
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/pytorch
| 20,271
|
Official instructions for how to build libtorch don't have same structure as prebuilt binaries
|
On Slack, Geoffrey Yu asked:
> Are there instructions for building libtorch from source? I feel like I'm missing something since I've tried building with `tools/build_libtorch.py`. However the build output doesn't seem to have the same structure as the prebuilt libtorch that you can download on pytorch.org
@pjh5 responded: "If you're curious, here's exactly what builds the libtorches https://github.com/pytorch/builder/blob/master/manywheel/build_common.sh#L120 . It's mostly tools/build_libtorch.py but also copies some header files from a wheel file"
This is not mentioned at all in the "how to build libtorch" documentation: https://github.com/pytorch/pytorch/blob/master/docs/libtorch.rst Normally we give build instructions in README but there are no libtorch build instructions in the README. Additionally, the C++ API docs https://pytorch.org/cppdocs/ don't explain how to build from source.
Some more users being confused about the matter:
* https://discuss.pytorch.org/t/building-libtorch-c-distribution-from-source/27519/2
* https://github.com/pytorch/pytorch/issues/20156
|
https://github.com/pytorch/pytorch/issues/20271
|
closed
|
[
"high priority",
"module: binaries",
"module: build",
"module: docs",
"module: cpp",
"triaged"
] | 2019-05-08T13:02:51Z
| 2019-05-30T19:52:28Z
| null |
ezyang
|
huggingface/transformers
| 591
|
What is the use of [SEP]?
|
Hello. I know that [CLS] means the start of a sentence and [SEP] makes BERT know the second sentence has begun. [SEP] can’t stop one sentence from extracting information from another sentence. However, I have a question.
If I have 2 sentences, which are s1 and s2., and our fine-tuning task is the same. In one way, I add special tokens and the input looks like [CLS]+s1+[SEP] + s2 + [SEP]. In another, I make the input look like [CLS] + s1 + s2 + [SEP]. When I input them to BERT respectively, what is the difference between them? Will the s1 in second one integrate more information from s2 than the s1 in first one does? Will the token embeddings change a lot between the 2 methods?
Thanks for any help!
|
https://github.com/huggingface/transformers/issues/591
|
closed
|
[] | 2019-05-07T04:12:16Z
| 2019-05-21T10:51:31Z
| null |
RomanShen
|
pytorch/pytorch
| 20,090
|
How to add dynamically allocated strings to Pickler?
|
The following code prints `111` and `111`, instead of `222` and `111`, because `222` is skipped [here](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/pickler.cpp#L68). Is this by design as Pickler only works for statically allocated strings? Or is there a way to correctly add dynamically allocated strings? (and all other types listed [here](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/pickler.cpp#L104-L114))?
```c++
std::string str1 = "111";
std::string str2 = "222";
std::vector<at::Tensor> tensor_table;
torch::jit::Pickler pickler(&tensor_table);
pickler.start();
pickler.addIValue(str1);
pickler.addIValue(str2);
pickler.finish();
auto buffer = new char[pickler.stack().size()];
memcpy(buffer, pickler.stack().data(), pickler.stack().size());
torch::jit::Unpickler unpickler(buffer, pickler.stack().size(), &tensor_table);
auto values = unpickler.parse_ivalue_list();
std::cout << values.back().toStringRef() << std::endl;
values.pop_back();
std::cout << values.back().toStringRef() << std::endl;
values.pop_back();
```
cc @zdevito
|
https://github.com/pytorch/pytorch/issues/20090
|
closed
|
[
"oncall: jit",
"triaged"
] | 2019-05-03T04:43:08Z
| 2019-05-17T21:45:41Z
| null |
mrshenli
|
huggingface/neuralcoref
| 157
|
Performance?
|
Hi there,
Thanks for the nice package!
Are there any performance comparisons with other systems? (say, Lee et el'18: https://arxiv.org/pdf/1804.05392.pdf).
|
https://github.com/huggingface/neuralcoref/issues/157
|
closed
|
[
"question",
"perf / accuracy"
] | 2019-04-30T21:38:56Z
| 2019-10-16T08:48:09Z
| null |
danyaljj
|
pytorch/examples
| 554
|
Where is the hook?
|
On the tutorial, I see it says this is an example of hook. So where is the hook?
|
https://github.com/pytorch/examples/issues/554
|
closed
|
[] | 2019-04-30T11:38:40Z
| 2019-05-27T21:00:53Z
| null |
yanbixing
|
pytorch/pytorch
| 19,908
|
c++/pytorch How to convert tensor to image array?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
I would like to convert a tensor to image array and use tensor.data<short>() method. But it doesn't work.
My function is showed below:
```
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
#include <sstream>
#include <string>
#include <vector>
#include "itkImage.h"
#include "itkImageFileReader.h"
#include "itkImageFileWriter.h"
#include "itkImageRegionIterator.h"
//////////////////////////////////////////////////////
//Goal: load jit script model and segment myocardium
//Step: 1. load jit script model
// 2. load input image
// 3. predict by model
// 4. save the result to file
//////////////////////////////////////////////////////
typedef short PixelType;
const unsigned int Dimension = 3;
typedef itk::Image<PixelType, Dimension> ImageType;
typedef itk::ImageFileReader<ImageType> ReaderType;
typedef itk::ImageRegionIterator<ImageType> IteratorType;
bool itk2tensor(ImageType::Pointer itk_img, torch::Tensor &tensor_img) {
typename ImageType::RegionType region = itk_img->GetLargestPossibleRegion();
const typename ImageType::SizeType size = region.GetSize();
std::cout << "Input size: " << size[0] << ", " << size[1]<< ", " << size[2] << std::endl;
int len = size[0] * size[1] * size[2];
short rowdata[len];
int count = 0;
IteratorType iter(itk_img, itk_img->GetRequestedRegion());
// convert itk to array
for (iter.GoToBegin(); !iter.IsAtEnd(); ++iter) {
rowdata[count] = iter.Get();
count++;
}
std::cout << "Convert itk to array DONE!" << std::endl;
// convert array to tensor
tensor_img = torch::from_blob(rowdata, {1, 1, (int)size[0], (int)size[1], (int)size[2]}, torch::kShort).clone();
tensor_img = tensor_img.toType(torch::kFloat);
tensor_img = tensor_img.to(torch::kCUDA);
tensor_img.set_requires_grad(0);
return true;
}
bool tensor2itk(torch::Tensor &t, ImageType::Pointer itk_img) {
std::cout << "tensor dtype = " << t.dtype() << std::endl;
std::cout << "tensor size = " << t.sizes() << std::endl;
t = t.toType(torch::kShort);
short * array = t.data<short>();
ImageType::IndexType start;
start[0] = 0; // first index on X
start[1] = 0; // first index on Y
start[2] = 0; // first index on Z
ImageType::SizeType size;
size[0] = t.size(2);
size[1] = t.size(3);
size[2] = t.size(4);
ImageType::RegionType region;
region.SetSize( size );
region.SetIndex( start );
itk_img->SetRegions( region );
itk_img->Allocate();
int len = size[0] * size[1] * size[2];
IteratorType iter(itk_img, itk_img->GetRequestedRegion());
int count = 0;
// convert array to itk
std::cout << "start!" << std::endl;
for (iter.GoToBegin(); !iter.IsAtEnd(); ++iter) {
short temp = *array++; // ERROR!
std::cout << temp << " ";
iter.Set(temp);
count++;
}
std::cout << "end!" << std::endl;
return true;
}
int main(int argc, const char* argv[]) {
int a, b, c;
if (argc != 4) {
std::cerr << "usage: automyo input jitmodel output\n";
return -1;
}
std::cout << "========= jit start =========\n";
// 1. load jit script model
std::cout << "Load script module: " << argv[2] << std::endl;
std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(argv[2]);
module->to(at::kCUDA);
// assert(module != nullptr);
std::cout << "Load script module DONE" << std::endl;
// 2. load input image
const char* img_path = argv[1];
std::cout << "Load image: " << img_path << std::endl;
ReaderType::Pointer reader = ReaderType::New();
if (!img_path) {
std::cout << "Load input file error!" << std::endl;
return false;
}
reader->SetFileName(img_path);
reader->Update();
std::cout << "Load image DONE!" << std::endl;
ImageType::Pointer itk_img = reader->GetOutput();
torch::Tensor tensor_img;
if (!itk2tensor(itk_img, tensor_img)) {
std::cerr << "itk2tensor ERROR!" << std::endl;
}
else {
std::cout << "Convert array to tensor DONE!" << std::endl;
}
std::vector<torch::jit::IValue> inputs;
inputs.push_back(tensor_img);
// 3. predict by model
torch::Tensor y = module->forward(inputs).toTensor();
std::cout << "Inference DONE!" << std::endl;
// 4. save the result to file
torch::Tensor seg = y.gt(0.5);
// std::cout << seg << std::endl;
ImageType::Pointer out_itk_img = ImageType::New();
if (!tensor2itk(seg, out_itk_img)) {
std::cerr << "tensor2itk ERROR!" << std::endl;
}
else {
std::cout << "Convert tensor to itk DONE!" << std::endl;
}
std::cout << out_itk_img << std::endl;
return true;
}
```
The runtime log is showed below:
> Load script module: model_myo_jit.pt
> Load script module DONE
> Load image: patch_6.nii.gz
> Load image DONE!
> Input size: 128,
|
https://github.com/pytorch/pytorch/issues/19908
|
closed
|
[] | 2019-04-29T07:49:29Z
| 2019-04-29T09:58:24Z
| null |
JingLiRaysightmed
|
pytorch/pytorch
| 19,822
|
How to use torch.tensor(n) in Python3 to adapt to ’ at::TensorImpl‘
|
## ❓ Questions and Help
Hi ,when nms_cpp compiled by cpp_extension ,it didnt work but work in pytorch0.4.0.:
## TypeError: gpu_nms(): incompatible function arguments. The following argument types are supported:
1. (arg0: at::TensorImpl, arg1: at::TensorImpl, arg2: at::TensorImpl, arg3:
float) -> int
## Invoked with:
tensor([ 2.5353e+09, 2.5238e+09, -4.5295e+18, ..., 4.7854e+18,
4.7424e+18, 4.7895e+18]), tensor([ 566]),
tensor([[ 146.1686, 111.1691, 242.2774, 288.5695, 0.8267],
[ 144.7030, 108.2768, 244.0824, 282.2564, 0.8234],
[ 144.5566, 110.4112, 243.3897, 283.4086, 0.8225],
...,
[ 100.9274, 81.2732, 155.0707, 130.5494, 0.0500],
[ 0.0000, 185.7541, 47.3124, 276.2884, 0.0500],
[ 4.5178, 57.4754, 37.1159, 115.0753, 0.0500]], device='cuda:0
'), //
0.5
## cpp file:
## Code
// ------------------------------------------------------------------
// Faster R-CNN
// Copyright (c) 2015 Microsoft
// Licensed under The MIT License [see fast-rcnn/LICENSE for details]
// Written by Shaoqing Ren
// ------------------------------------------------------------------
#include <torch/script.h>
#include<torch/serialize/tensor.h>
#include <THC/THC.h>
#include <ATen/ATen.h>//state
#include <TH/TH.h>
#include <THC/THCTensorCopy.h>
//#include <TH/generic/THTensorCopy.h>
#include <THC/generic/THCTensorCopy.h>//generic/THCTensorCopy.h
#include <THC/THCTensorCopy.hpp>
#include <math.h>
#include <stdio.h>
#include <cstddef>
#include <torch/torch.h>
#include <torch/script.h>
#include "cuda/nms_kernel2.h"
#include "nms.h"
//src/nms_cuda.cpp(27): error C2440: “初始化”: 无法从“
//std::unique_ptr<THCState,void (__cdecl *)(THCState *)>
//THCState *state = at::globalContext().thc_state;
//std::unique_ptr<THCState,void (__cdecl *)(THCState *)> state= at::globalContext().thc_state;
THCState *state;
int gpu_nms(THLongTensor * keep, THLongTensor* num_out, THCudaTensor * boxes, float nms_overlap_thresh) {
// boxes has to be sorted
THArgCheck(THLongTensor_isContiguous(keep), 0, "boxes must be contiguous");
THArgCheck(THCudaTensor_isContiguous(state, boxes), 2, "boxes must be contiguous");
// Number of ROIs
int64_t boxes_num = THCudaTensor_size(state, boxes, 0);
int64_t boxes_dim = THCudaTensor_size(state, boxes, 1);
float* boxes_flat = THCudaTensor_data(state, boxes);
const int64_t col_blocks = DIVUP(boxes_num, threadsPerBlock);
printf("100,%d,%d ,%d ,%d " , *state,boxes_num, boxes_dim, col_blocks);
//, *state
THCudaLongTensor * mask = THCudaLongTensor_newWithSize2d(state, boxes_num, col_blocks);
//#unsigned
unsigned long long* mask_flat = (unsigned long long* )THCudaLongTensor_data(state, mask);
//_mns from
_nms(boxes_num, boxes_flat, mask_flat, nms_overlap_thresh);
THLongTensor * mask_cpu = THLongTensor_newWithSize2d(boxes_num, col_blocks);
//THCudaTensor_copyFloat
//THLongTensor_copyCuda(state, mask_cpu, mask); #no found
//THCTensor_(copyAsyncCPU)
//THTensor_copyCuda(state, mask_cpu, mask);
//THLongTensor_copyCudaLong(state, mask_cpu, mask);
//not found cu file
//THCStorage_copyCudaLong(state, mask_cpu, mask);#
//THCTensor_copy(state, mask_cpu, mask);
//THCudaTensor_copyLong(state, mask_cpu, mask);
//THLongTensor_copyCudaLong(state, mask_cpu, mask);
//copy_from_cpu(state, mask_cpu, mask);
//ok mask 2 mask_cpu
//
THCudaLongTensor_freeCopyTo(state, mask_cpu, mask);
//Copy_Long(state, mask_cpu, mask);
//copyAsyncCuda
//THTensor_copyLong(state, mask_cpu, mask);
THCudaLongTensor_free(state, mask);
//unsigned
long long * mask_cpu_flat = THLongTensor_data(mask_cpu);
THLongTensor * remv_cpu = THLongTensor_newWithSize1d(col_blocks);
//unsigned
long long* remv_cpu_flat = THLongTensor_data(remv_cpu);
THLongTensor_fill(remv_cpu, 0);
int64_t * keep_flat = THLongTensor_data(keep);
long num_to_keep = 0;
int i, j;
for (i = 0; i < boxes_num; i++) {
int nblock = i / threadsPerBlock;
int inblock = i % threadsPerBlock;
if (!(remv_cpu_flat[nblock] & (1ULL << inblock))) {
keep_flat[num_to_keep++] = i;
long long *p = &mask_cpu_flat[0] + i * col_blocks;
for (j = nblock; j < col_blocks; j++) {
remv_cpu_flat[j] |= p[j];
}
}
}
int64_t * num_out_flat = THLongTensor_data(num_out);
* num_out_flat = num_to_keep;
THLongTensor_free(mask_cpu);
THLongTensor_free(remv_cpu);
//return 1;
return num_to_keep;
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("cpu_nms", &cpu_nms, "nms cpu_nms ");
m.def("gpu_nms", &gpu_nms, "nms gpu_nms (CUDA)");
}
|
https://github.com/pytorch/pytorch/issues/19822
|
closed
|
[] | 2019-04-27T08:40:06Z
| 2019-04-28T07:42:41Z
| null |
liuchanfeng165
|
pytorch/pytorch
| 19,744
|
How to select cl.exe for a config of cpp_extension?
