
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/diffusers
| 228
|
stable-diffusion-v1-4 link in release v0.2.3 is broken
|
### Describe the bug
@anton-l the link (https://huggingface.co/CompVis/stable-diffusion-v1-4) in the [release v0.2.3](https://github.com/huggingface/diffusers/releases/tag/v0.2.3) returns a 404.
### Reproduction
_No response_
### Logs
_No response_
### System Info
```shell
N/A
```
|
https://github.com/huggingface/diffusers/issues/228
|
closed
|
[
"question"
] | 2022-08-22T09:07:27Z
| 2022-08-22T20:53:00Z
| null |
leszekhanusz
|
huggingface/pytorch-image-models
| 1,424
|
[FEATURE] What hyperparameters is used to get the results stated in the paper with the ViT-B pretrained miil weights on imagenet1k?
|
**Is your feature request related to a problem? Please describe.**
What hyperparameters are used to get the results stated in this paper (https://arxiv.org/pdf/2104.10972.pdf) on ImageNet1k with the ViT-B pretrained miil weights from vision_transformer.py in line 164-167? I tried the hyperparemeters as stated in the paper for TResNet but I'm getting below average results. I'm not sure what other hyperparameter details i'm missing. How is the classifier head initialized? Do they use sgd momentum or without momentum? Do they use Hflip or random erasing? I think the hyperparameters stated in the paper is only applicable for TResNet and the code in https://github.com/Alibaba-MIIL/ImageNet21K is missing a lot of details in finetuning stage.
|
https://github.com/huggingface/pytorch-image-models/issues/1424
|
closed
|
[
"enhancement"
] | 2022-08-21T22:26:48Z
| 2022-08-22T04:17:43Z
| null |
Phuoc-Hoan-Le
|
huggingface/optimum
| 351
|
Add all available ONNX models to ORTConfigManager
|
This issue is linked to the [ONNXConfig for all](https://huggingface.co/OWG) working group created for implementing an ONNXConfig for all available models. Let's extend our work and try to add all models with a fully functional ONNXConfig implemented to ORTConfigManager.
Adding models to ORTConfigManager will allow 🤗 Optimum users to boost even more their model with ONNX optimization capacity!
Feel free to join us in this adventure! Join the org by clicking [here](https://huggingface.co/organizations/OWG/share/TskjfGaGjGnMXXssbPPXrQWEIbosGqZshZ)
Here is a non-exhaustive list of models that have one ONNXConfig and could be added to ORTConfigManager:
*This includes only models with ONNXConfig implemented, if your target model doesn't have an ONNXConfig, please open an issue/or implement it (even cooler) in the 🤗 Transformers repository. Check [this issue](https://github.com/huggingface/transformers/issues/16308) to know how to do*
* [x] Albert
* [x] BART
* [ ] BeiT
* [x] BERT
* [x] BigBird
* [ ] BigBirdPegasus
* [x] Blenderbot
* [ ] BlenderbotSmall
* [x] BLOOM
* [x] CamemBERT
* [ ] CLIP
* [x] CodeGen
* [ ] ConvNext
* [ ] ConvBert
* [ ] Data2VecText
* [ ] Data2VecVision
* [x] Deberta
* [x] Deberta-v2
* [ ] DeiT
* [ ] DETR
* [x] Distilbert
* [x] ELECTRA
* [ ] Flaubert
* [x] GptBigCode
* [x] GPT2
* [x] GPTJ
* [x] GPT-NEO
* [x] GPT-NEOX
* [ ] I-BERT
* [ ] LayoutLM
* [ ] LayoutLMv2
* [ ] LayoutLMv3
* [ ] LeViT
* [x] Llama
* [x] LongT5
* [x] M2M100
* [x] mBART
* [x] MT5
* [x] MarianMT
* [ ] MobileBert
* [ ] MobileViT
* [x] nystromformer
* [ ] OpenAIGPT-2
* [ ] PLBart
* [x] Pegasus
* [ ] Perceiver
* [ ] ResNet
* [ ] RoFormer
* [x] RoBERTa
* [ ] SqueezeBERT
* [x] T5
* [x] ViT
* [x] Whisper
* [ ] XLM
* [x] XLM-RoBERTa
* [ ] XLM-RoBERTa-XL
* [ ] YOLOS
If you want an example of implementation, I did one for `MT5` #341.
You need to check how the `attention_heads` number and `hidden_size` arguments are named in the original implementation of your target model in the 🤗 Transformers source code. And then add it to the `_conf` dictionary. Finally, add your implemented model to tests to make it fully functional.
|
https://github.com/huggingface/optimum/issues/351
|
open
|
[
"good first issue"
] | 2022-08-16T08:18:50Z
| 2025-11-19T13:24:40Z
| 3
|
chainyo
|
huggingface/optimum
| 350
|
Migrate metrics used in all examples from Datasets to Evaluate
|
### Feature request
Copied from https://github.com/huggingface/transformers/issues/18306
The metrics are slowly leaving [Datasets](https://github.com/huggingface/datasets) (they are being deprecated as we speak) to move to the [Evaluate](https://github.com/huggingface/evaluate) library. We are looking for contributors to help us with the move.
Normally, the migration should be as easy as replacing the import of `load_metric` from Datasets to the `load` function in Evaluate. See a use in this [Accelerate example](https://github.com/huggingface/accelerate/blob/1486fa35b19abc788ddb609401118a601e68ff5d/examples/nlp_example.py#L104). To fix all tests, a dependency to evaluate will need to be added in the [requirements file](https://github.com/huggingface/transformers/blob/main/examples/pytorch/_tests_requirements.txt) (this is the link for PyTorch, there is another one for the Flax examples).
If you're interested in contributing, please reply to this issue with the examples you plan to move.
### Motivation
/
### Your contribution
/
|
https://github.com/huggingface/optimum/issues/350
|
closed
|
[] | 2022-08-16T08:04:07Z
| 2022-10-27T10:07:58Z
| 0
|
fxmarty
|
huggingface/datasets
| 4,839
|
ImageFolder dataset builder does not read the validation data set if it is named as "val"
|
**Is your feature request related to a problem? Please describe.**
Currently, the `'imagefolder'` data set builder in [`load_dataset()`](https://github.com/huggingface/datasets/blob/2.4.0/src/datasets/load.py#L1541] ) only [supports](https://github.com/huggingface/datasets/blob/6c609a322da994de149b2c938f19439bca99408e/src/datasets/data_files.py#L31) the following names as the validation data set directory name: `["validation", "valid", "dev"]`. When the validation directory is named as `'val'`, the Data set will not have a validation split. I expected this to be a trivial task but ended up spending a lot of time before knowing that only the above names are supported.
Here's a minimal example of `val` not being recognized:
```python
import os
import numpy as np
import cv2
from datasets import load_dataset
# creating a dummy data set with the following structure:
# ROOT
# | -- train
# | ---- class_1
# | ---- class_2
# | -- val
# | ---- class_1
# | ---- class_2
ROOT = "data"
for which in ["train", "val"]:
for class_name in ["class_1", "class_2"]:
dir_name = os.path.join(ROOT, which, class_name)
if not os.path.exists(dir_name):
os.makedirs(dir_name)
for i in range(10):
cv2.imwrite(
os.path.join(dir_name, f"{i}.png"),
np.random.random((224, 224))
)
# trying to create a data set
dataset = load_dataset(
"imagefolder",
data_dir=ROOT
)
>> dataset
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 20
})
})
# ^ note how the dataset only has a 'train' subset
```
**Describe the solution you'd like**
The suggestion is to include `"val"` to [that list ](https://github.com/huggingface/datasets/blob/6c609a322da994de149b2c938f19439bca99408e/src/datasets/data_files.py#L31) as that's a commonly used phrase to name the validation directory.
Also, In the documentation, explicitly mention that only such directory names are supported as train/val/test directories to avoid confusion.
**Describe alternatives you've considered**
In the documentation, explicitly mention that only such directory names are supported as train/val/test directories without adding `val` to the above list.
**Additional context**
A question asked in the forum: [
Loading an imagenet-style image dataset with train/val directories](https://discuss.huggingface.co/t/loading-an-imagenet-style-image-dataset-with-train-val-directories/21554)
|
https://github.com/huggingface/datasets/issues/4839
|
closed
|
[
"enhancement"
] | 2022-08-12T13:26:00Z
| 2022-08-30T10:14:55Z
| 1
|
akt42
|
huggingface/datasets
| 4,836
|
Is it possible to pass multiple links to a split in load script?
|
**Is your feature request related to a problem? Please describe.**
I wanted to use a python loading script in hugging face datasets that use different sources of text (it's somehow a compilation of multiple datasets + my own dataset) based on how `load_dataset` [works](https://huggingface.co/docs/datasets/loading) I assumed I could do something like bellow in my loading script:
```python
...
_URL = "MY_DATASET_URL/resolve/main/data/"
_URLS = {
"train": [
"FIRST_URL_TO.txt",
_URL + "train-00000-of-00001-676bfebbc8742592.parquet"
]
}
...
```
but when loading the dataset it raises the following error:
```python
File ~/.local/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
...
668 if isinstance(a, str):
669 # Force-cast str subclasses to str (issue #21127)
670 parts.append(str(a))
TypeError: expected str, bytes or os.PathLike object, not list
```
**Describe the solution you'd like**
I believe since it's possible for `load_dataset` to get list of URLs instead of just a URL for `train` split it can be possible here too.
**Describe alternatives you've considered**
An alternative solution would be to download all needed datasets locally and `push_to_hub` them all, but since the datasets I'm talking about are huge it's not among my options.
**Additional context**
I think loading `text` beside the `parquet` is completely a different issue but I believe I can figure it out by proposing a config for my dataset to load each entry of `_URLS['train']` separately either by `load_dataset("text", ...` or `load_dataset("parquet", ...`.
|
https://github.com/huggingface/datasets/issues/4836
|
open
|
[
"enhancement"
] | 2022-08-12T11:06:11Z
| 2022-08-12T11:06:11Z
| 0
|
sadrasabouri
|
huggingface/datasets
| 4,820
|
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
|
Hi, when i try to run prepare_dataset function in [fine tuning ASR tutorial 4](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) , i got this error.
I got this error
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
There is no other logs available, so i have no clue what is the cause of it.
```
def prepare_dataset(batch):
audio = batch["path"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
data = data.map(prepare_dataset, remove_columns=data.column_names["train"],
num_proc=4)
```
Specify the actual results or traceback.
There is no traceback except
`Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4820
|
closed
|
[
"bug"
] | 2022-08-10T19:42:33Z
| 2022-08-10T19:53:10Z
| 1
|
talhaanwarch
|
huggingface/dataset-viewer
| 502
|
Improve the docs: what is needed to make the dataset viewer work?
|
See https://discuss.huggingface.co/t/the-dataset-preview-has-been-disabled-on-this-dataset/21339
|
https://github.com/huggingface/dataset-viewer/issues/502
|
closed
|
[
"documentation"
] | 2022-08-08T13:27:21Z
| 2022-09-19T09:12:00Z
| null |
severo
|
huggingface/dataset-viewer
| 498
|
Test cookie authentication
|
Testing token authentication is easy, see https://github.com/huggingface/datasets-server/issues/199#issuecomment-1205528302, but testing session cookie authentication might be a bit more complex since we need to log in to get the cookie. I prefer to get a dedicate issue for it.
|
https://github.com/huggingface/dataset-viewer/issues/498
|
closed
|
[
"question",
"tests"
] | 2022-08-04T17:06:31Z
| 2022-08-22T18:34:29Z
| null |
severo
|
huggingface/datasets
| 4,791
|
Dataset Viewer issue for Team-PIXEL/rendered-wikipedia-english
|
### Link
https://huggingface.co/datasets/Team-PIXEL/rendered-wikipedia-english/viewer/rendered-wikipedia-en/train
### Description
The dataset can be loaded fine but the viewer shows this error:
```
Server Error
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
```
I'm guessing this is because I recently renamed the dataset. Based on related issues (e.g. https://github.com/huggingface/datasets/issues/4759) , is there something server-side that needs to be refreshed?
### Owner
Yes
|
https://github.com/huggingface/datasets/issues/4791
|
closed
|
[
"dataset-viewer"
] | 2022-08-04T12:49:16Z
| 2022-08-04T13:43:16Z
| 1
|
xplip
|
huggingface/datasets
| 4,776
|
RuntimeError when using torchaudio 0.12.0 to load MP3 audio file
|
Current version of `torchaudio` (0.12.0) raises a RuntimeError when trying to use `sox_io` backend but non-Python dependency `sox` is not installed:
https://github.com/pytorch/audio/blob/2e1388401c434011e9f044b40bc8374f2ddfc414/torchaudio/backend/sox_io_backend.py#L21-L29
```python
def _fail_load(
filepath: str,
frame_offset: int = 0,
num_frames: int = -1,
normalize: bool = True,
channels_first: bool = True,
format: Optional[str] = None,
) -> Tuple[torch.Tensor, int]:
raise RuntimeError("Failed to load audio from {}".format(filepath))
```
Maybe we should raise a more actionable error message so that the user knows how to fix it.
UPDATE:
- this is an incompatibility of latest torchaudio (0.12.0) and the sox backend
TODO:
- [x] as a temporary solution, we should recommend installing torchaudio<0.12.0
- #4777
- #4785
- [ ] however, a stable solution must be found for torchaudio>=0.12.0
Related to:
- https://github.com/huggingface/transformers/issues/18379
|
https://github.com/huggingface/datasets/issues/4776
|
closed
|
[] | 2022-08-01T14:11:23Z
| 2023-03-02T15:58:16Z
| 3
|
albertvillanova
|
huggingface/optimum
| 327
|
Any workable example of exporting and inferencing with GPU?
|
### System Info
```shell
Been tried many methods, but never successfully done it. Thanks.
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model.save_pretrained(save_directory, file_name=file_name)
tokenizer.save_pretrained(save_directory)
optimization_config = OptimizationConfig(optimization_level=99, optimize_for_gpu=True)
optimizer = ORTOptimizer.from_pretrained(
model_checkpoint,
feature="sequence-classification",
)
optimizer.export(
onnx_model_path=onnx_path,
onnx_optimized_model_output_path=os.path.join(save_directory, "model-optimized.onnx"),
optimization_config=optimization_config,
)```
### Expected behavior
NA
|
https://github.com/huggingface/optimum/issues/327
|
closed
|
[
"bug"
] | 2022-08-01T05:12:15Z
| 2022-08-01T06:19:26Z
| 1
|
lkluo
|
huggingface/datasets
| 4,757
|
Document better when relative paths are transformed to URLs
|
As discussed with @ydshieh, when passing a relative path as `data_dir` to `load_dataset` of a dataset hosted on the Hub, the relative path is transformed to the corresponding URL of the Hub dataset.
Currently, we mention this in our docs here: [Create a dataset loading script > Download data files and organize splits](https://huggingface.co/docs/datasets/v2.4.0/en/dataset_script#download-data-files-and-organize-splits)
> If the data files live in the same folder or repository of the dataset script, you can just pass the relative paths to the files instead of URLs.
Maybe we should document better how relative paths are handled, not only when creating a dataset loading script, but also when passing to `load_dataset`:
- `data_dir`
- `data_files`
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4757
|
closed
|
[
"documentation"
] | 2022-07-28T08:46:27Z
| 2022-08-25T18:34:24Z
| 0
|
albertvillanova
|
huggingface/diffusers
| 143
|
Running difussers with GPU
|
Running the example codes i see that the CPU and not the GPU is used, is there a way to use GPU instead
|
https://github.com/huggingface/diffusers/issues/143
|
closed
|
[
"question"
] | 2022-07-28T08:34:12Z
| 2022-08-15T17:27:31Z
| null |
jfdelgad
|
huggingface/optimum
| 320
|
Feature request: allow user to provide tokenizer when loading transformer model
|
### Feature request
When I try to load a locally saved transformers model with `ORTModelForSequenceClassification.from_pretrained(<path>, from_transformers=True)` an error occurs ("unable to generate dummy inputs for model") unless I also save the tokenizer in the checkpoint. A reproducible example of this is below.
