
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/optimum
| 987
|
Have optimum supported BLIP-2 model converted to onnx?
|
Hi, have optimum supported BLIP-2 model converted to onnx?
|
https://github.com/huggingface/optimum/issues/987
|
closed
|
[] | 2023-04-20T07:07:53Z
| 2023-04-21T11:45:41Z
| 1
|
joewale
|
huggingface/setfit
| 364
|
Understanding the trainer parameters
|
I am looking at the SetFit example with SetFitHead:
```
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for contrastive learning
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
```
Here, what exactly is the meaning of `num_iterations`? And, why is `num_epochs =1`? Is that sufficient?
```
trainer.unfreeze(keep_body_frozen=False)
trainer.train(
num_epochs=25, # The number of epochs to train the head or the whole model (body and head)
batch_size=16,
body_learning_rate=1e-5, # The body's learning rate
learning_rate=1e-2, # The head's learning rate
l2_weight=0.0, # Weight decay on **both** the body and head. If `None`, will use 0.01.
)
metrics = trainer.evaluate()
```
Here the number of epochs is 25 and we are training the head and the body with different learning rates. Any reason why the per-epoch metrics are not displayed?
|
https://github.com/huggingface/setfit/issues/364
|
closed
|
[
"question"
] | 2023-04-19T15:19:42Z
| 2023-11-24T13:22:31Z
| null |
vahuja4
|
huggingface/diffusers
| 3,151
|
What is the format of the training data
|
Hello,I'm training Lora, but I don't know what the data format looks like,
The error is as follows:
--caption_column' value 'text' needs to be one of: image
What is the data format?
|
https://github.com/huggingface/diffusers/issues/3151
|
closed
|
[
"stale"
] | 2023-04-19T07:51:16Z
| 2023-08-04T10:20:18Z
| null |
WGS-note
|
huggingface/setfit
| 360
|
Token padding makes ONNX inference 6x slower, is attention_mask being used properly?
|
Here's some code that loads in my ONNX model and tokenizes 293 short examples. The longest length in the set is 153 tokens:
```python
input_text = test_ds['text']
import onnxruntime
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
inputs = tokenizer(
input_text,
max_length=512,
padding='longest',
truncation=True,
return_attention_mask=True,
return_token_type_ids=True,
return_tensors="np",
)
session = onnxruntime.InferenceSession(onnx_path)
```
```python
onnx_preds = session.run(None, dict(inputs))[0]
```
This runs in about 15-20 seconds for me. However, when I set `padding='max_length'` it takes about 1min20secs. Isn't the point of `attention_mask` to avoid this? The base model is `intfloat/e5-small`, Microsoft's e5 model which AFAICT is similar to mpnet.
|
https://github.com/huggingface/setfit/issues/360
|
open
|
[
"question"
] | 2023-04-18T15:33:01Z
| 2023-04-19T05:40:02Z
| null |
bogedy
|
huggingface/datasets
| 5,767
|
How to use Distill-BERT with different datasets?
|
### Describe the bug
- `transformers` version: 4.11.3
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.12.0+cu102 (True)
- Tensorflow version (GPU?): 2.10.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Steps to reproduce the bug
I recently read [this](https://huggingface.co/docs/transformers/quicktour#train-with-tensorflow:~:text=The%20most%20important%20thing%20to%20remember%20is%20you%20need%20to%20instantiate%20a%20tokenizer%20with%20the%20same%20model%20name%20to%20ensure%20you%E2%80%99re%20using%20the%20same%20tokenization%20rules%20a%20model%20was%20pretrained%20with.) and was wondering how to use distill-BERT (which is pre-trained with imdb dataset) with a different dataset (for eg. [this](https://huggingface.co/datasets/yhavinga/imdb_dutch) dataset)?
### Expected behavior
Distill-BERT should work with different datasets.
### Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 11.0.0
|
https://github.com/huggingface/datasets/issues/5767
|
closed
|
[] | 2023-04-18T06:25:12Z
| 2023-04-20T16:52:05Z
| 1
|
sauravtii
|
huggingface/transformers.js
| 93
|
[Feature Request] "slow tokenizer" format (`vocab.json` and `merges.txt`)
|
Wondering whether this code is supposed to work (or some variation on the repo URL - I tried a few different things):
```js
await import("https://cdn.jsdelivr.net/npm/@xenova/transformers@1.4.2/dist/transformers.min.js");
let tokenizer = await AutoTokenizer.from_pretrained("https://huggingface.co/cerebras/Cerebras-GPT-1.3B/resolve/main");
```
The `cerebras/Cerebras-GPT-1.3B` repo only has a `config.json` (no `tokenizer.json`), but the `config.json` has `"model_type": "gpt2",` and has `vocab.json` and `merges.txt`. It does load successfully with the Python Transformers lib.
|
https://github.com/huggingface/transformers.js/issues/93
|
closed
|
[
"question"
] | 2023-04-18T05:11:31Z
| 2023-04-23T07:41:27Z
| null |
josephrocca
|
huggingface/datasets
| 5,766
|
Support custom feature types
|
### Feature request
I think it would be nice to allow registering custom feature types with the 🤗 Datasets library. For example, allow to do something along the following lines:
```
from datasets.features import register_feature_type # this would be a new function
@register_feature_type
class CustomFeatureType:
def encode_example(self, value):
"""User-provided logic to encode an example of this feature."""
pass
def decode_example(self, value, token_per_repo_id=None):
"""User-provided logic to decode an example of this feature."""
pass
```
### Motivation
Users of 🤗 Datasets, such as myself, may want to use the library to load datasets with unsupported feature types (i.e., beyond `ClassLabel`, `Image`, or `Audio`). This would be useful for prototyping new feature types and for feature types that aren't used widely enough to warrant inclusion in 🤗 Datasets.
At the moment, this is only possible by monkey-patching 🤗 Datasets, which obfuscates the code and is prone to breaking with library updates. It also requires the user to write some custom code which could be easily avoided.
### Your contribution
I would be happy to contribute this feature. My proposed solution would involve changing the following call to `globals()` to an explicit feature type registry, which a user-facing `register_feature_type` decorator could update.
https://github.com/huggingface/datasets/blob/fd893098627230cc734f6009ad04cf885c979ac4/src/datasets/features/features.py#L1329
I would also provide an abstract base class for custom feature types which users could inherit. This would have at least an `encode_example` method and a `decode_example` method, similar to `Image` or `Audio`.
The existing `encode_nested_example` and `decode_nested_example` functions would also need to be updated to correctly call the corresponding functions for the new type.
|
https://github.com/huggingface/datasets/issues/5766
|
open
|
[
"enhancement"
] | 2023-04-17T15:46:41Z
| 2024-03-10T11:11:22Z
| 4
|
jmontalt
|
huggingface/transformers.js
| 92
|
[Question] ESM module import in the browser (via jsdelivr)
|
Wondering how to import transformers.js as a module (as opposed to `<script>`) in the browser? I've tried this:
```js
let { AutoTokenizer } = await import("https://cdn.jsdelivr.net/npm/@xenova/transformers@1.4.2/dist/transformers.min.js");
```
But it doesn't seem to export anything. I might be making a mistake here, but if not: Woudl it be possible to get a module-based js file for the browser?
---
Also, as an aside, can I suggest using a versioned URL in the readme? Or something like:
```
https://cdn.jsdelivr.net/npm/@xenova/transformers@X.Y.Z/dist/transformers.min.js
```
With a note telling them to replace `X.Y.Z` with the latest version. This allows you to make breaking changes in the future without breaking a bunch of sites. Often newbie devs don't realise that they have to swap for a versioned URL, and this can lead to "web rot" where old webpages eventuallly become broken or buggy.
|
https://github.com/huggingface/transformers.js/issues/92
|
closed
|
[
"question"
] | 2023-04-17T10:06:55Z
| 2023-04-22T19:17:56Z
| null |
josephrocca
|
huggingface/optimum
| 973
|
How to run the encoder part only of the model transformed by BetterTransformer?
|
### Feature request
If I want to run the encoder part of the model, e.g., "bert-large-uncased", skipping the word embedding stage, I could run with `nn.TransformerEncoder` as the Pytorch eager mode. How could I implement the BetterTransformer version encoder?
```
encoder_layer = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=head_num)
hf_encoder = nn.TransformerEncoder(encoder_layer, num_layers=layer_num).to(device)
```
Based on the code above, `BetterTransformer.transform` cannot accept `hf_encoder` as the input, it gave me the error `AttributeError: 'TransformerEncoder' object has no attribute 'config'`.
### Motivation
When I want to compare the performance of BetterTransformer and FasterTransformer ([link](https://github.com/NVIDIA/FasterTransformer/blob/main/docs/bert_guide.md#run-fastertransformer-bert-on-pytorch)) I need to run the encoder part of the model only to compare with FasterTransformer.
### Your contribution
I could add more guidelines into Docs/ README.
|
https://github.com/huggingface/optimum/issues/973
|
closed
|
[
"Stale"
] | 2023-04-17T02:29:44Z
| 2025-06-04T02:15:33Z
| 2
|
WarningRan
|
huggingface/datasets
| 5,759
|
Can I load in list of list of dict format?
|
### Feature request
my jsonl dataset has following format:
```
[{'input':xxx, 'output':xxx},{'input:xxx,'output':xxx},...]
[{'input':xxx, 'output':xxx},{'input:xxx,'output':xxx},...]
```
I try to use `datasets.load_dataset('json', data_files=path)` or `datasets.Dataset.from_json`, it raises
```
File "site-packages/datasets/arrow_dataset.py", line 1078, in from_json
).read()
File "site-packages/datasets/io/json.py", line 59, in read
self.builder.download_and_prepare(
File "site-packages/datasets/builder.py", line 872, in download_and_prepare
self._download_and_prepare(
File "site-packages/datasets/builder.py", line 967, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "site-packages/datasets/builder.py", line 1749, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "site-packages/datasets/builder.py", line 1892, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Motivation
I wanna use features like `Datasets.map` or `Datasets.shuffle`, so i need the dataset in memory to be `arrow_dataset.Datasets` format
### Your contribution
PR
|
https://github.com/huggingface/datasets/issues/5759
|
open
|
[
"enhancement"
] | 2023-04-16T13:50:14Z
| 2023-04-19T12:04:36Z
| 1
|
LZY-the-boys
|
huggingface/setfit
| 358
|
Domain adaptation
|
Does setfit cover Adapter Transformers? https://arxiv.org/pdf/2007.07779.pdf
|
https://github.com/huggingface/setfit/issues/358
|
closed
|
[
"question"
] | 2023-04-16T12:44:50Z
| 2023-12-05T14:49:36Z
| null |
Elahehsrz
|
huggingface/diffusers
| 3,120
|
The controlnet trained by diffusers scripts produce always same result no matter what the input images is
|
### Describe the bug
I train a controlnet with the base model Chilloutmix-Ni and datasets Abhilashvj/vto_hd_train using the train_controlnet.py script provided in diffuses repo
After training I got a controlnet model.
When I inference the image with the model, if I use the same prompt and seed, no matter how I change the control image I used, the pipeline always output the same image as result, which means that the controlnet model doesn't accept the control image as a condition at all.
### Reproduction
The train the controlnet with the scripts in example/controlnet
`accelerate launch train_controlnet.py --pretrained_model_name_or_path="/root/autodl-tmp/chilloutmixckpt" --output_dir="/root/autodl-tmp/mycontrolnet" --dataset_name=Abhilashvj/vto_hd_train --resolution=512 --learning_rate=2e-6 --train_batch_size=1 --gradient_accumulation_steps=4 --num_train_epochs=10 --tracker_project_name="train_controlnet" --checkpointing_steps=10000`
And the code I use for inference is as below
```
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler,DPMSolverMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "/root/autodl-tmp/chilloutmixckpt"
controlnet_path = "/root/autodl-tmp/mycontrolnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
#pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
control_image = load_image("https://datasets-server.huggingface.co/assets/Abhilashvj/vto_hd_train/--/Abhilashvj--vto_hd_train/train/5/conditioning_image/image.jpg")
control_image.save("./control8.png")
prompt = "1girl, best quality, ultra high res, high quality, ultra-detailed, professional lighting"
negative_prompt = 'paintings, sketches, extremely worst quality, worst quality, extremely low quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, missing fingers, extra fingers, bad teeth, bad anatomy, bad hands, bad feet, blurry face, bad eyes, slanted eyes, fused eye, skin spots, acnes, skin blemishes, age spot'
# generate image
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=20, generator=generator, image=control_image).images[0]
image.save("./output8.png")
```
### Logs
_No response_
### System Info
diffusers0.15.0
ubuntu
python3.8
|
https://github.com/huggingface/diffusers/issues/3120
|
closed
|
[
"bug",
"stale"
] | 2023-04-16T11:16:58Z
| 2023-07-08T15:03:12Z
| null |
garyhxfang
|
huggingface/transformers.js
| 87
|
Can whisper-tiny speech-to-text translate to English as well as transcribe foreign language?
|
I know there is a separate translation engine (t5-small), but I'm wondering if speech-to-text with whisper-tiny (not whisper-tiny.en) can return English translation alongside the foreign-language transcription? -- I read Whisper.ai can do this. It seems like it would just be a parameter, but I don't know where to look.
|
https://github.com/huggingface/transformers.js/issues/87
|
closed
|
[
"enhancement",
"question"
] | 2023-04-14T16:23:14Z
| 2023-06-23T19:07:31Z
| null |
patrickinminneapolis
|
huggingface/text-generation-inference
| 182
|
Is bert-base-uncased supported?
|
Hi,
I'm trying to deploy bert-base-uncased model by [v0.5.0](https://github.com/huggingface/text-generation-inference/tree/v0.5.0), but got an error: ValueError: BertLMHeadModel does not support `device_map='auto'` yet.