|
## ❓ Questions and Help
Hi, I got this error and dont wanna change vs15 again because the compiler keeps in OS,if I use cl.exe of VS2015 not VS2017 to compile my cpp_extension by setup.py and how to modify setup.py
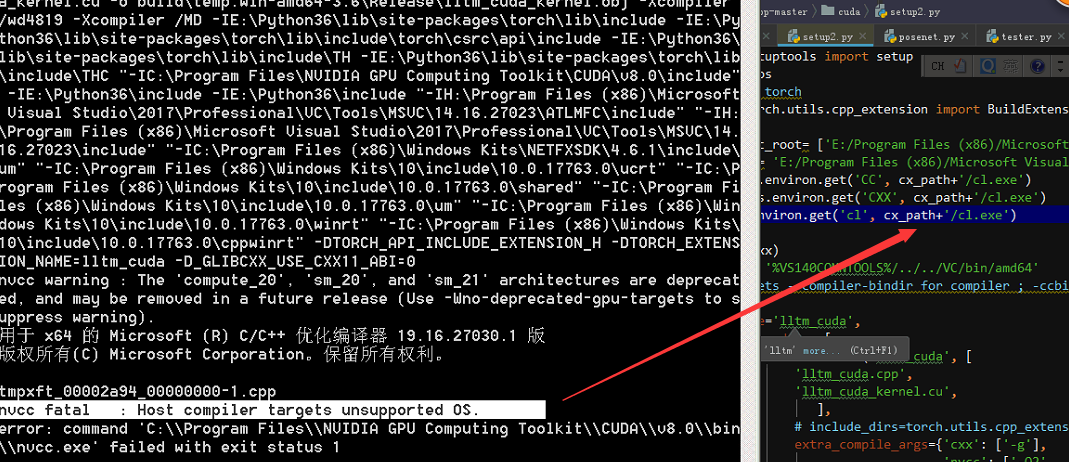
## setup.py
from setuptools import setup
import os
#import torch
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
_ext_src_root= ['E:/Program Files (x86)/Microsoft Visual Studio 14.0/VC'] #
cx_path= 'E:/Program Files (x86)/Microsoft Visual Studio 14.0/VC/bin/amd64'
cc = os.environ.get('CC', cx_path+'/cl.exe')
cxx = os.environ.get('CXX', cx_path+'/cl.exe')
cl=os.environ.get('cl', cx_path+'/cl.exe')
print(cxx)
vs_bin= '%VS140COMNTOOLS%/../../VC/bin/amd64'
#nvcc sets --compiler-bindir for compiler ; -ccbin
setup(
name='lltm_cuda',
ext_modules=[
CUDAExtension('lltm_cuda', [
'lltm_cuda.cpp',
'lltm_cuda_kernel.cu',
],
# include_dirs=torch.utils.cpp_extension.include_paths(),
extra_compile_args={'cxx': ['-g'],
'nvcc': ['-O2' , '--compiler-bindir' " {}".format(cx_path+'/cl.exe')]}
#extra_cflags
# extra_compile_args ={
# "cxx": ["-O2", "-I{}".format("{}/include".format(_ext_src_root))],
# # "nvcc": ["-O2", "-I{}".format("{}/include".format(_ext_src_root))],
# "cl": ["-O2", "-I{}".format("{}/include".format(_ext_src_root))],
# },
),
],
cmdclass={
'build_ext': BuildExtension
})
## add list
just to compile ' .cu' not '.cpp ', mabe modify there or not?
line 240 in cpp_extension.py :+1:
# Register .cu and .cuh as valid source extensions.
self.compiler.src_extensions += ['.cu', '.cuh']
# Save the original _compile method for later.
if self.compiler.compiler_type == 'msvc':
self.compiler._cpp_extensions += ['.cu', '.cuh']
original_compile = self.compiler.compile
original_spawn = self.compiler.spawn
else:
original_compile = self.compiler._compile
## Thanks a lot
|
https://github.com/pytorch/pytorch/issues/19744
|
closed
|
[] | 2019-04-25T16:29:54Z
| 2019-04-26T08:28:24Z
| null |
liuchanfeng165
|
pytorch/pytorch
| 19,611
|
How to understand the results of model. Eval () and how to obtain the predictive probability value?
|
Hello everyone
I've been using tensorflow before, but I met torch when I added functionality to a tool. My ultimate goal was to get the classification probability. On a binary classification problem, I used model. Eval () (inputs). numpy () to get the prediction results.
like this
2.19903 -2.06323
2.22841 -2.09061
2.20833 -2.07209
2.22888 -2.09125
2.22644 -2.08869
I don't know how to convert it to probability, or should I use other commands to get classification probability?
I hope I can get help. Thank you.
|
https://github.com/pytorch/pytorch/issues/19611
|
closed
|
[
"triaged"
] | 2019-04-23T09:29:27Z
| 2019-04-23T19:26:02Z
| null |
xujiameng
|
pytorch/pytorch
| 19,561
|
How to do prediction/inference for a batch of images at a time with libtorch?
|
Anybody knows how to do prediction/inference for a batch of images at a time with libtorch/pytorch C++?
any reply would be appreciated, thank you!
|
https://github.com/pytorch/pytorch/issues/19561
|
closed
|
[] | 2019-04-22T08:40:04Z
| 2019-04-22T20:59:27Z
| null |
asa008
|
pytorch/examples
| 547
|
where can I get the inference code for classification?
|
I have trained the resnet-18 model for classification on my own dataset with examples/imagenet/main.py. And now I want to infernece the images, but there is no inference code.
|
https://github.com/pytorch/examples/issues/547
|
closed
|
[] | 2019-04-22T03:20:25Z
| 2019-04-24T10:50:50Z
| 2
|
ShaneYS
|
pytorch/pytorch
| 19,453
|
How to load PyTorch model with LSTM using C++ api
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. Establish a PyTorch model with LSTM module using python, and store the script module after using torch.jit.trace. Python code like this:
```python
class MyModule(nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.lstm = nn.LSTM(M, M, batch_first=True)
self.linear = nn.Linear(M, 1)
def forward(self, inputs, h0, c0):
output, (_, _) = self.lstm(inputs, h0, c0)
output, _ = torch.max(output, dim=1)
# output, _ = torch.max(inputs, dim=1)
output = self.linear(output)
return output
batch_size = 8
h = 33
w = 45
model = MyModule(h, w)
data = np.random.normal(1, 1, size=(batch_size, h, w))
data = torch.Tensor(data)
h0, c0 = torch.zeros(1, batch_size, w), torch.zeros(1, batch_size, w)
traced_script_module = torch.jit.trace(model, (data, h0,c0))
traced_script_module.save('model.pt')
```
2. Load the model and move the model to GPU, then when the script exit, there is a core dump. However, If we don't move the model to gpu, the cpp script exits normally.My cpp script like this:
```c++
int main(int argc, const char* argv[]) {
if (argc != 2) {
std::cerr << "usage: example-app <path-to-exported-script-module>\n";
return -1;
}
// Deserialize the ScriptModule from a file using torch::jit::load().
std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(argv[1]);
assert(module != nullptr);
std::cout << "ok\n";
this->module->to(at::Device("cuda:0"))
vector<torch::jit::IValue> inputs;
int b = 2, h = 33, w = 45;
vector<float> data(b*h*w, 1.0);
torch::Tensor data_tensor = torch::from_blob(data.data(), {b, h, w}.to(at::Device("cuda:0"));
torch::Tensor h0 = torch::from_blob(vector<float>(1*b*w, 0.0), {b, h, w}).to(at::Device("cuda:0"));
torch::Tensor c0 = torch::from_blob(vector<float>(1*b*w, 0.0), {b, h, w}).to(at::Device("cuda:0"));
inputs.push_back(data_tensor);
inputs.push_back(h0);
inputs.push(c0);
torch::Tensor output = module->forward(inputs).toTensor().cpu();
auto accessor = output.accessor<float, 2>();
vector<float> answer(b);
for (int i=0; i<accessor.size(0); ++i){
answer[i] = accessor[i][0];
}
cout << "predict ok" << endl;
}
```
> Note: There is a bug to move init hidden state tensor of lstm to gpu [link](https://github.com/pytorch/pytorch/issues/15272) I use two methods to solve this problem, one is to specify the device in python model using hard code, another is to pass init hidden state as input parameter of forward in cpp script, which may cause a warning [link](https://discuss.pytorch.org/t/rnn-module-weights-are-not-part-of-single-contiguous-chunk-of-memory/6011/14)
the gdb trace info like this:
```shell
(gdb) where
#0 0x00007ffff61ca9fe in ?? () from /usr/local/cuda/lib64/libcudart.so.10.0
#1 0x00007ffff61cf96b in ?? () from /usr/local/cuda/lib64/libcudart.so.10.0
#2 0x00007ffff61e4be2 in cudaDeviceSynchronize () from /usr/local/cuda/lib64/libcudart.so.10.0
#3 0x00007fffb945dcf4 in cudnnDestroy () from repo/pytorch_cpp/libtorch/lib/libcaffe2_gpu.so
#4 0x00007fffb4fca17d in std::unordered_map<int, std::vector<at::native::(anonymous namespace)::Handle, std::allocator<at::native::(anonymous namespace)::Handle> >, std::hash<int>, std::equal_to<int>, std::allocator<std::pair<int const, std::vector<at::native::(anonymous namespace)::Handle, std::allocator<at::native::(anonymous namespace)::Handle> > > > >::~unordered_map() () from repo/pytorch_cpp/libtorch/lib/libcaffe2_gpu.so
#5 0x00007fffb31fe615 in __cxa_finalize (d=0x7fffe8519680) at cxa_finalize.c:83
#6 0x00007fffb4dd3ac3 in __do_global_dtors_aux () from repo/pytorch_cpp/libtorch/lib/libcaffe2_gpu.so
#7 0x00007fffffffe010 in ?? ()
#8 0x00007ffff7de5b73 in _dl_fini () at dl-fini.c:138
Backtrace stopped: frame did not save the PC
```
3. When I remove the LSTM in python model, then the cpp script exits normally.
4. I guess the hidden state of LSTM cause the core dump, maybe relate to the release the init hidden state memory?
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
So, When I want to load a model with LSTM using c++, how to deal with the hidden state, and how to avoid core dump?
## Environment
PyTorch version: 1.0.1.post2
Is debug build: No
CUDA used to build PyTorch: 10.0.130
OS: Ubuntu 18.04.2 LTS
GCC version: (Ubuntu 7.3.0-27ubuntu1~18.04) 7.3.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 10.0.130
GPU models and configuration:
GPU 0: GeForce RTX 2080 Ti
GPU 1: GeForce RTX 2080 Ti
Nvidia driver version: 410.48
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy==1
|
https://github.com/pytorch/pytorch/issues/19453
|
open
|
[
"module: cpp",
"triaged"
] | 2019-04-19T02:11:06Z
| 2024-07-24T20:52:00Z
| null |
SixerWang
|
pytorch/tutorials
| 484
|
different results
|
HI, i copied to code exactly and and ran with all the appropriate downloads and im not achieving the resutls stated with 40 epochs. the loss stays at around 2.2 with test accuracy of 100/837 .. around 11%..
is there something i need to change to get over 50% accuracy ?
|
https://github.com/pytorch/tutorials/issues/484
|
closed
|
[] | 2019-04-18T16:04:34Z
| 2021-06-16T17:49:27Z
| 1
|
taylerpauls
|
pytorch/examples
| 544
|
the error when I run the example for the imagenet
|
When I tried to run the model for the example/imagenet, I encounter such error.So could you tell me how to solve the problem?
python /home/zrz/code/imagenet_dist/examples-master/imagenet/main.py -a resnet18 -/home/zrz/dataset/imagenet/imagenet2012/ILSVRC2012/raw-data/imagenet-data
=> creating model 'resnet18'
Epoch: [0][ 0/320292] Time 3.459 ( 3.459) Data 0.295 ( 0.295) Loss 7.2399e+00 (7.2399e+00) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
Epoch: [0][ 10/320292] Time 0.043 ( 0.357) Data 0.000 ( 0.027) Loss 9.4861e+00 (1.3169e+01) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
Epoch: [0][ 20/320292] Time 0.046 ( 0.209) Data 0.000 ( 0.014) Loss 7.3722e+00 (1.0817e+01) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
Epoch: [0][ 30/320292] Time 0.032 ( 0.154) Data 0.000 ( 0.010) Loss 6.9166e+00 (9.5394e+00) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
/opt/conda/conda-bld/pytorch_1549630534704/work/aten/src/THCUNN/ClassNLLCriterion.cu:105: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [3,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "/home/zrz/code/imagenet_dist/examples-master/imagenet/main.py", line 417, in <module>
main()
File "/home/zrz/code/imagenet_dist/examples-master/imagenet/main.py", line 113, in main
main_worker(args.gpu, ngpus_per_node, args)
File "/home/zrz/code/imagenet_dist/examples-master/imagenet/main.py", line 239, in main_worker
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/zrz/code/imagenet_dist/examples-master/imagenet/main.py", line 286, in train
losses.update(loss.item(), input.size(0))
RuntimeError: CUDA error: device-side assert triggered
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: device-side assert triggered (insert_events at /opt/conda/conda-bld/pytorch_1549630534704/work/aten/src/THC/THCCachingAllocator.cpp:470)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7f099a50acf5 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: <unknown function> + 0x123b8c0 (0x7f099e7ee8c0 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libcaffe2_gpu.so)
frame #2: at::TensorImpl::release_resources() + 0x50 (0x7f099ac76c30 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libcaffe2.so)
frame #3: <unknown function> + 0x2a836b (0x7f099818b36b in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #4: <unknown function> + 0x30eff0 (0x7f09981f1ff0 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #5: torch::autograd::deleteFunction(torch::autograd::Function*) + 0x2f0 (0x7f099818dd70 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #6: std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release() + 0x45 (0x7f09c17f87f5 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #7: torch::autograd::Variable::Impl::release_resources() + 0x4a (0x7f09984001ba in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #8: <unknown function> + 0x12148b (0x7f09c181048b in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #9: <unknown function> + 0x31a49f (0x7f09c1a0949f in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #10: <unknown function> + 0x31a4e1 (0x7f09c1a094e1 in /home/zrz/miniconda3/envs/runze_env_name/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #11: <unknown function> + 0x1993cf (0x5574e4c9a3cf in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #12: <unknown function> + 0xf12b7 (0x5574e4bf22b7 in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #13: <unknown function> + 0xf1147 (0x5574e4bf2147 in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #14: <unknown function> + 0xf115d (0x5574e4bf215d in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #15: <unknown function> + 0xf115d (0x5574e4bf215d in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #16: <unknown function> + 0xf115d (0x5574e4bf215d in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #17: PyDict_SetItem + 0x3da (0x5574e4c37e7a in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #18: PyDict_SetItemString + 0x4f (0x5574e4c4078f in /home/zrz/miniconda3/envs/runze_env_name/bin/python3.6)
frame #19: PyImport_Cleanup + 0x99 (0x5574e4ca4709 in /ho
|
https://github.com/pytorch/examples/issues/544
|
closed
|
[] | 2019-04-14T06:22:38Z
| 2022-03-10T05:56:43Z
| 4
|
runzeer
|
pytorch/examples
| 543
|
[Important BUG] non-consistent behavior between "final evaluation" and "eval on each epoch" for mnist example
|
It is a common sense that, during evaluation, the model is not trained by the dev dataset.