A way to pass a tokenizer object to `from_pretrained()` would be helpful to avoid this problem.
```python
orig_model="prajjwal1/bert-tiny"
saved_model_path='saved_model'
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Load a model from the hub and save it locally
model = AutoModelForSequenceClassification.from_pretrained(orig_model)
model.save_pretrained(saved_model_path)
tokenizer=AutoTokenizer.from_pretrained(orig_model)
# attempt to load the locally saved model and convert to Onnx
loaded_model=ORTModelForSequenceClassification.from_pretrained(
saved_model_path,
from_transformers=True
)
```
Produces error:
```sh
Traceback (most recent call last):
File "optimum_loading_reprex.py", line 21, in <module>
loaded_model=ORTModelForSequenceClassification.from_pretrained(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/optimum/modeling_base.py", line 201, in from_pretrained
return cls._from_transformers(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/optimum/onnxruntime/modeling_ort.py", line 275, in _from_transformers
export(
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/convert.py", line 335, in export
return export_pytorch(preprocessor, model, config, opset, output, tokenizer=tokenizer, device=device)
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/convert.py", line 142, in export_pytorch
model_inputs = config.generate_dummy_inputs(preprocessor, framework=TensorType.PYTORCH)
File "/home/cambonator/anaconda3/envs/onnx/lib/python3.8/site-packages/transformers/onnx/config.py", line 334, in generate_dummy_inputs
raise ValueError(
ValueError: Unable to generate dummy inputs for the model. Please provide a tokenizer or a preprocessor.
```
Package versions
- transformers: 4.20.1
- optimum: 1.3.0
- onnxruntime: 1.11.1
- torch: 1.11.0
### Motivation
Saving the tokenizer to the model checkpoint is a step that could be eliminated if there were a way to provide a tokenizer to `ORTModelForSequenceClassification.from_pretrained()`
### Your contribution
I'm not currently sure where to start on implementing this feature, but would be happy to help with some guidance.
|
https://github.com/huggingface/optimum/issues/320
|
closed
|
[
"Stale"
] | 2022-07-27T20:01:32Z
| 2025-07-27T02:17:59Z
| 3
|
jessecambon
|
huggingface/datasets
| 4,744
|
Remove instructions to generate dummy data from our docs
|
In our docs, we indicate to generate the dummy data: https://huggingface.co/docs/datasets/dataset_script#testing-data-and-checksum-metadata
However:
- dummy data makes sense only for datasets in our GitHub repo: so that we can test their loading with our CI
- for datasets on the Hub:
- they do not pass any CI test requiring dummy data
- there are no instructions on how they can test their dataset locally using the dummy data
- the generation of the dummy data assumes our GitHub directory structure:
- the dummy data will be generated under `./datasets/<dataset_name>/dummy` even if locally there is no `./datasets` directory (which is the usual case). See issue:
- #4742
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4744
|
closed
|
[
"documentation"
] | 2022-07-26T07:32:58Z
| 2022-08-02T23:50:30Z
| 2
|
albertvillanova
|
huggingface/datasets
| 4,742
|
Dummy data nowhere to be found
|
## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co/datasets/BramVanroy/hebban-reviews). And even though the scripts runs and shows a message at the end that it succeeded, I cannot find the dummy data anywhere. Where is it?
## Expected results
To see the dummy data in the datasets' folder or in the folder where I ran the command.
## Actual results
I see the following message but I cannot find the dummy data anywhere.
```
Dummy data generation done and dummy data test succeeded for config 'filtered''.
Automatic dummy data generation succeeded for all configs of '.\datasets\hebban-reviews\'
```
## Environment info
- `datasets` version: 2.4.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.8
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4742
|
closed
|
[
"bug"
] | 2022-07-25T19:18:42Z
| 2022-11-04T14:04:24Z
| 3
|
BramVanroy
|
huggingface/dataset-viewer
| 466
|
Take decisions before launching in public
|
## Version
Should we integrate a version in the path or domain, to help with future breaking changes?
Three options:
1. domain based: https://v1.datasets-server.huggingface.co
2. path based: https://datasets-server.huggingface.co/v1/
3. no version (current): https://datasets-server.huggingface.co
I think 3 is OK. Not having a version means we have to try to make everything backward-compatible, which is not a bad idea. If it's really needed, we can switch to 1 or 2 afterward. Also: having a version means that if we do breaking changes, we should maintain at least two versions in parallel...
## Envelop
A common pattern is to always return a JSON object with `data` or `error`. This way, we know that we can always consume the API with:
```js
const {data, error} = fetch(...)
```
and test for the existence of data, or error. Otherwise, every endpoint might have different behavior. Also: it's useful to have the envelop when looking at the response without knowing the HTTP status code (eg: in our cache)
Options:
1. no envelop (current): the client must rely on the HTTP status code to get the type of response (error or OK)
2. envelop: we need to migrate all the endpoints, to add an intermediate "data" or "error" field.
## HTTP status codes
We currently only use 200, 400, and 500 for simplicity. We might want to return alternative status codes such as 404 (not found), or 401/403 (when we will protect some endpoints).
Options:
1. only use 200, 400, 500 (current)
2. add more status codes, like 404, 401, 403
I think it's OK to stay with 300, 400, and 500, and let the client use the details of the response to figure out what failed.
## Error codes
Currently, the errors have a "message" field, and optionally three more fields: "cause_exception", "cause_message" and "cause_traceback". We could add a "code" field, such as "NOT_STREAMABLE", to make it more reliable for the client to implement logic based on the type of error (indeed: the message is a long string that might be updated later. A short code should be more reliable). Also: having an error code could counterbalance the lack of detailed HTTP status codes (see the previous point).
Internally, having codes could help indirect the messages to a dictionary, and it would help to catalog all the possible types of errors in the same place.
Options:
1. no "code" field (current)
2. add a "code" field, such as "NOT_STREAMABLE"
I'm in favor of adding such a short code.
## Case
The endpoints with several words are currently using "spinal-case", eg "/first-rows". An alternative is to use "snake_case", eg "/first_rows". Nothing important here.
Options:
1. "/spinal-case" (current)
2. "/snake_case"
I think it's not important, we can keep with spinal-case, and it's coherent with Hub API: https://huggingface.co/docs/hub/api
|
https://github.com/huggingface/dataset-viewer/issues/466
|
closed
|
[
"question"
] | 2022-07-25T18:04:59Z
| 2022-07-26T14:39:46Z
| null |
severo
|
huggingface/dataset-viewer
| 458
|
Move /webhook to admin instead of api?
|
As we've done with the technical endpoints in https://github.com/huggingface/datasets-server/pull/457?
It might help to protect the endpoint (#95), even if it's not really dangerous to let people add jobs to refresh datasets IMHO for now.
|
https://github.com/huggingface/dataset-viewer/issues/458
|
closed
|
[
"question"
] | 2022-07-22T20:21:39Z
| 2022-09-16T17:24:05Z
| null |
severo
|
huggingface/dataset-viewer
| 455
|
what to do with /is-valid?
|
Currently, the endpoint /is-valid is not documented in https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json (but it is in https://github.com/huggingface/datasets-server/blob/main/services/api/README.md).
It's not used in the dataset viewer in moonlanding, but https://github.com/huggingface/model-evaluator uses it (cc @lewtun).
I have the impression that we could change this endpoint to something more precise, since "valid" is a bit loose, and will be less and less precise when other services will be added to the dataset server (statistics, random access, parquet file, etc). Instead, maybe we could create a new endpoint with more details about what services are working for the dataset. Or do we consider a dataset valid if all the services are available?
What should we do?
- [ ] keep it this way
- [ ] create a new endpoint with details of the available services
also cc @lhoestq
|
https://github.com/huggingface/dataset-viewer/issues/455
|
closed
|
[
"question"
] | 2022-07-22T19:29:08Z
| 2022-08-02T14:16:24Z
| null |
severo
|
huggingface/datasets
| 4,736
|
Dataset Viewer issue for deepklarity/huggingface-spaces-dataset
|
### Link
https://huggingface.co/datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is csv, so I'm not sure if it's supposed to take this much time or not.
```
Status code: 400
Exception: Status400Error
Message: The split is being processed. Retry later.
```
Is there any explicit step to be taken to get the viewer to work?
### Owner
Yes
|
https://github.com/huggingface/datasets/issues/4736
|
closed
|
[
"dataset-viewer"
] | 2022-07-22T12:14:18Z
| 2022-07-22T13:46:38Z
| 1
|
dk-crazydiv
|
huggingface/datasets
| 4,732
|
Document better that loading a dataset passing its name does not use the local script
|
As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/the_pile.py` loading script
- he tried to load it but using `load_dataset("the_pile")` instead of `load_dataset("datasets/the_pile")`
- as explained here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191040245:
- the former does not use the local script, but instead it downloads a copy of `the_pile.py` from our GitHub, caches it locally (inside `~/.cache/huggingface/modules`) and uses that.
He suggests adding a more clear explanation about this. He suggests adding it maybe in [Installation > source](https://huggingface.co/docs/datasets/installation))
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4732
|
closed
|
[
"documentation"
] | 2022-07-22T06:07:31Z
| 2022-08-23T16:32:23Z
| 3
|
albertvillanova
|
huggingface/datasets
| 4,719
|
Issue loading TheNoob3131/mosquito-data dataset
|

So my dataset is public in the Huggingface Hub, but when I try to load it using the load_dataset command, it shows that it is downloading the files, but throws a ValueError. When I went to my directory to see if the files were downloaded, the folder was blank.
Here is the error below:
ValueError Traceback (most recent call last)
Input In [8], in <cell line: 3>()
1 from datasets import load_dataset
----> 3 dataset = load_dataset("TheNoob3131/mosquito-data", split="train")
File ~\Anaconda3\lib\site-packages\datasets\load.py:1679, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1676 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1678 # Download and prepare data
-> 1679 builder_instance.download_and_prepare(
1680 download_config=download_config,
1681 download_mode=download_mode,
1682 ignore_verifications=ignore_verifications,
1683 try_from_hf_gcs=try_from_hf_gcs,
1684 use_auth_token=use_auth_token,
1685 )
1687 # Build dataset for splits
1688 keep_in_memory = (
1689 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1690 )
Is the dataset in the wrong format or is there some security permission that I should enable?
|
https://github.com/huggingface/datasets/issues/4719
|
closed
|
[] | 2022-07-19T17:47:37Z
| 2022-07-20T06:46:57Z
| 2
|
thenerd31
|
huggingface/datasets
| 4,711
|
Document how to create a dataset loading script for audio/vision
|
Currently, in our docs for Audio/Vision/Text, we explain how to:
- Load data
- Process data
However we only explain how to *Create a dataset loading script* for text data.
I think it would be useful that we add the same for Audio/Vision as these have some specificities different from Text.
See, for example:
- #4697
- and comment there: https://github.com/huggingface/datasets/issues/4697#issuecomment-1191502492
CC: @stevhliu
|
https://github.com/huggingface/datasets/issues/4711
|
closed
|
[
"documentation"
] | 2022-07-19T08:03:40Z
| 2023-07-25T16:07:52Z
| 1
|
albertvillanova
|
huggingface/optimum
| 306
|
`ORTModelForConditionalGeneration` did not have `generate()` module after converting from `T5ForConditionalGeneration`
|
### System Info
```shell
Machine: Apple M1 Pro
Optimum version: 1.3.0
Transformers version: 4.20.1
Onnxruntime version: 1.11.1
# Question
How to inference a quantized onnx model from class ORTModelForConditionalGeneration (previously using T5ForConditionalGeneration). I've successfully converted T5ForConditionalGeneration PyTorch model to onnx, then quantize it. But did not know why the `model.generate` was not found from ORTModelForConditionalGeneration model. How to inference?
A bit of context, this is text to text generation task. So generate a paraphrase from a sentence.
```
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Sample code:
```
import os
from optimum.onnxruntime.modeling_seq2seq import ORTModelForConditionalGeneration
from transformers import T5ForConditionalGeneration,T5Tokenizer
save_directory = "onnx/"
file_name = "model.onnx"
onnx_path = os.path.join(save_directory, "model.onnx")
# Load a model from transformers and export it through the ONNX format
# model_raw = T5ForConditionalGeneration.from_pretrained(f'model_{version}/t5_keyword')
model = ORTModelForConditionalGeneration.from_pretrained(f'model_{version}/t5_keyword', from_transformers=True)
tokenizer = T5Tokenizer.from_pretrained(f'model_{version}/t5_keyword')
# Save the onnx model and tokenizer
model.save_pretrained(save_directory, file_name=file_name)
tokenizer.save_pretrained(save_directory)
```
Quantization code:
```
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from optimum.onnxruntime import ORTQuantizer
# Define the quantization methodology
qconfig = AutoQuantizationConfig.arm64(is_static=False, per_channel=False)
quantizer = ORTQuantizer.from_pretrained(f'model_{version}/t5_keyword', feature="seq2seq-lm")
# Apply dynamic quantization on the model
quantizer.export(
onnx_model_path=onnx_path,
onnx_quantized_model_output_path=os.path.join(save_directory, "model-quantized.onnx"),
quantization_config=qconfig,
)
```
Reader:
```
from optimum.onnxruntime.modeling_seq2seq import ORTModelForConditionalGeneration
from transformers import pipeline, AutoTokenizer
model = ORTModelForConditionalGeneration.from_pretrained(save_directory, file_name="model-quantized.onnx")
tokenizer = AutoTokenizer.from_pretrained(save_directory)
```
Error when:
```
text = "Hotelnya bagus sekali"
encoding = tokenizer.encode_plus(text,padding=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"], encoding["attention_mask"]
beam_outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
)
```
`AttributeError: 'ORTModelForConditionalGeneration' object has no attribute 'generate'`
### Expected behavior
Can predict using same T5 class `generate`
|
https://github.com/huggingface/optimum/issues/306
|
closed
|
[
"bug"
] | 2022-07-19T07:14:48Z
| 2022-07-19T09:29:09Z
| 2
|
tiketdatailham
|
huggingface/datasets
| 4,694
|
Distributed data parallel training for streaming datasets
|
### Feature request
Any documentations for the the `load_dataset(streaming=True)` for (multi-node multi-GPU) DDP training?
### Motivation
Given a bunch of data files, it is expected to split them onto different GPUs. Is there a guide or documentation?
### Your contribution
Does it requires manually split on data files for each worker in `DatasetBuilder._split_generator()`? What is`IterableDatasetShard` expected to do?
|
https://github.com/huggingface/datasets/issues/4694
|
open
|
[
"enhancement"
] | 2022-07-17T01:29:43Z
| 2023-04-26T18:21:09Z
| 6
|
cyk1337
|
huggingface/datasets
| 4,684
|
How to assign new values to Dataset?
|

Hi, if I want to change some values of the dataset, or add new columns to it, how can I do it?
For example, I want to change all the labels of the SST2 dataset to `0`:
```python
from datasets import load_dataset
data = load_dataset('glue','sst2')
data['train']['label'] = [0]*len(data)
```
I will get the error:
```
TypeError: 'Dataset' object does not support item assignment
```
|
https://github.com/huggingface/datasets/issues/4684
|
closed
|
[
"enhancement"
] | 2022-07-15T04:17:57Z
| 2023-03-20T15:50:41Z
| 2
|
beyondguo
|
huggingface/datasets
| 4,682
|
weird issue/bug with columns (dataset iterable/stream mode)
|
I have a dataset online (CloverSearch/cc-news-mutlilingual) that has a bunch of columns, two of which are "score_title_maintext" and "score_title_description". the original files are jsonl formatted. I was trying to iterate through via streaming mode and grab all "score_title_description" values, but I kept getting key not found after a certain point of iteration. I found that some json objects in the file don't have "score_title_description". And in SOME cases, this returns a NONE and in others it just gets a key error. Why is there an inconsistency here and how can I fix it?
|
https://github.com/huggingface/datasets/issues/4682
|
open
|
[] | 2022-07-14T13:26:47Z
| 2022-07-14T13:26:47Z
| 0
|
eunseojo
|
huggingface/optimum
| 290
|
Quantized Model size difference when using Optimum vs. Onnxruntime
|
Package versions




While exporting a question answering model ("deepset/minilm-uncased-squad2") to ONNX and quantizing it(dynamic quantization) with Optimum, the model size is 68 MB.
