
text1 stringlengths 2 269k | text2 stringlengths 2 242k | label int64 0 1 |
|---|---|---|
x = tf.zeros([10])
tf.gradients(tf.reduce_prod(x, 0), [x])
Gives
more traceback
/home/***/.local/lib/python2.7/site-packages/tensorflow/python/ops/math_grad.pyc in _ProdGrad(op, grad)
128 reduced = math_ops.cast(op.inputs[1], dtypes.int32)
129 idx = math_ops.range(0, array_ops.rank(op.inputs[0]))
--> 130 other, _ = array_ops.listdiff(idx, reduced)
131 perm = array_ops.concat(0, [reduced, other])
132 reduced_num = math_ops.reduce_prod(array_ops.gather(input_shape, reduced))
more traceback
In line 128, `op.inputs[1]` could be a scalar, which will cause a shape
mismatch when passed to `array_ops.listdiff` in line 130.
TF version: master branch a week ago
|
Installed TensorFlow using pip package for v0.10.0rc0 on Ubuntu with python
2.7
Pip package
https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.10.0rc0-cp27-none-
linux_x86_64.whl
The same error appears in the GPU build.
The following minimal code example produces raise an exception at the
definition of z
u = tf.placeholder(dtype=tf.float64, shape=(30,30))
v = tf.reduce_prod(u, reduction_indices=[0])
w = tf.gradients( v, u )
x = tf.placeholder(dtype=tf.float64, shape=(30,30))
y = tf.reduce_prod(x, reduction_indices=0)
z = tf.gradients( y, x )
> z = tf.gradients( y, x )
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/ops/gradients.py", line 478, in gradients
> in_grads = _AsList(grad_fn(op, *out_grads))
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/ops/math_grad.py", line 130, in _ProdGrad
> other, _ = array_ops.listdiff(idx, reduced)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/ops/gen_array_ops.py", line 1201, in list_diff
> result = _op_def_lib.apply_op("ListDiff", x=x, y=y, name=name)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/framework/op_def_library.py", line 703, in
> apply_op
> op_def=op_def)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/framework/ops.py", line 2312, in create_op
> set_shapes_for_outputs(ret)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/framework/ops.py", line 1704, in
> set_shapes_for_outputs
> shapes = shape_func(op)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/ops/array_ops.py", line 1981, in _ListDiffShape
> op.inputs[1].get_shape().assert_has_rank(1)
> File "HOME/anaconda2/lib/python2.7/site-
> packages/tensorflow/python/framework/tensor_shape.py", line 621, in
> assert_has_rank
> raise ValueError("Shape %s must have rank %d" % (self, rank))
> ValueError: Shape () must have rank 1
The top code for u,v and w does not raise an error but the similar code for
x,y, and z does. It looks like the shape code for reduce_prod cannot cope with
the case where the reduction_indices is a single integer rather than a list.
If you replace reduce_prod with reduce_sum in the above snippet then it does
not raise an error.
| 1 |
**I'm submitting a ...** (check one with "x")
[x] bug report => search github for a similar issue or PR before submitting
[ ] feature request
[ ] support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
**Current behavior**
When using the currency pipe to format a number specifying the valid ISO 4217
currency code for South Africa 'ZAR' and setting the SymbolDisplay to true the
currency code is not replaced by the currency symbol, in this case 'R'.
**Expected behavior**
The expected behavior is for the projected property to display the currency
symbol instead of the currency code when symbolDisplay is true and
currencyCode is set to 'ZAR'.
**Minimal reproduction of the problem with instructions**
{{someamount | currency:'ZAR':true:'1.2-2'}}
**What is the motivation / use case for changing the behavior?**
We need to format currency with the South African currency symbol.
**Please tell us about your environment:**
macOS Sierra, webpack, ng serve (angular-cli: template used:
1.0.0-beta.11-webpack.9-4)
* **Angular version:** 2.0.0-rc.7
* **Browser:** all
* **Language:** all
* **Node (for AoT issues):** `node --version` =
|
I'm using the currency pipe with beta.0, and with the following code inside
ionic 2:
>
> <ion-card-content>
> Total: {{ total | currency:'COP':true }}
> </ion-card-content>
>
The output should be `Total: $ 110,000` but the actual output is this:

| 1 |
i want prevent atom-shell to start when had a atom-shell started, how can i do
that?
|
I want to disallow user to run the same app on running, and get the arguments
from command line.
Is there any way implement this, just like use 'single-instance' configuration
and 'open' event in node-webkit.
| 1 |
by **plnordahl** :
Running Mavericks 10.9.2 and using the patch from
https://groups.google.com/forum/#!msg/golang-codereviews/it4yhth9fWM/TxcE1Yx6AUMJ (issue
7510) on release-branch.go1.2, I'm not seeing the variable names of int, string, float,
or map variables in a simple program. I do however see names for slices, arrays, and
struct/struct members in the output. Below is some code to reproduce the behavior.
One program, which will be loaded for it's DWARF data:
package main
import "fmt"
func main() {
myInt := 42
mySecondInt := 41
fmt.Println(myInt, mySecondInt)
myArray := [2]string{"hello", "world"}
fmt.Println(myArray)
myString := "foo"
fmt.Println(myString)
mySlice := []int{1, 2, 3}
fmt.Println(mySlice)
myFloat := 42.424242
fmt.Println(myFloat)
myMap := make(map[string]string)
fmt.Println(myMap)
myStruct := myStructType{"bleh", 999, "hm"}
fmt.Println(myStruct)
}
type myStructType struct {
Bleh string
Blerg int
Foo string
}
...and the second, which just loads the Mach-O binary and prints each entry's offset,
tag, children, and fields (pipe the output of this program into grep to see the behavior
I describe).
package main
import (
"debug/macho"
"fmt"
"log"
)
func main() {
m, err := macho.Open("<put the path to where your test binary is located>")
if err != nil {
log.Fatalf("Couldn't open MACH-O file: %s\n", err)
}
d, err := m.DWARF()
if err != nil {
log.Fatalf("Couldn't read DWARF info: %s\n", err)
}
r := d.Reader()
for {
entry, err := r.Next()
if err != nil {
log.Fatalf("Current offset is invalid or undecodable. %s", err)
}
if entry == nil {
fmt.Println("Reached the end of the entry stream.")
return
}
fmt.Println("Entry --- offset: ", entry.Offset,
" tag: ", entry.Tag, " children: ", entry.Children,
" field: ", entry.Field)
}
return
}
|
by **seanerussell** :
What steps will reproduce the problem?
1. Compile the attached file (steps to compile listed below)
2. Execute on Windows
3. Watch the memory use with Resource Monitor
The application memory use increases at a rate of about 1KB every 5s until it exceeds
the stack (heap?) space and crashes.
I'm using Go 6d7136d74b65 weekly/weekly.2011-10-18 and am compiling on Linux,
cross-compiling for Windows using gb (go-gb.googlecode.com) via "GOOS=windows
gb"; 6g/l are the compilers being used.
The Linux machine is 2.6.32-32-generic #62-Ubuntu SMP, and the code is executing on
Windows Server 2008 R2 Standard, 6-core AMD Opteron 2425 HE 2.1GHz x 2, 32GB RAM, 64-bit.
I don't see similar behavior on Linux; the process memory use does grow very slowly for
a while, but appears to eventually plateau after a few minutes.
If this isn't a memory leak, but is explained by expected behavior, could I get a
pointer to a document describing the cause?
Attachments:
1. memconsumer.go (1308 bytes)
| 0 |
It seems that `document.hidden` is not working once the browser is controlled
by Playwright.
Given you open a browser tab (outside of playwright) and inject in the console
the script :
setInterval(() => {console.log(`document.hidden = ${document.hidden}`)}, 1000)
When you open a new browser tab
And you wait a few seconds
And you come back to the previous tab
Then you have the following logs in the console:
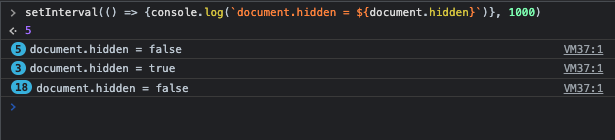
When you do the same steps in a browser controlled by Playwright
Then you have the following logs in the console :
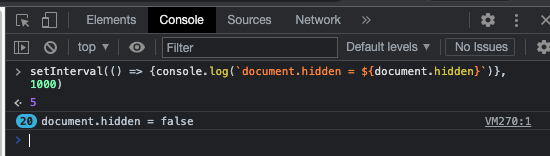
Unless I am wrong, `document.hidden` should be handled by Playwright.
This missing feature prevents to test the front stops specific activities (for
example the front stops to poll a rest API endpoint) when the user switches
from one browser tab to another, and vice-versa: the front should, for
example, restart it's polling activity when the browser tab becomes actif
again.
Regards
|
Presently Playwright treats all tabs as active. This can become an issue when
a tab we're not currently focusing on is running a lot of work.
I'll use the site MakeUseOf.com as an example. When this tab is active, it can
consume 25-30% CPU time on my brand new MBPro. Under normal Chromium, when the
tab is not the current tab Chromium will throttle timers (and whatever else it
may do) and the site will settle around 2% CPU.
Under Playwright, this inactive tab will continue to use full resources
(25-30% CPU).
I'd like to see a flag or an API call (`page.goToBack()` was suggested) that
would allow inactive tabs to sleep.
Here's a link to the original discussion.
Thanks!
| 1 |
When concatting two dataframes where there are a) there are duplicate columns
in one of the dataframes, and b) there are non-overlapping column names in
both, then you get a IndexError:
In [9]: df1 = pd.DataFrame(np.random.randn(3,3), columns=['A', 'A', 'B1'])
...: df2 = pd.DataFrame(np.random.randn(3,3), columns=['A', 'A', 'B2'])
In [10]: pd.concat([df1, df2])
Traceback (most recent call last):
File "<ipython-input-10-f61a1ab4009e>", line 1, in <module>
pd.concat([df1, df2])
...
File "c:\users\vdbosscj\scipy\pandas-joris\pandas\core\index.py", line 765, in take
taken = self.view(np.ndarray).take(indexer)
IndexError: index 3 is out of bounds for axis 0 with size 3
I don't know if it should work (although I suppose it should, as with only the
duplicate columns it does work), but at least the error message is not really
helpfull.
|
dti = pd.date_range('2016-09-23', periods=3, tz='US/Central')
df = pd.DataFrame(dti)
>>> df.T
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "pandas/core/frame.py", line 1941, in transpose
return super(DataFrame, self).transpose(1, 0, **kwargs)
File "pandas/core/generic.py", line 616, in transpose
new_values = self.values.transpose(axes_numbers)
File "pandas/core/base.py", line 697, in transpose
nv.validate_transpose(args, kwargs)
File "pandas/compat/numpy/function.py", line 54, in __call__
self.defaults)
File "pandas/util/_validators.py", line 218, in validate_args_and_kwargs
validate_kwargs(fname, kwargs, compat_args)
File "pandas/util/_validators.py", line 157, in validate_kwargs
_check_for_default_values(fname, kwds, compat_args)
File "pandas/util/_validators.py", line 69, in _check_for_default_values
format(fname=fname, arg=key)))
ValueError: the 'axes' parameter is not supported in the pandas implementation of transpose()
Looks like this is b/c `df.values` is a `DatetimeIndex`
| 0 |
CSS Grid layout excels at dividing a page into major regions, or defining the
relationship in terms of size, position, and layer, between parts of a control
built from HTML primitives.
Watched a youtube about CSS Grids: https://youtu.be/txZq7Laz7_4
Nice concept that seems to play nice with component based development.
Integration with Next.js may prove to solve CSS issues and the way we think
about making apps.
Probably goes against providing options to the developer but could image a
lean mean workflow.
Any thoughts?
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
Standard <style jsx> with built in support for grid layouts/fallback support.
## Current Behavior
Currently CSS can be a mess and look quite ugly with multiple nested divs and
leads to accessibility issues.
## Steps to Reproduce (for bugs)
1. To many options for front end CSS frameworks that don't work well with component based workflow.
2. Heavy CSS frameworks in the global space.
3. Incomplete CSS react libraries like Semantic UI.
4. Doing things the old way.
## Context
Providing a rich UX is one of the most complicating parts of developing an app
and Next.js definitely makes things easier and is also lightning fast. I
believe something like "CSS Grid" could make layouts of the components where
you want them easy while increasing performance.
## Links
https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Grid_Layout
https://css-tricks.com/snippets/css/complete-guide-grid/
https://www.w3.org/TR/css-grid-1/
|
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
Calling `Router.push({pathname: 'about'})` should work just as `<Link
href={{pathname: 'about'}}/>` does, and as described here.
## Current Behavior
Client side, it throws an error `Route name should start with a "/", got
"page"` (thrown from https://github.com/zeit/next.js/blob/v3-beta/lib/page-
loader.js#L22)
It then immediately falls back to the server side route, which then loads the
page as usual.
Depending on how long the server page takes to load, you may or may not see
the error above.
Note that absolute pathnames (`/about`) work as normal.
## Steps to Reproduce (for bugs)
1. https://github.com/tmeasday/next-routing-bug \- `git clone https://github.com/tmeasday/next-routing-bug; cd next-routing bug; npm install; npm run dev`
2. Click the "Link" or "Leading Slash" tags, notice normal behaviour.
3. Click the "No Leading Slash" tag, notice the error for 2 seconds (how long the "page" takes to load).
4. Inspect the server console and note that the "page" page loaded from the server.
## Context
I think the issue here is that the `Link` calls `url.resolve` here, where as
`Router.push` does not.
I suspect the `resolve` call should come somewhere deeper in the stack.
## Your Environment
Tech | Version
---|---
next | 2 + 3 betas
node | 8.1.0
OS | macOS 10.12.5
browser | Chrome
| 0 |
#### Summary
`maxBodyLength` is a option for follow-redirect which is default transport for
axios in node.js environment.
so, can't upload file > 10M
#### Context
* axios version: all version
* Environment: node all version
|
#### Summary
`follow-redirects` defaults to a `maxBodyLength` of 10mb. `axios` does not
override this default, even when the config specifies a `maxContentLength`
parameter greater than 10mb, thus capping `axios` at a maximum content length
of 10mb no matter what is configured, and returning an error that does not
make it obvious that `follow-redirects` is the cause.
`axios` should set the `maxBodyLength` option sent to `follow-redirects` to
match the `maxContentLength` config property set on the `AxiosOptions` object.
#### Context
* axios version: _v0.17.1_
* Environment: _Electron v1.4.3 or Node v6.5.0 with XHR polyfill, macOS v10.13.2_
#### Status
Pull request: #1287
| 1 |
function foo()
try
error("error in foo")
catch e
end
end
function bar()
try
error("error in bar")
catch e
foo()
rethrow(e)
end
end
bar()
produces the misleading
ERROR: error in bar
Stacktrace:
[1] foo() at ./REPL[1]:3
[2] bar() at ./REPL[2]:5
This just hit me in a really wicked situation: The stacktrace actually lead me
to a line erroneously throwing the reported exception. I fixed it (to throw
the correct exception), but the same error kept showing, leaving me completely
puzzled for quite some time...
|
`\varepsilon` is currently mapped to ɛ (U+025B latin small letter open e).
This is wrong. The correct mapping is ε (U+03B5 greek small letter epsilon).
| 0 |
If this is something that can't be added or isn't going to be supported, it
wouldn't be a bad thing to support hierarchical data in forms (adjacency list
model / nested set model).
Possibly having the option to force the selection of leafs without children
only, etc, etc. Can lead to a very powerful feature. =)
| Q | A
---|---
Bug report? | yes
Feature request? | no
BC Break report? | no
RFC? | no
Symfony version | 3.4.0-BETA1
Since upgrading to Symfony 3.4.0-BETA1 fom 3.3.10, suddenly all responses
started receiving `Cache-Control` header with `private, max-age=10800, no-
cache, private` value and a response code `304 Not Modified`, which means that
responses are cached in browsers for 3 hours and only hard reload with
`Ctrl+R` or `Shift+R` refreshes the page from backend.
`git bisect` says that the culprit is #24523. And indeed, reverting the commit
in that PR fixes the issue for me, meaning `Cache-Control` header is back to
`no-cache, private` and the response is `200 OK`.
| 0 |
### Problem
When going through the "Image tutorial" on Firefox or Edge, when you try
downloading the image of the stinkbug, it will only download as a `webp` file
and there is no option to download as `png`. That is even clicking the "View
Image" and trying to save it. Below is trying to save the image in Firefox.
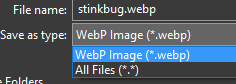
This is a problem for introductory students, trying to use this tutorial and
learning how to read tutorials. They believe they are doing something wrong
and wouldn't be sure how to convert it. As a more advanced user, I still could
not find out how to make it a `png` through the tutorial page.
* Tutorial Link: https://matplotlib.org/tutorials/introductory/images.html
* Image Link: https://matplotlib.org/_images/stinkbug.png (may say `png` but downloading it is as `webg`)
Operating System: Windows 10 Pro
### Suggested Improvement
The image needs to be updated to a `png` and maybe a direct link to download
the image (the latter is not as important).
If there is a way to do that with a module, that might be cool to include, but
just an idea. I can provide more information if necessary.
|
The image tutorial on matplotlib.org uses this sample image:
https://matplotlib.org/_images/stinkbug.png
and notes that it is a "24-bit RGB PNG image (8 bits for each of R, G, B)".
However, further inspection reveals that it is _not_ a 24-bit RGB, but rather
an 8-bit grayscale image.
$ curl -s 'https://matplotlib.org/_images/stinkbug.png' | file -
/dev/stdin: PNG image data, 500 x 375, 8-bit grayscale, non-interlaced
However, the source image in the github repository _is_ an RGB image:
$ curl -s 'https://raw.githubusercontent.com/matplotlib/matplotlib/master/doc/_static/stinkbug.png' | file -
/dev/stdin: PNG image data, 500 x 375, 8-bit/color RGB, non-interlaced
I noticed this because when I tried to follow the tutorial on my own machine,
I kept on getting this error in line 7:
In [7]: lum_img = img[:,:,0]
IndexError: too many indices for array
This is because `imread` stores a grayscale image as an ndarray with only two
dimensions, not three, as documented here:
> For grayscale images, the return array is MxN. For RGB images, the return
> value is MxNx3. For RGBA images the return value is MxNx4.
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.imread.html
So `img.shape` ends up as `(375, 500)` when it should be `(375, 500, 3)`.
Let me know if I should file this here instead:
https://github.com/matplotlib/matplotlib.github.com/issues
| 1 |
1. Does Code support showing vertical indent level line?
2. now `editor.renderWhitespace` only have `true` or `false`, can we have a option to only render whitespace when selection?
|
Hi, is there any chance we can get indent guides (the vertical lines that run
down to matching indents). Could not find reference to them anywhere in VS
code or the gallery. Thanks - Adolfo
| 1 |
rust-encoding builds fine in the previous nightly, but it triggers an ICE in
rustc 1.2.0-nightly (`0fc0476` 2015-05-24) (built 2015-05-24)
This looks similar to #24644, but it started more recently.
$ RUST_BACKTRACE=1 cargo build --verbose
Fresh encoding_index_tests v0.1.4 (file:///home/simon/projects/rust-encoding)
Compiling encoding v0.2.32 (file:///home/simon/projects/rust-encoding)
Running `rustc src/lib.rs --crate-name encoding --crate-type lib -g --out-dir /home/simon/projects/rust-encoding/target/debug --emit=dep-info,link -L dependency=/home/simon/projects/rust-encoding/target/debug -L dependency=/home/simon/projects/rust-encoding/target/debug/deps --extern encoding_index_tradchinese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_tradchinese-9031d0a206975cd9.rlib --extern encoding_index_singlebyte=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_singlebyte-80fddc2d153c158e.rlib --extern encoding_index_simpchinese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_simpchinese-06c5fe5964f3071e.rlib --extern encoding_index_korean=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_korean-bb2701334d42f010.rlib --extern encoding_index_japanese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_japanese-5e92eb13c020e4d8.rlib`
Fresh libc v0.1.6
Fresh encoding-index-singlebyte v1.20141219.5 (file:///home/simon/projects/rust-encoding)
Fresh encoding-index-simpchinese v1.20141219.5 (file:///home/simon/projects/rust-encoding)
Fresh encoding-index-korean v1.20141219.5 (file:///home/simon/projects/rust-encoding)
Fresh encoding-index-japanese v1.20141219.5 (file:///home/simon/projects/rust-encoding)
Fresh encoding-index-tradchinese v1.20141219.5 (file:///home/simon/projects/rust-encoding)
Fresh log v0.3.1
Fresh getopts v0.2.10
error: internal compiler error: unexpected panic
note: the compiler unexpectedly panicked. this is a bug.
note: we would appreciate a bug report: https://github.com/rust-lang/rust/blob/master/CONTRIBUTING.md#bug-reports
note: run with `RUST_BACKTRACE=1` for a backtrace
thread 'rustc' panicked at 'assertion failed: prev_const.is_none() || prev_const == Some(llconst)', /home/rustbuild/src/rust-buildbot/slave/nightly-dist-rustc-linux/build/src/librustc_trans/trans/consts.rs:291
stack backtrace:
1: 0x7f38ec7687e9 - sys::backtrace::write::he19dad14fe2b97b1w6r
2: 0x7f38ec7707a9 - panicking::on_panic::h330377024750b34dHMw
3: 0x7f38ec731482 - rt::unwind::begin_unwind_inner::h7703fc192c11eec8Rrw
4: 0x7f38eb4d782e - rt::unwind::begin_unwind::h7587717121668466740
5: 0x7f38eb549830 - trans::consts::const_expr::h6a02570a980db0cdhNs
6: 0x7f38eb5a1aea - trans::consts::get_const_expr_as_global::h8d682e42aa0c00a1pKs
7: 0x7f38eb51bf3f - trans::expr::trans::h063786072022aec6izA
8: 0x7f38eb5b80ce - trans::expr::trans_into::h0995470e7b548e00ZsA
9: 0x7f38eb53d9d2 - trans::expr::trans_adt::h7fc068c005b70b7fv8B
10: 0x7f38eb5e38b2 - trans::expr::trans_rvalue_dps_unadjusted::he15a7fa64af631b8MCB
11: 0x7f38eb5b831c - trans::expr::trans_into::h0995470e7b548e00ZsA
12: 0x7f38eb53ba66 - trans::controlflow::trans_block::h6757ec40476ddde4slv
13: 0x7f38eb5e3bbd - trans::expr::trans_rvalue_dps_unadjusted::he15a7fa64af631b8MCB
14: 0x7f38eb5b831c - trans::expr::trans_into::h0995470e7b548e00ZsA
15: 0x7f38eb53ba66 - trans::controlflow::trans_block::h6757ec40476ddde4slv
16: 0x7f38eb53a381 - trans::base::trans_closure::hdcc3c01c9bca642e7Uh
17: 0x7f38eb53c05a - trans::base::trans_fn::hf52d8c0c091fdef5P5h
18: 0x7f38eb53ee27 - trans::base::trans_item::he4dc60caaf1684eajui
19: 0x7f38eb53f738 - trans::base::trans_item::he4dc60caaf1684eajui
20: 0x7f38eb54ccfc - trans::base::trans_crate::hb11747a7cf1143a4sjj
21: 0x7f38eccc14a4 - driver::phase_4_translate_to_llvm::h29a0d7314fcd3b41nOa
22: 0x7f38ecc9d226 - driver::compile_input::h16cddbb7992cbbbaQba
23: 0x7f38ecd52f21 - run_compiler::h74084e004617dcdcb6b
24: 0x7f38ecd50772 - boxed::F.FnBox<A>::call_box::h10784738899208612549
25: 0x7f38ecd4ff49 - rt::unwind::try::try_fn::h5235027869346842134
26: 0x7f38ec7e9498 - rust_try_inner
27: 0x7f38ec7e9485 - rust_try
28: 0x7f38ec75c247 - rt::unwind::try::inner_try::hb6f04bd1baacc20eKnw
29: 0x7f38ecd5017a - boxed::F.FnBox<A>::call_box::h17245911238432039576
30: 0x7f38ec76f471 - sys::thread::Thread::new::thread_start::h285dd80d49b81cf50xv
31: 0x7f38e6798373 - start_thread
32: 0x7f38ec3c127c - clone
33: 0x0 - <unknown>
Could not compile `encoding`.
Caused by:
Process didn't exit successfully: `rustc src/lib.rs --crate-name encoding --crate-type lib -g --out-dir /home/simon/projects/rust-encoding/target/debug --emit=dep-info,link -L dependency=/home/simon/projects/rust-encoding/target/debug -L dependency=/home/simon/projects/rust-encoding/target/debug/deps --extern encoding_index_tradchinese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_tradchinese-9031d0a206975cd9.rlib --extern encoding_index_singlebyte=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_singlebyte-80fddc2d153c158e.rlib --extern encoding_index_simpchinese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_simpchinese-06c5fe5964f3071e.rlib --extern encoding_index_korean=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_korean-bb2701334d42f010.rlib --extern encoding_index_japanese=/home/simon/projects/rust-encoding/target/debug/deps/libencoding_index_japanese-5e92eb13c020e4d8.rlib` (exit code: 101)
|
## Code
trait Trait {}
struct Bar;
impl Trait for Bar {}
fn main() {
let x: &[&Trait] = &[{ &Bar }];
}
## Output
main.rs:7:9: 7:10 warning: unused variable: `x`, #[warn(unused_variables)] on by default
main.rs:7 let x: &[&Trait] = &[{ &Bar }];
^
error: internal compiler error: unexpected panic
note: the compiler unexpectedly panicked. this is a bug.
note: we would appreciate a bug report: https://github.com/rust-lang/rust/blob/master/CONTRIBUTING.md#bug-reports
note: run with `RUST_BACKTRACE=1` for a backtrace
thread 'rustc' panicked at 'assertion failed: prev_const.is_none() || prev_const == Some(llconst)', /Users/rustbuild/src/rust-buildbot/slave/nightly-dist-rustc-mac/build/src/librustc_trans/trans/consts.rs:321
stack backtrace:
1: 0x1054eb5cf - sys::backtrace::write::h9137c695ab290a14WRs
2: 0x1054f3b82 - panicking::on_panic::h0ae3cf09aff03bc05Pw
3: 0x1054a9d15 - rt::unwind::begin_unwind_inner::h36b4206cb80fb108Oxw
4: 0x102149fcf - rt::unwind::begin_unwind::h6767503471583286242
5: 0x1021c082c - trans::consts::const_expr::h1bbfa5560b941f32nvs
6: 0x102224922 - vec::Vec<T>.FromIterator<T>::from_iter::h7466739370638199104
7: 0x10221baea - trans::consts::const_expr_unadjusted::hd675727493ff08eezLs
8: 0x1021bfff7 - trans::consts::const_expr::h1bbfa5560b941f32nvs
9: 0x10221dc67 - trans::consts::const_expr_unadjusted::hd675727493ff08eezLs
10: 0x1021bfff7 - trans::consts::const_expr::h1bbfa5560b941f32nvs
11: 0x10221a9f9 - trans::consts::get_const_expr_as_global::h2f40511a988c5876yss
12: 0x10218f6ca - trans::expr::trans::h959669806b495bbffdA
13: 0x1022314e0 - trans::expr::trans_into::h43738e587d521f35W6z
14: 0x1022b4e21 - trans::_match::mk_binding_alloca::h2459388509959927399
15: 0x1021a09b9 - trans::base::init_local::h8acf9c70632535fdNVg
16: 0x1021b1453 - trans::controlflow::trans_block::hb872ebbfd195606cZ2u
17: 0x1021b0105 - trans::base::trans_closure::hbf7fcb6cfae5e775KCh
18: 0x1021b1d9e - trans::base::trans_fn::hb08e54207cb8d8e6sNh
19: 0x1021b5308 - trans::base::trans_item::h15647b08683789dbEbi
20: 0x1021c40f0 - trans::base::trans_crate::hdfbb43ad3281f84dE0i
21: 0x101c4fdde - driver::phase_4_translate_to_llvm::he9458af7df85ffb8lOa
22: 0x101c28344 - driver::compile_input::h3c162f55ed6be3a5Qba
23: 0x101cef853 - run_compiler::hae39edbb343296d3D4b
24: 0x101ced37a - boxed::F.FnBox<A>::call_box::h1927805197202631788
25: 0x101cec817 - rt::unwind::try::try_fn::h7355792964568869981
26: 0x10557d998 - rust_try_inner
27: 0x10557d985 - rust_try
28: 0x101cecaf0 - boxed::F.FnBox<A>::call_box::h2359980489235781969
29: 0x1054f26cd - sys::thread::create::thread_start::hfa406746e663ba1bNUv
30: 0x7fff81be3267 - _pthread_body
31: 0x7fff81be31e4 - _pthread_start
## Rust Version
rustc 1.0.0-nightly (1284be404 2015-04-18) (built 2015-04-17)
binary: rustc
commit-hash: 1284be4044420bc4c41767284ae26be61a38d331
commit-date: 2015-04-18
build-date: 2015-04-17
host: x86_64-apple-darwin
release: 1.0.0-nightly
| 1 |
You get a confusing error message when trying to concat on non-unique (but
also non-exactly-equal) indices. Small example:
In [57]: df1 = pd.DataFrame({'col1': [1, 2, 3]}, index=[0, 0, 1])
...: df2 = pd.DataFrame({'col2': [1, 2, 3]}, index=[0, 1, 2])
In [59]: pd.concat([df1, df2], axis=1)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-59-756087e4d415> in <module>()
----> 1 pd.concat([df1, df2], axis=1)
/home/joris/scipy/pandas/pandas/tools/concat.py in concat(objs, axis, join, join_axes, ignore_index, keys, levels, names, verify_integrity, copy)
205 verify_integrity=verify_integrity,
206 copy=copy)
--> 207 return op.get_result()
208
209
/home/joris/scipy/pandas/pandas/tools/concat.py in get_result(self)
405 new_data = concatenate_block_managers(
406 mgrs_indexers, self.new_axes, concat_axis=self.axis,
--> 407 copy=self.copy)
408 if not self.copy:
409 new_data._consolidate_inplace()
/home/joris/scipy/pandas/pandas/core/internals.py in concatenate_block_managers(mgrs_indexers, axes, concat_axis, copy)
4849 placement=placement) for placement, join_units in concat_plan]
4850
-> 4851 return BlockManager(blocks, axes)
4852
4853
/home/joris/scipy/pandas/pandas/core/internals.py in __init__(self, blocks, axes, do_integrity_check, fastpath)
2784
2785 if do_integrity_check:
-> 2786 self._verify_integrity()
2787
2788 self._consolidate_check()
/home/joris/scipy/pandas/pandas/core/internals.py in _verify_integrity(self)
2994 for block in self.blocks:
2995 if block._verify_integrity and block.shape[1:] != mgr_shape[1:]:
-> 2996 construction_error(tot_items, block.shape[1:], self.axes)
2997 if len(self.items) != tot_items:
2998 raise AssertionError('Number of manager items must equal union of '
/home/joris/scipy/pandas/pandas/core/internals.py in construction_error(tot_items, block_shape, axes, e)
4258 raise ValueError("Empty data passed with indices specified.")
4259 raise ValueError("Shape of passed values is {0}, indices imply {1}".format(
-> 4260 passed, implied))
4261
4262
ValueError: Shape of passed values is (2, 6), indices imply (2, 4)
* * *
Original reported issue by @gregsifr :
I am working with a large dataframe of customers which I was unable to concat.
After spending some time I narrowed the problem area down to the below
(pickled) dataframes and code.
When trying to concat the dataframes using the following code the error shown
below is returned:
import pandas as pd
import pickle
df1 = pickle.loads('ccopy_reg\n_reconstructor\np1\n(cpandas.core.frame\nDataFrame\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS\'_metadata\'\np6\n(lp7\nsS\'_typ\'\np8\nS\'dataframe\'\np9\nsS\'_data\'\np10\ng1\n(cpandas.core.internals\nBlockManager\np11\ng3\nNtRp12\n((lp13\ncpandas.core.index\n_new_Index\np14\n(cpandas.core.index\nMultiIndex\np15\n(dp16\nS\'labels\'\np17\n(lp18\ncnumpy.core.multiarray\n_reconstruct\np19\n(cpandas.core.base\nFrozenNDArray\np20\n(I0\ntS\'b\'\ntRp21\n(I1\n(L2L\ntcnumpy\ndtype\np22\n(S\'i1\'\nI0\nI1\ntRp23\n(I3\nS\'|\'\nNNNI-1\nI-1\nI0\ntbI00\nS\'\\x00\\x00\'\ntbag19\n(g20\n(I0\ntS\'b\'\ntRp24\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x01\'\ntbasS\'names\'\np25\n(lp26\nNaNasS\'levels\'\np27\n(lp28\ng14\n(cpandas.core.index\nIndex\np29\n(dp30\nS\'data\'\np31\ng19\n(cnumpy\nndarray\np32\n(I0\ntS\'b\'\ntRp33\n(I1\n(L1L\ntg22\n(S\'O8\'\nI0\nI1\ntRp34\n(I3\nS\'|\'\nNNNI-1\nI-1\nI63\ntbI00\n(lp35\nVCUSTOMER_A\np36\natbsS\'name\'\np37\nNstRp38\nag14\n(g29\n(dp39\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp40\n(I1\n(L2L\ntg34\nI00\n(lp41\nVVISIT_DT\np42\naVPURCHASE\np43\natbsg37\nNstRp44\nasS\'sortorder\'\np45\nNstRp46\nacpandas.tseries.index\n_new_DatetimeIndex\np47\n(cpandas.tseries.index\nDatetimeIndex\np48\n(dp49\nS\'tz\'\np50\nNsS\'freq\'\np51\nNsg31\ng19\n(g32\n(I0\ntS\'b\'\ntRp52\n(I1\n(L22L\ntg22\n(S\'M8\'\nI0\nI1\ntRp53\n(I4\nS\'<\'\nNNNI-1\nI-1\nI0\n((d(S\'ns\'\nI1\nI1\nI1\ntttbI00\nS\'\\x00\\x00\\x1c\\xca\\xf9\\xceO\\x10\\x00\\x00k[\\x8e\\x1dP\\x10\\x00\\x00\\xba\\xec"lP\\x10\\x00\\x00\\t~\\xb7\\xbaP\\x10\\x00\\x00X\\x0fL\\tQ\\x10\\x00\\x00\\xa7\\xa0\\xe0WQ\\x10\\x00\\x00\\x94T\\x9eCR\\x10\\x00\\x00\\xe3\\xe52\\x92R\\x10\\x00\\x002w\\xc7\\xe0R\\x10\\x00\\x00\\x81\\x08\\\\/S\\x10\\x00\\x00\\xd0\\x99\\xf0}S\\x10\\x00\\x00\\xbdM\\xaeiT\\x10\\x00\\x00\\x0c\\xdfB\\xb8T\\x10\\x00\\x00[p\\xd7\\x06U\\x10\\x00\\x00\\xaa\\x01lUU\\x10\\x00\\x00\\xf9\\x92\\x00\\xa4U\\x10\\x00\\x00\\xe6F\\xbe\\x8fV\\x10\\x00\\x005\\xd8R\\xdeV\\x10\\x00\\x00\\x84i\\xe7,W\\x10\\x00\\x00\\xd3\\xfa{{W\\x10\\x00\\x00"\\x8c\\x10\\xcaW\\x10\\x00\\x00\\x0f@\\xce\\xb5X\\x10\'\ntbsg37\nS\'date\'\np54\nstRp55\na(lp56\ng19\n(g32\n(I0\ntS\'b\'\ntRp57\n(I1\n(L2L\nL22L\ntg22\n(S\'f8\'\nI0\nI1\ntRp58\n(I3\nS\'<\'\nNNNI-1\nI-1\nI0\ntbI00\nS\'\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\'\ntba(lp59\ng14\n(g15\n(dp60\ng17\n(lp61\ng19\n(g20\n(I0\ntS\'b\'\ntRp62\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x00\'\ntbag19\n(g20\n(I0\ntS\'b\'\ntRp63\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x01\'\ntbasg25\n(lp64\nNaNasg27\n(lp65\ng14\n(g29\n(dp66\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp67\n(I1\n(L1L\ntg34\nI00\n(lp68\ng36\natbsg37\nNstRp69\nag14\n(g29\n(dp70\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp71\n(I1\n(L2L\ntg34\nI00\n(lp72\ng42\nag43\natbsg37\nNstRp73\nasg45\nNstRp74\na(dp75\nS\'0.14.1\'\np76\n(dp77\nS\'axes\'\np78\ng13\nsS\'blocks\'\np79\n(lp80\n(dp81\nS\'mgr_locs\'\np82\nc__builtin__\nslice\np83\n(I0\nI2\nL1L\ntRp84\nsS\'values\'\np85\ng57\nsasstbsb.')
df2 = pickle.loads('ccopy_reg\n_reconstructor\np1\n(cpandas.core.frame\nDataFrame\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS\'_metadata\'\np6\n(lp7\nsS\'_typ\'\np8\nS\'dataframe\'\np9\nsS\'_data\'\np10\ng1\n(cpandas.core.internals\nBlockManager\np11\ng3\nNtRp12\n((lp13\ncpandas.core.index\n_new_Index\np14\n(cpandas.core.index\nMultiIndex\np15\n(dp16\nS\'labels\'\np17\n(lp18\ncnumpy.core.multiarray\n_reconstruct\np19\n(cpandas.core.base\nFrozenNDArray\np20\n(I0\ntS\'b\'\ntRp21\n(I1\n(L2L\ntcnumpy\ndtype\np22\n(S\'i1\'\nI0\nI1\ntRp23\n(I3\nS\'|\'\nNNNI-1\nI-1\nI0\ntbI00\nS\'\\x00\\x00\'\ntbag19\n(g20\n(I0\ntS\'b\'\ntRp24\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x01\'\ntbasS\'names\'\np25\n(lp26\nNaNasS\'levels\'\np27\n(lp28\ng14\n(cpandas.core.index\nIndex\np29\n(dp30\nS\'data\'\np31\ng19\n(cnumpy\nndarray\np32\n(I0\ntS\'b\'\ntRp33\n(I1\n(L1L\ntg22\n(S\'O8\'\nI0\nI1\ntRp34\n(I3\nS\'|\'\nNNNI-1\nI-1\nI63\ntbI00\n(lp35\nVCUSTOMER_B\np36\natbsS\'name\'\np37\nNstRp38\nag14\n(g29\n(dp39\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp40\n(I1\n(L2L\ntg34\nI00\n(lp41\nVVISIT_DT\np42\naVPURCHASE\np43\natbsg37\nNstRp44\nasS\'sortorder\'\np45\nNstRp46\nacpandas.tseries.index\n_new_DatetimeIndex\np47\n(cpandas.tseries.index\nDatetimeIndex\np48\n(dp49\nS\'tz\'\np50\nNsS\'freq\'\np51\nNsg31\ng19\n(g32\n(I0\ntS\'b\'\ntRp52\n(I1\n(L24L\ntg22\n(S\'M8\'\nI0\nI1\ntRp53\n(I4\nS\'<\'\nNNNI-1\nI-1\nI0\n((d(S\'ns\'\nI1\nI1\nI1\ntttbI00\nS\'\\x00\\x00k[\\x8e\\x1dP\\x10\\x00\\x00\\xba\\xec"lP\\x10\\x00\\x00\\t~\\xb7\\xbaP\\x10\\x00\\x00X\\x0fL\\tQ\\x10\\x00\\x00\\xa7\\xa0\\xe0WQ\\x10\\x00\\x00\\x94T\\x9eCR\\x10\\x00\\x00\\xe3\\xe52\\x92R\\x10\\x00\\x002w\\xc7\\xe0R\\x10\\x00\\x00\\x81\\x08\\\\/S\\x10\\x00\\x00\\xd0\\x99\\xf0}S\\x10\\x00\\x00\\xbdM\\xaeiT\\x10\\x00\\x00\\x0c\\xdfB\\xb8T\\x10\\x00\\x00[p\\xd7\\x06U\\x10\\x00\\x00\\xaa\\x01lUU\\x10\\x00\\x00\\xf9\\x92\\x00\\xa4U\\x10\\x00\\x00\\xe6F\\xbe\\x8fV\\x10\\x00\\x005\\xd8R\\xdeV\\x10\\x00\\x00\\x84i\\xe7,W\\x10\\x00\\x00\\xd3\\xfa{{W\\x10\\x00\\x00"\\x8c\\x10\\xcaW\\x10\\x00\\x00\\xc0\\xae9gX\\x10\\x00\\x00\\xc0\\xae9gX\\x10\\x00\\x00\\xc0\\xae9gX\\x10\\x00\\x00\\x0f@\\xce\\xb5X\\x10\'\ntbsg37\nS\'date\'\np54\nstRp55\na(lp56\ng19\n(g32\n(I0\ntS\'b\'\ntRp57\n(I1\n(L2L\nL24L\ntg22\n(S\'f8\'\nI0\nI1\ntRp58\n(I3\nS\'<\'\nNNNI-1\nI-1\nI0\ntbI00\nS\'\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\xf0\\x0c$sA\\x00\\x00\\x00\\xf0\\x0c$sA\\x00\\x00\\x00\\xf0\\x0c$sA\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\\x00\\x00\\x00\\x00\\x00\\x00\\xf8\\x7f\'\ntba(lp59\ng14\n(g15\n(dp60\ng17\n(lp61\ng19\n(g20\n(I0\ntS\'b\'\ntRp62\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x00\'\ntbag19\n(g20\n(I0\ntS\'b\'\ntRp63\n(I1\n(L2L\ntg23\nI00\nS\'\\x00\\x01\'\ntbasg25\n(lp64\nNaNasg27\n(lp65\ng14\n(g29\n(dp66\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp67\n(I1\n(L1L\ntg34\nI00\n(lp68\ng36\natbsg37\nNstRp69\nag14\n(g29\n(dp70\ng31\ng19\n(g32\n(I0\ntS\'b\'\ntRp71\n(I1\n(L2L\ntg34\nI00\n(lp72\ng42\nag43\natbsg37\nNstRp73\nasg45\nNstRp74\na(dp75\nS\'0.14.1\'\np76\n(dp77\nS\'axes\'\np78\ng13\nsS\'blocks\'\np79\n(lp80\n(dp81\nS\'mgr_locs\'\np82\nc__builtin__\nslice\np83\n(I0\nI2\nL1L\ntRp84\nsS\'values\'\np85\ng57\nsasstbsb.')
customers, tables = ['CUSTOMER_A', 'CUSTOMER_B'], [df1.iloc[:], df2.iloc[:]]
tables = pd.concat(tables, keys=customers, axis=1)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-22-8096f8962dec> in <module>()
6
7 customers, tables = ['CUSTOMER_A', 'CUSTOMER_B'], [df1.iloc[:], df2.iloc[:]]
----> 8 tables = pd.concat(tables, keys=customers, axis=1)
/home/code/anaconda2/lib/python2.7/site-packages/pandas/tools/merge.pyc in concat(objs, axis, join, join_axes, ignore_index, keys, levels, names, verify_integrity, copy)
833 verify_integrity=verify_integrity,
834 copy=copy)
--> 835 return op.get_result()
836
837
/home/code/anaconda2/lib/python2.7/site-packages/pandas/tools/merge.pyc in get_result(self)
1023 new_data = concatenate_block_managers(
1024 mgrs_indexers, self.new_axes,
-> 1025 concat_axis=self.axis, copy=self.copy)
1026 if not self.copy:
1027 new_data._consolidate_inplace()
/home/code/anaconda2/lib/python2.7/site-packages/pandas/core/internals.pyc in concatenate_block_managers(mgrs_indexers, axes, concat_axis, copy)
4474 for placement, join_units in concat_plan]
4475
-> 4476 return BlockManager(blocks, axes)
4477
4478
/home/code/anaconda2/lib/python2.7/site-packages/pandas/core/internals.pyc in __init__(self, blocks, axes, do_integrity_check, fastpath)
2535
2536 if do_integrity_check:
-> 2537 self._verify_integrity()
2538
2539 self._consolidate_check()
/home/code/anaconda2/lib/python2.7/site-packages/pandas/core/internals.pyc in _verify_integrity(self)
2745 for block in self.blocks:
2746 if block._verify_integrity and block.shape[1:] != mgr_shape[1:]:
-> 2747 construction_error(tot_items, block.shape[1:], self.axes)
2748 if len(self.items) != tot_items:
2749 raise AssertionError('Number of manager items must equal union of '
/home/code/anaconda2/lib/python2.7/site-packages/pandas/core/internals.pyc in construction_error(tot_items, block_shape, axes, e)
3897 raise ValueError("Empty data passed with indices specified.")
3898 raise ValueError("Shape of passed values is {0}, indices imply {1}".format(
-> 3899 passed, implied))
3900
3901
ValueError: Shape of passed values is (4, 31), indices imply (4, 25)
However if the dataframes are sliced e.g. [:10] OR [10:], the concat works:
customers, tables = ['CUSTOMER_A', 'CUSTOMER_B'], [df1.iloc[:20], df2.iloc[:20]]
tables = pd.concat(tables, keys=customers, axis=1)
tables
Output of `pd.show_versions()`
INSTALLED VERSIONS
------------------
commit: None
python: 2.7.11.final.0
python-bits: 64
OS: Linux
OS-release: 3.19.0-58-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_AU.UTF-8
pandas: 0.18.0
nose: 1.3.7
pip: 8.1.1
setuptools: 20.6.7
Cython: 0.24
numpy: 1.10.4
scipy: 0.17.0
statsmodels: 0.6.1
xarray: None
IPython: 4.1.2
sphinx: 1.4.1
patsy: 0.4.1
dateutil: 2.5.2
pytz: 2016.3
blosc: None
bottleneck: 1.0.0
tables: 3.2.2
numexpr: 2.5.2
matplotlib: 1.5.1
openpyxl: 2.3.2
xlrd: 0.9.4
xlwt: 1.0.0
xlsxwriter: 0.8.4
lxml: 3.6.0
bs4: 4.4.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.0.12
pymysql: None
psycopg2: 2.6.1 (dt dec pq3 ext)
jinja2: 2.8
boto: 2.39.0
|
When concatting two dataframes where there are a) there are duplicate columns
in one of the dataframes, and b) there are non-overlapping column names in
both, then you get a IndexError:
In [9]: df1 = pd.DataFrame(np.random.randn(3,3), columns=['A', 'A', 'B1'])
...: df2 = pd.DataFrame(np.random.randn(3,3), columns=['A', 'A', 'B2'])
In [10]: pd.concat([df1, df2])
Traceback (most recent call last):
File "<ipython-input-10-f61a1ab4009e>", line 1, in <module>
pd.concat([df1, df2])
...
File "c:\users\vdbosscj\scipy\pandas-joris\pandas\core\index.py", line 765, in take
taken = self.view(np.ndarray).take(indexer)
IndexError: index 3 is out of bounds for axis 0 with size 3
I don't know if it should work (although I suppose it should, as with only the
duplicate columns it does work), but at least the error message is not really
helpfull.
| 1 |
This log is showing frequently if a gif image in Recyclerview is not visible
yet. But if gif image is visible the log stop? I use it without specifying it
if its asBitmap or asGif because I want to allow the user to be able to put
jpg or gif and load it to recyclerview.
|
**Glide Version/Integration library (if any)** :3.6.1 with okhttp-
integration:1.3.1@aar
**Device/Android Version** : Nexus 5X, v.6.0.
**Issue details/Repro steps/Use case background** :
I'm using Glide for displaying images in RecyclerView and in
FragmentStatePagerAdapter. On pre M versions of Android everything is going as
expected. I did not faced any issues mentioned in
https://github.com/bumptech/glide/wiki/Resource-re-use-in-Glide. But on the
Android 6 i'm getting this warning when scrolling the RecyclerView or
FragmentPages.
W/Bitmap: Called reconfigure on a bitmap that is in use! This may cause graphical corruption!
I put a method onViewRecycled to the RecyclerView adapter, and increased RV
pool size. It seems to be helping, but not completely. I'm still have this
problem in the FragmentPager, and when I return to the RecyclerView by
pressing back button, the warnings are back (I guess that can probably be
fixed by increasing RV pool size in onResume).
I'm loading the images from device as bitmaps. Can this be the source of the
issue?
**Glide load line** :
Glide.with(context)
.load(Uri.parse(filepath))
.asBitmap()
.centerCrop()
.diskCacheStrategy(DiskCacheStrategy.ALL)
.into(holder.guideCover);
I love to use Glide because is super fast. The application is running as