However, I noticed a strange different behavior between the two results:
(1) train 10 epoch, having final evaluate on test data
(2) train 10 epoch, having an evaluation after each training epoch on test data
## Prior knowledge:
Even though you set seed for everything
```
# set seed
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if use_cuda:
torch.cuda.manual_seed_all(args.seed) # if got GPU also set this seed
```
When you run `examples/mnist/main.py`, it still give different result on GPU.
```
run 1
-------------
Test set: Average loss: 0.1018, Accuracy: 9660/10000 (97%)
Test set: Average loss: 0.0611, Accuracy: 9825/10000 (98%)
Test set: Average loss: 0.0555, Accuracy: 9813/10000 (98%)
Test set: Average loss: 0.0409, Accuracy: 9862/10000 (99%)
Test set: Average loss: 0.0381, Accuracy: 9870/10000 (99%)
Test set: Average loss: 0.0339, Accuracy: 9891/10000 (99%)
Test set: Average loss: 0.0340, Accuracy: 9877/10000 (99%)
Test set: Average loss: 0.0399, Accuracy: 9872/10000 (99%)
Test set: Average loss: 0.0291, Accuracy: 9908/10000 (99%)
Test set: Average loss: 0.0315, Accuracy: 9896/10000 (99%)
run 2
--------------
Test set: Average loss: 0.1016, Accuracy: 9666/10000 (97%)
Test set: Average loss: 0.0608, Accuracy: 9828/10000 (98%)
Test set: Average loss: 0.0567, Accuracy: 9810/10000 (98%)
Test set: Average loss: 0.0408, Accuracy: 9864/10000 (99%)
Test set: Average loss: 0.0382, Accuracy: 9868/10000 (99%)
Test set: Average loss: 0.0339, Accuracy: 9894/10000 (99%)
Test set: Average loss: 0.0349, Accuracy: 9871/10000 (99%)
Test set: Average loss: 0.0396, Accuracy: 9876/10000 (99%)
Test set: Average loss: 0.0294, Accuracy: 9911/10000 (99%)
Test set: Average loss: 0.0304, Accuracy: 9895/10000 (99%)
```
As long as you set `torch.backends.cudnn.deterministic = True`
You could get consistent results:
```
====== parameters ========
batch_size: 64
do_eval: True
do_eval_each_epoch: True
epochs: 10
log_interval: 10
lr: 0.01
momentum: 0.5
no_cuda: False
save_model: False
seed: 42
test_batch_size: 1000
==========================
Test set: Average loss: 0.1034, Accuracy: 9679/10000 (97%)
Test set: Average loss: 0.0615, Accuracy: 9804/10000 (98%)
Test set: Average loss: 0.0484, Accuracy: 9847/10000 (98%)
Test set: Average loss: 0.0361, Accuracy: 9888/10000 (99%)
Test set: Average loss: 0.0341, Accuracy: 9887/10000 (99%)
Test set: Average loss: 0.0380, Accuracy: 9877/10000 (99%)
Test set: Average loss: 0.0302, Accuracy: 9899/10000 (99%)
Test set: Average loss: 0.0315, Accuracy: 9884/10000 (99%)
Test set: Average loss: 0.0283, Accuracy: 9909/10000 (99%)
Test set: Average loss: 0.0266, Accuracy: 9907/10000 (99%) -> epoch 10
====== parameters ========
batch_size: 64
do_eval: True
do_eval_each_epoch: True
epochs: 20
log_interval: 10
lr: 0.01
momentum: 0.5
no_cuda: False
save_model: False
seed: 42
test_batch_size: 1000
==========================
Test set: Average loss: 0.1034, Accuracy: 9679/10000 (97%)
Test set: Average loss: 0.0615, Accuracy: 9804/10000 (98%)
Test set: Average loss: 0.0484, Accuracy: 9847/10000 (98%)
Test set: Average loss: 0.0361, Accuracy: 9888/10000 (99%)
Test set: Average loss: 0.0341, Accuracy: 9887/10000 (99%)
Test set: Average loss: 0.0380, Accuracy: 9877/10000 (99%)
Test set: Average loss: 0.0302, Accuracy: 9899/10000 (99%)
Test set: Average loss: 0.0315, Accuracy: 9884/10000 (99%)
Test set: Average loss: 0.0283, Accuracy: 9909/10000 (99%)
Test set: Average loss: 0.0266, Accuracy: 9907/10000 (99%) -> epoch 10
Test set: Average loss: 0.0373, Accuracy: 9870/10000 (99%)
Test set: Average loss: 0.0286, Accuracy: 9909/10000 (99%)
Test set: Average loss: 0.0309, Accuracy: 9908/10000 (99%)
Test set: Average loss: 0.0302, Accuracy: 9899/10000 (99%)
Test set: Average loss: 0.0261, Accuracy: 9907/10000 (99%)
Test set: Average loss: 0.0258, Accuracy: 9913/10000 (99%)
Test set: Average loss: 0.0288, Accuracy: 9917/10000 (99%)
Test set: Average loss: 0.0280, Accuracy: 9904/10000 (99%)
Test set: Average loss: 0.0294, Accuracy: 9902/10000 (99%)
Test set: Average loss: 0.0257, Accuracy: 9914/10000 (99%) -> epoch 20
```
However, when you change the model to have `final evaluation` after epoch 10, the result becomes:
```
====== parameters ========
batch_size: 64
do_eval: True
do_eval_each_epoch: False
epochs: 10
log_interval: 10
lr: 0.01
momentum: 0.5
no_cuda: False
save_model: False
seed: 42
test_batch_size: 1000
==========================
Test set: Average loss: 0.0361, Accuracy: 9885/10000 (99%) -> epoch 10
```
I also tried to add `torch.backends.cudnn.benchmark = False`, it gives the same result.
Repeatability and consistent result is crucial in machine learning, do you guys know what is the r
|
https://github.com/pytorch/examples/issues/543
|
open
|
[
"help wanted",
"nlp"
] | 2019-04-12T06:09:13Z
| 2022-03-10T06:03:31Z
| 1
|
Jacob-Ma
|
pytorch/examples
| 542
|
non-deterministic behavior on PyTorch mnist example
|
I tried PyTorch `examples/mnist/main.py` example to check if it is deterministic.
Although I modified the code to set the seed on everything, it still gives quite different results on GPU.
Do you know how to make the code be deterministic? Thank you very much.
Below is the code I have run and the output.
```
from __future__ import print_function
import argparse
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
#if batch_idx % args.log_interval == 0:
#print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
#epoch, batch_idx * len(data), len(train_loader.dataset),
#100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
# set seed
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if use_cuda:
torch.cuda.manual_seed_all(args.seed) # if got GPU also set this seed
# torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Norm
|
https://github.com/pytorch/examples/issues/542
|
closed
|
[] | 2019-04-12T04:31:25Z
| 2019-04-12T05:53:14Z
| 1
|
Jacob-Ma
|
pytorch/tutorials
| 476
|
Example with torch.empty in What is PyTorch? is misleading
|
In this [example](https://github.com/pytorch/tutorials/blob/master/beginner_source/blitz/tensor_tutorial.py) the output of a `torch.empty` call looks the same result I would obtain with `torch.zeros`, while it should be filled with garbage values.
This might be misleading to beginners.
|
https://github.com/pytorch/tutorials/issues/476
|
closed
|
[] | 2019-04-11T09:19:06Z
| 2019-08-23T21:18:53Z
| null |
alexchapeaux
|
pytorch/pytorch
| 19,098
|
[C++ front end] how to use clamp to clip gradients?
|
## ❓ Questions and Help
hi, I wonder if this could clip the gradients:
for(int i=0; i<net.parameters().size(); i++)
{
net.parameters().at(i).grad() = torch::clamp(net.parameters().at(i).grad(), -GRADIENT_CLIP, GRADIENT_CLIP);
}
optimizer.step();
I found it doesn't seem to work, and I still got large output.
How can I use the "clamp“ correctly?
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/19098
|
closed
|
[] | 2019-04-10T05:37:24Z
| 2019-04-10T05:38:01Z
| null |
ZhuXingJune
|
pytorch/pytorch
| 19,012
|
I have a piece of code that is written in LUA and I want to know what is the pytorch equivalent of the code.?How do I implement these lines in pytorch .. Can somebody help me with it? The code is mentioned in the comment
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/19012
|
closed
|
[] | 2019-04-08T10:15:59Z
| 2019-04-08T10:30:32Z
| null |
AshishRMenon
|
pytorch/pytorch
| 18,951
|
Completed code with bug report for hdf5 dataset. How to fix?
|
Hello all, I want to report the issue of pytorch with hdf5 loader. The full source code and bug are provided
The problem is that I want to call the `test_dataloader.py` in two terminals. The file is used to load the custom hdf5 dataset (`custom_h5_loader`). To generate h5 files, you may need first run the file `convert_to_h5` to generate 100 random h5 files.
To reproduce the error. Please run follows steps
**Step 1:** Generate the hdf5
```
from __future__ import print_function
import h5py
import numpy as np
import random
import os
if not os.path.exists('./data_h5'):
os.makedirs('./data_h5')
for index in range(100):
data = np.random.uniform(0,1, size=(3,128,128))
data = data[None, ...]
print (data.shape)
with h5py.File('./data_h5/' +'%s.h5' % (str(index)), 'w') as f:
f['data'] = data
```
Step2: Create a python file custom_h5_loader.py and paste the code
```
import h5py
import torch.utils.data as data
import glob
import torch
import numpy as np
import os
class custom_h5_loader(data.Dataset):
def __init__(self, root_path):
self.hdf5_list = [x for x in glob.glob(os.path.join(root_path, '*.h5'))]
self.data_list = []
for ind in range (len(self.hdf5_list)):
self.h5_file = h5py.File(self.hdf5_list[ind])
data_i = self.h5_file.get('data')
self.data_list.append(data_i)
def __getitem__(self, index):
self.data = np.asarray(self.data_list[index])
return (torch.from_numpy(self.data).float())
def __len__(self):
return len(self.hdf5_list)
```
**Step 3:** Create a python file with name test_dataloader.py
```
from dataloader import custom_h5_loader
import torch
import torchvision.datasets as dsets
train_h5_dataset = custom_h5_loader('./data_h5')
h5_loader = torch.utils.data.DataLoader(dataset=train_h5_dataset, batch_size=2, shuffle=True, num_workers=4)
for epoch in range(100000):
for i, data in enumerate(h5_loader):
print (data.shape)
```
Step 4: Open first terminal and run (it worked)
> python test_dataloader.py
Step 5: Open the second terminal and run (Error report in below)
> python test_dataloader.py
The error is
```
Traceback (most recent call last):
File "/home/john/anaconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 162, in make_fid
fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl)
File "h5py/_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py/_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py/h5f.pyx", line 78, in h5py.h5f.open
OSError: Unable to open file (unable to lock file, errno = 11, error message = 'Resource temporarily unavailable')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/john/anaconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 165, in make_fid
fid = h5f.open(name, h5f.ACC_RDONLY, fapl=fapl)
File "h5py/_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py/_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py/h5f.pyx", line 78, in h5py.h5f.open
OSError: Unable to open file (unable to lock file, errno = 11, error message = 'Resource temporarily unavailable')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "test_dataloader.py", line 5, in <module>
train_h5_dataset = custom_h5_loader('./data_h5')
File "/home/john/test_hdf5/dataloader.py", line 13, in __init__
self.h5_file = h5py.File(self.hdf5_list[ind])
File "/home/john/anaconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 312, in __init__
fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)
File "/home/john/anaconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 167, in make_fid
fid = h5f.create(name, h5f.ACC_EXCL, fapl=fapl, fcpl=fcpl)
File "h5py/_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py/_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py/h5f.pyx", line 98, in h5py.h5f.create
OSError: Unable to create file (unable to open file: name = './data_h5/47.h5', errno = 17, error message = 'File exists', flags = 15, o_flags = c2)
```
This is my configuration
```
HDF5 Version: 1.10.2
Configured on: Wed May 9 23:24:59 UTC 2018
Features:
---------
Parallel HDF5: no
High-level library: yes
Threadsafety: yes
print (torch.__version__)
1.0.0.dev20181227
```
|
https://github.com/pytorch/pytorch/issues/18951
|
closed
|
[] | 2019-04-05T14:50:55Z
| 2019-04-06T12:36:34Z
| null |
John1231983
|
pytorch/pytorch
| 18,872
|
How to convert a cudnn.BLSTM model to nn.LSTM bidirectional model
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
I have a *.t7 model that consists in few convolution layers and 1 block of cudnn.BLSTM(). To convert the model to pytorch, I create the same architecture with pytorch and try to get the weights from the t7 file. I think the convolution layers were correct but I have a doubt about the cudnn.BLSTM. When I extract the BLSTM weighs, I got one dimentional list of millions of parameters which corresponds to the same numbers of parameters in pytorch LSTM. However, in pytorch the weights and biases are with well know structure and weight_ih_l0, weight_hh_l0,... bias_ih_l_0, bias_hh_l0, ... weight_ih_l0_reverse, ... but in the cuddnn.BLSTM(), all parameters are set in one flattened list, so how to know the order and the shape of weights and biases ??
I debug the cudnn.BLSTM structure on th terminal and I get some idea about the concatenation orders and the shape:
Exemple
```
# torch
rnn = cudnn.BLSTM(1,1, 2, false, 0.5)
# get the weights
weights = rnn:weights()
th> rnn:weights()
{
1 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
2 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
3 :
{
1 : CudaTensor - size: 2
2 : CudaTensor - size: 2
3 : CudaTensor - size: 2
4 : CudaTensor - size: 2
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
4 :
{
1 : CudaTensor - size: 2
2 : CudaTensor - size: 2
3 : CudaTensor - size: 2
4 : CudaTensor - size: 2
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
}
biases = rnn:biaises()
th> rnn:biases()
{
1 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
2 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
3 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
4 :
{
1 : CudaTensor - size: 1
2 : CudaTensor - size: 1
3 : CudaTensor - size: 1
4 : CudaTensor - size: 1
5 : CudaTensor - size: 1
6 : CudaTensor - size: 1
7 : CudaTensor - size: 1
8 : CudaTensor - size: 1
}
}
```
all_flattened_params = rnn:parameters()
with this small example: I see that the rnn:parameters() function put the weighs and after that the biases in the above order. So:
weights =all_flattened_params[:-32]
biases = all_flattened_params[-32:]
Now, How to know the order of weights and biases regarding the pytorch nn.LSTM() ?