<details>
```
root@nick-test1-8zjwg-135105-worker-0:/usr/local/bin# ./text-generation-launcher --model-id bert-base-uncased
2023-04-14T07:24:23.167920Z INFO text_generation_launcher: Args { model_id: "bert-base-uncased", revision: None, sharded: None, num_shard: Some(1), quantize: false, max_concurrent_requests: 128, max_best_of: 2, max_stop_sequences: 4, max_input_length: 1000, max_total_tokens: 1512, max_batch_size: 32, max_waiting_tokens: 20, port: 80, shard_uds_path: "/tmp/text-generation-server", master_addr: "localhost", master_port: 29500, huggingface_hub_cache: Some("/data"), weights_cache_override: None, disable_custom_kernels: false, json_output: false, otlp_endpoint: None, cors_allow_origin: [], watermark_gamma: None, watermark_delta: None }
2023-04-14T07:24:23.168401Z INFO text_generation_launcher: Starting shard 0
2023-04-14T07:24:29.874262Z ERROR shard-manager: text_generation_launcher: "Error when initializing model
Traceback (most recent call last):
File \"/opt/miniconda/envs/text-generation/bin/text-generation-server\", line 8, in <module>
sys.exit(app())
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/main.py\", line 311, in __call__
return get_command(self)(*args, **kwargs)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1130, in __call__
return self.main(*args, **kwargs)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/core.py\", line 778, in main
return _main(
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/core.py\", line 216, in _main
rv = self.invoke(ctx)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 760, in invoke
return __callback(*args, **kwargs)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/main.py\", line 683, in wrapper
return callback(**use_params) # type: ignore
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/cli.py\", line 55, in serve
server.serve(model_id, revision, sharded, quantize, uds_path)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py\", line 135, in serve
asyncio.run(serve_inner(model_id, revision, sharded, quantize))
File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/runners.py\", line 44, in run
return loop.run_until_complete(main)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 634, in run_until_complete
self.run_forever()
File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 601, in run_forever
self._run_once()
File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 1905, in _run_once
handle._run()
File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/events.py\", line 80, in _run
self._context.run(self._callback, *self._args)
> File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py\", line 104, in serve_inner
model = get_model(model_id, revision, sharded, quantize)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/__init__.py\", line 130, in get_model
return CausalLM(model_id, revision, quantize=quantize)
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/causal_lm.py\", line 308, in __init__
self.model = AutoModelForCausalLM.from_pretrained(
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/transformers-4.28.0.dev0-py3.9-linux-x86_64.egg/transformers/models/auto/auto_factory.py\", line 471, in from_pretrained
return model_class.from_pretrained(
File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/transformers-4.28.0.dev0-py3.9-linux-x86_64.egg/transformers/modeling_utils.py\", line 2644, in from_pretrained
raise ValueError(f\"{model.__class__.__name__} does not support `device_map='{device_map}'` yet.\")
ValueError: BertLMHeadModel does not support `device_map='auto'` yet.
" rank=0
2023-04-14T07:24:30.475420Z ERROR text_generation_launcher: Shard 0 failed to start.
2023-04-14T07:24:30.475495Z INFO text_generation_launcher: Shut
|
https://github.com/huggingface/text-generation-inference/issues/182
|
open
|
[
"question"
] | 2023-04-14T07:26:05Z
| 2023-11-17T09:20:30Z
| null |
nick1115
|
huggingface/setfit
| 355
|
ONNX conversion of multi-ouput classifier
|
Hi,
I am trying to do onnx conversion for multilabel model using the multioutputclassifier
`model = SetFitModel.from_pretrained(model_id, multi_target_strategy="multi-output")`.
When I tried `export_onnx(model.model_body,
model.model_head,
opset=12,
output_path=output_path)`, it gave me an error indicating there's no `coef_`, I understand there's no coef_ in the multioutput classifier, but is there a way to do onnx conversion for this model?
Thanks!
|
https://github.com/huggingface/setfit/issues/355
|
open
|
[
"question"
] | 2023-04-13T22:08:13Z
| 2023-04-20T17:00:48Z
| null |
jackiexue1993
|
huggingface/transformers.js
| 84
|
[Question] New demo type/use case: semantic search (SemanticFinder)
|
Hi @xenova,
first of all thanks for the amazing library - it's awesome to be able to play around with the models without a backend!
I just created [SemanticFinder](https://do-me.github.io/SemanticFinder/), a semantic search engine in the browser with the help of transformers.js and [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2).
You can find some technical details in the [blog post](https://geo.rocks/post/semanticfinder-semantic-search-frontend-only/).
I was wondering whether you'd be interested in showcasing semantic search as new demo type. Technically, it's not a new model but it's a new **use case** with an existing model so I don't know whether it's out of scope.
Anyway, just wanted to let you know that you're work is very much appreciated!
|
https://github.com/huggingface/transformers.js/issues/84
|
closed
|
[
"question"
] | 2023-04-12T18:57:38Z
| 2025-10-13T05:03:30Z
| null |
do-me
|
huggingface/diffusers
| 3,075
|
Create a Video ControlNet Pipeline
|
**Is your feature request related to a problem? Please describe.**
Stable Diffusion video generation lacks precise movement control and composition control. This is not surprising, since the model was not trained or fine-tuned with videos.
**Describe the solution you'd like**
By following an analogous extension process that gave Stable Diffusion more composition control with ControlNet, we can address this issue, extending the `TextToVideoZeroPipeline` with an additional ControlNet guidance image _sequence_.
Specifically, I believe this will involve creating `ControlNet3DModel` that extends to the `ControlNetModel` to provide the proper down and mid sample residuals to the a new `TextToVideoZeroControlNetPipeline`.
The `TextToVideoZeroControlPipeline` will extend the `TextToVideoZeroPipeline` so it can be initialized `ControlNet3DModel`. During the forward pass we will add an additional list of images (or 3D tensor) parameter. This will be passed to the `ControlNet3DModel` to create the residuals for the 3D U-Net.
**Describe alternatives you've considered**
Alternative one can create special purpose pipelines to use additional guidance image sequences. An example of this process is the "Follow Your Pose" approach: https://follow-your-pose.github.io/
However, extending a Stable Diffusion video pipeline with a `ControlNet3DModel` opens the door to numerous possible other extensions without the need to make a new pipeline. For example:
- A sketch temporal ControlNet would let users turn sketches to colored animations
- A optical flow ControlNet could transfer movement in a similar way to EBSynth
- A pose ControlNet could precisely control the movement of characters in a video.
**Additional context**
This is idea is part of the JAX/ControlNet sprint for the "Stable Diffusion for Animation" project. I was hoping that our work could lead to a PR that is acceptable for the repo, so I wanted to get a conversation going on the approach.
Tagging the maestro @takuma104 to get your thoughts as well.
|
https://github.com/huggingface/diffusers/issues/3075
|
closed
|
[
"question"
] | 2023-04-12T17:51:35Z
| 2023-04-13T16:21:28Z
| null |
jfischoff
|
huggingface/setfit
| 352
|
False Positives
|
I had built a model using a muti-label dataset. But I see that I am getting so many False Positive outputs during inference.
For eg:
FIRST NOTICE OF LOSS SENT TO AGENT'S CUSTOMER ACTIVITY ---> This is predicted as 'Total Loss' (Total Loss is one of my labels given fed through the dataset).
I see that there is a word 'Loss' present in the dataset but it is not supposed to be predicted as 'Total Loss'.
There are so many absurd outputs as well.
Here is the pre-trained model which I am using for fine-tuning :
Hyper-parameters : num_iterations = 30, batch_size = 16, num_epochs = 1
What went wrong?
|
https://github.com/huggingface/setfit/issues/352
|
closed
|
[
"question"
] | 2023-04-12T17:42:44Z
| 2023-05-18T16:19:27Z
| null |
cassinthangam4996
|
huggingface/setfit
| 349
|
Hard Negative Mining vs random sampling
|
Has anyone tried doing hard negative mining when generating the sentence pairs as opposed to random sampling? @tomaarsen - is random sampling the default?
|
https://github.com/huggingface/setfit/issues/349
|
open
|
[
"question"
] | 2023-04-12T09:24:53Z
| 2023-04-15T16:04:27Z
| null |
vahuja4
|
huggingface/tokenizers
| 1,216
|
What is the correct way to remove a token from the vocabulary?
|
I see that it works when I do something like this
```
del tokenizer.get_vocab()[unwanted_token]
```
~~And then it will work when running encode~~, but when I save the model the unwanted tokens remain in the json. Is there a blessed way to remove unwanted tokens?
EDIT:
Now that I tried again see that does not actually work.
|
https://github.com/huggingface/tokenizers/issues/1216
|
closed
|
[
"Stale"
] | 2023-04-11T15:40:48Z
| 2024-02-10T01:47:15Z
| null |
tvallotton
|
huggingface/optimum
| 964
|
onnx conversion for custom trained trocr base stage1
|
### Feature request
I have trained the base stage1 trocr on my custom dataset having multiline images. The trained model gives good results while using the default torch format for loading the model. But while converting the model to onnx, the model detects only first line or part of it in first line. I have used this [https://github.com/huggingface/transformers/issues/19811#issuecomment-1303072202](url)
for converting the model to onnx. Can you kindly provide the insights about what i should do differently, in order to get the desired multiline output from the onnx converted model.
### Motivation
How to update the onnx conversion of trocr in order to support multiline trocr trained model
### Your contribution
Trained a trocr base stage1 model for multiline dataset.
|
https://github.com/huggingface/optimum/issues/964
|
open
|
[
"onnx"
] | 2023-04-11T10:10:23Z
| 2023-10-16T14:20:42Z
| 1
|
Mir-Umar
|
huggingface/datasets
| 5,727
|
load_dataset fails with FileNotFound error on Windows
|
### Describe the bug
Although I can import and run the datasets library in a Colab environment, I cannot successfully load any data on my own machine (Windows 10) despite following the install steps:
(1) create conda environment
(2) activate environment
(3) install with: ``conda` install -c huggingface -c conda-forge datasets`
Then
```
from datasets import load_dataset
# this or any other example from the website fails with the FileNotFoundError
glue = load_dataset("glue", "ax")
```
**Below I have pasted the error omitting the full path**:
```
raise FileNotFoundError(
FileNotFoundError: Couldn't find a dataset script at C:\Users\...\glue\glue.py or any data file in the same directory. Couldn't find 'glue' on the Hugging Face Hub either: FileNotFoundError: [WinError 3] The system cannot find the path specified:
'C:\\Users\\...\\.cache\\huggingface'
```
### Steps to reproduce the bug
On Windows 10
1) create a minimal conda environment (with just Python)
(2) activate environment
(3) install datasets with: ``conda` install -c huggingface -c conda-forge datasets`
(4) import load_dataset and follow example usage from any dataset card.
### Expected behavior
The expected behavior is to load the file into the Python session running on my machine without error.
### Environment info
```
# Name Version Build Channel
aiohttp 3.8.4 py311ha68e1ae_0 conda-forge
aiosignal 1.3.1 pyhd8ed1ab_0 conda-forge
arrow-cpp 11.0.0 h57928b3_13_cpu conda-forge
async-timeout 4.0.2 pyhd8ed1ab_0 conda-forge
attrs 22.2.0 pyh71513ae_0 conda-forge
aws-c-auth 0.6.26 h1262f0c_1 conda-forge
aws-c-cal 0.5.21 h7cda486_2 conda-forge
aws-c-common 0.8.14 hcfcfb64_0 conda-forge
aws-c-compression 0.2.16 h8a79959_5 conda-forge
aws-c-event-stream 0.2.20 h5f78564_4 conda-forge
aws-c-http 0.7.6 h2545be9_0 conda-forge
aws-c-io 0.13.19 h0d2781e_3 conda-forge
aws-c-mqtt 0.8.6 hd211e0c_12 conda-forge
aws-c-s3 0.2.7 h8113e7b_1 conda-forge
aws-c-sdkutils 0.1.8 h8a79959_0 conda-forge
aws-checksums 0.1.14 h8a79959_5 conda-forge
aws-crt-cpp 0.19.8 he6d3b81_12 conda-forge
aws-sdk-cpp 1.10.57 h64004b3_8 conda-forge
brotlipy 0.7.0 py311ha68e1ae_1005 conda-forge
bzip2 1.0.8 h8ffe710_4 conda-forge
c-ares 1.19.0 h2bbff1b_0
ca-certificates 2023.01.10 haa95532_0
certifi 2022.12.7 pyhd8ed1ab_0 conda-forge
cffi 1.15.1 py311h7d9ee11_3 conda-forge
charset-normalizer 2.1.1 pyhd8ed1ab_0 conda-forge
colorama 0.4.6 pyhd8ed1ab_0 conda-forge
cryptography 40.0.1 py311h28e9c30_0 conda-forge
dataclasses 0.8 pyhc8e2a94_3 conda-forge
datasets 2.11.0 py_0 huggingface
dill 0.3.6 pyhd8ed1ab_1 conda-forge
filelock 3.11.0 pyhd8ed1ab_0 conda-forge
frozenlist 1.3.3 py311ha68e1ae_0 conda-forge
fsspec 2023.4.0 pyh1a96a4e_0 conda-forge
gflags 2.2.2 ha925a31_1004 conda-forge
glog 0.6.0 h4797de2_0 conda-forge
huggingface_hub 0.13.4 py_0 huggingface
idna 3.4 pyhd8ed1ab_0 conda-forge
importlib-metadata 6.3.0 pyha770c72_0 conda-forge
importlib_metadata 6.3.0 hd8ed1ab_0 conda-forge
intel-openmp 2023.0.0 h57928b3_25922 conda-forge
krb5 1.20.1 heb0366b_0 conda-forge
libabseil 20230125.0 cxx17_h63175ca_1 conda-forge
libarrow 11.0.0 h04c43f8_13_cpu conda-forge
libblas 3.9.0 16_win64_mkl conda-forge
libbrotlicommon 1.0.9 hcfcfb64_8 conda-forge
libbrotlidec 1.0.9 hcfcfb64_8 conda-forge
libbrotlienc 1.0.9 hcfcfb64_8 conda-forge
libcblas 3.9.0 16_win64_mkl conda-forge
libcrc32c 1.1.2 h0e60522_0
|
https://github.com/huggingface/datasets/issues/5727
|
closed
|
[] | 2023-04-10T23:21:12Z
| 2023-07-21T14:08:20Z
| 4
|
joelkowalewski
|
huggingface/datasets
| 5,725
|
How to limit the number of examples in dataset, for testing?
|
### Describe the bug
I am using this command:
`data = load_dataset("json", data_files=data_path)`
However, I want to add a parameter, to limit the number of loaded examples to be 10, for development purposes, but can't find this simple parameter.
### Steps to reproduce the bug
In the description.
