
input
stringlengths 50
13.9k
| output_program
stringlengths 5
655k
| output_answer
stringlengths 5
655k
| split
stringclasses 1
value | dataset
stringclasses 1
value |
|---|---|---|---|---|
You are given a binary string S of N bits. The bits in the string are indexed starting from 1. S[i] denotes the ith bit of S.
Let's say that a sequence i1, i2, …, iK(1 ≤ K; 1 ≤ i1 < i2 < … < iK ≤ N) produces a palindrome when applied to S, if the string S[i1] S[i2] … S[ik] is a palindrome (that is, reads the same backward or forward).
In addition, a sequence i1, i2, …, iK(1 ≤ K; 1 ≤ i1 < i2 < … < iK ≤ N) is said to be exponential, if ij + 1 = p * ij for each integer 1 ≤ j < K and for some integer p > 1. Note, that a sequence of one element is always exponential.
Your task is to count the number of exponential sequences that produce a palindrome when applied to S.
-----Input-----
The first line of input contains an integer T denoting the number of test cases. The description of T test cases follows.
The only line of description for each test case contains a binary string S of N bits.
-----Output-----
For each test case, output a single line containing the number of exponential sequences that produce a palindrome.
-----Constraints-----
- 1 ≤ T ≤ 10
- Subtask 1(20 points): 1 ≤ N ≤ 20
- Subtask 2(30 points): 1 ≤ N ≤ 1000
- Subtask 3(50 points): 1 ≤ N ≤ 5 × 105
-----Note-----
The first test of the first subtask is the example test. It's made for you to make sure that your solution produces the same verdict both on your machine and our server.
-----Time Limits-----
Time limit for the first and the second subtasks is 3s. Time limit for the third subtask is 6s.
-----Example-----
Input:
2
11010
101001011
Output:
9
18
-----Explanation of the first case in the example test-----
The following sequences are counted in the answer: {1}, {2}, {3}, {4}, {5}, {1, 2}, {1, 4}, {2, 4}, {1, 2, 4}. | def checkPalindrome(string):
if(string==string[::-1]):
return 1
else:
return 0
t=int(eval(input()))
while(t):
ip_string=input()
length_of_str=len(ip_string)
p=2
count=length_of_str
while(p<=length_of_str):
for i in range(1,length_of_str+1):
temp_str=ip_string[i-1]
j=i*p
while(j<=length_of_str):
temp_str+=ip_string[j-1]
if(checkPalindrome(temp_str)==1):
count+=1
j=j*p
p+=1
print(count)
t-=1 | def checkPalindrome(string):
if(string==string[::-1]):
return 1
else:
return 0
t=int(eval(input()))
while(t):
ip_string=input()
length_of_str=len(ip_string)
p=2
count=length_of_str
while(p<=length_of_str):
for i in range(1,length_of_str+1):
temp_str=ip_string[i-1]
j=i*p
while(j<=length_of_str):
temp_str+=ip_string[j-1]
if(checkPalindrome(temp_str)==1):
count+=1
j=j*p
p+=1
print(count)
t-=1 | train | APPS_structured |
Devu is a disastrous oracle: his predictions about various events of your life are horrifying. Instead of providing good luck, he "blesses" you with bad luck. The secret behind his wickedness is a hidden omen which is a string of length m. On your visit to him, you can ask a lot of questions about your future, each of which should be a string of length m. In total you asked him n such questions, denoted by strings s1, s2, ... , sn of length m each. Each of the question strings is composed of the characters 'a' and 'b' only.
Amount of bad luck this visit will bring you is equal to the length of longest common subsequence (LCS) of all the question strings and the hidden omen string. Of course, as the omen string is hidden, you are wondering what could be the least value of bad luck you can get.
Can you find out what could be the least bad luck you can get? Find it fast, before Devu tells you any bad omens.
-----Input-----
The first line of the input contains an integer T denoting the number of test cases. The description of T test cases follows.
First line of each test case contains a single integer n denoting number of strings.
For each of next n lines, the ith line contains the string si.
-----Output-----
For each test case, output a single integer corresponding to the answer of the problem.
-----Constraints-----
- All the strings (including the hidden omen) contain the characters 'a' and 'b' only.
Subtask #1: (40 points)
- 1 ≤ T, n, m ≤ 14
Subtask #2: (60 points)
- 1 ≤ T, n, m ≤ 100
-----Example-----
Input:3
2
ab
ba
2
aa
bb
3
aabb
abab
baab
Output:1
0
2
-----Explanation-----
In the first example, the minimum value of LCS of all the strings is 1, the string by oracle can be one of these {aa, ab, ba, bb}.
In the second example, whatever string oracle has does not matter, LCS will always be zero. | def lcs(A,B):
a,b=len(A),len(B)
lst=[[0]*(b+1) for _ in range(a+1)]
for x in range(1,a+1):
for y in range(1,b+1):
if A[x-1] == B[y-1]:
lst[x][y]= 1+lst[x-1][y-1]
else:
lst[x][y]=max(lst[x][y-1],lst[x-1][y])
return lst[a][b]
for _ in range(int(input())):
n=int(input())
lst=[]
for i in range(n):
stg=input()
m=len(stg)
lst.append(min(lcs(stg,m*'a'),lcs(stg,m*'b')))
print(min(lst))
| def lcs(A,B):
a,b=len(A),len(B)
lst=[[0]*(b+1) for _ in range(a+1)]
for x in range(1,a+1):
for y in range(1,b+1):
if A[x-1] == B[y-1]:
lst[x][y]= 1+lst[x-1][y-1]
else:
lst[x][y]=max(lst[x][y-1],lst[x-1][y])
return lst[a][b]
for _ in range(int(input())):
n=int(input())
lst=[]
for i in range(n):
stg=input()
m=len(stg)
lst.append(min(lcs(stg,m*'a'),lcs(stg,m*'b')))
print(min(lst))
| train | APPS_structured |
Chef has a sequence of positive integers $A_1, A_2, \ldots, A_N$. He wants to choose some elements of this sequence (possibly none or all of them) and compute their MEX, i.e. the smallest positive integer which does not occur among the chosen elements. For example, the MEX of $[1, 2, 4]$ is $3$.
Help Chef find the largest number of elements of the sequence $A$ which he can choose such that their MEX is equal to $M$, or determine that it is impossible.
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first line of each test case contains two space-separated integers $N$ and $M$.
- The second line contains $N$ space-separated integers $A_1, A_2, \ldots, A_N$.
-----Output-----
For each test case, print a single line containing one integer ― the maximum number of elements Chef can choose, or $-1$ if he cannot choose elements in such a way that their MEX is $M$.
-----Constraints-----
- $1 \le T \le 100$
- $2 \le M \le N \le 10^5$
- $1 \le A_i \le 10^9$ for each valid $i$
- the sum of $N$ over all test cases does not exceed $10^6$
-----Example Input-----
1
3 3
1 2 4
-----Example Output-----
3
-----Explanation-----
Example case 1: The MEX of whole array is 3. Hence, we can choose all the elements. | # cook your dish here
import bisect
t = int(input())
for _ in range(t):
n,m = map(int, input().split())
arr = list(map(int, input().split()))
seti = set(arr)
f = 1
for i in range(1,m):
if i not in seti:
f = 0
break
if f==0:
print(-1)
else:
if m in seti:
print(n-arr.count(m))
else:
print(n)
| # cook your dish here
import bisect
t = int(input())
for _ in range(t):
n,m = map(int, input().split())
arr = list(map(int, input().split()))
seti = set(arr)
f = 1
for i in range(1,m):
if i not in seti:
f = 0
break
if f==0:
print(-1)
else:
if m in seti:
print(n-arr.count(m))
else:
print(n)
| train | APPS_structured |
Leha plays a computer game, where is on each level is given a connected graph with n vertices and m edges. Graph can contain multiple edges, but can not contain self loops. Each vertex has an integer d_{i}, which can be equal to 0, 1 or - 1. To pass the level, he needs to find a «good» subset of edges of the graph or say, that it doesn't exist. Subset is called «good», if by by leaving only edges from this subset in the original graph, we obtain the following: for every vertex i, d_{i} = - 1 or it's degree modulo 2 is equal to d_{i}. Leha wants to pass the game as soon as possible and ask you to help him. In case of multiple correct answers, print any of them.
-----Input-----
The first line contains two integers n, m (1 ≤ n ≤ 3·10^5, n - 1 ≤ m ≤ 3·10^5) — number of vertices and edges.
The second line contains n integers d_1, d_2, ..., d_{n} ( - 1 ≤ d_{i} ≤ 1) — numbers on the vertices.
Each of the next m lines contains two integers u and v (1 ≤ u, v ≤ n) — edges. It's guaranteed, that graph in the input is connected.
-----Output-----
Print - 1 in a single line, if solution doesn't exist. Otherwise in the first line k — number of edges in a subset. In the next k lines indexes of edges. Edges are numerated in order as they are given in the input, starting from 1.
-----Examples-----
Input
1 0
1
Output
-1
Input
4 5
0 0 0 -1
1 2
2 3
3 4
1 4
2 4
Output
0
Input
2 1
1 1
1 2
Output
1
1
Input
3 3
0 -1 1
1 2
2 3
1 3
Output
1
2
-----Note-----
In the first sample we have single vertex without edges. It's degree is 0 and we can not get 1. | import sys
n, m = list(map(int, sys.stdin.readline().split()))
d = list(map(int, sys.stdin.readline().split()))
gph = [[] for _ in range(n)]
for _ in range(m):
u, v = list(map(int, sys.stdin.readline().split()))
u -= 1
v -= 1
gph[u].append((v, _))
gph[v].append((u, _))
t = -1
if d.count(1) % 2 == 1:
if -1 not in d:
print(-1)
return
t = d.index(-1)
ans = [False] * m
vis = [False] * n
ed = [(-1, -1)] * n
rets = [(d[u] == 1) or (u == t) for u in range(n)]
stk = [[0, iter(gph[0])]]
while len(stk) > 0:
u = stk[-1][0]
vis[u] = True
try:
while True:
v, i = next(stk[-1][1])
if not vis[v]:
ed[v] = (u, i)
stk.append([v, iter(gph[v])])
break
except StopIteration:
p, e = ed[u]
if p >= 0 and rets[u]:
rets[p] = not rets[p]
ans[e] = True
stk.pop()
pass
print(ans.count(True))
print("\n".join([str(i+1) for i in range(m) if ans[i]]))
#1231
| import sys
n, m = list(map(int, sys.stdin.readline().split()))
d = list(map(int, sys.stdin.readline().split()))
gph = [[] for _ in range(n)]
for _ in range(m):
u, v = list(map(int, sys.stdin.readline().split()))
u -= 1
v -= 1
gph[u].append((v, _))
gph[v].append((u, _))
t = -1
if d.count(1) % 2 == 1:
if -1 not in d:
print(-1)
return
t = d.index(-1)
ans = [False] * m
vis = [False] * n
ed = [(-1, -1)] * n
rets = [(d[u] == 1) or (u == t) for u in range(n)]
stk = [[0, iter(gph[0])]]
while len(stk) > 0:
u = stk[-1][0]
vis[u] = True
try:
while True:
v, i = next(stk[-1][1])
if not vis[v]:
ed[v] = (u, i)
stk.append([v, iter(gph[v])])
break
except StopIteration:
p, e = ed[u]
if p >= 0 and rets[u]:
rets[p] = not rets[p]
ans[e] = True
stk.pop()
pass
print(ans.count(True))
print("\n".join([str(i+1) for i in range(m) if ans[i]]))
#1231
| train | APPS_structured |
Your coworker was supposed to write a simple helper function to capitalize a string (that contains a single word) before they went on vacation.
Unfortunately, they have now left and the code they gave you doesn't work. Fix the helper function they wrote so that it works as intended (i.e. make the first character in the string "word" upper case).
Don't worry about numbers, special characters, or non-string types being passed to the function. The string lengths will be from 1 character up to 10 characters, but will never be empty. | def capitalize_word(word):
return str.capitalize(word) | def capitalize_word(word):
return str.capitalize(word) | train | APPS_structured |
# Esolang Interpreters #3 - Custom Paintfuck Interpreter
## About this Kata Series
"Esolang Interpreters" is a Kata Series that originally began as three separate, independent esolang interpreter Kata authored by [@donaldsebleung](http://codewars.com/users/donaldsebleung) which all shared a similar format and were all somewhat inter-related. Under the influence of [a fellow Codewarrior](https://www.codewars.com/users/nickkwest), these three high-level inter-related Kata gradually evolved into what is known today as the "Esolang Interpreters" series.
This series is a high-level Kata Series designed to challenge the minds of bright and daring programmers by implementing interpreters for various [esoteric programming languages/Esolangs](http://esolangs.org), mainly [Brainfuck](http://esolangs.org/wiki/Brainfuck) derivatives but not limited to them, given a certain specification for a certain Esolang. Perhaps the only exception to this rule is the very first Kata in this Series which is intended as an introduction/taster to the world of esoteric programming languages and writing interpreters for them.
## The Language
Paintfuck is a [borderline-esoteric programming language/Esolang](http://esolangs.org) which is a derivative of [Smallfuck](http://esolangs.org/wiki/Smallfuck) (itself a derivative of the famous [Brainfuck](http://esolangs.org/wiki/Brainfuck)) that uses a two-dimensional data grid instead of a one-dimensional tape.
Valid commands in Paintfuck include:
- `n` - Move data pointer north (up)
- `e` - Move data pointer east (right)
- `s` - Move data pointer south (down)
- `w` - Move data pointer west (left)
- `*` - Flip the bit at the current cell (same as in Smallfuck)
- `[` - Jump past matching `]` if bit under current pointer is `0` (same as in Smallfuck)
- `]` - Jump back to the matching `[` (if bit under current pointer is nonzero) (same as in Smallfuck)
The specification states that any non-command character (i.e. any character other than those mentioned above) should simply be ignored. The output of the interpreter is the two-dimensional data grid itself, best as animation as the interpreter is running, but at least a representation of the data grid itself after a certain number of iterations (explained later in task).
In current implementations, the 2D datagrid is finite in size with toroidal (wrapping) behaviour. This is one of the few major differences of Paintfuck from Smallfuck as Smallfuck terminates (normally) whenever the pointer exceeds the bounds of the tape.
Similar to Smallfuck, Paintfuck is Turing-complete **if and only if** the 2D data grid/canvas were unlimited in size. However, since the size of the data grid is defined to be finite, it acts like a finite state machine.
More info on this Esolang can be found [here](http://esolangs.org/wiki/Paintfuck).
## The Task
Your task is to implement a custom Paintfuck interpreter `interpreter()`/`Interpret` which accepts the following arguments in the specified order:
1. `code` - **Required**. The Paintfuck code to be executed, passed in as a string. May contain comments (non-command characters), in which case your interpreter should simply ignore them. If empty, simply return the initial state of the data grid.
2. `iterations` - **Required**. A non-negative integer specifying the number of iterations to be performed before the final state of the data grid is returned. See notes for definition of 1 iteration. If equal to zero, simply return the initial state of the data grid.
3. `width` - **Required**. The width of the data grid in terms of the number of data cells in each row, passed in as a positive integer.
4. `height` - **Required**. The height of the data grid in cells (i.e. number of rows) passed in as a positive integer.
A few things to note:
- Your interpreter should treat all command characters as **case-sensitive** so `N`, `E`, `S` and `W` are **not** valid command characters
- Your interpreter should initialize all cells within the data grid to a value of `0` regardless of the width and height of the grid
- In this implementation, your pointer must always start at the **top-left hand corner** of the data grid (i.e. first row, first column). This is important as some implementations have the data pointer starting at the middle of the grid.
- One iteration is defined as one step in the program, i.e. the number of command characters evaluated. For example, given a program `nessewnnnewwwsswse` and an iteration count of `5`, your interpreter should evaluate `nesse` before returning the final state of the data grid. **Non-command characters should not count towards the number of iterations.**
- Regarding iterations, the act of skipping to the matching `]` when a `[` is encountered (or vice versa) is considered to be **one** iteration regardless of the number of command characters in between. The next iteration then commences at the command **right after** the matching `]` (or `[`).
- Your interpreter should terminate normally and return the final state of the 2D data grid whenever **any** of the mentioned conditions become true: (1) All commands have been considered left to right, or (2) Your interpreter has already performed the number of iterations specified in the second argument.
- The return value of your interpreter should be a representation of the final state of the 2D data grid where each row is separated from the next by a CRLF (`\r\n`). For example, if the final state of your datagrid is
```
[
[1, 0, 0],
[0, 1, 0],
[0, 0, 1]
]
```
... then your return string should be `"100\r\n010\r\n001"`.
Good luck :D
## Kata in this Series
1. [Esolang Interpreters #1 - Introduction to Esolangs and My First Interpreter (MiniStringFuck)](https://www.codewars.com/kata/esolang-interpreters-number-1-introduction-to-esolangs-and-my-first-interpreter-ministringfuck)
2. [Esolang Interpreters #2 - Custom Smallfuck Interpreter](http://codewars.com/kata/esolang-interpreters-number-2-custom-smallfuck-interpreter)
3. **Esolang Interpreters #3 - Custom Paintfuck Interpreter**
4. [Esolang Interpreters #4 - Boolfuck Interpreter](http://codewars.com/kata/esolang-interpreters-number-4-boolfuck-interpreter) | def interpreter(code, iterations, width, height):
inter = Inter(code, width, height)
inter.run(iterations)
return '\r\n'.join(''.join(map(str, e)) for e in inter.grid)
class Inter:
_instruct = { 'w':'moveW', 'e':'moveE', 'n':'moveN', 's':'moveS', '*':'flip', '[':'jumpP', ']':'jumpB'}
_nonC = lambda x:None
def __init__(self, code, w, h):
self.grid = [[0]*w for e in range(h)]
self.com = code
self.w, self.h = w, h
self.x, self.y = 0, 0
self.i, self.it = 0, 0
def countIteration(f):
def wrap(cls):
cls.it += 1
return f(cls)
return wrap
def run(self, iterat):
while self.it < iterat and self.i < len(self.com):#
getattr(self, self._instruct.get(self.com[self.i],'_nonC'))()
self.i += 1
@countIteration
def moveE(self):
self.x = (self.x + 1)%self.w
@countIteration
def moveW(self):
self.x = (self.x - 1)%self.w
@countIteration
def moveN(self):
self.y = (self.y - 1)%self.h
@countIteration
def moveS(self):
self.y = (self.y + 1)%self.h
@countIteration
def flip(self):
self.grid[self.y][self.x] = int(not(self.grid[self.y][self.x]))
@countIteration
def jumpP(self):
if self.grid[self.y][self.x] == 0:
self._jump(1, ']', '[')
@countIteration
def jumpB(self):
if self.grid[self.y][self.x] == 1:
self._jump(-1, '[', ']')
def _jump(self, way, need, past, nest = 0):
while way:
self.i += way
if self.com[self.i] == need and not nest: break
if self.com[self.i] == need and nest: nest -= 1
if self.com[self.i] == past: nest += 1 | def interpreter(code, iterations, width, height):
inter = Inter(code, width, height)
inter.run(iterations)
return '\r\n'.join(''.join(map(str, e)) for e in inter.grid)
class Inter:
_instruct = { 'w':'moveW', 'e':'moveE', 'n':'moveN', 's':'moveS', '*':'flip', '[':'jumpP', ']':'jumpB'}
_nonC = lambda x:None
def __init__(self, code, w, h):
self.grid = [[0]*w for e in range(h)]
self.com = code
self.w, self.h = w, h
self.x, self.y = 0, 0
self.i, self.it = 0, 0
def countIteration(f):
def wrap(cls):
cls.it += 1
return f(cls)
return wrap
def run(self, iterat):
while self.it < iterat and self.i < len(self.com):#
getattr(self, self._instruct.get(self.com[self.i],'_nonC'))()
self.i += 1
@countIteration
def moveE(self):
self.x = (self.x + 1)%self.w
@countIteration
def moveW(self):
self.x = (self.x - 1)%self.w
@countIteration
def moveN(self):
self.y = (self.y - 1)%self.h
@countIteration
def moveS(self):
self.y = (self.y + 1)%self.h
@countIteration
def flip(self):
self.grid[self.y][self.x] = int(not(self.grid[self.y][self.x]))
@countIteration
def jumpP(self):
if self.grid[self.y][self.x] == 0:
self._jump(1, ']', '[')
@countIteration
def jumpB(self):
if self.grid[self.y][self.x] == 1:
self._jump(-1, '[', ']')
def _jump(self, way, need, past, nest = 0):
while way:
self.i += way
if self.com[self.i] == need and not nest: break
if self.com[self.i] == need and nest: nest -= 1
if self.com[self.i] == past: nest += 1 | train | APPS_structured |
Today, Chef has a fencing job at hand and has to fence up a surface covering N$N$ points.
To minimize his work, he started looking for an algorithm that had him fence the least amount of length.
He came up with the Convex Hull algorithm, but soon realized it gave him some random shape to fence. However, Chef likes rectangles and has a favourite number M$M$.
Help him find the minimum perimeter he has to fence if he wants to fence a rectangle, with slope of one of the sides as M$M$, to cover all the points.
-----Input:-----
- The first line contains two integers N$N$ and M$M$, the number of points and the Chef's favourite Number.
- The next n lines contain two space separated integers X$X$ and Y$Y$, the coordinates of the point.
-----Output:-----
Print a single decimal number, denoting the perimeter of the rectangle. Answer will considered correct if it has absolute error less than 10−6$10^{-6}$.
-----Constraints-----
- 2≤N≤1000000$2 \leq N \leq 1000000$
- −1000≤M≤1000$-1000 \leq M \leq 1000$
- −1000000≤X≤1000000$-1000000 \leq X \leq 1000000$
- −1000000≤Y≤1000000$-1000000 \leq Y \leq 1000000$
-----Sample Input:-----
4 1
0 1
0 -1
1 0
-1 0
-----Sample Output:-----
5.656854249492380
-----Note:-----
- As the input size is large, it is recommended to use Fast IO. | import math
n,m = map(int, input().split())
hyp = math.sqrt(1+m*m)
cosx = 1/hyp
sinx = m/hyp
pts = [[], []]
for i in range(n):
p = input().split()
px = int(p[0])
py = int(p[1])
pts[0].append(cosx*px+sinx*py)
pts[1].append(cosx*py-sinx*px)
w = max(pts[0])-min(pts[0])
l = max(pts[1])-min(pts[1])
print(2*l+2*w) | import math
n,m = map(int, input().split())
hyp = math.sqrt(1+m*m)
cosx = 1/hyp
sinx = m/hyp
pts = [[], []]
for i in range(n):
p = input().split()
px = int(p[0])
py = int(p[1])
pts[0].append(cosx*px+sinx*py)
pts[1].append(cosx*py-sinx*px)
w = max(pts[0])-min(pts[0])
l = max(pts[1])-min(pts[1])
print(2*l+2*w) | train | APPS_structured |
Write a function that takes a string of braces, and determines if the order of the braces is valid. It should return `true` if the string is valid, and `false` if it's invalid.
This Kata is similar to the [Valid Parentheses](https://www.codewars.com/kata/valid-parentheses) Kata, but introduces new characters: brackets `[]`, and curly braces `{}`. Thanks to `@arnedag` for the idea!
All input strings will be nonempty, and will only consist of parentheses, brackets and curly braces: `()[]{}`.
### What is considered Valid?
A string of braces is considered valid if all braces are matched with the correct brace.
## Examples
```
"(){}[]" => True
"([{}])" => True
"(}" => False
"[(])" => False
"[({})](]" => False
``` | def validBraces(s, previous = ''):
while s != previous: previous, s = s, s.replace('[]','').replace('{}','').replace('()','')
return not s | def validBraces(s, previous = ''):
while s != previous: previous, s = s, s.replace('[]','').replace('{}','').replace('()','')
return not s | train | APPS_structured |
Gigi is a clever monkey, living in the zoo, his teacher (animal keeper) recently taught him some knowledge of "0".
In Gigi's eyes, "0" is a character contains some circle(maybe one, maybe two).
So, a is a "0",b is a "0",6 is also a "0",and 8 have two "0" ,etc...
Now, write some code to count how many "0"s in the text.
Let us see who is smarter? You ? or monkey?
Input always be a string(including words numbers and symbols),You don't need to verify it, but pay attention to the difference between uppercase and lowercase letters.
Here is a table of characters:
one zeroabdegopq069DOPQR () <-- A pair of braces as a zerotwo zero%&B8
Output will be a number of "0". | two = "%&B8"
some = f"abdegopq069DOPQR{two}"
def countzero(string):
return sum(2 if c in two else 1 for c in string.replace("()", "0") if c in some) | two = "%&B8"
some = f"abdegopq069DOPQR{two}"
def countzero(string):
return sum(2 if c in two else 1 for c in string.replace("()", "0") if c in some) | train | APPS_structured |
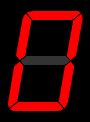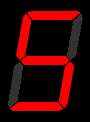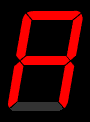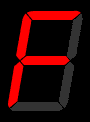
A **Seven Segment Display** is an electronic display device, used to display decimal or hexadecimal numerals. It involves seven led segments that are lit in specific combinations to represent a specific numeral. An example of each combination is shown below:
For this Kata, you must accept an integer in the range `0 - 999999` and print it as a string (in decimal format), with each digit being represented as its own seven segment display (6x seven segment displays in total). Each of the individual led segments per display should be represented by three hashes `###`. Vertical bars `|` (ASCII 124) represent the edges of each display, with a single whitespace on either side between the edge and the area of the led segments. An example of the expected output is shown below:
```
segment_display(123456) =
| | ### | ### | | ### | ### |
| # | # | # | # # | # | # |
| # | # | # | # # | # | # |
| # | # | # | # # | # | # |
| | ### | ### | ### | ### | ### |
| # | # | # | # | # | # # |
| # | # | # | # | # | # # |
| # | # | # | # | # | # # |
| | ### | ### | | ### | ### |
```
For clarity, the entire set of required combinations is provided below:
```
| ### | | ### | ### | | ### | ### | ### | ### | ### |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| | | ### | ### | ### | ### | ### | | ### | ### |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| ### | | ### | ### | | ### | ### | | ### | ### |
```
If the number is smaller than 6 digits, the result should be justified to the right, with the unused segments being blank (as they are not turned on). Refer to the sample test for an example.
**Note:** There should not be any trailing whitespace for any line.
Please rate and enjoy! | s = '''| ### | | ### | ### | | ### | ### | ### | ### | ### |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| | | ### | ### | ### | ### | ### | | ### | ### |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| ### | | ### | ### | | ### | ### | | ### | ### |
'''.splitlines()
segment_display=lambda n:'\n'.join(''.join(i)+'|'for i in [(['| ']*(6-len(str(n))))+[k[int(l)]for l in str(n)]for k in[[i[j:j+8]for j in range(0,len(i),8)]for i in s]]) | s = '''| ### | | ### | ### | | ### | ### | ### | ### | ### |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| # # | # | # | # | # # | # | # | # | # # | # # |
| | | ### | ### | ### | ### | ### | | ### | ### |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| # # | # | # | # | # | # | # # | # | # # | # |
| ### | | ### | ### | | ### | ### | | ### | ### |
'''.splitlines()
segment_display=lambda n:'\n'.join(''.join(i)+'|'for i in [(['| ']*(6-len(str(n))))+[k[int(l)]for l in str(n)]for k in[[i[j:j+8]for j in range(0,len(i),8)]for i in s]]) | train | APPS_structured |
There are $n$ persons who initially don't know each other. On each morning, two of them, who were not friends before, become friends.
We want to plan a trip for every evening of $m$ days. On each trip, you have to select a group of people that will go on the trip. For every person, one of the following should hold: Either this person does not go on the trip, Or at least $k$ of his friends also go on the trip.
Note that the friendship is not transitive. That is, if $a$ and $b$ are friends and $b$ and $c$ are friends, it does not necessarily imply that $a$ and $c$ are friends.
For each day, find the maximum number of people that can go on the trip on that day.
-----Input-----
The first line contains three integers $n$, $m$, and $k$ ($2 \leq n \leq 2 \cdot 10^5, 1 \leq m \leq 2 \cdot 10^5$, $1 \le k < n$) — the number of people, the number of days and the number of friends each person on the trip should have in the group.
The $i$-th ($1 \leq i \leq m$) of the next $m$ lines contains two integers $x$ and $y$ ($1\leq x, y\leq n$, $x\ne y$), meaning that persons $x$ and $y$ become friends on the morning of day $i$. It is guaranteed that $x$ and $y$ were not friends before.
-----Output-----
Print exactly $m$ lines, where the $i$-th of them ($1\leq i\leq m$) contains the maximum number of people that can go on the trip on the evening of the day $i$.
-----Examples-----
Input
4 4 2
2 3
1 2
1 3
1 4
Output
0
0
3
3
Input
5 8 2
2 1
4 2
5 4
5 2
4 3
5 1
4 1
3 2
Output
0
0
0
3
3
4
4
5
Input
5 7 2
1 5
3 2
2 5
3 4
1 2
5 3
1 3
Output
0
0
0
0
3
4
4
-----Note-----
In the first example, $1,2,3$ can go on day $3$ and $4$.