I supposed that this order:
weight_ih_l0, weight_hh_l0, weight_ih_l0_reverse, weight_hh_l0_reverse, weight_ih_l1, ....
bias_ih_l0, bias_hh_l0, bias_ih_l0_reverse, bias_hh_l0_reverse, .... but my model does not give the right output!!
|
https://github.com/pytorch/pytorch/issues/18872
|
closed
|
[] | 2019-04-04T18:30:20Z
| 2019-04-04T19:00:04Z
| null |
rafikg
|
pytorch/pytorch
| 18,837
|
How to use libtorch api torch::nn::parallel::data_parallel train on multi-gpu
|
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/docs is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
|
https://github.com/pytorch/pytorch/issues/18837
|
closed
|
[
"module: performance",
"oncall: distributed",
"module: multi-gpu",
"module: docs",
"module: cpp",
"module: nn",
"triaged"
] | 2019-04-04T02:48:41Z
| 2020-06-25T16:48:51Z
| null |
DDFlyInCode
|
pytorch/tutorials
| 468
|
auxilary net confusion Inception_v3 Vs. GoogLeNet in finetune script?
|
Hi, I followed the finetune tutorial (but using this script to train from scratch): for `inception` as there is only one `aux_logit` below snippet working fine.
```
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
```
correspoing `inception_v3` net file snippet:
```
if self.training and self.aux_logits:
aux = self.AuxLogits(x)
```
and the `fc` snippet:
```
self.fc = nn.Linear(768, num_classes)
```
Whereas for `GoogLeNet` has two auxilary outputs, the net file snippet has:
```
if self.training and self.aux_logits:
aux1 = self.aux1(x)
.....
if self.training and self.aux_logits:
aux2 = self.aux2(x)
```
and the `fc` snippets:
```
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
```
Now, my confusion is about using the `fc` in finetuning script, how to embed?
```
num_ftrs = model_ft.(aux1/aux2).(fc1/fc2).in_features
model_ft.(aux1/aux2).(fc1/fc2) = nn.Linear(num_ftrs, num_classes)
```
any thoughts?
|
https://github.com/pytorch/tutorials/issues/468
|
closed
|
[] | 2019-04-03T15:43:05Z
| 2019-04-07T10:52:28Z
| 0
|
rajasekharponakala
|
pytorch/pytorch
| 18,781
|
TORCH_CUDA_ARCH_LIST=All should know what is possible
|
## 🐛 Bug
When setting TORCH_CUDA_ARCH_LIST=All, I expect Torch to compile with all CUDA architectures available to my current version of CUDA. Instead, it attempted to build for cuda 2.0.
See error:
nvcc fatal : Unsupported gpu architecture 'compute_20'
## To Reproduce
Steps to reproduce the behavior:
1. Install CUDA >= 9.0
2. TORCH_CUDA_ARCH_LIST=All cmake -DUSE_CUDA=ON ..
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
Filters out 2.x architectures if CUDA >= 9.0
## Environment
CUDA 10.1
|
https://github.com/pytorch/pytorch/issues/18781
|
closed
|
[
"module: build",
"module: docs",
"module: cuda",
"module: molly-guard",
"triaged"
] | 2019-04-03T00:31:35Z
| 2024-08-04T05:06:56Z
| null |
xsacha
|
pytorch/tutorials
| 463
|
The input of a GRU is of shape (seq_len, batch, input_size). I wonder does seq_len means anything?
|
I noticed that in the documentation of pytorch GRU, the input shape should be (seq_len, batch, input_size), thus the input ought to be a sequence and the model will deal with the sequence inside itself. But in this notebook, the author passes a tensor only of length one in each iteration in function `train`. I mean if the model can deal with sequential inputs, why not just feed a sequence of sentence to it?
This is my first time to start an issue on github, please forgive me if there is anything wrong.
|
https://github.com/pytorch/tutorials/issues/463
|
closed
|
[] | 2019-04-02T09:32:10Z
| 2019-08-23T21:49:49Z
| 1
|
CSUN1997
|
pytorch/text
| 522
|
how to set random seed for BucketIterator to guarantee that it produce the same itrator every time you run the code ?
|
https://github.com/pytorch/text/issues/522
|
closed
|
[
"obsolete"
] | 2019-04-02T01:47:03Z
| 2022-01-25T04:04:42Z
| null |
zide05
|
|
pytorch/pytorch
| 18,677
|
How to compile/install caffe2 with cuda 9.0?
|
I'm building caffe2 on ubuntu 18.04 with CUDA 9.0? But when I run "python setup.py install" command, I have met issue about version of CUDA. It needs to CUDA 9.2 instead of 9.0 but i only want to build with 9.0.
How to pass it?
Thank you!
|
https://github.com/pytorch/pytorch/issues/18677
|
open
|
[
"caffe2"
] | 2019-04-01T06:54:50Z
| 2019-05-27T12:43:18Z
| null |
TuanHAnhVN
|
pytorch/tutorials
| 459
|
Inappropriate example code of vector-Jacobian product in (AUTOGRAD: AUTOMATIC DIFFERENTIATION)
|
I want to check the vector-Jacobian product. But in the example code the x is randomly generated and the the function relation between x and y is not clear. So how can I check if I correctly understand the vector-Jacobian product ? Can you improve it ?
|
https://github.com/pytorch/tutorials/issues/459
|
closed
|
[] | 2019-03-30T13:57:54Z
| 2021-06-16T20:24:11Z
| 2
|
guixianjin
|
pytorch/tutorials
| 458
|
how can i remove the layers in model.
|
I want to use the googlenet model to do finetuing, remove the fc layer, and then add other layers.
|
https://github.com/pytorch/tutorials/issues/458
|
closed
|
[] | 2019-03-30T08:28:08Z
| 2021-06-16T20:25:08Z
| 1
|
wangjue-wzq
|
pytorch/examples
| 534
|
when i run the main.py in imagenet,i encounter a problem
|

|
https://github.com/pytorch/examples/issues/534
|
open
|
[
"help wanted"
] | 2019-03-27T02:09:15Z
| 2022-03-10T06:03:41Z
| 0
|
Xavier-cvpr
|
pytorch/examples
| 531
|
Running examples/world_language_model
|
Hello, I am trying to run 'examples/world_language_model'.
However, when I do 'python main.py --cuda' in the above directory.
It prints an error like this.

Does anyone know how to solve this problem?
|
https://github.com/pytorch/examples/issues/531
|
closed
|
[] | 2019-03-21T11:51:02Z
| 2020-03-25T00:54:09Z
| 1
|
ohcurrent
|
huggingface/transformers
| 370
|
What is Synthetic Self-Training?
|
The current best performing model on[ SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) is BERT + N-Gram Masking + Synthetic Self-Training (ensemble):

What is Synthetic Self-Training?
|
https://github.com/huggingface/transformers/issues/370
|
closed
|
[
"Discussion",
"wontfix"
] | 2019-03-12T20:40:50Z
| 2019-07-13T20:58:32Z
| null |
hsm207
|
pytorch/examples
| 524
|
[super_resolution]How can I get 'model_epoch_500.pth' file?
|
When I run:
`python super_resolve.py --input_image dataset/BSDS300/images/test/16077.jpg --model model_epoch_500.pth --output_filename out.png` .
It outpus :
` [Errno 2] No such file or directory: 'model_epoch_500.pth'`
How can I get 'model_epoch_500.pth' file?
|
https://github.com/pytorch/examples/issues/524
|
closed
|
[] | 2019-03-08T11:08:17Z
| 2019-05-31T08:57:22Z
| 0
|
dyfloveslife
|
pytorch/pytorch
| 17,654
|
I want to know how to use the select(int64_t dim, int64_t index) in at::Tensor?What is the definition of a parameter ?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/17654
|
closed
|
[] | 2019-03-04T12:57:04Z
| 2019-03-04T17:05:24Z
| null |
SongyiGao
|
pytorch/tutorials
| 441
|
Add 'Open in Colab' Button to Tutorial Code
|
Is it possible to edit the downloadable Jupyter notebooks at the bottom of each 60-minute blitz section? In a utopian scenario there would be a button at the top of each file, allowing the user to 'Open in Colab'. If this button was present the user would fix the code so that each cell was ran with the output visible.
Here is an example with Keras, to explicate what I mean. There are some uploaded PyTorch Jupyter Notebook files in the same repository (along with the Keras Jupyter Notebooks) to gain a more comprehensive perspective.
https://github.com/PhillySchoolofAI/DL-Libraries/blob/master/KerasFunctionalAPI.ipynb
|
https://github.com/pytorch/tutorials/issues/441
|
closed
|
[] | 2019-03-04T12:26:51Z
| 2019-03-31T10:34:34Z
| 2
|
pynchmeister
|
pytorch/examples
| 518
|
How to train from scratch on custom model
|
Hi,
Thank you very much for the code.
I am new to pytorch (have worked a lot with tensorflow), and have a question which is probably basic, but I can't find the answer.
If I want to train ImageNet on a model which doesn't appear in the code list (under "model names"), but I do have the model as pth.tar file, how am I able to do the training?
Thanks!
|
https://github.com/pytorch/examples/issues/518
|
closed
|
[] | 2019-02-26T10:19:24Z
| 2022-03-10T05:28:08Z
| 1
|
jennyzu
|
huggingface/transformers
| 320
|
what is the batch size we can use for SQUAD task?
|
I am running the squad example.
I have a Tesla M60 GPU which has about 8GB of memory. For bert-large-uncased model, I can only take batch size as 2, even after I used --fp16. Is it normal?
|
https://github.com/huggingface/transformers/issues/320
|
closed
|
[] | 2019-02-26T08:56:20Z
| 2019-03-03T00:21:25Z
| null |
leonwyang
|
pytorch/examples
| 517
|
How to save model in mnist.cpp?
|
How to save the model in cpp api mnist.cpp?
model.save and torch::save(model,"mnisttrain.pkl")
All error
|
https://github.com/pytorch/examples/issues/517
|
open
|
[
"c++"
] | 2019-02-26T06:58:05Z
| 2022-03-09T20:49:34Z
| 5
|
engineer1109
|
pytorch/tutorials
| 437
|
A short tutorial showing the input arguments for NLL loss/ cross entropy loss would be incredibly helpful
|
The arguments NLL loss (and by proxy cross entropy loss) take are in a relatively weird format. The documentation for the function does all it can within reason of the original documentation, but there's an incredible number of questions posted about weird problems giving them the kind of arguments. Much more than for other comparable things, and most don't really have good reusable answers.
The obvious solution to this is for someone to create a simple example based tutorial of using NLL loss, and clearly showing exactly what format the arguments need to be in (perhaps starting with input and targets that are one hot encoded to make it as idiot proof as possible).
I've spent 4 hours trying to solve a problem exactly like this without success, and am about to refer to source over it. Someone please take mercy on future programmers.
|
https://github.com/pytorch/tutorials/issues/437
|
open
|
[] | 2019-02-26T05:35:50Z
| 2019-02-26T05:35:50Z
| 0
|
jkterry1
|
pytorch/pytorch
| 17,368
|
What is a version/git-hash of nightly build?
|
## 🚀 Feature
Nightly build does not include git-hash of pytorch.
So we can not know what the build is.
https://download.pytorch.org/libtorch/nightly/cpu/libtorch-shared-with-deps-latest.zip
I know the zip includes build_version which is like "1.0.0dev20190221".
Could you add git-hash of pytorch in build_version and include native_functions.yaml and the README of the yaml?
## Motivation
We are writing ffi-bindings by using nightly build and native_functions.yaml of pytorch-github.
Both the build and the yaml-spec's format are changed frequently and do not match version.
|
https://github.com/pytorch/pytorch/issues/17368
|
closed
|
[
"awaiting response (this tag is deprecated)"
] | 2019-02-21T19:54:41Z
| 2019-02-28T22:34:49Z
| null |
junjihashimoto
|
pytorch/ELF
| 142
|
what is meaning of outputs at verbose mode?
|
after I input quit at the df_console , it was still calulateing
```
D:\elfv2\play_opengo_v2\elf_gpu_full\elf>df_console --load d:/pretrained-go-19x19-v1.bin --num_block 20 --dim 224 --ver
bose
[2019-02-21 10:35:22.103] [elfgames::go::common::GoGameBase-12] [info] [0] Seed: 62127748, thread_id: 156604934899288204
? Invalid input
? Invalid input
genmove b
[2019-02-21 10:48:10.811] [elfgames::go::GoGameSelfPlay-0-15] [info] Current board:
A B C D E F G H J K L M N O P Q R S T
19 . . . . . . . . . . . . . . . . . . . 19
18 . . . . . . . . . . . . . . . . . . . 18
17 . . . . . . . . . . . . . . . . . . . 17
16 . . . + . . . . . + . . . . . + . . . 16
15 . . . . . . . . . . . . . . . . . . . 15
14 . . . . . . . . . . . . . . . . . . . 14
13 . . . . . . . . . . . . . . . . . . . 13
12 . . . . . . . . . . . . . . . . . . . 12
11 . . . . . . . . . . . . . . . . . . . 11 WHITE (O) has captured 0 stones
10 . . . + . . . . . + . . . . . + . . . 10 BLACK (X) has captured 0 stones
9 . . . . . . . . . . . . . . . . . . . 9
8 . . . . . . . . . . . . . . . . . . . 8
7 . . . . . . . . . . . . . . . . . . . 7
6 . . . . . . . . . . . . . . . . . . . 6
5 . . . . . . . . . . . . . . . . . . . 5
4 . . . + . . . . . + . . . . . + . . . 4
3 . . . . . . . . . . . . . . . . . . . 3
2 . . . . . . . . . . . . . . . . . . . 2
1 . . . . . . . . . . . . . . . . . . . 1
A B C D E F G H J K L M N O P Q R S T
Last move: C0, nextPlayer: Black
[1] Propose move [Q16][pp][352]
= Q16
? Invalid input
? Invalid input
? Invalid input
? Invalid input
quit
[2019-02-21 10:51:47.147] [elf::base::Context-3] [info] Prepare to stop ...