### Expected behavior
To be able to limit the number of examples
### Environment info
Nothing special
|
https://github.com/huggingface/datasets/issues/5725
|
closed
|
[] | 2023-04-10T08:41:43Z
| 2023-04-21T06:16:24Z
| 3
|
ndvbd
|
huggingface/transformers.js
| 75
|
[Question] WavLM support
|
This is a really good project. I was wondering if WavLM is supported in the project, I wanted to run a voice conversation model in the browser, also if Hifi-gan for voice synthesis.
|
https://github.com/huggingface/transformers.js/issues/75
|
closed
|
[
"question"
] | 2023-04-08T09:36:03Z
| 2023-09-08T13:17:07Z
| null |
Ashraf-Ali-aa
|
huggingface/datasets
| 5,719
|
Array2D feature creates a list of list instead of a numpy array
|
### Describe the bug
I'm not sure if this is expected behavior or not. When I create a 2D array using `Array2D`, the data has list type instead of numpy array. I think it should not be the expected behavior especially when I feed a numpy array as input to the data creation function. Why is it converting my array into a list?
Also if I change the first dimension of the `Array2D` shape to None, it's returning array correctly.
### Steps to reproduce the bug
Run this code:
```py
from datasets import Dataset, Features, Array2D
import numpy as np
# you have to change the first dimension of the shape to None to make it return an array
features = Features(dict(seq=Array2D((2,2), 'float32')))
ds = Dataset.from_dict(dict(seq=[np.random.rand(2,2)]), features=features)
a = ds[0]['seq']
print(a)
print(type(a))
```
The following will be printed in stdout:
```
[[0.8127174377441406, 0.3760348856449127], [0.7510159611701965, 0.4322739541530609]]
<class 'list'>
```
### Expected behavior
Each indexed item should be a list or numpy array. Currently, `Array((2,2))` yields a list but `Array((None,2))` yields an array.
### Environment info
- `datasets` version: 2.11.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.13
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 1.4.4
|
https://github.com/huggingface/datasets/issues/5719
|
closed
|
[] | 2023-04-07T21:04:08Z
| 2023-04-20T15:34:41Z
| 4
|
offchan42
|
huggingface/datasets
| 5,716
|
Handle empty audio
|
Some audio paths exist, but they are empty, and an error will be reported when reading the audio path.How to use the filter function to avoid the empty audio path?
when a audio is empty, when do resample , it will break:
`array, sampling_rate = sf.read(f) array = librosa.resample(array, orig_sr=sampling_rate, target_sr=self.sampling_rate)`
|
https://github.com/huggingface/datasets/issues/5716
|
closed
|
[] | 2023-04-07T09:51:40Z
| 2023-09-27T17:47:08Z
| 2
|
zyb8543d
|
huggingface/setfit
| 344
|
How to do I have multi text columns?
|
Text is not one column, there many columns. For example : The text columns are "sex","title","weather". What should I do?
|
https://github.com/huggingface/setfit/issues/344
|
closed
|
[
"question"
] | 2023-04-07T01:51:21Z
| 2023-04-10T00:45:38Z
| null |
freecui
|
huggingface/transformers.js
| 71
|
[Question] How to run test suit
|
Hi @xenova,
I want to work on adding new features, but when I try to run the tests of the project I get this error:
```
Error: File not found. Could not locate "/Users/yonatanchelouche/Desktop/passive-project/transformers.js/models/onnx/quantized/distilbert-base-uncased-finetuned-sst-2-english/sequence-classification/tokenizer.json".
at getModelFile (/Users/yonatanchelouche/Desktop/passive-project/transformers.js/src/utils.js:235:23)
at async fetchJSON (/Users/yonatanchelouche/Desktop/passive-project/transformers.js/src/utils.js:288:18)
at async Promise.all (index 0)
at async Function.from_pretrained (/Users/yonatanchelouche/Desktop/passive-project/transformers.js/src/tokenizers.js:2571:48)
at async Promise.all (index 0)
at async pipeline (/Users/yonatanchelouche/Desktop/passive-project/transformers.js/src/pipelines.js:1308:17)
at async text_classification (/Users/yonatanchelouche/Desktop/passive-project/transformers.js/tests/index.js:90:22)
at async /Users/yonatanchelouche/Desktop/passive-project/transformers.js/tests/index.js:897:25
```
I guess it is because the models are missing from the models dir. Is there a programmatic way to download them from the lib?
By the way, I was thinking about adding a CI on PRs to run the tests and perhaps adding jest as the test runner. What, do you think about that?
|
https://github.com/huggingface/transformers.js/issues/71
|
closed
|
[
"question"
] | 2023-04-06T17:03:09Z
| 2023-05-15T17:38:46Z
| null |
chelouche9
|
huggingface/transformers.js
| 69
|
How to convert bloomz model
|
While converting the [bloomz](https://huggingface.co/bigscience/bloomz-7b1l) model, I am getting the 'invalid syntax' error. Is conversion limited to only predefined model types?
If not, please provide the syntax for converting the above model with quantization.
(I will run the inference in nodejs and not in browser, so memory will not be an issue in inference.)
|
https://github.com/huggingface/transformers.js/issues/69
|
closed
|
[
"question"
] | 2023-04-04T14:51:16Z
| 2023-04-09T02:01:49Z
| null |
bil-ash
|
huggingface/transformers.js
| 68
|
[Feature request] whisper word level timestamps
|
I am new to both transformers.js and whisper, so I am sorry for a lame question in advance.
I am trying to make [return_timestamps](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline.__call__) parameter work...
I managed to customize [script.js](https://github.com/xenova/transformers.js/blob/main/assets/js/scripts.js#L447) from [transformer.js demo](https://xenova.github.io/transformers.js/) locally and added `data.generation.return_timestamps = "char"`; around line ~447 inside GENERATE_BUTTON click handler in order to pass the parameter. With that change in place I am seeing timestamp appears as chunks (`result` var in [worker.js](https://github.com/xenova/transformers.js/blob/main/assets/js/worker.js#L40)):
```
{
"text": " And so my fellow Americans ask not what your country can do for you ask what you can do for your country.",
"chunks": [
{
"timestamp": [0,8],
"text": " And so my fellow Americans ask not what your country can do for you"
},
{
"timestamp": [8,11],
"text": " ask what you can do for your country."
}
]
}
```
however the chunks are not "char level" granular as expected following the [return_timestamps](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline.__call__) doc.
I am looking for ideas how to achieve char/word level timestamp granularity with transform.js and whisper. Do some models/tools need to be updated and/or rebuild?
|
https://github.com/huggingface/transformers.js/issues/68
|
closed
|
[
"enhancement",
"question"
] | 2023-04-04T10:57:05Z
| 2023-07-09T22:48:31Z
| null |
jozefchutka
|
huggingface/datasets
| 5,705
|
Getting next item from IterableDataset took forever.
|
### Describe the bug
I have a large dataset, about 500GB. The format of the dataset is parquet.
I then load the dataset and try to get the first item
```python
def get_one_item():
dataset = load_dataset("path/to/datafiles", split="train", cache_dir=".", streaming=True)
dataset = dataset.filter(lambda example: example['text'].startswith('Ar'))
print(next(iter(dataset)))
```
However, this function never finish. I waited ~10mins, the function was still running so I killed the process. I'm now using `line_profiler` to profile how long it would take to return one item. I'll be patient and wait for as long as it needs.
I suspect the filter operation is the reason why it took so long. Can I get some possible reasons behind this?
### Steps to reproduce the bug
Unfortunately without my data files, there is no way to reproduce this bug.
### Expected behavior
With `IteralbeDataset`, I expect the first item to be returned instantly.
### Environment info
- datasets version: 2.11.0
- python: 3.7.12
|
https://github.com/huggingface/datasets/issues/5705
|
closed
|
[] | 2023-04-04T09:16:17Z
| 2023-04-05T23:35:41Z
| 2
|
HongtaoYang
|
huggingface/optimum
| 952
|
Enable AMP for BetterTransformer
|
### Feature request
Allow for the `BetterTransformer` models to be inferenced with AMP.
### Motivation
Models transformed with `BetterTransformer` raise error when used with AMP:
`bettertransformers.models.base`
```python
...
def forward_checker(self, *args, **kwargs):
if torch.is_autocast_enabled() or torch.is_autocast_cpu_enabled():
raise ValueError("Autocast is not supported for `BetterTransformer` integration.")
if self.training and not self.is_decoder:
raise ValueError(
"Training is not supported for `BetterTransformer` integration.",
" Please use `model.eval()` before running the model.",
)
...
```
Why is that? I tried setting `torch.is_autocast_enabled` to `lambda: False` and everything works just fine at least for `XLMRobertaModel`:
```python
>>> import torch
>>> from transformers import AutoModel
>>> from optimum.bettertransformer import BetterTransformer
>>> m = AutoModel.from_pretrained('xlm-roberta-base')
>>> BetterTransformer.transform(m, keep_original_model=False)
XLMRobertaModel(
(embeddings): XLMRobertaEmbeddings(
(word_embeddings): Embedding(250002, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): XLMRobertaEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayerBetterTransformer()
)
)
(pooler): XLMRobertaPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
>>> with torch.amp.autocast('cuda'):
... m(**{name: t.to('cuda') for name, t in m.dummy_inputs.items()})
...
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ <stdin>:2 in <module> │
│ │
│ /home/viktor-sch/Clones/talisman-ie/venv/lib/python3.10/site-packages/torch/nn/modules/module.py │
│ :1501 in _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ /home/viktor-sch/Clones/talisman-ie/venv/lib/python3.10/site-packages/transformers/models/xlm_ro │
│ berta/modeling_xlm_roberta.py:854 in forward │
│ │
│ 851 │ │ │ inputs_embeds=inputs_embeds, │
│ 852 │ │ │ past_key_values_length=past_key_values_length, │
│ 853 │ │ ) │
│ ❱ 854 │ │ encoder_outputs = self.encoder( │
│ 855 │ │ │ embedding_output, │
│ 856 │ │ │ attention_mask=extended_attention_mask, │
│ 857 │ │ │ head_mask=head_mask, │
│ │
│ /home/viktor-sch/Clones/talisman-ie/venv/lib/python3.10/site-packages/torch/nn/modules/module.py │
│ :1501 in _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks):
|
https://github.com/huggingface/optimum/issues/952
|
closed
|
[] | 2023-04-04T09:14:00Z
| 2023-07-26T17:08:42Z
| 6
|
viktor-shcherb
|
huggingface/controlnet_aux
| 18
|
When using openpose, what is the format of the input image? RGB format, or BGR format?
|


I saw that the image in BGR format is used as input in the open_pose/body.py file, but the huggingface demo uses a BGR format image. What is the impact of this?
|
https://github.com/huggingface/controlnet_aux/issues/18
|
open
|
[] | 2023-04-04T03:58:38Z
| 2023-04-04T11:23:33Z
| null |
ZihaoW123
|
huggingface/datasets
| 5,702
|
Is it possible or how to define a `datasets.Sequence` that could potentially be either a dict, a str, or None?
|
### Feature request
Hello! Apologies if my question sounds naive:
I was wondering if it’s possible, or how one would go about defining a 'datasets.Sequence' element in datasets.Features that could potentially be either a dict, a str, or None?
Specifically, I’d like to define a feature for a list that contains 18 elements, each of which has been pre-defined as either a `dict or None` or `str or None` - as demonstrated in the slightly misaligned data provided below:
```json
[
[
{"text":"老妇人","idxes":[0,1,2]},null,{"text":"跪","idxes":[3]},null,null,null,null,{"text":"在那坑里","idxes":[4,5,6,7]},null,null,null,null,null,null,null,null,null,null],
[
{"text":"那些水","idxes":[13,14,15]},null,{"text":"舀","idxes":[11]},null,null,null,null,null,{"text":"在那坑里","idxes":[4,5,6,7]},null,{"text":"出","idxes":[12]},null,null,null,null,null,null,null],
[
{"text":"水","idxes":[38]},
null,
{"text":"舀","idxes":[40]},
"假", // note this is just a standalone string
null,null,null,{"text":"坑里","idxes":[35,36]},null,null,null,null,null,null,null,null,null,null]]
```
### Motivation
I'm currently working with a dataset of the following structure and I couldn't find a solution in the [documentation](https://huggingface.co/docs/datasets/v2.11.0/en/package_reference/main_classes#datasets.Features).
```json
{"qid":"3-train-1058","context":"桑桑害怕了。从玉米地里走到田埂上,他遥望着他家那幢草房子里的灯光,知道母亲没有让他回家的意思,很伤感,有点想哭。但没哭,转身朝阿恕家走去。","corefs":[[{"text":"桑桑","idxes":[0,1]},{"text":"他","idxes":[17]}]],"non_corefs":[],"outputs":[[{"text":"他","idxes":[17]},null,{"text":"走","idxes":[11]},null,null,null,null,null,{"text":"从玉米地里","idxes":[6,7,8,9,10]},{"text":"到田埂上","idxes":[12,13,14,15]},null,null,null,null,null,null,null,null],[{"text":"他","idxes":[17]},null,{"text":"走","idxes":[66]},null,null,null,null,null,null,null,{"text":"转身朝阿恕家去","idxes":[60,61,62,63,64,65,67]},null,null,null,null,null,null,null],[{"text":"灯光","idxes":[30,31]},null,null,null,null,null,null,{"text":"草房子里","idxes":[25,26,27,28]},null,null,null,null,null,null,null,null,null,null],[{"text":"他","idxes":[17]},{"text":"他家那幢草房子","idxes":[21,22,23,24,25,26,27]},null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,"远"],[{"text":"他","idxes":[17]},{"text":"阿恕家","idxes":[63,64,65]},null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,"变近"]]}
```
### Your contribution
I'm going to provide the dataset at https://huggingface.co/datasets/2030NLP/SpaCE2022 .
|
https://github.com/huggingface/datasets/issues/5702
|
closed
|
[
"enhancement"
] | 2023-04-04T03:20:43Z
| 2023-04-05T14:15:18Z
| 4
|
gitforziio
|
huggingface/dataset-viewer
| 1,011
|
Remove authentication by cookie?
|
Currently, to be able to return the contents for gated datasets, all the endpoints check the request credentials if needed. The accepted credentials are: HF token, HF cookie, or a JWT in `X-Api-Key`. See https://github.com/huggingface/datasets-server/blob/ecb861b5e8d728b80391f580e63c8d2cad63a1fc/services/api/src/api/authentication.py#L26
Should we remove the cookie authentication?
cc @coyotte508 @SBrandeis @XciD @rtrompier
|
https://github.com/huggingface/dataset-viewer/issues/1011
|
closed
|
[
"question",
"P2"
] | 2023-04-03T12:12:56Z
| 2024-03-13T09:48:38Z
| null |
severo
|
huggingface/transformers.js
| 63
|
[Model request] Helsinki-NLP/opus-mt-ru-en (marian)
|
Sorry for this noob question, can somebody give me a kind of guideline to be able to convert and use
https://huggingface.co/Helsinki-NLP/opus-mt-ru-en/tree/main
thank you
|
https://github.com/huggingface/transformers.js/issues/63
|
closed
|
[
"enhancement",
"question"
] | 2023-03-31T09:18:28Z
| 2023-08-20T08:00:38Z
| null |
eviltik
|
huggingface/safetensors
| 222
|
Might not related but wanna ask: does there can have a c++ version?
|
Hello, wanna ask 2 questions:
1. will safetensors provides a c++ version, it looks more convenient then pth or onnx;
2. does it possible to load safetensors into some forward lib not just pytorch, such as onnxruntime etc?
|
https://github.com/huggingface/safetensors/issues/222
|
closed
|
[
"Stale"
] | 2023-03-31T05:14:29Z
| 2023-12-21T01:47:58Z
| 5
|
lucasjinreal
|
huggingface/transformers.js
| 62
|
[Feature request] nodejs caching
|
Hi, thank you for your works
I'm a nodejs user and i read that there is no model cache implementation right now, and you are working on it.