The same model exported while using ONNXRuntime is 32 MB.
Why is there a difference between both the exported models when the model is the same and the quantization too ?
**Optimum Code to convert the model to ONNX and Quantization.**
```python
from pathlib import Path
from optimum.onnxruntime import ORTModelForQuestionAnswering, ORTOptimizer
from optimum.onnxruntime.configuration import AutoQuantizationConfig, OptimizationConfig
from optimum.onnxruntime import ORTQuantizer
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
model_checkpoint = "deepset/minilm-uncased-squad2"
save_directory = Path.home()/'onnx/optimum/minilm-uncased-squad2'
save_directory.mkdir(exist_ok=True,parents=True)
file_name = "minilm-uncased-squad2.onnx"
onnx_path = save_directory/"minilm-uncased-squad2.onnx"
# Load a model from transformers and export it through the ONNX format
model = ORTModelForQuestionAnswering.from_pretrained(model_checkpoint, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
# Save the onnx model and tokenizer
model.save_pretrained(save_directory, file_name=file_name)
tokenizer.save_pretrained(save_directory)
# Define the quantization methodology
qconfig = AutoQuantizationConfig.avx2(is_static=False, per_channel=True)
quantizer = ORTQuantizer.from_pretrained(model_checkpoint, feature="question-answering")
# Apply dynamic quantization on the model
quantizer.export(
onnx_model_path=onnx_path,
onnx_quantized_model_output_path= save_directory/"minilm-uncased-squad2-quantized.onnx",
quantization_config=qconfig,
)
quantizer.model.config.save_pretrained(save_directory)
Path(save_directory/"minilm-uncased-squad2-quantized.onnx").stat().st_size/1024**2
```
**ONNX Runtime Code**
```python
from transformers.convert_graph_to_onnx import convert
from transformers import AutoTokenizer
from pathlib import Path
model_ckpt = "deepset/minilm-uncased-squad2"
onnx_model_path = Path("../../onnx/minilm-uncased-squad2.onnx")
tokenizer= AutoTokenizer.from_pretrained(model_ckpt)
convert(framework="pt", model=model_ckpt, tokenizer=tokenizer,
output=onnx_model_path, opset=12, pipeline_name="question-answering")
from onnxruntime.quantization import quantize_dynamic, QuantType
onnx_model_path = Path("../../../onnx/minilm-uncased-squad2.onnx")
model_output = "../../onnx/minilm-uncased-squad2.quant.onnx"
quantize_dynamic(onnx_model_path, model_output, weight_type=QuantType.QInt8)
Path(model_output).stat().st_size/1024**2
```
Thank you
|
https://github.com/huggingface/optimum/issues/290
|
closed
|
[] | 2022-07-13T10:12:45Z
| 2022-07-14T09:24:23Z
| 3
|
Shamik-07
|
huggingface/datasets
| 4,675
|
Unable to use dataset with PyTorch dataloader
|
## Describe the bug
When using `.with_format("torch")`, an arrow table is returned and I am unable to use it by passing it to a PyTorch DataLoader: please see the code below.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
ds = load_dataset(
"para_crawl",
name="enfr",
cache_dir="/tmp/test/",
split="train",
keep_in_memory=True,
)
dataloader = DataLoader(ds.with_format("torch"), num_workers=32)
print(next(iter(dataloader)))
```
Is there something I am doing wrong? The documentation does not say much about the behavior of `.with_format()` so I feel like I am a bit stuck here :-/
Thanks in advance for your help!
## Expected results
The code should run with no error
## Actual results
```
AttributeError: 'str' object has no attribute 'dtype'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-4.18.0-348.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.4
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
|
https://github.com/huggingface/datasets/issues/4675
|
open
|
[
"bug"
] | 2022-07-12T15:04:04Z
| 2022-07-14T14:17:46Z
| 1
|
BlueskyFR
|
huggingface/datasets
| 4,671
|
Dataset Viewer issue for wmt16
|
### Link
https://huggingface.co/datasets/wmt16
### Description
[Reported](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/12#62cb83f14c7f35284e796f9c) by a user of AutoTrain Evaluate. AFAIK this dataset was working 1-2 weeks ago, and I'm not sure how to interpret this error.
```
Status code: 400
Exception: NotImplementedError
Message: This is a abstract method
```
Thanks!
### Owner
No
|
https://github.com/huggingface/datasets/issues/4671
|
closed
|
[
"dataset-viewer"
] | 2022-07-11T08:34:11Z
| 2022-09-13T13:27:02Z
| 6
|
lewtun
|
huggingface/optimum
| 276
|
Force write of vanilla onnx model with `ORTQuantizer.export()`
|
### Feature request
Force write of the non-quantized onnx model with `ORTQuantizer.export()`, or add an option to force write.
### Motivation
Currently, if the `onnx_model_path` already exists, we don't write the non-quantized model in to the indicated path.
https://github.com/huggingface/optimum/blob/04a2a6d290ca6ea6949844d1ae9a208ca95a79da/optimum/onnxruntime/quantization.py#L313-L315
Meanwhile, the quantized model is always written, even if there is already a model at the `onnx_quantized_model_output_path` (see https://github.com/onnx/onnx/blob/60d29c10c53ef7aa580291cb2b6360813b4328a3/onnx/__init__.py#L170).
Is there any reason for this different behavior? It led me to unexpected behaviors, where the non-quantized / quantized models don't correspond if I change the model in my script. In this case, the `export()` reuses the old non-quantized model to generate the quantized model, and all the quantizer attributes are ignored!
### Your contribution
I can do this if approved
|
https://github.com/huggingface/optimum/issues/276
|
closed
|
[] | 2022-07-09T08:44:27Z
| 2022-07-11T10:38:48Z
| 2
|
fxmarty
|
huggingface/optimum
| 262
|
How can i set number of threads for Optimum exported model?
|
### System Info
```shell
optimum==1.2.3
onnxruntime==1.11.1
onnx==1.12.0
transformers==4.20.1
python version 3.7.13
```
### Who can help?
@JingyaHuang @echarlaix
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hi!
I can't specify the number of threads for inferencing Optimum ONNX models.
I didn't have such a problem with the default transformers model before.
Is there any Configuration in Optimum?
### Optimum doesn't have a config for assigning the number of threads
```
from onnxruntime import SessionOptions
SessionOptions().intra_op_num_threads = 1
```
### also limiting on OS level doesn't work:
```bash
taskset -c 0-16 python inference_onnx.py
```
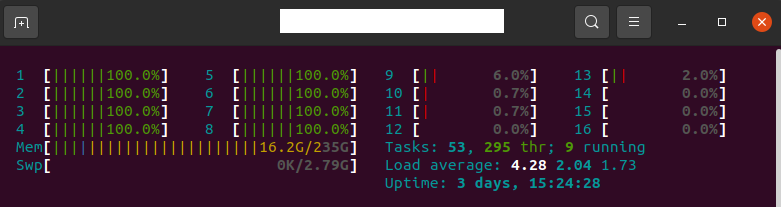
```bash
taskset -c 0 python inference_onnx.py
```
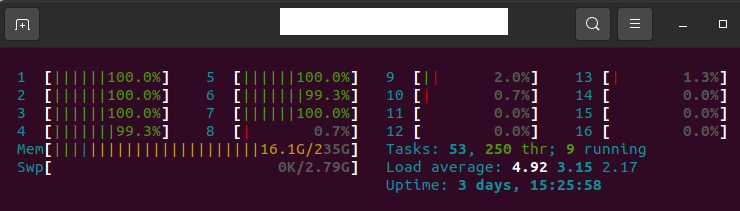
|
https://github.com/huggingface/optimum/issues/262
|
closed
|
[
"bug"
] | 2022-07-06T06:53:30Z
| 2022-09-19T11:25:23Z
| 1
|
MiladMolazadeh
|
huggingface/optimum
| 257
|
Optimum Inference next steps
|
# What is this issue for?
This issue is a list of potential next steps for improving inference experience using `optimum`. The current list applies to the main namespace of optimum but should be soon extended to other namespaces including `intel`, `habana`, `graphcore`.
## Next Steps/Features
- [x] #199
- [x] #254
- [x] #213
- [x] #258
- [x] #259
- [x] #260
- [x] #261
- [ ] add new Accelerators, INC, OpenVino.....
---
_Note: this issue will be continuously updated to keep track of the developments. If you are part of the community and interested in contributing feel free to pick on and open a PR._
|
https://github.com/huggingface/optimum/issues/257
|
closed
|
[
"inference",
"Stale"
] | 2022-07-06T05:02:12Z
| 2025-09-13T02:01:29Z
| 1
|
philschmid
|
huggingface/datasets
| 4,621
|
ImageFolder raises an error with parameters drop_metadata=True and drop_labels=False when metadata.jsonl is present
|
## Describe the bug
If you pass `drop_metadata=True` and `drop_labels=False` when a `data_dir` contains at least one `matadata.jsonl` file, you will get a KeyError. This is probably not a very useful case but we shouldn't get an error anyway. Asking users to move metadata files manually outside `data_dir` or pass features manually (when there is a tool that can infer them automatically) don't look like a good idea to me either.
## Steps to reproduce the bug
### Clone an example dataset from the Hub
```bash
git clone https://huggingface.co/datasets/nateraw/test-imagefolder-metadata
```
### Try to load it
```python
from datasets import load_dataset
ds = load_dataset("test-imagefolder-metadata", drop_metadata=True, drop_labels=False)
```
or even just
```python
ds = load_dataset("test-imagefolder-metadata", drop_metadata=True)
```
as `drop_labels=False` is a default value.
## Expected results
A DatasetDict object with two features: `"image"` and `"label"`.
## Actual results
```
Traceback (most recent call last):
File "/home/polina/workspace/datasets/debug.py", line 18, in <module>
ds = load_dataset(
File "/home/polina/workspace/datasets/src/datasets/load.py", line 1732, in load_dataset
builder_instance.download_and_prepare(
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 1227, in _download_and_prepare
super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 1218, in _prepare_split
example = self.info.features.encode_example(record)
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1596, in encode_example
return encode_nested_example(self, example)
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1165, in encode_nested_example
{
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1165, in <dictcomp>
{
File "/home/polina/workspace/datasets/src/datasets/utils/py_utils.py", line 249, in zip_dict
yield key, tuple(d[key] for d in dicts)
File "/home/polina/workspace/datasets/src/datasets/utils/py_utils.py", line 249, in <genexpr>
yield key, tuple(d[key] for d in dicts)
KeyError: 'label'
```
## Environment info
`datasets` master branch
- `datasets` version: 2.3.3.dev0
- Platform: Linux-5.14.0-1042-oem-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
- Pandas version: 1.4.1
|
https://github.com/huggingface/datasets/issues/4621
|
closed
|
[
"bug"
] | 2022-07-04T11:21:44Z
| 2022-07-15T14:24:24Z
| 0
|
polinaeterna
|
huggingface/datasets
| 4,619
|
np arrays get turned into native lists
|
## Describe the bug
When attaching an `np.array` field, it seems that it automatically gets turned into a list (see below). Why is this happening? Could it lose precision? Is there a way to make sure this doesn't happen?
## Steps to reproduce the bug
```python
>>> import datasets, numpy as np
>>> dataset = datasets.load_dataset("glue", "mrpc")["validation"]
Reusing dataset glue (...)
100%|███████████████████████████████████████████████| 3/3 [00:00<00:00, 1360.61it/s]
>>> dataset2 = dataset.map(lambda x: {"tmp": np.array([0.5])}, batched=False)
100%|██████████████████████████████████████████| 408/408 [00:00<00:00, 10819.97ex/s]
>>> dataset2[0]["tmp"]
[0.5]
>>> type(dataset2[0]["tmp"])
<class 'list'>
```
## Expected results
`dataset2[0]["tmp"]` should be an `np.ndarray`.
## Actual results
It's a list.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: mac, though I'm pretty sure it happens on a linux machine too
- Python version: 3.9.7
- PyArrow version: 6.0.1
|
https://github.com/huggingface/datasets/issues/4619
|
open
|
[
"bug"
] | 2022-07-02T17:54:57Z
| 2022-07-03T20:27:07Z
| 3
|
ZhaofengWu
|
huggingface/datasets
| 4,603
|
CI fails recurrently and randomly on Windows
|
As reported by @lhoestq,
The windows CI is currently flaky: some dependencies like `aiobotocore`, `multiprocess` and `seqeval` sometimes fail to install.
In particular it seems that building the wheels fail. Here is an example of logs:
```
Building wheel for seqeval (setup.py): started
Running command 'C:\tools\miniconda3\envs\py37\python.exe' -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"'; __file__='"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6'
No parent package detected, impossible to derive `name`
running bdist_wheel
running build
running build_py
package init file 'seqeval\__init__.py' not found (or not a regular file)
package init file 'seqeval\metrics\__init__.py' not found (or not a regular file)
C:\tools\miniconda3\envs\py37\lib\site-packages\setuptools\command\install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
setuptools.SetuptoolsDeprecationWarning,
installing to build\bdist.win-amd64\wheel
running install
running install_lib
warning: install_lib: 'build\lib' does not exist -- no Python modules to install
running install_egg_info
running egg_info
creating UNKNOWN.egg-info
writing UNKNOWN.egg-info\PKG-INFO
writing dependency_links to UNKNOWN.egg-info\dependency_links.txt
writing top-level names to UNKNOWN.egg-info\top_level.txt
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
reading manifest file 'UNKNOWN.egg-info\SOURCES.txt'
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
Copying UNKNOWN.egg-info to build\bdist.win-amd64\wheel\.\UNKNOWN-0.0.0-py3.7.egg-info
running install_scripts
creating build\bdist.win-amd64\wheel\UNKNOWN-0.0.0.dist-info\WHEEL
creating 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6\UNKNOWN-0.0.0-py3-none-any.whl' and adding 'build\bdist.win-amd64\wheel' to it
adding 'UNKNOWN-0.0.0.dist-info/METADATA'
adding 'UNKNOWN-0.0.0.dist-info/WHEEL'
adding 'UNKNOWN-0.0.0.dist-info/top_level.txt'
adding 'UNKNOWN-0.0.0.dist-info/RECORD'
removing build\bdist.win-amd64\wheel
Building wheel for seqeval (setup.py): finished with status 'done'
Created wheel for seqeval: filename=UNKNOWN-0.0.0-py3-none-any.whl size=963 sha256=67eb93a6e1ff4796c5882a13f9fa25bb0d3d103796e2525f9cecf3b2ef26d4b1
Stored in directory: c:\users\circleci\appdata\local\pip\cache\wheels\05\96\ee\7cac4e74f3b19e3158dce26a20a1c86b3533c43ec72a549fd7
WARNING: Built wheel for seqeval is invalid: Wheel has unexpected file name: expected 'seqeval', got 'UNKNOWN'
```
|
https://github.com/huggingface/datasets/issues/4603
|
closed
|
[
"bug"
] | 2022-06-30T10:59:58Z
| 2022-06-30T13:22:25Z
| 0
|
albertvillanova
|
huggingface/dataset-viewer
| 430
|
Shuffle the rows?
|
see https://github.com/huggingface/moon-landing/issues/3375
|
https://github.com/huggingface/dataset-viewer/issues/430
|
closed
|
[
"question",
"feature request",
"P2"
] | 2022-06-30T08:31:20Z
| 2023-09-08T13:41:42Z
| null |
severo
|
huggingface/datasets
| 4,591
|
Can't push Images to hub with manual Dataset
|
## Describe the bug
If I create a dataset including an 'Image' feature manually, when pushing to hub decoded images are not pushed,
instead it looks for image where image local path is/used to be.
