
[
"Batch normalization is most useful when building deep neural networks. To demonstrate this, we'll create a convolutional neural network with 20 convolutional layers, followed by a fully connected layer. We'll use it to classify handwritten digits in the MNIST dataset, which should be familiar to you by now.\n\nThis is **not** a good network for classfying MNIST digits. You could create a _much_ simpler network and get _better_ results. However, to give you hands-on experience with batch normalization, we had to make an example that was:\n1. Complicated enough that training would benefit from batch normalization.\n2. Simple enough that it would train quickly, since this is meant to be a short exercise just to give you some practice adding batch normalization.\n3. Simple enough that the architecture would be easy to understand without additional resources.",
"_____no_output_____"
],
[
"This notebook includes two versions of the network that you can edit. The first uses higher level functions from the `tf.layers` package. The second is the same network, but uses only lower level functions in the `tf.nn` package.\n\n1. [Batch Normalization with `tf.layers.batch_normalization`](#example_1)\n2. [Batch Normalization with `tf.nn.batch_normalization`](#example_2)",
"_____no_output_____"
],
[
"The following cell loads TensorFlow, downloads the MNIST dataset if necessary, and loads it into an object named `mnist`. You'll need to run this cell before running anything else in the notebook.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot=True, reshape=False)",
"/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
]
],
[
[
"# Batch Normalization using `tf.layers.batch_normalization`<a id=\"example_1\"></a>\n\nThis version of the network uses `tf.layers` for almost everything, and expects you to implement batch normalization using [`tf.layers.batch_normalization`](https://www.tensorflow.org/api_docs/python/tf/layers/batch_normalization) ",
"_____no_output_____"
],
[
"We'll use the following function to create fully connected layers in our network. We'll create them with the specified number of neurons and a ReLU activation function.\n\nThis version of the function does not include batch normalization.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDO NOT MODIFY THIS CELL\n\"\"\"\ndef fully_connected(prev_layer, num_units):\n \"\"\"\n Create a fully connectd layer with the given layer as input and the given number of neurons.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param num_units: int\n The size of the layer. That is, the number of units, nodes, or neurons.\n :returns Tensor\n A new fully connected layer\n \"\"\"\n layer = tf.layers.dense(prev_layer, num_units, activation=tf.nn.relu)\n return layer",
"_____no_output_____"
]
],
[
[
"We'll use the following function to create convolutional layers in our network. They are very basic: we're always using a 3x3 kernel, ReLU activation functions, strides of 1x1 on layers with odd depths, and strides of 2x2 on layers with even depths. We aren't bothering with pooling layers at all in this network.\n\nThis version of the function does not include batch normalization.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDO NOT MODIFY THIS CELL\n\"\"\"\ndef conv_layer(prev_layer, layer_depth):\n \"\"\"\n Create a convolutional layer with the given layer as input.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param layer_depth: int\n We'll set the strides and number of feature maps based on the layer's depth in the network.\n This is *not* a good way to make a CNN, but it helps us create this example with very little code.\n :returns Tensor\n A new convolutional layer\n \"\"\"\n strides = 2 if layer_depth % 3 == 0 else 1\n conv_layer = tf.layers.conv2d(prev_layer, layer_depth*4, 3, strides, 'same', activation=tf.nn.relu)\n return conv_layer",
"_____no_output_____"
]
],
[
[
"**Run the following cell**, along with the earlier cells (to load the dataset and define the necessary functions). \n\nThis cell builds the network **without** batch normalization, then trains it on the MNIST dataset. It displays loss and accuracy data periodically while training.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDO NOT MODIFY THIS CELL\n\"\"\"\ndef train(num_batches, batch_size, learning_rate):\n # Build placeholders for the input samples and labels \n inputs = tf.placeholder(tf.float32, [None, 28, 28, 1])\n labels = tf.placeholder(tf.float32, [None, 10])\n \n # Feed the inputs into a series of 20 convolutional layers \n layer = inputs\n for layer_i in range(1, 20):\n layer = conv_layer(layer, layer_i)\n\n # Flatten the output from the convolutional layers \n orig_shape = layer.get_shape().as_list()\n layer = tf.reshape(layer, shape=[-1, orig_shape[1] * orig_shape[2] * orig_shape[3]])\n\n # Add one fully connected layer\n layer = fully_connected(layer, 100)\n\n # Create the output layer with 1 node for each \n logits = tf.layers.dense(layer, 10)\n \n # Define loss and training operations\n model_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))\n train_opt = tf.train.AdamOptimizer(learning_rate).minimize(model_loss)\n \n # Create operations to test accuracy\n correct_prediction = tf.equal(tf.argmax(logits,1), tf.argmax(labels,1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n \n # Train and test the network\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for batch_i in range(num_batches):\n batch_xs, batch_ys = mnist.train.next_batch(batch_size)\n\n # train this batch\n sess.run(train_opt, {inputs: batch_xs, labels: batch_ys})\n \n # Periodically check the validation or training loss and accuracy\n if batch_i % 100 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: mnist.validation.images,\n labels: mnist.validation.labels})\n print('Batch: {:>2}: Validation loss: {:>3.5f}, Validation accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n elif batch_i % 25 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: batch_xs, labels: batch_ys})\n print('Batch: {:>2}: Training loss: {:>3.5f}, Training accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n\n # At the end, score the final accuracy for both the validation and test sets\n acc = sess.run(accuracy, {inputs: mnist.validation.images,\n labels: mnist.validation.labels})\n print('Final validation accuracy: {:>3.5f}'.format(acc))\n acc = sess.run(accuracy, {inputs: mnist.test.images,\n labels: mnist.test.labels})\n print('Final test accuracy: {:>3.5f}'.format(acc))\n \n # Score the first 100 test images individually. This won't work if batch normalization isn't implemented correctly.\n correct = 0\n for i in range(100):\n correct += sess.run(accuracy,feed_dict={inputs: [mnist.test.images[i]],\n labels: [mnist.test.labels[i]]})\n\n print(\"Accuracy on 100 samples:\", correct/100)\n\n\nnum_batches = 800\nbatch_size = 64\nlearning_rate = 0.002\n\ntf.reset_default_graph()\nwith tf.Graph().as_default():\n train(num_batches, batch_size, learning_rate)",
"Batch: 0: Validation loss: 0.69052, Validation accuracy: 0.10020\nBatch: 25: Training loss: 0.41248, Training accuracy: 0.07812\nBatch: 50: Training loss: 0.32848, Training accuracy: 0.04688\nBatch: 75: Training loss: 0.32555, Training accuracy: 0.07812\nBatch: 100: Validation loss: 0.32519, Validation accuracy: 0.11000\nBatch: 125: Training loss: 0.32458, Training accuracy: 0.07812\nBatch: 150: Training loss: 0.32654, Training accuracy: 0.12500\nBatch: 175: Training loss: 0.32703, Training accuracy: 0.03125\nBatch: 200: Validation loss: 0.32540, Validation accuracy: 0.11260\nBatch: 225: Training loss: 0.32345, Training accuracy: 0.18750\nBatch: 250: Training loss: 0.32359, Training accuracy: 0.07812\nBatch: 275: Training loss: 0.32836, Training accuracy: 0.07812\nBatch: 300: Validation loss: 0.32573, Validation accuracy: 0.11260\nBatch: 325: Training loss: 0.32430, Training accuracy: 0.07812\nBatch: 350: Training loss: 0.32710, Training accuracy: 0.07812\nBatch: 375: Training loss: 0.32377, Training accuracy: 0.15625\nBatch: 400: Validation loss: 0.32518, Validation accuracy: 0.09900\nBatch: 425: Training loss: 0.32419, Training accuracy: 0.09375\nBatch: 450: Training loss: 0.32710, Training accuracy: 0.04688\nBatch: 475: Training loss: 0.32596, Training accuracy: 0.09375\nBatch: 500: Validation loss: 0.32536, Validation accuracy: 0.11260\nBatch: 525: Training loss: 0.32429, Training accuracy: 0.03125\nBatch: 550: Training loss: 0.32544, Training accuracy: 0.09375\nBatch: 575: Training loss: 0.32535, Training accuracy: 0.12500\nBatch: 600: Validation loss: 0.32552, Validation accuracy: 0.10020\nBatch: 625: Training loss: 0.32403, Training accuracy: 0.10938\nBatch: 650: Training loss: 0.32617, Training accuracy: 0.09375\nBatch: 675: Training loss: 0.32527, Training accuracy: 0.12500\nBatch: 700: Validation loss: 0.32512, Validation accuracy: 0.11000\nBatch: 725: Training loss: 0.32503, Training accuracy: 0.17188\nBatch: 750: Training loss: 0.32640, Training accuracy: 0.09375\nBatch: 775: Training loss: 0.32589, Training accuracy: 0.07812\nFinal validation accuracy: 0.09860\nFinal test accuracy: 0.10100\nAccuracy on 100 samples: 0.11\n"
]
],
[
[
"With this many layers, it's going to take a lot of iterations for this network to learn. By the time you're done training these 800 batches, your final test and validation accuracies probably won't be much better than 10%. (It will be different each time, but will most likely be less than 15%.)\n\nUsing batch normalization, you'll be able to train this same network to over 90% in that same number of batches.\n\n\n# Add batch normalization\n\nWe've copied the previous three cells to get you started. **Edit these cells** to add batch normalization to the network. For this exercise, you should use [`tf.layers.batch_normalization`](https://www.tensorflow.org/api_docs/python/tf/layers/batch_normalization) to handle most of the math, but you'll need to make a few other changes to your network to integrate batch normalization. You may want to refer back to the lesson notebook to remind yourself of important things, like how your graph operations need to know whether or not you are performing training or inference. \n\nIf you get stuck, you can check out the `Batch_Normalization_Solutions` notebook to see how we did things.",
"_____no_output_____"
],
[
"**TODO:** Modify `fully_connected` to add batch normalization to the fully connected layers it creates. Feel free to change the function's parameters if it helps.",
"_____no_output_____"
]
],
[
[
"def fully_connected(prev_layer, num_units, is_training):\n \"\"\"\n Create a fully connectd layer with the given layer as input and the given number of neurons.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param num_units: int\n The size of the layer. That is, the number of units, nodes, or neurons.\n :returns Tensor\n A new fully connected layer\n \"\"\"\n layer = tf.layers.dense(prev_layer, num_units, use_bias=False, activation=None)\n layer = tf.layers.batch_normalization(layer, training=is_training)\n layer = tf.nn.relu(layer)\n return layer",
"_____no_output_____"
]
],
[
[
"**TODO:** Modify `conv_layer` to add batch normalization to the convolutional layers it creates. Feel free to change the function's parameters if it helps.",
"_____no_output_____"
]
],
[
[
"def conv_layer(prev_layer, layer_depth, is_training):\n \"\"\"\n Create a convolutional layer with the given layer as input.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param layer_depth: int\n We'll set the strides and number of feature maps based on the layer's depth in the network.\n This is *not* a good way to make a CNN, but it helps us create this example with very little code.\n :returns Tensor\n A new convolutional layer\n \"\"\"\n strides = 2 if layer_depth % 3 == 0 else 1\n conv_layer = tf.layers.conv2d(prev_layer, layer_depth*4, 3, strides, 'same', activation=None, use_bias=False)\n conv_layer = tf.layers.batch_normalization(conv_layer, training=is_training)\n conv_layer = tf.nn.relu(conv_layer)\n return conv_layer",
"_____no_output_____"
]
],
[
[
"**TODO:** Edit the `train` function to support batch normalization. You'll need to make sure the network knows whether or not it is training, and you'll need to make sure it updates and uses its population statistics correctly.",
"_____no_output_____"
]
],
[
[
"def train(num_batches, batch_size, learning_rate):\n # Build placeholders for the input samples and labels \n inputs = tf.placeholder(tf.float32, [None, 28, 28, 1])\n labels = tf.placeholder(tf.float32, [None, 10])\n\n # Add placeholder to indicate whether or not we're training the model\n is_training = tf.placeholder(tf.bool)\n\n # Feed the inputs into a series of 20 convolutional layers \n layer = inputs\n for layer_i in range(1, 20):\n layer = conv_layer(layer, layer_i, is_training)\n\n # Flatten the output from the convolutional layers \n orig_shape = layer.get_shape().as_list()\n layer = tf.reshape(layer, shape=[-1, orig_shape[1] * orig_shape[2] * orig_shape[3]])\n\n # Add one fully connected layer\n layer = fully_connected(layer, 100, is_training)\n\n # Create the output layer with 1 node for each \n logits = tf.layers.dense(layer, 10)\n \n # Define loss and training operations\n model_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))\n \n # Tell TensorFlow to update the population statistics while training\n with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):\n train_opt = tf.train.AdamOptimizer(learning_rate).minimize(model_loss)\n \n # Create operations to test accuracy\n correct_prediction = tf.equal(tf.argmax(logits,1), tf.argmax(labels,1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n \n # Train and test the network\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for batch_i in range(num_batches):\n batch_xs, batch_ys = mnist.train.next_batch(batch_size)\n\n # train this batch\n sess.run(train_opt, {inputs: batch_xs, labels: batch_ys, is_training: True})\n \n # Periodically check the validation or training loss and accuracy\n if batch_i % 100 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: mnist.validation.images,\n labels: mnist.validation.labels,\n is_training: False})\n print('Batch: {:>2}: Validation loss: {:>3.5f}, Validation accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n elif batch_i % 25 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: batch_xs, labels: batch_ys, is_training: False})\n print('Batch: {:>2}: Training loss: {:>3.5f}, Training accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n\n # At the end, score the final accuracy for both the validation and test sets\n acc = sess.run(accuracy, {inputs: mnist.validation.images,\n labels: mnist.validation.labels, \n is_training: False})\n print('Final validation accuracy: {:>3.5f}'.format(acc))\n acc = sess.run(accuracy, {inputs: mnist.test.images,\n labels: mnist.test.labels,\n is_training: False})\n print('Final test accuracy: {:>3.5f}'.format(acc))\n \n # Score the first 100 test images individually, just to make sure batch normalization really worked\n correct = 0\n for i in range(100):\n correct += sess.run(accuracy,feed_dict={inputs: [mnist.test.images[i]],\n labels: [mnist.test.labels[i]],\n is_training: False})\n\n print(\"Accuracy on 100 samples:\", correct/100)\n\n\nnum_batches = 800\nbatch_size = 64\nlearning_rate = 0.002\n\ntf.reset_default_graph()\nwith tf.Graph().as_default():\n train(num_batches, batch_size, learning_rate)",
"Batch: 0: Validation loss: 0.69111, Validation accuracy: 0.08680\nBatch: 25: Training loss: 0.58037, Training accuracy: 0.17188\nBatch: 50: Training loss: 0.46359, Training accuracy: 0.10938\nBatch: 75: Training loss: 0.39624, Training accuracy: 0.07812\nBatch: 100: Validation loss: 0.35559, Validation accuracy: 0.10020\nBatch: 125: Training loss: 0.34059, Training accuracy: 0.12500\nBatch: 150: Training loss: 0.33566, Training accuracy: 0.06250\nBatch: 175: Training loss: 0.32763, Training accuracy: 0.21875\nBatch: 200: Validation loss: 0.40874, Validation accuracy: 0.11260\nBatch: 225: Training loss: 0.41788, Training accuracy: 0.09375\nBatch: 250: Training loss: 0.50921, Training accuracy: 0.18750\nBatch: 275: Training loss: 0.40777, Training accuracy: 0.35938\nBatch: 300: Validation loss: 0.62787, Validation accuracy: 0.20260\nBatch: 325: Training loss: 0.46186, Training accuracy: 0.42188\nBatch: 350: Training loss: 0.20306, Training accuracy: 0.71875\nBatch: 375: Training loss: 0.06057, Training accuracy: 0.90625\nBatch: 400: Validation loss: 0.07048, Validation accuracy: 0.89720\nBatch: 425: Training loss: 0.00765, Training accuracy: 0.98438\nBatch: 450: Training loss: 0.01864, Training accuracy: 0.95312\nBatch: 475: Training loss: 0.02225, Training accuracy: 0.95312\nBatch: 500: Validation loss: 0.04807, Validation accuracy: 0.93200\nBatch: 525: Training loss: 0.02990, Training accuracy: 0.96875\nBatch: 550: Training loss: 0.06346, Training accuracy: 0.92188\nBatch: 575: Training loss: 0.07358, Training accuracy: 0.90625\nBatch: 600: Validation loss: 0.06977, Validation accuracy: 0.89360\nBatch: 625: Training loss: 0.00792, Training accuracy: 0.98438\nBatch: 650: Training loss: 0.04138, Training accuracy: 0.92188\nBatch: 675: Training loss: 0.05289, Training accuracy: 0.92188\nBatch: 700: Validation loss: 0.02661, Validation accuracy: 0.96060\nBatch: 725: Training loss: 0.03836, Training accuracy: 0.96875\nBatch: 750: Training loss: 0.03171, Training accuracy: 0.95312\nBatch: 775: Training loss: 0.02621, Training accuracy: 0.96875\nFinal validation accuracy: 0.95760\nFinal test accuracy: 0.96350\nAccuracy on 100 samples: 0.98\n"
]
],
[
[
"With batch normalization, you should now get an accuracy over 90%. Notice also the last line of the output: `Accuracy on 100 samples`. If this value is low while everything else looks good, that means you did not implement batch normalization correctly. Specifically, it means you either did not calculate the population mean and variance while training, or you are not using those values during inference.\n\n# Batch Normalization using `tf.nn.batch_normalization`<a id=\"example_2\"></a>\n\nMost of the time you will be able to use higher level functions exclusively, but sometimes you may want to work at a lower level. For example, if you ever want to implement a new feature – something new enough that TensorFlow does not already include a high-level implementation of it, like batch normalization in an LSTM – then you may need to know these sorts of things.\n\nThis version of the network uses `tf.nn` for almost everything, and expects you to implement batch normalization using [`tf.nn.batch_normalization`](https://www.tensorflow.org/api_docs/python/tf/nn/batch_normalization).\n\n**Optional TODO:** You can run the next three cells before you edit them just to see how the network performs without batch normalization. However, the results should be pretty much the same as you saw with the previous example before you added batch normalization. \n\n**TODO:** Modify `fully_connected` to add batch normalization to the fully connected layers it creates. Feel free to change the function's parameters if it helps.\n\n**Note:** For convenience, we continue to use `tf.layers.dense` for the `fully_connected` layer. By this point in the class, you should have no problem replacing that with matrix operations between the `prev_layer` and explicit weights and biases variables.",
"_____no_output_____"
]
],
[
[