[2019-02-21 10:51:47.521] [elfgames::go::GoGameSelfPlay-0-15] [info] Current board:
A B C D E F G H J K L M N O P Q R S T
19 . . . . . . . . . . . . . . . . . . . 19
18 . . . . . . . . . . . . . . . . . . . 18
17 . . . . . . . . . . . . . . . . . . . 17
16 . . . + . . . . . + . . . . . X). . . 16
15 . . . . . . . . . . . . . . . . . . . 15
14 . . . . . . . . . . . . . . . . . . . 14
13 . . . . . . . . . . . . . . . . . . . 13
12 . . . . . . . . . . . . . . . . . . . 12
11 . . . . . . . . . . . . . . . . . . . 11 WHITE (O) has captured 0 stones
10 . . . + . . . . . + . . . . . + . . . 10 BLACK (X) has captured 0 stones
9 . . . . . . . . . . . . . . . . . . . 9
8 . . . . . . . . . . . . . . . . . . . 8
7 . . . . . . . . . . . . . . . . . . . 7
6 . . . . . . . . . . . . . . . . . . . 6
5 . . . . . . . . . . . . . . . . . . . 5
4 . . . + . . . . . + . . . . . + . . . 4
3 . . . . . . . . . . . . . . . . . . . 3
2 . . . . . . . . . . . . . . . . . . . 2
1 . . . . . . . . . . . . . . . . . . . 1
A B C D E F G H J K L M N O P Q R S T
Last move: Q16, nextPlayer: White
[2] Propose move [D4][dd][88]
[2019-02-21 10:51:48.657] [elfgames::go::GoGameSelfPlay-0-15] [info] Current board:
A B C D E F G H J K L M N O P Q R S T
19 . . . . . . . . . . . . . . . . . . . 19
18 . . . . . . . . . . . . . . . . . . . 18
17 . . . . . . . . . . . . . . . . . . . 17
16 . . . + . . . . . + . . . . . X . . . 16
15 . . . . . . . . . . . . . . . . . . . 15
14 . . . . . . . . . . . . . . . . . . . 14
13 . . . . . . . . . . . . . . . . . . . 13
12 . . . . . . . . . . . . . . . . . . . 12
11 . . . . . . . . . . . . . . . . . . . 11 WHITE (O) has captured 0 stones
10 . . . + . . . . . + . . . . . + . . . 10 BLACK (X) has captured 0 stones
9 . . . . . . . . . . . . . . . . . . . 9
8 . . . . . . . . . . . . . . . . . . . 8
7 . . . . . . . . . . . . . . . . . . . 7
6 . . . . . . . . . . . . . . . . . . . 6
5 . . . . . . . . . . . . . . . . . . . 5
4 . . . O . . . . . + . . . . . + . . . 4
3 . . . . . . . . . . . . . . . . . . . 3
2 X). . . . . . . . . . . . . . . . . . 2
1 . . . . . . . . . . . . . . . . . . . 1
A B C D E F G H J K L M N O P Q R S T
Last move: A2, nextPlayer: White
[4] Propose move [F17][fq][363]
[2019-02-21 10:51:50.631] [elfgames::go::GoGameSelfPlay-0-15] [info] Current board:
A B C D E F G H J K L M N O P Q R S T
19 . . . . . . . . . . . . . . . . . . . 19
18 . . . . . . . . . . . . . . . . . . . 18
17 . . . . . O). . . . . . . . . . . . . 17
16 . . . + . . . . . + . . . . . X . . . 16
15 . . . . . . . . . . . . . . . . . . . 15
14 . . . . . . . . . . . . . . . . . . . 14
13 . . . . . . . . . . . . . . . . . . . 13
12 . . . . . . . . . . . . . . . . . . . 12
11 . . . . . . . . . . . . . . . . . . . 11 WHITE (O) has captured 0 stones
10 . . . + . . . . . + . . . . . + . . . 10 BLACK (X) has captured 0 stones
9 . . . . . . . . . . . . . . . . . . . 9
8 . . . . . . . . . . . . . . . . . . . 8
7 . . . . . . . . . . . . . . . . . . . 7
6 . . . . . . . . . . . . . . . . . . . 6
5 . . . . . . . . . . . . . . . . . . . 5
4 . . . O . . . . . + . . . . . + . . . 4
3 . . . . . . . . . . . . . . . . . . . 3
2 X . . . . . . .
|
https://github.com/pytorch/ELF/issues/142
|
open
|
[] | 2019-02-21T02:51:58Z
| 2019-02-21T02:51:58Z
| null |
l1t1
|
pytorch/examples
| 514
|
Why does discriminator's output change between batchsize:64 and batchsize:1 on inference.
|
I'm trying to get the discriminator output using train finished discriminator.
Procedure is below.
1. training dcgan.
2. preparing my image data and resize it 64 * 64.
3. load my image data using dataloader(same as training's one.)
4. I change only batch size at inference.
5. I got small Discriminator outputs(after sigmoid result).
for example)
I prepared 64 images under the dataroot directory. And I tried 2 experience.
I got a below's discriminator output at inference using batch size 64.
```
tensor([0.9955, 0.8801, 0.9727, 0.7377, 0.2667, 0.9432, 0.9941, 0.6896, 0.8638,
0.5006, 0.9766, 0.4148, 0.9577, 0.9065, 0.9849, 0.9027, 0.1619, 0.5418,
0.9256, 0.7502, 0.1467, 0.8197, 0.9100, 0.3416, 0.0066, 0.9521, 0.9973,
1.0000, 0.4952, 0.3026, 0.5347, 0.8695, 0.8033, 0.6709, 0.3602, 0.2145,
0.6901, 0.0129, 0.6780, 0.5321, 0.8195, 0.8662, 0.1759, 0.5599, 0.7313,
0.5138, 0.9396, 0.9256, 0.3011, 0.8163, 0.8046, 0.4802, 0.6256, 0.1656,
0.9368, 0.1080, 0.5960, 0.9493, 0.9533, 0.9609, 0.0137, 0.1603, 0.7717,
0.5684], device='cuda:0', grad_fn=<SqueezeBackward1>)
```
I got a below's discriminator output at inference using batch size 1.
```
tensor([0.6289], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.2455], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.8702], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.0000], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.0002], device='cuda:0', grad_fn=<SqueezeBackward1>)
............
tensor([0.0002], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.0022], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.9955], device='cuda:0', grad_fn=<SqueezeBackward1>)
tensor([0.1370], device='cuda:0', grad_fn=<SqueezeBackward1>)
```
I wonder why I got a small output(different from batch size64) on batch size1.
For instance, I got the 0.0000 on batch size 1, but at batch size 64 0.0000 is nothing.
Also I tried to match tensor size using torch.cat at batch size 1.
I changed from [1, 3, 64, 64] -> [64, 3, 64, 64], using same one image's tensor and torch.cat.
But I got different output value.
If you have any suggestions or point out then please let me know.
|
https://github.com/pytorch/examples/issues/514
|
closed
|
[] | 2019-02-20T09:07:47Z
| 2019-02-20T10:55:48Z
| 2
|
y-shirai-r
|
pytorch/examples
| 507
|
Is there a plan to make the imagenet example in this repository support `fp16`?
|
Thanks! :)
|
https://github.com/pytorch/examples/issues/507
|
closed
|
[] | 2019-02-14T19:38:58Z
| 2022-03-10T03:12:22Z
| 1
|
deepakn94
|
pytorch/pytorch
| 17,111
|
where is the code for the implement of loss?
|
i want to find the implement of nn.BCEWithLogitsLoss, but it returns F functions , and i cannot find where F functions is , i want to modify the loss
|
https://github.com/pytorch/pytorch/issues/17111
|
closed
|
[] | 2019-02-14T12:29:06Z
| 2019-02-14T15:29:47Z
| null |
Jasperty
|
pytorch/examples
| 503
|
I have some basic questions about training
|
Hi, I have some questions about training the model.
1. "neural_style.py train --dataset /Users/me/Downloads/examples-master/fast_neural_style/me0 --style-image /Users/met/Downloads/examples-master/fast_neural_style/images/content-images/amber.jpg --save-model-dir /Users/umit/Downloads/examples-master/fast_neural_style/me/11 --epochs 2 --cuda 0"
This is saving a .model file to my computer. What is the model format? How can i convert to onnx and eventually to coreml?
2. Training image set data is [80K/13GB] on here. What happens i use much less photos? Like around 100?
|
https://github.com/pytorch/examples/issues/503
|
open
|
[
"onnx"
] | 2019-02-03T08:40:43Z
| 2022-03-10T03:14:41Z
| 0
|
Umity
|
pytorch/examples
| 502
|
neural_style.py: error: unrecognized arguments: --export_onnx
|
I am getting this error when i use:
python neural_style/neural_style.py train --dataset /Users/me/Downloads/examples-master/fast_neural_style/me0 --style-image /Users/me/Downloads/examples-master/fast_neural_style/images/content-images/amber.jpg --save-model-dir /Users/me/Downloads/examples-master/fast_neural_style/me2 --epochs 2 --cuda 0 --export_onnx /Users/umit/Downloads/examples-master/fast_neural_style/me2/onnx/pytorch_model.onnx
how can i fix this?
|
https://github.com/pytorch/examples/issues/502
|
closed
|
[] | 2019-02-02T21:19:03Z
| 2019-02-03T08:30:05Z
| 0
|
Umity
|
pytorch/tutorials
| 431
|
cpp extension tutorial: not device agnostic?
|
Would the kerne calll in `lltm_cuda_forward` in the tutorial `tutorials/advanced_source/cpp_extension.rst` fail on multi gpu systems if the inputs are not on the default device, i.e., `device:0`?
To my understanding, some "magic" takes care of setting the right context if we add functionality do pytorch via custom kernels, [see here](https://github.com/pytorch/pytorch/tree/7d7855ea3124c16862ea7ed4758f4c7a804ca1ac/aten/src/ATen/native#device_guard).
However, it seems like in the tutorial this machinery is not used.
Explicit usage of `at::OptionalDeviceGuard` should resolve the issue (?) in the tutorial.
|
https://github.com/pytorch/tutorials/issues/431
|
open
|
[
"C++"
] | 2019-01-31T07:39:07Z
| 2023-03-15T02:14:36Z
| 1
|
c-hofer
|
pytorch/examples
| 501
|
why you set epoch to the sampler in the distributed example?
|
Hi,
Thanks for providing this helpful tutorial series. I am reading the part of training imagenet with distributed mode:
At [this line](https://github.com/pytorch/examples/blob/fe8abc3c810420df2856c6e668258f396b154cee/imagenet/main.py#L208), I do not understand the reason why shall I set epoch it the sampler. What is the difference between setting the epoch or not? Cannot I directly fetch data from the dataloader with this sampler as one args?
|
https://github.com/pytorch/examples/issues/501
|
closed
|
[] | 2019-01-30T03:44:09Z
| 2023-01-05T08:01:47Z
| 4
|
CoinCheung
|
huggingface/transformers
| 233
|
What is get_lr() meaning in the optimizer.py
|
I use a Model based on BertModel, and when I use the BertAdam the learning rate isn't changed. And when I use `get_lr()`, the return result is `[0]`. And I see the length of state isn't 0, but why I get that?
|
https://github.com/huggingface/transformers/issues/233
|
closed
|
[] | 2019-01-28T13:19:06Z
| 2019-02-05T16:12:33Z
| null |
kugwzk
|
pytorch/pytorch
| 16,439
|
What is the difference between F.cross_entropy() and F.nll_loss() ??
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/16439
|
closed
|
[] | 2019-01-28T11:06:23Z
| 2019-01-28T13:25:31Z
| null |
lakshmiumenon
|
pytorch/pytorch
| 16,438
|
What is the difference between F.cross_entropy() and F.nll_loss() ??
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/16438
|
closed
|
[] | 2019-01-28T11:06:21Z
| 2019-01-28T13:45:23Z
| null |
lakshmiumenon
|
pytorch/examples
| 500
|
_pickle.UnpicklingError: invalid load key, '\xff'.
|
May I know how to fix the following error
```
mahmood@orca:fast_neural_style$ python3.7 neural_style/neural_style.py eval --content-image images/content-images/amber.jpg --model images/style-images/mosaic.jpg --output-image a1.jpg --cuda 1
Traceback (most recent call last):
File "neural_style/neural_style.py", line 240, in <module>
main()
File "neural_style/neural_style.py", line 236, in main
stylize(args)
File "neural_style/neural_style.py", line 138, in stylize
state_dict = torch.load(args.model)
File "/home/mahmood/anaconda3/lib/python3.7/site-packages/torch/serialization.py", line 367, in load
return _load(f, map_location, pickle_module)
File "/home/mahmood/anaconda3/lib/python3.7/site-packages/torch/serialization.py", line 528, in _load
magic_number = pickle_module.load(f)
_pickle.UnpicklingError: invalid load key, '\xff'.
```
|
https://github.com/pytorch/examples/issues/500
|
open
|
[
"bug",
"vision",
"pickle"
] | 2019-01-26T15:37:28Z
| 2022-03-10T05:20:57Z
| 0
|
mahmoodn
|
pytorch/examples
| 499
|
Crash in mnist example with num_workers > 0
|
I'm getting a crash in the mnist example at the end of the 1st epoch when I run with any num_workers > 0 I'm running the python code in PyCharm debugger on a Ubuntu 16.04 system with PyTorch 1.0 with CUDA enabled.
raceback (most recent call last):
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1741, in <module>
Traceback (most recent call last):
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1741, in <module>
main()
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1735, in main
main()
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1735, in main
globals = debugger.run(setup['file'], None, None, is_module)
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1135, in run
globals = debugger.run(setup['file'], None, None, is_module)
File "/snap/pycharm-community/108/helpers/pydev/pydevd.py", line 1135, in run
pydev_imports.execfile(file, globals, locals) # execute the script
File "/snap/pycharm-community/108/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
pydev_imports.execfile(file, globals, locals) # execute the script
File "/snap/pycharm-community/108/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/home/ankur/dev/benchmark/mnist_main.py", line 119, in <module>
File "/home/ankur/dev/benchmark/mnist_main.py", line 119, in <module>
main()main()
File "/home/ankur/dev/benchmark/mnist_main.py", line 112, in main
File "/home/ankur/dev/benchmark/mnist_main.py", line 112, in main
test(args, model, device, test_loader)test(args, model, device, test_loader)
File "/home/ankur/dev/benchmark/mnist_main.py", line 49, in test
File "/home/ankur/dev/benchmark/mnist_main.py", line 49, in test
for data, target in test_loader:for data, target in test_loader:
File "/home/ankur/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 819, in __iter__
File "/home/ankur/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 631, in __next__
idx, batch = self._get_batch()
File "/home/ankur/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 601, in _get_batch
return _DataLoaderIter(self)
File "/home/ankur/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 560, in __init__
return self.data_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/home/ankur/miniconda3/lib/python3.7/queue.py", line 179, in get
w.start()
File "/home/ankur/miniconda3/lib/python3.7/multiprocessing/process.py", line 112, in start
self.not_empty.wait(remaining)
File "/home/ankur/miniconda3/lib/python3.7/threading.py", line 300, in wait
self._popen = self._Popen(self)
File "/home/ankur/miniconda3/lib/python3.7/multiprocessing/context.py", line 223, in _Popen
gotit = waiter.acquire(True, timeout)
return _default_context.get_context().Process._Popen(process_obj)
File "/home/ankur/miniconda3/lib/python3.7/multiprocessing/context.py", line 277, in _Popen
KeyboardInterrupt
return Popen(process_obj)
File "/home/ankur/miniconda3/lib/python3.7/multiprocessing/popen_fork.py", line 20, in __init__
self._launch(process_obj)
File "/home/ankur/miniconda3/lib/python3.7/multiprocessing/popen_fork.py", line 70, in _launch
self.pid = os.fork()
File "/snap/pycharm-community/108/helpers/pydev/_pydev_bundle/pydev_monkey.py", line 496, in new_fork
|
https://github.com/pytorch/examples/issues/499
|
open
|
[
"help wanted"
] | 2019-01-25T22:24:02Z
| 2022-03-10T06:03:51Z
| 0
|
ankur6ue
|
huggingface/transformers
| 205
|
What is the meaning of Attention Mask
|
Hi, I noticed that there is something called `Attention Mask` in the model.