This doesn't (at least didn't used to) happen with imagefolder. I want to build dataset manually because it is complicated.
This happens even though the dataset is looking like decoded images:
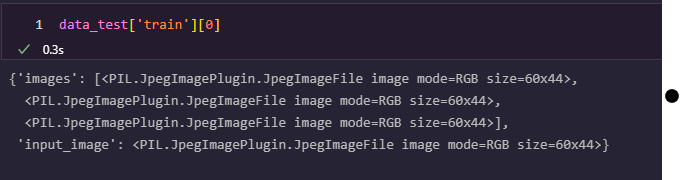
and I use `embed_external_files=True` while `push_to_hub` (same with false)
## Steps to reproduce the bug
```python
from PIL import Image
from datasets import Image as ImageFeature
from datasets import Features,Dataset
#manually create dataset
feats=Features(
{
"images": [ImageFeature()], #same even if explicitly ImageFeature(decode=True)
"input_image": ImageFeature(),
}
)
test_data={"images":[[Image.open("test.jpg"),Image.open("test.jpg"),Image.open("test.jpg")]], "input_image":[Image.open("test.jpg")]}
test_dataset=Dataset.from_dict(test_data,features=feats)
print(test_dataset)
test_dataset.push_to_hub("ceyda/image_test_public",private=False,token="",embed_external_files=True)
# clear cache rm -r ~/.cache/huggingface
# remove "test.jpg" # remove to see that it is looking for image on the local path
test_dataset=load_dataset("ceyda/image_test_public",use_auth_token="")
print(test_dataset)
print(test_dataset['train'][0])
```
## Expected results
should be able to push image bytes if dataset has `Image(decode=True)`
## Actual results
errors because it is trying to decode file from the non existing local path.
```
----> print(test_dataset['train'][0])
File ~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py:2154, in Dataset.__getitem__(self, key)
2152 def __getitem__(self, key): # noqa: F811
2153 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
-> 2154 return self._getitem(
2155 key,
2156 )
File ~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py:2139, in Dataset._getitem(self, key, decoded, **kwargs)
2137 formatter = get_formatter(format_type, features=self.features, decoded=decoded, **format_kwargs)
2138 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
-> 2139 formatted_output = format_table(
2140 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
2141 )
2142 return formatted_output
File ~/.local/lib/python3.8/site-packages/datasets/formatting/formatting.py:532, in format_table(table, key, formatter, format_columns, output_all_columns)
530 python_formatter = PythonFormatter(features=None)
531 if format_columns is None:
...
-> 3068 fp = builtins.open(filename, "rb")
3069 exclusive_fp = True
3071 try:
FileNotFoundError: [Errno 2] No such file or directory: 'test.jpg'
```
## Environment info
- `datasets` version: 2.3.2
- Platform: Linux-5.4.0-1074-azure-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/4591
|
closed
|
[
"bug"
] | 2022-06-29T00:01:23Z
| 2022-07-08T12:01:36Z
| 1
|
cceyda
|
huggingface/dataset-viewer
| 423
|
Add terms of service to the API?
|
See https://swagger.io/specification/#info-object
Maybe to mention a rate-limiter, if we implement one
|
https://github.com/huggingface/dataset-viewer/issues/423
|
closed
|
[
"question"
] | 2022-06-28T11:27:16Z
| 2022-09-16T17:30:38Z
| null |
severo
|
huggingface/datasets
| 4,571
|
move under the facebook org?
|
### Link
https://huggingface.co/datasets/gsarti/flores_101
### Description
It seems like streaming isn't supported for this dataset:
```
Server Error
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol for TAR archives like 'https://dl.fbaipublicfiles.com/flores101/dataset/flores101_dataset.tar.gz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.
```
### Owner
No
|
https://github.com/huggingface/datasets/issues/4571
|
open
|
[] | 2022-06-26T11:19:09Z
| 2023-09-25T12:05:18Z
| 3
|
lewtun
|
huggingface/datasets
| 4,570
|
Dataset sharding non-contiguous?
|
## Describe the bug
I'm not sure if this is a bug; more likely normal behavior but i wanted to double check.
Is it normal that `datasets.shard` does not produce chunks that, when concatenated produce the original ordering of the sharded dataset?
This might be related to this pull request (https://github.com/huggingface/datasets/pull/4466) but I have to admit I did not properly look into the changes made.
## Steps to reproduce the bug
```python
max_shard_size = convert_file_size_to_int('300MB')
dataset_nbytes = dataset.data.nbytes
num_shards = int(dataset_nbytes / max_shard_size) + 1
num_shards = max(num_shards, 1)
print(f"{num_shards=}")
for shard_index in range(num_shards):
shard = dataset.shard(num_shards=num_shards, index=shard_index)
shard.to_parquet(f"tokenized/tokenized-{shard_index:03d}.parquet")
os.listdir('tokenized/')
```
## Expected results
I expected the shards to match the order of the data of the original dataset; i.e. `dataset[10]` being the same as `shard_1[10]` for example
## Actual results
Only the first element is the same; i.e. `dataset[0]` is the same as `shard_1[0]`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-4.15.0-176-generic-x86_64-with-glibc2.31
- Python version: 3.10.4
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/4570
|
closed
|
[
"bug"
] | 2022-06-26T08:34:05Z
| 2022-06-30T11:00:47Z
| 5
|
cakiki
|
huggingface/datasets
| 4,569
|
Dataset Viewer issue for sst2
|
### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with ConnectionError
```
### Owner
No
|
https://github.com/huggingface/datasets/issues/4569
|
closed
|
[
"dataset-viewer"
] | 2022-06-26T07:32:54Z
| 2022-06-27T06:37:48Z
| 2
|
lewtun
|
huggingface/dataset-viewer
| 416
|
Remove the Kubernetes CPU "limits"?
|
https://github.com/robusta-dev/alert-explanations/wiki/CPUThrottlingHigh-%28Prometheus-Alert%29#why-you-dont-need-cpu-limits
> ## Why you don't need CPU limits
>
> As long as your pod has a CPU request, [Kubernetes maintainers like Tim Hockin recommend not using limits at all](https://twitter.com/thockin/status/1134193838841401345). This way pods are free to use spare CPU instead of letting the CPU stay idle.
>
> Contrary to common belief, [even if you remove this pod's CPU limit, other pods are still guaranteed the CPU they requested](https://github.com/kubernetes/design-proposals-archive/blob/8da1442ea29adccea40693357d04727127e045ed/node/resource-qos.md#compressible-resource-guaranteess). The CPU limit only effects how spare CPU is distributed.
|
https://github.com/huggingface/dataset-viewer/issues/416
|
closed
|
[
"question"
] | 2022-06-23T12:26:39Z
| 2022-07-22T13:15:41Z
| null |
severo
|
huggingface/dataset-viewer
| 415
|
Expose an endpoint with the column types/modalities of each dataset?
|
It could be used on the Hub to find all the "images" or "audio" datasets.
By the way, the info is normally already in the datasets-info.json (.features)
|
https://github.com/huggingface/dataset-viewer/issues/415
|
closed
|
[
"question"
] | 2022-06-23T10:36:01Z
| 2022-09-16T17:32:45Z
| null |
severo
|
huggingface/datasets
| 4,542
|
[to_tf_dataset] Use Feather for better compatibility with TensorFlow ?
|
To have better performance in TensorFlow, it is important to provide lists of data files in supported formats. For example sharded TFRecords datasets are extremely performant. This is because tf.data can better leverage parallelism in this case, and load one file at a time in memory.
It seems that using `tensorflow_io` we could have something similar for `to_tf_dataset` if we provide sharded Feather files: https://www.tensorflow.org/io/api_docs/python/tfio/arrow/ArrowFeatherDataset
Feather is a format almost equivalent to the Arrow IPC Stream format we're using in `datasets`: Feather V2 is equivalent to Arrow IPC File format, which is an extension of the stream format (it has an extra footer). Therefore we could store datasets as Feather instead of Arrow IPC Stream format without breaking the whole library.
Here are a few points to explore
- [ ] check the performance of ArrowFeatherDataset in tf.data
- [ ] check what would change if we were to switch to Feather if needed, in particular check that those are fine: memory mapping, typing, writing, reading to python objects, etc.
We would also need to implement sharding when loading a dataset (this will be done anyway for #546)
cc @Rocketknight1 @gante feel free to comment in case I missed anything !
I'll share some files and scripts, so that we can benchmark performance of Feather files with tf.data
|
https://github.com/huggingface/datasets/issues/4542
|
open
|
[
"generic discussion"
] | 2022-06-22T14:42:00Z
| 2022-10-11T08:45:45Z
| 48
|
lhoestq
|
huggingface/dataset-viewer
| 413
|
URL design
|
Currently, the API is available at the root, ie: https://datasets-server.huggingface.co/rows?...
This can lead to some issues:
- if we add other services, such as /doc or /search, the API will share the namespace with these other services. This means that we must take care of avoiding collisions between services and endpoints (I think it's OK), and that we cannot simply delegate a subroute to the `api` service (not really an issue either because we "just" have to treat all the other services first in the nginx config, then send the rest to the `api` service)
- version: if we break the API one day, we might want to serve two versions of the API, namely v1 and v2. Notes: 1. it's better not to break the API, 2. if we create a v2 API, we can still namespace it under /v2/, so: not really an issue
Which one do you prefer?
1. https://datasets-server.huggingface.co/ (current)
2. https://datasets-server.huggingface.co/api/
3. https://datasets-server.huggingface.co/api/v1/
|
https://github.com/huggingface/dataset-viewer/issues/413
|
closed
|
[
"question"
] | 2022-06-22T07:13:24Z
| 2022-06-28T08:48:02Z
| null |
severo
|
huggingface/datasets
| 4,538
|
Dataset Viewer issue for Pile of Law
|
### Link
https://huggingface.co/datasets/pile-of-law/pile-of-law
### Description
Hi, I would like to turn off the dataset viewer for our dataset without enabling access requests. To comply with upstream dataset creator requests/licenses, we would like to make sure that the data is not indexed by search engines and so would like to turn off dataset previews. But we do not want to collect user emails because it would violate single blind review, allowing us to deduce potential reviewers' identities. Is there a way that we can turn off the dataset viewer without collecting identity information?
Thanks so much!
### Owner
Yes
|
https://github.com/huggingface/datasets/issues/4538
|
closed
|
[
"dataset-viewer"
] | 2022-06-22T02:48:40Z
| 2022-06-27T07:30:23Z
| 5
|
Breakend
|
huggingface/datasets
| 4,522
|
Try to reduce the number of datasets that require manual download
|
> Currently, 41 canonical datasets require manual download. I checked their scripts and I'm pretty sure this number can be reduced to ≈ 30 by not relying on bash scripts to download data, hosting data directly on the Hub when the license permits, etc. Then, we will mostly be left with datasets with restricted access, which we can ignore
from https://github.com/huggingface/datasets-server/issues/12#issuecomment-1026920432
|
https://github.com/huggingface/datasets/issues/4522
|
open
|
[] | 2022-06-17T11:42:03Z
| 2022-06-17T11:52:48Z
| 0
|
severo
|
huggingface/dataset-viewer
| 394
|
Implement API pagination?
|
Should we add API pagination right now? Maybe useful for the "technical" endpoints like https://datasets-server.huggingface.co/queue-dump-waiting-started or https://datasets-server.huggingface.co/cache-reports
https://simonwillison.net/2021/Jul/1/pagnis/
|
https://github.com/huggingface/dataset-viewer/issues/394
|
closed
|
[
"question"
] | 2022-06-17T08:54:41Z
| 2022-08-01T19:02:00Z
| null |
severo
|
huggingface/dataset-viewer
| 390
|
How to best manage the datasets that we cannot process due to RAM?
|
The dataset worker pod is killed (OOMKilled) for:
```
bigscience/P3
Graphcore/gqa-lxmert
echarlaix/gqa-lxmert
```
and the split worker pod is killed (OOMKilled) for:
```
imthanhlv/binhvq_news21_raw / started / train
openclimatefix/nimrod-uk-1km / sample / train/test/validation
PolyAI/minds14 / zh-CN / train
```
With the current jobs management (https://github.com/huggingface/datasets-server/issues/264) the killed jobs remain marked as "STARTED" in the mongo db. If we "cancel" them with
```
kubectl exec datasets-server-prod-admin-79798989fb-scmjw -- make cancel-started-dataset-jobs
kubectl exec datasets-server-prod-admin-79798989fb-scmjw -- make cancel-started-split-jobs
```
they are re-enqueue with the status "WAITING" until they are processed and killed again.
Possibly we should allow up to 3 attempts, for example, maybe increasing the dedicated RAM (see https://github.com/huggingface/datasets-server/issues/264#issuecomment-1158596143). Even so, we cannot have more RAM than the underlying node (eg: 32 GiB on the current nodes) and some datasets will still fail.
In that case, we should mark them as ERROR with a proper error message.
|
https://github.com/huggingface/dataset-viewer/issues/390
|
closed
|
[
"bug",
"question"
] | 2022-06-17T08:04:45Z
| 2022-09-19T09:42:36Z
| null |
severo
|
huggingface/dataset-viewer
| 388
|
what happened to the pods?
|
```
$ k get pods -w
...
datasets-server-prod-datasets-worker-776b774978-g7mpk 1/1 Evicted 0 73m │DEBUG: 2022-06-16 18:42:46,966 - datasets_server.worker - try to process a split job
datasets-server-prod-datasets-worker-776b774978-cdb4b 0/1 Pending 0 1s │DEBUG: 2022-06-16 18:42:47,011 - datasets_server.worker - job assigned: 62ab6804a502851c834d7e43 for split 'test' from dataset 'luozhou
datasets-server-prod-datasets-worker-776b774978-cdb4b 0/1 Pending 0 1s │yang/dureader' with config 'robust'
datasets-server-prod-datasets-worker-776b774978-cdb4b 0/1 OutOfmemory 0 1s │INFO: 2022-06-16 18:42:47,012 - datasets_server.worker - compute split 'test' from dataset 'luozhouyang/dureader' with config 'robust'
datasets-server-prod-datasets-worker-776b774978-7hw4j 0/1 Pending 0 0s │Downloading builder script: 100%|██████████| 8.67k/8.67k [00:00<00:00, 4.85MB/s]
datasets-server-prod-datasets-worker-776b774978-7hw4j 0/1 Pending 0 0s │Downloading metadata: 100%|██████████| 2.85k/2.85k [00:00<00:00, 1.43MB/s]
datasets-server-prod-datasets-worker-776b774978-7hw4j 0/1 OutOfmemory 0 0s │Downloading builder script: 100%|██████████| 8.67k/8.67k [00:00<00:00, 5.07MB/s]
datasets-server-prod-datasets-worker-776b774978-qtmtd 0/1 Pending 0 0s │Downloading metadata: 100%|██████████| 2.85k/2.85k [00:00<00:00, 1.18MB/s]
datasets-server-prod-datasets-worker-776b774978-qtmtd 0/1 Pending 0 0s │Downloading builder script: 100%|██████████| 8.67k/8.67k [00:00<00:00, 4.52MB/s]
datasets-server-prod-datasets-worker-776b774978-qtmtd 0/1 OutOfmemory 0 0s │Downloading metadata: 100%|██████████| 2.85k/2.85k [00:00<00:00, 1.76MB/s]
datasets-server-prod-datasets-worker-776b774978-54zr6 0/1 Pending 0 0s │Downloading and preparing dataset dureader/robust (download: 19.57 MiB, generated: 57.84 MiB, post-processed: Unknown size, total: 77.4
datasets-server-prod-datasets-worker-776b774978-54zr6 0/1 Pending 0 0s │1 MiB) to /cache/datasets/luozhouyang___dureader/robust/1.0.0/bdab4855e88c197f2297db78cfc86259fb874c2b977134bbe80d3af8616f33b1...