In the second example, $2,4,5$ can go on day $4$ and $5$. $1,2,4,5$ can go on day $6$ and $7$. $1,2,3,4,5$ can go on day $8$.
In the third example, $1,2,5$ can go on day $5$. $1,2,3,5$ can go on day $6$ and $7$. | from collections import deque
def solve(adj, m, k, uv):
n = len(adj)
nn = [len(a) for a in adj]
q = deque()
for i in range(n):
if nn[i] < k:
q.append(i)
while q:
v = q.popleft()
for u in adj[v]:
nn[u] -= 1
if nn[u] == k-1:
q.append(u)
res = [0]*m
nk = len([1 for i in nn if i >= k])
res[-1] = nk
for i in range(m-1, 0, -1):
u1, v1 = uv[i]
if nn[u1] < k or nn[v1] < k:
res[i - 1] = nk
continue
if nn[u1] == k:
q.append(u1)
nn[u1] -= 1
if not q and nn[v1] == k:
q.append(v1)
nn[v1] -= 1
if not q:
nn[u1] -= 1
nn[v1] -= 1
adj[u1].remove(v1)
adj[v1].remove(u1)
while q:
v = q.popleft()
nk -= 1
for u in adj[v]:
nn[u] -= 1
if nn[u] == k - 1:
q.append(u)
res[i - 1] = nk
return res
n, m, k = map(int, input().split())
a = [set() for i in range(n)]
uv = []
for i in range(m):
u, v = map(int, input().split())
a[u - 1].add(v - 1)
a[v - 1].add(u - 1)
uv.append((u-1, v-1))
res = solve(a, m, k, uv)
print(str(res)[1:-1].replace(' ', '').replace(',', '\n')) | from collections import deque
def solve(adj, m, k, uv):
n = len(adj)
nn = [len(a) for a in adj]
q = deque()
for i in range(n):
if nn[i] < k:
q.append(i)
while q:
v = q.popleft()
for u in adj[v]:
nn[u] -= 1
if nn[u] == k-1:
q.append(u)
res = [0]*m
nk = len([1 for i in nn if i >= k])
res[-1] = nk
for i in range(m-1, 0, -1):
u1, v1 = uv[i]
if nn[u1] < k or nn[v1] < k:
res[i - 1] = nk
continue
if nn[u1] == k:
q.append(u1)
nn[u1] -= 1
if not q and nn[v1] == k:
q.append(v1)
nn[v1] -= 1
if not q:
nn[u1] -= 1
nn[v1] -= 1
adj[u1].remove(v1)
adj[v1].remove(u1)
while q:
v = q.popleft()
nk -= 1
for u in adj[v]:
nn[u] -= 1
if nn[u] == k - 1:
q.append(u)
res[i - 1] = nk
return res
n, m, k = map(int, input().split())
a = [set() for i in range(n)]
uv = []
for i in range(m):
u, v = map(int, input().split())
a[u - 1].add(v - 1)
a[v - 1].add(u - 1)
uv.append((u-1, v-1))
res = solve(a, m, k, uv)
print(str(res)[1:-1].replace(' ', '').replace(',', '\n')) | train | APPS_structured |
Write a function that when given a number >= 0, returns an Array of ascending length subarrays.
```
pyramid(0) => [ ]
pyramid(1) => [ [1] ]
pyramid(2) => [ [1], [1, 1] ]
pyramid(3) => [ [1], [1, 1], [1, 1, 1] ]
```
**Note:** the subarrays should be filled with `1`s | def pyramid(n):
return [[1]*x for x in range(1, n+1)] | def pyramid(n):
return [[1]*x for x in range(1, n+1)] | train | APPS_structured |
# An introduction to propositional logic
Logic and proof theory are fields that study the formalization of logical statements and the structure of valid proofs. One of the most common ways to represent logical reasonings is with **propositional logic**.
A propositional formula is no more than what you normally use in your *if statements*, but without functions or predicates. The basic unit for these formulas are **literals**. Let's see some examples:
```
f = p ∧ q
```
Here ```p``` and ```q``` would be the literals. This formula means that *f* evaluates to ```True``` only when both ```p``` **and** ```q``` are True too. The ```∧``` operator is formally called **conjunction** and is often called **and**.
```
f = p ∨ q
```
This formula means that *f* evaluates to ```True``` only when any of ```p``` **or** ```q``` are True. This includes the case when both are True. The ```∨``` operator is formally called **disjunction** and is often called **or**.
```
f = ¬p
```
The ```¬``` operator is analogous to the **not** operation. it evaluates to True only when its argument evaluates to False.
Normally, there are also two other operators called **implication** and **biconditional**, but we will ignore them for this kata (they can be expressed in terms of the other three anyways).
Once we know this, can construct what is called an **interpretation** in order to evaluate a propositional formula. This is a fancy name for any structure that tells us which literals are False and which ones are True. Normally, interpretations are given as a set:
```python
p = Literal('p')
q = Literal('q')
r = Literal('r')
f = p ∨ q ∨ ¬r
i_1 = {p, q} # p and q are True, r is False
i_2 = {r} # r is True, p and q are False
i_3 = {} # p, q and r are False
# Note: the 'evaluate' function is not given
evaluate(f, i_1) == True
evaluate(f, i_2) == False
evaluate(f, i_3) == True
```
As you can see, if the literal is in the set, we say it evaluates to True, else it is False.
As a final note, an interpretation that makes a formula True is called a **model** when all the literals in the set appear in the formula.
# The SAT problem
This is a famous NP problem that is stated as follows:
> Given a propositional formula *F*, does it exist an interpretation such that it evaluates to True? (i.e. is *F* **satisfiable**?)
Numerous algorithms exist for this purpose, and your task is to program one of them. Right now, you are not supposed to program an efficient algorithm, but I may create a performance version if this kata gets good reception :)
# Specification
Program a ```sat(f: Formula)``` function that returns the following:
- ```False``` if ```f``` is not satisfiable.
- An interpretation that makes ```f``` evaluate to True in the case that it is satisfiable.
# Preloaded code
You are given a class ```Formula``` that has the following members:
- ```args```: arguments of the operation if the formula is not a literal (children nodes of the formula's tree). They are given as a list of Formula objects that has one element in the case of the negation operator and two or more elements in the case of the conjunction and disjunction operators.
- ```is_literal()```: True if the formula is a literal (i.e. not an operation).
- ```is_and()```: True if the formula is a **conjunction**.
- ```is_or()```: True if the formula is a **disjunction**.
- ```is_not()```: True if the formula is a **negation**.
You are also given a class ```Literal``` that extends from ```Formula``` and has the following members:
- ```name```: string that represents the literal. Two literals with the same name **are the same literal**.
*Note: the rest of members are not guaranteed in the case of a literal*
The ```&``` operator is overloaded as the conjunction, ```|``` as the disjunction and ```~``` as the negation. Also, a ```__repr__``` function is given for debugging purposes.
# Extra examples
```
f = ¬(p ∨ q) # Satisfiable with {}
```
```
f = ¬(p ∧ q) # Satisfiable with {p}, {q} and {}
```
```
f = p ∧ (q ∨ r) # Satisfiable with {p, q}, {p, r} and {p, q, r}
```
```
f = ¬p ∨ ¬q # Satisfiable with {p}, {q} and {} (See De Morgan's Laws)
```
```
f = p ∧ ¬p # Not satisfiable
``` | from itertools import compress, product, chain
from functools import partial
def check(f, s):
if f.is_literal(): return f in s
elif f.is_and(): return all(check(e, s) for e in f.args)
elif f.is_or(): return any(check(e, s) for e in f.args)
elif f.is_not(): return not check(f.args[0], s)
def get_name(f):
if f.is_literal(): yield f
else: yield from chain.from_iterable(map(get_name, f.args))
def sat(f):
s = set(get_name(f))
return next(filter(partial(check, f), map(set, map(partial(compress, s), product((0,1), repeat=len(s))))), False) | from itertools import compress, product, chain
from functools import partial
def check(f, s):
if f.is_literal(): return f in s
elif f.is_and(): return all(check(e, s) for e in f.args)
elif f.is_or(): return any(check(e, s) for e in f.args)
elif f.is_not(): return not check(f.args[0], s)
def get_name(f):
if f.is_literal(): yield f
else: yield from chain.from_iterable(map(get_name, f.args))
def sat(f):
s = set(get_name(f))
return next(filter(partial(check, f), map(set, map(partial(compress, s), product((0,1), repeat=len(s))))), False) | train | APPS_structured |
You are given a rows x cols matrix grid. Initially, you are located at the top-left corner (0, 0), and in each step, you can only move right or down in the matrix.
Among all possible paths starting from the top-left corner (0, 0) and ending in the bottom-right corner (rows - 1, cols - 1), find the path with the maximum non-negative product. The product of a path is the product of all integers in the grid cells visited along the path.
Return the maximum non-negative product modulo 109 + 7. If the maximum product is negative return -1.
Notice that the modulo is performed after getting the maximum product.
Example 1:
Input: grid = [[-1,-2,-3],
[-2,-3,-3],
[-3,-3,-2]]
Output: -1
Explanation: It's not possible to get non-negative product in the path from (0, 0) to (2, 2), so return -1.
Example 2:
Input: grid = [[1,-2,1],
[1,-2,1],
[3,-4,1]]
Output: 8
Explanation: Maximum non-negative product is in bold (1 * 1 * -2 * -4 * 1 = 8).
Example 3:
Input: grid = [[1, 3],
[0,-4]]
Output: 0
Explanation: Maximum non-negative product is in bold (1 * 0 * -4 = 0).
Example 4:
Input: grid = [[ 1, 4,4,0],
[-2, 0,0,1],
[ 1,-1,1,1]]
Output: 2
Explanation: Maximum non-negative product is in bold (1 * -2 * 1 * -1 * 1 * 1 = 2).
Constraints:
1 <= rows, cols <= 15
-4 <= grid[i][j] <= 4 | class Solution:
def maxProductPath(self, grid: List[List[int]]) -> int:
rows = len(grid)
if (rows == 0):
return -1
cols = len(grid[0])
if (cols == 0):
return -1
dp = [(1,1)] * cols
for r, col in enumerate(grid):
for c, item in enumerate(col):
if (r == 0 and c == 0):
dp[c] = (item, item)
elif (r == 0):
dp[c] = (dp[c-1][0] * item, dp[c-1][1]* item)
elif (c == 0):
dp[c] = (dp[c][0] * item, dp[c][1]* item)
else:
candidate_1 = dp[c-1][0] * item
candidate_2 = dp[c-1][1]* item
candidate_3 = dp[c][0] * item
candidate_4 = dp[c][1]* item
m = min(candidate_1, candidate_2, candidate_3, candidate_4)
M = max(candidate_1, candidate_2, candidate_3, candidate_4)
dp[c] = (m, M)
if (dp[cols-1][1] >= 0):
return dp[cols-1][1] % (10**9+7)
else:
return -1 | class Solution:
def maxProductPath(self, grid: List[List[int]]) -> int:
rows = len(grid)
if (rows == 0):
return -1
cols = len(grid[0])
if (cols == 0):
return -1
dp = [(1,1)] * cols
for r, col in enumerate(grid):
for c, item in enumerate(col):
if (r == 0 and c == 0):
dp[c] = (item, item)
elif (r == 0):
dp[c] = (dp[c-1][0] * item, dp[c-1][1]* item)
elif (c == 0):
dp[c] = (dp[c][0] * item, dp[c][1]* item)
else:
candidate_1 = dp[c-1][0] * item
candidate_2 = dp[c-1][1]* item
candidate_3 = dp[c][0] * item
candidate_4 = dp[c][1]* item
m = min(candidate_1, candidate_2, candidate_3, candidate_4)
M = max(candidate_1, candidate_2, candidate_3, candidate_4)
dp[c] = (m, M)
if (dp[cols-1][1] >= 0):
return dp[cols-1][1] % (10**9+7)
else:
return -1 | train | APPS_structured |
Mohit(Ex GenSec ) is the most active member of the roasting club who loves giving tasks to other members. One day he observed that none of the members were paying attention to the online classes, so he decided to have some fun and overcome the boring lectures. He wrote N numbers on the virtual board (where the first number is 1, the last one is N and the ith number being i).
Then he asked M questions to every other member of the club. In each question, a number K was given by Mohit and the members had to give a single integer as an answer which will be the sum of all numbers present on the whiteboard.
There are some conditions that every member has to follow while answering.
- If K is already present on the whiteboard then swap the first and last number.
- Otherwise, replace the last number with K.
-----Input:-----
- First-line will consist of space-separated integers N and M. The board will contain the list of numbers from 1 to N and M is the number of questions that Mohit will ask.
- Next M lines contain the number Ki, which will be provided by Mohit and (1<=i<=M).
-----Output:-----
For each question, report the sum of all integers present
-----Constraints-----
- $1 \leq N,M \leq 1000000$
- $2 \leq K \leq 10^9$
-----Sample Input:-----
5 4
7
12
10
1
-----Sample Output:-----
17
22
20
20 | # cook your dish here
n,m=tuple(map(int,input().split()))
if(n>2):
arr=[1,n]
elif(n==1):
arr=[1]
elif(n==2):
arr=[1,2]
for i in range(m):
k=int(input())
if(n==1):
if(k!=arr[0]):
arr[0]=k
print(arr[0])
elif(n==2):
if(k==arr[0] or k==arr[1]):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
else:
arr[1]=k
print(arr[0]+arr[1])
else:
ans=int(n*(n+1)/2)-1-n
if(k==arr[0] or k==arr[1]):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
elif(k>1 and k<n):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
else:
arr[1]=k
ans+=arr[0]+arr[1]
print(ans)
| # cook your dish here
n,m=tuple(map(int,input().split()))
if(n>2):
arr=[1,n]
elif(n==1):
arr=[1]
elif(n==2):
arr=[1,2]
for i in range(m):
k=int(input())
if(n==1):
if(k!=arr[0]):
arr[0]=k
print(arr[0])
elif(n==2):
if(k==arr[0] or k==arr[1]):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
else:
arr[1]=k
print(arr[0]+arr[1])
else:
ans=int(n*(n+1)/2)-1-n
if(k==arr[0] or k==arr[1]):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
elif(k>1 and k<n):
temp=arr[0]
arr[0]=arr[1]
arr[1]=temp
else:
arr[1]=k
ans+=arr[0]+arr[1]
print(ans)
| train | APPS_structured |
Batman is about to face Superman so he decides to prepare for the battle by upgrading his Batmobile. He manufactures multiple duplicates of his standard Batmobile each tweaked in a different way such that the maximum speed of each is never less than that of the standard model.
After carrying out this process, he wishes to know how many of his prototypes are faster than his standard Batmobile?
-----Input-----
- The first line of the input contains an integer T denoting the number of test cases. The description of T test cases follow:
- The first line of each test case contains a single integer N denoting the number of copies of the standard Batmobile.
- The second line contains a sequence of N+1 space-separated integers, S0 to SN, sorted in non-decreasing order separated by space. S0 is the maximum speed of the standard Batmobile. S1 to SN denote the maximum speeds of the prototypes.
-----Output-----
- For each test case, output a single line containing an integer denoting the answer.
-----Constraints-----
- 1 ≤ T ≤ 1000
- 1 ≤ N ≤ 1000
- 1 ≤ Si ≤ 109
-----Example-----
Input:
2
4
1 2 3 4 5
5
1 10 100 1000 10000 100000
Output:
4
5 | for _ in range(eval(input())):
n=eval(input())
a=list(map(int,input().split()))
c=0
for i in range(1,n+1):
if a[0]<a[i]:
c+=1
print(c) | for _ in range(eval(input())):
n=eval(input())
a=list(map(int,input().split()))
c=0
for i in range(1,n+1):
if a[0]<a[i]:
c+=1
print(c) | train | APPS_structured |
You are given two integer arrays nums1 and nums2 sorted in ascending order and an integer k.
Define a pair (u,v) which consists of one element from the first array and one element from the second array.
Find the k pairs (u1,v1),(u2,v2) ...(uk,vk) with the smallest sums.
Example 1:
Given nums1 = [1,7,11], nums2 = [2,4,6], k = 3
Return: [1,2],[1,4],[1,6]
The first 3 pairs are returned from the sequence:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
Example 2:
Given nums1 = [1,1,2], nums2 = [1,2,3], k = 2
Return: [1,1],[1,1]
The first 2 pairs are returned from the sequence:
[1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]
Example 3:
Given nums1 = [1,2], nums2 = [3], k = 3
Return: [1,3],[2,3]
All possible pairs are returned from the sequence:
[1,3],[2,3]
Credits:Special thanks to @elmirap and @StefanPochmann for adding this problem and creating all test cases. | class Solution:
def kSmallestPairs(self, nums1, nums2, k):
"""
:type nums1: List[int]
:type nums2: List[int]
:type k: int
:rtype: List[List[int]]
"""
queue = []
def push(i, j):
if i < len(nums1) and j < len(nums2):
heapq.heappush(queue, [nums1[i] + nums2[j], i, j])
push(0, 0)
pairs = []
while queue and len(pairs) < k:
_, i, j = heapq.heappop(queue)
pairs.append([nums1[i], nums2[j]])
push(i, j + 1)
if j == 0:
push(i + 1, 0)
return pairs | class Solution:
def kSmallestPairs(self, nums1, nums2, k):
"""
:type nums1: List[int]
:type nums2: List[int]
:type k: int
:rtype: List[List[int]]
"""
queue = []
def push(i, j):
if i < len(nums1) and j < len(nums2):
heapq.heappush(queue, [nums1[i] + nums2[j], i, j])
push(0, 0)
pairs = []
while queue and len(pairs) < k:
_, i, j = heapq.heappop(queue)
pairs.append([nums1[i], nums2[j]])
push(i, j + 1)
if j == 0:
push(i + 1, 0)
return pairs | train | APPS_structured |
Given an array $A$ of length $N$.
We have to find the $maximum$ sum of elements of the subarray between $two$ nearest occurrences of $same$ elements (excluding both).
If both the elements are $even$ then the total number of $even$ elements in that subarray should be $even$ then and then only we consider that subarray and if both the elements are $odd$ then the total number of $odd$ element in that subarray should be $odd$ then and then only we consider that subarray.
If the condition never matches print $0$.
-----Input:-----
- First line contains $T$, number of test cases. Then the test cases follow.
- Each testcase consists of two lines:
The first line has $N$ : number of elements in the array and second-line has $N$ space separated integers: elements of the array.
-----Output:-----
- For each test case, output in a single line $maximum$ sum.
-----Constraints-----
- $1 \leq T \leq 10$
- $3 \leq N \leq 2*10^5$
- $1 \leq A[i] \leq 10^8$
$NOTE $: Use of Fast Input Output is recommended.
-----Sample Input:-----
1
10
1 2 3 2 1 5 1 2 8 2
-----Sample Output:-----
7
-----EXPLANATION:-----
The maximum sum is 7, between 1 at 1st position and 1 at 5th position i.e sum of 2,3,2 | # cook your dish here
from sys import stdin, stdout
from collections import defaultdict
for _ in range(int(stdin.readline())):
n=int(stdin.readline())
lst=list(map(int, stdin.readline().split()))
prefix_odd=[0]*n
prefix_even=[0]*n
odd_val=0
even_val=0
for i in range(n):
if lst[i]%2==0:
even_val+=1
else:
odd_val+=1
prefix_even[i]=even_val
prefix_odd[i]=odd_val
#print(prefix_odd,prefix_even)
prefix_sum=[0]*n
s=0
for i in range(n):
s+=lst[i]
prefix_sum[i]=s
#print(prefix_sum)
dict={}
count={}
for i in range(n):
if lst[i] not in dict:
dict[lst[i]]=i
count[lst[i]]=1
else:
dict[lst[i]]=i
count[lst[i]]+=1
#print(dict)
graph=defaultdict(list)
for i in range(n):
graph[lst[i]].append(i)
max_sum=0
for i in graph:
if len(graph[i])>1:
prev=graph[i][0]
for j in range(1,len(graph[i])):
index2=graph[i][j]
index1=prev
prev=index2
#print(index1,index2)
if i%2==0:
val=prefix_even[index2]-prefix_even[index1]-1
#print(val)
if val%2==0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-i
#print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
else:
val=prefix_odd[index2]-prefix_odd[index1]-1
#print(val)
if val%2!=0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-i
#print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
'''max_sum=-1
for i in range(n):
if count[lst[i]]>1:
index2=dict[lst[i]]
index1=i
print(index1,index2)
if lst[i]%2==0:
val=prefix_even[index2]-prefix_even[index1]-1
print(val)
if val%2==0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-lst[i]
print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
else:
val=prefix_odd[index2]-prefix_odd[index1]-1
print(val)
if val%2!=0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-lst[i]
print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum'''
stdout.write(str(max_sum)+'\n') | # cook your dish here
from sys import stdin, stdout
from collections import defaultdict
for _ in range(int(stdin.readline())):
n=int(stdin.readline())
lst=list(map(int, stdin.readline().split()))
prefix_odd=[0]*n
prefix_even=[0]*n
odd_val=0
even_val=0
for i in range(n):
if lst[i]%2==0:
even_val+=1
else:
odd_val+=1
prefix_even[i]=even_val
prefix_odd[i]=odd_val
#print(prefix_odd,prefix_even)
prefix_sum=[0]*n
s=0
for i in range(n):
s+=lst[i]
prefix_sum[i]=s
#print(prefix_sum)
dict={}
count={}
for i in range(n):
if lst[i] not in dict:
dict[lst[i]]=i
count[lst[i]]=1
else:
dict[lst[i]]=i
count[lst[i]]+=1
#print(dict)
graph=defaultdict(list)
for i in range(n):
graph[lst[i]].append(i)
max_sum=0
for i in graph:
if len(graph[i])>1:
prev=graph[i][0]
for j in range(1,len(graph[i])):
index2=graph[i][j]
index1=prev
prev=index2
#print(index1,index2)
if i%2==0:
val=prefix_even[index2]-prefix_even[index1]-1
#print(val)
if val%2==0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-i
#print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
else:
val=prefix_odd[index2]-prefix_odd[index1]-1
#print(val)
if val%2!=0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-i
#print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
'''max_sum=-1
for i in range(n):
if count[lst[i]]>1:
index2=dict[lst[i]]
index1=i
print(index1,index2)
if lst[i]%2==0:
val=prefix_even[index2]-prefix_even[index1]-1
print(val)
if val%2==0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-lst[i]
print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum
else:
val=prefix_odd[index2]-prefix_odd[index1]-1
print(val)
if val%2!=0:
temp_sum=prefix_sum[index2]-prefix_sum[index1]-lst[i]
print(temp_sum)
if temp_sum>max_sum:
max_sum=temp_sum'''
stdout.write(str(max_sum)+'\n') | train | APPS_structured |
Given an unsorted array of integers, find the length of longest increasing subsequence.
Example:
Input: [10,9,2,5,3,7,101,18]
Output: 4
Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.
Note:
There may be more than one LIS combination, it is only necessary for you to return the length.
Your algorithm should run in O(n2) complexity.
Follow up: Could you improve it to O(n log n) time complexity? | class Solution:
def lengthOfLIS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
import bisect
d = [0] * len(nums)
maxLen = 0
for n in nums:
i = bisect.bisect_left(d, n, 0, maxLen)
if i == maxLen:
maxLen += 1
d[i] = n
return maxLen | class Solution:
def lengthOfLIS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
import bisect
d = [0] * len(nums)
maxLen = 0
for n in nums:
i = bisect.bisect_left(d, n, 0, maxLen)
if i == maxLen:
maxLen += 1
d[i] = n
return maxLen | train | APPS_structured |
In this kata you will be given a random string of letters and tasked with returning them as a string of comma-separated sequences sorted alphabetically, with each sequence starting with an uppercase character followed by `n-1` lowercase characters, where `n` is the letter's alphabet position `1-26`.
## Example
```python
alpha_seq("ZpglnRxqenU") -> "Eeeee,Ggggggg,Llllllllllll,Nnnnnnnnnnnnnn,Nnnnnnnnnnnnnn,Pppppppppppppppp,Qqqqqqqqqqqqqqqqq,Rrrrrrrrrrrrrrrrrr,Uuuuuuuuuuuuuuuuuuuuu,Xxxxxxxxxxxxxxxxxxxxxxxx,Zzzzzzzzzzzzzzzzzzzzzzzzzz"
```
## Technical Details
- The string will include only letters.
- The first letter of each sequence is uppercase followed by `n-1` lowercase.
- Each sequence is separated with a comma.
- Return value needs to be a string. | def alpha_seq(string):
o = ord("a") -1
return ",".join((c * (ord(c) - o)).capitalize() for c in sorted(string.lower())) | def alpha_seq(string):
o = ord("a") -1
return ",".join((c * (ord(c) - o)).capitalize() for c in sorted(string.lower())) | train | APPS_structured |
#Sort the columns of a csv-file
You get a string with the content of a csv-file. The columns are separated by semicolons.
The first line contains the names of the columns.
Write a method that sorts the columns by the names of the columns alphabetically and incasesensitive.
An example:
```
Before sorting:
As table (only visualization):
|myjinxin2015|raulbc777|smile67|Dentzil|SteffenVogel_79|
|17945 |10091 |10088 |3907 |10132 |
|2 |12 |13 |48 |11 |
The csv-file:
myjinxin2015;raulbc777;smile67;Dentzil;SteffenVogel_79\n
17945;10091;10088;3907;10132\n
2;12;13;48;11
----------------------------------
After sorting:
As table (only visualization):
|Dentzil|myjinxin2015|raulbc777|smile67|SteffenVogel_79|
|3907 |17945 |10091 |10088 |10132 |
|48 |2 |12 |13 |11 |
The csv-file:
Dentzil;myjinxin2015;raulbc777;smile67;SteffenVogel_79\n
3907;17945;10091;10088;10132\n
48;2;12;13;11
```
There is no need for prechecks. You will always get a correct string with more than 1 line und more than 1 row. All columns will have different names.
Have fun coding it and please don't forget to vote and rank this kata! :-)
I have created other katas. Have a look if you like coding and challenges. | from collections import defaultdict
def sort_csv_columns(s):
d = defaultdict(list)
for i in s.splitlines():
for j, k in enumerate(i.split(";")):
d[j].append(k)
r = zip(*[i[1] for i in sorted(d.items(), key=lambda x:(x[1][0].lower(),x[1][0]))])
return "\n".join([";".join(i) for i in r]) | from collections import defaultdict
def sort_csv_columns(s):
d = defaultdict(list)
for i in s.splitlines():
for j, k in enumerate(i.split(";")):
d[j].append(k)
r = zip(*[i[1] for i in sorted(d.items(), key=lambda x:(x[1][0].lower(),x[1][0]))])
return "\n".join([";".join(i) for i in r]) | train | APPS_structured |
Barney lives in NYC. NYC has infinite number of intersections numbered with positive integers starting from 1. There exists a bidirectional road between intersections i and 2i and another road between i and 2i + 1 for every positive integer i. You can clearly see that there exists a unique shortest path between any two intersections. [Image]
Initially anyone can pass any road for free. But since SlapsGiving is ahead of us, there will q consecutive events happen soon. There are two types of events:
1. Government makes a new rule. A rule can be denoted by integers v, u and w. As the result of this action, the passing fee of all roads on the shortest path from u to v increases by w dollars.
2. Barney starts moving from some intersection v and goes to intersection u where there's a girl he wants to cuddle (using his fake name Lorenzo Von Matterhorn). He always uses the shortest path (visiting minimum number of intersections or roads) between two intersections.
Government needs your calculations. For each time Barney goes to cuddle a girl, you need to tell the government how much money he should pay (sum of passing fee of all roads he passes).
-----Input-----
The first line of input contains a single integer q (1 ≤ q ≤ 1 000).
The next q lines contain the information about the events in chronological order. Each event is described in form 1 v u w if it's an event when government makes a new rule about increasing the passing fee of all roads on the shortest path from u to v by w dollars, or in form 2 v u if it's an event when Barnie goes to cuddle from the intersection v to the intersection u.
1 ≤ v, u ≤ 10^18, v ≠ u, 1 ≤ w ≤ 10^9 states for every description line.
-----Output-----
For each event of second type print the sum of passing fee of all roads Barney passes in this event, in one line. Print the answers in chronological order of corresponding events.