"def fully_connected(prev_layer, num_units, is_training):\n \"\"\"\n Create a fully connectd layer with the given layer as input and the given number of neurons.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param num_units: int\n The size of the layer. That is, the number of units, nodes, or neurons.\n :param is_training: bool or Tensor\n Indicates whether or not the network is currently training, which tells the batch normalization\n layer whether or not it should update or use its population statistics.\n :returns Tensor\n A new fully connected layer\n \"\"\"\n\n layer = tf.layers.dense(prev_layer, num_units, use_bias=False, activation=None)\n\n gamma = tf.Variable(tf.ones([num_units]))\n beta = tf.Variable(tf.zeros([num_units]))\n\n pop_mean = tf.Variable(tf.zeros([num_units]), trainable=False)\n pop_variance = tf.Variable(tf.ones([num_units]), trainable=False)\n\n epsilon = 1e-3\n \n def batch_norm_training():\n batch_mean, batch_variance = tf.nn.moments(layer, [0])\n\n decay = 0.99\n train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay))\n train_variance = tf.assign(pop_variance, pop_variance * decay + batch_variance * (1 - decay))\n\n with tf.control_dependencies([train_mean, train_variance]):\n return tf.nn.batch_normalization(layer, batch_mean, batch_variance, beta, gamma, epsilon)\n \n def batch_norm_inference():\n return tf.nn.batch_normalization(layer, pop_mean, pop_variance, beta, gamma, epsilon)\n\n batch_normalized_output = tf.cond(is_training, batch_norm_training, batch_norm_inference)\n return tf.nn.relu(batch_normalized_output)",
"_____no_output_____"
]
],
[
[
"**TODO:** Modify `conv_layer` to add batch normalization to the fully connected layers it creates. Feel free to change the function's parameters if it helps.\n\n**Note:** Unlike in the previous example that used `tf.layers`, adding batch normalization to these convolutional layers _does_ require some slight differences to what you did in `fully_connected`. ",
"_____no_output_____"
]
],
[
[
"def conv_layer(prev_layer, layer_depth, is_training):\n \"\"\"\n Create a convolutional layer with the given layer as input.\n \n :param prev_layer: Tensor\n The Tensor that acts as input into this layer\n :param layer_depth: int\n We'll set the strides and number of feature maps based on the layer's depth in the network.\n This is *not* a good way to make a CNN, but it helps us create this example with very little code.\n :param is_training: bool or Tensor\n Indicates whether or not the network is currently training, which tells the batch normalization\n layer whether or not it should update or use its population statistics.\n :returns Tensor\n A new convolutional layer\n \"\"\"\n strides = 2 if layer_depth % 3 == 0 else 1\n \n in_channels = prev_layer.get_shape().as_list()[3]\n out_channels = layer_depth*4\n \n weights = tf.Variable(\n tf.truncated_normal([3, 3, in_channels, out_channels], stddev=0.05))\n \n layer = tf.nn.conv2d(prev_layer, weights, strides=[1,strides, strides, 1], padding='SAME')\n\n gamma = tf.Variable(tf.ones([out_channels]))\n beta = tf.Variable(tf.zeros([out_channels]))\n\n pop_mean = tf.Variable(tf.zeros([out_channels]), trainable=False)\n pop_variance = tf.Variable(tf.ones([out_channels]), trainable=False)\n\n epsilon = 1e-3\n \n def batch_norm_training():\n # Important to use the correct dimensions here to ensure the mean and variance are calculated \n # per feature map instead of for the entire layer\n batch_mean, batch_variance = tf.nn.moments(layer, [0,1,2], keep_dims=False)\n\n decay = 0.99\n train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay))\n train_variance = tf.assign(pop_variance, pop_variance * decay + batch_variance * (1 - decay))\n\n with tf.control_dependencies([train_mean, train_variance]):\n return tf.nn.batch_normalization(layer, batch_mean, batch_variance, beta, gamma, epsilon)\n \n def batch_norm_inference():\n return tf.nn.batch_normalization(layer, pop_mean, pop_variance, beta, gamma, epsilon)\n\n batch_normalized_output = tf.cond(is_training, batch_norm_training, batch_norm_inference)\n return tf.nn.relu(batch_normalized_output)",
"_____no_output_____"
]
],
[
[
"**TODO:** Edit the `train` function to support batch normalization. You'll need to make sure the network knows whether or not it is training.",
"_____no_output_____"
]
],
[
[
"def train(num_batches, batch_size, learning_rate):\n # Build placeholders for the input samples and labels \n inputs = tf.placeholder(tf.float32, [None, 28, 28, 1])\n labels = tf.placeholder(tf.float32, [None, 10])\n\n # Add placeholder to indicate whether or not we're training the model\n is_training = tf.placeholder(tf.bool)\n\n # Feed the inputs into a series of 20 convolutional layers \n layer = inputs\n for layer_i in range(1, 20):\n layer = conv_layer(layer, layer_i, is_training)\n\n # Flatten the output from the convolutional layers \n orig_shape = layer.get_shape().as_list()\n layer = tf.reshape(layer, shape=[-1, orig_shape[1] * orig_shape[2] * orig_shape[3]])\n\n # Add one fully connected layer\n layer = fully_connected(layer, 100, is_training)\n\n # Create the output layer with 1 node for each \n logits = tf.layers.dense(layer, 10)\n \n # Define loss and training operations\n model_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))\n train_opt = tf.train.AdamOptimizer(learning_rate).minimize(model_loss)\n \n # Create operations to test accuracy\n correct_prediction = tf.equal(tf.argmax(logits,1), tf.argmax(labels,1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n \n # Train and test the network\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for batch_i in range(num_batches):\n batch_xs, batch_ys = mnist.train.next_batch(batch_size)\n\n # train this batch\n sess.run(train_opt, {inputs: batch_xs, labels: batch_ys, is_training: True})\n \n # Periodically check the validation or training loss and accuracy\n if batch_i % 100 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: mnist.validation.images,\n labels: mnist.validation.labels,\n is_training: False})\n print('Batch: {:>2}: Validation loss: {:>3.5f}, Validation accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n elif batch_i % 25 == 0:\n loss, acc = sess.run([model_loss, accuracy], {inputs: batch_xs, labels: batch_ys, is_training: False})\n print('Batch: {:>2}: Training loss: {:>3.5f}, Training accuracy: {:>3.5f}'.format(batch_i, loss, acc))\n\n # At the end, score the final accuracy for both the validation and test sets\n acc = sess.run(accuracy, {inputs: mnist.validation.images,\n labels: mnist.validation.labels, \n is_training: False})\n print('Final validation accuracy: {:>3.5f}'.format(acc))\n acc = sess.run(accuracy, {inputs: mnist.test.images,\n labels: mnist.test.labels,\n is_training: False})\n print('Final test accuracy: {:>3.5f}'.format(acc))\n \n # Score the first 100 test images individually, just to make sure batch normalization really worked\n correct = 0\n for i in range(100):\n correct += sess.run(accuracy,feed_dict={inputs: [mnist.test.images[i]],\n labels: [mnist.test.labels[i]],\n is_training: False})\n\n print(\"Accuracy on 100 samples:\", correct/100)\n\n\nnum_batches = 800\nbatch_size = 64\nlearning_rate = 0.002\n\ntf.reset_default_graph()\nwith tf.Graph().as_default():\n train(num_batches, batch_size, learning_rate)",
"Batch: 0: Validation loss: 0.69128, Validation accuracy: 0.09580\nBatch: 25: Training loss: 0.58242, Training accuracy: 0.07812\nBatch: 50: Training loss: 0.46814, Training accuracy: 0.07812\nBatch: 75: Training loss: 0.40309, Training accuracy: 0.17188\nBatch: 100: Validation loss: 0.36373, Validation accuracy: 0.09900\nBatch: 125: Training loss: 0.35578, Training accuracy: 0.07812\nBatch: 150: Training loss: 0.33116, Training accuracy: 0.10938\nBatch: 175: Training loss: 0.34014, Training accuracy: 0.15625\nBatch: 200: Validation loss: 0.35679, Validation accuracy: 0.09900\nBatch: 225: Training loss: 0.36367, Training accuracy: 0.06250\nBatch: 250: Training loss: 0.48576, Training accuracy: 0.10938\nBatch: 275: Training loss: 0.45041, Training accuracy: 0.10938\nBatch: 300: Validation loss: 0.60292, Validation accuracy: 0.11260\nBatch: 325: Training loss: 0.90907, Training accuracy: 0.12500\nBatch: 350: Training loss: 1.21087, Training accuracy: 0.09375\nBatch: 375: Training loss: 0.84756, Training accuracy: 0.10938\nBatch: 400: Validation loss: 0.82665, Validation accuracy: 0.16000\nBatch: 425: Training loss: 0.45936, Training accuracy: 0.28125\nBatch: 450: Training loss: 0.70676, Training accuracy: 0.21875\nBatch: 475: Training loss: 0.22090, Training accuracy: 0.75000\nBatch: 500: Validation loss: 0.18597, Validation accuracy: 0.78500\nBatch: 525: Training loss: 0.06446, Training accuracy: 0.87500\nBatch: 550: Training loss: 0.03445, Training accuracy: 0.95312\nBatch: 575: Training loss: 0.03627, Training accuracy: 0.96875\nBatch: 600: Validation loss: 0.05220, Validation accuracy: 0.92260\nBatch: 625: Training loss: 0.01909, Training accuracy: 0.98438\nBatch: 650: Training loss: 0.02751, Training accuracy: 0.96875\nBatch: 675: Training loss: 0.00516, Training accuracy: 1.00000\nBatch: 700: Validation loss: 0.06646, Validation accuracy: 0.92720\nBatch: 725: Training loss: 0.03347, Training accuracy: 0.92188\nBatch: 750: Training loss: 0.06926, Training accuracy: 0.90625\nBatch: 775: Training loss: 0.02755, Training accuracy: 0.96875\nFinal validation accuracy: 0.96560\nFinal test accuracy: 0.96320\nAccuracy on 100 samples: 0.97\n"
]
],
[
[
"Once again, the model with batch normalization should reach an accuracy over 90%. There are plenty of details that can go wrong when implementing at this low level, so if you got it working - great job! If not, do not worry, just look at the `Batch_Normalization_Solutions` notebook to see what went wrong.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d00931c2f4d5069762a47113bb96ed0835a9ab3b
| 6,253 |
ipynb
|
Jupyter Notebook
|
Section_1/Video_1_5.ipynb
|
PacktPublishing/-Dynamic-Neural-Network-Programming-with-PyTorch
|
9ac0c1c5d6427e5aa140de158d79dc4b74ddd0ad
|
[
"MIT"
] | 18 |
2019-03-09T08:10:22.000Z
|
2021-11-08T13:12:01.000Z
|
Section_1/Video_1_5.ipynb
|
PacktPublishing/-Dynamic-Neural-Network-Programming-with-PyTorch
|
9ac0c1c5d6427e5aa140de158d79dc4b74ddd0ad
|
[
"MIT"
] | null | null | null |
Section_1/Video_1_5.ipynb
|
PacktPublishing/-Dynamic-Neural-Network-Programming-with-PyTorch
|
9ac0c1c5d6427e5aa140de158d79dc4b74ddd0ad
|
[
"MIT"
] | 4 |
2019-02-11T07:11:32.000Z
|
2021-03-16T08:29:06.000Z
| 20.170968 | 82 | 0.456101 |
[
[
[
"# PyTorch on GPU: first steps",
"_____no_output_____"
],
[
"### Put tensor to GPU",
"_____no_output_____"
]
],
[
[
"import torch\n\ndevice = torch.device(\"cuda:0\")",
"_____no_output_____"
],
[
"my_tensor = torch.Tensor([1., 2., 3., 4., 5.])\n\nmytensor = my_tensor.to(device)",
"_____no_output_____"
],
[
"mytensor",
"_____no_output_____"
],
[
"my_tensor",
"_____no_output_____"
]
],
[
[
"### Put model to GPU",
"_____no_output_____"
]
],
[
[
"from torch import nn\n\nclass Model(nn.Module):\n def __init__(self, input_size, output_size):\n super(Model, self).__init__()\n self.fc = nn.Linear(input_size, output_size)\n\n def forward(self, input):\n output = self.fc(input)\n print(\"\\tIn Model: input size\", input.size(),\n \"output size\", output.size())\n\n return output",
"_____no_output_____"
],
[
"input_size = 128\noutput_size = 128\nmodel = Model(input_size, output_size)",
"_____no_output_____"
],
[
"device = torch.device(\"cuda:0\")\nmodel.to(device)",
"_____no_output_____"
]
],
[
[
"### Data parallelism",
"_____no_output_____"
]
],
[
[
"from torch.nn import DataParallel",
"_____no_output_____"
],
[
"torch.cuda.is_available()",
"_____no_output_____"
],
[
"torch.cuda.device_count()",
"_____no_output_____"
]
],
[
[
"### Part on CPU, part on GPU",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda:0\")\n\nclass Model(nn.Module):\n\n def __init__(self, input_size, output_size):\n super(Model, self).__init__()\n self.fc = nn.Linear(input_size, 100) \n self.fc2 = nn.Linear(100, output_size).to(device)\n\n def forward(self, x):\n # Compute first layer on CPU\n x = self.fc(x)\n\n # Transfer to GPU\n x = x.to(device)\n\n # Compute second layer on GPU\n x = self.fc2(x)\n return x",
"_____no_output_____"
],
[
"input_size = 100\noutput_size = 50\n\ndata_length = 1000",
"_____no_output_____"
],
[
"data = torch.randn(data_length, input_size)",
"_____no_output_____"
],
[
"model = Model(input_size, output_size)\nmodel.forward(data)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d00939d70cb7b467116c12eb07a96eef12a7ad16
| 67,214 |
ipynb
|
Jupyter Notebook
|
Country_Economic_Conditions_for_Cargo_Carriers.ipynb
|
jamiemfraser/machine_learning
|
b5a9261db226de6e3bbe4d65ee11ab4a7268ac63
|
[
"CC0-1.0"
] | 1 |
2021-06-29T15:03:08.000Z
|
2021-06-29T15:03:08.000Z
|
Country_Economic_Conditions_for_Cargo_Carriers.ipynb
|
jamiemfraser/rocketfuel
|
b5a9261db226de6e3bbe4d65ee11ab4a7268ac63
|
[
"CC0-1.0"
] | null | null | null |
Country_Economic_Conditions_for_Cargo_Carriers.ipynb
|
jamiemfraser/rocketfuel
|
b5a9261db226de6e3bbe4d65ee11ab4a7268ac63
|
[
"CC0-1.0"
] | null | null | null | 67,214 | 67,214 | 0.763174 |
[
[
[
"# Country Economic Conditions for Cargo Carriers",
"_____no_output_____"
],
[
"This report is written from the point of view of a data scientist preparing a report to the Head of Analytics for a logistics company. The company needs information on economic and financial conditions is different countries, including data on their international trade, to be aware of any situations that could affect business.",
"_____no_output_____"
],
[
"## Data Summary",
"_____no_output_____"
],
[
"This dataset is taken from the International Monetary Fund (IMF) data bank. It lists country-level economic and financial statistics from all countries globally. This includes data such as gross domestic product (GDP), inflation, exports and imports, and government borrowing and revenue. The data is given in either US Dollars, or local currency depending on the country and year. Some variables, like inflation and unemployment, are given as percentages.",
"_____no_output_____"
],
[
"## Data Exploration",
"_____no_output_____"
],
[
"The initial plan for data exploration is to first model the data on country GDP and inflation, then to look further into trade statistics.",
"_____no_output_____"
]
],
[
[
"#Import required packages\nimport numpy as np\nimport pandas as pd\nfrom sklearn import linear_model\nfrom scipy import stats \nimport math\nfrom sklearn import datasets, linear_model\nfrom sklearn.linear_model import LinearRegression\nimport statsmodels.api as sm",
"_____no_output_____"
],
[
"#Import IMF World Economic Outlook Data from GitHub\nWEO = pd.read_csv('https://raw.githubusercontent.com/jamiemfraser/machine_learning/main/WEOApr2021all.csv')\nWEO=pd.DataFrame(WEO)\nWEO.head()",
"_____no_output_____"
],
[
"# Print basic details of the dataset\nprint(WEO.shape[0])\nprint(WEO.columns.tolist())\nprint(WEO.dtypes)\n\n#Shows that all numeric columns are type float, and string columns are type object",
"4289\n['CountryCode', 'Country', 'Indicator', 'Notes', 'Units', 'Scale', '2000', '2001', '2002', '2003', '2004', '2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\nCountryCode object\nCountry object\nIndicator object\nNotes object\nUnits object\nScale object\n2000 float64\n2001 float64\n2002 float64\n2003 float64\n2004 float64\n2005 float64\n2006 float64\n2007 float64\n2008 float64\n2009 float64\n2010 float64\n2011 float64\n2012 float64\n2013 float64\n2014 float64\n2015 float64\n2016 float64\n2017 float64\n2018 float64\n2019 float64\ndtype: object\n"
]
],
[
[
"### Data Cleaning and Feature Engineering",
"_____no_output_____"
]
],
[
[
"#We are only interested in the most recent year for which data is available, 2019\nWEO=WEO.drop(['2000', '2001', '2002', '2003', '2004', '2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018'], axis = 1)\n\n#Reshape the data so each country is one observation\nWEO=WEO.pivot_table(index=[\"Country\"], columns='Indicator', values='2019').reset_index()",
"_____no_output_____"
],
[
"WEO.columns = ['Country', 'Current_account', 'Employment', 'Net_borrowing', 'Government_revenue', 'Government_expenditure', 'GDP_percap_constant', 'GDP_percap_current', 'GDP_constant', 'Inflation', 'Investment', 'Unemployment', 'Volume_exports', 'Volume_imports']\nWEO.head()",
"_____no_output_____"
],
[
"#Describe the dataset\nWEO.dropna(inplace=True)\nWEO.describe()",
"_____no_output_____"
]
],
[
[
"### Key Findings and Insights",
"_____no_output_____"
]
],
[
[
"#Large differences betweeen the mean and median values could be an indication of outliers that are skewing the data\nWEO.agg([np.mean, np.median])",
"_____no_output_____"
],
[
"#Create a scatterplot\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nax = plt.axes()\n\nax.scatter(WEO.Volume_exports, WEO.Volume_imports)\n\n# Label the axes\nax.set(xlabel='Volume Exports',\n ylabel='Volume Imports',\n title='Volume of Exports vs Imports');",
"_____no_output_____"
],
[
"#Create a scatterplot\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nax = plt.axes()\n\nax.scatter(WEO.GDP_percap_constant, WEO.Volume_imports)\n\n# Label the axes\nax.set(xlabel='GDP per capita',\n ylabel='Volume Imports',\n title='GDP per capita vs Volume of Imports');",
"_____no_output_____"
],
[
"#Create a scatterplot\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nax = plt.axes()\n\nax.scatter(WEO.Investment, WEO.Volume_imports)\n\n# Label the axes\nax.set(xlabel='Investment',\n ylabel='Volume Imports',\n title='Investment vs Volume of Imports');",
"_____no_output_____"
]
],
[
[
"### Hypotheses",
"_____no_output_____"
],
[
"Hypothesis 1: GDP per capita and the level of investment will be significant in determining the volume of goods and services imports\n\nHypothesis 2: There will be a strong correlation between government revenues and government expenditures\n\nHypothesis 3: GDP per capita and inflation will be significant in determining the unemployment rate",
"_____no_output_____"
],
[
"### Significance Test",
"_____no_output_____"
],
[
"I will conduct a formal hypothesis test on Hypothesis #1, which states that GDP per capita and the level of investment will be significant in determining the volume of goods and services imports. I will use a linear regression model because the scatterplots shown above indicate there is likely a linear relationship between both GDP per capita and investment against the volume of imports. I will take a p-value of 0.05 or less to be an indication of significance.\n\nThe null hypothesis is that there is no significant relationship between GDP per capita or the level of investment and the volume of goods and services.\n\nThe alternative hypothesis is that there is a significant relationship between either GDP per capita or the level of investment and the volume of goods and services.",
"_____no_output_____"
]
],
[
[
"#Set up a linear regression model for GDP per capita and evaluate\nWEO=WEO.reset_index()\nX = WEO['GDP_percap_constant']\nX=X.values.reshape(-1,1)\ny = WEO['Volume_imports']\n\nX2 = sm.add_constant(X)\nest = sm.OLS(y, X2)\nest2 = est.fit()\nprint(est2.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: Volume_imports R-squared: 0.030\nModel: OLS Adj. R-squared: 0.001\nMethod: Least Squares F-statistic: 1.051\nDate: Wed, 11 Aug 2021 Prob (F-statistic): 0.313\nTime: 06:38:02 Log-Likelihood: -114.44\nNo. Observations: 36 AIC: 232.9\nDf Residuals: 34 BIC: 236.0\nDf Model: 1 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nconst 2.8106 1.028 2.734 0.010 0.722 4.900\nx1 -3.424e-07 3.34e-07 -1.025 0.313 -1.02e-06 3.36e-07\n==============================================================================\nOmnibus: 54.398 Durbin-Watson: 2.340\nProb(Omnibus): 0.000 Jarque-Bera (JB): 413.932\nSkew: 3.236 Prob(JB): 1.31e-90\nKurtosis: 18.300 Cond. No. 3.17e+06\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n[2] The condition number is large, 3.17e+06. This might indicate that there are\nstrong multicollinearity or other numerical problems.\n"