datasets-server-prod-datasets-worker-776b774978-54zr6 0/1 OutOfmemory 0 0s │Downloading data: 1%| | 163k/20.5M [01:45<3:40:25, 1.54kB/s]
datasets-server-prod-datasets-worker-776b774978-rxcb2 0/1 Pending 0 0s │DEBUG: 2022-06-16 18:44:44,235 - datasets_server.worker - job finished with error: 62ab6804a502851c834d7e43 for split 'test' from datas
datasets-server-prod-datasets-worker-776b774978-rxcb2 0/1 Pending 0 0s │et 'luozhouyang/dureader' with config 'robust'
datasets-server-prod-datasets-worker-776b774978-rxcb2 0/1 OutOfmemory 0 0s │DEBUG: 2022-06-16 18:44:44,236 - datasets_server.worker - try to process a split job
datasets-server-prod-datasets-worker-776b774978-d8m42 0/1 Pending 0 0s │DEBUG: 2022-06-16 18:44:44,281 - datasets_server.worker - job assigned: 62ab6804a502851c834d7e45 for split 'test' from dataset 'opencli
datasets-server-prod-datasets-worker-776b774978-d8m42 0/1 Pending 0 0s │matefix/nimrod-uk-1km' with config 'sample'
datasets-server-prod-datasets-worker-776b774978-d8m42 0/1 OutOfmemory 0 0s │INFO: 2022-06-16 18:44:44,281 - datasets_server.worker - compute split 'test' from dataset 'openclimatefix/nimrod-uk-1km' with config '
datasets-server-prod-datasets-worker-776b774978-xx7hv 0/1 Pending 0 0s │sample'
datasets-server-prod-datasets-worker-776b774978-xx7hv 0/1 Pending 0 0s │Downloading builder script: 100%|██████████| 15.2k/15.2k [00:00<00:00, 6.04MB/s]
datasets-server-prod-datasets-worker-776b774978-xx7hv 0/1 OutOfmemory 0 1s │Downloading builder script: 100%|██████████| 15.2k/15.2k [00:00<00:
|
https://github.com/huggingface/dataset-viewer/issues/388
|
closed
|
[
"question"
] | 2022-06-16T19:46:00Z
| 2022-06-17T07:48:20Z
| null |
severo
|
huggingface/pytorch_block_sparse
| 17
|
What is "custom" "custom-back" in dispatch_policies.h?
|
Hi! I am learning SGEMM and find in dispatch_policies.h has a "Custom", "CustomBack". Not sure what does this mean? Thank you!!!
|
https://github.com/huggingface/pytorch_block_sparse/issues/17
|
open
|
[] | 2022-06-16T05:46:42Z
| 2022-06-16T05:46:42Z
| null |
ziyuhuang123
|
huggingface/datasets
| 4,507
|
How to let `load_dataset` return a `Dataset` instead of `DatasetDict` in customized loading script
|
If the dataset does not need splits, i.e., no training and validation split, more like a table. How can I let the `load_dataset` function return a `Dataset` object directly rather than return a `DatasetDict` object with only one key-value pair.
Or I can paraphrase the question in the following way: how to skip `_split_generators` step in `DatasetBuilder` to let `as_dataset` gives a single `Dataset` rather than a list`[Dataset]`?
Many thanks for any help.
|
https://github.com/huggingface/datasets/issues/4507
|
closed
|
[
"enhancement"
] | 2022-06-15T18:56:34Z
| 2022-06-16T10:40:08Z
| 2
|
liyucheng09
|
huggingface/datasets
| 4,504
|
Can you please add the Stanford dog dataset?
|
## Adding a Dataset
- **Name:** *Stanford dog dataset*
- **Description:** *The dataset is about 120 classes for a total of 20.580 images. You can find the dataset here http://vision.stanford.edu/aditya86/ImageNetDogs/*
- **Paper:** *http://vision.stanford.edu/aditya86/ImageNetDogs/*
- **Data:** *[link to the Github repository or current dataset location](http://vision.stanford.edu/aditya86/ImageNetDogs/)*
- **Motivation:** *The dataset has been built using images and annotation from ImageNet for the task of fine-grained image categorization. It is useful for fine-grain purpose *
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
https://github.com/huggingface/datasets/issues/4504
|
closed
|
[
"good first issue",
"dataset request"
] | 2022-06-15T15:39:35Z
| 2024-12-09T15:44:11Z
| 16
|
dgrnd4
|
huggingface/datasets
| 4,502
|
Logic bug in arrow_writer?
|
https://github.com/huggingface/datasets/blob/88a902d6474fae8d793542d57a4f3b0d187f3c5b/src/datasets/arrow_writer.py#L475-L488
I got some error, and I found it's caused by `batch_examples` being `{}`. I wonder if the code should be as follows:
```
- if batch_examples and len(next(iter(batch_examples.values()))) == 0:
+ if not batch_examples or len(next(iter(batch_examples.values()))) == 0:
return
```
@lhoestq
|
https://github.com/huggingface/datasets/issues/4502
|
closed
|
[] | 2022-06-15T14:50:00Z
| 2022-06-18T15:15:51Z
| 10
|
changjonathanc
|
huggingface/optimum
| 219
|
Support to wav2vec2
|
### Feature request
Is there any plan to include wav2vec2 class to optimum?
```python
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from optimum.onnxruntime import ORTQuantizer
# The model we wish to quantize
model_checkpoint = "facebook/wav2vec2-base-960h"
# The type of quantization to apply
qconfig = AutoQuantizationConfig.arm64(is_static=False, per_channel=False)
quantizer = ORTQuantizer.from_pretrained(model_checkpoint, feature="sequence-classification")
# Quantize the model!
quantizer.export(
onnx_model_path="model.onnx",
onnx_quantized_model_output_path="model-quantized.onnx",
quantization_config=qconfig,
)
```
Output:
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-27-b874ded560cc>](https://localhost:8080/#) in <module>()
6 # The type of quantization to apply
7 qconfig = AutoQuantizationConfig.arm64(is_static=False, per_channel=False)
----> 8 quantizer = ORTQuantizer.from_pretrained(model_checkpoint, feature="sequence-classification")
9
10 # Quantize the model!
1 frames
[/usr/local/lib/python3.7/dist-packages/transformers/models/auto/auto_factory.py](https://localhost:8080/#) in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
446 return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)
447 raise ValueError(
--> 448 f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
449 f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
450 )
ValueError: Unrecognized configuration class <class 'transformers.models.wav2vec2.configuration_wav2vec2.Wav2Vec2Config'> for this kind of AutoModel: AutoModelForSequenceClassification.
Model type should be one of BartConfig, YosoConfig, NystromformerConfig, QDQBertConfig, FNetConfig, PerceiverConfig, GPTJConfig, LayoutLMv2Config, PLBartConfig, RemBertConfig, CanineConfig, RoFormerConfig, BigBirdPegasusConfig, GPTNeoConfig, BigBirdConfig, ConvBertConfig, LEDConfig, IBertConfig, MobileBertConfig, DistilBertConfig, AlbertConfig, CamembertConfig, XLMRobertaXLConfig, XLMRobertaConfig, MBartConfig, MegatronBertConfig, MPNetConfig, BartConfig, ReformerConfig, LongformerConfig, RobertaConfig, DebertaV2Config, DebertaConfig, FlaubertConfig, SqueezeBertConfig, BertConfig, OpenAIGPTConfig, GPT2Config, TransfoXLConfig, XLNetConfig, XLMConfig, CTRLConfig, ElectraConfig, FunnelConfig, LayoutLMConfig, TapasConfig, Data2VecTextConfig.
```
### Motivation
To get some speed up on wav2vec2 models.
### Your contribution
No at the moment, but I could help.
|
https://github.com/huggingface/optimum/issues/219
|
closed
|
[] | 2022-06-15T12:47:42Z
| 2022-07-08T10:34:33Z
| 4
|
asr-lord
|
huggingface/dataset-viewer
| 373
|
Add support for building GitHub Codespace dev environment
|
Add support for building a GitHub Codespace dev environment (as it was done for the [moon landing](https://github.com/huggingface/moon-landing/pull/3188) project) to make it easier to contribute to the project.
|
https://github.com/huggingface/dataset-viewer/issues/373
|
closed
|
[
"question"
] | 2022-06-14T14:37:58Z
| 2022-09-19T09:05:26Z
| null |
mariosasko
|
huggingface/datasets
| 4,491
|
Dataset Viewer issue for Pavithree/test
|
### Link
https://huggingface.co/datasets/Pavithree/test
### Description
I have extracted the subset of original eli5 dataset found at hugging face. However, while loading the dataset It throws ArrowNotImplementedError: Unsupported cast from string to null using function cast_null error. Is there anything missing from my end? Kindly help.
### Owner
_No response_
|
https://github.com/huggingface/datasets/issues/4491
|
closed
|
[
"dataset-viewer"
] | 2022-06-14T13:23:10Z
| 2022-06-14T14:37:21Z
| 1
|
Pavithree
|
huggingface/datasets
| 4,478
|
Dataset slow during model training
|
## Describe the bug
While migrating towards 🤗 Datasets, I encountered an odd performance degradation: training suddenly slows down dramatically. I train with an image dataset using Keras and execute a `to_tf_dataset` just before training.
First, I have optimized my dataset following https://discuss.huggingface.co/t/solved-image-dataset-seems-slow-for-larger-image-size/10960/6, which actually improved the situation from what I had before but did not completely solve it.
Second, I saved and loaded my dataset using `tf.data.experimental.save` and `tf.data.experimental.load` before training (for which I would have expected no performance change). However, I ended up with the performance I had before tinkering with 🤗 Datasets.
Any idea what's the reason for this and how to speed-up training with 🤗 Datasets?
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets import load_dataset
import os
dataset_dir = "./dataset"
prep_dataset_dir = "./prepdataset"
model_dir = "./model"
# Load Data
dataset = load_dataset("Lehrig/Monkey-Species-Collection", "downsized")
def read_image_file(example):
with open(example["image"].filename, "rb") as f:
example["image"] = {"bytes": f.read()}
return example
dataset = dataset.map(read_image_file)
dataset.save_to_disk(dataset_dir)
# Preprocess
from datasets import (
Array3D,
DatasetDict,
Features,
load_from_disk,
Sequence,
Value
)
import numpy as np
from transformers import ImageFeatureExtractionMixin
dataset = load_from_disk(dataset_dir)
num_classes = dataset["train"].features["label"].num_classes
one_hot_matrix = np.eye(num_classes)
feature_extractor = ImageFeatureExtractionMixin()
def to_pixels(image):
image = feature_extractor.resize(image, size=size)
image = feature_extractor.to_numpy_array(image, channel_first=False)
image = image / 255.0
return image
def process(examples):
examples["pixel_values"] = [
to_pixels(image) for image in examples["image"]
]
examples["label"] = [
one_hot_matrix[label] for label in examples["label"]
]
return examples
features = Features({
"pixel_values": Array3D(dtype="float32", shape=(size, size, 3)),
"label": Sequence(feature=Value(dtype="int32"), length=num_classes)
})
prep_dataset = dataset.map(
process,
remove_columns=["image"],
batched=True,
batch_size=batch_size,
num_proc=2,
features=features,
)
prep_dataset = prep_dataset.with_format("numpy")
# Split
train_dev_dataset = prep_dataset['test'].train_test_split(
test_size=test_size,
shuffle=True,
seed=seed
)
train_dev_test_dataset = DatasetDict({
'train': train_dev_dataset['train'],
'dev': train_dev_dataset['test'],
'test': prep_dataset['test'],
})
train_dev_test_dataset.save_to_disk(prep_dataset_dir)
# Train Model
import datetime
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.applications import InceptionV3
from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D, BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
from transformers import DefaultDataCollator
dataset = load_from_disk(prep_data_dir)
data_collator = DefaultDataCollator(return_tensors="tf")
train_dataset = dataset["train"].to_tf_dataset(
columns=['pixel_values'],
label_cols=['label'],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator
)
validation_dataset = dataset["dev"].to_tf_dataset(
columns=['pixel_values'],
label_cols=['label'],
shuffle=False,
batch_size=batch_size,
collate_fn=data_collator
)
print(f'{datetime.datetime.now()} - Saving Data')
tf.data.experimental.save(train_dataset, model_dir+"/train")
tf.data.experimental.save(validation_dataset, model_dir+"/val")
print(f'{datetime.datetime.now()} - Loading Data')
train_dataset = tf.data.experimental.load(model_dir+"/train")
validation_dataset = tf.data.experimental.load(model_dir+"/val")
shape = np.shape(dataset["train"][0]["pixel_values"])
backbone = InceptionV3(
include_top=False,
weights='imagenet',
input_shape=shape
)
for layer in backbone.layers:
layer.trainable = False
model = Sequential()
model.add(backbone)
model.add(GlobalAveragePooling2D())
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax'))
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
print(model.summary())
earlyStopping = EarlyStopping(
monitor='val_loss',
patience=10,
verbose=0,
mode='min'
)
mcp_save = ModelCheckp
|
https://github.com/huggingface/datasets/issues/4478
|
open
|
[
"bug"
] | 2022-06-11T19:40:19Z
| 2022-06-14T12:04:31Z
| 5
|
lehrig
|
huggingface/datasets
| 4,439
|
TIMIT won't load after manual download: Errors about files that don't exist
|
## Describe the bug
I get the message from HuggingFace that it must be downloaded manually. From the URL provided in the message, I got to UPenn page for manual download. (UPenn apparently want $250? for the dataset??) ...So, ok, I obtained a copy from a friend and also a smaller version from Kaggle. But in both cases the HF dataloader fails; it is looking for files that don't exist anywhere in the dataset: it is looking for files with lower-case letters like "**test*" (all the filenames in both my copies are uppercase) and certain file extensions that exclude the .DOC which is provided in TIMIT:
## Steps to reproduce the bug
```python
data = load_dataset('timit_asr', 'clean')['train']
```
## Expected results
The dataset should load with no errors.
## Actual results
This error message:
```
File "/home/ubuntu/envs/data2vec/lib/python3.9/site-packages/datasets/data_files.py", line 201, in resolve_patterns_locally_or_by_urls
raise FileNotFoundError(error_msg)
FileNotFoundError: Unable to resolve any data file that matches '['**test*', '**eval*']' at /home/ubuntu/datasets/timit with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'zip']
```
But this is a strange sort of error: why is it looking for lower-case file names when all the TIMIT dataset filenames are uppercase? Why does it exclude .DOC files when the only parts of the TIMIT data set with "TEST" in them have ".DOC" extensions? ...I wonder, how was anyone able to get this to work in the first place?
The files in the dataset look like the following:
```
³ PHONCODE.DOC
³ PROMPTS.TXT
³ SPKRINFO.TXT
³ SPKRSENT.TXT
³ TESTSET.DOC
```
...so why are these being excluded by the dataset loader?
## Environment info
- `datasets` version: 2.2.2
- Platform: Linux-5.4.0-1060-aws-x86_64-with-glibc2.27
- Python version: 3.9.9
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/4439
|
closed
|
[
"bug"
] | 2022-06-02T16:35:56Z
| 2022-06-03T08:44:17Z
| 3
|
drscotthawley
|
huggingface/dataset-viewer
| 332
|
Change moonlanding app token?
|
Should we replace `dataset-preview-backend`with `datasets-server`:
- here: https://github.com/huggingface/moon-landing/blob/f2ee3896cff3aa97aafb3476e190ef6641576b6f/server/models/App.ts#L16
- and here: https://github.com/huggingface/moon-landing/blob/82e71c10ed0b385e55a29f43622874acfc35a9e3/server/test/end_to_end_apps.ts#L243-L271
What are the consequences then? How to do it without too much downtime?
|
https://github.com/huggingface/dataset-viewer/issues/332
|
closed
|
[
"question"
] | 2022-06-01T09:29:12Z
| 2022-09-19T09:33:33Z
| null |
severo
|
huggingface/dataset-viewer
| 325
|
Test if /valid is a blocking request
|
https://github.com/huggingface/datasets-server/issues/250#issuecomment-1142013300
> > the requests to /valid are very long: do they block the incoming requests?)