expected, hoverer I'm a bit nervous of those warning messages.
What I'm doing wrong?
| 1 |
The following code snippet emits a very odd error message (requires the GSL
library):
type gsl_error_handler_t end
custom_gsl_error_handler = convert(Ptr{gsl_error_handler_t}, cfunction(error, Void, ()))
function set_error_handler(new_handler::Ptr{gsl_error_handler_t})
output_ptr = ccall( (:gsl_set_error_handler, :libgsl),
Ref{gsl_error_handler_t}, #<--- User error: should be Ptr{...}
(Ptr{gsl_error_handler_t}, ), new_handler )
end
set_error_handler(custom_gsl_error_handler)
Result:
ERROR: UndefVarError: result not defined
in include_from_node1 at ./loading.jl:316
in process_options at ./client.jl:275
in _start at ./client.jl:375
`result` is not defined in this code, nor is it ever used at the user level,
so this error is rather cryptic.
Observed on release-0.4 and master.
|
### TL;DR
This is a runtime debug option proposed by @carnaval to catch common misuse of
`ccall` which could otherwise cause corruption that's hard to debug.
### The problem
> ...... when someone trashed a tag. Often happens in pools with OOB stores,
> ...... Unfortunately it's
> the only "downside" of having an almost too easy C FFI.
> \-- Oscar Blumberg (@carnaval) at #11945 (comment) #11945 (comment)
The issue here is that it is very/too easy to pass a pointer to an object to a
C function with `ccall`. This is one of the awesomeness of Julia. However, if
the user makes a mistake about the C api, commonly not allocating enough
memory, the c function might write to memory that is not meant to be written
which could corrupt the GC managed memory and crashes with spectacular
backtrace (pages of `push_root`).
This happens surprisingly often. It can be caused by making mistake on the
c-interface or `ccall` (#11945), upstream abi breakage
(JuliaInterop/ZMQ.jl#83) or just not careful enough on refactoring
(JuliaGPU/OpenCL.jl#65) (I'm only aware of these but there's probably
more...).
This kind of issue is also relatively hard to debug as they happens randomly
and usually crashes in totally unrelated places. With @carnaval 's guide on GC
debugging, it is not impossibly to figure out the issue but is nontheless much
harder than using `ccall` (unless, of course, if someone can somehow integrate
lldb (or sth else) in julia).
### Solution
It's very hard (if not impossible) to detect this issue ahead of time but it
would really help debugging and fixing the issue if the error is raised as
early as possible (at the `ccall` site). One way to do that, proposed by
@carnaval , is to allocate some extra memory with known random content for
each object and check after each ccall to make sure the c function didn't
modify them.
### Implementation
AFAICT, one (only?) missing part for implementing this is to figure out on
which objects/memory regions this check should be performed. There are several
possibilities that I can think of:
1. Do it statically in codegen.
This is hard because `ccall` only see the pointer after `unsafe_convert` (or
the user may even convert using `pointer` directly).
2. Scan every objects.
This should be doable and should be relatively easy to implement (just add an
extra call into the GC after each `ccall` site). The obvious problem would be
performance. This can probably be implemented as a more aggressive mode to
catch corner cases but should probably not be the default one.
3. Let the GC figure out if the pointer should be sanitized.
I think this is the best compromise between performance and implementation
difficulty. The idea is to use the machinery for conservative stack scan to
figure out if a pointer is pointing to a GC object. The codegen will just pass
all pointer arguments to the GC and do all the work there. An additional
benefit of this is that it can be used to verify that the object is properly
rooted.
### Other concern
* Stack allocated memory
Currently only limited to the `&` `ccall` operator and can be special cased.
If we have more general stack allocation of mutable object, we can probably
keep track of them in this mode the same way we keep the gc frame.
* Concurrency
In order to support multiple thread using the same object, the random data in
the padding should probably be assigned at allocation time and never changes
afterword (i.e. cannot be filled just before `ccall`).
* Mixing generated code with and without option (e.g. running in this mode with sysimg generated without such option)
The GC should keep track of whether each object has padding allocated (heap
allocated ones should be consistent, stack allocation might need more detail
tracking) and do the check accordingly.
| 1 |
Running TensorBoard r0.9 results in graph visualizations as expected but all
events and histograms that successfully displayed in r0.8 are not.
Has r0.9 introduced a change to the command line that should be used to launch
TensorBoard, or to the code needed to generate events and histograms for
TensorBoard to display?
Note that neither new summaries and histograms written with recent runs using
r0.9 TensorFlow, nor existing ones written (and displayed) in the past, are
displayed. Graphs generated with both releases display as expected.
### Environment info
Operating System: OS X 10.11.5
TensorFlow: .9.0rc0
### Steps to reproduce
`tensorboard --logdir ./tflog --purge_orphaned_data`
### What have you tried?
Reverting to r0.8, which works as it originally did, displaying all events and
histograms present in the `tflog`directory provided as the `logdir`.
Reinstalling r0.9, which reproduces the error. A second attempt at
reinstalling r0.8 resulted in a TensorBoard that displays jus the menu (no
content) and uses a different style (a serif face).
|
Since about a week now there seems something wrong with the TensorBoard demo
at https://www.tensorflow.org/tensorboard/index.html#events. The graph shows
nicely, but neither events nor histograms show up. This problem seems to be
only with the demo -- everything shows up just fine when I run the
corresponding code (`mnist_tensorboard.py`) locally.
| 1 |
## Steps to Reproduce
I have a project when I try to run a drive test, I get
[drive-test]
flutter drive -t test_driver/all.dart
Using device Pixel XL.
Starting application: test_driver/all.dart
Initializing gradle...
Resolving dependencies...
Installing build/app/outputs/apk/app.apk...
Running 'gradlew assembleDebug'...
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:transformClassesWithJarMergingForDebug'.
> com.android.build.api.transform.TransformException: java.util.zip.ZipException: duplicate entry: com/google/android/gms/common/internal/zzq.class
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output.
Gradle build failed: 1
failed with exit code 1
I haven't found a `--stacktrace` option.
Perhaps
--[no-]trace-startup Start tracing during startup.
from `flutter drive -h` is meant?
## Logs
Run your application with `flutter run` and attach all the log output.
Run `flutter analyze` and attach any output of that command also.
## Flutter Doctor
(issue376_save_image) $ flutter doctor
[✓] Flutter (on Mac OS X 10.13.1 17B48, locale en-AT, channel alpha)
• Flutter at /Users/zoechi/flutter/flutter
• Framework revision e8aa40eddd (5 weeks ago), 2017-10-17 15:42:40 -0700
• Engine revision 7c4142808c
• Tools Dart version 1.25.0-dev.11.0
[✓] Android toolchain - develop for Android devices (Android SDK 27.0.1)
• Android SDK at /usr/local/opt/android-sdk
• Platform android-27, build-tools 27.0.1
• ANDROID_HOME = /usr/local/opt/android-sdk
• Java binary at: /Applications/Android Studio.app/Contents/jre/jdk/Contents/Home/bin/java
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-915-b08)
[✓] iOS toolchain - develop for iOS devices (Xcode 9.1)
• Xcode at /Applications/Xcode.app/Contents/Developer
• Xcode 9.1, Build version 9B55
• ios-deploy 1.9.2
• CocoaPods version 1.3.1
[✓] Android Studio (version 3.0)
• Android Studio at /Applications/Android Studio.app/Contents
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-915-b08)
[✓] IntelliJ IDEA Ultimate Edition (version 2017.2.6)
• Flutter plugin version 19.1
• Dart plugin version 172.4343.25
[✓] Connected devices
• Pixel XL • HT69V0203649 • android-arm • Android 8.0.0 (API 26)
|
 **Issue byafandria**
_Tuesday Aug 11, 2015 at 18:32 GMT_
_Originally opened ashttps://github.com/flutter/engine/issues/559_
* * *
Building a Standalone APK instructions are not clear enough.
It has been inconvenient to only be able to start my Sky app via `sky_tool`,
so I wanted to build my own APK. Unfortunately, the link to the stocks/example
does not have a `README.md` for how to build it. It appears that the
`BUILD.gn`, `sky.yaml`, and `apk/AndroidManifest.xml` files are important to
the process, but I am not sure what command(s) are needed to produce the APK.
| 0 |
# Checklist
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Mandatory Debugging Information
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
* I have included the contents of `pip freeze` in the issue.
* I have included all the versions of all the external dependencies required
to reproduce this bug.
## Optional Debugging Information
* I have tried reproducing the issue on more than one Python version
and/or implementation.
* I have tried reproducing the issue on more than one message broker and/or
result backend.
* I have tried reproducing the issue on more than one version of the message
broker and/or result backend.
* I have tried reproducing the issue on more than one operating system.
* I have tried reproducing the issue on more than one workers pool.
* I have tried reproducing the issue with autoscaling, retries,
ETA/Countdown & rate limits disabled.
* I have tried reproducing the issue after downgrading
and/or upgrading Celery and its dependencies.
## Related Issues and Possible Duplicates
#### Related Issues
* None
#### Possible Duplicates
* None
## Environment & Settings
**Celery version** :
**`celery report` Output:**
[root@shiny ~]# celery report
software -> celery:4.4.0rc2 (cliffs) kombu:4.6.3 py:3.6.8
billiard:3.6.0.0 py-amqp:2.5.0
platform -> system:Linux arch:64bit
kernel version:4.19.13-200.fc28.x86_64 imp:CPython
loader -> celery.loaders.default.Loader
settings -> transport:amqp results:disabled
# Steps to Reproduce
## Required Dependencies
* **Minimal Python Version** : N/A or Unknown
* **Minimal Celery Version** : N/A or Unknown
* **Minimal Kombu Version** : N/A or Unknown
* **Minimal Broker Version** : N/A or Unknown
* **Minimal Result Backend Version** : N/A or Unknown
* **Minimal OS and/or Kernel Version** : N/A or Unknown
* **Minimal Broker Client Version** : N/A or Unknown
* **Minimal Result Backend Client Version** : N/A or Unknown
### Python Packages
**`pip freeze` Output:**
[root@shiny ~]# pip3 freeze
amqp==2.5.0
anymarkup==0.7.0
anymarkup-core==0.7.1
billiard==3.6.0.0
celery==4.4.0rc2
configobj==5.0.6
gpg==1.10.0
iniparse==0.4
json5==0.8.4
kombu==4.6.3
pygobject==3.28.3
python-qpid-proton==0.28.0
pytz==2019.1
PyYAML==5.1.1
pyzmq==18.0.1
redis==3.2.1
rpm==4.14.2
six==1.11.0
smartcols==0.3.0
toml==0.10.0
ucho==0.1.0
vine==1.3.0
xmltodict==0.12.0
### Other Dependencies
N/A
## Minimally Reproducible Test Case
# Expected Behavior
Updating task_routes during runtime is possible and has effect
# Actual Behavior
Updating `task_routes` during runtime does not have effect - the config is
updated but the `router` in `send_task` seems to be reusing old configuration.
import celery
c = celery.Celery(broker='redis://localhost:6379/0',
backend='redis://localhost:6379/0')
c.conf.update(task_routes={'task.create_pr': 'queue.betka'})
c.send_task('task.create_pr')
print(c.conf.get('task_routes'))
c.conf.update(task_routes={'task.create_pr': 'queue.ferdinand'})
c.send_task('task.create_pr')
print(c.conf.get('task_routes'))
Output:
[root@shiny ~]# python3 repr.py
{'task.create_pr': 'queue.betka'}
{'task.create_pr': 'queue.ferdinand'}
So the configuration is updated but it seems the routes are still pointing to
queue.betka, since both tasks are sent to queue.betka and queue.ferdinand
didn't receive anything.
betka_1 | [2019-06-24 14:50:41,386: INFO/MainProcess] Received task: task.create_pr[54b28121-28cf-4301-b6f2-185d2e7c50cb]
betka_1 | [2019-06-24 14:50:41,386: DEBUG/MainProcess] TaskPool: Apply <function _fast_trace_task at 0x7fca7f4d6a60> (args:('task.create_pr', '54b28121-28cf-4301-b6f2-185d2e7c50cb', {'lang': 'py', 'task': 'task.create_pr', 'id': '54b28121-28cf-4301-b6f2-185d2e7c50cb', 'shadow': None, 'eta': None, 'expires': None, 'group': None, 'retries': 0, 'timelimit': [None, None], 'root_id': '54b28121-28cf-4301-b6f2-185d2e7c50cb', 'parent_id': None, 'argsrepr': '()', 'kwargsrepr': '{}', 'origin': 'gen68@shiny', 'reply_to': 'b7be085a-b1f8-3738-b65f-963a805f2513', 'correlation_id': '54b28121-28cf-4301-b6f2-185d2e7c50cb', 'delivery_info': {'exchange': '', 'routing_key': 'queue.betka', 'priority': 0, 'redelivered': None}}, b'[[], {}, {"callbacks": null, "errbacks": null, "chain": null, "chord": null}]', 'application/json', 'utf-8') kwargs:{})
betka_1 | [2019-06-24 14:50:41,387: INFO/MainProcess] Received task: task.create_pr[3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0]
betka_1 | [2019-06-24 14:50:41,388: DEBUG/MainProcess] Task accepted: task.create_pr[54b28121-28cf-4301-b6f2-185d2e7c50cb] pid:12
betka_1 | [2019-06-24 14:50:41,390: INFO/ForkPoolWorker-1] Task task.create_pr[54b28121-28cf-4301-b6f2-185d2e7c50cb] succeeded in 0.002012896991800517s: 'Maybe later :)'
betka_1 | [2019-06-24 14:50:41,390: DEBUG/MainProcess] TaskPool: Apply <function _fast_trace_task at 0x7fca7f4d6a60> (args:('task.create_pr', '3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0', {'lang': 'py', 'task': 'task.create_pr', 'id': '3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0', 'shadow': None, 'eta': None, 'expires': None, 'group': None, 'retries': 0, 'timelimit': [None, None], 'root_id': '3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0', 'parent_id': None, 'argsrepr': '()', 'kwargsrepr': '{}', 'origin': 'gen68@shiny', 'reply_to': 'b7be085a-b1f8-3738-b65f-963a805f2513', 'correlation_id': '3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0', 'delivery_info': {'exchange': '', 'routing_key': 'queue.betka', 'priority': 0, 'redelivered': None}}, b'[[], {}, {"callbacks": null, "errbacks": null, "chain": null, "chord": null}]', 'application/json', 'utf-8') kwargs:{})
betka_1 | [2019-06-24 14:50:41,391: DEBUG/MainProcess] Task accepted: task.create_pr[3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0] pid:12
betka_1 | [2019-06-24 14:50:41,391: INFO/ForkPoolWorker-1] Task task.create_pr[3bf8b0fb-cb4a-412b-84d4-1a52b794b4e0] succeeded in 0.0006862019945401698s: 'Maybe later :)'
Note: I managed to workaround it by adding `del c.amqp` right after update for
now
|
# Checklist
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Related Issues and Possible Duplicates
#### Related Issues
* None
#### Possible Duplicates
* None
## Environment & Settings
**Celery version** : celery==4.2.1
**`celery report` Output:**
job.save(backend=tasks.cel.backend)
File "/Users/shaunak/instabase-repo/instabase/venv/lib/python2.7/site-packages/celery/result.py", line 887, in save
return (backend or self.app.backend).save_group(self.id, self)
File "/Users/shaunak/instabase-repo/instabase/venv/lib/python2.7/site-packages/celery/backends/base.py", line 399, in save_group
return self._save_group(group_id, result)
AttributeError: 'CassandraBackend' object has no attribute '_save_group'
# Steps to Reproduce
1. Start celery with Cassandra as a backend
import celery
import time
cel = celery.Celery(
'experiments',
backend='cassandra://',
broker='amqp://localhost:5672'
)
cel.conf.update(
CELERYD_PREFETCH_MULTIPLIER = 1,
CELERY_REJECT_ON_WORKER_LOST=True,
CELERY_TASK_REJECT_ON_WORKER_LOST=True,
CASSANDRA_SERVERS=['localhost'],
)
2. Create a group and try to save the result
job = group_sig.delay()
job.save(backend=tasks.cel.backend)
# Expected Behavior
We expect that the result will be saved without throwing an error.
# Actual Behavior
We see the following error:
job.save(backend=tasks.cel.backend)
File "/Users/shaunak/instabase-repo/instabase/venv/lib/python2.7/site-packages/celery/result.py", line 887, in save
return (backend or self.app.backend).save_group(self.id, self)
File "/Users/shaunak/instabase-repo/instabase/venv/lib/python2.7/site-packages/celery/backends/base.py", line 399, in save_group
return self._save_group(group_id, result)
AttributeError: 'CassandraBackend' object has no attribute '_save_group'
| 0 |
**Do you want to request a _feature_ or report a _bug_?**
Bug
**What is the current behavior?**
DevTools extension does not persist state. For example, the “Welcome” dialog
displays upon every refresh.
**If the current behavior is a bug, please provide the steps to reproduce and
if possible a minimal demo of the problem. Your bug will get fixed much faster
if we can run your code and it doesn't have dependencies other than React.
Paste the link to your JSFiddle (https://jsfiddle.net/Luktwrdm/) or
CodeSandbox (https://codesandbox.io/s/new) example below:**
1. Open React DevTools in a React app.
2. Change DevTools settings.
3. Refresh app in browser.
**What is the expected behavior?**
Settings should be changed.
**Which versions of React, and which browser / OS are affected by this issue?
Did this work in previous versions of React?**
This is in a corporate install of Chrome 71. It’s possible that it blocks
whichever persistence API React DevTools is using (Chrome DevTools itself
persists settings successfully).
|
**Do you want to request a _feature_ or report a _bug_?**
Bug
**What is the current behavior?**
“Welcome to the new React DevTools!” message blocks the devtool panel every
time the it is opened.
**If the current behavior is a bug, please provide the steps to reproduce and
if possible a minimal demo of the problem. Your bug will get fixed much faster
if we can run your code and it doesn't have dependencies other than React.
Paste the link to your JSFiddle (https://jsfiddle.net/Luktwrdm/) or
CodeSandbox (https://codesandbox.io/s/new) example below:**
1. Open a website with React with DevTools installed.
2. Open the Component tab.
3. Dismiss the welcome screen.
4. Close the devtools and open it again.
**What is the expected behavior?**
Dismissing the “Welcome to the new React DevTools!” message should be
permanent.
**Which versions of React, and which browser / OS are affected by this issue?
Did this work in previous versions of React?**
DevTools: 4.0.5
Chrome: 77.0.3865.35
| 1 |
Getting the following error upon loading:
`Uncaught SyntaxError: Duplicate data property in object literal not allowed
in strict mode -- From line ... in .../bundle.js`
App runs well in modern browsers on PC/Mac, iOS UIWebview, mobile Safari,
Android (also 4.x) Chrome, and Android >5.x.
Consulting this table shows Android 4.4 supports ES5 well and should run
React.js applications just fine.
Any ideas?
|
React / ReactDOM: 16.4.2
I'm having trouble reproducing this, but I'm raising it in the hope that
someone can give me some clues as to the cause. I have a large application
which is using `Fragment` in a few places, like so:
<React.Fragment>
<div>Child 1-1</div>
<div>Child 1-2</div>
</React.Fragment>
<React.Fragment>
<div>Child 2-1</div>
<div>Child 2-2</div>
</React.Fragment>
In everything but Internet Explorer, this renders as you'd expect:
<div>Child 1-1</div>
<div>Child 1-2</div>
<div>Child 2-1</div>
<div>Child 2-2</div>
However, for some reason in Internet Explorer 11, these are being rendered as
some weird tags:
<jscomp_symbol_react.fragment16>
<div>Child 1-1</div>
<div>Child 1-2</div>
</jscomp_symbol_react.fragment16>
<jscomp_symbol_react.fragment16>
<div>Child 2-1</div>
<div>Child 2-2</div>
</jscomp_symbol_react.fragment16>
I've tried pausing the code at the transpiled
`_react.createElement(_react.Fragment)` line, and the `_react.Fragment` export
is a string with the same name as the tag (`jscomp_symbol_react.fragment16`).
I think this is just the correct way in which the symbol polyfill works and
that React should recognize it as something other than an HTML tag.
What's even weirder is that this only happens sometimes. If two components in
my app are using fragments, the first one to render may have the above issue,
the second may not. If an affected component re-renders, the rendered DOM will
be corrected. I haven't found a solid pattern to this yet.
I have a fairly typical webpack + babel setup, and using the babel-polyfill
for symbol support. I'm really not sure what parts of my setup are relevant to
this so please let me know if you need any extra info. Again, I'm trying to
create a reproduction outside of my application but if anyone can offer me
some clues in the meantime I'd be incredibly grateful.
| 0 |
axios/lib/core/mergeConfig.js
Line 19 in 16b5718
| var mergeDeepPropertiesKeys = ['headers', 'auth', 'proxy', 'params'];
---|---
keys in mergeDeepPropertiesKeys will be merged by utils.deepMerge but
utils.deepMerge can only merge objects. Array type field will be converted
like {‘0’: 'a', '1': 'b'}, no longer an array.
|
### Describe the issue
When I read the 'Axios' source code, I found that' utils. deepMerge() 'will
convert arrays to objects, which is unreasonable.
https://github.com/axios/axios/blob/master/lib/utils.js#L286
### Code
var deepMerge = require('./lib/utils').deepMerge;
var a = {foo: {bar: 111}, hnd: [444, 555, 666]};
var b = {foo: {baz: 456}, hnd: [456, 789]};
console.log(deepMerge(a, b));
### result
{ foo: { bar: 111, baz: 456 }, hnd: { '0': 456, '1': 789, '2': 666 } }
### Expected behavior
Executing 'utils.deepMerge()' does not change the data type.
{ foo: { bar: 111, baz: 456 }, hnd: [ 456, 789, 666 ] }
### Environment:
Axios Version 0.19.0
| 1 |
# Environment
Windows build number: Microsoft Windows [Version 10.0.19042.330]
PowerToys version: v0.19.1
PowerToy module for which you are reporting the bug (if applicable): FancyZones
# Steps to reproduce
1. Requires 2 monitors
1a. May require using a non-admin account
2. Show taskbar buttons on: Taskbar where window is open
3. Open Windows Terminal and use FancyZones to "snap" to zone on non-default monitor
4. Reboot computer (or possibly just sign out and back in)
5. Open Windows Terminal
# Expected behavior
Windows Terminal taskbar button and window will both appear on the non-default
monitor. Window will be "snapped" to same zone as before.
# Actual behavior
Windows Terminal taskber button appears on the default monitor while the
window will be "snapped" to the correct zone on the non-default monitor.
|
By default new windows are opened on primary monitor (some application
introduce their own special positioning). If we have zone history for some
application on secondary monitor, and that monitor is active, application
window will be opened there, otherwise we fallback to default windows behavior
and that window is opened on primary monitor.
Even if we don't have app history for that application on active monitor, we
should open it there, with respect of window width and height.
| 1 |
Operating system:XP W7-32
用bootstrap框架开发出的页面,在浏览器上下拉,翻页等都能实现,用electron不能,这是为什么,请教
|
jQuery contains something along this lines:
if ( typeof module === "object" && typeof module.exports === "object" ) {
// set jQuery in `module`
} else {
// set jQuery in `window`
}
module is defined, even in the browser-side scripts. This causes jQuery to
ignore the `window` object and use `module`, so the other scripts won't find
`$` nor `jQuery` in global scope..
I am not sure if this is a jQuery or atom-shell bug, but I wanted to put this
on the web, so others won't search as long as I did.
| 1 |
In the same vein as #1107, it would be super useful (at least to me) to have
the openapi models be available outside of FastAPI. I've been working on a
Python client generator (built with Typer!) which will hopefully be much
cleaner than the openapi-generator version, and I already use FastAPI for some
testing.
I don't want to ship a copy of FastAPI with my tool just to get the openapi
module, but it also feels silly to be rewriting a lot of what you already have
when I could just parse a spec into your models and work from there. So what
I'll probably do is extract a copy of the openapi module and use it (with
proper attribution of course), but it would be much cleaner to add your module
as a pip dependency.
https://github.com/triaxtec/openapi-python-client is the project in question,
just FYI.
|
### First Check
* I added a very descriptive title to this issue.
* I used the GitHub search to find a similar issue and didn't find it.
* I searched the FastAPI documentation, with the integrated search.
* I already searched in Google "How to X in FastAPI" and didn't find any information.
* I already read and followed all the tutorial in the docs and didn't find an answer.
* I already checked if it is not related to FastAPI but to Pydantic.
* I already checked if it is not related to FastAPI but to Swagger UI.
* I already checked if it is not related to FastAPI but to ReDoc.
### Commit to Help
* I commit to help with one of those options 👆
### Example Code
###This API takes id in request , creates temp path in container , searches path for this id in database and copies file from AWS s3b for this id in temp created path, does ML processing and deletes the temp path then returns the predicted data
from datetime import datetime
import uvicorn
from fastapi import Depends, FastAPI, HTTPException, Request
from starlette.middleware.cors import CORSMiddleware
# initializing FastAPI
from fastapi import FastAPI, Response, status
from fastapi.responses import JSONResponse
from pydantic import BaseModel
from fastapi import Security ,HTTPException
from fastapi.security.api_key import APIKeyHeader
import pathlib
temp = pathlib.PosixPath
#pathlib.PosixPath = pathlib.WindowsPath
import torch
# Logging
import logging, logging.config
logging.config.dictConfig(
{
'version': 1,
'disable_existing_loggers': True,
}
)
global logger
# logging.basicConfig(filename='app.log', filemode='w',format='%(asctime)s:%(levelname)s:%(message)s', level=logging.DEBUG)
app = FastAPI(docs_url="/", redoc_url=None,
title="First ML API",
description="First ML API",
version="V 1.0",
)
# FileDownload()
# SMBConnectionDownload()
config = readconfig()
API_KEY = config.API_KEY
API_KEY_NAME = config.API_KEY_NAME
api_key_header_auth = APIKeyHeader(name=API_KEY_NAME, auto_error=True)
async def get_api_key(api_key_header: str = Security(api_key_header_auth)):
if api_key_header != API_KEY:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid API Key",
)
origins = [
"http://localhost.tiangolo.com",
"https://localhost.tiangolo.com",
"http://localhost",
"http://localhost:8080",
"http://localhost:4200",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class Item(BaseModel):
id : str
logging.config.dictConfig(
{
'version': 1,
'disable_existing_loggers': True,
}
)
global logger
logger = logging.getLogger("main")
logger.setLevel(logging.INFO)
# create the logging file handler
fh = logging.FileHandler("app.log")
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
while logger.handlers:
logger.handlers.pop()
# add handler to logger object
logger.addHandler(fh)
logger.addHandler(ch)
logger.propagate = False
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
@app.get("/heartbeat")
def heartbeat():
return "Success"
@app.get('/predictdata',dependencies=[Security(get_api_key)])
def predictdata(id: str):
try:
res = {"id" : id , "prediction": "" , "StatusCode" : "200", "Validations" : []}
if not id.isdigit():
res["Validations"].append({"Type" : "Validation", "Description" : "id must be a integer"})
raise TypeError("id must be an integer")
logger.info("*** ML prediction API started for Id : {} ***".format(id))
logger.info("########################")
data = ML_Process(id, res)
res = data
logger.info(res)
return JSONResponse(status_code=int(res["StatusCode"]), content=res)
except Exception as ex:
traceback.print_exc()
error_trace = traceback.format_exc()
res["Validations"].append({"Type" : "Error","Description" : error_trace})
res["StatusCode"] = str(500)
logger.exception("Exception in my ML API")
logger.error(ex,exc_info=True)
return JSONResponse(status_code=500, content=res)
def ML_Process(id, res):
#get docpath from db by id , copy doc to temp path from s3b and run ML model on the doc
#after processing it deletes temp path and returns predicted data
# this is a long running process takes avg 25 second but can take sometime 1-2 minutes.
# Issue is observed only when it's a long running requests e.g Model takes more time to do inference
if __name__ == "__main__":
uvicorn.run(
app,
host="0.0.0.0",
port=8422
)
-------------------------------------
Dockerfile
FROM python:3
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
RUN apt-get update
RUN apt-get install poppler-utils -y && \
apt install ghostscript -y && \
apt-get install -y tesseract-ocr && \
COPY . .
WORKDIR /app
CMD uvicorn app:app --host 0.0.0.0 --port 5057
-------------------------------------------
Kubernetes pod logs of application which shows same request getting processed multiple times
i sent the request of id - 12 only once through the swagger and nobody else was using it
log :-
2022-08-11 04:27:22,070 - main - INFO - *** ML prediction API started for id : 12 ***
2022-08-11 04:27:22,071 - main - INFO - ########################
2022-08-11 04:27:22,072 - main - INFO - Temp folder structure created : /app/12_20220811042722071864
2022-08-11 04:27:22,104 - main - INFO - File existing in this id folder in S3B folder .
2022-08-11 04:27:22,105 - main - INFO - File existing in this id folder in S3B folder ..
2022-08-11 04:27:22,105 - main - INFO - File existing in this id folder in S3B folder 278692642.pdf
2022-08-11 04:27:22,591 - main - INFO - "278692642.pdf" file copied in temp directory
2022-08-11 04:27:27,518 - main - INFO - 278692642.pdf
2022-08-11 04:27:27,706 - main - INFO - /app/12_20220811042722071864/278692642.pdf
2022-08-11 04:28:56,711 - main - INFO - prediction = done
2022-08-11 04:28:56,711 - main - INFO - -----------------------------------------------------------------------------
2022-08-11 04:28:22,078 - main - INFO - *** ML prediction API started for id : 12 ***
2022-08-11 04:28:22,080 - main - INFO - ########################
2022-08-11 04:28:22,080 - main - INFO - Temp folder structure created : /app/12_20220811042822080625
2022-08-11 04:28:22,292 - main - INFO - File existing in this id folder in S3B folder .
2022-08-11 04:28:22,292 - main - INFO - File existing in this id folder in S3B folder ..
2022-08-11 04:28:22,292 - main - INFO - File existing in this id folder in S3B folder 278692642.pdf
2022-08-11 04:28:24,784 - main - INFO - "278692642.pdf" file copied in temp directory
2022-08-11 04:28:38,689 - main - INFO - 278692642.pdf
2022-08-11 04:28:39,986 - main - INFO - /app/12_20220811042822080625/278692642.pdf
2022-08-11 04:28:56,711 - main - INFO - prediction = done
2022-08-11 04:28:56,711 - main - INFO - -----------------------------------------------------------------------------
█
|----------------------------------------| 0.00% [0/1 00:00<?]
|████████████████████████████████████████| 100.00% [1/1 00:16<00:00]
█
|----------------------------------------| 0.00% [0/1 00:00<?]
|████████████████████████████████████████| 100.00% [1/1 00:14<00:00]
2022-08-11 04:29:22,145 - main - INFO - Deleted Temp folder : /app/12_20220811042722071864
2022-08-11 04:29:22,145 - main - INFO - ML prediction Done!!!
2022-08-11 04:29:22,145 - main - INFO - {"id" : 12,'prediction': 'predicted value here', 'StatusCode': '200', 'Validations': []}
2022-08-11 04:29:22,077 - main - INFO - *** ML prediction API started for id : 12 ***
2022-08-11 04:29:22,077 - main - INFO - ########################
2022-08-11 04:29:22,077 - main - INFO - Temp folder structure created : /app/12_20220811042922077785
2022-08-11 04:29:22,100 - main - INFO - File existing in this id folder in S3B folder .
2022-08-11 04:29:22,101 - main - INFO - File existing in this id folder in S3B folder ..
2022-08-11 04:29:22,101 - main - INFO - File existing in this id folder in S3B folder 278692642.pdf
2022-08-11 04:29:22,145 - main - INFO - Deleted Temp folder : /app/12_20220811042822080625
2022-08-11 04:29:22,145 - main - INFO - ML prediction Done!!!
2022-08-11 04:29:22,145 - main - INFO - {"id" : 12,'prediction': 'predicted value here', 'StatusCode': '200', 'Validations': []}
2022-08-11 04:28:38,689 - main - INFO - 278692642.pdf
2022-08-11 04:28:39,986 - main - INFO - /app/12_20220811042922077785/278692642.pdf
2022-08-11 04:28:56,711 - main - INFO - prediction = done
2022-08-11 04:28:56,711 - main - INFO - -----------------------------------------------------------------------------
----------------------| 0.00% [0/1 00:00<?]
|████████████████████████████████████████| 100.00% [1/1 00:00<00:00]
2022-08-11 04:29:40,316 - main - INFO - Deleted Temp folder : /app/12_20220811042922077785
2022-08-11 04:29:40,316 - main - INFO - ML prediction Done!!!
2022-08-11 04:29:40,318 - main - INFO - {"id" : 12,'prediction': 'predicted value here', 'StatusCode': '200', 'Validations': []}
----
here for first time, it took the request id started processing but before completing i.e before deleting temp path, second process/thread is initiated as i see this log again
**ML prediction API started for id : 12
and a new temp path is also created
2022-08-11 04:28:22,080 - main - INFO - Temp folder structure created : /app/12_20220811042822080625**
and starts processes same request again before first one is complete then again after few seconds third process/thread is initiated and starts processing on same request. it shouldn't process same request again and again. I don't have any multiprocessing or multithreading concept then why its processing same request again and again. plz guide
### Description
I don't have any multiprocessing or multithreading concept in my Fast API
Application then why its processing same request again and again. Its a simple
ML Processing Application
### Operating System
Linux
### Operating System Details
_No response_
### FastAPI Version
fastapi-0.68.2
### Python Version
3.8.5
### Additional Context
_No response_
| 0 |
### Bug report
**Bug summary**
I have a pcolormesh that has shading='gouraud', and I am trying to save it to
an .eps. Saving it to a pdf works fine, but trying to save to an eps gives an
error.
**Code for reproduction**
import matplotlib.pyplot as plt
import numpy as np
plt.pcolormesh(np.random.randn(10,10), shading='gouraud')
plt.gcf().savefig('test.eps')
**Actual outcome**
168 def quote_ps_string(s):
169 "Quote dangerous characters of S for use in a PostScript string constant."
--> 170 s=s.replace("\\", "\\\\")
171 s=s.replace("(", "\\(")
172 s=s.replace(")", "\\)")
TypeError: a bytes-like object is required, not 'str'
**Matplotlib version**
matplotlib 1.5.1
'3.5.1 |Anaconda 2.4.1 (x86_64)| (default, Dec 7 2015, 11:24:55) \n[GCC 4.2.1
(Apple Inc. build 5577)]'
OS X
I fixing this might just require adding a 'b' before these strings.
|
I'm running python 3.4 on Debian 8.3, and am using the Qt5Agg backend. When I
call savefig() or use the toolbar widget to save a figure that has a gouraud
shaded triangulation, I get the following stacktrace:
Traceback (most recent call last):
File "/home/tps/PyCharmProjects/test/test_PlotWindow.py", line 323, in saveFigRButtonClicked
savefig(fname)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/pyplot.py", line 688, in savefig
res = fig.savefig(*args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/figure.py", line 1565, in savefig
self.canvas.print_figure(*args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_qt5agg.py", line 196, in print_figure
FigureCanvasAgg.print_figure(self, *args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backend_bases.py", line 2232, in print_figure
**kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_ps.py", line 995, in print_eps
return self._print_ps(outfile, 'eps', *args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_ps.py", line 1023, in _print_ps
**kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_ps.py", line 1113, in _print_figure
self.figure.draw(renderer)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/artist.py", line 61, in draw_wrapper
draw(artist, renderer, *args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/figure.py", line 1159, in draw
func(*args)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/artist.py", line 61, in draw_wrapper
draw(artist, renderer, *args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/axes/_base.py", line 2324, in draw
a.draw(renderer)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/artist.py", line 61, in draw_wrapper
draw(artist, renderer, *args, **kwargs)
File "/usr/local/lib/python3.4/dist-packages/matplotlib/collections.py", line 1694, in draw
renderer.draw_gouraud_triangles(gc, verts, colors, transform.frozen())
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_ps.py", line 867, in draw_gouraud_triangles
stream = quote_ps_string(streamarr.tostring())
File "/usr/local/lib/python3.4/dist-packages/matplotlib/backends/backend_ps.py", line 170, in quote_ps_string
s=s.replace("\\", "\\\\")
TypeError: expected bytes, bytearray or buffer compatible object
| 1 |
I get very very strange numerical inconsistencies like these:

I could reproduce this in ipython and jupyter notebook but only on macOS, not
on Linux. Here is a gist with code to reproduce the error (Note that you need
to download and unzip a file first and then appropriately copy your value of
`vec_x` to `a`.) The error also happens for `np.dot` and possibly other
functions.
My system specs:
macOS 10.13.4 (17E202)
Python 3.6.4 :: Anaconda custom (64-bit)
jupyter-notebook 5.4.0
ipython 6.2.1
numpy 1.14.2
gensim 3.4.0
This is a cross post from this jupyter notebook issue (as I really don't know
who's the culprit in the end).
|
Running numpy.dot normally produces the expected answer:
$ python -c "import numpy ; f=numpy.ones(2,dtype=numpy.float32);print f.dot(f)"
2.0
If I import a PyQt5 module first, I get a different answer:
$ python -c "import PyQt5.QtWidgets ; import numpy ; f=numpy.ones(2,dtype=numpy.float32);print f.dot(f)"
0.0
Other folks appear to have found the issue here, with an implied implication
of the Accelerate library being loaded first. I could not discover the
resolution they used, and I would prefer one that did not require fixing
python import order.
| 1 |
When using `pd.DataFrame.describe`, if your percentiles are different only at
the 4th decimal place, a `ValueError` is thrown because the the percentiles
that vary at the 4th decimal place become the same value.
In [1]: s = Series(np.random.randn(10))
In [2]: s.describe()
Out[2]:
count 10.000000
mean 0.291571
std 1.057143
min -1.453547
25% -0.614614
50% 0.637435
75% 0.968905
max 1.823964
dtype: float64
In [3]: s.describe(percentiles=[0.0001, 0.0005, 0.001, 0.999, 0.9995, 0.9999])
Out[3]:
count 10.000000
mean 0.291571
std 1.057143
min -1.453547
0.0% -1.453107
0.1% -1.451348
0.1% -1.449149
50% 0.637435
99.9% 1.817201
100.0% 1.820583
100.0% 1.823288
max 1.823964
dtype: float64
|
#### Code Sample, a copy-pastable example if possible
import pandas
a = pandas.DataFrame({'a': ['0'], 'b': ['str']})
print('---')
print(a)
a.iloc[:, 0] = [int(v) for v in a.iloc[:, 0]]
print('---')
print(a)
b = pandas.concat([a, pandas.DataFrame({'b': ['str2']})], axis=1)
print('---')
print(b)
b.iloc[:, 2] = ['str3']
print('---')
print(b)
#### Problem description
The issue seems to be that if there is a DataFrame with duplicate column names
and mixed dtypes, if I try to replace one column with another value, using
`iloc`, another column with same name is replaced as well.
#### Expected Output
The final print should be:
a b b
0 0 str str3
And not:
a b b
0 0 str3 str3
It is interesting that if I change concat line to (see renaming of column `b`
to `c`):
b = pandas.concat([a, pandas.DataFrame({'c': ['str2']})], axis=1)
Then the output is correctly:
a b c
0 0 str str3
Also, if `a.iloc[:, 0] = [int(v) for v in a.iloc[:, 0]]` is commented out, it
works also correctly.
Moreover, the following also work correctly (see the change of `0` column
index into `[0]` column index, and similar for `2` (this latter change is not
really necessary to make it work)):
import pandas
a = pandas.DataFrame({'a': ['0'], 'b': ['str']})
print('---')
print(a)
a.iloc[:, [0]] = [int(v) for v in a.iloc[:, 0]]
print('---')
print(a)
b = pandas.concat([a, pandas.DataFrame({'b': ['str2']})], axis=1)
print('---')
print(b)
b.iloc[:, [2]] = ['str3']
print('---')
print(b)
#### Output of `pd.show_versions()`
## INSTALLED VERSIONS
commit: None
python: 3.6.3.final.0
python-bits: 64
OS: Linux
OS-release: 4.13.0-46-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: en_US.UTF-8
pandas: 0.23.3
pytest: None
pip: 18.0
setuptools: 40.0.0
Cython: None
numpy: 1.15.0
scipy: None
pyarrow: None
xarray: None
IPython: None
sphinx: None
patsy: None
dateutil: 2.7.3
pytz: 2018.5
blosc: None
bottleneck: None
tables: None
numexpr: None
feather: None
matplotlib: None
openpyxl: None
xlrd: None
xlwt: None
xlsxwriter: None
lxml: None
bs4: None
html5lib: None
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: None
s3fs: None
fastparquet: None
pandas_gbq: None
pandas_datareader: None
| 0 |
##### System information (version)
* OpenCV => master
* Operating System / Platform => Windows 64 Bit
* Compiler => Visual Studio 15 2017 Win64
##### Detailed description
When doing Configure on master branch in Windows with CV_DISABLE_OPTIMIZATION
checked, it causes the CMake configuration process to fail on errors like
these:
CMake Error at cmake/OpenCVUtils.cmake:331 (target_include_directories):
Cannot specify include directories for target "opencv_test_core_SSE4_1"
which is not built by this project.
Call Stack (most recent call first):
cmake/OpenCVModule.cmake:675 (ocv_target_include_directories)
cmake/OpenCVModule.cmake:1239 (ocv_target_include_modules)
modules/core/CMakeLists.txt:97 (ocv_add_accuracy_tests)
CMake Error at cmake/OpenCVUtils.cmake:331 (target_include_directories):
Cannot specify include directories for target "opencv_test_core_SSE4_2"
which is not built by this project.
Call Stack (most recent call first):
cmake/OpenCVModule.cmake:675 (ocv_target_include_directories)
cmake/OpenCVModule.cmake:1239 (ocv_target_include_modules)
modules/core/CMakeLists.txt:97 (ocv_add_accuracy_tests)
.....
and many more of the same error for the various components that are selected
for building.
##### Steps to reproduce
In Windows 10 x64, CMake (v3.7.2), clone the repo, checkout `master` branch,
and run CMake Configure with _Visual Studio 15 2017 Win64_ as the compiler.
|
##### System information (version)
* OpenCV => 4.1.2
* Operating System / Platform => Linux / Ubuntu 18.04
* Compiler => ❔
##### Detailed description
When running the code below that call `solvePnPGeneric` from Python the
program crashes because the C++ code expect a different type for
`reprojectionError` from the one passed by `solvePnPGeneric` by default. The
argument is however documented as optional. Passing the argument with the
correct type avoid the error.
I suspect that the binding of the `solvePnPGeneric` function do not pass the
correct argument type for `reprojectionError` by default.
The error:
Traceback (most recent call last):
File "error.py", line 15, in <module>
obj_points, img_points, cameraMatrix, distCoeffs #, reprojectionError=r
cv2.error: OpenCV(4.1.2) /io/opencv/modules/calib3d/src/solvepnp.cpp:1017: error: (-2:Unspecified error) in function 'int cv::solvePnPGeneric(cv::InputArray, cv::InputArray, cv::InputArray, cv::InputArray, cv::OutputArrayOfArrays, cv::OutputArrayOfArrays, bool, cv::SolvePnPMethod, cv::InputArray, cv::InputArray, cv::OutputArray)'
> Type of reprojectionError must be CV_32FC1 or CV_64FC1!:
> 'type == CV_32FC1 || type == CV_64FC1'
> where
> 'reprojectionError.type()' is 0 (CV_8UC1)
This might be closely linked to #16040 which is about Java binding of
solvePnPGeneric
##### Steps to reproduce
Run this code (OpenCV 4.1.2 / Python 3.6.8)
import numpy as np
import cv2
obj_points = np.array([[0, 0, 0], [0, 1, 0], [1, 1, 0], [1, 0, 0]], dtype=np.float32)
img_points = np.array(
[[700, 400], [700, 600], [900, 600], [900, 400]], dtype=np.float32
)
cameraMatrix = np.array(
[[712.0634, 0, 800], [0, 712.540, 500], [0, 0, 1]], dtype=np.float32
)
distCoeffs = np.array([[0, 0, 0, 0]], dtype=np.float32)
#r = np.array([], dtype=np.float32)
x, r, t, e = cv2.solvePnPGeneric(
obj_points, img_points, cameraMatrix, distCoeffs #, reprojectionError=r
)
print(e)
print(t)
The error can be bypassed by uncommenting the `#r = np.array([],
dtype=np.float32)` lines.
Thanks for the amazing work and happy to help or provide more information!
| 0 |
**Migrated issue, originally created by Anonymous**
This problem occurs in sqlalchemy 4.7.1, using oracle 9.
Case scenario:
I had a job table, and a task task, and a jabs2tasks table to create a many to
many relation. I created a job and a task, and added the job twice to the task
(using a relation that have a secondary). len(task.jobs) returned 2. Then I
saved the task and commited.
I was expecting that an exception would be thrown, but it didn't. When I
looked in at jobs2tasks in my SQLNavigator, I saw that only one entry was
enetered.
The problem is, that this behaviour is not expected. When I try to enter, for
example, a task that already exists in the db (the same task_id), sqlalchemy
throw a constraint exception. I think that this is exactly the same case, but
with a complex primary key.
Reported by Kobi Perl.
|
### Describe the bug
The `CreateSchema` DDL construct accepts a parameter `if_not_exists` via its
base class, `_CreateDropBase`. However, this parameter is ignored: for
example, `CreateSchema("myschema", if_not_exists=True)` produces `CREATE
SCHEMA myschema` rather than `CREATE SCHEMA myschema IF NOT EXISTS`.
### To Reproduce
# Assuming a Postgres server serving on localhost:5432
from sqlalchemy import create_engine
from sqlalchemy.engine import url
from sqlalchemy.sql.ddl import CreateSchema
db_url = url.URL.create(
"postgresql",
username="postgres",
password="postgres",
host="localhost",
port=5432,
database="postgres",
)
engine = create_engine(db_url)
engine.execute(CreateSchema("myschema", if_not_exists=True))
engine.execute(CreateSchema("myschema", if_not_exists=True))
### Error
/.../python "/.../scratch_13.py"
Traceback (most recent call last):
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1771, in _execute_context
self.dialect.do_execute(
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 717, in do_execute
cursor.execute(statement, parameters)
psycopg2.errors.DuplicateSchema: schema "myschema" already exists
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/.../scratch_13.py", line 16, in <module>
engine.execute(CreateSchema("myschema", if_not_exists=True))
File "<string>", line 2, in execute
File "/.../lib/python3.10/site-packages/sqlalchemy/util/deprecations.py", line 390, in warned
return fn(*args, **kwargs)
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3108, in execute
return connection.execute(statement, *multiparams, **params)
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1263, in execute
return meth(self, multiparams, params, _EMPTY_EXECUTION_OPTS)
File "/.../lib/python3.10/site-packages/sqlalchemy/sql/ddl.py", line 77, in _execute_on_connection
return connection._execute_ddl(
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1353, in _execute_ddl
ret = self._execute_context(
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1814, in _execute_context
self._handle_dbapi_exception(
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1995, in _handle_dbapi_exception
util.raise_(
File "/.../lib/python3.10/site-packages/sqlalchemy/util/compat.py", line 207, in raise_
raise exception
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1771, in _execute_context
self.dialect.do_execute(
File "/.../lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 717, in do_execute
cursor.execute(statement, parameters)
sqlalchemy.exc.ProgrammingError: (psycopg2.errors.DuplicateSchema) schema "myschema" already exists
[SQL: CREATE SCHEMA myschema]
(Background on this error at: https://sqlalche.me/e/14/f405)
### Versions
* OS: OSX 12.0.1
* Python: 3.10.2
* SQLAlchemy: 1.4.22
* Database: PostgreSQL 13.4
* DBAPI (eg: psycopg, cx_oracle, mysqlclient): psycopg
### Additional context
From inspection of the source, it seems that `CreateTable` and `CreateIndex`
are the only subclasses of `_CreateDropBase` that make use of the parameter;
from this it is not clear why the parameter exists on the base class instead
of the specific subclasses that actually use it.
I appreciate that implementing support for this might be confounded by
different support for this feature in different database engines. However I
see that it is supported for indices even though MySQL doesn't support that
syntax as far as I can see (and the `IF NOT EXISTS` is even added in the
`MySQLDDLCompiler`, strangely). If support is not feasible, it might be
worthwhile moving the `if_not_exists` parameters onto just the classes that
support it.
All of these observations also apply to the `if_exists` parameter too.
| 0 |
This was found during training using the core developer training dataset:
Getting all the term suggestions for framework
GET stack/_suggest
{
"mysuggest" : {
"text" : "framework",
"term" : {
"field" : "title",
"suggest_mode" : "always",
"sort" : "score",
"size" : 20
}
}
}
yields:
[{
"text": "frameworks",
"score": 0.8888889,
"freq": 16
}, {
"text": "framework2",
"score": 0.8888889,
"freq": 1
}, {
"text": "framwork",
"score": 0.875,
"freq": 5
}, {
"text": "framewok",
"score": 0.875,
"freq": 2
}, {
"text": "famework",
"score": 0.875,
"freq": 1
}, {
"text": "framework's",
"score": 0.7777778,
"freq": 1
}, {
"text": "freamwork",
"score": 0.7777778,
"freq": 1
}]
if we then pick any of the of these terms, except the most popular
`frameworks` and feed it to the term suggester using the missing option:
GET stack/_suggest
{
"mysuggest" : {
"text" : "framwork",
"term" : {
"field" : "title",
"suggest_mode" : "missing",
"sort" : "score",
"size" : 20
}
}
}
We still get back suggestions:
[{
"text": "framework",
"score": 0.875,
"freq": 197
}, {
"text": "frameworks",
"score": 0.75,
"freq": 9
}, {
"text": "framewok",
"score": 0.75,
"freq": 1
}, {
"text": "framework2",
"score": 0.75,
"freq": 1
}]
Only for the most `popular` term do we get back no suggestions.
For full reference here is how `framwork` gets analyzed:
`GET stack/_analyze?field=title&text=framwork`
{
"tokens": [
{
"token": "framwork",
"start_offset": 0,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 0
}
]
}
|
I have found a few odd cases where the phrase suggester with suggest_mode:
"missing" generates a suggestion even though the query returns results. I am
querying across two indexes but the query term only exists in one of the
indexes. I get the search results I expect, but I do not expect to get a
suggestion.
I am trying to come up with a curl recreation but I haven't been able to
reproduce it yet in a smaller corpus.
I believe what is happening is that the phrase suggestions are getting merged
together in the same way the query results are merged together across multiple
indexes. If I have query results from test_1 and no results from test_2, then
I expect to see results from test_1. But if I have a suggestion from test_1
and no suggestion from test_2 (due to suggest_mode: "missing"), I do not
expect to see a suggestion.
| 1 |
@fchollet and other kerasors,
We all know that if we are dealing with large scale of data such as ImageNet,
we could write a customized generator which produces batch data (often as
numpy.array) from disk. Then we could train our model with
`model.fit_generator()`. But, if we want to use `ImageDataGenerator` to do the
online data augmentation at the same time, what is the simplest way to
implement? Note that I would like to use its `flow()` method instead of
`flow_from_directory()` method.
|
Hello everyone, I have a tricky programming question. I want to implement an
exponentially moving average of centroids on hidden layers inputs activations
of an AutoEncoder to maximize ICC over several class in keras
(adding a loss penalizing this term).
It would require to know the final output of the classification for
calculating the centroids. I could do it by adding the output of this layer as
an extra output of neural network. But it would duplicate data. And it won t
be nice to work with in the case if I haven t to apply this on any hidden
layers.
Do you have any ideas how to do so ? Thank you
| 0 |
## Expected Behavior
After installing example and running `yarn test` the test should pass
## Current Behavior
After running `yarn test` we are getting an error
Plugin 0 specified in "/with-jest-app/node_modules/next/babel.js" provided an invalid property of "default" (While processing preset: "/with-jest-app/node_modules/next/babel.js")
## Steps to Reproduce (for bugs)
go to https://github.com/zeit/next.js/tree/canary/examples/with-jest and
follow readme installation steps
## Your Environment
Tech | Version
---|---
next | v6
node | v8.9.4
OS | High Sierra
|
when i run test from npm scripts i have error
C:\with-jest-app\jest.setup.js:1
({"Object.<anonymous>":function(module,exports,require,__dirname,__filename,global,jest){import { configure } from 'enzyme';
^
SyntaxError: Unexpected token {
at ScriptTransformer._transformAndBuildScript (node_modules/jest-runtime/build/script_transformer.js:316:17)
Tech | Version
---|---
next | 5.1.0
node | 10.0.0
| 1 |
**Alex Rau** opened **SPR-7842** and commented
DataBinder which is used by WebRequestDataBinder and ServletRequestDataBinder
grows automatically collections when "autoGrowNestedPaths" is on (AFAIK this
is the default for the DataBinder).
The behaviour of DataBinder when "autoGrowNestedPaths" is that a property with
a given index N will result in growing a collection to size N if the
collection is not large enough. Collection elements with index < N will be
initialized with default objects of the collection's type.
Based on WebRequestDataBinder it's therefore easily possible to DoS a web
application if it's allowed to bind against a collection property and the
client POSTs a single property using a very large index.
Sending a single request containing a parameter for a collection property with
index 99999999 caused an OOM on a JVM on MacOsX with default memory settings
(64MB?). The list type in this case contained 7 String properties and 2 Longs.
I think there are several things to follow-up:
1. It would be safer to set autoGrowNestedPaths to false by default. Use of DataBinder and autoGrowNestedPaths then would be more restrictive by default and require explicit action to enable autoGrowing.
2. The creation of "default" values in BeanWrapperImpl should be more flexible. A strategy for creating default values would allow clients to define how such default values should be created. In the case of WebRequestDataBinder creating empty (null) collection elements instead of default objects is certainly safer to fill the gaps in the collection - especially for exposed applications to the public. Furthermore this does not expose unwanted restrictions like a maximum allowed index limitation etc.
3. Presumably this could be solved with CustomPropertyEditors. However the majority of developers probably tries to stick with what is available out-of-the box and as the DataBinding in general for "standard" use-cases works fine dealing with the described issue is not obvious and could lead to wide-spread holes.
* * *
**Affects:** 3.0.5
**Issue Links:**
* #13022 Can make an OutOfMemoryException by sending a modified form list property with an high index ( _ **"is duplicated by"**_ )
* #10702 Data Binder: Auto-grow collections as needed to support nested property binding
* #14862 Limit auto grow collection size when using SpEL
7 votes, 7 watchers
|
**Colin Sampaleanu** opened **SPR-1319** and commented
If you try to use one bean factory post-processor it can't actually modify the
definion of a 2nd post-processor, even if that one has yet to run. This is
because the appcontext as a one time process builds up two lists (ordered and
non-ordered) of all the post-processors, and actually creates the objects
then. Any modified bean definition past that point will be irrelevant.
I'm not sure this can be resolved without some painful code, but I'm putting
the issue here so it can be either marked 'won't resolve' or 'working as
intended', or actually fixed, and people can find it when searching.
Here's a snippet of config that shows the problem. In this case, one
PropertyPlaceHolderConfigurer modifies the 2nd:
<bean id="fixProperties"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:remote-sync-client.properties"/>
<property name="ignoreUnresolvablePlaceholders" value="true"></property>
</bean>
<bean id="variableProperties" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer" depends-on="fixProperties">
<property name="location" value="file:${remote.sync.data.dir}/client.config"/>
</bean>
<bean id="pathProperties" class="org.springframework.beans.factory.config.PropertiesFactoryBean" depends-on="variableProperties">
<property name="location" value="file:${remote.sync.data.dir}/path.config"/>
</bean>
<bean id="clientConfiguration" class="com.tirawireless.remotesync.client.impl.ClientConfiguration" depends-on="pathProperties">
<property name="id" value="${client.id}"></property>
<property name="password" value="${client.password}"></property>
<property name="serverHost" value="${remote.sync.server.host}"></property>
<property name="serverPort" value="${remote.sync.server.port}"></property>
<property name="dataDirectory" value="${remote.sync.data.dir}"></property>
<property name="syncDirectories">
<ref local="pathProperties"/>
</property>
</bean>
* * *
**Affects:** 1.2.4
**Issue Links:**
* #5782 AbstractApplicationContext shouldn't eagerly instantiate all BeanFactoryPostProcessors ( _ **"duplicates"**_ )
| 0 |
http://kubekins.dls.corp.google.com:8081/job/kubernetes-pull-build-
test-e2e-gce/45191/consoleFull
Unfortunately we don't have logs.
@fejta @ixdy \- can you please take care of uploading logs in case of timeout?
|
The kubernetes tarball is extracted inside the container in dockerized e2e,
which gives us `kubernetes/cluster/log-dump.sh`. On timeout, we try to call
`log-dump.sh`, but do so outside the container, so it's no longer available.
We should probably move the timeout handling inside the dockerized e2e
container.
| 1 |
#### Describe the bug
This bugreport very similar to #315 which was implemented and fixed, however I
think this is not solved yet. When the query params parsing process itself
fails (before the request even started), the resulting error object does not
contain request information, making it hard to debug, especially with as error
reports.
#### To Reproduce
axios.get("", {
params: {
someParam: new Date(undefined)
}
}).catch((e) => {
console.log(e);
})
Only prints
RangeError: Invalid time value
at Date.toISOString (<anonymous>)
at parseValue (buildURL.js:53)
at Object.forEach (utils.js:219)
at serialize (buildURL.js:51)
at Object.forEach (utils.js:225)
at buildURL (buildURL.js:38)
at dispatchXhrRequest (xhr.js:45)
at new Promise (<anonymous>)
at xhrAdapter (xhr.js:13)
at dispatchRequest (dispatchRequest.js:53)
#### Expected behavior
I would expect the error to have information about the request (uri, config,
etc) just like when the error is thrown on server response error.
#### Environment
* Axios Version 0.21.1
* Adapter http
* Browser chromium
* Browser Version 87.0.4280.141
* Node.js Version 12.20.0
* OS: Manjaro 20.2.1
* Additional Library Versions none
#### Additional context/Screenshots
dont have any. – I dont think that omitting this category should result in the
automatic closing of an issue :-/
Cheers
|
Would be useful if `responseType` could be set to `stream` in the browser.
Right now, it only works in node.
| 0 |
julia> Pkg.checkout("DataStreams", "0.0.6")
INFO: Checking out DataStreams 0.0.6...
ERROR: GitError(Code:ERROR, Class:Merge, There is no tracking information for the current branch.)
in #123 at .\libgit2\libgit2.jl:414 [inlined]
in with(::Base.LibGit2.##123#128{Base.LibGit2.GitRepo}, ::Void) at .\libgit2\types.jl:638
in (::Base.LibGit2.##119#124{String,String,Bool,Base.LibGit2.MergeOptions,Base.LibGit2.CheckoutOptions,Base.LibGit2.GitRepo})(::Base.LibGit2.GitReference) at .\libgit2\libgit2.jl:412
in with(::Base.LibGit2.##119#124{String,String,Bool,Base.LibGit2.MergeOptions,Base.LibGit2.CheckoutOptions,Base.LibGit2.GitRepo}, ::Base.LibGit2.GitReference) at .\libgit2\types.jl:638
in (::Base.#kw##merge!)(::Array{Any,1}, ::Base.#merge!, ::Base.LibGit2.GitRepo) at .\<missing>:0
in (::Base.Pkg.Entry.##18#20{String,String,Bool,Bool})(::Base.LibGit2.GitRepo) at .\pkg\entry.jl:231
in transact(::Base.Pkg.Entry.##18#20{String,String,Bool,Bool}, ::Base.LibGit2.GitRepo) at .\libgit2\libgit2.jl:520
in with(::Base.Pkg.Entry.##17#19{String,String,Bool,Bool}, ::Base.LibGit2.GitRepo) at .\libgit2\types.jl:638
in checkout(::String, ::String, ::Bool, ::Bool) at .\pkg\entry.jl:227
in (::Base.Pkg.Dir.##2#3{Array{Any,1},Base.Pkg.Entry.#checkout,Tuple{String,String,Bool,Bool}})() at .\pkg\dir.jl:31
in cd(::Base.Pkg.Dir.##2#3{Array{Any,1},Base.Pkg.Entry.#checkout,Tuple{String,String,Bool,Bool}}, ::String) at .\file.jl:48
in #cd#1(::Array{Any,1}, ::Function, ::Function, ::String, ::Vararg{Any,N}) at .\pkg\dir.jl:31
in checkout(::String, ::String) at .\pkg\pkg.jl:170
julia> Pkg.status()
6 required packages:
- ExcelReaders 0.6.0
- Gallium 0.0.3
- Lora 0.5.4
- Mimi 0.2.0
- NamedTuples 1.0.0
- TypedTables 0.1.1+ julia-0-5
59 additional packages:
- ASTInterpreter 0.0.3
- AbstractTrees 0.0.3
- ArgParse 0.3.1
- BinDeps 0.4.2
- COFF 0.0.1
- CRC 1.1.1
- Calculus 0.1.15
- CategoricalArrays 0.0.2
- ColorTypes 0.2.5
- Colors 0.6.6
- Compat 0.8.6
- Conda 0.2.3
- DWARF 0.0.3
- DataArrays 0.3.8
- DataFrames 0.7.4+ nl/nullable
- DataStreams 0.0.7 0.0.6
- DataStructures 0.4.5
- Dates 0.4.4
- Distributions 0.10.2
- DocStringExtensions 0.1.0
- Docile 0.5.23
- Documenter 0.2.0
- ELF 0.0.3
- FileIO 0.1.0
- FixedPointNumbers 0.1.4
- Formatting 0.1.5
- ForwardDiff 0.2.2
- FunctionWrappers 0.0.0- master (unregistered)
- GZip 0.2.20
- Graphs 0.6.0
- JSON 0.6.0
- JuliaParser 0.7.4
- LegacyStrings 0.1.1
- LibExpat 0.2.0
- MachO 0.0.3
- MacroTools 0.3.2 master
- NaNMath 0.2.1
- NullableArrays 0.0.7
- ObjFileBase 0.0.3
- PDMats 0.4.2
- PyCall 1.7.0
- Query 0.0.0- master (unregistered)
- Reactive 0.3.4
- Reexport 0.0.3
- ReverseDiffSource 0.2.3
- Rmath 0.1.2
- SHA 0.2.0
- SQLite 0.3.3+ master
- SortingAlgorithms 0.1.0
- StatsBase 0.9.0
- StatsFuns 0.3.0
- StructIO 0.0.2
- TerminalUI 0.0.2
- TextWrap 0.1.6
- URIParser 0.1.6
- VT100 0.0.2
- WeakRefStrings 0.1.2
- WinRPM 0.2.0
- Zlib 0.1.12
julia>
Looking at the repo itself, there also seems some data corruption, in
particular the upstream info seems to be deleted:
C:\Users\anthoff\.julia\v0.5\DataStreams [0.0.6]> git status
On branch 0.0.6
Your branch is based on 'origin/0.0.6', but the upstream is gone.
(use "git branch --unset-upstream" to fixup)
nothing to commit, working directory clean
C:\Users\anthoff\.julia\v0.5\DataStreams [0.0.6]>
|
Starting from a tagged version:
julia> Pkg.checkout("TaylorSeries", "warningsv05")
INFO: Checking out TaylorSeries warningsv05...
ERROR: GitError(Code:ERROR, Class:Merge, There is no tracking information for the current branch.)
but this works if `master` is `checkout`ed first.
| 1 |
**Migrated issue, originally created by Michał Szczepański (@vane)**
When I'm trying to join two tables using String values that are duplicating in
each column I get less rows then expected
The query from database returns 10 rows but filtered is set to True and after
if filtered:
rows = util.unique_list(rows, filter_fn)
in sqlalchemy.orm.loading.py one row is left.
I think it's a problem with hashing.
def filter_fn(row):
return tuple(fn(x) for x, fn in zip(row, filter_fns))
Exist with 1.0.6 and below.
Script with full example in attachment with workaround.
Script create tables then execute bugged query and workaround query.
You can vary result number from bugged query by changing result_rows to number
from 1 to 10
s = Scaffold(db, result_rows=2)
Test script deletes the database file after run so it's always fresh start.
I tried it on 1.0.6 on debian and 0.9.8 on windows same results
* * *
Attachments: join_bug.py
|
**Migrated issue, originally created by Anonymous**
It appears that INSERTs and UPDATEs do not work under the following
conditions:
1. Table with composite primary key.
2. A hierarchy of classes polymorphically mapped to the table (single inheritance)
3. The polymorphic discriminator column is part of the primary key.
Also, while the 'insert' problem can be worked around (see bellow), fixing the
'update' requires patching SQLAlchemy's code.
Here's a test case:
from sqlalchemy import *
from sqlalchemy.orm import *
engine = create_engine('sqlite://')
metadata = MetaData()
test_table = Table("test", metadata,
Column("id1", Integer, primary_key=True),
Column("id2", UnicodeText, primary_key=True),
Column("data", UnicodeText)
)
class TestBase(object):
pass
class TestDeriv(TestBase):
pass
mapper(TestBase, test_table,
polymorphic_on=test_table.c.id2,
polymorphic_identity=u"base")
mapper(TestDeriv,
inherits=TestBase,
polymorphic_on=test_table.c.id2,
polymorphic_identity=u"deriv")
metadata.create_all(bind=engine)
session = sessionmaker(bind=engine, autoflush=False)()
t1 = TestDeriv()
t1.id1 = 0
# id2 is implied by instance's type, but we still
# have to assign it explicitly in order the insert to work
t1.id2 = u"deriv"
session.add(t1)
session.commit()
session.clear()
del t1
t1 = session.query(TestDeriv).get((0, u"deriv"))
t1.data = u"foo bar"
# The following line raises ConcurrentModificationError
# Logged SQL shows that id2 is bound to None
session.commit()
The fix (see the attached file, works against rev. 5098) is next to trivial
(it only modifies two lines), but I have no way to be sure that it won't break
something else.
* * *
Attachments: sqla1.diff
| 0 |
Not sure if this means I shouldn't use it, or if we just haven't documented it
yet :)
https://docs.flutter.io/flutter/widgets/Scrollable-class.html
|
I think we need some high level documentation of all the list and viewport
classes, including a class hierarchy diagram showing inheritance, mixins,
ownership, and who creates whom. It should probably lean on some other
documentation explaining the purpose of custom Element subclasses, too.
| 1 |
Given the use case of dynamically instantiating content children using the
NgFor of NgIf directives I've found this not working in alpha.52. I thought
this was working before in alpha.44 but after testing it seems this was never
working.
I'd expect this to work and I thought this was the reason for content children
being represented with a `QueryList` in the first place.
import {Component, Input, NgFor, NgIf} from 'angular2/angular2';
@Component({
selector: 'child'
template: `
<p>{{text}}</p>
`
})
export class Child {
@Input() text;
}
@Component({
selector: 'parent'
template: `
<section>
<strong>Content children:</strong>
<ng-content select="child"></ng-content>
</section>
`
})
export class Parent {}
@Component({
selector: 'app'
template: `
<section>
<strong>Outside of parent</strong>
<child *ngIf="true" text="Child in the wild"></child>
<child *ngFor="#t of text" [text]="t"></child>
</section>
<parent>
<child *ngIf="true" text="Child in the wild"></child>
<child *ngFor="#t of text" [text]="t"></child>
</parent>
`,
directives: [Parent, Child, NgFor, NgIf]
})
export class App {
text = ['Child 1', 'Child 2', 'Child 3']
}
http://plnkr.co/edit/aUSkWPQmT3XHf6QLqif5?p=preview
|
We have a Component template that looks like this:
<ng-content select="item-left"></ng-content>
<ion-item-content>
<ng-content></ng-content>
</ion-item-content>
But if you add `*ng-if="true"` on the `item-left` element it places this
element inside of the `ion-item-content` like this:
<ion-item-content>
<script></script>
<item-left></item-left>
</ion-item-content>
Removing the `*ng-if` places it in the proper place
<item-left></item-left>
<ion-item-content></ion-item-content>
Is there something we need to improve for this?
cc @IgorMinar @adamdbradley
| 1 |
I use **Pinyin - Simplified** to input Chinese character .