-----Example-----
Input
7
1 3 4 30
1 4 1 2
1 3 6 8
2 4 3
1 6 1 40
2 3 7
2 2 4
Output
94
0
32
-----Note-----
In the example testcase:
Here are the intersections used: [Image] Intersections on the path are 3, 1, 2 and 4. Intersections on the path are 4, 2 and 1. Intersections on the path are only 3 and 6. Intersections on the path are 4, 2, 1 and 3. Passing fee of roads on the path are 32, 32 and 30 in order. So answer equals to 32 + 32 + 30 = 94. Intersections on the path are 6, 3 and 1. Intersections on the path are 3 and 7. Passing fee of the road between them is 0. Intersections on the path are 2 and 4. Passing fee of the road between them is 32 (increased by 30 in the first event and by 2 in the second). | q = int(input())
def full_way(u):
res = set()
while u >= 1:
res.add(u)
u //= 2
return res
def get_way(u, v):
res1 = full_way(u)
res2 = full_way(v)
m = max(res1 & res2)
res = set()
for x in res1 | res2:
if x > m:
res.add(x)
return res
d = {}
for i in range(q):
a = input().split()
if a[0] == '1':
v, u, w = list(map(int, a[1:]))
for x in get_way(u, v):
if x not in d:
d[x] = 0
d[x] += w
else:
v, u = list(map(int, a[1:]))
res = 0
for x in get_way(u, v):
if x in d:
res += d[x]
print(res)
| q = int(input())
def full_way(u):
res = set()
while u >= 1:
res.add(u)
u //= 2
return res
def get_way(u, v):
res1 = full_way(u)
res2 = full_way(v)
m = max(res1 & res2)
res = set()
for x in res1 | res2:
if x > m:
res.add(x)
return res
d = {}
for i in range(q):
a = input().split()
if a[0] == '1':
v, u, w = list(map(int, a[1:]))
for x in get_way(u, v):
if x not in d:
d[x] = 0
d[x] += w
else:
v, u = list(map(int, a[1:]))
res = 0
for x in get_way(u, v):
if x in d:
res += d[x]
print(res)
| train | APPS_structured |
DNA is a biomolecule that carries genetic information. It is composed of four different building blocks, called nucleotides: adenine (A), thymine (T), cytosine (C) and guanine (G). Two DNA strands join to form a double helix, whereby the nucleotides of one strand bond to the nucleotides of the other strand at the corresponding positions. The bonding is only possible if the nucleotides are complementary: A always pairs with T, and C always pairs with G.
Due to the asymmetry of the DNA, every DNA strand has a direction associated with it. The two strands of the double helix run in opposite directions to each other, which we refer to as the 'up-down' and the 'down-up' directions.
Write a function `checkDNA` that takes in two DNA sequences as strings, and checks if they are fit to form a fully complementary DNA double helix. The function should return a Boolean `true` if they are complementary, and `false` if there is a sequence mismatch (Example 1 below).
Note:
- All sequences will be of non-zero length, and consisting only of `A`, `T`, `C` and `G` characters.
- All sequences **will be given in the up-down direction**.
- The two sequences to be compared can be of different length. If this is the case and one strand is entirely bonded by the other, and there is no sequence mismatch between the two (Example 2 below), your function should still return `true`.
- If both strands are only partially bonded (Example 3 below), the function should return `false`.
Example 1:
Example 2:
Example 3:
---
#### If you enjoyed this kata, check out also my other DNA kata: [**Longest Repeated DNA Motif**](http://www.codewars.com/kata/longest-repeated-dna-motif) | def check_DNA(seq1, seq2):
if len(seq1) < len(seq2): seq1, seq2 = seq2, seq1
seq2 = seq2[::-1].replace('C','g').replace('G','c').replace('T','a').replace('A','t').upper()
return seq1.find(seq2) >= 0 | def check_DNA(seq1, seq2):
if len(seq1) < len(seq2): seq1, seq2 = seq2, seq1
seq2 = seq2[::-1].replace('C','g').replace('G','c').replace('T','a').replace('A','t').upper()
return seq1.find(seq2) >= 0 | train | APPS_structured |
Consider the string `"1 2 36 4 8"`. Lets take pairs of these numbers, concatenate each pair and determine how many of them of divisible by `k`.
```Pearl
If k = 3, we get following numbers ['12', '18', '21', '24', '42', '48', '81', '84'], all divisible by 3.
Note:
-- 21 and 12 are different pairs.
-- Elements must be from different indices, so '3636` is not a valid.
```
Given a string of numbers and an integer `k`, return the number of pairs that when concatenated, are divisible by `k`.
```
solve("1 2 36 4 8", 3) = 8, because they are ['12', '18', '21', '24', '42', '48', '81', '84']
solve("1 3 6 3", 3) = 6. They are ['36', '33', '63', '63', '33', '36']
```
More examples in test cases. Good luck!
Please also try [Simple remove duplicates](https://www.codewars.com/kata/5ba38ba180824a86850000f7) | from itertools import permutations, filterfalse
def solve(s, k):
return len(list(filterfalse(lambda x: int(''.join(x))%k, permutations(s.split(), 2)))) | from itertools import permutations, filterfalse
def solve(s, k):
return len(list(filterfalse(lambda x: int(''.join(x))%k, permutations(s.split(), 2)))) | train | APPS_structured |
Write a function named sumDigits which takes a number as input and returns the sum of the absolute value of each of the number's decimal digits. For example:
```python
sum_digits(10) # Returns 1
sum_digits(99) # Returns 18
sum_digits(-32) # Returns 5
```
Let's assume that all numbers in the input will be integer values. | sum_digits=lambda n:sum(int(e)for e in str(abs(n))) | sum_digits=lambda n:sum(int(e)for e in str(abs(n))) | train | APPS_structured |
You're putting together contact information for all the users of your website to ship them a small gift. You queried your database and got back a list of users, where each user is another list with up to two items: a string representing the user's name and their shipping zip code. Example data might look like:
```python
[["Grae Drake", 98110], ["Bethany Kok"], ["Alex Nussbacher", 94101], ["Darrell Silver", 11201]]
```
Notice that one of the users above has a name but _doesn't_ have a zip code.
Write a function `user_contacts()` that takes a two-dimensional list like the one above and returns a dictionary with an item for each user where the key is the user's name and the value is the user's zip code. If your data doesn't include a zip code then the value should be `None`.
For example, using the input above, `user_contacts()` would return this dictionary:
```python
{
"Grae Drake": 98110,
"Bethany Kok": None,
"Alex Nussbacher": 94101,
"Darrell Silver": 11201,
}
```
You don't have to worry about leading zeros in zip codes. | def user_contacts(data):
return {a : b[0] if b else None for a, *b in data} | def user_contacts(data):
return {a : b[0] if b else None for a, *b in data} | train | APPS_structured |
Write a function that accepts a square matrix (`N x N` 2D array) and returns the determinant of the matrix.
How to take the determinant of a matrix -- it is simplest to start with the smallest cases:
A 1x1 matrix `|a|` has determinant `a`.
A 2x2 matrix `[ [a, b], [c, d] ]` or
```
|a b|
|c d|
```
has determinant: `a*d - b*c`.
The determinant of an `n x n` sized matrix is calculated by reducing the problem to the calculation of the determinants of `n` matrices of`n-1 x n-1` size.
For the 3x3 case, `[ [a, b, c], [d, e, f], [g, h, i] ]` or
```
|a b c|
|d e f|
|g h i|
```
the determinant is: `a * det(a_minor) - b * det(b_minor) + c * det(c_minor)` where `det(a_minor)` refers to taking the determinant of the 2x2 matrix created by crossing out the row and column in which the element a occurs:
```
|- - -|
|- e f|
|- h i|
```
Note the alternation of signs.
The determinant of larger matrices are calculated analogously, e.g. if M is a 4x4 matrix with first row `[a, b, c, d]`, then:
`det(M) = a * det(a_minor) - b * det(b_minor) + c * det(c_minor) - d * det(d_minor)` | import numpy as np
def determinant(matrix):
return np.linalg.det(matrix).round()
| import numpy as np
def determinant(matrix):
return np.linalg.det(matrix).round()
| train | APPS_structured |
Amicable numbers are two different numbers so related that the sum of the proper divisors of each is equal to the other number. (A proper divisor of a number is a positive factor of that number other than the number itself. For example, the proper divisors of 6 are 1, 2, and 3.)
For example, the smallest pair of amicable numbers is (220, 284); for the proper divisors of 220 are 1, 2, 4, 5, 10, 11, 20, 22, 44, 55 and 110, of which the sum is 284; and the proper divisors of 284 are 1, 2, 4, 71 and 142, of which the sum is 220.
Derive function ```amicableNumbers(num1, num2)``` which returns ```true/True``` if pair ```num1 num2``` are amicable, ```false/False``` if not.
See more at https://en.wikipedia.org/wiki/Amicable_numbers | def amicable_numbers(n1,n2):
divisors1 = [i for i in range(1,n1) if n1%i==0]
divisors2 = [i for i in range(1,n2) if n2%i==0]
return bool(sum(divisors1)==n2 and sum(divisors2)==n1) | def amicable_numbers(n1,n2):
divisors1 = [i for i in range(1,n1) if n1%i==0]
divisors2 = [i for i in range(1,n2) if n2%i==0]
return bool(sum(divisors1)==n2 and sum(divisors2)==n1) | train | APPS_structured |
This kata is about multiplying a given number by eight if it is an even number and by nine otherwise. | def simple_multiplication(number) :
if number%2:
answer = number*9
else:
answer = number * 8
return answer
| def simple_multiplication(number) :
if number%2:
answer = number*9
else:
answer = number * 8
return answer
| train | APPS_structured |
Given an array of integers arr, sort the array by performing a series of pancake flips.
In one pancake flip we do the following steps:
Choose an integer k where 1 <= k <= arr.length.
Reverse the sub-array arr[1...k].
For example, if arr = [3,2,1,4] and we performed a pancake flip choosing k = 3, we reverse the sub-array [3,2,1], so arr = [1,2,3,4] after the pancake flip at k = 3.
Return the k-values corresponding to a sequence of pancake flips that sort arr. Any valid answer that sorts the array within 10 * arr.length flips will be judged as correct.
Example 1:
Input: arr = [3,2,4,1]
Output: [4,2,4,3]
Explanation:
We perform 4 pancake flips, with k values 4, 2, 4, and 3.
Starting state: arr = [3, 2, 4, 1]
After 1st flip (k = 4): arr = [1, 4, 2, 3]
After 2nd flip (k = 2): arr = [4, 1, 2, 3]
After 3rd flip (k = 4): arr = [3, 2, 1, 4]
After 4th flip (k = 3): arr = [1, 2, 3, 4], which is sorted.
Notice that we return an array of the chosen k values of the pancake flips.
Example 2:
Input: arr = [1,2,3]
Output: []
Explanation: The input is already sorted, so there is no need to flip anything.
Note that other answers, such as [3, 3], would also be accepted.
Constraints:
1 <= arr.length <= 100
1 <= arr[i] <= arr.length
All integers in arr are unique (i.e. arr is a permutation of the integers from 1 to arr.length). | class Solution:
def pancakeSort(self, A: List[int]) -> List[int]:
n = len(A)
res = []
for x in range(n, 1, -1):
idx = A.index(x)
res.extend([idx + 1, x])
A = A[idx::-1] + A[idx+1:]
A = A[x-1::-1]
return res
| class Solution:
def pancakeSort(self, A: List[int]) -> List[int]:
n = len(A)
res = []
for x in range(n, 1, -1):
idx = A.index(x)
res.extend([idx + 1, x])
A = A[idx::-1] + A[idx+1:]
A = A[x-1::-1]
return res
| train | APPS_structured |
Farmer John has just given the cows a program to play with! The program contains two integer variables, x and y, and performs the following operations on a sequence a_1, a_2, ..., a_{n} of positive integers: Initially, x = 1 and y = 0. If, after any step, x ≤ 0 or x > n, the program immediately terminates. The program increases both x and y by a value equal to a_{x} simultaneously. The program now increases y by a_{x} while decreasing x by a_{x}. The program executes steps 2 and 3 (first step 2, then step 3) repeatedly until it terminates (it may never terminate). So, the sequence of executed steps may start with: step 2, step 3, step 2, step 3, step 2 and so on.
The cows are not very good at arithmetic though, and they want to see how the program works. Please help them!
You are given the sequence a_2, a_3, ..., a_{n}. Suppose for each i (1 ≤ i ≤ n - 1) we run the program on the sequence i, a_2, a_3, ..., a_{n}. For each such run output the final value of y if the program terminates or -1 if it does not terminate.
-----Input-----
The first line contains a single integer, n (2 ≤ n ≤ 2·10^5). The next line contains n - 1 space separated integers, a_2, a_3, ..., a_{n} (1 ≤ a_{i} ≤ 10^9).
-----Output-----
Output n - 1 lines. On the i-th line, print the requested value when the program is run on the sequence i, a_2, a_3, ...a_{n}.
Please do not use the %lld specifier to read or write 64-bit integers in С++. It is preferred to use the cin, cout streams or the %I64d specifier.
-----Examples-----
Input
4
2 4 1
Output
3
6
8
Input
3
1 2
Output
-1
-1
-----Note-----
In the first sample For i = 1, x becomes $1 \rightarrow 2 \rightarrow 0$ and y becomes 1 + 2 = 3. For i = 2, x becomes $1 \rightarrow 3 \rightarrow - 1$ and y becomes 2 + 4 = 6. For i = 3, x becomes $1 \rightarrow 4 \rightarrow 3 \rightarrow 7$ and y becomes 3 + 1 + 4 = 8. | n = int(input())
t = [0, 0] + list(map(int, input().split()))
a, b = [0] * (n + 1), [0] * (n + 1)
a[1] = b[1] = -1
def f(s, a, b, l):
nonlocal t
l.reverse()
j, n = 0, len(l)
while True:
s += t[l[j]]
a[l[j]] = s
j += 1
if j == n: return
s += t[l[j]]
b[l[j]] = s
j += 1
if j == n: return
def g(i, k):
nonlocal a, b
l = []
if k:
a[i] = -1
l.append(i)
i += t[i]
while True:
if i > n: return f(0, a, b, l)
if b[i] > 0: return f(b[i], a, b, l)
if b[i] == -1: return
b[i] = -1
l.append(i)
i -= t[i]
if i < 1: return f(0, b, a, l)
if a[i] > 0: return f(a[i], b, a, l)
if a[i] == -1: return
a[i] = -1
l.append(i)
i += t[i]
for i in range(2, n + 1):
if a[i] == 0: g(i, True)
if b[i] == 0: g(i, False)
for i in range(1, n):
if b[i + 1] > 0: t[i] = i + b[i + 1]
else: t[i] = -1
print('\n'.join(map(str, t[1: n]))) | n = int(input())
t = [0, 0] + list(map(int, input().split()))
a, b = [0] * (n + 1), [0] * (n + 1)
a[1] = b[1] = -1
def f(s, a, b, l):
nonlocal t
l.reverse()
j, n = 0, len(l)
while True:
s += t[l[j]]
a[l[j]] = s
j += 1
if j == n: return
s += t[l[j]]
b[l[j]] = s
j += 1
if j == n: return
def g(i, k):
nonlocal a, b
l = []
if k:
a[i] = -1
l.append(i)
i += t[i]
while True:
if i > n: return f(0, a, b, l)
if b[i] > 0: return f(b[i], a, b, l)
if b[i] == -1: return
b[i] = -1
l.append(i)
i -= t[i]
if i < 1: return f(0, b, a, l)
if a[i] > 0: return f(a[i], b, a, l)
if a[i] == -1: return
a[i] = -1
l.append(i)
i += t[i]
for i in range(2, n + 1):
if a[i] == 0: g(i, True)
if b[i] == 0: g(i, False)
for i in range(1, n):
if b[i + 1] > 0: t[i] = i + b[i + 1]
else: t[i] = -1
print('\n'.join(map(str, t[1: n]))) | train | APPS_structured |
In case you might be unlucky enough not to know the best dark fantasy franchise ever, Berserk tells the story of a man that, hating gratuitous violence, decided to become a mercenary (thus one who sells violence, no gratuity anymore!) and starts an epic struggle against apparently unsormountable odds, unsure if he really wants to pursue a path of vengeance or to try to focus on his remaining and new loved ones.
*The main character, Gatsu,ready to start yet another Tuesday*
Ok, the first part was a joke, but you can read more about the tale of the main character, a "Byronic hero" for wikipedia, in other pages like [here](https://en.wikipedia.org/wiki/Berserk_(manga%29).
After an insanely long waiting, finally fans got the [follow up](https://en.wikipedia.org/wiki/Berserk_(2016_TV_series%29) of [the acclaimed 90s show](https://en.wikipedia.org/wiki/Berserk_(1997_TV_series%29).
Regrettably, while the first adaption was considerably shortened, the latter was quite butchered, missing entire parts, like the "lost children" arc, but that would have actual children butchered and thus you might get why it was decided to skip it. And fan could somehow cope with it, if it was not for the very meager use of CG (Computer Graphic).
Luckily, I am a simple man and every time Gatsu swings his humongous sword, that is enough to make me forget about everything else.
Your goal is to build a Berserk Rater function that takes an array/list of events of each episode (as strings) and calculate a rating based on that: you start with a score of 0 (hey, it's a work from Miura-sensei, I have great expectations to satisfy!) and you have to:
* subtract 2 each time "CG" is mentioned (case insensitive);
* add 5 every time "Clang" is mentioned (case insensitive);
* if a sentence has both "Clang" and "CG", "Clang" wins (add 5);
* remove 1 every time neither is mentioned (I get bored easily, you know, particularly if you remove important parts and keep side character whining for half an episode).
You should then return a string, structured like this:
* if the finale score is less than 0: "worstest episode ever";
* if the score is between 0 and 10: the score itself, as a string;
* if the finale score is more than 10: "bestest episode ever".
Examples:
```python
berserk_rater(["is this the CG from a P2 game?","Hell, no! Even the CG in the Dreamcast game was more fluid than this!","Well, at least Gatsu does his clang even against a mere rabbit", "Hey, Cosette was not in this part of the story!", "Ops, everybody dead again! Well, how boring..."])=="worstest episode ever"
berserk_rater(["missing the Count arc","lame CG","Gatsu doing its clang against a few henchmen", "even more lame CG"])=="0"
berserk_rater(["Farnese unable to shut the fuck up","awful CG dogs assaulting everybody", "Gatsu clanging the pig apostle!"])=="2"
berserk_rater(["spirits of the dead attacking Gatsu and getting clanged for good", "but the wheel spirits where really made with bad CG", "Isidoro trying to steal the dragon Slayer and getting a sort of clang on his face", "Gatsu vs. the possessed horse: clang!", "Farnese whining again...","a shame the episode ends with that scrappy CG"])=="10"
berserk_rater(["Holy chain knights being dicks", "Serpico almost getting clanged by Gatsu, but without losing his composure","lame CG","Luka getting kicked","Gatsu going clang against the angels", "Gatsu clanging vs Mozgus, big time!"])=="bestest episode ever"
```
Extra cookies if you manage to solve it all using a `reduce/inject` approach.
Oh, and in case you might want a taste of clang to fully understand it, [click](https://www.youtube.com/watch?v=IZgxH8MJFno) (one of the least gory samples I managed to find). | from functools import reduce; berserk_rater=lambda s: (lambda score: "worstest episode ever" if score<0 else "bestest episode ever" if score>10 else str(score))(reduce(lambda a,b: a+(lambda b: 5 if "clang" in b else -2 if "cg" in b else -1)(b.lower()),s,0)) | from functools import reduce; berserk_rater=lambda s: (lambda score: "worstest episode ever" if score<0 else "bestest episode ever" if score>10 else str(score))(reduce(lambda a,b: a+(lambda b: 5 if "clang" in b else -2 if "cg" in b else -1)(b.lower()),s,0)) | train | APPS_structured |
The notorious hacker group "Sed" managed to obtain a string $S$ from their secret sources. The string contains only lowercase English letters along with the character '?'.
A substring of $S$ is a contiguous subsequence of that string. For example, the string "chef" is a substring of the string "codechef", but the string "codeh" is not a substring of "codechef".
A substring of $S$ is good if it is possible to choose a lowercase English letter $C$ such that the following process succeeds:
- Create a string $R$, which is a copy of the substring, but with each '?' replaced by the letter $c$. Note that all occurrences of '?' must be replaced by the same letter.
- For each lowercase English letter:
- Compute the number of times it occurs in $S$ and the number of times it occurs in $R$; let's denote them by $A$ and $B$ respectively. The '?' characters in the original string $S$ are ignored when computing $A$.
- Check the parity of $A$ and $B$. If they do not have the same parity, i.e. one of them is even while the other is odd, then this process fails.
- If the parities of the number of occurrences in $S$ and $R$ are the same for each letter, the process succeeds.
For different substrings, we may choose different values of $C$.
Help Sed find the number of good substrings in the string $S$.
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first and only line of each test case contains a single string $S$.
-----Output-----
For each test case, print a single line containing one integer ― the number of good substrings.
-----Constraints-----
- $1 \le T \le 10^5$
- $1 \le S \le 10^5$
- $S$ contains only lowercase English letters ('a' through 'z') and '?'
- the sum of $|S|$ over all test cases does not exceed $10^5$
-----Example Input-----
5
aa?
a???
????
asfhaslskfak
af??avvnfed?fav?faf????
-----Example Output-----
2
6
4
2
27
-----Explanation-----
Example case 1: All letters occur an even number of times in $S$. The six substrings of $S$ are "a", "a", "?", "aa", "a?" and "aa?" (note that "a" is counted twice). Which of them are good?
- "a" is not good as 'a' occurs an odd number of times in this substring and there are no '?' to replace.
- "?" is also not good as replacing '?' by any letter causes this letter to occur in $R$ an odd number of times.
- "aa" is a good substring because each letter occurs in it an even number of times and there are no '?' to replace.
- "a?" is also a good substring. We can replace '?' with 'a'. Then, $R$ is "aa" and each letter occurs in this string an even number of times. Note that replacing '?' e.g. with 'b' would not work ($R$ would be "ab", where both 'a' and 'b' occur an odd number of times), but we may choose the replacement letter $C$ appropriately.
- "aa?" is not a good substring. For any replacement letter $C$, we find that $C$ occurs an odd number of times in $R$.
Example case 2: We especially note that "a???" is not a good substring. Since all '?' have to be replaced by the same character, we can only get strings of the form "aaaa", "abbb", "accc", etc., but none of them match the criteria for a good substring.
Example case 3: Any substring with even length is good. | def convertToParitys(s):
"""
This converts the string s to an int, which is a bitMap of the parity of each letter
odd ? = first bit set
odd a = second bit set
odd b = third bit set
etc
"""
keys = '?abcdefghijklmnopqrstuvwxyz'
paritys = {c:0 for c in keys}
for c in s:
paritys[c] += 1
for c, v in paritys.items():
paritys[c] = v%2
out = 0
bitValue = 1
for c in keys:
if paritys[c]:
out += bitValue
bitValue *= 2
return out
def getSolutionBitMaps(s):
"""
these are the 27 valid bitmaps that a substring can have
even ? and the parities the same
26 cases of odd ? and one bit different in the parity compared to s
"""
out = []
sP = convertToParitys(s)
if sP%2:
sP -= 1 # to remove the '?' parity
#even case -
out.append(sP)
#odd cases - need to xor sP with 1 + 2**n n = 1 to 26 inc to flip ? bit and each of the others
for n in range(1,27):
out.append(sP^(1+2**n))
return out
def getLeadingSubStringBitMapCounts(s):
"""
This calculates the bit map of each of the len(s) substrings starting with the first character and stores as a dictionary.
Getting TLE calculating each individually, so calculating with a single pass
"""
out = {}
bM = 0
keys = '?abcdefghijklmnopqrstuvwxyz'
paritys = {c:0 for c in keys}
values = {c:2**i for i,c in enumerate(keys)}
out[bM] = out.setdefault(bM, 0) + 1 #add the null substring
bMis = []
i = 0
bMis = [0]
for c in s:
i += 1
if paritys[c]:
paritys[c] = 0
bM -= values[c]
else:
paritys[c] = 1
bM += values[c]
out[bM] = out.setdefault(bM, 0) + 1
bMis.append(bM)
return out,bMis
def solve(s):
out = 0
bMjCounts,bMis = getLeadingSubStringBitMapCounts(s)
#print('bMjCounts')
#print(bMjCounts)
solutions = getSolutionBitMaps(s)
#print('solutions')
#print(solutions)
for bMi in bMis:
for bMs in solutions:
if bMs^bMi in bMjCounts:
out += bMjCounts[bMs^bMi]
#print(i,bMi,bMs,bMs^bMi,bMjCounts[bMs^bMi])
if 0 in solutions:
out -= len(s) #remove all null substrings
out //= 2 # since j may be less that i each substring is counted twice
return out
T = int(input())
for tc in range(T):
s = input()
print(solve(s))
| def convertToParitys(s):
"""
This converts the string s to an int, which is a bitMap of the parity of each letter
odd ? = first bit set
odd a = second bit set
odd b = third bit set
etc
"""
keys = '?abcdefghijklmnopqrstuvwxyz'
paritys = {c:0 for c in keys}
for c in s:
paritys[c] += 1
for c, v in paritys.items():
paritys[c] = v%2
out = 0
bitValue = 1
for c in keys:
if paritys[c]:
out += bitValue
bitValue *= 2
return out
def getSolutionBitMaps(s):
"""
these are the 27 valid bitmaps that a substring can have
even ? and the parities the same
26 cases of odd ? and one bit different in the parity compared to s
"""
out = []
sP = convertToParitys(s)
if sP%2:
sP -= 1 # to remove the '?' parity
#even case -
out.append(sP)
#odd cases - need to xor sP with 1 + 2**n n = 1 to 26 inc to flip ? bit and each of the others
for n in range(1,27):
out.append(sP^(1+2**n))
return out
def getLeadingSubStringBitMapCounts(s):
"""
This calculates the bit map of each of the len(s) substrings starting with the first character and stores as a dictionary.
Getting TLE calculating each individually, so calculating with a single pass
"""
out = {}
bM = 0
keys = '?abcdefghijklmnopqrstuvwxyz'
paritys = {c:0 for c in keys}
values = {c:2**i for i,c in enumerate(keys)}
out[bM] = out.setdefault(bM, 0) + 1 #add the null substring
bMis = []
i = 0
bMis = [0]
for c in s:
i += 1
if paritys[c]:
paritys[c] = 0
bM -= values[c]
else:
paritys[c] = 1
bM += values[c]
out[bM] = out.setdefault(bM, 0) + 1
bMis.append(bM)
return out,bMis
def solve(s):
out = 0
bMjCounts,bMis = getLeadingSubStringBitMapCounts(s)
#print('bMjCounts')
#print(bMjCounts)
solutions = getSolutionBitMaps(s)
#print('solutions')
#print(solutions)
for bMi in bMis:
for bMs in solutions:
if bMs^bMi in bMjCounts:
out += bMjCounts[bMs^bMi]
#print(i,bMi,bMs,bMs^bMi,bMjCounts[bMs^bMi])
if 0 in solutions:
out -= len(s) #remove all null substrings
out //= 2 # since j may be less that i each substring is counted twice
return out
T = int(input())
for tc in range(T):
s = input()
print(solve(s))
| train | APPS_structured |
The goal of this Kata is to return the greatest distance of index positions between matching number values in an array or 0 if there are no matching values.
Example:
In an array with the values [0, 2, 1, 2, 4, 1] the greatest index distance is between the matching '1' values at index 2 and 5. Executing greatestDistance against this array would return 3. (i.e. 5 - 2)
Here's the previous example in test form:
```python
test.assert_equals(greatest_distance([0, 2, 1, 2, 4, 1]), 3)
```
This is based on a Kata I had completed only to realize I has misread the instructions. I enjoyed solving the problem I thought it was asking me to complete so I thought I'd add a new Kata for others to enjoy. There are no tricks in this one, good luck! | def greatest_distance(arr):
return max(i - arr.index(x) for i,x in enumerate(arr)) | def greatest_distance(arr):
return max(i - arr.index(x) for i,x in enumerate(arr)) | train | APPS_structured |
Maheshmati and Sangu are playing a game. First, Maheshmati gives Sangu a sequence of $N$ distinct integers $a_1, a_2, \dots, a_N$ (not necessarily sorted) and an integer $K$. Sangu has to create all subsequences of this sequence with length $K$. For each subsequence, he has to write down the product of $K-2$ integers: all elements of this subsequence except the minimum and maximum element.
Sangu wins the game if he is able to write down all these numbers and tell Maheshmati their product (modulo $10^9+7$, since it can be very large). However, Sangu is a very lazy child and thus wants you to help him win this game. Compute the number Sangu should tell Maheshmati!
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first line of each test case contains two space-separated integers $N$ and $K$.
- The second line contains $N$ space-separated integers $a_1, a_2, \dots, a_N$.
-----Output-----
For each test case, print a single line containing one integer — the product of all numbers written down by Sangu modulo $10^9+7$.
-----Constraints-----
- $1 \le T \le 10$
- $3 \le N \le 5,000$
- $3 \le K \le N$
- $1 \le a_i \le 10,000$ for each valid $i$
- the numbers $a_1, a_2, \dots, a_N$ are pairwise distinct
-----Subtasks-----
Subtask #1 (20 points): $1 \le N \le 10$
Subtask #2 (80 points): original constraints
-----Example Input-----
1
4 3
1 2 3 4
-----Example Output-----
36
-----Explanation-----
Example case 1: There are four possible subsequences:
- $[1, 2, 3]$ (Sangu should write down $2$.)
- $[1, 3, 4]$ (Sangu should write down $3$.)
- $[1, 2, 4]$ (Sangu should write down $2$.)
- $[2, 3, 4]$ (Sangu should write down $3$.)