> Depends on if your long running query is blocking the GIL or not. If you have async calls, it should be able to switch and take care of other requests, if it's computing something then yeah, probably blocking everything else.
- [ ] find if the long requests like /valid are blocking the concurrent requests
- [ ] if so: fix it
|
https://github.com/huggingface/dataset-viewer/issues/325
|
closed
|
[
"bug",
"question"
] | 2022-05-31T13:43:20Z
| 2022-09-16T17:39:20Z
| null |
severo
|
huggingface/datasets
| 4,419
|
Update `unittest` assertions over tuples from `assertEqual` to `assertTupleEqual`
|
**Is your feature request related to a problem? Please describe.**
So this is more a readability improvement rather than a proposal, wouldn't it be better to use `assertTupleEqual` over the tuples rather than `assertEqual`? As `unittest` added that function in `v3.1`, as detailed at https://docs.python.org/3/library/unittest.html#unittest.TestCase.assertTupleEqual, so maybe it's worth updating.
Find an example of an `assertEqual` over a tuple in 🤗 `datasets` unit tests over an `ArrowDataset` at https://github.com/huggingface/datasets/blob/0bb47271910c8a0b628dba157988372307fca1d2/tests/test_arrow_dataset.py#L570
**Describe the solution you'd like**
Start slowly replacing all the `assertEqual` statements with `assertTupleEqual` if the assertion is done over a Python tuple, as we're doing with the Python lists using `assertListEqual` rather than `assertEqual`.
**Additional context**
If so, please let me know and I'll try to go over the tests and create a PR if applicable, otherwise, if you consider this should stay as `assertEqual` rather than `assertSequenceEqual` feel free to close this issue! Thanks 🤗
|
https://github.com/huggingface/datasets/issues/4419
|
closed
|
[
"enhancement"
] | 2022-05-30T12:13:18Z
| 2022-09-30T16:01:37Z
| 3
|
alvarobartt
|
huggingface/datasets
| 4,417
|
how to convert a dict generator into a huggingface dataset.
|
### Link
_No response_
### Description
Hey there, I have used seqio to get a well distributed mixture of samples from multiple dataset. However the resultant output from seqio is a python generator dict, which I cannot produce back into huggingface dataset.
The generator contains all the samples needed for training the model but I cannot convert it into a huggingface dataset.
The code looks like this:
```
for ex in seqio_data:
print(ex[“text”])
```
I need to convert the seqio_data (generator) into huggingface dataset.
the complete seqio code goes here:
```
import functools
import seqio
import tensorflow as tf
import t5.data
from datasets import load_dataset
from t5.data import postprocessors
from t5.data import preprocessors
from t5.evaluation import metrics
from seqio import FunctionDataSource, utils
TaskRegistry = seqio.TaskRegistry
def gen_dataset(split, shuffle=False, seed=None, column="text", dataset_params=None):
dataset = load_dataset(**dataset_params)
if shuffle:
if seed:
dataset = dataset.shuffle(seed=seed)
else:
dataset = dataset.shuffle()
while True:
for item in dataset[str(split)]:
yield item[column]
def dataset_fn(split, shuffle_files, seed=None, dataset_params=None):
return tf.data.Dataset.from_generator(
functools.partial(gen_dataset, split, shuffle_files, seed, dataset_params=dataset_params),
output_signature=tf.TensorSpec(shape=(), dtype=tf.string, name=dataset_name)
)
@utils.map_over_dataset
def target_to_key(x, key_map, target_key):
"""Assign the value from the dataset to target_key in key_map"""
return {**key_map, target_key: x}
dataset_name = 'oscar-corpus/OSCAR-2109'
subset= 'mr'
dataset_params = {"path": dataset_name, "language":subset, "use_auth_token":True}
dataset_shapes = None
TaskRegistry.add(
"oscar_marathi_corpus",
source=seqio.FunctionDataSource(
dataset_fn=functools.partial(dataset_fn, dataset_params=dataset_params),
splits=("train", "validation"),
caching_permitted=False,
num_input_examples=dataset_shapes,
),
preprocessors=[
functools.partial(
target_to_key, key_map={
"targets": None,
}, target_key="targets")],
output_features={"targets": seqio.Feature(vocabulary=seqio.PassThroughVocabulary, add_eos=False, dtype=tf.string, rank=0)},
metric_fns=[]
)
dataset = seqio.get_mixture_or_task("oscar_marathi_corpus").get_dataset(
sequence_length=None,
split="train",
shuffle=True,
num_epochs=1,
shard_info=seqio.ShardInfo(index=0, num_shards=10),
use_cached=False,
seed=42
)
for _, ex in zip(range(5), dataset):
print(ex['targets'].numpy().decode())
```
### Owner
_No response_
|
https://github.com/huggingface/datasets/issues/4417
|
closed
|
[
"question"
] | 2022-05-29T16:28:27Z
| 2022-09-16T14:44:19Z
| null |
StephennFernandes
|
huggingface/dataset-viewer
| 309
|
Scale the worker pods depending on prometheus metrics?
|
We could scale the number of worker pods depending on:
- the size of the job queue
- the available resources
These data are available in prometheus, and we could use them to autoscale the pods.
|
https://github.com/huggingface/dataset-viewer/issues/309
|
closed
|
[
"question"
] | 2022-05-25T09:56:05Z
| 2022-09-19T09:30:49Z
| null |
severo
|
huggingface/dataset-viewer
| 307
|
Add a /metrics endpoint on every worker?
|
https://github.com/huggingface/dataset-viewer/issues/307
|
closed
|
[
"question"
] | 2022-05-25T09:52:28Z
| 2022-09-16T17:40:55Z
| null |
severo
|
|
huggingface/sentence-transformers
| 1,562
|
Why is "max_position_embeddings" 514 in sbert where as 512 in bert
|
Why is "max_position_embeddings" different in sbert then in Bert?
|
https://github.com/huggingface/sentence-transformers/issues/1562
|
open
|
[] | 2022-05-22T17:27:01Z
| 2022-05-22T20:52:40Z
| null |
omerarshad
|
huggingface/datasets
| 4,374
|
extremely slow processing when using a custom dataset
|
## processing a custom dataset loaded as .txt file is extremely slow, compared to a dataset of similar volume from the hub
I have a large .txt file of 22 GB which i load into HF dataset
`lang_dataset = datasets.load_dataset("text", data_files="hi.txt")`
further i use a pre-processing function to clean the dataset
`lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)`
the following processing takes astronomical time to process, while hoging all the ram.
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)`
the hours predicted to preprocess are as follows:
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
note: both the datasets are almost actually same, just provided by different sources with has +/- some samples, only one is hosted on the HF hub and the other is downloaded in a text format.
## Steps to reproduce the bug
```
import datasets
import psutil
import sys
import glob
from fastcore.utils import listify
import re
import gc
def remove_non_indic_sentences(example):
tmp_ls = []
eng_regex = r'[. a-zA-Z0-9ÖÄÅöäå _.,!"\'\/$]*'
for e in listify(example['text']):
matches = re.findall(eng_regex, e)
for match in (str(match).strip() for match in matches if match not in [""," ", " ", ",", " ,", ", ", " , "]):
if len(list(match.split(" "))) > 2:
e = re.sub(match," ",e,count=1)
tmp_ls.append(e)
gc.collect()
example['clean_text'] = tmp_ls
return example
lang_dataset = datasets.load_dataset("text", data_files="hi.txt")
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
## same thing work much faster when loading similar dataset from hub
lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", split="train", use_auth_token=True)
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
```
## Actual results
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)
**the hours predicted to preprocess are as follows:**
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
**i even tried the following:**
- sharding the large 22gb text files into smaller files and loading
- saving the file to disk and then loading
- using lesser num_proc
- using smaller batch size
- processing without batches ie : without `batched=True`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2.dev0
- Platform: Ubuntu 20.04 LTS
- Python version: 3.9.7
- PyArrow version:8.0.0
|
https://github.com/huggingface/datasets/issues/4374
|
closed
|
[
"bug",
"question"
] | 2022-05-19T14:18:05Z
| 2023-07-25T15:07:17Z
| null |
StephennFernandes
|
huggingface/optimum
| 198
|
Posibility to load an ORTQuantizer or ORTOptimizer from Onnx
|
FIrst, thanks a lot for this library, it make work so much easier.
I was wondering if it's possible to quantize and then optimize a model (or the reverse) but looking at the doc, it seems possible to do so only by passing a huggingface vanilla model.
Is it possible to do so with already compiled models?
Like : MyFineTunedModel ---optimize----> MyFineTunedOnnxOptimizedModel -----quantize-----> MyFinalReallyLightModel
```python
# Note that self.model_dir is my local folder with my custom fine-tuned hugginface model
onnx_path = self.model_dir.joinpath("model.onnx")
onnx_quantized_path = self.model_dir.joinpath("quantized_model.onnx")
onnx_chad_path = self.model_dir.joinpath("chad_model.onnx")
onnx_path.unlink(missing_ok=True)
onnx_quantized_path.unlink(missing_ok=True)
onnx_chad_path.unlink(missing_ok=True)
quantizer = ORTQuantizer.from_pretrained(self.model_dir, feature="token-classification")
quantized_path = quantizer.export(
onnx_model_path=onnx_path, onnx_quantized_model_output_path=onnx_quantized_path,
quantization_config=AutoQuantizationConfig.arm64(is_static=False, per_channel=False),
)
quantizer.model.save_pretrained(optimized_path.parent) # To have the model config.json
quantized_path.parent.joinpath("pytorch_model.bin").unlink() # To ensure that we're not loading the vanilla pytorch model
# Load an Optimizer from an onnx path...
# optimizer = ORTOptimizer.from_pretrained(quantized_path.parent, feature="token-classification") <-- this fails
# optimizer.export(
# onnx_model_path=onnx_path,
# onnx_optimized_model_output_path=onnx_chad_path,
# optimization_config=OptimizationConfig(optimization_level=99),
# )
model = ORTModelForTokenClassification.from_pretrained(quantized_path.parent, file_name="quantized_model.onnx")
# Ideally would load onnx_chad_path (with chad_model.onnx) if the commented section works.
tokenizer: PreTrainedTokenizer = AutoTokenizer.from_pretrained(self.model_dir)
self.pipeline = cast(TokenClassificationPipeline, pipeline(
model=model, tokenizer=tokenizer,
task="token-classification", accelerator="ort",
aggregation_strategy=AggregationStrategy.SIMPLE,
device=device_number(self.device),
))
```
Note that optimization alone works perfectly fine, quantization too, but I was hopping that both would be feasible.. unless optimization also does some kind of quantization or lighter model ?
Thanks in advance.
Have a great day
|
https://github.com/huggingface/optimum/issues/198
|
closed
|
[] | 2022-05-18T20:19:23Z
| 2022-06-30T08:33:58Z
| 1
|
ierezell
|
huggingface/datasets
| 4,352
|
When using `dataset.map()` if passed `Features` types do not match what is returned from the mapped function, execution does not except in an obvious way
|
## Describe the bug
Recently I was trying to using `.map()` to preprocess a dataset. I defined the expected Features and passed them into `.map()` like `dataset.map(preprocess_data, features=features)`. My expected `Features` keys matched what came out of `preprocess_data`, but the types i had defined for them did not match the types that came back. Because of this, i ended up in tracebacks deep inside arrow_dataset.py and arrow_writer.py with exceptions that [did not make clear what the problem was](https://github.com/huggingface/datasets/issues/4349). In short i ended up with overflows and the OS killing processes when Arrow was attempting to write. It wasn't until I dug into `def write_batch` and the loop that loops over cols that I figured out what was going on.
It seems like `.map()` could set a boolean that it's checked that for at least 1 instance from the dataset, the returned data's types match the types provided by the `features` param and error out with a clear exception if they don't. This would make the cause of the issue much more understandable and save people time. This could be construed as a feature but it feels more like a bug to me.
## Steps to reproduce the bug
I don't have explicit code to repro the bug, but ill show an example
Code prior to the fix:
```python
def preprocess(examples):
# returns an encoded data dict with keys that match the features, but the types do not match
...
def get_encoded_data(data):
dataset = Dataset.from_pandas(data)
unique_labels = data['audit_type'].unique().tolist()
features = Features({
'image': Array3D(dtype="uint8", shape=(3, 224, 224))),
'input_ids': Sequence(feature=Value(dtype='int64'))),
'attention_mask': Sequence(Value(dtype='int64'))),
'token_type_ids': Sequence(Value(dtype='int64'))),
'bbox': Array2D(dtype="int64", shape=(512, 4))),
'label': ClassLabel(num_classes=len(unique_labels), names=unique_labels),
})
encoded_dataset = dataset.map(preprocess_data, features=features, remove_columns=dataset.column_names)
```
The Features set that fixed it:
```python
features = Features({
'image': Sequence(Array3D(dtype="uint8", shape=(3, 224, 224))),
'input_ids': Sequence(Sequence(feature=Value(dtype='int64'))),
'attention_mask': Sequence(Sequence(Value(dtype='int64'))),
'token_type_ids': Sequence(Sequence(Value(dtype='int64'))),
'bbox': Sequence(Array2D(dtype="int64", shape=(512, 4))),
'label': ClassLabel(num_classes=len(unique_labels), names=unique_labels),
})
```
The difference between my original code (which was based on documentation) and the working code is the addition of the `Sequence(...)` to 4/5 features as I am working with paginated data and the doc examples are not.
## Expected results
Dataset.map() attempts to validate the data types for each Feature on the first iteration and errors out if they are not validated.
## Actual results
Specify the actual results or traceback.
Based on the value of `writer_batch_size`, execution errors out when Arrow attempts to write because the types do not match, though its error messages dont make this obvious
Example errors:
```
OverflowError: There was an overflow with type <class 'list'>. Try to reduce writer_batch_size to have batches smaller than 2GB.
(offset overflow while concatenating arrays)
```
```
zsh: killed python doc_classification.py
UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
datasets version: 2.1.0
Platform: macOS-12.2.1-arm64-arm-64bit
Python version: 3.9.12
PyArrow version: 6.0.1
Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/4352
|
open
|
[
"bug"
] | 2022-05-14T17:55:15Z
| 2022-05-16T15:09:17Z
| null |
plamb-viso
|
huggingface/optimum
| 191
|
Not possible to configure GPU in pipelines nor leveraging batch_size parallelisation
|
When setting the `device` variable in the `pipeline` function/class to `>= 0`, an error appears `AttributeError: 'ORTModelForCausalLM' object has no attribute 'to' - when running in GPU`. This was initially reported in #161 so opening this issue to encompass supporting the `device` parameter in the ORT classes. This is important as otherwise it won't be possible to allow configuration of CPU/GPU similar to normal transformer libraries.
