
text1 stringlengths 2 269k | text2 stringlengths 2 242k | label int64 0 1 |
|---|---|---|
Why this margin is needed?
bootstrap.css (5648 line)
body.modal-open,
.modal-open .navbar-fixed-top,
.modal-open .navbar-fixed-bottom {
margin-right: 15px;
}
|
When launching the modal component
(http://getbootstrap.com/javascript/#modals) the entire content will slightly
move to the left on mac OS (haven't tried it on windows yet). With the active
modal the scrollbar seem to disappear, while the content width still changes.
You can observer the problem on the bootstrap page
| 1 |
Maybe I'm missing something in the debug UI experience but I see no way to add
a condition to a function breakpoint even though the debug protocol supports
it.
|
* VSCode Version: 1.1.1
* OS Version: El Captian (10.11.5)

How can I remove those ugly brackets in the menu? are they shortcut hints? No
use to me at all.
| 0 |
Cast renders an anonymous alias contrary to the documentation
The example used in the documantation
from sqlalchemy import cast, Numeric, select
stmt = select([
cast(product_table.c.unit_price, Numeric(10, 4))
])
renders as
SELECT CAST(product_table.unit_price AS NUMERIC(10, 4)) AS anon_1 FROM product_table
instead of
SELECT CAST(unit_price AS NUMERIC(10, 4)) FROM product
I've tried sqlalchemy version 1.2.7 and 1.2.16 and both return the same result
|
We're having some issues with `back_populates` of relationships referring to
other relationships with `viewonly=True`. We get duplicates in the
relationship list that the `back_populates` refers to. Test case:
import sqlalchemy
from sqlalchemy import Column
from sqlalchemy import ForeignKey
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import attributes
from sqlalchemy.orm import relationship
Base = declarative_base()
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String)
boston_addresses = relationship(
"Address",
# primaryjoin="and_(User.id==Address.user_id, Address.city=='Boston')", # Not necessary but shows the use case
viewonly=True) # Setting viewonly = False prevents the issue
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user.id'))
user = relationship('User', back_populates='boston_addresses')
city = Column(String)
def main():
session = setup_database_and_session()
user = User()
session.add(user)
session.commit()
# user.boston_addresses # Reading the value here prevents the issue
address = Address(user=user, city='Boston')
actual = user.boston_addresses
expected = [address]
assert actual == expected, f"{actual} != {expected}"
def setup_database_and_session():
engine = sqlalchemy.create_engine("sqlite://")
session_maker = sqlalchemy.orm.sessionmaker(bind=engine)
session = session_maker()
Base.metadata.create_all(engine)
return session
if __name__ == "__main__":
main()
Result:
AssertionError: [<__main__.Address object at 0x10d95aeb8>, <__main__.Address object at 0x10d95aeb8>] != [<__main__.Address object at 0x10d95aeb8>]
| 0 |
This bug-tracker is monitored by Windows Console development team and other
technical types. **We like detail!**
If you have a feature request, please post to the UserVoice.
> **Important: When reporting BSODs or security issues, DO NOT attach memory
> dumps, logs, or traces to Github issues**. Instead, send dumps/traces to
> secure@microsoft.com, referencing this GitHub issue.
Please use this form and describe your issue, concisely but precisely, with as
much detail as possible
* Your Windows build number: 10.0.18362.30
* What you're doing and what's happening: Resize the terminal window to minimum, then resize the window to normal, the text will disappear.
### The normal window size