The required product is $2 \cdot 3 \cdot 2 \cdot 3 = 36$. | # cook your dish here
MOD = (10**9) + 7
def ncr(n, r, p):
# initialize numerator
# and denominator
num = den = 1
for i in range(r):
num = (num * (n - i)) % p
den = (den * (i + 1)) % p
return (num * pow(den,
p - 2, p)) % p
for _ in range(int(input())):
n , k = list(map( int, input().split()))
arr = list( map( int, input().split()) )
arr = sorted(arr)
value = ncr(n-1,k-1,MOD)
ans = 1
for x in range(1,n-1):
if (n - x - 1) >= (k-1) :
temp1 = ncr(n-x-1,k-1,MOD)
else:
temp1 = 0
if x >= (k-1):
temp2 = ncr(x,k-1,MOD)
else:
temp2 = 0
# print(value,ans,temp1,temp2)
ans = ( ans * (arr[x]**( value - temp2 - temp1 )) )%MOD
print(ans)
| # cook your dish here
MOD = (10**9) + 7
def ncr(n, r, p):
# initialize numerator
# and denominator
num = den = 1
for i in range(r):
num = (num * (n - i)) % p
den = (den * (i + 1)) % p
return (num * pow(den,
p - 2, p)) % p
for _ in range(int(input())):
n , k = list(map( int, input().split()))
arr = list( map( int, input().split()) )
arr = sorted(arr)
value = ncr(n-1,k-1,MOD)
ans = 1
for x in range(1,n-1):
if (n - x - 1) >= (k-1) :
temp1 = ncr(n-x-1,k-1,MOD)
else:
temp1 = 0
if x >= (k-1):
temp2 = ncr(x,k-1,MOD)
else:
temp2 = 0
# print(value,ans,temp1,temp2)
ans = ( ans * (arr[x]**( value - temp2 - temp1 )) )%MOD
print(ans)
| train | APPS_structured |
Allen and Bessie are playing a simple number game. They both know a function $f: \{0, 1\}^n \to \mathbb{R}$, i. e. the function takes $n$ binary arguments and returns a real value. At the start of the game, the variables $x_1, x_2, \dots, x_n$ are all set to $-1$. Each round, with equal probability, one of Allen or Bessie gets to make a move. A move consists of picking an $i$ such that $x_i = -1$ and either setting $x_i \to 0$ or $x_i \to 1$.
After $n$ rounds all variables are set, and the game value resolves to $f(x_1, x_2, \dots, x_n)$. Allen wants to maximize the game value, and Bessie wants to minimize it.
Your goal is to help Allen and Bessie find the expected game value! They will play $r+1$ times though, so between each game, exactly one value of $f$ changes. In other words, between rounds $i$ and $i+1$ for $1 \le i \le r$, $f(z_1, \dots, z_n) \to g_i$ for some $(z_1, \dots, z_n) \in \{0, 1\}^n$. You are to find the expected game value in the beginning and after each change.
-----Input-----
The first line contains two integers $n$ and $r$ ($1 \le n \le 18$, $0 \le r \le 2^{18}$).
The next line contains $2^n$ integers $c_0, c_1, \dots, c_{2^n-1}$ ($0 \le c_i \le 10^9$), denoting the initial values of $f$. More specifically, $f(x_0, x_1, \dots, x_{n-1}) = c_x$, if $x = \overline{x_{n-1} \ldots x_0}$ in binary.
Each of the next $r$ lines contains two integers $z$ and $g$ ($0 \le z \le 2^n - 1$, $0 \le g \le 10^9$). If $z = \overline{z_{n-1} \dots z_0}$ in binary, then this means to set $f(z_0, \dots, z_{n-1}) \to g$.
-----Output-----
Print $r+1$ lines, the $i$-th of which denotes the value of the game $f$ during the $i$-th round. Your answer must have absolute or relative error within $10^{-6}$.
Formally, let your answer be $a$, and the jury's answer be $b$. Your answer is considered correct if $\frac{|a - b|}{\max{(1, |b|)}} \le 10^{-6}$.
-----Examples-----
Input
2 2
0 1 2 3
2 5
0 4
Output
1.500000
2.250000
3.250000
Input
1 0
2 3
Output
2.500000
Input
2 0
1 1 1 1
Output
1.000000
-----Note-----
Consider the second test case. If Allen goes first, he will set $x_1 \to 1$, so the final value will be $3$. If Bessie goes first, then she will set $x_1 \to 0$ so the final value will be $2$. Thus the answer is $2.5$.
In the third test case, the game value will always be $1$ regardless of Allen and Bessie's play. | R = lambda:list(map(int,input().split()))
sum1 = 0
p1 = 1
a = [0]*263000
b = a
n,r = R()
p1 = 2**n
a = R()
sum1 = sum(a)
p2 = sum1 / p1
for i in range(r):
z,g=R()
sum1 = sum1 - a[z] + g
a[z] = g
b[i] = sum1/p1
print(p2)
for i in range(r):
print(b[i]) | R = lambda:list(map(int,input().split()))
sum1 = 0
p1 = 1
a = [0]*263000
b = a
n,r = R()
p1 = 2**n
a = R()
sum1 = sum(a)
p2 = sum1 / p1
for i in range(r):
z,g=R()
sum1 = sum1 - a[z] + g
a[z] = g
b[i] = sum1/p1
print(p2)
for i in range(r):
print(b[i]) | train | APPS_structured |
Indraneel has to sort the books in his library. His library has one long shelf. His books are numbered $1$ through $N$ and he wants to rearrange the books so that they appear in the sequence $1,2, ..., N$.
He intends to do this by a sequence of moves. In each move he can pick up any book from the shelf and insert it at a different place in the shelf. Suppose Indraneel has $5$ books and they are initially arranged in the order
21453214532 \quad 1 \quad 4 \quad 5 \quad 3
Indraneel will rearrange this in ascending order by first moving book $1$ to the beginning of the shelf to get
12453124531 \quad 2 \quad 4 \quad 5 \quad 3
Then, moving book $3$ to position $3$, he gets
12345123451 \quad 2 \quad 3 \quad 4 \quad 5
Your task is to write a program to help Indraneel determine the minimum number of moves that are necessary to sort his book shelf.
-----Input:-----
The first line of the input will contain a single integer $N$ indicating the number of books in Indraneel's library. This is followed by a line containing a permutation of $1, 2, ..., N$ indicating the intial state of Indraneel's book-shelf.
-----Output:-----
A single integer indicating the minimum number of moves necessary to sort Indraneel's book-shelf.
-----Constraints:-----
- $1 \leq N \leq 200000$.
- You may also assume that in $50 \%$ of the inputs, $1 \leq N \leq 5000$.
-----Sample Input-----
5
2 1 4 5 3
-----Sample Output-----
2 | n=int(input())
arr=[int(x) for x in input().split()]
l=[1]*n
if sorted(arr)==arr:
print('0')
else:
for i in range(0,len(arr)):
for j in range(i):
if arr[i]>=arr[j] and l[i]<l[j]+1:
l[i]=l[j]+1
print(n-max(l)) | n=int(input())
arr=[int(x) for x in input().split()]
l=[1]*n
if sorted(arr)==arr:
print('0')
else:
for i in range(0,len(arr)):
for j in range(i):
if arr[i]>=arr[j] and l[i]<l[j]+1:
l[i]=l[j]+1
print(n-max(l)) | train | APPS_structured |
There are n engineers numbered from 1 to n and two arrays: speed and efficiency, where speed[i] and efficiency[i] represent the speed and efficiency for the i-th engineer respectively. Return the maximum performance of a team composed of at most k engineers, since the answer can be a huge number, return this modulo 10^9 + 7.
The performance of a team is the sum of their engineers' speeds multiplied by the minimum efficiency among their engineers.
Example 1:
Input: n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 2
Output: 60
Explanation:
We have the maximum performance of the team by selecting engineer 2 (with speed=10 and efficiency=4) and engineer 5 (with speed=5 and efficiency=7). That is, performance = (10 + 5) * min(4, 7) = 60.
Example 2:
Input: n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 3
Output: 68
Explanation:
This is the same example as the first but k = 3. We can select engineer 1, engineer 2 and engineer 5 to get the maximum performance of the team. That is, performance = (2 + 10 + 5) * min(5, 4, 7) = 68.
Example 3:
Input: n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 4
Output: 72
Constraints:
1 <= n <= 10^5
speed.length == n
efficiency.length == n
1 <= speed[i] <= 10^5
1 <= efficiency[i] <= 10^8
1 <= k <= n | class Solution:
def maxPerformance(self, n: int, speed: List[int], efficiency: List[int], k: int) -> int:
sorting = sorted([(s,i) for i,s in enumerate(speed)])
speedset = set(i for _,i in sorting[len(sorting)-k:])
ssum = sum(s for s,_ in sorting[len(sorting)-k:])
removed = set()
idx = len(sorting)-k
ans = 0
for e,i in sorted([(e,i) for i,e in enumerate(efficiency)]):
if i in speedset:
ans = max(ans, e * ssum)
speedset.remove(i)
ssum -= speed[i]
idx -= 1
while idx >= 0 and sorting[idx][1] in removed:
idx -= 1
if idx >= 0:
speedset.add(sorting[idx][1])
ssum += sorting[idx][0]
else:
ans = max(ans, e * (ssum - sorting[idx][0] + speed[i]))
removed.add(i)
return ans % (10**9 + 7)
| class Solution:
def maxPerformance(self, n: int, speed: List[int], efficiency: List[int], k: int) -> int:
sorting = sorted([(s,i) for i,s in enumerate(speed)])
speedset = set(i for _,i in sorting[len(sorting)-k:])
ssum = sum(s for s,_ in sorting[len(sorting)-k:])
removed = set()
idx = len(sorting)-k
ans = 0
for e,i in sorted([(e,i) for i,e in enumerate(efficiency)]):
if i in speedset:
ans = max(ans, e * ssum)
speedset.remove(i)
ssum -= speed[i]
idx -= 1
while idx >= 0 and sorting[idx][1] in removed:
idx -= 1
if idx >= 0:
speedset.add(sorting[idx][1])
ssum += sorting[idx][0]
else:
ans = max(ans, e * (ssum - sorting[idx][0] + speed[i]))
removed.add(i)
return ans % (10**9 + 7)
| train | APPS_structured |
=====Function Descriptions=====
.intersection()
The .intersection() operator returns the intersection of a set and the set of elements in an iterable.
Sometimes, the & operator is used in place of the .intersection() operator, but it only operates on the set of elements in set.
The set is immutable to the .intersection() operation (or & operation).
>>> s = set("Hacker")
>>> print s.intersection("Rank")
set(['a', 'k'])
>>> print s.intersection(set(['R', 'a', 'n', 'k']))
set(['a', 'k'])
>>> print s.intersection(['R', 'a', 'n', 'k'])
set(['a', 'k'])
>>> print s.intersection(enumerate(['R', 'a', 'n', 'k']))
set([])
>>> print s.intersection({"Rank":1})
set([])
>>> s & set("Rank")
set(['a', 'k'])
=====Problem Statement=====
The students of District College have subscriptions to English and French newspapers. Some students have subscribed only to English, some have subscribed only to French, and some have subscribed to both newspapers.
You are given two sets of student roll numbers. One set has subscribed to the English newspaper, one set has subscribed to the French newspaper. Your task is to find the total number of students who have subscribed to both newspapers.
=====Input Format=====
The first line contains n, the number of students who have subscribed to the English newspaper.
The second line contains n space separated roll numbers of those students.
The third line contains b, the number of students who have subscribed to the French newspaper.
The fourth line contains b space separated roll numbers of those students.
=====Constraints=====
0 < Total number of students in college < 1000
=====Output Format=====
Output the total number of students who have subscriptions to both English and French newspapers. | #!/usr/bin/env python3
def __starting_point():
n = int(input().strip())
english = set(map(int, input().strip().split(' ')))
m = int(input().strip())
french = set(map(int, input().strip().split(' ')))
print(len(english.intersection(french)))
__starting_point() | #!/usr/bin/env python3
def __starting_point():
n = int(input().strip())
english = set(map(int, input().strip().split(' ')))
m = int(input().strip())
french = set(map(int, input().strip().split(' ')))
print(len(english.intersection(french)))
__starting_point() | train | APPS_structured |
Given the array of integers nums, you will choose two different indices i and j of that array. Return the maximum value of (nums[i]-1)*(nums[j]-1).
Example 1:
Input: nums = [3,4,5,2]
Output: 12
Explanation: If you choose the indices i=1 and j=2 (indexed from 0), you will get the maximum value, that is, (nums[1]-1)*(nums[2]-1) = (4-1)*(5-1) = 3*4 = 12.
Example 2:
Input: nums = [1,5,4,5]
Output: 16
Explanation: Choosing the indices i=1 and j=3 (indexed from 0), you will get the maximum value of (5-1)*(5-1) = 16.
Example 3:
Input: nums = [3,7]
Output: 12
Constraints:
2 <= nums.length <= 500
1 <= nums[i] <= 10^3 | class Solution:
def maxProduct(self, nums: List[int]) -> int:
a = max(nums)
nums.remove(a)
return (a-1)*(max(nums)-1)
| class Solution:
def maxProduct(self, nums: List[int]) -> int:
a = max(nums)
nums.remove(a)
return (a-1)*(max(nums)-1)
| train | APPS_structured |
Given an unsorted array, find the maximum difference between the successive elements in its sorted form.
Return 0 if the array contains less than 2 elements.
Example 1:
Input: [3,6,9,1]
Output: 3
Explanation: The sorted form of the array is [1,3,6,9], either
(3,6) or (6,9) has the maximum difference 3.
Example 2:
Input: [10]
Output: 0
Explanation: The array contains less than 2 elements, therefore return 0.
Note:
You may assume all elements in the array are non-negative integers and fit in the 32-bit signed integer range.
Try to solve it in linear time/space. | class Solution:
def maximumGap(self, num):
if len(num) < 2 or min(num) == max(num):
return 0
a, b = min(num), max(num)
import math
size = math.ceil((b - a) / (len(num) - 1))
bucket = [[None, None] for _ in range((b - a) // size + 1)]
for n in num:
b = bucket[(n - a) // size]
b[0] = n if b[0] is None else min(b[0], n)
b[1] = n if b[1] is None else max(b[1], n)
bucket = [b for b in bucket if b[0] is not None]
return max(bucket[i][0] - bucket[i - 1][1] for i in range(1, len(bucket))) | class Solution:
def maximumGap(self, num):
if len(num) < 2 or min(num) == max(num):
return 0
a, b = min(num), max(num)
import math
size = math.ceil((b - a) / (len(num) - 1))
bucket = [[None, None] for _ in range((b - a) // size + 1)]
for n in num:
b = bucket[(n - a) // size]
b[0] = n if b[0] is None else min(b[0], n)
b[1] = n if b[1] is None else max(b[1], n)
bucket = [b for b in bucket if b[0] is not None]
return max(bucket[i][0] - bucket[i - 1][1] for i in range(1, len(bucket))) | train | APPS_structured |
You will be given an array of numbers.
For each number in the array you will need to create an object.
The object key will be the number, as a string. The value will be the corresponding character code, as a string.
Return an array of the resulting objects.
All inputs will be arrays of numbers. All character codes are valid lower case letters. The input array will not be empty. | def num_obj(s):
return [{str(c): chr(c)} for c in s] | def num_obj(s):
return [{str(c): chr(c)} for c in s] | train | APPS_structured |
Chef is playing with an expression which consists of integer operands and the following binary
Bitwise operators - AND, OR and XOR. He is trying to figure out that what could be the Maximum possible answer of the expression, given that he can perform the operation in any order i.e not necessarily follow the rule of Precedence of operators while evaluating the expression.
After some time of consistent work Chef starts feeling exhausted and wants you to automate this process for him. Can you help him out?
The expression has Bitwise operators in symbol format:
- & stands for AND
- | stands for OR
- ^ stands for XOR
NOTE : It is guaranteed that the expression will always be valid, also each OPERATOR will always be preceded and succeeded by an OPERAND.
-----Input:-----
- The first line of input contains a single integer $T$ denoting the number of test cases.
- The only line of input for each test case is a $string$ which is the Chef's expression to evaluate.
-----Output:-----
For each test case print a single integer i.e the maximum possible value of Chef's expression.
-----Constraints-----
- $1 \leq T \leq 100$.
- The number of OPERATORS in the expression will be atleast 1 and atmost 10.
- Each OPERAND may range from 0 to $10^9$.
-----Subtasks-----
- 10 points : The number of OPERATORS in the expression will be atmost 5.
- 20 points : The number of OPERATORS in the expression will be atmost 8.
- 70 points : Original constraints.
-----Sample Input:-----
2
3^40|10^2
92^95|56&2&3
-----Sample Output:-----
43
95
-----EXPLANATION:-----CASE 2 :
- If we first compute (56 & 2), the expression becomes 92^95|0&3, since (56 & 2) yields $0$.
- Now on computing (95 | 0), the expression becomes 92^95&3.
- Further on computing (95 & 3), the expression becomes 92^3.
- Finally (92 ^ 3) yields 95, which is the maximum value of the expression. | def extract(s):
arr = []
news = ''
for x in s:
try:
x = int(x)
news += str(x)
except:
arr += [news]
news = ''
arr += [x]
arr += [news]
return arr
t = int(input())
for _ in range(t):
s = input()
arr = extract(s)
n = len(arr)//2 + 1
dp = [[0]*n for j in range(n)]
for i in range(n):
dp[i][i] = [int(arr[2*i])]
n = len(arr)
for i in range(3, n+1, 2):
for j in range(0, n-i+1, 2):
ans = []
for k in range(j+2, i+j+1, 2):
for x in dp[j//2][(k-1)//2]:
for y in dp[k//2][(i+j)//2]:
if arr[k-1] == '&':
ans += [x & y]
if arr[k-1] == '|':
ans += [x | y]
if arr[k-1] == '^':
ans += [x ^ y]
if i != n:
dp[j//2][k//2] = ans[:]
else:
print(max(ans))
| def extract(s):
arr = []
news = ''
for x in s:
try:
x = int(x)
news += str(x)
except:
arr += [news]
news = ''
arr += [x]
arr += [news]
return arr
t = int(input())
for _ in range(t):
s = input()
arr = extract(s)
n = len(arr)//2 + 1
dp = [[0]*n for j in range(n)]
for i in range(n):
dp[i][i] = [int(arr[2*i])]
n = len(arr)
for i in range(3, n+1, 2):
for j in range(0, n-i+1, 2):
ans = []
for k in range(j+2, i+j+1, 2):
for x in dp[j//2][(k-1)//2]:
for y in dp[k//2][(i+j)//2]:
if arr[k-1] == '&':
ans += [x & y]
if arr[k-1] == '|':
ans += [x | y]
if arr[k-1] == '^':
ans += [x ^ y]
if i != n:
dp[j//2][k//2] = ans[:]
else:
print(max(ans))
| train | APPS_structured |
Your task is to make two functions, ```max``` and ```min``` (`maximum` and `minimum` in PHP and Python) that take a(n) array/vector of integers ```list``` as input and outputs, respectively, the largest and lowest number in that array/vector.
#Examples
```python
maximun([4,6,2,1,9,63,-134,566]) returns 566
minimun([-52, 56, 30, 29, -54, 0, -110]) returns -110
maximun([5]) returns 5
minimun([42, 54, 65, 87, 0]) returns 0
```
#Notes
- You may consider that there will not be any empty arrays/vectors. | def minimum(arr):
mi=100000
for a in arr:
if a<mi:
mi=a
return mi
def maximum(arr):
ma=-1000000
for b in arr:
if b>ma:
ma=b
return ma | def minimum(arr):
mi=100000
for a in arr:
if a<mi:
mi=a
return mi
def maximum(arr):
ma=-1000000
for b in arr:
if b>ma:
ma=b
return ma | train | APPS_structured |
Your task is to create a new implementation of `modpow` so that it computes `(x^y)%n` for large `y`. The problem with the current implementation is that the output of `Math.pow` is so large on our inputs that it won't fit in a 64-bit float.
You're also going to need to be efficient, because we'll be testing some pretty big numbers. | def power_mod(base, exponent, modulus):
if base is 0: return 0
if exponent is 0: return 0
base = base % modulus
result = 1
while (exponent > 0):
if (exponent % 2 == 1):
result = (result * base) % modulus
exponent = exponent >> 1
base = (base * base) % modulus
return result | def power_mod(base, exponent, modulus):
if base is 0: return 0
if exponent is 0: return 0
base = base % modulus
result = 1
while (exponent > 0):
if (exponent % 2 == 1):
result = (result * base) % modulus
exponent = exponent >> 1
base = (base * base) % modulus
return result | train | APPS_structured |
Write a function ```convert_temp(temp, from_scale, to_scale)``` converting temperature from one scale to another.
Return converted temp value.
Round converted temp value to an integer(!).
Reading: http://en.wikipedia.org/wiki/Conversion_of_units_of_temperature
```
possible scale inputs:
"C" for Celsius
"F" for Fahrenheit
"K" for Kelvin
"R" for Rankine
"De" for Delisle
"N" for Newton
"Re" for Réaumur
"Ro" for Rømer
```
```temp``` is a number, ```from_scale``` and ```to_scale``` are strings.
```python
convert_temp( 100, "C", "F") # => 212
convert_temp( 40, "Re", "C") # => 50
convert_temp( 60, "De", "F") # => 140
convert_temp(373.15, "K", "N") # => 33
convert_temp( 666, "K", "K") # => 666
``` | convertToC = {'C':lambda t: t, 'F':lambda t: (t - 32) * 5 / 9, 'K':lambda t: t - 273.15, 'R':lambda t: (t - 491.67) * 5 / 9,
'De':lambda t: 100 - t * 2 / 3, 'N':lambda t: t * 100 / 33, 'Re':lambda t: t * 5 / 4, 'Ro':lambda t: (t - 7.5) * 40 / 21}
convertFromC = {'C':lambda t: t, 'F':lambda t: t * 9 / 5 + 32, 'K':lambda t: t + 273.15, 'R':lambda t: (t + 273.15) * 9 / 5,
'De':lambda t: (100 - t) * 3 / 2, 'N':lambda t: t * 33 / 100, 'Re':lambda t: t * 4 / 5, 'Ro':lambda t: t * 21 / 40 + 7.5}
def convert_temp(temp, from_scale, to_scale):
return round(convertFromC[to_scale](convertToC[from_scale](temp))) | convertToC = {'C':lambda t: t, 'F':lambda t: (t - 32) * 5 / 9, 'K':lambda t: t - 273.15, 'R':lambda t: (t - 491.67) * 5 / 9,
'De':lambda t: 100 - t * 2 / 3, 'N':lambda t: t * 100 / 33, 'Re':lambda t: t * 5 / 4, 'Ro':lambda t: (t - 7.5) * 40 / 21}
convertFromC = {'C':lambda t: t, 'F':lambda t: t * 9 / 5 + 32, 'K':lambda t: t + 273.15, 'R':lambda t: (t + 273.15) * 9 / 5,
'De':lambda t: (100 - t) * 3 / 2, 'N':lambda t: t * 33 / 100, 'Re':lambda t: t * 4 / 5, 'Ro':lambda t: t * 21 / 40 + 7.5}
def convert_temp(temp, from_scale, to_scale):
return round(convertFromC[to_scale](convertToC[from_scale](temp))) | train | APPS_structured |
People in Karunanagar are infected with Coronavirus. To understand the spread of disease and help contain it as early as possible, Chef wants to analyze the situation in the town. Therefore, he does the following:
- Chef represents the population of Karunanagar as a binary string of length $N$ standing in a line numbered from $1$ to $N$ from left to right, where an infected person is represented as $1$ and an uninfected person as $0$.
- Every day, an infected person in this binary string can infect an adjacent (the immediate left and right) uninfected person.
- Therefore, if before Day 1, the population is $00100$, then at the end of Day 1, it becomes $01110$ and at the end of Day 2, it becomes $11111$.
But people of Karunanagar are smart and they know that if they 'socially isolate' themselves as early as possible, they reduce the chances of the virus spreading. Therefore on $i$-th day, person numbered $P_i$ isolates himself from person numbered $P_i - 1$, thus cannot affect each other. This continues in the town for $D$ days.
Given the population binary string before Day 1, Chef wants to calculate the total number of infected people in Karunanagar at the end of the day $D$. Since Chef has gone to wash his hands now, can you help do the calculation for him?
-----Input:-----
- First line will contain $T$, number of testcases. Then the test cases follow.
- The first line of each test case contains a single integer $N$ denoting the length of the binary string.
- The next line contains a binary string of length $N$ denoting the population before the first day, with $1$ for an infected person and $0$ for uninfected.
- The next line contains a single integer $D$ - the number of days people isolate themselves.
- The next line contains $P$ - a list of $D$ distinct space-separated integers where each $P_{i}$ denotes that at the start of $i^{th}$ day, person $P_{i}$ isolated him/herself from the person numbered $P_i-1$.
-----Output:-----
For each test case, print a single integer denoting the total number of people who are infected after the end of $D^{th}$ day.
-----Constraints-----
- $1 \leq T \leq 200$
- $2 \leq N \leq 10^{4}$
- $1 \leq D < N$
- $2 \leq P_{i} \leq N$ for $1 \le i \le D$
-----Subtasks-----
Subtask #1(30 points): $1 \leq T \leq 100$, $2 \leq N \leq 2000$
Subtask #2(70 points): Original Constraints
-----Sample Input:-----
2
9
000010000
3
2 5 8
5
00001
1
5
-----Sample Output:-----
6
1
-----EXPLANATION:-----
For the purpose of this explanation, a social distance can be denoted with a '$|$'.
For the first testcase:
-
Before Day $1$, the population is: $0|00010000$
-
Before Day $2$, the population is: $0|001|11000$
-
Before Day $3$, the population is: $0|011|111|00$
-
Therefore, after Day $3$, the population will be: $0|111|111|00$
So, there are $6$ infected persons.
For the second testcase:
Before Day $1$, the population is: $0000|1$
Therefore, there is one infected person. | # cook your dish here
T = int(input())
for _ in range(T):
N = int(input())
s = list(input())
n = int(input())
days = list(map(int,input().split()))
total_infected = sum(1 for x in s if x == '1')
def seperate(s,d):
s.insert(d-1,'#')
return s
def infect(s,k,total_infected):
index_list = set()
if s[0] == '1' and s[1] == '0':
s[1] = '1'
total_infected += 1
for i in range(1,(N+k)):
present = s[i]
prev = s[i-1]
next = s[i+1]
if present == '1':
if prev == '0':
index_list.add(i-1)
if next == '0':
index_list.add(i+1)
for i in index_list:
s[i] = '1'
total_infected += 1
return (s, total_infected)
for i in range(n):
s = seperate(s,i+days[i])
s,total_infected = infect(s,i,total_infected)
print(total_infected) | # cook your dish here
T = int(input())
for _ in range(T):
N = int(input())
s = list(input())
n = int(input())
days = list(map(int,input().split()))
total_infected = sum(1 for x in s if x == '1')
def seperate(s,d):
s.insert(d-1,'#')
return s
def infect(s,k,total_infected):
index_list = set()
if s[0] == '1' and s[1] == '0':
s[1] = '1'
total_infected += 1
for i in range(1,(N+k)):
present = s[i]
prev = s[i-1]
next = s[i+1]
if present == '1':
if prev == '0':
index_list.add(i-1)
if next == '0':
index_list.add(i+1)
for i in index_list:
s[i] = '1'
total_infected += 1
return (s, total_infected)
for i in range(n):
s = seperate(s,i+days[i])
s,total_infected = infect(s,i,total_infected)
print(total_infected) | train | APPS_structured |
Given an array of n positive integers and a positive integer s, find the minimal length of a contiguous subarray of which the sum ≥ s. If there isn't one, return 0 instead.
Example:
Input: s = 7, nums = [2,3,1,2,4,3]
Output: 2
Explanation: the subarray [4,3] has the minimal length under the problem constraint.
Follow up:
If you have figured out the O(n) solution, try coding another solution of which the time complexity is O(n log n). | class Solution:
def minSubArrayLen(self, s, nums):
"""
:type s: int
:type nums: List[int]
:rtype: int
"""
if nums is None or len(nums) == 0:
return 0
running_sum = [nums[0]]
for num in nums[1:]:
running_sum.append(running_sum[-1] + num)
def sub_sum(i,j):
to_remove = 0 if i == 0 else running_sum[i-1]
to_add = 0 if j == 0 else running_sum[j-1]
return to_add - to_remove
min_seen = float('inf')
fast = 0
slow = 0
while fast < len(nums):
while sub_sum(slow, fast) < s and fast < len(nums):
fast += 1
while sub_sum(slow, fast) >= s and slow <= fast:
min_seen = min(min_seen, fast - slow)
slow += 1
return 0 if min_seen == float('inf') else min_seen
| class Solution:
def minSubArrayLen(self, s, nums):
"""
:type s: int
:type nums: List[int]
:rtype: int
"""
if nums is None or len(nums) == 0:
return 0
running_sum = [nums[0]]
for num in nums[1:]:
running_sum.append(running_sum[-1] + num)
def sub_sum(i,j):
to_remove = 0 if i == 0 else running_sum[i-1]
to_add = 0 if j == 0 else running_sum[j-1]
return to_add - to_remove
min_seen = float('inf')
fast = 0
slow = 0
while fast < len(nums):
while sub_sum(slow, fast) < s and fast < len(nums):
fast += 1
while sub_sum(slow, fast) >= s and slow <= fast:
min_seen = min(min_seen, fast - slow)
slow += 1
return 0 if min_seen == float('inf') else min_seen
| train | APPS_structured |
Debug the functions
Should be easy, begin by looking at the code. Debug the code and the functions should work.