When I begin typing, the input sources panel positioned unexpectedly.

It should perform like Sublime Text.

|
* Doing the vscode express smoke test I now get errors when I open any .js file that has a require
* e.g www/bin
* is there some setting I am missing
As for the node experience we seem to have worse support than before (what is
described in the smoke test)

| 0 |
Challenge http://freecodecamp.com/challenges/waypoint-bring-your-javascript-
slot-machine-to-life has an issue. Please describe how to reproduce it, and
include links to screenshots if possible.
Hi!
When I'm working on this way point I can only get as far as entering
$($('.slot')[0]).html(slotOne) before it freezes up and crashes. I tried
making it work on Safari and Google but they both crashed.
|
Challenge http://freecodecamp.com/challenges/waypoint-bring-your-javascript-
slot-machine-to-life has an issue. Please describe how to reproduce it, and
include links to screenshots if possible.
after typing "$($", chrome crashes.
| 1 |
### Version
2.5.13
### Reproduction link
https://jsfiddle.net/1m5vx6dc/1/
### Steps to reproduce
Say we have an array `list` `['a', 'b', 'c', 'd', 'e', 'f', 'g', ...]` and a
computed property `filtered` that extracts 4 items from that list based on a
start `index`. Then we run a `v-for` on the `filtered` computed list and
increase / decrease the `index`. We use the item value as the `:key`. If we
inspect the resulting DOM in chrome, we can see that if the filtered list is
moved to the right (index increased), all DOM nodes are replaced. If the index
is moved to the left, only the first node is replaced.
### What is expected?
I would expect that increasing or decreasing the index would yield the same
DOM patch, either re-creating only the first or the last node in the list.
### What is actually happening?
Increasing the index causes a full DOM refresh, decreasing the index yields
the expected behaviour.

|
### Version
2.5.2
### Reproduction link
https://codesandbox.io/s/mzvkppmvo8
### Steps to reproduce
1. I created component with scoped slot (AppSwitcher.vue)
2. Then I use it in another component with their own slot (HelloWorld.vue with slot "subtext")
3. Add some element to slot (div in App.vue)
### What is expected?
It should work without errors
### What is actually happening?
Changes in AppSwitcher.vue caus "Duplicate presence of slot "subtext" found in
the same render tree" error but there are no duplicates.
* * *
Also, adding `slot-scope` to div in App.vue solves problem and no error there,
but why it happens without `slot-scope`?
| 0 |
# Environment
Windows build number: 10.0.18999.1
Windows Terminal version (if applicable): Version: 0.5.2762.0
# Steps to reproduce
Start Windows Terminal in Ubuntu 18.04. Install Vim. Start Vim. Type a
sentence then move the cursor over a letter. See that the letter is obscured.
# Expected behavior
I'd expect the text underneath the cursor to be inverse of the cursor, or
something that isn't the same as the cursor color making it invisible. I've
tried almost every Vim setting for changing cursor color etc but it has no
effect. Changing the `cursorColor` in the profile has no effect.
Running the same test in Fluent Terminal (while having a blinking cursor by
default) does the right thing.
# Actual behavior
The cursor obscures the text underneath it:

|
# Summary of the new feature/enhancement
When `cursorShape` is set to `filledBox`, it hides the character under it:

(The command is `cat /etc/os-release`)
This is a bit annoying. It will be helpful if the character can still be
visible when the cursor is moved to its position.
| 1 |
**Migrated issue, originally created by Michael Bayer (@zzzeek)**
from sqlalchemy import *
from sqlalchemy.orm import *
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class A(Base):
__tablename__ = 'a'
id = Column(Integer, primary_key=True)
a = Column(Integer)
b = Column(Integer)
aplusb = column_property(
a + b, deferred=True
)
e = create_engine("sqlite://", echo=True)
Base.metadata.create_all(e)
s = Session(e)
s.add(A(a=1, b=2))
s.commit()
a1 = s.query(A).first()
assert 'aplusb' not in a1.__dict__
a1.b = 5
s.flush()
s.commit()
a1.b
assert 'aplusb' not in a1.__dict__
|
**Migrated issue, originally created by Anonymous**
Hi,
I noticed that the update() usage in /orm/extensions/sqlsoup.html is outdated:
> > > db.loans.update(db.loans.book_id==2, book_id=1)
This doesn't work anymore. There may be more out-of-date code in there, I
haven't checked.
| 0 |
ERROR: type should be string, got "\n\nhttps://k8s-gubernator.appspot.com/build/kubernetes-\njenkins/logs/kubernetes-e2e-gke-serial/1916/\n\nFailed: [k8s.io] Nodes [Disruptive] [k8s.io] Resize [Slow] should be able to\nadd nodes {Kubernetes e2e suite}\n\n \n \n /go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/resize_nodes.go:479\n Expected error:\n <*errors.errorString | 0xc8214da3b0>: {\n s: \"failed to wait for pods responding: timed out waiting for the condition\",\n }\n failed to wait for pods responding: timed out waiting for the condition\n not to have occurred\n /go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/resize_nodes.go:464\n \n\nPrevious issues for this test: #27470\n\n" |
Quite a few tests flake with:
an error on the server has prevented the request from succeeding (put replicasets.extensions frontend-
88237173); Current resource version 493
This seems to indicate:
* test should retry
* that's a lot of flake on GKE
eg: #29149, #30156, #30352 (comment), pretty much all the failures in #31188,
#31429 (comment), #31575, #31408
| 1 |
Challenge http://freecodecamp.com/challenges/waypoint-add-borders-around-your-
elements has an issue. Please describe how to reproduce it, and include links
to screenshots if possible.

|
Waypoint hints do not always appear after the page has loaded. Refreshing the
page does not always seem to work. Closed & reopened browser does not seem to
change behaviour. Issue is not specific to certain waypoints but started to
occur in the jQuery section.
Issue experienced on Chrome 44.0.2403.55 on Windows 8.1. Attached screenshot
for clarity.

| 1 |
I have installed tensorflow and keras. I have used virtualenviroment given in
tensorflow website. It is showing the below error when I try to import keras
with tensorflow as backend
CPU_COUNT = psutil.cpu_count()
AttributeError: 'module' object has no attribute 'cpu_count'
tensorflow version = Version: 1.3.0
keras = Version: 2.0.7
dask = Version: 0.15.0
pandas = Version: 0.20.3
For detailed error, attaching the image
|
### What related GitHub issues or StackOverflow threads have you found by
searching the web for your problem?
Some people report having similar problems with 'module' objects having no
attribute something-or-other and claim they were solved by upgrading.
### Environment info
Operating System:
Ubuntu 17.04 x64
Installed version of CUDA and cuDNN:
(please attach the output of `ls -l /path/to/cuda/lib/libcud*`):
-rw-r--r-- 1 root root 558720 сен 15 02:02 /usr/local/cuda/lib64/libcudadevrt.a
-rw-r--r-- 1 root root 383336 дек 23 01:26 /usr/local/cuda/lib64/libcudart.so
-rw-r--r-- 1 root root 383336 дек 23 01:25 /usr/local/cuda/lib64/libcudart.so.7.5
lrwxrwxrwx 1 root root 19 дек 23 02:17 /usr/local/cuda/lib64/libcudart.so.8.0 -> libcudart.so.8.0.44
-rw-r--r-- 1 root root 415432 сен 15 02:02 /usr/local/cuda/lib64/libcudart.so.8.0.44
-rw-r--r-- 1 root root 775162 сен 15 02:02 /usr/local/cuda/lib64/libcudart_static.a
lrwxrwxrwx 1 root root 13 дек 23 02:17 /usr/local/cuda/lib64/libcudnn.so -> libcudnn.so.5
lrwxrwxrwx 1 root root 17 дек 23 02:17 /usr/local/cuda/lib64/libcudnn.so.5 -> libcudnn.so.5.1.5
-rwxr-xr-x 1 root root 79337624 дек 22 04:25 /usr/local/cuda/lib64/libcudnn.so.5.1.5
-rw-r--r-- 1 root root 69756172 дек 22 04:25 /usr/local/cuda/lib64/libcudnn_static.a
(yes, it's an unholy mess, with russian date format. sorry)
If installed from binary pip package, provide:
1. A link to the pip package you installed:
https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-0.12.0-cp27-none-
linux_x86_64.whl
as per instructions
2. The output from `python -c "import tensorflow; print(tensorflow.__version__)"`.
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcudnn.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcurand.so locally
0.12.0
### If possible, provide a minimal reproducible example (We usually don't have
time to read hundreds of lines of your code)
cd example;
python /usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/tensorboard.py --logdir=/home/myname/example/log_simple_graph
### What other attempted solutions have you tried?
See above; I've tried to run the actual `tensorboard.py` instead of just
`tensorboard --logdir=`
### Logs or other output that would be helpful
Running `cd example; python /usr/local/lib/python2.7/dist-
packages/tensorflow/tensorboard/tensorboard.py
--logdir=/home/myname/example/log_simple_graph` results in:
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcudnn.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcurand.so locally
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/tensorboard.py", line 34, in <module>
from tensorflow.tensorboard.backend import server
File "/usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/backend/server.py", line 37, in <module>
from tensorflow.tensorboard.backend import handler
File "/usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/backend/handler.py", line 43, in <module>
from tensorflow.tensorboard.plugins import REGISTERED_PLUGINS
File "/usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/plugins/__init__.py", line 20, in <module>
from tensorflow.tensorboard.plugins.projector.plugin import ProjectorPlugin
File "/usr/local/lib/python2.7/dist-packages/tensorflow/tensorboard/plugins/projector/plugin.py", line 27, in <module>
from tensorflow.contrib.tensorboard.plugins.projector import PROJECTOR_FILENAME
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/__init__.py", line 27, in <module>
from tensorflow.contrib import factorization
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/factorization/__init__.py", line 24, in <module>
from tensorflow.contrib.factorization.python.ops.gmm import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/factorization/python/ops/gmm.py", line 30, in <module>
from tensorflow.contrib.learn.python.learn.estimators import estimator
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/__init__.py", line 66, in <module>
from tensorflow.contrib.learn.python.learn import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/__init__.py", line 23, in <module>
from tensorflow.contrib.learn.python.learn import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/__init__.py", line 27, in <module>
from tensorflow.contrib.learn.python.learn import estimators
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/__init__.py", line 269, in <module>
from tensorflow.contrib.learn.python.learn.estimators.classifier import Classifier
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/classifier.py", line 25, in <module>
from tensorflow.contrib.learn.python.learn.estimators import estimator
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 52, in <module>
from tensorflow.contrib.learn.python.learn.learn_io import data_feeder
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_io/__init__.py", line 22, in <module>
from tensorflow.contrib.learn.python.learn.learn_io.dask_io import extract_dask_data
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_io/dask_io.py", line 26, in <module>
import dask.dataframe as dd
File "/usr/local/lib/python2.7/dist-packages/dask/dataframe/__init__.py", line 5, in <module>
from .io import (from_array, from_pandas, from_bcolz,
File "/usr/local/lib/python2.7/dist-packages/dask/dataframe/io/__init__.py", line 6, in <module>
from .csv import read_csv, to_csv, read_table
File "/usr/local/lib/python2.7/dist-packages/dask/dataframe/io/csv.py", line 147, in <module>
CPU_COUNT = psutil.cpu_count()
AttributeError: 'module' object has no attribute 'cpu_count'
I've been following this intro, and the code from there worked perfectly for
me (apart from some warnings about deprecations).
| 1 |
##### System information (version)
* OpenCV => 4.5.5
* Operating System / Platform => Fedora 36
* Compiler => GCC 12
##### Detailed description
The version is not building in the debug mode because of the `Werror=return-
type` warning.
/home/user/.conan/data/opencv/4.5.5/_/_/build/c2ecc42c4fd20695e9185b38647d6dcb62ef4a3a/source_subfolder/modules/gapi/src/compiler/gislandmodel.cpp: In member function 'ade::NodeHandle cv::gimpl::GIsland::producer(const ade::Graph&, const ade::NodeHandle&) const':
/home/user/.conan/data/opencv/4.5.5/_/_/build/c2ecc42c4fd20695e9185b38647d6dcb62ef4a3a/source_subfolder/modules/gapi/src/compiler/gislandmodel.cpp:124:1: error: control reaches end of non-void function [-Werror=return-type]
124 | }
| ^
##### Steps to reproduce
Just compile with conan with `build_type` being `Debug`.
##### Issue submission checklist
* I report the issue, it's not a question
* I checked the problem with documentation, FAQ, open issues,
forum.opencv.org, Stack Overflow, etc and have not found any solution
* I updated to the latest OpenCV version and the issue is still there
* There is reproducer code and related data files: videos, images, onnx, etc
|
Compiler: GCC 12.1
Warnings are related to `GAPI_Assert(false ...);` code.
`GAPI_Error()` with "noreturn" attribute should be used instead.
[2464/3435] Building CXX object modules/gapi/CMakeFiles/opencv_gapi.dir/src/compiler/gislandmodel.cpp.o
/home/alalek/projects/opencv/dev/modules/gapi/src/compiler/gislandmodel.cpp: In member function ‘ade::NodeHandle cv::gimpl::GIsland::producer(const ade::Graph&, const ade::NodeHandle&) const’:
/home/alalek/projects/opencv/dev/modules/gapi/src/compiler/gislandmodel.cpp:124:1: warning: control reaches end of non-void function [-Wreturn-type]
124 | }
| ^
[2483/3435] Building CXX object modules/gapi/CMakeFiles/opencv_gapi.dir/src/executor/gstreamingexecutor.cpp.o
/home/alalek/projects/opencv/dev/modules/gapi/src/executor/gstreamingexecutor.cpp: In member function ‘bool cv::gimpl::GStreamingExecutor::pull(cv::GRunArgsP&&)’:
/home/alalek/projects/opencv/dev/modules/gapi/src/executor/gstreamingexecutor.cpp:1832:1: warning: control reaches end of non-void function [-Wreturn-type]
1832 | }
| ^
/home/alalek/projects/opencv/dev/modules/gapi/src/executor/gstreamingexecutor.cpp: In member function ‘bool cv::gimpl::GStreamingExecutor::pull(cv::GOptRunArgsP&&)’:
/home/alalek/projects/opencv/dev/modules/gapi/src/executor/gstreamingexecutor.cpp:1863:1: warning: control reaches end of non-void function [-Wreturn-type]
1863 | }
| ^
[2491/3435] Building CXX object modules/gapi/CMakeFiles/opencv_gapi.dir/src/backends/cpu/gcpustereo.cpp.o
In file included from /home/alalek/projects/opencv/dev/modules/core/include/opencv2/core/matx.hpp:52,
from /home/alalek/projects/opencv/dev/modules/core/include/opencv2/core/mat.hpp:51,
from /home/alalek/projects/opencv/dev/modules/gapi/include/opencv2/gapi/opencv_includes.hpp:13,
from /home/alalek/projects/opencv/dev/modules/gapi/include/opencv2/gapi/gmat.hpp:14,
from /home/alalek/projects/opencv/dev/modules/gapi/include/opencv2/gapi/stereo.hpp:10,
from /home/alalek/projects/opencv/dev/modules/gapi/src/backends/cpu/gcpustereo.cpp:7:
/home/alalek/projects/opencv/dev/modules/gapi/src/backends/cpu/gcpustereo.cpp: In static member function ‘static void GCPUStereo::run(const cv::Mat&, const cv::Mat&, cv::gapi::StereoOutputFormat, cv::Mat&, const StereoSetup&)’:
/home/alalek/projects/opencv/dev/modules/core/include/opencv2/core/base.hpp:342:32: warning: this statement may fall through [-Wimplicit-fallthrough=]
342 | #define CV_Assert( expr ) do { if(!!(expr)) ; else cv::error( cv::Error::StsAssert, #expr, CV_Func, __FILE__, __LINE__ ); } while(0)
| ^~
/home/alalek/projects/opencv/dev/modules/gapi/include/opencv2/gapi/own/assert.hpp:20:21: note: in expansion of macro ‘CV_Assert’
20 | #define GAPI_Assert CV_Assert
| ^~~~~~~~~
/home/alalek/projects/opencv/dev/modules/gapi/src/backends/cpu/gcpustereo.cpp:66:17: note: in expansion of macro ‘GAPI_Assert’
66 | GAPI_Assert(false && "This case may be supported in future.");
| ^~~~~~~~~~~
/home/alalek/projects/opencv/dev/modules/gapi/src/backends/cpu/gcpustereo.cpp:67:13: note: here
67 | default:
| ^~~~~~~
| 1 |
Json retrieved from API never contains Date objects. Instead dates are
transported as strings. When I run a DatePipe over a string it gives me
`Invalid argument '2014-11-20T05:11:03.277+00:00' for pipe 'DatePipe'`
Please note that angular 1 date filter worked just fine with strings.
|
The new date pipe only supports date objects or numbers but not ISO strings.
In ng1 this was valid and made displaying simple JSON from api's to the UI
very easy with little conversion process.
Plunker with ng1 behavior date filter ng1 iso
| 1 |
### Version
2.5.9
### Reproduction link
https://codepen.io/maple-leaf/pen/BmgaqG
### Steps to reproduce
1. open the codepen demo
2. open devtool if u are on chrome
3. click `change data which will raise error` button
4. now you should see an error like this: `TypeError: Cannot read property 'key' of undefined`.
5. refresh demo page
6. click `safe to change data here` button
7. now you should not see an error like before, and data being updated correctly
### What is expected?
maybe same behavior like both should raise an error, but if raise error, maybe
`duplicate key` error should be showed too **which will help developer easier
to find what data is killing page**.
### What is actually happening?
both data have duplicate keys, but behavior is different
* * *
why error being raise when you click `change data which will raise error`
button?
Because the data will raise error has some special changes. It remove all keys
except duplicate key 'b' compared to initial data and the order is different.
This will make `updateChildren` function in `vdom/patch.js` hit this code
section, which will create a `oldKeyToIdx`. And then when first key 'b' comes,
it will set value of `b` in `oldKeyToIdx` to `undefined`, and then next key
`b` comes, it will compare old node and new node via function sameNode. But
this time, index of old node which key is `b` is undefined now. So a js error
is being raised.
|
I want to load the template for a VueJS component dynamically. I'd like to
make an AJAX call using jQuery, and whatever the server returns should be the
template of the VueJS component. Here's a simplified version of the code with
the AJAX call removed since it's irrelevant where the data is coming from:
BoardFeed = Vue.extend
template: '<div>This should be replaced</div>'
data: ->
return items: null
created: ->
@template = "<div>Template returned from server, what I really want</div>"
In the above example I'm using the created hook which I thought would be
suitable for this, but the newer template is never rendered, only the older
one.
Is it possible to achieve this?
| 0 |
I am getting an "access to undefined reference" in code that used to work, and
that I believe is valid. It takes a very specific combination of details to
trigger the problem, so I think it is related to optimization.
As far as I can tell from Travis (assuming they update 0.3 regularly) this
behaviour started in the last day or two.
andrew@laptop:~/project/CRC> julia
_
_ _ _(_)_ | A fresh approach to technical computing
(_) | (_) (_) | Documentation: http://docs.julialang.org
_ _ _| |_ __ _ | Type "help()" to list help topics
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 0.3.0-prerelease+2697 (2014-04-22 02:46 UTC)
_/ |\__'_|_|_|\__'_| | Commit 9dc5e3f* (0 days old master)
|__/ | x86_64-suse-linux
julia> type Single{A}
table::Vector{A}
Single() = new()
end
julia>
julia> function crc(tables=Single)
make_tables(tables{Uint8}())
end
crc (generic function with 2 methods)
julia>
julia> function make_tables(tables::Single)
tables.table = Array(Uint8, 256)
tables.table[1] = 0x0
end
make_tables (generic function with 1 method)
julia>
julia> crc()
ERROR: access to undefined reference
in crc at none:2
I believe this is valid code - undefined members of a type seem to be
supported in general, as long as they are created before reading.
Note that much of the "mess" above is necessary in order to trigger this.
Below I'll add some minimally modified versions that work to illustrate this:
The type parameterization is needed:
julia> type Single
table::Vector{Uint8}
Single() = new()
end
julia>
julia> function crc(tables=Single)
make_tables(tables())
end
crc (generic function with 2 methods)
julia>
julia> function make_tables(tables::Single)
tables.table = Array(Uint8, 256)
tables.table[1] = 0x0
end
make_tables (generic function with 1 method)
julia>
julia> crc()
0x00
The default argument is needed:
julia> type Single{A}
table::Vector{A}
Single() = new()
end
julia>
julia> function crc(tables)
make_tables(tables{Uint8}())
end
crc (generic function with 1 method)
julia>
julia> function make_tables(tables::Single)
tables.table = Array(Uint8, 256)
tables.table[1] = 0x0
end
make_tables (generic function with 1 method)
julia>
julia> crc(Single)
0x00
The separate routine to set the value is needed:
julia> type Single{A}
table::Vector{A}
Single() = new()
end
julia>
julia> function crc(tables=Single)
t = tables{Uint8}()
t.table = Array(Uint8, 256)
t.table[1] = 0x0
end
crc (generic function with 2 methods)
julia>
julia> crc()
0x00
Finally, the example to cut+paste:
type Single{A}
table::Vector{A}
Single() = new()
end
function crc(tables=Single)
make_tables(tables{Uint8}())
end
function make_tables(tables::Single)
tables.table = Array(Uint8, 256)
tables.table[1] = 0x0
end
crc()
|
I'm moving the discussion from JuliaPy/pyjulia#173 to gather more attention. I
also describe in the last paragraphs how it may help not only PyJulia users
but also other Julia users.
(@stevengj, @Keno, please correct me or add more details if I'm missing
something)
Prior to Julia 0.7, PyJulia users could use multiple Python interpreters
without rebuilding PyCall.jl (PyJulia depends heavily on PyCall.jl) against
each Python interpreters. Considering it's a common practice to have multiple
Python virtual environments (with venv/virtualenv/conda), being able to use
PyJulia without recompiling PyCall.jl every time is an important feature.
However, supporting this feature in Julia ≥ 0.7 seems hard.
(Some details: Just to be clear, not all PyJulia users will notice this
effect. Notably, Windows or macOS users only using Python 3 (or only using
Python 2...) are unaffected. Linux users only using dynamically linked Python
3 (or 2) are also fine. However, Linux users using statically linked Python,
such as the ones distributed by Ubuntu and Anaconda, will not be able to use
PyJulia. I think those platforms are popular enough to pay a special
attention.)
PyJulia relies on `Base.LOAD_CACHE_PATH` in Julia 0.6 to separate the cache of
PyCall.jl. It inserts a private path to `Base.LOAD_CACHE_PATH[1]` if the
Python interpreter in which PyJulia is loaded is incompatible with the Python
interpreter with which PyCall.jl is configured:
# Add a private cache directory. PyCall needs a different
# configuration and so do any packages that depend on it.
self._call(u"unshift!(Base.LOAD_CACHE_PATH, abspath(Pkg.Dir._pkgroot()," +
"\"lib\", \"pyjulia%s-v$(VERSION.major).$(VERSION.minor)\"))" % sys.version_info[0])
\---
https://github.com/JuliaPy/pyjulia/blob/18d98e5b1b616a4d663273cc36cdd835ab0b33da/julia/core.py#L357-L360
This "hack" doesn't work in Julia ≥ 0.7 as `Base.LOAD_CACHE_PATH` is gone now.
Also, reading how `cache_file_entry` is used to locate the `.ji` files, I
couldn't find a way to implement a new "hack" other than duplicating the whole
`DEPOT_PATH[1]`.
julia/base/loading.jl
Lines 594 to 608 in d038f2f
| cache_file_entry(pkg::PkgId) = joinpath(
---|---
| "compiled",
| "v$(VERSION.major).$(VERSION.minor)",
| pkg.uuid === nothing ? "$(pkg.name).ji" : joinpath(pkg.name,
"$(package_slug(pkg.uuid)).ji")
| )
|
| function find_all_in_cache_path(pkg::PkgId)
| paths = String[]
| entry = cache_file_entry(pkg)
| for depot in DEPOT_PATH
| path = joinpath(depot, entry)
| isfile_casesensitive(path) && push!(paths, path)
| end
| return paths
| end
But creating a new `DEPOT_PATH[1]` for each incompatible Python interpreter
type is rather overkill and ignores Pkg3 working hard to de-duplicate
resources. It would be really nice to have a direct support from Julia and
Pkg3, if it is feasible.
### An idea: "build option" support
I think one way to directly support it is to add "build option" support in
Julia and Pkg3. What I mean by "build option" is something that altering it
changes the precompilation cache. Currently Julia packages do this via
environment variables. Concrete examples are `PYTHON` of PyCall.jl and
`CONDA_JL_HOME` of Conda.jl. If those options can be directly configured by
`Project.toml` file, and if compilation cache paths depend on such options,
PyJulia can just create a new `Project.toml` with appropriate options and
launch a new Julia interpreter. Importantly, the compilation cache path of a
package has to depend also on the build options of all its (direct and
indirect) dependencies.
I think the "build option" support can help other Julia users (who do not use
PyJulia) too. For example, you can change `CONDA_JL_HOME` for a particular
`Project.toml` to tweak versions of external libraries provided via `Conda.jl`
without contaminating other projects. (Maybe similar benefits can be gained
via BinaryProvider.jl too?) I think supporting 32-bit and 64-bit Julia
JuliaLang/Pkg.jl#93 can also be done by changing "build option" of the "root"
`julia` package. I suppose then it makes sense for `deps` directories to
depend on "build options" too (JuliaLang/Pkg.jl#93 (comment)).
| 0 |
Describe what you were doing when the bug occurred:
1. React dev tools profiler crashed when changing from "anonymous" to "overlay" and asked to report the issue
* * *
## Please do not remove the text below this line
DevTools version: 4.1.1-a9cd9a765
Call stack: at n.value (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:162685)
at m (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:331467)
at sc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:331684)
at oi (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:58733)
at Ri (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:66060)
at Jl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:104557)
at vc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:89163)
at Ac (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:89088)
at ac (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:86037)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:45275
Component stack: in sc
in div
in div
in _o
in Unknown
in n
in Unknown
in div
in div
in zi
in Ge
in un
in ba
in Rc
|
PLEASE INCLUDE REPRO INSTRUCTIONS AND EXAMPLE CODE
* * *
## Please do not remove the text below this line
DevTools version: 4.0.4-3c6a219
Call stack: at n.value (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:11:16721)
at m (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:56:293207)
at pl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:56:293442)
at Ha (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:55890)
at bi (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:62939)
at Xl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:99535)
at Hl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:84255)
at Fl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:81285)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:43:25363
at n.unstable_runWithPriority (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:56:4368)
Component stack: in pl
in div
in div
in Or
in Unknown
in n
in Unknown
in div
in div
in Ha
in le
in ve
in ko
in Ul
| 1 |
# Environment
Windows build number: Microsoft Windows [Version 10.0.18362.418]
Windows Terminal version (if applicable): All
# Steps to reproduce
1. Write some characters with linefeed in the notepad, such as:
a
b
c
d
e
2. Copy them
3. Open Windows Terminal and launch WSL
wsl
4. use `cat` command to write into a text file:
cat > test.txt << EOF
5. Paste the copied characters into the terminal
# Expected behavior
PS C:\Users\hez20> wsl
hez2010@DESKTOP-CD2C52F:/mnt/c/Users/hez20$ cd ~
hez2010@DESKTOP-CD2C52F:~$ cat > test.txt << EOF
> a
> b
> c
> d
> e
> f
# Actual behavior
PS C:\Users\hez20> wsl
hez2010@DESKTOP-CD2C52F:/mnt/c/Users/hez20$ cd ~
hez2010@DESKTOP-CD2C52F:~$ cat > test.txt << EOF
> a
>
> b
>
> c
>
> d
>
> e
>
> f
Each linefeed was repeated twice.
|
Multiline text pasted from the clipboard includes CRLF pairs in all cases;
this is inappropriate for "Unix-space" sessions, such as WSL.
# Environment
Windows build number: Microsoft Windows [Version 10.0.18362.145]
Windows Terminal version (if applicable): 71e19cd82528d66a0a7867cbed85990cfc1685f1
# Steps to reproduce
Select multiline text in Terminal.
Copy it (via right-click, ostensibly)
Paste it (again via right-click)
# Expected behavior
When pasting into a Unix-space session -- such as WSL -- pasted text should
have a reasonable set of line-ending characters.
# Actual behavior
Line endings are "doubled" on text paste to Unix-space sessions.
| 1 |
To reproduce:
* Launch the "Drop Down Button" from the material_gallery example
* Press the menu button
android: I/flutter : Exception caught while building _DropDownMenu
android: I/flutter : 'packages/flutter/src/widgets/basic.dart': Failed assertion: line 749: '() {
android: I/flutter : "Positioned must placed inside a Stack";
android: I/flutter : return ancestor is Stack;
android: I/flutter : }' is not true.
android: I/flutter : Stack trace:
android: I/flutter : #0 _AssertionError._throwNew (dart:core-patch/errors_patch.dart:27)
android: I/flutter : #1 Positioned.debugValidateAncestor (packages/flutter/src/widgets/basic.dart:749)
android: I/flutter : #2 ParentDataElement.mount.<anonymous closure> (packages/flutter/src/widgets/framework.dart:1226)
android: I/flutter : #3 ParentDataElement.mount (packages/flutter/src/widgets/framework.dart:1216)
android: I/flutter : #4 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #5 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #6 ComponentElement.performRebuild (packages/flutter/src/widgets/framework.dart:1082)
android: I/flutter : #7 BuildableElement.rebuild (packages/flutter/src/widgets/framework.dart:1011)
android: I/flutter : #8 ComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1057)
android: I/flutter : #9 StatefulComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1151)
android: I/flutter : #10 ComponentElement.mount (packages/flutter/src/widgets/framework.dart:1052)
android: I/flutter : #11 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #12 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #13 ComponentElement.performRebuild (packages/flutter/src/widgets/framework.dart:1082)
android: I/flutter : #14 BuildableElement.rebuild (packages/flutter/src/widgets/framework.dart:1011)
android: I/flutter : #15 ComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1057)
android: I/flutter : #16 ComponentElement.mount (packages/flutter/src/widgets/framework.dart:1052)
android: I/flutter : #17 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #18 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #19 ComponentElement.performRebuild (packages/flutter/src/widgets/framework.dart:1082)
android: I/flutter : #20 BuildableElement.rebuild (packages/flutter/src/widgets/framework.dart:1011)
android: I/flutter : #21 ComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1057)
android: I/flutter : #22 ComponentElement.mount (packages/flutter/src/widgets/framework.dart:1052)
android: I/flutter : #23 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #24 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #25 OneChildRenderObjectElement.mount (packages/flutter/src/widgets/framework.dart:1572)
android: I/flutter : #26 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #27 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #28 ComponentElement.performRebuild (packages/flutter/src/widgets/framework.dart:1082)
android: I/flutter : #29 BuildableElement.rebuild (packages/flutter/src/widgets/framework.dart:1011)
android: I/flutter : #30 ComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1057)
android: I/flutter : #31 ComponentElement.mount (packages/flutter/src/widgets/framework.dart:1052)
android: I/flutter : #32 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #33 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #34 ComponentElement.performRebuild (packages/flutter/src/widgets/framework.dart:1082)
android: I/flutter : #35 BuildableElement.rebuild (packages/flutter/src/widgets/framework.dart:1011)
android: I/flutter : #36 ComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1057)
android: I/flutter : #37 StatefulComponentElement._firstBuild (packages/flutter/src/widgets/framework.dart:1151)
android: I/flutter : #38 ComponentElement.mount (packages/flutter/src/widgets/framework.dart:1052)
android: I/flutter : #39 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #40 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
android: I/flutter : #41 OneChildRenderObjectElement.mount (packages/flutter/src/widgets/framework.dart:1572)
android: I/flutter : #42 Element._inflateWidget (packages/flutter/src/widgets/framework.dart:770)
android: I/flutter : #43 Element.updateChild (packages/flutter/src/widgets/framework.dart:649)
| 1 | |
**Describe the bug**
The `openapi.json` generated from the docs is not valid OpenAPI 3.0 schema and
doesn't pass validation. Can be checked against few available validators:
* https://apidevtools.org/swagger-parser/online/
* https://editor.swagger.io/
**Expected behavior**
Passes validation.
**Environment:**
* OS: macOS
* FastAPI Version: 0.33.0
* Python version: 3.7.3
**Additional context**
After looking at the schema I found some noticeable parts:
* Security definitions are duplicated multiple times is there are some dependencies with shared sub dependencies. In the schema it looks like:
"security": [
{
"My Auth": []
},
{
"My Auth": []
}
]
* For numeric values min/max validation flags should be boolean values instead of integers:
"schema": {
"title": "Size",
"maximum": 100,
"exclusiveMinimum": 0,
"type": "integer",
"description": "Number of records to return",
"default": 10
}
The `"exclusiveMinimum": 0,` should be in fact `"exclusiveMinimum": false,`
* Path parameters is referenced in multiple dependencies for a route get duplicated:
"parameters": [
{
"required": true,
"schema": {
"title": "User_Id",
"type": "string",
"format": "uuid"
},
"name": "user_id",
"in": "path"
},
{
"required": true,
"schema": {
"title": "User_Id",
"type": "string",
"format": "uuid"
},
"name": "user_id",
"in": "path"
}
]
* References are not properly defined and thus resolved, resulting in multiple errors such as:
Missing required property: $ref at #/user/roles
|
### First Check
* I added a very descriptive title to this issue.
* I used the GitHub search to find a similar issue and didn't find it.
* I searched the FastAPI documentation, with the integrated search.
* I already searched in Google "How to X in FastAPI" and didn't find any information.
* I already read and followed all the tutorial in the docs and didn't find an answer.
* I already checked if it is not related to FastAPI but to Pydantic.
* I already checked if it is not related to FastAPI but to Swagger UI.
* I already checked if it is not related to FastAPI but to ReDoc.
### Commit to Help
* I commit to help with one of those options 👆
### Example Code
import uvicorn
import threading
from typing import Optional
from datetime import datetime
from passlib.context import CryptContext
from beanie import Document, init_beanie
from motor.motor_asyncio import AsyncIOMotorClient
from fastapi import FastAPI
lock = threading.Lock()
app = FastAPI()
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
class User(Document):
username: str
full_name: Optional[str] = None
email: Optional[str] = None
class Settings:
name = "users"
def __repr__(self) -> str:
return f"<User {self.username}>"
def __str__(self) -> str:
return self.username
def __hash__(self) -> int:
return hash(self.username)
def __eq__(self, other: object) -> bool:
if isinstance(other, User):
return self.username == other.username
return False
@property
def created(self) -> datetime:
return self.id.generation_time
@classmethod
async def by_username(cls, username: str) -> "User":
"""Get a user by username"""
return await cls.find_one(cls.username == username)
class UserPW(User):
password: str
def hash_password(password: str) -> str:
return pwd_context.hash(password.encode())
async def create_admin_user(
username: str = "test",
password: str = "test"
):
# lock not working, still create 4 users
with lock:
found_user = await User.by_username(username)
if found_user is not None:
print("admin user already exists, pass!")
else:
user = UserPW(
username=username,
password=password
)
hashed = hash_password(user.password)
user.password = hashed
await user.create()
return User(**user.dict())
async def init_db(app: FastAPI):
app.db = AsyncIOMotorClient("mongodb://test:test@127.0.0.1:27017/pml_dev?authSource=admin")
col = getattr(app.db, "pml_dev")
await init_beanie(col, document_models=[
User
])
@app.on_event("startup")
async def init():
# init database
await init_db(app)
# create admin user if not exists
await create_admin_user()
# create 4 duplicate users
# uvicorn main:app --host=0.0.0.0 --port 5000 --workers 4
# only create 1 user on single worker
# uvicorn main:app --host=0.0.0.0 --port 5000
### Description
* I am current immigrate `flask` project to `fastapi`.
* on `startup` it will to `setup mongodb database` and `create 1 admin user` to provide `security` feature.
* some `api router` is sync due to `compatibility`, to improve performance so i run it on `4 workers`.
* but due to multiple workers threads, it create `4 users` instead of 1.
* I tried add `threading lock` or `async lock` and it's not working, how can we add lock on `startup event` to make sure only 1 event execute in multiple threading?
### Operating System
macOS
### Operating System Details
_No response_
### FastAPI Version
0.86.0
### Python Version
3.10
### Additional Context
_No response_
| 0 |
I have a problem with scheduler memory that continue to increase when i am
using docker image.
I am using Celery Executor