],
[
"#Set up a linear regression model for Investment and evaluate\nWEO=WEO.reset_index()\nX = WEO['Investment']\nX=X.values.reshape(-1,1)\ny = WEO['Volume_imports']\n\nX2 = sm.add_constant(X)\nest = sm.OLS(y, X2)\nest2 = est.fit()\nprint(est2.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: Volume_imports R-squared: 0.325\nModel: OLS Adj. R-squared: 0.305\nMethod: Least Squares F-statistic: 16.38\nDate: Wed, 11 Aug 2021 Prob (F-statistic): 0.000282\nTime: 06:38:22 Log-Likelihood: -107.91\nNo. Observations: 36 AIC: 219.8\nDf Residuals: 34 BIC: 223.0\nDf Model: 1 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nconst -12.6186 3.839 -3.287 0.002 -20.421 -4.816\nx1 0.6569 0.162 4.048 0.000 0.327 0.987\n==============================================================================\nOmnibus: 8.946 Durbin-Watson: 2.079\nProb(Omnibus): 0.011 Jarque-Bera (JB): 8.455\nSkew: 0.822 Prob(JB): 0.0146\nKurtosis: 4.713 Cond. No. 109.\n==============================================================================\n\nNotes:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
]
],
[
[
"The linear regression analyses show that while GDP per capita is not significant in determining the volume of imports, investment is significant. For GDP per capita, we obtain a p-value of 0.313 which is insignificant. For Investment, we obtain a p-value of 0.000, which is significant.",
"_____no_output_____"
],
[
"## Next Steps",
"_____no_output_____"
],
[
"Next steps in analysing the data would be to see if there are any other variables that are significant in determining the volume of imports. The data scientist could also try a multiple linear regression to determine if there are variables that together produce a significant effect.",
"_____no_output_____"
],
[
"### Data Quality",
"_____no_output_____"
],
[
"The quality of this dataset is questionable. The exploratory data analysis showed several outliers that could be skewing the data. Further, there is no defined uniformity for how this data is measured. It is reported on a country-by-country basis, which leaves open the possibility that variation in definitions or methods for measuring these variables could lead to inaccurate comparison between countries.\n\nFurther data that I would request is more detailed trade data. Specifically, because this analysis finds that investment is significant in determining the volume of imports, it would be interesting to see which types of goods are more affected by investment. This could inform business decisions for a logistics company by allowing it to predict what type of cargo would need to be moved depending on investment practices in an individual country.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0096606cb4ca3f22d250351e7bafdb75518d9cf
| 178,345 |
ipynb
|
Jupyter Notebook
|
notebooks/burglary_01.ipynb
|
drimal/chicagofood
|
7616351228311e0bb56ed9a2449f9995a5c45164
|
[
"MIT"
] | null | null | null |
notebooks/burglary_01.ipynb
|
drimal/chicagofood
|
7616351228311e0bb56ed9a2449f9995a5c45164
|
[
"MIT"
] | null | null | null |
notebooks/burglary_01.ipynb
|
drimal/chicagofood
|
7616351228311e0bb56ed9a2449f9995a5c45164
|
[
"MIT"
] | null | null | null | 216.175758 | 91,224 | 0.877552 |
[
[
[
"import warnings\nwarnings.filterwarnings('ignore')\nimport os\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as mdates\nimport pandas as pd\nimport seaborn as sns\nsns.set(rc={'figure.figsize':(12, 6),\"font.size\":20,\"axes.titlesize\":20,\"axes.labelsize\":20},style=\"darkgrid\")",
"_____no_output_____"
]
],
[
[
"Is there any connection with the crime and food inspection failures? May be ! For now, I am focusing on the burgalaries only. The burglary data is the chicago's crime data filtered for burgalaries only (in the same time window i.e. first 3 months of 2019).",
"_____no_output_____"
]
],
[
[
"burglary = pd.read_json('../data/raw/burglary.json', convert_dates=['date'])\nburglary.head()",
"_____no_output_____"
],
[
"shape = burglary.shape\nprint(\" There are %d rows and %d columns in the data\" % (shape[0], shape[1]))\nprint(burglary.info())",
" There are 29133 rows and 26 columns in the data\n<class 'pandas.core.frame.DataFrame'>\nInt64Index: 29133 entries, 0 to 9999\nData columns (total 26 columns):\narrest 29133 non-null bool\nbeat 29133 non-null int64\nblock 29133 non-null object\ncase_number 29133 non-null object\ncommunity_area 29133 non-null int64\ndate 29133 non-null datetime64[ns]\ndescription 29133 non-null object\ndistrict 29133 non-null int64\ndomestic 29133 non-null bool\nfbi_code 29133 non-null int64\nid 29133 non-null int64\niucr 29133 non-null int64\nlatitude 28998 non-null float64\nlocation 28998 non-null object\nlocation_address 28998 non-null object\nlocation_city 28998 non-null object\nlocation_description 29132 non-null object\nlocation_state 28998 non-null object\nlocation_zip 28998 non-null object\nlongitude 28998 non-null float64\nprimary_type 29133 non-null object\nupdated_on 29133 non-null object\nward 29133 non-null int64\nx_coordinate 28998 non-null float64\ny_coordinate 28998 non-null float64\nyear 29133 non-null int64\ndtypes: bool(2), datetime64[ns](1), float64(4), int64(8), object(11)\nmemory usage: 5.6+ MB\nNone\n"
]
],
[
[
"Let's check if there are any null values in the data. ",
"_____no_output_____"
]
],
[
[
"burglary.isna().sum()",
"_____no_output_____"
],
[
"burglary['latitude'].fillna(burglary['latitude'].mode()[0], inplace=True)\nburglary['longitude'].fillna(burglary['longitude'].mode()[0], inplace=True)",
"_____no_output_____"
],
[
"ax = sns.countplot(x=\"ward\", data=burglary)\nplt.title(\"Burglaries by Ward\")\nplt.show()",
"_____no_output_____"
],
[
"plt.rcParams['figure.figsize'] = 16, 5\nax = sns.countplot(x=\"community_area\", data=burglary)\nplt.title(\"Burglaries by Ward\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Burglaries HeatMap",
"_____no_output_____"
]
],
[
[
"import gmaps\nAPIKEY= os.getenv('GMAPAPIKEY')\ngmaps.configure(api_key=APIKEY)\n\ndef make_heatmap(locations, weights=None):\n fig = gmaps.figure()\n heatmap_layer = gmaps.heatmap_layer(locations)\n #heatmap_layer.max_intensity = 100\n heatmap_layer.point_radius = 8\n fig.add_layer(heatmap_layer)\n return fig\n ",
"_____no_output_____"
],
[
"locations = zip(burglary['latitude'], burglary['longitude'])\nfig = make_heatmap(locations)\nfig",
"_____no_output_____"
],
[
"burglary_per_day = pd.DataFrame()\nburglary_per_day = burglary[['date', 'case_number']]\nburglary_per_day = burglary_per_day.set_index(\n pd.to_datetime(burglary_per_day['date']))\nburglary_per_day = burglary_per_day.resample('D').count()\nplt.rcParams['figure.figsize'] = 12, 5\nfig, ax = plt.subplots()\nfig.autofmt_xdate()\n#\n#ax.xaxis.set_major_locator(mdates.MonthLocator())\n#ax.xaxis.set_minor_locator(mdates.DayLocator())\nmonthFmt = mdates.DateFormatter('%Y-%b')\nax.xaxis.set_major_formatter(monthFmt)\n\nplt.plot(burglary_per_day.index, burglary_per_day, 'r-')\nplt.xlabel('Date')\nplt.ylabel('Number of Cases Reported')\nplt.title('Burglaries Reported')\nplt.show()",
"_____no_output_____"
],
[
"burglary['event_date'] = burglary['date']\nburglary = burglary.set_index('event_date')\nburglary.sort_values(by='date', inplace=True)\nburglary.head()",
"_____no_output_____"
],
[
"burglary.to_csv('../data/processed/burglary_data_processed.csv')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0096cb02dc68507e2b0cfb172642550ef65c2c8
| 23,131 |
ipynb
|
Jupyter Notebook
|
code/Taxon profile analysis.ipynb
|
justinshaffer/Extraction_kit_benchmarking
|
95040463a3dc04409c1fe5a3bdbf2635bb01a55f
|
[
"MIT"
] | null | null | null |
code/Taxon profile analysis.ipynb
|
justinshaffer/Extraction_kit_benchmarking
|
95040463a3dc04409c1fe5a3bdbf2635bb01a55f
|
[
"MIT"
] | null | null | null |
code/Taxon profile analysis.ipynb
|
justinshaffer/Extraction_kit_benchmarking
|
95040463a3dc04409c1fe5a3bdbf2635bb01a55f
|
[
"MIT"
] | null | null | null | 34.783459 | 246 | 0.631447 |
[
[
[
"# Set-up notebook environment\n## NOTE: Use a QIIME2 kernel",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport scipy\nfrom scipy import stats\nimport matplotlib.pyplot as plt\nimport re\nfrom pandas import *\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom qiime2.plugins import feature_table\nfrom qiime2 import Artifact\nfrom qiime2 import Metadata\nimport biom\nfrom biom.table import Table\nfrom qiime2.plugins import diversity\nfrom scipy.stats import ttest_ind\nfrom scipy.stats.stats import pearsonr\n%config InlineBackend.figure_formats = ['svg']\nfrom qiime2.plugins.feature_table.methods import relative_frequency\nimport biom\nimport qiime2 as q2\nimport os\nimport math\n",
"_____no_output_____"
]
],
[
[
"# Import sample metadata",
"_____no_output_____"
]
],
[
[
"meta = q2.Metadata.load('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/sample_metadata/12201_metadata.txt').to_dataframe()\n",
"_____no_output_____"
]
],
[
[
"Separate round 1 and round 2 and exclude round 1 Zymo, Homebrew, and MagMAX Beta",
"_____no_output_____"
]
],
[
[
"meta_r1 = meta[meta['round'] == 1]\nmeta_clean_r1_1 = meta_r1[meta_r1['extraction_kit'] != 'Zymo MagBead']\nmeta_clean_r1_2 = meta_clean_r1_1[meta_clean_r1_1['extraction_kit'] != 'Homebrew']\nmeta_clean_r1 = meta_clean_r1_2[meta_clean_r1_2['extraction_kit'] != 'MagMax Beta']\nmeta_clean_r2 = meta[meta['round'] == 2]\n",
"_____no_output_____"
]
],
[
[
"Remove PowerSoil samples from each round - these samples will be used as the baseline ",
"_____no_output_____"
]
],
[
[
"meta_clean_r1_noPS = meta_clean_r1[meta_clean_r1['extraction_kit'] != 'PowerSoil']\nmeta_clean_r2_noPS = meta_clean_r2[meta_clean_r2['extraction_kit'] != 'PowerSoil']\n",
"_____no_output_____"
]
],
[
[
"Create tables including only round 1 or round 2 PowerSoil samples",
"_____no_output_____"
]
],
[
[
"meta_clean_r1_onlyPS = meta_clean_r1[meta_clean_r1['extraction_kit'] == 'PowerSoil']\nmeta_clean_r2_onlyPS = meta_clean_r2[meta_clean_r2['extraction_kit'] == 'PowerSoil']\n",
"_____no_output_____"
]
],
[
[
"Merge PowerSoil samples from round 2 with other samples from round 1, and vice versa - this will allow us to get the correlations between the two rounds of PowerSoil",
"_____no_output_____"
]
],
[
[
"meta_clean_r1_with_r2_PS = pd.concat([meta_clean_r1_noPS, meta_clean_r2_onlyPS])\nmeta_clean_r2_with_r1_PS = pd.concat([meta_clean_r2_noPS, meta_clean_r1_onlyPS])\n",
"_____no_output_____"
]
],
[
[
"## Collapse feature-table to the desired level (e.g., genus)",
"_____no_output_____"
],
[
"16S",
"_____no_output_____"
]
],
[
[
"qiime taxa collapse \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/10_filtered_data/dna_bothPS_16S_deblur_biom_lod_noChl_noMit_sepp_gg_noNTCs_noMock.qza \\\n --i-taxonomy /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/06_taxonomy/dna_all_16S_deblur_seqs_taxonomy_silva138.qza \\\n --p-level 6 \\\n --o-collapsed-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/10_filtered_data/dna_bothPS_16S_deblur_biom_lod_noChl_noMit_sepp_gg_noNTCs_noMock_taxa_collapse_genus.qza\n\nqiime feature-table summarize \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/10_filtered_data/dna_bothPS_16S_deblur_biom_lod_noChl_noMit_sepp_gg_noNTCs_noMock_taxa_collapse_genus.qza \\\n --o-visualization /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/10_filtered_data/dna_bothPS_16S_deblur_biom_lod_noChl_noMit_sepp_gg_noNTCs_noMock_taxa_collapse_genus.qzv\n\n# There are 846 samples and 1660 features\n",
"_____no_output_____"
]
],
[
[
"ITS",
"_____no_output_____"
]
],
[
[
"qiime taxa collapse \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/08_filtered_data/dna_bothPS_ITS_deblur_biom_lod_noNTCs_noMock.qza \\\n --i-taxonomy /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/06_taxonomy/dna_all_ITS_deblur_seqs_taxonomy_unite8.qza \\\n --p-level 6 \\\n --o-collapsed-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/08_filtered_data/dna_bothPS_ITS_deblur_biom_lod_noNTCs_noMock_taxa_collapse_genus.qza\n\nqiime feature-table summarize \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/08_filtered_data/dna_bothPS_ITS_deblur_biom_lod_noNTCs_noMock_taxa_collapse_genus.qza \\\n --o-visualization /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/08_filtered_data/dna_bothPS_ITS_deblur_biom_lod_noNTCs_noMock_taxa_collapse_genus.qzv\n\n# There are 978 samples and 791 features\n",
"_____no_output_____"
]
],
[
[
"Shotgun",
"_____no_output_____"
]
],
[
[
"qiime taxa collapse \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/03_filtered_data/dna_bothPS_shotgun_woltka_wol_biom_noNTCs_noMock.qza \\\n --i-taxonomy /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/wol_taxonomy.qza \\\n --p-level 6 \\\n --o-collapsed-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/03_filtered_data/dna_bothPS_shotgun_woltka_wol_biom_noNTCs_noMock_taxa_collapse_genus.qza\n\nqiime feature-table summarize \\\n --i-table /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/03_filtered_data/dna_bothPS_shotgun_woltka_wol_biom_noNTCs_noMock_taxa_collapse_genus.qza \\\n --o-visualization /Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/03_filtered_data/dna_bothPS_shotgun_woltka_wol_biom_noNTCs_noMock_taxa_collapse_genus.qzv\n\n# There are 1044 samples and 2060 features\n",
"_____no_output_____"
]
],
[
[
"# Import feature-tables",
"_____no_output_____"
]
],
[
[
"dna_bothPS_16S_genus_qza = q2.Artifact.load('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/16S/10_filtered_data/dna_bothPS_16S_deblur_biom_lod_noChl_noMit_sepp_gg_noNTCs_noMock_taxa_collapse_genus.qza')\ndna_bothPS_ITS_genus_qza = q2.Artifact.load('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/ITS/08_filtered_data/dna_bothPS_ITS_deblur_biom_lod_noNTCs_noMock_taxa_collapse_genus.qza')\ndna_bothPS_shotgun_genus_qza = q2.Artifact.load('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/data/shotgun/03_filtered_data/dna_bothPS_shotgun_woltka_wol_biom_noNTCs_noMock_taxa_collapse_genus.qza')\n",
"_____no_output_____"
]
],
[
[
"# Convert QZA to a Pandas DataFrame",
"_____no_output_____"
]
],
[
[
"dna_bothPS_16S_genus_df = dna_bothPS_16S_genus_qza.view(pd.DataFrame)\ndna_bothPS_ITS_genus_df = dna_bothPS_ITS_genus_qza.view(pd.DataFrame)\ndna_bothPS_shotgun_genus_df = dna_bothPS_shotgun_genus_qza.view(pd.DataFrame)\n",
"_____no_output_____"
]
],
[
[
"# Melt dataframes",
"_____no_output_____"
]
],
[
[
"dna_bothPS_16S_genus_df_melt = dna_bothPS_16S_genus_df.unstack()\ndna_bothPS_ITS_genus_df_melt = dna_bothPS_ITS_genus_df.unstack()\ndna_bothPS_shotgun_genus_df_melt = dna_bothPS_shotgun_genus_df.unstack()\n\ndna_bothPS_16S_genus = pd.DataFrame(dna_bothPS_16S_genus_df_melt)\ndna_bothPS_ITS_genus = pd.DataFrame(dna_bothPS_ITS_genus_df_melt)\ndna_bothPS_shotgun_genus = pd.DataFrame(dna_bothPS_shotgun_genus_df_melt)\n",
"_____no_output_____"
],
[
"dna_bothPS_16S_genus.reset_index(inplace=True)\ndna_bothPS_16S_genus.rename(columns={'level_0':'taxa','level_1':'sample',0:'counts'}, inplace=True)\n\ndna_bothPS_ITS_genus.reset_index(inplace=True)\ndna_bothPS_ITS_genus.rename(columns={'level_0':'taxa','level_1':'sample',0:'counts'}, inplace=True)\n\ndna_bothPS_shotgun_genus.reset_index(inplace=True)\ndna_bothPS_shotgun_genus.rename(columns={'level_0':'taxa','level_1':'sample',0:'counts'}, inplace=True)\n",
"_____no_output_____"
]
],
[
[
"# Wrangle data into long form for each kit",
"_____no_output_____"
],
[
"Wrangle metadata",
"_____no_output_____"
]
],
[
[
"# Create empty list of extraction kit IDs\next_kit_levels = [] \n\n\n# Create empty list of metadata subsets based on levels of variable of interest\next_kit = [] \n\n\n# Create empty list of baseline samples for each subset\nbl = []\n\n\n# Populate lists with round 1 data\nfor ext_kit_level, ext_kit_level_df in meta_clean_r1_with_r2_PS.groupby('extraction_kit_round'):\n ext_kit.append(ext_kit_level_df)\n \n powersoil_r1_bl = meta_clean_r1_onlyPS[meta_clean_r1_onlyPS.extraction_kit_round == 'PowerSoil r1']\n bl.append(powersoil_r1_bl)\n \n ext_kit_levels.append(ext_kit_level)\n \n print('Gathered data for',ext_kit_level)\n\n\n# Populate lists with round 2 data\nfor ext_kit_level, ext_kit_level_df in meta_clean_r2_with_r1_PS.groupby('extraction_kit_round'):\n ext_kit.append(ext_kit_level_df)\n\n powersoil_r2_bl = meta_clean_r2_onlyPS[meta_clean_r2_onlyPS['extraction_kit_round'] == 'PowerSoil r2']\n bl.append(powersoil_r2_bl)\n\n ext_kit_levels.append(ext_kit_level)\n\n print('Gathered data for',ext_kit_level)\n\n\n# Create empty list for concatenated subset-baseline datasets\nsubsets_w_bl = {}\n\n\n# Populate list with subset-baseline data\nfor ext_kit_level, ext_kit_df, ext_kit_bl in zip(ext_kit_levels, ext_kit, bl): \n\n new_df = pd.concat([ext_kit_bl,ext_kit_df]) \n subsets_w_bl[ext_kit_level] = new_df\n \n print('Merged data for',ext_kit_level)\n ",
"Gathered data for Norgen\nGathered data for PowerSoil Pro\nGathered data for PowerSoil r2\nGathered data for MagMAX Microbiome\nGathered data for NucleoMag Food\nGathered data for PowerSoil r1\nGathered data for Zymo MagBead\nMerged data for Norgen\nMerged data for PowerSoil Pro\nMerged data for PowerSoil r2\nMerged data for MagMAX Microbiome\nMerged data for NucleoMag Food\nMerged data for PowerSoil r1\nMerged data for Zymo MagBead\n"
]
],
[
[
"16S",
"_____no_output_____"
]
],
[
[
"list_of_lists = []\n\nfor key, value in subsets_w_bl.items():\n \n string = ''.join(key)\n \n #merge metadata subsets with baseline with taxonomy\n meta_16S_genera = pd.merge(value, dna_bothPS_16S_genus, left_index=True, right_on='sample')\n\n #create new column \n meta_16S_genera['taxa_subject'] = meta_16S_genera['taxa'] + meta_16S_genera['host_subject_id']\n\n #subtract out duplicates and pivot\n meta_16S_genera_clean = meta_16S_genera.drop_duplicates(subset = ['taxa_subject', 'extraction_kit_round'], keep = 'first')\n meta_16S_genera_pivot = meta_16S_genera_clean.pivot(index='taxa_subject', columns='extraction_kit_round', values='counts')\n meta_16S_genera_pivot_clean = meta_16S_genera_pivot.dropna()\n \n # Export dataframe to file\n meta_16S_genera_pivot_clean.to_csv('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/table_correlation_16S_genera_%s.txt'%string,\n sep = '\\t',\n index = False)\n ",
"_____no_output_____"
]
],
[
[
"ITS",
"_____no_output_____"
]
],
[
[
"list_of_lists = []\n\nfor key, value in subsets_w_bl.items():\n \n string = ''.join(key)\n \n #merge metadata subsets with baseline with taxonomy\n meta_ITS_genera = pd.merge(value, dna_bothPS_ITS_genus, left_index=True, right_on='sample')\n\n #create new column \n meta_ITS_genera['taxa_subject'] = meta_ITS_genera['taxa'] + meta_ITS_genera['host_subject_id']\n\n #subtract out duplicates and pivot\n meta_ITS_genera_clean = meta_ITS_genera.drop_duplicates(subset = ['taxa_subject', 'extraction_kit_round'], keep = 'first')\n meta_ITS_genera_pivot = meta_ITS_genera_clean.pivot(index='taxa_subject', columns='extraction_kit_round', values='counts')\n meta_ITS_genera_pivot_clean = meta_ITS_genera_pivot.dropna()\n \n # Export dataframe to file\n meta_ITS_genera_pivot_clean.to_csv('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/table_correlation_ITS_genera_%s.txt'%string,\n sep = '\\t',\n index = False)\n ",