There are three functions: ```Multiplication (x)``` ```Addition (+)``` and ```Reverse (!esreveR)```
i {
font-size:16px;
}
#heading {
padding: 2em;
text-align: center;
background-color: #0033FF;
width: 100%;
height: 5em;
} | def multi(l_st):
x=1
for ele in l_st:
x*=ele
return x
def add(l_st):
return sum(l_st)
def reverse(l_st):
return l_st[::-1] | def multi(l_st):
x=1
for ele in l_st:
x*=ele
return x
def add(l_st):
return sum(l_st)
def reverse(l_st):
return l_st[::-1] | train | APPS_structured |
You will be given a fruit which a farmer has harvested, your job is to see if you should buy or sell.
You will be given 3 pairs of fruit. Your task is to trade your harvested fruit back into your harvested fruit via the intermediate pair, you should return a string of 3 actions.
if you have harvested apples, you would buy this fruit pair: apple_orange, if you have harvested oranges, you would sell that fruit pair.
(In other words, to go from left to right (apples to oranges) you buy, and to go from right to left you sell (oranges to apple))
e.g.
apple_orange, orange_pear, apple_pear
1. if you have harvested apples, you would buy this fruit pair: apple_orange
2. Then you have oranges, so again you would buy this fruit pair: orange_pear
3. After you have pear, but now this time you would sell this fruit pair: apple_pear
4. Finally you are back with the apples
So your function would return a list: [“buy”,”buy”,”sell”]
If any invalid input is given, "ERROR" should be returned | def buy_or_sell(pairs,f):
out=[]
for pair in pairs:
if pair[0]==f:
f=pair[1]
out.append("buy")
elif pair[1]==f:
f=pair[0]
out.append("sell")
else:return "ERROR"
return out | def buy_or_sell(pairs,f):
out=[]
for pair in pairs:
if pair[0]==f:
f=pair[1]
out.append("buy")
elif pair[1]==f:
f=pair[0]
out.append("sell")
else:return "ERROR"
return out | train | APPS_structured |
Motivation
---------
When compressing sequences of symbols, it is useful to have many equal symbols follow each other, because then they can be encoded with a run length encoding. For example, RLE encoding of `"aaaabbbbbbbbbbbcccccc"` would give something like `4a 11b 6c`.
(Look [here](http://www.codewars.com/kata/run-length-encoding/) for learning more about the run-length-encoding.)
Of course, RLE is interesting only if the string contains many identical consecutive characters. But what bout human readable text? Here comes the Burrows-Wheeler-Transformation.
Transformation
-------------
There even exists a transformation, which brings equal symbols closer together, it is called the **Burrows-Wheeler-Transformation**. The forward transformation works as follows: Let's say we have a sequence with length n, first write every shift of that string into a *n x n* matrix:
```
Input: "bananabar"
b a n a n a b a r
r b a n a n a b a
a r b a n a n a b
b a r b a n a n a
a b a r b a n a n
n a b a r b a n a
a n a b a r b a n
n a n a b a r b a
a n a n a b a r b
```
Then we sort that matrix by its rows. The output of the transformation then is the **last column** and the **row index** in which the original string is in:
```
.-.
a b a r b a n a n
a n a b a r b a n
a n a n a b a r b
a r b a n a n a b
b a n a n a b a r <- 4
b a r b a n a n a
n a b a r b a n a
n a n a b a r b a
r b a n a n a b a
'-'
Output: ("nnbbraaaa", 4)
```
```if:java
To handle the two kinds of output data, we will use the preloaded class `BWT`, whose contract is the following:
public class BWT {
public String s;
public int n;
public BWT(String s, int n)
@Override public String toString()
@Override public boolean equals(Object o)
@Override public int hashCode()
}
```
Of course we want to restore the original input, therefore you get the following hints:
1. The output contains the last matrix column.
2. The first column can be acquired by sorting the last column.
3. **For every row of the table:** Symbols in the first column follow on symbols in the last column, in the same way they do in the input string.
4. You don't need to reconstruct the whole table to get the input back.
Goal
----
The goal of this Kata is to write both, the `encode` and `decode` functions. Together they should work as the identity function on lists. (*Note:* For the empty input, the row number is ignored.)
Further studies
--------------
You may have noticed that symbols are not always consecutive, but just in proximity, after the transformation. If you're interested in how to deal with that, you should have a look at [this Kata](http://www.codewars.com/kata/move-to-front-encoding/). | def encode(s):
if not s:
return '', 0
list_s = []
for x in range(len(s)):
list_s.append(s[x:] + s[:x])
sort_list_s = sorted(list_s)
final_word = ""
for e in sort_list_s:
final_word += e[-1]
return final_word, sort_list_s.index(s)
def decode(s, n):
s_list = list(s) # ['l', 'a', 'n', 'e', 'v']
s_list.sort()
s_list = ''.join(s_list)
final_list = []
count = 1
if not s:
return s
else:
while count < len(s):
for i in range(len(s)):
final_list.append(s[i] + s_list[i])
count += 1
s_list = sorted(final_list)
final_list = []
return s_list[n] | def encode(s):
if not s:
return '', 0
list_s = []
for x in range(len(s)):
list_s.append(s[x:] + s[:x])
sort_list_s = sorted(list_s)
final_word = ""
for e in sort_list_s:
final_word += e[-1]
return final_word, sort_list_s.index(s)
def decode(s, n):
s_list = list(s) # ['l', 'a', 'n', 'e', 'v']
s_list.sort()
s_list = ''.join(s_list)
final_list = []
count = 1
if not s:
return s
else:
while count < len(s):
for i in range(len(s)):
final_list.append(s[i] + s_list[i])
count += 1
s_list = sorted(final_list)
final_list = []
return s_list[n] | train | APPS_structured |
# Scenario
*Now that the competition gets tough it will* **_Sort out the men from the boys_** .
**_Men_** are the **_Even numbers_** and **_Boys_** are the **_odd_**  
___
# Task
**_Given_** an *array/list [] of n integers* , **_Separate_** *The even numbers from the odds* , or **_Separate_** **_the men from the boys_**  
___
# Notes
* **_Return_** *an array/list where* **_Even numbers_** **_come first then odds_**
* Since , **_Men are stronger than Boys_** , *Then* **_Even numbers_** in **_ascending order_** While **_odds in descending_** .
* **_Array/list_** size is *at least **_4_*** .
* **_Array/list_** numbers could be a *mixture of positives , negatives* .
* **_Have no fear_** , *It is guaranteed that no Zeroes will exists* . 
* **_Repetition_** of numbers in *the array/list could occur* , So **_(duplications are not included when separating)_**.
____
# Input >> Output Examples:
```
menFromBoys ({7, 3 , 14 , 17}) ==> return ({14, 17, 7, 3})
```
## **_Explanation_**:
**_Since_** , `{ 14 }` is the **_even number_** here , So it **_came first_** , **_then_** *the odds in descending order* `{17 , 7 , 3}` .
____
```
menFromBoys ({-94, -99 , -100 , -99 , -96 , -99 }) ==> return ({-100 , -96 , -94 , -99})
```
## **_Explanation_**:
* **_Since_** , `{ -100, -96 , -94 }` is the **_even numbers_** here , So it **_came first_** in *ascending order *, **_then_** *the odds in descending order* `{ -99 }`
* **_Since_** , **_(Duplications are not included when separating)_** , *then* you can see **_only one (-99)_** *was appeared in the final array/list* .
____
```
menFromBoys ({49 , 818 , -282 , 900 , 928 , 281 , -282 , -1 }) ==> return ({-282 , 818 , 900 , 928 , 281 , 49 , -1})
```
## **_Explanation_**:
* **_Since_** , `{-282 , 818 , 900 , 928 }` is the **_even numbers_** here , So it **_came first_** in *ascending order* , **_then_** *the odds in descending order* `{ 281 , 49 , -1 }`
* **_Since_** , **_(Duplications are not included when separating)_** , *then* you can see **_only one (-282)_** *was appeared in the final array/list* .
____
____
___
# [Playing with Numbers Series](https://www.codewars.com/collections/playing-with-numbers)
# [Playing With Lists/Arrays Series](https://www.codewars.com/collections/playing-with-lists-slash-arrays)
# [Bizarre Sorting-katas](https://www.codewars.com/collections/bizarre-sorting-katas)
# [For More Enjoyable Katas](http://www.codewars.com/users/MrZizoScream/authored)
___
## ALL translations are welcomed
## Enjoy Learning !!
# Zizou | def men_from_boys(arr):
arr=list(set(arr))
men=[i for i in arr if i%2==0]
boys=[i for i in arr if i%2==1]
men=sorted(men)
boys=sorted(boys,reverse=True)
return men+boys | def men_from_boys(arr):
arr=list(set(arr))
men=[i for i in arr if i%2==0]
boys=[i for i in arr if i%2==1]
men=sorted(men)
boys=sorted(boys,reverse=True)
return men+boys | train | APPS_structured |
There are $N$ sabotages available in the game Among Us, initially all at level $0$.
$N$ imposters are allotted the task to upgrade the level of the sabotages.
The $i^{th}$ imposter $(1 \leq i \leq N)$ increases the level of $x^{th}$ sabotage $(1 \leq x \leq N)$ by one level if $gcd(i,x)=i$.
You need to find the number of sabotages at LEVEL 5 after all the imposters have completed their tasks.
-----Input:-----
- First line will contain $T$, number of testcases. Then the testcases follow.
- Each testcase contains of a single line of input, one integer $N$.
-----Output:-----
For each testcase, output in a single line the number of sabotages at LEVEL 5.
-----Constraints-----
- $1 \leq T \leq 10^5$
- $1 \leq N \leq 10^{18}$
-----Sample Input:-----
1
6
-----Sample Output:-----
0
-----EXPLANATION:-----
The $1^{st}$ sabotage is at level $1$, the $2^{nd}$, $3^{rd}$ and $5^{th}$ sabotages are at level $2$, the $4^{th}$ sabotage is at level $3$ and the $6^{th}$ sabotage is at level $4$.
None of them reach level $5$. Hence the output is $0$. | from bisect import bisect
n = 32000
def primeSeive(n):
prime = [True for i in range(n + 1)]
primes = []
p = 2
while (p * p <= n):
if (prime[p] == True):
for i in range(p * 2, n + 1, p):
prime[i] = False
p += 1
prime[0] = False
prime[1] = False
for p in range(n + 1):
if prime[p]:
primes.append(p)
return primes
arr = primeSeive(n)
fin = []
for i in arr:
fin.append(pow(i,4))
for _ in range(int(input())):
n = int(input())
print(bisect(fin,n))
| from bisect import bisect
n = 32000
def primeSeive(n):
prime = [True for i in range(n + 1)]
primes = []
p = 2
while (p * p <= n):
if (prime[p] == True):
for i in range(p * 2, n + 1, p):
prime[i] = False
p += 1
prime[0] = False
prime[1] = False
for p in range(n + 1):
if prime[p]:
primes.append(p)
return primes
arr = primeSeive(n)
fin = []
for i in arr:
fin.append(pow(i,4))
for _ in range(int(input())):
n = int(input())
print(bisect(fin,n))
| train | APPS_structured |
Creatnx has $n$ mirrors, numbered from $1$ to $n$. Every day, Creatnx asks exactly one mirror "Am I beautiful?". The $i$-th mirror will tell Creatnx that he is beautiful with probability $\frac{p_i}{100}$ for all $1 \le i \le n$.
Some mirrors are called checkpoints. Initially, only the $1$st mirror is a checkpoint. It remains a checkpoint all the time.
Creatnx asks the mirrors one by one, starting from the $1$-st mirror. Every day, if he asks $i$-th mirror, there are two possibilities: The $i$-th mirror tells Creatnx that he is beautiful. In this case, if $i = n$ Creatnx will stop and become happy, otherwise he will continue asking the $i+1$-th mirror next day; In the other case, Creatnx will feel upset. The next day, Creatnx will start asking from the checkpoint with a maximal number that is less or equal to $i$.
There are some changes occur over time: some mirrors become new checkpoints and some mirrors are no longer checkpoints. You are given $q$ queries, each query is represented by an integer $u$: If the $u$-th mirror isn't a checkpoint then we set it as a checkpoint. Otherwise, the $u$-th mirror is no longer a checkpoint.
After each query, you need to calculate the expected number of days until Creatnx becomes happy.
Each of this numbers should be found by modulo $998244353$. Formally, let $M = 998244353$. It can be shown that the answer can be expressed as an irreducible fraction $\frac{p}{q}$, where $p$ and $q$ are integers and $q \not \equiv 0 \pmod{M}$. Output the integer equal to $p \cdot q^{-1} \bmod M$. In other words, output such an integer $x$ that $0 \le x < M$ and $x \cdot q \equiv p \pmod{M}$.
-----Input-----
The first line contains two integers $n$, $q$ ($2 \leq n, q \le 2 \cdot 10^5$) — the number of mirrors and queries.
The second line contains $n$ integers: $p_1, p_2, \ldots, p_n$ ($1 \leq p_i \leq 100$).
Each of $q$ following lines contains a single integer $u$ ($2 \leq u \leq n$) — next query.
-----Output-----
Print $q$ numbers – the answers after each query by modulo $998244353$.
-----Examples-----
Input
2 2
50 50
2
2
Output
4
6
Input
5 5
10 20 30 40 50
2
3
4
5
3
Output
117
665496274
332748143
831870317
499122211
-----Note-----
In the first test after the first query, the first and the second mirrors are checkpoints. Creatnx will ask the first mirror until it will say that he is beautiful, after that he will ask the second mirror until it will say that he is beautiful because the second mirror is a checkpoint. After that, he will become happy. Probabilities that the mirrors will say, that he is beautiful are equal to $\frac{1}{2}$. So, the expected number of days, until one mirror will say, that he is beautiful is equal to $2$ and the answer will be equal to $4 = 2 + 2$. | import sys
readline = sys.stdin.readline
from itertools import accumulate
from collections import Counter
from bisect import bisect as br, bisect_left as bl
class PMS:
#1-indexed
def __init__(self, A, B, issum = False):
#Aに初期状態の要素をすべて入れる,Bは値域のリスト
self.X, self.comp = self.compress(B)
self.size = len(self.X)
self.tree = [0] * (self.size + 1)
self.p = 2**(self.size.bit_length() - 1)
self.dep = self.size.bit_length()
CA = Counter(A)
S = [0] + list(accumulate([CA[self.X[i]] for i in range(self.size)]))
for i in range(1, 1+self.size):
self.tree[i] = S[i] - S[i - (i&-i)]
if issum:
self.sumtree = [0] * (self.size + 1)
Ssum = [0] + list(accumulate([CA[self.X[i]]*self.X[i] for i in range(self.size)]))
for i in range(1, 1+self.size):
self.sumtree[i] = Ssum[i] - Ssum[i - (i&-i)]
def compress(self, L):
#座圧
L2 = list(set(L))
L2.sort()
C = {v : k for k, v in enumerate(L2, 1)}
# 1-indexed
return L2, C
def leng(self):
#今入っている個数を取得
return self.count(self.X[-1])
def count(self, v):
#v(Bの元)以下の個数を取得
i = self.comp[v]
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def less(self, v):
#v(Bの元である必要はない)未満の個数を取得
i = bl(self.X, v)
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def leq(self, v):
#v(Bの元である必要はない)以下の個数を取得
i = br(self.X, v)
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def add(self, v, x):
#vをx個入れる,負のxで取り出す,iの個数以上取り出すとエラーを出さずにバグる
i = self.comp[v]
while i <= self.size:
self.tree[i] += x
i += i & -i
def get(self, i):
# i番目の値を取得
if i <= 0:
return -1
s = 0
k = self.p
for _ in range(self.dep):
if s + k <= self.size and self.tree[s+k] < i:
s += k
i -= self.tree[s]
k //= 2
return self.X[s]
def gets(self, v):
#累積和がv以下となる最大のindexを返す
v1 = v
s = 0
k = self.p
for _ in range(self.dep):
if s + k <= self.size and self.sumtree[s+k] < v:
s += k
v -= self.sumtree[s]
k //= 2
if s == self.size:
return self.leng()
return self.count(self.X[s]) + (v1 - self.countsum(self.X[s]))//self.X[s]
def addsum(self, i, x):
#sumを扱いたいときにaddの代わりに使う
self.add(i, x)
x *= i
i = self.comp[i]
while i <= self.size:
self.sumtree[i] += x
i += i & -i
def countsum(self, v):
#v(Bの元)以下のsumを取得
i = self.comp[v]
s = 0
while i > 0:
s += self.sumtree[i]
i -= i & -i
return s
def getsum(self, i):
#i番目までのsumを取得
x = self.get(i)
return self.countsum(x) - x*(self.count(x) - i)
N, Q = map(int, readline().split())
P = list(map(int, readline().split()))
MOD = 998244353
T = [100*pow(pi, MOD-2, MOD)%MOD for pi in P]
AT = [None]*N
AT[0] = T[0]
for i in range(1, N):
AT[i] = (AT[i-1]+1)*T[i]%MOD
AM = [None]*N
AMi = [None]*N
AM[0] = T[0]
for i in range(1, N):
AM[i] = AM[i-1]*T[i]%MOD
AMi[N-1] = pow(AM[N-1], MOD-2, MOD)
for i in range(N-2, -1, -1):
AMi[i] = AMi[i+1]*T[i+1]%MOD
AT += [0]
AM += [1]
AMi += [1]
Ans = [None]*Q
kk = set([0, N])
PM = PMS([0, N], list(range(N+1)))
ans = AT[N-1]
for qu in range(Q):
f = int(readline()) - 1
if f not in kk:
kk.add(f)
PM.add(f, 1)
fidx = PM.count(f)
fm = PM.get(fidx-1)
fp = PM.get(fidx+1)
am = (AT[f-1] - AM[f-1]*AMi[fm-1]*AT[fm-1])%MOD
ap = (AT[fp-1] - AM[fp-1]*AMi[f-1]*AT[f-1])%MOD
aa = (AT[fp-1] - AM[fp-1]*AMi[fm-1]*AT[fm-1])%MOD
ans = (ans - aa + am + ap)%MOD
else:
kk.remove(f)
fidx = PM.count(f)
fm = PM.get(fidx-1)
fp = PM.get(fidx+1)
PM.add(f, -1)
am = (AT[f-1] - AM[f-1]*AMi[fm-1]*AT[fm-1])%MOD
ap = (AT[fp-1] - AM[fp-1]*AMi[f-1]*AT[f-1])%MOD
aa = (AT[fp-1] - AM[fp-1]*AMi[fm-1]*AT[fm-1])%MOD
ans = (ans + aa - am - ap)%MOD
Ans[qu] = ans
print('\n'.join(map(str, Ans))) | import sys
readline = sys.stdin.readline
from itertools import accumulate
from collections import Counter
from bisect import bisect as br, bisect_left as bl
class PMS:
#1-indexed
def __init__(self, A, B, issum = False):
#Aに初期状態の要素をすべて入れる,Bは値域のリスト
self.X, self.comp = self.compress(B)
self.size = len(self.X)
self.tree = [0] * (self.size + 1)
self.p = 2**(self.size.bit_length() - 1)
self.dep = self.size.bit_length()
CA = Counter(A)
S = [0] + list(accumulate([CA[self.X[i]] for i in range(self.size)]))
for i in range(1, 1+self.size):
self.tree[i] = S[i] - S[i - (i&-i)]
if issum:
self.sumtree = [0] * (self.size + 1)
Ssum = [0] + list(accumulate([CA[self.X[i]]*self.X[i] for i in range(self.size)]))
for i in range(1, 1+self.size):
self.sumtree[i] = Ssum[i] - Ssum[i - (i&-i)]
def compress(self, L):
#座圧
L2 = list(set(L))
L2.sort()
C = {v : k for k, v in enumerate(L2, 1)}
# 1-indexed
return L2, C
def leng(self):
#今入っている個数を取得
return self.count(self.X[-1])
def count(self, v):
#v(Bの元)以下の個数を取得
i = self.comp[v]
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def less(self, v):
#v(Bの元である必要はない)未満の個数を取得
i = bl(self.X, v)
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def leq(self, v):
#v(Bの元である必要はない)以下の個数を取得
i = br(self.X, v)
s = 0
while i > 0:
s += self.tree[i]
i -= i & -i
return s
def add(self, v, x):
#vをx個入れる,負のxで取り出す,iの個数以上取り出すとエラーを出さずにバグる
i = self.comp[v]
while i <= self.size:
self.tree[i] += x
i += i & -i
def get(self, i):
# i番目の値を取得
if i <= 0:
return -1
s = 0
k = self.p
for _ in range(self.dep):
if s + k <= self.size and self.tree[s+k] < i:
s += k
i -= self.tree[s]
k //= 2
return self.X[s]
def gets(self, v):
#累積和がv以下となる最大のindexを返す
v1 = v
s = 0
k = self.p
for _ in range(self.dep):
if s + k <= self.size and self.sumtree[s+k] < v:
s += k
v -= self.sumtree[s]
k //= 2
if s == self.size:
return self.leng()
return self.count(self.X[s]) + (v1 - self.countsum(self.X[s]))//self.X[s]
def addsum(self, i, x):
#sumを扱いたいときにaddの代わりに使う
self.add(i, x)
x *= i
i = self.comp[i]
while i <= self.size:
self.sumtree[i] += x
i += i & -i
def countsum(self, v):
#v(Bの元)以下のsumを取得
i = self.comp[v]
s = 0
while i > 0:
s += self.sumtree[i]
i -= i & -i
return s
def getsum(self, i):
#i番目までのsumを取得
x = self.get(i)
return self.countsum(x) - x*(self.count(x) - i)
N, Q = map(int, readline().split())
P = list(map(int, readline().split()))
MOD = 998244353
T = [100*pow(pi, MOD-2, MOD)%MOD for pi in P]
AT = [None]*N
AT[0] = T[0]
for i in range(1, N):
AT[i] = (AT[i-1]+1)*T[i]%MOD
AM = [None]*N
AMi = [None]*N
AM[0] = T[0]
for i in range(1, N):
AM[i] = AM[i-1]*T[i]%MOD
AMi[N-1] = pow(AM[N-1], MOD-2, MOD)
for i in range(N-2, -1, -1):
AMi[i] = AMi[i+1]*T[i+1]%MOD
AT += [0]
AM += [1]
AMi += [1]
Ans = [None]*Q
kk = set([0, N])
PM = PMS([0, N], list(range(N+1)))
ans = AT[N-1]
for qu in range(Q):
f = int(readline()) - 1
if f not in kk:
kk.add(f)
PM.add(f, 1)
fidx = PM.count(f)
fm = PM.get(fidx-1)
fp = PM.get(fidx+1)
am = (AT[f-1] - AM[f-1]*AMi[fm-1]*AT[fm-1])%MOD
ap = (AT[fp-1] - AM[fp-1]*AMi[f-1]*AT[f-1])%MOD
aa = (AT[fp-1] - AM[fp-1]*AMi[fm-1]*AT[fm-1])%MOD
ans = (ans - aa + am + ap)%MOD
else:
kk.remove(f)
fidx = PM.count(f)
fm = PM.get(fidx-1)
fp = PM.get(fidx+1)
PM.add(f, -1)
am = (AT[f-1] - AM[f-1]*AMi[fm-1]*AT[fm-1])%MOD
ap = (AT[fp-1] - AM[fp-1]*AMi[f-1]*AT[f-1])%MOD
aa = (AT[fp-1] - AM[fp-1]*AMi[fm-1]*AT[fm-1])%MOD
ans = (ans + aa - am - ap)%MOD
Ans[qu] = ans
print('\n'.join(map(str, Ans))) | train | APPS_structured |
Find the number with the most digits.
If two numbers in the argument array have the same number of digits, return the first one in the array. | def find_longest(arr):
i = 0
max_len = arr[0]
while i != len(arr):
if len(str(arr[i])) > len(str(max_len)):
max_len = arr[i]
i += 1
return max_len | def find_longest(arr):
i = 0
max_len = arr[0]
while i != len(arr):
if len(str(arr[i])) > len(str(max_len)):
max_len = arr[i]
i += 1
return max_len | train | APPS_structured |
Storekeeper is a game in which the player pushes boxes around in a warehouse trying to get them to target locations.
The game is represented by a grid of size m x n, where each element is a wall, floor, or a box.
Your task is move the box 'B' to the target position 'T' under the following rules:
Player is represented by character 'S' and can move up, down, left, right in the grid if it is a floor (empy cell).
Floor is represented by character '.' that means free cell to walk.
Wall is represented by character '#' that means obstacle (impossible to walk there).
There is only one box 'B' and one target cell 'T' in the grid.
The box can be moved to an adjacent free cell by standing next to the box and then moving in the direction of the box. This is a push.
The player cannot walk through the box.
Return the minimum number of pushes to move the box to the target. If there is no way to reach the target, return -1.
Example 1:
Input: grid = [["#","#","#","#","#","#"],
["#","T","#","#","#","#"],
["#",".",".","B",".","#"],
["#",".","#","#",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: 3
Explanation: We return only the number of times the box is pushed.
Example 2:
Input: grid = [["#","#","#","#","#","#"],
["#","T","#","#","#","#"],
["#",".",".","B",".","#"],
["#","#","#","#",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: -1
Example 3:
Input: grid = [["#","#","#","#","#","#"],
["#","T",".",".","#","#"],
["#",".","#","B",".","#"],
["#",".",".",".",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: 5
Explanation: push the box down, left, left, up and up.
Example 4:
Input: grid = [["#","#","#","#","#","#","#"],
["#","S","#",".","B","T","#"],
["#","#","#","#","#","#","#"]]
Output: -1
Constraints:
m == grid.length
n == grid[i].length
1 <= m <= 20
1 <= n <= 20
grid contains only characters '.', '#', 'S' , 'T', or 'B'.
There is only one character 'S', 'B' and 'T' in the grid. | from collections import deque
class Solution:
def minPushBox(self, grid: List[List[str]]) -> int:
m, n = len(grid), len(grid[0])
def Can(i, j):
ss.add((i, j))
for x, y in ((i+1, j), (i-1, j), (i, j+1), (i, j-1)):
if 0 <= x < m and 0 <= y < n and (x, y) not in ss and grid[x][y] == '.':
Can(x, y)
for i in range(m):
for j in range(n):
if grid[i][j] == 'S':
ppl = (i, j)
grid[i][j] = '.'
elif grid[i][j] == 'B':
box = (i, j)
grid[i][j] = '.'
elif grid[i][j] == 'T':
target = (i, j)
grid[i][j] = '.'
visited = set()
queue = deque()
queue.append((box[0], box[1], 0, ppl[0], ppl[1]))
ss = set()
while queue:
x, y, count, p1, p2 = queue.popleft()
if (x, y) == target:
return count
ss = {(x, y)}
Can(p1, p2)
if x+1 < m and 0 <= x-1 and grid[x+1][y] == '.' and grid[x-1][y] == '.':
if (x-1, y, x, y) not in visited and (x-1, y) in ss:
visited.add((x-1, y, x, y))
queue.append( (x+1, y, count+1, x-1, y) )
if (x+1, y, x, y) not in visited and (x+1, y) in ss:
visited.add((x+1, y, x, y))
queue.append( (x-1, y, count+1, x+1, y) )
if y+1 < n and 0 <= y-1 and grid[x][y-1] == '.' and grid[x][y+1] == '.':
#print(\"{}.{}\".format(x, y))
if (x, y-1, x, y) not in visited and (x, y-1) in ss:
visited.add((x, y-1, x, y))
queue.append( (x, y+1, count+1, x, y-1) )
if (x, y+1, x, y) not in visited and (x, y+1) in ss:
visited.add((x, y+1, x, y))
queue.append( (x, y-1, count+1, x, y+1) )
return -1
| from collections import deque
class Solution:
def minPushBox(self, grid: List[List[str]]) -> int:
m, n = len(grid), len(grid[0])
def Can(i, j):
ss.add((i, j))
for x, y in ((i+1, j), (i-1, j), (i, j+1), (i, j-1)):
if 0 <= x < m and 0 <= y < n and (x, y) not in ss and grid[x][y] == '.':
Can(x, y)
for i in range(m):
for j in range(n):
if grid[i][j] == 'S':
ppl = (i, j)
grid[i][j] = '.'
elif grid[i][j] == 'B':
box = (i, j)
grid[i][j] = '.'
elif grid[i][j] == 'T':
target = (i, j)
grid[i][j] = '.'
visited = set()
queue = deque()
queue.append((box[0], box[1], 0, ppl[0], ppl[1]))
ss = set()
while queue:
x, y, count, p1, p2 = queue.popleft()
if (x, y) == target:
return count
ss = {(x, y)}
Can(p1, p2)
if x+1 < m and 0 <= x-1 and grid[x+1][y] == '.' and grid[x-1][y] == '.':
if (x-1, y, x, y) not in visited and (x-1, y) in ss:
visited.add((x-1, y, x, y))
queue.append( (x+1, y, count+1, x-1, y) )
if (x+1, y, x, y) not in visited and (x+1, y) in ss:
visited.add((x+1, y, x, y))
queue.append( (x-1, y, count+1, x+1, y) )
if y+1 < n and 0 <= y-1 and grid[x][y-1] == '.' and grid[x][y+1] == '.':
#print(\"{}.{}\".format(x, y))
if (x, y-1, x, y) not in visited and (x, y-1) in ss:
visited.add((x, y-1, x, y))
queue.append( (x, y+1, count+1, x, y-1) )
if (x, y+1, x, y) not in visited and (x, y+1) in ss:
visited.add((x, y+1, x, y))
queue.append( (x, y-1, count+1, x, y+1) )
return -1
| train | APPS_structured |
You have an array A of size N containing only positive numbers. You have to output the maximum possible value of A[i]%A[j] where 1<=i,j<=N.