### Resize it to minimum

### Then resize to normal, the text disappear

### Scroll up the window

* What's wrong / what should be happening instead: I don't know. Is this a bug?
|
When we paste anything in the Windows Terminal ubuntu instance using any
command like **vim abc.txt** , it automatically inserts new line after each
line, and eats up some characters from the beginning of the pasted text.
Here is the screenshot: https://i.imgur.com/pJ0Fsbw.png
Here the text copied to my clipboard copied was:
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
I ran command: **vim abc.txt**
And after paste, it became
ne 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.5.10
* Operating System version: windows7
* Java version: jdk1.8
when is use dubbo-2.5.10 startup my application ,show me the log is
[DUBBO] Using select timeout of 500, dubbo version: 2.0.1, current host: 192.168.1.18
About the issue of using the dubbo-2.5.10 boot log output version is 2.0.1
but if i use dubbo of 2.6.x ,it is no problem;
and when i see the MANIFEST.MF of 2.5.10 and 2.6.2,i found them:
dubbo-2.5.10 MANIFEST.MF file
Manifest-Version: 1.0
Implementation-Vendor: The Dubbo Project
Implementation-Title: Dubbo
Implementation-Version: 2.0.1
Implementation-Vendor-Id: com.alibaba
Built-By: ken.lj
Build-Jdk: 1.7.0_80
Specification-Vendor: The Dubbo Project
Specification-Title: Dubbo
Created-By: Apache Maven 3.1.1
Specification-Version: 2.0.0
Archiver-Version: Plexus Archiver
but when i see the dubbo-2.6.2 MANIFEST.MF file
Manifest-Version: 1.0
Implementation-Vendor: The Apache Software Foundation
Implementation-Title: dubbo-all
Implementation-Version: 2.6.2
Implementation-Vendor-Id: com.alibaba
Built-By: ken.lj
Build-Jdk: 1.7.0_80
Specification-Vendor: The Apache Software Foundation
Specification-Title: dubbo-all
Created-By: Apache Maven 3.5.0
Implementation-URL: https://github.com/apache/incubator-dubbo/dubbo
Specification-Version: 2.6
and the source code of
com.alibaba.dubbo.common.logger.support.FailsafeLogger
package com.alibaba.dubbo.common.logger.support;
import com.alibaba.dubbo.common.Version;
import com.alibaba.dubbo.common.logger.Logger;
import com.alibaba.dubbo.common.utils.NetUtils;
public class FailsafeLogger implements Logger {
private Logger logger;
public FailsafeLogger(Logger logger) {
this.logger = logger;
}
public Logger getLogger() {
return logger;
}
public void setLogger(Logger logger) {
this.logger = logger;
}
private String appendContextMessage(String msg) {
return " [DUBBO] " + msg + ", dubbo version: " + Version.getVersion() + ", current host: " + NetUtils.getLogHost();
}
.... other code
source code of com.alibaba.dubbo.common.Version
public static String getVersion(Class<?> cls, String defaultVersion) {
try {
// 首先查找MANIFEST.MF规范中的版本号
String version = cls.getPackage().getImplementationVersion();
if (version == null || version.length() == 0) {
version = cls.getPackage().getSpecificationVersion();
}
if (version == null || version.length() == 0) {
// 如果规范中没有版本号,基于jar包名获取版本号
CodeSource codeSource = cls.getProtectionDomain().getCodeSource();
if(codeSource == null) {
logger.info("No codeSource for class " + cls.getName() + " when getVersion, use default version " + defaultVersion);
}
else {
String file = codeSource.getLocation().getFile();
if (file != null && file.length() > 0 && file.endsWith(".jar")) {
file = file.substring(0, file.length() - 4);
int i = file.lastIndexOf('/');
if (i >= 0) {
file = file.substring(i + 1);
}
i = file.indexOf("-");
if (i >= 0) {
file = file.substring(i + 1);
}
while (file.length() > 0 && ! Character.isDigit(file.charAt(0))) {
i = file.indexOf("-");
if (i >= 0) {
file = file.substring(i + 1);
} else {
break;
}
}
version = file;
}
}
}
// 返回版本号,如果为空返回缺省版本号
return version == null || version.length() == 0 ? defaultVersion : version;
} catch (Throwable e) { // 防御性容错
// 忽略异常,返回缺省版本号
logger.error("return default version, ignore exception " + e.getMessage(), e);
return defaultVersion;
}
}
why the dubbo-2.5.x boot log output 2.0.1 ,can fix it?
|
# Weekly Report of Dubbo
This is a weekly report of Dubbo. It summarizes what have changed in the
project during the passed week, including pr merged, new contributors, and
more things in the future.
It is all done by @dubbo-bot which is a collaborate robot.
## Repo Overview
### Basic data
Baisc data shows how the watch, star, fork and contributors count changed in
the passed week.
Watch | Star | Fork | Contributors
---|---|---|---
3200 | 24432 (↑79) | 13832 (↑61) | 175 (↑2)
### Issues & PRs
Issues & PRs show the new/closed issues/pull requests count in the passed
week.
New Issues | Closed Issues | New PR | Merged PR
---|---|---|---
17 | 31 | 23 | 15
## PR Overview
Thanks to contributions from community, Dubbo team merged **15** pull requests
in the repository last week. They are:
* Apache parent pom version is updated to 21. (#3470)
* possibly bug fix (#3460)
* extract method to cache default extension name (#3456)
* [Dubbo-3237]fix connectionMonitor in RestProtocol seems not work #3237 (#3455)
* extract 2 methods: isSetter and getSetterProperty (#3453)
* Bugfix/timeout queue full (#3451)
* fix #2619: is there a problem in NettyBackedChannelBuffer.setBytes(...)? (#3448)
* Add delay export test case (#3447)
* remove duplicated unused method and move unit test (#3446)
* Add checkstyle rule for redundant import (#3444)
* Update junit to 5.4.0 release version (#3441)
* remove duplicated import (#3440)
* [Dubbo-Container] Fix Enhance the java doc of dubbo-container module (#3437)
* refactor javassist compiler: extract class CtClassBuilder (#3424)
* refactor adaptive extension class code creation: extract class AdaptiveClassCodeGenerator (#3419)
## Code Review Statistics
Dubbo encourages everyone to participant in code review, in order to improve
software quality. Every week @dubbo-bot would automatically help to count pull
request reviews of single github user as the following. So, try to help review
code in this project.
Contributor ID | Pull Request Reviews
---|---
@lixiaojiee | 6
@kezhenxu94 | 4
@LiZhenNet | 3
@CrazyHZM | 2
@beiwei30 | 2
@carryxyh | 2
@kexianjun | 2
@scxwhite | 2
@chickenlj | 1
@wanghbxxxx | 1
@khanimteyaz | 1
@htynkn | 1
## Contributors Overview
It is Dubbo team's great honor to have new contributors from community. We
really appreciate your contributions. Feel free to tell us if you have any
opinion and please share this open source project with more people if you
could. If you hope to be a contributor as well, please start from
https://github.com/apache/incubator-dubbo/blob/master/CONTRIBUTING.md .
Here is the list of new contributors:
@kamaci
@dreamer-nitj
Thanks to you all.
_Note: This robot is supported byCollabobot._
| 0 |
Use case: for classifiers with predict_proba I like to see precision/recall
data across different probability values. This would be really easy to return
from current cross_validation.py master if not for
if not isinstance(score, numbers.Number):
raise ValueError
in _cross_val_score
with this changed to a warning, cross_val_score can do the check before
converting scores to np.array, and return plain list for incompatible types.
|
I'd like to use cross_validation.cross_val_score with
metrics.precision_recall_fscore_support so that I can get all relevant cross-
validation metrics without having to run my cross-validation once for
accuracy, once for precision, once for recall, and once for f1. But when I try
this I get a ValueError:
from sklearn.datasets import fetch_20newsgroups
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import metrics
from sklearn import cross_validation
import numpy as np
data_train = fetch_20newsgroups(subset='train', #categories=categories,
shuffle=True, random_state=42)
clf = LinearSVC(loss='l1', penalty='l2')
vectorizer = TfidfVectorizer(
sublinear_tf=False,
max_df=0.5,
min_df=2,
ngram_range = (1,1),
use_idf=False,
stop_words='english')
X_train = vectorizer.fit_transform(data_train.data)
# Cross-validate:
scores = cross_validation.cross_val_score(
clf, X_train, data_train.target, cv=5,
scoring=metrics.precision_recall_fscore_support)
| 1 |
Referring the documentation provided by playwright, seems like the hooks
(example: afterAll / beforeAll) can be used only inside a spec/ test file as
below:
// example.spec.ts
import { test, expect } from '@playwright/test';
test.beforeAll(async () => {
console.log('Before tests');
});
test.afterAll(async () => {
console.log('After tests');
});
test('my test', async ({ page }) => {
// ...
});
My question: is there any support where there can be only one AfterAll() or
beforeAll() hook in one single file which will be called for every test files
? the piece of code that i want to have inside the afterAll and beforeAll is
common for all the test/ specs files and i dont want to have the same
duplicated in all the spec files/ test file.
Any suggestion or thoughts on this?
TIA
Allen
|
### System info
* Playwright Version: [v1.32.3]
* Operating System: [All, Windows] I only has Windows
* Browser: [Chromium, Firefox]
Page Visibility API : https://developer.mozilla.org/en-
US/docs/Web/API/Page_Visibility_API
**Steps**
* Start a test and wait for the browser opens (let the test wait log, we need do following steps manually )
* open inspect/'dev tool' in a tab
* In console panel run the following script
document.addEventListener("visibilitychange", () => {
console.log('visibilitychange work', document.visibilityState === 'visible')
});
* open another new tab --just open it manually
* switch to the previous tab and watch the console log
**Expected**
We can see the console log:
"visibilitychange work false"
"visibilitychange work true"
**Actual**
There is not such log. looks 'visibilitychange' event never triggered
Note: open the browser(Chromium) manually , Page Visibility API works OK.
But when running in test env, Page Visibility API does not work OK.
| 0 |
##### ISSUE TYPE
* Bug Report
##### COMPONENT NAME
???
##### ANSIBLE VERSION
ansible 2.6.0 (skipped_false 39251fc27b) last updated 2018/02/10 00:32:41 (GMT +200)
config file = None
configured module search path = ['/home/nikos/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /home/nikos/Projects/ansible/lib/ansible
executable location = /home/nikos/Projects/ansible/bin/ansible
python version = 3.6.4 (default, Jan 5 2018, 02:35:40) [GCC 7.2.1 20171224]
##### CONFIGURATION
Default
##### OS / ENVIRONMENT
Arch linux latest, tasks run against localhost
##### SUMMARY
It is not possible to define task vars from a dict variable
##### STEPS TO REPRODUCE
- hosts: localhost
tasks:
- set_fact:
dict: {'key': 'value'}
- debug:
msg: Test
vars: "{{ dict }}"
##### EXPECTED RESULTS
The second task should be executed successfully and the dict's contents should
become available as variables in the context of the task.
##### ACTUAL RESULTS
ERROR! Vars in a Task must be specified as a dictionary, or a list of dictionaries
The error appears to have been in '/home/nikos/Projects/playbook.yml': line 8, column 9, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
vars:
- dict
^ here
|
##### ISSUE TYPE
* Bug Report
##### COMPONENT NAME
lib/ansible/playbook/base.py
##### ANSIBLE VERSION
ansible 2.2.0.0
config file =
configured module search path = Default w/o overrides
##### CONFIGURATION
##### OS / ENVIRONMENT
N/A
##### SUMMARY
I am trying to set the vars for either a block: or an include_role: from a
dictionary.
I get one of these messages (depending on the case):
ERROR! Vars in a Block must be specified as a dictionary, or a list of
dictionaries
ERROR! Vars in a IncludeRole must be specified as a dictionary, or a list of
dictionaries
##### STEPS TO REPRODUCE
- set_fact:
_T_m3_inv_vars:
one_setting: "{{ some_other_var1 |mandatory }}"
two_setting: "{{ some_other_var2 |mandatory }}"
- block:
- debug: msg="YYYYYYYY"
vars: "{{ _T_m3_inv_vars }}"
- include_role:
name: "some_nice_role"
static: yes
private: yes
vars: "{{ _T_m3_inv_vars }}"
##### EXPECTED RESULTS
I would expect a similar result as having done the following
- block:
- debug: msg="YYYYYYYY"
vars:
one_setting: "{{ some_other_var1 |mandatory }}"
two_setting: "{{ some_other_var2 |mandatory }}"
- include_role:
name: "some_nice_role"
static: yes
private: yes
vars:
one_setting: "{{ some_other_var1 |mandatory }}"
two_setting: "{{ some_other_var2 |mandatory }}"
This is because I am indeed passing a dictionary to the vars: setting.
##### ACTUAL RESULTS
One of these messages (obtained by running the previous snippets separatellyI
ERROR! Vars in a Block must be specified as a dictionary, or a list of
dictionaries
ERROR! Vars in a IncludeRole must be specified as a dictionary, or a list of
dictionaries
| 1 |
##### System information (version)
* OpenCV => 3.4.1 (master seems to be same)
* Operating System / Platform => cygwin 64 bit
* Compiler => g++ (gcc 7.3.0)
##### Detailed description
In some (very rare) condition, "Error: Assertion failed" happens at:
opencv/modules/core/src/types.cpp
Line 154 in da7e1cf
| CV_Assert( abs(vecs[0].dot(vecs[1])) / (norm(vecs[0]) * norm(vecs[1])) <=
FLT_EPSILON );
---|---
`CV_Assert(abs(vecs[0].dot(vecs[1])) / (cv::norm(vecs[0]) * cv::norm(vecs[1]))
<= FLT_EPSILON);`
because `FLT_EPSILON` is too small to compare.
##### Steps to reproduce
I made a reproducible example:
https://github.com/takotakot/opencv_debug/tree/0a5d37dc2cc4aef22a33012bdcbb54597ae852a1
.
If we have `Point2d` rectangle, using `RotatedRect_2d` can eliminate the
problem.
Part of the code:
cv::Mat points = (cv::Mat_<double>(10, 2) <<
1357., 1337.,
1362., 1407.,
1367., 1474.,
1372., 1543.,
1375., 1625.,
1375., 1696.,
1377., 1734.,
1378., 1742.,
1382., 1801.,
1372., 1990.);
cv::PCA pca_points(points, cv::Mat(), CV_PCA_DATA_AS_ROW, 2);
cv::Point2d p1(564.45, 339.8819), p2, p3;
p2 = p1 - 1999 * cv::Point2d(pca_points.eigenvectors.row(0));
p3 = p2 - 1498.5295 * cv::Point2d(pca_points.eigenvectors.row(1));
cv::RotatedRect(p1, p2, p3);
##### Plans
I have some plans:
1. Multiple 2, 4 or some value to FLT_EPSILON
2. Make another constructor using `Point2d` for `Point2f` (and `Vec2d` for `Vec2f` etc. inside)
Note 1: If we use `DBL_EPSILON`, same problem may occur.
Note 2: If we only have `Point2f` rectangle, we cannot avoid assertion.
3. Calcurate the angle between two vectors and introduce another assersion.
I want to create PR for solving this issue. But I want some direction.
|
##### System information (version)
* OpenCV => 4.1.0
* Operating System / Platform => Ubuntu 18.04 LTS
* Compiler => clang-7
##### Detailed description
An issue was discovered in opencv 4.1.0, there is an out of bounds read in function cv::predictOrdered<cv::HaarEvaluator> in cascadedetect.hpp, which leads to denial of service.
source
511 double val = featureEvaluator(node.featureIdx);
512 idx = val < node.threshold ? node.left : node.right;
513 }
514 while( idx > 0 );
> 515 sum += \*bug=>*\ cascadeLeaves[leafOfs - idx];
516 nodeOfs += weak.nodeCount;
517 leafOfs += weak.nodeCount + 1;
518 }
519 if( sum < stage.threshold )
520 return -si;
debug
In file: /home/pwd/SofterWare/opencv-4.1.0/modules/objdetect/src/cascadedetect.hpp
510 CascadeClassifierImpl::Data::DTreeNode& node = cascadeNodes[root + idx];
511 double val = featureEvaluator(node.featureIdx);
512 idx = val < node.threshold ? node.left : node.right;
513 }
514 while( idx > 0 );
► 515 sum += cascadeLeaves[leafOfs - idx];
516 nodeOfs += weak.nodeCount;
517 leafOfs += weak.nodeCount + 1;
518 }
519 if( sum < stage.threshold )
520 return -si;
─────────────────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7fffc7ffe300 ◂— 0x8d80169006580d8
01:0008│ 0x7fffc7ffe308 ◂— 0xbba5787f80000000
02:0010│ 0x7fffc7ffe310 —▸ 0x7fffd53a5de0 ◂— 0xb1088000af4cb
03:0018│ 0x7fffc7ffe318 ◂— 0xffedb5a100000003
04:0020│ 0x7fffc7ffe320 ◂— 0xbf74af0fe0000000
05:0028│ 0x7fffc7ffe328 —▸ 0x6b7b70 ◂— 0x0
06:0030│ 0x7fffc7ffe330 ◂— 0x800000000000005d /* ']' */
07:0038│ 0x7fffc7ffe338 —▸ 0x66f4a4 ◂— 0x100000000
───────────────────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────────────────
► f 0 7ffff5e2c500
f 1 7ffff5e2bb21
f 2 7ffff5e3bd74
f 3 7fffef87dc59
f 4 7fffef87ea3b cv::ParallelJob::execute(bool)+603
f 5 7fffef87e21a cv::WorkerThread::thread_body()+890
f 6 7fffef880e05 cv::WorkerThread::thread_loop_wrapper(void*)+21
f 7 7fffee3d46db start_thread+219
Program received signal SIGSEGV (fault address 0xfffffffe006630f8)
pwndbg> p cascadeLeaves
$1 = (float *) 0x662e10
pwndbg> p leafOfs
$2 = 186
pwndbg> p idx
$3 = -2147483648
bug report
AddressSanitizer:DEADLYSIGNAL
=================================================================
==9176==ERROR: AddressSanitizer: SEGV on unknown address 0x623e000443e8 (pc 0x7fc9fc661bfa bp 0x7fc9daee70b0 sp 0x7fc9daee6f80 T1)
==9176==The signal is caused by a READ memory access.
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
AddressSanitizer:DEADLYSIGNAL
#0 0x7fc9fc661bf9 in int cv::predictOrdered<cv::HaarEvaluator>(cv::CascadeClassifierImpl&, cv::Ptr<cv::FeatureEvaluator>&, double&) /src/opencv/modules/objdetect/src/cascadedetect.hpp:515:17
#1 0x7fc9fc65f736 in cv::CascadeClassifierImpl::runAt(cv::Ptr<cv::FeatureEvaluator>&, cv::Point_<int>, int, double&) /src/opencv/modules/objdetect/src/cascadedetect.cpp:962:20
#2 0x7fc9fc692083 in cv::CascadeClassifierInvoker::operator()(cv::Range const&) const /src/opencv/modules/objdetect/src/cascadedetect.cpp:1029:46
#3 0x7fc9f294b0c3 in (anonymous namespace)::ParallelLoopBodyWrapper::operator()(cv::Range const&) const /src/opencv/modules/core/src/parallel.cpp:343:17
#4 0x7fc9f2d737e7 in cv::ParallelJob::execute(bool) /src/opencv/modules/core/src/parallel_impl.cpp:315:22
#5 0x7fc9f2d7125b in cv::WorkerThread::thread_body() /src/opencv/modules/core/src/parallel_impl.cpp:415:24
#6 0x7fc9f2d7f719 in cv::WorkerThread::thread_loop_wrapper(void*) /src/opencv/modules/core/src/parallel_impl.cpp:265:41
#7 0x7fc9f15e46b9 in start_thread (/lib/x86_64-linux-gnu/libpthread.so.0+0x76b9)
#8 0x7fc9f0cf841c in clone (/lib/x86_64-linux-gnu/libc.so.6+0x10741c)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /src/opencv/modules/objdetect/src/cascadedetect.hpp:515:17 in int cv::predictOrdered<cv::HaarEvaluator>(cv::CascadeClassifierImpl&, cv::Ptr<cv::FeatureEvaluator>&, double&)
Thread T1 created by T0 here:
#0 0x43428d in __interceptor_pthread_create /work/llvm/projects/compiler-rt/lib/asan/asan_interceptors.cc:204
#1 0x7fc9f2d79d58 in cv::WorkerThread::WorkerThread(cv::ThreadPool&, unsigned int) /src/opencv/modules/core/src/parallel_impl.cpp:227:15
#2 0x7fc9f2d76240 in cv::ThreadPool::reconfigure_(unsigned int) /src/opencv/modules/core/src/parallel_impl.cpp:510:53
#3 0x7fc9f2d7bb07 in cv::ThreadPool::run(cv::Range const&, cv::ParallelLoopBody const&, double) /src/opencv/modules/core/src/parallel_impl.cpp:548:9
#4 0x7fc9f2949a99 in parallel_for_impl(cv::Range const&, cv::ParallelLoopBody const&, double) /src/opencv/modules/core/src/parallel.cpp:590:9
#5 0x7fc9f2949a99 in cv::parallel_for_(cv::Range const&, cv::ParallelLoopBody const&, double) /src/opencv/modules/core/src/parallel.cpp:518
#6 0x7fc9fc673269 in cv::CascadeClassifierImpl::detectMultiScaleNoGrouping(cv::_InputArray const&, std::vector<cv::Rect_<int>, std::allocator<cv::Rect_<int> > >&, std::vector<int, std::allocator<int> >&, std::vector<double, std::allocator<double> >&, double, cv::Size_<int>, cv::Size_<int>, bool) /src/opencv/modules/objdetect/src/cascadedetect.cpp:1346:9
#7 0x7fc9fc677cb8 in cv::CascadeClassifierImpl::detectMultiScale(cv::_InputArray const&, std::vector<cv::Rect_<int>, std::allocator<cv::Rect_<int> > >&, std::vector<int, std::allocator<int> >&, std::vector<double, std::allocator<double> >&, double, int, int, cv::Size_<int>, cv::Size_<int>, bool) /src/opencv/modules/objdetect/src/cascadedetect.cpp:1365:5
#8 0x7fc9fc6786ee in cv::CascadeClassifierImpl::detectMultiScale(cv::_InputArray const&, std::vector<cv::Rect_<int>, std::allocator<cv::Rect_<int> > >&, double, int, int, cv::Size_<int>, cv::Size_<int>) /src/opencv/modules/objdetect/src/cascadedetect.cpp:1386:5
#9 0x7fc9fc686370 in cv::CascadeClassifier::detectMultiScale(cv::_InputArray const&, std::vector<cv::Rect_<int>, std::allocator<cv::Rect_<int> > >&, double, int, int, cv::Size_<int>, cv::Size_<int>) /src/opencv/modules/objdetect/src/cascadedetect.cpp:1659:9
#10 0x51d4bc in main /work/funcs/classifier.cc:34:24
#11 0x7fc9f0c1182f in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2082f)
==9176==ABORTING
others
from fuzz project pwd-opencv-classifier-00
crash name pwd-opencv-classifier-00-00000253-20190703.xml
Auto-generated by pyspider at 2019-07-03 07:57:31
please send email to teamseri0us360@gmail.com if you have any questions.
##### Steps to reproduce
commandline
classifier /work/funcs/appname.bmp @@
poc2.tar.gz
| 0 |
##### Description of the problem
I don't know if it is expected or if I miss something, but it looks like the
envmap textures generated by PMREGenerator and the renderer specified at that
time cannot be re-used with another renderer.
In this example, the envmap is generated using **renderer**.
If the scene is rendered with **renderer2** , it doesn't work.
* jsfiddle
Replace `var pmremGenerator = new THREE.PMREMGenerator( renderer );`
by `var pmremGenerator = new THREE.PMREMGenerator( renderer2 );`
on line 49 to check the difference.
##### Three.js version
* Dev
* r115
##### Browser
* All of them
##### OS
* All of them
|
##### Description of the problem
Using `PMREMGenerator.fromEquirectangular` in multiple simultaneous three.js
renderers causes only the last renderer to have a correctly functioning
texture (at least for use as an envMap)
This happens even when each renderer has its own instance of `pmremGenerator`
and calls `dispose` after use.
Here's a fiddle: https://jsfiddle.net/h37k2ztv/10/
I would expect that initializing a different `pmremGenerator` for each
renderer should be sufficient, but I had to work around it by reinstantiating
and recompiling the `pmremGenerator` immediately before each time it is used
(uncomment lines 63 and 64 in the fiddle to do this)
Issue #18842 reports this same issue, but perhaps even without multiple
renderers.
This merge request may have introduced the unexpected behavior.
##### Three.js version
* Dev
* r115
* ...
##### Browser
* All of them
* Chrome
* Firefox
* Internet Explorer
##### OS
* All of them
* Windows
* macOS
* Linux
* Android
* iOS
| 1 |
## Bug Report
### Which version of ShardingSphere did you use?
5.0.0
### Which project did you use? ShardingSphere-JDBC or ShardingSphere-Proxy?
ShardingSphere-JDBC
### Expected behavior
execute well
### Actual behavior
11-19 17:53:11.212 INFO 59884 --- [nio-8088-exec-1] ShardingSphere-SQL : Logic SQL: insert into coupon_limit(id, fk_coupon_id, type, sold_qty, sold_date) values (null, ?, ?, 1, str_to_date('9999-12-31','%Y-%m-%d') ) on DUPLICATE key update sold_qty = IF(sold_qty + 1 <= ?,sold_qty + 1, -1)
2021-11-19 17:53:11.213 INFO 59884 --- [nio-8088-exec-1] ShardingSphere-SQL : SQLStatement: MySQLInsertStatement(setAssignment=Optional.empty, onDuplicateKeyColumns=Optional[org.apache.shardingsphere.sql.parser.sql.common.segment.dml.column.OnDuplicateKeyColumnsSegment@5ee2c53c])
2021-11-19 17:53:11.213 INFO 59884 --- [nio-8088-exec-1] ShardingSphere-SQL : Actual SQL: ds-0 ::: insert into coupon_limit(id, fk_coupon_id, type, sold_qty, sold_date) values (null, ?, ?, 1, str_to_date('9999-12-31','%Y-%m-%d')) on DUPLICATE key update sold_qty = IF(sold_qty + 1 <= ?,sold_qty + 1, -1) ::: [1, 2]
2021-11-19 17:53:11.259 ERROR 59884 --- [nio-8088-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is java.sql.SQLException: No value specified for parameter 3] with root cause
java.sql.SQLException: No value specified for parameter 3
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129) ~[mysql-connector-java-8.0.26.jar:8.0.26]
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) ~[mysql-connector-java-8.0.26.jar:8.0.26]
at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:396) ~[mysql-connector-java-8.0.26.jar:8.0.26]
at com.zaxxer.hikari.pool.ProxyPreparedStatement.execute(ProxyPreparedStatement.java:44) ~[HikariCP-3.4.2.jar:na]
at com.zaxxer.hikari.pool.HikariProxyPreparedStatement.execute(HikariProxyPreparedStatement.java) ~[HikariCP-3.4.2.jar:na]
at org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement$2.executeSQL(ShardingSpherePreparedStatement.java:322) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement$2.executeSQL(ShardingSpherePreparedStatement.java:318) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutorCallback.execute(JDBCExecutorCallback.java:85) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutorCallback.execute(JDBCExecutorCallback.java:64) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.kernel.ExecutorEngine.syncExecute(ExecutorEngine.java:101) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.kernel.ExecutorEngine.parallelExecute(ExecutorEngine.java:97) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.kernel.ExecutorEngine.execute(ExecutorEngine.java:82) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutor.execute(JDBCExecutor.java:65) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutor.execute(JDBCExecutor.java:49) ~[shardingsphere-infra-executor-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.driver.executor.JDBCLockEngine.doExecute(JDBCLockEngine.java:116) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.driver.executor.JDBCLockEngine.execute(JDBCLockEngine.java:93) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.driver.executor.DriverJDBCExecutor.execute(DriverJDBCExecutor.java:127) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement.execute(ShardingSpherePreparedStatement.java:298) ~[shardingsphere-jdbc-core-5.0.0.jar:5.0.0]
at com.example.org.shardingjdbcmetadatatest.ShardingJdbcMetaDataTestApplication.simpleExecute(ShardingJdbcMetaDataTestApplication.java:82) ~[classes/:na]
at com.example.org.shardingjdbcmetadatatest.ShardingJdbcMetaDataTestApplication.sql(ShardingJdbcMetaDataTestApplication.java:46) ~[classes/:na]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_292]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_292]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_292]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_292]
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205) ~[spring-web-5.3.10.jar:5.3.10]
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:150) ~[spring-web-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:117) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:895) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:808) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1067) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:963) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) ~[spring-webmvc-5.3.10.jar:5.3.10]
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909) ~[spring-webmvc-5.3.10.jar:5.3.10]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:681) ~[tomcat-embed-core-9.0.53.jar:4.0.FR]
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883) ~[spring-webmvc-5.3.10.jar:5.3.10]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:764) ~[tomcat-embed-core-9.0.53.jar:4.0.FR]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) ~[tomcat-embed-websocket-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100) ~[spring-web-5.3.10.jar:5.3.10]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.3.10.jar:5.3.10]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93) ~[spring-web-5.3.10.jar:5.3.10]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.3.10.jar:5.3.10]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) ~[spring-web-5.3.10.jar:5.3.10]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.3.10.jar:5.3.10]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:197) ~[tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:540) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:135) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:382) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1726) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) [tomcat-embed-core-9.0.53.jar:9.0.53]
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) [tomcat-embed-core-9.0.53.jar:9.0.53]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_292]
### Actual behavior
|
For example:
insert into the_biz(id,ser_id,biz_time) values (1,1,now())
NoneShardingStrategy is default for no sharding tables,but error occurs
.because of sql checking?
When in no-sharding table cases,could we make shardingsphere look like it
doesn't exist?
| 0 |
[ yes ] I've searched for any related issues and avoided creating a duplicate
issue.
Description
Announcement, it's not a bug probably。
Firstly ,I run the standard wss ( ws over https server ) code by a single js
file, It worked.
and then , I copy the same code into the electron main.js, it can't be worked.
so ,i open wireshark to capture the package , and then I found the electron
svr send a little bytes other then never see any piece about how to handle the
upgrade handshake. :(
ps: i use the self-singed certification
Reproducible in:
version: ws ^7.1.2
Node.js version(s): v10.16.1
OS version(s): osx 10.14
Steps to reproduce:
1.server code :
const fs = require('fs');
const https = require('https');
const WebSocket = require('ws');
const path = require('path');
const hostname = 'aaa.abc.com';
const server = https.createServer({
cert: fs.readFileSync(path.resolve(certs/${hostname}.crt)),
key: fs.readFileSync(path.resolve(certs/${hostname}.key)),
// rejectUnauthorized: false
});
const wss = new WebSocket.Server({ server });
wss.on('connection', function connection(ws) {
ws.on('message', function incoming(message) {
console.log('received: %s', message);
});
ws.send('something');
});
server.listen(443,()=>{
console.log('start svr002')
});
client code
ws=new WebSocket('wss://aaa.abc.com/echo',{
rejectUnauthorized: false
});
ws.on('error',function (e) {
connectFlag=false;
console.error('error',e);
ws=null;
});
ws.on('close',function (e) {
connectFlag=false;
console.warn('close',e)
});
ws.on('open', function open() {
connectFlag=true;
console.log('connected');
ws.send('something');
ws.on('message', function incoming(data) {
console.log(data);
});
});
run in single.js : yes
node svr.js
node cli001.js or open in ie,ff,chrome
run embed in electron : not work
electrion .
node cli001.js or open in ie,ff,chrome
| ERROR: type should be string, got "\n\nhttps://i.imgur.com/mYtRTmJ.png\n\nhttps://electronjs.org/docs/api/browser-window\n\n" | 0 |
# Checklist
* I have verified that the issue exists against the `master` branch of Celery.
* This has already been asked to the discussions forum first.
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Mandatory Debugging Information
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
* I have included the contents of `pip freeze` in the issue.
* I have included all the versions of all the external dependencies required
to reproduce this bug.
## Optional Debugging Information
* I have tried reproducing the issue on more than one Python version
and/or implementation.
* I have tried reproducing the issue on more than one message broker and/or
result backend.
* I have tried reproducing the issue on more than one version of the message
broker and/or result backend.
* I have tried reproducing the issue on more than one operating system.
* I have tried reproducing the issue on more than one workers pool.
* I have tried reproducing the issue with autoscaling, retries,
ETA/Countdown & rate limits disabled.
* I have tried reproducing the issue after downgrading
and/or upgrading Celery and its dependencies.
## Related Issues and Possible Duplicates
#### Related Issues
Little bit related -
#6672
#5890
#### Possible Duplicates
* None
## Environment & Settings
**Celery version** : 5.2.7 (dawn-chorus)
**`celery report` Output:**
$ celery report
software -> celery:5.2.7 (dawn-chorus) kombu:5.2.4 py:3.9.9
billiard:3.6.4.0 py-amqp:5.1.1
platform -> system:Darwin arch:64bit
kernel version:21.4.0 imp:CPython
loader -> celery.loaders.default.Loader
settings -> transport:amqp results:disabled
deprecated_settings: None
# Steps to Reproduce
1. Here the global serializer is `json` which is the default setting in celery. Now we will declare a task with serialization set to `pickle`.
# In tasks.py
from celery import shared_task
@serial_task(serializer='pickle')
def pickle_seriliazable_args_task(nice_set):
print('Starting Task')
# This delay would indicate a long running task
# So that we have enough time to request the task stats from shell
sleep(200)
print('Task Finished')
2. Open a django-manage shell and run
In [1]: from myapp.apps.niceapp.tasks import pickle_serialized_task
In [2]: task = pickle_serialized_task.delay(set([1, 2, 3]))
In [3]: celery_hostname = 'celery@work' # update hostname as per your config
In [4]: celery_inspect = task.app.control.inspect([celery_hostname])
In [5]: celery_inspect.active()
On running `celery_inspect.active()` following error is thrown.
2022-07-01 15:07:50,791: INFO/MainProcess] Task myapp.apps.niceapp.tasks.pickle_serialized_task[e61f2103-1e19-4593-b2bd-6d69bd273a3c] received
[2022-07-01 15:07:50,815: WARNING/ForkPoolWorker-6] Starting Task
[2022-07-01 15:09:09,906: ERROR/MainProcess] Control command error: EncodeError(TypeError('Object of type set is not JSON serializable'))
Traceback (most recent call last):
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 39, in _reraise_errors
yield
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 210, in dumps
payload = encoder(data)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/utils/json.py", line 68, in dumps
return _dumps(s, cls=cls or _default_encoder,
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/__init__.py", line 234, in dumps
return cls(
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/utils/json.py", line 58, in default
return super().default(o)
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type set is not JSON serializable
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/celery/worker/pidbox.py", line 44, in on_message
self.node.handle_message(body, message)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/pidbox.py", line 141, in handle_message
return self.dispatch(**body)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/pidbox.py", line 108, in dispatch
self.reply({self.hostname: reply},
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/pidbox.py", line 145, in reply
self.mailbox._publish_reply(data, exchange, routing_key, ticket,
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/pidbox.py", line 275, in _publish_reply
producer.publish(
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/messaging.py", line 166, in publish
body, content_type, content_encoding = self._prepare(
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/messaging.py", line 254, in _prepare
body) = dumps(body, serializer=serializer)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 210, in dumps
payload = encoder(data)
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/contextlib.py", line 137, in __exit__
self.gen.throw(typ, value, traceback)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 43, in _reraise_errors
reraise(wrapper, wrapper(exc), sys.exc_info()[2])
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/exceptions.py", line 21, in reraise
raise value.with_traceback(tb)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 39, in _reraise_errors
yield
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/serialization.py", line 210, in dumps
payload = encoder(data)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/utils/json.py", line 68, in dumps
return _dumps(s, cls=cls or _default_encoder,
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/__init__.py", line 234, in dumps
return cls(
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "/Users/amitphulera/.pyenv/versions/3.9.9/envs/hq_celery/lib/python3.9/site-packages/kombu/utils/json.py", line 58, in default
return super().default(o)
File "/Users/amitphulera/.pyenv/versions/3.9.9/lib/python3.9/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
kombu.exceptions.EncodeError: Object of type set is not JSON serializable
## Required Dependencies
* **Minimal Python Version** : N/A or Unknown
* **Minimal Celery Version** : N/A or Unknown
* **Minimal Kombu Version** : N/A or Unknown
* **Minimal Broker Version** : N/A or Unknown
* **Minimal Result Backend Version** : N/A or Unknown
* **Minimal OS and/or Kernel Version** : N/A or Unknown
* **Minimal Broker Client Version** : N/A or Unknown
* **Minimal Result Backend Client Version** : N/A or Unknown
### Python Packages
**`pip freeze` Output:**
alabaster==0.7.12
alembic==1.7.7
amqp==5.1.1
appnope==0.1.3
architect==0.6.0
asgiref==3.5.0
asttokens==2.0.5
attrs==21.4.0
Babel==2.9.1
backcall==0.2.0
Beaker==1.11.0
beautifulsoup4==4.10.0
billiard==3.6.4.0
black==22.1.0
boto3==1.17.85
botocore==1.20.85
cachetools==5.0.0
case==1.5.3
celery==5.2.7
certifi==2020.6.20
cffi==1.14.3
chardet==3.0.4
click==8.1.3
click-didyoumean==0.3.0
click-plugins==1.1.1
click-repl==0.2.0
cloudant==2.14.0
colorama==0.4.3
contextlib2==21.6.0
coverage==5.5
cryptography==3.4.8
csiphash==0.0.5
datadog==0.39.0
ddtrace==0.44.0
debugpy==1.6.0
decorator==4.0.11
defusedxml==0.7.1
Deprecated==1.2.10
diff-match-patch==20200713
dimagi-memoized==1.1.3
Django==3.2.13
django-appconf==1.0.5
django-autoslug==1.9.8
django-braces==1.14.0
django-bulk-update==2.2.0
django-celery-results==2.4.0
django-compressor==2.4
django-countries==7.3.2
django-crispy-forms==1.10.0
django-cte==1.2.0
django-extensions==3.1.3
django-formtools==2.3
django-logentry-admin==1.0.6
django-oauth-toolkit==1.5.0
django-otp==0.9.4
django-phonenumber-field==5.2.0
django-prbac==1.0.1
django-recaptcha==2.0.6
django-redis==4.12.1
django-redis-sessions==0.6.2
django-statici18n==1.9.0
django-tastypie==0.14.4
django-transfer==0.4
django-two-factor-auth==1.13.2
django-user-agents==0.4.0
djangorestframework==3.12.2
dnspython==1.15.0
docutils==0.16
dropbox==9.3.0
elasticsearch2==2.5.1
elasticsearch5==5.5.6
email-validator==1.1.3
et-xmlfile==1.0.1
ethiopian-date-converter==0.1.5
eulxml==1.1.3
executing==0.8.3
fakecouch==0.0.15
Faker==5.0.2
fixture==1.5.11
flake8==3.9.2
flaky==3.7.0
flower==1.0.0
freezegun==1.1.0
future==0.18.2
gevent==21.8.0
ghdiff==0.4
git-build-branch==0.1.13
gnureadline==8.0.0
google-api-core==2.5.0
google-api-python-client==2.32.0
google-auth==2.6.0
google-auth-httplib2==0.1.0
google-auth-oauthlib==0.4.6
googleapis-common-protos==1.54.0
greenlet==1.1.2
gunicorn==20.0.4
hiredis==2.0.0
httpagentparser==1.9.0
httplib2==0.20.4
humanize==4.1.0
idna==2.10
imagesize==1.2.0
importlib-metadata==4.11.3
iniconfig==1.1.1
intervaltree==3.1.0
ipython==8.2.0
iso8601==0.1.13
isodate==0.6.1
jedi==0.18.1
Jinja2==2.11.3
jmespath==0.10.0
json-delta==2.0
jsonfield==2.1.1
jsonobject==2.0.0
jsonobject-couchdbkit==1.0.1
jsonschema==3.2.0
jwcrypto==0.8
kafka-python==1.4.7
kombu==5.2.4
laboratory==0.2.0
linecache2==1.0.0
lxml==4.7.1
Mako==1.1.3
mando==0.6.4
Markdown==3.3.6
MarkupSafe==1.1.1
matplotlib-inline==0.1.3
mccabe==0.6.1
mock==4.0.3
mypy-extensions==0.4.3
ndg-httpsclient==0.5.1
nose==1.3.7
nose-exclude==0.5.0
oauthlib==3.1.0
oic==1.3.0
openpyxl==3.0.9
packaging==20.4
parso==0.8.3
pathspec==0.9.0
pep517==0.10.0
pexpect==4.8.0
phonenumberslite==8.12.48
pickle5==0.0.11
pickleshare==0.7.5
Pillow==9.0.1
pip-tools==6.6.0
platformdirs==2.4.1
pluggy==1.0.0
ply==3.11
polib==1.1.1
prometheus-client==0.14.1
prompt-toolkit==3.0.26
protobuf==3.15.0
psutil==5.8.0
psycogreen==1.0.2
psycopg2==2.8.6
psycopg2cffi==2.9.0
ptyprocess==0.7.0
pure-eval==0.2.2
py==1.11.0
py-cpuinfo==8.0.0
py-KISSmetrics==1.1.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycodestyle==2.7.0
pycparser==2.20
pycryptodome==3.10.1
pycryptodomex==3.14.1
pyflakes==2.3.1
PyGithub==1.54.1
Pygments==2.11.2
pygooglechart==0.4.0
pyjwkest==1.4.2
PyJWT==1.7.1
pyOpenSSL==20.0.1
pyparsing==3.0.7
pyphonetics==0.5.3
pyrsistent==0.17.3
PySocks==1.7.1
pytest==7.1.2
pytest-benchmark==3.4.1
pytest-django==4.5.2
python-dateutil==2.8.2
python-editor==1.0.4
python-imap==1.0.0
python-magic==0.4.22
python-mimeparse==1.6.0
python-termstyle==0.1.10
python3-saml==1.12.0
pytz==2022.1
PyYAML==5.4.1
pyzxcvbn==0.8.0
qrcode==4.0.4
quickcache==0.5.4
radon==5.1.0
rcssmin==1.0.6
redis==3.5.3
reportlab==3.6.9
requests==2.25.1
requests-mock==1.9.3
requests-oauthlib==1.3.1
requests-toolbelt==0.9.1
rjsmin==1.1.0
rsa==4.8
s3transfer==0.4.2
schema==0.7.5
sentry-sdk==0.19.5
setproctitle==1.2.2
sh==1.14.2
simpleeval==0.9.10
simplejson==3.17.2
six==1.16.0
sniffer==0.4.1
snowballstemmer==2.0.0
socketpool==0.5.3
sortedcontainers==2.3.0
soupsieve==2.0.1
Sphinx==4.1.2
sphinx-rtd-theme==0.5.2
sphinxcontrib-applehelp==1.0.2
sphinxcontrib-devhelp==1.0.2
sphinxcontrib-django==0.5.1
sphinxcontrib-htmlhelp==2.0.0
sphinxcontrib-jsmath==1.0.1
sphinxcontrib-qthelp==1.0.3
sphinxcontrib-serializinghtml==1.1.5
sqlagg==0.17.2
SQLAlchemy==1.3.19
sqlalchemy-postgres-copy==0.5.0
sqlparse==0.3.1
stack-data==0.1.4
stripe==2.54.0
suds-py3==1.4.5.0
tenacity==6.2.0
testil==1.1
text-unidecode==1.3
tinys3==0.1.12
toml==0.10.2
tomli==2.0.1
toposort==1.7
tornado==6.1
traceback2==1.4.0
traitlets==5.1.1
tropo-webapi-python==0.1.3
turn-python==0.0.1
twilio==6.5.1
typing_extensions==4.1.1
ua-parser==0.10.0
Unidecode==1.2.0
unittest2==1.1.0
uritemplate==4.1.1
urllib3==1.26.5
user-agents==2.2.0
uWSGI==2.0.19.1
vine==5.0.0
wcwidth==0.2.5
Werkzeug==1.0.1
wrapt==1.12.1
xlrd==2.0.1
xlwt==1.3.0
xmlsec==1.3.12
yapf==0.31.0
zipp==3.7.0
zope.event==4.5.0
zope.interface==5.4.0
### Other Dependencies
N/A
## Minimally Reproducible Test Case
# run celery with `pickle_serialized_task` as defined in reproduction steps and run the snippet below
from myapp.apps.niceapp.tasks import pickle_serialized_task
task = pickle_serialized_task.delay(set([1, 2, 3]))
celery_hostname = 'celery@work'
celery_inspect = task.app.control.inspect([celery_hostname])
celery_inspect.active()
# Expected Behavior
This should list the details about the task.
# Actual Behavior
It is erroring out with the stack trace shared above.
|
## Related Issues and Possible Duplicates
#### Related Issues
* #6672, #5890
#### Related PRs
* #6757
# Steps to Reproduce
Here is the script that reproduces the issue:
import time
from celery import Celery
app = Celery('example')
app.conf.update(
backend_url='redis://localhost:6379',
broker_url='redis://localhost:6379',
result_backend='redis://localhost:6379',
task_serializer='json',
accept_content=['pickle', 'json'],
)
@app.task(name='task1', serializer='pickle')
def task1(*args, **kwargs):
print('Start', args, kwargs)
time.sleep(30)
print('Finish', args, kwargs)
def main():
task1.delay({1, 2, 3}) # set is not JSON serializable.
# inspect queue items
inspected = app.control.inspect()
active_tasks = inspected.active()
print(active_tasks)
if __name__ == '__main__':
main()
See also following discussion: #6757 (comment)
# Expected Behavior
Control/Inspect serialization should support custom per-task serializer
# Actual Behavior
Control/Inspect serialization is driven only by `task_serializer`
configuration.
| 1 |
At the moment, index signature parameter type must be string or number.
Now that Typescript supports String literal types, it would be great if it
could be used for index signature parameter type as well.
For example:
type MyString = "a" | "b" | "c";
var MyMap:{[id:MyString] : number} = {};
MyMap["a"] = 1; // valid
MyMap["asd"] = 2; //invalid
* * *
It would be also useful if it could also work with Enums. For example:
enum MyEnum {
a = <any>"a",
b = <any>"b",
c = <any>"c",
d = <any>"d",
}
var MyMap:{[id:MyEnum] : number} = {};
MyMap[MyEnum.a] = 1; // valid
MyMap["asd"] = 2; //invalid
var MyMap:{[id:MyEnum] : number} = {
[MyEnum.a]:1, // valid
"asdas":2, //invalid
}
|
Typescript requires that enums have number value types (hopefully soon, this
will also include string value types).
Attempting to use an enum as a key type for a hash results in this error:
"Index signature parameter type much be 'string' or 'number' ".-- An enum is
actually a number type.-- This shouldn't be an error.
Enums are a convenient way of defining the domain of number and string value
types, in cases such as
export interface UserInterfaceColors {
[index: UserInterfaceElement]: ColorInfo;
}
export interface ColorInfo {
r: number;
g: number;
b: number;
a: number;
}
export enum UserInterfaceElement {
ActiveTitleBar = 0,
InactiveTitleBar = 1,
}
| 1 |
Hello community and devs of PowerToys,
this is my first time here and I was ok with these tools until it stopped
working and an error message appears when I try to start it.
I followed istructions and copied the message below.
You can find the log here
Error Message:
Version: 1.0.0
OS Version: Microsoft Windows NT 10.0.19041.0
IntPtr Length: 8
x64: True
Date: 08/05/2020 11:06:02
Exception:
System.ObjectDisposedException: Cannot access a disposed object.
Object name: 'Timer'.
at System.Timers.Timer.set_Enabled(Boolean value)
at System.Timers.Timer.Start()
at PowerLauncher.MainWindow.OnVisibilityChanged(Object sender,
DependencyPropertyChangedEventArgs e)
at System.Windows.UIElement.RaiseDependencyPropertyChanged(EventPrivateKey
key, DependencyPropertyChangedEventArgs args)
at System.Windows.UIElement.OnIsVisibleChanged(DependencyObject d,
DependencyPropertyChangedEventArgs e)
at
System.Windows.DependencyObject.OnPropertyChanged(DependencyPropertyChangedEventArgs
e)
at
System.Windows.FrameworkElement.OnPropertyChanged(DependencyPropertyChangedEventArgs
e)
at
System.Windows.DependencyObject.NotifyPropertyChange(DependencyPropertyChangedEventArgs
args)
at System.Windows.UIElement.UpdateIsVisibleCache()
at System.Windows.PresentationSource.RootChanged(Visual oldRoot, Visual
newRoot)
at System.Windows.Interop.HwndSource.set_RootVisualInternal(Visual value)
at System.Windows.Interop.HwndSource.set_RootVisual(Visual value)
at System.Windows.Window.SetRootVisual()
at System.Windows.Window.SetRootVisualAndUpdateSTC()
at System.Windows.Window.SetupInitialState(Double requestedTop, Double
requestedLeft, Double requestedWidth, Double requestedHeight)
at System.Windows.Window.CreateSourceWindow(Boolean duringShow)
at System.Windows.Window.CreateSourceWindowDuringShow()
at System.Windows.Window.SafeCreateWindowDuringShow()
at System.Windows.Window.ShowHelper(Object booleanBox)
at System.Windows.Threading.ExceptionWrapper.InternalRealCall(Delegate
callback, Object args, Int32 numArgs)
at System.Windows.Threading.ExceptionWrapper.TryCatchWhen(Object source,
Delegate callback, Object args, Int32 numArgs, Delegate catchHandler)
|
Popup tells me to give y'all this.
2020-07-31.txt
Version: 1.0.0
OS Version: Microsoft Windows NT 10.0.19041.0
IntPtr Length: 8
x64: True
Date: 07/31/2020 17:29:59
Exception:
System.ObjectDisposedException: Cannot access a disposed object.
Object name: 'Timer'.
at System.Timers.Timer.set_Enabled(Boolean value)
at System.Timers.Timer.Start()
at PowerLauncher.MainWindow.OnVisibilityChanged(Object sender,
DependencyPropertyChangedEventArgs e)
at System.Windows.UIElement.RaiseDependencyPropertyChanged(EventPrivateKey
key, DependencyPropertyChangedEventArgs args)
at System.Windows.UIElement.OnIsVisibleChanged(DependencyObject d,
DependencyPropertyChangedEventArgs e)
at
System.Windows.DependencyObject.OnPropertyChanged(DependencyPropertyChangedEventArgs
e)
at
System.Windows.FrameworkElement.OnPropertyChanged(DependencyPropertyChangedEventArgs
e)
at
System.Windows.DependencyObject.NotifyPropertyChange(DependencyPropertyChangedEventArgs
args)
at System.Windows.UIElement.UpdateIsVisibleCache()
at System.Windows.PresentationSource.RootChanged(Visual oldRoot, Visual
newRoot)
at System.Windows.Interop.HwndSource.set_RootVisualInternal(Visual value)
at System.Windows.Interop.HwndSource.set_RootVisual(Visual value)
at System.Windows.Window.SetRootVisual()
at System.Windows.Window.SetRootVisualAndUpdateSTC()
at System.Windows.Window.SetupInitialState(Double requestedTop, Double
requestedLeft, Double requestedWidth, Double requestedHeight)
at System.Windows.Window.CreateSourceWindow(Boolean duringShow)
at System.Windows.Window.CreateSourceWindowDuringShow()
at System.Windows.Window.SafeCreateWindowDuringShow()
at System.Windows.Window.ShowHelper(Object booleanBox)
at System.Windows.Threading.ExceptionWrapper.InternalRealCall(Delegate
callback, Object args, Int32 numArgs)
at System.Windows.Threading.ExceptionWrapper.TryCatchWhen(Object source,
Delegate callback, Object args, Int32 numArgs, Delegate catchHandler)
| 1 |
So far I really like Atom 1.0 - it's got a long way to go, but it will get
there. We needed an editor like this.
Anyway: the only thing bothering me was how quickly it installed itself
(Windows 8.1, 64 bit). Even though that might sound like a _good_¨thing, it
isn't. When I double-click the installer I get no options, no information
whatsoever. Only a screen "Atom is installing and will launch when ready." For
some people this might be the best approach, but for a whole lot of others it
isn't.
Some options would be great. I am thinking: file association, installation
directory, packages to include with installation (I for one don't need all
packages that are included on default install) and so on. I could understand
that file association and package control aren't included (though I'd really
like that) but why not the ability to choose your own installation directory?
|
So far I really like Atom 1.0 - it's got a long way to go, but it will get
there. We needed an editor like this.
Anyway: the only thing bothering me was how quickly it installed itself
(Windows 8.1, 64 bit). Even though that might sound like a _good_¨thing, it
isn't. When I double-click the installer I get no options, no information
whatsoever. Only a screen "Atom is installing and will launch when ready." For
some people this might be the best approach, but for a whole lot of others it
isn't.
Some options would be great. I am thinking: file association, installation
directory, packages to include with installation (I for one don't need all
packages that are included on default install) and so on. I could understand
that file association and package control aren't included (though I'd really
like that) but why not the ability to choose your own installation directory?
| 1 |
> Issue originally made by @xfix
### Bug information
* **Babel version:** 6.2.1
* **Node version:** 5.1.0
* **npm version:** 3.5.0
### Options
--presets es2015
### Input code
let results = []
for (let i = 0; i < 3; i++) {
switch ('x') {
case 'x':
const x = i
results.push(() => x)
}
}
for (const result of results) {
console.log(result())
}
### Description
When I declare a block scoped variable in a switch block, it's not recognized
as a block scoped variable for purpose of functions, even when it's declared
inside a for loop. This example prints 2, 2, 2, when it should print 0, 1, 2.
(I outright apologize if this is a duplicate, finding duplicates with that bug
tracker is annoying)
|
## Bug Report
**Current Behavior**
I am getting following error. Can't figure out solution. I found many post
which looks duplicate here but, nothing work.
node_modules@babel\helper-plugin-utils\lib\index.js
throw Object.assign(err, {
Error: Requires Babel "^7.0.0-0", but was loaded with "6.26.3". If you are sure you have a compatible version of @babel/core, it is likely that something in your build process is loading the wrong version. Inspect the stack trace of this error to look for the first entry that doesn't mention "@babel/core" or "babel-core" to see what is calling Babel.
**Babel Configuration (.babelrc, package.json, cli command)**
"dependencies": {
"express": "^4.16.4",
"isomorphic-fetch": "^2.2.1",
"react": "^16.6.3",
"react-dom": "^16.6.3",
"react-redux": "^5.1.1",
"react-router": "^4.3.1",
"react-router-config": "^1.0.0-beta.4",
"react-router-dom": "^4.3.1",
"redux": "^4.0.1",
"redux-thunk": "^2.3.0"
},
"devDependencies": {
"@babel/cli": "^7.2.3",
"@babel/core": "^7.2.2",
"@babel/plugin-proposal-class-properties": "^7.2.0",
"@babel/plugin-transform-runtime": "^7.2.0",
"@babel/preset-env": "^7.3.1",
"@babel/preset-react": "^7.0.0",
"babel-core": "^7.0.0-bridge.0",
"babel-jest": "^24.0.0",
"babel-loader": "^7.1.5",
"css-loader": "^1.0.1",
"cypress": "^3.1.3",
"enzyme": "^3.8.0",
"enzyme-adapter-react-16": "^1.7.1",
"enzyme-to-json": "^3.3.5",
"extract-text-webpack-plugin": "^4.0.0-beta.0",
"html-webpack-plugin": "^3.2.0",
"jest": "^24.0.0",
"jest-fetch-mock": "^2.0.1",
"json-loader": "^0.5.7",
"nodemon": "^1.18.9",
"npm-run-all": "^4.1.5",
"open": "0.0.5",
"redux-devtools": "^3.4.2",
"redux-mock-store": "^1.5.3",
"regenerator-runtime": "^0.13.1",
"style-loader": "^0.23.1",
"uglifyjs-webpack-plugin": "^2.0.1",
"webpack": "^4.26.1",
"webpack-cli": "^3.1.2",
"webpack-dev-server": "^3.1.14",
"webpack-node-externals": "^1.7.2"
},
"babel": {
"presets": [
"@babel/preset-env",
"@babel/preset-react"
],
"plugins": [
"@babel/plugin-transform-runtime",
"@babel/plugin-proposal-class-properties"
]
}
**Environment**
* Babel version(s): [> v7]
* Node/npm version: [Node 8.12.0/npm 6.4.1]
* OS: [Windows 10]
Stackoverflow
| 0 |
### Vue.js version
2.0.0-rc.4
### Reproduction Link
https://jsbin.com/rifuxuxuxa/1/edit?js,console,output
### Steps to reproduce
1. After hitting 'Run with JS', click the 'click here' button
2. Wait till `this.show` is `true`(8 seconds), click the 'click here' button again
### What is Expected?
In step 1, prints '2333'
In step 2, prints '2333'
### What is actually happening?
In step 1, prints '2333'
In step 2, an error occurs 'o.fn is not a function'
This can only be reproduced when there is a `v-show` element around. I have
tried to put the `v-show` element (in this case, the 'balabalabala' span)
before the `slot`, after the `slot`, outside the `div`, and they all report
the same error after `this.show` is set to `true`.
This may have something to do with this.
|
I reported the same issue for `v-if` which got fixed in `vue@2.0.0-rc.4`.
However, with this version the same code using `v-show` – which previously
worked perfectly – does not work anymore.
### Vue.js version
2.0.0-rc.4
### Reproduction Link
http://codepen.io/analog-nico/pen/KgPKRq
### Steps to reproduce
1. Click the link "Open popup using v-show"
2. A badly designed popup opens
3. Click the "Close" link
### What is Expected?
* The popup closes successfully
### What is actually happening?
* Vue fails to call an internal function and throws: `TypeError: o.fn is not a function. (In 'o.fn(ev)', 'o.fn' is an instance of Object)`
* The `closePopupUsingVShow` function attached to the "Close" link's click event never gets called.
* The popup does not close.
For reference the codepen contains the exact same implementation of the popup
with the only difference that it uses `v-if` instead of `v-show` to show/hide
the popup. `v-if` works perfectly.
| 1 |
**Description**
I'd like to propose a few steps to improve the validation constraints:
* Deprecate empty strings (`""`) currently happily passing in string constraints (e.g. `Email`)
* https://docs.jboss.org/hibernate/stable/beanvalidation/api/javax/validation/constraints/Email.html
* Deprecate non string values in `NotBlank` / `Blank` and 'whitespaced' strings passing (`" "`)
* https://docs.jboss.org/hibernate/stable/beanvalidation/api/javax/validation/constraints/NotBlank.html
* allow for null (#27876)
* Consider `NotEmpty` / `Empty` as the current `NotBlank` / `Blank` constraints
* https://docs.jboss.org/hibernate/stable/beanvalidation/api/javax/validation/constraints/NotEmpty.html
* I dont think we should add these (but favor specific constraints) as `empty` in PHP is different as described above (ints, bools, etc). Not sure we should follow either one :) thus possible confusion
If this happens we'd do simply
* `@Email`
* `@NotNull @Email`
* `@NotNull @Length(min=3) @NotBlank`
* `@NotNull @NotBlank`
* `@Type(array) @Count(3)`
Thoughts?
|
**Description**
In most validators, there's a failsafe mecanism that prevent the validator
from validating if it's a `null` value, as there's a validator for that
(`NotNull`). I think `NotBlank` shouldn't bother on `null` values, especially
as `NotBlank` and `NotNull` are used together to prevent `null` values too.
Not really a feature request, but not really a bug too... more like a RFC but
for all versions. But I guess this would be a BC break though. :/ So maybe add
a deprecated on the validator if it's a null value or something, and remove
the `null` invalidation from the `NotBlank` on 5.0 ?
Currently, we need to reimplement the validator just to skip `null` values...
**Possible Solution**
Either deprecate the validation on `null` value in `NotBlank`, or do as in
most validators, (if `null` value, then skip). But as I mentionned, this would
probably be a bc break.
| 1 |
_Original tickethttp://projects.scipy.org/numpy/ticket/1880 on 2011-06-26 by
@nilswagner01, assigned to unknown._
======================================================================
FAIL: test_timedelta_scalar_construction (test_datetime.TestDateTime)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/nwagner/local/lib64/python2.6/site-packages/numpy/core/tests/test_datetime.py", line 189, in test_timedelta_scalar_construction
assert_equal(str(np.timedelta64(3, 's')), '3 seconds')
File "/home/nwagner/local/lib64/python2.6/site-packages/numpy/testing/utils.py", line 313, in assert_equal
raise AssertionError(msg)
AssertionError:
Items are not equal:
ACTUAL: '%lld seconds'
DESIRED: '3 seconds'
|
_Original tickethttp://projects.scipy.org/numpy/ticket/1887 on 2011-06-29 by
@dhomeier, assigned to unknown._
With Python versions 2.4-2.6, the output of np.timedelta only produces the
format string since (probably) merging the datetime branch, like this:
>>> np.__version__
'2.0.0.dev-f7c16d7'
>>> np.timedelta64(3)
numpy.timedelta64(%lld,'generic')
>>> str(np.timedelta64(3, 's'))
'%lld seconds'
or in the most recent version
>>> np.__version__
'2.0.0.dev-192ac74'
>>> np.timedelta64(3)
numpy.timedelta64(%lld)
making the corresponding tests fail, whereas with 2.7 and 3.2 the intended
output is produced:
>>> np.timedelta64(3)
numpy.timedelta64(3)
>>> str(np.timedelta64(3, 's'))
'3 seconds'
(Tested on MacOS X 10.5/ppc and 10.6/x86_64)
| 1 |
This is using a fresh install of Anaconda in an Ubuntu 15.10 based Google
Cloud VM. At first glance it seemed to relate to difficulties getting console
encoding (see `from pandas.core.format import detect_console_encoding` below)?
import pandas
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-f0ee645c240d> in <module>()
----> 1 import pandas as pd
2 import dask.dataframe as dd
3 from dask.diagostics import ProgressBar as pb
/home/michael/anaconda3/lib/python3.5/site-packages/pandas/__init__.py in <module>()
40
41 # let init-time option registration happen
---> 42 import pandas.core.config_init
43
44 from pandas.core.api import *
/home/michael/anaconda3/lib/python3.5/site-packages/pandas/core/config_init.py in <module>()
15 is_instance_factory, is_one_of_factory,
16 get_default_val)
---> 17 from pandas.core.format import detect_console_encoding
18
19
/home/michael/anaconda3/lib/python3.5/site-packages/pandas/core/format.py in <module>()
8 from pandas.core.base import PandasObject
9 from pandas.core.common import adjoin, notnull
---> 10 from pandas.core.index import Index, MultiIndex, _ensure_index
11 from pandas import compat
12 from pandas.compat import(StringIO, lzip, range, map, zip, reduce, u,
/home/michael/anaconda3/lib/python3.5/site-packages/pandas/core/index.py in <module>()
29 from pandas.core.strings import StringAccessorMixin
30 from pandas.core.config import get_option
---> 31 from pandas.io.common import PerformanceWarning
32
33
/home/michael/anaconda3/lib/python3.5/site-packages/pandas/io/common.py in <module>()
66
67 try:
---> 68 from boto.s3 import key
69 class BotoFileLikeReader(key.Key):
70 """boto Key modified to be more file-like
/home/michael/anaconda3/lib/python3.5/site-packages/boto/__init__.py in <module>()
1214 return storage_uri(uri_str)
1215
-> 1216 boto.plugin.load_plugins(config)
/home/michael/anaconda3/lib/python3.5/site-packages/boto/plugin.py in load_plugins(config)
90 return
91 directory = config.get('Plugin', 'plugin_directory')
---> 92 for file in glob.glob(os.path.join(directory, '*.py')):
93 _import_module(file)
/home/michael/anaconda3/lib/python3.5/posixpath.py in join(a, *p)
87 path += sep + b
88 except (TypeError, AttributeError, BytesWarning):
---> 89 genericpath._check_arg_types('join', a, *p)
90 raise
91 return path
/home/michael/anaconda3/lib/python3.5/genericpath.py in _check_arg_types(funcname, *args)
141 else:
142 raise TypeError('%s() argument must be str or bytes, not %r' %
--> 143 (funcname, s.__class__.__name__)) from None
144 if hasstr and hasbytes:
145 raise TypeError("Can't mix strings and bytes in path components") from None
TypeError: join() argument must be str or bytes, not 'NoneType'
|
When using the `read_gbq()` function on a BigQuery table, incorrect results
are returned.
I compare the output from `read_gbq()` to that of a CSV export from BigQuery
directly. Interestingly, there are the same number of rows in each output -
however, there are many duplicates in the `read_gbq()` output.
I'm using Pandas '0.13.0rc1-125-g4952858' on a Mac 10.9 using Python 2.7.
Numpy '1.8.0'.
The code I execute to load the data in pandas:
`churn_data = gbq.read_gbq(train_query, project_id = projectid)`
I can't share the underlying data. What additional data/info would be useful
for root causing?
The output data is ~400k lines.
| 0 |
It would be nice to have a busy indicator component. Almost every site I build
today uses ajax in some way, usually to handle form submissions so I have a
constant need for these indicators.