"_____no_output_____"
]
],
[
[
"Shotgun",
"_____no_output_____"
]
],
[
[
"list_of_lists = []\n\nfor key, value in subsets_w_bl.items():\n \n string = ''.join(key)\n \n #merge metadata subsets with baseline with taxonomy\n meta_shotgun_genera = pd.merge(value, dna_bothPS_shotgun_genus, left_index=True, right_on='sample')\n\n #create new column \n meta_shotgun_genera['taxa_subject'] = meta_shotgun_genera['taxa'] + meta_shotgun_genera['host_subject_id']\n\n #subtract out duplicates and pivot\n meta_shotgun_genera_clean = meta_shotgun_genera.drop_duplicates(subset = ['taxa_subject', 'extraction_kit_round'], keep = 'first')\n meta_shotgun_genera_pivot = meta_shotgun_genera_clean.pivot(index='taxa_subject', columns='extraction_kit_round', values='counts')\n meta_shotgun_genera_pivot_clean = meta_shotgun_genera_pivot.dropna()\n \n # Export dataframe to file\n meta_shotgun_genera_pivot_clean.to_csv('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/table_correlation_shotgun_genera_%s.txt'%string,\n sep = '\\t',\n index = False)\n ",
"_____no_output_____"
]
],
[
[
"# Code below is not used\n## NOTE: The first cell was originally appended to the cell above",
"_____no_output_____"
]
],
[
[
" # check pearson correlation\n x = meta_16S_genera_pivot_clean.iloc[:,1]\n y = meta_16S_genera_pivot_clean[key]\n corr = stats.pearsonr(x, y)\n int1, int2 = corr\n corr_rounded = round(int1, 2)\n corr_str = str(corr_rounded)\n x_key = key[0]\n y_key = key[1]\n \n list1 = []\n \n list1.append(corr_rounded)\n list1.append(key)\n list_of_lists.append(list1)\n ",
"_____no_output_____"
],
[
"list_of_lists",
"_____no_output_____"
],
[
"df = pd.DataFrame(list_of_lists, columns = ['Correlation', 'Extraction kit']) \n",
"_____no_output_____"
],
[
"df.to_csv('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/table_correlations_16S_genera.txt',\n sep = '\\t',\n index = False)\n",
"_____no_output_____"
],
[
"splot = sns.catplot(y=\"Correlation\", \n x=\"Extraction kit\", \n hue= \"Extraction kit\", \n kind='bar',\n data=df,\n dodge = False)\nsplot.set(ylim=(0, 1))\nplt.xticks(rotation=45,\n horizontalalignment='right')\n\n#new_labels = ['−20C','−20C after 1 week', '4C','Ambient','Freeze-thaw','Heat']\n#for t, l in zip(splot._legend.texts, new_labels):\n# t.set_text(l)\n \nsplot.savefig('correlation_16S_genera.png')\nsplot.savefig('correlation_16S_genera.svg', format='svg', dpi=1200)\n",
"_____no_output_____"
]
],
[
[
"### Individual correlation plots ",
"_____no_output_____"
]
],
[
[
"for key, value in subsets_w_bl.items():\n \n string = ''.join(key)\n \n #merge metadata subsets with baseline with taxonomy\n meta_16S_genera = pd.merge(value, dna_bothPS_16S_genus, left_index=True, right_on='sample')\n\n #create new column \n meta_16S_genera['taxa_subject'] = meta_16S_genera['taxa'] + meta_16S_genera['host_subject_id']\n\n #subtract out duplicates and pivot\n meta_16S_genera_clean = meta_16S_genera.drop_duplicates(subset = ['taxa_subject', 'extraction_kit_round'], keep = 'first')\n meta_16S_genera_pivot = meta_16S_genera_clean.pivot(index='taxa_subject', columns='extraction_kit_round', values='counts')\n meta_16S_genera_pivot_clean = meta_16S_genera_pivot.dropna()\n\n # check pearson correlation\n x = meta_16S_genera_pivot_clean.iloc[:,1]\n y = meta_16S_genera_pivot_clean[key]\n corr = stats.pearsonr(x, y)\n int1, int2 = corr\n corr_rounded = round(int1, 2)\n corr_str = str(corr_rounded)\n \n #make correlation plots\n meta_16S_genera_pivot_clean['x1'] = meta_16S_genera_pivot_clean.iloc[:,1]\n meta_16S_genera_pivot_clean['y1'] = meta_16S_genera_pivot_clean.iloc[:,0]\n ax=sns.lmplot(x='x1',\n y='y1',\n data=meta_16S_genera_pivot_clean, \n height=3.8)\n ax.set(yscale='log')\n ax.set(xscale='log')\n ax.set(xlabel='PowerSoil', ylabel=key)\n #plt.xlim(0.00001, 10000000)\n #plt.ylim(0.00001, 10000000)\n plt.title(string + ' (%s)' %corr_str)\n\n ax.savefig('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/figure_scatter_correlation_16S_genera_%s.png'%string)\n ax.savefig('/Users/Justin/Mycelium/UCSD/00_Knight_Lab/03_Extraction_test_12201/round_02/results/feature_abundance_correlation_images/figure_scatter_correlation_16S_genera_%s.svg'%string, format='svg',dpi=1200)\n ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0098128690e09635604f7ac64e677bfc67b5c76
| 16,193 |
ipynb
|
Jupyter Notebook
|
99-Miscel/02-bqplot-B.ipynb
|
dushyantkhosla/dataviz
|
05a004a390d180d87be2d09873c3f7283c2a2e27
|
[
"MIT"
] | null | null | null |
99-Miscel/02-bqplot-B.ipynb
|
dushyantkhosla/dataviz
|
05a004a390d180d87be2d09873c3f7283c2a2e27
|
[
"MIT"
] | 2 |
2021-03-25T22:11:43.000Z
|
2022-03-02T22:43:47.000Z
|
99-Miscel/02-bqplot-B.ipynb
|
dushyantkhosla/viz4ds
|
05a004a390d180d87be2d09873c3f7283c2a2e27
|
[
"MIT"
] | null | null | null | 26.330081 | 120 | 0.433953 |
[
[
[
"## Health, Wealth of Nations from 1800-2008",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np\nimport pandas as pd\nfrom pandas import Series, DataFrame",
"_____no_output_____"
],
[
"from bqplot import Figure, Tooltip, Label\nfrom bqplot import Axis, ColorAxis\nfrom bqplot import LogScale, LinearScale, OrdinalColorScale\nfrom bqplot import Scatter, Lines\nfrom bqplot import CATEGORY10",
"_____no_output_____"
],
[
"from ipywidgets import HBox, VBox, IntSlider, Play, jslink",
"_____no_output_____"
],
[
"from more_itertools import flatten",
"_____no_output_____"
]
],
[
[
"---\n### Get Data",
"_____no_output_____"
]
],
[
[
"year_start = 1800\n\ndf = pd.read_json(\"data_files/nations.json\")\ndf.head()",
"_____no_output_____"
],
[
"list_rows_to_drop = \\\n(df['income']\n .apply(len)\n .where(lambda i: i < 10)\n .dropna()\n .index\n .tolist()\n)\n\ndf.drop(list_rows_to_drop, inplace=True)",
"_____no_output_____"
],
[
"dict_dfs = {}\n\nfor COL in ['income', 'lifeExpectancy', 'population']:\n df1 = \\\n DataFrame(df\n .loc[:, COL]\n .map(lambda l: (DataFrame(l)\n .set_index(0)\n .squeeze()\n .reindex(range(1800, 2009))\n .interpolate()\n .to_dict()))\n .tolist())\n df1.index = df.name\n dict_dfs[COL] = df1",
"_____no_output_____"
],
[
"def get_data(year):\n \"\"\"\n \"\"\"\n income = dict_dfs['income'].loc[:, year]\n lifeExpectancy = dict_dfs['lifeExpectancy'].loc[:, year]\n population = dict_dfs['population'].loc[:, year]\n return income, lifeExpectancy, population\n\nget_min_max_from_df = lambda df: (df.min().min(), df.max().max())",
"_____no_output_____"
]
],
[
[
"---\n### Create Tooltip",
"_____no_output_____"
]
],
[
[
"tt = Tooltip(fields=['name', 'x', 'y'], \n labels=['Country', 'IncomePerCapita', 'LifeExpectancy'])",
"_____no_output_____"
]
],
[
[
"---\n### Create Scales",
"_____no_output_____"
]
],
[
[
"# Income \nincome_min, income_max = get_min_max_from_df(dict_dfs['income'])\nx_sc = LogScale(min=income_min, \n max=income_max)\n\n# Life Expectancy \nlife_exp_min, life_exp_max = get_min_max_from_df(dict_dfs['lifeExpectancy'])\ny_sc = LinearScale(min=life_exp_min, \n max=life_exp_max)\n\n# Population\npop_min, pop_max = get_min_max_from_df(dict_dfs['population'])\nsize_sc = LinearScale(min=pop_min, \n max=pop_max)\n\n# Color\nc_sc = OrdinalColorScale(domain=df['region'].unique().tolist(), \n colors=CATEGORY10[:6])",
"_____no_output_____"
]
],
[
[
"---\n### Create Axes",
"_____no_output_____"
]
],
[
[
"ax_y = Axis(label='Life Expectancy', \n scale=y_sc, \n orientation='vertical', \n side='left', \n grid_lines='solid')\n\nax_x = Axis(label='Income per Capita', \n scale=x_sc, \n grid_lines='solid')",
"_____no_output_____"
]
],
[
[
"---\n## Create Marks\n\n### 1. Scatter",
"_____no_output_____"
]
],
[
[
"cap_income, life_exp, pop = get_data(year_start)",
"_____no_output_____"
],
[
"scatter_ = Scatter(x=cap_income, \n y=life_exp, \n color=df['region'], \n size=pop,\n names=df['name'], \n display_names=False,\n scales={\n 'x': x_sc, \n 'y': y_sc, \n 'color': c_sc, \n 'size': size_sc\n },\n default_size=4112, \n tooltip=tt, \n animate=True, \n stroke='Black',\n unhovered_style={'opacity': 0.5})",
"_____no_output_____"
]
],
[
[
"### 2. Line",
"_____no_output_____"
]
],
[
[
"line_ = Lines(x=dict_dfs['income'].loc['Angola'].values, \n y=dict_dfs['lifeExpectancy'].loc['Angola'].values, \n colors=['Gray'],\n scales={\n 'x': x_sc, \n 'y': y_sc\n }, \n visible=False)",
"_____no_output_____"
]
],
[
[
"---\n### Create Label",
"_____no_output_____"
]
],
[
[
"year_label = Label(x=[0.75], \n y=[0.10],\n font_size=50, \n font_weight='bolder', \n colors=['orange'],\n text=[str(year_start)],\n enable_move=True)",
"_____no_output_____"
]
],
[
[
"---\n## Construct the Figure",
"_____no_output_____"
]
],
[
[
"time_interval = 10\n\nfig_ = \\\nFigure(\n marks=[scatter_, line_, year_label], \n axes=[ax_x, ax_y],\n title='Health and Wealth of Nations', \n animation_duration=time_interval\n)\n\nfig_.layout.min_width = '960px'\nfig_.layout.min_height = '640px'\n\nfig_",
"_____no_output_____"
]
],
[
[
"---\n## Add Interactivity\n\n- Update chart when year changes",
"_____no_output_____"
]
],
[
[
"slider_ = IntSlider(\n min=year_start, \n max=2008, \n step=1, \n description='Year: ', \n value=year_start)\n\ndef on_change_year(change):\n \"\"\"\n \"\"\"\n scatter_.x, scatter_.y, scatter_.size = get_data(slider_.value)\n year_label.text = [str(slider_.value)]\n\nslider_.observe(on_change_year, 'value')\n\nslider_",
"_____no_output_____"
]
],
[
[
"- Display line when hovered",
"_____no_output_____"
]
],
[
[
"def on_hover(change):\n \"\"\"\n \"\"\"\n if change.new is not None:\n display(change.new)\n line_.x = dict_dfs['income'].iloc[change.new + 1]\n line_.y = dict_dfs['lifeExpectancy'].iloc[change.new + 1]\n line_.visible = True\n else:\n line_.visible = False",
"_____no_output_____"
],
[
"scatter_.observe(on_hover, 'hovered_point')",
"_____no_output_____"
]
],
[
[
"---\n## Add Animation!",
"_____no_output_____"
]
],
[
[
"play_button = Play(\n min=1800, \n max=2008, \n interval=time_interval\n)\n\njslink(\n (play_button, 'value'), \n (slider_, 'value')\n)",
"_____no_output_____"
]
],
[
[
"---\n## Create the GUI",
"_____no_output_____"
]
],
[
[
"VBox([play_button, slider_, fig_])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d009889a0db25d988ced48c57ad6e5bcbc7d6364
| 977 |
ipynb
|
Jupyter Notebook
|
codes.ipynb
|
ltalirz/aiidalab-widgets-base
|
5aab8d8bfda9cc414c9591d94be313f315df2b84
|
[
"MIT"
] | null | null | null |
codes.ipynb
|
ltalirz/aiidalab-widgets-base
|
5aab8d8bfda9cc414c9591d94be313f315df2b84
|
[
"MIT"
] | null | null | null |
codes.ipynb
|
ltalirz/aiidalab-widgets-base
|
5aab8d8bfda9cc414c9591d94be313f315df2b84
|
[
"MIT"
] | null | null | null | 19.938776 | 71 | 0.568066 |
[
[
[
"from aiidalab_widgets_base import CodeDropdown\nfrom IPython.display import display\n\n# Select from installed codes for 'zeopp.network' input plugin\ndropdown = CodeDropdown(input_plugin='zeopp.network')\ndisplay(dropdown)",
"_____no_output_____"
],
[
"dropdown.selected_code",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
d0098fc60697b4daa8550da4cd99ff458e3130c5
| 17,190 |
ipynb
|
Jupyter Notebook
|
openbus_10_stuff.ipynb
|
cjer/open-bus-explore
|
150ff3463bc3f2a23a097782246adbe3971fe46b
|
[
"MIT"
] | 1 |
2019-10-22T13:34:07.000Z
|
2019-10-22T13:34:07.000Z
|
openbus_10_stuff.ipynb
|
cjer/open-bus-explore
|
150ff3463bc3f2a23a097782246adbe3971fe46b
|
[
"MIT"
] | 2 |
2018-02-25T08:00:17.000Z
|
2019-04-01T14:15:20.000Z
|
openbus_10_stuff.ipynb
|
cjer/open-bus-explore
|
150ff3463bc3f2a23a097782246adbe3971fe46b
|
[
"MIT"
] | 2 |
2018-02-24T17:10:27.000Z
|
2018-06-18T16:03:30.000Z
| 30.264085 | 161 | 0.42071 |
[
[
[
"I want to analyze changes over time in the MOT GTFS feed. \n\nAgenda:\n1. [Get data](#Get-the-data)\n\n3. [Tidy](#Tidy-it-up)\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport partridge as ptg\nfrom ftplib import FTP\nimport datetime\nimport re\nimport zipfile\nimport os\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (10, 5) # set default size of plots\n\nsns.set_style(\"white\")\nsns.set_context(\"talk\")\nsns.set_palette('Set2', 10)",
"_____no_output_____"
]
],
[
[
"## Get the data\nThere are two options - TransitFeeds and the workshop's S3 bucket.",
"_____no_output_____"
]
],
[
[
"#!aws s3 cp s3://s3.obus.hasadna.org.il/2018-04-25.zip data/gtfs_feeds/2018-04-25.zip",
"_____no_output_____"
]
],
[
[
"## Tidy it up\nAgain I'm using [partridge](https://github.com/remix/partridge/tree/master/partridge) for filtering on dates, and then some tidying up and transformations.",
"_____no_output_____"
]
],
[
[
"from gtfs_utils import *\n\nlocal_tariff_path = 'data/sample/180515_tariff.zip' ",
"_____no_output_____"
],
[
"conn = ftp_connect()\nget_ftp_file(conn, file_name = TARIFF_FILE_NAME, local_zip_path = local_tariff_path )",
"_____no_output_____"
],
[
"\n\ndef to_timedelta(df):\n '''\n Turn time columns into timedelta dtype\n '''\n cols = ['arrival_time', 'departure_time']\n numeric = df[cols].apply(pd.to_timedelta, unit='s')\n df = df.copy()\n df[cols] = numeric\n return df",
"_____no_output_____"
],
[
"%time f2 = new_get_tidy_feed_df(feed, [zones])",
"Wall time: 2min 16s\n"
],
[
"f2.head()",
"_____no_output_____"
],
[
"f2.columns",
"_____no_output_____"
],
[
"def get_tidy_feed_df(feed, zones):\n s = feed.stops\n r = feed.routes\n a = feed.agency\n t = (feed.trips\n # faster joins and slices with Categorical dtypes \n .assign(route_id=lambda x: pd.Categorical(x['route_id'])))\n f = (feed.stop_times[fields['stop_times']]\n .merge(s[fields['stops']], on='stop_id')\n .merge(zones, how='left')\n .assign(zone_name=lambda x: pd.Categorical(x['zone_name']))\n .merge(t[fields['trips']], on='trip_id', how='left')\n .assign(route_id=lambda x: pd.Categorical(x['route_id'])) \n .merge(r[fields['routes']], on='route_id', how='left')\n .assign(agency_id=lambda x: pd.Categorical(x['agency_id']))\n .merge(a[fields['agency']], on='agency_id', how='left')\n .assign(agency_name=lambda x: pd.Categorical(x['agency_name']))\n .pipe(to_timedelta)\n )\n return f",
"_____no_output_____"
],
[
"LOCAL_ZIP_PATH = 'data/gtfs_feeds/2018-02-01.zip' ",
"_____no_output_____"
],
[
"feed = get_partridge_feed_by_date(LOCAL_ZIP_PATH, datetime.date(2018,2 , 1))\nzones = get_zones()",
"_____no_output_____"
],
[
"'route_ids' in feed.routes.columns",
"_____no_output_____"
],
[
"feed.routes.shape",
"_____no_output_____"
],
[
"f = get_tidy_feed_df(feed, zones)",
"_____no_output_____"
],
[
"f.columns",
"_____no_output_____"
],
[
"f[f.route_short_name.isin(['20', '26', '136'])].groupby('stop_name').route_short_name.nunique().sort_values(ascending=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d00991f52c2b72a075432e0a7ce6388f6a55d1de
| 4,065 |
ipynb
|
Jupyter Notebook
|
NLP.ipynb
|
abewoycke/shel-nlp
|
0c9bdaa9529d2418b54fe77603a62cf2a82a3cb9
|
[
"MIT"
] | null | null | null |
NLP.ipynb
|
abewoycke/shel-nlp
|
0c9bdaa9529d2418b54fe77603a62cf2a82a3cb9
|
[
"MIT"
] | null | null | null |
NLP.ipynb
|
abewoycke/shel-nlp
|
0c9bdaa9529d2418b54fe77603a62cf2a82a3cb9
|
[
"MIT"
] | null | null | null | 25.40625 | 121 | 0.552276 |
[
[
[
"import numpy as np\nimport pandas as pd\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import Dropout\nfrom keras.layers import LSTM\nfrom keras.utils import np_utils\n\n%cd \"C:\\Users\\abewo\\Documents\\GitHub\\shel-nlp\\\"",
"_____no_output_____"
],
[
"# load the data\ntext=(open(\"shel_silverstein_training_corpus_with_line_breaks.txt\", encoding='utf-8').read())\ntext=text.lower()",
"_____no_output_____"
],
[
"# create character mappings (may change to word mappings later)\ncharacters = sorted(list(set(text)))\nn_to_char = {n:char for n, char in enumerate(characters)}\nchar_to_n = {char:n for n, char in enumerate(characters)}",
"_____no_output_____"
],
[
"# data preprocessing\nX = []\nY = []\nlength = len(text)\nseq_length = 100\nfor i in range(0, length-seq_length, 1):\n sequence = text[i:i + seq_length]\n label = text[i + seq_length]\n X.append([char_to_n[char] for char in sequence])\n Y.append(char_to_n[label])",
"_____no_output_____"
],
[
"# transform to LSTM inputs\nX_modified = np.reshape(X, (len(X), seq_length, 1))\nX_modified = X_modified / float(len(characters))\nY_modified = np_utils.to_categorical(Y)",
"_____no_output_____"
],
[
"# build model\nmodel = Sequential()\nmodel.add(LSTM(400, input_shape=(X_modified.shape[1], X_modified.shape[2]), return_sequences=True))\nmodel.add(Dropout(0.2))\nmodel.add(LSTM(400))\nmodel.add(Dropout(0.2))\nmodel.add(Dense(Y_modified.shape[1], activation='softmax'))\nmodel.compile(loss='categorical_crossentropy', optimizer='adam')",
"_____no_output_____"
],
[
"string_mapped = X[99]\nfull_string = [n_to_char[value] for value in string_mapped]\n# generating characters\nfor i in range(seq_length):\n x = np.reshape(string_mapped,(1,len(string_mapped), 1))\n x = x / float(len(characters))\n pred_index = np.argmax(model.predict(x, verbose=0))\n seq = [n_to_char[value] for value in string_mapped]\n string_mapped.append(pred_index)\n string_mapped = string_mapped[1:len(string_mapped)]",
"_____no_output_____"
],
[
"txt=\"\"\nfor char in full_string:\n txt = txt+char\ntxt",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d00994cb946ba99c745109af6e2db8bf8172d9a1
| 93,527 |
ipynb
|
Jupyter Notebook
|
content_raj/Practice - Pandas.ipynb
|
xbsd/CS109
|
a61c6861cfe68791451c4c59d2deeb3507c5f7f9
|
[
"MIT"
] | null | null | null |
content_raj/Practice - Pandas.ipynb
|
xbsd/CS109
|
a61c6861cfe68791451c4c59d2deeb3507c5f7f9
|
[
"MIT"
] | null | null | null |
content_raj/Practice - Pandas.ipynb
|
xbsd/CS109
|
a61c6861cfe68791451c4c59d2deeb3507c5f7f9
|
[
"MIT"
] | null | null | null | 26.271629 | 1,212 | 0.329755 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
d0099cc81b459a12e68cba2aa4bf49854a44bd5f
| 13,681 |
ipynb
|
Jupyter Notebook
|
python_hpc/3_intro_pandas/0-intro-python.ipynb
|
sdsc-scicomp/2018-11-02-comet-workshop-ucr
|
0189387422135db9e32ff5dfd42c333f4c258962
|
[
"BSD-3-Clause"
] | null | null | null |
python_hpc/3_intro_pandas/0-intro-python.ipynb
|
sdsc-scicomp/2018-11-02-comet-workshop-ucr
|
0189387422135db9e32ff5dfd42c333f4c258962
|
[
"BSD-3-Clause"
] | null | null | null |
python_hpc/3_intro_pandas/0-intro-python.ipynb
|
sdsc-scicomp/2018-11-02-comet-workshop-ucr
|
0189387422135db9e32ff5dfd42c333f4c258962
|
[
"BSD-3-Clause"
] | 1 |
2018-11-02T12:15:09.000Z
|
2018-11-02T12:15:09.000Z
| 17.208805 | 160 | 0.470507 |
[
[
[
"Write in the input space, click `Shift-Enter` or click on the `Play` button to execute.",
"_____no_output_____"
]
],
[
[
"(3 + 1 + 12) ** 2 + 2 * 18",
"_____no_output_____"
]
],
[
[
"Give a title to the notebook by clicking on `Untitled` on the very top of the page, better not to use spaces because it will be also used for the filename",
"_____no_output_____"
],
[
"Save the notebook with the `Diskette` button, check dashboard",
"_____no_output_____"
],
[
"Integer division gives integer result with truncation in Python 2, float result in Python 3:",
"_____no_output_____"
]
],
[
[
"5/3",
"_____no_output_____"
],
[
"1/3",
"_____no_output_____"
]
],
[
[
"### Quotes for strings",
"_____no_output_____"
]
],
[
[
"print(\"Hello world\")",
"Hello world\n"
],
[
"print('Hello world')",
"Hello world\n"
]
],
[
[
"### Look for differences",
"_____no_output_____"
]
],
[
[
"\"Hello world\"",
"_____no_output_____"
],
[
"print(\"Hello world\")",
"Hello world\n"
]
],
[
[
"### Multiple lines in a cell",