-----Input-----
The first line of each test case contains a single integer N denoting the size of the array. The next N lines contains integers A1, A2, ..., AN denoting the numbers
-----Output-----
Output a single integer answering what is asked in the problem.
-----Subtask 1 (20 points)-----
- 1 ≤ N ≤ 5000
- 1 ≤ A[i] ≤ 2*(10^9)
-----Subtask 2 (80 points)-----
- 1 ≤ N ≤ 1000000
- 1 ≤ A[i] ≤ 2*(10^9)
-----Example-----
Input:
2
1
2
Output:
1
-----Explanation-----
There will be four values, A[0]%A[0] = 0, A[0]%A[1]=1, A[1]%A[0]=0, A[1]%A[1]=0, and hence the output will be the maximum among them all, that is 1. | size = int(input())
array = []
for x in range(size):
array.append(int(input()))
diff = 0
if size < 1600 :
for i in range(size):
for j in range(i + 1, size):
if array[i]%array[j] > diff :
diff = array[i]%array[j]
else :
m1 = max(array)
array.pop(array.index(m1))
m2 = max(array)
diff = m2%m1
print(diff) | size = int(input())
array = []
for x in range(size):
array.append(int(input()))
diff = 0
if size < 1600 :
for i in range(size):
for j in range(i + 1, size):
if array[i]%array[j] > diff :
diff = array[i]%array[j]
else :
m1 = max(array)
array.pop(array.index(m1))
m2 = max(array)
diff = m2%m1
print(diff) | train | APPS_structured |
You are given an array of integers. Your task is to sort odd numbers within the array in ascending order, and even numbers in descending order.
Note that zero is an even number. If you have an empty array, you need to return it.
For example:
```
[5, 3, 2, 8, 1, 4] --> [1, 3, 8, 4, 5, 2]
odd numbers ascending: [1, 3, 5 ]
even numbers descending: [ 8, 4, 2]
``` | def sort_array(lst):
s = sorted(lst)
even = (n for n in s[::-1] if n & 1 == 0)
odd = (n for n in s if n & 1)
return [next(odd if n & 1 else even) for n in lst] | def sort_array(lst):
s = sorted(lst)
even = (n for n in s[::-1] if n & 1 == 0)
odd = (n for n in s if n & 1)
return [next(odd if n & 1 else even) for n in lst] | train | APPS_structured |
A very passive-aggressive co-worker of yours was just fired. While he was gathering his things, he quickly inserted a bug into your system which renamed everything to what looks like jibberish. He left two notes on his desk, one reads: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" while the other reads: "Uif usjdl up uijt lbub jt tjnqmf kvtu sfqmbdf fwfsz mfuufs xjui uif mfuufs uibu dpnft cfgpsf ju".
Rather than spending hours trying to find the bug itself, you decide to try and decode it.
If the input is not a string, your function must return "Input is not a string". Your function must be able to handle capital and lower case letters. You will not need to worry about punctuation. | def one_down(txt):
#your code here
if type(txt) is not str:
return "Input is not a string"
new_string = ""
for char in txt:
if char == " ":
new_string = new_string + " "
elif char == "A":
new_string = new_string + "Z"
elif char == "a":
new_string = new_string + "z"
elif char in "-+,.;:":
new_string = new_string + char
else:
new_string = new_string + chr(ord(char) - 1)
return new_string
| def one_down(txt):
#your code here
if type(txt) is not str:
return "Input is not a string"
new_string = ""
for char in txt:
if char == " ":
new_string = new_string + " "
elif char == "A":
new_string = new_string + "Z"
elif char == "a":
new_string = new_string + "z"
elif char in "-+,.;:":
new_string = new_string + char
else:
new_string = new_string + chr(ord(char) - 1)
return new_string
| train | APPS_structured |
# Task
Given an array `arr`, find the rank of the element at the ith position.
The `rank` of the arr[i] is a value equal to the number of elements `less than or equal to` arr[i] standing before arr[i], plus the number of elements `less than` arr[i] standing after arr[i].
# Example
For `arr = [2,1,2,1,2], i = 2`, the result should be `3`.
There are 2 elements `less than or equal to` arr[2] standing before arr[2]:
`arr[0] <= arr[2]`
`arr[1] <= arr[2]`
There is only 1 element `less than` arr[2] standing after arr[2]:
`arr[3] < arr[2]`
So the result is `2 + 1 = 3`.
# Input/Output
- `[input]` integer array `arr`
An array of integers.
`3 <= arr.length <= 50.`
- `[input]` integer `i`
Index of the element whose rank is to be found.
- `[output]` an integer
Rank of the element at the ith position. | def rank_of_element(arr, i):
return (
sum(n <= arr[i] for n in arr[:i]) +
sum(n < arr[i] for n in arr[i + 1:])) | def rank_of_element(arr, i):
return (
sum(n <= arr[i] for n in arr[:i]) +
sum(n < arr[i] for n in arr[i + 1:])) | train | APPS_structured |
Given an array of integers (x), and a target (t), you must find out if any two consecutive numbers in the array sum to t. If so, remove the second number.
Example:
x = [1, 2, 3, 4, 5]
t = 3
1+2 = t, so remove 2. No other pairs = t, so rest of array remains:
[1, 3, 4, 5]
Work through the array from left to right.
Return the resulting array. | def trouble(x, t):
n = x[:1]
for i in x[1:]:
if i + n[-1] != t:
n.append(i)
return n
| def trouble(x, t):
n = x[:1]
for i in x[1:]:
if i + n[-1] != t:
n.append(i)
return n
| train | APPS_structured |
## Story
John runs a shop, bought some goods, and then sells them. He used a special accounting method, like this:
```
[[60,20],[60,-20]]
```
Each sub array records the commodity price and profit/loss to sell (percentage). Positive mean profit and negative means loss.
In the example above, John's first commodity sold at a price of $60, he made a profit of 20%; Second commodities are sold at a price of $60 too, but he lost 20%.
Please calculate, whether his account is profit or loss in the end?
## Rules
Write a function ```profitLoss```, argument ```records``` is the list of sales.
return a number(positive or negative), round to two decimal places.
## Examples | def profitLoss(records):
return round(sum(pr * pe / (100+pe) for pr, pe in records), 2) | def profitLoss(records):
return round(sum(pr * pe / (100+pe) for pr, pe in records), 2) | train | APPS_structured |
You are given a matrix of integers $A$ with $N$ rows (numbered $1$ through $N$) and $M$ columns (numbered $1$ through $M$). Each element of this matrix is either $0$ or $1$.
A move consists of the following steps:
- Choose two different rows $r_1$ and $r_2$ or two different columns $c_1$ and $c_2$.
- Apply the bitwise OR operation with the second row/column on the first row/column. Formally, if you chose two rows, this means you should change $A_{r_1, k}$ to $A_{r_1, k} \lor A_{r_2, k}$ for each $1 \le k \le M$; if you chose two columns, then you should change $A_{k, c_1}$ to $A_{k, c_1} \lor A_{k, c_2}$ for each $1 \le k \le N$.
For each element of the matrix, compute the minimum number of moves required to make it equal to $1$ or determine that it is impossible. Note that these answers are independent, i.e. we are starting with the initial matrix for each of them.
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first line of each test case contains two space-separated integers $N$ and $M$.
- $N$ lines follow. For each $i$ ($1 \le i \le N$), the $i$-th of these lines contains $M$ integers $A_{i, 1}, A_{i, 2}, \dots, A_{i, M}$ NOT separated by spaces.
-----Output-----
For each test case, print $N$ lines. For each valid $i$, the $i$-th of these lines should contain $M$ space-separated integers; for each valid $j$, the $j$-th of these integers should be the minimum number of moves required to make $A_{i, j}$ equal to $1$, or $-1$ if it is impossible.
-----Constraints-----
- $1 \le T \le 100$
- $1 \le N, M \le 1,000$
- $A_{i, j} \in \{0, 1\}$ for each valid $i, j$
- the sum of $N \cdot M$ for all test cases does not exceed $1,000,000$
-----Example Input-----
1
3 3
010
000
001
-----Example Output-----
1 0 1
2 1 1
1 1 0 | # cook your dish here
t=int(input())
for _ in range(t):
flag=0
n,m=[int(x) for x in input().split()]
A=[None]*n
for i in range(n):
sint=input()
inp=[None]*m
for j in range(m):
inp[j]=int(sint[j])
A[i]=inp
# print("A=",A)
B=[[-1 for j in range(m)]for i in range(n)]
row={}
column={}
for i in range(n):
row[i]=0
for j in range(m):
column[j]=0
# print("B=",B)
for i in range(n):
for j in range(m):
if(A[i][j]==1):
flag=1
row[i]=1
column[j]=1
B[i][j]=0
if(flag==0):
pass
else:
for i in range(n):
for j in range(m):
if(A[i][j]==0):
if(row[i]==1 or column[j]==1):
B[i][j]=1
else:
B[i][j]=2
for i in range(n):
print(*B[i])
| # cook your dish here
t=int(input())
for _ in range(t):
flag=0
n,m=[int(x) for x in input().split()]
A=[None]*n
for i in range(n):
sint=input()
inp=[None]*m
for j in range(m):
inp[j]=int(sint[j])
A[i]=inp
# print("A=",A)
B=[[-1 for j in range(m)]for i in range(n)]
row={}
column={}
for i in range(n):
row[i]=0
for j in range(m):
column[j]=0
# print("B=",B)
for i in range(n):
for j in range(m):
if(A[i][j]==1):
flag=1
row[i]=1
column[j]=1
B[i][j]=0
if(flag==0):
pass
else:
for i in range(n):
for j in range(m):
if(A[i][j]==0):
if(row[i]==1 or column[j]==1):
B[i][j]=1
else:
B[i][j]=2
for i in range(n):
print(*B[i])
| train | APPS_structured |
Construct a function 'coordinates', that will return the distance between two points on a cartesian plane, given the x and y coordinates of each point.
There are two parameters in the function, ```p1``` and ```p2```. ```p1``` is a list ```[x1,y1]``` where ```x1``` and ```y1``` are the x and y coordinates of the first point. ```p2``` is a list ```[x2,y2]``` where ```x2``` and ```y2``` are the x and y coordinates of the second point.
The distance between the two points should be rounded to the `precision` decimal if provided, otherwise to the nearest integer. | from math import sqrt
def coordinates(p1, p2, precision=0):
x1, y1 = p1
x2, y2 = p2
distance = sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)
return round(distance, precision) | from math import sqrt
def coordinates(p1, p2, precision=0):
x1, y1 = p1
x2, y2 = p2
distance = sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)
return round(distance, precision) | train | APPS_structured |
This function takes two numbers as parameters, the first number being the coefficient, and the second number being the exponent.
Your function should multiply the two numbers, and then subtract 1 from the exponent. Then, it has to print out an expression (like 28x^7). `"^1"` should not be truncated when exponent = 2.
For example:
```
derive(7, 8)
```
In this case, the function should multiply 7 and 8, and then subtract 1 from 8. It should output `"56x^7"`, the first number 56 being the product of the two numbers, and the second number being the exponent minus 1.
```
derive(7, 8) --> this should output "56x^7"
derive(5, 9) --> this should output "45x^8"
```
**Notes:**
* The output of this function should be a string
* The exponent will never be 1, and neither number will ever be 0 | def derive(coefficient, exponent):
new_coefficient = coefficient*exponent
new_exponent = exponent-1
ans = str(new_coefficient)+"x^" + str(new_exponent)
return ans
| def derive(coefficient, exponent):
new_coefficient = coefficient*exponent
new_exponent = exponent-1
ans = str(new_coefficient)+"x^" + str(new_exponent)
return ans
| train | APPS_structured |
Write a function that receives two strings as parameter. This strings are in the following format of date: `YYYY/MM/DD`.
Your job is: Take the `years` and calculate the difference between them.
Examples:
```
'1997/10/10' and '2015/10/10' -> 2015 - 1997 = returns 18
'2015/10/10' and '1997/10/10' -> 2015 - 1997 = returns 18
```
At this level, you don't need validate months and days to calculate the difference. | def how_many_years (date1, date2):
get_year = lambda date: int(date.split('/')[0])
return abs(get_year(date1) - get_year(date2)) | def how_many_years (date1, date2):
get_year = lambda date: int(date.split('/')[0])
return abs(get_year(date1) - get_year(date2)) | train | APPS_structured |
=====Problem Statement=====
The defaultdict tool is a container in the collections class of Python. It's similar to the usual dictionary (dict) container, but the only difference is that a defaultdict will have a default value if that key has not been set yet. If you didn't use a defaultdict you'd have to check to see if that key exists, and if it doesn't, set it to what you want.
For example:
from collections import defaultdict
d = defaultdict(list)
d['python'].append("awesome")
d['something-else'].append("not relevant")
d['python'].append("language")
for i in d.items():
print i
This prints:
('python', ['awesome', 'language'])
('something-else', ['not relevant'])
In this challenge, you will be given 2 integers, n and m. There are n words, which might repeat, in word group A. There are m words belonging to word group B. For each m words, check whether the word has appeared in group A or not. Print the indices of each occurrence of m in group A. If it does not appear, print -1.
=====Constraints=====
1≤n≤10000
1≤m≤100
1≤length of each word in the input≤100
=====Input Format=====
The first line contains integers, n and m separated by a space.
The next n lines contains the words belonging to group A.
The next m lines contains the words belonging to group B.
=====Output Format=====
Output m lines.
The ith line should contain the 1-indexed positions of the occurrences of the ith word separated by spaces. | from collections import defaultdict
d = defaultdict(list)
n,m=list(map(int,input().split()))
for i in range(n):
w = input()
d[w].append(str(i+1))
for j in range(m):
w = input()
print((' '.join(d[w]) or -1))
| from collections import defaultdict
d = defaultdict(list)
n,m=list(map(int,input().split()))
for i in range(n):
w = input()
d[w].append(str(i+1))
for j in range(m):
w = input()
print((' '.join(d[w]) or -1))
| train | APPS_structured |
The n-queens puzzle is the problem of placing n queens on an n×n chessboard such that no two queens attack each other.
Given an integer n, return all distinct solutions to the n-queens puzzle.
Each solution contains a distinct board configuration of the n-queens' placement, where 'Q' and '.' both indicate a queen and an empty space respectively.
Example:
Input: 4
Output: [
[".Q..", // Solution 1
"...Q",
"Q...",
"..Q."],
["..Q.", // Solution 2
"Q...",
"...Q",
".Q.."]
]
Explanation: There exist two distinct solutions to the 4-queens puzzle as shown above. | class Solution:
def helper(self, n, currentIndex, aux, rowsWithQueen, alll):
for i in range(n):
if i not in rowsWithQueen:
# Verify first diagonal
x, y = currentIndex - 1, i - 1
while aux[x][y] != 'Q' and x >= 0 and y >= 0:
x -= 1
y -= 1
if x != -1 and y != -1:
continue
# Verify second diagonal
x, y = currentIndex - 1, i + 1
while x >= 0 and y < n and aux[x][y] != 'Q':
x -= 1
y += 1
if x != -1 and y != n:
continue
aux[currentIndex][i] = 'Q'
rowsWithQueen.append(i)
if currentIndex == (n - 1):
aw = [[0 for i in range(n)] for j in range(n)]
for a in range(n):
for b in range(n):
aw[a][b] = aux[a][b]
alll.append(aw)
else:
self.helper(n, currentIndex + 1, aux, rowsWithQueen, alll)
aux[currentIndex][i] = '.'
rowsWithQueen.pop()
def solveNQueens(self, n):
"""
:type n: int
:rtype: List[List[str]]
"""
aux = [['.' for i in range(n)] for j in range(n)]
rowsWithQueen = []
alll = []
self.helper(n, 0, aux, rowsWithQueen, alll)
aux = []
for sol in alll:
ax = []
for i in sol:
i = "".join(i)
ax.append(i)
aux.append(ax)
return aux
| class Solution:
def helper(self, n, currentIndex, aux, rowsWithQueen, alll):
for i in range(n):
if i not in rowsWithQueen:
# Verify first diagonal
x, y = currentIndex - 1, i - 1
while aux[x][y] != 'Q' and x >= 0 and y >= 0:
x -= 1
y -= 1
if x != -1 and y != -1:
continue
# Verify second diagonal
x, y = currentIndex - 1, i + 1
while x >= 0 and y < n and aux[x][y] != 'Q':
x -= 1
y += 1
if x != -1 and y != n:
continue
aux[currentIndex][i] = 'Q'
rowsWithQueen.append(i)
if currentIndex == (n - 1):
aw = [[0 for i in range(n)] for j in range(n)]
for a in range(n):
for b in range(n):
aw[a][b] = aux[a][b]
alll.append(aw)
else:
self.helper(n, currentIndex + 1, aux, rowsWithQueen, alll)
aux[currentIndex][i] = '.'
rowsWithQueen.pop()
def solveNQueens(self, n):
"""
:type n: int
:rtype: List[List[str]]
"""
aux = [['.' for i in range(n)] for j in range(n)]
rowsWithQueen = []
alll = []
self.helper(n, 0, aux, rowsWithQueen, alll)
aux = []
for sol in alll:
ax = []
for i in sol:
i = "".join(i)
ax.append(i)
aux.append(ax)
return aux
| train | APPS_structured |
Tejas has invited the Clash Team for a Dinner Party. He places V empty plates (numbered from 1 to V inclusive) in a straight line on a table. He has prepared 2 kinds of Delicious Dishes named dish A and dish B.
He has exactly V servings of Dish A and W servings of dish B.
Now he wants to serve the dishes in such a way that if theith plate has serving of Dish A then (i-1)th plate should not have serving of Dish B. Assuming all the Dishes are identical find number of ways Tejas can serve the Clash Team.
-----Input-----
- The first line of the input contains an integer T denoting the number of test cases . The description of T testcases follow.
- The first line of each test case contains two space seperated integers V W .
-----Output-----
For each test case, output the number of ways Tejas can serve the Clash Team.
-----Constraints-----
- 1 ≤ T ≤ 100
- 1 ≤ V ≤ 1000
- 1 ≤ W ≤ 1000
-----Example-----
Input:
1
3 3
Output:
4
-----Explanation-----
In the above example the 4 ways are:
AAA
AAB
ABB
BBB | t=int(input())
for z in range (t):
v,w=map(int,input().split())
if(w>=v):
print(v+1)
else:
print(w+1) | t=int(input())
for z in range (t):
v,w=map(int,input().split())
if(w>=v):
print(v+1)
else:
print(w+1) | train | APPS_structured |
Given an D-dimension array, where each axis is of length N, your goal is to find the sum of every index in the array starting from 0.
For Example if D=1 and N=10 then the answer would be 45 ([0,1,2,3,4,5,6,7,8,9])
If D=2 and N = 3 the answer is 18 which would be the sum of every number in the following:
```python
[
[(0,0), (0,1), (0,2)],
[(1,0), (1,1), (1,2)],
[(2,0), (2,1), (2,2)]
]
```
A naive solution could be to loop over every index in every dimension and add to a global sum. This won't work as the number of dimension is expected to be quite large.
Hint: A formulaic approach would be best
Hint 2: Gauss could solve the one dimensional case in his earliest of years, This is just a generalization.
~~~if:javascript
Note for JS version: Because the results will exceed the maximum safe integer easily, for such values you're only required to have a precision of at least `1 in 1e-9` to the actual answer.
~~~ | def super_sum(D, N):
return (D*(N-1)*(N**D))//2 | def super_sum(D, N):
return (D*(N-1)*(N**D))//2 | train | APPS_structured |
Recently, Chef studied the binary numeral system and noticed that it is extremely simple to perform bitwise operations like AND, XOR or bit shift on non-negative integers, while it is much more complicated to perform arithmetic operations (e.g. addition, multiplication or division).
After playing with binary operations for a while, Chef invented an interesting algorithm for addition of two non-negative integers $A$ and $B$:
function add(A, B):
while B is greater than 0:
U = A XOR B
V = A AND B
A = U
B = V * 2
return A
Now Chef is wondering how fast this algorithm is. Given the initial values of $A$ and $B$ (in binary representation), he needs you to help him compute the number of times the while-loop of the algorithm is repeated.
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first line of each test case contains a single string $A$.
- The second line contains a single string $B$.
-----Output-----
For each test case, print a single line containing one integer ― the number of iterations the algorithm will perform during addition of the given numbers $A$ and $B$.
-----Constraints-----
- $1 \le T \le 10^5$
- $1 \le |A|, |B| \le 10^5$
- $A$ and $B$ contain only characters '0' and '1'
- the sum of $|A| + |B|$ over all test cases does not exceed $10^6$
-----Subtasks-----
Subtask #1 (20 points): $|A|, |B| \le 30$
Subtask #2 (30 points):
- $|A|, |B| \le 500$
- the sum of $|A| + |B|$ over all test cases does not exceed $10^5$
Subtask #3 (50 points): original constraints
-----Example Input-----
3
100010
0
0
100010
11100
1010
-----Example Output-----
0
1
3
-----Explanation-----
Example case 1: The initial value of $B$ is $0$, so while-loop is not performed at all.
Example case 2: The initial values of $A$ and $B$ are $0_2 = 0$ and $100010_2 = 34$ respectively. When the while-loop is performed for the first time, we have:
- $U = 34$
- $V = 0$
- $A$ changes to $34$
- $B$ changes to $2 \cdot 0 = 0$
The while-loop terminates immediately afterwards, so it is executed only once.
Example case 3: The initial values of $A$ and $B$ are $11100_2 = 28$ and $1010_2 = 10$ respectively. After the first iteration, their values change to $22$ and $16$ respectively. After the second iteration, they change to $6$ and $32$, and finally, after the third iteration, to $38$ and $0$. | # cook your dish here
def binaryToDecimal(binary):
binary1 = binary
decimal, i, n = 0, 0, 0
while(binary != 0):
dec = binary % 10
decimal = decimal + dec * pow(2, i)
binary = binary//10
i += 1
return decimal
def add(a,b):
count=0
u=0
v=0
while b>0:
u=a^b
v=a&b
a=u
b=v*2
count = count+1
return count
t=int(input())
while t!=0:
a = int(input())
b = int(input())
a=int(binaryToDecimal(a))
b=int(binaryToDecimal(b))
#print(a)
#print(b)
print(add(a,b))
t=t-1
| # cook your dish here
def binaryToDecimal(binary):
binary1 = binary
decimal, i, n = 0, 0, 0
while(binary != 0):
dec = binary % 10
decimal = decimal + dec * pow(2, i)
binary = binary//10
i += 1
return decimal
def add(a,b):
count=0
u=0
v=0
while b>0:
u=a^b
v=a&b
a=u
b=v*2
count = count+1
return count
t=int(input())
while t!=0:
a = int(input())
b = int(input())
a=int(binaryToDecimal(a))
b=int(binaryToDecimal(b))
#print(a)
#print(b)
print(add(a,b))
t=t-1
| train | APPS_structured |
We have a tree with N vertices. The vertices are numbered 1, 2, ..., N. The i-th (1 ≦ i ≦ N - 1) edge connects the two vertices A_i and B_i.
Takahashi wrote integers into K of the vertices. Specifically, for each 1 ≦ j ≦ K, he wrote the integer P_j into vertex V_j. The remaining vertices are left empty. After that, he got tired and fell asleep.
Then, Aoki appeared. He is trying to surprise Takahashi by writing integers into all empty vertices so that the following condition is satisfied:
- Condition: For any two vertices directly connected by an edge, the integers written into these vertices differ by exactly 1.
Determine if it is possible to write integers into all empty vertices so that the condition is satisfied. If the answer is positive, find one specific way to satisfy the condition.
-----Constraints-----
- 1 ≦ N ≦ 10^5
- 1 ≦ K ≦ N
- 1 ≦ A_i, B_i ≦ N (1 ≦ i ≦ N - 1)
- 1 ≦ V_j ≦ N (1 ≦ j ≦ K) (21:18, a mistake in this constraint was corrected)
- 0 ≦ P_j ≦ 10^5 (1 ≦ j ≦ K)
- The given graph is a tree.
- All v_j are distinct.
-----Input-----
The input is given from Standard Input in the following format:
N
A_1 B_1
A_2 B_2
:
A_{N-1} B_{N-1}
K
V_1 P_1
V_2 P_2
:
V_K P_K
-----Output-----
If it is possible to write integers into all empty vertices so that the condition is satisfied, print Yes. Otherwise, print No.
If it is possible to satisfy the condition, print N lines in addition. The v-th (1 ≦ v ≦ N) of these N lines should contain the integer that should be written into vertex v. If there are multiple ways to satisfy the condition, any of those is accepted.
-----Sample Input-----
5
1 2
3 1
4 3
3 5
2
2 6
5 7
-----Sample Output-----
Yes
5
6
6
5
7
The figure below shows the tree when Takahashi fell asleep. For each vertex, the integer written beside it represents the index of the vertex, and the integer written into the vertex is the integer written by Takahashi.
Aoki can, for example, satisfy the condition by writing integers into the remaining vertices as follows:
This corresponds to Sample Output 1. Note that other outputs that satisfy the condition will also be accepted, such as:
Yes
7
6
8
7
7
| import heapq
import sys
input = sys.stdin.readline
INF = 10 ** 18
n = int(input())
edges = [list(map(int, input().split())) for i in range(n - 1)]
k = int(input())
info = [list(map(int, input().split())) for i in range(k)]
tree = [[] for i in range(n)]
for a, b in edges:
a -= 1
b -= 1
tree[a].append(b)
tree[b].append(a)
ans = [INF] * n
q = []
for v, val in info:
v -= 1
ans[v] = val
heapq.heappush(q, (-val, v))
for nxt_v in tree[v]:
if ans[nxt_v] != INF and abs(ans[v] - ans[nxt_v]) != 1:
print("No")
return
while q:
val, v = heapq.heappop(q)
val = -val
for nxt_v in tree[v]:
if ans[nxt_v] == INF:
ans[nxt_v] = val - 1
heapq.heappush(q, (-(val - 1), nxt_v))
else:
if abs(ans[v] - ans[nxt_v]) != 1:
print("No")
return
print("Yes")
for val in ans:
print(val) | import heapq
import sys
input = sys.stdin.readline
INF = 10 ** 18
n = int(input())
edges = [list(map(int, input().split())) for i in range(n - 1)]
k = int(input())
info = [list(map(int, input().split())) for i in range(k)]
tree = [[] for i in range(n)]
for a, b in edges:
a -= 1
b -= 1
tree[a].append(b)
tree[b].append(a)
ans = [INF] * n
q = []
for v, val in info:
v -= 1
ans[v] = val
heapq.heappush(q, (-val, v))
for nxt_v in tree[v]:
if ans[nxt_v] != INF and abs(ans[v] - ans[nxt_v]) != 1:
print("No")
return
while q:
val, v = heapq.heappop(q)
val = -val
for nxt_v in tree[v]:
if ans[nxt_v] == INF:
ans[nxt_v] = val - 1
heapq.heappush(q, (-(val - 1), nxt_v))
else:
if abs(ans[v] - ans[nxt_v]) != 1:
print("No")
return
print("Yes")
for val in ans:
print(val) | train | APPS_structured |
In this Kata, you will be given a number and your task will be to rearrange the number so that it is divisible by `25`, but without leading zeros. Return the minimum number of digit moves that are needed to make this possible. If impossible, return `-1` ( `Nothing` in Haskell ).
For example:
More examples in test cases.