|
Since v3.0 is on the horizon, perhaps #1371 could be revisited? Even just
including a GIF would be very convenient.
| 1 |
ERROR: type should be string, got "\n\nhttps://github.com/kevin1024/pytest-httpbin\n\n" | ERROR: type should be string, got "\n\nhttps://github.com/kevin1024/pytest-httpbin\n\n" | 1 |
Auto generated links are broken -- all google links points to Not Found page.
Example link from google:
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_rel.html
working link:
https://docs.scipy.org/doc/scipy/reference/reference/generated/scipy.stats.ttest_rel.html
doubled part '/reference'
|
The new theme seems to have introduced a duplicate `reference` in the URL,
e.g.,
* Before: https://docs.scipy.org/doc/scipy/reference/linalg.interpolative.html
* After: https://docs.scipy.org/doc/scipy/reference/reference/linalg.interpolative.html
The effect was that today all SciPy search engine results I found were broken.
The search engines will update eventually. But the double
`/reference/reference/` in the url is unnecessary, so it might be better
removed?
| 1 |
Getting script error while define more than on complex property in
**@input()** or
How to define complex property. Please find plnkr link.
https://plnkr.co/edit/NcvjuqZvo6jilmrdeZ1R?p=preview
`VM1920 zone.js:420 Unhandled Promise rejection: Template parse errors:
Can't bind to 'content.value' since it isn't a known property of 'custom-div'.
1. If 'custom-div' is an Angular component and it has 'content.value' input, then verify that it is part of this module.
2. If 'custom-div' is a Web Component then add "CUSTOM_ELEMENTS_SCHEMA" to the '@NgModule.schemas' of this component to suppress this message.
("
<custom-div [ERROR ->][content.value] = "content">
"): App@5:17 ; Zone: ; Task: Promise.then ; Value: SyntaxError
{__zone_symbol__error: Error: Template parse errors:
Can't bind to 'content.value' since it isn't a known property of 'cust…,
_nativeError: ZoneAwareError, __zone_symbol__stack: "Error: Template parse
errors:↵Can't bind to
'conte…ps://unpkg.com/zone.js@0.7.6/dist/zone.js:433:35)",
__zone_symbol__message: "Template parse errors:↵Can't bind to
'content.valu…t.value] = "content">↵ "): App@5:17"} Error: Template parse
errors:
Can't bind to 'content.value' since it isn't a known property of 'custom-div'.
3. If 'custom-div' is an Angular component and it has 'content.value' input, then verify that it is part of this module.
4. If 'custom-div' is a Web Component then add "CUSTOM_ELEMENTS_SCHEMA" to the '@NgModule.schemas' of this component to suppress this message.
("
<custom-div [ERROR ->][content.value] = "content">
"): App@5:17
at SyntaxError.ZoneAwareError
(https://unpkg.com/zone.js@0.7.6/dist/zone.js:811:33)
at SyntaxError.BaseError [as constructor]
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:1592:20)
at new SyntaxError
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:1795:20)
at TemplateParser.parse
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:11434:23)
at JitCompiler._compileTemplate
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:27568:72)
at eval (https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:27451:66)
at Set.forEach (native)
at JitCompiler._compileComponents
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:27451:23)
at createResult
(https://unpkg.com/@angular/compiler/bundles/compiler.umd.js:27333:23)
at ZoneDelegate.invoke (https://unpkg.com/zone.js@0.7.6/dist/zone.js:242:26)
at Zone.run (https://unpkg.com/zone.js@0.7.6/dist/zone.js:113:43)
at https://unpkg.com/zone.js@0.7.6/dist/zone.js:535:57
at ZoneDelegate.invokeTask
(https://unpkg.com/zone.js@0.7.6/dist/zone.js:275:35)
at Zone.runTask (https://unpkg.com/zone.js@0.7.6/dist/zone.js:151:47)
at drainMicroTaskQueue (https://unpkg.com/zone.js@0.7.6/dist/zone.js:433:35)`
|
**I'm submitting a ...** (check one with "x")
[ ] bug report => search github for a similar issue or PR before submitting
[x] feature request
[ ] support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
**Current behavior**
Right now it is possible to create a Directive using several selectors, but it
is not possible to assign several binding property names to the same property.
Consider the following example:
@Directive({
selector: 'my-group,[group]',
})
export class MyGroup {
@Input('group') instance;
.....
}
As I have got an additional attribute selector, I am kind of forced to use the
same property name for "instance", but I am not free to choose another name in
case I am using `<my-group>` selector. `<my-group group="myInstance">` looks
ugly and redundant.
**Expected behavior**
It should be possible to have something like:
`@Input("group", "instance") instance;`
| 1 |
* VSCode Version: 1.0.0
* OS Version: Ubuntu 16.04
Steps to Reproduce:
1. Ctrl+Shift+Alt+Down - default ubuntu hotkeys to move window to other desktop
I set Ctrl+Shift+D for me right now, but it will be nice to have OS dependency
of hotkeys out of the box
|
1. Create a new extension with yo code (just a TypeScript basic extension.
2. Publish to the gallery
3. Install on VS Code
4. Update the extension version and republish to the gallery
5. Extensions: Show Outdated Extensions
6. You see that a new version of the extension is available. Click Update extension.
The dropdown stays open with the Update extension button swirling. It never
stops.
If you change focus, the dropdown goes away but no Restart message comes up.
If you look under .vscode/extensions, the extension folder is still there
containing just the node-modules folder and the .vsixmanifest files.
| 0 |
Is it possible to install TF in windows environment?
I checked "pip install" is not supported in windows.
Any plan for it?
|
I was excited to see tensorflow, but as many other users, we are on Windows,
would be nice to see this support happen. Will you accept Windows port
contributions?
In the meantime, Microsoft recently released their Deep Learning toolkit which
scales on multiple machines with GPUs for both Linux and Windows.
https://github.com/Microsoft/CNTK
| 1 |
## ❓ Questions & Help
I want to use `mixed_precision`, and I found
tf.keras.mixed_precision.experimental.Policy.
So I put `tf.keras.mixed_precision.experimental.set_policy("mixed_float16")`
before `TFBertModel.from_pretrained(pretrained_weights)`. When I run the code,
I got the following error:
> InvalidArgumentError: cannot compute AddV2 as input #1(zero-based) was
> expected to be a half tensor but is a float tensor [Op:AddV2] name:
> tf_bert_model_1/bert/embeddings/add/
which happened at `ret = model(model.dummy_inputs, training=False) # build the
network with dummy inputs`.
I am not sure if I used it correctly. I think
`tf.keras.mixed_precision.experimental.set_policy` is supposed to be used
before constructing / build the model, as the tf page says `Policies can be
passed to the 'dtype' argument of layer constructors, or a global policy can
be set with 'tf.keras.mixed_precision.experimental.set_policy'`.
I wonder if I can use AMP with tf based transformer models and how. Thanks.
error.txt
|
# 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): 'ner' pipeline
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* the official example scripts: (give details below)
* my own modified scripts: (give details below)
The tasks I am working on is:
* an official GLUE/SQUaD task: (give the name)
* my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Have transformers 3.0.2 installed
2. Run the below code
from transformers import pipeline
nlp = pipeline('ner', grouped_entities=True)
nlp('Welcome to New York')
## Expected behavior
We should receive `[{'entity_group': 'I-LOC', 'score': 0.9984402656555176,
'word': 'New York'}`, but instead the output has duplicated 'New York':
`[{'entity_group': 'I-LOC', 'score': 0.9984402656555176, 'word': 'New York'},
{'entity_group': 'I-LOC', 'score': 0.9984402656555176, 'word': 'New York'}]`.
### The Cause of the Issue According to Me
After reading 3.0.2, I noticed that lines 1047-1049 were added. I think this
was done to fix a prior issue that caused the last named entity in the
sequence to be occasionally omitted when `grouped_entities=True`. Long story
short, I think this snippet was a patch that only shifted the problem from
being an occasional named entity omission to an occasional named entity
duplicate.
The for-loop that precedes this snippet is inconsistent in that sometimes the
last named entity gets successfully added anyway (e.g. if the `if` clause on
1025 (first iteration) or 1032 is entered on the last iteration). In this
case, there is a duplicate entry upon the calling of the new code at 1047. On
the converse, the last named entity won’t be added if the `else` clause in
line 1041 is entered on the last iteration. In this case, the final named
entity correctly gets added after the new code snippet is run.
In short, there is a duplicate (I think) if (i) there is only one recognized
named entity or (ii) the last named entity is one such that the tokenizer cut
it up into multiple tokens. Otherwise, there is no duplicate.
nlp(‘Welcome to Dallas’) -> duplicate 'Dallas' because 'Dallas' is the only
named entity
nlp(‘HuggingFace is not located in Dallas’) -> no duplicate because there are
multiple entities and the final one 'Dallas' is not tokenized into multiple
tokens
nlp(‘HuggingFace is located in New York City’) -> duplicate ‘New York City’
because the final named entity 'New York City' is tokenized into multiple
tokens
## Environment info
* `transformers` version: 3.0.2
* Platform: Linux-5.3.0-1031-azure-x86_64-with-glibc2.10
* Python version: 3.8.1
* PyTorch version (GPU?): 1.5.1 (False)
* Tensorflow version (GPU?): not installed (NA)
* Using GPU in script?: no
* Using distributed or parallel set-up in script?: no
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.4.1
* Operating System version: win7
* Java version: 1.8
Java Code:
package com.ghy.www;
import com.ghy.www.dubbo.provider.service.ISayHello;
import com.ghy.www.dubbo.provider.service.SayHello;
import org.apache.dubbo.config.ApplicationConfig;
import org.apache.dubbo.config.RegistryConfig;
import org.apache.dubbo.config.ServiceConfig;
import java.io.IOException;
public class Application1 {
public static void main(String[] args) throws IOException {
SayHello helloService = new SayHello();
// 服务配置
ServiceConfig serviceConfig = new ServiceConfig();
// 设置应用名称
serviceConfig.setApplication(new ApplicationConfig("dubbo2-server"));
// 设置注册中心
serviceConfig.setRegistry(new
RegistryConfig("multicast://224.5.6.7:1234?unicast=false"));
// 设置业务接口
serviceConfig.setInterface(ISayHello.class);
// 设置业务实现类
serviceConfig.setRef(helloService);
// 发布服务
serviceConfig.export();
// 进程不销毁
System.in.read();
}
}
run after show WARN:
main WARN multicast.MulticastRegistry: [DUBBO] Ignore empty notify urls for
subscribe url
provider://192.168.61.250:20880/com.ghy.www.dubbo.provider.service.ISayHello?anyhost=true&application=dubbo2-server&bind.ip=192.168.61.250&bind.port=20880&category=configurators&check=false&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.ghy.www.dubbo.provider.service.ISayHello&methods=sayHello&pid=9900&release=2.7.4.1&side=provider×tamp=1572321725880,
dubbo version: 2.7.4.1, current host: 192.168.61.250
why ?
thank very much!
|
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.0
* Operating System version: mac
* Java version: 1.8
### Steps to reproduce this issue
1. `AbstractClient#initConnectStatusCheckCommand` set break point at ` !isConnected()`.
2. `AbstractClient#close()` set break point here.
3. start client first, start provider and then shutdown provider gracefully , let method `AbstractClient.close()` be executed. Then select step `1` and trigger the thread to execute `!isConnected`, here will always try to connect the offline machine.
Pls. provide [GitHub address] to reproduce this issue.
### Expected Result
What do you expected from the above steps?
When the server goes offline, the client will not reconnect the offline
machine.
### Actual Result
What actually happens?
The client reconnects the offline machine every 2 seconds and causes a large
number of arp packets(because ip is recycled and not available now).
| 0 |
by **jaq@spacepants.org** :
I just downloaded the source code release branch from code.google.com per the
instructions, then ran all.bash:
hg clone ...
hg update release
cd go/src
./all.bash
...
--- FAIL: TestLookupHost (0.00 seconds)
hosts_test.go:65: LookupHost("localhost") = [127.0.0.1 127.0.0.1], has duplicate addresses
FAIL
FAIL net 2.379s
...
My /etc/hosts is managed by a config management tool and just happens to have put two
localhost entries in there (I didn't know this until now ;-)
cat /etc/hosts
...
127.0.0.1 gunstar localhost
...
127.0.0.1 localhost
The test seems a bit fragile because it relies on config outside the control of the Go
source code.
|
by **dave@lytics.io** :
Building with the race detector enabled sometimes blows up and consumes all available
memory. This happens for me with the package "labix.org/v2/mgo" .
What steps will reproduce the problem?
Download labix.org/v2/mgo and build it with -race:
{{{
$ mkdir ~/gopathtemp
$ export GOPATH=~/gopathtemp
$ go get labix.org/v2/mgo
$ cd $GOPATH/src/labix.org/v2/mgo
$ free -h
total used free shared buffers cached
Mem: 31G 11G 19G 0B 154M 1.4G
-/+ buffers/cache: 10G 20G
Swap: 0B 0B 0B
$ go build -v -race
labix.org/v2/mgo/bson
labix.org/v2/mgo
go build labix.org/v2/mgo: signal: killed
}}}
The final command "go build -race" takes about 30 seconds and uses 18G of RAM
before being OOM-killed. In /var/log/syslog, the following appears:
{{{Aug 20 13:55:34 dave2 kernel: [12453.191018] 6g invoked oom-killer: gfp_mask=0x280da,
order=0, oom_score_adj=0
Aug 20 13:55:34 dave2 kernel: [12453.191022] 6g cpuset=/ mems_allowed=0
Aug 20 13:55:34 dave2 kernel: [12453.191025] Pid: 6445, comm: 6g Tainted: GF
3.8.0-29-generic #42-Ubuntu
Aug 20 13:55:34 dave2 kernel: [12453.191026] Call Trace:
Aug 20 13:55:34 dave2 kernel: [12453.191042] [<ffffffff816c199e>]
dump_header+0x80/0x1c3
Aug 20 13:55:34 dave2 kernel: [12453.191046] [<ffffffff81132ec7>]
oom_kill_process+0x1b7/0x320
Aug 20 13:55:34 dave2 kernel: [12453.191049] [<ffffffff81065a45>] ?
has_ns_capability_noaudit+0x15/0x20
Aug 20 13:55:34 dave2 kernel: [12453.191051] [<ffffffff81065a67>] ?
has_capability_noaudit+0x17/0x20
Aug 20 13:55:34 dave2 kernel: [12453.191053] [<ffffffff81133607>]
out_of_memory+0x417/0x450
Aug 20 13:55:34 dave2 kernel: [12453.191056] [<ffffffff81138b96>]
__alloc_pages_nodemask+0x7e6/0x920
Aug 20 13:55:34 dave2 kernel: [12453.191060] [<ffffffff81175a75>]
alloc_pages_vma+0xa5/0x150
Aug 20 13:55:34 dave2 kernel: [12453.191063] [<ffffffff81158739>]
handle_pte_fault+0x2d9/0x450
Aug 20 13:55:34 dave2 kernel: [12453.191065] [<ffffffff81159209>]
handle_mm_fault+0x299/0x670
Aug 20 13:55:34 dave2 kernel: [12453.191068] [<ffffffff8115fa63>] ?
mmap_region+0x2a3/0x640
Aug 20 13:55:34 dave2 kernel: [12453.191071] [<ffffffff816d0c7d>]
__do_page_fault+0x18d/0x500
Aug 20 13:55:34 dave2 kernel: [12453.191073] [<ffffffff8116004d>] ?
do_mmap_pgoff+0x24d/0x340
Aug 20 13:55:34 dave2 kernel: [12453.191076] [<ffffffff8109297f>] ?
__dequeue_entity+0x2f/0x50
Aug 20 13:55:34 dave2 kernel: [12453.191079] [<ffffffff8114b7c8>] ?
vm_mmap_pgoff+0x88/0xb0
Aug 20 13:55:34 dave2 kernel: [12453.191082] [<ffffffff816d0ffe>]
do_page_fault+0xe/0x10
Aug 20 13:55:34 dave2 kernel: [12453.191084] [<ffffffff816cd618>]
page_fault+0x28/0x30
}}}
I'm running Ubuntu 13.04 AMD64, with 32G of RAM (see the "free -h" command
above):
{{{
$ uname -a
Linux dave2 3.8.0-29-generic #42-Ubuntu SMP Tue Aug 13 19:40:39 UTC 2013 x86_64 x86_64
x86_64 GNU/Linux
$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=13.04
DISTRIB_CODENAME=raring
DISTRIB_DESCRIPTION="Ubuntu 13.04"
}}}
What is the expected output?
"go build -race" should produce a binary and terminate. It does neither.
What do you see instead?
"go build -race" runs for 30 seconds before using all available memory and
being killed by the OOM killer.
Which compiler are you using (5g, 6g, 8g, gccgo)?
I'm using the go 1.1.2 tar distribution from golang.org and running "go build
-race".
Which operating system are you using?
Ubuntu 13.04 AMD64.
Which version are you using? (run 'go version')
1.1.2
Please provide any additional information below.
| 0 |
Compare these 1.15 docs with these 1.13 docs
|
I'm having difficulties displaying the NumPy reference in HTML format. There
seems to be some formatting shining through which isn't correctly translated
to HTML, or the rendering engine can't display the content properly.
The problem shows, for example, when looking at the ndarray reference,
subsection "Internal memory layout of an ndarray". Here I get garbled formulae
like this:
n_{\mathrm{offset}} = \sum_{k=0}^{N-1} s_k n_k
The problem occurs both with firefox and chromium on kubuntu 18.04, the docu
is version 1.15.
| 1 |
Describe what you were doing when the bug occurred:
1. Trying to access Components tab in Chrome Dev tools
2. 3.
* * *
## Please do not remove the text below this line
DevTools version: 4.10.0-11a2ae3a0d
Call stack: at store_Store.getElementAtIndex (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:21215:35)
at store_Store.getElementIDAtIndex (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:21231:26)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28667:63
at List.render (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:22923:18)
at si (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13506:76)
at ri (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13497:10)
at jk (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:16068:86)
at ik (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:15450:11)
at hk (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:15442:23)
at Zj (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:15426:5)
Component stack: at List (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:22618:30)
at div
at AutoSizer (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:3002:5)
at div
at div
at Tree_Tree (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28418:47)
at div
at div
at InspectedElementContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28910:3)
at OwnersListContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:27547:3)
at SettingsModalContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28195:3)
at Components_Components (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:33372:52)
at ErrorBoundary_ErrorBoundary (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29208:5)
at PortaledContent (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29325:32)
at div
at div
at ProfilerContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32923:3)
at TreeContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:24311:3)
at SettingsContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:24800:3)
at ModalDialogContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29393:3)
at DevTools_DevTools (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:36196:3)
|
Describe what you were doing when the bug occurred:
1. Open React Devtool
2. Select the Component tab
3. Got below error
* * *
## Please do not remove the text below this line
DevTools version: 4.8.2-fed4ae024
Call stack: at Store.getElementAtIndex (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:19359:35)
at Store.getElementIDAtIndex (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:19376:26)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:26594:18
at List.render (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:21229:18)
at li (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:11802:76)
at ki (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:11793:10)
at ck (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:14433:86)
at bk (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13779:11)
at ak (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13768:5)
at Sj (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13750:7)
Component stack: at List (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:20924:30)
at div
at AutoSizer (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:2786:5)
at div
at div
at Tree_Tree (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:26368:45)
at div
at div
at InspectedElementContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:26848:23)
at OwnersListContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:25520:23)
at SettingsModalContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:26139:23)
at Components_Components (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:30926:50)
at ErrorBoundary (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:27172:5)
at PortaledContent (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:27303:32)
at div
at div
at ProfilerContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:30463:23)
at TreeContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:22538:23)
at SettingsContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:23040:27)
at ModalDialogContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28328:23)
at DevTools_DevTools (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:33797:21)
| 1 |
This is how I broke our build.
% pwd
/home/rog/src/go/src/local/gobug
% ls
% cat > foo.go
package foo
var X = 0
^D
% cat > bar.go
package foo
var Y = 0
^D
% cat > foo_test.go
package foo_test
import (
"testing"
foo "local/gobug"
)
func TestX(t *testing.T){
_ = foo.X
}
^D
% go test
PASS
ok local/gobug 0.011s
% go install
% rm foo.go # as it happens, i actually moved it elsewhere.
% go build
% go install
% go test
PASS
ok local/gobug 0.011s
# everything looks just fine, so i pushed to trunk here, breaking
# the build.
% touch *.go
% go test
# local/gobug_test
./foo_test.go:7: undefined: foo.X
FAIL local/gobug [build failed]
%
I wonder if the go tool should look at the mtime of the
directory as well as the source files when determining
whether to rebuild.
|
What steps will reproduce the problem?
If possible, include a link to a program on play.golang.org.
1. hg pull ;hg update;hg id
gobuild@raspberrypi:~/go/src$ hg id
5e3661048f2e+ tip
gobuild@raspberrypi:~/go/src$
2. check GOARM setting.
gobuild@raspberrypi:~/go/src$ echo $GOARM
gobuild@raspberrypi:~/go/src$
3. cd src;./all.bash
What is the expected output?
No errors.
What do you see instead?
two test errors, fmt and eoncoding/gob(this is logged in another ticket).
ok flag 0.120s
--- FAIL: TestNaN (0.00 seconds)
scan_test.go:459: didn't get NaNs scanning "nan nan nan": got NaN +Inf NaN
scan_test.go:459: didn't get NaNs scanning "NAN NAN NAN": got NaN +Inf NaN
scan_test.go:459: didn't get NaNs scanning "NaN NaN NaN": got NaN +Inf NaN
FAIL
FAIL fmt 0.876s
ok go/ast 0.171s
Which operating system are you using?
gobuild@raspberrypi:~/go/src$ uname -a
Linux raspberrypi 3.1.9+ #90 Wed Apr 18 18:23:05 BST 2012 armv6l GNU/Linux
gobuild@raspberrypi:~/go/src$
Which version are you using? (run 'go version')
gobuild@raspberrypi:~/go/src$ go version
go version weekly.2012-03-27 +5e3661048f2e
gobuild@raspberrypi:~/go/src$
Please provide any addgobuild@raspberrypi:~/go/src$ hg id
5e3661048f2e+ tip
gobuild@raspberrypi:~/go/src$
itional information below.
| 0 |
**Migrated issue, originally created by Michael Bayer (@zzzeek)**
re: the "creator" function.
see #647 #2808 #3235 for what keeps coming up.
|
**Migrated issue, originally created by Sorin Sbarnea (@sorin)**
Instead of hardcoding the backend engine to use for postgresql, sql alchemy
should try to use pg8000 if the native module is not present.
| 0 |
I want to know how to handle cases where everything goes wrong, I am not too
much worry for the workers, queue or db. I already know how their up time or
how they handle crashes.
But, I am still not sure to understand how works airflow. I assume that you a
server or a process that know when to add stuff in the queue to respect the
dag. Am I right ? if yes, how can I handle a crashes ? (can I duplicate this
server/process on a other container ?).
|
\-->
**Apache Airflow version** : 1.10.10
**Kubernetes version (if you are using kubernetes)** (use `kubectl version`):
NA
**Environment** :
* **Cloud provider or hardware configuration** : AWS
* **OS** (e.g. from /etc/os-release): CentOS Linux release 7.7.1908 (Core)
* **Kernel** (e.g. `uname -a`): 3.10.0-1062.12.1.el7.x86_64 #1 SMP Tue Feb 4 23:02:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
* **Install tools** :
* **Others** :
**What happened** :
After upgrading 1.10.2 to 1.10.10 cant get into WebUI
* no RBAC
* no DAG Serialization
* postgres source\dest 11.5
* prepare new db from 1.10.2 snapshot
* connect it to Airflow 1.10.10 python env
* double check no live connections to db
* run airflow upgradedb
Alembic log
(airflow)$ airflow upgradedb
/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/configuration.py:631: DeprecationWarning: Specifying both AIRFLOW_HOME environment variable and airflow_home in the config file is deprecated. Please use only the AIRFLOW_HOME environment variable and remove the config file entry.
warnings.warn(msg, category=DeprecationWarning)
[2020-06-14 08:30:14,925] {rest_api_plugin.py:48} WARNING - [rest_api_plugin/REST_API_PLUGIN_EXPECTED_HTTP_TOKEN] value is empty
DB: postgresql://airflow:***@airflow-aws-test-airflowdb.*.us-east-1.rds.amazonaws.com:5432/airflow
[2020-06-14 08:30:15,214] {db.py:378} INFO - Creating tables
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 41f5f12752f8 -> c8ffec048a3b, add fields to dag
INFO [alembic.runtime.migration] Running upgrade c8ffec048a3b -> dd4ecb8fbee3, Add schedule interval to dag
INFO [alembic.runtime.migration] Running upgrade dd4ecb8fbee3 -> 939bb1e647c8, task reschedule fk on cascade delete
INFO [alembic.runtime.migration] Running upgrade 939bb1e647c8 -> 6e96a59344a4, Make TaskInstance.pool not nullable
INFO [alembic.runtime.migration] Running upgrade 6e96a59344a4 -> d38e04c12aa2, add serialized_dag table
Revision ID: d38e04c12aa2
Revises: 6e96a59344a4
Create Date: 2019-08-01 14:39:35.616417
INFO [alembic.runtime.migration] Running upgrade d38e04c12aa2 -> b3b105409875, add root_dag_id to DAG
Revision ID: b3b105409875
Revises: d38e04c12aa2
Create Date: 2019-09-28 23:20:01.744775
INFO [alembic.runtime.migration] Running upgrade 6e96a59344a4 -> 74effc47d867, change datetime to datetime2(6) on MSSQL tables
INFO [alembic.runtime.migration] Running upgrade 939bb1e647c8 -> 004c1210f153, increase queue name size limit
INFO [alembic.runtime.migration] Running upgrade c8ffec048a3b -> a56c9515abdc, Remove dag_stat table
INFO [alembic.runtime.migration] Running upgrade a56c9515abdc, 004c1210f153, 74effc47d867, b3b105409875 -> 08364691d074, Merge the four heads back together
INFO [alembic.runtime.migration] Running upgrade 08364691d074 -> fe461863935f, increase_length_for_connection_password
INFO [alembic.runtime.migration] Running upgrade fe461863935f -> 7939bcff74ba, Add DagTags table
INFO [alembic.runtime.migration] Running upgrade 7939bcff74ba -> a4c2fd67d16b, add pool_slots field to task_instance
INFO [alembic.runtime.migration] Running upgrade a4c2fd67d16b -> 852ae6c715af, Add RenderedTaskInstanceFields table
INFO [alembic.runtime.migration] Running upgrade 852ae6c715af -> 952da73b5eff, add dag_code table
After auth getting next screen constantly
Crush log from web-ui
-------------------------------------------------------------------------------
Node: airflow-master-test-1-10-10.dev.somehost.net
-------------------------------------------------------------------------------
Traceback (most recent call last):
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/app.py", line 2446, in wsgi_app
response = self.full_dispatch_request()
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/app.py", line 1951, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/app.py", line 1820, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/app.py", line 1949, in full_dispatch_request
rv = self.dispatch_request()
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/app.py", line 1935, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask_admin/base.py", line 69, in inner
return self._run_view(f, *args, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask_admin/base.py", line 368, in _run_view
return fn(self, *args, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask_login/utils.py", line 261, in decorated_view
return func(*args, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/utils/db.py", line 74, in wrapper
return func(*args, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/views.py", line 2330, in index
auto_complete_data=auto_complete_data)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/views.py", line 389, in render
return super(AirflowViewMixin, self).render(template, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask_admin/base.py", line 308, in render
return render_template(template, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/templating.py", line 140, in render_template
ctx.app,
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask/templating.py", line 120, in _render
rv = template.render(context)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/jinja2/asyncsupport.py", line 76, in render
return original_render(self, *args, **kwargs)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/jinja2/environment.py", line 1008, in render
return self.environment.handle_exception(exc_info, True)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/jinja2/environment.py", line 780, in handle_exception
reraise(exc_type, exc_value, tb)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/jinja2/_compat.py", line 37, in reraise
raise value.with_traceback(tb)
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/templates/airflow/dags.html", line 20, in top-level template code
{% extends "airflow/master.html" %}
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/templates/airflow/master.html", line 20, in top-level template code
{% extends "admin/master.html" %}
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/templates/admin/master.html", line 20, in top-level template code
{% extends 'admin/base.html' %}
File "/opt/python-envs/airflow/lib/python3.6/site-packages/flask_admin/templates/bootstrap3/admin/base.html", line 38, in top-level template code
{% block page_body %}
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/templates/admin/master.html", line 191, in block "page_body"
{% block body %}
File "/opt/python-envs/airflow/lib/python3.6/site-packages/airflow/www/templates/airflow/dags.html", line 84, in block "body"
<a href="{{ url_for('airflow.'+ dag.get_default_view(), dag_id=dag.dag_id) }}" title="{{ dag.description[0:80] + '...' if dag.description|length > 80 else dag.description }}">
TypeError: object of type 'NoneType' has no len()
**What you expected to happen** : WebUI works
**How to reproduce it** :
* Prepare some DAGs without description executed under Airflow 1.10.2
* Upgrade to Airflow 1.10.10
**Anything else we need to know** :
DB data which wont work (sensitive data removed)
airflow=> select dag_id,default_view,description from dag where (description = '') IS NOT FALSE limit 10;
dag_id | default_view | description
---------------------------------------------------------------------+--------------+-------------
hello_world | |
(10 rows)
Quick fix which helped (sensitive data removed)
airflow=> update dag SET description = 'Desc' where (description = '') IS NOT FALSE;
UPDATE 14
airflow=> select dag_id,default_view,description from dag where (description = '') IS NOT FALSE limit 10;
dag_id | default_view | description
--------+--------------+-------------
(0 rows)
airflow=> select dag_id,default_view,description from dag limit 10;
dag_id | default_view | description
---------------------------------------------------------------------+--------------+-------------
hello_world | | Desc
(10 rows)
| 0 |
I am interested in implementing a new connector for Superset to add MongoDB
support, and would like to know if others have started similar work too so as
to avoid duplicate effort.
### Inspiration
@priyankajuyal I think there're 3 methods to support mongodb in superset:
* Implement a mongodb in sqlalchemy, this requires a lot of work and may not be easy to do cause sqlalchemy is a object relational mapper library, while mongodb is not relational.
* Implement a new connector for superset. Right now superset has two connectors, one is for sqlalchemy, one is for druid, and similar things can be implemented for mongodb, this should be the right choice.
* Transform mongodb to some relational db, stripe has a deprecated project for this job: https://github.com/stripe/mosql.
_Originally posted by@xiaohanyu in #4231 (comment)_
|
Make sure these boxes are checked before submitting your issue - thank you!
* I have checked the superset logs for python stacktraces and included it here as text if there are any.
* I have reproduced the issue with at least the latest released version of superset.
* I have checked the issue tracker for the same issue and I haven't found one similar.
### Superset version
Lastest commit on master
### Expected results
Docker compose working
### Actual results
$ docker-compose up
superset_postgres_1 is up-to-date
superset_redis_1 is up-to-date
Creating superset_superset_1 ... done
Attaching to superset_postgres_1, superset_redis_1, superset_superset_1
superset_1 | + '[' 0 -ne 0 ']'
superset_1 | + '[' development = development ']'
superset_1 | + celery worker --app=superset.sql_lab:celery_app --pool=gevent -Ofair
superset_1 | + cd superset/assets/
superset_1 | + npm ci
postgres_1 | 2019-02-07 15:41:55.069 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
postgres_1 | 2019-02-07 15:41:55.069 UTC [1] LOG: listening on IPv6 address "::", port 5432
postgres_1 | 2019-02-07 15:41:55.109 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
postgres_1 | 2019-02-07 15:41:55.235 UTC [22] LOG: database system was shut down at 2019-02-07 15:31:58 UTC
postgres_1 | 2019-02-07 15:41:55.249 UTC [1] LOG: database system is ready to accept connections
postgres_1 | 2019-02-07 15:42:51.678 UTC [30] ERROR: duplicate key value violates unique constraint "ab_user_username_key"
postgres_1 | 2019-02-07 15:42:51.678 UTC [30] DETAIL: Key (username)=(admin) already exists.
postgres_1 | 2019-02-07 15:42:51.678 UTC [30] STATEMENT: INSERT INTO ab_user (id, first_name, last_name, username, password, active, email, last_login, login_count, fail_login_count, created_on, changed_on, created_by_fk, changed_by_fk) VALUES (nextval('ab_user_id_seq'), 'admin', 'user', 'admin', 'pbkdf2:sha256:50000$fgf6eYlb$bb1e6c1f420de4d894f7a917a72712c0b846dd969f51afb7cf386f0848508422', true, 'admin@fab.org', NULL, NULL, NULL, '2019-02-07T15:42:51.677213'::timestamp, '2019-02-07T15:42:51.677242'::timestamp, NULL, NULL) RETURNING ab_user.id
redis_1 | 1:C 07 Feb 15:41:55.444 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
redis_1 | _._
redis_1 | _.-``__ ''-._
redis_1 | _.-`` `. `_. ''-._ Redis 3.2.12 (00000000/0) 64 bit
redis_1 | .-`` .-```. ```\/ _.,_ ''-._
redis_1 | ( ' , .-` | `, ) Running in standalone mode
redis_1 | |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
redis_1 | | `-._ `._ / _.-' | PID: 1
redis_1 | `-._ `-._ `-./ _.-' _.-'
redis_1 | |`-._`-._ `-.__.-' _.-'_.-'|
redis_1 | | `-._`-._ _.-'_.-' | http://redis.io
redis_1 | `-._ `-._`-.__.-'_.-' _.-'
redis_1 | |`-._`-._ `-.__.-' _.-'_.-'|
redis_1 | | `-._`-._ _.-'_.-' |
redis_1 | `-._ `-._`-.__.-'_.-' _.-'
redis_1 | `-._ `-.__.-' _.-'
redis_1 | `-._ _.-'
redis_1 | `-.__.-'
redis_1 |
redis_1 | 1:M 07 Feb 15:41:55.446 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
redis_1 | 1:M 07 Feb 15:41:55.446 # Server started, Redis version 3.2.12
redis_1 | 1:M 07 Feb 15:41:55.446 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
redis_1 | 1:M 07 Feb 15:41:55.446 * DB loaded from disk: 0.000 seconds
redis_1 | 1:M 07 Feb 15:41:55.446 * The server is now ready to accept connections on port 6379
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T15_47_06_436Z-debug.log
postgres_1 | 2019-02-07 15:47:06.572 UTC [36] LOG: unexpected EOF on client connection with an open transaction
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T15_50_51_169Z-debug.log
postgres_1 | 2019-02-07 15:50:51.297 UTC [44] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T15_54_35_445Z-debug.log
postgres_1 | 2019-02-07 15:54:35.595 UTC [52] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T15_58_19_852Z-debug.log
postgres_1 | 2019-02-07 15:58:19.963 UTC [61] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T16_02_04_350Z-debug.log
postgres_1 | 2019-02-07 16:02:04.473 UTC [69] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T16_05_48_096Z-debug.log
postgres_1 | 2019-02-07 16:05:48.222 UTC [78] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
superset_1 | npm WARN prepare removing existing node_modules/ before installation
Note that the execution started on 2019-02-07 15:41:55.069 and the
"screenshot" was taken on 2019-02-07 16:05:48.222 without any result. It seems
that it is always repeating the:
superset_1 | npm WARN prepare removing existing node_modules/ before installation
superset_1 | npm ERR! path /home/superset/superset/assets/node_modules/core-js/fn/array/virtual
superset_1 | npm ERR! code ENOTEMPTY
superset_1 | npm ERR! errno -39
superset_1 | npm ERR! syscall rmdir
superset_1 | npm ERR! ENOTEMPTY: directory not empty, rmdir '/home/superset/superset/assets/node_modules/core-js/fn/array/virtual'
superset_1 |
superset_1 | npm ERR! A complete log of this run can be found in:
superset_1 | npm ERR! /home/superset/.npm/_logs/2019-02-07T16_05_48_096Z-debug.log
postgres_1 | 2019-02-07 16:05:48.222 UTC [78] LOG: unexpected EOF on client connection with an open transaction
superset_superset_1 exited with code 217
### Steps to reproduce
I followed these steps: https://github.com/apache/incubator-
superset/blob/master/docs/installation.rst
based on that commit 823555e
| 0 |
Several of the types in the Iterators package are widely useful, plus have
very small implementations that perform well. I would say these are: Count,
Take, Drop, Cycle, Repeat, and RepeatForever. It would make sense to have
these in Base.
Also, iterators are afflicted by a mild case of "lettercase hell". We export
both `Enumerate` and `enumerate`, etc. I would prefer to minimize the number
of exported things that differ only in case. There are a few ways to deal with
this:
1. Remove the lowercase versions entirely, and stick with the "uppercase means lazy" convention.
2. Rename the uppercase versions to something less appealing like `EnumerateIterator` so they are less easily confused.
3. Un-export (and possibly rename as well) the uppercase versions.
|
Mutually recursive type declarations such as
type A
a :: B
b
end
type B
c :: A
d
end
appear to be presently unsupported, as per this discussion:
https://groups.google.com/forum/#!msg/julia-users/LctRzct1R-M/s_vLVUxSyVcJ
More generally, "out of order" type declarations also appear to be
unsupported.
Mutually recursive declarations are important for many recursive data
structures: in complex cases, the workarounds required to produce singly
recursive declarations can produce highly unreadable code with excessive
redundancy and obscure relationships to the original concept.
"Out of order" declarations are important for some forms of generic
programming that depend on altering a subset of type definitions: in complex
cases, the workarounds required to organize the inclusions in ordered form
defeat much of the purpose of avoiding the unnecessary code duplication.
I believe this issue is already well known, but I did not find an open issue
on Github, which prevents easily checking its status.
| 0 |
# Description of the new enhancement
Currently windows terminal does not support vim (vim for windows) completely.
When vim is launched from the windows terminal, the document opens fine and
all of the vim features are available. The only issue is that the rendering of
the document is with blue color as opposed to normal terminal background-color
(say black)