"_____no_output_____"
]
],
[
[
"1 + 2\n3 + 4",
"_____no_output_____"
],
[
"print(1 + 2)\nprint(3 + 4)",
"3\n7\n"
],
[
"print(\"\"\"This is \na multiline\nHello world\"\"\")",
"This is \na multiline\nHello world\n"
]
],
[
[
"## Functions and help",
"_____no_output_____"
]
],
[
[
"abs(-2)",
"_____no_output_____"
]
],
[
[
"Write a function name followed by `?` to open the help for that function.\n\ntype in a cell and execute: `abs?`",
"_____no_output_____"
],
[
"# Heading 1",
"_____no_output_____"
],
[
"## Heading 2",
"_____no_output_____"
],
[
"Structured plain text format, it looks a lot like writing text **emails**,\nyou can do lists:\n\n* like\n* this\n\nwrite links like <http://google.com>, or [hyperlinking words](http://www.google.com)",
"_____no_output_____"
],
[
"go to <http://markdowntutorial.com/> to learn more",
"_____no_output_____"
],
[
"$b_n=\\frac{1}{\\pi}\\int\\limits_{-\\pi}^{\\pi}f(x)\\sin nx\\,\\mathrm{d}x=\\\\\n=\\frac{1}{\\pi}\\int\\limits_{-\\pi}^{\\pi}x^2\\sin nx\\,\\mathrm{d}x$",
"_____no_output_____"
],
[
"## Variables",
"_____no_output_____"
]
],
[
[
"weight_kg = 55",
"_____no_output_____"
]
],
[
[
"Once a variable has a value, we can print it:",
"_____no_output_____"
]
],
[
[
"print(weight_kg)",
"55\n"
]
],
[
[
"and do arithmetic with it:",
"_____no_output_____"
]
],
[
[
"print('weight in pounds:')\nprint(2.2 * weight_kg)",
"weight in pounds:\n121.0\n"
]
],
[
[
"We can also change a variable's value by assigning it a new one:",
"_____no_output_____"
]
],
[
[
"weight_kg = 57.5\nprint('weight in kilograms is now:')\nprint(weight_kg)",
"weight in kilograms is now:\n57.5\n"
]
],
[
[
"As the example above shows,\nwe can print several things at once by separating them with commas.\n\nIf we imagine the variable as a sticky note with a name written on it,\nassignment is like putting the sticky note on a particular value:",
"_____no_output_____"
],
[
"<img src=\"files/img/python-sticky-note-variables-01.svg\" alt=\"Variables as Sticky Notes\" />",
"_____no_output_____"
],
[
"This means that assigning a value to one variable does *not* change the values of other variables.\nFor example,\nlet's store the subject's weight in pounds in a variable:",
"_____no_output_____"
]
],
[
[
"weight_lb = 2.2 * weight_kg\nprint('weight in kilograms:')\nprint(weight_kg)\nprint('and in pounds:')\nprint(weight_lb)",
"weight in kilograms:\n57.5\nand in pounds:\n126.5\n"
]
],
[
[
"<img src=\"files/img/python-sticky-note-variables-02.svg\" alt=\"Creating Another Variable\" />",
"_____no_output_____"
],
[
"and then change `weight_kg`:",
"_____no_output_____"
]
],
[
[
"weight_kg = 100.0\nprint('weight in kilograms is now:')\nprint(weight_kg)\nprint('and weight in pounds is still:')\nprint(weight_lb)",
"weight in kilograms is now:\n100.0\nand weight in pounds is still:\n126.5\n"
]
],
[
[
"<img src=\"files/img/python-sticky-note-variables-03.svg\" alt=\"Updating a Variable\" />",
"_____no_output_____"
],
[
"Since `weight_lb` doesn't \"remember\" where its value came from,\nit isn't automatically updated when `weight_kg` changes.\nThis is different from the way spreadsheets work.",
"_____no_output_____"
],
[
"### Challenge",
"_____no_output_____"
]
],
[
[
"x = 5\ny = x\nx = x**2",
"_____no_output_____"
]
],
[
[
"How much is `x`? how much is `y`?",
"_____no_output_____"
],
[
"### Comments",
"_____no_output_____"
]
],
[
[
"weight_kg = 100.0 # assigning weight\n# now convert to pounds\nprint(2.2 * weight_kg)",
"220.0\n"
]
],
[
[
"### Strings slicing",
"_____no_output_____"
]
],
[
[
"my_string = \"Hello world\"",
"_____no_output_____"
],
[
"print(my_string)",
"Hello world\n"
]
],
[
[
"Python by convention starts indexing from `0`",
"_____no_output_____"
]
],
[
[
"print(my_string[0:3])",
"Hel\n"
],
[
"print(my_string[:3])",
"Hel\n"
]
],
[
[
"Python uses intervals open on the right: $ \\left[7, 9\\right[ $",
"_____no_output_____"
]
],
[
[
"print(my_string[7:9])",
"or\n"
]
],
[
[
"### Challenge",
"_____no_output_____"
],
[
"What happens if you print:",
"_____no_output_____"
]
],
[
[
"print(my_string[4:4])",
"\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
d009b35e8b14e758c2e8e11d720b3010856b0c49
| 887,053 |
ipynb
|
Jupyter Notebook
|
postreise/plot/demo/plot_curtailment_time_series_demo.ipynb
|
lanesmith/PostREISE
|
69d47968cf353bca57aa8b587cc035d127fa424f
|
[
"MIT"
] | 1 |
2022-01-31T16:53:40.000Z
|
2022-01-31T16:53:40.000Z
|
postreise/plot/demo/plot_curtailment_time_series_demo.ipynb
|
lanesmith/PostREISE
|
69d47968cf353bca57aa8b587cc035d127fa424f
|
[
"MIT"
] | 71 |
2021-01-22T20:09:47.000Z
|
2022-03-30T16:53:18.000Z
|
postreise/plot/demo/plot_curtailment_time_series_demo.ipynb
|
lanesmith/PostREISE
|
69d47968cf353bca57aa8b587cc035d127fa424f
|
[
"MIT"
] | 7 |
2021-04-02T14:45:21.000Z
|
2022-01-17T22:23:38.000Z
| 2,586.16035 | 253,872 | 0.962554 |
[
[
[
"from powersimdata.scenario.scenario import Scenario\nfrom postreise.plot.plot_curtailment_ts import plot_curtailment_time_series",
"_____no_output_____"
],
[
"t2c={\n \"wind_curtailment\":\"blue\",\n \"solar_curtailment\":\"blue\",\n}",
"_____no_output_____"
],
[
"s = Scenario(1270)",
"Failed to download ScenarioList.csv from server\nFalling back to local cache...\nFailed to download ExecuteList.csv from server\nFalling back to local cache...\nSCENARIO: Julia | USA2030HVDC_Design3_OB1_Mesh500x38\n\n--> State\nanalyze\n--> Loading grid\nLoading bus\nLoading plant\nLoading heat_rate_curve\nLoading gencost_before\nLoading gencost_after\nLoading branch\nLoading dcline\nLoading sub\nLoading bus2sub\n--> Loading ct\n"
],
[
"plot_curtailment_time_series(s, \"all\", [\"wind\",\"solar\"], time_freq=\"D\", title=\"USA\", t2c=t2c, percentage=False)",
"--> Loading PG\nReading bus.csv\nReading plant.csv\nReading gencost.csv\nReading branch.csv\nReading dcline.csv\nReading sub.csv\nReading bus2sub.csv\nReading zone.csv\n--> Loading demand\nMultiply demand in Maine (#1) by 0.95\nMultiply demand in New Hampshire (#2) by 0.95\nMultiply demand in Vermont (#3) by 0.95\nMultiply demand in Massachusetts (#4) by 0.95\nMultiply demand in Rhode Island (#5) by 0.95\nMultiply demand in Connecticut (#6) by 0.95\nMultiply demand in New York City (#7) by 0.98\nMultiply demand in Upstate New York (#8) by 0.98\nMultiply demand in New Jersey (#9) by 1.15\nMultiply demand in Pennsylvania Eastern (#10) by 1.09\nMultiply demand in Pennsylvania Western (#11) by 1.09\nMultiply demand in Delaware (#12) by 1.17\nMultiply demand in Maryland (#13) by 1.03\nMultiply demand in Virginia Mountains (#14) by 1.21\nMultiply demand in Virginia Tidewater (#15) by 1.21\nMultiply demand in North Carolina (#16) by 1.15\nMultiply demand in Western North Carolina (#17) by 1.15\nMultiply demand in South Carolina (#18) by 1.13\nMultiply demand in Georgia North (#19) by 1.03\nMultiply demand in Georgia South (#20) by 1.03\nMultiply demand in Florida Panhandle (#21) by 1.15\nMultiply demand in Florida North (#22) by 1.15\nMultiply demand in Florida South (#23) by 1.15\nMultiply demand in Alabama (#24) by 1.03\nMultiply demand in Mississippi (#25) by 1.21\nMultiply demand in Tennessee (#26) by 1.04\nMultiply demand in Kentucky (#27) by 1.13\nMultiply demand in West Virginia (#28) by 1.13\nMultiply demand in Ohio River (#29) by 0.99\nMultiply demand in Ohio Lake Erie (#30) by 0.99\nMultiply demand in Michigan Northern (#31) by 1.08\nMultiply demand in Michigan Southern (#32) by 1.08\nMultiply demand in Indiana (#33) by 1.17\nMultiply demand in Chicago North Illinois (#34) by 1.07\nMultiply demand in Illinois Downstate (#35) by 1.07\nMultiply demand in Wisconsin (#36) by 1.17\nMultiply demand in Minnesota Northern (#37) by 1.10\nMultiply demand in Minnesota Southern (#38) by 1.10\nMultiply demand in Iowa (#39) by 1.22\nMultiply demand in Missouri East (#40) by 1.13\nMultiply demand in Missouri West (#41) by 1.13\nMultiply demand in Arkansas (#42) by 1.17\nMultiply demand in Louisiana (#43) by 1.06\nMultiply demand in East Texas (#44) by 1.27\nMultiply demand in Texas Panhandle (#45) by 1.27\nMultiply demand in New Mexico Eastern (#46) by 1.08\nMultiply demand in Oklahoma (#47) by 1.17\nMultiply demand in Kansas (#48) by 1.09\nMultiply demand in Nebraska (#49) by 1.06\nMultiply demand in South Dakota (#50) by 1.25\nMultiply demand in North Dakota (#51) by 1.23\nMultiply demand in Montana Eastern (#52) by 1.18\nMultiply demand in Washington (#201) by 1.15\nMultiply demand in Oregon (#202) by 1.15\nMultiply demand in Northern California (#203) by 1.19\nMultiply demand in Bay Area (#204) by 1.19\nMultiply demand in Central California (#205) by 1.19\nMultiply demand in Southwest California (#206) by 1.19\nMultiply demand in Southeast California (#207) by 1.19\nMultiply demand in Nevada (#208) by 1.15\nMultiply demand in Arizona (#209) by 1.15\nMultiply demand in Utah (#210) by 1.15\nMultiply demand in New Mexico Western (#211) by 1.15\nMultiply demand in Colorado (#212) by 1.15\nMultiply demand in Wyoming (#213) by 1.15\nMultiply demand in Idaho (#214) by 1.15\nMultiply demand in Montana Western (#215) by 1.15\nMultiply demand in El Paso (#216) by 1.15\nMultiply demand in South (#304) by 1.36\nMultiply demand in West (#303) by 1.36\nMultiply demand in North (#302) by 1.36\nMultiply demand in East (#308) by 1.36\nMultiply demand in South Central (#306) by 1.36\nMultiply demand in Far West (#301) by 1.36\nMultiply demand in Coast (#307) by 1.36\nMultiply demand in North Central (#305) by 1.36\n--> Loading PG\n--> Loading wind\n--> Loading solar\nclip incomplet days\nclip incomplet days\nclip incomplet days\n"
],
[
"plot_curtailment_time_series(s, \"Eastern\", [\"wind\",\"solar\"], t2c=t2c)",
"--> Loading PG\n--> Loading demand\nMultiply demand in Maine (#1) by 0.95\nMultiply demand in New Hampshire (#2) by 0.95\nMultiply demand in Vermont (#3) by 0.95\nMultiply demand in Massachusetts (#4) by 0.95\nMultiply demand in Rhode Island (#5) by 0.95\nMultiply demand in Connecticut (#6) by 0.95\nMultiply demand in New York City (#7) by 0.98\nMultiply demand in Upstate New York (#8) by 0.98\nMultiply demand in New Jersey (#9) by 1.15\nMultiply demand in Pennsylvania Eastern (#10) by 1.09\nMultiply demand in Pennsylvania Western (#11) by 1.09\nMultiply demand in Delaware (#12) by 1.17\nMultiply demand in Maryland (#13) by 1.03\nMultiply demand in Virginia Mountains (#14) by 1.21\nMultiply demand in Virginia Tidewater (#15) by 1.21\nMultiply demand in North Carolina (#16) by 1.15\nMultiply demand in Western North Carolina (#17) by 1.15\nMultiply demand in South Carolina (#18) by 1.13\nMultiply demand in Georgia North (#19) by 1.03\nMultiply demand in Georgia South (#20) by 1.03\nMultiply demand in Florida Panhandle (#21) by 1.15\nMultiply demand in Florida North (#22) by 1.15\nMultiply demand in Florida South (#23) by 1.15\nMultiply demand in Alabama (#24) by 1.03\nMultiply demand in Mississippi (#25) by 1.21\nMultiply demand in Tennessee (#26) by 1.04\nMultiply demand in Kentucky (#27) by 1.13\nMultiply demand in West Virginia (#28) by 1.13\nMultiply demand in Ohio River (#29) by 0.99\nMultiply demand in Ohio Lake Erie (#30) by 0.99\nMultiply demand in Michigan Northern (#31) by 1.08\nMultiply demand in Michigan Southern (#32) by 1.08\nMultiply demand in Indiana (#33) by 1.17\nMultiply demand in Chicago North Illinois (#34) by 1.07\nMultiply demand in Illinois Downstate (#35) by 1.07\nMultiply demand in Wisconsin (#36) by 1.17\nMultiply demand in Minnesota Northern (#37) by 1.10\nMultiply demand in Minnesota Southern (#38) by 1.10\nMultiply demand in Iowa (#39) by 1.22\nMultiply demand in Missouri East (#40) by 1.13\nMultiply demand in Missouri West (#41) by 1.13\nMultiply demand in Arkansas (#42) by 1.17\nMultiply demand in Louisiana (#43) by 1.06\nMultiply demand in East Texas (#44) by 1.27\nMultiply demand in Texas Panhandle (#45) by 1.27\nMultiply demand in New Mexico Eastern (#46) by 1.08\nMultiply demand in Oklahoma (#47) by 1.17\nMultiply demand in Kansas (#48) by 1.09\nMultiply demand in Nebraska (#49) by 1.06\nMultiply demand in South Dakota (#50) by 1.25\nMultiply demand in North Dakota (#51) by 1.23\nMultiply demand in Montana Eastern (#52) by 1.18\nMultiply demand in Washington (#201) by 1.15\nMultiply demand in Oregon (#202) by 1.15\nMultiply demand in Northern California (#203) by 1.19\nMultiply demand in Bay Area (#204) by 1.19\nMultiply demand in Central California (#205) by 1.19\nMultiply demand in Southwest California (#206) by 1.19\nMultiply demand in Southeast California (#207) by 1.19\nMultiply demand in Nevada (#208) by 1.15\nMultiply demand in Arizona (#209) by 1.15\nMultiply demand in Utah (#210) by 1.15\nMultiply demand in New Mexico Western (#211) by 1.15\nMultiply demand in Colorado (#212) by 1.15\nMultiply demand in Wyoming (#213) by 1.15\nMultiply demand in Idaho (#214) by 1.15\nMultiply demand in Montana Western (#215) by 1.15\nMultiply demand in El Paso (#216) by 1.15\nMultiply demand in South (#304) by 1.36\nMultiply demand in West (#303) by 1.36\nMultiply demand in North (#302) by 1.36\nMultiply demand in East (#308) by 1.36\nMultiply demand in South Central (#306) by 1.36\nMultiply demand in Far West (#301) by 1.36\nMultiply demand in Coast (#307) by 1.36\nMultiply demand in North Central (#305) by 1.36\n--> Loading PG\n--> Loading wind\n--> Loading solar\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
d009c83c00d4a944b632622e246f5adbeb23d990
| 18,150 |
ipynb
|
Jupyter Notebook
|
Part 6 - Saving and Loading Models.ipynb
|
manganganath/DL_PyTorch
|
036970dc36b45067bac7a1d028c8604fe7f02c8d
|
[
"MIT"
] | 1 |
2019-01-11T20:29:59.000Z
|
2019-01-11T20:29:59.000Z
|
Part 6 - Saving and Loading Models.ipynb
|
manganganath/DL_PyTorch
|
036970dc36b45067bac7a1d028c8604fe7f02c8d
|
[
"MIT"
] | null | null | null |
Part 6 - Saving and Loading Models.ipynb
|
manganganath/DL_PyTorch
|
036970dc36b45067bac7a1d028c8604fe7f02c8d
|
[
"MIT"
] | 2 |
2019-01-27T17:14:29.000Z
|
2019-02-23T04:31:57.000Z
| 46.778351 | 4,328 | 0.668705 |
[
[
[
"# Saving and Loading Models\n\nIn this notebook, I'll show you how to save and load models with PyTorch. This is important because you'll often want to load previously trained models to use in making predictions or to continue training on new data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\n\nimport torch\nfrom torch import nn\nfrom torch import optim\nimport torch.nn.functional as F\nfrom torchvision import datasets, transforms\n\nimport helper\nimport fc_model",
"_____no_output_____"
],
[
"# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n# Download and load the training data\ntrainset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)\n\n# Download and load the test data\ntestset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=False, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"Here we can see one of the images.",
"_____no_output_____"
]
],
[
[
"image, label = next(iter(trainloader))\nhelper.imshow(image[0,:]);",
"_____no_output_____"
]
],
[
[
"# Train a network\n\nTo make things more concise here, I moved the model architecture and training code from the last part to a file called `fc_model`. Importing this, we can easily create a fully-connected network with `fc_model.Network`, and train the network using `fc_model.train`. I'll use this model (once it's trained) to demonstrate how we can save and load models.",
"_____no_output_____"
]
],
[
[
"# Create the network, define the criterion and optimizer\nmodel = fc_model.Network(784, 10, [512, 256, 128])\ncriterion = nn.NLLLoss()\noptimizer = optim.Adam(model.parameters(), lr=0.001)",
"_____no_output_____"
],
[
"fc_model.train(model, trainloader, testloader, criterion, optimizer, epochs=2)",
"Epoch: 1/2.. Training Loss: 1.673.. Test Loss: 0.934.. Test Accuracy: 0.662\nEpoch: 1/2.. Training Loss: 1.027.. Test Loss: 0.711.. Test Accuracy: 0.718\nEpoch: 1/2.. Training Loss: 0.857.. Test Loss: 0.669.. Test Accuracy: 0.740\nEpoch: 1/2.. Training Loss: 0.792.. Test Loss: 0.716.. Test Accuracy: 0.709\nEpoch: 1/2.. Training Loss: 0.759.. Test Loss: 0.624.. Test Accuracy: 0.768\nEpoch: 1/2.. Training Loss: 0.712.. Test Loss: 0.617.. Test Accuracy: 0.765\nEpoch: 1/2.. Training Loss: 0.713.. Test Loss: 0.579.. Test Accuracy: 0.773\nEpoch: 1/2.. Training Loss: 0.711.. Test Loss: 0.569.. Test Accuracy: 0.784\nEpoch: 1/2.. Training Loss: 0.662.. Test Loss: 0.560.. Test Accuracy: 0.788\nEpoch: 1/2.. Training Loss: 0.658.. Test Loss: 0.543.. Test Accuracy: 0.795\nEpoch: 1/2.. Training Loss: 0.612.. Test Loss: 0.545.. Test Accuracy: 0.801\nEpoch: 1/2.. Training Loss: 0.591.. Test Loss: 0.533.. Test Accuracy: 0.800\nEpoch: 1/2.. Training Loss: 0.611.. Test Loss: 0.532.. Test Accuracy: 0.799\nEpoch: 1/2.. Training Loss: 0.613.. Test Loss: 0.528.. Test Accuracy: 0.800\nEpoch: 1/2.. Training Loss: 0.638.. Test Loss: 0.542.. Test Accuracy: 0.801\nEpoch: 1/2.. Training Loss: 0.590.. Test Loss: 0.500.. Test Accuracy: 0.810\nEpoch: 1/2.. Training Loss: 0.606.. Test Loss: 0.490.. Test Accuracy: 0.824\nEpoch: 1/2.. Training Loss: 0.592.. Test Loss: 0.504.. Test Accuracy: 0.814\nEpoch: 1/2.. Training Loss: 0.571.. Test Loss: 0.496.. Test Accuracy: 0.818\nEpoch: 1/2.. Training Loss: 0.592.. Test Loss: 0.487.. Test Accuracy: 0.816\nEpoch: 1/2.. Training Loss: 0.592.. Test Loss: 0.482.. Test Accuracy: 0.818\nEpoch: 1/2.. Training Loss: 0.589.. Test Loss: 0.479.. Test Accuracy: 0.822\nEpoch: 1/2.. Training Loss: 0.563.. Test Loss: 0.482.. Test Accuracy: 0.825\nEpoch: 2/2.. Training Loss: 0.597.. Test Loss: 0.477.. Test Accuracy: 0.823\nEpoch: 2/2.. Training Loss: 0.509.. Test Loss: 0.487.. Test Accuracy: 0.822\nEpoch: 2/2.. Training Loss: 0.559.. Test Loss: 0.478.. Test Accuracy: 0.824\nEpoch: 2/2.. Training Loss: 0.567.. Test Loss: 0.485.. Test Accuracy: 0.826\nEpoch: 2/2.. Training Loss: 0.586.. Test Loss: 0.490.. Test Accuracy: 0.819\nEpoch: 2/2.. Training Loss: 0.555.. Test Loss: 0.465.. Test Accuracy: 0.828\nEpoch: 2/2.. Training Loss: 0.568.. Test Loss: 0.476.. Test Accuracy: 0.826\nEpoch: 2/2.. Training Loss: 0.544.. Test Loss: 0.468.. Test Accuracy: 0.829\nEpoch: 2/2.. Training Loss: 0.541.. Test Loss: 0.481.. Test Accuracy: 0.820\nEpoch: 2/2.. Training Loss: 0.504.. Test Loss: 0.450.. Test Accuracy: 0.835\nEpoch: 2/2.. Training Loss: 0.544.. Test Loss: 0.462.. Test Accuracy: 0.832\nEpoch: 2/2.. Training Loss: 0.528.. Test Loss: 0.452.. Test Accuracy: 0.834\nEpoch: 2/2.. Training Loss: 0.538.. Test Loss: 0.462.. Test Accuracy: 0.836\nEpoch: 2/2.. Training Loss: 0.504.. Test Loss: 0.469.. Test Accuracy: 0.826\nEpoch: 2/2.. Training Loss: 0.549.. Test Loss: 0.460.. Test Accuracy: 0.833\nEpoch: 2/2.. Training Loss: 0.494.. Test Loss: 0.445.. Test Accuracy: 0.837\nEpoch: 2/2.. Training Loss: 0.531.. Test Loss: 0.457.. Test Accuracy: 0.836\nEpoch: 2/2.. Training Loss: 0.543.. Test Loss: 0.455.. Test Accuracy: 0.833\nEpoch: 2/2.. Training Loss: 0.524.. Test Loss: 0.448.. Test Accuracy: 0.840\nEpoch: 2/2.. Training Loss: 0.531.. Test Loss: 0.439.. Test Accuracy: 0.844\nEpoch: 2/2.. Training Loss: 0.520.. Test Loss: 0.445.. Test Accuracy: 0.837\nEpoch: 2/2.. Training Loss: 0.507.. Test Loss: 0.452.. Test Accuracy: 0.832\nEpoch: 2/2.. Training Loss: 0.514.. Test Loss: 0.441.. Test Accuracy: 0.842\n"
]
],
[
[
"## Saving and loading networks\n\nAs you can imagine, it's impractical to train a network every time you need to use it. Instead, we can save trained networks then load them later to train more or use them for predictions.\n\nThe parameters for PyTorch networks are stored in a model's `state_dict`. We can see the state dict contains the weight and bias matrices for each of our layers.",