In the annotation of class `BertForQuestionAnswering`,
```python
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
input sequence length in the current batch. It's the mask that we typically use for attention when
a batch has varying length sentences.
```
And its usage is in class `BertSelfAttention`, function `forward`,
```python
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
```
It seems the attention_mask is used to add 1 to the scores for positions that is taken up by real tokens, and add 0 to the positions outside current sequence.
Then, why not set the scores to `-inf` where the positions are outside the current sequence. Then pass the scores to a softmax layer, those score will become 0 as we want.
|
https://github.com/huggingface/transformers/issues/205
|
closed
|
[] | 2019-01-18T14:04:11Z
| 2022-08-19T19:37:44Z
| null |
jianyucai
|
huggingface/neuralcoref
| 127
|
Can't find mention type in doc class
|
I can't find the mention type of a span, so I just copy get_span_type function to get mention types as follows.
Maybe it could be merged into doc object.
```
ACCEPTED_ENTS = ["PERSON", "NORP", "FACILITY", "ORG", "GPE", "LOC", "PRODUCT", "EVENT", "WORK_OF_ART", "LANGUAGE"]
MENTION_TYPE = {"PRONOMINAL": 0, "NOMINAL": 1, "PROPER": 2, "LIST": 3}
PRP_TAGS = ["PRP", "PRP$"]
CONJ_TAGS = ["CC", ","]
PROPER_TAGS = ["NNP", "NNPS"]
def get_span_type(span):
''' Find the type of a Span '''
if any(t.tag_ in CONJ_TAGS and t.ent_type_ not in ACCEPTED_ENTS for t in span):
mention_type = MENTION_TYPE["LIST"]
elif span.root.tag_ in PRP_TAGS:
mention_type = MENTION_TYPE["PRONOMINAL"]
elif span.root.ent_type_ in ACCEPTED_ENTS or span.root.tag_ in PROPER_TAGS:
mention_type = MENTION_TYPE["PROPER"]
else:
mention_type = MENTION_TYPE["NOMINAL"]
return mention_type
```
|
https://github.com/huggingface/neuralcoref/issues/127
|
closed
|
[
"question",
"wontfix"
] | 2019-01-16T07:46:38Z
| 2019-06-21T08:31:42Z
| null |
joe32140
|
pytorch/tutorials
| 411
|
ValueError low>=high in RandomCrop
|
Hello everyone,
First off, thanks for such detailed PyTorch tutorials! Recently, I was going through the data loading and processing tutorial [here](https://pytorch.org/tutorials/beginner/data_loading_tutorial.html). Maybe there's some misunderstanding from my side but in `beginner_source/data_loading_tutorial.py`, for class `RandomCrop`, when the value of `output_size` is greater than original image size, it throws a `ValueError: low >= high` as `h < new_h` and `w < new_w`.
So, can I get a confirmation as to whether or not this is a bug? If yes, I would be happy to fix it.
(**Note**: To reproduce the error try changing value of `crop` [here](https://github.com/pytorch/tutorials/blob/master/beginner_source/data_loading_tutorial.py#L304) to something greater such as `crop = RandomCrop(224)`)
Ping @chsasank
Thanks,
Gaurav
|
https://github.com/pytorch/tutorials/issues/411
|
closed
|
[] | 2019-01-11T23:54:39Z
| 2019-09-12T04:24:36Z
| 1
|
Demfier
|
pytorch/tutorials
| 410
|
TypeError : filename should be a str in beginner/nn_tutorial.py
|
I got a `TypeError` error in `beginner_source/nn_tutorial.py` while building tutorials with Python 3.5 on Ubuntu 16.04.
It seems like the type of parameter passed in `gzip.open()` in ["beginner_source/nn_tutorial.py(L64)"](https://github.com/pytorch/tutorials/blob/master/beginner_source/nn_tutorial.py#L64) should be converted.
The error message is like below:
```
WARNING: /home/ubuntu/tutorials/beginner_source/nn_tutorial.py failed to execute correctly: Traceback (most recent call last):
File "/home/ubuntu/tutorials/beginner_source/nn_tutorial.py", line 64, in <module>
with gzip.open(PATH / FILENAME, "rb") as f:
File "/usr/lib/python3.5/gzip.py", line 57, in open
raise TypeError("filename must be a str or bytes object, or a file")
TypeError: filename must be a str or bytes object, or a file
```
I think using `(PATH / FILENAME).as_posix()` more suitable.
If this error is visible to everyone, can I fix it?
|
https://github.com/pytorch/tutorials/issues/410
|
closed
|
[] | 2019-01-11T06:37:53Z
| 2019-02-08T20:26:28Z
| 1
|
9bow
|
pytorch/examples
| 483
|
different node has different parameters
|
I have tried it, but if I found that each model in all node has different gradients,so it results to different model among GPUs, At last I do like this:
#something to do###############
loss.backward()
self.average_gradients()
self.optimizer.step():
#other thing to do###############
def average_gradients(self):
world_size = distributed.get_world_size()
for p in self.net.parameters():
distributed.all_reduce(p.grad.data, op=distributed.reduce_op.SUM)
p.grad.data /= float(world_size)
It work normally,but I do not know whether it is right, cause official of pyTorch do not mention it.
could you tell me is it right? thank you!!!
And another question: I found I can not run on 2 or more machines, I do not know how to configure it, should I make a configur so that all machines in my group can access each other without password by ssh?
|
https://github.com/pytorch/examples/issues/483
|
closed
|
[] | 2018-12-24T11:54:04Z
| 2018-12-30T03:53:49Z
| 1
|
YihengJiang
|
pytorch/examples
| 482
|
Encountered IsADirectoryError at neural style eval
|
Hello, I am new in python and machine learning related field.
I caught the following error when trying to test a style from the examples:
```
/cygdrive/d/Downloaded Programs/git/examples/fast_neural_style
$ python neural_style/neural_style.py eval --content-image <images/content-images/amber.jpg> --model <saved_models/candy.pth> --output-image <images/output-images/> --content-scale 1 --cuda 1
Fatal Python error: init_sys_streams: can't initialize sys standard streams
IsADirectoryError: [Errno 21] Is a directory: 0
```
How can I fix this error?
Thanks for any suggestions!
|
https://github.com/pytorch/examples/issues/482
|
closed
|
[] | 2018-12-24T09:19:06Z
| 2022-03-10T05:47:27Z
| 1
|
HosinLau
|
pytorch/examples
| 481
|
the imagenet main when is use multi gpu(not set gpu args) then the input will not call input.cuda() why?
|

if i do't set args.gpu, the only target.cuda() call, why do this kind, but the code run success
|
https://github.com/pytorch/examples/issues/481
|
closed
|
[] | 2018-12-24T08:42:29Z
| 2018-12-30T03:45:44Z
| 1
|
mmxuan18
|
pytorch/tutorials
| 400
|
C++ Frontend Tutorial with GPU Support
|
I am following [this tutorial](https://pytorch.org/cppdocs/installing.html) on using PyTorch with C++ frontend. However, I would like to have a CUDA support, not a CPU only. I have also the `torch` package installed using `conda` but I guess it is not enough to compile C++ sources because I am getting the following error:
```
$ cmake -DCMAKE_PREFIX_PATH=/usr/lib/libtorch ..
CUDA_TOOLKIT_ROOT_DIR not found or specified
-- Could NOT find CUDA (missing: CUDA_TOOLKIT_ROOT_DIR CUDA_NVCC_EXECUTABLE CUDA_INCLUDE_DIRS CUDA_CUDART_LIBRARY) (Required is at least version "7.0")
CMake Warning at /usr/lib/libtorch/share/cmake/Caffe2/public/cuda.cmake:15 (message):
Caffe2: CUDA cannot be found. Depending on whether you are building Caffe2
or a Caffe2 dependent library, the next warning / error will give you more
info.
```
As I can see, I need a CUDA toolkit installed, and the env variable pointing to the installation. Could you please create a version of the tutorial that would explain how to better handle this? I would like to have _both_ Python package and to build programmes from C++ sources.
---
_I am not sure if I've submitted the issue into a right repository so let me know if this should be moved somewhere else._
|
https://github.com/pytorch/tutorials/issues/400
|
closed
|
[] | 2018-12-24T07:50:37Z
| 2021-06-16T20:45:56Z
| 0
|
i-zaitsev
|
pytorch/examples
| 479
|
Share dataloader in multi node multi gpus training with multiprocessing-distributed
|
In the example of [imagenet](https://github.com/pytorch/examples/blob/master/imagenet/main.py), `ngpus` process is created, so if I am training on 4 nodes with 4 gpus on each, there would be 16 processes in total.
Is there any way I could share the dataloader for the processes on the same node? Since I implemented a special dataloader with cost a lot of memory.
Many thanks.
|
https://github.com/pytorch/examples/issues/479
|
closed
|
[] | 2018-12-19T13:41:36Z
| 2020-09-11T12:57:16Z
| 0
|
xvjiarui
|
pytorch/examples
| 478
|
in imagenet example why the val need to first resize to 256 and then crop 224, if the input is 299 how to set the resize input?
|
when the model is inceptionv3 the input size is 299, while others is 224. so the resize parameter counld set to what? and why in val stage there need to first resize to a bigger size then crop, some example directly use resize(224)
|
https://github.com/pytorch/examples/issues/478
|
closed
|
[] | 2018-12-19T11:48:52Z
| 2019-03-27T18:01:58Z
| 1
|
mmxuan18
|
pytorch/examples
| 476
|
--resume fails after 1 epoch with Pytorch 1.0 release
|
Using --resume fails after 1 epoch with Pytorch 1.0 release with error below. I tried this with resnet50 and resnet18
```
Traceback (most recent call last):
File "main.py", line 398, in <module>
main()
File "main.py", line 110, in main
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
File "/home/tools/anaconda3-5.3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 167, in spawn
while not spawn_context.join():
File "/home/tools/anaconda3-5.3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 114, in join
raise Exception(msg)
Exception:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/tools/anaconda3-5.3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 19, in _wrap
fn(i, *args)
File "/space8T/mdflickner/pytorch/examples/imagenet/main.py", line 241, in main_worker
is_best = acc1 > best_acc1
RuntimeError: arguments are located on different GPUs at /pytorch/aten/src/THC/generic/THCTensorMathCompareT.cu:15
```
|
https://github.com/pytorch/examples/issues/476
|
open
|
[
"help wanted",
"vision"
] | 2018-12-17T17:04:15Z
| 2022-03-10T06:04:01Z
| 1
|
mdflickner
|
pytorch/examples
| 473
|
the sum of doc_topics is not equal 1
|
Hi, I have a question. when I run lda.py, I find the sum of `doc_topics` is not equal 1. In fact, they are decreasing in the training process. Is there something wrong?
|
https://github.com/pytorch/examples/issues/473
|
closed
|
[] | 2018-12-14T14:50:43Z
| 2018-12-19T22:17:36Z
| 2
|
dongfeng951
|
pytorch/examples
| 472
|
How can I find a reference to understand the meaning of pro.sample?
|
what is the meaning of `pyro.sample( ........, infer={"enumerate": "parallel"})`? How can I find a reference to understand the meaning of `pro.sample`? I cannot find it.
Thanks!
|
https://github.com/pytorch/examples/issues/472
|
closed
|
[] | 2018-12-14T13:33:42Z
| 2018-12-15T04:02:46Z
| 1
|
dongfeng951
|
pytorch/examples
| 471
|
How to invoke GPU?
|
Hi, when I run the example codes such as vae.py, the GPU cannot be invoked automatically and therefore the training is very slow.
But the pytorch can invoke GPU automatically.
So how to invoke GPU?
Thank you!
|
https://github.com/pytorch/examples/issues/471
|
closed
|
[] | 2018-12-14T08:14:46Z
| 2018-12-15T04:18:49Z
| 2
|
dongfeng951
|
pytorch/examples
| 470
|
The Volatile GPU-Util is always 0, in examples/imagenet
|
I run the example of imagenet in https://github.com/pytorch/examples/tree/master/imagenet, althougt I can run it successfully, but it is slow, and the Volatile GPU-Util is always 0 with command 'nvidia-smi'
```
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.87 Driver Version: 390.87 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:01:00.0 On | N/A |
| 31% 58C P2 70W / 250W | 9584MiB / 11170MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 947 G /usr/lib/xorg/Xorg 285MiB |
| 0 1752 G compiz 154MiB |
| 0 1930 G fcitx-qimpanel 9MiB |
| 0 4690 G ...quest-channel-token=4115043597718524916 72MiB |
| 0 26519 C python 9057MiB |
+-----------------------------------------------------------------------------+
```
|
https://github.com/pytorch/examples/issues/470
|
open
|
[
"question"
] | 2018-12-13T06:49:15Z
| 2022-03-10T16:46:35Z
| 10
|
wangxianrui
|
huggingface/transformers
| 114
|
What is the best dataset structure for BERT?
|
First I want to say thanks for setting up all this!
I am using BertForSequenceClassification and am wondering what the optimal way is to structure my sequences.
Right now my sequences are blog post which could be upwards to 400 words long.
Would it be better to split my blog posts in sentences and use the sentences as my sequences instead?
Thanks!
|
https://github.com/huggingface/transformers/issues/114
|
closed
|
[] | 2018-12-11T16:28:00Z
| 2018-12-11T20:57:45Z
| null |
wahlforss
|
pytorch/pytorch
| 14,889
|
what is the algorithm theory of torch.nn.AdaptiveMaxPool2d?
|
what is the algorithm theory of torch.nn.AdaptiveMaxPool2d?
Is there any papers about torch.nn.AdaptiveMaxPool2d?
And how to find the c++ of implementing torch.nn.AdaptiveMaxPool2d in pytorch?
|
https://github.com/pytorch/pytorch/issues/14889
|
closed
|
[] | 2018-12-07T10:16:15Z
| 2018-12-07T15:46:19Z
| null |
zsf23
|
pytorch/pytorch
| 14,850
|
Document what is C10
|
C10 seems to have an increasingly important role throughout the PyTorch code base (e.g., see #6325 or count the number of open issues containing "c10") yet I was unable to find a high-level description about it. There are only "rumors" to be found about C10, see for example [this post](https://discuss.pytorch.org/t/pytorch-and-caffe2-convergence/21713/4) at pytorch.org:
> I read on github, that there is a new backend called C10 in progress which combines features and backends from ATen and Caffe2. This backend should be a more generic one which means that adding new tensor types and similar stuff will be easier (the actual discussion was about introducing complex tensors).