Do you have an idea of when you will be able to push a release with a cache implementation ?
Just asking because i was at the point to code it on my side
|
https://github.com/huggingface/transformers.js/issues/62
|
closed
|
[
"enhancement",
"question"
] | 2023-03-31T04:27:57Z
| 2023-05-15T17:26:55Z
| null |
eviltik
|
huggingface/dataset-viewer
| 1,001
|
Add total_rows in /rows response?
|
Should we add the number of rows in a split (eg. in field `total_rows`) in response to /rows?
It would help avoid sending a request to /size to get it.
It would also help fix a bad query.
eg: https://datasets-server.huggingface.co/rows?dataset=glue&config=ax&split=test&offset=50000&length=100 returns:
```json
{
"features": [
...
],
"rows": []
}
```
We would have to know the number of rows to fix it.
|
https://github.com/huggingface/dataset-viewer/issues/1001
|
closed
|
[
"question",
"improvement / optimization"
] | 2023-03-30T13:54:19Z
| 2023-05-07T15:04:12Z
| null |
severo
|
huggingface/dataset-viewer
| 999
|
Use the huggingface_hub webhook server?
|
See https://github.com/huggingface/huggingface_hub/pull/1410
The/webhook endpoint could live in its pod with the huggingface_hub webhook server. Is it useful for our project? Feel free to comment.
|
https://github.com/huggingface/dataset-viewer/issues/999
|
closed
|
[
"question",
"refactoring / architecture"
] | 2023-03-30T08:44:49Z
| 2023-06-10T15:04:09Z
| null |
severo
|
huggingface/datasets
| 5,687
|
Document to compress data files before uploading
|
In our docs to [Share a dataset to the Hub](https://huggingface.co/docs/datasets/upload_dataset), we tell users to upload directly their data files, like CSV, JSON, JSON-Lines, text,... However, these extensions are not tracked by Git LFS by default, as they are not in the `.giattributes` file. Therefore, if they are too large, Git will fail to commit/upload them.
I think for those file extensions (.csv, .json, .jsonl, .txt), we should better recommend to **compress** their data files (using ZIP for example) before uploading them to the Hub.
- Compressed files are tracked by Git LFS in our default `.gitattributes` file
What do you think?
CC: @stevhliu
See related issue:
- https://huggingface.co/datasets/tcor0005/langchain-docs-400-chunksize/discussions/1
|
https://github.com/huggingface/datasets/issues/5687
|
closed
|
[
"documentation"
] | 2023-03-30T06:41:07Z
| 2023-04-19T07:25:59Z
| 3
|
albertvillanova
|
huggingface/datasets
| 5,685
|
Broken Image render on the hub website
|
### Describe the bug
Hi :wave:
Not sure if this is the right place to ask, but I am trying to load a huge amount of datasets on the hub (:partying_face: ) but I am facing a little issue with the `image` type

See this [dataset](https://huggingface.co/datasets/Francesco/cell-towers), basically for some reason the first image has numerical bytes inside, not sure if that is okay, but the image render feature **doesn't work**
So the dataset is stored in the following way
```python
builder.download_and_prepare(output_dir=str(output_dir))
ds = builder.as_dataset(split="train")
# [NOTE] no idea how to push it from the builder folder
ds.push_to_hub(repo_id=repo_id)
builder.as_dataset(split="validation").push_to_hub(repo_id=repo_id)
ds = builder.as_dataset(split="test")
ds.push_to_hub(repo_id=repo_id)
```
The build is this class
```python
class COCOLikeDatasetBuilder(datasets.GeneratorBasedBuilder):
VERSION = datasets.Version("1.0.0")
def _info(self):
features = datasets.Features(
{
"image_id": datasets.Value("int64"),
"image": datasets.Image(),
"width": datasets.Value("int32"),
"height": datasets.Value("int32"),
"objects": datasets.Sequence(
{
"id": datasets.Value("int64"),
"area": datasets.Value("int64"),
"bbox": datasets.Sequence(
datasets.Value("float32"), length=4
),
"category": datasets.ClassLabel(names=categories),
}
),
}
)
return datasets.DatasetInfo(
description=description,
features=features,
homepage=homepage,
license=license,
citation=citation,
)
def _split_generators(self, dl_manager):
archive = dl_manager.download(url)
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
gen_kwargs={
"annotation_file_path": "train/_annotations.coco.json",
"files": dl_manager.iter_archive(archive),
},
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION,
gen_kwargs={
"annotation_file_path": "test/_annotations.coco.json",
"files": dl_manager.iter_archive(archive),
},
),
datasets.SplitGenerator(
name=datasets.Split.TEST,
gen_kwargs={
"annotation_file_path": "valid/_annotations.coco.json",
"files": dl_manager.iter_archive(archive),
},
),
]
def _generate_examples(self, annotation_file_path, files):
def process_annot(annot, category_id_to_category):
return {
"id": annot["id"],
"area": annot["area"],
"bbox": annot["bbox"],
"category": category_id_to_category[annot["category_id"]],
}
image_id_to_image = {}
idx = 0
# This loop relies on the ordering of the files in the archive:
# Annotation files come first, then the images.
for path, f in files:
file_name = os.path.basename(path)
if annotation_file_path in path:
annotations = json.load(f)
category_id_to_category = {
category["id"]: category["name"]
for category in annotations["categories"]
}
print(category_id_to_category)
image_id_to_annotations = collections.defaultdict(list)
for annot in annotations["annotations"]:
image_id_to_annotations[annot["image_id"]].append(annot)
image_id_to_image = {
annot["file_name"]: annot for annot in annotations["images"]
}
elif file_name in image_id_to_image:
image = image_id_to_image[file_name]
objects = [
process_annot(annot, category_id_to_category)
for annot in image_id_to_annotations[image["id"]]
|
https://github.com/huggingface/datasets/issues/5685
|
closed
|
[] | 2023-03-29T15:25:30Z
| 2023-03-30T07:54:25Z
| 3
|
FrancescoSaverioZuppichini
|
huggingface/datasets
| 5,681
|
Add information about patterns search order to the doc about structuring repo
|
Following [this](https://github.com/huggingface/datasets/issues/5650) issue I think we should add a note about the order of patterns that is used to find splits, see [my comment](https://github.com/huggingface/datasets/issues/5650#issuecomment-1488412527). Also we should reference this page in pages about packaged loaders.
I have a déjà vu that it had already been discussed as some point but I don't remember....
|
https://github.com/huggingface/datasets/issues/5681
|
closed
|
[
"documentation"
] | 2023-03-29T11:44:49Z
| 2023-04-03T18:31:11Z
| 2
|
polinaeterna
|
huggingface/datasets
| 5,671
|
How to use `load_dataset('glue', 'cola')`
|
### Describe the bug
I'm new to use HuggingFace datasets but I cannot use `load_dataset('glue', 'cola')`.
- I was stacked by the following problem:
```python
from datasets import load_dataset
cola_dataset = load_dataset('glue', 'cola')
---------------------------------------------------------------------------
InvalidVersion Traceback (most recent call last)
File <timed exec>:1
(Omit because of long error message)
File /usr/local/lib/python3.8/site-packages/packaging/version.py:197, in Version.__init__(self, version)
195 match = self._regex.search(version)
196 if not match:
--> 197 raise InvalidVersion(f"Invalid version: '{version}'")
199 # Store the parsed out pieces of the version
200 self._version = _Version(
201 epoch=int(match.group("epoch")) if match.group("epoch") else 0,
202 release=tuple(int(i) for i in match.group("release").split(".")),
(...)
208 local=_parse_local_version(match.group("local")),
209 )
InvalidVersion: Invalid version: '0.10.1,<0.11'
```
- You can check this full error message in my repository: [MLOps-Basics/week_0_project_setup/experimental_notebooks/data_exploration.ipynb](https://github.com/makinzm/MLOps-Basics/blob/eabab4b837880607d9968d3fa687c70177b2affd/week_0_project_setup/experimental_notebooks/data_exploration.ipynb)
### Steps to reproduce the bug
- This is my repository to reproduce: [MLOps-Basics/week_0_project_setup](https://github.com/makinzm/MLOps-Basics/tree/eabab4b837880607d9968d3fa687c70177b2affd/week_0_project_setup)
1. cd `/DockerImage` and command `docker build . -t week0`
2. cd `/` and command `docker-compose up`
3. Run `experimental_notebooks/data_exploration.ipynb`
----
Just to be sure, I wrote down Dockerfile and requirements.txt
- Dockerfile
```Dockerfile
FROM python:3.8
WORKDIR /root/working
RUN apt-get update && \
apt-get install -y python3-dev python3-pip python3-venv && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip3 install --no-cache-dir jupyter notebook && pip install --no-cache-dir -r requirements.txt
CMD ["bash"]
```
- requirements.txt
```txt
pytorch-lightning==1.2.10
datasets==1.6.2
transformers==4.5.1
scikit-learn==0.24.2
```
### Expected behavior
There is no bug to implement `load_dataset('glue', 'cola')`
### Environment info
I already wrote it.
|
https://github.com/huggingface/datasets/issues/5671
|
closed
|
[] | 2023-03-26T09:40:34Z
| 2023-03-28T07:43:44Z
| 2
|
makinzm
|
huggingface/optimum
| 918
|
Support for LLaMA
|
### Feature request
A support for exporting LLaMA to ONNX
### Motivation
It would be great to have one, to apply optimizations and so on
### Your contribution
I could try implementing a support, but I would need an assist on model config even though it should be pretty simmilar to what is already done with GPT-J
|
https://github.com/huggingface/optimum/issues/918
|
closed
|
[
"onnx"
] | 2023-03-23T21:07:30Z
| 2023-04-17T14:32:37Z
| 2
|
nenkoru
|
huggingface/datasets
| 5,665
|
Feature request: IterableDataset.push_to_hub
|
### Feature request
It'd be great to have a lazy push to hub, similar to the lazy loading we have with `IterableDataset`.
Suppose you'd like to filter [LAION](https://huggingface.co/datasets/laion/laion400m) based on certain conditions, but as LAION doesn't fit into your disk, you'd like to leverage streaming:
```
from datasets import load_dataset
dataset = load_dataset("laion/laion400m", streaming=True, split="train")
```
Then you could filter the dataset based on certain conditions:
```
filtered_dataset = dataset.filter(lambda example: example['HEIGHT'] > 400)
```
In order to persist this dataset and push it back to the hub, one currently needs to first load the entire filtered dataset on disk and then push:
```
from datasets import Dataset
Dataset.from_generator(filtered_dataset.__iter__).push_to_hub(...)
```
It would be great if we can instead lazy push to the data to the hub (basically stream the data to the hub), not being limited by our disk size:
```
filtered_dataset.push_to_hub("my-filtered-dataset")
```
### Motivation
This feature would be very useful for people that want to filter huge datasets without having to load the entire dataset or a filtered version thereof on their local disk.
### Your contribution
Happy to test out a PR :)
|
https://github.com/huggingface/datasets/issues/5665
|
closed
|
[
"enhancement"
] | 2023-03-23T09:53:04Z
| 2025-06-06T16:13:22Z
| 13
|
NielsRogge
|
huggingface/datasets
| 5,660
|
integration with imbalanced-learn
|
### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I've looked online, asked gpt-4, but so far not making much progress.
### Your contribution
If I can get this working myself I can submit a PR with example code to go in the docs
|
https://github.com/huggingface/datasets/issues/5660
|
closed
|
[
"enhancement",
"wontfix"
] | 2023-03-22T11:05:17Z
| 2023-07-06T18:10:15Z
| 1
|
tansaku
|
huggingface/safetensors
| 202
|
`safetensor.torch.save_file()` throws `RuntimeError` - any recommended way to enforce?
|
was confronted with `RuntimeError: Some tensors share memory, this will lead to duplicate memory on disk and potential differences when loading them again`.