"_____no_output_____"
]
],
[
[
"print(\"Our model: \\n\\n\", model, '\\n')\nprint(\"The state dict keys: \\n\\n\", model.state_dict().keys())",
"Our model: \n\n Network(\n (hidden_layers): ModuleList(\n (0): Linear(in_features=784, out_features=512, bias=True)\n (1): Linear(in_features=512, out_features=256, bias=True)\n (2): Linear(in_features=256, out_features=128, bias=True)\n )\n (output): Linear(in_features=128, out_features=10, bias=True)\n (dropout): Dropout(p=0.5)\n) \n\nThe state dict keys: \n\n odict_keys(['hidden_layers.0.weight', 'hidden_layers.0.bias', 'hidden_layers.1.weight', 'hidden_layers.1.bias', 'hidden_layers.2.weight', 'hidden_layers.2.bias', 'output.weight', 'output.bias'])\n"
]
],
[
[
"The simplest thing to do is simply save the state dict with `torch.save`. For example, we can save it to a file `'checkpoint.pth'`.",
"_____no_output_____"
]
],
[
[
"torch.save(model.state_dict(), 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"Then we can load the state dict with `torch.load`.",
"_____no_output_____"
]
],
[
[
"state_dict = torch.load('checkpoint.pth')\nprint(state_dict.keys())",
"odict_keys(['hidden_layers.0.weight', 'hidden_layers.0.bias', 'hidden_layers.1.weight', 'hidden_layers.1.bias', 'hidden_layers.2.weight', 'hidden_layers.2.bias', 'output.weight', 'output.bias'])\n"
]
],
[
[
"And to load the state dict in to the network, you do `model.load_state_dict(state_dict)`.",
"_____no_output_____"
]
],
[
[
"model.load_state_dict(state_dict)",
"_____no_output_____"
]
],
[
[
"Seems pretty straightforward, but as usual it's a bit more complicated. Loading the state dict works only if the model architecture is exactly the same as the checkpoint architecture. If I create a model with a different architecture, this fails.",
"_____no_output_____"
]
],
[
[
"# Try this\nmodel = fc_model.Network(784, 10, [400, 200, 100])\n# This will throw an error because the tensor sizes are wrong!\nmodel.load_state_dict(state_dict)",
"_____no_output_____"
]
],
[
[
"This means we need to rebuild the model exactly as it was when trained. Information about the model architecture needs to be saved in the checkpoint, along with the state dict. To do this, you build a dictionary with all the information you need to compeletely rebuild the model.",
"_____no_output_____"
]
],
[
[
"checkpoint = {'input_size': 784,\n 'output_size': 10,\n 'hidden_layers': [each.out_features for each in model.hidden_layers],\n 'state_dict': model.state_dict()}\n\ntorch.save(checkpoint, 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"Now the checkpoint has all the necessary information to rebuild the trained model. You can easily make that a function if you want. Similarly, we can write a function to load checkpoints. ",
"_____no_output_____"
]
],
[
[
"def load_checkpoint(filepath):\n checkpoint = torch.load(filepath)\n model = fc_model.Network(checkpoint['input_size'],\n checkpoint['output_size'],\n checkpoint['hidden_layers'])\n model.load_state_dict(checkpoint['state_dict'])\n \n return model",
"_____no_output_____"
],
[
"model = load_checkpoint('checkpoint.pth')\nprint(model)",
"Network(\n (hidden_layers): ModuleList(\n (0): Linear(in_features=784, out_features=512, bias=True)\n (1): Linear(in_features=512, out_features=256, bias=True)\n (2): Linear(in_features=256, out_features=128, bias=True)\n )\n (output): Linear(in_features=128, out_features=10, bias=True)\n (dropout): Dropout(p=0.5)\n)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d009f1b31df7e8ebc2fa614f32900528948408ae
| 8,032 |
ipynb
|
Jupyter Notebook
|
writing multifile programs/headers.ipynb
|
frankhn/c-_course-udacity-nano-degree
|
4fbe9042083322a3cfc15cdc862dfe721626f871
|
[
"MIT"
] | null | null | null |
writing multifile programs/headers.ipynb
|
frankhn/c-_course-udacity-nano-degree
|
4fbe9042083322a3cfc15cdc862dfe721626f871
|
[
"MIT"
] | null | null | null |
writing multifile programs/headers.ipynb
|
frankhn/c-_course-udacity-nano-degree
|
4fbe9042083322a3cfc15cdc862dfe721626f871
|
[
"MIT"
] | null | null | null | 37.013825 | 905 | 0.614044 |
[
[
[
"Function Order in a Single File¶\nIn the following code example, the functions are out of order, and the code will not compile. Try to fix this by rearranging the functions to be in the correct order.",
"_____no_output_____"
],
[
"#include <iostream>\nusing std::cout;\n\nvoid OuterFunction(int i) \n{\n InnerFunction(i);\n}\n\nvoid InnerFunction(int i) \n{\n cout << \"The value of the integer is: \" << i << \"\\n\";\n}\n\nint main() \n{\n int a = 5;\n OuterFunction(a);\n}",
"_____no_output_____"
],
[
"In the mini-project for the first half of the course, the instructions were very careful to indicate where each function should be placed, so you didn't run into the problem of functions being out of order.\n\nUsing a Header\nOne other way to solve the code problem above (without rearranging the functions) would have been to declare each function at the top of the file. A function declaration is much like the first line of a function definition - it contains the return type, function name, and input variable types. The details of the function definition are not needed for the declaration though.\n\nTo avoid a single file from becomming cluttered with declarations and definitions for every function, it is customary to declare the functions in another file, called the header file. In C++, the header file will have filetype .h, and the contents of the header file must be included at the top of the .cpp file. See the following example for a refactoring of the code above into a header and a cpp file.",
"_____no_output_____"
],
[
"// The header file with just the function declarations.\n// When you click the \"Run Code\" button, this file will\n// be saved as header_example.h.\n#ifndef HEADER_EXAMPLE_H\n#define HEADER_EXAMPLE_H\n\nvoid OuterFunction(int);\nvoid InnerFunction(int);\n\n#endif",
"_____no_output_____"
],
[
"// The contents of header_example.h are included in \n// the corresponding .cpp file using quotes:\n#include \"header_example.h\"\n\n#include <iostream>\nusing std::cout;\n\nvoid OuterFunction(int i) \n{\n InnerFunction(i);\n}\n\nvoid InnerFunction(int i) \n{\n cout << \"The value of the integer is: \" << i << \"\\n\";\n}\n\nint main() \n{\n int a = 5;\n OuterFunction(a);\n}",
"_____no_output_____"
],
[
"Notice that the code from the first example was fixed without having to rearrange the functions! In the code above, you might also have noticed several other things:\n\nThe function declarations in the header file don't need variable names, just variable types. You can put names in the declaration, however, and doing this often makes the code easier to read.\nThe #include statement for the header used quotes \" \" around the file name, and not angle brackets <>. We have stored the header in the same directory as the .cpp file, and the quotes tell the preprocessor to look for the file in the same directory as the current file - not in the usual set of directories where libraries are typically stored.\nFinally, there is a preprocessor directive:\n#ifndef HEADER_EXAMPLE_H\n#define HEADER_EXAMPLE_H\nat the top of the header, along with an #endif at the end. This is called an \"include guard\". Since the header will be included into another file, and #include just pastes contents into a file, the include guard prevents the same file from being pasted multiple times into another file. This might happen if multiple files include the same header, and then are all included into the same main.cpp, for example. The ifndef checks if HEADER_EXAMPLE_H has not been defined in the file already. If it has not been defined yet, then it is defined with #define HEADER_EXAMPLE_H, and the rest of the header is used. If HEADER_EXAMPLE_H has already been defined, then the preprocessor does not enter the ifndef block. Note: There are other ways to do this. Another common way is to use an #pragma oncepreprocessor directive, but we won't cover that in detail here. See this Wikipedia article for examples.",
"_____no_output_____"
],
[
"Practice\nIn the following two cells, there is a blank header file and a short program that won't compile due to the functions being out of order. The code should take a vector of ints, add 1 to each of the vector entries, and then print the sum over the vector entries.\n\nWithout rearranging the functions in the main .cpp file, add some function declarations to the header file to fix this problem. Don't forget to include the \"header_practice.h\" file in your .cpp file!",
"_____no_output_____"
],
[
"Practice\nIn the following two cells, there is a blank header file and a short program that won't compile due to the functions being out of order. The code should take a vector of ints, add 1 to each of the vector entries, and then print the sum over the vector entries.\n\nWithout rearranging the functions in the main .cpp file, add some function declarations to the header file to fix this problem. Don't forget to include the \"header_practice.h\" file in your .cpp file!",
"_____no_output_____"
],
[
"// This file will be saved as \"header_practice.h\"",
"_____no_output_____"
],
[
"#include <iostream>\n#include <vector>\nusing std::vector;\nusing std::cout;\n\n\nint IncrementAndComputeVectorSum(vector<int> v) \n{\n int total = 0;\n AddOneToEach(v);\n\n for (auto i: v) {\n total += i;\n }\n return total;\n}\n\nvoid AddOneToEach(vector<int> &v) \n{\n // Note that the function passes a reference to v\n // and the for loop below uses references to \n // each item in v. This means the actual\n // ints that v holds will be incremented.\n for (auto& i: v) {\n i++;\n }\n}\n\nint main() \n{\n vector<int> v{1, 2, 3, 4};\n int total = IncrementAndComputeVectorSum(v);\n cout << \"The total is: \" << total << \"\\n\";\n}",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d009ffb009290f6ed8a9ac1f8b27749d5f216251
| 24,083 |
ipynb
|
Jupyter Notebook
|
filling missing values.ipynb
|
bharath1604/pandas
|
e23c4932cd0aaff7360ca85abea1de43171866c5
|
[
"MIT"
] | null | null | null |
filling missing values.ipynb
|
bharath1604/pandas
|
e23c4932cd0aaff7360ca85abea1de43171866c5
|
[
"MIT"
] | null | null | null |
filling missing values.ipynb
|
bharath1604/pandas
|
e23c4932cd0aaff7360ca85abea1de43171866c5
|
[
"MIT"
] | null | null | null | 35.520649 | 142 | 0.323465 |
[
[
[
"import packages",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"1.Load data and read",
"_____no_output_____"
]
],
[
[
"california=pd.read_csv('https://raw.githubusercontent.com/bharath1604/Handling_Missing_Values/master/california_cities.csv',header=None)",
"_____no_output_____"
],
[
"california",
"_____no_output_____"
]
],
[
[
"2.Drop the nan values by using (dropna()) [axis=0 means rows and axis=1 means columns]",
"_____no_output_____"
]
],
[
[
"california.dropna() ",
"_____no_output_____"
]
],
[
[
"3.Delete unwanted rows or columns",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d00a0608252cad958a837c586aab891ff11cd18f
| 767,805 |
ipynb
|
Jupyter Notebook
|
lesson4-week4/Art Generation with Neural Style Transfer - v2/Art+Generation+with+Neural+Style+Transfer+-+v2.ipynb
|
tryrus/Coursera-DeepLearning-AndrewNG-exercise
|
75df188b8a7ce05aa3ddeec1698f606247aa33f2
|
[
"Apache-2.0"
] | 1 |
2019-01-11T01:30:27.000Z
|
2019-01-11T01:30:27.000Z
|
lesson4-week4/Art Generation with Neural Style Transfer - v2/Art+Generation+with+Neural+Style+Transfer+-+v2.ipynb
|
tryrus/Coursera-DeepLearning-AndrewNG-exercise
|
75df188b8a7ce05aa3ddeec1698f606247aa33f2
|
[
"Apache-2.0"
] | null | null | null |
lesson4-week4/Art Generation with Neural Style Transfer - v2/Art+Generation+with+Neural+Style+Transfer+-+v2.ipynb
|
tryrus/Coursera-DeepLearning-AndrewNG-exercise
|
75df188b8a7ce05aa3ddeec1698f606247aa33f2
|
[
"Apache-2.0"
] | 1 |
2019-10-06T10:25:44.000Z
|
2019-10-06T10:25:44.000Z
| 561.671544 | 309,334 | 0.928676 |
[
[
[
"# Deep Learning & Art: Neural Style Transfer\n\nWelcome to the second assignment of this week. In this assignment, you will learn about Neural Style Transfer. This algorithm was created by Gatys et al. (2015) (https://arxiv.org/abs/1508.06576). \n\n**In this assignment, you will:**\n- Implement the neural style transfer algorithm \n- Generate novel artistic images using your algorithm \n\nMost of the algorithms you've studied optimize a cost function to get a set of parameter values. In Neural Style Transfer, you'll optimize a cost function to get pixel values!",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport scipy.io\nimport scipy.misc\nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import imshow\nfrom PIL import Image\nfrom nst_utils import *\nimport numpy as np\nimport tensorflow as tf\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## 1 - Problem Statement\n\nNeural Style Transfer (NST) is one of the most fun techniques in deep learning. As seen below, it merges two images, namely, a \"content\" image (C) and a \"style\" image (S), to create a \"generated\" image (G). The generated image G combines the \"content\" of the image C with the \"style\" of image S. \n\nIn this example, you are going to generate an image of the Louvre museum in Paris (content image C), mixed with a painting by Claude Monet, a leader of the impressionist movement (style image S).\n<img src=\"images/louvre_generated.png\" style=\"width:750px;height:200px;\">\n\nLet's see how you can do this. ",
"_____no_output_____"
],
[
"## 2 - Transfer Learning\n\nNeural Style Transfer (NST) uses a previously trained convolutional network, and builds on top of that. The idea of using a network trained on a different task and applying it to a new task is called transfer learning. \n\nFollowing the original NST paper (https://arxiv.org/abs/1508.06576), we will use the VGG network. Specifically, we'll use VGG-19, a 19-layer version of the VGG network. This model has already been trained on the very large ImageNet database, and thus has learned to recognize a variety of low level features (at the earlier layers) and high level features (at the deeper layers). \n\nRun the following code to load parameters from the VGG model. This may take a few seconds. ",
"_____no_output_____"
]
],
[
[
"model = load_vgg_model(\"pretrained-model/imagenet-vgg-verydeep-19.mat\")\nprint(model)",
"{'input': <tf.Variable 'Variable:0' shape=(1, 300, 400, 3) dtype=float32_ref>, 'conv1_1': <tf.Tensor 'Relu:0' shape=(1, 300, 400, 64) dtype=float32>, 'conv1_2': <tf.Tensor 'Relu_1:0' shape=(1, 300, 400, 64) dtype=float32>, 'avgpool1': <tf.Tensor 'AvgPool:0' shape=(1, 150, 200, 64) dtype=float32>, 'conv2_1': <tf.Tensor 'Relu_2:0' shape=(1, 150, 200, 128) dtype=float32>, 'conv2_2': <tf.Tensor 'Relu_3:0' shape=(1, 150, 200, 128) dtype=float32>, 'avgpool2': <tf.Tensor 'AvgPool_1:0' shape=(1, 75, 100, 128) dtype=float32>, 'conv3_1': <tf.Tensor 'Relu_4:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_2': <tf.Tensor 'Relu_5:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_3': <tf.Tensor 'Relu_6:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_4': <tf.Tensor 'Relu_7:0' shape=(1, 75, 100, 256) dtype=float32>, 'avgpool3': <tf.Tensor 'AvgPool_2:0' shape=(1, 38, 50, 256) dtype=float32>, 'conv4_1': <tf.Tensor 'Relu_8:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_2': <tf.Tensor 'Relu_9:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_3': <tf.Tensor 'Relu_10:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_4': <tf.Tensor 'Relu_11:0' shape=(1, 38, 50, 512) dtype=float32>, 'avgpool4': <tf.Tensor 'AvgPool_3:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_1': <tf.Tensor 'Relu_12:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_2': <tf.Tensor 'Relu_13:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_3': <tf.Tensor 'Relu_14:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_4': <tf.Tensor 'Relu_15:0' shape=(1, 19, 25, 512) dtype=float32>, 'avgpool5': <tf.Tensor 'AvgPool_4:0' shape=(1, 10, 13, 512) dtype=float32>}\n"
]
],
[
[
"The model is stored in a python dictionary where each variable name is the key and the corresponding value is a tensor containing that variable's value. To run an image through this network, you just have to feed the image to the model. In TensorFlow, you can do so using the [tf.assign](https://www.tensorflow.org/api_docs/python/tf/assign) function. In particular, you will use the assign function like this: \n```python\nmodel[\"input\"].assign(image)\n```\nThis assigns the image as an input to the model. After this, if you want to access the activations of a particular layer, say layer `4_2` when the network is run on this image, you would run a TensorFlow session on the correct tensor `conv4_2`, as follows: \n```python\nsess.run(model[\"conv4_2\"])\n```",
"_____no_output_____"
],
[
"## 3 - Neural Style Transfer \n\nWe will build the NST algorithm in three steps:\n\n- Build the content cost function $J_{content}(C,G)$\n- Build the style cost function $J_{style}(S,G)$\n- Put it together to get $J(G) = \\alpha J_{content}(C,G) + \\beta J_{style}(S,G)$. \n\n### 3.1 - Computing the content cost\n\nIn our running example, the content image C will be the picture of the Louvre Museum in Paris. Run the code below to see a picture of the Louvre.",
"_____no_output_____"
]
],
[
[
"content_image = scipy.misc.imread(\"images/louvre.jpg\")\nimshow(content_image)",
"_____no_output_____"
]
],
[
[