Any solution ??
Thanks in advance
|
**Apache Airflow version** : 2.0.1
**Kubernetes version (if you are using kubernetes)** (use `kubectl version`):
v1.17.4
**Environment** : Dev
* **OS** (e.g. from /etc/os-release): RHEL7
**What happened** :
After running fine for some time my airflow tasks got stuck in scheduled state
with below error in Task Instance Details:
"All dependencies are met but the task instance is not running. In most cases
this just means that the task will probably be scheduled soon unless: - The
scheduler is down or under heavy load If this task instance does not start
soon please contact your Airflow administrator for assistance."
**What you expected to happen** :
I restarted the scheduler then it started working fine. When i checked my
metrics i realized the scheduler has a memory leak and over past 4 days it has
reached up to 6GB of memory utilization
In version >2.0 we don't even have the run_duration config option to restart
scheduler periodically to avoid this issue until it is resolved.
**How to reproduce it** :
I saw this issue in multiple dev instances of mine all running Airflow 2.0.1
on kubernetes with KubernetesExecutor.
Below are the configs that i changed from the default config.
max_active_dag_runs_per_dag=32
parallelism=64
dag_concurrency=32
sql_Alchemy_pool_size=50
sql_Alchemy_max_overflow=30
**Anything else we need to know** :
The scheduler memory leaks occurs consistently in all instances i have been
running. The memory utilization keeps growing for scheduler.
| 1 |
This bug is present in Bootstrap's docs:
http://twbs.github.io/bootstrap/javascript/#modals
1. Launch the demo modal
2. Close the modal
3. Open the same modal again
4. The x button at the top and the close button at the bottom don't work
Clicking outside still works and pressing the escape key still works, so this
appears to be isolated to elements that use data-dismiss="modal".
Tested in Chrome 28.0.1500.95 and Safari 6.0.5.
|
Hi,
The code used on last Thursday worked fine. But after updated to latest code
on Monday (GMT+8), the modal dialog when clicks to dismiss for seconds onward
cannot be close.
I am checking on source code line 932, if I commented out this line then it is
working again.
this.$element
.removeClass('in')
.attr('aria-hidden', true)
//.off('click.dismiss.modal')
Am I missing anything...?
Sorry for the grammar. Thanks.
| 1 |
Challenge Bonfire: Search and Replace has an issue.
User Agent is: `Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/45.0.2454.101 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
The default code uses a "myReplace" function name, however the assertions by
default run against a "replace" function name. Thus either the default
assertions or the default boilerplate code must be altered to run against the
correct default function name.
My code:
function myReplace(str, before, after) {
return str;
}
myReplace("A quick brown fox jumped over the lazy dog", "jumped", "leaped");
|
I noticed that a couple weeks ago, someone raised an issue about the function
being called replace, and the issue was dealt with and renamed to myReplace.
It seems the tests are still running on the old-named function replace and
aren't accounting for the myReplace function.
The issue can be circumvented by simply renaming the function to replace, but
it might not be obvious right away to some campers. It would be best to modify
the tests to reflect the new name change.
| 1 |
## Steps to Reproduce
1. Navigate to flutter_gallery and run with `flutter run`
2. Navigate to the Icons demo page within the app
3. Notice the size 48.0 Icon displays incorrectly for certain colors.


The problem seems to be apparent for any Icon sizes between 40.5 -> 96.0,
inclusively.
Please note, I've only tested this on a Samsung S6.
|
Ensure Android architecture works with deep linking:
https://docs.google.com/document/d/1AKPWL50wzQFTSaEz2AbGZm5Fkm01uvunZH8AEoLJMRI/edit
| 0 |
Both **.dropdown-menu** and **.navbar** have same z-index:1000 so navbar
overriding dropdown menus.
Example:
http://getbootstrap.com/examples/theme/
Just click to first navbar's dropdown menu in Navbars section.
|
In the example at http://getbootstrap.com/examples/theme/

the dropdown appears below the other menu.
Firefox 23.0.1
| 1 |
`with-external-scoped-css` is not perfect.
In a slightly larger system, doing so will add a lot of work.
I think `style jsx` is not a good idea, it can not and other open source UI
framework very good integration.
Have you considered using `sass` \+ `css modules` as the main technical point
|
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
Is it possible to detect reliably if a next.js app is running from server or
via `next export` in `getInitialProps` and hence client side?
## Current Behavior
Currently, I am using the presence of `res` in `getIntialProps` to find out
but I realized that it won't be present for client-side navigation.
## Context
I am working on an app and testing the scenario where my backend is down. In
an exported site, I should have all the data available already but my JS code
calls backend in `getInitialProps` and crashes.
In the place where I am catching this error, I can trigger a
`location.reload()` to render the content statically and serve users without
the backend being up.
This is one of a few use cases.
## Your Environment
Tech | Version
---|---
next | v4.2.3
node | v8.4.0
OS | MacOS high sierra 10.13.3
browser | 63.0.3239.132
etc |
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behaviour
When on a mobile device, touching the ToolTip should activate it, showing the
configured text
## Current Behaviour
Chrome Device Emulator -> clicking on the icon itself does not activate the
ToolTip, only a small area to the right consistently activates it
iPhone 7 -> the ToolTip occasionally fires, it's hard to get is consistently
as the hit area isn't registering every touch.
## Steps to Reproduce (for bugs)
This can be reproduced by testing the demo page in device emulation or on an
actual device:
https://material-ui.com/demos/tooltips/
Start of the gif i'm clicking directly on the icon, after a couple of attempts
i find the hit area below the icon
## Your Environment
Tech | Version
---|---
Material-UI | 1.0.0-beta.30
React | 16.02
|
* [ x ] I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
I do not use any Subheader elements in my project. Bundling the project should
throw no errors.
## Current Behavior
Bundling the project folder, without Subheaders being used anywhere, throws
the below error:
/..../node_modules/material-ui/List/List.js:47:25: Cannot resolve dependency '../Subheader' at '/..../node_modules/material-ui/Subheader'
## Steps to Reproduce (for bugs)
`yarn add material-ui@next`
`yarn start` // which runs `parcel index.html`
## Context
I am working on a prototype React App, where @latest was installed. I wanted
to upgrade to the beta to start using the grid.
## Your Environment
Tech | Version
---|---
Material-UI | next / 1.0.0-beta.32
React | ^15.4
browser | Brave, Chrome, others / N/A - happens in the command line
bundler | Parcel
| 0 |
Say you have some some incomplete data on weirdly growing plants, and want to
plot it as below. You might want to explicitly exclude the _tree_ data for
_outdoor_ , as you just didn't test it and do not want to confuse anyone. How
can this be done? I would have expected `sharex=False` to accomplish this, but
apparently it does not. I this intended and can this be done in another way?
(In my real example I also have set `hue='other_attribute'` but it probably
does not play a role in this discussion.)
import seaborn as sns
from matplotlib import pyplot as plt
from pandas import DataFrame
data = DataFrame(
data=[
['grass', 'indoor', 30],
['bushes', 'indoor', 80],
['tree', 'indoor', 100],
['grass', 'outdoor', 50],
['bushes', 'outdoor', 120]
# this does not exist: ['tree', 'outdoor', 300],
],
columns=[
'type', 'where', 'height'
])
graph = sns.catplot(x="type", y="height", col="where", data=data,
kind="bar", orient="v")
plt.show()
|
I would have expected that I can visualize different categorical variables in
a count plot using `catplot` and `melt`.
However, it looks like the data is converted to categorical before grouping
for the columns, and so the categories are shared among all the count plots.
That doesn't really make sense if the different columns correspond to
different categories.
Am I overlooking something or is there a different way of doing this?
import pandas as pd
import seaborn as sns
ames = pd.read_excel("http://www.amstat.org/publications/jse/v19n3/decock/AmesHousing.xls")
cat_cols = ['MS Zoning', 'Street', 'Alley', 'Lot Shape', 'Land Contour',
'Utilities', 'Lot Config', 'Land Slope', 'Neighborhood', 'Condition 1',
'Condition 2', 'Bldg Type', 'House Style', 'Roof Style', 'Roof Matl',
'Exterior 1st', 'Exterior 2nd', 'Mas Vnr Type', 'Exter Qual',
'Exter Cond', 'Foundation', 'Bsmt Qual', 'Bsmt Cond', 'Bsmt Exposure',
'BsmtFin Type 1', 'BsmtFin Type 2', 'Heating', 'Heating QC',
'Central Air', 'Electrical', 'Kitchen Qual', 'Functional',
'Fireplace Qu', 'Garage Type', 'Garage Finish', 'Garage Qual',
'Garage Cond', 'Paved Drive', 'Pool QC', 'Fence', 'Misc Feature',
'Sale Type', 'Sale Condition']
ames_cat = ames[cat_cols]
sns.catplot(x='value', col='variable', data=ames_cat.melt(), sharex=False, sharey=False, col_wrap=5, kind='count')
| 1 |
Current tip (13699:21130d62eeb0), linux/386, run enough times on a parallel machine:
$ GOARCH=386 GOMAXPROCS=32 go test std
panic: runtime error: invalid memory address or nil pointer dereference [recovered]
panic: runtime error: invalid memory address or nil pointer dereference
[signal 0xb code=0x1 addr=0x0 pc=0x8073d94]
goroutine 50 [running]:
testing.func·003(0xf7756fd4, 0xf7756100)
/usr/local/google/home/dvyukov/go_vanilla/src/pkg/testing/testing.go:268 +0x123
----- stack segment boundary -----
runtime_test.TestStopTheWorldDeadlock(0x18855200, 0xe)
/usr/local/google/home/dvyukov/go_vanilla/src/pkg/runtime/proc_test.go:25 +0x24
testing.tRunner(0x18855200, 0x82b3dd4, 0x0)
/usr/local/google/home/dvyukov/go_vanilla/src/pkg/testing/testing.go:273 +0x71
created by testing.RunTests
/usr/local/google/home/dvyukov/go_vanilla/src/pkg/testing/testing.go:349 +0x711
The culprit is:
// mgc0.c
static struct {
uint64 full; // lock-free list of full blocks
uint64 empty; // lock-free list of empty blocks
...
} work;
8c does not align uint64 on 8-bytes, occasionally full/empty crosses cache-line boundary
and then
TEXT runtime·atomicload64(SB), 7, $0
MOVL 4(SP), BX
MOVL 8(SP), AX
// MOVQ (%EAX), %MM0
BYTE $0x0f; BYTE $0x6f; BYTE $0x00
// MOVQ %MM0, 0(%EBX)
BYTE $0x0f; BYTE $0x7f; BYTE $0x03
// EMMS
BYTE $0x0F; BYTE $0x77
RET
becomes not particularly atomic.
There are 2 ways to fix it:
1. Fix the compilers to properly align uint64 (I am not sure why they do not align it
now).
2. Just patch the GC to manually align the vars.
|
[This may be a duplicate of issue #770]
package main
import (
"reflect"
"fmt"
)
type X int
func (_ X) Foo() { }
func main() {
v := reflect.NewValue(X(0))
fmt.Printf("%d\n", v.Type().Method(0).Type.NumIn())
fmt.Printf("%d\n", v.Method(0).Type().(*reflect.FuncType).NumIn())
v.Method(0).Call([]reflect.Value{reflect.NewValue(X(0))})
}
this prints:
1
1
panic: FuncValue: wrong argument count
The type of the method should return the argument count
that the method is expected to be called with.
6g darwin 6d3022dfb42b+ tip
| 0 |
Anyway to make it so on a Desktop you can hover the menu rather than click?
|
Hi all, there is one issue I have with twbs, I really wish the dropdown menu
can drop on mouseover instead of on click.
Any help on this?
| 1 |
I am trying to use seaborn in a python standard shell environment , but I
always get an error when I use the basis palette function
sns.palplot(sns.diverging_palette(240, 10, n=9))
any Idea from where this could come from ???
Traceback (most recent call last):
File "C:\Users\meyringer\AppData\Local\Programs\Python\Python37-32\lib\site-
packages\numpy\core\function_base.py", line 117, in linspace
num = operator.index(num)
TypeError: 'float' object cannot be interpreted as an integer
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File
"C:/Users/meyringer/AppData/Local/Programs/Python/Python37-32/seabornpalette.py",
line 3, in
sns.palplot(sns.diverging_palette(240, 10, n=9))
File "C:\Users\meyringer\AppData\Local\Programs\Python\Python37-32\lib\site-
packages\seaborn\palettes.py", line 744, in diverging_palette
neg = palfunc((h_neg, s, l), 128 - (sep / 2), reverse=True, input="husl")
File "C:\Users\meyringer\AppData\Local\Programs\Python\Python37-32\lib\site-
packages\seaborn\palettes.py", line 641, in light_palette
return blend_palette(colors, n_colors, as_cmap)
File "C:\Users\meyringer\AppData\Local\Programs\Python\Python37-32\lib\site-
packages\seaborn\palettes.py", line 777, in blend_palette
pal = _ColorPalette(pal(np.linspace(0, 1, n_colors)))
File "< **array_function** internals>", line 6, in linspace
File "C:\Users\meyringer\AppData\Local\Programs\Python\Python37-32\lib\site-
packages\numpy\core\function_base.py", line 121, in linspace
.format(type(num)))
TypeError: object of type <class 'float'> cannot be safely interpreted as an
integer.
|
When using `row_template` on FactorGrid when `margin_titles=True`,
row_template will not render correctly as the earlier call to finalize_grid
already creates an annotated text for the row margin (See:
https://github.com/mwaskom/seaborn/blob/v0.7.1/seaborn/axisgrid.py#L731)
I think a fix will be to add a switch to map function which will ask if titles
need to created. Another, option will be to keep track of the created row
titles and edit their text (as they are created using ax.annotate
https://github.com/mwaskom/seaborn/blob/v0.7.1/seaborn/axisgrid.py#L939)
Code for replication:
df = pd.DataFrame(np.random.choice(["a", "b", "c"], size=(10,2)), columns=["col1", "col2"])
df["col_value"]=np.random.randint(10, size=df.shape[0])
g = (sns.FacetGrid(row="col1", col="col2", aspect=1.5, margin_titles=True,
data=df)
g = g.map(plt.hist, "col_value", bins=range(10))
g = g.set_titles(template="", col_template="{col_name}", row_template="{row_name}")
g.fig.tight_layout()
| 0 |
Fiddle: http://jsfiddle.net/adobi/hMvxQ/
The modal's hidden event gets executed on tooltips hidden event. Is this the
correct behaviour?
I know I can block the tooltip's event to be propagated, but wouldn't be a
nicer solution to namespance these event?
Thank you for your answer!
|
The triggered show and hide event bubbles to the modal dialog when using
tooltips in modal dialog. So, the show and hide of the modal dialog will also
be triggered.
Following should work as workaround:
$('[rel="tooltip"','.modal').tooltip().on('show', function(e)
{e.stopPropagation();}).on('hide', function(e) {e.stopPropagation();});
Possible fix:
Namespacing the triggered event to 'show.tooltip', to prevent bubbling to
'show.modal'.
| 1 |
**Hans Desmet** opened **SPR-6871** and commented
When you submit a form, with databinding on a command object with indexed
properties, the indexed properties of the command object are not filled in.
I think this bug is related to the correction that happened in #11506.
The characters [ and ] are not only removed from the id attrbute of the HTML
elements, but also (unnessesary) from the name attribute of the HTML elements.
You can see it happening via next example.
When you type 10 and 20 in the input fields, the output to the console is:
{Belgium=null, Switzerland=null}
while the output should have been {Belgium=10, Switzerland=20}
The class that acts as command object:
* * *
package org.example.entities;
import java.util.LinkedHashMap;
import java.util.Map;
public class Continent {
// key = name of country
// Integer= number of inhabitants
private Map<String, Integer> countries = new LinkedHashMap<String, Integer>();
public Continent() {
countries.put("Belgium", null);
countries.put("Switzerland", null);
}
public void setCountries(Map<String, Integer> countries) {
this.countries = countries;
}
public Map<String, Integer> getCountries() {
return countries;
}
}
The Controller class:
* * *
package org.example.web;
import org.example.entities.Continent;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.validation.BindingResult;
import org.springframework.web.bind.annotation.ModelAttribute;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
`@Controller`
public class ContinentController {
`@RequestMapping`(value = "/continent.htm", method = RequestMethod.GET)
public String continentForm(Model model) {
Continent continent = new Continent();
model.addAttribute(continent);
return "continent.jsp";
}
`@RequestMapping`(value = "/continent.htm", method = RequestMethod.POST)
public String continentForm(`@ModelAttribute` Continent continent,
BindingResult bindingResult) {
System.out.println(continent.getCountries()); // Here you can see the bug
return "continent.jsp";
}
}
continent.jsp
* * *
<?xml version="1.0" encoding="UTF-8"?>
<%`@page` contentType="text/html" pageEncoding="UTF-8" session="false"%>
<%`@taglib` prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<%`@taglib` prefix="form" uri="http://www.springframework.org/tags/form"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="nl" lang="nl">
<head>
<title>Continent example</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<form:form commandName="continent">
<c:forEach items="${continent.countries}" var="entry">
<div>
<form:label path="countries[${entry.key}]">${entry.key}</form:label>
<form:input path="countries[${entry.key}]" />
<form:errors path="countries[${entry.key}]" />
</div>
</c:forEach>
<div><input type="submit" /></div>
</form:form>
</body>
</html>
* * *
**Affects:** 3.0.1
**Issue Links:**
* #11586 Indexed properties not set correctly in form tags ( _ **"is duplicated by"**_ )
* #11702 form:select 3.0.1 regression bug when binding to a map ( _ **"is duplicated by"**_ )
* #11506 form:checkbox tag creates invalid HTML id when bound to indexed property
* #10055 org.springframework.web.servlet.tags.form.TagIdGenerator doesn't remove characters [] and double-quotes
**Referenced from:** commits `67b342d`
3 votes, 8 watchers
|
**Koen Serneels** opened **SPR-9480** and commented
#### Overview
There seems yet again another issue when using the Spring 3.1 -
Hibernate4(.1.3) integration.
This issue pops up so late since it only occurs in special circumstances: it
has to do with the hibernate "smart" flushing which is not working.
Hibernate guarantees that every modification you make (CUD) is flushed to the
database prior any other operation that can possibly be related to the
outstanding queries. This is to ensure that you don't work with stale data
within the same transaction.
For example:
1. Save an entity
2. Update the property of an entity
3. Query the entity using the value of the property changed in the previous step in the where clause
Hibernate will make sure that the changes by step2 (and possibly also the
insert of step1 - if not done already) are flushed before step3 is executed
(smart flush). If this didn't happen we would never be able to retrieve the
entity in step3.
The problem is that this smart flushing is not happening any more, since
Hibernate does not detect that it is in a transaction.
Taken from `SessionImpl` L1178:
protected boolean autoFlushIfRequired(Set querySpaces) throws HibernateException {
errorIfClosed();
if ( ! isTransactionInProgress() ) {
// do not auto-flush while outside a transaction
return false;
}
AutoFlushEvent event = new AutoFlushEvent( querySpaces, this );
for ( AutoFlushEventListener listener : listeners( EventType.AUTO_FLUSH ) ) {
listener.onAutoFlush( event );
}
return event.isFlushRequired();
}
What happens is before step3 is excecuted 'autoFlushIfRequired' is called
(good). However isTransactionInProgress() will returns false. If you drill
down in the code, you will see that it will call:
`transactionCoordinator.isTransactionInProgress()` which will then call
`getTransaction().isActive()`, which delegates to `JtaTransaction` L237:
@Override
public boolean isActive() throws HibernateException {
if ( getLocalStatus() != LocalStatus.ACTIVE ) {
return false;
}
final int status;
try {
status = userTransaction.getStatus();
}
catch ( SystemException se ) {
throw new TransactionException( "Could not determine transaction status: ", se );
}
return JtaStatusHelper.isActive( status );
}
The LocalStatus will be "NOT_ACTIVE" and the userTransaction is null. Why?
Because no one called "begin" on the JtaTransaction.
In case of the HibernateTransactionManager it will call begin() once a
transaction is started (in that case it will be JdbcTransaction rather then
JtaTransaction).
So while there is a transaction started and everything is working nicely there
is still a part of Hibernate which is unaware that a transaction is indeed
active, which results in strange behavior like illustrated here. Note that
everything else is working OK, the session will get flushed before transaction
completion and everything will be in the database.
However, within the transactions we now have a stale data problem. AFAIK this
is a bug in the integration, since there are no more secret properties we can
use to fix this one on hibernate level.
* * *
#### Examples
I supplied again 2 sample applications, one with hibernate3 and the same with
hibernate4 to illustrate the issue.
You can deploy the apps under context root hibernate3/hibernate4 and then
point the browser to `http://<host>:<port>/hibernate3/Persist` or
`http://<host>:<port>/hibernate4/Persist`.
The Servlet looks up a bean from the application context. It will then call
two transactional methods on the bean.
###### Method 1
* Start transaction 1
* Save an entity of type 'TestEntity'
* Change the property 'value' to literal 'SomeValue' on the saved entity
* Perform a query which selects all entities of type 'TestEntity' where their 'value' property matches 'SomeValue'
* return result
* display result
* End transaction 1
###### Method 2
* Start transaction 2
* Perform a query which selects all entities of type 'TestEntity' where their 'value' property matches 'SomeValue'
* return result
* display result
* End transaction 2
With hibernate3 you will see this output:
Saving... Done.
Result from read in TX: 1 Value:SomeValue
Read from table in separate TX: 1 Value:SomeValue
Which means that both in the same transaction and in the new transaction the
data was found in database after saving/updating.
In hibernate4 however:
Saving... Done.
Result from read in TX:
Read from table in separate TX: 1 Value:SomeValue
You see that in the same transaction the query did not return any results in
the second output line. This is because the save of the entity and/or the
update of the property where not flushed to database prior executing the
query.
Note: in the output we show two properties of the 'TestEntity'.
* The value '1' in the output is the value of the 'id' property which is the PK of the entity and auto-increment.
* 'SomeValue' is the literal value we assigned to the 'value' property of the entity after we saved the entity.
* * *
**Affects:** 3.1.1
**Reference URL:**
http://forum.springsource.org/showthread.php?126363-Session-not-flushed-with-
Hibernate-4-1-3-JTA-and-Spring-transaction-management-
integ&highlight=koen+serneels
**Attachments:**
* hibernate3.zip ( _7.31 kB_ )
* hibernate4.zip ( _7.36 kB_ )
**Issue Links:**
* #14040 Session not flushed with Hibernate 4.1.3, JTA and Spring transaction management integration ( _ **"is duplicated by"**_ )
* #18421 Hibernate 4 Autoflush does not work with Spring OpenSessionInViewInterceptor
**Referenced from:** commits `efabc6b`, `dda3197`
5 votes, 8 watchers
| 0 |
Hi all,
I have a collection of TypeScript files that, on Windows, compile under tsc
when run under node, but throw bogus errors (I can clearly see the source
contradicts them) when compiled via the Visual Studio TypeScript 1.7.6.0
extension which uses tsc.exe. I implemented a very temporary workaround by
creating my own `tsc.exe` which simply invokes the compiler via node and
overrwrote the default `tsc.exe`, found in `c:\Program Files (x86)\Microsoft
SDKs\TypeScript\1.7\` with my own.
It would be great if the Visual Studio extension allowed the user the option
to specify the compiler implementation to use, Node or tsc.exe.
|
Consider this implmentation of a ORM-like Model class:
class Model {
public static tableName: string;
public static findById(id: number): this { // error: a this type is only available in a non-static member of a class or interface
const rows = db.query(`SELECT * FROM ${this.tableName} WHERE id = ?`, [id]);
const instance = new this();
for (const column of rows[0]) {
instance[column] = rows[0][column];
}
return instance;
}
}
class User extends Model {
public static tableName = 'users';
public username: string;
}
const user = User.findById(1); // user instanceof User
Currently, this is not possible, because TypeScript does not allow `this` in
static members. There is no reason for this limitation: `this` inside a static
method is simply the class in JavaScript (aka `typeof Model` or `typeof User`,
depending on what class this is called on).
| 0 |
To reproduce:
https://github.com/PlasmaSheep/flask-bug
Clone repo and install flask (python2)
export FLASK_APP=/path/to/repo/flask-bug/autoapp.py
flask run
Notice the output:
[$]>>> flask run
Using config: development
Debug is: True
* Serving Flask app "autoapp"
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
So debug is enabled in the config, but the debugger is not actually active.
This does work if you set the `FLASK_DEBUG` env variable:
[$]>>> flask run
* Serving Flask app "autoapp"
* Forcing debug mode on
Using config: development
Debug is: True
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
Using config: development
Debug is: True
* Debugger is active!
* Debugger pin code: 155-859-497
However I think that the debug parameter should be specified in only one
place, and that place should be the application config file so that you don't
have to worry about setting environment variables for things you already
specified in the config.
|
I submitted a patch for this but learned that it was incomplete with further
testing. #1640
Basically, it would be nice to allow `DEBUG` on the application to control the
activation of the debugger and reloader when running the CLI like `app.run`
does.
| 1 |
Our Weather Zipline example is now broken. Aparently the API @AdventureBear
used on her Zipline no longer works.
https://www.evernote.com/l/AlwSsfX2kblJYoOSp9uAq-BKFosOSCg8-aAB/image.png
We need to find an API that works and doesn't require adding an API key, or we
need to make an API endpoint on Free Code Camp that campers can use (we don't
want people exposing API keys on CodePen).
Thanks to @martoncsikos for spotting this issue.
|
Less of a bug in that the student can just erase the commented code and pass
the challenge. That said, if you comment out the second if statement, you will
be met with the "You should have only one if statement" even though the code
effectively has only one if statement.
Maybe the pattern matching doesn't take into account commented code.
Challenge Comparisons with the Logical Or Operator has an issue.
User Agent is: `Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/55.0.2883.87 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
My code:
function testLogicalOr(val) {
// Only change code below this line
if (val > 20 || val < 10) {
return "Outside";
}
/*
if (val) {
return "Outside";
}
*/
// Only change code above this line
return "Inside";
}
// Change this value to test
testLogicalOr(15);
| 0 |
Browsersync not launching in beta.11
package.json:
...
"scripts": {
"postinstall": "npm run typings install",
"tsc": "tsc",
"tsc:w": "tsc -w",
"lite": "lite-server",
"start": "concurrent "npm run tsc:w" "npm run lite" ",
"typings": "typings"
},
"dependencies": {
"angular2": "^2.0.0-beta.11",
"es6-promise": "^3.1.2",
"es6-shim": "^0.35.0",
"reflect-metadata": "^0.1.3",
"rxjs": "^5.0.0-beta.2",
"systemjs": "^0.19.23",
"zone.js": "^0.6.2"
},
.....
Environment:
MAC/Chrome
"Issue":
When executing npm start, browsersyc does not appear to be starting. Changes
are detected but not refreshed in browser.
"Resolution:
Changing entry in package.json from "angular2": "^2.0.0-beta.11" to
("angular2": "^2.0.0-beta.9" or "angular2": "^2.0.0-beta.8") browsersyc works
as expected.
|
Directives like {If, Foreach, For ... etc.) are often used in many templates.
To simplify the process and in the spirit of writing less code and for the
sake of maintainability, It might be a good idea to have a `pre_loader` API
where the project can pass in the common directives in and on startup all
templates are pre-injected with the common directives.
**Example:**
import {pre_loader, If, For, Foreach} from 'angular2/angular2';
pre_loader('directives', [IF, For, Foreach]);
@template({
url: 'templates/main.html',
directives: [MyOwnDirective]
})
With the above approach, the directives passed into the template would be IF,
For, Foreach & MyOwnDirective.
The catch is to have `pre_loader('directives', [IF, For, Foreach]);` executed
before anything else.
The `pre_loader()` function can also be used for configs other than
directives.
| 0 |
It is dangerous to assume a number that has a distance unit omitted from it,
should be pixel-based.
Working within the SVG user space, it is sometimes required that number values
are left unitless, so that they're proportionate to the user-defined matrix.
The is also the additional overhead in maintaining a property (that accepts a
unitless number value) whitelist, instead of just allowing a pass-through.
|
It's weird that `style={{margin: '42'}}` gets turned into `margin: 42px;`. I
think we should only add `px` if the value is an actual number.
| 1 |
## System:
* OS: macOS Mojave 10.14.6
* CPU: (8) x64 Intel(R) Core(TM) i7-6820HQ CPU @ 2.70GHz
* Memory: 169.37 MB / 16.00 GB
* Shell: 3.2.57 - /bin/bash
## Binaries:
* Node: 11.14.0 - ~/.nvm/versions/node/v11.14.0/bin/node
* Yarn: 1.17.3 - /usr/local/bin/yarn
* npm: 6.7.0 - ~/.nvm/versions/node/v11.14.0/bin/npm
## npmPackages:
* styled-components: ^4.4.0 => 4.4.0
* jest: ^24.9.0
* react-test-renderer: ^16.10.1
* ts-jest: ^24.1.0
* typescript: 3.6.3
## Reproduction
Run `yarn test` on my example repo and look at the output from Demo.test.tsx.
https://github.com/Swazimodo/demo-broken-styled-components
## Steps to reproduce
* set a data tag for UI testing on a styled-component div
* render the component with react-test-renderer
* take the output and find all by props
* check the length of the selection
## Expected Behavior
* get one result for each rendered item
## Actual Behavior
* get 3x the results
## notes
* This works for regular react nodes but seems to blow up when you use styled-components
* I have created a snapshot with the rendered result to look at it and I do not see any duplicates 🤷♂
|
Describe what you were doing when the bug occurred:
1. Collapsed one component in the React devtools (tab 'components')
2. This error message is shown
3.
* * *
## Please do not remove the text below this line
DevTools version: 4.11.0-39713716aa
Call stack: at store_Store.getIndexOfElementID (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:22245:24)
at getCurrentValue (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29244:29)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:25898:23
at Yh (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13305:36)
at Zh (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13343:53)
at Object.useState (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13795:12)
at exports.useState (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:5320:20)
at useSubscription (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:25871:54)
at SelectedTreeHighlight_SelectedTreeHighlight (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29268:16)
at Rh (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:13245:7)
Component stack: at SelectedTreeHighlight_SelectedTreeHighlight (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29213:34)
at div
at InnerElementType (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29953:3)
at div
at List (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:23588:30)
at div
at AutoSizer (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:3111:5)
at div
at div
at Tree_Tree (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29531:47)
at div
at div
at OwnersListContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:28680:3)
at SettingsModalContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:29121:3)
at Components_Components (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:34645:52)
at ErrorBoundary_ErrorBoundary (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:30035:5)
at PortaledContent (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:30157:5)
at div
at div
at ProfilerContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:34264:3)
at TreeContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:25356:3)
at SettingsContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:25963:3)
at ModalDialogContextController (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:30300:3)
at DevTools_DevTools (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:37639:3)
| 0 |
* Electron version: 1.4
* Operating system: MacOS 10.12
### Expected behavior
The output image area should be the same as the area of the rectangle passed
into the `capturePage` method instead of the squeeze the currently visible
area of WebContent into the rectangle size.
### Actual behavior
The rectangle object is the output image size instead of the intended capture
area.
Read more detailed info. and screenshots at
http://stackoverflow.com/questions/42036126/how-to-capture-entire-webcontent-
inside-currentwindow
### How to reproduce
const remote = require('electron').remote;
const webContents = remote.getCurrentWebContents();
webContents.capturePage({
x: 0,
y: 0,
width: 1000,
height: 2000
}, (img) => {
remote.require('fs')
.writeFile(TEMP_URL, img.toPng());
});