Can we explicitly disregard "**potential** differences"?
|
https://github.com/huggingface/safetensors/issues/202
|
closed
|
[] | 2023-03-21T21:24:38Z
| 2024-06-06T02:29:48Z
| 26
|
drahnreb
|
huggingface/optimum
| 906
|
Optimum export of whisper raises ValueError: There was an error while processing timestamps, we haven't found a timestamp as last token. Was WhisperTimeStampLogitsProcessor used?
|
### System Info
```shell
optimum: 1.7.1
Python: 3.8.3
transformers: 4.27.2
platform: Windows 10
```
### Who can help?
@philschmid @michaelbenayoun
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
1. Convert the model to ONNX:
```
python -m optimum.exporters.onnx --model openai/whisper-tiny.en whisper_onnx/
```
2. Due to [another bug in the pipeline function](https://github.com/huggingface/optimum/issues/905), you may need to comment out the lines in the generate function which raises an error for unused model kwargs:
https://github.com/huggingface/transformers/blob/48327c57182fdade7f7797d1eaad2d166de5c55b/src/transformers/generation/utils.py#L1104-L1108
3. Try to transcribe longer audio clip:
```python
import onnxruntime
from transformers import pipeline, AutoProcessor
from optimum.onnxruntime import ORTModelForSpeechSeq2Seq
whisper_model_name = './whisper_onnx/'
processor = AutoProcessor.from_pretrained(whisper_model_name)
session_options = onnxruntime.SessionOptions()
model_ort = ORTModelForSpeechSeq2Seq.from_pretrained(
whisper_model_name,
use_io_binding=True,
session_options=session_options
)
generator_ort = pipeline(
task="automatic-speech-recognition",
model=model_ort,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
)
out = generator_ort(
'https://xenova.github.io/transformers.js/assets/audio/ted_60.wav',
return_timestamps=True,
chunk_length_s=30,
stride_length_s=5
)
print(f'{out=}')
```
4. This raises the error:
```python
│ 878 │ │ if return_timestamps: │
│ 879 │ │ │ # Last token should always be timestamps, so there shouldn't be │
│ 880 │ │ │ # leftover │
│ ❱ 881 │ │ │ raise ValueError( │
│ 882 │ │ │ │ "There was an error while processing timestamps, we haven't found a time │
│ 883 │ │ │ │ " WhisperTimeStampLogitsProcessor used?" │
│ 884 │ │ │ ) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
ValueError: There was an error while processing timestamps, we haven't found a timestamp as last token. Was WhisperTimeStampLogitsProcessor used?
```
### Expected behavior
The program should act like the transformers version and not crash:
```python
from transformers import pipeline
transcriber = pipeline('automatic-speech-recognition', 'openai/whisper-tiny.en')
text = transcriber(
'https://xenova.github.io/transformers.js/assets/audio/ted_60.wav',
return_timestamps=True,
chunk_length_s=30,
stride_length_s=5
)
print(f'{text=}')
# outputs correctly
```
|
https://github.com/huggingface/optimum/issues/906
|
closed
|
[
"bug"
] | 2023-03-21T13:45:10Z
| 2023-03-24T18:26:17Z
| 3
|
xenova
|
huggingface/datasets
| 5,653
|
Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented
|
### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_shards) explicitly says that it depends on `max_shard_size`, it should also mention `num_proc`.
### Environment info
datasets main document
|
https://github.com/huggingface/datasets/issues/5653
|
closed
|
[
"documentation",
"good first issue"
] | 2023-03-21T05:25:35Z
| 2023-03-24T16:36:23Z
| 1
|
RmZeta2718
|
huggingface/dataset-viewer
| 965
|
Change the limit of started jobs? all kinds -> per kind
|
Currently, the `QUEUE_MAX_JOBS_PER_NAMESPACE` parameter limits the number of started jobs for the same namespace (user or organization). Maybe we should enforce this limit **per job kind** instead of **globally**.
|
https://github.com/huggingface/dataset-viewer/issues/965
|
closed
|
[
"question",
"improvement / optimization"
] | 2023-03-20T17:40:45Z
| 2023-04-29T15:03:57Z
| null |
severo
|
huggingface/dataset-viewer
| 964
|
Kill a job after a maximum duration?
|
The heartbeat already allows to detect if a job has crashed and to generate an error in that case. But some jobs can take forever, while not crashing. Should we set a maximum duration for the jobs, in order to save resources and free the queue? I imagine that we could automatically kill a job that takes more than 20 minutes to run, and insert an error in the cache.
|
https://github.com/huggingface/dataset-viewer/issues/964
|
closed
|
[
"question",
"improvement / optimization"
] | 2023-03-20T17:37:35Z
| 2023-03-23T13:16:33Z
| null |
severo
|
huggingface/optimum
| 903
|
Support transformers export to ggml format
|
### Feature request
ggml is gaining traction (e.g. llama.cpp has 10k stars), and it would be great to extend optimum.exporters and enable the community to export PyTorch/Tensorflow transformers weights to the format expected by ggml, having a more streamlined and single-entry export.
This could avoid duplicates as
https://github.com/ggerganov/llama.cpp/blob/master/convert-pth-to-ggml.py
https://github.com/ggerganov/whisper.cpp/blob/master/models/convert-pt-to-ggml.py
https://github.com/ggerganov/ggml/blob/master/examples/gpt-j/convert-h5-to-ggml.py
### Motivation
/
### Your contribution
I could have a look at it and submit a POC, cc @NouamaneTazi @ggerganov
Open to contribution as well, I don't expect it to be too much work
|
https://github.com/huggingface/optimum/issues/903
|
open
|
[
"feature-request",
"help wanted",
"exporters"
] | 2023-03-20T12:51:51Z
| 2023-07-03T04:51:18Z
| 2
|
fxmarty
|
huggingface/datasets
| 5,650
|
load_dataset can't work correct with my image data
|
I have about 20000 images in my folder which divided into 4 folders with class names.
When i use load_dataset("my_folder_name", split="train") this function create dataset in which there are only 4 images, the remaining 19000 images were not added there. What is the problem and did not understand. Tried converting images and the like but absolutely nothing worked
|
https://github.com/huggingface/datasets/issues/5650
|
closed
|
[] | 2023-03-18T13:59:13Z
| 2023-07-24T14:13:02Z
| 21
|
WiNE-iNEFF
|
huggingface/dataset-viewer
| 924
|
Support webhook version 3?
|
The Hub provides different formats for the webhooks. The current version, used in the public feature (https://huggingface.co/docs/hub/webhooks) is version 3. Maybe we should support version 3 soon.
|
https://github.com/huggingface/dataset-viewer/issues/924
|
closed
|
[
"question",
"refactoring / architecture"
] | 2023-03-13T13:39:59Z
| 2023-04-21T15:03:54Z
| null |
severo
|
huggingface/datasets
| 5,632
|
Dataset cannot convert too large dictionnary
|
### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of my dictionnary, and then I have the error "OverflowError: Python int too large to convert to C long".
Do you know how to solve this problem?
Unfortunately I cannot give a reproductible code because I cannot share a so large file, but you can find the code below (it's a test on only a part of the validation data ~10Go, but it's already the case).
Thank you!
### Steps to reproduce the bug
SAVE_DIR = './data/'
features = h5py.File(SAVE_DIR+'features.hdf5','r')
valid_data = features["validation"]["data/features"]
v_array_values = [np.float32(item[()]) for item in valid_data.values()]
for i in range(len(v_array_values)):
v_array_values[i] = v_array_values[i].round(decimals=5)
dict_valid = datasets.Dataset.from_dict({'input_values': v_array_values})
### Expected behavior
The code is expected to give me a Huggingface dataset.
### Environment info
python: 3.8.15
numpy: 1.22.3
datasets: 2.3.2
pyarrow: 8.0.0
|
https://github.com/huggingface/datasets/issues/5632
|
open
|
[] | 2023-03-13T10:14:40Z
| 2023-03-16T15:28:57Z
| 1
|
MaraLac
|
huggingface/ethics-education
| 1
|
What is AI Ethics?
|
With the amount of hype around things like ChatGPT, AI art, etc., there are a lot of misunderstandings being propagated through the media! Additionally, many people are not aware of the ethical impacts of AI, and they're even less aware about the work that folks in academia + industry are doing to ensure that AI systems are being developed and deployed in ways that are equitable, sustainable, etc.
This is a great opportunity for us to put together a simple explainer, with some very high-level information aimed at non-technical people, that runs through what AI Ethics is and why people should care. Format-wise, I'm aiming towards something like a light blog post.
More specifically, it would be really cool to have something that ties into the categories outlined on [hf.co/ethics](https://hf.co/ethics). A more detailed description is available here on [Google Docs](https://docs.google.com/document/d/19Ga4PX0xbRxMlAwoK-q7Xjuy9B9Z0jFvFuVYdhfcKiY/edit).
If you're interested in helping out with this, a great first step would be to collect some resources and start outlining a bullet-point draft on a Google Doc that I can share with you 😄
I've also got plans for the actual distribution of it (e.g. design-wise, distribution), which I'll follow up with soon.
|
https://github.com/huggingface/ethics-education/issues/1
|
open
|
[
"help wanted",
"explainer",
"audience: non-technical"
] | 2023-03-09T20:58:02Z
| 2023-03-17T14:50:39Z
| null |
NimaBoscarino
|
huggingface/diffusers
| 2,633
|
Asymmetric tiling
|
Hello. I'm trying to achieve tiling asymmetrically using Diffusers, in a similar fashion to the asymmetric tiling in Automatic1111's extension https://github.com/tjm35/asymmetric-tiling-sd-webui.
My understanding is that I must traverse all layers to alter the padding, in my case circular in X and constant in Y, but I would love to get advice on how to make a such change to the conv2d system in DIffusers.
Your advice is highly appreciated, as it may also help others down the road facing the same need.
|
https://github.com/huggingface/diffusers/issues/2633
|
closed
|
[
"good first issue",
"question"
] | 2023-03-09T19:09:34Z
| 2025-07-29T08:48:27Z
| null |
alejobrainz
|
huggingface/optimum
| 874
|
Assistance exporting git-large to ONNX
|
Hello! I am looking to export an image captioning Hugging Face model to ONNX (specifically I was playing with the [git-large](https://huggingface.co/microsoft/git-large) model but if anyone knows of one that might be easier to deal with in terms of exporting that is great too)
I'm trying to follow [these](https://huggingface.co/docs/transformers/serialization#exporting-a-model-for-an-unsupported-architecture) instructions for exporting an unsupported architecture, and I am a bit stuck on figuring out what base class to inherit from and how to define the custom ONNX Configuration since I'm not sure what examples to look at (the model card says this is a transformer decoder model, but it looks like i that it has both encoding and decoding so I am a bit confused)
I also found [this](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb) notebook but I am again not sure if it would work with this sort of model.
Any comments, advice, or suggestions would be so helpful -- I am feeling a bit stuck with how to proceed in deploying this model in the school capstone project I'm working on. In a worst-case scenario, can I use `from_pretrained` in my application?
|
https://github.com/huggingface/optimum/issues/874
|
closed
|
[
"Stale"
] | 2023-03-09T18:25:57Z
| 2025-06-22T02:17:24Z
| 3
|
gracemcgrath
|
huggingface/safetensors
| 190
|
Rust save ndarray using safetensors
|
I've been loving this library!
I have a question, how can I save an ndarray using safetensors?
https://docs.rs/ndarray/latest/ndarray/
For context: I am preprocessing data in rust and would like to then load it in python to do machine learning with pytorch.
|
https://github.com/huggingface/safetensors/issues/190
|
closed
|
[
"Stale"
] | 2023-03-08T22:29:11Z
| 2024-01-10T16:48:07Z
| 7
|
StrongChris
|
huggingface/optimum
| 867
|
Auto-detect framework for large models at ONNX export
|
### System Info
- `transformers` version: 4.26.1
- Platform: Linux-4.4.0-142-generic-x86_64-with-glibc2.23
- Python version: 3.9.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger @muellerzr
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import torch
import torch.nn as nn
from transformers import GPT2Config, GPT2Tokenizer, GPT2Model
num_attention_heads = 40
num_layers = 40
hidden_size = 5120
configuration = GPT2Config(
n_embd=hidden_size,
n_layer=num_layers,
n_head=num_attention_heads
)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2Model(configuration)
tokenizer.save_pretrained('gpt2_checkpoint')
model.save_pretrained('gpt2_checkpoint')
```
```shell
python -m transformers.onnx --model=gpt2_checkpoint onnx/
```
### Expected behavior
I created a GPT2 with a parameter volume of 13B. Just for testing, refer to https://huggingface.co/docs/transformers/serialization, I save it to gpt2_checkpoint. Then convert it to onnx using transformers.onnx. Due to the large amount of parameters, `save_pretrained` saves the model as *-0001.bin, *-0002.bin and so on. Later, when running ‘python -m transformers.onnx --model=gpt2_checkpoint onnx/’, an error `FileNotFoundError: Cannot determine framework from given checkpoint location. There should be a pytorch_model.bin for PyTorch or tf_model.h5 for TensorFlow.` So, I would like to ask how to convert a model with a large number of parameters into onnx for inference.
|
https://github.com/huggingface/optimum/issues/867
|
closed
|
[
"feature-request",
"onnx"
] | 2023-03-08T03:43:53Z
| 2023-03-16T15:52:39Z
| 3
|
WangYizhang01
|
huggingface/datasets
| 5,615
|
IterableDataset.add_column is unable to accept another IterableDataset as a parameter.
|
### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
I wrote codes below to make it.
```py
def add_column(dataset: IterableDataset, name: str, add_dataset: IterableDataset, key: str) -> IterableDataset:
iter_add_dataset = iter(add_dataset)
def add_column_fn(example):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: next(iter_add_dataset)[key]}
return dataset.map(add_column_fn)
```
Is there other way to do it? Or is it intended?
### Steps to reproduce the bug
Thie codes below occurs `NotImplementedError`
```py
from datasets import IterableDataset
def gen(num):
yield {f"col{num}": 1}
yield {f"col{num}": 2}
yield {f"col{num}": 3}
ids1 = IterableDataset.from_generator(gen, gen_kwargs={"num": 1})
ids2 = IterableDataset.from_generator(gen, gen_kwargs={"num": 2})
new_ids = ids1.add_column("new_col", ids1)
for row in new_ids:
print(row)
```
### Expected behavior
`IterableDataset.add_column` is able to task `IterableDataset` and lazy evaluated values as a parameter since IterableDataset is lazy evalued.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-3.10.0-1160.36.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.7
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
https://github.com/huggingface/datasets/issues/5615
|
closed
|
[
"wontfix"
] | 2023-03-07T01:52:00Z
| 2023-03-09T15:24:05Z
| 1
|
zsaladin
|
huggingface/safetensors
| 188
|
How to extract weights from onnx to safetensors
|
How to extract weights from onnx to safetensors in rust?
|
https://github.com/huggingface/safetensors/issues/188
|
closed
|
[] | 2023-03-06T09:21:31Z
| 2023-03-07T14:23:16Z
| 2
|
oovm
|
huggingface/datasets
| 5,609
|
`load_from_disk` vs `load_dataset` performance.
|
### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_disk` and then use `load_from_disk` to load the filtered version.