"The content image (C) shows the Louvre museum's pyramid surrounded by old Paris buildings, against a sunny sky with a few clouds.\n\n** 3.1.1 - How do you ensure the generated image G matches the content of the image C?**\n\nAs we saw in lecture, the earlier (shallower) layers of a ConvNet tend to detect lower-level features such as edges and simple textures, and the later (deeper) layers tend to detect higher-level features such as more complex textures as well as object classes. \n\nWe would like the \"generated\" image G to have similar content as the input image C. Suppose you have chosen some layer's activations to represent the content of an image. In practice, you'll get the most visually pleasing results if you choose a layer in the middle of the network--neither too shallow nor too deep. (After you have finished this exercise, feel free to come back and experiment with using different layers, to see how the results vary.)\n\nSo, suppose you have picked one particular hidden layer to use. Now, set the image C as the input to the pretrained VGG network, and run forward propagation. Let $a^{(C)}$ be the hidden layer activations in the layer you had chosen. (In lecture, we had written this as $a^{[l](C)}$, but here we'll drop the superscript $[l]$ to simplify the notation.) This will be a $n_H \\times n_W \\times n_C$ tensor. Repeat this process with the image G: Set G as the input, and run forward progation. Let $$a^{(G)}$$ be the corresponding hidden layer activation. We will define as the content cost function as:\n\n$$J_{content}(C,G) = \\frac{1}{4 \\times n_H \\times n_W \\times n_C}\\sum _{ \\text{all entries}} (a^{(C)} - a^{(G)})^2\\tag{1} $$\n\nHere, $n_H, n_W$ and $n_C$ are the height, width and number of channels of the hidden layer you have chosen, and appear in a normalization term in the cost. For clarity, note that $a^{(C)}$ and $a^{(G)}$ are the volumes corresponding to a hidden layer's activations. In order to compute the cost $J_{content}(C,G)$, it might also be convenient to unroll these 3D volumes into a 2D matrix, as shown below. (Technically this unrolling step isn't needed to compute $J_{content}$, but it will be good practice for when you do need to carry out a similar operation later for computing the style const $J_{style}$.)\n\n<img src=\"images/NST_LOSS.png\" style=\"width:800px;height:400px;\">\n\n**Exercise:** Compute the \"content cost\" using TensorFlow. \n\n**Instructions**: The 3 steps to implement this function are:\n1. Retrieve dimensions from a_G: \n - To retrieve dimensions from a tensor X, use: `X.get_shape().as_list()`\n2. Unroll a_C and a_G as explained in the picture above\n - If you are stuck, take a look at [Hint1](https://www.tensorflow.org/versions/r1.3/api_docs/python/tf/transpose) and [Hint2](https://www.tensorflow.org/versions/r1.2/api_docs/python/tf/reshape).\n3. Compute the content cost:\n - If you are stuck, take a look at [Hint3](https://www.tensorflow.org/api_docs/python/tf/reduce_sum), [Hint4](https://www.tensorflow.org/api_docs/python/tf/square) and [Hint5](https://www.tensorflow.org/api_docs/python/tf/subtract).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_content_cost\n\ndef compute_content_cost(a_C, a_G):\n \"\"\"\n Computes the content cost\n \n Arguments:\n a_C -- tensor of dimension (1, n_H, n_W, n_C), \n hidden layer activations representing content of the image C \n a_G -- tensor of dimension (1, n_H, n_W, n_C), \n hidden layer activations representing content of the image G\n \n Returns: \n J_content -- scalar that you compute using equation 1 above.\n \"\"\"\n \n ### START CODE HERE ###\n # Retrieve dimensions from a_G (≈1 line)\n m, n_H, n_W, n_C = a_G.get_shape().as_list()\n \n # Reshape a_C and a_G (≈2 lines)\n a_C_unrolled = tf.transpose(tf.reshape(a_C, [-1]))\n a_G_unrolled = tf.transpose(tf.reshape(a_G, [-1]))\n \n # compute the cost with tensorflow (≈1 line)\n J_content = tf.reduce_sum((a_C_unrolled - a_G_unrolled)**2) \n / (4 * n_H * n_W * n_C)\n #J_content = tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled,\n # a_G_unrolled)))/ (4*n_H*n_W*n_C)\n ### END CODE HERE ###\n \n return J_content",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as test:\n tf.set_random_seed(1)\n a_C = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)\n a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)\n J_content = compute_content_cost(a_C, a_G)\n print(\"J_content = \" + str(J_content.eval()))",
"J_content = 6.76559\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **J_content**\n </td>\n <td>\n 6.76559\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- The content cost takes a hidden layer activation of the neural network, and measures how different $a^{(C)}$ and $a^{(G)}$ are. \n- When we minimize the content cost later, this will help make sure $G$ has similar content as $C$.",
"_____no_output_____"
],
[
"### 3.2 - Computing the style cost\n\nFor our running example, we will use the following style image: ",
"_____no_output_____"
]
],
[
[
"style_image = scipy.misc.imread(\"images/monet_800600.jpg\")\nimshow(style_image)",
"_____no_output_____"
]
],
[
[
"This painting was painted in the style of *[impressionism](https://en.wikipedia.org/wiki/Impressionism)*.\n\nLets see how you can now define a \"style\" const function $J_{style}(S,G)$. ",
"_____no_output_____"
],
[
"### 3.2.1 - Style matrix\n\nThe style matrix is also called a \"Gram matrix.\" In linear algebra, the Gram matrix G of a set of vectors $(v_{1},\\dots ,v_{n})$ is the matrix of dot products, whose entries are ${\\displaystyle G_{ij} = v_{i}^T v_{j} = np.dot(v_{i}, v_{j}) }$. In other words, $G_{ij}$ compares how similar $v_i$ is to $v_j$: If they are highly similar, you would expect them to have a large dot product, and thus for $G_{ij}$ to be large. \n\nNote that there is an unfortunate collision in the variable names used here. We are following common terminology used in the literature, but $G$ is used to denote the Style matrix (or Gram matrix) as well as to denote the generated image $G$. We will try to make sure which $G$ we are referring to is always clear from the context. \n\nIn NST, you can compute the Style matrix by multiplying the \"unrolled\" filter matrix with their transpose:\n\n<img src=\"images/NST_GM.png\" style=\"width:900px;height:300px;\">\n\nThe result is a matrix of dimension $(n_C,n_C)$ where $n_C$ is the number of filters. The value $G_{ij}$ measures how similar the activations of filter $i$ are to the activations of filter $j$. \n\nOne important part of the gram matrix is that the diagonal elements such as $G_{ii}$ also measures how active filter $i$ is. For example, suppose filter $i$ is detecting vertical textures in the image. Then $G_{ii}$ measures how common vertical textures are in the image as a whole: If $G_{ii}$ is large, this means that the image has a lot of vertical texture. \n\nBy capturing the prevalence of different types of features ($G_{ii}$), as well as how much different features occur together ($G_{ij}$), the Style matrix $G$ measures the style of an image. \n\n**Exercise**:\nUsing TensorFlow, implement a function that computes the Gram matrix of a matrix A. The formula is: The gram matrix of A is $G_A = AA^T$. If you are stuck, take a look at [Hint 1](https://www.tensorflow.org/api_docs/python/tf/matmul) and [Hint 2](https://www.tensorflow.org/api_docs/python/tf/transpose).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: gram_matrix\n\ndef gram_matrix(A):\n \"\"\"\n Argument:\n A -- matrix of shape (n_C, n_H*n_W)\n \n Returns:\n GA -- Gram matrix of A, of shape (n_C, n_C)\n \"\"\"\n \n ### START CODE HERE ### (≈1 line)\n GA = tf.matmul(A, tf.transpose(A))\n ### END CODE HERE ###\n \n return GA",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as test:\n tf.set_random_seed(1)\n A = tf.random_normal([3, 2*1], mean=1, stddev=4)\n GA = gram_matrix(A)\n \n print(\"GA = \" + str(GA.eval()))",
"GA = [[ 6.42230511 -4.42912197 -2.09668207]\n [ -4.42912197 19.46583748 19.56387138]\n [ -2.09668207 19.56387138 20.6864624 ]]\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **GA**\n </td>\n <td>\n [[ 6.42230511 -4.42912197 -2.09668207] <br>\n [ -4.42912197 19.46583748 19.56387138] <br>\n [ -2.09668207 19.56387138 20.6864624 ]]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 3.2.2 - Style cost",
"_____no_output_____"
],
[
"After generating the Style matrix (Gram matrix), your goal will be to minimize the distance between the Gram matrix of the \"style\" image S and that of the \"generated\" image G. For now, we are using only a single hidden layer $a^{[l]}$, and the corresponding style cost for this layer is defined as: \n\n$$J_{style}^{[l]}(S,G) = \\frac{1}{4 \\times {n_C}^2 \\times (n_H \\times n_W)^2} \\sum _{i=1}^{n_C}\\sum_{j=1}^{n_C}(G^{(S)}_{ij} - G^{(G)}_{ij})^2\\tag{2} $$\n\nwhere $G^{(S)}$ and $G^{(G)}$ are respectively the Gram matrices of the \"style\" image and the \"generated\" image, computed using the hidden layer activations for a particular hidden layer in the network. \n",
"_____no_output_____"
],
[
"**Exercise**: Compute the style cost for a single layer. \n\n**Instructions**: The 3 steps to implement this function are:\n1. Retrieve dimensions from the hidden layer activations a_G: \n - To retrieve dimensions from a tensor X, use: `X.get_shape().as_list()`\n2. Unroll the hidden layer activations a_S and a_G into 2D matrices, as explained in the picture above.\n - You may find [Hint1](https://www.tensorflow.org/versions/r1.3/api_docs/python/tf/transpose) and [Hint2](https://www.tensorflow.org/versions/r1.2/api_docs/python/tf/reshape) useful.\n3. Compute the Style matrix of the images S and G. (Use the function you had previously written.) \n4. Compute the Style cost:\n - You may find [Hint3](https://www.tensorflow.org/api_docs/python/tf/reduce_sum), [Hint4](https://www.tensorflow.org/api_docs/python/tf/square) and [Hint5](https://www.tensorflow.org/api_docs/python/tf/subtract) useful.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_layer_style_cost\n\ndef compute_layer_style_cost(a_S, a_G):\n \"\"\"\n Arguments:\n a_S -- tensor of dimension (1, n_H, n_W, n_C), \n hidden layer activations representing style of the image S \n a_G -- tensor of dimension (1, n_H, n_W, n_C), \n hidden layer activations representing style of the image G\n \n Returns: \n J_style_layer -- tensor representing a scalar value, \n style cost defined above by equation (2)\n \"\"\"\n \n ### START CODE HERE ###\n # Retrieve dimensions from a_G (≈1 line)\n m, n_H, n_W, n_C = a_G.get_shape().as_list()\n \n # Reshape the images to have them of shape (n_C, n_H*n_W) (≈2 lines)\n #a_S = tf.reshape(a_S, [n_C, n_H * n_W])\n #a_G = tf.reshape(a_G, [n_C, n_H * n_W])\n a_S = tf.transpose(tf.reshape(a_S, [n_H*n_W, n_C]))\n a_G = tf.transpose(tf.reshape(a_G, [n_H*n_W, n_C]))\n\n # Computing gram_matrices for both images S and G (≈2 lines)\n GS = gram_matrix(a_S)\n GG = gram_matrix(a_G)\n\n # Computing the loss (≈1 line)\n J_style_layer = tf.reduce_sum(tf.square((GS - GG)))\n / (4 * n_C**2 * (n_W * n_H)**2)\n \n ### END CODE HERE ###\n \n return J_style_layer",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as test:\n tf.set_random_seed(1)\n a_S = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)\n a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)\n J_style_layer = compute_layer_style_cost(a_S, a_G)\n \n print(\"J_style_layer = \" + str(J_style_layer.eval()))",
"J_style_layer = 9.19028\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **J_style_layer**\n </td>\n <td>\n 9.19028\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 3.2.3 Style Weights\n\nSo far you have captured the style from only one layer. We'll get better results if we \"merge\" style costs from several different layers. After completing this exercise, feel free to come back and experiment with different weights to see how it changes the generated image $G$. But for now, this is a pretty reasonable default: ",
"_____no_output_____"
]
],
[
[
"STYLE_LAYERS = [\n ('conv1_1', 0.2),\n ('conv2_1', 0.2),\n ('conv3_1', 0.2),\n ('conv4_1', 0.2),\n ('conv5_1', 0.2)]",
"_____no_output_____"
]
],
[
[
"You can combine the style costs for different layers as follows:\n\n$$J_{style}(S,G) = \\sum_{l} \\lambda^{[l]} J^{[l]}_{style}(S,G)$$\n\nwhere the values for $\\lambda^{[l]}$ are given in `STYLE_LAYERS`. \n",
"_____no_output_____"
],
[
"We've implemented a compute_style_cost(...) function. It simply calls your `compute_layer_style_cost(...)` several times, and weights their results using the values in `STYLE_LAYERS`. Read over it to make sure you understand what it's doing. \n\n<!-- \n2. Loop over (layer_name, coeff) from STYLE_LAYERS:\n a. Select the output tensor of the current layer. As an example, to call the tensor from the \"conv1_1\" layer you would do: out = model[\"conv1_1\"]\n b. Get the style of the style image from the current layer by running the session on the tensor \"out\"\n c. Get a tensor representing the style of the generated image from the current layer. It is just \"out\".\n d. Now that you have both styles. Use the function you've implemented above to compute the style_cost for the current layer\n e. Add (style_cost x coeff) of the current layer to overall style cost (J_style)\n3. Return J_style, which should now be the sum of the (style_cost x coeff) for each layer.\n!--> \n",
"_____no_output_____"
]
],
[
[
"def compute_style_cost(model, STYLE_LAYERS):\n \"\"\"\n Computes the overall style cost from several chosen layers\n \n Arguments:\n model -- our tensorflow model\n STYLE_LAYERS -- A python list containing:\n - the names of the layers we would like \n to extract style from\n - a coefficient for each of them\n \n Returns: \n J_style -- tensor representing a scalar value, style cost \n defined above by equation (2)\n \"\"\"\n \n # initialize the overall style cost\n J_style = 0\n\n for layer_name, coeff in STYLE_LAYERS:\n\n # Select the output tensor of the currently selected layer\n out = model[layer_name]\n\n # Set a_S to be the hidden layer activation from the layer \n # we have selected, by running the session on out\n a_S = sess.run(out)\n\n # Set a_G to be the hidden layer activation from same layer. \n # Here, a_G references model[layer_name] \n # and isn't evaluated yet. Later in the code, we'll assign \n # the image G as the model input, so that\n # when we run the session, this will be the activations \n # drawn from the appropriate layer, with G as input.\n a_G = out\n \n # Compute style_cost for the current layer\n J_style_layer = compute_layer_style_cost(a_S, a_G)\n\n # Add coeff * J_style_layer of this layer to overall style cost\n J_style += coeff * J_style_layer\n\n return J_style",
"_____no_output_____"
]
],
[
[
"**Note**: In the inner-loop of the for-loop above, `a_G` is a tensor and hasn't been evaluated yet. It will be evaluated and updated at each iteration when we run the TensorFlow graph in model_nn() below.\n\n<!-- \nHow do you choose the coefficients for each layer? The deeper layers capture higher-level concepts, and the features in the deeper layers are less localized in the image relative to each other. So if you want the generated image to softly follow the style image, try choosing larger weights for deeper layers and smaller weights for the first layers. In contrast, if you want the generated image to strongly follow the style image, try choosing smaller weights for deeper layers and larger weights for the first layers\n!-->\n\n\n<font color='blue'>\n**What you should remember**:\n- The style of an image can be represented using the Gram matrix of a hidden layer's activations. However, we get even better results combining this representation from multiple different layers. This is in contrast to the content representation, where usually using just a single hidden layer is sufficient.\n- Minimizing the style cost will cause the image $G$ to follow the style of the image $S$. \n</font color='blue'>\n\n",
"_____no_output_____"
],
[
"### 3.3 - Defining the total cost to optimize",
"_____no_output_____"
],
[
"Finally, let's create a cost function that minimizes both the style and the content cost. The formula is: \n\n$$J(G) = \\alpha J_{content}(C,G) + \\beta J_{style}(S,G)$$\n\n**Exercise**: Implement the total cost function which includes both the content cost and the style cost. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: total_cost\n\ndef total_cost(J_content, J_style, alpha = 10, beta = 40):\n \"\"\"\n Computes the total cost function\n \n Arguments:\n J_content -- content cost coded above\n J_style -- style cost coded above\n alpha -- hyperparameter weighting the importance of the content cost\n beta -- hyperparameter weighting the importance of the style cost\n \n Returns:\n J -- total cost as defined by the formula above.\n \"\"\"\n \n ### START CODE HERE ### (≈1 line)\n J = alpha * J_content + beta * J_style\n ### END CODE HERE ###\n \n return J",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as test:\n np.random.seed(3)\n J_content = np.random.randn() \n J_style = np.random.randn()\n J = total_cost(J_content, J_style)\n print(\"J = \" + str(J))",
"J = 35.34667875478276\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **J**\n </td>\n <td>\n 35.34667875478276\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- The total cost is a linear combination of the content cost $J_{content}(C,G)$ and the style cost $J_{style}(S,G)$\n- $\\alpha$ and $\\beta$ are hyperparameters that control the relative weighting between content and style",
"_____no_output_____"
],
[
"## 4 - Solving the optimization problem",
"_____no_output_____"
],
[
"Finally, let's put everything together to implement Neural Style Transfer!\n\n\nHere's what the program will have to do:\n<font color='purple'>\n\n1. Create an Interactive Session\n2. Load the content image \n3. Load the style image\n4. Randomly initialize the image to be generated \n5. Load the VGG16 model\n7. Build the TensorFlow graph:\n - Run the content image through the VGG16 model and compute the content cost\n - Run the style image through the VGG16 model and compute the style cost\n - Compute the total cost\n - Define the optimizer and the learning rate\n8. Initialize the TensorFlow graph and run it for a large number of iterations, updating the generated image at every step.\n\n</font>\nLets go through the individual steps in detail. ",
"_____no_output_____"
],
[
"You've previously implemented the overall cost $J(G)$. We'll now set up TensorFlow to optimize this with respect to $G$. To do so, your program has to reset the graph and use an \"[Interactive Session](https://www.tensorflow.org/api_docs/python/tf/InteractiveSession)\". Unlike a regular session, the \"Interactive Session\" installs itself as the default session to build a graph. This allows you to run variables without constantly needing to refer to the session object, which simplifies the code. \n\nLets start the interactive session.",
"_____no_output_____"
]
],
[
[
"# Reset the graph\ntf.reset_default_graph()\n\n# Start interactive session\nsess = tf.InteractiveSession()",
"_____no_output_____"
]
],
[
[
"Let's load, reshape, and normalize our \"content\" image (the Louvre museum picture):",
"_____no_output_____"
]
],
[
[
"content_image = scipy.misc.imread(\"images/louvre_small.jpg\")\ncontent_image = reshape_and_normalize_image(content_image)",
"_____no_output_____"
]
],
[
[
"Let's load, reshape and normalize our \"style\" image (Claude Monet's painting):",
"_____no_output_____"
]
],
[
[
"style_image = scipy.misc.imread(\"images/monet.jpg\")\nstyle_image = reshape_and_normalize_image(style_image)",
"_____no_output_____"
]
],
[
[
"Now, we initialize the \"generated\" image as a noisy image created from the content_image. By initializing the pixels of the generated image to be mostly noise but still slightly correlated with the content image, this will help the content of the \"generated\" image more rapidly match the content of the \"content\" image. (Feel free to look in `nst_utils.py` to see the details of `generate_noise_image(...)`; to do so, click \"File-->Open...\" at the upper-left corner of this Jupyter notebook.)",
"_____no_output_____"
]
],
[
[
"generated_image = generate_noise_image(content_image)\nimshow(generated_image[0])",
"_____no_output_____"
]
],
[
[
"Next, as explained in part (2), let's load the VGG16 model.",
"_____no_output_____"
]
],
[
[
"model = load_vgg_model(\"pretrained-model/imagenet-vgg-verydeep-19.mat\")",
"_____no_output_____"
]
],
[
[
"To get the program to compute the content cost, we will now assign `a_C` and `a_G` to be the appropriate hidden layer activations. We will use layer `conv4_2` to compute the content cost. The code below does the following:\n\n1. Assign the content image to be the input to the VGG model.\n2. Set a_C to be the tensor giving the hidden layer activation for layer \"conv4_2\".\n3. Set a_G to be the tensor giving the hidden layer activation for the same layer. \n4. Compute the content cost using a_C and a_G.",
"_____no_output_____"
]
],
[
[
"# Assign the content image to be the input of the VGG model. \nsess.run(model['input'].assign(content_image))\n\n# Select the output tensor of layer conv4_2\nout = model['conv4_2']\n\n# Set a_C to be the hidden layer activation from the layer we have selected\na_C = sess.run(out)\n\n# Set a_G to be the hidden layer activation from same layer. \n# Here, a_G references model['conv4_2'] \n# and isn't evaluated yet. Later in the code, we'll assign \n# the image G as the model input, so that\n# when we run the session, this will be the activations \n# drawn from the appropriate layer, with G as input.\na_G = out\n\n# Compute the content cost\nJ_content = compute_content_cost(a_C, a_G)",