Due to the improper rendering, the syntax highlighting feature of vim no
longer works.
When vim is launched from the terminal it should respect `.vimrc` file of the
user.
It will be helpful if I can use vim in the windows terminal directly :)
### A clear and concise description of what the problem is that the new
enhancement would solve.
Describe why and how a user would use this new functionality (if applicable).
It would be really helpful if I can use vim for windows on the windows
terminal. Ever since the new terminal was announced I was looking forward to
using vim on it. Currently, I use vim software for windows.
### A clear and concise description of what you want to happen.
It would be useful if something close to below happens:

|
I just installed Windows Terminal for the first time this morning and the
first thing I noticed -- before trying to make ANY changes to settings or even
using the command lines -- was the semi-transparent background in the CMD
tabs. I think it looks neat, but I am confused about why it is transparent
when the terminal window is in use but becomes solid when the terminal window
loses focus?
It would seem to make much more sense with those states reversed as it is much
easier to read text on a single, solid background color and it may be useful
to have an idea what is behind the inactive terminal window.
# Environment
Windows build number: Microsoft Windows [Version 10.0.18362.239]
Windows Terminal version (if applicable): 0.3.2171.0
Any other software? no
# Steps to reproduce
Open a CMD tab and focus then unfocus the terminal window to see the
background opacity change.
# Expected behavior
My preference would be for solid when in use and some transparency when
inactive. Or at least, I would like an option to choose that mode.
# Actual behavior
The CMD tab is semi-transparent when in use and becomes solid when inactive.
| 0 |
The get started part has a section MNIST for ML Beginners. In this tutorial
you should download the test data via:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
Unfortunately that's not working because of an connection error.
|
I was able to run the Inception-v3 model on Android just fine, and I now want
to run my own trained TensorFlow model on Android. I'm following the approach
from TensorFlow's image recognition tutorial and the Android TensorFlow demo,
and adapting as necessary. My changes include: (a) integrating Android OpenCV
as part of the bazel build (b) using own model and label file and (c)
adjusting parameters (img_size, input_mean, input_std, etc.) accordingly.
From Android logcat, running my model with the tensorflow android demo app
gives:
E/native: tensorflow_inference_jni.cc:202 Error during inference: Invalid argument: Session was not created with a graph before Run()!
...
E/native: tensorflow_inference_jni.cc:159 Output [output/Softmax:0] not found, aborting!
### What related GitHub issues or StackOverflow threads have you found by
searching the web for your problem?
Own (duplicate) SO thread:
http://stackoverflow.com/questions/40555749/running-own-tensorflow-model-on-
android-gives-native-inference-error-session-w
### Environment info
OS X Yosemite (10.10.5), LGE Nexus 5 (Android 6.0.1), Android SDK 23, Android
OpenCV SDK 23, Bazel 0.4.0.
### Steps taken
1. Saved own model's checkpoint (.ckpt) and graph definition (.pb) files separately using `tf.train.Saver()` then `tf.train.write_graph()`
2. Froze graph using freeze_graph.py (using bazel), gives 227.5 MB file
3. Optimized the graph using optimize_for_inference.py (additionally tried strip_unused.py)
4. Copied frozen, optimized, or stripped graph to android/assets
5. Doubled the total byte limit using `coded_stream.SetTotalBytesLimit()` in jni_utils.cc to handle my large model size
6. Built the tensorflow android app using bazel
7. Installed on android device using adb and bazel
As a sanity check, I have tested my model in C++ built with bazel following
the tutorial here label_image, and my model correctly outputs a prediction. I
have also tried playing with the order by which I save my graph def and
checkpoint files before freezing, but no change.
Any help would be great.
cc @drpngx @andrewharp
| 0 |
**I'm submitting a ...** (check one with "x")
[x] bug report
[ ] feature request
[ ] support request
**Current behavior**
When a web component is used inside an Angular component, attributes specified
on web component are not available inside `attachedCallback` of web component.
Also, when an attribute value for a web component is specified using an
interpolation operator `value="{{value}}"`, Angular changes attribute name
with a `ng-reflect-` prefix and manages it internally. Because of this there
is no way `attributeChangedCallback` could trigger appropriately.
**Expected behavior**
There should be a way to use web component inside Angular component in a way
such that attributes are available inside `attachedCallback` and
`attributeChangedCallback` is triggered correctly for appropriate attributes.
**Minimal reproduction of the problem with instructions**
This shows a sample Toggle Button web component used inside Angular component.
https://plnkr.co/edit/MwLh8ssnjOdqA8C4PhZq?p=preview
**Please tell us about your environment:**
* **Angular version:** 2.0.X
* **Browser:** [Chrome]
* **Language:** [ES6]
|
**I'm submitting a ...** (check one with "x")
[x] bug report
[ ] feature request
[ ] support request
**Current behavior**
I'm trying to integrate ChartIQ library which has HTML Custom Elements to my
angular 2 application.
Some of these elements have logic in createdCallback, but when it is firing
innerHTML of Custom element is empty.
**Expected behavior**
If I use Custom Elements without Angular, createdCallback is firing when the
full element (with all childrens added into it) inserted into DOM.
**Minimal reproduction of the problem with instructions**
http://plnkr.co/edit/OW500u9fr27aVteo3zJh
**What is the motivation / use case for changing the behavior?**
For now Angular 2 breaks some part of expected behavior of Custom Elements. It
needs to be fixed to allow using Custom Elements in Angular apps.
**Please tell us about your environment:**
Windows 8, WebStorm, npm
* **Angular version:**
2.2.1
* **Browser:**
Chrome 55
* **Language:**
all
* **Node (for AoT issues):** `node --version` =
6.7.0
| 1 |
The code completion functionality often gets in the way when typing prose into
a text file. For example, if I were writing this comment in a .txt file with
VS Code and tried to type the word fun immediately followed by the Enter key,
I'd automatically have the word "functionality" instead, because Code
"learned" from the first sentence above that "fun" might be the beginning of
"functionality."
It's great that this is apparently turned off by default in Markdown files.
Can the same default be applied to .txt files? It's unlikely that any useful
word-completion heuristic can be deduced from the content of most text files.
|
At the moment when none of the contributed completion processors returns any
proposals, the textual completion processor starts adding proposals.
That's fine for languages where we have no sophisticated completion processor,
but looks bad for languages that pretend to have a 'smart' completion
processor.
| 1 |
On current master (on macOS), I get these warnings when building Julia. I
suppose they are safe to ignore.
LINK usr/lib/julia/sys.dylib
ld: warning: could not create compact unwind for _julia_Dict_17462: stack subq instruction is too different from dwarf stack size
ld: warning: could not create compact unwind for _julia_Dict_17470: stack subq instruction is too different from dwarf stack size
➜ julia git:(master) ./julia
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.8.0-DEV.86 (2021-06-28)
_/ |\__'_|_|_|\__'_| | Commit 74fab49ffb (0 days old master)
|__/ |
|
On macOS 10.14.6, I've started to get these warning when building Julia, at
the very end:
$ make
...
LINK usr/lib/julia/sys.dylib
ld: warning: could not create compact unwind for _julia_Dict_16937: stack subq instruction is too different from dwarf stack size
ld: warning: could not create compact unwind for _julia_Dict_16945: stack subq instruction is too different from dwarf stack size
$
This also happens in the release-1.7 branch, but not in release-1.6, and also
didn't happen like a month or so ago.
| 1 |
Please add support for selecting multiple images at once using the
image_picker plugin.
|
Right now the picker defaults to single mode, it would be nice to be able to
have a multi-mode, by passing a parameter when you launch it, then an array is
returned of files instead of just one.
for android this might help speed things up
unique code
intent.putExtra(Intent.EXTRA_ALLOW_MULTIPLE, true);
full example
Intent intent = new Intent();
intent.setType("image/*");
intent.putExtra(Intent.EXTRA_ALLOW_MULTIPLE, true);
intent.setAction(Intent.ACTION_GET_CONTENT);
startActivityForResult(Intent.createChooser(intent,"Select Picture"), 1);
for iOS I think maybe using this library might help, and seems up to date.
https://github.com/hackiftekhar/IQMediaPickerController
| 1 |
### Describe the issue:
Hi,
I have recently created a new python environment using the 3.10.4 python
version.
I have installed the latest public version (1.22.3) and when I am trying to
catch the epsilon, I have an error that cannot allow me to use the command:
numpy.finfo(float).eps or numpy.finfo(numpy.float32).eps
This can be very inconvenient because I hwill use some solutions of Scikit-
Learn that calls this.
Sorry for the inconvenience. Best.
### Reproduce the code example:
import numpy as np
eps = np.finfo(float).eps
### Error message:
Traceback (most recent call last):**
File "C:\Users\ME\2022_deepl\lib\site-packages\numpy\core\getlimits.py", line 459, in __new__
dtype = numeric.dtype(dtype)
TypeError: 'numpy.dtype[bool_]' object is not callable
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\ME\AppData\Local\Temp\ipykernel_10948\2225752278.py", line 1, in <cell line: 1>
np.finfo(float).eps
File "C:\Users\ME\2022_deepl\lib\site-packages\numpy\core\getlimits.py", line 462, in __new__
dtype = numeric.dtype(type(dtype))
TypeError: 'numpy.dtype[bool_]' object is not callable
### NumPy/Python version information:
1.22.3 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit
(AMD64)]
|
Ravel and unravel are **synonyms** , but the methods where they appear
accomplish inverse operations.
See my SO question for details and example.
Can you consider introducing alternative methods that contain `unravel` in
their name (even functions containing ravel are IMHO not a happy choice)?
I propose to change e.g.
before | after
---|---
`unravel_index()` | `index_to_coord()`
`ravel_multi_index()` | `index_to_flat`
| 0 |
Consider the following code from `numpy/distutils/fcompiler/gnu.py`:
import sysconfig
target = sysconfig.get_config_var('MACOSX_DEPLOYMENT_TARGET')
if not target:
target = '10.9'
s = f'Env. variable MACOSX_DEPLOYMENT_TARGET set to {target}'
warnings.warn(s, stacklevel=2)
os.environ['MACOSX_DEPLOYMENT_TARGET'] = target
With OS X Big Sur, `sysconfig.get_config_var('MACOSX_DEPLOYMENT_TARGET')` can
return the int 11, but `os.environ[..] = target` wants `target` to be a
string. As a result, `numpy` won't compile from source. This arose in the
context of Sagemath, in which numpy is compiled from source.
### Error message:
Building from source results in
building library "npymath" sources
Traceback (most recent call last):
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/setup.py", line 508, in <module>
setup_package()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/setup.py", line 500, in setup_package
setup(**metadata)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/core.py", line 169, in setup
return old_setup(**new_attr)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/lib/python3.9/site-packages/setuptools/__init__.py", line 163, in setup
return distutils.core.setup(**attrs)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/core.py", line 148, in setup
dist.run_commands()
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/lib/python3.9/site-packages/wheel/bdist_wheel.py", line 299, in run
self.run_command('build')
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/build.py", line 40, in run
old_build.run(self)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/build_src.py", line 144, in run
self.build_sources()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/build_src.py", line 155, in build_sources
self.build_library_sources(*libname_info)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/build_src.py", line 288, in build_library_sources
sources = self.generate_sources(sources, (lib_name, build_info))
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/build_src.py", line 378, in generate_sources
source = func(extension, build_dir)
File "numpy/core/setup.py", line 658, in get_mathlib_info
st = config_cmd.try_link('int main(void) { return 0;}')
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/command/config.py", line 241, in try_link
self._check_compiler()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/command/config.py", line 80, in _check_compiler
self.fcompiler = new_fcompiler(compiler=self.fcompiler,
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/__init__.py", line 880, in new_fcompiler
compiler = get_default_fcompiler(plat, requiref90=requiref90,
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/__init__.py", line 851, in get_default_fcompiler
compiler_type = _find_existing_fcompiler(matching_compiler_types,
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/__init__.py", line 802, in _find_existing_fcompiler
c.customize(dist)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/__init__.py", line 526, in customize
linker_so_flags = self.flag_vars.linker_so
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/environment.py", line 37, in __getattr__
return self._get_var(name, conf_desc)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/environment.py", line 53, in _get_var
var = self._hook_handler(name, hook)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/__init__.py", line 705, in _environment_hook
return hook()
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/gnu.py", line 346, in get_flags_linker_so
flags = GnuFCompiler.get_flags_linker_so(self)
File "/Users/palmieri/Desktop/Sage/sage_builds/TESTING/sage-9.3.beta5/local/var/tmp/sage/build/numpy-1.19.4/src/numpy/distutils/fcompiler/gnu.py", line 136, in get_flags_linker_so
os.environ['MACOSX_DEPLOYMENT_TARGET'] = target
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/os.py", line 684, in __setitem__
value = self.encodevalue(value)
File "/usr/local/Cellar/python@3.9/3.9.1_2/Frameworks/Python.framework/Versions/3.9/lib/python3.9/os.py", line 756, in encode
raise TypeError("str expected, not %s" % type(value).__name__)
TypeError: str expected, not int
### NumPy/Python version information:
>>> print(sys.version)
3.9.1 (default, Dec 24 2020, 16:23:16)
[Clang 12.0.0 (clang-1200.0.32.28)]
Attempting to build numpy-1.19.4.
Suggested fix:
diff --git a/numpy/distutils/fcompiler/gnu.py b/numpy/distutils/fcompiler/gnu.py
index caa0854..ff8bfdd 100644
--- a/numpy/distutils/fcompiler/gnu.py
+++ b/numpy/distutils/fcompiler/gnu.py
@@ -133,7 +133,7 @@ class GnuFCompiler(FCompiler):
target = '10.9'
s = f'Env. variable MACOSX_DEPLOYMENT_TARGET set to {target}'
warnings.warn(s, stacklevel=2)
- os.environ['MACOSX_DEPLOYMENT_TARGET'] = target
+ os.environ['MACOSX_DEPLOYMENT_TARGET'] = str(target)
opt.extend(['-undefined', 'dynamic_lookup', '-bundle'])
else:
opt.append("-shared")
or insert a call to `str` when defining `target`:
target = str(sysconfig.get_config_var('MACOSX_DEPLOYMENT_TARGET'))
|
Not sure that this issue is related to NumPy.
When I try to install NumPy with Pipenv, it fails with a `TypeError`
exception.
This issue doesn't seem to happen if using `pip` directly.
### Steps to reproduce:
I could reproduce with this config:
* macOS 11.0 (Intel)
* Python 3.9.0
* pip 20.3.1
* pipenv, version 2020.11.15
$ mkdir my_project && cd my_project
$ pipenv --three
$ pipenv install numpy
### Error message:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pipenv/patched/notpip/_vendor/pep517/_in_process.py", line 257, in <module>
main()
File "/usr/local/lib/python3.9/site-packages/pipenv/patched/notpip/_vendor/pep517/_in_process.py", line 240, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "/usr/local/lib/python3.9/site-packages/pipenv/patched/notpip/_vendor/pep517/_in_process.py", line 110, in prepare_metadata_for_build_wheel
return hook(metadata_directory, config_settings)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-build-env-uhf9fd_v/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 157, in prepare_metadata_for_build_wheel
self.run_setup()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-build-env-uhf9fd_v/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 248, in run_setup
super(_BuildMetaLegacyBackend,
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-build-env-uhf9fd_v/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 142, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 508, in <module>
setup_package()
File "setup.py", line 500, in setup_package
setup(**metadata)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/core.py", line 169, in setup
return old_setup(**new_attr)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-build-env-uhf9fd_v/overlay/lib/python3.9/site-packages/setuptools/__init__.py", line 165, in setup
return distutils.core.setup(**attrs)
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/core.py", line 148, in setup
dist.run_commands()
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-build-env-uhf9fd_v/overlay/lib/python3.9/site-packages/setuptools/command/dist_info.py", line 31, in run
egg_info.run()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/egg_info.py", line 24, in run
self.run_command("build_src")
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/build_src.py", line 144, in run
self.build_sources()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/build_src.py", line 155, in build_sources
self.build_library_sources(*libname_info)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/build_src.py", line 288, in build_library_sources
sources = self.generate_sources(sources, (lib_name, build_info))
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/build_src.py", line 378, in generate_sources
source = func(extension, build_dir)
File "numpy/core/setup.py", line 658, in get_mathlib_info
st = config_cmd.try_link('int main(void) { return 0;}')
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/distutils/command/config.py", line 241, in try_link
self._check_compiler()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/command/config.py", line 80, in _check_compiler
self.fcompiler = new_fcompiler(compiler=self.fcompiler,
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/__init__.py", line 880, in new_fcompiler
compiler = get_default_fcompiler(plat, requiref90=requiref90,
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/__init__.py", line 851, in get_default_fcompiler
compiler_type = _find_existing_fcompiler(matching_compiler_types,
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/__init__.py", line 802, in _find_existing_fcompiler
c.customize(dist)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/__init__.py", line 526, in customize
linker_so_flags = self.flag_vars.linker_so
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/environment.py", line 37, in __getattr__
return self._get_var(name, conf_desc)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/environment.py", line 53, in _get_var
var = self._hook_handler(name, hook)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/__init__.py", line 705, in _environment_hook
return hook()
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/gnu.py", line 346, in get_flags_linker_so
flags = GnuFCompiler.get_flags_linker_so(self)
File "/private/var/folders/6n/lncv_nl546ndn321m0fgdsfm0000gn/T/pip-resolver-wlds30r_/numpy/numpy/distutils/fcompiler/gnu.py", line 136, in get_flags_linker_so
os.environ['MACOSX_DEPLOYMENT_TARGET'] = target
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/os.py", line 684, in __setitem__
value = self.encodevalue(value)
File "/usr/local/Cellar/python@3.9/3.9.0_5/Frameworks/Python.framework/Versions/3.9/lib/python3.9/os.py", line 756, in encode
raise TypeError("str expected, not %s" % type(value).__name__)
TypeError: str expected, not int
| 1 |
* Electron version: 1.7.x
* Operating system: Windows 10
### Expected behavior
You should be able to share any screen connected on the computer, see the
content of the screen you selected locally, as well as the other participants.
### Actual behavior
Once you select the screen you want to share on a multi-screen computer
running Windows 10, you immediately get a black screen as the local stream
when you select some of the screens. The other participants also get a black
screen as the remote stream.
### How to reproduce
1. On a Windows 10 computer or VM, with multiple screens connected, start sharing your screen with any Electron-based app. I reproduced the issue with the Symphony client, but also with this one which is fully open source:
$ git clone https://github.com/jitsi/jitsi-meet-electron/
$ npm install
$ npm start
2. Once you select the screen you want to share, you immediately get a black screen as the local stream. The other participants also get a black screen as the remote stream. The issue appears to affect the screens randomly, sometimes the impacted screens are the screens number 2, 4, 6, sometimes after a reboot, 4, 5, 6, etc...
### Root cause analysis
At the system level, the way Windows 10 enumerates the screens is slightly
different when a virtual video driver is involved.
On Electron, the picker window is managed by the DesktopCapturerSource object:
https://github.com/electron/electron/blob/master/docs/api/structures/desktop-
capturer-source.md and the mapping relies on a naming rule
https://github.com/electron/electron/blob/master/atom/browser/api/atom_api_desktop_capturer.cc
that fails when a non-conventional video driver is involved.
At Symphony, we experienced the exact same issue with CEF/Paragon. This is how
we fixed the problem of the screen IDs enumeration: symphonyoss/SFE-
DesktopClient-pgx@`85f0d71`#diff-7e750064e4ad7245e99d95316f830119
This fix also addresses a similar issue we had with one monitor, but with
Citrix XenDesktop installed (https://www.citrix.com/products/xenapp-
xendesktop/), which also alters how Windows enumerates the screens.
FYI, this is how the WebRTC native code that does enumeration:
https://webrtc.googlesource.com/src/+/master/modules/desktop_capture/win/screen_capture_utils.cc
|
* Electron version: 1.7.3 - not sure when this was introduced, works fine in latest production build based on 1.4.15
* Operating system: Windows
### Expected behavior
I have three screens connected to my computer.
`desktopCapturer.getSources({types: ['screen']})` correctly identifies three
sources.
I want to share my first screen and set `chromeMediaSourceId` to the matching
id `screen:0:0` in the constraints when requesting the MediaStream using
`navigator.mediaDevices.getUserMedia()`. I should get a MediaStream containing
a video track with the content of the first screen.
### Actual behavior
The stream returned will show the content of the second screen. If I ask for
the second screen, I get the third screen. If I ask for the third screen, I
get a black screen.
### How to reproduce
https://github.com/wireapp/wire-desktop
git clone https://github.com/wireapp/wire-desktop.git
npm install
npm run prod
* Log in or create a Wire account. Feel free to connect to me (@gregor)
* Start audio or video call
* Click on share your screen
* Select screen to be shared
| 1 |
I believe this is a bug, or if it isn't, I couldn't find anything in the
documentation that says it should act this way.
It seems like random.choice is ignoring the masked values. As you can see in
the code below, the output of random.choice gives values that have been
previously masked on the array.
### Reproducing code example:
import numpy as np
x = np.linspace(0,100,100)
xmask = np.ma.masked_where(x>75,x)
print(np.nanmax(xmask))
random_choice = np.random.choice(xmask,50)
print(np.nanmax(random_choice))
Output:
> 74.74747474747475
> 96.96969696969697
I've tried this several times, and the maximum value of random_choice always
seems to be between 90 and 100.
### Numpy/Python version information:
1.18.1 3.7.6 (default, Jan 8 2020, 19:59:22)
[GCC 7.3.0]
|
The subject says it all, but in case you missed it: the function
`numpy.show_config()` (an alias for `numpy.__config__.show()`) doesn't have a
docstring, and it does not appear in the online docs.
A docstring that explains the information printed by `show_config()` would be
helpful.
| 0 |
**David Harrigan** opened **SPR-8986** and commented
Hi,
In our application we have a rapidly growing number of JAXB2 annotated
classes. It is a right pain to add these classes manually to the
"classesToBeBound" property in the Jaxb2Marshaller. Given that other
components (I'm looking at you Hibernate : AnnotationSessionFactoryBean) have
the ability to automatically add classes from packages that match annotations,
why not then for the Jaxb2Marshaller (having to key in the classes manually is
**so** old skool).
I've extended Jaxb2Marshaller (file attached) that scans on the classpath for
appropriately annotated classes. Please do review and I hope that this can be
incorporated into the next release. I'm happy to make changes to the codebase
if required to bring it up to Spring coding standards.
It's a pity that afterPropertiesSet is marked as Final in Jaxb2Marshaller
since I can't override that method to set up the setClassesToBeBound before
then calling the super afterPropertiesSet. Currently as the code stands, I
have to provide a dummy setClassesToBeBound and setLazyInit to be true. This
dummy is then replaced by overriding the getJaxbContext. I think this needs
rewriting.
An example of use:
<bean id="marshaller" class="foo.bar.AnnotationJaxb2Marshaller">
<property name="lazyInit" value="true" />
<property name="classesToBeBound">
<list>
<value>foo.bar.Class</value>
</list>
</property>
<property name="packagesToScan">
<list>
<value>foo.bar.jaxb.model</value>
</list>
</property>
</bean>
-=david=-
* * *
**Affects:** 3.1 GA
**Attachments:**
* AnnotationJaxb2Marshaller_v2.java ( _5.10 kB_ )
* AnnotationJaxb2Marshaller.java ( _4.13 kB_ )
**Issue Links:**
* #13835 HTTP response code 308 ( _ **"is duplicated by"**_ )
* #13844 Add ClasspathScanningJaxb2Marshaller for spring OXM ( _ **"is duplicated by"**_ )
**Referenced from:** commits `8980ce7`, `79f32c7`, `ff9ad7a`
|
**Loren Rosen** opened **SPR-305** and commented
The shell scripts in samples/jpetstore/db/hsqldb has DOS line delimiters
instead of Unix delimiters. This can cause attempts to run this sample
application to fail.
What happens is that, when you start up the database via server.sh, the shell
sees the end of the command as '-database jpetstore\c', where by \c I mean the
carriage return character. Then when the sample code itself attempts to query
the database, it gets an error since the database jpetstore (with no
terminating carriage return) doesn't exist:
org.springframework.jdbc.BadSqlGrammarException: Bad SQL grammar [(mapped
statement)] in task 'SqlMapTemplate'; nested exception is
java.sql.SQLException: Table not found: CATEGORY in statement [select CATID,
NAME, DESCN from CATEGORY where CATID = 'CATS']
org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.translate(SQLErrorCodeSQLExceptionTranslator.java:254)
org.springframework.orm.ibatis.SqlMapTemplate.execute(SqlMapTemplate.java:116)
org.springframework.orm.ibatis.SqlMapTemplate.executeQueryForObject(SqlMapTemplate.java:152)
org.springframework.samples.jpetstore.dao.ibatis.SqlMapCategoryDao.getCategory(SqlMapCategoryDao.java:17)
org.springframework.samples.jpetstore.domain.logic.PetStoreImpl.getCategory(PetStoreImpl.java:124)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
java.lang.reflect.Method.invoke(Method.java:324)
org.springframework.aop.framework.AopProxyUtils.invokeJoinpointUsingReflection(AopProxyUtils.java:60)
org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:150)
org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:119)
org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:56)
org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:139)
org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:152)
$Proxy0.getCategory(Unknown Source)
org.springframework.samples.jpetstore.web.spring.ViewCategoryController.handleRequest(ViewCategoryController.java:31)
org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:44)
org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:495)
org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:321)
javax.servlet.http.HttpServlet.service(HttpServlet.java:810)
To the beginning user it simply appears that the samples are broken. Some
beginning users might even jump to the conclusion that spring itself doesn't
work, since here even the sample code gets errors about bad SQL grammar. It
took me most of a morning to figure out the problem.
Presumably the problem occurs with the scripts in the petclinic sample as
well, though I haven't tried them.
Note also that it's possible some Unix shells could treat DOS line delimiters
the same as Unix delimiters, and so not exhibit this bug. Here I'm using
GNU bash, version 2.05b.0(1)-release (powerpc-apple-darwin7.0)
* * *
**Affects:** 1.1 RC2
**Issue Links:**
* #7861 DOS chars in sample app shell scripts ( _ **"is duplicated by"**_ )
| 0 |
1. What is a short input program that triggers the error?
(compile with -race enabled)
package pdl
var (
codec1 = codec{newE, "application/pdf"}
codec2 = codec{newE, "text/plain"}
availableCodecs = [...]codec{codec1, codec2}
)
type encoder interface{}
type codec struct {
NewWriter func() encoder
MimeType string
}
type E struct{}
func newE() encoder { return new(E) }
2. What is the full compiler output?
./y.go:7: internal compiler error: found non-orig name node availableCodecs
3. What version of the compiler are you using? (Run it with the -V flag.)
go version go1.3beta2 +e165495e81bf Fri May 23 12:29:29 2014 +1000 linux/amd64
|
What steps will reproduce the problem?
1. Set your $INCLUDE environment variable to be longer than 500 characters.
2. Try to assemble any .s file. (I've been using
$GOROOT/src/pkg/runtime/$GOARCH/asm.s)
3. Get a segmentation fault.
I've reproduced with both 6a and 8a. I'm assuming 5a does the same thing.
Which revision are you using? (hg identify)
4d7f5eddd695 tip
The problem is due to a buffer overflow in macinc cc/macbody. symb is an
array of 500 characters and it's filled using strcpy without checking the
length of the source. $INCLUDE happens to be one of these sources and it's
easier than you might think to exceed 500 characters -- particularly in cygwin.
There might be other buffer overflows possible in this file through similar
means. There are a number of strcpy calls.
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.8-SNAPSHOT
* Operating System version: MacOS
* Java version: oraclejdk1.8
### Steps to reproduce this issue
1. xxx
2. xxx
3. xxx
Pls. provide [GitHub address] to reproduce this issue.
### Expected Result
What do you expected from the above steps?
### Actual Result
What actually happens?
If there is an exception, please attach the exception trace:
Just put your stack trace here!
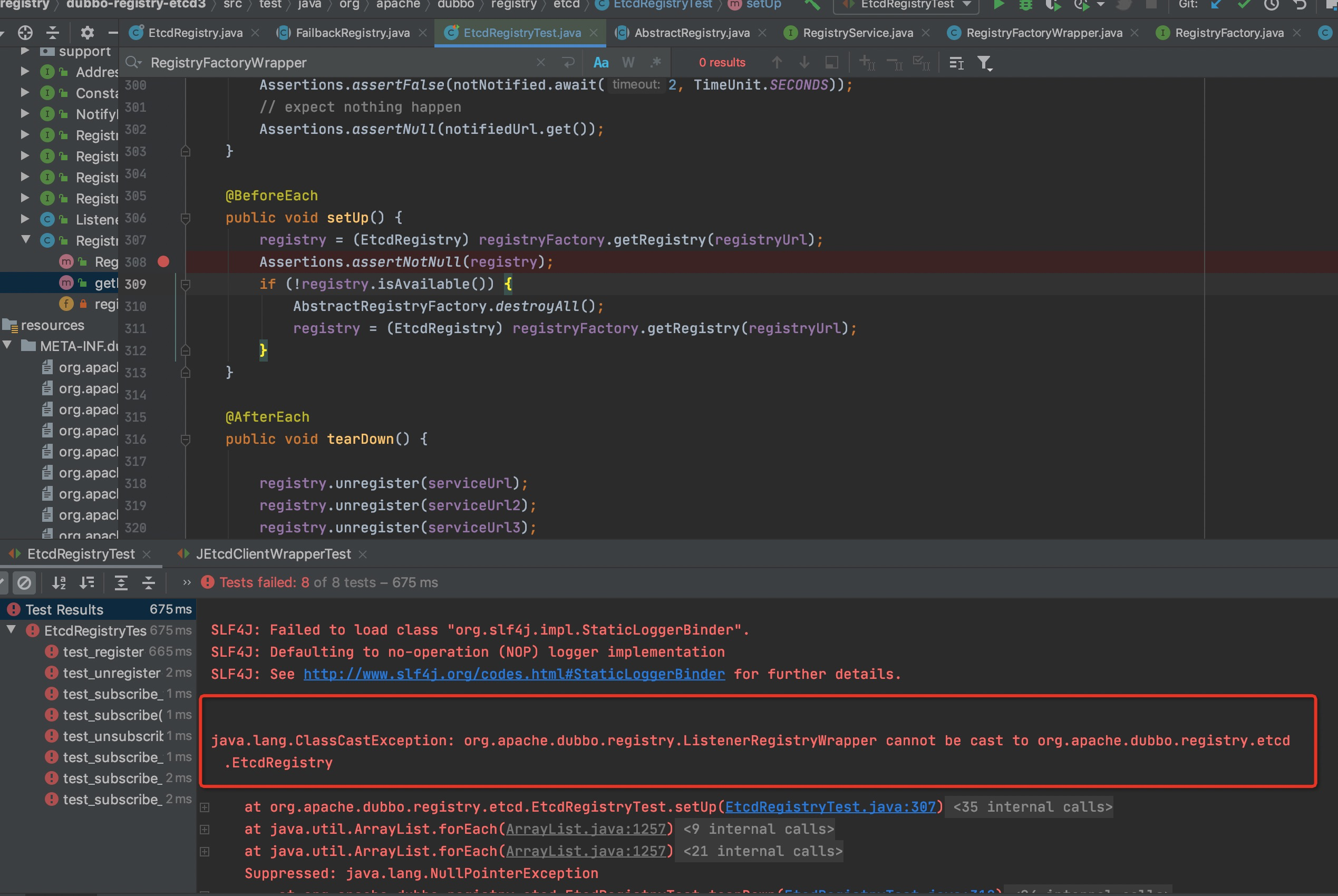
I will submit a pr.
|
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.6.9
* Operating System version: centos 6.4
* Java version: 1.8
### Steps to reproduce this issue
1. dubbo服务端口20880,服务启动成功。
2. 执行如下命令:
[root@serv87 ~]# telnet 192.168.128.187 20880
Trying 192.168.128.187...
Connected to 192.168.128.187.
Escape character is '^]'.
status -l
+------------+--------+--------------------------------------------------------+
| resource | status | message |
+------------+--------+--------------------------------------------------------+
| threadpool | OK | Pool status:OK, max:200, core:200, largest:19, active:1,
task:19, service port: 20880 |
| load | OK | load:0.51,cpu:8 |
| memory | OK | max:1969M,total:1969M,used:289M,free:1680M |
| registry | OK | 192.168.128.187:2880(connected) |
| server | OK | /192.168.128.187:20880(clients:13) |
| spring | OK | classpath*:spring-config/*.xml |
| summary | OK | |
+------------+--------+--------------------------------------------------------+
显示dubbo服务信息,客户安全扫描认为不安全
请问,如何解决这个问题?
| 0 |
Right now, it seems like the only way to set -Ofair is via the command line.
Is there also a way to set this programmatically in `celeryconfig.py`, or in
Django's `settings.py`?
|
Can Celery expose a configuration parameter for the optimisation
parameter(currently only passable on the command line as `-Ofair`.
| 1 |
Hey,
I found something weird... I have a routing system with a modular structure,
inside my general routing.yml there's an api_routing.yml and, inside it,
there's one .yml for every 'module' of my application, those are:
benefits_routing.yml
entities_routing.yml
user_routing.yml
Focusing on benefits, the general routing.yml take all /api routes to go to
api_routing.yml, that takes all /benefits routes to go to
benefits_routing.yml. Thus, if routes inside my benefits_routing.yml are:
##### benefits_routing.yml
api_list_benefits:
path: /
defaults: {_controller: "AppBundle:Benefits:list" }
methods: [GET]
api_new_benefits:
path: /
defaults: {_controller: "AppBundle:Benefits:new" }
methods: [POST]
Then, if I make a POST request to http://domain/api/benefits, the router
should match to the second route, right? Nope.
When I post to '/api/benefits' router throw a 405. Though, if I post to
'/api/benefits/' it works. Weird, huh? In addition, both '/api/benefits' or
'/api/benefits/' with GET method works...
I had a terrible hard time with this trouble and opened a question in stack
overflow:
http://stackoverflow.com/questions/37834923/symfony3-routing-in-production
And then I started playing with Symfony code. Suprise! In my generated
appProdUrlMatcher.php I found the following. For the first (GET) route, I
could see:
if (rtrim($pathinfo, '/') === '/api/entities') {
if (!in_array($this->context->getMethod(), array('GET', 'HEAD'))) {
//bla bla
}
}
Perfect, that's why GET works! It's "rtrimming" the route making the final
slash mean nothing.
Although, with the POST one:
if ($pathinfo === '/api/entities/') {
if ($this->context->getMethod() != 'POST') {
//bla bla
}
}
Wait... what? Why isn't it rtrimming my route?
Okey... Once found this, the solution was clear: go to the place where it's
generated and fix it. Several minutes later I found it:
#####
/Symfony/Component/Routing/Matcher/Dumper/PhpMatcherDumper.php::compileRoute
...
// GET and HEAD are equivalent
if (in_array('GET', $methods) && !in_array('HEAD', $methods)) {
$methods[] = 'HEAD';
}
....
$supportsTrailingSlash = $supportsRedirections && (!$methods || in_array('HEAD', $methods));
....
if ($supportsTrailingSlash && substr($m['url'], -1) === '/') {
$conditions[] = sprintf("rtrim(\$pathinfo, '/') === %s", var_export(rtrim(str_replace('\\', '', $m['url']), '/'), true));
$hasTrailingSlash = true;
} else {
$conditions[] = sprintf('$pathinfo === %s', var_export(str_replace('\\', '', $m['url']), true));
}
....
GET falls in the first condition, where it adds the rtrim, but POST does not.
I hope I have explained well the matter, it was not easy...
Question: Is this deliberated? If yes (I guess so), why? How can we fix then
the final slash problem?
Best and many thanks,
Ignacio
###### Edit:
I just realized that, if the request "supports trailing slash" it also adds:
if (substr($pathinfo, -1) !== '/') {
return $this->redirect($pathinfo.'/', 'api_list_entities');
}
Which actually breaks in POST, because the redirect is always GET, I guess
that's why the condition of GET or HEAD...
How to fix this? I have a patch for the PhpMatcherDumper.php::compileRoute
function, but I guess that's not the way to proceed.
Thanks!
|
There is currently a known limitation when using route imports that makes it
impossible to to have a root route `/` be imported under a prefix without a
trailing slash. See #4322 and silexphp/Silex#149
I propose to solve this problem in a generic way by offering an option when
importing routes to remove or add trailing slashes (which defaults to null,
meaning not modifying anything):
AcmeBusinessBundle_client:
resource: "@AcmeBusinessBundle/Resources/config/routing/client.yml"
prefix: /clients
trailing_slashes: true|false|null
This way, the users can unify the path on import the way they want.
So for example
acme_business_client_list:
path: /
defaults: { _controller: AcmeBusinessBundle:Client:list }
imported with `trailing_slashes: false` under `prefix: /clients` will result
in path `/clients` instead of `/clients/`.
The other case with `trailing_slashes: true` is helpful when you import third
party routes without trailing slash but you decided that you app should use
training slashes everywhere consistently.
| 1 |
Any `enum` type that references itself in a constructor appears to cause the
compiler to run out of stack. As a simple example, here's `ll.rs`:
enum list { nil, cons(int, list) }
fn main() {}
On compiling with backtrace:
$ RUST_LOG=rustc=0,::rt::backtrace rustc ll.rs
rust: task eaed20 ran out of stack
/usr/local/bin/../lib/librustrt.so(_ZN9rust_task4failEv+0x25)[0x7f44bdd105f5]
/usr/local/bin/../lib/librustrt.so(+0x199b5)[0x7f44bdd109b5]
/usr/local/bin/../lib/librustrt.so(_ZN9rust_task9new_stackEmPvm+0x3c)[0x7f44bdd10d1c]
/usr/local/bin/../lib/librustrt.so(upcall_s_new_stack+0x1d)[0x7f44bdd1305d]
/usr/local/bin/../lib/librustrt.so(+0x2cd39)[0x7f44bdd23d39]
/usr/local/bin/../lib/librustrt.so(upcall_new_stack+0x42)[0x7f44bdd14192]
/usr/local/bin/../lib/libstd-79ca5fac56b63fde-0.1.so(+0x5d7d5)[0x7f44be6517d5]
/usr/local/bin/../lib/libstd-79ca5fac56b63fde-0.1.so(_ZN3map7chained3get17_b22fd9d6e1cb5e02E+0x1dd)[0x7f44be62173d]
/usr/local/bin/../lib/libstd-79ca5fac56b63fde-0.1.so(+0x4ee94)[0x7f44be642e94]
/usr/local/bin/../lib/librustc-4171d83aef249987-0.1.so(_ZN6middle2ty12tag_variants17_438379e850418683E+0x5c)[0x7f44be06e0bc]
/usr/local/bin/../lib/librustc-4171d83aef249987-0.1.so(_ZN6middle2ty26type_structurally_contains17_ebae492368cb31bcE+0xa5)[0x7f44be060fb5]
/usr/local/bin/../lib/librustc-4171d83aef249987-0.1.so(_ZN6middle2ty26type_structurally_contains17_ebae492368cb31bcE+0x27d)[0x7f44be06118d]
error: internal compiler error unexpected failure
note: The compiler hit an unexpected failure path. This is a bug. Try running with RUST_LOG=rustc=0,::rt::backtrace to get further details and report the results to github.com/mozilla/rust/issues
rust: upcall fail 'explicit failure', src/comp/driver/rustc.rs:176
/usr/local/bin/../lib/librustrt.so(_ZN9rust_task4failEv+0x25)[0x7f44bdd105f5]
/usr/local/bin/../lib/librustrt.so(+0x2cd39)[0x7f44bdd23d39]
/usr/local/bin/../lib/librustrt.so(upcall_fail+0x39)[0x7f44bdd13ad9]
rustc[0x405222]
rustc[0x40545c]
/usr/local/bin/../lib/librustrt.so(task_start_wrapper+0x32)[0x7f44bdd0f812]
rust: domain main @0xe9cc60 root task failed
$ rustc --version
rustc 0.1
host: x86_64-unknown-linux-gnu
$
(There appears to be many issues similar to this but I lack the expertise to
determine whether they are the same bug. Those issues include #742. Is `tag`
an old keyword for `enum`? My compiler doesn't know about it.)
|
The `net` module has a few things which I would like to consider improving:
* Must the `Acceptor` and `Listener` traits exists? It's a shame having to import the traits just to make a simple server.
* Does the layout make sense? `std::io::net::ip` is quite long. Possibly a top-level `net` module? Possibly shorten using reexports?
* What more needs to be exported? The current primitives implement the basic Reader/Writer traits, but not much beyond that. There are many methods provided by librustuv/libnative which are not exported. Need to make sure the signatures are correct.
* "Unix pipes" are not unix pipes on windows (they are named pipes)
Wish list
* `TcpStream::open("google.com:80")` does not work
* I can clone a tcp stream, but I cannot close that duplicate tcp stream (from my owned stream)
* Creating a server is quite wordy. There are a number of imports, lots of ip addr configuration, lots of listening/accepting, etc.
Nominating, I believe it is quite important to have a solid networking story.
| 0 |
This is related to #2461. Essentially if we wrap a render call in a try catch
this works the first time. It seems like when `React.render` is called a
second time (the update case) it does not work. It seems that `React.render`
is async when updating an existing component tree.
I may be missing something but it seems like this leaves no way for developers
to catch errors when rendering children components.
I have a JSBin demoing this issue here:
http://jsbin.com/mifedepada/edit?js,console,output
|
So I'm trying to put some graceful error handling in case 1 of my views crap
out:
var MyGoodView = React.createClass({
render: function () {
return <p>Cool</p>;
}
});
var MyBadView = React.createClass({
render: function () {
throw new Error('crap');
}
});
try {
React.render(<MyBadView/>, document.body);
} catch (e) {
React.render(<MyGoodView/>, document.body);
}
However, `MyGoodView` does not get rendered w/ the following stack trace:

Seems like error throw React in a bad state where `renderedComponent` is
`undefined`, thus cannot be unmounted. How do I handle this scenario?
| 1 |
The docs pages for Send and Sync show duplicated and incorrect items in the
"Implementors" section.
Specifically, an incorrect positive impl for `Rc` is present and the correct
negative impl is present twice.
Also, impls for `Arc` and `ArcInner` appear multiple times, with and without
trait bounds and `where` clauses, with `Arc` having three appearances:
impl<T> Send for Arc<T> where T: Send + Sync
impl<T: Sync + Send> Send for Arc<T>
impl<T> Send for Arc<T>
|
# Issue
I noticed with a few of my crates that I have some redundancies between my
docs and the code in the crate, specifically testcases. As a example, here
`nice_example()` is duplicated:
//! docs docs docs
//! docs docs docs
//! ```
//! fn nice_example() { ... }
//! ```
...
#[test]
fn nice_example() { ... }
Now, there are right now two ways to deal with this:
* Keep both copies
* Con: redundant copies, code can start drifting apart unintentionally.
* Pro: If docs and tests diverge intentional, no additional work is needed.
* Remove the separate unit test copy of the code.
* Pro: The docs will get tested anyway
* Pro: No redundancy
* Con: Unit tests get split between two locations
* Con: Unit tests start mixing with documentation, a change to either might cause changes to both and/or moving the unit test code back and forth between the docs and the crate.
As an additional issue, having rust code in doc comments be highlighted as
rust code is kinda complicated - or at least not implemented in most
highlighters.
# Proposal
Have a way in doc comments to "include" the source code of an item in the
documented crate, eg:
//! docs docs docs
//! docs docs docs
//! ```
//! #rustdoc_include self::nice_example
//! ```
...
#[test]
fn nice_example() { ... }
* Pro: Only one copy of the actual code
* Pro: No redundancy
* Pro: Unit tests can be kept separate from the docs, even if they are nicely documented and used as example code in them.
* Pro: If the docs don't want to use that particular code example anymore, only the reference needs
to be deleted, and a nicely commented unit test remains.
* The one copy of the code is outside doc comments, and thus will get highlighted correctly.
* Con: More machinery for rustdoc to support
* Con: Harder to read and write the documentation directly in the source.
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
This should work:
// in pages/index.js
import { Layout } from 'layout'
export default () => <Layout />
// in layout/index.js
export { default as Layout } from './Layout'
## Current Behavior
export { default as Layout } from './Layout'
^^^^^^
SyntaxError: Unexpected token export
## Steps to Reproduce
1. Create a new next app.
2. Add a custom server.js.
3. Create a component outside of the pages directory.
4. Import that component from within pages/index.js.
5. `yarn dev`
## Your Environment
Tech | Version
---|---
next | 3.0.6
node | 8.2.1
OS | macOS Sierra 10.12.4
|
Hello! I'm just now getting started with next (using version 1.2.3), and I
have the following folder structure:
* package.json
* pages
* index.js
* lib
* components
* Test.js
I have a symlink: `node_modules/lib -> ../lib`.
I import my `Test` component with `import Test from 'lib/components/Test'`.
This works fine, but it seems to not be transpiled: if I `import` anything
from my `Test` component, I get the following error: `SyntaxError: Unexpected
token import`.
Any guidance here? I'd be fine having my `/components` under `/pages` but I
don't want them to be able to be served up standalone.
Thanks!
| 1 |
I like the scrollBeyondLastLine feature but it scrolls too much to my state
and i often find myself beeing scared to have cleared my file :s
That would be great if `editor.scrollBeyondLastLine` could be a boolean or an
integer that would represent the maximium of lines it would overscroll.
Thanks
|
We want to adopt tslint for checking our typescript code.
Most of our style guide should be checked by tslint.
## General
* Add initial tslint.json
* Add tslint to our gulp script
* Add a Code task with a problem matcher for tslint
* Document its use in the Contribution Guidelines
* Implement non externalised strings rule
* Add tslint to the pre-commit hygene (wait until we are down to 0 with the warnigs)
## Projects
Add tslint checking to other vscode projects
* vscode-omnisharp
* vscode-node-debugger-adapter
Others non-core projects
* vsce
* vscode-vscode
Extensions
* vscode-tslint
* vscode-eslint
* vscode-jslint
* vscode-editorConfig
## Rules
* no-unused-expression
* no-unreachable
* no-duplicate-variable
* no-unexternalized-strings
* no-duplicate-key (in object literals)
* no-unused-variable (includes imports) - 500 instances
* curly (braces for if/do/while, **in style guide** ) - 70 instances
* class-name (PacalCased class and interface names), **in style guide** ) - 3
* semicolon (semicolon at end of statements) - 220 instances
* no-unnecessary-semicolons - 60 instances
* no-duplicate-case - 3 instances
* tripple-equals - 10 instances
Candidates
* promise-must-complete - 10 instances (false positives?)
* no-switch-case-fall-through - 25
* forin (for ... statement must be filtered with an if) - 80 instances
* prefer-const (rule is in the TS repository) - ???
Future
* no-var-keyword - 5800
* indent tabs (covered by hygene tasks, _in style guide_ )
* jsdoc-format - 200
* no-trailing-whitespace
* whitespace ...
Rejected
* no-shadowed-variable - 300 instances
* no-string-literal (disallow object access via string literals) - 16
* no-unused-imports (subset of no-unused-variables) - 170 instances
* no-function-expression (use arrow functions, **in style guide** ) - 190 instances
* missing-optional-annotation - 10 instances
* no-use-before-declare
* no-empty-interfaces (we them in our service injection patterns)
* no-multiple-var-decl
* no-missing-visibility-modifiers
| 0 |
* [ x ] I tried using the latest `mongoose/mongoose.d.ts` `"@types/mongoose": "^4.6.1"` file in this repo and had problems.
* [ x ] I tried using the latest stable version of tsc. https://www.npmjs.com/package/typescript
* [ x ] I want to talk about `mongoose/mongoose.d.ts`.
* The authors of that type definition are cc/ @simonxca
Hi, there is the problem with mongoose middleware definitions:
According to the docs http://mongoosejs.com/docs/middleware.html function
signature for the hook post save is may looks like this (error: MongoError,
doc: Document, next: (err?: NativeError) => void)
schema.post('save', function(error, doc, next) {
if (error.name === 'MongoError' && error.code === 11000) {
next(new Error('There was a duplicate key error'));
} else {
next(error);
}
});
But typings has this
/**
* Defines a post hook for the document
* Post hooks fire on the event emitted from document instances of Models compiled
* from this schema.
* @param method name of the method to hook
* @param fn callback
*/
post<T extends Document>(method: string, fn: (doc: T, next: (err?: NativeError) => void,
...otherArgs: any[]) => void): this;
post<T extends Document>(method: string, fn: (doc: T) => void, ...args: any[]): this;
in other words, `error` signature was omitted
|
* I tried using the `@types/xxxx` package and had problems.
* I tried using the latest stable version of tsc. https://www.npmjs.com/package/typescript
* I have a question that is inappropriate for StackOverflow. (Please ask any appropriate questions there).
* Mention the authors (see `Definitions by:` in `index.d.ts`) so they can respond.
* Authors: @alloy @gyzerok @huhuanming @jeremistadler
* * *
Hey there! I'm combining Node, React, React DOM and React Native code in the
same codebase (So that I can generate simultaneously iOS, Android and Web apps
with Server-side rendering support), and I'm hitting the following errors in
the type definitions for React native:
ERROR in [at-loader] ./node_modules/@types/node/index.d.ts:60:13
TS2451: Cannot redeclare block-scoped variable 'global'.
ERROR in [at-loader] ./node_modules/@types/node/index.d.ts:84:13
TS2300: Duplicate identifier 'require'.
ERROR in [at-loader] ./node_modules/@types/react-native/index.d.ts:8872:11
TS2451: Cannot redeclare block-scoped variable 'global'.
ERROR in [at-loader] ./node_modules/@types/react-native/index.d.ts:8873:14
TS2300: Duplicate identifier 'require'.
ERROR in [at-loader] ./node_modules/@types/webpack-env/index.d.ts:186:13
TS2300: Duplicate identifier 'require'.
It looks like React Native redefines `global` and `require`:
declare global {
const global: GlobalStatic;
function require(name: string): any;
/**
* This variable is set to true when react-native is running in Dev mode
* Typical usage:
* <code> if (__DEV__) console.log('Running in dev mode')</code>
*/
var __DEV__: boolean
}
Since these are already defined by `@types/node`, the compiler complains. I
was able to work around the issue by adding the following option to my
`tsconfig.json` file, however I'd like to avoid doing that if possible:
{
"skipLibCheck": true
}
Thanks in advance
| 0 |
### Description
Currently, there is support only for one_success trigger_rule, which starts
the task instance the moment after one of the upstream tasks succeeds. The
idea for the new trigger_rule is to wait for all upstream tasks to be done and
at least one of them succeed.
### Use case/motivation
The use case is to allow a OR-like behavior to trigger_rules.
Maybe even XOR-like behavior could be added as a second extra trigger_rule.
### Related issues
_No response_
### Are you willing to submit a PR?
* Yes I am willing to submit a PR!
### Code of Conduct
* I agree to follow this project's Code of Conduct
|
**Description**
I would like to have a trigger rule that triggers a task if all the upstream
tasks have executed ( _all_done_ ) and there is atleast one successful
upstream task. This would be like the trigger rule: _one_success_ , except
it'll wait for all upstream tasks to finish.
**Use case / motivation**
I have downstream tasks that should run after all the upstream tasks have
finished execution. I can't trigger the downstream task if none of the
upstream tasks pass, but I need to trigger it if even one of them passes.
**Are you willing to submit a PR?**
I can work on a PR, if the feature is approved.
| 1 |
* * *
**STOP READING NOW**
If you get the error message from the caption, because it is useless and too
generic (are you sure that you build OpenCV library and not other make
project?).
Reason of your build problem is somewhere above this line, you need to grab it
instead.
To get right error message you should run "make" in verbose mode:
$ make VERBOSE=1
(without any -j options to prevent message lines mess)
* * *
##### System information (version)
* OpenCV => 3.1
* Operating System / Platform => Elementary OS (Loki)
* Compiler => make
##### Detailed description
* When I did just `cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..`, `make -j4` worked all right```
* When I tried to `make -j4 VERBOSE=1` with Examples and Modules, I got this error
...
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv_contrib/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching/CMakeFiles/opencv_surface_matching.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/surface_matching/CMakeFiles/opencv_surface_matching.dir/build.make modules/surface_matching/CMakeFiles/opencv_surface_matching.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/surface_matching/CMakeFiles/opencv_surface_matching.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 28%] Built target opencv_surface_matching
make -f modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/build.make modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv_contrib/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/build.make modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/surface_matching/CMakeFiles/example_surface_matching_ppf_load_match.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 28%] Built target example_surface_matching_ppf_load_match
make -f modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/build.make modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv_contrib/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/build.make modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/surface_matching/CMakeFiles/example_surface_matching_ppf_normal_computation.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 28%] Built target example_surface_matching_ppf_normal_computation
make -f modules/video/CMakeFiles/opencv_video.dir/build.make modules/video/CMakeFiles/opencv_video.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video/CMakeFiles/opencv_video.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/video/CMakeFiles/opencv_video.dir/build.make modules/video/CMakeFiles/opencv_video.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/video/CMakeFiles/opencv_video.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 29%] Built target opencv_video
make -f modules/video/CMakeFiles/opencv_test_video.dir/build.make modules/video/CMakeFiles/opencv_test_video.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video/CMakeFiles/opencv_test_video.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/video/CMakeFiles/opencv_test_video.dir/build.make modules/video/CMakeFiles/opencv_test_video.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/video/CMakeFiles/opencv_test_video.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 30%] Built target opencv_test_video
make -f modules/video/CMakeFiles/opencv_perf_video.dir/build.make modules/video/CMakeFiles/opencv_perf_video.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/video/CMakeFiles/opencv_perf_video.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/video/CMakeFiles/opencv_perf_video.dir/build.make modules/video/CMakeFiles/opencv_perf_video.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/video/CMakeFiles/opencv_perf_video.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 31%] Built target opencv_perf_video
make -f modules/dnn/CMakeFiles/opencv_dnn.dir/build.make modules/dnn/CMakeFiles/opencv_dnn.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv_contrib/modules/dnn /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/dnn /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/dnn/CMakeFiles/opencv_dnn.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/dnn/CMakeFiles/opencv_dnn.dir/build.make modules/dnn/CMakeFiles/opencv_dnn.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make[2]: Nothing to be done for 'modules/dnn/CMakeFiles/opencv_dnn.dir/build'.
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 33%] Built target opencv_dnn
make -f modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/build.make modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/depend
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build && /usr/bin/cmake -E cmake_depends "Unix Makefiles" /home/flipswitch/Programs/anaconda3/pkgs/opencv /home/flipswitch/Programs/anaconda3/pkgs/opencv_contrib/modules/dnn /home/flipswitch/Programs/anaconda3/pkgs/opencv/build /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/dnn /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/DependInfo.cmake --color=
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
make -f modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/build.make modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/build
make[2]: Entering directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
[ 33%] Linking CXX executable ../../bin/example_dnn_fcn_semsegm
cd /home/flipswitch/Programs/anaconda3/pkgs/opencv/build/modules/dnn && /usr/bin/cmake -E cmake_link_script CMakeFiles/example_dnn_fcn_semsegm.dir/link.txt --verbose=1
/usr/bin/c++ -fsigned-char -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wundef -Winit-self -Wpointer-arith -Wshadow -Wno-narrowing -Wno-delete-non-virtual-dtor -Wno-comment -fdiagnostics-show-option -Wno-long-long -pthread -fomit-frame-pointer -msse -msse2 -mno-avx -msse3 -mno-ssse3 -mno-sse4.1 -mno-sse4.2 -ffunction-sections -fvisibility=hidden -fvisibility-inlines-hidden -Wno-shadow -Wno-parentheses -Wno-maybe-uninitialized -Wno-sign-promo -Wno-missing-declarations -O3 -DNDEBUG -DNDEBUG CMakeFiles/example_dnn_fcn_semsegm.dir/samples/fcn_semsegm.cpp.o -o ../../bin/example_dnn_fcn_semsegm -rdynamic ../../lib/libopencv_dnn.so.3.1.0 ../../lib/libopencv_highgui.so.3.1.0 ../../lib/libopencv_videoio.so.3.1.0 ../../lib/libopencv_imgcodecs.so.3.1.0 ../../lib/libopencv_imgproc.so.3.1.0 ../../lib/libopencv_core.so.3.1.0 -Wl,-rpath,/home/flipswitch/Programs/anaconda3/pkgs/opencv/build/lib
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::DescriptorPool::FindFileByName(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::MessageFactory::InternalRegisterGeneratedFile(char const*, void (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&))'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteStringMaybeAliased(int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::ReadBytes(google::protobuf::io::CodedInputStream*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::GetTypeName[abi:cxx11]() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedOutputStream::WriteStringWithSizeToArray(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, unsigned char*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::InitializationErrorString[abi:cxx11]() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::empty_string_[abi:cxx11]'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteBytesMaybeAliased(int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteString(int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::ArenaStringPtr::AssignWithDefault(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const*, google::protobuf::internal::ArenaStringPtr)'
collect2: error: ld returned 1 exit status
modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/build.make:100: recipe for target 'bin/example_dnn_fcn_semsegm' failed
make[2]: *** [bin/example_dnn_fcn_semsegm] Error 1
make[2]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
CMakeFiles/Makefile2:3094: recipe for target 'modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/all' failed
make[1]: *** [modules/dnn/CMakeFiles/example_dnn_fcn_semsegm.dir/all] Error 2
make[1]: Leaving directory '/home/flipswitch/Programs/anaconda3/pkgs/opencv/build'
Makefile:160: recipe for target 'all' failed
make: *** [all] Error 2
##### Steps to reproduce
* Downloaded opencv and opencv_contrib
* Then `cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local -D OPENCV_EXTRA_MODULES_PATH=~/Programs/anaconda3/pkgs/opencv_contrib/modules -D INSTALL_C_EXAMPLES=OFF -D INSTALL_PYTHON_EXAMPLES=ON -D BUILD_EXAMPLES=ON -D WITH_IPP=OFF ..`
* Followed by `make -j4 VERBOSE=1`
* First time I tried without using `WITH_IPP=OFF`, it reached 50% and errored out with the same error.
* Next time I tried with it and it errored out at 23%
|
##### System information (version)
* OpenCV => :4.0.0.21:
* Operating System / Platform => : windows10:
* Compiler => :pre-build version from pip:
##### Detailed description
background: i wanna achieve opencv dnn model to detect face in an image
after accessing the model and prototxt from
opencv_extra/testdata/dnn/download_models.py, i learned some sample code to
test whether it works or not. And then, I got the following info:
[libprotobuf ERROR C:\projects\opencv-python\opencv\3rdparty\protobuf\src\google\protobuf\text_format.cc:288] Error parsing text-format opencv_caffe.NetParameter: 2:1: Invalid control characters encountered in text.
[libprotobuf ERROR C:\projects\opencv-python\opencv\3rdparty\protobuf\src\google\protobuf\text_format.cc:288] Error parsing text-format opencv_caffe.NetParameter: 2:2: Interpreting non ascii codepoint 162.
[libprotobuf ERROR C:\projects\opencv-python\opencv\3rdparty\protobuf\src\google\protobuf\text_format.cc:288] Error parsing text-format opencv_caffe.NetParameter: 2:2: Expected identifier, got: ?
Traceback (most recent call last):
File "src/facedetect/detector.py", line 103, in <module>
util.gainFaceByDNN(path, modelpath, deploypath)
File "src/facedetect/detector.py", line 26, in gainFaceByDNN
net = cv2.dnn.readNetFromCaffe(modelFile, configFile)
cv2.error: OpenCV(4.0.0) C:\projects\opencv-python\opencv\modules\dnn\src\caffe\caffe_io.cpp:1151: error: (-2:Unspecified error) FAILED: ReadProtoFromTextFile(param_file, param). Failed to parse NetParameter file: D:\project\python\IQA\src\facedetect\res10_300x300_ssd_iter_140000.caffemodel in function 'cv::dnn::ReadNetParamsFromTextFileOrDie'
i have tried to google error, and got some solutions to try but they all
failed, including checking the invisible content of the deploy.prototxt,
redownload the files, etc.
##### Steps to reproduce
below is the code i used for test and it goes wrong on the first code.
net = cv2.dnn.readNetFromCaffe(modelFile, configFile)
image = cv2.imread(imgPath)
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300,300)), 1.0, (300,300), (103.93, 116.77, 123.68), False)
net.setInput(blob)
detections = net.forward()
Is there any practical solutions ? thanks ~
| 0 |
.navbar-brand has max-width: 200px. Don't see why this constaint is there,
because some sites may wish to have wider logos. This can affect the centering
of the logo at mobile (< 768px) resolution
|
I am using the 3.0 RC1 scripts and styles and it seems the navbar-brand
(bootstrap.css line 2736) has its max-width set to 200px. Text beyond 200px
wrap around. For desktop mode 200px can be restrictive.
Was the 200px width enforced due to a previous feature request? If not,
dropping the max-width (or increasing by another 100px) maybe desirable for
the desktop style. Tablet and Mobiles styles can still use 200px.
| 1 |
When sending OPTION requests with token requests, IE11 and below said that the
list could not find the request header. They tried various methods, such as
reducing the browser blocking script, using es6-primise, using babel-polyfill.
All browsers except IE browser were normal, and asked for your help. Look at
the reason. Thank you.