Good luck! | from collections import Counter as C
def solve(n):
c, l, li = C(str(n)), len(str(n))-1, []
for i in '75 50 00 25'.split():
if not C(i) - c:
a, b, cn, t = i[0], i[1], 0, list(str(n))
bi = l - t[::-1].index(b)
t.insert(l, t.pop(bi))
ai = l - t[:-1][::-1].index(a) - 1
t.insert(l-1, t.pop(ai))
li.append((l-bi)+(l-ai-1)+[0,next(k for k,l in enumerate(t) if l!='0')][t[0]=='0'])
return min(li,default=-1) #headache | from collections import Counter as C
def solve(n):
c, l, li = C(str(n)), len(str(n))-1, []
for i in '75 50 00 25'.split():
if not C(i) - c:
a, b, cn, t = i[0], i[1], 0, list(str(n))
bi = l - t[::-1].index(b)
t.insert(l, t.pop(bi))
ai = l - t[:-1][::-1].index(a) - 1
t.insert(l-1, t.pop(ai))
li.append((l-bi)+(l-ai-1)+[0,next(k for k,l in enumerate(t) if l!='0')][t[0]=='0'])
return min(li,default=-1) #headache | train | APPS_structured |
The objective is to return all pairs of integers from a given array of integers that have a difference of 2.
The result array should be sorted in ascending order of values.
Assume there are no duplicate integers in the array. The order of the integers in the input array should not matter.
## Examples
~~~if-not:python
```
[1, 2, 3, 4] should return [[1, 3], [2, 4]]
[4, 1, 2, 3] should also return [[1, 3], [2, 4]]
[1, 23, 3, 4, 7] should return [[1, 3]]
[4, 3, 1, 5, 6] should return [[1, 3], [3, 5], [4, 6]]
```
~~~
~~~if:python
```
[1, 2, 3, 4] should return [(1, 3), (2, 4)]
[4, 1, 2, 3] should also return [(1, 3), (2, 4)]
[1, 23, 3, 4, 7] should return [(1, 3)]
[4, 3, 1, 5, 6] should return [(1, 3), (3, 5), (4, 6)]
```
~~~ | def twos_difference(l):
r = [(i,i+2) for i in sorted(l) if i+2 in l]
return r
twos_difference = lambda l: [(i,i+2) for i in sorted(l) if i+2 in l] | def twos_difference(l):
r = [(i,i+2) for i in sorted(l) if i+2 in l]
return r
twos_difference = lambda l: [(i,i+2) for i in sorted(l) if i+2 in l] | train | APPS_structured |
Bob has ladder. He wants to climb this ladder, but being a precocious child, he wonders about exactly how many ways he could to climb this `n` size ladder using jumps of up to distance `k`.
Consider this example...
n = 5\
k = 3
Here, Bob has ladder of length 5, and with each jump, he can ascend up to 3 steps (he can either jump step 1 or 2 or 3). This gives the below possibilities
```
1 1 1 1 1
1 1 1 2
1 1 2 1
1 2 1 1
2 1 1 1
1 2 2
2 2 1
2 1 2
1 1 3
1 3 1
3 1 1
2 3
3 2
```
Your task to calculate number of ways to climb ladder of length `n` with upto `k` steps for Bob. (13 in above case)
Constraints:
```python
1<=n<=50
1<=k<=15
```
_Tip: try fibonacci._ | from functools import lru_cache
@lru_cache(maxsize=None)
def count_ways(n, k):
if n < 0:
return 0
elif n <= 1:
return 1
return sum(count_ways(n-i, k) for i in range(1, k+1))
| from functools import lru_cache
@lru_cache(maxsize=None)
def count_ways(n, k):
if n < 0:
return 0
elif n <= 1:
return 1
return sum(count_ways(n-i, k) for i in range(1, k+1))
| train | APPS_structured |
Simple, remove the spaces from the string, then return the resultant string.
~~~if:c
For C, you must return a new dynamically allocated string.
~~~ | def no_space(x):
secondary = list()
for i in x:
if i != ' ':
secondary.append(i)
return ''.join(secondary) | def no_space(x):
secondary = list()
for i in x:
if i != ' ':
secondary.append(i)
return ''.join(secondary) | train | APPS_structured |
Story:
In the realm of numbers, the apocalypse has arrived. Hordes of zombie numbers have infiltrated and are ready to turn everything into undead. The properties of zombies are truly apocalyptic: they reproduce themselves unlimitedly and freely interact with each other. Anyone who equals them is doomed. Out of an infinite number of natural numbers, only a few remain. This world needs a hero who leads remaining numbers in hope for survival: The highest number to lead those who still remain.
Briefing:
There is a list of positive natural numbers. Find the largest number that cannot be represented as the sum of this numbers, given that each number can be added unlimited times. Return this number, either 0 if there are no such numbers, or -1 if there are an infinite number of them.
Example:
```
Let's say [3,4] are given numbers. Lets check each number one by one:
1 - (no solution) - good
2 - (no solution) - good
3 = 3 won't go
4 = 4 won't go
5 - (no solution) - good
6 = 3+3 won't go
7 = 3+4 won't go
8 = 4+4 won't go
9 = 3+3+3 won't go
10 = 3+3+4 won't go
11 = 3+4+4 won't go
13 = 3+3+3+4 won't go
```
...and so on. So 5 is the biggest 'good'. return 5
Test specs:
Random cases will input up to 10 numbers with up to 1000 value
Special thanks:
Thanks to Voile-sama, mathsisfun-sama, and Avanta-sama for heavy assistance. And to everyone who tried and beaten the kata ^_^ | import math
def survivor(zombies):
size = len(zombies)
if size == 0:
return -1
if (1 in zombies):
return 0
gcd = zombies[0]
for i in range(len(zombies) - 1):
gcd = math.gcd(gcd, zombies[1 + i])
if gcd != 1:
return -1
maxSize = (zombies[0] * zombies[1]) - zombies[0] - zombies[1]
posible = [False for _ in range(maxSize + 1)]
posible[0] = True
for zombie in zombies:
if zombie <= maxSize:
for i in range(zombie, maxSize + 1):
if not posible[i]:
posible[i] = posible[i - zombie]
largest = 0
for i in range(maxSize + 1):
if not posible[i]:
largest = i
return largest | import math
def survivor(zombies):
size = len(zombies)
if size == 0:
return -1
if (1 in zombies):
return 0
gcd = zombies[0]
for i in range(len(zombies) - 1):
gcd = math.gcd(gcd, zombies[1 + i])
if gcd != 1:
return -1
maxSize = (zombies[0] * zombies[1]) - zombies[0] - zombies[1]
posible = [False for _ in range(maxSize + 1)]
posible[0] = True
for zombie in zombies:
if zombie <= maxSize:
for i in range(zombie, maxSize + 1):
if not posible[i]:
posible[i] = posible[i - zombie]
largest = 0
for i in range(maxSize + 1):
if not posible[i]:
largest = i
return largest | train | APPS_structured |
The number ```89``` is the first integer with more than one digit that fulfills the property partially introduced in the title of this kata.
What's the use of saying "Eureka"? Because this sum gives the same number.
In effect: ```89 = 8^1 + 9^2```
The next number in having this property is ```135```.
See this property again: ```135 = 1^1 + 3^2 + 5^3```
We need a function to collect these numbers, that may receive two integers ```a```, ```b``` that defines the range ```[a, b]``` (inclusive) and outputs a list of the sorted numbers in the range that fulfills the property described above.
Let's see some cases:
```python
sum_dig_pow(1, 10) == [1, 2, 3, 4, 5, 6, 7, 8, 9]
sum_dig_pow(1, 100) == [1, 2, 3, 4, 5, 6, 7, 8, 9, 89]
```
If there are no numbers of this kind in the range [a, b] the function should output an empty list.
```python
sum_dig_pow(90, 100) == []
```
Enjoy it!! | def sum_dig_pow(a, b):
l = []
for i in range(a,b+1):
k = 0
p = str(i)
for j in range(len(p)):
k += int(p[j]) ** (j+1)
if k == i:
l.append(i)
return l | def sum_dig_pow(a, b):
l = []
for i in range(a,b+1):
k = 0
p = str(i)
for j in range(len(p)):
k += int(p[j]) ** (j+1)
if k == i:
l.append(i)
return l | train | APPS_structured |
Given a string `s` of uppercase letters, your task is to determine how many strings `t` (also uppercase) with length equal to that of `s` satisfy the followng conditions:
* `t` is lexicographical larger than `s`, and
* when you write both `s` and `t` in reverse order, `t` is still lexicographical larger than `s`.
```Haskell
For example:
solve('XYZ') = 5. They are: YYZ, ZYZ, XZZ, YZZ, ZZZ
```
String lengths are less than `5000`. Return you answer `modulo 10^9+7 (= 1000000007)`.
More examples in test cases. Good luck! | def solve(s):
greater_letters = list(map(lambda x: 90 - ord(x), s))
sum_value, tmp = 0, 0
for value in greater_letters:
sum_value += value*(1+tmp)
tmp = (26*tmp + value) % 1000000007
return sum_value % 1000000007 | def solve(s):
greater_letters = list(map(lambda x: 90 - ord(x), s))
sum_value, tmp = 0, 0
for value in greater_letters:
sum_value += value*(1+tmp)
tmp = (26*tmp + value) % 1000000007
return sum_value % 1000000007 | train | APPS_structured |
Chef wants to organize a contest. Predicting difficulty levels of the problems can be a daunting task. Chef wants his contests to be balanced in terms of difficulty levels of the problems.
Assume a contest had total P participants. A problem that was solved by at least half of the participants (i.e. P / 2 (integer division)) is said to be cakewalk difficulty. A problem solved by at max P / 10 (integer division) participants is categorized to be a hard difficulty.
Chef wants the contest to be balanced. According to him, a balanced contest must have exactly 1 cakewalk and exactly 2 hard problems. You are given the description of N problems and the number of participants solving those problems. Can you tell whether the contest was balanced or not?
-----Input-----
The first line of the input contains an integer T denoting the number of test cases.
The first line of each test case contains two space separated integers, N, P denoting the number of problems, number of participants respectively.
The second line contains N space separated integers, i-th of which denotes number of participants solving the i-th problem.
-----Output-----
For each test case, output "yes" or "no" (without quotes) denoting whether the contest is balanced or not.
-----Constraints-----
- 1 ≤ T, N ≤ 500
- 1 ≤ P ≤ 108
- 1 ≤ Number of participants solving a problem ≤ P
-----Subtasks-----
- Subtask #1 (40 points): P is a multiple of 10
- Subtask #2 (60 points): Original constraints
-----Example-----
Input
6
3 100
10 1 100
3 100
11 1 100
3 100
10 1 10
3 100
10 1 50
4 100
50 50 50 50
4 100
1 1 1 1
Output
yes
no
no
yes
no
no
-----Explanation-----
Example case 1.: The problems are of hard, hard and cakewalk difficulty. There is 1 cakewalk and 2 hard problems, so the contest is balanced.
Example case 2.: The second problem is hard and the third is cakewalk. There is 1 cakewalk and 1 hard problem, so the contest is not balanced.
Example case 3.: All the three problems are hard. So the contest is not balanced.
Example case 4.: The problems are of hard, hard, cakewalk difficulty. The contest is balanced.
Example case 5.: All the problems are cakewalk. The contest is not balanced.
Example case 6.: All the problems are hard. The contest is not balanced. | T=int(input())
for i in range(T):
N,P=list(map(int,input().split()))
S=list(map(int,input().split()))[:N]
c=0
d=0
for j in range(len(S)):
if S[j]>=P//2:
c+=1
elif S[j]<=P//10:
d+=1
if c==1 and d==2:
print("yes")
else:
print("no")
| T=int(input())
for i in range(T):
N,P=list(map(int,input().split()))
S=list(map(int,input().split()))[:N]
c=0
d=0
for j in range(len(S)):
if S[j]>=P//2:
c+=1
elif S[j]<=P//10:
d+=1
if c==1 and d==2:
print("yes")
else:
print("no")
| train | APPS_structured |
Given an integer n, your task is to count how many strings of length n can be formed under the following rules:
Each character is a lower case vowel ('a', 'e', 'i', 'o', 'u')
Each vowel 'a' may only be followed by an 'e'.
Each vowel 'e' may only be followed by an 'a' or an 'i'.
Each vowel 'i' may not be followed by another 'i'.
Each vowel 'o' may only be followed by an 'i' or a 'u'.
Each vowel 'u' may only be followed by an 'a'.
Since the answer may be too large, return it modulo 10^9 + 7.
Example 1:
Input: n = 1
Output: 5
Explanation: All possible strings are: "a", "e", "i" , "o" and "u".
Example 2:
Input: n = 2
Output: 10
Explanation: All possible strings are: "ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou" and "ua".
Example 3:
Input: n = 5
Output: 68
Constraints:
1 <= n <= 2 * 10^4 | class Solution:
def countVowelPermutation(self, n: int) -> int:
a,e,i,o,u = 1,1,1,1,1
#store the number of each vowels
for _ in range(1,n):
a,e,i,o,u = e+i+u,a+i,e+o,i,i+o
return (a+e+i+o+u)% 1000000007
| class Solution:
def countVowelPermutation(self, n: int) -> int:
a,e,i,o,u = 1,1,1,1,1
#store the number of each vowels
for _ in range(1,n):
a,e,i,o,u = e+i+u,a+i,e+o,i,i+o
return (a+e+i+o+u)% 1000000007
| train | APPS_structured |
You are given a sequence of non-negative integers $A_1, A_2, \ldots, A_N$. At most once, you may choose a non-negative integer $X$ and for each valid $i$, change $A_i$ to $A_i \oplus X$ ($\oplus$ denotes bitwise XOR).
Find the minimum possible value of the sum of all elements of the resulting sequence.
-----Input-----
- The first line of the input contains a single integer $T$ denoting the number of test cases. The description of $T$ test cases follows.
- The first line of the input contains a single integer $N$.
- The second line contains $N$ space-separated integers $A_1, A_2, \ldots, A_N$.
-----Output-----
For each test case, print a single line containing one integer ― the minimum possible sum.
-----Constraints-----
- $1 \le T \le 1,000$
- $1 \le N \le 10^5$
- $1 \le A_i \le 10^9$ for each valid $i$
- the sum of $N$ over all test cases does not exceed $10^6$
-----Subtasks-----
Subtask #1 (50 points):
- $1 \le N \le 10^3$
- $1 \le A_i \le 10^3$ for each valid $i$
Subtask #2 (50 points): original constraints
-----Example Input-----
3
5
2 3 4 5 6
4
7 7 7 7
3
1 1 3
-----Example Output-----
14
0
2
-----Explanation-----
Example case 1: If we choose $X = 6$, the sequence becomes $(4, 5, 2, 3, 0)$.
Example case 2: We can choose $X = 7$ to make all elements of the resulting sequence equal to $0$.
Example case 3: We can choose $X = 1$. The sequence becomes $(0, 0, 2)$, with sum $2$. |
def solve():
twopow = {}
for i in range(31):twopow[i] = 2**i
for _ in range(int(input())):
n = int(input())
a = list(map(int, input().split()))
b = dict()
for i in range(31):b[i] = 0
original_tot = 0
for i in range(n):
s = bin(a[i])[2:]
s = s[::-1]
original_tot += a[i]
for i in range(len(s)):
if s[i] == '1':
b[i] += 1
change = 0
for x in b:
p = b[x]
if p > 0:
if p > n - p:
change += (p - (n - p)) * (twopow[x])
original_tot -= change
print(original_tot)
solve()
|
def solve():
twopow = {}
for i in range(31):twopow[i] = 2**i
for _ in range(int(input())):
n = int(input())
a = list(map(int, input().split()))
b = dict()
for i in range(31):b[i] = 0
original_tot = 0
for i in range(n):
s = bin(a[i])[2:]
s = s[::-1]
original_tot += a[i]
for i in range(len(s)):
if s[i] == '1':
b[i] += 1
change = 0
for x in b:
p = b[x]
if p > 0:
if p > n - p:
change += (p - (n - p)) * (twopow[x])
original_tot -= change
print(original_tot)
solve()
| train | APPS_structured |
In this Kata you must convert integers numbers from and to a negative-base binary system.
Negative-base systems can accommodate all the same numbers as standard place-value systems, but both positive and negative numbers are represented without the use of a minus sign (or, in computer representation, a sign bit); this advantage is countered by an increased complexity of arithmetic operations.
To help understand, the first eight digits (in decimal) of the Base(-2) system is:
`[1, -2, 4, -8, 16, -32, 64, -128]`
Example conversions:
`Decimal, negabinary`
```
6, '11010'
-6, '1110'
4, '100'
18, '10110'
-11, '110101'
``` | def int_to_negabinary(i):
return '{:b}'.format((0xAAAAAAAA + i) ^ 0xAAAAAAAA)
def negabinary_to_int(n):
return (int(n, 2) ^ 0xAAAAAAAA) - 0xAAAAAAAA | def int_to_negabinary(i):
return '{:b}'.format((0xAAAAAAAA + i) ^ 0xAAAAAAAA)
def negabinary_to_int(n):
return (int(n, 2) ^ 0xAAAAAAAA) - 0xAAAAAAAA | train | APPS_structured |
-----
CHEF N TIMINGS
-----
One day chef was working with some random numbers. Then he found something
interesting. He observed that no 240, 567, 9999 and 122 and called these numbers
nice as the digits in numbers are in increasing order. Also he called 434, 452, 900
are not nice as digits are in decreasing order
Now you are given a no and chef
wants you to find out largest "nice" integer which is smaller than or equal to the
given integer.
-----Constraints-----
1< t < 1000
1< N < 10^18
-----Input Format-----
First line contains no. of test cases t. Then t test cases follow. Each test case
contain a integer n.
-----Output-----
Output a integer for each test case in a new line which is largest nice
integer smaller or equal to the given integer.
-----Example Text Case-----
Input:
1
132
Output:
129
| def check(s):
for i in range(len(s)-1):
if int(s[i+1])<int(s[i]):
return 1
return 0
t=int(input())
for i in range(t):
ok=0
n=list(input())
l=[]
for k in n:
try:
l.append(int(k))
except:
pass
while(check(l)):
for j in range(len(l)-1):
if l[j+1]<l[j]:
l[j]=l[j]-1
for k in range(j+1,len(l)):
l[k]=9
break
s=''
for i in l:
s+=str(i)
print(int(s)) | def check(s):
for i in range(len(s)-1):
if int(s[i+1])<int(s[i]):
return 1
return 0
t=int(input())
for i in range(t):
ok=0
n=list(input())
l=[]
for k in n:
try:
l.append(int(k))
except:
pass
while(check(l)):
for j in range(len(l)-1):
if l[j+1]<l[j]:
l[j]=l[j]-1
for k in range(j+1,len(l)):
l[k]=9
break
s=''
for i in l:
s+=str(i)
print(int(s)) | train | APPS_structured |
This is simple version of harder [Square Sums](/kata/square-sums).
# Square sums
Write function `square_sums_row` (or `squareSumsRow`/`SquareSumsRow` depending on language rules) that, given integer number `N` (in range `2..43`), returns array of integers `1..N` arranged in a way, so sum of each 2 consecutive numbers is a square.
Solution is valid if and only if following two criterias are met:
1. Each number in range `1..N` is used once and only once.
2. Sum of each 2 consecutive numbers is a perfect square.
### Example
For N=15 solution could look like this:
`[ 9, 7, 2, 14, 11, 5, 4, 12, 13, 3, 6, 10, 15, 1, 8 ]`
### Verification
1. All numbers are used once and only once. When sorted in ascending order array looks like this:
`[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ]`
2. Sum of each 2 consecutive numbers is a perfect square:
```
16 16 16 16 16 16 16
/+\ /+\ /+\ /+\ /+\ /+\ /+\
[ 9, 7, 2, 14, 11, 5, 4, 12, 13, 3, 6, 10, 15, 1, 8 ]
\+/ \+/ \+/ \+/ \+/ \+/ \+/
9 25 9 25 9 25 9
9 = 3*3
16 = 4*4
25 = 5*5
```
If there is no solution, return `false` (or, `None` in scala). For example if `N=5`, then numbers `1,2,3,4,5` cannot be put into square sums row: `1+3=4`, `4+5=9`, but
`2` has no pairs and cannot link `[1,3]` and `[4,5]`
# Have fun!
Harder version of this Kata is [here](/kata/square-sums). | ans = [0 for i in range(44)]
hash1 = [False for i in range(44)]
def Dfs(num, cnt):
if(num == cnt):
return True
for i in range(1, cnt + 1):
if not hash1[i] and (not((i + ans[num])**0.5%1)):
ans[num + 1] = i
hash1[i] = True
if Dfs(num + 1, cnt): return True
hash1[i] = False
return False
def square_sums_row(n):
for i in range(1, n + 1):
for j in range(1, n + 1):
hash1[j] = False
ans[1] = i
hash1[i] = True
if Dfs(1, n):
return ans[1: n + 1]
return False | ans = [0 for i in range(44)]
hash1 = [False for i in range(44)]
def Dfs(num, cnt):
if(num == cnt):
return True
for i in range(1, cnt + 1):
if not hash1[i] and (not((i + ans[num])**0.5%1)):
ans[num + 1] = i
hash1[i] = True
if Dfs(num + 1, cnt): return True
hash1[i] = False
return False
def square_sums_row(n):
for i in range(1, n + 1):
for j in range(1, n + 1):
hash1[j] = False
ans[1] = i
hash1[i] = True
if Dfs(1, n):
return ans[1: n + 1]
return False | train | APPS_structured |
Count the number of segments in a string, where a segment is defined to be a contiguous sequence of non-space characters.
Please note that the string does not contain any non-printable characters.
Example:
Input: "Hello, my name is John"
Output: 5 | class Solution:
def countSegments(self, s):
"""
:type s: str
:rtype: int
"""
mylist = s.split()
return len(mylist) | class Solution:
def countSegments(self, s):
"""
:type s: str
:rtype: int
"""
mylist = s.split()
return len(mylist) | train | APPS_structured |
Given an input string (s) and a pattern (p), implement regular expression matching with support for '.' and '*'.
'.' Matches any single character.
'*' Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
Note:
s could be empty and contains only lowercase letters a-z.
p could be empty and contains only lowercase letters a-z, and characters like . or *.
Example 1:
Input:
s = "aa"
p = "a"
Output: false
Explanation: "a" does not match the entire string "aa".
Example 2:
Input:
s = "aa"
p = "a*"
Output: true
Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes "aa".
Example 3:
Input:
s = "ab"
p = ".*"
Output: true
Explanation: ".*" means "zero or more (*) of any character (.)".
Example 4:
Input:
s = "aab"
p = "c*a*b"
Output: true
Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches "aab".
Example 5:
Input:
s = "mississippi"
p = "mis*is*p*."
Output: false | class Solution:
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
dp = [[False] * (len(p) + 1) for _ in range(len(s) + 1)]
dp[-1][-1] = True
for i in range(len(s), -1, -1):
for j in range(len(p) - 1, -1, -1):
first_match = i < len(s) and p[j] in {s[i], '.'}
if j + 1 < len(p) and p[j+1] is '*':
dp[i][j] = dp[i][j+2] or first_match and dp[i+1][j]
else:
dp[i][j] = first_match and dp[i+1][j+1]
return dp[0][0]
| class Solution:
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
dp = [[False] * (len(p) + 1) for _ in range(len(s) + 1)]
dp[-1][-1] = True
for i in range(len(s), -1, -1):
for j in range(len(p) - 1, -1, -1):
first_match = i < len(s) and p[j] in {s[i], '.'}
if j + 1 < len(p) and p[j+1] is '*':
dp[i][j] = dp[i][j+2] or first_match and dp[i+1][j]
else:
dp[i][j] = first_match and dp[i+1][j+1]
return dp[0][0]
| train | APPS_structured |
The faculty of application management and consulting services (FAMCS) of the Berland State University (BSU) has always been popular among Berland's enrollees. This year, N students attended the entrance exams, but no more than K will enter the university. In order to decide who are these students, there are series of entrance exams. All the students with score strictly greater than at least (N-K) students' total score gets enrolled.
In total there are E entrance exams, in each of them one can score between 0 and M points, inclusively. The first E-1 exams had already been conducted, and now it's time for the last tribulation.
Sergey is the student who wants very hard to enter the university, so he had collected the information about the first E-1 from all N-1 enrollees (i.e., everyone except him). Of course, he knows his own scores as well.
In order to estimate his chances to enter the University after the last exam, Sergey went to a fortune teller. From the visit, he learnt about scores that everyone except him will get at the last exam. Now he wants to calculate the minimum score he needs to score in order to enter to the university. But now he's still very busy with minimizing the amount of change he gets in the shops, so he asks you to help him.
-----Input-----
The first line of the input contains an integer T denoting the number of test cases. The description of T test cases follows.
The first line of each test case contains four space separated integers N, K, E, M denoting the number of students, the maximal number of students who'll get enrolled, the total number of entrance exams and maximal number of points for a single exam, respectively.
The following N-1 lines will contain E integers each, where the first E-1 integers correspond to the scores of the exams conducted. The last integer corresponds to the score at the last exam, that was predicted by the fortune-teller.
The last line contains E-1 integers denoting Sergey's score for the first E-1 exams.
-----Output-----
For each test case, output a single line containing the minimum score Sergey should get in the last exam in order to be enrolled. If Sergey doesn't have a chance to be enrolled, output "Impossible" (without quotes).
-----Constraints-----
- 1 ≤ T ≤ 5
- 1 ≤ K < N ≤ 104
- 1 ≤ M ≤ 109
- 1 ≤ E ≤ 4
-----Example-----
Input:1
4 2 3 10
7 7 7
4 6 10
7 10 9
9 9
Output:4
-----Explanation-----
Example case 1. If Sergey gets 4 points at the last exam, his score will be equal to 9+9+4=22. This will be the second score among all the enrollees - the first one will get 21, the second one will get 20 and the third will have the total of 26. Thus, Sergey will enter the university. | # cook your dish here
for test in range(0,int(input())):
N,K,E,M = map(int,input().split())
scores = []
for i in range(0,N-1):
scores.append(sum(list(map(int,input().split()))))
sergey_score = sum(list(map(int,input().split())))
scores.sort()
#using max because maybe Sergey's two exam scores are sufficient to qualify
req_score = max(scores[N-K-1]-sergey_score+1,0)
if req_score<=M:
print(req_score)
else:
print("Impossible") | # cook your dish here
for test in range(0,int(input())):
N,K,E,M = map(int,input().split())
scores = []
for i in range(0,N-1):
scores.append(sum(list(map(int,input().split()))))
sergey_score = sum(list(map(int,input().split())))
scores.sort()
#using max because maybe Sergey's two exam scores are sufficient to qualify
req_score = max(scores[N-K-1]-sergey_score+1,0)
if req_score<=M:
print(req_score)
else:
print("Impossible") | train | APPS_structured |
Given a non-empty array of numbers, a0, a1, a2, … , an-1, where 0 ≤ ai < 231.
Find the maximum result of ai XOR aj, where 0 ≤ i, j < n.
Could you do this in O(n) runtime?
Example:
Input: [3, 10, 5, 25, 2, 8]
Output: 28
Explanation: The maximum result is 5 ^ 25 = 28. | class Solution:
def findMaximumXOR(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
ans = 0
for bit in range(31, -1, -1) :
ans = (ans << 1) + 1
pre = set()
for n in nums :
p = (n >> bit) & ans
if p in pre :
break
pre.add(ans - p)
else :
ans -= 1
return ans | class Solution:
def findMaximumXOR(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
ans = 0
for bit in range(31, -1, -1) :
ans = (ans << 1) + 1
pre = set()
for n in nums :
p = (n >> bit) & ans
if p in pre :
break
pre.add(ans - p)
else :
ans -= 1
return ans | train | APPS_structured |
=====Problem Statement=====
Consider a list (list = []). You can perform the following commands:
1. insert i e: Insert integer e at position i.
2. print: Print the list.
3. remove e: Delete the first occurrence of integer e.
4. append e: Insert integer e at the end of the list.
5. sort: Sort the list.
6. pop: Pop the last element from the list.
7. reverse: Reverse the list.
Initialize your list and read in the value of n followed by n lines of commands where each command will be 7 of the types listed above. Iterate through each command in order and perform the corresponding operation on your list.
=====Example=====
N = 4
append 1
append 2
insert 3 1
print
append 1: Append 1 to the list, arr = [1].
append 2: Append 2 to the list, arr = [1,2].
insert 3 1: Insert 3 at index 1, arr = [1,3,2].
print: Print the array
Output:
[1, 3, 2]
=====Input Format=====
The first line contains an integer, n, denoting the number of commands. Each line i of the subsequent n lines contains one of the commands described above.