The performance of these two approaches is wildly different:
* Using `load_dataset` takes about 20 seconds to load the dataset, and a few seconds to re-filter (thanks to the brilliant filter/map caching)
* Using `load_from_disk` takes 14 minutes! And the second time I tried, the session just crashed (on a machine with 32GB of RAM)
I don't know if you'd call this a bug, but it seems like there shouldn't need to be two methods to load from disk, or that they should not take such wildly different amounts of time, or that one should not crash. Or maybe that the docs could offer some guidance about when to pick which method and why two methods exist, or just how do most people do it?
Something I couldn't work out from reading the docs was this: can I modify a dataset from the hub, save it (locally) and use `load_dataset` to load it? This [post seemed to suggest that the answer is no](https://discuss.huggingface.co/t/save-and-load-datasets/9260).
### Steps to reproduce the bug
See above
### Expected behavior
Load times should be about the same.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
https://github.com/huggingface/datasets/issues/5609
|
open
|
[] | 2023-03-05T05:27:15Z
| 2023-07-13T18:48:05Z
| 4
|
davidgilbertson
|
huggingface/sentence-transformers
| 1,856
|
What it is the ideal sentence size to train with TSDAE?
|
I have an unlabeled data that contains 80k texts, with about 250 tokens on average(with bert-base-multilingual-uncased tokenizer). I want to pre-train the model on my dataset, but I'm not sure if the texts are too large. It's possible to break in small sentences, but I'm afraid that some sentences lose context.
What it is the ideal sentence size to train with TSDAE?
|
https://github.com/huggingface/sentence-transformers/issues/1856
|
open
|
[] | 2023-03-04T21:16:14Z
| 2023-03-04T21:16:14Z
| null |
Diegobm99
|
huggingface/transformers
| 21,950
|
auto_find_batch_size should say what batch size it is using
|
### Feature request
When using `auto_find_batch_size=True` in the trainer I believe it identifies the right batch size but then it doesn't log it to the console anywhere?
It would be good if it could log what batch size it is using?
### Motivation
I'd like to know what batch size it is using because then I will know roughly how big a batch can fit in memory - this info would be useful elsewhere.
### Your contribution
N/A
|
https://github.com/huggingface/transformers/issues/21950
|
closed
|
[] | 2023-03-04T08:53:25Z
| 2023-06-28T15:03:39Z
| null |
p-christ
|
huggingface/datasets
| 5,604
|
Problems with downloading The Pile
|
### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
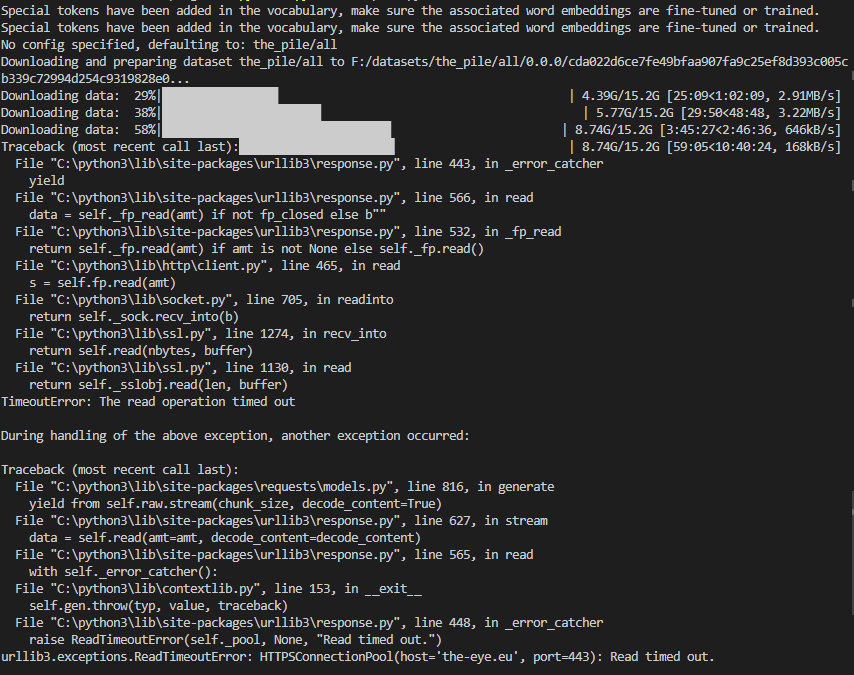
Here are the downloaded files:
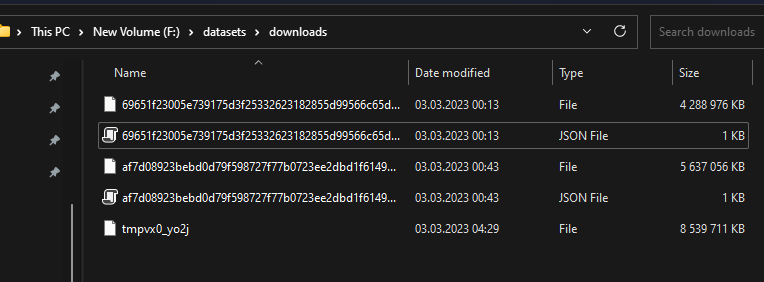
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2
|
https://github.com/huggingface/datasets/issues/5604
|
closed
|
[] | 2023-03-03T09:52:08Z
| 2023-10-14T02:15:52Z
| 7
|
sentialx
|
huggingface/optimum
| 842
|
Auto-TensorRT engine compilation, or improved documentation for it
|
### Feature request
For decoder models with cache, it can be painful to manually compile the TensorRT engine as ONNX Runtime does not give options to specify shapes. The engine build could maybe be done automatically.
The current doc is only for `use_cache=False`, which is not very interesting. It could be improved to show how to pre-build the TRT with use_cache=True.
References:
https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/gpu#tensorrt-engine-build-and-warmup
https://github.com/microsoft/onnxruntime/issues/13559
### Motivation
TensorRT is fast
### Your contribution
will work on it sometime
|
https://github.com/huggingface/optimum/issues/842
|
open
|
[
"feature-request",
"onnxruntime"
] | 2023-03-02T13:50:17Z
| 2023-05-31T12:47:40Z
| 4
|
fxmarty
|
huggingface/datasets
| 5,600
|
Dataloader getitem not working for DreamboothDatasets
|
### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset to load some images
2- error after loading when trying to visualise the images
### Expected behavior
I was expecting a numpy array of the image
### Environment info
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
|
https://github.com/huggingface/datasets/issues/5600
|
closed
|
[] | 2023-03-02T11:00:27Z
| 2023-03-13T17:59:35Z
| 1
|
salahiguiliz
|
huggingface/trl
| 180
|
what is AutoModelForCausalLMWithValueHead?
|
trl use `AutoModelForCausalLMWithValueHead`,which is base_model(eg: GPT2LMHeadModel) + fc layer,but I can't understand why need a fc head layer?
|
https://github.com/huggingface/trl/issues/180
|
closed
|
[] | 2023-02-28T07:46:49Z
| 2025-02-21T11:29:04Z
| null |
akk-123
|
huggingface/datasets
| 5,585
|
Cache is not transportable
|
### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I'm hoping that I can just copy/paste the cache files, but I notice that a lot of the file names start with the path name, e.g. `_home_davidg_.cache_huggingface_datasets_conll2003_default-451...98.lock` where `home/davidg` is where the cache is in WSL.
This seems to suggest that the cache is not portable/cannot be centralised or shared. Is this the case, or are the files that start with path names not integral to the caching mechanism? Because copying the cache files _seems_ to work, but I'm not filled with confidence that something isn't going to break.
A related issue, when trying to load a dataset that should come from cache (running in WSL, pointing to cache on the Windows host) it seemed to work fine, but it still uses a WSL directory for `.cache\huggingface\modules\datasets_modules`. I see nothing in the docs about this, or how to point it to a different place.
I have asked a related question on the forum: https://discuss.huggingface.co/t/is-datasets-cache-operating-system-agnostic/32656
### Steps to reproduce the bug
View the cache directory in WSL/Windows.
### Expected behavior
Cache can be shared between (virtual) machines and be transportable.
It would be nice to have a simple way to say "Dear Hugging Face packages, please put ALL your cache in `blah/de/blah`" and have all the Hugging Face packages respect that single location.
### Environment info
```
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
- ```
|
https://github.com/huggingface/datasets/issues/5585
|
closed
|
[] | 2023-02-28T00:53:06Z
| 2023-02-28T21:26:52Z
| 2
|
davidgilbertson
|
huggingface/dataset-viewer
| 857
|
Contribute to https://github.com/huggingface/huggingface.js?
|
https://github.com/huggingface/huggingface.js is a JS client for the Hub and inference. We could propose to add a client for the datasets-server.
|
https://github.com/huggingface/dataset-viewer/issues/857
|
closed
|
[
"question"
] | 2023-02-27T12:27:43Z
| 2023-04-08T15:04:09Z
| null |
severo
|
huggingface/dataset-viewer
| 852
|
Store the parquet metadata in their own file?
|
See https://github.com/huggingface/datasets/issues/5380#issuecomment-1444281177
> From looking at Arrow's source, it seems Parquet stores metadata at the end, which means one needs to iterate over a Parquet file's data before accessing its metadata. We could mimic Dask to address this "limitation" and write metadata in a _metadata/_common_metadata file in to_parquet/push_to_hub, which we could then use to optimize reads (if present). Plus, it's handy that PyArrow can also parse these metadata files.
|
https://github.com/huggingface/dataset-viewer/issues/852
|
closed
|
[
"question"
] | 2023-02-27T08:29:12Z
| 2023-05-01T15:04:07Z
| null |
severo
|
huggingface/datasets
| 5,570
|
load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub
|
### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet = load_dataset("imagenet-1k", split="train", streaming=True)
FileNotFoundError: Couldn't find a dataset script at /content/imagenet-1k/imagenet-1k.py or any data file in the same directory. Couldn't find 'imagenet-1k' on the Hugging Face Hub either: FileNotFoundError: Dataset 'imagenet-1k' doesn't exist on the Hub
```
tested on a colab notebook.
### Expected behavior
I would expect a specific error indicating that I have to login then accept the dataset licence.
I find this bug very relevant as this code is on a guide on the [Huggingface documentation for Datasets](https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable)
### Environment info
google colab cpu-only instance
|
https://github.com/huggingface/datasets/issues/5570
|
closed
|
[] | 2023-02-23T16:44:32Z
| 2023-07-24T15:18:50Z
| 2
|
buoi
|
huggingface/optimum
| 810
|
ORTTrainer using DataParallel instead of DistributedDataParallel causes downstream errors
|
### System Info
```shell
optimum 1.6.4
python 3.8
```
### Who can help?
@JingyaHuang @echarlaix
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
FROM mcr.microsoft.com/azureml/aifx/stable-ubuntu2004-cu117-py38-torch1131:latest
RUN git clone https://github.com/huggingface/optimum.git && cd optimum && python setup.py install
RUN python examples/onnxruntime/training/summarization/run_summarization.py --model_name_or_path t5-small --do_train --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --predict_with_generate --fp16
### Expected behavior
This is expected to run t5-small with ONNXRuntime, however the model defaults to pytorch execution. I believe this is due to optimum's usage of torch.nn.DataParallel in trainer.py [here](https://github.com/huggingface/optimum/blob/dbb43fb622727f2206fa2a2b3b479f6efe82945b/optimum/onnxruntime/trainer.py#L1576) which is incompatible with ONNXRuntime.
PyTorch's [official documentation](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) recommends using DistributedDataParallel over DataParallel for multi-gpu training. Is there a reason why DataParallel is used here and, if not, can it be changed to use DistributedDataParallel?
|
https://github.com/huggingface/optimum/issues/810
|
closed
|
[
"bug"
] | 2023-02-22T22:15:41Z
| 2023-03-19T19:01:32Z
| 2
|
prathikr
|
huggingface/optimum
| 809
|
Better Transformer with QA pipeline returns padding issue
|
### System Info
```shell
Optimum version: 1.6.4
Platform: Linux
Python version: 3.10
Transformers version: 4.26.1
Accelerate version: 0.16.0
Torch version: 1.13.1+cu117
```
### Who can help?
@philschmid
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Notebook link to reproduce the same: https://colab.research.google.com/drive/1g-EzDtvEMIO1VjYBFJDlYWuKoBjaHxDd?usp=sharing
Code snippet:
```python
from optimum.pipelines import pipeline
qa_model = "bert-large-uncased-whole-word-masking-finetuned-squad"
reader = pipeline("question-answering", qa_model, accelerator="bettertransformer")
reader(question=["What is your name?", "What do you like to do in your free time?"] * 10, context=["My name is Bookworm and I like to read books."] * 20, batch_size=16)
```
Error persists on both cpu and cuda device. Works as expected if batches passed in require no padding.
Error received:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/question_answering.py", line 393, in __call__
return super().__call__(examples, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1065, in __call__
outputs = [output for output in final_iterator]
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1065, in <listcomp>
outputs = [output for output in final_iterator]
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 124, in __next__
item = next(self.iterator)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 266, in __next__
processed = self.infer(next(self.iterator), **self.params)
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 628, in __next__
data = self._next_data()
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 671, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/app/.venv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
return self.collate_fn(data)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 169, in inner
padded[key] = _pad(items, key, _padding_value, padding_side)
File "/app/.venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 92, in _pad
tensor = torch.zeros((batch_size, max_length), dtype=dtype) + padding_value
TypeError: unsupported operand type(s) for +: 'Tensor' and 'NoneType'
```
The system versions mentioned above are from my server setup although it seems reproducible from the notebook with different torch/cuda installations!
### Expected behavior
Expected behavior is to produce correct results without error.
|
https://github.com/huggingface/optimum/issues/809
|
closed
|
[
"bug"
] | 2023-02-22T18:51:23Z
| 2023-02-27T11:29:09Z
| 2
|
vrdn-23
|
huggingface/setfit
| 315
|
Choosing the datapoints that need to be annotated?
|
Hello,
I have a large set of unlabelled data on which I need to do text classification. Since few-shot text classification uses only a handful of datapoints per class, is there a systematic way to choose which datapoints should be chosen for annotation?