Someone else on [Reddit](https://www.reddit.com/r/MachineLearning/comments/8xurkp/n_tensorflow_190_is_out/e27ewhz/):
> I'd never heard of C10 until you posted this, so caveat emptor, but from the few Google hits available it seems that the major motivations for C10 include:
>
> * Common Tensor ops for PyTorch and Caffe2 (only PyTorch uses ATen)
> * Pluggable tensor ops/backend (maybe easing future AMD, TPU, etc support?)
>
> There's also talk of C10 helping integration of Complex tensor support for PyTorch, which helps give an idea of the level of abstraction they are shooting for.
At the minimum, please add a README to the pytorch/c10 directory briefly describing the project.
|
https://github.com/pytorch/pytorch/issues/14850
|
closed
|
[
"module: docs",
"triaged"
] | 2018-12-06T16:00:51Z
| 2024-03-13T05:40:46Z
| null |
christoph-conrads
|
pytorch/examples
| 456
|
How can I get the name of each image in the whole imagenet training process?
|
I want to obtain the name and the true label of each image, how can I modify the code to do that ? I find the data_loader just return the input tensor and the label without the image name.
|
https://github.com/pytorch/examples/issues/456
|
closed
|
[] | 2018-11-30T06:40:48Z
| 2018-11-30T06:54:39Z
| 1
|
lith0613
|
huggingface/neuralcoref
| 113
|
what is the different between en_coref models?
|
for three models, en_coref_lg, en_coref_md, en_coref_sm, which one has best performance? only consider the performance, is lg best?
|
https://github.com/huggingface/neuralcoref/issues/113
|
closed
|
[] | 2018-11-30T06:36:43Z
| 2019-04-11T12:14:11Z
| null |
Jasperty
|
pytorch/pytorch
| 14,460
|
C++ API use model.pt in GPU . When I use lstm in model, there is what(): Expected object of backend CPU but got backend CUDA for argument #2 'mat2' (checked_tensor_unwrap at /pytorch/aten/src/ATen/Utils.h:70)
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
C++ code:
module->to(at::kCUDA);
auto gpu_tensor = img_var.to(at::kCUDA);
vector<torch::jit::IValue> inputs;
inputs.push_back(gpu_tensor);
auto out_tensor = module->forward(inputs).toTensor();
model:
# LSTM
self.lstm1 = nn.LSTM(input_size=64, hidden_size=64, num_layers=2, batch_first=True)
self.lstm2 = nn.LSTM(input_size=64, hidden_size=64, num_layers=2, batch_first=True)
#self.lstm2 = nn.Sequential(*lstm2)
self.lstm3 = nn.LSTM(input_size=64, hidden_size=64, num_layers=2, batch_first=True)
and
im6_1, hidden1 = self.lstm1(img5_1)
#self.encode5(a)
im6_2, hidden2 = self.lstm2(img5_2, hidden1)
#self.encode5(a)
im6_3, hidden3 = self.lstm3(img5_3, hidden2)
error:
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
- PyTorch Version ( 1.0):
- OS ( CentOS):
- Python version:2.7
- CUDA/cuDNN version:9.0
- GCC version:5.4.0
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/pytorch/issues/14460
|
closed
|
[] | 2018-11-28T07:58:33Z
| 2021-06-01T21:26:27Z
| null |
joy-yjl
|
pytorch/pytorch
| 14,456
|
What is wrong with my model? It slows many times after switching from version 0.4.1 to 1.0
|
This is the definition of my model:
```python
import torchvision
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, in_dim, out_dim, *args, **kwargs):
super(Model, self).__init__(*args, **kwargs)
vgg16 = torchvision.models.vgg16()
layers = []
layers.append(nn.Conv2d(in_dim, 64, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(128, 128, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(128, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(256, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 1, padding = 1))
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 1, padding = 1))
self.features = nn.Sequential(*layers)
classifier = []
classifier.append(nn.AvgPool2d(3, stride = 1, padding = 1))
classifier.append(nn.Conv2d(512,
1024,
kernel_size = 3,
stride = 1,
padding = 12,
dilation = 12))
classifier.append(nn.ReLU(inplace = True))
classifier.append(nn.Conv2d(1024, 1024, kernel_size = 1, stride = 1, padding = 0))
classifier.append(nn.ReLU(inplace = True))
classifier.append(nn.Dropout(p = 0.5))
classifier.append(nn.Conv2d(1024, out_dim, kernel_size = 1))
self.classifier = nn.Sequential(*classifier)
self.init_weights()
def forward(self, x):
im = x
x = self.features(x)
x = self.classifier(x)
return x
def init_weights(self):
vgg = torchvision.models.vgg16(pretrained = True)
state_vgg = vgg.features.state_dict()
self.features.load_state_dict(state_vgg)
for ly in self.classifier.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
nn.init.constant_(ly.bias, 0)
```
And this is my test script:
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
from model import Model
if __name__ == "__main__":
net = Model(3, 21)
net.train()
net.cuda()
net = nn.DataParallel(net)
Loss = nn.CrossEntropyLoss(ignore_index = 255)
Loss.cuda()
optim = torch.optim.SGD(net.parameters(), lr = 1e-3, momentum = 0.9, weight_decay = 5e-4)
st = time.time()
scale = [0.5, 0.75, 1]
loss_avg = []
for i in range(10000):
in_ten = torch.randn(70, 3, 224, 224)
label = torch.randint(0, 21, [70, 1, 224, 224])
in_ten = in_ten.cuda()
label = label.cuda()
label = torch.tensor(label).long().cuda()
optim.zero_grad()
H, W = in_ten.size()[2:]
for sub_i, s in enumerate(scale):
print(time.time() - st)
h, w = int(H * s), int(W * s)
in_ten_s = F.interpolate(in_ten, (h, w), mode = 'bilinear')
out = net(in_ten_s)
out = F.interpolate(out, [H, W], mode = 'bilinear')
|
https://github.com/pytorch/pytorch/issues/14456
|
closed
|
[
"module: performance"
] | 2018-11-28T06:44:26Z
| 2019-06-09T02:44:25Z
| null |
CoinCheung
|
pytorch/examples
| 453
|
Is the loss of the first word covered during the language model evaluation?
|
In the language model example, it seems that during the evaluation, the code starts from computing the loss of the second word. Thus, skipping the loss of the first word.
https://github.com/pytorch/examples/blob/537f6971872b839b36983ff40dafe688276fe6c3/word_language_model/main.py#L136
https://github.com/pytorch/examples/blob/537f6971872b839b36983ff40dafe688276fe6c3/word_language_model/main.py#L121-L125
Furthermore, the evaluation data is divided into 10 batches, hence, the losses of 10 words are skipped.
Am I right or I did miss something?
https://github.com/pytorch/examples/blob/537f6971872b839b36983ff40dafe688276fe6c3/word_language_model/main.py#L85-L88
|
https://github.com/pytorch/examples/issues/453
|
open
|
[
"good first issue",
"nlp"
] | 2018-11-26T10:28:03Z
| 2022-03-10T06:08:08Z
| 0
|
khassanoff
|
pytorch/examples
| 450
|
How to use trained model to classifier pictures?
|
I have trained a best model by imagenet,but code repo has given does not have test option,so how can I use the model have trained to classifier pictures with labels?
|
https://github.com/pytorch/examples/issues/450
|
open
|
[
"help wanted",
"vision"
] | 2018-11-25T03:27:13Z
| 2022-03-10T06:07:49Z
| 2
|
mohhao
|
pytorch/examples
| 448
|
which pytorch version can run the fast rcnn demo?
|
https://github.com/pytorch/examples/issues/448
|
closed
|
[] | 2018-11-21T10:42:41Z
| 2022-03-10T00:26:13Z
| 2
|
Bigwode
|
|
huggingface/neuralcoref
| 110
|
Doesn't work when span is merged.
|
```python
nlp = spacy.load('en_coref_sm')
text = nlp("Michelle Obama is the wife of former U.S. President Barack Obama. Prior to her role as first lady, she was a lawyer.")
spans = list(text.noun_chunks)
for span in spans:
span.merge()
for word in text:
print(word)
if(word._.in_coref):
print(text._.coref_clusters)
```
When the above code is run, it gives the following error:
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-98-4252d464f86d> in <module>()
1 for word in text:
2 print(word)
----> 3 if(word._.in_coref):
4 print(text._.coref_clusters)
~\Anaconda3\lib\site-packages\spacy\tokens\underscore.py in __getattr__(self, name)
29 default, method, getter, setter = self._extensions[name]
30 if getter is not None:
---> 31 return getter(self._obj)
32 elif method is not None:
33 return functools.partial(method, self._obj)
neuralcoref.pyx in __iter__()
span.pyx in __iter__()
span.pyx in spacy.tokens.span.Span._recalculate_indices()
IndexError: [E037] Error calculating span: Can't find a token ending at character offset 78.
```
|
https://github.com/huggingface/neuralcoref/issues/110
|
closed
|
[
"question",
"wontfix"
] | 2018-11-21T10:12:43Z
| 2019-06-17T14:22:21Z
| null |
lahsuk
|
pytorch/examples
| 443
|
DCGAN: Generate more number of images
|
Is there a way we can generate an arbitrary number of images? Right now the fake sample is outputting to 64 images with default settings. My goal is to get 250 fake images. Is this possible?
|
https://github.com/pytorch/examples/issues/443
|
closed
|
[] | 2018-11-16T04:49:33Z
| 2018-11-16T04:50:14Z
| 1
|
MonojitBanerjee
|
pytorch/pytorch
| 13,460
|
What is the net *.pb file encoding?
|
Hi there,
I am running the following code:
```python
with open(EXPORT_PATH + "mnist_init_net.pb", encoding="utf-8") as f:
init_net = f.read()
```
I get the following error:
```python
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 24: invalid continuation byte
```
It seems like the simple thing to do is to change the encoding type from not being utf-8 (which open() defaults to it seems in this case). What encoding should I use?
mnist_init_net.pb file is generated via:
```python
init_net, predict_net = c2.onnx_graph_to_caffe2_net(model)
with open(EXPORT_PATH + "mnist_init_net.pb", "wb") as f:
f.write(init_net.SerializeToString())
```
Is ISO-8859-1 correct?
----
```
python -c "import torch; print(torch.__version__)"
1.0.0.dev20181029
python -c "import onnx; print(onnx.__version__)"
1.3.0
OS: OS X 10.13
python --version
Python 3.6.6 :: Anaconda custom (64-bit)
```
|
https://github.com/pytorch/pytorch/issues/13460
|
closed
|
[] | 2018-11-01T18:26:20Z
| 2018-11-07T16:07:03Z
| null |
Suhail
|
pytorch/examples
| 431
|
How to run distributed training on multiple Node using ImageNet using ResNet model
|
The script mentioned in https://github.com/pytorch/examples/tree/master/imagenet does provides good guideline on single node training however it doesn't have good documentation on Distributed training on multiple Node.
I tried to use two machines with 8 gpus with below command
Machine-1 script
```
HOST_PORT="tcp://Machine-1-ip:13333"
NODE=0
RANKS_PER_NODE=8
for i in $(seq 0 7); do
LOCAL_RANK=$i
DISTRIBUTED_RANK=$((RANKS_PER_NODE * NODE + LOCAL_RANK))
NCCL_DEBUG=INFO NCCL_MIN_NRINGS=5 python /home/ubuntu/examples/imagenet/main.py \
--a resnet18 \
/home/ubuntu/mini_imagenet \
--dist-url $HOST_PORT \
--gpu $DISTRIBUTED_RANK \
--dist-backend nccl \
--world-size 16 &
PIDS[$LOCAL_RANK]=$!
done
```
On machine-2
```
HOST_PORT="tcp://Machine-1-ip:13333"
NODE=1
RANKS_PER_NODE=8
for i in $(seq 0 7); do
LOCAL_RANK=$i
DISTRIBUTED_RANK=$((RANKS_PER_NODE * NODE + LOCAL_RANK))
NCCL_DEBUG=INFO NCCL_MIN_NRINGS=5 python /home/ubuntu/examples/imagenet/main.py \
--a resnet18 \
/home/ubuntu/mini_imagenet \
--dist-url $HOST_PORT \
--gpu $DISTRIBUTED_RANK \
--dist-backend nccl \
--world-size 16 &
PIDS[$LOCAL_RANK]=$!
done
```
However it fails with below **error**
```
Traceback (most recent call last):
File "/home/ubuntu/examples/imagenet/main.py", line 347, in <module>
main()
File "/home/ubuntu/examples/imagenet/main.py", line 96, in main
world_size=args.world_size)
File "/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/distributed/__init__.py", line 94, in init_process_group
group_name, rank)
RuntimeError: the MPI backend is not available; try to recompile the THD package with MPI support at /opt/conda/conda-bld/pytorch_1532579245307/work/torch/lib/THD/process_group/General.cpp:17
```
|
https://github.com/pytorch/examples/issues/431
|
open
|
[
"distributed"
] | 2018-10-31T06:11:37Z
| 2022-06-15T10:40:29Z
| 12
|
goswamig
|
pytorch/examples
| 430
|
error in the backward pass while using the pytorch roi pooling
|
I am using [link](https://github.com/pytorch/examples/blob/d8d378c31d2766009db400ac03f41dd837a56c2a/fast_rcnn/roi_pooling.py#L38-L53) but i get error while doing the backward pass
```
File "/home/alireza/anaconda3/lib/python3.6/site-packages/spyder_kernels/customize/spydercustomize.py", line 668, in runfile
execfile(filename, namespace)
File "/home/alireza/anaconda3/lib/python3.6/site-packages/spyder_kernels/customize/spydercustomize.py", line 108, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "/home/alireza/RFCN/trainval_net.py", line 357, in <module>
loss.backward()
File "/home/alireza/anaconda3/lib/python3.6/site-packages/torch/autograd/variable.py", line 167, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, retain_variables)
File "/home/alireza/anaconda3/lib/python3.6/site-packages/torch/autograd/__init__.py", line 99, in backward
variables, grad_variables, retain_graph)
File "/home/alireza/anaconda3/lib/python3.6/site-packages/torch/autograd/function.py", line 195, in backward
raise NotImplementedError
NotImplementedError
```
any suggestion what should i do?
in the example of the code [link](https://github.com/pytorch/examples/blob/d8d378c31d2766009db400ac03f41dd837a56c2a/fast_rcnn/roi_pooling.py#L38-L53) mentioned that for backward i should use
`out.backward(out.data.clone().uniform_())`
but im not sure where should i use that?
im using the forward pass inside another function as below:
```
class PSRoIPoolingFunction(Function):
def __init__(self, pooled_height, pooled_width, spatial_scale, group_size, output_dim):
self.pooled_width = int(pooled_width)
self.pooled_height = int(pooled_height)
self.spatial_scale = float(spatial_scale)
self.group_size = int(group_size)
self.output_dim = int(output_dim)
self.output = None
self.mappingchannel = None
self.rois = None
self.feature_size = None
def forward(self, features, rois):
batch_size, num_channels, data_height, data_width = features.size()
num_rois = rois.size()[0]
output = torch.zeros(num_rois, self.output_dim, self.pooled_height, self.pooled_width)
# mappingchannel = torch.IntTensor(num_rois, self.output_dim, self.pooled_height, self.pooled_width).zero_()
# ROI Pooling
out2 = roi_pooling(features, rois, size=(self.pooled_height,self.pooled_width),
spatial_scale = self.spatial_scale)
# AVerage pooling for Position Sensitive
output = Variable(output.cuda())
chan= 0
for i in range(0,out2.size(1),self.pooled_height*self.pooled_width):
output[:,chan,:,:] = torch.mean(out2[:,i:i+self.pooled_height*self.pooled_width,:,:],1,keepdim=True)
chan += 1
return output.data
```
should i use the backward pass somewhere?