"_____no_output_____"
]
],
[
[
"**Note**: At this point, a_G is a tensor and hasn't been evaluated. It will be evaluated and updated at each iteration when we run the Tensorflow graph in model_nn() below.",
"_____no_output_____"
]
],
[
[
"# Assign the input of the model to be the \"style\" image \nsess.run(model['input'].assign(style_image))\n\n# Compute the style cost\nJ_style = compute_style_cost(model, STYLE_LAYERS)",
"_____no_output_____"
]
],
[
[
"**Exercise**: Now that you have J_content and J_style, compute the total cost J by calling `total_cost()`. Use `alpha = 10` and `beta = 40`.",
"_____no_output_____"
]
],
[
[
"### START CODE HERE ### (1 line)\nJ = total_cost(J_content, J_style, alpha = 10, beta = 40)\n### END CODE HERE ###",
"_____no_output_____"
]
],
[
[
"You'd previously learned how to set up the Adam optimizer in TensorFlow. Lets do that here, using a learning rate of 2.0. [See reference](https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer)",
"_____no_output_____"
]
],
[
[
"# define optimizer (1 line)\noptimizer = tf.train.AdamOptimizer(2.0)\n\n# define train_step (1 line)\ntrain_step = optimizer.minimize(J)",
"_____no_output_____"
]
],
[
[
"**Exercise**: Implement the model_nn() function which initializes the variables of the tensorflow graph, assigns the input image (initial generated image) as the input of the VGG16 model and runs the train_step for a large number of steps.",
"_____no_output_____"
]
],
[
[
"def model_nn(sess, input_image, num_iterations = 200):\n \n # Initialize global variables (you need to run \n # the session on the initializer)\n ### START CODE HERE ### (1 line)\n sess.run(tf.global_variables_initializer())\n ### END CODE HERE ###\n \n # Run the noisy input image (initial generated image) \n # through the model. Use assign().\n ### START CODE HERE ### (1 line)\n sess.run(model['input'].assign(input_image))\n ### END CODE HERE ###\n \n for i in range(num_iterations):\n \n # Run the session on the train_step to minimize the total cost\n ### START CODE HERE ### (1 line)\n _ = sess.run(train_step)\n ### END CODE HERE ###\n \n # Compute the generated image by running the session \n # on the current model['input']\n ### START CODE HERE ### (1 line)\n generated_image = sess.run(model['input'])\n ### END CODE HERE ###\n\n # Print every 20 iteration.\n if i%20 == 0:\n Jt, Jc, Js = sess.run([J, J_content, J_style])\n print(\"Iteration \" + str(i) + \" :\")\n print(\"total cost = \" + str(Jt))\n print(\"content cost = \" + str(Jc))\n print(\"style cost = \" + str(Js))\n \n # save current generated image in the \"/output\" directory\n save_image(\"output/\" + str(i) + \".png\", generated_image)\n \n # save last generated image\n save_image('output/generated_image.jpg', generated_image)\n \n return generated_image",
"_____no_output_____"
]
],
[
[
"Run the following cell to generate an artistic image. It should take about 3min on CPU for every 20 iterations but you start observing attractive results after ≈140 iterations. Neural Style Transfer is generally trained using GPUs.",
"_____no_output_____"
]
],
[
[
"model_nn(sess, generated_image)",
"Iteration 0 :\ntotal cost = 5.05035e+09\ncontent cost = 7877.67\nstyle cost = 1.26257e+08\nIteration 20 :\ntotal cost = 9.43276e+08\ncontent cost = 15186.9\nstyle cost = 2.35781e+07\nIteration 40 :\ntotal cost = 4.84898e+08\ncontent cost = 16785.0\nstyle cost = 1.21183e+07\nIteration 60 :\ntotal cost = 3.12574e+08\ncontent cost = 17465.8\nstyle cost = 7.80998e+06\nIteration 80 :\ntotal cost = 2.28137e+08\ncontent cost = 17715.0\nstyle cost = 5.699e+06\nIteration 100 :\ntotal cost = 1.80694e+08\ncontent cost = 17895.4\nstyle cost = 4.51288e+06\nIteration 120 :\ntotal cost = 1.49996e+08\ncontent cost = 18034.3\nstyle cost = 3.74539e+06\nIteration 140 :\ntotal cost = 1.27698e+08\ncontent cost = 18186.8\nstyle cost = 3.18791e+06\nIteration 160 :\ntotal cost = 1.10698e+08\ncontent cost = 18354.2\nstyle cost = 2.76287e+06\nIteration 180 :\ntotal cost = 9.73408e+07\ncontent cost = 18500.9\nstyle cost = 2.4289e+06\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **Iteration 0 : **\n </td>\n <td>\n total cost = 5.05035e+09 <br>\n content cost = 7877.67 <br>\n style cost = 1.26257e+08\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"You're done! After running this, in the upper bar of the notebook click on \"File\" and then \"Open\". Go to the \"/output\" directory to see all the saved images. Open \"generated_image\" to see the generated image! :)\n\nYou should see something the image presented below on the right:\n\n<img src=\"images/louvre_generated.png\" style=\"width:800px;height:300px;\">\n\nWe didn't want you to wait too long to see an initial result, and so had set the hyperparameters accordingly. To get the best looking results, running the optimization algorithm longer (and perhaps with a smaller learning rate) might work better. After completing and submitting this assignment, we encourage you to come back and play more with this notebook, and see if you can generate even better looking images. ",
"_____no_output_____"
],
[
"Here are few other examples:\n\n- The beautiful ruins of the ancient city of Persepolis (Iran) with the style of Van Gogh (The Starry Night)\n<img src=\"images/perspolis_vangogh.png\" style=\"width:750px;height:300px;\">\n\n- The tomb of Cyrus the great in Pasargadae with the style of a Ceramic Kashi from Ispahan.\n<img src=\"images/pasargad_kashi.png\" style=\"width:750px;height:300px;\">\n\n- A scientific study of a turbulent fluid with the style of a abstract blue fluid painting.\n<img src=\"images/circle_abstract.png\" style=\"width:750px;height:300px;\">",
"_____no_output_____"
],
[
"## 5 - Test with your own image (Optional/Ungraded)",
"_____no_output_____"
],
[
"Finally, you can also rerun the algorithm on your own images! \n\nTo do so, go back to part 4 and change the content image and style image with your own pictures. In detail, here's what you should do:\n\n1. Click on \"File -> Open\" in the upper tab of the notebook\n2. Go to \"/images\" and upload your images (requirement: (WIDTH = 300, HEIGHT = 225)), rename them \"my_content.png\" and \"my_style.png\" for example.\n3. Change the code in part (3.4) from :\n```python\ncontent_image = scipy.misc.imread(\"images/louvre.jpg\")\nstyle_image = scipy.misc.imread(\"images/claude-monet.jpg\")\n```\nto:\n```python\ncontent_image = scipy.misc.imread(\"images/my_content.jpg\")\nstyle_image = scipy.misc.imread(\"images/my_style.jpg\")\n```\n4. Rerun the cells (you may need to restart the Kernel in the upper tab of the notebook).\n\nYou can also tune your hyperparameters: \n- Which layers are responsible for representing the style? STYLE_LAYERS\n- How many iterations do you want to run the algorithm? num_iterations\n- What is the relative weighting between content and style? alpha/beta",
"_____no_output_____"
],
[
"## 6 - Conclusion\n\nGreat job on completing this assignment! You are now able to use Neural Style Transfer to generate artistic images. This is also your first time building a model in which the optimization algorithm updates the pixel values rather than the neural network's parameters. Deep learning has many different types of models and this is only one of them! \n\n<font color='blue'>\nWhat you should remember:\n- Neural Style Transfer is an algorithm that given a content image C and a style image S can generate an artistic image\n- It uses representations (hidden layer activations) based on a pretrained ConvNet. \n- The content cost function is computed using one hidden layer's activations.\n- The style cost function for one layer is computed using the Gram matrix of that layer's activations. The overall style cost function is obtained using several hidden layers.\n- Optimizing the total cost function results in synthesizing new images. \n\n\n",
"_____no_output_____"
],
[
"This was the final programming exercise of this course. Congratulations--you've finished all the programming exercises of this course on Convolutional Networks! We hope to also see you in Course 5, on Sequence models! \n",
"_____no_output_____"
],
[
"### References:\n\nThe Neural Style Transfer algorithm was due to Gatys et al. (2015). Harish Narayanan and Github user \"log0\" also have highly readable write-ups from which we drew inspiration. The pre-trained network used in this implementation is a VGG network, which is due to Simonyan and Zisserman (2015). Pre-trained weights were from the work of the MathConvNet team. \n\n- Leon A. Gatys, Alexander S. Ecker, Matthias Bethge, (2015). A Neural Algorithm of Artistic Style (https://arxiv.org/abs/1508.06576) \n- Harish Narayanan, Convolutional neural networks for artistic style transfer. https://harishnarayanan.org/writing/artistic-style-transfer/\n- Log0, TensorFlow Implementation of \"A Neural Algorithm of Artistic Style\". http://www.chioka.in/tensorflow-implementation-neural-algorithm-of-artistic-style\n- Karen Simonyan and Andrew Zisserman (2015). Very deep convolutional networks for large-scale image recognition (https://arxiv.org/pdf/1409.1556.pdf)\n- MatConvNet. http://www.vlfeat.org/matconvnet/pretrained/\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d00a0dc411c4f5b55b1645b2d3851de398099044
| 122,841 |
ipynb
|
Jupyter Notebook
|
Introduction to Neural Networks/StudentAdmissions.ipynb
|
kushkul/Facebook-Pytorch-Scholarship-Challenge
|
929234f9ac8277d1dc2e2fe9e854bdf8d5bdd959
|
[
"MIT"
] | null | null | null |
Introduction to Neural Networks/StudentAdmissions.ipynb
|
kushkul/Facebook-Pytorch-Scholarship-Challenge
|
929234f9ac8277d1dc2e2fe9e854bdf8d5bdd959
|
[
"MIT"
] | null | null | null |
Introduction to Neural Networks/StudentAdmissions.ipynb
|
kushkul/Facebook-Pytorch-Scholarship-Challenge
|
929234f9ac8277d1dc2e2fe9e854bdf8d5bdd959
|
[
"MIT"
] | null | null | null | 129.715945 | 28,116 | 0.831278 |
[
[
[
"# Predicting Student Admissions with Neural Networks\nIn this notebook, we predict student admissions to graduate school at UCLA based on three pieces of data:\n- GRE Scores (Test)\n- GPA Scores (Grades)\n- Class rank (1-4)\n\nThe dataset originally came from here: http://www.ats.ucla.edu/\n\n## Loading the data\nTo load the data and format it nicely, we will use two very useful packages called Pandas and Numpy. You can read on the documentation here:\n- https://pandas.pydata.org/pandas-docs/stable/\n- https://docs.scipy.org/",
"_____no_output_____"
]
],
[
[
"# Importing pandas and numpy\nimport pandas as pd\nimport numpy as np\n\n# Reading the csv file into a pandas DataFrame\ndata = pd.read_csv('student_data.csv')\n\n# Printing out the first 10 rows of our data\ndata[:10]",
"_____no_output_____"
]
],
[
[
"## Plotting the data\n\nFirst let's make a plot of our data to see how it looks. In order to have a 2D plot, let's ingore the rank.",
"_____no_output_____"
]
],
[
[
"# Importing matplotlib\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n# Function to help us plot\ndef plot_points(data):\n X = np.array(data[[\"gre\",\"gpa\"]])\n y = np.array(data[\"admit\"])\n admitted = X[np.argwhere(y==1)]\n rejected = X[np.argwhere(y==0)]\n plt.scatter([s[0][0] for s in rejected], [s[0][1] for s in rejected], s = 25, color = 'red', edgecolor = 'k')\n plt.scatter([s[0][0] for s in admitted], [s[0][1] for s in admitted], s = 25, color = 'cyan', edgecolor = 'k')\n plt.xlabel('Test (GRE)')\n plt.ylabel('Grades (GPA)')\n \n# Plotting the points\nplot_points(data)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Roughly, it looks like the students with high scores in the grades and test passed, while the ones with low scores didn't, but the data is not as nicely separable as we hoped it would. Maybe it would help to take the rank into account? Let's make 4 plots, each one for each rank.",
"_____no_output_____"
]
],
[
[
"# Separating the ranks\ndata_rank1 = data[data[\"rank\"]==1]\ndata_rank2 = data[data[\"rank\"]==2]\ndata_rank3 = data[data[\"rank\"]==3]\ndata_rank4 = data[data[\"rank\"]==4]\n\n# Plotting the graphs\nplot_points(data_rank1)\nplt.title(\"Rank 1\")\nplt.show()\nplot_points(data_rank2)\nplt.title(\"Rank 2\")\nplt.show()\nplot_points(data_rank3)\nplt.title(\"Rank 3\")\nplt.show()\nplot_points(data_rank4)\nplt.title(\"Rank 4\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"This looks more promising, as it seems that the lower the rank, the higher the acceptance rate. Let's use the rank as one of our inputs. In order to do this, we should one-hot encode it.\n\n## TODO: One-hot encoding the rank\nUse the `get_dummies` function in pandas in order to one-hot encode the data.\n\nHint: To drop a column, it's suggested that you use `one_hot_data`[.drop( )](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html).",
"_____no_output_____"
]
],
[
[
"# TODO: Make dummy variables for rank\none_hot_data = pd.concat([data, pd.get_dummies(data['rank'], prefix = 'rank_')], axis = 1)\n\n# TODO: Drop the previous rank column\none_hot_data = one_hot_data.drop(['rank'], axis = 1)\n\n# Print the first 10 rows of our data\none_hot_data[:10]",
"_____no_output_____"
]
],
[
[
"## TODO: Scaling the data\nThe next step is to scale the data. We notice that the range for grades is 1.0-4.0, whereas the range for test scores is roughly 200-800, which is much larger. This means our data is skewed, and that makes it hard for a neural network to handle. Let's fit our two features into a range of 0-1, by dividing the grades by 4.0, and the test score by 800.",
"_____no_output_____"
]
],
[
[
"# Making a copy of our data\nprocessed_data = one_hot_data[:]\n\n# TODO: Scale the columns\nprocessed_data['gpa'] = processed_data['gpa'] / 4.0\nprocessed_data['gre'] = processed_data['gre'] / 800\n\n# Printing the first 10 rows of our procesed data\nprocessed_data[:10]",
"_____no_output_____"
]
],
[
[
"## Splitting the data into Training and Testing",
"_____no_output_____"
],
[
"In order to test our algorithm, we'll split the data into a Training and a Testing set. The size of the testing set will be 10% of the total data.",
"_____no_output_____"
]
],
[
[
"sample = np.random.choice(processed_data.index, size=int(len(processed_data)*0.9), replace=False)\ntrain_data, test_data = processed_data.iloc[sample], processed_data.drop(sample)\n\nprint(\"Number of training samples is\", len(train_data))\nprint(\"Number of testing samples is\", len(test_data))\nprint(train_data[:10])\nprint(test_data[:10])",
"Number of training samples is 360\nNumber of testing samples is 40\n admit gre gpa rank__1 rank__2 rank__3 rank__4\n195 0 0.700 0.8975 0 1 0 0\n343 0 0.725 0.7650 0 1 0 0\n125 0 0.675 0.8450 0 0 0 1\n314 0 0.675 0.8650 0 0 0 1\n147 0 0.700 0.6775 0 0 1 0\n386 1 0.925 0.9650 0 1 0 0\n39 1 0.650 0.6700 0 0 1 0\n158 0 0.825 0.8725 0 1 0 0\n75 0 0.900 1.0000 0 0 1 0\n173 1 1.000 0.8575 0 1 0 0\n admit gre gpa rank__1 rank__2 rank__3 rank__4\n7 0 0.500 0.7700 0 1 0 0\n9 0 0.875 0.9800 0 1 0 0\n18 0 1.000 0.9375 0 1 0 0\n30 0 0.675 0.9450 0 0 0 1\n31 0 0.950 0.8375 0 0 1 0\n60 1 0.775 0.7950 0 1 0 0\n83 0 0.475 0.7275 0 0 0 1\n88 0 0.875 0.8200 1 0 0 0\n92 0 1.000 0.9750 0 1 0 0\n99 0 0.500 0.8275 0 0 1 0\n"
]
],
[
[
"## Splitting the data into features and targets (labels)\nNow, as a final step before the training, we'll split the data into features (X) and targets (y).",
"_____no_output_____"
]
],
[
[
"features = train_data.drop('admit', axis = 1)\ntargets = train_data['admit']\n\nfeatures_test = test_data.drop('admit', axis=1)\ntargets_test = test_data['admit']\n\nprint(features[:10])\nprint(targets[:10])\n",
" gre gpa rank__1 rank__2 rank__3 rank__4\n195 0.700 0.8975 0 1 0 0\n343 0.725 0.7650 0 1 0 0\n125 0.675 0.8450 0 0 0 1\n314 0.675 0.8650 0 0 0 1\n147 0.700 0.6775 0 0 1 0\n386 0.925 0.9650 0 1 0 0\n39 0.650 0.6700 0 0 1 0\n158 0.825 0.8725 0 1 0 0\n75 0.900 1.0000 0 0 1 0\n173 1.000 0.8575 0 1 0 0\n195 0\n343 0\n125 0\n314 0\n147 0\n386 1\n39 1\n158 0\n75 0\n173 1\nName: admit, dtype: int64\n"
]
],
[
[
"## Training the 2-layer Neural Network\nThe following function trains the 2-layer neural network. First, we'll write some helper functions.",
"_____no_output_____"
]
],
[
[
"# Activation (sigmoid) function\ndef sigmoid(x):\n return 1 / (1 + np.exp(-x))\ndef sigmoid_prime(x):\n return sigmoid(x) * (1-sigmoid(x))\ndef error_formula(y, output):\n return - y*np.log(output) - (1 - y) * np.log(1-output)",
"_____no_output_____"
]
],
[
[
"# TODO: Backpropagate the error\nNow it's your turn to shine. Write the error term. Remember that this is given by the equation $$ (y-\\hat{y}) \\sigma'(x) $$",
"_____no_output_____"
]
],
[
[
"# TODO: Write the error term formula\ndef error_term_formula(x, y, output):\n return (y - output) * sigmoid_prime(x)",
"_____no_output_____"
],
[
"# Neural Network hyperparameters\nepochs = 1000\nlearnrate = 0.5\n\n# Training function\ndef train_nn(features, targets, epochs, learnrate):\n \n # Use to same seed to make debugging easier\n np.random.seed(42)\n\n n_records, n_features = features.shape\n last_loss = None\n\n # Initialize weights\n weights = np.random.normal(scale=1 / n_features**.5, size=n_features)\n\n for e in range(epochs):\n del_w = np.zeros(weights.shape)\n for x, y in zip(features.values, targets):\n # Loop through all records, x is the input, y is the target\n\n # Activation of the output unit\n # Notice we multiply the inputs and the weights here \n # rather than storing h as a separate variable \n output = sigmoid(np.dot(x, weights))\n\n # The error, the target minus the network output\n error = error_formula(y, output)\n\n # The error term\n error_term = error_term_formula(x, y, output)\n\n # The gradient descent step, the error times the gradient times the inputs\n del_w += error_term * x\n\n # Update the weights here. The learning rate times the \n # change in weights, divided by the number of records to average\n weights += learnrate * del_w / n_records\n\n # Printing out the mean square error on the training set\n if e % (epochs / 10) == 0:\n out = sigmoid(np.dot(features, weights))\n loss = np.mean((out - targets) ** 2)\n print(\"Epoch:\", e)\n if last_loss and last_loss < loss:\n print(\"Train loss: \", loss, \" WARNING - Loss Increasing\")\n else:\n print(\"Train loss: \", loss)\n last_loss = loss\n print(\"=========\")\n print(\"Finished training!\")\n return weights\n \nweights = train_nn(features, targets, epochs, learnrate)",
"Epoch: 0\nTrain loss: 0.27336783372760837\n=========\nEpoch: 100\nTrain loss: 0.2144589591438936\n=========\nEpoch: 200\nTrain loss: 0.21248210601845877\n=========\nEpoch: 300\nTrain loss: 0.21145849287875826\n=========\nEpoch: 400\nTrain loss: 0.2108945778573249\n=========\nEpoch: 500\nTrain loss: 0.21055121998038537\n=========\nEpoch: 600\nTrain loss: 0.21031564296367067\n=========\nEpoch: 700\nTrain loss: 0.2101342506838123\n=========\nEpoch: 800\nTrain loss: 0.20998112157065615\n=========\nEpoch: 900\nTrain loss: 0.20984348241982478\n=========\nFinished training!\n"
]
],
[
[
"## Calculating the Accuracy on the Test Data",
"_____no_output_____"
]
],
[
[
"# Calculate accuracy on test data\ntest_out = sigmoid(np.dot(features_test, weights))\npredictions = test_out > 0.5\naccuracy = np.mean(predictions == targets_test)\nprint(\"Prediction accuracy: {:.3f}\".format(accuracy))",
"Prediction accuracy: 0.800\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.