Is there currently a workaround to ensure that the class is run on GPU? By default it seems this woudl eb set in CPU even when GPU is available:
```python
>>> m = ORTModelForCausalLM.from_pretrained("gpt2", from_transformers=True)
>>> t = AutoTokenizer.from_pretrained("gpt2")
>>> pp = pipeline("text-generation", model=m, tokenizer=t)
>>> pp.device
device(type='cpu')
```
This is still the case even with the `optimum[onnxruntime-gpu]` package. I have validated by testing against a normal transformer with `batch_size=X` (ie `pp = pipeline("text-generation", model=m, tokenizer=t, batch_size=128)`) and it seems there is no optimization with parallel processing with optimum, whereas normal transformer is orders of magnitude faster (which is most likely as it's not utilizing the parallelism)
I can confirm that the model is loaded with GPU correctly:
```python
>>> m.device
device(type='cuda', index=0)
```
And GPU is configured correctly:
```python
>>> from optimum.onnxruntime.utils import _is_gpu_available
>>> _is_gpu_available()
True
```
Is there a way to enable GPU for processing with batching in optimum?
|
https://github.com/huggingface/optimum/issues/191
|
closed
|
[
"inference"
] | 2022-05-14T05:05:51Z
| 2022-09-05T08:37:46Z
| 4
|
axsaucedo
|
huggingface/datasets
| 4,343
|
Metrics documentation is not accessible in the datasets doc UI
|
**Is your feature request related to a problem? Please describe.**
Search for a metric name like "seqeval" yields no results on https://huggingface.co/docs/datasets/master/en/index . One needs to go look in `datasets/metrics/README.md` to find the doc. Even in the `README.md`, it can be hard to understand what the metric expects as an input, for example for `squad` there is a [key `id`](https://github.com/huggingface/datasets/blob/1a4c185663a6958f48ec69624473fdc154a36a9d/metrics/squad/squad.py#L42) documented only in the function doc but not in the `README.md`, and one needs to go look into the code to understand what the metric expects.
**Describe the solution you'd like**
Have the documentation for metrics appear as well in the doc UI, e.g. this https://github.com/huggingface/datasets/blob/1a4c185663a6958f48ec69624473fdc154a36a9d/metrics/squad/squad.py#L21-L63
I know there are plans to migrate metrics to the evaluate library, but just pointing this out.
|
https://github.com/huggingface/datasets/issues/4343
|
closed
|
[
"enhancement",
"Metric discussion"
] | 2022-05-13T07:46:30Z
| 2022-06-03T08:50:25Z
| 1
|
fxmarty
|
huggingface/optimum
| 183
|
about run_glue.py
|
how to enable GPU when run run_glue.py
|
https://github.com/huggingface/optimum/issues/183
|
closed
|
[] | 2022-05-12T12:13:16Z
| 2022-06-23T13:35:25Z
| 1
|
yichuan-w
|
huggingface/dataset-viewer
| 255
|
Create a custom nginx image?
|
I think it would be clearer to create a custom nginx image, in /services/reverse-proxy, than the current "hack" with a template and env vars on the official nginx image.
This way, all the services (API, worker, reverse-proxy) would follow the same flow.
|
https://github.com/huggingface/dataset-viewer/issues/255
|
closed
|
[
"question"
] | 2022-05-12T08:48:12Z
| 2022-09-16T17:43:30Z
| null |
severo
|
huggingface/datasets
| 4,323
|
Audio can not find value["bytes"]
|
## Describe the bug
I wrote down _generate_examples like:

but where is the bytes?

## Expected results
value["bytes"] is not None, so i can make datasets with bytes, not path
## bytes looks like:
blah blah~~
\xfe\x03\x00\xfb\x06\x1c\x0bo\x074\x03\xaf\x01\x13\x04\xbc\x06\x8c\x05y\x05,\t7\x08\xaf\x03\xc0\xfe\xe8\xfc\x94\xfe\xb7\xfd\xea\xfa\xd5\xf9$\xf9>\xf9\x1f\xf8\r\xf5F\xf49\xf4\xda\xf5-\xf8\n\xf8k\xf8\x07\xfb\x18\xfd\xd9\xfdv\xfd"\xfe\xcc\x01\x1c\x04\x08\x04@\x04{\x06^\tf\t\x1e\x07\x8b\x06\x02\x08\x13\t\x07\x08 \x06g\x06"\x06\xa0\x03\xc6\x002\xff \xff\x1d\xff\x19\xfd?\xfb\xdb\xfa\xfc\xfa$\xfb}\xf9\xe5\xf7\xf9\xf7\xce\xf8.\xf9b\xf9\xc5\xf9\xc0\xfb\xfa\xfcP\xfc\xba\xfbQ\xfc1\xfe\x9f\xff\x12\x00\xa2\x00\x18\x02Z\x03\x02\x04\xb1\x03\xc5\x03W\x04\x82\x04\x8f\x04U\x04\xb6\x04\x10\x05{\x04\x83\x02\x17\x01\x1d\x00\xa0\xff\xec\xfe\x03\xfe#\xfe\xc2\xfe2\xff\xe6\xfe\x9a\xfe~\x01\x91\x08\xb3\tU\x05\x10\x024\x02\xe4\x05\xa8\x07\xa7\x053\x07I\n\x91\x07v\x02\x95\xfd\xbb\xfd\x96\xff\x01\xfe\x1e\xfb\xbb\xf9S\xf8!\xf8\xf4\xf5\xd6\xf3\xf7\xf3l\xf4d\xf6l\xf7d\xf6b\xf7\xc1\xfa(\xfd\xcf\xfd*\xfdq\xfe\xe9\x01\xa8\x03t\x03\x17\x04B\x07\xce\t\t\t\xeb\x06\x0c\x07\x95\x08\x92\t\xbc\x07O\x06\xfb\x06\xd2\x06U\x04\x00\x02\x92\x00\xdc\x00\x84\x00 \xfeT\xfc\xf1\xfb\x82\xfc\x97\xfb}\xf9\x00\xf8_\xf8\x0b\xf9\xe5\xf8\xe2\xf7\xaa\xf8\xb2\xfa\x10\xfbl\xfa\xf5\xf9Y\xfb\xc0\xfd\xe8\xfe\xec\xfe1\x00\xad\x01\xec\x02E\x03\x13\x03\x9b\x03o\x04\xce\x04\xa8\x04\xb2\x04\x1b\x05\xc0\x05\xd2\x04\xe8\x02z\x01\xbe\x00\xae\x00\x07\x00$\xff|\xff\x8e\x00\x13\x00\x10\xff\x98\xff0\x05{\x0b\x05\t\xaa\x03\x82\x01n\x03
blah blah~~
that function not return None
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:2.2.1
- Platform:ubuntu 18.04
- Python version:3.6.9
- PyArrow version:6.0.1
|
https://github.com/huggingface/datasets/issues/4323
|
closed
|
[
"bug"
] | 2022-05-12T08:31:58Z
| 2022-07-07T13:16:08Z
| 9
|
YooSungHyun
|
huggingface/dataset-viewer
| 241
|
Setup the users directly in the images, not in Kubernetes?
|
See the second point in https://snyk.io/blog/10-kubernetes-security-context-settings-you-should-understand/: using `runAsUser` / `runAsGroup` is a (relative) security risk.
|
https://github.com/huggingface/dataset-viewer/issues/241
|
closed
|
[
"question"
] | 2022-05-10T15:15:49Z
| 2022-09-19T08:57:20Z
| null |
severo
|
huggingface/datasets
| 4,304
|
Language code search does direct matches
|
## Describe the bug
Hi. Searching for bcp47 tags that are just the language prefix (e.g. `sq` or `da`) excludes datasets that have added extra information in their language metadata (e.g. `sq-AL` or `da-bornholm`). The example codes given in the [tagging app](https://huggingface.co/spaces/huggingface/datasets-tagging) encourages addition of the additional codes ("_expected format is BCP47 tags separated for ';' e.g. 'en-US;fr-FR'_") but this would lead to those datasets being hidden in datasets search.
## Steps to reproduce the bug
1. Add a dataset using a variant tag (e.g. [`sq-AL`](https://huggingface.co/datasets?languages=languages:sq-AL))
2. Look for datasets using the full code
3. Note that they're missing when just the language is searched for (e.g. [`sq`](https://huggingface.co/datasets?languages=languages:sq))
Some datasets are already affected by this - e.g. `AmazonScience/massive` is listed under `sq-AL` but not `sq`.
One workaround is for dataset creators to add an additional root language tag to dataset YAML metadata, but it's unclear how to communicate this. It might be possible to index the search on `languagecode.split('-')[0]` but I wanted to float this issue before trying to write any code :)
## Expected results
Datasets using longer bcp47 tags also appear under searches for just the language code; e.g. Quebecois datasets (`fr-CA`) would come up when looking for French datasets with no region specification (`fr`), or US English (`en-US`) datasets would come up when searching for English datasets (`en`).
## Actual results
The language codes seem to be directly string matched, excluding datasets with specific language tags from non-specific searches.
## Environment info
(web app)
|
https://github.com/huggingface/datasets/issues/4304
|
open
|
[
"bug"
] | 2022-05-10T11:59:16Z
| 2022-05-10T12:38:42Z
| 1
|
leondz
|
huggingface/datasets
| 4,238
|
Dataset caching policy
|
## Describe the bug
I cannot clean cache of my datasets files, despite I have updated the `csv` files on the repository [here](https://huggingface.co/datasets/loretoparisi/tatoeba-sentences). The original file had a line with bad characters, causing the following error
```
[/usr/local/lib/python3.7/dist-packages/datasets/features/features.py](https://localhost:8080/#) in str2int(self, values)
852 if value not in self._str2int:
853 value = str(value).strip()
--> 854 output.append(self._str2int[str(value)])
855 else:
856 # No names provided, try to integerize
KeyError: '\\N'
```
The file now is cleanup up, but I still get the error. This happens even if I inspect the local cached contents, and cleanup the files locally:
```python
from datasets import load_dataset_builder
dataset_builder = load_dataset_builder("loretoparisi/tatoeba-sentences")
print(dataset_builder.cache_dir)
print(dataset_builder.info.features)
print(dataset_builder.info.splits)
```
```
Using custom data configuration loretoparisi--tatoeba-sentences-e59b8ad92f1bb8dd
/root/.cache/huggingface/datasets/csv/loretoparisi--tatoeba-sentences-e59b8ad92f1bb8dd/0.0.0/433e0ccc46f9880962cc2b12065189766fbb2bee57a221866138fb9203c83519
None
None
```
and removing files located at `/root/.cache/huggingface/datasets/csv/loretoparisi--tatoeba-sentences-*`.
Is there any remote file caching policy in place? If so, is it possibile to programmatically disable it?
Currently it seems that the file `test.csv` on the repo [here](https://huggingface.co/datasets/loretoparisi/tatoeba-sentences/blob/main/test.csv) is cached remotely. In fact I download locally the file from raw link, the file is up-to-date; but If I use it within `datasets` as shown above, it gives to me always the first revision of the file, not the last.
Thank you.
## Steps to reproduce the bug
```python
from datasets import load_dataset,Features,Value,ClassLabel
class_names = ["cmn","deu","rus","fra","eng","jpn","spa","ita","kor","vie","nld","epo","por","tur","heb","hun","ell","ind","ara","arz","fin","bul","yue","swe","ukr","bel","que","ces","swh","nno","wuu","nob","zsm","est","kat","pol","lat","urd","sqi","isl","fry","afr","ron","fao","san","bre","tat","yid","uig","uzb","srp","qya","dan","pes","slk","eus","cycl","acm","tgl","lvs","kaz","hye","hin","lit","ben","cat","bos","hrv","tha","orv","cha","mon","lzh","scn","gle","mkd","slv","frm","glg","vol","ain","jbo","tok","ina","nds","mal","tlh","roh","ltz","oss","ido","gla","mlt","sco","ast","jav","oci","ile","ota","xal","tel","sjn","nov","khm","tpi","ang","aze","tgk","tuk","chv","hsb","dsb","bod","sme","cym","mri","ksh","kmr","ewe","kab","ber","tpw","udm","lld","pms","lad","grn","mlg","xho","pnb","grc","hat","lao","npi","cor","nah","avk","mar","guj","pan","kir","myv","prg","sux","crs","ckt","bak","zlm","hil","cbk","chr","nav","lkt","enm","arq","lin","abk","pcd","rom","gsw","tam","zul","awa","wln","amh","bar","hbo","mhr","bho","mrj","ckb","osx","pfl","mgm","sna","mah","hau","kan","nog","sin","glv","dng","kal","liv","vro","apc","jdt","fur","che","haw","yor","crh","pdc","ppl","kin","shs","mnw","tet","sah","kum","ngt","nya","pus","hif","mya","moh","wol","tir","ton","lzz","oar","lug","brx","non","mww","hak","nlv","ngu","bua","aym","vec","ibo","tkl","bam","kha","ceb","lou","fuc","smo","gag","lfn","arg","umb","tyv","kjh","oji","cyo","urh","kzj","pam","srd","lmo","swg","mdf","gil","snd","tso","sot","zza","tsn","pau","som","egl","ady","asm","ori","dtp","cho","max","kam","niu","sag","ilo","kaa","fuv","nch","hoc","iba","gbm","sun","war","mvv","pap","ary","kxi","csb","pag","cos","rif","kek","krc","aii","ban","ssw","tvl","mfe","tah","bvy","bcl","hnj","nau","nst","afb","quc","min","tmw","mad","bjn","mai","cjy","got","hsn","gan","tzl","dws","ldn","afh","sgs","krl","vep","rue","tly","mic","ext","izh","sma","jam","cmo","mwl","kpv","koi","bis","ike","run","evn","ryu","mnc","aoz","otk","kas","aln","akl","yua","shy","fkv","gos","fij","thv","zgh","gcf","cay","xmf","tig","div","lij","rap","hrx","cpi","tts","gaa","tmr","iii","ltg","bzt","syc","emx","gom","chg","osp","stq","frr","fro","nys","toi","new","phn","jpa","rel","drt","chn","pli","laa","bal","hdn","hax","mik","ajp","xqa","pal","crk","mni","lut","ayl","ood","sdh","ofs","nus","kiu","diq","qxq","alt","bfz","klj","mus","srn","guc","lim","zea","shi","mnr","bom","sat","szl"]
features = Features({ 'label': ClassLabel(names=class_names), 'text': Value('string')})
num_labels = features['label'].num_classes
data_files = { "train": "train.csv", "test": "test.csv" }
sentences = load_dataset(
"loretoparisi/tatoeba-sentences",
data_files=data_files,
delimiter='\t',
column_names=['label', 'text'],
)
# You can make this part faster with num_proc=<some int>
sentences = sentences.map(lambda ex: {"label" : features["label"].str2int(ex["label"]) if ex["label"] is no
|
https://github.com/huggingface/datasets/issues/4238
|
closed
|
[
"bug"
] | 2022-04-27T10:42:11Z
| 2022-04-27T16:29:25Z
| 3
|
loretoparisi
|
huggingface/datasets
| 4,235
|
How to load VERY LARGE dataset?
|
### System Info
```shell
I am using transformer trainer while meeting the issue.
The trainer requests torch.utils.data.Dataset as input, which loads the whole dataset into the memory at once. Therefore, when the dataset is too large to load, there's nothing I can do except using IterDataset, which loads samples of data seperately, and results in low efficiency.
I wonder if there are any tricks like Sharding in huggingface trainer.
Looking forward to your reply.
```
### Who can help?
Trainer: @sgugger
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
None
### Expected behavior
```shell
I wonder if there are any tricks like fairseq Sharding very large datasets https://fairseq.readthedocs.io/en/latest/getting_started.html.
Thanks a lot!
```
|
https://github.com/huggingface/datasets/issues/4235
|
closed
|
[
"bug"
] | 2022-04-27T07:50:13Z
| 2023-07-25T15:07:57Z
| 1
|
CaoYiqingT
|
huggingface/datasets
| 4,230
|
Why the `conll2003` dataset on huggingface only contains the `en` subset? Where is the German data?
|

But on huggingface datasets:

Where is the German data?
|
https://github.com/huggingface/datasets/issues/4230
|
closed
|
[
"enhancement"
] | 2022-04-27T00:53:52Z
| 2023-07-25T15:10:15Z
| null |
beyondguo
|
huggingface/datasets
| 4,221
|
Dictionary Feature
|
Hi, I'm trying to create the loading script for a dataset in which one feature is a list of dictionaries, which afaik doesn't fit very well the values and structures supported by Value and Sequence. Is there any suggested workaround, am I missing something?