How I should use it? :/
|
https://github.com/pytorch/examples/issues/430
|
closed
|
[] | 2018-10-30T20:00:14Z
| 2018-10-30T23:31:42Z
| 2
|
isalirezag
|
pytorch/examples
| 428
|
how to deal with backward pass in pytorch version of ROI Pooling
|
I am trying to make position sensitive roi pooling (PSROIPooling)which is proposed in RFCN work.
PSROIPooling is basically ROIPooling + average pooling.
I am using the `roi_pooling.py` that is written in pytorch and provided [here](https://github.com/pytorch/examples/blob/d8d378c31d2766009db400ac03f41dd837a56c2a/fast_rcnn/roi_pooling.py#L38-L53).
and trying to change [this part of the code](https://github.com/princewang1994/R-FCN.pytorch/blob/master/lib/model/psroi_pooling/functions/psroi_pooling.py) to be completely in pytorch (please note that the current version is in cuda, but i need to do some modification, so that is why im trying to change it to be in pytorch)
so I change that [file](https://github.com/princewang1994/R-FCN.pytorch/blob/master/lib/model/psroi_pooling/functions/psroi_pooling.py) from:
```
import torch
from torch.autograd import Function
from .._ext import psroi_pooling
class PSRoIPoolingFunction(Function):
def __init__(self, pooled_height, pooled_width, spatial_scale, group_size, output_dim):
self.pooled_width = int(pooled_width)
self.pooled_height = int(pooled_height)
self.spatial_scale = float(spatial_scale)
self.group_size = int(group_size)
self.output_dim = int(output_dim)
self.output = None
self.mappingchannel = None
self.rois = None
self.feature_size = None
def forward(self, features, rois):
batch_size, num_channels, data_height, data_width = features.size()
num_rois = rois.size()[0]
output = torch.zeros(num_rois, self.output_dim, self.pooled_height, self.pooled_width)
mappingchannel = torch.IntTensor(num_rois, self.output_dim, self.pooled_height, self.pooled_width).zero_()
output = output.cuda()
mappingchannel = mappingchannel.cuda()
psroi_pooling.psroi_pooling_forward_cuda(self.pooled_height, self.pooled_width, self.spatial_scale, self.group_size, self.output_dim, \
features, rois, output, mappingchannel)
self.output = output
self.mappingchannel = mappingchannel
self.rois = rois
self.feature_size = features.size()
return output
def backward(self, grad_output):
assert(self.feature_size is not None and grad_output.is_cuda)
batch_size, num_channels, data_height, data_width = self.feature_size
grad_input = torch.zeros(batch_size, num_channels, data_height, data_width).cuda()
psroi_pooling.psroi_pooling_backward_cuda(self.pooled_height, self.pooled_width, self.spatial_scale, self.output_dim, \
grad_output, self.rois, grad_input, self.mappingchannel)
return grad_input, None
```
to be like this:
```
import torch
from torch.autograd import Function
from .._ext import psroi_pooling
from .ROI_Pooling_PyTorch import *
from .ROI_Pooling_PyTorch import roi_pooling
from torch.autograd import Variable
class PSRoIPoolingFunction(Function):
def __init__(self, pooled_height, pooled_width, spatial_scale, group_size, output_dim):
self.pooled_width = int(pooled_width)
self.pooled_height = int(pooled_height)
self.spatial_scale = float(spatial_scale)
self.group_size = int(group_size)
self.output_dim = int(output_dim)
self.output = None
self.mappingchannel = None
self.rois = None
self.feature_size = None
def forward(self, features, rois):
batch_size, num_channels, data_height, data_width = features.size()
num_rois = rois.size()[0]
output = torch.zeros(num_rois, self.output_dim, self.pooled_height, self.pooled_width)
# mappingchannel = torch.IntTensor(num_rois, self.output_dim, self.pooled_height, self.pooled_width).zero_()
# ROI Pooling
out2 = roi_pooling(features, rois, size=(self.pooled_height,self.pooled_width),
spatial_scale = self.spatial_scale)
# AVerage pooling for Position Sensitive
output = Variable(output.cuda())
chan= 0
for i in range(0,out2.size(1),self.pooled_height*self.pooled_width):
output[:,chan,:,:] = torch.mean(out2[:,i:i+self.pooled_height*self.pooled_width,:,:],1,keepdim=True)
chan += 1
# mappingchannel = mappingchannel.cuda()
self.output = output
# self.mappingchannel = mappingchannel
self.rois = rois
self.feature_size = features.size()
return output.data
def backward(self, grad_output):
# =============================================================================
# What should i put here?????
# =============================================================================
```
the forward pass sounds like working, but the backwar
|
https://github.com/pytorch/examples/issues/428
|
closed
|
[] | 2018-10-30T02:08:40Z
| 2018-10-30T02:21:14Z
| 1
|
isalirezag
|
pytorch/examples
| 425
|
DCGAN: code and paper don't have the same feature maps?
|
## From the code
Input(100\*1\*1) --->((ngf\*8) \*4\*4)--->((ngf\*4) \*8\*8)--->((ngf\*2) \*16\*16)--->(ngf \*32\*32)--->(3\*64\*64)
according to the code, **ngf=64**. Therefore we have
**Input(100\*1\*1) --->(512\*4\*4)--->(256\*8\*8)--->(128\*16\*16)--->(64\*32\*32)--->(3\*64\*64)**
```python
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
```
## From the paper
**Input(100\*1\*1) --->(1024\*4\*4)--->(512\*8\*8)--->(256\*16\*16)--->(128\*32\*32)--->(3\*64\*64)**
## My question is
why the two generator's feature maps sizes don't match?
Thank you
|
https://github.com/pytorch/examples/issues/425
|
closed
|
[] | 2018-10-25T07:36:28Z
| 2018-11-03T04:24:48Z
| 1
|
zhibo-liu
|
pytorch/examples
| 421
|
what is spatial_scale in roi pooling
|
can you please explain to me what is spatial_scale here:
[Link](https://github.com/pytorch/examples/blob/d8d378c31d2766009db400ac03f41dd837a56c2a/fast_rcnn/roi_pooling.py#L38-L53)
also in ```[..., roi[2]:(roi[4]+1), roi[1]:(roi[3]+1)]```, what does `...` in the begining of the list do?
Thanks
|
https://github.com/pytorch/examples/issues/421
|
closed
|
[] | 2018-10-11T14:39:24Z
| 2018-10-11T19:06:28Z
| null |
isalirezag
|
pytorch/text
| 424
|
What is "parse_field" for?
|
In torchtext.datasets.SNLI.splits, there is a parameter named "parse_field". I found if setting this field with a "datasets.snli.ShiftReduceField" object, the vocabulary becomes much smaller and SNLI accuracy always improves (compared with default value). It is amazing! But I can't find any description about it...
|
https://github.com/pytorch/text/issues/424
|
closed
|
[] | 2018-09-27T04:45:10Z
| 2018-10-02T03:39:58Z
| null |
jueliangguke
|
pytorch/examples
| 412
|
RuntimeError: Found 0 images in subfolders of in AWS
|
Have anyone used torchvision.datasets.ImageFolder in AWS?
I met this error in predicting my pictures in my own folder
RuntimeError: Found 0 images in subfolders of: mine/1/2
Supported extensions are: .jpg,.jpeg,.png,.ppm,.bmp,.pgm,.tif
But, I have uploaded 3 jpg images in mine/1/2.
It also have found the folder
Is there anything I have missed?
Any suggestion will be appreciated
<img width="371" alt="2" src="https://user-images.githubusercontent.com/42711020/45485510-cfb75c80-b74f-11e8-8ce5-bbfc05ea19ad.png">
<img width="413" alt="2 2" src="https://user-images.githubusercontent.com/42711020/45485518-d2b24d00-b74f-11e8-91b3-c5953d27b165.png">
<img width="249" alt="2 1" src="https://user-images.githubusercontent.com/42711020/45485520-d7770100-b74f-11e8-9f3b-5d0fa0b47f3b.png">
|
https://github.com/pytorch/examples/issues/412
|
closed
|
[] | 2018-09-13T11:23:47Z
| 2021-09-07T03:11:15Z
| 2
|
Aaron4Fun
|
pytorch/examples
| 411
|
AlexNet code
|
Where can I find the AlexNet code? I would like to implement it in a distributed mode using MPI.
|
https://github.com/pytorch/examples/issues/411
|
closed
|
[] | 2018-09-11T13:08:24Z
| 2022-03-10T00:27:48Z
| 1
|
abidmalikwaterloo
|
pytorch/pytorch
| 11,130
|
where is the caffe2 folder?
|
Hi,
In the old version of caffe2, I could find the caffe2 folder ( "/usr/local/caffe2"). Where is the the caffe2 folder(within PYTORCH ) right now?
|
https://github.com/pytorch/pytorch/issues/11130
|
closed
|
[
"caffe2"
] | 2018-08-31T02:25:04Z
| 2018-09-07T02:59:19Z
| null |
ddeeppnneett
|
pytorch/examples
| 409
|
How to extract a trained model
|
Hi,
I have trained a model of resnet 152 using the code provided in 'examples/imagenet/main.py' I understand that it saves a checkpoint after every epoch, and at the end of the training it will save the best trained model.
My question is how can i extract this model?
|
https://github.com/pytorch/examples/issues/409
|
closed
|
[] | 2018-08-29T04:33:42Z
| 2022-03-10T05:45:07Z
| 3
|
mvk07
|
pytorch/examples
| 406
|
UserWarning: nn.Upsampling is deprecated. Use nn.functional.interpolate instead. warnings.warn("nn.Upsampling is deprecated. Use nn.functional.interpolate instead.")
|
UserWarning: nn.Upsampling is deprecated. Use nn.functional.interpolate instead.
warnings.warn("nn.Upsampling is deprecated. Use nn.functional.interpolate instead.")
How can I solve this problem?
|
https://github.com/pytorch/examples/issues/406
|
closed
|
[] | 2018-08-26T09:23:08Z
| 2022-03-10T06:01:35Z
| 1
|
u0251077
|
pytorch/tutorials
| 281
|
Question: neural_style_tutorial:how to adjust different input image size to achieve this?
|
I'm new to dl and pytorch.
neural_style_tutorial
this tutorial is about fixed size image.
but most image cant have the same size defined,how to adjust different input image size to this model?
many thanks, if you can help!!!
|
https://github.com/pytorch/tutorials/issues/281
|
closed
|
[] | 2018-08-10T06:02:04Z
| 2021-06-16T21:11:13Z
| 0
|
aohan237
|
pytorch/examples
| 399
|
Why don't we use MSE as a reconstruction loss for VAE ?
|
Hi,
I am wondering if there is a theoretical reason for using BCE as a reconstruction loss for variation auto-encoders ? Can't we simply use MSE or norm-based reconstruction loss instead ?
Best Regards
|
https://github.com/pytorch/examples/issues/399
|
open
|
[
"good first issue"
] | 2018-08-07T11:23:11Z
| 2022-03-10T06:02:04Z
| 7
|
ahmed-fau
|
pytorch/examples
| 393
|
How large batch size should I set for imagenet training
|
I just use the default setting of batch size 256 and 8 TiTAN XP gpus on resnet34, it takes about 1.5 hours for one epoch, I want to speed up the training process, Can I increase the batch size ?
|
https://github.com/pytorch/examples/issues/393
|
closed
|
[] | 2018-07-26T02:51:18Z
| 2018-07-27T04:04:14Z
| 1
|
lith0613
|
pytorch/examples
| 384
|
lm example:iteration over a 0-d tensor
|
I run example code , give me this error. I don't know how to solve this .
All error give from function repackage_hidden.
my pytorch version is .4
|
https://github.com/pytorch/examples/issues/384
|
closed
|
[] | 2018-07-13T10:53:35Z
| 2019-06-24T11:15:58Z
| 2
|
EricAugust
|
pytorch/pytorch
| 9,207
|
Where is the include and lib path for caffe2?
|
i installed pytorch with caffe2 from source by using 'python setup_caffe2.py install' command.
Can anyone tell that where is the default include and lib path for caffe2?
|
https://github.com/pytorch/pytorch/issues/9207
|
open
|
[
"caffe2"
] | 2018-07-06T14:44:20Z
| 2018-07-14T03:58:25Z
| null |
universewill
|
huggingface/pytorch-openai-transformer-lm
| 19
|
what is the use of dropout in the Transformer?
|
https://github.com/huggingface/pytorch-openai-transformer-lm/blob/55ba4d78407ae12c7454dc8f3342f476be3dece5/model_pytorch.py#L161
|
https://github.com/huggingface/pytorch-openai-transformer-lm/issues/19
|
open
|
[] | 2018-07-05T16:18:48Z
| 2018-07-09T13:59:41Z
| null |
teucer
|
pytorch/examples
| 376
|
trying to understand the meaning of model.train() and model.eval()
|
Hi
So i see in the main.py we have model.train() and model.val(), i dont understand how to use them. can someone explain it to me please.
For example in here:
`python main.py -a resnet18 [imagenet-folder with train and val folders]` we did not specify train or eval, so how do we know which one to use.
I know my question is stupid, please let me know if there is any good tutorial to read and understand it.
Thanks
|
https://github.com/pytorch/examples/issues/376
|
closed
|
[] | 2018-06-23T22:14:02Z
| 2018-06-23T22:18:09Z
| 1
|
isalirezag
|
pytorch/examples
| 374
|
About distributed training of Imagenet, I am confused there is no operation to collect grads from machines and average them before update grads.
|
I write a distributed training model refer to the code imagenet/main.py , and the models on different machine own their independent optimizer. But I noticed that after backward() there is no operation to collect param grads from other processes and average them to get new grads for update. Does pytorch accomplish the average task implicitly by the optimizer.step() function? I am so confused..
|
https://github.com/pytorch/examples/issues/374
|
closed
|
[] | 2018-06-14T11:41:15Z
| 2019-05-21T21:49:59Z
| 4
|
TobeyYang
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.