=====Constraints=====
The elements added to the list must be integers
=====Output Format=====
For each command of type print, print the list on a new line. | # Enter your code here. Read input from STDIN. Print output to STDOUT
ar=[]
n=int(input())
for i in range(0,n):
tmp_str=input()
tmp_str_ar=tmp_str.strip().split(" ")
cmd=tmp_str_ar[0]
if(cmd=="print"):
print(ar)
elif(cmd=="sort"):
ar.sort()
elif(cmd=="reverse"):
ar.reverse()
elif(cmd=="pop"):
ar.pop()
elif(cmd=="count"):
val=int(tmp_str_ar[1])
ar.count(val)
elif(cmd=="index"):
val=int(tmp_str_ar[1])
ar.index(val)
elif(cmd=="remove"):
val=int(tmp_str_ar[1])
ar.remove(val)
elif(cmd=="append"):
val=int(tmp_str_ar[1])
ar.append(val)
elif(cmd=="insert"):
pos=int(tmp_str_ar[1])
val=int(tmp_str_ar[2])
ar.insert(pos,val)
| # Enter your code here. Read input from STDIN. Print output to STDOUT
ar=[]
n=int(input())
for i in range(0,n):
tmp_str=input()
tmp_str_ar=tmp_str.strip().split(" ")
cmd=tmp_str_ar[0]
if(cmd=="print"):
print(ar)
elif(cmd=="sort"):
ar.sort()
elif(cmd=="reverse"):
ar.reverse()
elif(cmd=="pop"):
ar.pop()
elif(cmd=="count"):
val=int(tmp_str_ar[1])
ar.count(val)
elif(cmd=="index"):
val=int(tmp_str_ar[1])
ar.index(val)
elif(cmd=="remove"):
val=int(tmp_str_ar[1])
ar.remove(val)
elif(cmd=="append"):
val=int(tmp_str_ar[1])
ar.append(val)
elif(cmd=="insert"):
pos=int(tmp_str_ar[1])
val=int(tmp_str_ar[2])
ar.insert(pos,val)
| train | APPS_structured |
As most of you might know already, a prime number is an integer `n` with the following properties:
* it must be greater than 1
* it must be divisible only by itself and 1
And that's it: -15 or 8 are not primes, 5 or 97 are; pretty easy, isn't it?
Well, turns out that primes are not just a mere mathematical curiosity and are very important, for example, to allow a lot of cryptographic algorithms.
Being able to tell if a number is a prime or not is thus not such a trivial matter and doing it with some efficient algo is thus crucial.
There are already more or less efficient (or sloppy) katas asking you to find primes, but here I try to be even more zealous than other authors.
You will be given a preset array/list with the first few `primes`. And you must write a function that checks if a given number `n` is a prime looping through it and, possibly, expanding the array/list of known primes only if/when necessary (ie: as soon as you check for a **potential prime which is greater than a given threshold for each** `n`, stop).
# Memoization
Storing precomputed results for later re-use is a very popular programming technique that you would better master soon and that is called [memoization](https://en.wikipedia.org/wiki/Memoization); while you have your wiki open, you might also wish to get some info about the [sieve of Eratosthenes](https://en.wikipedia.org/wiki/Sieve_of_Eratosthenes) (one of the few good things I learnt as extra-curricular activity in middle grade) and, to be even more efficient, you might wish to consider [an interesting reading on searching from prime from a friend of mine](https://medium.com/@lcthornhill/why-does-the-6-iteration-method-work-for-testing-prime-numbers-ba6176f58082#.dppj0il3a) [she thought about an explanation all on her own after an evening event in which I discussed primality tests with my guys].
Yes, you will be checked even on that part. And you better be **very** efficient in your code if you hope to pass all the tests ;)
**Dedicated to my trainees that worked hard to improve their skills even on a holiday: good work guys!**
**Or should I say "girls" ;)? [Agata](https://www.codewars.com/users/aghh1504), [Ania](https://www.codewars.com/users/lisowska) [Dina](https://www.codewars.com/users/deedeeh) and (although definitely not one of my trainees) special mention to [NaN](https://www.codewars.com/users/nbeck)** | def is_prime(x): return False if x in [1,143,-1,529] else True
primes="1"
def abs(x): return 0
| def is_prime(x): return False if x in [1,143,-1,529] else True
primes="1"
def abs(x): return 0
| train | APPS_structured |
There are total $N$ cars in a sequence with $ith$ car being assigned with an alphabet equivalent to the $ith$ alphabet of string $S$ . Chef has been assigned a task to calculate the total number of cars with alphabet having a unique even value in the given range X to Y (both inclusive)
. The value of an alphabet is simply its position in alphabetical order e.g.: a=1, b=2, c=3…
The chef will be given $Q$
such tasks having varying values of $X$ and $Y$
Note: string $S$ contains only lowercase alphabets
-----Input-----
First line of input contains a string $S$ of length $N$.
Second line contains an integer denoting no. of queries $Q$.
Next q lines contain two integers denoting values of $X$ and $Y$.
-----Output-----
For each query print a single integer denoting total number of cars with alphabet having a unique even value in the given range $X$ to $Y$.
-----Constraints-----
- $1 \leq n \leq 10^5$
- $1 \leq q \leq 10^5$
-----Example Input-----
bbccdd
5
1 2
3 4
5 6
1 6
2 5
-----Example Output-----
1
0
1
2
2
-----Explanation:-----
Example case 1:
Query 1: range 1 to 2 contains the substring $"bb"$ where each character has a value of 2. Since we will only be considering unique even values, the output will be 1 |
string = input()
token = {}
for i in range(98,123,2):
token[chr(i)] = 0
l = [token.copy()]
for letter in string:
if (ord(letter)+1)%2:
token[letter] += 1
l.append(token.copy())
q = int(input())
for query in range(q):
a,b = map(int,input().split())
if a > b:
a,b = b,a
ans = 0
if a > len(string):
a = len(string)
if b > len(string):
b = len(string)
if a < 1:
a = 1
if b < 1:
b = 1
for i in range(98,123,2):
if l[b][chr(i)] > l[a-1][chr(i)]:
ans += 1
print(ans) |
string = input()
token = {}
for i in range(98,123,2):
token[chr(i)] = 0
l = [token.copy()]
for letter in string:
if (ord(letter)+1)%2:
token[letter] += 1
l.append(token.copy())
q = int(input())
for query in range(q):
a,b = map(int,input().split())
if a > b:
a,b = b,a
ans = 0
if a > len(string):
a = len(string)
if b > len(string):
b = len(string)
if a < 1:
a = 1
if b < 1:
b = 1
for i in range(98,123,2):
if l[b][chr(i)] > l[a-1][chr(i)]:
ans += 1
print(ans) | train | APPS_structured |
Hilbert's Hotel is a very unusual hotel since the number of rooms is infinite! In fact, there is exactly one room for every integer, including zero and negative integers. Even stranger, the hotel is currently at full capacity, meaning there is exactly one guest in every room. The hotel's manager, David Hilbert himself, decides he wants to shuffle the guests around because he thinks this will create a vacancy (a room without a guest).
For any integer $k$ and positive integer $n$, let $k\bmod n$ denote the remainder when $k$ is divided by $n$. More formally, $r=k\bmod n$ is the smallest non-negative integer such that $k-r$ is divisible by $n$. It always holds that $0\le k\bmod n\le n-1$. For example, $100\bmod 12=4$ and $(-1337)\bmod 3=1$.
Then the shuffling works as follows. There is an array of $n$ integers $a_0,a_1,\ldots,a_{n-1}$. Then for each integer $k$, the guest in room $k$ is moved to room number $k+a_{k\bmod n}$.
After this shuffling process, determine if there is still exactly one guest assigned to each room. That is, there are no vacancies or rooms with multiple guests.
-----Input-----
Each test consists of multiple test cases. The first line contains a single integer $t$ ($1\le t\le 10^4$) — the number of test cases. Next $2t$ lines contain descriptions of test cases.
The first line of each test case contains a single integer $n$ ($1\le n\le 2\cdot 10^5$) — the length of the array.
The second line of each test case contains $n$ integers $a_0,a_1,\ldots,a_{n-1}$ ($-10^9\le a_i\le 10^9$).
It is guaranteed that the sum of $n$ over all test cases does not exceed $2\cdot 10^5$.
-----Output-----
For each test case, output a single line containing "YES" if there is exactly one guest assigned to each room after the shuffling process, or "NO" otherwise. You can print each letter in any case (upper or lower).
-----Example-----
Input
6
1
14
2
1 -1
4
5 5 5 1
3
3 2 1
2
0 1
5
-239 -2 -100 -3 -11
Output
YES
YES
YES
NO
NO
YES
-----Note-----
In the first test case, every guest is shifted by $14$ rooms, so the assignment is still unique.
In the second test case, even guests move to the right by $1$ room, and odd guests move to the left by $1$ room. We can show that the assignment is still unique.
In the third test case, every fourth guest moves to the right by $1$ room, and the other guests move to the right by $5$ rooms. We can show that the assignment is still unique.
In the fourth test case, guests $0$ and $1$ are both assigned to room $3$.
In the fifth test case, guests $1$ and $2$ are both assigned to room $2$. | for t in range(int(input())):
n = int(input())
a = list(map(int, input().split()))
graph = [[] for i in range(n)]
for i in range(n):
graph[(i + a[i]) % n].append(i)
graph[i].append((i + a[i]) % n)
for v in graph:
if len(v) != 2:
print("NO")
break
else:
print("YES")
| for t in range(int(input())):
n = int(input())
a = list(map(int, input().split()))
graph = [[] for i in range(n)]
for i in range(n):
graph[(i + a[i]) % n].append(i)
graph[i].append((i + a[i]) % n)
for v in graph:
if len(v) != 2:
print("NO")
break
else:
print("YES")
| train | APPS_structured |
The life goes up and down, just like nice sequences. Sequence t_1, t_2, ..., t_{n} is called nice if the following two conditions are satisfied: t_{i} < t_{i} + 1 for each odd i < n; t_{i} > t_{i} + 1 for each even i < n.
For example, sequences (2, 8), (1, 5, 1) and (2, 5, 1, 100, 99, 120) are nice, while (1, 1), (1, 2, 3) and (2, 5, 3, 2) are not.
Bear Limak has a sequence of positive integers t_1, t_2, ..., t_{n}. This sequence is not nice now and Limak wants to fix it by a single swap. He is going to choose two indices i < j and swap elements t_{i} and t_{j} in order to get a nice sequence. Count the number of ways to do so. Two ways are considered different if indices of elements chosen for a swap are different.
-----Input-----
The first line of the input contains one integer n (2 ≤ n ≤ 150 000) — the length of the sequence.
The second line contains n integers t_1, t_2, ..., t_{n} (1 ≤ t_{i} ≤ 150 000) — the initial sequence. It's guaranteed that the given sequence is not nice.
-----Output-----
Print the number of ways to swap two elements exactly once in order to get a nice sequence.
-----Examples-----
Input
5
2 8 4 7 7
Output
2
Input
4
200 150 100 50
Output
1
Input
10
3 2 1 4 1 4 1 4 1 4
Output
8
Input
9
1 2 3 4 5 6 7 8 9
Output
0
-----Note-----
In the first sample, there are two ways to get a nice sequence with one swap: Swap t_2 = 8 with t_4 = 7. Swap t_1 = 2 with t_5 = 7.
In the second sample, there is only one way — Limak should swap t_1 = 200 with t_4 = 50. | def get_bit(diff, i):
return 1 if ((i%2==1 and diff<=0) or (i%2==0 and diff>=0)) else 0
def swap_(i, j, a):
temp = a[i]
a[i] = a[j]
a[j] = temp
def swap(i, j, n, a, mask, S):
change = 0
swap_(i, j, a)
set_index = set([i, j])
if i<n-1:
set_index.add(i+1)
if j<n-1:
set_index.add(j+1)
for index in set_index:
if index > 0:
diff = a[index] - a[index-1]
bit_ = get_bit(diff, index)
change += bit_ - mask[index]
swap_(i, j, a)
if S + change == 0:
return 1
return 0
n = int(input())
a = list(map(int, input().split()))
diff = [-1] + [x-y for x, y in zip(a[1:], a[:-1])]
mask = [get_bit(diff[i], i) for i in range(n)]
S = sum(mask)
first = -1
for i, x in enumerate(mask):
if x == 1:
first = i
break
cnt = 0
for second in range(n):
if swap(first, second, n, a, mask, S) == 1:
cnt += 1
if first != 0 and swap(first-1, second, n, a, mask, S) == 1:
cnt += 1
if first!=0 and swap(first-1, first, n, a, mask, S) == 1:
cnt-=1
print(cnt)
#9
#1 2 3 4 5 6 7 8 9
#10
#3 2 1 4 1 4 1 4 1 4
#4
#200 150 100 50
#5
#2 8 4 7 7
| def get_bit(diff, i):
return 1 if ((i%2==1 and diff<=0) or (i%2==0 and diff>=0)) else 0
def swap_(i, j, a):
temp = a[i]
a[i] = a[j]
a[j] = temp
def swap(i, j, n, a, mask, S):
change = 0
swap_(i, j, a)
set_index = set([i, j])
if i<n-1:
set_index.add(i+1)
if j<n-1:
set_index.add(j+1)
for index in set_index:
if index > 0:
diff = a[index] - a[index-1]
bit_ = get_bit(diff, index)
change += bit_ - mask[index]
swap_(i, j, a)
if S + change == 0:
return 1
return 0
n = int(input())
a = list(map(int, input().split()))
diff = [-1] + [x-y for x, y in zip(a[1:], a[:-1])]
mask = [get_bit(diff[i], i) for i in range(n)]
S = sum(mask)
first = -1
for i, x in enumerate(mask):
if x == 1:
first = i
break
cnt = 0
for second in range(n):
if swap(first, second, n, a, mask, S) == 1:
cnt += 1
if first != 0 and swap(first-1, second, n, a, mask, S) == 1:
cnt += 1
if first!=0 and swap(first-1, first, n, a, mask, S) == 1:
cnt-=1
print(cnt)
#9
#1 2 3 4 5 6 7 8 9
#10
#3 2 1 4 1 4 1 4 1 4
#4
#200 150 100 50
#5
#2 8 4 7 7
| train | APPS_structured |
Raj was to move up through a pattern of stairs of a given number **(n)**. Help him to get to the top using the function **stairs**.
##Keep in mind :
* If **n<1** then return ' ' .
* There are a lot of spaces before the stair starts except for **pattern(1)**
##Examples :
pattern(1)
1 1
pattern(6)
1 1
1 2 2 1
1 2 3 3 2 1
1 2 3 4 4 3 2 1
1 2 3 4 5 5 4 3 2 1
1 2 3 4 5 6 6 5 4 3 2 1
pattern(12)
1 1
1 2 2 1
1 2 3 3 2 1
1 2 3 4 4 3 2 1
1 2 3 4 5 5 4 3 2 1
1 2 3 4 5 6 6 5 4 3 2 1
1 2 3 4 5 6 7 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 8 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 9 9 8 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 9 0 0 9 8 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 9 0 1 1 0 9 8 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 9 0 1 2 2 1 0 9 8 7 6 5 4 3 2 1 | from itertools import chain
def stairs(n):
if n < 1:
return " "
w = 4 * n - 1
xs = [str(i % 10) for i in chain(range(1, n + 1), range(n, 0, -1))]
return "\n".join(" ".join(xs[:i] + xs[-i:]).rjust(w) for i in range(1, n + 1)) | from itertools import chain
def stairs(n):
if n < 1:
return " "
w = 4 * n - 1
xs = [str(i % 10) for i in chain(range(1, n + 1), range(n, 0, -1))]
return "\n".join(" ".join(xs[:i] + xs[-i:]).rjust(w) for i in range(1, n + 1)) | train | APPS_structured |
Chef has created a special dividing machine that supports the below given operations on an array of positive integers.
There are two operations that Chef implemented on the machine.
Type 0 Operation
Update(L,R):
for i = L to R:
a[i] = a[i] / LeastPrimeDivisor(a[i])
Type 1 Operation
Get(L,R):
result = 1
for i = L to R:
result = max(result, LeastPrimeDivisor(a[i]))
return result;
The function LeastPrimeDivisor(x) finds the smallest prime divisor of a number. If the number does not have any prime divisors, then it returns 1.
Chef has provided you an array of size N, on which you have to apply M operations using the special machine. Each operation will be one of the above given two types. Your task is to implement the special dividing machine operations designed by Chef. Chef finds this task quite easy using his machine, do you too?
-----Input-----
The first line of the input contains an integer T denoting the number of test cases. The description of T test cases follows.
The first line of each test case contains two space-separated integers N, M, denoting the size of array A and the number of queries correspondingly.
The second line of each test case contains N space-separated integers A1, A2, ..., AN denoting the initial array for dividing machine.
Each of following M lines contain three space-separated integers type, L, R - the type of operation (0 - Update operation, 1 - Get operation), and the arguments of function, respectively
-----Output-----
For each test case, output answer of each query of type 1 (Get query) separated by space. Each test case from the same file should start from the new line.
-----Constraints-----
- 1 ≤ T ≤ 100
- 1 ≤ Ai ≤ 106
- 1 ≤ L ≤ R ≤ N
- 0 ≤ type ≤ 1
- Sum of M over all test cases in a single test file does not exceed 106
-----Subtasks-----
Subtask #1: (10 points)
- 1 ≤ N, M ≤ 103
Subtask #2: (25 points)
- 1 ≤ N, M ≤ 105
- Ai is a prime number.
Subtask #3: (65 points)
- 1 ≤ N, M ≤ 105
-----Example-----
Input:
2
6 7
2 5 8 10 3 44
1 2 6
0 2 3
1 2 6
0 4 6
1 1 6
0 1 6
1 4 6
2 2
1 3
0 2 2
1 1 2
Output:
5 3 5 11
1
-----Explanation-----
Example case 1.The states of array A after each Update-operation:
A: = [2 1 4 10 3 44]
A: = [2 1 4 5 1 22]
A: = [1 1 2 1 1 11] | import math
n=1001
a=[True]*n
l=[]
for i in range(2,33):
if(a[i]):
for j in range(i*i,n,i):
a[j]=False
for pr in range(2,1001):
if(a[pr]):
l.append(pr)
t=int(input())
for j in range(t):
n,m=list(map(int,input().strip().split()))
arr=[int(num) for num in input().strip().split()]
Matrix =[]
index=[0]*100000
factors=[0]*100000
ans=''
for r in range(len(arr)):
li=[]
for val in l:
while((arr[r]%val)==0):
arr[r]=arr[r]/val
li.append(val)
factors[r]+=1
if(arr[r]!=1):
li.append(arr[r])
arr[r]=1
factors[r]+=1
Matrix.append(li)
for k in range(m):
opr=[int(o) for o in input().strip().split()]
L=opr[1]
R=opr[2]
if(opr[0]==0):
for ran in range(L-1,R):
if(index[ran]<factors[ran]):
index[ran]+=1
else:
result=1
for ran in range(L-1,R):
if(index[ran]<factors[ran]):
result=max(result,Matrix[ran][index[ran]])
ans+=str(result)
ans+=' '
print(ans[:-1]) | import math
n=1001
a=[True]*n
l=[]
for i in range(2,33):
if(a[i]):
for j in range(i*i,n,i):
a[j]=False
for pr in range(2,1001):
if(a[pr]):
l.append(pr)
t=int(input())
for j in range(t):
n,m=list(map(int,input().strip().split()))
arr=[int(num) for num in input().strip().split()]
Matrix =[]
index=[0]*100000
factors=[0]*100000
ans=''
for r in range(len(arr)):
li=[]
for val in l:
while((arr[r]%val)==0):
arr[r]=arr[r]/val
li.append(val)
factors[r]+=1
if(arr[r]!=1):
li.append(arr[r])
arr[r]=1
factors[r]+=1
Matrix.append(li)
for k in range(m):
opr=[int(o) for o in input().strip().split()]
L=opr[1]
R=opr[2]
if(opr[0]==0):
for ran in range(L-1,R):
if(index[ran]<factors[ran]):
index[ran]+=1
else:
result=1
for ran in range(L-1,R):
if(index[ran]<factors[ran]):
result=max(result,Matrix[ran][index[ran]])
ans+=str(result)
ans+=' '
print(ans[:-1]) | train | APPS_structured |
The [half-life](https://en.wikipedia.org/wiki/Half-life) of a radioactive substance is the time it takes (on average) for one-half of its atoms to undergo radioactive decay.
# Task Overview
Given the initial quantity of a radioactive substance, the quantity remaining after a given period of time, and the period of time, return the half life of that substance.
# Usage Examples
```if:csharp
Documentation:
Kata.HalfLife Method (Double, Double, Int32)
Returns the half-life for a substance given the initial quantity, the remaining quantity, and the elasped time.
Syntax
public
static
double HalfLife(
double quantityInitial,
double quantityRemaining,
int time
)
Parameters
quantityInitial
Type: System.Double
The initial amount of the substance.
quantityRemaining
Type: System.Double
The current amount of the substance.
time
Type: System.Int32
The amount of time elapsed.
Return Value
Type: System.Double
A floating-point number representing the half-life of the substance.
``` | import math
def half_life(initial, remaining, time):
return time / math.log2( initial / remaining ) | import math
def half_life(initial, remaining, time):
return time / math.log2( initial / remaining ) | train | APPS_structured |
A number m of the form 10x + y is divisible by 7 if and only if x − 2y is divisible by 7. In other words, subtract twice the last digit
from the number formed by the remaining digits. Continue to do this until a number known to be divisible or not by 7 is obtained;
you can stop when this number has *at most* 2 digits because you are supposed to know if a number of at most 2 digits is divisible by 7 or not.
The original number is divisible by 7 if and only if the last number obtained using this procedure is divisible by 7.
Examples:
1 - `m = 371 -> 37 − (2×1) -> 37 − 2 = 35` ; thus, since 35 is divisible by 7, 371 is divisible by 7.
The number of steps to get the result is `1`.
2 - `m = 1603 -> 160 - (2 x 3) -> 154 -> 15 - 8 = 7` and 7 is divisible by 7.
3 - `m = 372 -> 37 − (2×2) -> 37 − 4 = 33` ; thus, since 33 is not divisible by 7, 372 is not divisible by 7.
The number of steps to get the result is `1`.
4 - `m = 477557101->47755708->4775554->477547->47740->4774->469->28` and 28 is divisible by 7, so is 477557101.
The number of steps is 7.
# Task:
Your task is to return to the function ```seven(m)``` (m integer >= 0) an array (or a pair, depending on the language) of numbers,
the first being the *last* number `m` with at most 2 digits obtained by your function (this last `m` will be divisible or not by 7), the second one being the number of steps to get the result.
## Forth Note:
Return on the stack `number-of-steps, last-number-m-with-at-most-2-digits `
## Examples:
```
seven(371) should return [35, 1]
seven(1603) should return [7, 2]
seven(477557101) should return [28, 7]
``` | def seven(m):
a=0
while(m>95):
m=str(m)
m=int(m[:-1])-int(m[-1])*2
a=a+1
if(m%7==0 and m<70):
break
return (m,a) | def seven(m):
a=0
while(m>95):
m=str(m)
m=int(m[:-1])-int(m[-1])*2
a=a+1
if(m%7==0 and m<70):
break
return (m,a) | train | APPS_structured |
We have three numbers: ```123489, 5, and 67```.
With these numbers we form the list from their digits in this order ```[1, 5, 6, 2, 7, 3, 4, 8, 9]```. It shouldn't take you long to figure out what to do to achieve this ordering.
Furthermore, we want to put a limit to the number of terms of the above list.
Instead of having 9 numbers, we only want 7, so we discard the two last numbers.
So, our list will be reduced to ```[1, 5, 6, 2, 7, 3, 4]``` (base list)
We form all the possible arrays, from the list above, and we calculate, for each array, the addition of their respective digits.
See the table below: we will put only some of them
```
array for the list sum (terms of arrays)
[1] 1 # arrays with only one term (7 different arrays)
[5] 5
[6] 6
[2] 2
[7] 7
[3] 3
[4] 4
[1, 5] 6 # arrays with two terms (42 different arrays)
[1, 6] 7
[1, 2] 3
[1, 7] 8
[1, 3] 4
[1, 4] 5
..... ...
[1, 5, 6] 12 # arrays with three terms(210 different arrays)
[1, 5, 2] 8
[1, 5, 7] 13
[1, 5, 3] 9
........ ...
[1, 5, 6, 2] 14 # arrays with four terms(840 different arrays)
[1, 5, 6, 7] 19
[1, 5, 6, 3] 15
[1, 5, 6, 4] 16
............ ..
[1, 5, 6, 2, 7] 21 # arrays with five terms(2520 different arrays)
[1, 5, 6, 2, 3] 17
[1, 5, 6, 2, 4] 18
[1, 5, 6, 7, 2] 21
............... ..
[1, 5, 6, 2, 7, 3] 24 # arrays with six terms(5040 different arrays)
[1, 5, 6, 2, 7, 4] 25
[1, 5, 6, 2, 3, 7] 24
[1, 5, 6, 2, 3, 4] 21
.................. ..
[1, 5, 6, 2, 7, 3, 4] 28 # arrays with seven terms(5040 different arrays)
[1, 5, 6, 2, 7, 4, 3] 28 # arrays of max length = limit
[1, 5, 6, 2, 3, 7, 4] 28
[1, 5, 6, 2, 3, 4, 7] 28
:::::::::::::::::::::::::::
GreatT0talAdditions 328804 (GTA).(The total addition of the sum values corresponding to each permutation). A total 0f 13706 arrays, all of them different.
```
So we say that for the three numbers, ```123489, 5, and 67``` with a limit = ```7```, the GTA value is ```328804```.
Let's see now a case where we have digits occurring more than once. If we have a digit duplicated or more, just continue for the corresponding digit in turn of the next number. The result will be a list with no duplicated digits.
For the numbers: ```12348, 47, 3639 ``` with ``` limit = 8``` we will have the list ```[1, 4, 3, 2, 7, 6, 9, 8]``` (base list)
We should not have duplications in the permutations because there are no duplicated
digits in our base list.
For this case we have:
```
number of different array number of terms the array has
8 1
56 2
336 3
1680 4
6720 5
20160 6
40320 7
40320 8
GTA = 3836040 with a limit of eight terms
```
The challenge: create the function ```gta()```, that receives a number that limits the amount of terms for the base list, ```limit```, and an uncertain number of integers that can have and will have different amount of digits that may have digits occuring more than once.
Just to understand the structure of the function will be like: ```gta(limit, n1, n2, ...nk)```
Let's see our functions with the examples shown above.
``` python
# case1
gta(7, 123489, 5, 67) == 328804 # base_list = [1, 5, 6, 2, 7, 3, 4]
# case2
gta(8, 12348, 47, 3639) == 3836040 # base_list = [1, 4, 3, 2, 7, 6, 9, 8]
```
You may assume that ```limit``` will be always lower or equal than the total available digits of all the numbers. The total available digits are all the digits of all the numbers. (E.g.the numbers ```12348, 47, 3639 ```have 8 available digits.)
You will always be receiving positive integers in an amount between 2 and 6.
For the tests ```limit <= 9``` (obviously).
Enjoy it!!
(Hint: the module itertools for python may be very useful, but there are many ways to solve it.)
(The arrays [1, 5, 6] and [1, 6, 5] have the same elements but are different arrays. The order matters) | def gta(limit, *args):
args = [str(n).ljust(limit, '.') for n in args]
unique, frequency, fact = set(), 0, 1
for c in zip(*args):
for d in c:
if d == '.' or d in unique: continue
limit -= 1
unique.add(d)
frequency += fact * len(unique)
fact *= limit
if not limit:
return frequency * sum(map(int, unique)) | def gta(limit, *args):
args = [str(n).ljust(limit, '.') for n in args]
unique, frequency, fact = set(), 0, 1
for c in zip(*args):
for d in c:
if d == '.' or d in unique: continue
limit -= 1
unique.add(d)
frequency += fact * len(unique)
fact *= limit
if not limit:
return frequency * sum(map(int, unique)) | train | APPS_structured |
With a friend we used to play the following game on a chessboard
(8, rows, 8 columns).
On the first row at the *bottom* we put numbers:
`1/2, 2/3, 3/4, 4/5, 5/6, 6/7, 7/8, 8/9`
On row 2 (2nd row from the bottom) we have:
`1/3, 2/4, 3/5, 4/6, 5/7, 6/8, 7/9, 8/10`
On row 3:
`1/4, 2/5, 3/6, 4/7, 5/8, 6/9, 7/10, 8/11`
until last row:
`1/9, 2/10, 3/11, 4/12, 5/13, 6/14, 7/15, 8/16`
When all numbers are on the chessboard each in turn we toss a coin. The one who get "head" wins and
the other gives him, in dollars, the **sum of the numbers on the chessboard**.
We play for fun, the dollars come from a monopoly game!
### Task
How much can I (or my friend) win or loses for each game if the chessboard has n rows and n columns? Add all of the fractional values on an n by n sized board and give the answer as a simplified fraction.
- Ruby, Python, JS, Coffee, Clojure, PHP, Elixir, Crystal, Typescript, Go:
The function called 'game' with parameter n (integer >= 0) returns as result an irreducible fraction written as an array of integers: [numerator, denominator].
If the denominator is 1 return [numerator].
- Haskell:
'game' returns either a "Left Integer" if denominator is 1 otherwise
"Right (Integer, Integer)"
- Prolog:
'game' returns an irreducible fraction written as an array of integers: [numerator, denominator].
If the denominator is 1 return [numerator, 1].
- Java, C#, C++, F#, Swift, Reason, Kotlin:
'game' returns a string that mimicks the array returned in Ruby, Python, JS, etc...
- Fortran, Bash: 'game' returns a string
- Forth: return on the stack the numerator and the denominator (even if the denominator is 1)
- In Fortran - as in any other language - the returned string is not permitted
to contain any redundant trailing whitespace: you can use dynamically allocated character strings.
#### See Example Test Cases for each language | def game(n):
return [n * n, 2] if n%2 else [n*n//2] | def game(n):
return [n * n, 2] if n%2 else [n*n//2] | train | APPS_structured |