|
* Electron version: 1.4.13
* Operating system: MacOS 10.12.2 running on MacBook Pro (Retina, 13-inch, Early 2015)
### Expected behavior
webview.capturePage() without specifying a dimension should return an image
with the full viewable area on a Retina display. The dimensions of the
resulting image should be either the actual pixels of the viewable area or
perhaps the actual pixels * the device scale factor.
Specifying a dimension should return the viewable area of that dimension with
the resulting image being sized correctly (and consistently with the use case
of no rect specified).
### Actual behavior
Calling webview.capturePage() without specifying a dimension returns in image
that is the pixel size of the viewable area * the scale factor the area
covered by the viewable area divided by the scale factor.
For example, on a webview that is 524 pixels wide, the resulting image of
capturePage() is 1048 pixels wide, but only contains the image data from the
first 262 pixels. That image is then upsized by the scale factor twice to get
to the 1048 width. Not only does this not capture the full viewable page, it
also introduces significant scaling artifacts.
Similar results occur if a rect is specified to capturePage.
### How to reproduce
On a Retina display, create a page with a webview that loads some web site:
`<webview id="webview" src="http://www.msn.com/" ></webview>`
Capture the page:
// used to get the viewable dimensions of the webview
function getWebviewMeta(cb) {
var code = "var r = {}; \
r.totalHeight = document.body.offsetHeight; \
r.pageHeight = window.innerHeight; \
r.pageWidth = window.innerWidth; \
r;";
webview.executeJavaScript(code, false, function(r) {
let webviewMeta = {};
webviewMeta.captureHeight = r.pageHeight;
webviewMeta.captureWidth = r.pageWidth;
cb(webviewMeta);
});
}
getWebviewMeta(function(webviewMeta) {
let captureRect = {
x: 0, y: 0,
width: webviewMeta.captureWidth,
height: webviewMeta.captureHeight
};
webview.capturePage((img) => {
console.log("image size: ", img.getSize());
let jpgFile = img.toJPEG(90);
// save file as testDefault.jpg, I used jetpack.writeAsync
});
webview.capturePage(captureRect, (img) => {
console.log("image size: ", img.getSize());
let jpgFile = img.toJPEG(90);
// save file as testSetViewSize.jpg, I used jetpack.writeAsync
});
captureRect.width = +captureRect.width * electron.screen.getPrimaryDisplay().scaleFactor;
captureRect.height = +captureRect.height * electron.screen.getPrimaryDisplay().scaleFactor;
webview.capturePage(captureRect, (img) => {
console.log("image size: ", img.getSize());
let jpgFile = img.toJPEG(90);
// save file as testScaled.jpg, I used jetpack.writeAsync
});
});
The first two results, testDefault.jpg and testSetViewSize.jpg will be
identical. They will be captureRect * scale factor in size but will only
contain captureRect / scale factor from the webview.
The third result, testScaled.jpg, will contain the captureRect data from the
webview but will be captureRect * scale factor * scale factor in size.
All images have upscaling artifacts in them.
### Note
On non-retina displays (where the scale factor is 1), capturePage works as
expected.
Also, using webview.capturePage or webview.getWebContents().capturePage makes
no difference. It also does not matter if the code is executed in the main or
renderer process. I wouldn't expect there to be a difference in either, but I
did test both to make sure.
I have a discussion started about this but decided to enter an issue here
because I believe there is a bug in how the scale factor is used.
https://discuss.atom.io/t/webview-capturepage-doesnt-capture-full-page-on-
retina-display/37560
| 1 |
i try run my project , and i getting this error after i upgrade to deno
v.1.0.4
in deno version 1.0.2 this works.
I'm really stuck.
**Error :**
thread 'main' panicked at 'already borrowed: BorrowMutError', /rustc/4fb7144ed159f94491249e86d5bbd033b5d60550/src/libcore/cell.rs:878:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
fatal runtime error: failed to initiate panic, error 5
[1] 4387 abort deno run -A -c tsconfig.json app.ts
**i run :**
deno run -A -c tsconfig.json app.ts
**in this my configuration file :**
{
"compilerOptions": {
"experimentalDecorators": true,
"emitDecoratorMetadata": true
}
}
|
Received this error. For some additional info, I am only using the `std/path`
module and some function from the `Deno` global.
thread 'main' panicked at 'already borrowed: BorrowMutError', /rustc/4fb7144ed159f94491249e86d5bbd033b5d60550/src/libcore/cell.rs:878:9
stack backtrace:
0: backtrace::backtrace::libunwind::trace
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.44/src/backtrace/libunwind.rs:86
1: backtrace::backtrace::trace_unsynchronized
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.44/src/backtrace/mod.rs:66
2: std::sys_common::backtrace::_print_fmt
at src/libstd/sys_common/backtrace.rs:78
3: <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt
at src/libstd/sys_common/backtrace.rs:59
4: core::fmt::write
at src/libcore/fmt/mod.rs:1063
5: std::io::Write::write_fmt
at src/libstd/io/mod.rs:1426
6: std::sys_common::backtrace::_print
at src/libstd/sys_common/backtrace.rs:62
7: std::sys_common::backtrace::print
at src/libstd/sys_common/backtrace.rs:49
8: std::panicking::default_hook::{{closure}}
at src/libstd/panicking.rs:204
9: std::panicking::default_hook
at src/libstd/panicking.rs:224
10: std::panicking::rust_panic_with_hook
at src/libstd/panicking.rs:470
11: rust_begin_unwind
at src/libstd/panicking.rs:378
12: core::panicking::panic_fmt
at src/libcore/panicking.rs:85
13: core::option::expect_none_failed
at src/libcore/option.rs:1211
14: deno_core::bindings::send
15: <extern "C" fn(A0) .> R as rusty_v8::support::CFnFrom<F>>::mapping::c_fn
16: _ZN2v88internal25FunctionCallbackArguments4CallENS0_15CallHandlerInfoE
17: _ZN2v88internal12_GLOBAL__N_119HandleApiCallHelperILb0EEENS0_11MaybeHandleINS0_6ObjectEEEPNS0_7IsolateENS0_6HandleINS0_10HeapObjectEEESA_NS8_INS0_20FunctionTemplateInfoEEENS8_IS4_EENS0_16BuiltinArgumentsE
18: _ZN2v88internalL26Builtin_Impl_HandleApiCallENS0_16BuiltinArgumentsEPNS0_7IsolateE
19: Builtins_CEntry_Return1_DontSaveFPRegs_ArgvOnStack_BuiltinExit
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
fatal runtime error: failed to initiate panic, error 5
Aborted
| 1 |
Challenge http://www.freecodecamp.com/challenges/waypoint-manipulate-arrays-
with-pop has an issue.
The directions (including the comments) for this challenge are confusing. It
does not mention that the `var removed` should be changed in any way.

The end of this should probably read 'removed should contain the last value'
or something of the sort.
|
Challenge http://www.freecodecamp.com/challenges/waypoint-manipulate-arrays-
with-pop has an issue. Please describe how to reproduce it, and include links
to screenshots if possible.
The comments in the code instruct to only change code below line 9. This is
misleading, as the solution requires changing
var removed = myArray
to
var removed = myArray.pop()
| 1 |
I know there is an externalHelpers option, but I don't want to add things to
my global environment. I want my code to simply import helpers as needed, just
like with runtime, but without runtime's other feature of importing things
like Map and Set from core-js.
As far as I can tell this isn't possible?
|
I'm currently using **babelify** to transform my source code + global shimming
**babel-core/browser-polyfill.js** through a vendor file.
I noticed redefinitions of _createClass [et al] and the docs mentioned to use
`{ optional: 'runtime' }`, but this has the unfortunate side effect of also
including **regenerator/core-js** , extending the dev build time.
It would be nice if I can define `{ optional: 'runtime.helpers' }` and have it
include only the helpers.
| 1 |
Add keyword argument to HTML parser to take an integer / list for the rows to
interpret as header rows. If more than one, interpret as hierarchical columns
/ MultiIndex.
Presumably this would also allow you to round-trip Data Frame with
hierarchical columns.
I don't think this already exists.
related #4468
related #4679
related #4673
See for example:
http://www.sec.gov/Archives/edgar/data/47217/000104746913006802/a2215416z10-q.htm#CCSCI
|
related #4468
Add keyword argument to ExcelFile parser to take an integer / list for the
rows to interpret as header rows. If more than one, interpret as hierarchical
columns / MultiIndex.
Presumably this would also allow you to round-trip Data Frame with
hierarchical columns.
Basically, if you have something spanning two columns, just converts to two
cells with the data in the original cell, ending up just like what you need
for csv reader.
| 1 |
#### Code Sample, a copy-pastable example if possible
import pandas as pd
import numpy as np
a = pd.DataFrame({'numbers': np.arange(10), 'categories': list('abcabcabcd')})
a['categories'] = a['categories'].astype('category')
b = pd.DataFrame({'numbers': np.arange(10)})
print a.dtypes
print a.categories.cat.categories
print
merged = pd.merge(a, b, left_index=True, right_index=True)
print merged.dtypes
print merged['categories'].cat.categories
print 'Merge ok!'
print
merged = pd.merge(a, b, on=['numbers'], how='left')
print merged.dtypes
try:
print merged['categories'].cat.categories #crashes
except:
print 'Merge not ok!'
print
#### Expected Output
The try block should print "categories" 's categories the same way as above,
with:
`Index([u'a', u'b', u'c', u'd'], dtype='object')`
However, the data type is replaced to object/string.
This is not fixed by the v0.18.2 release, which fixes some of the merge issues
where int's would get casted to floats when merging.
#### output of `pd.show_versions()`
## INSTALLED VERSIONS
commit: None
python: 2.7.11.final.0
python-bits: 64
OS: Linux
OS-release: 2.6.32-431.23.3.el6.x86_64
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
pandas: 0.17.1
nose: 1.3.7
pip: 7.1.2
setuptools: 20.3.1
Cython: 0.23.4
numpy: 1.10.4
scipy: 0.16.0
statsmodels: 0.6.1
IPython: 4.0.1
sphinx: 1.3.1
patsy: 0.4.0
dateutil: 2.4.2
pytz: 2015.7
blosc: None
bottleneck: 1.0.0
tables: 3.2.2
numexpr: 2.4.4
matplotlib: 1.5.0
openpyxl: 2.2.6
xlrd: 0.9.4
xlwt: 1.0.0
xlsxwriter: 0.7.7
lxml: 3.4.4
bs4: 4.4.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.0.9
pymysql: None
psycopg2: None
Jinja2: None
|
xref #14351
None of the following merge operations retain the `category` types. Is this
expected? How can I keep them?
#### Merging on a `category` type:
Consider the following:
A = pd.DataFrame({'X': np.random.choice(['foo', 'bar'],size=(10,)),
'Y': np.random.choice(['one', 'two', 'three'], size=(10,))})
A['X'] = A['X'].astype('category')
B = pd.DataFrame({'X': np.random.choice(['foo', 'bar'],size=(10,)),
'Z': np.random.choice(['jjj', 'kkk', 'sss'], size=(10,))})
B['X'] = B['X'].astype('category')
if I do the merge, we end up with:
> pd.merge(A, B, on='X').dtypes
X object
Y object
Z object
dtype: object
#### Merging on a `non-category` type:
A = pd.DataFrame({'X': np.random.choice(['foo', 'bar'],size=(10,)),
'Y': np.random.choice(['one', 'two', 'three'], size=(10,))})
A['Y'] = A['Y'].astype('category')
B = pd.DataFrame({'X': np.random.choice(['foo', 'bar'],size=(10,)),
'Z': np.random.choice(['jjj', 'kkk', 'sss'], size=(10,))})
B['Z'] = B['Z'].astype('category')
if I do the merge, we end up with:
pd.merge(A, B, on='X').dtypes
X object
Y object
Z object
dtype: object
| 1 |
I am unable to install Playwright. This is what happens:
12:25:15 tmp % mkdir playwright
12:25:21 tmp % cd playwright
12:25:22 playwright % uname -a
Darwin IM00276.local 22.5.0 Darwin Kernel Version 22.5.0: Mon Apr 24 20:51:50 PDT 2023; root:xnu-8796.121.2~5/RELEASE_X86_64 x86_64
12:25:24 playwright % npm doctor
Check Value Recommendation/Notes
npm ping ok
npm -v ok current: v9.6.7, latest: v9.6.7
node -v ok current: v18.16.0, recommended: v18.16.0
npm config get registry ok using default registry (https://registry.npmjs.org/)
git executable in PATH ok /usr/local/bin/git
global bin folder in PATH ok /Users/.../.nvm/versions/node/v18.16.0/bin
Perms check on cached files ok
Perms check on local node_modules ok
Perms check on global node_modules ok
Perms check on local bin folder ok
Perms check on global bin folder ok
Verify cache contents ok verified 6 tarballs
12:25:32 playwright % npm list -g
/Users/.../.nvm/versions/node/v18.16.0/lib
├── corepack@0.17.0
└── npm@9.6.7
12:25:35 playwright % npm list
/Users/.../tmp/playwright
└── (empty)
12:25:40 playwright % npm install playwright
npm ERR! code 1
npm ERR! path /Users/.../tmp/playwright/node_modules/playwright
npm ERR! command failed
npm ERR! command sh -c node install.js
npm ERR! Removing unused browser at /Users/.../Library/Caches/ms-playwright/chromium-1064
npm ERR! Downloading Chromium 114.0.5735.35 (playwright build v1064) from https://playwright.azureedge.net/builds/chromium/1064/chromium-mac.zip
npm ERR! | | 0% of 129.1 Mb
npm ERR! |■■■■■■■■ | 10% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■ | 20% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■ | 30% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 40% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 50% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 60% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 70% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 80% of 129.1 Mb
npm ERR! |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ | 90% of 129.1 Mb
npm ERR! /Users/.../tmp/playwright/node_modules/playwright-core/lib/server/registry/index.js:651
npm ERR! throw new Error(`Failed to download ${title}, caused by\n${e.stack}`);
npm ERR! ^
npm ERR!
npm ERR! Error: Failed to download Chromium 114.0.5735.35 (playwright build v1064), caused by
npm ERR! Error: end of central directory record signature not found
npm ERR! at /Users/.../tmp/playwright/node_modules/playwright-core/lib/zipBundleImpl.js:1:24033
npm ERR! at /Users/.../tmp/playwright/node_modules/playwright-core/lib/zipBundleImpl.js:1:31712
npm ERR! at /Users/.../tmp/playwright/node_modules/playwright-core/lib/zipBundleImpl.js:1:17288
npm ERR! at FSReqCallback.wrapper [as oncomplete] (node:fs:682:5)
npm ERR! at /Users/.../tmp/playwright/node_modules/playwright-core/lib/server/registry/index.js:651:13
npm ERR! at async Registry._downloadExecutable (/Users/.../tmp/playwright/node_modules/playwright-core/lib/server/registry/index.js:650:5)
npm ERR! at async Registry.install (/Users/.../tmp/playwright/node_modules/playwright-core/lib/server/registry/index.js:614:9)
npm ERR! at async installBrowsersForNpmInstall (/Users/...tmp/playwright/node_modules/playwright-core/lib/server/registry/index.js:790:3)
npm ERR!
npm ERR! Node.js v18.16.0
**Expected**
The browsers should download and install.
**Actual**
The downloaded file is truncated and so the zip file is missing the central
directory record.
All browsers are affected.
The issue repeats every time.
I can download the ZIP files manually without problem.
Running the 'oopDownloadMain.js' file directly produces the same failure.
|
### System info
* Playwright Version: 1.31.2
* Operating System: Windows Server 2016
* Browser: N/A
* Other info:
### Source code
* [X ] I provided exact source code that allows reproducing the issue locally.
Teamcity build with the following build steps and a Windows server 2016 build
agent.
cinst python3 nodejs.install -y
PATH=%env.Path%;C:\Python39;C:\Program Files\nodejs
python.exe -m pip install --upgrade pip
pip install -U -r ./requirements.txt
rfbrowser init
robot --variable environment:%env.testenvironment% --variable browser:%env.browser% ./robot-framework-docker-MyDimensional/tests/%env.testapplication%
**Steps**
* Run the build
**Expected**
rfbrowser init should complete without errors.
**Actual**
[15:18:53]
[Step 2/3] 2023-03-28 15:18:53,966 [INFO ] Downloading Chromium playwright build v1050 from https://playwright.azureedge.net/builds/chromium/1050/chromium-win64.zip
[15:18:53]
[Step 2/3]
[15:18:54]
[Step 2/3] 2023-03-28 15:18:54,329 [INFO ] | | 0% of 113.3 Mb
[15:18:54]
[Step 2/3]
[15:18:55]
[Step 2/3] --- Logging error ---
[15:18:55]
[Step 2/3] Traceback (most recent call last):
[15:18:55]
[Step 2/3] File "C:\Python37\lib\logging\__init__.py", line 1037, in emit
[15:18:55]
[Step 2/3] stream.write(msg + self.terminator)
[15:18:55]
[Step 2/3] File "C:\Python37\lib\encodings\cp1252.py", line 19, in encode
[15:18:55]
[Step 2/3] return codecs.charmap_encode(input,self.errors,encoding_table)[0]
[15:18:55]
[Step 2/3] UnicodeEncodeError: 'charmap' codec can't encode characters in position 36-43: character maps to <undefined>
[15:18:55]
[Step 2/3] Call stack:
[15:18:55]
[Step 2/3] File "C:\Python37\lib\runpy.py", line 193, in _run_module_as_main
[15:18:55]
[Step 2/3] "__main__", mod_spec)
[15:18:55]
[Step 2/3] File "C:\Python37\lib\runpy.py", line 85, in _run_code
[15:18:55]
[Step 2/3] exec(code, run_globals)
[15:18:55]
[Step 2/3] File "C:\Python37\Scripts\rfbrowser.exe\__main__.py", line 7, in <module>
[15:18:55]
[Step 2/3] sys.exit(main())
[15:18:55]
[Step 2/3] File "C:\Python37\lib\site-packages\Browser\entry.py", line 298, in main
[15:18:55]
[Step 2/3] runner(command, skip_browsers, trace_file)
[15:18:55]
[Step 2/3] File "C:\Python37\lib\site-packages\Browser\entry.py", line 240, in runner
[15:18:55]
[Step 2/3] rfbrowser_init(skip_browsers)
[15:18:55]
[Step 2/3] File "C:\Python37\lib\site-packages\Browser\entry.py", line 62, in rfbrowser_init
[15:18:55]
[Step 2/3] _rfbrowser_init(skip_browser_install)
[15:18:55]
[Step 2/3] File "C:\Python37\lib\site-packages\Browser\entry.py", line 172, in _rfbrowser_init
[15:18:55]
[Step 2/3] logging.info(output)
[15:18:55]
[Step 2/3] Message: '|\u25a0\u25a0\u25a0\u25a0\u25a0\u25a0\u25a0\u25a0 | 10% of 113.3 Mb\n'
| 0 |
##### Issue Type:
Bug Report
##### Ansible Version:
ansible 1.6.6
##### Environment:
Host OS: OSX 10.9.4
Target OS: Oracle Linux Server release 6.5
##### Summary:
Installing a package with the yum module and option 'enablerepo' with 2 repo's
fails with the message:
failed: [localhost] => {"failed": true}
msg: Error setting/accessing repo puppetlabs-deps: Error getting repository data for puppetlabs-deps, repository not found
##### Steps To Reproduce:
After adding a new repo file to the /etc/yum.repos.d directory with all repo's
in there disabled, this snippet is used to install the package:
- name: Install puppet-server package
yum:
name=puppet-server
enablerepo=puppetlabs-products,puppetlabs-deps
##### Expected Results:
The package is installed
##### Actual Results:
The error described above is shown.
This works fine on CentOS 6.5
The yum module splits the enablerepo values and generates multiple
`--enablerepo` tags. This works fine on CentOS 6.5 but not on Oracle Linux
6.5. For Oracle Linux only one `--enablerepo` must be specified where multiple
repo's must be separated with a comma.
|
##### Issue Type:
"Bug Report:"
##### Ansible Version:
ansible 1.4.3, 1.5.3
##### Environment:
Oracle Enterprise Linux 6.4
##### Summary:
yum module enablerepo won't do multiple repositories
##### Steps to Reproduce:
ansible server1 -s -K -m yum -a "name=pkgname enablerepo=repo1,repo2 state=latest"
repo1 and repo2 are intentionally disabled by default in the yum.repo.d
configuration files and are enabled as required when installing packages
[repo1]
name=Repository 1
baseurl=http://reposerver/repository1
gpgkey=http://reposerver//RPM-GPG-KEY-repo1
gpgcheck=1
enabled=0
[repo2]
name=Repository 2
baseurl=http://reposerver/repository2
gpgkey=http://reposerver//RPM-GPG-KEY-repo2
gpgcheck=1
enabled=0
##### Expected Results:
The specified package and any dependencies it requires are successfully
installed on the target servers.
##### Actual Results:
ansible on the Ansible server outputs that it cannot find repository data for
the second specified repository (repo2). Swapping the order of the repository
names in the command line simply changes which repository data cannot be
located.
server1 | FAILED >> {
"failed": true,
"msg": "Error setting/accessing repo repo2: Error getting repository data for repo2, repository not found"
If I run ansible with '-vvv', the following is output:
<server1> ESTABLISH CONNECTION FOR USER: ansible on PORT 22 TO server1
<server1> REMOTE_MODULE yum name=ansible enablerepo=repo1,repo2 state=latest
<server1> EXEC /bin/sh -c 'mkdir -p $HOME/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236 && chmod a+rx $HOME/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236 && echo $HOME/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236'
<server1> PUT /tmp/tmpqjd93P TO /home/ansible/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236/yum
<server1> EXEC /bin/sh -c 'sudo -k && sudo -H -S -p "[sudo via ansible, key=ymortmfovnpsvcpoojkrmqfchlzqzlfm] password: " -u root /bin/sh -c '"'"'echo SUDO-SUCCESS-ymortmfovnpsvcpoojkrmqfchlzqzlfm; /usr/bin/python -tt /home/server1/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236/yum; rm -rf /home/server1/.ansible/tmp/ansible-tmp-1398273878.46-183006336271236/ >/dev/null 2>&1'"'"''
I have checked the log files on the repository server and used tcpdump to monitor traffic to and from the target server and I can see that the yum module is never reaching out to the repository server. It appears to be stuck at reading the yum.repos.d configuration files.
I have five Ansible servers, each in different data centers, I get the same results on on all five servers. I have tried different packages and different repositories, and it is always the same: the yum module fails on the second repository.
| 1 |
The new pollster should probably handle out of fds more gracefully.
Fixing an unrelated fd leak, I wrote a test to intentionally run out of file descriptors.
With the new scheduler, you get pages of this ~forever, EBADF from epoll_wait, I believe:
epollwait failed with epollwait failed with 99
epollwait failed with 9epollwait failed with 9
epollwait failed with
9
epollwait failed with epollwait failed with 9
9
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 9
9
epollwait failed with 9epollwait failed with 9
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with 9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with 9epollwait failed with
epollwait failed with 9
9
epollwait failed with 9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with
epollwait failed with 9
9
epollwait failed with epollwait failed with 99
epollwait failed with 9
epollwait failed with 9
epollwait failed with 9
epollwait failed with 9
epollwait failed with 9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with
epollwait failed with 9
9epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 99
epollwait failed with epollwait failed with 99
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
epollwait failed with
epollwait failed with 9
9epollwait failed with 9
|
`docker -v` works only on Linux and silently fails if you run a docker client
on a non-Linux machine. It creates confusion for those who are using the
following command as instructed as on the README to build their packages.
docker run -v $GOPATH/src:/src mobile /bin/bash -c 'cd /src/your/project && ./make.bash'
We should copy the package to be built and its dependencies from the host to
the container. But, Docker provides no additional tools to help us with this
issue.
One alternative is to vendor the dependencies and use ONBUILD ADD to build an
app builder image. It will only work if all dependencies are vendored under
the Dockerfile's directory, because Docker rejects to add files from outer
contexts. https://docs.docker.com/reference/builder/#add
FROM mobile:latest
ONBUILD ADD . /src/your/project/
RUN cd /src/your/project/ && ./all.bash
Then the user can do a docker cp to retrieve the apk.
| 0 |
Describe what you were doing when the bug occurred:
Profiled the new FB. Scrolled down to tail loads.
* * *
## Please do not remove the text below this line
DevTools version: 4.6.0-a2fb84beb
Call stack: at chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:345591
at Array.map ()
at chrome-extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:345397
at Ai (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:62580)
at zl (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:112694)
at jc (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:104789)
at Oc (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:104717)
at Tc (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:104585)
at gc (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:101042)
at chrome-extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:32:47376
Component stack: at chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:344679
at div
at div
at n (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:194307)
at div
at Cc (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:346311)
at div
at n (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:3:8163)
at div
at bc
at div
at div
at div
at Do (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:262081)
at chrome-extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:364048
at n (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:274563)
at chrome-extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:277138
at div
at div
at ol (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:323458)
at Ze (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:205764)
at pn (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:215038)
at $a (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:292153)
at ws (chrome-
extension://dnjnjgbfilfphmojnmhliehogmojhclc/build/main.js:40:369231)
|
Describe what you were doing when the bug occurred:
1. Add interaction tracing with unstable_trace
2. Record a profile, navigate to Profiler > Profiled Interactions
3. Error appears when scrolling view or immediately
## 
## Please do not remove the text below this line
DevTools version: 4.6.0-6cceaeb67
Call stack: at chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:344360
at Array.map ()
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:344166
at ci (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:59620)
at Ll (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:109960)
at qc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102381)
at Hc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102306)
at Vc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102171)
at Tc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:98781)
at chrome-extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:46014
Component stack: in Unknown
in Unknown
in div
in div
in n
in div
in bc
in div
in n
in div
in vc
in div
in div
in div
in So
in Unknown
in n
in Unknown
in div
in div
in rl
in Ze
in fn
in Ga
in _s
| 1 |
**Apache Airflow version** : 2.0.0b2
**Environment** :
* **Others** : No K8S
**What happened** :
In the The _Logs_ and _All Instances_ buttons in the task model in the web UI
are inoperative when _not_ using Kubernetes.
**What you expected to happen** :
The buttons to have working links.
The `dag.html` `updateModalUrls()` function assumes that
`buttons.rendered_k8s` is set, which is not the case when not using K8S.
This then results in an error and the buttons initialised after this point are
not wired up:
18:28:17.990 Uncaught TypeError: elm is undefined
updateButtonUrl http://.../tree?dag_id=full_pipeline:1595
updateModalUrls http://.../tree?dag_id=full_pipeline:1616
call_modal http://.../tree?dag_id=full_pipeline:1665
update http://.../tree?dag_id=full_pipeline:1427
$/< http://.../static/dist/d3.min.js:1
i http://.../static/dist/d3.min.js:1
each http://.../static/dist/d3.min.js:3
Y http://.../static/dist/d3.min.js:1
each http://158.101.169.4:8080/static/dist/d3.min.js:3
on http://158.101.169.4:8080/static/dist/d3.min.js:3
update http://158.101.169.4:8080/tree?dag_id=full_pipeline:1420
<anonymous> http://158.101.169.4:8080/tree?dag_id=full_pipeline:1339
tree:1595:7
The call needs to be protected by a `k8s_or_k8scelery_executor` check.
|
**Apache Airflow version** :2.0.0b2
**Kubernetes version (if you are using kubernetes)** (use `kubectl version`):
NA
**Environment** :
* **Cloud provider or hardware configuration** :
* **OS** (e.g. from /etc/os-release): macOS
* **Kernel** (e.g. `uname -a`):
* **Install tools** :
* **Others** :
**What happened** :
Clicking on the "Log" button in the popup for task instance in graph view
doesn't link to the logs view.
**What you expected to happen** :
The log view should show up.
**How to reproduce it** :
1. Run any dag.
2. Open Graph VIew.
3. Click on any task.
4. Click on the "Log" button.
**Anything else we need to know** :
Check this in action here.
| 1 |
## ℹ Computer information
* PowerToys version: v0.21.1
* PowerToy Utility: FancyZones
* Running PowerToys as Admin: No
* Windows build number: 20H2 19042.541
## 📝 Provide detailed reproduction steps (if any)
1. Open the fancyZones' setting interface
2. Pick the Zone highlight color and click in the color value in hexadecimal
3. Click the cross button in the typing block
### ✔️ Expected result
The hexadecimal value been cleaned and allow users to type.
### ❌ Actual result
The setting interface crushed
## 📷 Screenshots
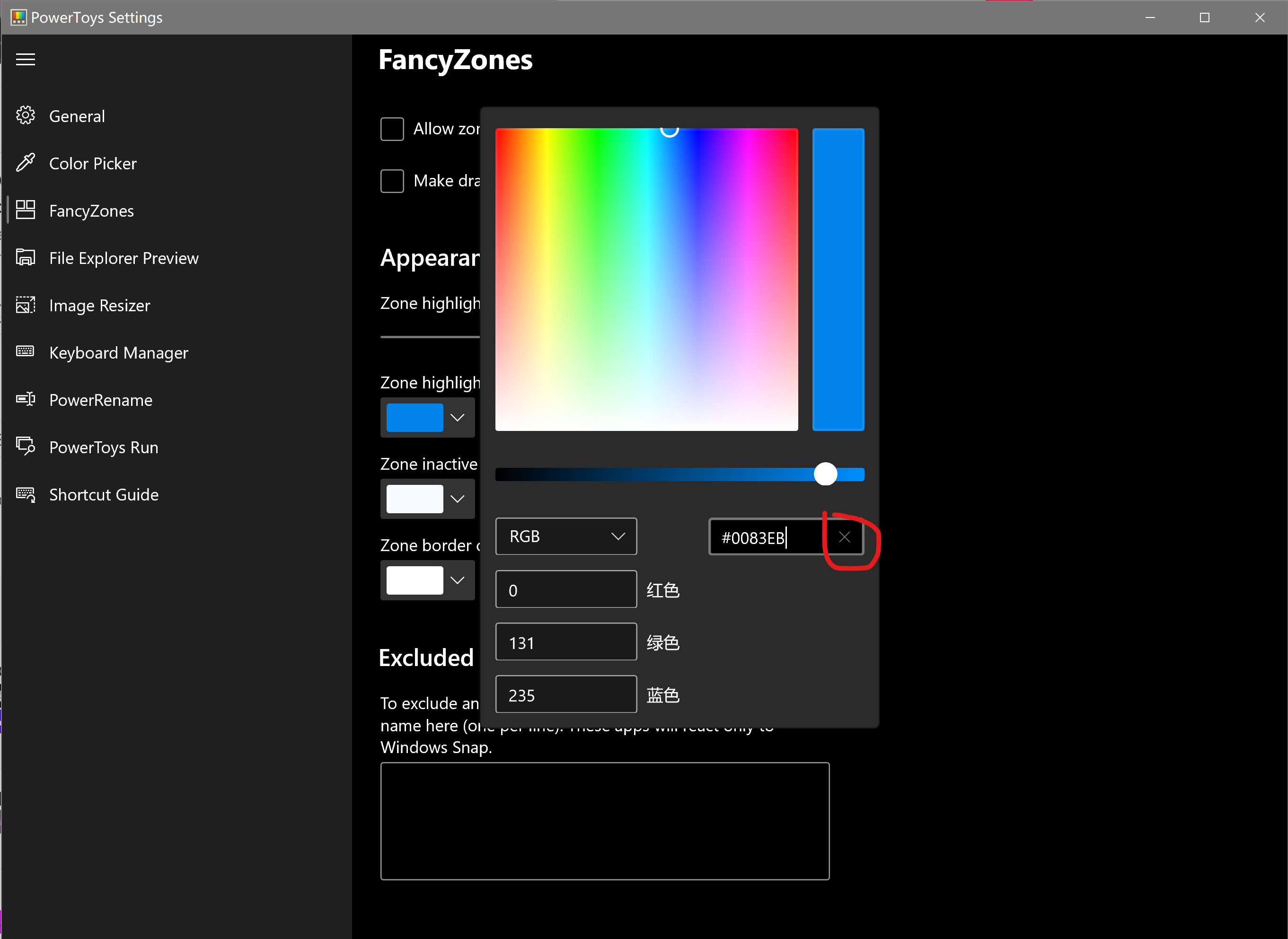
|
## ℹ Computer information
* PowerToys version: 0.20.1
* PowerToy Utility: Fancy Zones
* Running PowerToys as Admin: yes
* Windows build number: 10.0.19041.388
## 📝 Provide detailed reproduction steps (if any)
1. Open Settings: Fancy Zones
2. Go to edit one of the zone colors
3. In the color picker window, delete the #HEX value (ether manually or via the X button)
### ✔️ Expected result
_What is the expected result of the above steps?_
I think nothing? Similar to clearing one of the RGB boxes.
### ❌ Actual result
_What is the actual result of the above steps?_
UI freezes for one to five seconds and then closes.
PowerToys itself does not close all together.
## 📷 Screenshots
_Are there any useful screenshots? WinKey+Shift+S and then just paste them
directly into the form_