|
在有带token请求的情况下,IE11及以下发送OPTION请求的时候说列表找不到请求头,尝试了各种办法,比如降低浏览器阻止脚本、使用es6-primise、使用babel-
polyfill都尝试了依然不行,除了IE浏览器其他浏览器都正常,求大家的帮助帮看看是什么原因啊,谢谢。
| 1 |
The preview iframe on the right of the code window shows duplicate code.

When I checked the source code for the iframe, I did see the code duplicated
twice as well.
This occurs on many, if not all challenges that I have taken so far. A refresh
of the screen seems to temporarily resolve the issue at times, until I go to
the next challenge. At which time, the code duplicates again.
Using Firefox 41.0.1 on Linux Mint 17
|
Challenge http://www.freecodecamp.com/challenges/waypoint-line-up-form-
elements-responsively-with-bootstrap has an issue.
I think the problem is happening on all Waypoint pages; the device right side
of the screen where the CatPhotoApp page displays the information is being
displayed duplicated;
Another point is that the HTML / CSS code is not completely displayed when the
page is loaded, it is necessary to click or edit the code so that the code
from the previous lesson is displayed correctly;


| 1 |
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
I would like to have an Avatar component with the logged in person's image.
## Current Behavior
Does not work, only if I import the image at the top, and write a static
string as src.
## Steps to Reproduce (for bugs)
Here is my code. I get user.img from this.state. I checked, it is the right
value.
`<Avatar src={`img/${user.img}.jpg`}/>`
## Your Environment
Using create-react-app
Tech | Version
---|---
Material-UI | v0.19.2
React | v15.6.1
browser | Chrome 62
|
### Problem description
It's inconsistence, but seems like `TabIndicator`'s width does not calculated
correctly.
### Versions
* Material-UI: 1.0.0-alpha.21
* React: 15.6.1
* Browser: Safari
### Images & references
When defined with:
You get this:

* * *
When commenting out the width it works:
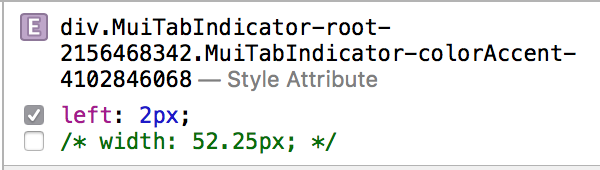

| 0 |
All of the base jumps refer us back to the "get set for basejumps" waypoint
for a review of cloud9, etc to setup the appropriate environment. However,
half the pages (as you step through the 14 pages for that waypoint) FORCE you
to open an external site in order to progress to the next page. It's a
horrible user experience the first time through, and even worse if you go back
to review and just want to refresh your memory and end up with half a dozen
pages open just to get to the info you wanted.
Also, all the base jumps say to go back to this section in order to review how
to setup Heroko, and there's no instructions for Heroku.
|
The GIF Style challenges are great for short introductions, but more
challenging for longer content, like "Get Set for Basejumps" there are several
improvements that would make them easier to use:
* **Enable "Previous" button on final screen**
Right now there is no "Previous" button on the "Finish Challenge" screen. If I
accidentally double-clicked or wanted to go back, I should be able to go back
from the final slide.
* **Add (Step X of Y) somewhere on the screen**
It would be helpful to be able to see how many steps there are and how many
are to go. As I am clicking through the "Get Set for BaseJumps" set, it seems
interminable and there is no clear end in sight.
* **Add sidebar navigation**
This would require giving each slide a title, but would make it significantly
easier to go back and forth between slides if you missed something or just
want to review. On first view, unvisited slides could be grayed out until
visited. This would also reinforce (or possibly replace) 1 above.
* **Add navigable anchors and`windows.history` entries for each slide**
This would make it possible to link to a specific slide, ties into the
navigation above.
Examples `#slide1`, `#slide-title-slug-here`, or `#slideX-title-here`
* **Disable force "Click To Open" if Waypoint has been previously completed**
I shouldn't be forced to click to open another window if I've completed the
challenge. If I'm just looking for a specific piece of information (especially
in longer step challenges), it's a drag to have to open all those windows.
| 1 |
## ℹ Computer information
* PowerToys version: v0.21.1
* PowerToy Utility: Fancy Zones
* Running PowerToys as Admin: Yes
* Windows build number: [run "winver"] Win10 Version 1909 (OS Build 18363.1082)
## 📝 Provide detailed reproduction steps (if any)
1. Set Allow Zones to span across monitors = YES
2. Set Show Zones on all Monitors while dragging = YES
3. Create 8 custom zones - 3 on left monitor; 3 on middle; 2 on right.
4. Apply custom zone
5. Drag window
NOTE - Settings Toggled: "Hold-Shift" (tried both on/off); "Show Zones on all
Monitors..." (tried both on/off); "Allow zones to span across monitors" (tried
on/off).
### ✔️ Expected result
Show zones....
### ❌ Actual result
Does NOT show zones
NOTE: The App works fine IF I Turn OFF "Allow Zones to span across monitors",
but it then only shows on the main monitor which is not my intent. ODDLY -
despite being toggle to "NOT" span monitors - it does now in a defunct manor
(see imgs)
## 📷 Screenshots
ZONE SETUP WORKS FINE:

8-Zone works fine if "Allow zones to span across monitors" = OFF

THEN I TRY - "Allow zones to span across monitors" = ON and reapply Custom
zone (Fancy Zones shows NO zones)

THEN I SWAP BACK to "Allow zones to span across monitors" = OFF (Fancy Zones
shows only 5 of the 8 zones but they're spanning the primary monitor, spilling
halfway onto the right monitor - however the zones disappear if I move my
mouse off of primary (middle) monitor)
8-Zone Custom: 
8-Zone Custom: MOUSE CANNOT CROSS PRIMARY MONITOR THRESHOLD without Zones
disappearing; NOTE ALSO - 3 of the 8 zones are missing

SAME THING HAPPENS IF I USE MY 3-Zone Custom template --> MONITOR SPAN = OFF,
BUT IT'S NOW WORKING ACROSS MONITORS BUT IN A DEFUNCT MANOR - Notice Zone 2
Label is missing & if drag over to Zone 2 or 3, it makes the window Cover both
2, 3, and the remaining Non-Zone left on the right monitor.
3-zone Custom:

3-Zone Custom: 
|
## ℹ Computer information
* PowerToys version: v0.21.1
* PowerToy Utility: FancyZones
* Running PowerToys as Admin: No
* Windows build number: Windows 10 Version 2004: 19041.450
## 📝 Provide detailed reproduction steps (if any)
1. Check the **Allow zones to span across monitors** checkbox
2. Configure a zone which uses multiple monitors via the **Launch zones editor** and Apply
3. Attempt to snap window to zones, or use Shift key to highlight zones while dragging
### ✔️ Expected result
* A window should snap to a zone
* Zone highlighting ought to be functional
* The **Allow zones to span across monitors** setting should persist even when closing settings
* If there are errors "Activating" the zones, these should be raised to the user
### ❌ Actual result
* A window will not snap to a zone when the **Allow zones to span across monitors** is configured
* Window zone highlighting is also not functional
* When FancyZones settings is closed and re-opened, the **Allow zones to span across monitors** checkbox is unchecked
* When **Allow zones to span across monitors** is toggled to checked, then unchecked, zone highlighting and snapping functions, though obviously not with the multi-monitor zones
### 📝 Other Notes
* There is a difference in framerate/refresh rate between the two monitors--could that be an issue?
* System is a SurfaceBook 2 in a Surface Dock which drives a 2560 x 1440 monitor at **60 fps** and a 2560 x 1440 monitor at **30 fps**
* The fps cannot be made the same as far as I can tell. Likely a hardware limitation.
* Display is an LG 49 ultra-wide ( 5120 x 1440)
## 📷 Screenshots
* FancyZones Settings:

* Zone Editor spanning monitors:

* Monitor configuration:

| 1 |
W0921 21:05:38.642280 11417 docker.go:265] found a container with the "k8s" prefix, but too few fields (2): "k8s_unidentified"
I0921 21:05:38.642486 11417 container_gc.go:140] Removing unidentified dead container "/k8s_unidentified" with ID "2876"
I0921 21:05:38.642860 11417 disk_manager.go:114] Running out of space on disk for "root": available 0 MB, threshold 250 MB
I0921 21:05:38.642971 11417 disk_manager.go:114] Running out of space on disk for "docker": available 1 MB, threshold 250 MB
I0921 21:05:38.643086 11417 disk_manager.go:114] Running out of space on disk for "root": available 9 MB, threshold 10 MB
I0921 21:05:38.643267 11417 disk_manager.go:114] Running out of space on disk for "root": available 9 MB, threshold 10 MB
I0921 21:05:38.643675 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 1024 bytes
I0921 21:05:38.643804 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 1024 bytes
I0921 21:05:38.643927 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 1024 bytes
I0921 21:05:38.644042 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 1024 bytes
I0921 21:05:38.644185 11417 image_manager.go:203] [ImageManager]: Disk usage on "" () is at 95% which is over the high threshold (90%). Trying to free 150 bytes
I0921 21:05:38.644229 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 450 bytes
I0921 21:05:38.644305 11417 image_manager.go:203] [ImageManager]: Disk usage on "" () is at 95% which is over the high threshold (90%). Trying to free 150 bytes
I0921 21:05:38.644337 11417 image_manager.go:255] [ImageManager]: Removing image "image-0" to free 50 bytes
W0921 21:05:38.646950 11417 kubelet.go:586] Data dir for pod "bothpod" exists in both old and new form, using new
W0921 21:05:38.647292 11417 kubelet.go:637] Data dir for pod "newpod", container "bothctr" exists in both old and new form, using new
--- FAIL: TestSyncLoopAbort-2 (0.00s)
kubelet_test.go:346: expected syncLoopIteration to return !ok since update chan was closed
E0921 21:05:38.663308 11417 kubelet.go:1609] Pod "_": HostPort is already allocated, ignoring: [[0].port: duplicate value '81/']
E0921 21:05:38.664016 11417 kubelet.go:1609] Pod "newpod_foo": HostPort is already allocated, ignoring: [[0].port: duplicate value '80/']
E0921 21:05:38.667189 11417 kubelet.go:1609] Pod "pod2_": HostPort is already allocated, ignoring: [[0].port: duplicate value '80/']
E0921 21:05:38.669280 11417 kubelet.go:1201] Deleting mirror pod "foo_ns" because it is outdated
W0921 21:05:38.673735 11417 kubelet.go:781] Port name conflicted, "fooContainer-foo" is defined more than once
W0921 21:05:38.673801 11417 kubelet.go:781] Port name conflicted, "fooContainer-TCP:80" is defined more than once
E0921 21:05:38.684049 11417 node_manager.go:478] Error updating node status, will retry: error getting node "127.0.0.1": Node "127.0.0.1" not found
E0921 21:05:38.684109 11417 node_manager.go:478] Error updating node status, will retry: error getting node "127.0.0.1": Node "127.0.0.1" not found
E0921 21:05:38.684211 11417 node_manager.go:478] Error updating node status, will retry: error getting node "127.0.0.1": Node "127.0.0.1" not found
E0921 21:05:38.684248 11417 node_manager.go:478] Error updating node status, will retry: error getting node "127.0.0.1": Node "127.0.0.1" not found
E0921 21:05:38.684286 11417 node_manager.go:478] Error updating node status, will retry: error getting node "127.0.0.1": Node "127.0.0.1" not found
I0921 21:05:38.784666 11417 node_manager.go:279] Node 127.0.0.1 was previously registered
I0921 21:05:38.784849 11417 plugins.go:56] Registering credential provider: .dockercfg
I0921 21:05:38.835534 11417 plugins.go:56] Registering credential provider: .dockercfg
I0921 21:05:38.835691 11417 plugins.go:56] Registering credential provider: .dockercfg
I0921 21:05:38.886180 11417 plugins.go:56] Registering credential provider: .dockercfg
W0921 21:05:38.886326 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_foo_new_12345678_0"
W0921 21:05:38.886347 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_foo_new_12345678_0"
W0921 21:05:38.886361 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886374 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886413 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_foo_new_12345678_0"
W0921 21:05:38.886453 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_foo_new_12345678_0"
W0921 21:05:38.886467 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886479 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886524 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_98765_0"
W0921 21:05:38.886539 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_98765_0"
W0921 21:05:38.886553 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886564 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886594 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886631 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886644 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_98765_0"
W0921 21:05:38.886655 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_98765_0"
W0921 21:05:38.886693 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_12345678_0"
W0921 21:05:38.886707 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_12345678_0"
W0921 21:05:38.886718 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886729 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886749 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_12345678_0"
W0921 21:05:38.886760 11417 docker.go:275] invalid container hash "hash123" in container "k8s_bar.hash123_bar_new_12345678_0"
W0921 21:05:38.886772 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
W0921 21:05:38.886782 11417 docker.go:275] invalid container hash "hash123" in container "k8s_POD.hash123_foo_new_12345678_0"
I0921 21:05:38.887038 11417 plugins.go:56] Registering credential provider: .dockercfg
I0921 21:05:38.887099 11417 runonce.go:71] waiting for 1 pods
I0921 21:05:38.887227 11417 runonce.go:135] Container "bar" not running: api.ContainerState{Waiting:(*api.ContainerStateWaiting)(0xc2081e9f80), Running:(*api.ContainerStateRunning)(nil), Terminated:(*api.ContainerStateTerminated)(nil)}
I0921 21:05:38.887250 11417 runonce.go:109] pod "foo" containers not running: syncing
E0921 21:05:38.887882 11417 manager.go:1491] DNS ResolvConfPath is empty.
I0921 21:05:38.888079 11417 hairpin.go:49] Unable to find pair interface, setting up all interfaces: exec: "nsenter": executable file not found in $PATH
W0921 21:05:38.891155 11417 docker.go:265] found a container with the "k8s" prefix, but too few fields (5): "k8s_net_foo.new.test_abcdefgh_42"
I0921 21:05:38.891249 11417 runonce.go:119] pod "foo" containers synced, waiting for 1ms
W0921 21:05:38.892523 11417 docker.go:265] found a container with the "k8s" prefix, but too few fields (5): "k8s_net_foo.new.test_abcdefgh_42"
E0921 21:05:38.892555 11417 manager.go:859] Error examining the container: parse docker container name "/k8s_net_foo.new.test_abcdefgh_42" error: Docker container name "k8s_net_foo.new.test_abcdefgh_42" has less parts than expected [k8s net foo.new.test abcdefgh 42]
W0921 21:05:38.892673 11417 docker.go:265] found a container with the "k8s" prefix, but too few fields (5): "k8s_net_foo.new.test_abcdefgh_42"
I0921 21:05:38.892701 11417 runonce.go:106] pod "foo" containers running
I0921 21:05:38.892717 11417 runonce.go:81] started pod "foo"
I0921 21:05:38.892753 11417 runonce.go:87] 1 pods started
W0921 21:05:39.253084 11417 connection.go:126] Stream rejected: Unable to parse '' as a port: strconv.ParseUint: parsing "": invalid syntax
W0921 21:05:39.257265 11417 connection.go:126] Stream rejected: Unable to parse 'abc' as a port: strconv.ParseUint: parsing "abc": invalid syntax
W0921 21:05:39.273529 11417 connection.go:126] Stream rejected: Unable to parse '-1' as a port: strconv.ParseUint: parsing "-1": invalid syntax
W0921 21:05:39.277341 11417 connection.go:126] Stream rejected: Unable to parse '65536' as a port: strconv.ParseUint: parsing "65536": value out of range
W0921 21:05:39.281039 11417 connection.go:126] Stream rejected: Port '0' must be greater than 0
FAIL
|
Hi!
$ ./cluster/kube-up.sh
... Starting cluster using provider: vagrant
... calling verify-prereqs
... calling kube-up
Bringing machine 'master' up with 'virtualbox' provider...
Bringing machine 'node-1' up with 'virtualbox' provider...
==> master: Importing base box 'kube-fedora23'...
==> master: Matching MAC address for NAT networking...
==> master: Setting the name of the VM: kubernetes_master_1465131057159_61370
==> master: Fixed port collision for 22 => 2222. Now on port 2200.
==> master: Clearing any previously set network interfaces...
==> master: Preparing network interfaces based on configuration...
master: Adapter 1: nat
master: Adapter 2: hostonly
==> master: Forwarding ports...
master: 22 (guest) => 2200 (host) (adapter 1)
==> master: Running 'pre-boot' VM customizations...
==> master: Booting VM...
==> master: Waiting for machine to boot. This may take a few minutes...
master: SSH address: 127.0.0.1:2200
master: SSH username: vagrant
master: SSH auth method: private key
master:
master: Vagrant insecure key detected. Vagrant will automatically replace
master: this with a newly generated keypair for better security.
master:
master: Inserting generated public key within guest...
master: Removing insecure key from the guest if it's present...
master: Key inserted! Disconnecting and reconnecting using new SSH key...
==> master: Machine booted and ready!
==> master: Checking for guest additions in VM...
==> master: Configuring and enabling network interfaces...
==> master: Exporting NFS shared folders...
==> master: Preparing to edit /etc/exports. Administrator privileges will be required...
● nfs-server.service - NFS server and services
Loaded: loaded (/lib/systemd/system/nfs-server.service; enabled; vendor preset: enabled)
Active: active (exited) since Fri 2016-06-03 07:44:24 EDT; 2 days ago
Main PID: 1029 (code=exited, status=0/SUCCESS)
Tasks: 0
Memory: 0B
CPU: 0
CGroup: /system.slice/nfs-server.service
Jun 03 07:44:24 Monster systemd[1]: Starting NFS server and services...
Jun 03 07:44:24 Monster systemd[1]: Started NFS server and services.
exportfs: duplicated export entries:
exportfs: 10.245.1.2:/mnt/linux-data/Code/Code9/kubernetes
exportfs: 10.245.1.2:/mnt/linux-data/Code/Code9/kubernetes
==> master: Mounting NFS shared folders...
The following SSH command responded with a non-zero exit status.
Vagrant assumes that this means the command failed!
mount -o 'vers=3,udp' 10.245.1.1:'/mnt/linux-data/Code/Code9/kubernetes' /vagrant
Stdout from the command:
mount.nfs: access denied by server while mounting 10.245.1.1:/mnt/linux-data/Code/Code9/kubernetes
Stderr from the command:
I have already entered my password for sudo rights in that terminal in the
last few minutes, but the first time I tried the command it asked me for my
password.
| 0 |
## 🐛 Bug
CTCLoss occassionally causes segfault
## To Reproduce
Steps to reproduce the behavior:
# model
class StrippedResnet(nn.Module):
def __init__(self, base_model: nn.Module, n_classes: int):
super().__init__()
self.base = nn.Sequential(*list(base_model.children())[:-2])
self.last_conv = nn.Conv2d(
512,
n_classes,
(2, 3),
stride=1,
padding=(10, 1), # This has to be padded to get shape of [1,95,/23/,1]
bias=False
)
nn.init.kaiming_normal_(
self.last_conv.weight,
mode='fan_out',
nonlinearity='relu'
)
def forward(self, x):
x = self.base(x)
x = self.last_conv(x)
return x
# script.py
batch_size = 1
loader = get_loader()
model = resnet18(pretrained=True)
model = StrippedResnet(model, num_classes)
criterion = nn.CTCLoss()
model = model.train()
for data in loader:
features = data['image'].type('torch.DoubleTensor')
model = model.double()
labels = bat_to_tensor(data['text'])
logits = model.forward(features)
probs = nn.functional.log_softmax(logits, 2)
_, preds = torch.max(logits, 2)
pred_lens = Tensor([preds.size(0)] * batch_size).cpu()
label_lens = Tensor(batch_size).cpu()
probs = torch.squeeze(probs, 3).view(23, batch_size, num_classes).cpu()
# line that usually causes the segfault
loss = criterion(probs, labels, pred_lens, label_lens)
Bottom of the stack trace after running the script in gdb:
`gdb --args python script.py`
...
Program received signal SIGSEGV, Segmentation fault.
0x00007fffbca762cc in std::tuple<at::Tensor, at::Tensor> at::native::(anonymous namespace)::ctc_loss_cpu_template<double, (c10::ScalarType)3
>(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) ()
from /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so
Valgrind finds multiple instances of this error in the program:
valgrind --tool=memcheck \
--suppressions=valgrind-python.supp \
--error-limit=no \
python script.py
...
==14765== Conditional jump or move depends on uninitialised value(s)
==14765== at 0x5A8B53D: __ieee754_exp_avx (e_exp.c:67)
==14765== by 0x5A51F62: exp (w_exp.c:26)
==14765== by 0x17DF6309: std::tuple<at::Tensor, at::Tensor> at::native::(anonymous namespace)::ctc_loss_cpu_template<double, (c10::ScalarType)3>(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x17DF9BFF: at::native::ctc_loss_cpu(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long)::{lambda()#1}::operator()() const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x17DFC018: at::native::ctc_loss_cpu(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x17F30CE1: at::CPUDoubleType::_ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x1C531226: torch::autograd::VariableType::_ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
==14765== by 0x17DF3E88: at::native::ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x17DF45AA: at::native::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x1802D723: at::TypeDefault::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==14765== by 0x1C542301: torch::autograd::VariableType::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
==14765== by 0x16F37E5A: ??? (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
==14765==
...
==29498== Use of uninitialised value of size 8
==29498== at 0x17DF62D2: std::tuple<at::Tensor, at::Tensor> at::native::(anonymous namespace)::ctc_loss_cpu_template<double, (c10::ScalarType)3>(at::Tensor const&, at::Tensorconst&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x17DF9BFF: at::native::ctc_loss_cpu(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long)::{lambda()#1}::operator()() const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x17DFC018: at::native::ctc_loss_cpu(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x17F30CE1: at::CPUDoubleType::_ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x1C531226: torch::autograd::VariableType::_ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
==29498== by 0x17DF3E88: at::native::ctc_loss(at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, long, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x17DF45AA: at::native::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x1802D723: at::TypeDefault::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libcaffe2.so)
==29498== by 0x1C542301: torch::autograd::VariableType::ctc_loss(at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long) const (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
==29498== by 0x16F37E5A: ??? (in /data2/asher_scratch/miniconda3/envs/torch/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
==29498== by 0x281003: ??? (in /data2/asher_scratch/miniconda3/envs/torch/bin/python3.7)
==29498== by 0x2A629047: ???
...
==29498== HEAP SUMMARY:
==29498== in use at exit: 1,644,916,800 bytes in 1,389,021 blocks
==29498== total heap usage: 3,098,608 allocs, 1,709,587 frees, 2,819,434,323 bytes allocated
==29498==
==29498== LEAK SUMMARY:
==29498== definitely lost: 3,791 bytes in 34 blocks
==29498== indirectly lost: 3,024 bytes in 35 blocks
==29498== possibly lost: 629,908,519 bytes in 173,375 blocks
==29498== still reachable: 1,015,001,466 bytes in 1,215,577 blocks
==29498== suppressed: 0 bytes in 0 blocks
This finds errors starting in `ctc_loss_cpu` and `ctc_loss_cpu_template`.
## Expected behavior
Normal loss calculation
## Environment
PyTorch version: 1.0.0
Is debug build: No
CUDA used to build PyTorch: 8.0.61
OS: Ubuntu 14.04.5 LTS
GCC version: (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
CMake version: version 3.2.2
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: TITAN X (Pascal)
GPU 1: TITAN X (Pascal)
GPU 2: TITAN X (Pascal)
GPU 3: TITAN X (Pascal)
Nvidia driver version: 375.39
cuDNN version: Probably one of the following:
/usr/local/cuda-7.5_cudnn-4/lib64/libcudnn.so.4.0.7
/usr/local/cuda-7.5_cudnn-4/lib64/libcudnn_static.a
/usr/local/cuda-8.0/lib64/libcudnn.so.6.0.21
/usr/local/cuda-8.0/lib64/libcudnn_static.a
/usr/local/cuda-8.0_cudnn-4/lib64/libcudnn.so.4.0.7
/usr/local/cuda-8.0_cudnn-4/lib64/libcudnn_static.a
/usr/local/cuda-8.0_cudnn-5/lib64/libcudnn.so.5.1.5
/usr/local/cuda-8.0_cudnn-5/lib64/libcudnn_static.a
/usr/local/cuda-9.2/lib64/libcudnn.so.7.1.4
/usr/local/cuda-9.2/lib64/libcudnn_static.a
## Additional context
Does not fault every run
|
## 🐛 Bug
torch.seed() fails with `Overflow when unpacking long` after a tensor is
copied to cuda
## To Reproduce
to reproduce:
# test.py
import torch
print(f"Torch version: {torch.__version__}")
x = torch.tensor(data=[[1,2],[3,4]], dtype=torch.long, device=None)
x = x.to('cuda:0')
seed = torch.seed()
$ python tests/test.py
Torch version: 1.5.1
Traceback (most recent call last):
File "tests/test.py", line 10, in <module>
seed = torch.seed()
File "/home/stas/anaconda3/envs/main/lib/python3.7/site-packages/torch/random.py", line 45, in seed
torch.cuda.manual_seed_all(seed)
File "/home/stas/anaconda3/envs/main/lib/python3.7/site-packages/torch/cuda/random.py", line 111, in manual_seed_all
_lazy_call(cb)
File "/home/stas/anaconda3/envs/main/lib/python3.7/site-packages/torch/cuda/__init__.py", line 99, in _lazy_call
callable()
File "/home/stas/anaconda3/envs/main/lib/python3.7/site-packages/torch/cuda/random.py", line 109, in cb
default_generator.manual_seed(seed)
RuntimeError: Overflow when unpacking long
It fails about 75% of time.
## Expected behavior
It shouldn't fail.
## Additional info
It seems to be related to: #33546
While CI passes, on my machine`huggingface/transformers` tests fail with this
error.
## Environment
PyTorch version: 1.5.1
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: 10.0.130
GPU models and configuration:
GPU 0: GeForce GTX TITAN X
GPU 1: GeForce GTX TITAN X
Nvidia driver version: 440.95.01
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
Versions of relevant libraries:
[pip3] numpy==1.13.3
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] mkl 2020.0 166
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.15 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] numpy 1.18.1 pypi_0 pypi
[conda] numpy-base 1.18.1 py37hde5b4d6_1
[conda] numpydoc 0.9.2 py_0
[conda] pytorch 1.5.1 py3.7_cuda10.2.89_cudnn7.6.5_0 pytorch
[conda] pytorch-lightning 0.8.1 pypi_0 pypi
[conda] pytorch-nlp 0.5.0 pypi_0 pypi
[conda] pytorch-pretrained-bert 0.6.2 pypi_0 pypi
[conda] pytorch-transformers 1.1.0 pypi_0 pypi
[conda] torch 1.5.0 pypi_0 pypi
[conda] torchtext 0.5.1 pypi_0 pypi
[conda] torchvision 0.6.1 py37_cu102 pytorch
cc @ezyang @gchanan @zou3519 @ngimel
| 0 |
1. What version of Go are you using (go version)?
* 1.4
* tip +9ef10fde754f
2. What operating system and processor architecture are you using?
OS X 10.10.1 amd64
3. What did you do?
package main
func main() {
_ = complex(0)
}
http://play.golang.org/p/BdgB06q5te
4. What did you expect to see?
prog.go:4: not enough arguments in call to complex
[process exited with non-zero status]
5. What did you see instead?
prog.go:4: internal compiler error: fault
[process exited with non-zero status]
|
http://play.golang.org/p/gOwL0S64NQ
reported by lvd
package main
import (
"fmt"
"math"
)
func main() {
for i := 0; i < 4; i++ {
ii := float64(i)
e := ii * (math.Log(4/2) - math.Log(ii))
fmt.Println(e, math.Jn(i, 4))
}
var c complex128
c = math.Sqrt2 / 2
fmt.Println(c)
var f float64
f = 2
c *= complex(f)
fmt.Println(c)
}
| 1 |
### Bug report
**Bug summary**
On macOS with PyQt4, when placing a `FigureCanvasQTAgg` and a `QGraphicsView`
in the same widget, some QWidget recursive repaint and Core Graphics errors
(see below) occur when showing the widget.
**Code for reproduction**
from PyQt4 import Qt
import matplotlib
matplotlib.use('Qt4Agg')
from matplotlib.backends.backend_qt4agg import FigureCanvasQTAgg
from matplotlib.figure import Figure
app = Qt.QApplication([])
fig = Figure()
ax = fig.add_subplot(111)
ax.plot([0, 1])
canvas = FigureCanvasQTAgg(fig)
scene = Qt.QGraphicsScene()
scene.addRect(0, 0, 10, 10)
view = Qt.QGraphicsView(scene)
layout = Qt.QHBoxLayout()
layout.addWidget(canvas)
layout.addWidget(view)
widget = Qt.QWidget()
widget.setLayout(layout)
widget.show()
app.exec_()
**Actual outcome**
The widgets show correctly, but the following errors are displayed in the
console:
QWidget::repaint: Recursive repaint detected
QWidget::repaint: Recursive repaint detected
Oct 2 14:23:47 python[52865] <Error>: CGContextGetCTM: invalid context 0x0. If you want to see the backtrace, please set CG_CONTEXT_SHOW_BACKTRACE environmental variable.
Oct 2 14:23:47 python[52865] <Error>: CGContextConcatCTM: invalid context 0x0. If you want to see the backtrace, please set CG_CONTEXT_SHOW_BACKTRACE environmental variable.
[...]
**Expected outcome**
This does not occur with PyQt5 (tested with 5.9).
This does not occur with matplotlib 2.0.2 and PyQt4.
Also, commenting the call to `processEvents` in `FigureCanvasQTAggBase
.paintEvent` solves the issue:
matplotlib/lib/matplotlib/backends/backend_qt5agg.py
Line 75 in 793635c
| QtWidgets.QApplication.instance().processEvents()
---|---
**Matplotlib version**
* Operating System: macOS Sierra 10.12.5
* Matplotlib Version: 2.1.0rc1
* Python Version: Tested with 2.7 (both system and macPorts) and 3.6 (macPorts)
* Jupyter Version (if applicable):
* Other Libraries: PyQt4 4.12.1
|
### Bug report
**Bug summary**
As of master,
$ python examples/images_contours_and_fields/plot_streamplot.py
QWidget::repaint: Recursive repaint detected
Fatal Python error: Segmentation fault
(Qt5Agg backend)
**Code for reproduction**
See above.
**Actual outcome**
NA
**Expected outcome**
Don't crash.
**Matplotlib version**
* Operating System: Arch Linux
* Matplotlib Version: master
* Python Version: 3.6
* Jupyter Version (if applicable):
* Other Libraries: Qt5.9 from pypi in a venv. _does not occur with Arch repo PyQt5_ (recursive repaint message occurs sometimes, but does not crash even then)
bisects back to `d0eeddb` which is the merge commit for #9103; however,
interestingly, the tip of that commit does _not_ crash so something went wrong
during the merge.
| 1 |
I upgraded from ansible 1.3 to ansible 1.6 and my asynchronous tasks are not
working properly when those have to be SKIPPED. (when are not skipped
everything works ok). This is my task to reproduce the error:
- name: Create screen session to run dd on new disk (async mode)
shell: /bin/dd if={{ ebs_device }} of=/dev/null bs=1024k
async: 36000
poll: 0
tags: rundd
when: ebs_iops != 0
This is executed as follows (Note: ebs_iops=0)
ansible-playbook -i cluster-oe setup.yml -s --ask-vault-pass --tags rundd
Output:
TASK: [common | Create screen session to run dd on new disk (async mode)] *****
skipping: [X.X.X.X]
Traceback (most recent call last):
File "/usr/bin/ansible-playbook", line 317, in <module>
sys.exit(main(sys.argv[1:]))
File "/usr/bin/ansible-playbook", line 257, in main
pb.run()
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 291, in run
if not self._run_play(play):
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 644, in _run_play
if not self._run_task(play, task, False):
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 421, in _run_task
results = self._run_task_internal(task)
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 385, in _run_task_internal
self.runner_callbacks.on_async_ok(host, res, poller.runner.vars_cache[host]['ansible_job_id'])
KeyError: 'ansible_job_id'
TASK: [common | Create screen session to run dd on new disk (async mode)] *****
skipping: [X.X.X.X]
Traceback (most recent call last):
File "/usr/bin/ansible-playbook", line 317, in <module>
sys.exit(main(sys.argv[1:]))
File "/usr/bin/ansible-playbook", line 257, in main
pb.run()
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 291, in run
if not self._run_play(play):
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 644, in _run_play
if not self._run_task(play, task, False):
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 421, in _run_task
results = self._run_task_internal(task)
File "/usr/lib/python2.6/site-packages/ansible/playbook/__init__.py", line 385, in _run_task_internal
self.runner_callbacks.on_async_ok(host, res, poller.runner.vars_cache[host]['ansible_job_id'])
KeyError: 'ansible_job_id'
Ansible version:
ansible --version
ansible 1.6.1
|
##### Issue Type: Bug Report
##### Ansible Version:
1.6.1, devel
##### Environment:
Centos 6.5, OS X 10.9.2
##### Summary:
An async task with 'poll: 0' fails only when the 'when' condition causes it to
be skipped. If I remove the poll option or set it to a number higher than 0,
the task is successfully skipped. If I remove the 'when' condition, the async
task is successful with 'poll' set to 0.
##### Steps To Reproduce:
Create an async task with 'poll: 0' and a when condition that causes it to be
skipped.
- name: test
hosts: localhost
tasks:
- name: a local task
shell: echo hello
async: 30
poll: 0
when: a_variable is defined
##### Expected Results:
The async task should be skipped.
##### Actual Results:
TASK: [a local task] **********************************************************
skipping: [localhost]
Traceback (most recent call last):
File "/Users/jyoung/lib/ansible-main/bin/ansible-playbook", line 317, in <module>
sys.exit(main(sys.argv[1:]))
File "/Users/jyoung/lib/ansible-main/bin/ansible-playbook", line 257, in main
pb.run()
File "/Users/jyoung/lib/ansible-main/lib/ansible/playbook/__init__.py", line 319, in run
if not self._run_play(play):
File "/Users/jyoung/lib/ansible-main/lib/ansible/playbook/__init__.py", line 673, in _run_play
if not self._run_task(play, task, False):
File "/Users/jyoung/lib/ansible-main/lib/ansible/playbook/__init__.py", line 449, in _run_task
results = self._run_task_internal(task)
File "/Users/jyoung/lib/ansible-main/lib/ansible/playbook/__init__.py", line 413, in _run_task_internal
self.runner_callbacks.on_async_ok(host, res, poller.runner.vars_cache[host]['ansible_job_id'])
KeyError: 'ansible_job_id'
| 1 |
**Migrated issue, originally created by Sheer El Showk (@sheer)**
This bug was discussed on stack overview here:
[http://stackoverflow.com/questions/33888539/getting-sqlalchemy-to-do-on-
duplicate-key-update-inside-an-orm-cascade-in-
mys?noredirect=1#comment55890922_33888539
](Link URL)
We create a simple object hierarchy: Groups contain Users and Users have Email
addresses. We want the email address to be stored uniquely even if its shared
between users. Constructing two users with the same address and using
session.merge() to add them has the correct behaviour (the same key is reused
and no error is thrown). If, on the other hand, we add the two users to a
group and then use session.merge() on the group instead them the two identical
addresses lead to a unique key exception on address (due to an insert many).
Here is the relevant code:
from sqlalchemy import create_engine, Column, types
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.orm import Session
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship, backref
engine = create_engine('sqlite:///:memory:', echo=False)
Base = declarative_base()
session = scoped_session(sessionmaker(bind=engine))
class Group(Base):
__tablename__ = "groups"
gid = Column(types.Integer, primary_key=True)
name = Column(types.String(255))
users = relationship("User", backref="group")
def __repr__(self):
ret = "Group(name=%r)" % self.name
for user in self.users:
ret += str(user)
class User(Base):
__tablename__ = "users"
login = Column(types.String(50), primary_key=True)
name = Column(types.String(255))
group_id = Column(types.Integer, ForeignKey('groups.gid'))
address = Column(types.String(200),
ForeignKey('addresses.email_address'))
email = relationship("Address")
def __repr__(self):
return "User(login=%r, name=%r)\n%s" % (self.login, self.name,
str(self.email))
class Address(Base):
__tablename__ = 'addresses'
email_address = Column(types.String(200), nullable=False, primary_key=True)
#user_login = Column(types.String(50), ForeignKey('users.login'))
def __repr__(self):
return "<Address(email_address='%s')>" % self.email_address
Base.metadata.create_all(engine)
if __name__ == '__main__':
# this works correctly even though we reuse a unique key
u1 = User(login='Guy', name="Some Guy")
u1.email=Address(email_address='nameless@yahoo.com')
u2 = User(login='Gal', name="Some Gal")
u2.email=Address(email_address='nameless@yahoo.com')
session.merge(u1)
session.merge(u2)
session.commit()
print("two users with addresses")
for u in session.query(User):
print(u)
# though this is similar it ends up using insertmany and throws a unique key
# constraint even with the merge
u3 = User(login='Mr. User', name="A dude")
u3.email=Address(email_address='james@yahoo.com')
u4 = User(login='Mrs. User', name="A dudette")
u4.email=Address(email_address='jill@yahoo.com')
u5 = User(login='Mrs. User2', name="A dudette2")
u5.email=Address(email_address='jill@yahoo.com')
g1 = Group(name="G1")
g1.users.append(u3)
g1.users.append(u4)
g1.users.append(u5)
session.merge(g1)
session.commit()
print(g1)
|
Replace the asyncpg paramstyle from format to numeric, using `$` instead of
the standard `:`.
The main advantage of this style is that allows repeated parameters to not be
duplicated
| 0 |
# Checklist
Please add the ability to specify `https` scheme for results backend. Right
now, it seems that http is the default with no way to change it. If this
already exists can you please point me to it?
celery/celery/backends/elasticsearch.py
Line 38 in 6be4523
| scheme = 'http'
---|---
* I have checked the issues list
for similar or identical enhancement to an existing feature.
* I have checked the pull requests list
for existing proposed enhancements.
* I have checked the commit log
to find out if the if the same enhancement was already implemented in the
master branch.
* I have included all related issues and possible duplicate issues in this issue
(If there are none, check this box anyway).
## Related Issues and Possible Duplicates
#### Related Issues
* None
#### Possible Duplicates
* None
# Brief Summary
# Design
## Architectural Considerations
None
## Proposed Behavior
## Proposed UI/UX
## Diagrams
N/A
## Alternatives
None
|
# Checklist
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Mandatory Debugging Information
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
* I have included the contents of `pip freeze` in the issue.
* I have included all the versions of all the external dependencies required
to reproduce this bug.
## Optional Debugging Information
* I have tried reproducing the issue on more than one Python version
and/or implementation.
* I have tried reproducing the issue on more than one message broker and/or
result backend.
* I have tried reproducing the issue on more than one version of the message
broker and/or result backend.
* I have tried reproducing the issue on more than one operating system.
* I have tried reproducing the issue on more than one workers pool.
* I have tried reproducing the issue with autoscaling, retries,
ETA/Countdown & rate limits disabled.
* I have tried reproducing the issue after downgrading
and/or upgrading Celery and its dependencies.
## Related Issues and Possible Duplicates
#### Related Issues
* #3926
#### Possible Duplicates
* None
## Environment & Settings
**Celery version** : 4.3.0
**`celery report` Output:**
software -> celery:4.3.0 (rhubarb) kombu:4.6.4 py:3.6.0
billiard:3.6.1.0 librabbitmq:2.0.0
platform -> system:Linux arch:64bit, ELF
kernel version:4.19.71-1-lts imp:CPython
loader -> celery.loaders.default.Loader
settings -> transport:librabbitmq results:disabled
# Steps to Reproduce
## Required Dependencies
* **Minimal Python Version** : 3.6.0
* **Minimal Celery Version** : 4.3.0
* **Minimal Kombu Version** : 4.6.4
* **Minimal Broker Version** : RabbitMQ 3.7.15
* **Minimal Result Backend Version** : N/A or Unknown
* **Minimal OS and/or Kernel Version** : Linux 4.19.71-1-lts
* **Minimal Broker Client Version** : N/A or Unknown
* **Minimal Result Backend Client Version** : N/A or Unknown
### Python Packages
**`pip freeze` Output:**
amqp==2.5.1
asn1crypto==0.24.0
atomicwrites==1.3.0
attrs==19.1.0
Automat==0.7.0
backcall==0.1.0
billiard==3.6.1.0
case==1.5.3
celery==4.3.0
cffi==1.12.3
constantly==15.1.0
cryptography==2.7
cssselect==1.1.0
decorator==4.4.0
hyperlink==19.0.0
idna==2.8
importlib-metadata==0.23
incremental==17.5.0
ipython==7.8.0
ipython-genutils==0.2.0
jedi==0.15.1
kombu==4.6.4
librabbitmq==2.0.0
linecache2==1.0.0
lxml==4.4.1
mock==3.0.5
more-itertools==7.2.0
mysqlclient==1.4.4
nose==1.3.7
packaging==19.2
parsel==1.5.2
parso==0.5.1
pexpect==4.7.0
pickleshare==0.7.5
pluggy==0.13.0
prompt-toolkit==2.0.9
ptyprocess==0.6.0
py==1.8.0
pyasn1==0.4.7
pyasn1-modules==0.2.6
pycparser==2.19
PyDispatcher==2.0.5
Pygments==2.4.2
PyHamcrest==1.9.0
pyOpenSSL==19.0.0
pyparsing==2.4.2
pytest==5.2.1
pytz==2019.2
queuelib==1.5.0
Scrapy==1.7.3
scrapy-selenium==0.0.7
selenium==3.141.0
service-identity==18.1.0
six==1.12.0
SQLAlchemy==1.3.8
traceback2==1.4.0
traitlets==4.3.2
Twisted==19.7.0
unittest2==1.1.0
urllib3==1.25.6
vine==1.3.0
w3lib==1.21.0
wcwidth==0.1.7
zipp==0.6.0
zope.interface==4.6.0
### Other Dependencies
N/A
## Minimally Reproducible Test Case
celeryconfig.py:
broker_url = 'amqp://guest:guest@localhost:5672//'
task_default_queue = 'default'
task_default_exchange = 'tasks'
task_default_exchange_type = 'topic'
task_default_routing_key = 'tasks.default'
task_queues = (
Queue('default', routing_key='tasks.#'),
Queue('test', routing_key='test.#'),
)
celery.py:
app = Celery('scan_worker')
app.conf.task_default_exchange = 'tasks'
app.conf.task_default_exchange_type = 'topic'
app.config_from_object('test_celery.celeryconfig', force=True)
# Expected Behavior
According to the document:
> If you don't set the exchange or exchange type values for a key, these will
> be taken from the task_default_exchange and task_default_exchange_type
> settings
The worker should automatically create queues that binding to the exchange
with `task_default_exchange` and `task_default_exchange_type`
# Actual Behavior
The output of the command `celery worker -A test_celery -l info`:
-------------- celery@arch v4.3.0 (rhubarb)
---- **** -----
--- * *** * -- Linux-4.19.71-1-lts-x86_64-with-arch 2019-10-10 20:13:55
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: scan_worker:0x7efdc5430a58
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: disabled://
- *** --- * --- .> concurrency: 9 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> default exchange=(direct) key=tasks.#
.> test exchange=(direct) key=test.#
the queues are bound to the exchange that not match `task_default_exchange`
and `task_default_exchange_type`
| 0 |
## Checklist
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
## Steps to reproduce
**I am using celery version 3.0.23 and scheduling the tasks using apply_async
the issue is that the i encountered that the tasks are being duplicated by 15x
so our users are getting 15 push notifications instead of one. The duplicacy
of the tasks can be seen in the file attached below:**
bug.txt
## Expected behavior
## Actual behavior
|
# Checklist
* I have checked the issues list
for similar or identical feature requests.
* I have checked the pull requests list
for existing proposed implementations of this feature.
* I have checked the commit log
to find out if the if the same feature was already implemented in the
master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Related Issues and Possible Duplicates
#### Related Issues
* #4551
* #4525
#### Possible Duplicates
* #4551
# Brief Summary
Memory leaks can be difficult to track down, especially when they are caused
by 3rd party packages. In theory these obviously should be fixed, but in real
life, where one needs to keep things running, one might be happy enough if the
memory leaks were contained.
So I'd like to propose a solution to _quarantene_ memory leaks in task
specific processes in order to avoid an increasing memory usage of the Celery
workers, which appears to be a common reason for restarting the workers.
# Design
## Architectural Considerations
None
## Proposed Behavior
My proposal looks as follows:
* The Celery workers fork/spawn/... a new child process before executing a task.
* Task execution is done in this child process.
* The result is retrieved from the child process
* The child process is terminated.
* The results is handed to the result backend by the worker process
In a variation, this proposal might be extended to allow processing of a chunk
in child process or the delegation of the task execution might be made
optional.
In all other regards (e.g. errors, exceptions) this feature should behave
identically to the current behavior.
## Proposed UI/UX
## Diagrams
This diagram illustrates the basic idea. If a task leaks memory, the memory
consumption will rise until the Worker process (e.g. the Celery systemd
service) is restarted. If the execution of such a task is contained in a
separate child process, memory is freed after each task.
## Alternatives
Instead of including this feature in Celery itself, one could implement this
feature in a subclass of `celery.Task`?
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
Grow transition honors the enter/leave durations propagated from the Dialog
component.
## Current Behavior
`Dialog` accepts enter and leaveTransitionDuration props but the `Grow`
transition only accepts the transitionDuration prop. This effectively ignores
the props given to the Dialog.
## Steps to Reproduce (for bugs)
https://codesandbox.io/s/l476j33mjq
1. Click 'Show dialog'
2. Observe that react warning in console
## Context
One can use props directly on a Grow transition (and in fact the defaults are
great in my case) so not a super important bug but it might rear it's head in
other places.
## Your Environment
Tech | Version
---|---
Material-UI | 1.0.0-beta.12
React | 16 rc3
browser | chrome
|
Tooltip in a narrow table head cell wraps its content while tooltips in
ordinary table cells don't.
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
I expect it to behave the same as a tooltip in any other table cell
## Current Behavior
I added tooltips in the first column of the table:
https://codesandbox.io/s/9yqjyx68o
## Your Environment
Tech | Version
---|---
Material-UI | 1.0.0-beta.19
React | 16.0.0
browser | Chrome
| 0 |
julia> collect(Iterators.Stateful(2x for x in 1:3))
2-element Vector{Int64}:
2
4
The input has 3 elements, I would therefore expect the output also to have 3
elements, but there are only 2.
On the other hand, the problem disappears if
* we remove the generator
collect(Iterators.Stateful(1:3))
3-element Vector{Int64}:
1
2
3
* we use `iterate` directly
julia> s = Iterators.Stateful(2x for x in 1:3);
julia> iterate(s)
(2, nothing)
julia> iterate(s, ans[2])
(4, nothing)
julia> iterate(s, ans[2])
(6, nothing)
julia> iterate(s, ans[2])
julia>
# versioninfo
julia> versioninfo()
Julia Version 1.6.1
Commit 6aaedecc44 (2021-04-23 05:59 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
CPU: Intel(R) Core(TM) i7-3632QM CPU @ 2.20GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-11.0.1 (ORCJIT, ivybridge)
julia>
The problem also appears in julia 1.3.1, but it seems to be behaving as
expected in 1.0.
Edit:
My 1.3.1 trial was in an online REPL (https://replit.com/languages/julia)
which claims to be 1.3.1 but `versioninfo()` shows 1.4.1
julia version 1.3.1
versioninfo()
Julia Version 1.4.1
Commit 381693d3df* (2020-04-14 17:20 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
CPU: Intel(R) Xeon(R) CPU @ 2.30GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-8.0.1 (ORCJIT, haswell)
collect(Iterators.Stateful(2x for x in 1:3))
2-element Array{Int64,1}:
2
4
|
Strage behaviour of Stateful iterator:
Although
julia> for a in Iterators.Stateful([1,2,3])
print(a)
end
123
works as it should,
With list comprehension it fails to iterate over last element
julia> [a for a in Iterators.Stateful([1,2,3])]
2-element Array{Int64,1}:
1
2
julia> [a for a in Iterators.Stateful([1])]
ERROR: BoundsError: attempt to access 0-element Array{Int64,1} at index [1]
tried on Julia 1.3.1, Julia 1.4.0 and Julia 1.4.1.
More details in https://discourse.julialang.org/t/strange-behavior-with-list-
comprehensions-using-iterators-stateful/29715
| 1 |
**Oliver Drotbohm** opened **SPR-6467** and commented
Currently `ContentNegotiatingViewResolver` acts lenient as it returns `null`
when it can not resolve any view to indicate that further `ViewResolvers`
configured shall step in and try to resolve the view.
In cases when `ContentNegotiatingViewResolver` is the only resolver
configured, not resolving the view should be answered with a `406 Not
Acceptable` status code. A quick hack I did was to add a property `beStrict`
to `CNVR` an implement an inner class to return the appropriate statuscode.
See applied patch.
This solves the problem at a first glance but I think it would be more clean
to prevent processing of the request entirely if no valid accept header was
set by using the algorithm `getmediaTypes(..)` in `CNVR`. Currently this
method is not public, but I could imagine a `HandlerInterceptor`
implementation that gets a reference to the `CNVR` injected and call to
`getMediaType(..)` to decide whether to process the request at all.
* * *
**Affects:** 3.0 RC2
**Attachments:**
* bestrict.patch ( _2.43 kB_ )
**Issue Links:**
* #11559 exotic MIME-Type leads to 500 Internal Server Error ( _ **"is duplicated by"**_ )
**Referenced from:** commits `1cd0a97`
|
**Chris Beams** opened **SPR-9779** and commented
Per email.
* * *
This issue is a sub-task of #14349
**Issue Links:**
* #14417 Upgrade to JUnit 4.11 snapshot in support of JDK7 ( _ **"depends on"**_ )
* #14350 Build against JDK 7, test against JDK 6+7 ( _ **"is depended on by"**_ )
* #14625 AdvisorAdapterRegistrationTests fails intermittently under Java 7 ( _ **"is duplicated by"**_ )
* #14625 AdvisorAdapterRegistrationTests fails intermittently under Java 7
**Referenced from:** commits `a9a90ca`
| 0 |
Consider i have the following directory tree in my application:
- app.js
- locale/
- es/
- module1/
- form1.json
- form2.json
- module2/
- form3.json
- form4.json
- en/
- module1/
- form1.json
- form2.json
- module2/
- form3.json
- form4.json
And app.js has this content:
/* ... */
function loadLazyModule (moduleName)
{
require.ensure ([], function ()
{
var lang = /* Browser language */;
var forms = ['form1', 'form2'] /* Get dynamically the array of forms? */
for (var i = 0; i < forms.length; i++)
{
var translations = require (
'locale/'+ lang +'/'+ moduleName +'/'+ form[i] +'.json');
registerTranslations (translations);
}
});
}
/* ... */
I need a main chunk with the core of my app, but i need to split every
language translations of every module in diferent chunks and load them only
when requested from the user. Im already using the json-loader for json files
and the 'split-by-name-webpack-plugin' but it doesn't works with dynamic
loading (require.ensure).
The output should be as follows:
* myApp.js
* locale.module1.es.js
* locale.module2.es.js
* locale.module1.en.js
* locale.module2.en.js
Thanks.
|
I'm having a hard time figuring this out. I have all these node_modules which
include the css files I need but I can only get the javascript from the
require.
For example require('bootstrap') will only return the js file and not the css.
I've tried
require("!style!css!bootstrap/dist/css");
but I just get this error:
> ERROR in ./app/js/loader.js
> Module not found: Error: Cannot resolve module 'bootstrap.css' in
> C:\Users\Administrator\Dropbox\projects\spDash\app\js
> @ ./app/js/loader.js 10:0-24
>
> ERROR in ./app/js/loader.js
> Module not found: Error: Cannot resolve module 'bootstrap/dist/css' in
> C:\Users\Administrator\Dropbox\projects\spDash\app\js
> @ ./app/js/loader.js 19:0-40
My config looks like this:
var webpack = require('webpack')
module.exports = {
entry: {
'spdash': './app/js/loader.js'
},
output: {
filename: 'bundle.js',
},
devtool: 'source-map',
module: {
loaders: [
// the url-loader uses DataUrls.
// the file-loader emits files.
{ test: /\.woff(2)?(\?v=[0-9]\.[0-9]\.[0-9])?$/, loader: "url-loader?limit=10000&minetype=application/font-woff" },
{ test: /\.(ttf|eot|svg)(\?v=[0-9]\.[0-9]\.[0-9])?$/, loader: "file-loader" },
{
test: /\.css$/, // Only .css files
loader: 'style!css' // Run both loaders
},
{ test: /\.less$/, loader: 'style-loader!css-loader!less-loader' }, // use ! to chain loaders
{ test: /\.css$/, loader: 'style-loader!css-loader' },
{test: /\.(png|jpg)$/, loader: 'url-loader?limit=8192'} // inline base64 URLs for <=8k images, direct URLs for the rest
]
},
plugins: [
new webpack.optimize.UglifyJsPlugin({
minimize: true,
compress: {
warnings: false
}
}),
new webpack.IgnorePlugin(/^\.\/locale$/, [/moment$/])
]
};
| 0 |
I am replacing the last softmax layer (with 1000 output units) of the original
model (VGG16) with a new softmax layer (with 10 output units):
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
model.load_weights('./vgg16_weights.h5')
model.layers.pop()
model.layers.pop()
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
However, when I check input_shape and output_shape of the last three layers I
find:
> > > model.layers[-1].output_shape
> (None, 10)
> model.layers[-1].input_shape
> (None, 1000)
> model.layers[-2].input_shape
> (None, 1000)
> model.layers[-2].output_shape
> (None, 1000)
> model.layers[-3].output_shape
> (None, 4096)
> model.layers[-2].name
> 'dropout_3'
> model.layers[-3].name
> 'dense_2'
> model.layers[-1].name
> 'dense_4'
Apparently, model.layers.pop() does not fully update the model. I have OS X
10.11.5 and I just updated keras and tensorflow (I cannot use Theano since it
produces Illegal instruction: 4 error)
|
I'm trying to start https://github.com/iamaaditya/VQA_Demo which uses pre-
trained VGG16 model
(https://github.com/iamaaditya/VQA_Demo/blob/master/models/CNN/VGG.py). The
last 2 layers are removed with layers.pop(). This doesn't seem to work,
however. The message "ValueError: could not broadcast input array from shape
(1000) into shape (4096)" is displayed, and I see the layers were not removed
when I do "plot(image_model, to_file='model_vgg.png', show_shapes=True)".
Thank you.
| 1 |
**Description:**
When Deno is called from a directory that used to exist but doesn't anymore
(i.e. deleted externally), it will panic.
**Steps to Reproduce:**
1. `mkdir /tmp/testing && cd /tmp/testing`
2. `deno` or `deno repl` or `deno run https://deno.land/std/examples/welcome.ts`
3. Observe that it works
- _in another terminal_ -
`rm -rf /tmp/testing`
- _back to the original terminal_ -
4. Re-run the command.
5. Observe panic.
**Backtrace:** backtrace.txt
|
~ RUST_BACKTRACE=1 deno run -A cli.ts
============================================================
Deno has panicked. This is a bug in Deno. Please report this
at https://github.com/denoland/deno/issues/new.
If you can reliably reproduce this panic, include the
reproduction steps and re-run with the RUST_BACKTRACE=1 env
var set and include the backtrace in your report.
Platform: macos x86_64
Version: 1.22.3
Args: ["deno", "run", "-A", "cli.ts"]
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }', core/module_specifier.rs:141:28
stack backtrace:
0: _rust_begin_unwind
1: core::panicking::panic_fmt
2: core::result::unwrap_failed
3: deno_core::module_specifier::resolve_path
4: deno_core::module_specifier::resolve_url_or_path
5: deno::run_command::{{closure}}
6: deno::main::{{closure}}
7: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
8: deno_runtime::tokio_util::run_basic
9: deno::main
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
~ RUST_BACKTRACE=full deno run -A cli.ts
============================================================
Deno has panicked. This is a bug in Deno. Please report this
at https://github.com/denoland/deno/issues/new.
If you can reliably reproduce this panic, include the
reproduction steps and re-run with the RUST_BACKTRACE=1 env
var set and include the backtrace in your report.
Platform: macos x86_64
Version: 1.22.3
Args: ["deno", "run", "-A", "cli.ts"]
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }', core/module_specifier.rs:141:28
stack backtrace:
0: 0x1023aaf8b - <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt::h4cae82d438451481
1: 0x101a744eb - core::fmt::write::hb68c3045179d0cad
2: 0x1023a51ae - std::io::Write::write_fmt::haf84c797e63d79f0
3: 0x1023afde0 - std::panicking::default_hook::{{closure}}::he18137441e51da1f
4: 0x1023afb01 - std::panicking::default_hook::ha3efe84526f027fa
5: 0x101a076a1 - deno::setup_panic_hook::{{closure}}::h40c42abbafe06a7a
6: 0x1023b0a40 - std::panicking::rust_panic_with_hook::h429a7ddefa5f0258
7: 0x1023b0734 - std::panicking::begin_panic_handler::{{closure}}::h9b033a6b15b84a74
8: 0x1023b06a9 - std::sys_common::backtrace::__rust_end_short_backtrace::hcdd3bec8e0e38aa6
9: 0x1023b0665 - _rust_begin_unwind
10: 0x1035ee173 - core::panicking::panic_fmt::hf7d6e5207e013f69
11: 0x1035ee485 - core::result::unwrap_failed::h95d9e30ede493473
12: 0x101b575eb - deno_core::module_specifier::resolve_path::hb9a126f04a986351
13: 0x101b56cfc - deno_core::module_specifier::resolve_url_or_path::h85e8466bb4c632ef
14: 0x1019648f3 - deno::run_command::{{closure}}::h4b081d1b1f5edb22
15: 0x1016f4ceb - deno::main::{{closure}}::h9a70f756620d74a8
16: 0x1016e8d8f - <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll::h75b1e0a291c5e2cc
17: 0x1016e6049 - deno_runtime::tokio_util::run_basic::hd2be911e11342f3d
18: 0x1016e5588 - deno::main::h3ebfe1366267437f
19: 0x1016e4d9c - std::sys_common::backtrace::__rust_begin_short_backtrace::h366f15b72859e8b1
20: 0x1016e505c - _main
| 1 |
With the new preview tabs, there's currently not a way to keep a tab opened
without making changes to the file's contents. In sublime, double clicking a
file prevents the preview from being closed when switching to another file.
This would be useful behaviour in atom's preview tabs as well.
|
Using Atom v0.206.0-4941229 on Mac OS X 10.10.3.