Thank you in advance.
|
https://github.com/huggingface/datasets/issues/4221
|
closed
|
[
"question"
] | 2022-04-26T12:50:18Z
| 2022-04-29T14:52:19Z
| null |
jordiae
|
huggingface/datasets
| 4,181
|
Support streaming FLEURS dataset
|
## Dataset viewer issue for '*name of the dataset*'
https://huggingface.co/datasets/google/fleurs
```
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol for TAR archives like 'https://storage.googleapis.com/xtreme_translations/FLEURS/af_za.tar.gz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.
```
Am I the one who added this dataset ? Yes
Can I fix this somehow in the script? @lhoestq @severo
|
https://github.com/huggingface/datasets/issues/4181
|
closed
|
[
"dataset bug"
] | 2022-04-19T11:09:56Z
| 2022-07-25T11:44:02Z
| 9
|
patrickvonplaten
|
huggingface/optimum
| 147
|
Support for electra model
|
I came across this tool and it looks very interesting but i am trying to use electra model and i can see this is not supported. By this
`"electra is not supported yet. Only ['albert', 'bart', 'mbart', 'bert', 'ibert', 'camembert', 'distilbert', 'longformer', 'marian', 'roberta', 't5', 'xlm-roberta', 'gpt2', 'gpt-neo', 'layoutlm'] are supported. If you want to support electra please propose a PR or open up an issue`.
is any plans for electra models in future.
Example of models https://huggingface.co/german-nlp-group/electra-base-german-uncased
|
https://github.com/huggingface/optimum/issues/147
|
closed
|
[] | 2022-04-15T11:03:21Z
| 2022-04-21T07:24:48Z
| 1
|
OriAlpha
|
huggingface/tokenizers
| 979
|
What is the correct format for file for tokenizer.train_from_files?
|
I am trying to use this library and train a new model with my own data. But before I start building my corpora, I want to understand what file format should I be looking for, if I am feeding it to [`train_from_files`](https://docs.rs/tokenizers/0.11.3/tokenizers/tokenizer/struct.TokenizerImpl.html#method.train_from_files)? Is there a standard for that? It would be great if that can be documented.
|
https://github.com/huggingface/tokenizers/issues/979
|
closed
|
[] | 2022-04-12T22:54:39Z
| 2022-04-14T07:05:58Z
| null |
winston0410
|
huggingface/datasets
| 4,141
|
Why is the dataset not visible under the dataset preview section?
|
## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
|
https://github.com/huggingface/datasets/issues/4141
|
closed
|
[
"dataset-viewer"
] | 2022-04-11T08:36:42Z
| 2022-04-11T18:55:32Z
| 0
|
Nid989
|
huggingface/datasets
| 4,139
|
Dataset viewer issue for Winoground
|
## Dataset viewer issue for 'Winoground'
**Link:** [*link to the dataset viewer page*](https://huggingface.co/datasets/facebook/winoground/viewer/facebook--winoground/train)
*short description of the issue*
Getting 401, message='Unauthorized'
The dataset is subject to authorization, but I can access the files from the interface, so I assume I'm granted to access it. I'd assume the permission somehow doesn't propagate to the dataset viewer tool.
Am I the one who added this dataset ? No
|
https://github.com/huggingface/datasets/issues/4139
|
closed
|
[
"dataset-viewer",
"dataset-viewer-gated"
] | 2022-04-11T06:11:41Z
| 2022-06-21T16:43:58Z
| 11
|
alcinos
|
huggingface/datasets
| 4,138
|
Incorrect Russian filenames encoding after extraction by datasets.DownloadManager.download_and_extract()
|
## Dataset viewer issue for 'MalakhovIlya/RuREBus'
**Link:** https://huggingface.co/datasets/MalakhovIlya/RuREBus
**Description**
Using os.walk(topdown=False) in DatasetBuilder causes following error:
Status code: 400
Exception: TypeError
Message: xwalk() got an unexpected keyword argument 'topdown'
Couldn't find where "xwalk" come from. How can I fix this?
Am I the one who added this dataset ? Yes
|
https://github.com/huggingface/datasets/issues/4138
|
closed
|
[] | 2022-04-11T02:07:13Z
| 2022-04-19T03:15:46Z
| 5
|
iluvvatar
|
huggingface/datasets
| 4,134
|
ELI5 supporting documents
|
if i am using dense search to create supporting documents for eli5 how much time it will take bcz i read somewhere that it takes about 18 hrs??
|
https://github.com/huggingface/datasets/issues/4134
|
open
|
[
"question"
] | 2022-04-08T23:36:27Z
| 2022-04-13T13:52:46Z
| null |
saurabh-0077
|
huggingface/dataset-viewer
| 204
|
Reduce the size of the endpoint responses?
|
Currently, the data contains a lot of redundancy, for example every row of the `/rows` response contains three fields for the dataset, config and split, and their value is the same for all the rows. It comes from a previous version in which we were able to request rows for several configs or splits at the same time.
Changing the format would require changing the moon-landing client.
|
https://github.com/huggingface/dataset-viewer/issues/204
|
closed
|
[
"question"
] | 2022-04-08T15:31:35Z
| 2022-08-24T18:03:38Z
| null |
severo
|
huggingface/datasets
| 4,101
|
How can I download only the train and test split for full numbers using load_dataset()?
|
How can I download only the train and test split for full numbers using load_dataset()?
I do not need the extra split and it will take 40 mins just to download in Colab. I have very short time in hand. Please help.
|
https://github.com/huggingface/datasets/issues/4101
|
open
|
[
"enhancement"
] | 2022-04-05T16:00:15Z
| 2022-04-06T13:09:01Z
| 1
|
Nakkhatra
|
huggingface/datasets
| 4,074
|
Error in google/xtreme_s dataset card
|
**Link:** https://huggingface.co/datasets/google/xtreme_s
Not a big deal but Hungarian is considered an Eastern European language, together with Serbian, Slovak, Slovenian (all correctly categorized; Slovenia is mostly to the West of Hungary, by the way).
|
https://github.com/huggingface/datasets/issues/4074
|
closed
|
[
"documentation",
"dataset bug"
] | 2022-03-31T18:07:45Z
| 2022-04-01T08:12:56Z
| 1
|
wranai
|
huggingface/datasets
| 4,041
|
Add support for IIIF in datasets
|
This is a feature request for support for IIIF in `datasets`. Apologies for the long issue. I have also used a different format to the usual feature request since I think that makes more sense but happy to use the standard template if preferred.
## What is [IIIF](https://iiif.io/)?
IIIF (International Image Interoperability Framework)
> is a set of open standards for delivering high-quality, attributed digital objects online at scale. It’s also an international community developing and implementing the IIIF APIs. IIIF is backed by a consortium of leading cultural institutions.
The tl;dr is that IIIF provides various specifications for implementing useful functionality for:
- Institutions to make available images for various use cases
- Users to have a consistent way of interacting/requesting these images
- For developers to have a common standard for developing tools for working with IIIF images that will work across all institutions that implement a particular IIIF standard (for example the image viewer for the BNF can also work for the Library of Congress if they both use IIIF).
Some institutions that various levels of support IIF include: The British Library, Internet Archive, Library of Congress, Wikidata. There are also many smaller institutions that have IIIF support. An incomplete list can be found here: https://iiif.io/guides/finding_resources/
## IIIF APIs
IIIF consists of a number of APIs which could be integrated with datasets. I think the most obvious candidate for inclusion would be the [Image API](https://iiif.io/api/image/3.0/)
### IIIF Image API
The Image API https://iiif.io/api/image/3.0/ is likely the most suitable first candidate for integration with datasets. The Image API offers a consistent protocol for requesting images via a URL:
```{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}```
A concrete example of this:
```https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/full/0/default.jpg```
As you can see the scheme offers a number of options that can be specified in the URL, for example, size. Using the example URL we return:

We can change the size to request a size of 250 by 250, this is done by changing the size from `full` to `250,250` i.e. switching the URL to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/250,250/0/default.jpg`

We can also request the image with max width 250, max height 250 whilst maintaining the aspect ratio using `!w,h`. i.e. change the url to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/!250,250/0/default.jpg`

A full overview of the options for size can be found here: https://iiif.io/api/image/3.0/#42-size
## Why would/could this be useful for datasets?
There are a few reasons why support for the IIIF Image API could be useful. Broadly the ability to have more control over how an image is returned from a server is useful for many ML workflows:
- images can be requested in the right size, this prevents having to download/stream large images when the actual desired size is much smaller
- can select a subset of an image: it is possible to select a sub-region of an image, this could be useful for example when you already have a bounding box for a subset of an image and then want to use this subset of an image for another task. For example, https://github.com/Living-with-machines/nnanno uses IIIF to request parts of a newspaper image that have been detected as 'photograph', 'illustration' etc for downstream use.
- options for quality, rotation, the format can all be encoded in the URL request.
These may become particularly useful when pre-training models on large image datasets where the cost of downloading images with 1600 pixel width when you actually want 240 has a larger impact.
## What could this look like in datasets?
I think there are various ways in which support for IIIF could potentially be included in `datasets`. These suggestions aren't fully fleshed out but hopefully, give a sense of possible approaches that match existing `datasets` methods in their approach.
### Use through datasets scripts
Loading images via URL is already supported. There are a few possible 'extras' that could be included when using IIIF. One option is to leverage the IIIF protocol in datasets scripts, i.e. the dataset script can expose the IIIF options via the dataset script:
```python
ds = load_dataset("iiif_dataset", image_size="250,250", fmt="jpg")
```
This is already possible. The approach to parsing the IIIF URLs would be left to the person creating the dataset script.
### Sup
|
https://github.com/huggingface/datasets/issues/4041
|
open
|
[
"enhancement"
] | 2022-03-28T15:19:25Z
| 2022-04-05T18:20:53Z
| 1
|
davanstrien
|
huggingface/datasets
| 4,027
|
ElasticSearch Indexing example: TypeError: __init__() missing 1 required positional argument: 'scheme'
|
## Describe the bug
I am following the example in the documentation for elastic search step by step (on google colab): https://huggingface.co/docs/datasets/faiss_es#elasticsearch
```
from datasets import load_dataset
squad = load_dataset('crime_and_punish', split='train[:1000]')
```
When I run the line:
`squad.add_elasticsearch_index("context", host="localhost", port="9200")`
I get the error:
`TypeError: __init__() missing 1 required positional argument: 'scheme'`
## Expected results
No error message
## Actual results
```
TypeError Traceback (most recent call last)
[<ipython-input-23-9205593edef3>](https://localhost:8080/#) in <module>()
1 import elasticsearch
----> 2 squad.add_elasticsearch_index("text", host="localhost", port="9200")
6 frames
[/usr/local/lib/python3.7/dist-packages/elasticsearch/_sync/client/utils.py](https://localhost:8080/#) in host_mapping_to_node_config(host)
209 options["path_prefix"] = options.pop("url_prefix")
210
--> 211 return NodeConfig(**options) # type: ignore
212
213
TypeError: __init__() missing 1 required positional argument: 'scheme'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.0
- Platform: Linux, Google Colab
- Python version: Google Colab (probably 3.7)
- PyArrow version: ?
|
https://github.com/huggingface/datasets/issues/4027
|
closed
|
[
"bug",
"duplicate"
] | 2022-03-25T16:22:28Z
| 2022-04-07T10:29:52Z
| 2
|
MoritzLaurer
|
huggingface/datasets
| 3,881
|
How to use Image folder
|
Ran this code
```
load_dataset("imagefolder", data_dir="./my-dataset")
```
`https://raw.githubusercontent.com/huggingface/datasets/master/datasets/imagefolder/imagefolder.py` missing
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
/tmp/ipykernel_33/1648737256.py in <module>
----> 1 load_dataset("imagefolder", data_dir="./my-dataset")
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1684 revision=revision,
1685 use_auth_token=use_auth_token,
-> 1686 **config_kwargs,
1687 )
1688
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, use_auth_token, script_version, **config_kwargs)
1511 download_config.use_auth_token = use_auth_token
1512 dataset_module = dataset_module_factory(
-> 1513 path, revision=revision, download_config=download_config, download_mode=download_mode, data_files=data_files
1514 )
1515
/opt/conda/lib/python3.7/site-packages/datasets/load.py in dataset_module_factory(path, revision, download_config, download_mode, force_local_path, dynamic_modules_path, data_files, **download_kwargs)
1200 f"Couldn't find a dataset script at {relative_to_absolute_path(combined_path)} or any data file in the same directory. "
1201 f"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}"
-> 1202 ) from None
1203 raise e1 from None
1204 else:
FileNotFoundError: Couldn't find a dataset script at /kaggle/working/imagefolder/imagefolder.py or any data file in the same directory. Couldn't find 'imagefolder' on the Hugging Face Hub either: FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/imagefolder/imagefolder.py
```
|
https://github.com/huggingface/datasets/issues/3881
|
closed
|
[
"question"
] | 2022-03-09T21:18:52Z
| 2022-03-11T08:45:52Z
| null |
rozeappletree
|
huggingface/datasets
| 3,854
|
load only England English dataset from common voice english dataset
|
training_data = load_dataset("common_voice", "en",split='train[:250]+validation[:250]')
testing_data = load_dataset("common_voice", "en", split="test[:200]")
I'm trying to load only 8% of the English common voice data with accent == "England English." Can somebody assist me with this?
**Typical Voice Accent Proportions:**
- 24% United States English
- 8% England English
- 5% India and South Asia (India, Pakistan, Sri Lanka)
- 3% Australian English
- 3% Canadian English
- 2% Scottish English
- 1% Irish English
- 1% Southern African (South Africa, Zimbabwe, Namibia)
- 1% New Zealand English
Can we replicate this for Age as well?
**Age proportions of the common voice:-**
- 24% 19 - 29
- 14% 30 - 39
- 10% 40 - 49
- 6% < 19
- 4% 50 - 59
- 4% 60 - 69
- 1% 70 – 79
|
https://github.com/huggingface/datasets/issues/3854
|
closed
|
[
"question"
] | 2022-03-08T09:40:52Z
| 2024-03-23T12:40:58Z
| null |
amanjaiswal777
|
huggingface/nn_pruning
| 33
|
What is the difference between "finetune" and "final-finetune" in `/example`.
|
Hello,
Thanks for the amazing repo!
I'm wondering what is the difference between "finetune" and "final-finetune" in `/example`.
Do we train the model and the mask score in the finetune stage, and only train the optimized model in the final-finetune stage?
Is there a way to directly save the optimized model and load the optimized model instead of loading the patched model and optimizing to get the pruned model?
Big thanks again for the great work!
|
https://github.com/huggingface/nn_pruning/issues/33
|
open
|
[] | 2022-02-11T03:25:13Z
| 2023-01-08T14:27:37Z
| null |
eric8607242
|
huggingface/transformers
| 15,404
|
what is the equivalent manner for those lines?
|
https://github.com/huggingface/transformers/issues/15404
|
closed
|
[] | 2022-01-29T16:03:12Z
| 2022-02-18T21:37:08Z
| null |
mathshangw
|
|
huggingface/dataset-viewer
| 124
|
Cache /valid?
|
<strike>It is called multiple times per second by moon landing, and it impacts a lot the loading time of the /datasets page (https://github.com/huggingface/moon-landing/issues/1871#issuecomment-1024414854).</strike>
Currently, several queries are done to check all the valid datasets on every request
|
https://github.com/huggingface/dataset-viewer/issues/124
|
closed
|
[
"question"
] | 2022-01-28T17:37:47Z
| 2022-01-31T20:31:41Z
| null |
severo
|
huggingface/transformers
| 15,223
|
where is the 4.16.0dev??
|
I'm running the run_mlm.py script.
There is such a line,
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.16.0.dev0")
but where is it?
can't find by pip,no in github too.
|
https://github.com/huggingface/transformers/issues/15223
|
closed
|
[] | 2022-01-19T11:41:04Z
| 2022-02-27T15:02:00Z
| null |
sipie800
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.