Thank you!
|
https://github.com/huggingface/setfit/issues/315
|
open
|
[
"question"
] | 2023-02-16T05:25:03Z
| 2023-03-06T20:56:22Z
| null |
vahuja4
|
huggingface/setfit
| 314
|
Question: train and deploy via Sagemaker
|
Hi
I'm trying to setup training (and hyperparameter tuning) using Amazon SageMaker.
Because SetFit is not a standard model on HugginFace I'm guessing that the examples provided in the HuggingFace/SageMaker integration are not useable: [example](https://github.com/huggingface/notebooks/tree/ef21344eb20fe19f881c846d5e36c8e19d99647c/sagemaker/01_getting_started_pytorch).
What would the best way to tackle hyperparameter tuning (tuning body and head separately) on SageMaker and track the results?
|
https://github.com/huggingface/setfit/issues/314
|
open
|
[
"question"
] | 2023-02-15T12:23:33Z
| 2024-03-28T15:10:28Z
| null |
lbelpaire
|
huggingface/setfit
| 313
|
Setfit no support evaluate each epoch or step and save model each epoch or step
|
Hi everyone, can u give me about evaluate each epoch and save checkpoint model ? thanks everyone
|
https://github.com/huggingface/setfit/issues/313
|
closed
|
[
"question"
] | 2023-02-15T04:14:24Z
| 2023-12-06T13:20:50Z
| null |
batman-do
|
huggingface/optimum
| 776
|
Loss of accuracy when Longformer for SequenceClassification model is exported to ONNX
|
### Edit: This is a crosspost to [pytorch #94810](https://github.com/pytorch/pytorch/issues/94810). I don't know, where the issue lies.
### System info
- `transformers` version: 4.26.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- PyTorch version (GPU?): 1.13.0 (False)
- onnx: 1.13.0
- onnxruntime: 1.13.1
### Who can help?
I think
@younesbelkada
would be a great help :)
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This model is trained on client data and I'm not allowed to share the data or the weights, which makes any reproduction of this issue much harder. Please let me know when you need more information.
Here is the code snippet for the onnx conversion:
I follow this [tutorial](https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html), but I also tried your [tutorial](https://huggingface.co/docs/transformers/serialization). The onnx conversion with optimum is not available for Longformer so far and I haven't figured out yet, how to add it.
conversion:
```python
import numpy as np
from onnxruntime import InferenceSession
from tqdm.auto import tqdm
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("deployment/best_model/")
model = AutoModelForSequenceClassification.from_pretrained("deployment/best_model/")
model.to("cpu")
model.eval()
example_input = tokenizer(
dataset["test"]["text"][0], max_length=512, truncation=True, return_tensors="pt"
)
_ = model(**example_input)
torch.onnx.export(
model,
tuple(example_input.values()),
f="model.onnx",
input_names=["input_ids", "attention_mask"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size", 1: "sequence"},
"attention_mask": {0: "batch_size", 1: "sequence"},
"logits": {0: "batch_size", 1: "sequence"},
},
do_constant_folding=True,
opset_version=16,
)
```
Calculating the accuracy:
```python
session = InferenceSession("deployment/model.onnx", providers=["CPUExecutionProvider"])
y_hat_torch = []
y_hat_onnx = []
for text in dataset["test"]["text"]:
tok_text = tokenizer(
text, padding="max_length", max_length=512, truncation=True, return_tensors="np"
)
pred = session.run(None, input_feed=dict(tok_text))
pred = np.argsort(pred[0][0])[::-1][0]
y_hat_onnx.append(int(pred))
tok_text = tokenizer(
text, padding="max_length", max_length=512, truncation=True, return_tensors="pt"
)
pred = model(**tok_text)
pred = torch.argsort(pred[0][0], descending=True)[0].numpy()
y_hat_torch.append(int(pred))
print(
f"Accuracy onnx:{sum([int(i)== int(j) for I, j in zip(y_hat_onnx, dataset['test']['label'])]) / len(y_hat_onnx):.2f}"
)
print(
f"Accuracy torch:{sum([int(i)== int(j) for I, j in zip(y_hat_torch, dataset['test']['label'])]) / len(y_hat_torch):.2f}"
)
```
I also looked into the models' weights and the weights for the attention layer differ between torch and onnx. Here is an example:
```python
import torch
import onnx
from onnx import numpy_helper
import numpy as np
from numpy.testing import assert_almost_equal
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("deployment/best_model/")
onnx_model = onnx.load("deployment/model.onnx")
graph = onnx_model.graph
initalizers = dict()
for init in graph.initializer:
initalizers[init.name] = numpy_helper.to_array(init).astype(np.float16)
model_init = dict()
for name, p in model.named_parameters():
model_init[name] = p.detach().numpy().astype(np.float16)
assert len(initalizers) == len(model_init.keys()) # 53 layers
assert_almost_equal(initalizers['longformer.embeddings.word_embeddings.weight'],
model_init['longformer.embeddings.word_embeddings.weight'], decimal=5)
assert_almost_equal(initalizers['classifier.dense.weight'],
model_init['classifier.dense.weight'], decimal=5)
```
For the layer longformer.encoder.layer.0.output.dense.weight, which aligns with onnx::MatMul_6692 in shape and position:
```
assert_almost_equal(initalizers['onnx::MatMul_6692'],
model_init['longformer.encoder.layer.0.output.dense.weight'], decimal=4)
```
I get
```python
AssertionError:
Arrays are not almost equal to 4 decimals
Mismatched elements: 2356293 / 2359296 (99.9%)
Max absolute difference: 1.776
Max relative difference: inf
x: array([[ 0.0106, 0.1076, 0.0801, ..., 0.0425, 0.1548, 0.0123],
[-0.0399, -0.1415, 0.0916, ..., 0.0181, -0.1277, -0.133
|
https://github.com/huggingface/optimum/issues/776
|
closed
|
[] | 2023-02-14T10:22:12Z
| 2023-02-17T13:55:17Z
| 8
|
SteffenHaeussler
|
huggingface/setfit
| 310
|
How does predict_proba work exactly ?
|
Hi everyone !
Thanks for this amazing package first ! it is more than useful for a project at my work currently ! and the 0.6.0 was much needed on my side !
BUT i'd like to have some clarifications on how the function predict_proba works because I have a hard understanding.
This table :
<html>
<body>
<!--StartFragment-->
score | predicted | pred_proba_0 | pred_proba_1
-- | -- | -- | --
1 | 1 | 0.866082 | 0.133918
1 | 1 | 0.762696 | 0.237304
1 | 1 | 0.730971 | 0.269029
1 | 1 | 0.871808 | 0.128192
1 | 1 | 0.671637 | 0.328363
1 | 1 | 0.780433 | 0.219567
1 | 1 | 0.652668 | 0.347332
1 | 0 | 0.767050 | 0.232950
<!--EndFragment-->
</body>
</html>
The score column is the true outcome, predicted is what the predict method gives me when I'm doing inference.
pred_proba_0 and pred_proba_1 are given from this code :
validate_dataset['pred_proba_0'] = trainer.model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)[:,0]
validate_dataset['pred_proba_1'] = trainer.model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)[:,1]
Also when I use this code :
model.predict_proba(validate_dataset['Fulltext_clean_translated+metadata_clean_translated'].to_list(),as_numpy=True)
I have this output :
array([[9.1999289e-07, 9.9999905e-01],
[7.2725675e-07, 9.9999928e-01],
[8.1967613e-07, 9.9999917e-01],
...,
[9.4037086e-06, 9.9999058e-01],
[9.1749916e-07, 9.9999905e-01],
[1.2628381e-06, 9.9999869e-01]], dtype=float32)
my question is , i'd like to know if the predict_proba output gives (probability to predict 0 , probability to predict 1) ?
It doesn't seem like it because of this line :
<html>
<body>
<!--StartFragment-->
229 | 0 | 1 | 0.694485 | 0.305515
-- | -- | -- | -- | --
<!--EndFragment-->
</body>
</html>
something is strange also train.model.predict_proba doesn't give the same result as model.predict_proba... can someone please explain to help me understand ?
Thank you very much !
|
https://github.com/huggingface/setfit/issues/310
|
open
|
[
"question",
"needs verification"
] | 2023-02-10T14:13:13Z
| 2023-11-15T08:24:38Z
| null |
doubianimehdi
|
huggingface/setfit
| 308
|
[QUESTION] Using callbacks (early stopping, logging, etc)
|
Hi all, thanks for your work here!
**TLDR**: Is there a way to add callbacks for early stopping and logging (for example, with W&B?).
I am using setfit for a project, but I could not figure out a way to add early stopping. I am afraid that I am overfitting to the training set. I also cant really say that I am, because I am not sure how I can log the training metrics (train/eval performance across epochs).
I saw that the script [run_full.py](https://github.com/huggingface/setfit/blob/ebee18ceaecb4414482e0a6b92c97f3f99309d56/scripts/transformers/run_full.py#L104) has it, but I couldn't figure out how to do it with SetFit API.
thanks!
|
https://github.com/huggingface/setfit/issues/308
|
closed
|
[
"question"
] | 2023-02-08T19:39:20Z
| 2023-02-27T16:25:26Z
| null |
FMelloMascarenhas-Cohere
|
huggingface/optimum
| 763
|
Documented command "optimum-cli onnxruntime" doesn't exist?
|
### System Info
```shell
Python 3.9, Ubuntu 20.04, Miniconda. CUDA GPU available
Packages installed (the important stuff):
onnx==1.13.0
onnxruntime==1.13.1
optimum==1.6.3
tokenizers==0.13.2
torch==1.13.1
transformers==4.26.0
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
```
### Who can help?
@lewtun, @michaelbenayoun
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I have an existing ONNX model, which I am trying to optimize with different scenarios. When attempting to follow the documented instructions for optimizing an existing ONNX model, the command does not exist. I am using the instructions from this page: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization
NOTE: I am using zsh, which requires escaping brackets
```bash
pip install optimum
pip install optimum\[onnxruntime\]
pip install optimum\[exporters\]
```
Command execution:
```bash
optimum-cli onnxruntime optimize --onnx_model ../output/sentence-transformers/all-MiniLM-L6-v2/model.onnx -o output/sentence-transformers/all-MiniLM-L6-v2/model-optimized.onnx -04
```
Result:
```
usage: optimum-cli <command> [<args>]
Optimum CLI tool: error: invalid choice: 'onnxruntime' (choose from 'export', 'env')
```
### Expected behavior
I'd expect for the command to exist, or to understand which command to use for experimenting with different ONNX optimizations. I tried using the optimum-cli export onnx command, but that does not have options for optimization types.
I'd be happy to start from a torch model instead of using an existing ONNX model - but I'd also like to be able to specify different optimizations (-01 | -02 | -03 | -04)
Thanks!
|
https://github.com/huggingface/optimum/issues/763
|
closed
|
[
"bug"
] | 2023-02-08T18:19:52Z
| 2023-02-08T18:25:52Z
| 2
|
binarymax
|
huggingface/datasets
| 5,513
|
Some functions use a param named `type` shouldn't that be avoided since it's a Python reserved name?
|
Hi @mariosasko, @lhoestq, or whoever reads this! :)
After going through `ArrowDataset.set_format` I found out that the `type` param is actually named `type` which is a Python reserved name as you may already know, shouldn't that be renamed to `format_type` before the 3.0.0 is released?
Just wanted to get your input, and if applicable, tackle this issue myself! Thanks 🤗
|
https://github.com/huggingface/datasets/issues/5513
|
closed
|
[] | 2023-02-08T15:13:46Z
| 2023-07-24T16:02:18Z
| 4
|
alvarobartt
|
huggingface/setfit
| 298
|
apply the optimized parameters
|
I did my hyperparameter search optimization on one computer and now I'm trying to apply the obtained parameters on another computer, so I could not use this code "trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
trainer.train()". I put the obtained parameters manually in my new trainer instead. But I have two sets of the parameters, and I'm not sure which set to use. For example, in the line above I have seed =9, but below seed = 8.
Here are the obtained parameters from the optimization:
Trial 14 finished with value: 0.8711734693877551 and parameters: {'learning_rate': 1.0472016582222107e-05, 'num_epochs': 1, 'batch_size': 4, 'num_iterations': 40, 'seed': 9, 'max_iter': 54, 'solver': 'lbfgs', 'model_id': 'sentence-transformers/all-mpnet-base-v2'}. Best is trial 14 with value: 0.8711734693877551.
Trial: {'learning_rate': 5.786637612112363e-05, 'num_epochs': 1, 'batch_size': 4, 'num_iterations': 20, 'seed': 8, 'max_iter': 52, 'solver': 'lbfgs', 'model_id': 'sentence-transformers/all-mpnet-base-v2'}
model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
***** Running training *****
Num examples = 73160
Num epochs = 1
Total optimization steps = 18290
Total train batch size = 4
Thank you so much!!
|
https://github.com/huggingface/setfit/issues/298
|
closed
|
[
"question"
] | 2023-02-03T18:31:59Z
| 2023-02-16T08:00:52Z
| null |
zoezhupingli
|
huggingface/setfit
| 297
|
Comparing setfit with a simpler approach
|
Hi,
I am trying to compare setfit with another approach. The other approach is like this:
1. Define a list of representative sentences per class, call it `rep_sent`
2. Compute sentence embeddings for `rep_sent` using `mpnet-base-v2`
3. Define a list of test sentences, call it 'test_sent'.
4. Compute sentence embeddings for 'test_sent'
5. Now, in order to assign a class to the sentences in `test_sent`, compute the cosine similarity with `rep_sent` and choose the class based on the highest cosine sim.
If we consider a particular test set sentence: "Remove maiden name from account", then the results from the two approaches are as follows:
setfit predicts this to be 'manage account transfer'
other approach predicts this to be 'edit account details'
Can someone please help me to understand how setfit's performance can be improved.