### Repro Steps
1. Open Atom
2. Open Settings View
3. Navigate to Tabs package settings
4. Ensure "Use Preview Tabs" is checked
5. Close Settings View
6. Double-click any file in Tree View
**Expected:** Tab's title to not be italic (italic is the indicator that it is
temporary)
**Actual:** Tab's title is italic
1. Double-click another file in Tree View
**Expected:** Second tab to open
**Actual:** New file overwrites the tab of the original file
| 1 |
* [x ] I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
When using a grid that scrolls vertically, a horizontal scrollbar should not
be necessary.
## Current Behavior
The grid looks like it generates double the needed spacing on the right side,
resulting in a layout that is slightly too wide for the screen, and needs a
horizontal scrollbar.
## Steps to Reproduce (for bugs)
1. Add spacing to a grid container
2. Sometimes the issue happens
Here's the issue
Adding some padding to an outer div prevents it from happening
Tech | Version
---|---
Material-UI | 1.0.0-beta.18
React | 16.0.0
browser | chrome 61.0.3163.100
|
The `<Grid container>` extends beyond its parent, with half of spacing size.
I have marked the extra width in red, also setting spacing to zero fixes the
problem.

Here is a working example: https://codesandbox.io/s/Y8nzGm5W.
Similar code with a zero spacing works as expected:
https://codesandbox.io/s/NxvYxvQpL.
| 1 |
#### Code Sample
If test.csv file looks like:
a,b,c
0,1,2
1,2,3
Reading in the file with the header given in a list of length 0 results in no
warnings or errors, but each line is interpreted as NaNs.
>>> import pandas as pd
>>> pd.read_csv("test.csv", header=[0])
a b c
0 NaN NaN NaN
1 NaN NaN NaN
#### Problem description
Single-length lists are not a problem elsewhere in pandas or within read_csv.
For example, passing `index_col=[0]` does not cause pandas to read a csv file
incorrectly. Preferably pandas would read in the csv file correctly given a
list of header rows with one element. Raising an error or warning would also
be an improvement over the current functionality.
#### Expected Output
>>> import pandas as pd
>>> pd.read_csv("test.csv", header=[0])
a b c
0 0 1 2
1 1 2 3
#### Output of `pd.show_versions()`
OS: macOS Sierra Python: 2.7.13 pandas: 0.20.2 pytest: None pip: 9.0.1
setuptools: 27.2.0 Cython: 0.25.2 numpy: 1.13.1 scipy: 0.19.1 xarray: None
IPython: 5.3.0 sphinx: None patsy: 0.4.1 dateutil: 2.6.0 pytz: 2017.2 blosc:
None bottleneck: None tables: None numexpr: None feather: None matplotlib:
2.0.2 openpyxl: None xlrd: None xlwt: None xlsxwriter: None lxml: None bs4:
None html5lib: 0.999 sqlalchemy: None pymysql: None psycopg2: None jinja2:
2.9.6 s3fs: None pandas_gbq: None pandas_datareader: None
|
`read_csv` with a single-row header either breaks any names that might be on
the index, or reads all data as `NaN`. This problem might exist because
`pd.read_csv` hasn't caught up to #7589.
In [1]: import pandas as pd
In [2]: from StringIO import StringIO
In [3]: pd.read_csv(StringIO('''\
alpha,,A,B
foo,bar,,
this,x,1,2
this,y,5,6
that,x,3,4
that,y,7,8'''), header=0, index_col=[0,1])
Out[3]:
A B
alpha Unnamed: 1
foo bar NaN NaN
this x 1 2
y 5 6
that x 3 4
y 7 8
In [4]: pd.read_csv(StringIO('''\
alpha,,A,B
foo,bar,,
this,x,1,2
this,y,5,6
that,x,3,4
that,y,7,8'''), header=[0], index_col=[0,1])
Out[4]:
alpha A B
foo bar
this x NaN NaN
y NaN NaN
that x NaN NaN
y NaN NaN
In [5]: pd.read_csv(StringIO('''\
alpha,,A,B
beta,,Y,Z
foo,bar,,
this,x,1,2
this,y,5,6
that,x,3,4
that,y,7,8'''), header=[0,1], index_col=[0,1])
Out[5]:
alpha A B
beta Y Z
foo bar
this x 1 2
y 5 6
that x 3 4
y 7 8
| 1 |
See demo code which was taken straight from the blog post.
|
The example from release notes is not working for me with `babel --version //
5.1.13`
.babelrc
{
"stage": 0,
"optional": [
"es7.decorators"
]
}
decorators.js
function concat(...args) {
let sep = args.pop();
return function(target, key, descriptor) {
descriptor.initializer = function() {
return args.map(arg => this[arg]).join(sep);
}
}
}
function autobind(target, key, descriptor) {
var fn = descriptor.value;
delete descriptor.value;
delete descriptor.writable;
descriptor.get = function () {
return this[key] = fn.bind(this);
};
}
class Person {
firstName = "Sebastian";
lastName = "McKenzie";
@concat("firstName", "lastName", " ") fullName;
@concat("lastName", "firstName", ", ") formalName;
@autobind
getFullName() {
return `${this.first} ${this.last}`;
}
}
console.log(new Person().firstName)
console.log(new Person().lastName)
console.log(new Person().fullName)
console.log(new Person().formalName)
console.log(new Person().getFullName)
assert(new Person().fullName, "Sebastian McKenzie");
assert(new Person().formalName, "McKenzie, Sebastian");
assert(new Person().getFullName.call(null), "Sebastian McKenzie");
When after compilation `babel descriptors.js -o compiled.js` and running `node
compiled.js` I'm getting the following error
$ node scripts/compileds.js
Sebastian
McKenzie
,
/Users/marcin.kumorek/projects/es6-today/scripts/compileds.js:32
return this[key] = fn.bind(this);
^
TypeError: Cannot set property getFullName of #<Person> which has only a getter
at Person.descriptor.get (/Users/marcin.kumorek/projects/es6-today/scripts/compileds.js:32:22)
at Object.<anonymous> (/Users/marcin.kumorek/projects/es6-today/scripts/compileds.js:75:25)
at Module._compile (module.js:460:26)
at Object.Module._extensions..js (module.js:478:10)
at Module.load (module.js:355:32)
at Function.Module._load (module.js:310:12)
at Function.Module.runMain (module.js:501:10)
at startup (node.js:129:16)
at node.js:814:3
There are two issues here:
* first the output from console.logs are wrong (fullName returns '' and formalName ',')
* second the @autoBind is not working correctly resulting in a TypeError
I'm running `node -v0.12`
| 1 |
As of today one needs to enumerate all the directives used by a given `@View`.
This is very verbose and repetitive process, especially for simpler cases /
components where one uses only standard / built-in directives.
Assuming that I'm building a simple components that only consumes built-in
directives I need to write:
import {Component, Template, bootstrap} from 'angular2/angular2';
import {If} from 'angular2/angular2';
@Component({
....
})
@View({
inline: '...',
directives: [If]
})
class Simple {
...
}
In a nutshell it means that for every directive I need to:
* import it
* reference in `directives`
While I understand the benefits of this approach as well as technical
limitations here, it is still very repetitive in practice, especially for very
often (application-wide) directives (built-ins, directives used in most of the
pages, etc.).
Here are few ideas of how to make it easier on people:
* allow omit `directives` and assume that all built-in directives are available
* allow omit `directives` and assume that all directives specified by an app developer are available
This is not urgent / critical piece but would make things significantly easier
on people.
|
This is something that is bothering me.
<someComponent *ngfor="#video in videos" [video]='video'>
I'm repeating video 3 times, and I'm creating an extra temp variable.
<someComponent *ngfor="[video] in videos">
Makes much more sense to me. Is this something that is possible? Or is it a
bad idea to begin with?
| 0 |
Right now you have to type `</` and press enter to close the last tag it would
be much simpler to just press enter and have it close
|
in html file-type
vscode version 0.10.6
My User Settings config says:
"editor.autoClosingBrackets": true,
but it still doesn't work.
For example, when you type in "<script" the IntelliSense suggestions pops up
and you press enter on "script" it doesn't close the tag like this:
<script>
</script>
but it stays like this:
<script>
| 1 |
**Describe the feature** : At the moment there is no single point of truth of
all possible Elasticsearch settings.
By that i mean both settings that are configured in the `elasticsearch.yml` &
ones that are configured on a specific index (For example in a template).
It would be extremely helpful to have a single page where you can just search
for settings and read about them.
Thanks
|
We currently build pom files for elasticsearch artifacts when running `gradle
assemble`. We should validate these pom files, eg to ensure they don't contain
broken xml, duplicate sections, valid tag names, etc.
| 0 |
**TypeScript Version:**
nightly (1.9.0-dev.20160303)
**Code**
interface Foo {
foo( key: string ): string;
foo( keys: string[] ): string[];
}
declare var foo: Foo;
declare const bar: string|string[];
const baz = foo.foo( bar );
**Expected behavior:**
The code is valid and compiles without warning, because interface `Foo`
contains a signature for a method `foo` corresponding to each type in the
union `string|string[]`. The `foo` method can accept a parameter list of
`string`, and it can also accept a parameter list of `string[]`, therefore an
argument list of `string|string[]` is satisfiable.
I would expect the return type for `foo.foo` invoked in this faction to be the
type union of the return types of all matching signatures (so
`string|string[]`). This code produces the same error even if all matching
signatures have the same return type.
**Actual behavior:**
`Argument of type 'string | string[]' is not assignable to parameter of type
'string[]' Type 'string' is not assignable to type 'string[]'.`
|
It would be enormously helpful if `this` recognized type parameters:
abstract class Functor<a> {
abstract map<b>(map: (value: a) => b): this<b>;
}
abstract class Monad<a> extends Functor<a> {
abstract bind<b>(bind: (value: a) => this<b>): this<b>;
}
| 0 |
What does 'go version' print?
go version go1.3 linux/amd64
go version devel +f7e7857afd88 Fri Aug 01 16:45:33 2014 -0700 linux/amd64
What steps reproduce the problem?
If possible, include a link to a program on play.golang.org.
1. Run code at http://play.golang.org/p/41yjG2bL40
What happened?
Displays errors "json: cannot unmarshal number 1e2 into Go value of type
*int*" for all int types.
What should have happened instead?
No errors should be reported (and correct number should be unmarshaled).
The behaviour clearly is inline with strconv.{ParseInt,ParseUint}, but that does
arguably not agree with the JSON specification - unless int types are determined to not
be numbers.
|
Go version: `go version go1.5.1 linux/amd64`
What I did: used gofmt on my source code
What I expected: have spaces around bitwise `&` everywhere
What I saw: in one occasion there was no spaces around the operator
I have put "before" and "after" code into a gist, so from the diff you can
easily see the changes applied by gofmt
| 0 |
just in case this is not present as another issue
Details are from a discourse post
|
It's interesting that this is valid syntax in Julia and Lua:
function rec()
return rec()
end
The difference is that in Lua, when you call `rec()` it will stare at you and
engage your motherboard's built-in space heater until you ctrl-C out. In
Julia:
julia> rec()
ERROR: stack overflow
in rec at none:2 (repeats 80000 times)
So the stack 80000 things deep. That's interesting.
Why does this matter? I'm not sure. But some people care a lot:
http://www.lua.org/pil/6.3.html
| 0 |
Challenge Waypoint: Use appendTo to Move Elements with jQuery has an issue.
User Agent is: `Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
My code:
<script>
$(document).ready(function() {
$("#target1").css("color", "red");
$("#target1").prop("disabled", true);
$("#target4").remove();
<!-- Note that this code works because it uses the appendTo() method correctly -->
$("#target2").appendTo($("#right-well"));
<!-- Intended code based on instructions, which will not function -->
$("#target2").appendTo("#right-well");
});
</script>
'''
The instructions in the referenced waypoint misguide coders to use the appendTo() method of jQuery incorrectly. Github would not let me attach my screenshot :(
|
A bug seems to be present: Chrome 46.0.2490.86 m; Windows 8.1 with respect to
`appendTo()` function.
`$("#target2").appendTo($("#right-well"));` does work, but not the
`$("#target2").appendTo("#right-well");`, the latter being suggested in the
tutorial.
Hard reload and cache clearing did not seem to solve the problem.
| 1 |
I have a navbar-fixed-top navbar. Links that include "scroll to id" (as in
href="#myid") don't adjust scroll position to account for the 50px of the
navbar.
Can you add some JS to detect this situation on the URL and adjust the scroll
position back by the height of the navbar?
|
navbar covers first lines of a section called via <a
href='#section'>Section</a>
| 1 |
### Apache Airflow version
2.2.1 (latest released)
### Operating System
debian
### Versions of Apache Airflow Providers
apache-airflow==2.2.1
apache-airflow-providers-amazon==2.3.0
apache-airflow-providers-ftp==2.0.1
apache-airflow-providers-google==6.0.0
apache-airflow-providers-http==2.0.1
apache-airflow-providers-imap==2.0.1
apache-airflow-providers-jira==2.0.1
apache-airflow-providers-mysql==2.1.1
apache-airflow-providers-postgres==2.3.0
apache-airflow-providers-redis==2.0.1
apache-airflow-providers-sqlite==2.0.1
apache-airflow-providers-ssh==2.2.0
### Deployment
Other Docker-based deployment
### Deployment details
Dask executor, custom-built Docker images, postgres 12.7 backend
### What happened
1. Shut off Airflow cluster
2. Upgraded database from 2.0.2 to 2.2.1
3. Restarted Airflow cluster
4. The scheduler failed to start
5. I checked the logs, and found this:
2021-11-04 21:15:35,566 ERROR - Exception when executing SchedulerJob._run_scheduler_loop
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 628, in _execute
self._run_scheduler_loop()
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 709, in _run_scheduler_loop
num_queued_tis = self._do_scheduling(session)
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 782, in _do_scheduling
self._create_dagruns_for_dags(guard, session)
File "/usr/local/lib/python3.9/site-packages/airflow/utils/retries.py", line 76, in wrapped_function
for attempt in run_with_db_retries(max_retries=retries, logger=logger, **retry_kwargs):
File "/usr/local/lib/python3.9/site-packages/tenacity/__init__.py", line 382, in __iter__
do = self.iter(retry_state=retry_state)
File "/usr/local/lib/python3.9/site-packages/tenacity/__init__.py", line 349, in iter
return fut.result()
File "/usr/local/lib/python3.9/concurrent/futures/_base.py", line 438, in result
return self.__get_result()
File "/usr/local/lib/python3.9/concurrent/futures/_base.py", line 390, in __get_result
raise self._exception
File "/usr/local/lib/python3.9/site-packages/airflow/utils/retries.py", line 85, in wrapped_function
return func(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 847, in _create_dagruns_for_dags
self._create_dag_runs(query.all(), session)
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 917, in _create_dag_runs
self._update_dag_next_dagruns(dag, dag_model, active_runs_of_dags[dag.dag_id])
File "/usr/local/lib/python3.9/site-packages/airflow/jobs/scheduler_job.py", line 926, in _update_dag_next_dagruns
if total_active_runs >= dag_model.max_active_runs:
TypeError: '>=' not supported between instances of 'int' and 'NoneType'
6. I checked the code and saw that dag_model.max_active_runs comes directly from the database and is nullable
7. I updated all values for dag.max_active_runs to be non-null
8. Restarted the scheduler
9. Everything ran fine
### What you expected to happen
In this case, I would expect the code to properly handle nullable columns,
probably by using the default value provided in the configs.
### How to reproduce
This is easily reproducible. Start a fresh instance of Airflow with a database
at version 2.2.1 and follow these steps:
1. Add a DAG to the instance
2. Manually set dag.max_active_runs to null in the database
3. Enable the DAG to cause the scheduler to attempt to parse/schedule it
4. BOOM! The scheduler will crash
### Anything else
Newly registered DAGs have this value populated in the database with the
default value, so this issue will likely only occur on a database upgrade.
### Are you willing to submit PR?
* Yes I am willing to submit a PR!
### Code of Conduct
* I agree to follow this project's Code of Conduct
|
### Apache Airflow version
2.2.1 (latest released)
### Operating System
Linux (ubuntu 20.04)
### Versions of Apache Airflow Providers
apache-airflow-providers-ftp==2.0.1
apache-airflow-providers-http==2.0.1
apache-airflow-providers-imap==2.0.1
apache-airflow-providers-microsoft-azure==3.1.0
apache-airflow-providers-microsoft-mssql==2.0.0
apache-airflow-providers-postgres==2.0.0
apache-airflow-providers-salesforce==3.1.0
apache-airflow-providers-sqlite==2.0.1
apache-airflow-providers-ssh==2.1.0
### Deployment
Other
### Deployment details
Airflow installed on Azure virtual machine (Standard D8s v3 (8 vcpus, 32 GiB
memory)), the VM is dedicated for Airflow only
### What happened
After I updated Airflow from 2.1.3 to 2.2.1 and run db update, I run `airflow
scheduler` and got an error:
[2021-11-02 11:43:20,846] {scheduler_job.py:644} ERROR - Exception when executing SchedulerJob._run_scheduler_loop
Traceback (most recent call last):
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 628, in _execute
self._run_scheduler_loop()
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 709, in _run_scheduler_loop
num_queued_tis = self._do_scheduling(session)
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 782, in _do_scheduling
self._create_dagruns_for_dags(guard, session)
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/utils/retries.py", line 76, in wrapped_function
for attempt in run_with_db_retries(max_retries=retries, logger=logger, **retry_kwargs):
File "/home/DataPipeline/.local/lib/python3.8/site-packages/tenacity/__init__.py", line 382, in __iter__
do = self.iter(retry_state=retry_state)
File "/home/DataPipeline/.local/lib/python3.8/site-packages/tenacity/__init__.py", line 349, in iter
return fut.result()
File "/usr/lib/python3.8/concurrent/futures/_base.py", line 437, in result
return self.__get_result()
File "/usr/lib/python3.8/concurrent/futures/_base.py", line 389, in __get_result
raise self._exception
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/utils/retries.py", line 85, in wrapped_function
return func(*args, **kwargs)
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 847, in _create_dagruns_for_dags
self._create_dag_runs(query.all(), session)
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 917, in _create_dag_runs
self._update_dag_next_dagruns(dag, dag_model, active_runs_of_dags[dag.dag_id])
File "/home/DataPipeline/.local/lib/python3.8/site-packages/airflow/jobs/scheduler_job.py", line 926, in _update_dag_next_dagruns
if total_active_runs >= dag_model.max_active_runs:
TypeError: '>=' not supported between instances of 'int' and 'NoneType'
The scheduler is not able to run.
### What you expected to happen
This behaviour happens right after the update. I have another VM with Airflow
(the two machines are similar, the difference in location of the VM).
### How to reproduce
after the update to 2.2.1, change the config in accordance with Warnings and
run `airflow scheduler`
### Anything else
_No response_
### Are you willing to submit PR?
* Yes I am willing to submit a PR!
### Code of Conduct
* I agree to follow this project's Code of Conduct
| 1 |
**Symfony version(s) affected** : 3.x, 4.x
**Description**
Due to update in php-intl library this loop is infinite.
symfony/src/Symfony/Component/Intl/Data/Bundle/Reader/BundleEntryReader.php
Line 81 in 95932df
| while (null !== $currentLocale) {
---|---
**How to reproduce**
Update php-intl to the latest version and try to get country names for en
locale for example.
**Possible Solution**
For BC it would be great to loop until locale is empty so check could be
!empty($currentlocale)
**Additional context**
Ive been struggling with this all morning, later I had to code on my laptop
and this error was not present, Ive updated php-intl and error became present
as on my work PC.
|
PHP 7.2.17-1+ubuntu18.04.1+deb.sury.org+3
SYMFONY: Symfony 4.2.4
locale_parse('root') now return an empty array as opposed to previos php
versions which makes the Symfony\Component\Intl\Data\Bundle\Reader loop
through fallback locales as
"en" => "root" => "" => "root" => "" and so on without it becoming null to
break the loop
when reading from the regions because in the
Symfony\Component\Intl\Locale::getFallback()
we never get inside the if (1 === \count($localeSubTags))
| 1 |
# Description of the new feature/enhancement
Customizing Terminal settings should be allowed to be loaded from my OneDrive
folder or my own github repository, just like my powershell settings are or my
VIM settings.
Currently, when I login into a new machine I have to merge or manually copy
settings for Terminal, I don't have this problem in PowerShell or VIM as all I
need to do is git clone and redirect to my settings folder.
# Proposed technical implementation details (optional)
Here are some options:
1. Allow for an arbitrary folder to be configured to read settings.
2. Read from ~.terminal folder (but allow redirection)
After configuring the "reditected" folder, all my settings and profile are
restored.
|
# Description of the new feature/enhancement
There should be an option for choosing default shell. Currently, If one wishes
to use WSL, it has to open terminal, then open new tab with wsl. previously,
one could simply pin wsl to taskbar, and when needed, one could open the wsl
directly. furthermore, it would be nice to be able to pin terminal multiple
times with different default shells. When pinned, it would be preferable to
show default shell's icon or something that identifies what is the default
shell that will be launched.
# Proposed technical implementation details (optional)
| 0 |
### Bug summary
`contourf()` by default does not draw borders between adjacent levels.
However, including the `alpha` keyword argument makes these borders visible.
Desired behavior is to not draw these lines even with `alpha` specified.
### Code for reproduction
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-3, 5, 150).reshape(1, -1)
y = np.linspace(-3, 5, 120).reshape(-1, 1)
z = np.cos(x) + np.sin(y)
x, y = x.flatten(), y.flatten()
fig, ax = plt.subplots(nrows=2,ncols=1)
ax[0].set_title('Actual outcome')
ax[0].contourf(x, y, z, levels=15, vmin=0.5, vmax=1.0, cmap='cividis', alpha=0.9)
ax[1].set_title('Expected outcome')
ax[1].contourf(x, y, z, levels=15, vmin=0.5, vmax=1.0, cmap='cividis')
plt.show()
### Actual outcome

### Expected outcome
### Additional information
_No response_
### Operating system
Ubuntu 20.04
### Matplotlib Version
3.5.1
### Matplotlib Backend
QtAgg
### Python version
3.8.8
### Jupyter version
_No response_
### Installation
conda
|
This is the underlying problem raised in #1178.
It is illustrated by the test below; note that boundary anomalies are visible
in all forms--agg on the screen, and pdf and svg displayed with a viewer--but
in different places depending on the viewer and the size of the figure as
rendered.
Note that the colorbar is rendered using pcolormesh, which has its own
renderer with agg but otherwise is handled by draw_path_collection.
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(150)
z.shape = (10,15)
fig, axs = plt.subplots(2,2)
ax = axs[0,0]
cs0 = ax.contourf(z, 20)
cbar0 = fig.colorbar(cs0, ax=ax)
ax = axs[0,1]
cs1 = ax.contourf(z, 20, alpha=0.3)
cbar1 = fig.colorbar(cs1, ax=ax)
ax = axs[1,0]
im2 = ax.imshow(z, interpolation='nearest')
cbar2 = fig.colorbar(im2, ax=ax)
ax = axs[1,1]
im3 = ax.imshow(z, interpolation='nearest', alpha=0.3)
cbar3 = fig.colorbar(im3, ax=ax)
plt.savefig("test1.pdf")
plt.savefig("test1.svg")
plt.show()
| 1 |
### Describe your issue.
This is fine on linux, but on OSX with an M1, `stats.beta().interval()`
produces an overflow warning for completely reasonable values that should not
cause overflow issues.
### Reproducing Code Example
from scipy import stats
stats.beta(4, 2).interval(0.95)
### Error message
/Users/twiecki/miniforge3/envs/pymc4/lib/python3.10/site-packages/scipy/stats/_continuous_distns.py:624: RuntimeWarning: overflow encountered in _beta_ppf
return _boost._beta_ppf(q, a, b)
### SciPy/NumPy/Python version information
1.7.3 1.22.4 sys.version_info(major=3, minor=10, micro=4,
releaselevel='final', serial=0)
|
### Describe your issue
Several statistical distribution methods emit warnings stemming from Boost.
This issue tracks the status of all of them.
* `beta.ppf` as reported here; should be fixed by boostorg/math#827
* `ncf` as reported in gh-17101, should be fixed by boostorg/math#846
* `nct` \- I'm not sure that this has been reported separately yet. Is it caused by the same sort of thing?
* `ncx2` \- Ditto.
gh-17272 will silence the failures in SciPy's tests temporarily, but as many
of these marks as possible should be removed when gh-17207 merges.
* * *
_Original Post_
### Describe your issue.
macOS CI is failing due to an overflow. I am still trying to reproduce
locally.
NumPy was updated to 1.21.3, could be this or another dependency.
https://github.com/scipy/scipy/runs/3960228039
### Reproducing Code Example
# from scipy/stats/tests/test_distributions.py:2878: in test_issue_12796
import numpy as np
from scipy import stats
q = 0.999995
a = np.array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
b = np.array([99999, 99998, 99997, 99996, 99995, 99994, 99993, 99992, 99991, 99990, 99989, 99988, 99987, 99986, 99985, 99984, 99983, 99982, 99981])
stats.beta.ppf(q, a, b)
### Error message
FAILED scipy/stats/tests/test_distributions.py::TestBeta::test_issue_12635 - ...
927
FAILED scipy/stats/tests/test_distributions.py::TestBeta::test_issue_12794 - ...
928
FAILED scipy/stats/tests/test_distributions.py::TestBeta::test_issue_12796 - ...
...
scipy/stats/_continuous_distns.py:626: in _ppf
916
return _boost._beta_ppf(q, a, b)
917
E RuntimeWarning: overflow encountered in _beta_ppf
### SciPy/NumPy/Python version information
master on macOS/CI
| 1 |
The string "0.6" appears 35 times in our tree and we don't have an obvious way
to eliminate this duplication. Something like `include_lit!` might do the job.
|
Consider
extern crate innercrate; //defines only one public item `from_inner_crate`
pub use inner::{inner_fn, from_inner_crate};
/// Top level documentation
pub fn top_level(){}
pub mod inner {
pub use innercrate::from_inner_crate;
/// Defined inside inner module
pub fn inner_fn(){}
}
Documentation renders from_inner_crate as if it was defined at the top level
of crate rather than showing it as an reexport from inner module.

| 0 |
import pandas as pd
dates = [ 20140101, 20140102, 20140103]
states = [ "CA", "NY", "CA"]
x = pd.DataFrame({ 'dates' : dates, 'states' : states })
#y = pandas.DataFrame({ 'state' : [ 'CA', 'OR' ], 'value' : [ 1, 2]})
y = pd.DataFrame({ 'states' : [ "CA", "NY" ], 'stateid' : [ 1, 2]})
z = pd.merge(x, y, how='left', on='states',)
x=
dates states
0 20140101 CA
1 20140102 NY
2 20140103 CA
y=
stateid states
0 1 CA
1 2 NY
z= dates states stateid
0 20140101 CA 1
1 20140103 CA 1
2 20140102 NY 2
* * *
Note z is always sorted by "states" column whether argument sort=True or
False.
This only happens when the x's states column is not unique. If x.states is
unique(such as NY, CA, CT), sort=True and False behaves as expected.
This causes inconvenience when x is a time series and merge does not
preserve the time sequence.
|
Using floor on a DatetimeIndex that has a timezone with DST fails when
converting the result back to the tz as there may be ambiguous time (see
example below).
# create 15' date range with Brussels tz
idx = pandas.date_range("2016-01-01","2017-01-01",freq="15T", tz="Europe/Brussels")
# transform the index to get rid of minutes
idx_h = idx.floor("H")
#### Expected Output
idx_h rounded to the hour
#### Actual Output
excepection raised when relocalizing the index after applying the rouding
Traceback (most recent call last):
File "...", line 118, in <module>
idx_h = idx.floor("H")
File "...\lib\site-packages\pandas\tseries\base.py", line 98, in floor
return self._round(freq, np.floor)
File "...\lib\site-packages\pandas\tseries\base.py", line 89, in _round
result = result.tz_localize(self.tz)#, ambiguous=[d.dst() for d in self])
File "...\lib\site-packages\pandas\util\decorators.py", line 91, in wrapper
return func(*args, **kwargs)
File "...\lib\site-packages\pandas\tseries\index.py", line 1857, in tz_localize
ambiguous=ambiguous)
File "pandas\tslib.pyx", line 4087, in pandas.tslib.tz_localize_to_utc (pandas\tslib.c:69556)
pytz.exceptions.AmbiguousTimeError: Cannot infer dst time from Timestamp('2016-10-30 02:00:00'), try using the 'ambiguous' argument
#### Possible solution
The code to reconvert to local tz need to have 'ambiguous' defined and can use
the original array of dst flags.
Lines 87-89 in ...\Lib\site-packages\pandas\tseries\base.py
# reconvert to local tz
if getattr(self, 'tz', None) is not None:
result = result.tz_localize(self.tz)
to be replaced by
Lines 87-89 in ...\Lib\site-packages\pandas\tseries\base.py
# reconvert to local tz
if getattr(self, 'tz', None) is not None:
result = result.tz_localize(self.tz, ambiguous=[d.dst() for d in self])
Would it be also useful to have a DatetimeIndex.dst function to return a
boolean array reuseable in tz_localize ?
#### Output of `pd.show_versions()`
# Paste the output here ## INSTALLED VERSIONS
commit: None
python: 2.7.11.final.0
python-bits: 32
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 61 Stepping 4, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.18.0
nose: 1.3.7
pip: 8.1.1
setuptools: 20.3
Cython: 0.23.4
numpy: 1.10.4
scipy: 0.17.0
statsmodels: 0.6.1
xarray: None
IPython: 4.1.2
sphinx: 1.3.5
patsy: 0.4.0
dateutil: 2.5.1
pytz: 2016.2
blosc: None
bottleneck: 1.0.0
tables: 3.2.2
numexpr: 2.5
matplotlib: 1.5.1
openpyxl: 2.3.2
xlrd: 0.9.4
xlwt: 1.0.0
xlsxwriter: 0.8.4
lxml: 3.6.0
bs4: 4.4.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.0.12
pymysql: None
psycopg2: None
jinja2: 2.8
boto: 2.39.0
| 0 |
We can obviously have the task bar on multiple displays, but currently only
one display will show system icons on one display at a time, without using
third party software.
Would it be possible to add a feature to show them on all displays at once?
Thanks
* * *
If you'd like to see this feature implemented, add a 👍 reaction to this post.
|
# .NET Core 3 upgrade
Update all sections that use .NET to .NET Core 3
## .NET Framework 4.7.2
* ColorPicker <\- done by @snickler
* MarkdownPreviewHandler <\- #8405
* PreviewHandlerCommon <\- #8405
* SvgPreviewHandler <\- #8405
* SVGThumbnailProvider <\- #8405
### Tests
* Microsoft.Interop.Tests <\- done by @eriawan
* PreviewPaneUnitTests <\- #8405
* UnitTests-PreviewHandlerCommon <\- #8405
* UnitTests-SvgPreviewHandler <\- #8405
* UnitTests-SvgThumbnailProvider <\- #8405
* PowerToysTests <\- done by @riverar WinAppDriver tests
## .NET Standard 2.0
* Managed Common
* Telemetry
* Settings.UI.Library
* PowerLauncher.Telemetry
## .NET Core 3.1
* FancyZonesEditor
* Settings.UI.Runner
* Settings.UI.UnitTests
* UnitTest-ColorPicker
* ImageResizerUI
* ImageResizerUITests
* PowerLauncher
* Wox.Infrastructure
* Wox.Plugin
* Wox.Test
## UWP
* Settings.UI
## Things to include
* **ReadyToRun** should be timed to verify boost. see blog post
* **PublishTrimmed** to reduce file size. see blog post
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.