| 1 |
As far as I know, polyfill functions are repeated in each file they are
needed, resulting in lot of duplicate code.
I suggest to optionally emit them as a module, so that they appear once in a
bundled project.
E.g. instead of:
var __extends = (this && this.__extends) || function (d, b) {
for (var p in b) if (b.hasOwnProperty(p)) d[p] = b[p];
function __() { this.constructor = d; }
d.prototype = b === null ? Object.create(b) : (__.prototype = b.prototype, new __());
};
var myclass= (function (_super) {
__extends(myclass, _super);
// ...
emit this:
var __extends = require("typescript-polyfills").extends;
var myclass= (function (_super) {
__extends(myclass, _super);
// ...
|
I request a runtime type checking system that perhaps looks something like
this:
function square(x: number!) {
return x * x;
}
Where the `!` tells the compiler to generate a runtime type check for a
number, something akin to tcomb.js.
Of course, this gets much more complicated with interfaces, but you get the
idea.
| 0 |
the following does not work
julia> let
global @inline function foo(x::T) where {T}
T
end
end
but the following does work
julia> let
global @inline function foo{T}(x::T)
T
end
end
|
According the the manual
`Profile.print` should take a kwarg saying how many columns to print.
This is a useful feature I would like to use.
Here is what happens when I run the example code:
s = open("/tmp/prof.txt","w")
Profile.print(s,cols = 500)
close(s)
MethodError: no method matching print(::IOStream, ::Array{UInt64,1}, ::Dict{UInt64,Array{StackFrame,1}}; cols=500)
you may have intended to import Base.print
Closest candidates are:
print{T<:Unsigned}(::IO, ::Array{T<:Unsigned,1}, ::Dict{K,V}; format, C, combine, sortedby, maxdepth) at profile.jl:88 got unsupported keyword argument "cols"
print{T<:Unsigned}(::IO, ::Array{T<:Unsigned,1}) at profile.jl:88 got unsupported keyword argument "cols"
print(::IO) at profile.jl:88 got unsupported keyword argument "cols"
in (::Base.Profile.#kw##print)(::Array{Any,1}, ::Base.Profile.#print, ::IOStream, ::Array{UInt64,1}, ::Dict{UInt64,Array{StackFrame,1}}) at <missing>:0
in (::Base.Profile.#kw##print)(::Array{Any,1}, ::Base.Profile.#print, ::IOStream) at <missing>:0
in include_string(::String, ::String) at loading.jl:441
in eval(::Module, ::Any) at boot.jl:234
in (::Atom.##65#68)() at eval.jl:40
in withpath(::Atom.##65#68, ::Void) at utils.jl:30
in withpath(::Function, ::Void) at eval.jl:46
in macro expansion at eval.jl:109 [inlined]
in (::Atom.##64#67{Dict{String,Any}})() at task.jl:60
Looking in the source
it seems that now the number of columns is being determined by the
displaysize.
Which has serveral problems:
* Doesn't match docs
* Not at all useful for deeply nestested code. I know my code, which isn't even that deep, is down to just a few letters for each function name, before it is cut-off, which makes it nearly useless
* displaysize doesn't make sense when the output is not going to STDOUT anyway.
| 0 |
I recently purchased new Mac Pro w/ Mac Os X 11.0.1 & Apple Silicon M1.
I installed homebrew (when enabling Rosetta) and managed to install python3.9
and other packages through brew (numpy==1.19.5 & scipy==1.6.0, amongst
others).
However, executing my one-liner script yields a "bus error". That happens when
I try to import curve_fit from scipy.optimize. Any ideas how to solve that?
I believe this is hardware related and is due to non optimal compilation of
scipy for the M1 architecture (data are lost somewhere on the memory bus?
https://www.quora.com/Why-there-is-a-bus-error-in-the-Python-program-when-it-
recurs-over-18-713-times ).
Python code:
from scipy.optimize import curve_fit
Error:
zsh: bus error
Tail lines when running this code in python3.9 with -v option.
import 'scipy.sparse.linalg.dsolve' # <_frozen_importlib_external.SourceFileLoader object at 0x1182ad040>
# /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/__pycache__/__init__.cpython-39.pyc matches /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/__init__.py
# code object from '/opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/__pycache__/__init__.cpython-39.pyc'
# /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/__pycache__/__init__.cpython-39.pyc matches /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/__init__.py
# code object from '/opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/__pycache__/__init__.cpython-39.pyc'
# /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/__pycache__/arpack.cpython-39.pyc matches /opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/arpack.py
# code object from '/opt/homebrew/lib/python3.9/site-packages/scipy/sparse/linalg/eigen/arpack/__pycache__/arpack.cpython-39.pyc'
zsh: bus error python3.9 -v debug.py
I also posted this question on stack overflow:
https://stackoverflow.com/questions/65838231/importing-scipy-in-
python-3-9-1-yields-zsh-bus-error-apple-silicon-m1-mac-os-1
|
My issue is about NaNs produced using scipy.interpolate.griddata.
Consider that the values from `values.csv` are defined for each point from
`points.csv`.
We would like to get interpolated values for points from `xi.csv`.
In the following code snippet I check whether the interpolated values contain
any NaNs.
### Reproducing code example:
from scipy.interpolate import griddata
import numpy as np
import pandas as pd
points = pd.read_csv('points.csv').values
values = pd.read_csv('values.csv').values
xi = pd.read_csv('xi.csv').values
interpolated = griddata(points, values, xi, method='linear', rescale=True)
idx_nan = np.where(np.isnan(interpolated))[0]
if idx_nan.any():
print('NaNs are present')
print(xi[idx_nan])
else:
print('Success')
I used two sets of inputs for points and values: `with_duplicates` and
`no_duplicates`.
In the former ones there are points with the duplicate coordinates, while in
the other one they are eliminated.
### Outputs
#### With Duplicates
NaNs are present
[[ 2. 0. 0. 30. ]
[ 2. 0. 0. 50. ]
[ 2. 0. 0. 70. ]
[ 2.5 0. 0. 30. ]
[ 2.5 0. 0. 50. ]
[ 2.5 0. 0. 70. ]
[ 3. 0. 0. 30. ]
[ 3. 0. 0. 50. ]
[ 3. 0. 0. 70. ]
[ 3.5 0. 0. 30. ]
[ 3.5 0. 0. 50. ]
[ 3.5 0. 0. 70. ]
[ 4. 0. 0. 30. ]
[ 4. 0. 0. 50. ]
[ 4. 0. 0. 70. ]
[ 4.5 0. 0. 30. ]
[ 4.5 0. 0. 50. ]
[ 4.5 0. 0. 70. ]
[ 5. 0. 0. 30. ]
[ 5. 0. 0. 50. ]
[ 5. 0. 0. 70. ]]
I wonder why the NaNs were generated not for all points.
Note, that there were no NaNs for `[1 0 0 30]` point, for example.
The points, where we have NaNs as a results on interpolation are actually
present in `points.csv`, for example `[5, 0, 0, 30]` is there.
Thus, it is surprising why interpolation led to NaNs even if there is a
perfect match in the `points` array.
#### No Duplicates
Success
I removed duplicate points and re-ran the code snippet. Now it was a success.
It is not clear, though, why there would be such a behavior with
`with_duplicates`. If the point from `xi` matches point from `points` array,
then it seems that the algorithm should just pick the corresponding value.
### Scipy/Numpy/Python version information:
import sys, scipy, numpy; print(scipy.__version__, numpy.__version__, sys.version_info)
1.2.1 1.16.3 sys.version_info(major=3, minor=7, micro=3, releaselevel='final', serial=0)
## Files with data
xi.zip
with_duplicates.zip
no_duplicates.zip
| 0 |
**Symfony version(s) affected** : 4.1.0
**Description**
Symfony does not throw an exception `Circular reference detected for service
"%s", path: "%s".` whenever I am using `!tagged` syntax.
**How to reproduce**
1. Create the following class:
<?php
namespace App\Services;
class MyService
{
private $services;
public function __construct(iterable $services)
{
$this->services = $services;
}
}
2. Create the following configuration:
App\Services\MyService:
arguments: ['@App\Services\MyService']
Now we will get `Circular reference detected for service
"App\Services\MyService", path: "App\Services\MyService ->
App\Services\MyService".`, it is fine.
3. Replace the configuration by the following code:
App\Services\MyService:
arguments:
- !tagged my-service
tags:
- {name: 'my-service'}
Symfony does not warn by exception about circular dependency. My real example
was much more complex and actually it was my bug, but anyway would be nice to
be informed about bug by semantic exception.
**Possible Solution**
Throw
`Symfony\Component\DependencyInjection\Exception\ServiceCircularReferenceException`
in such cases, or add simple console commend to check if we have circular
dependency.
| Q | A
---|---
Bug report? | yes/no
Feature request? | no
BC Break report? | no
RFC? | no
Symfony version | 3.4.3
class SomeInterface
{
public function supports(object $obj);
}
class ChainSome implements SomeInterface
{
/*
* @var SomeInterface[]
*/
private $somes;
public function __construct(iterable $somes)
{
$this->somes = $somes;
}
public function supports(object $obj)
{
foreach ($this->somes as $some) {
if ($some->supports($obj)) {
return true;
}
}
}
}
services:
_instanceof:
SomeInterface:
tags:
- { name: 'app.some' }
ChainSome:
arguments:
$somes: !tagged app.some
In this example `ChainSome` receive instance of self and code reach infinity
loop.
Is this behavior is valid?
Maybe possible exclude self injection?
| 1 |
### version
current latest master (`bfce376`)
### How to reproduce
1. create a file named `main.js`with the following content:
console.log('hello');
2. start running deno watcher by `cargo run -- run --watch --unstable main.js`. At this point we can see an output like:
hello
Watcher Process terminated! Restarting on file change...
3. create a new file named `new.js`. Nothing happens on the terminal.
export const world = 'world';
4. edit `main.js` to the following and save it:
+import { world } from "./new.js";
console.log("hello");
+console.log(world);
When saving it, we get:
Watcher File change detected! Restarting!
hello
world
Watcher Process terminated! Restarting on file change...
5. edit the value of `world` in `new.js` and save it:
-export const world = "world";
+export const world = "Deno!";
When saving it, nothing happens although we expect `hello\nDeno!` to be
printed.
I've already found the cause of this problem in the watcher implementation.
This is because module resolution is done only once at the starting of the
watcher. Basically we should resolve module every time any event is detected.
I'll look into this problem deeply and try to elabolate a solution.
|
to reproduce:
watching A.ts
creating B.ts
editing A.ts to import B
editing B.ts
watcher doesn't restart
| 1 |
Like this:
import { prefixes } from "https://ip-ranges.amazonaws.com/ip-ranges.json" assert {type: "json"}
> error: Uncaught SyntaxError: The requested module 'https://ip-
> ranges.amazonaws.com/ip-ranges.json' does not provide an export named
> 'prefixes'
But you can look `deno` hints for `deno` plugins. And in fact, this json has
`prefixes` fields.
This is my deno version
deno --version ─╯
deno 1.34.1 (release, x86_64-unknown-linux-gnu)
v8 11.5.150.2
typescript 5.0.4
|
Hi, I'm really curious about this behavior; when importing a json in this way:
Works good. However this way:
It breaks.
I'm not sure about the standard about this but if the latest is not supported,
the Deno lsp should inform this is an error.
Thanks.
| 1 |
**TypeScript Version:** 1.8.0-beta
VS Code's Javascript Salsa language service seems to break down as soon as I
type a dynamic require into the buffer. I lose all language features:
intellisense, mark occurrences, etc. I can only get out of that state by
reloading Code's window.
require('' + '');

|
So I was googling and asking on StackOverflow. For now no clear answer. So
decided to ask here as for me it is a blocker.
How can use the newest methods for existing JS types (like Array, Number)?
`Array.from(someIterable)` throws an error: `error TS2339: Property 'from'
does not exist on type 'ArrayConstructor'`
I would appreciate any tip, how to make it work.
| 0 |
When overriding an unknown style the following warning is logged: `You are
trying to overrides a style that do not exist.`.
Apart from the obvious typing error in the warning message, which should be
fixed, I would like to suggest that the warning message also shows the
respective style key.
Source file: https://github.com/callemall/material-
ui/blob/fb8bcd94abf9f33e27bc60cda6d9e74d166f699e/src/styles/getStylesCreator.js#L18
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
When overriding a style which does not exist, I would like to know _which_
style, which key respectively, does not exist.
## Current Behavior
The shown warning in the console does not give any information about the wrong
style key.
## Steps to Reproduce (for bugs)
1. Create a theme override with an invalid style key, e.g.:
const theme = createMuiTheme({
overrides: {
invalidKey : { }
});
2. Open the _JavaScript_ console.
3. The console shows `bundle.js:6820 Warning: You are trying to overrides a style that do not exist.`
## Context
I recently updated to the most recent beta version and it seems that some
style overrides are not longer available. I would like to track down the wrong
style key without searching for it one-by-one.
## Your Environment
Tech | Version
---|---
Material-UI | @next
|
### Checkbox value as number
Right now i will get an error if I try to pass number as value in Checkbox.
I don't think that there should be any restriction only on string?
`Warning: Failed prop type: Invalid prop `value` of type `number` supplied to
`Checkbox`, expected `string`.`
Tech | Version
---|---
Material-UI | v1.0.0-beta.24
React | 16.2.0
browser | Any
| 0 |
Are there any plans to add type stubs for PEP484-compliant static typing?
|
I am trying to set up a flask application on my new machine. First I checked
out the sources from our server - I am pretty sure the application directory
structure is correct, as we are using it exactly like this on other machines.
However, when I try to run the app on my new computer I get the following
error:
$ FLASK_ENV="development" FLASK_APP="run.py" flask run
* Serving Flask app 'run.py' (lazy loading)
* Environment: development
* Debug mode: on
Usage: flask run [OPTIONS]
Try 'flask run --help' for help.
Error: While importing 'run', an ImportError was raised.
Problem is: No more output is printed, in particular no stack trace. So I
don't know what exactly the problem is. How can I tell flask to print the
stack trace?
Environment:
* Python version: 3.8.10
* Flask version: 2.0.2
| 0 |
* [x ] I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
NextJS sample application should load without any issue.
## Current Behavior
v1.0.0-beta.28 broke something in theming. My code still works fine with
v1.0.0-beta.27. Getting the following error in v1.0.0-beta.28
TypeError: Cannot read property 'charAt' of undefined
at decomposeColor (/user_code/node_modules/material-
ui/styles/colorManipulator.js:80:12)
at lighten (/user_code/node_modules/material-
ui/styles/colorManipulator.js:226:11)
at createPalette (/user_code/node_modules/material-
ui/styles/createPalette.js:144:51)
at createMuiTheme (/user_code/node_modules/material-
ui/styles/createMuiTheme.js:71:45)
at Object. (/user_code/next/dist/components/getPageContext.js:31:40)
at Module._compile (module.js:570:32)
at Object.Module._extensions..js (module.js:579:10)
at Module.load (module.js:487:32)
at tryModuleLoad (module.js:446:12)
at Function.Module._load (module.js:438:3)
## Steps to Reproduce (for bugs)
Run the sample NextJS app with v1.0.0-beta.28 and v1.0.0-beta.27. In
v1.0.0-beta.28, you'll get the above error.
## Environment
Tech | Version
---|---
"next": "^4.2.1",
"react": "^16.2.0",
"react-dom": "^16.2.0",
"material-ui": "v1.0.0-beta.28",
|
I am using the latest "v1.0.0-beta.20".
const theme = createMuiTheme({
palette: {
primary: grey[100],
secondary: blue['A400']
},
});
TypeError: Cannot read property 'charAt' of undefined
decomposeColor
node_modules/material-ui/styles/colorManipulator.js:106
103 | * @returns {{type: string, values: number[]}} A MUI color object
104 | */
105 | function decomposeColor(color) {
> 106 | if (color.charAt(0) === '#') {
107 | return decomposeColor(convertHexToRGB(color));
108 | }
109 |
where as this works, Any idea whats happening here ?
const theme = createMuiTheme({
palette: {
primary: grey,
secondary: blue
},
});
| 1 |
by **alexandru@mosoi.ro** :
What steps will reproduce the problem?
If possible, include a link to a program on play.golang.org.
1. This bug is a duplicate of bug 3511 which was not correctly fixed
https://golang.org/issue/3511
If req.Method == 'POST' (anything other than GET and HEAD) the bug can be still
reproduced.
2. Here is how to patch test to reproduce the failure.
diff -r 1e84edee3397 src/pkg/net/http/client_test.go
--- a/src/pkg/net/http/client_test.go Tue Aug 21 20:59:02 2012 +1000
+++ b/src/pkg/net/http/client_test.go Tue Aug 21 22:45:37 2012 +0200
@@ -284,6 +284,10 @@
req, _ := NewRequest("GET", us, nil)
client.Do(req) // Note: doesn't hit network
matchReturnedCookies(t, expectedCookies, tr.req.Cookies())
+
+ req, _ = NewRequest("POST", us, nil)
+ client.Do(req) // Note: doesn't hit network
+ matchReturnedCookies(t, expectedCookies, tr.req.Cookies())
}
// Just enough correctness for our redirect tests. Uses the URL.Host as the
3. Currently if req.Method == 'POST', send() is invoked which doesn't set the cookies.
The fix to bug 3511 did not set the cookies on all possible code paths.
What is the expected output?
HTTP cookies set for all methods.
What do you see instead?
HTTP cookies are not set for POST, PUT, etc.
Which compiler are you using (5g, 6g, 8g, gccgo)?
6g
Which operating system are you using?
Ubuntu 12.04 LTS (with custom go installation).
Which version are you using? (run 'go version')
go version weekly.2012-03-27 +1e84edee3397
|
by **parenthephobia** :
What steps will reproduce the problem?
package main
func main () {
a := make(map[int] int);
b := make(map[int] int);
c := make(map[int] int);
k := 1;
a[k], b[k], c[k] = 1, 2, 3;
}
I expected:
No output, but successful compilation.
But instead got:
The compiler segfaults without comment.
What is your $GOOS? $GOARCH?
linux, 386
Which revision are you using? (hg identify)
I don't know at the moment. I did hg pull -u before reporting the bug,
but unfortunately the build is broken on my current revision.
Please provide any additional information below.
Presumably this is caused by the way maps are handled. It looks like Go
doesn't handle parallel assignments when some of the places being assigned
to are maps.
| 0 |
Any plan to support redis-cluster?
I think redis-cluster can be simply implement by inheriting
`celery.backend.redis.RedisBackend`, Is there any plan to do that?
|
The python Redis Cluster lib **Grokzen/redis-py-cluster** is considered
production ready, therefore suitable for integrating Redis Cluster into Celery
(in the future _redis-py-cluster_ will be integrated in _redis-py_ , currently
used by Celery).
As far as I can understand, Redis Cluster should be integrated in Kombu first
(celery/kombu#526)
| 1 |
### Bug summary
distutils is deprecated in Python 3.10:
https://docs.python.org/3/library/distutils.html
Matplotlib (as of 3.4.3) currently uses `distutils`, so users are met with
`DeprecationWarning`s when using on Python 3.10.
from matplotlib import pyplot
.tox/py/lib/python3.10/site-packages/matplotlib/__init__.py:88: in <module>
from distutils.version import LooseVersion
/usr/local/lib/python3.10/distutils/__init__.py:19: in <module>
warnings.warn(_DEPRECATION_MESSAGE,
E DeprecationWarning: The distutils package is deprecated and slated for removal in Python 3.12. Use setuptools or check PEP 632 for potential alternatives
### Code for reproduction
from matplotlib import pyplot
### Actual outcome
`DeprecationWarning` raised per summary.
### Expected outcome
No `DeprecationWarning`s raised
### Additional information
_No response_
### Operating system
macOS
### Matplotlib Version
3.4.3
### Matplotlib Backend
_No response_
### Python version
Python 3.10.0
### Jupyter version
_No response_
### Installation
pip
|
### Bug summary
Python 3.10 formally deprecated distutils.
DeprecationWarning: The distutils package is deprecated and slated for removal in Python 3.12. Use setuptools or check PEP 632 for potential alternatives
matplotlib still contains a few occurrences which should probably be removed:
setup.py:from distutils.errors import CompileError
setup.py:from distutils.dist import Distribution
setup.py:setup( # Finally, pass this all along to distutils to do the heavy lifting.
setupext.py:from distutils import ccompiler, sysconfig
setupext.py:from distutils.core import Extension
setupext.py: Return or yield a list of C extensions (`distutils.core.Extension`
### Code for reproduction
-
### Actual outcome
*
### Expected outcome
*
### Operating system
Ubuntu
### Matplotlib Version
master
### Matplotlib Backend
_No response_
### Python version
_No response_
### Jupyter version
_No response_
### Other libraries
_No response_
### Installation
_No response_
### Conda channel
_No response_
| 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.