As far as setfit goes, it has been trained use 'rep_sent' as the training set. Here is how it looks like:
`text,label
I want to close my account,accountClose
Close my credit card,accountClose
Mortgage payoff,accountClose
Loan payoff,accountClose
Loan pay off,accountClose
pay off,accountClose
lease payoff,accountClose
lease pay off,accountClose
account close,accountClose
close card account,accountClose
I want to open an account,accountOpenGeneral
I want to get a card,accountOpenGeneral
I want a loan,accountOpenGeneral
Refinance my car,accountOpenGeneral
Buy a car,accountOpenGeneral
Open checking,accountOpenGeneral
Open savings,accountOpenGeneral
Lease a vehicle,accountOpenGeneral
Link external bank account,accountTransferManage
verify external account,accountTransferManage
Add external account,accountTransferManage
Edit external account,accountTransferManage
Remove external account,accountTransferManage
Mortgage payment,billPaySchedulePayment
Setup Loan payment,billPaySchedulePayment
Setup auto loan payment,billPaySchedulePayment
Schedule bill payment,billPaySchedulePayment
Setup bill payment,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Setup auto pay,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Setup automatic payment,billPaySchedulePayment
Modify account details,editAccountDetails
Modify name on my account,editAccountDetails
Change address in my account,editAccountDetails`
|
https://github.com/huggingface/setfit/issues/297
|
closed
|
[
"question"
] | 2023-02-03T10:11:44Z
| 2023-02-06T13:01:02Z
| null |
vahuja4
|
huggingface/setfit
| 295
|
Question: How the number of categories affect the training and accuracy?
|
I have found that increasing the number of categories reduce the accuracy results. Has anyone studied how the increased number of samples per category affect the results?
|
https://github.com/huggingface/setfit/issues/295
|
open
|
[
"question"
] | 2023-02-02T18:43:33Z
| 2023-07-26T19:30:21Z
| null |
rubensmau
|
huggingface/dataset-viewer
| 762
|
Handle the case where the DatasetInfo is too big
|
In the /parquet-and-dataset-info processing step, if DatasetInfo is over 16MB, we will not be able to store it in MongoDB (https://pymongo.readthedocs.io/en/stable/api/pymongo/errors.html#pymongo.errors.DocumentTooLarge). We have to handle this case, and return a clear error to the user.
See https://huggingface.slack.com/archives/C04L6P8KNQ5/p1675332303097889 (internal). It's a similar issue to https://github.com/huggingface/datasets-server/issues/731 (should be raised for that dataset, btw)
|
https://github.com/huggingface/dataset-viewer/issues/762
|
closed
|
[
"bug"
] | 2023-02-02T10:25:19Z
| 2023-02-13T13:48:06Z
| null |
severo
|
huggingface/datasets
| 5,494
|
Update audio installation doc page
|
Our [installation documentation page](https://huggingface.co/docs/datasets/installation#audio) says that one can use Datasets for mp3 only with `torchaudio<0.12`. `torchaudio>0.12` is actually supported too but requires a specific version of ffmpeg which is not easily installed on all linux versions but there is a custom ubuntu repo for it, we have insctructions in the code: https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L327
So we should update the doc page. But first investigate [this issue](5488).
|
https://github.com/huggingface/datasets/issues/5494
|
closed
|
[
"documentation"
] | 2023-02-01T19:07:50Z
| 2023-03-02T16:08:17Z
| 4
|
polinaeterna
|
huggingface/diffusers
| 2,167
|
Im using jupyter notebook and every time it stacks ckpt file but I don't know where it is
|
every time I try using diffusers, it downloads all .bin files and ckpt files but it piles up somewhere in the server.
i thought it got piled up in anaconda3/env but it wasn't.
where would it downloads the files be? my server its full of memory:(
|
https://github.com/huggingface/diffusers/issues/2167
|
closed
|
[] | 2023-01-31T00:58:18Z
| 2023-02-02T02:51:10Z
| null |
jakeyahn
|
huggingface/datasets
| 5,475
|
Dataset scan time is much slower than using native arrow
|
### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that explains this phenomenon?
### Steps to reproduce the bug
https://colab.research.google.com/drive/11EtHDaGAf1DKCpvYnAPJUW-LFfAcDzHY?usp=sharing
### Expected behavior
I expect scan times to be on par with using pyarrow directly.
### Environment info
standard colab environment
|
https://github.com/huggingface/datasets/issues/5475
|
closed
|
[] | 2023-01-27T01:32:25Z
| 2023-01-30T16:17:11Z
| 3
|
jonny-cyberhaven
|
huggingface/setfit
| 289
|
[question]: creating a custom dataset class like `sst` to fit into `setfit`, throws `Cannot index by location index with a non-integer key`
|
I'm trying to experiment with PyTorch some model; the dataset they were using for the experiment is [`sst`][1]
But I'm also learning PyTorch, so I thought it would be better to play with `Dataset` class and create my own dataset.
So this was my approach:
```
class CustomDataset(Dataset):
def __init__(self, dataframe):
self.dataframe = dataframe
self.column_names = ['text','label']
def __getitem__(self, index):
print('index: ',index)
row = self.dataframe.iloc[index].to_numpy()
features = row[1:]
label = row[0]
return features, label
def __len__(self):
return len(self.dataframe)
df = pd.DataFrame(np.array([
["hello", 0] ,
["sex", 1] ,
["beshi kore sex", 1],]),
columns=['text','label'])
dataset = CustomDataset(dataframe=df)
```
Instead of creating sub-categories like validation/test/train, I'm just trying to create one custom `Dataset` class at first.
And it keeps giving me **`Cannot index by location index with a non-integer key`** During conceptual development, I tried this: `df.iloc[0].to_numpy()`, and it works absolutely fine. But it's sending `index: text` for some reason. I even tried putting an 'id' column.
But I'm sure that there must be some other way to achieve this. **_How can I resolve this issue?_** As my code worked fine for sst, as this not working any longer. I'm pretty sure, this is not one to one mapping.
Complete code:
```
#!pip install sentence_transformers -q
#!pip install setfit -q
from sentence_transformers.losses import CosineSimilarityLoss
from torch.utils.data import Dataset
import pandas as pd
import numpy as np
from setfit import SetFitModel, SetFitTrainer, sample_dataset
class CustomDataset(Dataset):
def __init__(self, dataframe):
self.dataframe = dataframe
self.column_names = ['id','text','label']
def __getitem__(self, index):
print('index: ',index)
row = self.dataframe.iloc[index].to_numpy()
features = row[1:]
label = row[0]
return features, label
def __len__(self):
return len(self.dataframe)
df = pd.DataFrame(np.array([ [1,"hello", 0] ,
[2,"sex", 1] ,
[3,"beshi kore sex", 1],]),columns=['id','text','label'])
# df.head()
dataset = CustomDataset(dataframe=df)
# Load a dataset from the Hugging Face Hub
# dataset = load_dataset("sst2") # HERE, previously I was simply using sst/sst2
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = dataset
eval_dataset = dataset
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=1, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for contrastive learning
)
# Train and evaluate
trainer.train()
```
[1]: https://pytorch.org/text/_modules/torchtext/datasets/sst.html
|
https://github.com/huggingface/setfit/issues/289
|
closed
|
[
"question"
] | 2023-01-25T10:22:35Z
| 2023-01-27T15:53:44Z
| null |
maifeeulasad
|
huggingface/transformers
| 21,287
|
[docs] TrainingArguments default label_names is not what is described in the documentation
|
### System Info
- `transformers` version: 4.25.1
- Platform: macOS-12.6.1-arm64-arm-64bit
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger, @stevhliu and @MKhalusova
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Create a model with a `forward` that has more than one label. For example:
```
def forward(
self,
input_ids,
bbox,
attention_mask,
token_type_ids,
labels,
reference_labels
)
```
2. Create a trainer for your model with `trainer = Trainer(model, ...)`. Make sure to not set `label_names` and let it default.
3. Check `trainer.label_names` and see that it returns `["labels", "reference_labels"]`
### Expected behavior
[The documentation](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.label_names) states that:
> Will eventually default to ["labels"] except if the model used is one of the XxxForQuestionAnswering in which case it will default to ["start_positions", "end_positions"].
[This PR](https://github.com/huggingface/transformers/pull/16526) changed the behaviour that the documentation describes.
|
https://github.com/huggingface/transformers/issues/21287
|
closed
|
[] | 2023-01-24T18:24:47Z
| 2023-01-24T19:48:26Z
| null |
fredsensibill
|
huggingface/setfit
| 282
|
Loading a trained SetFit model without setfit?
|
SetFit team, first off, thanks for the awesome library!
I'm running into trouble trying to load and run inference on a trained SetFit model without using `SetFitModel.from_pretrained()`. Instead, I'd like to load the model using torch, transformers, sentence_transformers, or some combination thereof. Is there a clear-cut example anywhere of how to do this?
Here's my current code, which does not return clean predictions. Thank you in advance for the help. For reference, this was trained as a multiclass classification model with 18 potential classes:
```from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
inputs = ['xxx', 'yyy', 'zzz']
encoded_inputs = tokenizer(inputs,
padding = True,
truncation = True,
return_tensors = 'pt')
model = AutoModel.from_pretrained('/path/to/trained/setfit/model/')
with torch.no_grad():
preds = model(**encoded_inputs)
preds```
|
https://github.com/huggingface/setfit/issues/282
|
closed
|
[
"question"
] | 2023-01-20T01:08:00Z
| 2024-05-21T08:11:08Z
| null |
ZQ-Dev8
|
huggingface/datasets
| 5,442
|
OneDrive Integrations with HF Datasets
|
### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive** account and I want to move between drive and Hugging face repo or vis versa
### Motivation
make the dataset section more flexible with other possible storage
like the integration between Google Collab and Google drive the storage
### Your contribution
Can be done using Hugging face CLI
|
https://github.com/huggingface/datasets/issues/5442
|
closed
|
[
"enhancement"
] | 2023-01-19T23:12:08Z
| 2023-02-24T16:17:51Z
| 2
|
Mohammed20201991
|
huggingface/diffusers
| 2,012
|
Reduce Imagic Pipeline Memory Consumption
|
I'm running the [Imagic Stable Diffusion community pipeline](https://github.com/huggingface/diffusers/blob/main/examples/community/imagic_stable_diffusion.py) and it's routinely allocating 25-38 GiB GPU vRAM which seems excessively high.
@MarkRich any ideas on how to reduce memory usage? Xformers and attention slicing brings it down to 20-25 GiB but fp16 doesn't work and memory consumption in general seems excessively high (trying to deploy on serverless GPUs)
|
https://github.com/huggingface/diffusers/issues/2012
|
closed
|
[
"question",
"stale"
] | 2023-01-16T23:43:03Z
| 2023-02-24T15:03:35Z
| null |
andreemic
|
huggingface/optimum
| 697
|
Custom model output
|
### System Info
```shell
Copy-and-paste the text below in your GitHub issue:
- `optimum` version: 1.6.1
- `transformers` version: 4.25.1
- Platform: Linux-5.19.0-29-generic-x86_64-with-glibc2.36
- Python version: 3.10.8
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.1 (cuda availabe: True)
```
### Who can help?
@michaelbenayoun @lewtun @fxm
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
no code
### Expected behavior
Sorry in advance if it does exists already, but I didn't find any doc on this.
In transformers it is possible to custom the output of a model by adding some boolean input arguments such as `output_attentions` and `output_hiddens`. How to make them available in my exported ONNX model?
If it is not possible yet, I will update this thread into a feature request :)
Thanks in advance.
|
https://github.com/huggingface/optimum/issues/697
|
open
|
[
"bug"
] | 2023-01-16T14:08:12Z
| 2023-04-11T12:30:04Z
| 3
|
jplu
|
huggingface/datasets
| 5,424
|
When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset?
|
### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduce the behaviour:
1. Import
`from datasets import load_dataset, ReadInstruction`
2. Instruction to load the dataset
```
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="test", from_=0, to=5, unit='%', rounding='closest')
]
```
3. Load
`dataset = load_dataset('csv', data_dir="data/", data_files={"train":"train.tsv", "dev":"dev.tsv", "test":"test.tsv"}, delimiter="\t", split=instructions)`
### Expected behavior
**Current behaviour**
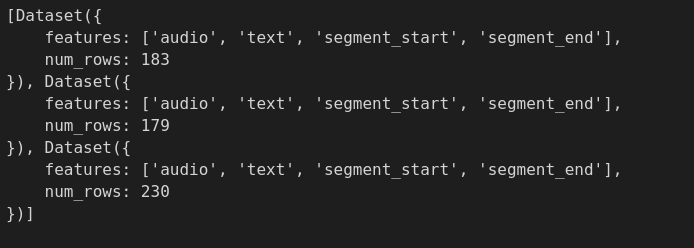
:
**Expected behaviour**
### Environment info
``datasets==2.8.0
``
`Python==3.8.5
`
`Platform - Ubuntu 20.04.4 LTS`
|
https://github.com/huggingface/datasets/issues/5424
|
closed
|
[] | 2023-01-16T06:54:28Z
| 2023-02-24T16:19:00Z
| 1
|
macabdul9
|
huggingface/setfit
| 260
|
How to use .predict() function
|
Hi,
I am new at using the setfit. I will be running many tunings for models and currently achieved getting evaluation metrics using ("trainer.evaluate())
However, is there any way to do something like the following to save the trained model's predictions?
trainer = SetFitTrainer(......)
trainer.train()
**predictions=trainer.predict(testX)**
SetFitTrainer has no predict function
I can achieve that with trainer.push_to_hub() and downloading back with SetFitModel.from_pretrained() but there is probably a better way without publishing on the hub?
|
https://github.com/huggingface/setfit/issues/260
|
closed
|
[
"question"
] | 2023-01-08T23:18:56Z
| 2023-01-09T10:00:38Z
| null |
yafsin
|
huggingface/setfit
| 256
|
Contrastive training number of epochs
|
The `SentenceTransformer` number of epochs is the same as the number of epochs for the classification head.
Even when `SetFitTrainer` is initialized with `num_epochs=1` and then `trainer.train(num_epochs=10)`, the sentence transformer runs with 10 epochs. Ideally, senatence transformer should run 1 epoch and the classifier should run for 10.
The reason for this is that in `trainer.py`, the `model_body.fit()` is called with `num_epochs` rather than `self.num_epochs`. Is this intended??
I can write a PR to fix this if needed.
|
https://github.com/huggingface/setfit/issues/256
|
closed
|
[
"question"
] | 2023-01-06T02:26:30Z
| 2023-01-09T10:54:45Z
| null |
abhinav-kashyap-asus
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.